CN114861078A - Collaborative Recommendation Algorithm Based on Tensor Decomposition and Fuzzy C-Means Clustering - Google Patents
Collaborative Recommendation Algorithm Based on Tensor Decomposition and Fuzzy C-Means ClusteringDownload PDFInfo
- Publication number
- CN114861078A CN114861078ACN202210313853.5ACN202210313853ACN114861078ACN 114861078 ACN114861078 ACN 114861078ACN 202210313853 ACN202210313853 ACN 202210313853ACN 114861078 ACN114861078 ACN 114861078A
- Authority
- CN
- China
- Prior art keywords
- tensor
- algorithm
- item
- user
- fuzzy
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images







Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/95—Retrieval from the web
- G06F16/953—Querying, e.g. by the use of web search engines
- G06F16/9536—Search customisation based on social or collaborative filtering
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/10—Pre-processing; Data cleansing
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/23—Clustering techniques
- G06F18/232—Non-hierarchical techniques
- G06F18/2321—Non-hierarchical techniques using statistics or function optimisation, e.g. modelling of probability density functions
- G06F18/23213—Non-hierarchical techniques using statistics or function optimisation, e.g. modelling of probability density functions with fixed number of clusters, e.g. K-means clustering
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2216/00—Indexing scheme relating to additional aspects of information retrieval not explicitly covered by G06F16/00 and subgroups
- G06F2216/03—Data mining
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- Databases & Information Systems (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Bioinformatics & Computational Biology (AREA)
- Evolutionary Computation (AREA)
- Evolutionary Biology (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Life Sciences & Earth Sciences (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Artificial Intelligence (AREA)
- Probability & Statistics with Applications (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本发明涉及协同过滤推荐算法技术领域,尤其涉及基于张量分解和模糊C-均值聚类的协同推荐算法。The invention relates to the technical field of collaborative filtering recommendation algorithms, in particular to a collaborative recommendation algorithm based on tensor decomposition and fuzzy C-means clustering.
背景技术Background technique
随着互联网技术的快速发展以及大数据时代的来临,信息过载问题日益严重,用户想要从海量信息中找到自己所需要的信息越来越难。目前,大部分的电影在线平台,如迅雷、豆瓣电影等,都不同程度地应用推荐系统为用户推荐适合的影片,由此可见,个性化推荐技术能有效解决信息过载问题。与此同时,研究者们也越发关注如何为用户提供高效、准确的推荐服务这一热点问题。With the rapid development of Internet technology and the advent of the era of big data, the problem of information overload is becoming more and more serious, and it is more and more difficult for users to find the information they need from the massive information. At present, most online movie platforms, such as Xunlei, Douban Movies, etc., apply recommendation systems to different degrees to recommend suitable movies for users. It can be seen that personalized recommendation technology can effectively solve the problem of information overload. At the same time, researchers are paying more and more attention to the hot issue of how to provide users with efficient and accurate recommendation services.
协同过滤算法是推荐系统中具有代表性的一种算法。它一般分为基于内存的协同过滤算法和基于模型的协同过滤算法。其中,基于内存的协同过滤算法是通过计算用户或项目之间的相似度来预测用户对项目的喜好程度;基于模型的协同过滤算法是利用机器学习的思想建模来预测空白的物品和数据之间的评分关系,并找到最高评分的物品推荐给用户。另外,研究者们也将多种推荐算法进行融合,提出混合推荐算法,从而提高推荐精度。然而,协同过滤也面临着各种各样的挑战,如冷启动、可扩展性差、数据稀疏等问题。大数据时代,随着用户和项目数量的迅猛增长,在某些购物网站上,受多种因素影响,用户对所购买商品很少进行评分,这就导致了用户项目评分数据矩阵异常稀疏,在这种情况下,采用传统的协同过滤推荐算法为用户进行推荐,推荐质量明显下降。Collaborative filtering algorithm is a representative algorithm in recommender systems. It is generally divided into memory-based collaborative filtering algorithms and model-based collaborative filtering algorithms. Among them, the memory-based collaborative filtering algorithm predicts the user's preference for items by calculating the similarity between users or items; the model-based collaborative filtering algorithm uses the idea of machine learning to model to predict the relationship between blank items and data. The relationship between the ratings, and find the highest rated items to recommend to users. In addition, researchers have also combined multiple recommendation algorithms to propose hybrid recommendation algorithms to improve recommendation accuracy. However, collaborative filtering also faces various challenges, such as cold start, poor scalability, and data sparsity. In the era of big data, with the rapid growth of the number of users and items, on some shopping websites, due to various factors, users rarely rate the purchased items, which leads to an abnormally sparse user item rating data matrix. In this case, the traditional collaborative filtering recommendation algorithm is used to recommend users, and the quality of the recommendation is significantly reduced.
为了解决数据稀疏性问题,所以亟需一种基于张量分解和模糊 C-均值聚类的协同推荐算法来改变这一现状。In order to solve the problem of data sparsity, a collaborative recommendation algorithm based on tensor decomposition and fuzzy C-means clustering is urgently needed to change this situation.
发明内容SUMMARY OF THE INVENTION
本发明的目的是为了解决现有技术中存在的缺点,而提出的基于张量分解和模糊C-均值聚类的协同推荐算法。其优点在于具有很好的推荐性能。The purpose of the present invention is to propose a collaborative recommendation algorithm based on tensor decomposition and fuzzy C-means clustering in order to solve the shortcomings in the prior art. The advantage is that it has good recommendation performance.
为了实现上述目的,本发明采用了如下技术方案:In order to achieve the above object, the present invention adopts the following technical solutions:
基于张量分解和模糊C-均值聚类的协同推荐算法,包括以下步骤:A collaborative recommendation algorithm based on tensor decomposition and fuzzy C-means clustering includes the following steps:
S1:首先,捕捉一些个性化的信息,在传统的用户项目的二元关系基础上,增加项目类型等多个维度的信息,构成张量;S1: First, capture some personalized information, and add information of multiple dimensions such as item type on the basis of the traditional binary relationship of user items to form a tensor;
S2:综合考虑用户、项目和项目类别三个方面,构建一个三阶张量,通过张量分解可以充分挖掘数据的隐含信息,采用梯度下降对三阶张量进行分解,得到用户特征矩阵、项目特征矩阵和项目类别特征矩阵,从而求得缺失值,解决张量的稀疏性;S2: Considering the three aspects of users, items and item categories, construct a third-order tensor. Through tensor decomposition, the hidden information of the data can be fully mined, and gradient descent is used to decompose the third-order tensor to obtain the user feature matrix, Item feature matrix and item category feature matrix, so as to obtain missing values and solve the sparsity of tensors;
S3:将张量分解的过程看作是一个低秩逼近问题,如果简单地使总的误差最小,那么,可以将张量分解的逼近问题转化为一个无约束的优化问题,并得到优化公式;S3: The process of tensor decomposition is regarded as a low-rank approximation problem. If the total error is simply minimized, then the approximation problem of tensor decomposition can be transformed into an unconstrained optimization problem, and the optimization formula can be obtained;
S4:根据以上思路,设计基于张量分解的稀疏张量填充算法,得到的用户特征矩阵、项目特征矩阵、类别特征矩阵以及填充后的张量。S4: According to the above ideas, design a sparse tensor filling algorithm based on tensor decomposition, and obtain the user feature matrix, item feature matrix, category feature matrix, and filled tensors.
通过采用以上技术方案:一方面,利用张量分解对缺失数据进行填充,降低其稀疏性,并挖掘潜在信息,去除噪声;另一方面,基于填充后的矩阵,采用模糊C-均值聚类算法对用户进行分类,减小目标用户的最近邻搜索空间,提高算法的可扩展性,最后用传统推荐算法在目标用户所在的类中产生推荐结果,具有很好的推荐性能。By adopting the above technical solutions: on the one hand, tensor decomposition is used to fill the missing data to reduce its sparsity, and potential information is mined to remove noise; on the other hand, based on the filled matrix, a fuzzy C-means clustering algorithm is used. Classify users, reduce the nearest neighbor search space of the target user, improve the scalability of the algorithm, and finally use the traditional recommendation algorithm to generate recommendation results in the class of the target user, which has good recommendation performance.
本发明进一步设置为,所述张量的稀疏性分解公式为
通过采用以上技术方案:可计算出张量R在位置索引上的评分估计值。By adopting the above technical solution: the estimated score value of the tensor R on the position index can be calculated.
本发明进一步设置为,所述优化公式为
通过采用以上技术方案:通过优化公式可以使得总的误差最小。By adopting the above technical solutions: the total error can be minimized by optimizing the formula.
本发明进一步设置为,所述稀疏张量填充算法包括第一算法和第二算法。The present invention further provides that the sparse tensor filling algorithm includes a first algorithm and a second algorithm.
通过采用以上技术方案:两种算法可以针对不同的条件进行计算,降低了计算时的转化难度。By adopting the above technical solution, the two algorithms can be calculated according to different conditions, which reduces the conversion difficulty during calculation.
本发明进一步设置为,所述第一算法为输入原始张量R,用户数m、项目数n、迭代步长η以及项目类别数c;The present invention is further provided that the first algorithm is to input the original tensor R, the number of users m, the number of items n, the iteration step size η and the number of item categories c;
输出:U、V、C、
BeginBegin
1Initialize the U∈Rm×k,V∈Rn×k,C∈Rc×k1Initialize the U∈Rm×k ,V∈Rn×k ,C∈Rc×k
2For Rmnc≠0do2For Rmnc ≠0do
3
4
5
6
7 End7 End
8 ReturnU、V、C、
End。End.
通过采用以上技术方案:第1行初始化用户特征矩阵、项目特征矩阵和类别特征矩阵;第2~7行进行张量分解,并通过迭代法填充稀疏张量;第8行返回得到的用户特征矩阵、项目特征矩阵、类别特征矩阵以及填充后的张量。By adopting the above technical solutions:
本发明进一步设置为,所述第二算法为输入用户项目评分数据集 A,项目类别数据集B,模糊系数m1,聚类数c1,收敛精度epsm,迭代次数t。The present invention further provides that the second algorithm is input user item rating data set A, item category data set B, fuzzy coefficient m1 , number of clusters c1 , convergence accuracy epsm, and iteration number t.
输出:目标用户u对未评分项目i的预测评分Pui。Output: Predicted rating Pui of target user u for unrated item i.
BeginBegin
1 m1←2,c1←3,epsm←1.0e-6,t←100,
2 R←Data(A,B)2 R←Data(A,B)
3
4[S,V',obj]←FCM(U,c1,t,m1,epsm)4[S,V',obj]←FCM(U,c1 ,t,m1 ,epsm)
5 UserCategory←max(S)5 UserCategory ←max(S)
6 Cu←(UserCategory,u)6 Cu ←(UserCategory ,u)
7 For v∈Cu∩v≠u∩rvi≠07 For v∈Cu ∩v≠u∩rvi ≠0
8 N←N∪v8 N←N∪v
9 End9 End
10
11.Return Pui11.Return Pui
End。End.
通过采用以上技术方案:第1行进行初始化;第2行基于评分矩阵及项目类别矩阵构造用户-项目-类别三维张量;第3行基于张量分解填充稀疏张量得到用户特征矩阵、项目特征矩阵和类别特征矩阵;第4行基于得到的用户特征矩阵对用户进行模糊聚类;第5行通过求最大隶属度得到用户所属类别矩阵;第6行找到用户u所属类别;第 7~9行得到用户u所属类别里对项目i进行评分的用户集合;第10~11 行计算用户u对项目i的预测评分并返回。By adopting the above technical solutions: the first line is initialized; the second line constructs a user-item-category three-dimensional tensor based on the rating matrix and the item category matrix; the third line is based on tensor decomposition and fills the sparse tensor to obtain the user feature matrix and item feature. Matrix and category feature matrix;
本发明进一步设置为,根据随机梯度下降法对umk、vnk和cck进行迭代更新,公式如下所示:

通过采用以上技术方案:根据随机梯度下降法对umk、vnk和cck进行迭代更新可进一步方便使得总的误差最小,提高了计算的便捷性。By adopting the above technical solution: iteratively updatingumk , vnk and cck according to the stochastic gradient descent method can further facilitate to minimize the total error and improve the convenience of calculation.
本发明进一步设置为,所述第一算法和第二算法算出的结果均需进行试验与评价,评价计算公式为
其中,N为测试集大小,pui为推荐算法的预测评分,rui为用户的真实评分;Among them, N is the size of the test set, pui is the predicted score of the recommendation algorithm, and rui is the real score of the user;
另外,衡量推荐结果的准确性也可以采用准确率(Precision)和召回率(Recall),它们的数值越大,表示推荐效果越好;In addition, the accuracy of the recommendation results can also be measured by the precision rate (Precision) and the recall rate (Recall), the larger their values, the better the recommendation effect;
准确率(Precision)公式如下:The accuracy formula is as follows:

召回率(Recall)公式如下:The recall formula is as follows:

其中,P(u)表示系统为用户u推荐的项目集合,T(u)表示用户u喜好的项目集合。Among them, P(u) represents the set of items recommended by the system for user u, and T(u) represents the set of items that user u likes.
通过采用以上技术方案:可以更加直观的反映出协同推荐算法相对于现有算法的优势,同时可以验证协同推荐算法是否合理。By adopting the above technical solutions, the advantages of the collaborative recommendation algorithm relative to the existing algorithms can be more intuitively reflected, and at the same time, whether the collaborative recommendation algorithm is reasonable can be verified.
本发明的有益效果为:The beneficial effects of the present invention are:
本发明针对传统协同过滤推荐算法中的数据稀疏性问题,提出了基于张量分解和模糊聚类的协同过滤推荐算法,一方面,利用张量分解对缺失数据进行填充,降低其稀疏性,并挖掘潜在信息,去除噪声;另一方面,基于填充后的矩阵,采用模糊C-均值聚类算法对用户进行分类,减小目标用户的最近邻搜索空间,提高算法的可扩展性,最后用传统推荐算法在目标用户所在的类中产生推荐结果,具有很好的推荐性能。Aiming at the data sparsity problem in the traditional collaborative filtering recommendation algorithm, the present invention proposes a collaborative filtering recommendation algorithm based on tensor decomposition and fuzzy clustering. Mining potential information and removing noise; on the other hand, based on the filled matrix, the fuzzy C-means clustering algorithm is used to classify users, reducing the nearest neighbor search space of the target user and improving the scalability of the algorithm. Finally, traditional The recommendation algorithm produces recommendation results in the class of the target user, and has good recommendation performance.
附图说明Description of drawings
图1为本发明提出的基于张量分解和模糊C-均值聚类的协同推荐算法的流程结构示意图;FIG. 1 is a schematic flowchart of a collaborative recommendation algorithm based on tensor decomposition and fuzzy C-means clustering proposed by the present invention;
图2为本发明提出的基于张量分解和模糊C-均值聚类的协同推荐算法的张量建模结构示意图;2 is a schematic diagram of the tensor modeling structure of the collaborative recommendation algorithm based on tensor decomposition and fuzzy C-means clustering proposed by the present invention;
图3为本发明提出的基于张量分解和模糊C-均值聚类的协同推荐算法的张量分解填充结构示意图;3 is a schematic diagram of the tensor decomposition filling structure of the collaborative recommendation algorithm based on tensor decomposition and fuzzy C-means clustering proposed by the present invention;
图4为本发明提出的基于张量分解和模糊C-均值聚类的协同推荐算法的基于FCM的协同推荐结构示意图。FIG. 4 is a schematic diagram of the collaborative recommendation structure based on FCM of the collaborative recommendation algorithm based on tensor decomposition and fuzzy C-means clustering proposed by the present invention.
图5为本发明提出的基于张量分解和模糊C-均值聚类的协同推荐算法的k值对实际预测结果的影响的结构示意图。FIG. 5 is a schematic structural diagram of the influence of the k value on the actual prediction result of the collaborative recommendation algorithm based on tensor decomposition and fuzzy C-means clustering proposed by the present invention.
图6为本发明提出的基于张量分解和模糊C-均值聚类的协同推荐算法的聚类数对推荐精度的影响的结构示意图。FIG. 6 is a schematic structural diagram of the influence of the number of clusters on the recommendation accuracy of the collaborative recommendation algorithm based on tensor decomposition and fuzzy C-means clustering proposed by the present invention.
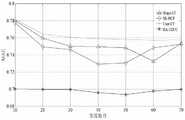
图7为本发明提出的基于张量分解和模糊C-均值聚类的协同推荐算法的目标用户邻居数目对MAE值的影响的结构示意图。FIG. 7 is a schematic structural diagram of the influence of the number of neighbors of a target user on the MAE value of the collaborative recommendation algorithm based on tensor decomposition and fuzzy C-means clustering proposed by the present invention.
图8为本发明提出的基于张量分解和模糊C-均值聚类的协同推荐算法的准确率和召回率的结构示意图。FIG. 8 is a schematic structural diagram of the precision rate and recall rate of the collaborative recommendation algorithm based on tensor decomposition and fuzzy C-means clustering proposed by the present invention.
具体实施方式Detailed ways
下面结合具体实施方式对本专利的技术方案作进一步详细地说明。The technical solution of the present patent will be described in further detail below in conjunction with specific embodiments.
参照图1-4,基于张量分解和模糊C-均值聚类的协同推荐算法,包括以下步骤:Referring to Figure 1-4, the collaborative recommendation algorithm based on tensor decomposition and fuzzy C-means clustering includes the following steps:
S1:首先,捕捉一些个性化的信息,在传统的用户项目的二元关系基础上,增加项目类型等多个维度的信息,构成张量;S1: First, capture some personalized information, and add information of multiple dimensions such as item type on the basis of the traditional binary relationship of user items to form a tensor;
S2:综合考虑用户、项目和项目类别三个方面,构建一个三阶张量,通过张量分解可以充分挖掘数据的隐含信息,采用梯度下降对三阶张量进行分解,得到用户特征矩阵、项目特征矩阵和项目类别特征矩阵,从而求得缺失值,解决张量的稀疏性;S2: Considering the three aspects of users, items and item categories, construct a third-order tensor. Through tensor decomposition, the hidden information of the data can be fully mined, and gradient descent is used to decompose the third-order tensor to obtain the user feature matrix, Item feature matrix and item category feature matrix, so as to obtain missing values and solve the sparsity of tensors;
S3:将张量分解的过程看作是一个低秩逼近问题,如果简单地使总的误差最小,那么,可以将张量分解的逼近问题转化为一个无约束的优化问题,并得到优化公式;S3: The process of tensor decomposition is regarded as a low-rank approximation problem. If the total error is simply minimized, then the approximation problem of tensor decomposition can be transformed into an unconstrained optimization problem, and the optimization formula can be obtained;
S4:根据以上思路,设计基于张量分解的稀疏张量填充算法,得到的用户特征矩阵、项目特征矩阵、类别特征矩阵以及填充后的张量。S4: According to the above ideas, design a sparse tensor filling algorithm based on tensor decomposition, and obtain the user feature matrix, item feature matrix, category feature matrix, and filled tensors.
一方面,利用张量分解对缺失数据进行填充,降低其稀疏性,并挖掘潜在信息,去除噪声;另一方面,基于填充后的矩阵,采用模糊 C-均值聚类算法对用户进行分类,减小目标用户的最近邻搜索空间,提高算法的可扩展性,最后用传统推荐算法在目标用户所在的类中产生推荐结果,具有很好的推荐性能。On the one hand, tensor decomposition is used to fill missing data to reduce its sparsity, and potential information is mined to remove noise; on the other hand, based on the filled matrix, fuzzy C-means clustering algorithm is used to classify users, reduce The nearest neighbor search space of small target users improves the scalability of the algorithm. Finally, the traditional recommendation algorithm is used to generate recommendation results in the class of target users, which has good recommendation performance.
本实施例中,所述张量的稀疏性分解公式为
本实施例中,所述优化公式为
本实施例中,所述稀疏张量填充算法包括第一算法和第二算法。通过两种算法可以针对不同的条件进行计算,降低了计算时的转化难度。In this embodiment, the sparse tensor filling algorithm includes a first algorithm and a second algorithm. The two algorithms can be used for calculation under different conditions, which reduces the conversion difficulty during calculation.
本实施例中,所述第一算法为输入原始张量R,用户数m、项目数n、迭代步长η以及项目类别数c;In this embodiment, the first algorithm is to input the original tensor R, the number of users m, the number of items n, the iteration step size η and the number of item categories c;
输出:U、V、C、
BeginBegin
1 Initialize the U∈Rm×k,V∈Rn×k,C∈Rc×k1 Initialize the U∈Rm×k , V∈Rn×k , C∈Rc×k
2 For Rmnc≠0do2 For Rmnc ≠0do
3
4
5
6
7 End7 End
8 ReturnU、V、C、
End。End.
第1行初始化用户特征矩阵、项目特征矩阵和类别特征矩阵;第 2~7行进行张量分解,并通过迭代法填充稀疏张量;第8行返回得到的用户特征矩阵、项目特征矩阵、类别特征矩阵以及填充后的张量。
本实施例中,所述第二算法为输入用户项目评分数据集A,项目类别数据集B,模糊系数m1,聚类数c1,收敛精度epsm,迭代次数t。In this embodiment, the second algorithm is to input user item rating data set A, item category data set B, fuzzy coefficient m1 , number of clusters c1 , convergence precision epsm, and iteration number t.
输出:目标用户u对未评分项目i的预测评分Pui。Output: Predicted rating Pui of target user u for unrated item i.
BeginBegin
1 m1←2,c1←3,epsm←1.0e-6,t←100,
2 R←Data(A,B)2 R←Data(A,B)
3
4[S,V',obj]←FCM(U,c1,t,m1,epsm)4[S,V',obj]←FCM(U,c1 ,t,m1 ,epsm)
5 UserCategory←max(S)5 UserCategory ←max(S)
6 Cu←(UserCategory,u)6 Cu ←(UserCategory ,u)
7 For v∈Cu∩v≠u∩rvi≠07 For v∈Cu ∩v≠u∩rvi ≠0
8 N←N∪v8 N←N∪v
9 End9 End
10
11.Return Pui11.Return Pui
End。End.
第1行进行初始化;第2行基于评分矩阵及项目类别矩阵构造用户-项目-类别三维张量;第3行基于张量分解填充稀疏张量得到用户特征矩阵、项目特征矩阵和类别特征矩阵;第4行基于得到的用户特征矩阵对用户进行模糊聚类;第5行通过求最大隶属度得到用户所属类别矩阵;第6行找到用户u所属类别;第7~9行得到用户u所属类别里对项目i进行评分的用户集合;第10~11行计算用户u对项目i 的预测评分并返回。The first line is initialized; the second line constructs a user-item-category three-dimensional tensor based on the rating matrix and the item category matrix; the third line fills the sparse tensor based on tensor decomposition to obtain the user feature matrix, item feature matrix and category feature matrix; The fourth line performs fuzzy clustering on the user based on the obtained user feature matrix; the fifth line obtains the user category matrix by finding the maximum membership degree; the sixth line finds the category to which user u belongs; Set of users who rated item i;
本实施例中,根据随机梯度下降法对umk、vnk和cck进行迭代更新,公式如下所示:

本实施例中,所述第一算法和第二算法算出的结果均需进行试验与评价,评价计算公式为
其中,N为测试集大小,pui为推荐算法的预测评分,rui为用户的真实评分。Among them, N is the test set size, pui is the predicted score of the recommendation algorithm, and rui is the real score of the user.
另外,衡量推荐结果的准确性也可以采用准确率(Precision)和召回率(Recall),它们的数值越大,表示推荐效果越好。In addition, the accuracy of the recommendation results can also be measured by the precision rate and the recall rate (Recall). The larger their values, the better the recommendation effect.
准确率(Precision)公式如下:The accuracy formula is as follows:

召回率(Recall)公式如下:The recall formula is as follows:

其中,P(u)表示系统为用户u推荐的项目集合,T(u)表示用户u喜好的项目集合。通过试验与评价可以更加直观的反映出协同推荐算法相对于现有算法的优势,同时可以验证协同推荐算法是否合理。Among them, P(u) represents the set of items recommended by the system for user u, and T(u) represents the set of items that user u likes. Through experiments and evaluations, the advantages of the collaborative recommendation algorithm compared with the existing algorithms can be more intuitively reflected, and at the same time, the reasonableness of the collaborative recommendation algorithm can be verified.
在第一个试验中,基于张量分解填充后的数据进行协同过滤推荐,测试不同的k值(张量的秩)对实际预测结果的影响,设置k的取值范围为[10,60],对得出结果用MAE评价,实验结果参照图5所示。In the first experiment, collaborative filtering recommendation is performed based on the data after tensor decomposition and filling, and the influence of different k values (the rank of the tensor) on the actual prediction results is tested, and the value range of k is set to [10,60] , MAE is used to evaluate the obtained results, and the experimental results are shown in Figure 5.
由图可知,在不同的k值下分解张量,随着k值的增加,MAE的值减小,即随着k的增加推荐精度提高,在k=50时,推荐精度最高。因此选取50为张量的秩,在保证推荐精度的基础上降低了算法的计算复杂度。It can be seen from the figure that when the tensor is decomposed under different k values, as the k value increases, the value of MAE decreases, that is, as the k increases, the recommendation accuracy improves. When k=50, the recommendation accuracy is the highest. Therefore, selecting 50 as the rank of the tensor reduces the computational complexity of the algorithm while ensuring the recommendation accuracy.
本文算法的推荐效果不仅与张量的秩相关,也取决于聚类个数 c1的大小。因此,在第二个实验中,需要研究聚类个数对推荐准确度的影响。同时,探究FCM聚类相较于传统的K-Means聚类和层次聚类的优势。首先,令k=50,c1=3,聚类数每次增加1,直到c1=8,并依次得出其分别对应的MAE值,以此探究聚类数对推荐精度的影响,如图6所示。The recommendation effect of the algorithm in this paper is not only related to the rank of the tensor, but also depends on the size of the number of clusters c1. Therefore, in the second experiment, the effect of the number of clusters on the recommendation accuracy needs to be studied. At the same time, the advantages of FCM clustering compared with traditional K-Means clustering and hierarchical clustering are explored. First, let k=50, c1=3, increase the number of clusters by 1 each time until c1=8, and obtain their corresponding MAE values in turn, so as to explore the influence of the number of clusters on the recommendation accuracy, as shown in Figure 6 shown.
由图所知,在三种聚类算法中,总体上,FCM算法的聚类效果最好,并且当c1=4时,取得其全局最优点,MAE的值最小,推荐精度最高。As can be seen from the figure, among the three clustering algorithms, on the whole, the FCM algorithm has the best clustering effect, and when c1=4, the global optimal point is obtained, the value of MAE is the smallest, and the recommendation accuracy is the highest.
为了验证本文算法的性能,将本文所提出的算法CF-TDFC和以下 4种算法进行对比实验分析。In order to verify the performance of the algorithm in this paper, the algorithm CF-TDFC proposed in this paper is compared with the following four algorithms for experimental analysis.
(1)User-CF[25]:基于用户协同过滤推荐算法。(1) User-CF [25]: User-based collaborative filtering recommendation algorithm.
(2)Item-CF[26]:基于项目的协同过滤推荐算法。(2) Item-CF [26]: Item-based collaborative filtering recommendation algorithm.
(3)Slope-CF[19]:基于slope-one算法改进评分矩阵填充的协同过滤算法研究。(3) Slope-CF[19]: Research on collaborative filtering algorithm based on slope-one algorithm to improve scoring matrix filling.
(4)SK-HCF[27]:基于SVD填充和用户属性特征聚类的混合推荐算法。(4) SK-HCF [27]: A hybrid recommendation algorithm based on SVD filling and user attribute feature clustering.
将以上5种算法在数据集Movielens上进行对比实验,设置邻居区间为[10,70],间隔为10,并使用MAE值来衡量推荐精度的大小,以探究邻居数目对MAE的影响,并求得最优解,其值越小则说明推荐精度越高。The above five algorithms are compared on the dataset Movielens, the neighbor interval is set to [10,70], the interval is 10, and the MAE value is used to measure the recommendation accuracy, so as to explore the influence of the number of neighbors on the MAE, and find The optimal solution is obtained, and the smaller the value is, the higher the recommendation accuracy is.
由图7的实验数据表明:总体上,User-CF、Slope-CF、SK-HCF 及CF-TDFC这4种协同过滤推荐算法的MAE值会随着目标用户邻居数目的增加而逐渐减小,并且它们分别在邻居数目为60、60、40及50 时取得全局最优解,而Item-CF的MAE值与邻居数目无关。此外,无论邻居数目的取值大小,本文提出的基于张量分解和模糊C-均值聚类的协同过滤推荐算法的MAE值都是最小的,主要是因为CF-TDFC算法利用张量分解对缺失数据进行填充,有效缓解了数据稀疏性问题,提高了评分预测的准确性,在MAE衡量标准上,与Item-CF、User-CF、Slope-CF及SK-HCF算法相比有较好的精确度。The experimental data in Fig. 7 show that: in general, the MAE values of the four collaborative filtering recommendation algorithms, User-CF, Slope-CF, SK-HCF and CF-TDFC, will gradually decrease with the increase of the number of neighbors of the target user. And they obtain the global optimal solution when the number of neighbors is 60, 60, 40 and 50 respectively, and the MAE value of Item-CF has nothing to do with the number of neighbors. In addition, regardless of the value of the number of neighbors, the MAE value of the collaborative filtering recommendation algorithm based on tensor decomposition and fuzzy C-means clustering proposed in this paper is the smallest, mainly because the CF-TDFC algorithm uses tensor decomposition to detect missing values. The data is filled, which effectively alleviates the problem of data sparsity and improves the accuracy of score prediction. In terms of MAE measurement standard, it has better accuracy than Item-CF, User-CF, Slope-CF and SK-HCF algorithms. Spend.
为了进一步说明实验的有效性,基于Movielens数据集采用准确率和召回率评价推荐结果的准确性,准确率和召回率的数值越大,则推荐质量越好。In order to further illustrate the effectiveness of the experiment, the accuracy of the recommendation results is evaluated based on the Movielens dataset using precision and recall. The higher the precision and recall, the better the recommendation quality.
从图8看出,Item-CF和User-CF算法的准确率和召回率差距不大,Slope-CF和SK-HCF算法相较于传统的算法推荐效率有一定的提高,而本文所提的CF-TDFC算法的准确率和召回率均优于图中其他4 种算法,是由于算法CF-TDFC不仅利用张量分解缓解了极端稀疏性张量的弊端,还用FCM算法减小最近邻搜索范围,有效缓解了相似度计算过程中,用户数量巨大引起的可扩展性问题,降低了计算复杂度,提高了算法推荐质量。It can be seen from Figure 8 that the accuracy and recall rates of the Item-CF and User-CF algorithms are not much different. Compared with the traditional algorithms, the Slope-CF and SK-HCF algorithms have a certain improvement in the recommendation efficiency. The accuracy and recall rate of the CF-TDFC algorithm are better than the other four algorithms in the figure, because the algorithm CF-TDFC not only uses tensor decomposition to alleviate the drawbacks of extreme sparse tensors, but also uses the FCM algorithm to reduce the nearest neighbor search. It effectively alleviates the scalability problem caused by the huge number of users in the similarity calculation process, reduces the computational complexity, and improves the algorithm recommendation quality.
为了评价算法的时间复杂度,根据本文算法和对比算法的模型训练时间来对比分析算法的时间性能。In order to evaluate the time complexity of the algorithm, the time performance of the algorithm is compared and analyzed according to the model training time of the algorithm in this paper and the comparison algorithm.


由上述数据可知,算法CF-TDFC的模型训练时间较长,由于该算法首先需要进行张量分解和模糊聚类操作,并对用户特征矩阵、项目特征矩阵和类别特征矩阵进行迭代运算;其次是算法SK-HCF,主要包括SVD分解和k-means聚类操作以及对用户特征矩阵和项目特征矩阵的迭代运算,算法User-CF、Item-CF及Slope-CF算法用时相差不大。对于在线预测时间而言,5种算法用时都相差无几,时间很短。It can be seen from the above data that the model training time of the algorithm CF-TDFC is long, because the algorithm first needs to perform tensor decomposition and fuzzy clustering operations, and iterative operations on the user feature matrix, item feature matrix and category feature matrix; Algorithm SK-HCF mainly includes SVD decomposition and k-means clustering operations, as well as iterative operations on user feature matrix and item feature matrix. For the online prediction time, the five algorithms have almost the same time, and the time is very short.
经由以上一系列对比实验表明,本文提出的CF-TDFC算法在保证时间效率的前提下,推荐性能优于现有的其他算法。The above series of comparative experiments show that the CF-TDFC algorithm proposed in this paper has better recommendation performance than other existing algorithms under the premise of ensuring time efficiency.
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。The above description is only a preferred embodiment of the present invention, but the protection scope of the present invention is not limited to this. The equivalent replacement or change of the inventive concept thereof shall be included within the protection scope of the present invention.
Claims (8)
Translated fromChinese












Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210313853.5ACN114861078B (en) | 2022-03-28 | 2022-03-28 | Collaborative recommendation algorithm based on tensor decomposition and fuzzy C-means clustering |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210313853.5ACN114861078B (en) | 2022-03-28 | 2022-03-28 | Collaborative recommendation algorithm based on tensor decomposition and fuzzy C-means clustering |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN114861078Atrue CN114861078A (en) | 2022-08-05 |
| CN114861078B CN114861078B (en) | 2025-09-23 |
Family
ID=82629853
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210313853.5AActiveCN114861078B (en) | 2022-03-28 | 2022-03-28 | Collaborative recommendation algorithm based on tensor decomposition and fuzzy C-means clustering |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114861078B (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116992131A (en)* | 2023-07-04 | 2023-11-03 | 湖北楚天高速数字科技有限公司 | A tensor-based hybrid recommendation method and system |
Citations (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20090299705A1 (en)* | 2008-05-28 | 2009-12-03 | Nec Laboratories America, Inc. | Systems and Methods for Processing High-Dimensional Data |
| JP2014164612A (en)* | 2013-02-26 | 2014-09-08 | Nippon Telegr & Teleph Corp <Ntt> | Missing value estimation device, method, and program |
| CN104077357A (en)* | 2014-05-31 | 2014-10-01 | 浙江工商大学 | User based collaborative filtering hybrid recommendation method |
| CN105354330A (en)* | 2015-11-27 | 2016-02-24 | 南京邮电大学 | Sparse data preprocessing based collaborative filtering recommendation method |
| CN106997550A (en)* | 2017-03-17 | 2017-08-01 | 常州大学 | A kind of method of the ad click rate prediction based on stack self-encoding encoder |
| CN107180088A (en)* | 2017-05-10 | 2017-09-19 | 广西师范学院 | News based on Fuzzy C-Means Cluster Algorithm recommends method |
| US20180165554A1 (en)* | 2016-12-09 | 2018-06-14 | The Research Foundation For The State University Of New York | Semisupervised autoencoder for sentiment analysis |
| CN109902235A (en)* | 2019-03-06 | 2019-06-18 | 太原理工大学 | User preference clustering collaborative filtering recommendation algorithm based on bat optimization |
| CN110765364A (en)* | 2019-10-22 | 2020-02-07 | 哈尔滨理工大学 | Collaborative filtering method based on local optimization dimensionality reduction and clustering |
| CN111259255A (en)* | 2020-02-11 | 2020-06-09 | 汕头大学 | A Recommendation Method Based on Iterative Padding of 3D Tensors |
| CN111259267A (en)* | 2020-02-20 | 2020-06-09 | 南京理工大学 | A Distributed Hybrid Collaborative Intelligent Recommendation Method Based on Sparsity Awareness |
| AU2020101885A4 (en)* | 2020-08-19 | 2020-09-24 | Xinjiang University | A Novel Tensor Factorization Using Trust and Rating for Recommendation, system and method thereof |
| CN112100512A (en)* | 2020-04-10 | 2020-12-18 | 南京邮电大学 | A collaborative filtering recommendation method based on user clustering and item association analysis |
| CN113158039A (en)* | 2021-04-06 | 2021-07-23 | 深圳先进技术研究院 | Application recommendation method, system, terminal and storage medium |
| CN114065031A (en)* | 2021-11-12 | 2022-02-18 | 云南师范大学 | A personalized learning path recommendation method based on fuzzy cognitive graph |
- 2022
- 2022-03-28CNCN202210313853.5Apatent/CN114861078B/enactiveActive
Patent Citations (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20090299705A1 (en)* | 2008-05-28 | 2009-12-03 | Nec Laboratories America, Inc. | Systems and Methods for Processing High-Dimensional Data |
| JP2014164612A (en)* | 2013-02-26 | 2014-09-08 | Nippon Telegr & Teleph Corp <Ntt> | Missing value estimation device, method, and program |
| CN104077357A (en)* | 2014-05-31 | 2014-10-01 | 浙江工商大学 | User based collaborative filtering hybrid recommendation method |
| CN105354330A (en)* | 2015-11-27 | 2016-02-24 | 南京邮电大学 | Sparse data preprocessing based collaborative filtering recommendation method |
| US20180165554A1 (en)* | 2016-12-09 | 2018-06-14 | The Research Foundation For The State University Of New York | Semisupervised autoencoder for sentiment analysis |
| CN106997550A (en)* | 2017-03-17 | 2017-08-01 | 常州大学 | A kind of method of the ad click rate prediction based on stack self-encoding encoder |
| CN107180088A (en)* | 2017-05-10 | 2017-09-19 | 广西师范学院 | News based on Fuzzy C-Means Cluster Algorithm recommends method |
| CN109902235A (en)* | 2019-03-06 | 2019-06-18 | 太原理工大学 | User preference clustering collaborative filtering recommendation algorithm based on bat optimization |
| CN110765364A (en)* | 2019-10-22 | 2020-02-07 | 哈尔滨理工大学 | Collaborative filtering method based on local optimization dimensionality reduction and clustering |
| CN111259255A (en)* | 2020-02-11 | 2020-06-09 | 汕头大学 | A Recommendation Method Based on Iterative Padding of 3D Tensors |
| CN111259267A (en)* | 2020-02-20 | 2020-06-09 | 南京理工大学 | A Distributed Hybrid Collaborative Intelligent Recommendation Method Based on Sparsity Awareness |
| CN112100512A (en)* | 2020-04-10 | 2020-12-18 | 南京邮电大学 | A collaborative filtering recommendation method based on user clustering and item association analysis |
| AU2020101885A4 (en)* | 2020-08-19 | 2020-09-24 | Xinjiang University | A Novel Tensor Factorization Using Trust and Rating for Recommendation, system and method thereof |
| CN113158039A (en)* | 2021-04-06 | 2021-07-23 | 深圳先进技术研究院 | Application recommendation method, system, terminal and storage medium |
| CN114065031A (en)* | 2021-11-12 | 2022-02-18 | 云南师范大学 | A personalized learning path recommendation method based on fuzzy cognitive graph |
Non-Patent Citations (2)
| Title |
|---|
| 肖晓丽;钱娅丽;李旦江;谭柳斌;: "基于用户兴趣和社交信任的聚类推荐算法", 计算机应用, no. 05, 10 May 2016 (2016-05-10), pages 1273 - 1278* |
| 贾伟;华庆一;张敏军;陈锐;姬翔;王博;: "基于冲突度和协同过滤的移动用户界面模式推荐", 计算机科学, no. 10, 15 October 2018 (2018-10-15), pages 209 - 213* |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116992131A (en)* | 2023-07-04 | 2023-11-03 | 湖北楚天高速数字科技有限公司 | A tensor-based hybrid recommendation method and system |
| CN116992131B (en)* | 2023-07-04 | 2025-09-09 | 湖北楚天高速数字科技有限公司 | Mixed recommendation method and system based on tensor |
Also Published As
| Publication number | Publication date |
|---|---|
| CN114861078B (en) | 2025-09-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Choi et al. | A new similarity function for selecting neighbors for each target item in collaborative filtering | |
| Jannach et al. | Accuracy improvements for multi-criteria recommender systems | |
| kumar Bokde et al. | Role of matrix factorization model in collaborative filtering algorithm: A survey | |
| CN104199818B (en) | Method is recommended in a kind of socialization based on classification | |
| CN109840833B (en) | Bayesian collaborative filtering recommendation method | |
| CN106709037B (en) | A Movie Recommendation Method Based on Heterogeneous Information Network | |
| CN110348906B (en) | Improved commodity recommendation method based on multi-type implicit feedback | |
| CN110033127B (en) | A cold-start item recommendation method based on embedded feature selection | |
| CN109740924B (en) | Article scoring prediction method integrating attribute information network and matrix decomposition | |
| CN104933156A (en) | Collaborative filtering method based on shared neighbor clustering | |
| WO2023179689A1 (en) | Knowledge graph-based recommendation method for internet of things | |
| CN103617259A (en) | Matrix decomposition recommendation method based on Bayesian probability with social relations and project content | |
| CN113987363A (en) | Cold start recommendation algorithm based on hidden factor prediction | |
| CN114880559A (en) | User-project fused neighbor entity representation recommendation method | |
| Hazrati et al. | Entity representation for pairwise collaborative ranking using restricted Boltzmann machine | |
| Du et al. | Personalized product service scheme recommendation based on trust and cloud model | |
| CN106651461A (en) | Film personalized recommendation method based on gray theory | |
| Wu et al. | How Airbnb tells you will enjoy sunset sailing in Barcelona? Recommendation in a two-sided travel marketplace | |
| Murty et al. | Content-based collaborative filtering with hierarchical agglomerative clustering using user/item based ratings | |
| Girase et al. | Role of matrix factorization model in collaborative filtering algorithm: a survey | |
| CN114861078A (en) | Collaborative Recommendation Algorithm Based on Tensor Decomposition and Fuzzy C-Means Clustering | |
| CN114491055B (en) | Recommendation method based on knowledge graph | |
| Mao et al. | Hybrid Movie Recommendation System With User Partitioning and Log Likelihood Content Comparison | |
| CN114913028A (en) | A group recommendation method based on knowledge graph extraction tendency | |
| CN114997476A (en) | Commodity prediction method fusing commodity incidence relation |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |