CN114708185A - Target detection method, system and equipment based on big data enabling and model flow - Google Patents
Target detection method, system and equipment based on big data enabling and model flowDownload PDFInfo
- Publication number
- CN114708185A CN114708185ACN202111258992.4ACN202111258992ACN114708185ACN 114708185 ACN114708185 ACN 114708185ACN 202111258992 ACN202111258992 ACN 202111258992ACN 114708185 ACN114708185 ACN 114708185A
- Authority
- CN
- China
- Prior art keywords
- model
- target detection
- current scene
- image
- training
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images


Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/0002—Inspection of images, e.g. flaw detection
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/22—Matching criteria, e.g. proximity measures
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/30—Semantic analysis
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/084—Backpropagation, e.g. using gradient descent
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- General Physics & Mathematics (AREA)
- Artificial Intelligence (AREA)
- General Engineering & Computer Science (AREA)
- Life Sciences & Earth Sciences (AREA)
- Evolutionary Computation (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Evolutionary Biology (AREA)
- Bioinformatics & Computational Biology (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Quality & Reliability (AREA)
- Image Analysis (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本发明属于计算机视觉及模式识别领域,具体涉及了一种基于大数据赋能和模型流的目标检测方法、系统及设备。The invention belongs to the field of computer vision and pattern recognition, and specifically relates to a target detection method, system and device based on big data empowerment and model flow.
背景技术Background technique
目标检测是一个重要且具有挑战性的计算机视觉任务,在安防监控、智能视频分析、自动驾驶等领域具有广泛的应用。在各个应用场景下,要想使数据集达到类似COCO标注数量级,成本太高,难以实现。一般只能获取少量低成本的标注数据,而数据受限导致模型训练十分困难,难以尽可能的发挥模型的性能。与此同时,在各种不同的应用场景下,可使用的硬件资源差异十分明显,能够部署的模型也不相同,在新的场景下需要重新根据人类专家经验从头开始选取新的模型进行重新训练,模型的复用性很差,十分浪费硬件资源。Object detection is an important and challenging computer vision task, which has a wide range of applications in security monitoring, intelligent video analysis, autonomous driving and other fields. In various application scenarios, the cost is too high to achieve a data set similar to the COCO labeling order of magnitude. Generally, only a small amount of low-cost labeled data can be obtained, and the limited data makes it very difficult to train the model, and it is difficult to maximize the performance of the model. At the same time, in various application scenarios, the hardware resources that can be used are very different, and the models that can be deployed are also different. In new scenarios, it is necessary to select a new model from scratch based on the experience of human experts for retraining. , the reusability of the model is very poor, and it is a waste of hardware resources.
发明内容SUMMARY OF THE INVENTION
为了解决现有技术中的上述问题,即现有目标检测模型受限于训练数据不够充分导致模型性能不高,以及在不同应用场景下由于硬件需求发生改变需要更改模型需要重新训练的复用性差问题,本发明提供了一种基于大数据赋能和模型流的目标检测方法,该目标检测方法包括:In order to solve the above problems in the prior art, that is, the existing target detection model is limited by insufficient training data, resulting in low model performance, and in different application scenarios, due to changes in hardware requirements, the model needs to be changed and the re-training needs to be re-trained. Problem, the present invention provides a target detection method based on big data empowerment and model flow, and the target detection method includes:
步骤S10,获取当前场景待目标检测图像,并通过Word2vector模型将图像的类别信息转换为语义信息向量;Step S10, acquiring the image to be detected in the current scene, and converting the category information of the image into a semantic information vector through the Word2vector model;
步骤S20,进行所述语义信息向量与所有公开的目标检测数据集图像类别信息的语义信息向量的余弦相似度匹配;Step S20, performing cosine similarity matching between the semantic information vector and the semantic information vector of the image category information of all disclosed target detection data sets;
步骤S30,以匹配值最高的类别在宽度和深度可变的超网中的分类全连接权重进行当前场景的目标检测模型的初始化;Step S30, initialize the target detection model of the current scene with the classification fully connected weight of the category with the highest matching value in the supernet with variable width and depth;
步骤S40,预先指定模型的浮点运算次数和参数量,在模型采样空间中逐一遍历,获得当前场景的K个目标检测子模型;Step S40, pre-specifying the number of floating-point operations and parameter quantities of the model, and traversing one by one in the model sampling space to obtain K target detection sub-models of the current scene;
步骤S50,分别采用当前场景的训练图像进行所述K个目标检测子模型的预训练,并以mAP值最大的预训练后的子模型作为当前场景的最终目标检测模型;Step S50, respectively use the training images of the current scene to perform pre-training of the K target detection sub-models, and use the pre-trained sub-model with the largest mAP value as the final target detection model of the current scene;
步骤S60,通过所述当前场景的最终目标检测模型进行当前场景待目标检测图像的目标检测,获得目标检测结果。Step S60 , performing target detection of the image to be detected in the current scene by using the final target detection model of the current scene to obtain a target detection result.
在一些优选的实施例中,所述模型采样空间,其获取方法为:In some preferred embodiments, the acquisition method of the model sampling space is:
步骤A10,将获取的所有公开的目标检测数据集中的图像归一化,并通过Word2vector模型将图像对应的类别信息转换为语义信息向量;Step A10, normalize the images in all the obtained public target detection data sets, and convert the category information corresponding to the images into semantic information vectors through the Word2vector model;
步骤A20,计算各类别语义信息向量之间的余弦相似度,并将余弦相似度大于预设阈值的类别合并后,进行标签重映射;Step A20, calculating the cosine similarity between the semantic information vectors of each category, and merging the categories whose cosine similarity is greater than a preset threshold, and performing label remapping;
步骤A30,选取任一深度学习目标检测模型,并针对模型的特征提取骨干网络设定模型的宽度和深度采样空间,获得模型采样空间。Step A30, select any deep learning target detection model, and set the width and depth sampling space of the model for the feature extraction backbone network of the model to obtain the model sampling space.
在一些优选的实施例中,所述宽度和深度可变的超网,其构建和训练方法为:In some preferred embodiments, the supernet with variable width and depth is constructed and trained as follows:
步骤B10,将标签重映射后的图像集划分为设定大小的批次,通过所述特征提取骨干网络提取任一批次图像的特征,并在所述模型采样空间中随机采样一个模型;Step B10, dividing the image set after label remapping into batches of a set size, extracting the features of any batch of images through the feature extraction backbone network, and randomly sampling a model in the model sampling space;
步骤B20,将当前批次图像的特征输入对应的随机采样模型的分类和边界框回归分支进行前向传播,并计算模型全局损失;Step B20, input the features of the current batch of images into the classification and bounding box regression branches of the corresponding random sampling model for forward propagation, and calculate the global loss of the model;
步骤B30,通过反向传播法和随机梯度下降法减小所述全局损失进行模型参数更新,迭代训练直至达到设定训练结束条件,获得宽度和深度可变的超网。Step B30, reducing the global loss by backpropagation and stochastic gradient descent to update model parameters, iterative training until reaching the set training end condition, and obtaining a supernet with variable width and depth.
在一些优选的实施例中,步骤B10中将标签重映射后的图像集划分为设定大小的批次之前,还设置有图像集扩充步骤,其方法为:In some preferred embodiments, before dividing the image set after label remapping into batches of a set size in step B10, an image set expansion step is further provided, and the method is as follows:
将所述标签重映射后的图像进行随机的多尺度缩放和多角度翻转操作,获得扩充后的图像集。Perform random multi-scale scaling and multi-angle flip operations on the image after the label remap to obtain an expanded image set.
在一些优选的实施例中,所述全局损失,其表示为:In some preferred embodiments, the global loss, which is expressed as:
Lall=λLrcnn+LrpnLall =λL rcnn +Lrpn
其中,Lrcnn代表模型的分类和边界框回归损失,Lrpn模型的区域提案网络部分损失,λ为用于平衡两种损失的平衡因子。Among them, Lrcnn represents the classification and bounding box regression loss of the model, Lrpn is the loss of the region proposal network part of the model, and λ is the balance factor used to balance the two losses.
在一些优选的实施例中,所述模型的分类和边界框回归损失,其表示为:In some preferred embodiments, the classification and bounding box regression loss of the model is expressed as:

其中,k代表预测框的序号,pki代表第k个预测框被预测为第i类的预测概率,

在一些优选的实施例中,所述模型的区域提案网络部分损失,其表示为:In some preferred embodiments, the region proposal network part loss of the model is expressed as:

其中,k表示代表预测框的序号,pi代表第k个预测框是否包含物体的预测概率,

本发明的另一方面,提出了一种基于大数据赋能和模型流的目标检测系统,该目标检测系统包括以下模块:In another aspect of the present invention, a target detection system based on big data empowerment and model flow is proposed. The target detection system includes the following modules:
语义信息向量提取模块,配置为获取当前场景待目标检测图像,并通过Word2vector模型将图像的类别信息转换为语义信息向量;The semantic information vector extraction module is configured to obtain the image to be detected in the current scene, and convert the category information of the image into a semantic information vector through the Word2vector model;
匹配模块,配置为进行所述语义信息向量与所有公开的目标检测数据集图像类别信息的语义信息向量的余弦相似度匹配;a matching module, configured to perform cosine similarity matching between the semantic information vector and the semantic information vector of all public target detection dataset image category information;
初始化模块,配置为以匹配值最高的类别在宽度和深度可变的超网中的分类全连接权重进行当前场景的目标检测模型的初始化;The initialization module is configured to initialize the target detection model of the current scene with the classification fully connected weight of the category with the highest matching value in the supernet with variable width and depth;
子模型筛选模块,配置为预先指定模型的浮点运算次数和参数量,在模型采样空间中逐一遍历,获得当前场景的K个目标检测子模型;The sub-model screening module is configured to pre-specify the number of floating-point operations and parameter quantities of the model, traverse one by one in the model sampling space, and obtain K target detection sub-models of the current scene;
模型训练模块,配置为分别采用当前场景的训练图像进行所述K个目标检测子模型的预训练,并以mAP值最大的预训练后的子模型作为当前场景的最终目标检测模型;A model training module, configured to respectively use the training images of the current scene to perform pre-training of the K target detection sub-models, and use the pre-trained sub-model with the largest mAP value as the final target detection model of the current scene;
目标检测模块,配置为通过所述当前场景的最终目标检测模型进行当前场景待目标检测图像的目标检测,获得目标检测结果。The target detection module is configured to perform target detection of the image to be detected in the current scene through the final target detection model of the current scene to obtain the target detection result.
本发明的第三方面,提出了一种电子设备,包括:In a third aspect of the present invention, an electronic device is proposed, comprising:
至少一个处理器;以及at least one processor; and
与至少一个所述处理器通信连接的存储器;其中,a memory communicatively coupled to at least one of the processors; wherein,
所述存储器存储有可被所述处理器执行的指令,所述指令用于被所述处理器执行以实现上述的基于大数据赋能和模型流的目标检测方法。The memory stores instructions executable by the processor, and the instructions are used to be executed by the processor to implement the above-mentioned object detection method based on big data empowerment and model flow.
本发明的第四方面,提出了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机指令,所述计算机指令用于被所述计算机执行以实现上述的基于大数据赋能和模型流的目标检测方法。In a fourth aspect of the present invention, a computer-readable storage medium is provided, and the computer-readable storage medium stores computer instructions, and the computer instructions are used to be executed by the computer to realize the above-mentioned big data-based empowerment and Object detection method for model flow.
本发明的有益效果:Beneficial effects of the present invention:
(1)本发明基于大数据赋能和模型流的目标检测方法,通过整合公开可用的大型目标检测数据集,构建从深度到宽度均可动态变化的超网,通过大数据加持给超网进行赋能,可以大幅度的提升模型的适应性能,并达到同时训练几十万子模型的效果。(1) The target detection method based on big data empowerment and model flow of the present invention, by integrating publicly available large-scale target detection data sets, constructs a supernet that can dynamically change from depth to width, and supports the supernet through big data. Empowerment can greatly improve the adaptive performance of the model, and achieve the effect of training hundreds of thousands of sub-models at the same time.
(2)本发明基于大数据赋能和模型流的目标检测方法,训练好的模型因为经过百万数量级的数据集训练,具有极强的泛化能力,可以作为下游实际部署场景的极佳初始化模型,具体部署场景只需要提供很少的有标签数据,模型就可以达到十分优异的性能。(2) The target detection method of the present invention is based on big data empowerment and model flow. The trained model has strong generalization ability because it has been trained with millions of data sets, and can be used as an excellent initialization for downstream actual deployment scenarios. Model, the specific deployment scenario only needs to provide a small amount of labeled data, and the model can achieve very good performance.
(3)本发明基于大数据赋能和模型流的目标检测方法,利用相同域分布的图像在网络的全连接层特征图相近的特点,对下游部署场景提供的图片从超网训练的数据库中进行匹配选取最接近的有标注图片加入到模型部署的训练当中,进一步给模型带来性能的提升。(3) The target detection method based on big data empowerment and model flow of the present invention utilizes the characteristics that the images distributed in the same domain are similar in the feature maps of the fully connected layer of the network, and the images provided for the downstream deployment scenarios are obtained from the database trained by the supernet. Matching and selecting the closest annotated image is added to the training of model deployment, which further improves the performance of the model.
(4)本发明基于大数据赋能和模型流的目标检测方法,在最初的超网训练过程中,通过动态结构的设计,实现了包含子网的同时训练,到各种不同场景进行部署时,只需根据对应场景的各种需求从训练好的子网进行直接抽取,节省了各个环境下的模型部署消耗。(4) The target detection method of the present invention based on big data empowerment and model flow, in the initial supernet training process, through the design of the dynamic structure, the simultaneous training including subnets is realized, and when deploying in various scenarios , it is only necessary to directly extract from the trained subnet according to various requirements of the corresponding scene, which saves the consumption of model deployment in each environment.
附图说明Description of drawings
通过阅读参照以下附图所作的对非限制性实施例所作的详细描述,本申请的其它特征、目的和优点将会变得更明显:Other features, objects and advantages of the present application will become more apparent by reading the detailed description of non-limiting embodiments made with reference to the following drawings:
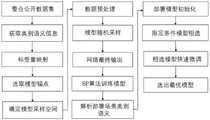
图1是本发明基于大数据赋能和模型流的目标检测方法的流程示意图;1 is a schematic flowchart of a target detection method based on big data empowerment and model flow of the present invention;
图2是本发明基于大数据赋能和模型流的目标检测方法的框架示意图;Fig. 2 is the framework schematic diagram of the target detection method based on big data empowerment and model flow of the present invention;
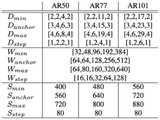
图3是本发明基于大数据赋能和模型流的目标检测方法一种实施例的采用残差神经网络作为骨干网络时的搜索空间示意图;3 is a schematic diagram of a search space when a residual neural network is used as a backbone network according to an embodiment of the target detection method based on big data empowerment and model flow of the present invention;
图4是本发明基于大数据赋能和模型流的目标检测方法一种实施例的稀疏数据场景下相似图像提取示意图。FIG. 4 is a schematic diagram of extracting similar images in a sparse data scenario according to an embodiment of the target detection method based on big data empowerment and model flow according to the present invention.
具体实施方式Detailed ways
下面结合附图和实施例对本申请作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅用于解释相关发明,而非对该发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与有关发明相关的部分。The present application will be further described in detail below with reference to the accompanying drawings and embodiments. It should be understood that the specific embodiments described herein are only used to explain the related invention, but not to limit the invention. In addition, it should be noted that, for the convenience of description, only the parts related to the related invention are shown in the drawings.
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本申请。It should be noted that the embodiments in the present application and the features of the embodiments may be combined with each other in the case of no conflict. The present application will be described in detail below with reference to the accompanying drawings and in conjunction with the embodiments.
本发明提供一种基于大数据赋能和模型流的目标检测方法,针对现有技术在目标检测问题中遇到的难题,一方面针对现有目标检测模型在少样本场景下性能比较低的现状,另一方面针对模型部署的复杂性和浪费资源的情况,通过整合大型目标检测数据集与构建灵活的动态超网,一次性完成数十万子模型训练。在具体的使用场景中,根据词向量模型选取训练数据库中最接近的语义类别对应的权重进行初始化,使用少量使用场景下的标注数据进行快速微调即可达到优异的目标检测性能。在对应使用场景标注数据比较稀疏的情况下,会根据标注数据在网络全连接层特征图分布特征,从训练数据库中选出相近数据,用来辅助部署训练,进一步增强模型的性能。The invention provides a target detection method based on big data empowerment and model flow, aiming at the difficulties encountered in the target detection problem in the prior art, and on the one hand, aiming at the current situation that the performance of the existing target detection model is relatively low in the scenario of few samples , on the other hand, in view of the complexity of model deployment and the waste of resources, by integrating large target detection datasets and building a flexible dynamic supernet, hundreds of thousands of sub-models can be trained at one time. In specific usage scenarios, the weights corresponding to the closest semantic categories in the training database are selected for initialization according to the word vector model, and excellent target detection performance can be achieved by fast fine-tuning with a small amount of labeled data in usage scenarios. In the case of sparse labeled data corresponding to the usage scenario, similar data will be selected from the training database according to the distribution characteristics of the labeled data in the feature map of the fully connected layer of the network to assist in deployment training and further enhance the performance of the model.
本发明的一种基于大数据赋能和模型流的目标检测方法,该目标检测方法包括:A target detection method based on big data empowerment and model flow of the present invention, the target detection method includes:
步骤S10,获取当前场景待目标检测图像,并通过Word2vector模型将图像的类别信息转换为语义信息向量;Step S10, acquiring the image to be detected in the current scene, and converting the category information of the image into a semantic information vector through the Word2vector model;
步骤S20,进行所述语义信息向量与所有公开的目标检测数据集图像类别信息的语义信息向量的余弦相似度匹配;Step S20, performing cosine similarity matching between the semantic information vector and the semantic information vector of the image category information of all disclosed target detection data sets;
步骤S30,以匹配值最高的类别在宽度和深度可变的超网中的分类全连接权重进行当前场景的目标检测模型的初始化;Step S30, initialize the target detection model of the current scene with the classification fully connected weight of the category with the highest matching value in the supernet with variable width and depth;
步骤S40,预先指定模型的浮点运算次数和参数量,在模型采样空间中逐一遍历,获得当前场景的K个目标检测子模型;Step S40, pre-specifying the number of floating-point operations and parameter quantities of the model, and traversing one by one in the model sampling space to obtain K target detection sub-models of the current scene;
步骤S50,分别采用当前场景的训练图像进行所述K个目标检测子模型的预训练,并以mAP值最大的预训练后的子模型作为当前场景的最终目标检测模型;Step S50, respectively use the training images of the current scene to perform pre-training of the K target detection sub-models, and use the pre-trained sub-model with the largest mAP value as the final target detection model of the current scene;
步骤S60,通过所述当前场景的最终目标检测模型进行当前场景待目标检测图像的目标检测,获得目标检测结果。Step S60 , performing target detection of the image to be detected in the current scene by using the final target detection model of the current scene to obtain a target detection result.
为了更清晰地对本发明基于大数据赋能和模型流的目标检测方法进行说明,下面结合图1和图2对本发明实施例中各步骤展开详述。In order to more clearly describe the target detection method based on big data empowerment and model flow of the present invention, each step in the embodiment of the present invention is described in detail below with reference to FIG. 1 and FIG. 2 .
本发明第一实施例的基于大数据赋能和模型流的目标检测方法,各步骤详细描述如下:In the target detection method based on big data empowerment and model flow according to the first embodiment of the present invention, each step is described in detail as follows:
步骤A10,将获取的所有公开的目标检测数据集中的图像归一化,并通过Word2vector模型将图像对应的类别信息转换为语义信息向量。本发明一个实施例中,将所有图像的短边长度同一调整为800像素。Step A10: Normalize the images in all the obtained public target detection data sets, and convert the category information corresponding to the images into semantic information vectors through the Word2vector model. In an embodiment of the present invention, the length of the short side of all images is adjusted to be 800 pixels.
步骤A20,计算各类别语义信息向量之间的余弦相似度,并将余弦相似度大于预设阈值的类别合并后,进行标签重映射。本发明一个实施例中,预设阈值为0.8。Step A20: Calculate the cosine similarity between the semantic information vectors of each category, and perform label remapping after merging the categories with the cosine similarity greater than a preset threshold. In an embodiment of the present invention, the preset threshold is 0.8.
步骤A30,选取任一深度学习目标检测模型,并针对模型的特征提取骨干网络设定模型的宽度和深度采样空间,获得模型采样空间。Step A30, select any deep learning target detection model, and set the width and depth sampling space of the model for the feature extraction backbone network of the model to obtain the model sampling space.
本发明一个实施例中,选用两阶段目标检测器FasterRCNN模型作为目标检测模型,选用残差网络Resnet作为模型的骨干网络,选用Resnet50网络或Resnet77网络或Resnet101网络作为模型锚点。In one embodiment of the present invention, the two-stage target detector FasterRCNN model is selected as the target detection model, the residual network Resnet is selected as the backbone network of the model, and the Resnet50 network or the Resnet77 network or the Resnet101 network is selected as the model anchor.
如图3所示,为本发明基于大数据赋能和模型流的目标检测方法一种实施例的采用残差神经网络作为骨干网络时的搜索空间示意图,AR50、AR77和AR101分别代表Resnet50、Resnet77和Resnet101网络,Dmin代表最小网络的深度、Danchor代表对应锚点模型的深度、Dmax代表最大网络的深度、Dstep代表网络从最小深度到最大深度可动态改变的步长、Wmin代表最大网络的宽度、Wanchor代表对应锚点模型的宽度、Wmax代表对应最大模型的深度、Wstep代表网络从最小宽度到最大宽度可动态改变的步长、Smin代表网络最小输入分辨率、Sanchor代表基准输入分辨率、Smax代表网络最大输入分辨率、Sstep代表网络接受输入分辨率从最大到最小变化的步长。As shown in FIG. 3, it is a schematic diagram of the search space when the residual neural network is used as the backbone network of an embodiment of the target detection method based on big data empowerment and model flow. AR50, AR77 and AR101 represent Resnet50 and Resnet77 respectively. And Resnet101 network, Dmin represents the depth of the minimum network, Danchor represents the depth of the corresponding anchor model, Dmax represents the depth of the largest network, Dstep represents the step size of the network that can be dynamically changed from the minimum depth to the maximum depth, Wmin represents the width of the largest network, Wanchor represents the width of the corresponding anchor model, Wmax represents the depth corresponding to the largest model, Wstep represents the step size of the network that can be dynamically changed from the minimum width to the maximum width, Smin represents the minimum input resolution of the network, Sanchor represents the reference input resolution, Smax represents The maximum input resolution of the network, Sstep represents the step size that the network accepts the input resolution from maximum to minimum.
将所述标签重映射后的图像进行随机的多尺度缩放和多角度翻转操作,获得扩充后的图像集。Perform random multi-scale scaling and multi-angle flip operations on the image after the label remap to obtain an expanded image set.
步骤B10,将标签重映射后的图像集(或扩充后的图像集)划分为设定大小的批次,通过所述特征提取骨干网络提取任一批次图像的特征,并在所述模型采样空间中随机采样一个模型。Step B10: Divide the image set (or the expanded image set) after label remap into batches of set size, extract the features of any batch of images through the feature extraction backbone network, and sample the model in the model. Randomly sample a model in space.
步骤B20,将当前批次图像的特征输入对应的随机采样模型的分类和边界框回归分支进行前向传播,并计算模型全局损失,如式(1)所示:Step B20, input the features of the current batch of images into the classification and bounding box regression branches of the corresponding random sampling model for forward propagation, and calculate the global loss of the model, as shown in formula (1):
Lall=λLrcnn+Lrpn (1)Lall =λL rcnn +Lrpn (1)
其中,Lrcnn代表模型的分类和边界框回归损失,Lrpn模型的区域提案网络部分损失,λ为用于平衡两种损失的平衡因子。Among them, Lrcnn represents the classification and bounding box regression loss of the model, Lrpn is the loss of the region proposal network part of the model, and λ is the balance factor used to balance the two losses.
模型的分类和边界框回归损失,其表示如式(2)所示:
其中,k代表预测框的序号,pki代表第k个预测框被预测为第i类的预测概率,

模型的区域提案网络部分损失,其表示如式(3)所示:The loss of the region proposal network part of the model, which is expressed as Eq. (3):

其中,k表示代表预测框的序号,pi代表第k个预测框是否包含物体的预测概率,

步骤B30,通过反向传播法和随机梯度下降法减小所述全局损失进行模型参数更新,迭代训练直至达到设定训练结束条件,获得宽度和深度可变的超网。Step B30, reducing the global loss by backpropagation and stochastic gradient descent to update model parameters, iterative training until reaching the set training end condition, and obtaining a supernet with variable width and depth.
步骤S10,获取当前场景(即需要部署的下游目标检测场景)待目标检测图像,并通过Word2vector模型将图像的类别信息转换为语义信息向量。In step S10, the image to be detected in the current scene (ie, the downstream target detection scene to be deployed) is acquired, and the category information of the image is converted into a semantic information vector through the Word2vector model.
步骤S20,进行所述语义信息向量与所有公开的目标检测数据集图像类别信息的语义信息向量的余弦相似度匹配。Step S20, performing cosine similarity matching between the semantic information vector and the semantic information vector of the image category information of all public target detection data sets.
步骤S30,以匹配值最高的类别在宽度和深度可变的超网中的分类全连接权重进行当前场景的目标检测模型的初始化。Step S30, initialize the target detection model of the current scene with the classification fully connected weight of the category with the highest matching value in the supernet with variable width and depth.
步骤S40,预先指定模型的浮点运算次数(FLOPs,浮点运算次数,可以用来衡量算法/模型复杂度)和参数量,在模型采样空间中逐一遍历,筛选出符合限制要求的子模型,并将筛选出的子模型随机采样出K个,获得当前场景的K个目标检测子模型。Step S40, pre-specify the number of floating-point operations (FLOPs, the number of floating-point operations, which can be used to measure the algorithm/model complexity) and parameter quantities of the model, traverse one by one in the model sampling space, and filter out sub-models that meet the restriction requirements, And randomly sample K of the selected sub-models to obtain K target detection sub-models of the current scene.
步骤S50,分别采用当前场景的训练图像(即需要部署的下游目标检测场景的数据集)进行所述K个目标检测子模型的预训练,得到mAP,并根据mAP结果选取K个目标检测子模型中结果最好的预训练后的子模型作为当前场景的最终目标检测模型(即需要部署的下游目标检测场景的最终的部署模型)。Step S50, respectively using the training images of the current scene (that is, the data set of the downstream target detection scene to be deployed) to perform pre-training of the K target detection sub-models to obtain mAP, and select K target detection sub-models according to the mAP results The pre-trained sub-model with the best result is used as the final target detection model of the current scene (that is, the final deployment model of the downstream target detection scene that needs to be deployed).
步骤S60,通过所述当前场景的最终目标检测模型进行当前场景待目标检测图像的目标检测,获得目标检测结果。Step S60 , performing target detection of the image to be detected in the current scene by using the final target detection model of the current scene to obtain a target detection result.
如图4所示,为本发明基于大数据赋能和模型流的目标检测方法一种实施例的稀疏数据场景下相似图像提取示意图,通过从本地维护的巨大数据库中可以提供和部署场景十分类似的有标注图片,深度学习算法随着数据量的提升,性能会有很大的提升。As shown in FIG. 4 , it is a schematic diagram of similar image extraction in a sparse data scenario according to an embodiment of the target detection method based on big data empowerment and model flow, which can be provided and deployed from a huge database maintained locally. There are labeled pictures, and the performance of the deep learning algorithm will be greatly improved with the increase of the amount of data.
本发明挖掘出大规模数据集的潜在能力,使训练好的模型具有极佳的迁移能力,在其他未见过的数据域中,只需要很少的相关域数据就可以达到优异的目标检测性能。在实际应用场景中,经常会有数据稀疏的情况,本发明不仅提供好的模型初始化,还通过图片在网络中特征图的分布所具有的特点,从训练使用的标注数据库中,针对部署的特定数据域选取最相近的相关数据,辅助具体下游模型部署训练,在数据稀疏的场景下也取得优异的目标检测性能。。The invention mines the potential ability of large-scale data sets, so that the trained model has excellent migration ability, and in other unseen data domains, only a small amount of relevant domain data can achieve excellent target detection performance . In practical application scenarios, there are often sparse data. The present invention not only provides good model initialization, but also uses the characteristics of the distribution of feature maps of pictures in the network, from the annotation database used for training, for specific deployment. The data domain selects the most similar relevant data to assist in the deployment and training of specific downstream models, and achieves excellent target detection performance in scenarios with sparse data. .
上述实施例中虽然将各个步骤按照上述先后次序的方式进行了描述,但是本领域技术人员可以理解,为了实现本实施例的效果,不同的步骤之间不必按照这样的次序执行,其可以同时(并行)执行或以颠倒的次序执行,这些简单的变化都在本发明的保护范围之内。Although the various steps are described in the above-mentioned order in the above-mentioned embodiment, those skilled in the art can understand that, in order to achieve the effect of this embodiment, different steps need not be performed in such an order, which can be performed simultaneously ( parallel) or in reverse order, simple variations of these are within the scope of the present invention.
本发明第二实施例的基于大数据赋能和模型流的目标检测系统,该目标检测系统包括以下模块:The target detection system based on big data empowerment and model flow according to the second embodiment of the present invention, the target detection system includes the following modules:
语义信息向量提取模块,配置为获取当前场景待目标检测图像,并通过Word2vector模型将图像的类别信息转换为语义信息向量;The semantic information vector extraction module is configured to obtain the image to be detected in the current scene, and convert the category information of the image into a semantic information vector through the Word2vector model;
匹配模块,配置为进行所述语义信息向量与所有公开的目标检测数据集图像类别信息的语义信息向量的余弦相似度匹配;a matching module, configured to perform cosine similarity matching between the semantic information vector and the semantic information vector of all public target detection dataset image category information;
初始化模块,配置为以匹配值最高的类别在宽度和深度可变的超网中的分类全连接权重进行当前场景的目标检测模型的初始化;The initialization module is configured to initialize the target detection model of the current scene with the classification fully connected weight of the category with the highest matching value in the supernet with variable width and depth;
子模型筛选模块,配置为预先指定模型的浮点运算次数和参数量,在模型采样空间中逐一遍历,获得当前场景的K个目标检测子模型;The sub-model screening module is configured to pre-specify the number of floating-point operations and parameter quantities of the model, traverse one by one in the model sampling space, and obtain K target detection sub-models of the current scene;
模型训练模块,配置为分别采用当前场景的训练图像进行所述K个目标检测子模型的预训练,并以mAP值最大的预训练后的子模型作为当前场景的最终目标检测模型;A model training module, configured to respectively use the training images of the current scene to perform pre-training of the K target detection sub-models, and use the pre-trained sub-model with the largest mAP value as the final target detection model of the current scene;
目标检测模块,配置为通过所述当前场景的最终目标检测模型进行当前场景待目标检测图像的目标检测,获得目标检测结果。The target detection module is configured to perform target detection of the image to be detected in the current scene through the final target detection model of the current scene to obtain the target detection result.
所属技术领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的系统的具体工作过程及有关说明,可以参考前述方法实施例中的对应过程,在此不再赘述。Those skilled in the art can clearly understand that, for the convenience and brevity of description, for the specific working process and related description of the system described above, reference may be made to the corresponding process in the foregoing method embodiments, which will not be repeated here.
需要说明的是,上述实施例提供的基于大数据赋能和模型流的目标检测系统,仅以上述各功能模块的划分进行举例说明,在实际应用中,可以根据需要而将上述功能分配由不同的功能模块来完成,即将本发明实施例中的模块或者步骤再分解或者组合,例如,上述实施例的模块可以合并为一个模块,也可以进一步拆分成多个子模块,以完成以上描述的全部或者部分功能。对于本发明实施例中涉及的模块、步骤的名称,仅仅是为了区分各个模块或者步骤,不视为对本发明的不当限定。It should be noted that the target detection system based on big data empowerment and model flow provided in the above-mentioned embodiments is only illustrated by the division of the above-mentioned functional modules. That is, the modules or steps in the embodiments of the present invention are decomposed or combined. For example, the modules in the above-mentioned embodiments can be combined into one module, or can be further split into multiple sub-modules, so as to complete all the above descriptions. or some functions. The names of the modules and steps involved in the embodiments of the present invention are only for distinguishing each module or step, and should not be regarded as an improper limitation of the present invention.
本发明第三实施例的一种电子设备,包括:An electronic device according to a third embodiment of the present invention includes:
至少一个处理器;以及at least one processor; and
与至少一个所述处理器通信连接的存储器;其中,a memory communicatively coupled to at least one of the processors; wherein,
所述存储器存储有可被所述处理器执行的指令,所述指令用于被所述处理器执行以实现上述的基于大数据赋能和模型流的目标检测方法。The memory stores instructions executable by the processor, and the instructions are used to be executed by the processor to implement the above-mentioned object detection method based on big data empowerment and model flow.
本发明第四实施例的一种计算机可读存储介质,所述计算机可读存储介质存储有计算机指令,所述计算机指令用于被所述计算机执行以实现上述的基于大数据赋能和模型流的目标检测方法。A computer-readable storage medium according to the fourth embodiment of the present invention, the computer-readable storage medium stores computer instructions, and the computer instructions are used to be executed by the computer to realize the above-mentioned big data-based enabling and model streaming target detection method.
所属技术领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的存储装置、处理装置的具体工作过程及有关说明,可以参考前述方法实施例中的对应过程,在此不再赘述。Those skilled in the art can clearly understand that, for the convenience and brevity of description, the specific working process and relevant description of the storage device and processing device described above can refer to the corresponding process in the foregoing method embodiments, which is not repeated here. Repeat.
本领域技术人员应该能够意识到,结合本文中所公开的实施例描述的各示例的模块、方法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,软件模块、方法步骤对应的程序可以置于随机存储器(RAM)、内存、只读存储器(ROM)、电可编程ROM、电可擦除可编程ROM、寄存器、硬盘、可移动磁盘、CD-ROM、或技术领域内所公知的任意其它形式的存储介质中。为了清楚地说明电子硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以电子硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。本领域技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。Those skilled in the art should be aware that the modules and method steps of each example described in conjunction with the embodiments disclosed herein can be implemented by electronic hardware, computer software or a combination of the two, and the programs corresponding to the software modules and method steps Can be placed in random access memory (RAM), internal memory, read only memory (ROM), electrically programmable ROM, electrically erasable programmable ROM, registers, hard disk, removable disk, CD-ROM, or as known in the art in any other form of storage medium. In order to clearly illustrate the interchangeability of electronic hardware and software, the components and steps of each example have been described generally in terms of functionality in the foregoing description. Whether these functions are performed in electronic hardware or software depends on the specific application and design constraints of the technical solution. Skilled artisans may use different methods of implementing the described functionality for each particular application, but such implementations should not be considered beyond the scope of the present invention.
术语“第一”、“第二”等是用于区别类似的对象,而不是用于描述或表示特定的顺序或先后次序。The terms "first," "second," etc. are used to distinguish between similar objects, and are not used to describe or indicate a particular order or sequence.
术语“包括”或者任何其它类似用语旨在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备/装置不仅包括那些要素,而且还包括没有明确列出的其它要素,或者还包括这些过程、方法、物品或者设备/装置所固有的要素。The term "comprising" or any other similar term is intended to encompass a non-exclusive inclusion such that a process, method, article or device/means comprising a list of elements includes not only those elements but also other elements not expressly listed, or Also included are elements inherent to these processes, methods, articles or devices/devices.
至此,已经结合附图所示的优选实施方式描述了本发明的技术方案,但是,本领域技术人员容易理解的是,本发明的保护范围显然不局限于这些具体实施方式。在不偏离本发明的原理的前提下,本领域技术人员可以对相关技术特征做出等同的更改或替换,这些更改或替换之后的技术方案都将落入本发明的保护范围之内。So far, the technical solutions of the present invention have been described with reference to the preferred embodiments shown in the accompanying drawings, however, those skilled in the art can easily understand that the protection scope of the present invention is obviously not limited to these specific embodiments. Without departing from the principle of the present invention, those skilled in the art can make equivalent changes or substitutions to the relevant technical features, and the technical solutions after these changes or substitutions will fall within the protection scope of the present invention.
Claims (10)






Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111258992.4ACN114708185B (en) | 2021-10-28 | 2021-10-28 | Target detection method, system and device based on big data empowerment and model flow |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111258992.4ACN114708185B (en) | 2021-10-28 | 2021-10-28 | Target detection method, system and device based on big data empowerment and model flow |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN114708185Atrue CN114708185A (en) | 2022-07-05 |
| CN114708185B CN114708185B (en) | 2025-03-18 |
Family
ID=82166424
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202111258992.4AActiveCN114708185B (en) | 2021-10-28 | 2021-10-28 | Target detection method, system and device based on big data empowerment and model flow |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114708185B (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2024012179A1 (en)* | 2022-07-15 | 2024-01-18 | 马上消费金融股份有限公司 | Model training method, target detection method and apparatuses |
| CN119360010A (en)* | 2024-12-27 | 2025-01-24 | 杭州智元研究院有限公司 | A cross-dataset object detection method |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111563592A (en)* | 2020-05-08 | 2020-08-21 | 北京百度网讯科技有限公司 | Method and device for generating neural network model based on hypernetwork |
| CN111723719A (en)* | 2020-06-12 | 2020-09-29 | 中国科学院自动化研究所 | Video target detection method, system and device based on category external memory |
| CN112966697A (en)* | 2021-03-17 | 2021-06-15 | 西安电子科技大学广州研究院 | Target detection method, device and equipment based on scene semantics and storage medium |
- 2021
- 2021-10-28CNCN202111258992.4Apatent/CN114708185B/enactiveActive
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111563592A (en)* | 2020-05-08 | 2020-08-21 | 北京百度网讯科技有限公司 | Method and device for generating neural network model based on hypernetwork |
| CN111723719A (en)* | 2020-06-12 | 2020-09-29 | 中国科学院自动化研究所 | Video target detection method, system and device based on category external memory |
| CN112966697A (en)* | 2021-03-17 | 2021-06-15 | 西安电子科技大学广州研究院 | Target detection method, device and equipment based on scene semantics and storage medium |
Non-Patent Citations (1)
| Title |
|---|
| BU, XY: "GAIA: A Transfer Learning System of Object Detection that Fits Your Needs", 《 2021 IEEE/CVF CONFERENCE ON COMPUTER VISION AND PATTERN RECOGNITION, CVPR 2021》, 25 June 2021 (2021-06-25), pages 274 - 283, XP034010158, DOI: 10.1109/CVPR46437.2021.00034* |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2024012179A1 (en)* | 2022-07-15 | 2024-01-18 | 马上消费金融股份有限公司 | Model training method, target detection method and apparatuses |
| CN119360010A (en)* | 2024-12-27 | 2025-01-24 | 杭州智元研究院有限公司 | A cross-dataset object detection method |
Also Published As
| Publication number | Publication date |
|---|---|
| CN114708185B (en) | 2025-03-18 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110472627B (en) | An end-to-end SAR image recognition method, device and storage medium | |
| CN109816009B (en) | Multi-label image classification method, device and equipment based on graph convolution | |
| CN110070067B (en) | Video classification method, training method and device of video classification method model and electronic equipment | |
| CN110569901B (en) | A weakly supervised object detection method based on channel selection for adversarial elimination | |
| CN112966691A (en) | Multi-scale text detection method and device based on semantic segmentation and electronic equipment | |
| CN110598603A (en) | Face recognition model acquisition method, device, equipment and medium | |
| CN105528794A (en) | Moving object detection method based on Gaussian mixture model and superpixel segmentation | |
| WO2016138838A1 (en) | Method and device for recognizing lip-reading based on projection extreme learning machine | |
| CN109284767B (en) | A pedestrian retrieval method based on augmented samples and multi-stream layers | |
| EP3867808A1 (en) | Method and device for automatic identification of labels of image | |
| Nguyen et al. | Satellite image classification using convolutional learning | |
| CN112131944B (en) | Video behavior recognition method and system | |
| CN114708185A (en) | Target detection method, system and equipment based on big data enabling and model flow | |
| Bejiga et al. | Gan-based domain adaptation for object classification | |
| CN113849679B (en) | Image retrieval method, device, electronic device and storage medium | |
| CN118786440A (en) | Training object discovery neural networks and feature representation neural networks using self-supervised learning | |
| Feng et al. | A novel saliency detection method for wild animal monitoring images with WMSN | |
| Fu et al. | A case study of utilizing YOLOT based quantitative detection algorithm for marine benthos | |
| CN116910571A (en) | Open-domain adaptation method and system based on prototype comparison learning | |
| CN115797735A (en) | Target detection method, device, equipment and storage medium | |
| CN106355210A (en) | Method for expressing infrared image features of insulators on basis of depth neuron response modes | |
| CN110135435B (en) | Saliency detection method and device based on breadth learning system | |
| Bouteldja et al. | A comparative analysis of SVM, K-NN, and decision trees for high resolution satellite image scene classification | |
| CN111860465A (en) | Remote sensing image extraction method, device, equipment and storage medium based on superpixels | |
| CN115937565A (en) | Hyperspectral Image Classification Method Based on Adaptive L-BFGS Algorithm |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |