CN114816742A - Request processing method and device, electronic equipment and storage medium - Google Patents
Request processing method and device, electronic equipment and storage mediumDownload PDFInfo
- Publication number
- CN114816742A CN114816742ACN202210402668.3ACN202210402668ACN114816742ACN 114816742 ACN114816742 ACN 114816742ACN 202210402668 ACN202210402668 ACN 202210402668ACN 114816742 ACN114816742 ACN 114816742A
- Authority
- CN
- China
- Prior art keywords
- request
- processing
- component
- intermediate data
- model
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images











Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5005—Allocation of resources, e.g. of the central processing unit [CPU] to service a request
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5005—Allocation of resources, e.g. of the central processing unit [CPU] to service a request
- G06F9/5027—Allocation of resources, e.g. of the central processing unit [CPU] to service a request the resource being a machine, e.g. CPUs, Servers, Terminals
Landscapes
- Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本公开涉及计算机技术领域,尤其涉及深度学习、智能搜索等人工智能技术领域以及芯片技术领域。The present disclosure relates to the field of computer technology, and in particular to the field of artificial intelligence technology such as deep learning and intelligent search, and the field of chip technology.
背景技术Background technique
随着计算机技术的发展,需要计算机处理的数据也越来越多,处理难度越来越大,为了满足用户日益增长的使用需求,请求处理技术也不断面临着新的挑战。因此,如何更加高效的对接收到的请求进行处理并得到对应的处理结果,就成为需要解决的问题。With the development of computer technology, more and more data needs to be processed by computers, and the processing difficulty is becoming more and more difficult. In order to meet the increasing demands of users, the request processing technology is constantly facing new challenges. Therefore, how to process the received request more efficiently and obtain the corresponding processing result becomes a problem that needs to be solved.
发明内容SUMMARY OF THE INVENTION
本公开提供了一种请求处理方法、装置、电子设备及存储介质。The present disclosure provides a request processing method, apparatus, electronic device and storage medium.
根据本公开的第一方面,提供了一种请求处理方法,包括:According to a first aspect of the present disclosure, a request processing method is provided, comprising:
在控制第一部件第i次处理第一请求的过程中,控制第二部件第k次处理第二请求;i、k为大于1的整数;In the process of controlling the first component to process the first request for the i-th time, the second component is controlled to process the second request for the k-th time; i and k are integers greater than 1;
在确定第一部件第i次处理第一请求得到第一请求的第i个中间数据的情况下,控制第二部件根据第i个中间数据第i+1次处理第一请求,得到第一请求的第i+1个中间数据;In the case of determining that the first component processes the first request for the i-th time to obtain the i-th intermediate data of the first request, the second component is controlled to process the first request for the i+1-th time according to the i-th intermediate data to obtain the first request. The i+1th intermediate data of ;
根据第一请求的第i+1个中间数据,得到第一请求的处理结果,并根据第二部件第k次处理第二请求得到的第二请求的第k个中间数据,得到第二请求的处理结果。According to the i+1 th intermediate data of the first request, the processing result of the first request is obtained, and according to the k th intermediate data of the second request obtained by the second component processing the second request for the k th time, the second request is obtained. process result.
根据本公开的第二方面,提供了一种请求处理装置,包括:According to a second aspect of the present disclosure, there is provided a request processing apparatus, comprising:
第一处理模块,用于在控制第一部件第i次处理第一请求的过程中,控制第二部件第k次处理第二请求;i、k为大于1的整数;a first processing module, configured to control the second component to process the second request for the kth time during the process of controlling the first component to process the first request for the i-th time; i and k are integers greater than 1;
第二处理模块,用于在确定第一部件第i次处理第一请求得到第一请求的第i个中间数据的情况下,控制第二部件根据第i个中间数据第i+1次处理第一请求,得到第一请求的第i+1个中间数据;The second processing module is configured to control the second component to process the i-th intermediate data i+1-th time according to the i-th intermediate data when it is determined that the first component processes the first request for the i-th time to obtain the i-th intermediate data of the first request. One request, obtain the i+1 th intermediate data of the first request;
第一处理结果模块,用于根据第一请求的第i+1个中间数据,得到第一请求的处理结果;a first processing result module, configured to obtain the processing result of the first request according to the i+1 th intermediate data of the first request;
第二处理结果模块,用于根据第二部件第k次处理第二请求得到的第二请求的第k个中间数据,得到第二请求的处理结果。The second processing result module is configured to obtain the processing result of the second request according to the k-th intermediate data of the second request obtained by the second component processing the second request for the k-th time.
根据本公开的第三方面,提供了一种电子设备,包括:According to a third aspect of the present disclosure, there is provided an electronic device, comprising:
至少一个处理器;以及at least one processor; and
与该至少一个处理器通信连接的存储器;其中,a memory communicatively coupled to the at least one processor; wherein,
该存储器存储有可被该至少一个处理器执行的指令,该指令被该至少一个处理器执行,以使该至少一个处理器能够执行前述第一方面的信息展示方法。The memory stores instructions executable by the at least one processor, the instructions being executed by the at least one processor to enable the at least one processor to perform the information presentation method of the aforementioned first aspect.
根据本公开的第四方面,提供了一种存储有计算机指令的非瞬时计算机可读存储介质,该计算机指令用于使该计算机执行前述方法。According to a fourth aspect of the present disclosure, there is provided a non-transitory computer-readable storage medium storing computer instructions for causing the computer to perform the aforementioned method.
根据本公开的第五方面,提供了一种计算机程序产品,包括计算机程序,该计算机程序在被处理器执行时实现前述方法。According to a fifth aspect of the present disclosure, there is provided a computer program product comprising a computer program which, when executed by a processor, implements the aforementioned method.
应当理解,本部分所描述的内容并非旨在标识本公开的实施例的关键或重要特征,也不用于限制本公开的范围。本公开的其它特征将通过以下的说明书而变得容易理解。It should be understood that what is described in this section is not intended to identify key or critical features of embodiments of the disclosure, nor is it intended to limit the scope of the disclosure. Other features of the present disclosure will become readily understood from the following description.
本实施例提供的方案,能够在控制第一部件处理第一请求得到第一请求的中间数据的过程中,同步制第二部件第k次处理第二请求,从而可将不同的请求先后输入第一部件或第二部件,控制第一部件和第二部件并行执行请求处理操作,提高请求处理效率和处理资源的利用率。In the solution provided by this embodiment, in the process of controlling the first component to process the first request to obtain the intermediate data of the first request, the second component can be synchronized to process the second request for the kth time, so that different requests can be input into the first request successively. A component or a second component controls the first component and the second component to execute request processing operations in parallel, so as to improve request processing efficiency and processing resource utilization.
附图说明Description of drawings
附图用于更好地理解本方案,不构成对本公开的限定。其中:The accompanying drawings are used for better understanding of the present solution, and do not constitute a limitation to the present disclosure. in:
图1是根据本公开一实施例的请求处理方法的流程示意图;1 is a schematic flowchart of a request processing method according to an embodiment of the present disclosure;
图2是根据本公开另一实施例的请求处理方法的流程示意图;2 is a schematic flowchart of a request processing method according to another embodiment of the present disclosure;
图3是根据本公开另一实施例的请求处理方法的流程另一示意图;3 is another schematic flow chart of a request processing method according to another embodiment of the present disclosure;
图4是根据本公开一示例的目标模型示意图;4 is a schematic diagram of a target model according to an example of the present disclosure;
图5是根据本公开一示例的单卡执行示意图;5 is a schematic diagram of a single card execution according to an example of the present disclosure;
图6是根据本公开一示例的两个流水线阶段示意图;6 is a schematic diagram of two pipeline stages according to an example of the present disclosure;
图7A、7B是顺序执行和采用本公开实施例提供的方法执行的效率对比示意图;7A and 7B are schematic diagrams illustrating the efficiency comparison between sequential execution and execution using the method provided by an embodiment of the present disclosure;
图8是根据本公开一实施例的请求处理装置的一种组成结构示意图;FIG. 8 is a schematic diagram of a composition structure of a request processing apparatus according to an embodiment of the present disclosure;
图9是根据本公开一实施例的请求处理装置的另一种组成结构示意图;9 is a schematic diagram of another composition structure of a request processing apparatus according to an embodiment of the present disclosure;
图10是根据本公开另一实施例的请求处理装置的一种组成结构示意图;FIG. 10 is a schematic diagram of a composition structure of a request processing apparatus according to another embodiment of the present disclosure;
图11是根据本公开另一实施例的请求处理装置的另一种组成结构示意图;11 is a schematic diagram of another composition structure of a request processing apparatus according to another embodiment of the present disclosure;
图12是根据本公开又一实施例的请求处理装置的一种组成结构示意图;FIG. 12 is a schematic diagram of a composition structure of a request processing apparatus according to another embodiment of the present disclosure;
图13是根据本公开又一实施例的请求处理装置的另一种组成结构示意图;13 is a schematic diagram of another composition structure of a request processing apparatus according to another embodiment of the present disclosure;
图14是用来实现本公开实施例的请求处理方法的电子设备的框图。FIG. 14 is a block diagram of an electronic device used to implement the request processing method of an embodiment of the present disclosure.
具体实施方式Detailed ways
以下结合附图对本公开的示范性实施例做出说明,其中包括本公开实施例的各种细节以助于理解,应当将它们认为仅仅是示范性的。因此,本领域普通技术人员应当认识到,可以对这里描述的实施例做出各种改变和修改,而不会背离本公开的范围和精神。同样,为了清楚和简明,以下的描述中省略了对公知功能和结构的描述。Exemplary embodiments of the present disclosure are described below with reference to the accompanying drawings, which include various details of the embodiments of the present disclosure to facilitate understanding and should be considered as exemplary only. Accordingly, those of ordinary skill in the art will recognize that various changes and modifications of the embodiments described herein can be made without departing from the scope and spirit of the present disclosure. Also, descriptions of well-known functions and constructions are omitted from the following description for clarity and conciseness.
本公开第一方面实施例提供一种请求处理方法,如图1所示,包括:An embodiment of the first aspect of the present disclosure provides a request processing method, as shown in FIG. 1 , including:
步骤S101:在控制第一部件第i次处理第一请求的过程中,控制第二部件第k次处理第二请求;i、k为大于1的整数;Step S101: in the process of controlling the first component to process the first request for the i-th time, control the second component to process the second request for the k-th time; i and k are integers greater than 1;
步骤S102:在确定第一部件第i次处理第一请求得到第一请求的第i个中间数据的情况下,控制第二部件根据第i个中间数据第i+1次处理第一请求,得到第一请求的第i+1个中间数据;Step S102: In the case where it is determined that the first component processes the first request for the i-th time to obtain the i-th intermediate data of the first request, control the second component to process the first request for the i+1-th time according to the i-th intermediate data, and obtain: i+1 intermediate data of the first request;
步骤S103:根据第一请求的第i+1个中间数据,得到第一请求的处理结果,并根据第二部件第k次处理第二请求得到的第二请求的第k个中间数据,得到第二请求的处理结果。Step S103: Obtain the processing result of the first request according to the i+1-th intermediate data of the first request, and obtain the k-th intermediate data of the second request obtained by processing the second request for the k-th time by the second component. 2. The processing result of the request.
本实施例提供的方案可以应用于电子设备,尤其是终端设备,比如个人电脑、平板电脑、手机等等。The solution provided in this embodiment can be applied to electronic devices, especially terminal devices, such as personal computers, tablet computers, mobile phones, and the like.
上述第一部件可以是用于处理数据的资源,可以包括软件资源,比如算子;也可以包括多种资源,比如算子和算子对应的运行空间。前述运行空间可以通过处理器提供,比如CPU(Central Processing Unit,中央处理单元)、GPU(Graphics Processing Unit,图形处理单元)、MCU(Microcontroller Unit,微控制单元)等。The above-mentioned first component may be a resource for processing data, and may include software resources, such as operators; and may also include multiple resources, such as operators and operating spaces corresponding to the operators. The aforementioned running space may be provided by a processor, such as a CPU (Central Processing Unit, central processing unit), a GPU (Graphics Processing Unit, graphics processing unit), an MCU (Microcontroller Unit, micro control unit), and the like.
上述第一部件也可以是硬件,比如CPU(Central Processing Unit,中央处理单元)、GPU(Graphics Processing Unit,图形处理单元)、MCU(Microcontroller Unit,微控制单元)等The above-mentioned first component may also be hardware, such as CPU (Central Processing Unit, central processing unit), GPU (Graphics Processing Unit, graphics processing unit), MCU (Microcontroller Unit, micro control unit), etc.
在本公开所有实施例中,第一请求的处理过程可以与第二请求的处理过程相同。In all embodiments of the present disclosure, the processing procedure of the first request may be the same as the processing procedure of the second request.
上述第二部件可以是与第一部件种类、结构相同的其它处理部件,比如,第一部件和第二部件均是CPU。上述第一请求每次经过一个部件处理,即可产生一个第一请求的中间结果。在接收到最初未经处理的第一请求的情况下,可控制第一部件对第一请求执行第1次处理,得到第一请求的第1个中间数据。The above-mentioned second component may be other processing components of the same type and structure as the first component, for example, both the first component and the second component are CPUs. Each time the first request is processed by one component, an intermediate result of the first request can be generated. In the case of receiving the first unprocessed first request, the first component can be controlled to perform the first processing on the first request to obtain the first intermediate data of the first request.
在另一种可能的实现方式中,控制第一部件第i次处理第一请求,可以是控制第一部件第1次处理第一请求。控制第一部件第i次处理第一请求,也可以是控制第一部件基于其他部件处理第一请求产生的第一请求的中间数据,处理第一请求。In another possible implementation manner, controlling the first component to process the first request for the i-th time may be controlling the first component to process the first request for the first time. Controlling the first component to process the first request for the i-th time may also be controlling the first component to process the first request based on the intermediate data of the first request generated by other components processing the first request.
在一种实现方式中,仅存在第一部件、第二部件的情况下,第一请求、第二请求分别需要依次经过第一部件、第二部件的处理。可以控制第一部件按照第一请求的处理流程的第一阶段步骤,对第一请求进行处理,得到第一请求的第1个中间数据,控制第二部件按照第一请求处理流程的第二阶段步骤,基于第一请求的第1个中间数据,对第一请求进行第2次处理,得到第一请求的第2个中间数据。In an implementation manner, when only the first component and the second component exist, the first request and the second request respectively need to be processed by the first component and the second component in sequence. The first component can be controlled to process the first request according to the first stage steps of the processing flow of the first request to obtain the first intermediate data of the first request, and the second component can be controlled according to the second stage of the processing flow of the first request In the step, based on the first intermediate data of the first request, perform the second processing on the first request to obtain the second intermediate data of the first request.
在一种实现方式中,第一部件对第一请求执行的操作,和第二部件对第一请求执行的操作,可以为处理第一请求过程中的两部分时序相邻的操作。In an implementation manner, the operation performed by the first component on the first request and the operation performed by the second component on the first request may be two operations in the process of processing the first request that are adjacent in time sequence.
在其它实现方式中,可存在更多的部件,同理,也可以使得其它部件和第一部件、第二部件同步处理多个请求。比如,可在同一个处理时间段内,同步控制第一部件处理第一请求、控制第二部件处理第二请求、控制第三部件处理第三请求。In other implementation manners, there may be more components, and similarly, other components may be made to process multiple requests synchronously with the first component and the second component. For example, in the same processing time period, the first component may be controlled to process the first request, the second component may be controlled to process the second request, and the third component may be controlled to process the third request.
在其它实现方式中,如果存在更多的部件,第一部件并不一定指时序上第一阶段的操作对应的部件,第二部件也并不一定指时序上第二阶段操作对应的部件。In other implementation manners, if there are more components, the first component does not necessarily refer to the component corresponding to the operation in the first stage in timing, and the second component does not necessarily refer to the component corresponding to the operation in the second stage in timing.
示例性的,可控制第一部件、第二部件分别执行第一请求处理过程中时序相邻的两个处理阶段的操作。比如,从第一请求到第一请求的处理结果,需要经过A、B、C、D等阶段,可以控制第一部件执行A阶段,控制第二部件执行B阶段。或者,可以控制第一部件执行B阶段,控制第二部件执行C阶段。或者,可以控制第一部件执行D阶段,控制第二部件执行C阶段。Exemplarily, the first component and the second component may be controlled to respectively execute operations in two processing stages adjacent in time sequence in the first request processing process. For example, from the first request to the processing result of the first request, it needs to go through stages A, B, C, D, etc., the first component can be controlled to execute the A stage, and the second component can be controlled to execute the B stage. Alternatively, the first component may be controlled to perform phase B and the second component may be controlled to perform phase C. Alternatively, the first component may be controlled to perform phase D and the second component may be controlled to perform phase C.
在本公开实施例控制多个部件处理请求的情况下,任意两个用于处理相邻时序的处理阶段的部件,可按照图1所示的第一部件和第二部件的步骤处理请求并得出相应的中间数据。In the case where the embodiment of the present disclosure controls multiple components to process requests, any two components used to process processing stages of adjacent time sequences can process requests according to the steps of the first component and the second component shown in FIG. 1 and obtain output the corresponding intermediate data.
在一种可能的实现方式中,第一部件和第二部件所分别执行的两个相邻时序的处理阶段,可以通过对第一请求或第二请求的处理过程进行切分获得。In a possible implementation manner, the processing stages of two adjacent time sequences executed by the first component and the second component respectively may be obtained by dividing the processing process of the first request or the second request.
在一种可能的实现方式中,由于第一部件和第二部件所分别执行的两个相邻时序的处理阶段,第一部件对第一请求的处理可能依赖于第二部件对第一请求的上次处理的中间结果,或者第二部件对第一请求的处理可能依赖于第一部件对第一请求的上次处理的中间结果。In a possible implementation manner, due to the processing stages of two adjacent time sequences executed by the first component and the second component respectively, the processing of the first request by the first component may depend on the processing of the first request by the second component. The intermediate result of the last processing, or the processing of the first request by the second component, may depend on the intermediate result of the last processing of the first request by the first component.
在另一种可能的实现方式中,如果将第一请求或第二请求的处理过程切分为两个子过程,则每个子过程对应一个操作,第一部件可以用于处理其中一个子过程对应的操作,第二部件可以用于处理另一个子过程对应的操作。In another possible implementation manner, if the processing process of the first request or the second request is divided into two sub-processes, each sub-process corresponds to an operation, and the first component can be used to process the corresponding operation of one of the sub-processes. operation, the second component can be used to process the operation corresponding to another sub-process.
示例性的,在控制第一部件第i次处理第一请求的过程中,控制第二部件第k次处理第二请求,可以是指控制第一部件第i次处理第一请求的过程和第二部件第k次处理第二请求的过程至少部分并行,并行部分的时间比超过设定阈值。比如,设定阈值为x%(x可以大于0),第一部件处理第i次处理第一请求得到第一请求的第i个中间数据的时长为X1,第二部件第k次处理处理第二请求得到第二请求的第k个中间数据的时长为X2,则可以选择X1、X2中较小值,乘以x%,得到第一部件处理第一请求的过程和第二部件处理第二请求的过程同步进行的具体时长。Exemplarily, in the process of controlling the first component to process the first request for the i-th time, controlling the second component to process the second request for the k-th time may refer to the process of controlling the first component to process the first request for the i-th time and the process of controlling the first component to process the first request for the i-th time. The process of processing the second request by the two components for the kth time is at least partially parallel, and the time ratio of the parallel part exceeds the set threshold. For example, if the threshold is set to x% (x can be greater than 0), the time for the first component to process the i-th first request to obtain the i-th intermediate data of the first request is X1, and the second component to process the k-th time to process the i-th intermediate data The duration of the second request to obtain the kth intermediate data of the second request is X2, then you can select the smaller value of X1 and X2, multiply by x%, and obtain the process of the first component processing the first request and the second component processing the second The specific length of time that the requested process is synchronized.
示例性的,可以控制第一部件和第二部件执行一个请求处理模块的子模块的步骤。前述请求处理模块比如可以是模型、函数等,前述请求处理模块可以具备固定的用于接收输入数据的输入子模块,第一请求和第二请求可以是先后输入到输入子模块的数据,请求处理模块可以根据第一请求和第二请求分别执行对应的子模块的步骤,得到对应的请求处理结果。Illustratively, the first component and the second component may be controlled to execute the steps of a submodule of the request processing module. The aforementioned request processing module may be, for example, a model, a function, etc. The aforementioned request processing module may have a fixed input sub-module for receiving input data, and the first request and the second request may be data input to the input sub-module successively. The module may execute the steps of the corresponding sub-modules according to the first request and the second request, respectively, to obtain the corresponding request processing result.
本实施例中,可以控制第二部件执行第一部件对应的请求处理阶段之后相邻时序的处理阶段。这种情况下,可在控制第一部件第i次处理完毕第一请求,得到第一请求的第i个中间数据时,触发第二部件,控制第二部件第i+1次处理第一请求。示例性的,可在产生第一请求的第i个中间数据时,将第一请求的第i个中间数据存入指定存储地址,在该存储地址中存入新的数据时,可产生用于触发第二部件的信息,使得能够控制第二部件在当前任务结束后立即基于新存入的数据进行请求的处理。In this embodiment, the second component may be controlled to execute the processing phase of the adjacent sequence after the request processing phase corresponding to the first component. In this case, when the first component is controlled to process the first request for the i-th time, and the i-th intermediate data of the first request is obtained, the second component can be triggered to control the second component to process the first request for the i+1-th time. . Exemplarily, when the i-th intermediate data of the first request is generated, the i-th intermediate data of the first request can be stored in a specified storage address, and when new data is stored in the storage address, a data for The information that triggers the second component makes it possible to control the second component to perform the requested processing based on the newly stored data immediately after the current task ends.
在一种可能的实现方式中,可在产生第一请求的第i个中间数据时,产生用于触发第二部件的信息,使得能够控制第二部件在当前任务结束后立即基于第一请求的第i个中间数据对第一请求进行处理。In a possible implementation manner, information for triggering the second component may be generated when the i-th intermediate data of the first request is generated, so that the second component can be controlled based on the first request immediately after the end of the current task. The i-th intermediate data processes the first request.
在另一种具体实现方式中,根据第一请求的第i+1个中间数据,得到第一请求的处理结果,可以是对第一请求的第i+1个中间数据再次执行类似步骤S101-S103的操作,经过至少一次循环后,得到第一请求的处理结果。In another specific implementation manner, to obtain the processing result of the first request according to the i+1 th intermediate data of the first request, it may be that similar steps S101- are performed again on the i+1 th intermediate data of the first request. In the operation of S103, after at least one cycle, the processing result of the first request is obtained.
在另一种具体实现方式中,根据第一请求的第i+1个中间数据,得到第一请求的处理结果,可以是将第一请求的第i+1个中间数据直接作为第一请求处理结果,或者作为第一请求处理结果的一部分。In another specific implementation manner, to obtain the processing result of the first request according to the i+1 th intermediate data of the first request, the i+1 th intermediate data of the first request may be directly processed as the first request result, or as part of the first request processing result.
在另一种具体实现方式中,控制第二部件根据第i个中间数据第i+1次处理第一请求的过程中,可以控制第一部件第n次处理第三请求。或者,控制第二部件根据第i个中间数据第i+1次处理第一请求的过程中,可以控制第一部件第k+1次处理第二请求。In another specific implementation manner, in the process of controlling the second component to process the first request for the i+1th time according to the i-th intermediate data, the first component may be controlled to process the third request for the nth time. Alternatively, in the process of controlling the second component to process the first request for the i+1th time according to the i-th intermediate data, the first component may be controlled to process the second request for the k+1th time.
本公开实施例提供的方法,可以应用于深度学习模型、机器学习模型,还可以应用于其它具有数据计算、转换、解析等功能的请求处理模块。前述深度学习模型、机器学习模型可以是天气预测模型、生物生长预测模型、交通流量预测模型、用户喜好预测模型等预测类别的模型,也可以是文本处理模型、数值处理模型等分析类的模型,还可以是音频、视频处理模型,或者是其它根据输入数据生成输出数据的模型。The methods provided by the embodiments of the present disclosure can be applied to deep learning models, machine learning models, and other request processing modules with functions such as data calculation, conversion, and analysis. The aforementioned deep learning models and machine learning models may be models of prediction categories such as weather prediction models, biological growth prediction models, traffic flow prediction models, and user preference prediction models, or may be analytical models such as text processing models and numerical processing models. It can also be an audio, video processing model, or other models that generate output data from input data.
在本公开的方法应用于模型的情况下,可控制第一部件、第二部件执行相邻时序的模型阶段,相邻时序的模型阶段可根据模型内部的层、层间关系、层所包括的算子或函数生成。第一请求的处理结果可以是模型根据第一请求输出的结果。When the method of the present disclosure is applied to a model, the first component and the second component can be controlled to execute model stages of adjacent time sequences, and the model stages of adjacent time sequences can Operator or function generation. The processing result of the first request may be a result output by the model according to the first request.
可以看出,通过上述方案,能够在控制第一部件处理第一请求得到第一请求的中间数据的过程中,同步制第二部件第k次处理第二请求,从而可将不同的请求先后输入第一部件或第二部件,控制第一部件和第二部件并行执行请求处理操作,提高请求处理效率和部件等请求处理资源在单位时间内的利用率,在需要处理的请求量较大的情况下,具有更为显著的效率提升效果。It can be seen that, through the above solution, in the process of controlling the first component to process the first request to obtain the intermediate data of the first request, the second component can be synchronized to process the second request for the kth time, so that different requests can be input successively The first component or the second component controls the first component and the second component to perform request processing operations in parallel, so as to improve the request processing efficiency and the utilization rate of request processing resources such as components within a unit time. In the case of a large amount of requests to be processed It has a more significant efficiency improvement effect.
在一种实施方式中,根据第一请求的第i+1个中间数据,得到第一请求的处理结果,包括:In one embodiment, the processing result of the first request is obtained according to the i+1 th intermediate data of the first request, including:
根据第一请求的第i+1个中间数据,确定第一请求的循环处理次数;According to the i+1 th intermediate data of the first request, determine the cycle processing times of the first request;
在循环处理次数达到预设的循环阈值的情况下,将第一请求的第i+1个中间数据作为第一请求的处理结果。When the number of loop processing times reaches the preset loop threshold value, the i+1 th intermediate data of the first request is used as the processing result of the first request.
可见,通过上述实施例,能够将并行的处理方式应用于请求的循环处理过程中,使得在一个请求的循环处理过程中,可同时并行处理其它请求,进一步提高请求的处理效率。It can be seen that through the above embodiments, the parallel processing method can be applied to the cyclic processing process of requests, so that in the cyclic processing process of one request, other requests can be processed in parallel at the same time, thereby further improving the processing efficiency of requests.
在一种实施方式中,请求处理方法还包括:In one embodiment, the request processing method further includes:
在循环处理次数未达到预设的循环阈值的情况下,控制第一部件和第二部件,根据第一请求的第i+1个中间数据更新循环处理次数。When the number of loop processing times does not reach the preset loop threshold value, the first component and the second component are controlled to update the number of loop processing times according to the i+1 th intermediate data of the first request.
在更新循环处理次数之后,可以继续对第一请求执行循环处理。循环处理此处更新之后的循环处理的过程仍然可以与图1所示的过程类似,或者包括图1所示的步骤。After the loop processing number is updated, loop processing may continue to be performed on the first request. The cyclic processing process of the cyclic processing after the update here can still be similar to the process shown in FIG. 1 , or include the steps shown in FIG. 1 .
可见,本实施例中,能够将并行的处理方式应用于请求的循环处理过程中,使得在一个请求的循环处理过程中,可同时并行处理其它请求,进一步提高请求的处理效率。It can be seen that in this embodiment, the parallel processing method can be applied to the cyclic processing process of requests, so that in the cyclic processing process of one request, other requests can be processed in parallel at the same time, thereby further improving the processing efficiency of requests.
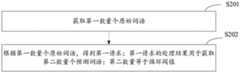
在一种实施方式中,如图2所示,请求处理方法还包括:In one embodiment, as shown in Figure 2, the request processing method further includes:
步骤S201:获取第一数量个原始词语;Step S201: obtaining the first number of original words;
步骤S202:根据第一数量个原始词语,得到第一请求;第一请求的处理结果用于获取第二数量个预测词语;第二数量等于循环阈值。Step S202: Obtain a first request according to the first number of original words; the processing result of the first request is used to obtain a second number of predicted words; the second number is equal to the cycle threshold.
在本公开实施例中,第二请求的处理过程、产生过程均可以与第一请求类似或相同。In this embodiment of the present disclosure, the processing process and the generating process of the second request may be similar to or the same as those of the first request.
在第二数量等于循环阈值的情况下,每次循环处理过程中,控制部件执行最后一个请求处理的阶段后,可生成一个预测词;从而,在循环次数达到循环阈值后,可以生成等同于循环阈值的数量的预测词语。In the case where the second number is equal to the loop threshold, during each loop process, the control unit may generate a predictor after the stage of the last request processing; thus, after the number of loops reaches the loop threshold, a prediction word equivalent to the loop may be generated Threshold number of predicted words.
可见,通过上述实施例,能够根据一定数量个原始词语,生成另一数量的预测词语,从而在文本处理的过程中,实现根据已有词语生成预测词语的目的。通过本实施例,在文本处理的过程中,可同时对不同的原始词语生成的原始数据进行处理,提高文本处理的效率。It can be seen that through the above embodiment, another number of predicted words can be generated according to a certain number of original words, so that the purpose of generating predicted words according to existing words is achieved in the process of text processing. Through this embodiment, in the process of text processing, the original data generated by different original words can be processed at the same time, thereby improving the efficiency of text processing.
在一种实施方式中,控制第一部件第i次处理第一请求,包括控制第一部件通过第一模型层第i次处理第一请求;第一模型层为目标模型中至少一个模型层中的一个;In an implementation manner, controlling the first component to process the first request for the i-th time includes controlling the first component to process the first request through the first model layer for the i-th time; the first model layer is at least one model layer in the target model. one of;
控制第二部件第k次处理第二请求,包括:控制第二部件通过第二模型层第k次处理第二请求;第二模型层为目标模型中至少一个模型层中之一,第二模型层与第一模型层不同。Controlling the second component to process the second request for the kth time includes: controlling the second component to process the second request for the kth time through the second model layer; the second model layer is one of at least one model layer in the target model, and the second model layer layer is different from the first model layer.
上述目标模型可以为生成类型的模型,即用于根据输入的原始数据生成用户需要的输出结果,比如各类预测模型、图像处理模型、文字处理模型等深度学习模型或机器学习模型。The above target model may be a generation type model, that is, it is used to generate the output results required by the user according to the input raw data, such as various prediction models, image processing models, word processing models and other deep learning models or machine learning models.
示例性的,目标模型可以切分为多个模型层,每个模型层部署于一个部件上。或者将目标模型的一部分切分为多个模型层,每个模型层部署于一个部件上。Exemplarily, the target model can be divided into multiple model layers, and each model layer is deployed on a component. Or split a portion of the target model into multiple model layers, each of which is deployed on a component.
示例性的,至少一个模型层为M个模型层。Exemplarily, at least one model layer is M model layers.
示例性的,目标模型用于对需要处理的请求执行循环处理操作,或者目标模型中的一部分用于对需要处理的请求执行循环处理操作。Exemplarily, the target model is used to perform cyclic processing operations on requests that need to be processed, or a part of the target model is used to perform cyclic processing operations on requests that need to be processed.
通过本实施例,能够使得目标模型中用于对请求执行循环处理操作的至少部分层并行处理不同的请求的中间数据,在提高部件利用率的同时,提高目标模型处理请求的效率。同时本实施例能够将目标模型切分为多个模型层,当目标模型体积增大时,也能够在提高模型处理效率的同时降低模型部署难度。This embodiment enables at least some layers in the target model for performing cyclic processing operations on requests to process the intermediate data of different requests in parallel, thereby improving the efficiency of the target model processing requests while improving the utilization of components. At the same time, in this embodiment, the target model can be divided into multiple model layers, and when the volume of the target model increases, the difficulty of model deployment can also be reduced while improving the model processing efficiency.
在一种实施方式中,如图3所示,请求处理方法还包括:In one embodiment, as shown in Figure 3, the request processing method further includes:
步骤S301:根据原始模型所包括的请求处理算子以及不同的请求处理算子之间的关系,得到原始模型的算子图;Step S301: Obtain an operator graph of the original model according to the request processing operators included in the original model and the relationship between different request processing operators;
步骤S302:根据原始模型的算子图,删除请求处理算子中的冗余算子,或根据原始模型的算子图,合并请求处理算子中的重复算子,得到处理后的算子图;Step S302: Delete redundant operators in the request processing operators according to the operator graph of the original model, or merge duplicate operators in the request processing operators according to the operator graph of the original model to obtain a processed operator graph ;
步骤S303:根据处理后的算子图,得到目标模型。Step S303: Obtain a target model according to the processed operator graph.
本实施例中,请求处理算子可以是模型内部的函数或者其它用于处理数据的子网络。In this embodiment, the request processing operator may be a function inside the model or another sub-network for processing data.
通过本实施例,能够对目标模型进行优化,从多个方面提高对目标模型的输入数据进行处理的效率。Through this embodiment, the target model can be optimized, and the efficiency of processing the input data of the target model can be improved from various aspects.
在自然语言处理的领域,生成类的模型为一种较为常见的预测类模型,该类别的模型根据输入的X个词生成Y个词。在预测推理的过程中,每一次计算只会生成一个词,通过循环Y次的方式来实现生成Y个词的目的,即模型包括循环体(while block)。在模型部署于单卡执行预测时,模型的循环体的存在不会带来问题。但是当将生成模型应用到分布式预测流水线并行场景的时候,while block的存在为分布式预测提出了功能与性能上的挑战:In the field of natural language processing, the generative class model is a relatively common prediction class model, and the model of this class generates Y words according to the input X words. In the process of predictive inference, only one word is generated for each calculation, and the purpose of generating Y words is achieved by looping Y times, that is, the model includes a loop body (while block). The existence of the loop body of the model does not pose a problem when the model is deployed on a single card to perform predictions. However, when the generative model is applied to the parallel scenario of the distributed prediction pipeline, the existence of the while block presents functional and performance challenges for the distributed prediction:
首先,针对流水线并行场景,模型可部署于多卡,比如可部署于多个GPU(相当于前述实施例的部件)。从而在流水线预测的过程中,循环的终止条件需要在各个GPU之间进行传播,以便各个GPU正确执行循环处理操作。循环过程中被更改的变量值也需要在各个GPU之间进行同步。同时,流水线并行的预测模式是在第一个pipeline stage(流水线阶段)进行feed(输入)数据后,在最后一个pipeline stage进行fetch(获取)结果,这与预测机制中,在哪张GPU上feed数据就从哪张GPU上fetch数据的逻辑相违背。First, for the pipeline parallel scenario, the model can be deployed on multiple cards, such as multiple GPUs (equivalent to the components in the foregoing embodiments). Therefore, in the process of pipeline prediction, the termination condition of the loop needs to be propagated among each GPU, so that each GPU can correctly perform the loop processing operation. Variable values that are changed during the loop also need to be synchronized across GPUs. At the same time, the prediction mode of pipeline parallelism is that after feeding (input) data in the first pipeline stage (pipeline stage), the fetch (acquiring) results are performed in the last pipeline stage, which is similar to the prediction mechanism, which GPU is fed on The logic of which GPU to fetch the data from is contrary to the logic.
第二,当使用流水线并行的技术进行分布式推理预测时,如果没有一定的保障机制,会造成整体硬件利用率的低下:在pipeline degree(流水线度,可以指模型拆分的模型层个数,可以等于部件的总个数)为2的流水线并行预测、在两张GPU(GPU1和GPU0)上运行模型的场景下,如果使用传统的顺序执行器,当GPU0结束当前循环的预测计算,等待下一个循环,同时GPU1正在进行当前循环的预测计算时候,GPU0只能单纯的等待GPU1的计算完成,而没有进行有效的计算。这样会造成该两卡的系统永远只有一张卡在进行有效的预测计算,造成硬件资源的浪费。这种硬件资源的浪费在流水线并行粒度提升后更为明显,当pipeline degree为N的时候,在同一时间,只有一个pipeline stage在进行预测,整体机器利用率为1/N。Second, when using the pipeline parallel technology for distributed reasoning and prediction, if there is no certain guarantee mechanism, the overall hardware utilization rate will be low: the pipeline degree can refer to the number of model layers in which the model is split, Can be equal to the total number of components) for the pipeline parallel prediction of 2, in the scenario of running the model on two GPUs (GPU1 and GPU0), if the traditional sequential executor is used, when GPU0 ends the prediction calculation of the current loop, wait for the next In a loop, while GPU1 is performing the prediction calculation of the current loop, GPU0 can only simply wait for the calculation of GPU1 to complete without performing effective calculation. In this way, in the two-card system, only one card will always perform effective prediction calculation, resulting in a waste of hardware resources. This waste of hardware resources is more obvious after the parallel granularity of the pipeline is improved. When the pipeline degree is N, only one pipeline stage is making predictions at the same time, and the overall machine utilization is 1/N.
此外,随着模型体积的增大,如何进行高效的分布式大模型推理也是一个非常棘手的问题。In addition, with the increase of model size, how to perform efficient distributed large model inference is also a very difficult problem.
本公开实施例能够应用于生成类模型,当生成类模型部署于多个处理器时,可将模型进行切分,切分得到的模型层各部署于一个处理器,最终处理结果同步发送到用于接收原始数据的第一部件,从而实现在哪里输入数据就从哪里输出数据,循环终止的条件可设置于第一个处理单元和最后一个处理单元,各个处理单元顺序执行循环步骤,由最后一个处理单元进行循环条件变更的更新。除了处理初始输入的请求的阶段,和生成请求的最终结果的阶段,其余阶段的处理效率均可以达到接近100%。此外,处理请求的模型体积增大时,降低模型部署难度,进一步提高分布式模型推理效率。The embodiments of the present disclosure can be applied to the generative class model. When the generative class model is deployed on multiple processors, the model can be segmented, the segmented model layers are each deployed on one processor, and the final processing result is synchronously sent to the user. For the first component that receives the original data, the data is output from where the data is input, and the conditions for terminating the loop can be set in the first processing unit and the last processing unit. The processing unit performs the update of the loop condition change. Except for the stage of processing the initial input request and the stage of generating the final result of the request, the processing efficiency of the remaining stages can reach nearly 100%. In addition, when the size of the model for processing requests increases, the difficulty of model deployment is reduced, and the inference efficiency of the distributed model is further improved.
在一种实施方式中,在控制第一部件接收第一请求的情况下,请求处理方法还包括:In one embodiment, in the case of controlling the first component to receive the first request, the request processing method further includes:
将第一请求的处理结果发送给第一部件。The processing result of the first request is sent to the first component.
本实施例中,将第一请求的处理结果发送给第一部件,可以包括将第一请求的处理结果发送给第一部件的第一存储单元。第一存储单元可以是第一部件具有访问、读取权限的存储单元,可以通过第一存储地址进行表示。第二部件可对应第二存储单元,该第二存储单元可以是第二部件具有访问、读取权限的存储单元,可以通过第二存储地址进行表示。In this embodiment, sending the processing result of the first request to the first component may include sending the processing result of the first request to the first storage unit of the first component. The first storage unit may be a storage unit to which the first component has access and read permissions, and may be represented by a first storage address. The second component may correspond to a second storage unit, and the second storage unit may be a storage unit to which the second component has access and read permissions, and may be represented by a second storage address.
在本实施例中,还可以将第二部件处理第一请求或第二请求需要的中间数据,存入第二存储单元。以及将第一部件处理第一请求或第二请求需要的中间数据,存入第一存储单元。In this embodiment, the intermediate data required by the second component to process the first request or the second request may also be stored in the second storage unit. and storing the intermediate data required by the first component to process the first request or the second request into the first storage unit.
可以看出,第一部件、第二部件处理原始数据或中间数据时,都能够从各自对应具备访问读取权限的存储单元中获取,保证并行处理多个原始数据的过程的顺利进行。It can be seen that when the first component and the second component process the original data or the intermediate data, they can be obtained from the corresponding storage units with access and read permissions, so as to ensure the smooth progress of the process of processing multiple original data in parallel.
在文本预测场景下,通过并行方式执行预测过程中的循环操作的产品可以包括Deep Speed(深速)和Fast Transformer(快速转换器)。Deep Speed对于分布式大模型预测使用了张量并行(大模型的一二层以及其它相关层都放在一个GPU上)的方法来进行预测。In the context of text prediction, products that perform cyclic operations in the prediction process in parallel can include Deep Speed and Fast Transformer. Deep Speed uses tensor parallelism for distributed large model prediction (one or two layers of the large model and other related layers are placed on one GPU) for prediction.
Fast Transformer实现了大模型推理中的张量并行与流水线并行,但是由于循环体的存在,Fast Transformer中无法高效的对硬件进行利用。Fast Transformer implements tensor parallelism and pipeline parallelism in large model inference, but due to the existence of loop bodies, Fast Transformer cannot efficiently utilize hardware.
对于性能优化方面,Deep Speed与Fast Transformer均采用了fuse kernel(算子融合)、fp16(Half-precisionfloating-point16,16位半精度浮点数据)计算、int8(initial 8,8位整数)量化等方案来提升预测的速度。For performance optimization, Deep Speed and Fast Transformer both use fuse kernel (operator fusion), fp16 (Half-precisionfloating-point16, 16-bit half-precision floating-point data) calculation, int8 (initial 8, 8-bit integer) quantization, etc. scheme to improve the speed of forecasting.
Deep Speed对于分布式推理不支持流水线并行,在需要模型过大需要使用机器间通讯的时候,会造成通讯开销的增加。Fast Transformer中由于缺少对循环体的支持,在进行预测推理时,顺序执行器会造成硬件资源的浪费,无法进行最高效的硬件资源利用。DeepSpeed与Fast Transformer中的优化手段并没有很好的复用训练中的一些已有的优化,产生了一定的二次开发成本。有鉴于Deep Speed和Fast Transformer等工具的缺点,本公开一种示例中,由while block的推理组网(即只包含前向计算的模型网络)进行流水线并行推理的支持,在此基础上,本公开示例将模型按常规的流水线并行的方法进行切分,对于原流水线并行中各pipeline stage之间本身就需要传输的pipeline checkpoint(输入输出点,即不同处理阶段之间的节点)变量,仍然由上游pipeline stage计算完成后send(发送)给下游pipeline stage。该步与常规的pipeline(流水线)并行逻辑相同。Deep Speed does not support pipeline parallelism for distributed reasoning. When the model is too large and requires the use of inter-machine communication, it will increase the communication overhead. Due to the lack of support for the loop body in the Fast Transformer, the sequential executor will waste hardware resources when performing predictive inference, and cannot make the most efficient use of hardware resources. The optimization methods in DeepSpeed and Fast Transformer do not reuse some existing optimizations in training well, resulting in a certain secondary development cost. In view of the shortcomings of tools such as Deep Speed and Fast Transformer, in an example of the present disclosure, pipeline parallel inference is supported by the inference network of the while block (that is, the model network that only includes forward computation). The public example divides the model according to the conventional pipeline parallel method. For the pipeline checkpoint (input and output points, that is, the nodes between different processing stages) variables that need to be transmitted between the pipeline stages in the original pipeline parallel are still set by After the calculation of the upstream pipeline stage is completed, it is sent to the downstream pipeline stage. This step is the same as the conventional pipeline (pipeline) parallel logic.
本公开示例中,对于while block的循环控制变量(在生成模型中为一个计数器),由最后一个pipeline stage进行更新,并将该计数器的值在更新后同步其余的给每一个pipeline stage对应的处理器(比如GPU)。In the example of the present disclosure, the loop control variable of the while block (a counter in the generative model) is updated by the last pipeline stage, and the value of the counter is updated to synchronize the rest to the corresponding processing of each pipeline stage device (such as a GPU).
本公开示例中,进一步的,while block中的被更新的变量值,由最后一个pipeline stage在计算并更新过后,通过将中间数据发送给对应的部件对应的存储地址,将已经更新的值同步给对于该值有需要的pipeline stage。由于流水线并行进行推理的特点,所有的while block中需要更新的变量均会在最后一个pipeline stage得到最终的更新。In the example of the present disclosure, further, after the updated variable value in the while block is calculated and updated by the last pipeline stage, by sending the intermediate data to the storage address corresponding to the corresponding component, the updated value is synchronized to the There are required pipeline stages for this value. Due to the parallel inference of the pipeline, all the variables that need to be updated in the while block will be finally updated in the last pipeline stage.
示例性的,对于程序最终的输出,最后一个pipeline stage新增一个send操作,将最后的结果同步给第一个pipeline stage(即发送到第一部件)。以此达到在哪个GPU上feed数据,就在哪个GPU上fetch数据的功能。Exemplarily, for the final output of the program, a send operation is added to the last pipeline stage, and the final result is synchronized to the first pipeline stage (ie, sent to the first component). In this way, the function of feeding data on which GPU can be fetched on which GPU is achieved.
基于异步流水执行器的消息驱动、异步执行的特点,针对while block的流水线并行预测推理进行了上述适配,使得有while block的推理组网在流水线并行模式下提升整体硬件(GPU)的利用率。Based on the message-driven and asynchronous execution characteristics of asynchronous pipeline executors, the above adaptation is made for the pipeline parallel prediction and reasoning of while block, so that the reasoning network with while block can improve the utilization rate of the overall hardware (GPU) in pipeline parallel mode. .
以两卡流水线并行来举例,按以下的步骤进行流水线并行预测,一次来提升GPU的利用率,在每个时刻(T),模型以及模型的每个处理单元对应的操作包括:Taking the parallel pipeline of two cards as an example, the pipeline parallel prediction is performed according to the following steps to improve the utilization rate of the GPU. At each time (T), the operations corresponding to the model and each processing unit of the model include:
T0:模型收到两个请求query(请求)0与query(请求)1(相当于前述实施例的第一请求和第二请求),两个请求均需要进行Y词的生成(进行Y次循环);T0: The model receives two requests query (request) 0 and query (request) 1 (equivalent to the first request and the second request in the previous embodiment), and both requests need to generate Y words (perform Y cycles );
T1:GPU0(相当于部署第一部分模型层的第一部件)对query0进行第一次的循环计算,将中间结果保存到scope0(相当于前述实施例的第一存储单元)当中;T1: GPU0 (equivalent to deploying the first component of the first part of the model layer) performs the first cyclic calculation on query0, and saves the intermediate result to scope0 (equivalent to the first storage unit in the foregoing embodiment);
T2:GPU1(相当于部署第二部分模型层的第二部件)对query0进行第一次的循环计算,将中间结果保存到scope0当中。同时,GPU0对query1进行第一次的循环计算,将中间结果保存到scope1(相当于前述实施例的第二存储单元)当中;T2: GPU1 (equivalent to deploying the second component of the second part of the model layer) performs the first loop calculation on query0, and saves the intermediate results to scope0. At the same time, GPU0 performs the first loop calculation on query1, and saves the intermediate result in scope1 (equivalent to the second storage unit in the foregoing embodiment);
T3:GPU0基于scope0中的保存结果,对query0进行第二次循环计算,并将中间结果更新到scope0当中。同时,GPU1对query1进行第一次循环计算,将中间结果保存到scope1当中;T3: GPU0 performs a second loop calculation on query0 based on the saved results in scope0, and updates the intermediate results to scope0. At the same time, GPU1 performs the first loop calculation on query1, and saves the intermediate results to scope1;
T4:GPU1基于scope0中的保存结果,对query0进行第二次循环计算,并将中间结果更新到scope0当中。同时GPU1基于scope1中的结果,对query1进行第二次循环,并将中间结果更新到scope1当中;T4: GPU1 performs a second loop calculation on query0 based on the saved results in scope0, and updates the intermediate results to scope0. At the same time, GPU1 performs a second loop on query1 based on the results in scope1, and updates the intermediate results to scope1;
以此类推,And so on,
T(2Y-1):GPU0对query0进行第Y次循环,GPU1对query1进行第Y-1次循环;T(2Y-1): GPU0 performs the Y-th cycle on query0, and GPU1 performs the Y-1-th cycle on query1;
T(2Y):GPU0对query1进行第Y次循环,GPU1对query0进行第Y次循环,query0的结果已产出;T(2Y): GPU0 performs the Y-th cycle on query1, GPU1 performs the Y-th cycle on query0, and the result of query0 has been output;
T(2Y+1):GPU1对query1进行第Y次循环,query1的结果已产出;T(2Y+1): GPU1 performs the Y-th loop on query1, and the result of query1 has been output;
整体流程上来看,除最开始T0以及最后TN+2时刻只有一张GPU在进行有效运算外(整体利用率50%),其余时间两张GPU均在进行有效的计算(整体利用率100%)。相对于纯循序执行器,流水线并行的耗时可以从原先4Y降低至(2Y+1)。并且,当pipeline并行的规模进一步提升到N个pipeline stage之后,传统的顺序执行器的整体GPU利用率只有(1/N),然而通过本方案的策略可以使得整体的GPU利用率在流水线warmup(预热)阶段(即第一部件对初次输入的请求进行第一次处理)过后,一直维持在100%,大幅的提升了整体硬件资源的使用效率。In terms of the overall process, except for the first time T0 and the last TN+2, only one GPU is performing effective calculations (the overall utilization rate is 50%), and both GPUs are performing effective calculations at the rest of the time (the overall utilization rate is 100%). . Compared with pure sequential executors, the time-consuming of pipeline parallelism can be reduced from 4Y to (2Y+1). Moreover, when the parallel scale of the pipeline is further increased to N pipeline stages, the overall GPU utilization of the traditional sequential executor is only (1/N). However, the strategy of this scheme can make the overall GPU utilization in the pipeline warmup ( After the preheating) stage (that is, the first component performs the first processing on the first input request), it is always maintained at 100%, which greatly improves the utilization efficiency of the overall hardware resources.
该方案的可行性是通过异步流水执行器消息驱动、异步执行的特点而实现的。GPU0计算完成后通过消息来触发GPU1的计算。当GPU1上一轮计算结束后,通过发送消息的方法来触发GPU0的下一轮计算的。这样的机制保障下,当GPU0对query0计算结束后,在没有收到GPU1对于query0的中间数据的消息时,可以对query1进行计算。无需像顺序执行器那样,通过send/recv(收/发)的依赖关系来控制GPU0/GPU1(在GPU0上输入的数据,可以从GPU0上发出,GPU1可以为根据消息触发,GPU0可根据数据触发)的运行,造成GPU0在计算结束后hang(挂)在recv GPU1(接收GPU1)的结果处,无法进行其余有效的计算。The feasibility of the scheme is realized through the message-driven and asynchronous execution characteristics of the asynchronous pipeline executor. After the calculation of GPU0 is completed, the calculation of GPU1 is triggered by a message. When the previous round of calculation of GPU1 is finished, the next round of calculation of GPU0 is triggered by sending a message. Under the guarantee of such a mechanism, when GPU0 completes the calculation of query0, and does not receive the message of the intermediate data of query0 from GPU1, it can calculate query1. There is no need to control GPU0/GPU1 through the dependency of send/recv (receive/transmit) like a sequential executor (the data input on GPU0 can be sent from GPU0, GPU1 can be triggered according to the message, and GPU0 can be triggered according to the data. ) operation, causing GPU0 to hang (hang) at the result of recv GPU1 (receive GPU1) after the calculation, and the rest of the effective calculations cannot be performed.
在一种可能的实现方式中,为减少二次开发成本,在预测的过程中复用了训练过程中的所有优化手段。通过在PaaS(Platform as Service,平台即服务)接入的方式提升性能。并且,在系统加载模型组网之后,可以使用graph(图)优化的方式,首先将用户需要推理的组网(模型或模型组成部分)转化成一张graph,并通过图编译、图优化的手段对整体组网进行优化。通过这两种手段共同来提升推理预测的效率。In a possible implementation, in order to reduce the cost of secondary development, all optimization methods in the training process are reused in the prediction process. Improve performance by accessing in PaaS (Platform as Service). In addition, after the system loads the model network, you can use the graph (graph) optimization method to first convert the network (model or model component) that the user needs to reason into a graph, and use graph compilation and graph optimization. The overall networking is optimized. Through these two methods, the efficiency of inference and prediction can be improved.
在一种具体示例中,如图4所示,目标模型可以包括主体(Main Block)401、循环体402、束搜索(Beam Search)403等组成部分。对于一个X个词的query,该生成组网会先通过main block对于该query进行编码,之后在每一次while block与相应的Beam Search会对下一个词进行预测,当进行了Y次while loop(while循环)之后,输出最终结果,从而实现了根据X词生成的query(原始数据)来预测Y个词的功能。In a specific example, as shown in FIG. 4 , the target model may include a main block (Main Block) 401, a
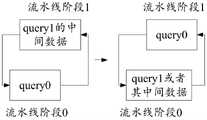
在具体示例中,可单独对循环体进行切分。一般情况下,若不切分循环体,则循环体可以部署于单个处理器上,进行单卡运行,如图5所示:In a specific example, the loop body can be segmented separately. In general, if the loop body is not split, the loop body can be deployed on a single processor and run on a single card, as shown in Figure 5:
步骤500,设置循环次数的计数器值(counter)=0;
步骤501,判断计数器值是否小于设定阈值(condition);在确定计数器值小于设定阈值的情况下,执行步骤502,否则,在满足计数器值等于设定阈值的情况下,输出最终结果(final result)。
步骤502,获取处理第一请求的第i-1个中间数据;
步骤503,对第一请求的第i-1个中间数据进行处理得到第一请求的第i个中间数据并更新(update val 1)。Step 503: Process the i-1 th intermediate data of the first request to obtain the i th intermediate data of the first request, and update (update val 1).
步骤504,更新计数器。具体的,本次循环结束(得到val 1)后更新计数器(updatecounter),后再返回判定步骤501。
在具体示例中,对循环体进行切分后,得到两个处理单元,即第一部件、第二部件,流水线操作过程包括如图6所示的流水线阶段0和流水线阶段1,每个处理单元各自统计循环次数,在初始阶段,设置第一部件的第一计数器值=0,并设置第二部件的第二计数器值=0。在流水线阶段0,初始化第一计数器值之后,执行判断步骤600,判断第一计数器值是否小于循环阈值,如果小于,则执行步骤601;否则,确定流水阶段0结束。In a specific example, after dividing the loop body, two processing units are obtained, namely the first part and the second part. The pipeline operation process includes pipeline stage 0 and pipeline stage 1 as shown in FIG. 6 . Each processing unit The number of cycles is counted respectively, and in the initial stage, the first counter value of the first part is set=0, and the second counter value of the second part is set=0. In pipeline stage 0, after initializing the first counter value, execute
步骤601,将第一请求的第i-1个中间数据发送给流水阶段1对应的第二部件。Step 601: Send the i-1 th intermediate data of the first request to the second component corresponding to pipeline stage 1.
具体可以为:获取第一请求的第i-1个中间数据(update val 0),即获取val 0。然后同时发送第一请求的第i-1个中间数据(update val 0)以及空值数据,以表示需要流水阶段1对应的第二部件更新该空值数据作为第一请求的第i个中间数据(val 1),即发送val0、val 1。Specifically, it may be: obtaining the i-1 th intermediate data (update val 0) of the first request, that is, obtaining val 0. Then, the i-1 th intermediate data (update val 0) of the first request and the null value data are simultaneously sent to indicate that the second component corresponding to pipeline stage 1 needs to update the null value data as the i th intermediate data of the first request. (val 1), that is, send val0, val 1.
流水阶段1中,执行判断步骤610,判断第二计数器值是否小于循环阈值,如果小于,则执行步骤611;否则,确定流水阶段1结束,生成最终结果。In pipeline stage 1, execute
步骤611,接收第一部件发来的第一请求的第i-1个中间数据。Step 611: Receive the i-1 th intermediate data of the first request sent by the first component.
也就是,第二部件接收val 0(第一请求的第i-1个中间数据)、val 1(第一请求的第i个中间数据),此时val 1为空值。That is, the second component receives val 0 (the i-1 th intermediate data of the first request), val 1 (the ith intermediate data of the first request), and val 1 is null at this time.
步骤612,得到第一请求的第i个中间数据。Step 612: Obtain the i-th intermediate data of the first request.
具体可以为,第二部件根据所述第i-1个中间数据第i+1次处理所述第一请求,得到所述第一请求的第i个中间数据。也就是得到更新的第一请求的第i个中间数据(更新val1),得到更新后的val 0、val 1。Specifically, the second component may process the first request for the i+1th time according to the i-1th intermediate data, and obtain the i-th intermediate data of the first request. That is, the i-th intermediate data of the updated first request (update val1) is obtained, and the updated val 0 and val 1 are obtained.
本步骤还可以包括:更新流水阶段1的第二计数器值。This step may further include: updating the second counter value of pipeline stage 1.
步骤613,发送第一请求的第i-1个中间数据、第一请求的第i个中间数据至第一部件。Step 613: Send the i-1 th intermediate data of the first request and the i th intermediate data of the first request to the first component.
具体可以为:控制第二部件发送val 0、val 1、第二计数器值到流水阶段0的第一部件并返回判断步骤610。Specifically, it may be: controlling the second component to send val 0, val 1, and the second counter value to the first component in pipeline stage 0, and returning to the
第一部件在流水阶段0继续执行步骤602,接收第一请求的第i-1个中间数据、第一请求的第i个中间数据。The first component continues to execute
具体的,可以为第一部件接收val 0、val 1、第二计数器值,据此更新第一计数器值,并据此返回判断步骤600。在流水阶段0的判断步骤600执行时确定不满足判定条件的情况下,流水阶段0结束。在流水阶段1的判断步骤610中确定不满足判定条件的情况下,生成最终结果。最后再将最终结果同步至流水线阶段0对应的第一部件。Specifically, the first component may receive val 0, val 1, and the second counter value, update the first counter value accordingly, and return to the
一般情况下,若采用顺序执行的方式,则如图7A所示,在流水线阶段0对应的第一部件处理query0或者其中间数据时,流水线阶段1对应的第二部件空置,接着流水线阶段1对应的第二部件处理query0的中间数据时,流水线阶段0对应的第一部件空置。而采用本公开示例提供的方法,则如图7B所示,在流水线阶段0对应的第一部件处理query0或者其中间数据时,流水线阶段1对应的第二部件可处理query1的中间数据,流水线阶段1对应的第二部件处理query0的中间数据时,流水线阶段0对应的第一部件处理query1或者其中间数据,进而显著提高各处理单元的使用率。In general, if the sequential execution method is adopted, as shown in FIG. 7A , when the first component corresponding to pipeline stage 0 processes query0 or its intermediate data, the second component corresponding to pipeline stage 1 is vacant, and then pipeline stage 1 corresponds to When the second part of 's is processing the intermediate data of query0, the first part corresponding to pipeline stage 0 is vacant. However, using the method provided by the example of the present disclosure, as shown in FIG. 7B , when the first component corresponding to pipeline stage 0 processes query0 or its intermediate data, the second component corresponding to pipeline stage 1 can process the intermediate data of query1, and the pipeline stage When the second component corresponding to 1 processes the intermediate data of query0, the first component corresponding to pipeline stage 0 processes query1 or its intermediate data, thereby significantly improving the utilization rate of each processing unit.
通过本公开实施例,使得分布式推理支持while block的流水线并行预测。相对于Deep Speed,大幅降低了多机间通讯的成本。并且,通过流水线并行中对于while block的特殊处理,结合异步流水执行器消息驱动,异步执行的特点,使得预测过程中GPU或者其它处理器的利用率得到大幅提升。此外,通过接入训练的优化PaaS以及预测阶段的graph(图)编译优化,进一步提升分布式大模型预测的效率。Through the embodiments of the present disclosure, distributed reasoning supports pipeline parallel prediction of while blocks. Compared with Deep Speed, the cost of communication between multiple machines is greatly reduced. In addition, through the special processing of the while block in the parallel pipeline, combined with the message-driven and asynchronous execution characteristics of the asynchronous pipeline executor, the utilization rate of the GPU or other processors in the prediction process is greatly improved. In addition, by accessing the optimized PaaS for training and the optimization of graph compilation in the prediction stage, the efficiency of distributed large model prediction is further improved.
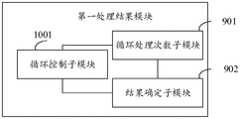
本公开实施例还提供一种请求处理装置,如图8所示,包括:An embodiment of the present disclosure further provides a request processing apparatus, as shown in FIG. 8 , including:
第一处理模块801,用于在控制第一部件第i次处理第一请求的过程中,控制第二部件第k次处理第二请求;i、k为大于1的整数;The
第二处理模块802,用于在确定第一部件第i次处理第一请求得到第一请求的第i个中间数据的情况下,控制第二部件根据第i个中间数据第i+1次处理第一请求,得到第一请求的第i+1个中间数据;The
第一处理结果模块803,用于根据第一请求的第i+1个中间数据,得到第一请求的处理结果;The first
第二处理结果模块804,用于根据第二部件第k次处理第二请求得到的第二请求的第k个中间数据,得到第二请求的处理结果。The second
在一种实施方式中,如图9所示,第一处理结果模块包括:In one embodiment, as shown in Figure 9, the first processing result module includes:
循环处理次数子模块901,用于根据第一请求的第i+1个中间数据,确定第一请求的循环处理次数;The cycle processing times sub-module 901 is used to determine the cycle processing times of the first request according to the i+1 th intermediate data of the first request;
结果确定子模块902,用于在循环处理次数达到预设的循环阈值的情况下,将第一请求的第i+1个中间数据作为第一请求的处理结果。The
在一种实施方式中,如图10所示,第一处理结果模块还包括:In one embodiment, as shown in Figure 10, the first processing result module further includes:
循环控制子模块1001,用于在循环处理次数未达到预设的循环阈值的情况下,控制第一部件和第二部件,根据第一请求的第i+1个中间数据更新循环处理次数。The loop control sub-module 1001 is configured to control the first component and the second component to update the number of loop processing according to the i+1 th intermediate data of the first request when the number of loop processing times does not reach a preset loop threshold value.
在一种实施方式中,如图11所示,请求处理装置还包括:In an implementation manner, as shown in FIG. 11 , the request processing apparatus further includes:
原始词语模块1101,用于获取第一数量个原始词语;The
第一请求生成模块1102,用于根据第一数量个原始词语,得到第一请求;第一请求的处理结果用于获取第二数量个预测词语;第二数量等于循环阈值。The first
在一种实施方式中,如图12所示,第一处理模块包括:In one embodiment, as shown in Figure 12, the first processing module includes:
第一模型层调用子模块1201,用于控制第一部件通过第一模型层第i次处理第一请求;第一模型层为目标模型中至少一个模型层中的一个;The first model layer invokes a
第二模型层调用子模块1202,用于控制第二部件通过第二模型层第k次处理第二请求;第二模型层为目标模型中至少一个模型层中之一,第二模型层与第一模型层不同。The second model layer invokes the
在一种实施方式中,如图13所示,请求处理装置还包括:In an implementation manner, as shown in FIG. 13 , the request processing apparatus further includes:
算子图模块1301,用于根据原始模型所包括的请求处理算子以及不同的请求处理算子之间的关系,得到原始模型的算子图;The
优化模块1302,用于根据原始模型的算子图,删除请求处理算子中的冗余算子,或根据原始模型的算子图,合并请求处理算子中的重复算子,得到处理后的算子图;The
目标模型生成模块1303,用于根据处理后的算子图,得到目标模型。The target
本公开的技术方案中,所涉及的用户个人信息的获取,存储和应用等,均符合相关法律法规的规定,且不违背公序良俗。In the technical solution of the present disclosure, the acquisition, storage and application of the user's personal information involved are all in compliance with the provisions of relevant laws and regulations, and do not violate public order and good customs.
根据本公开的实施例,本公开还提供了一种电子设备、一种可读存储介质和一种计算机程序产品。According to embodiments of the present disclosure, the present disclosure also provides an electronic device, a readable storage medium, and a computer program product.
图14示出了可以用来实施本公开的实施例的示例电子设备1400的示意性框图。电子设备旨在表示各种形式的数字计算机,诸如,膝上型计算机、台式计算机、工作台、个人数字助理、服务器、刀片式服务器、大型计算机、和其它适合的计算机。电子设备还可以表示各种形式的移动装置,诸如,个人数字处理、蜂窝电话、智能电话、可穿戴设备和其它类似的计算装置。本文所示的部件、它们的连接和关系、以及它们的功能仅仅作为示例,并且不意在限制本文中描述的和/或者要求的本公开的实现。14 shows a schematic block diagram of an example
如图14所示,电子设备1400包括计算单元1401,其可以根据存储在只读存储器(ROM)1402中的计算机程序或者从存储单元1408加载到随机访问存储器(RAM)1403中的计算机程序,来执行各种适当的动作和处理。在RAM 1403中,还可存储电子设备1400操作所需的各种程序和数据。计算单元1401、ROM 1402以及RAM 1403通过总线1404彼此相连。输入/输出(I/O)接口1405也连接至总线1404。As shown in FIG. 14 , the
电子设备1400中的多个部件连接至I/O接口1405,包括:输入单元1406,例如键盘、鼠标等;输出单元1407,例如各种类型的显示器、扬声器等;存储单元1408,例如磁盘、光盘等;以及通信单元1409,例如网卡、调制解调器、无线通信收发机等。通信单元1409允许电子设备1400通过诸如因特网的计算机网络和/或各种电信网络与其他设备交换信息/数据。Various components in the
计算单元1401可以是各种具有处理和计算能力的通用和/或专用处理组件。计算单元1401的一些示例包括但不限于中央处理单元(CPU)、图形处理单元(GPU)、各种专用的人工智能(AI)计算芯片、各种运行机器学习模型算法的计算单元、数字信号处理器(DSP)、以及任何适当的处理器、控制器、微控制器等。计算单元1401执行上文所描述的请求处理方法。例如,在一些实施例中,上文所描述的请求处理方法可被实现为计算机软件程序,其被有形地包含于机器可读介质,例如存储单元1408。在一些实施例中,计算机程序的部分或者全部可以经由ROM 1402和/或通信单元1409而被载入和/或安装到电子设备1400上。当计算机程序加载到RAM 1403并由计算单元1401执行时,可以执行上文所描述的请求处理方法的一个或多个步骤。备选地,在其他实施例中,计算单元1401可以通过其他任何适当的方式(例如,借助于固件)而被配置为执行上文所描述的请求处理方法。
本文中以上描述的系统和技术的各种实施方式可以在数字电子电路系统、集成电路系统、场可编程门阵列(FPGA)、专用集成电路(ASIC)、专用标准产品(ASSP)、芯片上系统的系统(SOC)、负载可编程逻辑设备(CPLD)、计算机硬件、固件、软件、和/或它们的组合中实现。这些各种实施方式可以包括:实施在一个或者多个计算机程序中,该一个或者多个计算机程序可在包括至少一个可编程处理器的可编程系统上执行和/或解释,该可编程处理器可以是专用或者通用可编程处理器,可以从存储系统、至少一个输入装置、和至少一个输出装置接收数据和指令,并且将数据和指令传输至该存储系统、该至少一个输入装置、和该至少一个输出装置。Various implementations of the systems and techniques described herein above may be implemented in digital electronic circuitry, integrated circuit systems, field programmable gate arrays (FPGAs), application specific integrated circuits (ASICs), application specific standard products (ASSPs), systems on chips system (SOC), load programmable logic device (CPLD), computer hardware, firmware, software, and/or combinations thereof. These various embodiments may include being implemented in one or more computer programs executable and/or interpretable on a programmable system including at least one programmable processor that The processor, which may be a special purpose or general-purpose programmable processor, may receive data and instructions from a storage system, at least one input device, and at least one output device, and transmit data and instructions to the storage system, the at least one input device, and the at least one output device an output device.
用于实施本公开的方法的程序代码可以采用一个或多个编程语言的任何组合来编写。这些程序代码可以提供给通用计算机、专用计算机或其他可编程请求处理装置的处理器或控制器,使得程序代码当由处理器或控制器执行时使流程图和/或框图中所规定的功能/操作被实施。程序代码可以完全在机器上执行、部分地在机器上执行,作为独立软件包部分地在机器上执行且部分地在远程机器上执行或完全在远程机器或服务器上执行。Program code for implementing the methods of the present disclosure may be written in any combination of one or more programming languages. The program code may be provided to a processor or controller of a general purpose computer, special purpose computer or other programmable request processing device such that the program code, when executed by the processor or controller, causes the functions/functions specified in the flowcharts and/or block diagrams Action is implemented. The program code may execute entirely on the machine, partly on the machine, partly on the machine and partly on a remote machine as a stand-alone software package or entirely on the remote machine or server.
在本公开的上下文中,机器可读介质可以是有形的介质,其可以包含或存储以供指令执行系统、装置或设备使用或与指令执行系统、装置或设备结合地使用的程序。机器可读介质可以是机器可读信号介质或机器可读储存介质。机器可读介质可以包括但不限于电子的、磁性的、光学的、电磁的、红外的、或半导体系统、装置或设备,或者上述内容的任何合适组合。机器可读存储介质的更具体示例会包括基于一个或多个线的电气连接、便携式计算机盘、硬盘、随机存取存储器(RAM)、只读存储器(ROM)、可擦除可编程只读存储器(EPROM或快闪存储器)、光纤、便捷式紧凑盘只读存储器(CD-ROM)、光学储存设备、磁储存设备、或上述内容的任何合适组合。In the context of the present disclosure, a machine-readable medium may be a tangible medium that may contain or store a program for use by or in connection with the instruction execution system, apparatus or device. The machine-readable medium may be a machine-readable signal medium or a machine-readable storage medium. Machine-readable media may include, but are not limited to, electronic, magnetic, optical, electromagnetic, infrared, or semiconductor systems, devices, or devices, or any suitable combination of the foregoing. More specific examples of machine-readable storage media would include one or more wire-based electrical connections, portable computer disks, hard disks, random access memory (RAM), read only memory (ROM), erasable programmable read only memory (EPROM or flash memory), fiber optics, compact disk read only memory (CD-ROM), optical storage, magnetic storage, or any suitable combination of the foregoing.
为了提供与用户的交互,可以在计算机上实施此处描述的系统和技术,该计算机具有:用于向用户显示信息的显示装置(例如,CRT(阴极射线管)或者LCD(液晶显示器)监视器);以及键盘和指向装置(例如,鼠标或者轨迹球),用户可以通过该键盘和该指向装置来将输入提供给计算机。其它种类的装置还可以用于提供与用户的交互;例如,提供给用户的反馈可以是任何形式的传感反馈(例如,视觉反馈、听觉反馈、或者触觉反馈);并且可以用任何形式(包括声输入、语音输入、或者触觉输入)来接收来自用户的输入。To provide interaction with a user, the systems and techniques described herein may be implemented on a computer having a display device (eg, a CRT (cathode ray tube) or LCD (liquid crystal display) monitor) for displaying information to the user ); and a keyboard and pointing device (eg, a mouse or trackball) through which a user can provide input to the computer. Other kinds of devices can also be used to provide interaction with the user; for example, the feedback provided to the user can be any form of sensory feedback (eg, visual feedback, auditory feedback, or tactile feedback); and can be in any form (including acoustic input, voice input, or tactile input) to receive input from the user.
可以将此处描述的系统和技术实施在包括后台部件的计算系统(例如,作为数据服务器)、或者包括中间件部件的计算系统(例如,应用服务器)、或者包括前端部件的计算系统(例如,具有图形用户界面或者网络浏览器的用户计算机,用户可以通过该图形用户界面或者该网络浏览器来与此处描述的系统和技术的实施方式交互)、或者包括这种后台部件、中间件部件、或者前端部件的任何组合的计算系统中。可以通过任何形式或者介质的数字数据通信(例如,通信网络)来将系统的部件相互连接。通信网络的示例包括:局域网(LAN)、广域网(WAN)和互联网。The systems and techniques described herein may be implemented on a computing system that includes back-end components (eg, as a data server), or a computing system that includes middleware components (eg, an application server), or a computing system that includes front-end components (eg, a user's computer having a graphical user interface or web browser through which a user may interact with implementations of the systems and techniques described herein), or including such backend components, middleware components, Or any combination of front-end components in a computing system. The components of the system may be interconnected by any form or medium of digital data communication (eg, a communication network). Examples of communication networks include: Local Area Networks (LANs), Wide Area Networks (WANs), and the Internet.
计算机系统可以包括客户端和服务器。客户端和服务器一般远离彼此并且通常通过通信网络进行交互。通过在相应的计算机上运行并且彼此具有客户端-服务器关系的计算机程序来产生客户端和服务器的关系。服务器可以是云服务器,也可以为分布式系统的服务器,或者是结合了区块链的服务器。A computer system can include clients and servers. Clients and servers are generally remote from each other and usually interact through a communication network. The relationship of client and server arises by computer programs running on the respective computers and having a client-server relationship to each other. The server can be a cloud server, a distributed system server, or a server combined with blockchain.
应该理解,可以使用上面所示的各种形式的流程,重新排序、增加或删除步骤。例如,本公开中记载的各步骤可以并行地执行也可以顺序地执行也可以不同的次序执行,只要能够实现本公开公开的技术方案所期望的结果,本文在此不进行限制。It should be understood that steps may be reordered, added or deleted using the various forms of flow shown above. For example, the steps described in the present disclosure can be executed in parallel, sequentially, or in different orders, as long as the desired results of the technical solutions disclosed in the present disclosure can be achieved, no limitation is imposed herein.
上述具体实施方式,并不构成对本公开保护范围的限制。本领域技术人员应该明白的是,根据设计要求和其他因素,可以进行各种修改、组合、子组合和替代。任何在本公开的精神和原则之内所作的修改、等同替换和改进等,均应包含在本公开保护范围之内。The above-mentioned specific embodiments do not constitute a limitation on the protection scope of the present disclosure. It should be understood by those skilled in the art that various modifications, combinations, sub-combinations and substitutions may occur depending on design requirements and other factors. Any modifications, equivalent replacements, and improvements made within the spirit and principles of the present disclosure should be included within the protection scope of the present disclosure.
Claims (15)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210402668.3ACN114816742A (en) | 2022-04-18 | 2022-04-18 | Request processing method and device, electronic equipment and storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210402668.3ACN114816742A (en) | 2022-04-18 | 2022-04-18 | Request processing method and device, electronic equipment and storage medium |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN114816742Atrue CN114816742A (en) | 2022-07-29 |
Family
ID=82536087
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210402668.3APendingCN114816742A (en) | 2022-04-18 | 2022-04-18 | Request processing method and device, electronic equipment and storage medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114816742A (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116934571A (en)* | 2023-07-20 | 2023-10-24 | 北京百度网讯科技有限公司 | Task processing methods, devices, electronic devices and storage media |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20030195938A1 (en)* | 2000-06-26 | 2003-10-16 | Howard Kevin David | Parallel processing systems and method |
| CN111309479A (en)* | 2020-02-14 | 2020-06-19 | 北京百度网讯科技有限公司 | Method, device, equipment and medium for realizing task parallel processing |
| CN112114969A (en)* | 2020-09-23 | 2020-12-22 | 北京百度网讯科技有限公司 | Data processing method and device, electronic equipment and storage medium |
| CN112154462A (en)* | 2018-05-23 | 2020-12-29 | 微软技术许可有限责任公司 | High-performance pipelined parallel deep neural network training |
| US20210067173A1 (en)* | 2019-09-03 | 2021-03-04 | Nvidia Corporation | Performing cyclic redundancy checks using parallel computing architectures |
| CN113377520A (en)* | 2021-07-07 | 2021-09-10 | 北京百度网讯科技有限公司 | Resource scheduling method, device, equipment and storage medium |
- 2022
- 2022-04-18CNCN202210402668.3Apatent/CN114816742A/enactivePending
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20030195938A1 (en)* | 2000-06-26 | 2003-10-16 | Howard Kevin David | Parallel processing systems and method |
| CN112154462A (en)* | 2018-05-23 | 2020-12-29 | 微软技术许可有限责任公司 | High-performance pipelined parallel deep neural network training |
| US20210067173A1 (en)* | 2019-09-03 | 2021-03-04 | Nvidia Corporation | Performing cyclic redundancy checks using parallel computing architectures |
| CN111309479A (en)* | 2020-02-14 | 2020-06-19 | 北京百度网讯科技有限公司 | Method, device, equipment and medium for realizing task parallel processing |
| CN112114969A (en)* | 2020-09-23 | 2020-12-22 | 北京百度网讯科技有限公司 | Data processing method and device, electronic equipment and storage medium |
| CN113377520A (en)* | 2021-07-07 | 2021-09-10 | 北京百度网讯科技有限公司 | Resource scheduling method, device, equipment and storage medium |
Non-Patent Citations (2)
| Title |
|---|
| CHEN WENPING 等: "Multiple request oriented parallel volume rendering algorithm", JOURNAL OF TSINGHUA UNIVERSITY (SCIENCE AND TECHNOLOGY), 31 January 2004 (2004-01-31)* |
| 段晨东 等: "基于多MCU通信的实时数据采集处理系统的设计", 工业仪表与自动化装置, 15 October 2003 (2003-10-15)* |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116934571A (en)* | 2023-07-20 | 2023-10-24 | 北京百度网讯科技有限公司 | Task processing methods, devices, electronic devices and storage media |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2020182989A1 (en) | Scheduling computation graphs using neural networks | |
| CN110262901A (en) | A kind of data processing method and data processing system | |
| CN114860412B (en) | Task processing method, device, electronic device and medium | |
| CN116934571B (en) | Task processing method, device, electronic device and storage medium | |
| JP7635396B2 (en) | Text generation method, apparatus, electronic device and computer-readable medium | |
| CN116502680A (en) | Parallel training method and device for mixed expert model | |
| CN112463189B (en) | Distributed deep learning multi-step delayed update method based on communication operation sparsification | |
| CN115759232B (en) | Method, device, equipment and medium for multitasking parallel processing of deep learning framework | |
| CN120068846B (en) | Language task processing method, system, device, storage medium and program product | |
| CN116341652A (en) | Cloud environment-oriented large model distributed training method and related equipment | |
| CN115759260B (en) | Inference methods, devices, electronic devices and storage media for deep learning models | |
| CN114816742A (en) | Request processing method and device, electronic equipment and storage medium | |
| CN119829282A (en) | Large language model system and request response method thereof | |
| CN119578561A (en) | Large-scale hybrid expert language model reasoning method and architecture based on heterogeneous many-core | |
| CN118690837A (en) | Operator fusion method, device and electronic equipment | |
| CN118569358A (en) | Distributed computation scheduling method, device and equipment for model and storage medium | |
| CN115630677B (en) | Task processing methods, devices, electronic equipment and media | |
| CN115470901B (en) | Mixed-precision training method and device supporting mobile heterogeneous processor load sharing | |
| US20220237045A1 (en) | Method, device, and program product for managing computing system | |
| CN115658307A (en) | Intelligent load processing method and system based on compressed data direct calculation | |
| CN112965836A (en) | Service control method and device, electronic equipment and readable storage medium | |
| CN119759520B (en) | Task scheduling method, device, electronic equipment, readable storage medium and computer program product | |
| CN120598063A (en) | Model training optimization method, device, electronic equipment, storage medium and program | |
| CN120256068B (en) | A task parallel processing intelligent scheduling method and system for large model services | |
| US20250117710A1 (en) | Method of deploying multimodal large model, electronic device and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |