CN114491158A - Data analysis method, device, equipment and storage medium - Google Patents
Data analysis method, device, equipment and storage mediumDownload PDFInfo
- Publication number
- CN114491158A CN114491158ACN202011150360.1ACN202011150360ACN114491158ACN 114491158 ACN114491158 ACN 114491158ACN 202011150360 ACN202011150360 ACN 202011150360ACN 114491158 ACN114491158 ACN 114491158A
- Authority
- CN
- China
- Prior art keywords
- path
- target
- node
- data
- data source
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images



Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/901—Indexing; Data structures therefor; Storage structures
- G06F16/9024—Graphs; Linked lists
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/903—Querying
- G06F16/90335—Query processing
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q30/00—Commerce
- G06Q30/02—Marketing; Price estimation or determination; Fundraising
- G06Q30/0201—Market modelling; Market analysis; Collecting market data
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Databases & Information Systems (AREA)
- Business, Economics & Management (AREA)
- Development Economics (AREA)
- Strategic Management (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Finance (AREA)
- Accounting & Taxation (AREA)
- General Engineering & Computer Science (AREA)
- Entrepreneurship & Innovation (AREA)
- Software Systems (AREA)
- Computational Linguistics (AREA)
- Game Theory and Decision Science (AREA)
- Economics (AREA)
- Marketing (AREA)
- General Business, Economics & Management (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本申请涉及数据统计领域,尤其涉及一种数据分析方法、装置、设备及存储介质。The present application relates to the field of data statistics, and in particular, to a data analysis method, apparatus, device and storage medium.
背景技术Background technique
对交易过程中的交易数据进行分析的过程可以称为商业智能(BusinessIntelligence)分析。在传统的交易过程中,数据源的类型相对比较单一,但是随着大数据技术的普及,数据源的类型也越来越多样化,传统的BI分析工具也需逐渐适应多种不同类型数据源情况下的大数据查询与分析。目前,常用统一结构化查询语言(Structured QueryLanguage,SQL)查询引擎,来实现相同或不同类型数据源之间的跨数据源查询及分析,具体实现过程可以是对跨数据源进行SQL的代理与解析,生成抽象语法树(Abstract SyntaxTree,AST),并将AST转换成逻辑执行计划后生成物理执行计划,根据物理执行计划执行每个子SQL,最终将每个子SQL的查询结果聚合,返回得到最终结果。The process of analyzing the transaction data in the transaction process may be called business intelligence (Business Intelligence) analysis. In the traditional transaction process, the types of data sources are relatively simple, but with the popularization of big data technology, the types of data sources are becoming more and more diverse, and traditional BI analysis tools also need to gradually adapt to a variety of different types of data sources Big data query and analysis under the circumstances. At present, a unified Structured Query Language (SQL) query engine is commonly used to implement cross-data source query and analysis between the same or different types of data sources. The specific implementation process can be SQL proxy and analysis for cross data sources. , generate an abstract syntax tree (Abstract SyntaxTree, AST), and convert the AST into a logical execution plan to generate a physical execution plan, execute each sub-SQL according to the physical execution plan, and finally aggregate the query results of each sub-SQL, and return the final result.
但是,在目前上述实现过程中针对某一个SQL时,需对同一数据源进行多次访问,这样,严重增加了网络输入输出(Input/Output,IO)的开销,亟需对这种缺陷进行优化。However, in the current implementation process for a certain SQL, it is necessary to access the same data source multiple times, which seriously increases the network input/output (IO) overhead, and it is urgent to optimize this defect. .
申请内容Application content
为解决上述技术问题,本申请期望提供一种数据分析方法、装置、设备及存储介质,解决了目前网络IO开销较大的问题,降低了网络IO的开销,有效提高了BI分析的分析效率。In order to solve the above-mentioned technical problems, the present application expects to provide a data analysis method, device, device and storage medium, which solves the problem that the current network IO overhead is relatively large, reduces the network IO overhead, and effectively improves the analysis efficiency of BI analysis.
本申请的技术方案是这样实现的:The technical solution of the present application is realized as follows:
第一方面,一种数据分析方法,所述方法包括:A first aspect, a data analysis method, the method includes:
确定目标智能分析过程中使用的至少一个待分析数据源;Determine at least one data source to be analyzed used in the target intelligent analysis process;
基于所述至少一个待分析数据源,生成所述至少一个待分析数据源对应的目标有向无环图;其中,所述目标有向无环图包括k条路径,k为大于或等于1的整数;Based on the at least one data source to be analyzed, a target directed acyclic graph corresponding to the at least one data source to be analyzed is generated; wherein, the target directed acyclic graph includes k paths, and k is greater than or equal to 1 integer;
从所述目标有向无环图中的目标路径的路径起点节点开始,按照所述目标路径的路径方向,基于属于同一数据源且路径节点相邻的关系,对所述目标路径中的路径节点进行分组,得到所述目标路径的至少一组路径节点;其中,所述目标路径用于表示所述k条路径中的每一条路径;Starting from the path starting point node of the target path in the target directed acyclic graph, according to the path direction of the target path, based on the relationship between the path nodes belonging to the same data source and the adjacent path nodes, the path nodes in the target path are determined. Grouping is performed to obtain at least one set of path nodes of the target path; wherein, the target path is used to represent each path in the k paths;
从所述目标路径的每一组路径节点对应的目标数据源中,按照所述目标路径的路径方向获取对应的每一组路径节点的节点数据并进行分析,确定所述目标路径的执行结果;其中,所述目标路径的每一组路径节点对应的目标数据源属于所述至少一个待分析数据源;From the target data source corresponding to each group of path nodes of the target path, obtain and analyze the node data of each group of path nodes corresponding to the path direction of the target path, and determine the execution result of the target path; Wherein, the target data source corresponding to each group of path nodes of the target path belongs to the at least one data source to be analyzed;
汇总所述k条路径的执行结果,得到针对目标智能分析的目标分析结果。Summarize the execution results of the k paths to obtain the target analysis result for target intelligent analysis.
第二方面,一种数据分析装置,所述装置包括:确定单元、生成单元、处理单元和汇总单元;其中:In a second aspect, a data analysis device includes: a determining unit, a generating unit, a processing unit and a summarizing unit; wherein:
所述确定单元,用于确定目标智能分析过程中使用的至少一个待分析数据源;The determining unit is configured to determine at least one data source to be analyzed used in the target intelligent analysis process;
所述生成单元,用于基于所述至少一个待分析数据源,生成所述至少一个待分析数据源对应的目标有向无环图;其中,所述目标有向无环图包括k条路径,k为大于或等于1的整数;The generating unit is configured to generate a target directed acyclic graph corresponding to the at least one data source to be analyzed based on the at least one data source to be analyzed; wherein, the target directed acyclic graph includes k paths, k is an integer greater than or equal to 1;
所述处理单元,用于从所述目标有向无环图中的目标路径的路径起点节点开始,按照所述目标路径的路径方向,基于属于同一数据源且路径节点相邻的关系,对所述目标路径中的路径节点进行分组,得到所述目标路径的至少一组路径节点;其中,所述目标路径用于表示所述k条路径中的每一条路径;The processing unit is configured to start from the path starting point node of the target path in the target directed acyclic graph, according to the path direction of the target path, based on the relationship between the same data source and the adjacent path nodes, for all the path nodes. The path nodes in the target path are grouped to obtain at least one group of path nodes of the target path; wherein, the target path is used to represent each path in the k paths;
所述处理单元,还用于从所述目标路径的每一组路径节点对应的目标数据源中,按照所述目标路径的路径方向获取对应的每一组路径节点的节点数据并进行分析,确定所述目标路径的执行结果;其中,所述目标路径的每一组路径节点对应的目标数据源属于所述至少一个待分析数据源;The processing unit is further configured to obtain, from the target data source corresponding to each group of path nodes of the target path, the node data of each corresponding group of path nodes according to the path direction of the target path and analyze it to determine The execution result of the target path; wherein, the target data source corresponding to each group of path nodes of the target path belongs to the at least one data source to be analyzed;
所述汇总单元,用于汇总所述k条路径的执行结果,得到针对目标智能分析的目标分析结果。The summarizing unit is used for summarizing the execution results of the k paths to obtain a target analysis result for target intelligent analysis.
第三方面,一种数据分析设备,所述设备包括存储器、处理器和通信总线;其中:A third aspect, a data analysis device, the device includes a memory, a processor and a communication bus; wherein:
所述存储器,用于存储可执行指令;the memory for storing executable instructions;
所述通信总线,用于实现所述处理器和所述存储器之间的通信连接;the communication bus for realizing the communication connection between the processor and the memory;
所述处理器,用于执行所述存储器中存储的数据分析程序,实现如上述任一项所述的数据分析方法的步骤。The processor is configured to execute the data analysis program stored in the memory to implement the steps of the data analysis method described in any one of the above.
第四方面,一种存储介质,所述存储介质上存储有数据分析程序,所述数据分析程序被处理器执行时实现如上述任一项所述的数据分析方法的步骤。In a fourth aspect, a storage medium stores a data analysis program, and when the data analysis program is executed by a processor, implements the steps of the data analysis method described in any one of the above.
本申请实施例提供了一种数据分析方法、装置、设备及存储介质,通过确定目标智能分析过程中使用的至少一个待分析数据源,基于至少一个待分析数据源,生成至少一个待分析数据源对应的目标有向无环图后,从目标有向无环图中的目标路径的路径起点节点开始,按照目标路径的路径方向,基于属于同一数据源且路径节点相邻的关系,对目标路径中的路径节点进行分组,得到目标路径的至少一组路径节点,从目标路径的每一组路径节点对应的目标数据源中,按照目标路径的路径方向获取对应的每一组路径节点的节点数据并进行分析,确定目标路径的执行结果,并汇总k条路径的执行结果,得到针对目标智能分析的目标分析结果。这样,进行跨数据源查询与分析时,将至少一个待分析数据源生成对应的目标有向无环图,然后对目标有向无环图中每一目标路径中的路径节点进行分组,得到目标路径的至少一组路径节点,并从每一组路径节点对应的目标数据源中获取该组路径节点的节点数据并进行分析,以得到每一目标路径的执行结果,最后对k条路径的执行结果进行汇总,得到针对目标智能分析的目标分析结果,实现了将属于同一目标数据源的相邻节点的节点数据同时从目标数据源中取出的技术方案,解决了目前网络IO开销较大的问题,降低了网络IO的开销,有效提高了BI分析的分析效率。The embodiments of the present application provide a data analysis method, apparatus, device, and storage medium. By determining at least one data source to be analyzed used in the target intelligent analysis process, at least one data source to be analyzed is generated based on the at least one data source to be analyzed. After the corresponding target directed acyclic graph, starting from the path start node of the target path in the target directed acyclic graph, according to the path direction of the target path, based on the relationship between the same data source and the adjacent path nodes, the target path is determined. The path nodes in the target path are grouped to obtain at least one group of path nodes of the target path, and from the target data source corresponding to each group of path nodes of the target path, the node data of each group of path nodes corresponding to the path direction of the target path is obtained. And carry out analysis, determine the execution result of the target path, and summarize the execution results of the k paths to obtain the target analysis result for the target intelligent analysis. In this way, when performing cross-data source query and analysis, generate a corresponding target directed acyclic graph for at least one data source to be analyzed, and then group the path nodes in each target path in the target directed acyclic graph to obtain the target At least one group of path nodes of the path, and obtain the node data of the group of path nodes from the target data source corresponding to each group of path nodes and analyze it to obtain the execution result of each target path, and finally execute the execution of k paths The results are summarized, and the target analysis results for the target intelligent analysis are obtained, and the technical scheme of simultaneously extracting the node data of adjacent nodes belonging to the same target data source from the target data source is realized, which solves the current problem of large network IO overhead. , which reduces the overhead of network IO and effectively improves the analysis efficiency of BI analysis.
附图说明Description of drawings
图1为本申请实施例提供的一种数据分析方法的流程示意图;1 is a schematic flowchart of a data analysis method provided in an embodiment of the present application;
图2为本申请实施例提供的另一种数据分析方法的流程示意图;2 is a schematic flowchart of another data analysis method provided in an embodiment of the present application;
图3为本申请实施例提供的一种目标有向无环图的示意图;FIG. 3 is a schematic diagram of a target directed acyclic graph according to an embodiment of the present application;
图4为本申请实施例提供的一种数据分析装置的结构示意图;4 is a schematic structural diagram of a data analysis device provided by an embodiment of the present application;
图5为本申请实施例提供的一种数据分析设备的结构示意图。FIG. 5 is a schematic structural diagram of a data analysis device provided by an embodiment of the present application.
具体实施方式Detailed ways
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述。The technical solutions in the embodiments of the present application will be clearly and completely described below with reference to the accompanying drawings in the embodiments of the present application.
本申请的实施例提供一种数据分析方法,参照图1所示,方法应用于数据分析设备,该方法包括以下步骤:An embodiment of the present application provides a data analysis method. Referring to FIG. 1 , the method is applied to a data analysis device, and the method includes the following steps:
步骤101、确定目标智能分析过程中使用的至少一个待分析数据源。Step 101: Determine at least one data source to be analyzed used in the target intelligent analysis process.
在本申请实施例中,目标智能分析例如可以是针对某一商业活动进行智能分析,以得到该商业活动中的数据产生相应价值的过程,还可以是对其他数据进行分析的一个过程。在目前商业活动过程中,由于大数据技术的普及,在对目标商业智能分析过程中出现多个数据源的情况,因此,在进行目标商业智能分析过程时,先确定目标商业智能分析包括的至少一个待分析数据源。数据分析设备可以是计算机设备,也可以是服务器设备。In this embodiment of the present application, the target intelligent analysis may be, for example, a process of performing intelligent analysis on a certain business activity to obtain the corresponding value generated by the data in the business activity, or may be a process of analyzing other data. In the process of current business activities, due to the popularization of big data technology, there are multiple data sources in the process of analyzing the target business intelligence. Therefore, when conducting the target business intelligence analysis process, first determine that the target business intelligence analysis includes at least A data source to analyze. The data analysis device can be a computer device or a server device.
步骤102、基于至少一个待分析数据源,生成至少一个待分析数据源对应的目标有向无环图。
其中,目标有向无环图包括k条路径,k为大于或等于1的整数。The target directed acyclic graph includes k paths, where k is an integer greater than or equal to 1.
在本申请实施例中,在数学,特别是图论和计算机科学中,有向无环图指的是一个无回路的有向图。通过对至少一个待分析数据源进行分析,可以确定每一待分析数据源中的结构和至少一个待分析数据源之间的关联关系,以此生成至少一个待分析数据源对应的目标有向无环图。其中,至少一个待分析数据源之间的关联关系可以是执行的前后逻辑关系,例如可以是时间先后顺序。目标路径为目标有向无环图中的一条从路径起点节点开始至对应的路径终点节点的完整路径。In the embodiments of the present application, in mathematics, especially in graph theory and computer science, a directed acyclic graph refers to a directed graph without loops. By analyzing at least one data source to be analyzed, the association relationship between the structure in each data source to be analyzed and the at least one data source to be analyzed can be determined, so as to generate a target directional or non-directional target corresponding to the at least one data source to be analyzed. Ring Diagram. Wherein, the association relationship between at least one data source to be analyzed may be a logical relationship before and after execution, for example, may be a time sequence. The target path is a complete path in the target directed acyclic graph from the start node of the path to the corresponding end node of the path.
步骤103、从目标有向无环图中的目标路径的路径起点节点开始,按照目标路径的路径方向,基于属于同一数据源且路径节点相邻的关系,对目标路径中的路径节点进行分组,得到目标路径的至少一组路径节点。Step 103: Starting from the path starting point node of the target path in the target directed acyclic graph, according to the path direction of the target path, based on the relationship between the path nodes belonging to the same data source and adjacent to the path nodes, group the path nodes in the target path, Obtain at least one set of path nodes of the target path.
其中,目标路径用于表示k条路径中的每一条路径。Among them, the target path is used to represent each of the k paths.
在本申请实施例中,对目标有向无环图中目标路径中的路径节点进行分组处理,分组方式为将目标路径中属于同一个数据源且相邻的路径节点划分为一组路径节点,这样,目标路径可以由至少一组路径节点组成。目标路径的路径起点节点为目标路径的路径开始的路径节点。In the embodiment of the present application, grouping processing is performed on the path nodes in the target path in the target directed acyclic graph, and the grouping method is to divide the adjacent path nodes belonging to the same data source in the target path into a group of path nodes, In this way, the target path may consist of at least one set of path nodes. The path start node of the target path is the path node where the path of the target path starts.
步骤104、从目标路径的每一组路径节点对应的目标数据源中,按照目标路径的路径方向获取对应的每一组路径节点的节点数据并进行分析,确定目标路径的执行结果。Step 104: From the target data source corresponding to each group of path nodes of the target path, obtain the node data of each group of path nodes corresponding to the path direction of the target path and analyze it to determine the execution result of the target path.
其中,目标路径的每一组路径节点对应的目标数据源属于至少一个待分析数据源。The target data source corresponding to each group of path nodes of the target path belongs to at least one data source to be analyzed.
在本申请实施例中,需要对目标有向无环图中的每一目标路径进行单独并行处理,且为了减少对目标数据源的访问次数,可以一次性从每一组路径节点对应的目标数据源中获取该组路径节点的全部路径节点的节点数据,然后按照该组路径节点在目标路径中的路径方向对对应的每一路径节点的节点数据进行分析,直至最终得到每一目标路径的执行结果。目标有向无环图中的每一目标路径的分析可以是并行进行的。In the embodiment of the present application, each target path in the target directed acyclic graph needs to be processed separately and in parallel, and in order to reduce the number of visits to the target data source, the target data corresponding to each group of path nodes can be retrieved at one time. Obtain the node data of all path nodes of the group of path nodes from the source, and then analyze the node data of each corresponding path node according to the path direction of the group of path nodes in the target path, until the execution of each target path is finally obtained. result. The analysis of each goal path in the goal directed acyclic graph can be performed in parallel.
步骤105、汇总k条路径的执行结果,得到针对目标智能分析的目标分析结果。Step 105: Summarize the execution results of the k paths to obtain a target analysis result for target intelligent analysis.
在本申请实施例中,k条路径的路径终点节点为同一个节点,因此,可以基于k条路径的路径终点节点,将对k条路径进行分析得到的执行结果进行汇总,从而得到针对目标智能分析的目标分析结果。路径终点节点为每一条路径的最后一个路径节点。In the embodiment of the present application, the path end nodes of the k paths are the same node. Therefore, the execution results obtained by analyzing the k paths can be summarized based on the path end nodes of the k paths, so as to obtain the target intelligence The goal of the analysis is the analysis result. The path end node is the last path node of each path.
本申请实施例提供了一种数据分析方法,通过确定目标智能分析过程中使用的至少一个待分析数据源,基于至少一个待分析数据源,生成至少一个待分析数据源对应的目标有向无环图后,从目标有向无环图中的目标路径的路径起点节点开始,按照目标路径的路径方向,基于属于同一数据源且路径节点相邻的关系,对目标路径中的路径节点进行分组,得到目标路径的至少一组路径节点,从目标路径的每一组路径节点对应的目标数据源中,按照目标路径的路径方向获取对应的每一组路径节点的节点数据并进行分析,确定目标路径的执行结果,并汇总k条路径的执行结果,得到针对目标智能分析的目标分析结果。这样,进行跨数据源查询与分析时,将至少一个待分析数据源生成对应的目标有向无环图,然后对目标有向无环图中每一目标路径中的路径节点进行分组,得到目标路径的至少一组路径节点,并从每一组路径节点对应的目标数据源中获取该组路径节点的节点数据并进行分析,以得到每一目标路径的执行结果,最后对k条路径的执行结果进行汇总,得到针对目标智能分析的目标分析结果,实现了将属于同一目标数据源的相邻节点的节点数据同时从目标数据源中取出的技术方案,解决了目前网络IO开销较大的问题,降低了网络IO的开销,有效提高了BI分析的分析效率。The embodiment of the present application provides a data analysis method, by determining at least one data source to be analyzed used in the process of target intelligent analysis, and based on the at least one data source to be analyzed, generating a target directed acyclic loop corresponding to at least one data source to be analyzed After the graph, starting from the path starting point node of the target path in the target directed acyclic graph, according to the path direction of the target path, based on the relationship between the same data source and the adjacent path nodes, the path nodes in the target path are grouped, Obtain at least one group of path nodes of the target path, obtain the node data of each group of path nodes corresponding to the path direction of the target path from the target data source corresponding to each group of path nodes of the target path, and analyze them to determine the target path The execution results of k paths are summarized, and the target analysis results for target intelligent analysis are obtained. In this way, when performing cross-data source query and analysis, generate a corresponding target directed acyclic graph for at least one data source to be analyzed, and then group the path nodes in each target path in the target directed acyclic graph to obtain the target At least one group of path nodes of the path, and obtain the node data of the group of path nodes from the target data source corresponding to each group of path nodes and analyze it to obtain the execution result of each target path, and finally execute the execution of k paths The results are summarized, and the target analysis results for the target intelligent analysis are obtained, and the technical scheme of simultaneously extracting the node data of adjacent nodes belonging to the same target data source from the target data source is realized, which solves the current problem of large network IO overhead. , which reduces the overhead of network IO and effectively improves the analysis efficiency of BI analysis.
基于前述实施例,本申请的实施例提供一种数据分析方法,参照图2所示,方法应用于数据分析设备,该方法包括以下步骤:Based on the foregoing embodiments, the embodiments of the present application provide a data analysis method. Referring to FIG. 2 , the method is applied to a data analysis device, and the method includes the following steps:
步骤201、确定目标智能分析过程中使用的至少一个待分析数据源。Step 201: Determine at least one data source to be analyzed used in the target intelligent analysis process.
在本申请实施例中,数据分析设备在确定需进行目标智能分析时,确定该目标智能分析涉及到的至少一个待分析数据源。In this embodiment of the present application, when determining that target intelligent analysis needs to be performed, the data analysis device determines at least one to-be-analyzed data source involved in the target intelligent analysis.
步骤202、基于至少一个待分析数据源,生成抽象语法树AST。Step 202: Generate an abstract syntax tree AST based on at least one data source to be analyzed.
在本申请实施例中,抽象语法树(Abstract Syntax Tree,AST),或简称语法树(Syntax tree),是源代码语法结构的一种抽象表示,它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构。数据分析设备对至少一个待分析数据源进行分析,确定每一待分析数据源中的逻辑结构,并基于逻辑结构和待分析数据源之间的依赖关系,生成AST。In this embodiment of the present application, an abstract syntax tree (Abstract Syntax Tree, AST), or simply a syntax tree (Syntax tree), is an abstract representation of the syntax structure of a source code, which expresses the syntax structure of a programming language in a tree-like form , each node on the tree represents a structure in the source code. The data analysis device analyzes at least one data source to be analyzed, determines the logical structure in each data source to be analyzed, and generates an AST based on the dependency between the logical structure and the data source to be analyzed.
在本申请其他实施例中,步骤202可以由步骤a11~a14来实现:In other embodiments of the present application,
步骤a11、确定至少一个待分析数据源中每一待分析数据源的参考维度参数和参考度量参数。Step a11: Determine a reference dimension parameter and a reference metric parameter of each data source to be analyzed in the at least one data source to be analyzed.
在本申请实施例中,对每一待分析数据源中的数据进行模型建立,具体过程包括确定每一待分析数据源中的每一维度参数即参考维度参数和每一度量参数即参考度量参数等信息。In the embodiment of the present application, model building is performed on the data in each data source to be analyzed, and the specific process includes determining each dimension parameter in each data source to be analyzed, that is, the reference dimension parameter and each measurement parameter, that is, the reference measurement parameter. and other information.
步骤a12、基于每一待分析数据源的参考维度参数和参考度量参数,对每一待分析数据源中的数据进行分类封装,得到每一待分析数据源的封装数据。Step a12: Classify and encapsulate the data in each data source to be analyzed based on the reference dimension parameters and reference measurement parameters of each data source to be analyzed, to obtain the encapsulated data of each data source to be analyzed.
在本申请实施例中,对每一待分析数据源的每一参考维度参数对应的数据进行分类封装存储,对每一待分析数据源的每一参考度量参数进行分类封装存储,得到每一待分析数据源的封装数据。In the embodiment of the present application, the data corresponding to each reference dimension parameter of each data source to be analyzed is classified, packaged and stored, and each reference metric parameter of each data source to be analyzed is classified, packaged and stored to obtain each data source to be analyzed. Analyze the packaged data of the data source.
步骤a13、获取目标处理参数。Step a13, acquiring target processing parameters.
其中,目标处理参数包括目标维度参数和/或目标度量参数。The target processing parameters include target dimension parameters and/or target measurement parameters.
在本申请实施例中,目标维度参数和目标度量参数可以是用户通过输入设备输入的,例如可以是通过键盘、鼠标或者麦克风等设备实现输入过程的。目标维度参数至少包括一个维度参数,和/或目标度量参数至少包括一个度量参数。即在一些应用场景中,用户可以只选择维度参数作为目标维度参数进行商业智能分析,也可以只选择度量参数作为目标度量参数进行智能分析。目标处理参数中可以包括至少一种处理参数,即包括目标维度参数和/或目标度量参数的至少一种任意组合得到的参数。In this embodiment of the present application, the target dimension parameter and the target measurement parameter may be input by the user through an input device, for example, the input process may be implemented through a device such as a keyboard, a mouse, or a microphone. The target dimension parameter includes at least one dimension parameter, and/or the target metric parameter includes at least one metric parameter. That is, in some application scenarios, the user may only select dimension parameters as target dimension parameters for business intelligence analysis, or may only select measurement parameters as target measurement parameters for intelligent analysis. The target processing parameters may include at least one processing parameter, that is, a parameter obtained by any combination of at least one target dimension parameter and/or target measurement parameter.
步骤a14、基于目标处理参数,对至少一个待分析数据源的封装数据进行处理,得到AST。Step a14: Process the packaged data of at least one data source to be analyzed based on the target processing parameters to obtain an AST.
在本申请实施例中,对确定的至少一个待分析数据源的封装数据采用目标处理参数进行分析处理,以生成得到AST。In the embodiment of the present application, the package data of the determined at least one data source to be analyzed is analyzed and processed using target processing parameters to generate an AST.
在本申请其他实施例中,步骤a14可以由步骤a141~a142来实现:In other embodiments of the present application, step a14 may be implemented by steps a141 to a142:
步骤a141、将目标处理参数,按照预设的SQL语句规则生成SQL查询语句。Step a141: Generate an SQL query statement according to the preset SQL statement rules according to the target processing parameters.
步骤a142、通过开源SQL解析工具,基于SQL查询语句,对至少一个待分析数据源的封装数据进行解析,得到AST。Step a142: Using an open source SQL parsing tool, based on the SQL query statement, parse the packaged data of at least one data source to be analyzed to obtain an AST.
步骤203、基于AST,生成目标有向无环图。Step 203: Generate a target directed acyclic graph based on the AST.
在本申请实施例中,对AST中的每一节点进行预处理,生成得到目标有向无环图。In the embodiment of the present application, each node in the AST is preprocessed to generate the target directed acyclic graph.
在本申请其他实施例中,步骤203可以由步骤b11~b12来实现:In other embodiments of the present application,
步骤b11、验证AST每一节点中的语法结构对象。Step b11, verify the grammatical structure object in each node of the AST.
在本申请实施例中,对AST中的每一节点进行预处理的过程包括:对AST每一节点中的语法结构对象进行验证,具体验证内容至少包括判断数据库对象的集合(XML Schema,简称Schema)、字段、函数等是否存在,和/或SQL语句是否合法等。In the embodiment of the present application, the process of preprocessing each node in the AST includes: verifying the grammatical structure objects in each node of the AST, and the specific verification content at least includes judging a set of database objects (XML Schema, referred to as Schema for short). ), the existence of fields, functions, etc., and/or whether the SQL statement is legal, etc.
步骤b12、若AST每一节点中的语法结构对象验证通过,合并AST中相同的子树,得到目标有向无环图。Step b12: If the grammatical structure object in each node of the AST passes the verification, merge the same subtrees in the AST to obtain the target directed acyclic graph.
在本申请实施例中,在AST每一节点中的语法结构对象均验证通过后,将AST中相同的子树进行合并,从而得到目标有向无环图。这样目标有向无环图可以体现出多数据源以及每一节点代表的数据之间的依赖关系。In the embodiment of the present application, after the grammatical structure objects in each node of the AST are verified, the same subtrees in the AST are merged to obtain the target directed acyclic graph. In this way, the target directed acyclic graph can reflect the dependencies between multiple data sources and the data represented by each node.
步骤204、从目标有向无环图中的目标路径的路径起点节点开始,按照目标路径的路径方向,基于属于同一数据源且路径节点相邻的关系,对目标路径中的路径节点进行分组,得到目标路径的至少一组路径节点。Step 204: Starting from the path starting point node of the target path in the target directed acyclic graph, according to the path direction of the target path, based on the relationship between the path nodes belonging to the same data source and adjacent to the path nodes, group the path nodes in the target path, Obtain at least one set of path nodes of the target path.
其中,目标路径用于表示k条路径中的每一条路径;Among them, the target path is used to represent each of the k paths;
在本申请实施例中,数据分析设备执行步骤204后,可以选择执行步骤205~206,或者步骤207~215。其中,若目标有向无环图的目标路径包括一组路径节点,选择执行步骤205~206;若目标有向无环图的目标路径包括至少两组路径节点,选择执行步骤207~215。需说明的是,在目标有向无环图中,存在部分路径中除最后一个路径终点节点外的所有路径节点均属于一个目标数据源,部分路径中除最后一个路径终点节点外的路径节点属于至少两个目标数据源,这样,数据分析设备可以针对不同路径,同时选择执行对应的步骤205~206和步骤207~215。In this embodiment of the present application, after the data analysis device performs
步骤205、若目标路径包括一组路径节点,从一组路径节点对应的目标数据源中获取一组路径节点的第一节点数据。Step 205: If the target path includes a group of path nodes, acquire first node data of a group of path nodes from a target data source corresponding to the group of path nodes.
其中,一组路径节点包括目标路径中除路径终点节点外的路径节点。The set of path nodes includes path nodes in the target path except the path end node.
在本申请实施例中,以某一路径包括3个路径节点A、B和C为例进行说明,路径为A→B→C,若A和B两个路径节点属于一个目标数据源,因此可以确定A和B属于同一组路径节点,对应的可以从该目标数据源中同时获取A和B这两个路径节点对应的数据,得到第一节点数据。In the embodiment of the present application, a path includes three path nodes A, B, and C as an example for description, and the path is A→B→C. If the two path nodes A and B belong to one target data source, it can be It is determined that A and B belong to the same group of path nodes, and correspondingly, data corresponding to the two path nodes A and B can be simultaneously obtained from the target data source to obtain the first node data.
步骤206、按照目标路径的路径方向,依次基于第一节点数据中每一路径节点对应的第一子数据执行一组路径节点中每一路径节点的目标任务,得到目标路径的执行结果。
在本申请实施例中,对第一节点数据中A路径节点对应的数据进行A路径节点的目标任务处理,得到A路径节点的子执行结果,然后将A路径节点的子执行结果与第一节点数据中B路径节点对应的数据进行B路径节点的目标任务处理,得到B路径节点的子执行结果,并将B路径节点的子执行结果作为路径为A→B→C的执行结果。In the embodiment of the present application, the target task processing of the A-path node is performed on the data corresponding to the A-path node in the first node data to obtain the sub-execution result of the A-path node, and then the sub-execution result of the A-path node is compared with the first node. The data corresponding to the B-path node in the data is processed by the target task of the B-path node, and the sub-execution result of the B-path node is obtained, and the sub-execution result of the B-path node is used as the execution result of the path A→B→C.
步骤207、若目标路径包括至少两组路径节点,按照目标路径的路径方向,确定包括目标路径的路径起点节点的第一组路径节点对应的目标数据源。Step 207: If the target path includes at least two groups of path nodes, according to the path direction of the target path, determine the target data source corresponding to the first group of path nodes including the path start point node of the target path.
在本申请实施例中,以某一路径包括6个路径节点E、F、G、H、I和J为例进行说明,目标路径为E→F→G→H→I→J,路径起点节点E属于第一目标数据源,与路径起点节点E相邻的路径节点为F,判断路径节点F是否属于第一目标数据源,如果路径节点F不属于第一目标数据源,因此,可以确定E为一组路径节点,即对应的为第一组路径节点。In the embodiment of the present application, a certain path includes 6 path nodes E, F, G, H, I and J as an example for description, the target path is E→F→G→H→I→J, and the path starting point node is E→F→G→H→I→J. E belongs to the first target data source, and the path node adjacent to the path starting point node E is F. It is determined whether the path node F belongs to the first target data source. If the path node F does not belong to the first target data source, it can be determined that E is a group of path nodes, that is, corresponding to the first group of path nodes.
步骤208、从第一组路径节点对应的目标数据源中,获取第一组路径节点的第二节点数据。Step 208: Acquire second node data of the first group of path nodes from the target data source corresponding to the first group of path nodes.
在本申请实施例中,从第一组路径节点对应的目标数据源中,获取第一组路径节点E的第二节点数据。In this embodiment of the present application, the second node data of the first group of path nodes E is obtained from the target data source corresponding to the first group of path nodes.
步骤209、按照目标路径的路径方向,基于第二节点数据中每一路径节点对应的第二子数据执行第一组路径节点中对应的每一路径节点的目标任务,得到第一子执行结果。Step 209: Execute the target task of each path node corresponding to the first group of path nodes based on the second sub-data corresponding to each path node in the second node data according to the path direction of the target path, and obtain a first sub-execution result.
在本申请实施例中,由于第一组路径节点中只有一个路径节点E,所以,此时第二节点数据为路径节点E对应的第二子数据,对应的,根据路径节点E的目标任务对第二子数据进行分析,得到第一子执行结果。In the embodiment of the present application, since there is only one path node E in the first group of path nodes, the second node data is the second sub-data corresponding to the path node E at this time. Correspondingly, according to the target task of the path node E, the The second sub-data is analyzed to obtain the first sub-execution result.
步骤210、在目标路径的路径方向上,确定与第一组路径节点对应的目标数据源相邻的第二组路径节点对应的目标数据源。Step 210: In the path direction of the target path, determine the target data source corresponding to the second group of path nodes adjacent to the target data source corresponding to the first group of path nodes.
在本申请实施例中,假设路径节点F属于第二目标数据源,与路径节点F相邻的路径节点G也属于第二目标数据源,与路径节点G相邻的路径节点H也属于第二目标数据源,对应的,可以确定路径节点F、路径节点G和路径节点H属于第二组路径节点,与路径节点H相邻的路径节点I属于第一目标数据源,对应的,可以确定路径节点I属于第三组路径节点,需说明的是,由于路径节点J虽然也属于第一目标数据源,但是由于路径节点J与路径节点E不相邻,因此,路径节点不属于第一组路径节点。。In the embodiment of the present application, it is assumed that the path node F belongs to the second target data source, the path node G adjacent to the path node F also belongs to the second target data source, and the path node H adjacent to the path node G also belongs to the second target data source. The target data source, correspondingly, it can be determined that the path node F, the path node G and the path node H belong to the second group of path nodes, and the path node I adjacent to the path node H belongs to the first target data source. Correspondingly, it can be determined that the path Node I belongs to the third group of path nodes. It should be noted that although path node J also belongs to the first target data source, since path node J is not adjacent to path node E, the path node does not belong to the first group of paths. node. .
步骤211、从第二组路径节点对应的目标数据源中获取第二组路径节点的第三节点数据。Step 211: Acquire third node data of the second group of path nodes from the target data source corresponding to the second group of path nodes.
在本申请实施例中,从第二目标数据源中获取第二参考路径节点F、G和H的第三节点数据。In this embodiment of the present application, the third node data of the second reference path nodes F, G, and H are acquired from the second target data source.
步骤212、按照目标路径的路径方向,基于第一子执行结果和第三节点数据中每一路径节点对应的第三子数据执行第二组路径节点中对应的每一路径节点的目标任务,得到第二子执行结果。Step 212: According to the path direction of the target path, perform the target task of each path node corresponding to the second group of path nodes based on the first sub-execution result and the third sub-data corresponding to each path node in the third node data, to obtain: The second sub-execution result.
在本申请实施例中,根据目标路径,可以确定路径节点F与路径节点E之间存在前后逻辑关系,因此,可以基于路径节点F对应的目标任务对第一子执行结果和路径节点F对应的第三子数据进行分析,得到路径节点F的分析结果,然后基于路径节点G对应的目标任务对路径节点F的分析结果与路径节点G对应的第三至数据进行分析,得到路径节点G的分析结果,基于路径节点H对应的目标任务对路径节点G的分析结果和路径节点H对应的第三至数据进行分析,得到路径节点H对应的分析结果,并将路径节点F对应的分析结果作为第二子执行结果。In the embodiment of the present application, according to the target path, it can be determined that there is a logical relationship between the path node F and the path node E. Therefore, the first sub-execution result and the path node F corresponding to the first sub-execution result can be based on the target task corresponding to the path node F. The third sub-data is analyzed to obtain the analysis result of the path node F, and then the analysis result of the path node F and the third data corresponding to the path node G are analyzed based on the target task corresponding to the path node G, and the analysis of the path node G is obtained. As a result, based on the target task corresponding to the path node H, the analysis result of the path node G and the third data corresponding to the path node H are analyzed to obtain the analysis result corresponding to the path node H, and the analysis result corresponding to the path node F is used as the first step. Second child execution result.
在本申请实施例中,数据分析设备执行步骤212后,选择执行步骤213或步骤214~215。若第二组路径节点包括目标路径中与路径终点节点相邻的路径节点,选择执行步骤213,若第二组路径节点包括的是除目标路径中与路径终点节点相邻的路径节点外的至少一个路径节点,选择执行步骤214~215。In this embodiment of the present application, after the data analysis device executes
步骤213、若第二组路径节点包括目标路径中与目标路径的路径终点节点相邻的路径节点,确定目标路径的执行结果为第二子执行结果。Step 213: If the second group of path nodes includes a path node in the target path that is adjacent to the path end node of the target path, determine that the execution result of the target path is the second sub-execution result.
步骤214、若第二组路径节点包括的是除目标路径中与目标路径的路径终点节点相邻的路径节点外的至少一个路径节点,在目标路径的路径方向上,确定与第二组路径节点对应的目标数据源相邻的第三组路径节点对应的目标数据源。Step 214: If the second group of path nodes includes at least one path node in the target path other than the path node adjacent to the path end node of the target path, in the path direction of the target path, determine the path node with the second group of path nodes. The target data source corresponding to the third group of path nodes adjacent to the corresponding target data source.
在本申请实施例中,假设第三组路径节点对应的目标数据源与第一组路径节点对应的目标数据源相同,路径节点I为与路径终点节点J相邻的路径节点,由于第二组路径节点不包括路径节点I,所以数据分析设备继续执行步骤214。第三组路径节点对应的目标数据源即第一目标数据源。In the embodiment of the present application, it is assumed that the target data source corresponding to the third group of path nodes is the same as the target data source corresponding to the first group of path nodes, and the path node I is the path node adjacent to the path end node J. The path nodes do not include path node I, so the data analysis device proceeds to step 214. The target data source corresponding to the third group of path nodes is the first target data source.
步骤215、从第三组路径节点对应的目标数据源中获取第三组路径节点的第四节点数据,如此重复,直至基于第三子执行结果和第五节点数据中每一路径节点对应的第五子数据执行对应的每一路径节点的目标任务,得到目标路径的执行结果。Step 215: Obtain the fourth node data of the third group of path nodes from the target data source corresponding to the third group of path nodes, and repeat this until the third sub-execution result and the fifth node data corresponding to each path node in the fifth node data. The five sub-data execute the target task corresponding to each path node, and obtain the execution result of the target path.
其中,第五节点数据是从包括目标路径中与路径终点节点相邻的路径节点的第四组路径节点对应的目标数据源中针对第四组路径节点获取得到的,第三子执行结果为对第四组路径节点对应的目标数据源相邻的前一目标数据源中的数据执行对应的任务得到的。The fifth node data is obtained for the fourth group of path nodes from the target data source corresponding to the fourth group of path nodes including the path nodes adjacent to the path end node in the target path, and the third sub-execution result is a pair of The data in the previous target data source adjacent to the target data source corresponding to the fourth group of path nodes is obtained by executing the corresponding task.
在本申请实施例中,由于路径节点I是目标路径中与路径终点节点相邻的路径节点,所以此时第四参考节点为第三参考节点,第五节点数为第四节点数据,对应的得到的是第三子执行结果,并将第三子执行结果作为该路径的执行结果。对应的,从第一目标数据源中获取路径节点I的第四节点数据,并基于路径节点I对应的目标任务对第二子执行结果和路径节点I的第四节点数据进行分析,得到目标路径E→F→G→H→I→J的执行结果。In the embodiment of the present application, since the path node I is the path node adjacent to the path end node in the target path, the fourth reference node is the third reference node at this time, the fifth node number is the fourth node data, and the corresponding What is obtained is the third sub-execution result, and the third sub-execution result is used as the execution result of the path. Correspondingly, the fourth node data of the path node I is obtained from the first target data source, and based on the target task corresponding to the path node I, the second sub-execution result and the fourth node data of the path node I are analyzed to obtain the target path. The execution result of E→F→G→H→I→J.
步骤216、确定目标有向无环图中k条路径共同的路径终点节点所属的第五目标数据源。Step 216: Determine the fifth target data source to which the path end node common to the k paths in the target directed acyclic graph belongs.
步骤217、从第五目标数据源中获取路径终点节点的第六节点数据。Step 217: Obtain the sixth node data of the path end node from the fifth target data source.
步骤218、基于第六节点数据和k条路径的执行结果,得到针对目标智能分析的目标分析结果。
也就是说,步骤205~218实现的是:主要对有向无环图的依赖关系进行分析,按照有向无环图的方向进行计算任务分析,对于每一路径节点的数据源的计算任务,先进行缓存,直到在计算任务链即每一目标路径方向上遇到需要跨数据源的计算任务时,可一次性将之前缓存的属于同一数据源的计算任务在单节点上执行完成,并且对不同的计算任务链做并行计算处理,即多个执行引擎同时处理,处理完后再聚合,最终返回执行结果。需说明的是,针对每一计算任务链可以采用一个执行引擎来实现。That is to say, what steps 205 to 218 achieve is: mainly analyze the dependencies of the directed acyclic graph, and analyze the computing tasks according to the direction of the directed acyclic graph. For the computing task of the data source of each path node, Cache is performed first, until a computing task that needs to cross data sources is encountered in the computing task chain, that is, in the direction of each target path, the previously cached computing tasks belonging to the same data source can be executed on a single node at one time. Different computing task chains are processed in parallel, that is, multiple execution engines process at the same time, and then aggregate after processing, and finally return the execution result. It should be noted that, one execution engine may be used for each computing task chain.
基于前述实施例,本申请实施例提供一种数据分析方法的应用场景,如图3所示为通过本申请实施例方法得到的目标有向无环图,在该目标有向无环图中,包括两个数据源:数据源1和数据源2,由两个不同的路径即路径31和路径32组成,其中,路径31从路径起点节点1开始,依次包括:路径节点1、路径节点2、路径节点3、路径节点5、路径节点6和路径节点8,路径32从路径起点节点4和路径节点8,沿着箭头的方向,用于表示各任务之间的依赖关系。其中,路径节点1、路径节点2、路径节点3和路径节点4属于数据源1,路径节点5、路径节点6、路径节点7和路径节点8属于数据源2。其中:Based on the foregoing embodiments, an embodiment of the present application provides an application scenario of a data analysis method. As shown in FIG. 3, a directed acyclic graph of a target obtained by the method of the embodiment of the present application is shown. In the directed acyclic graph of the target, It includes two data sources: data source 1 and data source 2, which are composed of two different paths, namely
针对路径31,步骤1、从数据源1中获取路径节点1、路径节点2、路径节点3对应的数据,并对路径节点1、路径节点2、路径节点3对应的数据进行计算,得到对路径节点1、路径节点2、路径节点3对应的第一子执行结果;步骤2、从第二数据源2中获取路径节点6对应的数据;步骤3、对路径节点1、路径节点2、路径节点3对应的第一子执行结果和路径节点6对应的数据进行计算,得到路径31的执行结果。For
针对路径32,步骤4、从数据源1中获取路径节点4对应的数据,并对路径节点4对应的数据进行计算,得到路径节点4对应的第一子执行结果;步骤5、从第二数据源2中获取路径节点7对应的数据;步骤6、对路径节点4对应的第一子执行结果和路径节点7对应的数据进行计算,得到路径32的执行结果。需说明的是,步骤1~3和步骤4~6是并行执行的,并没有执行的先后逻辑顺序。For the
步骤7、基于路径节点8,对路径31的执行结果和路径32的执行结果进行汇总聚合,得到目标分析结果。Step 7: Based on the path node 8, summarize and aggregate the execution result of the
需要说明的是,本实施例中与其它实施例中相同步骤和相同内容的说明,可以参照其它实施例中的描述,此处不再赘述。It should be noted that, for the description of the same steps and the same content in this embodiment as in other embodiments, reference may be made to the descriptions in other embodiments, and details are not repeated here.
本申请实施例提供的一种数据分析方法,通过确定目标智能分析过程中使用的至少一个待分析数据源,基于至少一个待分析数据源,生成至少一个待分析数据源对应的目标有向无环图后,从目标有向无环图中的目标路径的路径起点节点开始,按照目标路径的路径方向,基于属于同一数据源且路径节点相邻的关系,对目标路径中的路径节点进行分组,得到目标路径的至少一组路径节点,从目标路径的每一组路径节点对应的目标数据源中,按照目标路径的路径方向获取对应的每一组路径节点的节点数据并进行分析,确定目标路径的执行结果,并汇总k条路径的执行结果,得到针对目标智能分析的目标分析结果。这样,进行跨数据源查询与分析时,将至少一个待分析数据源生成对应的目标有向无环图,然后对目标有向无环图中每一目标路径中的路径节点进行分组,得到目标路径的至少一组路径节点,并从每一组路径节点对应的目标数据源中获取该组路径节点的节点数据并进行分析,以得到每一目标路径的执行结果,最后对k条路径的执行结果进行汇总,得到针对目标智能分析的目标分析结果,实现了将属于同一目标数据源的相邻节点的节点数据同时从目标数据源中取出的技术方案,解决了目前网络IO开销较大的问题,降低了网络IO的开销,有效提高了BI分析的分析效率。并通过SQL来生成AST,并通过得到的AST得到目标有向无环图进行商业智能分析,实现以统一SAL查询引擎为基础核心,同时从同一数据源中获取不同路径节点的数据进行分析,提高了SQL引擎执行效率,减少了BI分析工具查询的响应时间,实现更加丰富的数据分析能力。In a data analysis method provided by an embodiment of the present application, by determining at least one data source to be analyzed used in the target intelligent analysis process, and based on the at least one data source to be analyzed, a target directed acyclic target corresponding to the at least one data source to be analyzed is generated After the graph, starting from the path starting point node of the target path in the target directed acyclic graph, according to the path direction of the target path, based on the relationship between the same data source and the adjacent path nodes, the path nodes in the target path are grouped, Obtain at least one group of path nodes of the target path, obtain the node data of each group of path nodes corresponding to the path direction of the target path from the target data source corresponding to each group of path nodes of the target path, and analyze them to determine the target path The execution results of k paths are summarized, and the target analysis results for target intelligent analysis are obtained. In this way, when performing cross-data source query and analysis, generate a corresponding target directed acyclic graph for at least one data source to be analyzed, and then group the path nodes in each target path in the target directed acyclic graph to obtain the target At least one group of path nodes of the path, and obtain the node data of the group of path nodes from the target data source corresponding to each group of path nodes and analyze it to obtain the execution result of each target path, and finally execute the execution of k paths The results are summarized, and the target analysis results for the target intelligent analysis are obtained, and the technical solution of simultaneously extracting the node data of adjacent nodes belonging to the same target data source from the target data source is realized, which solves the current problem of high network IO overhead. , which reduces the overhead of network IO and effectively improves the analysis efficiency of BI analysis. And generate AST through SQL, and obtain the target directed acyclic graph through the obtained AST for business intelligence analysis, realize the unified SAL query engine as the basic core, and obtain the data of different path nodes from the same data source for analysis, improve the It improves the execution efficiency of the SQL engine, reduces the response time of BI analysis tool queries, and realizes richer data analysis capabilities.
基于前述实施例,本申请的实施例提供一种数据分析装置,该装置可以应用于图1~2对应的实施例提供的数据分析方法中,参照图4所示,该数据分析装置4可以包括:确定单元41、生成单元42、处理单元43和汇总单元44,其中:Based on the foregoing embodiments, the embodiments of the present application provide a data analysis apparatus, which can be applied to the data analysis methods provided by the embodiments corresponding to FIGS. 1 to 2 . Referring to FIG. 4 , the
确定单元41,用于确定目标智能分析过程中使用的至少一个待分析数据源;A
生成单元42,用于基于至少一个待分析数据源,生成至少一个待分析数据源对应的目标有向无环图;其中,目标有向无环图包括k条路径,k为大于或等于1的整数;The generating
处理单元43,用于从目标有向无环图中的目标路径的路径起点节点开始,按照目标路径的路径方向,基于属于同一数据源且路径节点相邻的关系,对目标路径中的路径节点进行分组,得到目标路径的至少一组路径节点;其中,目标路径用于表示k条路径中的每一条路径;The
处理单元43,还用于从目标路径的每一组路径节点对应的目标数据源中,按照目标路径的路径方向获取对应的每一组路径节点的节点数据并进行分析,确定目标路径的执行结果;其中,目标路径的每一组路径节点对应的目标数据源属于至少一个待分析数据源;The
汇总单元44,用于汇总k条路径的执行结果,得到针对目标智能分析的目标分析结果。The summarizing
在本申请其他实施例中,生成单元42包括:第一生成模块和第二生成模块;其中:In other embodiments of the present application, the generating
第一生成模块,用于基于至少一个待分析数据源,生成抽象语法树AST;a first generation module, configured to generate an abstract syntax tree AST based on at least one data source to be analyzed;
第二生成模块,用于基于AST,生成目标有向无环图。The second generation module is used for generating the target directed acyclic graph based on the AST.
在本申请其他实施例中,第一生成模块用于实现以下步骤:In other embodiments of the present application, the first generation module is configured to implement the following steps:
确定至少一个待分析数据源中每一待分析数据源的参考维度参数和参考度量参数;Determining reference dimension parameters and reference metric parameters of each data source to be analyzed in the at least one data source to be analyzed;
基于每一待分析数据源的参考维度参数和参考度量参数,对每一待分析数据源中的数据进行分类封装,得到每一待分析数据源的封装数据;Based on the reference dimension parameters and reference measurement parameters of each data source to be analyzed, classify and encapsulate the data in each data source to be analyzed, and obtain the encapsulated data of each data source to be analyzed;
获取目标处理参数;其中,目标处理参数包括目标维度参数和/或目标度量参数;Obtaining target processing parameters; wherein the target processing parameters include target dimension parameters and/or target measurement parameters;
基于目标处理参数,对至少一个待分析数据源的封装数据进行处理,得到AST。Based on the target processing parameters, the encapsulated data of at least one data source to be analyzed is processed to obtain an AST.
在本申请其他实施例中,第一生成模块用于实现步骤基于目标处理参数,对至少一个待分析数据源的封装数据进行处理,得到AST时,具体通过以下步骤来实现:In other embodiments of the present application, the first generation module is used for the implementation step to process the packaged data of at least one data source to be analyzed based on the target processing parameters, and when obtaining the AST, it is specifically implemented through the following steps:
将目标处理参数,按照预设的SQL语句规则生成SQL查询语句;The target processing parameters are generated according to the preset SQL statement rules to generate SQL query statements;
通过开源SQL解析工具,基于SQL查询语句,对至少一个待分析数据源的封装数据进行解析,得到AST。An open source SQL parsing tool is used to parse the encapsulated data of at least one data source to be analyzed based on the SQL query statement to obtain an AST.
在本申请其他实施例中,第二生成模块具体用于实现以下步骤:In other embodiments of the present application, the second generation module is specifically configured to implement the following steps:
验证AST每一节点中的语法结构对象;Verify the grammar structure object in each node of the AST;
若AST每一节点中的语法结构对象验证通过,合并AST中相同的子树,得到目标有向无环图。If the grammatical structure objects in each node of the AST pass the verification, the same subtrees in the AST are merged to obtain the target directed acyclic graph.
在本申请其他实施例中,处理单元43包括:第一获取模块和第一处理模块;其中:In other embodiments of the present application, the
第一获取模块,用于若目标路径包括一组路径节点,从一组路径节点对应的目标数据源中获取一组路径节点的第一节点数据;其中,一组路径节点包括目标路径中除路径终点节点外的路径节点;A first obtaining module, configured to obtain first node data of a set of path nodes from a target data source corresponding to a set of path nodes if the target path includes a set of path nodes; wherein, a set of path nodes includes a path except a path in the target path Path nodes outside the destination node;
第一处理模块,用于按照目标路径的路径方向,依次基于第一节点数据中每一路径节点对应的第一子数据执行一组路径节点中每一路径节点的目标任务,得到目标路径的执行结果。The first processing module is configured to execute the target task of each path node in a group of path nodes based on the first sub-data corresponding to each path node in the first node data in turn according to the path direction of the target path, to obtain the execution of the target path result.
在本申请其他实施例中,处理单元43还包括:第一确定模块;其中:In other embodiments of the present application, the
第一确定模块,用于若目标路径包括至少两组路径节点,按照目标路径的路径方向,确定包括目标路径的路径起点节点的第一组路径节点对应的目标数据源;a first determining module, configured to determine the target data source corresponding to the first group of path nodes including the path start point node of the target path according to the path direction of the target path if the target path includes at least two groups of path nodes;
第一获取模块,还用于从第一组路径节点对应的目标数据源中,获取第一组路径节点的第二节点数据;The first obtaining module is further configured to obtain the second node data of the first group of path nodes from the target data source corresponding to the first group of path nodes;
第一处理模块,还用于按照目标路径的路径方向,基于第二节点数据中每一路径节点对应的第二子数据执行第一组路径节点中对应的每一路径节点的目标任务,得到第一子执行结果;The first processing module is further configured to execute the target task of each path node corresponding to each path node in the first group of path nodes based on the second sub-data corresponding to each path node in the second node data according to the path direction of the target path, to obtain the first processing module. One child execution result;
第一确定模块,还用于在目标路径的路径方向上,确定与第一组路径节点对应的目标数据源相邻的第二组路径节点对应的目标数据源;The first determining module is further configured to determine, in the path direction of the target path, the target data source corresponding to the second group of path nodes adjacent to the target data source corresponding to the first group of path nodes;
第一获取模块,还用于从第二组路径节点对应的目标数据源中获取第二组路径节点的第三节点数据;The first obtaining module is further configured to obtain the third node data of the second group of path nodes from the target data source corresponding to the second group of path nodes;
第一处理模块,还用于按照目标路径的路径方向,基于第一子执行结果和第三节点数据中每一路径节点对应的第三子数据执行第二组路径节点中对应的每一路径节点的目标任务,得到第二子执行结果;The first processing module is further configured to execute each path node corresponding to the second group of path nodes based on the first sub-execution result and the third sub-data corresponding to each path node in the third node data according to the path direction of the target path , get the second sub-execution result;
第一确定模块,还用于若第二组路径节点包括目标路径中与目标路径的路径终点节点相邻的路径节点,确定目标路径的执行结果为第二子执行结果。The first determining module is further configured to determine that the execution result of the target path is the second sub-execution result if the second group of path nodes includes a path node in the target path that is adjacent to the path end node of the target path.
在本申请其他实施例中,处理单元43还包括:重复模块;其中:In other embodiments of the present application, the
第一确定模块,还用于若第二组路径节点包括的是除目标路径中与目标路径的路径终点节点相邻的路径节点外的至少一个路径节点,在目标路径的路径方向上,确定与第二组路径节点对应的目标数据源相邻的第三组路径节点对应的目标数据源;The first determining module is further configured to, in the path direction of the target path, determine the path node with the path node adjacent to the path end node of the target path if the second group of path nodes includes at least one path node in the target path. The target data source corresponding to the third group of path nodes adjacent to the target data source corresponding to the second group of path nodes;
重复模块,用于从第三组路径节点对应的目标数据源中获取第三组路径节点的第四节点数据,如此重复,直至基于第三子执行结果和第五节点数据中每一路径节点对应的第五子数据执行对应的每一路径节点的目标任务,得到目标路径的执行结果;其中,第五节点数据是从包括目标路径中与路径终点节点相邻的路径节点的第四组路径节点对应的目标数据源中针对第四组路径节点获取得到的,第三子执行结果为对第四组路径节点对应的目标数据源相邻的前一目标数据源中的数据执行对应的任务得到的。The repeating module is used to obtain the fourth node data of the third group of path nodes from the target data source corresponding to the third group of path nodes, and repeat this until the third sub-execution result corresponds to each path node in the fifth node data The fifth sub-data executes the corresponding target task of each path node, and obtains the execution result of the target path; wherein, the fifth node data is obtained from the fourth group of path nodes including the path node adjacent to the path end node in the target path The corresponding target data source is obtained for the fourth group of path nodes, and the third sub-execution result is obtained by executing the corresponding task on the data in the previous target data source adjacent to the target data source corresponding to the fourth group of path nodes. .
在本申请其他实施例中,汇总单元44包括:第二确定模块、第二获取模块和第二处理模块;其中:In other embodiments of the present application, the summarizing
第二确定模块,用于确定目标有向无环图中k条路径共同的路径终点节点所属的第五目标数据源;The second determination module is used to determine the fifth target data source to which the common path endpoint node of the k paths in the target directed acyclic graph belongs;
第二获取模块,用于从第五目标数据源中获取路径终点节点的第六节点数据;The second obtaining module is used to obtain the sixth node data of the path end node from the fifth target data source;
第二处理模块,用于基于第六节点数据和k条路径的执行结果,得到针对目标智能分析的目标分析结果。The second processing module is configured to obtain target analysis results for target intelligent analysis based on the sixth node data and the execution results of the k paths.
需要说明的是,本实施例中数据分析装置所执行的步骤的具体实现过程,可以参照图1~2对应的实施例提供的数据分析方法中的实现过程,此处不再赘述。It should be noted that, for the specific implementation process of the steps executed by the data analysis apparatus in this embodiment, reference may be made to the implementation process in the data analysis method provided by the embodiments corresponding to FIGS. 1 to 2 , which will not be repeated here.
本申请实施例提供了一种数据分析装置,通过确定目标智能分析过程中使用的至少一个待分析数据源,基于至少一个待分析数据源,生成至少一个待分析数据源对应的目标有向无环图后,从目标有向无环图中的目标路径的路径起点节点开始,按照目标路径的路径方向,基于属于同一数据源且路径节点相邻的关系,对目标路径中的路径节点进行分组,得到目标路径的至少一组路径节点,从目标路径的每一组路径节点对应的目标数据源中,按照目标路径的路径方向获取对应的每一组路径节点的节点数据并进行分析,确定目标路径的执行结果,并汇总k条路径的执行结果,得到针对目标智能分析的目标分析结果。这样,进行跨数据源查询与分析时,将至少一个待分析数据源生成对应的目标有向无环图,然后对目标有向无环图中每一目标路径中的路径节点进行分组,得到目标路径的至少一组路径节点,并从每一组路径节点对应的目标数据源中获取该组路径节点的节点数据并进行分析,以得到每一目标路径的执行结果,最后对k条路径的执行结果进行汇总,得到针对目标智能分析的目标分析结果,实现了将属于同一目标数据源的相邻节点的节点数据同时从目标数据源中取出的技术方案,解决了目前网络IO开销较大的问题,降低了网络IO的开销,有效提高了BI分析的分析效率。并通过SQL来生成AST,并通过得到的AST得到目标有向无环图进行商业智能分析,实现以统一SAL查询引擎为基础核心,同时从同一数据源中获取不同路径节点的数据进行分析,提高了SQL引擎执行效率,减少了BI分析工具查询的响应时间,实现更加丰富的数据分析能力。An embodiment of the present application provides a data analysis device, which generates a target directed acyclic loop corresponding to at least one data source to be analyzed based on the at least one data source to be analyzed by determining at least one data source to be analyzed used in the target intelligent analysis process. After the graph, starting from the path starting point node of the target path in the target directed acyclic graph, according to the path direction of the target path, based on the relationship between the same data source and the adjacent path nodes, the path nodes in the target path are grouped, Obtain at least one group of path nodes of the target path, obtain the node data of each group of path nodes corresponding to the path direction of the target path from the target data source corresponding to each group of path nodes of the target path, and analyze it to determine the target path The execution results of k paths are summarized, and the target analysis results for target intelligent analysis are obtained. In this way, when performing cross-data source query and analysis, generate a corresponding target directed acyclic graph for at least one data source to be analyzed, and then group the path nodes in each target path in the target directed acyclic graph to obtain the target At least one group of path nodes of the path, and obtain the node data of the group of path nodes from the target data source corresponding to each group of path nodes and analyze it to obtain the execution result of each target path, and finally execute the execution of k paths The results are summarized, and the target analysis results for the target intelligent analysis are obtained, and the technical solution of simultaneously extracting the node data of adjacent nodes belonging to the same target data source from the target data source is realized, which solves the current problem of large network IO overhead. , which reduces the overhead of network IO and effectively improves the analysis efficiency of BI analysis. And generate AST through SQL, and obtain the target directed acyclic graph through the obtained AST for business intelligence analysis, realize the unified SAL query engine as the basic core, and obtain the data of different path nodes from the same data source for analysis, improve the It improves the execution efficiency of the SQL engine, reduces the response time of BI analysis tool queries, and realizes richer data analysis capabilities.
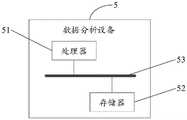
基于前述实施例,本申请的实施例提供一种数据分析设备,该数据分析设备可以应用于图1~2对应的实施例提供的数据分析方法中,参照图5所示,该数据分析设备5可以包括:处理器51、存储器52和通信总线53,其中:Based on the foregoing embodiments, the embodiments of the present application provide a data analysis device, which can be applied to the data analysis methods provided by the embodiments corresponding to FIGS. 1 to 2 . Referring to FIG. 5 , the
通信总线53,用于实现处理器51和存储器52之间的通信连接;A
处理器51,用于执行存储器52中存储的数据分析程序,以实现图1~2对应的实施例提供的数据分析方法中的实现过程,此处不再赘述。The
基于前述实施例,本申请的实施例提供一种计算机可读存储介质,简称为存储介质,该计算机可读存储介质存储有一个或者多个程序,该一个或者多个程序可被一个或者多个处理器执行,以实现参照图1~2对应的实施例提供的数据分析方法中的实现过程,此处不再赘述。Based on the foregoing embodiments, the embodiments of the present application provide a computer-readable storage medium, referred to as a storage medium for short, and the computer-readable storage medium stores one or more programs, and the one or more programs can be stored by one or more programs. The processor executes to implement the implementation process in the data analysis method provided by the embodiments corresponding to FIGS. 1-2 , and details are not repeated here.
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用硬件实施例、软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器和光学存储器等)上实施的计算机程序产品的形式。As will be appreciated by those skilled in the art, the embodiments of the present application may be provided as a method, a system, or a computer program product. Accordingly, the application may take the form of a hardware embodiment, a software embodiment, or an embodiment combining software and hardware aspects. Furthermore, the present application may take the form of a computer program product embodied on one or more computer-usable storage media having computer-usable program code embodied therein, including but not limited to disk storage, optical storage, and the like.
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。The present application is described with reference to flowchart illustrations and/or block diagrams of methods, apparatus (systems), and computer program products according to embodiments of the present application. It will be understood that each process and/or block in the flowchart illustrations and/or block diagrams, and combinations of processes and/or blocks in the flowchart illustrations and/or block diagrams, can be implemented by computer program instructions. These computer program instructions may be provided to the processor of a general purpose computer, special purpose computer, embedded processor or other programmable data processing device to produce a machine such that the instructions executed by the processor of the computer or other programmable data processing device produce Means for implementing the functions specified in a flow or flow of a flowchart and/or a block or blocks of a block diagram.
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。These computer program instructions may also be stored in a computer-readable memory capable of directing a computer or other programmable data processing apparatus to function in a particular manner, such that the instructions stored in the computer-readable memory result in an article of manufacture comprising instruction means, the instructions The apparatus implements the functions specified in the flow or flow of the flowcharts and/or the block or blocks of the block diagrams.
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。These computer program instructions can also be loaded on a computer or other programmable data processing device to cause a series of operational steps to be performed on the computer or other programmable device to produce a computer-implemented process such that The instructions provide steps for implementing the functions specified in the flow or blocks of the flowcharts and/or the block or blocks of the block diagrams.
以上所述,仅为本申请的较佳实施例而已,并非用于限定本申请的保护范围。The above descriptions are only preferred embodiments of the present application, and are not intended to limit the protection scope of the present application.
Claims (12)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011150360.1ACN114491158B (en) | 2020-10-23 | 2020-10-23 | Data analysis method, device, equipment and storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011150360.1ACN114491158B (en) | 2020-10-23 | 2020-10-23 | Data analysis method, device, equipment and storage medium |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN114491158Atrue CN114491158A (en) | 2022-05-13 |
| CN114491158B CN114491158B (en) | 2025-09-23 |
Family
ID=81470823
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202011150360.1AActiveCN114491158B (en) | 2020-10-23 | 2020-10-23 | Data analysis method, device, equipment and storage medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114491158B (en) |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20100094851A1 (en)* | 2008-10-09 | 2010-04-15 | International Business Machines Corporation | Node-level sub-queries in distributed databases |
| WO2017028930A1 (en)* | 2015-08-20 | 2017-02-23 | Telefonaktiebolaget Lm Ericsson (Publ) | Methods and apparatus for running an analytics function |
| CN108874954A (en)* | 2018-06-04 | 2018-11-23 | 深圳市华傲数据技术有限公司 | A kind of optimization method of data base querying, medium and equipment |
| CN109063056A (en)* | 2018-07-20 | 2018-12-21 | 阿里巴巴集团控股有限公司 | A kind of data query method, system and terminal device |
| CN111625692A (en)* | 2020-05-27 | 2020-09-04 | 北京字节跳动网络技术有限公司 | Feature extraction method, device, electronic equipment and computer readable medium |
| CN111666321A (en)* | 2019-03-05 | 2020-09-15 | 百度在线网络技术(北京)有限公司 | Method and device for operating multiple data sources |
- 2020
- 2020-10-23CNCN202011150360.1Apatent/CN114491158B/enactiveActive
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20100094851A1 (en)* | 2008-10-09 | 2010-04-15 | International Business Machines Corporation | Node-level sub-queries in distributed databases |
| WO2017028930A1 (en)* | 2015-08-20 | 2017-02-23 | Telefonaktiebolaget Lm Ericsson (Publ) | Methods and apparatus for running an analytics function |
| CN108874954A (en)* | 2018-06-04 | 2018-11-23 | 深圳市华傲数据技术有限公司 | A kind of optimization method of data base querying, medium and equipment |
| CN109063056A (en)* | 2018-07-20 | 2018-12-21 | 阿里巴巴集团控股有限公司 | A kind of data query method, system and terminal device |
| CN111666321A (en)* | 2019-03-05 | 2020-09-15 | 百度在线网络技术(北京)有限公司 | Method and device for operating multiple data sources |
| CN111625692A (en)* | 2020-05-27 | 2020-09-04 | 北京字节跳动网络技术有限公司 | Feature extraction method, device, electronic equipment and computer readable medium |
Non-Patent Citations (2)
| Title |
|---|
| GITEE极速下载: "quicksql", Retrieved from the Internet <URL:https://so.gitee.com/?q=quicksql>* |
| 姜燕,胡凯,杨志斌,等: "基于扩展的随机DAG的并行任务调度算法研究", 计算机科学, vol. 35, no. 07, 25 July 2008 (2008-07-25), pages 57 - 60* |
Also Published As
| Publication number | Publication date |
|---|---|
| CN114491158B (en) | 2025-09-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US8239847B2 (en) | General distributed reduction for data parallel computing | |
| CN105022691B (en) | A kind of increasingly automated method for testing software based on uml diagram | |
| Wadden et al. | ANMLzoo: a benchmark suite for exploring bottlenecks in automata processing engines and architectures | |
| US11106437B2 (en) | Lookup table optimization for programming languages that target synchronous digital circuits | |
| US10769147B2 (en) | Batch data query method and apparatus | |
| CN112100054A (en) | A program static analysis method and system for data management and control | |
| US20140344817A1 (en) | Converting a hybrid flow | |
| CN107844415B (en) | Model detection path reduction method based on interpolation and computer | |
| CN104020994B (en) | Stream process definition device and stream process based on streaming system define method | |
| CN106371887B (en) | Compiling system and method for MSVL language | |
| JP6763072B2 (en) | Compile data processing graph | |
| US20140250429A1 (en) | Code analysis for simulation efficiency improvement | |
| CN102609451A (en) | SQL (structured query language) query plan generation method oriented to streaming data processing | |
| CN103116540A (en) | Dynamic symbol execution method and device based on global superblock domination graph | |
| CN110187988A (en) | Static function call graph construction method suitable for virtual functions and function pointers | |
| CN116368494A (en) | Neural network compiling optimization method and related device | |
| CN114564726B (en) | A software vulnerability analysis method and system based on big data office | |
| CN111045670A (en) | Method and device for identifying multiplexing relationship between binary code and source code | |
| CN108647146A (en) | The method for generating test case of combined covering is judged based on correction conditions | |
| CN107330098A (en) | A kind of querying method of self-defined report, calculate node and inquiry system | |
| CN103455362A (en) | Automatic hardware language transformation system | |
| CN114491158A (en) | Data analysis method, device, equipment and storage medium | |
| CN116467220B (en) | A loop code processing method and device for software static analysis | |
| Chen et al. | Automatic test transition paths generation approach from EFSM using state tree | |
| Martin et al. | Definition of the DISPEL Language |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |