CN115068940A - Control method of virtual object in virtual scene, computer device and storage medium - Google Patents
Control method of virtual object in virtual scene, computer device and storage mediumDownload PDFInfo
- Publication number
- CN115068940A CN115068940ACN202110260263.6ACN202110260263ACN115068940ACN 115068940 ACN115068940 ACN 115068940ACN 202110260263 ACN202110260263 ACN 202110260263ACN 115068940 ACN115068940 ACN 115068940A
- Authority
- CN
- China
- Prior art keywords
- target
- facial
- face
- image
- area
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images













Classifications
- A—HUMAN NECESSITIES
- A63—SPORTS; GAMES; AMUSEMENTS
- A63F—CARD, BOARD, OR ROULETTE GAMES; INDOOR GAMES USING SMALL MOVING PLAYING BODIES; VIDEO GAMES; GAMES NOT OTHERWISE PROVIDED FOR
- A63F13/00—Video games, i.e. games using an electronically generated display having two or more dimensions
- A63F13/50—Controlling the output signals based on the game progress
- A63F13/52—Controlling the output signals based on the game progress involving aspects of the displayed game scene
- A—HUMAN NECESSITIES
- A63—SPORTS; GAMES; AMUSEMENTS
- A63F—CARD, BOARD, OR ROULETTE GAMES; INDOOR GAMES USING SMALL MOVING PLAYING BODIES; VIDEO GAMES; GAMES NOT OTHERWISE PROVIDED FOR
- A63F13/00—Video games, i.e. games using an electronically generated display having two or more dimensions
- A63F13/55—Controlling game characters or game objects based on the game progress
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Evolutionary Computation (AREA)
- Computing Systems (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Data Mining & Analysis (AREA)
- Life Sciences & Earth Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Artificial Intelligence (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Health & Medical Sciences (AREA)
- Human Computer Interaction (AREA)
- Processing Or Creating Images (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本申请实施例涉及人工智能技术领域,特别涉及一种虚拟场景中虚拟对象的控制方法、计算机设备及存储介质。The embodiments of the present application relate to the technical field of artificial intelligence, and in particular, to a method for controlling virtual objects in a virtual scene, a computer device, and a storage medium.
背景技术Background technique
如今,随着人工智能的日益发展,人工智能技术在生活中的应用越来越广泛,其中包括进行面部动作分析算法。Today, with the increasing development of artificial intelligence, the application of artificial intelligence technology in daily life is more and more extensive, including facial motion analysis algorithms.
在相关技术中,传统的人脸面部动作分析算法是通过获取连续的人脸图像对应的特征点,基于特征点的位置分布,确定属于同一面部器官的各个特征点构成的线条形状,按照该面部器官特征点构成的线条形状的变化情况,确定该人脸图像正在执行的面部动作。In the related art, the traditional facial motion analysis algorithm is to obtain the feature points corresponding to continuous face images, and based on the position distribution of the feature points, determine the line shape formed by each feature point belonging to the same facial organ, according to the face The change of the line shape formed by the feature points of the organ determines the facial action that the face image is performing.
然而,采用上述方案进行人脸图像对应的面部动作分析时,需要记录各个特征点的变化情况从而动态的分析各个特征点的变化,从而确定当前时刻执行的面部动作,这就导致了无法基于静态的人脸图像准确的对面部动作进行分析。However, when the above scheme is used to analyze the facial action corresponding to the face image, it is necessary to record the changes of each feature point so as to dynamically analyze the change of each feature point, so as to determine the facial action performed at the current moment, which leads to the inability to perform static The facial images are accurately analyzed for facial movements.
发明内容SUMMARY OF THE INVENTION
本申请实施例提供了一种虚拟场景中虚拟对象的控制方法、计算机设备及存储介质,可以提高对面部动作进行分析的效率。该技术方案如下:The embodiments of the present application provide a control method, a computer device and a storage medium for a virtual object in a virtual scene, which can improve the efficiency of analyzing facial movements. The technical solution is as follows:
一方面,提供了一种虚拟场景中虚拟对象的控制方法,所述方法包括:In one aspect, a method for controlling virtual objects in a virtual scene is provided, the method comprising:
响应于检测到目标图像中存在目标人脸图像,获取所述目标人脸图像中至少两个面部区域对应的人脸特征点;所述人脸特征点用于指示所述面部区域对应的位置信息;In response to detecting that there is a target face image in the target image, obtain face feature points corresponding to at least two face regions in the target face image; the face feature points are used to indicate the position information corresponding to the face region ;
基于至少两个所述面部区域对应的人脸特征点,获取至少两个所述面部区域对应的区域面积;Based on the face feature points corresponding to at least two of the face areas, obtain the area areas corresponding to at least two of the face areas;
基于至少两个所述面部区域对应的区域面积确定所述目标人脸图像对应的面部动作;Determine the facial action corresponding to the target face image based on the area areas corresponding to at least two of the facial areas;
响应于所述面部动作由第一面部动作变化为第二面部动作,控制所述虚拟场景中的第一虚拟对象由执行第一动作切换为执行第二动作。In response to the change of the facial action from the first facial action to the second facial action, the first virtual object in the virtual scene is controlled to switch from executing the first action to executing the second action.
一方面,提供了一种虚拟场景中虚拟对象的控制方法,所述方法包括:In one aspect, a method for controlling virtual objects in a virtual scene is provided, the method comprising:
响应于检测到目标图像中存在目标人脸图像,展示所述虚拟场景对应的运行初始画面;所述运行初始画面中包括目标平台以及位于所述目标平台上的第一虚拟对象;所述目标平台是所述虚拟场景开始运行时所述第一虚拟对象所在的平台;In response to detecting that there is a target face image in the target image, an initial operation image corresponding to the virtual scene is displayed; the operation initial image includes a target platform and a first virtual object located on the target platform; the target platform is the platform where the first virtual object is located when the virtual scene starts to run;
响应于所述第一虚拟对象位于目标平台上,且检测到所述目标人脸图像对应的面部动作符合第一面部动作,控制所述第一虚拟对象沿着所述目标平台向第一方向进行移动;In response to the first virtual object being located on the target platform, and detecting that the facial action corresponding to the target face image conforms to the first facial action, controlling the first virtual object to move in a first direction along the target platform to move;
响应于所述第一虚拟对象位于所述目标平台上,且检测到所述面部动作符合第二面部动作,控制所述第一虚拟对象沿着所述目标平台向第二方向进行移动;所述第二方向是与所述第一方向相反的方向;In response to the first virtual object being located on the target platform and detecting that the facial motion matches the second facial motion, controlling the first virtual object to move in a second direction along the target platform; the The second direction is the opposite direction to the first direction;
响应于所述第一虚拟对象的移动范围超过所述目标平台,修改虚拟对象失败次数;In response to the movement range of the first virtual object exceeding the target platform, modifying the number of failures of the virtual object;
响应于所述虚拟场景的运行时长达到指定时长,展示场景运行结果;所述场景运行结果是基于所述虚拟对象失败次数确定的。In response to the running duration of the virtual scene reaching a specified duration, a scene running result is displayed; the scene running result is determined based on the number of failures of the virtual object.
又一方面,提供了一种虚拟场景中虚拟对象的控制装置,所述装置包括:In another aspect, a device for controlling virtual objects in a virtual scene is provided, the device comprising:
特征获取模块,用于响应于检测到目标图像中存在目标人脸图像,获取所述目标人脸图像中至少两个面部区域对应的人脸特征点;所述人脸特征点用于指示所述面部区域对应的位置信息;A feature acquisition module, configured to acquire face feature points corresponding to at least two face regions in the target face image in response to detecting that a target face image exists in the target image; the face feature points are used to indicate the The location information corresponding to the face area;
面积获取模块,用于基于至少两个所述面部区域对应的人脸特征点,获取至少两个所述面部区域对应的区域面积;an area acquisition module, configured to acquire the area areas corresponding to at least two of the facial areas based on the face feature points corresponding to at least two of the facial areas;
动作确定模块,用于基于至少两个所述面部区域对应的区域面积确定所述目标人脸图像对应的面部动作;an action determination module, configured to determine the facial action corresponding to the target face image based on the area areas corresponding to at least two of the face regions;
动作切换模块,用于响应于所述面部动作由第一面部动作变化为第二面部动作,控制所述虚拟场景中的第一虚拟对象由执行第一动作切换为执行第二动作。The action switching module is configured to control the first virtual object in the virtual scene to switch from executing the first action to executing the second action in response to the change of the facial action from the first facial action to the second facial action.
在一种可能的实现方式中,所述动作确定模块,包括:In a possible implementation manner, the action determination module includes:
数值获取子模块,用于获取第一比例数值,所述第一比例数值是至少两个所述面部区域中的第一面部区域的区域面积,与所述面部区域中的第二面部区域的区域面积之间的比值;A numerical value acquisition sub-module, configured to obtain a first proportional value, where the first proportional value is the area area of the first facial area in the at least two facial areas, and the area of the second facial area in the facial area the ratio between the area areas;
动作确定子模块,用于基于所述第一比例数值与比例阈值之间的大小关系,确定所述目标人脸图像对应的面部动作。The action determination submodule is configured to determine the facial action corresponding to the target face image based on the magnitude relationship between the first proportional value and the proportional threshold.
在一种可能的实现方式中,所述装置还包括:In a possible implementation, the apparatus further includes:
阈值获取子模块,用于基于所述第一比例数值与比例阈值之间的大小关系,确定所述目标人脸图像对应的面部动作之前,基于所述第一面部区域的部位种类以及所述第二面部区域的部位种类,获取所述比例阈值。A threshold acquisition sub-module is used for determining the facial action corresponding to the target face image based on the magnitude relationship between the first proportional value and the proportional threshold, based on the part type of the first facial region and the The part type of the second face region, and the proportional threshold is obtained.
在一种可能的实现方式中,所述面部区域的所述部位种类包括人脸外轮廓区域、眼睛区域、鼻子区域、外唇区域以及内唇区域中的至少两种。In a possible implementation manner, the types of parts of the facial region include at least two of the outer contour region of the human face, the eye region, the nose region, the outer lip region and the inner lip region.
在一种可能的实现方式中,响应于所述第一面部区域的部位种类是外唇区域,且所述第二面部区域的部位种类是内唇区域;In a possible implementation manner, in response to the part type of the first facial region is the outer lip region, and the part type of the second facial region is the inner lip region;
所述动作确定子模块,包括:The action determination sub-module includes:
闭嘴确定单元,用于响应于所述第一比例数值大于所述第一比例阈值,确定所述目标人脸图像对应的面部动作为闭嘴动作;a shut-mouth determination unit, configured to determine that the facial action corresponding to the target face image is a shut-mouth action in response to the first proportional value being greater than the first proportional threshold;
张嘴确定单元,用于响应于所述第一比例数值小于或者等于所述第一比例阈值,确定所述目标人脸图像对应的面部动作为张嘴动作。The mouth opening determination unit is configured to determine that the facial action corresponding to the target face image is the mouth opening action in response to the first proportional value being less than or equal to the first proportional threshold.
在一种可能的实现方式中,所述张嘴确定单元,用于,In a possible implementation manner, the mouth opening determining unit is configured to:
响应于所述第一比例数值小于或者等于所述第一比例阈值,获取所述目标人脸图像中,对应在所述内唇区域内部的第一区域图像;In response to the first scale value being less than or equal to the first scale threshold, acquiring an image of the first region in the target face image corresponding to the inside of the inner lip region;
在所述第一区域图像中进行牙齿检测;performing tooth detection in the first region image;
响应于在所述第一区域图像中检测到牙齿,确定所述目标人脸图像对应的所述面部动作为所述张嘴动作。In response to detecting teeth in the first region image, determining the facial action corresponding to the target face image as the mouth opening action.
在一种可能的实现方式中,所述面积获取模块,包括:In a possible implementation, the area acquisition module includes:
顶点获取子模块,用于获取目标凸包顶点;所述目标凸包顶点是所述目标面部区域中用于构成凸包的所述人脸特征点;所述目标面部区域是至少两个面部区域中的任意一个;Vertex acquisition submodule, used for acquiring target convex hull vertices; the target convex hull vertices are the face feature points used to form the convex hull in the target face area; the target face area is at least two face areas any one of;
面积获取子模块,用于基于所述目标凸包顶点,获取所述目标面部区域的区域面积。The area acquisition submodule is configured to acquire the area area of the target face region based on the target convex hull vertex.
在一种可能的实现方式中,所述特征获取模块,包括:In a possible implementation, the feature acquisition module includes:
图像获取子模块,用于获取所述目标图像;an image acquisition submodule for acquiring the target image;
信息获取子模块,用于将所述目标图像输入目标人脸定位模型,获得由所述目标人脸定位模型输出的目标人脸图像信息;所述目标人脸定位模型包括底层网络、中间层网络以及头部层网络;所述底层网络用于进行图像特征提取;中间层网络用于进行连续的区域特征聚集;所述头部层网络用于通过线性回归算法输出所述目标人脸图像信息;所述目标人脸图像信息用于指示所述目标人脸图像所处的位置;an information acquisition sub-module, used for inputting the target image into a target face localization model to obtain target face image information output by the target face localization model; the target face localization model includes a bottom layer network and a middle layer network and a head layer network; the bottom layer network is used for image feature extraction; the middle layer network is used for continuous regional feature aggregation; the head layer network is used for outputting the target face image information through a linear regression algorithm; The target face image information is used to indicate the position where the target face image is located;
特征获取子模块,用于将所述目标人脸图像信息对应的所述目标人脸图像输入特征点识别模型,获得由所述特征点识别模型输出的至少两个面部区域对应的所述人脸特征点。A feature acquisition sub-module, configured to input the target face image corresponding to the target face image information into a feature point recognition model, and obtain the faces corresponding to at least two facial regions output by the feature point recognition model Feature points.
在一种可能的实现方式中,响应于所述面部区域包括人脸外轮廓区域以及内部器官区域;In a possible implementation manner, in response to the facial area including the outer contour area of the human face and the internal organ area;
所述特征获取子模块,包括:The feature acquisition submodule includes:
第一获取单元,用于将所述目标人脸图像输入所述特征点识别模型,通过所述特征点识别模型中第一数量的级联网络输出所述内部器官区域对应的所述人脸特征点;The first acquisition unit is used to input the target face image into the feature point recognition model, and output the face feature corresponding to the internal organ region through the first number of cascaded networks in the feature point recognition model point;
第二获取单元,用于通过第二数量的级联网络输出所述人脸外轮廓区域对应的所述人脸特征点;a second acquisition unit, configured to output the face feature points corresponding to the outer contour area of the face through a second number of cascaded networks;
其中,所述第一数量大于所述第二数量。Wherein, the first number is greater than the second number.
在一种可能的实现方式中,所述装置还包括:In a possible implementation, the apparatus further includes:
第一初始模块,用于基于至少两个所述面部区域对应的区域面积确定所述目标人脸图像对应的面部动作之前,控制所述第一虚拟对象沿着目标平台向初始方向进行移动;所述初始方向是第一方向或者第二方向;a first initial module, configured to control the first virtual object to move to the initial direction along the target platform before determining the facial action corresponding to the target face image based on the area areas corresponding to at least two of the face areas; The initial direction is the first direction or the second direction;
或者,or,
第二初始模块,用于在所述目标平台的中心位置处展示所述第一虚拟对象,且不进行移动。The second initial module is used for displaying the first virtual object at the center position of the target platform without moving.
又一方面,提供了一种虚拟场景中虚拟对象的控制装置,所述装置包括:In another aspect, a device for controlling virtual objects in a virtual scene is provided, the device comprising:
初始画面展示模块,用于展示响应于检测到目标图像中存在目标人脸图像,展示所述虚拟场景对应的运行初始画面;所述运行初始画面中包括目标平台以及位于所述目标平台上的第一虚拟对象;所述目标平台是所述虚拟场景开始运行时所述第一虚拟对象所在的平台;The initial picture display module is used to display the initial picture of operation corresponding to the virtual scene in response to detecting that there is a target face image in the target image; the initial picture of operation includes the target platform and the first image located on the target platform a virtual object; the target platform is the platform where the first virtual object is located when the virtual scene starts to run;
第一移动模块,用于响应于所述第一虚拟对象位于目标平台上,且检测到所述目标人脸图像对应的面部动作符合第一面部动作,控制所述第一虚拟对象沿着所述目标平台向第一方向进行移动;The first moving module is configured to control the first virtual object to move along the target platform in response to the first virtual object being located on the target platform and detecting that the facial motion corresponding to the target face image conforms to the first facial motion. The target platform is moved to the first direction;
第二移动模块,用于响应于所述第一虚拟对象位于所述目标平台上,且检测到所述面部动作符合第二面部动作,控制所述第一虚拟对象沿着所述目标平台向第二方向进行移动;所述第二方向是与所述第一方向相反的方向;A second moving module, configured to control the first virtual object to move toward the first virtual object along the target platform in response to the first virtual object being located on the target platform and detecting that the facial motion conforms to the second facial motion Move in two directions; the second direction is the opposite direction to the first direction;
次数修改模块,用于响应于所述第一虚拟对象的移动范围超过所述目标平台,修改虚拟对象失败次数;A times modification module, configured to modify the number of failures of the virtual object in response to the movement range of the first virtual object exceeding the target platform;
结果展示模块,用于响应于所述虚拟场景的运行时长达到指定时长,展示场景运行结果;所述场景运行结果是基于所述虚拟对象失败次数确定的。A result display module, configured to display a scene running result in response to the virtual scene's running duration reaching a specified duration; the scene running result is determined based on the number of failures of the virtual object.
另一方面,提供了一种计算机设备,所述计算机设备包含处理器和存储器,所述存储器中存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或指令集由所述处理器加载并执行以实现如上所述的虚拟场景中虚拟对象的控制方法。In another aspect, a computer device is provided, the computer device comprising a processor and a memory, the memory stores at least one instruction, at least a section of a program, a code set or an instruction set, the at least one instruction, the at least one A piece of program, the code set or the instruction set is loaded and executed by the processor to implement the above-mentioned method for controlling a virtual object in a virtual scene.
另一方面,提供了一种计算机可读存储介质,所述存储介质中存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或指令集由处理器加载并执行以实现如上所述的虚拟场景中虚拟对象的控制方法。In another aspect, a computer-readable storage medium is provided, wherein the storage medium stores at least one instruction, at least one piece of program, code set or instruction set, the at least one instruction, the at least one piece of program, the code The set or instruction set is loaded and executed by the processor to implement the control method of the virtual object in the virtual scene as described above.
根据本申请的一个方面,提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行上述方面的各种可选实现方式中提供的虚拟场景中虚拟对象的控制方法。According to one aspect of the present application, there is provided a computer program product or computer program comprising computer instructions stored in a computer readable storage medium. The processor of the computer device reads the computer instructions from the computer-readable storage medium, and the processor executes the computer instructions, so that the computer device executes the method for controlling virtual objects in a virtual scene provided in various optional implementations of the foregoing aspects.
本申请提供的技术方案可以包括以下有益效果:The technical solution provided by this application can include the following beneficial effects:
在本申请实施例所示的方案中,通过检测目标图像获取目标图像中的目标人脸图像,并且获取目标人脸图像中用于指示至少两个面部区域对应的位置信息的人脸特征点。基于人脸特征点确定至少两个面部区域对应的区域面积,基于至少两个面部区域对应的区域面积确定对应的面部动作,同时基于确定的面部动作控制第一虚拟对象执行不同的动作。通过上述方案,可以基于获取到的静态目标人脸图像中至少两个面部区域对应的区域面积确定该目标人脸图像对应的面部动作,并且基于确定的面部动作实现对第一虚拟对象的相应控制,避免了为了确定面部动作需要获取一段时间内人脸特征点的持续变化的情况,从而提高了进行面部动作分析的效率。In the solution shown in the embodiment of the present application, the target face image in the target image is obtained by detecting the target image, and the face feature points in the target face image used to indicate the position information corresponding to at least two face regions are obtained. Areas corresponding to the at least two facial regions are determined based on the facial feature points, corresponding facial actions are determined based on the regions corresponding to the at least two facial regions, and the first virtual object is controlled to perform different actions based on the determined facial actions. Through the above solution, the facial action corresponding to the target face image can be determined based on the area areas corresponding to at least two face regions in the obtained static target face image, and the corresponding control of the first virtual object can be realized based on the determined facial action. , to avoid the situation that continuous changes of facial feature points need to be acquired over a period of time in order to determine the facial motion, thereby improving the efficiency of facial motion analysis.
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本申请。It is to be understood that both the foregoing general description and the following detailed description are exemplary and explanatory only and are not limiting of the present application.
附图说明Description of drawings
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本申请的实施例,并与说明书一起用于解释本申请的原理。The accompanying drawings, which are incorporated in and constitute a part of this specification, illustrate embodiments consistent with the application and together with the description serve to explain the principles of the application.
图1是根据一示例性实施例示出的一种虚拟场景中虚拟对象控制方法的流程图;FIG. 1 is a flowchart of a method for controlling virtual objects in a virtual scene according to an exemplary embodiment;
图2是根据一示例性实施例示出的一种终端的结构示意图;FIG. 2 is a schematic structural diagram of a terminal according to an exemplary embodiment;
图3是根据一示例性实施例示出的一种虚拟场景的显示界面示意图;3 is a schematic diagram of a display interface of a virtual scene according to an exemplary embodiment;
图4是根据一示例性实施例示出的一种虚拟场景中虚拟对象控制方法的流程图;FIG. 4 is a flowchart of a method for controlling virtual objects in a virtual scene according to an exemplary embodiment;
图5是根据一示例性实施例示出的一种虚拟场景中虚拟对象控制方法的流程图;FIG. 5 is a flowchart of a method for controlling virtual objects in a virtual scene according to an exemplary embodiment;
图6是图5所示实施例涉及的一种目标人脸定位模型的架构图;Fig. 6 is the architecture diagram of a kind of target face localization model involved in the embodiment shown in Fig. 5;
图7是图5所示实施例涉及的一种特征点识别模型网络结构图;Fig. 7 is a kind of feature point recognition model network structure diagram involved in the embodiment shown in Fig. 5;
图8是图5所示实施例涉及的一种内唇面积与外唇面积计算示意图;Fig. 8 is a kind of inner lip area and outer lip area calculation schematic diagram involved in the embodiment shown in Fig. 5;
图9是图5所示实施例涉及的一种基于表情分析的虚拟对象控制方法流程图;9 is a flowchart of a virtual object control method based on expression analysis according to the embodiment shown in FIG. 5;
图10是根据一示例性实施例示出的一种虚拟场景界面示意图;10 is a schematic diagram of a virtual scene interface according to an exemplary embodiment;
图11是根据一示例性实施例示出的一种虚拟场景中虚拟对象的控制装置的框图;FIG. 11 is a block diagram of a control device for a virtual object in a virtual scene according to an exemplary embodiment;
图12是根据一示例性实施例示出的一种虚拟场景中虚拟对象的控制装置的框图;Fig. 12 is a block diagram of an apparatus for controlling virtual objects in a virtual scene according to an exemplary embodiment;
图13是根据一示例性实施例示出的一种计算机设备的结构示意图;13 is a schematic structural diagram of a computer device according to an exemplary embodiment;
图14是根据一示例性实施例示出的计算机设备的结构框图。FIG. 14 is a structural block diagram of a computer device according to an exemplary embodiment.
具体实施方式Detailed ways
这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本申请相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本申请的一些方面相一致的装置和方法的例子。Exemplary embodiments will be described in detail herein, examples of which are illustrated in the accompanying drawings. Where the following description refers to the drawings, the same numerals in different drawings refer to the same or similar elements unless otherwise indicated. The implementations described in the illustrative examples below are not intended to represent all implementations consistent with this application. Rather, they are merely examples of apparatus and methods consistent with some aspects of the present application as recited in the appended claims.
应当理解的是,在本文中提及的“若干个”是指一个或者多个,“多个”是指两个或两个以上。“和/或”,描述关联对象的关联关系,表示可以存在三种关系,例如,A和/或B,可以表示:单独存在A,同时存在A和B,单独存在B这三种情况。字符“/”一般表示前后关联对象是一种“或”的关系。It should be understood that reference herein to "several" refers to one or more, and "plurality" refers to two or more. "And/or", which describes the association relationship of the associated objects, means that there can be three kinds of relationships, for example, A and/or B, which can mean that A exists alone, A and B exist at the same time, and B exists alone. The character "/" generally indicates that the associated objects are an "or" relationship.
本申请后续各个实施例所示的方案,可以借助于人工智能(ArtificialIntelligence,AI)中的图像识别技术,在虚拟场景运行过程中通过获取目标人脸图像,并且获取目标人脸图像中至少两个面部区域对应的人脸特征点,基于至少两个面部区域对应的人脸特征点获取至少两个面部区域对应的区域面积,从而确定目标人脸图像对应的面部动作,并且由确定的面部动作控制虚拟场景中的第一虚拟对象。从而解决了虚拟场景运行过程中仅可以通过触控操作控制虚拟对象,而导致的操作方式单一的问题,扩展了通过面部动作控制虚拟对象的操作方式。为了方便理解,下面对本公开实施例中涉及的名词进行说明。The solutions shown in the subsequent embodiments of the present application can use the image recognition technology in artificial intelligence (Artificial Intelligence, AI) to obtain the target face image during the running process of the virtual scene, and obtain at least two of the target face images. The face feature points corresponding to the face regions, based on the face feature points corresponding to the at least two face regions, obtain the region areas corresponding to at least two face regions, thereby determining the facial motion corresponding to the target face image, and controlled by the determined facial motion The first virtual object in the virtual scene. Therefore, the problem of a single operation mode caused by only being able to control the virtual object through the touch operation during the running of the virtual scene is solved, and the operation mode of controlling the virtual object through the facial action is expanded. For the convenience of understanding, the terms involved in the embodiments of the present disclosure are described below.
1)人工智能AI1) Artificial Intelligence AI
AI是利用数字计算机或者数字计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法、技术及应用系统。换句话说,人工智能是计算机科学的一个综合技术,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器。人工智能也就是研究各种智能机器的设计原理与实现方法,使机器具有感知、推理与决策的功能。AI is a theory, method, technology and application system that uses digital computers or machines controlled by digital computers to simulate, extend and expand human intelligence, perceive the environment, acquire knowledge and use knowledge to obtain the best results. In other words, artificial intelligence is a comprehensive technique of computer science that attempts to understand the essence of intelligence and produce a new kind of intelligent machine that can respond in a similar way to human intelligence. Artificial intelligence is to study the design principles and implementation methods of various intelligent machines, so that the machines have the functions of perception, reasoning and decision-making.
人工智能技术是一门综合学科,涉及领域广泛,既有硬件层面的技术也有软件层面的技术。人工智能基础技术一般包括如传感器、专用人工智能芯片、云计算、分布式存储、大数据处理技术、操作/交互系统、机电一体化等技术。人工智能软件技术主要包括计算机视觉技术、语音处理技术、自然语言处理技术以及机器学习/深度学习等几大方向。Artificial intelligence technology is a comprehensive discipline, involving a wide range of fields, including both hardware-level technology and software-level technology. The basic technologies of artificial intelligence generally include technologies such as sensors, special artificial intelligence chips, cloud computing, distributed storage, big data processing technology, operation/interaction systems, and mechatronics. Artificial intelligence software technology mainly includes computer vision technology, speech processing technology, natural language processing technology, and machine learning/deep learning.
随着人工智能技术研究和进步,人工智能技术在多个领域展开研究和应用,例如常见的智能家居、智能穿戴设备、虚拟助理、智能音箱、智能营销、无人驾驶、自动驾驶、无人机、机器人、智能医疗、智能客服、智能视频服务等,随着技术的发展,人工智能技术将在更多的领域得到应用,并发挥越来越重要的价值。With the research and progress of artificial intelligence technology, artificial intelligence technology has been researched and applied in many fields, such as common smart homes, smart wearable devices, virtual assistants, smart speakers, smart marketing, unmanned driving, autonomous driving, drones , robots, intelligent medical care, intelligent customer service, intelligent video services, etc. With the development of technology, artificial intelligence technology will be applied in more fields and play an increasingly important value.
2)计算机视觉技术(Computer Vision,CV)2) Computer Vision Technology (Computer Vision, CV)
计算机视觉是一门研究如何使机器“看”的科学,更进一步的说,就是指用摄影机和电脑代替人眼对目标进行识别、跟踪和测量等机器视觉,并进一步做图形处理,使电脑处理成为更适合人眼观察或传送给仪器检测的图像。作为一个科学学科,计算机视觉研究相关的理论和技术,试图建立能够从图像或者多维数据中获取信息的人工智能系统。计算机视觉技术通常包括图像处理、图像识别、图像语义理解、图像检索、OCR(Optical CharacterRecognition,光学字符识别)、视频处理、视频语义理解、视频内容/行为识别、三维物体重建、3D(3Dimensions)技术、虚拟现实、增强现实、同步定位与地图构建等技术,还包括常见的人脸识别、指纹识别等生物特征识别技术。Computer vision is a science that studies how to make machines "see". More specifically, it refers to the use of cameras and computers instead of human eyes to identify, track, and measure targets, and further perform graphics processing to make computer processing. It becomes an image that is more suitable for human observation or transmitted to the instrument for detection. As a scientific discipline, computer vision studies related theories and technologies, trying to build artificial intelligence systems that can obtain information from images or multidimensional data. Computer vision technology usually includes image processing, image recognition, image semantic understanding, image retrieval, OCR (Optical Character Recognition, Optical Character Recognition), video processing, video semantic understanding, video content/behavior recognition, 3D object reconstruction, 3D (3Dimensions) technology , virtual reality, augmented reality, simultaneous positioning and map construction and other technologies, as well as common biometric identification technologies such as face recognition and fingerprint recognition.
3)机器学习(Machine Learning,ML)3) Machine Learning (ML)
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。机器学习是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域。机器学习和深度学习通常包括人工神经网络、置信网络、强化学习、迁移学习、归纳学习、示教学习等技术。Machine learning is a multi-domain interdisciplinary subject involving probability theory, statistics, approximation theory, convex analysis, algorithm complexity theory and other disciplines. It specializes in how computers simulate or realize human learning behaviors to acquire new knowledge or skills, and to reorganize existing knowledge structures to continuously improve their performance. Machine learning is the core of artificial intelligence and the fundamental way to make computers intelligent, and its applications are in all fields of artificial intelligence. Machine learning and deep learning usually include artificial neural networks, belief networks, reinforcement learning, transfer learning, inductive learning, teaching learning and other techniques.
4)人脸识别(Face Recognition)4)Face Recognition
人脸识别是基于人的脸部特征信息进行身份识别的一种生物识别技术。Face recognition is a kind of biometric identification technology based on human facial feature information.
人脸识别利用摄像机或摄像头采集含有人脸的图像或视频流,并自动在图像中检测和跟踪人脸,进而对检测到的人脸图像进行一系列的相关应用操作。技术上包括图像采集、特征定位、身份的确认和查找等。Face recognition uses cameras or cameras to collect images or video streams containing faces, and automatically detects and tracks faces in the images, and then performs a series of related application operations on the detected face images. Technically, it includes image acquisition, feature location, identity confirmation and search, etc.
5)虚拟场景5) Virtual scene
虚拟场景是应用程序在终端上运行时显示(或提供)的虚拟的场景。该虚拟场景可以是对真实世界的仿真环境场景,也可以是半仿真半虚构的三维环境场景,还可以是纯虚构的三维环境场景。虚拟场景可以是二维虚拟场景、2.5维虚拟场景和三维虚拟场景中的任意一种,可选地,该虚拟场景可用于展示至少一个虚拟对象的移动状态。可选地,该虚拟场景还可用于至少一个虚拟对象在指定时间内完成指定动作。A virtual scene is a virtual scene displayed (or provided) when the application is running on the terminal. The virtual scene may be a simulated environment scene of the real world, a semi-simulated and semi-fictional three-dimensional environment scene, or a purely fictional three-dimensional environment scene. The virtual scene may be any one of a two-dimensional virtual scene, a 2.5-dimensional virtual scene, and a three-dimensional virtual scene. Optionally, the virtual scene may be used to display the movement state of at least one virtual object. Optionally, the virtual scene can also be used for at least one virtual object to complete a specified action within a specified time.
虚拟场景通常由终端等计算机设备中的应用程序生成基于终端中的硬件(比如屏幕)进行展示。该终端可以是智能手机、平板电脑或者电子书阅读器等移动终端;或者,该终端也可以是笔记本电脑或者固定式计算机的个人计算机设备。The virtual scene is usually generated by an application program in a computer device such as a terminal and displayed based on hardware (such as a screen) in the terminal. The terminal may be a mobile terminal such as a smart phone, a tablet computer, or an e-book reader; or, the terminal may also be a personal computer device such as a notebook computer or a stationary computer.
6)虚拟对象6) Virtual Objects
虚拟对象是指在虚拟场景中的可活动对象。该可活动对象可以是虚拟人物、虚拟动物、虚拟载具中的至少一种。可选地,当虚拟场景为三维虚拟场景时,虚拟对象是基于动画骨骼技术创建的三维立体模型。每个虚拟对象在三维虚拟场景中具有自身的形状、体积以及朝向,并占据三维虚拟场景中的一部分空间。Virtual objects refer to movable objects in a virtual scene. The movable object may be at least one of a virtual character, a virtual animal, and a virtual vehicle. Optionally, when the virtual scene is a three-dimensional virtual scene, the virtual object is a three-dimensional solid model created based on animation skeleton technology. Each virtual object has its own shape, volume and orientation in the three-dimensional virtual scene, and occupies a part of the space in the three-dimensional virtual scene.
本申请实施例提供的方案涉及人工智能的计算机视觉技术、机器学习等技术,具体通过如下实施例进行说明。The solutions provided in the embodiments of the present application relate to technologies such as artificial intelligence, computer vision technology, machine learning, etc., and are specifically described by the following embodiments.
图1是根据一示例性实施例示出的一种虚拟场景中虚拟对象控制方法的流程图。该虚拟场景中虚拟对象控制方法可以由计算机设备执行。比如,该计算机设备可以是具有图像采集功能的终端。如图1所示,该虚拟场景中虚拟对象控制方法包括的步骤如下:Fig. 1 is a flowchart of a method for controlling virtual objects in a virtual scene according to an exemplary embodiment. The virtual object control method in the virtual scene may be executed by a computer device. For example, the computer device may be a terminal with an image acquisition function. As shown in Figure 1, the steps included in the virtual object control method in the virtual scene are as follows:
步骤101,响应于检测到目标图像中存在目标人脸图像,获取目标人脸图像中至少两个面部区域对应的人脸特征点;人脸特征点用于指示面部区域对应的位置信息。
在本申请实施例中,计算机设备检测目标图像中是否存在目标人脸图像,目标图像基于人脸检测定位算法,可以输出目标图像中目标人脸图像的位置信息,然后,通过人脸特征点检测算法可以输出该目标人脸图像对应的各个人脸特征点的位置信息。In the embodiment of the present application, the computer device detects whether there is a target face image in the target image, and the target image can output the position information of the target face image in the target image based on the face detection and positioning algorithm. The algorithm can output the position information of each face feature point corresponding to the target face image.
其中,人脸特征点可以基于目标人脸图像中各个面部区域对应的部位种类进行分类。各个面部区域可以通过各自对应的人脸特征点进行位置标注。The facial feature points may be classified based on the types of parts corresponding to each facial region in the target facial image. Each facial region can be marked with its corresponding facial feature points.
在一种可能的实现方式中,响应于检测到目标图像中存在目标人脸图像,仅获取目标人脸图像中的两个不同的面部区域对应的人脸特征点。In a possible implementation manner, in response to detecting that the target face image exists in the target image, only face feature points corresponding to two different face regions in the target face image are acquired.
通过获取目标人脸图像中的部分人脸特征点,可以减轻计算机设备运行特征点检测算法时产生的计算压力,一定程度上可以提高计算机设备的运算速度。By acquiring some face feature points in the target face image, the computational pressure generated when the computer equipment runs the feature point detection algorithm can be reduced, and the computing speed of the computer equipment can be improved to a certain extent.
比如,若计算机设备准备运行的虚拟场景需要检测的仅为嘴部动作,在检测到目标图像中存在目标人脸图像之后,则只需要获取嘴部对应区域的人脸特征点以及另外一个面部区域中的人脸特征点。For example, if the virtual scene to be run by the computer equipment only needs to detect the action of the mouth, after detecting the existence of the target face image in the target image, it is only necessary to obtain the face feature points of the corresponding region of the mouth and another facial region. facial feature points in .
步骤102,基于至少两个面部区域对应的人脸特征点,获取至少两个面部区域对应的区域面积。
在本申请实施例中,计算机设备基于至少两个面部区域对应的人脸特征点,获取至少两个面部区域对应的区域面积。In the embodiment of the present application, the computer device acquires the area areas corresponding to the at least two facial areas based on the facial feature points corresponding to the at least two facial areas.
在一种可能的实现方式中,计算面部区域对应的区域面积可以通过直接计算的方式,或者通过间接计算的方式,间接计算是利用人脸面积减去其它区域面积获得。In a possible implementation manner, the area area corresponding to the face area can be calculated by direct calculation, or by indirect calculation. The indirect calculation is obtained by subtracting the area of other areas from the area of the face.
步骤103,基于至少两个面部区域对应的区域面积确定目标人脸图像对应的面部动作。Step 103: Determine the facial action corresponding to the target face image based on the area areas corresponding to the at least two facial areas.
在本申请实施例中,计算机设备基于至少两个面部区域对应的区域面积,可以确定该目标人脸图像对应的面部动作。In this embodiment of the present application, the computer device may determine the facial action corresponding to the target face image based on the area areas corresponding to at least two facial areas.
在一种可能的实现方式中,至少两个面部区域对应的区域面积可以基于任意一种计算逻辑进行计算,获得计算结果,从而确定目标人脸图像对应的面部动作。In a possible implementation manner, the area areas corresponding to the at least two facial areas may be calculated based on any calculation logic to obtain a calculation result, thereby determining the facial action corresponding to the target face image.
比如,若获取到面部区域A对应的区域面积以及面部区域B对应的区域面积,则将面部区域A对应的区域面积以及面部区域B对应的区域面积进行减法运算,基于该减法运算的运算结果确定目标人脸图像对应的面部动作。For example, if the area corresponding to the face area A and the area corresponding to the face area B are obtained, the area corresponding to the face area A and the area corresponding to the face area B are subtracted and determined based on the operation result of the subtraction operation. The facial action corresponding to the target face image.
在一种可能的实现方式中,面部动作是基于至少一个面部器官进行运动生成的。In one possible implementation, the facial action is generated based on the motion of at least one facial organ.
其中,面部动作可以包括基于嘴部进行运动生成的张嘴运动以及闭嘴运动,基于眼睛进行运动生成的睁眼动作以及闭眼动作,基于鼻子进行运动生成的耸鼻运动等。The facial motion may include mouth opening motion and mouth closing motion generated based on mouth motion, eye opening motion and eye closing motion generated based on eye motion, and nose shrugging motion generated based on nose motion.
步骤104,响应于面部动作由第一面部动作变化为第二面部动作,控制虚拟场景中的第一虚拟对象由执行第一动作切换为执行第二动作。
在本申请实施例中,计算机设备基于获取到的不同的面部动作,实现对虚拟场景中由该计算机设备主控的第一虚拟对象的不同的控制。In the embodiment of the present application, the computer device implements different controls on the first virtual object controlled by the computer device in the virtual scene based on the acquired different facial movements.
在一种可能的实现方式中,基于面部动作控制虚拟场景中的第一虚拟对象。In a possible implementation manner, the first virtual object in the virtual scene is controlled based on the facial action.
在一种可能的实现方式中,对第一虚拟对象的控制即第一动作以及第二动作包括控制第一虚拟对象进行移动,控制虚拟对象的移动方向、控制虚拟对象执行的动作中的至少一种。In a possible implementation manner, the control of the first virtual object, that is, the first action and the second action include at least one of controlling the first virtual object to move, controlling the moving direction of the virtual object, and controlling the actions performed by the virtual object kind.
其中,面部动作与对第一虚拟对象的控制种类之间具有指定的对应关系,该对应关系可以是预先存储在该虚拟场景对应的服务器中,或者该对应关系也可以是基于虚拟场景的标识进行确定的。There is a specified correspondence between the facial action and the control type of the first virtual object, and the correspondence may be pre-stored in a server corresponding to the virtual scene, or the correspondence may also be performed based on the identification of the virtual scene definite.
比如,虚拟场景对应的服务器中存储有对应关系表格,该对应关系表格包括在虚拟场景1中展示的第一虚拟对象,张嘴动作与控制第一虚拟对象向左移动相对应,闭嘴动作与控制第一虚拟对象向右移动相对应。在虚拟场景标识2中,张嘴动作与控制第一虚拟对象进行跳跃相对应,闭嘴动作与控制第一虚拟对象执行蹲下动作相对应。For example, a server corresponding to the virtual scene stores a correspondence table, the correspondence table includes the first virtual object displayed in the virtual scene 1, the mouth opening action corresponds to controlling the first virtual object to move to the left, the mouth closing action corresponds to the control The first virtual object moves to the right correspondingly. In the virtual scene identifier 2, the action of opening the mouth corresponds to controlling the first virtual object to jump, and the action of closing the mouth corresponds to controlling the first virtual object to perform the action of squatting.
在一种可能的实现方式中,计算机设备获取到当前目标人脸图像对应的面部动作,基于该面部动作与对应关系进行匹配,生成对应的控制指令,基于该控制指令实现对第一虚拟对象的控制。In a possible implementation manner, the computer device obtains the facial action corresponding to the current target face image, matches the facial action with the corresponding relationship, generates a corresponding control instruction, and implements the control instruction for the first virtual object based on the control instruction. control.
其中,控制指令用于控制第一虚拟对象执行对应的动作;对应关系用于指示面部动作与对应的动作。The control instruction is used to control the first virtual object to perform a corresponding action; the corresponding relationship is used to indicate the facial action and the corresponding action.
综上所述,在本申请实施例所示的方案中,通过检测目标图像获取目标图像中的目标人脸图像,并且获取目标人脸图像中用于指示至少两个面部区域对应的位置信息的人脸特征点。基于人脸特征点确定至少两个面部区域对应的区域面积,基于至少两个面部区域对应的区域面积确定对应的面部动作,同时基于确定的面部动作控制第一虚拟对象执行不同的动作。通过上述方案,可以基于获取到的静态目标人脸图像中至少两个面部区域对应的区域面积确定该目标人脸图像对应的面部动作,并且基于确定的面部动作实现对第一虚拟对象的相应控制,避免了为了确定面部动作需要获取一段时间内人脸特征点的持续变化的情况,从而提高了进行面部动作分析的效率。To sum up, in the solution shown in the embodiment of the present application, the target face image in the target image is obtained by detecting the target image, and the information used to indicate the position information corresponding to at least two face regions in the target face image is obtained. face feature points. Areas corresponding to the at least two facial regions are determined based on the facial feature points, corresponding facial actions are determined based on the regions corresponding to the at least two facial regions, and the first virtual object is controlled to perform different actions based on the determined facial actions. Through the above solution, the facial action corresponding to the target face image can be determined based on the area areas corresponding to at least two face regions in the obtained static target face image, and the corresponding control of the first virtual object can be realized based on the determined facial action. , to avoid the situation that continuous changes of facial feature points need to be acquired over a period of time in order to determine the facial motion, thereby improving the efficiency of facial motion analysis.
本申请上述实施例所示的方案,可以应用在锻炼面部肌肉的场景下。The solutions shown in the above embodiments of the present application can be applied to the scene of exercising facial muscles.
比如,为了保持面部肌肉的紧实,为面部塑性提供更好的支持,让面部更饱满,更年轻,可以设计上述实施例所示方案的游戏规律性进行指定时间的面部肌肉训练。For example, in order to maintain the firmness of facial muscles, provide better support for facial plasticity, and make the face fuller and younger, the game of the scheme shown in the above embodiment can be designed to regularly perform facial muscle training for a specified time.
再比如,面神经炎是以面部表情肌群运动障碍为主要特征的一种疾病,主要表现为口斜眼歪。因此,也称这种疾病为面瘫。针对面神经炎的康复治疗方法有很多,包括按摩,针灸,激光治疗等。针对急性期面瘫患者,需要进行手术或药物治疗。其中,进行主动康复训练有助于康复,主动康复训练包括抬眉训练、闭眼训练、耸鼻训练、示齿训练、努嘴训练以及鼓腮训练。For another example, facial neuritis is a disease mainly characterized by the movement disorder of facial expression muscles, mainly manifested as squinting and crooked eyes. Therefore, this disease is also called facial paralysis. There are many rehabilitation treatments for facial neuritis, including massage, acupuncture, and laser therapy. For patients with acute facial paralysis, surgery or drug treatment is required. Among them, active rehabilitation training is helpful for recovery. Active rehabilitation training includes eyebrow raising training, eye closing training, nose shrugging training, teeth showing training, mouth nuzzling training and cheek drumming training.
其中,抬眉动作的完成主要依靠枕额肌额腹的运动。闭眼的功能主要依靠眼轮匝肌的运动收缩完成。训练闭眼时,需要患者开始时轻轻地闭眼,两眼同时闭合10~20次,如不能完全闭合眼睑,露白时可用示指的指腹沿着眶下缘轻轻的按摩一下,然后再用力闭眼10次,有助于眼睑闭合功能的恢复。耸鼻运动主要靠提上唇肌及压鼻肌的运动收缩来完成。示齿动作主要靠颧大、小肌、提口角肌及笑肌的收缩来完成。需要患者口角向两侧同时运动,避免只向一侧用力练成一种习惯性的口角偏斜运动。努嘴主要靠口轮匝肌收缩来完成。进行努嘴训练时,用力收缩口唇并向前努嘴,努嘴时要用力。鼓腮训练有助于口轮匝肌及颊肌运动功能的恢复。Among them, the completion of the eyebrow raising action mainly relies on the movement of the occipital frontalis muscle frontal abdomen. The function of closing the eyes mainly depends on the motor contraction of the orbicularis oculi muscle. When training to close the eyes, the patient needs to close the eyes gently at the beginning, and close both eyes 10 to 20 times at the same time. Forcefully close your eyes 10 times to help restore the eyelid closure function. The nose cocking movement is mainly completed by the movement and contraction of the levator upper lip muscle and the nasal depressor muscle. The tooth-showing action is mainly completed by the contraction of the zygomatic major and minor muscles, the levator angiitis and the laughing muscle. It is necessary for the patient to move the corner of the mouth to both sides at the same time, so as to avoid practicing a habitual deflection movement of the corner of the mouth only on one side. Nuzui is mainly completed by the contraction of the orbicularis oris muscle. When doing chin training, squeeze your lips hard and push your mouth forward, using force as you push your lips. Gill drumming training is helpful for the recovery of the motor function of the orbicularis oris and cheek muscles.
现有技术中患者只能按照医嘱的训练方式,进行各项动作的主动训练,无法准确确定动作完成是否正确与有效,并且每一组动作需要训练的次数不同,人工进行计数可能会出现遗漏现象,尤其基于统计得知病患中的老年人居多,从而导致康复训练效率较低,且没有趣味性。In the prior art, patients can only perform active training of various movements in accordance with the training method prescribed by the doctor, and it is impossible to accurately determine whether the completion of the movements is correct and effective, and the number of training times required for each group of movements is different, and omissions may occur in manual counting. , especially based on statistics, it is known that most of the patients are elderly, resulting in low efficiency of rehabilitation training and no fun.
通过上述实施例所示方案,患者在游戏过程中通过执行康复训练规定的动作,控制虚拟场景中的第一虚拟对象,在游戏中完成了辅助康复训练,无须接触或操作电子产品即可使用,在玩游戏的同时便完成了面部肌肉训练,既达到日常锻炼的目的,也增加了老年人的生活乐趣。同时,由于游戏中的游戏运行时间以及需要执行的动作均可设置,所以大大提高了辅助康复训练的效率。Through the solution shown in the above embodiment, the patient controls the first virtual object in the virtual scene by performing the actions prescribed by the rehabilitation training during the game, and completes the auxiliary rehabilitation training in the game, and can use the electronic product without touching or operating the electronic product. Facial muscle training is completed while playing games, which not only achieves the purpose of daily exercise, but also increases the joy of life for the elderly. At the same time, since the running time of the game and the actions to be performed in the game can be set, the efficiency of the auxiliary rehabilitation training is greatly improved.
图2是本申请一个示例性的实施例提供的一种终端的结构示意图。如图2所示,该终端包括主板110、外部输出/输入设备120、存储器130、外部接口140、触控系统150以及电源160。FIG. 2 is a schematic structural diagram of a terminal provided by an exemplary embodiment of the present application. As shown in FIG. 2 , the terminal includes a main board 110 , an external input/
其中,主板110中集成有处理器和控制器等处理元件。The mainboard 110 integrates processing elements such as a processor and a controller.
外部输出/输入设备120可以包括显示组件(比如显示屏)、图像采集组件(比如摄像头)、声音播放组件(比如扬声器)、声音采集组件(比如麦克风)以及各类按键等。The external output/
存储器130中存储有程序代码和数据。Program codes and data are stored in the memory 130 .
外部接口140可以包括耳机接口、充电接口以及数据接口等。The external interface 140 may include a headphone interface, a charging interface, a data interface, and the like.
人脸识别系统150可以集成在外部输出/输入设备120中,人脸识别系统150用于检测图像采集组件采集到的用户人脸图像,并且对人脸图像进行面部分析,生成对应的控制指令的操作。该控制指令用于控制虚拟场景中的虚拟对象。The face recognition system 150 can be integrated in the external output/
电源160用于对终端中的其它各个部件进行供电。The power supply 160 is used to power various other components in the terminal.
在本申请实施例中,主板110中的处理器可以通过执行或者调用存储器中存储的程序代码和数据生成虚拟场景,并将生成的虚拟场景通过外部输出/输入设备120进行展示。在展示虚拟场景的过程中,可以通过人脸识别系统150中检测到的用户对应的面部分析结果对应的控制指令,控制虚拟场景中的虚拟对象进行控制指令对应的动作。In this embodiment of the present application, the processor in the mainboard 110 may generate a virtual scene by executing or calling program codes and data stored in the memory, and display the generated virtual scene through the external output/
其中,虚拟场景可以是三维虚拟场景,或者,虚拟场景也可以是二维虚拟场景。请参考图3,其示出了本申请一个示例性的实施例提供的虚拟场景的显示界面示意图。如图3所示,虚拟场景的显示界面包含场景画面200,该场景画面200中包括虚拟对象210、虚拟场景的环境画面220、提示消息230以及显示头像240。其中,虚拟对象210可以是由该终端对应的用户控制的虚拟对象。提示消息230可以是以图案的形式展示提示的需要执行的面部动作,或者也可以是以文字的方式提示需要执行的面部动作。可选的,显示头像中显示的面部动作可以是用户当前执行的面部动作,或者,也可以是提示用户需要执行的面部动作。The virtual scene may be a three-dimensional virtual scene, or the virtual scene may also be a two-dimensional virtual scene. Please refer to FIG. 3 , which shows a schematic diagram of a display interface of a virtual scene provided by an exemplary embodiment of the present application. As shown in FIG. 3 , the display interface of the virtual scene includes a
图4是根据一示例性实施例示出的一种虚拟场景中虚拟对象控制方法的流程图。该虚拟场景中虚拟对象控制方法可以由计算机设备执行。比如,该计算机设备可以是具有图像采集功能的终端。如图4所示,该虚拟场景中虚拟对象控制方法包括的步骤如下:Fig. 4 is a flow chart of a method for controlling virtual objects in a virtual scene according to an exemplary embodiment. The virtual object control method in the virtual scene may be executed by a computer device. For example, the computer device may be a terminal with an image acquisition function. As shown in FIG. 4 , the steps included in the virtual object control method in the virtual scene are as follows:
步骤401,响应于检测到目标图像中存在目标人脸图像,展示虚拟场景对应的运行初始画面;运行初始画面中包括目标平台以及位于目标平台上的第一虚拟对象;目标平台是虚拟场景开始运行时第一虚拟对象所在的平台。
步骤402,响应于第一虚拟对象位于目标平台上,且检测到目标人脸图像对应的面部动作符合第一面部动作,控制第一虚拟对象沿着目标平台向第一方向进行移动。
步骤403,响应于第一虚拟对象位于目标平台上,且检测到面部动作符合第二面部动作,控制第一虚拟对象沿着目标平台向第二方向进行移动;第二方向是与第一方向相反的方向。
步骤404,响应于第一虚拟对象的移动范围超过目标平台,修改虚拟对象失败次数。
步骤405,响应于虚拟场景的运行时长达到指定时长,展示场景运行结果;场景运行结果是基于虚拟对象失败次数确定的。
综上所述,通过检测目标图像获取目标图像中的目标人脸图像,并且获取目标人脸图像中用于指示至少两个面部区域对应的位置信息的人脸特征点。基于人脸特征点确定至少两个面部区域对应的区域面积,基于至少两个面部区域对应的区域面积确定对应的面部动作,同时基于确定的面部动作控制第一虚拟对象执行不同的动作。通过上述方案,可以基于获取到的静态目标人脸图像中至少两个面部区域对应的区域面积确定该目标人脸图像对应的面部动作,并且基于确定的面部动作实现对第一虚拟对象的相应控制,避免了为了确定面部动作需要获取一段时间内人脸特征点的持续变化的情况,从而提高了进行面部动作分析的效率。To sum up, the target face image in the target image is obtained by detecting the target image, and the face feature points in the target face image that are used to indicate the position information corresponding to at least two face regions are obtained. Areas corresponding to the at least two facial regions are determined based on the facial feature points, corresponding facial actions are determined based on the regions corresponding to the at least two facial regions, and the first virtual object is controlled to perform different actions based on the determined facial actions. Through the above solution, the facial action corresponding to the target face image can be determined based on the area areas corresponding to at least two face regions in the obtained static target face image, and the corresponding control of the first virtual object can be realized based on the determined facial action. , to avoid the situation that continuous changes of facial feature points need to be acquired over a period of time in order to determine the facial motion, thereby improving the efficiency of facial motion analysis.
图5是根据一示例性实施例示出的一种虚拟场景中虚拟对象控制方法的流程图。该虚拟场景中虚拟对象控制方法可以由计算机设备执行。比如,该计算机设备可以是具有图像采集功能的终端。如图5所示,该虚拟场景中虚拟对象控制方法包括的步骤如下:Fig. 5 is a flow chart of a method for controlling virtual objects in a virtual scene according to an exemplary embodiment. The virtual object control method in the virtual scene may be executed by a computer device. For example, the computer device may be a terminal with an image acquisition function. As shown in Figure 5, the steps included in the virtual object control method in the virtual scene are as follows:
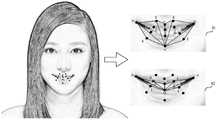
步骤501,响应于检测到目标图像中存在目标人脸图像,获取目标人脸图像中至少两个面部区域对应的人脸特征点。
在本申请实施例中,计算机设备可以通过图像采集功能获取到当前时刻的目标图像,若检测到目标图像中存在目标人脸图像,获取目标人脸图像中至少两个面部区域对应的人脸特征点。In the embodiment of the present application, the computer device can obtain the target image at the current moment through the image acquisition function, and if it is detected that the target face image exists in the target image, the face features corresponding to at least two face regions in the target face image are obtained. point.
其中,人脸特征点用于指示面部区域对应的位置信息。Among them, the facial feature points are used to indicate the position information corresponding to the facial region.
在一种可能的实现方式中,计算机设备通过人脸检测定位算法确定目标图像中是否存在目标人脸图像,并且确定目标人脸图像在目标图像中的位置信息。In a possible implementation manner, the computer device determines whether a target face image exists in the target image through a face detection and positioning algorithm, and determines the position information of the target face image in the target image.
其中,计算机设备获取目标图像,将目标图像输入目标人脸定位模型,获得由目标人脸定位模型输出的目标人脸图像信息。目标人脸图像信息用于指示目标人脸图像所处的位置。The computer equipment acquires the target image, inputs the target image into the target face localization model, and obtains the target face image information output by the target face localization model. The target face image information is used to indicate where the target face image is located.
示例性的,人脸检测定位算法可以是目标检测任务的分支算法,目标检测任务用于在图像中识别目标位置,并且返回目标的图像坐标,目标检测任务需要检测的目标种类和目标数量可以通过调整相关参数以及模型来实现。人脸检测定位算法是目标种类确定为人脸时的目标检测任务,人脸检测定位算法仅要求在目标图像中检测到人脸的位置坐标,因此,通过修改目标检测任务对应的模型识别的目标类型为人脸即可获得目标人脸定位模型。Exemplarily, the face detection and localization algorithm can be a branch algorithm of the target detection task. The target detection task is used to identify the target position in the image and returns the image coordinates of the target. The target type and target number to be detected by the target detection task can be determined by Adjust related parameters and models to achieve. The face detection and positioning algorithm is a target detection task when the target type is determined as a face. The face detection and positioning algorithm only requires the position coordinates of the face to be detected in the target image. Therefore, by modifying the target type identified by the model corresponding to the target detection task The target face localization model can be obtained if it is a face.
其中,目标图像可以是通过计算机设备的图像采集模块实时获取的图像,该目标图像可以是RGB(色彩)图像。The target image may be an image acquired in real time by an image acquisition module of a computer device, and the target image may be an RGB (color) image.
在一种可能的实现方式中,目标人脸定位模型是一个端到端的深度学习模型,目标人脸定位模型是用于对目标图像进行图像特征提取并且对图像特征进行识别分类的神经网络模型。In a possible implementation manner, the target face localization model is an end-to-end deep learning model, and the target face localization model is a neural network model for extracting image features from target images and identifying and classifying image features.
其中,目标人脸定位模型包括底层网络、中间层网络以及头部层网络;底层网络用于进行图像特征提取;中间层网络基于RoIAlign算法进行连续的区域特征聚集;头部层网络用于通过线性回归算法输出目标人脸图像信息。Among them, the target face localization model includes the bottom layer network, the middle layer network and the head layer network; the bottom layer network is used for image feature extraction; the middle layer network is based on the RoIAlign algorithm for continuous regional feature aggregation; the head layer network is used for linear The regression algorithm outputs the target face image information.
示例性的,目标人脸定位模型可以采用ReseNet-FPN进行底层特征提取。Exemplarily, the target face localization model can use ReseNet-FPN to perform underlying feature extraction.
其中,将目标图像输入目标人脸定位模型,基于目标人脸定位模型可以识别目标图像中是否存在目标人脸图像,同时目标人脸定位模型可以计算出用于标注目标人脸图像所处位置的矩形框上,位于左上以及右下位置的坐标信息,基于该坐标信息可以确定矩形框的具体位置,基于该矩形框将目标图像中矩形框中的图像作为目标人脸图像进行切割,由目标人脸定位模型输出该目标人脸图像。The target image is input into the target face localization model. Based on the target face localization model, it can identify whether there is a target face image in the target image. At the same time, the target face localization model can calculate the location of the target face image. On the rectangular frame, the coordinate information located at the upper left and lower right positions. Based on the coordinate information, the specific position of the rectangular frame can be determined. Based on the rectangular frame, the image in the rectangular frame in the target image is cut as the target face image, and the target person The face localization model outputs the target face image.
在一种可能的实现方式中,目标人脸定位模型具有三层网络,分别为底层网络、中间层网络以及头部层网络。底层网络为卷积神经网络,目标图像经过该底层的特征基础层网络使用卷积神经网络算法进行图像特征提取,得到目标图像对应的特征图,利用中间层网络中的区域生成网络部分(Region Proposal Network,RPN)对特征图进行一系列的矩形框提取,通过RoIAlign算法进行连续的区域特征聚集,从而生成特征图中对应的指定大小的目标区域,中间层网络输出的包括目标区域对应的聚集特征,头部层网络包括全连接层,可以通过全连接层中的分类回归算法确定目标区域的聚集特征对应的目标物类别,若目标物类别是人脸,则使用头部层网络中的线性回归算法回归目标区域位置坐标,最终完成目标人脸检测定位任务。In a possible implementation manner, the target face localization model has three layers of networks, namely a bottom layer network, a middle layer network and a head layer network. The underlying network is a convolutional neural network, and the target image passes through the underlying feature base layer network to extract image features using the convolutional neural network algorithm to obtain the feature map corresponding to the target image, and use the regions in the middle layer network to generate the network part (Region Proposal). Network, RPN) extracts a series of rectangular boxes from the feature map, and performs continuous regional feature aggregation through the RoIAlign algorithm to generate a target area of a specified size corresponding to the feature map. The output of the intermediate layer network includes the aggregated features corresponding to the target area. , the head layer network includes a fully connected layer. The classification and regression algorithm in the fully connected layer can be used to determine the target object category corresponding to the aggregated features of the target area. If the target object category is a face, the linear regression in the head layer network is used. The algorithm returns to the position coordinates of the target area, and finally completes the target face detection and positioning task.
示例性的,图6是本申请实施例涉及的一种目标人脸定位模型的架构图,如图6所示,目标图像输入作为特征基础层61的卷积神经网络进行特征提取,获得特征图62,将卷积神经网络输出的特征图62通过区域生成网络65,对特征图进行一系列的矩形框提取,然后通过RoIAlign算法进行连续的区域特征聚集,从而生成特征图中对应的指定大小的目标区域63,将指定大小的目标区域63通过全连接层64,进行边框回归(box regression)以及目标分类(classification),若分类回归算法确定目标区域的聚集特征对应的目标物类别是人脸,则对指定大小的目标区域63进行分割,生成目标人脸图像66。Exemplarily, FIG. 6 is an architecture diagram of a target face localization model involved in the embodiment of the present application. As shown in FIG. 6 , the target image is input as the convolutional neural network of the
上述目标人脸定位模型由于使用了ReseNet-FPN作为底层特征提取方法,提升了特征基础层模型的特征提取能力。同时,通过添加使用RoIAlign算法处理特征图的位置偏差,可以提高目标人脸检测的准确度。The above target face localization model uses ReseNet-FPN as the underlying feature extraction method, which improves the feature extraction capability of the feature base layer model. At the same time, the accuracy of target face detection can be improved by adding the positional deviation of the feature map processed by the RoIAlign algorithm.
在一种可能的实现方式中,将目标人脸图像信息对应的目标人脸图像输入特征点识别模型,获得由特征点识别模型输出的至少两个面部区域对应的人脸特征点。In a possible implementation manner, the target face image corresponding to the target face image information is input into the feature point recognition model, and the face feature points corresponding to at least two facial regions output by the feature point recognition model are obtained.
其中,特征点识别模型可以是由两个级联的卷积神经网络构成的神经网络模型。The feature point recognition model may be a neural network model composed of two cascaded convolutional neural networks.
在一种可能的实现方式中,面部区域包括人脸外轮廓区域以及内部器官区域。将目标人脸图像输入特征点识别模型,通过特征点识别模型中第一数量的级联网络输出内部器官区域对应的人脸特征点;通过第二数量的级联网络输出人脸外轮廓区域对应的人脸特征点;其中,第一数量大于第二数量。In a possible implementation manner, the facial area includes an outer contour area of a human face and an internal organ area. Input the target face image into the feature point recognition model, and output the face feature points corresponding to the internal organ area through the first number of cascade networks in the feature point recognition model; output the corresponding face outer contour area through the second number of cascade networks The facial feature points; wherein, the first number is greater than the second number.
其中,人脸外轮廓区域上具有轮廓特征点,内部器官区域上具有内部特征点。内部特征点可以包含眉毛、眼睛、鼻子、嘴巴共计51个特征点,轮廓特征点可以包含17个特征点。通过该特征点识别模型可以实现68个人脸关键点的高精度定位。Among them, there are contour feature points on the outer contour area of the face, and internal feature points on the internal organ area. The internal feature points can contain a total of 51 feature points for eyebrows, eyes, nose, and mouth, and the contour feature points can contain 17 feature points. The feature point recognition model can achieve high-precision positioning of 68 face key points.
示例性的,针对内部器官区域上具有的51个内部特征点,可以采用四个层级的级联网络进行特征点检测。其中,第一层级的级联网络的主要作用可以是获得面部器官的边界框;第二层级的级联网络的输出可以是51个特征点的预测位置,其中,这里的预测位置为特征点的粗略定位,可以起到粗定位的作用,目的是为了给第三层级的级联网络进行初始化;第三层级的级联网络会依据不同器官,从粗到精进行特征点定位;第四层级的级联网络的输入是将第三层级的级联网络的输出进行一定的旋转,最终,第四层级的级联网络将51个特征点的位置进行输出。针对外轮廓区域对应的17个特征点,可以仅采用两个层级的级联网络进行检测,即可以仅通过第一层级的级联网络以及第二层级的级联网络进行特征点检测。其中,第一层级的级联网络与内部特征点检测的作用一样,目的主要是获得轮廓的边界框;第二层级的级联网络可以直接预测17个特征点的位置,由于外轮廓区域对应的特征点的区域较大,无需从粗到精定位的过程,若与内部特征点同样需要加上第三层级的级联网络和第四层级的级联网络进行逐步定位,会消耗较多时间,进行特征点检测的效率会较低。最终,各个面部区域对应的68个特征点可以由两个级联卷积神经网络的输出进行叠加得到。Exemplarily, for the 51 internal feature points on the internal organ region, a four-level cascade network can be used for feature point detection. Among them, the main function of the cascade network of the first level can be to obtain the bounding box of facial organs; the output of the cascade network of the second level can be the predicted positions of 51 feature points, wherein the predicted positions here are the predicted positions of the feature points. Rough positioning can play the role of coarse positioning, the purpose is to initialize the cascade network of the third level; the cascade network of the third level will locate feature points from coarse to fine according to different organs; The input of the cascade network is to rotate the output of the cascade network of the third level to a certain extent, and finally, the cascade network of the fourth level outputs the positions of 51 feature points. For the 17 feature points corresponding to the outer contour area, only two levels of cascade networks can be used for detection, that is, feature point detection can be performed only through the cascade network of the first level and the cascade network of the second level. Among them, the cascade network of the first level has the same function as the detection of internal feature points, and the purpose is to obtain the bounding box of the outline; the cascade network of the second level can directly predict the positions of 17 feature points. The area of the feature points is relatively large, and there is no need for the process of coarse-to-fine positioning. If the same as the internal feature points, the cascade network of the third level and the cascade network of the fourth level need to be added for gradual positioning, which will consume more time. The efficiency of feature point detection will be lower. Finally, the 68 feature points corresponding to each face region can be obtained by superimposing the outputs of two cascaded convolutional neural networks.
比如,图7是本申请所述实施例涉及的一种特征点识别模型网络结构图。如图7所示,目标人脸图像输入到特征点识别模型中的第一层级的级联网络71中,通过边框回归判定分别对面部器官以及外轮廓划分边界框,将目标人脸图像按照边界框进行剪裁,将剪裁后的人脸图像分别输入第二层级的级联网络72,通过初步预测,分别确定面部器官对应的特征点以及外轮廓对应的特征点的粗略定位位置,将面部器官对应的特征点粗定位位置输入第三层级的级联网络73,按照面部器官对特征点进行分割,并且按照不同器官,从粗到精进行特征点定位,然后输入第四层的级联网络74对各个面部器官对应的特征点进行一定的旋转。最终,将第四层的级联网络74输出的内部面部器官对应的特征点以及第二层级的级联网络72输出的外轮廓特征点结合作为各个面部区域对应的人脸特征点。For example, FIG. 7 is a network structure diagram of a feature point recognition model involved in the embodiment of the present application. As shown in FIG. 7 , the target face image is input into the
上述把人脸特征点的定位问题,划分为内部特征点和外轮廓特征点分开进行预测,可以有效的避免了损失函数不均衡的问题,在内部特征点检测部分,并未像深度卷积神经网络那样每个特征点均采用两个卷积神经网络进行预测,而是每个面部器官采用一个卷积神经网络进行预测,从而大大减少了计算量,相比深度卷积神经网络,没有直接采用人脸检测器返回的结果作为输入,而是增加一个边界框检测层,即第一层级的级联网络,大大提高了特征点进行粗定位时的网络精度。The above-mentioned positioning problem of facial feature points is divided into internal feature points and outer contour feature points for separate prediction, which can effectively avoid the problem of unbalanced loss function. In the detection part of internal feature points, it is not like deep convolution neural network Like the network, each feature point is predicted by two convolutional neural networks, but each facial organ is predicted by one convolutional neural network, which greatly reduces the amount of calculation. Compared with the deep convolutional neural network, it does not directly use The result returned by the face detector is used as the input, but a bounding box detection layer is added, that is, the cascade network of the first level, which greatly improves the network accuracy when the feature points are coarsely located.
在一种可能的实现方式中,响应于目标图像中检测到目标人脸图像,计算机设备开始运行虚拟场景,并且控制虚拟场景中的第一虚拟对象沿着目标平台向初始方向进行移动。In a possible implementation manner, in response to detecting the target face image in the target image, the computer device starts to run the virtual scene, and controls the first virtual object in the virtual scene to move toward the initial direction along the target platform.
其中,初始方向可以是第一方向或者第二方向的随机一种,或者基于计算机设备接收到的选择操作选择的第一方向或者第二方向。The initial direction may be a random one of the first direction or the second direction, or the first direction or the second direction selected based on a selection operation received by the computer device.
比如,当第一方向是左侧时,第二方向是右侧;当第一方向是右侧时,第二方向是左侧。For example, when the first direction is the left side, the second direction is the right side; when the first direction is the right side, the second direction is the left side.
在另一种可能的实现方式中,响应于目标图像中检测到目标人脸图像,展示运行初始画面,运行初始画面中在目标平台的中心位置处展示第一虚拟对象,且第一虚拟对象不进行移动。In another possible implementation manner, in response to the target face image being detected in the target image, an initial image of running is displayed, and in the initial running image, a first virtual object is displayed at the center of the target platform, and the first virtual object does not make a move.
在一种可能的实现方式中,计算机设备展示指定时长的初始运行画面,响应于虚拟场景运行时长达到指定时长,开始基于确定的面部动作控制第一虚拟对象。In a possible implementation manner, the computer device displays an initial running screen of a specified duration, and starts to control the first virtual object based on the determined facial action in response to the running duration of the virtual scene reaching the specified duration.
步骤502,基于至少两个面部区域对应的人脸特征点,获取至少两个面部区域对应的区域面积。
在本申请实施例中,计算机设备在确定目标图像中存在目标人脸图像后,基于获取到的目标人脸图像中至少两个面部区域对应的人脸特征点,获取至少两个面部区域分别对应的区域面积。In the embodiment of the present application, after determining that the target face image exists in the target image, the computer device obtains at least two face regions corresponding to the at least two face regions based on the obtained face feature points corresponding to the at least two face regions in the target face image. area of the area.
其中,面部区域可以基于面部区域对应的各个人脸特征点生成该面部区域对应的凸包图形,该凸包图形对应的凸包面积是该面部区域对应的区域面积。Wherein, the facial area may generate a convex hull graph corresponding to the facial area based on each face feature point corresponding to the facial area, and the convex hull area corresponding to the convex hull graph is the area corresponding to the facial area.
在一种可能的实现方式中,获取目标凸包顶点,目标凸包顶点是目标面部区域中用于构成凸包的人脸特征点;目标面部区域是至少两个面部区域中的任意一个;基于目标凸包顶点,获取目标面部区域的区域面积。In a possible implementation manner, the target convex hull vertex is obtained, and the target convex hull vertex is the face feature point used to form the convex hull in the target face area; the target face area is any one of at least two face areas; based on Target convex hull vertex, get the area of the target face area.
其中,计算机设备获取第一凸包顶点以及第二凸包顶点,基于第一凸包顶点以及第二凸包顶点,获取第一区域面积以及第二区域面积。第一凸包顶点是第一面部区域中用于构成凸包的人脸特征点,第二凸包顶点是第二面部区域中用于构成的凸包的人脸特征点。The computer device acquires the vertex of the first convex hull and the vertex of the second convex hull, and acquires the area of the first area and the area of the second area based on the vertex of the first convex hull and the vertex of the second convex hull. The first convex hull vertices are the face feature points used to form the convex hull in the first face region, and the second convex hull vertices are the face feature points used to form the convex hull in the second face region.
在一种可能的实现方式中,通过Graham扫描法,以时间复杂度为O(nlgn)按照逆时针方向输出对应的凸包顶点,或者,通过Jarvis步进法,以时间复杂度为O(nh)按照逆时针方向输出对应的凸包顶点。In a possible implementation manner, the Graham scanning method is used to output the corresponding convex hull vertices in the counterclockwise direction with a time complexity of O(nlgn), or the Jarvis stepping method is used to output the corresponding convex hull vertices with a time complexity of O(nh ) outputs the corresponding convex hull vertices in a counterclockwise direction.
其中,凸包顶点是人脸特征点中用于作为顶点构成凸包的特征点。The convex hull vertices are the feature points used as vertices to form the convex hull in the face feature points.
在一种可能的实现方式中,响应于获得第一凸包顶点,选择第一凸包顶点中的一个顶点作为公共顶点,然后将公共顶点与所有其他凸包顶点相连,将第一凸包顶点构成的凸多边形分割为n-2个三角形,将n-2个三角形对应的面积之和确定为第一区域面积。其中,n为凸多边形的顶点个数。In one possible implementation, in response to obtaining the first convex hull vertex, one of the first convex hull vertices is selected as a common vertex, and then the common vertex is connected with all other convex hull vertices, and the first convex hull vertex is connected The formed convex polygon is divided into n-2 triangles, and the sum of the areas corresponding to the n-2 triangles is determined as the area of the first region. where n is the number of vertices of the convex polygon.
示例性的,图8是本申请实施例涉及的一种内唇面积与外唇面积计算示意图。如图8所示,终端获取到唇部区域对应的人脸特征点,基于凸包顶点确定算法,可以确定凸包顶点a、b、c、d、e、f、g以及o为外唇区域81对应的区域面积,以其中的凸包顶点o为公共顶点,将公共顶点与所有其他凸包顶点相连,可以将8个凸包顶点构成的凸包切分为6个小三角形,分别计算6个小三角形的面积,将面积之和确定为外唇区域81对应的区域面积。同时,也可以确定凸包顶点a、h、i、j、e、k、l以及O为内唇区域82对应的区域面积,以其中的凸包顶点O为公共顶点,将公共顶点与所有其他凸包顶点相连,可以将8个凸包顶点构成的凸包切分为6个小三角形,分别计算6个小三角形的面积,将面积之和确定为内唇区域81对应的区域面积。Exemplarily, FIG. 8 is a schematic diagram of calculating the inner lip area and the outer lip area involved in the embodiment of the present application. As shown in Figure 8, the terminal obtains the face feature points corresponding to the lip area, and based on the convex hull vertex determination algorithm, the convex hull vertices a, b, c, d, e, f, g and o can be determined as the outer lip area The area corresponding to 81, taking the convex hull vertex o as the common vertex, and connecting the common vertex with all other convex hull vertices, the convex hull formed by the 8 convex hull vertices can be divided into 6 small triangles, and calculate 6 The area of each small triangle, and the sum of the areas is determined as the area corresponding to the
步骤503,获取第一比例数值。
在本申请实施例中,计算机设备将至少两个面部区域中的第一面部区域的区域面积与面部区域中的第二面部区域的区域面积之间的比值确定为第一比例数值。In the embodiment of the present application, the computer device determines the ratio between the area area of the first facial area in the at least two facial areas and the area area of the second facial area in the facial area as the first proportional value.
其中,第一比例数值是至少两个面部区域中的第一面部区域的区域面积,与面部区域中的第二面部区域的区域面积之间的比值。The first proportional value is a ratio between the area area of the first facial area in the at least two facial areas and the area area of the second facial area in the facial area.
示例性的,若第一面部区域的区域面积是内唇面积,第二面部区域的区域面积是外唇面积,为了判断嘴部动作,需要计算内唇面积与外唇面积之间的比例来判断,将该比值确定为第一比值数据。Exemplarily, if the area of the first facial area is the area of the inner lip, and the area of the second facial area is the area of the outer lip, in order to judge the mouth movement, it is necessary to calculate the ratio between the area of the inner lip and the area of the outer lip. It is judged that the ratio is determined as the first ratio data.
另外,若第一面部区域的区域面积是外轮廓面积,第二面部区域的区域面积是内唇面积,同样可以基于外轮廓面积与内唇面积之间的比例确定为第一比值数据,判断嘴部动作。In addition, if the area of the first facial area is the outer contour area and the area of the second facial area is the inner lip area, the ratio between the outer contour area and the inner lip area can also be determined as the first ratio data. mouth movements.
步骤504,基于第一面部区域的部位种类以及第二面部区域的部位种类,获取比例阈值。Step 504: Obtain a proportional threshold based on the part type of the first facial area and the part type of the second facial area.
在一种可能的实现方式中,计算机设备获取第一面部区域的部位种类以及第二面部区域的部位种类,通过查询预先存储的对应关系,获取上述两种部位种类对应的比例阈值。In a possible implementation manner, the computer device acquires the part types of the first facial region and the part types of the second facial region, and obtains the proportional thresholds corresponding to the above two types of parts by querying the pre-stored correspondence.
在一种可能的实现方式中,面部区域的部位种类包括人脸外轮廓区域、眼睛区域、鼻子区域、外唇区域以及内唇区域中的至少两种。In a possible implementation manner, the types of parts of the facial region include at least two of the outer contour region of the human face, the eye region, the nose region, the outer lip region, and the inner lip region.
示例性的,第一面部区域的部位种类是人脸外轮廓区域、第二面部区域的部位种类为外唇区域时对应的比例阈值与,第一面部区域的部位种类是内唇区域、第二面部区域的部位种类为外唇区域时对应的比例阈值可以是不同的。Exemplarily, when the part type of the first facial area is the outer contour area of the human face, and the corresponding proportional threshold value when the part type of the second facial area is the outer lip area, the part type of the first facial area is the inner lip area, When the part type of the second facial region is the outer lip region, the corresponding proportional thresholds may be different.
步骤505,基于第一比例数值与比例阈值之间的大小关系,确定目标人脸图像对应的面部动作。Step 505: Determine the facial action corresponding to the target face image based on the magnitude relationship between the first proportional value and the proportional threshold.
在一种可能的实现方式中,响应于第一面部区域的部位种类是外唇区域,且第二面部区域的部位种类是内唇区域;响应于第一比例数值大于第一比例阈值,确定目标人脸图像对应的面部动作为闭嘴动作;响应于第一比例数值小于或者等于第一比例阈值,确定目标人脸图像对应的面部动作为张嘴动作。In a possible implementation manner, in response to the part type of the first facial area being the outer lip area, and the part type of the second facial area being the inner lip area; in response to the first proportional value being greater than the first proportional threshold, determining The facial action corresponding to the target face image is the mouth closing action; in response to the first proportional value being less than or equal to the first proportional threshold, it is determined that the facial action corresponding to the target face image is the mouth opening action.
其中,通过至少两个区域面积之间的比值作为第一比例数值与比例阈值进行大小关系比较,可以解决由于人脸靠近摄像头较近时对应的单一区域面积过大,或者人脸距离摄像头较远时对应的单一区域面积过小,从而无法准确判断面部动作的问题。The ratio between the areas of at least two regions is used as the first proportional value to compare the size relationship with the proportional threshold, which can solve the problem that the corresponding single region area is too large when the face is close to the camera, or the face is far from the camera. When the corresponding single area is too small, it is impossible to accurately judge the problem of facial movements.
比如,当内唇面积占外唇面积的比例,即第一比例数值大于25%,则可以判断此时嘴巴的动作为张开状态,若第一比例数值小于25%时,可以判断嘴巴的动作为闭合状态。For example, when the ratio of the area of the inner lip to the area of the outer lip, that is, the value of the first ratio is greater than 25%, it can be judged that the action of the mouth at this time is an open state, and if the value of the first ratio is less than 25%, the action of the mouth can be judged is closed.
在另一种可能的实现方式中,响应于第一比例数值小于或者等于第一比例阈值,获取目标人脸图像中,对应在内唇区域内部的第一区域图像;在第一区域图像中进行牙齿检测;响应于在第一区域图像中检测到牙齿,确定目标人脸图像对应的面部动作为张嘴动作。In another possible implementation manner, in response to the first scale value being less than or equal to the first scale threshold value, acquire the first area image corresponding to the inner lip area in the target face image; Tooth detection; in response to detecting teeth in the first area image, determining that the facial action corresponding to the target face image is a mouth-opening action.
也就是说,通过第一比例数值与比例阈值之间的大小关系之后,增加检测第一区域图像中是否存在牙齿或者存在牙齿的面积,可以提高确定目标人脸图像对应的面部动作为张嘴动作或者呲牙动作的精确度。That is to say, after the magnitude relationship between the first proportional value and the proportional threshold value, increasing the detection of whether there are teeth or the area where teeth exist in the first area image can improve the determination that the facial action corresponding to the target face image is the mouth opening action or The precision of the gnashing action.
步骤506,基于面部动作控制虚拟场景中的第一虚拟对象向目标方向进行移动。
在本申请实施例中,计算机设备可以基于确定的面部动作,可以获取与面部动作对应的指令,基于指令控制第一虚拟对象向对应的目标方向进行移动。In this embodiment of the present application, the computer device may acquire an instruction corresponding to the facial motion based on the determined facial motion, and control the first virtual object to move in a corresponding target direction based on the instruction.
其中,目标方向是基于面部动作确定的第一虚拟对象的移动方向。The target direction is the movement direction of the first virtual object determined based on the facial action.
在一种可能的实现方式中,响应于第一虚拟对象位于目标平台上,且检测到面部动作符合第一面部动作,控制第一虚拟对象沿着目标平台向第一方向进行移动。响应于第一虚拟对象位于目标平台上,且检测到面部动作符合第二面部动作,控制第一虚拟对象沿着目标平台向第二方向进行移动;第二方向是与第一方向相反的方向。In a possible implementation manner, in response to the first virtual object being located on the target platform and detecting that the facial action conforms to the first facial action, the first virtual object is controlled to move in the first direction along the target platform. In response to the first virtual object being located on the target platform and detecting that the facial action conforms to the second facial action, the first virtual object is controlled to move along the target platform to a second direction; the second direction is a direction opposite to the first direction.
其中,目标平台是虚拟场景开始运行时第一虚拟对象所在的平台。The target platform is the platform where the first virtual object is located when the virtual scene starts to run.
在一种可能的实现方式中,获取第一虚拟对象相对于目标平台的中心位置的偏移方向;响应于偏移方向是第一方向,展示第一提示消息;第一提示消息用于提示第二面部动作;响应于偏移方向是第二方向,展示第二提示消息;第二提示消息用于提示第一面部动作。In a possible implementation manner, the offset direction of the first virtual object relative to the center position of the target platform is obtained; in response to the offset direction being the first direction, a first prompt message is displayed; the first prompt message is used to prompt the first Two facial actions; in response to the offset direction being the second direction, a second prompt message is displayed; the second prompt message is used to prompt the first facial action.
其中,第一提示消息可以是文字形式或者是图案形式的,用于提示当前时刻用户需要执行的面部动作。The first prompt message may be in the form of text or in the form of a pattern, and is used to prompt the facial action that the user needs to perform at the current moment.
在一种可能的实现方式中,基于虚拟场景的运行时长,确定第一虚拟对象在目标平台上的移动速度,运行时长与移动速度成正相关。In a possible implementation manner, the moving speed of the first virtual object on the target platform is determined based on the running duration of the virtual scene, and the running duration is positively correlated with the moving speed.
示例性的,在虚拟场景运行的过程中,第一虚拟对象的移动速度将会越来越快,从而使得用户控制第一虚拟对象的难度增加,达到训练用户执行指定的面部动作的目的。Exemplarily, during the running of the virtual scene, the moving speed of the first virtual object will become faster and faster, thereby making it more difficult for the user to control the first virtual object, so as to achieve the purpose of training the user to perform a specified facial action.
步骤507,响应于第一虚拟对象移动范围超过目标平台,修改虚拟对象失败次数,响应于虚拟场景的运行时长达到指定时长,展示场景运行结果。
其中,场景运行结果是基于虚拟对象失败次数确定的。The scene running result is determined based on the number of failures of the virtual object.
比如,虚拟场景中的第一虚拟对象在目标平台(如平衡木)上的移动速度可以随着虚拟场景结束的倒计时,即虚拟场景的运行时间加快,从而逐渐增加游戏难度,同时,第一虚拟对象从平衡木上掉落后可以自动复活,继续进行游戏,直至虚拟场景运行倒计时结束,最终计算确定场景运行结果(如游戏得分)。控制第一虚拟对象以指定加速度以及指定初始速度进行移动。若S为第一虚拟对象的移动速度,单位为像素/秒,可以表示第一虚拟对象每秒钟移动经过的像素个数。T为虚拟场景运行的倒计时数值,初始值可以是30s,随着虚拟场景的运行时间增加,倒计时随时间减小。若第一虚拟对象的初始速度为250像素/秒,加速度为10像素/秒。第一虚拟对象的移动速度如下所示:For example, the moving speed of the first virtual object in the virtual scene on the target platform (such as a balance beam) can be counted down with the end of the virtual scene, that is, the running time of the virtual scene is accelerated, thereby gradually increasing the difficulty of the game. At the same time, the first virtual object After falling from the balance beam, it can be automatically resurrected and continue to play the game until the virtual scene running countdown ends, and finally calculate and determine the scene running result (such as game score). The first virtual object is controlled to move at a specified acceleration and a specified initial speed. If S is the moving speed of the first virtual object, and the unit is pixels/second, it can represent the number of pixels that the first virtual object moves through per second. T is the countdown value for running the virtual scene, and the initial value can be 30s. As the running time of the virtual scene increases, the countdown decreases with time. If the initial speed of the first virtual object is 250 pixels/second, the acceleration is 10 pixels/second. The moving speed of the first virtual object is as follows:
S=250+10×(30-T)S=250+10×(30-T)
假设30s倒计时过程中第一虚拟对象共从平衡木掉出N次,场景运行结果即游戏得分(Score)的计算方法如下所示:Assuming that the first virtual object falls out of the balance beam N times during the 30s countdown, the calculation method of the scene running result, namely the game score (Score) is as follows:
Score=100–5×NScore=100–5×N
其中,每从平衡木掉出1次,游戏得分减5分,若从平衡木掉出大于20次,则分数直接判为0分。Among them, every time you fall from the balance beam, the game score will be reduced by 5 points. If you fall from the balance beam more than 20 times, the score will be directly judged as 0 points.
图9是本申请实施例涉及的一种基于表情分析的虚拟对象控制方法流程图。如图9所示,在规定时间内,用户通过执行呲牙动作或闭嘴动作的方式,控制平衡木上的虚拟对象左右移动,避免虚拟对象从平衡木上掉落,平衡木下方设置了小怪兽,虚拟对象掉落后将被小怪兽吞噬,吞噬后虚拟对象可以自动复活,继续游戏,直至倒计时结束,根据虚拟对象自动复活次数计算游戏得分。在游戏过程中,在虚拟场景画面的右上方,可以设置有卡通头像,该卡通头像可以根据虚拟对象当前时刻行走方向变化嘴形,提示玩家当前时刻应该执行闭嘴动作或者呲牙动作。具体的虚拟对象控制过程如下所示。FIG. 9 is a flowchart of a method for controlling a virtual object based on expression analysis according to an embodiment of the present application. As shown in Figure 9, within the specified time, the user controls the virtual object on the balance beam to move left and right by performing the action of baring teeth or closing the mouth, so as to avoid the virtual object falling from the balance beam. A small monster is set under the balance beam. After the object is dropped, it will be swallowed by the little monster. After swallowing, the virtual object can be automatically resurrected, and the game will continue until the countdown ends, and the game score will be calculated according to the number of automatic resurrection of the virtual object. During the game, on the upper right of the virtual scene screen, a cartoon avatar can be set. The cartoon avatar can change the shape of the mouth according to the current walking direction of the virtual object, prompting the player to perform a shut-mouth action or a baring action at the current moment. The specific virtual object control process is shown below.
首先,启动人脸检测与定位算法,对获取到的目标图像进行计算(S91),基于人脸检测与定位算法的计算结果,判断是否在目标图像中检测到目标人脸图像,若检测到目标人脸图像从目标图像中获取目标人脸图像的位置(S92),若终端没有检测到目标人脸图像,在终端显示屏上可以显示该虚拟场景对应的游戏开始画面,即未运行虚拟场景的画面(S93),若终端检测到目标人脸图像,则基于获取目标人脸图像的位置进行人脸特征点检测,获取至少两个面部区域对应的人脸特征点(S94),然后基于至少两个面部区域对应的人脸特征点进行表情分析(S95),若通过分析得到目标人脸图像中正在执行呲牙张嘴的面部动作,则控制虚拟场景中的第一虚拟对象向左进行奔跑(S96),若通过分析得到目标人脸图像中正在闭嘴的面部动作,则控制虚拟场景中的第一虚拟对象向右进行奔跑(S97),当虚拟场景的运行时间达到运行时长时,统计第一虚拟对象的移动情况,基于第一虚拟对象的移动情况确定该局虚拟场景运行过程中的游戏得分(S98)。First, start the face detection and localization algorithm, calculate the obtained target image (S91), and judge whether the target face image is detected in the target image based on the calculation result of the face detection and localization algorithm, and if the target is detected The face image obtains the position of the target face image from the target image (S92), if the terminal does not detect the target face image, the game start screen corresponding to the virtual scene can be displayed on the terminal display screen, that is, the virtual scene is not running. Screen (S93), if the terminal detects the target face image, then based on the position where the target face image is obtained, the face feature point detection is carried out, and the face feature points corresponding to at least two facial regions are obtained (S94), and then based on at least two The facial feature points corresponding to each facial region are subjected to expression analysis (S95), and if the facial action of baring teeth and opening mouth is being performed in the target facial image through the analysis, the first virtual object in the virtual scene is controlled to run to the left (S96). ), if the facial movement that is closing the mouth in the target face image is obtained by analysis, then the first virtual object in the virtual scene is controlled to run to the right (S97), when the running time of the virtual scene reaches the running time length, the first virtual object is counted The movement of the virtual object is based on the movement of the first virtual object to determine the game score during the running of the virtual scene of the round (S98).
综上所述,在本申请实施例所示的方案中,通过检测目标图像获取目标图像中的目标人脸图像,并且获取目标人脸图像中用于指示至少两个面部区域对应的位置信息的人脸特征点。基于人脸特征点确定至少两个面部区域对应的区域面积,基于至少两个面部区域对应的区域面积确定对应的面部动作,同时基于确定的面部动作控制第一虚拟对象执行不同的动作。通过上述方案,可以基于获取到的静态目标人脸图像中至少两个面部区域对应的区域面积确定该目标人脸图像对应的面部动作,并且基于确定的面部动作实现对第一虚拟对象的相应控制,避免了为了确定面部动作需要获取一段时间内人脸特征点的持续变化的情况,从而提高了进行面部动作分析的效率。To sum up, in the solution shown in the embodiment of the present application, the target face image in the target image is obtained by detecting the target image, and the information used to indicate the position information corresponding to at least two face regions in the target face image is obtained. face feature points. Areas corresponding to the at least two facial regions are determined based on the facial feature points, corresponding facial actions are determined based on the regions corresponding to the at least two facial regions, and the first virtual object is controlled to perform different actions based on the determined facial actions. Through the above solution, the facial action corresponding to the target face image can be determined based on the area areas corresponding to at least two face regions in the obtained static target face image, and the corresponding control of the first virtual object can be realized based on the determined facial action. , to avoid the situation that continuous changes of facial feature points need to be acquired over a period of time in order to determine the facial motion, thereby improving the efficiency of facial motion analysis.
基于上述方案可以设计一款基于面部动作控制虚拟对象移动的游戏。图10是根据一示例性实施例示出的一种虚拟场景界面示意图。如图10所示,在虚拟场景运行的初始阶段,具有指定时长的准备阶段1001,准备阶段1001可以对用户进行游戏玩法指导,由于考虑到该游戏的受众主要是老年人,因此游戏玩法在准备阶段1001需要进行玩法演示,用户需要面朝摄像头,在演示过程中,具有用户需要执行的面部动作的提示文字,当平衡木的左侧翘起时,玩家通过呲牙并张嘴可控制游戏小人往左侧奔跑避免掉落,当平衡木的右侧翘起时,玩家通过闭嘴控制游戏小人往右侧奔跑避免掉落。其中,准备阶段1001可以提供10s的试玩和熟悉玩法时间,并在屏幕显示指导文字,如“平衡的左侧翘起,呲牙控制小人往左侧方向奔跑避免掉落”或“平衡的右侧翘起,呲牙控制小人往右侧方向奔跑避免掉落”。准备阶段结束后,计时游戏开始。界面上可以显示“Ready GO”提示玩家进入计时游戏阶段1002,小人可以落到平衡木中央并往左走,同时开启30s的倒计时并在屏幕上方显示计时,此时需要玩家呲牙张嘴,控制小人往右走,当小人到达平衡木右侧时,需要玩家闭嘴控制小人往左走,如玩家不做任何操作,小人会朝一个方向继续走,直到从平衡木掉落,同时,计算一次小人死亡次数,同时小人会自动复活,继续游戏,直至倒计时结束。在游戏过程中,小人的移动速度会慢慢变快,从而提高游戏难度。当倒计时结束时,游戏结束显示场景运行结果画面1003。通过计算玩家死亡次数,得到玩家游戏得分,并返回相应的结束语激励玩家。根据玩家得分不同分别设置了相应的结束语言,比如,得分小于等于20分时,展示“初显身手,反应速度还可以更快,再接再厉哦”的提示语,得分大于20小于60分时,展示“熟能生巧,不错哦,你已经超越80%的玩家”的提示语,得分大于60小于80时,展示“实力超强,反应极快,你的反应速度简直太快了”的提示语,得分大于80小于等于100时,展示“出神入化,反应超神,你的速度超过99%的人”的提示语。Based on the above scheme, a game that controls the movement of virtual objects based on facial movements can be designed. Fig. 10 is a schematic diagram of a virtual scene interface according to an exemplary embodiment. As shown in FIG. 10 , in the initial stage of the virtual scene running, there is a
或者,基于上述方案可以设计另一款基于面部动作控制虚拟对象移动的游戏,虚拟场景中包括主控的第一虚拟对象,当虚拟场景开始运行时,即游戏进行过程中,在终端的显示屏幕上可以显示一个提示信息,该提示信息用于提示需要用户执行的面部动作,比如,提示信息对应的面部动作可以包括呲牙动作以及耸鼻动作,当用户按照该提示信息执行对应的呲牙动作时,显示屏幕上的该提示信息消失,替换为另一个为耸鼻动作的提示信息,同时,控制第一虚拟对象执行呲牙动作对应的迈左腿的动作;然后,当用户按照当前提示信息执行对应的耸鼻动作时,显示屏幕上的该提示信息消失,再次替换为呲牙动作对应的提示信息,同时,控制第一虚拟对象执行耸鼻动作对应的迈右腿的动作,当用户基于两种提示信息交替执行呲牙动作以及耸鼻动作时,可以控制虚拟场景中的第一虚拟对象迈左腿的动作以及迈右腿的动作交替执行,从而控制第一虚拟对象移动。Alternatively, based on the above solution, another game that controls the movement of virtual objects based on facial movements can be designed. The virtual scene includes the first virtual object of the master control. When the virtual scene starts to run, that is, during the game, the display screen of the terminal will be displayed on the display screen of the terminal. A prompt message can be displayed on the screen, and the prompt message is used to prompt the facial action that the user needs to perform. For example, the facial action corresponding to the prompt message can include a tooth barring action and a nose shrugging action. When the user performs the corresponding tooth barking action according to the prompt information , the prompt information on the display screen disappears, and is replaced with another prompt information for the nose-raising action. When performing the corresponding nose shrugging action, the prompt information on the display screen disappears, and is replaced with the prompt information corresponding to the gnawing action again. When the two kinds of prompt information alternately perform the baring action and the nose-raising action, the first virtual object in the virtual scene can be controlled to alternately perform the action of stepping on the left leg and the action of stepping on the right leg, thereby controlling the movement of the first virtual object.
综上所述,在本申请实施例所示的方案中,通过检测目标图像获取目标图像中的目标人脸图像,并且获取目标人脸图像中用于指示至少两个面部区域对应的位置信息的人脸特征点。基于人脸特征点确定至少两个面部区域对应的区域面积,基于至少两个面部区域对应的区域面积确定对应的面部动作,同时基于确定的面部动作控制第一虚拟对象执行不同的动作。通过上述方案,可以基于获取到的静态目标人脸图像中至少两个面部区域对应的区域面积确定该目标人脸图像对应的面部动作,并且基于确定的面部动作实现对第一虚拟对象的相应控制,避免了为了确定面部动作需要获取一段时间内人脸特征点的持续变化的情况,从而提高了进行面部动作分析的效率。To sum up, in the solution shown in the embodiment of the present application, the target face image in the target image is obtained by detecting the target image, and the information used to indicate the position information corresponding to at least two face regions in the target face image is obtained. face feature points. Areas corresponding to the at least two facial regions are determined based on the facial feature points, corresponding facial actions are determined based on the regions corresponding to the at least two facial regions, and the first virtual object is controlled to perform different actions based on the determined facial actions. Through the above solution, the facial action corresponding to the target face image can be determined based on the area areas corresponding to at least two face regions in the obtained static target face image, and the corresponding control of the first virtual object can be realized based on the determined facial action. , to avoid the situation that continuous changes of facial feature points need to be acquired over a period of time in order to determine the facial motion, thereby improving the efficiency of facial motion analysis.
图11是本申请一个示例性实施例提供的虚拟场景中虚拟对象的控制装置的结构框图,该装置可以设置于图2所示终端中,该装置包括:11 is a structural block diagram of an apparatus for controlling virtual objects in a virtual scene provided by an exemplary embodiment of the present application. The apparatus may be set in the terminal shown in FIG. 2 , and the apparatus includes:
特征获取模块1110,用于响应于检测到目标图像中存在目标人脸图像,获取所述目标人脸图像中至少两个面部区域对应的人脸特征点;所述人脸特征点用于指示所述面部区域对应的位置信息;The
面积获取模块1120,用于基于至少两个所述面部区域对应的人脸特征点,获取至少两个所述面部区域对应的区域面积;an
动作确定模块1130,用于基于至少两个所述面部区域对应的区域面积确定所述目标人脸图像对应的面部动作;an
动作切换模块1140,用于响应于所述面部动作由第一面部动作变化为第二面部动作,控制所述虚拟场景中的第一虚拟对象由执行第一动作切换为执行第二动作。The
在一种可能的实现方式中,所述动作确定模块1130,包括:In a possible implementation manner, the
数值获取子模块,用于获取第一比例数值,所述第一比例数值是至少两个所述面部区域中的第一面部区域的区域面积,与所述面部区域中的第二面部区域的区域面积之间的比值;A numerical value acquisition sub-module, configured to obtain a first proportional value, where the first proportional value is the area area of the first facial area in the at least two facial areas, and the area of the second facial area in the facial area the ratio between the area areas;
动作确定子模块,用于基于所述第一比例数值与比例阈值之间的大小关系,确定所述目标人脸图像对应的面部动作。The action determination submodule is configured to determine the facial action corresponding to the target face image based on the magnitude relationship between the first proportional value and the proportional threshold.
在一种可能的实现方式中,所述装置还包括:In a possible implementation, the apparatus further includes:
阈值获取子模块,用于基于所述第一比例数值与比例阈值之间的大小关系,确定所述目标人脸图像对应的面部动作之前,基于所述第一面部区域的部位种类以及所述第二面部区域的部位种类,获取所述比例阈值。A threshold acquisition sub-module is used for determining the facial action corresponding to the target face image based on the magnitude relationship between the first proportional value and the proportional threshold, based on the part type of the first facial region and the The part type of the second face region, and the proportional threshold is obtained.
在一种可能的实现方式中,所述面部区域的所述部位种类包括人脸外轮廓区域、眼睛区域、鼻子区域、外唇区域以及内唇区域中的至少两种。In a possible implementation manner, the types of parts of the facial region include at least two of the outer contour region of the human face, the eye region, the nose region, the outer lip region and the inner lip region.
在一种可能的实现方式中,响应于所述第一面部区域的部位种类是外唇区域,且所述第二面部区域的部位种类是内唇区域;In a possible implementation manner, in response to the part type of the first facial region is the outer lip region, and the part type of the second facial region is the inner lip region;
所述动作确定子模块,包括:The action determination sub-module includes:
闭嘴确定单元,用于响应于所述第一比例数值大于所述第一比例阈值,确定所述目标人脸图像对应的面部动作为闭嘴动作;a shut-mouth determination unit, configured to determine that the facial action corresponding to the target face image is a shut-mouth action in response to the first proportional value being greater than the first proportional threshold;
张嘴确定单元,用于响应于所述第一比例数值小于或者等于所述第一比例阈值,确定所述目标人脸图像对应的面部动作为张嘴动作。The mouth opening determination unit is configured to determine that the facial action corresponding to the target face image is the mouth opening action in response to the first proportional value being less than or equal to the first proportional threshold.
在一种可能的实现方式中,所述张嘴确定单元,用于,In a possible implementation manner, the mouth opening determining unit is configured to:
响应于所述第一比例数值小于或者等于所述第一比例阈值,获取所述目标人脸图像中,对应在所述内唇区域内部的第一区域图像;In response to the first scale value being less than or equal to the first scale threshold, acquiring an image of the first region in the target face image corresponding to the inside of the inner lip region;
在所述第一区域图像中进行牙齿检测;performing tooth detection in the first region image;
响应于在所述第一区域图像中检测到牙齿,确定所述目标人脸图像对应的所述面部动作为所述张嘴动作。In response to detecting teeth in the first region image, determining the facial action corresponding to the target face image as the mouth opening action.
在一种可能的实现方式中,所述面积获取模块1120,包括:In a possible implementation manner, the
顶点获取子模块,用于获取目标凸包顶点;所述目标凸包顶点是所述目标面部区域中用于构成凸包的所述人脸特征点;所述目标面部区域是至少两个面部区域中的任意一个;Vertex acquisition submodule, used for acquiring target convex hull vertices; the target convex hull vertices are the face feature points used to form the convex hull in the target face area; the target face area is at least two face areas any one of;
面积获取子模块,用于基于所述目标凸包顶点,获取所述目标面部区域的区域面积。The area acquisition submodule is configured to acquire the area area of the target face region based on the target convex hull vertex.
在一种可能的实现方式中,所述特征获取模块1110,包括:In a possible implementation, the
图像获取子模块,用于获取所述目标图像;an image acquisition submodule for acquiring the target image;
信息获取子模块,用于将所述目标图像输入目标人脸定位模型,获得由所述目标人脸定位模型输出的目标人脸图像信息;所述目标人脸定位模型包括底层网络、中间层网络以及头部层网络;所述底层网络用于进行图像特征提取;中间层网络用于进行连续的区域特征聚集;所述头部层网络用于通过线性回归算法输出所述目标人脸图像信息;所述目标人脸图像信息用于指示所述目标人脸图像所处的位置;an information acquisition sub-module, used for inputting the target image into a target face localization model to obtain target face image information output by the target face localization model; the target face localization model includes a bottom layer network and a middle layer network and a head layer network; the bottom layer network is used for image feature extraction; the middle layer network is used for continuous regional feature aggregation; the head layer network is used for outputting the target face image information through a linear regression algorithm; The target face image information is used to indicate the position where the target face image is located;
特征获取子模块,用于将所述目标人脸图像信息对应的所述目标人脸图像输入特征点识别模型,获得由所述特征点识别模型输出的至少两个面部区域对应的所述人脸特征点。A feature acquisition sub-module, configured to input the target face image corresponding to the target face image information into a feature point recognition model, and obtain the faces corresponding to at least two facial regions output by the feature point recognition model Feature points.
在一种可能的实现方式中,响应于所述面部区域包括人脸外轮廓区域以及内部器官区域;In a possible implementation manner, in response to the facial area including the outer contour area of the human face and the internal organ area;
所述特征获取子模块,包括:The feature acquisition submodule includes:
第一获取单元,用于将所述目标人脸图像输入所述特征点识别模型,通过所述特征点识别模型中第一数量的级联网络输出所述内部器官区域对应的所述人脸特征点;The first acquisition unit is used to input the target face image into the feature point recognition model, and output the face feature corresponding to the internal organ region through the first number of cascaded networks in the feature point recognition model point;
第二获取单元,用于通过第二数量的级联网络输出所述人脸外轮廓区域对应的所述人脸特征点;a second acquisition unit, configured to output the face feature points corresponding to the outer contour area of the face through a second number of cascaded networks;
其中,所述第一数量大于所述第二数量。Wherein, the first number is greater than the second number.
在一种可能的实现方式中,所述装置还包括:In a possible implementation, the apparatus further includes:
第一初始模块,用于基于至少两个所述面部区域对应的区域面积确定所述目标人脸图像对应的面部动作之前,控制所述第一虚拟对象沿着目标平台向初始方向进行移动;所述初始方向是第一方向或者第二方向;a first initial module, configured to control the first virtual object to move to the initial direction along the target platform before determining the facial action corresponding to the target face image based on the area areas corresponding to at least two of the face areas; The initial direction is the first direction or the second direction;
或者,or,
第二初始模块,用于在所述目标平台的中心位置处展示所述第一虚拟对象,且不进行移动。The second initial module is used for displaying the first virtual object at the center position of the target platform without moving.
综上所述,在本申请实施例所示的方案中,通过检测目标图像获取目标图像中的目标人脸图像,并且获取目标人脸图像中用于指示至少两个面部区域对应的位置信息的人脸特征点。基于人脸特征点确定至少两个面部区域对应的区域面积,基于至少两个面部区域对应的区域面积确定对应的面部动作,同时基于确定的面部动作控制第一虚拟对象执行不同的动作。通过上述方案,可以基于获取到的静态目标人脸图像中至少两个面部区域对应的区域面积确定该目标人脸图像对应的面部动作,并且基于确定的面部动作实现对第一虚拟对象的相应控制,避免了为了确定面部动作需要获取一段时间内人脸特征点的持续变化的情况,从而提高了进行面部动作分析的效率。To sum up, in the solution shown in the embodiment of the present application, the target face image in the target image is obtained by detecting the target image, and the information used to indicate the position information corresponding to at least two face regions in the target face image is obtained. face feature points. Areas corresponding to the at least two facial regions are determined based on the facial feature points, corresponding facial actions are determined based on the regions corresponding to the at least two facial regions, and the first virtual object is controlled to perform different actions based on the determined facial actions. Through the above solution, the facial action corresponding to the target face image can be determined based on the area areas corresponding to at least two face regions in the obtained static target face image, and the corresponding control of the first virtual object can be realized based on the determined facial action. , to avoid the situation that continuous changes of facial feature points need to be acquired over a period of time in order to determine the facial motion, thereby improving the efficiency of facial motion analysis.
图12是本申请一个示例性实施例提供的虚拟场景中虚拟对象的控制装置的结构框图,该装置可以设置于图2所示终端中,该装置包括:12 is a structural block diagram of an apparatus for controlling virtual objects in a virtual scene provided by an exemplary embodiment of the present application. The apparatus may be set in the terminal shown in FIG. 2 , and the apparatus includes:
初始画面展示模块1210,用于展示响应于检测到目标图像中存在目标人脸图像,展示所述虚拟场景对应的运行初始画面;所述运行初始画面中包括目标平台以及位于所述目标平台上的第一虚拟对象;所述目标平台是所述虚拟场景开始运行时所述第一虚拟对象所在的平台;The initial
第一移动模块1220,用于响应于所述第一虚拟对象位于目标平台上,且检测到所述目标人脸图像对应的面部动作符合第一面部动作,控制所述第一虚拟对象沿着所述目标平台向第一方向进行移动;The
第二移动模块1230,用于响应于所述第一虚拟对象位于所述目标平台上,且检测到所述面部动作符合第二面部动作,控制所述第一虚拟对象沿着所述目标平台向第二方向进行移动;所述第二方向是与所述第一方向相反的方向;The
次数修改模块1240,用于响应于所述第一虚拟对象的移动范围超过所述目标平台,修改虚拟对象失败次数;A
结果展示模块1250,用于响应于所述虚拟场景的运行时长达到指定时长,展示场景运行结果;所述场景运行结果是基于所述虚拟对象失败次数确定的。The
综上所述,在本申请实施例所示的方案中,通过检测目标图像获取目标图像中的目标人脸图像,并且获取目标人脸图像中用于指示至少两个面部区域对应的位置信息的人脸特征点。基于人脸特征点确定至少两个面部区域对应的区域面积,基于至少两个面部区域对应的区域面积确定对应的面部动作,同时基于确定的面部动作控制第一虚拟对象执行不同的动作。通过上述方案,可以基于获取到的静态目标人脸图像中至少两个面部区域对应的区域面积确定该目标人脸图像对应的面部动作,并且基于确定的面部动作实现对第一虚拟对象的相应控制,避免了为了确定面部动作需要获取一段时间内人脸特征点的持续变化的情况,从而提高了进行面部动作分析的效率。To sum up, in the solution shown in the embodiment of the present application, the target face image in the target image is obtained by detecting the target image, and the information used to indicate the position information corresponding to at least two face regions in the target face image is obtained. face feature points. Areas corresponding to the at least two facial regions are determined based on the facial feature points, corresponding facial actions are determined based on the regions corresponding to the at least two facial regions, and the first virtual object is controlled to perform different actions based on the determined facial actions. Through the above solution, the facial action corresponding to the target face image can be determined based on the area areas corresponding to at least two face regions in the obtained static target face image, and the corresponding control of the first virtual object can be realized based on the determined facial action. , to avoid the situation that continuous changes of facial feature points need to be acquired over a period of time in order to determine the facial motion, thereby improving the efficiency of facial motion analysis.
图13是根据一示例性实施例示出的一种计算机设备的结构示意图。所述计算机设备1300包括中央处理单元(Central Processing Unit,CPU)1301、包括随机存取存储器(Random Access Memory,RAM)1302和只读存储器(Read-Only Memory,ROM)1303的系统存储器1304,以及连接系统存储器1304和中央处理单元1301的系统总线1305。所述计算机设备1300还包括帮助计算机设备内的各个器件之间传输信息的基本输入/输出系统(Input/Output,I/O系统)1306,和用于存储操作系统1313、应用程序1314和其他程序模块1315的大容量存储设备1307。Fig. 13 is a schematic structural diagram of a computer device according to an exemplary embodiment. The
所述基本输入/输出系统1306包括有用于显示信息的显示器1308和用于用户输入信息的诸如鼠标、键盘之类的输入设备1309。其中所述显示器1308和输入设备1309都通过连接到系统总线1305的输入输出控制器1310连接到中央处理单元1301。所述基本输入/输出系统1306还可以包括输入输出控制器1310以用于接收和处理来自键盘、鼠标、或电子触控笔等多个其他设备的输入。类似地,输入输出控制器1310还提供输出到显示屏、打印机或其他类型的输出设备。The basic input/
所述大容量存储设备1307通过连接到系统总线1305的大容量存储控制器(未示出)连接到中央处理单元1301。所述大容量存储设备1307及其相关联的计算机设备可读介质为计算机设备1300提供非易失性存储。也就是说,所述大容量存储设备1307可以包括诸如硬盘或者只读光盘(Compact Disc Read-Only Memory,CD-ROM)驱动器之类的计算机设备可读介质(未示出)。The
不失一般性,所述计算机设备可读介质可以包括计算机设备存储介质和通信介质。计算机设备存储介质包括以用于存储诸如计算机设备可读指令、数据结构、程序模块或其他数据等信息的任何方法或技术实现的易失性和非易失性、可移动和不可移动介质。计算机设备存储介质包括RAM、ROM、可擦除可编程只读存储器(Erasable Programmable ReadOnly Memory,EPROM)、带电可擦可编程只读存储器(Electrically ErasableProgrammable Read-Only Memory,EEPROM),CD-ROM、数字视频光盘(Digital Video Disc,DVD)或其他光学存储、磁带盒、磁带、磁盘存储或其他磁性存储设备。当然,本领域技术人员可知所述计算机设备存储介质不局限于上述几种。上述的系统存储器1304和大容量存储设备1307可以统称为存储器。Without loss of generality, the computer device readable medium may include computer device storage media and communication media. Computer device storage media includes volatile and nonvolatile, removable and non-removable media implemented in any method or technology for storage of information such as computer device readable instructions, data structures, program modules or other data. The storage media of computer equipment include RAM, ROM, Erasable Programmable ReadOnly Memory (EPROM), Electrically Erasable Programmable Read-Only Memory (EEPROM), CD-ROM, digital Digital Video Disc (DVD) or other optical storage, cassette, magnetic tape, magnetic disk storage or other magnetic storage device. Of course, those skilled in the art know that the storage medium of the computer device is not limited to the above-mentioned ones. The
根据本公开的各种实施例,所述计算机设备1300还可以通过诸如因特网等网络连接到网络上的远程计算机设备运行。也即计算机设备1300可以通过连接在所述系统总线1305上的网络接口单元1311连接到网络1312,或者说,也可以使用网络接口单元1311来连接到其他类型的网络或远程计算机设备系统(未示出)。According to various embodiments of the present disclosure, the
所述存储器还包括一个或者一个以上的程序,所述一个或者一个以上程序存储于存储器中,中央处理器1301通过执行该一个或一个以上程序来实现图1、图4或图5所示的方法的全部或者部分步骤。The memory also includes one or more programs, the one or more programs are stored in the memory, and the
图14是根据一示例性实施例示出的计算机设备1400的结构框图。该计算机设备1400可以是图2所示的终端。FIG. 14 is a structural block diagram of a
通常,计算机设备1400包括有:处理器1401和存储器1402。Generally,
处理器1401可以包括一个或多个处理核心,比如4核心处理器、8核心处理器等。处理器1401可以采用DSP(Digital Signal Processing,数字信号处理)、FPGA(Field-Programmable Gate Array,现场可编程门阵列)、PLA(Programmable Logic Array,可编程逻辑阵列)中的至少一种硬件形式来实现。处理器1401也可以包括主处理器和协处理器,主处理器是用于对在唤醒状态下的数据进行处理的处理器,也称CPU(Central ProcessingUnit,中央处理器);协处理器是用于对在待机状态下的数据进行处理的低功耗处理器。在一些实施例中,处理器1401可以在集成有GPU(Graphics Processing Unit,图像处理器),GPU用于负责显示屏所需要显示的内容的渲染和绘制。一些实施例中,处理器1401还可以包括AI(Artificial Intelligence,人工智能)处理器,该AI处理器用于处理有关机器学习的计算操作。The
存储器1402可以包括一个或多个计算机可读存储介质,该计算机可读存储介质可以是非暂态的。存储器1402还可包括高速随机存取存储器,以及非易失性存储器,比如一个或多个磁盘存储设备、闪存存储设备。在一些实施例中,存储器1402中的非暂态的计算机可读存储介质用于存储至少一个指令,该至少一个指令用于被处理器1401所执行以实现本申请中方法实施例提供的方法。
在一些实施例中,计算机设备1400还可选包括有:外围设备接口1403和至少一个外围设备。处理器1401、存储器1402和外围设备接口1403之间可以通过总线或信号线相连。各个外围设备可以通过总线、信号线或电路板与外围设备接口1403相连。具体地,外围设备包括:射频电路1404、显示屏1405、摄像头组件1406、音频电路1407、定位组件1408和电源1409中的至少一种。In some embodiments, the
外围设备接口1403可被用于将I/O(Input/Output,输入/输出)相关的至少一个外围设备连接到处理器1401和存储器1402。在一些实施例中,处理器1401、存储器1402和外围设备接口1403被集成在同一芯片或电路板上;在一些其他实施例中,处理器1401、存储器1402和外围设备接口1403中的任意一个或两个可以在单独的芯片或电路板上实现,本实施例对此不加以限定。The
射频电路1404用于接收和发射RF(Radio Frequency,射频)信号,也称电磁信号。射频电路1404通过电磁信号与通信网络以及其他通信设备进行通信。射频电路1404将电信号转换为电磁信号进行发送,或者,将接收到的电磁信号转换为电信号。可选地,射频电路1404包括:天线系统、RF收发器、一个或多个放大器、调谐器、振荡器、数字信号处理器、编解码芯片组、用户身份模块卡等等。射频电路1404可以通过至少一种无线通信协议来与其它终端进行通信。该无线通信协议包括但不限于:万维网、城域网、内联网、各代移动通信网络(2G、3G、4G及5G)、无线局域网和/或WiFi(Wireless Fidelity,无线保真)网络。在一些实施例中,射频电路1404还可以包括NFC(Near Field Communication,近距离无线通信)有关的电路,本申请对此不加以限定。The
显示屏1405用于显示UI(User Interface,用户界面)。该UI可以包括图形、文本、图标、视频及其它们的任意组合。当显示屏1405是触摸显示屏时,显示屏1405还具有采集在显示屏1405的表面或表面上方的触摸信号的能力。该触摸信号可以作为控制信号输入至处理器1401进行处理。此时,显示屏1405还可以用于提供虚拟按钮和/或虚拟键盘,也称软按钮和/或软键盘。在一些实施例中,显示屏1405可以为一个,设置计算机设备1400的前面板;在另一些实施例中,显示屏1405可以为至少两个,分别设置在计算机设备1400的不同表面或呈折叠设计;在再一些实施例中,显示屏1405可以是柔性显示屏,设置在计算机设备1400的弯曲表面上或折叠面上。甚至,显示屏1405还可以设置成非矩形的不规则图形,也即异形屏。显示屏1405可以采用LCD(Liquid Crystal Display,液晶显示屏)、OLED(OrganicLight-Emitting Diode,有机发光二极管)等材质制备。The
摄像头组件1406用于采集图像或视频。可选地,摄像头组件1406包括前置摄像头和后置摄像头。通常,前置摄像头设置在终端的前面板,后置摄像头设置在终端的背面。在一些实施例中,后置摄像头为至少两个,分别为主摄像头、景深摄像头、广角摄像头、长焦摄像头中的任意一种,以实现主摄像头和景深摄像头融合实现背景虚化功能、主摄像头和广角摄像头融合实现全景拍摄以及VR(Virtual Reality,虚拟现实)拍摄功能或者其它融合拍摄功能。在一些实施例中,摄像头组件1406还可以包括闪光灯。闪光灯可以是单色温闪光灯,也可以是双色温闪光灯。双色温闪光灯是指暖光闪光灯和冷光闪光灯的组合,可以用于不同色温下的光线补偿。The
音频电路1407可以包括麦克风和扬声器。麦克风用于采集用户及环境的声波,并将声波转换为电信号输入至处理器1401进行处理,或者输入至射频电路1404以实现语音通信。出于立体声采集或降噪的目的,麦克风可以为多个,分别设置在计算机设备1400的不同部位。麦克风还可以是阵列麦克风或全向采集型麦克风。扬声器则用于将来自处理器1401或射频电路1404的电信号转换为声波。扬声器可以是传统的薄膜扬声器,也可以是压电陶瓷扬声器。当扬声器是压电陶瓷扬声器时,不仅可以将电信号转换为人类可听见的声波,也可以将电信号转换为人类听不见的声波以进行测距等用途。在一些实施例中,音频电路1407还可以包括耳机插孔。
定位组件1408用于定位计算机设备1400的当前地理位置,以实现导航或LBS(Location Based Service,基于位置的服务)。定位组件1408可以是基于美国的GPS(Global Positioning System,全球定位系统)、中国的北斗系统或俄罗斯的伽利略系统的定位组件。The
电源1409用于为计算机设备1400中的各个组件进行供电。电源1409可以是交流电、直流电、一次性电池或可充电电池。当电源1409包括可充电电池时,该可充电电池可以是有线充电电池或无线充电电池。有线充电电池是通过有线线路充电的电池,无线充电电池是通过无线线圈充电的电池。该可充电电池还可以用于支持快充技术。
在一些实施例中,计算机设备1400还包括有一个或多个传感器1410。该一个或多个传感器1410包括但不限于:加速度传感器1411、陀螺仪传感器1412、压力传感器1413、指纹传感器1414、光学传感器1415以及接近传感器1416。In some embodiments,
加速度传感器1411可以检测以计算机设备1400建立的坐标系的三个坐标轴上的加速度大小。比如,加速度传感器1411可以用于检测重力加速度在三个坐标轴上的分量。处理器1401可以根据加速度传感器1411采集的重力加速度信号,控制触摸显示屏1405以横向视图或纵向视图进行用户界面的显示。加速度传感器1411还可以用于游戏或者用户的运动数据的采集。The acceleration sensor 1411 can detect the magnitude of acceleration on the three coordinate axes of the coordinate system established by the
陀螺仪传感器1412可以检测计算机设备1400的机体方向及转动角度,陀螺仪传感器1412可以与加速度传感器1411协同采集用户对计算机设备1400的3D动作。处理器1401根据陀螺仪传感器1412采集的数据,可以实现如下功能:动作感应(比如根据用户的倾斜操作来改变UI)、拍摄时的图像稳定、游戏控制以及惯性导航。The gyroscope sensor 1412 can detect the body direction and rotation angle of the
压力传感器1413可以设置在计算机设备1400的侧边框和/或触摸显示屏1405的下层。当压力传感器1413设置在计算机设备1400的侧边框时,可以检测用户对计算机设备1400的握持信号,由处理器1401根据压力传感器1413采集的握持信号进行左右手识别或快捷操作。当压力传感器1413设置在触摸显示屏1405的下层时,由处理器1401根据用户对触摸显示屏1405的压力操作,实现对UI界面上的可操作性控件进行控制。可操作性控件包括按钮控件、滚动条控件、图标控件、菜单控件中的至少一种。The pressure sensor 1413 may be disposed on the side frame of the
指纹传感器1414用于采集用户的指纹,由处理器1401根据指纹传感器1414采集到的指纹识别用户的身份,或者,由指纹传感器1414根据采集到的指纹识别用户的身份。在识别出用户的身份为可信身份时,由处理器1401授权该用户执行相关的敏感操作,该敏感操作包括解锁屏幕、查看加密信息、下载软件、支付及更改设置等。指纹传感器1414可以被设置计算机设备1400的正面、背面或侧面。当计算机设备1400上设置有物理按键或厂商Logo时,指纹传感器1414可以与物理按键或厂商Logo集成在一起。The fingerprint sensor 1414 is used to collect the user's fingerprint, and the
光学传感器1415用于采集环境光强度。在一个实施例中,处理器1401可以根据光学传感器1415采集的环境光强度,控制触摸显示屏1405的显示亮度。具体地,当环境光强度较高时,调高触摸显示屏1405的显示亮度;当环境光强度较低时,调低触摸显示屏1405的显示亮度。在另一个实施例中,处理器1401还可以根据光学传感器1415采集的环境光强度,动态调整摄像头组件1406的拍摄参数。Optical sensor 1415 is used to collect ambient light intensity. In one embodiment, the
接近传感器1416,也称距离传感器,通常设置在计算机设备1400的前面板。接近传感器1416用于采集用户与计算机设备1400的正面之间的距离。在一个实施例中,当接近传感器1416检测到用户与计算机设备1400的正面之间的距离逐渐变小时,由处理器1401控制触摸显示屏1405从亮屏状态切换为息屏状态;当接近传感器1416检测到用户与计算机设备1400的正面之间的距离逐渐变大时,由处理器1401控制触摸显示屏1405从息屏状态切换为亮屏状态。Proximity sensor 1416, also known as a distance sensor, is typically provided on the front panel of
本领域技术人员可以理解,图14中示出的结构并不构成对计算机设备1400的限定,可以包括比图示更多或更少的组件,或者组合某些组件,或者采用不同的组件布置。Those skilled in the art can understand that the structure shown in FIG. 14 does not constitute a limitation on the
在一示例性实施例中,还提供了一种包括指令的非临时性计算机可读存储介质,例如包括至少一条指令、至少一段程序、代码集或指令集的存储器,上述至少一条指令、至少一段程序、代码集或指令集可由处理器执行以完成上述图1、图4或图5任一实施例所示的方法的全部或者部分步骤。例如,非临时性计算机可读存储介质可以是ROM、RAM、CD-ROM、磁带、软盘和光数据存储设备等。In an exemplary embodiment, there is also provided a non-transitory computer-readable storage medium including instructions, such as a memory including at least one instruction, at least one segment of program, code set or instruction set, the above at least one instruction, at least one segment The program, code set or instruction set can be executed by the processor to complete all or part of the steps of the method shown in any of the above-mentioned embodiments of FIG. 1 , FIG. 4 or FIG. 5 . For example, the non-transitory computer-readable storage medium may be ROM, RAM, CD-ROM, magnetic tapes, floppy disks, optical data storage devices, and the like.
本领域技术人员应该可以意识到,在上述一个或多个示例中,本公开实施例所描述的功能可以用硬件、软件、固件或它们的任意组合来实现。当使用软件实现时,可以将这些功能存储在计算机设备可读介质中或者作为计算机设备可读介质上的一个或多个指令或代码进行传输。计算机设备可读介质包括计算机设备存储介质和通信介质,其中通信介质包括便于从一个地方向另一个地方传送计算机设备程序的任何介质。存储介质可以是通用或专用计算机设备能够存取的任何可用介质。Those skilled in the art should realize that, in one or more of the above examples, the functions described in the embodiments of the present disclosure may be implemented by hardware, software, firmware, or any combination thereof. When implemented in software, the functions may be stored on or transmitted over as one or more instructions or code on a computer device-readable medium. Computer device-readable media includes both computer device storage media and communication media including any medium that facilitates transfer of a program for a computer device from one place to another. A storage medium can be any available medium that can be accessed by a general purpose or special purpose computer device.
根据本申请的一个方面,提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行上述方面的各种可选实现方式中提供的虚拟场景中虚拟对象的控制方法。According to one aspect of the present application, there is provided a computer program product or computer program comprising computer instructions stored in a computer readable storage medium. The processor of the computer device reads the computer instructions from the computer-readable storage medium, and the processor executes the computer instructions, so that the computer device executes the method for controlling virtual objects in a virtual scene provided in various optional implementations of the foregoing aspects.
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本申请的其它实施方案。本申请旨在涵盖本申请的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本申请的一般性原理并包括本申请未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本申请的真正范围和精神由下面的权利要求指出。Other embodiments of the present application will readily occur to those skilled in the art upon consideration of the specification and practice of the invention disclosed herein. This application is intended to cover any variations, uses or adaptations of this application that follow the general principles of this application and include common knowledge or conventional techniques in the technical field not disclosed in this application . The specification and examples are to be regarded as exemplary only, with the true scope and spirit of the application being indicated by the following claims.
应当理解的是,本申请并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本申请的范围仅由所附的权利要求来限制。It is to be understood that the present application is not limited to the precise structures described above and illustrated in the accompanying drawings and that various modifications and changes may be made without departing from the scope thereof. The scope of the application is limited only by the appended claims.
Claims (15)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110260263.6ACN115068940A (en) | 2021-03-10 | 2021-03-10 | Control method of virtual object in virtual scene, computer device and storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110260263.6ACN115068940A (en) | 2021-03-10 | 2021-03-10 | Control method of virtual object in virtual scene, computer device and storage medium |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN115068940Atrue CN115068940A (en) | 2022-09-20 |
Family
ID=83240469
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110260263.6APendingCN115068940A (en) | 2021-03-10 | 2021-03-10 | Control method of virtual object in virtual scene, computer device and storage medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN115068940A (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115793490A (en)* | 2023-02-06 | 2023-03-14 | 南通弈匠智能科技有限公司 | Intelligent household energy-saving control method based on big data |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101393599A (en)* | 2007-09-19 | 2009-03-25 | 中国科学院自动化研究所 | A Game Character Control Method Based on Facial Expressions |
| WO2018033155A1 (en)* | 2016-08-19 | 2018-02-22 | 北京市商汤科技开发有限公司 | Video image processing method, apparatus and electronic device |
| WO2020173036A1 (en)* | 2019-02-26 | 2020-09-03 | 博众精工科技股份有限公司 | Localization method and system based on deep learning |
| CN111860451A (en)* | 2020-08-03 | 2020-10-30 | 宿州小马电子商务有限公司 | A game interaction method based on facial expression recognition |
- 2021
- 2021-03-10CNCN202110260263.6Apatent/CN115068940A/enactivePending
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101393599A (en)* | 2007-09-19 | 2009-03-25 | 中国科学院自动化研究所 | A Game Character Control Method Based on Facial Expressions |
| WO2018033155A1 (en)* | 2016-08-19 | 2018-02-22 | 北京市商汤科技开发有限公司 | Video image processing method, apparatus and electronic device |
| WO2020173036A1 (en)* | 2019-02-26 | 2020-09-03 | 博众精工科技股份有限公司 | Localization method and system based on deep learning |
| CN111860451A (en)* | 2020-08-03 | 2020-10-30 | 宿州小马电子商务有限公司 | A game interaction method based on facial expression recognition |
Non-Patent Citations (5)
| Title |
|---|
| LOVEMISS-Y: "【个人整理】实例分割模型Mask-RCNN网络原理与架构详解", pages 2, Retrieved from the Internet <URL:https://blog.csdn.net/qq_27825451/article/details/89677068>* |
| RAQUEL BREEJON ROBINSON等: "\'In the Same Boat\': A Game of Mirroring Emotions for Enhancing Social Play", 《CHI EA \'19: EXTENDED ABSTRACTS OF THE 2019 CHI CONFERENCE ON HUMAN FACTORS IN COMPUTING SYSTEMS》, 2 May 2019 (2019-05-02), pages 1 - 4* |
| ZOMI酱: "人脸关键点检测综述", pages 9, Retrieved from the Internet <URL:https://zhuanlan.zhihu.com/p/42968117>* |
| 林启万: "基于情绪计算的驾驶行为研究", 《中国优秀硕士学位论文全文数据库》, 15 October 2014 (2014-10-15), pages 39 - 41* |
| 汤君友: "《虚拟现实技术与应用》", 31 August 2020, 南京:东南大学出版社, pages: 264 - 265* |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115793490A (en)* | 2023-02-06 | 2023-03-14 | 南通弈匠智能科技有限公司 | Intelligent household energy-saving control method based on big data |
| CN115793490B (en)* | 2023-02-06 | 2023-04-11 | 南通弈匠智能科技有限公司 | Intelligent household energy-saving control method based on big data |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US12415136B2 (en) | Model training method and apparatus, storage medium, and device | |
| US12148250B2 (en) | AI-based face recognition method and apparatus, device, and medium | |
| CN112911182B (en) | Game interaction method, device, terminal and storage medium | |
| JP2022529757A (en) | How to display virtual character faces, devices, computer devices, and computer programs | |
| CN111698564B (en) | Information recommendation method, device, equipment and storage medium | |
| Cordeiro et al. | ARZombie: A mobile augmented reality game with multimodal interaction | |
| US20240073402A1 (en) | Multi-perspective augmented reality experience | |
| CN110942479A (en) | Virtual object control method, storage medium, and electronic device | |
| CN113570645A (en) | Image registration method, apparatus, computer equipment and medium | |
| CN115129164A (en) | Interaction control method and system based on virtual reality and virtual reality equipment | |
| CN112306332B (en) | Method, device and equipment for determining selected target and storage medium | |
| CN116962776A (en) | Method, device, equipment and medium for updating score condition of sports event | |
| CN115068940A (en) | Control method of virtual object in virtual scene, computer device and storage medium | |
| CN114741559A (en) | Method, device and storage medium for determining video cover | |
| CN116883561B (en) | Animation generation method, training method, device and equipment of action controller | |
| CN111290579B (en) | Control method and device of virtual content, electronic equipment and computer readable medium | |
| HK40072454A (en) | Control method for virtual objects in virtual scene, computer equipment and storage medium | |
| US20220321772A1 (en) | Camera Control Method and Apparatus, and Terminal Device | |
| CN113559513A (en) | Motion generation model training method, motion generation method, device and equipment | |
| CN115543135A (en) | Display screen control method, device and equipment | |
| CN114519779B (en) | Motion generation model training method, device, equipment and storage medium | |
| CN102024448A (en) | System and method for adjusting image | |
| HK40024425A (en) | Artificial intelligence-based face recognition method and apparatus, device and medium | |
| HK40024425B (en) | Artificial intelligence-based face recognition method and apparatus, device and medium | |
| HK40053511A (en) | Training method of action generation model, action generation method, device, equipment |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| REG | Reference to a national code | Ref country code:HK Ref legal event code:DE Ref document number:40072454 Country of ref document:HK | |
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |