CN114445909A - Method, device, storage medium and device for training an automatic recognition model of cue words - Google Patents
Method, device, storage medium and device for training an automatic recognition model of cue wordsDownload PDFInfo
- Publication number
- CN114445909A CN114445909ACN202111601585.9ACN202111601585ACN114445909ACN 114445909 ACN114445909 ACN 114445909ACN 202111601585 ACN202111601585 ACN 202111601585ACN 114445909 ACN114445909 ACN 114445909A
- Authority
- CN
- China
- Prior art keywords
- model
- server
- training
- clue
- client
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images









Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/25—Fusion techniques
- G06F18/253—Fusion techniques of extracted features
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/044—Recurrent networks, e.g. Hopfield networks
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Life Sciences & Earth Sciences (AREA)
- Artificial Intelligence (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Evolutionary Computation (AREA)
- Bioinformatics & Computational Biology (AREA)
- Computational Linguistics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Evolutionary Biology (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Image Analysis (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本发明属于模型训练技术领域,尤其涉及一种线索语自动识别模型训练方法、装置、存储介质及设备。The invention belongs to the technical field of model training, and in particular relates to a method, device, storage medium and equipment for automatic recognition model training of clues.
背景技术Background technique
随着当前社会的发展和生活质量的提高,残疾人之间的交流问题越来越受到社会的重视。据世界卫生组织(WHO)的报告,全球现在约有4.66亿人有听力障碍,其中3400万是儿童。With the development of the current society and the improvement of the quality of life, the issue of communication among persons with disabilities has been paid more and more attention by the society. According to the World Health Organization (WHO), about 466 million people worldwide are now hearing impaired, of which 34 million are children.
唇读(Lip reading)是较早出现的帮助聋哑人之间感知语音的方式。但是,据研究,由于唇读中的不同语音可能会有相似的唇形,例如[u]和[y],这种混淆导致仅靠唇形的语音识别效果不佳。为了解决该不足,美国Gallaudet大学的R. Orin Cornett教授于1967年发明了一种利用手势来辅助唇读的交流方法,称作 Cued Speech(CS),中文译为线索语。在此系统中,手的位置用于编码元音,而手形用于编码辅音。具体来说,在英语CS中,4种手位置用来编码单元音,两种手的移动编码双元音以及8种手形编码辅音。Lip reading is an early way to help deaf people perceive speech. However, according to research, since different voices in lip reading may have similar lip shapes, such as [u] and [y], this confusion leads to poor performance of speech recognition based on lip shape alone. In order to solve this deficiency, Professor R. Orin Cornett of Gallaudet University in the United States invented a communication method using gestures to assist lip reading, called Cued Speech (CS), which is translated into cue language in Chinese. In this system, hand position is used to encode vowels and hand shape is used to encode consonants. Specifically, in English CS, 4 kinds of hand positions are used to encode vowels, two kinds of hand movements are used to encode diphthongs, and 8 kinds of hand shapes are used to encode consonants.
鉴于听力障碍人群在全球的广泛分布以及CS越来越普遍的应用,为了使聋哑人的沟通更加便利和高效,亟待开发一个基于人工智能的CS视频到文本的自动识别模型受到越来越多来自国家、社会、业界以及学术界的关注。利用人工智能技术对CS图像视频内容的智能分析和建模已成为我国残疾人事业发展应用中的重大关键技术,对推动残疾人辅助智慧系统化以及保障智能健康产品的创新发展等都将发挥重要的作用。In view of the wide distribution of hearing-impaired people in the world and the increasingly common application of CS, in order to make the communication of deaf people more convenient and efficient, it is urgent to develop an AI-based CS video-to-text automatic recognition model. Attention from the state, society, industry and academia. The intelligent analysis and modeling of CS image and video content using artificial intelligence technology has become a major key technology in the development and application of the cause of the disabled in my country. effect.
发明内容SUMMARY OF THE INVENTION
本发明实施例提供一种线索语自动识别模型训练方法、装置、存储介质及设备,旨在解决背景技术当中的至少一问题。Embodiments of the present invention provide a method, device, storage medium, and device for training a cue language automatic recognition model, aiming to solve at least one problem in the background art.
本发明实施例是这样实现的,一种线索语自动识别模型训练方法,应用于服务器当中,所述服务器与多个客户端通讯连接,所述方法包括:The embodiments of the present invention are implemented in the following way: a method for training a cue language automatic recognition model is applied to a server, where the server is connected to a plurality of clients in communication, and the method includes:
S01,获取开源的线索语视频数据集,并采用所述开源的线索语视频数据集对服务器模型进行训练;S01, obtaining an open source clue language video data set, and using the open source clue language video data set to train a server model;
S02,随机选取多个目标客户端,并将所述服务器模型的当前全局模型参数下发给各个所述目标客户端,以使所述目标客户端基于所述当前全局模型参数和预设训练集对各自的客户端模型进行训练,所述客户端模型和所述服务器模型的架构相同;S02: Randomly select multiple target clients, and issue the current global model parameters of the server model to each of the target clients, so that the target clients are based on the current global model parameters and a preset training set training the respective client models, the client models and the server models have the same architecture;
S03,接收各所述目标客户端上传的当前客户端模型参数,并对各所述当前客户端模型参数进行聚合,并采用聚合后的模型参数对所述服务器模型进行更新,得到新的服务器模型;S03: Receive current client model parameters uploaded by each of the target clients, aggregate the current client model parameters, and update the server model by using the aggregated model parameters to obtain a new server model ;
重复执行步骤S02-步骤S03,直到服务器模型收敛,以训练得到线索语自动识别模型。Steps S02 to S03 are repeatedly executed until the server model converges, so as to obtain a clue word automatic recognition model through training.
优选地,在所述随机选取多个目标客户端,并将所述服务器模型的当前全局模型参数下发给各个所述目标客户端的步骤之前,还包括:Preferably, before the step of randomly selecting multiple target clients and issuing the current global model parameters of the server model to each of the target clients, the method further includes:
获取多个客户端上传的经预设加密算法加密之后的线索语视频,得到由获取的加密线索语视频组成的共享数据集。Acquire the clue video uploaded by multiple clients after encryption by the preset encryption algorithm, and obtain a shared data set composed of the obtained encrypted clue video.
优选地,所述随机选取多个目标客户端,并将所述服务器模型的当前全局模型参数下发给各个所述目标客户端的步骤包括:Preferably, the step of randomly selecting multiple target clients and issuing the current global model parameters of the server model to each of the target clients includes:
随机选取多个目标客户端,并将所述服务器模型的当前全局模型参数下发给各个所述目标客户端,并按预设比例从所述共享数据集当中选取部分共享数据下发到各所述目标客户端;Randomly select a plurality of target clients, and issue the current global model parameters of the server model to each of the target clients, and select a portion of the shared data from the shared data set according to a preset ratio and issue it to each institute. the target client;
其中,所述预设训练集包括所述目标客户端的本地数据集和所述服务器当前下发的部分共享数据。The preset training set includes the local data set of the target client and part of the shared data currently delivered by the server.
优选地,所述目标客户端在上传当前客户端模型参数之前,对当前客户端模型进行裁剪并引入拉普拉斯噪声。Preferably, before uploading the parameters of the current client model, the target client clips the current client model and introduces Laplacian noise.
优选地,所述客户端模型和所述服务器模型的架构均包括:Preferably, the architectures of the client model and the server model include:
自监督增量学习联合模型,用于从数据集当中提取手形特征和嘴唇特征;Self-supervised incremental learning joint model for extracting hand and lip features from the dataset;
手位置识别识别模型,用于从数据集当中提取手位置特征;A recognition model for hand position recognition, which is used to extract hand position features from the dataset;
异步异质多模态时序对齐模型,用于基于手形特征、嘴唇特征和手位置特征,对手形和手位置的运动相对于嘴唇运动的超前量进行统计建模与预测,并利用预测得到的超前量在时序上调整手形特征和手位置特征,得到初步时序对齐的手形特征、嘴唇特征和手位置特征;Asynchronous heterogeneous multimodal time-series alignment model for statistical modeling and prediction based on hand shape features, lip features, and hand position features, and predicting the lead of the motion of the hand and hand position relative to the lip motion, and using the predicted lead Quantitatively adjust the hand shape feature and hand position feature in time sequence, and obtain the hand shape feature, lip feature and hand position feature of preliminary time sequence alignment;
融合模型,用于基于所述初步时序对齐的手形特征、嘴唇特征和手位置特征对线索语的音素类别进行预测识别。The fusion model is used for predicting and identifying the phoneme category of the cue speech based on the hand shape feature, lip feature and hand position feature of the preliminary time sequence alignment.
优选地,所述融合模型为由识别器、生成器和鉴别器构成的基于生成对抗训练的多模态融合模型。Preferably, the fusion model is a multimodal fusion model based on generative adversarial training composed of a discriminator, a generator and a discriminator.
本发明实施例还提供了一种线索语自动识别模型训练装置,应用于服务器当中,所述服务器与多个客户端通讯连接,所述装置包括:The embodiment of the present invention also provides a cue language automatic recognition model training device, which is applied to a server, where the server is communicatively connected with a plurality of clients, and the device includes:
预训练模块,用于获取开源的线索语视频数据集,并采用所述开源的线索语视频数据集对服务器模型进行训练;a pre-training module, used to obtain an open-source cue language video data set, and use the open source cue language video data set to train the server model;
数据下发模块,用于随机选取多个目标客户端,并将所述服务器模型的当前全局模型参数下发给各个所述目标客户端,以使所述目标客户端基于所述当前全局模型参数和预设训练集对各自的客户端模型进行训练,所述客户端模型和所述服务器模型的架构相同;A data distribution module is used to randomly select multiple target clients, and distribute the current global model parameters of the server model to each of the target clients, so that the target clients are based on the current global model parameters training the respective client models with the preset training set, and the client models and the server models have the same architecture;
模型更新模块,用于接收各所述目标客户端上传的当前客户端模型参数,并对各所述当前客户端模型参数进行聚合,并采用聚合后的模型参数对所述服务器模型进行更新,得到新的服务器模型;A model update module, configured to receive the current client model parameters uploaded by each of the target clients, aggregate the current client model parameters, and use the aggregated model parameters to update the server model to obtain new server model;
所述数据下发模块和所述模型更新模块重复执行,直到服务器模型收敛,以训练得到线索语自动识别模型。The data issuing module and the model updating module are repeatedly executed until the server model converges, so as to obtain a clue word automatic recognition model through training.
本发明实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上述的线索语自动识别模型训练方法。Embodiments of the present invention also provide a computer-readable storage medium, on which a computer program is stored, and when the program is executed by a processor, implements the above-mentioned training method for an automatic recognition model of clues.
本发明实施例还提供了一种服务器,包括存储器、处理器以及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述的线索语自动识别模型训练方法。An embodiment of the present invention further provides a server, including a memory, a processor, and a computer program stored in the memory and running on the processor, when the processor executes the program, the automatic recognition model for clue words as described above is implemented training method.
本发明所达到的有益效果为:通过提出一套训练线索语自动识别模型的方法,以期促进CS自动识别的研究成果真正走向应用,造福于聋哑人士以及更多有需要的人,与此同时,本方法由服务器和客户端共同完成对线索语自动识别模型的训练,使得客户端的隐私线索语视频(如自录CS视频)无需上传服务器,很好的保护了用户隐私,这样就能够使得更多的客户端愿意将其隐私线索语视频拿出来做模型训练,给模型训练提供充足的数据基础。The beneficial effects achieved by the invention are as follows: by proposing a set of methods for training the automatic recognition model of cue words, it is expected to promote the real application of the research results of automatic recognition of CS, so as to benefit the deaf people and more people in need, and at the same time In this method, the server and the client jointly complete the training of the automatic recognition model of cue words, so that the client's private cue language video (such as self-recorded CS video) does not need to be uploaded to the server, which well protects the user's privacy, so that more Many clients are willing to take out their privacy cue videos for model training, providing sufficient data foundation for model training.
附图说明Description of drawings
图1是本发明实施例一当中的线索语自动识别模型训练方法的流程图;1 is a flowchart of a method for training a cue language automatic recognition model in
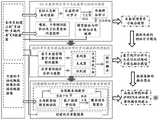
图2是本发明实施例提供的线索语自动识别模型训练方法的技术线路图;2 is a technical circuit diagram of a method for training a cue language automatic recognition model provided by an embodiment of the present invention;
图3是本发明实施例提供的自监督增量学习联合模型的结构图;3 is a structural diagram of a self-supervised incremental learning joint model provided by an embodiment of the present invention;
图4是本发明实施例提供的变量为目标时刻t情形下的几个重要统计量;Fig. 4 is several important statistics under the situation that the variable provided by the embodiment of the present invention is the target time t;
图5是本发明实施例提供的基于生成对抗训练的多模态融合模型的结构图;5 is a structural diagram of a multimodal fusion model based on generative adversarial training provided by an embodiment of the present invention;
图6是本发明实施例提供的多模态特征融合模块的结构图;6 is a structural diagram of a multimodal feature fusion module provided by an embodiment of the present invention;
图7是本发明实施例提供的基于联邦学习的CS视听识别整体模型框架;7 is an overall model framework of CS audio-visual recognition based on federated learning provided by an embodiment of the present invention;
图8是本发明实施例提供的服务器模型和客户端模型的基准模型架构图;Fig. 8 is the benchmark model architecture diagram of the server model and the client model provided by an embodiment of the present invention;
图9是本发明实施例提供的m=3时的安全混合算法图例;FIG. 9 is an example of a security hybrid algorithm when m=3 provided by an embodiment of the present invention;
图10为本发明实施例三当中的线索语自动识别模型训练装置的结构框图;FIG. 10 is a structural block diagram of the apparatus for training an automatic recognition model for cue words in Embodiment 3 of the present invention;
图11是本发明实施例四当中的服务器的结构框图。FIG. 11 is a structural block diagram of a server in Embodiment 4 of the present invention.
具体实施方式Detailed ways
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。In order to make the objectives, technical solutions and advantages of the present invention clearer, the present invention will be further described in detail below with reference to the accompanying drawings and embodiments. It should be understood that the specific embodiments described herein are only used to explain the present invention, but not to limit the present invention.
尽管CS自动识别的研究在近些年取得了比较好的发展,但距离一个高效且带隐私保护的CS自动识别模型还有很大一步。综上所述,此领域的理论研究仍有以下三点不足与挑战。本发明也旨在解决这三个关键的科学问题。Although the research on CS automatic identification has achieved relatively good development in recent years, there is still a big step away from an efficient and privacy-protected CS automatic identification model. To sum up, the theoretical research in this field still has the following three deficiencies and challenges. The present invention also aims to solve these three key scientific problems.
(1)带噪标注与数据分布不平衡下的CS多模态特征表征能力受限:之前的自动CS手形特征提取方法要么对外界环境条件要求高,要么依赖大规模的准确标注数据。然而大量CS视频数据的标注需要耗费巨大的代价,同时要求标注者掌握CS的相关专业背景知识。用自动的标注方法会产生噪声标签。另外,由于真实世界中数据分布的不平衡特性,采集到的CS数据往往呈现手形类别分布不平衡的现象。值得注意的是,随着视频数据流的时序递增,视频数据的不平衡现象会逐步加重。深度学习模型在不平衡视频数据集上进行训练很难学习到公平高质量的特征,容易忽略样本数量较少的类别。因此,有必要对不依赖标注的无监督学习和数据分布无偏学习的协同机制进行深入研究。利用无监督深度神经网络进行更强的特征表征学习是CS自动识别研究面临的第一个重要挑战。(1) CS multi-modal feature representation capability is limited under noisy annotation and data distribution imbalance: previous automatic CS hand-shape feature extraction methods either require high external environmental conditions or rely on large-scale accurate annotation data. However, the annotation of a large amount of CS video data requires a huge cost, and at the same time requires the annotator to master the relevant professional background knowledge of CS. Using automatic labeling methods will generate noisy labels. In addition, due to the unbalanced nature of data distribution in the real world, the collected CS data often presents an unbalanced distribution of hand-shaped categories. It is worth noting that, as the timing of the video data stream increases, the imbalance of the video data will gradually increase. It is difficult for deep learning models to learn fair and high-quality features when trained on imbalanced video datasets, and it is easy to ignore categories with a small number of samples. Therefore, it is necessary to conduct in-depth research on the synergistic mechanism of label-independent unsupervised learning and data distribution unbiased learning. The use of unsupervised deep neural networks for stronger feature representation learning is the first important challenge for CS automatic recognition research.
(2)CS异步多模态对齐与融合效果不佳:CS视频多模态间时序的异步性会造成信息融合中模态间时序信息互相干扰,多个异质模态的信息难以互相补充和增强。受CS数据量小(即小样本)、带噪标注及类别分布不平衡的影响,之前的CS融合研究以及现有的显式、隐式对齐融合方法都不能有效地减少异步多模态之间信息不对齐带来的干扰。因此,有必要对异步多模态信息对齐和信息融合方式的优化机制进行深入研究。利用多模态数据的互补和增强性质对异步异质多模态CS视频数据进行充分融合是CS自动识别研究面临的第二个重要挑战。(2) The effect of CS asynchronous multi-modal alignment and fusion is not good: the asynchrony of the CS video multi-modal timing will cause the inter-modal timing information to interfere with each other in the information fusion, and the information of multiple heterogeneous modalities is difficult to complement each other. enhanced. Affected by the small amount of CS data (i.e., small samples), noisy annotations, and unbalanced class distribution, previous CS fusion research and existing explicit and implicit alignment fusion methods cannot effectively reduce the number of asynchronous multimodal interactions. Disturbance caused by misalignment of information. Therefore, it is necessary to conduct in-depth research on the optimization mechanism of asynchronous multimodal information alignment and information fusion. Using the complementary and augmented properties of multimodal data to fully fuse asynchronous heterogeneous multimodal CS video data is the second important challenge for CS automatic identification research.
(3)缺乏带数据隐私保护的CS自动识别模型:之前的CS自动识别方法主要关注如何提高模型性能,缺乏对CS训练数据隐私保护的深入研究。聋哑人数据的隐私保护对CS自动识别模型的进一步发展、实际落地和应用推广是一个亟需解决的问题。直接将客户端中的数据上传到服务器上进行共享训练容易暴露用户隐私信息,同时来自不同CS编码者视频数据的非独立同分布也对视频隐私信息保护造成一定困难。我们指出,如果能保护模型训练时数据提供者的隐私,会大大激励数据录制者或机构给我们提供更多的数据。这将在很大程度上帮助我们解决上述数据获取的困难。因此,有必要对带隐私保护的CS自动识别模型的训练机制进行深入研究。在保证CS自动识别高准确率的同时探索联邦学习加密共享训练机制对CS自动识别中数据隐私进行保护是本发明的第三个重要挑战。(3) Lack of CS automatic identification models with data privacy protection: The previous CS automatic identification methods mainly focused on how to improve model performance, and lacked in-depth research on CS training data privacy protection. The privacy protection of deaf-mute data is an urgent problem to be solved for the further development, practical implementation and application promotion of CS automatic identification model. Uploading the data from the client directly to the server for shared training is easy to expose user privacy information, and the non-IID distribution of video data from different CS encoders also makes it difficult to protect video privacy information. We point out that if the privacy of data providers during model training can be protected, data recorders or institutions will be greatly incentivized to provide us with more data. This will help us to a large extent to solve the above-mentioned difficulties in data acquisition. Therefore, it is necessary to conduct in-depth research on the training mechanism of the CS automatic recognition model with privacy protection. The third important challenge of the present invention is to explore the federated learning encryption sharing training mechanism to protect data privacy in CS automatic identification while ensuring high accuracy of CS automatic identification.
针对上述CS自动识别研究中的三点不足与挑战,本发明实施例提出了一种线索语自动识别模型训练方法,以能够建立一个基于联邦学习理论框架的带隐私保护的CS自动识别模型,以期促进CS自动识别的研究成果真正走向应用,造福于聋哑人士以及更多有需要的人。这具有重要的社会经济意义。同时,本发明拟解决的三个科学问题在其他领域也备受关注。例如,听力障碍者早期教育、语音纠正和治疗、视听识别中的隐私保护、机器人、视听转换以及人机互动等领域。Aiming at the above three deficiencies and challenges in the research on CS automatic identification, the embodiment of the present invention proposes a method for training a cue language automatic identification model, so as to be able to establish a CS automatic identification model with privacy protection based on the theoretical framework of federated learning, in order to The research results that promote the automatic identification of CS are truly applied, benefiting the deaf and the needy. This has important socioeconomic implications. At the same time, the three scientific problems to be solved by the present invention have also attracted much attention in other fields. For example, early education for the hearing impaired, speech correction and treatment, privacy protection in audiovisual recognition, robotics, audiovisual conversion, and human-computer interaction.
实施例一Example 1
请参阅图1,所示为本发明实施例一当中的线索语自动识别模型训练方法,应用于服务器当中,所述服务器与多个客户端通讯连接,所述方法具体包括步骤S01-步骤S04。Referring to FIG. 1 , a method for training an automatic recognition model of clue words in
步骤S01,获取开源的线索语视频数据集,并采用所述开源的线索语视频数据集对服务器模型进行训练。In step S01, an open-source clue language video data set is obtained, and the server model is trained by using the open source clue language video data set.
其中,开源的线索语视频数据集可以为网络上公开的线索语视频,即采用收集到的公开线索语视频先对服务器模型进行预训练,使模型具备初始的全局模型参数。Among them, the open source video data set of clues can be the videos of clues published on the Internet, that is, the collected public clues videos are used to pre-train the server model, so that the model has the initial global model parameters.
步骤S02,随机选取多个目标客户端,并将所述服务器模型的当前全局模型参数下发给各个所述目标客户端,以使所述目标客户端基于所述当前全局模型参数和预设训练集对各自的客户端模型进行训练,所述客户端模型和所述服务器模型的架构相同。Step S02, randomly select multiple target clients, and issue the current global model parameters of the server model to each of the target clients, so that the target clients are trained based on the current global model parameters and preset parameters Sets to train respective client models, the client model and the server model have the same architecture.
其中,目标客户端在上传当前客户端模型参数之前,对当前客户端模型进行裁剪并引入拉普拉斯噪声,即将客户端模型参数裁剪分段上传并加入拉普拉斯噪声,以此来避免恶意的服务器或外部攻击者通过参与者上传的模型参数窃取数据信息。Among them, before uploading the current client model parameters, the target client clips the current client model and introduces Laplacian noise, that is, uploads the client model parameters clipping in sections and adds Laplacian noise to avoid Malicious servers or external attackers steal data information through model parameters uploaded by participants.
步骤S03,接收各所述目标客户端上传的当前客户端模型参数,并对各所述当前客户端模型参数进行聚合,并采用聚合后的模型参数对所述服务器模型进行更新,得到新的服务器模型。Step S03: Receive current client model parameters uploaded by each of the target clients, aggregate the current client model parameters, and use the aggregated model parameters to update the server model to obtain a new server Model.
步骤S04,重复执行步骤S02-步骤S03,直到服务器模型收敛,以训练得到线索语自动识别模型。In step S04, steps S02 to S03 are repeatedly executed until the server model converges, so as to obtain a clue word automatic recognition model through training.
具体地,在本实施例一些较佳实施例当中,如图5和图8所示,所述客户端模型和所述服务器模型的基准架构均包括:Specifically, in some preferred embodiments of this embodiment, as shown in FIG. 5 and FIG. 8 , the reference architectures of the client model and the server model include:
自监督增量学习联合模型,用于从数据集当中提取手形特征和嘴唇特征;Self-supervised incremental learning joint model for extracting hand and lip features from the dataset;
手位置识别识别模型,用于从数据集当中提取手位置特征,所述手位置识别识别模型具体由YOLO算法来实现;A hand position recognition and recognition model is used to extract hand position features from the data set, and the hand position recognition and recognition model is specifically implemented by the YOLO algorithm;
异步异质多模态时序对齐模型,用于基于手形特征、嘴唇特征和手位置特征,对手形和手位置的运动相对于嘴唇运动的超前量进行统计建模与预测,并利用预测得到的超前量在时序上调整手形特征和手位置特征,得到初步时序对齐的手形特征、嘴唇特征和手位置特征;Asynchronous heterogeneous multimodal time-series alignment model for statistical modeling and prediction based on hand shape features, lip features, and hand position features, and predicting the lead of the motion of the hand and hand position relative to the lip motion, and using the predicted lead Quantitatively adjust the hand shape feature and hand position feature in time sequence, and obtain the hand shape feature, lip feature and hand position feature of preliminary time sequence alignment;
融合模型,用于基于所述初步时序对齐的手形特征、嘴唇特征和手位置特征对线索语的音素类别进行预测识别。所述融合模型具体为由识别器、生成器和鉴别器构成的基于生成对抗训练的多模态融合模型,如图5所示。The fusion model is used for predicting and identifying the phoneme category of the cue speech based on the hand shape feature, lip feature and hand position feature of the preliminary time sequence alignment. The fusion model is specifically a multimodal fusion model based on generative adversarial training composed of a discriminator, a generator and a discriminator, as shown in FIG. 5 .
实施例二Embodiment 2
本发明实施例二也提出一种线索语自动识别模型训练方法,本实施例当中的线索语自动识别模型训练方法与实施例一当中的线索语自动识别模型训练方法的不同之处在于:The second embodiment of the present invention also provides a method for training a cue language automatic recognition model. The difference between the cue language automatic recognition model training method in this embodiment and the cue language automatic recognition model training method in the first embodiment is:
在所述随机选取多个目标客户端,并将所述服务器模型的当前全局模型参数下发给各个所述目标客户端的步骤之前,还包括:Before the step of randomly selecting multiple target clients and issuing the current global model parameters of the server model to each of the target clients, the method further includes:
获取多个客户端上传的经预设加密算法加密之后的线索语视频,得到由获取的加密线索语视频组成的共享数据集。Acquire the clue video uploaded by multiple clients after encryption by the preset encryption algorithm, and obtain a shared data set composed of the obtained encrypted clue video.
基于此,所述随机选取多个目标客户端,并将所述服务器模型的当前全局模型参数下发给各个所述目标客户端的步骤包括:Based on this, the steps of randomly selecting multiple target clients and issuing the current global model parameters of the server model to each of the target clients include:
随机选取多个目标客户端,并将所述服务器模型的当前全局模型参数下发给各个所述目标客户端,并按预设比例从所述共享数据集当中选取部分共享数据下发到各所述目标客户端;Randomly select a plurality of target clients, and issue the current global model parameters of the server model to each of the target clients, and select a portion of the shared data from the shared data set according to a preset ratio and issue it to each institute. the target client;
其中,所述预设训练集包括所述目标客户端的本地数据集和所述服务器当前下发的部分共享数据。The preset training set includes the local data set of the target client and part of the shared data currently delivered by the server.
请参阅图2,本发明实施例当中的线索语自动识别模型训练方法的技术路线为:首先,基于自监督学习机制和无偏学习的协同建模,高效提取CS视频中的手形特征和嘴形特征;然后,为这些异步异质多模态特征流探索最优的融合方法;最后,在联邦学习的理论框架下,构建一个高效且带隐私保护的CS 自动识别模型。具体阐述为如下三部分。Referring to FIG. 2 , the technical route of the method for training a cue language automatic recognition model in the embodiment of the present invention is as follows: first, based on the self-supervised learning mechanism and collaborative modeling of unbiased learning, the hand shape features and mouth shapes in the CS video are efficiently extracted features; then, explore the optimal fusion method for these asynchronous heterogeneous multimodal feature streams; finally, under the theoretical framework of federated learning, an efficient and privacy-preserving CS automatic recognition model is constructed. The detailed description is divided into the following three parts.
一、针对上述CS自动识别研究中的第(1)点不足与挑战,本实施例提出了CS多模态特征的自监督对比学习与无偏学习的协同建模,此研究共分为三个阶段。第一阶段是针对自监督对比学习的理论分析和建模,第二阶段是构建自监督增量学习联合模型(如图3所示),第三阶段是测试验证和评估。1. In view of the shortcomings and challenges of point (1) in the above-mentioned CS automatic identification research, this embodiment proposes the self-supervised contrastive learning of CS multi-modal features and the collaborative modeling of unbiased learning. This research is divided into three stage. The first stage is theoretical analysis and modeling for self-supervised contrastive learning, the second stage is to build a joint model of self-supervised incremental learning (as shown in Figure 3), and the third stage is test verification and evaluation.
(1)构建自监督对比学习中高效生成正负样本对的方法:发明拟采取自监督对比学习方法减小在CS手形特征提取过程中数据带噪标注的影响。其中,对比学习中最关键的一步是数据变换模块中生成合适的正负样本对进行对比学习。之前的研究大多都是基于启发式的选取方法,没有量化的指标规定正负样本对选取的具体标准。本发明将探究视频数据的时空约束关系,提出一种由互信息控制的时空一致性变换方法,以期寻找最优的正负样本对的数据变换方法。具体技术路线及关键技术阐述如下:(1) Build a method for efficiently generating positive and negative sample pairs in self-supervised contrastive learning: The invention proposes to adopt a self-supervised contrastive learning method to reduce the influence of noisy data annotations in the process of CS hand shape feature extraction. Among them, the most critical step in comparative learning is to generate suitable positive and negative sample pairs in the data transformation module for comparative learning. Most of the previous studies are based on heuristic selection methods, and there is no quantitative index to specify the specific criteria for the selection of positive and negative samples. The present invention will explore the space-time constraint relationship of video data, and propose a space-time consistency transformation method controlled by mutual information, in order to find the optimal data transformation method for positive and negative sample pairs. The specific technical route and key technologies are described as follows:
互信息控制的时空一致性变换:现有的对比学习算法大都采用人工设计(即选取相邻帧做为正样本,时间上远离的帧作为负样本),以及自动搜索的数据变换方法生成正负样本对。为了获得一组好的数据变换方法,往往需要进行大量的实验,并且这些数据变换方法通常具有随机性,无法可控地生成所需的正负样本对。由此,本发明针对视频数据流提出一种基于互信息控制的时空相似度一致性变换的方法。该方法可以适用于各种传统的数据变换方法,并且能够通过控制互信息来生成最佳的样本对。首先,在自监督对比学习的场景下,从视频的时间维度出发,将视频进行语义聚类,抽取时序上具有相同语义的两帧进行特征变换作为正样本对,以克服传统算法对视频中的每一帧都进行数据变换来生成正样本对,没有考虑到视频帧语义(即标签)是否相同的问题。其次,从图像的空间特征角度出发,通过控制不同数据变换的强度得到具有适宜大小互信息的样本。Spatial-temporal consistency transformation controlled by mutual information: Most of the existing contrastive learning algorithms use manual design (that is, select adjacent frames as positive samples, and temporally distant frames as negative samples), and the data transformation method of automatic search generates positive and negative samples. sample pair. In order to obtain a good set of data transformation methods, a large number of experiments are often required, and these data transformation methods are usually random and cannot controllably generate the required positive and negative sample pairs. Therefore, the present invention proposes a method for coherent transformation of spatiotemporal similarity based on mutual information control for video data streams. This method can be applied to various traditional data transformation methods, and can generate optimal sample pairs by controlling mutual information. First, in the context of self-supervised contrastive learning, starting from the time dimension of the video, the video is semantically clustered, and two frames with the same semantics in time sequence are extracted for feature transformation as a positive sample pair to overcome the traditional algorithm. Data transformation is performed for each frame to generate positive sample pairs, without considering whether the video frame semantics (i.e. labels) are the same. Secondly, from the perspective of the spatial characteristics of the image, the samples with suitable size mutual information are obtained by controlling the intensity of different data transformations.
在InfoMin理论中,有以下命题1,其中I≥0为互信息。In InfoMin theory, there is the following
命题1:给定图片样本x,标签为y,x生成的最佳正样本对u*和v*为:Proposition 1: Given a picture sample x, the label is y, the best positive sample pair u* and v* generated by x is:
(u*,v*)=argminu,uI(u,v),(u* ,v* )=argminu,u I(u,v),
s.t.I(u,y)=I(v,y)=I(x,y).s.t.I(u,y)=I(v,y)=I(x,y).
根据命题1,InfoMin给出的方法是针对静态图片,只考虑到了图片空间特征的关系,不适用于本发明我们自身任务的特点。现在,我们同时考虑时空一致性约束,得出以下命题:According to
命题2:假设fi∈A是任意数据变换,A是包含多种数据变换的集合。τi,τj(τi≠τj)是从视频中采样图片的两个不同时刻,V代表视频数据,



andy1=y2,y3=y4,y1≠y3.andy1 =y2 , y3 =y4 , y1 ≠y3 .
因此,视频V生成的良好正样本对为


上述优化问题以InfoMin理论为支撑,针对视频数据的特点,加入时序语义信息和空间特征的信息协同约束,从时域上对视频帧进行语义划分(聚类),将具有相同隐标签的样本作为正样本,实现语义均衡的对比学习,避免了对标签出现多样本的无效学习;同时,此方法通过最小化样本的互信息减少正样本对之间的冗余信息,以期进一步提升模型训练的有效性。至此,我们将自监督对比学习中生成良好正负样本对的问题转化为上述命题2中的优化问题,通过利用互信息来控制样本对之间的时空信息量进行正负样本对的生成。The above optimization problem is supported by InfoMin theory. According to the characteristics of video data, the information synergy constraints of time-series semantic information and spatial features are added, and the video frames are semantically divided (clustered) from the time domain, and the samples with the same latent label are used as Positive samples, achieve semantically balanced comparative learning, and avoid invalid learning of multiple samples for labels; at the same time, this method reduces redundant information between positive sample pairs by minimizing the mutual information of samples, in order to further improve the effectiveness of model training. sex. So far, we have transformed the problem of generating good positive and negative sample pairs in self-supervised contrastive learning into the optimization problem in Proposition 2 above, by using mutual information to control the amount of spatiotemporal information between sample pairs to generate positive and negative sample pairs.
(2)构建自监督增量学习联合模型:初始阶段,首先基于CS视频数据流,通过重采样技术进行数据处理,用于构建无偏的验证样本集,然后结合上述基于互信息控制的时空相似度一致性变换的自监督对比学习,提取高质量样本特征。中期阶段,针对不同时刻的视频数据流,引入两种梯度约束来对模型进行增量训练:1)通过不同时刻参数间的梯度内积进行约束,防止模型的灾难性遗忘;2)通过同一时刻训练集和验证集上参数间的梯度内积进行约束,保证模型的无偏学习。后期阶段,随着视频数据流的不断更新,特征提取模型通过以上增量的方式持续学习,同时可扩展到不同数据或不同任务,直到视频数据流停止或无新任务出现。基于此增量学习框架,我们预期得到更适应于现实CS多模态数据流的特征表征学习模型。具体技术路线以及关键技术可阐述如下:(2) Constructing a self-supervised incremental learning joint model: In the initial stage, firstly, based on the CS video data stream, the data is processed by resampling technology to construct an unbiased verification sample set, and then combined with the above-mentioned spatial-temporal similarity based on mutual information control Self-supervised contrastive learning of degree-consistent transformations to extract high-quality sample features. In the middle stage, two gradient constraints are introduced to incrementally train the model for video data streams at different times: 1) Constraints by the gradient inner product between parameters at different times to prevent catastrophic forgetting of the model; 2) Through the same moment The gradient inner product between the parameters on the training set and the validation set is constrained to ensure unbiased learning of the model. In the later stage, with the continuous update of the video data stream, the feature extraction model continues to learn through the above incremental methods, and can be extended to different data or different tasks until the video data stream stops or no new tasks appear. Based on this incremental learning framework, we expect to obtain a feature representation learning model that is more suitable for real CS multimodal data flow. The specific technical route and key technologies can be described as follows:
对于数据分布不平衡或噪声标签影响下的有偏数据分布,首先要约束视频数据流对模型的增量更新。对于不同时刻的数据流,在t时刻,将样本表示为(xt, yt),损失函数表示为l(f(xt,θt),yt),则关于模型参数θt的梯度可表示为:For biased data distribution under the influence of unbalanced data distribution or noisy labels, the incremental update of the model by the video data stream should be constrained first. For data streams at different times, at time t, the sample is represented as (xt , yt ), and the loss function is represented as l(f(xt , θt ), yt ), then the gradient of the model parameter θt can be expressed as:

同理,我们可以得到关于模型参数在k(k<t)时刻的梯度表示。为了防止新增数据造成的模型灾难性遗忘问题(即一旦使用新数据集训练已有模型,该模型将会失去对原数据集识别的能力),我们令t时刻的模型参数为以下优化问题的解:In the same way, we can get the gradient representation of the model parameters at time k (k < t). In order to prevent the catastrophic forgetting problem of the model caused by the new data (that is, once the existing model is trained with the new data set, the model will lose the ability to recognize the original data set), we set the model parameters at time t as the following optimization problems untie:
minl(f(xt,θt),yt),minl(f(xt ,θt ),yt ),
s.t.l(f(xt,θt),yt)≤l(f(xk,θk),yk),for all k<t.stl(f(xt ,θt ),yt )≤l(f(xk ,θk ),yk ),for all k<t.
为了避免保存所有时刻的模型参数状态并简化上述约束条件,可将其改写为以下梯度形式:To avoid saving the state of the model parameters at all times and to simplify the above constraints, it can be rewritten in the following gradient form:

为了防止有偏数据分布破坏模型的正常学习,我们首先要获得一个干净子集(xclean,yclean),简写为(xc,yc),即数据分布平衡且标签准确的样本集合。根据验证集的作用机制,模型在训练集上的学习和更新不能降低模型在验证集上的性能,即模型在训练集和验证集上的学习方向不冲突,从而可以保证模型在训练集上学习的无偏性。因此验证子集对模型的梯度应满足如下约束:In order to prevent the biased data distribution from destroying the normal learning of the model, we first need to obtain a clean subset (xclean , yclean ), abbreviated as (xc , yc ), that is, a set of samples with balanced data distribution and accurate labels. According to the action mechanism of the validation set, the learning and updating of the model on the training set cannot reduce the performance of the model on the validation set, that is, the learning directions of the model on the training set and the validation set do not conflict, so that the model can be guaranteed to learn on the training set. of unbiasedness. Therefore, the gradient of the validation subset to the model should satisfy the following constraints:

其中,

最终可通过求解如下的二次优化问题,得到在t时刻的模型参数梯度

通过以上两种条件的约束,在模型和视频数据流的增量更新过程中,模型的学习能够约束模型的更新朝着无偏的方向进行,同时可以防止新数据引起的灾难性遗忘问题。此方法在具体实施时,可能存在的不确定性问题有复杂样本分布重叠或者困难样本(如噪声样本)等。根据实际情况,我们还将探索样本分布解耦以及困难样本挖掘(如梯度和谐机制)等算法来克服这些可能的挑战。Through the constraints of the above two conditions, in the incremental update process of the model and video data stream, the learning of the model can constrain the update of the model to proceed in an unbiased direction, and at the same time, it can prevent the catastrophic forgetting problem caused by new data. During the specific implementation of this method, the possible uncertainty problems include overlapping distribution of complex samples or difficult samples (such as noise samples). Depending on the actual situation, we will also explore algorithms such as sample distribution decoupling and hard sample mining (such as gradient harmony mechanism) to overcome these possible challenges.
(3)模型验证与评估-特征分类任务:在模型验证与评估阶段,我们拟将全部CS数据分成训练集(占80%)和测试集(占20%)。在使用无标注数据完成自监督对比增量学习之后,我们拟用10%人工标注数据对下游手形特征分类模型进行微调,一方面可以得到更适应于CS数据的特征表征模型参数,另一方面能通过微调模型给出的预测结果对模型进行公正的验证与评估。我们拟使用两层非线性全连接层作为此模块的神经网络模型,并使用交叉熵损失函数,对自监督对比增量学习特征表征学习模块和特征分类任务模块的模型参数同时进行微调。(3) Model validation and evaluation - feature classification task: In the model validation and evaluation stage, we plan to divide all CS data into training set (80%) and test set (20%). After using unlabeled data to complete self-supervised comparative incremental learning, we plan to use 10% manually labeled data to fine-tune the downstream hand feature classification model. Unbiased validation and evaluation of the model by fine-tuning the predictions given by the model. We intend to use two non-linear fully connected layers as the neural network model of this module, and use the cross-entropy loss function to simultaneously fine-tune the model parameters of the self-supervised contrastive incremental learning feature representation learning module and the feature classification task module.
二、针对上述CS自动识别研究中的第(2)点不足与挑战,本实施例提出了关于异步异质多模态时序对齐以及生成对抗融合模型的设计与分析。2. In view of the deficiencies and challenges of point (2) in the above CS automatic identification research, this embodiment proposes the design and analysis of asynchronous heterogeneous multimodal timing alignment and generative adversarial fusion models.
CS多模态融合的两个重点是:1)分析异步多模态之间的对齐关系;2)对异步异质多模态进行充分的融合。因此,此研究分为以下两个阶段。具体阐述如下:The two focuses of CS multimodal fusion are: 1) to analyze the alignment relationship between asynchronous multimodalities; 2) to fully fuse asynchronous heterogeneous multimodalities. Therefore, this study is divided into the following two phases. The details are as follows:
(1)基于统计分析的多模态异步量化分析:之前的研究表明,在CS编码过程中,手运动通常会超前于嘴唇的运动。此异步问题是CS多模态融合的一个难点。之前的方法由于CS数据体量不够、带噪标注及数据分布不平衡等问题,不能很好地解决CS异步异构多模态融合问题。为了避免上述问题,并从统计意义上可解释地探究CS多模态之间异步量的规律,本发明拟结合申请人对CS 编码的先验知识,对CS多模态间的异步超前量进行精细的量化统计分析。(1) Multimodal asynchronous quantification analysis based on statistical analysis: Previous studies have shown that hand motion usually leads the lip motion during CS encoding. This asynchronous problem is a difficulty in CS multimodal fusion. Due to the problems of insufficient CS data volume, noisy annotation, and unbalanced data distribution, the previous methods cannot well solve the problem of CS asynchronous heterogeneous multimodal fusion. In order to avoid the above problems, and to explore the law of the asynchrony between CS multi-modalities in an interpretable statistical sense, the present invention intends to combine the applicant's prior knowledge of CS coding to carry out the analysis of the asynchronous lead between CS multi-modalities. Sophisticated quantitative statistical analysis.
请参阅图4,所示为变量为目标时刻t情形下的几个重要统计量。其中tv代表声音信号到达元音v的目标时刻,ttar_v代表手位置到达该元音的目标时刻,Δv=tv-ttar_v表示在实现元音v时,手位置超前于嘴唇的异步量。同理,对辅音元音c,Δc=tc-ttar_c为手形超前于嘴唇的异步量。Please refer to Figure 4, which shows several important statistics when the variable is the target time t. where tv represents the target moment when the sound signal reaches the vowel v, ttar_v represents the target moment when the hand position reaches the vowel, and Δv =tv -ttar_v indicates that when the vowel v is achieved, the hand position leads the asynchrony of the lips quantity. Similarly, for the consonant vowel c, Δc =tc -ttar_c is the asynchronous amount that the hand shape leads the lips.
我们首先人工标注数据集的10%个句子的手位置、手形以及嘴唇在实现音素的目标时刻,并计算它们对应的超前量(见图4),然后根据申请人之前对于 CS编码方面的先验知识,从三个角度着手,利用统计方差分析、假设检验以及逐步回归建模对得到的音素相应的异步量和音素所对应在句子中出现的归一化时刻(t)、音素类别(y)以及上下文相关的三音素类别(ytri)进行以下步骤的后向逐步回归建模:We first manually annotate the hand positions, hand shapes, and lips of 10% of the sentences in the dataset at the target moment of achieving the phoneme, and calculate their corresponding lead (see Figure 4), and then according to the applicant's prior CS coding Knowledge, starting from three perspectives, using statistical variance analysis, hypothesis testing and stepwise regression modeling to obtain the corresponding asynchrony of the phoneme and the normalized time (t) and phoneme category (y) that appear in the sentence corresponding to the phoneme and context-dependent triphone categories (ytri ) for backward stepwise regression modeling with the following steps:
1)建立t,y,ytri与异步量Δ的回归方程。对方程中的3个自变量进行F检验,取最小值



2)建立t,y与异步量Δ的回归方程。对方程中的回归系数进行F检验,取最小值



3)一直迭代下去,直到各变量的回归系数F值均大于临界值,即方程中没有变量可以剔除为止,此时的回归方程就是最优的。3) Iterate until the regression coefficient F value of each variable is greater than the critical value, that is, there is no variable in the equation that can be eliminated, and the regression equation at this time is optimal.
基于以上得到的最优回归方程,我们可以对手形和手位置的运动相对于嘴唇运动的超前量进行统计建模与预测,然后利用预测得到的超前量在时序上调整手特征,得到初步对齐的特征。本发明将在后续工作中结合实际统计数据的分布特点,进一步细化探索拟建立的回归方程的形式(例如线性回归、逻辑回归或者多项式回归等)。Based on the optimal regression equation obtained above, we can statistically model and predict the lead of the movement of the hand and hand position relative to the lip movement, and then use the predicted lead to adjust the hand features in time series to obtain a preliminary aligned feature. The present invention will further refine and explore the form of the regression equation to be established (such as linear regression, logistic regression, or polynomial regression, etc.) in the follow-up work in combination with the distribution characteristics of actual statistical data.
(2)基于生成对抗训练的多模态融合模型设计:进一步针对CS多模态异步异质的特点,为充分利用已有知识和挖掘数据内部隐含的空间及语义知识以达到不同模态信息互相增强的目的,本发明拟提出基于生成对抗训练的多模态融合模型。不同于传统的生成对抗网络仅通过生成器G和鉴别器D的两方博弈产生更好的输出,我们将创新性地引入第三方的识别器用于和生成器与鉴别器分别进行合作与竞争,形成三方游戏问题,其框架如图5所示。该框架由三方(即生成器、鉴别器、识别器)组成。多模态融合过程中,识别器模型训练包含音素类别信息,可以看作语义级别的约束。生成器与鉴别器的对抗训练更加关注图像细节信息,可以看作图像结构级别的约束。此框架将语义信息和结构信息同时引入到多模态融合中,能使得融合的特征更加鲁棒。(2) Design of multi-modal fusion model based on generative adversarial training: further aiming at the multi-modal asynchronous heterogeneity of CS, in order to make full use of existing knowledge and mine the hidden spatial and semantic knowledge in the data to achieve different modal information For the purpose of mutual reinforcement, the present invention proposes a multimodal fusion model based on generative adversarial training. Different from the traditional generative adversarial network, which only produces better output through the two-party game between the generator G and the discriminator D, we innovatively introduce a third-party discriminator to cooperate and compete with the generator and discriminator, respectively. The three-party game problem is formed, and its framework is shown in Figure 5. The framework consists of three parties (i.e. generator, discriminator, recognizer). In the multimodal fusion process, the recognizer model training contains phoneme category information, which can be regarded as a semantic-level constraint. The adversarial training of the generator and the discriminator pays more attention to the details of the image, which can be regarded as the constraints of the image structure level. This framework introduces both semantic information and structural information into multimodal fusion, which can make the fused features more robust.
在提出的多模态融合模型中,首先利用前面提出的自监督增量联合模型提取手形和嘴唇特征,并基于YOLO算法提取手位置特征。通过我们设计的特征融合模型(见图6)分别得到嘴唇-手位置特征、嘴唇-手形特征,并将这两个特征拼接融合作为最终的分类特征用以进行音素类别的预测识别。生成器合成嘴唇和手形图像,鉴别器对真实的图像和合成的图像进行辨别形成一种“竞争”关系,而识别器与生成器“合作”获取更多的数据提升模型的识别能力,在“合作竞争”的机制下统一求解多模态异质小样本数据融合问题。在优化的目标函数中,识别器的类别约束作为正则项,利用在线融合的不同模态样本进行迭代训练,实现在数据外观和语义特征上,同时提升音素类别预测质量。总的损失函数定义如下:In the proposed multimodal fusion model, the hand shape and lip features are first extracted using the previously proposed self-supervised incremental joint model, and hand position features are extracted based on the YOLO algorithm. The lip-hand position feature and lip-hand shape feature are obtained through the feature fusion model we designed (see Figure 6), and these two features are spliced and fused as the final classification feature for phoneme category prediction and recognition. The generator synthesizes lips and hand images, the discriminator discriminates between real images and synthetic images to form a "competitive" relationship, and the recognizer and the generator "cooperate" to obtain more data to improve the recognition ability of the model. Under the mechanism of "cooperative competition", the problem of multimodal heterogeneous small sample data fusion is solved uniformly. In the optimized objective function, the category constraint of the recognizer is used as a regular term, and different modal samples fused online are used for iterative training to achieve data appearance and semantic features, while improving the quality of phoneme category prediction. The total loss function is defined as follows:
L=LG+LD+βLR,L=LG +LD +βLR ,
其中,in,

这里LG,LD,LR分别是生成器、鉴别器和识别器的优化损失,x1,x2分别表示嘴唇和手形数据,G(x1,x2)是真实图像I合成的图像。w是识别器f的参数,用于对融合后的特征向量oi进行预测,y是对应的音素类别标签,常数α和β用于平衡各项的影响。Here LG , LD ,LR are the optimization losses of the generator, discriminator, and discriminator, respectively, x1 , x2 represent lips and hand shape data, respectively, G(x1 , x2 ) is the synthetic image of the real image I . w is the parameter of the recognizer f, which is used to predict the fused feature vector oi , y is the corresponding phoneme class label, and the constants α and β are used to balance the influence of each term.
下面对此模型的三个重要组成部分(识别器、生成器和鉴别器)进行详细阐述:The three important components of this model (recognizer, generator, and discriminator) are elaborated below:
1)识别器:在CS多模态学习过程中,融合不同模态之间的互补信息对于提高模型的性能有着非常重要的作用。本发明拟提出一种基于高效的多模态特征融合的识别器模型,从上一步初对齐后的多模态数据中挖掘模态间的关系,实现高效和高鲁棒性的音素类别预测。具体地,在前面基于数据分析的多模态异步量化分析获得初对齐多模态数据后,以自然图像上预训练的特征提取模型作为初始化,利用第一个研究方案中提出的自监督增量学习联合模型分别得到嘴唇特征、手位置特征和手形特征,并将其中两种特征进行组合(如嘴唇-手位置,嘴唇-手形),然后对组合后的特征进行拼接输入到全连接层进行音素预测。1) Recognizer: In the CS multimodal learning process, the fusion of complementary information between different modalities plays a very important role in improving the performance of the model. The present invention proposes a recognizer model based on efficient multi-modal feature fusion, which mines the relationship between modalities from the multi-modal data after initial alignment in the previous step, so as to achieve efficient and robust phoneme category prediction. Specifically, after obtaining the initial aligned multi-modal data from the multi-modal asynchronous quantitative analysis based on data analysis, the pre-trained feature extraction model on natural images is used as initialization, and the self-supervised increment proposed in the first research scheme is used as initialization. The joint model is learned to obtain the lip feature, hand position feature and hand shape feature respectively, and combine the two features (such as lip-hand position, lip-hand shape), and then splicing the combined features and input them to the fully connected layer for phoneme processing. predict.
另外,为了充分利用融合的多模态数据,我们将设计一种高效的多模态特征融合模型(见图6)。对于不同模态的数据,融合模型使用元素级加法+、元素级乘法×,以及最大化操作Max实现自适应和高效的联合多模态特征融合。融合后的特征使用拼接保留原始的信息,然后经过卷积层Conv恢复到原来的维度。由于上述多模态特征融合模型仅涉及元素级操作和简单的卷积操作,因此其可以嵌入到识别器中,实现端到端的训练以提升特征融合的效果。更进一步,在此融合模型中引入跨模态自注意力机制对上述初步对齐特征进行进一步隐式对齐将在后续研究中进行探索。Additionally, to fully utilize the fused multimodal data, we will design an efficient multimodal feature fusion model (see Figure 6). For data of different modalities, the fusion model uses element-level addition +, element-level multiplication ×, and the maximization operation Max to achieve adaptive and efficient joint multi-modal feature fusion. The fused features use concatenation to retain the original information, and then restore to the original dimension through the convolutional layer Conv. Since the above multimodal feature fusion model only involves element-level operations and simple convolution operations, it can be embedded in the recognizer to achieve end-to-end training to improve the effect of feature fusion. Going a step further, introducing a cross-modal self-attention mechanism in this fusion model to further implicitly align the above preliminary aligned features will be explored in follow-up research.
2)生成器:生成器的目的是合成可用的数据。合成后的数据不仅能够弥补 CS数据匮乏的问题,还能为识别器的更新迭代提供丰富的知识。为此,不同于传统的生成对抗网络中仅采用单个样本作为输入,我们的生成器将同时输入嘴唇和手形两种模态的数据,迫使网络合成两种模态的图像。生成器的网络采用编码器-解码器的深度网络结构,并利用空洞卷积作为卷积层捕获更多的嘴唇和手形局部信息。在训练阶段,生成器与识别器构成“合作”关系。生成器由于要产生更加逼真的图像,因此更加关注图像的局部信息,与识别器模型的语义知识互为补充。二者在统一的多模态融合框架中共同促进特征融合的有效性。训练完成后的生成器模型可以用来产生无标签的样本。考虑到拟建立的多模态融合模型在对抗训练过程中可能存在模式奔溃(即生成器产生单个或有限的模式) 的风险,我们在后续的研究中将针对此具体细化探讨,从数据多样性方法中的小批量歧视和特征映射这两个角度来研究更稳定的三方“合作-竞争”对抗训练框架。2) Generator: The purpose of the generator is to synthesize the available data. The synthesized data can not only make up for the lack of CS data, but also provide rich knowledge for the update iteration of the recognizer. To this end, unlike traditional generative adversarial networks that only take a single sample as input, our generator will input data from both lip and hand modalities simultaneously, forcing the network to synthesize images from both modalities. The generator network adopts an encoder-decoder deep network structure and utilizes atrous convolution as a convolutional layer to capture more local information of lips and hands. During the training phase, the generator and the recognizer form a "cooperative" relationship. Since the generator needs to generate more realistic images, it pays more attention to the local information of the image, which complements the semantic knowledge of the recognizer model. The two jointly promote the effectiveness of feature fusion in a unified multimodal fusion framework. The trained generator model can be used to generate unlabeled samples. Considering that the multimodal fusion model to be established may have the risk of mode collapse (that is, the generator generates a single or limited mode) during the adversarial training process, we will discuss this in detail in the follow-up research, from the data Two perspectives of mini-batch discrimination and feature mapping in diversity methods to study a more stable three-way "cooperative-competitive" adversarial training framework.
3)鉴别器:一方面,这里的鉴别器用于判断生成器输出的合成图像是否真实,与生成器组成博弈对抗的关系。为了与生成器进行竞争对抗,它通过迭代训练不断提升自身对图像真伪的鉴别能力。另一方面,生成器能不断提升自己的伪造能力以绕过鉴别器的鉴别。鉴别器是一个二元分类网络,并将采用预训练的深度卷积网络进行模型初始化。它的作用在于其和生成器形成“竞争”关系,以学习更好的生成器,进而提供更加准确的语义约束和高质量的训练样本。3) Discriminator: On the one hand, the discriminator here is used to judge whether the synthetic image output by the generator is real, and form a game confrontation relationship with the generator. In order to compete with the generator, it continuously improves its ability to discriminate the authenticity of images through iterative training. On the other hand, the generator can continuously improve its forgery ability to bypass the identification of the discriminator. The discriminator is a binary classification network and will initialize the model with a pretrained deep convolutional network. Its role is that it forms a "competitive" relationship with the generator to learn a better generator, which in turn provides more accurate semantic constraints and high-quality training samples.
三、针对上述CS自动识别研究中的第(3)点不足与挑战,本实施例提出了高效且带隐私保护的CS自动识别整体模型的设计和实现。3. In view of the shortcomings and challenges of point (3) in the above CS automatic identification research, this embodiment proposes the design and implementation of an efficient and privacy-protected CS automatic identification overall model.
此阶段属于本发明的整体建模阶段,将结合前面的特征学习以及多模态融合两个阶段的成果,构建一个高效且带隐私保护且的CS自动识别神经网络模型。鉴于对提供数据者的数据隐私进行保护这个亟需解决的问题,本发明主要研究带隐私保护的联邦学习框架(见图7)。其中,一个强泛化能力的全局服务器模型对于最终模型的好坏起到至关重要的作用。它能通过处理并聚合各个本地客户端设备上传的CS自动识别模型的参数,确保其能和所有参与训练的设备通信。本发明拟创新性地提出一种利用基于安全混合算法的样本插值来构建共享数据集参与训练的方法,获得鲁棒且强泛化能力的全局模型。具体可阐述为以下两点。This stage belongs to the overall modeling stage of the present invention, and will combine the results of the previous two stages of feature learning and multimodal fusion to build an efficient and privacy-protected CS automatic recognition neural network model. In view of the urgent problem of protecting the data privacy of the data provider, the present invention mainly studies a federated learning framework with privacy protection (see FIG. 7 ). Among them, a global server model with strong generalization ability plays a crucial role in the quality of the final model. It can automatically identify the parameters of the model by processing and aggregating the CS uploaded by each local client device to ensure that it can communicate with all the devices participating in the training. The present invention intends to innovatively propose a method for constructing a shared data set to participate in training by using sample interpolation based on a secure hybrid algorithm, so as to obtain a robust global model with strong generalization ability. Specifically, it can be described as the following two points.
这里的客户端、服务器及最后测试模型的基准模型都是图下端所示结构。其中的Bi-LSTM为音素解码器。CTC作为损失函数,直接输出音素序列预测的概率。Here, the client, server, and the benchmark model of the final test model are the structures shown at the bottom of the figure. Among them, Bi-LSTM is a phoneme decoder. As a loss function, CTC directly outputs the predicted probability of the phoneme sequence.
(1)基本联邦学习CS自动识别框架的建立(1) Establishment of basic federated learning CS automatic identification framework
根据现有的联邦学习框架,我们首先用预训练方法对全局服务端模型进行初始化,并引入客户端差分隐私算法对客户端参数进行扰动以增加数据的隐蔽性,避免外部恶意攻击。我们初步设计的基本CS自动识别联邦学习模型流程如下:According to the existing federated learning framework, we first use the pre-training method to initialize the global server-side model, and introduce a client-side differential privacy algorithm to perturb the client-side parameters to increase the concealment of data and avoid external malicious attacks. The basic CS automatic recognition federated learning model process we initially designed is as follows:
1)考虑到CS自动识别和手语识别以及唇语识别有较强的相关性,我们将收集多个开源的手语视频数据集和唇语视频数据集,整合为一个样本充足的预训练数据集。然后用此数据集对全局服务端模型进行预训练初始化;1) Considering the strong correlation between CS automatic recognition and sign language recognition and lip language recognition, we will collect multiple open source sign language video datasets and lip language video datasets and integrate them into a pre-training dataset with sufficient samples. Then use this dataset to pre-train and initialize the global server model;
2)服务器随机选择一部分设备,将模型初始化参数通过网络下传给选择的客户端设备模型;2) The server randomly selects a part of the equipment, and downloads the model initialization parameters to the selected client equipment model through the network;
3)客户端设备下载模型参数后,将本地CS视频数据用于其模型的训练(为保证CS自动识别模型的高效性,这里客户端和服务端的基准模型将利用前两个研究方案中提出的特征学习模型和多模态融合模型),并计算损失值和梯度;3) After the client device downloads the model parameters, the local CS video data is used for the training of its model (in order to ensure the efficiency of the CS automatic identification model, the benchmark models of the client and server here will use the methods proposed in the first two research schemes. feature learning model and multimodal fusion model), and calculate the loss value and gradient;
4)更新模型参数并上传到服务器。这里为了加强对参与者数据隐私的保护,我们提出在模型训练阶段应用客户端差分隐私算法,即在客户端模型上传前对模型参数进行裁剪并引入拉普拉斯噪声,以此来避免恶意的服务器或外部攻击者通过参与者上传的模型参数窃取数据信息;4) Update the model parameters and upload to the server. In order to strengthen the protection of participants' data privacy, we propose to apply the client-side differential privacy algorithm in the model training phase, that is, before the client-side model is uploaded, the model parameters are clipped and Laplacian noise is introduced to avoid malicious Servers or external attackers steal data information through model parameters uploaded by participants;
5)服务器在收集到所有选中设备上传的模型参数或超过一定时限后,将获得的模型参数进行聚合,得到一个新的全局服务端模型;5) After the server collects the model parameters uploaded by all selected devices or exceeds a certain time limit, it aggregates the obtained model parameters to obtain a new global server model;
6)重复步骤2-5直到收敛。6) Repeat steps 2-5 until convergence.
(2)基于安全混合算法样本插值的加密共享训练的设计(2) Design of encrypted shared training based on sample interpolation of secure hybrid algorithm
在上述基本框架的重要步骤5)中,由于不同编码者CS视频拍摄的设备、方式以及背景可能不同,导致上述算法中每个参与训练的设备上的视频样本有很大的差异,即Pi(x|y)≠Pj(x|y),其中i,j表示设备,x表示数据,y表示数据对应的标签。另外,不同设备的样本分布也可能不同,即Pi(y)≠Pj(y)。这两点使得由这些客户端训练出的模型所聚合得到的全局服务端模型性能不佳,甚至训练无法收敛。这就是联邦学习所面对的数据非独立同分布问题。针对该问题,目前大部分研究工作采取定制化策略,即在训练全局模型的基础上,使每个客户端有全局模型的变体以更好地适应自己的数据分布。这种方法虽然能在参与训练的客户端上有好的表现,但是应对未知分布的数据集的泛化能力较弱。也有方法是利用服务器上的共享数据集参与训练,但是这种直接从各个客户端中取用数据的方式会暴露用户的部分隐私,而若采用其他数据又难以保证其分布接近整体数据集(各个客户端数据集的总和)的分布。为此,本发明拟提出一种基于安全混合算法的样本插值来构建共享数据集参与训练的方法。具体阐述如下:In the important step 5) of the above basic framework, since the equipment, methods and backgrounds of CS video shooting of different encoders may be different, the video samples on each device participating in the training in the above algorithm are very different, that is, Pi (x|y)≠Pj (x|y), where i and j represent the device, x represents the data, and y represents the label corresponding to the data. In addition, the sample distribution of different devices may also be different, that is, Pi (y)≠Pj (y). These two points make the performance of the global server-side model aggregated by the models trained by these clients poor, and even the training fails to converge. This is the data non-IID problem faced by federated learning. In response to this problem, most of the current research work adopts a customized strategy, that is, on the basis of training the global model, each client has a variant of the global model to better adapt to its own data distribution. Although this method can perform well on clients participating in training, its generalization ability for datasets with unknown distribution is weak. There is also a method to use the shared data set on the server to participate in training, but this way of directly fetching data from each client will expose part of the user's privacy, and if other data is used, it is difficult to ensure that its distribution is close to the overall data set (each the sum of the client datasets) distribution. To this end, the present invention proposes a method for constructing a shared data set to participate in training based on sample interpolation of a secure hybrid algorithm. The details are as follows:
1)根据联邦学习的思想,由于数据来自不同客户端,使得服务器上构建的共享数据集分布可以近似看作客户端上数据集分布的线性组合。结合先验知识,利用特征向量的线性插值可以扩展全局模型训练集的数据分布,从而缓解数据的非独立同分布问题,使得到的全局模型更容易收敛。但是如果直接取不同客户端的样本和标签进行随机线性插值混合,会导致客户端数据隐私的泄露。为此,我们拟采用Diffie-Hellma(DH)密钥交换协议实现一种安全混合算法对样本进行加密,使得服务器只能获得最终客户端生成的混合数据,而无法得知各个客户端参与混合的真实数据。DH协议的目的是使双方在不直接传递密钥的情况下完成密钥交换,流程大致如下:1) According to the idea of federated learning, since the data comes from different clients, the shared dataset distribution constructed on the server can be approximately regarded as a linear combination of the dataset distribution on the client. Combined with prior knowledge, the data distribution of the global model training set can be expanded by linear interpolation of eigenvectors, thereby alleviating the non-IID problem of the data and making the resulting global model easier to converge. However, if the samples and labels of different clients are directly mixed with random linear interpolation, it will lead to the leakage of client data privacy. To this end, we plan to use the Diffie-Hellma (DH) key exchange protocol to implement a secure mixing algorithm to encrypt the sample, so that the server can only obtain the mixed data generated by the final client, but cannot know the mixed data that each client participates in. real data. The purpose of the DH protocol is to enable the two parties to complete the key exchange without directly passing the key. The process is roughly as follows:



在执行完上述基本框架中的第一个步骤后,基于该安全协议,服务器每次选择m个客户端,并让这m个客户端之间相互通信,各自生成密钥{Sij},其中i, j表示从中取的不同设备。之后每个客户端对自己将要上传的数据Qi={xi,yi}进行如下DH加密(如图9)得到

2)服务器将来自m个客户端的b个加密数据进行如下线性插值混合:2) The server mixes the b encrypted data from m clients by linear interpolation as follows:

其中λ1+λ2+…+λm=1,0≤λi≤1。λi由服务器生成并下传给客户端,其值随着迭代次数的增加会逐渐接近1/m。where λ1 +λ2 +...+λm =1, 0≤λi ≤1. λi is generated by the server and transmitted to the client, and its value will gradually approach 1/m with the increase of the number of iterations.
经过上述操作,可得到b个新样本及标签。之后,服务器再重复上述步骤直到生成N个新数据,得到共享数据集Q′。这个步骤将在上述基本框架的第一个步骤后进行。基于上述产生的共享数据集Q′,初始化的全局服务器模型先在Q′上进行预热,然后再正式进入模型训练阶段。服务器在每个通信轮次选择客户端后,按照比例α在Q′中随机选择一部分数据下传到所选客户端中和本地数据集一同参与训练。α的最优值在不同数据集和场景下会有所不同。注意在该算法中,因为整个过程只需进行数轮,且参与数据混合的客户端只需与服务器进行一轮通信,这在一定程度上规避了通信成本问题和客户端掉线的问题。但该算法在实际场景下,可能会有恶意攻击的危险。为此,我们后续还将探索基于梯度的异常检测等方法来应对数据中毒等对模型的攻击。After the above operations, b new samples and labels can be obtained. After that, the server repeats the above steps until N new data are generated, and the shared data set Q' is obtained. This step will follow the first step of the basic framework above. Based on the shared data set Q' generated above, the initialized global server model is first warmed up on Q', and then formally enters the model training phase. After the server selects a client in each communication round, it randomly selects a part of the data in Q' according to the ratio α and downloads it to the selected client and participates in the training together with the local data set. The optimal value of α will vary in different datasets and scenarios. Note that in this algorithm, because the whole process only needs several rounds, and the client participating in the data mixing only needs to communicate with the server for one round, which avoids the problem of communication cost and the problem of client disconnection to a certain extent. However, in practical scenarios, the algorithm may be at risk of malicious attacks. To this end, we will explore methods such as gradient-based anomaly detection to deal with attacks on the model such as data poisoning.
综上,本实施例当中的线索语自动识别模型训练方法,至少具有以下有益效果:To sum up, the training method for the automatic recognition model of cue words in this embodiment has at least the following beneficial effects:
1)高效且鲁棒的多模态特征表征学习:a)拟从无监督学习的角度来提取特征,以摆脱之前方法对数据标签的强依赖和带噪标注带来的影响;b)进一步提出基于视频图片时空信息约束的自监督对比学习与数据分布无偏学习的协同建模方法,建立基于多模态信息和自监督特征的CS视频特征无偏学习模型,以期从模型优化的角度来解决数据类别分布不平衡的问题。该方法可以被后续扩展到其他有带噪标注和数据有偏分布的问题中,具有很好的延续性和潜在的影响力。1) Efficient and robust multi-modal feature representation learning: a) It is proposed to extract features from the perspective of unsupervised learning, so as to get rid of the strong dependence on data labels and the influence of noisy annotations by previous methods; b) Further proposed A collaborative modeling method of self-supervised contrastive learning and data distribution unbiased learning based on spatio-temporal information constraints of video images, establishes an unbiased learning model of CS video features based on multimodal information and self-supervised features, in order to solve the problem from the perspective of model optimization. The problem of imbalanced distribution of data categories. This method can be subsequently extended to other problems with noisy annotations and data biased distribution, with good continuity and potential impact.
2)精细且优化的异步异质多模态特征融合:a)首先结合对CS编码理论的先验知识以及用统计分析方法从多模态数据中挖掘的异步延迟量之间的关系,可解释地对两两异步模态进行初步对齐;b)然后创新性地引入识别器、鉴别器和生成器一起形成了三方“竞争-合作”的关系,提出一整套切实可行的生成对抗训练的多模态融合解决方案。该模型引入的基于生成对抗训练的融合方式将为多模态融合打开一个新的视角,并且先初对齐再融合的顺序优化机制也对揭示异步融合这个难题的内在机理有很好的启发意义。2) Refined and optimized asynchronous heterogeneous multimodal feature fusion: a) First, combining the prior knowledge of CS coding theory and the relationship between asynchronous delay amounts mined from multimodal data with statistical analysis methods, can explain initial alignment of pairwise asynchronous modalities; b) then innovatively introduce the discriminator, the discriminator and the generator together to form a three-way “competition-cooperation” relationship, and propose a set of practical multi-modalities for generative adversarial training. Convergence solution. The fusion method based on generative adversarial training introduced by this model will open a new perspective for multimodal fusion, and the sequential optimization mechanism of initial alignment and fusion is also very enlightening for revealing the inherent mechanism of the asynchronous fusion problem.
3)高效且带隐私保护的CS自动识别整体建模:本项目拟建立的基于联邦学习的视听识别整体模型将首次考虑到保护CS编码者隐私的问题,构建基于安全混合算法的样本插值来生成共享数据集参与训练的方法,并将其应用于联邦学习框架下的CS自动识别模型的训练。该研究将为目前人工智能模型在隐私保护方面的探索提供宝贵的思路。3) Overall modeling of CS automatic recognition with high efficiency and privacy protection: The overall model of audio-visual recognition based on federated learning to be established in this project will first consider the issue of protecting the privacy of CS coders, and build a sample interpolation based on a secure hybrid algorithm to generate The method of sharing data set to participate in training and applying it to the training of CS automatic recognition model under the framework of federated learning. This research will provide valuable ideas for the current exploration of artificial intelligence models in privacy protection.
实施例三Embodiment 3
另一方面,本发明还提出一种线索语自动识别模型训练装置,请参阅图10,所示为本发明实施例三提供的线索语自动识别模型训练装置,应用于服务器当中,所述服务器与多个客户端通讯连接,所述装置包括:On the other hand, the present invention also provides an apparatus for training a model for automatic recognition of clues. Please refer to FIG. 10 , which shows the apparatus for training an automatic recognition model for clues provided in Embodiment 3 of the present invention, which is applied to a server. A plurality of client communication connections, the device includes:
预训练模块11,用于获取开源的线索语视频数据集,并采用所述开源的线索语视频数据集对服务器模型进行训练;The
数据下发模块12,用于随机选取多个目标客户端,并将所述服务器模型的当前全局模型参数下发给各个所述目标客户端,以使所述目标客户端基于所述当前全局模型参数和预设训练集对各自的客户端模型进行训练,所述客户端模型和所述服务器模型的架构相同;The
模型更新模块13,用于接收各所述目标客户端上传的当前客户端模型参数,并对各所述当前客户端模型参数进行聚合,并采用聚合后的模型参数对所述服务器模型进行更新,得到新的服务器模型;The
所述数据下发模块12和所述模型更新模块13重复执行,直到服务器模型收敛,以训练得到线索语自动识别模型。The
优选地,在本发明一些可选实施例当中,所述线索语自动识别模型训练装置还包括:Preferably, in some optional embodiments of the present invention, the apparatus for training an automatic recognition model for clues further includes:
共享数据集构建模块,用于获取多个客户端上传的经预设加密算法加密之后的线索语视频,得到由获取的加密线索语视频组成的共享数据集;The shared data set building module is used to obtain the clue video uploaded by multiple clients after being encrypted by the preset encryption algorithm, and obtain a shared data set composed of the obtained encrypted clue video;
其中,所述数据下发模块12还用于随机选取多个目标客户端,并将所述服务器模型的当前全局模型参数下发给各个所述目标客户端,并按预设比例从所述共享数据集当中选取部分共享数据下发到各所述目标客户端;Wherein, the
其中,所述预设训练集包括所述目标客户端的本地数据集和所述服务器当前下发的部分共享数据。The preset training set includes the local data set of the target client and part of the shared data currently delivered by the server.
优选地,在本发明一些可选实施例当中,所述目标客户端在上传当前客户端模型参数之前,对当前客户端模型进行裁剪并引入拉普拉斯噪声。Preferably, in some optional embodiments of the present invention, before uploading the parameters of the current client model, the target client trims the current client model and introduces Laplacian noise.
优选地,在本发明一些可选实施例当中,所述客户端模型和所述服务器模型的架构均包括:Preferably, in some optional embodiments of the present invention, the architectures of the client model and the server model include:
自监督增量学习联合模型,用于从数据集当中提取手形特征和嘴唇特征;Self-supervised incremental learning joint model for extracting hand and lip features from the dataset;
手位置识别识别模型,用于从数据集当中提取手位置特征;A recognition model for hand position recognition, which is used to extract hand position features from the dataset;
异步异质多模态时序对齐模型,用于基于手形特征、嘴唇特征和手位置特征,对手形和手位置的运动相对于嘴唇运动的超前量进行统计建模与预测,并利用预测得到的超前量在时序上调整手形特征和手位置特征,得到初步时序对齐的手形特征、嘴唇特征和手位置特征;Asynchronous heterogeneous multimodal time-series alignment model for statistical modeling and prediction based on hand shape features, lip features, and hand position features, and predicting the lead of the motion of the hand and hand position relative to the lip motion, and using the predicted lead Quantitatively adjust the hand shape feature and hand position feature in time sequence, and obtain the hand shape feature, lip feature and hand position feature of preliminary time sequence alignment;
融合模型,用于基于所述初步时序对齐的手形特征、嘴唇特征和手位置特征对线索语的音素类别进行预测识别。The fusion model is used for predicting and identifying the phoneme category of the cue speech based on the hand shape feature, lip feature and hand position feature of the preliminary time sequence alignment.
优选地,在本发明一些可选实施例当中,所述融合模型为由识别器、生成器和鉴别器构成的基于生成对抗训练的多模态融合模型。Preferably, in some optional embodiments of the present invention, the fusion model is a multimodal fusion model based on generative adversarial training composed of a discriminator, a generator and a discriminator.
上述各模块、单元被执行时所实现的功能或操作步骤与上述方法实施例大体相同,在此不再赘述。The functions or operation steps implemented by the foregoing modules and units when executed are substantially the same as those in the foregoing method embodiments, and will not be repeated here.
实施例四Embodiment 4
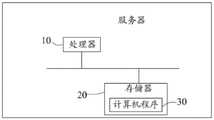
请参阅图11,本发明实施例四提出一种服务器,包括处理器10、存储器 20以及存储在存储器上并可在处理器上运行的计算机程序30,所述处理器10 执行所述程序30时实现如上述的线索语自动识别模型训练方法。Referring to FIG. 11 , Embodiment 4 of the present invention provides a server, including a
其中,处理器10在一些实施例中可以是中央处理器(Central Processing Unit,CPU)、控制器、微控制器、微处理器或其他数据处理芯片,用于运行存储器 20中存储的程序代码或处理数据,例如执行访问限制程序等。Wherein, the
其中,存储器20至少包括一种类型的可读存储介质,所述可读存储介质包括闪存、硬盘、多媒体卡、卡型存储器(例如,SD或DX存储器等)、磁性存储器、磁盘、光盘等。存储器20在一些实施例中可以是服务器的内部存储单元,例如该服务器的硬盘。存储器20在另一些实施例中也可以是服务器的外部存储装置,例如服务器上配备的插接式硬盘,智能存储卡(Smart Media Card,SMC),安全数字(Secure Digital,SD)卡,闪存卡(Flash Card)等。优选地,存储器 20还可以既包括服务器的内部存储单元也包括外部存储装置。存储器20不仅可以用于存储安装于服务器的应用软件及各类数据,还可以用于暂时地存储已经输出或者将要输出的数据。The
需要指出的是,图11示出的结构并不构成对服务器的限定,在其它实施例当中,该服务器可以包括比图示更少或者更多的部件,或者组合某些部件,或者不同的部件布置。It should be noted that the structure shown in FIG. 11 does not constitute a limitation on the server. In other embodiments, the server may include fewer or more components than the one shown in the figure, or combine some components, or different components layout.
本发明实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上述的线索语自动识别模型训练方法。Embodiments of the present invention also provide a computer-readable storage medium, on which a computer program is stored, and when the program is executed by a processor, implements the above-mentioned training method for an automatic recognition model of clues.
本领域技术人员可以理解,在流程图中表示或在此以其他方式描述的逻辑和/或步骤,例如,可以被认为是用于实现逻辑功能的可执行指令的定序列表,可以具体实现在任何计算机可读介质中,以供指令执行系统、装置或设备(如基于计算机的系统、包括处理器的系统或其他可以从指令执行系统、装置或设备取指令并执行指令的系统)使用,或结合这些指令执行系统、装置或设备而使用。就本说明书而言,“计算机可读介质”可以是任何可以包含、存储、通信、传播或传输程序以供指令执行系统、装置或设备或结合这些指令执行系统、装置或设备而使用的装置。Those skilled in the art will appreciate that logic and/or steps represented in flowcharts or otherwise described herein, for example, may be considered an ordered listing of executable instructions for implementing logical functions, may be embodied in in any computer-readable medium for use by an instruction execution system, apparatus, or device (such as a computer-based system, a system including a processor, or other system that can fetch and execute instructions from an instruction execution system, apparatus, or device), or Used in conjunction with these instruction execution systems, apparatus or devices. For the purposes of this specification, a "computer-readable medium" can be any device that can contain, store, communicate, propagate, or transport the program for use by or in connection with an instruction execution system, apparatus, or apparatus.
计算机可读介质的更具体的示例(非穷尽性列表)包括以下:具有一个或多个布线的电连接部(电子装置),便携式计算机盘盒(磁装置),随机存取存储器(RAM),只读存储器(ROM),可擦除可编辑只读存储器(EPROM 或闪速存储器),光纤装置,以及便携式光盘只读存储器(CDROM)。另外,计算机可读介质甚至可以是可在其上打印所述程序的纸或其他合适的介质,因为可以例如通过对纸或其他介质进行光学扫描,接着进行编辑、解译或必要时以其他合适方式进行处理来以电子方式获得所述程序,然后将其存储在计算机存储器中。More specific examples (non-exhaustive list) of computer readable media include the following: electrical connections with one or more wiring (electronic devices), portable computer disk cartridges (magnetic devices), random access memory (RAM), Read Only Memory (ROM), Erasable Editable Read Only Memory (EPROM or Flash Memory), Fiber Optic Devices, and Portable Compact Disc Read Only Memory (CDROM). In addition, the computer readable medium may even be paper or other suitable medium on which the program may be printed, as the paper or other medium may be optically scanned, for example, followed by editing, interpretation, or other suitable medium as necessary process to obtain the program electronically and then store it in computer memory.
应当理解,本发明的各部分可以用硬件、软件、固件或它们的组合来实现。在上述实施方式中,多个步骤或方法可以用存储在存储器中且由合适的指令执行系统执行的软件或固件来实现。例如,如果用硬件来实现,和在另一实施方式中一样,可用本领域公知的下列技术中的任一项或它们的组合来实现:具有用于对数据信号实现逻辑功能的逻辑门电路的离散逻辑电路,具有合适的组合逻辑门电路的专用集成电路,可编程门阵列(PGA),现场可编程门阵列(FPGA) 等。It should be understood that various parts of the present invention may be implemented in hardware, software, firmware or a combination thereof. In the above-described embodiments, various steps or methods may be implemented in software or firmware stored in memory and executed by a suitable instruction execution system. For example, if implemented in hardware, as in another embodiment, it can be implemented by any one or a combination of the following techniques known in the art: Discrete logic circuits, application specific integrated circuits with suitable combinational logic gates, Programmable Gate Arrays (PGA), Field Programmable Gate Arrays (FPGA), etc.
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。In the description of this specification, description with reference to the terms "one embodiment," "some embodiments," "example," "specific example," or "some examples", etc., mean specific features described in connection with the embodiment or example , structure, material or feature is included in at least one embodiment or example of the present invention. In this specification, schematic representations of the above terms do not necessarily refer to the same embodiment or example. Furthermore, the particular features, structures, materials or characteristics described may be combined in any suitable manner in any one or more embodiments or examples.
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。The above descriptions are only preferred embodiments of the present invention and are not intended to limit the present invention. Any modifications, equivalent replacements and improvements made within the spirit and principles of the present invention shall be included in the protection of the present invention. within the range.
Claims (10)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111601585.9ACN114445909B (en) | 2021-12-24 | 2021-12-24 | Method, device, storage medium and equipment for training model of automatic clue language recognition |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111601585.9ACN114445909B (en) | 2021-12-24 | 2021-12-24 | Method, device, storage medium and equipment for training model of automatic clue language recognition |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN114445909Atrue CN114445909A (en) | 2022-05-06 |
| CN114445909B CN114445909B (en) | 2025-05-27 |
Family
ID=81363067
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202111601585.9AActiveCN114445909B (en) | 2021-12-24 | 2021-12-24 | Method, device, storage medium and equipment for training model of automatic clue language recognition |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114445909B (en) |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115062721A (en)* | 2022-07-01 | 2022-09-16 | 中国电信股份有限公司 | Network intrusion detection method and device, computer readable medium and electronic equipment |
| CN115114982A (en)* | 2022-06-28 | 2022-09-27 | 重庆大学 | A distributed model training method and related device for deep learning in edge computing |
| CN115410187A (en)* | 2022-09-05 | 2022-11-29 | 武汉言平科技有限公司 | Video recognition text adaptive adjustment method and system |
| CN116301389A (en)* | 2023-05-17 | 2023-06-23 | 广东皮阿诺科学艺术家居股份有限公司 | Multi-mode intelligent furniture control method based on deep learning |
| CN117540829A (en)* | 2023-10-18 | 2024-02-09 | 广西壮族自治区通信产业服务有限公司技术服务分公司 | Knowledge sharing large language model collaborative optimization method and system |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20210150269A1 (en)* | 2019-11-18 | 2021-05-20 | International Business Machines Corporation | Anonymizing data for preserving privacy during use for federated machine learning |
| CN113762530A (en)* | 2021-09-28 | 2021-12-07 | 北京航空航天大学 | Privacy protection-oriented precision feedback federal learning method |
- 2021
- 2021-12-24CNCN202111601585.9Apatent/CN114445909B/enactiveActive
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20210150269A1 (en)* | 2019-11-18 | 2021-05-20 | International Business Machines Corporation | Anonymizing data for preserving privacy during use for federated machine learning |
| CN113762530A (en)* | 2021-09-28 | 2021-12-07 | 北京航空航天大学 | Privacy protection-oriented precision feedback federal learning method |
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115114982A (en)* | 2022-06-28 | 2022-09-27 | 重庆大学 | A distributed model training method and related device for deep learning in edge computing |
| CN115062721A (en)* | 2022-07-01 | 2022-09-16 | 中国电信股份有限公司 | Network intrusion detection method and device, computer readable medium and electronic equipment |
| CN115062721B (en)* | 2022-07-01 | 2023-10-31 | 中国电信股份有限公司 | Network intrusion detection method and device, computer readable medium and electronic equipment |
| CN115410187A (en)* | 2022-09-05 | 2022-11-29 | 武汉言平科技有限公司 | Video recognition text adaptive adjustment method and system |
| CN116301389A (en)* | 2023-05-17 | 2023-06-23 | 广东皮阿诺科学艺术家居股份有限公司 | Multi-mode intelligent furniture control method based on deep learning |
| CN116301389B (en)* | 2023-05-17 | 2023-09-01 | 广东皮阿诺科学艺术家居股份有限公司 | Multi-mode intelligent furniture control method based on deep learning |
| CN117540829A (en)* | 2023-10-18 | 2024-02-09 | 广西壮族自治区通信产业服务有限公司技术服务分公司 | Knowledge sharing large language model collaborative optimization method and system |
| CN117540829B (en)* | 2023-10-18 | 2024-05-17 | 广西壮族自治区通信产业服务有限公司技术服务分公司 | Knowledge sharing large language model collaborative optimization method and system |
Also Published As
| Publication number | Publication date |
|---|---|
| CN114445909B (en) | 2025-05-27 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20240185602A1 (en) | Cross-Modal Processing For Vision And Language | |
| Gao et al. | Video captioning with attention-based LSTM and semantic consistency | |
| CN117711001B (en) | Image processing method, device, equipment and medium | |
| Xia et al. | Deliberation networks: Sequence generation beyond one-pass decoding | |
| Shao et al. | Survey of different large language model architectures: Trends, benchmarks, and challenges | |
| CN114445909A (en) | Method, device, storage medium and device for training an automatic recognition model of cue words | |
| CN112084331A (en) | Text processing method, text processing device, model training method, model training device, computer equipment and storage medium | |
| CN111930992A (en) | Neural network training method and device and electronic equipment | |
| CN113505193B (en) | A data processing method and related equipment | |
| CN113762322A (en) | Video classification method, device and equipment based on multi-modal representation and storage medium | |
| CN112131366A (en) | Method, device and storage medium for training text classification model and text classification | |
| CN117876940A (en) | Video language task execution and model training method, device, equipment and medium thereof | |
| CN116975350A (en) | Image-text retrieval method, device, equipment and storage medium | |
| CN112668347B (en) | Text translation method, device, equipment and computer readable storage medium | |
| CN115131638A (en) | Training method, device, medium and equipment for visual text pre-training model | |
| CN114282055A (en) | Video feature extraction method, device and equipment and computer storage medium | |
| Zhang et al. | Hierarchical vision-language alignment for video captioning | |
| CN113421551A (en) | Voice recognition method and device, computer readable medium and electronic equipment | |
| Zhou et al. | Learning with annotation of various degrees | |
| CN116522142A (en) | Method for training feature extraction model, feature extraction method and device | |
| WO2025055581A1 (en) | Speech encoder training method and apparatus, and device, medium and program product | |
| CN116975347A (en) | Image generation model training method and related device | |
| Gao et al. | Generalized pyramid co-attention with learnable aggregation net for video question answering | |
| CN113591493A (en) | Translation model training method and translation model device | |
| Zeng et al. | An explainable multi-view semantic fusion model for multimodal fake news detection |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |