CN114936224A - Rail inspection data service system based on Hadoop - Google Patents
Rail inspection data service system based on HadoopDownload PDFInfo
- Publication number
- CN114936224A CN114936224ACN202210648201.7ACN202210648201ACN114936224ACN 114936224 ACN114936224 ACN 114936224ACN 202210648201 ACN202210648201 ACN 202210648201ACN 114936224 ACN114936224 ACN 114936224A
- Authority
- CN
- China
- Prior art keywords
- data
- inspection data
- file
- module
- service system
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images















Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/245—Query processing
- G06F16/2453—Query optimisation
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/245—Query processing
- G06F16/2455—Query execution
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/27—Replication, distribution or synchronisation of data between databases or within a distributed database system; Distributed database system architectures therefor
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Databases & Information Systems (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- Computing Systems (AREA)
- Machines For Laying And Maintaining Railways (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本发明涉及数据处理技术领域,特别涉及一种基于Hadoop的轨检数据服务系统。The invention relates to the technical field of data processing, in particular to a Hadoop-based rail inspection data service system.
背景技术Background technique
“互联网+”已然成为当前我国各产业共同发展的重大策略。互联网、大数据、云计算等高科技信息技术发展迅猛,“互联网+”将这些信息技术与各领域融合,使传统业务数据化、在线化,实现了传统产业的创新与转型。"Internet +" has become a major strategy for the common development of various industries in my country. High-tech information technologies such as the Internet, big data, and cloud computing are developing rapidly. "Internet +" integrates these information technologies with various fields, digitizes and online traditional businesses, and realizes the innovation and transformation of traditional industries.
以往对轨道检测数据的分析与处理基本是基于单机或C/S架构的模式,容易形成“信息孤岛”,基础数据难以系统性地分类保存,形成的分析结果不够全面、不具宏观性。借助于当下“互联网+”的新技术将大量的轨道检测数据通过互联网汇集到一块进行系统性分类存储和挖掘分析,打破“信息孤岛”壁垒,形成统一的大数据分析云平台,提供全面、宏观的数据可视化分析结果,已成为当下轨检数据挖掘分析的发展方向和市场热点。In the past, the analysis and processing of orbit detection data were basically based on the single-machine or C/S architecture mode, which was easy to form "information islands". With the help of the current "Internet +" new technology, a large amount of track detection data is collected through the Internet for systematic classification, storage, mining and analysis, breaking the "information island" barrier, forming a unified big data analysis cloud platform, providing comprehensive, macroscopic The results of data visualization analysis have become the development direction and market focus of current rail inspection data mining analysis.
轨检数据服务平台是顺应当前社会信息化技术高水平发展、服务轨道检测系统改革的数据平台。它的主要目的是强化轨道检测分析,建立规范化管理体系,推进轨道系统数据之间的共享和各业务之间的相互配合,为决策提供高效、精准、牢靠的数据依据,提高轨道维护工作的预见性和针对性。当前轨检信息的管理存在一些问题:The rail inspection data service platform is a data platform that conforms to the current high-level development of social information technology and serves the reform of the rail inspection system. Its main purpose is to strengthen track detection and analysis, establish a standardized management system, promote the sharing of track system data and the mutual cooperation between various businesses, provide efficient, accurate and reliable data basis for decision-making, and improve track maintenance work. Sex and pertinence. There are some problems in the management of current track inspection information:
(1)不能满足轨道检测各项业务产生的各类文件的高效存储和分类管理,各类不同信息的兼容性较差,无法做到统一访问、高效率的精确查询与统计,这是当前轨检信息的一大弊病;(1) It cannot meet the efficient storage and classification management of various files generated by various orbit detection services. The compatibility of various types of information is poor, and it is impossible to achieve unified access and efficient accurate query and statistics. This is the current orbit. A major drawback of checking information;
(2)各类数据没有做到分层管理,在使用上也比较混乱,没有统一的数据存储管理中心和数据应用平台;(2) All kinds of data are not managed in layers, and the use is also confusing, and there is no unified data storage management center and data application platform;
(3)应用业务与应用模式没有良好的可扩展性,不能分阶段地完善平台业务功能;(3) The application business and application model do not have good scalability, and the platform business functions cannot be improved in stages;
(4)兼容性较差,无法与其他的信息系统较好地融合在一起,系统运维成本较高;(4) The compatibility is poor, it cannot be well integrated with other information systems, and the system operation and maintenance costs are high;
(5)对数据的价值挖掘不足,无法深度探索和发现隐藏在海量数据之中的模式、规律和关系,无法从低价值密度的数据中萃取高价值密度的知识,处在“数据有余,信息不足”的阶段;(5) Insufficient mining of the value of data, unable to deeply explore and discover patterns, laws and relationships hidden in massive data, unable to extract high-value-density knowledge from low-value-density data, in a situation of "more data, more information" insufficient" stage;
(6)没有良好的容灾能力,数据中心自动瞬时故障转移能力较弱,数据的安全性得不到保障。(6) There is no good disaster recovery capability, and the automatic instantaneous failover capability of the data center is weak, and the security of data cannot be guaranteed.
发明内容SUMMARY OF THE INVENTION
基于此,本发明的目的是提供一种基于Hadoop的轨检数据服务系统,以至少解决上述技术中的不足。Based on this, the purpose of the present invention is to provide a rail inspection data service system based on Hadoop, so as to at least solve the deficiencies in the above technologies.
本发明提出一种基于Hadoop的轨检数据服务系统,包括数据采集模块以及数据处理模块:The present invention provides a Hadoop-based rail inspection data service system, including a data acquisition module and a data processing module:
所述数据采集模块,用于采集各轨检设备的当前轨检数据;The data acquisition module is used to collect the current rail inspection data of each rail inspection equipment;
所述数据处理模块,包括数据对齐单元以及数据处理单元,所述数据对齐单元用于利用历史轨检数据对各所述当前轨检数据进行局部插值及压缩,以实现所述历史轨检数据和各所述当前轨检数据的特征点匹配,进而得到数据对齐的轨检数据;The data processing module includes a data alignment unit and a data processing unit, and the data alignment unit is used to perform local interpolation and compression on each of the current track inspection data using historical track inspection data, so as to realize the historical track inspection data and The feature points of each of the current track inspection data are matched, and then the track inspection data with data alignment is obtained;
所述数据处理单元用于将所述数据对齐的轨检数据进行数据预处理,以得到多组预处理的轨检数据,并对所述多组预处理的轨检数据进行分布式处理,以判断所述数据对齐的轨检数据是否符合预设要求,若所述数据对齐的轨检数据符合预设要求,则生成对应的数据报表,以实现用户与各所述轨检设备的信息交互。The data processing unit is configured to perform data preprocessing on the data-aligned track inspection data to obtain multiple groups of preprocessed track inspection data, and perform distributed processing on the multiple groups of preprocessed track inspection data to obtain multiple groups of preprocessed track inspection data. It is judged whether the data-aligned track inspection data meets the preset requirements, and if the data-aligned track inspection data meets the preset requirements, a corresponding data report is generated to realize information interaction between the user and each of the track inspection devices.
进一步的,所述基于Hadoop的轨检数据服务系统还包括数据库支持模块,所述数据库支持模块用于根据利用各轨检设备所获取的轨检数据生成多个轨检台账数据库、以及根据用户权限生成多个权限管理数据库,所述多个轨检台账数据库至少包括平面曲线数据库、竖曲线数据库、CP3数据库以及轨枕信息数据库,所述多个权限管理数据库至少包括规范管理数据库。Further, the Hadoop-based rail inspection data service system further includes a database support module, and the database support module is used to generate a plurality of rail inspection ledger databases according to the rail inspection data obtained by using each rail inspection equipment, and according to the user. The authority generates a plurality of authority management databases, the plurality of rail inspection ledger databases at least include a plane curve database, a vertical curve database, a CP3 database and a sleeper information database, and the plurality of authority management databases at least include a normative management database.
进一步的,所述数据处理模块还包括文件存储单元,所述文件存储单元用于将小于预设存储大小的文件按照所占内存空间进行均匀分布,以使合并后的文件符合预设的数据块最大阈值。Further, the data processing module further includes a file storage unit, and the file storage unit is used to evenly distribute the files smaller than the preset storage size according to the occupied memory space, so that the merged file conforms to the preset data block. maximum threshold.
进一步的,所述文件存储单元具体用于:Further, the file storage unit is specifically used for:
当接收到文件存储请求时,初始化数据队列、并创建多个临时队列、多个合并队列以及多个文件信息映射表,其中,所述临时队列的个数小于所述合并队列的个数;When receiving a file storage request, initialize a data queue, and create multiple temporary queues, multiple merge queues, and multiple file information mapping tables, wherein the number of the temporary queues is less than the number of the merge queues;
获取当前上传的文件,并比较所述当前上传的文件的存储大小与所述临时队列的剩余存储空间,若所述临时队列的剩余存储空间大于所述当前上传的文件的存储大小,则将所述当前上传的文件存储到所述临时队列中、并查看所述文件信息映射表中是否存在所述当前上传的文件;Obtain the currently uploaded file, and compare the storage size of the currently uploaded file with the remaining storage space of the temporary queue, if the remaining storage space of the temporary queue is greater than the storage size of the currently uploaded file, then Store the currently uploaded file in the temporary queue, and check whether the currently uploaded file exists in the file information mapping table;
若所述文件信息映射表中存在所述当前上传的文件,则判断所述临时队列中所有文件所占空间是否达到所述临时队列的预设阈值空间的第一阈值;If there is the currently uploaded file in the file information mapping table, then determine whether the space occupied by all files in the temporary queue reaches the first threshold of the preset threshold space of the temporary queue;
若所述临时队列中所有文件所占空间达到所述临时队列的预设阈值空间的第一阈值,则将所述临时队列中所有文件进行合并,直到达到所述临时队列的预设阈值空间,得到所述临时队列所对应的合并队列;If the space occupied by all files in the temporary queue reaches the first threshold of the preset threshold space of the temporary queue, then merge all the files in the temporary queue until the preset threshold space of the temporary queue is reached, obtain the merged queue corresponding to the temporary queue;
找到所述临时队列中所占存储空间最大的文件,并判断所述所占存储空间最大的文件的存储大小是否大于所述临时队列的预设阈值空间的第二阈值;Find the file with the largest storage space in the temporary queue, and determine whether the storage size of the file with the largest storage space is greater than the second threshold of the preset threshold space of the temporary queue;
若所述所占存储空间最大的文件的存储大小大于所述临时队列的预设阈值空间的第二阈值,则将所述当前上传的文件存放在所述临时队列所对应的合并队列中,并在其他的临时队列中寻找友好文件,并将寻找到的所有友好文件均存入所述临时队列所对应的合并队列中进行文件打包上传。If the storage size of the file with the largest storage space is greater than the second threshold of the preset threshold space of the temporary queue, the currently uploaded file is stored in the merge queue corresponding to the temporary queue, and Search for friendly files in other temporary queues, and store all the found friendly files in the merge queue corresponding to the temporary queue for file packaging and uploading.
进一步的,所述文件存储单元还用于:Further, the file storage unit is also used for:
若所述所占存储空间最大的文件的存储大小不大于所述临时队列的预设阈值空间的第二阈值,则持续向所述临时队列中上传文件,直到所述临时队列中所有文件所占空间大于等于所述临时队列的预设阈值空间的第二阈值;If the storage size of the file with the largest storage space is not greater than the second threshold of the preset threshold space of the temporary queue, continue uploading files to the temporary queue until all files in the temporary queue occupy The space is greater than or equal to the second threshold of the preset threshold space of the temporary queue;
将所述当前上传的文件存放在所述临时队列所对应的合并队列中,并在其他的临时队列中寻找友好文件,并将寻找到的所有友好文件均存入所述临时队列所对应的合并队列中进行文件打包上传。Store the currently uploaded file in the merged queue corresponding to the temporary queue, and look for friendly files in other temporary queues, and store all the friendly files found in the merged corresponding to the temporary queue. The files are packaged and uploaded in the queue.
进一步的,所述数据对齐单元具体用于:Further, the data alignment unit is specifically used for:
在所述历史轨检数据和各所述当前轨检数据中给定两个等时间间隔的相同特征序列,并计算出两所述相同特征序列之间任意两点的距离,以得到两所述相同特征序列的距离矩阵;Two identical feature sequences at equal time intervals are given in the historical track inspection data and each of the current track inspection data, and the distance between any two points between the two identical feature sequences is calculated to obtain the two identical feature sequences. The distance matrix of the same feature sequence;
利用动态规划法计算出两所述相同特征序列的距离矩阵的最优规划路径,根据所述最优规划路径计算出两所述相同特征序列的最小动态时间规整距离,以使两所述相同特征序列进行数据对齐。Use the dynamic programming method to calculate the optimal planning path of the distance matrix of the two identical feature sequences, and calculate the minimum dynamic time warping distance of the two identical feature sequences according to the optimal planning path, so that the two identical feature sequences can be sequence for data alignment.
进一步的,所述基于Hadoop的轨检数据服务系统还包括分析模块,所述分析模块用于对所述数据采集模块所采集的数据进行数据分析,所述数据分析至少包括轮廓数据分析、波磨数据分析、板翘分析以及焊缝平直度分析。Further, the Hadoop-based rail inspection data service system further includes an analysis module, and the analysis module is used to perform data analysis on the data collected by the data acquisition module, and the data analysis at least includes profile data analysis, wave grinding Data analysis, warpage analysis and weld straightness analysis.
进一步的,所述基于Hadoop的轨检数据服务系统还包括报表生成模块,所述报表生成模块用于将各模块所输出的数据转换成对应的数据报表,以使用户进行查看。Further, the Hadoop-based rail inspection data service system further includes a report generation module, and the report generation module is used to convert the data output by each module into a corresponding data report, so that the user can view it.
进一步的,所述基于Hadoop的轨检数据服务系统还包括数据共享模块,所述数据共享模块用于创建数据共享规则,并利用所述数据共享规则向各平台提供统一的数据分发出口服务。Further, the Hadoop-based rail inspection data service system further includes a data sharing module, and the data sharing module is used for creating data sharing rules, and using the data sharing rules to provide a unified data distribution export service to each platform.
进一步的,还包括数据可视化模块,所述数据可视化模块包括第一可视化模块以及第二可视化模块,所述第一可视化模块用于将不同时间下所述数据采集模块所采集的采样数据进行连接,以展示所述数据采集模块的测量信号与时间的变化程度;所述第二可视化模块用于对所述数据采集模块所采样的数据信号进行积分处理,以展示所述数据采集模块的当前信号强度。Further, it also includes a data visualization module, the data visualization module includes a first visualization module and a second visualization module, and the first visualization module is used to connect the sampling data collected by the data acquisition module at different times, to display the degree of change between the measurement signal of the data acquisition module and time; the second visualization module is used to integrate the data signal sampled by the data acquisition module to display the current signal strength of the data acquisition module .
与现有技术相比,本发明的有益效果是:通过数据对齐单元将各当前轨检数据与历史轨检数据以特征点为标志进行数据对齐,为后续数据分析排除里程误差干扰;通过将数据对齐的轨检数据进行拆分,并对多组预处理的轨检数据进行分布式处理,进而提高轨检数据的高效利用以及分类管理,以使用户能够做到统一访问、高效率的精确查询和统计。Compared with the prior art, the present invention has the beneficial effects of: aligning the current track inspection data and the historical track inspection data with the feature points as marks by the data alignment unit, so as to eliminate mileage error interference for subsequent data analysis; The aligned rail inspection data is split, and multiple groups of pre-processed rail inspection data are processed in a distributed manner, thereby improving the efficient use and classification management of rail inspection data, so that users can achieve unified access and efficient accurate query. and statistics.
附图说明Description of drawings
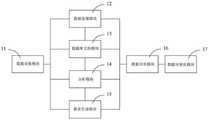
图1为本发明实施例中基于Hadoop的轨检数据服务系统的结构框图;Fig. 1 is the structural block diagram of the track inspection data service system based on Hadoop in the embodiment of the present invention;
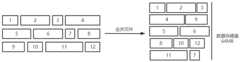
图2为本发明实施例中数据处理模块的结构框图;2 is a structural block diagram of a data processing module in an embodiment of the present invention;
图3为本发明实施例中基于Hadoop的轨检数据服务系统的模型分布图;3 is a model distribution diagram of a Hadoop-based rail inspection data service system in an embodiment of the present invention;
图4为本发明实施例中统一认证和权限控制涉及数据库各表;FIG. 4 shows the tables of databases involved in unified authentication and authority control in an embodiment of the present invention;
图5为本发明实施例中铁路部门的组织结构图;Fig. 5 is the organizational structure diagram of the railway department in the embodiment of the present invention;
图6为本发明实施例中星绘法的示例图;6 is an example diagram of a star drawing method in an embodiment of the present invention;
图7为本发明实施例中面向对象类结构继承图;7 is an object-oriented class structure inheritance diagram in an embodiment of the present invention;
图8为本发明实施例中优化后算法合并示意图;FIG. 8 is a schematic diagram of merging algorithms after optimization in an embodiment of the present invention;
图9为本发明实施例中轨检数据服务系统的整体架构示意图;9 is a schematic diagram of the overall architecture of a rail inspection data service system in an embodiment of the present invention;
图10为本发明实施例中轨检数据服务系统的技术架构图;10 is a technical architecture diagram of a rail inspection data service system in an embodiment of the present invention;
图11为本发明实施例中轨检数据服务系统的权限管理示意图;FIG. 11 is a schematic diagram of the authority management of the track inspection data service system in the embodiment of the present invention;
图12为本发明实施例中Cloudera Manager各服务组件的界面图;12 is an interface diagram of each service component of Cloudera Manager in an embodiment of the present invention;
图13为本发明实施例中轨检数据服务系统的用户管理界面图;13 is a user management interface diagram of a rail inspection data service system in an embodiment of the present invention;
图14为本发明实施例中轨检数据服务系统的机构管理界面图;14 is a diagram of an organization management interface of a rail inspection data service system in an embodiment of the present invention;
图15为本发明实施例中轨检数据服务系统的角色管理界面图;Fig. 15 is the role management interface diagram of the track inspection data service system in the embodiment of the present invention;
图16为本发明实施例中轨检数据服务系统的菜单管理界面图;16 is a menu management interface diagram of the track inspection data service system in the embodiment of the present invention;
图17为本发明实施例中轨检数据服务系统的SQL监控界面图;Fig. 17 is the SQL monitoring interface diagram of the rail inspection data service system in the embodiment of the present invention;
图18为本发明实施例中轨检数据服务系统的操作日志界面图;18 is an interface diagram of an operation log of the track inspection data service system in an embodiment of the present invention;
图19为本发明实施例中轨检数据服务系统的错误日志界面图。FIG. 19 is an interface diagram of an error log of the track inspection data service system in the embodiment of the present invention.
主要元件符号说明:Description of main component symbols:


如下具体实施方式将结合上述附图进一步说明本发明。The following specific embodiments will further illustrate the present invention in conjunction with the above drawings.
具体实施方式Detailed ways
为了便于理解本发明,下面将参照相关附图对本发明进行更全面的描述。附图中给出了本发明的若干实施例。但是,本发明可以以许多不同的形式来实现,并不限于本文所描述的实施例。相反地,提供这些实施例的目的是使对本发明的公开内容更加透彻全面。In order to facilitate understanding of the present invention, the present invention will be described more fully hereinafter with reference to the related drawings. Several embodiments of the invention are presented in the accompanying drawings. However, the present invention may be embodied in many different forms and is not limited to the embodiments described herein. Rather, these embodiments are provided so that this disclosure will be thorough and complete.
需要说明的是,当元件被称为“固设于”另一个元件,它可以直接在另一个元件上或者也可以存在居中的元件。当一个元件被认为是“连接”另一个元件,它可以是直接连接到另一个元件或者可能同时存在居中元件。本文所使用的术语“垂直的”、“水平的”、“左”、“右”以及类似的表述只是为了说明的目的。It should be noted that when an element is referred to as being "fixed to" another element, it can be directly on the other element or intervening elements may also be present. When an element is referred to as being "connected" to another element, it can be directly connected to the other element or intervening elements may also be present. The terms "vertical," "horizontal," "left," "right," and similar expressions are used herein for illustrative purposes only.
除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。本文中在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本发明。本文所使用的术语“及/或”包括一个或多个相关的所列项目的任意的和所有的组合。Unless otherwise defined, all technical and scientific terms used herein have the same meaning as commonly understood by one of ordinary skill in the art to which this invention belongs. The terms used herein in the description of the present invention are for the purpose of describing specific embodiments only, and are not intended to limit the present invention. As used herein, the term "and/or" includes any and all combinations of one or more of the associated listed items.
首先需要说明的是,随着铁路的快速发展,而在列车检修过程中所产生的海量数据并没有有效地利用起来,这些数据对设备的自诊断、轨道智能分析、信息融合和数据后处理具有重大的意义。轨检数据服务平台顺应当前信息化技术的发展水平,构建以大数据分析、云计算等技术为基础的轨检数据智能服务平台,实现列车日常运用检修作业中各类信息的高效采集,各类检修设备的互联互通,各类信息平台的数据共享。First of all, it should be noted that, with the rapid development of railways, the massive data generated in the process of train maintenance has not been effectively utilized. These data have important effects on equipment self-diagnosis, track intelligent analysis, information fusion and data post-processing. great significance. The rail inspection data service platform conforms to the current development level of information technology, and builds an intelligent rail inspection data service platform based on big data analysis, cloud computing and other technologies to realize the efficient collection of various types of information in the daily operation and maintenance of trains. Interconnection of maintenance equipment and data sharing of various information platforms.
本发明采用Hadoop作为大数据基础架构来实现轨检数据服务系统的建设,在本申请中,所述轨检数据服务系统包括日常检修数据的录入、检修产生报表文件的存储、对检修数据的处理,用户能够通过PC、手机等移动终端在所述轨检数据服务系统上查看经过处理后的信息,包括各类报表的在线查看,轨检仪检修工作数据的实时展示。The present invention adopts Hadoop as the big data infrastructure to realize the construction of the rail inspection data service system. In this application, the rail inspection data service system includes the input of daily maintenance data, the storage of report files generated by maintenance, and the processing of maintenance data. , users can view the processed information on the rail inspection data service system through mobile terminals such as PCs and mobile phones, including online viewing of various reports and real-time display of rail inspection instrument maintenance work data.
Hadoop是Apache Nutch上的一个开源分布式计算平台,不仅为用户提供分布式的基础架构,而且它的系统底层细节也非常透明。同时,由于Hadoop主要是采用Java语言进行开发的,Hadoop也继承了Java语言优秀的跨平台特性,最重要的是Hadoop能够很好的降低成本。Hadoop is an open source distributed computing platform on Apache Nutch, which not only provides users with a distributed infrastructure, but also the underlying details of its system are very transparent. At the same time, since Hadoop is mainly developed in the Java language, Hadoop also inherits the excellent cross-platform features of the Java language. The most important thing is that Hadoop can reduce costs very well.
请参阅图1至图3,所示为本发明实施例中的基于Hadoop的轨检数据服务系统,包括但不限于数据采集模块、数据库支持模块、数据处理模块、分析模块、报表生成模块、数据共享模块以及数据可视化模块,所述数据采集模块用于采集各轨检设备的轨检数据,所述轨检设备包括但不限于轨道检查仪、轨道测量仪、波磨仪、结构巡检仪、接触网监测仪以及数值道尺,该数据采集模块将上述的轨检设备所上传的轨检数据传递至对应的模块中进行对应的分析和处理,并将处理后的数据进行分类保存,以使用户通过对应的用户界面进行查看。Please refer to FIG. 1 to FIG. 3, which show a Hadoop-based rail inspection data service system in an embodiment of the present invention, including but not limited to a data acquisition module, a database support module, a data processing module, an analysis module, a report generation module, and a data A shared module and a data visualization module, the data acquisition module is used to collect the rail inspection data of each rail inspection equipment, the rail inspection equipment includes but is not limited to a rail inspection instrument, a rail measurement instrument, a wave mill, a structure inspection instrument, A catenary monitor and a numerical ruler, the data acquisition module transmits the rail inspection data uploaded by the above-mentioned rail inspection equipment to the corresponding module for corresponding analysis and processing, and classifies and saves the processed data, so that the The user views through the corresponding user interface.
本申请中的基于Hadoop的轨检数据服务系统还具有预警功能,当各模块对其输入数据的分析和处理后,检测到该输入数据出现异常时,及时发送预警信息,以提醒操作人员利用对应的轨检设备进行重新检测。The Hadoop-based rail inspection data service system in this application also has an early warning function. After each module analyzes and processes the input data and detects that the input data is abnormal, it sends early warning information in time to remind the operator to use the corresponding The track inspection equipment is re-inspected.
具体的,所述数据处理模块包括数据对齐单元以及数据处理单元,所述数据对齐单元用于利用历史轨检数据对各所述当前轨检数据进行局部插值及压缩,以实现所述历史轨检数据和各所述当前轨检数据的特征点匹配,进而得到数据对齐的轨检数据;Specifically, the data processing module includes a data alignment unit and a data processing unit, and the data alignment unit is used to perform local interpolation and compression on each of the current track inspection data by using historical track inspection data, so as to realize the historical track inspection data. The data is matched with the feature points of each of the current track inspection data, and then the track inspection data of data alignment is obtained;
需要说明的是,本实施例采用动态规整算法即DTW(Dynamic Time Warping)算法,利用前次测量结果为模板,将本次测量的数据作为待对齐数据,对本次测量的数据的特征进行局部插值与压缩,以实现特征点的匹配,达到两次测量数据的高精度对齐。It should be noted that this embodiment adopts a dynamic warping algorithm, namely the DTW (Dynamic Time Warping) algorithm, uses the previous measurement result as a template, uses the data measured this time as the data to be aligned, and performs localization on the characteristics of the data measured this time. Interpolation and compression are used to achieve feature point matching and achieve high-precision alignment of two measurement data.
进一步的,所述数据对齐单元具体用于:Further, the data alignment unit is specifically used for:
在所述历史轨检数据和各所述当前轨检数据中给定两个等时间间隔的相同特征序列,并计算出两所述相同特征序列之间任意两点的距离,以得到两所述相同特征序列的距离矩阵D;Two identical feature sequences at equal time intervals are given in the historical track inspection data and each of the current track inspection data, and the distance between any two points between the two identical feature sequences is calculated to obtain the two identical feature sequences. The distance matrix D of the same feature sequence;
在具体实施时,在所述历史轨检数据和各所述当前轨检数据中给定两个等时间间隔的相同特征序列,分别为查询序列S={s1,s2,…,sm},匹配序列M={m1,m2,…,mn},按照下述公式计算出查询序列与匹配序列之间任意两点的距离:In the specific implementation, two identical feature sequences with equal time intervals are given in the historical track inspection data and each of the current track inspection data, which are respectively the query sequence S={s1 , s2 , . . . , sm }, the matching sequence M={m1 , m2 , ..., mn }, and the distance between any two points between the query sequence and the matching sequence is calculated according to the following formula:
d(i,j)=||si-mj||w;d(i, j)=||si -mj ||w ;
式中,i=1,2,…,m,j=1,2,…,n;当w=1时,为曼哈顿距离;当w=2时,为欧几里得距离。In the formula, i=1,2,...,m,j=1,2,...,n; when w=1, it is the Manhattan distance; when w=2, it is the Euclidean distance.
得到的距离矩阵为:The resulting distance matrix is:

进一步的,借助DP(动态规划)方法按照以下公式求距离矩阵D的最优规划路径:Further, with the help of the DP (dynamic programming) method, the optimal planning path of the distance matrix D is obtained according to the following formula:
Pbest={p1,p2,…,pk,…,pK};Pbest = {p1 , p2 , ..., pk , ..., pK };
式中pk表示路径规划位置,即pk=(i,j)k表示sm与mn对齐,其中max(m,n)≤K≤m+n-1。In the formula, pk represents the path planning position, that is, pk =(i, j)k represents that sm is aligned with mn , where max(m, n)≤K≤m+n-1.
其中,为了保证搜索到的所有路径都具有意义,搜索到的任意路径都必须符合以下约束条件:Among them, in order to ensure that all the searched paths are meaningful, any searched paths must meet the following constraints:
(1)边界性:最短路径的起点与终点固定,即以下公式所示:(1) Boundary: The start and end points of the shortest path are fixed, as shown in the following formula:

(2)单调性:同一次测量中,经过计算后前一刻的特征不能出现在后一刻特征之后,即当给定pk=(si,mj)与pk+1=(si′,mj′)时,i′≤i+1,j′≤j+1。(2) Monotonicity: in the same measurement, the features of the previous moment cannot appear after the features of the next moment after the calculation, that is, when pk =(si , mj ) and pk+1 =(si′ are given , mj′ ), i′≤i+1, j′≤j+1.
p1与pK之间的规整路径pk,通过构造代价矩阵确定,矩阵元素γ(i,j)定义为:The regular path pk between p1 and pK is determined by constructing a cost matrix, and the matrix element γ(i, j) is defined as:
γ(i,j)=d(i,j)+min[γ(i-1,j-1),γ(i-1,j),γ(i,j-1)];γ(i,j)=d(i,j)+min[γ(i-1,j-1),γ(i-1,j),γ(i,j-1)];
式中,i∈{1,2,…,m},j∈{1,2,…,n},γ(0,0)=0,γ(i,0)=γ(0,j)=∞。In the formula, i∈{1,2,...,m}, j∈{1,2,...,n}, γ(0,0)=0, γ(i,0)=γ(0,j)= ∞.
最优规整路径Pbest的动态时间规整距离DTW(S,M)应使得S和M的累计距离值最小,动态时间规整距离计算如以下公式所示:The dynamic time warping distance DTW(S, M) of the optimal warping path Pbest should minimize the cumulative distance between S and M. The dynamic time warping distance is calculated as shown in the following formula:

进一步的,所述数据处理单元用于将所述数据对齐的轨检数据进行数据预处理,以得到多组预处理的轨检数据,并对所述多组预处理的轨检数据进行分布式处理,以判断所述数据对齐的轨检数据是否符合预设要求,若所述数据对齐的轨检数据符合预设要求,则生成对应的数据报表,以实现用户与各所述轨检设备的信息交互。Further, the data processing unit is configured to perform data preprocessing on the data-aligned track inspection data to obtain multiple groups of preprocessed track inspection data, and distribute the multiple groups of preprocessed track inspection data. processing to determine whether the data-aligned track inspection data meets the preset requirements, and if the data-aligned track inspection data meets the preset requirements, a corresponding data report is generated to realize the communication between the user and each of the track inspection equipment. Information exchange.
在具体实施时,所述数据处理单元将上述的数据对齐的轨检数据进行拆分,会得到多组拆分后的轨检数据,在进行拆分时会产生很多<key,value>形式的中间结果,具有相同的中间结果的轨检数据会被划分到同一处理子单元中进行处理,并判断上述的数据对齐的轨检数据是否符合其对应的处理子单元的要求,若所述数据对齐的轨检数据符合要求,则意味着轨检设备所检测的轨检数据是正常的,即该轨检设备所检测的轨道处于正常状态,在处理子单元进行数据处理后,无论是否符合预设要求,均会产生对应的数据报表,以实现用户和各轨检设备的信息交互。During specific implementation, the data processing unit splits the above-mentioned data-aligned track inspection data to obtain multiple sets of split track inspection data. When splitting, many sets of <key, value> forms are generated. For the intermediate result, the track inspection data with the same intermediate result will be divided into the same processing sub-unit for processing, and it is judged whether the above-mentioned data-aligned track inspection data meets the requirements of its corresponding processing sub-unit, if the data is aligned If the track inspection data meets the requirements, it means that the track inspection data detected by the track inspection device is normal, that is, the track detected by the track inspection device is in a normal state. If required, corresponding data reports will be generated to realize the information exchange between users and various rail inspection equipment.
在一些可选实施例中,所述基于Hadoop的轨检数据服务系统还包括数据库支持模块,所述数据库支持模块用于根据利用各轨检设备所获取的轨检数据生成多个轨检台账数据库、以及根据用户权限生成多个权限管理数据库,所述多个轨检台账数据库至少包括平面曲线数据库、竖曲线数据库、CP3数据库以及轨枕信息数据库,所述多个权限管理数据库至少包括规范管理数据库。In some optional embodiments, the Hadoop-based rail inspection data service system further includes a database support module, and the database support module is configured to generate a plurality of rail inspection ledgers according to the rail inspection data obtained by using each rail inspection equipment database, and generate a plurality of authority management databases according to user authority, the plurality of rail inspection ledger databases at least include a plane curve database, a vertical curve database, a CP3 database and a sleeper information database, and the plurality of authority management databases at least include standard management databases database.
其中,所述平面曲线数据库和所述竖曲线数据库是根据各轨检设备所获取的轨检数据所统计出平面曲线、竖曲线所涉及的相关要素和属性。信息如下:Wherein, the plane curve database and the vertical curve database are related elements and attributes involved in the plane curve and the vertical curve calculated according to the track inspection data obtained by each track inspection equipment. Message as follows:
平面曲线所涉及相关属性主要有:交点号、纬距(m)、经距(m)(或北坐标m、东坐标m、高程m)、转向、半径(m)、缓长1(m)、缓长2(m)、切线长(m)、曲线长(m)、直缓点(Km)、缓直点(Km)、夹直线长(m)、超高(mm)、轨距加宽(mm)、断点里程(Km)、修正里程(Km)、直线顺坡(m)、顺坡总长(m)、备注、备注2。平面曲线数据库表结构如下表1所示。The related attributes involved in the plane curve mainly include: intersection number, latitude distance (m), longitude distance (m) (or north coordinate m, east coordinate m, elevation m), turning, radius (m), slow length 1 (m) , slow length 2 (m), tangent length (m), curve length (m), straight slow point (Km), slow straight point (Km), clip straight line length (m), superelevation (mm), gauge plus Width (mm), breakpoint mileage (Km), correction mileage (Km), straight slope (m), total length of the slope (m), remarks,
表1Table 1


竖曲线所涉及相关属性主要有:序号、变坡点里程(Km)、轨面高程(m)、坡率(‰)、坡长(m)、半径(m)、切线长T1(m)、切线长T2(m)、外矢距E(m)、备注。竖曲线数据库表结构如下表2所示。The relevant attributes involved in the vertical curve mainly include: serial number, mileage of variable slope point (Km), rail surface elevation (m), slope rate (‰), slope length (m), radius (m), tangent length T1 (m), Tangent length T2 (m), external vector distance E (m), remarks. The vertical curve database table structure is shown in Table 2 below.
表2Table 2


平面曲线、竖曲线的要素信息具有很强的结构化特征,后台对该数据的存储和维护采用关系型数据库MySQL。The element information of plane curves and vertical curves has strong structural characteristics, and the relational database MySQL is used for the storage and maintenance of the data in the background.
除了建立相应的数据表对平面曲线、竖曲线信息进行存储,为便于系统索引、维护这两个数据表中的信息,还需要建立具体线路信息(所属单位部门、线路名、行别等)与之关联,线路信息表与平面曲线、竖曲线表之间是一对多的关系。线路信息数据库表结构如下表3所示。In addition to establishing corresponding data tables to store the information of plane curves and vertical curves, in order to facilitate the system indexing and maintenance of the information in these two data tables, it is also necessary to establish specific line information (unit department, line name, line type, etc.) and There is a one-to-many relationship between the line information table and the plane curve and vertical curve table. The structure of the line information database table is shown in Table 3 below.
表3table 3
表3.3线路信息数据库表结构Table 3.3 Route information database table structure


该表3与系统部门表相关联形成多对一的关系。在建立相应的数据表对信息进行存储之后需要确定平台相应的操作功能以完成对信息的维护。The table 3 is associated with the system department table to form a many-to-one relationship. After establishing the corresponding data table to store the information, it is necessary to determine the corresponding operation function of the platform to complete the maintenance of the information.
进一步的,所述CP3数据库中包含有CP3坐标信息,该CP3坐标信息所涉及的相关属性包括:CP3控制点编号、北坐标(m)、东坐标(m)、高程(m)等。CP3坐标信息表数据库表结构如表4所示。Further, the CP3 database contains CP3 coordinate information, and the related attributes involved in the CP3 coordinate information include: CP3 control point number, north coordinate (m), east coordinate (m), elevation (m), and the like. The structure of the database table of the CP3 coordinate information table is shown in Table 4.
表4Table 4

而与之相关联的主要有具体线路信息表、控制点详细数量表。该表4与CP3控制点详细数量表关联形成多对一的关系。具体路线信息表与表3一致。CP3控制点详细数量表可获取相关属性:埋设点名称、起始里程、终止里程、长度(m)、CPⅢ数量(对)等。CP3控制点详细数量数据库表结构如表5所示。It is mainly associated with the specific line information table and the detailed quantity table of control points. The table 4 is associated with the detailed quantity table of CP3 control points to form a many-to-one relationship. The specific route information table is consistent with Table 3. The detailed quantity table of CP3 control points can obtain relevant attributes: name of buried point, starting mileage, ending mileage, length (m), CPIII quantity (pair), etc. The structure of the database table of the detailed quantity of CP3 control points is shown in Table 5.
表5table 5

平台同时提供与平面曲线、竖曲线服务模块类似的维护操作功能,在满足规定模板的情况下支持批量导入功能。The platform also provides maintenance and operation functions similar to those of the plane curve and vertical curve service modules, and supports batch import functions when the specified templates are met.
进一步的,所述轨枕信息数据表中相关属性包括:设计里程、轨枕号、扣件类型、扣件参数(左、右、内侧、外侧、调高)、线路特征(桥、涵、隧等)、限位等;同时该信息还与具体线路信息产生关联。Further, the relevant attributes in the sleeper information data table include: design mileage, sleeper number, fastener type, fastener parameters (left, right, inner side, outer side, height adjustment), line features (bridge, culvert, tunnel, etc.) , limit, etc.; at the same time, this information is also associated with specific line information.
其中扣件类型取值范围为:WJ-7(A)、WJ-7(B)、WJ-8(A)、WJ-8(B)、SFC(直列式)、SFC(错列式)、300-1a、300-1u等。轨枕列表信息数据库表结构如表6所示。The value range of the fastener type is: WJ-7(A), WJ-7(B), WJ-8(A), WJ-8(B), SFC (in-line), SFC (staggered), 300-1a, 300-1u, etc. The structure of the sleeper list information database table is shown in Table 6.
表6Table 6


该表6的信息通过外键line_id与具体线路信息表形成多对一的关系。系统同时提供维护操作功能,在满足规定模板的情况下支持批量导入功能。The information in Table 6 forms a many-to-one relationship with the specific line information table through the foreign key line_id. The system also provides maintenance operation functions, and supports batch import functions when the specified templates are met.
在本实施例中,所述权限管理数据库还包括设备授权码管理数据库,其中,所述设备授权码管理数据库中相关属性包括:申请用户、授权时间、设备型号、设备名称、授权电脑型号、授权电脑序列号(或机器码等)、授权码、注销用户、注销时间、注销标志位等信息,同时该信息还与系统部门表进行关联形成多对一的关系,以指定设备授权码的归属,便于以后数据的查询和统计。设备授权码管理数据库表结构如表7所示。In this embodiment, the rights management database further includes a device authorization code management database, wherein the relevant attributes in the device authorization code management database include: application user, authorization time, device model, device name, authorized computer model, authorization Computer serial number (or machine code, etc.), authorization code, logout user, logout time, logout flag and other information, and this information is also associated with the system department table to form a many-to-one relationship to specify the ownership of the device authorization code. It is convenient for future data query and statistics. The structure of the device authorization code management database table is shown in Table 7.
表7Table 7


上述数据表7中设置申请用户、申请时间、注销用户、注销时间等附加信息,再结合系统日志信息,便于管理员随时掌握设备授权码从申请、使用到注销整个生命周期的状态。Additional information such as application user, application time, logout user, logout time, etc. are set in the above data table 7, and combined with the system log information, it is convenient for the administrator to grasp the status of the entire life cycle of the device authorization code from application, use to logout at any time.
所述规范管理数据库中包括有一个管理系统(web)和门户网站(web),多个系统共用一个服务后端,后端使用shiro框架进行统一登录认证和权限控制。统一认证和权限控制涉及数据库各表如图4所示。The standard management database includes a management system (web) and a portal website (web), multiple systems share a service backend, and the backend uses the shiro framework to perform unified login authentication and authority control. The tables of the database involved in unified authentication and authority control are shown in Figure 4.
针对图4中,各表的说明如表8所示:For Figure 4, the description of each table is shown in Table 8:
表8Table 8


进一步的,所述基于Hadoop的轨检数据服务系统还包括分析模块,所述分析模块用于对所述数据采集模块所采集的数据进行数据分析,所述数据分析至少包括轮廓数据分析、波磨数据分析、板翘分析以及焊缝平直度分析;所述基于Hadoop的轨检数据服务系统还包括报表生成模块,所述报表生成模块用于将各模块所输出的数据转换成对应的数据报表,以使用户进行查看。Further, the Hadoop-based rail inspection data service system further includes an analysis module, and the analysis module is used to perform data analysis on the data collected by the data acquisition module, and the data analysis at least includes profile data analysis, wave grinding Data analysis, plate warpage analysis and weld straightness analysis; the Hadoop-based rail inspection data service system further includes a report generation module, which is used to convert the data output by each module into a corresponding data report , so that users can view it.
需要说明的是,在系统运行中,对整个系统的运行状态进行实时监控,运行过程中产生的错误通过报表生成模块保存至数据库错误日志表,便于管理员发现平台BUG。错误日志数据表结构如表9所示。It should be noted that, during system operation, the running status of the entire system is monitored in real time, and errors generated during operation are saved to the database error log table through the report generation module, which is convenient for administrators to find platform bugs. The structure of the error log data table is shown in Table 9.
表9Table 9

应当理解的,在系统运行时会存在系统日志,对整个系统的所有登录用户的操作进行记录,便于分析人员及时掌握系统的高访问量页面和操作、发生的时间,以及一些系统漏洞,开发人员针对分析结果对系统进行优化。系统日志数据表结构如表10所示。It should be understood that there will be a system log when the system is running, to record the operations of all logged-in users in the entire system, so that analysts can grasp the high-traffic pages and operations of the system, the time of occurrence, and some system vulnerabilities, developers. The system is optimized for the analysis results. The structure of the system log data table is shown in Table 10.
表10Table 10


所述规范管理数据库还包括机构管理,其中,铁路部门(以南昌铁路局为例)的组织结构如图5所示:The normative management database also includes institutional management, wherein the organizational structure of the railway department (taking Nanchang Railway Bureau as an example) is shown in Figure 5:
各个铁路局的上属单位为中国铁路总公司,各段下设相应的车间、工区部门。轨检数据服务平台对机构组织管理采取树结构的形式。机构管理数据表结构如表11所示。The subordinate unit of each railway bureau is China Railway Corporation, and each section has corresponding workshops and work area departments. The rail inspection data service platform takes the form of a tree structure for the organization and management of institutions. The structure of the organization management data table is shown in Table 11.
表11Table 11

在本实施例中,所述基于Hadoop的轨检数据服务系统还包括数据可视化模块,所述数据可视化模块包括第一可视化模块以及第二可视化模块,所述第一可视化模块用于将不同时间下所述数据采集模块所采集的采样数据进行连接,以展示所述数据采集模块的测量信号与时间的变化程度;所述第二可视化模块用于对所述数据采集模块所采样的数据信号进行积分处理,以展示所述数据采集模块的当前信号强度。In this embodiment, the Hadoop-based rail inspection data service system further includes a data visualization module, the data visualization module includes a first visualization module and a second visualization module, and the first visualization module is used to The sampling data collected by the data collection module are connected to show the degree of change between the measurement signal of the data collection module and time; the second visualization module is used to integrate the data signal sampled by the data collection module Processed to display the current signal strength of the data acquisition module.
需要说明的是,轨检数据服务系统主要应用的是多维数据可视化、层次信息可视化与时间序列数据可视化这三类。It should be noted that the rail inspection data service system mainly applies three types of multi-dimensional data visualization, hierarchical information visualization and time series data visualization.
1、多维数据可视化1. Multidimensional data visualization
多维数据可视化是一种将高维数据展示在二维的平面中的一种方式。传统的算法较为复杂、耗时长而且兼容性差。多维数据可视化基于数据特征可分为基于几何的可视化方法与基于图标的可视化方法。Multidimensional data visualization is a way of presenting high-dimensional data in a two-dimensional plane. Traditional algorithms are complex, time-consuming and have poor compatibility. Multidimensional data visualization can be divided into geometry-based visualization methods and icon-based visualization methods based on data features.
基于几何的可视化方法可以使用平行竖曲线来代表不同的维度,在坐标轴上描绘多维数据的数值并连接数轴上的坐标点,进而在二维空间展示多维数据。Geometry-based visualization methods can use parallel vertical curves to represent different dimensions, depict the values of multi-dimensional data on the coordinate axis and connect the coordinate points on the number axis, and then display the multi-dimensional data in two-dimensional space.
基于图标的可视化方法主要是用几何图形作为图标对多维数据进行描绘,图标的特征属性体现出信息的维度,利用图标与多维数据之间的联系反应可视化效果。基于图标的可视化方法的代表性方法是星绘法,通过点到线的方式映射出信息维度,线段的长度代表数值的大小,如图6所示。Icon-based visualization methods mainly use geometric figures as icons to describe multi-dimensional data. The characteristic attributes of icons reflect the dimension of information, and the relationship between icons and multi-dimensional data is used to reflect the visualization effect. The representative method of the icon-based visualization method is the star drawing method, which maps the information dimension through the point-to-line method, and the length of the line segment represents the size of the value, as shown in Figure 6.
2、层次信息可视化2. Hierarchical information visualization
计算机文件、Java类的继承就是非常典型的层次信息,Java类继承如图7所示。这类层次信息具有非常明显的结构特性。层次信息的可视化主要通过节点连接来实现。The inheritance of computer files and Java classes is a very typical hierarchical information. The inheritance of Java classes is shown in Figure 7. This kind of hierarchical information has very obvious structural characteristics. The visualization of hierarchical information is mainly achieved through node connections.
节点连接主要用来绘制不同节点表示信息的数据内容,节点之间的连线表示数据之间的关系。在图7中,各个类名代表各个节点,蓝色的实线代表实际继承的父类,绿色虚线则表示该类实现的父接口。Node connection is mainly used to draw the data content of information represented by different nodes, and the connection between nodes represents the relationship between data. In Figure 7, each class name represents each node, the solid blue line represents the actual inherited parent class, and the green dotted line represents the parent interface implemented by the class.
3、时间序列数据可视化3. Time series data visualization
时间序列可视化即对随着时间采样的数据进行可视化的展示,主要的展现方式有三种,分别为线形图、堆积图与地平线图。Time series visualization is the visual display of data sampled over time. There are three main display methods, namely line graph, stacked graph and horizon graph.
线形图:将不同时间的采样值进行连接,可以直观的展示测量的信号随时间变化的程度。Line graph: Connect the sampled values at different times to visually display the degree of change of the measured signal over time.
堆积图:对随时间采样的信号进行积分处理,算出面积,这种可视化方式可以很好的展示当前信号的量的大小,但是,当信号出现负数时,可视化的效果就会大打折扣。Stacked chart: Integrate the signal sampled over time to calculate the area. This visualization method can well display the magnitude of the current signal. However, when the signal has a negative number, the visualization effect will be greatly reduced.
地平线图:地平线图即对所测量的信号进行微分处理,在地平线图中可以清晰的观察到信号随时间的编号率,颜色的深浅即表示变动的效果。Horizon map: The horizon map is to differentiate the measured signal, and the number rate of the signal over time can be clearly observed in the horizon map, and the depth of the color indicates the effect of the change.
在其他可选实施例中,所述数据可视化模块对系统的菜单和功能按钮进行动态定制和精细化控制,为系统的功能扩展提供标准的扩展手段。菜单数据表结构如表12所示。In other optional embodiments, the data visualization module dynamically customizes and finely controls the menus and function buttons of the system, and provides standard expansion means for the function expansion of the system. The structure of the menu data table is shown in Table 12.
表12Table 12


其中,菜单URL类型:1.普通页面(如用户管理,/sys/user)2.嵌套完整外部页面,以http(s)开头的链接3.嵌套服务器页面,使用iframe:前缀+目标URL(如SQL监控,iframe:/druid/login.html,iframe:前缀会替换成服务器地址)。Among them, the menu URL type: 1. Ordinary page (such as user management, /sys/user) 2. Nested complete external pages, links starting with http(s) 3. Nested server pages, using iframe: prefix + target URL (Such as SQL monitoring, iframe:/druid/login.html, iframe: prefix will be replaced with the server address).
具体的,在所述数据可视化模块的可视界面中,系统角色支持无限创建和扩展,具体系统服务菜单和功能可动态赋予任意角色,由角色来决定系统具体的可使用服务和功能范围。角色数据表结构如表13所示。Specifically, in the visual interface of the data visualization module, system roles support unlimited creation and expansion, specific system service menus and functions can be dynamically assigned to any role, and the role determines the specific usable services and functional scope of the system. The role data table structure is shown in Table 13.
表13Table 13


在本系统中,角色和部门(机构)之间应该是多对多的关系,当给某一部门(机构)赋予相应的角色之后,属于该部门(机构)下的所有人员将具有该角色所拥有的平台服务和功能。可免除对每个人员进行逐一角色绑定。角色与机构对应关系表结构如表14所示。In this system, there should be a many-to-many relationship between roles and departments (organizations). Owned platform services and features. One-by-one role binding for each person can be dispensed with. The structure of the correspondence table between roles and institutions is shown in Table 14.
表14Table 14

应当理解的,同样的,在本系统中,角色和菜单(功能按钮)之间应该是多对多的关系,同一角色具有多项菜单(功能按钮)使用权,某一菜单(功能按钮)又可为不同的角色所同时拥有。角色与菜单对应关系表结构如表15所示。It should be understood that, similarly, in this system, there should be a many-to-many relationship between roles and menus (function buttons). The same role has the right to use multiple menus (function buttons). Can be owned by different roles at the same time. The structure of the correspondence table between roles and menus is shown in Table 15.
表15Table 15

本实施例中,系统对用户敏感信息进行加密处理,系统超级管理员可对用户进行禁用和启用。用户与部门(机构)之间应该是多对一的关系,某一部门包含多个用户,某一用户只能属于某一部门。用户信息数据表结构如表16所示。In this embodiment, the system encrypts the user's sensitive information, and the system super administrator can disable and enable the user. There should be a many-to-one relationship between users and departments (organizations). A department contains multiple users, and a user can only belong to a department. The structure of the user information data table is shown in Table 16.
表16Table 16

本系统中,用户和角色之间同样应该是多对多的关系,同一用户可拥有多个角色,某一角色又可为不同的用户所同时拥有。一个用户所拥有的角色是自身对应的角色和所在部门(机构)对应角色的合集。用户与角色对应关系表结构如表17所示。In this system, there should also be a many-to-many relationship between users and roles. The same user can have multiple roles, and a certain role can be owned by different users at the same time. A role owned by a user is a collection of its own corresponding role and the corresponding role of its department (organization). The structure of the user-role correspondence table is shown in Table 17.
表17Table 17

在本实施例中,一个用户在登录系统成功之后将由平台返回一串的访问码(该访问码唯一,具有过期时间限制,如有特殊控制需求可考虑增设IP或MAC字段进行组合式访问控制),用户在接下来的平台服务和功能的访问过程中将必须携带该唯一的访问码,否则平台将对访问请求拒绝,用户token表结构如表18所示:In this embodiment, after a user successfully logs in to the system, the platform will return a string of access codes (the access codes are unique and have an expiration time limit. If there are special control requirements, you can consider adding IP or MAC fields for combined access control) , the user must carry the unique access code in the next access process of platform services and functions, otherwise the platform will reject the access request. The structure of the user token table is shown in Table 18:
表18Table 18

进一步的,为了克服普通存储方法浪费空间的问题,更好地利用空间,轨检数据服务系统采用一种基于空间最优的小文件存储办法。所述数据处理单元还包括文件存储单元,把小于预设存储大小(5MB)的文件作为小文件进行存储,算法的实现过程如图8所示。将小文件按照所占内存空间大小均匀分布,使得合并后的文件能达到设置的数据块最大阈值。该算法与简单算法相比,优势在于可以更好地利用每一个数据块的空间,降低存储的开销;Further, in order to overcome the problem of wasting space in common storage methods and make better use of space, the orbit inspection data service system adopts a space-optimized small file storage method. The data processing unit further includes a file storage unit, which stores files smaller than the preset storage size (5MB) as small files. The implementation process of the algorithm is shown in FIG. 8 . The small files are evenly distributed according to the size of the memory space they occupy, so that the combined files can reach the set maximum threshold of data blocks. Compared with the simple algorithm, the advantage of this algorithm is that it can make better use of the space of each data block and reduce the storage overhead;
具体的,所述文件存储单元具体用于:Specifically, the file storage unit is specifically used for:
当接收到文件存储请求时,初始化数据队列、并创建多个临时队列、多个合并队列以及多个文件信息映射表,其中,所述临时队列的个数小于所述合并队列的个数;When receiving a file storage request, initialize a data queue, and create multiple temporary queues, multiple merge queues, and multiple file information mapping tables, wherein the number of the temporary queues is less than the number of the merge queues;
获取当前上传的文件,并比较所述当前上传的文件的存储大小与所述临时队列的剩余存储空间,若所述临时队列的剩余存储空间大于所述当前上传的文件的存储大小,则将所述当前上传的文件存储到所述临时队列中、并查看所述文件信息映射表中是否存在所述当前上传的文件;Obtain the currently uploaded file, and compare the storage size of the currently uploaded file with the remaining storage space of the temporary queue, if the remaining storage space of the temporary queue is greater than the storage size of the currently uploaded file, then Store the currently uploaded file in the temporary queue, and check whether the currently uploaded file exists in the file information mapping table;
若所述文件信息映射表中存在所述当前上传的文件,则判断所述临时队列中所有文件所占空间是否达到所述临时队列的预设阈值空间的第一阈值;If there is the currently uploaded file in the file information mapping table, then determine whether the space occupied by all files in the temporary queue reaches the first threshold of the preset threshold space of the temporary queue;
若所述临时队列中所有文件所占空间达到所述临时队列的预设阈值空间的第一阈值,则将所述临时队列中所有文件进行合并,直到达到所述临时队列的预设阈值空间,得到所述临时队列所对应的合并队列;If the space occupied by all files in the temporary queue reaches the first threshold of the preset threshold space of the temporary queue, then merge all the files in the temporary queue until the preset threshold space of the temporary queue is reached, obtain the merged queue corresponding to the temporary queue;
找到所述临时队列中所占存储空间最大的文件,并判断所述所占存储空间最大的文件的存储大小是否大于所述临时队列的预设阈值空间的第二阈值;Find the file with the largest storage space in the temporary queue, and determine whether the storage size of the file with the largest storage space is greater than the second threshold of the preset threshold space of the temporary queue;
若所述所占存储空间最大的文件的存储大小大于所述临时队列的预设阈值空间的第二阈值,则将所述当前上传的文件存放在所述临时队列所对应的合并队列中,并在其他的临时队列中寻找友好文件,并将寻找到的所有友好文件均存入所述临时队列所对应的合并队列中进行文件打包上传;If the storage size of the file with the largest storage space is greater than the second threshold of the preset threshold space of the temporary queue, the currently uploaded file is stored in the merge queue corresponding to the temporary queue, and Search for friendly files in other temporary queues, and store all the found friendly files in the merged queue corresponding to the temporary queue for file packaging and uploading;
若所述所占存储空间最大的文件的存储大小不大于所述临时队列的预设阈值空间的第二阈值,则持续向所述临时队列中上传文件,直到所述临时队列中所有文件所占空间大于等于所述临时队列的预设阈值空间的第二阈值;If the storage size of the file with the largest storage space is not greater than the second threshold of the preset threshold space of the temporary queue, continue uploading files to the temporary queue until all files in the temporary queue occupy The space is greater than or equal to the second threshold of the preset threshold space of the temporary queue;
将所述当前上传的文件存放在所述临时队列所对应的合并队列中,并在其他的临时队列中寻找友好文件,并将寻找到的所有友好文件均存入所述临时队列所对应的合并队列中进行文件打包上传。Store the currently uploaded file in the merged queue corresponding to the temporary queue, and look for friendly files in other temporary queues, and store all the friendly files found in the merged corresponding to the temporary queue. The files are packaged and uploaded in the queue.
在具体实施时,算法具体步骤说明如下:In the specific implementation, the specific steps of the algorithm are described as follows:
(1)接收到文件存储请求后,对数据队列进行初始化,读取配置文件中包括合并阈值等的配置信息创建临时队列、合并队列和文件信息映射表。其中,临时队列的个数小于合并队列的个数。(1) After receiving the file storage request, initialize the data queue, and read the configuration information including the merge threshold in the configuration file to create a temporary queue, a merge queue and a file information mapping table. The number of temporary queues is smaller than the number of merged queues.
(2)对传入文件的大小与临时队列中剩余的空间进行比较,如果临时队列的剩余空间大于传入的文件所占空间的大小,则存储该队列,否则,将该文件大小与其他的临时队列进行比较,如果所有临时队列比较完毕后没有满足要求的临时队列,则新建一个临时队列,将文件存储到其中。(2) Compare the size of the incoming file with the remaining space in the temporary queue. If the remaining space of the temporary queue is greater than the size of the space occupied by the incoming file, store the queue, otherwise, compare the file size with other Temporary queues are compared. If there is no temporary queue that meets the requirements after all the temporary queues are compared, a new temporary queue is created and the files are stored in it.
(3)查看文件信息映射表中是否有当前上传的文件,如果有则进行文件的合并,若没有,则将文件信息记录到文件信息映射表中去。(3) Check whether there is a currently uploaded file in the file information mapping table, if so, merge the files, if not, record the file information in the file information mapping table.
(4)判断临时队列中的文件所占空间是否达到了所设阈值空间的90%,若达到了,则这一临时队列的文件开始合并。(4) Judging whether the space occupied by the files in the temporary queue has reached 90% of the set threshold space, and if so, the files in the temporary queue start to be merged.
(5)临时队列达到阈值,找出占空间最大的文件,如果该文件的体积大于阈值的1/2,则进入第六步,否则进入第七步。(5) When the temporary queue reaches the threshold, find the file with the largest space. If the volume of the file is greater than 1/2 of the threshold, enter the sixth step, otherwise enter the seventh step.
(6)将该文件存入合并队列,在剩余的临时队列中寻找友好文件,即空间最适合填充到当前合并队列的文件,直至找不到友好文件。进入第八步。(6) The file is stored in the merge queue, and friendly files are searched in the remaining temporary queues, that is, the files whose space is most suitable to be filled into the current merge queue, until no friendly files are found. Go to step eight.
(7)该文件所在的队列不发生改变,等到队列的总空间大于等于阈值的1/2时,回到第六步。(7) The queue where the file is located does not change, and when the total space of the queue is greater than or equal to 1/2 of the threshold, go back to the sixth step.
(8)将合并队列中的文件打包上传到HDFS。(8) Package and upload the files in the merge queue to HDFS.
进一步的,在本实施例中,所述轨检数据服务系统还包括数据共享模块,其数据传输环节安全措施主要通过HTTPS等技术手段构建加密传输链路,同时直接对数据进行加密,以密文形式传输,保障数据传输过程的安全;Further, in this embodiment, the rail inspection data service system further includes a data sharing module, whose data transmission link security measures mainly use HTTPS and other technical means to construct an encrypted transmission link, and at the same time directly encrypt the data, with ciphertext. Form transmission to ensure the security of the data transmission process;
另外,数据使用环节安全防护的目标是保障数据在授权范围内被访问、处理,防止数据遭窃取、泄漏、损毁。除了双机热备份、防火墙、入侵检测、防病毒、防DDoS攻击、漏洞检测等网络安全防护技术措施外,还包括:In addition, the goal of data use security protection is to ensure that data is accessed and processed within the authorized scope, and to prevent data from being stolen, leaked, and damaged. In addition to network security protection technical measures such as dual-system hot backup, firewall, intrusion detection, anti-virus, anti-DDoS attack, and vulnerability detection, it also includes:
(1)账号权限管理(1) Account authority management
建立统一账号权限管理子系统,对各类业务系统的账号及访问范围实现统一管理,保障数据在授权范围内被使用,落实账号权限管理及审批制度。Establish a unified account authority management subsystem to achieve unified management of accounts and access scope of various business systems, ensure that data is used within the authorized scope, and implement account authority management and approval systems.
(2)数据脱敏(2) Data desensitization
从保护敏感数据机密性的角度出发,在进行数据展示时,根据具体的业务需求平台支持对敏感数据进行模糊化处理。From the perspective of protecting the confidentiality of sensitive data, the platform supports fuzzing of sensitive data according to specific business needs when displaying data.
(3)日志管理和审计(3) Log management and auditing
日志管理和审计方面的技术能力要求主要是对账号管理操作日志、权限审批日志、数据访问操作日志等进行记录和审计,以辅助相关管理制度的落地执行。技术实现上,根据业务需求,建设统一的日志管理和审计子系统。The technical capability requirements for log management and auditing are mainly to record and audit account management operation logs, permission approval logs, data access operation logs, etc., to assist the implementation of relevant management systems. In terms of technical implementation, a unified log management and audit subsystem is built according to business requirements.
(4)异常操作实时监督(4) Real-time supervision of abnormal operations
相对于日志记录和安全审计等“事后”追查性质的安全技术措施,异常行为实时监控是实现“事前”、“事中”环节监测预警和实时处置的必要措施。异常行为监控系统应当能够对数据的非授权访问、数据文件的敏感操作等危险行为进行实时监测。Compared with the security technical measures of "post-event" tracing nature such as logging and security audit, real-time monitoring of abnormal behavior is a necessary measure to realize the monitoring, early warning and real-time disposal of "before" and "in-event" links. The abnormal behavior monitoring system should be able to conduct real-time monitoring of dangerous behaviors such as unauthorized access to data and sensitive operations on data files.
数据共享环节涉及向第三方提供数据服务,建立数据共享安全相关管理制度规定,同时为平台提供统一的数据分发出口服务,有效的管理数据共享行为,防范数据遭窃取、泄漏等安全风险。数据分发出口服务需要根据数据共享业务需求和相关的数据标准进行设计。The data sharing link involves providing data services to third parties, establishing data sharing security-related management systems, and at the same time providing platforms with unified data distribution and export services, effectively managing data sharing behaviors, and preventing data theft, leakage and other security risks. Data distribution and export services need to be designed according to data sharing business requirements and related data standards.
对于系统数据的销毁环节,在保障存储空间足量的情况下,原则上不进行数据的物理删除,只对数据进行删除标记位赋值即可。For the destruction of system data, in the case of ensuring sufficient storage space, in principle, the physical deletion of data is not performed, and only the deletion flag bit is assigned to the data.
请参阅图9,所示为本发明中轨检数据服务系统的总体架构,基于Hadoop分布式处理架构,轨检数据服务系统采用分层次自下而上的系统设计,一共分为五个层次,分别为:数据层、分析层、集成层、业务层、可视化层。Please refer to FIG. 9, which shows the overall architecture of the rail inspection data service system in the present invention. Based on the Hadoop distributed processing architecture, the rail inspection data service system adopts a hierarchical bottom-up system design, which is divided into five levels in total. They are: data layer, analysis layer, integration layer, business layer, visualization layer.
1、数据层1. Data layer
数据层是整个轨检数据服务系统的基础层,是数据资源的源头和保障,其中包括了结构型数据和非结构型数据。The data layer is the base layer of the entire orbit inspection data service system, and is the source and guarantee of data resources, including structured data and unstructured data.
结构型数据指的是可以使用关系型数据库进行表示和存储的数据,表现为二维形态的数据。系统中涉及到的结构型数据有轨检仪、波磨仪等设备的原始数据和北斗卫星的定位数据。这些数据的存储采用MySQL关系型数据库来进行存储。Structural data refers to data that can be represented and stored using a relational database, and is represented as two-dimensional data. The structural data involved in the system include the original data of the orbit detector, the wave mill and other equipment and the positioning data of the Beidou satellite. These data are stored using MySQL relational database.
非结构型数据指的是没有规律性结构的数据,各种报表、图像、视/音频等都属于非结构型数据。系统中涉及到的非结构型数据主要有轨检仪产生的各类报表、巡检仪采集的图片数据和头盔设备采集的音频/视频数据。对于非结构型数据的存储,将这些数据以文件的方式存储在HDFS中,指向文件的链接或路径存储在MySQL关系型数据库中。Unstructured data refers to data without regular structure. Various reports, images, video/audio, etc. belong to unstructured data. The unstructured data involved in the system mainly include various reports generated by the track detector, picture data collected by the patrol detector, and audio/video data collected by the helmet equipment. For the storage of unstructured data, these data are stored in HDFS in the form of files, and the links or paths to the files are stored in the MySQL relational database.
2、分析层2. Analysis layer
分析层的建立是为了解决当前轨道检修数据量大、数据分散与数据得不到分析与应用的问题。首先,在集成和云存储阶段,对各种类型的未处理的原始数据做好数据清理工作。随后,具体分析用户的实际需求,把数据层的数据取出后进行分析与封装,通过Sqoop传输到数据分析层,在数据分析层对数据进行基于实际需求的解析。至此经过处理的数据已经具备了一定的可读性,数据分析层会将这些数据封装成JSON形式的数据,传给可视化层进行数据的展示。The establishment of the analysis layer is to solve the problems of the large amount of data in the current track maintenance, the scattered data and the lack of analysis and application of the data. First, in the integration and cloud storage phase, data cleaning is done on various types of raw raw data that are not processed. Subsequently, the actual needs of users are analyzed in detail, the data in the data layer is taken out, analyzed and packaged, and then transmitted to the data analysis layer through Sqoop, where the data is analyzed based on actual needs. So far, the processed data has a certain degree of readability. The data analysis layer will encapsulate the data into JSON data and pass it to the visualization layer for data display.
3、集成层3. Integration layer
集成层作用是为了建立统一标准的支持模块,集成实现相关应用组件(历史数据支持、智能分析支持、信息融合支持、后处理支持、卫星定位支持等)的有效整合,基于这些支持组件,可以在业务层快速搭建相应的功能模块。The function of the integration layer is to establish a unified standard support module, and integrate the relevant application components (historical data support, intelligent analysis support, information fusion support, post-processing support, satellite positioning support, etc.) The business layer quickly builds corresponding functional modules.
4、业务层4. Business layer
业务层直接展示了轨检数据服务系统的各项功能,在集成层的基础上实现了各个应用。The business layer directly displays various functions of the rail inspection data service system, and realizes various applications on the basis of the integration layer.
业务层严格执行各类应用的分类标准,整体应用的开发和管理都有统一的管理模式来运行,各个应用模块之间的数据可以共享,系统提供了统一的数据接口,为业务的实现提供了更丰富的数据来源。The business layer strictly implements the classification standards of various applications. The development and management of the overall application are run in a unified management mode. The data between each application module can be shared. The system provides a unified data interface for the realization of the business. Richer data sources.
5、可视化层5. Visualization layer
轨检数据服务系统的各类数据分析可以通过Web网站的方式进行展现,基于数据安全的需要,不同岗位身份工作人员在登录系统后,依据自身的权限,可以在平台上获取相应的资源,同时也能进行资源的管理,例如导入、共享、删除等。All kinds of data analysis of the rail inspection data service system can be displayed through the web site. Based on the needs of data security, after logging in to the system, staff with different positions can obtain corresponding resources on the platform according to their own permissions, and at the same time It can also manage resources, such as import, share, delete, etc.
进一步的,轨检数据服务系统承载各个业务的子系统(轨检仪分析、轨检数据管理、轮廓数据分析、波磨数据分析、三维约束、单撬作业分析等),考虑到各个子系统体系结构的统一化和分布式部署的特点,对各个子系统的体系结构采用微服务架构解决的方案。技术架构如图10所示。Further, the rail inspection data service system carries the subsystems of each business (rail inspection instrument analysis, rail inspection data management, contour data analysis, wave grinding data analysis, three-dimensional constraints, single skid operation analysis, etc.), considering the various subsystems. Due to the unification of the structure and the characteristics of distributed deployment, the micro-service architecture solution is adopted for the architecture of each subsystem. The technical architecture is shown in Figure 10.
在轨检数据服务系统架构中,Hadoop分布式计算框架通过服务器自行搭建,在此基础上自行研发分布式调度框架和具体的微服务(即提供业务逻辑服务的模块),其中服务注册中心(Eureka Server)、服务配置中心(Spring Cloud Config)、服务监控中心(SpringAdmin)、消息总线(Rabbit MQ)、服务API网关(Spring Cloud Zuul)、单点服务登录、负载均衡(Ribbon、Nginx)等功能可为各个子系统复用,构成统一的分布式系统调度架构,对内部各个微服务进行统一的管理和资源调度。In the orbit inspection data service system architecture, the Hadoop distributed computing framework is built by the server itself, and on this basis, the distributed scheduling framework and specific microservices (that is, the modules that provide business logic services) are developed by themselves. Among them, the service registry (Eureka Server), service configuration center (Spring Cloud Config), service monitoring center (SpringAdmin), message bus (Rabbit MQ), service API gateway (Spring Cloud Zuul), single sign-on service, load balancing (Ribbon, Nginx) and other functions are available It is reused for each subsystem to form a unified distributed system scheduling architecture, and performs unified management and resource scheduling for each internal microservice.
各个子系统在设计时不用再考虑系统结构的问题,只需要在该分布式系统框架下根据自身的业务特点进行业务的逻辑拆分,设计满足需要的服务模块并加以部署即可,在这种模式下开发的软件更具有一致性,扩展性也更好,同时成本也更低,能大大缩短系统的开发时间。Each subsystem does not need to consider the system structure when designing. It only needs to divide the business logic according to its own business characteristics under the framework of the distributed system, and design and deploy the service modules that meet the needs. The software developed in this mode is more consistent, more scalable, and lower in cost, which can greatly shorten the development time of the system.
进一步的,轨检数据服务系统拥有许多内部敏感数据,鉴于当前网络环境的安全需求,轨检数据服务系统充分考虑了Web应用的认证授权的安全问题,在架构的过程中,权限管理框架就已经被充分规划。根据用户的身份、部门、岗位等多个要素,设定不同的系统权限,授予对数据增删改查和命令发布的不同权限。Further, the rail inspection data service system has many internal sensitive data. In view of the security requirements of the current network environment, the rail inspection data service system fully considers the security issues of authentication and authorization of web applications. During the construction process, the rights management framework has been is fully planned. According to the user's identity, department, position and other factors, different system permissions are set, and different permissions are granted for data addition, deletion, modification, and command issuance.
同时,系统内的敏感资源受到全面保护,各类敏感数据都会被加密、添加水印,防止数据泄露。轨检数据服务系统权限管理设计如图11所示At the same time, the sensitive resources in the system are fully protected, and all kinds of sensitive data will be encrypted and watermarked to prevent data leakage. The design of authority management of rail inspection data service system is shown in Figure 11
在本申请中,基于Hadoop的轨检数据服务系统采用三台服务器搭建了具有三个节点的测试集群,每台服务器的配置如表19所示:In this application, the Hadoop-based rail inspection data service system uses three servers to build a test cluster with three nodes, and the configuration of each server is shown in Table 19:
表19Table 19

轨检数据服务系统采用CDH(Cloudera’s Distribution Including ApacheHadoop)进行离线部署,CDH集成了自动化集群安装、故障监控与邮件报警等功能,有效地降低了集群的安装成本,同时也降低了后期的维护成本,提高了管理效率。集群具体部署步骤如下:The rail inspection data service system adopts CDH (Cloudera's Distribution Including ApacheHadoop) for offline deployment. CDH integrates functions such as automatic cluster installation, fault monitoring and email alarm, which effectively reduces the installation cost of the cluster and the maintenance cost in the later period. Improve management efficiency. The specific deployment steps of the cluster are as follows:
(1)规划各个服务器,服务器IP与名称如表20所示。(1) Plan each server. The server IP and name are shown in Table 20.
表20Table 20

(2)修改主机名配置各个服务器的hosts文件,配置cm-server使其可以免密登录其他节点。其次,在cm-server上安装mariadb,用于后期数据的存储。随后配置Java环境,最后配置各个节点的服务器需求。(2) Modify the host name to configure the hosts file of each server, and configure the cm-server so that it can log in to other nodes without password. Second, install mariadb on cm-server for later data storage. Then configure the Java environment, and finally configure the server requirements of each node.
(3)接下来安装Cloudera Manager,首先下载加压相关的软件包,创建用户及初始化数据,随后将cm-server修改完成的文件分发到各个节点,然后创建本地源,最后在cm-server启动Server与Agent服务,在其他节点启动Agent服务。服务都启动后,可访问cm-server的7180端口登录Cloudera Manager。(3) Next, install Cloudera Manager, first download the software packages related to pressurization, create users and initialize data, then distribute the modified files of cm-server to each node, then create local sources, and finally start Server in cm-server With the Agent service, start the Agent service on other nodes. After the services are started, you can log in to Cloudera Manager by accessing port 7180 of cm-server.
随后就可以根据需要添加相应的组件,在组件服务中可对服务的角色进行划分,实现负载均衡。本集群使用到了HDFS、Yarn、Zookeeper、Hive、Flume等组件,组件界面如图12所示。Then you can add the corresponding components as needed, and divide the roles of the services in the component service to achieve load balancing. This cluster uses components such as HDFS, Yarn, Zookeeper, Hive, and Flume. The component interface is shown in Figure 12.
该轨检数据服务系统根据用户的部门、岗位与角色来授予登录权限。权限的设置根据用户的身份及超级管理员的人工验证来实现。The rail inspection data service system grants login rights according to the user's department, position and role. Permissions are set according to the user's identity and the manual verification of the super administrator.
用户的认证主要是将请求登录用户输入的信息与用户信息数据表中的信息进行搜索对比,若用户存在且当前账号处于可用状态,则判断用户登录合法。用户信息数据表中记录的信息是可以访问轨检数据平台授权用户的详细信息,是用户管理中最重要的一张表。User authentication is mainly to search and compare the information entered by the user requesting to log in with the information in the user information data table. If the user exists and the current account is available, it is judged that the user's login is legal. The information recorded in the user information data table is the detailed information of the authorized users who can access the orbit inspection data platform, and it is the most important table in user management.
在用户信息表中最重要的属性是用户名(name)、密码(password)与盐(salt),密码通过盐加密存储在用户信息表中,保证了用户的安全,这样的设置是为了阻止未授权或者是非法用户登录系统,造成系统的破坏或数据泄露。只有用户名与密码正确时,才能进入轨检数据服务平台,否则,将始终停留在登录界面。在这里需要强调,用户密码需要包含大小写字母、数字及特殊符号才能合格。登录后,用户可以根据权限查询平台中相应的内容。The most important attributes in the user information table are the user name (name), password (password) and salt (salt). The password is encrypted and stored in the user information table through the salt, which ensures the security of the user. This setting is to prevent unauthorized access. Authorized or illegal users log in to the system, causing system damage or data leakage. Only when the user name and password are correct can you enter the orbit inspection data service platform, otherwise, it will always stay on the login interface. It needs to be emphasized here that the user password needs to contain uppercase and lowercase letters, numbers and special symbols to be qualified. After logging in, users can query the corresponding content in the platform according to their permissions.
进一步的,根据第三章轨检数据服务平台的需求分析,该平台对轨检数据管理实现了用户管理、机构管理、角色管理、菜单管理、SQL监控、接口文档、系统日志等功能。Further, according to the demand analysis of the track inspection data service platform in
在本实施例中,系统具有用户管理功能、机构管理功能、角色管理以及菜单管理,超级管理员可在用户管理界面实现用户的增删改查功能。通过超级管理员创建的合法用户可以登录轨检数据服务平台进行数据的查询。用户管理界面如图13所示。In this embodiment, the system has user management functions, organization management functions, role management and menu management, and the super administrator can implement the functions of adding, deleting, modifying and checking users on the user management interface. Legal users created by super administrators can log in to the orbit inspection data service platform to query data. The user management interface is shown in Figure 13.
在机构管理页面,管理员可根据公司实际机构的组成来创建各个机构,通过机构来赋予不同机构不同部门的工作人员不一样的权限,使得工作人员根据自己的权限在轨检数据服务系统上获取自己权限范围内的信息。机构管理界面如图14所示。On the institution management page, the administrator can create various institutions according to the composition of the company's actual institutions, and grant different permissions to the staff of different departments and departments of different institutions through the institutions, so that the staff can obtain access to the rail inspection data service system according to their own permissions. information within the scope of its own authority. The organization management interface is shown in Figure 14.
系统内的角色在不触及数据库最大容量的情况下可以自由扩展,系统具体的服务菜单和功能可以动态地赋予任意一个角色,角色决定了用户可以使用的平台的范围和服务。角色管理界面如图15所示。The roles in the system can be freely expanded without touching the maximum capacity of the database. The specific service menu and functions of the system can be dynamically assigned to any role, and the role determines the scope and services of the platform that users can use. The role management interface is shown in Figure 15.
通过菜单管理可以为平台添加扩展功能,菜单管理界面如图16所示。在菜单管理中添加是系统标准的扩展手段,统一标准的流程可以减少系统扩展是出现的不规范定义,能提升后续系统功能开发的效率。You can add extended functions to the platform through menu management. The menu management interface is shown in Figure 16. Adding in the menu management is an extension method of the system standard. The unified standard process can reduce the irregular definition of system expansion and improve the efficiency of subsequent system function development.
在本实施例中,该系统具有SQL监控功能,能发现系统中的异常行为,如查询速度很慢时可以通过分析SQL监控的报表来分析具体是哪一个服务出现了问题,是用户查询时出错还是开发时编写SQL语句是没有考虑到加索引的问题。SQL监控界面如图17所示。In this embodiment, the system has a SQL monitoring function, which can detect abnormal behaviors in the system. For example, when the query speed is very slow, it can analyze which service has a problem by analyzing the report of SQL monitoring, and it is the user's query error. Or the problem of adding indexes is not considered when writing SQL statements during development. The SQL monitoring interface is shown in Figure 17.
同时该监控模块不仅仅只有SQL监控的功能,它还具有监控Web应用、URI监控、Session监控和Spring监控等功能,对非授权访问、数据文件的敏感操作等危险行为进行实时地检测。At the same time, the monitoring module not only has the function of SQL monitoring, but also has functions such as monitoring Web applications, URI monitoring, Session monitoring, and Spring monitoring, and can detect dangerous behaviors such as unauthorized access and sensitive operations of data files in real time.
需要说明的是,任意用户使用系统的任意功能都会留下操作日志,操作日志中有着用户的IP,用户访问的URL,用户访问是否成功的状态码,以及用户访问的时间。通过这些信息管理员能高效地了解各个用户使用系统的情况。操作日志界面如图18所示。It should be noted that any user using any function of the system will leave an operation log. The operation log contains the user's IP, the URL accessed by the user, the status code of whether the user access is successful, and the time of the user access. Through this information, administrators can efficiently understand the situation of each user's use of the system. The operation log interface is shown in Figure 18.
通过对操作日志的分析,可以分析出到系统的哪些功能是高频使用的,哪些是鲜有人使用的。分析完毕后可以合理调用平台的资源,给高频使用的服务更多的资源,从而提升服务器的使用效率,合理分配服务器资源。By analyzing the operation log, you can analyze which functions of the system are frequently used and which are rarely used. After the analysis is completed, the resources of the platform can be reasonably called to provide more resources for frequently used services, thereby improving the efficiency of server use and rationally allocating server resources.
同时,如果系统出现意外,例如数据丢失等问题,可以通过操作日志,恢复一部分数据,提升平台的容灾性,降低出现意外时的损失。At the same time, if there is an accident in the system, such as data loss, etc., you can restore part of the data through the operation log, improve the disaster tolerance of the platform, and reduce the loss in the event of an accident.
每当系统发生错误时就会把错误信息记录下来,后端把错误的信息记录到错误日志数据库中,在前端页面展现出来。这些错误日志有助于管理员排查轨检数据服务系统出现的bug,能有效地提升发现bug、处理bug的效率,能够促进平台长期稳定地运行。错误日志界面如图19所示Whenever an error occurs in the system, the error information will be recorded, and the backend will record the error information in the error log database and display it on the front-end page. These error logs help administrators to troubleshoot bugs in the track inspection data service system, effectively improve the efficiency of bug discovery and bug handling, and promote long-term and stable operation of the platform. The error log interface is shown in Figure 19
综上,本发明上述实施例中的基于Hadoop的轨检数据服务系统,通过数据对齐单元将各当前轨检数据与历史轨检数据以特征点为标志进行数据对齐,为后续数据分析排除里程误差干扰;通过将数据对齐的轨检数据进行拆分,并对多组预处理的轨检数据进行分布式处理,进而提高轨检数据的高效利用以及分类管理,以使用户能够做到统一访问、高效率的精确查询和统计。To sum up, in the Hadoop-based rail inspection data service system in the above-mentioned embodiments of the present invention, each current rail inspection data and historical rail inspection data are aligned with feature points through the data alignment unit, so as to eliminate mileage errors for subsequent data analysis. Interference; by splitting the data-aligned orbital inspection data, and distributed processing of multiple groups of preprocessed orbital inspection data, the efficient utilization and classified management of orbital inspection data can be improved, so that users can achieve unified access, Efficient and precise query and statistics.
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。The technical features of the above-described embodiments can be combined arbitrarily. For the sake of brevity, all possible combinations of the technical features in the above-described embodiments are not described. However, as long as there is no contradiction between the combinations of these technical features, All should be regarded as the scope described in this specification.
以上所述实施例仅表达了本申请的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本申请构思的前提下,还可以做出若干变形和改进,这些都属于本申请的保护范围。因此,本申请专利的保护范围应以所附权利要求为准。The above-mentioned embodiments only represent several embodiments of the present application, and the descriptions thereof are specific and detailed, but should not be construed as a limitation on the scope of the invention patent. It should be pointed out that for those skilled in the art, without departing from the concept of the present application, several modifications and improvements can be made, which all belong to the protection scope of the present application. Therefore, the scope of protection of the patent of the present application shall be subject to the appended claims.
Claims (10)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210648201.7ACN114936224B (en) | 2022-06-09 | 2022-06-09 | Track inspection data service system based on Hadoop |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210648201.7ACN114936224B (en) | 2022-06-09 | 2022-06-09 | Track inspection data service system based on Hadoop |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN114936224Atrue CN114936224A (en) | 2022-08-23 |
| CN114936224B CN114936224B (en) | 2025-04-18 |
Family
ID=82867496
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210648201.7AActiveCN114936224B (en) | 2022-06-09 | 2022-06-09 | Track inspection data service system based on Hadoop |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114936224B (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115576714A (en)* | 2022-10-19 | 2023-01-06 | 深圳市中兴新云服务有限公司 | Method for ensuring accuracy of message queue consumption sequence based on MQ framework |
| CN115619056A (en)* | 2022-10-08 | 2023-01-17 | 江西日月明测控科技股份有限公司 | A track detection data processing method and system |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109272155A (en)* | 2018-09-11 | 2019-01-25 | 郑州向心力通信技术股份有限公司 | A kind of corporate behavior analysis system based on big data |
| WO2020233077A1 (en)* | 2019-05-21 | 2020-11-26 | 深圳壹账通智能科技有限公司 | System service monitoring method, device, and apparatus, and storage medium |
| CN112015782A (en)* | 2020-08-27 | 2020-12-01 | 青岛地铁集团有限公司运营分公司 | Subway track dynamic detection data management analysis system and method thereof |
| CN113689012A (en)* | 2021-08-26 | 2021-11-23 | 成都地铁运营有限公司 | Rail transit online monitoring and intelligent operation and maintenance system and method |
| CN113886390A (en)* | 2021-09-30 | 2022-01-04 | 京东城市(北京)数字科技有限公司 | Track data processing method and device, computer equipment and storage medium |
- 2022
- 2022-06-09CNCN202210648201.7Apatent/CN114936224B/enactiveActive
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109272155A (en)* | 2018-09-11 | 2019-01-25 | 郑州向心力通信技术股份有限公司 | A kind of corporate behavior analysis system based on big data |
| WO2020233077A1 (en)* | 2019-05-21 | 2020-11-26 | 深圳壹账通智能科技有限公司 | System service monitoring method, device, and apparatus, and storage medium |
| CN112015782A (en)* | 2020-08-27 | 2020-12-01 | 青岛地铁集团有限公司运营分公司 | Subway track dynamic detection data management analysis system and method thereof |
| CN113689012A (en)* | 2021-08-26 | 2021-11-23 | 成都地铁运营有限公司 | Rail transit online monitoring and intelligent operation and maintenance system and method |
| CN113886390A (en)* | 2021-09-30 | 2022-01-04 | 京东城市(北京)数字科技有限公司 | Track data processing method and device, computer equipment and storage medium |
Non-Patent Citations (1)
| Title |
|---|
| 宋扬;: "基于微服务及大数据的通号智能维护系统的研发及其应用", 铁路通信信号工程技术, no. 09, 25 September 2020 (2020-09-25)* |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115619056A (en)* | 2022-10-08 | 2023-01-17 | 江西日月明测控科技股份有限公司 | A track detection data processing method and system |
| CN115576714A (en)* | 2022-10-19 | 2023-01-06 | 深圳市中兴新云服务有限公司 | Method for ensuring accuracy of message queue consumption sequence based on MQ framework |
Also Published As
| Publication number | Publication date |
|---|---|
| CN114936224B (en) | 2025-04-18 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN109492991B (en) | Intelligent integrated management system for power distribution project construction | |
| US10140453B1 (en) | Vulnerability management using taxonomy-based normalization | |
| CN113094385B (en) | Data sharing fusion platform and method based on software defined open tool set | |
| CN110543464A (en) | Big data platform applied to smart park and operation method | |
| CN105450636B (en) | A kind of cloud computing management system | |
| WO2019214311A1 (en) | Blockchain-based information supervision method and device | |
| CN105357201A (en) | Access control method and system for object cloud storage | |
| CN111125228A (en) | A data sharing method and device based on forestry data sharing service platform | |
| JP2019527417A (en) | System and method for providing a secure data monitoring system executed in a factory or plant | |
| CN114936224A (en) | Rail inspection data service system based on Hadoop | |
| CN111694743A (en) | Service system detection method and device | |
| CN113535846B (en) | Big data platform and construction method thereof | |
| CN105577677A (en) | Remote login method and system based on J2EE | |
| CN106487770B (en) | Method for authenticating and authentication device | |
| CN111177480A (en) | Block chain directory file system | |
| CN112837194A (en) | Intelligent system | |
| CN104468818B (en) | A kind of internet of things service processing system and its method | |
| CN119829683A (en) | Government affair data sharing system, method, equipment and storage medium | |
| CN114969716A (en) | Authority management method, device, electronic equipment and medium | |
| CN113793158A (en) | Textile inspection detection information query method and system | |
| CN107465688A (en) | A kind of identification method of status monitoring evaluation system network application authority | |
| Lu et al. | Research on agricultural internet of things data sharing system based on blockchain | |
| CN117522293A (en) | An ERP management system suitable for power grid engineering | |
| Qingbin et al. | Research on application of blockchain technology in airport aviation security | |
| US20230138622A1 (en) | Emergency Access Control for Cross-Platform Computing Environment |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |