CN114840401A - Data processing method and device, electronic equipment and storage medium - Google Patents
Data processing method and device, electronic equipment and storage mediumDownload PDFInfo
- Publication number
- CN114840401A CN114840401ACN202210467924.7ACN202210467924ACN114840401ACN 114840401 ACN114840401 ACN 114840401ACN 202210467924 ACN202210467924 ACN 202210467924ACN 114840401 ACN114840401 ACN 114840401A
- Authority
- CN
- China
- Prior art keywords
- node
- nodes
- target
- data flow
- data
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images





Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/30—Monitoring
- G06F11/34—Recording or statistical evaluation of computer activity, e.g. of down time, of input/output operation ; Recording or statistical evaluation of user activity, e.g. usability assessment
- G06F11/3409—Recording or statistical evaluation of computer activity, e.g. of down time, of input/output operation ; Recording or statistical evaluation of user activity, e.g. usability assessment for performance assessment
- G06F11/3428—Benchmarking
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/30—Monitoring
- G06F11/34—Recording or statistical evaluation of computer activity, e.g. of down time, of input/output operation ; Recording or statistical evaluation of user activity, e.g. usability assessment
- G06F11/3466—Performance evaluation by tracing or monitoring
Landscapes
- Engineering & Computer Science (AREA)
- General Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Computer Hardware Design (AREA)
- Quality & Reliability (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本公开涉及数据处理技术领域,尤其涉及数据处理方法、装置、电子设备及存储介质。The present disclosure relates to the technical field of data processing, and in particular, to a data processing method, apparatus, electronic device, and storage medium.
背景技术Background technique
数据流图(Data Flow Diagram,DFD)是结构化分析方法中使用的工具,它以图形的方式描绘数据在系统中流动和处理的过程,数据流图以图形方式表达系统的逻辑功能、数据在系统内部的逻辑流向和逻辑变换过程。Data Flow Diagram (DFD) is a tool used in structured analysis methods, which graphically depicts the process of data flow and processing in the system. The logic flow and logic transformation process within the system.
目前,随着人工智能技术的发展,在电子设备上部署机器学习模型已成为发展趋势,在将机器学习模型训练结束后,将机器学习模型以数据流图的方式提交到电子设备,电子设备解析该数据流图,并为数据流图中的各个节点在用于加速计算的处理器中分配计算资源,而数据流图结构复杂,会占用用于加速计算的处理器的较多计算资源,降低用于加速计算的处理器的计算速度。At present, with the development of artificial intelligence technology, it has become a development trend to deploy machine learning models on electronic devices. After the training of the machine learning model is completed, the machine learning model is submitted to the electronic device in the form of a data flow graph, and the electronic device analyzes it. This data flow graph allocates computing resources to the processors used for accelerated computing for each node in the data flow graph. However, the complex structure of the data flow graph will occupy more computing resources of the processor used for accelerated computing, reducing the The calculation speed of the processor used to accelerate the calculation.
发明内容SUMMARY OF THE INVENTION
本公开提供一种数据处理方法、装置、电子设备及存储介质,以至少解决相关技术中数据流图会占用用于加速计算的处理器的较多计算资源,降低用于加速计算的处理器的计算速度的问题。本公开的技术方案如下:The present disclosure provides a data processing method, device, electronic device and storage medium, so as to at least solve the problem that the data flow graph in the related art will occupy more computing resources of a processor used for accelerated computing, and reduce the consumption of a processor used for accelerated computing. The problem of calculation speed. The technical solutions of the present disclosure are as follows:
根据本公开实施例的第一方面,提供一种数据处理方法,包括:According to a first aspect of the embodiments of the present disclosure, there is provided a data processing method, including:
获取目标应用对应的目标数据流图中各个节点分别对应的性能指标信息;所述目标数据流图包括节点以及所述节点间的数据流的链路,所述目标数据流图用于描述数据在所述节点和所述节点间的数据流的链路间的逻辑运算过程;Obtain performance index information corresponding to each node in the target data flow graph corresponding to the target application; the target data flow graph includes nodes and links of data flows between the nodes, and the target data flow graph is used to describe the data in the the logical operation process between the nodes and the links of the data flow between the nodes;
在所述各个节点中,选取出性能指标信息符合预设性能指标条件的关键节点;Among the nodes, select key nodes whose performance index information meets preset performance index conditions;
在所述节点间的数据流的链路中,选取所述关键节点对应的关键路径,在目标执行器上执行所述关键路径。In the link of the data flow between the nodes, the critical path corresponding to the critical node is selected, and the critical path is executed on the target executor.
可选地,在所述节点间的数据流的链路中,选取所述关键节点对应的关键路径,包括:Optionally, in the link of the data flow between the nodes, select the key path corresponding to the key node, including:
在所述节点间的数据流的链路中,选取所述关键节点所在的数据传播路径;In the link of the data flow between the nodes, select the data propagation path where the key node is located;
在所述数据传播路径中,选取路径长度符合预设路径长度条件的关键节点对应的关键路径;所述预设路径长度条件包括路径长度的最大值或路径长度大于设定值。In the data propagation path, a key path corresponding to a key node whose path length meets a preset path length condition is selected; the preset path length condition includes a maximum path length or a path length greater than a set value.
可选地,所述获取目标应用对应的目标数据流图中各个节点分别对应的性能指标信息,包括:Optionally, the obtaining performance indicator information corresponding to each node in the target data flow graph corresponding to the target application includes:
针对目标应用对应的目标数据流图中每一个节点:For each node in the target data flow graph corresponding to the target application:
确定所述节点对应的关联节点,所述节点与所述关联节点之间存在数据输入关系或数据输出关系;Determine the associated node corresponding to the node, and there is a data input relationship or a data output relationship between the node and the associated node;
确定所述关联节点与所述节点间的目标指标;所述目标指标用于指示数据在节点间的执行时间或计算复杂度;Determine the target index between the associated node and the node; the target index is used to indicate the execution time or computational complexity of data between nodes;
基于所述目标指标,确定所述目标数据流图中所述节点对应的所述性能指标信息。Based on the target indicator, the performance indicator information corresponding to the node in the target data flow graph is determined.
可选地,所述基于所述目标指标,确定目标数据流图中所述节点对应的所述性能指标信息,包括:Optionally, the determining, based on the target indicator, the performance indicator information corresponding to the node in the target data flow graph includes:
将所述关联节点与所述节点间的目标指标的总和,确定为所述节点对应的性能指标信息。The sum of the target indicators between the associated node and the node is determined as the performance indicator information corresponding to the node.
可选地,所述基于所述目标指标,确定目标数据流图中所述节点对应的所述性能指标信息,包括:Optionally, the determining, based on the target indicator, the performance indicator information corresponding to the node in the target data flow graph includes:
确定所述关联节点对应的预设影响系数;determining a preset influence coefficient corresponding to the associated node;
将所述关联节点与所述节点间的目标指标与所述预设影响系数的计算结果,确定为所述节点对应的性能指标信息。The calculation result of the target index between the associated node and the node and the preset influence coefficient is determined as the performance index information corresponding to the node.
可选地,所述方法还包括:Optionally, the method further includes:
获取完整数据流图;所述完整数据流图包括所述目标应用对应的全部节点以及全部节点间的数据流的链路,所述完整数据流图用于描述数据在所述全部节点和所述全部节点间的数据流的链路间的逻辑运算过程;Obtain a complete data flow graph; the complete data flow graph includes all nodes corresponding to the target application and links of data flows between all nodes, and the complete data flow graph is used to describe the data in all nodes and the The logical operation process between the links of the data flow between all nodes;
对所述完整数据流图进行划分,获取至少两个所述目标数据流图。The complete data flow graph is divided to obtain at least two target data flow graphs.
可选地,所述方法还包括:Optionally, the method further includes:
设置内存资源共享池,所述内存资源共享池由所述目标数据流图对应的执行器组成,不同执行器内存数据共享,所述执行器包括所述目标执行器。A shared memory resource pool is set up, the shared memory resource pool is composed of executors corresponding to the target data flow graph, different executors share memory data, and the executors include the target executors.
根据本公开实施例的第二方面,提供一种数据处理装置,包括:According to a second aspect of the embodiments of the present disclosure, there is provided a data processing apparatus, including:
信息获取模块,被配置为获取目标应用对应的目标数据流图中各个节点分别对应的性能指标信息,所述目标数据流图包括节点以及所述节点间的数据流的链路,所述目标数据流图用于描述数据在所述节点和所述节点间的数据流的链路间的逻辑运算过程;an information acquisition module, configured to acquire performance index information corresponding to each node in a target data flow graph corresponding to a target application, where the target data flow graph includes nodes and links of data flows between the nodes, and the target data The flow graph is used to describe the logical operation process of data between the nodes and the links of the data flow between the nodes;
节点确定模块,被配置为在所述各个节点中,选取出性能指标信息符合预设性能指标条件的关键节点;a node determination module, configured to select, among the nodes, key nodes whose performance index information meets preset performance index conditions;
路径确定模块,被配置为在所述节点间的数据流的链路中,选取所述关键节点对应的关键路径,在目标执行器上执行所述关键路径。The path determination module is configured to select the critical path corresponding to the key node in the link of the data flow between the nodes, and execute the critical path on the target executor.
可选地,所述路径确定模块,包括:Optionally, the path determination module includes:
第一确定单元,被配置为在所述节点间的数据流的链路中,选取所述关键节点所在的数据传播路径;a first determining unit, configured to select a data propagation path where the key node is located in the link of the data flow between the nodes;
第二确定单元,被配置为在所述数据传播路径中,选取路径长度符合预设路径长度条件的关键节点对应的关键路径;所述预设路径长度条件包括路径长度的最大值或路径长度大于设定值。The second determining unit is configured to, in the data propagation path, select a key path corresponding to a key node whose path length meets a preset path length condition; the preset path length condition includes the maximum value of the path length or the path length greater than set value.
可选地,所述信息获取模块,包括:Optionally, the information acquisition module includes:
第三确定单元,被配置为针对目标应用对应的目标数据流图中每一个节点:确定所述节点对应的关联节点,所述节点与所述关联节点之间存在数据输入关系或数据输出关系;The third determining unit is configured to, for each node in the target data flow graph corresponding to the target application: determine an associated node corresponding to the node, and a data input relationship or a data output relationship exists between the node and the associated node;
第四确定单元,被配置为确定所述关联节点与所述节点间的目标指标;所述目标指标用于指示数据在节点间的执行时间或计算复杂度;a fourth determining unit, configured to determine a target indicator between the associated node and the node; the target indicator is used to indicate the execution time or computational complexity of data between nodes;
第五确定单元,被配置为基于所述目标指标,确定所述目标数据流图中所述节点对应的所述性能指标信息。A fifth determining unit is configured to determine, based on the target indicator, the performance indicator information corresponding to the node in the target data flow graph.
可选地,所述第五确定单元,被配置为将所述关联节点与所述节点间的目标指标的总和,确定为所述节点对应的性能指标信息。Optionally, the fifth determining unit is configured to determine the sum of the target indicators between the associated node and the node as the performance indicator information corresponding to the node.
可选地,所述第五确定单元,被配置为确定所述关联节点对应的预设影响系数;将所述关联节点与所述节点间的目标指标与所述预设影响系数的计算结果,确定为所述节点对应的性能指标信息。Optionally, the fifth determination unit is configured to determine a preset influence coefficient corresponding to the associated node; the calculation result of the target index between the associated node and the node and the preset influence coefficient, Determine the performance index information corresponding to the node.
可选地,所述装置还包括:流图划分模块;Optionally, the apparatus further includes: a flow graph division module;
所述流图划分模块被配置为获取完整数据流图;所述完整数据流图包括所述目标应用对应的全部节点以及全部节点间的数据流的链路,所述完整数据流图用于描述数据在所述全部节点和所述全部节点间的数据流的链路间的逻辑运算过程;对所述完整数据流图进行划分,获取至少两个所述目标数据流图。The flow graph dividing module is configured to obtain a complete data flow graph; the complete data flow graph includes all nodes corresponding to the target application and links of data flows between all nodes, and the complete data flow graph is used to describe The logical operation process of the data between the all nodes and the links of the data flow between the all nodes; dividing the complete data flow graph to obtain at least two target data flow graphs.
可选地,所述装置还包括:Optionally, the device further includes:
共享处理模块,被配置为设置内存资源共享池,所述内存资源共享池由所述目标数据流图对应的执行器组成,不同执行器内存数据共享,所述执行器包括所述目标执行器。The shared processing module is configured to set a memory resource shared pool, the memory resource shared pool is composed of executors corresponding to the target data flow graph, and different executors share memory data, and the executors include the target executors.
根据本公开实施例的第三方面,提供一种电子设备,包括:According to a third aspect of the embodiments of the present disclosure, there is provided an electronic device, comprising:
处理器;processor;
用于存储所述处理器可执行指令的存储器;a memory for storing the processor-executable instructions;
其中,所述处理器被配置为执行所述指令,以实现如第一方面所述的数据处理方法。Wherein, the processor is configured to execute the instructions to implement the data processing method according to the first aspect.
根据本公开实施例的第四方面,提供一种存储介质,当所述存储介质中的指令由电子设备的处理器执行时,使得所述电子设备能够执行如第一方面所述的数据处理方法。According to a fourth aspect of the embodiments of the present disclosure, there is provided a storage medium, when an instruction in the storage medium is executed by a processor of an electronic device, the electronic device can execute the data processing method according to the first aspect .
根据本公开实施例的第五方面,提供一种计算机程序产品,该计算机程序产品包括可读性程序代码,该可读性程序代码由电子设备的处理器执行时,使得电子设备能够执行如第一方面所述的数据处理方法。According to a fifth aspect of the embodiments of the present disclosure, a computer program product is provided, the computer program product includes readable program code, and when the readable program code is executed by a processor of an electronic device, enables the electronic device to execute as described in the first The data processing method described in one aspect.
本公开的实施例提供的技术方案至少带来以下有益效果:The technical solutions provided by the embodiments of the present disclosure bring at least the following beneficial effects:
本公开在获取目标数据流图后,确定目标数据流图中各个节点分别对应的性能指标信息,其中目标数据流图由节点以及在各个节点之间的数据流的链路组成,该目标数据流图用于描述数据在节点和节点间的数据流的链路间的逻辑运算过程,性能指标信息为用于表征节点性能的数据,不同的节点可以对应不同的性能指标信息。进一步在各个节点中,选取出性能指标信息符合预设性能指标条件的关键节点,进而在节点间的数据流的链路中,选取关键节点对应的关键路径,选取出的关键路径为目标数据流图全部路径中的部分路径,通过在目标执行器上执行关键路径,可以避免目标数据流图中关键路径以外的其他节点在目标执行器上执行,有效减少目标数据流图对目标执行器的资源占用,保证目标执行器的执行速度。After acquiring the target data flow graph, the present disclosure determines the performance index information corresponding to each node in the target data flow graph, wherein the target data flow graph is composed of nodes and links of data flows between each node. The graph is used to describe the logical operation process of data between the nodes and the links of the data flow between the nodes. The performance index information is the data used to characterize the node performance, and different nodes may correspond to different performance index information. Further, in each node, select the key node whose performance index information meets the preset performance index condition, and then select the key path corresponding to the key node in the link of the data flow between the nodes, and the selected key path is the target data flow Part of the path in the entire path of the graph, by executing the critical path on the target executor, other nodes other than the critical path in the target data flow graph can be avoided from executing on the target executor, effectively reducing the target data flow graph's resources to the target executor Occupied to ensure the execution speed of the target executor.
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。It is to be understood that the foregoing general description and the following detailed description are exemplary and explanatory only and are not restrictive of the present disclosure.
附图说明Description of drawings
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本公开的实施例,并与说明书一起用于解释本公开的原理,并不构成对本公开的不当限定。The accompanying drawings, which are incorporated into and constitute a part of this specification, illustrate embodiments consistent with the present disclosure, and together with the description, serve to explain the principles of the present disclosure and do not unduly limit the present disclosure.
图1是根据一示例性实施例示出的一种数据处理方法的流程图一;1 is a
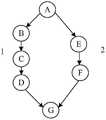
图2是根据一示例性实施例示出的一种数据处理方法中目标数据流图的示意图;2 is a schematic diagram of a target data flow diagram in a data processing method according to an exemplary embodiment;
图3是根据一示例性实施例示出的一种数据处理方法的流程图二;3 is a second flowchart of a data processing method according to an exemplary embodiment;
图4是根据一示例性实施例示出的一种数据处理方法的流程图三;FIG. 4 is a third flowchart of a data processing method according to an exemplary embodiment;
图5是根据一示例性实施例示出的一种数据处理装置的框图;5 is a block diagram of a data processing apparatus according to an exemplary embodiment;
图6是根据一示例性实施例示出的一种电子设备的框图。Fig. 6 is a block diagram of an electronic device according to an exemplary embodiment.
具体实施方式Detailed ways
为了使本领域普通人员更好地理解本公开的技术方案,下面将结合附图,对本公开实施例中的技术方案进行清楚、完整地描述。In order to make those skilled in the art better understand the technical solutions of the present disclosure, the technical solutions in the embodiments of the present disclosure will be clearly and completely described below with reference to the accompanying drawings.
需要说明的是,本公开的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本公开的实施例能够以除了在这里图示或描述的那些以外的顺序实施。以下示例性实施例中所描述的实施方式并不代表与本公开相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本公开的一些方面相一致的装置和方法的例子。It should be noted that the terms "first", "second" and the like in the description and claims of the present disclosure and the above drawings are used to distinguish similar objects, and are not necessarily used to describe a specific sequence or sequence. It is to be understood that the data so used may be interchanged under appropriate circumstances such that the embodiments of the disclosure described herein can be practiced in sequences other than those illustrated or described herein. The implementations described in the illustrative examples below are not intended to represent all implementations consistent with this disclosure. Rather, they are merely examples of apparatus and methods consistent with some aspects of the present disclosure as recited in the appended claims.
图1是根据一示例性实施例示出的一种数据处理方法的流程图,包括以下步骤。Fig. 1 is a flowchart of a data processing method according to an exemplary embodiment, which includes the following steps.
在步骤S11中,获取目标应用对应的目标数据流图中各个节点分别对应的性能指标信息;所述目标数据流图包括节点以及所述节点间的数据流的链路,所述目标数据流图用于描述数据在所述节点和所述节点间的数据流的链路间的逻辑运算过程。In step S11, the performance index information corresponding to each node in the target data flow graph corresponding to the target application is obtained; the target data flow graph includes nodes and links of data flows between the nodes, and the target data flow graph It is used to describe the logical operation process between the links of the data flow between the nodes and the nodes.
在本步骤中,对目标应用的类型不做具体限定。例如,目标应用可以是视频应用、即时通信应用、浏览器应用、教育应用、直播应用等,目标应用可以与执行某种任务的机器学习模型相对应,将机器学习模型以数据流图的方式提交到电子设备上,该电子设备可以为移动终端,从而在电子设备上会存在有目标应用对应的目标数据流图。目标数据流图由节点以及节点间的数据流的链路组成,其中节点表示数据处理操作,不同的节点可以对应相同或不同的数据处理操作。具体地包括输入节点、加工处理节点和输出节点,加工处理节点包括但不限于加法操作、乘法操作或构建变量的初始值操作。节点间的数据流的链路代表数据间的依赖关系,进行数据值的传递,如一个节点的运算输出成为另一个节点的输入,两个节点之间有tensor(张量)流动,即目标数据流图用于描述数据在节点和节点间的数据流的链路间的逻辑运算过程。In this step, the type of the target application is not specifically limited. For example, the target application can be a video application, an instant messaging application, a browser application, an educational application, a live broadcast application, etc. The target application can correspond to a machine learning model that performs a certain task, and the machine learning model is submitted in the form of a data flow graph On the electronic device, the electronic device may be a mobile terminal, so there will be a target data flow graph corresponding to the target application on the electronic device. The target data flow graph is composed of nodes and data flow links between nodes, where nodes represent data processing operations, and different nodes may correspond to the same or different data processing operations. Specifically, it includes an input node, a processing node, and an output node, and the processing node includes, but is not limited to, an addition operation, a multiplication operation, or an operation of constructing an initial value of a variable. The link of the data flow between the nodes represents the dependency between the data, and the data value is transferred. For example, the operation output of one node becomes the input of another node, and there is a tensor (tensor) flow between the two nodes, that is, the target data. A flow graph is used to describe the logical operation process of data between nodes and the links of the data flow between nodes.
目标数据流图中的每个节点存在各自对应的性能指标信息,性能指标信息为用于表征节点性能的指标数据。具体地,性能指标信息可以为关于计算复杂度的数据,或关于执行时间的数据。在获取到目标数据流图中各个节点分别对应的性能指标信息后,即可以利用性能指标信息对节点进行评价。Each node in the target data flow graph has its own corresponding performance indicator information, and the performance indicator information is indicator data used to characterize the performance of the node. Specifically, the performance indicator information may be data about computational complexity or data about execution time. After obtaining the performance index information corresponding to each node in the target data flow graph, the node can be evaluated by using the performance index information.
在一实施例中,所述步骤S11获取目标应用对应的目标数据流图中各个节点分别对应的性能指标信息,包括:In one embodiment, the step S11 obtains performance index information corresponding to each node in the target data flow graph corresponding to the target application, including:
在步骤S111中,针对目标应用对应的目标数据流图中每一个节点:确定所述节点对应的关联节点,所述节点与所述关联节点之间存在数据输入关系或数据输出关系。In step S111, for each node in the target data flow graph corresponding to the target application: determine an associated node corresponding to the node, and there is a data input relationship or a data output relationship between the node and the associated node.
在本步骤中,不同的节点存在不同的输入节点和输出节点,因此根据目标数据流图中节点间的数据流的链路,可以确定与节点存在数据输入关系或数据输出关系的关联节点。In this step, different nodes have different input nodes and output nodes. Therefore, according to the data flow links between the nodes in the target data flow graph, the associated nodes that have a data input relationship or a data output relationship with the node can be determined.
在一种可能的实现方式中,关联节点为数据输入节点,则确定每一个节点分别对应的关联节点具体为确定每一节点分别对应的所有数据输入节点。举例来说,存在如图2所述的目标数据流图,图中字母A至字母G分别代表节点A至节点G,节点间的连线即为节点间的数据流的链路,箭头的方向即为数据的流向,在图2中节点B的数据输入节点有节点A,即节点A为节点B的关联节点;节点C的数据输入节点有节点A和节点B,即节点A和节点B为节点C的关联节点;节点D的数据输入节点有节点A、节点B和节点C,即节点A、节点B和节点C为节点D的关联节点;节点E的数据输入节点有节点A,即节点A为节点E的关联节点;节点F的数据输入节点有节点A和节点E,即节点A和节点E为节点F的关联节点;节点G的数据输入节点有节点A至节点F,即节点A至节点F均为节点G的关联节点。In a possible implementation manner, if the associated node is a data input node, then determining the associated node corresponding to each node is specifically determining all data input nodes corresponding to each node. For example, there is a target data flow diagram as shown in Figure 2, in which letters A to G represent node A to node G respectively, and the connection between the nodes is the link of the data flow between the nodes, and the direction of the arrow It is the flow of data. In Figure 2, the data input node of node B has node A, that is, node A is the associated node of node B; the data input node of node C has node A and node B, that is, node A and node B are The associated node of node C; the data input nodes of node D include node A, node B and node C, that is, node A, node B and node C are the associated nodes of node D; the data input node of node E has node A, namely node A is the associated node of node E; the data input nodes of node F include node A and node E, that is, node A and node E are the associated nodes of node F; the data input nodes of node G include node A to node F, namely node A To node F are all associated nodes of node G.
在一种可能的实现方式中,关联节点为数据输出节点,则确定每一个节点分别对应的关联节点具体为确定每一个节点分别对应的数据输出节点。举例来说,存在如图2所述的目标数据流图,节点A的数据输出节点有节点B至节点G,即节点B至节点G为节点A的关联节点;节点B的数据输出节点有节点C、节点D和节点G,即节点C、节点D和节点G为节点B的关联节点;节点C的数据输出节点有节点D和节点G,即节点D和节点G为节点C的关联节点;节点D的数据输出节点有节点G,即节点G为节点D的关联节点;节点E的数据输出节点有节点F和节点G,即节点F和节点G为节点E的关联节点;节点F的数据输出节点有节点G,即节点G为节点E的关联节点。In a possible implementation manner, if the associated node is a data output node, then determining the associated node corresponding to each node is specifically determining the data output node corresponding to each node. For example, there is a target data flow graph as shown in Figure 2, the data output node of node A has node B to node G, that is, node B to node G are the associated nodes of node A; the data output node of node B has node B C, node D and node G, that is, node C, node D and node G are the associated nodes of node B; the data output nodes of node C include node D and node G, that is, node D and node G are associated nodes of node C; The data output nodes of node D include node G, that is, node G is the associated node of node D; the data output nodes of node E include node F and node G, that is, node F and node G are associated nodes of node E; the data of node F The output node has node G, that is, node G is the associated node of node E.
在步骤S112中,确定所述关联节点与所述节点间的目标指标;所述目标指标用于指示数据在节点间的执行时间或计算复杂度。In step S112, a target indicator between the associated node and the node is determined; the target indicator is used to indicate the execution time or computational complexity of data between nodes.
在本步骤中,预先设置目标指标,目标指标用于指示节点与各个关联节点间的性能,具体地,目标指标可以用于指示数据在节点间的执行时间或计算复杂度。In this step, a target indicator is preset, and the target indicator is used to indicate the performance between the node and each associated node. Specifically, the target indicator can be used to indicate the execution time or computational complexity of data between nodes.
在一种可能的实现方式中,在关联节点为数据输入节点时,每一个关联节点与节点Vi的目标指标是每一个Vi的数据输入节点到Vi的计算复杂度或执行时间。举例来说,图2中节点D的数据输入节点有节点A、节点B和节点C,即确定数据从节点A到节点D的第一执行时间、数据从节点B到节点D的第二执行时间、数据从节点C到节点D的第三执行时间,其中第一执行时间、第二执行时间、第三执行时间即为确定出的目标指标。In a possible implementation manner, when the associated node is a data input node, the target index of each associated node and node Vi is the computational complexity or execution time from each data input node of Vi to Vi. For example, the data input nodes of node D in FIG. 2 include node A, node B and node C, that is, the first execution time of data from node A to node D and the second execution time of data from node B to node D are determined. . The third execution time of the data from node C to node D, wherein the first execution time, the second execution time, and the third execution time are the determined target indicators.
在一种可能的实现方式中,在关联节点为数据输出节点时,节点Vi与每一个关联节点的目标指标是从Vi出发的数据到每一个数据输出节点的计算复杂度或执行时间。举例来说,节点C的数据输出节点有节点D和节点G,即确定数据从节点C到节点D的第四执行时间、数据从节点C到节点G的第五执行时间,其中,第四执行时间和第五执行时间即为确定出的目标指标。In a possible implementation, when the associated node is a data output node, the target index of the node Vi and each associated node is the computational complexity or execution time from the data from Vi to each data output node. For example, the data output nodes of node C include node D and node G, that is, the fourth execution time of data from node C to node D and the fifth execution time of data from node C to node G are determined, wherein the fourth execution time is determined. The time and the fifth execution time are the determined target indicators.
在步骤S113中,基于所述目标指标,确定所述目标数据流图中所述节点对应的所述性能指标信息。In step S113, based on the target indicator, determine the performance indicator information corresponding to the node in the target data flow graph.
在本步骤中,针对每一个节点,对该节点的关联节点与该节点的目标指标进行计算,确定出目标数据流图中各个节点分别对应的性能指标信息。在本实施例中,将节点的关联节点与节点对应的性能指标信息建立联系,通过充分考虑关联节点,使得确定出的节点的性能指标信息更能反映节点的整体性能,避免对每一个节点进行单独考虑,割裂各个节点之间的联系,进而保证确定出节点的性能指标信息的准确性。In this step, for each node, the associated node of the node and the target index of the node are calculated, and the performance index information corresponding to each node in the target data flow graph is determined. In this embodiment, a relationship is established between the associated node of the node and the performance index information corresponding to the node, and by fully considering the associated node, the determined performance index information of the node can better reflect the overall performance of the node, avoiding the need for each node. Considering it separately, the connection between each node is separated, so as to ensure the accuracy of the performance index information of the determined node.
可选地,所述基于所述目标指标,确定目标数据流图中所述节点对应的所述性能指标信息,包括:将所述关联节点与所述节点间的目标指标的总和,确定为所述节点对应的性能指标信息。通过将各个节点对应的关联节点与节点间的目标指标的总和,确定为各个节点对应的性能指标信息,可以简单、快速地建立关联节点的目标指标与节点对应的性能指标信息的联系,保证性能指标信息的确定效率性。Optionally, the determining, based on the target indicator, the performance indicator information corresponding to the node in the target data flow graph includes: determining the sum of the target indicator between the associated node and the node as the The performance index information corresponding to the above node. By determining the sum of the target indicators between the associated nodes corresponding to each node and the nodes as the performance indicator information corresponding to each node, the connection between the target indicator of the associated node and the performance indicator information corresponding to the node can be simply and quickly established to ensure performance. Deterministic efficiency of indicator information.
在一种可能的实现方式中,在关联节点为数据输入节点时,节点Vi的性能指标信息是Vi的所有输入节点到Vi的计算复杂度的总和或执行时间的总和。举例来说,确定出图2中数据从节点A到节点D的第一执行时间、数据从节点B到节点D的第二执行时间、数据从节点C到节点D的第三执行时间后,将第一执行时间、第二执行时间和第三执行时间的总和确定为节点D的性能指标信息,此时的性能指标信息可以称为下排名。In a possible implementation manner, when the associated node is a data input node, the performance index information of the node Vi is the sum of the computational complexity or the sum of the execution time from all input nodes of Vi to Vi. For example, after determining the first execution time of data from node A to node D, the second execution time of data from node B to node D, and the third execution time of data from node C to node D in FIG. The sum of the first execution time, the second execution time, and the third execution time is determined as the performance index information of node D, and the performance index information at this time may be referred to as a lower ranking.
在一种可能的实现方式中,在关联节点为数据输出节点时,节点Vi的性能指标信息是从Vi出发的数据到所有输出节点的计算复杂度的总和或执行时间的总和。举例来说,确定出图2中数据从节点C到节点D的第四执行时间、数据从节点C到节点G的第五执行时间后,将第四执行时间和第五执行时间的总和确定为节点D的性能指标信息,此时的性能指标信息可以称为上排名。In a possible implementation manner, when the associated node is a data output node, the performance index information of the node Vi is the sum of the computational complexity or the sum of the execution time from the data from Vi to all output nodes. For example, after determining the fourth execution time of data from node C to node D and the fifth execution time of data from node C to node G in FIG. 2, the sum of the fourth execution time and the fifth execution time is determined as The performance index information of the node D, the performance index information at this time may be referred to as the upper ranking.
可选地,所述基于所述目标指标,确定目标数据流图中所述节点对应的所述性能指标信息,包括:确定所述关联节点对应的预设影响系数;将所述关联节点与所述节点间的目标指标与所述预设影响系数的计算结果,确定为所述节点对应的性能指标信息。预先确定不同关联节点分别对应的影响系数,影响系数体现不同关联节点的重要程度,通过考虑不同关联节点的重要程度,准确地建立关联节点的目标指标与节点对应的性能指标信息的联系,保证确定出的性能指标信息的准确性。Optionally, the determining, based on the target indicator, the performance indicator information corresponding to the node in the target data flow graph includes: determining a preset influence coefficient corresponding to the associated node; The calculation result of the target index between the nodes and the preset influence coefficient is determined as the performance index information corresponding to the node. The influence coefficients corresponding to different associated nodes are determined in advance, and the influence coefficients reflect the importance of different associated nodes. By considering the importance of different associated nodes, the relationship between the target indicators of the associated nodes and the performance index information corresponding to the nodes is accurately established to ensure the determination of The accuracy of the performance indicator information obtained.
在一种可能的实现方式中,在关联节点为数据输入节点时,节点Vi的性能指标信息是Vi的所有输入节点到Vi的计算复杂度与预设影响系数的加权平均值,或节点Vi的性能指标信息是Vi的所有输入节点到Vi的执行时间与预设影响系数的加权平均值。举例来说,确定出图2中数据从节点A到节点D的第一执行时间、数据从节点B到节点D的第二执行时间、数据从节点C到节点D的第三执行时间后,确定节点A对应的第一预设影响系数、节点B对应的第二预设影响系数,节点C对应的第三预设影响系数,将第一执行时间与第一预设影响系数的第一乘积结果、第二执行时间与第二预设影响系数的第二乘积结果以及第三执行时间与第三预设影响系数的第三乘积结果的加和结果除以3得到加权平均值,将该加权平均值确定为节点D的性能指标信息。In a possible implementation manner, when the associated node is a data input node, the performance index information of the node Vi is the weighted average of the computational complexity from all input nodes of Vi to Vi and the preset influence coefficient, or the The performance index information is the weighted average of the execution time from all input nodes of Vi to Vi and the preset influence coefficient. For example, after determining the first execution time of data from node A to node D, the second execution time of data from node B to node D, and the third execution time of data from node C to node D in FIG. 2, determine The first preset influence coefficient corresponding to node A, the second preset influence coefficient corresponding to node B, and the third preset influence coefficient corresponding to node C are the result of the first product of the first execution time and the first preset influence coefficient , the second product result of the second execution time and the second preset influence coefficient and the addition result of the third execution time and the third product result of the third preset influence coefficient divided by 3 to obtain a weighted average value, and the weighted average The value is determined as the performance index information of node D.
在步骤S12中,在所述各个节点中,选取出性能指标信息符合预设性能指标条件的关键节点。In step S12, among the nodes, key nodes whose performance index information meets preset performance index conditions are selected.
在本步骤中,预先设置性能指标条件,利用预设性能指标条件对各个节点进行选取,选取出性能指标信息较高的关键节点,即根据预设性能指标条件选取出的关键节点的运算复杂度较大、占用的计算资源较多。对于预设性能指标条件的具体内容本实施例不作限定,在一种可能的实现方式中,预设性能指标条件包括性能指标信息的最大值或性能指标信息大于预设值。In this step, the performance index conditions are preset, each node is selected by using the preset performance index conditions, and the key nodes with higher performance index information are selected, that is, the computational complexity of the key nodes selected according to the preset performance index conditions It is larger and takes up more computing resources. The specific content of the preset performance index condition is not limited in this embodiment. In a possible implementation manner, the preset performance index condition includes the maximum value of the performance index information or the performance index information is greater than the preset value.
具体地,对各个节点对应的性能指标信息进行由大到小排序,在预设性能指标条件为性能指标信息的最大值时,将排序在第一位的节点选取为关键节点,此时关键节点的数量为一个。在预设性能指标条件为性能指标消息大于预设值时,其中预设值可以为固态设定值,即预先确定一个数值,将各个节点中性能指标信息大于该数值的节点选取为关键节点,此时可能确定出多个关键节点;预设值也可以为动态设定值,如根据排序在预设位的数值确定该预设值,此时可以确定出多个关键节点。Specifically, the performance index information corresponding to each node is sorted from large to small, and when the preset performance index condition is the maximum value of the performance index information, the node ranked first is selected as the key node. At this time, the key node The number is one. When the preset performance index condition is that the performance index information is greater than the preset value, the preset value may be a solid-state set value, that is, a value is predetermined, and the node whose performance index information is greater than the value in each node is selected as the key node, At this time, multiple key nodes may be determined; the preset value may also be a dynamic set value. For example, if the preset value is determined according to the value sorted in the preset position, multiple key nodes may be determined at this time.
在步骤S13中,在所述节点间的数据流的链路中,选取所述关键节点对应的关键路径,在目标执行器上执行所述关键路径。In step S13, in the link of the data flow between the nodes, the critical path corresponding to the key node is selected, and the critical path is executed on the target executor.
在本步骤中,不同的节点与链路会组成不同的数据传播路径。图2中由节点A至节点G存在两条不同的数据传播路径,即数据传播路径1和数据传播路径2,数据传播路径1由节点A、节点B、节点C、节点D和节点G组成,数据传播路径2由节点A、节点E、节点F和节点G组成。在确定出关键节点后,在不同数据传播路径中确定出关键节点对应的关键路径,因关键节点为对各个节点进行选取的结果,因此关键节点为目标数据流图中全部节点中的部分节点,进一步根据关键节点在全部数据传播路径中进行选取,选取出全部数据传播路径中关键节点对应的关键路径,关键路径为全部数据传播路径中的部分路径,因此在利用目标执行器执行关键路径时,可以避免目标数据流图中关键路径以外的其他节点在目标执行器上执行,有效减少目标数据流图对目标执行器的资源占用,保证目标执行器的执行速度。其中目标执行器为电子设备中用于加速计算的处理器,具体地可以为GPU(GraphicsProcessing Unit,图形处理器)。In this step, different nodes and links will form different data propagation paths. In Figure 2, there are two different data propagation paths from node A to node G, namely
在一实施例中,所述步骤S13在所述节点间的数据流的链路中,选取所述关键节点对应的关键路径,包括:In an embodiment, the step S13 selects the key path corresponding to the key node in the link of the data flow between the nodes, including:
在步骤S131中,在所述节点间的数据流的链路中,选取所述关键节点所在的数据传播路径。In step S131, in the links of the data flow between the nodes, the data propagation path where the key node is located is selected.
在步骤S132中,在所述数据传播路径中,选取路径长度符合预设路径长度条件的关键节点对应的关键路径;所述预设路径长度条件包括路径长度的最大值或路径长度大于设定值。In step S132, in the data propagation path, the key path corresponding to the key node whose path length meets the preset path length condition is selected; the preset path length condition includes the maximum value of the path length or the path length is greater than the set value .
在本实施例中,在节点间的数据流的链路中,确定出关键节点所在的数据传播路径。并进一步在关键节点所在的数据传播路径中,确定出路径长度符合预设路径长度条件的关键节点对应的关键路径。In this embodiment, in the link of the data flow between the nodes, the data propagation path where the key node is located is determined. Further, in the data propagation path where the key node is located, the key path corresponding to the key node whose path length meets the preset path length condition is determined.
可选地,预设路径长度条件可以为路径长度的最大值,即将关键节点所在的数据传播路径中的最长数据传播路径确定为关键路径。在利用性能指标信息准确地确定出关键节点后,通过关键节点对应的路径长度最大值快速、准确地确定出关键路径,有效地确定出目标数据流图中占用计算资源较多的关键路径,在目标执行器执行关键路径时,避免对目标执行器的过多占用,同时使得目标数据流图中对整体性能存在重要影响的关键路径得到了运行。Optionally, the preset path length condition may be the maximum value of the path length, that is, the longest data propagation path in the data propagation paths where the key nodes are located is determined as the critical path. After using the performance index information to accurately determine the key nodes, the key paths are quickly and accurately determined by the maximum path length corresponding to the key nodes, and the key paths that occupy more computing resources in the target data flow graph are effectively determined. When the target executor executes the critical path, it avoids excessive occupation of the target executor, and at the same time enables the critical path that has an important impact on the overall performance in the target data flow graph to be run.
可选地,预设路径长度条件也可以为路径长度大于设定值,设定值可以为预先设定,也可以根据确定出当前路径长度进行动态确定,如存在多条关键节点所在的数据传播路径,对多条关键节点所在的数据传播路径按路径长度进行由大到小的排序,将前预设位出的路径长度确定为设定值。从而通过预设路径长度条件,对关键节点所在的数据传播路径进行有效筛选,筛选出占用目标执行器较多计算资源的关键路径。Optionally, the preset path length condition can also be that the path length is greater than the set value, and the set value can be preset, or it can be dynamically determined according to the determined current path length, for example, there are data propagation where multiple key nodes are located. Path, sort the data propagation paths where the multiple key nodes are located in descending order according to the path length, and determine the path length previously preset as the set value. Therefore, by presetting the path length condition, the data propagation paths where the key nodes are located are effectively screened, and the critical paths occupying more computing resources of the target executor are screened out.
具体地,在确定关键节点后,若关联节点为数据输入节点,确定关键节点的前驱节点,以确定出关键节点所在的数据传播路径;若关联节点为数据输出节点,确定关联节点的后继节点,以确定出关键节点所在的数据传播路径。Specifically, after determining the key node, if the associated node is a data input node, determine the precursor node of the key node to determine the data propagation path where the key node is located; if the associated node is a data output node, determine the successor node of the associated node, To determine the data propagation path where key nodes are located.
举例来说,当关联节点为数据输入节点时,如图2所示,确定节点A到节点G的性能指标信息,其中节点Vi的性能指标信息是Vi的所有输入节点到Vi的计算复杂度的总和或执行时间的总和,在节点A到节点G中,节点G以节点A至节点F为数据输入节点,因此节点G的性能指标信息值最大,符合预设性能指标条件(性能指标信息值最大),选取节点G为关键节点,确定关键节点的前驱节点,即节点D和节点F;确定节点F的前驱节点,即节点E;确定节点E的前驱节点,即节点A(源顶点);确定节点D的前驱节点,即节点C;确定节点C的前驱节点,即节点B;确定节点B的前驱节点,即节点A(源顶点)。从而确定出两条数据传播路径,其中1条数据传播路径的长度为5,一条数据传播路径的长度为3,长度为5的数据传播路径符合预设路径长度条件(路径长度的最大值),将长度为5的数据传播路径确定为关键路径。当然可以进一步将不符合所述预设路径长度条件的数据传播路径确定为非关键路径。For example, when the associated node is a data input node, as shown in Figure 2, the performance index information of node A to node G is determined, wherein the performance index information of node Vi is the calculation complexity of all input nodes of Vi to Vi. The sum or the sum of execution time, in node A to node G, node G takes node A to node F as the data input node, so the performance index information value of node G is the largest, which meets the preset performance index condition (the maximum performance index information value is ), select node G as the key node, determine the precursor nodes of the key node, namely node D and node F; determine the precursor node of node F, namely node E; determine the precursor node of node E, namely node A (source vertex); determine The predecessor node of node D is node C; the predecessor node of node C is determined, that is node B; the predecessor node of node B is determined, that is node A (source vertex). Thereby, two data propagation paths are determined, wherein one data propagation path has a length of 5, a data propagation path has a length of 3, and the data propagation path with a length of 5 meets the preset path length condition (the maximum value of the path length), The data propagation path of length 5 is determined as the critical path. Of course, a data propagation path that does not meet the preset path length condition may be further determined as a non-critical path.
在一种可能的应用场景中,在移动终端上安装tflite(一种机器学习模型,可以直接通过移动电子设备实现语音识别、视频分割等功能),此时目标数据流图与tflite相对应,在移动电子设备上运行tflite时,常常会使用到GPU,而图形处理器同时为其他功能服务,如视频和渲染,因此存在运行tflite时与其他功能抢占GPU资源的问题,通过本实施例提供的方法,在tflite对应的目标数据流图中确定出关键路径,在GPU上运行该关键路径,可以防止过多占用GPU,同时在GPU上运行对tflite的运行中最影响性能的关键路径。In a possible application scenario, install tflite (a machine learning model, which can directly realize functions such as speech recognition and video segmentation through mobile electronic devices) on the mobile terminal. At this time, the target data flow graph corresponds to tflite, and in the When running tflite on a mobile electronic device, the GPU is often used, and the graphics processor serves other functions at the same time, such as video and rendering, so there is a problem of preempting GPU resources with other functions when running tflite. The method provided by this embodiment is used , determine the critical path in the target data flow graph corresponding to tflite, and run the critical path on the GPU to prevent excessive use of the GPU, and at the same time run the critical path that most affects the performance of tflite in the operation of the GPU.
在上述实施例中,在获取目标数据流图后,确定目标数据流图中各个节点分别对应的性能指标信息,其中目标数据流图由节点以及在各个节点之间的数据流的链路组成,该目标数据流图用于描述数据在节点和节点间的数据流的链路间的逻辑运算过程,性能指标信息为用于表征节点性能的数据,不同的节点可能对应不同的性能指标信息。进一步在各个节点中,选取出性能指标信息符合预设性能指标条件的关键节点;进而在节点间的数据流的链路中,选取关键节点对应的关键路径,选取出的关键路径为目标数据流图全部路径中的部分路径,通过在目标执行器上执行关键路径,可以避免目标数据流图中关键路径以外的其他节点在目标执行器上执行,有效减少目标数据流图对目标执行器的资源占用,保证目标执行器的执行速度。In the above embodiment, after acquiring the target data flow graph, the performance index information corresponding to each node in the target data flow graph is determined, wherein the target data flow graph is composed of nodes and links of data flows between the nodes, The target data flow graph is used to describe the logical operation process of the data between the nodes and the links of the data flow between the nodes. The performance index information is data used to characterize the node performance, and different nodes may correspond to different performance index information. Further, in each node, select the key node whose performance index information meets the preset performance index condition; and then select the key path corresponding to the key node in the link of the data flow between the nodes, and the selected key path is the target data flow Part of the path in the entire path of the graph, by executing the critical path on the target executor, other nodes other than the critical path in the target data flow graph can be avoided from executing on the target executor, effectively reducing the target data flow graph's resources to the target executor Occupied to ensure the execution speed of the target executor.
可选地,目标数据流图为完整数据流图中的一步分,即如图3所示,在一实施例中,所述方法还包括:Optionally, the target data flow graph is a step in the complete data flow graph, that is, as shown in FIG. 3 , in one embodiment, the method further includes:
在步骤S14中,获取完整数据流图;所述完整数据流图包括所述目标应用对应的全部节点以及全部节点间的数据流的链路,所述完整数据流图用于描述数据在所述全部节点和所述全部节点间的数据流的链路间的逻辑运算过程;对所述完整数据流图进行划分,获取至少两个所述目标数据流图。In step S14, a complete data flow graph is obtained; the complete data flow graph includes all nodes corresponding to the target application and links of data flows between all nodes, and the complete data flow graph is used to describe the data in the The logical operation process between all nodes and the links of the data flow among all the nodes; dividing the complete data flow graph to obtain at least two target data flow graphs.
在本实施例中,完整数据流图对应训练好的机器学习模型的整体神经网络,包括目标应用对应的全部节点以及全部节点间的数据流图的链路,该完整数据流图用于描述数据在全部节点和全部节点间的数据流的链路间的逻辑运算过程。完整数据流图中往往包括大量的节点,因此可以对完整数据流图进行划分,获取到至少两个目标数据流图。进而可以筛选出每一个目标数据流图中的关键路径,通过对完整数据流图进行划分,可以快速地确定出各个目标数据流图中关键路径,将每个目标数据流图中的并发分支减少为关键路径,有效的减少目标数据流图对目标执行器的资源占有。需要说明的是,在本实施例中对完整数据流图的划分方式和划分次数不作具体限定,用户可以预先设置划分规则,根据预设划分规则对完整数据流图进行划分,获取至少两个目标数据流图。In this embodiment, the complete data flow graph corresponds to the overall neural network of the trained machine learning model, including all nodes corresponding to the target application and links of the data flow graph between all nodes, and the complete data flow graph is used to describe the data The logical operation process between all nodes and the links of the data flow between all nodes. A complete data flow graph often includes a large number of nodes, so the complete data flow graph can be divided to obtain at least two target data flow graphs. Then, the key paths in each target data flow graph can be filtered out. By dividing the complete data flow graph, the key paths in each target data flow graph can be quickly determined, and the concurrent branches in each target data flow graph can be reduced. It is the critical path, which effectively reduces the resource occupation of the target executor by the target data flow graph. It should be noted that, in this embodiment, the division method and division times of the complete data flow graph are not specifically limited. The user can preset division rules, divide the complete data flow graph according to the preset division rules, and obtain at least two targets. Data flow diagram.
可选地,目标数据流图即为目标应用对应的完整数据流图。具体地,目标数据流图对应完整数据流图还是对应完整数据流图中的一部分,用户可以根据实际应用场景进行选取。Optionally, the target data flow graph is a complete data flow graph corresponding to the target application. Specifically, whether the target data flow graph corresponds to the complete data flow graph or corresponds to a part of the complete data flow graph can be selected by the user according to the actual application scenario.
在一实施例中,所述方法还包括:In one embodiment, the method further includes:
在步骤S15中,设置内存资源共享池,所述内存资源共享池由所述目标数据流图对应的执行器组成,不同执行器内存数据共享,所述执行器包括所述目标执行器。In step S15, a shared memory resource pool is set up, the shared memory resource pool is composed of executors corresponding to the target data flow graph, and memory data is shared among different executors, and the executors include the target executor.
在上述实施例中,设置内存资源共享池,内存资源共享池内的不同执行器可以对内存数据进行共享,从而在不同的执行器中执行相同的内容时,无需在不同的执行器间进行数据的拷贝,而是将通过内存数据共享的方式使得不同的执行器获取该部分的内容,其中不同的执行器代表电子设备内的不同硬件,通过设置内存资源共享池实现不同硬件设备的零拷贝技术,有效减少IO(Input/Output,输入/输出)开销。In the above embodiment, a memory resource shared pool is set up, and different executors in the memory resource shared pool can share memory data, so that when the same content is executed in different executors, there is no need to perform data sharing between different executors. Instead, different executors will obtain the content of this part through memory data sharing. Different executors represent different hardware in the electronic device. By setting the memory resource sharing pool, the zero-copy technology of different hardware devices is realized. Effectively reduce IO (Input/Output, input/output) overhead.
图4是根据一示例性实施例示出的一种数据处理方法的流程图,包括以下步骤:4 is a flowchart of a data processing method according to an exemplary embodiment, including the following steps:
在步骤41中,获取目标应用对应的完整数据流图;对所述完整数据流图进行划分,获取至少两个所述目标数据流图。In step 41, a complete data flow graph corresponding to the target application is obtained; the complete data flow graph is divided to obtain at least two target data flow graphs.
在本步骤中,先获取到目标应用对应的完整数据流图,该完整数据流图结构复杂,为了快速、精细地在完整数据流图中确定出关键路径,对完整数据流图进行划分,获取到至少两个目标数据流图,也就是目标数据流图是完整数据流图中的一部分,需要说明的是,在对完整数据流图进行划分时,可以不只进行一次划分。In this step, the complete data flow graph corresponding to the target application is obtained first. The complete data flow graph has a complex structure. In order to quickly and precisely determine the key path in the complete data flow graph, the complete data flow graph is divided and obtained To at least two target data flow graphs, that is, the target data flow graph is a part of the complete data flow graph, it should be noted that when dividing the complete data flow graph, more than one division may be performed.
在步骤42中,设置内存资源共享池,所述内存资源共享池由所述完整数据流图对应的执行器组成,不同执行器内存数据共享。In step 42, a shared memory resource pool is set up, the shared memory resource pool is composed of executors corresponding to the complete data flow graph, and memory data is shared among different executors.
在本步骤中,为了有效减少数据在不同执行器间的IO开销,设置内存资源共享池,内存资源共享池内的执行器内存数据共享,从而在执行后续步骤时,数据通过共享的方式在不同执行器内进行传递,避免在不同执行器内进行数据拷贝。In this step, in order to effectively reduce the IO overhead of data between different executors, a memory resource sharing pool is set up, and the executors in the memory resource sharing pool share the memory data, so that when the subsequent steps are performed, the data is shared between different executions. The transfer is performed within the executor to avoid data copying in different executors.
在步骤43中,针对每一个所述目标数据流图:确定所述目标数据流图中每一个节点分别对应的关联节点;确定每一个节点分别对应的关联节点与节点间的目标指标;基于所述目标指标,确定所述目标数据流图中各个节点分别对应的性能指标信息。In step 43, for each target data flow graph: determine the associated node corresponding to each node in the target data flow graph; determine the target index between the associated node and the node corresponding to each node; The target index is determined, and the performance index information corresponding to each node in the target data flow graph is determined.
在本步骤中,确定完整数据流图划分出的每一个目标数据流图,针对每一个目标数据流图:确定目标数据流图中每一个节点分别对应的关联节点;确定每一个节点分别对应的关联节点与该节点间的目标指标;将每一个节点分别对应的关联节点与该节点间的目标指标的总和,确定为该节点的性能指标信息。In this step, determine each target data flow graph divided by the complete data flow graph, and for each target data flow graph: determine the associated nodes corresponding to each node in the target data flow graph; The target indicator between the associated node and the node; the sum of the target indicators between the associated node corresponding to each node and the node is determined as the performance indicator information of the node.
在步骤44中,针对每一个目标数据流图:在各个节点中,选取出性能指标信息符合预设性能指标条件的关键节点;在所述节点间的数据流的链路中,选取所述关键节点所在的数据传播路径;在所述数据传播路径中,选取路径长度符合预设路径长度条件的关键节点对应的关键路径;在目标执行器上执行所述关键路径;In step 44, for each target data flow graph: in each node, select the key node whose performance index information meets the preset performance index condition; in the link of the data flow between the nodes, select the key node the data propagation path where the node is located; in the data propagation path, select the critical path corresponding to the key node whose path length meets the preset path length condition; execute the critical path on the target executor;
其中,所述预设性能指标条件包括性能指标信息的最大值或性能指标信息大于第一设定值;所述预设路径长度条件包括路径长度的最大值或路径长度大于第二设定值;所述目标执行器为所述完整数据流图对应的执行器中的至少一个。Wherein, the preset performance index condition includes the maximum value of the performance index information or the performance index information is greater than the first set value; the preset path length condition includes the maximum value of the path length or the path length is greater than the second set value; The target executor is at least one of the executors corresponding to the complete data flow graph.
在本步骤中,通过预设性能指标条件,选取关键节点,通过预设路径长度条件,选取关键路径,选取出的关键路径为目标数据流图全部数据传播路径中的部分路径。通过在目标执行器上执行关键路径,可以避免目标数据流图中关键路径以外的其他节点在目标执行器上执行,有效减少目标数据流图对目标执行器的资源占用,保证目标执行器的执行速度。确定出每一个目标数据流图分别对应的关键路径,从而在整体数据流图中选取出对整体性能存在重要影响的多个关键路径,对多个关键路径利用目标执行器进行执行,避免对执行器的过多占用,并且在不同执行器进行执行时,采用内存共享的方式获取数据,有效减少不同执行器的IO开销。In this step, key nodes are selected according to preset performance index conditions, and key paths are selected according to preset path length conditions, and the selected key paths are part of all data propagation paths in the target data flow graph. By executing the critical path on the target executor, other nodes other than the critical path in the target data flow graph can be prevented from being executed on the target executor, effectively reducing the resource occupation of the target data flow graph on the target executor and ensuring the execution of the target executor. speed. Determine the key paths corresponding to each target data flow graph, so as to select multiple key paths that have an important impact on the overall performance in the overall data flow graph, and use target executors to execute multiple critical paths to avoid execution. Excessive occupation of executors, and when different executors execute, use memory sharing to obtain data, effectively reducing the IO overhead of different executors.
图5是根据一示例性实施例示出的一种数据处理装置的框图。该装置包括信息获取模块51、节点确定模块52、路径确定模块53;Fig. 5 is a block diagram of a data processing apparatus according to an exemplary embodiment. The device includes an
该信息获取模块51,被配置为获取目标应用对应的目标数据流图中各个节点分别对应的性能指标信息,所述目标数据流图包括节点以及所述节点间的数据流的链路,所述目标数据流图用于描述数据在所述节点和所述节点间的数据流的链路间的逻辑运算过程;The
该节点确定模块52,被配置为在所述各个节点中,选取出性能指标信息符合预设性能指标条件的关键节点;The
该路径确定模块53,被配置为在所述节点间的数据流的链路中,选取所述关键节点对应的关键路径,在目标执行器上执行所述关键路径。The
在本公开一示例性实施例中,所述路径确定模块,包括:In an exemplary embodiment of the present disclosure, the path determination module includes:
第一确定单元,被配置为在所述节点间的数据流的链路中,选取所述关键节点所在的数据传播路径;a first determining unit, configured to select a data propagation path where the key node is located in the link of the data flow between the nodes;
第二确定单元,被配置为在所述数据传播路径中,选取路径长度符合预设路径长度条件的关键节点对应的关键路径;所述预设路径长度条件包括路径长度的最大值或路径长度大于设定值。The second determining unit is configured to, in the data propagation path, select a key path corresponding to a key node whose path length meets a preset path length condition; the preset path length condition includes the maximum value of the path length or the path length greater than set value.
在本公开一示例性实施例中,所述信息获取模块,包括:In an exemplary embodiment of the present disclosure, the information acquisition module includes:
第三确定单元,被配置为针对目标应用对应的目标数据流图中每一个节点:确定所述节点对应的关联节点,所述节点与所述关联节点之间存在数据输入关系或数据输出关系;The third determining unit is configured to, for each node in the target data flow graph corresponding to the target application: determine an associated node corresponding to the node, and a data input relationship or a data output relationship exists between the node and the associated node;
第四确定单元,被配置为确定所述关联节点与所述节点间的目标指标;所述目标指标用于指示数据在节点间的执行时间或计算复杂度;a fourth determining unit, configured to determine a target indicator between the associated node and the node; the target indicator is used to indicate the execution time or computational complexity of data between nodes;
第五确定单元,被配置为基于所述目标指标,确定所述目标数据流图中所述节点对应的所述性能指标信息。A fifth determining unit is configured to determine, based on the target indicator, the performance indicator information corresponding to the node in the target data flow graph.
在本公开一示例性实施例中,所述第五确定单元,被配置为将所述关联节点与所述节点间的目标指标的总和,确定为所述节点对应的性能指标信息;In an exemplary embodiment of the present disclosure, the fifth determining unit is configured to determine the sum of the target indicators between the associated node and the node as performance indicator information corresponding to the node;
在本公开一示例性实施例中,所述第五确定单元,被配置为确定所述关联节点对应的预设影响系数;将所述关联节点与所述节点间的目标指标与所述预设影响系数的计算结果,确定为所述节点对应的性能指标信息。In an exemplary embodiment of the present disclosure, the fifth determining unit is configured to determine a preset influence coefficient corresponding to the associated node; compare the target index between the associated node and the node with the preset The calculation result of the influence coefficient is determined as the performance index information corresponding to the node.
在本公开一示例性实施例中,所述装置还包括:流图划分模块;In an exemplary embodiment of the present disclosure, the apparatus further includes: a flow graph division module;
所述流图划分模块被配置为获取完整数据流图;所述完整数据流图包括所述目标应用对应的全部节点以及全部节点间的数据流的链路,所述完整数据流图用于描述数据在所述全部节点和所述全部节点间的数据流的链路间的逻辑运算过程;对所述完整数据流图进行划分,获取至少两个所述目标数据流图。The flow graph dividing module is configured to obtain a complete data flow graph; the complete data flow graph includes all nodes corresponding to the target application and links of data flows between all nodes, and the complete data flow graph is used to describe The logical operation process of the data between the all nodes and the links of the data flow between the all nodes; dividing the complete data flow graph to obtain at least two target data flow graphs.
在本公开一示例性实施例中,所述装置还包括:In an exemplary embodiment of the present disclosure, the apparatus further includes:
共享处理模块,被配置为设置内存资源共享池,所述内存资源共享池由所述目标数据流图对应的执行器组成,不同执行器内存数据共享,所述执行器包括所述目标执行器。The shared processing module is configured to set a memory resource shared pool, the memory resource shared pool is composed of executors corresponding to the target data flow graph, and different executors share memory data, and the executors include the target executors.
关于上述实施例中的装置,其中各个模块执行操作的具体方式已经在有关该方法的实施例中进行了详细描述,此处将不做详细阐述说明。Regarding the apparatus in the above-mentioned embodiment, the specific manner in which each module performs operations has been described in detail in the embodiment of the method, and will not be described in detail here.
图6是根据一示例性实施例示出的一种电子设备的框图。例如,该电子设备600可以是移动电话,计算机,数字广播终端,消息收发设备,游戏控制台,平板设备,医疗设备,健身设备,个人数字助理等。Fig. 6 is a block diagram of an electronic device according to an exemplary embodiment. For example, the
参照图6,电子设备600可以包括以下一个或多个组件:处理组件602,存储器604,电力组件606,多媒体组件608,音频组件610,输入/输出(I/O)的接口612,传感器组件614,以及通信组件616。6,
处理组件602通常控制电子设备600的整体操作,诸如与显示,电话呼叫,数据通信,相机操作和记录操作相关联的操作。处理组件602可以包括一个或多个处理器620来执行指令,以完成上述的方法的全部或部分步骤。此外,处理组件602可以包括一个或多个模块,便于处理组件602和其他组件之间的交互。例如,处理组件602可以包括多媒体模块,以方便多媒体组件608和处理组件602之间的交互。The
存储器604被配置为存储各种类型的数据以支持在电子设备600的操作。这些数据的示例包括用于在电子设备600上操作的任何应用程序或方法的指令,联系人数据,电话簿数据,消息,图片,视频等。存储器604可以由任何类型的易失性或非易失性存储设备或者它们的组合实现,如静态随机存取存储器(SRAM),电可擦除可编程只读存储器(EEPROM),可擦除可编程只读存储器(EPROM),可编程只读存储器(PROM),只读存储器(ROM),磁存储器,快闪存储器,磁盘或光盘。
电源组件606为电子设备600的各种组件提供电力。电源组件606可以包括电源管理系统,一个或多个电源,及其他与为电子设备600生成、管理和分配电力相关联的组件。
多媒体组件608包括在所述电子设备600和用户之间的提供一个输出接口的屏幕。在一些实施例中,屏幕可以包括液晶显示器(LCD)和触摸面板(TP)。如果屏幕包括触摸面板,屏幕可以被实现为触摸屏,以接收来自用户的输入信号。触摸面板包括一个或多个触摸传感器以感测触摸、滑动和触摸面板上的手势。所述触摸传感器可以不仅感测触摸或滑动动作的边界,而且还检测与所述触摸或滑动操作相关的持续时间和压力。在一些实施例中,多媒体组件608包括一个前置摄像头和/或后置摄像头。当电子设备600处于操作模式,如拍摄模式或视频模式时,前置摄像头和/或后置摄像头可以接收外部的多媒体数据。每个前置摄像头和后置摄像头可以是一个固定的光学透镜系统或具有焦距和光学变焦能力。
音频组件610被配置为输出和/或输入音频信号。例如,音频组件610包括一个麦克风(MIC),当电子设备600处于操作模式,如呼叫模式、记录模式和语音识别模式时,麦克风被配置为接收外部音频信号。所接收的音频信号可以被进一步存储在存储器604或经由通信组件616发送。在一些实施例中,音频组件610还包括一个扬声器,用于输出音频信号。
I/O接口612为处理组件602和外围接口模块之间提供接口,上述外围接口模块可以是键盘,点击轮,按钮等。这些按钮可包括但不限于:主页按钮、音量按钮、启动按钮和锁定按钮。The I/
传感器组件614包括一个或多个传感器,用于为电子设备600提供各个方面的状态评估。例如,传感器组件614可以检测到电子设备600的打开/关闭状态,组件的相对定位,例如所述组件为电子设备600的显示器和小键盘,传感器组件614还可以检测电子设备600或电子设备600一个组件的位置改变,用户与电子设备600接触的存在或不存在,电子设备600方位或加速/减速和电子设备600的温度变化。传感器组件614可以包括接近传感器,被配置用来在没有任何的物理接触时检测附近物体的存在。传感器组件614还可以包括光传感器,如CMOS或CCD图像传感器,用于在成像应用中使用。在一些实施例中,该传感器组件614还可以包括加速度传感器,陀螺仪传感器,磁传感器,压力传感器或温度传感器。
通信组件616被配置为便于电子设备600和其他设备之间有线或无线方式的通信。电子设备600可以接入基于通信标准的无线网络,如WiFi,运营商网络(如2G、3G、4G或6G),或它们的组合。在一个示例性实施例中,通信组件616经由广播信道接收来自外部广播管理系统的广播信号或广播相关信息。在一个示例性实施例中,所述通信组件616还包括近场通信(NFC)模块,以促进短程通信。例如,在NFC模块可基于射频识别(RFID)技术,红外数据协会(IrDA)技术,超宽带(UWB)技术,蓝牙(BT)技术和其他技术来实现。
在示例性实施例中,电子设备600可以被一个或多个应用专用集成电路(ASIC)、数字信号处理器(DSP)、数字信号处理设备(DSPD)、可编程逻辑器件(PLD)、现场可编程门阵列(FPGA)、控制器、微控制器、微处理器或其他电子元件实现,用于执行上述数据处理方法。In an exemplary embodiment,
在示例性实施例中,还提供了一种包括指令的存储介质,当所述存储介质中的指令由服务器的处理器执行时,使得服务器能够执行如上述任一方法实施例所述数据处理方法。可选地,存储介质可以是非临时性计算机可读存储介质,例如,所述非临时性计算机可读存储介质可以是ROM、随机存取存储器(RAM)、CD-ROM、磁带、软盘和光数据存储设备等。In an exemplary embodiment, a storage medium including instructions is also provided, when the instructions in the storage medium are executed by the processor of the server, the server can execute the data processing method described in any of the above method embodiments . Alternatively, the storage medium may be a non-transitory computer-readable storage medium, for example, the non-transitory computer-readable storage medium may be ROM, random access memory (RAM), CD-ROM, magnetic tape, floppy disk, and optical data storage equipment, etc.
在示例性实施例中,还提供了一种计算机程序产品,该计算机程序产品包括可读性程序代码,该可读性程序代码可由处理器执行以完成上述数据处理方法。可选地,该程序代码可以存储在电子设备的存储介质中,该存储介质可以是非临时性计算机可读存储介质,例如,所述非临时性计算机可读存储介质可以是ROM、随机存取存储器(RAM)、CD-ROM、磁带、软盘和光数据存储设备等。本领域技术人员在考虑说明书及实践这里公开的公开后,将容易想到本公开的其它实施方案。本申请旨在涵盖本公开的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本公开的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本公开的真正范围和精神由下面的权利要求指出。In an exemplary embodiment, a computer program product is also provided, the computer program product comprising readable program code executable by a processor to perform the above data processing method. Optionally, the program code may be stored in a storage medium of the electronic device, and the storage medium may be a non-transitory computer-readable storage medium, for example, the non-transitory computer-readable storage medium may be a ROM, a random access memory (RAM), CD-ROM, magnetic tape, floppy disk, and optical data storage devices, etc. Other embodiments of the present disclosure will readily occur to those skilled in the art upon consideration of the specification and practice of the disclosure disclosed herein. This application is intended to cover any variations, uses, or adaptations of the present disclosure that follow the general principles of the present disclosure and include common knowledge or techniques in the technical field not disclosed by the present disclosure . The specification and examples are to be regarded as exemplary only, with the true scope and spirit of the disclosure being indicated by the following claims.
应当理解的是,本公开并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本公开的范围仅由所附的权利要求来限制。It is to be understood that the present disclosure is not limited to the precise structures described above and illustrated in the accompanying drawings, and that various modifications and changes may be made without departing from the scope thereof. The scope of the present disclosure is limited only by the appended claims.
Claims (10)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210467924.7ACN114840401A (en) | 2022-04-29 | 2022-04-29 | Data processing method and device, electronic equipment and storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210467924.7ACN114840401A (en) | 2022-04-29 | 2022-04-29 | Data processing method and device, electronic equipment and storage medium |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN114840401Atrue CN114840401A (en) | 2022-08-02 |
Family
ID=82568592
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210467924.7APendingCN114840401A (en) | 2022-04-29 | 2022-04-29 | Data processing method and device, electronic equipment and storage medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114840401A (en) |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101630275A (en)* | 2009-07-31 | 2010-01-20 | 清华大学 | Realizing method of configuration information for generating cycle task and device thereof |
| CN104239141A (en)* | 2014-09-05 | 2014-12-24 | 北京邮电大学 | Task optimized-scheduling method in data center on basis of critical paths of workflow |
| CN106506188A (en)* | 2015-09-08 | 2017-03-15 | 阿里巴巴集团控股有限公司 | A kind of method and apparatus for determining key node |
| CN110058932A (en)* | 2019-04-19 | 2019-07-26 | 中国科学院深圳先进技术研究院 | A kind of storage method and storage system calculated for data flow driven |
| US20220121967A1 (en)* | 2020-10-15 | 2022-04-21 | Sas Institute Inc. | Automatically generating rules for event detection systems |
- 2022
- 2022-04-29CNCN202210467924.7Apatent/CN114840401A/enactivePending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101630275A (en)* | 2009-07-31 | 2010-01-20 | 清华大学 | Realizing method of configuration information for generating cycle task and device thereof |
| CN104239141A (en)* | 2014-09-05 | 2014-12-24 | 北京邮电大学 | Task optimized-scheduling method in data center on basis of critical paths of workflow |
| CN106506188A (en)* | 2015-09-08 | 2017-03-15 | 阿里巴巴集团控股有限公司 | A kind of method and apparatus for determining key node |
| CN110058932A (en)* | 2019-04-19 | 2019-07-26 | 中国科学院深圳先进技术研究院 | A kind of storage method and storage system calculated for data flow driven |
| US20220121967A1 (en)* | 2020-10-15 | 2022-04-21 | Sas Institute Inc. | Automatically generating rules for event detection systems |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR20210050485A (en) | Method and device for compressing neural network model, method and device for corpus translation, electronic device, program and recording medium | |
| CN113032112A (en) | Resource scheduling method and device, electronic equipment and storage medium | |
| CN109858614B (en) | Neural network training method and device, electronic equipment and storage medium | |
| CN112668707B (en) | Operation method, device and related product | |
| CN110297970B (en) | Information recommendation model training method and device | |
| CN111582432B (en) | Network parameter processing method and device | |
| CN113268325A (en) | Method, device and storage medium for scheduling task | |
| CN113064739B (en) | Inter-thread communication method, device, electronic device and storage medium | |
| CN115098107B (en) | Code generation method and device for neural network tasks | |
| CN112766498B (en) | Model training method and device | |
| CN113110931A (en) | Kernel operation optimization method, device and system | |
| CN107480773B (en) | Method, device and storage medium for training convolutional neural network model | |
| CN111259675B (en) | Neural network calculation-based method and device | |
| CN119473531A (en) | Distributed task scheduling method, device, system, electronic device and storage medium | |
| CN110163372B (en) | Operation method, device and related product | |
| CN108563487B (en) | User interface updating method and device | |
| CN115512116B (en) | Image segmentation model optimization method and device, electronic equipment and readable storage medium | |
| CN110909886B (en) | A machine learning network operation method, device and medium | |
| CN114840401A (en) | Data processing method and device, electronic equipment and storage medium | |
| CN111198760B (en) | A data processing method and device | |
| CN108984294A (en) | Resource regulating method, device and storage medium | |
| CN115953710A (en) | Behavior recognition method and device, electronic equipment and storage medium | |
| CN114265960A (en) | Query condition analysis method and device and electronic equipment | |
| CN114022248A (en) | Product recommendation calculation method, device and equipment | |
| CN108427568B (en) | User interface updating method and device |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |