CN114512128A - Speech recognition method, device, equipment and computer readable storage medium - Google Patents
Speech recognition method, device, equipment and computer readable storage mediumDownload PDFInfo
- Publication number
- CN114512128A CN114512128ACN202210118048.7ACN202210118048ACN114512128ACN 114512128 ACN114512128 ACN 114512128ACN 202210118048 ACN202210118048 ACN 202210118048ACN 114512128 ACN114512128 ACN 114512128A
- Authority
- CN
- China
- Prior art keywords
- speech
- classification
- end point
- voice
- frame
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images










Classifications
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L17/00—Speaker identification or verification techniques
- G10L17/04—Training, enrolment or model building
Landscapes
- Engineering & Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Computational Linguistics (AREA)
- Telephonic Communication Services (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本申请涉及人工智能技术领域,尤其涉及一种语音识别方法、装置、设备及计算机可读存储介质。The present application relates to the technical field of artificial intelligence, and in particular, to a speech recognition method, apparatus, device, and computer-readable storage medium.
背景技术Background technique
随着人工智能技术的不断发展,智能语音客服也在不断替代人工客服,而在智能语音客服工作中,通过采用自动语音识别技术对用户的语音数据进行识别,与用户进行语音交互的场景也越来越普遍,语音识别的技术效果也直接影响到智能语音客服在与用户交互过程中识别的准确性和交互的体验感。现有的智能语音客服大多采用电话信道通信,音频采样率为8KHZ普遍低于手机和PC端等通道的16KHZ或44.1KHZ,尤其在嘈杂的环境中,电话信道通信语音质量差,电话信道丢失的信息较多,语音识别效果差,进而直接影响到智能语音客服和用户交互的准确性。With the continuous development of artificial intelligence technology, intelligent voice customer service is also constantly replacing manual customer service. In the work of intelligent voice customer service, the use of automatic voice recognition technology to recognize the user's voice data, the scene of voice interaction with users is becoming more and more It is becoming more and more common, and the technical effect of voice recognition also directly affects the recognition accuracy and interactive experience of intelligent voice customer service in the process of interacting with users. Most of the existing intelligent voice customer service use telephone channel communication, and the audio sampling rate of 8KHZ is generally lower than 16KHZ or 44.1KHZ of channels such as mobile phones and PCs. Especially in noisy environments, the voice quality of telephone channel communication is poor and the telephone channel is lost. There is a lot of information, and the voice recognition effect is poor, which directly affects the accuracy of intelligent voice customer service and user interaction.
为了提升噪声环境下语音识别的效果,现有的技术一方面是在信号预处理步骤,通过噪声抑制等技术来去除部分噪声,以此来提升噪声环境下语音质量;另一方面是通过不断优化语音识别步骤的声学模型,来提高识别准确率。In order to improve the effect of speech recognition in a noisy environment, on the one hand, the existing technology removes part of the noise through noise suppression and other technologies in the signal preprocessing step, so as to improve the speech quality in a noisy environment; on the other hand, it continuously optimizes Acoustic models of speech recognition steps to improve recognition accuracy.
在现有的技术方案中,噪声抑制的方法能够一定程度上减少语音帧中的噪声信号,提高静音检测模块的准确性,但是去噪算法会对原始语音信号进行一定程度的转换,影响声学模型的识别效果;声学模型优化的方法对数据依赖程度大,操作较为复杂,对噪声环境下语音识别的优化效果有限,传统基于能量的静音检测方法在噪声环境中效果较差。In the existing technical solution, the noise suppression method can reduce the noise signal in the speech frame to a certain extent and improve the accuracy of the silence detection module, but the denoising algorithm will convert the original speech signal to a certain extent, which affects the acoustic model. The method of acoustic model optimization is highly dependent on data, the operation is more complicated, and the optimization effect of speech recognition in noise environment is limited, and the traditional energy-based silence detection method is less effective in noise environment.
发明内容SUMMARY OF THE INVENTION
本发明的主要目的在于提供一种语音识别方法、装置及计算机可读存储介质,旨在提高噪声环境下电话信道实时语音识别的效果。The main purpose of the present invention is to provide a speech recognition method, device and computer-readable storage medium, aiming at improving the effect of real-time speech recognition of a telephone channel in a noisy environment.
为实现上述目的,本发明提供了一种语音识别方法,所述语音识别方法包括:In order to achieve the above object, the present invention provides a speech recognition method, the speech recognition method includes:
获取待识别的原始语音信号;Obtain the original speech signal to be recognized;
基于预先训练的分类模型,对所述原始语音信号中的初始语音帧进行分类处理,得到语音帧分类结果;Based on the pre-trained classification model, the initial speech frame in the original speech signal is classified and processed to obtain a speech frame classification result;
根据所述语音帧分类结果并结合预设的判定规则,检测得到有效语音段的前端点和后端点;According to the classification result of the voice frame and in combination with the preset judgment rule, the front end point and the back end point of the valid speech segment are detected;
将所述前端点和后端点间的有效语音段输入预先训练的声学模型,进行文本转写,获得对应的目标转写结果。Input the valid speech segment between the front end point and the back end point into a pre-trained acoustic model, perform text transcription, and obtain a corresponding target transcription result.
可选地,所述获取待识别的原始语音信号的步骤之后还包括:Optionally, after the step of acquiring the original voice signal to be recognized, the step further includes:
对所述原始语音信号的字节流进行截取并进行归一化处理,得到所述原始语音信号的一维浮点型矩阵式的初始语音帧信息。The byte stream of the original speech signal is intercepted and normalized to obtain the initial speech frame information of the original speech signal in the form of a one-dimensional floating point matrix.
可选地,所述基于预先训练好的分类模型为二分类模型,所述二分类模型包括:浅层特征提取层、多尺度一维卷积残差层、整合层和输出层;所述基于预先训练好的分类模型,对所述原始语音信号中的初始语音帧进行分类处理,得到语音帧分类结果的步骤包括:Optionally, the pre-trained classification model is a two-class model, and the two-class model includes: a shallow feature extraction layer, a multi-scale one-dimensional convolution residual layer, an integration layer, and an output layer; The pre-trained classification model performs classification processing on the initial speech frame in the original speech signal, and the steps of obtaining the classification result of the speech frame include:
将所述一维浮点型矩阵式的初始语音帧信息输入到预先训练好的二分类模型;Inputting the initial speech frame information of the one-dimensional floating-point matrix into the pre-trained two-class model;
通过所述二分类模型中的浅层特征提取层对所述初始语音帧进行特征提取,得到初级特征,其中,浅层特征提取层包括批量归一化Batch Normalization层、最大池化MaxPooling层和一维卷积层;Feature extraction is performed on the initial speech frame through the shallow feature extraction layer in the binary classification model to obtain primary features, wherein the shallow feature extraction layer includes a Batch Normalization layer, a MaxPooling layer and a MaxPooling layer. dimensional convolutional layer;
通过堆叠的所述多尺度一维卷积残差层对所述初级特征进行不同尺度的卷积计算,获得计算后的高级特征,其中,所述多尺度一维卷积残差层包含m路不同尺度一维卷积残差层,每路一维卷积残差层包含n个相同卷积核大小的一维卷积残差块和平均池化AvgPooling层,其中,m、n为正整数;The primary features are subjected to convolution calculations at different scales by stacking the multi-scale one-dimensional convolution residual layers to obtain calculated advanced features, wherein the multi-scale one-dimensional convolution residual layers include m channels One-dimensional convolution residual layers of different scales, each one-dimensional convolution residual layer contains n one-dimensional convolution residual blocks with the same convolution kernel size and average pooling AvgPooling layer, where m and n are positive integers ;
将所述高级特征链接到所述二分类模型的整合层进行整合,得到对应的整合结果;Linking the high-level features to the integration layer of the two-class model for integration to obtain a corresponding integration result;
将所述整合结果输入输出层的全连接层和softmax层,获得所述初始语音帧属于不同类别的概率矩阵;The integration result is input into the fully connected layer and the softmax layer of the output layer to obtain the probability matrix that the initial speech frame belongs to different categories;
将获取的概率矩阵与预先设定好的阈值进行匹配,得到初始语音帧的语音帧分类结果。Match the acquired probability matrix with a preset threshold to obtain the speech frame classification result of the initial speech frame.
可选地,所述根据所述语音帧分类结果并结合预设的判定规则,检测得到有效语音段的前端点和后端点的步骤包括:Optionally, the step of detecting and obtaining the front end point and the back end point of the valid speech segment according to the voice frame classification result and in combination with the preset judgment rule includes:
基于所述原始语音信号中的初始语音帧的分类结果,获得所述原始语音信号的分类结果序列,其中,所述分类结果包括活动语音帧和非活动语音帧;obtaining a sequence of classification results of the original speech signal based on the classification result of the initial speech frame in the original speech signal, wherein the classification result includes an active speech frame and an inactive speech frame;
根据所述分类结果序列,结合预设的前端点与后端点判定规则,获取所述原始语音信号的有效语音段的前端点与后端点。According to the classification result sequence, combined with the preset front-end point and back-end point determination rules, the front-end point and the back-end point of the valid speech segment of the original speech signal are acquired.
可选地,所述根据所述分类结果序列,结合预设的前端点与后端点判定规则,获取所述原始语音信号的有效语音段的前端点与后端点的步骤包括:Optionally, the step of obtaining the front end and the back end of the valid speech segment of the original voice signal according to the classification result sequence in combination with the preset front end and back end judgment rules includes:
从所述分类结果序列中获取第一分类结果子序列,所述第一分类结果子序列包括:连续的N帧语音帧的分类结果;Obtain a first classification result subsequence from the classification result sequence, where the first classification result subsequence includes: classification results of consecutive N frames of speech frames;
若所述第一分类结果子序列中活动性语音帧的个数达到第一阈值,则判定所述第一分类结果子序列的最前端对应的语音帧为有效语音段的前端点;If the number of active speech frames in the first classification result subsequence reaches the first threshold, it is determined that the speech frame corresponding to the foremost end of the first classification result subsequence is the front end of the valid speech segment;
基于所述前端点,从所述分类结果序列中获取第二分类结果子序列,所述第二分类结果子序列包括:在所述前端点之后,连续的M帧语音帧的分类结果;Based on the front end point, a second classification result subsequence is obtained from the classification result sequence, and the second classification result subsequence includes: after the front end point, the classification results of consecutive M frames of speech frames;
若所述第二分类结果子序列中非活动性语音帧的个数达到第二阈值,则判定所述第二分类结果子序列的最后端对应的语音帧为有效语音段的后端点。If the number of inactive speech frames in the second classification result subsequence reaches the second threshold, it is determined that the speech frame corresponding to the last end of the second classification result subsequence is the end end of the valid speech segment.
可选地,所将所述前端点和后端点间的有效语音段输入预先训练的声学模型,进行文本转写,获得对应的目标转写结果的步骤包括:Optionally, the effective speech segment between the front end point and the back end point is input into a pre-trained acoustic model, and the text is transcribed, and the steps of obtaining the corresponding target transcription result include:
将所述前端点和后端点之间的有效语音段传入预先训练好的声学模型;Passing the valid speech segment between the front end point and the back end point into the pre-trained acoustic model;
通过所述声学模型对所述有效语音段进行解码,实现文本转写,获得所述有效语音段对应的的目标转写结果。The effective speech segment is decoded by the acoustic model to realize text transcription, and a target transcription result corresponding to the effective speech segment is obtained.
可选地,在所述获取待识别的原始语音信号的步骤之前,所述语音识别方法还包括:Optionally, before the step of acquiring the original speech signal to be recognized, the speech recognition method further includes:
获取训练数据的样本音频,提取所述样本音频的样本特征,其中,所述样本音频具有对应的分类结果;Obtain the sample audio of the training data, and extract the sample features of the sample audio, wherein the sample audio has a corresponding classification result;
基于所述样本特征,建立样本特征数据集;Based on the sample features, establish a sample feature data set;
构建多尺度一维残差神经网络,基于所述样本特征数据集对所述多尺度一维残差神经网络进行深度学习,得到初始的二分类模型。A multi-scale one-dimensional residual neural network is constructed, and deep learning is performed on the multi-scale one-dimensional residual neural network based on the sample feature data set to obtain an initial two-class model.
可选地,在所述构建多尺度一维残差神经网络,基于所述样本特征数据集对所述多尺度一维残差神经网络进行深度学习,得到初始的二分类模型的步骤之后,所述语音识别方法还包括:Optionally, after the step of constructing a multi-scale one-dimensional residual neural network and performing deep learning on the multi-scale one-dimensional residual neural network based on the sample feature data set to obtain an initial two-class model, the The speech recognition method further includes:
将所述初始的二分类模型进行电话信道语音数据测试,验证所述初始二分类模型的分类效果;Carrying out the telephone channel voice data test on the initial two-class model to verify the classification effect of the initial two-class model;
若分类效果未达到预设标准,则需返回对样本音频进行数据加强,获得优化训练数据的样本音频;If the classification effect does not meet the preset standard, it is necessary to return to the sample audio to enhance the data to obtain the sample audio of the optimized training data;
根据所述优化训练数据的样本音频对所述初始的二分类模型进行微调训练,获得训练后的二分类模型;Perform fine-tuning training on the initial two-class model according to the sample audio of the optimized training data to obtain a trained two-class model;
若分类效果达到预设标准,则将所述初始的二分类模型作为训练后的二分类模型。If the classification effect reaches the preset standard, the initial two-class model is used as the trained two-class model.
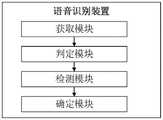
此外,为实现上述目的,本发明还提供一种语音识别装置,所述语音识别装置包括:In addition, in order to achieve the above purpose, the present invention also provides a voice recognition device, the voice recognition device comprising:
获取模块,用于获取待识别的原始语音信号;an acquisition module for acquiring the original speech signal to be recognized;
判定模块,用于基于预先训练的分类模型,对所述原始语音信号中的初始语音帧进行分类处理,得到语音帧分类结果;A determination module, used for classifying and processing the initial speech frame in the original speech signal based on a pre-trained classification model, to obtain a speech frame classification result;
检测模块,用于根据所述语音帧分类结果并结合预设的判定规则,检测得到有效语音段的前端点和后端点;a detection module, configured to detect the front end and back end of the valid speech segment according to the classification result of the speech frame and in combination with a preset judgment rule;
确定模块,用于将所述前端点和后端点间的有效语音段输入预先训练的声学模型,进行文本转写,获得对应的目标转写结果。The determining module is used for inputting the valid speech segment between the front end point and the back end point into the pre-trained acoustic model, to perform text transcription, and obtain the corresponding target transcription result.
此外,为实现上述目的,本发明还提供一种智能设备,所述智能设备包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的语音识别程序,所述语音识别程序被所述处理器执行时实现如上文所述的语音识别方法的步骤。In addition, in order to achieve the above object, the present invention also provides a smart device, the smart device includes a memory, a processor and a speech recognition program stored in the memory and running on the processor, the speech recognition program The program, when executed by the processor, implements the steps of the speech recognition method as described above.
此外,为实现上述目的,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质上存储有语音识别程序,所述语音识别程序被处理器执行时实现如上文所述的语音识别方法的步骤。In addition, in order to achieve the above object, the present invention also provides a computer-readable storage medium on which a speech recognition program is stored, and when the speech recognition program is executed by a processor, the above-mentioned speech is realized. Identify the steps of the method.
本发明实施例提出的语音识别方法、装置、设备及计算机可读存储介质,通过获取待识别的原始语音信号;基于预先训练的分类模型,对所述原始语音信号中的初始语音帧进行分类处理,得到语音帧分类结果;根据所述语音帧分类结果并结合预设的判定规则,检测得到有效语音段的前端点和后端点;将所述前端点和后端点间的有效语音段输入预先训练的声学模型,进行文本转写,获得对应的目标转写结果。The speech recognition method, apparatus, device, and computer-readable storage medium proposed by the embodiments of the present invention obtain the original speech signal to be recognized; and based on a pre-trained classification model, the initial speech frame in the original speech signal is classified and processed , obtain the speech frame classification result; According to the described speech frame classification result and in conjunction with the preset judgment rule, detect the front end point and the back end point of the valid speech segment; Input the valid speech segment between the front end point and the back end point into pre-training The acoustic model is used for text transcription, and the corresponding target transcription results are obtained.
本发明在获取到待识别的原始语音信号之后,对语音信号进行分类处理,分类处理的步骤包括通过预先训练好分类模型判断原始语音信号每一帧语音的活动性,即得到原始语音信号中每一帧语音帧的分类结果,获取到对应的分类结果之后,将这些分类结果组合获取与原始语音信号对应的分类结果序列,根据分类结果序列判断有效语音段的前端点和后端点,得到处于前段点和后端点之间的有效语音段。将有效语音段传入声学模型进行语音识别,得到识别结果后进行文本转写,进而获得目标转写结果,本方案在通过分类模型得到原始语音信号中每一帧语音帧的分类结果,判定前端点和后端点得到有效语音段,对有效语音段进行声学模型的语音识别方法,提高了在电话信道中实时语音识别获取目标语音识别结果的正确性,优化了噪音环境下实时语音的识别效果。After obtaining the original speech signal to be recognized, the present invention performs classification processing on the speech signal. The step of classification processing includes judging the activity of each frame of speech of the original speech signal by pre-training the classification model, that is, to obtain each frame of speech in the original speech signal. The classification results of one frame of speech frame, after obtaining the corresponding classification results, combine these classification results to obtain the classification result sequence corresponding to the original speech signal, and judge the front end and back end of the valid speech segment according to the classification result sequence, and obtain the front end point of the valid speech segment. A valid speech segment between the point and the back point. The valid speech segment is passed into the acoustic model for speech recognition, and after the recognition result is obtained, the text is transcribed, and then the target transcription result is obtained. This scheme obtains the classification result of each speech frame in the original speech signal through the classification model, and determines the front-end The voice recognition method using the acoustic model to obtain the valid speech segment from the point and the back end point, improves the accuracy of the target speech recognition result obtained by real-time speech recognition in the telephone channel, and optimizes the real-time speech recognition effect in the noise environment.
附图说明Description of drawings
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本发明的实施例,并与说明书一起用于解释本发明的原理。The accompanying drawings, which are incorporated in and constitute a part of this specification, illustrate embodiments consistent with the invention and together with the description serve to explain the principles of the invention.
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,对于本领域普通技术人员而言,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。In order to more clearly illustrate the embodiments of the present invention or the technical solutions in the prior art, the following briefly introduces the accompanying drawings that need to be used in the description of the embodiments or the prior art. In other words, on the premise of no creative labor, other drawings can also be obtained from these drawings.
图1为本发明实施例提供的一种实施方式的硬件结构示意图;FIG. 1 is a schematic diagram of a hardware structure of an implementation manner provided by an embodiment of the present invention;
图2为本申请语音识别方法第一实施例的流程示意图;2 is a schematic flowchart of the first embodiment of the speech recognition method of the application;
图3为本申请语音识别方法第一实施例的细化流程步骤的示意图;3 is a schematic diagram of the refinement process steps of the first embodiment of the speech recognition method of the present application;
图4为本申请语音识别方法第二实施例的流程示意图;4 is a schematic flowchart of a second embodiment of the speech recognition method of the present application;
图5为本申请语音识别方法第三实施例的流程示意图;5 is a schematic flowchart of a third embodiment of the speech recognition method of the present application;
图6为本申请语音识别方法第三实施例中二分类模型的结构示意图;6 is a schematic structural diagram of a two-class model in the third embodiment of the speech recognition method of the application;
图7为本申请语音识别方法第三实施例中二分类模型中一维残差卷积块的结构示意图;7 is a schematic structural diagram of a one-dimensional residual convolution block in a two-class model in the third embodiment of the speech recognition method of the present application;
图8为本申请语音识别方法第四实施例的流程示意图;FIG. 8 is a schematic flowchart of the fourth embodiment of the speech recognition method of the present application;
图9为本申请语音识别方法第四实施例中根据所述语音帧分类结果并结合预设的判定规则,检测得到有效语音段的前端点和后端点的细化流程示意图;9 is a schematic diagram of a refinement process for detecting the front end and back end of a valid speech segment according to the speech frame classification result in combination with the preset judgment rule in the fourth embodiment of the speech recognition method of the present application;
图10为本发明语音识别方法第五实施例的流程示意图;10 is a schematic flowchart of a fifth embodiment of a speech recognition method according to the present invention;
图11为本发明语音识别方法实施例的装置模块示意图。FIG. 11 is a schematic diagram of a device module according to an embodiment of the speech recognition method of the present invention.
具体实施方式Detailed ways
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。It should be understood that the specific embodiments described herein are only used to explain the present invention, but not to limit the present invention.
如图1所示,图1是本发明实施例方案涉及的硬件运行环境的设备结构示意图。As shown in FIG. 1 , FIG. 1 is a schematic diagram of a device structure of a hardware operating environment involved in an embodiment of the present invention.
本发明实施例设备可以是移动终端或服务器设备。The device in this embodiment of the present invention may be a mobile terminal or a server device.
如图1所示,该设备可以包括:处理器1001,例如CPU,网络接口1004,用户接口1003,存储器1005,通信总线1002。其中,通信总线1002用于实现这些组件之间的连接通信。用户接口1003可以包括显示屏(Display)、输入单元比如键盘(Keyboard),可选用户接口1003还可以包括标准的有线接口、无线接口。网络接口1004可选的可以包括标准的有线接口、无线接口(如WI-FI接口)。存储器1005可以是高速RAM存储器,也可以是稳定的存储器(non-volatile memory),例如磁盘存储器。存储器1005可选的还可以是独立于前述处理器1001的存储装置。As shown in FIG. 1 , the device may include: a
本领域技术人员可以理解,图1中示出的设备结构并不构成对设备的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。Those skilled in the art can understand that the device structure shown in FIG. 1 does not constitute a limitation on the device, and may include more or less components than the one shown, or combine some components, or arrange different components.
如图1所示,作为一种计算机存储介质的存储器1005中可以包括操作系统、网络通信模块、用户接口模块以及语音识别程序。As shown in FIG. 1 , the
其中,操作系统是管理和控制实时语音识别设备与软件资源的程序,支持网络通信模块、用户接口模块、实时语音识别程序以及其他程序或软件的运行;网络通信模块用于管理和控制网络接口1002;用户接口模块用于管理和控制用户接口1003。The operating system is a program that manages and controls real-time speech recognition equipment and software resources, and supports the operation of network communication modules, user interface modules, real-time speech recognition programs, and other programs or software; the network communication module is used to manage and control the
在图1所示的实时语音识别设备中,所述实时语音识别设备通过处理器1001调用存储器1005中存储的实时语音识别程序,并执行下述语音识别方法各个实施例中的操作。In the real-time speech recognition device shown in FIG. 1, the real-time speech recognition device invokes the real-time speech recognition program stored in the
基于上述硬件结构,提出本发明语音识别方法的实施例。Based on the above hardware structure, an embodiment of the speech recognition method of the present invention is proposed.
参照图2,图2为本发明语音识别方法第一实施例的流程示意图,需要说明的是,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤,本实施例语音识别方法的步骤包括:Referring to FIG. 2, FIG. 2 is a schematic flowchart of the first embodiment of the speech recognition method of the present invention. It should be noted that although the logical sequence is shown in the flowchart, in some cases, different The steps shown or described are performed in sequence, and the steps of the speech recognition method of this embodiment include:
步骤S10,获取待识别的原始语音信号;Step S10, obtaining the original speech signal to be recognized;
步骤S20,基于预先训练好的分类模型,对所述原始语音信号中的初始语音帧进行分类处理,得到语音帧分类结果;Step S20, based on the pre-trained classification model, classifying the initial speech frame in the original speech signal to obtain a speech frame classification result;
步骤S30,根据所述语音帧分类结果并结合预设的判定规则,检测得到有效语音段的前端点和后端点;Step S30, according to the voice frame classification result and in conjunction with the preset judgment rule, detect the front end and the back end of the valid speech segment;
步骤S40,将所述前端点和后端点间的有效语音段输入预先训练的声学模型,进行文本转写,获得对应的目标转写结果。Step S40: Input the valid speech segment between the front end point and the back end point into a pre-trained acoustic model, perform text transcription, and obtain a corresponding target transcription result.
在本实施例中,为了解决在噪声环境下,电话信道的实时语音识别效果差的问题,本实施例提出的将原始语音信号进行截取获得原始语音信号中的初始语音帧,将初始语音帧输入预先训练好的分类模型中,得到对应的语音帧分类结果,根据语音帧分类结果结合预设判定规则,得到有效语音段的前段点和后端点,将处于前端点和后端点之间的有效语音段传入声学模型进行文本转写,获得目标转写结果,提高了电话信道中实时语音识别获取目标语音识别结果的正确性,优化了噪音环境下实时语音的识别效果。In this embodiment, in order to solve the problem that the real-time speech recognition effect of the telephone channel is poor in a noisy environment, the present embodiment proposes to intercept the original speech signal to obtain the initial speech frame in the original speech signal, and input the initial speech frame into In the pre-trained classification model, the corresponding speech frame classification results are obtained. According to the speech frame classification results combined with the preset judgment rules, the front and rear end points of the effective speech segment are obtained. The segment is passed into the acoustic model for text transcription, and the target transcription result is obtained, which improves the accuracy of the target speech recognition result obtained by the real-time speech recognition in the telephone channel, and optimizes the real-time speech recognition effect in the noise environment.
以下针对每个步骤进行详细说明:Each step is explained in detail below:
步骤S10,获取待识别的原始语音信号;Step S10, obtaining the original speech signal to be recognized;
在本实施例中,待识别的语音信号,是指在通过电话信道实时语音通话的过程中,从用户端获取的实时语音音频数据,将该实时语音音频数据进行转化得到待识别的原始语音信号,获取以语音信号字节流的形式存在的待识别的原始语音信号。In this embodiment, the voice signal to be recognized refers to the real-time voice and audio data obtained from the client during the real-time voice call through the telephone channel, and the real-time voice and audio data is converted to obtain the original voice signal to be recognized. , to obtain the original speech signal to be recognized in the form of speech signal byte stream.
原始语音信号经过处理可以得到其中的初始语音帧。The original speech frame can be obtained by processing the original speech signal.
步骤S20,基于预先训练好的分类模型,对所述原始语音信号中的初始语音帧进行分类处理,得到语音帧分类结果;Step S20, based on the pre-trained classification model, classifying the initial speech frame in the original speech signal to obtain a speech frame classification result;
在本实施例中,基于预先训练好的分类模型对原始语音信号中的初始语音帧进行分类处理,处理后获得对应的语音帧分类结果。In this embodiment, the initial speech frame in the original speech signal is classified based on a pre-trained classification model, and a corresponding speech frame classification result is obtained after processing.
其中,预先训练好的分类模型为二分类模型,利用该二分类模型对上述以语音信号字节流形式存在的原始语音信号对应的初始语音帧进行分类处理,得到对应的语音帧分类结果,上述语音帧分类结果包括活动性语音帧和非活动性语音帧。The pre-trained classification model is a two-class model, and the two-class model is used to classify and process the initial speech frame corresponding to the original speech signal existing in the form of a speech signal byte stream to obtain the corresponding speech frame classification result. The speech frame classification results include active speech frames and inactive speech frames.
具体地,获取分类结果的方式具体可以包括:Specifically, the manner of obtaining the classification result may include:
通过分类模型的每个不同特征提取层,获取原始语音信号每一帧语音帧的特征,将不断提取的这些语音帧特征连接到整合层,在整合层对语音帧的特征进行整合之后,将整合好的特征从分类模型中输出,输出的结果为原始语音信号每一帧语音帧对应的语音帧分类结果。该语音帧分类结果包括活动性语音帧和非活动性语音帧。Through each different feature extraction layer of the classification model, the features of each voice frame of the original voice signal are obtained, and the continuously extracted features of these voice frames are connected to the integration layer. After the integration layer integrates the features of the voice frames, the integration The good features are output from the classification model, and the output result is the speech frame classification result corresponding to each speech frame of the original speech signal. The speech frame classification result includes active speech frames and inactive speech frames.
步骤S30,根据所述语音帧分类结果并结合预设的判定规则,检测得到有效语音段的前端点和后端点;Step S30, according to the voice frame classification result and in conjunction with the preset judgment rule, detect the front end and the back end of the valid speech segment;
在本实施例中,要判定在原始语音信号中的有效语音段,一方面是需要对有效语音段中的每一语音帧进行活动性的判定,得到每一帧语音帧对应的语音帧的分类结果,另一方面则是要检测到有效语音段的前端点和后端点,获取到前端点与后端点之间的有效语音段,对处于前端点和后端点之间的有效语音段进行语音识别。In this embodiment, to determine the valid speech segment in the original speech signal, on the one hand, it is necessary to determine the activity of each speech frame in the valid speech segment to obtain the classification of the speech frame corresponding to each speech frame. As a result, on the other hand, it is necessary to detect the front end point and the back end point of the valid speech segment, obtain the valid speech segment between the front end point and the back end point, and perform speech recognition on the valid speech segment between the front end point and the back end point. .
本实施例考虑到:在电话信道用户和智能语音客服进行对话的场景中,用户与智能语音客服进行对话的过程常会出现用户段时间停顿、背景环境偶发音量较大的噪声和人声等情况,因此,仅将从语音帧分类模型中获取的分类结果作为判定有效语音段的唯一标准是片面的,使用该标准判定语音段的有效性无法优化实时语音识别效果,因此,判定语音段的有效性还需要根据不同用户的使用习惯,预先制定相应的判定规则,检测有效语音段的前端点和后端点,进而获得处于前端点和后端点之间的有效语音段。This embodiment takes into account: in the scenario where the telephone channel user and the intelligent voice customer service are in a dialogue, the process of the user and the intelligent voice customer service in the dialogue often occurs when the user pauses for a period of time, and the background environment has occasional loud noises and human voices, etc. Therefore, it is one-sided to use only the classification results obtained from the speech frame classification model as the only criterion for judging valid speech segments. Using this criterion to determine the validity of speech segments cannot optimize the effect of real-time speech recognition. Therefore, judging the validity of speech segments It is also necessary to formulate corresponding judgment rules in advance according to the usage habits of different users, to detect the front end point and the back end point of the valid speech segment, and then obtain the valid speech segment between the front end point and the back end point.
步骤S40,将所述前端点和后端点间的有效语音段输入预先训练的声学模型,进行文本转写,获得对应的目标转写结果;Step S40, input the effective speech segment between the front end point and the back end point into the pre-trained acoustic model, carry out text transcription, and obtain the corresponding target transcription result;
通过上述已获取到的有效语音段的前端点和后端点,得到前段点和后端点之间的有效语音段,将该有效语音段输入预先训练好的声学模型,对上述有效语音段进行解码,实现文本转写,获得对应的目标转写结果。Obtain the valid speech segment between the front segment point and the back end point through the front end point and back end point of the obtained valid speech segment, input the valid speech segment into the pre-trained acoustic model, and decode the above valid speech segment, Implement text transcription and obtain the corresponding target transcription results.
本方案中提出的语音识别方法,通过结合对有效语音帧活动性判定的分类结果和有效语音段的前端点和后端点,优化了实时语音的分类结果,通过获取进行文本转写的有效语音段,使识别结果更加准确,实时语音识别效果也得到优化,同时也提高了电话信道中实时语音识别时,获取目标语音识别结果的正确性,优化了噪音环境下实时语音的识别效果。The speech recognition method proposed in this scheme optimizes the classification result of real-time speech by combining the classification result of the activity determination of the valid speech frame and the front end and back end of the valid speech segment, and obtains the valid speech segment for text transcription by obtaining , so that the recognition results are more accurate, and the real-time speech recognition effect is also optimized. At the same time, it also improves the correctness of the target speech recognition results when real-time speech recognition in the telephone channel is used, and optimizes the real-time speech recognition effect in noisy environments.
在本实施例中,为了解决在噪声环境下,电话信道的实时语音识别效果差的问题,本实施例将原始语音信号对应的初始语音帧的语音字节流输入分类模型进行活动性判定,让实时输入的原始语音信号的每一帧语音帧都有相对应的分类结果,在语音识别过程中结合分类结果进行识别,提高实时语音识别的准确性,优化实时语音的识别效果。In this embodiment, in order to solve the problem that the real-time speech recognition effect of the telephone channel is poor in a noisy environment, in this embodiment, the speech byte stream of the initial speech frame corresponding to the original speech signal is input into the classification model to determine the activity, so that Each voice frame of the real-time input original voice signal has a corresponding classification result, which is combined with the classification results in the speech recognition process to improve the accuracy of real-time speech recognition and optimize the real-time speech recognition effect.
进一步地,根据语音帧分类结果结合预设判定规则,得到有效语音段的前段点和后端点,上述预设的前端点与后端点判定规则可以通过结合用户的不同使用习惯制定,让进行语音识别的有效语音段的端点判定规则更加灵活,基于上述分类结果再结合前端点与后端点的预设判定规则,获取到前端点与后端点之间的有效语音段,将处于前端点和后端点之间的有效语音段传入声学模型进行文本转写,获得目标转写结果。Further, according to the voice frame classification result and the preset judgment rule, the front end point and the back end point of the valid speech segment are obtained, and the above-mentioned preset front end point and back end point judgment rule can be formulated by combining the different usage habits of users, so that the speech recognition can be performed. The endpoint judgment rule of the valid voice segment is more flexible. Based on the above classification results, combined with the preset judgment rules of the front end point and the back end point, the valid speech segment between the front end point and the back end point is obtained, and the valid speech segment between the front end point and the back end point is obtained. The valid speech segments in between are passed into the acoustic model for text transcription, and the target transcription results are obtained.
本方案中提出的语音识别方法,通过结合对有效语音帧活动性判定的分类结果和有效语音段的前端点和后端点,优化了实时语音的分类结果,获取进行文本转写的有效语音段,使识别结果更加准确,实时语音识别效果也得到优化,同时也提高在电话信道中实时语音识别获取目标语音识别结果的正确性,优化了噪音环境下实时语音的识别效果。The speech recognition method proposed in this solution optimizes the classification result of real-time speech by combining the classification result of the activity judgment of the valid speech frame and the front end and back end of the valid speech segment, and obtains the valid speech segment for text transcription, The recognition result is more accurate, and the real-time speech recognition effect is also optimized. At the same time, the accuracy of the target speech recognition result obtained by real-time speech recognition in the telephone channel is improved, and the real-time speech recognition effect in the noise environment is optimized.
本实施例具体的细化流程步骤可以参照图3所示。Refer to FIG. 3 for the specific detailed process steps in this embodiment.
进一步地,基于第一实施例,提出本发明语音识别方法的第二实施例,本实施例的流程参照图4。语音识别方法的第二实施例与语音识别方法的第一实施例的区别在于,在步骤S10之后还包括:Further, based on the first embodiment, a second embodiment of the speech recognition method of the present invention is proposed, and the flowchart of this embodiment is referred to FIG. 4 . The difference between the second embodiment of the speech recognition method and the first embodiment of the speech recognition method is that after step S10, it further includes:
步骤S101,对所述原始语音信号的字节流进行截取并进行归一化处理,得到所述原始语音信号的一维浮点型矩阵式的初始语音帧信息。Step S101 , intercepting and normalizing the byte stream of the original voice signal to obtain initial voice frame information in the form of a one-dimensional floating-point matrix of the original voice signal.
从电话信道中获取实时语音的音频数据,对该音频数据进行处理之后,得到对应的的原始语音信号,缓存与该原始语音信号对应的语音信号字节流,对该语音信号字节流进行截取,截取长度为一个固定值,此固定长度在真实使用的过程中可以按照实际情况确定一个阈值,当缓存中字节数达到阈值时,对缓存中的原始语音信号字节流进行处理,按照固定大小对字节流处理,该预设阈值长度的的语音信号字节为一个初始语音帧,对这些初始语音帧的字节流进行归一化处理,生成初始语音帧对应的一维浮点型矩阵,获取到一个以一维浮点型矩阵形式存在的初始语音帧。Acquire real-time voice audio data from the telephone channel, process the audio data to obtain the corresponding original voice signal, buffer the voice signal byte stream corresponding to the original voice signal, and intercept the voice signal byte stream , the interception length is a fixed value. This fixed length can be determined according to the actual situation in the process of actual use. When the number of bytes in the buffer reaches the threshold, the original voice signal byte stream in the buffer is processed, according to the fixed length. The size of the byte stream is processed. The speech signal bytes of the preset threshold length are an initial speech frame, and the byte stream of these initial speech frames is normalized to generate a one-dimensional floating point type corresponding to the initial speech frame. Matrix to obtain an initial speech frame in the form of a one-dimensional floating-point matrix.
在本实施例中,通过对原始语音信号进行字节流转换,获取到原始语音信号对应的语音信号字节流,并对该语音信号字节流进行固定长度的截取,得到一段固定长度的语音信号字节流,上述固定长度按照预设阈值进行设定,且该预设阈值可动态设定。In this embodiment, a byte stream of the voice signal corresponding to the original voice signal is obtained by converting the byte stream of the original voice signal, and the byte stream of the voice signal is intercepted with a fixed length to obtain a fixed length of voice For the signal byte stream, the above-mentioned fixed length is set according to a preset threshold, and the preset threshold can be dynamically set.
本方案提出的语音识别方法让进行语音识别的语音信号字节流形式上更加规范,降低了识别过程中对实时语音信号的识别难度,在一定程度上优化了实时语音的识别效果。The speech recognition method proposed in this solution makes the speech signal byte stream for speech recognition more standardized, reduces the difficulty of recognizing real-time speech signals during the recognition process, and optimizes the real-time speech recognition effect to a certain extent.
进一步地,基于第一实施例以及第二实施例,提出本发明语音识别方法的第三实施例,本实施例的流程参照图5。Further, based on the first embodiment and the second embodiment, a third embodiment of the speech recognition method of the present invention is proposed, and the flowchart of this embodiment refers to FIG. 5 .
本语音识别方法的第三实施例与语音识别方法的其他实施例的区别在于,本实施例对上述步骤S20,基于预先训练好的分类模型,对所述原始语音信号中的初始语音帧进行分类处理,得到语音帧分类结果进行了细化。The difference between the third embodiment of the present speech recognition method and the other embodiments of the speech recognition method is that in the present embodiment, the above step S20 is to classify the initial speech frame in the original speech signal based on the pre-trained classification model After processing, the obtained speech frame classification results are refined.
具体地,在本实施例中,预先训练好的分类模型为二分类模型,所述二分类模型包括:浅层特征提取层、多尺度一维卷积残差层、整合层和输出层;所述基于预先训练好的分类模型,对所述原始语音信号中的初始语音帧进行分类处理,得到语音帧分类结果的步骤包括:Specifically, in this embodiment, the pre-trained classification model is a two-class model, and the two-class model includes: a shallow feature extraction layer, a multi-scale one-dimensional convolution residual layer, an integration layer and an output layer; Based on the pre-trained classification model, the initial speech frame in the original speech signal is classified and processed, and the steps of obtaining the classification result of the speech frame include:
步骤S201,将所述一维浮点型矩阵式的初始语音帧信息输入到预先训练好的二分类模型;Step S201, inputting the initial speech frame information of the one-dimensional floating-point matrix into the pre-trained two-class model;
在一实施例中,将获取到的原始语音信号对应的以一维浮点型矩阵形式存在的初始语音帧信息输入到预先训练好的分类模型中,该预先训练好的分类模型包括上述二分类模型,例如,VAD分类模型,上述VAD分类模型包括浅层特征提取层、多尺度一维卷积残差层、整合层和输出层,将上述初始语音帧信息输入VAD分类模型中的浅层特征提取层,让训练好的VAD分类模型接收到原始语音信号对应的以一维浮点型矩阵形式存在的初始语音帧信息。In one embodiment, the initial speech frame information in the form of a one-dimensional floating-point matrix corresponding to the acquired original speech signal is input into a pre-trained classification model, and the pre-trained classification model includes the above-mentioned two classifications. Model, for example, a VAD classification model, the above-mentioned VAD classification model includes a shallow feature extraction layer, a multi-scale one-dimensional convolution residual layer, an integration layer and an output layer, and the above-mentioned initial speech frame information is input into the shallow feature in the VAD classification model The extraction layer allows the trained VAD classification model to receive the initial speech frame information in the form of a one-dimensional floating-point matrix corresponding to the original speech signal.
步骤S202,通过所述二分类模型中的浅层特征提取层对所述初始语音帧进行特征提取,得到初级特征,其中浅层提取层包括批量归一化Batch Normalization层、最大池化MaxPooling层和一维卷积层;Step S202, perform feature extraction on the initial speech frame through the shallow feature extraction layer in the two-class model to obtain primary features, wherein the shallow extraction layer includes batch normalization Batch Normalization layer, maximum pooling MaxPooling layer and One-dimensional convolutional layer;
具体地,MaxPooling层是在做出特征选择之后,选出了分类辨识度更高的特征,提供了非线性,根据相关理论,特征提取的误差主要来自两个方面:一方面是,邻域大小受限造成的估计值方差增大;另一方面,卷积层参数误差造成估计均值的偏移,一般来说,MaxPooling层能减小第二种误差,更多地保留纹理信息。Specifically, the MaxPooling layer selects features with higher classification recognition after making feature selection, and provides nonlinearity. According to related theories, the error of feature extraction mainly comes from two aspects: on the one hand, the size of the neighborhood The variance of the estimated value caused by the limitation increases; on the other hand, the parameter error of the convolution layer causes the deviation of the estimated mean value. Generally speaking, the MaxPooling layer can reduce the second error and retain more texture information.
在一实施例中,将上述初始语音帧信息输入至VAD分类模型中的浅层提取层,在浅层提取层中通过两个一维卷积层的一维Batch Normalization层和一维MaxPooling层分别提取到语音帧信息的初级特征。In one embodiment, the above-mentioned initial speech frame information is input into the shallow extraction layer in the VAD classification model, and in the shallow extraction layer, the one-dimensional Batch Normalization layer and the one-dimensional MaxPooling layer of two one-dimensional convolutional layers are respectively Extract the primary features of speech frame information.
步骤S203,通过堆叠的所述多尺度一维卷积残差层对所述初级特征进行不同尺度的卷积计算,获得计算后的高级特征,其中,所述多尺度一维卷积残差层包含m路不同尺度一维卷积残差层,每路一维卷积残差层包含n个相同卷积核大小的一维卷积残差块和平均池化AvgPooling层,其中,m、n为正整数;Step S203, performing different scale convolution calculations on the primary features through the stacked multi-scale one-dimensional convolution residual layers to obtain calculated advanced features, wherein the multi-scale one-dimensional convolution residual layers Contains m channels of 1D convolution residual layers of different scales, each channel 1D convolution residual layer contains n 1D convolution residual blocks with the same convolution kernel size and an average pooling AvgPooling layer, where m, n is a positive integer;
其中,通过堆叠的所述多尺度一维卷积残差层对所述初级特征进行不同尺度的卷积计算,其中,每个一维卷积残差块使用了跳跃连接,将输入和网络输出进行相加,缓解了在深度神经网络中增加深度带来的梯度消失问题。Wherein, different scales of convolution calculations are performed on the primary features through the stacked multi-scale one-dimensional convolutional residual layers, wherein each one-dimensional convolutional residual block uses a skip connection to connect the input and network output. The addition is performed to alleviate the gradient vanishing problem caused by increasing depth in deep neural networks.
另外,AvgPooling层应用于全局平均池化操作,往往放在卷积层的后面,针对于一个特征进行采样,加快分类模型的运行速度,若在一特征提取层需要的采取特征的对象偏向于整体特性,AvgPooling层具有防止丢失太多的高维信息的功能。In addition, the AvgPooling layer is applied to the global average pooling operation, which is often placed after the convolutional layer to sample a feature to speed up the running speed of the classification model. Features, the AvgPooling layer has the function of preventing too much loss of high-dimensional information.
在一实施例中,将上述由浅层提取层得到的初级特征输入VAD分类模型中的多路不同尺度卷积残差网络块,即多尺度一维卷积残差层,在该多尺度一维卷积残差层中包含了m路不同尺度一维卷积残差层,且每路一维卷积残差层包含了n个相同卷积核大小的一维卷积残差块和AvgPooling层,其中,m、n为正整数。In one embodiment, the above-mentioned primary features obtained by the shallow extraction layer are input into the multi-channel different scale convolution residual network block in the VAD classification model, that is, the multi-scale one-dimensional convolution residual layer, in the multi-scale one-dimensional convolution residual layer. The 2D convolution residual layer contains m channels of 1D convolution residual layers of different scales, and each channel 1D convolution residual layer contains n 1D convolution residual blocks with the same convolution kernel size and AvgPooling layer, where m and n are positive integers.
在VAD分类模型中,多尺度一维卷积残差层通过m路不同尺度一维卷积残差层包含n个不同卷积核大小的一维卷积残差块和平均池化AvgPooling层的特征提取,特征提取完成之后,分别在不同尺度、相同卷积核大小的一维卷积残差块之后的一维AvgPooling层对这些提取特征进行计算,获取到在多尺度一维卷积残差层计算后的高级特征。In the VAD classification model, the multi-scale one-dimensional convolution residual layer contains n one-dimensional convolution residual blocks with different convolution kernel sizes and the average pooling AvgPooling layer through m channels of different scale one-dimensional convolution residual layers. Feature extraction. After the feature extraction is completed, these extracted features are calculated in the one-dimensional AvgPooling layer after the one-dimensional convolution residual blocks of different scales and the same convolution kernel size, and the multi-scale one-dimensional convolution residuals are obtained. Advanced features after layer computation.
步骤S204,将所述高级特征链接到所述二分类模型的整合层进行整合,得到对应的整合结果;Step S204, linking the high-level feature to the integration layer of the two-class model for integration to obtain a corresponding integration result;
步骤S205,将所述整合结果输入输出层的全连接层和softmax层,获得所述初始语音帧属于不同类别的概率矩阵;Step S205, inputting the integration result into the fully connected layer and the softmax layer of the output layer to obtain the probability matrix that the initial speech frame belongs to different categories;
步骤S206,将获取的概率矩阵与预先设定好的阈值进行匹配,得到初始语音帧的语音帧分类结果。Step S206: Match the acquired probability matrix with a preset threshold to obtain a speech frame classification result of the initial speech frame.
其中,整合层通过把不同类型、格式、特点性质的数据特征在逻辑上或物理上有机地集中,使得数据更好地在系统之间交流、共享和融合,将有机集中后的特征数据作为整合层后得到的整合结果。Among them, the integration layer integrates the data features of different types, formats, and characteristics in a logical or physical way, so that the data can be better communicated, shared and integrated between systems, and the organically concentrated feature data is used as the integration. The integration results obtained after layers.
另外,全连接层是在每一个结点都与上一层的所有结点相连,用来把前边提取到的特征综合起来,由于其全相连的特性,一般全连接层的参数也是最多的;归一化指数函数sofmax层则是解决多类回归问题的算法,是当前深度学习研究中广泛使用在深度网络有监督学习部分的分类器,能将一个含任意实数的K维向量z“压缩”到另一个K维实向量σ(z)中,使得每一个元素的范围都在(0,1)之间,并且所有元素的和为1。该函数多于多分类问题中概率矩阵是用来描述一个马尔可夫链的转变的矩阵,它的每一项都是一个表示概率的非负实数,概率矩阵可用以表示机率,而矩阵相乘的结果可用以预测未来事件发生的机率,上述得到的概率矩阵即可表示所述初始语音帧的不同类别几率。In addition, the fully connected layer is connected to all nodes of the previous layer at each node, which is used to synthesize the features extracted in the front. Due to its fully connected feature, the parameters of the fully connected layer are generally the most; The normalized exponential function sofmax layer is an algorithm for solving multi-class regression problems. It is a classifier widely used in the supervised learning part of deep networks in current deep learning research. It can "compress" a K-dimensional vector z containing any real number. into another K-dimensional real vector σ(z), so that each element is in the range (0,1) and the sum of all elements is 1. This function is more than a multi-class problem. The probability matrix is a matrix used to describe the transition of a Markov chain. Each item of it is a non-negative real number representing probability. The probability matrix can be used to represent the probability, and matrix multiplication The result of can be used to predict the probability of future events, and the probability matrix obtained above can represent the probability of different categories of the initial speech frame.
在一实施例中,将上述得到的高级特征连接至整合层进行整合,通过一个全连接层和softmax层得到原始语音信号对应的初始语音帧的概率矩阵,将该概率矩阵与设定好的阈值进行匹配,得到输入的一维浮点型矩阵式的初始语音帧信息对应的的分类结果。In one embodiment, the high-level features obtained above are connected to the integration layer for integration, the probability matrix of the initial speech frame corresponding to the original speech signal is obtained through a fully connected layer and the softmax layer, and the probability matrix and the set threshold value are obtained. Matching is performed to obtain a classification result corresponding to the input one-dimensional floating-point matrix-type initial speech frame information.
上述初始语音帧分类结果包括活动语音帧和非活动语音帧,其中,活动语音帧是包含有效人声语音的当前语音帧;非活动语音帧则是包括静音帧、噪音帧等无有效人声的语音。The above-mentioned initial voice frame classification results include active voice frames and inactive voice frames, wherein the active voice frame is the current voice frame that contains valid human voice; the inactive voice frame includes mute frames, noise frames, etc. without valid voices. voice.
如图6所示,VAD分类模型的结构示意图,该模型包括浅层特征提取层、多路不同尺度的一维卷积残差层、整合层和输出层。As shown in Figure 6, a schematic diagram of the structure of the VAD classification model, the model includes a shallow feature extraction layer, a multi-channel one-dimensional convolution residual layer of different scales, an integration layer and an output layer.
其中,多路不同尺度的卷积残差网络块包括三路:Among them, the multi-channel convolutional residual network blocks of different scales include three channels:
第一路包括级联的三个一维卷积残差块,其中卷积核大小为1*3,一层一维AvgPooling层;The first path includes three cascaded one-dimensional convolution residual blocks, in which the size of the convolution kernel is 1*3, and one layer of one-dimensional AvgPooling layer;
第二路包括级联的三个一维卷积残差块,其中卷积核大小为1*5,一层一维AvgPooling层;The second path includes three cascaded one-dimensional convolution residual blocks, in which the size of the convolution kernel is 1*5, and one layer of one-dimensional AvgPooling layer;
第三路包括级联的三个一维卷积残差块,其中卷积核大小为1*7,一层一维AvgPooling层。The third path includes three cascaded one-dimensional convolution residual blocks, where the convolution kernel size is 1*7, and a one-dimensional AvgPooling layer is used.
具体地,一维残差卷积块的具体结构示意图参照图7,每个一维残差卷积块由一维卷积层、一维Batch Normalization层、ReLU层、一维卷积层、一维Batch Normalization层级联组成,再将第二个Batch Normalization层的输出和一维残差卷积块的输入相加后一起作为最后一个ReLU层的输入,这种结构叫作残差网络,能在一定程度上缓解整个神经网络在训练过程中的梯度问题,并且能够学习到更多的局部信息。Specifically, refer to FIG. 7 for a schematic diagram of the specific structure of the one-dimensional residual convolution block. Each one-dimensional residual convolution block consists of a one-dimensional convolution layer, a one-dimensional Batch Normalization layer, a ReLU layer, a one-dimensional convolution layer, a The dimensional Batch Normalization layer is cascaded, and then the output of the second Batch Normalization layer and the input of the one-dimensional residual convolution block are added together as the input of the last ReLU layer. This structure is called a residual network, which can be used in To a certain extent, the gradient problem in the training process of the entire neural network is alleviated, and more local information can be learned.
从上述多路不同尺度的卷积残差网络块对上述初级特征进行特征的二次提取,获得从多路不同尺度卷积残差网络块中输出的特征,并将该输出特征传至VAD分类模型的下一层整合层进行不同特征的整合,在通过全连接层以及Softmax层计算后得到原始语音信号对应的语音帧分类结果。Perform secondary feature extraction on the above primary features from the above-mentioned multiple convolutional residual network blocks of different scales, obtain the features output from the multiple convolutional residual network blocks of different scales, and transmit the output features to the VAD classification The next integration layer of the model integrates different features, and after calculating through the fully connected layer and the Softmax layer, the classification result of the speech frame corresponding to the original speech signal is obtained.
在一实施例中,提出的将原始语音信号对应的初始语音帧的语音字节流输入分类模型进行活动性判定,判定活动性的方法是通过VAD分类模型对原始语音信号的每一语音帧进行分类,让实时输入的原始语音信号的每一帧语音帧都有相对应的分类结果,使得进一步的识别步骤得出的结果更加的准确,且通过包括浅层特征提取层、多尺度一维卷积残差层、整合层和输出层的VAD分类模型,得到的原始语音信号每帧语音帧的分类结果正确性都得到提高,在语音识别过程中结合分类结果进行识别,提高实时语音识别对活动性语音的命中率,优化实时语音的识别效果。In one embodiment, it is proposed to input the voice byte stream of the initial voice frame corresponding to the original voice signal into the classification model to determine the activity, and the method for determining the activity is to carry out each voice frame of the original voice signal by the VAD classification model. Classification, so that each voice frame of the real-time input original voice signal has a corresponding classification result, so that the results obtained by further identification steps are more accurate, and by including shallow feature extraction layer, multi-scale one-dimensional volume By integrating the VAD classification model of the residual layer, the integration layer and the output layer, the accuracy of the classification results of each speech frame of the original speech signal obtained is improved, and the classification results are combined in the speech recognition process for recognition, which improves the real-time speech recognition. The hit rate of sexual speech is optimized, and the recognition effect of real-time speech is optimized.
进一步地,基于上述各实施例提出本发明语音识别方法的第四实施例,本实施例的流程参照图8所示,本实施例中根据所述语音帧分类结果并结合预设的判定规则,检测得到有效语音段的前端点和后端点的细化流程可以参照图9所示。Further, a fourth embodiment of the speech recognition method of the present invention is proposed based on the above-mentioned embodiments. The flowchart of this embodiment is shown in FIG. 8 . In this embodiment, according to the speech frame classification result and the preset judgment rule, The refinement process of detecting the front end point and the back end point of the valid speech segment can be referred to as shown in FIG. 9 .
本实施例与实施各实施例的区别在于:本实施例对上述步骤S30,根据所述语音帧分类结果并结合预设的判定规则,检测得到有效语音段的前端点和后端点的步骤进行细化,具体包括:The difference between this embodiment and the implementation of each embodiment is that: in this embodiment, the steps of obtaining the front end point and the back end point of the valid speech segment are detailed according to the speech frame classification result in combination with the preset judgment rule in the above step S30. , including:
步骤S301,基于所述原始语音信号中的初始语音帧的分类结果,获得所述原始语音信号的分类结果序列,其中,所述分类结果包括活动语音帧和非活动语音帧。Step S301, obtaining a sequence of classification results of the original speech signal based on the classification result of the initial speech frame in the original speech signal, wherein the classification result includes active speech frames and inactive speech frames.
通过上述二分类模型,对原始语音信号的初始语音帧进行活动性判定,在本实施例中,使用VAD分类模型对原始语音信号中的每帧语音帧进行判断,获得每帧语音帧对应的分类结果,获得到每帧语音帧的分类结果后,进而取得包含一个或多个语音帧的语音帧片段的分类结果,将该语音帧片段的分类结果作为原始语音信号对应的分类结果序列,该语音帧分类序列是包含0和1的序列。Through the above two classification model, the activity of the initial speech frame of the original speech signal is judged. In this embodiment, the VAD classification model is used to judge each speech frame in the original speech signal, and the classification corresponding to each speech frame is obtained. As a result, after the classification result of each frame of speech frame is obtained, the classification result of the speech frame segment containing one or more speech frames is further obtained, and the classification result of the speech frame segment is used as the classification result sequence corresponding to the original speech signal. A frame classification sequence is a sequence containing 0s and 1s.
步骤S302,根据所述分类结果序列,结合预设的前端点与后端点判定规则,获取所述原始语音信号的有效语音段的前端点与后端点。Step S302 , according to the classification result sequence and in combination with the preset front-end and back-end determination rules, acquire the front-end and back-end of the valid speech segment of the original speech signal.
在电话信道用户和智能语音客服进行对话的场景中,用户与智能语音客服进行对话的过程常会出现用户段时间停顿、背景环境偶发音量较大的噪声和人声等情况,因此需要根据用户的使用习惯,预先制定相应的判定规则,检测原始语音信号有效语音段的前端点和后端点。In the scenario where the phone channel user and the intelligent voice customer service are talking, the dialogue between the user and the intelligent voice customer service often occurs when the user pauses for a period of time, and there are occasional loud noises and human voices in the background environment. It is customary to formulate corresponding judgment rules in advance to detect the front end and back end of the valid speech segment of the original speech signal.
进一步地,在一实施例中,在步骤S302中,所述根据所述分类结果序列,结合预设的前端点与后端点判定规则,获取所述原始语音信号的有效语音段的前端点与后端点包括:Further, in an embodiment, in step S302, according to the classification result sequence, the front end and the back end of the valid speech segment of the original speech signal are obtained in combination with the preset front end and back end judgment rules. Endpoints include:
步骤a1,从所述分类结果序列中获取第一分类结果子序列,所述第一分类结果子序列包括:连续的N帧语音帧的分类结果。Step a1: Obtain a first classification result subsequence from the classification result sequence, where the first classification result subsequence includes: classification results of consecutive N frames of speech frames.
在电话信道实时语音通话的过程中,实时语音的原始语音信号在通过分类模块后,以0和1表示的语音帧分类结果序列输出,判断有效语音段的前端点与后端点,对实时语音当前通话语音帧的分类结果进行缓存,当实时语音当前通话语音帧的数量为N时,将N个分类结果组成一个结果序列,获取到第一分类结果子序列,该第一分类结果子序列包含了连续的N帧语音帧的分类结果。In the process of real-time voice call on the telephone channel, after passing through the classification module, the original voice signal of real-time voice is output in a sequence of voice frame classification results represented by 0 and 1, and the front-end and back-end points of the valid voice segment are judged. The classification results of the call voice frames are cached. When the number of real-time voice current call voice frames is N, the N classification results are formed into a result sequence, and the first classification result subsequence is obtained. The first classification result subsequence includes Classification results of consecutive N speech frames.
步骤a2,若所述第一分类结果子序列中活动性语音帧的个数达到第一阈值,则判定所述第一分类结果子序列的最前端对应的语音帧为有效语音段的前端点。Step a2, if the number of active speech frames in the first classification result subsequence reaches a first threshold, determine that the speech frame corresponding to the foremost end of the first classification result subsequence is the front end of the valid speech segment.
若上述第一分类结果子序列中的活动语音帧数量达到第一预设阈值时,则判定在当前帧的前N帧到当前帧的有效语音段中,当前帧的前N帧为该有效语音段的前端点,例如,在需要对三帧的分类结果序列进行判定时,假设当前帧为第n帧,则对应的第一分类结果子序列为:[第n-2帧,第n-1帧,第n帧],当序列中活动语音帧的个数为2,即活动语音帧的数量等于2时,则判定第n-2帧为有效语音段的前端点。If the number of active speech frames in the above-mentioned first classification result subsequence reaches the first preset threshold, it is determined that in the valid speech segment from the first N frames of the current frame to the current frame, the first N frames of the current frame are the valid speech For example, when the classification result sequence of three frames needs to be judged, assuming that the current frame is the nth frame, the corresponding first classification result subsequence is: [n-2th frame, n-1th frame frame, nth frame], when the number of active speech frames in the sequence is 2, that is, when the number of active speech frames is equal to 2, it is determined that the n-2th frame is the front end of the valid speech segment.
步骤a3,基于所述前端点,从所述分类结果序列中获取第二分类结果子序列,所述第二分类结果子序列包括:在所述前端点之后,连续的M帧语音帧的分类结果。Step a3, based on the front point, obtain a second classification result subsequence from the classification result sequence, and the second classification result subsequence includes: after the front point, the classification results of consecutive M frames of speech frames .
在已经识别到有效语音段的前端点后,从前端点后缓存数量为M的实时语音当前通话语音帧,将M个分类结果组成一个结果序列,获取到第二分类结果子序列,该第二分类结果子序列包含了连续的M帧语音帧的分类结果。After the front-end point of the valid speech segment has been identified, the number of M real-time speech current call speech frames is buffered from the front-end point, the M classification results are formed into a result sequence, and the second classification result subsequence is obtained. The resulting subsequence contains the classification results of consecutive M speech frames.
步骤a4,若所述第二分类结果子序列中非活动性语音帧的个数达到第二阈值,则判定所述第二分类结果子序列的最后端对应的语音帧为有效语音段的后端点。Step a4, if the number of inactive speech frames in the second classification result subsequence reaches the second threshold, then it is determined that the speech frame corresponding to the last end of the second classification result subsequence is the rear end point of the effective speech segment .
若上述第二分类结果子序列中的非活动语音帧数量达到第二预设阈值时,则判定在前端点语音帧到前端点语音帧后的M帧中,当前帧前端点语音帧后的M帧为该有效语音段的后端点,例如,当识别到语音流的前端点后,从前端点的第6帧开始,缓存当前帧的前5帧,对包含当前帧在内的6帧的分类结果序列进行判断,当序列中0的个数为5,即非活动语音帧的数量等于5时,当前帧即为有效语音段的后端点。If the number of inactive speech frames in the subsequence of the second classification result reaches the second preset threshold, it is determined that M frames after the speech frame at the front end of the current frame are M frames after the speech frame at the front end point to the M frames after the speech frame at the front end point. The frame is the end point of the valid speech segment. For example, when the front end point of the speech stream is recognized, starting from the 6th frame of the front end point, the first 5 frames of the current frame are buffered, and the classification result of the 6 frames including the current frame is obtained. The sequence is judged. When the number of 0s in the sequence is 5, that is, when the number of inactive speech frames is equal to 5, the current frame is the end point of the valid speech segment.
在本实施例中,为了解决在噪声环境下,电话信道的实时语音识别效果差的问题,根据语音帧分类结果结合预设判定规则,得到有效语音段的前段点和后端点,上述预设的前端点与后端点判定规则是通过结合用户的使用习惯制定,让语音识别过程更加灵活。In this embodiment, in order to solve the problem that the real-time speech recognition effect of the telephone channel is poor in a noisy environment, the pre- and post-end points of the valid speech segment are obtained according to the speech frame classification result combined with the preset judgment rule. The front-end and back-end judgment rules are formulated in combination with the user's usage habits, making the speech recognition process more flexible.
进一步地,将处于前端点和后端点之间的有效语音段传入声学模型进行文本转写,获得目标转写结果,本方案中通过获取前端点和后端点之间的有效语音段,得到进行文本转写的有效语音段,使识别结果更加准确,实时语音识别效果也得到优化。在本实施例中,本方案提出的语音识别方法优化了实时语音的分类结果,提高了电话信道中实时语音识别获取目标语音识别结果的正确性,优化了噪音环境下实时语音的识别效果。Further, the effective speech segment between the front end point and the back end point is passed into the acoustic model for text transcription, and the target transcription result is obtained. In this scheme, the effective speech segment between the front end point and the back end point is obtained. The effective speech segment of text transcription makes the recognition result more accurate, and the real-time speech recognition effect is also optimized. In this embodiment, the speech recognition method proposed in this solution optimizes the classification result of real-time speech, improves the accuracy of the target speech recognition result obtained by real-time speech recognition in the telephone channel, and optimizes the recognition effect of real-time speech in a noise environment.
进一步地,基于上述各实施例提出本发明语音识别方法的第五实施例。流程图参照图10,语音识别方法的第五实施例与上述实施例的区别在于,在步骤S10之前,还包括建立分类模型,具体包括:Further, based on the above embodiments, a fifth embodiment of the speech recognition method of the present invention is proposed. Referring to FIG. 10 for the flowchart, the difference between the fifth embodiment of the speech recognition method and the above embodiments is that before step S10, it further includes establishing a classification model, which specifically includes:
步骤S50,获取训练数据的样本音频,提取所述样本音频的样本特征,其中,所述样本音频具有对应的分类结果;Step S50, obtaining sample audio of the training data, and extracting sample features of the sample audio, wherein the sample audio has a corresponding classification result;
步骤S60,基于所述样本特征,建立样本特征数据集;Step S60, based on the sample features, establish a sample feature data set;
步骤S70,构建多尺度一维残差神经网络,基于所述样本特征数据集对所述多尺度一维残差神经网络进行深度学习,得到初始的二分类模型;Step S70, constructing a multi-scale one-dimensional residual neural network, and performing deep learning on the multi-scale one-dimensional residual neural network based on the sample feature data set to obtain an initial two-class model;
步骤S80,将所述初始的二分类模型进行电话信道语音数据测试,验证所述初始的二分类模型的分类效果;Step S80, performing a telephone channel voice data test on the initial two-class model to verify the classification effect of the initial two-class model;
步骤S90,若所述分类效果未达到预设标准,则返回对所述训练数据的样本音频进行数据加强,获得优化训练数据的样本音频;Step S90, if the classification effect does not reach the preset standard, return to perform data enhancement on the sample audio of the training data to obtain the sample audio of the optimized training data;
步骤S100,根据所述优化训练数据的样本音频对所述初始的二分类模型进行微调训练,获得训练后的二分类模型;Step S100, performing fine-tuning training on the initial two-class model according to the sample audio of the optimized training data, to obtain a trained two-class model;
步骤S110,若分类效果达到预设标准,则将所述初始的二分类模型作为训练后的二分类模型。Step S110, if the classification effect reaches a preset standard, the initial two-class model is used as the trained two-class model.
在利用二分类模型对输入语音进行分类预测前,需要创建一个能够进行活动性判定的二分类模型,并对该二分类模型进行训练,所述二分类模型的创建和训练过程包括训练数据准备、模型训练、模型测试、训练语料调整和模型微调等步骤,经过上述步骤得到训练好的二分类模型。Before using the two-class model to classify and predict the input speech, it is necessary to create a two-class model capable of determining activity, and train the two-class model. The creation and training process of the two-class model includes training data preparation, Steps such as model training, model testing, training corpus adjustment, and model fine-tuning are performed to obtain a trained two-class model after the above steps.
在一实施例中,在利用二分类模型对原始语音信号中的语音帧进行分类之前,需要收集训练数据对二分类模型进行分类结果训练,以得到二分类模型。In one embodiment, before using the two-class model to classify the speech frames in the original speech signal, it is necessary to collect training data to train the classification result of the two-class model, so as to obtain the two-class model.
以下对各步骤进行详细阐述:Each step is described in detail below:
步骤S50,获取训练数据的样本音频,提取所述样本音频的样本特征,其中,所述样本音频具有对应的分类结果;Step S50, obtaining sample audio of the training data, and extracting sample features of the sample audio, wherein the sample audio has a corresponding classification result;
步骤S60,基于所述样本特征,建立样本特征数据集;Step S60, based on the sample features, establish a sample feature data set;
将需要进行二分类模型训练的训练数据样本音频处理成一维矩阵,对该训练数据样本音频对应的一维矩阵进行处理,提取训练数据的样本音频的样本特征。The training data sample audio that needs to be trained for the two-class model is processed into a one-dimensional matrix, the one-dimensional matrix corresponding to the training data sample audio is processed, and the sample features of the training data sample audio are extracted.
具体地,训练数据的样本音频包括四个部分:不含噪音的人声、含噪音的人声、不含人声的噪音和含人声的噪音,训练数据样本音频分为人声和噪音,噪音和人声有其对应的特征,其中,不含噪音的人声与含噪音的人声组成正样本,不含人声的噪音与含人声的噪音组成负样本,对不含噪音的人声部分,额外按照特定比例叠加不同的噪音。为了保证训练数据样本音频的均衡,在分类模型进行训练的过程中,一个batch中的正负样本音频的数量应该保持相当。收集这些具有对应样本特征的人声与噪音作为训练数据样本音频,并将上述具有样本特征的训练数据音频组成样本特征数据集。Specifically, the sample audio of the training data includes four parts: human voice without noise, human voice with noise, noise without human voice, and noise with human voice. The training data sample audio is divided into human voice and noise, noise and human voices have their corresponding characteristics. Among them, the human voice without noise and the human voice with noise form positive samples, and the noise without human voice and the noise with human voice form negative samples. part, and additionally superimpose different noises in a specific proportion. In order to ensure the audio balance of the training data samples, the number of positive and negative audio samples in a batch should be kept equal during the training of the classification model. Collect these human voices and noises with corresponding sample features as training data sample audio, and form the above-mentioned training data audio with sample features into a sample feature data set.
步骤S70,构建多尺度一维残差神经网络,基于所述样本特征数据集对所述多尺度一维残差神经网络进行训练,得到初始的二分类模型;Step S70, constructing a multi-scale one-dimensional residual neural network, and training the multi-scale one-dimensional residual neural network based on the sample feature data set to obtain an initial two-class model;
在本实施例中,上述二分类模型采用深度学习的方法,通过构建一个多尺度一维残差神经网络,并基于上述收集到的样本特征数据集,对上述多尺度一维残差神经网络进行训练。In this embodiment, the above-mentioned two-classification model adopts the deep learning method. By constructing a multi-scale one-dimensional residual neural network, and based on the above-mentioned collected sample feature data set, the above-mentioned multi-scale one-dimensional residual neural network is analyzed. train.
步骤S80,将所述初始的二分类模型进行电话信道语音数据测试,验证所述初始的二分类模型的分类效果;Step S80, performing a telephone channel voice data test on the initial two-class model to verify the classification effect of the initial two-class model;
将训练好的二分类模型放在真实电话信道中,接收实时语音数据,并对该实时语音数据对应的实时语音信号进行分类测试,根据对实时语音的原始语音信号进行分类后得到的分类结果来验证该初始的二分类模型的分类效果。若二分类模型的分类效果不佳,则需要增加在电话信道中真实人声片段和噪声片段作为增强训练数据,来调整二分类模型的训练语料,通过对二分类模型进行微调训练,进而得到训练后的二分类模型。Put the trained two-class model in the real telephone channel, receive real-time voice data, and perform a classification test on the real-time voice signal corresponding to the real-time voice data. According to the classification result obtained after classifying the original voice signal of the real-time voice Verify the classification effect of the initial binary classification model. If the classification effect of the two-class model is not good, it is necessary to add real human voice fragments and noise fragments in the telephone channel as enhanced training data to adjust the training corpus of the two-class model, and then obtain the training by fine-tuning the two-class model. The latter two-class model.
步骤S90,若所述分类效果未达到预设标准,则返回对样本音频进行数据加强,获得优化训练数据的样本音频。Step S90, if the classification effect does not reach the preset standard, return to performing data enhancement on the sample audio to obtain sample audio of the optimized training data.
步骤S100,根据所述优化训练数据的样本音频对所述初始二分类模型进行微调训练,获得训练后的二分类模型;Step S100, performing fine-tuning training on the initial two-class model according to the sample audio of the optimized training data, to obtain a trained two-class model;
步骤S110,若分类效果达到预设标准,则将所述初始的二分类模型作为训练后的二分类模型。Step S110, if the classification effect reaches a preset standard, the initial two-class model is used as the trained two-class model.
在本实施例中,对上述二分类模型进行分类测试,将训练好的分类模型在真实电话信道中进行实时语音数据分类测试,对实时语音的原始语音信号中的语音帧进行活动性分类,根据得到的分类结果来验证该初始的二分类模型在电话信道中区分原始语音信号中每一帧语音帧为活动性语音帧或非活动性语音帧的效果。In this embodiment, the classification test is performed on the above-mentioned two-classification model, and the trained classification model is used for the real-time voice data classification test in the real telephone channel, and the activity classification is performed on the voice frames in the original voice signal of the real-time voice. The obtained classification results are used to verify the effect of the initial binary classification model in distinguishing each speech frame in the original speech signal as an active speech frame or an inactive speech frame in the telephone channel.
若二分类模型的分类效果未达到预设标准,则需要增加电话信道真实人声片段和噪声片段作为增强训练数据,来调整二分类模型的训练语料,调整方式包括:对获取到的原始音频信号做二分类标注,通过对二分类模型进行对调整后的训练语料进行微调训练,得到微调训练后的二分类模型。If the classification effect of the two-class model does not reach the preset standard, it is necessary to add real human voice clips and noise clips of the telephone channel as enhanced training data to adjust the training corpus of the two-class model. Make two-category annotations, and fine-tune the adjusted training corpus by fine-tuning the two-category model to obtain a fine-tuned trained two-category model.
在本实施例中,通过构建一个对原始语音信号的语音帧进行活动性分类的二分类模型,从而获取到进行语音识别的原始语音信号中每一帧的语音帧分类结果,对原始语音信号中的每一帧语音帧进行活动性分类,可提高语音识别的正确率,以及在电话信道中,高噪音环境下实时语音的识别效果。In this embodiment, by constructing a binary classification model that classifies the activity of the speech frames of the original speech signal, the speech frame classification result of each frame in the original speech signal for speech recognition is obtained, and the classification results of the speech frames in the original speech signal are obtained. The activity classification of each frame of speech frame can improve the accuracy of speech recognition, and the recognition effect of real-time speech in the telephone channel and high noise environment.
在利用分类模型对输入语音进行分类预测前,需要创建一个能够进行活动性判定的二分类模型,在本实施例中,上述二分类模型是一个经过正负样本音频数据训练得到的二分类模型,通过上述分类模型多层次地对样本特征数据集进行深度学习,提高了在电话信道中、高噪音环境下实时语音的识别效果。在对该模型进行训练,包括分类模型的创建和训练过程,其中,训练过程又包括数据准备、模型训练、模型测试、训练语料调整和模型微调,通过分类结果测试之后的二分类模型,对原始语音识别信号中的语音帧有着更高的识别正确率,也提升了在高噪音环境下实时语音的识别效果。Before using the classification model to classify and predict the input speech, it is necessary to create a two-class model capable of determining the activity. In this embodiment, the above-mentioned two-class model is a two-class model obtained by training positive and negative sample audio data. The above-mentioned classification model performs in-depth learning on the sample feature data set at multiple levels, which improves the recognition effect of real-time speech in a telephone channel and a high-noise environment. When training the model, including the creation and training process of the classification model, the training process also includes data preparation, model training, model testing, training corpus adjustment and model fine-tuning. The speech frame in the speech recognition signal has a higher recognition accuracy rate, and also improves the real-time speech recognition effect in a high-noise environment.
本发明还提供一种语音识别装置,所述语音识别装置包括:The present invention also provides a voice recognition device, the voice recognition device comprising:
获取模块,用于获取待识别的原始语音信号;an acquisition module for acquiring the original speech signal to be recognized;
判定模块,用于基于预先训练的分类模型,对所述原始语音信号中的初始语音帧进行分类处理,得到语音帧分类结果;A determination module, used for classifying and processing the initial speech frame in the original speech signal based on a pre-trained classification model, to obtain a speech frame classification result;
检测模块,用于根据所述语音帧分类结果并结合预设的判定规则,检测得到有效语音段的前端点和后端点;a detection module, configured to detect the front end and back end of the valid speech segment according to the classification result of the speech frame and in combination with a preset judgment rule;
确定模块,用于将所述前端点和后端点间的有效语音段输入预先训练的声学模型,进行文本转写,获得对应的目标转写结果。The determining module is used for inputting the valid speech segment between the front end point and the back end point into the pre-trained acoustic model, to perform text transcription, and obtain the corresponding target transcription result.
本实施例具体实施方式与上述语音识别方法各实施例基本相同,在此不再赘述。The specific implementation manner of this embodiment is basically the same as the above-mentioned embodiments of the speech recognition method, and details are not repeated here.
此外,为实现上述目的,本发明还提供一种语音识别装置,所述语音识别装置包括:In addition, in order to achieve the above purpose, the present invention also provides a voice recognition device, the voice recognition device comprising:
语音流截断模块,用于输入电话语音流作固定长度截短处理;Voice stream truncation module, used for inputting phone voice stream for fixed length truncation processing;
对输入的原始语音信号字节流进行缓存,在真实使用过程中可以按照实际情况确定一个阈值。当缓存中字节数达到阈值时对缓存中字节流进行处理,按照固定大小对字节流进行截取,即对一个语音帧进行截取,并对每帧字节流做归一化处理,生成相应的一维浮点型矩阵,作为后续模块的输入。The input original voice signal byte stream is buffered, and a threshold can be determined according to the actual situation in the actual use process. When the number of bytes in the cache reaches the threshold, the byte stream in the cache is processed, and the byte stream is intercepted according to a fixed size, that is, a voice frame is intercepted, and the byte stream of each frame is normalized to generate The corresponding one-dimensional floating-point matrix, as input to subsequent modules.
语音帧分类模块,用于对输入的固定长度的语音帧进行分类,确定该语音帧的类别;A voice frame classification module, used to classify the input fixed-length voice frame, and determine the category of the voice frame;
语音帧分类模块采用深度学习方法,通过构建一个多尺度一维残差神经网络来实现一个二分类模型,输入为固定大小的语音字节流即一个语音帧,在这里模型输入的大小为2048,输出为该语音帧的分类结果,即为活动语音帧或非活动语音帧,活动语音帧指当前帧包含有效人声语音,非活动语音帧包括静音帧、噪声帧等无有效人声的语音帧。The speech frame classification module adopts the deep learning method to realize a two-class classification model by constructing a multi-scale one-dimensional residual neural network. The input is a fixed-size speech byte stream, that is, a speech frame. The output is the classification result of the voice frame, that is, the active voice frame or the inactive voice frame. The active voice frame means that the current frame contains valid human voice, and the inactive voice frame includes silent frames, noise frames and other voice frames without valid voice. .
具体的,上述多尺度一维残差神经网络包括浅层特征提取层、多尺度一维卷积残差层、整合层、输出层。Specifically, the above-mentioned multi-scale one-dimensional residual neural network includes a shallow feature extraction layer, a multi-scale one-dimensional convolution residual layer, an integration layer, and an output layer.
前后端点判定模块,用于根据连续语音流每帧的分类结果判断有效语音段的前端点和后端点。The front and rear end point determination module is used to determine the front end point and the back end point of the valid speech segment according to the classification result of each frame of the continuous speech stream.
根据每一帧语音的分类结果来检测当前电话信道中连续实时语音流中有效语音的前端点和后端点,过滤非有效语音片段,只将有效语音片段传给后续的声学模型进行识别,提高语音识别的效果。According to the classification results of each frame of speech, the front end and back end of the valid speech in the continuous real-time speech stream in the current telephone channel are detected, the ineffective speech segments are filtered, and only the valid speech segments are passed to the subsequent acoustic model for recognition, so as to improve the speech recognition effect.
在语音帧分类模块中,每帧语音字节流大小是2048,电话信道语音采样率为8KHZ,比特数为16bits,通过计算得到每帧语音流相当于128ms的语音。在电话信道用户和智能语音客服进行对话的场景中,用户在说话过程中常会出现短时间停顿、背景环境偶发音量较大的噪声和人声等情况,因此不能仅将语音帧分类模块对每帧语音的分类结果作为该帧是否属于有效语音片段的判断依据,需要根据用户使用习惯,制定相应规则,来判定有效语音片段的前后端点。语音帧分类模块的输出为包含0和1的序列,在进行语音活动检测时,需要根据接收到的语音流实时检测出前后端点。In the voice frame classification module, the size of each frame of voice byte stream is 2048, the phone channel voice sampling rate is 8KHZ, and the number of bits is 16bits. Through calculation, each frame of voice stream is equivalent to 128ms of voice. In the scenario where the phone channel user and the intelligent voice customer service are having a conversation, the user often has a short pause during the speech, and occasional loud noise and human voice in the background environment. Therefore, the speech frame classification module cannot only classify each frame The classification result of the speech is used as the basis for judging whether the frame belongs to a valid speech segment, and corresponding rules need to be formulated according to the user's usage habits to determine the front and rear endpoints of the valid speech segment. The output of the voice frame classification module is a sequence containing 0 and 1. When detecting the voice activity, it is necessary to detect the front and rear endpoints in real time according to the received voice stream.
此外,本发明实施例还提出一种计算机可读存储介质。In addition, the embodiments of the present invention also provide a computer-readable storage medium.
所述计算机可读存储介质上存储有实时语音识别程序,所述实时语音识别程序被处理器执行时实现如上述任一项实施例中的语音识别方法的步骤。本发明计算机可读存储介质具体实施方式与上述语音识别方法各实施例基本相同,在此不再赘述。The computer-readable storage medium stores a real-time speech recognition program, and when the real-time speech recognition program is executed by the processor, implements the steps of the speech recognition method in any of the foregoing embodiments. The specific implementations of the computer-readable storage medium of the present invention are basically the same as the above-mentioned embodiments of the speech recognition method, and are not repeated here.
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其它变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者系统不仅包括那些要素,而且还包括没有明确列出的其它要素,或者是还包括为这种过程、方法、物品或者系统所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、方法、物品或者系统中还存在另外的相同要素。It should be noted that, herein, the terms "comprising", "comprising" or any other variation thereof are intended to encompass non-exclusive inclusion, such that a process, method, article or system comprising a series of elements includes not only those elements, It also includes other elements not expressly listed or inherent to such a process, method, article or system. Without further limitation, an element qualified by the phrase "comprising a..." does not preclude the presence of additional identical elements in the process, method, article or system that includes the element.
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。The above-mentioned serial numbers of the embodiments of the present invention are only for description, and do not represent the advantages or disadvantages of the embodiments.
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质(如ROM/RAM、磁碟、光盘)中,执行本发明各个实施例所述的方法。From the description of the above embodiments, those skilled in the art can clearly understand that the method of the above embodiment can be implemented by means of software plus a necessary general hardware platform, and of course can also be implemented by hardware, but in many cases the former is better implementation. Based on this understanding, the technical solutions of the present invention can be embodied in the form of software products in essence or the parts that make contributions to the prior art, and the computer software products are stored in a storage medium (such as ROM/RAM, magnetic disk, CD-ROM), execute the method described in each embodiment of the present invention.
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其它相关的技术领域,均同理包括在本发明的专利保护范围内。The above are only preferred embodiments of the present invention, and are not intended to limit the scope of the present invention. Any equivalent structure or equivalent process transformation made by using the contents of the description and drawings of the present invention, or directly or indirectly applied in other related technical fields , are similarly included in the scope of patent protection of the present invention.
Claims (11)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210118048.7ACN114512128B (en) | 2022-02-08 | 2022-02-08 | Speech recognition method, device, equipment and computer-readable storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210118048.7ACN114512128B (en) | 2022-02-08 | 2022-02-08 | Speech recognition method, device, equipment and computer-readable storage medium |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN114512128Atrue CN114512128A (en) | 2022-05-17 |
| CN114512128B CN114512128B (en) | 2025-07-04 |
Family
ID=81551172
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210118048.7AActiveCN114512128B (en) | 2022-02-08 | 2022-02-08 | Speech recognition method, device, equipment and computer-readable storage medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114512128B (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115022466A (en)* | 2022-07-07 | 2022-09-06 | 科讯嘉联信息技术有限公司 | Call state detection classification method based on deep learning model |
| CN120564768A (en)* | 2025-07-30 | 2025-08-29 | 中电信人工智能科技(北京)有限公司 | Intelligent sentence segmentation active speech detection method and device based on multi-state temporal modeling |
Citations (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109935243A (en)* | 2019-02-25 | 2019-06-25 | 重庆大学 | Speech emotion recognition method based on VTLP data enhancement and multi-scale time-frequency domain hole convolution model |
| CN110148408A (en)* | 2019-05-29 | 2019-08-20 | 上海电力学院 | A kind of Chinese speech recognition method based on depth residual error |
| CN110378208A (en)* | 2019-06-11 | 2019-10-25 | 杭州电子科技大学 | A kind of Activity recognition method based on depth residual error network |
| CN110428843A (en)* | 2019-03-11 | 2019-11-08 | 杭州雄迈信息技术有限公司 | A kind of voice gender identification deep learning method |
| CN110706694A (en)* | 2019-09-26 | 2020-01-17 | 成都数之联科技有限公司 | Voice endpoint detection method and system based on deep learning |
| US20200090682A1 (en)* | 2017-09-13 | 2020-03-19 | Tencent Technology (Shenzhen) Company Limited | Voice activity detection method, method for establishing voice activity detection model, computer device, and storage medium |
| CN110930989A (en)* | 2019-11-27 | 2020-03-27 | 深圳追一科技有限公司 | Speech intention recognition method and device, computer equipment and storage medium |
| CN111048082A (en)* | 2019-12-12 | 2020-04-21 | 中国电子科技集团公司第二十八研究所 | An Improved End-to-End Speech Recognition Approach |
| CN112199548A (en)* | 2020-09-28 | 2021-01-08 | 华南理工大学 | Music audio classification method based on convolution cyclic neural network |
| CN112329690A (en)* | 2020-11-16 | 2021-02-05 | 河北工业大学 | Continuous sign language recognition method based on spatiotemporal residual network and temporal convolutional network |
| US20210043216A1 (en)* | 2019-10-31 | 2021-02-11 | Alipay (Hangzhou) Information Technology Co., Ltd. | System and method for determining voice characteristics |
| CN112530408A (en)* | 2020-11-20 | 2021-03-19 | 北京有竹居网络技术有限公司 | Method, apparatus, electronic device, and medium for recognizing speech |
| CN113920985A (en)* | 2021-06-18 | 2022-01-11 | 清华大学苏州汽车研究院(相城) | A voice endpoint detection method and module suitable for in-vehicle voice recognition system |
- 2022
- 2022-02-08CNCN202210118048.7Apatent/CN114512128B/enactiveActive
Patent Citations (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20200090682A1 (en)* | 2017-09-13 | 2020-03-19 | Tencent Technology (Shenzhen) Company Limited | Voice activity detection method, method for establishing voice activity detection model, computer device, and storage medium |
| CN109935243A (en)* | 2019-02-25 | 2019-06-25 | 重庆大学 | Speech emotion recognition method based on VTLP data enhancement and multi-scale time-frequency domain hole convolution model |
| CN110428843A (en)* | 2019-03-11 | 2019-11-08 | 杭州雄迈信息技术有限公司 | A kind of voice gender identification deep learning method |
| CN110148408A (en)* | 2019-05-29 | 2019-08-20 | 上海电力学院 | A kind of Chinese speech recognition method based on depth residual error |
| CN110378208A (en)* | 2019-06-11 | 2019-10-25 | 杭州电子科技大学 | A kind of Activity recognition method based on depth residual error network |
| CN110706694A (en)* | 2019-09-26 | 2020-01-17 | 成都数之联科技有限公司 | Voice endpoint detection method and system based on deep learning |
| US20210043216A1 (en)* | 2019-10-31 | 2021-02-11 | Alipay (Hangzhou) Information Technology Co., Ltd. | System and method for determining voice characteristics |
| CN110930989A (en)* | 2019-11-27 | 2020-03-27 | 深圳追一科技有限公司 | Speech intention recognition method and device, computer equipment and storage medium |
| CN111048082A (en)* | 2019-12-12 | 2020-04-21 | 中国电子科技集团公司第二十八研究所 | An Improved End-to-End Speech Recognition Approach |
| CN112199548A (en)* | 2020-09-28 | 2021-01-08 | 华南理工大学 | Music audio classification method based on convolution cyclic neural network |
| CN112329690A (en)* | 2020-11-16 | 2021-02-05 | 河北工业大学 | Continuous sign language recognition method based on spatiotemporal residual network and temporal convolutional network |
| CN112530408A (en)* | 2020-11-20 | 2021-03-19 | 北京有竹居网络技术有限公司 | Method, apparatus, electronic device, and medium for recognizing speech |
| CN113920985A (en)* | 2021-06-18 | 2022-01-11 | 清华大学苏州汽车研究院(相城) | A voice endpoint detection method and module suitable for in-vehicle voice recognition system |
Non-Patent Citations (1)
| Title |
|---|
| 胡章芳;徐轩;付亚芹;夏志广;马苏东;: "基于ResNet-BLSTM的端到端语音识别", 计算机工程与应用, no. 18, 31 December 2020 (2020-12-31)* |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115022466A (en)* | 2022-07-07 | 2022-09-06 | 科讯嘉联信息技术有限公司 | Call state detection classification method based on deep learning model |
| CN120564768A (en)* | 2025-07-30 | 2025-08-29 | 中电信人工智能科技(北京)有限公司 | Intelligent sentence segmentation active speech detection method and device based on multi-state temporal modeling |
Also Published As
| Publication number | Publication date |
|---|---|
| CN114512128B (en) | 2025-07-04 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110600017B (en) | Training method of voice processing model, voice recognition method, system and device | |
| CN111292764B (en) | Identification system and identification method | |
| CN112185352B (en) | Voice recognition method, device and electronic equipment | |
| US11508366B2 (en) | Whispering voice recovery method, apparatus and device, and readable storage medium | |
| CN111128223B (en) | Text information-based auxiliary speaker separation method and related device | |
| CN109360572B (en) | Call separation method and device, computer equipment and storage medium | |
| CN108597496A (en) | Voice generation method and device based on generation type countermeasure network | |
| CN110503956B (en) | Voice recognition method, device, medium and electronic equipment | |
| JP7592636B2 (en) | Speech processing method, speech processing device, and human-computer interaction system | |
| CN114067793B (en) | Audio processing method and device, electronic device and readable storage medium | |
| CN105654955B (en) | Speech recognition method and device | |
| CN112992191A (en) | Voice endpoint detection method and device, electronic equipment and readable storage medium | |
| US20230186943A1 (en) | Voice activity detection method and apparatus, and storage medium | |
| CN114512128A (en) | Speech recognition method, device, equipment and computer readable storage medium | |
| CN113450793B (en) | User emotion analysis method, device, computer-readable storage medium, and server | |
| CN109688271A (en) | The method, apparatus and terminal device of contact information input | |
| CN116564315A (en) | Voiceprint recognition method, voiceprint recognition device, voiceprint recognition equipment and storage medium | |
| CN117935789A (en) | Speech recognition method, system, device, and storage medium | |
| CN116884410A (en) | Cognitive detection method, cognitive detection device, electronic equipment and storage medium | |
| EP4475121A1 (en) | Interactive speech signal processing method, related device and system | |
| CN115831125A (en) | Speech recognition method, device, equipment, storage medium and product | |
| CN112530421B (en) | Voice recognition method, electronic equipment and storage device | |
| CN118737156A (en) | Speaker voice segmentation and clustering method, device and electronic equipment | |
| CN115688868B (en) | Model training method and computing equipment | |
| EP4099320A2 (en) | Method and apparatus of processing speech, electronic device, storage medium, and program product |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |