CN114694641A - Voice recognition method and electronic equipment - Google Patents
Voice recognition method and electronic equipmentDownload PDFInfo
- Publication number
- CN114694641A CN114694641ACN202011639265.8ACN202011639265ACN114694641ACN 114694641 ACN114694641 ACN 114694641ACN 202011639265 ACN202011639265 ACN 202011639265ACN 114694641 ACN114694641 ACN 114694641A
- Authority
- CN
- China
- Prior art keywords
- phoneme
- probability
- target
- sequence
- text
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images















Classifications
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/26—Speech to text systems
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Machine Translation (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本申请涉及终端技术领域,尤其涉及一种语音识别方法及电子设备。The present application relates to the field of terminal technologies, and in particular, to a speech recognition method and electronic device.
背景技术Background technique
随着电子设备的计算能力的提升,当前语音识别的趋势是将语音交互系统部署于电子设备,以提高语音识别的用户体验,降低成本。然而,由于电子设备的存储能力有限,通常用于存储语音交互系统的空间较小,限制了语音交互系统占用的空间的大小。With the improvement of the computing power of electronic devices, the current trend of speech recognition is to deploy a speech interaction system in electronic devices to improve the user experience of speech recognition and reduce costs. However, due to the limited storage capacity of the electronic device, the space for storing the voice interactive system is usually small, which limits the size of the space occupied by the voice interactive system.
传统的语音交互系统通常由声学模型(如隐马尔科夫模型(hidden markovmodel,HMM)、高斯混合模型(gaussian mixture model,GMM))和语言模型(如N元文法N-Gram)两部分组成。语言模型基于大量的文本数据进行训练,从而语音交互系统识别精度高。然而,语言模型占用的存储空间通常较大,若想要将传统的语音交互系统部署于电子设备,需要对语言模型进行压缩,但是,利用压缩后的语音交互系统进行语音识别,会大幅度降低识别精度。Traditional speech interaction systems usually consist of two parts, an acoustic model (such as a hidden Markov model (HMM), a Gaussian mixture model (GMM)) and a language model (such as an N-gram N-Gram). The language model is trained based on a large amount of text data, so that the recognition accuracy of the speech interaction system is high. However, the storage space occupied by the language model is usually large. If you want to deploy the traditional voice interaction system on electronic devices, you need to compress the language model. However, using the compressed voice interaction system for speech recognition will greatly reduce recognition accuracy.
现有的流式端到端的模型可以部署于电子设备,可以将音频直接映射成文本序列,如循环神经网络变换器(recurrent neural network transducer,RNN-T)。但是,该模型只依据音频数据进行训练,且采用的训练样本有限,导致在语音识别过程中,流式端到端的模型对于大量未经过训练的文本的识别精度低。Existing streaming end-to-end models that can be deployed on electronic devices can directly map audio to text sequences, such as recurrent neural network transducers (RNN-T). However, the model is only trained on audio data, and the training samples used are limited, resulting in low recognition accuracy of the streaming end-to-end model for a large number of untrained texts during the speech recognition process.
发明内容SUMMARY OF THE INVENTION
本申请实施例提供一种语音识别方法及电子设备,可以提高电子设备的语音识别精度。Embodiments of the present application provide a speech recognition method and an electronic device, which can improve the speech recognition accuracy of the electronic device.
为达到上述目的,本申请采用如下技术方案:To achieve the above object, the application adopts the following technical solutions:
第一方面,提供一种语音识别方法。该语音识别方法包括:根据第一概率矩阵和第二概率矩阵,获取目标概率最大的N个目标音素序列,对N个目标音素序列进行翻译,获取N个目标音素序列分别对应的第三概率矩阵,根据第三概率矩阵和N个目标音素序列对应的目标概率,确定出至少一个第一文本序列中概率最大的一个第一文本序列,显示概率最大的一个第一文本序列。在一种实施例中,还可以确定出概率排在前几位(比如前三位)的几个第一文本序列来进行显示。In a first aspect, a speech recognition method is provided. The speech recognition method includes: obtaining N target phoneme sequences with the largest target probability according to the first probability matrix and the second probability matrix, translating the N target phoneme sequences, and obtaining third probability matrices corresponding to the N target phoneme sequences respectively , according to the third probability matrix and the target probabilities corresponding to the N target phoneme sequences, determine a first text sequence with the highest probability among the at least one first text sequence, and display a first text sequence with the highest probability. In one embodiment, several first text sequences whose probabilities are ranked at the top (for example, the top three) may also be determined for display.
其中,第一概率矩阵包括目标语音信号帧对应的一个音素所对应的音素词表中包括的多个音素中各个音素的概率,第二概率矩阵包括多个第一音素序列的下一可能音素对应的音素词表中包括的多个音素中各个音素的概率,多个第一音素序列中每个第一音素序列包括起始音素和目标语音信号帧之前的一个或多个语音信号帧对应的多个音素序列中的一个音素序列,目标概率为每个目标音素序列的概率,每个目标音素序列由多个第一音素序列中的一个第一音素序列和目标语音信号帧对应的一个音素组成,N为大于或等于1的整数,目标语音信号帧为当前待识别的一个语音信号帧。第三概率矩阵包括N个目标音素序列中的一个目标音素序列被翻译为至少一个第一文本序列的概率。Wherein, the first probability matrix includes the probability of each phoneme in the phoneme vocabulary included in the phoneme vocabulary corresponding to a phoneme corresponding to the target speech signal frame, and the second probability matrix includes the next possible phoneme corresponding to the first phoneme sequence The probability of each phoneme in the plurality of phonemes included in the phoneme vocabulary, and each first phoneme sequence in the plurality of first phoneme sequences includes a start phoneme and one or more speech signal frames before the target speech signal frame. A phoneme sequence in the phoneme sequences, the target probability is the probability of each target phoneme sequence, and each target phoneme sequence is composed of a first phoneme sequence in a plurality of first phoneme sequences and a phoneme corresponding to the target speech signal frame, N is an integer greater than or equal to 1, and the target speech signal frame is a speech signal frame to be recognized currently. The third probability matrix includes the probability that one of the N target phoneme sequences is translated into at least one first text sequence.
基于第一方面所述的语音识别方法,终端根据目标语音信号帧对应的音素的概率矩阵和第一音素序列的下一可能音素的概率矩阵,获取目标概率最大的N个目标音素序列。然后,对该N个目标音素序列进行翻译,获取该N个目标音素序列分别对应的至少一个第一文本序列和至少一个第一文本序列中每个第一文本序列的第三概率,根据第三概率和N个目标音素序列对应的目标概率,确定出至少一个第一文本序列中概率最大的一个第一文本序列,显示该概率最大的第一文本序列,从而可以提高语音识别的精度。Based on the speech recognition method described in the first aspect, the terminal obtains N target phoneme sequences with the highest target probability according to the probability matrix of the phonemes corresponding to the target speech signal frame and the probability matrix of the next possible phoneme of the first phoneme sequence. Then, the N target phoneme sequences are translated to obtain at least one first text sequence corresponding to the N target phoneme sequences and the third probability of each first text sequence in the at least one first text sequence, according to the third probability The probability and the target probability corresponding to the N target phoneme sequences are used to determine a first text sequence with the highest probability among the at least one first text sequence, and display the first text sequence with the highest probability, thereby improving the accuracy of speech recognition.
在一种可能的设计中,第一方面所述的语音识别方法,还可以包括:根据目标语音信号帧和多个第一音素序列中的一个第一音素序列获取如下一项或多项:第一概率矩阵、至少一个第二音素序列和第四概率矩阵。其中,至少一个第二音素序列中每个第二音素序列由多个第一音素序列中的一个第一音素序列和目标语音信号帧对应的一个音素组成,第四概率矩阵包括至少一个第二音素序列中每个第二音素序列对应的概率,第二音素序列作为目标语音信号帧的下一语音信号帧对应的第一音素序列。如此,可以基于目标语音信号帧获取对应的音素的第一概率矩阵、第二音素序列和第四概率矩阵,以提高语音识别的精度。In a possible design, the speech recognition method described in the first aspect may further include: obtaining one or more of the following according to the target speech signal frame and one of the multiple first phoneme sequences: A probability matrix, at least one second phoneme sequence, and a fourth probability matrix. Wherein, each second phoneme sequence in the at least one second phoneme sequence is composed of a first phoneme sequence among a plurality of first phoneme sequences and a phoneme corresponding to the target speech signal frame, and the fourth probability matrix includes at least one second phoneme The probability corresponding to each second phoneme sequence in the sequence, and the second phoneme sequence is used as the first phoneme sequence corresponding to the next speech signal frame of the target speech signal frame. In this way, the first probability matrix, the second phoneme sequence, and the fourth probability matrix of the corresponding phonemes can be obtained based on the target speech signal frame, so as to improve the accuracy of speech recognition.
在一种可能的设计中,第一方面所述的语音识别方法,还可以包括:根据第一音素序列的语义,获取第二概率矩阵。其中,第一音素序列的语义可以表示第一音素序列的表达的语言含义。如此,可以根据第一音素序列的语言含义,获取第一音素序列的下一可能音素的概率,以提高语音识别精度。In a possible design, the speech recognition method described in the first aspect may further include: acquiring a second probability matrix according to the semantics of the first phoneme sequence. The semantics of the first phoneme sequence may represent the linguistic meaning of the expression of the first phoneme sequence. In this way, the probability of the next possible phoneme of the first phoneme sequence can be obtained according to the linguistic meaning of the first phoneme sequence, so as to improve the accuracy of speech recognition.
在一种可能的设计中,上述根据第一概率矩阵和第二概率矩阵,获取目标概率最大的N个目标音素序列,可以包括:对第一概率矩阵和第二概率矩阵进行融合,获取第五概率矩阵,根据目标语音信号帧之前的一个或多个语音信号帧和目标语音信号帧分别对应的第五概率矩阵,获取目标概率最大的N个目标音素序列。其中,第五概率矩阵可以包括目标语音信号帧对应的一个音素所对应的音素词表中包括的多个音素中各个音素的融合概率。也就是说,对第一概率矩阵和第二概率矩阵进行融合后,获得的下一可能音素的概率矩阵的精度更高,从而可以提高语音识别精度。In a possible design, obtaining N target phoneme sequences with the largest target probability according to the first probability matrix and the second probability matrix may include: fusing the first probability matrix and the second probability matrix to obtain the fifth The probability matrix is to obtain N target phoneme sequences with the highest target probability according to the fifth probability matrix corresponding to one or more speech signal frames before the target speech signal frame and the target speech signal frame respectively. Wherein, the fifth probability matrix may include the fusion probability of each phoneme in the phoneme vocabulary included in the phoneme vocabulary corresponding to one phoneme corresponding to the target speech signal frame. That is to say, after the first probability matrix and the second probability matrix are fused, the obtained probability matrix of the next possible phoneme has higher precision, so that the speech recognition precision can be improved.
在一种可能的设计中,第一方面所述的语音识别方法,还可以包括:对目标语音信号帧对应的音素词表中包括的多个音素中的一个或多个音素进行翻译,获得一个或多个音素分别对应的文本概率矩阵。其中,文本概率矩阵可以包括对应的音素被翻译为文本词表中包括的多个文本符号中各个文本符号的概率。如此,可对语音流中包括的一个或多个语音信号帧分别对应的一个或多个音素进行翻译,获得各个音素对应的文本概率矩阵。In a possible design, the speech recognition method described in the first aspect may further include: translating one or more phonemes among the multiple phonemes included in the phoneme vocabulary corresponding to the target speech signal frame to obtain a Or text probability matrix corresponding to multiple phonemes respectively. The text probability matrix may include the probability that the corresponding phoneme is translated into each text symbol of the plurality of text symbols included in the text vocabulary. In this way, one or more phonemes corresponding to one or more speech signal frames included in the speech stream can be translated to obtain a text probability matrix corresponding to each phoneme.
在一种可能的设计中,第一方面所述的语音识别方法,还可以包括:获取第一栅格结构。其中,第一栅格结构的横坐标为完整音素序列中的各个音素,纵坐标为完整音素序列中的各个音素分别对应的文本概率矩阵,完整音素序列为语音流中最后一个语音信号帧作为目标语音信号帧时获得的目标音素序列。也就是说,获得的第一栅格结构包括完整音素序列中的各个音素分别对应的文本概率矩阵。In a possible design, the speech recognition method described in the first aspect may further include: acquiring the first grid structure. The abscissa of the first grid structure is each phoneme in the complete phoneme sequence, the ordinate is the text probability matrix corresponding to each phoneme in the complete phoneme sequence, and the complete phoneme sequence is the last speech signal frame in the speech stream as the target The target phoneme sequence obtained when the speech signal is framed. That is to say, the obtained first grid structure includes text probability matrices corresponding to each phoneme in the complete phoneme sequence.
在一种可能的设计中,第一方面所述的语音识别方法,还可以包括:对第一栅格结构进行裁剪,获取第二栅格结构,对第二栅格结构进行解码,获取并显示第二文本序列。如此,通过对第一栅格结构进行裁剪,调整第一栅格结构中的文本符号的概率,实现对模糊音的纠正,获得更准确的文本序列,从而进一步提高语音识别的精度。In a possible design, the speech recognition method described in the first aspect may further include: cropping the first grid structure, acquiring the second grid structure, decoding the second grid structure, acquiring and displaying The second text sequence. In this way, by trimming the first grid structure, the probability of text symbols in the first grid structure is adjusted, so as to correct the fuzzy sound, obtain a more accurate text sequence, and further improve the accuracy of speech recognition.
在一种可能的设计中,上述对第一栅格结构进行裁剪,获取第二栅格结构,可以包括:基于混淆音矩阵和音素文本矩阵,获得音素文本混淆矩阵,基于音素文本混淆矩阵对第一栅格结构进行剪裁,获取第二栅格结构。其中,混淆音矩阵用于表示音素词表中包括的多个音素中各个音素被识别为音素词表中包括的多个音素中各个音素的概率,音素文本矩阵用于表示文本词表中包括的多个文本符号中各个文本符号与音素词表中包括的多个音素中各个音素的对应关系。如此,通过音素文本混淆矩阵剪裁第一栅格结构,获得的第二栅格结构中各个音素分别对应的文本概率的精度更高,从而可以进一步提高语音识别的精度。In a possible design, the above-mentioned trimming the first grid structure to obtain the second grid structure may include: obtaining a phoneme text confusion matrix based on a confusion sound matrix and a phoneme text matrix; A grid structure is trimmed to obtain a second grid structure. The confusion matrix is used to represent the probability that each phoneme in the multiple phonemes included in the phoneme vocabulary is recognized as each phoneme in the multiple phonemes included in the phoneme vocabulary, and the phoneme text matrix is used to represent the text included in the vocabulary. Correspondence between each text symbol in the plurality of text symbols and each phoneme in the plurality of phonemes included in the phoneme vocabulary. In this way, by trimming the first grid structure through the phoneme-text confusion matrix, the obtained text probability corresponding to each phoneme in the second grid structure has higher accuracy, thereby further improving the accuracy of speech recognition.
第二方面,提供一种电子设备。该电子设备包括:处理器、存储器和显示屏,存储器、显示屏与处理器耦合,存储器用于存储计算机程序代码,计算机程序代码包括计算机指令,当处理器从存储器中读取计算机指令,使得电子设备执行第一方面中任意一种可能的实现方式所述的语音识别方法。In a second aspect, an electronic device is provided. The electronic device includes: a processor, a memory and a display screen, the memory and the display screen are coupled to the processor, the memory is used to store computer program codes, and the computer program codes include computer instructions, when the processor reads the computer instructions from the memory, so that the electronic The device executes the speech recognition method described in any possible implementation manner of the first aspect.
第二方面所述的电子设备的技术效果可以参考第一方面所述的语音识别方法的技术效果,此处不再赘述。For the technical effect of the electronic device described in the second aspect, reference may be made to the technical effect of the speech recognition method described in the first aspect, which will not be repeated here.
第三方面,提供一种计算机可读存储介质,该计算机可读存储介质上存储有计算机程序或指令,当计算机程序或指令在计算机上运行时,使得计算机执行第一方面中任意一种可能的实现方式所述的语音识别方法。In a third aspect, a computer-readable storage medium is provided, on which a computer program or instruction is stored, and when the computer program or instruction is executed on a computer, the computer is made to execute any one of the possible possibilities in the first aspect. The speech recognition method described in the implementation manner is implemented.
第四方面,提供一种计算机程序产品,该计算机程序产品包括:计算机程序或指令,当计算机程序或指令在计算机上运行时,使得计算机执行第一方面中任意一种可能的实现方式所述的语音识别方法。In a fourth aspect, a computer program product is provided, the computer program product includes: a computer program or an instruction, when the computer program or instruction is run on a computer, the computer executes any one of the possible implementations described in the first aspect speech recognition method.
第五方面,本申请实施例提供一种芯片系统,包括至少一个处理器和至少一个接口电路,至少一个接口电路用于执行收发功能,并将指令发送给至少一个处理器,当至少一个处理器执行指令时,至少一个处理器执行如上述第一方面及其中任一种可能的实现方式中所述的语音识别方法。In a fifth aspect, an embodiment of the present application provides a chip system, including at least one processor and at least one interface circuit, where the at least one interface circuit is configured to perform a transceiving function and send instructions to the at least one processor. When executing the instructions, at least one processor executes the speech recognition method described in the first aspect and any one of the possible implementations.
附图说明Description of drawings
图1为本申请实施例提供的电子设备的结构示意图一;FIG. 1 is a schematic structural diagram 1 of an electronic device provided by an embodiment of the present application;
图2为本申请实施例提供的电子设备的软件结构框图;2 is a block diagram of a software structure of an electronic device provided by an embodiment of the present application;
图3为本申请实施例提供的语音识别模块的结构示意图;3 is a schematic structural diagram of a speech recognition module provided by an embodiment of the present application;
图4为本申请实施例提供的声学模型、音素预测器和音素翻译器的结构示意图;4 is a schematic structural diagram of an acoustic model, a phoneme predictor, and a phoneme translator provided by an embodiment of the present application;
图5为本申请实施例提供的整流器的结构示意图;5 is a schematic structural diagram of a rectifier provided by an embodiment of the present application;
图6为本申请实施例提供的语音识别方法的流程示意图一;FIG. 6 is a
图7为本申请实施例提供的语音识别方法的应用示意图一;FIG. 7 is a schematic diagram 1 of the application of the speech recognition method provided by the embodiment of the present application;
图8为本申请实施例提供的语音识别方法的应用示意图二;FIG. 8 is a second application schematic diagram of the speech recognition method provided by the embodiment of the present application;
图9为本申请实施例提供的语音识别方法的应用示意图三;FIG. 9 is an application schematic diagram 3 of the speech recognition method provided by the embodiment of the present application;
图10为本申请实施例提供的语音识别方法的应用示意图四;FIG. 10 is a fourth application schematic diagram of the speech recognition method provided by the embodiment of the present application;
图11为本申请实施例提供的语音识别方法的应用示意图五;11 is a schematic diagram five of the application of the speech recognition method provided by the embodiment of the present application;
图12为本申请实施例提供的语音识别方法的应用示意图六;FIG. 12 is a schematic diagram 6 of the application of the speech recognition method provided by the embodiment of the present application;
图13为本申请实施例提供的语音识别方法的应用示意图七;FIG. 13 is a seventh application schematic diagram of the speech recognition method provided by the embodiment of the present application;
图14为本申请实施例提供的语音识别方法的流程示意图二;14 is a second schematic flowchart of a speech recognition method provided by an embodiment of the present application;
图15为本申请实施例提供的第一栅格结构的结构示意图;FIG. 15 is a schematic structural diagram of a first grid structure provided by an embodiment of the present application;
图16为本申请实施例提供的语音识别方法的应用示意图八;FIG. 16 is an eighth application schematic diagram of the speech recognition method provided by the embodiment of the present application;
图17为本申请实施例提供的语音识别方法的应用示意图九;17 is a schematic diagram 9 of the application of the speech recognition method provided by the embodiment of the present application;
图18为本申请实施例提供的电子设备的结构示意图二。FIG. 18 is a second schematic structural diagram of an electronic device provided by an embodiment of the present application.
具体实施方式Detailed ways
下面结合附图对本申请实施例提供的语音识别方法及电子设备进行详细地描述。The speech recognition method and electronic device provided by the embodiments of the present application will be described in detail below with reference to the accompanying drawings.
本申请的描述中所提到的术语“包括”和“具有”以及它们的任何变形,意图在于覆盖不排他的包含。例如包含了一系列步骤或单元的过程、方法、系统、产品或设备没有限定于已列出的步骤或单元,而是可选地还包括其他没有列出的步骤或单元,或可选地还包括对于这些过程、方法、产品或设备固有的其它步骤或单元。References in the description of the present application to the terms "comprising" and "having" and any variations thereof are intended to cover non-exclusive inclusion. For example, a process, method, system, product or device comprising a series of steps or units is not limited to the listed steps or units, but optionally also includes other unlisted steps or units, or optionally also Include other steps or units inherent to these processes, methods, products or devices.
需要说明的是,本申请实施例中,“示例性的”或者“例如”等词用于表示作例子、例证或说明。本申请实施例中被描述为“示例性的”或者“例如”的任何实施例或设计方案不应被解释为比其它实施例或设计方案更优选或更具优势。确切而言,使用“示例性的”或者“例如”等词旨在以具体方式呈现相关概念。It should be noted that, in the embodiments of the present application, words such as "exemplary" or "for example" are used to represent examples, illustrations, or illustrations. Any embodiments or designs described in the embodiments of the present application as "exemplary" or "such as" should not be construed as preferred or advantageous over other embodiments or designs. Rather, the use of words such as "exemplary" or "such as" is intended to present the related concepts in a specific manner.
在本申请的描述中,除非另有说明,“多个”的含义是指两个或两个以上。本文中的“和/或”仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,A和/或B,可以表示:单独存在A,同时存在A和B,单独存在B这三种情况。In the description of this application, unless otherwise stated, the meaning of "plurality" refers to two or more. In this article, "and/or" is only an association relationship to describe the associated objects, which means that there can be three kinds of relationships, for example, A and/or B, which can mean that A exists alone, A and B exist at the same time, and B exists alone these three situations.
本申请实施例中,有时候下标如W1可能会笔误为非下标的形式如W1,在不强调其区别时,其所要表达的含义是一致的。In the embodiments of the present application, sometimesa subscript such as W1 may be mistakenly written in a non-subscript form such as W1. When the difference is not emphasized, the meaning to be expressed is the same.
首先,为了便于理解,下面先对本申请实施例可能涉及的相关术语和概念进行介绍。First, for ease of understanding, related terms and concepts that may be involved in the embodiments of the present application are first introduced below.
(1)音素(1) Phoneme
本申请实施例中的音素可以包括但不限于如下一项或多项:带声调的拼音、不带声调的拼音、元音音素和辅音音素。以语音流是中文为例,例如,音素可以为带声调的拼音,如“tiān”或“tian1”,其中,“1”可用于表示声调为一声,又例如,音素可以为不带声调的拼音,如由元音音素和辅音音素组成的“tian”。需要说明的是,为了便于描述,本申请实施例利用拼音后面的数字表示声调,例如,“1”可用于表示声调为一声,“2”用于表示声调为二声,“3”用于表示声调为三声,“4”用于表示声调为四声。以语音流是中文以外的语言为例,本申请实施例中的音素可以包括元音音素和/或辅音音素,如英文“good”对应的音素可以为“gu”和“d”。本申请实施例不对音素的具体实现方式进行限定。The phonemes in the embodiments of the present application may include, but are not limited to, one or more of the following: pinyin with tones, pinyin without tones, vowel phonemes, and consonant phonemes. For example, the phoneme can be pinyin with tone, such as "tiān" or "tian1", where "1" can be used to indicate that the tone is one sound, and for example, the phoneme can be pinyin without tone , such as "tian" consisting of vowel phonemes and consonant phonemes. It should be noted that, for the convenience of description, in this embodiment of the present application, the numbers following the pinyin are used to represent the tones. For example, "1" can be used to indicate that the tone is one tone, "2" can be used to indicate that the tone is two, and "3" is used to indicate that the tone is one tone. The tone is three, and "4" is used to indicate that the tone is four. Taking the speech stream being a language other than Chinese as an example, the phonemes in this embodiment of the present application may include vowel phonemes and/or consonant phonemes. For example, the phonemes corresponding to English "good" may be "gu" and "d". The embodiments of the present application do not limit the specific implementation manner of the phoneme.
(2)词向量(2) Word vector
词向量(word vector)还可称为词嵌入(word embedding),用于将文本词表中的文本映射为实数向量。A word vector, also known as a word embedding, is used to map text in a text vocabulary to a real vector.
(3)梅尔倒谱系数(3) Mel cepstral coefficient
梅尔倒谱系数(Mel-scale frequency cepstral coefficients,MFCC)是在Mel标度频率域提取出来的倒谱参数,Mel标度用于描述人耳频率的非线性特性。MFCC可以包括预加重、分帧、加窗、快速傅里叶变换(FFT)、梅尔滤波器组、离散余弦变换等。MFCC用于对一段语音进行声学特征提取。由于语音信号中的某些信息与语音识别无关,并会使语音识别更加繁琐,对语音信号进行声学特征提取,可以通过给定数量的信号分量来描述语音信号,提取出对语音识别有帮助的信号。Mel-scale frequency cepstral coefficients (MFCC) are cepstral parameters extracted from the Mel-scale frequency domain, and the Mel-scale is used to describe the nonlinear characteristics of human ear frequencies. MFCCs may include pre-emphasis, framing, windowing, Fast Fourier Transforms (FFTs), Mel filter banks, discrete cosine transforms, and the like. MFCC is used to extract acoustic features from a piece of speech. Since some information in the speech signal has nothing to do with speech recognition and will make speech recognition more cumbersome, the acoustic feature extraction of the speech signal can describe the speech signal by a given number of signal components, and extract the information that is helpful to speech recognition. Signal.
本申请实施例提供一种语音识别方法及电子设备,能够应用于语音助手、语音输入法、听写系统、智能家居、车载导航等场景,可以提高语音识别的精度。本申请实施例提供语音识别方法可应用于电子设备100中,或者应用于包含电子设备100的系统中。The embodiments of the present application provide a voice recognition method and electronic device, which can be applied to scenarios such as voice assistants, voice input methods, dictation systems, smart homes, vehicle navigation, etc., and can improve the accuracy of voice recognition. The speech recognition method provided in the embodiment of the present application can be applied to the electronic device 100 or a system including the electronic device 100 .
可选的,电子设备100具体可以是手机、平板电脑、车载设备、增强现实(augmentedreality,AR)/虚拟现实(virtual reality,VR)设备、笔记本电脑、超级移动个人计算机(ultra-mobile personal computer,UMPC)、上网本、个人数字助理(personal digitalassistant,PDA)、人工智能(artificial intelligence)设备、可穿戴设备等具有语音识别功能的终端设备,可穿戴设备可以是智能手表、智能手环、无线耳机、智能眼镜、智能头盔、血糖仪、血压仪等。本申请实施例对电子设备100的具体类型不作任何限制。Optionally, the electronic device 100 may specifically be a mobile phone, a tablet computer, a vehicle-mounted device, an augmented reality (AR)/virtual reality (VR) device, a notebook computer, an ultra-mobile personal computer (ultra-mobile personal computer, UMPC), netbooks, personal digital assistants (personal digital assistants, PDA), artificial intelligence (artificial intelligence) devices, wearable devices and other terminal devices with voice recognition function, wearable devices can be smart watches, smart bracelets, wireless headphones, Smart glasses, smart helmets, blood glucose meters, blood pressure meters, etc. This embodiment of the present application does not impose any limitation on the specific type of the electronic device 100 .
示例性的,图1示出了电子设备100的一种结构示意图。电子设备100可以包括处理器110,外部存储器接口120,内部存储器121,通用串行总线(universal serial bus,USB)接口130,充电管理模块140,电源管理模块141,电池142,天线1,天线2,移动通信模块150,无线通信模块160,音频模块170,传感器模块190,按键190,马达191,指示器192,摄像头193,显示屏194,以及用户标识模块(subscriber identification module,SIM)卡接口195等。Exemplarily, FIG. 1 shows a schematic structural diagram of an electronic device 100 . The electronic device 100 may include a
处理器110可以包括一个或多个处理单元,例如:处理器110可以包括应用处理器(application processor,AP),调制解调处理器,图形处理器(graphics processingunit,GPU),图像信号处理器(image signal processor,ISP),控制器,存储器,视频编解码器,数字信号处理器(digital signal processor,DSP),基带处理器,和/或神经网络处理器(neural-network processing unit,NPU)等。其中,不同的处理单元可以是独立的器件,也可以集成在一个或多个处理器中。The
其中,控制器可以是电子设备100的神经中枢和指挥中心。控制器可以根据指令操作码和时序信号,产生操作控制信号,完成取指令和执行指令的控制。The controller may be the nerve center and command center of the electronic device 100 . The controller can generate an operation control signal according to the instruction operation code and timing signal, and complete the control of fetching and executing instructions.
处理器110中还可以设置存储器,用于存储指令和数据。在一些实施例中,处理器110中的存储器为高速缓冲存储器。该存储器可以保存处理器110刚用过或循环使用的指令或数据。如果处理器110需要再次使用该指令或数据,可从存储器中直接调用。避免了重复存取,减少了处理器110的等待时间,因而提高了系统的效率。A memory may also be provided in the
在本申请的一些实施例中,电子设备100可以利用处理器110对语音流进行处理,获得文本序列。In some embodiments of the present application, the electronic device 100 may use the
充电管理模块140用于从充电器接收充电输入。其中,充电器可以是无线充电器,也可以是有线充电器。The charging management module 140 is used to receive charging input from the charger. The charger may be a wireless charger or a wired charger.
电源管理模块141用于连接电池142、充电管理模块140与处理器110。电源管理模块141接收电池142和/或充电管理模块140的输入,为处理器110,内部存储器121,外部存储器,显示屏194,摄像头193,和无线通信模块160等供电。The
电子设备100的无线通信功能可以通过天线1、天线2、移动通信模块150、无线通信模块160、调制解调处理器以及基带处理器等实现。The wireless communication function of the electronic device 100 may be implemented by the
移动通信模块150可以提供应用在电子设备100上的包括2G/3G/4G/5G等无线通信的解决方案。移动通信模块150可以包括至少一个滤波器,开关,功率放大器,低噪声放大器(low noise amplifier,LNA)等。The
无线通信模块160可以提供应用在电子设备100上的包括无线局域网(wirelesslocal area networks,WLAN)(如无线保真(wireless fidelity,Wi-Fi)网络),蓝牙(bluetooth,BT),全球导航卫星系统(global navigation satellite system,GNSS),调频(frequency modulation,FM),近距离无线通信技术(near field communication,NFC),红外技术(infrared,IR)等无线通信的解决方案。The
电子设备100通过GPU,显示屏194,以及应用处理器等实现显示功能。GPU为图像处理的微处理器,连接显示屏194和应用处理器。GPU用于执行数学和几何计算,用于图形渲染。处理器110可包括一个或多个GPU,其执行程序指令以生成或改变显示信息。The electronic device 100 implements a display function through a GPU, a display screen 194, an application processor, and the like. The GPU is a microprocessor for image processing, and is connected to the display screen 194 and the application processor. The GPU is used to perform mathematical and geometric calculations for graphics rendering.
显示屏194用于显示图像,视频等。在一些实施例中,电子设备100可以包括1个或N个显示屏194,N为大于1的正整数。在本申请的一些实施例中,显示屏194可以用于显示文字符号、文本序列。Display screen 194 is used to display images, videos, and the like. In some embodiments, the electronic device 100 may include one or N display screens 194 , where N is a positive integer greater than one. In some embodiments of the present application, the display screen 194 may be used to display text symbols, text sequences.
电子设备100可以通过ISP、摄像头193、视频编解码器、GPU、显示屏194以及应用处理器等实现拍摄功能。The electronic device 100 may implement a shooting function through an ISP, a camera 193, a video codec, a GPU, a display screen 194, an application processor, and the like.
摄像头193用于捕获静态图像或视频。Camera 193 is used to capture still images or video.
外部存储器接口120可以用于连接外部存储卡,例如Micro SD卡,实现扩展电子设备100的存储能力。The external memory interface 120 may be used to connect an external memory card, such as a Micro SD card, to expand the storage capacity of the electronic device 100 .
内部存储器121可以用于存储计算机可执行程序代码,所述可执行程序代码包括指令。内部存储器121可以包括存储程序区和存储数据区。内部存储器121可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件,闪存器件,通用闪存存储器(universal flash storage,UFS)等。处理器110通过运行存储在内部存储器121的指令,和/或存储在设置于处理器中的存储器的指令,执行电子设备100的各种功能应用以及数据处理。在本申请的一些实施例中,内部存储器121可以用于存储声学模型、音素预测器、和音素翻译器等,可选地,内部存储器121还可以用于存储整流器。Internal memory 121 may be used to store computer executable program code, which includes instructions. The internal memory 121 may include a storage program area and a storage data area. The internal memory 121 may include high-speed random access memory, and may also include non-volatile memory, such as at least one magnetic disk storage device, flash memory device, universal flash storage (UFS), and the like. The
音频模块170包括扬声器,受话器,麦克风,耳机接口等。The audio module 170 includes speakers, receivers, microphones, headphone jacks, and the like.
音频模块170用于将数字音频数据转换成模拟音频电信号输出,也用于将模拟音频电信号输入转换为数字音频数据,音频模块170可以包括模/数转换器和数/模转换器。在本申请的一些实施例中,音频模块170可以用于采集语音流、音频信号、语音信号等。The audio module 170 is used for converting digital audio data into analog audio electrical signal output, and also for converting analog audio electrical signal input into digital audio data, and the audio module 170 may include an analog/digital converter and a digital/analog converter. In some embodiments of the present application, the audio module 170 may be used to collect voice streams, audio signals, voice signals, and the like.
在一些实施例中,电子设备100可以通过音频模块170,以及应用处理器等实现音频功能。例如音乐播放,录音等。In some embodiments, the electronic device 100 may implement audio functions through the audio module 170, an application processor, and the like. Such as music playback, recording, etc.
传感器模块190可以包括压力传感器,陀螺仪传感器,气压传感器,磁传感器,加速度传感器,距离传感器,接近光传感器,指纹传感器,温度传感器,触摸传感器,环境光传感器,骨传导传感器等。The sensor module 190 may include a pressure sensor, a gyro sensor, an air pressure sensor, a magnetic sensor, an acceleration sensor, a distance sensor, a proximity light sensor, a fingerprint sensor, a temperature sensor, a touch sensor, an ambient light sensor, a bone conduction sensor, and the like.
可以理解的是,本申请实施例示意的结构并不构成对电子设备100的具体限定。在本申请另一些实施例中,电子设备100可以包括比图示更多或更少的部件,或者组合某些部件,或者拆分某些部件,或者不同的部件布置。图示的部件可以以硬件,软件或软件和硬件的组合实现。It can be understood that the structures illustrated in the embodiments of the present application do not constitute a specific limitation on the electronic device 100 . In other embodiments of the present application, the electronic device 100 may include more or less components than shown, or combine some components, or separate some components, or arrange different components. The illustrated components may be implemented in hardware, software, or a combination of software and hardware.
电子设备100的软件系统可以采用分层架构、事件驱动架构、微核架构,微服务架构、或云架构。本发明实施例以分层架构的Android系统为例,示例性说明电子设备100的软件结构。The software system of the electronic device 100 may adopt a layered architecture, an event-driven architecture, a microkernel architecture, a microservice architecture, or a cloud architecture. The embodiment of the present invention takes an Android system with a layered architecture as an example to illustrate the software structure of the electronic device 100 as an example.
图2是本发明实施例的电子设备100的软件结构框图。FIG. 2 is a block diagram of a software structure of an electronic device 100 according to an embodiment of the present invention.
分层架构将软件分成若干个层,每一层都有清晰的角色和分工。层与层之间通过软件接口通信。在一些实施例中,将Android系统分为四层,从上至下分别为应用程序层,应用程序框架层,安卓运行时(Android runtime)和系统库,以及内核层。The layered architecture divides the software into several layers, and each layer has a clear role and division of labor. Layers communicate with each other through software interfaces. In some embodiments, the Android system is divided into four layers, which are, from top to bottom, an application layer, an application framework layer, an Android runtime (Android runtime) and system libraries, and a kernel layer.
应用程序层可以包括一系列应用程序包。The application layer can include a series of application packages.
如图2所示,应用程序包可以包括相机,日历,地图,WLAN,音乐,短信息,图库,通话,导航,第一应用等应用程序。As shown in FIG. 2, the application package may include applications such as camera, calendar, map, WLAN, music, short message, gallery, call, navigation, first application and so on.
其中,本申请实施例中的语音识别可以实现为第一应用,第一应用用于对语音流进行处理,获得文本序列。The speech recognition in this embodiment of the present application may be implemented as a first application, and the first application is used to process a speech stream to obtain a text sequence.
应用程序框架层为应用程序层的应用程序提供应用编程接口(applicationprogramming interface,API)和编程框架。应用程序框架层包括一些预先定义的函数。The application framework layer provides an application programming interface (application programming interface, API) and a programming framework for the applications of the application layer. The application framework layer includes some predefined functions.
如图2所示,应用程序框架层可以包括窗口管理器,内容提供器,视图系统,电话管理器,资源管理器,通知管理器等。As shown in Figure 2, the application framework layer may include window managers, content providers, view systems, telephony managers, resource managers, notification managers, and the like.
在一些实施例中,语音识别也可以实现为电子设备应用程序框架层中的模块,如语音识别模块。In some embodiments, speech recognition may also be implemented as a module in the electronic device application framework layer, such as a speech recognition module.
窗口管理器用于管理窗口程序。窗口管理器可以获取显示屏大小,判断是否有状态栏,锁定屏幕,截取屏幕等。A window manager is used to manage window programs. The window manager can get the size of the display screen, determine whether there is a status bar, lock the screen, take screenshots, etc.
内容提供器用来存放和获取数据,并使这些数据可以被应用程序访问。所述数据可以包括视频,图像,音频,拨打和接听的电话,浏览历史和书签,电话簿等。Content providers are used to store and retrieve data and make these data accessible to applications. The data may include video, images, audio, calls made and received, browsing history and bookmarks, phone book, etc.
视图系统包括可视控件,例如显示文字的控件,显示图片的控件等。视图系统可用于构建应用程序。显示界面可以由一个或多个视图组成的。例如,包括短信通知图标的显示界面,可以包括显示文字的视图以及显示图片的视图。The view system includes visual controls, such as controls for displaying text, controls for displaying pictures, and so on. View systems can be used to build applications. A display interface can consist of one or more views. For example, the display interface including the short message notification icon may include a view for displaying text and a view for displaying pictures.
电话管理器用于提供电子设备100的通信功能。例如通话状态的管理(包括接通,挂断等)。The phone manager is used to provide the communication function of the electronic device 100 . For example, the management of call status (including connecting, hanging up, etc.).
资源管理器为应用程序提供各种资源,比如本地化字符串,图标,图片,布局文件,视频文件等等。The resource manager provides various resources for the application, such as localization strings, icons, pictures, layout files, video files and so on.
通知管理器使应用程序可以在状态栏中显示通知信息,可以用于传达告知类型的消息,可以短暂停留后自动消失,无需用户交互。比如通知管理器被用于告知下载完成,消息提醒等。通知管理器还可以是以图表或者滚动条文本形式出现在系统顶部状态栏的通知,例如后台运行的应用程序的通知,还可以是以对话窗口形式出现在屏幕上的通知。例如在状态栏提示文本信息,发出提示音,指示灯闪烁等。The notification manager enables applications to display notification information in the status bar, which can be used to convey notification-type messages, and can disappear automatically after a brief pause without user interaction. For example, the notification manager is used to notify download completion, message reminders, etc. The notification manager can also display notifications in the status bar at the top of the system in the form of graphs or scroll bar text, such as notifications of applications running in the background, and notifications on the screen in the form of dialog windows. For example, text information is prompted in the status bar, a prompt sound is issued, and the indicator light flashes.
Android Runtime包括核心库和虚拟机。Android runtime负责安卓系统的调度和管理。Android Runtime includes core libraries and a virtual machine. The Android runtime is responsible for the scheduling and management of the Android system.
核心库包含两部分:一部分是java语言需要调用的功能函数,另一部分是安卓的核心库。The core library consists of two parts: one is the function functions that the java language needs to call, and the other is the core library of Android.
应用程序层和应用程序框架层运行在虚拟机中。虚拟机将应用程序层和应用程序框架层的java文件执行为二进制文件。虚拟机用于执行对象生命周期的管理,堆栈管理,线程管理,安全和异常的管理,以及垃圾回收等功能。The application layer and the application framework layer run in virtual machines. The virtual machine executes the java files of the application layer and the application framework layer as binary files. The virtual machine is used to perform functions such as object lifecycle management, stack management, thread management, safety and exception management, and garbage collection.
系统库可以包括多个功能模块。例如:表面管理器(surface manager),媒体库(Media Libraries),三维图形处理库(例如:OpenGL ES),2D图形引擎(例如:SGL)等。A system library can include multiple functional modules. For example: surface manager (surface manager), media library (Media Libraries), 3D graphics processing library (eg: OpenGL ES), 2D graphics engine (eg: SGL) and so on.
表面管理器用于对显示子系统进行管理,并且为多个应用程序提供了2D和3D图层的融合。The Surface Manager is used to manage the display subsystem and provides a fusion of 2D and 3D layers for multiple applications.
媒体库支持多种常用的音频,视频格式回放和录制,以及静态图像文件等。媒体库可以支持多种音视频编码格式,例如:MPEG4,H.264,MP3,AAC,AMR,JPG,PNG等。The media library supports playback and recording of a variety of commonly used audio and video formats, as well as still image files. The media library can support a variety of audio and video encoding formats, such as: MPEG4, H.264, MP3, AAC, AMR, JPG, PNG, etc.
三维图形处理库用于实现三维图形绘图,图像渲染,合成,和图层处理等。The 3D graphics processing library is used to implement 3D graphics drawing, image rendering, compositing, and layer processing.
2D图形引擎是2D绘图的绘图引擎。2D graphics engine is a drawing engine for 2D drawing.
内核层是硬件和软件之间的层。内核层至少包含显示驱动,摄像头驱动,音频驱动,传感器驱动。The kernel layer is the layer between hardware and software. The kernel layer contains at least display drivers, camera drivers, audio drivers, and sensor drivers.
图3为本申请实施例提供的语音识别模块的结构示意图。FIG. 3 is a schematic structural diagram of a speech recognition module provided by an embodiment of the present application.
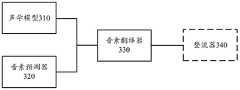
如图3所示,本申请实施例提供的语音识别模块可以包括声学模型(acousticmodel,AM)310、音素预测器(predictor)320、音素翻译器(translator)330。可选地,语音识别系统还可以包括整流器(pass)340。As shown in FIG. 3 , the speech recognition module provided by this embodiment of the present application may include an acoustic model (acoustic model, AM) 310 , a phoneme predictor (predictor) 320 , and a phoneme translator (translator) 330 . Optionally, the speech recognition system may also include a pass 340 .
其中,声学模型310可以为变换器(transducer)结构的神经网络模型。声学模型310的训练样本可以是音频数据。声学模型310主要基于目标语音信号帧获取对应音素的相关信息。例如,声学模型310可以根据目标语音信号帧和已解码输出的音素序列获取对应音素的相关信息。The acoustic model 310 may be a neural network model of a transducer structure. The training samples for the acoustic model 310 may be audio data. The acoustic model 310 mainly acquires the relevant information of the corresponding phoneme based on the target speech signal frame. For example, the acoustic model 310 may obtain the relevant information of the corresponding phoneme according to the target speech signal frame and the decoded output phoneme sequence.
本申请实施例中,目标语音信号帧可以为当前待识别的一个语音信号帧。已解码输出的音素序列可以包括起始音素和目标语音信号帧之前的一个或多个语音信号帧对应的多个音素序列中的一个音素序列,该已解码输出的音素序列可以是通过声学模型310获取的。目标语音信号帧对应的音素的相关信息包括但不限于:第一概率矩阵、音素序列、和音素序列的概率。In this embodiment of the present application, the target speech signal frame may be a speech signal frame currently to be recognized. The decoded output phoneme sequence may include a start phoneme and one phoneme sequence among a plurality of phoneme sequences corresponding to one or more speech signal frames before the target speech signal frame, and the decoded output phoneme sequence may be obtained through the acoustic model 310. obtained. The related information of the phonemes corresponding to the target speech signal frame includes, but is not limited to: the first probability matrix, the phoneme sequence, and the probability of the phoneme sequence.
其中,第一概率矩阵包括目标语音信号帧对应的一个音素所对应的音素词表中包括的多个音素中各个音素的概率。音素词表中包括一个或多个汉字对应的音素、和/或一个或多个英文单词对应的音素。可以理解为,第一概率矩阵包括目标语音信号帧被识别为音素词表中的各个音素的概率。Wherein, the first probability matrix includes the probability of each phoneme in the phoneme vocabulary included in the phoneme vocabulary corresponding to one phoneme corresponding to the target speech signal frame. The phoneme vocabulary includes phonemes corresponding to one or more Chinese characters and/or phonemes corresponding to one or more English words. It can be understood that the first probability matrix includes the probability that the target speech signal frame is recognized as each phoneme in the phoneme vocabulary.
图4为本申请实施例提供的声学模型、音素预测器和音素翻译器的结构示意图。FIG. 4 is a schematic structural diagram of an acoustic model, a phoneme predictor, and a phoneme translator provided by an embodiment of the present application.
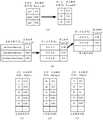
如图4中(a)所示,声学模型310可以包括编码器(encoder)311、预测网络(predictnetwork)312和联合网络(joint network)313。As shown in (a) of FIG. 4 , the acoustic model 310 may include an encoder 311 , a prediction network 312 and a
例如,编码器311可以为卷积神经网络(convolution neural network,CNN)结构、或循环神经网络(recurrent neural network,RNN)结构、或变压器(transformer)结构的神经网络等。其中,编码器311可以实现为残差神经网络(residual neural network,ResNet)结构、多层长短时记忆网络(long short term memory,LSTM)结构、或transformer结构等。如图4中(a)所示,编码器311的输入为经过Mel功率谱处理的音频信号,输出为固定维度的特征向量。For example, the encoder 311 may have a convolutional neural network (CNN) structure, a recurrent neural network (RNN) structure, or a neural network with a transformer (transformer) structure, or the like. The encoder 311 may be implemented as a residual neural network (residual neural network, ResNet) structure, a multi-layer long short term memory (LSTM) structure, or a transformer structure, or the like. As shown in (a) of FIG. 4 , the input of the encoder 311 is the audio signal processed by the Mel power spectrum, and the output is a feature vector with a fixed dimension.
例如,预测网络312可以为CNN结构、或RNN结构的神经网络模型等。其中,预测网络312可以实现为1维卷积结构、或多层LSTM结构等。如图4中(a)所示,预测网络312的输入为经过词向量处理的已解码输出的音素序列,如“jin1/tian1/tian1”,输出为固定维度的特征向量。For example, the prediction network 312 may be a CNN structure, a neural network model with an RNN structure, or the like. The prediction network 312 may be implemented as a 1-dimensional convolution structure, a multi-layer LSTM structure, or the like. As shown in (a) of FIG. 4 , the input of the prediction network 312 is the decoded output phoneme sequence after word vector processing, such as “jin1/tian1/tian1”, and the output is a feature vector of fixed dimension.
例如,联合网络313可以包括一个或多个全连接层。其中,若隐藏层每一个结点都与上一层的所有结点相连,并把上一层提取到的特征综合起来,则该隐藏层可称为全连接层。如图4中(a)所示,联合网络313对编码器311输出的固定维度的特征向量和预测网络312输出的固定维度的特征向量进行拼接操作、或直接相加等,预测下一音素,获得目标语音信号帧对应的音素的相关信息。For example,
示例性地,音素预测器320可以为CNN结构、或RNN结构、或transformer结构的神经网络模型等。例如,音素预测器320可以实现为多层LSTM结构、或transformer结构等。音素预测器320的训练样本可以是文本数据。音素预测器320主要基于语义获取音素的相关信息。如图4中(b)所示,音素预测器320可根据经过词向量处理的已解码输出的音素序列获取已解码输出的音素序列的下一个音素的相关信息。Exemplarily, the
在本申请实施例中,下一个音素的相关信息包括但不限于:第二概率矩阵、音素序列、和音素序列的概率。第二概率矩阵包括多个已解码输出的音素序列的下一可能音素对应的音素词表中包括的多个音素中各个音素的概率。In this embodiment of the present application, the related information of the next phoneme includes, but is not limited to: the second probability matrix, the phoneme sequence, and the probability of the phoneme sequence. The second probability matrix includes the probability of each phoneme in the plurality of phonemes included in the phoneme vocabulary corresponding to the next possible phoneme of the plurality of decoded output phoneme sequences.
示例性地,音素翻译器330可以为CNN结构、或RNN结构、或transformer结构的神经网络模型等。例如,音素翻译器330可以实现为1维卷积结构、或transformer结构等。音素翻译器330的训练样本可以是文本数据。如图4中(c)所示,音素翻译器330,可将经过词向量处理的音素序列翻译成对应的文本序列,如将“jin1/tian1/tian1/qi4”翻译为“今天天气”,还可获取文本序列对应的翻译概率,音素序列与文本序列一一对应。可选地,音素翻译器输出的文本序列的长度小于或等于音素序列的长度。若文本序列长度小于音素序列的长度,可以在文本序列中添加占位符,使文本序列的长度等于音素序列的长度。Exemplarily, the
在一些实施例中,音素翻译器330还可用于获取音素序列中每个音素被翻译为文本词表中包括的多个文本符号中各个文本符号的概率。如图4中(c)所示,“jin1”被翻译为“今”的概率为0.8,此处不一一列举。当音素翻译器对语音流对应的完整音素序列翻译完成后,得到第一栅格结构,第一栅格结构包括音素序列对应文本的概率矩阵。In some embodiments, the
示例性地,可以采用上述声学模型310、音素预测器320、音素翻译器330对语音流进行流式识别。以语音流为“今天天气好”为例,声学模型310对语音信号帧“今”进行处理后,声学模型310开始对语音信号“天”进行处理,可提高识别效率。类似地,音素翻译器330对语音信号帧“今”对应的数据进行处理后,显示语音信号帧“今”对应的文本,接着对语音信号“天”对应的数据进行处理,流式显示语音信号序列“今天”对应的文本序列,类似地,完成整句语音流的流式识别,流式识别结果可以为最终识别结果。Exemplarily, the above-mentioned acoustic model 310 ,
上述声学模型310是基于音频数据训练的模型,且可基于目标语音信号帧获得音素相关的信息。音素预测器320是基于文本数据训练的模型,且可基于语义获得下一个音素的相关信息。音素翻译器330是基于文本数据训练的模型,且可将音素翻译为文本。这些模型占用的存储空间小,可部署于电子设备,从而实现流识别,训练样本丰富,既包括音频数据,又包括文本数据,识别精度高。The above-mentioned acoustic model 310 is a model trained based on audio data, and can obtain phoneme-related information based on the target speech signal frame. The
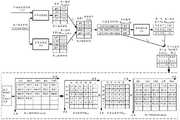
可选地,结合图5,整流器340可以包括混淆音矩阵、音素文本矩阵和加权有限状态转换器(weighted finite state transducer,WFST)(图5中未示出)。整流器340可以采用混淆音矩阵和音素文本矩阵对第一栅格结构进行剪裁,获取第二栅格结构,采用WFST对第二栅格结构进行维特比(Viterbi)算法解码,得出最终的文本序列。Optionally, in conjunction with FIG. 5 , the rectifier 340 may include an obfuscated tone matrix, a phoneme text matrix, and a weighted finite state transducer (WFST) (not shown in FIG. 5 ). The rectifier 340 can use the obfuscated sound matrix and the phoneme text matrix to trim the first grid structure, obtain the second grid structure, and use WFST to perform Viterbi algorithm decoding on the second grid structure to obtain the final text sequence. .
示例性地,混淆音矩阵为采用训练样本对声学模型310进行统计获得,混淆音矩阵用于表示音素词表中每一音素被声学模型310识别为全体音素中每一音素的概率。例如,结合图5,音素“a1”被识别为音素“a1”的概率为0.5,被识别为音素“a2”的概率为0.2,此处不再赘述。Exemplarily, the confusion matrix is obtained by using training samples to statistically obtain the acoustic model 310, and the confusion matrix is used to represent the probability that each phoneme in the phoneme vocabulary is recognized by the acoustic model 310 as each phoneme in the whole phoneme. For example, referring to FIG. 5 , the probability that the phoneme "a1" is recognized as the phoneme "a1" is 0.5, and the probability of being recognized as the phoneme "a2" is 0.2, which will not be repeated here.
示例性地,音素文本矩阵是一个0-1矩阵,用于表示文本符号对应的音素。以中文语音识别为例,音素文本矩阵可表示汉字和拼音的对应关系,例如,结合图5,汉字“啊”能发出“a1”的拼音,则“啊”对应音素“a1”的值为1,汉字“啊”不能发出“a2”的拼音,则“啊”对应音素“a2”的值为0。Exemplarily, the phoneme text matrix is a 0-1 matrix used to represent the phonemes corresponding to the text symbols. Taking Chinese speech recognition as an example, the phoneme text matrix can represent the correspondence between Chinese characters and pinyin. For example, in conjunction with Figure 5, the Chinese character "ah" can pronounce the pinyin of "a1", then the value of "ah" corresponding to the phoneme "a1" is 1 , the Chinese character "ah" cannot pronounce the pinyin of "a2", then the value of "ah" corresponding to the phoneme "a2" is 0.
在完成整句语音流的流式识别后,整流器340可对模糊音进行纠正,对第一栅格结构中的文本的概率进行微调,获得更准确的文本序列,从而进一步提高语音识别的精度。After completing the stream recognition of the entire speech stream, the rectifier 340 can correct the fuzzy sound, and fine-tune the probability of the text in the first grid structure to obtain a more accurate text sequence, thereby further improving the accuracy of speech recognition.
需要说明的是,本申请实施例不对声学模型310、音素预测器320、音素翻译器330和整流器340的具体实现方式进行限定,例如,不对其以哪种神经网络模型实现进行限定,以能够实现本申请实施例记载的相应功能为准。It should be noted that the embodiments of the present application do not limit the specific implementations of the acoustic model 310, the
以下将以电子设备为具有图1和图2所示结构的终端为例,对本申请实施例提供的语音识别方法进行阐述。The speech recognition method provided by the embodiment of the present application will be described below by taking the electronic device as a terminal having the structure shown in FIG. 1 and FIG. 2 as an example.
示例性的,图6为本申请实施例提供的语音识别方法的流程示意图一。参见图6,该语音识别流程包括S601-S606。下面以语音流为“今天天气好”为例,结合附图对本申请实施例提供的技术方案进行详细说明。Exemplarily, FIG. 6 is a first schematic flowchart of a speech recognition method provided by an embodiment of the present application. Referring to Fig. 6, the speech recognition process includes S601-S606. Hereinafter, the technical solutions provided by the embodiments of the present application will be described in detail with reference to the accompanying drawings, taking the voice stream as "the weather is good today" as an example.
S601,终端根据目标语音信号帧和多个第一音素序列中的一个第一音素序列获取第一概率矩阵。S601, the terminal obtains a first probability matrix according to the target speech signal frame and one first phoneme sequence among the multiple first phoneme sequences.
其中,语音流包括至少一个语音信号帧,终端可以采用音频功率谱、Mel功率谱、或MFCC对语音流进行声学特征提取。目标语音信号帧为当前待识别的一个语音信号帧。例如,语音流为“今天天气好”,若终端界面当前显示“今天天”,则语音信号帧“今天天”为已识别出的语音信号帧,语音信号帧“气”可以为目标语音信号帧。The voice stream includes at least one voice signal frame, and the terminal may use audio power spectrum, Mel power spectrum, or MFCC to perform acoustic feature extraction on the voice stream. The target speech signal frame is a speech signal frame to be recognized currently. For example, the voice stream is "good weather today", if the terminal interface currently displays "today's day", the voice signal frame "today's day" is the recognized voice signal frame, and the voice signal frame "qi" can be the target voice signal frame .
示例性地,第一音素序列的数量可以为多个,多个第一音素序列中每个第一音素序列可以包括起始音素和目标语音信号帧之前的一个或多个语音信号帧对应的多个音素序列中的一个音素序列,第一音素序列可以是经过词向量处理的,起始音素可以包括空字符。Exemplarily, the number of the first phoneme sequences may be multiple, and each first phoneme sequence in the multiple first phoneme sequences may include multiple numbers corresponding to the start phoneme and one or more speech signal frames before the target speech signal frame. A phoneme sequence in the phoneme sequence, the first phoneme sequence may be processed by the word vector, and the starting phoneme may include a null character.
例如,当目标语音信号帧为语音流中的第一个语音信号帧时,如目标语音信号帧为“今”时,则第一音素序列可以为空字符。For example, when the target speech signal frame is the first speech signal frame in the speech stream, such as when the target speech signal frame is "now", the first phoneme sequence may be a null character.
例如,目标语音信号帧为语音流中第一个“天”时,则每个第一音素序列可以包括语音信号帧“今”对应的一个音素序列,如“jin1”、“xin1”、或“a1”等。又例如,目标语音信号帧为“气”时,则每个第一音素序列可以包括语音信号帧序列“今天天”对应的一个音素序列,如“jin1/tian1/tian1”、或“jin1/tian1/tian2”等。For example, when the target speech signal frame is the first "day" in the speech stream, each first phoneme sequence may include a phoneme sequence corresponding to the speech signal frame "jin", such as "jin1", "xin1", or " a1" etc. For another example, when the target speech signal frame is "qi", each first phoneme sequence may include a phoneme sequence corresponding to the speech signal frame sequence "today's day", such as "jin1/tian1/tian1", or "jin1/tian1" /tian2" etc.
可选地,终端可以分别根据目标语音信号帧和多个第一音素序列中的每个音素序列执行上述S601。例如,目标语音信号帧为“气”,多个第一音素序列包括“jin1/tian1/tian1”、和“jin1/tian1/tian2”。终端可以根据目标语音信号帧“气”和第一音素序列“jin1/tian1/tian1”获取对应的第一概率矩阵,根据目标语音信号帧“气”和第一音素序列“jin1/tian1/tian2”获取对应的第一概率矩阵。Optionally, the terminal may perform the foregoing S601 according to the target speech signal frame and each phoneme sequence in the plurality of first phoneme sequences, respectively. For example, the target speech signal frame is "qi", and the plurality of first phoneme sequences include "jin1/tian1/tian1" and "jin1/tian1/tian2". The terminal can obtain the corresponding first probability matrix according to the target speech signal frame "qi" and the first phoneme sequence "jin1/tian1/tian1", and according to the target speech signal frame "qi" and the first phoneme sequence "jin1/tian1/tian2" Obtain the corresponding first probability matrix.
在一些实施例中,第一概率矩阵可以包括目标语音信号帧对应的一个音素所对应的音素词表中包括的多个音素中各个音素的概率。其中,音素词表包括一个或多个汉字对应的音素、和/或一个或多个英文单词对应的音素。In some embodiments, the first probability matrix may include the probability of each phoneme among the plurality of phonemes included in the phoneme vocabulary corresponding to one phoneme corresponding to the target speech signal frame. The phoneme vocabulary table includes phonemes corresponding to one or more Chinese characters and/or phonemes corresponding to one or more English words.
例如,如表1所示,当目标语音信号帧为“今”时,第一概率矩阵可以包括目标语音信号帧“今”被确定为音素词表中“jin1”的第一概率为0.7、被确定为“jing1”的第一概率为0.2、被确定为“jun1”的第一概率为0.05、被确定为“jin4”的第一概率为0.02等,本申请实施例不一一列举。For example, as shown in Table 1, when the target speech signal frame is "jin", the first probability matrix may include that the first probability that the target speech signal frame "jin" is determined as "jin1" in the phoneme vocabulary is 0.7, The first probability determined as "jing1" is 0.2, the first probability determined as "jun1" is 0.05, the first probability determined as "jin4" is 0.02, etc., which are not listed one by one in the embodiments of the present application.
表1Table 1
又例如,如表2所示,当目标语音信号帧为“气”时,第一概率矩阵可以包括目标语音信号帧“气”被确定为音素词表中“qi4”的第一概率为0.7,被确定为“qu4”的第一概率为0.1,被确定为“qie4”的第一概率为0.05,被确定为“ji4”的第一概率为0.01等,本申请实施例不一一列举。For another example, as shown in Table 2, when the target speech signal frame is "qi", the first probability matrix may include that the first probability that the target speech signal frame "qi" is determined as "qi4" in the phoneme vocabulary is 0.7, The first probability of being determined to be "qu4" is 0.1, the first probability of being determined to be "qie4" is 0.05, the first probability of being determined to be "ji4" is 0.01, etc. The embodiments of this application will not list them one by one.
表2Table 2
需要说明的是,本申请实施例不对语音流为“今天天气好”中的各个语音信号帧对应的第一概率矩阵进行一一列举。It should be noted that, the embodiment of the present application does not list the first probability matrices corresponding to each speech signal frame in which the speech stream is "good weather today" one by one.
在一种可能的设计方案中,终端根据目标语音信号帧和多个第一音素序列中的一个第一音素序列获取至少一个第二音素序列和/或第四概率矩阵。其中,至少一个第二音素序列中每个第二音素序列由多个第一音素序列中的一个第一音素序列和目标语音信号帧对应的一个音素组成,第四概率矩阵包括至少一个第二音素序列中每个第二音素序列对应的概率。第四概率矩阵可以包括第四概率,第四概率为每个第二音素序列对应的概率。In a possible design solution, the terminal acquires at least one second phoneme sequence and/or a fourth probability matrix according to the target speech signal frame and one of the multiple first phoneme sequences. Wherein, each second phoneme sequence in the at least one second phoneme sequence is composed of a first phoneme sequence among a plurality of first phoneme sequences and a phoneme corresponding to the target speech signal frame, and the fourth probability matrix includes at least one second phoneme The probability corresponding to each second phoneme sequence in the sequence. The fourth probability matrix may include a fourth probability, where the fourth probability is a probability corresponding to each second phoneme sequence.
以目标语音信号帧为语音流中的第一个语音信号帧为例,例如,目标语音信号帧为“今”,结合表3,终端根据目标语音信号帧“今”和空字符,确定出的至少一个第二音素序列可以包括“jin1”、“jing1”、“jun1”、和“jin4”等。其中,第二音素序列“jin1”对应的第四概率为0.7、“jing1”对应的第四概率为0.2,“jun1”对应的第四概率为0.05、“jun4”对应的第四概率为0.02等,本申请实施例不一一列举。Taking the target voice signal frame as the first voice signal frame in the voice stream as an example, for example, the target voice signal frame is "now", in combination with Table 3, the terminal determines the target voice signal frame "now" and null characters. The at least one second phoneme sequence may include "jin1", "jing1", "jun1", and "jin4", among others. The fourth probability corresponding to the second phoneme sequence "jin1" is 0.7, the fourth probability corresponding to "jing1" is 0.2, the fourth probability corresponding to "jun1" is 0.05, and the fourth probability corresponding to "jun4" is 0.02, etc. , the embodiments of the present application are not listed one by one.
表3table 3
表4Table 4
以目标语音信号帧不是语音流中的第一个语音信号帧为例,例如,目标语音信号帧为“气”,第一音素序列为“jin1/tian1/tian1”。如表4所示,确定出的至少一个第二音素序列可以包括“jin1/tian1/tian1/qi4”、“jin1/tian1/tian1/qu4”、“jin1/tian1/tian1/qie4”和“jin1/tian1/tian1/ji4”等。其中,第二音素序列“jin1/tian1/tian1/qi4”对应的第四概率为0.4、“jin1/tian1/tian1/qu4”对应的第四概率为0.1,“jin1/tian1/tian1/qie4”对应的第四概率为0.03、“jin1/tian1/tian1/ji4”对应的第四概率为0.01等,本申请实施例不一一列举。Taking the target speech signal frame not being the first speech signal frame in the speech stream as an example, for example, the target speech signal frame is "qi", and the first phoneme sequence is "jin1/tian1/tian1". As shown in Table 4, the determined at least one second phoneme sequence may include "jin1/tian1/tian1/qi4", "jin1/tian1/tian1/qu4", "jin1/tian1/tian1/qie4" and "jin1/ tian1/tian1/ji4" etc. Among them, the fourth probability corresponding to the second phoneme sequence "jin1/tian1/tian1/qi4" is 0.4, the fourth probability corresponding to "jin1/tian1/tian1/qu4" is 0.1, and "jin1/tian1/tian1/qie4" corresponds to The fourth probability of is 0.03, the fourth probability corresponding to "jin1/tian1/tian1/ji4" is 0.01, etc., which are not listed one by one in the embodiments of this application.
需要说明的是,本申请不限定获取第一概率矩阵与获取至少一个第二音素序列和/或第四概率矩阵的先后顺序。例如,终端可在获取第一概率矩阵的同时,获取至少一个第二音素序列和/或第四概率矩阵。It should be noted that the present application does not limit the sequence of acquiring the first probability matrix and acquiring at least one second phoneme sequence and/or fourth probability matrix. For example, the terminal may acquire at least one second phoneme sequence and/or a fourth probability matrix while acquiring the first probability matrix.
在一些实施例中,目标语音信号帧对应的第二音素序列可作为目标语音信号帧的下一语音信号帧对应的第一音素序列。In some embodiments, the second phoneme sequence corresponding to the target speech signal frame may be used as the first phoneme sequence corresponding to the next speech signal frame of the target speech signal frame.
例如,结合上述表3,目标语音信号帧为“今”时,获得的至少一个第二音素序列“jin1”、“jing1”、“jun1”、和“jin4”等可作为语音流中的语音信号帧第一个“天”的对应的第一音素序列。也就是说,当语音信号帧第一个“天”为目标语音信号帧时,终端可以以“jin1”、“jing1”、“jun1”或“jin4”等作为第一音素序列执行本申请实施例提供的方法,如执行上述S601,终端可以根据语音信号帧“天”和第一音素序列(“jin1”、“jing1”、“jun1”或“jin4”等)获取第一概率矩阵。For example, in combination with the above Table 3, when the target speech signal frame is "jin", the obtained at least one second phoneme sequence "jin1", "jing1", "jun1", and "jin4" can be used as the speech signal in the speech stream The corresponding first phoneme sequence for the first "day" of the frame. That is to say, when the first "day" of the voice signal frame is the target voice signal frame, the terminal may use "jin1", "jing1", "jun1" or "jin4" as the first phoneme sequence to execute the embodiment of the present application In the provided method, such as performing the above S601, the terminal can obtain the first probability matrix according to the speech signal frame "day" and the first phoneme sequence ("jin1", "jing1", "jun1" or "jin4", etc.).
又例如,结合上述表4,目标语音信号帧为“气”时,获得的至少一个第二音素序列“jin1/tian1/tian1/qi4”、“jin1/tian1/tian1/qu4”、“jin1/tian1/tian1/qie4”和“jin1/tian1/tian1/ji4”等可作为语音流中的语音信号帧“好”的对应的第一音素序列。也就是说,当语音信号帧“好”为目标语音信号帧时,终端可以以“jin1/tian1/tian1/qi4”、“jin1/tian1/tian1/qu4”、“jin1/tian1/tian1/qie4”或“jin1/tian1/tian1/ji4”等作为第一音素序列执行本申请实施例提供的方法,例如,终端可以根据目标语音信号帧“好”和第一音素序列(“jin1/tian1/tian1/qi4”、“jin1/tian1/tian1/qu4”、“jin1/tian1/tian1/qie4”或“jin1/tian1/tian1/ji4”等)获取至少一个第二音素序列和/或第四概率矩阵。For another example, in combination with the above Table 4, when the target speech signal frame is "Qi", the obtained at least one second phoneme sequence "jin1/tian1/tian1/qi4", "jin1/tian1/tian1/qu4", "jin1/tian1" /tian1/qie4" and "jin1/tian1/tian1/ji4" can be used as the corresponding first phoneme sequence of the speech signal frame "good" in the speech stream. That is to say, when the voice signal frame "good" is the target voice signal frame, the terminal can use "jin1/tian1/tian1/qi4", "jin1/tian1/tian1/qu4", "jin1/tian1/tian1/qie4" Or "jin1/tian1/tian1/ji4" etc. are used as the first phoneme sequence to execute the method provided in this embodiment of the present application. qi4", "jin1/tian1/tian1/qu4", "jin1/tian1/tian1/qie4" or "jin1/tian1/tian1/ji4", etc.) to obtain at least one second phoneme sequence and/or fourth probability matrix.
可选地,终端可以将目标语音信号帧对应的至少一个第二音素序列中每个第二音素序列作为目标语音信号帧的下一语音信号帧对应的第一音素序列,或者,终端可以将至少一个第二音素序列中部分第二音素序列作为目标语音信号帧的下一语音信号帧对应的第一音素序列。例如,终端可以根据第二音素序列对应的概率确定第一音素序列,如将概率最大的第二音素序列作为目标语音信号帧的下一语音信号帧对应的第一音素序列。Optionally, the terminal may use each second phoneme sequence in the at least one second phoneme sequence corresponding to the target voice signal frame as the first phoneme sequence corresponding to the next voice signal frame of the target voice signal frame, or the terminal may use at least one phoneme sequence. Part of the second phoneme sequence in a second phoneme sequence is used as the first phoneme sequence corresponding to the next speech signal frame of the target speech signal frame. For example, the terminal may determine the first phoneme sequence according to the probability corresponding to the second phoneme sequence, such as taking the second phoneme sequence with the highest probability as the first phoneme sequence corresponding to the next speech signal frame of the target speech signal frame.
在一种可能的设计方案中,终端可以利用声学模型对目标语音信号帧和多个第一音素序列中的一个第一音素序列进行处理,获取如下一项或多项:第一概率矩阵、至少一个第二音素序列和第四概率矩阵。In a possible design solution, the terminal may use the acoustic model to process the target speech signal frame and one of the multiple first phoneme sequences to obtain one or more of the following: a first probability matrix, at least A second phoneme sequence and fourth probability matrix.
结合图7中(a),以目标语音信号帧是语音信号帧“今”为例,声学模型310对目标语音信号帧“今”和第一音素序列空字符进行处理,获得目标语音信号帧“今”对应的第一概率矩阵、目标语音信号帧“今”对应的多个第二音素序列、该多个第二音素序列分别对应的第四概率。In conjunction with (a) in Figure 7, taking the target speech signal frame being the speech signal frame "Jin" as an example, the acoustic model 310 processes the target speech signal frame "Jin" and the null character of the first phoneme sequence to obtain the target voice signal frame "Jin". The first probability matrix corresponding to "jin", the plurality of second phoneme sequences corresponding to the target speech signal frame "jin", and the fourth probability corresponding to the plurality of second phoneme sequences respectively.
结合图7中(b),以目标语音信号帧是语音信号帧“气””、对应的第一音素序列是“jin1/tian1/tian1”为例,声学模型310可以对目标语音信号帧“气”和第一音素序列“jin1/tian1/tian1”进行处理,获得目标语音信号帧“气”对应的第一概率矩阵、目标语音信号帧“气”对应的多个第二音素序列、该多个第二音素序列分别对应的第四概率。With reference to (b) in FIG. 7 , taking the target speech signal frame being the speech signal frame "Qi" and the corresponding first phoneme sequence being "jin1/tian1/tian1" as an example, the acoustic model 310 can determine the target speech signal frame "Qi". " and the first phoneme sequence "jin1/tian1/tian1" to obtain the first probability matrix corresponding to the target speech signal frame "qi", multiple second phoneme sequences corresponding to the target speech signal frame "qi", the multiple The fourth probability corresponding to the second phoneme sequence respectively.
在一些实施例中,终端可以利用声学模型310的编码器311对目标语音信号帧进行处理,获取固定维度的特征向量Fencoder,利用声学模型310的预测网络312对第一音素序列进行处理,获取固定维度的特征向量FpredNet,本申请实施例不对获取Fencoder和FpredNet的先后顺序进行限定。然后,利用联合网络313对Fencoder和FpredNet进行拼接操作、或直接相加等,获得目标语音信号帧对应的第一概率矩阵、多个第二音素序列和多个第二音素序列分别对应的第四概率,第一概率矩阵包括第一概率PAM(td)。In some embodiments, the terminal may use the encoder 311 of the acoustic model 310 to process the target speech signal frame, obtain a feature vector Fencoder of a fixed dimension, and use the prediction network 312 of the acoustic model 310 to process the first phoneme sequence to obtain For the feature vector FpredNet of a fixed dimension, the order of obtaining Fencoder and FpredNet is not limited in this embodiment of the present application. Then, use the
其中,t表示目标语音信号帧,t可以为目标语音信号帧在语音流中的排序,t为大于或等于1的整数,第一语音序列的长度可以为t-1,d表示音素,PAM(td)表示目标语音信号帧t对应音素d的概率。Among them, t represents the target speech signal frame, t can be the order of the target speech signal frame in the speech stream, t is an integer greater than or equal to 1, the length of the first speech sequence can be t-1, d represents the phoneme, PAM (td ) represents the probability that the target speech signal frame t corresponds to the phoneme d.
结合图7中(c),以目标语音信号帧是“气”、对应的第一音素序列是“jin1/tian1/tian1”为例。编码器311对目标语音信号帧“气”进行处理,获得固定维度的特征向量Fencoder。预测网络312对第一音素序列“jin1/tian1/tian1”进行处理,获得固定维度的特征向量FpredNet。联合网络313对Fencoder和FpredNet进行拼接操作、或直接相加等,获得目标语音信号帧“气”对应的第一概率矩阵、多个第二音素序列和多个第二音素序列分别对应的第四概率。With reference to (c) in FIG. 7 , it is taken as an example that the target speech signal frame is "qi" and the corresponding first phoneme sequence is "jin1/tian1/tian1". The encoder 311 processes the target speech signal frame "Qi" to obtain a feature vector Fencoder of a fixed dimension. The prediction network 312 processes the first phoneme sequence "jin1/tian1/tian1" to obtain a fixed-dimensional feature vector FpredNet . The
S602,终端根据第一音素序列的语义,获取第二概率矩阵。S602, the terminal obtains a second probability matrix according to the semantics of the first phoneme sequence.
可选地,第一音素序列的语义表示所述第一音素序列的表达的语言含义,第二概率矩阵包括多个第一音素序列的下一可能音素对应的音素词表中包括的多个音素中各个音素的概率。如此,终端可以根据第一音素序列的语义获取第一音素序列的下一可能音素被确定为音素词表中包括的多个音素中各个音素的概率。Optionally, the semantics of the first phoneme sequence represents the language meaning expressed by the first phoneme sequence, and the second probability matrix includes a plurality of phonemes included in the phoneme vocabulary corresponding to the next possible phoneme of the plurality of first phoneme sequences. The probability of each phoneme in . In this way, the terminal can obtain the probability that the next possible phoneme of the first phoneme sequence is determined as each phoneme in the plurality of phonemes included in the phoneme vocabulary according to the semantics of the first phoneme sequence.
例如,当目标语音信号帧为语音流中的第一个语音信号帧时,结合表5,终端可以基于空字符,获得语音流的第一个音素被确定为音素词表中的音素“jin1”的概率为0.2,被确定为音素“wo3”的概率为0.1,被确定为音素“jing1”的概率为0.01,被确定为音素“hao3”的第二概率为0.01等,本申请实施例不一一列举。For example, when the target speech signal frame is the first speech signal frame in the speech stream, in combination with Table 5, the terminal can obtain the first phoneme of the speech stream based on the null character and determine that the phoneme "jin1" in the phoneme vocabulary The probability of being determined as the phoneme "wo3" is 0.1, the probability of being determined as the phoneme "jing1" is 0.01, the second probability of being determined as the phoneme "hao3" is 0.01, etc., the embodiments of this application are different an enumeration.
表5table 5
以第一音素序列是“jin1/tian1/tian1”为例,结合表6,终端基于“jin1/tian1/tian1”的可能要表达的语言含义,可以获得第一音素序列“jin1/tian1/tian1”的下一可能音素被确定为音素“qi4”的概率为0.2,被确定为音素“qu4”的概率为0.01,被确定为音素“leng3”的概率为0.05,被确定为音素“yin1”的概率为0.05等,本申请实施例不一一列举。Taking the first phoneme sequence as "jin1/tian1/tian1" as an example, in combination with Table 6, the terminal can obtain the first phoneme sequence "jin1/tian1/tian1" based on the possible linguistic meaning of "jin1/tian1/tian1" The next possible phoneme of is identified as phoneme "qi4" with probability 0.2, identified as phoneme "qu4" with probability 0.01, identified as phoneme "leng3" with probability 0.05, and identified as phoneme "yin1" with probability 0.05 is 0.05, etc., the examples of this application are not listed one by one.
表6Table 6
在一些实施例中,终端可以利用音素预测器根据第一音素序列的语义,获取第二概率矩阵,第二概率矩阵包括第二概率PPredictor(td)。In some embodiments, the terminal may use a phoneme predictor to obtain a second probability matrix according to the semantics of the first phoneme sequence, where the second probability matrix includes a second probability PPredictor (td ).
其中,t为第一音素序列的下一可能音素对应的语音信号帧(即目标语音信号帧)在语音流中的排序,t为大于或等于1的整数,第一音素序列的长度可以为t-1,d表示音素,PPredictor(td)表示第一音素序列的下一可能音素t对应音素词表中包括的多个音素中音素d的概率。Wherein, t is the order of the speech signal frame (that is, the target speech signal frame) corresponding to the next possible phoneme of the first phoneme sequence in the speech stream, t is an integer greater than or equal to 1, and the length of the first phoneme sequence can be t -1, d represents a phoneme, and PPredictor (td ) represents the probability that the next possible phoneme t of the first phoneme sequence corresponds to the phoneme d in the plurality of phonemes included in the phoneme vocabulary.
结合图8,以第一音素序列是“jin1/tian1/tian1”、t=4为例,音素预测器320根据第一音素序列“jin1/tian1/tian1”的语义,可以获得第一音素序列“jin1/tian1/tian1”的下一可能音素被确定为音素“qi4”的概率PPredictor(4qi4)=0.2,被确定为音素“qing2”的概率PPredictor(4qing2)=0.1,被确定为音素“leng3”的概率PPredictor(4leng3)=0.05,被确定为音素“qu4”的概率PPredictor(4qu4)=0.01等,本申请实施例不一一列举。8, taking the first phoneme sequence as "jin1/tian1/tian1" and t=4 as an example, the
S603,终端根据第一概率矩阵和第二概率矩阵,获取目标概率最大的N个目标音素序列。S603: The terminal acquires N target phoneme sequences with the largest target probability according to the first probability matrix and the second probability matrix.
其中,每个目标音素序列由步骤四和目标语音信号帧帧对应的一个音素组成,N为预设置的或预配置的,N为大于或等于1的整数,目标概率为每个目标音素序列的概率。也就是说,终端可以保留概率最高的N个目标音素序列,能够避免只选取概率最高的音素,错过全局最优的音素序列,可以提高语音识别的精度。Wherein, each target phoneme sequence is composed of a phoneme corresponding to step 4 and the target speech signal frame, N is preset or preconfigured, N is an integer greater than or equal to 1, and the target probability is the value of each target phoneme sequence. probability. That is to say, the terminal can retain the N target phoneme sequences with the highest probability, which can avoid selecting only the phoneme with the highest probability and miss the globally optimal phoneme sequence, which can improve the accuracy of speech recognition.
在一种可能的设计方案中,上述S603,可以包括:步骤一,终端根据第一概率矩阵和第二概率矩阵获取第五概率矩阵。步骤二,终端根据目标语音信号帧之前的一个或多个语音信号帧和目标语音信号帧分别对应的第五概率矩阵,获取目标概率最大的N个目标音素序列。In a possible design solution, the above S603 may include:
下面对步骤一,终端根据第一概率矩阵和第二概率矩阵获取第五概率矩阵进行具体阐述。Hereinafter, in
可选地,第五概率矩阵包括目标语音信号帧对应的一个音素所对应的音素词表中包括的多个音素中各个音素的融合概率。第五概率矩阵包括第五概率,第五概率为目标语音信号帧对应的一个音素所对应的音素词表中包括的多个音素中一个音素的概率。也就是说,终端可以对第一概率矩阵与第二概率矩阵进行融合,获得下一可能音素的最终概率。Optionally, the fifth probability matrix includes the fusion probability of each phoneme in the phoneme vocabulary included in the phoneme vocabulary corresponding to one phoneme corresponding to the target speech signal frame. The fifth probability matrix includes a fifth probability, and the fifth probability is the probability of one phoneme in the phoneme vocabulary included in the phoneme vocabulary corresponding to one phoneme corresponding to the target speech signal frame. That is, the terminal may fuse the first probability matrix and the second probability matrix to obtain the final probability of the next possible phoneme.
在一些实施例中,可以采用下述公式(1)对第一概率PAM(td)和第二概率PPredictor(td)进行融合,获得第五概率P(td)。In some embodiments, the following formula (1) may be used to fuse the first probability PAM (td ) and the second probability PPredictor (td ) to obtain the fifth probability P(td ).
P(td)=PAM(td)+λ1×PPredictor(td) (1)P(td )=PAM (td )+λ1 ×PPredictor (td ) (1)
在上述公式(1)中,P(td)为目标语音信号帧t对应音素d的融合概率,λ1为融合参数,λ1的取值范围为0≤λ1≤1,λ1可根据用于训练声学模型和/或音素预测器的训练样本调整得到。In the above formula (1), P(td ) is the fusion probability of the target speech signal frame t corresponding to the phoneme d, λ1 is the fusion parameter, the value range of λ1 is 0≤λ1 ≤1, and λ1 can be determined according to The training samples used to train the acoustic model and/or the phoneme predictor are adjusted.
以目标语音信号帧为语音流中的第一个语音信号帧、t为1以及d为音素“jin1”为例。结合图9中(a),PAM(1jin1)=0.7,PPredictor(1jin1)=0.2,假设λ1=0.3,则语音流中的第一个语音信号帧对应音素“jin1”的融合概率为P(1jin1)=0.7+0.3×0.2=0.76。类似地,还可以采用上述公式(1)计算语音流中的第一个语音信号帧对应其它音素d的融合概率,本申请实施例不一一列举。Take the target speech signal frame as the first speech signal frame in the speech stream, t being 1 and d being the phoneme "jin1" as an example. With reference to (a) in Figure 9, PAM (1jin1 )=0.7, PPredictor (1jin1 )=0.2, assuming λ1 =0.3, the first speech signal frame in the speech stream corresponds to the fusion of the phoneme "jin1" The probability is P(1jin1 )=0.7+0.3×0.2=0.76. Similarly, the above formula (1) can also be used to calculate the fusion probability of the first speech signal frame in the speech stream corresponding to other phonemes d, which are not listed in the embodiments of the present application.
以目标语音信号帧是语音流中的第四个语音信号帧、t为4以及d为音素“qi4”为例。结合图9中(b),PAM(4qi4)=0.7,PPredictor(4qi4)=0.2,假设λ1=0.5,则语音流中的第四个语音信号帧对应音素“qi4”的融合概率为P(4qi4)=0.7+0.5×0.2=0.8。类似地,还可以采用上述公式(1)计算语音流中的第四个语音信号帧对应其它音素d的融合概率,本申请实施例不一一列举。It is assumed that the target speech signal frame is the fourth speech signal frame in the speech stream, t is 4, and d is the phoneme "qi4". With reference to (b) in Figure 9, PAM (4qi4 )=0.7, PPredictor (4qi4 )=0.2, and assuming λ1 =0.5, the fourth speech signal frame in the speech stream corresponds to the fusion of the phoneme "qi4" The probability is P(4qi4 )=0.7+0.5×0.2=0.8. Similarly, the above formula (1) may also be used to calculate the fusion probability of the fourth speech signal frame in the speech stream corresponding to other phonemes d, which are not listed one by one in the embodiments of the present application.
在一些实施例中,可以采用下述公式(2)对第一概率PAM(td)和第二概率PPredictor(td)进行融合,获得第五概率P(td)。In some embodiments, the following formula (2) may be used to fuse the first probability PAM (td ) and the second probability PPredictor (td ) to obtain the fifth probability P(td ).
P(td)=λ2×PAM(td)+λ1×PPredictor(td) (2)P(td )=λ2 ×PAM (td )+λ1 ×PPredictor (td ) (2)
在上述公式(2)中,λ2为融合参数,λ2的取值范围为0≤λ2≤1,λ2是根据用于训练声学模型和/或音素预测器的训练样本得到的。In the above formula (2), λ2 is a fusion parameter, the value range of λ2 is 0≤λ2 ≤1, and λ2 is obtained according to the training samples used for training the acoustic model and/or the phoneme predictor.
以目标语音信号帧为语音流中的第一个语音信号帧、t为1以及d为音素“jing1”为例。结合图9中(a),PAM(1jing1)=0.2,PPredictor(1jing1)=0.01,假设λ2=0.2,λ1=1,则语音流中的第一个语音信号帧对应音素“jing1”的融合概率为P(1jing1)=0.2×0.2+0.01×1=0.05。类似地,还可以采用上述公式(2)计算语音流中的第一个语音信号帧对应其它音素d的融合概率,本申请实施例不再赘述。Take the target speech signal frame as the first speech signal frame in the speech stream, t being 1 and d being the phoneme "jing1" as an example. With reference to (a) in Figure 9, PAM (1jing1 )=0.2, PPredictor (1jing1 )=0.01, assuming λ2 =0.2, λ1 =1, then the first speech signal frame in the speech stream corresponds to the phoneme The fusion probability of "jing1" is P(1jing1 )=0.2×0.2+0.01×1=0.05. Similarly, the above formula (2) can also be used to calculate the fusion probability of the first speech signal frame in the speech stream corresponding to other phonemes d, which is not repeated in this embodiment of the present application.
在一些实施例中,可以采用下述公式(3)对第一概率PAM(td)和第二概率PPredictor(td)进行融合,获得第五概率P(td)。In some embodiments, the following formula (3) may be used to fuse the first probability PAM (td ) and the second probability PPredictor (td ) to obtain the fifth probability P(td ).
P(td)=λ2×PAM(td)+PPredictor(td) (3)P(td )=λ2 ×PAM (td )+PPredictor (td ) (3)
以目标语音信号帧是语音流中的第四个语音信号帧、t为4以及d为音素“qu4”为例。结合图9中(b),PAM(4qu4)=0.1,PPredictor(4qu4)=0.01,假设λ2=0.4,则语音流中的第一个语音信号帧对应音素“qu4”的融合概率为P(4qu4)=0.4×0.1+0.01=0.05。类似地,还可以采用上述公式(3)计算语音流中的第四个语音信号帧对应其它音素d的融合概率,本申请实施例不一一列举。It is assumed that the target speech signal frame is the fourth speech signal frame in the speech stream, t is 4, and d is the phoneme "qu4". With reference to (b) in Figure 9, PAM (4qu4 )=0.1, PPredictor (4qu4 )=0.01, and assuming λ2 =0.4, the first speech signal frame in the speech stream corresponds to the fusion of the phoneme "qu4" The probability is P(4qu4 )=0.4×0.1+0.01=0.05. Similarly, the above formula (3) can also be used to calculate the fusion probability of the fourth speech signal frame in the speech stream corresponding to other phonemes d, which are not listed one by one in the embodiments of the present application.
需要说明的是,本申请不对λ1的取值进行限定。示例性地,在获取第五概率P(td)时,语音信号帧t相同且音素d不同时,采用的λ1的取值可以不相同。例如,当目标语音信号帧为语音流中的第一个语音信号帧时,获取P(1jin1)采用的λ1的取值与获取P(1jun1)采用的λ1的取值可以不相同。示例性地,在获取第五概率矩阵P(td)时,语音信号帧t不相同时,采用的λ1的取值可以不相同。例如,获取P(1jin1)采用的λ1的取值与获取P(4qi4)采用的λ1的取值可以不相同。类似地,本申请不对λ2的取值进行限定,此处不再赘述。It should be noted that this application does not limit the value of λ1 . Exemplarily, when acquiring the fifth probability P(td ), when the speech signal frame t is the same and the phoneme d is different, the value of λ1 may be different. For example, when the target speech signal frame is the first speech signal frame in the speech stream, the value of λ1 used to obtain P(1jin1 ) may be different from the value of λ1 used to obtain P(1jun1 ) . Exemplarily, when acquiring the fifth probability matrix P(td ), when the speech signal frames t are different, the value of λ1 used may be different. For example, the value of λ1 used to obtain P(1jin1 ) may be different from the value of λ1 used to obtain P(4qi4 ). Similarly, the present application does not limit the value of λ2 , and details are not described here.
需要说明的是,终端可以采用上述公式(1)、公式(2)和公式(3)中的一项或多项获取第五概率P(td)。示例性地,上述公式(1)、公式(2)和公式(3)之间可以单独使用,例如,在识别语音流“今天天气好”时,终端只采用上述公式(1)获取第五概率P(td)。又示例性地,上述公式(1)、公式(2)和公式(3)之间可以结合使用。例如,当目标语音信号帧为语音流中的第一个语音信号帧时,终端采用公式(1)获取第五概率P(td),当目标语音信号帧为语音流中的第二个语音信号时,终端采用公式(3)获取第五概率P(td)。或者,当目标语音信号帧为语音流中的第一个语音信号帧时,终端采用上述公式(1)获取语音信号帧对应音素“jin1”的概率P(1jin1),采用上述公式(2)获取语音信号帧对应其它音素(如“jing1”)的概率P(1jing1)。It should be noted that, the terminal may obtain the fifth probability P(td ) by using one or more of the above formula (1), formula (2) and formula (3). Exemplarily, the above formula (1), formula (2) and formula (3) can be used independently. For example, when recognizing the voice stream "the weather is good today", the terminal only uses the above formula (1) to obtain the fifth probability. P(td ). For another example, the above formula (1), formula (2) and formula (3) can be used in combination. For example, when the target voice signal frame is the first voice signal frame in the voice stream, the terminal uses formula (1) to obtain the fifth probability P(td ), and when the target voice signal frame is the second voice frame in the voice stream signal, the terminal adopts formula (3) to obtain the fifth probability P(td ). Or, when the target voice signal frame is the first voice signal frame in the voice stream, the terminal adopts the above formula (1) to obtain the probability P(1jin1 ) of the phoneme "jin1" corresponding to the voice signal frame, and adopts the above formula (2) Obtain the probability P(1jing1 ) that the speech signal frame corresponds to other phonemes (eg "jing1").
下面对上述步骤二,终端根据目标语音信号帧之前的一个或多个语音信号帧和目标语音信号帧分别对应的第五概率矩阵,获取目标概率最大的N个目标音素序列进行具体阐述。In the second step above, the terminal acquires N target phoneme sequences with the largest target probability according to the fifth probability matrix corresponding to one or more voice signal frames before the target voice signal frame and the target voice signal frame respectively.
以目标语音信号帧为语音流中的第一个语音信号帧为例,结合图10中(a),假设N为3,终端可以对第一个语音信号帧“今”对应的音素的概率P(1d)进行排序,得出目标概率Pphone-seq(i)最大的3个目标音素序列,如分别为“jin1”、“jing1”、“jun1”。其中,i表示目标音素序列。Taking the target voice signal frame as the first voice signal frame in the voice stream as an example, in combination with (a) in Figure 10, assuming that N is 3, the terminal can determine the probability P of the phoneme corresponding to the first voice signal frame "now". (1d ) Perform sorting to obtain three target phoneme sequences with the largest target probability Pphone-seq (i), such as “jin1”, “jing1”, and “jun1” respectively. where i represents the target phoneme sequence.
以目标语音信号帧为语音流中的第四个语音信号帧为例,结合图10中(b),假设N为3,终端可以根据第一个语音信号帧“今”对应的音素的概率P(1d)至第四个语音信号帧“气””对应的音素的概率P(4d),得出目标概率Pphone-seq(i)最大的3个目标音素序列,如分别为“jin1/tian1/tian1/qi4”、“jin1/tian1/tian1/qu4”、“jin1/tian1/tian1/qing2”。Taking the target voice signal frame as the fourth voice signal frame in the voice stream as an example, with reference to (b) in Figure 10, assuming that N is 3, the terminal can use the probability P of the phoneme corresponding to the first voice signal frame "today". (1d ) to the probability P(4d ) of the phoneme corresponding to the fourth speech signal frame “Qi”, obtain the 3 target phoneme sequences with the largest target probability Pphone-seq (i), such as “jin1” respectively /tian1/tian1/qi4", "jin1/tian1/tian1/qu4", "jin1/tian1/tian1/qing2".
在一些实施例中,上述步骤二,可以包括:终端根据目标语音信号帧之前的一个或多个语音信号帧和目标语音信号帧分别对应的第五概率矩阵,获取至少一个目标音素序列以及至少一个目标概率。然后,从至少一个目标音素序列中,获取目标概率最大的N个目标音素序列。其中,目标音素序列与目标概率一一对应。In some embodiments, the second step above may include: the terminal obtains at least one target phoneme sequence and at least one target phoneme sequence according to one or more voice signal frames preceding the target voice signal frame and a fifth probability matrix corresponding to the target voice signal frame respectively target probability. Then, from at least one target phoneme sequence, N target phoneme sequences with the largest target probability are obtained. Among them, the target phoneme sequence corresponds to the target probability one-to-one.
以目标语音信号帧为语音流中的第四个语音信号帧为例,结合图10中(c),假设N为3,终端可以根据第一个语音信号帧“今”对应的音素的概率P(1d)至第四个语音信号帧“气””对应的音素的概率P(4d),得出多个目标音素序列i和目标音素序列对应的目标概率Pphone-seq(i)。终端可从多个目标音素序列中,获得目标概率Pphone-seq(i)最大的3个目标音素序列,如分别为“jin1/tian1/tian1/qi4”、“jin1/tian1/tian1/qu4”、“jin1/tian1/tian1/qing2”。Taking the target voice signal frame as the fourth voice signal frame in the voice stream as an example, in combination with (c) in Figure 10, assuming that N is 3, the terminal can use the probability P of the phoneme corresponding to the first voice signal frame "today". (1d ) to the probability P(4d ) of the phoneme corresponding to the fourth speech signal frame “Qi”, and obtain multiple target phoneme sequences i and target probability Pphone-seq (i) corresponding to the target phoneme sequence. The terminal can obtain 3 target phoneme sequences with the largest target probability Pphone-seq (i) from multiple target phoneme sequences, such as "jin1/tian1/tian1/qi4", "jin1/tian1/tian1/qu4" respectively , "jin1/tian1/tian1/qing2".
在一些实施例中,终端可以采用波束搜索(beam search)算法根据目标语音信号帧之前的一个或多个语音信号帧和目标语音信号帧分别对应的第五概率矩阵,获取目标概率最大的N个目标音素序列。In some embodiments, the terminal may use a beam search (beam search) algorithm to obtain N with the largest target probability according to the fifth probability matrix corresponding to one or more voice signal frames preceding the target voice signal frame and the target voice signal frame respectively target phoneme sequence.
波束搜索算法是序列到序列(sequence to sequence)深度自然语言处理算法中的搜索策略,波束搜索算法基于条件概率在每个时间步长为输入序列选择多个备选方案。如此,终端保留概率最高的N个目标音素序列,可以避免只选取概率最高的音素,错过全局最优的音素序列,从而可以提高语音识别的精度。Beam search algorithms are search strategies in sequence to sequence deep natural language processing algorithms that select multiple alternatives for an input sequence at each time step based on conditional probabilities. In this way, the terminal retains the N target phoneme sequences with the highest probability, which can avoid only selecting the phoneme with the highest probability and miss the globally optimal phoneme sequence, thereby improving the accuracy of speech recognition.
S604,终端对N个目标音素序列进行翻译,获取第三概率矩阵。S604, the terminal translates the N target phoneme sequences to obtain a third probability matrix.
其中,第三概率矩阵包括N个目标音素序列中的一个目标音素序列被翻译为至少一个第一文本序列的概率。示例性地,终端可以根据同一目标音素序列获得一个或多个第一文本序列以及对应的第三概率矩阵。第三概率矩阵包括第三概率,第三概率Ptranslator(ie)为目标音素序列i被翻译为第一文本序列e的概率,e表示第一文本序列或文本符号。Wherein, the third probability matrix includes the probability that one target phoneme sequence in the N target phoneme sequences is translated into at least one first text sequence. Exemplarily, the terminal may obtain one or more first text sequences and a corresponding third probability matrix according to the same target phoneme sequence. The third probability matrix includes a third probability, the third probability Ptranslator (ie ) is the probability that the target phoneme sequence i is translated into the first text sequence e, and e represents the first text sequence or text symbol.
以目标语音信号帧为语音流中的第一个语音信号帧为例,结合图11中(a),终端可以对目标音素序列“jin1”进行翻译,获得至少一个第一文本序列,如“今”,Ptranslator(jin1今)=0.75,又如“金”等,本申请实施例不一一列举。对目标音素序列“jing1”进行翻译,获得至少一个第一文本序列,如“经”,Ptranslator(jing1经)=0.5;对目标音素序列“jun1”进行翻译,获得至少一个第一文本序列,如“军”,Ptranslator(jun1军)=0.6。Taking the target voice signal frame as the first voice signal frame in the voice stream as an example, in conjunction with (a) in Figure 11, the terminal can translate the target phoneme sequence "jin1" to obtain at least one first text sequence, such as "now". ”, Ptranslator (jin1now )=0.75, another example is “gold”, etc. The embodiments of this application are not listed one by one. Translate the target phoneme sequence "jing1" to obtain at least one first text sequence, such as "jing", Ptranslator (jing1 jing)=0.5; translatethe target phoneme sequence "jun1" to obtain at least one first text sequence, Such as "jun", Ptranslator (jun1jun ) = 0.6.
以目标语音信号帧为语音流中的第四个语音信号帧为例,结合图11中(b),终端可以对目标音素序列“jin1/tian1/tian1/qi4”进行翻译,获得至少一个第一文本序列,如“今天天气”,Ptranslator(jin1/tian1/tian1/qi4今天天气)=0.98,又如“今天天器”等,本申请实施例不一一列举。对目标音素序列“jin1/tian1/tian1/qu4”进行翻译,获得至少一个第一文本序列,如“今天天去”,Ptranslator(jin1/tian1/tian1/qu4今天天去)=0.84;对目标音素序列“jin1/tian1/tian1/qing2”进行翻译,获得至少一个第一文本序列,如“今天天晴”,Ptranslator(jin1/tian1/tian1/qing2今天天晴)=0.9。Taking the target speech signal frame as the fourth speech signal frame in the speech stream as an example, with reference to (b) in Figure 11, the terminal can translate the target phoneme sequence "jin1/tian1/tian1/qi4" to obtain at least one first The text sequence, such as "today's weather", Ptranslator (jin1/tian1/tian1/qi4today's weather ) = 0.98, or "today's celestial device", etc., the embodiments of this application will not list them one by one. Translate the target phoneme sequence "jin1/tian1/tian1/qu4" to obtain at least one first text sequence, such as "today's day to go", Ptranslator (jin1/tian1/tian1/qu4 totoday's day to go ) = 0.84; for the target Translate the phoneme sequence "jin1/tian1/tian1/qing2" to obtain at least one first text sequence, such as "it is sunny today", Ptranslator (jin1/tian1/tian1/qing2is sunny today )=0.9.
在一种可能的设计方案中,终端可以对目标语音信号帧对应的音素词表中包括的多个音素中的一个或多个音素进行翻译,获得文本概率矩阵。其中,文本概率矩阵包括对应的音素被翻译为文本词表中包括的多个文本符号中各个文本符号的概率,文本概率矩阵包括文本概率H(te),文本概率H(te)包括音素t被翻译为文本词表中包括的多个文本符号中文本符号e的概率。In a possible design solution, the terminal may translate one or more phonemes among the multiple phonemes included in the phoneme vocabulary corresponding to the target speech signal frame to obtain a text probability matrix. Wherein, the text probability matrix includes the probability that the corresponding phoneme is translated into each text symbol in the plurality of text symbols included in the text vocabulary, the text probability matrix includes the text probability H(te ), and the text probability H(te ) includes the phoneme t is translated to the probability of text symbol e among the plurality of text symbols included in the text vocabulary.
示例性地,以目标语音信号帧是“今”为例,结合图11中(c),例如,目标语音信号帧“今”对应的音素为“jin1”,终端可以获得音素“jin1”被翻译为文本符号“今”的概率H(jin1今)=0.75,被翻译为文本符号“金”的概率H(jin1金)=0.10,被翻译为文本符号“晶”的概率H(jin1晶)=0.05,被翻译为文本符号“津”的概率H(jin1津)=0.02,被翻译为文本符号“军”的概率H(jin1军)=0.01,本申请实施例不一一列举。Exemplarily, taking the target speech signal frame as "jin" as an example, in conjunction with (c) in Figure 11, for example, the phoneme corresponding to the target speech signal frame "jin" is "jin1", and the terminal can obtain the phoneme "jin1" to be translated. The probability H(jin1jin )=0.75 for the text symbol "jin", the probability H(jin1jin)=0.10 for being translated as the text symbol "jin", the probability H(jin1jin )=0.10 for being translated as the text symbol "crystal " 0.05, the probability H(jin1jin)=0.02 of being translated into the text symbol "Jin", and the probability H(jin1jun )=0.01 of being translated into the text symbol "Jun ", which are not listed one by one in the embodiments of this application.
示例性地,以目标语音信号帧是“今”为例,结合图11中(d),例如目标语音信号帧“今”对应的音素为“jing1”,终端可以获得音素“jing1”被翻译为文本符号“经”的概率H(jing1经)=0.5,被翻译为文本符号“晶”的概率H(jing1晶)=0.2,被翻译为文本符号“惊”的概率H(jing1惊)=0.05,被翻译为文本符号“京”的概率H(jing1京)=0.02,被翻译为文本符号“今”的概率H(jing1今)=0.01,本申请实施例不一一列举。Exemplarily, taking the target voice signal frame as "jin" as an example, in conjunction with (d) in Figure 11, for example, the phoneme corresponding to the target voice signal frame "jin" is "jing1", the terminal can obtain the phoneme "jing1" and be translated as The probability H(jing1jing )=0.5 of the text symbol "jing", the probability H(jing1jing )=0.2 of being translated into the text symbol "jing", the probability H(jing1jing )=0.05 of being translated into the text symbol "jing" , the probability H(jing1jing)=0.02 of being translated as the text symbol "Jing ", the probability H(jing1jin )=0.01 of being translated as the text symbol "jin", the embodiments of this application are not listed one by one.
示例性地,以目标语音信号帧是“气”为例,结合图11中(e),例如,目标语音信号帧“气”对应的音素为“qi4”,终端可以获得音素“qi4”被翻译为文本符号“气”的概率H(qi4气)=0.6,被翻译为文本符号“器”的概率H(qi4器)=0.2,被翻译为文本符号“弃”的概率H(qi4弃)=0.1,被翻译为文本符号“去”的概率H(qi4去)=0.02,被翻译为文本符号“却”的概率H(qi4却)=0.01,本申请实施例不一一列举。Exemplarily, taking the target speech signal frame as "qi" as an example, in conjunction with (e) in Figure 11, for example, the phoneme corresponding to the target speech signal frame "qi" is "qi4", and the terminal can obtain the phoneme "qi4" to be translated. The probability H(qi4qi ) = 0.6 for the text symbol "Qi", the probability H(qi4device ) = 0.2 for being translated as the text symbol "Qi", the probability H(qi4abandoning ) for being translated as the text symbol "Abandonment" = 0.1, the probability of being translated as the text symbol “go” H(qi4go )=0.02, the probability of being translated as the text symbol “que” H(qi4but )=0.01, the embodiments of this application will not list them one by one.
需要说明的是,终端可以获得目标语音信号帧“今”对应的其他音素(如“jun1”)被翻译为文本词表中包括的多个文本符号中各个文本符号的概率,可以获得语音流中其它语音信号(如“好”)对应的音素被翻译为文本词表中包括的多个文本符号中各个文本符号的概率,本申请实施例不一一列举。It should be noted that the terminal can obtain the probability that other phonemes (such as "jun1") corresponding to the target speech signal frame "jin" are translated into each text symbol among the multiple text symbols included in the text vocabulary, and can obtain the probability of each text symbol in the speech stream. The probability that the phonemes corresponding to other speech signals (such as "good") are translated into each text symbol among the multiple text symbols included in the text vocabulary are not listed one by one in this embodiment of the present application.
在一种可能的设计方案中,终端可以采用音素翻译器对N个目标音素序列进行翻译,获取N个目标音素序列分别对应的第三概率矩阵。In a possible design solution, the terminal may use a phoneme translator to translate the N target phoneme sequences, and obtain third probability matrices corresponding to the N target phoneme sequences respectively.
以目标语音信号帧为语音流中的第四个语音信号帧为例,结合图12,终端可以采用音素翻译器330对目标音素序列“jin1/tian1/tian1/qi4”进行翻译,获得至少一个第一文本序列,如“今天天气”,Ptranslator(jin1/tian1/tian1/qi4今天天气)=0.98,又如“今天天器”等,本申请实施例不一一列举。当然,终端可以对目标音素序列“jin1/tian1/tian1/qu4”、“jin1/tian1/tian1/qing2”进行翻译,此处不一一列举。Taking the target voice signal frame as the fourth voice signal frame in the voice stream as an example, in conjunction with FIG. 12 , the terminal can use the
在一种可能的设计方案中,终端可以根据音素翻译器对目标语音信号帧对应的音素词表中包括的多个音素中的一个或多个音素进行翻译,获得文本概率矩阵。In a possible design solution, the terminal may translate one or more phonemes among the multiple phonemes included in the phoneme vocabulary corresponding to the target speech signal frame according to the phoneme translator to obtain a text probability matrix.
示例性地,结合图12,当目标语音信号帧是“今”时,终端可以采用音素翻译器330对目标语音信号帧“今”对应的音素为“jin1”进行翻译,获得音素“jin1”被翻译为文本符号“今”的概率H(jin1今)=0.75,被翻译为文本符号“金”的概率H(jin1金)=0.01,此处不一一列举。终端还可以采用音素翻译器330,获得目标语音信号帧“今”对应的其他音素(如“jing1”、“jun1”等)被翻译为文本词表中包括的多个文本符号中各个文本符号的概率。类似地,语音流中的每一个语音信号帧作为目标语音信号帧时,终端均可采用音素翻译器330对目标语音信号帧对应音素词表中包括的多个音素中的一个或多个音素进行翻译,获得对应的文本概率矩阵,本申请实施例不一一列举。12, when the target speech signal frame is "jin", the terminal can use the
可选地,终端可对文本概率矩阵进行存储,可以根据语音流中排序在后的语音信号帧对应的文本概率矩阵调整排序在前的语音信号帧对应的文本概率矩阵。Optionally, the terminal may store the text probability matrix, and may adjust the text probability matrix corresponding to the previously sorted voice signal frame according to the text probability matrix corresponding to the later sorted voice signal frame in the voice stream.
结合图12,当目标语音信号帧是“今”时,终端可以采用音素翻译器330获得H(jin1今)=0.75,H(jin1金)=0.10,并存储。当目标语音信号帧变为“今”的下一语音信号帧“天”时,终端可以目标语音信号帧“天”对应的文本概率矩阵调整H(jin1今)、和/或H(jin1金)的取值。当目标语音信号帧变为“气”时,终端可以目标语音信号帧“气”对应的文本概率矩阵调整H(jin1今)、和/或H(jin1金)的取值。12 , when the target speech signal frame is "jin", the terminal can use the
需要说明的是,本申请不限定终端对目标语音信号帧对应的音素词表中包括的多个音素中的一个或多个音素进行翻译与终端对N个目标音素序列进行翻译的先后顺序。It should be noted that this application does not limit the sequence in which the terminal translates one or more phonemes included in the phoneme vocabulary corresponding to the target speech signal frame and the terminal translates the N target phoneme sequences.
S605,终端根据所述第三概率矩阵和N个目标音素序列对应的目标概率,确定出至少一个第一文本序列中概率最大的一个第一文本序列。S605: The terminal determines, according to the third probability matrix and target probabilities corresponding to the N target phoneme sequences, a first text sequence with the highest probability among the at least one first text sequence.
在一些实施例中,可以采用下述公式(4)对目标概率Pphone-seq(i)和第三概率Ptranslator(ie)进行融合,获得第一文本序列的概率P(ie)。In some embodiments, the following formula (4) can be used to fuse the target probability Pphone-seq (i) and the third probability Ptranslator (ie ) to obtain the probability P(ie ) of the first text sequence.
P(ie)=Pphone-seq(i)+λ3×Ptranslator(ie) (4)P(ie )=Pphone-seq (i)+λ3 ×Ptranslator (ie ) (4)
在上述公式(4)中,i表示目标音素序列,e表示第一文本序列,第一文本序列的概率P(ie)为目标音素序列i对应第一文本序列e的融合概率,λ3为融合参数,λ3的取值范围为0≤λ3≤1,λ3可根据训练样本调整得到,如用于训练音素翻译器的训练样本。In the above formula (4), i represents the target phoneme sequence, e represents the first text sequence, the probability P(ie ) of the first text sequence is the fusion probability of the target phoneme sequence i corresponding to the first text sequence e, and λ3 is Fusion parameter, the value range of λ3 is 0≤λ3 ≤ 1, and λ3 can be adjusted according to the training sample, such as the training sample used to train the phoneme translator.
结合图13中(a),以目标语音信号帧为语音信号帧“今”为例,Pphone-seq(jin1)=0.8,Ptranslator(jin1今)=0.75,假设λ3=0.2,则目标音素序列“jin1”对应第一文本序列“今”的融合概率为P(jin1今)=0.8+0.2×0.75=0.95。类似地,还可以采用上述公式(4)计算目标音素序列“jin1”对应其它第一文本序列(如“金”)的融合概率,本申请实施例不再赘述。With reference to (a) in FIG. 13 , taking the target speech signal frame as the speech signal frame “jin” as an example, Pphone-seq (jin1)=0.8, Ptranslator (jin1jin )=0.75, assuming λ3 =0.2, then the target The fusion probability of the phoneme sequence "jin1" corresponding to the first text sequence "jin" is P(jin1jin )=0.8+0.2×0.75=0.95. Similarly, the above formula (4) can also be used to calculate the fusion probability of the target phoneme sequence "jin1" corresponding to other first text sequences (such as "jin"), which is not repeated in this embodiment of the present application.
结合图13中(b),以目标语音信号帧为语音信号帧“气””为例,Pphone-seq(jin1/tian1/tian1/qi4)=0.5,Ptranslator(jin1/tian1/tian1/qi4今天天气)=0.98,假设λ3=0.2,则目标音素序列“jin1/tian1/tian1/qi4”对应第一文本序列“今天天气”的融合概率为P(jin1/tian1/tian1/qi4今天天气)=0.5+0.2×0.98=0.696。类似地,还可以采用上述公式(4)计算目标音素序列“jin1/tian1/tian1/qi4”对应其它第一文本序列(如“今天天漆”)的融合概率,本申请实施例不再赘述。With reference to (b) in FIG. 13 , taking the target speech signal frame as the speech signal frame "Qi" as an example, Pphone-seq (jin1/tian1/tian1/qi4)=0.5, Ptranslator (jin1/tian1/tian1/qi4Today's weather ) = 0.98, assuming λ3 =0.2, then the fusion probability of the target phoneme sequence "jin1/tian1/tian1/qi4" corresponding to the first text sequence "today's weather" is P(jin1/tian1/tian1/qi4today's weather ) =0.5+0.2×0.98=0.696. Similarly, the above formula (4) can also be used to calculate the fusion probability of the target phoneme sequence "jin1/tian1/tian1/qi4" corresponding to other first text sequences (such as "today's lacquer") , which is not repeated in this embodiment of the present application.
在一些实施例中,可以采用下述公式(5)对目标概率Pphone-seq(i)和第三概率Ptranslator(ie)进行融合,获得第一文本序列的概率P(ie)。In some embodiments, the following formula (5) may be used to fuse the target probability Pphone-seq (i) and the third probability Ptranslator (ie ) to obtain the probability P(ie ) of the first text sequence.
P(ie)=λ4×Pphone-seq(i)+λ3×Ptranslator(ie) (5)P(ie )=λ4 ×Pphone-seq (i)+λ3 ×Ptranslator (ie ) (5)
在上述公式(5)中,λ4为融合参数,λ4的取值范围为0≤λ4≤1,λ4是根据用于训练样本得到的,如用于训练音素翻译器的训练样本。In the above formula (5), λ4 is a fusion parameter, the value range of λ4 is 0≤λ4 ≤1, and λ4 is obtained according to a training sample, such as a training sample used for training a phoneme translator.
结合图13中(b),以目标语音信号帧为语音信号帧“气”为例,Pphone-seq(jin1/tian1/tian1/qu4)=0.03,Ptranslator(jin1/tian1/tian1/qu4今天天去)=0.84,假设λ4=0.9,λ3=0.3,则目标音素序列“jin1/tian1/tian1/qi4”对应第一文本序列“今天天去”的融合概率为P(jin1/tian1/tian1/qu4今天天去)=0.9×0.03+0.3×0.84=0.279。类似地,还可以采用上述公式(5)计算目标音素序列“jin1/tian1/tian1/qu4”对应其它第一文本序列(如“今天天趣”)的融合概率,本申请实施例不再赘述。With reference to (b) in Figure 13, taking the target speech signal frame as the speech signal frame "Qi" as an example, Pphone-seq (jin1/tian1/tian1/qu4)=0.03, Ptranslator (jin1/tian1/tian1/qu4today tian go )=0.84, assuming λ4 =0.9, λ3 =0.3, then the fusion probability of the target phoneme sequence "jin1/tian1/tian1/qi4" corresponding to the first text sequence "day day today" is P(jin1/tian1/ tian1/qu4go today )=0.9×0.03+0.3×0.84=0.279. Similarly, the above formula (5) can also be used to calculate the fusion probability of the target phoneme sequence "jin1/tian1/tian1/qu4" corresponding to other first text sequences (such as "Today Tianqu"), which is not repeated in this embodiment of the present application.
在一些实施例中,可以采用下述公式(6)对目标概率Pphone-seq(i)和第三概率Ptranslator(ie)进行融合,获得第一文本序列的概率P(ie)。In some embodiments, the following formula (6) can be used to fuse the target probability Pphone-seq (i) and the third probability Ptranslator (ie ) to obtain the probability P(ie ) of the first text sequence.
P(ie)=λ4×Pphone-seq(i)+Ptranslator(ie) (6)P(ie )=λ4 ×Pphone-seq (i)+Ptranslator (ie ) (6)
结合图13中(a),以目标语音信号帧为语音信号帧“今”为例,Pphone-seq(jing1)=0.05,Ptranslator(jing1经)=0.05,假设λ4=0.9,则目标音素序列“jing1”对应第一文本序列“经”的融合概率为P(jing1经)=0.9×0.05+0.05=0.095。类似地,还可以采用上述公式(6)计算目标音素序列“jing1”对应其它第一文本序列(如“晶”)的融合概率,本申请实施例不再赘述。With reference to (a) in FIG. 13 , taking the target speech signal frame as the speech signal frame “Jin” as an example, Pphone-seq (jing1)=0.05, Ptranslator (jing1Jing )=0.05, assuming λ4 =0.9, then the target The fusion probability ofthe phoneme sequence "jing1" corresponding to the first text sequence "jing" is P(jing1 jing)=0.9×0.05+0.05=0.095. Similarly, the above formula (6) can also be used to calculate the fusion probability of the target phoneme sequence "jing1" corresponding to other first text sequences (such as "crystal"), which is not repeated in this embodiment of the present application.
需要说明的是,终端可以采用上述公式(4)、公式(5)和公式(6)中的一项或多项获取第一文本序列的概率。示例性地,上述公式(4)、公式(5)和公式(6)之间可以单独使用,也可以结合使用。It should be noted that the terminal may obtain the probability of the first text sequence by using one or more of the above formula (4), formula (5) and formula (6). Exemplarily, the above formula (4), formula (5) and formula (6) can be used alone or in combination.
如此,终端采用对目标概率和第三概率融合的方式,可以获取更准确的第一文本序列的概率,从而可以进一步提高语音识别的精度。In this way, the terminal can obtain a more accurate probability of the first text sequence by merging the target probability and the third probability, thereby further improving the accuracy of speech recognition.
S606,终端显示概率最大的一个第一文本序列。S606, the terminal displays a first text sequence with the highest probability.
也就是说,终端可以确定各个第一文本序列对应的概率的大小,显示概率最大的一个第一文本序列。That is, the terminal can determine the size of the probability corresponding to each first text sequence, and display the one first text sequence with the highest probability.
结合图13中(a),当第一文本序列为目标语音信号帧为“今”时的目标音素序列对应的文本序列时,终端根据第一文本序列的概率对第一文本序列进行排序。其中,目标音素序列“jin1”对应的概率最大的第一文本序列为“气”,目标音素序列“jing1”对应的概率最大的第一文本序列为“经”,目标音素序列“jun1”对应的概率最大的第一文本序列为“军”。终端对第一文本序列为“气”、“经”以及“军”对应的概率进行排序,得出第一文本序列“今”的概率最大,为0.95,则终端显示第一文本序列“今”。Referring to (a) in FIG. 13 , when the first text sequence is the text sequence corresponding to the target phoneme sequence when the target speech signal frame is "now", the terminal sorts the first text sequence according to the probability of the first text sequence. Among them, the first text sequence with the highest probability corresponding to the target phoneme sequence "jin1" is "qi", the first text sequence corresponding to the target phoneme sequence "jing1" with the highest probability is "jing", and the target phoneme sequence "jun1" corresponds to the first text sequence with the highest probability. The first text sequence with the highest probability is "jun". The terminal sorts the probabilities that the first text sequence is "Qi", "Jing" and "Army", and finds that the probability of the first text sequence "Jin" is the largest, which is 0.95, then the terminal displays the first text sequence "Jin" .
结合图13中(b),当第一文本序列为目标语音信号帧为“气”时的目标音素序列对应的文本序列时,终端根据第一文本序列的概率对第一文本序列进行排序。与上述当第一文本序列为目标语音信号帧为“今”时的目标音素序列对应的文本序列时,终端根据概率对第一文本序列进行排序类似,终端对第一文本序列为“今天天气”、“今天天去”以及“今天天晴”对应的概率进行排序,得出第一文本序列“今天天气”的概率最大,为0.696,则终端显示第一文本序列“今天天气”。类似地,完成整句语音流的流式识别,流式识别结果可以为最终识别结果。Referring to (b) in FIG. 13 , when the first text sequence is the text sequence corresponding to the target phoneme sequence when the target speech signal frame is “Qi”, the terminal sorts the first text sequence according to the probability of the first text sequence. Similar to the above when the first text sequence is the text sequence corresponding to the target phoneme sequence when the target speech signal frame is "today", the terminal sorts the first text sequence according to the probability, and the terminal sorts the first text sequence as "today's weather". , "Today's going" and "Today's sunny" corresponding probabilities are sorted, and the probability of the first text sequence "Today's weather" is the largest, which is 0.696, and the terminal displays the first text sequence "Today's weather". Similarly, the stream recognition of the entire speech stream is completed, and the stream recognition result can be the final recognition result.
基于图6所示的语音识别方法,终端根据目标语音信号帧对应的音素的概率矩阵和第一音素序列的下一可能音素的概率矩阵,获取目标概率最大的N个目标音素序列。然后,对该N个目标音素序列进行翻译,获取该N个目标音素序列分别对应的至少一个第一文本序列和至少一个第一文本序列中每个第一文本序列的第三概率,根据第三概率和N个目标音素序列对应的目标概率,确定出至少一个第一文本序列中概率最大的一个第一文本序列,显示该概率最大的第一文本序列,从而可以提高语音识别的精度。Based on the speech recognition method shown in FIG. 6 , the terminal obtains N target phoneme sequences with the highest target probability according to the probability matrix of the phoneme corresponding to the target speech signal frame and the probability matrix of the next possible phoneme of the first phoneme sequence. Then, the N target phoneme sequences are translated to obtain at least one first text sequence corresponding to the N target phoneme sequences respectively and the third probability of each first text sequence in the at least one first text sequence, according to the third probability The probability and the target probability corresponding to the N target phoneme sequences are used to determine a first text sequence with the highest probability among the at least one first text sequence, and display the first text sequence with the highest probability, thereby improving the accuracy of speech recognition.
示例性的,图14为本申请实施例提供的语音识别方法的流程示意图二。上述S601-S606可以作为终端流式显示文本序列的过程,当终端执行上述S601-S606,流式显示语音流对应的完整文本序列(如“今天天气好”)的基础上,还可以执行下述S1401-S1403,具体参见图14。Exemplarily, FIG. 14 is a second schematic flowchart of the speech recognition method provided by this embodiment of the present application. The above S601-S606 can be used as a process for the terminal to stream the text sequence. When the terminal executes the above S601-S606, on the basis of the complete text sequence corresponding to the voice stream (such as "the weather is good today"), the terminal can also perform the following: S1401-S1403, see FIG. 14 for details.
S1401,终端获取第一栅格结构。S1401, the terminal acquires the first grid structure.
可选地,第一栅格(lattice)结构的横坐标为语音流对应的完整音素序列中的各个音素,纵坐标为完整音素序列中的各个音素分别对应的文本概率矩阵。Optionally, the abscissa of the first lattice structure is each phoneme in the complete phoneme sequence corresponding to the speech stream, and the ordinate is the text probability matrix corresponding to each phoneme in the complete phoneme sequence respectively.
图15为本申请实施例提供的第一栅格结构的结构示意图。结合图15,以语音流对应的完整音素序列“jin1/tian1/tian1/qi4/hao3”为例,第一栅格结构包括音素“jin1”对应的文本概率矩阵、音素“tian1”对应的文本概率矩阵、音素“tian1”对应的文本概率矩阵、音素“qi4”对应的文本概率矩阵、和音素“hao3”对应的文本概率矩阵。FIG. 15 is a schematic structural diagram of a first grid structure provided by an embodiment of the present application. With reference to Figure 15, taking the complete phoneme sequence "jin1/tian1/tian1/qi4/hao3" corresponding to the speech stream as an example, the first grid structure includes the text probability matrix corresponding to the phoneme "jin1" and the text probability corresponding to the phoneme "tian1". matrix, the text probability matrix corresponding to the phoneme "tian1", the text probability matrix corresponding to the phoneme "qi4", and the text probability matrix corresponding to the phoneme "hao3".
示例性地,第一栅格结构的大小可以为T×Le,Le为文本词表中文本符号的数量,T为语音流包括的语音信号帧的数量或语音流对应的完整音素序列中音素的数量。例如,图15所示的第一栅格结构的大小可以为4×Le。Exemplarily, the size of the first grid structure may be T×Le , whereLe is the number of text symbols in the text vocabulary, and T is the number of speech signal frames included in the speech stream or in the complete phoneme sequence corresponding to the speech stream. number of phonemes. For example, the size of the first grid structure shown in FIG. 15 may be 4×Le .
在一些实施例中,终端可以对至少一个完整音素序列进行解码,获取第一栅格结构。其中,完整音素序列可以为目标语音信号帧为语音流中最后一个语音信号帧时获得的目标音素序列。In some embodiments, the terminal may decode at least one complete phoneme sequence to obtain the first trellis structure. The complete phoneme sequence may be the target phoneme sequence obtained when the target speech signal frame is the last speech signal frame in the speech stream.
示例性地,语音流可以对应一个或多个完整音素序列,如语音流“今天天气好”对应完整音素序列“jin1/tian1/tian1/qi4/hao3”、“jin1/tian1/tian1/qi4/huo3”、“jin1/tian1/tian1/qi4/gao1”等,终端可以获取完整音素序列“jin1/tian1/tian1/qi4/hao3”、“jin1/tian1/tian1/qi4/huo3”、“jin1/tian1/tian1/qi4/gao1”分别对应的第一栅格结构。Exemplarily, the speech stream may correspond to one or more complete phoneme sequences, for example, the speech stream "the weather is good today" corresponds to the complete phoneme sequences "jin1/tian1/tian1/qi4/hao3", "jin1/tian1/tian1/qi4/huo3" ", "jin1/tian1/tian1/qi4/gao1", etc., the terminal can obtain the complete phoneme sequence "jin1/tian1/tian1/qi4/hao3", "jin1/tian1/tian1/qi4/huo3", "jin1/tian1/ tian1/qi4/gao1" respectively correspond to the first grid structure.
可选地,终端可以对概率最大的完整文本序列对应的完整音素序列进行解码,获取第一栅格结构。其中,概率最大的完整文本序列是流式显示过程中显示的完整文本序列(如“今天天气好”)。如此,终端可以只对概率最大的完整文本序列对应的音素序列进行解码,以降低语音识别的复杂度。Optionally, the terminal may decode the complete phoneme sequence corresponding to the complete text sequence with the highest probability to obtain the first grid structure. Among them, the complete text sequence with the highest probability is the complete text sequence displayed during the streaming display process (eg "The weather is nice today"). In this way, the terminal can only decode the phoneme sequence corresponding to the complete text sequence with the highest probability, so as to reduce the complexity of speech recognition.
需要说明的是,本申请实施例不限定S1401与上述S604-S606的先后顺序,如第一栅格结构可以是在终端翻译目标音素序列的过程中或之后获取的,也可以是在显示文本序列的过程中或之后获取的,本申请对此不进行限定。It should be noted that this embodiment of the present application does not limit the sequence of S1401 and the above-mentioned S604-S606. For example, the first grid structure may be acquired during or after the terminal translates the target phoneme sequence, or may be displayed during the display of the text sequence. obtained during or after the process, this application does not limit it.
S1402,终端对第一栅格结构进行裁剪,获取第二栅格结构。S1402, the terminal trims the first grid structure to obtain the second grid structure.
在一些实施例中,终端可以采用整流器对第一栅格结构进行裁剪,获取第二栅格结构。具体可以包括下述步骤三至步骤四。In some embodiments, the terminal may use a rectifier to trim the first grid structure to obtain the second grid structure. Specifically, the following steps 3 to 4 may be included.
步骤三,终端基于混淆音矩阵Md-d和音素文本矩阵Md-e,获得音素文本混淆矩阵Mconfusion。Step 3, the terminal obtains a phoneme text confusion matrix Mconfusion based on the confusion sound matrix Mdd and the phoneme text matrix Mde .
其中,混淆音矩阵的大小为Ld×Ld,音素文本矩阵的大小为Ld×Le,Ld为音素词表中音素的数量,Le为文本词表中文本符号的数量。The size of the confusion matrix is Ld ×Ld , the size of the phoneme text matrix is Ld ×Le , Ld is the number of phonemes in the phoneme vocabulary, andLe is the number of text symbols in the text vocabulary.
可选地,音素文本混淆矩阵Mconfusion是混淆音矩阵Md-d和音素文本矩阵Md-e矩阵相乘得到的,例如采用下述公式(7)。Optionally, the phoneme text confusion matrix Mconfusion is obtained by multiplying the confusion sound matrix Mdd and the phoneme text matrix Mde matrix, for example, using the following formula (7).
Mconfusion=Md-d×Md-e (7)Mconfusion =Mdd ×Mde (7)
在上述公式(7)中,音素文本混淆矩阵Mconfusion的大小为Ld×Le。结合图16中(a),将混淆音矩阵Md-d和音素文本矩阵Md-e矩阵相乘,得到音素文本混淆矩阵Mconfusion。In the above formula (7), the size of the phoneme-text confusion matrix Mconfusion is Ld ×Le . With reference to (a) in FIG. 16 , the confusion matrix Mdd and the phoneme text matrix Mde are multiplied to obtain the phoneme text confusion matrix Mconfusion .
步骤四,终端基于音素文本混淆矩阵Mconfusion对第一栅格结构Lattice进行剪裁,获取第二栅格结构。Step 4: The terminal trims the first lattice structure Lattice based on the phoneme-text confusion matrix Mconfusion to obtain the second lattice structure.
可选地,第二栅格结构可以是音素文本混淆矩阵Mconfusion与第一栅格结构Lattice的对应元素相乘获得的,如采用下述公式(8)。Optionally, the second lattice structure may be obtained by multiplying the phoneme-text confusion matrix Mconfusion by the corresponding elements of the first lattice structure Lattice, for example, using the following formula (8).
Lattice’(t) = Lattice(t)×Mconfusion (dt) (8)Lattice'(t) = Lattice(t)×Mconfusion (dt ) (8)
在上述公式(8)中,Lattice’(t)表示第二栅格结构Lattice’中音素t对应的列数据,Lattice(t)表示第一栅格结构中音素t对应的列数据,Mconfusion(dt)表示音素文本混淆矩阵Mconfusion中音素t对应的行数据。In the above formula (8), Lattice'(t) represents the column data corresponding to the phoneme t in the second grid structure Lattice', Lattice(t) represents the column data corresponding to the phoneme t in the first grid structure, Mconfusion ( dt ) represents the row data corresponding to phoneme t in the phoneme-text confusion matrix Mconfusion .
结合图16中(b),以对第一栅格结构Lattice的第一列进行剪裁为例,第一栅格结构Lattice的第一列为音素“jin1”对应的数据,记为Lattice(jin1)。音素文本混淆矩阵Mconfusion中的音素“jin1”对应的行数据,记为Mconfusion(djin1)。将第一栅格结构Lattice中音素“jin1”对应文本符号“今”的值0.75,与音素文本混淆矩阵Mconfusion中音素“jin1”对应文本符号“今”的值1(图16中未示出,假设为1)相乘,得到第二栅格结构Lattice’中音素“jin1”对应文本符号“今”的值0.75,类似地,计算第一列的其它数据,去掉计算结果为0的值。类似地,采用相同的方法对第一栅格结构Lattice的其它列进行剪裁,得出第二栅格结构Lattice’。需要说明的是,图16仅为本申请的一个示例。With reference to (b) in FIG. 16 , taking the clipping of the first column of the first lattice structure Lattice as an example, the first column of the first lattice structure Lattice corresponds to the data corresponding to the phoneme "jin1", denoted as Lattice(jin1) . The line data corresponding to the phoneme "jin1" in the phoneme text confusion matrix Mconfusion is denoted as Mconfusion (djin1 ). The phoneme "jin1" in the first lattice structure Lattice corresponds to the value of 0.75 for the text symbol "jin", and the phoneme "jin1" in the phoneme-text confusion matrix Mconfusion corresponds to the
S1403,终端对第二栅格结构进行解码,获取并显示第二文本序列。S1403, the terminal decodes the second grid structure, and acquires and displays the second text sequence.
可选地,第二文本序列与概率最大的第一文本序列可以相同或不同。该第一文本序列为目标语音信号帧为语音流中最后一个语音信号帧时获得的文本序列。Optionally, the second text sequence and the first text sequence with the highest probability may be the same or different. The first text sequence is a text sequence obtained when the target speech signal frame is the last speech signal frame in the speech stream.
示例性地,利用加权有限状态转换器WFST对第二栅格结构进行维特比算法解码,获得第二文本序列,该第二文本序列可作为最终的文本序列。Exemplarily, the Viterbi algorithm is used to decode the second grid structure by using the weighted finite state converter WFST to obtain a second text sequence, and the second text sequence can be used as the final text sequence.
示例性地,第二文本序列可能与第一文本序列相同,也可能不相同。若语音流中存在容易混淆的语音信号帧,如语音流“打电话给邹杰伦”中的语音信号帧“邹”,该语音信号帧“邹”容易与语音信号帧“周”混淆,通过图7所示的方法获得的第一文本序列可能为“打电话给周杰伦”,通过图14所述的方法可将“打电话给周杰伦”纠正为“打电话给邹杰伦”,获得第二文本序列“打电话给邹杰伦”。Exemplarily, the second text sequence may or may not be the same as the first text sequence. If there are easily confused voice signal frames in the voice stream, such as the voice signal frame "Zou" in the voice stream "Call Zou Jielun", the voice signal frame "Zou" is easily confused with the voice signal frame "Zhou", through Figure 7 The first text sequence obtained by the method shown may be "Call Jay Chou", and the method described in Figure 14 can correct "Call Jay Chou" to "Call Jay Chou", and obtain the second text sequence "Call Jay Chou". Call Jay Zou."
基于图14所示的语音识别方法,通过对第一栅格结构进行裁剪,可对第一栅格结构中的文本符号的概率进行微调,获得的第二栅格结构Lattice’中的音素对应的文本符号的顺序可能与第一栅格结构不同,对第二栅格结构进行解码获取第二文本序列,可以实现对模糊音的纠正,例如将“打电话给周杰伦”纠正为“打电话给邹杰伦”,可以进一步提高语音识别的精度。Based on the speech recognition method shown in FIG. 14 , by trimming the first lattice structure, the probability of the text symbols in the first lattice structure can be fine-tuned, and the obtained phonemes in the second lattice structure Lattice' correspond to The order of text symbols may be different from the first grid structure. Decoding the second grid structure to obtain the second text sequence can correct the fuzzy sound, for example, correct "call Jay Chou" to "Call Jay Chou" ”, which can further improve the accuracy of speech recognition.
图17为本申请实施例提供的语音识别方法的应用示意图九。下面以语音流为“今天天气好”、目标语音信号帧为“气”为例,对本申请实施例提供的语音识别方法的进行阐述。FIG. 17 is a schematic diagram 9 of the application of the speech recognition method provided by the embodiment of the present application. The speech recognition method provided by the embodiment of the present application is described below by taking the speech stream as "the weather is good today" and the target speech signal frame as "qi" as an example.
如图17所示,声学模型310对目标语音信号帧“气”和第一音素序列“jin1/tian1/tian1”进行处理,获得目标语音信号帧“气”对应的第一概率矩阵。音素预测器320根据第一音素序列“jin1/tian1/tian1”的语义,获得第一音素序列“jin1/tian1/tian1”的下一可能音素对应的第二概率矩阵。然后,采用融合参数λ1和/或融合参数λ2对第一概率矩阵中每个音素的第一概率和第二概率矩阵中对应音素的第二概率进行融合,获得第五概率矩阵。As shown in FIG. 17 , the acoustic model 310 processes the target speech signal frame “Qi” and the first phoneme sequence “jin1/tian1/tian1” to obtain a first probability matrix corresponding to the target speech signal frame “Qi”. The
根据目标语音信号帧之前的一个或多个语音信号帧(“今”“天”“天”)和目标语音信号帧“气”分别对应的第五概率矩阵,获取目标概率最大的3个目标音素序列,如“jin1/tian1/tian1/qi4”、“jin1/tian1/tian1/qu4”、“jin1/tian1/tian1/qing2”以及“jin1/tian1/tian1/qi4”、“jin1/tian1/tian1/qu4”、“jin1/tian1/tian1/qing2”分别对应的目标概率。According to the fifth probability matrix corresponding to one or more speech signal frames (“now”, “tian”, “tian”) before the target speech signal frame and the target speech signal frame “qi”, respectively, obtain the 3 target phonemes with the highest target probability Sequences such as "jin1/tian1/tian1/qi4", "jin1/tian1/tian1/qu4", "jin1/tian1/tian1/qing2" and "jin1/tian1/tian1/qi4", "jin1/tian1/tian1/ qu4" and "jin1/tian1/tian1/qing2" respectively correspond to the target probability.
采用音素翻译器330对目标概率最大的3个目标音素序列进行翻译,获取这3个目标音素序列分别对应的至少一个第一文本序列和至少一个第一文本序列中每个第一文本序列对应的概率(图17中针对每个目标音素序列只示出了对应的一个第一文本序列和该一个第一文本序列对应的第三概率)。采用融合参数λ1和/或融合参数λ2对至少一个第一文本序列中每个第一文本序列对应的第三概率和对应的目标概率进行融合,获得第一文本序列的概率,如P(jin1/tian1/tian1/qi4今天天气)=0.696,终端显示概率最大的一个第一文本序列“今天天气”。类似地,以目标语音信号帧为“气”,获取并显示对应的概率最大的一个第一文本序列,完成整句语音流的流式识别。The
可选地,终端采用混淆音矩阵Md-d和音素文本矩阵Md-e对第一栅格结构进行裁剪,获取第二栅格结构,利用WFST的维特比搜索,根据第二栅格结构获得第二文本序列,该第二文本序列可能与第一文本序列相同,也可能不相同,终端显示第二文本序列,可以实现对模糊音的纠正,可以进一步提高语音识别的精度。Optionally, the terminal adopts the confusion sound matrix Mdd and the phoneme text matrix Mde to trim the first grid structure, obtains the second grid structure, utilizes the Viterbi search of WFST, and obtains the second text according to the second grid structure. The second text sequence may or may not be the same as the first text sequence. The terminal displays the second text sequence, which can correct the ambiguity and further improve the accuracy of speech recognition.
可以理解的是,为了实现上述功能,电子设备包含了执行各个功能相应的硬件和/或软件模块。结合本文中所公开的实施例描述的各示例的算法步骤,本申请能够以硬件或硬件和计算机软件的结合形式来实现。某个功能究竟以硬件还是计算机软件驱动硬件的方式来执行,取决于技术方案的特定应用和设计约束条件。本领域技术人员可以结合实施例对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本申请的范围。It can be understood that, in order to realize the above-mentioned functions, the electronic device includes corresponding hardware and/or software modules for executing each function. The present application can be implemented in hardware or in the form of a combination of hardware and computer software in conjunction with the algorithm steps of each example described in conjunction with the embodiments disclosed herein. Whether a function is performed by hardware or computer software driving hardware depends on the specific application and design constraints of the technical solution. Those skilled in the art may use different methods to implement the described functionality for each particular application in conjunction with the embodiments, but such implementations should not be considered beyond the scope of this application.
本实施例可以根据上述方法示例对电子设备进行功能模块的划分,例如,可以对应各个功能划分各个功能模块,也可以将两个或两个以上的功能集成在一个处理模块中。上述集成的模块可以采用硬件的形式实现。需要说明的是,本实施例中对模块的划分是示意性的,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式。In this embodiment, the electronic device can be divided into functional modules according to the above method examples. For example, each functional module can be divided corresponding to each function, or two or more functions can be integrated into one processing module. The above-mentioned integrated modules can be implemented in the form of hardware. It should be noted that, the division of modules in this embodiment is schematic, and is only a logical function division, and there may be other division manners in actual implementation.
如图18所示,本申请实施例公开了一种电子设备的结构示意图。该电子设备1800可用于实现以上各个方法实施例中记载的方法。示例性的,该电子设备1800具体可以包括:获取单元1801和输出单元1802。其中,获取单元1801用于支持电子设备1800执行图6中的步骤S601-S605。和/或,获取单元1801用于支持电子设备1800执行图14中的步骤S1401-S1403。和/或,获取单元1801还用于支持电子设备1800执行本申请实施例中电子设备执行的其他步骤。输出单元1802用于支持电子设备1800执行图6中的步骤S606。和/或,输出单元1802用于支持电子设备1800执行图14中的步骤S1403。和/或,输出单元1802还用于支持电子设备1800执行本申请实施例中电子设备执行的其他步骤。As shown in FIG. 18 , an embodiment of the present application discloses a schematic structural diagram of an electronic device. The electronic device 1800 can be used to implement the methods described in the above method embodiments. Exemplarily, the electronic device 1800 may specifically include: an
可选的,图18所示的电子设备1800还可以包括采集单元1803,该采集单元1803,用于支持电子设备1800执行本申请实施例中电子设备执行的采集语音流或语音信号帧的步骤。Optionally, the electronic device 1800 shown in FIG. 18 may further include a
可选的,图18所示的电子设备1800还可以包括存储单元(图18中未示出),该存储单元存储有程序或指令。当处理单元执行该程序或指令时,使得图18所示的电子设备1800可以执行图6和图14所示的语音识别方法。Optionally, the electronic device 1800 shown in FIG. 18 may further include a storage unit (not shown in FIG. 18 ), where the storage unit stores programs or instructions. When the processing unit executes the program or instruction, the electronic device 1800 shown in FIG. 18 can execute the speech recognition method shown in FIG. 6 and FIG. 14 .
图18所示的电子设备1800的技术效果可以参考图6和图14所示的语音识别方法的技术效果,此处不再赘述。For the technical effect of the electronic device 1800 shown in FIG. 18 , reference may be made to the technical effect of the speech recognition method shown in FIG. 6 and FIG. 14 , which will not be repeated here.
图18所示的电子设备1800中涉及的获取单元可以由处理器或处理器相关电路组件实现,可以为处理器或处理模块。采集单元1803以及输出单元1802可以合并为收发单元,收发单元可以由收发器或收发器相关电路组件实现,可以为收发器或收发模块。The acquiring unit involved in the electronic device 1800 shown in FIG. 18 may be implemented by a processor or a circuit component related to the processor, and may be a processor or a processing module. The
本申请实施例还提供一种芯片系统,包括:处理器,所述处理器与存储器耦合,所述存储器用于存储程序或指令,当所述程序或指令被所述处理器执行时,使得该芯片系统实现上述任一方法实施例中的方法。An embodiment of the present application further provides a chip system, including: a processor, where the processor is coupled with a memory, the memory is used to store a program or an instruction, and when the program or instruction is executed by the processor, the The chip system implements the method in any of the foregoing method embodiments.
可选地,该芯片系统中的处理器可以为一个或多个。该处理器可以通过硬件实现也可以通过软件实现。当通过硬件实现时,该处理器可以是逻辑电路、集成电路等。当通过软件实现时,该处理器可以是一个通用处理器,通过读取存储器中存储的软件代码来实现。Optionally, the number of processors in the chip system may be one or more. The processor can be implemented by hardware or by software. When implemented in hardware, the processor may be a logic circuit, an integrated circuit, or the like. When implemented in software, the processor may be a general-purpose processor implemented by reading software codes stored in memory.
可选地,该芯片系统中的存储器也可以为一个或多个。该存储器可以与处理器集成在一起,也可以和处理器分离设置,本申请并不限定。示例性的,存储器可以是非瞬时性处理器,例如只读存储器ROM,其可以与处理器集成在同一块芯片上,也可以分别设置在不同的芯片上,本申请对存储器的类型,以及存储器与处理器的设置方式不作具体限定。Optionally, there may also be one or more memories in the chip system. The memory may be integrated with the processor, or may be provided separately from the processor, which is not limited in this application. Exemplarily, the memory can be a non-transitory processor, such as a read-only memory ROM, which can be integrated with the processor on the same chip, or can be provided on different chips. The setting method of the processor is not particularly limited.
示例性的,该芯片系统可以是现场可编程门阵列(field programmable gatearray,FPGA),可以是专用集成芯片(application specific integrated circuit,ASIC),还可以是系统芯片(system on chip,SoC),还可以是中央处理器(central processorunit,CPU),还可以是网络处理器(network processor,NP),还可以是数字信号处理电路(digital signal processor,DSP),还可以是微控制器(micro controller unit,MCU),还可以是可编程控制器(programmable logic device,PLD)或其他集成芯片。Exemplarily, the chip system may be a field programmable gate array (FPGA), an application specific integrated circuit (ASIC), a system on chip (SoC), or a system on chip (SoC). It can be a central processing unit (CPU), a network processor (NP), a digital signal processor (DSP), or a microcontroller (micro controller unit). , MCU), can also be a programmable logic device (programmable logic device, PLD) or other integrated chips.
应理解,上述方法实施例中的各步骤可以通过处理器中的硬件的集成逻辑电路或者软件形式的指令完成。结合本申请实施例所公开的方法步骤可以直接体现为硬件处理器执行完成,或者用处理器中的硬件及软件模块组合执行完成。It should be understood that, each step in the above method embodiments may be implemented by a hardware integrated logic circuit in a processor or an instruction in the form of software. The method steps disclosed in combination with the embodiments of the present application may be directly embodied as being executed by a hardware processor, or executed by a combination of hardware and software modules in the processor.
本申请实施例提供一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序或指令,当计算机程序或指令在计算机上运行时,使得该计算机执行上述方法实施例所述的语音识别方法。The embodiments of the present application provide a computer-readable storage medium, where computer programs or instructions are stored on the computer-readable storage medium, and when the computer programs or instructions are run on a computer, the computer is made to perform the speech recognition described in the foregoing method embodiments. method.
本申请实施例提供一种计算机程序产品,该计算机程序产品包括:计算机程序或指令,当计算机程序或指令在计算机上运行时,使得该计算机执行上述方法实施例所述的语音识别方法。An embodiment of the present application provides a computer program product, the computer program product includes: a computer program or an instruction, when the computer program or instruction runs on a computer, the computer is made to execute the speech recognition method described in the above method embodiments.
另外,本申请的实施例还提供一种装置,该装置具体可以是组件或模块,该装置可包括相连的处理器和存储器;其中,存储器用于存储计算机执行指令,当装置运行时,处理器可执行存储器存储的计算机执行指令,以使装置执行上述各方法实施例中的网页鉴权方法。In addition, embodiments of the present application further provide an apparatus, which may specifically be a component or a module, and the apparatus may include a connected processor and a memory; wherein, the memory is used to store instructions for execution by a computer, and when the apparatus is running, the processor The computer-executed instructions stored in the executable memory can be executed, so that the apparatus executes the web page authentication methods in the foregoing method embodiments.
其中,本申请实施例提供的终端设备、计算机可读存储介质、计算机程序产品或芯片均用于执行上文所提供的对应的方法,因此,其所能达到的有益效果可参考上文所提供的对应的方法中的有益效果,此处不再赘述。The terminal device, computer-readable storage medium, computer program product, or chip provided in the embodiments of the present application are all used to execute the corresponding methods provided above. Therefore, for the beneficial effects that can be achieved, reference may be made to the above-mentioned methods. The beneficial effects in the corresponding method are not repeated here.
通过以上的实施方式的描述,所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将装置的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。上述描述的系统,装置和单元的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。From the description of the above embodiments, those skilled in the art can clearly understand that for the convenience and brevity of the description, only the division of the above functional modules is used as an example for illustration. In practical applications, the above functions can be allocated as required. It is completed by different functional modules, that is, the internal structure of the device is divided into different functional modules to complete all or part of the functions described above. For the specific working process of the system, apparatus and unit described above, reference may be made to the corresponding process in the foregoing method embodiments, and details are not described herein again.
在本申请所提供的几个实施例中,应该理解到,所揭露的方法,可以通过其它的方式实现。例如,以上所描述的终端设备实施例仅仅是示意性的,例如,所述模块或单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,模块或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。In the several embodiments provided in this application, it should be understood that the disclosed method may be implemented in other manners. For example, the terminal device embodiments described above are only illustrative. For example, the division of the modules or units is only a logical function division. In actual implementation, there may be other division methods, such as multiple units or components. May be combined or may be integrated into another system, or some features may be omitted, or not implemented. On the other hand, the shown or discussed mutual coupling or direct coupling or communication connection may be through some interfaces, indirect coupling or communication connection of modules or units, and may be in electrical, mechanical or other forms.
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。The units described as separate components may or may not be physically separated, and components displayed as units may or may not be physical units, that is, may be located in one place, or may be distributed to multiple network units. Some or all of the units may be selected according to actual needs to achieve the purpose of the solution in this embodiment.
另外,在本申请各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。In addition, each functional unit in each embodiment of the present application may be integrated into one processing unit, or each unit may exist physically alone, or two or more units may be integrated into one unit. The above-mentioned integrated units may be implemented in the form of hardware, or may be implemented in the form of software functional units.
所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)或处理器执行本申请各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:快闪存储器、移动硬盘、只读存储器、随机存取存储器、磁碟或者光盘等各种可以存储程序指令的介质。The integrated unit, if implemented in the form of a software functional unit and sold or used as an independent product, may be stored in a computer-readable storage medium. Based on this understanding, the technical solutions of the present application can be embodied in the form of software products in essence, or the parts that contribute to the prior art, or all or part of the technical solutions, and the computer software products are stored in a storage medium , which includes several instructions for causing a computer device (which may be a personal computer, a server, or a network device, etc.) or a processor to execute all or part of the steps of the methods described in the various embodiments of the present application. The aforementioned storage medium includes: flash memory, removable hard disk, read-only memory, random access memory, magnetic disk or optical disk and other media that can store program instructions.
以上所述,仅为本申请的具体实施方式,但本申请的保护范围并不局限于此,任何在本申请揭露的技术范围内的变化或替换,都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应以所述权利要求的保护范围为准。The above are only specific embodiments of the present application, but the protection scope of the present application is not limited to this, and any changes or substitutions within the technical scope disclosed in the present application should be covered within the protection scope of the present application. . Therefore, the protection scope of the present application should be subject to the protection scope of the claims.
Claims (11)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011639265.8ACN114694641B (en) | 2020-12-31 | 2020-12-31 | Speech recognition method and electronic equipment |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011639265.8ACN114694641B (en) | 2020-12-31 | 2020-12-31 | Speech recognition method and electronic equipment |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN114694641Atrue CN114694641A (en) | 2022-07-01 |
| CN114694641B CN114694641B (en) | 2025-07-25 |
Family
ID=82135691
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202011639265.8AActiveCN114694641B (en) | 2020-12-31 | 2020-12-31 | Speech recognition method and electronic equipment |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114694641B (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115346520A (en)* | 2022-08-15 | 2022-11-15 | 北京有竹居网络技术有限公司 | Method, apparatus, electronic device and medium for speech recognition |
| CN116682432A (en)* | 2022-09-23 | 2023-09-01 | 荣耀终端有限公司 | Speech recognition method, electronic device and readable medium |
Citations (18)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GB0028144D0 (en)* | 2000-11-17 | 2001-01-03 | Canon Kk | Speech processing apparatus and method |
| CN1705978A (en)* | 2002-10-15 | 2005-12-07 | 佳能株式会社 | Lattice encoding |
| CN101145341A (en)* | 2006-09-04 | 2008-03-19 | 美商富迪科技股份有限公司 | Method, system and apparatus for improved voice recognition |
| CN101755301A (en)* | 2007-07-18 | 2010-06-23 | 斯沃克斯公司 | Method for voice recognition |
| US20140222431A1 (en)* | 2012-07-31 | 2014-08-07 | Novospeech Ltd. | Method and apparatus for speech recognition |
| CN104899240A (en)* | 2014-03-05 | 2015-09-09 | 卡西欧计算机株式会社 | VOICE SEARCH DEVICE and VOICE SEARCH METHOD |
| CN105976812A (en)* | 2016-04-28 | 2016-09-28 | 腾讯科技(深圳)有限公司 | Voice identification method and equipment thereof |
| US20170004824A1 (en)* | 2015-06-30 | 2017-01-05 | Samsung Electronics Co., Ltd. | Speech recognition apparatus, speech recognition method, and electronic device |
| CN107331384A (en)* | 2017-06-12 | 2017-11-07 | 平安科技(深圳)有限公司 | Audio recognition method, device, computer equipment and storage medium |
| CN107644638A (en)* | 2017-10-17 | 2018-01-30 | 北京智能管家科技有限公司 | Audio recognition method, device, terminal and computer-readable recording medium |
| CN108574933A (en)* | 2017-03-07 | 2018-09-25 | 华为技术有限公司 | User track recovery method and device |
| CN109817197A (en)* | 2019-03-04 | 2019-05-28 | 天翼爱音乐文化科技有限公司 | Song generation method, device, computer equipment and storage medium |
| CN109863554A (en)* | 2016-10-27 | 2019-06-07 | 香港中文大学 | Acoustic Glyph Models and Acoustic Glyph Phoneme Models for Computer Aided Pronunciation Training and Speech Processing |
| CN110808034A (en)* | 2019-10-31 | 2020-02-18 | 北京大米科技有限公司 | Voice conversion method, device, storage medium and electronic equipment |
| CN111091824A (en)* | 2019-11-30 | 2020-05-01 | 华为技术有限公司 | Voice matching method and related equipment |
| CN111524534A (en)* | 2020-03-20 | 2020-08-11 | 北京捷通华声科技股份有限公司 | Voice analysis method, system, device and storage medium |
| US20200311453A1 (en)* | 2018-04-16 | 2020-10-01 | Tencent Technology (Shenzhen) Company Limited | Method and terminal for recognizing object node in image, and computer-readable storage medium |
| CN111883102A (en)* | 2020-07-14 | 2020-11-03 | 中国科学技术大学 | A double-layer autoregressive decoding method and system for sequence-to-sequence speech synthesis |
- 2020
- 2020-12-31CNCN202011639265.8Apatent/CN114694641B/enactiveActive
Patent Citations (19)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GB0028144D0 (en)* | 2000-11-17 | 2001-01-03 | Canon Kk | Speech processing apparatus and method |
| CN1705978A (en)* | 2002-10-15 | 2005-12-07 | 佳能株式会社 | Lattice encoding |
| CN101145341A (en)* | 2006-09-04 | 2008-03-19 | 美商富迪科技股份有限公司 | Method, system and apparatus for improved voice recognition |
| CN101755301A (en)* | 2007-07-18 | 2010-06-23 | 斯沃克斯公司 | Method for voice recognition |
| US20140222431A1 (en)* | 2012-07-31 | 2014-08-07 | Novospeech Ltd. | Method and apparatus for speech recognition |
| CN104899240A (en)* | 2014-03-05 | 2015-09-09 | 卡西欧计算机株式会社 | VOICE SEARCH DEVICE and VOICE SEARCH METHOD |
| CN106328127A (en)* | 2015-06-30 | 2017-01-11 | 三星电子株式会社 | Speech recognition apparatus, speech recognition method, and electronic device |
| US20170004824A1 (en)* | 2015-06-30 | 2017-01-05 | Samsung Electronics Co., Ltd. | Speech recognition apparatus, speech recognition method, and electronic device |
| CN105976812A (en)* | 2016-04-28 | 2016-09-28 | 腾讯科技(深圳)有限公司 | Voice identification method and equipment thereof |
| CN109863554A (en)* | 2016-10-27 | 2019-06-07 | 香港中文大学 | Acoustic Glyph Models and Acoustic Glyph Phoneme Models for Computer Aided Pronunciation Training and Speech Processing |
| CN108574933A (en)* | 2017-03-07 | 2018-09-25 | 华为技术有限公司 | User track recovery method and device |
| CN107331384A (en)* | 2017-06-12 | 2017-11-07 | 平安科技(深圳)有限公司 | Audio recognition method, device, computer equipment and storage medium |
| CN107644638A (en)* | 2017-10-17 | 2018-01-30 | 北京智能管家科技有限公司 | Audio recognition method, device, terminal and computer-readable recording medium |
| US20200311453A1 (en)* | 2018-04-16 | 2020-10-01 | Tencent Technology (Shenzhen) Company Limited | Method and terminal for recognizing object node in image, and computer-readable storage medium |
| CN109817197A (en)* | 2019-03-04 | 2019-05-28 | 天翼爱音乐文化科技有限公司 | Song generation method, device, computer equipment and storage medium |
| CN110808034A (en)* | 2019-10-31 | 2020-02-18 | 北京大米科技有限公司 | Voice conversion method, device, storage medium and electronic equipment |
| CN111091824A (en)* | 2019-11-30 | 2020-05-01 | 华为技术有限公司 | Voice matching method and related equipment |
| CN111524534A (en)* | 2020-03-20 | 2020-08-11 | 北京捷通华声科技股份有限公司 | Voice analysis method, system, device and storage medium |
| CN111883102A (en)* | 2020-07-14 | 2020-11-03 | 中国科学技术大学 | A double-layer autoregressive decoding method and system for sequence-to-sequence speech synthesis |
Non-Patent Citations (1)
| Title |
|---|
| 黄晓辉等: "基于循环神经网络的藏语语音识别声学模型", 中文信息学报, vol. 32, no. 5, 31 May 2018 (2018-05-31), pages 49 - 55* |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115346520A (en)* | 2022-08-15 | 2022-11-15 | 北京有竹居网络技术有限公司 | Method, apparatus, electronic device and medium for speech recognition |
| CN116682432A (en)* | 2022-09-23 | 2023-09-01 | 荣耀终端有限公司 | Speech recognition method, electronic device and readable medium |
| CN116682432B (en)* | 2022-09-23 | 2024-05-31 | 荣耀终端有限公司 | Voice recognition method, electronic device and readable medium |
Also Published As
| Publication number | Publication date |
|---|---|
| CN114694641B (en) | 2025-07-25 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US12182919B2 (en) | Joint audio-video facial animation system | |
| CN110473546B (en) | Method and device for recommending media files | |
| US10388284B2 (en) | Speech recognition apparatus and method | |
| CN109741732B (en) | Named entity recognition method, named entity recognition device, equipment and medium | |
| US20230298562A1 (en) | Speech synthesis method, apparatus, readable medium, and electronic device | |
| CN111369971B (en) | Speech synthesis method, device, storage medium and electronic equipment | |
| CN106887225B (en) | Acoustic feature extraction method and device based on convolutional neural network and terminal equipment | |
| US20240212671A1 (en) | Speech decoding method and apparatus, computer device, and storage medium | |
| KR102809252B1 (en) | Electronic apparatus for processing user utterance and controlling method thereof | |
| CN107256706B (en) | Computing device and storage medium thereof | |
| CN113421547A (en) | Voice processing method and related equipment | |
| JP7158217B2 (en) | Speech recognition method, device and server | |
| EP4336376A1 (en) | Electronic device and method for providing search result related to query statement | |
| CN110914898A (en) | System and method for speech recognition | |
| JP7717822B2 (en) | Audio similarity determination method, device, and program product | |
| CN114242093A (en) | Voice tone conversion method, device, computer equipment and storage medium | |
| CN114694641A (en) | Voice recognition method and electronic equipment | |
| CN112749550B (en) | Data storage method and device, computer equipment and storage medium | |
| CN111028828A (en) | Voice interaction method based on screen drawing, screen drawing and storage medium | |
| CN114168706A (en) | Intelligent dialogue ability test method, medium and test equipment | |
| CN118471222B (en) | A voice wake-up method and related device | |
| CN117076702B (en) | Image search method and electronic device | |
| CN115527547B (en) | Noise processing method and electronic equipment | |
| US20250078828A1 (en) | Automated audio caption correction using false alarm and miss detection | |
| HK40044514B (en) | Data storage method and apparatus, computer device and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |