CN114973286A - Document element extraction method, device, equipment and storage medium - Google Patents
Document element extraction method, device, equipment and storage mediumDownload PDFInfo
- Publication number
- CN114973286A CN114973286ACN202210679246.0ACN202210679246ACN114973286ACN 114973286 ACN114973286 ACN 114973286ACN 202210679246 ACN202210679246 ACN 202210679246ACN 114973286 ACN114973286 ACN 114973286A
- Authority
- CN
- China
- Prior art keywords
- text line
- document
- text
- word
- model
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images






Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/40—Document-oriented image-based pattern recognition
- G06V30/41—Analysis of document content
- G06V30/413—Classification of content, e.g. text, photographs or tables
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
- G06V30/14—Image acquisition
- G06V30/1444—Selective acquisition, locating or processing of specific regions, e.g. highlighted text, fiducial marks or predetermined fields
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
- G06V30/14—Image acquisition
- G06V30/148—Segmentation of character regions
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
- G06V30/19—Recognition using electronic means
- G06V30/191—Design or setup of recognition systems or techniques; Extraction of features in feature space; Clustering techniques; Blind source separation
- G06V30/19147—Obtaining sets of training patterns; Bootstrap methods, e.g. bagging or boosting
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
- G06V30/19—Recognition using electronic means
- G06V30/191—Design or setup of recognition systems or techniques; Extraction of features in feature space; Clustering techniques; Blind source separation
- G06V30/19173—Classification techniques
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
- G06V30/19—Recognition using electronic means
- G06V30/191—Design or setup of recognition systems or techniques; Extraction of features in feature space; Clustering techniques; Blind source separation
- G06V30/1918—Fusion techniques, i.e. combining data from various sources, e.g. sensor fusion
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/40—Document-oriented image-based pattern recognition
- G06V30/41—Analysis of document content
- G06V30/414—Extracting the geometrical structure, e.g. layout tree; Block segmentation, e.g. bounding boxes for graphics or text
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Computer Vision & Pattern Recognition (AREA)
- General Physics & Mathematics (AREA)
- Multimedia (AREA)
- Artificial Intelligence (AREA)
- General Health & Medical Sciences (AREA)
- Biophysics (AREA)
- Evolutionary Computation (AREA)
- Computational Linguistics (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Biomedical Technology (AREA)
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Computer Graphics (AREA)
- Geometry (AREA)
- Character Input (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本申请涉及自然语言处理技术领域,更具体地说,涉及一种文档要素抽取方法、装置、设备及存储介质。The present application relates to the technical field of natural language processing, and more particularly, to a document element extraction method, apparatus, device and storage medium.
背景技术Background technique
要素抽取的工作主要是从无结构化文本中抽取结构化的信息,是自然语言处理中非常重要的一个子领域。目前已有的文档要素抽取方法以基于深度学习的模型为主,但目前的文档要素抽取方法的准确性较差。The work of feature extraction is mainly to extract structured information from unstructured text, which is a very important subfield in natural language processing. The existing document feature extraction methods are mainly based on deep learning models, but the accuracy of the current document feature extraction methods is poor.
发明内容SUMMARY OF THE INVENTION
有鉴于此,本申请提供了一种文档要素抽取方法、装置、设备及存储介质,以提高文档要素抽取的准确性。In view of this, the present application provides a document element extraction method, apparatus, device and storage medium to improve the accuracy of document element extraction.
为了实现上述目的,现提出的方案如下:In order to achieve the above purpose, the proposed scheme is as follows:
一种文档要素抽取方法,包括:A document feature extraction method, comprising:
获得所述文档的版面结构信息;obtain the layout structure information of the document;
根据所述版面结构信息,对所述文档中的各个字进行编码;encoding each word in the document according to the layout structure information;
根据各个字的编码结果确定各个字所属的要素标签。The element label to which each word belongs is determined according to the encoding result of each word.
上述方法,优选的,所述获得所述文档的版面结构信息包括:In the above method, preferably, the obtaining the layout structure information of the document includes:
对包含所述文档的图片进行处理,得到所述文档中各个字的语义特征,以及各个文本行对应的位置特征;Process the picture containing the document to obtain the semantic features of each word in the document and the positional feature corresponding to each text line;
对于每个文本行,将该文本行中的各个字的语义特征及对应的位置特征进行融合,得到该文本行的编码特征;For each text line, the semantic features and corresponding position features of each word in the text line are fused to obtain the coding feature of the text line;
对各个文本行的编码特征进行解码,得到所述文档的版面结构信息。The coding features of each text line are decoded to obtain the layout structure information of the document.
上述方法,优选的,获得各个文本行的编码特征,以及所述文档的版面结构信息的过程,包括:The above method, preferably, the process of obtaining the coding feature of each text line and the layout structure information of the document includes:
将每个文本行中的各个字的语义特征及对应的位置特征输入文档要素抽取模型中的版面分析模型,得到所述版面分析模型对于每个文本行,将该文本行中的各个字的语义特征及对应的位置特征进行融合,得到该文本行的编码特征,对各个文本行的编码特征进行解码而输出的版面结构信息;Input the semantic features and corresponding position features of each word in each text line into the layout analysis model in the document element extraction model to obtain the layout analysis model. For each text line, the semantics of each word in the text line is obtained. The feature and the corresponding position feature are fused to obtain the coding feature of the text line, and the output layout structure information is decoded by decoding the coding feature of each text line;
所述版面分析模型为,以样本图片的每个文本行中的各个字的语义特征及对应的位置特征为输入,以标注的所述样本图片的版面结构信息为样本标签,以所述版面分析模型输出的版面结构信息趋近于所述样本标签为目标训练得到。The layout analysis model is that the semantic features of each word in each text line of the sample picture and the corresponding positional feature are used as input, the layout structure information of the marked sample picture is used as a sample label, and the layout analysis is used as the input. The layout structure information output by the model is close to the sample label as the target training.
上述方法,优选的,所述对包含所述文档的图片进行处理,得到所述文档中各个字的语义特征,以及各个文本行对应的位置特征,包括:In the above method, preferably, the process of processing the picture containing the document to obtain the semantic features of each word in the document and the positional feature corresponding to each text line, including:
通过所述文档要素抽取模型中的字符识别模型对所述图片进行光学字符识别,得到所述文档中的每个文本行,以及文本行的坐标;Perform optical character recognition on the picture by using the character recognition model in the document element extraction model to obtain each text line in the document and the coordinates of the text line;
通过所述文档要素抽取模型中的上下文表示模型对每个文本行中的各个字进行第一编码,得到各个字的语义特征;First encode each word in each text line by using the context representation model in the document element extraction model to obtain the semantic feature of each word;
通过所述文档要素抽取模型中的文本行位置特征提取模型的第一特征提取模块对所述图片进行特征提取,获得特征图;通过所述文本行位置特征提取模型的第二特征提取模块根据每个文本行的坐标在所述特征图中提取每个文本行对应的位置特征;所述第一特征提取模块为预先训练好的文本行边界检测模型的特征提取模块。Perform feature extraction on the picture through the first feature extraction module of the text line position feature extraction model in the document element extraction model to obtain a feature map; through the second feature extraction module of the text line position feature extraction model according to each The coordinates of each text line are extracted from the feature map corresponding to the position feature of each text line; the first feature extraction module is a feature extraction module of a pre-trained text line boundary detection model.
上述方法,优选的,所述文本行边界检测模型通过如下方式训练得到:In the above method, preferably, the text line boundary detection model is obtained by training in the following manner:
将样本图片输入所述文本行边界检测模型,通过所述文本行边界检测模型的特征提取模块对输入的样本图片进行特征提取,得到所述样本图片的特征图;Input the sample picture into the text line boundary detection model, and perform feature extraction on the input sample picture through the feature extraction module of the text line boundary detection model to obtain a feature map of the sample picture;
通过所述文本行边界检测模型的输出模块对所述样本图片的特征图进行处理,得到所述样本图片中的文本行边界坐标;The feature map of the sample picture is processed by the output module of the text line boundary detection model to obtain the text line boundary coordinates in the sample picture;
以所述文本行边界检测模型输出的文本行边界坐标趋近于所述样本图片的标签为目标对所述文本行边界检测模型的参数进行更新;The parameters of the text line boundary detection model are updated with the target that the text line boundary coordinates output by the text line boundary detection model approach the label of the sample picture;
所述样本图片的标签为:针对所述样本图片标注的各个文本行的边界坐标。The label of the sample picture is: the boundary coordinates of each text line marked for the sample picture.
上述方法,优选的,所述文本行边界检测模型通过如下方式训练得到:In the above method, preferably, the text line boundary detection model is obtained by training in the following manner:
将样本图片输入所述文本行边界检测模型,通过所述文本行边界检测模型的特征提取模块对输入的样本图片进行特征提取,得到所述样本图片的特征图;Input the sample picture into the text line boundary detection model, and perform feature extraction on the input sample picture through the feature extraction module of the text line boundary detection model to obtain a feature map of the sample picture;
通过所述文本行边界检测模型的输出模块对所述样本图片的特征图进行处理,得到所述样本图片中的文本行边界坐标,以及每个文本行边界坐标的对应区域的类别;The feature map of the sample picture is processed by the output module of the text line boundary detection model to obtain the text line boundary coordinates in the sample picture, and the category of the corresponding area of each text line boundary coordinate;
以所述文本行边界检测模型输出的文本行边界坐标以及每个文本行边界坐标的对应区域的类别,趋近于所述样本图片的标签为目标对所述文本行边界检测模型的参数进行更新;The parameters of the text line boundary detection model are updated with the text line boundary coordinates output by the text line boundary detection model and the category of the corresponding area of each text line boundary coordinate, approaching the label of the sample picture as the target ;
所述样本图片的标签为:针对所述样本图片标注的各个文本行的边界坐标,以及每个文本行边界坐标的对应区域的类别。The label of the sample picture is: the boundary coordinates of each text line marked for the sample picture, and the category of the corresponding region of the boundary coordinates of each text line.
上述方法,优选的,所述根据所述版面结构信息,对所述文档中的各个字进行编码,根据各个字的编码结果确定各个字所属的要素标签,包括:In the above method, preferably, according to the layout structure information, each word in the document is encoded, and the element label to which each word belongs is determined according to the encoding result of each word, including:
通过所述文档要素抽取模型中的抽取模型,根据所述版面结构信息,对所述文档中的各个字进行编码,根据各个字的编码结果确定各个字所属的要素标签;所述抽取模型通过如下方式训练得到:Through the extraction model in the document element extraction model, each word in the document is encoded according to the layout structure information, and the element label to which each word belongs is determined according to the encoding result of each word; the extraction model is as follows way to train to get:
将所述版面结构信息以及所述文档中的各个文本行输入所述抽取模型,得到所述抽取模型根据输入的版面结构信息,对输入的文本行中的各个字进行编码,根据各个字的编码结果确定的各个字所属的要素标签;Inputting the layout structure information and each text line in the document into the extraction model, and obtaining the extraction model to encode each word in the input text line according to the input layout structure information, and according to the encoding of each word The element label to which each word determined by the result belongs;
以所述抽取模型输出的各个字所属的要素标签趋近于所述样本图片的标签为目标,对所述抽取模型的参数进行更新;The parameters of the extraction model are updated with the goal that the element labels to which each word output by the extraction model belongs is close to the label of the sample picture;
所述样本图片的标签为:针对所述样本图片标注的各个字所属的要素标签。The label of the sample picture is: the element label to which each word marked for the sample picture belongs.
上述方法,优选的,所述版面结构信息至少包括:段落的划分、标题层级、页眉、页脚。In the above method, preferably, the layout structure information includes at least: paragraph division, title level, page header, and page footer.
上述方法,优选的,所述根据所述版面结构信息,对所述文档中的各个字进行编码,包括:In the above method, preferably, the encoding of each word in the document according to the layout structure information includes:
根据所述版面结构信息,基于所述文档构建异构图,所述异构图中的节点包括字节点、标题节点、文本段节点;所述异构图中的边包括:字与字的关系、字与文本段的关系、文本段与标题的关系;According to the layout structure information, a heterogeneous graph is constructed based on the document, and the nodes in the heterogeneous graph include byte points, title nodes, and text segment nodes; and the edges in the heterogeneous graph include: word and word Relationship, relationship between word and text segment, relationship between text segment and title;
对所述异构图进行图卷积,得到各个节点的编码结果;Perform graph convolution on the heterogeneous graph to obtain the encoding result of each node;
将各个字的编码结果和对应的标题节点的编码结果融合,得到各个字的编码结果。The encoding result of each word is fused with the encoding result of the corresponding title node to obtain the encoding result of each word.
上述方法,优选的,所述异构图中的标题节点为所述文档中的各个标题;所述异构图中的文本段节点为所述文档中的各个文本段;In the above method, preferably, the title node in the heterogeneous graph is each title in the document; the text segment node in the heterogeneous graph is each text segment in the document;
或者,or,
所述异构图中的标题节点为所述文档中的目标标题,所述目标标题的层级高于目标层级;所述异构图中的文本段节点包括所述文当中的非目标标题,各个文本段;非目标标题的层级低于或等于目标层级。The title node in the heterogeneous graph is the target title in the document, and the level of the target title is higher than the target level; the text segment node in the heterogeneous graph includes the non-target title in the text, each Text segment; non-target headings are at a level lower than or equal to the target level.
上述方法,优选的,所述异构图中的各个节点的初始值通过如下方式确定:In the above method, preferably, the initial value of each node in the heterogeneous graph is determined in the following manner:
以所述文档中的文本单元为单位,对每个文本单元中的各个字分别进行第二编码,得到每个文本单元中的各个字在所在文本单元中的上下文特征表示,作为所述异构图中的各个字节点的初始值;每个文本单元为一个标题或一个文本段;Taking the text unit in the document as a unit, the second encoding is performed on each word in each text unit to obtain the context feature representation of each word in each text unit in the text unit where it is located, as the heterogeneous The initial value of each byte point in the figure; each text unit is a title or a text segment;
对于任意一个标题节点,将该标题节点的标题中的各个字的上下文特征表示进行融合,得到该标题节点的初始值;For any title node, the context feature representation of each word in the title node's title is fused to obtain the initial value of the title node;
对于任意一个文本段节点,将该文本段节点的标题或文本段中的各个字的上下文特征表示进行融合,得到该文本段节点的初始值。For any text segment node, the title of the text segment node or the context feature representation of each word in the text segment are fused to obtain the initial value of the text segment node.
一种文档要素抽取装置,包括:A device for extracting document elements, comprising:
获得单元,用于获得所述文档的版面结构信息;an obtaining unit for obtaining the layout structure information of the document;
编码单元,用于根据所述版面结构信息,对所述文档中的各个字进行编码;an encoding unit, configured to encode each word in the document according to the layout structure information;
抽取单元,用于根据各个字的编码结果确定各个字所属的要素标签。The extraction unit is used for determining the element label to which each word belongs according to the encoding result of each word.
一种文档要素抽取设备,包括存储器和处理器;A document element extraction device, including a memory and a processor;
所述存储器,用于存储程序;the memory for storing programs;
所述处理器,用于执行所述程序,实现如上任一项所述的文档要素抽取方法的各个步骤。The processor is configured to execute the program to implement each step of the document element extraction method described in any one of the above.
一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时,实现如上任一项所述的文档要素抽取方法的各个步骤。A computer-readable storage medium on which a computer program is stored, characterized in that, when the computer program is executed by a processor, each step of the document element extraction method described in any one of the above is implemented.
从上述的技术方案可以看出,本申请实施例提供的文档要素抽取方法、装置、设备及存储介质,获得文档的版面结构信息;根据文档的版面结构信息,对文档中的各个字进行编码;根据各个字的编码结果确定各个字所属的要素标签。本申请在对文档中的各个字进行编码时,融入了文档的版面结构信息,基于融合了文档编码结构信息的字编码结果确定各个字所属的要素标签,提高了文档要素抽取的准确性。It can be seen from the above technical solutions that the document element extraction method, device, device and storage medium provided by the embodiments of the present application obtain the layout structure information of the document; according to the layout structure information of the document, each word in the document is encoded; The element label to which each word belongs is determined according to the encoding result of each word. When encoding each word in the document, the present application incorporates the layout structure information of the document, and determines the element label to which each word belongs based on the word encoding result fused with the document encoding structure information, which improves the accuracy of document element extraction.
附图说明Description of drawings
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的实施例,对于本领域技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。In order to more clearly illustrate the embodiments of the present application or the technical solutions in the prior art, the following briefly introduces the accompanying drawings required for the description of the embodiments or the prior art. Obviously, the drawings in the following description are only It is an embodiment of the present application. For those skilled in the art, other drawings can also be obtained according to the provided drawings without any creative effort.
图1为本申请实施例公开的文档要素抽取方法的一种实现流程图;FIG. 1 is a flowchart of an implementation of a method for extracting document elements disclosed in an embodiment of the present application;
图2为本申请实施例公开的要素识别结果的一种示例图;FIG. 2 is an exemplary diagram of an element identification result disclosed in an embodiment of the present application;
图3为本申请实施例公开的获得文档的版面结构信息的一种实现流程图;FIG. 3 is a flow chart of an implementation of obtaining the layout structure information of a document disclosed by an embodiment of the present application;
图4为本申请实施例公开的文档要素抽取模型的一种结构示意图;4 is a schematic structural diagram of a document element extraction model disclosed in an embodiment of the present application;
图5为本申请实施例公开的根据版面结构信息,对文档中的各个字进行编码的一种实现流程图;FIG. 5 is a flowchart of an implementation of encoding each word in a document according to layout structure information disclosed in an embodiment of the application;
图6为本申请实施例公开的文档要素抽取模型的另一种示意图;FIG. 6 is another schematic diagram of a document element extraction model disclosed in an embodiment of the present application;
图7为本申请实施例公开的文档要素抽取装置的一种结构示意图;FIG. 7 is a schematic structural diagram of a document element extraction device disclosed in an embodiment of the present application;
图8为本申请实施例公开的文档要素抽取设备的硬件结构框图。FIG. 8 is a block diagram of a hardware structure of a document element extraction device disclosed in an embodiment of the present application.
具体实施方式Detailed ways
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。The technical solutions in the embodiments of the present application will be clearly and completely described below with reference to the drawings in the embodiments of the present application. Obviously, the described embodiments are only a part of the embodiments of the present application, but not all of the embodiments. Based on the embodiments in this application, all other embodiments obtained by those skilled in the art without creative efforts shall fall within the protection scope of this application.
目前基于深度学习模型的文档要素抽取方法是获得文档中各个字的向量表示,将各个字的向量表示输入预先训练好的神经网络,得到各个字所属的要素标签。这种要素抽取方法的准确性较低。为了提高文档要素抽取的准确性,提出本申请方案。The current document feature extraction method based on the deep learning model is to obtain the vector representation of each word in the document, and input the vector representation of each word into a pre-trained neural network to obtain the element label to which each word belongs. This feature extraction method is less accurate. In order to improve the accuracy of document element extraction, the proposal of this application is proposed.
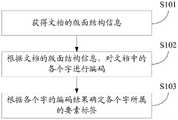
如图1所示,为本申请实施例提供的文档要素抽取方法的一种实现流程图,可以包括:As shown in FIG. 1, an implementation flowchart of the document element extraction method provided by the embodiment of the present application may include:
步骤S101:获得文档的版面结构信息。Step S101: Obtain the layout structure information of the document.
可选的,本申请中的文档可以是任意领域的文档,作为示例,可以是金融领域的文档(比如,合同文本),也可以是其它领域的文档,比如,可以是法律领域的文档(比如,判决文书),或者,可以是医学领域的文档(比如,病历)等等。Optionally, the documents in this application may be documents in any field, as an example, may be documents in the financial field (for example, contract text), or may be documents in other fields, for example, may be documents in the legal field (such as , judgment documents), or can be documents in the medical field (eg, medical records) and so on.
作为示例,可以通过对包含文档的图片(即图片格式的文档,为便于叙述,记为图片文档)进行处理,得到文档的版面结构信息。As an example, the layout structure information of the document can be obtained by processing a picture containing a document (ie, a document in a picture format, which is recorded as a picture document for convenience of description).
作为示例,版面结构信息可以包括但不限于:段落的划分、标题层级、页眉、页脚等信息。As an example, the layout structure information may include, but is not limited to: paragraph division, heading level, header, footer and other information.
步骤S102:根据文档的版面结构信息,对文档中的各个字进行编码。Step S102: Encode each word in the document according to the layout structure information of the document.
本申请基于文档的版面结构信息对文档中的各个字进行编码,使得每个字的编码结果融合了文档的版面结构信息。The present application encodes each word in the document based on the layout structure information of the document, so that the encoding result of each word incorporates the layout structure information of the document.
步骤S103:根据各个字的编码结果确定各个字所属的要素标签。Step S103: Determine the element label to which each word belongs according to the encoding result of each word.
作为示例,可以通过条件随机场(conditional random field,CRF)模型对各个字的编码结果进行解码,得到各个字所属的要素标签。As an example, a conditional random field (conditional random field, CRF) model can be used to decode the encoding result of each word to obtain the element label to which each word belongs.
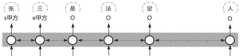
如图2所示,为本申请实施例提供的要素识别结果的一种示例图,该示例中,识别到了<甲方>这一要素,即“张三”被识别成了要素:甲方。As shown in FIG. 2 , an example diagram of an element identification result provided by an embodiment of the present application, in this example, the element <Party A> is identified, that is, "Zhang San" is identified as an element: Party A.
由于要素在文档中的位置与文档的版面结构是有一定的关联关系的,比如,一个标题名为“1.合同甲方基本信息”,那么在此标题下的段落中,有很大可能存在<甲方>这一要素。因此,基于融合了文档的版面结构信息的字的编码结果确定各个字所属的要素标签,可以提高文档要素抽取的准确性。Since the position of the element in the document is related to the layout structure of the document, for example, if a title is named "1. Basic Information of Contract Party A", then in the paragraphs under this title, there is a high possibility that there are <Party A> this element. Therefore, the element label to which each word belongs is determined based on the encoding result of the word fused with the layout structure information of the document, which can improve the accuracy of document element extraction.
在一可选的实施例中,上述获得文档的版面结构信息的一种实现流程图如图3所示,可以包括:In an optional embodiment, an implementation flowchart of the above-mentioned obtaining the layout structure information of the document is shown in FIG. 3 , and may include:
步骤S301:对包含文档的图片进行处理,得到文档中各个字的语义特征,以及各个文本行对应的位置特征。Step S301: Process the pictures including the document to obtain the semantic features of each word in the document and the positional features corresponding to each text line.
对于英文文档而言,文档中的每个单词为一个字。For English documents, each word in the document is a word.
作为示例,可以对图片文档进行光学字符识别(Optical CharacterRecognition,OCR),得到文档中的每个文本行,以及各个文本行的坐标,每个文本行(为便于描述和区分,记为第i个文本行)的坐标可以通过覆盖该第i个文本行的矩形框的四个顶点的坐标表示。As an example, Optical Character Recognition (OCR) can be performed on a picture document to obtain each text line in the document, as well as the coordinates of each text line, each text line (for the convenience of description and distinction, denoted as the ith The coordinates of the text line) can be represented by the coordinates of the four vertices of the rectangular box covering the ith text line.
对该第i个文本行中的各个字进行编码(为便于描述和区分,记为第一编码),得到该第i个文本行中各个字的语义特征。i=1,2,3,……,N;N为文档包含的文本行的总数。可选的,可以将第i个文本行输入预训练上下文表示模型得到第i个文本行中每个字的上下文特征表示。作为示例,预训练上下文表示模型可以为预训练BERT模型。Each word in the i-th text line is encoded (for convenience of description and distinction, it is denoted as the first encoding), and the semantic features of each word in the i-th text line are obtained. i=1, 2, 3, ..., N; N is the total number of text lines contained in the document. Optionally, the ith text line may be input into the pretrained context representation model to obtain the context feature representation of each word in the ith text line. As an example, the pretrained context representation model may be a pretrained BERT model.
基于第i个文本行的坐标确定第i个文本行的位置特征。作为示例,可以通过如下两种方式中的任意一种方式确定第i个文本行的位置特征:The position feature of the ith text line is determined based on the coordinates of the ith text line. As an example, the location feature of the i-th text line can be determined in either of the following two ways:
方式一,将第i个文本行的坐标确定为第i个文本行的位置特征。In a first way, the coordinates of the ith text line are determined as the position feature of the ith text line.
方式二,通过文本行位置特征提取模型的第一特征提取模块对图片文档进行特征提取,获得特征图;通过文本行位置特征提取模型的第二特征提取模块根据第i个文本行的坐标在特征图中提取第i个文本行对应的位置特征。The second method is to perform feature extraction on the image document through the first feature extraction module of the text line position feature extraction model, and obtain a feature map; In the figure, the position feature corresponding to the i-th text line is extracted.
其中,第一特征提取模块为预先训练好的文本行边界检测模型的特征提取模块。作为示例,文本行边界检测模型可以通过基于预选区域的串级卷积神经网络(cascaderegion-based convolutional neural network,Cascade-RCNN)实现。The first feature extraction module is a feature extraction module of a pre-trained text line boundary detection model. As an example, the text line boundary detection model can be implemented by a cascade region-based convolutional neural network (Cascade-RCNN) based on preselected regions.
在一种可选的的实现方式中,文本行边界检测模型的输入为包含文档的图片(即图片文档),文本行边界检测模型的输出为输入的图片文档中的文本行边界坐标(可以是覆盖文本行的矩形框的顶点坐标)。用于对文本行边界检测模型进行训练的样本为包含文档的图片(可以称为样本图片),样本标签为:针对样本图片标注的各个文本行的边界坐标。可以通过如下方式对文本行边界检测模型进行训练:In an optional implementation manner, the input of the text line boundary detection model is a picture containing a document (that is, a picture document), and the output of the text line boundary detection model is the text line boundary coordinates in the input picture document (which can be vertex coordinates of the rectangle covering the text line). The samples used for training the text line boundary detection model are pictures containing documents (which may be referred to as sample pictures), and the sample labels are: the boundary coordinates of each text line marked with respect to the sample pictures. A text line boundary detection model can be trained as follows:
将样本图片输入文本行边界检测模型,得到文本行边界检测模型通过特征提取模块对输入的样本图片进行特征提取,获得特征图,通过输出模块对特征图进行处理而输出的文本行边界坐标;以文本行边界检测模型输出的文本行边界坐标趋近于样本标签为目标对文本行边界检测模型的参数进行更新,直至满足训练结束条件。Input the sample image into the text line boundary detection model, and obtain the text line boundary detection model through the feature extraction module to perform feature extraction on the input sample image to obtain the feature map, and process the feature map through the output module to output the text line boundary coordinates; The text line boundary coordinates output by the text line boundary detection model approach the sample label as the target, and the parameters of the text line boundary detection model are updated until the training end condition is met.
在另一种可选的实现方式中,文本行边界检测模型的输入为包含文档的图片(即图片文档),文本行边界检测模型的输出为输入的图片文档中的文本行边界坐标(可以是覆盖文本行的矩形框的顶点坐标),以及每个文本行边界坐标的对应区域的类别(比如,文本行、表格等)。用于对文本行边界检测模型进行训练的样本为包含文档的图片,样本标签为:针对样本图片标注的各个文本行的边界坐标,以及各个文本行区域的类别。可以通过如下方式对文本行边界检测模型进行训练:In another optional implementation manner, the input of the text line boundary detection model is a picture containing a document (that is, a picture document), and the output of the text line boundary detection model is the text line boundary coordinates in the input picture document (which can be vertex coordinates of the rectangle that covers the text line), and the category of the corresponding region (eg, text line, table, etc.) for the bounding coordinates of each text line. The samples used for training the text line boundary detection model are pictures containing documents, and the sample labels are: the boundary coordinates of each text line marked for the sample picture, and the category of each text line area. A text line boundary detection model can be trained as follows:
将样本图片输入文本行边界检测模型,得到文本行边界检测模型通过特征提取模块对输入的样本图片进行特征提取,获得特征图,通过输出模块对特征图进行处理而输出的文本行边界坐标,以及文本行边界坐标对应的区域的类别;以文本行边界检测模型输出的文本行边界坐标,以及区域类别趋近于样本标签为目标对文本行边界检测模型的参数进行更新,直至满足训练结束条件。Input the sample image into the text line boundary detection model, and obtain the text line boundary detection model. The feature extraction module performs feature extraction on the input sample image to obtain a feature map, and the output module processes the feature map and outputs the text line boundary coordinates, and The category of the region corresponding to the text line boundary coordinates; the text line boundary coordinates output by the text line boundary detection model and the region category approaching the sample label are used to update the parameters of the text line boundary detection model until the training end condition is met.
可选的,方式二中,第二特征提取模块根据第i个文本行的坐标在特征图中提取第i个文本行对应的位置特征的一种实现方式可以为:Optionally, in the second method, an implementation manner in which the second feature extraction module extracts the position feature corresponding to the ith text line in the feature map according to the coordinates of the ith text line may be:
根据该第i个文本行的坐标确定第i个文本行对应的边界框。The bounding box corresponding to the ith text line is determined according to the coordinates of the ith text line.
获得特征图相对于图片(即包含文档的图片)的缩放比例。Get the scaling of the feature map relative to the picture (i.e. the picture containing the document).
按照获得的缩放比例对第i个文本行的边界框进行缩放,使得缩放后的边界框相对于缩放前的边界框的缩放比例等于特征图相对于图片的缩放比例。The bounding box of the ith text line is scaled according to the obtained scaling ratio, so that the scaling ratio of the scaled bounding box relative to the bounding box before scaling is equal to the scaling ratio of the feature map relative to the image.
在特征图中提取位于缩放后的边界框区域内的特征作为第i个文本行对应的位置特征。也就是说,将特征图中位于缩放后的边界框区域内的特征作为第i个文本行对应的位置特征。The feature located in the scaled bounding box region is extracted from the feature map as the position feature corresponding to the i-th text line. That is, the feature located in the scaled bounding box region in the feature map is used as the position feature corresponding to the i-th text line.
步骤S302:对于每个文本行,将该文本行中的各个字的语义特征及对应的位置特征进行融合,得到该文本行的编码特征。Step S302: For each text line, fuse the semantic features and corresponding position features of each word in the text line to obtain the encoding feature of the text line.
作为示例,可以通过预先训练好的版面分析模型中的特征融合模块将该文本行中的各个字的语义特征及对应的位置特征进行融合。具体的,As an example, the semantic feature and the corresponding position feature of each word in the text line may be fused by the feature fusion module in the pre-trained layout analysis model. specific,
版面分析模型可以通过特征融合模块将该第i个文本行中的各个字的语义特征求均值,得到第i个文本行的语义特征(即将各个字的语义特征求和,将和值除以第i个文本行中字的个数,得到第i个文本行的语义特征),将第i个文本行的语义特征与该第i个文本行的位置特征拼接,通过双向长短期记忆网络(Long Short-Term Memory,LSTM)或者RNN(Recurrent Neural Network,循环神经网络)对拼接得到的特征进行编码,得到第i个文本行的编码特征。The layout analysis model can average the semantic features of each word in the ith text line through the feature fusion module to obtain the semantic features of the ith text line (that is, sum the semantic features of each word, and divide the sum by the ith text. The number of words in the i text line, the semantic feature of the i text line is obtained), the semantic feature of the i text line is spliced with the position feature of the i text line, and the bidirectional long short-term memory network (Long Short -Term Memory, LSTM) or RNN (Recurrent Neural Network, Recurrent Neural Network) encodes the features obtained by splicing, and obtains the encoded feature of the i-th text line.
步骤S303:对各个文本行的编码特征进行解码,得到文档的版面结构信息。Step S303: Decode the coding features of each text line to obtain the layout structure information of the document.
可以通过预先训练好的版面分析模型中的解码模块(为便于区分,记为第一解码模块)对各个文本行的编码特征进行解码。作为示例,第一解码模块可以基于两层单向GRU网络实现。两层单项GRU串联连接。其中,父GRU用于对当前待解码文本行(为便于区分和描述,记为第i个文本行)的编码特征及其上一文本行(即第i-1个文本行)的隐层特征进行融合,得到目标融合特征(为便于区分和描述,记为第一目标融合特征),对第一目标融合特征进行解码,得到当前待解码文本行(即第i个文本行)的部分解码结果(记为第一解码结果),子GRU用于对当前文本行(即第i个文本行)的编码特征以及父GRU输出的第一目标融合特征进行融合,得到另一个目标融合特征(为便于区分和描述,记为第二目标融合特征),对第二目标融合特征进行解码,得到当前待解码文本行的另一部分解码结果(记为第二解码结果)。The encoding feature of each text line can be decoded by the decoding module (denoted as the first decoding module for the convenience of distinction) in the pre-trained layout analysis model. As an example, the first decoding module may be implemented based on a two-layer unidirectional GRU network. Two layers of single-item GRUs are connected in series. Among them, the parent GRU is used to encode the encoding feature of the current text line to be decoded (for the convenience of distinction and description, denoted as the i-th text line) and the hidden layer feature of the previous text line (ie the i-1-th text line) Perform fusion to obtain the target fusion feature (for the convenience of distinction and description, denoted as the first target fusion feature), decode the first target fusion feature, and obtain the partial decoding result of the current text line to be decoded (that is, the ith text line) (denoted as the first decoding result), the child GRU is used to fuse the encoding feature of the current text line (ie the ith text line) and the first target fusion feature output by the parent GRU to obtain another target fusion feature (for the convenience of Distinguish and describe, denoted as the second target fusion feature), decode the second target fusion feature, and obtain another part of the decoding result of the current text line to be decoded (denoted as the second decoding result).
其中,第一解码结果为第i个文本行的属性。文本行的属性为如下几种属性中的一种:标题级别、文本段落、页眉、页脚。Wherein, the first decoding result is the attribute of the ith text line. The attributes of a text line are one of the following attributes: heading level, text paragraph, header, footer.
第二解码结果为第i个文本行的关联文本行,以及第i个文本行与关联文本行的关系。The second decoding result is the associated text line of the ith text line, and the relationship between the ith text line and the associated text line.
也就是说,本申请中,对于每个文本行,第一解码模块的输出有三个,分别为:文本行的属性、文本行的关联文本行,以及文本行与关联文本行的关系。That is to say, in this application, for each text line, the first decoding module has three outputs, which are: the attributes of the text line, the associated text line of the text line, and the relationship between the text line and the associated text line.
其中,第i个文本行的关联文本行可能是第i个文本行的上一行,也可能是第i个文本行之前的某个标题的一行。Wherein, the associated text line of the ith text line may be the previous line of the ith text line, or may be a line of a title before the ith text line.
第i个文本行与关联文本行的关系为如下几种关系中的一种:并列关系(比如,第一层级的某个标题下有两个子标题,这两个子标题都属于第二层级的标题,则这两个子标题中的文本行(属于不同的子标题)属于并列关系;相邻的两个文本段中的前一文本段的最后一行与下一文本段的第一行是并列关系)、递进关系(比如,前述第二层级的子标题的文本行与第一层级的某个标题中的文本行是递进关系)、连接关系(比如,同一个文本段中的相邻两个文本行是连接关系)。The relationship between the i-th text line and the associated text line is one of the following relationships: a side-by-side relationship (for example, there are two subtitles under a title at the first level, and both subtitles belong to the title at the second level , then the text lines in the two subtitles (belonging to different subtitles) belong to a juxtaposed relationship; the last line of the previous text segment and the first line of the next text segment in the two adjacent text segments are in a juxtaposed relationship) , Progressive relationship (for example, the text line of the subtitle of the second level is a progressive relationship with the text line in a title of the first level), connection relationship (for example, the adjacent two in the same text segment Lines of text are connections).
可选的,上述对当前待解码文本行(即第i个文本行)的编码特征及其上一文本行(即第i-1个文本行)的隐层特征进行融合得一种实现方式可以为:将当前待解码文本行的编码特征及其上一文本行的隐层特征进行拼接,对拼接后的特征进行维度变换,得到第一目标融合特征。Optionally, the encoding feature of the current text line to be decoded (that is, the ith text line) and the hidden layer feature of the previous text line (that is, the ith-1th text line) are fused to obtain an implementation that can be implemented. The steps are: splicing the encoding feature of the current text line to be decoded and the hidden layer feature of the previous text line, and performing dimension transformation on the spliced features to obtain the first target fusion feature.
可选的,上述对当前文本行(即第i个文本行)的编码特征以及父GRU输出的第一目标融合特征进行融合的一种实现方式可以为:将当前待解码文本行的编码特征与第一目标融合特征进行拼接,对拼接后的特征进行维度变换,得到第二目标融合特征。Optionally, an implementation manner of fusing the encoding feature of the current text line (that is, the i-th text line) and the first target fusion feature output by the parent GRU may be: combining the encoding feature of the current text line to be decoded with the first target fusion feature output by the parent GRU. The first target fusion features are spliced, and the spliced features are dimensionally transformed to obtain the second target fusion features.
可选的,第i-1个文本行的隐层特征为上一时刻的第二目标融合特征,也就是:子GRU解码第i-1个文本行的关联文本行及第i-1个文本行与关联文本行的关系时得到的第二目标融合特征。Optionally, the hidden layer feature of the i-1 th text line is the second target fusion feature at the previous moment, that is, the sub-GRU decodes the i-1 th text line's associated text line and the i-1 th text. The second target fusion feature obtained when the relationship between the line and the associated text line.
可选的,在第i个文本行为首个文本行的情况下,上一文本行的隐层特征可以为文档中的各个文本行的编码特征的均值。Optionally, in the case of the i-th text line being the first text line, the hidden layer feature of the previous text line may be the mean value of the encoding features of each text line in the document.
可选的,版面分析模型的输入为基于步骤S301对包含文档的图片进行处理得到的每各文本行中的各个字的语义特征及对应的位置特征。版面分析模型的输出为各个文本行的属性(文本段、标题、页眉或页脚),以及每个文本行的关联文本行和每个文本行与关联文本行的关系。Optionally, the input of the layout analysis model is the semantic feature and the corresponding position feature of each word in each text line obtained by processing the picture containing the document in step S301. The output of the layout analysis model is the attributes of each text line (text segment, title, header or footer), as well as the associated text line for each text line and the relationship of each text line to the associated text line.
用于对版面分析模型进行训练的样本为包含文档的图片,样本标签为:针对样本图片标注的各个文本行的属性,每个文本行的关联文本行,以及每个文本行与关联文本行的关系。其中,The samples used to train the layout analysis model are pictures containing documents, and the sample labels are: the attributes of each text line marked for the sample picture, the associated text line of each text line, and the relationship between each text line and the associated text line. relation. in,
如果一个文本行的属性为文本段、页眉或页脚,则该文本行的关联文本行为该文本行的上一行,此时该文本行与关联文本行的关系为并列关系或连接关系。If the attribute of a text line is a text segment, a header or a footer, the associated text line of the text line is the previous line of the text line, and the relationship between the text line and the associated text line is a parallel relationship or a connection relationship.
如果一个文本行的属性为第一层级的标题,则该文本行的关联文本行为属于标题的文本行。其中,如果第一层级的标题的前一个标题也为第一层级的标题,则该文本行的关联文本行为属于前一个标题的文本行,此时该文本行与关联文本行的关系为并列关系;如果第一层级的标题的前一个标题为第二层级的标题,且第二层级高于第一层级,则该文本行的关联文本行为属于前一个标题的文本行,此时该文本行与关联文本行的关系为递进关系;如果第一层级的标题的前一个标题为第二层级的标题,且第二层级低于第一层级,则该文本行的关联文本行为该文本行之前距离该文本行最近的第一层级的标题所在的文本行,此时该文本行与关联文本行的关系为并列关系。If the attribute of a text line is a first-level heading, the associated text line of the text line belongs to the heading's text line. Among them, if the previous title of the title of the first level is also the title of the first level, the associated text row of the text row belongs to the text row of the previous title, and the relationship between the text row and the associated text row is a parallel relationship. ;If the previous title of the title of the first level is the title of the second level, and the second level is higher than the first level, the associated text line of the text line belongs to the text line of the previous title, and the text line is the same as ; The relationship between the associated text lines is a progressive relationship; if the title preceding the title of the first level is the title of the second level, and the second level is lower than the first level, the associated text line of the text line is the distance before the text line The text line where the title of the first level closest to the text line is located. At this time, the relationship between the text line and the associated text line is a parallel relationship.
版面分析模型的训练过程可以包括:The training process of the layout analysis model can include:
通过步骤S301对样本图片进行处理,得到样本图片中每个文本行中的各个字的语义特征及对应的位置特征,将各个文本行中的各个字的语义特征及对应的位置特征输入版面分析模型,得到版面分析模型输出的各个文本行的属性、每个文本行的关联文本行以及每个文本行与关联文本行的关系;以版面分析模型输出的各个文本行的属性、每个文本行的关联文本行以及每个文本行与关联文本行的关系趋近于样本标签为目标,对版面分析模型的参数进行更新,直至满足训练结束条件。Through step S301, the sample picture is processed to obtain the semantic feature and corresponding position feature of each word in each text line in the sample picture, and the semantic feature and corresponding position feature of each word in each text line are input into the layout analysis model to obtain the attributes of each text line output by the layout analysis model, the associated text line of each text line, and the relationship between each text line and the associated text line; the attributes of each text line output by the layout analysis model, the The associated text line and the relationship between each text line and the associated text line approach the sample label as the target, and the parameters of the layout analysis model are updated until the training end condition is met.
可选的,本申请实施例提供的文档要素抽取方法可以通过文档要素抽取模型实现。如图4所示,为本申请实施例提供的文档要素抽取模型的一种结构示意图,可以包括:Optionally, the document element extraction method provided by the embodiment of the present application may be implemented by a document element extraction model. As shown in FIG. 4 , a schematic structural diagram of a document element extraction model provided by an embodiment of the present application may include:
字符识别模型401,上下文表示模型402,文本行位置特征提取模型403,版面分析模型404,抽取模型405;其中,
其中,字符识别模型401用于对包含文档的图片(即为图片文档)进行光学字符识别,得到文档中的每个文本行,以及文本行的坐标。作为示例,字符识别模型401可以为OCR模型。The
上下文表示模型402用于对字符识别模型401输出的每个文本行中的各个字进行第一编码,得到各个字的语义特征。上下文表示模型402可以为预训练的BERT模型。The
文本行位置特征提取模型403用于通过第一特征提取模块对上述包含文档的图片进行特征提取,获得特征图;通过第二特征提取模块根据字符识别模型401输出的每个文本行的坐标在特征图中提取每个文本行对应的位置特征。第一特征提取模块为预先训练好的文本行边界检测模型的特征提取模块。文本行边界检测模型的训练过程参看前述实施例,这里不再赘述。The text line position
版面分析模型404用于通过特征融合模块对字符识别模型401输出的每个文本行,将该文本行中的各个字的语义特征及文本行位置特征提取模型403输出的对应的位置特征进行融合,得到该文本行的编码特征;通过第一解码模块对各个文本行的编码特征进行解码,得到文档的版面结构信息。The
显然,步骤S301由字符识别模型401,上下文表示模型402和文本行位置特征提取模型403实现。步骤S302-S303由版面分析模型404实现。也就是说,步骤S101由字符识别模型401,上下文表示模型402、文本行位置特征提取模型403和版面分析模型404实现。Obviously, step S301 is realized by the
抽取模型405用于根据版面分析模型404输出的版面结构信息,对字符识别模型401输出的每个文本中的各个字进行编码,根据各个字的编码结果确定各个字所属的要素标签。The
显然,步骤S102-S103由抽取模型405实现。Obviously, steps S102-S103 are implemented by the
可选的,字符识别模型401、上下文表示模型402、文本行边界检测模型、版面分析模型404和抽取模型405可以分别独立训练得到。Optionally, the
其中,字符识别模型401和上下文表示模型402的训练过程可以参看已有的实现方案,这里不再详述。For the training process of the
文本行边界检测模型和版面分析模型404的训练过程可以参看前述实施例,这里不再赘述。For the training process of the text line boundary detection model and the
对抽取模型405进行训练的样本为文档,以及文档的版面结构信息,样本中的版面结构信息可以是人为标注的,也可以是通过前述字符识别模型401,上下文表示模型402、文本行位置特征提取模型403和版面分析模型404对包含文档的图片进行处理得到的;样本标签为:针对文档中各个字标注的各个字所属的要素标签。The samples for training the
抽取模型405的输入为文档以及文档的版面结构信息,抽取模型405的输出为输入的文档中的各个字所属的要素标签。The input of the
可以通过如下方法对抽取模型405进行训练:The
将作为样本的文档以及文档的版面结构信息输入抽取模型405,得到抽取模型405输出的各个字所属的要素标签。The document as a sample and the layout structure information of the document are input into the
以抽取模型405输出各个字所属的要素标签趋近于样本标签为目标对抽取模型405的参数进行更新,直至满足训练结束条件。The parameters of the
可选的,字符识别模型401、上下文表示模型402、文本行边界检测模型可以单独训练得到,版面分析模型404和抽取模型405可以联合训练得到。Optionally, the
对版面分析模型404和抽取模型405进行联合训练的样本为包含文档的图片(即图片文本),样本标签为:针对图片文档标注的各个文本行的属性,每个文本行的关联文本行,每个文本行与关联文本行的关系,以及文档中各个字所属的要素标签。The sample for joint training of the
对版面分析模型404和抽取模型405进行联合训练的过程可以包括:The process of jointly training the
通过字符识别模型401对样本图片进行光学字符识别,得到样本图片包含的文档中的每个文本行,以及文本行的坐标。Optical character recognition is performed on the sample picture through the
通过上下文表示模型402对字符识别模型401输出的每个文本中的各个字进行第一编码,得到各个字的语义特征。The first encoding is performed on each word in each text output by the
通过文本行位置特征提取模型403对样本图片进行特征提取,获得特征图;根据字符识别模型401输出的每个文本行的坐标在特征图中提取每个文本行对应的位置特征。The
将样本图片中的每个文本行中的各个字的语义特征以及文本行对应的位置特征输入版面分析模型404,得到版面分析模型404输出的版面结构信息(包括样本中的各个文本行的属性,每个文本行的关联文本行,以及每个文本行与关联文本行的关系)。The semantic feature of each word in each text line in the sample picture and the positional feature corresponding to the text line are input into the
将版面分析模型404输出的版面结构信息,以及字符识别模型401输出的样本中的文本行输入抽取模型405,得到抽取模型405输出的文本行中的各个字所属的要素标签。The layout structure information output by the
以版面分析模型404输出的版面结构信息,以及抽取模型405输出的各个字的要素标签趋近于样本标签为目标,对版面分析模型404和抽取模型405的参数进行更新,直至满足训练结束条件。With the layout structure information output by the
在一可选的实施例中,上述根据版面结构信息,对文档中的各个字进行编码的一种实现流程图如图5所示,可以包括:In an optional embodiment, the above-mentioned implementation flow chart of encoding each word in the document according to the layout structure information, as shown in Figure 5, may include:
步骤S501:根据文档的版面结构信息,基于文档构建异构图,该异构图中的节点包括字节点、标题节点、文本段节点;异构图中的边包括:字与字的关系、字与文本段的关系、文本段与标题的关系。Step S501: According to the layout structure information of the document, build a heterogeneous graph based on the document, the nodes in the heterogeneous graph include byte points, title nodes, and text segment nodes; the edges in the heterogeneous graph include: the relationship between words, The relationship between the word and the text segment, the relationship between the text segment and the title.
本申请根据版面结构信息,从文档中确定标题和文本段,进而根据文档中的字、标题和文本段构建异构图。The present application determines the title and text segment from the document according to the layout structure information, and then constructs a heterogeneous graph according to the word, title and text segment in the document.
在确定标题时,各个层级的标题均确定。When determining the title, the title of each level is determined.
可以由抽取模型405中的图卷积模块根据文档的版面结构信息,基于文档构建异构图。The heterogeneous graph can be constructed based on the document by the graph convolution module in the
本申请中,异构图中的节点包括三类,分别为:字节点,标题节点和文本段节点;异构图中的边体现节点间的关系,也包括三种,分别为:字与字的关系、字与文本段的关系、文本段与标题的关系。其中,字与字的关系可以为共现频率或共现次数等;字与文本段的关系可以为字对于文本段的重要程度,比如,字的tf-idf(term frequency–inverse documentfrequency);文本段与标题的关系可以为文本段与标题是否相关,其中,如果文本段属于标题下的内容,则文本段与标题相关,否则,文本段与标题不相关。In this application, the nodes in the heterogeneous graph include three types, namely: byte point, title node and text segment node; the edge in the heterogeneous graph reflects the relationship between nodes, and also includes three types, namely: word and The relationship between words, the relationship between words and text segments, and the relationship between text segments and titles. Among them, the relationship between words can be the frequency of co-occurrence or the number of co-occurrences, etc.; the relationship between words and text segments can be the importance of words to the text segment, for example, tf-idf (term frequency–inverse document frequency) of words; text The relationship between the segment and the title may be whether the text segment is related to the title, wherein, if the text segment belongs to the content under the title, the text segment is related to the title, otherwise, the text segment is not related to the title.
作为示例,异构图中的标题节点为文档中的各个标题,即每个标题均作为一个标题节点;异构图中的文本段节点为文档中的各个文本段。As an example, the title node in the heterogeneous graph is each title in the document, that is, each title acts as a title node; the text segment node in the heterogeneous graph is each text segment in the document.
作为示例,异构图中的标题节点为文档中的目标标题,目标标题的层级高于目标层级;异构图中的文本段节点包括文档中的非目标标题,各个文本段;非目标标题的层级低于或等于目标层级。也就是说,本申请仅将部分标题(即层级高于目标层级的标题)作为异构图中的标题节点,而另一部分标题(即层级低于或等于目标层级的标题)则作为异构图中的部分文本段节点,则异构图中的文本段节点包括两部分:一部分文本段节点为文档中不属于标题的文本段,一部分文本段节点是标题。As an example, the title node in the heterogeneous graph is the target title in the document, and the level of the target title is higher than the target level; the text segment nodes in the heterogeneous graph include non-target titles and various text segments in the document; The level is lower than or equal to the target level. That is to say, in this application, only some titles (that is, titles whose levels are higher than the target level) are used as title nodes in the heterogeneous graph, while another part of the titles (that is, titles whose levels are lower than or equal to the target level) are used as heterogeneous graphs. If there are some text segment nodes in the document, the text segment nodes in the heterogeneous graph include two parts: some text segment nodes are text segments that do not belong to titles in the document, and some text segment nodes are titles.
步骤S502:对异构图进行图卷积(Graph Convolution),得到各个节点的编码结果。Step S502: Perform a graph convolution (Graph Convolution) on the heterogeneous graph to obtain the coding result of each node.
可以通过图卷积网络(Graph Convolutional Networks)对异构图进行图卷积,得到各个节点的编码结果。具体实现过程不是本申请的关注重点,可以参看已有的实现方式,这里不再详述。Graph convolution can be performed on heterogeneous graphs through Graph Convolutional Networks to obtain the encoding results of each node. The specific implementation process is not the focus of the present application, and reference may be made to the existing implementation manner, which will not be described in detail here.
可以由抽取模型405中的图卷积模块(即图卷积网络)对异构图进行图卷积。Graph convolution may be performed on heterogeneous graphs by a graph convolution module (ie, a graph convolution network) in the
步骤S503:将各个字的编码结果和对应的标题节点的编码结果融合,得到各个字的编码结果。Step S503: Integrate the encoding result of each word with the encoding result of the corresponding title node to obtain the encoding result of each word.
一个字W对应的标题节点为该字W所在的文本段所属的标题节点。比如,The title node corresponding to a word W is the title node to which the text segment where the word W is located belongs. for example,
假设一个一级标题T1下有两个二级标题T11和T12,每个二级标题下都有一个文本段,假设二级标题T11下的文本段为D1,二级标题T12下的文本段为D2。那么,Suppose there are two second-level headings T11 and T12 under a first-level heading T1, and each second-level heading has a text segment. Suppose the text segment under the second-level heading T11 is D1, and the text segment under the second-level heading T12 is D2. So,
如果一级标题T1、二级标题T11和T12均为标题节点,W属于文本段D1,则,字W对应的标题节点为T11。If the primary title T1, the secondary titles T11 and T12 are all title nodes, and W belongs to the text segment D1, then the title node corresponding to the word W is T11.
如果只有一级标题T1为标题节点,而二级标题T11和T12均为文本段节点,则,字W对应的标题节点为T1。If only the primary title T1 is the title node, and the secondary titles T11 and T12 are both text segment nodes, then the title node corresponding to the word W is T1.
作为示例,可以对标题节点的编码结果进行线性变换,使得变换后的编码结果的维度与字W的编码结果的维度相同,然后,将标题节点的变换后的编码结果与字W的编码结果拼接或求平均,得到字W的编码结果。As an example, a linear transformation may be performed on the encoding result of the title node, so that the dimension of the transformed encoding result is the same as the dimension of the encoding result of word W, and then the transformed encoding result of the title node and the encoding result of word W are spliced Or take the average to get the encoding result of the word W.
可以由抽取模型405中的图卷积模块将各个字的编码结果和对应的标题节点的编码结果融合,得到各个字的编码结果。The encoding result of each word can be obtained by merging the encoding result of each word with the encoding result of the corresponding title node by the graph convolution module in the
在得到各个字的编码结果后,可以由抽取模型405的解码模块(为便于区分,记为第二解码模块)对图卷积模块输出的各个字的编码结果进行解码,得到各个字所属的要素标签。第二解码模块可以通过条件随机场(conditional random field,CRF)模型对各个字的编码结果进行解码,得到各个字所属的要素标签。After obtaining the encoding result of each word, the decoding module of the extraction model 405 (denoted as the second decoding module for the convenience of distinction) can decode the encoding result of each word output by the graph convolution module to obtain the element to which each word belongs. Label. The second decoding module can decode the coding result of each word by using a conditional random field (CRF) model to obtain the element label to which each word belongs.
在一可选的实施例中,异构图中的各个节点的初始值可以通过如下方式确定:In an optional embodiment, the initial value of each node in the heterogeneous graph can be determined in the following manner:
以文档中的文本单元为单位,对每个文本单元(为便于区分和描述,记为第j各文本单元)中的各个字分别进行编码(为便于描述和区分,记为第二编码),得到每个文本单元中的各个字在所在文本单元中的上下文特征表示,作为异构图中的各个字节点的初始值。j=1,2,3,……,M;M为文本单元的总数。每个文本单元为一个标题或者一个文本段。Taking the text unit in the document as a unit, each word in each text unit (for the convenience of distinction and description, denoted as the jth text unit) is encoded respectively (for the convenience of description and distinction, denoted as the second code), The context feature representation of each word in each text unit in the text unit is obtained as the initial value of each byte point in the heterogeneous graph. j=1, 2, 3, ..., M; M is the total number of text units. Each text unit is a heading or a text segment.
作为示例,可以通过抽取模型405中的上下文表示模块对第j个文本单元进行处理,得到第j个文本单元中每个字在第j个文本单元中的上下文特征表示。As an example, the jth text unit may be processed by the context representation module in the
对于任意一个标题节点,将该标题节点的标题中的各个字的上下文特征表示进行融合,得到该标题节点的初始值。For any title node, the context feature representation of each word in the title node's title is fused to obtain the initial value of the title node.
作为示例,可以将该标题节点的标题中的各个字的上下文特征表示求均值,得到该标题节点的初始值。As an example, the initial value of the title node can be obtained by averaging the context feature representations of each word in the title of the title node.
对于任意一个文本段节点,将该文本段节点的标题或文本段中的各个字的上下文特征表示进行融合,得到该文本段节点的初始值。即,如果该文本段节点为标题,将该文本段节点的标题中的各个字的上下文特征表示进行融合,得到该文本段节点的初始值。如果该文本段节点为文本段,将该文本段节点的文本段中的各个字的上下文特征表示进行融合,得到该文本段节点的初始值。For any text segment node, the title of the text segment node or the context feature representation of each word in the text segment are fused to obtain the initial value of the text segment node. That is, if the text segment node is a title, the context feature representation of each word in the title of the text segment node is fused to obtain the initial value of the text segment node. If the text segment node is a text segment, the context feature representation of each word in the text segment of the text segment node is fused to obtain the initial value of the text segment node.
作为示例,可以将文本段节点的标题中的各个字的上下文特征表示求均值,得到该文本段节点的初始值。或者,将文本段节点的文本段中的各个字的上下文特征表示求均值,得到该文本段节点的初始值。As an example, the context feature representation of each word in the title of the text segment node can be averaged to obtain the initial value of the text segment node. Alternatively, the context feature representation of each word in the text segment of the text segment node is averaged to obtain the initial value of the text segment node.
如图6所示,为本申请实施例提供的文档要素抽取模型的另一种结构示意图。与图4的区别主要在于,给出了抽取模型405的一种结构示意图,该示例中,As shown in FIG. 6, another schematic structural diagram of the document element extraction model provided by the embodiment of the present application. The main difference from FIG. 4 is that a schematic structural diagram of the
抽取模型405可以先通过上下文表示模块根据版面结构信息,以文档中的文本单元为单位,对每个文本单元中的各个字分别进行第二编码,得到每个文本单元中的各个字在所在文本单元中的上下文特征表示,将属于同一个文本单元的各个字的上下文特征表示进行融合,得到文本单元的特征表示;The
然后抽取模型405通过图卷积模块根据版面结构信息构建异构图,并将上下文表示模块得到的字的上下文特征表示,以及各个文本单元的特征表示作为异构图的节点的初始值,对异构图进行图卷积,得到各个节点的编码结果;将各个字的编码结果和对应的标题节点的编码结果融合,得到各个字的编码结果。Then the
最后抽取模型405通过条件随机场解码模块对各个字的编码结果进行解码,得到各个字所属的要素标签。Finally, the
与方法实施例相对应,本申请还提供一种文档要素抽取装置,本申请实施例提供的文档要素抽取装置的一种结构示意图如图7所示,可以包括:Corresponding to the method embodiment, the present application further provides a document element extraction apparatus. A schematic structural diagram of the document element extraction apparatus provided by the embodiment of the present application is shown in FIG. 7 , which may include:
获得单元701,编码单元702和抽取单元703;其中Obtaining
获得单元701用于获得所述文档的版面结构信息;The obtaining
编码单元702用于根据所述版面结构信息,对所述文档中的各个字进行编码;The
抽取单元703用于根据各个字的编码结果确定各个字所属的要素标签。The
本申请实施例提供的文档要素抽取装置,在对文档中的各个字进行编码时,融入了文档的版面结构信息,基于融合了文档编码结构信息的字编码结果确定各个字所属的要素标签,提高了文档要素抽取的准确性。The document element extraction device provided by the embodiment of the present application incorporates the layout structure information of the document when encoding each word in the document, and determines the element label to which each word belongs based on the word encoding result fused with the document coding structure information, thereby improving the performance of the document. The accuracy of document feature extraction is improved.
在一可选的实施例中,所述获得单元701包括:In an optional embodiment, the obtaining
特征提取单元,用于对包含所述文档的图片进行处理,得到所述文档中各个字的语义特征,以及各个文本行对应的位置特征;a feature extraction unit, configured to process the picture containing the document to obtain the semantic features of each word in the document and the positional feature corresponding to each text line;
第一融合单元,用户对于每个文本行,将该文本行中的各个字的语义特征及对应的位置特征进行融合,得到该文本行的编码特征;In the first fusion unit, for each text line, the user fuses the semantic feature of each word in the text line and the corresponding position feature to obtain the coding feature of the text line;
解码单元,用于对各个文本行的编码特征进行解码,得到所述文档的版面结构信息。The decoding unit is used for decoding the encoding feature of each text line to obtain the layout structure information of the document.
在一可选的实施例中,所述第一融合单元获得各个文本行的编码特征,以及所述解码单元获得文档的版面结构信息时,用于:In an optional embodiment, when the first fusion unit obtains the coding features of each text line, and when the decoding unit obtains the layout structure information of the document, it is used for:
将每个文本行中的各个字的语义特征及对应的位置特征输入文档要素抽取模型中的版面分析模型,得到所述版面分析模型对于每个文本行,将该文本行中的各个字的语义特征及对应的位置特征进行融合,得到该文本行的编码特征,对各个文本行的编码特征进行解码而输出的版面结构信息;Input the semantic features and corresponding position features of each word in each text line into the layout analysis model in the document element extraction model to obtain the layout analysis model. For each text line, the semantics of each word in the text line is obtained. The feature and the corresponding position feature are fused to obtain the coding feature of the text line, and the output layout structure information is decoded by decoding the coding feature of each text line;
所述版面分析模型为,以样本图片的每个文本行中的各个字的语义特征及对应的位置特征为输入,以标注的所述样本图片的版面结构信息为样本标签,以所述版面分析模型输出的版面结构信息趋近于所述样本标签为目标训练得到。The layout analysis model is that the semantic features of each word in each text line of the sample picture and the corresponding positional feature are used as input, the layout structure information of the marked sample picture is used as a sample label, and the layout analysis is used as the input. The layout structure information output by the model is close to the sample label as the target training.
在一可选的实施例中,所述特征提取单元对包含所述文档的图片进行处理,得到所述文档中各个字的语义特征,以及各个文本行对应的位置特征时,用于:In an optional embodiment, when the feature extraction unit processes a picture containing the document to obtain the semantic features of each word in the document and the positional feature corresponding to each text line, it is used for:
通过所述文档要素抽取模型中的字符识别模型对所述图片进行光学字符识别,得到所述文档中的每个文本行,以及文本行的坐标;Perform optical character recognition on the picture by using the character recognition model in the document element extraction model to obtain each text line in the document and the coordinates of the text line;
通过所述文档要素抽取模型中的上下文表示模型对每个文本行中的各个字进行第一编码,得到各个字的语义特征;First encode each word in each text line by using the context representation model in the document element extraction model to obtain the semantic feature of each word;
通过所述文档要素抽取模型中的文本行位置特征提取模型的第一特征提取模块对所述图片进行特征提取,获得特征图;通过所述文本行位置特征提取模型的第二特征提取模块根据每个文本行的坐标在所述特征图中提取每个文本行对应的位置特征;所述第一特征提取模块为预先训练好的文本行边界检测模型的特征提取模块。Perform feature extraction on the picture through the first feature extraction module of the text line position feature extraction model in the document element extraction model to obtain a feature map; through the second feature extraction module of the text line position feature extraction model according to each The coordinates of each text line are extracted from the feature map corresponding to the position feature of each text line; the first feature extraction module is a feature extraction module of a pre-trained text line boundary detection model.
在一可选的实施例中,还包括训练模块,用于对所述文本行边界检测模型进行训练,包括:In an optional embodiment, it also includes a training module for training the text line boundary detection model, including:
将样本图片输入所述文本行边界检测模型,通过所述文本行边界检测模型的特征提取模块对输入的样本图片进行特征提取,得到所述样本图片的特征图;Input the sample picture into the text line boundary detection model, and perform feature extraction on the input sample picture through the feature extraction module of the text line boundary detection model to obtain a feature map of the sample picture;
通过所述文本行边界检测模型的输出模块对所述样本图片的特征图进行处理,得到所述样本图片中的文本行边界坐标;The feature map of the sample picture is processed by the output module of the text line boundary detection model to obtain the text line boundary coordinates in the sample picture;
以所述文本行边界检测模型输出的文本行边界坐标趋近于所述样本图片的标签为目标对所述文本行边界检测模型的参数进行更新;The parameters of the text line boundary detection model are updated with the target that the text line boundary coordinates output by the text line boundary detection model approach the label of the sample picture;
所述样本图片的标签为:针对所述样本图片标注的各个文本行的边界坐标。The label of the sample picture is: the boundary coordinates of each text line marked for the sample picture.
在一可选的实施例中,还包括训练模块,用于对所述文本行边界检测模型进行训练,包括:In an optional embodiment, it also includes a training module for training the text line boundary detection model, including:
将样本图片输入所述文本行边界检测模型,通过所述文本行边界检测模型的特征提取模块对输入的样本图片进行特征提取,得到所述样本图片的特征图;Input the sample picture into the text line boundary detection model, and perform feature extraction on the input sample picture through the feature extraction module of the text line boundary detection model to obtain a feature map of the sample picture;
通过所述文本行边界检测模型的输出模块对所述样本图片的特征图进行处理,得到所述样本图片中的文本行边界坐标,以及每个文本行边界坐标的对应区域的类别;The feature map of the sample picture is processed by the output module of the text line boundary detection model to obtain the text line boundary coordinates in the sample picture, and the category of the corresponding area of each text line boundary coordinate;
以所述文本行边界检测模型输出的文本行边界坐标以及每个文本行边界坐标的对应区域的类别,趋近于所述样本图片的标签为目标对所述文本行边界检测模型的参数进行更新;The parameters of the text line boundary detection model are updated with the text line boundary coordinates output by the text line boundary detection model and the category of the corresponding area of each text line boundary coordinate, approaching the label of the sample picture as the target ;
所述样本图片的标签为:针对所述样本图片标注的各个文本行的边界坐标,以及每个文本行边界坐标的对应区域的类别。The label of the sample picture is: the boundary coordinates of each text line marked for the sample picture, and the category of the corresponding region of the boundary coordinates of each text line.
在一可选的实施例中,所述编码单元702根据所述版面结构信息,对所述文档中的各个字进行编码,所述抽取单元703根据各个字的编码结果确定各个字所属的要素标签时,用于:In an optional embodiment, the
通过所述文档要素抽取模型中的抽取模型,根据所述版面结构信息,对所述文档中的各个字进行编码,根据各个字的编码结果确定各个字所属的要素标签;所述抽取模型通过如下方式训练得到:Through the extraction model in the document element extraction model, each word in the document is encoded according to the layout structure information, and the element label to which each word belongs is determined according to the encoding result of each word; the extraction model is as follows way to train to get:
将所述版面结构信息以及所述文档中的各个文本行输入所述抽取模型,得到所述抽取模型根据输入的版面结构信息,对输入的文本行中的各个字进行编码,根据各个字的编码结果确定的各个字所属的要素标签;Inputting the layout structure information and each text line in the document into the extraction model, and obtaining the extraction model to encode each word in the input text line according to the input layout structure information, and according to the encoding of each word The element label to which each word determined by the result belongs;
以所述抽取模型输出的各个字所属的要素标签趋近于所述样本图片的标签为目标,对所述抽取模型的参数进行更新;The parameters of the extraction model are updated with the goal that the element labels to which each word output by the extraction model belongs is close to the label of the sample picture;
所述样本图片的标签为:针对所述样本图片标注的各个字所属的要素标签。The label of the sample picture is: the element label to which each word marked for the sample picture belongs.
在一可选的实施例中,所述版面结构信息至少包括:段落的划分、标题层级、页眉、页脚。In an optional embodiment, the layout structure information includes at least: paragraph division, title level, page header, and page footer.
在一可选的实施例中,所述编码单元702包括:In an optional embodiment, the
提取单元,用户根据所述版面结构信息,在所述文档中提取文本单元;每个文本单元为一个标题,或者,一个文本段;Extraction unit, the user extracts text units in the document according to the layout structure information; each text unit is a title, or a text segment;
构图单元,用于基于所述文档构建异构图,所述异构图中的节点包括字节点、标题节点、文本段节点;所述异构图中的边包括:字与字的关系、字与文本段的关系、文本段与标题的关系;A graph composition unit, configured to construct a heterogeneous graph based on the document, the nodes in the heterogeneous graph include byte points, title nodes, and text segment nodes; the edges in the heterogeneous graph include: the relationship between words, The relationship between the word and the text segment, the relationship between the text segment and the title;
图卷积单元,用于对所述异构图进行图卷积,得到各个节点的编码结果;The graph convolution unit is used to perform graph convolution on the heterogeneous graph to obtain the encoding result of each node;
第二融合单元,用于将各个字的编码结果和对应的标题节点的编码结果融合,得到各个字的编码结果。The second fusion unit is configured to fuse the encoding result of each word with the encoding result of the corresponding title node to obtain the encoding result of each word.
在一可选的实施例中,所述异构图中的标题节点为所述文档中的各个标题;所述异构图中的文本段节点为所述文档中的各个文本段;In an optional embodiment, the title node in the heterogeneous graph is each title in the document; the text segment node in the heterogeneous graph is each text segment in the document;
或者,or,
所述异构图中的标题节点为所述文档中的目标标题,所述目标标题的层级高于目标层级;所述异构图中的文本段节点包括所述文当中的非目标标题,各个文本段;非目标标题的层级低于或等于目标层级。The title node in the heterogeneous graph is the target title in the document, and the level of the target title is higher than the target level; the text segment node in the heterogeneous graph includes the non-target title in the text, each Text segment; non-target headings are at a level lower than or equal to the target level.
在一可选的实施例中,所述图卷积单元通过如下方式确定异构图中的各个节点的初始值:In an optional embodiment, the graph convolution unit determines the initial value of each node in the heterogeneous graph in the following manner:
以所述文档中的文本单元为单位,对每个文本单元中的各个字分别进行第二编码,得到每个文本单元中的各个字在所在文本单元中的上下文特征表示,作为所述异构图中的各个字节点的初始值;每个文本单元为一个标题或一个文本段;Taking the text unit in the document as a unit, the second encoding is performed on each word in each text unit to obtain the context feature representation of each word in each text unit in the text unit where it is located, as the heterogeneous The initial value of each byte point in the figure; each text unit is a title or a text segment;
对于任意一个标题节点,将该标题节点的标题中的各个字的上下文特征表示进行融合,得到该标题节点的初始值;For any title node, the context feature representation of each word in the title node's title is fused to obtain the initial value of the title node;
对于任意一个文本段节点,将该文本段节点的标题中的各个字的上下文特征表示进行融合,得到该文本段节点的初始值。For any text segment node, the context feature representation of each word in the title of the text segment node is fused to obtain the initial value of the text segment node.
本申请实施例提供的文档要素抽取装置可应用于文档要素抽取设备,如PC终端、云平台、服务器及服务器集群等。可选的,图8示出了文档要素抽取设备的硬件结构框图,参照图8,文档要素抽取设备的硬件结构可以包括:至少一个处理器1,至少一个通信接口2,至少一个存储器3和至少一个通信总线4;The device for extracting document elements provided by the embodiments of the present application can be applied to a document element extraction device, such as a PC terminal, a cloud platform, a server, a server cluster, and the like. Optionally, FIG. 8 shows a block diagram of the hardware structure of the document element extraction device. Referring to FIG. 8, the hardware structure of the document element extraction device may include: at least one
在本申请实施例中,处理器1、通信接口2、存储器3、通信总线4的数量为至少一个,且处理器1、通信接口2、存储器3通过通信总线4完成相互间的通信;In the embodiment of the present application, the number of the
处理器1可能是一个中央处理器CPU,或者是特定集成电路ASIC(ApplicationSpecific Integrated Circuit),或者是被配置成实施本发明实施例的一个或多个集成电路等;The
存储器3可能包含高速RAM存储器,也可能还包括非易失性存储器(non-volatilememory)等,例如至少一个磁盘存储器;The
其中,存储器存储有程序,处理器可调用存储器存储的程序,所述程序用于:Wherein, the memory stores a program, and the processor can call the program stored in the memory, and the program is used for:
获得所述文档的版面结构信息;obtain the layout structure information of the document;
根据所述版面结构信息,对所述文档中的各个字进行编码;encoding each word in the document according to the layout structure information;
根据各个字的编码结果确定各个字所属的要素标签。The element label to which each word belongs is determined according to the encoding result of each word.
可选的,所述程序的细化功能和扩展功能可参照上文描述。Optionally, the refinement function and extension function of the program may refer to the above description.
本申请实施例还提供一种存储介质,该存储介质可存储有适于处理器执行的程序,所述程序用于:An embodiment of the present application further provides a storage medium, where the storage medium can store a program suitable for the processor to execute, and the program is used for:
获得所述文档的版面结构信息;obtain the layout structure information of the document;
根据所述版面结构信息,对所述文档中的各个字进行编码;encoding each word in the document according to the layout structure information;
根据各个字的编码结果确定各个字所属的要素标签。The element label to which each word belongs is determined according to the encoding result of each word.
可选的,所述程序的细化功能和扩展功能可参照上文描述。Optionally, the refinement function and extension function of the program may refer to the above description.
本领域技术人员可以意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、或者计算机软件和电子硬件的结合来实现。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本申请的范围。Those skilled in the art can realize that the units and algorithm steps of each example described in conjunction with the embodiments disclosed herein can be implemented by electronic hardware, or a combination of computer software and electronic hardware. Whether these functions are performed in hardware or software depends on the specific application and design constraints of the technical solution. Skilled artisans may implement the described functionality using different methods for each particular application, but such implementations should not be considered beyond the scope of this application.
在本申请所提供的几个实施例中,应该理解到,所揭露的系统、装置和方法,可以通过其它的方式实现。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。In the several embodiments provided in this application, it should be understood that the disclosed system, apparatus and method may be implemented in other manners. On the other hand, the shown or discussed mutual coupling or direct coupling or communication connection may be through some interfaces, indirect coupling or communication connection of devices or units, and may be in electrical, mechanical or other forms.
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。The units described as separate components may or may not be physically separated, and components displayed as units may or may not be physical units, that is, may be located in one place, or may be distributed to multiple network units. Some or all of the units may be selected according to actual needs to achieve the purpose of the solution in this embodiment.
另外,在本申请各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。In addition, each functional unit in each embodiment of the present application may be integrated into one processing unit, or each unit may exist physically alone, or two or more units may be integrated into one unit.
所述功能如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本申请各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器(ROM,Read-Only Memory)、随机存取存储器(RAM,Random Access Memory)、磁碟或者光盘等各种可以存储程序代码的介质。The functions, if implemented in the form of software functional units and sold or used as independent products, may be stored in a computer-readable storage medium. Based on this understanding, the technical solution of the present application can be embodied in the form of a software product in essence, or the part that contributes to the prior art or the part of the technical solution. The computer software product is stored in a storage medium, including Several instructions are used to cause a computer device (which may be a personal computer, a server, or a network device, etc.) to execute all or part of the steps of the methods described in the various embodiments of the present application. The aforementioned storage medium includes: U disk, mobile hard disk, Read-Only Memory (ROM, Read-Only Memory), Random Access Memory (RAM, Random Access Memory), magnetic disk or optical disk and other media that can store program codes .
最后,还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。Finally, it should also be noted that in this document, relational terms such as first and second are used only to distinguish one entity or operation from another, and do not necessarily require or imply these entities or that there is any such actual relationship or sequence between operations. Moreover, the terms "comprising", "comprising" or any other variation thereof are intended to encompass a non-exclusive inclusion such that a process, method, article or device that includes a list of elements includes not only those elements, but also includes not explicitly listed or other elements inherent to such a process, method, article or apparatus. Without further limitation, an element qualified by the phrase "comprising a..." does not preclude the presence of additional identical elements in a process, method, article or apparatus that includes the element.
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。The various embodiments in this specification are described in a progressive manner, and each embodiment focuses on the differences from other embodiments, and the same and similar parts between the various embodiments can be referred to each other.
对所公开的实施例的上述说明,使本领域技术人员能够实现或使用本申请。对这些实施例的多种修改对本领域的技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本申请的精神或范围的情况下,在其它实施例中实现。因此,本申请将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。The above description of the disclosed embodiments enables any person skilled in the art to make or use the present application. Various modifications to these embodiments will be readily apparent to those skilled in the art, and the generic principles defined herein may be implemented in other embodiments without departing from the spirit or scope of the present application. Therefore, this application is not intended to be limited to the embodiments shown herein, but is to be accorded the widest scope consistent with the principles and novel features disclosed herein.
Claims (14)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210679246.0ACN114973286B (en) | 2022-06-16 | 2022-06-16 | Document element extraction method, device, equipment and storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210679246.0ACN114973286B (en) | 2022-06-16 | 2022-06-16 | Document element extraction method, device, equipment and storage medium |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN114973286Atrue CN114973286A (en) | 2022-08-30 |
| CN114973286B CN114973286B (en) | 2025-08-05 |
Family
ID=82963351
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210679246.0AActiveCN114973286B (en) | 2022-06-16 | 2022-06-16 | Document element extraction method, device, equipment and storage medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114973286B (en) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115439868A (en)* | 2022-09-14 | 2022-12-06 | 阿里巴巴(中国)有限公司 | Layout analysis and model training method, device, electronic device and storage medium |
| CN115661847A (en)* | 2022-09-14 | 2023-01-31 | 北京百度网讯科技有限公司 | Table structure recognition and model training method, device, equipment and storage medium |
| CN117095422A (en)* | 2023-10-17 | 2023-11-21 | 企查查科技股份有限公司 | Document information analysis method, device, computer equipment and storage medium |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2010244412A (en)* | 2009-04-08 | 2010-10-28 | Konica Minolta Business Technologies Inc | Apparatus, method and program for processing document |
| CN102200966A (en)* | 2011-06-01 | 2011-09-28 | 潍坊北大青鸟华光照排有限公司 | Method for extracting and processing layout information |
| CN110569846A (en)* | 2019-09-16 | 2019-12-13 | 北京百度网讯科技有限公司 | Image character recognition method, device, equipment and storage medium |
| CN112508115A (en)* | 2020-12-15 | 2021-03-16 | 北京百度网讯科技有限公司 | Method, apparatus, device and computer storage medium for building node representation model |
| CN112733658A (en)* | 2020-12-31 | 2021-04-30 | 北京华宇信息技术有限公司 | Electronic document filing method and device |
| CN113342944A (en)* | 2021-04-29 | 2021-09-03 | 腾讯科技(深圳)有限公司 | Corpus generalization method, apparatus, device and storage medium |
| CN113408251A (en)* | 2021-06-30 | 2021-09-17 | 北京百度网讯科技有限公司 | Layout document processing method and device, electronic equipment and readable storage medium |
- 2022
- 2022-06-16CNCN202210679246.0Apatent/CN114973286B/enactiveActive
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2010244412A (en)* | 2009-04-08 | 2010-10-28 | Konica Minolta Business Technologies Inc | Apparatus, method and program for processing document |
| CN102200966A (en)* | 2011-06-01 | 2011-09-28 | 潍坊北大青鸟华光照排有限公司 | Method for extracting and processing layout information |
| CN110569846A (en)* | 2019-09-16 | 2019-12-13 | 北京百度网讯科技有限公司 | Image character recognition method, device, equipment and storage medium |
| CN112508115A (en)* | 2020-12-15 | 2021-03-16 | 北京百度网讯科技有限公司 | Method, apparatus, device and computer storage medium for building node representation model |
| CN112733658A (en)* | 2020-12-31 | 2021-04-30 | 北京华宇信息技术有限公司 | Electronic document filing method and device |
| CN113342944A (en)* | 2021-04-29 | 2021-09-03 | 腾讯科技(深圳)有限公司 | Corpus generalization method, apparatus, device and storage medium |
| CN113408251A (en)* | 2021-06-30 | 2021-09-17 | 北京百度网讯科技有限公司 | Layout document processing method and device, electronic equipment and readable storage medium |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115439868A (en)* | 2022-09-14 | 2022-12-06 | 阿里巴巴(中国)有限公司 | Layout analysis and model training method, device, electronic device and storage medium |
| CN115661847A (en)* | 2022-09-14 | 2023-01-31 | 北京百度网讯科技有限公司 | Table structure recognition and model training method, device, equipment and storage medium |
| CN115661847B (en)* | 2022-09-14 | 2023-11-21 | 北京百度网讯科技有限公司 | Table structure recognition and model training method, device, equipment and storage medium |
| CN117095422A (en)* | 2023-10-17 | 2023-11-21 | 企查查科技股份有限公司 | Document information analysis method, device, computer equipment and storage medium |
| CN117095422B (en)* | 2023-10-17 | 2024-02-09 | 企查查科技股份有限公司 | Document information analysis method, device, computer equipment and storage medium |
Also Published As
| Publication number | Publication date |
|---|---|
| CN114973286B (en) | 2025-08-05 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110349568B (en) | Voice retrieval method, device, computer equipment and storage medium | |
| CN112100332B (en) | Word embedding representation learning method and device, text recall method and device | |
| JP5128629B2 (en) | Part-of-speech tagging system, part-of-speech tagging model training apparatus and method | |
| CN114973286B (en) | Document element extraction method, device, equipment and storage medium | |
| CN113807098A (en) | Model training method and device, electronic equipment and storage medium | |
| CN111160031A (en) | A social media named entity recognition method based on affix awareness | |
| CN112507153B (en) | Method, computing device, and computer storage medium for image retrieval | |
| CN112818091A (en) | Object query method, device, medium and equipment based on keyword extraction | |
| WO2025086680A1 (en) | Sentiment analysis method and apparatus and large language model training method and apparatus | |
| CN115630145A (en) | A dialogue recommendation method and system based on multi-granularity emotion | |
| CN116578688A (en) | Text processing method, device, equipment and storage medium based on multiple rounds of questions and answers | |
| CN112287100A (en) | Text recognition method, spelling error correction method and speech recognition method | |
| CN113408287A (en) | Entity identification method and device, electronic equipment and storage medium | |
| CN111966832A (en) | Evaluation object extraction method and device and electronic equipment | |
| CN116384403A (en) | A Scene Graph Based Multimodal Social Media Named Entity Recognition Method | |
| CN114036246A (en) | Commodity map vectorization method, device, electronic device and storage medium | |
| CN115329766A (en) | A Named Entity Recognition Method Based on Dynamic Word Information Fusion | |
| CN116611450A (en) | Method, device and equipment for extracting document information and readable storage medium | |
| CN115577095A (en) | A graph theory-based power standard information recommendation method | |
| CN119938884A (en) | A document retrieval enhancement method, device and equipment for large language model | |
| CN114416923A (en) | A method and system for linking news entities based on rich text features | |
| CN113919338B (en) | Method and device for processing text data | |
| CN118503411A (en) | Outline generation method, model training method, device and medium | |
| CN117034916A (en) | Method, device and equipment for constructing word vector representation model and word vector representation | |
| CN112765937B (en) | Text regularization method, device, electronic device and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |