CN114443819A - An End-to-End Generative Psychological Consultation Dialogue System - Google Patents
An End-to-End Generative Psychological Consultation Dialogue SystemDownload PDFInfo
- Publication number
- CN114443819A CN114443819ACN202210125572.7ACN202210125572ACN114443819ACN 114443819 ACN114443819 ACN 114443819ACN 202210125572 ACN202210125572 ACN 202210125572ACN 114443819 ACN114443819 ACN 114443819A
- Authority
- CN
- China
- Prior art keywords
- reply
- dialogue
- input
- model
- keywords
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images













Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/3331—Query processing
- G06F16/334—Query execution
- G06F16/3344—Query execution using natural language analysis
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/335—Filtering based on additional data, e.g. user or group profiles
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/338—Presentation of query results
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/084—Backpropagation, e.g. using gradient descent
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H20/00—ICT specially adapted for therapies or health-improving plans, e.g. for handling prescriptions, for steering therapy or for monitoring patient compliance
- G16H20/70—ICT specially adapted for therapies or health-improving plans, e.g. for handling prescriptions, for steering therapy or for monitoring patient compliance relating to mental therapies, e.g. psychological therapy or autogenous training
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Artificial Intelligence (AREA)
- Health & Medical Sciences (AREA)
- Evolutionary Computation (AREA)
- General Health & Medical Sciences (AREA)
- Databases & Information Systems (AREA)
- Life Sciences & Earth Sciences (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Biophysics (AREA)
- Biomedical Technology (AREA)
- Child & Adolescent Psychology (AREA)
- Psychology (AREA)
- Social Psychology (AREA)
- Epidemiology (AREA)
- Psychiatry (AREA)
- Medical Informatics (AREA)
- Primary Health Care (AREA)
- Public Health (AREA)
- Hospice & Palliative Care (AREA)
- Developmental Disabilities (AREA)
- Evolutionary Biology (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Bioinformatics & Computational Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Machine Translation (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本公开涉及深度学习与自然语言处理技术,特别涉及端到端生成式的心理咨询对话系统、基于语言模型的回复推断方法、用于推断对话回复的训练方法、以及基于语言模型的对话系统。The present disclosure relates to deep learning and natural language processing technologies, and in particular, to an end-to-end generative psychological counseling dialogue system, a language model-based reply inference method, a training method for inferring a dialogue reply, and a language model-based dialogue system.
背景技术Background technique
基于文本的对话系统起源于上个世纪60年代,早期最知名的聊天机器人如ELIZA和PARRY等带给了人们对于人工智能最直观的感受并且对后来的研究工作产生深远的影响。The text-based dialogue system originated in the 1960s. The most well-known early chatbots such as ELIZA and PARRY brought people the most intuitive feeling for artificial intelligence and had a profound impact on subsequent research work.
目前常用的对话系统从使用目的上主要可以分为两类:1.任务导向型对话系统,如Siri,Google Assistant,Alexa,小爱机器人等。其应用通常为执行流程化较为明确的有限集中的任务,例如通过对话帮助用户完成寻路、订餐、购票等明确具体的任务。2.端到端对话系统,如微软小冰等。其可以就多方面的话题和知识与用户交流,并应对各式各样的用户反馈。从回复方式上可以分为三类:1.规则式回复。最早期的ELIZA和PARRY都是如此,通过大量人工制定的规则(例如接收什么输入就输出什么)来进行回复。2.抽取式回复。通过神经网络理解对话输入的语义,再从大量语料中自动找寻出适合的回复语句。3.生成式回复。在理解对话输入的语义的基础上,也智能运算出需要回复的内容。At present, the commonly used dialogue systems can be mainly divided into two categories from the purpose of use: 1. Task-oriented dialogue systems, such as Siri, Google Assistant, Alexa, Xiaoai robot, etc. Its application is usually to perform limited and centralized tasks with a relatively clear process, such as helping users complete specific tasks such as wayfinding, ordering meals, and purchasing tickets through dialogue. 2. End-to-end dialogue system, such as Microsoft Xiaoice, etc. It can communicate with users on a variety of topics and knowledge, and respond to a variety of user feedback. From the way of reply, it can be divided into three categories: 1. Regular reply. This was true of the earliest ELIZA and PARRY, with a large number of human-made rules (such as receiving what input and output what) to reply. 2. Extractive reply. Understand the semantics of dialogue input through neural network, and then automatically find suitable reply sentences from a large number of corpus. 3. Generative responses. On the basis of understanding the semantics of the dialogue input, it also intelligently calculates the content that needs to be replied.
目前端到端生成式的闲聊机器人,如微软的DialoGPT等,可以使用户和聊天机器人通过文字自由对话,但对话内容的连贯性与多样性比真人仍有较大差距。此外,目前应用于心理咨询领域的对话系统均是任务导向型的,例如woebot、连小信等,其聊天范围与沟通方式都比较有限,只能通过既定的选项或极少的自由输入,在设计好的流程内进行对话。At present, end-to-end generative chatbots, such as Microsoft's DialoGPT, can enable users and chatbots to communicate freely through text, but there is still a big gap between the coherence and diversity of conversation content compared to real people. In addition, the dialogue systems currently used in the field of psychological counseling are all task-oriented, such as woebot, Lian Xiaoxin, etc., whose chatting scope and communication methods are relatively limited, and can only be used through established options or very little free input. Conversation within the designed process.
发明内容SUMMARY OF THE INVENTION
本公开的目的之一是提供端到端生成式的心理咨询对话系统、基于语言模型的回复推断方法、用于推断对话回复的训练方法、以及基于语言模型的对话系统。One of the objectives of the present disclosure is to provide an end-to-end generative psychological counseling dialogue system, a language model-based response inference method, a training method for inferring dialogue responses, and a language model-based dialogue system.
根据本公开的第一方面,提供了一种端到端生成式的心理咨询对话方法,包括:接收对话输入;使用基于心理咨询对话数据集建立的生成模型生成一组或更多组候选回复,每组候选回复包括针对所述对话输入的一个或更多个回复关键词和基于所述一个或更多个回复关键词生成的回复语句;使用基于心理咨询对话数据集建立的筛选模型,从各组候选回复所包括的各回复语句中筛选出最佳回复语句;以及输出所述最佳回复语句。According to a first aspect of the present disclosure, an end-to-end generative psychological counseling dialogue method is provided, comprising: receiving a dialogue input; generating one or more groups of candidate responses using a generative model established based on a psychological counseling dialogue dataset, Each set of candidate replies includes one or more reply keywords input for the dialogue and reply sentences generated based on the one or more reply keywords; using the screening model established based on the psychological counseling dialogue data set, from each Filtering out the best reply sentence from each reply sentence included in the group candidate reply; and outputting the best reply sentence.
根据本公开的第二方面,提供了一种端到端生成式的心理咨询对话方法,包括:接收对话输入;使用基于心理咨询对话数据集建立的生成模型,生成针对所述对话输入的一个或更多个回复语句;将所述一个或更多个回复语句拼接后输入到基于心理咨询对话数据集建立的筛选模型;以及使用所述筛选模型,基于所述对话输入,从所述一个或更多个回复语句中筛选出最佳回复语句;以及输出所述最佳回复语句。According to a second aspect of the present disclosure, an end-to-end generative psychological counseling dialogue method is provided, comprising: receiving a dialogue input; using a generative model established based on a psychological counseling dialogue dataset to generate one or more more reply sentences; splicing and inputting the one or more reply sentences into a screening model established based on a psychological counseling dialogue dataset; and using the screening model, based on the dialogue input, from the one or more filtering out the best reply sentence from the plurality of reply sentences; and outputting the best reply sentence.
根据本公开的第三方面,提供了一种基于语言模型的回复推断方法,包括:接收对话输入;使用基于预训练语言模型建立的生成模型生成一组或更多组候选回复,每组候选回复包括针对所述对话输入的一个或更多个回复关键词和基于所述一个或更多个回复关键词生成的回复语句;以及使用基于预训练语言模型建立的筛选模型,从各组候选回复所包括的各回复语句中推断出最佳回复语句。According to a third aspect of the present disclosure, there is provided a language model-based reply inference method, comprising: receiving a dialogue input; using a generative model established based on a pre-trained language model to generate one or more groups of candidate replies, each group of candidate replies including one or more reply keywords input for the dialogue and reply sentences generated based on the one or more reply keywords; The best reply sentence is deduced from each included reply sentence.
根据本公开的第四方面,提供了一种基于语言模型的回复推断方法,包括:接收对话输入;使用基于预训练语言模型建立的生成模型,生成针对所述对话输入的一个或更多个回复语句;将所述一个或更多个回复语句拼接后输入到基于预训练语言模型建立的筛选模型;以及使用所述筛选模型,基于所述对话输入,从所述一个或更多个回复语句中推断出最佳回复语句。According to a fourth aspect of the present disclosure, there is provided a language model-based reply inference method, comprising: receiving a dialogue input; using a generative model established based on a pre-trained language model to generate one or more responses to the dialogue input sentence; splicing and inputting the one or more reply sentences into a screening model established based on a pre-trained language model; and using the screening model, based on the dialogue input, from the one or more reply sentences Infer the best reply sentence.
根据本公开的第五方面,提供了一种基于语言模型的回复推断方法,包括:接收对话输入;使用基于预训练语言模型建立的生成模型生成一组或更多组候选回复,每组候选回复包括一个或更多个回复关键词与基于所述一个或更多个回复关键词生成的回复语句的拼接;将各组候选回复所包括的各回复语句、所述对话输入以及与所述对话输入相关联的历史对话数据拼接后输入到基于预训练语言模型建立的筛选模型;以及使用所述筛选模型,基于所述对话输入和所述历史对话数据,从各组候选回复所包括的各回复语句中推断出最佳回复语句。According to a fifth aspect of the present disclosure, a language model-based reply inference method is provided, comprising: receiving a dialogue input; generating one or more groups of candidate replies using a generative model established based on a pre-trained language model, each group of candidate replies including the splicing of one or more reply keywords and reply sentences generated based on the one or more reply keywords; combining each reply sentence included in each group of candidate replies, the dialogue input, and the dialogue input The associated historical dialogue data is spliced and input into the screening model established based on the pre-trained language model; and using the screening model, based on the dialogue input and the historical dialogue data, from each group of candidate replies to each included reply statement Infer the best reply sentence.
根据本公开的第六方面,提供了一种用于推断对话回复的训练方法,包括:获取第一训练数据集,所述第一训练数据集包括对话上文和对应的对话回复,其中每条对话回复中被标注一个或更多个关键词;以及使用所述第一训练数据集对第一预训练语言模型进行训练,其中,所述第一预训练语言模型待拟合的输出包括针对输入的一个或更多个回复关键词和基于所述一个或更多个回复关键词生成的回复语句两者。According to a sixth aspect of the present disclosure, there is provided a training method for inferring dialogue responses, comprising: acquiring a first training data set, where the first training data set includes dialogue above and corresponding dialogue responses, wherein each One or more keywords are marked in the dialogue reply; and a first pre-training language model is trained using the first training data set, wherein the output to be fitted by the first pre-training language model includes a Both the one or more reply keywords and the reply sentences generated based on the one or more reply keywords.
根据本公开的第七方面,提供了一种基于语言模型的对话系统,包括:输入设备,被配置为接收对话输入;计算设备,被配置为:使用基于预训练语言模型建立的生成模型生成一组或更多组候选回复,每组候选回复包括针对所述对话输入的一个或更多个回复关键词和基于所述一个或更多个回复关键词生成的回复语句;以及使用基于预训练语言模型建立的筛选模型,从各组候选回复所包括的各回复语句中推断出最佳回复语句;输出设备,被配置为输出所述最佳回复语句。According to a seventh aspect of the present disclosure, there is provided a dialogue system based on a language model, comprising: an input device configured to receive dialogue input; a computing device configured to: generate a groups or groups of candidate replies, each group of candidate replies including one or more reply keywords entered for the dialogue and reply sentences generated based on the one or more reply keywords; and using a pretrained language-based language The screening model established by the model infers the best reply sentence from each reply sentence included in each group of candidate replies; the output device is configured to output the best reply sentence.
根据本公开的第八方面,提供了一种基于语言模型的对话系统,包括:输入设备,被配置为接收对话输入;计算设备,被配置为:使用基于预训练语言模型建立的生成模型,生成针对所述对话输入的一个或更多个回复语句;将所述一个或更多个回复语句拼接后输入到基于预训练语言模型建立的筛选模型;以及使用所述筛选模型,基于所述对话输入,从所述一个或更多个回复语句中推断出最佳回复语句;输出设备,被配置为输出所述最佳回复语句。According to an eighth aspect of the present disclosure, there is provided a language model-based dialogue system, comprising: an input device configured to receive dialogue input; a computing device configured to: generate a one or more reply sentences for the dialogue input; splicing the one or more reply sentences and inputting them into a screening model established based on a pre-trained language model; and using the screening model, based on the dialogue input , an optimal reply sentence is inferred from the one or more reply sentences; and an output device is configured to output the optimal reply sentence.
根据本公开的第九方面,提供了一种基于语言模型的对话系统,包括:输入设备,被配置为接收对话输入;计算设备,被配置为:使用基于预训练语言模型建立的生成模型生成一组或更多组候选回复,每组候选回复包括一个或更多个回复关键词与基于所述一个或更多个回复关键词生成的回复语句的拼接;将各组候选回复所包括的各回复语句、所述对话输入以及与所述对话输入相关联的历史对话数据拼接后输入到基于预训练语言模型建立的筛选模型;以及使用所述筛选模型,基于所述对话输入和所述历史对话数据,从各组候选回复所包括的各回复语句中推断出最佳回复语句;输出设备,被配置为输出所述最佳回复语句。According to a ninth aspect of the present disclosure, there is provided a language model-based dialogue system, comprising: an input device configured to receive dialogue input; a computing device configured to: generate a Group or more groups of candidate replies, each group of candidate replies includes a splicing of one or more reply keywords and reply sentences generated based on the one or more reply keywords; each reply included in each group of candidate replies is combined The sentence, the dialogue input and the historical dialogue data associated with the dialogue input are spliced and input into the screening model established based on the pre-trained language model; and using the screening model, based on the dialogue input and the historical dialogue data , infer the best reply sentence from each reply sentence included in each group of candidate replies; the output device is configured to output the best reply sentence.
根据本公开的第十方面,提供了一种基于语言模型的对话系统,包括:一个或更多个处理器;以及一个或更多个存储器,所述一个或更多个存储器被配置为存储一系列计算机可执行的指令,其中,当所述一系列计算机可执行的指令被所述一个或更多个处理器执行时,使得所述一个或更多个处理器进行如上所述的方法。According to a tenth aspect of the present disclosure, there is provided a language model-based dialogue system, comprising: one or more processors; and one or more memories configured to store a A series of computer-executable instructions, wherein the series of computer-executable instructions, when executed by the one or more processors, cause the one or more processors to perform the method as described above.
根据本公开的第十一方面,提供了一种非临时性计算机可读存储介质,其特征在于,所述非临时性计算机可读存储介质上存储有一系列计算机可执行的指令,当所述一系列计算机可执行的指令被一个或更多个计算装置执行时,使得所述一个或更多个计算装置进行如上所述的方法。According to an eleventh aspect of the present disclosure, a non-transitory computer-readable storage medium is provided, wherein a series of computer-executable instructions are stored on the non-transitory computer-readable storage medium, and when the one The series of computer-executable instructions, when executed by one or more computing devices, cause the one or more computing devices to perform a method as described above.
通过以下参照附图对本公开的示例性实施例的详细描述,本公开的其它特征及其优点将会变得清楚。Other features of the present disclosure and advantages thereof will become apparent from the following detailed description of exemplary embodiments of the present disclosure with reference to the accompanying drawings.
附图说明Description of drawings
构成说明书的一部分的附图描述了本公开的实施例,并且连同说明书一起用于解释本公开的原理。The accompanying drawings, which form a part of the specification, illustrate embodiments of the present disclosure and together with the description serve to explain the principles of the present disclosure.
参照附图,根据下面的详细描述,可以更加清楚地理解本公开,其中:The present disclosure may be more clearly understood from the following detailed description with reference to the accompanying drawings, wherein:
图1为基于语言模型的对话系统的功能示意图。Figure 1 is a functional schematic diagram of a language model-based dialogue system.
图2为根据本公开实施例的端到端生成式的心理咨询对话方法的示例性流程图。FIG. 2 is an exemplary flowchart of an end-to-end generative psychological counseling dialogue method according to an embodiment of the present disclosure.
图3为根据本公开实施例的端到端生成式的心理咨询对话方法的示意图。FIG. 3 is a schematic diagram of an end-to-end generative psychological counseling dialogue method according to an embodiment of the present disclosure.
图4为根据本公开实施例的端到端生成式的心理咨询对话方法的示意图。FIG. 4 is a schematic diagram of an end-to-end generative psychological counseling dialogue method according to an embodiment of the present disclosure.
图5为根据本公开实施例的端到端生成式的心理咨询对话方法中的生成模型的示例性结构图。FIG. 5 is an exemplary structural diagram of a generative model in an end-to-end generative psychological counseling dialogue method according to an embodiment of the present disclosure.
图6为图5中的编码器和解码器的示例性结构图。FIG. 6 is an exemplary structural diagram of the encoder and decoder in FIG. 5 .
图7为根据本公开实施例的端到端生成式的心理咨询对话方法的示例性流程图。FIG. 7 is an exemplary flowchart of an end-to-end generative psychological counseling dialogue method according to an embodiment of the present disclosure.
图8为根据本公开实施例的端到端生成式的心理咨询对话方法的示意图。FIG. 8 is a schematic diagram of an end-to-end generative psychological counseling dialogue method according to an embodiment of the present disclosure.
图9为根据本公开实施例的端到端生成式的心理咨询对话方法中的筛选模型的示例性结构图。FIG. 9 is an exemplary structural diagram of a screening model in an end-to-end generative psychological counseling dialogue method according to an embodiment of the present disclosure.
图10为根据本公开实施例的端到端生成式的心理咨询对话方法的示意图。FIG. 10 is a schematic diagram of an end-to-end generative psychological counseling dialogue method according to an embodiment of the present disclosure.
图11为根据本公开实施例的端到端生成式的心理咨询对话方法的示意图。FIG. 11 is a schematic diagram of an end-to-end generative psychological counseling dialogue method according to an embodiment of the present disclosure.
图12为示意性地示出根据本公开实施例的基于语言模型的对话系统的至少一部分的结构图。FIG. 12 is a structural diagram schematically illustrating at least a part of a language model-based dialogue system according to an embodiment of the present disclosure.
图13为示意性地示出根据本公开实施例的基于语言模型的对话系统的至少一部分的结构图。FIG. 13 is a structural diagram schematically illustrating at least a part of a language model-based dialogue system according to an embodiment of the present disclosure.
图14为示意性地示出根据本公开实施例的基于语言模型的对话系统的至少一部分的结构图。FIG. 14 is a structural diagram schematically illustrating at least a part of a language model-based dialogue system according to an embodiment of the present disclosure.
图15为可应用于根据本公开一个或多个示例性实施例的通用硬件系统的示例性框图。15 is an exemplary block diagram of a general-purpose hardware system applicable in accordance with one or more exemplary embodiments of the present disclosure.
图16为根据本公开实施例的方法与系统中使用的生成模型生成回复的实例的示意图。16 is a schematic diagram of an example of a generative model used in a method and system to generate a reply according to an embodiment of the present disclosure.
注意,在以下说明的实施方式中,有时在不同的附图之间共同使用同一附图标记来表示相同部分或具有相同功能的部分,而省略其重复说明。在一些情况中,使用相似的标号和字母表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步讨论。Note that, in the embodiments described below, the same reference numerals are used in common between different drawings to denote the same parts or parts having the same function, and repeated descriptions thereof may be omitted. In some instances, similar numerals and letters are used to denote similar items, so once an item is defined in one figure, it does not require further discussion in subsequent figures.
具体实施方式Detailed ways
以下将参照附图描述本公开,其中的附图示出了本公开的若干实施例。然而应当理解的是,本公开可以以多种不同的方式呈现出来,并不局限于下文描述的实施例;事实上,下文描述的实施例旨在使本公开的公开更为完整,并向本领域技术人员充分说明本公开的保护范围。还应当理解的是,本公开的实施例能够以各种方式进行组合,从而提供更多额外的实施例。The present disclosure will be described below with reference to the accompanying drawings, which illustrate several embodiments of the disclosure. It should be understood, however, that this disclosure may be presented in many different forms and is not limited to the embodiments described below; Those skilled in the art will fully explain the protection scope of the present disclosure. It should also be understood that the embodiments of the present disclosure can be combined in various ways to provide still further embodiments.
应当理解的是,本公开中的用语仅用于描述特定的实施例,并不旨在限定本公开。本公开使用的所有术语(包括技术术语和科学术语)除非另外定义,均具有本领域技术人员通常理解的含义。为简明和/或清楚起见,公知的功能或结构可以不再详细说明。It should be understood that the terms in the present disclosure are used to describe particular embodiments only, and are not intended to limit the present disclosure. All terms (including technical and scientific terms) used in this disclosure have the meanings commonly understood by those skilled in the art unless otherwise defined. Well-known functions or constructions may not be described in detail for brevity and/or clarity.
在本公开中,用语“A或B”包括“A和B”以及“A或B”,而不是排他地仅包括“A”或者仅包括“B”,除非另有特别说明。In the present disclosure, the term "A or B" includes "A and B" and "A or B" rather than exclusively "A" or only "B" unless specifically stated otherwise.
在本公开中,对“一个实施例”、“一些实施例”的提及意味着结合该实施例描述的特征、结构或特性包含在本公开的至少一个实施例、至少一些实施例中。因此,短语“在一个实施例中”、“在一些实施例中”在本公开的各处的出现未必是指同一个或同一些实施例。此外,在一个或多个实施例中,可以任何合适的组合和/或子组合来组合特征、结构或特性。In this disclosure, reference to "one embodiment" or "some embodiments" means that a feature, structure or characteristic described in connection with the embodiment is included in at least one embodiment, at least some embodiments of the present disclosure. Thus, appearances of the phrases "in one embodiment" and "in some embodiments" in various places in this disclosure are not necessarily referring to the same embodiment or embodiments. Furthermore, the features, structures or characteristics may be combined in any suitable combination and/or subcombination in one or more embodiments.
在本公开中,用语“示例性的”意指“用作示例、实例或说明”,而不是作为将被精确复制的“模型”。在此示例性描述的任意实现方式并不一定要被解释为比其它实现方式优选的或有利的。而且,本公开不受在上述技术领域、背景技术、发明内容或具体实施方式中所给出的任何所表述的或所暗示的理论所限定。In this disclosure, the term "exemplary" means "serving as an example, instance, or illustration" rather than as a "model" to be exactly reproduced. Any implementation illustratively described herein is not necessarily to be construed as preferred or advantageous over other implementations. Furthermore, the present disclosure is not to be bound by any expressed or implied theory presented in the preceding technical field, background, brief summary or detailed description.
另外,仅仅为了参考的目的,还可以在本公开中使用“第一”、“第二”等类似术语,并且因而并非意图限定。例如,除非上下文明确指出,否则涉及结构或元件的词语“第一”、“第二”和其它此类数字词语并没有暗示顺序或次序。Also, terms like "first," "second," and the like may also be used in this disclosure for reference purposes only, and are thus not intended to be limiting. For example, the terms "first," "second," and other such numerical terms referring to structures or elements do not imply a sequence or order unless the context clearly dictates otherwise.
还应理解,“包括/包含”一词在本公开中使用时,说明存在所指出的特征、整体、步骤、操作、单元和/或组件,但是并不排除存在或增加一个或更多个其它特征、整体、步骤、操作、单元和/或组件以及/或者它们的组合。It is also to be understood that the word "comprising/comprising" when used in this disclosure indicates the presence of the indicated feature, integer, step, operation, unit and/or component, but does not preclude the presence or addition of one or more other Features, integers, steps, operations, units and/or components and/or combinations thereof.
在本公开中,术语“部件”和“系统”意图是涉及一个与计算机有关的实体,或者硬件、硬件和软件的组合、软件、或执行中的软件。例如,一个部件可以是,但是不局限于,在处理器上运行的进程、对象、可执行态、执行线程、和/或程序等。通过举例说明,在一个服务器上运行的应用程序和所述服务器两者都可以是一个部件。一个或多个部件可以存在于一个执行的进程和/或线程的内部,并且一个部件可以被定位于一台计算机上和/或被分布在两台或更多计算机之间。In this disclosure, the terms "component" and "system" are intended to refer to a computer-related entity, or hardware, a combination of hardware and software, software, or software in execution. For example, a component may be, but is not limited to, a process, object, executable state, thread of execution, and/or program, etc. running on a processor. By way of example, both an application running on a server and the server can be one component. One or more components may exist within an executing process and/or thread, and a component may be localized on one computer and/or distributed between two or more computers.
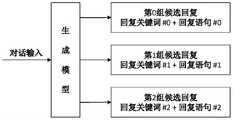
近几年随着预训练(pre-training)技术的兴起和Transformer网络结构在自然语言处理领域大放异彩,端到端的生成式对话机器人已经在世界范围内引起广泛关注并迅速发展。在当前较为先进的对话系统中,除了基本的语言生成模型(generator)之外,大都还额外引入了回复筛选模型(selector/ranker),它们所使用的一种sample-and-rank方式被证明可以较为稳定的生成高质量回复。其生成回复的流程大致如图1所示:(1)用户输入用于语义理解;(2)由基本的语言生成模型计算出回复内容的语言分布,并从分布中采样出多条候选回复;(3)将候选回复送入筛选模型,选出置信度最高的一条;(4)最终回复发送给用户。In recent years, with the rise of pre-training (pre-training) technology and the Transformer network structure in the field of natural language processing, end-to-end generative dialogue robots have attracted widespread attention and developed rapidly around the world. In the current more advanced dialogue systems, in addition to the basic language generation model (generator), most of them also introduce an additional response screening model (selector/ranker), and a sample-and-rank method they use has been proved to be It is more stable to generate high-quality responses. The process of generating a reply is roughly as shown in Figure 1: (1) User input is used for semantic understanding; (2) The language distribution of the reply content is calculated by the basic language generation model, and multiple candidate replies are sampled from the distribution; (3) The candidate replies are sent to the screening model, and the one with the highest confidence is selected; (4) The final reply is sent to the user.
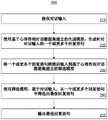
图2为根据本公开实施例的端到端生成式的心理咨询对话方法100的示例性流程图。方法100可以由安装到电子设备的应用程序或小程序来执行,以向用户提供服务。方法100包括:接收对话输入(步骤110);使用基于心理咨询对话数据集建立的生成模型生成一组或更多组候选回复,每组候选回复包括针对对话输入的一个或更多个回复关键词和基于一个或更多个回复关键词生成的回复语句(步骤120);使用基于心理咨询对话数据集建立的筛选模型,从各组候选回复所包括的各回复语句中筛选出最佳回复语句(步骤130);以及输出最佳回复语句(步骤140)。FIG. 2 is an exemplary flowchart of an end-to-end generative psychological
能够执行方法100的系统,例如下文所述的根据本公开实施例的基于语言模型的对话系统,可以从用户接收(例如通过下文所述的输入设备)以自然语言表达的输入,即本文所说的“对话输入”,例如图1所示的“It’s so cold today,and the wind outside isso strong.”;并生成并输出(例如通过下文所述的输出设备)针对该对话输入的回复语句,例如图1所示的“It seems like winter is coming soon.”,从而完成一次对话。用户对根据本公开实施例的系统以自然语言表达的输入,可以是文字形式的也可以是语音形式的,本发明不作限制。在用户以语音形式进行输入的情况下,根据本公开实施例的系统中的输入设备可以具有语音识别功能,以便将来自用户的语音形式的输入转换为文字形式并传输给后续的处理设备,例如下文所述的计算设备。A system capable of performing
当本文提及“历史对话数据”,指的是在本次对话之前、系统与当前用户的全部对话或部分对话。应当理解,除另有说明,部分对话应包括最接近本次对话的一次或更多次对话。应当理解,当提及“对话”,通常指的是完整的对话,即包括用户的输入以及系统的输出,但每次用户的输入或系统的输出均可以包括一个或更多个语句(可以是完整的语句、也可以是不完整的语句)。但根据实际情况,对话也可以是不完整的,例如仅包括用户的输入(例如系统未响应用户的输入、或系统尚未响应但用户又进行下一次输入等情况)或仅包括系统的输出(例如系统在预定时间内未等到用户的输入而主动输出等情况)。本文还提及“对话上文”,其在本公开实施例中使用时,包括历史对话数据和对话输入。When this article refers to "historical conversation data", it refers to all or part of the conversation between the system and the current user before this conversation. It should be understood that, unless otherwise stated, a portion of a conversation should include one or more conversations that are closest to this conversation. It should be understood that when referring to a "dialogue", it usually refers to a complete dialogue, that is, including the user's input and the system's output, but each time the user's input or the system's output may include one or more sentences (which may be complete statement or incomplete statement). However, depending on the actual situation, the dialog can also be incomplete, for example, it only includes the user's input (for example, the system does not respond to the user's input, or the system has not yet responded but the user makes the next input, etc.) or only includes the output of the system (for example, The system does not wait for the user's input within a predetermined time and actively outputs, etc.). Reference is also made herein to "dialogue above," which, when used in embodiments of the present disclosure, includes historical dialogue data and dialogue input.
方法100的步骤120中使用的生成模型是基于心理咨询对话数据集建立的。对于生成模型,存在“一对多映射”的问题,即同样的对话输入,可能对应多个不同的正确回复,这些回复都很合理但是彼此之间的语义天差地别(参考图1中生成模型所生成的多个回复语句)。本公开的发明人发现,在现有的对生成模型进行训练的方法中,这种一对多映射的现象对拟合数据造成很大的难度,导致生成的回复内容不同于任何一个合理回复。例如,对于一个对话输入有R1、R2、R3三个合理回复,而现有训练方法中生成模型学习出来的东西会是R1、R2和R3的均值,可能不属于任何一个合理回复。The generative model used in
鉴于此,不同于现有技术中用生成模型直接生成回复的方法,本公开提出了使生成模型先预测出在回复中需要包含的关键词,再通过关键词“造句”生成整个回复语句。因为在生成了关键词后,这条回复内容的方向就比较明确了,会明显倾向于某个合理回复。还是以图1所示的内容为例,如果生成模型先生成了关键词“hair style”,则其最后生成的回复语句就会明显偏向于第二种合理回复。如果没有关键词,很可能实际使用中,生成模型会综合考虑三种回复,最终生成类似于“Winter is cold.”这种比较简短无趣的平均回复。In view of this, different from the method in the prior art that uses a generative model to directly generate a reply, the present disclosure proposes to make the generative model first predict the keywords that need to be included in the reply, and then generate the entire reply sentence by using the keyword "sentence". Because after the keywords are generated, the direction of the reply content is relatively clear, and it will obviously tend to a reasonable reply. Taking the content shown in Figure 1 as an example, if the generative model first generates the keyword "hair style", the reply sentence generated at the end will obviously be biased towards the second reasonable reply. If there are no keywords, it is likely that in actual use, the generative model will comprehensively consider three responses, and finally generate a relatively short and uninteresting average response similar to "Winter is cold.".
方法100使用的心理咨询对话数据集可以包括收集的真实心理咨询对话语料以用于训练生成模型,例如可以来自由专业的心理咨询师进行线上(例如与心理咨询相关的应用程序或小程序等)或线下的心理咨询。还需要对这些真实的对话预料进行清洗与标注,以标注出回复中的关键词。应当理解,本文所称的“关键词”包括单字词和多字词。标注可以由人工进行,例如由专业的心理咨询师进行标注;也可以由机器自动标注,例如,通过无监督方法TF-IDF进行标注。TF-IDF是常用于文档检索的方法,许多搜索引擎基于该方法实现。TF-IDF会根据搜索的关键词和目标文档进行匹配,找到要搜索的文档。本公开用TF-IDF可以自动化地标注回复中的关键词。标注后的聊天数据形成心理咨询对话数据集。The psychological counseling dialogue data set used in the
本公开实施例提供了用于生成模型的训练方法,其使用训练数据集对预训练语言模型进行训练。训练数据集包括对话上文和对应的对话回复,其中每条对话回复中被标注一个或更多个关键词,例如可以是上文提及的心理咨询对话数据集。通常一个回复语句中可以被标注例如一个或两个关键词,当然也可以被标注更多个关键词。预训练语言模型具有transformer网络结构,例如为BART模型或其他合适的预训练语言模型。在训练过程中,使得预训练语言模型待拟合的输出包括针对输入的一个或更多个回复关键词和基于一个或更多个回复关键词生成的回复语句两者,并且训练的优化目标为交叉熵损失函数。在一些实施例中,预训练语言模型待拟合的输出还可以包括用于提示预训练语言模型生成回复关键词的提示语,例如包括提示语、一个或更多个回复关键词以及回复语句的拼接。Embodiments of the present disclosure provide a training method for generating a model that uses a training dataset to train a pretrained language model. The training data set includes the above dialogue and corresponding dialogue responses, wherein each dialogue response is marked with one or more keywords, for example, the above-mentioned psychological counseling dialogue data set. Usually, a reply sentence can be marked with one or two keywords, of course, more keywords can be marked. The pre-trained language model has a transformer network structure, such as a BART model or other suitable pre-trained language models. In the training process, the output of the pre-trained language model to be fitted includes both the one or more reply keywords for the input and the reply sentences generated based on the one or more reply keywords, and the optimization objective of the training is Cross-entropy loss function. In some embodiments, the to-be-fitted output of the pre-trained language model may further include a prompt for prompting the pre-trained language model to generate a reply keyword, for example, including a prompt, one or more reply keywords, and a reply sentence stitching.
提示语是一种已知的技术,可以用来告诉模型现在要做什么。可以根据需要模型完成的任务来制定任务特定的提示语。在一些实施例中,提示语可以是特定的一个或更多个文本模板,例如手工设计的离散提示语(handcraft discrete prompt),其可以包括多个标准的字符,例如“回复关键词:”。在一些实施例中,提示语可以是具有实际语义的自然语言文本或不具有实际语义的文本,例如连续提示语(continuous prompt),其可以包括作为提示用的一个不具有实际语义的向量。Hints are a known technique that can be used to tell the model what to do now. Task-specific prompts can be formulated based on the tasks that require the model to complete. In some embodiments, the prompt may be a specific one or more text templates, such as a handcraft discrete prompt, which may include a number of standard characters, such as "reply keywords:". In some embodiments, the prompt may be natural language text with actual semantics or text without actual semantics, such as a continuous prompt, which may include a vector with no actual semantics as a prompt.
下面一个具体的示例说明根据本公开实施例的用于生成模型的训练方法。模型训练时,需要拟合的输出为prompt+keywords+[start]+response。prompt即提示语,用于提示模型目前需要先生成关键词。在该具体的示例中,提示语为手工设计的离散提示语,例如“回复关键词:”。keywords为需要拟合的关键词,response为需要拟合的回复语句。此外,在该具体的示例中,模型的待拟合输出还包括拼接在一个或更多个回复关键词之后、回复语句之前的特定标记[start],其表示关键词的生成已经结束了,之后继续生成回复语句。训练时仍然使用交叉熵损失函数作为优化目标,但与现有技术不同,参与优化的部分不只是response本身,而是完整的prompt+keywords+[start]+response。The following specific example illustrates a training method for generating a model according to an embodiment of the present disclosure. During model training, the output that needs to be fitted is prompt+keywords+[start]+response. Prompt is a prompt, which is used to prompt the model to generate keywords first. In this specific example, the prompts are discrete prompts designed manually, such as "reply to keywords:". keywords are the keywords that need to be fitted, and response is the reply sentence that needs to be fitted. In addition, in this specific example, the to-be-fitted output of the model also includes a specific tag [start] spliced after one or more reply keywords and before the reply sentence, which indicates that the generation of the keyword has ended, and then Continue generating reply statements. The cross-entropy loss function is still used as the optimization target during training, but unlike the existing technology, the part involved in the optimization is not just the response itself, but the complete prompt+keywords+[start]+response.
在一些实施例中,预训练语言模型的解码策略采用top-p采样(top-p sampling),并且其中,用于生成回复关键词的阈值p低于用于生成回复语句的阈值p。由于关键词的困惑度比回复语句的困惑度更高,因此在top-p采样的时候,关键词的top-p比例要明显低于回复语句的top-p比例,即p值设置得更低,以使其指向性更明确。在一个具体的示例中,用于生成回复关键词的阈值p小于或等于0.3,用于生成回复语句的阈值p为0.75~0.95。参考图16所示的生成模型生成回复的实例,其中区域A1中显示的是对话上文,区域A2中显示的是生成模型针对所示的对话上文生成的各组候选回复,每组候选回复包括关键词和基于该关键词生成的回复语句。区域A2-1中显示的为top-p采样的用于生成回复关键词的p值和用于生成回复语句的p值均设置为0.9的情况下所生成的回复;区域A2-2中显示的为top-p采样的用于生成回复关键词的p值设置为0.25、用于生成回复语句的p值设置为0.9的情况下所生成的回复。可以看出,区域A2-2中显示的各个候选回复中的回复语句,比区域A2-1中的回复,具有更高的内容连贯性。In some embodiments, the decoding strategy of the pretrained language model employs top-p sampling, and wherein the threshold p for generating reply keywords is lower than the threshold p for generating reply sentences. Since the perplexity of keywords is higher than that of reply sentences, when top-p sampling is performed, the top-p ratio of keywords is significantly lower than the top-p ratio of reply sentences, that is, the p value is set lower. , to make it more directional. In a specific example, the threshold p for generating reply keywords is less than or equal to 0.3, and the threshold p for generating reply sentences ranges from 0.75 to 0.95. Referring to the example of generating a reply by the generative model shown in FIG. 16 , in which area A1 shows the above dialogue, and area A2 shows each group of candidate replies generated by the generative model for the shown dialogue above, each group of candidate replies. Include keywords and reply sentences generated based on the keywords. Shown in area A2-1 are the replies generated when both the top-p sampling p-value used to generate reply keywords and the p-value used to generate reply sentences are set to 0.9; shown in area A2-2 Replies generated with the top-p sampled p-value for generating reply keywords set to 0.25 and p-value for generating reply sentences to 0.9. It can be seen that the reply sentences in each candidate reply displayed in the area A2-2 have higher content coherence than the replies in the area A2-1.
在一些实施例中,生成模型可以包括用于生成针对对话输入的一个或更多个回复关键词的第一子模型,和与第一子模型级联的、用于基于一个或更多个回复关键词生成回复语句的第二子模型。在这种情况下的模型训练,可以对第一子模型和第二字模型的输出分别进行拟合。使用两个生成子模型分别进行关键词和回复语句的预测,在计算设备的计算能力相同的情况下,其预测速度通常慢于使用一个生成模型共同进行关键词和回复语句的预测,并且其存储的模型参数也更多。In some embodiments, the generative model may include a first sub-model for generating one or more reply keywords for the dialogue input, and cascaded with the first sub-model for generating one or more reply keywords based on the dialogue input The keyword generates a second submodel of the reply sentence. In the model training in this case, the outputs of the first sub-model and the second word model can be fitted separately. Using two generative sub-models to predict keywords and reply sentences respectively, when the computing power of the computing device is the same, the prediction speed is usually slower than using one generative model to jointly predict keywords and reply sentences, and its storage also has more model parameters.
在方法100的步骤120中,如图3所示,使用根据上文所述的方法训练的生成模型,根据步骤110中接收的对话输入,生成一组或更多组候选回复,在图3的具体示例中包括三组候选回复,分别示出为第0、1、2组候选回复。每组候选回复包括针对对话输入的一个或更多个关键词(三组候选回复中的回复关键词分别示出为回复关键词#0、#1、#2)和基于一个或更多个回复关键词生成的回复语句(三组候选回复中的回复语句分别示出为回复语句#0、#1、#2)。在一些实施例中,每组候选回复还可以包括用于提示生成模型生成回复关键词的提示语;和/或每组候选回复包括一个或更多个回复关键词与回复语句的拼接、以及在一个或更多个回复关键词之后、回复语句之前还包括特定标记,例如上文描述的[start]。在一个具体的示例中,每组候选回复可以是prompt+keywords+[start]+response,其示例可以是“回复关键词:冷,帽子[start]今天好冷,我把帽子都带上了!”In
如图4所示,在生成模型包括两个子模型(图4中分别示出为生成子模型#0、#1)的情况下,生成子模型#0根据步骤110中接收的对话输入生成一组或更多组回复关键词(分别示出为回复关键词#0、#1、#2),其中每组回复关键词可以包括一个或更多个回复关键词。生成子模型#1分别基于每组回复关键词生成对应的回复语句(分别示出为回复语句#0、#1、#2)。As shown in FIG. 4 , in the case where the generative model includes two sub-models (respectively shown as generative
还需要将生成模型生成的各回复语句输入到筛选模型,以使得方法100在步骤130中,从各回复语句中筛选出最佳回复语句,并在步骤140中向用户输出该最佳回复语句。在图3所述的实施例中,可以将各组候选回复所包括的各回复语句输入到筛选模型,例如将候选回复中的特定标记之后的内容截取出来输入到筛选模型。在图4所示的实施例中,可以将第二子模型的输出输入到筛选模型。在步骤130中使用的筛选模型,可以是现有技术中已知的筛选模型,也可以是如下文所述的在根据本公开实施例的方法和系统中所使用的筛选模型。It is also necessary to input each reply sentence generated by the generation model into the screening model, so that in step 130, the
如上文所述,用于建立生成模型的预训练语言模型具有transformer网络结构。transformer网络结构是基于注意力机制的encoder-decoder(编码器-解码器)模型。根据不同的应用需求,transformer网络结构可以既包括编码器也包括解码器,还可以只包括编码器或只包括解码器。如图5所示,用于建立生成模型的transformer网络结构既包括编码器也包括解码器,其中编码器和解码器都是由多个相同的相应编码层或相应解码层(例如各6层、12层、18层等,本公开对此不作限制)堆叠而成。单个编码层和单个解码层的内部简化结构如图6所示。编码层由自注意力(self-attention)子层和前馈神经网络子层组成,其中自注意力子层能帮助当前节点关注除当前词之外的内容,从而可以更好地获取到输入信息的上下文语义。在解码层中,除了编码层所涉及的两个网络子层外,还包括在这两个网络子层中间的编码器-解码器注意力子层,用于得到解码阶段当前时刻的输出与编码阶段每一时刻的输入之间的相关关系,以帮助当前节点获取到当前需要关注的重点内容。应当理解,图6为单个编码层和单个解码层的结构的简化示意图,单个编码层或单个解码层还可以包括具有其他功能的网络子层。此外,transformer网络结构还包括输入层(例如可以包括嵌入(embedding)子层和位置编码子层等)和输出层(例如可以包括全连接子层和softmax子层等)。As mentioned above, the pretrained language model used to build the generative model has a transformer network structure. The transformer network structure is an encoder-decoder (encoder-decoder) model based on an attention mechanism. According to different application requirements, the transformer network structure can include both the encoder and the decoder, or only the encoder or only the decoder. As shown in Figure 5, the transformer network structure used to build the generative model includes both an encoder and a decoder, wherein the encoder and the decoder are both composed of multiple identical corresponding encoding layers or corresponding decoding layers (for example, 6 layers, 12 layers, 18 layers, etc., which are not limited in the present disclosure) are stacked. The internal simplified structure of a single encoding layer and a single decoding layer is shown in Figure 6. The encoding layer is composed of a self-attention sub-layer and a feed-forward neural network sub-layer. The self-attention sub-layer can help the current node focus on content other than the current word, so that the input information can be better obtained. contextual semantics. In the decoding layer, in addition to the two network sub-layers involved in the encoding layer, it also includes an encoder-decoder attention sub-layer between the two network sub-layers, which is used to obtain the output and encoding at the current moment of the decoding stage. The correlation between the inputs at each moment of the stage helps the current node to obtain the key content that needs to be paid attention to. It should be understood that FIG. 6 is a simplified schematic diagram of the structure of a single encoding layer and a single decoding layer, and a single encoding layer or a single decoding layer may also include network sublayers with other functions. In addition, the transformer network structure also includes an input layer (for example, it may include an embedding sublayer and a position encoding sublayer, etc.) and an output layer (for example, it may include a fully connected sublayer and a softmax sublayer, etc.).
图7为根据本公开实施例的端到端生成式的心理咨询对话方法200的示例性流程图。方法200可以由安装到电子设备的应用程序或小程序来执行,以向用户提供服务。方法200包括:接收对话输入(步骤210);使用基于心理咨询对话数据集建立的生成模型,生成针对对话输入的一个或更多个回复语句(步骤220);将一个或更多个回复语句拼接后输入到基于心理咨询对话数据集建立的筛选模型(步骤230);使用筛选模型,基于对话输入,从一个或更多个回复语句中筛选出最佳回复语句(步骤240);以及输出最佳回复语句(步骤250)。FIG. 7 is an exemplary flowchart of an end-to-end generative psychological
能够执行方法200的系统,例如下文所述的根据本公开实施例的基于语言模型的对话系统,在步骤210中可以从用户接收对话输入,并在步骤220中使用基于心理咨询对话数据集建立的生成模型,生成针对对话输入的一个或更多个回复语句。步骤220中使用的生成模型可以是现有技术中已知的生成模型,也可以是如上文所述的在根据本公开实施例的方法和系统中所使用的生成模型。A system capable of executing
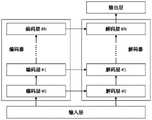
方法200的步骤230和240中使用的筛选模型是基于心理咨询对话数据集建立的。对于筛选模型,现有技术中已知的工作方式是结合对话输入和单条候选回复让模型进行理解和打分,分数范围通常是0-1,1分代表这条回复完全恰当,0分代表这条回复完全不合适。使用时,需要轮流给多条候选回复打分,将置信度(分数)最高的一条候选回复作为最佳回复。本公开提出了基于对话输入(优选地,为对话上文)和全部多条候选回复让筛选模型进行理解和打分的方法。由此,模型可以在各条回复之间进行更加细微的比较,并且使用时可以一次性选出最佳回复。The screening model used in
本公开实施例提供了用于筛选模型的训练方法,其使用训练数据集对预训练语言模型进行训练。训练数据集包括对话上文、正样本回复以及一个或更多个负样本回复。用于训练在方法200中使用的筛选模型的训练数据集是基于实际的心理咨询对话语料建立的。预训练语言模型具有transformer网络结构,例如为BERT模型或其他合适的预训练语言模型。如上所述,本公开提出了将全部多条候选回复共同后输入到筛选模型进行理解和打分的方法,因此,在对筛选模型的训练过程中,对预训练语言模型的训练输入包括正样本回复以及一个或更多个负样本回复的拼接。Embodiments of the present disclosure provide a training method for screening models, which uses a training dataset to train a pre-trained language model. The training dataset includes dialogue text, positive sample responses, and one or more negative sample responses. The training data set used to train the screening model used in
在一些实施例中,筛选模型包括单个编码器(也可以称为交叉编码器(crossencoder)结构)。用于建立筛选模型的transformer网络结构可以仅包括编码器,如图9所示,其中该编码器由多个相同的编码层堆叠而成。在这种情况下,可以将对话上文和正样本回复以及一个或更多个负样本回复拼接后输入到预训练语言模型的单个编码器,如图10所示,以对预训练语言模型进行训练。在一些实施例中,筛选模型包括两个编码器(即第一编码器和第二编码器,在图11中分别示出为编码器#0、#1)和位于两个编码器的输出处的交叉注意力层,如图11所示。在这种情况下,可以将对话上文输入到预训练语言模型的第一编码器、并将正样本回复以及一个或更多个负样本回复拼接后输入到预训练语言模型的第二编码器,以对预训练语言模型进行训练。两个编码器分别对对话上文和多个候选回复进行理解,两个编码器的运算结果在交叉注意力层中再进行运算,以判断哪个候选回复是最佳回复。两个编码器可以共享参数,以减少需要存储的模型参数量(即相对于单个编码器,使得需存储的参数量没有增加)。相比于单个编码器的模型结构,具有两个编码器的筛选模型由于可以并行处理针对对话上文和各候选回复的运算,因此其运算速度更快;但由于其仅在两个编码器的输出处才在对话上文信息和各候选回复的信息之间具有信息交换,因此其理解效果不如在每个编码层都具有对话上文和各候选回复之间的信息交换的单个编码器的模型结构。在图9至11所示的筛选模型结构中,每个编码层的内部简化结构如图6所示,每个输入层和输出层的结构如上所述,此处不再赘述。In some embodiments, the screening model includes a single encoder (which may also be referred to as a crossencoder structure). The transformer network structure used to build the screening model can only include the encoder, as shown in Figure 9, where the encoder is formed by stacking multiple identical encoding layers. In this case, the dialogue text and positive sample responses and one or more negative sample responses can be concatenated and input into a single encoder of the pre-trained language model, as shown in Figure 10, to train the pre-trained language model . In some embodiments, the screening model includes two encoders (ie, a first encoder and a second encoder, shown in FIG. 11 as
下面以一个具体的示例说明根据本公开实施例的用于筛选模型的训练方法,在该具体的示例中,筛选模型包括两个编码器,如图11所示。模型训练时,将对话上文(包括历史对话数据和对话输入)输入到编码器#0,将所有的候选回复(包括一个正样本、和一个或更多个负样本)输入到编码器#1。对话上文,在以下公式中表示为ctxt,为历史对话数据和对话输入的拼接,即[cls]+x1+…+xn+[sep]。其中,[cls]和[sep]分别为作为起止标识的特殊字符,x1,…,xn分别为历史对话数据中的各次对话输入语句的向量以及本次对话输入语句的向量。在其他的示例中,可以仅包括[cls]和[sep]中的一个以表示分隔。应当理解,由于编码器的输入容量是有限的,因此x1,…,xn为在输入容量允许的条件下、包括本次对话输入在内的与当前对话最临近的n个对话语句。候选回复,在以下公式中表示为cand,为各条候选回复的拼接,即[cls]+y1+[sep]+…+[cls]+yk+[sep]。其中,y1,…,yk分别为k条候选回复语句的向量。编码器#0和编码器#1处理后的结果表示如下:The following describes a training method for a screening model according to an embodiment of the present disclosure with a specific example. In this specific example, the screening model includes two encoders, as shown in FIG. 11 . During model training, input the dialogue above (including historical dialogue data and dialogue input) into
Hctxt=encode1(ctxt)Hctxt = encode1 (ctxt)
Hall_cand=encode2({cand1,...,candk})。Hall_cand = encode2 ({cand1 , . . . , candk }).
之后将Hctxt与Hall_cand通过交叉注意力层得出Hcross:After that, Hctxt and Hall_cand are passed through the cross attention layer to obtain Hcross:
Hcross=Attention(Hall_cand,Hctxt,Hctxt)。Hcross = Attention(Hall_cand , Hctxt , Hctxt ).
将Hcross中每个候选回复所对应的embedding汇总,并通过前馈神经网络层将每个均值embedding投射成单一logit(Ecand),最后对于所有的logit进行softmax函数变换,以得出模型预测的最佳回复Ypred:Summarize the embeddings corresponding to each candidate reply in Hcross, and project each mean embedding into a single logit (Ecand) through the feedforward neural network layer, and finally perform a softmax function transformation on all logits to obtain the best model predicted by the model. Jia replied to Ypred:

将模型的预测与标注的真实答案Ylabel计算交叉熵损失,并通过反向传播优化模型:Calculate the cross-entropy loss by comparing the model's predictions with the labeled ground-truth answer Ylabel, and optimize the model by backpropagation:
l=cross_entropy(Ypred,Ylabel)。l=cross_entropy(Ypred , Ylabel ).
直到模型输出准确率满足预设条件,从而完成筛选模型的训练。Until the output accuracy of the model meets the preset conditions, the training of the screening model is completed.
通过以上方法训练完成的筛选模型可以用在方法200的步骤230和240中。在以上描述的训练方法中,用于模型训练的对话上文包括当前对话输入和历史对话数据。在一些实施例中,在模型的使用时,例如在方法200中,可以将与对话输入相关联的历史对话数据、本次的对话输入以及生成模型所生成的一个或更多个回复语句都输入到筛选模型。应当理解,在其他一些实施例中,在模型的使用时,例如在方法200中,也可以仅将本次的对话输入作为对话上文、连同生成模型所生成的一个或更多个回复语句输入到筛选模型,而并不输入历史对话数据,如图8所示的那样。此外,根据筛选模型所包括的编码器的个数不同,步骤230中对输入到筛选模型的数据的处理也会不同。在筛选模型包括单个编码器的实施例中,将历史对话数据、本次的对话输入、以及生成模型生成的一个或更多个回复语句拼接后,例如[cls]+x1+…+xn+[sep]+[cls]+y1+[sep]+…+[cls]+yk+[sep],输入到该单个编码器。在筛选模型包括两个编码器的实施例中,将历史对话数据和对话输入拼接后,例如[cls]+x1+…+xn+[sep],输入到一个编码器,将生成模型生成的一个或更多个回复语句拼接后,例如[cls]+y1+[sep]+…+[cls]+yk+[sep],输入到另一个编码器。The screening model trained by the above method can be used in
本领域技术人员应当意识到,在以上描述的各方法中,步骤或操作之间的边界仅仅是说明性的。多个步骤或操作可以结合成单个步骤或操作,单个步骤或操作可以分布于附加的步骤或操作中,并且步骤或操作可以在时间上至少部分重叠地执行。而且,另选的实施例可以包括特定步骤或操作的多个实例,并且在其他各种实施例中可以改变步骤或操作的执行顺序。但是,其它的修改、变化和替换同样是可能的。因此,本说明书和附图应当被看作是说明性的,而非限制性的。Those skilled in the art will appreciate that in the various methods described above, the boundaries between steps or operations are merely illustrative. Multiple steps or operations may be combined into a single step or operation, a single step or operation may be distributed among additional steps or operations, and steps or operations may be performed at least partially overlapping in time. Furthermore, alternative embodiments may include multiple instances of a particular step or operation, and in other various embodiments the order of performance of the steps or operations may be changed. However, other modifications, changes and substitutions are equally possible. Accordingly, the specification and drawings are to be regarded in an illustrative rather than a restrictive sense.
图12是示意性地示出根据本公开实施例的基于语言模型的对话系统300的至少一部分的结构图。系统300包括输入设备310、计算设备320和输出设备330。输入设备310被配置为接收对话输入,输出设备330被配置为输出最佳回复语句。FIG. 12 is a structural diagram schematically illustrating at least a part of a language model-based
在一些实施例中,计算设备320被配置为:使用基于预训练语言模型建立的生成模型生成一组或更多组候选回复,每组候选回复包括针对对话输入的一个或更多个回复关键词和基于一个或更多个回复关键词生成的回复语句;以及使用基于预训练语言模型建立的筛选模型,从各组候选回复所包括的各回复语句中推断出最佳回复语句。In some embodiments,
在一些实施例中,计算设备320被配置为:使用基于预训练语言模型建立的生成模型,生成针对对话输入的一个或更多个回复语句;将一个或更多个回复语句拼接后输入到基于预训练语言模型建立的筛选模型;以及使用筛选模型,基于对话输入,从一个或更多个回复语句中推断出最佳回复语句。In some embodiments, the
在一些实施例中,计算设备320被配置为:使用基于预训练语言模型建立的生成模型生成一组或更多组候选回复,每组候选回复包括一个或更多个回复关键词与基于一个或更多个回复关键词生成的回复语句的拼接;将各组候选回复所包括的各回复语句、对话输入以及与对话输入相关联的历史对话数据拼接后输入到基于预训练语言模型建立的筛选模型;以及使用筛选模型,基于对话输入和历史对话数据,从各组候选回复所包括的各回复语句中推断出最佳回复语句。In some embodiments,
本公开的发明人还进行了实验以验证本公开所提出的方法和系统的改进效果。The inventors of the present disclosure also conducted experiments to verify the improved effects of the methods and systems proposed in the present disclosure.
发明人测试了使用本公开提出的训练方法得到的生成模型(称为“被测模型”)与现有技术中已知的生成模型(称为“对比模型”)的性能对比。在该实验中,被测模型和对比模型均以BART模型为基础,在DailyDialog数据集上分别测试两个生成模型所生成的回复语句的语言困惑度(perplexity,其值越低代表回复语句与对话上文的连贯性越高)。实验结果表明,对比模型所生成的回复语句的语言困惑度为6.9,被测模型所生成的回复语句的语言困惑度为5.48。可见,相比于现有技术中已知的生成模型,使用本公开提出的训练方法得到的生成模型能够使得生成模型所生成的回复语句的语言困惑度明显下降。The inventors tested the performance comparison of the generative model obtained using the training method proposed in the present disclosure (referred to as a "tested model") and a generative model known in the prior art (referred to as a "comparative model"). In this experiment, both the tested model and the comparison model are based on the BART model, and the language perplexity (perplexity) of the reply sentences generated by the two generative models is tested on the DailyDialog data set. The higher the coherence above). The experimental results show that the language perplexity of the reply sentences generated by the comparison model is 6.9, and the language perplexity of the reply sentences generated by the tested model is 5.48. It can be seen that, compared with the generative models known in the prior art, the generative model obtained by using the training method proposed in the present disclosure can significantly reduce the language confusion of the reply sentences generated by the generative model.
此外,发明人还测试了使用本公开提出的训练方法得到的筛选模型(称为“被测模型”)与现有技术中已知的筛选模型(称为“对比模型”)的性能对比。在该实验中,被测模型和对比模型均以BERT模型为基础,在ConvAI2数据集上测试分别测试两个筛选模型从多个样本中选出最佳回复的正确率。实验采用指标R1@20,即从20个样本中选出最佳回复的正确率。实验结果表明,对比模型的R1@20为84.9,被测模型的R1@20为85.2。可见,相比于现有技术中已知的筛选模型,使用本公开提出的训练方法得到的筛选模型可以使筛选的正确率明显提升。此外发明人还测试了被测模型与对比模型的处理速度。在实验中,使用的GPU最大存储空间为1.85GB,输入模型的候选回复76740条,对比模型的处理时间为73.0秒,被测模型的处理时间为14.7秒。可见,在使用同样计算资源的情况下,被测模型比对比模型可以提速近80%。In addition, the inventors also tested the performance comparison of the screening model obtained using the training method proposed in the present disclosure (referred to as a "tested model") and a screening model known in the prior art (referred to as a "comparative model"). In this experiment, both the tested model and the comparison model are based on the BERT model, and the two screening models are tested on the ConvAI2 dataset to test the correct rate of selecting the best response from multiple samples. The experiment adopts the index R1@20, that is, the correct rate of selecting the best reply from 20 samples. The experimental results show that the R1@20 of the comparison model is 84.9, and the R1@20 of the tested model is 85.2. It can be seen that, compared with the screening models known in the prior art, the screening model obtained by using the training method proposed in the present disclosure can significantly improve the screening accuracy. In addition, the inventors also tested the processing speed of the tested model and the comparison model. In the experiment, the maximum storage space of the GPU used is 1.85GB, the input model has 76740 candidate replies, the processing time of the comparison model is 73.0 seconds, and the processing time of the tested model is 14.7 seconds. It can be seen that under the condition of using the same computing resources, the tested model can be nearly 80% faster than the comparison model.
最后,发明人还测试了使用本公开所提出的训练方法得到的生成模型和筛选模型两者的对话系统(称为“被测系统”),与使用现有技术中已知的生成模型和筛选模型的对话系统(称为“对比系统”)的性能对比。从真实心理咨询对话语料库中随机选取若干条(例如>=50条)对话样本,并根据每个对话样本中的对话上文,分别通过被测系统和对比系统生成最佳回复语句。其中,对话样本中的回复语句称为“真人回复”,被测系统生成的最佳回复语句称为“被测回复”,对比系统生成的最佳回复语句称为“对比回复”。在不知道当前的回复语句是真人回复、被测回复还是对比回复的情况下,请专业的心理咨询师(例如>=5人)针对每一次的对话上文对每个回复进行选择,分别从回复的自然度(语句是否连贯、多样)、宜人性(是否愿意和其聊天)、以及专业的咨询效果三方面去选择哪个回复更好。测试结果显示,在对比回复与真人回复的较量中,对比回复被选择的比例为28%、真人回复被选择的比例为72%;而在被测回复与真人回复的较量中,被测回复被选择的比例为37.8%、真人回复被选择的比例为62.2%。可见,相比与对比系统,被测系统的性能的人工评估的分数明显提升了。Finally, the inventors also tested a dialogue system (referred to as a "system under test") using both the generative model and the screening model obtained by the training method proposed in the present disclosure, in contrast to those using generative models and screening models known in the art The performance comparison of the model's dialogue system (called the "contrast system"). Several (eg >=50) dialogue samples are randomly selected from the real psychological counseling dialogue corpus, and according to the dialogue above in each dialogue sample, the best reply sentence is generated by the tested system and the comparison system respectively. Among them, the reply sentences in the dialogue samples are called "human replies", the best reply sentences generated by the system under test are called "test replies", and the best reply sentences generated by the comparison system are called "comparison replies". If you don't know whether the current reply sentence is a real reply, a tested reply or a comparative reply, please ask a professional psychological consultant (eg >= 5 people) to select each reply for each conversation above, and choose from The naturalness of the reply (whether the sentence is coherent and diverse), the agreeableness (whether it is willing to chat with it), and the effect of professional consultation are three aspects to choose which reply is better. The test results show that in the contest between the comparison responses and the real responses, 28% of the comparison responses were selected, and 72% of the real responses were selected; while in the contest between the tested responses and the real responses, the tested responses were The proportion of selection was 37.8%, and the proportion of real people who responded was 62.2%. It can be seen that compared with the comparison system, the score of the manual evaluation of the performance of the tested system is significantly improved.
图13是示意性地示出根据本公开的实施例的基于语言模型的对话系统400的至少一部分的结构图。本领域技术人员可以理解,系统400只是一个示例,不应将其视为限制本公开的范围或本公开所描述的特征。在该示例中,系统400可以包括一个或多个存储装置410、一个或多个电子设备420、以及一个或多个计算装置430,其可以通过网络或总线440互相通信连接。一个或多个存储装置410为一个或多个电子设备420、以及一个或多个计算装置430提供存储服务。虽然一个或多个存储装置410在系统400中以独立于一个或多个电子设备420、以及一个或多个计算装置430之外的单独的框示出,应当理解,一个或多个存储装置410可以实际存储在系统400所包括的其他实体420、430中的任何一个上。一个或多个电子设备420以及一个或多个计算装置430中的每一个可以位于网络或总线440的不同节点处,并且能够直接地或间接地与网络或总线440的其他节点通信。本领域技术人员可以理解,系统400还可以包括图13未示出的其他装置,其中每个不同的装置均位于网络或总线440的不同节点处。FIG. 13 is a structural diagram schematically illustrating at least a part of a language model-based
一个或多个存储装置410可以被配置为存储上文所述的任何数据,包括但不限于:接收的对话输入、一组或更多组候选回复、最佳回复语句、心理咨询对话数据集、训练数据集、生成模型、筛选模型、训练数据集、各步骤/操作的中间计算结果和输出结果、以及应用程序的文件等数据。一个或多个计算装置430可以被配置为执行上述方法100、200中的一个或多个,和/或一个或多个方法100、200中的一个或多个步骤/操作。一个或多个电子设备420可以被配置为为用户提供服务,其可以向用户输出最佳回复语句,从而向用户提供对话服务,例如端到端生成式的心理咨询对话服务。一个或多个电子设备420还可以被配置为执行方法100、200中的一个或多个步骤。One or
网络或总线440可以是任何有线或无线的网络,也可以包括线缆。网络或总线440可以是互联网、万维网、特定内联网、广域网或局域网的一部分。网络或总线440可以利用诸如以太网、WiFi和HTTP等标准通信协议、对于一个或多个公司来说是专有的协议、以及前述协议的各种组合。网络或总线440还可以包括但不限于工业标准体系结构(ISA)总线、微通道架构(MCA)总线、增强型ISA(EISA)总线、视频电子标准协会(VESA)本地总线、和外围部件互连(PCI)总线。The network or
一个或多个电子设备420和一个或多个计算装置430中的每一个可以被配置为与图14所示的系统500类似,即具有一个或多个处理器510、一个或多个存储器520、以及指令和数据。一个或多个电子设备420和一个或多个计算装置430中的每一个可以是意在由用户使用的个人计算装置或者由企业使用的商业计算机装置,并且具有通常与个人计算装置或商业计算机装置结合使用的所有组件,诸如中央处理单元(CPU)、存储数据和指令的存储器(例如,RAM和内部硬盘驱动器)、诸如显示器(例如,具有屏幕的监视器、触摸屏、投影仪、电视或可操作来显示信息的其他装置)、鼠标、键盘、触摸屏、麦克风、扬声器、和/或网络接口装置等的一个或多个I/O设备。Each of the one or more
一个或多个电子设备420还可以包括用于捕获静态图像或记录视频流的一个或多个相机、以及用于将这些元件彼此连接的所有组件。虽然一个或多个电子设备420可以各自包括全尺寸的个人计算装置,但是它们可能可选地包括能够通过诸如互联网等网络与服务器无线地交换数据的移动计算装置。举例来说,一个或多个电子设备420可以是移动电话,或者是诸如带无线支持的PDA、平板PC或能够经由互联网获得信息的上网本等装置。在另一个示例中,一个或多个电子设备420可以是可穿戴式计算系统。The one or more
图14是示意性地示出根据本公开的一个实施例的基于语言模型的对话系统500的至少一部分的结构图。系统500包括一个或多个处理器510、一个或多个存储器520、以及通常存在于计算机等装置中的其他组件(未示出)。一个或多个存储器520中的每一个可以存储可由一个或多个处理器510访问的内容,包括可以由一个或多个处理器510执行的指令521、以及可以由一个或多个处理器510来检索、操纵或存储的数据522。FIG. 14 is a structural diagram schematically illustrating at least a part of a language model-based
指令521可以是将由一个或多个处理器510直接地执行的任何指令集,诸如机器代码,或者间接地执行的任何指令集,诸如脚本。本公开中的术语“指令”、“应用”、“过程”、“步骤”和“程序”在本公开中可以互换使用。指令521可以存储为目标代码格式以便由一个或多个处理器510直接处理,或者存储为任何其他计算机语言,包括按需解释或提前编译的独立源代码模块的脚本或集合。指令521可以包括引起诸如一个或多个处理器510来充当本公开中的各神经网络的指令。本公开其他部分更加详细地解释了指令521的功能、方法和例程。
一个或多个存储器520可以是能够存储可由一个或多个处理器510访问的内容的任何临时性或非临时性计算机可读存储介质,诸如硬盘驱动器、存储卡、ROM、RAM、DVD、CD、USB存储器、能写存储器和只读存储器等。一个或多个存储器520中的一个或多个可以包括分布式存储系统,其中指令521和/或数据522可以存储在可以物理地位于相同或不同的地理位置处的多个不同的存储装置上。一个或多个存储器520中的一个或多个可以经由网络连接至一个或多个第一装置510,和/或可以直接地连接至或并入一个或多个处理器510中的任何一个中。The one or
一个或多个处理器510可以根据指令521来检索、存储或修改数据522。存储在一个或多个存储器520中的数据522可以包括上文所述的一个或多个存储装置410中存储的各项中一项或多项的至少部分。举例来说,虽然本公开所描述的主题不受任何特定数据结构限制,但是数据522还可能存储在计算机寄存器(未示出)中,作为具有许多不同的字段和记录的表格或XML文档存储在关系型数据库中。数据522可以被格式化为任何计算装置可读格式,诸如但不限于二进制值、ASCII或统一代码。此外,数据522可以包括足以识别相关信息的任何信息,诸如编号、描述性文本、专有代码、指针、对存储在诸如其他网络位置处等其他存储器中的数据的引用或者被函数用于计算相关数据的信息。One or
一个或多个处理器510可以是任何常规处理器,诸如市场上可购得的中央处理单元(CPU)、图形处理单元(GPU)等。可替换地,一个或多个处理器510还可以是专用组件,诸如专用集成电路(ASIC)或其他基于硬件的处理器。虽然不是必需的,但是一个或多个处理器510可以包括专门的硬件组件来更快或更有效地执行特定的计算过程,诸如对影像进行图像处理等。The one or
虽然图14中示意性地将一个或多个处理器510以及一个或多个存储器520示出在同一个框内,但是系统500可以实际上包括可能存在于同一个物理壳体内或不同的多个物理壳体内的多个处理器或存储器。例如,一个或多个存储器520中的一个可以是位于与与上文所述的一个或多个计算装置(未示出)中的每一个的壳体不同的壳体中的硬盘驱动器或其他存储介质。因此,引用处理器、计算机、计算装置或存储器应被理解成包括引用可能并行操作或可能非并行操作的处理器、计算机、计算装置或存储器的集合。Although FIG. 14 schematically shows one or
图15是可应用于根据本公开一个或多个示例性实施例的通用硬件系统600的示例性框图。现在将参考图15描述系统600,其是可以应用于本公开的各方面的硬件设备的示例。上述各实施例中的系统300、400、500中的任一个可以包括系统600的全部或部分。系统600可以是被配置为执行处理和/或计算的任何机器,可以是但不限于工作站、服务器、台式计算机、膝上型计算机、平板计算机、个人数据助理、智能电话、车载电脑、或其任何组合。FIG. 15 is an exemplary block diagram of a general-
系统600可以包括可能经由一个或多个接口与总线602连接或与总线602通信的元件。例如,系统600可以包括总线602,以及一个或多个处理器604,一个或多个输入设备606和一个或多个输出设备608。一个或多个处理器604可以是任何类型的处理器,可以包括但不限于一个或多个通用处理器和/或一个或多个专用处理器(例如特殊处理芯片)。上文所述的方法中的各个操作和/或步骤均可以通过一个或多个处理器604执行指令来实现。
输入设备606可以是可以向计算设备输入信息的任何类型的设备,可以包括但不限于鼠标、键盘、触摸屏、麦克风和/或遥控器。输出设备608可以是可以呈现信息的任何类型的设备,可以包括但不限于显示器、扬声器、视频/音频输出终端、振动器和/或打印机。
系统600还可以包括非暂时性存储设备610或者与非暂时性存储设备610连接。非暂时性存储设备610可以是非暂时性的并且可以实现数据存储的任何存储设备,可以包括但不限于磁盘驱动器、光学存储设备、固态存储器、软盘、硬盘、磁带或任何其他磁介质、光盘或任何其他光学介质、ROM(只读存储器)、RAM(随机存取存储器)、高速缓冲存储器、和/或任何其他存储器芯片/芯片组、和/或计算机可从其读取数据、指令和/或代码的任何其他介质。非暂时性存储设备610可以从接口拆卸。非暂时性存储设备610可以具有用于实现上述方法、操作、步骤和过程的数据/指令/代码。
系统600还可以包括通信设备612。通信设备612可以是能够与外部设备和/或与网络通信的任何类型的设备或系统,可以包括但不限于调制解调器、网卡、红外通信设备、无线通信设备、和/或芯片组,例如蓝牙设备、802.11设备、WiFi设备、WiMax设备、蜂窝通信设备、卫星通信设备、和/或类似物。
总线602可以包括但不限于工业标准体系结构(ISA)总线、微通道架构(MCA)总线、增强型ISA(EISA)总线、视频电子标准协会(VESA)本地总线、和外围部件互连(PCI)总线。特别地,对于车载设备,总线602还可以包括控制器区域网络(CAN)总线或设计用于在车辆上应用的其他架构。
系统600还可以包括工作存储器614,其可以是可以存储对处理器604的工作有用的指令和/或数据的任何类型的工作存储器,可以包括但不限于随机存取存储器和/或只读存储设备。
软件元素可以位于工作存储器614中,包括但不限于操作系统616、一个或多个应用程序618、驱动程序、和/或其他数据和代码。用于执行上述方法、操作和步骤的指令可以包括在一个或多个应用程序618中。软件元素的指令的可执行代码或源代码可以存储在非暂时性计算机可读存储介质中,例如上述存储设备610,并且可以通过编译和/或安装被读入工作存储器614中。还可以从远程位置下载软件元素的指令的可执行代码或源代码。Software elements may reside in working memory 614, including, but not limited to,
还应该理解,可以根据具体要求进行变化。例如,也可以使用定制硬件,和/或可以用硬件、软件、固件、中间件、微代码、硬件描述语言或其任何组合来实现特定元件。此外,可以采用与诸如网络输入/输出设备之类的其他计算设备的连接。例如,根据本公开实施例的方法或装置中的一些或全部可以通过使用根据本公开的逻辑和算法的、用汇编语言或硬件编程语言(诸如VERILOG,VHDL,C++)的编程硬件(例如,包括现场可编程门阵列(FPGA)和/或可编程逻辑阵列(PLA)的可编程逻辑电路)来实现。It should also be understood that variations may be made according to specific requirements. For example, custom hardware may also be used, and/or particular elements may be implemented in hardware, software, firmware, middleware, microcode, hardware description languages, or any combination thereof. Additionally, connections to other computing devices such as network input/output devices may be employed. For example, some or all of the methods or apparatus according to embodiments of the present disclosure may be implemented by programming hardware in assembly language or hardware programming languages (such as VERILOG, VHDL, C++) (eg, including Field Programmable Gate Array (FPGA) and/or Programmable Logic Array (PLA) Programmable Logic Circuit).
还应该理解,系统600的组件可以分布在网络上。例如,可以使用一个处理器执行一些处理,而可以由远离该一个处理器的另一个处理器执行其他处理。系统600的其他组件也可以类似地分布。这样,系统600可以被解释为在多个位置执行处理的分布式计算系统。It should also be understood that the components of
另外,本公开的实施方式还可以包括以下示例:In addition, the embodiments of the present disclosure may also include the following examples:
1.一种端到端生成式的心理咨询对话方法,包括:1. An end-to-end generative psychological counseling dialogue method, including:
接收对话输入;receive dialog input;
使用基于心理咨询对话数据集建立的生成模型生成一组或更多组候选回复,每组候选回复包括针对所述对话输入的一个或更多个回复关键词和基于所述一个或更多个回复关键词生成的回复语句;One or more sets of candidate responses are generated using a generative model based on a psychological counseling dialogue dataset, each set of candidate responses including one or more response keywords entered for the dialogue and based on the one or more responses Reply sentences generated by keywords;
使用基于心理咨询对话数据集建立的筛选模型,从各组候选回复所包括的各回复语句中筛选出最佳回复语句;以及Using the screening model established based on the psychological counseling dialogue dataset, select the best reply sentence from each reply sentence included in each group of candidate replies; and
输出所述最佳回复语句。The best reply sentence is output.
2.根据1所述的方法,其中,每组候选回复还包括:用于提示所述生成模型生成回复关键词的提示语。2. The method according to 1, wherein each group of candidate replies further comprises: prompt words for prompting the generation model to generate reply keywords.
3.根据2所述的方法,其中,所述提示语为特定的一个或更多个文本模板。3. The method according to 2, wherein the prompt is a specific one or more text templates.
4.根据2所述的方法,其中,所述提示语为具有实际语义的自然语言文本或不具有实际语义的文本。4. The method according to 2, wherein the prompt is a natural language text with actual semantics or a text without actual semantics.
5.根据1所述的方法,其中,每组候选回复包括所述一个或更多个回复关键词与回复语句的拼接,并且每组候选回复在所述一个或更多个回复关键词之后、所述回复语句之前还包括特定标记。5. The method according to 1, wherein each group of candidate replies includes a concatenation of the one or more reply keywords and reply sentences, and each group of candidate replies is after the one or more reply keywords, The reply sentence is also preceded by a specific token.
6.根据5所述的方法,还包括:6. The method according to 5, further comprising:
将候选回复中的所述特定标记之后的内容输入到所述筛选模型。The content following the specific token in the candidate reply is input to the screening model.
7.根据1所述的方法,其中,所述生成模型包括:7. The method of 1, wherein the generative model comprises:
用于生成针对所述对话输入的一个或更多个回复关键词的第一子模型,和a first submodel for generating one or more reply keywords for the dialogue input, and
与所述第一子模型级联的、用于基于所述一个或更多个回复关键词生成回复语句的第二子模型。A second sub-model cascaded with the first sub-model for generating reply sentences based on the one or more reply keywords.
8.根据7所述的方法,还包括:8. The method according to 7, further comprising:
将所述第二子模型的输出输入到所述筛选模型。The output of the second submodel is input to the screening model.
9.根据1所述的方法,还包括:9. The method according to 1, further comprising:
将各组候选回复所包括的各回复语句拼接后输入到所述筛选模型,以便所述筛选模型从各组候选回复所包括的各回复语句中筛选出最佳回复语句。Each reply sentence included in each group of candidate replies is spliced and input into the screening model, so that the screening model can filter out the best reply sentence from each reply sentence included in each group of candidate replies.
10.根据1或9所述的方法,还包括:10. The method according to 1 or 9, further comprising:
还将与所述对话输入相关联的历史对话数据输入到所述筛选模型,以便所述筛选模型从各组候选回复所包括的各回复语句中筛选出最佳回复语句。The historical dialogue data associated with the dialogue input is also input to the screening model, so that the screening model filters out the best reply sentences from each reply sentence included in each set of candidate replies.
11.根据10所述的方法,其中,所述筛选模型包括编码器,所述方法还包括:11. The method of 10, wherein the screening model comprises an encoder, the method further comprising:
将各组候选回复所包括的各回复语句、所述对话输入以及所述历史对话数据拼接后输入到所述编码器。Each reply sentence included in each group of candidate replies, the dialogue input and the historical dialogue data are spliced and input to the encoder.
12.根据10所述的方法,其中,所述筛选模型包括其输出之间具有交叉注意力机制的第一编码器和第二编码器,所述方法还包括:12. The method of 10, wherein the screening model includes a first encoder and a second encoder with a cross-attention mechanism between their outputs, the method further comprising:
将拼接后的各回复语句输入到所述第一编码器、以及将所述对话输入和所述历史对话数据输入到所述第二编码器。The concatenated reply sentences are input into the first encoder, and the dialogue input and the historical dialogue data are input into the second encoder.
13.根据12所述的方法,其中,所述第一编码器和所述第二编码器共享参数。13. The method of 12, wherein the first encoder and the second encoder share parameters.
14.根据1所述的方法,其中,所述生成模型和所述筛选模型均是基于预训练语言模型和所述心理咨询对话数据集建立的。14. The method according to 1, wherein both the generative model and the screening model are established based on a pre-trained language model and the psychological counseling dialogue dataset.
15.根据14所述的方法,其中,所述预训练语言模型具有transformer网络结构。15. The method of 14, wherein the pretrained language model has a transformer network structure.
16.一种端到端生成式的心理咨询对话方法,包括:16. An end-to-end generative psychological counseling dialogue method, comprising:
接收对话输入;receive dialog input;
使用基于心理咨询对话数据集建立的生成模型,生成针对所述对话输入的一个或更多个回复语句;generating one or more reply sentences for the dialogue input using a generative model based on a psychological counseling dialogue dataset;
将所述一个或更多个回复语句拼接后输入到基于心理咨询对话数据集建立的筛选模型;The one or more reply sentences are spliced and input into the screening model established based on the psychological counseling dialogue dataset;
使用所述筛选模型,基于所述对话输入,从所述一个或更多个回复语句中筛选出最佳回复语句;以及using the screening model, based on the dialogue input, to filter out an optimal reply sentence from the one or more reply sentences; and
输出所述最佳回复语句。The best reply sentence is output.
17.根据16所述的方法,还包括:17. The method of 16, further comprising:
还将与所述对话输入相关联的历史对话数据输入到所述筛选模型。Historical dialog data associated with the dialog input is also input to the screening model.
18.根据17所述的方法,其中,所述筛选模型包括编码器,所述方法还包括:18. The method of 17, wherein the screening model comprises an encoder, the method further comprising:
将所述一个或更多个回复语句、所述对话输入以及所述历史对话数据拼接后输入到所述编码器。The one or more reply sentences, the dialogue input, and the historical dialogue data are concatenated and input to the encoder.
19.根据17所述的方法,其中,所述筛选模型包括其输出之间具有交叉注意力机制的第一编码器和第二编码器,所述方法还包括:19. The method of 17, wherein the screening model includes a first encoder and a second encoder with a cross-attention mechanism between their outputs, the method further comprising:
将所述一个或更多个回复语句拼接后输入到所述第一编码器,并且将所述对话输入和所述历史对话数据输入到所述第二编码器。The one or more reply sentences are concatenated and input into the first encoder, and the dialogue input and the historical dialogue data are input into the second encoder.
20.根据19所述的方法,其中,所述第一编码器和所述第二编码器共享参数。20. The method of 19, wherein the first encoder and the second encoder share parameters.
21.根据16所述的方法,还包括:21. The method of 16, further comprising:
使用所述生成模型生成一组或更多组候选回复,每组候选回复包括针对所述对话输入的一个或更多个回复关键词和基于所述一个或更多个回复关键词生成的回复语句。generating one or more sets of candidate replies using the generative model, each set of candidate replies including one or more reply keywords entered for the dialogue and reply sentences generated based on the one or more reply keywords .
22.根据21所述的方法,其中,每组候选回复还包括:用于提示所述生成模型生成回复关键词的提示语。22. The method according to 21, wherein each group of candidate replies further comprises: prompt words for prompting the generation model to generate reply keywords.
23.根据22所述的方法,其中,所述提示语为特定的一个或更多个文本模板。23. The method according to 22, wherein the prompt is a specific one or more text templates.
24.根据22所述的方法,其中,所述提示语为具有实际语义的自然语言文本或不具有实际语义的文本。24. The method according to 22, wherein the prompt is natural language text with actual semantics or text without actual semantics.
25.根据21所述的方法,其中,每组候选回复包括所述一个或更多个回复关键词与回复语句的拼接,并且每组候选回复在所述一个或更多个回复关键词之后、所述回复语句之前还包括特定标记。25. The method according to 21, wherein each group of candidate replies comprises a concatenation of the one or more reply keywords and reply sentences, and each group of candidate replies is after the one or more reply keywords, The reply sentence is also preceded by a specific token.
26.根据25所述的方法,还包括:26. The method according to 25, further comprising:
将候选回复中的所述特定标记之后的内容输入到所述筛选模型。The content following the specific token in the candidate reply is input to the screening model.
27.根据21所述的方法,其中,所述生成模型包括:27. The method of 21, wherein the generative model comprises:
用于生成针对所述对话输入的一个或更多个回复关键词的第一子模型,和a first submodel for generating one or more reply keywords for the dialogue input, and
与所述第一子模型级联的、用于基于所述一个或更多个回复关键词生成回复语句的第二子模型。A second sub-model cascaded with the first sub-model for generating reply sentences based on the one or more reply keywords.
28.根据27所述的方法,还包括:28. The method according to 27, further comprising:
将所述第二子模型的输出输入到所述筛选模型。The output of the second submodel is input to the screening model.
29.根据16所述的方法,其中,所述生成模型和所述筛选模型均是基于预训练语言模型和所述心理咨询对话数据集建立的。29. The method of 16, wherein both the generative model and the screening model are built based on a pretrained language model and the psychological counseling dialogue dataset.
30.根据29所述的方法,其中,所述预训练语言模型具有transformer网络结构。30. The method of 29, wherein the pretrained language model has a transformer network structure.
31.一种基于语言模型的回复推断方法,包括:31. A reply inference method based on a language model, comprising:
接收对话输入;receive dialog input;
使用基于预训练语言模型建立的生成模型生成一组或更多组候选回复,每组候选回复包括针对所述对话输入的一个或更多个回复关键词和基于所述一个或更多个回复关键词生成的回复语句;以及generating one or more sets of candidate replies using a generative model based on the pre-trained language model, each set of candidate replies including one or more reply keywords for the dialogue input and based on the one or more reply keywords word-generated reply sentences; and
使用基于预训练语言模型建立的筛选模型,从各组候选回复所包括的各回复语句中推断出最佳回复语句。Using the screening model established based on the pre-trained language model, the best reply sentence is inferred from each reply sentence included in each group of candidate replies.
32.根据31所述的方法,其中,每组候选回复包括所述一个或更多个回复关键词与回复语句的拼接。32. The method of 31, wherein each set of candidate replies comprises a concatenation of the one or more reply keywords and reply sentences.
33.根据32所述的方法,其中,每组候选回复在所述一个或更多个回复关键词之前还包括用于提示所述生成模型生成回复关键词的提示语。33. The method according to 32, wherein each group of candidate replies further comprises a prompt for prompting the generation model to generate reply keywords before the one or more reply keywords.
34.根据32所述的方法,其中,每组候选回复在所述一个或更多个回复关键词之后、所述回复语句之前还包括特定标记。34. The method of 32, wherein each set of candidate replies further includes a specific token after the one or more reply keywords and before the reply sentence.
35.根据31所述的方法,还包括:35. The method of 31, further comprising:
将各组候选回复所包括的各回复语句拼接后输入到所述筛选模型,以便所述筛选模型从各组候选回复所包括的各回复语句中推断出最佳回复语句。Each reply sentence included in each group of candidate replies is concatenated and input into the screening model, so that the screening model infers the best reply sentence from each reply sentence included in each group of candidate replies.
36.根据31所述的方法,还包括:36. The method of 31, further comprising:
将各组候选回复所包括的各回复语句、所述对话输入以及与所述对话输入相关联的历史对话数据拼接后输入到所述筛选模型的单个编码器,以便所述筛选模型从各组候选回复所包括的各回复语句中推断出最佳回复语句。Each reply sentence included in each group of candidate replies, the dialogue input, and the historical dialogue data associated with the dialogue input are spliced and input into a single encoder of the screening model, so that the screening model can extract the candidate responses from each group of candidates. The best reply sentence is deduced from each reply sentence included in the reply.
37.根据31所述的方法,还包括:37. The method of 31, further comprising:
将各组候选回复所包括的各回复语句拼接后输入到所述筛选模型的第一编码器,并将所述对话输入和与所述对话输入相关联的历史对话数据拼接后输入到所述筛选模型的第二编码器,以便所述筛选模型从各组候选回复所包括的各回复语句中推断出最佳回复语句,其中,The reply sentences included in each group of candidate replies are spliced and input into the first encoder of the screening model, and the dialogue input and the historical dialogue data associated with the dialogue input are spliced and input into the screening a second encoder of the model, so that the screening model infers the best reply sentence from each reply sentence included in each set of candidate replies, wherein,
所述第一编码器和所述第二编码器并联连接,并在其输出处共同连接到交叉注意力层。The first encoder and the second encoder are connected in parallel and are commonly connected to a cross-attention layer at their outputs.
38.根据31所述的方法,其中,所述预训练语言模型具有transformer网络结构。38. The method of 31, wherein the pretrained language model has a transformer network structure.
39.一种基于语言模型的回复推断方法,包括:39. A reply inference method based on a language model, comprising:
接收对话输入;receive dialog input;
使用基于预训练语言模型建立的生成模型,生成针对所述对话输入的一个或更多个回复语句;generating one or more reply sentences for the dialogue input using a generative model based on the pretrained language model;
将所述一个或更多个回复语句拼接后输入到基于预训练语言模型建立的筛选模型;以及The one or more reply sentences are spliced and input into the screening model established based on the pre-trained language model; and
使用所述筛选模型,基于所述对话输入,从所述一个或更多个回复语句中推断出最佳回复语句。Using the screening model, an optimal reply sentence is inferred from the one or more reply sentences based on the dialogue input.
40.根据39所述的方法,还包括:40. The method according to 39, further comprising:
还将与所述对话输入相关联的历史对话数据输入到所述筛选模型。Historical dialog data associated with the dialog input is also input to the screening model.
41.根据40所述的方法,还包括:41. The method according to 40, further comprising:
将所述一个或更多个回复语句、所述对话输入以及所述历史对话数据拼接后输入到所述筛选模型的单个编码器。The one or more reply sentences, the dialogue input, and the historical dialogue data are concatenated and input into a single encoder of the screening model.
42.根据40所述的方法,还包括:42. The method according to 40, further comprising:
将所述一个或更多个回复语句拼接后输入到所述筛选模型的第一编码器,并将所述对话输入和所述历史对话数据拼接后输入到所述筛选模型的第二编码器,其中,The one or more reply sentences are spliced and input into the first encoder of the screening model, and the dialogue input and the historical dialogue data are spliced and input into the second encoder of the screening model, in,
所述第一编码器和所述第二编码器并联连接,并在其输出处共同连接到交叉注意力层。The first encoder and the second encoder are connected in parallel and are commonly connected to a cross-attention layer at their outputs.
43.根据39所述的方法,还包括:43. The method according to 39, further comprising:
使用所述生成模型生成一组或更多组候选回复,每组候选回复包括针对所述对话输入的一个或更多个回复关键词和基于所述一个或更多个回复关键词生成的回复语句。generating one or more sets of candidate replies using the generative model, each set of candidate replies including one or more reply keywords entered for the dialogue and reply sentences generated based on the one or more reply keywords .
44.根据43所述的方法,其中,每组候选回复包括所述一个或更多个回复关键词与回复语句的拼接。44. The method of 43, wherein each set of candidate replies comprises a concatenation of the one or more reply keywords and reply sentences.
45.根据43所述的方法,其中,每组候选回复在所述一个或更多个回复关键词之前还包括用于提示所述生成模型生成回复关键词的提示语。45. The method according to 43, wherein each group of candidate replies further comprises a prompt for prompting the generation model to generate reply keywords before the one or more reply keywords.
46.根据43所述的方法,其中,每组候选回复在所述一个或更多个回复关键词之后、所述回复语句之前还包括特定标记。46. The method of 43, wherein each set of candidate replies further includes a specific token after the one or more reply keywords and before the reply sentence.
47.根据39所述的方法,其中,所述预训练语言模型具有transformer网络结构。47. The method of 39, wherein the pretrained language model has a transformer network structure.
48.一种基于语言模型的回复推断方法,包括:48. A reply inference method based on a language model, comprising:
接收对话输入;receive dialog input;
使用基于预训练语言模型建立的生成模型生成一组或更多组候选回复,每组候选回复包括一个或更多个回复关键词与基于所述一个或更多个回复关键词生成的回复语句的拼接;Using the generative model established based on the pre-trained language model to generate one or more sets of candidate responses, each set of candidate responses includes one or more response keywords and a response sentence generated based on the one or more response keywords. splicing;
将各组候选回复所包括的各回复语句、所述对话输入以及与所述对话输入相关联的历史对话数据拼接后输入到基于预训练语言模型建立的筛选模型;以及Each reply sentence included in each group of candidate replies, the dialogue input and the historical dialogue data associated with the dialogue input are spliced and input into the screening model established based on the pre-trained language model; and
使用所述筛选模型,基于所述对话输入和所述历史对话数据,从各组候选回复所包括的各回复语句中推断出最佳回复语句。Using the screening model, based on the dialogue input and the historical dialogue data, an optimal reply sentence is inferred from each reply sentence included in each set of candidate replies.
49.根据48所述的方法,还包括:49. The method according to 48, further comprising:
将各组候选回复所包括的各回复语句、所述对话输入以及与所述对话输入相关联的历史对话数据拼接后输入到所述筛选模型的单个编码器。Each reply sentence included in each group of candidate replies, the dialogue input, and the historical dialogue data associated with the dialogue input are spliced and input into a single encoder of the screening model.
50.根据48所述的方法,还包括:50. The method according to 48, further comprising:
将各组候选回复所包括的各回复语句拼接后输入到所述筛选模型的第一编码器,并将所述对话输入和与所述对话输入相关联的历史对话数据拼接后输入到所述筛选模型的第二编码器,其中,The reply sentences included in each group of candidate replies are spliced and input into the first encoder of the screening model, and the dialogue input and the historical dialogue data associated with the dialogue input are spliced and input into the screening the second encoder of the model, where,
所述第一编码器和所述第二编码器并联连接,并在其输出处共同连接到交叉注意力层。The first encoder and the second encoder are connected in parallel and are commonly connected to a cross-attention layer at their outputs.
51.一种用于推断对话回复的训练方法,包括:51. A training method for inferring dialogue responses, comprising:
获取第一训练数据集,所述第一训练数据集包括对话上文和对应的对话回复,其中每条对话回复中被标注一个或更多个关键词;以及obtaining a first training data set, where the first training data set includes a dialogue above and a corresponding dialogue reply, wherein each dialogue reply is marked with one or more keywords; and
使用所述第一训练数据集对第一预训练语言模型进行训练,其中,所述第一预训练语言模型待拟合的输出包括针对输入的一个或更多个回复关键词和基于所述一个或更多个回复关键词生成的回复语句两者。A first pre-trained language model is trained using the first training data set, wherein the output to be fitted by the first pre-trained language model includes one or more reply keywords for the input and based on the one or both of the reply sentences generated by the reply keywords.
52.根据51所述的方法,其中,所述第一预训练语言模型待拟合的输出还包括用于提示所述第一预训练语言模型生成回复关键词的提示语。52. The method according to 51, wherein the output to be fitted by the first pre-trained language model further comprises a prompt for prompting the first pre-trained language model to generate reply keywords.
53.根据52所述的方法,其中,所述第一预训练语言模型待拟合的输出包括所述提示语、所述一个或更多个回复关键词以及所述回复语句的拼接。53. The method of 52, wherein the output to be fitted by the first pre-trained language model comprises the prompt, the one or more reply keywords, and a concatenation of the reply sentences.
54.根据53所述的方法,其中,所述第一预训练语言模型待拟合的输出还包括拼接在所述一个或更多个回复关键词之后、所述回复语句之前的特定标记。54. The method according to 53, wherein the to-be-fitted output of the first pre-trained language model further comprises a specific token spliced after the one or more reply keywords and before the reply sentence.
55.根据51所述的方法,其中,所述第一预训练语言模型的解码策略采用top-p采样,并且其中,用于生成回复关键词的阈值p低于用于生成回复语句的阈值p。55. The method of 51, wherein the decoding strategy of the first pretrained language model adopts top-p sampling, and wherein the threshold p for generating reply keywords is lower than the threshold p for generating reply sentences .
56.根据55所述的方法,其中,用于生成回复关键词的阈值p小于或等于0.3,用于生成回复语句的阈值p为0.75~0.95。56. The method according to 55, wherein the threshold p for generating reply keywords is less than or equal to 0.3, and the threshold p for generating reply sentences is 0.75-0.95.
57.根据51所述的方法,其中,所述第一预训练语言模型具有transformer网络结构。57. The method of 51, wherein the first pretrained language model has a transformer network structure.
58.根据51所述的方法,其中,所述第一预训练语言模型为BART模型。58. The method of 51, wherein the first pretrained language model is a BART model.
59.根据51所述的方法,其中,训练所述第一预训练语言模型的优化目标为交叉熵损失函数。59. The method of 51, wherein an optimization objective for training the first pre-trained language model is a cross-entropy loss function.
60.根据51所述的方法,还包括:60. The method according to 51, further comprising:
获取第二训练数据集,所述第二训练数据集包括对话上文、正样本回复以及一个或更多个负样本回复;以及obtaining a second training data set, the second training data set including conversational text, positive sample responses, and one or more negative sample responses; and
使用所述第二训练数据集对第二预训练语言模型进行训练。A second pretrained language model is trained using the second training dataset.
61.根据60所述的方法,其中,对所述第二预训练语言模型的训练输入包括所述正样本回复以及一个或更多个负样本回复的拼接。61. The method of 60, wherein the training input to the second pretrained language model comprises a concatenation of the positive sample replies and one or more negative sample replies.
62.根据60所述的方法,还包括:62. The method according to 60, further comprising:
将所述对话上文和所述正样本回复以及一个或更多个负样本回复拼接后输入到所述第二预训练语言模型的单个编码器,以对所述第二预训练语言模型进行训练。The dialogue above and the positive sample responses and one or more negative sample responses are concatenated and input into a single encoder of the second pre-trained language model to train the second pre-trained language model .
63.根据60所述的方法,还包括:63. The method according to 60, further comprising:
将所述对话上文输入到所述第二预训练语言模型的第一编码器、并将所述正样本回复以及一个或更多个负样本回复拼接后输入到所述第二预训练语言模型的第二编码器,以对所述第二预训练语言模型进行训练。inputting the dialogue above into the first encoder of the second pre-trained language model, and splicing the positive sample replies and one or more negative sample replies into the second pre-training language model the second encoder to train the second pre-trained language model.
64.根据60所述的方法,其中,所述第二预训练语言模型具有transformer网络结构。64. The method of 60, wherein the second pretrained language model has a transformer network structure.
65.根据60所述的方法,其中,所述第二预训练语言模型为BERT模型。65. The method of 60, wherein the second pre-trained language model is a BERT model.
66.根据60所述的方法,其中,训练所述第二预训练语言模型的优化目标为交叉熵损失函数。66. The method of 60, wherein the optimization objective for training the second pre-trained language model is a cross-entropy loss function.
67.根据60所述的方法,其中,所述第一训练数据集和所述第二训练数据集是基于实际的心理咨询对话语料建立的。67. The method of 60, wherein the first training data set and the second training data set are established based on actual psychological counseling dialogue materials.
68.一种基于语言模型的对话系统,包括:68. A language model-based dialogue system, comprising:
输入设备,被配置为接收对话输入;an input device, configured to receive dialog input;
计算设备,被配置为:A computing device, configured as:
使用基于预训练语言模型建立的生成模型生成一组或更多组候选回复,每组候选回复包括针对所述对话输入的一个或更多个回复关键词和基于所述一个或更多个回复关键词生成的回复语句;以及generating one or more sets of candidate replies using a generative model based on the pre-trained language model, each set of candidate replies including one or more reply keywords entered for the dialogue and based on the one or more reply keywords word-generated reply sentences; and
使用基于预训练语言模型建立的筛选模型,从各组候选回复所包括的各回复语句中推断出最佳回复语句;Using the screening model established based on the pre-trained language model, infer the best reply sentence from each reply sentence included in each group of candidate replies;
输出设备,被配置为输出所述最佳回复语句。An output device configured to output the best reply sentence.
69.一种基于语言模型的对话系统,包括:69. A language model-based dialogue system, comprising:
输入设备,被配置为接收对话输入;an input device, configured to receive dialog input;
计算设备,被配置为:A computing device, configured as:
使用基于预训练语言模型建立的生成模型,生成针对所述对话输入的一个或更多个回复语句;generating one or more reply sentences for the dialogue input using a generative model based on the pretrained language model;
将所述一个或更多个回复语句拼接后输入到基于预训练语言模型建立的筛选模型;以及The one or more reply sentences are spliced and input into the screening model established based on the pre-trained language model; and
使用所述筛选模型,基于所述对话输入,从所述一个或更多个回复语句中推断出最佳回复语句;inferring an optimal reply sentence from the one or more reply sentences based on the dialogue input using the screening model;
输出设备,被配置为输出所述最佳回复语句。An output device configured to output the best reply sentence.
70.一种基于语言模型的对话系统,包括:70. A language model-based dialogue system, comprising:
输入设备,被配置为接收对话输入;an input device, configured to receive dialog input;
计算设备,被配置为:A computing device, configured as:
使用基于预训练语言模型建立的生成模型生成一组或更多组候选回复,每组候选回复包括一个或更多个回复关键词与基于所述一个或更多个回复关键词生成的回复语句的拼接;Using the generative model established based on the pre-trained language model to generate one or more groups of candidate replies, each group of candidate replies includes one or more reply keywords and the reply sentences generated based on the one or more reply keywords. splicing;
将各组候选回复所包括的各回复语句、所述对话输入以及与所述对话输入相关联的历史对话数据拼接后输入到基于预训练语言模型建立的筛选模型;以及Each reply sentence included in each group of candidate replies, the dialogue input and the historical dialogue data associated with the dialogue input are spliced and input into the screening model established based on the pre-trained language model; and
使用所述筛选模型,基于所述对话输入和所述历史对话数据,从各组候选回复所包括的各回复语句中推断出最佳回复语句;Using the screening model, based on the dialogue input and the historical dialogue data, infer the best reply sentence from each reply sentence included in each group of candidate replies;
输出设备,被配置为输出所述最佳回复语句。An output device configured to output the best reply sentence.
71.一种基于语言模型的对话系统,包括:71. A language model-based dialogue system, comprising:
一个或更多个处理器;以及one or more processors; and
一个或更多个存储器,所述一个或更多个存储器被配置为存储一系列计算机可执行的指令,one or more memories configured to store a series of computer-executable instructions,
其中,当所述一系列计算机可执行的指令被所述一个或更多个处理器执行时,使得所述一个或更多个处理器进行如1-67中任一项所述的方法。wherein the series of computer-executable instructions, when executed by the one or more processors, cause the one or more processors to perform the method of any one of 1-67.
72.一种非临时性计算机可读存储介质,其特征在于,所述非临时性计算机可读存储介质上存储有一系列计算机可执行的指令,当所述一系列计算机可执行的指令被一个或更多个计算装置执行时,使得所述一个或更多个计算装置进行如1-67中任一项所述的方法。72. A non-transitory computer-readable storage medium, wherein a series of computer-executable instructions are stored on the non-transitory computer-readable storage medium, when the series of computer-executable instructions are stored by one or When executed by more computing devices, the one or more computing devices are caused to perform the method of any one of 1-67.
尽管到目前为止已经参考附图描述了本公开的各方面,但是上述方法,系统和设备仅仅是示例性示例,并且本公开的范围不受这些方面的限制,而是仅由以下方面限定:所附权利要求及其等同物。可以省略各种元件,或者可以用等效元件代替。另外,可以以与本公开中描述的顺序不同的顺序执行这些步骤。此外,可以以各种方式组合各种元件。同样重要的是,随着技术的发展,所描述的许多元素可以由在本公开之后出现的等同元素代替。Although aspects of the present disclosure have been described so far with reference to the accompanying drawings, the above-described methods, systems, and devices are merely illustrative examples, and the scope of the present disclosure is not limited by these aspects, but only by: The appended claims and their equivalents. Various elements may be omitted, or equivalent elements may be substituted. Additionally, the steps may be performed in an order different from that described in this disclosure. Furthermore, the various elements may be combined in various ways. It is also important that, as technology develops, many of the elements described may be replaced by equivalent elements that appear after this disclosure.
Claims (10)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210125572.7ACN114443819A (en) | 2022-02-10 | 2022-02-10 | An End-to-End Generative Psychological Consultation Dialogue System |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210125572.7ACN114443819A (en) | 2022-02-10 | 2022-02-10 | An End-to-End Generative Psychological Consultation Dialogue System |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN114443819Atrue CN114443819A (en) | 2022-05-06 |
Family
ID=81371112
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210125572.7APendingCN114443819A (en) | 2022-02-10 | 2022-02-10 | An End-to-End Generative Psychological Consultation Dialogue System |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114443819A (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2024216304A1 (en)* | 2023-04-12 | 2024-10-17 | Microsoft Technology Licensing, Llc | Natural language training and/or augmentation with large language models |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109086329A (en)* | 2018-06-29 | 2018-12-25 | 出门问问信息科技有限公司 | Dialogue method and device are taken turns in progress based on topic keyword guidance more |
| CN111177339A (en)* | 2019-12-06 | 2020-05-19 | 百度在线网络技术(北京)有限公司 | Dialog generation method and device, electronic equipment and storage medium |
| CN113505198A (en)* | 2021-07-09 | 2021-10-15 | 和美(深圳)信息技术股份有限公司 | Keyword-driven generative dialogue reply method, device and electronic device |
- 2022
- 2022-02-10CNCN202210125572.7Apatent/CN114443819A/enactivePending
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109086329A (en)* | 2018-06-29 | 2018-12-25 | 出门问问信息科技有限公司 | Dialogue method and device are taken turns in progress based on topic keyword guidance more |
| CN111177339A (en)* | 2019-12-06 | 2020-05-19 | 百度在线网络技术(北京)有限公司 | Dialog generation method and device, electronic equipment and storage medium |
| CN113505198A (en)* | 2021-07-09 | 2021-10-15 | 和美(深圳)信息技术股份有限公司 | Keyword-driven generative dialogue reply method, device and electronic device |
Non-Patent Citations (1)
| Title |
|---|
| CHIYU SONG 等: "Global-Selector: A New Benchmark Dataset and Model Architecture for Multi-turn Response Selection", ARXIV, 2 June 2021 (2021-06-02), pages 3* |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2024216304A1 (en)* | 2023-04-12 | 2024-10-17 | Microsoft Technology Licensing, Llc | Natural language training and/or augmentation with large language models |
| US20240346254A1 (en)* | 2023-04-12 | 2024-10-17 | Microsoft Technology Licensing, Llc | Natural language training and/or augmentation with large language models |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2023065617A1 (en) | Cross-modal retrieval system and method based on pre-training model and recall and ranking | |
| CN112000818A (en) | A text- and image-oriented cross-media retrieval method and electronic device | |
| CN108780464A (en) | Method and system for processing input queries | |
| CN109657054A (en) | Abstraction generating method, device, server and storage medium | |
| WO2022252636A1 (en) | Artificial intelligence-based answer generation method and apparatus, device, and storage medium | |
| CN107066464A (en) | Semantic Natural Language Vector Space | |
| CN112463935B (en) | Open domain dialogue generation method and system with generalized knowledge selection | |
| WO2025060773A1 (en) | Multi-modal knowledge-based question answering method and system for 5g message | |
| CN113705315A (en) | Video processing method, device, equipment and storage medium | |
| US20240037335A1 (en) | Methods, systems, and media for bi-modal generation of natural languages and neural architectures | |
| US20210233520A1 (en) | Contextual multi-channel speech to text | |
| CN115630145A (en) | A dialogue recommendation method and system based on multi-granularity emotion | |
| CN119357679B (en) | Model training method and sample determining method for model training | |
| WO2024220266A1 (en) | Using fixed-weight language models to create and interact with a retrieval index | |
| Vasquez-Correa et al. | One system to rule them all: A universal intent recognition system for customer service chatbots | |
| CN119918545A (en) | A multimodal dialogue summarization method based on multi-level visual guidance | |
| Guo et al. | NUAA-QMUL at SemEval-2020 task 8: Utilizing BERT and DenseNet for Internet meme emotion analysis | |
| Liu et al. | Image-text fusion transformer network for sarcasm detection | |
| CN113010662A (en) | Hierarchical conversational machine reading understanding system and method | |
| Li et al. | CCMA: CapsNet for audio–video sentiment analysis using cross-modal attention | |
| US20220382805A1 (en) | Information retrieval system and method of information retrieval | |
| CN118377909B (en) | Customer label determining method and device based on call content and storage medium | |
| CN114443819A (en) | An End-to-End Generative Psychological Consultation Dialogue System | |
| CN119248924A (en) | A sentiment analysis method and device for promoting multimodal information fusion | |
| CN118520091A (en) | Multi-mode intelligent question-answering robot and construction method thereof |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |