CN114462410A - Entity identification method, device, terminal and storage medium - Google Patents
Entity identification method, device, terminal and storage mediumDownload PDFInfo
- Publication number
- CN114462410A CN114462410ACN202210128678.2ACN202210128678ACN114462410ACN 114462410 ACN114462410 ACN 114462410ACN 202210128678 ACN202210128678 ACN 202210128678ACN 114462410 ACN114462410 ACN 114462410A
- Authority
- CN
- China
- Prior art keywords
- recognition result
- entity
- word
- determining
- words
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images


Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/289—Phrasal analysis, e.g. finite state techniques or chunking
- G06F40/295—Named entity recognition
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/237—Lexical tools
- G06F40/242—Dictionaries
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Character Discrimination (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本公开涉及终端技术领域,尤其涉及一种实体识别方法、装置、终端及存储介质。The present disclosure relates to the technical field of terminals, and in particular, to an entity identification method, device, terminal and storage medium.
背景技术Background technique
人工交互的应用场景中,需要先将人的语音转换成文本,然后经过后续处理让机器理解人的意图,最后选择相关的后续策略来应对。其中,语音识别和实体识别(即对实体词的识别)都至关重要,而且实体识别处在语音识别之后。人的口音、年龄、说话习惯、文化程度,以及说话时的环境噪声等复杂原因,不仅对语音识别的准确性影响很大,同样也会严重影响语句中实体词的识别的准确率,目前已经有很多方法优化语音识别,但是实体识别的方法并不多,准确率也较差。In the application scenario of human interaction, it is necessary to convert human speech into text, and then make the machine understand the human intention through subsequent processing, and finally select relevant follow-up strategies to deal with it. Among them, both speech recognition and entity recognition (that is, the recognition of entity words) are very important, and entity recognition is after speech recognition. People's accent, age, speaking habits, educational level, and environmental noise when speaking, not only have a great impact on the accuracy of speech recognition, but also seriously affect the accuracy of entity word recognition in sentences. There are many ways to optimize speech recognition, but there are not many methods for entity recognition, and the accuracy rate is poor.
发明内容SUMMARY OF THE INVENTION
为克服相关技术中存在的问题,本公开提供一种实体识别方法、装置、终端及存储介质。In order to overcome the problems existing in the related art, the present disclosure provides an entity identification method, device, terminal and storage medium.
根据本公开实施例的第一方面,提供一种实体识别方法,应用于终端,所述方法包括:According to a first aspect of the embodiments of the present disclosure, an entity identification method is provided, which is applied to a terminal, and the method includes:
获取待识别语句;Get the sentence to be recognized;
基于设定词典库对所述待识别语句进行识别,确定第一识别结果;Recognizing the sentence to be recognized based on the set dictionary library, and determining a first recognition result;
若确定所述第一识别结果未包括所述待识别语句的全部实体词,则基于互信息和左右信息熵对所述待识别语句进行识别,确定待定识别结果;If it is determined that the first recognition result does not include all the entity words of the to-be-recognized sentence, then the to-be-recognized sentence is recognized based on mutual information and left and right information entropy, and the to-be-determined recognition result is determined;
根据所述第一识别结果和所述待定识别结果,确定目标识别结果。A target recognition result is determined according to the first recognition result and the pending recognition result.
可选地,所述根据所述第一识别结果和所述待定识别结果,确定目标识别结果,包括:Optionally, determining the target recognition result according to the first recognition result and the pending recognition result includes:
将所述待定识别结果中,与所述第一识别结果的实体词不同的词,确定为待定实体词;In the undetermined recognition result, words different from the entity words of the first recognition result are determined as undetermined entity words;
根据满足第一设定条件的待定实体词,确定第二识别结果;Determine the second recognition result according to the undetermined entity word that satisfies the first set condition;
根据所述第一识别结果和所述第二识别结果,确定所述目标识别结果。The target recognition result is determined according to the first recognition result and the second recognition result.
可选地,所述根据满足第一设定条件的待定实体词,确定第二识别结果,包括:Optionally, the determining of the second recognition result according to the undetermined entity words that satisfy the first set condition includes:
若确定所述待定实体词的第一模型值大于或等于第一阈值,且确定此待定实体词的第二模型值大于或等于第二阈值,则将此待定实体词确定为第二实体词;If it is determined that the first model value of the pending entity word is greater than or equal to the first threshold, and the second model value of the pending entity word is determined to be greater than or equal to the second threshold, determining the pending entity word as the second entity word;
将全部第二实体词构成的识别结果,确定为所述第二识别结果。The recognition results formed by all the second entity words are determined as the second recognition results.
可选地,所述方法还包括:Optionally, the method further includes:
若确定所述第一识别结果包括所述待识别语句的全部实体词,则将所述第一识别结果确定为所述目标识别结果。If it is determined that the first recognition result includes all the entity words of the to-be-recognized sentence, the first recognition result is determined as the target recognition result.
可选地,所述设定词典库通过以下方式得到:Optionally, the set dictionary library is obtained in the following manner:
根据设定领域的语句,确定语句库;Determine the statement library according to the statement of the set field;
对所述语句库中的语句进行分词处理,确定第一词语库;Perform word segmentation processing on the sentences in the sentence database to determine the first word database;
基于互信息和左右信息熵对所述语句库的语句进行识别,确定待定词语库;Identifying sentences in the sentence database based on mutual information and left and right information entropy, and determining a pending word database;
根据所述第一词语库和所述待定词语库,确定所述设定词典库。The set dictionary database is determined according to the first word database and the pending word database.
可选地,所述根据所述第一词语库和所述待定词语库,确定所述设定词典库,包括:Optionally, the determining the set dictionary database according to the first word database and the pending word database includes:
将所述待定词语库中,与所述第一词语库的设定词不同的词,确定为待定设定词;Determining words that are different from the preset words in the first vocabulary library as the undetermined preset words in the undetermined vocabulary database;
根据满足第二设定条件的待定设定词,确定第二词语库;According to the undetermined set words that satisfy the second set condition, determine the second word database;
根据所述第一词语库和所述第二词语库,确定所述设定词典库。The set dictionary database is determined according to the first word database and the second word database.
可选地,所述根据满足第二设定条件的所述待定设定词,确定第二词语库,包括:Optionally, determining the second word library according to the pending set words that satisfy the second setting condition, including:
若确定所述待定设定词的第一模型值大于或等于第三阈值,且确定此待定设定词的第二模型值大于或等于第四阈值,则将此待定设定词确定为第二设定词;If it is determined that the first model value of the pending setting word is greater than or equal to the third threshold, and it is determined that the second model value of the pending setting word is greater than or equal to the fourth threshold, then the pending setting word is determined to be the second set word;
将全部第二设定词构成的词典库,确定为所述第二词语库。A dictionary database composed of all the second set words is determined as the second word database.
根据本公开实施例的第二方面,提供一种实体识别装置,应用于终端,所述装置包括:According to a second aspect of the embodiments of the present disclosure, there is provided an entity identification device, which is applied to a terminal, and the device includes:
获取模块,用于获取待识别语句;The acquisition module is used to acquire the statement to be recognized;
确定模块,用于基于设定词典库对所述待识别语句进行识别,确定第一识别结果;a determining module, configured to identify the to-be-recognized sentence based on the set dictionary library, and determine a first recognition result;
还用于若确定所述第一识别结果未包括所述待识别语句的全部实体词,则基于互信息和左右信息熵对所述待识别语句进行识别,确定待定识别结果;It is also used to identify the to-be-recognized sentence based on mutual information and left and right information entropy if it is determined that the first recognition result does not include all the entity words of the to-be-recognized sentence, and to determine the to-be-determined recognition result;
还用于根据所述第一识别结果和所述待定识别结果,确定目标识别结果。It is also used for determining a target recognition result according to the first recognition result and the pending recognition result.
可选地,所述确定模块,用于:Optionally, the determining module is used for:
将所述待定识别结果中,与所述第一识别结果的实体词不同的词,确定为待定实体词;In the undetermined recognition result, words different from the entity words of the first recognition result are determined as undetermined entity words;
根据满足第一设定条件的待定实体词,确定第二识别结果;Determine the second recognition result according to the undetermined entity word that satisfies the first set condition;
根据所述第一识别结果和所述第二识别结果,确定所述目标识别结果。The target recognition result is determined according to the first recognition result and the second recognition result.
可选地,所述确定模块,用于:Optionally, the determining module is used for:
若确定所述待定实体词的第一模型值大于或等于第一阈值,且确定此待定实体词的第二模型值大于或等于第二阈值,则将此待定实体词确定为第二实体词;If it is determined that the first model value of the pending entity word is greater than or equal to the first threshold, and the second model value of the pending entity word is determined to be greater than or equal to the second threshold, determining the pending entity word as the second entity word;
将全部第二实体词构成的识别结果,确定为所述第二识别结果。The recognition results formed by all the second entity words are determined as the second recognition results.
可选地,所述确定模块,用于:Optionally, the determining module is used for:
若确定所述第一识别结果包括所述待识别语句的全部实体词,则将所述第一识别结果确定为所述目标识别结果。If it is determined that the first recognition result includes all the entity words of the to-be-recognized sentence, the first recognition result is determined as the target recognition result.
根据本公开实施例的第三方面,提供一种终端,所述终端包括:According to a third aspect of the embodiments of the present disclosure, there is provided a terminal, the terminal comprising:
处理器;processor;
用于存储所述处理器可执行指令的存储器;a memory for storing the processor-executable instructions;
其中,所述处理器被配置为执行如第一方面所述的方法。Wherein, the processor is configured to perform the method of the first aspect.
根据本公开实施例的第四方面,提供一种非临时性计算机可读存储介质,当所述存储介质中的指令由终端的处理器执行时,使得所述终端能够执行如第一方面所述的方法。According to a fourth aspect of the embodiments of the present disclosure, there is provided a non-transitory computer-readable storage medium, when an instruction in the storage medium is executed by a processor of a terminal, the terminal can execute the method described in the first aspect. Methods.
本公开的实施例提供的技术方案可以包括以下有益效果:该方法中,基于设定词典库以及互信息和左右信息熵,进行实体词的识别,不需要准备大量数据进行模型训练或部署,以进行冷启动,难度较低,效率和准确率更好。另外,该方法不仅可应用于智能客服领域,也可应用于其他涉及实体词识别的领域,适用性较广。The technical solutions provided by the embodiments of the present disclosure may include the following beneficial effects: In the method, entity words are identified based on the set dictionary base and mutual information and left and right information entropy, without preparing a large amount of data for model training or deployment, so as to Cold start is less difficult, and the efficiency and accuracy are better. In addition, this method can be applied not only to the field of intelligent customer service, but also to other fields involving entity word recognition, and has wide applicability.
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。It is to be understood that the foregoing general description and the following detailed description are exemplary and explanatory only and are not restrictive of the present disclosure.
附图说明Description of drawings
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本公开的实施例,并与说明书一起用于解释本公开的原理。The accompanying drawings, which are incorporated in and constitute a part of this specification, illustrate embodiments consistent with the disclosure and together with the description serve to explain the principles of the disclosure.
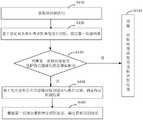
图1是根据一示例性实施例示出的实体识别方法的流程图。FIG. 1 is a flowchart of an entity identification method according to an exemplary embodiment.
图2是根据一示例性实施例示出的实体识别装置的框图。Fig. 2 is a block diagram of an entity identification device according to an exemplary embodiment.
图3是根据一示例性实施例示出的终端的框图。FIG. 3 is a block diagram of a terminal according to an exemplary embodiment.
具体实施方式Detailed ways
这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本公开相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本公开的一些方面相一致的装置和方法的例子。Exemplary embodiments will be described in detail herein, examples of which are illustrated in the accompanying drawings. Where the following description refers to the drawings, the same numerals in different drawings refer to the same or similar elements unless otherwise indicated. The implementations described in the illustrative examples below are not intended to represent all implementations consistent with this disclosure. Rather, they are merely examples of apparatus and methods consistent with some aspects of the present disclosure as recited in the appended claims.
相关技术中,主要通过深度学习方法或拼音纠错方法,或者上述两种方法相结合,来进行实体词的识别(简称实体识别)。深度学习方法需要大量数据进行模型的训练,模型训练耗时长,并且需要针对不同的模型进行模型不同的训练。拼音纠错方法针对一些垂直领域(简称垂域)需要建立专门的词典库,而且该方法的准确率较低。In the related art, entity word recognition (referred to as entity recognition) is mainly performed through a deep learning method or a pinyin error correction method, or a combination of the above two methods. Deep learning methods require a large amount of data for model training, model training takes a long time, and different models need to be trained for different models. The pinyin error correction method needs to establish a special dictionary library for some vertical fields (referred to as vertical fields), and the accuracy of this method is low.
本公开提供了一种实体识别方法,应用于终端。该方法中,基于设定词典库以及互信息和左右信息熵,进行实体词的识别,不需要准备大量数据进行模型训练或部署,以进行冷启动,难度较低,效率和准确率更好。另外,该方法不仅可应用于智能客服领域,也可应用于其他涉及实体词识别的领域,适用性较广。The present disclosure provides an entity identification method, which is applied to a terminal. In this method, entity word recognition is performed based on the set dictionary base, mutual information and left and right information entropy, and it is not necessary to prepare a large amount of data for model training or deployment for cold start, which is less difficult, and has better efficiency and accuracy. In addition, this method can be applied not only to the field of intelligent customer service, but also to other fields involving entity word recognition, and has wide applicability.
在一个示例性实施例中,提供了一种实体识别方法,应用于终端。参考图1所示,该方法包括:In an exemplary embodiment, an entity identification method is provided, which is applied to a terminal. Referring to Figure 1, the method includes:
S110、获取待识别语句;S110, obtaining the sentence to be recognized;
S120、基于设定词典库对待识别语句进行识别,确定第一识别结果;S120, identifying the sentence to be identified based on the set dictionary base, and determining a first identification result;
S130、判断第一识别结果是否包括待识别语句的全部实体词;若确定第一识别结果包括待识别语句的全部实体词,则执行步骤S140;若确定第一识别结果未包括待识别语句的全部实体词,则执行步骤S150和S160;S130, determine whether the first recognition result includes all the entity words of the sentence to be recognized; if it is determined that the first recognition result includes all the entity words of the sentence to be recognized, then execute step S140; if it is determined that the first recognition result does not include all of the sentence to be recognized entity word, then perform steps S150 and S160;
S140、将第一识别结果确定为目标识别结果;S140, determining the first recognition result as the target recognition result;
S150、基于互信息和左右信息熵对待识别语句进行识别,确定待定识别结果;S150, identifying the sentence to be identified based on mutual information and left and right information entropy, and determining a pending identification result;
S160、根据第一识别结果和待定识别结果,确定目标识别结果。S160. Determine the target recognition result according to the first recognition result and the pending recognition result.
在步骤S110中,待识别语句可以是用户通过手动方式输入的,也可以是用户通过语音方式输入的,也可以是终端识别的非用户的语音,或者终端从其他终端接收的,对此不作限定。需要说明的是,当终端接收到语音信息后,需要通过语音识别将语音信息转换为文本形式的待识别语句,以使得终端获取待识别语句。In step S110, the sentence to be recognized may be input by the user manually, or input by the user by voice, or may be a non-user's voice recognized by the terminal, or received by the terminal from other terminals, which is not limited. . It should be noted that, after the terminal receives the voice information, the voice information needs to be converted into a sentence to be recognized in the form of text through voice recognition, so that the terminal can obtain the sentence to be recognized.
在步骤S120中,设定词典库可以是终端出厂前设置的,也可以是终端出厂后设置的,另外,设定词典库设置完成后,后续也可对其进行修改。其中,设定词典库可包括多组设定词对,设定词对可以包括设定词和该设定词的拼音,设定词为实体词。另外,对设定词典库的修改可包括,删除设定词典库中的设定词、在设定词典库增加新的设定词、修改设定词典库中的设定词等等,对此不作限定。In step S120, the setting dictionary base may be set before the terminal leaves the factory, or it may be set after the terminal leaves the factory. In addition, after the setting of the setting dictionary base is completed, it may be modified subsequently. The set dictionary library may include multiple sets of set word pairs, the set word pairs may include a set word and the pinyin of the set word, and the set word is an entity word. In addition, the modification to the setting dictionary base may include deleting set words in the setting dictionary base, adding new setting words to the setting dictionary base, modifying setting words in the setting dictionary base, and so on. Not limited.
其中,设定词典库可根据实际需要设置,对此不作限定。例如,设定词典库可以是一个或多个(包括两个)垂直领域的设定词构成的词典库,也就是,设定词典库可以用于识别设定的垂直领域的实体词,也可以用于识别广域(即多个垂直领域)的实体词。其中,垂直领域可包括智能客服领域、医疗领域、娱乐领域、教育领域以及体育领域等等。Wherein, the set dictionary library can be set according to actual needs, which is not limited. For example, the set dictionary base can be a dictionary base composed of set words in one or more (including two) vertical fields, that is, the set dictionary base can be used to identify the entity words of the set vertical fields, or it can be Entity words used to identify broad domains (i.e. multiple vertical domains). Among them, vertical fields can include intelligent customer service field, medical field, entertainment field, education field, sports field and so on.
该步骤中,可通过设定词典库对待识别语句进行实体词的识别,然后由识别出的实体词构成第一识别结果。识别出的实体词在设定词典库中均存在对应的设定词对。示例地,可基于设定词典库使用正则匹配(又称为规则匹配)的方式对待识别语句进行实体识别。In this step, entity words can be identified by setting a dictionary base for the sentences to be identified, and then a first identification result is formed by the identified entity words. The identified entity words all have corresponding set word pairs in the set dictionary database. For example, the to-be-recognized sentence can be recognized by the way of regular matching (also known as rule matching) based on setting the dictionary base.
在步骤S130中,从第一识别结果中确定待识别语句中的最后一个实体词,确定此实体词在待识别语句中的位置,然后确定待识别语句的上述实体词后的剩余字的数量,记为剩余字数量。另外,确定第一识别结果中每个实体词包括的字的数量,记为实体词字数量。In step S130, the last entity word in the sentence to be recognized is determined from the first recognition result, the position of the entity word in the sentence to be recognized is determined, and then the number of remaining words after the above entity word of the sentence to be recognized is determined, Record as the number of remaining words. In addition, the number of characters included in each entity word in the first recognition result is determined, which is recorded as the number of entity words.
若每个实体词对应的实体词字数量均大于剩余字数量,则说明剩余字无法构成实体词,便可确定第一识别结果包括待识别语句的全部实体词。若至少一个实体词对应的实体词字数量小于或等于剩余字数量,则说明剩余字可能构成实体词,便可确定第一识别结果未包括待识别语句的全部实体词。If the number of entity words corresponding to each entity word is greater than the number of remaining words, it means that the remaining words cannot constitute entity words, and it can be determined that the first recognition result includes all the entity words of the sentence to be recognized. If the number of entity words corresponding to at least one entity word is less than or equal to the number of remaining words, it indicates that the remaining words may constitute entity words, and it can be determined that the first recognition result does not include all the entity words of the sentence to be recognized.
示例1,Example 1,
使用词典和正则匹配方式对待识别语句进行实体词识别,确定由实体词A、实体词B和实体词C构成的第一识别结果。然后,确定待识别语句中最后一个实体词为实体词C,然后确定待识别语句中实体词C后剩余字的数量,记为剩余字数量i。另外,确定实体词A的字数量,记为实体词字数量a;确定实体词B的字数量,记为实体词字数量b;确定实体词C的字数量,记为实体词字数量c。将剩余字数量i分别与实体词字数量a、实体词字数量b和实体词字数量c进行比较。若剩余字数量i大于或等于实体词字数量a、实体词字数量b和实体词字数量c任意一个实体词字数量,则确定第一识别结果未包括待识别语句的全部实体词;若剩余字数量i均小于实体词字数量a、实体词字数量b和实体词字数量c,则确定第一识别结果包括待识别语句的全部实体词。Entity word recognition is performed on the to-be-recognized sentence using a dictionary and regular matching, and a first recognition result consisting of entity word A, entity word B, and entity word C is determined. Then, it is determined that the last entity word in the sentence to be recognized is the entity word C, and then the number of remaining words after the entity word C in the sentence to be recognized is determined, which is recorded as the number of remaining words i. In addition, determine the number of characters of the entity word A, denoted as the number of entity words a; determine the number of characters of the entity word B, denoted as the number of entity words b; determine the number of characters of the entity word C, denoted as the number of entity words c. The remaining number of words i is compared with the number of entity words a, the number of entity words b, and the number of entity words c. If the number of remaining words i is greater than or equal to the number of entity words a, the number b of entity words and the number of entity words c, it is determined that the first recognition result does not include all the entity words of the sentence to be recognized; If the number of words i is all smaller than the number a of entity words, the number of entity words b, and the number of entity words c, it is determined that the first recognition result includes all the entity words of the sentence to be recognized.
在步骤S140中,由于已确定第一识别结果包括待识别语句的全部实体词,因此,便可直接将第一识别结果确定为实体识别的目标识别结果。也就是,将基于设定词典库得到的识别结果确定为目标识别结果。In step S140, since it has been determined that the first recognition result includes all the entity words of the sentence to be recognized, the first recognition result can be directly determined as the target recognition result of entity recognition. That is, the recognition result obtained based on the set dictionary base is determined as the target recognition result.
在步骤S150中,由于已确定第一识别结果未包括待识别语句的全部实体词,也就是,待识别语句中可能还包括其他实体词,因此,便可基于互信息和左右信息熵对待识别语句进行识别,将识别出的词确定为待定词,然后可将全部待定词构成的识别结果确定为待定识别结果。其中,左右信息熵又可简称为左右熵。In step S150, since it is determined that the first recognition result does not include all the entity words of the sentence to be recognized, that is, the sentence to be recognized may also include other entity words, therefore, the recognized sentence can be treated based on mutual information and left and right information entropy Recognition is performed, the recognized words are determined as undetermined words, and then the recognition result composed of all undetermined words can be determined as the undetermined recognition result. Among them, the left and right information entropy can also be referred to as left and right entropy.
在步骤S160中,可使用待定识别结果对第一识别结果进行修正,并将修正后的识别结果确定为目标识别结果,由于互信息和左右信息熵的实体识别结果较准确,因此,通过待定识别结果对第一识别结果进行修正,可以提高实体识别的可靠性。In step S160, the first recognition result can be modified by using the pending identification result, and the corrected identification result is determined as the target identification result. Since the entity identification results of mutual information and left and right information entropy are more accurate, the pending identification As a result, the first recognition result is modified, which can improve the reliability of entity recognition.
该方法中,基于设定词典库以及互信息和左右信息熵,进行实体词的识别,不需要准备大量数据进行模型训练或部署,以进行冷启动,难度较低,效率和准确率更好。另外,该方法不仅可应用于智能客服领域,也可应用于其他涉及实体词识别的领域,适用性较广,进一步提升用户的使用体验。In this method, entity word recognition is performed based on the set dictionary base, mutual information and left and right information entropy, and it is not necessary to prepare a large amount of data for model training or deployment for cold start, which is less difficult, and has better efficiency and accuracy. In addition, the method can be applied not only to the field of intelligent customer service, but also to other fields involving entity word recognition, and has wide applicability, further improving the user experience.
在一个示例性实施例中,提供了一种实体识别方法,应用于终端。该方法中,根据第一识别结果和待定识别结果,确定目标识别结果,可包括:In an exemplary embodiment, an entity identification method is provided, which is applied to a terminal. In the method, determining the target recognition result according to the first recognition result and the pending recognition result may include:
S210、将待定识别结果中,与第一识别结果的实体词不同的词,确定为待定实体词;S210, in the pending identification result, the word that is different from the entity word of the first identification result is determined as the pending entity word;
S230、根据满足第一设定条件的待定实体词,确定第二识别结果;S230, determining the second recognition result according to the undetermined entity word that satisfies the first set condition;
S240、根据第一识别结果和第二识别结果,确定目标识别结果。S240. Determine the target recognition result according to the first recognition result and the second recognition result.
在步骤S210中,待定识别结果包括多个待定词。可比较待定识别结果中的待定词与第一识别结果中的实体词,然后可将与全部实体词均不同的待定词,确定为待定实体词。In step S210, the pending recognition result includes a plurality of pending words. The pending word in the pending recognition result can be compared with the entity word in the first identification result, and then the pending word that is different from all the entity words can be determined as the pending entity word.
在步骤S220中,需要说明的是,使用互信息和左右信息熵对待识别语句进行识别时,可确定每个待定词对应的第一模型值和第二模型值。其中,第一模型值由互信息对应的模型计算得到,第二模型值由左右信息熵对应的模型计算得到。In step S220, it should be noted that when the to-be-identified sentence is recognized using mutual information and left-right information entropy, the first model value and the second model value corresponding to each undetermined word can be determined. The first model value is calculated from the model corresponding to the mutual information, and the second model value is calculated from the model corresponding to the left and right information entropy.
其中,待定实体词对应的第一模型值越大,说明此待定实体词为实体词的可能性越大;待定实体词对应的第二模型值越大,也说明此待定实体词为实体词的可能性越大。Among them, the larger the value of the first model corresponding to the undetermined entity word, the greater the possibility that the undetermined entity word is an entity word; the greater the second model value corresponding to the undetermined entity word, it also indicates that the undetermined entity word is an entity word. more likely.
该步骤中,若确定待定实体词对应的第一模型值大于或等于第一阈值,且确定此待定实体词对应的第二模型值大于或等于第二阈值,便可确定此待定实体词满足第一设定条件,便可将此待定实体词确定为第二实体词。然后将全部第二实体词构成的识别结果,确定为第二识别结果。In this step, if it is determined that the first model value corresponding to the pending entity word is greater than or equal to the first threshold, and it is determined that the second model value corresponding to the pending entity word is greater than or equal to the second threshold, it can be determined that the pending entity word satisfies the first threshold. Once the condition is set, the pending entity word can be determined as the second entity word. Then, the recognition results formed by all the second entity words are determined as the second recognition results.
其中,第一阈值可以是终端出厂前设置的,也可以是终端出厂后设置的,第一阈值设置完成后,后续也可对其进行修改。第一阈值的具体数值可根据实际需求设置,对此不作限定。例如,第一阈值可大于或等于0.75且小于或等于1。The first threshold may be set before the terminal leaves the factory, or may be set after the terminal leaves the factory. After the first threshold is set, it may be modified later. The specific value of the first threshold can be set according to actual requirements, which is not limited. For example, the first threshold may be greater than or equal to 0.75 and less than or equal to 1.
第二阈值的设置方式可参考第一阈值,第二阈值的具体数值可根据实际需求设置,对此不作限定。例如,第二阈值可大于或等于0.75且小于或等于1。The setting method of the second threshold may refer to the first threshold, and the specific value of the second threshold may be set according to actual requirements, which is not limited. For example, the second threshold may be greater than or equal to 0.75 and less than or equal to 1.
需要说明的是,第一阈值与第二阈值可以相同,也可以不同,对此不作限定。例如,第一阈值为0.75,第二阈值为0.75。再例如,第一阈值为0.85,第二阈值为0.80。另外,根据统计,第一阈值为0.85且第二阈值为0.80时,本方法的实体识别结果较好。It should be noted that, the first threshold and the second threshold may be the same or different, which are not limited. For example, the first threshold is 0.75 and the second threshold is 0.75. For another example, the first threshold is 0.85, and the second threshold is 0.80. In addition, according to statistics, when the first threshold is 0.85 and the second threshold is 0.80, the entity recognition result of this method is better.
示例1,Example 1,
第一阈值为0.85,第二阈值为0.80。The first threshold is 0.85 and the second threshold is 0.80.
待定识别结果中,与第一识别结果的实体词不同的词可包括,待定实体词D’、待定实体词E’和待定实体词F’。其中,待定实体词D’对应的第一模型值记为mD′1,待定实体词D’对应的第二模型值记为mD′2;待定实体词E’对应的第一模型值记为mE′1,待定实体词E’对应的第二模型值记为mE′2;待定实体词F’对应的第一模型值记为mF′1,待定实体词F’对应的第二模型值记为mF′2。In the pending recognition result, words different from the entity word of the first recognition result may include the pending entity word D', the pending entity word E', and the pending entity word F'. The first model value corresponding to the pending entity word D' is denoted as mD'1 , the second model value corresponding to the pending entity word D' is denoted as mD'2 ; the first model value corresponding to the pending entity word E' is denoted as m D'2 . is mE′1 , the second model value corresponding to the undetermined entity word E’ is marked as mE′2 ; the first model value corresponding to the undetermined entity word F’ is marked as mF′1 , and the first model value corresponding to the undetermined entity word F’ is marked as m F′1 . The two-model value is denoted as mF′2 .
其中,第一模型值mD′1小于0.85,第二模型值mD′2小于0.80,说明待定实体词D’不是实体词。第一模型值mE′1大于或等于0.85,第二模型值mE′2大于或等于0.80,说明待定实体词E’是实体词,便可将待定实体词E’确定为第二实体词E。第一模型值mF′1大于或等于0.85,第二模型值mF′2小于0.80,说明待定实体词F’不是实体词。Wherein, the first model value mD'1 is less than 0.85, and the second model value mD'2 is less than 0.80, indicating that the undetermined entity word D' is not an entity word. The first model value mE'1 is greater than or equal to 0.85, and the second model value mE'2 is greater than or equal to 0.80, indicating that the pending entity word E' is an entity word, and the pending entity word E' can be determined as the second entity word E. The first model value mF'1 is greater than or equal to 0.85, and the second model value mF'2 is less than 0.80, indicating that the undetermined entity word F' is not an entity word.
由此可知,该示例中,可将待定实体词E’确定为第二实体词E,第二识别结果包括第二实体词E。It can be seen that, in this example, the pending entity word E' can be determined as the second entity word E, and the second recognition result includes the second entity word E.
在步骤S240中,第一识别结果包括的实体词可记为第一实体词,第二识别结果包括的实体词可记为第二实体词。In step S240, the entity word included in the first recognition result may be recorded as the first entity word, and the entity word included in the second recognition result may be recorded as the second entity word.
在确定了第二识别结果后,便可由第一识别结果中的第一实体词和第二识别结果中的第二实体词构成识别结果,并可将此识别结果确定为目标识别结果,以此来确保实体识别的可靠性。After the second recognition result is determined, the recognition result can be composed of the first entity word in the first recognition result and the second entity word in the second recognition result, and the recognition result can be determined as the target recognition result, so as to to ensure the reliability of entity recognition.
示例2,Example 2,
第一识别结果包括第一实体词A、第一实体词B和第一实体词C,其中,确定待识别语句中最后一个实体词为第一实体词C。需要说明的是,此处的最后一个实体词指的是第一识别结果中位于待识别语句中位置最靠后的实体词。The first recognition result includes a first entity word A, a first entity word B, and a first entity word C, wherein the last entity word in the sentence to be recognized is determined to be the first entity word C. It should be noted that the last entity word here refers to the entity word located at the rearmost position in the sentence to be recognized in the first recognition result.
然后确定待识别语句中第一实体词C后剩余字的数量,记为剩余字数量i。另外,确定第一实体词A的字数量,记为实体词字数量a;确定第一实体词B的字数量,记为实体词字数量b;确定第一实体词C的字数量,记为实体词字数量c。将剩余字数量i分别与实体词字数量a、实体词字数量b和实体词字数量c进行比较。Then determine the number of remaining words after the first entity word C in the sentence to be recognized, and denote it as the number of remaining words i. In addition, determine the number of characters of the first entity word A, denoted as the number of entity words a; determine the number of characters of the first entity word B, denoted as the number of entity words b; determine the number of words of the first entity word C, denoted as The number of entity words c. The remaining number of words i is compared with the number of entity words a, the number of entity words b, and the number of entity words c.
其中,剩余字数量i大于或等于实体词字数量a、实体词字数量b和实体词字数量c任意一个实体词字数量,因此确定第一识别结果未包括待识别语句的全部实体词,然后基于互信息和左右信息熵对待识别语句进行识别,确定待定识别结果。Among them, the number of remaining words i is greater than or equal to the number of entity words a, the number of entity words b, and the number of entity words c. Therefore, it is determined that the first recognition result does not include all the entity words of the sentence to be recognized, and then Based on mutual information and left and right information entropy, the sentence to be recognized is recognized, and the pending recognition result is determined.
待定识别结果包括待定实体词A’、待定实体词B’、待定实体词C’、待定实体词D’、待定实体词E’和待定实体词F’。其中,待定实体词A’与第一实体词A相同,待定实体词B’与第一实体词B相同,待定实体词C’与第一实体词C相同,待定实体词D’、待定实体词E’和待定实体词F与上述三个第一实体词(即第一实体词A、第一实体词B和第一实体词C)均不同。The pending recognition result includes pending entity word A', pending entity word B', pending entity word C', pending entity word D', pending entity word E' and pending entity word F'. Among them, the pending entity word A' is the same as the first entity word A, the pending entity word B' is the same as the first entity word B, the pending entity word C' is the same as the first entity word C, the pending entity word D', the pending entity word E' and the undetermined entity word F are different from the above three first entity words (ie, the first entity word A, the first entity word B, and the first entity word C).
该示例2中,第一阈值为0.85,第二阈值为0.80。,待定实体词D’对应的第一模型值记为mD′1,待定实体词D’对应的第二模型值记为mD′2;待定实体词E’对应的第一模型值记为mE′1,待定实体词E’对应的第二模型值记为mE′2;待定实体词F’对应的第一模型值记为mF′1,待定实体词F’对应的第二模型值记为mF′2。In this example 2, the first threshold is 0.85, and the second threshold is 0.80. , the first model value corresponding to the pending entity word D' is denoted as mD'1 , the second model value corresponding to the pending entity word D' is denoted as mD'2 ; the first model value corresponding to the pending entity word E' is denoted as mE'1 , the second model value corresponding to the undetermined entity word E' is marked as mE'2 ; the first model value corresponding to the undetermined entity word F' is marked as mF'1 , and the second model value corresponding to the undetermined entity word F' The model value is denoted as mF′2 .
其中,第一模型值mD′1小于0.85,第二模型值mD′2小于0.80,说明待定实体词D’不是实体词。第一模型值mE′1大于或等于0.85,第二模型值mE′2大于或等于0.80,说明待定实体词E’是实体词,便可将待定实体词E’确定为第二实体词E。第一模型值mF′1大于或等于0.85,第二模型值mF′2小于0.80,说明待定实体词F’不是实体词。Wherein, the first model value mD'1 is less than 0.85, and the second model value mD'2 is less than 0.80, indicating that the undetermined entity word D' is not an entity word. The first model value mE'1 is greater than or equal to 0.85, and the second model value mE'2 is greater than or equal to 0.80, indicating that the pending entity word E' is an entity word, and the pending entity word E' can be determined as the second entity word E. The first model value mF'1 is greater than or equal to 0.85, and the second model value mF'2 is less than 0.80, indicating that the undetermined entity word F' is not an entity word.
由此可知,该示例中,可将待定实体词E’确定为第二实体词E,然后将第二实体词E构成的识别结果,确定为第二识别结果。也就是,第二识别结果包括第二实体词E。It can be seen from this that in this example, the pending entity word E' can be determined as the second entity word E, and then the recognition result formed by the second entity word E can be determined as the second recognition result. That is, the second recognition result includes the second entity word E.
然后将第一识别结果包括的第一实体词A、第一实体词B和第一实体词C,以及第二识别结果包括的第二实体词E,构成新的识别结果,该识别结果确定为目标识别结果。目标识别结果包括第一实体词A、第一实体词B、第一实体词C以及第二实体词E。Then, the first entity word A, the first entity word B and the first entity word C included in the first recognition result, and the second entity word E included in the second recognition result constitute a new recognition result, and the recognition result is determined as target recognition result. The target recognition result includes the first entity word A, the first entity word B, the first entity word C, and the second entity word E.
该方法中,可通过互信息和左右信息熵的识别结果对第一识别结果进行修订,从而得到更加实体识别更加准确的目标识别结果,提升了用户使用体验。In this method, the first recognition result can be revised based on the recognition results of mutual information and left and right information entropy, so as to obtain a target recognition result with more entity recognition and more accurate, and improve the user experience.
在一个示例性实施例中,提供了一种实体识别方法,应用于终端。该方法中,设定词典库可通过以下方式得到:In an exemplary embodiment, an entity identification method is provided, which is applied to a terminal. In this method, the set dictionary library can be obtained in the following ways:
S310、根据设定领域的语句,确定语句库;S310. Determine a statement library according to the statement in the set field;
S320、对语句库中的语句进行分词处理,确定第一词语库;S320, performing word segmentation processing on the sentences in the sentence database to determine the first word database;
S330、基于互信息和左右信息熵对语句库的语句进行识别,确定待定词语库;S330, identifying the sentences in the sentence database based on mutual information and left and right information entropy, and determining the to-be-determined word database;
S340、根据第一词语库和待定词语库,确定设定词典库。S340. Determine and set a dictionary database according to the first word database and the pending word database.
在步骤S310中,设定领域可以包括至少一个垂直领域,设定领域也可以是广域,即设定领域可不限定于垂直领域。需要说明的是,广域与垂域(即垂直领域)是对应的概念,本方法中,广域指不限定于一个或多个(包括两个)垂直领域的领域,广域可以理解为全域。In step S310, the set domain may include at least one vertical domain, and the set domain may also be a wide domain, that is, the set domain may not be limited to the vertical domain. It should be noted that wide area and vertical area (ie, vertical area) are corresponding concepts. In this method, wide area refers to a field that is not limited to one or more (including two) vertical areas, and wide area can be understood as the whole area .
其中,当设定领域包括至少一个垂直领域时,设定词典库可以用于识别上述至少一个垂直领域的实体词。当设定领域为广域时,设定词典库可以用于识别广域的实体词,也就是可用于识别任意领域的实体词。其中,垂直领域可包括智能客服领域、医疗领域、娱乐领域、教育领域以及体育领域等等。Wherein, when the set domain includes at least one vertical domain, the set dictionary base can be used to identify the entity words of the at least one vertical domain. When the set domain is a wide domain, the set dictionary base can be used to identify entity words in a wide domain, that is, can be used to identify entity words in any domain. Among them, vertical fields can include intelligent customer service field, medical field, entertainment field, education field, sports field and so on.
该步骤中,可收集大量的设定领域的语句,并由收集到的语句构成语句库。其中,语句库中的语句数量越多,最终确定的设定词典库中的设定词对越丰富,本方法的实体识别结果的可靠性越高。In this step, a large number of sentences for setting the field can be collected, and a sentence library can be formed from the collected sentences. The greater the number of sentences in the sentence base, the more abundant the set word pairs in the set dictionary base finally determined, and the higher the reliability of the entity recognition result of the method.
在步骤S320中,可通过分词工具对语句库中的语句进行分词处理,以确定多个实体词,并将确定出的实体词确定为设定词,然后由全部设定词构成第一词语库。也就是,第一词语库包括多个设定词。其中,分词工具可包括hanLP(Han Language Processing,汉语言处理包)、Jieba(又称结巴分词)或开源的CRF++(其中CRF又称为条件随机场)等等,对此不作限定。In step S320, a word segmentation tool can be used to perform word segmentation on the sentences in the sentence database to determine a plurality of entity words, and the determined entity words are determined as setting words, and then the first word database is composed of all the setting words . That is, the first word bank includes a plurality of set words. The word segmentation tool may include hanLP (Han Language Processing, Chinese language processing package), Jieba (also known as stuttering word segmentation), or open source CRF++ (where CRF is also known as conditional random field), etc., which are not limited.
在步骤S330中,可基于互信息与左右信息熵对语句库的语句进行识别,并由识别出的词构成待定词语库。In step S330, the sentences in the sentence library may be identified based on the mutual information and the left and right information entropy, and the undetermined word library is formed from the identified words.
其中,基于互信息和左右信息熵对语句库的语句进行识别,可参考基于互信息和左右信息熵对待识别语句进行识别的过程,对此不作赘述。Wherein, to identify sentences in the sentence library based on mutual information and left and right information entropy, reference may be made to the process of identifying sentences to be identified based on mutual information and left and right information entropy, which will not be repeated.
在步骤S340中,可使用待定词语库对第一词语库进行修正,然后对修正后词语库中的设定词进行拼音转换,得到每个设定词对应的拼音,并将每个设定词以及该设定词对应的拼音,确定为一个设定词对。最后,由全部设定词对构成设定词典库。其中,可使用拼音转换工具确定设定词对应的拼音。In step S340, the first word database may be modified by using the undetermined word database, and then the set words in the corrected word database are converted into pinyin to obtain the corresponding pinyin of each set word, and each set word is converted into pinyin. And the corresponding pinyin of the set word is determined as a set word pair. Finally, a set dictionary library is formed from all set word pairs. The pinyin corresponding to the set word can be determined by using a pinyin conversion tool.
其中,由于互信息和左右信息熵的实体识别结果较准确,因此,通过待定词语库对第一词语库进行修正,可以提高设定词典库的可靠性,进而提升本方法的实体识别结果的可靠性。Among them, since the entity recognition results of mutual information and left and right information entropy are relatively accurate, the first word database is modified through the pending word database, which can improve the reliability of the set dictionary database, thereby improving the reliability of the entity recognition result of this method. sex.
该方法中,基于分词工具以及互信息和左右信息熵,对语句库中的语句进行识别,自动生成设定词典库,不需要过多的人工参与,节省成本,且可提高构建设定词典库的效率以及设定词典库的可靠性。另外,该方法不仅可应用于构建智能客服领域的设定词典库,也可应用于其他涉及实体词识别的领域的设定词典库,进而扩大本方法的实体识别的适用领域。In this method, based on the word segmentation tool, mutual information and left and right information entropy, the sentences in the sentence library are identified, and the set dictionary library is automatically generated, which does not require too much manual participation, saves costs, and can improve the construction of the set dictionary library. efficiency and reliability of setting the dictionary base. In addition, the method can not only be applied to construct a set dictionary base in the field of intelligent customer service, but also can be applied to set dictionary bases in other fields involving entity word recognition, thereby expanding the applicable field of entity recognition of this method.
在一个示例性实施例中,提供了一种实体识别方法,应用于终端。该方法中,根据第一词语库和待定词语库,确定设定词典库,可包括:In an exemplary embodiment, an entity identification method is provided, which is applied to a terminal. In the method, according to the first word database and the pending word database, determining and setting the dictionary database may include:
S410、将待定词语库中,与第一词语库的设定词不同的词,确定为待定设定词;S410, determining words in the undetermined word library that are different from the set words of the first word library as undetermined set words;
S420、根据满足第二设定条件的待定设定词,确定第二词语库;S420, according to the pending set words that satisfy the second set condition, determine the second word database;
S430、根据第一词语库和第二词语库,确定设定词典库。S430: Determine and set a dictionary database according to the first word database and the second word database.
其中,步骤S410可参考其他实施例中的步骤S210,步骤S420可参考其他实施例中的步骤S220。Wherein, step S410 may refer to step S210 in other embodiments, and step S420 may refer to step S220 in other embodiments.
在步骤S410中,待定词语库可包括多个待定词。可比较待定词语库中的待定词与第一词语库中的设定词,然后可将与任意设定词均不同的待定词,确定为待定设定词。In step S410, the pending word database may include a plurality of pending words. The undetermined words in the undetermined word database can be compared with the set words in the first word database, and then the undetermined words that are different from any set words can be determined as the undetermined set words.
在步骤S420中,若确定待定设定词对应的第一模型值大于或等于第三阈值,且确定此待定设定词对应的第二模型值大于或等于第四阈值,便可确定此待定设定词满足第二设定条件,便可将此待定设定词确定为第二设定词。然后将全部第二设定词构成的词语库,确定为第二词语库。In step S420, if it is determined that the first model value corresponding to the pending setting word is greater than or equal to the third threshold, and it is determined that the second model value corresponding to the pending setting word is greater than or equal to the fourth threshold, the pending setting can be determined If the determiner satisfies the second setting condition, the pending setting word can be determined as the second setting word. Then, the word database composed of all the second set words is determined as the second word database.
其中,第三阈值与第一阈值可以相同,也可以不同,对此不作限定。第四阈值与第二阈值可以相同,也可以不同,对此不作限定。示例地,第一阈值、第二阈值、第三阈值和第四阈值均可大于或等于0.75且小于或等于1。The third threshold and the first threshold may be the same or different, which is not limited. The fourth threshold and the second threshold may be the same or different, which is not limited. For example, the first threshold, the second threshold, the third threshold and the fourth threshold may all be greater than or equal to 0.75 and less than or equal to 1.
例如,第一阈值和第三阈值均为0.85,第二阈值和第四阈值均为0.80。For example, the first and third thresholds are both 0.85, and the second and fourth thresholds are both 0.80.
在步骤S430中,第一词语库包括的设定词可记为第一设定词,第二词语库包括的设定词可记为第二设定词。In step S430 , the setting words included in the first word database may be recorded as first setting words, and the setting words included in the second word database may be recorded as second setting words.
在确定了第二词语库后,便可由第一词语库中的第一设定词和第二词语库中的第二设定词构成新的词语库,该词语库可记为目标词语库。然后可使用拼音转换工具对目标词语库中的设定词进行拼音转换,确定每个设定词对应的拼音,并将每个设定词以及该设定词对应的拼音确定为该设定词对应的设定词对,然后由全部设定词对应的设定词对构成设定词典库。也就是,设定词典库包括多个设定词对,以此来确保设定词典库的可靠性,进而提升本方法的实体识别的可靠性。After the second word database is determined, a new word database can be formed by the first set words in the first word database and the second set words in the second word database, and the word database can be recorded as a target word database. Then, the pinyin conversion tool can be used to convert the set words in the target word database into pinyin, determine the corresponding pinyin of each set word, and determine each set word and the corresponding pinyin of the set word as the set word The corresponding set word pairs, and then the set word pairs corresponding to all the set words constitute the set dictionary library. That is, the set dictionary base includes a plurality of set word pairs, so as to ensure the reliability of the set dictionary base, thereby improving the reliability of entity recognition of the present method.
该方法中,可通过互信息和左右信息熵识别得到的待定词语库对第一词语库进行修订,从而得到可靠性更好的设定词典库,进而提升本方法的实体识别的可靠性,提升用户使用体验。In this method, the first word database can be revised through the pending word database identified by mutual information and left and right information entropy, so as to obtain a set dictionary database with better reliability, thereby improving the reliability of entity recognition in this method, and improving the User experience.
在一个示例性实施例中,提供一种实体识别装置,应用于终端。该装置用于实施上述的方法,示例地,参考图2所示,该装置可包括获取模块101和确定模块102,该装置在实施上述方法的过程中,In an exemplary embodiment, an entity identification apparatus is provided, which is applied to a terminal. The apparatus is used to implement the above-mentioned method. For example, as shown in FIG. 2 , the apparatus may include an
获取模块101,用于获取待识别语句;an
确定模块102,用于基于设定词典库对待识别语句进行识别,确定第一识别结果;A
还用于若确定第一识别结果未包括待识别语句的全部实体词,则基于互信息和左右信息熵对待识别语句进行识别,确定待定识别结果;It is also used to identify the to-be-recognized sentence based on mutual information and left and right information entropy, and determine the to-be-determined recognition result if it is determined that the first recognition result does not include all the entity words of the sentence to be recognized;
还用于根据第一识别结果和待定识别结果,确定目标识别结果。It is also used for determining the target recognition result according to the first recognition result and the pending recognition result.
在一个示例性实施例中,提供一种实体识别装置,应用于终端。参考图2所示,该装置中,确定模块102,用于:In an exemplary embodiment, an entity identification apparatus is provided, which is applied to a terminal. Referring to Fig. 2, in the apparatus, the determining
将待定识别结果中,与第一识别结果的实体词不同的词,确定为待定实体词;In the pending recognition result, words that are different from the entity words of the first recognition result are determined as pending entity words;
根据满足第一设定条件的待定实体词,确定第二识别结果;Determine the second recognition result according to the undetermined entity word that satisfies the first set condition;
根据第一识别结果和第二识别结果,确定目标识别结果。According to the first recognition result and the second recognition result, the target recognition result is determined.
在一个示例性实施例中,提供一种实体识别装置,应用于终端。参考图2所示,该装置中,确定模块102,用于:In an exemplary embodiment, an entity identification apparatus is provided, which is applied to a terminal. Referring to Fig. 2, in the apparatus, the determining
若确定待定实体词的第一模型值大于或等于第一阈值,且确定此待定实体词的第二模型值大于或等于第二阈值,则将此待定实体词确定为第二实体词;If it is determined that the first model value of the pending entity word is greater than or equal to the first threshold, and it is determined that the second model value of the pending entity word is greater than or equal to the second threshold, determining the pending entity word as the second entity word;
将全部第二实体词构成的识别结果,确定为第二识别结果。The recognition results formed by all the second entity words are determined as the second recognition results.
在一个示例性实施例中,提供一种实体识别装置,应用于终端。参考图2所示,该装置中,确定模块102,用于:In an exemplary embodiment, an entity identification apparatus is provided, which is applied to a terminal. Referring to Fig. 2, in the apparatus, the determining
若确定第一识别结果包括待识别语句的全部实体词,则将第一识别结果确定为目标识别结果。If it is determined that the first recognition result includes all the entity words of the sentence to be recognized, the first recognition result is determined as the target recognition result.
在一个示例性实施例中,提供了一种终端,终端例如为手机、笔记本电脑、平板电脑以及可穿戴设备等。In an exemplary embodiment, a terminal is provided, such as a mobile phone, a notebook computer, a tablet computer, a wearable device, and the like.
参考图3所示,终端400可以包括以下一个或多个组件:处理组件402,存储器404,电源组件406,多媒体组件408,音频组件410,输入/输出(I/O)的接口412,传感器组件414,以及通信组件416。3, the terminal 400 may include one or more of the following components: a
处理组件402通常控制终端400的整体操作,诸如与显示,电话呼叫,数据通信,相机操作和记录操作相关联的操作。处理组件402可以包括一个或多个处理器420来执行指令,以完成上述的方法的全部或部分步骤。此外,处理组件402可以包括一个或多个模块,便于处理组件402和其他组件之间的交互。例如,处理组件402可以包括多媒体模块,以方便多媒体组件408和处理组件402之间的交互。The
存储器404被配置为存储各种类型的数据以支持在终端400的操作。这些数据的示例包括用于在终端400上操作的任何应用程序或方法的指令,联系人数据,电话簿数据,消息,图片,视频等。存储器404可以由任何类型的易失性或非易失性存储终端或者它们的组合实现,如静态随机存取存储器(SRAM),电可擦除可编程只读存储器(EEPROM),可擦除可编程只读存储器(EPROM),可编程只读存储器(PROM),只读存储器(ROM),磁存储器,快闪存储器,磁盘或光盘。
电源组件406为终端400的各种组件提供电力。电源组件406可以包括电源管理系统,一个或多个电源,及其他与为终端400生成、管理和分配电力相关联的组件。
多媒体组件408包括在终端400和用户之间的提供一个输出接口的屏幕。在一些实施例中,屏幕可以包括液晶显示器(LCD)和触摸面板(TP)。如果屏幕包括触摸面板,屏幕可以被实现为触摸屏,以接收来自用户的输入信号。触摸面板包括一个或多个触摸传感器以感测触摸、滑动和触摸面板上的手势。触摸传感器可以不仅感测触摸或滑动动作的边界,而且还检测与触摸或滑动操作相关的持续时间和压力。在一些实施例中,多媒体组件408包括一个前置相机应用和/或后置相机应用。当终端400处于操作模式,如拍摄模式或视频模式时,前置相机应用和/或后置相机应用可以接收外部的多媒体数据。每个前置相机应用和后置相机应用可以是一个固定的光学透镜系统或具有焦距和光学变焦能力。
音频组件410被配置为输出和/或输入音频信号。例如,音频组件410包括一个麦克风(MIC),当终端400处于操作模式,如呼叫模式、记录模式和语音识别模式时,麦克风被配置为接收外部音频信号。所接收的音频信号可以被进一步存储在存储器404或经由通信组件416发送。在一些实施例中,音频组件410还包括一个扬声器,用于输出音频信号。
I/O接口412为处理组件402和外围接口模块之间提供接口,上述外围接口模块可以是键盘,点击轮,按钮等。这些按钮可包括但不限于:主页按钮、音量按钮、启动按钮和锁定按钮。The I/
传感器组件414包括一个或多个传感器,用于为终端400提供各个方面的状态评估。例如,传感器组件414可以检测到终端400的打开/关闭状态,组件的相对定位,例如组件为终端400的显示器和小键盘,传感器组件414还可以检测终端400或终端400一个组件的位置改变,用户与终端400接触的存在或不存在,终端400方位或加速/减速和终端400的温度变化。传感器组件414可以包括接近传感器,被配置用来在没有任何的物理接触时检测附近物体的存在。传感器组件414还可以包括光传感器,如CMOS或CCD图像传感器,用于在成像应用中使用。在一些实施例中,该传感器组件414还可以包括加速度传感器,陀螺仪传感器,磁传感器,压力传感器或温度传感器。
通信组件416被配置为便于终端400和其他终端之间有线或无线方式的通信。终端700可以接入基于通信标准的无线网络,如WiFi、2G、3G、4G、5G或它们的组合。在一个示例性实施例中,通信组件416经由广播信道接收来自外部广播管理系统的广播信号或广播相关信息。在一个示例性实施例中,通信组件416还包括近场通信(NFC)模块,以促进短程通信。例如,在NFC模块可基于射频识别(RFID)技术,红外数据协会(IrDA)技术,超宽带(UWB)技术,蓝牙(BT)技术和其他技术来实现。
在示例性实施例中,终端400可以被一个或多个应用专用集成电路(ASIC)、数字信号处理器(DSP)、数字信号处理终端(DSPD)、可编程逻辑器件(PLD)、现场可编程门阵列(FPGA)、控制器、微控制器、微处理器或其他电子元件实现,用于执行上述的方法。In an exemplary embodiment, terminal 400 may be implemented by one or more application specific integrated circuits (ASICs), digital signal processors (DSPs), digital signal processing terminals (DSPDs), programmable logic devices (PLDs), field programmable A gate array (FPGA), controller, microcontroller, microprocessor or other electronic component implementation for performing the above-described method.
在一个示例性实施例中,还提供了一种包括指令的非临时性计算机可读存储介质,例如包括指令的存储器404,上述指令可由终端400的处理器420执行以完成上述方法。例如,非临时性计算机可读存储介质可以是ROM、随机存取存储器(RAM)、CD-ROM、磁带、软盘和光数据存储终端等。当存储介质中的指令由终端的处理器执行时,使得终端能够执行上述实施例中示出的方法。In an exemplary embodiment, a non-transitory computer-readable storage medium including instructions, such as a
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本公开的其它实施方案。本公开旨在涵盖本公开的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本公开的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本公开的真正范围和精神由权利要求指出。Other embodiments of the present disclosure will readily occur to those skilled in the art upon consideration of the specification and practice of the invention disclosed herein. This disclosure is intended to cover any variations, uses, or adaptations of this disclosure that follow the general principles of this disclosure and include common general knowledge or techniques in the technical field not disclosed by this disclosure . The specification and examples are to be regarded as exemplary only, with the true scope and spirit of the disclosure being indicated by the claims.
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本公开的其它实施方案。本公开旨在涵盖本公开的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本公开的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本公开的真正范围和精神由下面的权利要求指出。Other embodiments of the present disclosure will readily occur to those skilled in the art upon consideration of the specification and practice of the invention disclosed herein. This disclosure is intended to cover any variations, uses, or adaptations of this disclosure that follow the general principles of this disclosure and include common general knowledge or techniques in the technical field not disclosed by this disclosure . The specification and examples are to be regarded as exemplary only, with the true scope and spirit of the disclosure being indicated by the following claims.
应当理解的是,本公开并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本公开的范围仅由所附的权利要求来限制。It is to be understood that the present disclosure is not limited to the precise structures described above and illustrated in the accompanying drawings, and that various modifications and changes may be made without departing from the scope thereof. The scope of the present disclosure is limited only by the appended claims.
Claims (13)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210128678.2ACN114462410A (en) | 2022-02-11 | 2022-02-11 | Entity identification method, device, terminal and storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210128678.2ACN114462410A (en) | 2022-02-11 | 2022-02-11 | Entity identification method, device, terminal and storage medium |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN114462410Atrue CN114462410A (en) | 2022-05-10 |
Family
ID=81412676
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210128678.2APendingCN114462410A (en) | 2022-02-11 | 2022-02-11 | Entity identification method, device, terminal and storage medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114462410A (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115034211A (en)* | 2022-05-19 | 2022-09-09 | 一点灵犀信息技术(广州)有限公司 | Unknown word discovery method and device, electronic equipment and storage medium |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108021558A (en)* | 2017-12-27 | 2018-05-11 | 北京金山安全软件有限公司 | Keyword recognition method and device, electronic equipment and storage medium |
| CN110826335A (en)* | 2019-11-14 | 2020-02-21 | 北京明略软件系统有限公司 | A method and apparatus for named entity recognition |
| CN111651990A (en)* | 2020-04-14 | 2020-09-11 | 车智互联(北京)科技有限公司 | Entity identification method, computing equipment and readable storage medium |
| WO2021051872A1 (en)* | 2019-09-18 | 2021-03-25 | 平安科技(深圳)有限公司 | Entity identification method, device, apparatus, and computer readable storage medium |
- 2022
- 2022-02-11CNCN202210128678.2Apatent/CN114462410A/enactivePending
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108021558A (en)* | 2017-12-27 | 2018-05-11 | 北京金山安全软件有限公司 | Keyword recognition method and device, electronic equipment and storage medium |
| WO2021051872A1 (en)* | 2019-09-18 | 2021-03-25 | 平安科技(深圳)有限公司 | Entity identification method, device, apparatus, and computer readable storage medium |
| CN110826335A (en)* | 2019-11-14 | 2020-02-21 | 北京明略软件系统有限公司 | A method and apparatus for named entity recognition |
| CN111651990A (en)* | 2020-04-14 | 2020-09-11 | 车智互联(北京)科技有限公司 | Entity identification method, computing equipment and readable storage medium |
Non-Patent Citations (1)
| Title |
|---|
| 姜涛等: "无监督分词算法在新词识别中的应用", 小型微型计算机系统, no. 04, 9 April 2020 (2020-04-09)* |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115034211A (en)* | 2022-05-19 | 2022-09-09 | 一点灵犀信息技术(广州)有限公司 | Unknown word discovery method and device, electronic equipment and storage medium |
| CN115034211B (en)* | 2022-05-19 | 2023-04-18 | 一点灵犀信息技术(广州)有限公司 | Unknown word discovery method and device, electronic equipment and storage medium |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102338918B1 (en) | Method, device and storage medium for training machine translation model | |
| CN107944447B (en) | Image classification method and device | |
| WO2021208666A1 (en) | Character recognition method and apparatus, electronic device, and storage medium | |
| CN111461304B (en) | Classification neural network training methods, text classification methods, devices and equipment | |
| CN109360197B (en) | Image processing method and device, electronic equipment and storage medium | |
| CN107564526B (en) | Processing method, apparatus and machine-readable medium | |
| CN113420553B (en) | Text generation method, device, storage medium and electronic device | |
| CN110633470A (en) | Named entity recognition method, device and storage medium | |
| CN107832691B (en) | Micro-expression identification method and device | |
| CN110619325A (en) | Text recognition method and device | |
| CN110135349A (en) | Recognition methods, device, equipment and storage medium | |
| CN112631435B (en) | Input method, device, equipment and storage medium | |
| CN110389666B (en) | Input error correction method and device | |
| CN108241438B (en) | Input method, input device and input device | |
| CN114462410A (en) | Entity identification method, device, terminal and storage medium | |
| CN111984765B (en) | Knowledge base question-answering process relation detection method and device | |
| CN112331194B (en) | Input method and device and electronic equipment | |
| CN112002313B (en) | Interaction method and device, sound box, electronic equipment and storage medium | |
| EP4586131A1 (en) | Entity information determining method and apparatus, and device | |
| CN113807540B (en) | A data processing method and device | |
| CN114443814A (en) | Reply information output method, device, device and storage medium | |
| CN114328989B (en) | Media information processing method, device, electronic device and storage medium | |
| CN111178086A (en) | Data processing method, apparatus and medium | |
| CN114690912B (en) | Input method, device and electronic device | |
| CN112926343B (en) | Data processing method, device and electronic equipment |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |