CN114758419A - AR-based multidimensional intelligent application system - Google Patents
AR-based multidimensional intelligent application systemDownload PDFInfo
- Publication number
- CN114758419A CN114758419ACN202210420619.2ACN202210420619ACN114758419ACN 114758419 ACN114758419 ACN 114758419ACN 202210420619 ACN202210420619 ACN 202210420619ACN 114758419 ACN114758419 ACN 114758419A
- Authority
- CN
- China
- Prior art keywords
- interaction
- gesture
- recognition
- application system
- modal
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images




Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/241—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches
- G06F18/2415—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches based on parametric or probabilistic models, e.g. based on likelihood ratio or false acceptance rate versus a false rejection rate
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/01—Input arrangements or combined input and output arrangements for interaction between user and computer
- G06F3/017—Gesture based interaction, e.g. based on a set of recognized hand gestures
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- Life Sciences & Earth Sciences (AREA)
- Artificial Intelligence (AREA)
- Computing Systems (AREA)
- Software Systems (AREA)
- Molecular Biology (AREA)
- Computational Linguistics (AREA)
- Biophysics (AREA)
- Biomedical Technology (AREA)
- Mathematical Physics (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Probability & Statistics with Applications (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Evolutionary Biology (AREA)
- Human Computer Interaction (AREA)
- User Interface Of Digital Computer (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本发明涉及AR增强现实领域,将多模态识别与交互、多技术融合与交互方式融合于一个智能化多维平台,每个模块独立运行与交互,应用于医疗领域、军事航空领域、工业自动化智能化维修、娱乐游戏、市政规划与建设、水利水电勘察等领域;特别涉及一种基于AR的多维智能应用系统。The invention relates to the field of AR augmented reality, integrates multi-modal recognition and interaction, multi-technology integration and interaction mode into an intelligent multi-dimensional platform, each module operates and interacts independently, and is applied to the medical field, military aviation field, and industrial automation intelligence Chemical maintenance, entertainment games, municipal planning and construction, water conservancy and hydropower survey and other fields; especially an AR-based multi-dimensional intelligent application system.
背景技术Background technique
增强现实(AR,Augmented Reality)技术是近年来随着虚拟现实技术的发展兴起的一项新技术,利用计算机渲染生成虚拟场景,并将此虚拟场景与真实世界精确的融合在一起,最终利用显示设备将融合的场景呈现给用户,从而极大地提高了用户的视觉体验。其关键技术之一是将系统生成的虚拟信息与现实环境叠加融合,早期的研究大多是集中在三维注册技术和虚实融合技术上,实现了标志特征点、自然特征点、设备物理信息等注册方式,同时在虚实融合方面通过几何一致性和光照一致性的无缝融合技术,实现更具沉浸感的虚实交互融合效果。Augmented reality (AR, Augmented Reality) technology is a new technology that has emerged with the development of virtual reality technology in recent years. It uses computer rendering to generate virtual scenes, and accurately integrates this virtual scene with the real world, and finally uses display. The device presents the integrated scene to the user, thereby greatly improving the user's visual experience. One of its key technologies is to superimpose and integrate the virtual information generated by the system with the real environment. Most of the early researches focused on the three-dimensional registration technology and the virtual-real fusion technology, and realized the registration methods such as sign feature points, natural feature points, and equipment physical information. At the same time, in terms of virtual-real fusion, a more immersive virtual-real interactive fusion effect is achieved through the seamless fusion technology of geometric consistency and lighting consistency.
为了体现AR虚实融合和实时交互的特点,营造更具沉浸感的交互体验,应用中结合多维通道的信息输入与人机交互模式。通过AR增强现实研究现状可知,国内外研究者都在尝试基于AR实现更多的交互方式,但大多数都结合虚实融合效果做的技术探索,更多的是结合某个设备或使用某项技术实现一种小的交互方式,并未从交互设计角度进行分析总结,也没有成型的交互设计和体系架构,而且每个模块都是独立分散的,目前并没有一套成形的体系平台,将基于AR的多种技术融合于一体。In order to reflect the characteristics of AR virtual-real integration and real-time interaction and create a more immersive interactive experience, the application combines the information input of multi-dimensional channels and the human-computer interaction mode. From the research status of AR augmented reality, it can be seen that researchers at home and abroad are trying to realize more interactive methods based on AR, but most of them are technical explorations combined with the effect of virtual-real fusion, and more are combined with a certain device or using a certain technology To achieve a small interaction method, there is no analysis and summary from the perspective of interaction design, and there is no formed interaction design and system architecture, and each module is independent and scattered. At present, there is no formed system platform, which will be based on A variety of AR technologies are integrated into one.
基于上述缺点,本专利着力开发一种基于AR的多维智能应用系统,实现从交互设计的角度出发,将基于AR的多种技术的交互方式进行合理有效地融合的平台,实现多模态虚实交互与人机交互等多种交互方式。Based on the above shortcomings, this patent focuses on the development of an AR-based multi-dimensional intelligent application system, which realizes a platform that reasonably and effectively integrates the interaction methods of various AR-based technologies from the perspective of interaction design, and realizes multi-modal virtual-real interaction. A variety of interaction methods such as human-computer interaction.
发明内容SUMMARY OF THE INVENTION
本发明为了解决现有技术中的存在的问题,而提供一种基于AR的多维智能应用系统,。In order to solve the existing problems in the prior art, the present invention provides an AR-based multi-dimensional intelligent application system.
本发明解决其技术问题所采用的技术方案是:The technical scheme adopted by the present invention to solve its technical problems is:
一种基于AR的多维智能应用系统,多维智能应用系统采用AlexNet网络结构,包括多模态融合的导航式交互、多模态识别与交互、传感器交互、AR手势与交互、多媒体智能化交互和态势感知与识别交互;A multi-dimensional intelligent application system based on AR, the multi-dimensional intelligent application system adopts the AlexNet network structure, including multi-modal fusion navigation interaction, multi-modal recognition and interaction, sensor interaction, AR gesture and interaction, multimedia intelligent interaction and situation Perception and recognition interaction;
所述多模态融合的导航式交互采用多模态融合的交互,包括视觉、听觉和触觉三种模态信息;建立多模态信息数据集,分析交互意图,建立多模态信息相交并函数和信息独立函数,构建融合策略以理解用户意图,实现语音导航提示引导用户完成操作;The navigation interaction of the multi-modal fusion adopts the interaction of multi-modal fusion, including three modal information of vision, hearing and touch; establishes a multi-modal information data set, analyzes the interaction intention, and establishes a multi-modal information intersection and union function. and information-independent functions, build a fusion strategy to understand user intent, and implement voice navigation prompts to guide users to complete operations;
所述AR手势与交互利用手势和虚拟场景进行交互设计,手势识别后,当用户做五指抓的动作时触发指环震动;The AR gesture and interaction uses gestures and virtual scenes for interaction design, and after gesture recognition, when the user performs a five-finger grasping action, the ring is triggered to vibrate;
所述多媒体智能化交互基于多媒体机器学习框架MediaPipe算法;The multimedia intelligent interaction is based on the multimedia machine learning framework MediaPipe algorithm;
所述态势感知与识别交互,增强现实技术来提高驾驶员的态势感知能力,预测周围态势,并及时作出响应。The situational awareness and recognition interact with augmented reality technology to improve the driver's situational awareness, predict the surrounding situation, and respond in a timely manner.
作为上述技术方案的进一步改进,多模态识别与交互包括两个阶段,两个阶段分别为多模态识别与多模态应用交互;多模态识别阶段包括视觉模态和听觉模态;所述视觉模态包括模型建立阶段和手势交互阶段;模型建立阶段包括手势数据集、数据处理、手势识别模型和识别结果输出;所述听觉模态为Windows语音识别API;Windows语音识别API基于预设关键词进行关键词识别,融合自然语言处理技术,通过引入马尔科夫模型,将语音转化为文本数据以达到精准识别。As a further improvement of the above technical solution, the multimodal recognition and interaction includes two stages, the two stages are multimodal recognition and multimodal application interaction respectively; the multimodal recognition stage includes visual modality and auditory modality; The visual modality includes a model establishment stage and a gesture interaction stage; the model establishment stage includes a gesture dataset, data processing, gesture recognition model and recognition result output; the auditory modality is a Windows speech recognition API; the Windows speech recognition API is based on preset Keywords are used for keyword recognition, natural language processing technology is integrated, and Markov model is introduced to convert speech into text data to achieve accurate recognition.
作为上述技术方案的进一步改进,将视觉模态和听觉模态的模态信息进行封装成dll、exe;Windows语音识别API识别的Python模块基于PyInstaller进行封装成exe。As a further improvement of the above technical solution, the modal information of the visual modality and the auditory modality is encapsulated into dll and exe; the Python module recognized by the Windows speech recognition API is encapsulated into exe based on PyInstaller.
作为上述技术方案的进一步改进,传感器交互包括Kinect、数据手套、立体式头盔、Google的AR眼镜和体感设备。As a further improvement of the above technical solutions, sensor interactions include Kinect, data gloves, stereoscopic helmets, Google's AR glasses and somatosensory devices.
作为上述技术方案的进一步改进,在所述AR手势与交互时的手势识别时,首先对手势识别模型进行AlexNet_gesture进行封装,Unity中调用AlexNet_gesture,然后建立手部坐标和虚拟坐标的一致性。As a further improvement of the above technical solution, in the gesture recognition during AR gesture and interaction, the gesture recognition model is first encapsulated by AlexNet_gesture, and AlexNet_gesture is called in Unity, and then the consistency of hand coordinates and virtual coordinates is established.
作为上述技术方案的进一步改进,手势识别交互算法步骤如下:输入:手势深度图;输出:手势交互效果;As a further improvement of the above technical solution, the steps of the gesture recognition interaction algorithm are as follows: input: gesture depth map; output: gesture interaction effect;
Step1:在摄像头下,获得第n帧的深度图,输入到AlexNet模型,以输出手势识别结果;Step1: Under the camera, obtain the depth map of the nth frame and input it to the AlexNet model to output the gesture recognition result;
Step2:再次获得第n+1帧手势深度图,获取在不同时刻的两个关节点坐标Sn(θn)和Sn+1(θn+1),其中θn为相机的深度三维坐标;Step2: Obtain the gesture depth map of the n+1th frame again, and obtain the coordinates of the two joint points Sn(θn) and Sn+1(θn+1) at different times, where θn is the depth three-dimensional coordinate of the camera;
Step3:判断两个关节点坐标是否相等;如果相等,判断当前手势,否则再次执行手势训练。Step3: Determine whether the coordinates of the two joint points are equal; if they are equal, determine the current gesture, otherwise perform gesture training again.
作为上述技术方案的进一步改进,AlexNet网络结构采用Relu函数作为激活函数,包括了6000万个参数和65000万个神经元、5个卷积层以及池化层、3个全连接层,输出为Softmax层。As a further improvement of the above technical solutions, the AlexNet network structure uses the Relu function as the activation function, including 60 million parameters and 650 million neurons, 5 convolutional layers, pooling layers, and 3 fully connected layers. The output is Softmax Floor.
作为上述技术方案的进一步改进,AlexNet网络结构,采用层叠的卷积层、池化层来提取图像特征;池化过程中,每次移步的步长小于池化的窗口长度,AlexNet结构池化窗口大小为3x3的正方形,每次池化移动步长为2。As a further improvement of the above technical solutions, the AlexNet network structure uses stacked convolutional layers and pooling layers to extract image features; during the pooling process, the step size of each step is smaller than the pooling window length, and the AlexNet structure pools The window size is a 3x3 square, and each pooling moves with a stride of 2.
作为上述技术方案的进一步改进,AlexNet网络结构采用随机失活Dropout和数据增强抑制过拟合现象。As a further improvement of the above technical solutions, the AlexNet network structure uses random deactivation Dropout and data augmentation to suppress overfitting.
作为上述技术方案的进一步改进,Dropout通过修改神经网络本身结构来实现,对于某一层的神经元,通过定义的概率将神经元置为0,神经元不参与前向和后向传播,同时保持输入层和输出层神经元的个数保持不变,然后按照神经网络的学习方法进行参数更新,在下次迭代中,又重新随机删除一些神经元,直至训练结束。As a further improvement of the above technical solution, Dropout is implemented by modifying the structure of the neural network itself. For neurons in a certain layer, the neurons are set to 0 by a defined probability, and the neurons do not participate in forward and backward propagation, while maintaining The number of neurons in the input layer and output layer remains unchanged, and then the parameters are updated according to the learning method of the neural network. In the next iteration, some neurons are randomly deleted again until the training ends.
从以上技术方案可以看出,本发明的有益效果是:本发明采用基于深度图像的卷积神经网络,基于AlexNet网络结构分别训练各算法模块模型,实现更高维的图像特征;As can be seen from the above technical solutions, the beneficial effects of the present invention are as follows: the present invention adopts a convolutional neural network based on depth images, and trains each algorithm module model based on the AlexNet network structure to realize higher-dimensional image features;
在决策层通过多模态信息相交相并和信息独立的处理方式,融合不同模态的信息,并利用有向状态图整合不同通道的信息构成多模态融合策略;In the decision-making layer, the information of different modalities is fused through the processing method of multimodal information intersection and information independence, and the directed state diagram is used to integrate the information of different channels to form a multimodal fusion strategy;
附图说明Description of drawings
为了更清楚地说明本发明的技术方案,下面将对描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。In order to illustrate the technical solutions of the present invention more clearly, the accompanying drawings required in the description will be briefly introduced below. Obviously, the accompanying drawings in the following description are only some embodiments of the present invention, which are not relevant to ordinary skills in the art. As far as personnel are concerned, other drawings can also be obtained from these drawings on the premise of no creative work.
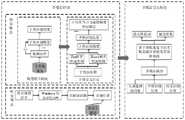
图1是本发明具体实施方式的系统组成架构示意图。FIG. 1 is a schematic diagram of a system composition structure according to a specific embodiment of the present invention.
图2是本发明具体实施方式多模态识别与交互的整体框架示意图。FIG. 2 is a schematic diagram of an overall framework of multimodal recognition and interaction according to a specific embodiment of the present invention.
图3是本发明具体实施方式AlexNet结构示意图。FIG. 3 is a schematic structural diagram of AlexNet according to a specific embodiment of the present invention.
图4是本发明具体实施方式多模态融合交互的总体框架示意图。FIG. 4 is a schematic diagram of an overall framework of multi-modal fusion interaction according to a specific embodiment of the present invention.
图5是本发明具体实施方式系统平台初始界面示意图。FIG. 5 is a schematic diagram of an initial interface of a system platform according to an embodiment of the present invention.
具体实施方式Detailed ways
为使得本发明的目的、特征、优点能够更加的明显和易懂,下面将结合本具体实施例中的附图,对本发明中的技术方案进行清楚、完整地描述,显然,下面所描述的实施例仅仅是本发明一部分实施例,而非全部的实施例。基于本专利中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本专利保护的范围。In order to make the objects, features and advantages of the present invention more obvious and understandable, the technical solutions in the present invention will be clearly and completely described below with reference to the accompanying drawings in the specific embodiments. Obviously, the implementation described below Examples are only some embodiments of the present invention, but not all embodiments. Based on the embodiments in this patent, all other embodiments obtained by persons of ordinary skill in the art without creative efforts shall fall within the scope of protection of this patent.
参考图1所示,本发明提供一种基于AR的多维智能应用系统,多维智能应用系统采用AlexNet网络结构,包括多模态融合的导航式交互、多模态识别与交互、传感器交互、AR手势与交互设计、多媒体智能化交互、态势感知与识别交互六大模块。Referring to Figure 1, the present invention provides an AR-based multi-dimensional intelligent application system. The multi-dimensional intelligent application system adopts the AlexNet network structure, including multi-modal fusion navigation interaction, multi-modal recognition and interaction, sensor interaction, AR gestures There are six modules of interaction design, multimedia intelligent interaction, situational awareness and recognition interaction.
具体的,多模态融合的导航式交互:基于增强现实环境,融合视觉、听觉和触觉三种模态,在决策层通过多模态信息相交相并和信息独立的处理方式,融合不同模态的信息,并利用有向状态图整合不同通道的信息构成多模态融合策略。Specifically, the navigation interaction of multi-modal fusion: based on the augmented reality environment, the three modalities of vision, hearing and touch are integrated, and different modalities are integrated at the decision-making layer through the intersection of multi-modal information and the processing of information independence. information, and use the directed state graph to integrate the information of different channels to form a multi-modal fusion strategy.
采用视觉、听觉和触觉三种模态信息,采用多模态融合的交互设计,首先建立多模态信息数据集,分析交互意图,然后建立多模态信息相交并函数和信息独立函数,构建融合策略以理解用户意图,实现语音导航提示引导用户完成操作,有效解决了在数据少、时间分散的多模态融合交互问题。最后通过统计性实验证明多模态交互的操作负荷远小于单模态的负荷。Using visual, auditory and tactile modal information, the interaction design of multi-modal fusion is adopted. First, the multi-modal information data set is established, the interaction intention is analyzed, and then the multi-modal information intersection function and information independent function are established to construct the fusion. The strategy is to understand the user's intention, realize the voice navigation prompt to guide the user to complete the operation, and effectively solve the multi-modal fusion interaction problem with less data and scattered time. Finally, it is proved by statistical experiments that the operational load of multimodal interaction is much smaller than that of single mode.
多模态识别与交互:多模态识别的总体框架结构包括两个阶段,分别为多模态识别与多模态应用交互。多模态识别阶段包括视觉模态、听觉模态。其中视觉模态包括模型建立阶段、手势交互阶段。模型建立阶段包括手势数据集、数据处理、手势识别模型及识别结果输出。听觉模态包括Windows语音识别API,基于预设关键词进行关键词识别,融合自然语言处理技术,通过引入马尔科夫模型,将语音转化为文本数据以达到精准识别的目的。Multimodal recognition and interaction: The overall framework of multimodal recognition consists of two stages, namely multimodal recognition and multimodal application interaction. The multimodal recognition stage includes visual modality and auditory modality. The visual modality includes the model building stage and the gesture interaction stage. The model building stage includes gesture dataset, data processing, gesture recognition model and recognition result output. The auditory modality includes the Windows speech recognition API, performs keyword recognition based on preset keywords, integrates natural language processing technology, and converts speech into text data by introducing the Markov model to achieve accurate recognition.
最后将每种模态信息进行封装成dll、exe等多种类型。语音识别的Python模块可基于PyInstaller进行封装成exe。Finally, each modal information is encapsulated into dll, exe and other types. The Python module of speech recognition can be packaged into exe based on PyInstaller.
通过融合多模态信息实现基于增强现实环境下的智能化多维应用系统,其框架如图2所示。The intelligent multi-dimensional application system based on the augmented reality environment is realized by fusing multi-modal information, and its framework is shown in Figure 2.
传感器交互:常用的传感器设备包括Kinect、数据手套、立体式头盔、Google的AR眼镜以及体感设备等传感器设备,显然为了实现上述目的,所述传感器交互还包括其它传感器交互的方式。Sensor interaction: Commonly used sensor devices include Kinect, data gloves, stereo helmets, Google's AR glasses, and somatosensory devices. Obviously, to achieve the above purpose, the sensor interaction also includes other sensor interaction methods.
AR手势与交互设计:用户利用手势和虚拟场景进行交互设计,手势识别后,当用户做五指抓的动作时触发指环震动。在交互算法中,首先对手势识别模型进行AlexNet_gesture进行封装,Unity中调用AlexNet_gesture,然后建立手部坐标和虚拟坐标的一致性。从而实现增强现实环境下的手势识别与交互模块。AR Gesture and Interaction Design: The user uses gestures and virtual scenes for interaction design. After the gesture is recognized, the ring will vibrate when the user performs a five-finger grasping action. In the interaction algorithm, the gesture recognition model is first encapsulated by AlexNet_gesture, and AlexNet_gesture is called in Unity, and then the consistency of hand coordinates and virtual coordinates is established. So as to realize the gesture recognition and interaction module in the augmented reality environment.
手势识别交互算法步骤如下:The steps of the gesture recognition interaction algorithm are as follows:
输入:手势深度图Input: Gesture Depth Map
输出:手势交互效果Output: gesture interaction effect
Step1:在摄像头下,获得第n帧的深度图,输入到AlexNet模型,以输出手势识别结果。Step1: Under the camera, obtain the depth map of the nth frame and input it to the AlexNet model to output the gesture recognition result.
Step2:再次获得第n+1帧手势深度图,获取在不同时刻的两个关节点坐标Sn(θn)和Sn+1(θn+1),其中θn为相机的深度三维坐标。Step2: Obtain the gesture depth map of the n+1th frame again, and obtain the coordinates Sn(θn) and Sn+1(θn+1) of the two joint points at different times, where θn is the depth three-dimensional coordinate of the camera.
Step3:判断两个关节点坐标是否相等。如果相等,判断当前手势,否则再次执行手势训练。Step3: Determine whether the coordinates of the two joint points are equal. If they are equal, judge the current gesture, otherwise perform gesture training again.
多媒体智能化交互:基于谷歌开源的多媒体机器学习框架MediaPipe算法进行设计与开发,用来构建跨平台多模态应用平台,包含很多算法,如姿态识别、手势识别及人脸检测等各种各样的模型及机器学习算法,用于构建跨平台多模态应用框架。其核心框架由C++实现,并提供Java及C等语言的支持,主要概念包括数据包、数据流、计算单元、图及子图。Multimedia intelligent interaction: Design and development based on Google's open source multimedia machine learning framework MediaPipe algorithm to build a cross-platform multimodal application platform, including many algorithms, such as gesture recognition, gesture recognition and face detection, etc. Models and machine learning algorithms for building cross-platform multimodal application frameworks. Its core framework is implemented by C++ and supports languages such as Java and C. The main concepts include data packets, data streams, computing units, graphs and subgraphs.
态势感知与识别交互:基于现有先进的增强现实技术可广泛应用于船舶航行、飞机与汽车的辅助驾驶等领域。以船舶航行为例,通过增强现实技术来提高驾驶员的态势感知能力,预测周围态势,并及时作出响应。Situational awareness and recognition interaction: Based on the existing advanced augmented reality technology, it can be widely used in the fields of ship navigation, assisted driving of aircraft and automobiles, etc. Taking ship navigation as an example, augmented reality technology is used to improve the driver's situational awareness, predict the surrounding situation, and respond in time.
参考图3所示,本专利采用基于深度图像的卷积神经网络,基于AlexNet网络结构分别训练各算法模块模型,实现更高维的图像特征,Referring to Figure 3, this patent uses a convolutional neural network based on depth images, and trains each algorithm module model based on the AlexNet network structure to achieve higher-dimensional image features,
AlexNet结构包括6000万个参数和65000万个神经元,5个卷积层以及池化层,3个全连接层,输出为Softmax层。该结构具有如下优势:使用Relu函数作为激活函数,其训练速度要比传统的神经网络快几倍。使用层叠的卷积层、池化层来提取图像特征,在池化过程中,每次移步的步长小于池化的窗口长度,AlexNet结构池化窗口大小为3x3的正方形,每次池化移动步长为2,这样就会出现重叠现象,重叠池化可以在一定程度上防止过拟合。采用随机失活Dropout和数据增强(Data Augment)形式来有效抑制过拟合现象,在神经网络结构中,Dropout通过修改神经网络本身结构来实现,对于某一层的神经元,通过定义的概率将神经元置为0,这个神经元就不参与前向和后向传播,同时保持输入层和输出层神经元的个数保持不变,然后按照神经网络的学习方法进行参数更新,在下次迭代中,又重新随机删除一些神经元(指置为0的神经元),直至训练结束。The AlexNet structure includes 60 million parameters and 650 million neurons, 5 convolutional layers and pooling layers, 3 fully connected layers, and the output is a Softmax layer. This structure has the following advantages: using the Relu function as the activation function, its training speed is several times faster than the traditional neural network. Use stacked convolutional layers and pooling layers to extract image features. During the pooling process, the step size of each step is smaller than the pooling window length. The pooling window size of the AlexNet structure is a 3x3 square, and each pooling The moving step size is 2, so there will be overlap, and overlap pooling can prevent overfitting to a certain extent. Random inactivation Dropout and Data Augment are used to effectively suppress the over-fitting phenomenon. In the neural network structure, Dropout is realized by modifying the structure of the neural network itself. For neurons in a certain layer, the defined probability will When the neuron is set to 0, this neuron will not participate in the forward and backward propagation, while keeping the number of neurons in the input layer and output layer unchanged, and then update the parameters according to the learning method of the neural network. In the next iteration , and randomly delete some neurons (referring to the neurons set to 0) until the end of training.
本发明的说明书和权利要求书及上述附图中的术语“上”、“下”、“外侧”“内侧”等如果存在是用于区别位置上的相对关系,而不必给予定性。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本发明的实施例能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含。The terms "upper", "lower", "outside", "inside", etc. in the description and claims of the present invention and the above-mentioned drawings, if present, are used to distinguish the relative relationship in position, and are not necessarily qualitative. It is to be understood that the data so used may be interchanged under appropriate circumstances such that the embodiments of the invention described herein can be practiced in sequences other than those illustrated or described herein. Furthermore, the terms "comprising" and "having", and any variations thereof, are intended to cover non-exclusive inclusion.
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。The above description of the disclosed embodiments enables any person skilled in the art to make or use the present invention. Various modifications to these embodiments will be readily apparent to those skilled in the art, and the generic principles defined herein may be implemented in other embodiments without departing from the spirit or scope of the invention. Thus, the present invention is not intended to be limited to the embodiments shown herein, but is to be accorded the widest scope consistent with the principles and novel features disclosed herein.
Claims (10)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210420619.2ACN114758419A (en) | 2022-04-20 | 2022-04-20 | AR-based multidimensional intelligent application system |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210420619.2ACN114758419A (en) | 2022-04-20 | 2022-04-20 | AR-based multidimensional intelligent application system |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN114758419Atrue CN114758419A (en) | 2022-07-15 |
Family
ID=82330745
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210420619.2APendingCN114758419A (en) | 2022-04-20 | 2022-04-20 | AR-based multidimensional intelligent application system |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114758419A (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN120078518A (en)* | 2025-05-06 | 2025-06-03 | 华中科技大学同济医学院附属协和医院 | A multi-dimensional interaction method, system and storage medium of a laparoscopic surgical robot |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7225414B1 (en)* | 2002-09-10 | 2007-05-29 | Videomining Corporation | Method and system for virtual touch entertainment |
| WO2017129148A1 (en)* | 2016-01-25 | 2017-08-03 | 亮风台(上海)信息科技有限公司 | Method and devices used for implementing augmented reality interaction and displaying |
| WO2017129149A1 (en)* | 2016-01-25 | 2017-08-03 | 亮风台(上海)信息科技有限公司 | Multimodal input-based interaction method and device |
| CN108139876A (en)* | 2015-03-04 | 2018-06-08 | 杭州凌感科技有限公司 | The system and method generated for immersion and interactive multimedia |
| CN110286762A (en)* | 2019-06-21 | 2019-09-27 | 济南大学 | A Virtual Experiment Platform with Multimodal Information Processing Function |
| CN110286763A (en)* | 2019-06-21 | 2019-09-27 | 济南大学 | A Navigational Experiment Interaction Device with Cognitive Function |
| CN110554774A (en)* | 2019-07-22 | 2019-12-10 | 济南大学 | AR-oriented navigation type interactive normal form system |
- 2022
- 2022-04-20CNCN202210420619.2Apatent/CN114758419A/enactivePending
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7225414B1 (en)* | 2002-09-10 | 2007-05-29 | Videomining Corporation | Method and system for virtual touch entertainment |
| CN108139876A (en)* | 2015-03-04 | 2018-06-08 | 杭州凌感科技有限公司 | The system and method generated for immersion and interactive multimedia |
| WO2017129148A1 (en)* | 2016-01-25 | 2017-08-03 | 亮风台(上海)信息科技有限公司 | Method and devices used for implementing augmented reality interaction and displaying |
| WO2017129149A1 (en)* | 2016-01-25 | 2017-08-03 | 亮风台(上海)信息科技有限公司 | Multimodal input-based interaction method and device |
| CN110286762A (en)* | 2019-06-21 | 2019-09-27 | 济南大学 | A Virtual Experiment Platform with Multimodal Information Processing Function |
| CN110286763A (en)* | 2019-06-21 | 2019-09-27 | 济南大学 | A Navigational Experiment Interaction Device with Cognitive Function |
| CN110554774A (en)* | 2019-07-22 | 2019-12-10 | 济南大学 | AR-oriented navigation type interactive normal form system |
Non-Patent Citations (2)
| Title |
|---|
| "xR4DRAMA:Enhancing situation awareness using immersive (XR) technologies", 2021 IEEE INTERNATIONAL CONFERENCE ON INTELLIGENT REALITY, 14 July 2021 (2021-07-14)* |
| 谭启蒙;陈磊;周永辉;孙沂昆;王耀兵;高升;: "一种空间服务机器人在轨人机交互系统设计", 载人航天, no. 03, 15 June 2018 (2018-06-15)* |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN120078518A (en)* | 2025-05-06 | 2025-06-03 | 华中科技大学同济医学院附属协和医院 | A multi-dimensional interaction method, system and storage medium of a laparoscopic surgical robot |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN111665941B (en) | Virtual experiment-oriented multi-mode semantic fusion human-computer interaction system and method | |
| CN106997236B (en) | Based on the multi-modal method and apparatus for inputting and interacting | |
| CN104750397B (en) | A kind of Virtual mine natural interactive method based on body-sensing | |
| WO2022116716A1 (en) | Cloud robot system, cloud server, robot control module, and robot | |
| CN108170816A (en) | A kind of intelligent vision Question-Answering Model based on deep neural network | |
| CN110851760B (en) | Human-computer interaction system for integrating visual question answering in web3D environment | |
| CN111124117B (en) | Augmented reality interaction method and device based on hand-drawn sketches | |
| CN110554774A (en) | AR-oriented navigation type interactive normal form system | |
| CN107808191A (en) | The output intent and system of the multi-modal interaction of visual human | |
| CN113221726A (en) | Hand posture estimation method and system based on visual and inertial information fusion | |
| CN117773920A (en) | A natural language driven robotic grasping method | |
| CN113723327A (en) | Real-time Chinese sign language recognition interactive system based on deep learning | |
| CN116429111A (en) | Visual language navigation method based on dual semantic understanding and fusion | |
| CN115661830A (en) | Text guidance image segmentation method based on structured multi-mode fusion network | |
| WO2025176156A1 (en) | Human-machine interaction method, apparatus and device, and storage medium | |
| CN106502390A (en) | A kind of visual human's interactive system and method based on dynamic 3D Handwritten Digit Recognitions | |
| CN106462255A (en) | A method, system and robot for generating interactive content of robot | |
| CN116185182A (en) | Controllable image description generation system and method for fusing eye movement attention | |
| CN115716278A (en) | Robot target searching method based on active sensing and interactive operation cooperation and robot simulation platform | |
| CN114758419A (en) | AR-based multidimensional intelligent application system | |
| CN116778034A (en) | Virtual object editor, virtual object editing method and related device | |
| CN118916698A (en) | Human-computer interaction closed-loop feedback body-equipped large model training method and system | |
| CN104751564A (en) | Independent selling method of service robot on basis of semantic comprehension and answer set programming | |
| CN115922692B (en) | A human-robot multimodal interaction method for teleoperation | |
| CN117215408A (en) | Park operation system and park operation method |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |