CN114528588A - Cross-modal privacy semantic representation method, device, equipment and storage medium - Google Patents
Cross-modal privacy semantic representation method, device, equipment and storage mediumDownload PDFInfo
- Publication number
- CN114528588A CN114528588ACN202210089691.1ACN202210089691ACN114528588ACN 114528588 ACN114528588 ACN 114528588ACN 202210089691 ACN202210089691 ACN 202210089691ACN 114528588 ACN114528588 ACN 114528588A
- Authority
- CN
- China
- Prior art keywords
- data
- modal
- privacy
- semantic representation
- cross
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images





Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F21/00—Security arrangements for protecting computers, components thereof, programs or data against unauthorised activity
- G06F21/60—Protecting data
- G06F21/62—Protecting access to data via a platform, e.g. using keys or access control rules
- G06F21/6218—Protecting access to data via a platform, e.g. using keys or access control rules to a system of files or objects, e.g. local or distributed file system or database
- G06F21/6227—Protecting access to data via a platform, e.g. using keys or access control rules to a system of files or objects, e.g. local or distributed file system or database where protection concerns the structure of data, e.g. records, types, queries
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/31—Indexing; Data structures therefor; Storage structures
- G06F16/313—Selection or weighting of terms for indexing
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/36—Creation of semantic tools, e.g. ontology or thesauri
- G06F16/367—Ontology
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/901—Indexing; Data structures therefor; Storage structures
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F21/00—Security arrangements for protecting computers, components thereof, programs or data against unauthorised activity
- G06F21/60—Protecting data
- G06F21/602—Providing cryptographic facilities or services
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F21/00—Security arrangements for protecting computers, components thereof, programs or data against unauthorised activity
- G06F21/60—Protecting data
- G06F21/62—Protecting access to data via a platform, e.g. using keys or access control rules
- G06F21/6218—Protecting access to data via a platform, e.g. using keys or access control rules to a system of files or objects, e.g. local or distributed file system or database
- G06F21/6245—Protecting personal data, e.g. for financial or medical purposes
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/30—Semantic analysis
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Databases & Information Systems (AREA)
- General Health & Medical Sciences (AREA)
- Software Systems (AREA)
- Health & Medical Sciences (AREA)
- Bioethics (AREA)
- Data Mining & Analysis (AREA)
- Computer Hardware Design (AREA)
- Computer Security & Cryptography (AREA)
- Computational Linguistics (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Artificial Intelligence (AREA)
- Life Sciences & Earth Sciences (AREA)
- Animal Behavior & Ethology (AREA)
- Medical Informatics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本发明涉及数据处理技术领域,尤其涉及一种跨模态隐私语义表征方法、装置、设备及存储介质。The present invention relates to the technical field of data processing, and in particular, to a cross-modal privacy semantic representation method, device, device and storage medium.
背景技术Background technique
随着互联网技术的发展和云服务技术的普及,大数据共享和隐私保护之间的矛盾愈演愈烈。基于此,跨模态数据的检索成为云服务和大数据时代下的刚性需求,而跨模态数据的语义表征又是跨模态数据检索系统的关键组成部分。With the development of Internet technology and the popularization of cloud service technology, the contradiction between big data sharing and privacy protection has intensified. Based on this, the retrieval of cross-modal data has become a rigid requirement in the era of cloud services and big data, and the semantic representation of cross-modal data is a key component of a cross-modal data retrieval system.
跨模态语义表征技术是通过模型对不同模态数据进行编码,得到关键词,使同一语义的不同模态数据的关键词之间可以具备较高的关联性并可以进行显式计算。跨模态隐私语义表征技术是在跨模态语义表征技术的基础上,添加隐私保护需求的技术,该技术要求检索系统在不将明文数据上传到云服务器的前提下,能够进行跨模态数据的编码,得到密态关键词,进而根据密态关键词进行隐私语义的检索。但目前的跨模态隐私语义表征技术存在密态关键词之间的语义关联性较差的问题。Cross-modal semantic representation technology encodes different modal data through models to obtain keywords, so that keywords of different modal data with the same semantics can have high correlation and can be explicitly calculated. Cross-modal privacy semantic representation technology is a technology that adds privacy protection requirements on the basis of cross-modal semantic representation technology. This technology requires the retrieval system to be able to perform cross-modal data processing without uploading plaintext data to the cloud server. to obtain secret keywords, and then search for privacy semantics according to secret keywords. However, the current cross-modal privacy semantic representation technology has the problem of poor semantic correlation between secret keywords.
发明内容SUMMARY OF THE INVENTION
本发明的主要目的在于:提供一种跨模态隐私语义表征方法、装置、设备及存储介质,旨在解决现有技术中存在密态关键词之间的语义关联性较差的技术问题。The main purpose of the present invention is to provide a cross-modal privacy semantic representation method, device, device and storage medium, which aims to solve the technical problem of poor semantic correlation between secret state keywords in the prior art.
为实现上述目的,本发明采用如下技术方案:To achieve the above object, the present invention adopts the following technical solutions:
第一方面,本发明提供了一种跨模态隐私语义表征方法,所述方法包括:In a first aspect, the present invention provides a cross-modal privacy semantic representation method, the method comprising:
获取多模态数据;Get multimodal data;
根据所述多模态数据,获得对应的文本数据;obtaining corresponding text data according to the multimodal data;
对所述文本数据进行关键词提取和加密,得到密态关键词;Perform keyword extraction and encryption on the text data to obtain secret keywords;
根据所述密态关键词,对所述预设知识图谱进行分割,得到密态子图;According to the dense state keyword, the preset knowledge graph is segmented to obtain a dense state subgraph;
对所述密态子图进行图嵌入,得到与所述密态关键词对应的密态表征向量,以得到所述多模态数据的语义表征结果。Graph embedding is performed on the dense state subgraph to obtain a dense state representation vector corresponding to the dense state keyword, so as to obtain a semantic representation result of the multimodal data.
可选地,上述跨模态隐私语义表征方法中,所述多模态数据包括至少两种不同模态的数据信息;Optionally, in the above cross-modal privacy semantic representation method, the multimodal data includes data information of at least two different modalities;
所述根据所述多模态数据,获得对应的文本数据的步骤包括:The step of obtaining corresponding text data according to the multimodal data includes:
当所述多模态数据包括语音模态的第一模态数据时,利用语音识别技术,将所述第一模态数据转换为第一文本数据;When the multimodal data includes the first modality data of the voice modality, using a voice recognition technology to convert the first modality data into first text data;
当所述多模态数据包括视频模态的第二模态数据时,利用训练好的文本生成模型,将所述第二模态数据转换为第二文本数据;When the multimodal data includes the second modality data of the video modality, the trained text generation model is used to convert the second modality data into second text data;
当所述多模态数据包括文本模态的第三模态数据时,直接将所述第三模态数据确定为第三文本数据。When the multimodal data includes the third modality data of the text modality, the third modality data is directly determined as the third text data.
可选地,上述跨模态隐私语义表征方法中,所述对所述文本数据进行关键词提取和加密,得到密态关键词的步骤包括:Optionally, in the above-mentioned cross-modal privacy semantic representation method, the step of performing keyword extraction and encryption on the text data to obtain secret-state keywords includes:
对所述第一文本数据、第二文本数据和/或第三文本数据进行关键词提取和加密,得到密态关键词。Perform keyword extraction and encryption on the first text data, the second text data and/or the third text data to obtain encrypted keywords.
可选地,上述跨模态隐私语义表征方法中,所述对所述文本数据进行关键词提取和加密,得到密态关键词的步骤包括:Optionally, in the above-mentioned cross-modal privacy semantic representation method, the step of performing keyword extraction and encryption on the text data to obtain secret-state keywords includes:
通过无监督学习算法对所述文本数据进行关键词提取,得到关键词;Extracting keywords from the text data through an unsupervised learning algorithm to obtain keywords;
通过对称加密算法对所述关键词进行加密处理,得到密态关键词。The keyword is encrypted by a symmetric encryption algorithm to obtain a secret keyword.
可选地,上述跨模态隐私语义表征方法中,所述通过无监督学习算法对所述文本数据进行关键词提取,得到关键词的步骤包括:Optionally, in the above cross-modal privacy semantic representation method, the step of extracting keywords from the text data by using an unsupervised learning algorithm, and obtaining the keywords includes:
对所述文本数据进行分词处理,得到多个词汇;Perform word segmentation processing on the text data to obtain a plurality of words;
根据所述多个词汇,绘制词汇网络图;其中,所述词汇网络图的网络节点对应于所述词汇,连接两个网络节点的边具有属性值,所述属性值根据所述多个词汇的共现关系确定;Draw a lexical network graph according to the multiple vocabularies; wherein, the network nodes of the lexical network graph correspond to the vocabularies, and the edge connecting the two network nodes has an attribute value, and the attribute value is based on the multiple vocabularies. Co-occurrence relationship is determined;
根据所述词汇网络图,对所述多个词汇进行排序和筛选,得到表征所述文本数据的关键词。According to the vocabulary network graph, the plurality of vocabulary words are sorted and filtered to obtain keywords that characterize the text data.
可选地,上述跨模态隐私语义表征方法中,所述根据所述密态关键词,对所述预设知识图谱进行分割,得到密态子图的步骤之前,所述方法还包括:Optionally, in the above cross-modal privacy semantic representation method, before the step of segmenting the preset knowledge graph according to the secret state keyword to obtain a secret state subgraph, the method further includes:
通过开源知识图谱确定一基础知识图谱;Determine a basic knowledge map through an open source knowledge map;
对所述基础知识图谱进行加密处理,得到预设知识图谱;其中,所述加密处理采用的加密算法与所述对所述文本数据进行加密时采用的加密算法一致。The basic knowledge graph is encrypted to obtain a preset knowledge graph; wherein, the encryption algorithm used in the encryption process is consistent with the encryption algorithm used in the encryption of the text data.
可选地,上述跨模态隐私语义表征方法中,所述根据所述密态关键词,对所述预设知识图谱进行分割,得到密态子图的步骤包括:Optionally, in the above cross-modal privacy semantic representation method, the step of dividing the preset knowledge graph according to the secret state keyword to obtain the secret state subgraph includes:
根据所述密态关键词,在所述预设知识图谱中匹配与所述密态关键词对应的实体,获得知识节点;According to the secret state keyword, the entity corresponding to the secret state keyword is matched in the preset knowledge graph, and a knowledge node is obtained;
在所述预设知识图谱中,以所述知识节点为中心,根据预设裁剪距离进行分割,得到密态子图;其中,所述预设裁剪距离的长度单位为两个实体之间的边,所述密态子图为以所述知识节点为中心的预设裁剪距离范围内的实体与边的集合。In the preset knowledge graph, with the knowledge node as the center, segmentation is performed according to a preset clipping distance to obtain a dense state subgraph; wherein, the length unit of the preset clipping distance is the edge between two entities , the dense state subgraph is a set of entities and edges within a preset clipping distance centered on the knowledge node.
第二方面,本发明提供了一种跨模态隐私语义表征装置,所述装置包括:In a second aspect, the present invention provides a cross-modal privacy semantic representation device, the device comprising:
数据获取模块,用于获取多模态数据;Data acquisition module for acquiring multimodal data;
文本描述模块,用于根据所述多模态数据,获得对应的文本数据;a text description module, configured to obtain corresponding text data according to the multimodal data;
关键词提取模块,用于对所述文本数据进行关键词提取和加密,得到密态关键词;A keyword extraction module, used for performing keyword extraction and encryption on the text data to obtain encrypted keywords;
图谱分割模块,用于根据所述密态关键词,对所述预设知识图谱进行分割,得到密态子图;a graph segmentation module, configured to segment the preset knowledge graph according to the dense state keywords to obtain dense state subgraphs;
图嵌入模块,用于对所述密态子图进行图嵌入,得到与所述密态关键词对应的密态表征向量,以得到所述多模态数据的语义表征结果。The graph embedding module is configured to perform graph embedding on the dense state subgraph to obtain a dense state representation vector corresponding to the dense state keyword, so as to obtain a semantic representation result of the multimodal data.
第三方面,本发明提供了一种跨模态隐私语义表征设备,所述设备包括处理器和存储器,所述存储器中存储有跨模态隐私语义表征程序,所述跨模态隐私语义表征程序被所述处理器执行时,实现如上述的跨模态隐私语义表征方法。In a third aspect, the present invention provides a cross-modal privacy semantic representation device, the device includes a processor and a memory, the memory stores a cross-modal privacy semantic representation program, the cross-modal privacy semantic representation program When executed by the processor, the cross-modal privacy semantic representation method as described above is implemented.
第四方面,本发明提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序可被一个或多个处理器执行,以实现如上述的跨模态隐私语义表征方法。In a fourth aspect, the present invention provides a computer-readable storage medium on which a computer program is stored, and the computer program can be executed by one or more processors to implement the above-mentioned cross-modal privacy semantic representation method.
本发明提供的上述一个或多个技术方案,可以具有如下优点或至少实现了如下技术效果:The above-mentioned one or more technical solutions provided by the present invention may have the following advantages or at least achieve the following technical effects:
本发明提出的一种跨模态隐私语义表征方法、装置、设备及存储介质,通过根据获取的多模态数据获得对应的文本数据后,对文本数据进行关键词提取和加密,得到密态关键词,可保护数据隐私,保证数据安全;再通过根据密态关键词对预设知识图谱进行分割,得到密态子图,以子知识图谱的形式有效扩充密态关键词的语义信息,可以更全面地表达密态关键词的语义概念,与密态关键词保持较强的相关性;还通过对密态子图进行图嵌入,得到与密态关键词对应的密态表征向量,从而得到多模态数据的语义表征结果,将更加丰富的语义信息进行编码,保证密态关键词之间的语义信息关联性。本发明在保障用户数据隐私的前提下,实现对跨模态数据的语义表征,不仅可以保证密态关键词之间的语义关联,还可以为后续进行隐私语义的检索提供准确的语义表征,同时,支持的模态数据,可以根据业务需求动态增减,更有灵活性。A cross-modal privacy semantic representation method, device, equipment and storage medium proposed by the present invention obtain the corresponding text data according to the acquired multi-modal data, and then perform keyword extraction and encryption on the text data to obtain the secret key word, which can protect data privacy and ensure data security; and then divide the preset knowledge graph according to the secret state keyword to obtain the secret state subgraph, and effectively expand the semantic information of the secret state keyword in the form of the sub-knowledge map, which can be more It comprehensively expresses the semantic concept of dense state keywords, and maintains a strong correlation with dense state keywords; also through the graph embedding of dense state subgraphs, dense state representation vectors corresponding to dense state keywords are obtained, thereby obtaining multi-state representation vectors. The semantic representation result of modal data encodes richer semantic information to ensure the relevance of semantic information between secret state keywords. On the premise of ensuring user data privacy, the present invention realizes the semantic representation of cross-modal data, which can not only ensure the semantic association between secret state keywords, but also provide accurate semantic representation for subsequent retrieval of privacy semantics. , the supported modal data can be dynamically increased or decreased according to business requirements, which is more flexible.
附图说明Description of drawings
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的这些附图获得其他的附图。In order to explain the embodiments of the present invention or the technical solutions in the prior art more clearly, the following briefly introduces the accompanying drawings that need to be used in the description of the embodiments or the prior art. Obviously, the accompanying drawings in the following description are only These are some embodiments of the present invention. For those of ordinary skill in the art, other drawings can also be obtained according to the provided drawings without creative efforts.
图1为本发明跨模态隐私语义表征方法第一实施例的流程示意图;1 is a schematic flowchart of a first embodiment of a cross-modal privacy semantic representation method according to the present invention;
图2为本发明涉及的跨模态隐私语义表征设备的硬件结构示意图;2 is a schematic diagram of the hardware structure of the cross-modal privacy semantic representation device involved in the present invention;
图3为本发明跨模态隐私语义表征方法第二实施例的流程示意图;3 is a schematic flowchart of the second embodiment of the cross-modal privacy semantic representation method according to the present invention;
图4为本发明跨模态隐私语义表征方法第二实施例中基础知识图谱的示意图;4 is a schematic diagram of a basic knowledge graph in the second embodiment of the cross-modal privacy semantic representation method of the present invention;
图5为本发明跨模态隐私语义表征方法第二实施例中密态子图的示意图;5 is a schematic diagram of a dense state subgraph in the second embodiment of the cross-modal privacy semantic representation method of the present invention;
图6为本发明跨模态隐私语义表征装置第一实施例的功能模块示意图。FIG. 6 is a schematic diagram of functional modules of the first embodiment of the cross-modal privacy semantic representation apparatus according to the present invention.
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。The realization, functional characteristics and advantages of the present invention will be further described with reference to the accompanying drawings in conjunction with the embodiments.
具体实施方式Detailed ways
为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例只是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。In order to make the purpose, technical solutions and advantages of the present invention clearer, the technical solutions in the embodiments of the present invention will be clearly and completely described below with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only the Some, but not all, embodiments of the invention. Based on the embodiments of the present invention, all other embodiments obtained by those of ordinary skill in the art without creative work fall within the protection scope of the present invention.
需要说明,在本发明中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者系统不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者系统所固有的要素。在没有更多限制的情况下,由语句“包括……”限定的要素,并不排除在包括该要素的过程、方法、物品或者系统中还存在另外的相同要素。另外,全文中出现的“和/或”的含义,包括三个并列的方案,以“A和/或B”为例,包括A方案、或B方案、或A和B同时满足的方案。It should be noted that, in the present invention, the terms "comprising", "comprising" or any other variation thereof are intended to encompass non-exclusive inclusion, such that a process, method, article or system comprising a series of elements includes not only those elements, but also Also included are other elements not expressly listed or inherent to such a process, method, article or system. Without further limitation, an element defined by the phrase "comprises" does not preclude the presence of additional identical elements in a process, method, article or system that includes the element. In addition, the meaning of "and/or" in the whole text includes three parallel schemes. Taking "A and/or B" as an example, it includes scheme A, scheme B, or scheme satisfying both of A and B.
在本发明中,若有涉及“第一”、“第二”等的描述,则该“第一”、“第二”等的描述仅用于描述目的,而不能理解为指示或暗示其相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。在本发明中,使用用于表示元件的诸如“模块”、“部件”或“单元”的后缀仅为了有利于本发明的说明,其本身没有特定的意义。因此,“模块”、“部件”或“单元”可以混合地使用。In the present invention, if there are descriptions involving "first", "second", etc., the descriptions of "first", "second", etc. are only for the purpose of description, and should not be construed as indicating or implying their relative Importance or implicitly indicates the number of technical features indicated. Thus, a feature delimited with "first", "second" may expressly or implicitly include at least one of that feature. In the present invention, suffixes such as "module", "component" or "unit" used to represent elements are used only to facilitate the description of the present invention, and have no specific meaning per se. Thus, "module", "component" or "unit" may be used interchangeably.
对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本发明中的具体含义。另外,各个实施例的技术方案可以相互结合,但是必须是以本领域普通技术人员能够实现为基础,当技术方案的结合出现相互矛盾或无法实现时,应当认为这种技术方案的结合不存在,也不在本发明要求的保护范围之内。For those of ordinary skill in the art, the specific meanings of the above terms in the present invention can be understood according to specific situations. In addition, the technical solutions of the various embodiments can be combined with each other, but must be based on being able to be realized by those of ordinary skill in the art. When the combination of technical solutions is contradictory or cannot be realized, it should be considered that the combination of such technical solutions does not exist, It is not within the scope of protection claimed by the present invention.
对现有技术的分析发现,随着互联网技术的发展和云服务技术的普及,大数据共享和隐私保护之间的矛盾愈演愈烈。检索是大数据场景中的常用功能,一般通过一套检索系统来实现。在当前背景下,即要保障数据隐私安全,又要提高数据检索能力的要求对检索系统来说是很重要的。同时,随着技术水平的提升和人们精神追求的发展,人们对隐私和数据的概念不断丰富。隐私不再是狭义的身份信息、财务信息等传统敏感信息,生活、出行等数据也越来越多地被赋予隐私概念;数据也从文本、表格等传统数据概念,逐步演化到视频、音频、地理等多种模态并存的概念。The analysis of the existing technology found that with the development of Internet technology and the popularization of cloud service technology, the contradiction between big data sharing and privacy protection has intensified. Retrieval is a common function in big data scenarios, and is generally implemented through a retrieval system. In the current context, it is very important for retrieval systems to ensure data privacy and security and to improve data retrieval capabilities. At the same time, with the improvement of technology level and the development of people's spiritual pursuit, people's concepts of privacy and data are constantly enriched. Privacy is no longer narrowly defined as traditional sensitive information such as identity information and financial information, and data such as life and travel are increasingly given the concept of privacy; data has gradually evolved from traditional data concepts such as text and tables to video, audio, The concept of coexistence of multiple modalities such as geography.
基于此,跨模态数据的检索成为云服务和大数据时代下的刚性需求,而跨模态数据的语义表征又是跨模态数据检索系统的关键组成部分。Based on this, the retrieval of cross-modal data has become a rigid requirement in the era of cloud services and big data, and the semantic representation of cross-modal data is a key component of a cross-modal data retrieval system.
跨模态语义表征技术是将不同模态的数据进行联合建模,得到的模型可以对不同模态数据进行编码,得到关键词,使同一语义的不同模态数据的关键词之间可以具备较高的关联性并可以进行显式计算。例如,使用文本模态的“很多人正在会议室开会”和图像模态的一张会议室图片分别输入模型进行编码,得到的文本关键词与图像关键词的语义关联性相比与其他语义内容的数据编码得到的关键词的语义关联性更高。The cross-modal semantic representation technology is to jointly model the data of different modalities, and the obtained model can encode the data of different modalities to obtain keywords, so that the keywords of different modal data of the same semantics can be compared with each other. High associativity and can be explicitly calculated. For example, using the text modal "many people are meeting in the conference room" and a picture of a conference room in the image modal are respectively input into the model for encoding, the semantic relevance of the obtained text keywords and image keywords is compared with other semantic content The semantic relevance of the keywords obtained by the data encoding is higher.
跨模态隐私语义表征技术是在跨模态语义表征技术的基础上,添加隐私保护需求的技术,该技术要求检索系统在不将明文数据上传到云服务器的前提下,能够进行跨模态数据的编码,得到密态关键词,进而根据密态关键词进行隐私语义的检索。Cross-modal privacy semantic representation technology is a technology that adds privacy protection requirements on the basis of cross-modal semantic representation technology. This technology requires the retrieval system to be able to perform cross-modal data processing without uploading plaintext data to the cloud server. to obtain secret keywords, and then search for privacy semantics according to secret keywords.
目前的跨模态隐私语义表征技术还存在着一些问题,比如:There are still some problems in the current cross-modal privacy semantic representation technology, such as:
1.跨模态数据的关键词提取困难;1. It is difficult to extract keywords from cross-modal data;
2.支持的模态较少,并且很难扩增;2. There are fewer supported modalities, and it is difficult to expand;
3.密态关键词之间的语义关联性较差。3. The semantic correlation between the keywords in the dense state is poor.
鉴于现有技术中存在密态关键词之间的语义关联性较差的技术问题,本发明提供了一种跨模态隐私语义表征方法,总体思路如下:In view of the technical problem of poor semantic correlation between secret state keywords in the prior art, the present invention provides a cross-modal privacy semantic representation method, and the general idea is as follows:
获取多模态数据;根据所述多模态数据,获得对应的文本数据;对所述文本数据进行关键词提取和加密,得到密态关键词;根据所述密态关键词,对所述预设知识图谱进行分割,得到密态子图;对所述密态子图进行图嵌入,得到与所述密态关键词对应的密态表征向量,以得到所述多模态数据的语义表征结果。Obtain multi-modal data; obtain corresponding text data according to the multi-modal data; perform keyword extraction and encryption on the text data to obtain secret-state keywords; Suppose the knowledge graph is segmented to obtain a dense state subgraph; perform graph embedding on the dense state subgraph to obtain a dense state representation vector corresponding to the dense state keyword, so as to obtain the semantic representation result of the multimodal data .
通过上述技术方案,根据获取的多模态数据获得对应的文本数据后,对文本数据进行关键词提取和加密,得到密态关键词,可保护数据隐私,保证数据安全;再通过根据密态关键词对预设知识图谱进行分割,得到密态子图,以子知识图谱的形式有效扩充密态关键词的语义信息,可以更全面地表达密态关键词的语义概念,与密态关键词保持较强的相关性;还通过对密态子图进行图嵌入,得到与密态关键词对应的密态表征向量,从而得到多模态数据的语义表征结果,将更加丰富的语义信息进行编码,保证密态关键词之间的语义信息关联性。本发明在保障用户数据隐私的前提下,实现对跨模态数据的语义表征,不仅可以保证密态关键词之间的语义关联,还可以为后续进行隐私语义的检索提供准确的语义表征,同时,支持的模态数据,可以根据业务需求动态增减,更有灵活性。Through the above technical solution, after obtaining corresponding text data according to the acquired multimodal data, keyword extraction and encryption are performed on the text data to obtain encrypted keywords, which can protect data privacy and ensure data security; Words segment the preset knowledge graph to obtain dense state sub-graphs, which can effectively expand the semantic information of dense state keywords in the form of sub-knowledge graphs, which can express the semantic concepts of dense state keywords more comprehensively, and keep the same as dense state keywords. In addition, by embedding the dense state subgraph, the dense state representation vector corresponding to the dense state keyword is obtained, so as to obtain the semantic representation result of the multimodal data, and encode more abundant semantic information. Guarantee the semantic information correlation between secret keywords. On the premise of ensuring user data privacy, the present invention realizes the semantic representation of cross-modal data, which can not only ensure the semantic association between secret state keywords, but also provide accurate semantic representation for subsequent retrieval of privacy semantics. , the supported modal data can be dynamically increased or decreased according to business requirements, which is more flexible.
下面结合附图,通过具体的实施例和实施方式对本发明提供的跨模态隐私语义表征方法、装置、设备及存储介质进行详细说明。The cross-modal privacy semantic representation method, device, device and storage medium provided by the present invention will be described in detail below with reference to the accompanying drawings through specific embodiments and implementations.
实施例一Example 1
参照图1的流程示意图,提出本发明跨模态隐私语义表征方法的第一实施例,该方法应用于跨模态隐私语义表征设备。所述跨模态隐私语义表征设备是指能够实现网络连接的终端设备或网络设备,可以是手机、电脑、平板电脑等终端设备,也可以是服务器、云平台等网络设备。该方法还可以应用于包括终端设备和网络设备的语义检索系统,当该方法应用于语义检索系统时,可以使该方法的一部分步骤在终端设备上进行,得到的结果发送至网络设备后,剩下的部分步骤继续在网络设备上进行。Referring to the schematic flowchart of FIG. 1 , a first embodiment of the cross-modal privacy semantic representation method of the present invention is proposed, and the method is applied to a cross-modal privacy semantic representation device. The cross-modal privacy semantic representation device refers to a terminal device or a network device that can realize network connection, which can be a terminal device such as a mobile phone, a computer, and a tablet computer, or a network device such as a server and a cloud platform. The method can also be applied to a semantic retrieval system including a terminal device and a network device. When the method is applied to a semantic retrieval system, part of the steps of the method can be performed on the terminal device. After the obtained result is sent to the network device, the rest of the Some of the steps below continue on the network device.
如图2所示,为跨模态隐私语义表征设备的硬件结构示意图。所述设备可以包括:处理器1001,例如CPU(Central Processing Unit,中央处理器),通信总线1002,用户接口1003,网络接口1004,存储器1005。本领域技术人员可以理解,图2中示出的硬件结构并不构成对本发明跨模态隐私语义表征设备的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。As shown in Figure 2, it is a schematic diagram of the hardware structure of the cross-modal privacy semantic representation device. The device may include: a
具体的,通信总线1002用于实现这些组件之间的连接通信;Specifically, the
用户接口1003用于连接客户端,与客户端进行数据通信,用户接口1003可以包括输出单元,如显示屏、输入单元,如键盘,可选的,用户接口1003还可以包括其他输入/输出接口,比如标准的有线接口、无线接口;The
网络接口1004用于连接后台服务器,与后台服务器进行数据通信,网络接口1004可以包括输入/输出接口,比如标准的有线接口、无线接口,如Wi-Fi接口;The
存储器1005用于存储各种类型的数据,这些数据例如可以包括该跨模态隐私语义表征设备中任何应用程序或方法的指令,以及应用程序相关的数据,存储器1005可以是高速RAM存储器,也可以是稳定的存储器,例如磁盘存储器,可选的,存储器1005还可以是独立于所述处理器1001的存储装置;The
具体的,继续参照图2,存储器1005中可以包括操作系统、网络通信模块、用户接口模块以及跨模态隐私语义表征程序,其中,网络通信模块主要用于连接服务器,与服务器进行数据通信;2, the
处理器1001用于调用存储器1005中存储的跨模态隐私语义表征程序,并执行以下操作:The
获取多模态数据;Get multimodal data;
根据所述多模态数据,获得对应的文本数据;obtaining corresponding text data according to the multimodal data;
对所述文本数据进行关键词提取和加密,得到密态关键词;Perform keyword extraction and encryption on the text data to obtain secret keywords;
根据所述密态关键词,对所述预设知识图谱进行分割,得到密态子图;According to the dense state keyword, the preset knowledge graph is segmented to obtain a dense state subgraph;
对所述密态子图进行图嵌入,得到与所述密态关键词对应的密态表征向量,以得到所述多模态数据的语义表征结果。Graph embedding is performed on the dense state subgraph to obtain a dense state representation vector corresponding to the dense state keyword, so as to obtain a semantic representation result of the multimodal data.
基于上述的跨模态隐私语义表征设备,下面结合图1所示的流程示意图,对本实施例的跨模态隐私语义表征方法进行详细描述。所述方法可以包括以下步骤:Based on the above-mentioned cross-modal privacy semantic representation device, the cross-modal privacy semantic representation method of this embodiment is described in detail below with reference to the schematic flowchart shown in FIG. 1 . The method may include the following steps:
步骤S110:获取多模态数据。Step S110: Acquire multimodal data.
多模态数据是指具有多种不同模态的数据信息,比如,视频数据、音频数据、图像数据、文本数据等等模态的数据。用户可以通过设备的用户接口手动输入,也可以通过设备的网络接口接收其他设备传送的数据。此处获取的数据可以是包括多种模态的数据,也可以只包括一种模态的数据,此处仅对包括多种模态的数据为例进行说明。Multimodal data refers to data information with multiple different modalities, such as video data, audio data, image data, text data, and other modal data. The user can manually input through the user interface of the device, and can also receive data transmitted by other devices through the network interface of the device. The data acquired here may be data including multiple modalities, or may only include data of one modality, and only the data including multiple modalities will be described here as an example.
步骤S120:根据所述多模态数据,获得对应的文本数据。Step S120: Obtain corresponding text data according to the multimodal data.
对于步骤S110获取的多模态数据,当其中包含图像、音频或视频等非文本模态的数据时,需要进行模态的转换,将数据由非文本模态转换为文本模态,当其中包含文本模态的数据时,则不需要进行模态转换,直接以该文本模态的数据作为该步骤最终得到的文本数据。非文本模态的数据进行模态转换时,可以结合图片、音频或视频等非文本模态的数据自身特点训练得到的模型来进行文本识别,得到描述该非文本模态数据的文本,可提高对该非文本模态的数据进行文本描述的准确性。For the multi-modal data obtained in step S110, when it contains non-text modal data such as images, audio or video, it is necessary to perform modal conversion to convert the data from non-text modal to text modal. When the data of the text mode is used, the mode conversion is not required, and the data of the text mode is directly used as the text data finally obtained in this step. When non-text modal data is modally converted, a model trained by combining the characteristics of non-text modal data such as pictures, audio or video can be used for text recognition, and text describing the non-text modal data can be obtained. The accuracy of the textual description of the data for this non-text modality.
在具体实施过程中,当多模态数据包含图像数据时,可以利用图像识别技术来获得图像数据对应的文本数据,具体可以利用预训练的深度学习模型进行文本描述;当多模态数据包含音频数据时,可以利用语音识别技术来获得音频数据对应的文本数据,具体可以利用Deep Speech V2等深度学习模型进行文本描述;当多模态数据包含视频数据时,可以利用文本描述生成技术来获得视频数据对应的文本数据,具体可以利用预训练的VideoBERT等文本生成模型进行文本描述。需要说明的是,不管多模态数据包括有多少种模态的数据,在分别将非文本模态数据转换为文本模态数据后,对所有的文本模态数据,即包括原本就是文本模态的数据和转换的得到的文本模态数据进行汇总,以得到与获取的多模态数据对应的文本数据。In the specific implementation process, when the multimodal data includes image data, image recognition technology can be used to obtain text data corresponding to the image data, and specifically, a pre-trained deep learning model can be used for text description; when the multimodal data includes audio When data is used, speech recognition technology can be used to obtain text data corresponding to audio data. Specifically, deep learning models such as Deep Speech V2 can be used for text description; when multimodal data includes video data, text description generation technology can be used to obtain video. The text data corresponding to the data, specifically, text generation models such as pre-trained VideoBERT can be used for text description. It should be noted that no matter how many modal data the multimodal data includes, after the non-text modal data is converted into text modal data, all the text modal data, including the original text modal data The data and the converted text modal data are summarized to obtain text data corresponding to the acquired multi-modal data.
步骤S130:对所述文本数据进行关键词提取和加密,得到密态关键词。Step S130: Perform keyword extraction and encryption on the text data to obtain encrypted keywords.
由于文本数据可能存在词汇较多或非必要词汇容易影响语义表征准确性等原因,因此对文本数据进行关键词提取;又由于要保证数据的隐私性,因此对提取到的关键词进行加密,从而得到多模态数据的密态关键词。其中,可以通过Text Rank算法进行关键词提取,还可以通过对称加密算法对提取得到的关键词进行加密,比如,DES(Data EncryptionStandard,数据加密标准)算法、RC(Rivest Cipher,流加密)算法、BlowFish算法(分组密码算法)等等。需要说明,当本实施例的方法在终端设备或网络设备上进行时,后续可以继续对密态关键词进行处理,以获得跨模态数据的语义表征结果,当本实施例的方法在包括终端设备和网络设备的语义检索系统上进行时,终端设备执行步骤S110~S130后,便可以将得到的密态关键词发送给网络设备,网络设备可以在接收到密态关键词之后,对密态关键词进行处理,以获得跨模态数据的语义表征结果,其中,发送和接收的过程都是加密的,因此仍可以保证数据的隐私性。Since there may be many words in the text data or unnecessary words may easily affect the accuracy of semantic representation, the text data is extracted with keywords; and because the privacy of the data is to be ensured, the extracted keywords are encrypted, thereby Obtain dense state keywords for multimodal data. Among them, keywords can be extracted by Text Rank algorithm, and the extracted keywords can also be encrypted by symmetric encryption algorithm, for example, DES (Data Encryption Standard, data encryption standard) algorithm, RC (Rivest Cipher, stream encryption) algorithm, BlowFish algorithm (block cipher algorithm) and so on. It should be noted that when the method of this embodiment is performed on a terminal device or a network device, the secret state keywords may be processed subsequently to obtain a semantic representation result of cross-modal data. When the method of this embodiment includes the terminal When performing on the semantic retrieval system of the device and the network device, after the terminal device executes steps S110 to S130, it can send the obtained encrypted state keyword to the network device, and the network device can, after receiving the encrypted state keyword, search for the encrypted state keyword. Keywords are processed to obtain semantic representation results of cross-modal data, in which the process of sending and receiving are encrypted, so the privacy of data can still be guaranteed.
步骤S140:根据所述密态关键词,对所述预设知识图谱进行分割,得到密态子图。Step S140: Segment the preset knowledge graph according to the dense state keyword to obtain a dense state subgraph.
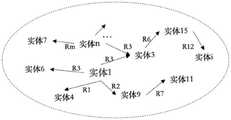
预设知识图谱是将词汇实体以节点的形式,并将实体间的关系以边的形式进行可视化描述的图结构,可以显式描述词汇之间的关联。该预设知识图谱为加密后的Wikidata等开源知识图谱,其中,加密方式和密钥与步骤S30中对关键词进行加密的加密方式和密钥一致,可以保证在密钥匹配后,对密态关键词进行处理,并保证数据的隐私性。根据密态关键词,对预设知识图谱进行分割是将密态关键词与预设知识图谱中的节点进行匹配,依据设定的裁剪距离,获取以密态关键词为中心的子知识图谱,该子知识图谱包括密态关键词对应的实体、在该实体周围的设定裁剪距离范围内的其他实体、以及表示这些实体之间关联关系的边的集合,由于预设知识图谱是加密状态,裁剪得到的子知识图谱也为加密状态,即获得密态子图。其中,密态子图的数量与密态关键词的数量一致,也就是说密态子图是与密态关键词一一对应的。The preset knowledge graph is a graph structure that visually describes lexical entities in the form of nodes and the relationship between entities in the form of edges, which can explicitly describe the association between words. The preset knowledge graph is an encrypted open source knowledge graph such as Wikidata, wherein the encryption method and key are the same as the encryption method and key used for encrypting the keyword in step S30, which can ensure that after the key is matched, the encrypted state Key words are processed and the privacy of the data is guaranteed. According to the dense state keywords, the preset knowledge graph is segmented by matching the dense state keywords with the nodes in the preset knowledge graph, and obtaining the sub-knowledge graph centered on the dense state keywords according to the set clipping distance. The sub-knowledge graph includes the entity corresponding to the dense state keyword, other entities within the set clipping distance around the entity, and a set of edges representing the association relationship between these entities. Since the preset knowledge graph is in an encrypted state, The cropped sub-knowledge graph is also in an encrypted state, that is, a dense-state sub-graph is obtained. Among them, the number of dense state subgraphs is consistent with the number of dense state keywords, that is to say, the dense state subgraphs are in one-to-one correspondence with dense state keywords.
此处使用密态关键词为中心的子知识图谱作为密态关键词的表达,使用与密态关键词相关性极强的实体和关系来联合表征密态关键词,不仅可以更加全面的表达密态关键词的语义概念,并且可以通过其他相关实体和对应的关系来精确表征密态关键词的语义概念,使得易混淆的密态关键词有更加明显的区分度。Here, the sub-knowledge graph centered on the dense keyword is used as the expression of the dense keyword, and the entities and relationships that are strongly related to the dense keyword are used to jointly represent the dense keyword, which can not only express the dense keyword more comprehensively. The semantic concept of dense state keywords can be accurately represented by other related entities and corresponding relationships, so that confusing dense state keywords can be more clearly distinguished.
步骤S150:对所述密态子图进行图嵌入,得到与所述密态关键词对应的密态表征向量,以得到所述多模态数据的语义表征结果。Step S150: Embedding the dense state subgraph to obtain a dense state representation vector corresponding to the dense state keyword, so as to obtain a semantic representation result of the multimodal data.
每个密态关键词都可以对应得到一个密态子图,在步骤S140得到密态子图后,基于随机游走算法对该密态子图进行图嵌入操作,得到其密态表征向量,也就是与密态关键词对应的密态表征向量,该向量即为对应的密态关键词的语义表示。在对所有密态关键词分别获取对应的密态子图,并分别进行图嵌入操作,得到密态表征向量后,进行汇总后,可以得到一个向量集,即本实施例的多模态数据的语义表征结果。该语义表征结果可直接用于语义检索的输入,从而得到检索结果,以此实现跨模态数据的检索,比如,用户可以在设备上直接输入多模态数据,通过本实施例的方法后,得到语义表征结果后,再将该语义表征结果输入检索系统,进行检索,便可得到最终的跨模态检索结果。Each dense state keyword can correspond to a dense state subgraph. After the dense state subgraph is obtained in step S140, a graph embedding operation is performed on the dense state subgraph based on the random walk algorithm to obtain its dense state representation vector. It is the dense state representation vector corresponding to the dense state keyword, and the vector is the semantic representation of the corresponding dense state keyword. After obtaining the corresponding dense state subgraphs for all dense state keywords, and performing the graph embedding operation respectively, after obtaining the dense state representation vector, after summarizing, a vector set can be obtained, that is, the multimodal data of this embodiment. Semantic representation results. The semantic representation result can be directly used for the input of semantic retrieval, so as to obtain the retrieval result, so as to realize the retrieval of cross-modal data. For example, the user can directly input multi-modal data on the device. After the semantic representation result is obtained, the semantic representation result is input into the retrieval system for retrieval, and the final cross-modal retrieval result can be obtained.
本实施例提供的跨模态隐私语义表征方法,通过根据获取的多模态数据获得对应的文本数据后,对文本数据进行关键词提取和加密,得到密态关键词,可保护数据隐私,保证数据安全;再通过根据密态关键词对预设知识图谱进行分割,得到密态子图,以子知识图谱的形式有效扩充密态关键词的语义信息,可以更全面地表达密态关键词的语义概念,与密态关键词保持较强的相关性;还通过对密态子图进行图嵌入,得到与密态关键词对应的密态表征向量,从而得到多模态数据的语义表征结果,将更加丰富的语义信息进行编码,保证密态关键词之间的语义信息关联性。本发明在保障用户数据隐私的前提下,实现对跨模态数据的语义表征,不仅可以保证密态关键词之间的语义关联,还可以为后续进行隐私语义的检索提供准确的语义表征,同时,支持的模态数据,可以根据业务需求动态增减,更有灵活性。In the cross-modal privacy semantic representation method provided in this embodiment, after obtaining corresponding text data according to the acquired multi-modal data, keywords are extracted and encrypted on the text data to obtain encrypted keywords, which can protect data privacy and ensure Data security; then by segmenting the preset knowledge graph according to the secret state keywords, the dense state subgraph is obtained, and the semantic information of the secret state keyword can be effectively expanded in the form of the sub-knowledge graph, which can express the information of the secret state keyword more comprehensively. The semantic concept maintains a strong correlation with the dense state keywords; and the dense state representation vector corresponding to the dense state keywords is obtained by embedding the dense state subgraph, so as to obtain the semantic representation results of the multimodal data. Encode richer semantic information to ensure the semantic information correlation between secret keywords. On the premise of ensuring user data privacy, the present invention realizes the semantic representation of cross-modal data, which can not only ensure the semantic association between secret state keywords, but also provide accurate semantic representation for subsequent retrieval of privacy semantics. , the supported modal data can be dynamically increased or decreased according to business requirements, which is more flexible.
实施例二Embodiment 2
基于同一发明构思,参照图3至图5,提出本发明跨模态隐私语义表征方法的第二实施例,该方法应用于跨模态隐私语义表征设备,该方法可以进一步应用于在所述设备上运行的跨模态隐私语义检索系统,该系统在通过该方法对多模态数据进行隐私语义表征后,再根据语义表征结果进行隐私语义检索,获得语义检索结果。语义检索是通过正确分析语法格式,在理解语义和词汇之间关系的条件下,根据要求从语义层面上自动从信息源中查询和提取有关信息的过程,隐私语义检索可以基于隐私数据进行检索,更要求隐私数据的安全性。Based on the same inventive concept, referring to FIG. 3 to FIG. 5 , a second embodiment of the cross-modal privacy semantic representation method of the present invention is proposed. The method is applied to a cross-modal privacy semantic representation device, and the method can be further applied to the device. A cross-modal privacy semantic retrieval system running on the system, the system performs privacy semantic retrieval on multi-modal data through this method, and then performs privacy semantic retrieval according to the semantic representation results to obtain semantic retrieval results. Semantic retrieval is the process of automatically querying and extracting relevant information from the information source at the semantic level according to requirements under the condition of understanding the relationship between semantics and vocabulary by correctly analyzing the grammatical format. Privacy semantic retrieval can be based on privacy data. The security of private data is also required.
下面结合图3所示的流程示意图,对本实施例的跨模态隐私语义表征方法进行详细描述。所述方法可以包括以下步骤:The following describes the cross-modal privacy semantic representation method in this embodiment in detail with reference to the schematic flowchart shown in FIG. 3 . The method may include the following steps:
步骤S210:获取多模态数据。Step S210: Obtain multimodal data.
具体的,所述多模态数据包括至少两种不同模态的数据信息。此处,多模态数据中的模态数据类型并不限制,模态数据数量也不限制,可以根据业务需求自行增减模态数据类型和模态数据数量。本实施例以包括语音、视频、文本这三种模态数据的多模态数据,并以英语作为示例语言进行举例说明。Specifically, the multimodal data includes data information of at least two different modalities. Here, the type of modal data in the multimodal data is not limited, and the quantity of modal data is not limited, and the modal data type and quantity of modal data can be increased or decreased according to business requirements. In this embodiment, multi-modal data including three modal data of voice, video, and text is used for illustration, and English is used as an example language for illustration.
步骤S220:根据所述多模态数据,获得对应的文本数据。Step S220: Obtain corresponding text data according to the multimodal data.
在具体实施过程中,可以利用文本生成模型,根据多模态数据获得对应的文本数据。具体将多模态数据作为文本生成模型的输入,然后将各模态数据分别输入相应的文本生成模型,以分别输出文本模态数据,从而获得描述该多模态数据的文本数据。In a specific implementation process, a text generation model can be used to obtain corresponding text data according to the multimodal data. Specifically, the multimodal data is used as the input of the text generation model, and then each modal data is input into the corresponding text generation model to output the textual modal data respectively, thereby obtaining text data describing the multimodal data.
具体的,步骤S220可以包括:Specifically, step S220 may include:
步骤S221:当所述多模态数据包括语音模态的第一模态数据时,利用语音识别技术,将所述第一模态数据转换为第一文本数据。Step S221 : when the multi-modal data includes the first modality data of the voice modality, use a voice recognition technology to convert the first modality data into first text data.
其中,语音识别技术是将包含人类语言声音的数据转换成文本,构建文本和语音之间的映射关系的技术。对非文本模态数据进行模态转换是跨模态数据语义表征和检索的关键,本实施例中,可以利用Deep Speech V2模型作为语音识别模型,该模型可以利用设定语言的语音数据来进行模型训练,此处则使用英文语音数据进行模型训练,训练得到语音识别模型。实施过程中,将第一模态数据作为该模型的输入,直接输出对应的文本描述。Among them, speech recognition technology is a technology that converts data containing human language and voice into text and builds a mapping relationship between text and speech. Performing modal conversion on non-text modal data is the key to semantic representation and retrieval of cross-modal data. In this embodiment, the Deep Speech V2 model can be used as a speech recognition model, and this model can be performed by using the speech data of the set language. Model training, where English speech data is used for model training, and a speech recognition model is obtained by training. In the implementation process, the first modal data is used as the input of the model, and the corresponding text description is directly output.
步骤S222:当所述多模态数据包括视频模态的第二模态数据时,利用训练好的文本生成模型,将所述第二模态数据转换为第二文本数据。Step S222: When the multimodal data includes the second modality data of the video modality, use the trained text generation model to convert the second modality data into second text data.
其中,训练好的文本生成模型基于同时具备文本描述和视频内容的数据集作为训练数据训练得到。实施过程中,利用训练好的文本生成模型,将第二模态数据作为该模型的输入,直接输出对应的文本描述。Among them, the trained text generation model is obtained based on the data set with both text description and video content as training data. In the implementation process, the trained text generation model is used, the second modality data is used as the input of the model, and the corresponding text description is directly output.
本实施例中,文本生成模型采用Video BERT模型,Video BERT模型利用语言模型中的BERT模型及自监督学习训练方法进行训练,训练该文本生成模型时,以包括文本描述数据和视频内容数据的数据集作为训练数据。训练方法如下:首先,从视频内容数据中提取出特征向量,再通过聚类方法对该特征向量进行离散化处理,构建视觉词汇,然后结合文本描述数据,组成跨模态词汇;再从跨模态词汇中导出视觉标记(token)和语言学标记,输入到待训练的文本生成模型,模型学习这些标记序列上的双向联合分布,从而构建视觉标记和语言学标记之间的映射关系,得到训练好的文本生成模型。In this embodiment, the text generation model adopts the Video BERT model, and the Video BERT model is trained by using the BERT model in the language model and the self-supervised learning training method. When training the text generation model, the data including the text description data and the video content data are used for training. set as training data. The training method is as follows: first, extract the feature vector from the video content data, then discretize the feature vector through the clustering method to construct a visual vocabulary, and then combine the text description data to form a cross-modal vocabulary; The visual tokens and linguistic tokens are derived from the state vocabulary, and input to the text generation model to be trained. Good text generation model.
步骤S223:当所述多模态数据包括文本模态的第三模态数据时,直接将所述第三模态数据确定为第三文本数据。Step S223: When the multimodal data includes the third modality data of the text modality, directly determine the third modality data as the third text data.
文本数据本身作为文本模态数据,无需进行处理,可直接进行下一步操作,下一步操作可以包括在将转换得到的文本数据和文本模态的数据汇总,得到文本数据后,对该文本数据进行关键词提取和加密,也可以是直接对转换得到的文本数据或文本模态数据进行关键词提取和加密,具体看多模态数据的类型和数量,再根据实际情况设定。The text data itself, as text modal data, does not need to be processed, and the next step can be performed directly. The next step can include summarizing the converted text data and the data of the text modal, and after obtaining the text data, performing the processing on the text data. The keyword extraction and encryption can also be performed directly on the converted text data or text modal data, depending on the type and quantity of the multimodal data, and then set according to the actual situation.
本实施例中,根据上述步骤分别对语音、视频、文本这三种模态数据的多模态数据进行处理,得到三个文本数据后进行汇总,从而得到文本数据。将各模态数据统一为文本模态,无模态数量限制,无模态种类限制,当新模态数据加入时,仅需添加相应的文本描述生成模型即可,该方法具有拓展性。In this embodiment, according to the above steps, the multi-modal data of the three modal data of voice, video and text are processed respectively, and three text data are obtained and then aggregated, thereby obtaining the text data. The modal data is unified into text modal, there is no limitation on the number of modals, and there is no limitation on the type of modal. When new modal data is added, it is only necessary to add the corresponding text description to generate the model. This method is scalable.
步骤S230:对所述文本数据进行关键词提取和加密,得到密态关键词。Step S230: Perform keyword extraction and encryption on the text data to obtain encrypted keywords.
在一种实施方式中,步骤230可以包括:In one embodiment, step 230 may include:
步骤231:对所述第一文本数据、第二文本数据和/或第三文本数据进行关键词提取和加密,得到密态关键词。Step 231: Perform keyword extraction and encryption on the first text data, the second text data and/or the third text data to obtain encrypted keywords.
由于多模态数据的模态数据类型可以增减并可以有多个,因此,对应得到的文本数据也会有多个,当存在多个文本数据时,比如本实施例的三个文本数据时,可以将其中的部分或者全部进行汇总后,直接进行关键词提取和加密处理,得到该多模态数据对应的密态关键词。Since the modal data types of the multi-modal data can be increased or decreased, and there can be multiple types, the corresponding obtained text data will also be multiple. When there are multiple text data, such as the three text data in this embodiment , some or all of them can be aggregated, and then keyword extraction and encryption processing can be directly performed to obtain the dense-state keywords corresponding to the multi-modal data.
在另一种实施方式中,步骤230可以包括:In another embodiment, step 230 may include:
步骤232:通过无监督学习算法对所述文本数据进行关键词提取,得到关键词。Step 232: Extract keywords from the text data through an unsupervised learning algorithm to obtain keywords.
关键词一般是单个词或者由多个词组成的短语,是指能反映文本主题或者意思的概括性词或者短语。本实施例中,使用Text Rank算法进行文本关键词提取,该算法是无监督算法,可以以单个文档或文本数据作为输入。其算法原理是把文本拆分成词汇作为网络节点,组成词汇网络图,将词汇间的相关关系看成是一种推荐或投票关系,使其可以计算出每一个词汇的重要性,然后筛选得到前N个词汇作为表征整篇文档或整个文本数据的关键词。A keyword is generally a single word or a phrase composed of multiple words, and refers to a general word or phrase that can reflect the theme or meaning of the text. In this embodiment, Text Rank algorithm is used to extract text keywords, which is an unsupervised algorithm and can take a single document or text data as input. The algorithm principle is to split the text into words as network nodes to form a word network graph, and regard the correlation between words as a recommendation or voting relationship, so that the importance of each word can be calculated, and then filtered to get The top N words are used as keywords to characterize the entire document or the entire text data.
具体的,步骤232可以包括:Specifically, step 232 may include:
步骤232.1:对所述文本数据进行分词处理,得到多个词汇。Step 232.1: Perform word segmentation on the text data to obtain multiple words.
具体实施过程中,可以对文本数据进行分词、词性标注和去除停用词等操作,其中,分词时,采用结巴分词,保留普通名词、专有名词、普通动词、副动词、名动词、形容词、副词等7种词性的词语,最终可以得到多个词汇。In the specific implementation process, operations such as word segmentation, part-of-speech tagging, and removal of stop words can be performed on the text data. Among them, during word segmentation, stuttering word segmentation is used, and common nouns, proper nouns, common verbs, adverbs, nouns, adjectives, Words with 7 parts of speech such as adverbs can finally get multiple words.
本实施例中,对步骤S220得到的文本数据进行分词处理,可以得到多个词汇。In this embodiment, word segmentation processing is performed on the text data obtained in step S220, and multiple words can be obtained.
步骤232.2:根据所述多个词汇,绘制词汇网络图;其中,所述词汇网络图的网络节点对应于所述词汇,连接两个网络节点的边具有属性值,所述属性值根据所述多个词汇的共现关系确定。Step 232.2: Draw a vocabulary network graph according to the plurality of vocabulary; wherein, the network nodes of the vocabulary network graph correspond to the vocabulary, and the edge connecting two network nodes has an attribute value, and the attribute value is based on the plurality of vocabulary. The co-occurrence relationship of the words is determined.
具体实施过程中,将一个词汇作为一个网络节点,绘制多个词汇的词汇网络图,图中,网络节点与网络节点之间,也就是词汇与词汇之间的边具有属性值,该属性值根据这两个网络节点所表示的词汇的共现关系确定。In the specific implementation process, a vocabulary is used as a network node, and a vocabulary network graph of multiple vocabulary is drawn. The co-occurrence relationship of the words represented by the two network nodes is determined.
本实施例中,根据步骤S232.1得到的多个词汇,绘制词汇网络图,其中,词汇网络图的网络节点集由该多个词汇组成,通过分析网络节点集中任意两个网络节点所表示的词汇之间的共现关系,来确定该两个网络节点的边,也就是说,仅当两个网络节点对应的词汇在长度为K的窗口中共现,才绘制这两个网络节点之间的边,其中,K表示窗口大小,即最多共现K个词汇。In this embodiment, a vocabulary network graph is drawn according to the plurality of vocabulary obtained in step S232.1, wherein the network node set of the vocabulary network graph is composed of the plurality of vocabulary words, and by analyzing the expressions represented by any two network nodes in the network node set The co-occurrence relationship between the words is used to determine the edges of the two network nodes, that is, only when the words corresponding to the two network nodes co-occur in a window of length K, the edge between the two network nodes is drawn. edge, where K represents the window size, that is, at most K words co-occur.
步骤232.3:根据所述词汇网络图,对所述多个词汇进行排序和筛选,得到表征所述文本数据的关键词。Step 232.3: According to the vocabulary network graph, sort and filter the plurality of vocabulary to obtain keywords representing the text data.
在词汇网络图中,根据迭代算法计算各网络节点即各词汇的权重,直至收敛;然后对各词汇的权重进行排序,筛选得到预设数量的词汇,这预设数量的词汇即为表征所述文本数据的关键词。在实际实施时,排序方式和该预设数量均可以根据实际情况设定。In the vocabulary network diagram, the weight of each network node, that is, each vocabulary, is calculated according to an iterative algorithm until convergence; then the weights of each vocabulary are sorted, and a preset number of vocabulary is obtained. Keywords for text data. In actual implementation, the sorting method and the preset number can be set according to the actual situation.
步骤233:通过对称加密算法对所述关键词进行加密处理,得到密态关键词。Step 233: Encrypt the keyword through a symmetric encryption algorithm to obtain a secret keyword.
对步骤S232.3得到的关键词进行加密处理,具体采用对称加密算法,该算法计算量小、加密速度快、加密效率高,可以实现高速度的加解密处理,并可以使用长密钥,具有难破解性,可保证多模态数据的隐私性和安全性,还可以提高该方法的处理速度。Perform encryption processing on the keywords obtained in step S232.3, and specifically adopt a symmetric encryption algorithm, which has a small amount of calculation, fast encryption speed, and high encryption efficiency, can realize high-speed encryption and decryption processing, and can use long keys. It is difficult to crack, which can ensure the privacy and security of multimodal data, and can also improve the processing speed of the method.
步骤S240:获取预设知识图谱。Step S240: Acquire a preset knowledge graph.
具体的,步骤S240可以包括:Specifically, step S240 may include:
步骤S241:通过开源知识图谱确定一基础知识图谱;Step S241: Determine a basic knowledge graph through the open source knowledge graph;
知识图谱是一种知识库,其中的知识通过图结构的数据模型或拓扑整合而成,使用图结构将知识实体以节点的形式可视化描述,还将知识实体间的关系以边的形式可视化描述,从而显式描述知识之间的关联。A knowledge graph is a knowledge base in which knowledge is integrated through a graph-structured data model or topology. The graph structure is used to visually describe knowledge entities in the form of nodes, and also visualize the relationships between knowledge entities in the form of edges. Thereby explicitly describing the association between knowledge.
如图4所示为本实施例的预设知识图谱的示意图。该图中,具有多个实体,一个实体即表示一个节点。本实施例中,基于前述设定的示例语言为英语,使用开源知识图谱Wikidata作为基础知识库,该开源知识图谱是一个大型数据库,存储了维基百科、Freebase中的海量信息,具备常见事物的描述能力,可以满足本实施例的需求。FIG. 4 is a schematic diagram of the preset knowledge graph of the present embodiment. In this figure, there are multiple entities, and an entity represents a node. In this embodiment, the example language based on the above setting is English, and the open source knowledge graph Wikidata is used as the basic knowledge base. The open source knowledge graph is a large database, which stores massive information in Wikipedia and Freebase, and has descriptions of common things. capability, which can meet the requirements of this embodiment.
步骤S242:对所述基础知识图谱进行加密处理,得到预设知识图谱;其中,所述加密处理采用的加密算法与所述对所述文本数据进行加密时采用的加密算法一致。Step S242: Encrypting the basic knowledge graph to obtain a preset knowledge graph; wherein, the encryption algorithm used in the encryption process is consistent with the encryption algorithm used in encrypting the text data.
对基础知识图谱进行加密,保障了数据的隐私性。需要说明,此处加密处理的加密方式与步骤S233中对关键词进行加密处理采用的加密方式一致,并且使用的密钥也一致,方便后续密态关键词与预设知识图谱可以成功进行匹配。The basic knowledge graph is encrypted to ensure the privacy of the data. It should be noted that the encryption method of the encryption processing here is the same as the encryption method used for the encryption processing of the keywords in step S233, and the keys used are also the same, so that the subsequent encrypted keywords can be successfully matched with the preset knowledge graph.
使用对称加密方法对文本关键词和知识图谱进行加密,可以保障数据隐私安全,还可以保持密态关键词的匹配能力。Using the symmetric encryption method to encrypt text keywords and knowledge graphs can ensure data privacy and security, and can also maintain the matching ability of encrypted keywords.
步骤S250:根据所述密态关键词,对所述预设知识图谱进行分割,得到密态子图。Step S250: According to the dense state keyword, segment the preset knowledge graph to obtain a dense state subgraph.
具体的,步骤S250可以包括:Specifically, step S250 may include:
步骤S251:根据所述密态关键词,在所述预设知识图谱中匹配与所述密态关键词对应的实体,获得知识节点;Step S251: According to the secret state keyword, match the entity corresponding to the secret state keyword in the preset knowledge graph to obtain a knowledge node;
根据密态关键词,在预设知识图谱中进行实体匹配,即在预设知识图谱中查找所述密态关键词对应的实体,将该实体确定为知识节点。当具有多个密态关键词时,可以得到多个知识节点,这些知识节点在预设知识图谱中可以没有关联,也可以有关联。According to the secret state keyword, entity matching is performed in the preset knowledge graph, that is, the entity corresponding to the secret state keyword is searched in the preset knowledge graph, and the entity is determined as a knowledge node. When there are multiple secret state keywords, multiple knowledge nodes can be obtained, and these knowledge nodes may be unrelated or related in the preset knowledge graph.
本实施例中,以一个密态关键词为例,在图4所示的知识图谱中,用实体1表示该密态关键词对应的知识节点。In this embodiment, taking a secret keyword as an example, in the knowledge graph shown in FIG. 4 , entity 1 is used to represent the knowledge node corresponding to the secret keyword.
步骤S252:在所述预设知识图谱中,以所述知识节点为中心,根据预设裁剪距离进行分割,得到密态子图;其中,所述预设裁剪距离的长度单位为两个实体之间的边,所述密态子图为以所述知识节点为中心的预设裁剪距离范围内的实体与边的集合。Step S252: In the preset knowledge graph, take the knowledge node as the center, divide according to the preset clipping distance, and obtain the dense state subgraph; wherein, the length unit of the preset clipping distance is the sum of the two entities. The dense state subgraph is a set of entities and edges within a preset clipping distance centered on the knowledge node.
具体的,以该知识节点为中心,根据预设裁剪距离进行子知识图谱分割,得到密态关键词对应的密态子图,也就是以知识节点为中心的预设裁剪距离范围内的实体与边的集合。其中,每个密态关键词均可以得到一个对应的密态子图。如图4所示,预设裁剪距离的长度单位为两个实体之间的边R,也就是两个实体间的关联关系,每条边用不同序列表示为R1、R2、…、Rm。本实施例中,在图4的知识图谱中,以实体1为中心,根据预设裁剪距离进行分割,得到如图5所示的密态子图示意图。其中,图5(a)表示裁剪距离为1个单位时得到的密态子图,在裁剪时,以实体1作为中心,将与实体1之间仅需要一条边就可以触达的实体和边进行分割,得到的实体和边的集即为实体1所表示的密态关键词的密态子图;图5(b)表示裁剪距离为2个单位时得到的密态子图,在裁剪时,以实体1作为中心,将与实体1之间需要两条或更少的边即可触达的实体和边进行分割,得到的实体和边的集即为实体1所表示的密态关键词的密态子图;同理,图5(c)表示裁剪距离为3个单位时得到的密态子图。Specifically, with the knowledge node as the center, the sub-knowledge graph is segmented according to the preset clipping distance, and the dense-state sub-graph corresponding to the dense-state keyword is obtained, that is, the entities within the preset clipping distance centered on the knowledge node and the collection of edges. Among them, each dense state keyword can obtain a corresponding dense state subgraph. As shown in Figure 4, the length unit of the preset cropping distance is the edge R between two entities, that is, the association relationship between the two entities, and each edge is represented by a different sequence as R1, R2, ..., Rm. In this embodiment, in the knowledge graph of FIG. 4 , with entity 1 as the center, segmentation is performed according to a preset clipping distance, and a schematic diagram of a dense state subgraph as shown in FIG. 5 is obtained. Among them, Figure 5(a) shows the dense state subgraph obtained when the clipping distance is 1 unit. When clipping, with entity 1 as the center, the entities and edges that can be reached with only one edge between entity 1 After dividing, the set of entities and edges obtained is the dense state subgraph of the dense state keyword represented by entity 1; Figure 5(b) shows the dense state subgraph obtained when the clipping distance is 2 units. , take entity 1 as the center, divide the entities and edges that can be reached with two or less edges from entity 1, and the set of entities and edges obtained is the dense state keyword represented by entity 1 Similarly, Figure 5(c) shows the dense state subgraph obtained when the clipping distance is 3 units.
使用以密态关键词为中心的子知识图谱作为密态关键词的表达,使用与密态关键词相关性极强的实体和关系联合表征密态关键词,不仅可以更加全面的表达密态关键词的语义概念,并且可以通过其他相关实体和关系精确表征密态关键词的语义概念,使得易混淆的密态关键词有更加明显的区分度,可以在保障用户数据隐私的前提下,更好的保留多模态数据编码的语义关联性。Using the sub-knowledge graph centered on the dense keyword as the expression of the dense keyword, and using the entities and relationships that are strongly related to the dense keyword to jointly represent the dense keyword, not only can express the dense keyword more comprehensively The semantic concept of the word, and can accurately represent the semantic concept of the secret keyword through other related entities and relationships, so that the confusing secret keyword has a more obvious degree of distinction, which can be better on the premise of ensuring user data privacy. The preservation of semantic associativity in multimodal data encoding.
步骤S260:对所述密态子图进行图嵌入,得到与所述密态关键词对应的密态表征向量,以得到所述多模态数据的语义表征结果。Step S260: Embedding the dense state subgraph to obtain a dense state representation vector corresponding to the dense state keyword, so as to obtain a semantic representation result of the multimodal data.
每个密态关键词都可以被表示为一个子知识图谱,基于此子知识图谱,对其进行图嵌入操作,得到其密态表征向量,该向量即为对密态关键词的语义表示,其中,可以采用随机游走算法(Deep Walk算法)进行图嵌入操作。Each dense state keyword can be represented as a sub-knowledge graph. Based on this sub-knowledge graph, the graph embedding operation is performed on it to obtain its dense state representation vector, which is the semantic representation of the dense state keyword, where , the random walk algorithm (Deep Walk algorithm) can be used for the graph embedding operation.
本实施例中,采用Deep Walk算法进行图嵌入操作,该算法包含生成和更新两部分,随机游走生成器(Random Walk Generator)用于产生类似句子的随机路径;随机游走更新程序(Update Procedure)用于将随机路径输入Skip-Gram模型,得到密态子图中的节点的隐藏表示。具体实施过程为,随机游走生成器在密态子图上用均匀分布采样出一个点,作为随机路径的起始点,再任意确定一个当前点,下一点则由该当前点的所有邻居中用均匀分布采样得到,然后再将该点确定为当前点,一直重复直到设定的最大长度后停止,也可以在当前点没邻居时停止,停止后,将所有点连接,即为随机游走生成器得到的随机路径,其中,每条随机路径的长度可能不同,但最长不会超过设定的最大长度;按此方法,对密态子图中的每个节点均生成一条随机路径。随机路径产生后,随机游走更新程序将其视作一个句子,输入Skip-Gram模型中,计算目标函数,更新密态子图中的节点的隐藏表示,其中,目标函数为:In this embodiment, the Deep Walk algorithm is used to perform the graph embedding operation. The algorithm includes two parts: generation and update. A random walk generator (Random Walk Generator) is used to generate a random path similar to a sentence; a random walk update procedure (Update Procedure) ) is used to input random paths into the Skip-Gram model to obtain hidden representations of nodes in dense-state subgraphs. The specific implementation process is that the random walk generator uses a uniform distribution to sample a point on the dense state subgraph as the starting point of the random path, and then arbitrarily determines a current point, and the next point is selected from all neighbors of the current point. It is obtained by uniformly distributed sampling, and then the point is determined as the current point, and it is repeated until the set maximum length and then stops. It can also be stopped when the current point has no neighbors. After stopping, all points are connected to generate a random walk. The random path obtained by the controller, where the length of each random path may be different, but the longest will not exceed the set maximum length; according to this method, a random path is generated for each node in the dense state subgraph. After the random path is generated, the random walk update program treats it as a sentence, inputs it into the Skip-Gram model, calculates the objective function, and updates the hidden representation of the nodes in the dense state subgraph, where the objective function is:
j(Φ)=-logPr(uk|vj;Φ),j(Φ)=-logPr (uk |vj ;Φ),
其中,vj表示随机路径上的第j个点,uk表示密态子图中不包括vj的节点,Pr(uk|vj;Φ)表示在给定vj的条件下,uk出现的条件概率,Φ表示可训练参数。Among them, vj represents thejth point on the random path, uk represents the node that does not include vj in the dense state subgraph, and Pr (uk |vj ; Φ) represents that under the condition of given vj , Conditional probability of occurrence of uk , Φ represents a trainable parameter.
本实施例的方法在保障用户数据隐私和模态数据相关性的前提下,实现了跨模态数据的隐私语义表征。The method of this embodiment realizes the privacy semantic representation of cross-modal data under the premise of ensuring user data privacy and modal data correlation.
在步骤S210~S260的实施方式中更多实施细节可以参考实施例一中基于步骤S110~S150的实施方式中的描述,为了说明书的简洁,此处不再赘述。For more implementation details in the implementation of steps S210-S260, reference may be made to the description in the implementation based on steps S110-S150 in the first embodiment, and for the sake of brevity of the description, details are not repeated here.
本实施例提供的跨模态隐私语义表征方法,不仅能够保证密态关键词之间的语义关联,并且支持的模态可以根据业务需求动态增减,保障后续进行隐私语义检索的灵活性和语义准确性,从而保障检索的精确度,对满足用户隐私安全和跨模态数据的检索需求具有重要意义。The cross-modal privacy semantic representation method provided in this embodiment can not only ensure the semantic association between confidential keywords, but also the supported modalities can be dynamically increased or decreased according to business requirements, ensuring the flexibility and semantics of subsequent private semantic retrieval. Therefore, it is of great significance to ensure the accuracy of retrieval, which is of great significance to meet the retrieval needs of user privacy security and cross-modal data.
实施例三Embodiment 3
基于同一发明构思,参照图6,提出本发明跨模态隐私语义表征装置的第一实施例,该跨模态隐私语义表征装置可以为虚拟装置,应用于跨模态隐私语义表征设备。Based on the same inventive concept, referring to FIG. 6 , a first embodiment of the cross-modal privacy semantic representation device of the present invention is proposed. The cross-modal privacy semantic representation device may be a virtual device and is applied to a cross-modal privacy semantic representation device.
下面结合图6所示的功能模块示意图,对本实施例提供的跨模态隐私语义表征装置进行详细描述,所述装置可以包括:The cross-modal privacy semantic representation device provided in this embodiment is described in detail below with reference to the schematic diagram of the functional modules shown in FIG. 6 , and the device may include:
数据获取模块,用于获取多模态数据;Data acquisition module for acquiring multimodal data;
文本描述模块,用于根据所述多模态数据,获得对应的文本数据;a text description module, configured to obtain corresponding text data according to the multimodal data;
关键词提取模块,用于对所述文本数据进行关键词提取和加密,得到密态关键词;A keyword extraction module, used for performing keyword extraction and encryption on the text data to obtain encrypted keywords;
图谱分割模块,用于根据所述密态关键词,对所述预设知识图谱进行分割,得到密态子图;a graph segmentation module, configured to segment the preset knowledge graph according to the dense state keywords to obtain dense state subgraphs;
图嵌入模块,用于对所述密态子图进行图嵌入,得到与所述密态关键词对应的密态表征向量,以得到所述多模态数据的语义表征结果。The graph embedding module is configured to perform graph embedding on the dense state subgraph to obtain a dense state representation vector corresponding to the dense state keyword, so as to obtain a semantic representation result of the multimodal data.
进一步地,所述多模态数据包括至少两种不同模态的数据信息;所述文本描述模块可以包括:Further, the multimodal data includes data information of at least two different modalities; the text description module may include:
第一数据处理单元,用于当所述多模态数据包括语音模态的第一模态数据时,利用语音识别技术,将所述第一模态数据转换为第一文本数据;a first data processing unit, configured to convert the first modal data into first text data by using a speech recognition technology when the multimodal data includes the first modal data of a voice modality;
第二数据处理单元,用于当所述多模态数据包括视频模态的第二模态数据时,利用训练好的文本生成模型,将所述第二模态数据转换为第二文本数据;a second data processing unit, configured to convert the second modal data into second text data by using the trained text generation model when the multi-modal data includes the second modal data of the video modality;
第三数据处理单元,用于当所述多模态数据包括文本模态的第三模态数据时,直接将所述第三模态数据确定为第三文本数据。The third data processing unit is configured to directly determine the third modal data as the third text data when the multimodal data includes the third modal data of the text modality.
更进一步地,所述关键词提取模块可以包括:Further, the keyword extraction module may include:
第一关键词提取单元,与所述第一数据处理单元、所述第一数据处理单元和/或所述第三数据处理单元连接,用于对所述第一文本数据、第二文本数据和/或第三文本数据进行关键词提取和加密,得到密态关键词。A first keyword extracting unit, connected to the first data processing unit, the first data processing unit and/or the third data processing unit, and configured to analyze the first text data, the second text data and the /or performing keyword extraction and encryption on the third text data to obtain encrypted keywords.
进一步地,所述关键词提取模块可以包括:Further, the keyword extraction module may include:
关键词提取子模块,用于通过无监督学习算法对所述文本数据进行关键词提取,得到关键词;A keyword extraction sub-module is used to extract keywords from the text data through an unsupervised learning algorithm to obtain keywords;
加密子模块,用于通过对称加密算法对所述关键词进行加密处理,得到密态关键词。The encryption sub-module is used for encrypting the keyword through a symmetric encryption algorithm to obtain a secret keyword.
更进一步地,所述关键词提取子模块可以包括:Further, the keyword extraction submodule may include:
拆分单元,用于对所述文本数据进行分词处理,得到多个词汇;a splitting unit for performing word segmentation processing on the text data to obtain a plurality of words;
绘图单元,用于根据所述多个词汇,绘制词汇网络图;其中,所述词汇网络图的网络节点对应于所述词汇,连接两个网络节点的边具有属性值,所述属性值根据所述多个词汇的共现关系确定;a drawing unit for drawing a vocabulary network graph according to the plurality of vocabulary; wherein, the network nodes of the vocabulary network graph correspond to the vocabulary, and the edge connecting the two network nodes has an attribute value, and the attribute value is based on the Determine the co-occurrence relationship of multiple words;
筛选单元,用于根据所述词汇网络图,对所述多个词汇进行排序和筛选,得到表征所述文本数据的关键词。A screening unit, configured to sort and filter the plurality of words according to the word network graph to obtain keywords that characterize the text data.
进一步地,所述装置还可以包括:Further, the device may also include:
预设知识图谱获取模块,用于通过开源知识图谱确定一基础知识图谱;对所述基础知识图谱进行加密处理,得到预设知识图谱;其中,所述加密处理采用的加密算法与所述对所述文本数据进行加密时采用的加密算法一致。A preset knowledge graph acquisition module, used for determining a basic knowledge graph through an open source knowledge graph; encrypting the basic knowledge graph to obtain a preset knowledge graph; wherein, the encryption algorithm used in the encryption processing is the same as that used in the encryption process. The encryption algorithm used when encrypting the text data is the same.
进一步地,所述图谱分割模块可以包括:Further, the map segmentation module may include:
匹配单元,用于根据所述密态关键词,在所述预设知识图谱中匹配与所述密态关键词对应的实体,获得知识节点;a matching unit, configured to match entities corresponding to the secret state keywords in the preset knowledge graph according to the secret state keywords, and obtain knowledge nodes;
分割单元,用于在所述预设知识图谱中,以所述知识节点为中心,根据预设裁剪距离进行分割,得到密态子图;其中,所述预设裁剪距离的长度单位为两个实体之间的边,所述密态子图为以所述知识节点为中心的预设裁剪距离范围内的实体与边的集合。A segmentation unit, configured to divide the knowledge node as the center in the preset knowledge graph according to the preset clipping distance to obtain a dense state subgraph; wherein, the length unit of the preset clipping distance is two Edges between entities, the dense state subgraph is a set of entities and edges within a preset clipping distance range centered on the knowledge node.
需要说明,本实施例提供的跨模态隐私语义表征装置中各个模块可实现的功能和对应达到的技术效果可以参照本发明跨模态隐私语义表征方法各个实施例中具体实施方式的描述,为了说明书的简洁,此处不再赘述。It should be noted that, for the functions that can be implemented by each module and the corresponding technical effects achieved in the cross-modal privacy semantic representation device provided in this embodiment, reference may be made to the description of specific implementations in each embodiment of the cross-modal privacy semantic representation method of the present invention. The description is concise and will not be repeated here.
实施例四Embodiment 4
基于同一发明构思,参照图2,为本发明各实施例涉及的跨模态隐私语义表征设备的硬件结构示意图。本实施例提供了一种跨模态隐私语义表征设备,所述设备可以包括处理器和存储器,所述存储器中存储有跨模态隐私语义表征程序,所述跨模态隐私语义表征程序被所述处理器执行时,实现本发明跨模态隐私语义表征方法各个实施例的全部或部分步骤。Based on the same inventive concept, referring to FIG. 2 , it is a schematic diagram of a hardware structure of a cross-modal privacy semantic representation device involved in various embodiments of the present invention. This embodiment provides a cross-modal privacy semantic representation device, the device may include a processor and a memory, the memory stores a cross-modal privacy semantic representation program, and the cross-modal privacy semantic representation program is When executed by the processor, all or part of the steps of each embodiment of the cross-modal privacy semantic representation method of the present invention are implemented.
具体的,所述跨模态隐私语义表征设备是指能够实现网络连接的终端设备或网络设备,可以是手机、电脑、平板电脑、便携计算机等终端设备,也可以是服务器、云平台等网络设备。Specifically, the cross-modal privacy semantic representation device refers to a terminal device or a network device that can realize network connection, which can be a terminal device such as a mobile phone, a computer, a tablet computer, a portable computer, etc., or a network device such as a server and a cloud platform. .
可以理解,所述设备还可以包括通信总线,用户接口和网络接口。It will be appreciated that the device may also include a communication bus, a user interface and a network interface.
其中,通信总线用于实现这些组件之间的连接通信。Among them, the communication bus is used to realize the connection communication between these components.
用户接口用于连接客户端,与客户端进行数据通信,用户接口可以包括输出单元,如显示屏、输入单元,如键盘,可选的,用户接口还可以包括其他输入/输出接口,比如标准的有线接口、无线接口。The user interface is used to connect the client and communicate data with the client. The user interface may include an output unit, such as a display screen, an input unit, such as a keyboard. Optionally, the user interface may also include other input/output interfaces, such as standard Wired interface, wireless interface.
网络接口用于连接后台服务器,与后台服务器进行数据通信,网络接口可以包括输入/输出接口,比如标准的有线接口、无线接口,如Wi-Fi接口。The network interface is used to connect to the backend server and perform data communication with the backend server. The network interface may include an input/output interface, such as a standard wired interface, and a wireless interface, such as a Wi-Fi interface.
存储器用于存储各种类型的数据,这些数据例如可以包括该跨模态隐私语义表征设备中任何应用程序或方法的指令,以及应用程序相关的数据。存储器可以由任何类型的易失性或非易失性存储设备或者它们的组合实现,例如静态随机存取存储器(StaticRandom Access Memory,简称SRAM),随机存取存储器(Random Access Memory,简称RAM),电可擦除可编程只读存储器(Electrically Erasable Programmable Read-Only Memory,简称EEPROM),可擦除可编程只读存储器(Erasable Programmable Read-Only Memory,简称EPROM),可编程只读存储器(Programmable Read-Only Memory,简称PROM),只读存储器(Read-Only Memory,简称ROM),磁存储器,快闪存储器,磁盘或光盘,可选的,存储器还可以是独立于所述处理器的存储装置。The memory is used to store various types of data, which may include, for example, instructions for any application or method in the cross-modal privacy semantic representation device, and application-related data. The memory can be implemented by any type of volatile or non-volatile storage device or a combination thereof, such as Static Random Access Memory (SRAM), Random Access Memory (RAM), Electrically Erasable Programmable Read-Only Memory (EEPROM for short), Erasable Programmable Read-Only Memory (EPROM for short), Programmable Read-Only Memory (EPROM) -Only Memory, PROM for short), read-only memory (Read-Only Memory, ROM for short), magnetic memory, flash memory, magnetic disk or optical disk, optionally, the memory may also be a storage device independent of the processor.
处理器用于调用存储器中存储的跨模态隐私语义表征程序,并执行如上述的跨模态隐私语义表征方法,处理器可以是专用集成电路(Application Specific IntegratedCircuit,简称ASIC)、数字信号处理器(Digital Signal Processor,简称DSP)、数字信号处理设备(Digital Signal Processing Device,简称DSPD)、可编程逻辑器件(ProgrammableLogic Device,简称PLD)、现场可编程门阵列(Field Programmable Gate Array,简称FPGA)、控制器、微控制器、微处理器或其他电子元件,用于执行如上述跨模态隐私语义表征方法各个实施例的全部或部分步骤。The processor is used to call the cross-modal privacy semantic representation program stored in the memory, and execute the above-mentioned cross-modal privacy semantic representation method, the processor may be an application specific integrated circuit (Application Specific Integrated Circuit, ASIC for short), digital signal processor ( Digital Signal Processor (DSP), Digital Signal Processing Device (DSPD), Programmable Logic Device (PLD), Field Programmable Gate Array (FPGA), Control A controller, microcontroller, microprocessor or other electronic component for executing all or part of the steps of the various embodiments of the above-mentioned cross-modal privacy semantic representation method.
实施例五Embodiment 5
基于同一发明构思,本实施例提供了一种计算机可读存储介质,如闪存、硬盘、多媒体卡、卡型存储器(例如,SD或DX存储器等)、随机访问存储器(RAM)、静态随机访问存储器(SRAM)、只读存储器(ROM)、电可擦除可编程只读存储器(EEPROM)、可编程只读存储器(PROM)、磁性存储器、磁盘、光盘、服务器、App应用商城等等,所述存储介质上存储有计算机程序,所述计算机程序可被一个或多个处理器执行,所述计算机程序被处理器执行时可以实现本发明跨模态隐私语义表征方法各个实施例的全部或部分步骤。Based on the same inventive concept, this embodiment provides a computer-readable storage medium, such as flash memory, hard disk, multimedia card, card-type memory (eg, SD or DX memory, etc.), random access memory (RAM), static random access memory (SRAM), Read Only Memory (ROM), Electrically Erasable Programmable Read Only Memory (EEPROM), Programmable Read Only Memory (PROM), Magnetic Memory, Disk, Optical Disc, Server, App Store, etc., the A computer program is stored on the storage medium, and the computer program can be executed by one or more processors. When the computer program is executed by the processor, all or part of the steps of each embodiment of the cross-modal privacy semantic representation method of the present invention can be implemented. .
需要说明,上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。It should be noted that the above-mentioned serial numbers of the embodiments of the present invention are only for description, and do not represent the advantages and disadvantages of the embodiments.
以上所述仅为本发明的可选实施例,并非因此限制本发明的专利范围,凡是在本发明的发明构思下,利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均包括在本发明的专利保护范围内。The above descriptions are only optional embodiments of the present invention, and are not intended to limit the scope of the present invention. Under the inventive concept of the present invention, the equivalent structure or equivalent process transformation made by using the contents of the description and the accompanying drawings of the present invention, Or directly or indirectly used in other related technical fields, are all included in the scope of patent protection of the present invention.
Claims (10)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210089691.1ACN114528588B (en) | 2022-01-25 | 2022-01-25 | Cross-modal privacy semantic representation method, device, equipment and storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210089691.1ACN114528588B (en) | 2022-01-25 | 2022-01-25 | Cross-modal privacy semantic representation method, device, equipment and storage medium |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN114528588Atrue CN114528588A (en) | 2022-05-24 |
| CN114528588B CN114528588B (en) | 2025-03-07 |
Family
ID=81623828
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210089691.1AActiveCN114528588B (en) | 2022-01-25 | 2022-01-25 | Cross-modal privacy semantic representation method, device, equipment and storage medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114528588B (en) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115757915A (en)* | 2023-01-09 | 2023-03-07 | 佰聆数据股份有限公司 | Electronic file online generation method and device |
| CN116362221A (en)* | 2023-04-14 | 2023-06-30 | 中国航空综合技术研究所 | Keyword Similarity Judgment Method for Aviation Literature Based on Multimodal Semantic Association Graph |
| CN117113385A (en)* | 2023-10-25 | 2023-11-24 | 成都乐超人科技有限公司 | Data extraction method and system applied to user information encryption |
| CN117195913A (en)* | 2023-11-08 | 2023-12-08 | 腾讯科技(深圳)有限公司 | Text processing method, text processing device, electronic equipment, storage medium and program product |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111061839A (en)* | 2019-12-19 | 2020-04-24 | 过群 | Combined keyword generation method and system based on semantics and knowledge graph |
| CN111931505A (en)* | 2020-05-22 | 2020-11-13 | 北京理工大学 | Cross-language entity alignment method based on subgraph embedding |
| CN112200317A (en)* | 2020-09-28 | 2021-01-08 | 西南电子技术研究所(中国电子科技集团公司第十研究所) | Multimodal knowledge graph construction method |
| CN113643821A (en)* | 2021-10-13 | 2021-11-12 | 浙江大学 | Multi-center knowledge graph joint decision support method and system |
- 2022
- 2022-01-25CNCN202210089691.1Apatent/CN114528588B/enactiveActive
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111061839A (en)* | 2019-12-19 | 2020-04-24 | 过群 | Combined keyword generation method and system based on semantics and knowledge graph |
| CN111931505A (en)* | 2020-05-22 | 2020-11-13 | 北京理工大学 | Cross-language entity alignment method based on subgraph embedding |
| CN112200317A (en)* | 2020-09-28 | 2021-01-08 | 西南电子技术研究所(中国电子科技集团公司第十研究所) | Multimodal knowledge graph construction method |
| CN113643821A (en)* | 2021-10-13 | 2021-11-12 | 浙江大学 | Multi-center knowledge graph joint decision support method and system |
Non-Patent Citations (1)
| Title |
|---|
| 郭皓洁: "基于跨模态语义表征一致性的新闻事件搜索系统", 中国优秀硕士论文学位论文全文数据库, no. 1, 15 January 2022 (2022-01-15), pages 138 - 3453* |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115757915A (en)* | 2023-01-09 | 2023-03-07 | 佰聆数据股份有限公司 | Electronic file online generation method and device |
| CN116362221A (en)* | 2023-04-14 | 2023-06-30 | 中国航空综合技术研究所 | Keyword Similarity Judgment Method for Aviation Literature Based on Multimodal Semantic Association Graph |
| CN117113385A (en)* | 2023-10-25 | 2023-11-24 | 成都乐超人科技有限公司 | Data extraction method and system applied to user information encryption |
| CN117113385B (en)* | 2023-10-25 | 2024-03-01 | 成都乐超人科技有限公司 | Data extraction method and system applied to user information encryption |
| CN117195913A (en)* | 2023-11-08 | 2023-12-08 | 腾讯科技(深圳)有限公司 | Text processing method, text processing device, electronic equipment, storage medium and program product |
| CN117195913B (en)* | 2023-11-08 | 2024-02-27 | 腾讯科技(深圳)有限公司 | Text processing method, text processing device, electronic equipment, storage medium and program product |
Also Published As
| Publication number | Publication date |
|---|---|
| CN114528588B (en) | 2025-03-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11017178B2 (en) | Methods, devices, and systems for constructing intelligent knowledge base | |
| US9798818B2 (en) | Analyzing concepts over time | |
| US9626622B2 (en) | Training a question/answer system using answer keys based on forum content | |
| CN111832276B (en) | Rich message embedding for dialogue de-interleaving | |
| CN114528588B (en) | Cross-modal privacy semantic representation method, device, equipment and storage medium | |
| CN108153901A (en) | The information-pushing method and device of knowledge based collection of illustrative plates | |
| WO2022088671A1 (en) | Automated question answering method and apparatus, device, and storage medium | |
| CN114579876B (en) | False information detection method, device, equipment and medium | |
| US10169466B2 (en) | Persona-based conversation | |
| CN113806588B (en) | Method and device for searching videos | |
| CN111523019B (en) | Method, apparatus, device and storage medium for outputting information | |
| CN114328838A (en) | Event extraction method, apparatus, electronic device, and readable storage medium | |
| US10558760B2 (en) | Unsupervised template extraction | |
| WO2021063089A1 (en) | Rule matching method, rule matching apparatus, storage medium and electronic device | |
| CN110362815A (en) | Text vector generation method and device | |
| WO2023168997A9 (en) | Cross-modal retrieval method and related device | |
| WO2023227030A1 (en) | Intention recognition method and apparatus, storage medium and electronic device | |
| CN116975363A (en) | Video tag generation method and device, electronic equipment and storage medium | |
| CN110442696A (en) | Query processing method and device | |
| US10102289B2 (en) | Ingesting forum content | |
| CN113435523B (en) | Method, device, electronic device and storage medium for predicting content click-through rate | |
| WO2023000782A1 (en) | Method and apparatus for acquiring video hotspot, readable medium, and electronic device | |
| WO2021103594A1 (en) | Tacitness degree detection method and device, server and readable storage medium | |
| CN114385819B (en) | Ontology construction method, device and related equipment in the field of environmental justice | |
| US9484033B2 (en) | Processing and cross reference of realtime natural language dialog for live annotations |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |