CN114708847A - Voice synthesis method, device, equipment and storage medium - Google Patents
Voice synthesis method, device, equipment and storage mediumDownload PDFInfo
- Publication number
- CN114708847A CN114708847ACN202210252704.2ACN202210252704ACN114708847ACN 114708847 ACN114708847 ACN 114708847ACN 202210252704 ACN202210252704 ACN 202210252704ACN 114708847 ACN114708847 ACN 114708847A
- Authority
- CN
- China
- Prior art keywords
- timbre
- voice data
- dimension
- speaker
- user
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images




Classifications
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/02—Methods for producing synthetic speech; Speech synthesisers
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/08—Text analysis or generation of parameters for speech synthesis out of text, e.g. grapheme to phoneme translation, prosody generation or stress or intonation determination
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Machine Translation (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本申请涉及语音合成技术领域,尤其涉及一种语音合成方法、装置、设备及存储介质。The present application relates to the technical field of speech synthesis, and in particular, to a speech synthesis method, apparatus, device and storage medium.
背景技术Background technique
语音合成是一种将文字转换成语音的智能语音技术,它是实现人机交互的关键技术之一。合成语音的音色是影响用户对于语音合成产品使用感受的因素之一,符合用户喜好的合成语音音色能够带来好的产品体验,提升产品价值。Speech synthesis is an intelligent speech technology that converts text into speech, and it is one of the key technologies for realizing human-computer interaction. The timbre of the synthesized speech is one of the factors that affects the user's experience of using speech synthesis products. The synthesized speech timbre that meets the user's preferences can bring a good product experience and enhance the product value.
然而,目前的语音合成方案只能合成出单一固定音色的语音数据,可以理解的是,不同用户对于合成语音音色的喜好通常不同,单一固定音色不可能受所有用户的喜爱,可见,目前的语音合成方案并不能满足用户对于合成语音音色的个性化需求。However, the current speech synthesis solution can only synthesize speech data with a single fixed timbre. It is understandable that different users usually have different preferences for the synthesized voice timbre, and a single fixed timbre cannot be loved by all users. It can be seen that the current voice The synthesis scheme cannot meet the user's individual needs for the synthesized voice tone.
发明内容SUMMARY OF THE INVENTION
有鉴于此,本申请提供了一种语音合成方法、装置、设备及存储介质,用以解决现有的语音合成方案只能合成出单一固定音色的语音数据,无法满足用户对于合成语音音色的个性化需求的问题,其技术方案如下:In view of this, the application provides a speech synthesis method, device, equipment and storage medium, in order to solve the problem that the existing speech synthesis solution can only synthesize the speech data of a single fixed timbre, and cannot satisfy the user's individuality for the synthesized voice timbre. The technical solutions are as follows:
一种语音合成方法,包括:A speech synthesis method, comprising:
获取用于进行语音合成的文本特征以及指定说话人的语音数据;Obtain text features for speech synthesis and speech data of a specified speaker;
对所述指定说话人的语音数据提取说话人特征,作为原始音色特征向量;Extracting speaker features from the voice data of the designated speaker as the original timbre feature vector;
基于所述原始音色特征向量、设定音色维度下由用户决定的音色调整参数以及所述设定音色维度下的音色拉伸向量,确定用户定制音色的音色特征向量;Determine the timbre feature vector of the user-customized timbre based on the original timbre feature vector, the timbre adjustment parameter determined by the user under the set timbre dimension, and the timbre stretch vector under the set timbre dimension;
基于所述文本特征和所述用户定制音色的音色特征向量,合成用户定制音色的语音数据。Based on the text feature and the timbre feature vector of the user-customized timbre, the voice data of the user-customized timbre is synthesized.
可选的,所述基于所述原始音色特征向量、设定音色维度下由用户决定的音色调整参数以及所述设定音色维度下的音色拉伸向量,确定用户定制音色的音色特征向量,包括:Optionally, the timbre feature vector of the user-customized timbre is determined based on the original timbre feature vector, the timbre adjustment parameters determined by the user under the set timbre dimension, and the timbre stretch vector under the set timbre dimension, including: :
根据所述设定音色维度下的音色调整参数和所述设定音色维度下的音色拉伸向量,确定所述设定音色维度下的音色特征调整向量;Determine the timbre feature adjustment vector under the set timbre dimension according to the timbre adjustment parameter under the set timbre dimension and the timbre stretch vector under the set timbre dimension;
根据所述原始音色特征向量和所述设定音色维度下的音色特征调整向量,确定用户定制音色的音色特征向量。The timbre feature vector of the user-customized timbre is determined according to the original timbre feature vector and the timbre feature adjustment vector in the set timbre dimension.
可选的,所述基于所述文本特征和所述用户定制音色的音色特征向量,合成用户定制音色的语音数据,包括:Optionally, the voice data of the user-customized timbre is synthesized based on the text feature and the timbre feature vector of the user-customized timbre, including:
根据所述文本特征和所述说话人特征,获取帧级的特征向量序列;obtaining a frame-level feature vector sequence according to the text feature and the speaker feature;
根据所述帧级的特征向量序列和所述用户定制音色的音色特征向量,合成用户定制音色的语音数据。According to the frame-level feature vector sequence and the timbre feature vector of the user-customized timbre, the voice data of the user-customized timbre is synthesized.
可选的,所述根据所述文本特征和所述说话人特征,获取帧级的特征向量序列,包括:Optionally, obtaining a frame-level feature vector sequence according to the text feature and the speaker feature, including:
根据所述文本特征,获取音素级别的上下文特征向量;According to the text feature, obtain the context feature vector of the phoneme level;
以所述音素级别的上下文特征向量和所述说话人特征为依据,预测音素的发音时长帧数;Based on the context feature vector of the phoneme level and the speaker feature, predict the number of frames of pronunciation duration of the phoneme;
以所述音素的发音时长帧数为依据,将所述音素级别的上下文特征向量展开成帧级的特征向量序列。The phoneme-level context feature vector is expanded into a frame-level feature vector sequence based on the phoneme's pronunciation duration frame number.
可选的,所述设定音色维度包括一个或多个音色维度;Optionally, the set timbre dimension includes one or more timbre dimensions;
确定所述设定音色维度下的音色拉伸向量,包括:Determine the timbre stretch vector under the set timbre dimension, including:
获取语音数据总集,所述语音数据总集中包括多个说话人的语音数据,每个说话人的语音数据标注有所述设定音色维度下的音色属性的音色属性值;Acquiring a voice data collection, the voice data collection includes the voice data of a plurality of speakers, and the voice data of each speaker is marked with the timbre attribute value of the timbre attribute under the set timbre dimension;
将所述设定音色维度包含的每个音色维度作为目标音色维度,根据所述语音数据总集中的语音数据标注的音色属性值,从所述语音数据总集中获取与所述目标音色维度相关的语音数据;Taking each timbre dimension included in the set timbre dimension as the target timbre dimension, according to the timbre attribute value marked by the voice data in the voice data set, obtain the target timbre dimension from the voice data set. voice data;
根据与所述目标音色维度相关的语音数据,确定所述目标音色维度下的音色拉伸向量。According to the speech data related to the target timbre dimension, a timbre stretch vector under the target timbre dimension is determined.
可选的,为一说话人的语音数据标注所述设定音色维度下的音色属性的音色属性值的过程包括:Optionally, the process of marking the timbre attribute value of the timbre attribute under the set timbre dimension for the voice data of a speaker includes:
获取多个标注人员分别根据该说话人的语音数据在所述设定音色维度下的音色属性上标注的音色属性值,以得到多个标注人员的标注结果;Acquiring the timbre attribute values marked on the timbre attribute under the set timbre dimension according to the voice data of the speaker respectively by a plurality of labelers, to obtain the labelling results of the plurality of labelers;
根据所述多个标注人员的标注结果,确定该说话人的语音数据在所述设定音色维度下的音色属性的音色属性值,并为该说话人的语音数据标注确定出的音色属性值。According to the annotation results of the multiple annotators, the timbre attribute value of the timbre attribute of the speaker's voice data in the set timbre dimension is determined, and the determined timbre attribute value is annotated for the speaker's voice data.
可选的,所述根据所述语音数据总集中的语音数据标注的音色属性值,从所述语音数据总集中获取与所述目标音色维度相关的语音数据,包括:Optionally, obtaining the voice data related to the target timbre dimension from the voice data set according to the timbre attribute value marked by the voice data in the voice data set, including:
从所述语音数据总集中获取第一音色属性的属性值为第一目标属性值的语音数据,组成第一语音数据集,其中,所述第一音色属性为与所述目标音色维度相关的音色属性,所述第一目标属性值为与所述目标音色维度相关的属性值;The voice data whose attribute value of the first timbre attribute is the first target attribute value is obtained from the voice data collection to form a first voice data set, wherein the first timbre attribute is the timbre related to the target timbre dimension attribute, the first target attribute value is an attribute value related to the target timbre dimension;
从所述语音数据总集中获取第二音色属性的属性值为第二目标属性值的语音数据,组成第二语音数据集,其中,所述第二音色属性为与所述第一音色属性相关的音色属性,所述第二目标属性值为与所述第一音色属性相关的属性值。Acquire voice data whose attribute value of the second timbre attribute is the second target attribute value from the voice data collection to form a second voice data set, wherein the second timbre attribute is related to the first timbre attribute The timbre attribute, the second target attribute value is an attribute value related to the first timbre attribute.
可选的,所述根据与所述目标音色维度相关的语音数据,确定所述目标音色维度下的音色拉伸向量,包括:Optionally, determining the timbre stretch vector under the target timbre dimension according to the voice data related to the target timbre dimension, including:
对所述第一语音数据集中每个说话人的语音数据提取说话人特征,并计算对所述第一语音数据集中的语音数据提取的若干说话人特征的均值,计算得到的均值作为所述目标音色维度下的第一平均音色向量;Extracting speaker features from the voice data of each speaker in the first voice data set, and calculating the mean value of several speaker features extracted from the voice data in the first voice data set, and using the calculated mean value as the target the first average timbre vector in the timbre dimension;
对所述第二语音数据集中每个说话人的语音数据提取说话人特征,并计算对所述第二语音数据集中的语音数据提取的若干说话人特征的均值,计算得到的均值作为所述目标音色维度下的第二平均音色向量;Extracting speaker features from the voice data of each speaker in the second voice data set, and calculating the mean value of several speaker features extracted from the voice data in the second voice data set, and using the calculated mean value as the target the second average timbre vector in the timbre dimension;
根据所述目标音色维度下的第一平均音色向量和所述目标音色维度下的第二平均音色向量,确定所述目标音色维度下的音色拉伸向量。The timbre stretching vector in the target timbre dimension is determined according to the first average timbre vector in the target timbre dimension and the second average timbre vector in the target timbre dimension.
可选的,所述对所述指定说话人的语音数据提取说话人特征,包括:Optionally, extracting speaker features from the voice data of the designated speaker includes:
利用预先构建的语音生成模块,对所述指定说话人的语音数据提取说话人特征;Utilize a pre-built speech generation module to extract speaker features from the speech data of the designated speaker;
所述基于所述文本特征和所述用户定制音色的音色特征向量,合成用户定制音色的语音数据,包括:Described based on the text feature and the timbre feature vector of the user-customized timbre, synthesizing the voice data of the user-customized timbre, including:
基于所述语音生成模块、所述文本特征和所述用户定制音色的音色特征向量,合成用户定制音色的语音数据。Based on the voice generation module, the text feature, and the timbre feature vector of the user-customized timbre, the voice data of the user-customized timbre is synthesized.
可选的,所述语音生成模块为语音合成模型,所述语音合成模型采用多个说话人的多条训练语音数据和所述多条训练语音数据分别对应的训练文本训练得到;Optionally, the speech generation module is a speech synthesis model, and the speech synthesis model is obtained by training multiple pieces of training speech data of multiple speakers and training texts corresponding to the multiple pieces of training speech data respectively;
所述基于所述语音生成模块、所述文本特征和所述用户定制音色的音色特征向量,合成用户定制音色的语音数据,包括:Described based on the voice generation module, the text feature and the timbre feature vector of the user-customized timbre, synthesizing the voice data of the user-customized timbre, including:
基于所述语音合成模型的文本编码模块,对所述文本特征进行编码,以得到音素级别的上下文特征向量;Based on the text encoding module of the speech synthesis model, the text feature is encoded to obtain a phoneme-level context feature vector;
基于所述语音合成模型的时长预测模块,以所述音素级别的上下文特征向量和所述说话人特征为依据,预测音素的发音时长帧数;Based on the duration prediction module of the speech synthesis model, based on the context feature vector of the phoneme level and the speaker feature, predict the number of frames of pronunciation duration of the phoneme;
基于所述语音合成模型的长度调整模块,以所述音素的发音时长帧数为依据,将所述音素级别的上下文特征向量展开成帧级的特征向量序列;Based on the length adjustment module of the speech synthesis model, the phoneme-level context feature vector is expanded into a frame-level feature vector sequence based on the phoneme's pronunciation duration frame number;
基于所述语音合成模型的解码模块,以所述帧级的特征向量序列和所述用户定制音色的音色特征向量为依据,预测频谱特征;Based on the decoding module of the speech synthesis model, based on the frame-level feature vector sequence and the timbre feature vector of the user-customized timbre, predict spectral features;
根据所述频谱特征,合成用户定制音色的语音数据。According to the spectral features, the voice data of the user-customized timbre is synthesized.
可选的,所述基于所述语音合成模型、所述文本特征和所述用户定制音色的音色特征向量,合成用户定制音色的语音数据,包括:Optionally, the voice data of the user-customized timbre is synthesized based on the speech synthesis model, the text feature and the timbre feature vector of the user-customized timbre, including:
基于所述语音合成模型的文本编码模块,对所述文本特征进行编码,以得到音素级别的上下文特征向量;Based on the text encoding module of the speech synthesis model, the text feature is encoded to obtain a phoneme-level context feature vector;
基于所述语音合成模型的时长预测模块,以所述音素级别的上下文特征向量和所述说话人特征为依据,预测音素的发音时长帧数;Based on the duration prediction module of the speech synthesis model, based on the context feature vector of the phoneme level and the speaker feature, predict the number of frames of pronunciation duration of the phoneme;
基于所述语音合成模型的长度调整模块,以所述音素的发音时长帧数为依据,将所述音素级别的上下文特征向量展开成帧级的特征向量序列;Based on the length adjustment module of the speech synthesis model, the phoneme-level context feature vector is expanded into a frame-level feature vector sequence based on the phoneme's pronunciation duration frame number;
基于所述语音合成模型中的解码模块,以所述帧级的特征向量序列和所述用户定制音色的音色特征向量为依据,预测频谱特征;Based on the decoding module in the speech synthesis model, the spectral features are predicted based on the frame-level feature vector sequence and the timbre feature vector of the user-customized timbre;
根据所述频谱特征,合成用户定制音色的语音数据。According to the spectral features, the voice data of the user-customized timbre is synthesized.
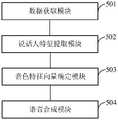
一种语音合成装置,包括:数据获取模块、说话人特征提取模块、音色特征向量确定模块和语音合成模块;A speech synthesis device, comprising: a data acquisition module, a speaker feature extraction module, a timbre feature vector determination module and a speech synthesis module;
所述数据获取模块,用于获取用于进行语音合成的文本特征以及指定说话人的语音数据;The data acquisition module is used to acquire the text features used for speech synthesis and the voice data of the designated speaker;
所述说话人特征提取模块,用于对所述指定说话人的语音数据提取说话人特征,作为原始音色特征向量;The speaker feature extraction module is used for extracting speaker features from the voice data of the designated speaker as an original timbre feature vector;
所述音色特征向量确定模块,用于基于所述原始音色特征向量、设定音色维度下由用户决定的音色调整参数以及所述设定音色维度下的音色拉伸向量,确定用户定制音色的音色特征向量;The timbre feature vector determination module is used to determine the timbre of the user-customized timbre based on the original timbre feature vector, the timbre adjustment parameters determined by the user under the set timbre dimension, and the timbre stretch vector under the set timbre dimension Feature vector;
所述语音合成模块,用于基于所述文本特征和所述用户定制音色的音色特征向量,合成用户定制音色的语音数据。The speech synthesis module is configured to synthesize the speech data of the user-customized timbre based on the text feature and the timbre feature vector of the user-customized timbre.
一种语音合成设备,包括:存储器和处理器;A speech synthesis device, comprising: a memory and a processor;
所述存储器,用于存储程序;the memory for storing programs;
所述处理器,用于执行所述程序,实现上述任一项所述的语音合成方法的各个步骤。The processor is configured to execute the program to implement each step of the speech synthesis method described in any one of the above.
一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现上述任一项所述的语音合成方法的各个步骤。A computer-readable storage medium on which a computer program is stored, and when the computer program is executed by a processor, implements each step of the speech synthesis method described in any one of the above.
本申请提供的语音合成方法、装置、设备及存储介质,首先获取用于进行语音合成的文本特征以及指定说话人的语音数据,然后对指定说话人的语音数据提取说话人特征,以得到原始音色特征向量,接着基于原始音色特征向量、设定音色维度下由用户决定的音色调整参数以及设定音色维度下的音色拉伸向量,确定用户定制音色的音色特征向量,最后基于文本特征和用户定制音色的音色特征向量,合成用户定制音色的语音数据。经由本申请提供的语音合成方法能够合成出用户深入定制音色的语音数据,合成出的语音数据更加符合用户的喜好,可见,本申请提供的语音合成方法能够满足用户对于合成语音音色的个性化需求,另外,让用户深度参与合成语音音色的选择,使得语音合成更具趣味性和交互性,从而能够提升用户体验。In the speech synthesis method, device, device and storage medium provided by the present application, the text features used for speech synthesis and the voice data of the designated speaker are first obtained, and then the speaker features are extracted from the voice data of the designated speaker to obtain the original timbre feature vector, and then determine the timbre feature vector of the user-customized timbre based on the original timbre feature vector, the timbre adjustment parameters determined by the user in the set timbre dimension, and the timbre stretch vector in the set timbre dimension, and finally based on the text features and user-defined timbre The timbre feature vector of the timbre is used to synthesize the voice data of the user-customized timbre. The speech synthesis method provided by the application can synthesize the voice data that the user deeply customizes the timbre, and the synthesized speech data is more in line with the user's preference. It can be seen that the speech synthesis method provided by the application can meet the user's personalized needs for the synthesized voice timbre. , In addition, allowing users to deeply participate in the selection of synthesized speech sounds makes speech synthesis more interesting and interactive, thereby improving user experience.
附图说明Description of drawings
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。In order to explain the embodiments of the present invention or the technical solutions in the prior art more clearly, the following briefly introduces the accompanying drawings that need to be used in the description of the embodiments or the prior art. Obviously, the accompanying drawings in the following description are only It is an embodiment of the present invention. For those of ordinary skill in the art, other drawings can also be obtained according to the provided drawings without creative work.
图1为本申请实施例提供的语音合成方法的流程示意图;1 is a schematic flowchart of a speech synthesis method provided by an embodiment of the present application;
图2为本申请实施例提供的基于语音合成模型实现语音合成的流程示意图;2 is a schematic flowchart of implementing speech synthesis based on a speech synthesis model provided by an embodiment of the present application;
图3为本申请实施例提供的语音合成模型的一结构示意图;3 is a schematic structural diagram of a speech synthesis model provided by an embodiment of the present application;
图4为本申请实施例提供的确定设定音色维度下的音色拉伸向量的流程示意图;4 is a schematic flowchart of determining a timbre stretching vector under a set timbre dimension provided by an embodiment of the present application;
图5为本申请实施例提供的语音合成装置的结构示意图;5 is a schematic structural diagram of a speech synthesis apparatus provided by an embodiment of the present application;
图6为本申请实施例提供的语音合成设备的结构示意图。FIG. 6 is a schematic structural diagram of a speech synthesis device provided by an embodiment of the present application.
具体实施方式Detailed ways
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。The technical solutions in the embodiments of the present invention will be clearly and completely described below with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only a part of the embodiments of the present invention, but not all of the embodiments. Based on the embodiments of the present invention, all other embodiments obtained by those of ordinary skill in the art without creative efforts shall fall within the protection scope of the present invention.
由于目前的语音合成方案只能合成出单一固定音色的语音数据,因此,其不能满足用户对于合成语音音色的个性化需求,有鉴于此,申请人进行了研究,起初的思路是,在一个场景下为用户提供具有多个音色的音库,让用户按照个人喜好选择使用,然而在实际应用时,可提供的音色通常有限,这意味着用户对音色的选择范围有限,用户仍然只能被动接受提供的音色。Since the current speech synthesis solution can only synthesize speech data with a single fixed timbre, it cannot meet the individual needs of users for synthesizing speech timbre. In view of this, the applicant has conducted research. The initial idea is that in a scene Provide users with a sound bank with multiple timbres, allowing users to choose and use according to their personal preferences. However, in practical applications, the timbres that can be provided are usually limited, which means that users have a limited range of timbre choices, and users can only passively accept them. provided tone.
针对上述思路的缺陷,申请人想到,若能让用户深入参与到合成语音音色的选择(即,让用户深入定制自己喜爱的合成语音音色),将大大提升用户体验,让用户深入参与到合成语音音色的选择,一方面能够合成出更加符合用户个人喜好的语音,另一方面能够提升语音合成产品的趣味性和交互性,沿着上述思路,申请人继续进行研究,通过不断研究,最终提供了一种语音合成方法,该语音合成方法可合成出用户定制音色的语音。In view of the shortcomings of the above-mentioned ideas, the applicant thinks that if users can be deeply involved in the selection of synthesized voice timbres (that is, allowing users to deeply customize their favorite synthesized voice timbres), the user experience will be greatly improved, and users will be able to deeply participate in the synthesis of voice timbres. The choice of timbre, on the one hand, can synthesize voice that is more in line with the user's personal preferences, and on the other hand can improve the interest and interactivity of the speech synthesis product. Following the above ideas, the applicant continues to conduct research, and through continuous research, finally provides A voice synthesis method, which can synthesize the voice of the user-customized timbre.
本申请提供的语音合成方法可应用于具有处理能力的电子设备,该电子设备可以为网络侧的服务器(服务器可以是一台服务器,也可以是由多台服务器组成的服务器集群,或者是一个云计算服务器中心),也可以为用户侧使用的终端(终端可以但并不限定为PC、笔记本、智能手机、车载终端、智能家居设备、可穿戴设备等),网络侧的服务器或用户侧使用的终端可按本申请提供的语音合成方法合成出音色更加符合用户个人喜好的语音。本领域技术人员应能理解,上述列举的服务器、终端仅为举例,其它现有的或今后可能出现的服务器、终端如可适用于本申请,也应包含在本申请保护范围以内,并在此以引用方式包含于此。The speech synthesis method provided by this application can be applied to an electronic device with processing capability, and the electronic device can be a server on the network side (the server can be a server, a server cluster composed of multiple servers, or a cloud computing server center), it can also be a terminal used by the user side (the terminal can be but not limited to PC, notebook, smart phone, vehicle terminal, smart home equipment, wearable device, etc.), the server on the network side or the terminal used by the user side The terminal can synthesize the voice whose timbre is more in line with the user's personal preference according to the voice synthesis method provided in this application. Those skilled in the art should understand that the servers and terminals listed above are only examples. If other existing or future servers and terminals are applicable to this application, they should also be included in the protection scope of this application, and here Incorporated herein by reference.
接下来,通过下述实施例对本申请提供的语音合成方法进行介绍。Next, the speech synthesis method provided by the present application will be introduced through the following embodiments.
第一实施例first embodiment
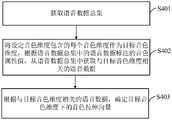
请参阅图1,示出了本申请实施例提供的语音合成方法的流程示意图,该方法可以包括:Please refer to FIG. 1, which shows a schematic flowchart of a speech synthesis method provided by an embodiment of the present application. The method may include:
步骤S101:获取用于进行语音合成的文本特征以及指定说话人的语音数据。Step S101: Acquire text features for speech synthesis and speech data of a designated speaker.
其中,用于进行语音合成的文本特征根据用于语音合成的文本获取,文本特征可以包括音素信息、声调信息、韵律分词信息等。需要说明的是,声调信息为音素层面的信息,韵律分词信息也是音素层面的信息,其通过将词层面的韵律分词信息处理到音素层面而得到,总的来说,本实施例中用于进行语音合成的文本特征包含的信息为音素级别的信息。The text features used for speech synthesis are obtained according to the text used for speech synthesis, and the text features may include phoneme information, tone information, prosodic word segmentation information, and the like. It should be noted that the tone information is information at the phoneme level, and the prosodic word segmentation information is also information at the phoneme level, which is obtained by processing the prosodic word segmentation information at the word level to the phoneme level. The information contained in the text features of speech synthesis is information at the phoneme level.
步骤S102:对指定说话人的语音数据提取说话人特征,作为原始音色特征向量。Step S102 : extracting speaker features from the voice data of the designated speaker as the original timbre feature vector.
本实施例将对指定说话人的语音数据提取的说话人特征作为原始音色特征向量,原始音色特征向量为指定说话人的原始音色的特征向量。In this embodiment, the speaker feature extracted from the speech data of the specified speaker is used as the original timbre feature vector, and the original timbre feature vector is the feature vector of the original timbre of the specified speaker.
步骤S103:基于原始音色特征向量、设定音色维度下由用户决定的音色调整参数以及设定音色维度下的音色拉伸向量,确定用户定制音色的音色特征向量。Step S103: Determine the timbre feature vector of the user-customized timbre based on the original timbre feature vector, the timbre adjustment parameters determined by the user in the set timbre dimension, and the timbre stretching vector in the set timbre dimension.
其中,设定音色维度为用户可调整的音色维度,其可根据人对音色的感知维度设定,设定音色维度可以包括一个音色维度,也可以包括多个音色维度,具体的音色维度和音色维度的具体数量可根据具体的应用场景设定。示例性的,设定音色维度可以包括与性别无关的“鼻音感”维度、与性别有关的“女声甜美”维度和“男声浑厚”维度。The set timbre dimension is a user-adjustable timbre dimension, which can be set according to a person's perception of timbre. The set timbre dimension may include one timbre dimension or multiple timbre dimensions. The specific timbre dimension and timbre dimension The specific number of dimensions can be set according to specific application scenarios. Exemplarily, the preset timbre dimension may include a gender-independent dimension of "nasal feeling", a gender-related dimension of "sweetness of a female voice", and a dimension of "strong male voice".
其中,设定音色维度下的音色拉伸向量为用于调整音色的基础向量,设定音色维度下的音色拉伸向量预先确定,即在实际进行语音合成之前确定,设定音色维度下的音色拉伸向量的确定方式将在后续实施例介绍。Among them, the timbre stretching vector in the timbre dimension is set as the basic vector for adjusting timbre, and the timbre stretching vector in the timbre dimension is set in advance, that is, it is determined before the actual speech synthesis, and the timbre in the timbre dimension is set The manner of determining the stretch vector will be introduced in the following embodiments.
其中,音色调整参数为用于调整音色的参数,其由用户决定,可选的,可展示音色调节界面,用户可基于音色调节界面改变音色调整参数,进而基于音色调整参数同时结合音色拉伸向量实现对音色的调整。Among them, the timbre adjustment parameter is a parameter used to adjust the timbre, which is determined by the user. Optionally, a timbre adjustment interface can be displayed. The user can change the timbre adjustment parameter based on the timbre adjustment interface, and then combine the timbre adjustment parameter based on the timbre adjustment parameter and the timbre stretch vector. Realize the adjustment of tone.
步骤S104:基于文本特征和用户定制音色的音色特征向量,合成用户定制音色的语音数据。Step S104: Synthesize the voice data of the user-customized timbre based on the text feature and the timbre feature vector of the user-customized timbre.
可选的,基于文本特征和用户定制音色的音色特征向量,合成用户定制音色的语音数据的过程可以包括:根据文本特征和说话人特征,获取帧级的特征向量序列;根据帧级的特征向量序列和用户定制音色的音色特征向量,合成用户定制音色的语音数据。Optionally, based on the text feature and the timbre feature vector of the user-customized timbre, the process of synthesizing the voice data of the user-customized timbre may include: obtaining a frame-level feature vector sequence according to the text feature and the speaker feature; The sequence and the timbre feature vector of the user-customized timbre are used to synthesize the voice data of the user-customized timbre.
其中,根据文本特征和说话人特征,获取帧级的特征向量序列的过程包括包括:根据文本特征,获取音素级别的上下文特征向量;以音素级别的上下文特征向量和所述说话人特征为依据,预测音素的发音时长帧数;以音素的发音时长帧数为依据,将音素级别的上下文特征向量展开成帧级的特征向量序列。Wherein, according to the text feature and the speaker feature, the process of obtaining the frame-level feature vector sequence includes: obtaining the phoneme-level context feature vector according to the text feature; based on the phoneme-level context feature vector and the speaker feature, Predict the phoneme pronunciation duration frame number; based on the phoneme pronunciation duration frame number, expand the phoneme-level context feature vector into a frame-level feature vector sequence.
由于最终合成语音数据所基于的音色特征向量为用户定制音色的音色特征向量,因此基于文本特征和用户定制音色的音色特征向量能够合成出用户定制音色的语音数据,用户定制音色的语音数据为音色符合用户个人喜好的语音数据。Since the timbre feature vector based on the final synthesized speech data is the timbre feature vector of the user-customized timbre, the voice data of the user-customized timbre can be synthesized based on the text feature and the timbre feature vector of the user-customized timbre, and the voice data of the user-customized timbre is the timbre Voice data that matches the user's personal preferences.
本申请实施例提供的语音合成方法,首先获取用于进行语音合成的文本特征以及指定说话人的语音数据,然后对指定说话人的语音数据提取说话人特征,以得到原始音色特征向量,接着基于原始音色特征向量、设定音色维度下由用户决定的音色调整参数以及设定音色维度下的音色拉伸向量,确定用户定制音色的音色特征向量,最后基于文本特征和用户定制音色的音色特征向量,合成用户定制音色的语音数据。经由本申请实施例提供的语音合成方法能够合成出用户深入定制音色的语音数据,合成出的语音数据更加符合用户的喜好,可见,本申请实施例提供的语音合成方法能够满足用户对于合成语音音色的个性化需求,另外,让用户深度参与合成语音音色的选择,使得语音合成更具趣味性和交互性,从而能够提升用户体验。The speech synthesis method provided by the embodiment of the present application first acquires the text features used for speech synthesis and the speech data of the designated speaker, and then extracts the speaker characteristics from the speech data of the designated speaker to obtain the original timbre feature vector, and then based on The original timbre feature vector, the timbre adjustment parameters determined by the user in the set timbre dimension, and the timbre stretch vector in the set timbre dimension, determine the timbre feature vector of the user-customized timbre, and finally, based on the text features and the timbre feature vector of the user-customized timbre , synthesizing the voice data of the user-customized timbre. The speech synthesis method provided by the embodiment of the present application can synthesize the voice data that the user deeply customizes the timbre, and the synthesized voice data is more in line with the user's preference. It can be seen that the speech synthesis method provided by the embodiment of the present application can satisfy the user's desire for synthesized voice timbre. In addition, allowing users to deeply participate in the selection of synthesized speech timbres makes speech synthesis more interesting and interactive, thereby improving user experience.
第二实施例Second Embodiment
本申请提供的语音合成方法可基于预先构建的语音生成模块实现,可选的,语音生成模块可以为语音合成模型,当然,本实施例并不限定于此,语音生成模块除了可以为模型,还可以为其它形式的模块,比如基于语音生成规则的模块,本实施例对语音生成模块的具体形式不做限定。The speech synthesis method provided by the present application may be implemented based on a pre-built speech generation module. Optionally, the speech generation module may be a speech synthesis model. Of course, this embodiment is not limited to this. In addition to a model, the speech generation module may also be a model. It may be a module in other forms, such as a module based on speech generation rules, and the specific form of the speech generation module is not limited in this embodiment.
其中,语音合成模型采用训练语音数据和训练语音数据对应的训练文本训练得到,训练语音数据对应的训练文本即为训练语音数据的标注文本。优选的,为了能够合成不同说话人的语音数据,用于训练语音合成模型的训练语音数据采用多个(比如上千个)不同说话人的语音数据(比如,说话人A的语音数据、说话人B的语音数据、说话人C的语音数据、…),每个说话人的语音数据为多条(比如100条以上),优选的,每个说话人的每条语音数据的时长可在十秒左右。The speech synthesis model is obtained by training the training speech data and the training text corresponding to the training speech data, and the training text corresponding to the training speech data is the labeled text of the training speech data. Preferably, in order to be able to synthesize the speech data of different speakers, the training speech data for training the speech synthesis model adopts the speech data of multiple (for example, thousands) different speakers (for example, the speech data of the speaker A, the speech data of the speaker The voice data of B, the voice data of speaker C, ...), there are multiple pieces of voice data for each speaker (for example, more than 100 pieces), preferably, the duration of each piece of voice data for each speaker can be within ten seconds about.
需要说明的是,为了使得基于语音合成模型能够较好合成出用户从设定音色维度定制音色的语音数据,在收集训练语音数据时,需要考虑设定音色维度,示例性的,设定音色维度包括“女声甜美”、“男声浑厚”和“鼻音感”,则要收集男女比例均衡(比如收集600个男性说话人的语音数据,收集600个女性说话人的语音数据),且同时具有“鼻音感”、“女声甜美”和“男声浑厚”特点的说话人的语音数据,并保证具有“鼻音感”、“女声甜美”和“男声浑厚”特点的说话人在五十人以上,比如,收集的所有语音数据中需要包括60个具有“鼻音感”特点的说话人的语音数据,65个具有“女声甜美”特点的说话人的语音数据,60个具有“男声浑厚”特点的说话人的语音数据。It should be noted that, in order to better synthesize the voice data based on the speech synthesis model for the user to customize the timbre from the set timbre dimension, when collecting training voice data, it is necessary to consider the set timbre dimension, exemplarily, set the timbre dimension. Including "female voice sweet", "male voice strong" and "nasal sound", it is necessary to collect a balanced ratio of male and female speakers (for example, collect the voice data of 600 male speakers, and collect the voice data of 600 female speakers), and at the same time have a "nasal voice" The voice data of the speakers with the characteristics of "feeling", "female sweet" and "male strong", and ensure that there are more than 50 speakers with the characteristics of "nasal feeling", "female sweet" and "male strong". For example, collect All the voice data of 60 speakers with the characteristics of "nasal sound", 65 speakers with the characteristics of "sweet female voice", and 60 speakers with the characteristics of "strong male voice" data.
接下来以语音生成模块为语音合成模型为例,对基于语音合成模型实现语音合成的过程进行介绍。Next, the process of realizing speech synthesis based on the speech synthesis model is introduced by taking the speech generation module as the speech synthesis model as an example.
请参阅图2,示出了基于语音合成模型实现语音合成的流程示意图,可以包括:Please refer to FIG. 2, which shows a schematic flowchart of implementing speech synthesis based on a speech synthesis model, which may include:
步骤S201:获取用于进行语音合成的文本特征以及指定说话人的语音数据。Step S201: Acquire text features for speech synthesis and speech data of a designated speaker.
其中,用于进行语音合成的文本特征根据用于语音合成的文本获取,用于进行语音合成的文本特征可以包括音素信息、声调信息、韵律分词信息等。The text features used for speech synthesis are obtained according to the text used for speech synthesis, and the text features used for speech synthesis may include phoneme information, tone information, prosodic word segmentation information, and the like.
步骤S202:基于语音合成模型,对指定说话人的语音数据提取说话人特征,提取的说话人特征作为原始音色特征向量。Step S202: Based on the speech synthesis model, speaker features are extracted from the speech data of the designated speaker, and the extracted speaker features are used as the original timbre feature vector.
具体的,如图3所示,语音合成模型可以包括说话人编码模块301,可基于语音合成模型的说话人编码模块对指定说话人的语音数据提取说话人特征,将提取的说话人特征作为原始音色特征向量。Specifically, as shown in FIG. 3, the speech synthesis model may include a
步骤S203:基于原始音色特征向量、设定音色维度下由用户决定的音色调整参数以及设定音色维度下的音色拉伸向量,确定用户定制音色的音色特征向量。Step S203: Determine the timbre feature vector of the user-customized timbre based on the original timbre feature vector, the timbre adjustment parameters determined by the user in the set timbre dimension, and the timbre stretching vector in the set timbre dimension.
具体的,基于原始音色特征向量、设定音色维度下由用户决定的音色调整参数以及设定音色维度下的音色拉伸向量,确定用户定制音色的音色特征向量的过程可以包括:Specifically, based on the original timbre feature vector, the timbre adjustment parameters determined by the user in the setting timbre dimension, and the timbre stretching vector in the setting timbre dimension, the process of determining the timbre feature vector of the user-customized timbre may include:
步骤S2031、根据设定音色维度下的音色调整参数和音色拉伸向量,确定设定音色维度下的音色特征调整向量。Step S2031 , according to the timbre adjustment parameters and the timbre stretching vector in the set timbre dimension, determine the timbre feature adjustment vector in the set timbre dimension.
其中,设定音色维度下的音色特征调整向量为用于在设定音色维度对原始音色特征向量进行调整的向量。The timbre feature adjustment vector in the set timbre dimension is a vector used to adjust the original timbre feature vector in the set timbre dimension.
具体的,根据设定音色维度下的音色调整参数和音色拉伸向量,确定设定音色维度下的音色特征调整向量的过程可以包括:将设定音色维度下的音色调整参数与音色拉伸向量相乘,相乘结果作为设定音色维度下的音色特征调整向量。需要说明的是,在设定音色维度包括多个音色维度的情况下,将同一维度下的音色调整参数与音色拉伸向量相乘,从而得到每个音色维度下的音色拉伸向量。Specifically, according to the timbre adjustment parameters and the timbre stretch vector in the set timbre dimension, the process of determining the timbre feature adjustment vector in the set timbre dimension may include: combining the timbre adjustment parameters and the timbre stretch vector in the set timbre dimension Multiply, and the multiplication result is used as the timbre feature adjustment vector under the set timbre dimension. It should be noted that, when the timbre dimension is set to include multiple timbre dimensions, the timbre adjustment parameters in the same dimension are multiplied by the timbre stretch vector, so as to obtain the timbre stretch vector in each timbre dimension.
步骤S2032、根据原始音色特征向量和设定音色维度下的音色特征调整向量,确定用户定制音色的音色特征向量。Step S2032: Determine the timbre feature vector of the user-customized timbre according to the original timbre feature vector and the timbre feature adjustment vector in the set timbre dimension.
具体的,根据原始音色特征向量和设定音色维度下的音色特征调整向量,确定用户定制音色的音色特征向量的过程可以包括:将原始音色特征向量与设定音色维度下的音色特征调整向量求和,求和结果作为用户定制音色的音色特征向量。Specifically, according to the original timbre feature vector and the timbre feature adjustment vector under the set timbre dimension, the process of determining the timbre feature vector of the user-customized timbre may include: calculating the original timbre feature vector and the timbre feature adjustment vector under the set timbre dimension to obtain sum, and the summation result is used as the timbre feature vector of the user-customized timbre.
示例性的,设定音色维度包括“女声甜美”、“男声浑厚”和“鼻音感”,其中,“女声甜美”这一音色维度下的音色调整参数为λ甜美,“男声浑厚”这一音色维度下的音色调整参数为λ浑厚,“鼻音感”这一音色维度下的音色调整参数为λ鼻音,“女声甜美”这一音色维度下的音色拉伸向量为d甜美,“男声浑厚”这一音色维度下的音色拉伸向量为d浑厚,“鼻音感”这一音色维度下的音色拉伸向量为d鼻音,则“女声甜美”这一音色维度下的音色特征调整向量为λ甜美×d甜美,“男声浑厚”这一音色维度下的音色特征调整向量为λ浑厚×d浑厚,“鼻音感”这一音色维度下的音色特征调整向量为λ鼻音×d鼻音,用户定制音色的音色特征向量s定制为:Exemplarily, the set timbre dimension includes "sweet female voice", "strong male voice", and "nasal feeling", wherein the timbre adjustment parameter under the timbre dimension of "sweet female voice" is λsweet , and the timbre of "strong male voice". The timbre adjustment parameter in the dimension is λrich and thick, the timbre adjustment parameter in the timbre dimension of "nasal sense" is λnasal , the timbre stretching vector in the timbre dimension of "female voice is sweet" is dsweet , and the timbre of "male voice is thick". The timbre stretch vector in the timbre dimension of a timbre is d andthick , and the timbre stretch vector in the timbre dimension of "nasal feeling" is dnasal , then the timbre feature adjustment vector in the timbre dimension of "female voice is sweet" is λsweet × d issweet , the timbre feature adjustment vector under the timbre dimension of "male voice is thick and thick" is λthick × dthick , and the timbre feature adjustment vector under the timbre dimension "nasal feeling" is λnasal × dnasal , the timbre of the user-customized timbre The eigenvector s iscustomized as:
s定制=s原始+λ甜美×d甜美+λ浑厚×d浑厚+λ鼻音×d鼻音 (1)scustom = soriginal + λsweet × dsweet + λthick × dthick + λnasal × dnasal (1)
其中,s原始表示原始音色特征向量,λ甜美、λ浑厚、λ鼻音为连续值,取值范围为[0,1]。需要说明的是,当λ甜美、λ浑厚、λ鼻音均为0时,合成语音的音色为指定说话人的原始音色,当λ甜美、λ浑厚、λ鼻音中任一个为非0值时,合成语音的音色不再为指定说话人的原始音色,而是新的音色,用户可以调整λ甜美、λ浑厚、λ鼻音以生成不同音色,从容满足自己的个性化需求。Among them, soriginal represents the original timbre feature vector, λsweet , λvigorous , and λnasal are continuous values, and the value range is [0, 1]. It should be noted that when λsweet , λthick , and λnasal areall 0, thetimbre of the synthesized speech is the original timbre of the designated speaker. The timbre of the voice is no longer the original timbre of the designated speaker, but a new timbre. Users can adjust λsweet , λthick , and λnasal to generate different timbres to meet their individual needs calmly.
步骤S204:基于语音合成模型、文本特征和用户定制音色的音色特征向量为依据,合成用户定制音色的语音数据。Step S204: Synthesize the voice data of the user-customized timbre based on the speech synthesis model, the text feature, and the timbre feature vector of the user-customized timbre.
具体的,如图3所示,语音合成模型除了包括上述的说话人编码模块301外,还包括文本编码模块302、时长预测模块303、长度调整模块304和解码模块305,则基于语音合成模型、文本特征和用户定制音色的音色特征向量为依据,合成用户定制音色的语音数据的过程可以包括:Specifically, as shown in FIG. 3, the speech synthesis model includes, in addition to the above-mentioned
步骤S2041、基于语音合成模型的文本编码模块302,对文本特征进行编码,以得到音素级别的上下文特征向量。Step S2041 , the
具体的,将文本特征输入语音合成模型的文本编码模块302进行编码,文本编码模块302输出音素级别的上下文特征向量。Specifically, the text feature is input into the
步骤S2042、基于语音合成模型中的时长预测模块303,以音素级别的上下文特征向量和说话人特征为依据,预测音素的发音时长帧数。Step S2042: Based on the
具体的,将文本编码模块302输出的音素级别的上下文特征向量和说话人编码模块301输出的说话人特征,输入语音合成模型中的时长预测模块303,语音合成模型中的时长预测部分303输出预测的每个音素的发音时长帧数。需要说明的是,为了保留指定说话人的时长语速韵律特征,输入时长预测模块的为直接对指定说话人的语音数据提取的说话人特征。Specifically, the phoneme-level context feature vector output by the
步骤S2043、基于语音合成模型中的长度调整模块304,以音素的发音时长帧数为依据,将音素级别的上下文特征向量展开成帧级的特征向量序列。Step S2043 , based on the
步骤S2044、基于语音合成模型中的解码模块305,以帧级的特征向量序列和用户定制音色的音色特征向量为依据,预测频谱特征。Step S2044: Based on the
预测出的频谱特征即为待合成语音的频谱特征。The predicted spectral feature is the spectral feature of the speech to be synthesized.
步骤S2045、根据频谱特征,合成用户定制音色的语音数据。Step S2045 , synthesizing the voice data of the user-customized timbre according to the spectral characteristics.
具体的,可将解码部分305输出的频谱特征输入声码器,从而得到用户定制音色的合成语音。Specifically, the spectral features output by the
接下来对采用训练语音和训练语音对应的训练文本对语音合成模型进行训练的过程进行介绍。Next, the process of training the speech synthesis model by using the training speech and the training text corresponding to the training speech will be introduced.
采用训练语音数据和训练语音数据对应的训练文本训练语音合成模型的过程可以包括:The process of using the training speech data and the training text corresponding to the training speech data to train the speech synthesis model may include:
步骤a1、获取训练语音数据和训练语音数据对应的训练文本,并根据训练文本获取文本特征,获取的文本特征作为训练文本特征。In step a1, the training speech data and the training text corresponding to the training speech data are obtained, and text features are obtained according to the training text, and the obtained text features are used as the training text features.
其中,训练文本特征包括训练文本的音素信息、声调信息、韵律分词信息等。The training text features include phoneme information, tone information, prosodic word segmentation information, and the like of the training text.
步骤a2、基于语音合成模型对训练语音数据提取说话人特征,提取的说话人特征作为训练说话人特征。Step a2: Extract speaker features from the training speech data based on the speech synthesis model, and use the extracted speaker features as training speaker features.
具体的,获取训练语音的频谱特征,将训练语音数据的频谱特征输入语音合成模型的说话人编码模块,说话人编码模块从训练语音数据的频谱特征中提取句子级别的说话人表征特征,即说话人特征。Specifically, the spectral features of the training speech are acquired, and the spectral features of the training speech data are input into the speaker coding module of the speech synthesis model, and the speaker coding module extracts sentence-level speaker representation features from the spectral features of the training speech data, that is, speaking human characteristics.
步骤a3、基于语音合成模型、训练文本特征和训练说话人特征,预测频谱特征,并根据预测的频谱特征合成语音数据。Step a3 , predicting spectral features based on the speech synthesis model, training text features and training speaker features, and synthesizing speech data according to the predicted spectral features.
具体的,基于语音合成模型、训练文本特征和训练说话人特征,预测频谱特征的过程包括:Specifically, based on the speech synthesis model, training text features and training speaker features, the process of predicting spectral features includes:
步骤a31、基于语音合成模型的文本编码模块,对训练文本特征进行编码,以得到训练文本对应的音素级别的上下文特征向量。Step a31: Encode the training text feature based on the text encoding module of the speech synthesis model to obtain a phoneme-level context feature vector corresponding to the training text.
具体的,将训练文本特征输入语音合成模型的文本编码模块进行编码,文本编码模块输出训练文本对应的音素级别的上下文特征向量。Specifically, the training text feature is input into the text encoding module of the speech synthesis model for encoding, and the text encoding module outputs the phoneme-level context feature vector corresponding to the training text.
步骤a32、基于语音合成模型中的长度调整模块,以音素的实际发音时长帧数为依据,将训练文本对应的音素级别的上下文特征向量展开成帧级的特征向量序列,以得到训练文本对应的帧级的特征向量序列。Step a32, based on the length adjustment module in the speech synthesis model, based on the actual pronunciation duration frame number of the phoneme, expand the context feature vector of the phoneme level corresponding to the training text into a frame-level feature vector sequence, to obtain the corresponding training text. Frame-level sequence of feature vectors.
其中,音素的实际发音时长帧数指的是根据训练文本获得的每个音素的实际发音时长,音素的实际发音时长帧数可基于训练语音数据确定。Wherein, the actual pronunciation duration frame number of the phoneme refers to the actual pronunciation duration of each phoneme obtained according to the training text, and the actual pronunciation duration frame number of the phoneme can be determined based on the training speech data.
步骤a33、基于语音合成模型中的解码部分,以训练文本对应的帧级的特征向量序列和训练说话人特征为依据,预测频谱特征,并根据预测的频谱特征合成语音数据。Step a33: Based on the decoding part in the speech synthesis model, based on the frame-level feature vector sequence corresponding to the training text and the training speaker feature, predict the spectral features, and synthesize speech data according to the predicted spectral features.
步骤a4、基于预测的频谱特征、实际的频谱特征、实际的音素信息以及预测的音素信息,确定语音合成模型的预测损失。Step a4: Determine the prediction loss of the speech synthesis model based on the predicted spectral features, the actual spectral features, the actual phoneme information, and the predicted phoneme information.
其中,实际的频谱特征为训练语音数据的频谱特征,实际的音素信息为根据训练文本获得的音素信息,比如,根据训练文本获得的音素时长信息、音素状态时长等,预测的音素信息为根据合成的语音数据对应的文本获得的音素信息,比如,根据合成的语音数据对应的文本获得的音素时长信息、音素状态时长等。Wherein, the actual spectral feature is the spectral feature of the training speech data, the actual phoneme information is the phoneme information obtained according to the training text, for example, the phoneme duration information, the phoneme state duration, etc. obtained according to the training text, and the predicted phoneme information is obtained according to the synthesis The phoneme information obtained from the text corresponding to the synthesized speech data, for example, the phoneme duration information, the phoneme state duration, etc. obtained according to the text corresponding to the synthesized speech data.
具体的,可基于下式确定语音合成模型的预测损失L:Specifically, the prediction loss L of the speech synthesis model can be determined based on the following formula:

其中,T为训练语音数据的总帧数,yi表示训练语音数据的第i帧的频谱特征,

步骤a5、根据语音合成模型的预测损失对语音合成模型进行参数更新。Step a5: Update the parameters of the speech synthesis model according to the prediction loss of the speech synthesis model.
按上述步骤a1~步骤a5的方式对语音合成模型进行多次训练,直至满足训练结束条件。The speech synthesis model is trained multiple times in the manner of the above steps a1 to a5 until the training end condition is satisfied.
第三实施例Third Embodiment
上述第一实施例提到,为了能够合成用户定制音色的语音数据,需要基于原始音色特征向量、设定音色维度下由用户决定的音色调整参数以及设定音色维度下的音色拉伸向量,本实施例重点对确定设定音色维度下的音色拉伸向量的具体实现过程进行介绍。The above-mentioned first embodiment mentioned that in order to be able to synthesize the voice data of the user-customized timbre, it is necessary to set the timbre adjustment parameters determined by the user in the timbre dimension based on the original timbre feature vector, and the timbre stretching vector in the set timbre dimension. The embodiment focuses on the introduction of the specific implementation process of determining the timbre stretch vector under the set timbre dimension.
请参阅图4,示出了确定设定音色维度下的音色拉伸向量的流程示意图,可以包括:Please refer to FIG. 4 , which shows a schematic flowchart of determining the timbre stretch vector under the set timbre dimension, which may include:
步骤S401:获取语音数据总集。Step S401: Acquire a voice data set.
本实施例中的语音数据总集中包括对上述用于训练语音合成模型的语音数据进行音色属性值标注后的数据,即,语音数据总集中包括多个说话人的语音数据(比如,说话人A的语音数据、说话人B的语音数据、说话人C的语音数据…),每个说话人的语音数据标注有设定音色维度下的音色属性的音色属性值,示例性的,设定音色维度包括“女声甜美”、“男声浑厚”、“鼻音感”,设定音色维度下的音色属性包括“性别属性”、“甜美属性”、“浑厚属性”、“鼻音属性”,则语音数据总集中每个说话人的语音数据标注有“性别属性”的属性值、“甜美属性”的属性值、“浑厚属性”的属性值、鼻“鼻音属性”的属性值。The voice data set in this embodiment includes the data marked with the timbre attribute value of the above-mentioned voice data used for training the speech synthesis model, that is, the voice data set includes the voice data of multiple speakers (for example, speaker A The voice data of speaker B, the voice data of speaker C, the voice data of speaker C...), the voice data of each speaker is marked with the timbre attribute value of the timbre attribute under the set timbre dimension, exemplarily, the set timbre dimension Including "female voice sweet", "male voice thick", and "nasal sound", and the timbre attributes under the timbre dimension are set to include "gender attribute", "sweet attribute", "rich attribute", and "nasal attribute", then the voice data is always concentrated in the The speech data of each speaker is marked with the attribute value of "gender attribute", the attribute value of "sweet attribute", the attribute value of "rich attribute", and the attribute value of nasal "nasal attribute".
在对多个说话人的语音数据进行音色属性标注时,可针对设定音色维度下的音色属性,对每个说话人的语音数据进行音色属性值的标注。为了能够获得鲁棒一致的音色属性值,本实施例优选为采用整合多人标注结果的方式,即,针对每个说话人的语音数据,首先获取多个标注人员对该说话人的语音数据在设定音色维度下的音色属性上标注的音色属性值,然后根据多个标注人员的标注结果确定该说话人的语音数据在设定音色维度下的音色属性上的最终音色属性值,最后为该说话人的语音数据标注确定出的最终音色属性值。When the timbre attribute is marked on the voice data of multiple speakers, the timbre attribute value can be marked on the voice data of each speaker according to the timbre attribute in the set timbre dimension. In order to obtain robust and consistent timbre attribute values, this embodiment preferably adopts the method of integrating the annotation results of multiple people, that is, for the voice data of each speaker, first obtain the voice data of the speaker from multiple annotators in Set the timbre attribute value marked on the timbre attribute under the timbre dimension, and then determine the final timbre attribute value of the speaker's voice data on the timbre attribute under the set timbre dimension according to the annotation results of multiple annotators, and finally the The voice data of the speaker is marked with the determined final timbre attribute value.
接下来通过一具体实例对为一说话人的语音数据标注设定音色维度下的音色属性的音色属性值的实现过程进行说明:Next, the implementation process of setting the timbre attribute value of the timbre attribute under the timbre dimension for the voice data annotation of a speaker will be described through a specific example:
设定音色维度包括“女声甜美”、“男声浑厚”、“鼻音感”,设定音色维度下的音色属性包括“性别属性”、“甜美属性”、“浑厚属性”、“鼻音属性”,标注人员在对一说话人的语音数据进行音色属性值的标注时,对于“性别属性”,若声音为女声,则将“性别属性”的音色属性值标注为“女”,若声音为男声,则将“性别属性”的音色属性值标注为“男”,对于“甜美属性”,若为女声且声音甜美,则将“甜美属性”的音色属性值标注为“1”,否则,将“甜美属性”的音色属性值标注为“0”,对于“浑厚属性”,若为男声且声音浑厚,则将“浑厚属性”的音色属性值标注为“1”,否则,将“浑厚属性”的音色属性值标注为“0”,对于“鼻音属性”,若声音音色有鼻音,则将“鼻音属性”的属性值标注为“1”,否则将“鼻音属性”的属性值标注为“0”。Set the timbre dimension to include "female voice sweet", "male voice thick", and "nasal sound", and set the timbre attributes under the timbre dimension to include "gender attribute", "sweet attribute", "rich attribute", and "nasal sound attribute". When a person marks the timbre attribute value of a speaker's voice data, for the "gender attribute", if the voice is a female voice, the timbre attribute value of the "gender attribute" will be marked as "female"; if the voice is a male voice, then Mark the timbre attribute value of "gender attribute" as "male", for "sweet attribute", if it is a female voice and the voice is sweet, mark the timbre attribute value of "sweet attribute" as "1", otherwise, mark the "sweet attribute" as "sweet attribute" ” is marked as “0”, and for the “thickness property”, if it is a male voice and the voice is thick, the timbre property value of the “thickness property” is marked as “1”, otherwise, the tone property of the “thickness property” is marked as “1”. The value is marked as "0". For the "Nasal Attribute", if the sound timbre has a nasal sound, the attribute value of the "Nasal Attribute" is marked as "1"; otherwise, the attribute value of the "Nasal Attribute" is marked as "0".
针对一说话人A的语音数据,可获取6个标注人员(优选为3男3女)的标注结果,根据6个标注人员的标注结果确定最终的标注结果。可选的,可从说话人A的所有语音数据中抽取一条语音数据,每个标注人员根据该条语音数据进行标注。需要说明的是,上述标注人员的数量6仅为示例,标注人员的数量还可为其它,比如8、10等。For the speech data of a speaker A, the labeling results of 6 labelers (preferably 3 males and 3 females) can be obtained, and the final labeling result is determined according to the labeling results of the 6 labelers. Optionally, a piece of speech data may be extracted from all the speech data of speaker A, and each labeler performs labeling according to the piece of speech data. It should be noted that the above-mentioned number 6 of labeling personnel is only an example, and the number of labeling personnel may be other, such as 8, 10, and so on.
具体的,对于“性别属性”,获取6个标注人员人对说话人A的语音数据在“性别属性”上标注的音色属性值,根据6个标注人员对说话人A的语音数据在“性别属性”上的标注结果确定说话人A的语音数据在“性别属性”上的最终标注结果,具体的,若6个标注人员对说话人A的语音数据在“性别属性”上的标注结果不一致,则将说话人A的语音数据在“性别属性”上的最终属性值标注为“invalid”,即lgender=invalid,若6个标注人员对说话人A的语音数据在“性别属性”上的标注结果一致,且均为“男”,则将说话人A的语音数据在“性别属性”上的最终属性值标注为“男”,即lgender=男,若6个标注人员对说话人A的语音数据在性别属性上的标注结果一致,且均为“女”,则将说话人A的语音数据在性别属性上的最终属性值标注为女,即lgender=女。Specifically, for the "gender attribute", obtain the timbre attribute values marked on the "gender attribute" of the speech data of the speaker A by the six annotators, and according to the voice data of the six annotators to the speaker A in the "gender attribute" ” determines the final labeling result of speaker A’s voice data on “gender attribute”. Specifically, if the six annotators have inconsistent annotation results on speaker A’s voice data on “gender attribute”, then Mark the final attribute value of speaker A's speech data on "gender attribute" as "invalid", that is, lgender = invalid, if six annotators mark the result of speaker A's voice data on "gender attribute" If the final attribute value of the speech data of speaker A on the "gender attribute" is "male", that is, lgender = male, if 6 labelers have If the labeling results of the data on the gender attribute are consistent and all are "female", the final attribute value on the gender attribute of the speech data of speaker A is labeled as female, that is, lgender = female.
对于“甜美属性”,获取6个标注人员对说话人A的语音数据在“甜美属性”上标注的音色属性值,根据6个标注人员对说话人A的语音数据在“甜美属性”上的标注结果确定说话人A的语音数据在“甜美属性”上的最终标注结果,具体的,若6个标注人员对说话人A的语音数据在“甜美属性”上的标注结果一致且均为“1”,则将说话人A的语音数据在“甜美属性”上的最终属性值标注为1,即l甜美女声=1,若6个标注人员对说话人A的语音数据在“甜美属性”上的标注结果一致且均为0,或者,6个标注人员对说话人A的语音数据在“甜美属性”上的标注结果不一致,则将说话人A的语音数据在“甜美属性”上的最终属性值标注为0,即l甜美女声=0。For the "sweet attribute", obtain the timbre attribute value marked on the "sweet attribute" of the speech data of speaker A by the six annotators, and according to the annotation of the speech data of speaker A on the "sweet attribute" by the six annotators The result determines the final labeling result of speaker A's speech data on the "sweet attribute". Specifically, if six labelers have the same labeling results on the "sweet attribute" of speaker A's speech data as "1" , then mark the final attribute value of speaker A's speech data on the "sweet attribute" as 1, that is, lsweet beautiful voice = 1. If six labelers mark the speech data of speaker A on the "sweet attribute" If the results are consistent and both are 0, or if the labeling results of speaker A's speech data on the "sweet attribute" are inconsistent, the final attribute value of speaker A's speech data on the "sweet attribute" is annotated is 0, that is, lsweet beauty =0.
对于“浑厚属性”,获取6个标注人员对说话人A的语音数据在“浑厚属性”上标注的音色属性值,根据6个标注人员对说话人A的语音数据在“浑厚属性”上的标注结果确定说话人A的语音数据在“浑厚属性”上的最终标注结果,具体的,若6个标注人员对说话人A的语音数据在“浑厚属性”上的标注结果一致且均为“1”,则将说话人A的语音数据在“浑厚属性”上的最终音色属性值标注为“1”,即l浑厚男声=1,若6个标注人员对说话人A的语音数据在“浑厚属性”上的标注结果一致且均为“0”,或者,6个标注人员对说话人A的语音数据在“浑厚属性”上的标注结果不一致,则将说话人A的语音数据在“浑厚属性”上的最终音色属性值标注为“0”,即l浑厚男声=0。For the "Vivid Attribute", obtain the timbre attribute values marked on the "Vivid Attribute" of the speech data of Speaker A by 6 annotators, and according to the annotations of the 6 annotators on the "Vivid Attribute" of the speech data of Speaker A The result determines the final labeling result of speaker A's speech data on the "rich attribute". Specifically, if the six labelers have the same labeling results on the "rich attribute" of speaker A's voice data as "1" , then mark the final timbre attribute value of speaker A's voice data on the "rich attribute" as "1", that is, lthick male voice = 1. The labeling results are consistent and are all "0", or, if the labeling results of speaker A's voice data on the "rich attribute" are inconsistent, the speaker A's voice data will be listed on the "rich attribute". The final timbre attribute value of 1 is marked as "0", that is, lthick male voice = 0.
对于“鼻音属性”,获取6个标注人员对说话人A的语音数据在“鼻音属性”上标注的音色属性值,根据6个标注人员对说话人A的语音数据在“鼻音属性”上的标注结果确定说话人A的语音数据在“鼻音属性”上的最终标注结果,具体的,若6个标注人员对说话人A的语音数据在“鼻音属性”上的标注结果一致且均为“1”,则将说话人A的语音数据在“鼻音属性”上的最终音色属性值标注为“1”,即l鼻音=1,若6个标注人员对说话人A的语音数据在“鼻音属性”上的标注结果一致且均为“0”,或者,6个标注人员对说话人A的语音数据在“鼻音属性”上的标注结果不一致,则将说话人A的语音数据在“鼻音属性”上的最终音色属性值标注为“0”,即l鼻音=0。For the "nasal attribute", obtain the timbre attribute values marked on the "nasal attribute" of the speech data of speaker A by the six annotators, and according to the annotations on the "nasal attribute" of the speech data of the speaker A by the six annotators The result determines the final labeling result of speaker A's speech data on the "nasal attribute". Specifically, if the labeling results of speaker A's speech data on the "nasal attribute" are consistent and all are "1" , the final timbre attribute value of speaker A's speech data on the "nasal attribute" is marked as "1", that is, 1nasal = 1. If the six labelling personnel are on the "nasal attribute" of the voice data of speaker A on the "nasal attribute" The labeling results are consistent and are all "0", or, if the labeling results of speaker A's voice data on the "nasal attribute" are inconsistent, the voice data of speaker A on the "nasal attribute" will be marked. The final timbre attribute value is marked as "0", that is, 1nasal sound =0.
步骤S402:将设定音色维度包含的每个音色维度作为目标音色维度,根据语音数据总集中的语音数据标注的音色属性值,从语音数据总集中获取与目标音色维度相关的语音数据。Step S402: Take each timbre dimension included in the set timbre dimension as the target timbre dimension, and obtain voice data related to the target timbre dimension from the voice data set according to the timbre attribute values marked by the voice data in the voice data set.
具体的,根据语音数据总集中的语音数据标注的音色属性值,从语音数据总集中获取与目标音色维度相关的语音数据的实现过程可以包括:从语音数据总集中获取第一音色属性的属性值为第一目标属性值的语音数据,组成第一语音数据集;从语音数据总集中获取第二音色属性的属性值为第二目标属性值的语音数据,组成第二语音数据集;第一语音数据集中的语音数据和第二语音数据集中的语音数据作为与目标音色维度相关的语音数据。可选的,在从语音数据总集中获取第一音色属性的属性值为第一目标属性值的语音数据时,针对一个说话人可只获取一条语音数据,同样的,在从语音数据总集中获取第二音色属性的属性值为第二目标属性值的语音数据时,针对一个说话人可只获取一条语音数据。Specifically, according to the timbre attribute value marked by the voice data in the voice data set, the implementation process of acquiring the voice data related to the target timbre dimension from the voice data set may include: obtaining the attribute value of the first timbre attribute from the voice data set is the voice data of the first target attribute value, and forms a first voice data set; obtains voice data whose attribute value of the second timbre attribute is the second target attribute value from the total set of voice data, and forms a second voice data set; the first voice The voice data in the data set and the voice data in the second voice data set are used as the voice data related to the target timbre dimension. Optionally, when acquiring the speech data whose attribute value of the first timbre attribute is the first target attribute value from the speech data collection, only one piece of speech data may be obtained for one speaker. Similarly, when obtaining the speech data from the speech data collection When the attribute value of the second timbre attribute is the voice data of the second target attribute value, only one piece of voice data may be acquired for one speaker.
其中,第一音色属性为与目标音色维度相关的音色属性,第一音色属性具有多个可选音色属性值,第一目标属性值为第一音色属性的多个可选音色属性值中与目标音色维度相关的属性值,第二音色属性为与第一音色属性相关的音色属性,第二音色属性具有多个可选音色属性值,第二目标属性值为第二音色属性的多个可选音色属性值中与第一音色属性相关的属性值。The first timbre attribute is a timbre attribute related to the dimension of the target timbre, the first timbre attribute has multiple optional timbre attribute values, and the first target attribute value is the same as the target Attribute values related to the timbre dimension, the second timbre attribute is a timbre attribute related to the first timbre attribute, the second timbre attribute has multiple optional timbre attribute values, and the second target attribute value is a plurality of optional timbre attributes of the second timbre attribute The attribute value related to the first timbre attribute among the timbre attribute values.
示例性的,目标音色维度为“女声甜美”,则第一音色属性为“甜美属性”,第二音色属性为“性别属性”,第一目标属性值为“1”,第二目标属性值为“女”,从语音数据总集中获取与“女声甜美”相关的语音数据的过程包括:从语音数据总集中获取“甜美属性”的属性值为“1”(即l甜美女声=1)的语音数据,组成第一语音数据集,从语音数据总集中获取“性别属性”的属性值为“女”(即lgender=女)的语音数据,组成第二语音数据集。Exemplarily, if the target timbre dimension is "sweet female voice", the first timbre attribute is "sweet attribute", the second timbre attribute is "gender attribute", the value of the first target attribute is "1", and the value of the second target attribute is "1". "Female", the process of obtaining the voice data related to "sweet female voice" from the voice data collection includes: obtaining the voice whose attribute value of "sweet attribute" is "1" (that is, lsweet beautiful voice =1) from the voice data collection The first voice data set is formed, and the voice data whose attribute value of "gender attribute" is "female" (ie,gender =female) is obtained from the general voice data set to form a second voice data set.
示例性的,目标音色维度为“男声浑厚”,则第一音色属性为“浑厚属性”,第二音色属性为“性别属性”,第一目标属性值为“1”,第二目标属性值为“男”,从语音数据总集中获取与“男声浑厚”相关的语音数据的过程包括:从语音数据总集中获取“浑厚属性”的属性值为“1”(即l浑厚男声=1)的语音数据,组成第一语音数据集,从语音数据总集中获取“性别属性”的属性值为“男”(即lgender=男)的语音数据,组成第二语音数据集。Exemplarily, if the dimension of the target timbre is "masculine voice", then the first timbre attribute is "vigorous attribute", the second timbre attribute is "gender attribute", the value of the first target attribute is "1", and the value of the second target attribute is "1". "Male", the process of obtaining the voice data related to the "Male Voice" from the voice data collection includes: obtaining the voice whose attribute value of the "Male attribute" is "1" (that is, 1vigorous male voice = 1) from the voice data collection The first voice data set is formed, and the voice data whose attribute value of "gender attribute" is "male" (ie,gender =male) is obtained from the general voice data set to form a second voice data set.
示例性的,目标音色维度为“鼻音感”,则第一音色属性为“鼻音属性”,第二音色属性为“性别属性”,第一目标属性值为“1”,第二目标属性值为“男”和“女”,从语音数据总集中获取与“鼻音感”相关的语音数据的过程包括:从语音数据总集中获取“鼻音属性”的属性值为“1”(即l鼻音=1)的语音数据,组成第一语音数据集,从语音数据总集中获取“性别属性”的属性值为“男”(即lgender=男)的语音数据以及“性别属性”的属性值为“女”(即lgender=女),组成第二语音数据集。Exemplarily, if the target timbre dimension is "sense of nasal sound", then the first timbre attribute is "nasal sound attribute", the second timbre attribute is "gender attribute", the value of the first target attribute is "1", and the value of the second target attribute is "1". "Male" and "Female", the process of acquiring the speech data related to the "nasal sound" from the speech data collection includes: the attribute value of the "nasal attribute" obtained from the speech data collection is "1" (that is, 1nasal = 1 ) of the voice data to form the first voice data set, and obtain the voice data with the attribute value of "gender attribute" as "male" (ie,gender = male) and the attribute value of "gender attribute" from the total set of voice data. ” (ie lgender = female), which constitutes the second speech dataset.
步骤S403:根据与目标音色维度相关的语音数据,确定目标音色维度下的音色拉伸向量。Step S403: Determine the timbre stretching vector in the target timbre dimension according to the speech data related to the target timbre dimension.
具体的,基于第一语音数据集和第二语音数据集,确定目标音色维度下的音色拉伸向量。Specifically, based on the first voice data set and the second voice data set, a timbre stretching vector in the target timbre dimension is determined.
更为具体的,基于第一语音数据集和第二语音数据集,确定目标音色维度下的音色拉伸向量的过程可以包括:对第一语音数据集中每个说话人的语音数据提取说话人特征(比如,第一语音数据集中包括100个说话人的语音数据,则对每个说话人的语音数据提取说话人特征后,会得到100个说话人特征),并计算对第一语音数据集中的语音数据提取的若干说话人特征的均值,计算得到的均值作为所述目标音色维度下的第一平均音色向量;对第二语音数据集中每个说话人的语音数据提取说话人特征(比如,第二语音数据集中包括150个说话人的语音数据,则对每个说话人的语音数据提取说话人特征后,会得到150个说话人特征),并计算对第二语音数据集中的语音数据提取的若干说话人特征的均值,计算得到的均值作为目标音色维度下的第二平均音色向量;根据目标音色维度下的第一平均音色向量和目标音色维度下的第二平均音色向量,确定目标音色维度下的音色拉伸向量。More specifically, based on the first voice data set and the second voice data set, the process of determining the timbre stretch vector in the target timbre dimension may include: extracting speaker features from the voice data of each speaker in the first voice data set. (For example, if the first voice data set includes the voice data of 100 speakers, after the speaker features are extracted from the voice data of each speaker, 100 speaker features will be obtained), and calculate the number of voice data in the first voice data set. The mean value of several speaker features extracted from the voice data, and the calculated mean value is used as the first average timbre vector under the target timbre dimension; the speaker feature (for example, the first average timbre vector) is extracted from the voice data of each speaker in the second voice data set. The second voice data set includes the voice data of 150 speakers, after the speaker features are extracted from each speaker's voice data, 150 speaker features will be obtained), and the extracted voice data in the second voice data set are calculated. The mean value of several speaker characteristics, the calculated mean value is used as the second average timbre vector under the target timbre dimension; the target timbre dimension is determined according to the first average timbre vector under the target timbre dimension and the second average timbre vector under the target timbre dimension The timbre stretch vector below.
示例性的,目标音色维度为“女声甜美”,第一语音数据集中包括l甜美女声=1的语音数据,第二语音数据集中包括lgender=女的语音数据,则“女声甜美”这一音色维度下的第一平均音色向量s甜美女声和第二平均音色向量sf可表示为:Exemplarily, the target timbre dimension is "sweet female voice", the first voice data set includes voice data of lsweet female voice = 1, and the second voice data set includes lgender = female voice data, then the timbre of "female voice is sweet" The first averagetimbre vector s and the second average timbre vector sf under the dimension can be expressed as:


式(3)中的N甜美女声表示第一语音数据集中的语音数据所涉及的说话人的数量,比如,第一语音数据集中包括100个说话人的语音数据,则式(3)中的N甜美女声=100,式(3)中的si表示第一语音数据集中的语音数据所涉及的N甜美女声个说话人中第i个说话人的说话人特征,式(4)中的Nf表示第二语音数据集中的语音数据所涉及的说话人的数量,比如,第二语音数据集中包括150个说话人的语音数据,则Nf=150,式(4)中sj表示第二语音数据集中的语音数据所涉及的Nf个说话人中第j个说话人的说话人特征。Nsweet voices in formula (3) represent the number of speakers involved in the voice data in the first voice data set. For example, if the first voice data set includes voice data of 100 speakers, then N in formula (3)Sweet voice = 100,si in formula (3) represents the speaker feature of the ith speaker among the Nsweet voice speakers involved in the speech data in the first voice data set, Nf in formula (4) represents the number of speakers involved in the speech data in the second speech data set. For example, if the second speech data set includes the speech data of 150 speakers, then Nf =150, and sj in formula (4) represents the second speech The speaker characteristics of the jth speaker among the Nf speakers involved in the speech data in the dataset.
在获得“女声甜美”这一音色维度下的第一平均音色向量s甜美女声和第二平均音色向量sf后,可根据下式确定“女声甜美”这一音色维度下的音色拉伸向量d甜美:After obtaining the first average timbre vector s and the second average timbre vector sf under the timbre dimension of "sweet female voice", the timbre stretching vector d under the timbre dimension of "sweet female voice" can be determined according to the following formulasweet :
d甜美=s甜美女声-sf (5)dsweet = ssweet voice- sf (5)
示例性的,目标音色维度为“男声浑厚”,第一语音数据集中包括l浑厚男声=1的语音数据,第二语音数据集中包括lgender=男的语音数据,则“男声浑厚”这一音色维度下的第一平均音色向量s浑厚男声和第二平均音色向量sm可表示为:Exemplarily, the target timbre dimension is "male voice is thick", the first voice data set includes the voice data of lthick male voice = 1, the second voice data set includes lgender = male voice data, then the timbre of "male voice is thick". The first averagetimbre vector s and the second average timbre vector sm under the dimension can be expressed as:


式(6)中的N浑厚男声表示第一语音数据集中的语音数据所涉及的说话人的数量,式(6)中的si表示第一语音数据集中的语音数据所涉及的N浑厚男声个说话人中第i个说话人的说话人特征,式(7)中的Nm表示第二语音数据集中的语音数据所涉及的说话人的数量,式(7)中的sj表示第二语音数据集中的语音数据所涉及的Nm个说话人中第j个说话人的说话人特征。The Nthick male voices in the formula (6) represent the number of speakers involved in the speech data in the first voice data set, andsi in the formula (6) represents the Nthick male voices involved in the speech data in the first voice data set. The speaker characteristics of the i-th speaker among the speakers, Nm in equation (7) represents the number of speakers involved in the speech data in the second speech data set, and sj in equation (7) represents the second speech The speaker characteristics of the jth speaker among the Nm speakers involved in the speech data in the dataset.
在获得“男声浑厚”这一音色维度下的第一平均音色向量s浑厚男声和第二平均音色向量sm后,可根据下式确定“男声浑厚”这一音色维度下的音色拉伸向量d浑厚:After obtaining the first average timbre vector s and the second average timbre vector sm in the timbre dimension of "male voice is strong andthick ", the timbre stretching vector d in the timbre dimension of "male voice is strong and thick" can be determined according to the following formulaThick :
d浑厚=s浑厚男声-sm (8)dthick = sthick male voice - sm (8)
示例性的,目标音色维度为“鼻音感”,第一语音数据集中包括l鼻音=1的语音数据,第二语音数据集中包括lgender=男的语音数据和lgender=女的语音数据,则“鼻音感”这一音色维度下的第一平均音色向量s鼻音和第二平均音色向量savg可表示为:Exemplarily, the target timbre dimension is "sense of nasal sound", the first voice data set includes the voice data of lnasal = 1, the second voice data set includes lgender = male voice data and lgender = female voice data, then The first average timbre vector snasal and the second average timbre vector savg under the timbre dimension of "nasal sense" can be expressed as:


式(9)中的N鼻音表示第一语音数据集中的语音数据所涉及的说话人的数量,式(9)中的si表示第一语音数据集中的语音数据所涉及的N鼻音个说话人中第i个说话人的说话人特征,式(10)中的N表示第二语音数据集中的语音数据所涉及的说话人的数量,式(10)中的sj表示第二语音数据集中的语音数据所涉及的N个说话人中第j个说话人的说话人特征。The Nnasals in equation (9) represent the number of speakers involved in the speech data in the first speech data set, andsi in equation (9) represents the Nnasal speakers involved in the speech data in the first speech data set The speaker feature of the i-th speaker in the formula (10) represents the number of speakers involved in the speech data in the second speech data set, and sj in the formula (10) represents the second speech data set. Speaker characteristics of the jth speaker among the N speakers involved in the speech data.
在获得“鼻音感”这一音色维度下的第一平均音色向量s鼻音和第二平均音色向量savg后,可根据下式确定“鼻音感”这一音色维度下的音色拉伸向量d鼻音:After obtaining the first average timbre vector snasal and the second average timbre vector savg under the timbre dimension of "nasal sense", the timbre stretching vector dnasal under the timbre dimension of "nasal sense" can be determined according to the following formula :
d鼻音=s鼻音-savg (11)dnasal = snasal - savg (11)
经由本实施例提供的方法可确定出设定音色维度下的音色拉伸向量,比如,“女声甜美”这一音色维度下的音色拉伸向量、“男声浑厚”这一音色维度下的音色拉伸向量、“鼻音感”这一音色维度下的音色拉伸向量。Through the method provided in this embodiment, the timbre stretch vector in the set timbre dimension can be determined, for example, the timbre stretch vector in the timbre dimension of "sweet female voice" and the timbre stretch vector in the timbre dimension of "male voice is thick". The stretch vector and the timbre stretch vector under the timbre dimension of "nasal feel".
第四实施例Fourth Embodiment
本申请实施例还提供了一种语音合成装置,下面对本申请实施例提供的语音合成装置进行描述,下文描述的语音合成装置与上文描述的语音合成方法可相互对应参照。An embodiment of the present application further provides a speech synthesis apparatus. The speech synthesis apparatus provided by the embodiment of the present application is described below. The speech synthesis apparatus described below and the speech synthesis method described above can be referred to each other correspondingly.
请参阅图5,示出了本申请实施例提供的语音合成装置的结构示意图,可以包括:数据获取模块501、说话人特征提取模块502、音色特征向量确定模块503和语音合成模块504。Referring to FIG. 5 , a schematic structural diagram of a speech synthesis apparatus provided by an embodiment of the present application is shown, which may include: a
数据获取模块501,用于获取用于进行语音合成的文本特征以及指定说话人的语音数据。The
说话人特征提取模块502,用于对所述指定说话人的语音数据提取说话人特征,作为原始音色特征向量。The speaker
音色特征向量确定模块503用于基于所述原始音色特征向量、设定音色维度下由用户决定的音色调整参数以及所述设定音色维度下的音色拉伸向量,确定用户定制音色的音色特征向量。The timbre feature
语音合成模块504,用于基于所述文本特征和所述用户定制音色的音色特征向量,合成用户定制音色的语音数据。The
可选的,音色特征向量确定模块503在基于所述原始音色特征向量、设定音色维度下由用户决定的音色调整参数以及所述设定音色维度下的音色拉伸向量,确定用户定制音色的音色特征向量时,具体用于:Optionally, the timbre feature
根据所述设定音色维度下的音色调整参数和所述设定音色维度下的音色拉伸向量,确定所述设定音色维度下的音色特征调整向量;Determine the timbre feature adjustment vector under the set timbre dimension according to the timbre adjustment parameter under the set timbre dimension and the timbre stretch vector under the set timbre dimension;
根据所述原始音色特征向量和所述设定音色维度下的音色特征调整向量,确定用户定制音色的音色特征向量。The timbre feature vector of the user-customized timbre is determined according to the original timbre feature vector and the timbre feature adjustment vector in the set timbre dimension.
可选的,语音合成模块504在基于所述文本特征和所述用户定制音色的音色特征向量,合成用户定制音色的语音数据时,具体用于:Optionally, the
根据所述文本特征和所述说话人特征,获取帧级的特征向量序列;obtaining a frame-level feature vector sequence according to the text feature and the speaker feature;
根据所述帧级的特征向量序列和所述用户定制音色的音色特征向量,合成用户定制音色的语音数据。According to the frame-level feature vector sequence and the timbre feature vector of the user-customized timbre, the voice data of the user-customized timbre is synthesized.
可选的,语音合成模块504在根据所述文本特征和所述说话人特征,获取帧级的特征向量序列时,具体用于:Optionally, when the
根据所述文本特征,获取音素级别的上下文特征向量;According to the text feature, obtain the context feature vector of the phoneme level;
以所述音素级别的上下文特征向量和所述说话人特征为依据,预测音素的发音时长帧数;Based on the context feature vector of the phoneme level and the speaker feature, predict the number of frames of pronunciation duration of the phoneme;
以所述音素的发音时长帧数为依据,将所述音素级别的上下文特征向量展开成帧级的特征向量序列。The phoneme-level context feature vector is expanded into a frame-level feature vector sequence based on the phoneme's pronunciation duration frame number.
可选的,所述设定音色维度包括一个或多个音色维度。Optionally, the set timbre dimension includes one or more timbre dimensions.
可选的,本申请实施例提供的语音合成装置还包括:用于确定所述设定音色维度下的音色拉伸向量的音色拉伸向量确定模块。音色拉伸向量确定模块在确定所述设定音色维度下的音色拉伸向量时,具体用于:Optionally, the speech synthesis apparatus provided in this embodiment of the present application further includes: a timbre stretch vector determining module for determining a timbre stretch vector in the set timbre dimension. When the timbre stretch vector determining module determines the timbre stretch vector under the set timbre dimension, it is specifically used for:
获取语音数据总集,所述语音数据总集中包括多个说话人的语音数据,每个说话人的语音数据标注有所述设定音色维度下的音色属性的音色属性值;Acquiring a voice data collection, the voice data collection includes the voice data of a plurality of speakers, and the voice data of each speaker is marked with the timbre attribute value of the timbre attribute under the set timbre dimension;
将所述设定音色维度包含的每个音色维度作为目标音色维度,根据所述语音数据总集中的语音数据标注的音色属性值,从所述语音数据总集中获取与所述目标音色维度相关的语音数据;Taking each timbre dimension included in the set timbre dimension as the target timbre dimension, according to the timbre attribute value marked by the voice data in the voice data set, obtain the target timbre dimension from the voice data set. voice data;
根据与所述目标音色维度相关的语音数据,确定所述目标音色维度下的音色拉伸向量。According to the speech data related to the target timbre dimension, a timbre stretch vector under the target timbre dimension is determined.
可选的,本申请实施例提供的语音合成装置还包括:音色属性值标注模块。Optionally, the speech synthesis apparatus provided in this embodiment of the present application further includes: a timbre attribute value labeling module.
音色属性值标注模块在为一说话人的语音数据标注所述设定音色维度下的音色属性的音色属性值时,具体用于:When the timbre attribute value marking module marks the timbre attribute value of the timbre attribute under the set timbre dimension for the voice data of a speaker, it is specifically used for:
获取多个标注人员分别根据该说话人的语音数据在所述设定音色维度下的音色属性上标注的音色属性值,以得到多个标注人员的标注结果;Acquiring the timbre attribute values marked on the timbre attribute under the set timbre dimension according to the voice data of the speaker respectively by a plurality of labelers, to obtain the labelling results of the plurality of labelers;
根据所述多个标注人员的标注结果,确定该说话人的语音数据在所述设定音色维度下的音色属性的音色属性值,并为该说话人的语音数据标注确定出的音色属性值。According to the annotation results of the multiple annotators, the timbre attribute value of the timbre attribute of the speaker's voice data in the set timbre dimension is determined, and the determined timbre attribute value is annotated for the speaker's voice data.
可选的,音色拉伸向量确定模块在根据所述语音数据总集中的语音数据标注的音色属性值,从所述语音数据总集中获取与所述目标音色维度相关的语音数据时,具体用于:Optionally, the timbre stretch vector determination module is specifically used for acquiring the voice data related to the target timbre dimension from the voice data set according to the timbre attribute value marked by the voice data in the voice data set. :
从所述语音数据总集中获取第一音色属性的属性值为第一目标属性值的语音数据,组成第一语音数据集,其中,所述第一音色属性为与所述目标音色维度相关的音色属性,所述第一目标属性值为与所述目标音色维度相关的属性值;The voice data whose attribute value of the first timbre attribute is the first target attribute value is obtained from the voice data collection to form a first voice data set, wherein the first timbre attribute is the timbre related to the target timbre dimension attribute, the first target attribute value is an attribute value related to the target timbre dimension;
从所述语音数据总集中获取第二音色属性的属性值为第二目标属性值的语音数据,组成第二语音数据集,其中,所述第二音色属性为与所述第一音色属性相关的音色属性,所述第二目标属性值为与所述第一音色属性相关的属性值。Acquire voice data whose attribute value of the second timbre attribute is the second target attribute value from the voice data collection to form a second voice data set, wherein the second timbre attribute is related to the first timbre attribute The timbre attribute, the second target attribute value is an attribute value related to the first timbre attribute.
可选的,音色拉伸向量确定模块在根据与所述目标音色维度相关的语音数据,确定所述目标音色维度下的音色拉伸向量时,具体用于:Optionally, when determining the timbre stretch vector under the target timbre dimension according to the voice data related to the target timbre dimension, the timbre stretching vector determination module is specifically used for:
对所述第一语音数据集中每个说话人的语音数据提取说话人特征,并计算对所述第一语音数据集中的语音数据提取的若干说话人特征的均值,计算得到的均值作为所述目标音色维度下的第一平均音色向量;Extracting speaker features from the voice data of each speaker in the first voice data set, and calculating the mean value of several speaker features extracted from the voice data in the first voice data set, and using the calculated mean value as the target the first average timbre vector in the timbre dimension;
对所述第二语音数据集中每个说话人的语音数据提取说话人特征,并计算对所述第二语音数据集中的语音数据提取的若干说话人特征的均值,计算得到的均值作为所述目标音色维度下的第二平均音色向量;Extracting speaker features from the voice data of each speaker in the second voice data set, and calculating the mean value of several speaker features extracted from the voice data in the second voice data set, and using the calculated mean value as the target the second average timbre vector in the timbre dimension;
根据所述目标音色维度下的第一平均音色向量和所述目标音色维度下的第二平均音色向量,确定所述目标音色维度下的音色拉伸向量。The timbre stretching vector in the target timbre dimension is determined according to the first average timbre vector in the target timbre dimension and the second average timbre vector in the target timbre dimension.
可选的,说话人特征提取模块502在对所述指定说话人的语音数据提取说话人特征时,具体用于:Optionally, when the speaker
利用预先构建的语音生成模块,对所述指定说话人的语音数据提取说话人特征。Using a pre-built speech generation module, speaker features are extracted from the speech data of the designated speaker.
语音合成模块504在基于所述文本特征和所述用户定制音色的音色特征向量,合成用户定制音色的语音数据时,具体用于:When synthesizing the voice data of the user-customized timbre based on the text feature and the timbre feature vector of the user-customized timbre, the
基于所述语音生成模块、所述文本特征和所述用户定制音色的音色特征向量,合成用户定制音色的语音数据。Based on the voice generation module, the text feature, and the timbre feature vector of the user-customized timbre, the voice data of the user-customized timbre is synthesized.
可选的,所述语音生成模块为语音合成模型,所述语音合成模型采用多个说话人的多条训练语音数据和所述多条训练语音数据分别对应的训练文本训练得到。Optionally, the speech generation module is a speech synthesis model, and the speech synthesis model is obtained by training multiple pieces of training speech data of multiple speakers and training texts corresponding to the multiple pieces of training speech data respectively.
语音合成模块504在基于所述语音生成模块、所述文本特征和所述用户定制音色的音色特征向量,合成用户定制音色的语音数据时,具体用于:When synthesizing the voice data of the user-customized timbre based on the voice generation module, the text feature and the timbre feature vector of the user-customized timbre, the
基于所述语音合成模型的文本编码模块,对所述文本特征进行编码,以得到音素级别的上下文特征向量;Based on the text encoding module of the speech synthesis model, the text feature is encoded to obtain a phoneme-level context feature vector;
基于所述语音合成模型的时长预测模块,以所述音素级别的上下文特征向量和所述说话人特征为依据,预测音素的发音时长帧数;Based on the duration prediction module of the speech synthesis model, based on the context feature vector of the phoneme level and the speaker feature, predict the number of frames of pronunciation duration of the phoneme;
基于所述语音合成模型的长度调整模块,以所述音素的发音时长帧数为依据,将所述音素级别的上下文特征向量展开成帧级的特征向量序列;Based on the length adjustment module of the speech synthesis model, the phoneme-level context feature vector is expanded into a frame-level feature vector sequence based on the phoneme's pronunciation duration frame number;
基于所述语音合成模型中的解码模块,以所述帧级的特征向量序列和所述用户定制音色的音色特征向量为依据,预测频谱特征;Based on the decoding module in the speech synthesis model, the spectral features are predicted based on the frame-level feature vector sequence and the timbre feature vector of the user-customized timbre;
根据所述频谱特征,合成用户定制音色的语音数据。According to the spectral features, the voice data of the user-customized timbre is synthesized.
本申请实施例提供的语音合成装置,首先获取用于进行语音合成的文本特征以及指定说话人的语音数据,然后对指定说话人的语音数据提取说话人特征,以得到原始音色特征向量,接着基于原始音色特征向量、设定音色维度下由用户决定的音色调整参数以及设定音色维度下的音色拉伸向量,确定用户定制音色的音色特征向量,最后基于文本特征和用户定制音色的音色特征向量,合成用户定制音色的语音数据。经由本申请实施例提供的语音合成装置能够合成出用户深入定制音色的语音数据,合成出的语音数据更加符合用户的喜好,可见,本申请实施例提供的语音合成装置能够满足用户对于合成语音音色的个性化需求,另外,让用户深度参与合成语音音色的选择,使得语音合成更具趣味性和交互性,从而能够提升用户体验。The speech synthesis device provided by the embodiment of the present application first acquires text features for speech synthesis and speech data of a designated speaker, and then extracts speaker characteristics from the speech data of the designated speaker to obtain an original timbre feature vector, and then based on The original timbre feature vector, the timbre adjustment parameters determined by the user in the set timbre dimension, and the timbre stretch vector in the set timbre dimension, determine the timbre feature vector of the user-customized timbre, and finally, based on the text features and the timbre feature vector of the user-customized timbre , synthesizing the voice data of the user-customized timbre. The voice synthesis device provided by the embodiment of the present application can synthesize the voice data for the user to deeply customize the timbre, and the synthesized voice data is more in line with the user's preference. It can be seen that the voice synthesis device provided by the embodiment of the present application can satisfy the user's desire for synthesized voice timbre. In addition, allowing users to deeply participate in the selection of synthesized speech timbres makes speech synthesis more interesting and interactive, thereby improving user experience.
第五实施例Fifth Embodiment
本申请实施例还提供了一种语音合成设备,请参阅图6,示出了该语音合成设备的结构示意图,该语音合成设备可以包括:至少一个处理器601,至少一个通信接口602,至少一个存储器603和至少一个通信总线604;An embodiment of the present application further provides a speech synthesis device. Please refer to FIG. 6, which shows a schematic structural diagram of the speech synthesis device. The speech synthesis device may include: at least one
在本申请实施例中,处理器601、通信接口602、存储器603、通信总线604的数量为至少一个,且处理器601、通信接口602、存储器603通过通信总线604完成相互间的通信;In this embodiment of the present application, the number of the
处理器601可能是一个中央处理器CPU,或者是特定集成电路ASIC(ApplicationSpecific Integrated Circuit),或者是被配置成实施本发明实施例的一个或多个集成电路等;The
存储器603可能包含高速RAM存储器,也可能还包括非易失性存储器(non-volatile memory)等,例如至少一个磁盘存储器;The
其中,存储器存储有程序,处理器可调用存储器存储的程序,所述程序用于:Wherein, the memory stores a program, and the processor can call the program stored in the memory, and the program is used for:
获取用于进行语音合成的文本特征以及指定说话人的语音数据;Obtain text features for speech synthesis and speech data of a specified speaker;
对所述指定说话人的语音数据提取说话人特征,作为原始音色特征向量;Extracting speaker features from the voice data of the designated speaker as the original timbre feature vector;
基于所述原始音色特征向量、设定音色维度下由用户决定的音色调整参数以及所述设定音色维度下的音色拉伸向量,确定用户定制音色的音色特征向量;Determine the timbre feature vector of the user-customized timbre based on the original timbre feature vector, the timbre adjustment parameter determined by the user under the set timbre dimension, and the timbre stretch vector under the set timbre dimension;
基于所述文本特征和所述用户定制音色的音色特征向量,合成用户定制音色的语音数据。Based on the text feature and the timbre feature vector of the user-customized timbre, the voice data of the user-customized timbre is synthesized.
可选的,所述程序的细化功能和扩展功能可参照上文描述。Optionally, the refinement function and extension function of the program may refer to the above description.
第六实施例Sixth Embodiment
本申请实施例还提供一种计算机可读存储介质,该计算机可读存储介质可存储有适于处理器执行的程序,所述程序用于:Embodiments of the present application further provide a computer-readable storage medium, where the computer-readable storage medium can store a program suitable for execution by a processor, where the program is used for:
获取用于进行语音合成的文本特征以及指定说话人的语音数据;Obtain text features for speech synthesis and speech data of a specified speaker;
对所述指定说话人的语音数据提取说话人特征,作为原始音色特征向量;Extracting speaker features from the voice data of the designated speaker as the original timbre feature vector;
基于所述原始音色特征向量、设定音色维度下由用户决定的音色调整参数以及所述设定音色维度下的音色拉伸向量,确定用户定制音色的音色特征向量;Determine the timbre feature vector of the user-customized timbre based on the original timbre feature vector, the timbre adjustment parameter determined by the user under the set timbre dimension, and the timbre stretch vector under the set timbre dimension;
基于所述文本特征和所述用户定制音色的音色特征向量,合成用户定制音色的语音数据。Based on the text feature and the timbre feature vector of the user-customized timbre, the voice data of the user-customized timbre is synthesized.
可选的,所述程序的细化功能和扩展功能可参照上文描述。Optionally, the refinement function and extension function of the program may refer to the above description.
最后,还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。Finally, it should also be noted that in this document, relational terms such as first and second are used only to distinguish one entity or operation from another, and do not necessarily require or imply these entities or that there is any such actual relationship or sequence between operations. Moreover, the terms "comprising", "comprising" or any other variation thereof are intended to encompass a non-exclusive inclusion such that a process, method, article or device that includes a list of elements includes not only those elements, but also includes not explicitly listed or other elements inherent to such a process, method, article or apparatus. Without further limitation, an element qualified by the phrase "comprising a..." does not preclude the presence of additional identical elements in a process, method, article or apparatus that includes the element.
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。The various embodiments in this specification are described in a progressive manner, and each embodiment focuses on the differences from other embodiments, and the same and similar parts between the various embodiments can be referred to each other.
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。The above description of the disclosed embodiments enables any person skilled in the art to make or use the present invention. Various modifications to these embodiments will be readily apparent to those skilled in the art, and the generic principles defined herein may be implemented in other embodiments without departing from the spirit or scope of the invention. Thus, the present invention is not intended to be limited to the embodiments shown herein, but is to be accorded the widest scope consistent with the principles and novel features disclosed herein.
Claims (13)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210252704.2ACN114708847A (en) | 2022-03-15 | 2022-03-15 | Voice synthesis method, device, equipment and storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210252704.2ACN114708847A (en) | 2022-03-15 | 2022-03-15 | Voice synthesis method, device, equipment and storage medium |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN114708847Atrue CN114708847A (en) | 2022-07-05 |
Family
ID=82169077
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210252704.2APendingCN114708847A (en) | 2022-03-15 | 2022-03-15 | Voice synthesis method, device, equipment and storage medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114708847A (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116469369A (en)* | 2022-11-08 | 2023-07-21 | 科大讯飞股份有限公司 | Virtual sound synthesis method and device and related equipment |
| CN116580695A (en)* | 2023-04-28 | 2023-08-11 | 北京捷通华声科技股份有限公司 | Speech synthesis device, method, mobile terminal and storage medium |
Citations (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20190213995A1 (en)* | 2016-05-18 | 2019-07-11 | Baidu Online Network Technology (Beijing) Co., Ltd | Speech synthesis method terminal and storage medium |
| KR20200092505A (en)* | 2019-01-13 | 2020-08-04 | 네오데우스 주식회사 | Method for generating speaker-adapted speech synthesizer model with a few samples using a fine-tuning based on deep convolutional neural network ai |
| CN112002302A (en)* | 2020-07-27 | 2020-11-27 | 北京捷通华声科技股份有限公司 | Speech synthesis method and device |
| CN112735373A (en)* | 2020-12-31 | 2021-04-30 | 科大讯飞股份有限公司 | Speech synthesis method, apparatus, device and storage medium |
| CN112802448A (en)* | 2021-01-05 | 2021-05-14 | 杭州一知智能科技有限公司 | Speech synthesis method and system for generating new tone |
| CN113096634A (en)* | 2021-03-30 | 2021-07-09 | 平安科技(深圳)有限公司 | Speech synthesis method, apparatus, server and storage medium |
| CN113327580A (en)* | 2021-06-01 | 2021-08-31 | 北京有竹居网络技术有限公司 | Speech synthesis method, device, readable medium and electronic equipment |
| CN113539237A (en)* | 2021-07-15 | 2021-10-22 | 思必驰科技股份有限公司 | Speech synthesis method, electronic device and storage medium |
| CN113889070A (en)* | 2021-09-30 | 2022-01-04 | 北京搜狗科技发展有限公司 | Voice synthesis method and device for voice synthesis |
- 2022
- 2022-03-15CNCN202210252704.2Apatent/CN114708847A/enactivePending
Patent Citations (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20190213995A1 (en)* | 2016-05-18 | 2019-07-11 | Baidu Online Network Technology (Beijing) Co., Ltd | Speech synthesis method terminal and storage medium |
| KR20200092505A (en)* | 2019-01-13 | 2020-08-04 | 네오데우스 주식회사 | Method for generating speaker-adapted speech synthesizer model with a few samples using a fine-tuning based on deep convolutional neural network ai |
| CN112002302A (en)* | 2020-07-27 | 2020-11-27 | 北京捷通华声科技股份有限公司 | Speech synthesis method and device |
| CN112735373A (en)* | 2020-12-31 | 2021-04-30 | 科大讯飞股份有限公司 | Speech synthesis method, apparatus, device and storage medium |
| CN112802448A (en)* | 2021-01-05 | 2021-05-14 | 杭州一知智能科技有限公司 | Speech synthesis method and system for generating new tone |
| CN113096634A (en)* | 2021-03-30 | 2021-07-09 | 平安科技(深圳)有限公司 | Speech synthesis method, apparatus, server and storage medium |
| CN113327580A (en)* | 2021-06-01 | 2021-08-31 | 北京有竹居网络技术有限公司 | Speech synthesis method, device, readable medium and electronic equipment |
| CN113539237A (en)* | 2021-07-15 | 2021-10-22 | 思必驰科技股份有限公司 | Speech synthesis method, electronic device and storage medium |
| CN113889070A (en)* | 2021-09-30 | 2022-01-04 | 北京搜狗科技发展有限公司 | Voice synthesis method and device for voice synthesis |
Non-Patent Citations (1)
| Title |
|---|
| CLARA BORRELLI ET AL: "《Synthetic speech detection through short-term and long-term prediction traces》", 《EURASIP JOURNAL ON INFORMATION SECURITY》, no. 2, 31 December 2021 (2021-12-31), pages 1 - 14* |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116469369A (en)* | 2022-11-08 | 2023-07-21 | 科大讯飞股份有限公司 | Virtual sound synthesis method and device and related equipment |
| CN116580695A (en)* | 2023-04-28 | 2023-08-11 | 北京捷通华声科技股份有限公司 | Speech synthesis device, method, mobile terminal and storage medium |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN106373580B (en) | Method and device for synthesizing singing voice based on artificial intelligence | |
| US12027165B2 (en) | Computer program, server, terminal, and speech signal processing method | |
| CN111785246B (en) | Virtual character voice processing method and device and computer equipment | |
| CN101622659B (en) | Sound quality editing device and sound quality editing method | |
| WO2022141678A1 (en) | Speech synthesis method and apparatus, device, and storage medium | |
| JP2023022150A (en) | Two-way speech translation system, two-way speech translation method and program | |
| WO2022178969A1 (en) | Voice conversation data processing method and apparatus, and computer device and storage medium | |
| WO2019214047A1 (en) | Method and apparatus for establishing voice print model, computer device, and storage medium | |
| CN106486121B (en) | Voice optimization method and device applied to intelligent robot | |
| JP2020034883A (en) | Speech synthesis device and program | |
| CN114299908A (en) | A kind of voice conversion method and related equipment | |
| CN114121006A (en) | Image output method, device, equipment and storage medium of virtual character | |
| CN114005430B (en) | Training method, device, electronic device and storage medium for speech synthesis model | |
| CN114283781A (en) | Speech synthesis method and related device, electronic equipment and storage medium | |
| CN114708847A (en) | Voice synthesis method, device, equipment and storage medium | |
| CN115101046A (en) | Method and device for synthesizing voice of specific speaker | |
| CN112233649A (en) | Method, device and equipment for dynamically synthesizing machine simultaneous interpretation output audio | |
| CN107221344A (en) | A kind of speech emotional moving method | |
| CN113555027A (en) | Voice emotion conversion method and device, computer equipment and storage medium | |
| CN114613353B (en) | Speech synthesis method, device, electronic equipment and storage medium | |
| CN114928755B (en) | Video production method, electronic equipment and computer readable storage medium | |
| CN114333902A (en) | Voice conversion method and device, electronic equipment and storage medium | |
| CN112652309A (en) | Dialect voice conversion method, device, equipment and storage medium | |
| Li et al. | Intelligibility enhancement via normal-to-lombard speech conversion with long short-term memory network and bayesian Gaussian mixture model | |
| CN116469369A (en) | Virtual sound synthesis method and device and related equipment |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| TA01 | Transfer of patent application right | Effective date of registration:20230519 Address after:230026 Jinzhai Road, Baohe District, Hefei, Anhui Province, No. 96 Applicant after:University of Science and Technology of China Applicant after:IFLYTEK Co.,Ltd. Address before:NO.666, Wangjiang West Road, hi tech Zone, Hefei City, Anhui Province Applicant before:IFLYTEK Co.,Ltd. | |
| TA01 | Transfer of patent application right |