CN115035372A - A Rebar Detection Method Based on Target Detection - Google Patents
A Rebar Detection Method Based on Target DetectionDownload PDFInfo
- Publication number
- CN115035372A CN115035372ACN202210544283.0ACN202210544283ACN115035372ACN 115035372 ACN115035372 ACN 115035372ACN 202210544283 ACN202210544283 ACN 202210544283ACN 115035372 ACN115035372 ACN 115035372A
- Authority
- CN
- China
- Prior art keywords
- feature
- feature map
- module
- network
- steel bars
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images






Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/77—Processing image or video features in feature spaces; using data integration or data reduction, e.g. principal component analysis [PCA] or independent component analysis [ICA] or self-organising maps [SOM]; Blind source separation
- G06V10/80—Fusion, i.e. combining data from various sources at the sensor level, preprocessing level, feature extraction level or classification level
- G06V10/806—Fusion, i.e. combining data from various sources at the sensor level, preprocessing level, feature extraction level or classification level of extracted features
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/762—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using clustering, e.g. of similar faces in social networks
- G06V10/763—Non-hierarchical techniques, e.g. based on statistics of modelling distributions
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/764—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using classification, e.g. of video objects
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/766—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using regression, e.g. by projecting features on hyperplanes
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/82—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using neural networks
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V2201/00—Indexing scheme relating to image or video recognition or understanding
- G06V2201/06—Recognition of objects for industrial automation
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V2201/00—Indexing scheme relating to image or video recognition or understanding
- G06V2201/07—Target detection
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02P—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN THE PRODUCTION OR PROCESSING OF GOODS
- Y02P90/00—Enabling technologies with a potential contribution to greenhouse gas [GHG] emissions mitigation
- Y02P90/30—Computing systems specially adapted for manufacturing
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Evolutionary Computation (AREA)
- Physics & Mathematics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Software Systems (AREA)
- Medical Informatics (AREA)
- General Health & Medical Sciences (AREA)
- Databases & Information Systems (AREA)
- Computing Systems (AREA)
- Artificial Intelligence (AREA)
- Health & Medical Sciences (AREA)
- General Physics & Mathematics (AREA)
- Multimedia (AREA)
- Probability & Statistics with Applications (AREA)
- Image Analysis (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本发明属于密集目标检测技术领域,涉及一种基于目标检测的钢筋检测方法。The invention belongs to the technical field of dense target detection, and relates to a steel bar detection method based on target detection.
背景技术Background technique
近年来,随着人工智能技术的不断发展,将目标检测、神经网络等人工智能技术与其他传统行业结合起来,不仅能够提高效率和降低成本,还提高各行各业生产的产能。目前,钢筋计数通常是人工手动标记,依次计数。但是对于数量较多、堆积密集的一捆钢筋来说,这种人工计数方法费力费时且容易出错。因此,利用目标检测技术对成捆的密集钢筋进行准确检测具有重要的研究意义。相比人工计数,利用目标检测技术的优点不仅在于准确率高这一方面,更加能够促进工业生产的自动化和高效率发展,早日向智能化生产方向靠拢。In recent years, with the continuous development of artificial intelligence technology, combining artificial intelligence technologies such as target detection and neural networks with other traditional industries can not only improve efficiency and reduce costs, but also increase the production capacity of various industries. Currently, rebar counts are usually manually marked and counted sequentially. But for large, densely packed bundles of rebar, this manual counting method is laborious, time-consuming and error-prone. Therefore, it is of great significance to use target detection technology to accurately detect bundles of dense steel bars. Compared with manual counting, the advantage of using target detection technology is not only in the aspect of high accuracy, but also can promote the automation and high-efficiency development of industrial production, and move closer to the direction of intelligent production as soon as possible.
现有技术的钢筋检测方法主要存在以下两个问题There are the following two problems in the detection method of steel bars in the prior art
1、在钢筋检测的实际场景中,钢筋在图像中所占像素相对较小,相关特征的提取比较困难,并且在经过网络之后,小目标的特征信息会丢失导致检测结果的漏检率和误检率较高。1. In the actual scene of steel bar detection, the pixels occupied by steel bars in the image are relatively small, and it is difficult to extract relevant features, and after passing through the network, the feature information of small targets will be lost, resulting in missed detection rates and errors in detection results. The detection rate is high.
2、多捆钢筋堆积在一起会造成它们的边界难以区分,如果直接将所有钢筋一次性检测,会导致图片边缘的钢筋因相邻钢筋的遮挡而漏检。2. The stacking of multiple bundles of steel bars will make their boundaries difficult to distinguish. If all steel bars are directly detected at one time, the steel bars on the edge of the picture will be missed due to the occlusion of adjacent steel bars.
故针对现有技术的缺陷,实有必要提出一种技术方案以解决现有技术存在的技术问题。Therefore, in view of the defects of the prior art, it is necessary to propose a technical solution to solve the technical problems existing in the prior art.
发明内容SUMMARY OF THE INVENTION
为解决上述问题,本发明提供一种基于目标检测的钢筋检测方法,包括以下步骤:In order to solve the above problems, the present invention provides a method for detecting steel bars based on target detection, comprising the following steps:
S1,对钢筋图像数据进行预处理,并对模型进行预训练;S1, preprocessing the steel bar image data and pretraining the model;
S2,将图像输入到特征提取网络,输出特征图F″;S2, input the image to the feature extraction network, and output the feature map F";
S3,将S2得到的特征图F″进行特征融合;S3, perform feature fusion on the feature map F″ obtained in S2;
S4,对提取到的特征处理进行分类和回归,回归时通过非极大值抑制法抑制掉多余的预测框,保留一个最接近的作为最终输出的预测框;S4, classify and regress the extracted feature processing, suppress the redundant prediction frame by the non-maximum value suppression method during regression, and retain a closest prediction frame as the final output;
S5,统计S4最终输出的预测框数量,将其作为钢筋数量以实现钢筋计数的功能。S5, count the number of prediction boxes finally output by S4, and use it as the number of steel bars to realize the function of counting steel bars.
优选地,所述S1,对钢筋图像数据进行预处理,并对模型进行预训练,具体包括以下步骤:Preferably, in the S1, preprocessing the steel bar image data and pretraining the model, which specifically includes the following steps:
S11,通过数据增强来丰富钢筋数据集;S11, enrich the steel bar dataset through data augmentation;
S12,使用公开数据集PASCAL VOC2007在yolo-v4网络上进行预训练,加载yolo-v4中DarkNet53和PANet部分的权重;S12, use the public dataset PASCAL VOC2007 for pre-training on the yolo-v4 network, and load the weights of the DarkNet53 and PANet parts in yolo-v4;
S13,修改预训练模型中的Anchor尺寸,使用K-means聚类算法对钢筋数据集进行聚类,得到钢筋数据集的Anchor尺寸。S13, modify the Anchor size in the pre-training model, and use the K-means clustering algorithm to cluster the steel bar data set to obtain the Anchor size of the steel bar data set.
优选地,所述S11,通过数据增强来丰富钢筋数据集,具体包括以下步骤:Preferably, the S11, enriching the steel bar data set through data enhancement, specifically includes the following steps:
S111,保持图像的尺寸大小不变,随机调节对比度与亮度,同时采用噪声和图片模糊方法加强网络对图片的鲁棒性;S111, keeping the size of the image unchanged, randomly adjusting the contrast and brightness, and using noise and image blur methods to enhance the robustness of the network to the image;
S112,改变图片的尺寸,即将图片随机进行任意角度的旋转和翻转,同时将图片进行拉伸和压缩来扩大不同尺寸图片的数量。S112 , changing the size of the picture, that is, randomly rotating and flipping the picture at any angle, and simultaneously stretching and compressing the picture to expand the number of pictures of different sizes.
优选地,所述S13,修改预训练模型中的Anchor尺寸,具体包括以下步骤:Preferably, the S13, modifying the Anchor size in the pre-training model, specifically includes the following steps:
S131,随机选取K个聚类中心,将标注框划分到距离最近的聚类中心所在的类,所有的标注框都进行归类;S131, randomly select K cluster centers, divide the labeling frame into the class where the closest clustering center is located, and classify all the labeling frames;
S132,计算所有框宽和高的平均值,更新聚类中心;S132, calculate the average value of all frame widths and heights, and update the cluster center;
S133,重复S131和S132,直到聚类中心不变,得到Anchor尺寸。In S133, S131 and S132 are repeated until the cluster center remains unchanged, and the Anchor size is obtained.
优选地,所述S2,将图像输入到特征提取网络,输出特征图F″,具体为特征提取网络基于CSPDarknet53网络上进行改进,将CSPx模块尾部的CBM模块替换成CBAM模块,CBM模块由卷积层Conv、批量归一化BN、Mish激活函数组成,CSPx模块包括卷积模块,多个残差网络结构,合并模块Concat和CBAM模块。Preferably, in the S2, the image is input into the feature extraction network, and the feature map F" is output. Specifically, the feature extraction network is improved based on the CSPDarknet53 network, and the CBM module at the end of the CSPx module is replaced by a CBAM module, and the CBM module is composed of convolutional modules. Layer Conv, batch normalization BN, Mish activation function, CSPx module includes convolution module, multiple residual network structures, merging module Concat and CBAM module.
优选地,所述S2,将图像输入到特征提取网络,输出特征图F″,具体包括以下步骤:Preferably, in the S2, the image is input to the feature extraction network, and the feature map F" is output, which specifically includes the following steps:
S21,将特征图F输入到通道注意力模块,输出通道注意力特征图Mc(F),与原特征图F按对应元素相乘得到
S22,将特征图F′输入到空间注意力模块,得到最终的特征图F″。S22, input the feature map F' to the spatial attention module to obtain the final feature map F".
优选地,所述S21具体包括以下步骤:Preferably, the S21 specifically includes the following steps:
S211,将输入特征图F分别进行最大池化和平均池化得到




S212,特征图




其中,σ是Sigmoid函数,W0和W1是多层感知器的共享权重;where σ is the sigmoid function, and W0 and W1 are the shared weights of the multilayer perceptron;
S213,将通道注意力特征图Mc(F)进行广播,与原特征图F按对应元素相乘得到
优选地,所述S22具体包括以下步骤:Preferably, the S22 specifically includes the following steps:
S221,将S21得到的F′进行最大池化和平均池化,得到





S222,通过7×7卷积层将特征图Fcat的通道数量减少到1,经过Sigmoid函数生成空间注意力模块输出的特征图Ms(F′),计算公式为:S222, reduce the number of channels of the feature map Fcat to 1 through the 7×7 convolution layer, and generate the feature map Ms (F′) output by the spatial attention module through the Sigmoid function. The calculation formula is:
Ms(F′)=σ(f7×7(Fcat))Ms (F′)=σ(f7×7 (Fcat ))
其中,f代表卷积操作,7×7是卷积核大小;Among them, f represents the convolution operation, and 7×7 is the size of the convolution kernel;
S223,将注意力特征图Ms(F′)进行广播,与原特征图F′按元素相乘得到
优选地,所述S3,将S2得到的特征图F″进行特征融合中,特征融合网络在yolo-v4中的PANet网络中引入自适应空间特征融合模块,具体包括以下步骤:Preferably, in the S3, the feature map F" obtained in S2 is subjected to feature fusion, and the feature fusion network introduces an adaptive spatial feature fusion module into the PANet network in yolo-v4, which specifically includes the following steps:
S31,通过空间金字塔池化和特征金字塔网络得到三层尺寸和大小不同的特征图X1,X2,X3;S31, obtain three layers of feature maps X1 , X2 , X3 with different sizes and sizes through spatial pyramid pooling and feature pyramid network;
S32,将输出的三个特征图进行融合操作,各层特征图融合时作相加操作,并且计算每层的权重参数,然后将三层特征图分别与计算出的权重参数相乘,输出最后相加的结果,公式为:S32, perform a fusion operation on the output three feature maps, perform an addition operation when the feature maps of each layer are fused, and calculate the weight parameters of each layer, and then multiply the three-layer feature maps with the calculated weight parameters respectively, and output the final The result of the addition, the formula is:
yi=αi·X1→i+βi·X2→i+γi·X3→ii=1,2,3yi =αi ·X1→i +βi ·X2→i +γi ·X3→i i=1, 2, 3
其中,X1→i、X2→i、X3→i分别为三个不同层要与第i层特征图大小相同时获得的特征向量,αi、βi、γi分别为从三个不同层融合到第i层时对应的权重参数,由网络自适应学习,参数大小在0到1之间,且αi+βi+γi=1。Among them, X1→i , X2→i , X3→i are the feature vectors obtained when three different layers have the same size as the feature map of the i-th layer, respectively, αi , βi , γi are from the three The corresponding weight parameters when different layers are fused to the i-th layer are adaptively learned by the network, the parameter size is between 0 and 1, and αi +βi +γi =1.
优选地,所述S4具体为使用Soft-DIoU-NMS算法,其策略是不把那些超出阈值的框抑制掉,而是先将它们的置信度降低,使它们暂时保留下来,Soft-DIoU-NMS的公式为:Preferably, the S4 specifically uses the Soft-DIoU-NMS algorithm, and its strategy is not to suppress those frames that exceed the threshold, but to reduce their confidence first, so that they are temporarily retained, Soft-DIoU-NMS The formula is:

其中,S是置信度得分,X是所有候选框中置信度最高的框,Y是其余候选框,IoU(X,γ)表示两个候选框的交并比,n是设定的阈值,默认设为0.5;ρ2(,)表示两点之间距离的平方,a、b分别为候选框X和Y的中心点,l是候选框X和Y的最小外接框的对角线长度。Among them, S is the confidence score, X is the frame with the highest confidence in all candidate frames, Y is the remaining candidate frames, IoU(X, γ) represents the intersection ratio of the two candidate frames, n is the set threshold, the default Set to 0.5; ρ2 (,) represents the square of the distance between two points, a and b are the center points of candidate frames X and Y, respectively, and l is the diagonal length of the minimum bounding frame of candidate frames X and Y.
本发明有益效果至少包括:The beneficial effects of the present invention at least include:
1、在特征提取网络的CSPx模块中增加了CBAM模块来改善模型对钢筋的检测性能,从通道和空间两个方向对钢筋特征提取部分进行优化,将相关特征的权重增大,将无关特征的权重减小,使网络更加关注包含重要信息的区域,而抑制不相关信息的区域,提高钢筋检测的整体准确度,有效缓解钢筋之间间距密集并且尺寸较小导致的检测精度低的问题;1. The CBAM module is added to the CSPx module of the feature extraction network to improve the detection performance of the model for steel bars. The feature extraction part of the steel bar is optimized from the two directions of the channel and space, and the weight of the relevant features is increased. The reduction of the weight makes the network pay more attention to the areas containing important information, while suppressing the areas with irrelevant information, which improves the overall accuracy of steel bar detection, and effectively alleviates the problem of low detection accuracy caused by dense spacing and small size between steel bars;
2、在特征融合网络引入的ASFF模块可以保留底层信息在传递过程中的特征表达能力并且减少不相关特征的干扰。避免因堆叠钢筋间距较密的时候,个别钢筋被旁边的钢筋遮挡导致特征缺失或者提取不充分的问题,降低了漏检率;2. The ASFF module introduced in the feature fusion network can retain the feature expression ability of the underlying information in the transfer process and reduce the interference of irrelevant features. Avoid the problem of missing features or insufficient extraction due to the fact that individual steel bars are blocked by adjacent steel bars when the spacing between stacked steel bars is relatively close, and the missed detection rate is reduced;
3、对小目标检测的时候,相邻检测框会由于重叠面积过大被非极大值抑制法筛选掉,根据钢筋检测的实际情况在预测阶段采用了更加柔和的Soft-DIoU-NMS算法。改进后的预测模型提高了检测钢筋时的准确率。3. When detecting small targets, the adjacent detection frames will be screened out by the non-maximum value suppression method due to the excessive overlapping area. According to the actual situation of steel bar detection, a softer Soft-DIoU-NMS algorithm is adopted in the prediction stage. The improved predictive model increases the accuracy of detecting rebar.
附图说明Description of drawings
图1为本发明基于目标检测的钢筋检测方法的步骤流程图;Fig. 1 is the step flow chart of the steel bar detection method based on target detection of the present invention;
图2为本发明基于目标检测的钢筋检测方法的网络整体结构图;Fig. 2 is the overall network structure diagram of the steel bar detection method based on target detection of the present invention;
图3为本发明基于目标检测的钢筋检测方法的特征提取网络结构图;Fig. 3 is the feature extraction network structure diagram of the steel bar detection method based on target detection of the present invention;
图4为本发明基于目标检测的钢筋检测方法的注意力机制模块结构图;Fig. 4 is the structure diagram of the attention mechanism module of the steel bar detection method based on target detection of the present invention;
图5为本发明基于目标检测的钢筋检测方法的通道注意力模块结构图;Fig. 5 is the structure diagram of the channel attention module of the steel bar detection method based on target detection of the present invention;
图6为本发明基于目标检测的钢筋检测方法的空间注意力模块结构图;6 is a structural diagram of a spatial attention module of the steel bar detection method based on target detection of the present invention;
图7为本发明基于目标检测的钢筋检测方法的特征融合网络结构图。FIG. 7 is a feature fusion network structure diagram of the target detection-based steel bar detection method of the present invention.
具体实施方式Detailed ways
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。In order to make the objectives, technical solutions and advantages of the present invention clearer, the present invention will be further described in detail below with reference to the accompanying drawings and embodiments. It should be understood that the specific embodiments described herein are only used to explain the present invention, but not to limit the present invention.
相反,本发明涵盖任何由权利要求定义的在本发明的精髓和范围上做的替代、修改、等效方法以及方案。进一步,为了使公众对本发明有更好的了解,在下文对本发明的细节描述中,详尽描述了一些特定的细节部分。对本领域技术人员来说没有这些细节部分的描述也可以完全理解本发明。On the contrary, the present invention covers any alternatives, modifications, equivalents and arrangements within the spirit and scope of the present invention as defined by the appended claims. Further, in order to give the public a better understanding of the present invention, some specific details are described in detail in the following detailed description of the present invention. The present invention can be fully understood by those skilled in the art without the description of these detailed parts.
参见图1,为本发明实施例的本发明的技术方案为基于目标检测的钢筋检测方法的示意图,包括以下步骤:Referring to FIG. 1, it is a schematic diagram of a method for detecting steel bars based on target detection according to an embodiment of the present invention, which includes the following steps:
S1,对钢筋图像数据进行预处理,并对模型进行预训练;S1, preprocessing the steel bar image data and pretraining the model;
S2,将图像输入到特征提取网络,输出特征图F″;S2, input the image to the feature extraction network, and output the feature map F";
S3,将S2得到的特征图F″进行特征融合;S3, perform feature fusion on the feature map F″ obtained in S2;
S4,对提取到的特征处理进行分类和回归,回归时通过非极大值抑制法抑制掉多余的预测框,保留一个最接近的作为最终输出的预测框;S4, classify and regress the extracted feature processing, suppress the redundant prediction frame by the non-maximum value suppression method during regression, and retain a closest prediction frame as the final output;
S5,统计S4最终输出的预测框数量,将其作为钢筋数量以实现钢筋计数的功能。S5, count the number of prediction boxes finally output by S4, and use it as the number of steel bars to realize the function of counting steel bars.
图2为本发明方法对应的网络结构图,从输入图像(Input)经过预处理、特征提取网络、特征融合网络后输出预测框。FIG. 2 is a network structure diagram corresponding to the method of the present invention, and a prediction frame is output from an input image (Input) after preprocessing, a feature extraction network, and a feature fusion network.
对于S1,对钢筋图像数据进行预处理,并对模型进行预训练,具体包括以下步骤:For S1, the rebar image data is preprocessed and the model is pretrained, which includes the following steps:
S11,通过数据增强来丰富钢筋数据集;S11, enrich the steel bar dataset through data augmentation;
S12,使用公开数据集PASCAL VOC2007在yolo-v4网络上进行预训练,加载yolo-v4中DarkNet53和PANet部分的权重;S12, use the public dataset PASCAL VOC2007 for pre-training on the yolo-v4 network, and load the weights of the DarkNet53 and PANet parts in yolo-v4;
S13,修改预训练模型中的Anchor尺寸,使用K-means聚类算法对钢筋数据集进行聚类,得到钢筋数据集的Anchor尺寸。S13, modify the Anchor size in the pre-training model, and use the K-means clustering algorithm to cluster the steel bar data set to obtain the Anchor size of the steel bar data set.
其中,S11,通过数据增强来丰富钢筋数据集,具体包括以下步骤:Among them, S11, enriching the reinforcement data set through data enhancement, specifically includes the following steps:
S111,保持图像的尺寸大小不变,随机调节对比度与亮度,同时采用噪声和图片模糊方法加强网络对图片的鲁棒性;S111, keeping the size of the image unchanged, randomly adjusting the contrast and brightness, and using noise and image blur methods to enhance the robustness of the network to the image;
S112,改变图片的尺寸,即将图片随机进行任意角度的旋转和翻转,同时将图片进行拉伸和压缩来扩大不同尺寸图片的数量。S112 , changing the size of the picture, that is, randomly rotating and flipping the picture at any angle, and simultaneously stretching and compressing the picture to expand the number of pictures of different sizes.
S13,修改预训练模型中的Anchor尺寸,具体包括以下步骤:S13, modify the Anchor size in the pre-training model, which specifically includes the following steps:
S131,随机选取K个聚类中心,将标注框划分到距离最近的聚类中心所在的类,所有的标注框都进行归类;S131, randomly select K cluster centers, divide the labeling frame into the class where the closest clustering center is located, and classify all the labeling frames;
S132,计算所有框宽和高的平均值,更新聚类中心;S132, calculate the average value of all frame widths and heights, and update the cluster center;
S133,重复S131和S132,直到聚类中心几乎不变,得到Anchor尺寸。In S133, S131 and S132 are repeated until the cluster center is almost unchanged, and the Anchor size is obtained.
S2,将图像输入到图3所示的特征提取网络,输出特征图F″,具体为特征提取网络基于CSPDarknet53网络上进行改进,将CSPx(Cross stage partial Network,跨阶段局部网络),模块尾部的CBM(卷积)模块替换成CBAM(Convolutional Block Attention Module,注意力机制)模块,CBM模块由卷积层Conv、批量归一化BN、Mish激活函数组成,CSPx模块包括卷积模块,多个残差网络结构,合并模块Concat和CBAM模块,首先经过一个卷积模块,然后一部分经过多个残差网络结构,另一部分经过常规卷积处理。最后将两部分进行合并(Concat),经过CBAM模块。S2, input the image to the feature extraction network shown in Figure 3, and output the feature map F". Specifically, the feature extraction network is improved based on the CSPDarknet53 network, and the CSPx (Cross stage partial Network, cross-stage partial network), the module tail The CBM (convolution) module is replaced by the CBAM (Convolutional Block Attention Module, attention mechanism) module. The CBM module consists of the convolutional layer Conv, batch normalized BN, and Mish activation function. The CSPx module includes a convolution module, multiple residuals Difference network structure, merge module Concat and CBAM module, first go through a convolution module, then part through multiple residual network structures, and the other part through conventional convolution processing. Finally, the two parts are merged (Concat) and passed through the CBAM module.
CBAM的结构参见图4。特征图F(图4中Input Feature)进入CBAM模块会先经过通道注意力模块,按照通道特征的重要性突出钢筋相关特征,减小无关特征,输出的特征图Mc(F)与原特征图F相乘得到F′作为空间注意力模块的输入,在空间上进一步对钢筋特征进行增强,输出的特征图Ms(F′)与特征图F′相乘得到最终的特征图F″(图4中RefinedFeature)。公式如下所示:The structure of CBAM is shown in Figure 4. When the feature map F (Input Feature in Figure 4) enters the CBAM module, it will first pass through the channel attention module, highlight the relevant features of the steel bar according to the importance of the channel features, and reduce the irrelevant features. The output feature map Mc (F) is the same as the original feature map. F ismultiplied to obtain F' as the input of the spatial attention module, and the reinforcement features are further enhanced in space. 4 in RefinedFeature). The formula is as follows:

其中Mc(F)是通道注意力模块21的输出,Ms(F′)是空间注意力模块22输出的特征图,F″是CBAM模块输出的特征图。whereMc (F) is the output of the channel attention module 21, Ms(F′) is the feature map output by the spatial attention module 22, and F″ is the feature map output by theCBAM module.
S2,将图像输入到特征提取网络,输出特征图F″,具体包括以下步骤:S2, input the image into the feature extraction network, and output the feature map F", which specifically includes the following steps:
S21,将特征图F(图5中Input Feature)输入到图5所示的通道注意力模块21,输出通道注意力特征图Mc(F)(图5中Channel Attention),与原特征图F按对应元素相乘得到
S22,将特征图F′输入到空间注意力模块,得到最终的特征图F″。S22, input the feature map F' to the spatial attention module to obtain the final feature map F".
S21具体包括以下步骤:S21 specifically includes the following steps:
S211,将输入特征图F分别进行最大池化(MaxPool)和平均池化(AvgPool)得到



S212,特征图




其中,σ是Sigmoid函数,W0和W1是多层感知器的共享权重;where σ is the sigmoid function, and W0 and W1 are the shared weights of the multilayer perceptron;
S213,将通道注意力特征图Mc(F)进行广播,与原特征图F按对应元素相乘得到
S22具体包括以下步骤:S22 specifically includes the following steps:
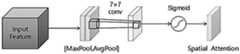
S221,将S21得到的F′(图6中Input Feature)输入图6所示的空间注意力模块22,进行最大池化和平均池化,得到




S222,通过7×7卷积层将特征图Fcat的通道数量减少到1,经过Sigmoid函数生成空间注意力模块输出的特征图Ms(F′)(图6中Spatial Attention),计算公式为:S222, the number of channels of the feature map Fcat is reduced to 1 through the 7×7 convolutional layer, and the feature map Ms (F′) output by the spatial attention module is generated by the Sigmoid function (Spatial Attention in Figure 6). The calculation formula is :
Ms(F′)=σ(f7×7(Fcat))Ms (F′)=σ(f7×7 (Fcat ))
其中,f代表卷积操作,7×7是卷积核大小;Among them, f represents the convolution operation, and 7×7 is the size of the convolution kernel;
S223,将注意力特征图Ms(F′)进行广播,与原特征图F′按元素相乘得到
S3,将S2得到的特征图F″进行特征融合中,特征融合网络参见图7,在yolo-v4中的PANet网络中引入自适应空间特征融合模块,具体包括以下步骤:S3, perform feature fusion on the feature map F″ obtained in S2, the feature fusion network is shown in Figure 7, and an adaptive spatial feature fusion module is introduced into the PANet network in yolo-v4, which specifically includes the following steps:
S31,通过空间金字塔池化(Spatial Pyramid Pooling,SPP)和特征金字塔网络(Feature Pyramid Networks,FPN)得到三层尺寸和大小不同的特征图X1,X2,X3;S31, obtain three layers of feature maps X1 , X2 , X3 with different sizes and sizes through Spatial Pyramid Pooling (Spatial Pyramid Pooling, SPP) and Feature Pyramid Networks (Feature Pyramid Networks, FPN);
S32,将输出的三个特征图进行融合操作(ASFF,Adaptively Spatial FeatureFusion),各层特征图融合时作相加操作,并且计算每层的权重参数,然后将三层特征图分别与计算出的权重参数相乘,输出最后相加的结果,公式为:S32, perform a fusion operation on the three output feature maps (ASFF, Adaptively Spatial FeatureFusion), perform an addition operation when the feature maps of each layer are fused, and calculate the weight parameters of each layer, and then combine the three-layer feature maps with the calculated The weight parameters are multiplied, and the final addition result is output. The formula is:
yi=αi·X1→i+βi·X2→i+γi·X3→ii=1,2,3yi =αi ·X1→i +βi ·X2→i +γi ·X3→i i=1, 2, 3
其中,X1→i、X2→i、X3→i分别为三个不同层要与第i层特征图大小相同时获得的特征向量,αi、βi、γi分别为从三个不同层融合到第i层时对应的权重参数,由网络自适应学习,参数大小在0到1之间,且αi+βi+γi=1。αi的学习方法可以表示为以下步骤,βi与γi的学习方法与αi相同。Among them, X1→i , X2→i , X3→i are the feature vectors obtained when three different layers have the same size as the feature map of the i-th layer, respectively, αi , βi , γi are from the three The corresponding weight parameters when different layers are fused to the i-th layer are adaptively learned by the network, the parameter size is between 0 and 1, and αi +βi +γi =1. The learning method of αi can be expressed as the following steps, and the learning methods of βi and γi are the same as αi .
S321,将X1→i、X2→i、X3→i进行1x1的卷积得到
S322,通过softmax算法得到αi的值,公式为S322, the value of αi is obtained by the softmax algorithm, and the formula is

S4具体为使用Soft-DIoU-NMS算法,其策略是不把那些超出阈值的框抑制掉,而是先将它们的置信度降低,使它们暂时保留下来,Soft-DIoU-NMS的公式为:S4 specifically uses the Soft-DIoU-NMS algorithm. The strategy is not to suppress those boxes that exceed the threshold, but to reduce their confidence first to keep them temporarily. The formula of Soft-DIoU-NMS is:

其中,S是置信度得分,X是所有候选框中置信度最高的框,Y是其余候选框,IoU(X,Y)表示两个候选框的交并比,n是设定的阈值,默认设为0.5;ρ2(,)表示两点之间距离的平方,a、b分别为候选框X和Y的中心点,l是候选框X和Y的最小外接框的对角线长度。Among them, S is the confidence score, X is the frame with the highest confidence in all candidate frames, Y is the remaining candidate frames, IoU(X, Y) represents the intersection ratio of the two candidate frames, n is the set threshold, the default Set to 0.5; ρ2 (,) represents the square of the distance between the two points, a and b are the center points of the candidate frames X and Y, respectively, and l is the diagonal length of the minimum bounding frame of the candidate frames X and Y.
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。The above descriptions are only preferred embodiments of the present invention and are not intended to limit the present invention. Any modifications, equivalent replacements and improvements made within the spirit and principles of the present invention shall be included in the protection of the present invention. within the range.
Claims (10)




















Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210544283.0ACN115035372A (en) | 2022-05-18 | 2022-05-18 | A Rebar Detection Method Based on Target Detection |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210544283.0ACN115035372A (en) | 2022-05-18 | 2022-05-18 | A Rebar Detection Method Based on Target Detection |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN115035372Atrue CN115035372A (en) | 2022-09-09 |
Family
ID=83121243
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210544283.0APendingCN115035372A (en) | 2022-05-18 | 2022-05-18 | A Rebar Detection Method Based on Target Detection |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN115035372A (en) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115578628A (en)* | 2022-09-29 | 2023-01-06 | 中铁第四勘察设计院集团有限公司 | Deep learning-based reinforcement bar number identification and positioning method |
| CN116994244A (en)* | 2023-08-16 | 2023-11-03 | 临海市特产技术推广总站(临海市柑桔产业技术协同创新中心) | Method for evaluating fruit yield of citrus tree based on Yolov8 |
| CN119832317A (en)* | 2024-12-23 | 2025-04-15 | 安徽大学 | Point counting-based steel bar semi-finished product point inspection embedded system |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20200013170A1 (en)* | 2017-03-31 | 2020-01-09 | Olympus Corporation | Information processing apparatus, rebar counting apparatus, and method |
| CN111127457A (en)* | 2019-12-25 | 2020-05-08 | 上海找钢网信息科技股份有限公司 | Reinforcing steel bar number statistical model training method, statistical method, device and equipment |
| CN113888513A (en)* | 2021-09-30 | 2022-01-04 | 电子科技大学 | Reinforcing steel bar detection counting method based on deep neural network model |
| CN114202672A (en)* | 2021-12-09 | 2022-03-18 | 南京理工大学 | A small object detection method based on attention mechanism |
| CN114330529A (en)* | 2021-12-24 | 2022-04-12 | 重庆邮电大学 | Real-time pedestrian shielding detection method based on improved YOLOv4 |
- 2022
- 2022-05-18CNCN202210544283.0Apatent/CN115035372A/enactivePending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20200013170A1 (en)* | 2017-03-31 | 2020-01-09 | Olympus Corporation | Information processing apparatus, rebar counting apparatus, and method |
| CN111127457A (en)* | 2019-12-25 | 2020-05-08 | 上海找钢网信息科技股份有限公司 | Reinforcing steel bar number statistical model training method, statistical method, device and equipment |
| CN113888513A (en)* | 2021-09-30 | 2022-01-04 | 电子科技大学 | Reinforcing steel bar detection counting method based on deep neural network model |
| CN114202672A (en)* | 2021-12-09 | 2022-03-18 | 南京理工大学 | A small object detection method based on attention mechanism |
| CN114330529A (en)* | 2021-12-24 | 2022-04-12 | 重庆邮电大学 | Real-time pedestrian shielding detection method based on improved YOLOv4 |
Non-Patent Citations (5)
| Title |
|---|
| SONGTAO LIU ET AL.: "Learning Spatial Fusion for Single-Shot Object Detection", 《ARXIV:1911.09516V1 [CS.CV]》* |
| 李姚舜 等: "嵌入注意力机制的轻量级钢筋检测网络", 《计算机应用》* |
| 石京磊: "基于卷积神经网络的钢筋计数算法研究", 《中国优秀硕士学位论文全文数据库 工程科技Ⅱ辑》* |
| 蔡舒平 等: "基于改进型YOLOv4的果园障碍物实时检测方法", 《农业工程学报》* |
| 赵博研 等: "改进YOLOv4算法的GFRP内部缺陷检测与识别", 《空军工程大学学报(自然科学版)》* |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115578628A (en)* | 2022-09-29 | 2023-01-06 | 中铁第四勘察设计院集团有限公司 | Deep learning-based reinforcement bar number identification and positioning method |
| CN116994244A (en)* | 2023-08-16 | 2023-11-03 | 临海市特产技术推广总站(临海市柑桔产业技术协同创新中心) | Method for evaluating fruit yield of citrus tree based on Yolov8 |
| CN119832317A (en)* | 2024-12-23 | 2025-04-15 | 安徽大学 | Point counting-based steel bar semi-finished product point inspection embedded system |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN115035372A (en) | A Rebar Detection Method Based on Target Detection | |
| CN108133188B (en) | Behavior identification method based on motion history image and convolutional neural network | |
| CN111882002A (en) | A low-light target detection method based on MSF-AM | |
| CN111539343B (en) | Black smoke vehicle detection method based on convolution attention network | |
| CN111062297B (en) | Violent abnormal behavior detection method based on EANN deep learning model | |
| CN113052006B (en) | Image target detection method, system and readable storage medium based on convolutional neural network | |
| CN111814889B (en) | A single-stage object detection method using anchor-free module and enhanced classifier | |
| Arkin et al. | A survey of object detection based on CNN and transformer | |
| CN109101897A (en) | Object detection method, system and the relevant device of underwater robot | |
| CN109919032B (en) | Video abnormal behavior detection method based on motion prediction | |
| CN115439743B (en) | Method for accurately extracting static features of visual SLAM in parking scene | |
| CN112307982A (en) | Human behavior recognition method based on staggered attention-enhancing network | |
| CN115294563A (en) | 3D point cloud analysis method and device based on Transformer and capable of enhancing local semantic learning ability | |
| CN113486764A (en) | Pothole detection method based on improved YOLOv3 | |
| CN109948607A (en) | A candidate bounding box generation and object detection method based on deep learning deconvolution network | |
| CN113378775B (en) | Video shadow detection and elimination method based on deep learning | |
| CN116664643B (en) | Railway train image registration method and equipment based on SuperPoint algorithm | |
| CN114220126A (en) | A target detection system and acquisition method | |
| CN114627150A (en) | Method and device for data processing and motion estimation based on event camera | |
| CN116798070A (en) | A cross-modal person re-identification method based on spectral perception and attention mechanism | |
| CN115546171A (en) | Shadow detection method and device based on attention shadow boundary and feature correction | |
| CN108764244A (en) | Potential target method for detecting area based on convolutional neural networks and condition random field | |
| CN116503726A (en) | Multi-scale light smoke image segmentation method and device | |
| CN115565150A (en) | A pedestrian and vehicle target detection method and system based on improved YOLOv3 | |
| CN117689631A (en) | Defect detection method and system of two-stage lightweight network based on hybrid supervision |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| RJ01 | Rejection of invention patent application after publication | ||
| RJ01 | Rejection of invention patent application after publication | Application publication date:20220909 |