CN114464151A - Sound repairing method and device - Google Patents
Sound repairing method and deviceDownload PDFInfo
- Publication number
- CN114464151A CN114464151ACN202210377923.3ACN202210377923ACN114464151ACN 114464151 ACN114464151 ACN 114464151ACN 202210377923 ACN202210377923 ACN 202210377923ACN 114464151 ACN114464151 ACN 114464151A
- Authority
- CN
- China
- Prior art keywords
- voice data
- timbre
- user
- data
- audio data
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images









Classifications
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H1/00—Details of electrophonic musical instruments
- G10H1/0008—Associated control or indicating means
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H1/00—Details of electrophonic musical instruments
- G10H1/0091—Means for obtaining special acoustic effects
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H2210/00—Aspects or methods of musical processing having intrinsic musical character, i.e. involving musical theory or musical parameters or relying on musical knowledge, as applied in electrophonic musical tools or instruments
- G10H2210/325—Musical pitch modification
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H2210/00—Aspects or methods of musical processing having intrinsic musical character, i.e. involving musical theory or musical parameters or relying on musical knowledge, as applied in electrophonic musical tools or instruments
- G10H2210/375—Tempo or beat alterations; Music timing control
- G10H2210/385—Speed change, i.e. variations from preestablished tempo, tempo change, e.g. faster or slower, accelerando or ritardando, without change in pitch
Landscapes
- Physics & Mathematics (AREA)
- Engineering & Computer Science (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Soundproofing, Sound Blocking, And Sound Damping (AREA)
- Telephone Function (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本申请涉及音频技术领域,尤其涉及一种修音方法及装置。The present application relates to the field of audio technology, and in particular, to a method and device for modifying sound.
背景技术Background technique
对于喜欢音乐的用户来说,用户可以在电子设备上安装音乐应用程序(Application,APP),音乐应用程序可以提供录音和K歌等模式(也可以称为功能),用户通过音乐APP的录音模式或K歌模式完成一首歌曲的演唱,以得到该歌曲的音频数据。但是在用户演唱过程中,用户的音准和节奏可以影响歌曲的效果,因此如何提高歌曲的效果是亟需解决的问题。For users who like music, the user can install a music application (Application, APP) on the electronic device, and the music application can provide modes such as recording and karaoke (also called functions), and the user can use the music APP's recording mode Or complete the singing of a song in karaoke mode to obtain the audio data of the song. However, during the user's singing process, the user's pitch and rhythm can affect the effect of the song, so how to improve the effect of the song is an urgent problem to be solved.
发明内容SUMMARY OF THE INVENTION
本申请提供了一种修音方法及装置,目的在于提高用户录制歌曲的效果。为了实现上述目的,本申请提供了以下技术方案:The present application provides a sound repairing method and device, with the purpose of improving the effect of a user recording a song. In order to achieve the above purpose, the application provides the following technical solutions:
第一方面,本申请提供一种修音方法,方法包括:获取第一语音数据,第一语音数据具有第一对象的音色;对第一语音数据进行划分,得到至少两条第二语音数据;确定第二语音数据对应的第二对象;其中,第二对象中存在至少一个第二对象的类型为第一类型,且存在至少一个第二对象的类型为第二类型;对第二语音数据进行音色转换,得到第三语音数据,第三语音数据具有第二语音数据对应的第二对象的音色;至少对第三语音数据进行融合,获得第四语音数据,第四语音数据至少具有第一类型的第二对象的音色和第二类型的第二对象的音色。在本实施例中,电子设备可以对具有第一对象的音色的第一语音数据进行划分,得到至少两条第二语音数据,然后确定第二语音数据对应的第二对象,对第二语音数据进行音色转换,得到具有第二对象的音色的第三语音数据,根据第三语音数据获得第四语音数据,第四语音数据至少具有第一类型的第二对象的音色和第二类型的第二对象的音色,即第四语音数据至少具有两种类型的第二对象的音色,通过音色转换达到多人合成一条语音数据的效果。对第三语音数据的融合可以是对第三语音数据的拼接/组合,例如电子设备在对每条第二语音数据进行音色转换后,按照第二语音数据在第一语音数据中的顺序,对所有第三语音数据进行拼接,得到第四语音数据,第四语音数据的语音内容与第一语音数据的语音内容相同,但第四语音数据的音色和第一语音数据的音色不同。In a first aspect, the present application provides a sound modification method, the method comprising: acquiring first voice data, the first voice data having the timbre of a first object; dividing the first voice data to obtain at least two pieces of second voice data; determining a second object corresponding to the second voice data; wherein, the type of at least one second object existing in the second object is the first type, and the type of at least one second object existing in the second object is the second type; timbre conversion to obtain third voice data, where the third voice data has the timbre of the second object corresponding to the second voice data; at least the third voice data is fused to obtain fourth voice data, and the fourth voice data at least has the first type The timbre of the second object and the timbre of the second object of the second type. In this embodiment, the electronic device may divide the first voice data with the timbre of the first object to obtain at least two pieces of second voice data, and then determine the second object corresponding to the second voice data, and then divide the second voice data Perform timbre conversion to obtain third voice data with the timbre of the second object, obtain fourth voice data according to the third voice data, and the fourth voice data at least have the timbre of the second object of the first type and the second voice of the second type. The timbre of the object, that is, the fourth voice data has at least two types of timbres of the second object, and the effect of synthesizing one piece of voice data by multiple people is achieved through timbre conversion. The fusion of the third voice data may be the splicing/combination of the third voice data. For example, after the electronic device performs timbre conversion on each piece of second voice data, according to the order of the second voice data in the first voice data, All third voice data are spliced to obtain fourth voice data. The voice content of the fourth voice data is the same as the voice content of the first voice data, but the timbre of the fourth voice data is different from that of the first voice data.
其中第一类型和第二类型可以有多种形式,在一种示例中,第一类型和第二类型可以指第二对象的音色,通过音色区分第二对象。在另一种示例中,第一类型和第二类型可以指第二对象的性别和/或年龄,通过性别和/或年龄区分第二对象。例如,成年男性和青少年男性是不同的第二对象。在其他示例中,第一类型和第二类型可以指第二对象的音色、性别和年龄中的至少一个;在其他示例中,第一类型和第二类型可以指第二对象的对象类别,如真实人物、虚拟人物等等。The first type and the second type may have various forms. In one example, the first type and the second type may refer to the timbre of the second object, and the second object is distinguished by the timbre. In another example, the first type and the second type may refer to the gender and/or age of the second subject by which the second subject is distinguished. For example, adult males and teenage males are different secondary subjects. In other examples, the first type and the second type may refer to at least one of the timbre, gender, and age of the second object; in other examples, the first type and the second type may refer to the object category of the second object, such as Real people, virtual people, etc.
在一些示例中,修音方法的一种场景可以是没有原唱场景(如用户录用场景);在一些示例中,修音方法的一种场景可以是有原唱场景(如用户K歌场景);在这两个场景下,电子设备可以获取到用户的语音数据(对应第一语音数据),该语音数据具有用户(对应第一对象)的音色。电子设备可以对该语音数据进行划分,并对划分出的每部分(对应第二语音数据)进行音色转换,得到至少具有两个目标用户的音色的语音数据(对应第四语音数据),目标用户为第二对象。其中第一语音数据可以是从一个音频数据中提取出,如对该音频数据进行背景音乐和语音分离,得到第一语音数据,分离是可选的,在完成音色转换后,电子设备可以将第四语音数据和背景音乐数据合成,得到目标音频数据,目标音频数据具有至少两种类型的第二对象的音色,达到多人合成一条音频数据的目的;如果音频数据中没有背景音乐,那么音频数据可以视为是第一语音数据。In some examples, a scene of the sound repair method may be a scene without original singing (such as a user recording scene); in some examples, a scene of the sound repair method may be a scene with original singing (such as a user K song scene) ; In these two scenarios, the electronic device can acquire the user's voice data (corresponding to the first voice data), and the voice data has the timbre of the user (corresponding to the first object). The electronic device may divide the voice data, and perform timbre conversion on each of the divided parts (corresponding to the second voice data) to obtain voice data (corresponding to the fourth voice data) with at least two target users' timbres. for the second object. The first voice data can be extracted from a piece of audio data. For example, the audio data can be separated from the background music and the voice to obtain the first voice data. The separation is optional. After the tone conversion is completed, the electronic device can Four voice data and background music data are synthesized to obtain target audio data, and the target audio data has at least two types of timbres of the second object, so as to achieve the purpose of synthesizing one piece of audio data by multiple people; if there is no background music in the audio data, then the audio data It can be regarded as the first voice data.
在一种可能的实现方式中,方法还包括:获取第五语音数据,第五语音数据具有第三对象的音色,第五语音数据和第一语音数据对应同一内容;从第五语音数据中提取出内容参数;基于内容参数,对第一语音数据进行美音处理,得到第六语音数据;基于第四语音数据和第六语音数据,得到第七语音数据,第七语音数据至少具有第一类型的第二对象的音色和第二类型的第二对象的音色,第七语音数据的内容参数与从第五语音数据中提取出的内容参数匹配。电子设备可以获取到对应同一内容的第一语音数据和第五语音数据,利用第五语音数据的内容参数,对第一语音数据进行美音处理,得到第六语音数据,第六语音数据的内容参数与从第五语音数据中提取出的内容参数匹配;然后基于第四语音数据和第六语音数据,得到第七语音数据,使得第七语音数据可以具有至少两种类型的第二对象的音色,且第七语音数据的内容参数与从第五语音数据中提取出的内容参数匹配,其中匹配是指两条语音数据的内容参数相似或相接近。In a possible implementation manner, the method further includes: acquiring fifth voice data, the fifth voice data has the timbre of the third object, and the fifth voice data and the first voice data correspond to the same content; extracting from the fifth voice data The content parameter is obtained; based on the content parameter, the first voice data is subjected to American accent processing to obtain sixth voice data; based on the fourth voice data and the sixth voice data, seventh voice data is obtained, and the seventh voice data has at least the first type of voice data. The timbre of the second object and the timbre of the second object of the second type, the content parameters of the seventh voice data match the content parameters extracted from the fifth voice data. The electronic device can obtain the first voice data and the fifth voice data corresponding to the same content, and use the content parameter of the fifth voice data to perform American accent processing on the first voice data to obtain the sixth voice data and the content parameter of the sixth voice data. Matching with the content parameter extracted from the fifth voice data; then based on the fourth voice data and the sixth voice data, obtain the seventh voice data, so that the seventh voice data can have the timbre of at least two types of second objects, And the content parameter of the seventh voice data matches the content parameter extracted from the fifth voice data, wherein the matching means that the content parameters of the two voice data are similar or close.
例如将第四语音数据和第六语音数据融合,使得第七语音数据保留第四语音数据的音色、第七语音数据保留第六语音数据的内容参数,达到多人合成一条语音数据的效果的同时,可以使其内容参数与其他语音数据的内容参数相匹配,因为第六语音数据是基于第三语音数据的内容参数进行美音处理得到,即第六语音数据是美音处理后的语音数据,第六语音数据可以保留第三语音数据的内容参数,第七语音数据可以保留第六语音数据的内容参数,所以第七语音数据可以保留第三语音数据的内容参数。比如在有原唱场景中,电子设备可以获取到原唱的语音数据(对应第三语音数据),利用原唱的语音数据的内容参数对用户的语音数据进行美音处理,从而在达到多人合唱歌曲的目的的同时降低跑调几率。在原唱场景中,第七语音数据可以和背景音乐数据合成,得到目标音频数据,目标音频数据在达到多人合唱歌曲的目的的同时降低跑调几率。For example, the fourth voice data and the sixth voice data are fused, so that the seventh voice data retains the timbre of the fourth voice data, and the seventh voice data retains the content parameters of the sixth voice data, so as to achieve the effect of multiple people synthesizing one voice data at the same time. , can make its content parameters match the content parameters of other voice data, because the sixth voice data is obtained by performing American accent processing based on the content parameters of the third voice data, that is, the sixth voice data is the voice data after American accent processing, and the sixth voice data is The voice data can retain the content parameters of the third voice data, and the seventh voice data can retain the content parameters of the sixth voice data, so the seventh voice data can retain the content parameters of the third voice data. For example, in a scene with original singing, the electronic device can obtain the voice data of the original singing (corresponding to the third voice data), and use the content parameters of the original singing voice data to process the user's voice data in beautiful accent, so as to achieve multi-person chorus. The purpose of the song while reducing the chance of being out of tune. In the original singing scene, the seventh voice data can be synthesized with the background music data to obtain the target audio data, and the target audio data can reduce the probability of out-of-tune while achieving the purpose of multi-person singing.
在一种可能的实现方式中,内容参数包括:每句的起始位置和结束位置、每个字的起始位置和结束位置、每个字的发音和每个字的音高;基于内容,对第一语音数据进行美音处理包括:基于每个字的起始位置和结束位置,得到每个字的基频和包络;基于每个字的发音,得到每个字的辅音信息;利用每个字的基频、每个字的包络、每个字的辅音信息、每个字的音高、每个字的起始位置和结束位置、每句的起始位置和结束位置,对第一语音数据的音调和语速进行调整,使得第六语音数据的音调与第三语音数据的音调相匹配、第六语音数据的语速与第三语音数据的语速相匹配。In a possible implementation manner, the content parameters include: the starting position and ending position of each sentence, the starting position and ending position of each character, the pronunciation of each character, and the pitch of each character; based on the content, The first phonetic data is carried out to American pronunciation and includes: based on the starting position and the ending position of each character, obtain the fundamental frequency and envelope of each character; Based on the pronunciation of each character, obtain the consonant information of each character; The fundamental frequency of each character, the envelope of each character, the consonant information of each character, the pitch of each character, the starting position and ending position of each character, the starting position and ending position of each sentence, for the first The pitch and speed of a voice data are adjusted so that the pitch of the sixth voice data matches the pitch of the third voice data, and the speed of the sixth voice data matches that of the third voice data.
其中,对第一语音数据的音调和语速的调整是通过对第一语音数据中每个字和每句调整实现,例如利用每个字的基频和包络,调整第一语音数据中该字的基频和包络,使两条语音数据(第一语音数据和第三语音数据)中该字的基频之间的差异缩小;利用每个字的辅音信息,调整第一语音数据中该字的辅音信息,使两条语音数据该字的辅音信息相同;利用每字的音高,调整第一语音数据该字的音高,使两条语音数据中该字的音高之间的差异缩小,通过基频、包络、辅音信息和音高的调整,实现对第一语音数据的音调的调整。利用每个字的起始位置和结束位置,调整该字在第一语音数据中的时长,在完成一句中字的时长调整后,可以利用该句的起始位置和结束位置,对第一语音数据中该句的时长进行调整,实现对第一语音数据的语速的调整。因为美音处理后的第一语音数据(即第六语音数据)中每个字的参数与第三语音数据中对应字的参数相一致,以及美音处理后的第一语音数据中每句的参数与第三语音数据中对应句的参数相一致,所以美音处理后的第一语音数据可以保留第三语音数据的特性。在有原唱场景中,美音处理后的第一语音数据可以包括原唱的语音数据的特性,使得美音处理后的第一语音数据可以接近原唱的语音数据,从而降低跑调几率。Wherein, the adjustment of the pitch and speech rate of the first voice data is achieved by adjusting each word and each sentence in the first voice data, for example, by using the fundamental frequency and envelope of each word, to adjust the The fundamental frequency and envelope of the word can reduce the difference between the fundamental frequencies of the word in the two voice data (the first voice data and the third voice data); use the consonant information of each character to adjust the first voice data. The consonant information of the word makes the consonant information of the word in the two speech data the same; using the pitch of each word, adjust the pitch of the word in the first speech data, so that the pitch between the pitches of the word in the two speech data is the same. The difference is reduced, and the pitch of the first speech data is adjusted by adjusting the fundamental frequency, the envelope, the consonant information and the pitch. Use the start position and end position of each word to adjust the duration of the word in the first voice data. After completing the adjustment of the duration of the word in a sentence, you can use the start position and end position of the sentence to adjust the duration of the first voice data. The duration of the sentence is adjusted in order to realize the adjustment of the speech rate of the first speech data. Because the parameters of each character in the first voice data processed by American accent (that is, the sixth voice data) are consistent with the parameters of the corresponding word in the third voice data, and the parameters of each sentence in the first voice data processed by American accent are the same as those of the corresponding character in the third voice data. The parameters of the corresponding sentences in the third speech data are consistent, so the first speech data after the American accent processing can retain the characteristics of the third speech data. In a scenario with an original singing, the first voice data processed by the beautiful sound may include the characteristics of the original singing voice data, so that the first voice data processed by the beautiful singing can be close to the voice data of the original singing, thereby reducing the probability of out-of-tune.
在一种可能的实现方式中,对第一语音数据进行划分,得到至少两条第二语音数据包括:对第一语音数据进行声纹识别,以确定第一语音数据中至少一部分的识别结果;基于至少一部分的识别结果,对第一语音数据进行划分,得到至少两条第二语音数据,实现通过声纹识别对第一语音数据的划分。在一些示例中,识别结果可以是每部分所属历史对象(如所属历史用户),基于每部分所属历史对象对第一语音数据进行划分。例如电子设备可以将属于一个历史对象的一部分划分成一条第二语音数据,也可以将属于两个不同历史对象的相连的至少两部分划分成一条第二语音数据,实现将一条第一语音数据划分成多条第二语音数据的目的。In a possible implementation manner, dividing the first voice data to obtain at least two pieces of second voice data includes: performing voiceprint recognition on the first voice data to determine a recognition result of at least a part of the first voice data; Based on at least a part of the recognition results, the first voice data is divided to obtain at least two pieces of second voice data, so as to realize the division of the first voice data through voiceprint recognition. In some examples, the recognition result may be a historical object to which each part belongs (eg, a historical user to which it belongs), and the first voice data is divided based on the historical object to which each part belongs. For example, the electronic device can divide a part belonging to one historical object into a piece of second voice data, or can divide at least two connected parts belonging to two different historical objects into a piece of second voice data, so as to realize the division of a piece of first voice data into multiple pieces of second voice data.
在一些示例中,识别结果可以是每部分所属对象性别,将对应一个对象性别的一部分划分成一条第二语音数据。例如识别结果可以是每部分所属用户性别,如男性或女性,电子设备可以将属于男性的一部分划分成一条第二语音数据。如果属于男性的多部分之间穿插有属于女性的部分,电子设备可以以穿插有女性的部分作为分割点进行划分。例如0秒(s)至3s属于男性,3s至10s属于男性,10s至20s属于女性,20s至35s属于男性,电子设备可以将0s至10s划分成一条第二语音数据,10s至20s划分成一条第二语音数据,20s至35s划分成一条第二语音数据。In some examples, the recognition result may be the gender of the object to which each part belongs, and a part corresponding to one gender of the object is divided into a piece of second speech data. For example, the recognition result may be the gender of the user to which each part belongs, such as male or female, and the electronic device may divide the male part into a piece of second voice data. If parts belonging to men are interspersed with parts belonging to women, the electronic device may use the part interspersed with women as dividing points for division. For example, 0 seconds (s) to 3s belong to men, 3s to 10s belong to men, 10s to 20s belong to women, and 20s to 35s belong to men. The electronic device can divide 0s to 10s into a second voice data, and 10s to 20s into a second voice data The second voice data is divided into a piece of second voice data from 20s to 35s.
在一种可能的实现方式中,基于至少一部分的识别结果,对第一语音数据进行划分,得到至少两条第二语音数据包括:基于至少一部分的识别结果,对第一语音数据进行划分,得到划分结果;接收针对划分结果的调整指令;响应调整指令,基于调整指令中的调整参数,对划分结果进行调整,以得到至少两条第二语音数据。也就是说,电子设备通过声纹识别的识别结果对第一语音数据进行一次划分后,可以对划分结果再次进行划分,在粗划分基础上进行细化分。例如用户可以对划分结果再次进行划分,用户可以调整划分结果的时长,以使得第二语音数据满足用户要求。In a possible implementation manner, dividing the first voice data based on at least a part of the recognition results to obtain at least two pieces of second voice data includes: dividing the first voice data based on at least a part of the recognition results to obtain dividing the result; receiving an adjustment instruction for the division result; in response to the adjustment instruction, adjusting the division result based on the adjustment parameters in the adjustment instruction to obtain at least two pieces of second voice data. That is to say, after the electronic device divides the first voice data once based on the recognition result of the voiceprint recognition, the division result can be divided again, and the fine division is performed on the basis of the rough division. For example, the user may divide the division result again, and the user may adjust the duration of the division result so that the second voice data meets the user's requirements.
在一种可能的实现方式中,对第一语音数据进行声纹识别,以确定第一语音数据中至少一部分的识别结果包括:从第一语音数据中提取第一特征数据;调用声纹判别模型对第一特征数据进行处理,获得声纹判别模型输出的声纹判别结果,声纹判别结果包括第一语音数据中每部分的识别结果;其中,声纹判别模型利用多个历史对象的语音数据训练得到。每部分的识别结果可以是每部分历史对象,或者是每部分的识别结果为对象的性别,通过声纹判别模型自动完成声纹识别。In a possible implementation manner, performing voiceprint recognition on the first voice data to determine a recognition result of at least a part of the first voice data includes: extracting first feature data from the first voice data; calling a voiceprint discrimination model The first feature data is processed to obtain a voiceprint identification result output by the voiceprint identification model, and the voiceprint identification result includes the identification result of each part in the first voice data; wherein, the voiceprint identification model utilizes the voice data of a plurality of historical objects Trained to get. The recognition result of each part can be the historical object of each part, or the recognition result of each part can be the gender of the object, and the voiceprint recognition is automatically completed by the voiceprint discrimination model.
在一种可能的实现方式中,对第一语音数据进行划分,得到至少两条第二语音数据包括:接收针对第一语音数据的划分指令;响应划分指令,基于划分指令中的划分参数,对第一语音数据进行划分,得到至少两条第二语音数据。例如用户可以对第一语音数据进行划分,划分参数是用户给出的参数,这样用户可以手动划分第一语音数据。In a possible implementation manner, dividing the first voice data to obtain at least two pieces of second voice data includes: receiving a division instruction for the first voice data; responding to the division instruction, based on division parameters in the division instruction, The first voice data is divided to obtain at least two pieces of second voice data. For example, the user can divide the first voice data, and the dividing parameters are parameters given by the user, so that the user can manually divide the first voice data.
在一种可能的实现方式中,划分参数包括时间参数和/或歌词参数。时间参数可以为用户手动输入时长或用户手动控制时间控件选择时长,时间控件可以是进度条;歌词参数可以为用户手动输入的所述第二语音数据包含的歌词数量,通过时长和/或歌词来划分第一语音数据。以基于歌词参数进行划分为例,如指定X句歌词划分成一段,X为大于或等于1的自然数,每条第二语音数据含有的歌词数量可以相同也可以不同。当然电子设备也可以根据歌词自动划分,如每间隔两段歌词划分一条第二语音数据,或者使每条第二语音数据中的歌词数量相同或相接近。In one possible implementation, the division parameters include time parameters and/or lyrics parameters. The time parameter can be the user's manual input duration or the user manually controls the time control to select the duration, and the time control can be a progress bar; the lyrics parameter can be the number of lyrics contained in the second voice data manually input by the user, and is determined by the duration and/or the lyrics. The first voice data is divided. Taking the division based on lyrics parameters as an example, for example, specifying X sentences of lyrics to be divided into one paragraph, X is a natural number greater than or equal to 1, and the number of lyrics contained in each second voice data may be the same or different. Of course, the electronic device can also automatically divide the lyrics according to the lyrics, for example, divide a piece of second voice data every two pieces of lyrics, or make the number of lyrics in each piece of second voice data the same or similar.
在一种可能的实现方式中,时间参数为用户手动输入时长或用户手动控制时间控件选择时长;方法还包括:如果用户手动控制时间控件选择时长,在检测到选择一个时长后,输出提示信息;基于划分指令中的时间参数,对第一语音数据进行划分包括:响应针对提示信息的确认指令,基于所选择的时长对第一语音数据进行划分。其中,提示信息是一个划分提示,用于提示是否在该时间点进行划分。确认指令表示在该时间点进行划分,由此在接收到确认指令后,电子设备可以基于该时间点对第一语音数据进行划分,从而在划分时达到提示的目的。In a possible implementation, the time parameter is the user manually inputting the duration or the user manually controlling the time control to select the duration; the method further includes: if the user manually controls the time control to select the duration, after detecting that a duration is selected, outputting prompt information; The dividing the first voice data based on the time parameter in the dividing instruction includes: dividing the first voice data based on the selected duration in response to the confirmation instruction for the prompt information. The prompt information is a division prompt, which is used to prompt whether to divide at this time point. The confirmation instruction indicates that the division is performed at the time point, so after receiving the confirmation instruction, the electronic device can divide the first voice data based on the time point, so as to achieve the purpose of prompting during division.
在一种可能的实现方式中,对第一语音数据进行划分,得到至少两条第二语音数据包括:对第五语音数据进行声纹识别,以确定第五语音数据中至少一部分的识别结果,第五语音数据具有第三对象的音色,第五语音数据和第一语音数据对应同一内容;基于至少一部分的识别结果,对第一语音数据进行划分,得到至少两条第二语音数据,实现利用第五语音数据的识别结果对第一语音数据的划分。例如在有原唱场景中,电子设备可以获取到原唱的语音数据和用户的语音数据,对原唱的语音数据进行声纹识别,得到原唱的语音数据中每部分的识别结果,利用原唱的语音数据中每部分的识别结果对用户的语音数据进行划分。In a possible implementation manner, dividing the first voice data to obtain at least two pieces of second voice data includes: performing voiceprint recognition on the fifth voice data to determine a recognition result of at least a part of the fifth voice data, The fifth voice data has the timbre of the third object, and the fifth voice data and the first voice data correspond to the same content; based on at least a part of the recognition results, the first voice data is divided to obtain at least two pieces of second voice data, and the use of The division of the first voice data by the recognition result of the fifth voice data. For example, in a scene with original singing, the electronic device can obtain the original singing voice data and the user's voice data, perform voiceprint recognition on the original singing voice data, and obtain the recognition result of each part of the original singing voice data. The recognition result of each part in the sung voice data divides the user's voice data.
在一种可能的实现方式中,确定第二语音数据对应的第二对象包括:获取用户为第二语音数据确定的第二对象;或者,获取隶属不同对象的音色的得分,从得分满足预设条件的对象中选择第二语音数据对应的第二对象;或者,获取第一对象的音色特征和第二对象的音色特征之间的相似度,基于相似度选择第二语音数据对应的第二对象;或者,确定第一对象的音色所属类型,基于第一对象的音色所属类型选择第二语音数据对应的第二对象。用户确定是一种手动选择方式,基于得分、相似度和音色所属类型是自动选择方式。In a possible implementation manner, determining the second object corresponding to the second voice data includes: obtaining the second object determined by the user for the second voice data; The second object corresponding to the second voice data is selected from the objects of the condition; or, the similarity between the timbre feature of the first object and the timbre feature of the second object is obtained, and the second object corresponding to the second voice data is selected based on the similarity or, determining the type of the timbre of the first object, and selecting the second object corresponding to the second voice data based on the type of the timbre of the first object. User determination is a manual selection method, and an automatic selection method is based on the score, similarity and the type of timbre.
如果用户为第二语音数据确定第二对象,用户可以为每条第二语音数据确定第二对象,或者根据第二语音数据对应的性别确定第二对象,如相同性别对应一个第二对象。如果基于不同对象的音色的得分确定第二对象,电子设备可以从得分较高的音色中选择,在选择过程中也可以考虑性别,选择与第一对象的性别相同的第二对象,其中得分可根据使用次数得到,使用次数越多得分越高。如果基于音色特征选择,电子设备可以基于相似度选择音色接近或音色差距较大的第二对象,音色接近那么在播放时可以降低突兀感,音色差距较大那么在播放时可以更好的引起用户的注意。如果基于音色所属类型选择,电子设备可以选择音色与第一对象的音色属于同一类型的第二对象。If the user determines the second object for the second voice data, the user can determine the second object for each piece of second voice data, or determine the second object according to the gender corresponding to the second voice data, for example, the same gender corresponds to one second object. If the second object is determined based on the scores of the timbres of different objects, the electronic device may select from the timbres with higher scores, and gender may also be considered in the selection process, and select the second object of the same gender as the first object, where the score may be According to the number of uses, the higher the number of uses, the higher the score. If based on the timbre feature selection, the electronic device can select a second object with a similar timbre or a larger timbre difference based on the similarity. If the timbre is close, the abruptness can be reduced during playback, and the larger timbre difference can better attract the user during playback. attention. If selected based on the type to which the timbre belongs, the electronic device may select a second object whose timbre belongs to the same type as the timbre of the first object.
在一种可能的实现方式中,对第二语音数据进行音色转换,得到第三语音数据包括:获取第二语音数据的音色特征;调用第二对象的音色表征模型,对音色特征进行处理,以获得音色表征模型输出的第三语音数据,其中,音色表征模型利用第二对象的多条语音数据训练得到,第二对象和音色表征模型是一对一的关系,因为每个对象的音色各种不同,所以为每个第二对象训练一个音色表征模型,使得该音色表征模型可以学习到该第二对象的音色特性,提高准确度。In a possible implementation manner, performing timbre conversion on the second voice data to obtain the third voice data includes: acquiring timbre features of the second voice data; calling a timbre representation model of the second object to process the timbre features to obtain The third speech data output by the timbre representation model is obtained, wherein the timbre representation model is obtained by training multiple pieces of speech data of the second object, and the second object and the timbre representation model are in a one-to-one relationship, because each object has various timbres. Therefore, a timbre representation model is trained for each second object, so that the timbre representation model can learn the timbre characteristics of the second object and improve the accuracy.
在一种可能的实现方式中,获取第二语音数据的音色特征包括:从第二语音数据中提取第二特征数据;调用音色提取模型对第二特征数据进行处理,获得音色提取模型输出的音色特征。In a possible implementation manner, acquiring the timbre feature of the second voice data includes: extracting the second feature data from the second voice data; invoking the timbre extraction model to process the second feature data to obtain the timbre output by the timbre extraction model feature.
在一种可能的实现方式中,至少对第三语音数据进行融合,获得第四语音数据包括:如果所有第二语音数据中的部分第二语音数据没有进行音色转换,对所有第二语音数据中没有进行音色转换的第二语音数据和第三语音数据进行融合,获得第四语音数据,第四语音数据具有第二对象的音色和第一对象的音色。其中第四语音数据可以保留第一对象的音色,使得第四语音数据的音色更加多样化,且能够保留第一对象的音色特性。In a possible implementation manner, at least merging the third voice data to obtain the fourth voice data includes: if part of the second voice data in all the second voice data is not subjected to timbre conversion, performing timbre conversion on part of the second voice data in all the second voice data. The second voice data without timbre conversion and the third voice data are fused to obtain fourth voice data, and the fourth voice data has the timbre of the second object and the timbre of the first object. The fourth voice data can retain the timbre of the first object, so that the timbre of the fourth voice data is more diverse, and the timbre characteristics of the first object can be retained.
第二方面,本申请提供一种电子设备,电子设备包括:处理器和存储器;其中,存储器用于存储一个或多个计算机程序代码,计算机程序代码包括计算机指令,当处理器执行计算机指令时,处理器执行上述修音方法。In a second aspect, the present application provides an electronic device, the electronic device includes: a processor and a memory; wherein, the memory is used to store one or more computer program codes, and the computer program codes include computer instructions, and when the processor executes the computer instructions, The processor executes the above-mentioned sound modification method.
第三方面,本申请提供一种计算机存储介质,计算机存储介质包括计算机指令,当计算机指令在电子设备上运行时,使得电子设备执行上述修音方法。In a third aspect, the present application provides a computer storage medium, where the computer storage medium includes computer instructions, and when the computer instructions are executed on an electronic device, the electronic device is made to execute the above pronunciation modification method.
附图说明Description of drawings
图1为本申请提供的电子设备的硬件结构图;1 is a hardware structure diagram of an electronic device provided by the application;
图2为本申请提供的电子设备的软件架构图;2 is a software architecture diagram of an electronic device provided by the application;
图3为本申请提供的一种修音方法的示意图;Fig. 3 is the schematic diagram of a kind of pronunciation modification method that this application provides;
图4为本申请提供的训练声纹判别模型和音色表征模型的流程图;Fig. 4 is the flow chart of training voiceprint discrimination model and timbre representation model provided by this application;
图5为本申请提供的一种修音方法的流程图;Fig. 5 is the flow chart of a kind of pronunciation modification method that this application provides;
图6为本申请提供的另一种修音方法的示意图;Fig. 6 is the schematic diagram of another kind of pronunciation modification method that this application provides;
图7为本申请提供的修音方法中美音处理的流程图;Fig. 7 is the flow chart of Chinese and American pronunciation processing of the pronunciation modification method that this application provides;
图8至图10为本申请提供的修音方法对应的UI示意图。FIG. 8 to FIG. 10 are UI schematic diagrams corresponding to the pronunciation modification method provided by the present application.
具体实施方式Detailed ways
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述。以下实施例中所使用的术语只是为了描述特定实施例的目的,而并非旨在作为对本申请的限制。如在本申请的说明书和所附权利要求书中所使用的那样,单数表达形式“一个”、“一种”、“所述”、“上述”、“该”和“这一”旨在也包括例如“一个或多个”这种表达形式,除非其上下文中明确地有相反指示。还应当理解,在本申请实施例中,“一个或多个”是指一个、两个或两个以上;“和/或”,描述关联对象的关联关系,表示可以存在三种关系;例如,A和/或B,可以表示:单独存在A,同时存在A和B,单独存在B的情况,其中A、B可以是单数或者复数。字符“/”一般表示前后关联对象是一种“或”的关系。The technical solutions in the embodiments of the present application will be clearly and completely described below with reference to the accompanying drawings in the embodiments of the present application. The terms used in the following embodiments are for the purpose of describing particular embodiments only, and are not intended to be limitations of the present application. As used in the specification of this application and the appended claims, the singular expressions "a," "an," "the," "above," "the," and "the" are intended to also Expressions such as "one or more" are included unless the context clearly dictates otherwise. It should also be understood that, in this embodiment of the present application, "one or more" refers to one, two or more; "and/or", which describes the association relationship of associated objects, indicates that there may be three kinds of relationships; for example, A and/or B can mean that A exists alone, A and B exist simultaneously, and B exists independently, wherein A and B can be singular or plural. The character "/" generally indicates that the associated objects are an "or" relationship.
在本说明书中描述的参考“一个实施例”或“一些实施例”等意味着在本申请的一个或多个实施例中包括结合该实施例描述的特定特征、结构或特点。由此,在本说明书中的不同之处出现的语句“在一个实施例中”、“在一些实施例中”、“在其他一些实施例中”、“在另外一些实施例中”等不是必然都参考相同的实施例,而是意味着“一个或多个但不是所有的实施例”,除非是以其他方式另外特别强调。术语“包括”、“包含”、“具有”及它们的变形都意味着“包括但不限于”,除非是以其他方式另外特别强调。References in this specification to "one embodiment" or "some embodiments" and the like mean that a particular feature, structure, or characteristic described in connection with the embodiment is included in one or more embodiments of the present application. Thus, appearances of the phrases "in one embodiment," "in some embodiments," "in other embodiments," "in other embodiments," etc. in various places in this specification are not necessarily All refer to the same embodiment, but mean "one or more but not all embodiments" unless specifically emphasized otherwise. The terms "including", "including", "having" and their variants mean "including but not limited to" unless specifically emphasized otherwise.
本申请实施例涉及的多个,是指大于或等于两个。需要说明的是,在本申请实施例的描述中,“第一”、“第二”等词汇,仅用于区分描述的目的,而不能理解为指示或暗示相对重要性,也不能理解为指示或暗示顺序。The multiple involved in the embodiments of the present application refers to greater than or equal to two. It should be noted that, in the description of the embodiments of the present application, words such as "first" and "second" are only used for the purpose of distinguishing the description, and should not be interpreted as indicating or implying relative importance, nor should it be understood as indicating or implied order.
在用户录制(如录歌)过程中,电子设备可以获取用户的音频数据,并对音频数据可以进行后期处理,如对音频数据可以进行修音处理。其中,对音频数据的修音处理可以是对音色和音调等中的至少一种进行调整。修音处理方式可以包括如下两种:In the process of user recording (eg, recording a song), the electronic device can obtain the user's audio data, and can perform post-processing on the audio data, such as sound modification processing on the audio data. Wherein, the sound modification processing of the audio data may be to adjust at least one of timbre and pitch. There are two kinds of sound modification processing methods:
一种方式是,调整音频数据的音色。例如电子设备可以接收音色转换指令,加载目标角色的音色转换模型,通过该音色转换模型将原始角色输出的第一音频数据转换为目标角色输出的第二音频数据,实现将音频数据转换为目标角色。不同角色的音色不同,电子设备在得到目标角色的第二音频数据后,以目标角色的音色播放语音。在进行音频数据转换时,用户可以选择喜欢的目标角色,由用户喜欢的目标角色的音色转换模型来转换音频数据,电子设备所播放的音频是目标角色复述的音频,满足用户的听觉需求,提高了用户体验。One way is to adjust the timbre of the audio data. For example, the electronic device can receive the timbre conversion instruction, load the timbre conversion model of the target character, and convert the first audio data output by the original character into the second audio data output by the target character through the timbre conversion model, so as to convert the audio data into the target character. . Different characters have different timbres. After obtaining the second audio data of the target character, the electronic device plays the voice with the timbre of the target character. When converting audio data, the user can select the target character they like, and the audio data is converted by the timbre conversion model of the target character that the user likes. The audio played by the electronic device is the audio recited by the target character, which meets the user's auditory needs and improves the user experience.
另一种方式是,在保留用户的音色的基础上,调整音频数据的基频。其中基频的高低可以影响音调,通过调整基频实现对音调的调整。Another way is to adjust the fundamental frequency of the audio data on the basis of preserving the user's timbre. The pitch of the fundamental frequency can be affected, and the pitch can be adjusted by adjusting the fundamental frequency.
例如电子设备获取到用户的音频数据后,通过特征提取算法,提取出用户的音频数据中每个字的基频、包络和辅音信息,每个字提取出预设数量的基频,预设数量根据提取频率确定,用户的音频数据可以是用户念出歌曲的歌词的音频数据;对于每个字,将字的预设数量的基频调整为歌曲中字的音高频率,歌曲中每个字的音高频率为歌曲中每个字的音高对应的频率;对调整后的基频、每个字的包络和辅音信息进行合成处理,得到合成音频;根据歌曲中每个字的时长,对合成音频中每个字的时长进行调整,得到合成的歌声,这样对于唱歌不好的用户来说,用户可以念出歌曲的歌词,电子设备可以获取到该歌曲的音频数据,然后通过调整基频和每个字的时长的方式,合成出与用户声音接近的歌曲。For example, after the electronic device obtains the user's audio data, the feature extraction algorithm is used to extract the fundamental frequency, envelope and consonant information of each word in the user's audio data, and each word extracts a preset number of fundamental frequencies. The number is determined according to the extraction frequency, and the user's audio data can be the audio data of the lyrics of the song read by the user; for each word, the fundamental frequency of the preset number of words is adjusted to the pitch frequency of the words in the song, and each word in the song is The pitch frequency is the frequency corresponding to the pitch of each word in the song; the adjusted fundamental frequency, the envelope of each word and the consonant information are synthesized and processed to obtain synthesized audio; according to the duration of each word in the song, Adjust the duration of each word in the synthesized audio to obtain the synthesized singing voice, so that for users who are not good at singing, the user can read the lyrics of the song, and the electronic device can obtain the audio data of the song, and then adjust the base by adjusting the base. The frequency and the duration of each word are used to synthesize songs that are close to the user's voice.
因为电子设备合成过程中保留了用户的声音的包络和辅助信息,使得用户的音色被保留,所以合成出的歌声与用户声音接近,在美音的同时可以保留用户的声音。在合成过程中,电子设备对音频数据中基频的调整,实现对音调的调整。此外电子设备还可以对音频数据中每个字的时长进行调整。Because the envelope and auxiliary information of the user's voice are preserved during the synthesis process of the electronic device, the user's timbre is preserved, so the synthesized singing voice is close to the user's voice, and the user's voice can be preserved while maintaining the beautiful tone. In the synthesis process, the electronic device adjusts the fundamental frequency in the audio data to realize the adjustment of the pitch. In addition, the electronic device can also adjust the duration of each word in the audio data.
一种场景是,电子设备上可以安装音乐APP,音乐APP可以提供录音模式和K歌模式等模式。录音模式和K歌模式可以向用户提供录制歌曲的功能,通过录制歌曲的功能获取到用户的音频数据,用户的音频数据能够还原出一首歌曲。在得到用户的音频数据后,电子设备可以调用音乐APP中的修音模式对用户的音频数据进行修音。在一种示例中,电子设备调用修音模式,将音频数据的音色调整成单一目标角色的音色,虽然电子设备可以调整音频数据的音色,但是缺少个性化调整,也无法达到多人合唱歌曲的效果。在另一种示例中,电子设备可以调用修音模式,对用户的音频数据进行美音。例如电子设备可以通过修音模式,调整音频数据的基频和音频数据中每个字的时长。在基频和字的时长调整过程中,电子设备没有改变音频数据的音色,保留了用户的音色。In one scenario, a music APP can be installed on the electronic device, and the music APP can provide modes such as a recording mode and a karaoke mode. The recording mode and the karaoke mode can provide users with the function of recording songs, and the user's audio data can be obtained through the function of recording songs, and the user's audio data can be restored to a song. After obtaining the user's audio data, the electronic device can call the audio modification mode in the music APP to modify the user's audio data. In one example, the electronic device invokes the timbre mode to adjust the timbre of the audio data to the timbre of a single target character. Although the electronic device can adjust the timbre of the audio data, it lacks personalized adjustment and cannot achieve the timbre of a multi-person chorus song. Effect. In another example, the electronic device may invoke an audio trimming mode to tune the user's audio data. For example, the electronic device can adjust the fundamental frequency of the audio data and the duration of each word in the audio data through the audio modification mode. During the adjustment of the fundamental frequency and the duration of the word, the electronic device does not change the timbre of the audio data, and retains the user's timbre.
针对上述技术问题,本申请提供一种修音方法,在获取到用户的音频数据后,将用户的音频数据划分成至少两部分,对至少两部分进行音色转换,使得用户的音频数据具有至少两个目标音色,通过音色转换达到多人合成歌曲的效果。除了对至少两部分进行音色转换之外,修音方法还可以对用户的音频数据进行美音处理,如通过调整用户的音频数据的基频来调整音频数据的音调,通过调整每个字的时长来调整音频数据的语速。In view of the above-mentioned technical problems, the present application provides a sound modification method. After obtaining the user's audio data, the user's audio data is divided into at least two parts, and timbre conversion is performed on the at least two parts, so that the user's audio data has at least two parts. A target timbre, through timbre conversion to achieve the effect of multi-person synthesis of songs. In addition to the tone conversion of at least two parts, the tone modification method can also perform beautiful tone processing on the user's audio data, such as adjusting the pitch of the audio data by adjusting the fundamental frequency of the user's audio data, and adjusting the duration of each word to Adjust the speech rate of audio data.
修音方法可以应用到电子设备中。在一些实施例中,该电子设备可以是手机、平板电脑、桌面型电脑、膝上型电脑、笔记本电脑、超级移动个人计算机(ultra-mobilepersonal computer,UMPC)、手持计算机、上网本、个人数字助理(personal digitalassistant,PDA)、可穿戴电子设备、智能手表等设备。本申请对电子设备的具体形式不做特殊限定。The sound modification method can be applied to electronic devices. In some embodiments, the electronic device may be a cell phone, tablet, desktop, laptop, notebook, ultra-mobile personal computer (UMPC), handheld computer, netbook, personal digital assistant ( personal digital assistant, PDA), wearable electronic devices, smart watches and other devices. The specific form of the electronic device is not specifically limited in this application.
如图1所示,该电子设备可以包括:处理器,外部存储器接口,内部存储器,通用串行总线(universal serial bus,USB)接口,充电管理模块,电源管理模块,电池,天线1,天线2,移动通信模块,无线通信模块,传感器模块,按键,马达,指示器,摄像头,显示屏,以及用户标识模块(subscriber identification module,SIM)卡接口等。其中音频模块可以包括扬声器,受话器,麦克风,耳机接口等,传感器模块可以包括压力传感器,陀螺仪传感器,气压传感器,磁传感器,加速度传感器,距离传感器,接近光传感器,指纹传感器,温度传感器,触摸传感器,环境光传感器,骨传导传感器等。As shown in FIG. 1 , the electronic device may include: a processor, an external memory interface, an internal memory, a universal serial bus (USB) interface, a charging management module, a power management module, a battery, an antenna 1 , and an antenna 2 , mobile communication module, wireless communication module, sensor module, button, motor, indicator, camera, display screen, and user identification module (subscriber identification module, SIM) card interface, etc. The audio module may include speakers, receivers, microphones, headphone jacks, etc., and the sensor modules may include pressure sensors, gyroscope sensors, air pressure sensors, magnetic sensors, acceleration sensors, distance sensors, proximity light sensors, fingerprint sensors, temperature sensors, and touch sensors. , ambient light sensor, bone conduction sensor, etc.
可以理解的是,本实施例示意的结构并不构成对电子设备的具体限定。在另一些实施例中,电子设备可以包括比图示更多或更少的部件,或者组合某些部件,或者拆分某些部件,或者不同的部件布置。图示的部件可以以硬件,软件或软件和硬件的组合实现。It can be understood that the structure illustrated in this embodiment does not constitute a specific limitation on the electronic device. In other embodiments, the electronic device may include more or fewer components than shown, or some components may be combined, or some components may be split, or a different arrangement of components. The illustrated components may be implemented in hardware, software, or a combination of software and hardware.
处理器可以包括一个或多个处理单元,例如:处理器可以包括应用处理器(application processor,AP),调制解调处理器,图形处理器(graphics processingunit,GPU),图像信号处理器(image signal processor,ISP),控制器,视频编解码器,数字信号处理器(digital signal processor,DSP),基带处理器,和/或神经网络处理器(neural-network processing unit,NPU)等。其中,不同的处理单元可以是独立的器件,也可以集成在一个或多个处理器中。处理器是电子设备的神经中枢和指挥中心,控制器可以根据指令操作码和时序信号,产生操作控制信号,完成取指令和执行指令的控制。The processor may include one or more processing units, for example, the processor may include an application processor (application processor, AP), a modem processor, a graphics processor (graphics processing unit, GPU), an image signal processor (image signal processor) processor, ISP), controller, video codec, digital signal processor (DSP), baseband processor, and/or neural-network processing unit (NPU), etc. Wherein, different processing units may be independent devices, or may be integrated in one or more processors. The processor is the nerve center and command center of the electronic equipment. The controller can generate operation control signals according to the instruction operation code and timing signal, and complete the control of fetching and executing instructions.
显示屏用于显示图像,视频、一系列图形用户界面(graphical user interface,GUI)等,如显示K歌APP的界面、显示K歌APP中的修音模式、显示用户的音频数据等。The display screen is used to display images, videos, a series of graphical user interfaces (GUI), etc., such as displaying the interface of the K song APP, displaying the sound modification mode in the K song APP, displaying the user's audio data, etc.
外部存储器接口可以用于连接外部存储卡,例如Micro SD卡,实现扩展电子设备的存储能力。外部存储卡通过外部存储器接口与处理器通信,实现数据存储功能。例如将修音方法使用的模型等保存在外部存储卡中。内部存储器可以用于存储计算机可执行程序代码,所述可执行程序代码包括指令。处理器通过运行存储在内部存储器的指令,从而执行电子设备的各种功能应用以及数据处理。例如,在本申请中,处理器通过运行内部存储器中存储的指令,使得电子设备执行本申请提供的修音方法。The external memory interface can be used to connect an external memory card, such as a Micro SD card, to expand the storage capacity of the electronic device. The external memory card communicates with the processor through the external memory interface to realize the data storage function. For example, the model used by the sound modification method is saved in an external memory card. Internal memory may be used to store computer executable program code, which includes instructions. The processor executes various functional applications and data processing of the electronic device by executing the instructions stored in the internal memory. For example, in the present application, the processor causes the electronic device to execute the pronunciation modification method provided by the present application by running the instructions stored in the internal memory.
电子设备可以通过音频模块、扬声器、受话器、麦克风、耳机接口以及应用处理器等实现音频功能。例如音乐播放,录音等。Electronic devices can implement audio functions through audio modules, speakers, receivers, microphones, headphone jacks, and application processors. Such as music playback, recording, etc.
音频模块用于将数字音频信息转换成模拟音频信号输出,也用于将模拟音频输入转换为数字音频信号。音频模块还可以用于对音频信号编码和解码。在一些实施例中,音频模块可以设置于处理器中,或将音频模块的部分功能模块设置于处理器中。The audio module is used to convert digital audio information into analog audio signal output, and also used to convert analog audio input to digital audio signal. The audio module can also be used to encode and decode audio signals. In some embodiments, the audio module may be provided in the processor, or some functional modules of the audio module may be provided in the processor.
扬声器,也称“喇叭”,用于将音频电信号转换为声音信号。电子设备可以通过扬声器收听音乐,或收听免提通话,或播放歌曲等。Speakers, also known as "horns", are used to convert audio electrical signals into sound signals. Electronic devices can listen to music through speakers, or listen to hands-free calls, or play songs, etc.
受话器,也称“听筒”,用于将音频电信号转换成声音信号。当电子设备接听电话或音频数据时,可以通过将受话器靠近人耳接听音频。A receiver, also known as a "handset", is used to convert audio electrical signals into sound signals. When an electronic device receives a call or audio data, the audio can be received by placing the receiver close to the human ear.
麦克风,也称“话筒”,“传声器”,用于将声音信号转换为电信号,声音信号和电信号中携带有用户的音频数据。例如当拨打电话或发送音频数据时,用户可以通过人嘴靠近麦克风发声,将声音信号输入到麦克风。电子设备可以设置至少一个麦克风。在另一些实施例中,电子设备可以设置两个麦克风,除了采集声音信号,还可以实现降噪功能。在另一些实施例中,电子设备还可以设置三个,四个或更多麦克风,实现采集声音信号,降噪,还可以识别声音来源,实现定向录音功能等。Microphones, also known as "microphones" and "microphones", are used to convert sound signals into electrical signals, and the sound signals and electrical signals carry the user's audio data. For example, when making a call or sending audio data, the user can make a sound through the human mouth close to the microphone, and input the sound signal into the microphone. The electronic device may be provided with at least one microphone. In other embodiments, the electronic device may be provided with two microphones, which may implement a noise reduction function in addition to collecting sound signals. In other embodiments, the electronic device may be further provided with three, four or more microphones to collect sound signals, reduce noise, identify sound sources, and implement directional recording functions.
耳机接口用于连接有线耳机。耳机接口可以是USB接口,也可以是3.5mm的开放移动电子设备平台(open mobile terminal platform,OMTP)标准接口,美国蜂窝电信工业协会(cellular telecommunications industry association of the USA,CTIA)标准接口。The headphone jack is used to connect wired headphones. The earphone interface may be a USB interface, or a 3.5mm open mobile terminal platform (OMTP) standard interface, and a cellular telecommunications industry association of the USA (CTIA) standard interface.
电子设备的无线通信功能可以通过天线1,天线2,移动通信模块,无线通信模块,调制解调处理器以及基带处理器等实现。电子设备可以利用无线通信功能下载音频数据,处理器可以基于所下载的音频数据,训练出声纹判别模型和音色表征模型。电子设备可以调用声纹判别模型和音色表征模型,实施修音方法。The wireless communication function of the electronic device can be realized by the antenna 1, the antenna 2, the mobile communication module, the wireless communication module, the modem processor and the baseband processor. The electronic device can use the wireless communication function to download audio data, and the processor can train a voiceprint discrimination model and a timbre representation model based on the downloaded audio data. The electronic device can call the voiceprint discrimination model and the timbre representation model to implement the sound modification method.
另外,在上述部件之上,运行有操作系统。例如苹果公司所开发的iOS操作系统,谷歌公司所开发的Android开源操作系统,微软公司所开发的Windows操作系统等。在该操作系统上可以安装运行应用程序。In addition, an operating system runs on the above-mentioned components. For example, the iOS operating system developed by Apple, the Android open source operating system developed by Google, and the Windows operating system developed by Microsoft. Applications can be installed and run on this operating system.
电子设备的操作系统可以采用分层架构,事件驱动架构,微核架构,微服务架构,或云架构。本申请实施例以分层架构的Android系统为例,示例性说明电子设备的软件结构。图2是电子设备的软硬件结构框图。软件结构采用分层架构,分层架构将软件分成若干个层,每一层都有清晰的角色和分工。层与层之间通过软件接口通信。以Android系统为例,在一些实施例中,将Android系统分为四层,从上至下分别为应用程序层,应用程序框架层(Framework),硬件抽象层(HAL)以及系统内核层(Kernel)。The operating system of the electronic device may adopt a layered architecture, an event-driven architecture, a microkernel architecture, a microservice architecture, or a cloud architecture. The embodiments of the present application take an Android system with a layered architecture as an example to exemplarily describe the software structure of an electronic device. FIG. 2 is a block diagram of the software and hardware structure of the electronic device. The software structure adopts a layered architecture, which divides the software into several layers, and each layer has a clear role and division of labor. Layers communicate with each other through software interfaces. Taking the Android system as an example, in some embodiments, the Android system is divided into four layers, which are an application layer, an application framework layer (Framework), a hardware abstraction layer (HAL) and a system kernel layer (Kernel layer) from top to bottom. ).
其中,应用程序层可以包括一系列应用程序包。应用程序包可以包括相机,图库,日历,通话,地图,WLAN,音乐,视频,录音和K歌等APP。应用程序框架层为应用程序层的应用程序提供应用编程接口(application programming interface,API)和编程框架。应用程序框架层包括一些预先定义的函数。例如应用程序框架层可以包括窗口管理器,内容提供器,视图系统,电话管理器,资源管理器,通知管理器等。Among them, the application layer may include a series of application packages. The application package can include apps such as camera, gallery, calendar, call, map, WLAN, music, video, recording and karaoke. The application framework layer provides an application programming interface (API) and a programming framework for applications in the application layer. The application framework layer includes some predefined functions. For example, the application framework layer may include window managers, content providers, view systems, telephony managers, resource managers, notification managers, and the like.
HAL可以包含多个库模块和多个模型,其中库模块和模型可以被调用。例如HAL包括声纹判别模型和音色表征模型。应用程序层中的录音APP和K歌APP在运行过程中,录音APP和K歌APP可以调用声纹判别模型和音色表征模型。例如录音APP和K歌APP通过麦克风可以获取到用户的音频数据,声纹判别模型可以识别音频数据的声纹,利用声纹对音频数据进行划分,以按照声纹将音频数据划分成至少两部分;音色表征模型可以对划分的至少两部分进行音色转换,以通过对声纹判别模型和音色表征模型的调用,实施本申请所述的修音方法。系统内核层是硬件和软件之间的层。内核层至少包含显示驱动,摄像头驱动,音频驱动,传感器驱动。A HAL can contain multiple library modules and multiple models, where the library modules and models can be called. For example, HAL includes a voiceprint discrimination model and a timbre representation model. During the running process of the recording APP and the karaoke APP in the application layer, the recording APP and the karaoke APP can call the voiceprint discrimination model and the timbre representation model. For example, the recording APP and the K song APP can obtain the user's audio data through the microphone. The voiceprint discrimination model can identify the voiceprint of the audio data, and use the voiceprint to divide the audio data to divide the audio data into at least two parts according to the voiceprint. The timbre representation model can perform timbre conversion on the divided at least two parts, so as to implement the timbre modification method described in this application by calling the voiceprint discrimination model and the timbre representation model. The system kernel layer is the layer between hardware and software. The kernel layer contains at least display drivers, camera drivers, audio drivers, and sensor drivers.
声纹判别模型可以选择卷积神经网络(convolutional neural network,CNN)、长短期记忆人工神经网络(long-short term memory,LSTM)、卷积循环神经网络(convolutional recurrent neural network,CRNN)等基础网络模型。音色表征模型可以选择生成式对抗网络(generative adversarial networks,GAN)。如在一些示例中,电子设备可以选择CRNN模型作为声纹判别模型,利用训练样本对CRNN模型进行训练,训练结束后的CRNN模型可以学习到不同用户的声纹特性,训练结束后的CRNN模型可以基于不同用户的声纹特征识别出音频数据所属用户身份,训练结束后的CRNN可以作为声纹判别模型使用。对于音色表征模型来说,电子设备可以选择GAN模型作为音色表征模型,利用训练样本对GAN模型进行训练,训练结束后的GAN模型可以学习到用户的音色特性,完成从一个音色向另一个音色的转换,那么训练结束后的GAN模型可以作为音色表征模型使用。声纹判别模型的训练样本和音色表征模型的训练样本可以相同也可以不同。The voiceprint discrimination model can choose basic networks such as convolutional neural network (CNN), long-short term memory (LSTM), and convolutional recurrent neural network (CRNN). Model. The timbre representation model can choose generative adversarial networks (GAN). For example, in some examples, the electronic device can select the CRNN model as the voiceprint discrimination model, and use the training samples to train the CRNN model. The CRNN model after the training can learn the voiceprint characteristics of different users, and the CRNN model after the training can Based on the voiceprint features of different users, the identity of the user to which the audio data belongs is identified, and the CRNN after training can be used as a voiceprint discrimination model. For the timbre representation model, the electronic device can select the GAN model as the timbre representation model, and use the training samples to train the GAN model. After the training, the GAN model can learn the timbre characteristics of the user and complete the transformation from one timbre to another timbre. Conversion, then the GAN model after training can be used as a timbre representation model. The training samples of the voiceprint discrimination model and the training samples of the timbre representation model may be the same or different.
下面结合场景对本申请提供的修音方法、声纹判别模型和音色表征模型进行说明。请参见图3,其示出了本申请实施例提供的一种修音方法的示意图,图3所示修音方法针对的是没有原唱场景,没有原唱场景可以是用户录音场景。如用户录制歌曲场景,在用户录音过程中没有播放原唱,或者,用户录制一首新歌等等。其中,修音方法可以包括准备阶段和使用阶段,在准备阶段,电子设备完成声纹判别模型和音色表征模型的训练。在使用阶段,电子设备可以调用音色表征模型对用户的音频数据进行音色转换,电子设备还可以调用声纹判别模型对用户的音频数据进行划分,以将用户的音频数据划分成至少两个部分。The voice modification method, voiceprint discrimination model and timbre representation model provided by the present application will be described below in combination with the scenarios. Please refer to FIG. 3 , which shows a schematic diagram of a sound modification method provided by an embodiment of the present application. The sound modification method shown in FIG. 3 is aimed at a scene without original singing, and the scene without original singing may be a user recording scene. For example, when the user records a song scene, the original song is not played during the user's recording, or the user records a new song, and so on. Among them, the method of revising the sound may include a preparation stage and a use stage. In the preparation stage, the electronic device completes the training of the voiceprint discrimination model and the timbre representation model. In the use stage, the electronic device can call the timbre representation model to perform timbre conversion on the user's audio data, and the electronic device can also call the voiceprint discrimination model to divide the user's audio data, so as to divide the user's audio data into at least two parts.
声纹判别模型和音色表征模型可以以不同历史用户的音频数据为训练样本,历史用户的音频数据可以是历史用户在唱歌过程中采集到,历史用户可以包括明星(如原唱歌手、翻唱歌手、演员)、网络歌手、直播用户、虚拟人物和普通用户等。电子设备可以获取到不同历史用户的多条音频数据,电子设备也可以获取到同一个历史用户的多条音频数据。电子设备利用不同历史用户的多条音频数据对声纹判别模型进行训练,使得声纹判别模型可以学习到每个历史用户的声纹特性,得到与多个历史用户的声纹特性匹配的声纹判别模型;利用任一历史用户的多条音频数据对音色表征模型进行训练,使得音色表征模型可以识别到该历史用户的音色特性,得到与该历史用户的音色特性匹配的音色表征模型。The voiceprint discrimination model and the timbre representation model can use the audio data of different historical users as training samples. The audio data of historical users can be collected during the singing process of historical users, and historical users can include celebrities (such as original singers, cover singers, Actors), Internet singers, live broadcast users, virtual characters and ordinary users, etc. The electronic device can acquire multiple pieces of audio data of different historical users, and the electronic device can also acquire multiple pieces of audio data of the same historical user. The electronic device uses multiple pieces of audio data of different historical users to train the voiceprint discrimination model, so that the voiceprint discrimination model can learn the voiceprint characteristics of each historical user, and obtain a voiceprint matching the voiceprint characteristics of multiple historical users. Discriminant model: Use multiple pieces of audio data of any historical user to train the timbre representation model, so that the timbre representation model can identify the timbre characteristics of the historical user, and obtain a timbre representation model matching the timbre characteristics of the historical user.
也就是说,声纹判别模型和历史用户的关系是,一个声纹判别模型对应多个历史用户,电子设备可以利用多个历史用户的音频数据,训练声纹判别模型。音色表征模型和历史用户的关系是,一个音色表征模型对应一个历史用户,即音色表征模型和历史用户是一对一的关系,电子设备可以以任一历史用户的音频数据为训练样本,训练出与该历史用户的音色特性匹配的音色表征模型。电子设备以不同历史用户的音频数据,训练声纹判别模型和音色表征模型的过程可以参见图4所示,包括以下步骤:That is to say, the relationship between the voiceprint discrimination model and historical users is that one voiceprint discrimination model corresponds to multiple historical users, and the electronic device can use the audio data of multiple historical users to train the voiceprint discrimination model. The relationship between the timbre representation model and the historical user is that a timbre representation model corresponds to a historical user, that is, the timbre representation model and the historical user are in a one-to-one relationship. The electronic device can use the audio data of any historical user as a training sample to train A timbre representation model that matches the timbre characteristics of the historical user. Figure 4 shows the process of training the voiceprint discrimination model and the timbre representation model for the electronic device using the audio data of different historical users, including the following steps:
S101、对每个历史用户的音频数据进行背景音乐和人声分离,得到历史用户的语音数据。历史用户的语音数据可以还原历史用户的声音。S101. Perform background music and vocal separation on the audio data of each historical user to obtain the voice data of the historical user. The voice data of historical users can restore the voices of historical users.
S102、对语音数据进行身份标注,以标注出语音数据中每部分对应的历史用户身份标识。历史用户身份标识可以是历史用户的姓名,历史用户身份标识可以是历史用户的性别。S102: Perform identity labeling on the voice data to label the historical user identity corresponding to each part of the speech data. The historical user ID can be the name of the historical user, and the historical user ID can be the gender of the historical user.
S103、从语音数据中提取出梅尔频率导频系数(mel-frequency cepstralcoefficients,MFCC)特征,从语音数据中提取出Fbank(Filter Bank)特征。MFCC特征和Fbank特征可以体现历史用户的声纹特性,Fbank特征中的信息量大于MFCC特征中的信息量,且在提取MFCC特征过程中增加了离散余弦变换(discrete cosine transform,DCT),在某种程度上可能损失语音数据,使得MFCC特征的准确度低于Fbank特征的准确度,因此在训练声纹判别模型时使用Fbank特征,在训练音色表征模型时使用MFCC特征。S103 , extracting mel-frequency cepstral coefficients (MFCC) features from the voice data, and extracting Fbank (Filter Bank) features from the voice data. MFCC features and Fbank features can reflect the voiceprint features of historical users. The amount of information in Fbank features is greater than that in MFCC features, and discrete cosine transform (DCT) is added in the process of extracting MFCC features. To some extent, speech data may be lost, making the accuracy of the MFCC feature lower than that of the Fbank feature. Therefore, the Fbank feature is used when training the voiceprint discrimination model, and the MFCC feature is used when training the timbre representation model.
S104、将Fbank特征输入到声纹判别模型中,声纹判别模型输出声纹判别结果,声纹判别结果可以指示语音数据中各部分所属历史用户。S104: Input the Fbank feature into the voiceprint discrimination model, and the voiceprint discrimination model outputs a voiceprint discrimination result, and the voiceprint discrimination result can indicate the historical users to which each part of the voice data belongs.
S105、基于声纹判别结果(如预测的历史用户身份标识)、标注的历史用户身份标识和损失函数,调整声纹判别模型的模型参数。S105 , based on the voiceprint discrimination result (such as the predicted historical user ID), the marked historical user ID, and the loss function, adjust the model parameters of the voiceprint discrimination model.
电子设备通过对声纹判别模型的模型参数的多次调整,以完成对声纹判别模型的训练。在完成对声纹判别模型的训练后,声纹判别模型可以学习到每个历史用户的声纹特性,这样在使用声纹判别模型进行声纹判别时,声纹判别模型可以判别出语音数据所属用户身份是否是训练时的历史用户,如果是,声纹判别模型可以输出语音数据所属历史用户身份标识;如果不是,声纹判别模型的输出为空。由此,电子设备在获取到用户的音频数据后,电子设备可以对用户的音频数据进行背景音乐和人声分离,得到用户的语音数据,从语音数据中提取出Fbank特征,然后调用声纹判别模型对语音数据中各部分的用户身份进行识别,得到语音数据中各部分所属用户身份标识。The electronic device completes the training of the voiceprint discrimination model by adjusting the model parameters of the voiceprint discrimination model for many times. After completing the training of the voiceprint discrimination model, the voiceprint discrimination model can learn the voiceprint characteristics of each historical user, so that when the voiceprint discrimination model is used for voiceprint discrimination, the voiceprint discrimination model can discriminate the voice data to which it belongs. Whether the user identity is a historical user during training, if so, the voiceprint discrimination model can output the historical user identity to which the voice data belongs; if not, the output of the voiceprint discrimination model is empty. As a result, after the electronic device acquires the user's audio data, the electronic device can separate the user's audio data from background music and human voice, obtain the user's voice data, extract the Fbank feature from the voice data, and then call the voiceprint discrimination. The model recognizes the user identity of each part in the voice data, and obtains the user identity of each part in the voice data.
S106、将MFCC特征输入到音色提取模型中,音色提取模型输出音色特征。S106, the MFCC feature is input into the timbre extraction model, and the timbre extraction model outputs the timbre feature.
S107、将音色特征输入到音色表征模型的生成器中,生成器输出音频数据。S107: Input the timbre feature into the generator of the timbre representation model, and the generator outputs audio data.
S108、将生成器输出的音频数据输入到音色表征模型的判别器中,判别器输出判别结果,判别结果可以指示生成器输出的音频数据与MFCC特征所属历史用户的音频数据之间的差异。一种示例中,判别结果用于指示生成器输出的音频数据是真实音频数据还是伪造音频数据,真实音频数据表明生成器输出的音频数据与MFCC特征所属历史用户的音频数据相同/相似,伪造音频数据表明生成器输出的音频数据与MFCC特征所属历史用户的音频数据不同/不相似。S108, input the audio data output by the generator into the discriminator of the timbre representation model, and the discriminator outputs the discrimination result, and the discrimination result can indicate the difference between the audio data output by the generator and the audio data of the historical user to which the MFCC feature belongs. In an example, the discrimination result is used to indicate whether the audio data output by the generator is real audio data or fake audio data, and the real audio data indicates that the audio data output by the generator is the same/similar to the audio data of the historical user to which the MFCC feature belongs, and the fake audio data The data indicates that the audio data output by the generator is different/dissimilar from the audio data of the historical user to which the MFCC feature belongs.
S109、基于判别结果调整生成器和判别器的模型参数。S109. Adjust the model parameters of the generator and the discriminator based on the discrimination result.
生成器的损失函数可以是:







电子设备通过对生成器和判别器的模型参数的多次调整,以完成对音色表征模型的训练。在基于一个历史用户的多条音频数据完成对音色表征模型的训练后,判别器提高了识别真实音频数据和伪造音频数据的能力,生成器可以学习到该历史用户的音色特性,使生成器输出与该历史用户的音色匹配的音频数据,与该历史用户的音色匹配的音频数据相当于是历史用户说话时电子设备采集到的音频数据,达到以假乱真的目的。The electronic device completes the training of the timbre representation model through multiple adjustments to the model parameters of the generator and the discriminator. After completing the training of the timbre representation model based on multiple pieces of audio data of a historical user, the discriminator improves the ability to identify real audio data and fake audio data, and the generator can learn the timbre characteristics of the historical user, so that the generator outputs The audio data matching the timbre of the historical user, the audio data matching the timbre of the historical user is equivalent to the audio data collected by the electronic device when the historical user speaks, so as to achieve the purpose of mixing the fake with the real.
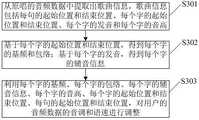
电子设备利用图4所示流程完成对声纹判别模型和音色表征模型的训练,电子设备在获取到用户的音频数据后,可以对当前获取到的音频数据进行修音,在修音过程中电子设备可以调用声纹判别模型和音色表征模型,修音方法的流程图如图5所示,可以包括以下步骤:The electronic device uses the process shown in Figure 4 to complete the training of the voiceprint discrimination model and the timbre representation model. After the electronic device obtains the user's audio data, it can modify the audio data currently obtained. The device can call the voiceprint discrimination model and the timbre representation model. The flowchart of the voice modification method is shown in Figure 5, which can include the following steps:
S201、电子设备获取用户的音频数据。在没有原唱场景中,电子设备可以运行录音APP,录音APP可以录制歌曲等音频数据。在电子设备运行录音APP过程中,电子设备可以调用麦克风采集用户的音频数据。S201. The electronic device acquires audio data of the user. In the scene without original singing, the electronic device can run the recording APP, and the recording APP can record audio data such as songs. During the process of running the recording APP on the electronic device, the electronic device can call the microphone to collect the audio data of the user.
S202、对当前获取到的用户的音频数据进行背景音乐和人声分离,得到用户的语音数据。在本实施例中,步骤S202是可选的,如果用户的音频数据中没有背景音色,用户的音频数据即是用户的语音数据,那么电子设备可以跳过步骤S202,执行步骤S203。S202. Perform background music and vocal separation on the currently acquired audio data of the user to obtain the user's voice data. In this embodiment, step S202 is optional. If there is no background tone in the user's audio data, and the user's audio data is the user's voice data, the electronic device may skip step S202 and execute step S203.
S203、从用户的语音数据中提取出Fbank特征。S203. Extract the Fbank feature from the user's voice data.
S204、将Fbank特征输入到声纹判别模型中,获得声纹判别模型输出的声纹判别结果,声纹判别结果可以指示语音数据中各部分所属历史用户。也就是说通过声纹判别模型可以将语音数据中的各部分与历史用户对应,从而通过声纹判别模型完成对语音数据中各部分所属用户身份的自动标注。S204. Input the Fbank feature into the voiceprint discrimination model, and obtain a voiceprint discrimination result output by the voiceprint discrimination model. The voiceprint discrimination result may indicate the historical users to which each part of the voice data belongs. That is to say, each part of the voice data can be corresponding to the historical users through the voiceprint discrimination model, so that the automatic labeling of the user identity of each part in the voice data can be completed through the voiceprint discrimination model.
在一种示例中,声纹判别模型可以记录历史用户的声纹特征向量,利用历史用户的声纹特征向量得到声纹判别结果。例如,电子设备可以从语音数据的各部分中提取出Fbank特征,将各部分的Fbank特征输入到声纹判别模型中,声纹判别模型可以生成Fbank特征所属部分的声纹特征向量,将当前生成的声纹特征向量与记录的所有历史用户的声纹特征向量进行距离计算,以确定当前生成的声纹特征向与记录的声纹特征向量是否匹配,如果与记录的声纹特征向量匹配,那么Fbank特征所属部分的用户身份标识是匹配的声纹特征向量对应的历史用户,从而将Fbank特征所属部分的用户身份标识标注为匹配的声纹特征向量对应的历史用户,完成对Fbank特征所属部分的声纹识别。In an example, the voiceprint discrimination model may record the voiceprint feature vectors of historical users, and obtain the voiceprint discrimination results by using the voiceprint feature vectors of historical users. For example, the electronic device can extract the Fbank feature from each part of the speech data, and input the Fbank feature of each part into the voiceprint discrimination model. Calculate the distance between the recorded voiceprint feature vector and the recorded voiceprint feature vector of all historical users to determine whether the currently generated voiceprint feature vector matches the recorded voiceprint feature vector. If it matches the recorded voiceprint feature vector, then The user ID of the part to which the Fbank feature belongs is the historical user corresponding to the matched voiceprint feature vector, so the user ID of the part to which the Fbank feature belongs is marked as the historical user corresponding to the matched voiceprint feature vector, and the identification of the part to which the Fbank feature belongs is completed. Voiceprint recognition.
在一种示例中,声纹判别结果可以是声纹判别模型预测的历史用户身份标识,如声纹判别模型预测出历史用户的姓名,对于历史用户的语音数据的各部分,声纹判别模型可以识别各部分对应的历史用户的姓名。例如对于语音数据中的任一部分,声纹判别模型输出该部分隶属不同历史用户的概率,将概率最大的历史用户标注为该部分所属用户身份。In one example, the voiceprint discrimination result may be the historical user identity predicted by the voiceprint discrimination model. For example, the voiceprint discrimination model predicts the name of the historical user. For each part of the voice data of the historical user, the voiceprint discrimination model may Identify the name of the historical user corresponding to each part. For example, for any part of the speech data, the voiceprint discrimination model outputs the probability that the part belongs to different historical users, and marks the historical user with the highest probability as the user identity to which the part belongs.
S205、参照声纹判别模型输出的声纹判别结果,将用户的语音数据划分成至少两部分。S205 , with reference to the voiceprint discrimination result output by the voiceprint discrimination model, divide the user's voice data into at least two parts.
在一种示例中,声纹判别结果指示出语音数据中各部分所属历史用户,那么在对语音数据进行划分时,按照各部分所属历史用户,对用户的语音数据进行划分,例如属于一个历史用户的部分被划分成独立段落,从而将属于不同历史用户的各部分独立出来,完成对语音数据的自动划分。In an example, the voiceprint discrimination result indicates that each part of the voice data belongs to a historical user, then when dividing the voice data, the voice data of the user is divided according to the historical user to which each part belongs, for example, belonging to a historical user The parts of the voice data are divided into independent paragraphs, so as to separate the parts belonging to different historical users, and complete the automatic division of voice data.
在另一种示例中,声纹判别结果作为语音数据划分的参照,电子设备可以输出声纹判别结果,然后用户可参照声纹判别结果对语音数据进行划分。例如语音数据中0秒(s)至3s属于历史用户A,3s至10s属于历史用户B,10s至20s属于历史用户A,20s至35s属于历史用户C,电子设备可以按照此种方式对语音数据进行划分,也可以在此种划分基础上进行调整,如将0s至20s划分成一部分,将20s至35s划分成一部分。In another example, the voiceprint discrimination result is used as a reference for the division of voice data, the electronic device may output the voiceprint discrimination result, and then the user may divide the voice data with reference to the voiceprint discrimination result. For example, in the voice data, 0 seconds (s) to 3s belong to historical user A, 3s to 10s belong to historical user B, 10s to 20s belong to historical user A, and 20s to 35s belong to historical user C. The division can also be adjusted on the basis of such division, such as dividing 0s to 20s into a part, and dividing 20s to 35s into a part.
S206、获取用户为划分出的每部分选择的目标用户。其中,目标用户是所有历史用户中的一个历史用户,用户可以为语音数据被划分的每个部分选择一个目标用户,即语音数据被划分的一个部分对应一个目标用户,目标用户的音色为该部分的目标音色。语音数据被划分的不同部分对应的目标用户可以相同,也可以不同。S206: Obtain a target user selected by the user for each of the divided parts. Among them, the target user is a historical user among all historical users. The user can select a target user for each part of the divided voice data, that is, a part of the divided voice data corresponds to a target user, and the timbre of the target user is the part. target sound. Target users corresponding to different parts of the divided voice data may be the same or different.
S207、调用目标用户的音色表征模型,以语音数据中与该目标用户对应的部分为输入,获得该目标用户的音色表征模型输出的目标语音数据,该目标语音数据的音色为目标用户的音色,完成语音数据从一个用户的音色向目标用户的音色的转换。例如对于语音数据划分出的每部分,电子设备提取该部分的MFCC特征,将该部分的MFCC特征输入到音色提取模型中,由音色提取模型输出该部分的音色特征,将该部分的音色特征和该部分输入到目标用户的音色表征模型中,获得目标用户的音色表征模型输出的目标语音数据,完成对语音数据中该部分的音色转换。S207, call the timbre representation model of the target user, take the part corresponding to the target user in the voice data as an input, obtain the target voice data output by the timbre representation model of the target user, and the timbre of the target voice data is the timbre of the target user, Complete the conversion of voice data from a user's timbre to the target user's timbre. For example, for each part divided by the voice data, the electronic device extracts the MFCC feature of the part, inputs the MFCC feature of the part into the timbre extraction model, and outputs the timbre feature of the part from the timbre extraction model, and the timbre feature of the part and This part is input into the timbre representation model of the target user, the target voice data output by the timbre representation model of the target user is obtained, and the timbre conversion of this part in the speech data is completed.
S208、组合各目标语音数据,以得到目标音频数据。其中,目标音频数据包括各目标语音数据,各目标语音数据的音色为目标用户的音色,使得目标音频数据至少具有目标用户的音色,目标音频数据可以作为用户的音频数据输出,这样电子设备可以输出至少具有目标用户的音色的音频数据,完成对音频数据的音色转换。S208. Combine each target voice data to obtain target audio data. The target audio data includes each target voice data, and the timbre of each target voice data is the timbre of the target user, so that the target audio data at least has the timbre of the target user, and the target audio data can be output as the user's audio data, so that the electronic device can output At least the audio data of the timbre of the target user is provided, and the timbre conversion of the audio data is completed.
例如在用户录制歌曲的场景中,电子设备可以采集到用户的音频数据,用户的音频数据具有用户的音色,如果是一个用户录制歌曲,那么用户的音频数据具有单一音色。电子设备可以利用上述图5所示修音方法对该用户的音频数据进行音色转换,得到至少具有目标用户的音色的目标音频数据,目标音频数据可以具有至少两个目标用户的音色,从而经过图5所示修音方法的处理后,电子设备获取到一个具有至少两个目标用户的音色的目标音频数据,在单一用户录制歌曲场景中可以实现多人合唱的目的。For example, in a scenario where a user records a song, the electronic device may collect the user's audio data, and the user's audio data has the user's timbre. If a user records a song, the user's audio data has a single timbre. The electronic device can use the above-mentioned tone modification method shown in FIG. 5 to perform timbre conversion on the audio data of the user to obtain target audio data having at least the timbre of the target user, and the target audio data can have the timbre of at least two target users, thereby passing through the timbre of the target user. After the sound modification method shown in 5 is processed, the electronic device obtains a target audio data with the timbres of at least two target users, which can achieve the purpose of multi-person chorus in the scene of a single user recording a song.
上述修音方法中,电子设备采集到一个用户的音频数据后,对当前采集到的音频数据进行背景音乐和人声分离,得到用户的语音数据。电子设备可以调用声纹判别模型对用户的语音数据进行声纹判别,利用声纹判别模型输出的声纹判别结果对语音数据进行划分,以将语音数据划分成至少两部分。在为划分的各部分选择目标用户后,分别调用每个目标用户的音色表征模型,对与目标用户对应的部分进行音色转换,得到每个目标用户的音色表征模型输出的目标语音数据,然后组合各目标语音数据,以得到目标音频数据,电子设备可以输出目标音频数据。目标音频数据可以具有至少两个目标用户的音色,使得电子设备可以以至少两个目标用户的音色输出目标音频数据,达到音频数据从单一音色向多音色的转换的目的,实现多人参与录音的目的。In the above sound modification method, after the electronic device collects the audio data of a user, it separates the background music from the human voice on the currently collected audio data to obtain the user's voice data. The electronic device can call the voiceprint discrimination model to discriminate the voiceprint of the user's voice data, and use the voiceprint discrimination result output by the voiceprint discrimination model to divide the speech data to divide the speech data into at least two parts. After selecting the target users for the divided parts, call the timbre representation model of each target user respectively, perform timbre conversion on the part corresponding to the target user, obtain the target speech data output by the timbre representation model of each target user, and then combine Each target voice data is obtained to obtain target audio data, and the electronic device can output the target audio data. The target audio data can have the timbres of at least two target users, so that the electronic device can output the target audio data with the timbres of at least two target users, so as to achieve the purpose of converting the audio data from a single timbre to multiple timbres, and realize a multi-person recording. Purpose.
请参见图6,其示出了本申请实施例提供的另一种修音方法的示意图,图6所示修音方法针对的是有原唱场景,有原唱场景可以是用户录音场景,在用户录音过程中播放原唱,或者,有原唱场景可以是用户K歌场景等等。其中,图6所示修音方法可以包括准备阶段和使用阶段,在准备阶段,电子设备完成声纹判别模型和音色表征模型的训练,声纹判别模型和音色表征模型的训练过程请参见上述图4所示流程,此处不再详述。在使用阶段,电子设备可以调用音色表征模型对用户的音频数据进行音色转换,电子设备还可以调用声纹判别模型对用户的音频数据进行划分,以将用户的音频数据划分成至少两个部分,至少两个部分的音色转换可通过音色表征模型完成,在使用阶段中音色表征模型和声纹判别模型的使用过程请参见上述图5所示流程,此处不再详述。除了对用户的音频数据进行音色转换之外,在使用阶段,电子设备可以对用户的音频数据进行美音处理。电子设备将完成音色转换后的音频数据和完成美音处理后的音频数据合成,输出合成后的音频数据。Please refer to FIG. 6, which shows a schematic diagram of another sound modification method provided by an embodiment of the present application. The sound modification method shown in FIG. 6 is aimed at a scene with original singing, and the scene with original singing may be a user recording scene. During the recording process of the user, the original song is played, or the scene with the original song may be the scene of the user's K song, and so on. Among them, the voice modification method shown in FIG. 6 may include a preparation stage and a use stage. In the preparation stage, the electronic device completes the training of the voiceprint discrimination model and the timbre representation model. For the training process of the voiceprint discrimination model and the timbre representation model, please refer to the above figure. The process shown in 4 will not be described in detail here. In the use stage, the electronic device can call the timbre representation model to perform timbre conversion on the user's audio data, and the electronic device can also call the voiceprint discrimination model to divide the user's audio data, so as to divide the user's audio data into at least two parts, The timbre conversion of at least two parts can be completed by the timbre representation model. For the usage process of the timbre representation model and the voiceprint discrimination model in the use stage, please refer to the flow shown in FIG. 5 above, and will not be described in detail here. In addition to performing timbre conversion on the user's audio data, the electronic device may perform melody processing on the user's audio data during the use phase. The electronic device synthesizes the audio data after timbre conversion and the audio data after melody processing, and outputs the synthesized audio data.
在实施图6所示修音方法时,电子设备可以开启两个线程,一个线程用于进行音色转换,另一个线程用于进行美音处理。音色转换可以在完成音频数据采集后进行,美音处理可以在采集音频数据过程中进行,以在采集音频数据的同时进行美音处理,这样在采集到完整的音频数据后,电子设备完成对音频数据的美音处理。电子设备可以利用更多资源对音频数据进行音色转换,提高对音频数据的处理效率。在有原唱场景中,电子设备可以采集到两个音频数据,一个是用户的音频数据,一个是原唱的音频数据。音色转换和美音处理是针对用户的音频数据的。When implementing the sound modification method shown in FIG. 6 , the electronic device can open two threads, one thread is used for timbre conversion, and the other thread is used for melody processing. Tone conversion can be performed after the audio data collection is completed, and melody processing can be performed during the process of collecting audio data, so that melody processing can be performed at the same time as the audio data is collected. Beautiful sound processing. The electronic device can use more resources to perform timbre conversion on the audio data, so as to improve the processing efficiency of the audio data. In a scene with original singing, the electronic device can collect two audio data, one is the user's audio data, and the other is the original singing audio data. Tonal conversion and melody processing are specific to the user's audio data.
例如在用户K歌场景中,当用户利用K歌软件演唱歌曲时,电子设备开启两个线程,一个线程在电子设备采集到完整的用户的音频数据后启用,该线程对用户的音频数据进行划分,以将用户音频数据划分成至少两部分,再对至少两部分进行音色转换;另一个线程可以在采集用户的音频数据的过程中对用户的音频数据进行美音处理。在完成音色转换和美音处理后,电子设备可以将音色转换后的音频数据和美音处理后的音频数据合成,输出合成后的音频数据,合成后的音频数据可以作为用户演唱的歌曲的音频数据。音色转换使得音频数据可以具有多种音色,美音处理使得音频数据除音色之外的音频特征与原唱的音频特征相匹配,那么歌曲的音频数据可以具有多种音色、除音色之外的音频特征与原唱的音频特征匹配。电子设备播放歌曲的音频数据时可以以多种音色和原唱的音频特征来播放歌曲,降低跑调几率、达到多人合唱歌曲的目的,原唱是歌曲的演唱者。For example, in the user karaoke scene, when the user uses the karaoke software to sing a song, the electronic device opens two threads, one thread is activated after the electronic device collects the complete user's audio data, and the thread divides the user's audio data , so as to divide the user audio data into at least two parts, and then perform timbre conversion on the at least two parts; another thread can perform beautiful tone processing on the user's audio data during the process of collecting the user's audio data. After the timbre conversion and melody processing are completed, the electronic device can synthesize the audio data after timbre conversion and the melody-processed audio data, and output the synthesized audio data, and the synthesized audio data can be used as the audio data of the song sung by the user. The timbre conversion enables the audio data to have multiple timbres, and the American tone processing makes the audio features of the audio data other than the timbre match the audio features of the original singing, so the audio data of the song can have multiple timbres and audio features other than the timbre. Matches the audio characteristics of the original vocals. When the electronic device plays the audio data of the song, it can play the song with a variety of timbres and the audio characteristics of the original singer, which reduces the probability of out-of-tune and achieves the purpose of multi-person chorus of the song. The original singer is the singer of the song.
在本实施例中,电子设备对用户的音频数据进行美音处理的过程如图7所示,可以包括以下步骤:In the present embodiment, the process of the electronic device performing American accent processing on the user's audio data is shown in Figure 7, and may include the following steps:
S301、从原唱的音频数据中提取出歌曲信息,歌曲信息包括每句的起始位置和结束位置、每个字的起始位置和结束位置、每个字的发音和每个字的音高等。歌曲信息主要是从原唱的音频数据的语音数据中提取。S301, extract song information from the audio data of the original singing, the song information includes the starting position and ending position of each sentence, the starting position and ending position of each character, the pronunciation of each character and the pitch of each character, etc. . The song information is mainly extracted from the voice data of the original sung audio data.
电子设备可以利用语音对齐技术或者语音活动检测(voice activitydetection,VAD)技术等对原唱的音频数据中每句及每个字的起始位置和结束位置进行标注,起始位置和结束位置可以以毫秒(ms)或者帧长为划分单位。发音通过获取原唱的音频数据中每个字的拼音得到,例如原唱的音频数据是一首歌曲的音频数据,将歌词转换为拼音来获得发音。The electronic device can use voice alignment technology or voice activity detection (voice activity detection, VAD) technology to mark the starting position and ending position of each sentence and each word in the audio data of the original singing. The millisecond (ms) or frame length is the division unit. Pronunciation is obtained by obtaining the pinyin of each word in the audio data of the original singing, for example, the audio data of the original singing is the audio data of a song, and the lyrics are converted into pinyin to obtain the pronunciation.
音高可以通过多音部音高提取算法从原唱的音频数据中提取出,例如通过polyphonic music(多音部)音高提取算法,提取原唱的音频数据的音高数据,多音部音高提取算法可以是melodia(一种算法名称)算法等。原唱的音频数据的音高数据可以记做X=[x(1),x(2)…x(N)],其中,N为正整数,x(n)为音频数据中不同时间点的音高值。原唱的音频数据可能包括多个演唱者的语音数据,电子设备可以利用monophnic music(单音部)音高提取算法,分别提取每个演唱者的人声音高数据,单音部音高提取算法可以是pYIN(一种算法名称)算法等。单个演唱者的人声音高数据可以记做Yk=[yk(1),yk(2)…yk(N)],其中,N为正整数,k=1、2、…k,yk(n)为音频数据中任一人声音频在不同时间点的音高值。此外,电子设备可以通过乐器数字接口(musical instrument digital interface,MIDI)文件获取到音高。The pitch can be extracted from the audio data of the original singing through the multi-voice pitch extraction algorithm. The high extraction algorithm may be a melodia (an algorithm name) algorithm or the like. The pitch data of the original sung audio data can be written as X=[x(1), x(2)...x(N)], where N is a positive integer, and x(n) is the audio data at different time points. pitch value. The audio data of the original singing may include the voice data of multiple singers. The electronic device can use the monophnic music (monophonic) pitch extraction algorithm to extract the vocal pitch data of each singer separately. The monophonic music pitch extraction algorithm Can be pYIN (an algorithm name) algorithm, etc. The vocal pitch data of a single singer can be written as Yk=[yk(1), yk(2)...yk(N)], where N is a positive integer, k=1, 2,...k, yk(n) is the pitch value of any vocal audio in the audio data at different time points. In addition, electronic devices can acquire pitch through musical instrument digital interface (MIDI) files.
S302、基于每个字的起始位置和结束位置,得到每个字的基频和包络;基于每个字的发音,得到每个字的辅音信息。S302, obtaining the fundamental frequency and envelope of each character based on the starting position and ending position of each character; obtaining consonant information of each character based on the pronunciation of each character.
包络是将不同频率的振幅最高点连接形成的曲线,也就是说包络对应的是不同频率的振幅最高点,基频是所有频率中的最小频率。电子设备可以利用时域提取方法或频域提取方法提取每个字的基频,获得音频数据的线性预测编码系数;根据线性预测编码系数得到每个字的包络。The envelope is a curve formed by connecting the highest amplitude points of different frequencies, that is to say, the envelope corresponds to the highest amplitude points of different frequencies, and the fundamental frequency is the smallest frequency among all frequencies. The electronic device can extract the fundamental frequency of each word by using the time domain extraction method or the frequency domain extraction method to obtain the linear predictive coding coefficients of the audio data; and obtain the envelope of each word according to the linear predictive coding coefficients.
其中,利用时域提取方法提取字的基频的过程可以是,通过分析字的波形的周期变化来提取字的基频,其中字的波形的周期变化可基于该字的起始位置和结束位置得到。字的自相关函数也是周期的,所以字的自相关函数也是根据周期的性质估计字的基频。字在基音周期的各个整数点的位置对应一个大峰值,通过分析自相关函数的第一个大峰值和k=0点的距离,以估算出字的基频,k表示的是延时。当k=0时,自相关函数具有最大的峰值。利用频域提取方法提取字的基频的过程可以是,对时域的字的波形进行傅里叶变换并取对数,处理后的波形在频域内是一个准周期性信号,这个信号周期即为字的基频。Wherein, the process of using the time domain extraction method to extract the fundamental frequency of the word can be, by analyzing the periodic variation of the waveform of the word to extract the fundamental frequency of the word, wherein the periodic variation of the waveform of the word can be based on the starting position and ending position of the word. get. The autocorrelation function of the word is also periodic, so the autocorrelation function of the word also estimates the fundamental frequency of the word according to the nature of the period. The position of the word at each integer point of the pitch cycle corresponds to a large peak. By analyzing the distance between the first large peak of the autocorrelation function and k=0 point, the fundamental frequency of the word is estimated, and k represents the delay. When k=0, the autocorrelation function has the largest peak. The process of using the frequency domain extraction method to extract the fundamental frequency of a word can be as follows: Fourier transform is performed on the waveform of the word in the time domain and logarithm is taken. The processed waveform is a quasi-periodic signal in the frequency domain, and the signal period is is the fundamental frequency of the word.
字的发音是由元音和辅音等组成,由此,电子设备可以直接从字的发音中提取到辅音信息。The pronunciation of a word is composed of vowels and consonants, so that the electronic device can directly extract the consonant information from the pronunciation of the word.
S303、利用每个字的基频、每个字的包络、每个字的辅音信息、每个字的音高、每个字的起始位置和结束位置、每句的起始位置和结束位置,对用户的音频数据的音调和语速进行调整,以完成对用户的音频数据的美音处理。其中,对用户的音频数据的音调和语速的调整是对用户的音频数据中语音数据的音调和语速的调整。S303, using the fundamental frequency of each character, the envelope of each character, the consonant information of each character, the pitch of each character, the starting position and ending position of each character, the starting position and ending position of each sentence position, and adjust the pitch and speech rate of the user's audio data, so as to complete the aesthetic processing of the user's audio data. The adjustment of the pitch and the speech rate of the user's audio data is the adjustment of the pitch and the speech rate of the speech data in the user's audio data.
在本实施例中,对用户的音频数据的音调和语速的调整可以是对用户的音频数据中每个字的信息进行调整实现的,如对用户的音频数据中每个字的基频、每个字的包络、每个字的辅音信息、用户的音频数据中每句的起始位置和结束位置的调整。In this embodiment, the adjustment of the pitch and speech rate of the user's audio data may be achieved by adjusting the information of each word in the user's audio data, such as the fundamental frequency of each word in the user's audio data, The envelope of each word, the consonant information of each word, the adjustment of the start and end positions of each sentence in the user's audio data.
一种实现方式是,利用步骤S302从原唱的音频数据中获取到的任意一个字的基频和包络,调整用户的音频数据中该字的基频和包络,使该字的基频与步骤S302中提取到的基频之间的差异缩小;利用步骤S302从原唱的音频数据中获取到的任意一个字的辅音信息,调整用户的音频数据中该字的辅音信息,使该字的辅音信息与步骤S302中提取到的辅音信息相同;利用步骤S301从原唱的音频数据中获取到的任意一个字的音高,调整该字的音高,使该字的音高与步骤S301中提取到的音高之间的差异缩小,通过基频、包络、辅音信息和音高的调整,实现对用户的音频数据的音调的调整。其中所调整的该字在用户的音频数据中的位置和在原唱的音频数据中的位置可以相同。One implementation is to utilize the fundamental frequency and the envelope of any word obtained from the audio data of the original singing in step S302, to adjust the fundamental frequency and the envelope of the word in the audio data of the user, so that the fundamental frequency of the word is adjusted. The difference between the fundamental frequencies extracted in step S302 is reduced; Utilize the consonant information of any word obtained from the audio data of the original singing in step S302, adjust the consonant information of the word in the audio data of the user, and make the word The consonant information is the same as the consonant information extracted in step S302; using the pitch of any word obtained from the audio data of the original singing in step S301, adjust the pitch of the word so that the pitch of the word is the same as that of step S301 The difference between the extracted pitches is reduced, and the pitch adjustment of the user's audio data is realized through the adjustment of the fundamental frequency, the envelope, the consonant information and the pitch. The adjusted position of the word in the audio data of the user may be the same as the position in the audio data of the original song.
利用步骤S301从原唱的音频数据中获取到的任意一个字的起始位置和结束位置,调整该字在用户的音频数据中的时长,在完成一句中字的时长调整后,可以利用步骤S301中提取到的该句的起始位置和结束位置,对该句的时长进行调整,实现对用户的音频数据的语速的调整。其中所调整的该字在用户的音频数据中的位置和在原唱的音频数据中的位置可以相同,所调整的句子在用户的音频数据中的位置和在原唱的音频数据中的位置可以相同。Utilize the starting position and ending position of any word obtained from the audio data of the original singing in step S301 to adjust the duration of the word in the user's audio data. The extracted start position and end position of the sentence are used to adjust the duration of the sentence, so as to adjust the speech rate of the user's audio data. The adjusted position of the word in the audio data of the user and the position in the audio data of the original song may be the same, and the position of the adjusted sentence in the audio data of the user and the position in the audio data of the original song may be same.
在完成对用户的音频数据的美音处理后,电子设备可以对美音处理后的音频数据和音色转换后的音频数据进行合成,即将两个音频数据融合成一个音频数据,两个音频数据的合成可以是两个音频数据的频谱的合成。一种示例中,基于两个音频数据中一个音频数据的频谱,调整另一个音频数据的频谱,例如以音色转换后的音频数据的频谱为主,缩小美音处理后的音频数据的频谱与音色转换后的音频数据的频谱之间的差异;又例如按照音色转换后的音频数据的频谱的比例调整美音处理后的音频数据的频谱。另一种示例中,将两个音频数据的频谱进行相加处理,如将两个音频数据的频谱进行加权求和。频谱合成可以是针对两个音频数据中的语音数据的频谱,对两个音频数据中的语音数据的频谱进行合成。After completing the beautifying processing of the user's audio data, the electronic device may synthesize the audio data after the beautifying process and the audio data after the timbre conversion, that is, fuse the two audio data into one audio data, and the synthesis of the two audio data can is the synthesis of the spectrum of two audio data. In an example, based on the spectrum of one audio data in the two audio data, the spectrum of the other audio data is adjusted, for example, the spectrum of the audio data after the timbre conversion is mainly used, and the spectrum of the audio data after the melody processing is reduced and the timbre conversion is performed. The difference between the frequency spectra of the audio data after the sound conversion; another example is to adjust the frequency spectrum of the audio data after the American tone processing according to the proportion of the frequency spectrum of the audio data after the timbre conversion. In another example, the spectrums of the two audio data are added, such as weighted summation of the spectrums of the two audio data. The spectrum synthesis may be to synthesize the spectrum of the voice data in the two audio data with respect to the spectrum of the voice data in the two audio data.
上述图3至图6阐述了对用户的音频数据进行音色转换,音色转换可以将用户的语音数据划分成至少两部分,由用户指定每部分对应的目标用户,再调用目标用户的音色表征模型,对该目标用户对应的部分进行音色转换。对用户的语音数据的划分可以是基于声纹判别模型输出的声纹判别结果,对应的用户界面(user interface,UI)如图8所示。The above-mentioned Fig. 3 to Fig. 6 have explained that the audio data of the user is converted into timbre, and the timbre conversion can divide the user's voice data into at least two parts, and the target user corresponding to each part is specified by the user, and then the timbre representation model of the target user is called, Tone conversion is performed on the part corresponding to the target user. The division of the user's voice data may be based on the voiceprint discrimination result output by the voiceprint discrimination model, and the corresponding user interface (user interface, UI) is shown in FIG. 8 .
在图8所示UI中,声纹判别模型对用户的语音数据进行声纹判别,确定语音数据对应两个声纹,两个声纹分别是明星1和明星2。并且图8所示UI中显示一个提示信息,该提示信息指示是否按人声自动分段,如果电子设备接收到按人声自动分段后,那么电子设备可以按照声纹判别模型判别出的两个声纹对语音数据进行自动分段,例如声纹判别模型判别出语音数据中的0s至10s对应明星1,10s至25s对应明星2,25s至40s对应明星1,那么电子设备可以按照0s至10s、10s至25s和25s至40s进行自动分段。In the UI shown in FIG. 8 , the voiceprint discrimination model performs voiceprint discrimination on the user's voice data, and determines that the voice data corresponds to two voiceprints, and the two voiceprints are star 1 and star 2 respectively. And a prompt message is displayed in the UI shown in FIG. 8, this prompt message indicates whether to automatically segment by human voice, if the electronic device receives automatic segmentation by human voice, then the electronic device can distinguish the two according to the voiceprint discrimination model. The voice data is automatically segmented by each voiceprint. For example, the voiceprint discrimination model determines that 0s to 10s in the voice data corresponds to star 1, 10s to 25s corresponds to star 2, and 25s to 40s corresponds to star 1, then the electronic device can use 0s to 10s to correspond to star 1. 10s, 10s to 25s and 25s to 40s for automatic segmentation.
在图8所示UI中,用户可以指定目标音色,例如可以指定目标用户,目标用户的音色作为目标音色使用,如在图8中指定将明星1的音色转换为明星3的音色,将明星2的音色转换为明星4的音色。在用户点击确认后,电子设备调用明星3的音色表征模型对0s至10s、25s至40s的音频数据进行音色转换,调用明星4的音色表征模型对10s至25s的音频数据进行音色转换。In the UI shown in Figure 8, the user can specify the target timbre, for example, the target user can be specified, and the timbre of the target user can be used as the target timbre. The timbre is converted to the timbre of Star 4. After the user clicks OK, the electronic device calls the timbre representation model of
在没有原唱场景中,电子设备可以采集到一个音频数据,调用声纹判别模型对采集到的音频数据中的语音数据进行声纹判别,然后利用声纹判别结果对语音数据进行自动划分。在有原唱场景中,电子设备可以采集到两个音频数据,一个是原唱的音频数据,一个是用户(也可以称为演唱者)的音频数据,电子设备可以调用声纹判别模型对两个音频数据中的语音数据分别进行声纹判别,利用原唱的声纹判别结果或者用户的声纹判别结果对用户的音频数据中的语音数据进行自动划分。In the scene without original singing, the electronic device can collect a piece of audio data, call the voiceprint discrimination model to discriminate the voice data in the collected audio data, and then use the voiceprint discrimination result to automatically divide the voice data. In a scene with original singing, the electronic device can collect two audio data, one is the audio data of the original singing, and the other is the audio data of the user (also called the singer). Voiceprint discrimination is performed on the voice data in each audio data respectively, and the voice data in the user's audio data is automatically divided by using the voiceprint discrimination result of the original song or the user's voiceprint discrimination result.
声纹判别模型除了可以判别出语音数据所属用户身份之外,声纹判别模型可以判别语音数据所属用户性别,那么电子设备在对语音数据进行划分时可以根据性别进行划分。如图9示出了按照性别对语音数据进行自动划分,用户可以指定与性别相匹配的目标用户;例如性别是男,则选择男性目标用户,性别是女,则选择女性目标用户。之后电子设备调用目标用户的音色表征模型进行音色转换。In addition to identifying the identity of the user to which the voice data belongs, the voiceprint identification model can identify the gender of the user to which the voice data belongs. Then, the electronic device can classify the voice data according to gender. Figure 9 shows the automatic division of voice data according to gender, and the user can specify a target user that matches the gender; for example, if the gender is male, select the male target user, and if the gender is female, select the female target user. After that, the electronic device calls the timbre representation model of the target user to perform timbre conversion.
图8和图9是电子设备利用声纹判别模型的声纹判别结果对语音数据的自动划分,图8和图9中的对号表示利用声纹判别结果对语音数据的自动划分。除了自动划分之外,用户可以手动划分语音数据,用户手动划分语音数据可以是根据时间划分,按照时间划分的方式可以是每间隔M秒划分或者用户手动选择划分时间点,在手动选择划分时间点时用户可以拖动进度条划分,拖动到一个位置弹出划分提示,划分提示用于提示用户是否在该时间点进行划分,如果选择是则在该时间点进行划分,否则不进行划分,M为自然数。用户手动划分语音数据可以根据歌词划分,如指定X句歌词划分成一段,X为大于或等于1的自然数,每部分含有的歌词数量可以相同也可以不同。当然电子设备也可以根据歌词自动划分。图10示出了用户按照时间划分语音数据,用户可以手动输入每部分的起始时间点和结束时间点,也可以手动输入每部分对应的目标用户。之后电子设备调用目标用户的音色表征模型进行音色转换。Figures 8 and 9 show the automatic division of voice data by the electronic device using the voiceprint discrimination results of the voiceprint discrimination model. In addition to automatic division, the user can manually divide the voice data. The user can manually divide the voice data according to the time division. The time division method can be divided every M seconds or the user manually selects the division time point. When manually selecting the division time point At the same time, the user can drag the progress bar to divide, and drag it to a position to pop up a division prompt. The division prompt is used to prompt the user whether to divide at this time point. If yes, it will be divided at this time point, otherwise it will not be divided, M is Natural number. The user can manually divide the voice data according to the lyrics, such as specifying X sentences to divide the lyrics into a paragraph, X is a natural number greater than or equal to 1, and the number of lyrics contained in each part can be the same or different. Of course, the electronic device can also be automatically divided according to the lyrics. FIG. 10 shows that the user divides the voice data according to time. The user can manually input the start time point and end time point of each part, and can also manually input the target user corresponding to each part. After that, the electronic device calls the timbre representation model of the target user to perform timbre conversion.
目标音色可以是由用户指定,目标音色还可以采用其他方式指定。在一种示例中,电子设备可以统计不同音色的得分,将得分较高的至少一个音色作为目标音色,不同音色的得分可以是根据使用次数得到,使用次数越多得分越高。在另一种示例中,获得用户的音色特征和历史用户的音色特征之间的相似度,基于相似度确定出目标音色,如基于相似度选择音色接近或音色差距较大的音色作为目标音色。在另一种示例中,电子设备可以预先对音色进行类型划分,在确定当前采集到的音频数据的音色所属类型后,基于音色所属类型选择一个音色作为目标音色,如从音色所属类型中选择一个音色作为目标音色。The target timbre can be specified by the user, and the target timbre can also be specified in other ways. In an example, the electronic device may count the scores of different timbres, and use at least one timbre with a higher score as the target timbre. The scores of different timbres may be obtained according to the number of times of use, and the higher the number of times of use, the higher the score. In another example, the similarity between the timbre characteristics of the user and the timbre characteristics of historical users is obtained, and the target timbre is determined based on the similarity, for example, a timbre with a similar timbre or a relatively large timbre difference is selected as the target timbre based on the similarity. In another example, the electronic device may classify the timbres by type in advance, and after determining the type of timbre of the currently collected audio data, select a timbre as the target timbre based on the type of timbre to which the timbre belongs, such as selecting a timbre from the types to which the timbre belongs. Voice as the target Voice.
此外,电子设备在对音频数据进行音色转换时,电子设备可以对音频数据中的部分数据进行音色转换。例如用户利用图10所示UI指定音频数据中进行音色转换的部分;又例如电子设备预先指定音频数据中的待划分数据,调用声纹判别模型对待划分数据进行划分,或者,用户手动划分待划分数据,或者在声纹判别模型划分的基础上进行调整等等,这样音频数据既可以具有用户原本的音色,又增加了目标音色。在其他示例中,电子设备对音频数据进行音色转换后,将音色转换得到的音频数据与电子设备采集到的用户的音频数据进行融合,得到一个音频数据,融合过程可以是两个音频数据的频谱的融合,此处不再详述。In addition, when the electronic device performs timbre conversion on the audio data, the electronic device may perform timbre conversion on part of the audio data. For example, the user uses the UI shown in FIG. 10 to specify the part of the audio data that performs timbre conversion; for example, the electronic device pre-specifies the data to be divided in the audio data, and calls the voiceprint discrimination model to divide the data to be divided, or the user manually divides the data to be divided The audio data can be adjusted on the basis of the division of the voiceprint discrimination model, etc., so that the audio data can not only have the user's original timbre, but also increase the target timbre. In other examples, after the electronic device performs tone color conversion on the audio data, the audio data obtained by the tone color conversion and the user's audio data collected by the electronic device are fused to obtain one audio data, and the fusion process may be the frequency spectrum of the two audio data. , which will not be described in detail here.
本申请实施例还提供一种电子设备,电子设备包括:处理器和存储器;其中,存储器用于存储一个或多个计算机程序代码,计算机程序代码包括计算机指令,当处理器执行计算机指令时,处理器执行上述修音方法。The embodiments of the present application also provide an electronic device, the electronic device includes: a processor and a memory; wherein, the memory is used to store one or more computer program codes, and the computer program codes include computer instructions, when the processor executes the computer instructions, the processing The device performs the above-mentioned tuning method.
本申请实施例还提供一种计算机存储介质,计算机存储介质包括计算机指令,当计算机指令在电子设备上运行时,使得电子设备执行上述修音方法。Embodiments of the present application further provide a computer storage medium, where the computer storage medium includes computer instructions, and when the computer instructions are executed on the electronic device, the electronic device is made to execute the above-mentioned pronunciation modification method.
Claims (16)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210377923.3ACN114464151B (en) | 2022-04-12 | 2022-04-12 | Sound repairing method and device |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210377923.3ACN114464151B (en) | 2022-04-12 | 2022-04-12 | Sound repairing method and device |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN114464151Atrue CN114464151A (en) | 2022-05-10 |
| CN114464151B CN114464151B (en) | 2022-08-23 |
Family
ID=81417688
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210377923.3AActiveCN114464151B (en) | 2022-04-12 | 2022-04-12 | Sound repairing method and device |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114464151B (en) |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2010095622A1 (en)* | 2009-02-17 | 2010-08-26 | 国立大学法人京都大学 | Music acoustic signal generating system |
| CN103514883A (en)* | 2013-09-26 | 2014-01-15 | 华南理工大学 | Method for achieving self-adaptive switching of male voice and female voice |
| CN104464725A (en)* | 2014-12-30 | 2015-03-25 | 福建星网视易信息系统有限公司 | Method and device for singing imitation |
| CN108305636A (en)* | 2017-11-06 | 2018-07-20 | 腾讯科技(深圳)有限公司 | A kind of audio file processing method and processing device |
| CN112331222A (en)* | 2020-09-23 | 2021-02-05 | 北京捷通华声科技股份有限公司 | Method, system, equipment and storage medium for converting song tone |
| CN113836344A (en)* | 2021-09-30 | 2021-12-24 | 广州艾美网络科技有限公司 | Personalized song file generation method and device and music singing equipment |
- 2022
- 2022-04-12CNCN202210377923.3Apatent/CN114464151B/enactiveActive
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2010095622A1 (en)* | 2009-02-17 | 2010-08-26 | 国立大学法人京都大学 | Music acoustic signal generating system |
| CN103514883A (en)* | 2013-09-26 | 2014-01-15 | 华南理工大学 | Method for achieving self-adaptive switching of male voice and female voice |
| CN104464725A (en)* | 2014-12-30 | 2015-03-25 | 福建星网视易信息系统有限公司 | Method and device for singing imitation |
| CN108305636A (en)* | 2017-11-06 | 2018-07-20 | 腾讯科技(深圳)有限公司 | A kind of audio file processing method and processing device |
| CN112331222A (en)* | 2020-09-23 | 2021-02-05 | 北京捷通华声科技股份有限公司 | Method, system, equipment and storage medium for converting song tone |
| CN113836344A (en)* | 2021-09-30 | 2021-12-24 | 广州艾美网络科技有限公司 | Personalized song file generation method and device and music singing equipment |
Also Published As
| Publication number | Publication date |
|---|---|
| CN114464151B (en) | 2022-08-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10789290B2 (en) | Audio data processing method and apparatus, and computer storage medium | |
| CN106898340B (en) | Song synthesis method and terminal | |
| US12027165B2 (en) | Computer program, server, terminal, and speech signal processing method | |
| CN111445892B (en) | Song generation method and device, readable medium and electronic equipment | |
| CN111798821B (en) | Sound conversion method, device, readable storage medium and electronic equipment | |
| CN110675886A (en) | Audio signal processing method, audio signal processing device, electronic equipment and storage medium | |
| CN109523986A (en) | Phoneme synthesizing method, device, equipment and storage medium | |
| US20240004606A1 (en) | Audio playback method and apparatus, computer readable storage medium, and electronic device | |
| CN114121006A (en) | Image output method, device, equipment and storage medium of virtual character | |
| US20070061145A1 (en) | Methods and apparatus for formant-based voice systems | |
| CN111105779A (en) | Text playing method and device for mobile client | |
| CN112992109B (en) | Auxiliary singing system, auxiliary singing method and non-transient computer readable recording medium | |
| CN110782869A (en) | Speech synthesis method, apparatus, system and storage medium | |
| CN115329057A (en) | Voice interaction method and device, electronic equipment and storage medium | |
| CN118098199B (en) | Personalized speech synthesis method, electronic device, server and storage medium | |
| JP5598516B2 (en) | Voice synthesis system for karaoke and parameter extraction device | |
| CN117153175A (en) | Audio processing method, device, equipment, medium and product | |
| CN114283789B (en) | Singing voice synthesis method, device, computer equipment and storage medium | |
| US20240169962A1 (en) | Audio data processing method and apparatus | |
| CN107025902B (en) | Data processing method and device | |
| CN114464151B (en) | Sound repairing method and device | |
| WO2021102647A1 (en) | Data processing method and apparatus, and storage medium | |
| CN113421544B (en) | Singing voice synthesizing method, singing voice synthesizing device, computer equipment and storage medium | |
| CN106649643B (en) | A kind of audio data processing method and its device | |
| JP6003352B2 (en) | Data generation apparatus and data generation method |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| TA01 | Transfer of patent application right | Effective date of registration:20220608 Address after:100095 floors 2-14, building 3, yard 5, honeysuckle Road, Haidian District, Beijing Applicant after:Beijing Honor Device Co.,Ltd. Address before:Unit 3401, unit a, building 6, Shenye Zhongcheng, No. 8089, Hongli West Road, Donghai community, Xiangmihu street, Futian District, Shenzhen, Guangdong 518040 Applicant before:Honor Device Co.,Ltd. | |
| TA01 | Transfer of patent application right | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |