CN115082430B - Image analysis method and device and electronic equipment - Google Patents
Image analysis method and device and electronic equipmentDownload PDFInfo
- Publication number
- CN115082430B CN115082430BCN202210851146.1ACN202210851146ACN115082430BCN 115082430 BCN115082430 BCN 115082430BCN 202210851146 ACN202210851146 ACN 202210851146ACN 115082430 BCN115082430 BCN 115082430B
- Authority
- CN
- China
- Prior art keywords
- image
- layer
- visual
- sequence
- analyzed
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images










Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/0002—Inspection of images, e.g. flaw detection
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T9/00—Image coding
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/40—Extraction of image or video features
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/10—Human or animal bodies, e.g. vehicle occupants or pedestrians; Body parts, e.g. hands
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/30—Subject of image; Context of image processing
- G06T2207/30196—Human being; Person
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Multimedia (AREA)
- Quality & Reliability (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Human Computer Interaction (AREA)
- Image Analysis (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本发明涉及计算机视觉技术领域,尤其涉及一种图像分析方法、装置及电子设备。The invention relates to the technical field of computer vision, in particular to an image analysis method, device and electronic equipment.
背景技术Background technique
计算机视觉是使用计算机模仿人类视觉系统的科学,能够使计算机拥有类似人类提取、处理、理解和分析图像及图像序列的能力,在安防、制造、政务、医疗等领域中发挥着越来越重要的作用。Computer vision is a science that uses computers to imitate the human visual system. It enables computers to have the ability to extract, process, understand and analyze images and image sequences similar to humans. It plays an increasingly important role in security, manufacturing, government affairs, medical care and other fields. effect.
在计算机视觉任务中,不同于自然语言可以被建模成序列至序列的特点,视觉任务的定义通常有着巨大的差异,不同的视觉任务需要设计不同的模型结构分别处理。虽然目前有提出用统一的视觉分析模型处理多个视觉任务,比如多任务学习,但这种方式主要是将多个任务的专用模型结构和一个共享的主干模型网络进行共同训练,只能处理有限且固定的任务组合,一旦有新的任务出现,又需要额外设计新的模型结构并重新训练,任务处理效率低且开发成本较高。In computer vision tasks, unlike the feature that natural language can be modeled as sequence-to-sequence, the definition of vision tasks usually has huge differences, and different vision tasks need to design different model structures to deal with them separately. Although it is currently proposed to use a unified visual analysis model to handle multiple visual tasks, such as multi-task learning, this method is mainly to jointly train the dedicated model structure of multiple tasks and a shared backbone model network, which can only handle limited And the fixed task combination, once a new task appears, it needs to design a new model structure and retrain, the task processing efficiency is low and the development cost is high.
发明内容Contents of the invention
本发明提供一种图像分析方法、装置及电子设备,用以解决现有技术中不同的视觉任务需要使用不同结构的模型进行处理而导致处理效率低且开发成本高的缺陷,实现多种视觉任务输出结果的统一序列化表示。The present invention provides an image analysis method, device and electronic equipment, which are used to solve the defects in the prior art that different visual tasks need to be processed by models with different structures, resulting in low processing efficiency and high development costs, and realize various visual tasks Uniform serialized representation of output results.
本发明提供一种图像分析方法,包括:The invention provides an image analysis method, comprising:
获取目标视觉任务的待分析图像;Obtain the image to be analyzed of the target vision task;
将所述待分析图像输入视觉分析模型,获得所述视觉分析模型输出的所述待分析图像中针对所述目标视觉任务的每一个目标物体特征的属性序列;Inputting the image to be analyzed into a visual analysis model, and obtaining an attribute sequence of each target object feature for the target visual task in the image to be analyzed output by the visual analysis model;
其中,所述视觉分析模型用于基于所述目标视觉任务对所述待分析图像进行图像特征中目标物体特征的提取,并生成描述所述目标物体特征的属性序列;Wherein, the visual analysis model is used to extract target object features from image features of the image to be analyzed based on the target visual task, and generate an attribute sequence describing the target object features;
所述视觉分析模型是基于所述目标视觉任务对应的样本图像和所述样本图像对应的标签数据训练得到的。The visual analysis model is trained based on the sample image corresponding to the target visual task and the label data corresponding to the sample image.
根据本发明提供的一种图像分析方法,所述将所述待分析图像输入视觉分析模型,获得所述视觉分析模型输出的所述待分析图像中针对目标视觉任务的每一个目标物体特征的属性序列,包括:According to an image analysis method provided by the present invention, the image to be analyzed is input into a visual analysis model, and the attribute of each target object feature for the target visual task in the image to be analyzed output by the visual analysis model is obtained sequence, including:
将所述待分析图像输入所述视觉分析模型的图像特征编码层,获得所述图像特征编码层输出的所述待分析图像的图像特征;Inputting the image to be analyzed into the image feature encoding layer of the visual analysis model, and obtaining the image features of the image to be analyzed output by the image feature encoding layer;
将所述图像特征输入所述视觉分析模型的自注意力解码层,获得所述自注意力解码层输出的所述图像特征中针对所述目标视觉任务的目标物体特征;The image feature is input into the self-attention decoding layer of the visual analysis model, and the target object feature for the target visual task is obtained in the image feature output by the self-attention decoding layer;
将所述目标物体特征输入所述视觉分析模型的序列生成层,获得所述序列生成层输出的所述目标物体特征的属性序列。Inputting the target object features into the sequence generation layer of the visual analysis model, and obtaining the attribute sequence of the target object features output by the sequence generation layer.
根据本发明提供的一种图像分析方法,所述序列生成层按照时序输出所述目标物体特征的属性序列;所述序列生成层包括序列自注意力层、图像互注意力层和线性层;According to an image analysis method provided by the present invention, the sequence generation layer outputs the attribute sequence of the target object feature in time sequence; the sequence generation layer includes a sequence self-attention layer, an image mutual attention layer and a linear layer;
所述序列自注意力层,用于以当前时刻的输入特征为查询、当前时刻的输入特征及之前所有的输入特征为键值对进行自注意力计算;The sequence self-attention layer is used to perform self-attention calculations with the input features of the current moment as queries, the input features of the current moment and all previous input features as key-value pairs;
所述图像互注意力层,用于以所述图像特征为键值对所述序列自注意力层的输出进行互注意力计算;The image mutual attention layer is used to perform mutual attention calculation on the output of the sequence self-attention layer using the image feature as a key value;
所述线性层,用于对所述图像互注意力层的输出进行数值化处理,得到所述属性序列。The linear layer is used to digitize the output of the image mutual attention layer to obtain the attribute sequence.
根据本发明提供的一种图像分析方法,所述将所述目标物体特征输入所述视觉分析模型的序列生成层,获得所述序列生成层输出的所述目标物体特征的属性序列,包括:According to an image analysis method provided by the present invention, the inputting the characteristics of the target object into the sequence generation layer of the visual analysis model, and obtaining the attribute sequence of the characteristics of the target object output by the sequence generation layer include:
将所述图像互注意力层前一时刻的输出特征作为当前时刻的输入特征输入所述序列自注意力层,获得所述序列自注意力层输出的当前时刻的自注意力值,所述序列自注意力层初始时刻的输入特征为所述目标物体特征;The output feature of the previous moment of the image mutual attention layer is input into the sequence self-attention layer as the input feature of the current moment, and the self-attention value of the current moment output by the sequence self-attention layer is obtained, and the sequence The input feature at the initial moment of the self-attention layer is the target object feature;
将所述当前时刻的自注意力值输入所述图像互注意力层,获得所述图像互注意力层输出的当前时刻的输出特征;The self-attention value of the current moment is input into the image mutual attention layer, and the output characteristics of the current moment output by the image mutual attention layer are obtained;
将所述当前时刻的输出特征输入所述线性层,获得所述线性层输出的当前时刻的属性元素,所述属性元素构成所述属性序列。Inputting the output features at the current moment into the linear layer to obtain attribute elements output by the linear layer at the current moment, where the attribute elements constitute the attribute sequence.
根据本发明提供的一种图像分析方法,所述将所述待分析图像输入所述视觉分析模型的图像特征编码层,获得所述图像特征编码层输出的所述待分析图像的图像特征,包括:According to an image analysis method provided by the present invention, the input of the image to be analyzed into the image feature encoding layer of the visual analysis model, and obtaining the image features of the image to be analyzed output by the image feature encoding layer include: :
将所述待分析图像输入所述视觉分析模型的图像特征编码层的残差网络层,获得所述残差网络层输出的所述待分析图像的初始图像特征,所述残差网络层用于将所述待分析图像映射至图像特征空间;The image to be analyzed is input into the residual network layer of the image feature coding layer of the visual analysis model, and the initial image features of the image to be analyzed output by the residual network layer are obtained, and the residual network layer is used for mapping the image to be analyzed to an image feature space;
将所述初始图像特征输入所述图像特征编码层的自注意力编码层,获得所述自注意力编码层输出的所述待分析图像的图像特征,所述自注意力编码层用于进行自注意力编码。The initial image feature is input into the self-attention coding layer of the image feature coding layer, and the image feature of the image to be analyzed outputted by the self-attention coding layer is obtained, and the self-attention coding layer is used for self-attention coding layer Attention encoding.
根据本发明提供的一种图像分析方法,所述属性序列的长度基于所述目标视觉任务确定。According to an image analysis method provided by the present invention, the length of the attribute sequence is determined based on the target visual task.
本发明还提供一种图像分析装置,包括:The present invention also provides an image analysis device, comprising:
获取模块,用于获取目标视觉任务的待分析图像;An acquisition module, configured to acquire the image to be analyzed of the target vision task;
分析模块,用于将所述待分析图像输入视觉分析模型,获得所述视觉分析模型输出的所述待分析图像中针对所述目标视觉任务的每一个目标物体特征的属性序列;An analysis module, configured to input the image to be analyzed into a visual analysis model, and obtain an attribute sequence for each target object feature of the target visual task in the image to be analyzed output by the visual analysis model;
其中,所述视觉分析模型用于基于所述目标视觉任务对所述待分析图像进行图像特征中目标物体特征的提取,并生成描述所述目标物体特征的属性序列;所述视觉分析模型是基于所述目标视觉任务对应的样本图像和所述样本图像对应的标签数据训练得到的。Wherein, the visual analysis model is used to extract the target object features in the image features of the image to be analyzed based on the target visual task, and generate an attribute sequence describing the target object features; the visual analysis model is based on The sample image corresponding to the target visual task and the label data corresponding to the sample image are obtained through training.
根据本发明提供的一种图像分析装置,所述分析模块包括:According to an image analysis device provided by the present invention, the analysis module includes:
第一分析单元,用于将所述待分析图像输入所述视觉分析模型的图像特征编码层,获得所述图像特征编码层输出的所述待分析图像的图像特征;A first analysis unit, configured to input the image to be analyzed into the image feature encoding layer of the visual analysis model, and obtain the image features of the image to be analyzed output by the image feature encoding layer;
第二分析单元,用于将所述图像特征输入所述视觉分析模型的自注意力解码层,获得所述自注意力解码层输出的所述图像特征中针对所述目标视觉任务的目标物体特征;The second analysis unit is used to input the image features into the self-attention decoding layer of the visual analysis model, and obtain the target object features for the target visual task in the image features output by the self-attention decoding layer ;
第三分析单元,用于将所述目标物体特征输入所述视觉分析模型的序列生成层,获得所述序列生成层输出的所述目标物体特征的属性序列。The third analysis unit is configured to input the target object features into the sequence generation layer of the visual analysis model, and obtain the attribute sequence of the target object features output by the sequence generation layer.
本发明还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上述任一种所述图像分析方法。The present invention also provides an electronic device, including a memory, a processor, and a computer program stored on the memory and operable on the processor. When the processor executes the computer program, the image analysis described above can be realized. method.
本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如上述任一种所述图像分析方法。The present invention also provides a non-transitory computer-readable storage medium, on which a computer program is stored, and when the computer program is executed by a processor, any one of the image analysis methods described above can be realized.
本发明提供的图像分析方法、装置及电子设备,通过获取待分析图像,并将待分析图像输入视觉分析模型,可以获得视觉分析模型输出的待分析图像中针对目标视觉任务的每一个目标物体特征的属性序列。其中的视觉分析模型是基于目标视觉任务对应的样本图像和样本图像对应的标签数据训练得到的,可以基于目标视觉任务对待分析图像进行图像特征中目标物体特征的提取,并生成描述该目标物体特征的属性序列,这样,对于任一目标视觉任务,都可以以待分析图像中该视觉任务对应的目标物体特征为基本单元,获得描述该目标物体特征的属性序列,该属性序列提供了一种通用的视觉任务目标的表现形式,能够将不同视觉任务统一成对待分析图像中物体的序列描述问题,可以使用同样结构的视觉分析模型实现多种不同视觉任务的处理,提高了视觉分析模型在多种视觉任务上的通用性,进而提高了视觉任务处理的效率,降低了开发成本。The image analysis method, device and electronic equipment provided by the present invention can obtain the characteristics of each target object for the target visual task in the image to be analyzed output by the visual analysis model by acquiring the image to be analyzed and inputting the image to be analyzed into the visual analysis model sequence of attributes. The visual analysis model is trained based on the sample image corresponding to the target visual task and the label data corresponding to the sample image. Based on the target visual task, the target object feature can be extracted from the image features of the image to be analyzed, and the feature describing the target object can be generated. In this way, for any target visual task, the target object feature corresponding to the visual task in the image to be analyzed can be used as the basic unit to obtain the attribute sequence describing the feature of the target object. The attribute sequence provides a general The expression form of the visual task target can unify different visual tasks into the sequence description problem of the object in the image to be analyzed, and can use the visual analysis model of the same structure to realize the processing of various visual tasks, which improves the visual analysis model in a variety of The versatility of visual tasks improves the efficiency of visual task processing and reduces development costs.
附图说明Description of drawings
为了更清楚地说明本发明或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。In order to more clearly illustrate the present invention or the technical solutions in the prior art, the accompanying drawings that need to be used in the description of the embodiments or the prior art will be briefly introduced below. Obviously, the accompanying drawings in the following description are the present invention. For some embodiments of the invention, those skilled in the art can also obtain other drawings based on these drawings without creative effort.
图1是本发明提供的图像分析方法的流程示意图之一;Fig. 1 is one of the flow diagrams of the image analysis method provided by the present invention;
图2是本发明提供的视觉分析模型的结构示意图;Fig. 2 is a schematic structural diagram of a visual analysis model provided by the present invention;
图3是本发明提供的图像分析方法的流程示意图之二;Fig. 3 is the second schematic flow diagram of the image analysis method provided by the present invention;
图4是本发明提供的序列生成层的结构示意图;Fig. 4 is a schematic structural diagram of the sequence generation layer provided by the present invention;
图5是本发明提供的图像分析方法的流程示意图之三;Fig. 5 is the third schematic flow diagram of the image analysis method provided by the present invention;
图6是本发明提供的序列生成层的工作原理示意图;Fig. 6 is a schematic diagram of the working principle of the sequence generation layer provided by the present invention;
图7是本发明提供的视觉分析模型的工作原理示意图;Fig. 7 is a schematic diagram of the working principle of the visual analysis model provided by the present invention;
图8是本发明提供的序列生成层在执行目标检测任务时的运行逻辑示意图;Fig. 8 is a schematic diagram of the operation logic of the sequence generation layer provided by the present invention when performing the target detection task;
图9是本发明提供的序列生成层在执行人体姿态估计任务时的运行逻辑示意图;Fig. 9 is a schematic diagram of the operation logic of the sequence generation layer provided by the present invention when performing the human pose estimation task;
图10是本发明提供的图像分析装置的结构示意图;Fig. 10 is a schematic structural diagram of an image analysis device provided by the present invention;
图11是本发明提供的电子设备的实体结构示意图。Fig. 11 is a schematic diagram of the physical structure of the electronic device provided by the present invention.
具体实施方式detailed description
为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明中的附图,对本发明中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。In order to make the purpose, technical solutions and advantages of the present invention clearer, the technical solutions in the present invention will be clearly and completely described below in conjunction with the accompanying drawings in the present invention. Obviously, the described embodiments are part of the embodiments of the present invention , but not all examples. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without creative efforts fall within the protection scope of the present invention.
在自然语言处理中,出现了许多大型通用语言模型,语言任务往往都可以被建模成为序列至序列(Seq2Seq)的生成问题,并可以用同样的自注意力变换器模型处理大量不同问题,比如Transformer模型等。可以在少量训练数据下训练出许多大规模预训练语言模型,这些模型可以应用到大量语言任务上,满足大量语音任务的需求。In natural language processing, many large-scale general-purpose language models have emerged. Language tasks can often be modeled as sequence-to-sequence (Seq2Seq) generation problems, and the same self-attention transformer model can be used to handle a large number of different problems, such as Transformer model, etc. Many large-scale pre-trained language models can be trained with a small amount of training data, and these models can be applied to a large number of language tasks to meet the needs of a large number of speech tasks.
鉴于自然语言处理领域取得的这一重大成就,如果在视觉任务中也可以设计出类似的通用模型结构来处理多种视觉任务,将有助于提高视觉任务的处理效率,降低视觉任务处理的开发成本。In view of this major achievement in the field of natural language processing, if a similar general model structure can be designed to handle multiple visual tasks in visual tasks, it will help improve the processing efficiency of visual tasks and reduce the development of visual task processing. cost.
然而,在计算机视觉领域中,视觉任务的定义往往有着巨大的差异,不同于均由序列组成的自然语言,这些视觉任务很难被统一用同一种形式来表示,因而在面对不同的视觉任务时需要设计不同的模型结构分别处理。However, in the field of computer vision, the definitions of visual tasks often have huge differences. Unlike natural languages, which are all composed of sequences, these visual tasks are difficult to be expressed in the same form. Therefore, in the face of different visual tasks Different model structures need to be designed and processed separately.
相关技术中,视觉任务使用的统一视觉大模型大多是预训练的主干网络模型,这些主干网络模型可以用来提取图像特征,但针对每个视觉任务仍需要设计额外的独特结构。多任务学习是一种将多个任务的专用模型结构和一个共享的主干网络模型共同训练的方式,这种方式只能处理有限且固定的任务组合,一旦有新的任务出现,又需要额外设计新的模型结构并重新训练。In related technologies, most of the large unified vision models used in vision tasks are pre-trained backbone network models. These backbone network models can be used to extract image features, but additional unique structures still need to be designed for each vision task. Multi-task learning is a way to jointly train a dedicated model structure for multiple tasks and a shared backbone network model. This method can only handle a limited and fixed combination of tasks. Once a new task appears, additional design is required. New model structure and retrain.
基于此,本发明实施例提供了一种图像分析方法,可以获取目标视觉任务的待分析图像,将该待分析图像输入视觉分析模型,由视觉分析模型基于目标视觉任务对待分析图像进行图像特征中目标物体特征的提取并生成描述该目标物体特征的属性序列,获得视觉分析模型输出的待分析图像中针对目标视觉任务的每一个目标物体特征的属性序列。其中的视觉分析模型是基于目标视觉任务对应的样本图像和样本图像对应的标签数据训练得到的。其中的属性序列提供了一种通用的视觉任务目标的表现形式,这样,可以将不同的视觉任务统一成对待分析图像中物体的序列描述任务,提高了视觉分析模型在多种视觉任务中的通用性。Based on this, an embodiment of the present invention provides an image analysis method, which can acquire the image to be analyzed of the target visual task, input the image to be analyzed into the visual analysis model, and the visual analysis model performs image feature classification based on the target visual task of the image to be analyzed. Extract the features of the target object and generate an attribute sequence describing the features of the target object, and obtain the attribute sequence of each target object feature for the target vision task in the image to be analyzed output by the vision analysis model. The visual analysis model is trained based on the sample image corresponding to the target visual task and the label data corresponding to the sample image. The attribute sequence provides a general representation of visual task goals, so that different visual tasks can be unified into a sequence description task of the object in the image to be analyzed, which improves the generality of the visual analysis model in various visual tasks sex.
下面结合图1-图9对本发明的图像分析方法进行描述。该图像分析方法可以应用于服务器、手机、电脑等电子设备,也可以应用于设置在服务器、手机、电脑等电子设备中的图像分析装置中,该图像分析装置可以通过软件或软件与硬件的结合来实现。The image analysis method of the present invention will be described below with reference to FIGS. 1-9 . The image analysis method can be applied to electronic devices such as servers, mobile phones, and computers, and can also be applied to image analysis devices installed in electronic devices such as servers, mobile phones, and computers. The image analysis device can use software or a combination of software and hardware. to fulfill.
图1示例性示出了本发明实施例提供的图像分析方法的流程示意图之一,参照图1所示,该图像分析方法可以包括如下的步骤110~步骤120。FIG. 1 exemplarily shows one of the schematic flowcharts of an image analysis method provided by an embodiment of the present invention. Referring to FIG. 1 , the image analysis method may include the following
步骤110:获取目标视觉任务的待分析图像。Step 110: Obtain the image to be analyzed of the target vision task.
目标视觉任务比如可以包括目标检测、人体姿态估计或图像分类等任务。待分析图像可以是图片或者视频中的帧图像。电子设备可以从图像采集设备(如摄像头、照相机等)中实时获取目标视觉任务的待分析图像,或者从存储器中存储的图像中获取待分析图像。Target vision tasks may include tasks such as target detection, human pose estimation, or image classification, for example. The image to be analyzed may be a picture or a frame image in a video. The electronic device can acquire the image to be analyzed of the target vision task in real time from the image acquisition device (such as a camera, camera, etc.), or acquire the image to be analyzed from the images stored in the memory.
步骤120:将待分析图像输入视觉分析模型,获得视觉分析模型输出的待分析图像中针对目标视觉任务的每一个目标物体特征的属性序列,其中,视觉分析模型可以用于基于目标视觉任务对待分析图像进行图像特征中目标物体特征的提取,并生成描述目标物体特征的属性序列。该属性序列提供了一种通用的视觉任务目标的表现形式,该属性序列中的元素可以根据不同的目标视觉任务赋予不同的含义。这样,可以将不同的视觉任务统一成对待分析图像中物体的序列描述任务,统一了不同视觉任务在输出形式上的差异。Step 120: Input the image to be analyzed into the visual analysis model, and obtain the attribute sequence of each target object feature for the target visual task in the image to be analyzed output by the visual analysis model, wherein the visual analysis model can be used for analysis based on the target visual task The image extracts the features of the target object in the image features, and generates an attribute sequence describing the features of the target object. The attribute sequence provides a general representation of the visual task target, and the elements in the attribute sequence can have different meanings according to different target visual tasks. In this way, different visual tasks can be unified into a sequence description task of objects in the image to be analyzed, and the differences in output forms of different visual tasks can be unified.
在此基础上,该视觉分析模型可以基于目标视觉任务对应的样本图像和样本图像对应的标签数据训练得到,也就是说,对于不同的目标视觉任务,只要利用该目标视觉任务对应的样本图像和样本图像对应的标签数据进行视觉分析模型的训练,即可获得用于处理该目标视觉任务的视觉分析模型,而不需要改变视觉分析模型的结构,能够方便地扩展到多种不同的目标视觉任务上,具有较强的通用性。On this basis, the visual analysis model can be trained based on the sample image corresponding to the target visual task and the label data corresponding to the sample image, that is to say, for different target visual tasks, as long as the sample image corresponding to the target visual task and The label data corresponding to the sample image is used to train the visual analysis model, and the visual analysis model for processing the target visual task can be obtained without changing the structure of the visual analysis model, which can be easily extended to a variety of different target visual tasks , with strong versatility.
比如,目标视觉任务是目标检测,比如检测图像中的行人,则可以获取第一样本图像,并对该第一样本图像中的行人标注第一标签信息,然后将标注处理后的第一样本图像作为训练样本进行视觉分析模型的训练,训练好的视觉分析模型即可用于进行行人检测。For example, if the target vision task is target detection, such as detecting pedestrians in an image, the first sample image can be obtained, and the pedestrians in the first sample image can be labeled with the first label information, and then the labeled first The sample images are used as training samples to train the visual analysis model, and the trained visual analysis model can be used for pedestrian detection.
再比如,目标视觉任务更换为了人体姿态估计,则可以根据人体姿态估计任务重新训练视觉分析模型即可。具体的,可以获取第二样本图像,并将该第二样本图像中的人体骨骼点标注为第二标签信息,然后将标注处理后的第二样本图像作为训练样本进行视觉分析模型的训练,训练好的视觉分析模型即可用于人体姿态估计。For another example, if the target visual task is replaced by human body pose estimation, the visual analysis model can be retrained according to the human body pose estimation task. Specifically, the second sample image can be obtained, and the human skeleton points in the second sample image can be marked as the second label information, and then the marked second sample image can be used as a training sample for training of the visual analysis model. A good visual analysis model can be used for human pose estimation.
其中,属性序列的长度可以基于目标视觉任务进行确定。比如目标视觉任务是目标检测时,每个目标物体需要用类别得分score、位置坐标(x,y)以及检测框的长w和宽h来表示,则属性序列是一个长度为5的序列。再比如,目标视觉任务是人体姿态估计时,每个物体需要用置信度和17个关键点来表示,则属性序列是一个长度为35的序列。Wherein, the length of the attribute sequence can be determined based on the target vision task. For example, when the target vision task is target detection, each target object needs to be represented by category score score, position coordinates (x, y), and length w and width h of the detection frame, then the attribute sequence is a sequence of length 5. For another example, when the target vision task is human body pose estimation, each object needs to be represented by confidence and 17 key points, then the attribute sequence is a sequence with a length of 35.
本发明实施例提供的图像分析方法,通过获取目标视觉任务的待分析图像,并将该待分析图像输入视觉分析模型,可以获得视觉分析模型输出的待分析图像中针对目标视觉任务的每一个目标物体特征的属性序列。其中的视觉分析模型是基于目标视觉任务对应的样本图像和样本图像对应的标签数据训练得到的,可以基于目标视觉任务对待分析图像进行图像特征中目标物体特征的提取,并生成描述该目标物体特征的属性序列,这样,对于任一目标视觉任务,都可以以待分析图像中该视觉任务对应的目标物体特征为基本单元,获得描述该目标物体特征的属性序列,该属性序列提供了一种通用的视觉任务目标的表现形式,能够将不同视觉任务统一成对待分析图像中物体的序列描述问题,可以使用同样结构的视觉分析模型实现多种不同视觉任务的处理,提高了视觉分析模型在多种视觉任务上的通用性,进而提高了视觉任务处理的效率,降低了开发成本。In the image analysis method provided by the embodiment of the present invention, by acquiring the image to be analyzed of the target visual task and inputting the image to be analyzed into the visual analysis model, each target for the target visual task in the image to be analyzed output by the visual analysis model can be obtained A sequence of attributes for object features. The visual analysis model is trained based on the sample image corresponding to the target visual task and the label data corresponding to the sample image. Based on the target visual task, the target object feature can be extracted from the image features of the image to be analyzed, and the feature describing the target object can be generated. In this way, for any target visual task, the target object feature corresponding to the visual task in the image to be analyzed can be used as the basic unit to obtain the attribute sequence describing the feature of the target object. The attribute sequence provides a general The expression form of the visual task target can unify different visual tasks into the sequence description problem of the object in the image to be analyzed, and can use the visual analysis model of the same structure to realize the processing of various visual tasks, which improves the visual analysis model in a variety of The versatility of visual tasks improves the efficiency of visual task processing and reduces development costs.
基于图1对应实施例的图像分析方法,图2示例性示出了视觉分析模型的结构示意图,参照图2所示,该视觉分析模型可以包括图像特征编码层、自注意力解码层和序列生成层,其中,图像特征编码层可以用于进行图像特征提取,自注意力解码层可以用于从图像特征中提取物体特征,序列生成层可以将物体特征转换为属性序列。Based on the image analysis method of the corresponding embodiment in FIG. 1, FIG. 2 exemplarily shows a schematic structural diagram of a visual analysis model. Referring to FIG. 2, the visual analysis model may include an image feature encoding layer, a self-attention decoding layer, and a sequence generation Layers, where the image feature encoding layer can be used for image feature extraction, the self-attention decoding layer can be used to extract object features from image features, and the sequence generation layer can convert object features into attribute sequences.
基于图2对应实施例的视觉分析模型的结构,在一种示例实施例中,图3示例性示出了本发明提供的图像分析方法的流程示意图之二,该示例实施例提供了上述步骤120的一种示例实施方式,参照图3所示,可以包括如下的步骤121~步骤123。Based on the structure of the visual analysis model of the embodiment corresponding to FIG. 2, in an exemplary embodiment, FIG. 3 exemplarily shows the second schematic flow diagram of the image analysis method provided by the present invention, and this exemplary embodiment provides the above-mentioned
步骤121:将待分析图像输入视觉分析模型的图像特征编码层,获得图像特征编码层输出的待分析图像的图像特征。Step 121: Input the image to be analyzed into the image feature encoding layer of the visual analysis model, and obtain the image features of the image to be analyzed outputted by the image feature encoding layer.
例如,对于一张待分析图像I,对其进行目标视觉任务处理时,可以将其输入视觉分析模型的图像特征编码层,图像特征编码层可以采用自注意力机制对该待分析图像I进行图像特征的提取,输出该待分析图像I的图像特征。For example, for an image I to be analyzed, when performing target visual task processing on it, it can be input into the image feature encoding layer of the visual analysis model, and the image feature encoding layer can use the self-attention mechanism to perform image processing on the image I to be analyzed. The feature extraction is to output the image features of the image I to be analyzed.
示例性的,图像特征编码层可以包括残差网络层和自注意力编码层,残差网络层可以用于将待分析图像映射至图像特征空间,自注意力编码层可以用于进行自注意力编码,即可以对输入的数据采用自注意力机制进行编码。相应的,步骤121可以包括:将待分析图像输入视觉分析模型的图像特征编码层的残差网络层,获得残差网络层输出的待分析图像的初始图像特征;将初始图像特征输入图像特征编码层的自注意力编码层,获得自注意力编码层输出的待分析图像的图像特征。Exemplarily, the image feature encoding layer may include a residual network layer and a self-attention encoding layer, the residual network layer may be used to map the image to be analyzed to the image feature space, and the self-attention encoding layer may be used for self-attention Encoding, that is, the input data can be encoded using a self-attention mechanism. Correspondingly, step 121 may include: inputting the image to be analyzed into the residual network layer of the image feature encoding layer of the visual analysis model, obtaining the initial image features of the image to be analyzed output by the residual network layer; inputting the initial image features into the image feature encoding The self-attention encoding layer of the layer obtains the image features of the image to be analyzed output by the self-attention encoding layer.
步骤122:将图像特征输入视觉分析模型的自注意力解码层,获得自注意力解码层输出的图像特征中针对目标视觉任务的目标物体特征。Step 122: Input the image features into the self-attention decoding layer of the visual analysis model, and obtain the target object features for the target vision task among the image features output from the self-attention decoding layer.
自注意力解码层可以用于处理目标物体特征,例如,目标视觉任务为目标检测,比如进行目标行人检测,将图像特征输入视觉分析模型的自注意力解码层后,自注意力解码层可以基于自注意力机制来丰富图像特征更高层的细节信息,从图像特征中提取出目标行人的特征。The self-attention decoding layer can be used to process target object features. For example, the target visual task is target detection, such as target pedestrian detection. After inputting image features into the self-attention decoding layer of the visual analysis model, the self-attention decoding layer can be based on The self-attention mechanism enriches the higher-level detail information of image features, and extracts the features of target pedestrians from image features.
步骤123:将目标物体特征输入视觉分析模型的序列生成层,获得序列生成层输出的目标物体特征的属性序列。Step 123: Input the target object feature into the sequence generation layer of the visual analysis model, and obtain the attribute sequence of the target object feature output by the sequence generation layer.
序列生成层可以用于对每一个目标物体特征进行序列化处理,生成一系列用于描述该目标物体的属性,即属性序列,该属性序列可以以标量数的形式呈现。The sequence generation layer can be used to serialize the characteristics of each target object, and generate a series of attributes used to describe the target object, that is, an attribute sequence, which can be presented in the form of a scalar number.
具体的,在获得目标物体特征之后,每一个目标物体特征被送入序列生成层,序列生成层会对输入的目标物体特征进行序列化处理,将目标物体特征从图像表征空间转换到标量数值空间,获得每一个目标物体特征的属性序列,以标量数的形式描述目标视觉任务中的目标物体。Specifically, after obtaining the target object features, each target object feature is sent to the sequence generation layer, and the sequence generation layer will serialize the input target object features, and convert the target object features from the image representation space to the scalar value space , obtain the attribute sequence of each target object feature, and describe the target object in the target vision task in the form of a scalar number.
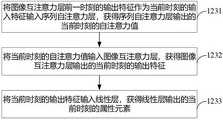
一种示例实施例中,序列生成层可以按照时序输出目标物体特征的属性序列。图4示例性示出了序列生成层的结构示意图,参照图4所示,序列生成层可以包括序列自注意力层、图像互注意力层和线性层。其中,序列自注意力层可以用于以当前时刻的输入特征为查询Query、当前时刻的输入特征及当前时刻之前的所有的输入特征为键值对(Key-Value),进行自注意力计算;图像互注意力层可以用于以图像特征为键值(Key),对序列自注意力层的输出进行互注意力计算;线性层可以用于对图像互注意力层的输出进行数值化处理,得到属性序列。In an example embodiment, the sequence generation layer may output the attribute sequence of the target object feature in time sequence. FIG. 4 exemplarily shows a schematic structural diagram of a sequence generation layer. Referring to FIG. 4 , the sequence generation layer may include a sequence self-attention layer, an image mutual attention layer, and a linear layer. Among them, the sequential self-attention layer can be used to use the input features at the current moment as the query query, the input features at the current moment, and all the input features before the current moment as key-value pairs (Key-Value) to perform self-attention calculations; The image mutual attention layer can be used to perform mutual attention calculation on the output of the sequence self-attention layer with the image feature as the key value (Key); the linear layer can be used to numerically process the output of the image mutual attention layer, Get the attribute sequence.
基于图4对应实施例的序列生成层,本发明实施例提供的图像分析方法在使用视觉分析模型对待分析图像I进行分析以获得视觉分析模型输出的待分析图像中针对目标视觉任务的每一个目标物体特征的属性序列的过程中,图像特征编码层首先从待分析图像I中提取图像特征



基于图4对应实施例的序列生成层,图5示例性示出了本发明提供的图像分析方法的流程示意图之三,该示例实施例提供了上述步骤123的一种示例实施方式,参照图5所示,可以包括如下的步骤1231~步骤1233。Based on the sequence generation layer of the embodiment corresponding to FIG. 4, FIG. 5 exemplarily shows the third schematic flow diagram of the image analysis method provided by the present invention. This example embodiment provides an example implementation of the above-mentioned
步骤1231:将图像互注意力层前一时刻的输出特征作为当前时刻的输入特征输入序列自注意力层,获得序列自注意力层输出的当前时刻的自注意力值。其中,序列自注意力层初始时刻的输入特征为目标物体特征。Step 1231: Input the output feature of the image mutual attention layer at the previous moment as the input feature of the current moment into the sequence self-attention layer, and obtain the current moment self-attention value output by the sequence self-attention layer. Among them, the input feature at the initial moment of the sequential self-attention layer is the target object feature.
步骤1232:将当前时刻的自注意力值输入图像互注意力层,获得图像互注意力层输出的当前时刻的输出特征。Step 1232: Input the self-attention value at the current moment into the image mutual attention layer, and obtain the output features at the current moment output by the image mutual attention layer.
步骤1233:将当前时刻的输出特征输入线性层,获得线性层输出的当前时刻的属性元素。该属性元素用于构成属性序列。Step 1233: Input the output feature at the current moment into the linear layer, and obtain the attribute element at the current moment output by the linear layer. This attribute element is used to form an attribute sequence.
基于图4对应实施例的序列生成层的结构和图5对应实施例的方法,图6示例性示出了序列生成层的工作原理示意图,参照图6所示,序列生成层可以以目标物体的单个目标物体特征
















假设目标视觉任务需要输出长度为T的属性序列,则每一时刻的输入特征


具体的,公式一为
公式二为
公式三为
其中,




基于上述工作原理,序列生成层输出的属性序列可以根据具体的视觉任务解释为任意需要的含义,不再需要与具体视觉任务相关的网络参数。也就是说,序列生成层输出了一种通用的目标表示形式,使用一个属性序列作为视觉任务的输出,可以将同样的视觉分析模型结构泛化应用到不同的视觉任务上,该视觉分析模型具有较强的多视觉任务扩展性。Based on the above working principle, the attribute sequence output by the sequence generation layer can be interpreted as any desired meaning according to the specific visual task, and the network parameters related to the specific visual task are no longer needed. That is to say, the sequence generation layer outputs a general target representation, using an attribute sequence as the output of the visual task, the same visual analysis model structure can be generalized and applied to different visual tasks. The visual analysis model has Strong multi-vision task scalability.
下面以目标检测任务和人体姿态估计任务为例,对本发明实施例提供的图像分析方法在具体视觉任务上的应用进行描述。The application of the image analysis method provided by the embodiment of the present invention to specific vision tasks will be described below by taking the target detection task and the human body pose estimation task as examples.
图7示例性示出了视觉分析模型的工作原理示意图,参照图7所示,待分析图像I输入图像特征编码层,图像特征编码层的残差网络层和自注意力编码层首先从待分析图像I中提取图像特征

结合图7,图8示例性示出了序列生成层在执行目标检测任务时的运行逻辑示意图,参照图8所示,针对目标检测任务,每个目标物体需要用一个长度为5的属性序列来表示,属性元素分别是类别得分score、目标检测框的坐标值x和y以及宽w和高h。In conjunction with Fig. 7, Fig. 8 exemplarily shows the schematic diagram of the operation logic of the sequence generation layer when performing the target detection task. Referring to Fig. 8, for the target detection task, each target object needs to be represented by an attribute sequence with a length of 5 Indicates that the attribute elements are the category score score, the coordinate values x and y of the target detection frame, and the width w and height h.
在利用本发明实施例提供的视觉分析模型执行目标检测任务前,需要先基于目标检测任务对该视觉分析模型进行训练。在本发明的一种示例实施例中,可以基于二分匹配损失构建训练目标。具体的,可以对所有目标物体集合






示例性的,对于输出的类别得分score,可以使用焦点损失函数Focal( )进行监督,对于坐标回归,可以同时使用


基于此,针对目标检测任务,视觉分析模型训练时的目标检测损失函数

其中,N表示执行目标检测任务时输出物体的个数,

公式四可以表示为:Formula 4 can be expressed as:

其中,











在进行针对目标检测任务的视觉分析模型训练时,可以获取第一样本图像,并对该第一样本图像中的检测目标标注第一标签信息,然后将标注处理后的第一样本图像作为训练样本,利用损失函数
结合图7和图8,在进行目标检测时,可以将需要进行目标检测的待分析图像输入图像特征编码层进行图像特征提取,接着将提取的图像特征输入自注意力解码层处理,获得目标物体特征,然后将每一个目标物体特征输入序列生成层进行序列化处理以得到各目标物体特征的属性序列。比如对于目标物体特征








结合图7,图9示例性示出了序列生成层在执行人体姿态估计任务时的运行逻辑示意图,参照图9所示,针对人体姿态估计任务,每个目标物体需要用一个长度为35的属性序列来表示,属性元素分别是置信度con和17个关键点的坐标

在利用本发明实施例提供的视觉分析模型执行人体姿态估计任务前,需要先基于人体姿态估计任务对该视觉分析模型进行训练。在本发明的一种示例实施例中,可以使用二分匹配损失构建训练目标,其构建原理可参照上述执行目标检测任务时的描述,此处不再赘述。Before using the visual analysis model provided by the embodiment of the present invention to perform the human body pose estimation task, the visual analysis model needs to be trained based on the human body pose estimation task. In an example embodiment of the present invention, the training target can be constructed using the bipartite matching loss, and its construction principle can refer to the above description when performing the target detection task, and will not be repeated here.
示例性的,对于输出的置信度con,可以使用二值交叉熵(Binary Cross Entropy,BCE)损失函数


基于此,针对人体姿态估计任务,视觉分析模型训练时的姿态估计损失函数

其中,M表示执行人体姿态估计任务时输出物体的个数,

公式五可以表示为:Equation 5 can be expressed as:

其中,









在进行针对人体姿态估计任务的视觉分析模型训练时,可以获取第二样本图像,并对该第二样本图像中的人体关键点标注第二标签信息,然后将标注处理后的第二样本图像作为训练样本,利用损失函数
结合图7和图9,在进行人体姿态估计时,可以将需要进行人体姿态估计的待分析图像输入图像特征编码层进行图像特征提取,接着将提取的图像特征输入自注意力解码层处理,获得目标物体特征,然后将每一个目标物体特征输入序列生成层进行序列化处理以得到各目标物体特征的属性序列。比如对于目标物体特征










本发明实施例提供的图像分析方法,通过获取目标视觉任务的待分析图像,并将该待分析图像输入基于目标视觉任务对应的样本图像和样本图像对应的标签数据训练得到的视觉分析模型,可以获得该视觉分析模型输出的待分析图像中针对目标视觉任务的每一个目标物体特征的属性序列。一方面,可以将多种不同的视觉任务重新定义为描述每个目标物体的属性序列生成问题,统一了不同视觉任务的任务输出形式,而且,输出的属性序列可以根据目标视觉任务的不同,被灵活地定义为目标视觉任务所需的能够描述目标物体的含义,可以满足多样化的需求,因而可以使用同样结构的视觉分析模型实现多种不同视觉任务的处理,提高了视觉分析模型在多种视觉任务上的通用性,进而提高了视觉任务处理的效率,降低了开发成本。另一方面,充分考虑了待分析图像内的层级结构信息,能够以“物体”为基本单元组织图像特征,提高了图像特征提取的准确性。The image analysis method provided by the embodiment of the present invention can obtain the image to be analyzed of the target visual task, and input the image to be analyzed into the visual analysis model based on the training of the sample image corresponding to the target visual task and the label data corresponding to the sample image. The attribute sequence of each target object feature for the target vision task in the image to be analyzed output by the vision analysis model is obtained. On the one hand, a variety of different visual tasks can be redefined as the problem of attribute sequence generation describing each target object, and the task output forms of different visual tasks are unified. Moreover, the output attribute sequence can be determined according to the different target visual tasks. It can be flexibly defined as the meaning of the target object that can describe the target object required by the target visual task, and can meet diverse needs. Therefore, the visual analysis model with the same structure can be used to process a variety of different visual tasks, which improves the visual analysis model in a variety of The versatility of visual tasks improves the efficiency of visual task processing and reduces development costs. On the other hand, the hierarchical structure information in the image to be analyzed is fully considered, and the image features can be organized with "object" as the basic unit, which improves the accuracy of image feature extraction.
下面对本发明提供的图像分析装置进行描述,下文描述的图像分析装置与上文描述的图像分析方法可相互对应参照。The image analysis device provided by the present invention is described below, and the image analysis device described below and the image analysis method described above can be referred to in correspondence.
图10示例性示出了本发明实施例提供的图像分析装置的结构示意图,参照图10所示,图像分析装置1000可以包括获取模块1010和分析模块1020。其中,获取模块1010可以用于获取目标视觉任务的待分析图像;分析模块1020可以用于将待分析图像输入视觉分析模型,获得视觉分析模型输出的待分析图像中针对目标视觉任务的每一个目标物体特征的属性序列;其中,视觉分析模型用于基于目标视觉任务对待分析图像进行图像特征中目标物体特征的提取,并生成描述目标物体特征的属性序列;视觉分析模型是基于目标视觉任务对应的样本图像和样本图像对应的标签数据训练得到的。FIG. 10 exemplarily shows a schematic structural diagram of an image analysis device provided by an embodiment of the present invention. Referring to FIG. 10 , the
一种示例实施例中,分析模块1020可以包括:第一分析单元,用于将待分析图像输入视觉分析模型的图像特征编码层,获得图像特征编码层输出的待分析图像的图像特征;第二分析单元,用于将图像特征输入视觉分析模型的自注意力解码层,获得自注意力解码层输出的图像特征中针对目标视觉任务的目标物体特征;第三分析单元,用于将目标物体特征输入视觉分析模型的序列生成层,获得序列生成层输出的目标物体特征的属性序列。In an exemplary embodiment, the
一种示例实施例中,序列生成层可以按照时序输出目标物体特征的属性序列;序列生成层可以包括序列自注意力层、图像互注意力层和线性层。其中,序列自注意力层可以用于以当前时刻的输入特征为查询、当前时刻的输入特征及之前所有的输入特征为键值对进行自注意力计算;图像互注意力层可以用于以图像特征为键值对序列自注意力层的输出进行互注意力计算;线性层可以用于对图像互注意力层的输出进行数值化处理,得到属性序列。In an example embodiment, the sequence generation layer may output the attribute sequence of the target object feature in time sequence; the sequence generation layer may include a sequence self-attention layer, an image mutual attention layer and a linear layer. Among them, the sequence self-attention layer can be used to perform self-attention calculation with the input feature at the current moment as the query, the input feature at the current moment and all previous input features as key-value pairs; the image mutual attention layer can be used to use the image The feature is that the key-value pair performs mutual attention calculation on the output of the sequence self-attention layer; the linear layer can be used to numerically process the output of the image mutual attention layer to obtain the attribute sequence.
一种示例实施例中,第三分析单元可以包括:第一分析子单元,可以用于将图像互注意力层前一时刻的输出特征作为当前时刻的输入特征输入序列自注意力层,获得序列自注意力层输出的当前时刻的自注意力值,其中,序列自注意力层初始时刻的输入特征为目标物体特征;第二分析子单元,可以用于将当前时刻的自注意力值输入图像互注意力层,获得图像互注意力层输出的当前时刻的输出特征;第三分析子单元,可以用于将当前时刻的输出特征输入线性层,获得线性层输出的当前时刻的属性元素,属性元素构成属性序列。In an exemplary embodiment, the third analysis unit may include: a first analysis subunit, which may be used to input the output features of the image mutual attention layer at the previous moment as the input features of the current moment into the sequence self-attention layer, and obtain the sequence The self-attention value at the current moment output by the self-attention layer, wherein the input feature at the initial moment of the sequence self-attention layer is the target object feature; the second analysis subunit can be used to input the self-attention value at the current moment into the image The mutual attention layer obtains the output feature of the current moment output by the image mutual attention layer; the third analysis subunit can be used to input the output feature of the current moment into the linear layer, and obtain the attribute element of the current moment output by the linear layer, attribute Elements form a sequence of attributes.
在一种示例实施例中,第一分析单元可以包括:第四分析子单元,可以用于将待分析图像输入视觉分析模型的图像特征编码层的残差网络层,获得残差网络层输出的待分析图像的初始图像特征,其中的残差网络层可以用于将待分析图像映射至图像特征空间;第五分析子单元,可以用于将初始图像特征输入图像特征编码层的自注意力编码层,获得自注意力编码层输出的待分析图像的图像特征,其中的自注意力编码层可以用于进行自注意力编码。In an example embodiment, the first analysis unit may include: a fourth analysis subunit, which may be used to input the image to be analyzed into the residual network layer of the image feature coding layer of the visual analysis model, and obtain the output of the residual network layer The initial image features of the image to be analyzed, where the residual network layer can be used to map the image to be analyzed to the image feature space; the fifth analysis subunit can be used to input the initial image features into the self-attention encoding of the image feature encoding layer The layer obtains the image features of the image to be analyzed outputted by the self-attention coding layer, and the self-attention coding layer can be used for self-attention coding.
在一种示例实施例中,视觉分析模型输出的属性序列的长度基于目标视觉任务确定。In an example embodiment, the length of the attribute sequence output by the vision analysis model is determined based on the target vision task.
图11示例了一种电子设备的实体结构示意图,如图11所示,该电子设备1100可以包括:处理器(processor)1110、通信接口(Communication Interface)1120、存储器(memory)1130和通信总线1140,其中,处理器1110,通信接口1120,存储器1130通过通信总线1140完成相互间的通信。处理器1110可以调用存储器1130中的逻辑指令,以执行上述各方法实施例提供的图像分析方法,该方法可以包括:获取目标视觉任务的待分析图像;将待分析图像输入视觉分析模型,获得视觉分析模型输出的待分析图像中针对目标视觉任务的每一个目标物体特征的属性序列;其中,视觉分析模型用于基于目标视觉任务对待分析图像进行图像特征中目标物体特征的提取,并生成描述目标物体特征的属性序列;视觉分析模型是基于目标视觉任务对应的样本图像和样本图像对应的标签数据训练得到的。FIG. 11 illustrates a schematic diagram of the physical structure of an electronic device. As shown in FIG. 11 , the
此外,上述的存储器1130中的逻辑指令可以通过软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器(ROM,Read-Only Memory)、随机存取存储器(RAM,Random Access Memory)、磁碟或者光盘等各种可以存储程序代码的介质。In addition, the above-mentioned logic instructions in the
另一方面,本发明还提供一种计算机程序产品,所述计算机程序产品包括计算机程序,计算机程序可存储在非暂态计算机可读存储介质上,所述计算机程序被处理器执行时,计算机能够执行上述各方法实施例所提供的图像分析方法,该方法可以包括:获取目标视觉任务的待分析图像;将待分析图像输入视觉分析模型,获得视觉分析模型输出的待分析图像中针对目标视觉任务的每一个目标物体特征的属性序列;其中,视觉分析模型用于基于目标视觉任务对待分析图像进行图像特征中目标物体特征的提取,并生成描述目标物体特征的属性序列;视觉分析模型是基于目标视觉任务对应的样本图像和样本图像对应的标签数据训练得到的。On the other hand, the present invention also provides a computer program product. The computer program product includes a computer program that can be stored on a non-transitory computer-readable storage medium. When the computer program is executed by a processor, the computer can Executing the image analysis method provided by the above method embodiments, the method may include: acquiring the image to be analyzed of the target visual task; inputting the image to be analyzed into the visual analysis model, and obtaining the target visual task in the image to be analyzed output by the visual analysis model The attribute sequence of each target object feature; wherein, the visual analysis model is used to extract the target object features in the image features of the image to be analyzed based on the target visual task, and generate an attribute sequence describing the target object features; the visual analysis model is based on the target The sample images corresponding to the visual tasks and the label data corresponding to the sample images are trained.
又一方面,本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现以执行上述各方法实施例所提供的图像分析方法,该方法可以包括:获取目标视觉任务的待分析图像;将待分析图像输入视觉分析模型,获得视觉分析模型输出的待分析图像中针对目标视觉任务的每一个目标物体特征的属性序列;其中,视觉分析模型用于基于目标视觉任务对待分析图像进行图像特征中目标物体特征的提取,并生成描述目标物体特征的属性序列;视觉分析模型是基于目标视觉任务对应的样本图像和样本图像对应的标签数据训练得到的。In yet another aspect, the present invention also provides a non-transitory computer-readable storage medium, on which a computer program is stored, and when the computer program is executed by a processor, the image analysis method provided by the above-mentioned method embodiments is implemented. The method may include: acquiring the image to be analyzed of the target visual task; inputting the image to be analyzed into the visual analysis model, and obtaining the attribute sequence of each target object feature for the target visual task in the image to be analyzed output by the visual analysis model; wherein, the visual analysis The model is used to extract the characteristics of the target object in the image features of the image to be analyzed based on the target visual task, and generate an attribute sequence describing the characteristics of the target object; the visual analysis model is based on the sample image corresponding to the target visual task and the label data corresponding to the sample image. owned.
以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性的劳动的情况下,即可以理解并实施。The device embodiments described above are only illustrative, and the units described as separate components may or may not be physically separated, and the components shown as units may or may not be physical units, that is, they may be located in One place, or it can be distributed to multiple network elements. Part or all of the modules can be selected according to actual needs to achieve the purpose of the solution of this embodiment. It can be understood and implemented by those skilled in the art without any creative efforts.
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到各实施方式可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件。基于这样的理解,上述技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在计算机可读存储介质中,如ROM/RAM、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行各个实施例或者实施例的某些部分所述的方法。Through the above description of the implementations, those skilled in the art can clearly understand that each implementation can be implemented by means of software plus a necessary general-purpose hardware platform, and of course also by hardware. Based on this understanding, the essence of the above technical solution or the part that contributes to the prior art can be embodied in the form of software products, and the computer software products can be stored in computer-readable storage media, such as ROM/RAM, magnetic CD, CD, etc., including several instructions to make a computer device (which may be a personal computer, server, or network device, etc.) execute the methods described in various embodiments or some parts of the embodiments.
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。Finally, it should be noted that: the above embodiments are only used to illustrate the technical solutions of the present invention, rather than to limit them; although the present invention has been described in detail with reference to the foregoing embodiments, those of ordinary skill in the art should understand that: it can still be Modifications are made to the technical solutions described in the foregoing embodiments, or equivalent replacements are made to some of the technical features; and these modifications or replacements do not make the essence of the corresponding technical solutions deviate from the spirit and scope of the technical solutions of the various embodiments of the present invention.
Claims (10)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210851146.1ACN115082430B (en) | 2022-07-20 | 2022-07-20 | Image analysis method and device and electronic equipment |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210851146.1ACN115082430B (en) | 2022-07-20 | 2022-07-20 | Image analysis method and device and electronic equipment |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN115082430A CN115082430A (en) | 2022-09-20 |
| CN115082430Btrue CN115082430B (en) | 2022-12-06 |
Family
ID=83259426
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210851146.1AActiveCN115082430B (en) | 2022-07-20 | 2022-07-20 | Image analysis method and device and electronic equipment |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN115082430B (en) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115830330B (en)* | 2022-12-28 | 2025-02-28 | 北京有竹居网络技术有限公司 | Method, apparatus, device and medium for processing visual tasks using a general model |
Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112992308A (en)* | 2021-03-25 | 2021-06-18 | 腾讯科技(深圳)有限公司 | Training method of medical image report generation model and image report generation method |
| CN113449538A (en)* | 2020-03-24 | 2021-09-28 | 顺丰科技有限公司 | Visual model training method, device, equipment and storage medium |
| CN113705325A (en)* | 2021-06-30 | 2021-11-26 | 天津大学 | Deformable single-target tracking method and device based on dynamic compact memory embedding |
| CN113761888A (en)* | 2021-04-27 | 2021-12-07 | 腾讯科技(深圳)有限公司 | Text translation method, device, computer equipment and storage medium |
| CN113792112A (en)* | 2020-07-31 | 2021-12-14 | 北京京东尚科信息技术有限公司 | Visual language task processing system, training method, device, equipment and medium |
| CN114529758A (en)* | 2022-01-25 | 2022-05-24 | 哈尔滨工业大学 | Multi-modal emotion analysis method based on contrast learning and multi-head self-attention mechanism |
| CN114550313A (en)* | 2022-02-18 | 2022-05-27 | 北京百度网讯科技有限公司 | Image processing method, neural network and its training method, equipment and medium |
| CN114638960A (en)* | 2022-03-22 | 2022-06-17 | 平安科技(深圳)有限公司 | Model training method, image description generation method and device, equipment, medium |
Family Cites Families (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8489627B1 (en)* | 2008-08-28 | 2013-07-16 | Adobe Systems Incorporated | Combined semantic description and visual attribute search |
| JP6670698B2 (en)* | 2016-07-04 | 2020-03-25 | 日本電信電話株式会社 | Image recognition model learning device, image recognition device, method, and program |
| US11195048B2 (en)* | 2020-01-23 | 2021-12-07 | Adobe Inc. | Generating descriptions of image relationships |
| CN112257727B (en)* | 2020-11-03 | 2023-10-27 | 西南石油大学 | A feature image extraction method based on deep learning adaptive deformable convolution |
| CN112418330A (en)* | 2020-11-26 | 2021-02-26 | 河北工程大学 | Improved SSD (solid State drive) -based high-precision detection method for small target object |
| CN114332479B (en)* | 2021-12-23 | 2024-12-13 | 浪潮(北京)电子信息产业有限公司 | A training method and related device for target detection model |
| CN114443763B (en)* | 2022-01-06 | 2024-10-01 | 山东大学 | Big data synchronization method based on distributed network |
| CN114581682B (en)* | 2022-02-22 | 2025-07-15 | 杭州阿里巴巴海外互联网产业有限公司 | Image feature extraction method, device and equipment based on self-attention mechanism |
- 2022
- 2022-07-20CNCN202210851146.1Apatent/CN115082430B/enactiveActive
Patent Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113449538A (en)* | 2020-03-24 | 2021-09-28 | 顺丰科技有限公司 | Visual model training method, device, equipment and storage medium |
| CN113792112A (en)* | 2020-07-31 | 2021-12-14 | 北京京东尚科信息技术有限公司 | Visual language task processing system, training method, device, equipment and medium |
| CN112992308A (en)* | 2021-03-25 | 2021-06-18 | 腾讯科技(深圳)有限公司 | Training method of medical image report generation model and image report generation method |
| CN113761888A (en)* | 2021-04-27 | 2021-12-07 | 腾讯科技(深圳)有限公司 | Text translation method, device, computer equipment and storage medium |
| CN113705325A (en)* | 2021-06-30 | 2021-11-26 | 天津大学 | Deformable single-target tracking method and device based on dynamic compact memory embedding |
| CN114529758A (en)* | 2022-01-25 | 2022-05-24 | 哈尔滨工业大学 | Multi-modal emotion analysis method based on contrast learning and multi-head self-attention mechanism |
| CN114550313A (en)* | 2022-02-18 | 2022-05-27 | 北京百度网讯科技有限公司 | Image processing method, neural network and its training method, equipment and medium |
| CN114638960A (en)* | 2022-03-22 | 2022-06-17 | 平安科技(深圳)有限公司 | Model training method, image description generation method and device, equipment, medium |
Also Published As
| Publication number | Publication date |
|---|---|
| CN115082430A (en) | 2022-09-20 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN113095415B (en) | A cross-modal hashing method and system based on multimodal attention mechanism | |
| CN111368993B (en) | Data processing method and related equipment | |
| CN109460737A (en) | A kind of multi-modal speech-emotion recognition method based on enhanced residual error neural network | |
| WO2023236977A1 (en) | Data processing method and related device | |
| CN110288665A (en) | Image description method based on convolutional neural network, computer-readable storage medium, electronic device | |
| CN112633419A (en) | Small sample learning method and device, electronic equipment and storage medium | |
| Wang et al. | TASTA: text‐assisted spatial and temporal attention network for video question answering | |
| Wang et al. | A deep clustering via automatic feature embedded learning for human activity recognition | |
| CN118916497B (en) | Unsupervised cross-modal retrieval method, system, medium and device based on hypergraph convolution | |
| CN114564593A (en) | Completion method and device of multi-mode knowledge graph and electronic equipment | |
| CN113159053A (en) | Image recognition method and device and computing equipment | |
| CN117743614B (en) | Remote sensing image text retrieval method based on remote sensing multimodal basic model | |
| Dong et al. | Research on image classification based on capsnet | |
| CN112801078A (en) | Point of interest (POI) matching method and device, electronic equipment and storage medium | |
| CN116955644A (en) | Knowledge fusion method, system and storage medium based on knowledge graph | |
| CN115292533A (en) | Cross-modal pedestrian retrieval method driven by visual positioning | |
| CN115033674A (en) | Question-answer matching method, question-answer matching device, electronic equipment and storage medium | |
| CN119206209A (en) | Lung image segmentation method, device and storage medium | |
| CN115082430B (en) | Image analysis method and device and electronic equipment | |
| Dey et al. | Recognition of wh-question sign gestures in video streams using an attention driven c3d-bilstm network | |
| CN113961701B (en) | Message text clustering method and device | |
| CN112115347B (en) | Search result acquisition method and device and storage medium | |
| Saini et al. | A novel approach of image caption generator using deep learning | |
| Qiao et al. | Two-Stream Convolutional Neural Network for Video Action Recognition | |
| CN118132788A (en) | Image text semantic matching method and system applied to image-text retrieval |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant | ||
| TR01 | Transfer of patent right | Effective date of registration:20240620 Address after:200-19, 2nd Floor, Building B, Wanghai Building, No.10 West Third Ring Middle Road, Haidian District, Beijing, 100036 Patentee after:Zhongke Zidong Taichu (Beijing) Technology Co.,Ltd. Country or region after:China Address before:100190 No. 95 East Zhongguancun Road, Beijing, Haidian District Patentee before:INSTITUTE OF AUTOMATION, CHINESE ACADEMY OF SCIENCES Country or region before:China | |
| TR01 | Transfer of patent right |