CN114764380A - Distributed cluster control method and device based on ETCD - Google Patents
Distributed cluster control method and device based on ETCDDownload PDFInfo
- Publication number
- CN114764380A CN114764380ACN202110055020.9ACN202110055020ACN114764380ACN 114764380 ACN114764380 ACN 114764380ACN 202110055020 ACN202110055020 ACN 202110055020ACN 114764380 ACN114764380 ACN 114764380A
- Authority
- CN
- China
- Prior art keywords
- service
- cmserver
- state
- etcd
- main
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images


Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/16—Error detection or correction of the data by redundancy in hardware
- G06F11/20—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements
- G06F11/202—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements where processing functionality is redundant
- G06F11/2023—Failover techniques
- G06F11/2033—Failover techniques switching over of hardware resources
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/16—Error detection or correction of the data by redundancy in hardware
- G06F11/20—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements
- G06F11/202—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements where processing functionality is redundant
- G06F11/2041—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements where processing functionality is redundant with more than one idle spare processing component
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Quality & Reliability (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Hardware Redundancy (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本发明属于计算机技术领域,具体涉及一种基于ETCD的分布式集群控制方法和装置。The invention belongs to the field of computer technology, and in particular relates to an ETCD-based distributed cluster control method and device.
背景技术Background technique
随着大数据时代的到来,传统集中式单机服务系统已经不能满足大数据场景下的存储和处理要求,分布式的服务设计和集群化部署越来越多被研究和应用于大数据处理场景中。在分布式集群环境中,为了充分利用多个物理服务器的计算和存储资源,通常会在集群内部署多组应用服务,服务进程分别部署在集群内的不同节点上。为了满足集群在单点故障场景下服务的高可用性,服务通常设计和部署为一主机一备机,或一主机和多个备机的模式。With the advent of the era of big data, traditional centralized single-machine service systems can no longer meet the storage and processing requirements in big data scenarios. Distributed service design and cluster deployment are increasingly being studied and applied in big data processing scenarios. . In a distributed cluster environment, in order to make full use of the computing and storage resources of multiple physical servers, multiple sets of application services are usually deployed in the cluster, and the service processes are deployed on different nodes in the cluster. In order to meet the high availability of cluster services in a single point of failure scenario, services are usually designed and deployed as one host and one standby, or one host and multiple standbys.
如何高效自动地完成对集群内各应用服务的管理,实现集群服务的启动、停止,服务状态的查询和切换,以及集群内发生软硬件故障时的服务异常发现和自动恢复处理等,都是分布式集群控制要解决的重要问题。How to efficiently and automatically complete the management of each application service in the cluster, realize the start and stop of cluster services, query and switch service status, as well as service exception discovery and automatic recovery processing when software and hardware failures occur in the cluster, etc., are distributed It is an important problem to be solved by the cluster control.
ETCD服务是一个开源分布式的Key-Value键值对存储服务,由Go语言实现,使用Raft一致性算法来管理日志,达到高可用和强一致性的存储。ETCD service is an open source distributed Key-Value key-value pair storage service, implemented by Go language, using Raft consensus algorithm to manage logs to achieve high availability and strong consistency of storage.
发明内容SUMMARY OF THE INVENTION
本发明提供一种基于ETCD的分布式集群控制方法和装置,充分利用ETCD的高可用和强一致性的Key-Value存储服务,解决了集群内各应用服务的管理效率低以及集群内发生软硬件故障时的服务异常发现和自动恢复处理效率低的问题。The invention provides a distributed cluster control method and device based on ETCD, which fully utilizes the highly available and strongly consistent Key-Value storage service of ETCD, and solves the problem of low management efficiency of each application service in the cluster and the occurrence of hardware and software in the cluster. Service exception discovery and automatic recovery during failures deal with low efficiency.
为实现上述目的,本发明提供了如下的技术方案:一种基于ETCD的分布式集群控制方法,包括:To achieve the above object, the present invention provides the following technical scheme: a distributed cluster control method based on ETCD, comprising:
在集群内不同物理节点上部署运行多个集群管理服务,即CMServer服务,该服务进程启动后,会向集群内的ETCD服务进行抢占式事务写操作,若成功将本节点的CMServer服务信息写入,则表示该节点的CMServer成功注册为主服务;Deploy and run multiple cluster management services, namely CMServer services, on different physical nodes in the cluster. After the service process starts, it will perform preemptive transaction write operations to the ETCD service in the cluster. If the CMServer service information of the node is successfully written , it means that the CMServer of the node is successfully registered as the main service;
集群内各节点部署的代理Agent进程与CMServer主服务进行连接,周期性监控各节点上部署运行的各类服务进程状态,发送本节点各服务进程的状态消息和心跳消息给CMServer主服务;The agent agent process deployed on each node in the cluster is connected to the CMServer main service, periodically monitors the status of various service processes deployed and running on each node, and sends status messages and heartbeat messages of each service process of this node to the CMServer main service;
CMServer主服务接收到各个服务进程的状态消息和心跳消息,将各服务进程的状态写入到ETCD服务存储的键值中,同时刷新存储服务状态键值的租约时间;The CMServer main service receives the status messages and heartbeat messages of each service process, writes the status of each service process into the key value stored by the ETCD service, and refreshes the lease time for storing the service status key value;
若CMServer主服务检测到有服务状态租约过期,则判定并更新该服务为异常状态,并根据当前状态判断是否进行该服务的选主操作;If the CMServer main service detects that a service state lease has expired, it will determine and update the service as an abnormal state, and determine whether to perform the main selection operation of the service according to the current state;
ETCD服务在集群中用来存储集群的初始化配置信息和各类服务的状态信息。The ETCD service is used in the cluster to store the initial configuration information of the cluster and the status information of various services.
进一步的,所述向集群内部署的ETCD服务进行抢占式事务写操作,包括:Further, the preemptive transaction write operation to the ETCD service deployed in the cluster includes:
通过向集群内部署的ETCD服务里固定键值的抢占式事务写操作,将CMServer服务的本节点IP地址写入该键值内,并将CMServer服务的状态超时时间设置为存储键值的租约过期时间;Through the preemptive transaction write operation of the fixed key value in the etcd service deployed in the cluster, the IP address of the current node of the CMServer service is written into the key value, and the status timeout time of the CMServer service is set to the expiration of the lease for storing the key value. time;
集群内各节点部署的Agent进程只能连接到CMServer的主服务,过程包括:The Agent process deployed on each node in the cluster can only connect to the main service of CMServer. The process includes:
各Agent进程先从ETCD服务获得CMServer主服务的IP地址,然后根据该IP与CMServer主服务进行连接。Each Agent process first obtains the IP address of the CMServer main service from the ETCD service, and then connects with the CMServer main service according to the IP.
进一步的,在集群内部署奇数个ETCD服务进程实例,且分布运行在不同的物理节点上。Further, an odd number of etcD service process instances are deployed in the cluster and distributed and run on different physical nodes.
进一步的,所述集群内每个节点均部署Agent进程,该进程作为本节点所有部署的其他服务进程的父进程优先启动运行,Agent进程启动后,通过查询ETCD服务上各节点的集群服务配置信息,顺序启动所运行节点的其他各类服务进程实例。Further, each node in the cluster deploys an Agent process, and this process starts and runs preferentially as the parent process of all other service processes deployed by this node. After the Agent process is started, by querying the cluster service configuration information of each node on the ETCD service. , and sequentially start other various service process instances of the running node.
进一步的,所述Agent进程周期性监控本节点上运行服务的状态,将服务进程的状态信息通过消息或心跳消息发送给CMServer主服务,包括:Further, the Agent process periodically monitors the state of the service running on this node, and sends the state information of the service process to the CMServer main service through a message or a heartbeat message, including:
若某一个服务的进程状态发生改变,Agent会立即发送新的状态消息通知CMServer主服务,该服务进程的状态变化;If the process status of a service changes, the Agent will immediately send a new status message to notify the CMServer main service that the status of the service process changes;
若各服务进程的状态没有发生变化,Agent会在状态租约超时前周期性发送心跳消息给CMServer主服务,保证各服务状态租约正常刷新。If the status of each service process does not change, the Agent will periodically send a heartbeat message to the CMServer main service before the status lease expires to ensure that the status lease of each service is refreshed normally.
进一步的,所述通过ETCD存储键值的lease租约机制设置服务状态的超时过期时间;CMServer主服务每次收到服务进程的状态消息或心跳消息,都会刷新该服务状态的租约时间,避免状态超时。Further, set the timeout expiration time of the service state through the lease mechanism of storing key values in ETCD; every time the CMServer main service receives the status message or heartbeat message of the service process, it will refresh the lease time of the service state to avoid state timeout. .
进一步的,所述当集群中某服务状态出现异常或租约到期时,CMServer主服务会根据服务之前的主备状态判断是否进行选主操作,包括:Further, when the state of a service in the cluster is abnormal or the lease expires, the CMServer master service will judge whether to perform the master selection operation according to the master and backup state before the service, including:
若异常的服务进程之前为主服务,则CMServer主服务根据各节点负载状态选择一个备服务作为新的主服务;If the abnormal service process was the main service before, the CMServer main service selects a standby service as the new main service according to the load status of each node;
若异常的服务进程之前为备服务,且其主服务状态正常,则CMServer主服务只需更新该服务为异常状态,不需要进行选主操作。If the abnormal service process was previously a standby service, and its main service status is normal, the CMServer main service only needs to update the service to the abnormal status, and does not need to select the main service.
一种基于ETCD的分布式集群控制装置,包括:An ETCD-based distributed cluster control device, comprising:
CMServer主服务选举模块,集群内不同节点部署的集群管理服务CMServer服务启动后,向集群内部署的ETCD服务进行抢占式事务写操作,若成功将本节点的CMServer服务信息写入,则表示该节点的CMServer成功注册为主服务;CMServer main service election module. After the cluster management service CMServer service deployed on different nodes in the cluster is started, it performs preemptive transaction write operation to the ETCD service deployed in the cluster. If the CMServer service information of this node is successfully written, it means that this node The CMServer is successfully registered as the main service;
状态消息监控模块,集群内各节点部署的Agent进程与CMServer主服务进行连接和消息通信,Agent进程周期性监控所在节点部署运行的所有服务进程状态,发送节点服务进程的状态消息和心跳消息给CMServer主服务,由状态消息监控模块写入和更新ETCD服务中存储的服务状态和租约;Status message monitoring module, the Agent process deployed on each node in the cluster connects and communicates with the CMServer main service, the Agent process periodically monitors the status of all service processes deployed and running on the node, and sends the status message and heartbeat message of the node service process to the CMServer The main service, the service status and lease stored in the ETCD service are written and updated by the status message monitoring module;
异常发现和处理模块,CMServer主服务检测到有服务状态租约过期,则判定该服务进程状态异常并在ETCD服务中更新该服务为异常状态,并根据该服务主备状态,决定是否进行选主操作;如果服务异常状态前是主服务,则进行选主操作。ETCD服务用于存储集群的初始化部署配置信息和服务的运行状态信息。Abnormal discovery and processing module, CMServer main service detects that there is a service status lease expired, it determines that the service process status is abnormal and updates the service to the abnormal status in the ETCD service, and decides whether to perform the main selection operation according to the active and standby status of the service. ; If the service is the main service before the abnormal state, select the main service. The ETCD service is used to store the initial deployment configuration information of the cluster and the running status information of the service.
进一步的,所述向集群内部署的ETCD服务进行抢占式事务写操作,实现CMServer服务自身的选主过程,包括:Further, the preemptive transaction write operation is carried out to the ETCD service deployed in the cluster to realize the main selection process of the CMServer service itself, including:
通过向集群内部署的ETCD服务里固定键值的抢占式事务写操作,将CMServer服务的本节点IP地址写入该键值内,并将CMServer服务的状态超时时间设置为存储键值的租约过期时间;Through the preemptive transaction write operation of the fixed key value in the etcd service deployed in the cluster, the IP address of the current node of the CMServer service is written into the key value, and the status timeout time of the CMServer service is set to the expiration of the lease for storing the key value. time;
集群内各节点部署的Agent进程只能连接到CMServer的主服务,过程包括:The Agent process deployed on each node in the cluster can only connect to the main service of CMServer. The process includes:
各Agent进程先从ETCD服务获得CMServer主服务的IP地址,然后根据该IP与CMServer主服务进行连接。Each Agent process first obtains the IP address of the CMServer main service from the ETCD service, and then connects with the CMServer main service according to the IP.
进一步的,所述集群内每个节点均部署Agent进程,该进程作为本节点所有部署的其他服务进程的父进程优先启动运行,Agent进程启动后,通过查询ETCD服务上各节点的集群服务配置信息,顺序启动所运行节点的其他各类服务进程实例;Further, each node in the cluster deploys an Agent process, and this process starts and runs preferentially as the parent process of all other service processes deployed by this node. After the Agent process is started, by querying the cluster service configuration information of each node on the ETCD service. , and sequentially start other various service process instances of the running node;
若某一服务进程状态发生改变,Agent发送状态消息通知CMServer主服务;If the status of a service process changes, the Agent sends a status message to notify the CMServer main service;
若节点各服务进程状态没有变化,则定时发送心跳消息给CMServer主服务,使其刷新租约时间防止状态超时;If the status of each service process of the node does not change, it will periodically send a heartbeat message to the CMServer main service to refresh the lease time to prevent status timeout;
通过ETCD服务的lease租约机制设置服务状态的租约过期时间;CMServer主服务每次收到服务进程的状态消息或心跳消息,均刷新该服务状态租约时间。The lease expiration time of the service state is set through the lease lease mechanism of the ETCD service; every time the CMServer main service receives the status message or heartbeat message of the service process, the lease time of the service state is refreshed.
当集群中某服务状态出现异常或租约到期时,CMServer主服务会根据服务之前的主备状态判断是否进行选主操作,包括:When the status of a service in the cluster is abnormal or the lease expires, the CMServer master service will determine whether to perform the master selection operation according to the previous master and backup status of the service, including:
若异常的服务进程之前为主服务,则CMServer主服务根据各节点负载状态选择一个备服务作为新的主服务;If the abnormal service process was the main service before, the CMServer main service selects a standby service as the new main service according to the load status of each node;
若异常的服务进程之前为备服务,且其主服务状态正常,则CMServer主服务只需更新该服务为异常状态,不需要进行选主操作。If the abnormal service process was previously a standby service, and its main service status is normal, the CMServer main service only needs to update the service to the abnormal status, and does not need to select the main service.
本发明的有益效果:本发明通过在集群的节点中部署ETCD服务、CMServer服务以及代理Agent进程,通过CMServer自行选主,代理Agent将节点中的各个服务的状态周期性地发送给主CMServer,主CMServer将集群内各服务进程状态存储到高可用且强一致的ETCD服务中,并刷新服务状态租约时间,主CMServer检测到有服务的状态租约过期,则会判定和更新该服务为Timeout异常状态,并根据该服务最后的主备机状态信息判断是否对服务进行选主操作;本发明充分利用ETCD服务高可用的分布式一致性存储能力,实现对分布式集群环境下各种服务的部署和管理功能,可以有效提高集群服务的管理能力,以及发生单点故障场景下保持服务的高可用性,为整个集群服务的可用性提供有力支撑。Beneficial effects of the present invention: the present invention deploys the ETCD service, the CMServer service and the agent agent process in the nodes of the cluster, selects the master by itself through the CMServer, and the agent agent periodically sends the status of each service in the node to the master CMServer. The CMServer stores the state of each service process in the cluster into the highly available and strongly consistent ETCD service, and refreshes the service state lease time. The master CMServer detects that the state lease of a service has expired, and it will determine and update the service as a Timeout abnormal state. And according to the last main and standby machine status information of the service, it is judged whether to carry out the main selection operation for the service; the present invention makes full use of the highly available distributed consistent storage capability of the ETCD service to realize the deployment and management of various services in a distributed cluster environment This function can effectively improve the management capability of cluster services and maintain high availability of services in the event of a single point of failure, providing strong support for the availability of the entire cluster services.
本发明方法集群内各应用服务的管理效率高,且集群内发生软硬件故障时的服务异常能够自动发现和自动恢复,效率高。The method of the invention has high management efficiency of each application service in the cluster, and the service abnormality when the software and hardware failure occurs in the cluster can be automatically discovered and automatically recovered, and the efficiency is high.
附图说明Description of drawings
图1为本发明一种基于ETCD的分布式集群管理方法流程示意图;Fig. 1 is a kind of schematic flow chart of the distributed cluster management method based on ETCD of the present invention;
图2为本发明一种基于ETCD的分布式集群管理服务故障处理流程图;Fig. 2 is a kind of ETCD-based distributed cluster management service fault processing flowchart of the present invention;
图3为本发明一种基于ETCD的分布式集群管理系统架构图。FIG. 3 is an architectural diagram of an ETCD-based distributed cluster management system of the present invention.
具体实施方式Detailed ways
下面将结合本发明中的附图,对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动条件下所获得的所有其它实施例,都属于本发明保护的范围。The technical solutions of the present invention will be clearly and completely described below with reference to the accompanying drawings of the present invention. Obviously, the described embodiments are only a part of the embodiments of the present invention, not all of the embodiments. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without creative efforts shall fall within the protection scope of the present invention.
实施例1:Example 1:
如图1所示,本实施例提供了一种基于ETCD的分布式集群控制方法,包括以下步骤:As shown in FIG. 1 , this embodiment provides an ETCD-based distributed cluster control method, including the following steps:
(1)集群内部署ETCD服务,在ETCD服务中存储集群的初始化配置信息和服务状态信息;(1) Deploy the ETCD service in the cluster, and store the initial configuration information and service status information of the cluster in the ETCD service;
为了保证ETCD服务的高可用性,需要确保在集群内部署奇数个(如3个以上)的ETCD实例,且分布运行在不同的物理节点上。ETCD服务作为集群管理服务的持久化存储服务使用,集群初始化配置信息在安装部署时写入ETCD服务,ETCD服务是集群的配置管理中心。In order to ensure the high availability of the ETCD service, it is necessary to ensure that an odd number (such as more than 3) ETCD instances are deployed in the cluster and distributed and run on different physical nodes. The ETCD service is used as a persistent storage service for the cluster management service. The initial configuration information of the cluster is written to the ETCD service during installation and deployment. The ETCD service is the configuration management center of the cluster.
(2)集群内每个节点上都部署代理Agent进程,Agent启动后根据本节点的配置信息启动所有服务进程;(2) The agent agent process is deployed on each node in the cluster. After the agent is started, all service processes are started according to the configuration information of the node;
集群内每个节点上部署的Agent进程作为集群管理服务的代理,并且作为每个节点所有部署的其他服务进程的父进程优先启动运行,Agent进程启动后,通过查询ETCD服务上各节点的集群服务配置信息,顺序启动所运行节点的其他各类服务进程实例。The Agent process deployed on each node in the cluster acts as the agent of the cluster management service, and is the parent process of all other service processes deployed on each node. Configuration information, and sequentially start other various service process instances of the running node.
Agent也作为其他服务进程的守护进程,会循环检测各进程状态并在服务进程异常退出后,自动拉起异常退出的服务进程。在具体实施中,CMServer和ETCD服务实例进程也都可以由Agent进行启动和监控。Agent also acts as a daemon process of other service processes. It will cyclically detect the status of each process and automatically start the service process that exits abnormally after the service process exits abnormally. In a specific implementation, both the CMServer and the ETCD service instance process can also be started and monitored by the Agent.
(3)不同节点部署的集群管理服务CMServer启动后,通过抢占式写操作,将本节点IP地址写入ETCD存储主CMServer的键值内(如(3) After the cluster management service CMServer deployed on different nodes is started, the IP address of this node is written into the key value of the main CMServer stored in etcD through a preemptive write operation (such as
/CMMasterNode),并设置租约过期时间(如30秒),成功写入则成为集群管理主服务,即:CMServer主服务;/CMMasterNode), and set the lease expiration time (such as 30 seconds), the successful write will become the cluster management main service, namely: CMServer main service;
具体地,集群管理主CMServer服务用于建立与代理Agent之间的连接,接收代理Agent发送的服务进程状态信息和心跳消息,将各服务进程状态写入和更新到ETCD存储服务中;Specifically, the cluster management main CMServer service is used to establish a connection with the agent agent, receive service process status information and heartbeat messages sent by the agent agent, and write and update the status of each service process into the ETCD storage service;
集群管理CMServer是主备机服务模式,启动后需要先借助ETCD存储服务完成选主过程,由于ETCD的强一致存储特点,同一时刻只有一个CMServer能成功将自己的IP信息写入ETCD存储中固定的键值对中,所以CMServer在故障场景下也不会出现双主等异常状态,导致集群管理功能失效。The cluster management CMServer is an active/standby server mode. After startup, you need to use the ETCD storage service to complete the master selection process. Due to the strong consistent storage characteristics of ETCD, only one CMServer can successfully write its own IP information into the ETCD storage at the same time. In the key-value pair, the CMServer will not have abnormal states such as dual masters in a fault scenario, resulting in the failure of the cluster management function.
集群管理服务CMServer的选主过程为:CMServer启动后,默认初始为备机服务状态;连接ETCD服务并查询当前CMServer主服务的注册信息,本实施例中即查询该[/CMMasterNode]键值的存储信息,如果值为空则通过抢占式事务写操作,将本节点的IP写入该键值存储中,并设置租约过期时间,本实施例中设置为30秒。成功经过该过程向ETCD中写入本节点IP的CMServer服务成为集群管理的主CMServer服务,其他节点的CMServer服务能查询到该键值信息,获取当前主CMServer的节点IP地址,就以备机状态继续运行,通过Watch机制等待租约过期后重新抢占式选主。The master selection process of the cluster management service CMServer is as follows: after the CMServer is started, the default initial state is the standby server service state; connect the ETCD service and query the registration information of the current CMServer master service, in this embodiment, query the storage of the [/CMMasterNode] key value If the value is empty, the IP of the node is written into the key-value store through a preemptive transaction write operation, and the lease expiration time is set, which is set to 30 seconds in this embodiment. After this process is successful, the CMServer service that writes the IP of the current node to the ETCD becomes the main CMServer service managed by the cluster. The CMServer services of other nodes can query the key value information and obtain the node IP address of the current main CMServer, and then use the standby state. Continue to run, and wait for the lease to expire and re-preempt the master election through the Watch mechanism.
由于集群内服务进程的状态信息都存储在ETCD服务上,所以集群管理服务不需要将服务状态持久化存储在本地磁盘存储中,主CMServer服务会周期性刷新[/CMMasterNode]键值的租约,防止租约超时过期。Since the state information of the service processes in the cluster is stored in the ETCD service, the cluster management service does not need to persist the service state in the local disk storage. The main CMServer service will periodically refresh the lease of the [/CMMasterNode] key value to prevent Lease timeout expired.
(4)各节点Agent会从ETCD服务获取主CMServer服务的IP并进行连接,周期性监控本节点上部署运行的所有服务进程状态,周期性发送各节点服务进程的状态消息或心跳消息,上报给主CMServer服务;(4) Each node agent will obtain the IP of the main CMServer service from the ETCD service and connect it, periodically monitor the status of all service processes deployed and running on this node, periodically send the status message or heartbeat message of each node service process, and report it to main CMServer service;
具体地,CMServer服务选主成功后,各节点Agent会从ETCD上获取主CMServer服务的IP地址,连接主CMServer并开始周期性发送服务状态消息和心跳消息。如果某一服务进程的状态发生改变,Agent会立即发送新状态消息给主CMServer服务;若服务状态保持不变,为了减少重复的状态消息发送,可以周期性只发送心跳消息,以保持ETCD中存储的服务状态租约得到及时刷新。Specifically, after the CMServer service is successfully selected, each node Agent will obtain the IP address of the main CMServer service from the ETCD, connect to the main CMServer, and start to periodically send service status messages and heartbeat messages. If the status of a service process changes, the Agent will immediately send a new status message to the main CMServer service; if the service status remains unchanged, in order to reduce repeated status message sending, only heartbeat messages can be sent periodically to keep the storage in ETCD. The service status of the lease is refreshed in time.
具体实施时:Agent发送状态消息和心跳消息的周期间隔可以设置为5秒,租约超时时间设置为30秒。In specific implementation: the periodic interval for the Agent to send status messages and heartbeat messages can be set to 5 seconds, and the lease timeout time can be set to 30 seconds.
在具体实施中,每组服务的进程状态可以分为:Running运行状态,Stopped停止状态,Failure故障状态,Timeout超时异常状态等;服务的主备关系状态可以分为:Master主机,Slave备机和Initial初始态等。In the specific implementation, the process status of each group of services can be divided into: Running running status, Stopped stopped status, Failure fault status, Timeout timeout abnormal status, etc.; Initial initial state, etc.
(5)集群管理主服务CMServer接收到各个服务进程的状态消息,会更新ETCD服务上存储的服务状态记录,并重置刷新服务状态的租约时间;(5) The cluster management main service CMServer receives the status message of each service process, it will update the service status record stored on the ETCD service, and reset the lease time for refreshing the service status;
集群管理主CMServer服务会接收到每一组服务进程的状态消息,并将服务当前状态信息存储在ETCD服务上,同时通过lease租约机制设置该服务状态的租约过期时间;主CMServer每次收到服务的状态消息或心跳消息,都要刷新重置该服务状态的租约时间,防止租约过期导致服务状态异常。The cluster management main CMServer service will receive the status message of each group of service processes, and store the current status information of the service in the ETCD service, and set the lease expiration time of the service state through the lease lease mechanism; the main CMServer receives the service every time. The status message or heartbeat message of the service must be refreshed and reset the lease time of the service state, so as to prevent the service state from being abnormal due to the expiration of the lease.
通过ETCD服务的租约机制,可以高效的发现服务状态由网络或其他软硬件故障导致的异常情况,即如果出现服务状态的租约过期,则说明该服务状态消息和心跳消息在租约超时这段时间内无法成功发送给主CMServer,租约超时的服务进程或节点出现了故障场景。Through the lease mechanism of the ETCD service, it is possible to efficiently discover the abnormal situation of the service state caused by network or other hardware and software failures. That is, if the lease of the service state expires, it means that the service state message and heartbeat message are within the lease timeout period. Failed to send to the main CMServer successfully, and the service process or node whose lease has timed out has a failure scenario.
(6)发生节点故障或网络异常时,Agent无法成功发送各服务状态消息给主CMServer,导致ETCD服务上的服务状态租约无法周期性刷新重置,(6) When a node failure or network abnormality occurs, the Agent cannot successfully send each service status message to the main CMServer, so that the service status lease on the ETCD service cannot be periodically refreshed and reset.
发生租约过期超时;Lease expiration timeout occurs;
如果出现服务状态租约过期,则判定该服务出现异常导致心跳消息超时。If the service status lease expires, it is determined that the service is abnormal and the heartbeat message times out.
(7)主CMServer检测到有服务的状态租约过期,则会判定和更新该服务为Timeout异常状态,并根据该服务最后的主备机状态信息,判断是否进行选主操作。(7) When the primary CMServer detects that the state lease of the service has expired, it will determine and update the service as a Timeout abnormal state, and judge whether to perform the primary selection operation according to the last primary and secondary machine status information of the service.
具体地,集群管理主CMServer服务通过收到的消息周期性地刷新服务状态和租约,并检测服务状态租约过期来发现是否有服务异常,主CMServer更新租约过期服务的状态为Timeout,然后根据该服务的主备机关系进行判断是否要进行选主操作;如果异常状态的服务为Master主机状态,则主CMServer服务会对该组服务进行选主。Specifically, the cluster management main CMServer service periodically refreshes the service status and lease through the received messages, and detects whether the service status lease expires to find out whether there is a service abnormality. The main CMServer updates the lease expired service status to Timeout, and then according to the service status If the service in the abnormal state is in the Master host state, the main CMServer service will select the master for this group of services.
具体实施中,选主由主CMServer根据各节点负载状态选择一个合适的备机服务使其成为该服务新的Master主机。In the specific implementation, the primary CMServer selects a suitable standby server service according to the load status of each node to make it the new master host of the service.
如图2所示,为集群管理服务故障检测和处理流程:集群管理主CMServer通过检查ETCD服务上服务状态租约过期,来发现状态异常的服务进程,将Timeout异常状态更新在ETCD服务中;如果异常状态的服务是该组服务的Master主机,则会触发对该组服务的选主过程;如果是Slave备机,则只需要更新该服务进程为异常状态,不需要选主操作。As shown in Figure 2, it is the fault detection and processing process for the cluster management service: the main CMServer of the cluster management detects the abnormal service process by checking the expiration of the service status lease on the ETCD service, and updates the Timeout abnormal status in the ETCD service; if abnormal If the service in the state is the master host of the group of services, it will trigger the master selection process for the group of services; if it is the slave standby machine, only the service process needs to be updated to an abnormal state, and no master selection operation is required.
具体实施中,集群管理组件还会提供客户端工具,提供人工操作集群的接口,通过客户端工具可以完成对集群的启动、停止,服务状态查询和切换等操作。In the specific implementation, the cluster management component will also provide a client tool to provide an interface for manually operating the cluster, and the client tool can complete operations such as starting, stopping, querying and switching the service status of the cluster.
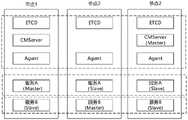
如图3所示,为本发明实施例中的一种基于ETCD的分布式集群控制系统3个物理节点的架构图。图中系统内部署有两组服务:服务A和服务B。两组服务每个节点都部署运行一个实例进程,服务A的Master运行在节点1上,服务B的Master运行在节点2上,其他实例都为Slave服务。As shown in FIG. 3 , it is an architecture diagram of three physical nodes of an ETCD-based distributed cluster control system in an embodiment of the present invention. In the figure, there are two groups of services deployed in the system: service A and service B. Each node of the two groups of services deploys and runs an instance process. The master of service A runs on node 1, the master of service B runs on node 2, and other instances serve as slaves.
综上所述:In summary:
本发明充分利用ETCD服务高可用的分布式一致性存储能力,实现对分布式集群环境下各种服务的部署和管理功能,可以有效提高集群服务的管理能力,以及发生单点故障场景下保持服务的高可用性,为整个集群服务的可用性提供有力支撑。The invention makes full use of the highly available distributed and consistent storage capability of the ETCD service, realizes the deployment and management functions of various services in a distributed cluster environment, can effectively improve the management capability of cluster services, and maintain services in the event of a single point of failure. high availability, providing strong support for the availability of the entire cluster service.
实施例2:Example 2:
一种基于ETCD的分布式集群控制装置,包括:An ETCD-based distributed cluster control device, comprising:
CMServer主服务选举模块,集群内不同节点部署的集群管理服务CMServer服务启动后,向集群内部署的ETCD服务进行抢占式事务写操作,若成功将本节点的CMServer服务信息写入,则表示该节点的CMServer成功注册为主服务;CMServer main service election module. After the cluster management service CMServer service deployed on different nodes in the cluster is started, it performs preemptive transaction write operation to the ETCD service deployed in the cluster. If the CMServer service information of this node is successfully written, it means that this node The CMServer is successfully registered as the main service;
状态消息监控模块,集群内各节点部署的Agent进程与CMServer主服务进行连接和消息通信,Agent进程周期性监控所在节点部署运行的所有服务进程状态,发送节点服务进程的状态消息和心跳消息给CMServer主服务,由状态消息监控模块写入和更新ETCD服务中存储的服务状态和租约;Status message monitoring module, the Agent process deployed on each node in the cluster connects and communicates with the CMServer main service, the Agent process periodically monitors the status of all service processes deployed and running on the node, and sends the status message and heartbeat message of the node service process to the CMServer The main service, the service status and lease stored in the ETCD service are written and updated by the status message monitoring module;
异常发现和处理模块,CMServer主服务检测到有服务状态租约过期,则判定该服务进程状态异常并在ETCD服务中更新该服务为异常状态,并根据该服务主备状态,决定是否进行选主操作;如果服务异常状态前是主服务,则进行选主操作。ETCD服务用于存储集群的初始化部署配置信息和服务的运行状态信息。Abnormal discovery and processing module, CMServer main service detects that there is a service status lease expired, it determines that the service process status is abnormal and updates the service to the abnormal status in the ETCD service, and decides whether to perform the main selection operation according to the active and standby status of the service. ; If the service is the main service before the abnormal state, select the main service. The ETCD service is used to store the initial deployment configuration information of the cluster and the running status information of the service.
进一步的,所述向集群内部署的ETCD服务进行抢占式事务写操作,实现CMServer服务自身的选主过程,包括:Further, the preemptive transaction write operation is carried out to the ETCD service deployed in the cluster to realize the main selection process of the CMServer service itself, including:
通过向集群内部署的ETCD服务里固定键值的抢占式事务写操作,将CMServer服务的本节点IP地址写入该键值内,并将CMServer服务的状态超时时间设置为存储键值的租约过期时间;Through the preemptive transaction write operation of the fixed key value in the etcd service deployed in the cluster, the IP address of the current node of the CMServer service is written into the key value, and the status timeout time of the CMServer service is set to the expiration of the lease for storing the key value. time;
集群内各节点部署的Agent进程只能连接到CMServer的主服务,过程包括:The Agent process deployed on each node in the cluster can only connect to the main service of CMServer. The process includes:
各Agent进程先从ETCD服务获得CMServer主服务的IP地址,然后根据该IP与CMServer主服务进行连接。Each Agent process first obtains the IP address of the CMServer main service from the ETCD service, and then connects with the CMServer main service according to the IP.
进一步的,所述集群内每个节点均部署Agent进程,该进程作为本节点所有部署的其他服务进程的父进程优先启动运行,Agent进程启动后,通过查询ETCD服务上各节点的集群服务配置信息,顺序启动所运行节点的其他各类服务进程实例;Further, each node in the cluster deploys an Agent process, and this process starts and runs preferentially as the parent process of all other service processes deployed by this node. After the Agent process is started, by querying the cluster service configuration information of each node on the ETCD service. , and sequentially start other various service process instances of the running node;
若某一服务进程状态发生改变,Agent发送状态消息通知CMServer主服务;If the status of a service process changes, the Agent sends a status message to notify the CMServer main service;
若节点各服务进程状态没有变化,则定时发送心跳消息给CMServer主服务,使其刷新租约时间防止状态超时;If the status of each service process of the node does not change, it will periodically send a heartbeat message to the CMServer main service to refresh the lease time to prevent status timeout;
通过ETCD服务的lease租约机制设置服务状态的租约过期时间;CMServer主服务每次收到服务进程的状态消息或心跳消息,均刷新该服务状态租约时间。The lease expiration time of the service state is set through the lease lease mechanism of the ETCD service; every time the CMServer main service receives the status message or heartbeat message of the service process, the lease time of the service state is refreshed.
进一步地,当集群中某服务状态出现异常或租约到期时,CMServer主服务会根据服务之前的主备状态判断是否进行选主操作,包括:Further, when the status of a service in the cluster is abnormal or the lease expires, the CMServer master service will determine whether to perform the master selection operation according to the previous master and backup status of the service, including:
若异常的服务进程之前为主服务,则CMServer主服务根据各节点负载状态选择一个备服务作为新的主服务;If the abnormal service process was the main service before, the CMServer main service selects a standby service as the new main service according to the load status of each node;
若异常的服务进程之前为备服务,且其主服务状态正常,则CMServer主服务只需更新该服务为异常状态,不需要进行选主操作。If the abnormal service process was previously a standby service, and its main service status is normal, the CMServer main service only needs to update the service to the abnormal status, and does not need to select the main service.
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。The basic principles and main features of the present invention and the advantages of the present invention have been shown and described above. Those skilled in the art should understand that the present invention is not limited by the above-mentioned embodiments, and the descriptions in the above-mentioned embodiments and the description are only to illustrate the principle of the present invention. Without departing from the spirit and scope of the present invention, the present invention will have Various changes and modifications fall within the scope of the claimed invention. The claimed scope of the present invention is defined by the appended claims and their equivalents.
Claims (10)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110055020.9ACN114764380A (en) | 2021-01-15 | 2021-01-15 | Distributed cluster control method and device based on ETCD |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110055020.9ACN114764380A (en) | 2021-01-15 | 2021-01-15 | Distributed cluster control method and device based on ETCD |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN114764380Atrue CN114764380A (en) | 2022-07-19 |
Family
ID=82363876
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110055020.9APendingCN114764380A (en) | 2021-01-15 | 2021-01-15 | Distributed cluster control method and device based on ETCD |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114764380A (en) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115174660A (en)* | 2022-08-03 | 2022-10-11 | 以萨技术股份有限公司 | Service registration and discovery method, device, electronic equipment and storage medium |
| CN115421971A (en)* | 2022-08-16 | 2022-12-02 | 江苏安超云软件有限公司 | ETCD disaster recovery backup fault recovery method and application |
| CN116938881A (en)* | 2023-09-18 | 2023-10-24 | 深圳创新科技术有限公司 | A method, system, device and readable storage medium for implementing a dynamic IP pool |
| CN119341892A (en)* | 2024-12-18 | 2025-01-21 | 山东省城市商业银行合作联盟有限公司 | Method and device for processing abnormal endpoints of Pod service after node failure |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20030051930A (en)* | 2001-12-20 | 2003-06-26 | 한국전자통신연구원 | Apparatus and method for embodying high availability in cluster system |
| JP2007199962A (en)* | 2006-01-25 | 2007-08-09 | Internatl Business Mach Corp <Ibm> | Control of service failover in clustered storage system network |
| CN102231681A (en)* | 2011-06-27 | 2011-11-02 | 中国建设银行股份有限公司 | High availability cluster computer system and fault treatment method thereof |
| CN106161090A (en)* | 2016-07-12 | 2016-11-23 | 许继集团有限公司 | The monitoring method of a kind of subregion group system and device |
| CN111371599A (en)* | 2020-02-26 | 2020-07-03 | 山东汇贸电子口岸有限公司 | Cluster disaster recovery management system based on ETCD |
- 2021
- 2021-01-15CNCN202110055020.9Apatent/CN114764380A/enactivePending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20030051930A (en)* | 2001-12-20 | 2003-06-26 | 한국전자통신연구원 | Apparatus and method for embodying high availability in cluster system |
| JP2007199962A (en)* | 2006-01-25 | 2007-08-09 | Internatl Business Mach Corp <Ibm> | Control of service failover in clustered storage system network |
| CN102231681A (en)* | 2011-06-27 | 2011-11-02 | 中国建设银行股份有限公司 | High availability cluster computer system and fault treatment method thereof |
| CN106161090A (en)* | 2016-07-12 | 2016-11-23 | 许继集团有限公司 | The monitoring method of a kind of subregion group system and device |
| CN111371599A (en)* | 2020-02-26 | 2020-07-03 | 山东汇贸电子口岸有限公司 | Cluster disaster recovery management system based on ETCD |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115174660A (en)* | 2022-08-03 | 2022-10-11 | 以萨技术股份有限公司 | Service registration and discovery method, device, electronic equipment and storage medium |
| CN115421971A (en)* | 2022-08-16 | 2022-12-02 | 江苏安超云软件有限公司 | ETCD disaster recovery backup fault recovery method and application |
| CN116938881A (en)* | 2023-09-18 | 2023-10-24 | 深圳创新科技术有限公司 | A method, system, device and readable storage medium for implementing a dynamic IP pool |
| CN116938881B (en)* | 2023-09-18 | 2024-02-09 | 深圳创新科技术有限公司 | Method, system, equipment and readable storage medium for realizing dynamic IP pool |
| CN119341892A (en)* | 2024-12-18 | 2025-01-21 | 山东省城市商业银行合作联盟有限公司 | Method and device for processing abnormal endpoints of Pod service after node failure |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN114764380A (en) | Distributed cluster control method and device based on ETCD | |
| CN105933407B (en) | method and system for realizing high availability of Redis cluster | |
| US8055735B2 (en) | Method and system for forming a cluster of networked nodes | |
| US20080281938A1 (en) | Selecting a master node in a multi-node computer system | |
| CN111427728B (en) | State management method, main/standby switching method and electronic equipment | |
| CN102394914A (en) | Cluster brain-split processing method and device | |
| CN102360324B (en) | Failure recovery method and equipment for failure recovery | |
| US20080288812A1 (en) | Cluster system and an error recovery method thereof | |
| CN101136728A (en) | Cluster system and method for backing up a replica in a cluster system | |
| TWI677797B (en) | Management method, system and equipment of master and backup database | |
| CN108243031B (en) | Method and device for realizing dual-computer hot standby | |
| CN109144748B (en) | Server, distributed server cluster and state driving method thereof | |
| CN109189854B (en) | Method and node equipment for providing continuous service | |
| CN116185697B (en) | Container cluster management method, device, system, electronic equipment and storage medium | |
| CN112702206A (en) | Main and standby cluster deployment method and system | |
| CN117692500A (en) | Operation method, device, equipment and storage medium | |
| CN117667523A (en) | Database cluster maintenance method and system for improving high availability of Oracle DG | |
| CN117714386A (en) | Distributed system deployment methods, configuration methods, systems, equipment and media | |
| CN113596195B (en) | Public IP address management method, device, main node and storage medium | |
| CN116303795A (en) | Data synchronization method, device, electronic equipment, medium and product | |
| CN116346582A (en) | Method, device, equipment and storage medium for realizing redundancy of main network and standby network | |
| CN109344015B (en) | A method and system for preventing dual-primary nodes by using HA for database services | |
| CN113890880A (en) | A method, system, device and storage medium for data synchronization between multiple nodes | |
| CN119324858B (en) | Method and system for switching multiple Redis clusters in alarm processing | |
| CN115766753B (en) | A storage gateway high availability method, system and electronic device |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |