CN114511329A - Account identification method and device, storage medium and electronic equipment - Google Patents
Account identification method and device, storage medium and electronic equipmentDownload PDFInfo
- Publication number
- CN114511329A CN114511329ACN202210156951.2ACN202210156951ACN114511329ACN 114511329 ACN114511329 ACN 114511329ACN 202210156951 ACN202210156951 ACN 202210156951ACN 114511329 ACN114511329 ACN 114511329A
- Authority
- CN
- China
- Prior art keywords
- account
- account data
- data
- training
- account identification
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images


Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q20/00—Payment architectures, schemes or protocols
- G06Q20/38—Payment protocols; Details thereof
- G06Q20/40—Authorisation, e.g. identification of payer or payee, verification of customer or shop credentials; Review and approval of payers, e.g. check credit lines or negative lists
- G06Q20/401—Transaction verification
- G06Q20/4016—Transaction verification involving fraud or risk level assessment in transaction processing
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/243—Classification techniques relating to the number of classes
- G06F18/24323—Tree-organised classifiers
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F21/00—Security arrangements for protecting computers, components thereof, programs or data against unauthorised activity
- G06F21/60—Protecting data
- G06F21/602—Providing cryptographic facilities or services
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N5/00—Computing arrangements using knowledge-based models
- G06N5/01—Dynamic search techniques; Heuristics; Dynamic trees; Branch-and-bound
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q20/00—Payment architectures, schemes or protocols
- G06Q20/38—Payment protocols; Details thereof
- G06Q20/40—Authorisation, e.g. identification of payer or payee, verification of customer or shop credentials; Review and approval of payers, e.g. check credit lines or negative lists
- G06Q20/401—Transaction verification
- G06Q20/4014—Identity check for transactions
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Business, Economics & Management (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Accounting & Taxation (AREA)
- General Engineering & Computer Science (AREA)
- Computer Security & Cryptography (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Finance (AREA)
- General Business, Economics & Management (AREA)
- Bioinformatics & Computational Biology (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Evolutionary Biology (AREA)
- Strategic Management (AREA)
- Life Sciences & Earth Sciences (AREA)
- Software Systems (AREA)
- Computer Hardware Design (AREA)
- Computing Systems (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Bioethics (AREA)
- Health & Medical Sciences (AREA)
- Mathematical Physics (AREA)
- Financial Or Insurance-Related Operations Such As Payment And Settlement (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本发明涉及金融技术领域,特别涉及一种账户识别方法、装置、存储介质和电子设备。The present invention relates to the field of financial technology, and in particular, to an account identification method, device, storage medium and electronic device.
背景技术Background technique
随着通信技术的发展,越来越多的不法分子借助于手机、固定电话、网络等通信技术进行非法宣传和金融诈骗,给很多用户带来了经济损失,扰乱了正常社会秩序。而在众多诈骗案件中,大部分都是通过银行账户给嫌疑人进行转账汇款。如果可以在受害人转账的时候,能够识别出涉诈银行账户,对其进行冻结并终止交易,能减少受害人的损失。With the development of communication technology, more and more criminals use mobile phones, landline phones, networks and other communication technologies to conduct illegal propaganda and financial fraud, which has brought economic losses to many users and disrupted the normal social order. In many fraud cases, most of the money transfers are made to suspects through bank accounts. If the fraudulent bank account can be identified when the victim transfers money, frozen and terminated, the loss of the victim can be reduced.
目前还没有可以准确识别出具有诈骗嫌疑的银行账户的技术方案。There is currently no technical solution that can accurately identify bank accounts suspected of fraud.
发明内容SUMMARY OF THE INVENTION
鉴于上述问题,本发明提供一种克服上述问题或者至少部分地解决上述问题的账户识别方法、装置、存储介质和电子设备。In view of the above problems, the present invention provides an account identification method, apparatus, storage medium and electronic device that overcome the above problems or at least partially solve the above problems.
第一方面,一种账户识别方法,包括:A first aspect provides an account identification method, comprising:
从数据库中获取第一银行账户的账户数据;Obtain the account data of the first bank account from the database;
对所述账户数据进行特征工程处理,从而提取得到至少一个维度的目标特征;Perform feature engineering processing on the account data, thereby extracting target features of at least one dimension;
将所述目标特征输入至预先训练好的账户识别模型,从而通过所述账户识别模型识别所述银行账户是否为涉诈账户。The target feature is input into a pre-trained account identification model, so as to identify whether the bank account is a fraudulent account through the account identification model.
结合第一方面,在某些可选的实施方式中,所述账户识别模型的训练过程,包括:With reference to the first aspect, in some optional embodiments, the training process of the account identification model includes:
从数据库中获取多个银行账户的账户数据;Fetch account data for multiple bank accounts from a database;
对各所述账户数据进行特征工程处理,从而提取得到相应至少一个维度的目标特征;Perform feature engineering processing on each of the account data, so as to extract and obtain target features corresponding to at least one dimension;
将各所述目标特征划分为训练集和测试集,并将所述训练集输入至XGBoost算法,以对所述XGBoost算法进行训练;Each described target feature is divided into a training set and a test set, and the training set is input to the XGBoost algorithm to train the XGBoost algorithm;
将所述测试集输入至所述XGBoost算法,以对经过所述训练的XGBoost算法进行测试,从而训练得到所述账户识别模型。The test set is input into the XGBoost algorithm to test the trained XGBoost algorithm, thereby obtaining the account identification model through training.
结合上一个实施方式,在某些可选的实施方式中,在所述从数据库中获取多个银行账户的账户数据之后,所述方法还包括:With reference to the previous implementation, in some optional implementations, after acquiring the account data of the multiple bank accounts from the database, the method further includes:
对各所述账户数据中的身份证信息进行加密;Encrypt the ID card information in each of the account data;
对各所述账户数据中的用户位置信息进行偏转处理。Deflection processing is performed on the user location information in each of the account data.
结合上一个实施方式,在某些可选的实施方式中,在所述对各所述账户数据中的用户位置信息进行偏转处理之后,所述方法还包括:With reference to the previous implementation manner, in some optional implementation manners, after the deflecting processing is performed on the user location information in each of the account data, the method further includes:
将各所述账户数据中错误的信息进行删除;delete erroneous information in each said account data;
将各所述账户数据中缺失的信息补齐为相应的预设信息。The missing information in each of the account data is filled into corresponding preset information.
结合第二个实施方式,在某些可选的实施方式中,所述对各所述账户数据进行特征工程处理,从而提取得到相应至少一个维度的目标特征,包括:With reference to the second embodiment, in some optional embodiments, the feature engineering processing is performed on each of the account data, so as to extract and obtain target features of at least one dimension, including:
根据预先建立的业务指标和技术指标,直接从各所述账户数据中分别筛选得到至少一个维度的目标特征。According to the pre-established business indicators and technical indicators, the target features of at least one dimension are obtained by directly filtering each of the account data.
结合第二个实施方式,在某些可选的实施方式中,所述对各所述账户数据进行特征工程处理,从而提取得到相应至少一个维度的目标特征,包括:With reference to the second embodiment, in some optional embodiments, the feature engineering processing is performed on each of the account data, so as to extract and obtain target features of at least one dimension, including:
通过对各所述账户数据在业务和时序层面的统计,从而统计得到至少一个维度的目标特征。Through the statistics of each of the account data at the business and time series levels, the target characteristics of at least one dimension are obtained by statistics.
第二方面,一种账户识别装置,包括:第一数据获取单元、第一特征工程单元和账户识别单元;In a second aspect, an account identification device includes: a first data acquisition unit, a first feature engineering unit, and an account identification unit;
所述第一数据获取单元,用于从数据库中获取第一银行账户的账户数据;The first data acquisition unit is used to acquire account data of the first bank account from the database;
所述第一特征工程单元,用于对所述账户数据进行特征工程处理,从而提取得到至少一个维度的目标特征;The first feature engineering unit is configured to perform feature engineering processing on the account data, thereby extracting target features of at least one dimension;
所述账户识别单元,用于将所述目标特征输入至预先训练好的账户识别模型,从而通过所述账户识别模型识别所述银行账户是否为涉诈账户。The account identification unit is configured to input the target feature into a pre-trained account identification model, so as to identify whether the bank account is a fraudulent account through the account identification model.
结合上一个实施方式,在某些可选的实施方式中,所述装置还包括:模型训练单元;With reference to the previous embodiment, in some optional embodiments, the apparatus further includes: a model training unit;
所述模型训练单元包括:账户数据获取子单元、特征工程子单元、模型训练子单元和模型测试子单元;The model training unit includes: an account data acquisition subunit, a feature engineering subunit, a model training subunit and a model testing subunit;
所述模型训练单元,用于执行所述账户识别模型的训练过程;the model training unit, configured to perform the training process of the account identification model;
所述账户数据获取子单元,用于从数据库中获取多个银行账户的账户数据;The account data acquisition subunit is used to acquire account data of a plurality of bank accounts from the database;
所述特征工程子单元,用于对各所述账户数据进行特征工程处理,从而提取得到相应至少一个维度的目标特征;The feature engineering subunit is used to perform feature engineering processing on each of the account data, so as to extract and obtain target features corresponding to at least one dimension;
所述模型训练子单元,用于将各所述目标特征划分为训练集和测试集,并将所述训练集输入至XGBoost算法,以对所述XGBoost算法进行训练;The model training subunit is used to divide each described target feature into a training set and a test set, and input the training set to the XGBoost algorithm to train the XGBoost algorithm;
所述模型测试子单元,用于将所述测试集输入至所述XGBoost算法,以对经过所述训练的XGBoost算法进行测试,从而训练得到所述账户识别模型。The model testing subunit is configured to input the test set into the XGBoost algorithm to test the trained XGBoost algorithm, thereby obtaining the account identification model through training.
第三方面,一种计算机可读存储介质,其上存储有程序,所述程序被处理器执行时实现上述任一项所述的账户识别方法。In a third aspect, a computer-readable storage medium stores a program thereon, and when the program is executed by a processor, implements the account identification method described in any one of the above.
第四方面,一种电子设备,所述电子设备包括至少一个处理器、以及与所述处理器连接的至少一个存储器、总线;其中,所述处理器、所述存储器通过所述总线完成相互间的通信;所述处理器用于调用所述存储器中的程序指令,以执行上述任一项所述的账户识别方法。In a fourth aspect, an electronic device includes at least one processor, and at least one memory and a bus connected to the processor; wherein the processor and the memory communicate with each other through the bus. communication; the processor is configured to invoke the program instructions in the memory to execute the account identification method described in any one of the above.
借由上述技术方案,本发明提供的账户识别方法、装置、存储介质和电子设备,可以通过从数据库中获取第一银行账户的账户数据;对所述账户数据进行特征工程处理,从而提取得到至少一个维度的目标特征;将所述目标特征输入至预先训练好的账户识别模型,从而通过所述账户识别模型识别所述银行账户是否为涉诈账户。由此可以看出,本发明可以通过账户识别模型准确识别出各个银行账户是否为涉诈账户,效率高且准确率较高。With the above technical solutions, the account identification method, device, storage medium and electronic device provided by the present invention can obtain the account data of the first bank account from the database; perform feature engineering processing on the account data, thereby extracting at least A target feature of one dimension; the target feature is input into the pre-trained account identification model, so as to identify whether the bank account is a fraudulent account through the account identification model. It can be seen from this that the present invention can accurately identify whether each bank account is a fraudulent account through the account identification model, with high efficiency and high accuracy.
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。The above description is only an overview of the technical solutions of the present invention, in order to be able to understand the technical means of the present invention more clearly, it can be implemented according to the content of the description, and in order to make the above and other objects, features and advantages of the present invention more obvious and easy to understand , the following specific embodiments of the present invention are given.
附图说明Description of drawings
通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:Various other advantages and benefits will become apparent to those of ordinary skill in the art upon reading the following detailed description of the preferred embodiments. The drawings are for the purpose of illustrating preferred embodiments only and are not to be considered limiting of the invention. Also, the same components are denoted by the same reference numerals throughout the drawings. In the attached image:
图1示出了本发明提供的一种账户识别方法的流程图;1 shows a flowchart of an account identification method provided by the present invention;
图2示出了本发明提供的一种账户识别装置的结构示意图;FIG. 2 shows a schematic structural diagram of an account identification device provided by the present invention;
图3示出了本发明提供的一种电子设备的结构示意图。FIG. 3 shows a schematic structural diagram of an electronic device provided by the present invention.
具体实施方式Detailed ways
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。Exemplary embodiments of the present disclosure will be described in more detail below with reference to the accompanying drawings. While exemplary embodiments of the present disclosure are shown in the drawings, it should be understood that the present disclosure may be embodied in various forms and should not be limited by the embodiments set forth herein. Rather, these embodiments are provided so that the present disclosure will be more thoroughly understood, and will fully convey the scope of the present disclosure to those skilled in the art.
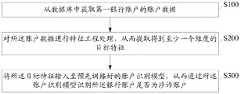
如图1所示,本发明提供了一种账户识别方法,包括:S100、S200和S300;As shown in FIG. 1, the present invention provides an account identification method, including: S100, S200 and S300;
S100、从数据库中获取第一银行账户的账户数据;S100, acquiring account data of the first bank account from the database;
可选的,银行账户的账户数据可以存储在Hbase数据库中,以便于本发明的执行主体实时获取大量的银行账户的账户数据。当然,本发明不限制于Hbase数据库,任何可行的方式均属于本发明的保护范围。Optionally, the account data of the bank account can be stored in the Hbase database, so that the executive body of the present invention can obtain the account data of a large number of bank accounts in real time. Of course, the present invention is not limited to the Hbase database, and any feasible manner falls within the protection scope of the present invention.
可选的,由于数据库存储的账户数据中可能存在一些重要的信息。对于重要的信息可以进行适当的保护,例如,对于身份证信息可以进行加密,对于用户位置信息可以进行偏转,本发明对此不做限制。Optionally, there may be some important information in the account data stored in the database. Important information can be properly protected, for example, ID card information can be encrypted, and user location information can be deflected, which is not limited in the present invention.
可选的,数据库存储的账户数据中还可能存在一些异常的数据,例如信息缺失的数据和信息错误的数据等。对于信息缺失的数据,本发明可以采取用预设信息进行补齐的方式进行处理;对于信息错误的数据,本发明可以采取用预设信息进行替换或者直接删除的方式进行处理,本发明对此不做限制。Optionally, there may also be some abnormal data in the account data stored in the database, such as data with missing information and data with incorrect information. For the data with missing information, the present invention can use the preset information to complete the processing; for the data with wrong information, the present invention can use the preset information to replace or directly delete the data for processing. No restrictions.
S200、对所述账户数据进行特征工程处理,从而提取得到至少一个维度的目标特征;S200, performing feature engineering processing on the account data, thereby extracting target features of at least one dimension;
可选的,本发明可以在经过对获取的账户数据进行上述加密、偏转和补齐,以及替换或者删除等数据清洗处理之后,对账户数据进行特征工程处理。Optionally, the present invention can perform feature engineering processing on the account data after performing the above-mentioned data cleaning processes such as encryption, deflection and complementation, and replacement or deletion on the acquired account data.
可选的,特征工程处理就是把原始数据转化为机器识别的特征过程。即把经过数据清洗处理之后的账户数据转化为后续账户识别模型可以识别的特征,而通过这些特征又能很好的承载原始的账户数据。特征工程处理具体可以包括:特征筛选、特征衍生和特征选择等过程。Optionally, feature engineering is the process of converting raw data into machine-recognized features. That is, the account data after data cleaning is converted into features that can be identified by the subsequent account identification model, and the original account data can be well carried by these features. The feature engineering process may specifically include: feature screening, feature derivation, and feature selection.
其中,本发明进行特征筛选是因为数据库中读取的账户数据的数据表多和数据字段复杂(200多个字段),所以需要对数据字段进行数据分析,筛选出有用的数据字段。本发明可以从业务指标和技术指标两大类对账户数据进行特征筛选,本发明对此不做限制。Among them, the present invention performs feature screening because the account data read in the database has many data tables and complex data fields (more than 200 fields), so it is necessary to perform data analysis on the data fields to filter out useful data fields. The present invention can perform feature screening on account data from two categories of business indicators and technical indicators, which is not limited in the present invention.
本发明进行特征衍生是因为账户数据中的很多数据字段不能直接使用,所以可以从业务和时序等层面对账户进行统计分析之后,生成新的衍生字段进行使用。例如,日转账次数、日转账总金额、大额对私交易次数和大额交易金额等数据字段。The present invention performs feature derivation because many data fields in the account data cannot be used directly, so new derived fields can be generated for use after statistical analysis of the account from the business and time sequence levels. For example, data fields such as the number of daily transfers, the total amount of daily transfers, the number of large-value private transactions, and the large-value transaction amount.
由于特征筛选以及特征衍生构建了一系列基础特征、时序特征、业务特征、组合特征和离散特征等,所有特征加起来高达数百维。高维的特征一方面可能会导致维数灾难,另一方面很容易导致模型过拟合。所以本发明可以通过特征选择来降低特征的维度。例如,本发明通过过滤法和集成法相结合,最终选择了12个账户特征和多个交易特征共同作为目标特征,其中,账户特征可以包括:账户ID、开户人性别、开户人年龄、账户的银行卡数、银行账户绑定的手机号、客户的性质、账户状态、最近30天的交易总金额、最近30天交易次数、单笔大额交易次数(2万以上)、单笔小额交易次数(小于2000)和是否有外汇交易等;交易特征可以包括:日转账次数、日转账总金额、大额对私交易次数、大额交易金额和外币结汇金额等,本发明对此不做限制。Due to feature screening and feature derivation, a series of basic features, time series features, business features, combined features and discrete features are constructed, all of which add up to hundreds of dimensions. On the one hand, high-dimensional features may lead to the curse of dimensionality, and on the other hand, it is easy to lead to model overfitting. Therefore, the present invention can reduce the dimension of features through feature selection. For example, the present invention combines the filtering method and the integration method, and finally selects 12 account characteristics and multiple transaction characteristics as the target characteristics, wherein the account characteristics may include: account ID, account holder gender, account holder age, account bank The number of cards, the mobile phone number bound to the bank account, the nature of the customer, the account status, the total transaction amount in the last 30 days, the number of transactions in the last 30 days, the number of single large-value transactions (more than 20,000), and the number of single small-value transactions (less than 2000) and whether there are foreign exchange transactions, etc.; transaction characteristics may include: daily transfer times, total daily transfer amount, large-value private transaction times, large-value transaction amount and foreign currency settlement amount, etc., which is not limited in the present invention.
S300、将所述目标特征输入至预先训练好的账户识别模型,从而通过所述账户识别模型识别所述银行账户是否为涉诈账户。S300. Input the target feature into a pre-trained account identification model, so as to identify whether the bank account is a fraudulent account through the account identification model.
可选的,本发明所说的账户识别模型可以是预先经过训练并评估通过的机器学习模型。通过账户识别模型可以快速准确地识别出第一银行账户是否为涉诈账户,效率较高且准确率较高。Optionally, the account identification model mentioned in the present invention may be a machine learning model that has been trained and evaluated in advance. Whether the first bank account is a fraudulent account can be quickly and accurately identified through the account identification model, with high efficiency and high accuracy.
可选的,本发明可以从精准率、召回率和F1-score指标分别对账户识别模型进行评估。Optionally, the present invention can evaluate the account identification model separately from the precision rate, recall rate and F1-score index.
其中,Precision(精准率)=TP÷(TP+FP),Recall(召回率)=TP÷(TP+FN),F1-score=2*Precision*Recall/(Precision+Recall)。其中,TP代表样本为正,预测结果为正的个数,FP代表样本为负,预测结果为正的个数,FN代表样本为正,预测结果为负的个数。score为精确率和召回率的调和平均数,最大为1,最小为0。Among them, Precision (precision rate)=TP÷(TP+FP), Recall (recall rate)=TP÷(TP+FN), F1-score=2*Precision*Recall/(Precision+Recall). Among them, TP represents the number of positive samples and positive prediction results, FP represents the number of negative samples and positive prediction results, and FN represents the number of positive samples and negative prediction results. score is the harmonic mean of precision and recall, with a maximum of 1 and a minimum of 0.
可选的,本发明对于账户识别模型的训练过程不做具体限制,训练过程与账户识别模型所使用的算法有关。例如,结合图1所示的实施方式,在某些可选的实施方式中,所述账户识别模型的训练过程,包括:步骤1.1、步骤1.2、步骤1.3和步骤1.4;Optionally, the present invention does not specifically limit the training process of the account identification model, and the training process is related to the algorithm used by the account identification model. For example, with reference to the embodiment shown in FIG. 1, in some optional embodiments, the training process of the account identification model includes: step 1.1, step 1.2, step 1.3 and step 1.4;
步骤1.1、从数据库中获取多个银行账户的账户数据;Step 1.1. Obtain the account data of multiple bank accounts from the database;
可选的,前述S100至S300描述的是在训练好账户识别模型之后,从数据库中获取银行账户的账户数据,并使用账户识别模型识别银行账户是否为涉诈账户的过程。而步骤1.1至步骤1.4描述的是在账户识别模型训练好之前,获取多个银行账户的账户数据,并对账户识别模型进行训练的过程,本发明对此不做限制。Optionally, the foregoing S100 to S300 describe the process of acquiring the account data of the bank account from the database after training the account identification model, and using the account identification model to identify whether the bank account is a fraudulent account. Steps 1.1 to 1.4 describe the process of acquiring account data of multiple bank accounts and training the account identification model before the account identification model is trained, which is not limited in the present invention.
所以,步骤1.1中所描述的数据库可以是与S100所描述的数据库一致,也可以是不同的数据库,本发明对此不做限制。Therefore, the database described in step 1.1 may be the same as the database described in S100, or may be a different database, which is not limited in the present invention.
一般而言,用于训练的数据量越大,对于账户识别模型的训练结果越好,所以本发明不限制步骤1.1中的银行账户的数量。Generally speaking, the larger the amount of data used for training, the better the training result for the account identification model, so the present invention does not limit the number of bank accounts in step 1.1.
步骤1.2、对各所述账户数据进行特征工程处理,从而提取得到相应至少一个维度的目标特征;Step 1.2, perform feature engineering processing on each of the account data, so as to extract and obtain target features corresponding to at least one dimension;
可选的,对于步骤1.2中所描述的特征工程处理,可以参见前述S200对于特征工程处理的解释,本发明对此不做赘述。需要说明的是,对于任何一个账户数据而言,均可以提取多个不同维度的目标特征,具体需要提取哪些目标特征,本发明可以根据实际需要进行设定。Optionally, for the feature engineering process described in step 1.2, reference may be made to the explanation of the feature engineering process in the foregoing S200, which is not repeated in the present invention. It should be noted that, for any account data, multiple target features of different dimensions can be extracted, and which target features need to be extracted can be set according to actual needs in the present invention.
步骤1.3、将各所述目标特征划分为训练集和测试集,并将所述训练集输入至XGBoost算法,以对所述XGBoost算法进行训练;Step 1.3, each described target feature is divided into training set and test set, and described training set is input to XGBoost algorithm, to carry out training to described XGBoost algorithm;
可选的,本发明可以采用十则交叉验证的方式,将目标特征分成10份,其中,9份作为训练集,1份作为测试集,本发明发明对此不做限制。Optionally, the present invention may use ten cross-validation methods to divide the target features into 10 parts, of which 9 parts are used as training sets and 1 part is used as test sets, which are not limited in the invention.
可选的,Boosting是一族可将弱学习器提升为强学习器的算法。这族算法的工作机制类似:先从初始训练集训练出一个基学习器,再根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续受到更多关注,然后基于调整后的样本分布来训练下一个基学习器。如此重复进行,直至基学习器数目达到事先指定的值m,最终将这m个基学习器进行加权结合。具体可以通过公式:
而XGBoost算法属于集成学习中的Boosting分支,是以CART树中的回归树作为基分类器,在给定训练数据后,其单个树的结构(叶子节点个数、树深度等等)基本可以确定了。但XGBoost并不是简单重复的将几个CART树进行组合。它是一种加法模型,将模型上次预测(由t-1棵树组合而成的模型)产生的误差作为参考进行下一棵树(第t棵树)的建立。以此,每加入一棵树,将其损失函数不断降低。The XGBoost algorithm belongs to the Boosting branch of ensemble learning. It uses the regression tree in the CART tree as the base classifier. After the training data is given, the structure of a single tree (the number of leaf nodes, tree depth, etc.) can basically be determined. . But XGBoost is not a simple and repetitive combination of several CART trees. It is an additive model that uses the error generated by the model's last prediction (a model composed of t-1 trees) as a reference to build the next tree (the t-th tree). In this way, each time a tree is added, its loss function is continuously reduced.
CART回归树是假设树为二叉树,通过不断将特征进行分裂。比如当前树结点是基于第j个特征值进行分裂的,设该特征值小于s的样本划分为左子树,大于s的样本划分为右子树。The CART regression tree assumes that the tree is a binary tree and divides the features continuously. For example, the current tree node is split based on the jth eigenvalue, and the samples with the eigenvalue less than s are divided into the left subtree, and the samples larger than s are divided into the right subtree.
XGBoost算法的思想就是不断地添加树,不断地进行特征分裂来生长一棵树,每次添加一个树,其实是学习一个新函数,去拟合上次预测的残差。当我们训练完成得到k棵树,我们要预测一个样本的分数,其实就是根据这个样本的特征,在每棵树中会落到对应的一个叶子节点,每个叶子节点就对应一个分数,最后只需要将每棵树对应的分数加起来就是该样本的预测值。XGBoost目标函数定义为:

目标函数共分两大项,前一项是每个样本的损失和,XGBoost的损失函数是可以自定义的,并且其自带的损失函数也有很多种。第二项是正则项,包含两个部分,一个是对树进行制约,一个是对叶子节点进行制约,都能够避免过拟合。公式中
误差函数可以是square loss和logloss等,正则项可以是L1正则和L2正则等。The error function can be square loss and logloss, etc., and the regular term can be L1 regular and L2 regular, etc.
本发明的XGBoost算法所采用的损失函数可以为:
步骤1.4、将所述测试集输入至所述XGBoost算法,以对经过所述训练的XGBoost算法进行测试,从而训练得到所述账户识别模型。Step 1.4: Input the test set into the XGBoost algorithm to test the trained XGBoost algorithm, thereby obtaining the account identification model through training.
可选的,测试的过程主要是模拟实际使用过程,将测试集输入至账户识别模型,并获得识别结果,然后根据识别结果对账户识别模型的模型参数进行调整。Optionally, the testing process is mainly to simulate the actual use process, input the test set into the account identification model, obtain the identification result, and then adjust the model parameters of the account identification model according to the identification result.
可选的,如前所述,在实际使用过程中,需要对获得的账户数据进行数据清洗处理,同理,在进行模型训练之前,也可以对账户数据进行数据清洗处理。例如,结合上一个实施方式,在某些可选的实施方式中,在所述从数据库中获取多个银行账户的账户数据之后,所述方法还包括:步骤2.1和步骤2.2;Optionally, as mentioned above, in the actual use process, it is necessary to perform data cleaning processing on the obtained account data. Similarly, before performing model training, data cleaning processing can also be performed on the account data. For example, in combination with the previous implementation, in some optional implementations, after acquiring the account data of multiple bank accounts from the database, the method further includes: step 2.1 and step 2.2;
步骤2.1、对各所述账户数据中的身份证信息进行加密;Step 2.1, encrypt the ID card information in each described account data;
可选的,本发明对于加密的过程不做具体限制,任何可行的方案均属于本发明的保护范围。例如,本发明可以通过截取身份证号的部分数据的方式进行加密。Optionally, the present invention does not specifically limit the encryption process, and any feasible solution falls within the protection scope of the present invention. For example, the present invention can perform encryption by intercepting part of the data of the ID card number.
步骤2.2、对各所述账户数据中的用户位置信息进行偏转处理。Step 2.2, performing deflection processing on the user location information in each of the account data.
可选的,本发明对于偏转处理的过程不做具体限制,任何可行的方案均属于本发明的保护范围。例如,本发明可以采用将用户所在位置的经纬度偏转一定度数的方式对用户位置信息进行偏转处理。Optionally, the present invention does not specifically limit the deflection processing process, and any feasible solution falls within the protection scope of the present invention. For example, the present invention can deflect the user's location information by deflecting the latitude and longitude of the user's location by a certain number of degrees.
可选的,除了进行上述数据清洗处理,本发明还可以进行其它数据清洗处理。例如,结合上一个实施方式,在某些可选的实施方式中,在所述对各所述账户数据中的用户位置信息进行偏转处理之后,所述方法还包括:步骤3.1和步骤3.2;Optionally, in addition to the above data cleaning process, the present invention may also perform other data cleaning processes. For example, in combination with the previous embodiment, in some optional embodiments, after the deflecting processing is performed on the user location information in each of the account data, the method further includes: step 3.1 and step 3.2;
步骤3.1、将各所述账户数据中错误的信息进行删除;Step 3.1, delete the wrong information in the account data;
步骤3.2、将各所述账户数据中缺失的信息补齐为相应的预设信息。Step 3.2. Fill in the missing information in each of the account data into corresponding preset information.
可选的,针对不同字段的信息,本发明均可以预设相应的预设信息,以便于在确定账户数据中缺失某个字段的信息时,及时补齐为相应的预设信息,本发明对此不做限制。Optionally, for the information of different fields, the present invention can preset corresponding preset information, so that when it is determined that the information of a certain field is missing in the account data, it can be filled up as the corresponding preset information in time. This does not limit.
结合第二个实施方式,在某些可选的实施方式中,所述对各所述账户数据进行特征工程处理,从而提取得到相应至少一个维度的目标特征,包括:With reference to the second embodiment, in some optional embodiments, the feature engineering processing is performed on each of the account data, so as to extract and obtain target features of at least one dimension, including:
根据预先建立的业务指标和技术指标,直接从各所述账户数据中分别筛选得到至少一个维度的目标特征。According to the pre-established business indicators and technical indicators, the target features of at least one dimension are obtained by directly filtering each of the account data.
可选的,如前所述,本发明需要提前确定提取哪些目标特征,即可以预先建立相应的业务指标和技术指标,提取相应指标对应的目标特征,本发明对此不做限制。Optionally, as mentioned above, the present invention needs to determine which target features to extract in advance, that is, corresponding business indicators and technical indicators can be established in advance, and the target features corresponding to the corresponding indicators can be extracted, which is not limited in the present invention.
结合上一个实施方式,在某些可选的实施方式中,所述对各所述账户数据进行特征工程处理,从而提取得到相应至少一个维度的目标特征,还包括:In combination with the previous implementation, in some optional implementations, the feature engineering process performed on each of the account data, so as to extract and obtain target features corresponding to at least one dimension, further includes:
通过对各所述账户数据在业务和时序层面的统计,从而统计得到至少一个维度的目标特征。Through the statistics of each of the account data at the business and time series levels, the target characteristics of at least one dimension are obtained by statistics.
可选的,如前所述,有些目标特征可以直接从账户数据中提取得到,而有些目标特征需要进行统计后才能得到。针对这些需要统计后才能得到的目标特征,可以从业务层面和时序层面进行统计,本发明对此不做限制。Optionally, as mentioned above, some target features can be directly extracted from account data, while some target features need to be counted before they can be obtained. For these target features that can only be obtained after statistics, statistics can be performed from the business level and the time sequence level, which is not limited in the present invention.
如图2所示,本发明提供了一种账户识别装置,包括:第一数据获取单元100、第一特征工程单元200和账户识别单元300;As shown in FIG. 2, the present invention provides an account identification device, including: a first
所述第一数据获取单元100,用于从数据库中获取第一银行账户的账户数据;The first
所述第一特征工程单元200,用于对所述账户数据进行特征工程处理,从而提取得到至少一个维度的目标特征;The first
所述账户识别单元300,用于将所述目标特征输入至预先训练好的账户识别模型,从而通过所述账户识别模型识别所述银行账户是否为涉诈账户。The
结合上一个实施方式,在某些可选的实施方式中,所述装置还包括:模型训练单元;With reference to the previous embodiment, in some optional embodiments, the apparatus further includes: a model training unit;
所述模型训练单元包括:账户数据获取子单元、特征工程子单元、模型训练子单元和模型测试子单元;The model training unit includes: an account data acquisition subunit, a feature engineering subunit, a model training subunit and a model testing subunit;
所述模型训练单元,用于执行所述账户识别模型的训练过程;the model training unit, configured to perform the training process of the account identification model;
所述账户数据获取子单元,用于从数据库中获取多个银行账户的账户数据;The account data acquisition subunit is used to acquire account data of a plurality of bank accounts from the database;
所述特征工程子单元,用于对各所述账户数据进行特征工程处理,从而提取得到相应至少一个维度的目标特征;The feature engineering subunit is used to perform feature engineering processing on each of the account data, so as to extract and obtain target features corresponding to at least one dimension;
所述模型训练子单元,用于将各所述目标特征划分为训练集和测试集,并将所述训练集输入至XGBoost算法,以对所述XGBoost算法进行训练;The model training subunit is used to divide each described target feature into a training set and a test set, and input the training set to the XGBoost algorithm to train the XGBoost algorithm;
所述模型测试子单元,用于将所述测试集输入至所述XGBoost算法,以对经过所述训练的XGBoost算法进行测试,从而训练得到所述账户识别模型。The model testing subunit is configured to input the test set into the XGBoost algorithm to test the trained XGBoost algorithm, thereby obtaining the account identification model through training.
结合上一个实施方式,在某些可选的实施方式中,所述装置还包括:加密单元和偏转单元;In combination with the previous embodiment, in some optional embodiments, the device further includes: an encryption unit and a deflection unit;
所述加密单元,用于在所述从数据库中获取多个银行账户的账户数据之后,对各所述账户数据中的身份证信息进行加密;The encryption unit is configured to encrypt the ID card information in each of the account data after acquiring the account data of a plurality of bank accounts from the database;
所述偏转单元,用于在所述从数据库中获取多个银行账户的账户数据之后,对各所述账户数据中的用户位置信息进行偏转处理。The deflection unit is configured to perform deflection processing on the user location information in each of the account data after the account data of the plurality of bank accounts is acquired from the database.
结合上一个实施方式,在某些可选的实施方式中,所述装置还包括:删除单元和补齐单元;In combination with the previous embodiment, in some optional embodiments, the device further includes: a deletion unit and a complementing unit;
所述删除单元,用于在所述对各所述账户数据中的用户位置信息进行偏转处理之后,将各所述账户数据中错误的信息进行删除;The deletion unit is configured to delete erroneous information in each of the account data after the deflecting process is performed on the user position information in each of the account data;
所述补齐单元,用于在所述对各所述账户数据中的用户位置信息进行偏转处理之后,将各所述账户数据中缺失的信息补齐为相应的预设信息。The complementing unit is configured to complement the missing information in each of the account data into corresponding preset information after performing the deflection processing on the user position information in each of the account data.
结合第二个实施方式,在某些可选的实施方式中,所述特征工程子单元,包括:直接提取子单元;With reference to the second embodiment, in some optional embodiments, the feature engineering subunit includes: a direct extraction subunit;
所述直接提取子单元,用于根据预先建立的业务指标和技术指标,直接从各所述账户数据中分别筛选得到至少一个维度的目标特征。The direct extraction sub-unit is used to directly select the target features of at least one dimension from the account data according to the pre-established business indicators and technical indicators.
结合第二个实施方式,在某些可选的实施方式中,所述特征工程子单元,包括:特征工程子单元;With reference to the second embodiment, in some optional embodiments, the feature engineering subunit includes: a feature engineering subunit;
所述特征工程子单元,用于通过对各所述账户数据在业务和时序层面的统计,从而统计得到至少一个维度的目标特征。The feature engineering sub-unit is configured to obtain target features of at least one dimension through statistics of each of the account data at the business and time sequence levels.
本发明提供了一种计算机可读存储介质,其上存储有程序,所述程序被处理器执行时实现上述任一项所述的账户识别方法。The present invention provides a computer-readable storage medium on which a program is stored, and when the program is executed by a processor, implements the account identification method described in any one of the above.
如图3所示,本发明提供了一种电子设备70,所述电子设备70包括至少一个处理器701、以及与所述处理器701连接的至少一个存储器702、总线703;其中,所述处理器701、所述存储器702通过所述总线703完成相互间的通信;所述处理器701用于调用所述存储器702中的程序指令,以执行上述任一项所述的账户识别方法。As shown in FIG. 3, the present invention provides an
在本申请中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。In this application, relational terms such as first and second, etc. are only used to distinguish one entity or operation from another entity or operation, and do not necessarily require or imply that any such relationship exists between these entities or operations. an actual relationship or sequence. Moreover, the terms "comprising", "comprising" or any other variation thereof are intended to encompass non-exclusive inclusion such that a process, method, article or device comprising a list of elements includes not only those elements, but also includes not explicitly listed or other elements inherent to such a process, method, article or apparatus. Without further limitation, an element qualified by the phrase "comprising a..." does not preclude the presence of additional identical elements in a process, method, article or apparatus that includes the element.
本说明书中的各个实施例均采用相关的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于系统实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。Each embodiment in this specification is described in a related manner, and the same and similar parts between the various embodiments may be referred to each other, and each embodiment focuses on the differences from other embodiments. In particular, for the system embodiments, since they are basically similar to the method embodiments, the description is relatively simple, and for related parts, please refer to the partial descriptions of the method embodiments.
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。The above description of the disclosed embodiments enables any person skilled in the art to make or use the present invention. Various modifications to these embodiments will be readily apparent to those skilled in the art, and the generic principles defined herein may be implemented in other embodiments without departing from the spirit or scope of the invention. Thus, the present invention is not intended to be limited to the embodiments shown herein, but is to be accorded the widest scope consistent with the principles and novel features disclosed herein.
以上所述仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内所作的任何修改、等同替换、改进等,均包含在本发明的保护范围内。The above descriptions are only preferred embodiments of the present invention, and are not intended to limit the protection scope of the present invention. Any modification, equivalent replacement, improvement, etc. made within the spirit and principle of the present invention are included in the protection scope of the present invention.
Claims (10)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210156951.2ACN114511329A (en) | 2022-02-21 | 2022-02-21 | Account identification method and device, storage medium and electronic equipment |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210156951.2ACN114511329A (en) | 2022-02-21 | 2022-02-21 | Account identification method and device, storage medium and electronic equipment |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN114511329Atrue CN114511329A (en) | 2022-05-17 |
Family
ID=81550818
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210156951.2APendingCN114511329A (en) | 2022-02-21 | 2022-02-21 | Account identification method and device, storage medium and electronic equipment |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114511329A (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115034509A (en)* | 2022-06-30 | 2022-09-09 | 中国建设银行股份有限公司 | Data processing method, apparatus, equipment and storage medium |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110335144A (en)* | 2019-07-10 | 2019-10-15 | 中国工商银行股份有限公司 | Personal electric bank account safety detection method and device |
| CN111383027A (en)* | 2020-03-10 | 2020-07-07 | 中国建设银行股份有限公司 | Account case-involved detection method, device, equipment and storage medium |
| CN113902037A (en)* | 2021-11-08 | 2022-01-07 | 中国联合网络通信集团有限公司 | Abnormal bank account identification method, system, electronic device and storage medium |
- 2022
- 2022-02-21CNCN202210156951.2Apatent/CN114511329A/enactivePending
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110335144A (en)* | 2019-07-10 | 2019-10-15 | 中国工商银行股份有限公司 | Personal electric bank account safety detection method and device |
| CN111383027A (en)* | 2020-03-10 | 2020-07-07 | 中国建设银行股份有限公司 | Account case-involved detection method, device, equipment and storage medium |
| CN113902037A (en)* | 2021-11-08 | 2022-01-07 | 中国联合网络通信集团有限公司 | Abnormal bank account identification method, system, electronic device and storage medium |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115034509A (en)* | 2022-06-30 | 2022-09-09 | 中国建设银行股份有限公司 | Data processing method, apparatus, equipment and storage medium |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN114187112B (en) | Training method of account risk model and determining method of risk user group | |
| TW201946013A (en) | Credit risk prediction method and device based on LSTM (Long Short Term Memory) model | |
| Voican | Credit Card Fraud Detection using Deep Learning Techniques. | |
| Suryanarayana et al. | Machine learning approaches for credit card fraud detection | |
| CN113706258B (en) | Product recommendation method, device, equipment and storage medium based on combined model | |
| CN110599336A (en) | Financial product purchase prediction method and system | |
| CN109584037A (en) | Calculation method, device and the computer equipment that user credit of providing a loan scores | |
| CN110675269A (en) | Text auditing method and device | |
| Lohokare et al. | Automated data collection for credit score calculation based on financial transactions and social media | |
| CN110930038A (en) | Loan demand identification method, loan demand identification device, loan demand identification terminal and loan demand identification storage medium | |
| CN112967134A (en) | Network training method, risk user identification method, device, equipment and medium | |
| CN113628033A (en) | Decision tree-based repayment capacity prediction method, device, equipment and storage medium | |
| CN116800831B (en) | Service data pushing method, device, storage medium and processor | |
| Sadgali et al. | Bidirectional gated recurrent unit for improving classification in credit card fraud detection | |
| CN109377347B (en) | Network credit early warning method, system and electronic equipment based on feature selection | |
| CN117633500A (en) | Risk anti-fraud identification method, device, equipment and storage medium | |
| CN110866672B (en) | Data processing method, device, terminal and medium | |
| CN112632219A (en) | Method and device for intercepting junk short messages | |
| Upreti et al. | Detection of banking financial frauds using hyper-parameter tuning of DL in cloud computing environment | |
| CN114511329A (en) | Account identification method and device, storage medium and electronic equipment | |
| CN115392916A (en) | Abnormal consumption control method and device, electronic equipment and storage medium | |
| CN118735675A (en) | A business risk prediction method and system | |
| Si et al. | Credit risk assessment by a comparison application of two boosting algorithms | |
| CN116051258A (en) | Account risk classification method and device, terminal equipment and storage medium | |
| CN116777639A (en) | Case risk rating method, device, computer equipment and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |