CN114792086A - Information extraction method, device, equipment and medium supporting text cross coverage - Google Patents
Information extraction method, device, equipment and medium supporting text cross coverageDownload PDFInfo
- Publication number
- CN114792086A CN114792086ACN202110105562.2ACN202110105562ACN114792086ACN 114792086 ACN114792086 ACN 114792086ACN 202110105562 ACN202110105562 ACN 202110105562ACN 114792086 ACN114792086 ACN 114792086A
- Authority
- CN
- China
- Prior art keywords
- sequence
- target
- word
- label
- probability value
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images



Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/12—Use of codes for handling textual entities
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/205—Parsing
- G06F40/216—Parsing using statistical methods
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Probability & Statistics with Applications (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本公开的实施例涉及计算机技术领域,具体涉及信息抽取方法、装置、设备和计算机可读介质。Embodiments of the present disclosure relate to the field of computer technologies, and in particular, to information extraction methods, apparatuses, devices, and computer-readable media.
背景技术Background technique
信息抽取是从自然语言文本中抽取指定对象的实体、关系、事件等信息的一项文本处理技术。现有信息抽取方法一般是将信息抽取任务转化为序列标注的问题,即给文本中的每个字打上标签,从而抽取一部分字作为信息。Information extraction is a text processing technology that extracts entities, relationships, events and other information of specified objects from natural language texts. Existing information extraction methods generally convert the information extraction task into a sequence labeling problem, that is, label each word in the text to extract a part of the word as information.
然而,当采用上述方式对进行信息抽取时,经常会存在如下技术问题:However, when using the above method to extract information, there are often the following technical problems:
第一,很多应用场景需要抽取的信息往往存在交叉或者覆盖等情况,而现有的序列标注方法只能将每个字抽取一次,导致抽取的信息不完整。First, the information that needs to be extracted in many application scenarios often overlaps or overlaps, and the existing sequence labeling methods can only extract each word once, resulting in incomplete extracted information.
第二,很多应用场景进行信息抽取时,没有均衡语义和字对应的标签之间的关系,导致抽取的信息准确度偏低。Second, in many application scenarios for information extraction, the relationship between semantics and labels corresponding to words is not balanced, resulting in low accuracy of extracted information.
发明内容SUMMARY OF THE INVENTION
本公开的内容部分用于以简要的形式介绍构思,这些构思将在后面的具体实施方式部分被详细描述。本公开的内容部分并不旨在标识要求保护的技术方案的关键特征或必要特征,也不旨在用于限制所要求的保护的技术方案的范围。This summary of the disclosure serves to introduce concepts in a simplified form that are described in detail in the detailed description that follows. The content section of this disclosure is not intended to identify key features or essential features of the claimed technical solution, nor is it intended to be used to limit the scope of the claimed technical solution.
本公开的一些实施例提出了信息抽取方法,来解决以上背景技术部分提到的技术问题中的一项或多项。Some embodiments of the present disclosure propose information extraction methods to solve one or more of the technical problems mentioned in the above background section.
第一方面,本公开的一些实施例提供了一种用于信息抽取方法,该方法包括:获取目标文本;对目标文本中的每个字进行编码以生成字向量,得到字向量序列;确定字向量序列中的每个字向量对应的目标概率值组,得到目标概率值组序列;基于目标概率值组序列和标签组集,生成对象向量序列集;基于对象向量序列集和对象转移矩阵集,生成标签序列集;从目标文本中抽取出与标签序列集中的每个标签序列对应的对象信息,得到对象信息集。In a first aspect, some embodiments of the present disclosure provide a method for information extraction, the method comprising: obtaining a target text; encoding each word in the target text to generate a word vector to obtain a sequence of word vectors; determining a word The target probability value group corresponding to each word vector in the vector sequence is obtained, and the target probability value group sequence is obtained; based on the target probability value group sequence and the label group set, the object vector sequence set is generated; based on the object vector sequence set and the object transition matrix set, Generate a label sequence set; extract the object information corresponding to each label sequence in the label sequence set from the target text, and obtain the object information set.
第二方面,本公开的一些实施例提供了一种信息抽取装置,装置包括:获取单元,被配置成获取目标文本;编码单元,被配置成对目标文本中的每个字进行编码以生成字向量,得到字向量序列;确定单元,被配置成确定字向量序列中的每个字向量对应的目标概率值组,得到目标概率值组序列;第一生成单元,被配置成基于目标概率值组序列和标签组集,生成对象向量序列集;第二生成单元,被配置成基于对象向量序列集和对象转移矩阵集,生成标签序列集;抽取单元,被配置成从目标文本中抽取出与标签序列集中的每个标签序列对应的对象信息,得到对象信息集。In a second aspect, some embodiments of the present disclosure provide an information extraction apparatus, the apparatus includes: an acquisition unit configured to acquire target text; and an encoding unit configured to encode each word in the target text to generate a word vector, to obtain a sequence of word vectors; a determination unit, configured to determine a target probability value group corresponding to each word vector in the sequence of word vectors, to obtain a sequence of target probability value groups; a first generation unit, configured to be based on the target probability value group Sequence and label group set, generating the object vector sequence set; the second generating unit is configured to generate the label sequence set based on the object vector sequence set and the object transition matrix set; the extraction unit is configured to extract from the target text and the label The object information corresponding to each label sequence in the sequence set is obtained to obtain the object information set.
第三方面,本公开的一些实施例提供了一种电子设备,包括:一个或多个处理器;存储装置,其上存储有一个或多个程序,当一个或多个程序被一个或多个处理器执行,使得一个或多个处理器实现上述第一方面任一实现方式所描述的方法。In a third aspect, some embodiments of the present disclosure provide an electronic device, comprising: one or more processors; a storage device on which one or more programs are stored, when one or more programs are stored by one or more The processor executes, causing one or more processors to implement the method described in any implementation manner of the above first aspect.
第四方面,本公开的一些实施例提供了一种计算机可读介质,其上存储有计算机程序,其中,程序被处理器执行时实现上述第一方面任一实现方式所描述的方法。In a fourth aspect, some embodiments of the present disclosure provide a computer-readable medium on which a computer program is stored, wherein, when the program is executed by a processor, the method described in any implementation manner of the above-mentioned first aspect is implemented.
本公开的上述各个实施例具有如下有益效果:通过对获取的目标文本中的每个字进行编码以生成字向量,这些编码得到的字向量具有文本信息和位置信息,底层共享的设计使得训练数贫乏的对象得到充分的训练,提高了整个过程的学习能力。通过对目标文本中每个字赋予与各个目标对象相关的标签,使得能初步抽取出各个对象对应的对象信息。之后,引入标签转移矩阵,更准确地表达了两两相邻的字之间关系,从而实现对重叠信息的准确提取。The above-mentioned embodiments of the present disclosure have the following beneficial effects: by encoding each word in the acquired target text to generate word vectors, the encoded word vectors have text information and position information, and the underlying shared design makes the training data Poor subjects are fully trained, improving the learning ability of the whole process. By assigning a label related to each target object to each word in the target text, the object information corresponding to each object can be preliminarily extracted. After that, a label transition matrix is introduced to more accurately express the relationship between adjacent words, so as to achieve accurate extraction of overlapping information.
附图说明Description of drawings
结合附图并参考以下具体实施方式,本公开各实施例的上述和其他特征、优点及方面将变得更加明显。贯穿附图中,相同或相似的附图标记表示相同或相似的元素。应当理解附图是示意性的,元件和元素不一定按照比例绘制。The above and other features, advantages and aspects of various embodiments of the present disclosure will become more apparent when taken in conjunction with the accompanying drawings and with reference to the following detailed description. Throughout the drawings, the same or similar reference numbers refer to the same or similar elements. It should be understood that the drawings are schematic and that elements and elements are not necessarily drawn to scale.
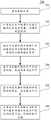
图1是根据本公开的一些实施例的信息抽取方法的一个应用场景的示意图;1 is a schematic diagram of an application scenario of an information extraction method according to some embodiments of the present disclosure;
图2是根据本公开的信息抽取方法的一些实施例的流程图;2 is a flowchart of some embodiments of information extraction methods according to the present disclosure;
图3是根据本公开的信息抽取装置的一些实施例的流程图;3 is a flowchart of some embodiments of an information extraction apparatus according to the present disclosure;
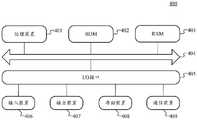
图4是适于用来实现本公开的一些实施例的电子设备的结构示意图;4 is a schematic structural diagram of an electronic device suitable for implementing some embodiments of the present disclosure;
图5是根据本公开的一些实施例的信息抽取方法的另一个应用场景的示意图。FIG. 5 is a schematic diagram of another application scenario of the information extraction method according to some embodiments of the present disclosure.
具体实施方式Detailed ways
下面将参照附图更详细地描述本公开的实施例。虽然附图中显示了本公开的某些实施例,然而应当理解的是,本公开可以通过各种形式来实现,而且不应该被解释为限于这里阐述的实施例。相反,提供这些实施例是为了更加透彻和完整地理解本公开。应当理解的是,本公开的附图及实施例仅用于示例性作用,并非用于限制本公开的保护范围。Embodiments of the present disclosure will be described in more detail below with reference to the accompanying drawings. While certain embodiments of the present disclosure are shown in the drawings, it should be understood that the present disclosure may be embodied in various forms and should not be construed as limited to the embodiments set forth herein. Rather, these embodiments are provided for a thorough and complete understanding of the present disclosure. It should be understood that the drawings and embodiments of the present disclosure are only for exemplary purposes, and are not intended to limit the protection scope of the present disclosure.
另外还需要说明的是,为了便于描述,附图中仅示出了与有关发明相关的部分。在不冲突的情况下,本公开中的实施例及实施例中的特征可以相互组合。In addition, it should be noted that, for the convenience of description, only the parts related to the related invention are shown in the drawings. The embodiments of this disclosure and features of the embodiments may be combined with each other without conflict.
需要注意,本公开中提及的“一个”、“多个”的修饰是示意性而非限制性的,本领域技术人员应当理解,除非在上下文另有明确指出,否则应该理解为“一个或多个”。It should be noted that the modifications of "a" and "a plurality" mentioned in the present disclosure are illustrative rather than restrictive, and those skilled in the art should understand that unless the context clearly indicates otherwise, they should be understood as "one or a plurality of". multiple".
下面将参考附图并结合实施例来详细说明本公开。The present disclosure will be described in detail below with reference to the accompanying drawings and in conjunction with embodiments.
图1是本公开的一些实施例的信息抽取方法的一个应用场景的示意图。FIG. 1 is a schematic diagram of an application scenario of the information extraction method according to some embodiments of the present disclosure.
在图1的应用场景中,首先,计算设备101可以获取目标文本102;接着,计算设备101可以对目标文本102中的每个字进行编码以生成字向量,得到字向量序列103;然后,计算设备101可以确定字向量序列103中的每个字向量对应的目标概率值组,得到目标概率值组序列104;之后,计算设备101可以基于目标概率值组序列104和标签组集105,生成对象向量序列集106;再之后,计算设备101可以基于对象向量序列集106和对象转移矩阵集107,生成标签序列集108;最后,计算设备101可以从目标文本102中抽取出与标签序列集108中的每个标签序列对应的对象信息,得到对象信息集109。In the application scenario of FIG. 1, first, the computing device 101 can obtain the
需要说明的是,上述计算设备101可以是硬件,也可以是软件。当计算设备为硬件时,可以实现成多个服务器或终端设备组成的分布式集群,也可以实现成单个服务器或单个终端设备。当计算设备体现为软件时,可以安装在上述所列举的硬件设备中。其可以实现成例如用来提供分布式服务的多个软件或软件模块,也可以实现成单个软件或软件模块。在此不做具体限定。It should be noted that the above computing device 101 may be hardware or software. When the computing device is hardware, it can be implemented as a distributed cluster composed of multiple servers or terminal devices, or can be implemented as a single server or a single terminal device. When a computing device is embodied as software, it may be installed in the hardware devices listed above. It can be implemented, for example, as multiple software or software modules for providing distributed services, or as a single software or software module. There is no specific limitation here.
应该理解,图1中的计算设备的数目仅仅是示意性的。根据实现需要,可以具有任意数目的计算设备。It should be understood that the number of computing devices in FIG. 1 is merely illustrative. There may be any number of computing devices depending on implementation needs.
继续参考图2,示出了根据本公开的信息抽取方法的一些实施例的流程200。该信息抽取方法,包括以下步骤:With continued reference to FIG. 2, a
步骤201,获取目标文本。
在一些实施例中,信息抽取方法的执行主体(例如,计算设备101)可以通过网页,文本文件,图片等各种方式获取目标文本。其中,上述目标文本可以是文章,段落或句子。目标对象可以是根据应用场景需要,预先确定好的名词。In some embodiments, the execution body (for example, the computing device 101 ) of the information extraction method may obtain the target text through various methods such as web pages, text files, pictures, and the like. Wherein, the above target text can be an article, a paragraph or a sentence. The target object can be a pre-determined noun according to the needs of the application scenario.
作为示例,上述目标对象可以是猪肉,目标文本可以是“玉米猪肉大涨”。As an example, the above-mentioned target object may be pork, and the target text may be "corn pork surge".
步骤202,对目标文本中的每个字进行编码以生成字向量,得到字向量序列。Step 202: Encode each word in the target text to generate a word vector to obtain a sequence of word vectors.
在一些实施例中,上述执行主体可以将目标文本对应的字序列输入至长短期记忆人工神经网络进行编码,从而得到上述字向量序列。字序列是目标文本中所有字构成的序列,字向量是通过上述网络对字进行编码得到的该字对应的向量。作为示例,字向量可以是[1,0,1,0,0,1,0,1,1,1]。In some embodiments, the above-mentioned execution body may input the word sequence corresponding to the target text into a long short-term memory artificial neural network for encoding, so as to obtain the above-mentioned word vector sequence. The word sequence is a sequence composed of all words in the target text, and the word vector is the vector corresponding to the word obtained by encoding the word through the above network. As an example, the word vector may be [1, 0, 1, 0, 0, 1, 0, 1, 1, 1].
在一些实施例的一些可选的实现方式中,上述执行主体可以将上述目标文本输入至预训练的文本编码模型,得到字向量序列。In some optional implementations of some embodiments, the above-mentioned execution body may input the above-mentioned target text into a pre-trained text encoding model to obtain a sequence of word vectors.
作为示例,文本编码模型可以是BERT(Bidirectional Encoder Representationsfrom Transformers,基于变换的双向编码表示)。As an example, the text encoding model may be BERT (Bidirectional Encoder Representations from Transformers).
步骤203,确定字向量序列中的每个字向量对应的目标概率值组,得到目标概率值组序列。Step 203: Determine a target probability value group corresponding to each word vector in the sequence of word vectors, and obtain a sequence of target probability value groups.
在一些实施例中,上述执行主体可以将字向量序列依次输入一个全连接层,得到初步降维的字向量序列,之后可以输入一个下采样层,得到第二次降维后的字向量序列,最后可以输入一个全连接层,得到第三次降维后的字向量序列。可以对该序列中的每个字向量进行归一化处理以生成目标概率值组,得到目标概率值组序列。其中,目标概率值组中目标概率值的个数等于标签的数目。第i个目标概率值表示上述字向量对应的字被赋予第i个标签的概率。其中,i可以取1到2N+1之间的任一整数,N表示目标对象的数目。In some embodiments, the above-mentioned execution body may sequentially input the sequence of word vectors into a fully connected layer to obtain a sequence of word vectors with initial dimension reduction, and then may input a down-sampling layer to obtain a sequence of word vectors after the second dimension reduction, Finally, a fully connected layer can be input to obtain the word vector sequence after the third dimension reduction. Each word vector in the sequence can be normalized to generate a target probability value group to obtain a sequence of target probability value groups. Among them, the number of target probability values in the target probability value group is equal to the number of labels. The ith target probability value represents the probability that the word corresponding to the above word vector is assigned the ith label. Among them, i can take any integer between 1 and 2N+1, and N represents the number of target objects.
在一些实施例的一些可选的实现方式中,上述执行主体可以将字向量序列输入至预训练的至少一个全连接层,得到目标概率值组序列。通过上述至少一个全连接层,对每个字向量均可得到一个对应的目标概率值组。In some optional implementations of some embodiments, the above-mentioned executive body may input the sequence of word vectors into at least one fully connected layer of pre-training to obtain the sequence of target probability value groups. Through the above at least one fully connected layer, a corresponding target probability value group can be obtained for each word vector.
步骤204,基于目标概率值组序列和标签组集,生成对象向量序列集。
在一些实施例中,上述执行主体可以根据标签组,对上述目标概率值组序列中的目标概率值进行筛选。例如,从“今年猪肉玉米大涨”提取猪肉价格的变动信息,此时目标对象可以为猪肉,将B-猪肉,I-猪肉和O这三类标签作为一个标签组,若玉米为另一个目标对象,则可以将B-玉米,I-玉米和O这3个标签作为另一个标签组。每个目标对象可以对应一个标签组,所有的目标对象可以对应一个标签组集。目标文本中的每个字可以对应一个目标概率值组,每个目标概率值可以对应一个标签,其中,目标概率值表示该字被判定为当前标签的概率。于是,依次从目标概率值组序列中的每个目标概率值组中,选出目标标签组中的每个标签对应的目标概率值,得到目标标签组中的每个标签对应目标概率值序列。之后,依次取标签“B-X”,“I-X”和“O”对应的序列中的同样位置的目标概率值,组成一个三元组,将该三元组作为对象向量。由目标标签组的三个标签对应的三个序列,可以得到对象向量序列。其中,目标标签组为标签组集中的标签组。In some embodiments, the above-mentioned execution body may filter the target probability values in the above-mentioned target probability value group sequence according to the tag group. For example, to extract the change information of pork prices from "Pork and corn have risen sharply this year", the target object can be pork, and the three types of labels B-pork, I-pork and O are used as a label group, if corn is another target object, the 3 tags B-corn, I-corn and O can be used as another tag group. Each target object can correspond to a tag group, and all target objects can correspond to a tag group set. Each word in the target text may correspond to a target probability value group, and each target probability value may correspond to a label, wherein the target probability value represents the probability that the word is judged as the current label. Therefore, from each target probability value group in the target probability value group sequence, the target probability value corresponding to each tag in the target tag group is selected in turn, and the target probability value sequence corresponding to each tag in the target tag group is obtained. After that, take the target probability values of the same position in the sequence corresponding to the labels "B-X", "I-X" and "O" in turn to form a triple, and use the triple as the object vector. From the three sequences corresponding to the three labels of the target label group, the sequence of object vectors can be obtained. The target label group is a label group in the label group set.
在一些实施例的一些可选的实现方式中,上述执行主体可以通过以下步骤得到对象向量序列集:In some optional implementation manners of some embodiments, the above-mentioned execution body may obtain the object vector sequence set through the following steps:
第一步,依次从目标概率值组序列中选出与目标标签组中每个目标标签对应的目标概率值,得到目标概率值序列,其中,目标标签组为标签组集中的标签组。In the first step, the target probability value corresponding to each target label in the target label group is sequentially selected from the sequence of target probability value groups, and the target probability value sequence is obtained, wherein the target label group is the label group in the label group set.
作为示例,目标文本可以是“今年猪肉大涨”,目标对象有两种:猪肉和玉米。标签有五种:“B-猪肉”、“I-猪肉”、“B-玉米”、“I-玉米”和“O”。“猪肉”对应的标签组包括“B-猪肉”、“I-猪肉”和“O”三个标签。目标概率值组序列可以是[0.2,0.5,0.6,0.1,0.3],[0.2,0.8,0.3,0.9,0.2],[0.5,0.8,0.3,0.4,0.5],[0.4,0.2,0.7,0.6,0.1],[0.1,0.2,0.5,0.3,0.8],[0.7,0.3,0.2,0.5,0.2]。为了提取猪肉价格的变动信息,从上述序列中选出目标对象“猪肉”对应的标签组中每个标签对应的目标概率值,对于标签“B-猪肉”,可选出目标概率值序列0.2,0.2,0.5,0.4,0.1,0.7,对于标签“I-猪肉”,可选出目标概率值序列0.5,0.8,0.8,0.2,0.2,0.3,对于标签“O”,可选出目标概率值序列0.3,0.2,0.5,0.1,0.8,0.2。As an example, the target text can be "Pork has risen sharply this year", and there are two target objects: pork and corn. There are five labels: "B-Pork", "I-Pork", "B-Corn", "I-Corn" and "O". The tag group corresponding to "pork" includes three tags: "B-pork", "I-pork" and "O". The sequence of target probability value groups can be [0.2, 0.5, 0.6, 0.1, 0.3], [0.2, 0.8, 0.3, 0.9, 0.2], [0.5, 0.8, 0.3, 0.4, 0.5], [0.4, 0.2, 0.7, 0.6, 0.1], [0.1, 0.2, 0.5, 0.3, 0.8], [0.7, 0.3, 0.2, 0.5, 0.2]. In order to extract the change information of pork price, the target probability value corresponding to each label in the label group corresponding to the target object "pork" is selected from the above sequence. For the label "B-pork", the target probability value sequence 0.2 can be selected, 0.2, 0.5, 0.4, 0.1, 0.7, for the label "I-pork", the target probability value sequence 0.5, 0.8, 0.8, 0.2, 0.2, 0.3 can be selected, and for the label "O", the target probability value sequence can be selected 0.3, 0.2, 0.5, 0.1, 0.8, 0.2.
第二步,基于所得到的目标概率值序列,生成对象向量序列集。其中,对任一标签组,通过第一步都能得到该标签组中每个标签对应的目标概率值序列。从上述三个目标概率值序列中,选择序列中相同位置的元素,组成三元组,将该三元组作为对象向量,得到一个对象向量序列。In the second step, an object vector sequence set is generated based on the obtained target probability value sequence. Among them, for any label group, the target probability value sequence corresponding to each label in the label group can be obtained through the first step. From the above three target probability value sequences, select elements at the same position in the sequence to form a triplet, and use the triplet as an object vector to obtain an object vector sequence.
作为示例,从第一步中选出的3个目标概率值序列中选择序列中相同位置的元素,得到如下对象向量:(0.2,0.5,0.3),(0.2,0.8,0.2),(0.5,0.8,0.5),(0.4,0.2,0.1),(0.1,0.2,0.8),(0.7,0.3,0.2),根据选择时元素在相应序列中的位置,由这些对象向量可得到一个对象向量序列。其中,该序列中的对象向量分别对应“今”“年”“猪”“肉”“大”“涨”这几个字。As an example, select elements at the same position in the sequence from the 3 target probability value sequences selected in the first step to obtain the following object vectors: (0.2, 0.5, 0.3), (0.2, 0.8, 0.2), (0.5, 0.8, 0.5), (0.4, 0.2, 0.1), (0.1, 0.2, 0.8), (0.7, 0.3, 0.2), according to the position of the element in the corresponding sequence at the time of selection, a sequence of object vectors can be obtained from these object vectors . Among them, the object vectors in the sequence correspond to the words "now", "year", "pig", "meat", "big" and "rise" respectively.
步骤205,基于对象向量序列集和对象转移矩阵集,生成标签序列集。
在一些实施例中,上述执行主体可以将对象向量序列集作为标签序列集,此时所有的对象转移矩阵中的元素为一个常量。对象转移矩阵中的元素是标签之间的转移概率的值。对象转移矩阵为3×3的矩阵,其中,N是目标对象的数目。例如,目标对象为猪肉,目的是提取出猪肉价格的变动信息,那么可以将“今年猪肉价格大涨”赋予标签序列“O O O O O OB-猪肉I-猪肉”,假设上述执行主体将“今”赋予标签“O”,当对“年”赋予标签时,会利用“今”的标签为“O”的信息,给出“年”被赋予各个标签的概率。从而提高“年”被赋予正确的标签的概率。这个过程中的,由当前的字的标签,推测下一个字被赋予某一个标签的概率,称为标签到标签的转移概率。In some embodiments, the above-mentioned execution body may use the object vector sequence set as the label sequence set, and in this case, all elements in the object transition matrix are a constant. The elements in the object transition matrix are the values of transition probabilities between labels. The object transition matrix is a 3×3 matrix, where N is the number of target objects. For example, if the target object is pork, and the purpose is to extract the change information of pork prices, then the tag sequence "O O O O O OB-pork I-pork" can be assigned to "the price of pork has risen sharply this year", assuming that the above-mentioned executive entity assigns the tag "today" "O", when a label is assigned to "year", the information that the label of "this" is "O" will be used to give the probability that "year" is assigned each label. Thereby increasing the probability of "year" being given the correct label. In this process, the probability that the next word is assigned a certain label is inferred from the label of the current word, which is called the transition probability from label to label.
在一些实施例的一些可选的实现方式中,上述执行主体可以对于对象向量序列集中的每个对象向量序列和该对象向量序列对应的对象转移矩阵,利用维特比算法,生成标签序列。其中,目标对象X对应的对象向量序列可以以如下方式生成一个矩阵:将上述序列中每个对象向量依次对应为矩阵的第一列,第二列,...,第M列;将上述对象向量中的元素依次赋予对应的列中第一行,第二行和第三行的元素。其中,M为任一向量序列的长度。将上述生成的矩阵称为目标文本的目标对象X的发射矩阵。由上述发射矩阵和对象转移矩阵。通过维特比算法,可以得到一条最优序列,将该序列作为标签序列。In some optional implementations of some embodiments, the above-mentioned executive body may use the Viterbi algorithm to generate a label sequence for each object vector sequence in the object vector sequence set and the object transition matrix corresponding to the object vector sequence. Wherein, the sequence of object vectors corresponding to the target object X can generate a matrix in the following manner: each object vector in the above sequence is corresponding to the first column, the second column, ..., the Mth column of the matrix in turn; The elements in the vector are assigned to the elements of the first row, the second row and the third row in the corresponding column in turn. where M is the length of any vector sequence. The above-generated matrix is referred to as the emission matrix of the target object X of the target text. From the above emission matrix and object transfer matrix. Through the Viterbi algorithm, an optimal sequence can be obtained, which is used as the label sequence.
在一些实施例的一些可选的实现方式中,上述执行主体可以对于对象向量序列集中的每个对象向量序列和对象向量序列对应的对象转移矩阵,通过以下公式,得到待选标签序列的得分:In some optional implementations of some embodiments, the above-mentioned execution body can obtain the score of the tag sequence to be selected by using the following formula for each object vector sequence in the object vector sequence set and the object transition matrix corresponding to the object vector sequence:

其中,







然后,从所得到的待选标签序列的得分中选出最大的得分对应的待选标签序列作为标签序列。将最大的
作为示例,上述至少一个全连接层和对象转移矩阵集可以通过以下步骤得到:As an example, the above at least one fully connected layer and the set of object transition matrices can be obtained through the following steps:
第一步,获取训练样本集,其中,训练样本为根据目标对象选定的不超过预设长度的文本。其中,预设长度可以是100个字的长度。The first step is to obtain a training sample set, wherein the training samples are texts with a length not exceeding a preset length selected according to the target object. Wherein, the preset length may be a length of 100 words.
第二步,对训练样本集进行BIO标注,得到训练样本对应的标签序列。之后,将训练样本输入BERT,得到每个字的向量表示。将上述向量作为字向量,于是,上述训练样本对应的一个字向量序列。其中,BIO标注是基于目标对象集合,给文本中的每个字赋予一个标签,标签是对字的一种标识。其中,每个目标对象有三类标签。比如,对于目标对象X,三类标签分别是“B-X”,“I-X”和“O”。将上述三类标签组成一个集合,称该集合为目标对象X的标签组。其中,字被赋予标签“B-X”,表示该字所在的词语用于描述目标对象X的信息,且该字在该词语的起始位置。字被赋予标签“I-X”表示该字所在的词语用于描述目标对象X的信息,且该字在该词语的非起始位置,字被赋予标签“O”表示该字表达的信息与目标对象X无关。例如,目标对象为猪肉,目的是提取出猪肉价格的变动信息,那么可以将“今年猪肉价格大涨”赋予标签序列“O O O O O O B-猪肉I-猪肉”。The second step is to perform BIO labeling on the training sample set to obtain the label sequence corresponding to the training sample. After that, the training samples are fed into BERT to get a vector representation of each word. Taking the above vector as a word vector, then, a word vector sequence corresponding to the above training sample. Among them, the BIO annotation is based on the target object set, and assigns a label to each word in the text, and the label is a kind of identification of the word. Among them, each target object has three types of labels. For example, for the target object X, the three types of labels are "B-X", "I-X" and "O" respectively. The above three types of tags are formed into a set, and the set is called the tag group of the target object X. Among them, a word is given the label "B-X", indicating that the word in which the word is located is used to describe the information of the target object X, and the word is at the starting position of the word. A word is given the label "I-X" to indicate that the word in which the word is located is used to describe the information of the target object X, and the word is in the non-starting position of the word, and the word is given the label "O" to indicate that the information expressed by the word is related to the target object. X is irrelevant. For example, if the target object is pork, and the purpose is to extract the change information of pork price, then "the price of pork has risen sharply this year" can be assigned to the label sequence "O O O O O O B-pork I-pork".
第三步,将该字向量序列输入若干个前后连接的全连接层,输出训练样本中每个字对应的概率值组,得到概率值组序列。其中,第一个全连接层的神经元个数可以是预设长度乘以字向量的长度,最后一个全连接层的神经元个数可以是预设长度。输出时,每个字对应的维度为标签的数目2N+1。其中,N是目标对象的数目。上述概率值组与目标概率值组,仅用于区分训练时和测试时的不同输出结果,除了包含的概率值可能不同外,其余没有任何区别。依次将概率值组序列中的每个概率值组对应为矩阵的一列。概率值组的中第一个元素对应为矩阵对应列中的第一个元素,其余元素依序放置。称上述得到的矩阵为该训练样本的发射矩阵。通过取出发射矩阵中的各个列的元素,可得到对应的概率值组序列。In the third step, the word vector sequence is input into several fully connected layers connected before and after, and the probability value group corresponding to each word in the training sample is output to obtain the probability value group sequence. The number of neurons in the first fully-connected layer may be the preset length multiplied by the length of the word vector, and the number of neurons in the last fully-connected layer may be the preset length. When outputting, the dimension corresponding to each word is the number of labels 2N+1. where N is the number of target objects. The above probability value group and target probability value group are only used to distinguish different output results during training and testing, and there is no difference except that the included probability values may be different. Each probability value group in the sequence of probability value groups is corresponding to a column of the matrix in turn. The first element in the probability value group corresponds to the first element in the corresponding column of the matrix, and the remaining elements are placed in sequence. The matrix obtained above is called the emission matrix of the training sample. By taking out the elements of each column in the emission matrix, the corresponding sequence of probability value groups can be obtained.
第四步,根据上述发射矩阵和转移矩阵,通过维特比算法,可得到对应的最优序列的概率。最优序列即第二步标注的训练样本对应的标签序列。目标函数为使该最优序列的概率达到最大的函数,通过梯度下降法,可以不断更新至少一个全连接层的所有权重和转移矩阵,最终得到一个训练好的至少一个全连接层和转移矩阵。将训练好的转移矩阵称为标签转移矩阵。其中,转移矩阵每一行对应唯一的标签,称为行标签,每一列也对应唯一的标签,称为列标签。转移矩阵中的元素为所有2N+1个标签中两两标签之间的转移概率,N表示目标对象的数目。In the fourth step, according to the above-mentioned emission matrix and transition matrix, the probability of the corresponding optimal sequence can be obtained through the Viterbi algorithm. The optimal sequence is the label sequence corresponding to the training samples marked in the second step. The objective function is to maximize the probability of the optimal sequence. Through the gradient descent method, all weights and transition matrices of at least one fully connected layer can be continuously updated, and finally a trained at least one fully connected layer and transition matrix can be obtained. The trained transition matrix is called the label transition matrix. Among them, each row of the transition matrix corresponds to a unique label, called a row label, and each column also corresponds to a unique label, called a column label. The elements in the transition matrix are the transition probabilities between all 2N+1 labels, and N represents the number of target objects.
第五步,对于目标对象X,从上述标签转移矩阵中依次选出行标签为“B-X”,列标签分别为“B-X”“I-X”和“O”的元素,得到第一个三元组;再依次选出行标签为“I-X”,列标签分别为“B-X”“I-X”和“O”的元素,得到第二个三元组;再依次选出行标签为“O”,列标签分别为“B-X”“I-X”和“O”的元素,得到第三个三元组。将上述得到的第一个三元组中的三个元素分别作为一个3×3矩阵的第一行的第一列,第一行的第二列和第一行的第三列的元素。得到的另外两个三元组按同样规则放入矩阵,得到目标对象X的对象转移矩阵。同理,可得到其余目标对象的对象转移矩阵。The fifth step, for the target object X, select the elements whose row labels are "B-X" and the column labels are respectively "B-X", "I-X" and "O" from the above label transition matrix to obtain the first triplet; Then select the elements whose row labels are "I-X", and the column labels are "B-X", "I-X" and "O" respectively, and get the second triple; For the elements of "B-X", "I-X" and "O", a third triple is obtained. The three elements in the first triple obtained above are taken as the elements of the first column of the first row, the second column of the first row, and the third column of the first row of a 3×3 matrix, respectively. The other two triples obtained are put into the matrix according to the same rules, and the object transition matrix of the target object X is obtained. Similarly, the object transition matrix of the remaining target objects can be obtained.
上述公式以及相关内容作为本公开的实施例的一个发明点,解决了背景技术提及的技术问题二“很多应用场景进行信息抽取时,没有均衡语义和字属性的关系,导致抽取的信息准确度偏低”。导致造成准确度偏低的因素往往如下:未充分考虑语义和字对应的标签之间的关系。如果解决了上述因素,就能达到提高信息抽取的准确度的效果。为了达到这一效果,本公开引入了调控因子以提高信息抽取的准确度。当应用更关注目标文本的语义信息时,可以缩小调控因子,来得到更多的语义信息。当应用更关注目标文本的字对应的标签之间的关系时,可以增大调控因子,使抽取的信息在语法上具有较高的准确度。The above formula and related content are an inventive point of the embodiment of the present disclosure, which solves the technical problem mentioned in the background art. "When performing information extraction in many application scenarios, the relationship between semantics and word attributes is not balanced, resulting in the accuracy of the extracted information. low". The factors that lead to low accuracy are often as follows: The relationship between semantics and labels corresponding to words is not fully considered. If the above factors are solved, the effect of improving the accuracy of information extraction can be achieved. To achieve this effect, the present disclosure introduces regulatory factors to improve the accuracy of information extraction. When the application pays more attention to the semantic information of the target text, the regulatory factors can be narrowed to obtain more semantic information. When the application pays more attention to the relationship between the tags corresponding to the words of the target text, the control factor can be increased, so that the extracted information has a higher grammatical accuracy.
步骤206,从目标文本中抽取出与标签序列集中的每个标签序列对应的对象信息,得到对象信息集。Step 206: Extract object information corresponding to each tag sequence in the tag sequence set from the target text to obtain an object information set.
在一些实施例中,上述执行主体可以从目标文本中取出标签序列中非“O”标签对应的字,得到一条对象信息。In some embodiments, the above-mentioned execution body may extract words corresponding to non-"O" tags in the tag sequence from the target text to obtain a piece of object information.
作为示例,如图5,目标对象为猪肉和玉米,文本“猪肉玉米大涨”对应的标签序列为“O O O O B-猪肉I-猪肉”,从而可提取出猪肉“大涨”;文本“猪肉玉米大涨”对应的标签序列为“O O O O B-玉米I-玉米”,从而可提取出玉米“大涨”。As an example, as shown in Figure 5, the target objects are pork and corn, and the tag sequence corresponding to the text "Pork and corn boom" is "O O O O B-pork I-pork", so the pork "zhang" can be extracted; the text "pork corn boom" The tag sequence corresponding to "big rise" is "OOOO B-maize I-corn", so that corn "big rise" can be extracted.
本公开的上述各个实施例具有如下有益效果:通过对获取的目标文本中的每个字进行编码以生成字向量,这些编码得到的字向量具有文本信息和位置信息,底层共享的设计使得训练数贫乏的对象得到充分的训练,提高了整个过程的学习能力。通过对目标文本中每个字赋予与各个目标对象相关的标签,使得能初步抽取出各个对象对应的对象信息。之后,引入多个对象转移矩阵,更准确地表达了两两相邻的字之间关系,从而实现对重叠信息的准确提取。The above-mentioned embodiments of the present disclosure have the following beneficial effects: by encoding each word in the acquired target text to generate word vectors, the encoded word vectors have text information and position information, and the underlying shared design makes the training data Poor subjects are fully trained, improving the learning ability of the whole process. By assigning a label related to each target object to each word in the target text, the object information corresponding to each object can be preliminarily extracted. After that, multiple object transition matrices are introduced to more accurately express the relationship between adjacent words, so as to achieve accurate extraction of overlapping information.
进一步参考图3,作为对上述所示方法的实现,本公开提供了一种信息抽取装置的一些实施例,这些装置实施例与图2所示的那些方法实施例相对应,该装置具体可以应用于各种电子设备中。With further reference to FIG. 3 , as an implementation of the method shown above, the present disclosure provides some embodiments of an information extraction apparatus, these apparatus embodiments correspond to those method embodiments shown in FIG. 2 , and the apparatus can be specifically applied in various electronic devices.
如图3所示,一些实施例的信息抽取装置300包括:获取单元301、编码单元302、确定单元303、第一生成单元304、第二生成单元305和抽取单元306。其中,获取单元301被配置成获取目标文本;编码单元302被配置成对目标文本中的每个字进行编码以生成字向量,得到字向量序列;确定单元303被配置成确定字向量序列中的每个字向量对应的目标概率值组,得到目标概率值组序列;第一生成单元304被配置成基于目标概率值组序列和标签组集,生成对象向量序列集;第二生成单元305被配置成基于对象向量序列集和对象转移矩阵集,生成标签序列集;抽取单元306被配置成从目标文本中抽取出与标签序列集中的每个标签序列对应的对象信息,得到对象信息集。As shown in FIG. 3 , the
可以理解的是,该装置300中记载的诸单元与参考图2描述的方法中的各个步骤相对应。由此,上文针对方法描述的操作、特征以及产生的有益效果同样适用于装置300及其中包含的单元,在此不再赘述。It can be understood that the units recorded in the
下面参考图4,其示出了适于用来实现本公开的一些实施例的电子设备(例如图1中的计算设备101)400的结构示意图。图4示出的电子设备仅仅是一个示例,不应对本公开的实施例的功能和使用范围带来任何限制。Referring now to FIG. 4 , a schematic structural diagram of an electronic device (eg, computing device 101 in FIG. 1 ) 400 suitable for implementing some embodiments of the present disclosure is shown. The electronic device shown in FIG. 4 is only an example, and should not impose any limitation on the function and scope of use of the embodiments of the present disclosure.
如图4所示,电子设备400可以包括处理装置(例如中央处理器、图形处理器等)401,其可以根据存储在只读存储器(ROM)402中的程序或者从存储装置408加载到随机访问存储器(RAM)403中的程序而执行各种适当的动作和处理。在RAM 403中,还存储有电子设备400操作所需的各种程序和数据。处理装置401、ROM 402以及RAM 403通过总线404彼此相连。输入/输出(I/O)接口405也连接至总线404。As shown in FIG. 4 , an
通常,以下装置可以连接至I/O接口405:包括例如触摸屏、触摸板、键盘、鼠标、摄像头、麦克风、加速度计、陀螺仪等的输入装置406;包括例如液晶显示器(LCD)、扬声器、振动器等的输出装置407;包括例如磁带、硬盘等的存储装置408;以及通信装置409。通信装置409可以允许电子设备400与其他设备进行无线或有线通信以交换数据。虽然图4示出了具有各种装置的电子设备400,但是应理解的是,并不要求实施或具备所有示出的装置。可以替代地实施或具备更多或更少的装置。图4中示出的每个方框可以代表一个装置,也可以根据需要代表多个装置。Typically, the following devices may be connected to the I/O interface 405:
特别地,根据本公开的一些实施例,上文参考流程图描述的过程可以被实现为计算机软件程序。例如,本公开的一些实施例包括一种计算机程序产品,其包括承载在计算机可读介质上的计算机程序,该计算机程序包含用于执行流程图所示的方法的程序代码。在这样的一些实施例中,该计算机程序可以通过通信装置409从网络上被下载和安装,或者从存储装置408被安装,或者从ROM 402被安装。在该计算机程序被处理装置401执行时,执行本公开的一些实施例的方法中限定的上述功能。In particular, according to some embodiments of the present disclosure, the processes described above with reference to the flowcharts may be implemented as computer software programs. For example, some embodiments of the present disclosure include a computer program product comprising a computer program carried on a computer-readable medium, the computer program containing program code for performing the method illustrated in the flowchart. In some such embodiments, the computer program may be downloaded and installed from the network via the
需要说明的是,本公开的一些实施例中记载的计算机可读介质可以是计算机可读信号介质或者计算机可读存储介质或者是上述两者的任意组合。计算机可读存储介质例如可以是——但不限于——电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。计算机可读存储介质的更具体的例子可以包括但不限于:具有一个或多个导线的电连接、便携式计算机磁盘、硬盘、随机访问存储器(RAM)、只读存储器(ROM)、可擦式可编程只读存储器(EPROM或闪存)、光纤、便携式紧凑磁盘只读存储器(CD-ROM)、光存储器件、磁存储器件、或者上述的任意合适的组合。在本公开的一些实施例中,计算机可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。而在本公开的一些实施例中,计算机可读信号介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了计算机可读的程序代码。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任意合适的组合。计算机可读信号介质还可以是计算机可读存储介质以外的任何计算机可读介质,该计算机可读信号介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。计算机可读介质上包含的程序代码可以用任何适当的介质传输,包括但不限于:电线、光缆、RF(射频)等等,或者上述的任意合适的组合。It should be noted that the computer-readable medium described in some embodiments of the present disclosure may be a computer-readable signal medium or a computer-readable storage medium, or any combination of the above two. The computer-readable storage medium can be, for example, but not limited to, an electrical, magnetic, optical, electromagnetic, infrared, or semiconductor system, apparatus or device, or a combination of any of the above. More specific examples of computer readable storage media may include, but are not limited to, electrical connections with one or more wires, portable computer disks, hard disks, random access memory (RAM), read only memory (ROM), erasable Programmable read only memory (EPROM or flash memory), fiber optics, portable compact disk read only memory (CD-ROM), optical storage devices, magnetic storage devices, or any suitable combination of the foregoing. In some embodiments of the present disclosure, a computer-readable storage medium can be any tangible medium that contains or stores a program that can be used by or in conjunction with an instruction execution system, apparatus, or device. Rather, in some embodiments of the present disclosure, a computer-readable signal medium may include a data signal propagated in baseband or as part of a carrier wave, carrying computer-readable program code therein. Such propagated data signals may take a variety of forms, including but not limited to electromagnetic signals, optical signals, or any suitable combination of the foregoing. A computer-readable signal medium can also be any computer-readable medium other than a computer-readable storage medium that can transmit, propagate, or transport the program for use by or in connection with the instruction execution system, apparatus, or device . Program code embodied on a computer readable medium may be transmitted using any suitable medium including, but not limited to, electrical wire, optical fiber cable, RF (radio frequency), etc., or any suitable combination of the foregoing.
在一些实施方式中,客户端、服务器可以利用诸如HTTP(HyperText TransferProtocol,超文本传输协议)之类的任何当前已知或未来研发的网络协议进行通信,并且可以与任意形式或介质的数字数据通信(例如,通信网络)互连。通信网络的示例包括局域网(“LAN”),广域网(“WAN”),网际网(例如,互联网)以及端对端网络(例如,ad hoc端对端网络),以及任何当前已知或未来研发的网络。In some embodiments, the client and server can communicate using any currently known or future developed network protocol such as HTTP (HyperText Transfer Protocol), and can communicate with digital data in any form or medium (eg, a communications network) interconnected. Examples of communication networks include local area networks ("LAN"), wide area networks ("WAN"), the Internet (eg, the Internet), and peer-to-peer networks (eg, ad hoc peer-to-peer networks), as well as any currently known or future development network of.
上述计算机可读介质可以是上述电子设备中所包含的;也可以是单独存在,而未装配入该电子设备中。上述计算机可读介质承载有一个或者多个程序,当上述一个或者多个程序被该电子设备执行时,使得该电子设备:获取目标文本;对目标文本中的每个字进行编码以生成字向量,得到字向量序列;确定字向量序列中的每个字向量对应的目标概率值组,得到目标概率值组序列;基于目标概率值组序列和标签组集,生成对象向量序列集;基于对象向量序列集和对象转移矩阵集,生成标签序列集;从目标文本中抽取出与标签序列集中的每个标签序列对应的对象信息,得到对象信息集。The above-mentioned computer-readable medium may be included in the above-mentioned electronic device; or may exist alone without being assembled into the electronic device. The above-mentioned computer-readable medium carries one or more programs that, when executed by the electronic device, cause the electronic device to: acquire target text; encode each word in the target text to generate a word vector , obtain the word vector sequence; determine the target probability value group corresponding to each word vector in the word vector sequence, and obtain the target probability value group sequence; based on the target probability value group sequence and the label group set, generate the object vector sequence set; A sequence set and an object transition matrix set are used to generate a tag sequence set; the object information corresponding to each tag sequence in the tag sequence set is extracted from the target text to obtain an object information set.
可以以一种或多种程序设计语言或其组合来编写用于执行本公开的一些实施例的操作的计算机程序代码,上述程序设计语言包括面向对象的程序设计语言—诸如Java、Smalltalk、C++,还包括常规的过程式程序设计语言—诸如“C”语言或类似的程序设计语言。程序代码可以完全地在用户计算机上执行、部分地在用户计算机上执行、作为一个独立的软件包执行、部分在用户计算机上部分在远程计算机上执行、或者完全在远程计算机或服务器上执行。在涉及远程计算机的情形中,远程计算机可以通过任意种类的网络——包括局域网(LAN)或广域网(WAN)——连接到用户计算机,或者,可以连接到外部计算机(例如利用因特网服务提供商来通过因特网连接)。Computer program code for carrying out operations of some embodiments of the present disclosure may be written in one or more programming languages, including object-oriented programming languages—such as Java, Smalltalk, C++, or a combination thereof, Also included are conventional procedural programming languages - such as the "C" language or similar programming languages. The program code may execute entirely on the user's computer, partly on the user's computer, as a stand-alone software package, partly on the user's computer and partly on a remote computer, or entirely on the remote computer or server. In the case of a remote computer, the remote computer may be connected to the user's computer through any kind of network, including a local area network (LAN) or a wide area network (WAN), or may be connected to an external computer (eg, using an Internet service provider to via Internet connection).
附图中的流程图和框图,图示了按照本公开各种实施例的系统、方法和计算机程序产品的可能实现的体系架构、功能和操作。在这点上,流程图或框图中的每个方框可以代表一个模块、程序段、或代码的一部分,该模块、程序段、或代码的一部分包含一个或多个用于实现规定的逻辑功能的可执行指令。也应当注意,在有些作为替换的实现中,方框中所标注的功能也可以以不同于附图中所标注的顺序发生。例如,两个接连地表示的方框实际上可以基本并行地执行,它们有时也可以按相反的顺序执行,这依所涉及的功能而定。也要注意的是,框图和/或流程图中的每个方框、以及框图和/或流程图中的方框的组合,可以用执行规定的功能或操作的专用的基于硬件的系统来实现,或者可以用专用硬件与计算机指令的组合来实现。The flowchart and block diagrams in the Figures illustrate the architecture, functionality, and operation of possible implementations of systems, methods and computer program products according to various embodiments of the present disclosure. In this regard, each block in the flowchart or block diagrams may represent a module, segment, or portion of code that contains one or more logical functions for implementing the specified functions executable instructions. It should also be noted that, in some alternative implementations, the functions noted in the blocks may occur out of the order noted in the figures. For example, two blocks shown in succession may, in fact, be executed substantially concurrently, or the blocks may sometimes be executed in the reverse order, depending upon the functionality involved. It is also noted that each block of the block diagrams and/or flowchart illustrations, and combinations of blocks in the block diagrams and/or flowchart illustrations, can be implemented in dedicated hardware-based systems that perform the specified functions or operations , or can be implemented in a combination of dedicated hardware and computer instructions.
描述于本公开的一些实施例中的单元可以通过软件的方式实现,也可以通过硬件的方式来实现。所描述的单元也可以设置在处理器中,例如,可以描述为:一种处理器包括获取单元、编码单元、确定单元、第一生成单元、第二生成单元和抽取单元。其中,这些单元的名称在某种情况下并不构成对该单元本身的限定,例如,获取单元还可以被描述为“获取目标文本的单元”。The units described in some embodiments of the present disclosure may be implemented by means of software, and may also be implemented by means of hardware. The described unit may also be provided in a processor, for example, it may be described as: a processor includes an acquisition unit, an encoding unit, a determination unit, a first generation unit, a second generation unit, and an extraction unit. Wherein, the names of these units do not constitute a limitation on the unit itself under certain circumstances, for example, the acquisition unit may also be described as "a unit for acquiring target text".
本文中以上描述的功能可以至少部分地由一个或多个硬件逻辑部件来执行。例如,非限制性地,可以使用的示范类型的硬件逻辑部件包括:现场可编程门阵列(FPGA)、专用集成电路(ASIC)、专用标准产品(ASSP)、片上系统(SOC)、复杂可编程逻辑设备(CPLD)等等。The functions described herein above may be performed, at least in part, by one or more hardware logic components. For example, without limitation, exemplary types of hardware logic components that may be used include: Field Programmable Gate Arrays (FPGAs), Application Specific Integrated Circuits (ASICs), Application Specific Standard Products (ASSPs), Systems on Chips (SOCs), Complex Programmable Logical Devices (CPLDs) and more.
以上描述仅为本公开的一些较佳实施例以及对所运用技术原理的说明。本领域技术人员应当理解,本公开的实施例中所涉及的发明范围,并不限于上述技术特征的特定组合而成的技术方案,同时也应涵盖在不脱离上述发明构思的情况下,由上述技术特征或其等同特征进行任意组合而形成的其它技术方案。例如上述特征与本公开的实施例中公开的(但不限于)具有类似功能的技术特征进行互相替换而形成的技术方案。The above descriptions are merely some preferred embodiments of the present disclosure and illustrations of the applied technical principles. Those skilled in the art should understand that the scope of the invention involved in the embodiments of the present disclosure is not limited to the technical solution formed by the specific combination of the above-mentioned technical features, and should also cover, without departing from the above-mentioned inventive concept, the above-mentioned Other technical solutions formed by any combination of technical features or their equivalent features. For example, a technical solution is formed by replacing the above-mentioned features with the technical features disclosed in the embodiments of the present disclosure (but not limited to) with similar functions.
Claims (9)
Translated fromChinese







Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110105562.2ACN114792086A (en) | 2021-01-26 | 2021-01-26 | Information extraction method, device, equipment and medium supporting text cross coverage |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110105562.2ACN114792086A (en) | 2021-01-26 | 2021-01-26 | Information extraction method, device, equipment and medium supporting text cross coverage |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN114792086Atrue CN114792086A (en) | 2022-07-26 |
Family
ID=82459573
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110105562.2APendingCN114792086A (en) | 2021-01-26 | 2021-01-26 | Information extraction method, device, equipment and medium supporting text cross coverage |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114792086A (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116030272A (en)* | 2023-03-30 | 2023-04-28 | 之江实验室 | Target detection method, system and device based on information extraction |
Citations (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20110213742A1 (en)* | 2010-02-26 | 2011-09-01 | Lemmond Tracy D | Information extraction system |
| CN107783960A (en)* | 2017-10-23 | 2018-03-09 | 百度在线网络技术(北京)有限公司 | Method, apparatus and equipment for Extracting Information |
| CN109446523A (en)* | 2018-10-23 | 2019-03-08 | 重庆誉存大数据科技有限公司 | Entity attribute extraction model based on BiLSTM and condition random field |
| CN109710930A (en)* | 2018-12-20 | 2019-05-03 | 重庆邮电大学 | A Chinese resume parsing method based on deep neural network |
| CN109902145A (en)* | 2019-01-18 | 2019-06-18 | 中国科学院信息工程研究所 | A method and system for joint entity relation extraction based on attention mechanism |
| CN109977402A (en)* | 2019-03-11 | 2019-07-05 | 北京明略软件系统有限公司 | A kind of name entity recognition method and system |
| CN110334217A (en)* | 2019-05-10 | 2019-10-15 | 科大讯飞股份有限公司 | A kind of element abstracting method, device, equipment and storage medium |
| CN110377903A (en)* | 2019-06-24 | 2019-10-25 | 浙江大学 | A kind of Sentence-level entity and relationship combine abstracting method |
| CN110472198A (en)* | 2018-05-10 | 2019-11-19 | 腾讯科技(深圳)有限公司 | A kind of determination method of keyword, the method for text-processing and server |
| CN111222317A (en)* | 2019-10-16 | 2020-06-02 | 平安科技(深圳)有限公司 | Sequence labeling method, system and computer equipment |
| CN111310471A (en)* | 2020-01-19 | 2020-06-19 | 陕西师范大学 | A Tourism Named Entity Recognition Method Based on BBLC Model |
| CN111444723A (en)* | 2020-03-06 | 2020-07-24 | 深圳追一科技有限公司 | Information extraction model training method and device, computer equipment and storage medium |
| CN111563380A (en)* | 2019-01-25 | 2020-08-21 | 浙江大学 | Named entity identification method and device |
| CN111639498A (en)* | 2020-04-21 | 2020-09-08 | 平安国际智慧城市科技股份有限公司 | Knowledge extraction method and device, electronic equipment and storage medium |
| CN111666418A (en)* | 2020-04-23 | 2020-09-15 | 北京三快在线科技有限公司 | Text regeneration method and device, electronic equipment and computer readable medium |
| WO2020232861A1 (en)* | 2019-05-20 | 2020-11-26 | 平安科技(深圳)有限公司 | Named entity recognition method, electronic device and storage medium |
- 2021
- 2021-01-26CNCN202110105562.2Apatent/CN114792086A/enactivePending
Patent Citations (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20110213742A1 (en)* | 2010-02-26 | 2011-09-01 | Lemmond Tracy D | Information extraction system |
| CN107783960A (en)* | 2017-10-23 | 2018-03-09 | 百度在线网络技术(北京)有限公司 | Method, apparatus and equipment for Extracting Information |
| CN110472198A (en)* | 2018-05-10 | 2019-11-19 | 腾讯科技(深圳)有限公司 | A kind of determination method of keyword, the method for text-processing and server |
| CN109446523A (en)* | 2018-10-23 | 2019-03-08 | 重庆誉存大数据科技有限公司 | Entity attribute extraction model based on BiLSTM and condition random field |
| CN109710930A (en)* | 2018-12-20 | 2019-05-03 | 重庆邮电大学 | A Chinese resume parsing method based on deep neural network |
| CN109902145A (en)* | 2019-01-18 | 2019-06-18 | 中国科学院信息工程研究所 | A method and system for joint entity relation extraction based on attention mechanism |
| CN111563380A (en)* | 2019-01-25 | 2020-08-21 | 浙江大学 | Named entity identification method and device |
| CN109977402A (en)* | 2019-03-11 | 2019-07-05 | 北京明略软件系统有限公司 | A kind of name entity recognition method and system |
| CN110334217A (en)* | 2019-05-10 | 2019-10-15 | 科大讯飞股份有限公司 | A kind of element abstracting method, device, equipment and storage medium |
| WO2020232861A1 (en)* | 2019-05-20 | 2020-11-26 | 平安科技(深圳)有限公司 | Named entity recognition method, electronic device and storage medium |
| CN110377903A (en)* | 2019-06-24 | 2019-10-25 | 浙江大学 | A kind of Sentence-level entity and relationship combine abstracting method |
| CN111222317A (en)* | 2019-10-16 | 2020-06-02 | 平安科技(深圳)有限公司 | Sequence labeling method, system and computer equipment |
| CN111310471A (en)* | 2020-01-19 | 2020-06-19 | 陕西师范大学 | A Tourism Named Entity Recognition Method Based on BBLC Model |
| CN111444723A (en)* | 2020-03-06 | 2020-07-24 | 深圳追一科技有限公司 | Information extraction model training method and device, computer equipment and storage medium |
| CN111639498A (en)* | 2020-04-21 | 2020-09-08 | 平安国际智慧城市科技股份有限公司 | Knowledge extraction method and device, electronic equipment and storage medium |
| CN111666418A (en)* | 2020-04-23 | 2020-09-15 | 北京三快在线科技有限公司 | Text regeneration method and device, electronic equipment and computer readable medium |
Non-Patent Citations (4)
| Title |
|---|
| A. R. MISHRA ET AL: "Extractive Text Summarization - An effective approach to extract information from Text", 《2019 INTERNATIONAL CONFERENCE ON CONTEMPORARY COMPUTING AND INFORMATICS 》, 31 December 2019 (2019-12-31), pages 252 - 255, XP033753996, DOI: 10.1109/IC3I46837.2019.9055636* |
| 刘卫平等: "基于迁移表示学习的军事命名实体识别", 《指挥信息系统与技术》, vol. 11, no. 2, 30 April 2020 (2020-04-30), pages 64 - 69* |
| 吴赛赛等: "面向领域实体关系联合抽取的标注方法", 《计算机应用》, 24 December 2020 (2020-12-24), pages 1 - 10* |
| 黄胜等: "基于深度学习的简历信息实体抽取方法", 《计算机工程与设计》, vol. 39, no. 12, 31 December 2018 (2018-12-31), pages 3873 - 3878* |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116030272A (en)* | 2023-03-30 | 2023-04-28 | 之江实验室 | Target detection method, system and device based on information extraction |
| CN116030272B (en)* | 2023-03-30 | 2023-07-14 | 之江实验室 | A target detection method, system and device based on information extraction |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7112536B2 (en) | Method and apparatus for mining entity attention points in text, electronic device, computer-readable storage medium and computer program | |
| CN111090987B (en) | Method and apparatus for outputting information | |
| CN111523640B (en) | Training methods and devices for neural network models | |
| CN110298019A (en) | Name entity recognition method, device, equipment and computer readable storage medium | |
| JP2022039973A (en) | Method and apparatus for quality control, electronic device, storage medium, and computer program | |
| CN116166271A (en) | Code generation method, device, storage medium and electronic equipment | |
| CN114385780B (en) | Program interface information recommendation method and device, electronic equipment and readable medium | |
| CN113255327B (en) | Text processing method and device, electronic equipment and computer readable storage medium | |
| CN113392197B (en) | Question answering reasoning method, device, storage medium and electronic equipment | |
| CN116882591A (en) | Information generation method, apparatus, electronic device and computer readable medium | |
| CN115640815A (en) | Translation method, device, readable medium and electronic equipment | |
| CN111859985B (en) | AI customer service model test method and device, electronic equipment and storage medium | |
| CN115525750B (en) | Robot speech detection visualization method, device, electronic device and storage medium | |
| CN112489652B (en) | Text acquisition method and device for voice information and storage medium | |
| CN114792086A (en) | Information extraction method, device, equipment and medium supporting text cross coverage | |
| CN117743555B (en) | Reply decision information transmission method, device, equipment and computer readable medium | |
| CN117131152B (en) | Information storage method, apparatus, electronic device, and computer readable medium | |
| CN111523639A (en) | Method and apparatus for training a super network | |
| CN115640523B (en) | Text similarity measurement method, device, equipment, storage medium and program product | |
| CN114579757B (en) | A text processing method and device based on knowledge graph assistance | |
| CN119648818A (en) | Image generation method, device, system, electronic device, and computer-readable medium | |
| CN113705234B (en) | Named entity recognition method, device, computer readable medium and electronic device | |
| CN117271870A (en) | Recommendation information generation method, device, electronic equipment and computer readable medium | |
| CN115129845A (en) | Text information processing method, device and electronic device | |
| CN119693941B (en) | Food description information display method, apparatus, device and computer readable medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |