CN114528861A - Foreign language translation training method and device based on corpus - Google Patents
Foreign language translation training method and device based on corpusDownload PDFInfo
- Publication number
- CN114528861A CN114528861ACN202210204937.5ACN202210204937ACN114528861ACN 114528861 ACN114528861 ACN 114528861ACN 202210204937 ACN202210204937 ACN 202210204937ACN 114528861 ACN114528861 ACN 114528861A
- Authority
- CN
- China
- Prior art keywords
- corpus
- translation
- word segmentation
- module
- training
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
Images

Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/40—Processing or translation of natural language
- G06F40/58—Use of machine translation, e.g. for multi-lingual retrieval, for server-side translation for client devices or for real-time translation
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/205—Parsing
- G06F40/211—Syntactic parsing, e.g. based on context-free grammar [CFG] or unification grammars
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/289—Phrasal analysis, e.g. finite state techniques or chunking
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Computational Linguistics (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Biomedical Technology (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- Evolutionary Computation (AREA)
- Data Mining & Analysis (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Biophysics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Machine Translation (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本发明涉及自然语言处理技术领域,更具体的说是涉及一种基于语料库的外语翻译训练方法及装置。The present invention relates to the technical field of natural language processing, and more particularly to a corpus-based foreign language translation training method and device.
背景技术Background technique
自然语言处理是计算机学科人工智能的一个重要研究方向。它研究如何使得人与计算机之间能够使用自然语言进行有效通信,是一门融语言学、计算机科学、数学于一体的学科。Natural language processing is an important research direction of artificial intelligence in computer science. It studies how to enable effective communication between humans and computers using natural language, and is a subject that integrates linguistics, computer science, and mathematics.
其中,神经机器翻译是一个不容忽视的重要任务。近年来,神经机器翻译引起了学术界和工业界的广泛关注。神经网络机器翻译模型能取得良好的性能得益于大规模的、高质量的双语平行训练语料,而就目前而言,高质量的平行语料常常只存在于少量的几种语言之间,并且往往受限于某些特定的领域,比如政府文件、新闻等;因此如何保证在有限的平行训练语料中,保证翻译模型结果的精准性是本领域技术人员亟需解决的问题。Among them, neural machine translation is an important task that cannot be ignored. In recent years, neural machine translation has attracted extensive attention from academia and industry. The good performance of the neural network machine translation model is due to the large-scale, high-quality bilingual parallel training corpus. At present, high-quality parallel corpus often only exists between a small number of languages, and often Limited to some specific fields, such as government documents, news, etc.; therefore, how to ensure the accuracy of the translation model results in the limited parallel training corpus is an urgent problem for those skilled in the art.
发明内容SUMMARY OF THE INVENTION
有鉴于此,本发明提供了一种基于语料库的外语翻译训练方法及装置,克服上述缺陷。In view of this, the present invention provides a corpus-based foreign language translation training method and device to overcome the above-mentioned defects.
为了实现上述目的,本发明提供如下技术方案:In order to achieve the above object, the present invention provides the following technical solutions:
一种基于语料库的外语翻译训练方法,具体步骤为:A corpus-based foreign language translation training method, the specific steps are:
在任一平行语料库中随机提取预设数量的训练语料,构建第一平行语料库;Randomly extract a preset number of training corpora from any parallel corpus to construct the first parallel corpus;
依据第一平行语料库构建并训练初始翻译模型;Build and train an initial translation model according to the first parallel corpus;
利用初始翻译模型将任一单语语料库中源语言语句翻译为目标语言语句,获取翻译语料库;Use the initial translation model to translate the source language sentences in any monolingual corpus into the target language sentences, and obtain the translation corpus;
计算翻译语料库中任一语句的翻译置信度评分,并与预设评价阈值进行比较;Calculate the translation confidence score of any sentence in the translation corpus and compare it with a preset evaluation threshold;
根据比较结果,更新翻译语料库,并与任一单语语料库拼接,获得第二平行语料库;According to the comparison result, update the translation corpus, and splicing it with any monolingual corpus to obtain a second parallel corpus;
根据任一平行语料库与第二平行语料库获取整体语料库,再次训练初始翻译模型。Obtain the overall corpus according to any parallel corpus and the second parallel corpus, and train the initial translation model again.
可选的,初始翻译模型的构建步骤为:Optionally, the construction steps of the initial translation model are:
对第一平行语料库中的语句进行预处理,得到预处理文本;Preprocessing the sentences in the first parallel corpus to obtain preprocessed text;
根据自动分词模型对预处理文本进行分词处理,得到分词文本信息;Perform word segmentation processing on the preprocessed text according to the automatic word segmentation model to obtain word segmentation text information;
基于分词文本信息,利用循环神经网络进行训练,建立并训练初始翻译模型。Based on the word segmentation text information, a recurrent neural network is used for training, and an initial translation model is established and trained.
可选的,自动分词模型的获取步骤为:Optionally, the steps for obtaining the automatic word segmentation model are:
获取预处理文本,对预处理文本进行分词处理,得到字符级别的分词文本信息;Obtain the preprocessed text, perform word segmentation processing on the preprocessed text, and obtain the word segmentation text information at the character level;
获取分词文本信息的词性标签以及分词标签;Obtain part-of-speech tags and word segmentation tags of word segmentation text information;
将分词文本信息的词性标签以及分词标签结合得到二元标签信息;Combining the part-of-speech tags and the word segmentation tags of the word segmentation text information to obtain binary tag information;
基于分词文本信息以及二元标签信息,利用循环神经网络进行训练,构建自动分词模型。Based on word segmentation text information and binary label information, a recurrent neural network is used for training to build an automatic word segmentation model.
可选的,任一语句的翻译置信度评分的获取步骤为:Optionally, the steps for obtaining the translation confidence score of any sentence are:
根据历史数据,获取翻译置信度评价指标;Obtain translation confidence evaluation indicators based on historical data;
获取各个翻译置信度评价指标的权重;Obtain the weight of each translation confidence evaluation index;
根据各个翻译置信度评价指标以及对应的权重获得任一语句的翻译置信度评分。The translation confidence score of any sentence is obtained according to each translation confidence evaluation index and the corresponding weight.
可选的,翻译置信度评分的计算公式为:Optionally, the calculation formula of the translation confidence score is:

式中,i为翻译置信度评价指标的个数;λi为第i个翻译置信度评价指标的权重;hi为第i个翻译置信度评价指标。In the formula, i is the number of translation confidence evaluation indexes; λi is the weight of the ith translation confidence evaluation index; hi is theith translation confidence evaluation index.
可选的,更新翻译语料库的步骤具体为:Optionally, the steps for updating the translation corpus are as follows:
计算翻译语料库中任一语句的翻译置信度评分,并与预设评价阈值进行比较;大于或等于第二评价阈值,则不更新翻译语料库;若小于第一评价阈值,则按照预设长度对翻译语料库中任一语句进行文本识别;Calculate the translation confidence score of any sentence in the translation corpus and compare it with the preset evaluation threshold; if it is greater than or equal to the second evaluation threshold, the translation corpus will not be updated; if it is less than the first evaluation threshold, the translation will be evaluated according to the preset length Text recognition of any sentence in the corpus;
将识别的文本与源语言语句中的文本进行匹配;matching the recognized text with the text in the source language statement;
根据目标语言的单语语料库获取待置换的文本;Obtain the text to be replaced according to the monolingual corpus of the target language;
将待置换的文本与识别的文本中对应内容进行替换,获得第二翻译语句;Replacing the text to be replaced with the corresponding content in the recognized text to obtain a second translation sentence;
计算第二翻译语句的翻译置信度评分,若小于第一评价阈值,则逐一对取待置换的文本进行替换,并分别计算翻译置信度评分,获得最佳翻译语句并更新翻译语料库;若大于等于第二评价阈值,则将第二翻译语句保存至翻译语料库,对翻译语料库进行更新。Calculate the translation confidence score of the second translation sentence, if it is less than the first evaluation threshold, replace the texts to be replaced one by one, and calculate the translation confidence score respectively, obtain the best translation sentence and update the translation corpus; if it is greater than or equal to For the second evaluation threshold, the second translation sentence is stored in the translation corpus, and the translation corpus is updated.
一种基于语料库的外语翻译训练装置,包括初始训练模块、评估模块、第一语料库构建模块、第二语料库构建模块、再次训练模块;A corpus-based foreign language translation training device, comprising an initial training module, an evaluation module, a first corpus construction module, a second corpus construction module, and a retraining module;
所述初始训练模块,用于根据第一平行语料库构建并训练初始翻译模型;The initial training module is used to construct and train an initial translation model according to the first parallel corpus;
所述评估模块,用于计算翻译语料库中任一语句的翻译置信度评分,并与预设评价阈值进行比较;根据比较结果更新翻译语料库;The evaluation module is used to calculate the translation confidence score of any sentence in the translation corpus, and compare it with a preset evaluation threshold; update the translation corpus according to the comparison result;
所述第一语料库构建模块,用于对更新的翻译语料库与任一单语语料库拼接,获得第二平行语料库;The first corpus building module is used for splicing the updated translation corpus with any monolingual corpus to obtain a second parallel corpus;
所述第二语料库构建模块,用于根据任一平行语料库与第二平行语料库获取整体语料库;The second corpus building module is used to obtain the overall corpus according to any parallel corpus and the second parallel corpus;
所述再次训练模块,用于根据整体语料库,再次训练初始翻译模型。The retraining module is used to retrain the initial translation model according to the overall corpus.
可选的,所述初始训练模块包括语料提取模块、预处理模块、自动分词模块、模型训练模块;Optionally, the initial training module includes a corpus extraction module, a preprocessing module, an automatic word segmentation module, and a model training module;
所述语料提取模块,用于提取预设数量的训练语料,构建第一平行语料库;The corpus extraction module is used to extract a preset number of training corpora to construct a first parallel corpus;
所述预处理模块,用于对第一平行语料库中语句进行预处理,得到预处理文本;The preprocessing module is used to preprocess the sentences in the first parallel corpus to obtain preprocessed text;
所述自动分词模块,用于对预处理文本进行分词处理,得到分词文本信息;The automatic word segmentation module is used to perform word segmentation processing on the preprocessed text to obtain word segmentation text information;
所述模型训练模块,用于建立并训练初始翻译模型。The model training module is used to establish and train an initial translation model.
经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种基于语料库的外语翻译训练方法及装置,通过扩大平行语料库的规模以保证翻译模型结果的精准性,且扩大平行语料库保证了被并入原有平行语料库中翻译语句的准确性,以保证训练的翻译模型更加精确。As can be seen from the above technical solutions, compared with the prior art, the present invention provides a corpus-based foreign language translation training method and device, which ensures the accuracy of translation model results by expanding the scale of the parallel corpus, and expands the parallel corpus. The accuracy of the translated sentences incorporated into the original parallel corpus is guaranteed to ensure that the trained translation model is more accurate.
附图说明Description of drawings
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。In order to illustrate the embodiments of the present invention or the technical solutions in the prior art more clearly, the following briefly introduces the accompanying drawings that are used in the description of the embodiments or the prior art. Obviously, the drawings in the following description are only It is an embodiment of the present invention. For those of ordinary skill in the art, other drawings can also be obtained according to the provided drawings without creative efforts.
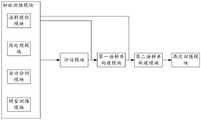
图1为本发明的方法流程示意图;Fig. 1 is the method flow schematic diagram of the present invention;
图2为本发明的装置结构示意图。FIG. 2 is a schematic diagram of the device structure of the present invention.
具体实施方式Detailed ways
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。The technical solutions in the embodiments of the present invention will be clearly and completely described below with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only a part of the embodiments of the present invention, rather than all the embodiments. Based on the embodiments of the present invention, all other embodiments obtained by those of ordinary skill in the art without creative efforts shall fall within the protection scope of the present invention.
本发明实施例公开了一种基于语料库的外语翻译训练方法及装置,其方法的步骤如图1所式,具体为:The embodiment of the present invention discloses a corpus-based foreign language translation training method and device. The steps of the method are as shown in FIG. 1 , specifically:
步骤1、在任一平行语料库中随机提取预设数量的训练语料,构建第一平行语料库;Step 1. Randomly extract a preset number of training corpora from any parallel corpus to construct a first parallel corpus;
其中,平行语料库又称翻译语料库,是由原文和译文共同组成的语料库,用于机器翻译模型的训练、测试等,例如可以是由汉语与满语、汉语与英语、汉语与日语、日语与汉语等原文和译文共同组成的语料库。Among them, the parallel corpus, also known as the translation corpus, is a corpus composed of the original text and the translated text, which is used for the training and testing of the machine translation model. For example, it can be composed of Chinese and Manchu, Chinese and English, Chinese and Japanese, Japanese and Chinese. A corpus composed of the original text and the translation.
在本实施例中,从汉-英翻译语料库中随机抽取1500对汉语与英语组成的语对作为训练语料,并为这些训练语料单独建立一个语料库,定义为第一平行语料库;在本实施例中定义汉语为源语言,英语为目标语言。In this embodiment, 1500 pairs of Chinese and English are randomly selected from the Chinese-English translation corpus as the training corpus, and a separate corpus is established for these training corpora, which is defined as the first parallel corpus; in this embodiment Define Chinese as the source language and English as the target language.
步骤2、依据第一平行语料库构建并训练初始翻译模型,具体为:Step 2. Build and train an initial translation model according to the first parallel corpus, specifically:
对第一平行语料库中的语句进行预处理,得到预处理文本;Preprocessing the sentences in the first parallel corpus to obtain preprocessed text;
根据自动分词模型对预处理文本进行分词处理,得到分词文本信息;Perform word segmentation processing on the preprocessed text according to the automatic word segmentation model to obtain word segmentation text information;
基于分词文本信息,利用双向循环神经网络进行训练,建立并训练初始翻译模型;Based on the word segmentation text information, the bidirectional recurrent neural network is used for training, and the initial translation model is established and trained;
更进一步的,利用双向循环神经网络进行训练的过程为:基于双向RNN编码器从正向和反向对分词文本信息进行编码,确定双向RNN编码器在每一时间步的隐状态,以及,基于无向RNN解码器对双向RNN编码器的每一时间步的隐状态和语义向量进行解码,用于建立初始翻译模型,并对初始翻译模型进行训练。Further, the process of using the bidirectional recurrent neural network for training is: based on the bidirectional RNN encoder to encode the word segmentation text information from the forward and reverse directions, determine the hidden state of the bidirectional RNN encoder at each time step, and, based on The undirected RNN decoder decodes the hidden state and semantic vector of each time step of the bidirectional RNN encoder, which is used to build the initial translation model and train the initial translation model.
在本实施例中,通过双向循环神经网络从正反两个方向进行编码并且确定每一时间步的隐状态和语义向量,避免了将所有时间步的隐状态和语义向量均压缩在一个定长向量中,以提高初始翻译模型对语句翻译的准确度。In this embodiment, the bidirectional recurrent neural network is used to encode from both positive and negative directions and determine the hidden state and semantic vector of each time step, so as to avoid compressing the hidden state and semantic vector of all time steps into a fixed length vector to improve the accuracy of sentence translation by the initial translation model.
其中,自动分词模型的构建步骤为:Among them, the construction steps of the automatic word segmentation model are:
获取预处理文本,对预处理文本进行分词处理,得到字符级别的分词文本信息;Obtain the preprocessed text, perform word segmentation processing on the preprocessed text, and obtain the word segmentation text information at the character level;
获取分词文本信息的词性标签以及分词标签;Obtain part-of-speech tags and word segmentation tags of word segmentation text information;
将分词文本信息的词性标签以及分词标签结合得到二元标签信息;Combining the part-of-speech tags and the word segmentation tags of the word segmentation text information to obtain binary tag information;
基于分词文本信息以及二元标签信息,利用长短期记忆网络进行训练,得到自动分词模型;Based on the word segmentation text information and binary label information, the long short-term memory network is used for training to obtain an automatic word segmentation model;
其中,预处理为训练语料进行规则化、纠错、数字正则化等处理;Among them, the preprocessing is the regularization, error correction, and digital regularization of the training corpus;
在本实施例中为:对第一平行语料库中的数据依次进行乱码过滤处理、中文半角字符转全角处理、中文分词处理以及英文语料小写化处理,并建立对应的词表。In this embodiment, the data in the first parallel corpus are sequentially subjected to garbled filtering processing, Chinese half-width character conversion to full-width processing, Chinese word segmentation processing, and English corpus lowercase processing, and a corresponding vocabulary is established.
更进一步的,利用获取的分词文本信息对长短期记忆网络进行训练,直至当前迭代次数大于等于预设的最大迭代次数或长短期记忆网络输出的二元标签信息的正确率大于预设的正确率阈值,即获得自动分词模型。Further, the long-term and short-term memory network is trained by using the obtained word segmentation text information until the current number of iterations is greater than or equal to the preset maximum number of iterations or the correct rate of the binary label information output by the long-term and short-term memory network is greater than the preset correct rate. Threshold, that is, to obtain an automatic word segmentation model.
步骤3、利用初始翻译模型将任一单语语料库中源语言语句翻译为目标语言语句,获取翻译语料库,具体为:Step 3. Use the initial translation model to translate the source language sentences in any monolingual corpus into the target language sentences, and obtain the translation corpus, specifically:
在现有的汉语语料库中指定任意一个语料库,然后通过初始翻译模型将汉语语料库中的所有语句均翻译为英语语句,并将所有的英语语句按照翻译次序保存在语料库中,将其定义为翻译语料库;Specify any corpus in the existing Chinese corpus, and then translate all the sentences in the Chinese corpus into English sentences through the initial translation model, and save all the English sentences in the corpus according to the translation order, and define it as the translation corpus ;
步骤4、计算翻译语料库中任一语句的翻译置信度评分,并与预设评价阈值进行比较;具体为:Step 4. Calculate the translation confidence score of any sentence in the translation corpus, and compare it with the preset evaluation threshold; specifically:
根据历史数据,获取翻译置信度评价指标;Obtain translation confidence evaluation indicators based on historical data;
获取各个翻译置信度评价指标的权重;Obtain the weight of each translation confidence evaluation index;
根据各个翻译置信度评价指标以及对应的权重获得任一语句的翻译置信度评分;Obtain the translation confidence score of any sentence according to each translation confidence evaluation index and the corresponding weight;
将翻译置信度评分与预设评价阈值比较。Compare the translation confidence score to a preset evaluation threshold.
其中,翻译置信度评价指标可以包括为:翻译语句的流利程度、源语言语句与翻译语句中的词之间的翻译概率、描述源语言句子与翻译语句中的短语之间的翻译概率;Wherein, the translation confidence evaluation index may include: the fluency of the translated sentence, the translation probability between the source language sentence and the words in the translated sentence, and the description of the translation probability between the source language sentence and the phrase in the translated sentence;
翻译概率与源语言语句与翻译语句即英语的语言习惯、固定搭配以及所在领域相关。The translation probability is related to the language habit, fixed collocation, and field of the source language sentence and the translated sentence, that is, English.
其中,翻译置信度评分的计算公式为:Among them, the calculation formula of the translation confidence score is:

式中,i为翻译置信度评价指标的个数;λi为第i个翻译置信度评价指标的权重;hi为翻译置信度评价指标。In the formula, i is the number of translation confidence evaluation indexes; λi is the weight of theith translation confidence evaluation index; hi is the translation confidence evaluation index.
步骤5、根据比较结果,更新翻译语料库,并与任一单语语料库拼接,获得第二平行语料库;Step 5, according to the comparison result, update the translation corpus, and splicing with any monolingual corpus to obtain a second parallel corpus;
其中,更新翻译语料库的步骤为:Among them, the steps of updating the translation corpus are:
计算翻译语料库中任一语句的翻译置信度评分,并与预设评价阈值进行比较;大于等于最佳评价阈值,则不更新翻译语料库;若小于最低评价阈值,则按照预设长度对翻译语料库中任一语句进行文本识别;Calculate the translation confidence score of any sentence in the translation corpus and compare it with the preset evaluation threshold; if it is greater than or equal to the best evaluation threshold, the translation corpus will not be updated; if it is less than the minimum evaluation threshold, the translation corpus will be evaluated according to the preset length. Text recognition for any sentence;
将识别的文本与源语言语句中的文本进行匹配;matching the recognized text with the text in the source language statement;
根据目标语言的单语语料库获取待置换的文本;Obtain the text to be replaced according to the monolingual corpus of the target language;
将待置换的文本与识别的文本对应内容进行替换,获得新的翻译语句;Replace the text to be replaced with the corresponding content of the recognized text to obtain a new translation sentence;
对新的翻译语句进行翻译置信度评分计算,若小于最低评价阈值,则逐一对取待置换的文本进行替换,并分别计算翻译置信度评分,获得最佳翻译语句并更新翻译语料库;若大于等于第二评价阈值,则将完成替换的语句保存至翻译语料库,对翻译语料库进行更新。Calculate the translation confidence score for the new translation sentence. If it is less than the minimum evaluation threshold, replace the text to be replaced one by one, and calculate the translation confidence score separately to obtain the best translation sentence and update the translation corpus; if it is greater than or equal to For the second evaluation threshold, the replaced sentences are stored in the translation corpus, and the translation corpus is updated.
步骤6、根据任一平行语料库与第二平行语料库获取整体语料库,再次训练初始翻译模型。Step 6: Acquire the overall corpus according to any parallel corpus and the second parallel corpus, and train the initial translation model again.
本实施例还包括一种基于语料库的外语翻译训练装置,如图2所示,其结构包括初始训练模块、评估模块、第一语料库构建模块、第二语料库构建模块、再次训练模块;This embodiment also includes a corpus-based foreign language translation training device, as shown in FIG. 2 , whose structure includes an initial training module, an evaluation module, a first corpus construction module, a second corpus construction module, and a retraining module;
初始训练模块,用于根据第一平行语料库构建并训练初始翻译模型;an initial training module for constructing and training an initial translation model according to the first parallel corpus;
评估模块,用于计算翻译语料库中任一语句的翻译置信度评分,并与预设评价阈值进行比较;根据比较结果更新翻译语料库;The evaluation module is used to calculate the translation confidence score of any sentence in the translation corpus, and compare it with the preset evaluation threshold; update the translation corpus according to the comparison result;
第一语料库构建模块,用于对更新的翻译语料库与任一单语语料库拼接,获得第二平行语料库;The first corpus building module is used for splicing the updated translation corpus with any monolingual corpus to obtain the second parallel corpus;
第二语料库构建模块,用于根据任一平行语料库与第二平行语料库获取整体语料库;The second corpus building module is used to obtain the overall corpus according to any parallel corpus and the second parallel corpus;
再次训练模块,用于根据整体语料库,再次训练初始翻译模型。The retraining module is used to retrain the initial translation model based on the overall corpus.
其中,初始训练模块包括语料提取模块、预处理模块、自动分词模块、模型训练模块;Among them, the initial training module includes a corpus extraction module, a preprocessing module, an automatic word segmentation module, and a model training module;
语料提取模块,用于提取预设数量的训练语料,构建第一平行语料库;The corpus extraction module is used to extract a preset number of training corpora to construct the first parallel corpus;
预处理模块,用于对第一平行语料库中语句进行预处理,得到预处理文本;The preprocessing module is used to preprocess the sentences in the first parallel corpus to obtain the preprocessed text;
自动分词模块,用于对预处理文本进行分词处理,得到分词文本信息;The automatic word segmentation module is used to perform word segmentation processing on the preprocessed text to obtain word segmentation text information;
模型训练模块,用于建立并训练初始翻译模型。The model training module is used to build and train the initial translation model.
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。The various embodiments in this specification are described in a progressive manner, and each embodiment focuses on the differences from other embodiments, and the same and similar parts between the various embodiments can be referred to each other. For the device disclosed in the embodiment, since it corresponds to the method disclosed in the embodiment, the description is relatively simple, and the relevant part can be referred to the description of the method.
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。The above description of the disclosed embodiments enables any person skilled in the art to make or use the present invention. Various modifications to these embodiments will be readily apparent to those skilled in the art, and the generic principles defined herein may be implemented in other embodiments without departing from the spirit or scope of the invention. Thus, the present invention is not intended to be limited to the embodiments shown herein, but is to be accorded the widest scope consistent with the principles and novel features disclosed herein.
Claims (8)
Translated fromChinese
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210204937.5ACN114528861A (en) | 2022-03-02 | 2022-03-02 | Foreign language translation training method and device based on corpus |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210204937.5ACN114528861A (en) | 2022-03-02 | 2022-03-02 | Foreign language translation training method and device based on corpus |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN114528861Atrue CN114528861A (en) | 2022-05-24 |
Family
ID=81626033
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210204937.5AWithdrawnCN114528861A (en) | 2022-03-02 | 2022-03-02 | Foreign language translation training method and device based on corpus |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114528861A (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN117094335A (en)* | 2023-08-28 | 2023-11-21 | 郑州大学 | External cross utterance emotion analysis and intelligent translation system and method under political equivalent framework |
- 2022
- 2022-03-02CNCN202210204937.5Apatent/CN114528861A/ennot_activeWithdrawn
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN117094335A (en)* | 2023-08-28 | 2023-11-21 | 郑州大学 | External cross utterance emotion analysis and intelligent translation system and method under political equivalent framework |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN109635288B (en) | Resume extraction method based on deep neural network | |
| CN110489760A (en) | Based on deep neural network text auto-collation and device | |
| US8131539B2 (en) | Search-based word segmentation method and device for language without word boundary tag | |
| CN109241540B (en) | A method and system for automatic conversion of Chinese to blind based on deep neural network | |
| US20050289463A1 (en) | Systems and methods for spell correction of non-roman characters and words | |
| CN115455988A (en) | High-risk statement processing method and system | |
| CN1954315A (en) | Systems and methods for translating chinese pinyin to chinese characters | |
| CN111178009B (en) | Text multilingual recognition method based on feature word weighting | |
| CN105404621A (en) | Method and system for blind people to read Chinese character | |
| KR102043353B1 (en) | Apparatus and method for recognizing Korean named entity using deep-learning | |
| CN114781380A (en) | Chinese named entity recognition method, equipment and medium fusing multi-granularity information | |
| CN112417823B (en) | A Chinese text word order adjustment and quantifier completion method and system | |
| CN114818717A (en) | Chinese named entity recognition method and system fusing vocabulary and syntax information | |
| Arvanitis et al. | Translation of sign language glosses to text using sequence-to-sequence attention models | |
| CN118113810A (en) | Patent retrieval system combining patent image and text semantics | |
| CN114021549B (en) | Chinese named entity recognition method and device based on vocabulary enhancement and multi-features | |
| CN114398943A (en) | Sample enhancement method and device therefor | |
| CN113268576A (en) | Deep learning-based department semantic information extraction method and device | |
| CN115249019A (en) | Method and device for constructing target multi-language neural machine translation model | |
| Sen et al. | Bangla natural language processing: A comprehensive review of classical machine learning and deep learning based methods | |
| CN107168953A (en) | The new word discovery method and system that word-based vector is characterized in mass text | |
| CN113012685B (en) | Audio recognition method, device, electronic device and storage medium | |
| Yadav et al. | Different models of transliteration-a comprehensive review | |
| Sharma et al. | Full-page handwriting recognition and automated essay scoring for in-the-wild essays | |
| CN114528861A (en) | Foreign language translation training method and device based on corpus |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| WW01 | Invention patent application withdrawn after publication | Application publication date:20220524 | |
| WW01 | Invention patent application withdrawn after publication |