CN114926826A - Scene text detection system - Google Patents
Scene text detection systemDownload PDFInfo
- Publication number
- CN114926826A CN114926826ACN202210451005.0ACN202210451005ACN114926826ACN 114926826 ACN114926826 ACN 114926826ACN 202210451005 ACN202210451005 ACN 202210451005ACN 114926826 ACN114926826 ACN 114926826A
- Authority
- CN
- China
- Prior art keywords
- feature
- branch
- attention
- convolution
- original image
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images






Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/25—Fusion techniques
- G06F18/253—Fusion techniques of extracted features
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/048—Activation functions
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Life Sciences & Earth Sciences (AREA)
- Artificial Intelligence (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Evolutionary Computation (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Software Systems (AREA)
- Mathematical Physics (AREA)
- Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Computing Systems (AREA)
- Molecular Biology (AREA)
- General Health & Medical Sciences (AREA)
- Evolutionary Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Image Analysis (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本发明属于文本检测领域,具体涉及场景文本检测系统。The invention belongs to the field of text detection, in particular to a scene text detection system.
背景技术Background technique
文字已经成为当代世界传递信息的必不可少手段之一,本例生活的社会场景中存在有各种各样的文字信息。自然场景文本检测就是在一幅图像中通过检测网络定位出文字区域,并用多边形边界框将文字区域表示出来,准确的检测结果有利于广泛的实际应用,如即时翻译、图像检索、场景解析、地理定位和车牌识别等,在计算机视觉领域与文档分析领域备受关注。近年来,随着卷积神经网络(CNN)的快速发展,场景文本检测取得了很大进展。本例可以将现有的基于CNN的文本检测算法大致分为两类:基于回归的方法和基于分割的方法。Words have become one of the indispensable means of transmitting information in the contemporary world. There are various types of written information in the social scene of this example. Natural scene text detection is to locate the text area in an image through the detection network, and use the polygon bounding box to represent the text area. Accurate detection results are beneficial to a wide range of practical applications, such as real-time translation, image retrieval, scene analysis, geography Localization and license plate recognition have attracted much attention in the field of computer vision and document analysis. In recent years, scene text detection has made great progress with the rapid development of convolutional neural networks (CNNs). In this example, existing CNN-based text detection algorithms can be roughly divided into two categories: regression-based methods and segmentation-based methods.
对于基于回归的场景文本检测算法,通常采用具有特定方向的矩形框或四边形框的形式表示。虽然检测速度快,可以避免累积多个阶段的错误产生,但大多数现有的基于回归的方法由于文本表示形式的有限(轴对齐的矩形、旋转的矩形或四边形)已经无法准确且有效地解决文字检测问题,特别是用来检测Total-Text等数据集上任意形状的文本时性能不是很好,这对整个光学字符识别引擎中的后续文本识别是非常不利的。For regression-based scene text detection algorithms, it is usually represented in the form of a rectangular box or quadrilateral box with a specific orientation. Although the detection speed is fast and can avoid accumulating errors in multiple stages, most existing regression-based methods have been unable to solve accurately and efficiently due to the limited text representation (axis-aligned rectangle, rotated rectangle or quadrilateral) The problem of text detection, especially when it is used to detect arbitrary-shaped text on datasets such as Total-Text, is not very good, which is very detrimental to the subsequent text recognition in the entire optical character recognition engine.
对于基于分割的场景文本检测算法主要通过对像素进行分类来定位文本实例。虽然最近的方法在场景文本检测任务中取得了显著的改进,同时研究的重点也已经从横向文本转向多向文本和更具挑战性的任意形状文本(如弯曲文本),但由于场景文本的特定属性,例如颜色、比例、方向、纵横比和形状的显著变化使其明显不同于一般目标对象,外加自然图像的属性不同,例如图像模糊程度、光照条件等,在任意形状的场景文本检测中仍存在挑战。For segmentation-based scene text detection algorithms, text instances are located mainly by classifying pixels. Although recent methods have achieved significant improvements in the task of scene text detection, and the research focus has also shifted from horizontal text to multi-directional text and more challenging arbitrary-shaped text (such as curved text), due to the specific nature of scene text Significant changes in properties, such as color, scale, orientation, aspect ratio, and shape, make them significantly different from general target objects, plus different properties of natural images, such as image blur, lighting conditions, etc., are still in the scene text detection of arbitrary shapes. There are challenges.
自然场景中的文本具有丰富、明确的语义信息,利用计算机技术快速、准确地提取场景图像中的文本信息是计算机视觉和模式识别领域当下热门的研究课题之一。场景文本检测技术是文本识别的基础,在人们的日常生活和生产中有着广泛的应用。与传统OCR相比,自然场景图像中的文本检测面临背景复杂、文本尺度和字体多样、图像质量的不确定性等诸多困难和挑战。近年来,随着深度学习技术的迅速发展,深度学习的方法在文本检测任务上效果显著,现有的卷积神经网络已经具备很好的表征能力,但是网络的感受野不足,定位能力不强,对文本的定位不准确,会导致在检测较长文本或者较大文本时容易出现误检或者漏检。另一方面,特征金字塔网络虽可以融合不同尺度的特征,但小尺度文本的高级语义信息在网络高层已经丢失,导致模型对多尺度文本的检测能力不强。Text in natural scenes has rich and clear semantic information. Using computer technology to quickly and accurately extract text information in scene images is one of the hot research topics in the field of computer vision and pattern recognition. Scene text detection technology is the basis of text recognition, and has a wide range of applications in people's daily life and production. Compared with traditional OCR, text detection in natural scene images faces many difficulties and challenges, such as complex backgrounds, diverse text scales and fonts, and uncertainty in image quality. In recent years, with the rapid development of deep learning technology, deep learning methods have achieved remarkable results in text detection tasks. The existing convolutional neural networks already have good representation capabilities, but the network has insufficient receptive fields and weak localization capabilities. , the positioning of the text is not accurate, which will easily lead to false detection or missed detection when detecting longer or larger text. On the other hand, although the feature pyramid network can fuse features of different scales, the high-level semantic information of small-scale texts has been lost in the upper layers of the network, resulting in the model's weak detection ability for multi-scale texts.
自然场景下的文本信息通常具有多样性和不规则性的特点,以及自然场景下任意形状文本检测的复杂性。由于采用手工设计特征的方式,传统的自然场景文字检测方法缺乏鲁棒性,而已有的基于深度学习的文本检测方法在各层网络提取特征的过程中存在丢失重要特征信息的问题。基于分割的文本检测方法是最近非常流行的检测方法之一,分割结果更能直观的描述各种形状的场景文本。原始的DB(Differentiable Binarization)算法利用可微分二值化算法简化后处理过程,解决了训练带来的梯度不可微问题,提高了场景文本检测的效率,但对网络中的语义信息和空间信息利用不充分,限制了网络的分类能力和定位能力。尽管基于分割的算法在检测任意形状的文本时具有优势,但由于缺乏足够的上下文信息也会造成误报或漏检。Text information in natural scenes usually has the characteristics of diversity and irregularity, as well as the complexity of text detection of arbitrary shapes in natural scenes. Due to the way of hand-designed features, the traditional natural scene text detection methods lack robustness, and the existing deep learning-based text detection methods have the problem of losing important feature information in the process of extracting features from each layer of the network. The segmentation-based text detection method is one of the most popular detection methods recently, and the segmentation results can more intuitively describe scene texts of various shapes. The original DB (Differentiable Binarization) algorithm uses the differentiable binarization algorithm to simplify the post-processing process, solves the problem of non-differentiable gradients caused by training, and improves the efficiency of scene text detection. Insufficient, limiting the classification and localization capabilities of the network. Although segmentation-based algorithms have advantages in detecting arbitrarily shaped text, they can also cause false positives or missed detections due to lack of sufficient contextual information.
发明内容SUMMARY OF THE INVENTION
本发明的目的是针对现有技术中DBNet文本检测网络对网络中的语义信息和空间信息利用不充分,限制了网络的分类能力和定位能力,同时缺乏足够的上下文信息造成误报或漏检的问题提出场景文本检测系统,从而使DBNet文本检测网络在特征提取过程中能够得到更深层次的语义信息以及明确重点文本特征。The purpose of the present invention is to aim at the insufficient utilization of semantic information and spatial information in the network by the DBNet text detection network in the prior art, which limits the classification ability and positioning ability of the network, and at the same time lacks sufficient context information to cause false positives or missed detections. The problem proposes a scene text detection system, so that the DBNet text detection network can obtain deeper semantic information and clarify key text features in the feature extraction process.
本发明解决上述技术问题,采用的技术方案是,场景文本检测系统,包括:图像获取单元,特征融合单元以及可微分二值化模块,其特征在于:The present invention solves the above-mentioned technical problems, and adopts the technical scheme that a scene text detection system includes: an image acquisition unit, a feature fusion unit and a differentiable binarization module, and is characterized in that:
所述图像获取单元,用于获取原始图像;the image acquisition unit for acquiring the original image;
所述特征提取单元,用于使用Resnet提取原始图像的特征图;所述Resnet骨干网络中嵌入残差校正支路;所述残差校正支路,用于在Resnet对原始图像进行常规卷积获得输入特征后,构成两个支路;其中一支路通过下采样将输入特征转换为低维嵌入,由该低维嵌入来校准另一支路中卷积核的卷积变换,最终得到原始图像的特征图;The feature extraction unit is used to extract the feature map of the original image by using Resnet; a residual correction branch is embedded in the Resnet backbone network; the residual correction branch is used to perform conventional convolution on the original image in Resnet to obtain After inputting the features, two branches are formed; one branch converts the input features into a low-dimensional embedding by downsampling, and the low-dimensional embedding is used to calibrate the convolution transformation of the convolution kernel in the other branch, and finally the original image is obtained. The feature map of ;
所述特征融合单元,用于使用FPN对所述特征图进行特征融合,最终取得目标特征图;The feature fusion unit is used to perform feature fusion on the feature map using FPN, and finally obtain the target feature map;
所述可微分二值化模块,用于根据目标特征图确定图像中的目标文本区域。The differentiable binarization module is used for determining the target text area in the image according to the target feature map.
在本发明实施例中,所述残差校正支路的两个支路分别为第一支路及第二支路;In the embodiment of the present invention, the two branches of the residual correction branch are respectively a first branch and a second branch;
所述第一支路用于,对输入特征进行常规卷积提取第一支路特征;The first branch is used to perform conventional convolution on the input feature to extract the first branch feature;
所述第二支路用于,对输入特征进行平均池化下采样r倍后进行卷积后进行上采样,最后经过Sigmoid激活函数后得到第二支路特征;The second branch is used to perform average pooling downsampling r times on the input features, perform convolution and then upsampling, and finally obtain the second branch feature after passing through the sigmoid activation function;
所述残差校正支路还用于,对第一支路特征及第二支路特征进行点乘操作,得到输出特征;输出特征与原始图像进行加和后,经过Relu激活函数后得到原始图像的特征图。The residual correction branch is also used to perform a dot product operation on the first branch feature and the second branch feature to obtain an output feature; after adding the output feature and the original image, the original image is obtained after the Relu activation function. feature map.
在本发明实施例中,采用平均池化下采样r倍,计算公式如下:In the embodiment of the present invention, the average pooling is used to downsample r times, and the calculation formula is as follows:
x′2=AvgPoolr(x2)x′2 =AvgPoolr (x2 )
其中,x2为第二支路的输入特征;x′2为第二支路的特征转换;r=4。Wherein, x2 is the input feature of the second branch; x′2 is the feature transformation of the second branch; r=4.
在本发明实施例中,经过Sigmoid激活函数后得到第二支路特征的计算公式如下:In the embodiment of the present invention, the calculation formula for obtaining the second branch feature after the sigmoid activation function is as follows:

其中,y2为第二支路特征;Up(·)是最近邻插值上采样;x′2为第二支路的特征转换;k2表示卷积操作。Among them, y2 is the second branch feature; Up(·) is the nearest neighbor interpolation upsampling; x′2 is the feature transformation of the second branch; k2 represents the convolution operation.
在本发明实施例中,第一支路特征的计算公式如下:In the embodiment of the present invention, the calculation formula of the first branch characteristic is as follows:

其中,y1为第一分支特征;x1为第一支路的输入特征;k1表示卷积操作。Among them, y1 is the first branch feature; x1 is the input feature of the first branch; k1 represents the convolution operation.
在本发明实施例中,所述FPN结构中嵌入双分支注意特征融合模块;In the embodiment of the present invention, a dual-branch attention feature fusion module is embedded in the FPN structure;
所述双分支注意特征融合模块,用于增强多尺度场景文本的特征表达,使其检测的准确性得到提高。The dual-branch attention feature fusion module is used to enhance the feature expression of multi-scale scene text, so that the detection accuracy is improved.
在本发明实施例中,所述双分支注意特征融合模块包括全局特征通道以及局部特征通道;In the embodiment of the present invention, the dual-branch attention feature fusion module includes a global feature channel and a local feature channel;
所述FPN,用于对原始图像的任意两个特征图进行初始融合后,得到初始融合特征;The FPN is used to obtain initial fusion features after initial fusion of any two feature maps of the original image;
所述全局特征通道,用于对初始融合特征进行全局平均池化处理,再对其进行卷积提取全局特征通道注意力;The global feature channel is used to perform global average pooling on the initial fusion feature, and then perform convolution on it to extract global feature channel attention;
所述局部特征通道,用于对初始融合特征进行卷积提取局部特征通道注意力;The local feature channel is used to convolve the initial fusion feature to extract local feature channel attention;
双分支注意特征融合模块,还用于将全局特征通道注意力与局部特征通道注意力进行加和后,再对其进行激活,然后再与原始图像的特征图中较大尺寸特征图进行逐元素相乘,从而最终确定目标特征图。The dual-branch attention feature fusion module is also used to add global feature channel attention and local feature channel attention, and then activate it, and then perform element-by-element comparison with the larger-sized feature map in the feature map of the original image. Multiply to finally determine the target feature map.
在本发明实施例中,全局特征通道注意力的计算公式如下:In the embodiment of the present invention, the calculation formula of the global feature channel attention is as follows:
g(X)=B(PWConv2(δ(B(PWConv1(Avg(X))))))g(X)=B(PWConv2 (δ(B(PWConv1 (Avg(X))))))
其中,g(X)表示全局特征通道注意力;B表示BatchNorm层;PWConv表示逐点卷积;δ表示Relu激活函数,X表示初始融合特征;Avg表示全局平均池化。Among them, g(X) represents global feature channel attention; B represents BatchNorm layer; PWConv represents pointwise convolution; δ represents Relu activation function, X represents initial fusion feature; Avg represents global average pooling.
在本发明实施例中,局部特征通道注意力的计算公式如下:In the embodiment of the present invention, the calculation formula of local feature channel attention is as follows:
L(X)=B(PWConv2(δ(B(PWConv1(X)))))L(X)=B(PWConv2 (δ(B(PWConv1 (X)))))
其中,L(X)表示局部特征通道注意力;B表示BatchNorm层;PWConv表示逐点卷积;δ表示Relu激活函数,X表示初始融合特征。Among them, L(X) represents the local feature channel attention; B represents the BatchNorm layer; PWConv represents the point-wise convolution; δ represents the Relu activation function, and X represents the initial fusion feature.
在本发明实施例中,将全局特征通道注意力与局部特征通道注意力进行加和后,再对其进行激活后与原始图像的特征图中较大尺寸特征图进行逐元素相乘,获取目标特征图的计算公式如下:In the embodiment of the present invention, the global feature channel attention and the local feature channel attention are added, and then activated and then multiplied element by element with the larger size feature map in the feature map of the original image to obtain the target The calculation formula of the feature map is as follows:

其中,X′表示目标特征图;
本发明的有益效果在于,本发明在DBNet算法的基础上改进了特征提取网络,改进的ResNet轻量化特征提取网络和更好的特征融合方法将不同深度的特征有效的融合在一起指导分割。ResNet引入了残差校正支路(RCB)来扩大感受野,提升获取上下文信息的能力,从而获得更大感受野的上下文信息。同时,为了提高对特征的使用效率,在FPN结构中加入双分支注意特征融合(TB-AFF)模块,通过结合全局和局部注意力机制来精确定位文本区域,准确检测自然场景下的文本位置。最后通过可微分二值化模块,将二值化的过程加入到模型的训练过程中,自适应地设置二值化阈值,将分割方法产生的概率图转化为文本区域,取得更好的文本检测效果。整个模型既保证了特征提取的质量,同时因为本身属于轻量级网络,在速度和精度方面达到了很好的平衡。在不牺牲速度的前提下,扩大了网络的感受野,学习到了更精细的文本位置信息,对文本区域进一步精准定位。The beneficial effect of the present invention is that the present invention improves the feature extraction network on the basis of the DBNet algorithm, and the improved ResNet lightweight feature extraction network and a better feature fusion method effectively fuse features of different depths together to guide segmentation. ResNet introduces a residual correction branch (RCB) to expand the receptive field and improve the ability to obtain contextual information, so as to obtain contextual information of a larger receptive field. At the same time, in order to improve the use efficiency of features, a dual-branch attention feature fusion (TB-AFF) module is added to the FPN structure to accurately locate text regions by combining global and local attention mechanisms, and accurately detect text positions in natural scenes. Finally, through the differentiable binarization module, the binarization process is added to the training process of the model, the binarization threshold is set adaptively, and the probability map generated by the segmentation method is converted into a text area to achieve better text detection. Effect. The entire model not only ensures the quality of feature extraction, but also achieves a good balance in terms of speed and accuracy because it is a lightweight network. Without sacrificing speed, the receptive field of the network is expanded, more precise text location information is learned, and the text area is further accurately positioned.
附图说明Description of drawings
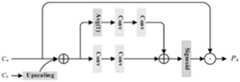
图1为本发明实施例1中场景文本检测系统结构图。FIG. 1 is a structural diagram of a scene text detection system in
图2为本发明实施例1中残差校正支路结构图。FIG. 2 is a structural diagram of a residual error correction branch in
图3为本发明实施例1中双分支注意特征融合模块结构图。FIG. 3 is a structural diagram of a dual-branch attention feature fusion module in
图4为本发明实施例1中可微二值化的结构图。FIG. 4 is a structural diagram of differentiable binarization in
图5为本发明实施例2中不同类型的文本示例上的可视化结果。FIG. 5 is a visualization result on different types of text examples in Embodiment 2 of the present invention.
图6为本发明实施例2中Baseline和本发明的可视化结果。FIG. 6 is the visualization result of Baseline and the present invention in Example 2 of the present invention.
图7为本发明实施例2中不同类型的文本示例上的可视化结果显示FIG. 7 is a visualization result display on different types of text examples in Embodiment 2 of the present invention
具体实施方式Detailed ways
实施例1Example 1
本发明针对现有技术中DBNet文本检测网络对网络中的语义信息和空间信息利用不充分,限制了网络的分类能力和定位能力,同时缺乏足够的上下文信息造成误报或漏检的问题提供一种场景文本检测系统,包括:图像获取单元,特征提取单元,特征融合单元以及可微分二值化模块,所述图像获取单元,用于获取原始图像;工作流程图如图1所示。The invention provides a solution for the problem that the DBNet text detection network in the prior art does not fully utilize the semantic information and spatial information in the network, limits the classification ability and positioning ability of the network, and at the same time lacks sufficient context information to cause false positives or missed detections. A scene text detection system includes: an image acquisition unit, a feature extraction unit, a feature fusion unit and a differentiable binarization module, the image acquisition unit is used to acquire an original image; the work flow chart is shown in Figure 1.
1、关于特征提取单元,介绍如下:1. About the feature extraction unit, the introduction is as follows:
系统使用Resnet提取原始图像的特征图,所述Resnet骨干网络中嵌入了残差校正支路(RCB)。系统工作时,Resnet对原始图像进行常规卷积获得输入特征后,残差校正支路中的两个分支;其中一支路通过下采样将输入特征转换为低维嵌入,由该低维嵌入来校准另一支路中卷积核的卷积变换,并最终得到原始图像的特征图。具体而言,残差校正支路(RCB)不单单是对原始空间中的输入执行传统卷积,而是首先通过下采样将输入转换为低维嵌入,由该低维嵌入来校准另一个支路中卷积核的卷积变换。得益于这种卷积和卷积核间的通信,空间上的每一个点都有其附近区域的信息和通道上的交互信息,避免了整个全局信息中无关区域的干扰。同时也可以有效地扩大每个空间位置的感受野,从而关注更多的上下文信息。The system uses Resnet to extract the feature map of the original image, and the Resnet backbone network has a residual correction branch (RCB) embedded in it. When the system is working, after Resnet performs conventional convolution on the original image to obtain the input features, two branches in the residual correction branch are corrected; one branch converts the input features into low-dimensional embeddings through downsampling, which is derived from the low-dimensional embeddings. The convolution transformation of the convolution kernel in the other branch is calibrated, and the feature map of the original image is finally obtained. Specifically, the Residual Correction Branch (RCB) does not simply perform traditional convolution on the input in the original space, but first converts the input into a low-dimensional embedding by downsampling, which calibrates the other branch The convolution transform of the convolution kernel in the path. Thanks to the communication between the convolution and the convolution kernel, each point in space has the information of its nearby area and the interaction information on the channel, avoiding the interference of irrelevant areas in the whole global information. At the same time, it can effectively expand the receptive field of each spatial location, so as to focus on more contextual information.
其中,残差校正支路(RCB),结构如图2所示,包括第一支路及第二支路;Among them, the residual correction branch (RCB), as shown in Figure 2, includes a first branch and a second branch;
所述第一支路用于,对输入特征进行常规卷积提取第一支路特征;The first branch is used to perform conventional convolution on the input feature to extract the first branch feature;
所述第二支路用于,对输入特征进行平均池化下采样r倍后进行卷积后进行上采样,最后经过Sigmoid激活函数后得到第二支路特征;The second branch is used to perform average pooling downsampling r times on the input features, perform convolution and then upsampling, and finally obtain the second branch feature after passing through the sigmoid activation function;
第二支路上首先采用平均池化下采样r倍,计算公式如下:On the second branch, the average pooling is first used to downsample r times, and the calculation formula is as follows:
x′2=AvgPoolr(x2)x′2 =AvgPoolr (x2 )
其中,x2为第二支路的输入特征;x′2为特征转换;r=4。Among them, x2 is the input feature of the second branch; x'2 is the feature transformation; r=4.
经过Sigmoid激活函数后得到第二支路特征的计算公式如下:The calculation formula of the second branch feature obtained after the sigmoid activation function is as follows:

其中,y2为第二支路特征;k2表示卷积操作;Up(·)是最近邻插值上采样,目的是将中间过程从小尺度空间映射到原始特征空间。Sigmoid激活函数可以增加神经网络模型的非线性,以便增加对样本非线性关系的拟合能力。相比于原始支路上的标准卷积,残差校正支路可以自适应地为每个通道和空间位置的周围环境建立依赖关系,允许每个通道和空间位置将其周围信息环境自适应地视为来自潜在空间的输入,以作为来自原始比例空间的响应中的标量,从而生成更具判别力的特征,提取出更加丰富的上下文信息,因此可以有效扩大具有残差校正支路的网络的视场。Among them, y2 is the second branch feature; k2 represents the convolution operation; Up ( ) is the nearest neighbor interpolation upsampling, the purpose is to map the intermediate process from the small-scale space to the original feature space. The sigmoid activation function can increase the nonlinearity of the neural network model in order to increase the ability to fit the nonlinear relationship of the samples. Compared with the standard convolution on the original branch, the residual correction branch can adaptively establish dependencies for the surrounding environment of each channel and spatial location, allowing each channel and spatial location to adaptively view its surrounding information environment. The input from the latent space is used as the scalar in the response from the original scale space, so as to generate more discriminative features and extract richer contextual information, so it can effectively expand the visual field of the network with the residual correction branch. field.
第一支路特征的计算公式如下:The calculation formula of the first branch feature is as follows:

其中,y1为第一分支特征;x1为第一支路的输入特征;k1表示卷积操作。第一支路的输入特征与第二支路的输入特征一致,均为Resnet对原始图像进行常规卷积获得的输入特征。Among them, y1 is the first branch feature; x1 is the input feature of the first branch; k1 represents the convolution operation. The input features of the first branch are consistent with the input features of the second branch, and both are input features obtained by conventional convolution of the original image by Resnet.
然后,对第一支路特征及第二支路特征进行点乘操作,得到输出特征;输出特征与该模块最开始的输入进行加和(即残差连接)后,经过Relu激活函数后得到原始图像的特征图。Then, perform a dot product operation on the first branch feature and the second branch feature to obtain the output feature; after the output feature is summed with the initial input of the module (ie, residual connection), the original output feature is obtained after the Relu activation function. Feature map of the image.
残差校正支路(RCB)能够产生全局的感受野,充分获取分割图像的上下文信息。这在应用于卷积层时极大地增加了视野,可以达到扩增卷积感受野的目的,有助于很好地捕获整个判别区域。它使每个空间位置能够自适应地编码来自周围区域的信息上下文,增加了特征信息的提取能力。同时还考虑到了通道间的信息的增强,产生更丰富和更有判别性的特征表示,进而增强输出特征的多样性,改善了卷积网络的性能。The residual correction branch (RCB) can generate a global receptive field and fully acquire the context information of the segmented image. This greatly increases the field of view when applied to the convolutional layer, which can achieve the purpose of expanding the convolutional receptive field and help to capture the entire discriminative region well. It enables each spatial location to adaptively encode information context from surrounding regions, increasing the extraction capability of feature information. At the same time, the enhancement of information between channels is also considered, resulting in a richer and more discriminative feature representation, which in turn enhances the diversity of output features and improves the performance of convolutional networks.
另一方面,残差校正支路不收集全局上下文信息,而仅考虑每个通道和空间位置周围的上下文信息,从而在某种程度上避免了来自无关区域(非文本区域)的某些污染信息。因此,可以精准地定位目标物体。而且从图中可以看出,残差校正支路模块通用性强,方便使用,可以很容易地运用在标准卷积层上。此外,众所周知,一般大多数基于注意力或非局部的方法都需要额外的可学习参数来构建相应的模块,然后将它们插入到构建块中。与之不同的是,我们的残差校正支路不用依赖任何额外的可学习参数,适用于多种任务,可以很容易地嵌入到现代分类网络中。On the other hand, the residual correction branch does not collect global contextual information, but only considers contextual information around each channel and spatial location, thus avoiding some contamination information from irrelevant regions (non-text regions) to some extent . Therefore, the target object can be positioned precisely. And it can be seen from the figure that the residual correction branch module is highly versatile and easy to use, and can be easily applied to the standard convolution layer. Furthermore, it is well known that in general most attention-based or non-local methods require additional learnable parameters to build the corresponding modules, which are then inserted into the building blocks. In contrast, our residual correction branch does not rely on any additional learnable parameters, is suitable for a variety of tasks, and can be easily embedded into modern classification networks.
2、关于特征融合单元,介绍如下:2. About the feature fusion unit, the introduction is as follows:
本例的特征融合单元,用于使用FPN对所述特征图进行特征融合,最终取得目标特征图。The feature fusion unit in this example is used to perform feature fusion on the feature map using FPN, and finally obtain the target feature map.
对于FPN结构来说,越深层的特征意味着更多的通道数,但是各层特征进行融合时都是自顶向下传播,所以顶层特征势必会减少更多的通道数,由于减少了特征通道必然会导致上下文信息的丢失,最高层的特征往往会丢失更多的信息,而图像的上下文语义信息对于分割网络有着至关重要的作用。For the FPN structure, the deeper features mean more channels, but the features of each layer are propagated from top to bottom when fused, so the top-level features will inevitably reduce the number of channels, due to the reduction of feature channels. It will inevitably lead to the loss of contextual information, and the features of the highest level often lose more information, and the contextual semantic information of the image plays a crucial role in the segmentation network.
为了保留更多的上下文信息,本例选择FPN作为最常见场景的示例:长跳跃连接,并在FPN中加入双分支注意特征融合(TB-AFF)模块,充分利用网络各层提取到的特征来应对文本的尺度变化,可以保留更多的深层特征信息,提高金字塔的特征的性能。具体来说,将TB-AFF添加到了FPN中,以获得注意力网络,我们称为多尺度注意力融合网络(MSAFN)。其结构如图3所示,FPN结构中嵌入双分支注意特征融合(TB-AFF)模块,可以增强多尺度场景文本的特征表达,使其检测的准确性得到提高。In order to retain more contextual information, this example selects FPN as an example of the most common scenario: long skip connection, and adds a dual-branch attention feature fusion (TB-AFF) module to the FPN, making full use of the features extracted by each layer of the network to In response to the scale change of the text, more deep feature information can be retained and the performance of pyramid features can be improved. Specifically, TB-AFF is added to FPN to obtain an attention network, which we call Multi-Scale Attention Fusion Network (MSAFN). Its structure is shown in Figure 3. The dual-branch attention feature fusion (TB-AFF) module is embedded in the FPN structure, which can enhance the feature expression of multi-scale scene text and improve the detection accuracy.
双分支注意特征融合(TB-AFF)模块是由长跳跃连接引起的特征融合,将CNN中的局部特征和全局特征相结合,汇集空间注意力的思想,在注意力模块内聚合多尺度特征上下文信息,生成的融合权重与特征图的大小相同,从而以逐元素的方式动态选择,适用于大多数常见场景。The Bi-Branch Attention Feature Fusion (TB-AFF) module is a feature fusion caused by long skip connections, combining local features and global features in CNN, pooling the idea of spatial attention, and aggregating multi-scale feature context within the attention module information, the resulting fusion weights are the same size as the feature maps, which are dynamically selected in an element-wise manner, suitable for most common scenarios.
所述双分支注意特征融合(TB-AFF)模块,包括全局特征通道以及局部特征通道;该全局特征通道基于SENet,但是全连接层换成了pointwise conv(逐点卷积),也就是卷积核为1的正常卷积;局部特征通道采用pointwise conv(逐点卷积)提取局部特征的通道注意力,对SENet而言只利用了全局通道注意力,它偏向于全局范围的上下文,而提出的TB-AFF还聚合了局部通道上下文注意力,这有助于网络包含更少的背景杂波,更有利于小目标的检测。通过在双分支注意特征融合(TB-AFF)模块中加入跨层连接,可以实现多尺度特征信息的互补,以获得反映上下文信息的最终表示The dual-branch attention feature fusion (TB-AFF) module includes a global feature channel and a local feature channel; the global feature channel is based on SENet, but the fully connected layer is replaced by pointwise conv (point-by-point convolution), that is, convolution The normal convolution with a kernel of 1; the local feature channel uses pointwise conv (point-by-point convolution) to extract the channel attention of local features. For SENet, only the global channel attention is used, which is biased towards the context of the global scope, and proposed The TB-AFF also aggregates local channel contextual attention, which helps the network contain less background clutter and is more conducive to the detection of small objects. By incorporating cross-layer connections in the Bi-Branch Attention Feature Fusion (TB-AFF) module, the complementarity of multi-scale feature information can be achieved to obtain a final representation that reflects contextual information
其工作流程如下:FPN对原始图像的任意两个特征图进行初始融合,得到初始融合特征后;全局特征通道,对初始融合特征进行全局平均池化处理,再对其进行卷积提取全局特征通道注意力;局部特征通道,对初始融合特征进行卷积提取局部特征通道注意力,目的是为了保留细节。然后,将全局特征通道注意力与局部特征通道注意力进行加和后,再对其进行激活,然后再与原始图像的特征图中较大尺寸特征图进行逐元素相乘,从而最终确定目标特征图。通过TB-AFF模块将全局特征通道注意力与局部特征通道注意力融合,对特征图上的每个文本位置特征进行attention调整,通过加权求和所有位置的聚合特征来更新特征,并聚焦到文本区域上。The workflow is as follows: FPN performs initial fusion of any two feature maps of the original image to obtain initial fusion features; global feature channel, performs global average pooling on the initial fusion features, and then performs convolution to extract global feature channels. Attention; local feature channel, the initial fusion feature is convolved to extract local feature channel attention, the purpose is to retain details. Then, the global feature channel attention and the local feature channel attention are added, and then activated, and then multiplied element by element with the larger size feature map in the feature map of the original image to finally determine the target feature picture. The global feature channel attention and the local feature channel attention are fused through the TB-AFF module, the attention is adjusted for each text position feature on the feature map, and the features are updated by weighted summing the aggregated features of all positions, and focus on the text on the area.
其中,对初始融合特征进行全局平均池化处理,再对其进行卷积提取全局通道上下文的计算公式如下:Among them, the global average pooling process is performed on the initial fusion feature, and then the calculation formula for extracting the global channel context by convolution is as follows:
g(X)=B(PWConv2(δ(B(PWConv1(Avg(X))))))g(X)=B(PWConv2 (δ(B(PWConv1 (Avg(X))))))
其中,g(X)表示全局通道上下文;B表示BatchNorm层;PWConv表示逐点卷积δ表示Relu激活函数,X表示初始融合特征;Avg表示全局平均池化。这里的通道注意力机制采用逐点卷积的方式,逐步压缩通道改变卷积方向,为文本区域表现出高响应的通道分配更大的权重。与L(X)的不同点就是,对输入的X要先进行一次全局平均池化操作Global AveragePooling(GAP),以此来获得全局注意信息。Among them, g(X) represents the global channel context; B represents the BatchNorm layer; PWConv represents the pointwise convolution δ represents the Relu activation function, X represents the initial fusion feature; Avg represents the global average pooling. The channel attention mechanism here adopts a point-by-point convolution method, gradually compressing the channel to change the convolution direction, and assigning greater weight to the channel that exhibits high response in the text area. The difference from L(X) is that a global average pooling operation Global Average Pooling (GAP) is first performed on the input X to obtain global attention information.
同样,利用视觉注意层来加强局部细节的关注点的提取。局部特征的通道注意力的计算公式
L(X)=B(PWConv2(δ(B(PWConv1(X)))))L(X)=B(PWConv2 (δ(B(PWConv1 (X)))))
其中,L(X)表示局部通道上下文;B表示BatchNorm层;PWConv表示逐点卷积δ表示Relu激活函数,X表示初始融合特征。L(X)与输入特征具有相同的形状,可以保留和突出低级特征中的细微细节。Among them, L(X) represents the local channel context; B represents the BatchNorm layer; PWConv represents the pointwise convolution δ represents the Relu activation function, and X represents the initial fusion feature. L(X) has the same shape as the input features, which can preserve and highlight subtle details in low-level features.
对全局和局部注意力进行汇集,明确需要关注的特征。将全局通道上下文与局部通道上下文进行加和后,再对其进行激活后与原始图像的特征图中较大尺寸特征图进行逐元素相乘,获取目标特征图的计算公式如下:Aggregate global and local attention to identify the features that need attention. After adding the global channel context and the local channel context, and then activating it, it is multiplied element by element with the larger size feature map in the feature map of the original image, and the calculation formula to obtain the target feature map is as follows:

其中,X′表示目标特征图;T(X)表示注意力权重;P表示原始图像的特征图中较大尺寸特征图;考虑到学习到的凸显关键区域的特征向量可能具有局限性,再将其和原始输入特征向量进行对应元素相加的操作,以学习到更为全面的特征。σ表示Sigmoid激活函数,使用sigmoid函数来激活,使注意力通道每个元素值在[0,1]之间,可以达到注意力模块强化有用图像信息和抑制无用信息的效果。Among them, X′ represents the target feature map; T(X) represents the attention weight; P represents the larger-size feature map in the feature map of the original image; considering that the learned feature vector highlighting the key area may have limitations, then the It performs the operation of adding corresponding elements to the original input feature vector to learn more comprehensive features. σ represents the sigmoid activation function, and the sigmoid function is used to activate, so that the value of each element of the attention channel is between [0, 1], which can achieve the effect of the attention module strengthening useful image information and suppressing useless information.
这里是因为全局特征通道注意力使用了全局平均池化操作,因此得到的特征高宽形状为1*1,而局部特征通道注意力与输入特征保持有相同的高宽尺寸,因此两者相加需要采取广播操作。
综上,双分支注意特征融合(TB-AFF)模块结合了局部和全局的特征信息,以及两个输入特征,使用尺度不同的两个特征图来提取注意力权重,主要贡献如下:In summary, the dual-branch attention feature fusion (TB-AFF) module combines local and global feature information, as well as two input features, and uses two feature maps with different scales to extract attention weights. The main contributions are as follows:
(1)提出了通道注意中的尺寸问题,TB-AFF通过逐点卷积来关注通道的尺度问题,而不是大小不同的卷积核。使用逐点卷积是为了让TB-AFF尽可能的轻量化。(1) The size problem in channel attention is proposed. TB-AFF pays attention to the scale problem of the channel through point-by-point convolution instead of convolution kernels of different sizes. The point-wise convolution is used to make TB-AFF as lightweight as possible.
(2)TB-AFF不是在骨干网络中,而是在特征金字塔注意模块(FPN)中聚合全局和局部特征上下文信息。(2) TB-AFF aggregates global and local feature context information not in the backbone network but in the Feature Pyramid Attention Module (FPN).
3、关于可微分二值化模块,介绍如下:3. Regarding the differentiable binarization module, the introduction is as follows:
系统使用分割网络(segmentation network)对目标特征图进行分割产生概率图(probability map P),P∈RH×W,其中H和W分别表示输入图像的高度和宽度,要将概率图转化为二值图,二值化函数是至关重要的,标准二值化函数如下所示:The system uses a segmentation network to segment the target feature map to generate a probability map P, P∈RH×W , where H and W represent the height and width of the input image, respectively, and the probability map should be converted into two. Value map, the binarization function is crucial, the standard binarization function is as follows:

其中,值为1的像素被认为是有效的文本区域。t为设定的阈值,(i,j)表示图中的坐标点。标准二值化函数,是不可微的,所以不能随着分割网络而优化。为了解决二值化函数不可微的问题,本例使用如下公式进行二值化:Among them, a pixel with a value of 1 is considered a valid text area. t is the set threshold, (i, j) represents the coordinate point in the graph. The standard binarization function, which is non-differentiable, cannot be optimized with the segmentation network. In order to solve the problem that the binarization function is not differentiable, this example uses the following formula for binarization:

其中B’是近似二值图,T是从网络中学习的自适应阈值图,K是放大系数,在训练过程中,K的作用就是在反向传播中放大传播的梯度,这对于大多数的错误预测区域的改善是比较友好的,有利于产生更显著的预测。本例设置K=50,该近似二值化函数与标准二值化函数相似,且具有可微性,可以在训练期间随分割网络进行优化。可微二值化可以自适应设定阈值T,这样的方法不仅能够很好地区分前景和背景,而且可以分离出连接紧密的文本实例。where B' is an approximate binary map, T is an adaptive threshold map learned from the network, and K is an amplification factor. During training, the role of K is to amplify the propagated gradient in backpropagation. This is for most of the The improvement of the mispredicted region is friendly and conducive to producing more significant predictions. This example sets K=50, the approximate binarization function is similar to the standard binarization function, and has differentiability, which can be optimized with the segmentation network during training. Differentiable binarization can adaptively set the threshold T, such a method can not only distinguish the foreground and background well, but also can separate closely connected text instances.
具体来说,就是利用特征F对概率图(P)和阈值图(T)进行预测,根据可微二值化模块将概率图和阈值图结合得到二值图,自适应预测每个位置的阈值。最后通过边界框形成从近似二值图中获得文本的检测框。可微二值化的结构如图4所示。路径1代表标准二值化过程,虚线仅代表推理过程,路径2是本例使用的可微二值化,它自适应地预测图像每个位置的阈值。Specifically, the feature F is used to predict the probability map (P) and the threshold map (T). According to the differentiable binarization module, the probability map and the threshold map are combined to obtain a binary map, and the threshold of each position is adaptively predicted. . Finally, the bounding box is used to form the detection box of the text obtained from the approximate binary image. The structure of differentiable binarization is shown in Figure 4.
损失函数在深度神经网络中扮演着至关重要的角色,本例使用L1损失函数和二元交叉熵损失函数来优化本例的网络。本例的损失函数在训练过程中由三部分组成:概率图损失Ls、二值化图损失Lb、自适应阈值图损失Lt,表示如下:Loss functions play a crucial role in deep neural networks, and this example uses L1loss function and binary cross-entropy loss function to optimize the network in this example. The loss function of this example consists of three parts in the training process: probability map loss Ls , binarization map loss Lb , and adaptive threshold map loss Lt , which are expressed as follows:
L=LS+α×Lb+β×LtL=LS +α×Lb +β×Lt
其中,α和β是权重参数,α设置为1,β设置为10。其中对概率图损失Ls和二值化图损失Lb采用二元交叉熵损失函数,其公式如下,还采用了hard negative mining来克服正负样本的不平衡。where α and β are weight parameters, α is set to 1 and β is set to 10. Among them, the binary cross-entropy loss function is used for the probability map loss Ls and the binarized map loss Lb , and its formula is as follows, and hard negative mining is also used to overcome the imbalance of positive and negative samples.

其中,S1表示对图像进行正负样本比例为1∶3的采样样本,对自适应阈值图损失Lt采用L1损失函数,其公式为:Among them, S1 represents sampling samples with a positive and negative sample ratio of 1:3 for the image, and the L1 loss function is used for the adaptive threshold map loss Lt , and its formula is:

其中,Rd为该区域内像素的索引,y*为自适应阈值图的标签。where Rd is the index of the pixel within the region and y* is the label of the adaptive threshold map.
综上,可微分二值化模块根据目标特征图,可以有效的确定图像中的目标文本区域。To sum up, the differentiable binarization module can effectively determine the target text area in the image according to the target feature map.
实施例2Example 2
为了验证本发明中场景文本检测系统的有效性,本例还对三个具有挑战性的公共数据集进行了实验,分别是多方向文本数据集ICDAR2015、弯曲文本数据Total-Text以及多语言文本数据集MSRA-TD500。本例方法在不同类型的文本示例上的可视化结果如图5所示。包括弯曲的(e)和(f)、多方向的(a)和(b)、多语言的文本(c)和(d)。对于图5中的每个单元,概率图在第二列,阈值图在第三列,而二值化图在第四列。In order to verify the effectiveness of the scene text detection system in the present invention, this example also conducts experiments on three challenging public datasets, namely the multi-directional text dataset ICDAR2015, the curved text data Total-Text and the multilingual text data Set MSRA-TD500. The visualization results of this method on different types of text examples are shown in Figure 5. Includes curved (e) and (f), multi-directional (a) and (b), and multilingual text (c) and (d). For each cell in Figure 5, the probability map is in the second column, the threshold map is in the third column, and the binarization map is in the fourth column.
1、训练配置1. Training configuration
本例的实验使用Python 3.7作为编程语言,使用的深度学习框架是Pytorch1.5。本例采用Adam优化器训练模型,并采用余弦学习率衰减作为学习率调度,初始学习率为0.001,训练批次大小为16。对训练数据采用在(-10°,10°)范围内随机旋转角度、随机裁剪和翻转的方式进行数据增强,所有的图片都重新调整640×640。所有实验均在TITAN RTX上进行。初始学习率设置为0.007。在这三个数据集中,所有模型都在相同的策略下进行训练,在相同的设置下进行测试,这里就不过多介绍了。The experiments in this example use Python 3.7 as the programming language, and the deep learning framework used is Pytorch1.5. This example uses the Adam optimizer to train the model and uses cosine learning rate decay as the learning rate schedule, with an initial learning rate of 0.001 and a training batch size of 16. The training data is augmented by random rotation angles, random cropping and flipping within the range of (-10°, 10°), and all images are rescaled to 640×640. All experiments were performed on TITAN RTX. The initial learning rate is set to 0.007. In these three datasets, all models are trained under the same strategy and tested under the same settings, so I won't go into too much detail here.
2、实验与讨论2. Experiment and discussion
为了更好地证明本例提出的各个模块的实现,本例在多方向文本数据集ICDAR2015、曲线文本数据集Total-Text、多语言文本数据集MSRA-TD500上都进行了详细的消融研究,主要考虑3个性能参数:准确率、召回率以及综合评价指标,评估该模型的检测性能,证明了本例提出的残差校正支路(RCB)和双分支注意特征融合(TB-AFF)模块的影响。在网络训练过程中,相同的环境下进行实验,打“√"的地方表示使用了该方法。结果列于表1中。In order to better prove the implementation of each module proposed in this example, this example has carried out detailed ablation research on the multi-directional text data set ICDAR2015, the curve text data set Total-Text, and the multi-language text data set MSRA-TD500. Considering three performance parameters: precision rate, recall rate and comprehensive evaluation index, the detection performance of the model is evaluated, which proves that the residual correction branch (RCB) and the dual branch attention feature fusion (TB-AFF) module proposed in this example are effective. influences. In the process of network training, experiments are carried out in the same environment, and the place marked with "√" indicates that this method is used. The results are listed in Table 1.
表1 ICDAR2015数据集中的测试结果Table 1 Test results in the ICDAR2015 dataset

表2 Total-Text数据集中的测试结果Table 2 Test results in the Total-Text dataset

表3 MSRA-TD500数据集中的测试结果Table 3 Test results in MSRA-TD500 dataset


从表1、标2及表3可以看出,在ICDAR2015数据集、Total-Text数据集以及MSRA-TD500数据集上,加入RCB模块和/或TB-AFF模块后,召回率以及综合评价指标均得到了不同层的的提高。且,可以看出结合这两个模块的优点的网络的检测性能优于单独应用RCB模块或TB-AFF模块的网络。From Table 1, Standard 2 and Table 3, it can be seen that in the ICDAR2015 dataset, Total-Text dataset and MSRA-TD500 dataset, after adding the RCB module and/or the TB-AFF module, the recall rate and the comprehensive evaluation index are all Different layers of enhancements have been obtained. And, it can be seen that the detection performance of the network combining the advantages of these two modules is better than the network applying the RCB module or the TB-AFF module alone.
RCB模块中,引入平均池化下采样操作来实现自校准,平均池化在整个池化窗口内建立位置之间的连接,这样可以更好地捕获上下文信息。实验结果表明,采用18层主干网络,使用所提出的残差校正分支可以大大提高基线结果。这一现象表明,采用残差校正支路的网络可以比原始支路上普通卷积生成更丰富、更有区别的特征表示,有助于发现更完整的目标物体,尽管它们的尺寸很小。当目标对象较小时,本例的网络还可以更好地局限于语义区域。同时,为了克服输入特征之间的语义和尺度不一致问题,本例的双分支注意特征融合(TB-AFF)模块将局部通道上下文添加到全局通道统计中。实验结果表明,所提出的基于TB-AFF的网络可以在小的参数预算下提高先进网络的性能。这表明人们应该关注深度神经网络中的特征融合,复杂的特征融合注意机制有可能产生更好的效果。进一步说明了与其盲目地增加网络的深度,不如更关注特征融合的质量。与线性方法(即加法和连接)相比,具有双分支注意特征融合(TB-AFF)模块的多尺度注意力融合网络(MSAFN)始终提供更好的性能。In the RCB module, the average pooling downsampling operation is introduced to achieve self-calibration, and the average pooling establishes connections between positions within the entire pooling window, which can better capture contextual information. Experimental results show that with an 18-layer backbone network, using the proposed residual correction branch can greatly improve the baseline results. This phenomenon suggests that the network with the residual correction branch can generate richer and more discriminative feature representations than ordinary convolutions on the original branch, helping to discover more complete target objects despite their small size. When the target object is small, the network in this example can also better localize to the semantic region. Meanwhile, to overcome the problem of semantic and scale inconsistency among input features, the bi-branch attention feature fusion (TB-AFF) module in this example adds local channel context to global channel statistics. Experimental results show that the proposed TB-AFF based network can improve the performance of advanced networks with a small parameter budget. This suggests that one should pay attention to feature fusion in deep neural networks, and that sophisticated feature fusion attention mechanisms have the potential to produce better results. It further illustrates that instead of blindly increasing the depth of the network, we should pay more attention to the quality of feature fusion. Multi-scale Attention Fusion Network (MSAFN) with Bi-Branch Attention Feature Fusion (TB-AFF) module consistently provides better performance compared to linear methods (i.e., addition and concatenation).
图6显示了baseline和本发明的方法的可视化结果。对于图中的每个单元,概率图在第二列,阈值图在第三列,而二值化图在第四列。从实验结果可以看出,残差校正支路(RCB)和双分支注意特征融合(TB-AFF)模块在模型训练中对特征的提取发挥了重要的作用,有效增强了模型对文本特征的关注,对提取出来的文本特征进行了有效利用,在一定程度上提高了场景文本的检测精度。Figure 6 shows the visualization results of the baseline and the method of the present invention. For each cell in the map, the probability map is in the second column, the threshold map is in the third column, and the binarization map is in the fourth column. It can be seen from the experimental results that the residual correction branch (RCB) and dual branch attention feature fusion (TB-AFF) modules play an important role in feature extraction during model training, effectively enhancing the model's attention to text features , the extracted text features are effectively used, and the detection accuracy of scene text is improved to a certain extent.
图7展示了本发明与原始DBNet在不同类型的文本示例上的可视化结果,值得注意的是,这里的图像是从三个数据集中随机选择的,可以更好地证明本例模型的鲁棒性。对于图7(a),相较于Baseline和Ours,Baseline漏检了图中一部分文字(即"CA"),而本例的方法可以将其检测出来;对于图7(b)和图7(c),Baseline误检了非文本,将非文本区域作为文本区域检测出来,而本例的方法相比Baseline却可以很好地避免误检;对于图7(d),相较于Baseline和Ours,Baseline漏检了图中一部分文字(即"1"),而本例的方法可以将其检测出来;对于图7(e),Baseline漏检了中间的英文文字,而本例的方法却可以准确地检测出来;对于图7(f),Baseline将“COFFEE”作为两部分文字检测,而实际“COFFEE”表示的是一个语义信息,应该作为一个整体的文字区域被检测出来。Figure 7 shows the visualization results of the present invention and the original DBNet on different types of text examples. It is worth noting that the images here are randomly selected from three datasets, which can better prove the robustness of the model in this example. . For Figure 7(a), compared to Baseline and Ours, Baseline misses a part of the text (ie "CA") in the figure, but the method in this example can detect it; for Figure 7(b) and Figure 7( c), Baseline detects non-text by mistake, and detects non-text areas as text areas, while the method in this example can avoid false detections better than Baseline; for Figure 7(d), compared to Baseline and Ours , Baseline missed a part of the text in the figure (ie "1"), and the method in this example can detect it; for Figure 7(e), Baseline missed the middle English text, but the method in this example can Accurately detected; for Figure 7(f), Baseline detects "COFFEE" as a two-part text, while the actual "COFFEE" represents a semantic information, which should be detected as a whole text area.
实验结果表明,本发明提升了在多方向文本数据集ICDAR2015、弯曲文本数据集Total-Text以及多语言文本数据集MSRA-TD500上的检测能力。本例可以看到本发明在自然场景文本检测数据集下都很好,具有较好的性能,准确率、召回率及综合评价指标值指标值。通过加入残差校正支路(RCB)和双分支注意特征融合(TB-AFF)模块对于提取文本和方位的特征信息的增强,扩大了文本检测视野,有效改善了对于多尺度文本的检测效果。在没有损失检测效率的同时提高了原算法的检测精度,并在一定程度上优于当前针对自然场景下的文本检测。在不均匀照明、低分辨率、背景复杂等各种有挑战的场景中,本例模型能有效地应对文本剧烈的尺度变化,准确地检测出场景文本。一方面,残差校正支路包含自适应响应校准操作,有助于更精确地定位目标物体的准确位置。具有残差校正支路的ResNet可以更精确、更完整地定位目标物体(文本区域),不会包括过多的背景部分,即使是在较低的网络深度。另一方面,双分支注意特征融合(TB-AFF)方法具有优越的性能,且具有良好的通用性,可使神经网络更有效率地抽取特征,可以有效改善现有的模型,会去注重在跟标签相关的目标上,展现了它强大的定位能力。这也证明了早期的特征融合对注意力特征融合也是有一定影响的。The experimental results show that the invention improves the detection ability on the multi-directional text data set ICDAR2015, the curved text data set Total-Text and the multi-language text data set MSRA-TD500. In this example, it can be seen that the present invention is very good in the natural scene text detection data set, and has better performance, accuracy rate, recall rate and comprehensive evaluation index value index value. By adding residual correction branch (RCB) and dual-branch attention feature fusion (TB-AFF) modules to enhance the feature information of extracted text and orientation, the text detection field of view is expanded, and the detection effect of multi-scale text is effectively improved. The detection accuracy of the original algorithm is improved without loss of detection efficiency, and to a certain extent, it is better than the current text detection in natural scenes. In various challenging scenes such as uneven lighting, low resolution, and complex background, the model in this example can effectively deal with the dramatic scale changes of text and accurately detect scene text. On the one hand, the residual correction branch contains an adaptive response calibration operation, which helps to locate the exact position of the target object more precisely. ResNet with a residual correction branch can locate the target object (text region) more accurately and completely without including excessive background parts, even at lower network depths. On the other hand, the dual-branch attention feature fusion (TB-AFF) method has superior performance and good generality, which enables the neural network to extract features more efficiently, and can effectively improve the existing models. On the target related to the label, it shows its powerful positioning ability. This also proves that the early feature fusion also has a certain influence on the attention feature fusion.
综上,本发明为了弥补轻量级网络提取特征能力和感受野不足的缺陷,为骨干网络嵌入残差校正支路(RCB)以增强其提取特征的能力;为FPN嵌入双分支注意特征融合(TB-AFF)模块,用于增强多尺度场景文本的特征表达,使其检测的准确性得到提高。To sum up, in order to make up for the shortcomings of lightweight network feature extraction capability and insufficient receptive field, the present invention embeds a residual correction branch (RCB) for the backbone network to enhance its feature extraction capability; embeds dual-branch attention feature fusion for FPN ( TB-AFF) module, which is used to enhance the feature expression of multi-scale scene text, so that its detection accuracy is improved.
Claims (10)
Translated fromChinese



Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210451005.0ACN114926826B (en) | 2022-04-27 | 2022-04-27 | Scene text detection system |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210451005.0ACN114926826B (en) | 2022-04-27 | 2022-04-27 | Scene text detection system |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN114926826Atrue CN114926826A (en) | 2022-08-19 |
| CN114926826B CN114926826B (en) | 2025-09-02 |
Family
ID=82805910
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210451005.0AActiveCN114926826B (en) | 2022-04-27 | 2022-04-27 | Scene text detection system |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114926826B (en) |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115424276A (en)* | 2022-08-30 | 2022-12-02 | 青岛励图高科信息技术有限公司 | Ship license plate number detection method based on deep learning technology |
| CN116311006A (en)* | 2022-09-07 | 2023-06-23 | 国网江苏省电力有限公司盐城供电分公司 | A method for identifying and classifying foreign objects in underground cable duct scenes |
| CN116343208A (en)* | 2023-02-24 | 2023-06-27 | 浙江理工大学 | SFE-DBnet-based medical laboratory sheet image text detection method |
| CN116778497A (en)* | 2022-12-29 | 2023-09-19 | 北京东土拓明科技有限公司 | A manual well number identification method, device, computer equipment and storage medium |
| CN117576699A (en)* | 2023-11-06 | 2024-02-20 | 华南理工大学 | Locomotive work order information intelligent recognition method and system based on deep learning |
| CN118429813A (en)* | 2024-05-29 | 2024-08-02 | 山东锋士信息技术有限公司 | Abnormal floating object detection method in river channel based on self-similarity enhancement and dense processing |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20190272438A1 (en)* | 2018-01-30 | 2019-09-05 | Baidu Online Network Technology (Beijing) Co., Ltd. | Method and apparatus for detecting text |
| CN111242126A (en)* | 2020-01-15 | 2020-06-05 | 上海眼控科技股份有限公司 | Irregular text correction method and device, computer equipment and storage medium |
| CN112364864A (en)* | 2020-10-23 | 2021-02-12 | 西安科锐盛创新科技有限公司 | License plate recognition method and device, electronic equipment and storage medium |
- 2022
- 2022-04-27CNCN202210451005.0Apatent/CN114926826B/enactiveActive
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20190272438A1 (en)* | 2018-01-30 | 2019-09-05 | Baidu Online Network Technology (Beijing) Co., Ltd. | Method and apparatus for detecting text |
| CN111242126A (en)* | 2020-01-15 | 2020-06-05 | 上海眼控科技股份有限公司 | Irregular text correction method and device, computer equipment and storage medium |
| CN112364864A (en)* | 2020-10-23 | 2021-02-12 | 西安科锐盛创新科技有限公司 | License plate recognition method and device, electronic equipment and storage medium |
Non-Patent Citations (3)
| Title |
|---|
| MAYIRE IBRAYIM 等: "Scene Text Detection Based on Two-Branch Feature Extraction", 《SENSORS》, 20 August 2022 (2022-08-20), pages 1 - 19* |
| YUANQIANG CAI: "Scale-Residual Learning Network for Scene Text Detection", 《IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY》, vol. 31, no. 7, 31 July 2021 (2021-07-31), pages 2725 - 2738, XP011864468, DOI: 10.1109/TCSVT.2020.3029167* |
| 潘多 等: "单细胞数据的整合方法综述", 《生物医学工程学杂志》, vol. 38, no. 5, 31 October 2021 (2021-10-31), pages 1010 - 1017* |
Cited By (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115424276A (en)* | 2022-08-30 | 2022-12-02 | 青岛励图高科信息技术有限公司 | Ship license plate number detection method based on deep learning technology |
| CN115424276B (en)* | 2022-08-30 | 2023-09-22 | 青岛励图高科信息技术有限公司 | Ship license plate number detection method based on deep learning technology |
| CN116311006A (en)* | 2022-09-07 | 2023-06-23 | 国网江苏省电力有限公司盐城供电分公司 | A method for identifying and classifying foreign objects in underground cable duct scenes |
| CN116778497A (en)* | 2022-12-29 | 2023-09-19 | 北京东土拓明科技有限公司 | A manual well number identification method, device, computer equipment and storage medium |
| CN116343208A (en)* | 2023-02-24 | 2023-06-27 | 浙江理工大学 | SFE-DBnet-based medical laboratory sheet image text detection method |
| CN117576699A (en)* | 2023-11-06 | 2024-02-20 | 华南理工大学 | Locomotive work order information intelligent recognition method and system based on deep learning |
| CN118429813A (en)* | 2024-05-29 | 2024-08-02 | 山东锋士信息技术有限公司 | Abnormal floating object detection method in river channel based on self-similarity enhancement and dense processing |
Also Published As
| Publication number | Publication date |
|---|---|
| CN114926826B (en) | 2025-09-02 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN111950453B (en) | Random shape text recognition method based on selective attention mechanism | |
| CN111401384B (en) | Transformer equipment defect image matching method | |
| CN114926826A (en) | Scene text detection system | |
| US20210081695A1 (en) | Image processing method, apparatus, electronic device and computer readable storage medium | |
| CN114863236A (en) | Image target detection method based on double attention mechanism | |
| CN111178121B (en) | Pest image positioning and identifying method based on spatial feature and depth feature enhancement technology | |
| CN114663371B (en) | Image salient object detection method based on modal unique and common feature extraction | |
| CN116612292A (en) | A small target detection method based on deep learning | |
| CN115661482B (en) | A RGB-T Salient Object Detection Method Based on Joint Attention | |
| Oyama et al. | Influence of image classification accuracy on saliency map estimation | |
| CN113408549A (en) | Few-sample weak and small target detection method based on template matching and attention mechanism | |
| CN113610024B (en) | A multi-strategy deep learning remote sensing image small target detection method | |
| Wu et al. | STR transformer: a cross-domain transformer for scene text recognition | |
| CN118587449A (en) | A RGB-D saliency detection method based on progressive weighted decoding | |
| CN116229104A (en) | A salient object detection method based on edge feature guidance | |
| Zhou et al. | Attention transfer network for nature image matting | |
| CN120375207B (en) | Remote sensing image change detection method, device, equipment and medium | |
| CN115937205A (en) | Surface defect tile image generation method, device, equipment and storage medium | |
| Qu et al. | MDSC-Net: multi-directional spatial connectivity for road extraction in remote sensing images | |
| CN119992528A (en) | Scene text detection method and device | |
| CN119206855A (en) | A lightweight pedestrian detection method based on BASFPN multi-scale feature fusion | |
| CN118628765A (en) | Multi-feature target tracking method based on Siamese network integrating LBP and attention | |
| CN117456185A (en) | Remote sensing image segmentation method based on adaptive pattern matching and nested modeling | |
| CN117152750A (en) | A method of constructing a semantic segmentation model for landscape paintings | |
| CN117218037A (en) | Image definition evaluation method and device, equipment and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant |