CN114419054A - Retinal blood vessel image segmentation method and device and related equipment - Google Patents
Retinal blood vessel image segmentation method and device and related equipmentDownload PDFInfo
- Publication number
- CN114419054A CN114419054ACN202210059594.8ACN202210059594ACN114419054ACN 114419054 ACN114419054 ACN 114419054ACN 202210059594 ACN202210059594 ACN 202210059594ACN 114419054 ACN114419054 ACN 114419054A
- Authority
- CN
- China
- Prior art keywords
- blood vessel
- segmentation
- retinal blood
- image
- training
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images






Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/10—Segmentation; Edge detection
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/25—Fusion techniques
- G06F18/253—Fusion techniques of extracted features
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/10—Image acquisition modality
- G06T2207/10072—Tomographic images
- G06T2207/10101—Optical tomography; Optical coherence tomography [OCT]
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20081—Training; Learning
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/30—Subject of image; Context of image processing
- G06T2207/30004—Biomedical image processing
- G06T2207/30041—Eye; Retina; Ophthalmic
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/30—Subject of image; Context of image processing
- G06T2207/30004—Biomedical image processing
- G06T2207/30101—Blood vessel; Artery; Vein; Vascular
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- General Physics & Mathematics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Evolutionary Biology (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- General Engineering & Computer Science (AREA)
- Life Sciences & Earth Sciences (AREA)
- Image Processing (AREA)
- Eye Examination Apparatus (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本发明涉及图像处理领域,尤其涉及一种视网膜血管图像分割方法、装置及相关设备。The present invention relates to the field of image processing, and in particular, to a retinal blood vessel image segmentation method, device and related equipment.
背景技术Background technique
视网膜检查可为糖尿病视网膜病变等多种视网膜疾病的诊断提供重要临床信息。但人工视网膜检查,需要具有专业知识的临床医生或专家筛查大量的视网膜,这个过程费时乏味并很难实现批处理,且易导致误诊。为了缓解医疗资源的短缺和减轻专家的负担,需要研发出自动、高性能的视网膜血管图像分割装置来进行预筛查和其他检查。视网膜血管图像自动分割装置可快速准确地分割视网膜血管结构特征,其中分支点和弯曲能用于辅助心血管疾病和糖尿病视网膜病变的诊断和分析,而视网膜血管宽度的变化特征,可检测和分析高血压。因此,当前研究视网膜血管图像自动分割方法对相关视网膜疾病的研究具有重要意义。Retinal examination can provide important clinical information for the diagnosis of various retinal diseases such as diabetic retinopathy. However, artificial retinal examination requires clinicians or experts with professional knowledge to screen a large number of retinas. This process is time-consuming, tedious, difficult to achieve batch processing, and prone to misdiagnosis. In order to alleviate the shortage of medical resources and reduce the burden on experts, it is necessary to develop an automatic, high-performance retinal blood vessel image segmentation device for pre-screening and other examinations. The retinal blood vessel image automatic segmentation device can quickly and accurately segment the structural features of retinal blood vessels, among which branch points and curvature can be used to assist the diagnosis and analysis of cardiovascular disease and diabetic retinopathy, and the variation characteristics of retinal blood vessel width can be detected and analyzed. blood pressure. Therefore, the current research on automatic segmentation of retinal vascular images is of great significance for the study of related retinal diseases.
一直以来,视网膜血管自动分割技术都在不断地快速发展,研究人员提出了大量的视网膜血管分割方法。一些传统方法成功地对视网膜血管图像进行了自动化分割,并获得了良好的分割结果,但不能完全的表征图像的特征,造成视网膜结构特点检测不充分,导致分割精度不理想,仍不能满足辅助眼科医生临床诊断的需要。For a long time, the automatic segmentation technology of retinal blood vessels has been developing rapidly, and researchers have proposed a large number of retinal blood vessel segmentation methods. Some traditional methods have successfully performed automatic segmentation on retinal blood vessel images, and obtained good segmentation results, but they cannot fully characterize the features of the images, resulting in insufficient detection of retinal structural features, resulting in unsatisfactory segmentation accuracy, which still cannot meet the needs of auxiliary ophthalmology. Physician's clinical diagnosis needs.
与传统方法相比,CNN方法综合了医学图像分割方法和语义分割方法的优点,使得它们取得了显著的性能。之前有很多优秀的工作在视网膜血管分割中都表现出优秀的分割性能,证明了CNN具有很强的特征表示学习和识别能力。但由于卷积运算固有的局域性,随着训练数据的扩大和网络层的增加,这些方法很难学习显式的全局和长距离的语义信息交互,导致算法分割结果在细微血管分叉处不连续、复杂曲度形态血管丢失,视网膜血管边缘和背景区域之间特征区分不明显。Compared with traditional methods, CNN methods combine the advantages of medical image segmentation methods and semantic segmentation methods, making them achieve remarkable performance. There are many excellent works before that have shown excellent segmentation performance in retinal blood vessel segmentation, proving that CNN has strong feature representation learning and recognition capabilities. However, due to the inherent locality of convolution operations, with the expansion of training data and the increase of network layers, it is difficult for these methods to learn explicit global and long-distance semantic information interaction, resulting in algorithm segmentation results at the bifurcation of fine blood vessels Discontinuous, complex tortuous morphological vessels were lost, and features were not clearly distinguished between retinal vessel margins and background regions.
Transformer作为一种高效的网络结构,依靠自注意力来捕捉长距离的全局信息,已经在自然语言处理领域取得了显著的成就。很多人考虑到计算机视觉任务中也急需全局信息,合适的Transformer应用有助于克服CNN的局限性,所以研究人员付出大量的努力致力于探索适用于视觉任务中的Transformer。例如,Hu尝试使用CNN来提取深层特征,然后这些特征被馈送到Transformer中进行处理和回归。Dosovitskiy和Cao都提出纯Transformer网络,分别对图像进行分类和分割,并获得了巨大的成功。他们将图像分割为多个图像块,并将每个向量化的图像块当做NLP中的一个词/标记,以便可以应用合适的Transformer。随后,在VIT的成功基础上,出现了大量更好的基于Transformer的体系结构的文献,并取得了比CNN更好的性能。然而,视觉变压器仍然存在计算量大,局部信息提取不足而导致精度不高的问题。Transformer, as an efficient network structure that relies on self-attention to capture long-range global information, has achieved remarkable achievements in the field of natural language processing. Many people consider that global information is also urgently needed in computer vision tasks, and suitable Transformer applications can help overcome the limitations of CNN, so researchers have devoted a lot of effort to explore Transformers suitable for vision tasks. For example, Hu tried using CNNs to extract deep features, which were then fed into Transformers for processing and regression. Both Dosovitskiy and Cao proposed pure Transformer networks to classify and segment images, respectively, with great success. They split the image into patches and treat each vectorized patch as a word/token in NLP so that the appropriate Transformer can be applied. Subsequently, building on the success of VIT, a large body of literature on better Transformer-based architectures emerged and achieved better performance than CNNs. However, the visual transformer still has the problems of large amount of computation and insufficient extraction of local information, resulting in low accuracy.
因此,现有方式分割视网膜血管图像存在分割精度低的问题。Therefore, the existing methods for segmenting retinal blood vessel images have the problem of low segmentation accuracy.
发明内容SUMMARY OF THE INVENTION
本发明实施例提供一种视网膜血管图像分割方法和装置,以提高对视网膜血管图像的分割精度。Embodiments of the present invention provide a retinal blood vessel image segmentation method and device, so as to improve the segmentation accuracy of retinal blood vessel images.
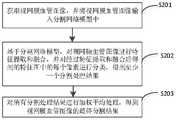
为了解决上述技术问题,本申请实施例提供一种视网膜血管图像分割方法,包括:In order to solve the above technical problems, the embodiments of the present application provide a retinal blood vessel image segmentation method, including:
获取视网膜血管图像,并将所述视网膜血管图像输入分割网络模型中;acquiring retinal blood vessel images, and inputting the retinal blood vessel images into the segmentation network model;
基于所述分割网络模型的编码器-解码器模块,对所述视网膜血管图像进行特征提取和融合,并对经过特征提取和融合后得到的特征图中的每个像素进行分类,得到至少一个分割处理结果;Based on the encoder-decoder module of the segmentation network model, feature extraction and fusion are performed on the retinal blood vessel image, and each pixel in the feature map obtained after feature extraction and fusion is classified to obtain at least one segmentation process result;
对所有所述分割处理结果进行加权平均处理,得到所述视网膜血管图像的最终分割结果。A weighted average process is performed on all the segmentation processing results to obtain the final segmentation result of the retinal blood vessel image.
为了解决上述技术问题,本申请实施例还提供一种基于Transformer优化的视网膜血管图像分割装置,包括:In order to solve the above-mentioned technical problems, the embodiment of the present application also provides a retinal blood vessel image segmentation device based on Transformer optimization, including:
视网膜血管图像获取模块,用于获取视网膜血管图像,并将所述视网膜血管图像输入分割网络模型中;a retinal blood vessel image acquisition module, used for acquiring retinal blood vessel images, and inputting the retinal blood vessel images into the segmentation network model;
分割模块,用于基于所述分割网络模型的编码器-解码器模块,对所述视网膜血管图像进行特征提取和融合,并对经过特征提取和融合后得到的特征图中的每个像素进行分类,得到至少一个分割处理结果;The segmentation module is used to extract and fuse the features of the retinal blood vessel image based on the encoder-decoder module of the segmentation network model, and classify each pixel in the feature map obtained after the feature extraction and fusion , obtain at least one segmentation result;
分割结果获取模块,用于对所有所述分割处理结果进行加权平均处理,得到所述视网膜血管图像的最终分割结果。The segmentation result acquisition module is configured to perform weighted average processing on all the segmentation processing results to obtain the final segmentation result of the retinal blood vessel image.
为了解决上述技术问题,本申请实施例还提供一种计算机设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述视网膜血管图像分割方法的步骤。In order to solve the above technical problem, an embodiment of the present application further provides a computer device, including a memory, a processor, and a computer program stored in the memory and running on the processor, where the processor executes the computer In the program, the steps of the above-mentioned retinal blood vessel image segmentation method are realized.
为了解决上述技术问题,本申请实施例还提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述视网膜血管图像分割方法的步骤。In order to solve the above technical problems, the embodiments of the present application further provide a computer-readable storage medium, where the computer-readable storage medium stores a computer program, and when the computer program is executed by a processor, implements the steps of the above method for segmenting retinal blood vessel images .
本发明实施例提供的一种视网膜血管图像分割方法,通过获取视网膜血管图像,并将所述视网膜血管图像输入分割网络模型中;基于所述分割网络模型的编码器-解码器模块,对所述视网膜血管图像进行特征提取和融合,并对经过特征提取和融合后得到的特征图中的每个像素进行分类,得到至少一个分割处理结果;对所有所述分割处理结果进行加权平均处理,得到所述视网膜血管图像的最终分割结果。针对视网膜血管图像分割提出的基于Transformer优化的网络结构,是一种基于Transformer优化的U形对称网络,不仅具有对称的编码器-解码器结构,而且在编码器部分和解码器部分之间添加了跳跃连接。在实现视网膜血管图像端到端分割的同时,能在有限的数据集上得到精确的分割结果,提高对视网膜血管图像的分割精度。An embodiment of the present invention provides a retinal blood vessel image segmentation method, by acquiring a retinal blood vessel image and inputting the retinal blood vessel image into a segmentation network model; an encoder-decoder module based on the segmentation network model, for the Perform feature extraction and fusion on retinal blood vessel images, and classify each pixel in the feature map obtained after feature extraction and fusion to obtain at least one segmentation processing result; perform weighted average processing on all the segmentation processing results to obtain all the segmentation processing results. The final segmentation result of the retinal blood vessel image. The network structure based on Transformer optimization proposed for retinal blood vessel image segmentation is a U-shaped symmetric network based on Transformer optimization, which not only has a symmetrical encoder-decoder structure, but also adds between the encoder part and the decoder part. skip connection. While realizing the end-to-end segmentation of retinal blood vessel images, accurate segmentation results can be obtained on a limited data set, and the segmentation accuracy of retinal blood vessel images can be improved.
附图说明Description of drawings
为了更清楚地说明本发明实施例的技术方案,下面将对本发明实施例的描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。In order to illustrate the technical solutions of the embodiments of the present invention more clearly, the following briefly introduces the drawings that are used in the description of the embodiments of the present invention. Obviously, the drawings in the following description are only some embodiments of the present invention. , for those of ordinary skill in the art, other drawings can also be obtained from these drawings without creative labor.
图1是本发明提出的视网膜血管图像分割方法的一个实施例的流程图;1 is a flowchart of an embodiment of a retinal blood vessel image segmentation method proposed by the present invention;
图2本发明提供的基于Transformer优化的网络模型结构示意图;Fig. 2 the network model structure schematic diagram based on Transformer optimization provided by the present invention;
图3为本发明中优化的Transformer模块的细节图;Fig. 3 is the detailed diagram of the Transformer module optimized in the present invention;
图4为对DRIVE数据集中的血管图像分割结果;Figure 4 is the segmentation result of the blood vessel image in the DRIVE dataset;
图5为对DRIVE数据集中的血管图像分割结果;Figure 5 is the segmentation result of the blood vessel image in the DRIVE dataset;
图6为对STARE数据集中的血管图像分割结果;Figure 6 is the segmentation result of the blood vessel image in the STARE dataset;
图7是根据本申请的视网膜血管图像分割装置的一个实施例的结构示意图;7 is a schematic structural diagram of an embodiment of a retinal blood vessel image segmentation device according to the present application;
图8是根据本申请的计算机设备的一个实施例的结构示意图。FIG. 8 is a schematic structural diagram of an embodiment of a computer device according to the present application.
具体实施方式Detailed ways
除非另有定义,本文所使用的所有的技术和科学术语与属于本申请的技术领域的技术人员通常理解的含义相同;本文中在申请的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本申请;本申请的说明书和权利要求书及上述附图说明中的术语“包括”和“具有”以及它们的任何变形,意图在于覆盖不排他的包含。本申请的说明书和权利要求书或上述附图中的术语“第一”、“第二”等是用于区别不同对象,而不是用于描述特定顺序。Unless otherwise defined, all technical and scientific terms used herein have the same meaning as commonly understood by one of ordinary skill in the technical field of this application; the terms used herein in the specification of the application are for the purpose of describing specific embodiments only It is not intended to limit the application; the terms "comprising" and "having" and any variations thereof in the description and claims of this application and the above description of the drawings are intended to cover non-exclusive inclusion. The terms "first", "second" and the like in the description and claims of the present application or the above drawings are used to distinguish different objects, rather than to describe a specific order.
在本文中提及“实施例”意味着,结合实施例描述的特定特征、结构或特性可以包含在本申请的至少一个实施例中。在说明书中的各个位置出现该短语并不一定均是指相同的实施例,也不是与其它实施例互斥的独立的或备选的实施例。本领域技术人员显式地和隐式地理解的是,本文所描述的实施例可以与其它实施例相结合。Reference herein to an "embodiment" means that a particular feature, structure, or characteristic described in connection with the embodiment can be included in at least one embodiment of the present application. The appearances of the phrase in various places in the specification are not necessarily all referring to the same embodiment, nor a separate or alternative embodiment that is mutually exclusive of other embodiments. It is explicitly and implicitly understood by those skilled in the art that the embodiments described herein may be combined with other embodiments.
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。The technical solutions in the embodiments of the present invention will be clearly and completely described below with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are part of the embodiments of the present invention, but not all of the embodiments. Based on the embodiments of the present invention, all other embodiments obtained by those of ordinary skill in the art without creative efforts shall fall within the protection scope of the present invention.
请参阅图1,图1示出本发明实施例提供的一种视网膜血管图像分割方法,详述如下:Please refer to FIG. 1. FIG. 1 shows a retinal blood vessel image segmentation method provided by an embodiment of the present invention, and the details are as follows:
S201、获取视网膜血管图像,并将视网膜血管图像输入分割网络模型中。S201. Acquire a retinal blood vessel image, and input the retinal blood vessel image into a segmentation network model.
在步骤S201中,上述获取视网膜血管图像的方式包括但不限于公开训练集获取图像,如DRIVE、STARE和CHASE_DB1,基于影像医学诊断技术获取图像,如OCT影像医学诊断技术。In step S201, the above-mentioned ways of obtaining retinal blood vessel images include, but are not limited to, obtaining images from public training sets, such as DRIVE, STARE, and CHASE_DB1, and obtaining images based on medical imaging technology, such as OCT medical imaging technology.
上述分割网络模型是指预先训练好的用于分割视网膜血管图像的模型。该模型为基于Transformer优化的视网膜血管图像分割网络模型。The above-mentioned segmentation network model refers to a pre-trained model for segmenting retinal blood vessel images. This model is an optimized retinal blood vessel image segmentation network model based on Transformer.
通过基于Transformer优化的分割网络模型,能够实现端到端的网络训练,不需要复杂的后处理方法。在分割结果中,大尺度血管不会出现中空和断裂,低对比的微血管和边缘血管也较好的保留了,综合提升了对血管分割的准确度以及细小血管的检测灵敏度,从而提高了对视网膜血管图像的分割精度。Through the segmentation network model based on Transformer optimization, end-to-end network training can be achieved without complex post-processing methods. In the segmentation results, large-scale blood vessels do not appear hollow and fractured, and low-contrast microvessels and marginal vessels are also well preserved, which comprehensively improves the accuracy of blood vessel segmentation and the detection sensitivity of small blood vessels, thereby improving the detection of retinal vessels. Segmentation accuracy of blood vessel images.
在本实施例的一些可选的实现方式中,在步骤201之前,该视网膜血管图像分割方法还包括:In some optional implementations of this embodiment, before step 201, the retinal blood vessel image segmentation method further includes:
S101、获取训练图像。S101. Acquire a training image.
S102、对训练图像进行数据增强处理,得到增强图像。S102. Perform data enhancement processing on the training image to obtain an enhanced image.
S103、将训练图像和增强图像作为训练样本。S103. Use the training image and the enhanced image as training samples.
S104、对训练样本进行预处理,得到预处理训练样本。S104 , preprocessing the training sample to obtain a preprocessing training sample.
S105、将预处理训练样本输入初始分割网络模型中进行训练,得到分割网络模型。S105 , input the preprocessing training samples into the initial segmentation network model for training, and obtain the segmentation network model.
对于步骤S101,上述训练图像包括但不限于公开的训练集,如现有公开的视网膜血管数据集DRIVE、STARE和CHASE_DB1。例如,在DRIVE数据集随机选取20张图像为训练图像,STARE数据集随机选取16张图像为训练图像,CHASE_DB1数据集选取前20张图像为训练图像。For step S101, the above-mentioned training images include but are not limited to public training sets, such as the existing public retinal blood vessel datasets DRIVE, STARE and CHASE_DB1. For example, 20 images are randomly selected as training images in DRIVE dataset, 16 images are randomly selected as training images in STARE dataset, and the first 20 images are selected as training images in CHASE_DB1 dataset.
对于步骤S102,上述数据增强包括但不限于直方图拉伸、图像翻转、图像旋转。For step S102, the above-mentioned data enhancement includes but is not limited to histogram stretching, image flipping, and image rotation.
通过对视网膜血管图像采用数据增强方法,进行训练样本扩充,将训练图像和通过数据增强获得的增强图像一起作为分割网络模型的训练样本。By adopting the data augmentation method for retinal blood vessel images, the training samples are augmented, and the training images and the augmented images obtained by data augmentation are used as the training samples of the segmentation network model.
优选地,基于直方图拉伸方式,对训练图像进行数据增强处理,得到增强图像。Preferably, based on the histogram stretching method, data enhancement processing is performed on the training image to obtain an enhanced image.
通过对视网膜血管图像采用直方图拉伸的方法,生成增强图像,将训练样本扩充一倍。将训练图像和增强图像一起作为分割网络模型的训练样本。增加训练数据,使数据达到一定数量来避免训练过拟合,提高分割网络模型的泛化能力。By applying histogram stretching method to retinal blood vessel images, an enhanced image is generated, and the training samples are doubled. Take the training image and the augmented image together as training samples for the segmentation network model. Increase the training data so that the data reaches a certain amount to avoid training overfitting and improve the generalization ability of the segmentation network model.
对于步骤S104,上述预处理包括但不限于归一化、高斯变换,随机旋转、随机水平翻转和颜色校正处理。For step S104, the above-mentioned preprocessing includes, but is not limited to, normalization, Gaussian transformation, random rotation, random horizontal flip, and color correction processing.
优选地,对训练图像依次进行高斯变换,随机旋转、随机水平翻转和颜色校正处理,得到预处理训练样本。Preferably, the training images are sequentially subjected to Gaussian transformation, random rotation, random horizontal flipping and color correction to obtain preprocessing training samples.
应理解,此处预处理可根据实际应用场景进行相应变化。It should be understood that the preprocessing here can be changed accordingly according to actual application scenarios.
下面以一例子对步骤S104进行解释说明,如对每一张彩色视网膜血管图像进行概率为0.5的高斯变换,其中Sigma=(0,0.5);接着对该图像进行[0,20°]范围内的随机旋转和概率为0.5的随机水平翻转;最后对图像应用[0.5,2]范围内的Gamma颜色校正来调节图像的对比度。Step S104 is explained below with an example, such as performing a Gaussian transformation with a probability of 0.5 on each color retinal blood vessel image, where Sigma=(0, 0.5); A random rotation of , and a random horizontal flip with probability 0.5; finally, a Gamma color correction in the range [0.5, 2] is applied to the image to adjust the contrast of the image.
通过对训练图像进行预处理,增强训练图像的对比度,以便于提高后续对图像进行特征提取等处理的准确率,从而提高分割网络模型对视网膜血管图像的分割精度。By preprocessing the training image, the contrast of the training image is enhanced, so as to improve the accuracy of subsequent processing such as feature extraction on the image, thereby improving the segmentation accuracy of the retinal blood vessel image by the segmentation network model.
通过上述步骤,获取分割网络模型,够实现端到端的网络训练,不需要复杂的后处理方法。在分割结果中,大尺度血管不会出现中空和断裂,低对比的微血管和边缘血管也较好的保留了,综合提升了对血管分割的准确度以及细小血管的检测灵敏度,从而提高分割网络模型对视网膜血管图像的分割精度。Through the above steps, the segmentation network model is obtained, which enables end-to-end network training without complex post-processing methods. In the segmentation results, large-scale vessels do not appear hollow and fractured, and low-contrast microvessels and marginal vessels are well preserved, which comprehensively improves the accuracy of vessel segmentation and the detection sensitivity of small vessels, thereby improving the segmentation network model. Segmentation accuracy on retinal vessel images.
S202、基于分割网络模型中的编码模块和解码模块,对视网膜血管图像进行进行特征提取和融合,并对经过特征提取和融合后得到的特征图中的每个像素进行分类,得到至少一个分割处理结果。S202, based on the encoding module and the decoding module in the segmentation network model, perform feature extraction and fusion on the retinal blood vessel image, and classify each pixel in the feature map obtained after the feature extraction and fusion to obtain at least one segmentation process result.
在步骤S202中,上述分割网络模型是指用于分割视网膜血管图像的网络模型。该分割网络模型包括但不限于基于Transformer优化的分割网络模型,基于机器学习的分割网络模型。In step S202, the above-mentioned segmentation network model refers to a network model for segmenting retinal blood vessel images. The segmentation network model includes but is not limited to a segmentation network model based on Transformer optimization and a segmentation network model based on machine learning.
优选地,此处采用基于Transformer优化的分割网络模型,如图2所示,该基于Transformer优化的分割网络模型的结构分为编码器、解码器、跳跃连接和侧面输出。Preferably, a segmentation network model based on Transformer optimization is used here. As shown in FIG. 2 , the structure of the segmentation network model based on Transformer optimization is divided into encoder, decoder, skip connection and side output.
其中,编码器和解码器都包括Transformer模块,该Transformer模块为本发明提出的优化的Transformer。Wherein, both the encoder and the decoder include a Transformer module, and the Transformer module is the optimized Transformer proposed by the present invention.
此处需要说明的是,每一个优化的Transformer模块由LayerNorm归一化层、多头注意力模块、残差连接和多层感知层组成。本发明中两个连续的Transformer模块采用的多头注意力模块分别为交叉图像块卷积自注意力(Cross Patches Convolution Self-Attention:CPCA)模块和内部图像块卷积自注意力(Inner Patches Convolution Self-Attention:IPCA)。其中,CPCA模块用于提取一个特征图中图像块交叉间的注意力,而IPCA模块用于提取并整合其中一个图像块中像素间的全局特征信息。It should be noted here that each optimized Transformer module consists of a LayerNorm normalization layer, a multi-head attention module, residual connections, and a multi-layer perception layer. The multi-head attention modules adopted by the two continuous Transformer modules in the present invention are respectively the Cross Patches Convolution Self-Attention (CPCA) module and the Inner Patches Convolution Self-Attention (Inner Patches Convolution Self-Attention: CPCA) module. -Attention:IPCA). Among them, the CPCA module is used to extract the attention between the intersections of image blocks in a feature map, and the IPCA module is used to extract and integrate the global feature information between pixels in one of the image blocks.
两个连续的优化后的Transformer模块,可按照如下公式(1)至(4)进行注意力计算:For two consecutive optimized Transformer modules, the attention calculation can be performed according to the following formulas (1) to (4):




其中,Yn-1和Yn+1分别是本发明中的Transformer模块的输入和输出,

编码器包括四个编码模块,依次为顺序连接的第一编码模块、第二编码模块、第三编码模块和第四编码模块。第一编码模块包括一个嵌入模块和两个连续的Transformer模块,第二编码模块和第三编码模块都是由一个合并模块和两个连续的Transformer模块组成,而第四编码模块只包含一个合并模块。The encoder includes four encoding modules, which are sequentially connected first encoding module, second encoding module, third encoding module and fourth encoding module. The first encoding module includes an embedding module and two consecutive Transformer modules, the second encoding module and the third encoding module are both composed of a merging module and two consecutive Transformer modules, and the fourth encoding module only includes a merging module .
此处需要说明的是,第一编码模块中的嵌入模块由一个上采样和线性投影层组成,它将512×512的输入图像进行2倍的上采样,扩大至1024×1024像素的图像,然后把它分成不重叠的256×256的图像块,并将通道数增加到96。合并模块对输入的特征图进行×2的下采样和增加特征图的通道数。而还原模块对特征图进行×2的上采样和减少特征图的通道数。It should be noted here that the embedding module in the first encoding module consists of an upsampling and linear projection layer, which upsamples the 512×512 input image by a factor of 2, expands it to a 1024×1024 pixel image, and then Divide it into non-overlapping 256x256 image blocks and increase the number of channels to 96. The merging module downsamples the input feature map by ×2 and increases the number of channels of the feature map. And the restoration module performs ×2 upsampling on the feature map and reduces the number of channels of the feature map.
与编码器对称的解码器也包括四个解码模块,依次为顺序连接的第一解码模块、第二解码模块、第三解码模块和第四解码模块。除了第一解码模块只包含一个还原模块,其余解码模块都由一个还原模块和两个连续的Transformer模块组成。The decoder symmetrical to the encoder also includes four decoding modules, which are sequentially connected first decoding module, second decoding module, third decoding module and fourth decoding module. Except that the first decoding module contains only one restoration module, the other decoding modules are composed of one restoration module and two consecutive Transformer modules.
在该分割网络模型底部,由4个Transformer模块组成的Bottom Block用于连接编码器和解码器。At the bottom of the segmentation network model, the Bottom Block composed of 4 Transformer modules is used to connect the encoder and decoder.
除此之外,将第一编码模块的输出先后与第二解码模块中Transformer模块的输入和输出进行融合、将第二编码模块的输出先后与第三解码模块中Transformer模块的输入和输出进行融合、将第三编码模块的输出先后与第四解码模块中Transformer模块的输入和输出进行融合,从而形成跳跃连接。In addition, the output of the first encoding module is successively fused with the input and output of the Transformer module in the second decoding module, and the output of the second encoding module is successively fused with the input and output of the Transformer module in the third decoding module. . The output of the third encoding module is successively fused with the input and output of the Transformer module in the fourth decoding module, thereby forming a skip connection.
侧面输出包括四个卷积模块,将每层卷积模块的输出取加权平均作为最后的分割结果。The side output includes four convolution modules, and the weighted average of the output of each layer of convolution modules is used as the final segmentation result.
此处需要说明的是,卷积模块包含顺序连接的一个3×3的卷积,批标准化BatchNormalization,激活函数ReLU,以及一个上采样和一个1×1的卷积。恢复每层在下采样过程中丢失的空间信息,将图片恢复到与网络输入图片的大小相等,以实现端到端的分割。It should be noted here that the convolution module consists of a 3×3 convolution connected sequentially, BatchNormalization, activation function ReLU, and an upsampling and a 1×1 convolution. The spatial information lost in the downsampling process of each layer is recovered, and the picture is restored to the same size as the network input picture to achieve end-to-end segmentation.
下面以一具体实施例对分割网络模型进行详细说明,本发明提出的基于Transformer优化的网络结构参数,如表一所示:The segmentation network model is described in detail below with a specific embodiment, and the network structure parameters based on Transformer optimization proposed by the present invention are shown in Table 1:
表一、基于Transformer优化的网络结构参数Table 1. Network structure parameters optimized based on Transformer


在本实例中,网络训练设置250个epoch来训练网络,初始学习率为0.001,每50个epoch衰减10次,批次大小设置为4,并使用Adam优化器和二元交叉熵损失函数训练基于Transformer优化的网络。整个网络从头开始训练,不使用额外的训练数据。我们在DRIVE、STARE和CHASE_DB1训练集上训练网络,并在每个数据集的各自验证集上进行评估。本实施例的实验是在NVIDIA Tesla V100 32GB GPU上用PyTorch框架作为后端实现进行的。In this example, the network training is set to 250 epochs to train the network, the initial learning rate is 0.001, the decay is 10 times every 50 epochs, the batch size is set to 4, and the training is based on Adam optimizer and binary cross-entropy loss function. Transformer-optimized network. The entire network is trained from scratch without using additional training data. We train the network on the DRIVE, STARE and CHASE_DB1 training sets and evaluate on the respective validation set of each dataset. The experiments of this example are performed on NVIDIA Tesla V100 32GB GPU with PyTorch framework as the backend implementation.
为了评估本发明提出的模型性能,将分割结果与专家分割图(Groungtruth,将专家分割结果作为标准即训练数据的标签)进行比较,并将每个像素的比较结果分为真阳性(TP)、假阳性(FP)、假阴性(FN)和真阴性(TN)。然后,我们采用敏感性(Se)、特异性(Sp)、准确性(Acc)、F1-Score(F1)和接收器工作特性(ROC)下面积(AUC)作为衡量指标来评估模型的性能,公式如下:In order to evaluate the performance of the model proposed by the present invention, the segmentation result is compared with the expert segmentation map (Groungtruth, the expert segmentation result is used as the standard, that is, the label of the training data), and the comparison result of each pixel is divided into true positive (TP), False Positive (FP), False Negative (FN) and True Negative (TN). Then, we employ Sensitivity (Se), Specificity (Sp), Accuracy (Acc), F1-Score (F1) and Area Under Receiver Operating Characteristic (ROC) (AUC) as metrics to evaluate the performance of the model, The formula is as follows:





其中,TP表示在预测图像中正确分类出专家分割图中的一个血管像素时的真值为正,TN表示在预测图像中正确分类出专家分割图中的一个非血管像素时的真值为负,FN是将专家分割图中的血管像素错误分类为预测图像中的非血管像素,FP是将专家分割图中的非血管像素错误标记为预测图像中的血管像素。Precision和Recall分别是精确率和召回率,而ROC曲线表示将血管正确分类为血管像素的比例与错误分类为非血管像素的比例。而AUC指的是ROC曲线下面积,可以用来衡量分割的性能,AUC值越接近1,系统性能越接近完美。Among them, TP indicates that the true value is positive when a blood vessel pixel in the expert segmentation map is correctly classified in the predicted image, and TN indicates that the true value is negative when a non-vessel pixel in the expert segmentation map is correctly classified in the predicted image. , FN is the misclassification of vessel pixels in the expert segmentation map as non-vessel pixels in the predicted image, and FP is the mislabeled non-vessel pixels in the expert segmentation map as blood vessel pixels in the predicted image. Precision and Recall are precision and recall, respectively, while the ROC curve represents the proportion of correctly classified vessels as vessel pixels versus the proportion of misclassified as non-vessel pixels. AUC refers to the area under the ROC curve, which can be used to measure the performance of segmentation. The closer the AUC value is to 1, the closer the system performance is to perfection.
需要说明的是,在不同方法的网络结构比较中,为了对模型的性能进行基准测试,使用DRIVE、STARE和CHASE_DB1视网膜血管分割数据集来进行不同网络结构体系比较。在一具体示例中,如表二、表三和表四所示,分别在三个公共数据集上,对本申请提出的方法与U-Net网络、R2UNet网络、DFUNet网络、DenseBlock-UNet网络、和IterNet网络进行测试,并对测试性能进行对比,在AUC、ACC、SP上都优于其他方法,分别为0.9869/0.9627/0.9902、0.9945/0.9772/0.9903、0.9917/0.9805/0.9963,敏感性和F1值也有明显的提高。可以清晰的对比出本发明提出的方法取得了最优的性能。It should be noted that in the network structure comparison of different methods, in order to benchmark the performance of the model, the DRIVE, STARE and CHASE_DB1 retinal vessel segmentation datasets are used to compare different network structure architectures. In a specific example, as shown in Table 2, Table 3 and Table 4, on three public data sets, respectively, the method proposed in this application is related to U-Net network, R2UNet network, DFUNet network, DenseBlock-UNet network, and The IterNet network was tested, and the test performance was compared, and it was superior to other methods in AUC, ACC, SP, respectively 0.9869/0.9627/0.9902, 0.9945/0.9772/0.9903, 0.9917/0.9805/0.9963, sensitivity and F1 value There is also a marked improvement. It can be clearly compared that the method proposed by the present invention achieves the best performance.
表二:DRIVE数据集上的性能比较Table 2: Performance comparison on the DRIVE dataset


表三:STARE数据集上的性能比较Table 3: Performance comparison on the STARE dataset

表四:CHASE_DB数据集上的性能比较Table 4: Performance comparison on CHASE_DB dataset

如图4、图5和图6所示,(a)为原视网膜血管图像;(b)为掩膜;(c)为金标准;(d)本发明的分割结果。从图4、图5和图6可以看到本发明中的视网膜血管分割结果很接近金标准,证明本发明提供的基于Transformer优化的视网膜血管分割方法具有较好的血管分割性能,提高了低对比度的微血管的检测能力,且所分割的血管主干具有较好的连通性,减少血管断裂。As shown in Figure 4, Figure 5 and Figure 6, (a) is the original retinal blood vessel image; (b) is the mask; (c) is the gold standard; (d) the segmentation result of the present invention. It can be seen from Figure 4, Figure 5 and Figure 6 that the retinal blood vessel segmentation results in the present invention are very close to the gold standard, which proves that the retinal blood vessel segmentation method based on Transformer optimization provided by the present invention has better blood vessel segmentation performance and improves low contrast. The detection ability of microvessels, and the segmented vascular trunks have better connectivity, reducing vascular rupture.
本发明针对视网膜血管图像样本较少以及低对比的微血管检测度低的问题,提出一种视网膜血管图像分割方法。通过构建基于Transformer的Encoder-Decoder的对称结构和在Transformer模块的多头注意力加入卷积层,能更好的获取长距离像素的依赖关系和较好的补充血管局部细节信息,将分割结果中低对比度的微血管较好地保留,综合提升了对血管分割的准确度以及细小血管的检测灵敏度。Aiming at the problems of few retinal blood vessel image samples and low detection degree of low-contrast microvessels, the invention proposes a retinal blood vessel image segmentation method. By constructing the symmetrical structure of the Transformer-based Encoder-Decoder and adding a convolutional layer to the multi-head attention of the Transformer module, the dependencies of long-distance pixels can be better obtained and the local detail information of blood vessels can be better supplemented. The contrast microvessels are well preserved, which comprehensively improves the accuracy of blood vessel segmentation and the detection sensitivity of small blood vessels.
基于Transformer优化的分割网络模型采用了解码器-编码器的对称结构。解码器和编码器都是基于Transformer构建的,并采用了跳跃连接将这两部分连接,使得网络可以在上采样过程中获取在下采样过程中因缩小图片大小而丢失的信息,同时能够获得足够的上下文信息和语义信息,由此得到更好的分割效果。在Transformer模块中的多头注意力加入了卷积层,Transformer本身具有全局的感受野,能更好的获取长距离的依赖,但对于获取局部细节信息有欠缺,本发明加入了3×3的卷积层,能较好的补充局部细节特征信息。通过分割网络模型,对视网膜血管图像进行分割处理,提高分割网络模型对视网膜血管图像的分割精度。The segmentation network model based on Transformer optimization adopts a symmetrical decoder-encoder structure. Both the decoder and the encoder are built based on Transformer, and skip connections are used to connect the two parts, so that the network can obtain the information lost during the downsampling process due to the reduction of the image size during the upsampling process, and can obtain enough information at the same time. Context information and semantic information, so as to get better segmentation effect. The multi-head attention in the Transformer module adds a convolution layer. The Transformer itself has a global receptive field, which can better obtain long-distance dependencies, but it is lacking in obtaining local detailed information. The present invention adds a 3×3 volume The layered layer can better supplement the local detailed feature information. By segmenting the network model, the retinal blood vessel image is segmented to improve the segmentation accuracy of the retinal blood vessel image by the segmentation network model.
在本实施例的一些可选的实现方式中,在步骤S202中,其具体包括如下步骤S2021至步骤S2025:In some optional implementations of this embodiment, in step S202, it specifically includes the following steps S2021 to S2025:
S2021、基于分割网络模型的编码器对应的多层编码块,对视网膜血管图像进行下采样处理,得到每一层编码块对应的下采样特征。S2021 , performing down-sampling processing on the retinal blood vessel image based on the multi-layer coding blocks corresponding to the encoder of the segmentation network model to obtain down-sampling features corresponding to each layer of coding blocks.
S2022、将分割网络模型的最底层编码块对应的下采样特征作为当前特征图,并将当前特征图对应的分割网络模型的解码器中的解码块作为当前解码块。S2022: Use the down-sampling feature corresponding to the bottommost coding block of the segmentation network model as the current feature map, and use the decoding block in the decoder of the segmentation network model corresponding to the current feature map as the current decoding block.
S2023、将当前特征图输入到当前解码块中,并基于当前解码块,对当前特征图进行特征还原处理,得到还原特征。S2023: Input the current feature map into the current decoding block, and perform feature restoration processing on the current feature map based on the current decoding block to obtain restored features.
S2024、将当前特征图对应的编码块的上一层编码块中的下采样特征与还原特征进行融合处理,得到上采样特征,并将上采样特征与当前特征图对应的上一层编码块中的下采样特征进行融合,得到融合特征。S2024. Perform fusion processing on the down-sampling feature in the coding block of the upper layer of the coding block corresponding to the current feature map and the restoration feature to obtain the up-sampling feature, and combine the up-sampling feature with the coding block of the upper layer corresponding to the current feature map The down-sampling features are fused to obtain fused features.
S2025、将当前解码块对应的上一层解码块作为当前解码块,将融合特征作为当前特征图,返回将当前特征图输入到当前解码块中,并基于当前解码块,对当前特征图进行特征还原处理,得到还原特征步骤继续执行,直到当前解码块为分割网络模型的最高层解码块为止。S2025. Use the upper layer decoding block corresponding to the current decoding block as the current decoding block, use the fusion feature as the current feature map, return to input the current feature map into the current decoding block, and perform a feature feature on the current feature map based on the current decoding block The restoration process, the step of obtaining restoration features, continues to execute until the current decoding block is the highest-level decoding block of the segmentation network model.
对于步骤S2021,采用隔行隔列复制方法来实现图像的下采样,从而降低图像的分辨率和增加通道数。For step S2021, the down-sampling of the image is realized by the method of copying between rows and columns, thereby reducing the resolution of the image and increasing the number of channels.
对于步骤S2023,采用分割网络模型的解码器的还原模块进行上采样,图像尺寸变大2倍,通道减小2倍,通过反卷积实现上采样,以恢复像素空间和重建目标的细节。For step S2023, the restoration module of the decoder of the segmentation network model is used for up-sampling, the image size is increased by 2 times, the channel is reduced by 2 times, and up-sampling is realized by deconvolution to restore the pixel space and the details of the reconstruction target.
对于步骤S2024,示例性地,以图2中的结构示意图为例进行说明,该结构示意图中,包含最底层编码块、第三层编码块、第二层编码块和最高层编码块。在对当前特征图进行特征还原处理,得到还原特征后,将最底层编码块的上一层编码块,也即第三层编码模块的下采样特征,与得到的还原特征(经过最底层解码块解码得到)一起输入到当前解码块中的Transformer中进行融合处理,得到上采样特征,然后再将上采样特征与第三个编码模块的下采样特征进行进一步的细节特征融合处理,得到融合特征,进而将当前解码块对应的上一层解码块(第三层解码块)作为当前解码块,将融合特征作为当前特征图,将当前特征图输入到当前解码块中,并基于当前解码块,对当前特征图进行特征还原处理,得到还原特征;将第二层编码模块的下采样特征与还原特征一起输入到当前解码块中的Transformer中进行融合处理,得到上采样特征,然后再将上采样特征与第二个编码模块的下采样特征进行的细节特征融合处理,得到融合特征。进而将当前解码块对应的上一层解码块(最高层解码块)作为当前解码块,将融合特征作为当前特征图,将当前特征图输入到当前解码块中,并基于当前解码块,对当前特征图进行特征还原处理,得到还原特征;将第一层编码模块的下采样特征与还原特征一起输入到当前解码块中的Transformer中进行融合处理,得到上采样特征,然后再将上采样特征与第一个编码模块的下采样特征进行的细节特征融合处理,得到融合特征。Step S2024 is exemplarily described by taking the schematic structural diagram in FIG. 2 as an example. The schematic structural diagram includes the coding block of the lowest layer, the coding block of the third layer, the coding block of the second layer and the coding block of the highest layer. After the feature restoration process is performed on the current feature map, after the restoration features are obtained, the upper layer coding block of the lowest layer coding block, that is, the downsampling feature of the third layer coding module, is combined with the obtained restoration features (after the lowest layer decoding block) decoded) are input into the Transformer in the current decoding block for fusion processing to obtain the up-sampling feature, and then the up-sampling feature and the down-sampling feature of the third encoding module are further detailed feature fusion processing to obtain the fusion feature, Then, the upper layer decoding block (third layer decoding block) corresponding to the current decoding block is used as the current decoding block, the fusion feature is used as the current feature map, the current feature map is input into the current decoding block, and based on the current decoding block, the Perform feature restoration processing on the current feature map to obtain restored features; input the down-sampling features of the second-layer coding module together with the restored features into the Transformer in the current decoding block for fusion processing to obtain up-sampling features, and then add the up-sampling features The fusion features are obtained by the fusion processing of the detail features with the down-sampled features of the second encoding module. Then, the upper-layer decoding block (the highest-level decoding block) corresponding to the current decoding block is used as the current decoding block, the fusion feature is used as the current feature map, the current feature map is input into the current decoding block, and based on the current decoding block, the current decoding block is used. The feature map is subjected to feature restoration processing to obtain restored features; the down-sampling features of the first-layer coding module and the restored features are input into the Transformer in the current decoding block for fusion processing to obtain up-sampling features, and then the up-sampling features are combined with the restored features. The detail feature fusion process performed by the down-sampling feature of the first encoding module obtains the fusion feature.
需要说明的是,按照图2所示的示意图,将最下面的解码块,作为最底层解码块,将最底层解码块上一层的解码块作为第三层解码块,以此类推,将最上面一层的解码块作为最高层解码块,解码块的数量,具体可根据实际需要进行选择,此处不作限定,作为一种优选方式,本实施例中解码块的层数为4。It should be noted that, according to the schematic diagram shown in FIG. 2, the lowermost decoding block is taken as the bottommost decoding block, the decoding block one layer above the bottommost decoding block is taken as the third layer decoding block, and so on, the most The decoding block of the upper layer is used as the highest layer decoding block, and the number of decoding blocks can be selected according to actual needs, which is not limited here. As a preferred way, the number of layers of decoding blocks in this embodiment is 4.
对于步骤S2025,上述融合处理通过跳跃连接实现。For step S2025, the above-mentioned fusion processing is implemented by skip connection.
通过在解码器和编码器中添加的跳跃连接使得每个解码模块的输入为上一层的输出和相应编码模块的输出的融合,此操作能让上采样过程同时获取足够的上下文信息和语义信息。By adding skip connections in the decoder and encoder, the input of each decoding module is the fusion of the output of the previous layer and the output of the corresponding encoding module. This operation allows the upsampling process to obtain sufficient context information and semantic information at the same time. .
通过基于Transformer构建编码器和解码器,并采用了跳跃连接将这两部分连接,使得网络可以在上采样过程中获取在下采样过程中因缩小图片大小而丢失的信息,同时能够获得足够的上下文信息和语义信息,提高分割网络模型对视网膜血管图像的分割精度。By building an encoder and a decoder based on Transformer, and using a skip connection to connect the two parts, the network can obtain the information lost during the downsampling process due to the reduction of the image size during the upsampling process, and can obtain enough context information at the same time and semantic information to improve the segmentation accuracy of the segmentation network model for retinal blood vessel images.
在步骤S203中,对所有分割处理结果进行加权平均处理,得到视网膜血管图像的最终分割结果。In step S203, weighted average processing is performed on all the segmentation processing results to obtain the final segmentation result of the retinal blood vessel image.
在步骤S204中,将视网膜血管图像输入已训练好的网络模型中,然后每层的解码模块的输出结果再通过卷积模块,输出每一层的预测分割结果。本发明对每层预测结果进行加权平均来获得每个像素的分类概率,最终得到视网膜血管图像的分割结果。In step S204, the retinal blood vessel image is input into the trained network model, and then the output result of the decoding module of each layer passes through the convolution module to output the predicted segmentation result of each layer. The present invention performs weighted average on the prediction results of each layer to obtain the classification probability of each pixel, and finally obtains the segmentation result of the retinal blood vessel image.
通过用训练好的分割网络模型对的视网膜血管图像进行血管分割时,对每层解码模块输出的预测结果进行加权平均来获得每个像素的分类概率,以此作为最后的血管分割结果,进一步提高视网膜血管图像分割的准确度。When the retinal blood vessel image is segmented by the trained segmentation network model, the weighted average of the prediction results output by the decoding module of each layer is used to obtain the classification probability of each pixel, which is used as the final blood vessel segmentation result to further improve the Accuracy of retinal vessel image segmentation.
本发明实施例提供的视网膜血管图像分割方法,通过获取视网膜血管图像,并将视网膜血管图像输入分割网络模型中;基于分割网络模型的编码器-解码器模块,对视网膜血管图像进行特征提取和融合,并对经过特征提取和融合后得到的特征图中的每个像素进行分类,得到至少一个分割处理结果;对所有分割处理结果进行加权平均处理,得到视网膜血管图像的最终分割结果,通过针对视网膜血管图像分割提出的基于Transformer优化的网络结构,是一种基于Transformer构建的U形对称网络,不仅具有对称的编码器-解码器结构,并在编码器部分和解码器部分之间添加了跳跃连接。在实现视网膜血管图像端到端的分割的同时,能在有限的数据集上得到精确的分割结果,提高对视网膜血管图像的分割精度。The retinal blood vessel image segmentation method provided by the embodiment of the present invention obtains the retinal blood vessel image and inputs the retinal blood vessel image into the segmentation network model; the encoder-decoder module based on the segmentation network model performs feature extraction and fusion on the retinal blood vessel image. , and classify each pixel in the feature map obtained after feature extraction and fusion to obtain at least one segmentation processing result; perform weighted average processing on all segmentation processing results to obtain the final segmentation result of the retinal blood vessel image. The network structure based on Transformer optimization proposed for blood vessel image segmentation is a U-shaped symmetrical network constructed based on Transformer, which not only has a symmetrical encoder-decoder structure, but also adds skip connections between the encoder part and the decoder part . While realizing the end-to-end segmentation of retinal blood vessel images, accurate segmentation results can be obtained on limited data sets, and the segmentation accuracy of retinal blood vessel images can be improved.
应理解,上述实施例中各步骤的序号的大小并不意味着执行顺序的先后,各过程的执行顺序应以其功能和内在逻辑确定,而不应对本发明实施例的实施过程构成任何限定。It should be understood that the size of the sequence numbers of the steps in the above embodiments does not mean the sequence of execution, and the execution sequence of each process should be determined by its functions and internal logic, and should not constitute any limitation to the implementation process of the embodiments of the present invention.
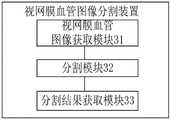
图7示出与上述实施例视网膜血管图像分割方法一一对应的视网膜血管图像分割装置的原理框图。如图7所示,该视网膜血管图像分割装置包括视网膜血管图像获取模块31、分割模块32和分割结果获取模块33。各功能模块详细说明如下:FIG. 7 shows a principle block diagram of a retinal blood vessel image segmentation apparatus corresponding to the retinal blood vessel image segmentation method in the above-mentioned embodiment. As shown in FIG. 7 , the retinal blood vessel image segmentation device includes a retinal blood vessel image acquisition module 31 , a segmentation module 32 and a segmentation result acquisition module 33 . The detailed description of each functional module is as follows:
视网膜血管图像获取模块31,用于获取视网膜血管图像,并将视网膜血管图像输入分割网络模型中。The retinal blood vessel image acquisition module 31 is used for acquiring retinal blood vessel images and inputting the retinal blood vessel images into the segmentation network model.
分割模块32,用于基于分割网络模型的编码模块和解码模块,对视网膜血管图像进行特征提取和融合,并对经过特征提取和融合后得到的特征图中的每个像素进行分类,得到至少一个分割处理结果。The segmentation module 32 is used to perform feature extraction and fusion on the retinal blood vessel image based on the encoding module and the decoding module of the segmentation network model, and classify each pixel in the feature map obtained after the feature extraction and fusion to obtain at least one. Segmentation processing result.
分割结果获取模块33,用于对所有分割处理结果进行加权平均处理,得到视网膜血管图像的最终分割结果。The segmentation result obtaining module 33 is configured to perform weighted average processing on all segmentation processing results to obtain the final segmentation result of the retinal blood vessel image.
在其中一个实施例中,在视网膜血管图像获取模块31之前,视网膜血管图像分割装置还包括:In one embodiment, before the retinal blood vessel image acquisition module 31, the retinal blood vessel image segmentation apparatus further includes:
训练图像获取模块,用于获取训练图像。The training image acquisition module is used to acquire training images.
数据增强模块,用于对训练图像进行数据增强处理,得到增强图像。The data enhancement module is used to perform data enhancement processing on the training images to obtain enhanced images.
训练样本获取模块,用于将训练图像和增强图像作为训练样本。The training sample acquisition module is used to take training images and augmented images as training samples.
预处理模块,用于对训练样本进行预处理,得到预处理训练样本。The preprocessing module is used to preprocess the training samples to obtain the preprocessed training samples.
模型训练模块,用于将预处理训练样本输入初始分割网络模型中进行训练,得到分割网络模型。The model training module is used to input the preprocessing training samples into the initial segmentation network model for training to obtain the segmentation network model.
在其中一个实施例中,数据增强模块进一步包括:In one embodiment, the data enhancement module further includes:
直方图拉伸单元,用于基于直方图拉伸方式,对训练图像进行数据增强处理,得到增强图像。The histogram stretching unit is used to perform data enhancement processing on the training image based on the histogram stretching method to obtain an enhanced image.
在其中一个实施例中,预处理模块进一步包括:In one embodiment, the preprocessing module further includes:
预处理单元,用于对训练图像依次进行高斯变换,随机旋转、随机水平翻转和颜色校正处理,得到预处理训练样本。The preprocessing unit is used to sequentially perform Gaussian transformation, random rotation, random horizontal flip and color correction processing on the training images to obtain preprocessing training samples.
在其中一个实施例中,分割模块32进一步包括:In one embodiment, the segmentation module 32 further includes:
下采样单元,用于基于分割网络模型的编码器对应的多层编码块,对视网膜血管图像进行下采样处理,得到每一层编码块对应的下采样特征。The down-sampling unit is used for down-sampling the retinal blood vessel image based on the multi-layer coding blocks corresponding to the encoder of the segmentation network model to obtain down-sampling features corresponding to each layer of coding blocks.
当前编码块获取单元,用于将分割网络模型的最底层编码块对应的下采样特征作为当前特征图,并将当前特征图对应的分割网络模型的解码器中的解码块作为当前解码块。The current coding block obtaining unit is used to use the down-sampling feature corresponding to the bottom coding block of the segmentation network model as the current feature map, and use the decoding block in the decoder of the segmentation network model corresponding to the current feature map as the current decoding block.
特征还原单元,用于将当前特征图输入到当前解码块中,并基于当前解码块,对当前特征图进行特征还原处理,得到还原特征。The feature restoration unit is used to input the current feature map into the current decoding block, and based on the current decoding block, perform feature restoration processing on the current feature map to obtain restored features.
融合单元,用于将当前特征图对应的编码块的上一层编码块中的下采样特征与还原特征进行融合处理,得到上采样特征,并将上采样特征与当前特征图对应的上一层编码块中的下采样特征进行融合,得到融合特征。The fusion unit is used to fuse the down-sampling features in the coding block of the upper layer of the coding block corresponding to the current feature map with the restored features to obtain the up-sampling features, and fuse the up-sampling features with the upper layer corresponding to the current feature map. The down-sampled features in the coding block are fused to obtain fused features.
循环单元,用于将当前解码块对应的上一层解码块作为当前解码块,将融合特征作为当前特征图,返回将当前特征图输入到当前解码块中,并基于当前解码块,对当前特征图进行特征还原处理,得到还原特征步骤继续执行,直到当前解码块为分割网络模型的最高层解码块为止。The loop unit is used to take the upper layer decoding block corresponding to the current decoding block as the current decoding block, take the fusion feature as the current feature map, return the current feature map to the current decoding block, and based on the current decoding block, analyze the current feature map. The feature restoration process is performed on the graph, and the step of obtaining restoration features continues to execute until the current decoding block is the highest-level decoding block of the segmentation network model.
在其中一个实施例中,下采样单元进一步包括:In one of the embodiments, the downsampling unit further includes:
下采样特征获取单元,用于基于分割网络模型的编码器对应的多层编码块中的合并模块和Transformer模块,对视网膜血管图像进行下采样处理,得到每一层编码块对应的下采样特征。The down-sampling feature acquisition unit is used for the merging module and the Transformer module in the multi-layer coding block corresponding to the encoder based on the segmentation network model to down-sample the retinal blood vessel image to obtain the down-sampling feature corresponding to each layer of coding blocks.
关于视网膜血管图像分割装置的具体限定可以参见上文中对于视网膜血管图像分割方法的限定,在此不再赘述。上述视网膜血管图像分割装置中的各个模块可全部或部分通过软件、硬件及其组合来实现。上述各模块可以硬件形式内嵌于或独立于计算机设备中的处理器中,也可以以软件形式存储于计算机设备中的存储器中,以便于处理器调用执行以上各个模块对应的操作。For the specific definition of the retinal blood vessel image segmentation device, reference may be made to the definition of the retinal blood vessel image segmentation method above, which will not be repeated here. Each module in the above-mentioned retinal blood vessel image segmentation apparatus can be implemented in whole or in part by software, hardware and combinations thereof. The above modules can be embedded in or independent of the processor in the computer device in the form of hardware, or stored in the memory in the computer device in the form of software, so that the processor can call and execute the operations corresponding to the above modules.
为解决上述技术问题,本申请实施例还提供计算机设备。具体请参阅图8,图8为本实施例计算机设备基本结构框图。To solve the above technical problems, the embodiments of the present application also provide computer equipment. For details, please refer to FIG. 8 , which is a block diagram of a basic structure of a computer device according to this embodiment.
所述计算机设备4包括通过系统总线相互通信连接存储器41、处理器42、网络接口43。需要指出的是,图中仅示出了具有组件连接存储器41、处理器42、网络接口43的计算机设备4,但是应理解的是,并不要求实施所有示出的组件,可以替代的实施更多或者更少的组件。其中,本技术领域技术人员可以理解,这里的计算机设备是一种能够按照事先设定或存储的指令,自动进行数值计算和/或信息处理的设备,其硬件包括但不限于微处理器、专用集成电路(Application Specific Integrated Circuit,ASIC)、可编程门阵列(Field-Programmable Gate Array,FPGA)、数字处理器(Digital Signal Processor,DSP)、嵌入式设备等。The
本申请还提供了另一种实施方式,即提供一种计算机可读存储介质,所述计算机可读存储介质存储有界面显示程序,所述界面显示程序可被至少一个处理器执行,以使所述至少一个处理器执行如上述的视网膜血管图像分割方法的步骤。The present application also provides another implementation manner, which is to provide a computer-readable storage medium, where an interface display program is stored in the computer-readable storage medium, and the interface display program can be executed by at least one processor, so that all The at least one processor executes the steps of the retinal blood vessel image segmentation method as described above.
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质(如ROM/RAM、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是手机,计算机,服务器,空调器,或者网络设备等)执行本申请各个实施例所述的方法。From the description of the above embodiments, those skilled in the art can clearly understand that the method of the above embodiment can be implemented by means of software plus a necessary general hardware platform, and of course can also be implemented by hardware, but in many cases the former is better implementation. Based on this understanding, the technical solution of the present application can be embodied in the form of a software product in essence or in a part that contributes to the prior art, and the computer software product is stored in a storage medium (such as ROM/RAM, magnetic disk, CD-ROM), including several instructions to make a terminal device (which may be a mobile phone, a computer, a server, an air conditioner, or a network device, etc.) execute the methods described in the various embodiments of this application.
显然,以上所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例,附图中给出了本申请的较佳实施例,但并不限制本申请的专利范围。本申请可以以许多不同的形式来实现,相反地,提供这些实施例的目的是使对本申请的公开内容的理解更加透彻全面。尽管参照前述实施例对本申请进行了详细的说明,对于本领域的技术人员来而言,其依然可以对前述各具体实施方式所记载的技术方案进行修改,或者对其中部分技术特征进行等效替换。凡是利用本申请说明书及附图内容所做的等效结构,直接或间接运用在其他相关的技术领域,均同理在本申请专利保护范围之内。Obviously, the above-described embodiments are only a part of the embodiments of the present application, rather than all of the embodiments. The accompanying drawings show the preferred embodiments of the present application, but do not limit the scope of the patent of the present application. This application may be embodied in many different forms, rather these embodiments are provided so that a thorough and complete understanding of the disclosure of this application is provided. Although the present application has been described in detail with reference to the foregoing embodiments, those skilled in the art can still modify the technical solutions described in the foregoing specific embodiments, or perform equivalent replacements for some of the technical features. . Any equivalent structures made by using the contents of the description and drawings of this application, which are directly or indirectly used in other related technical fields, are all within the scope of protection of the patent of this application.
Claims (10)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210059594.8ACN114419054B (en) | 2022-01-19 | 2022-01-19 | Retina blood vessel image segmentation method and device and related equipment |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210059594.8ACN114419054B (en) | 2022-01-19 | 2022-01-19 | Retina blood vessel image segmentation method and device and related equipment |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN114419054Atrue CN114419054A (en) | 2022-04-29 |
| CN114419054B CN114419054B (en) | 2024-12-17 |
Family
ID=81273761
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210059594.8AActiveCN114419054B (en) | 2022-01-19 | 2022-01-19 | Retina blood vessel image segmentation method and device and related equipment |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114419054B (en) |
Cited By (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114926460A (en)* | 2022-07-19 | 2022-08-19 | 合肥综合性国家科学中心人工智能研究院(安徽省人工智能实验室) | Training method of fundus image classification model, and fundus image classification method and system |
| CN114998366A (en)* | 2022-05-24 | 2022-09-02 | 苏州微清医疗器械有限公司 | A method and system for segmentation and integration of lesions in fundus sugar network images |
| CN115018874A (en)* | 2022-07-04 | 2022-09-06 | 浙江工业大学 | Fundus blood vessel segmentation domain generalization method based on frequency domain analysis |
| CN115063351A (en)* | 2022-05-24 | 2022-09-16 | 中国科学院深圳先进技术研究院 | A deep learning-based fetal MRI brain tissue segmentation method and device |
| CN115115656A (en)* | 2022-06-30 | 2022-09-27 | 中国科学院宁波材料技术与工程研究所 | Cerebrovascular segmentation method and neural network segmentation model based on multicenter TOF-MRA images |
| CN115170808A (en)* | 2022-09-05 | 2022-10-11 | 中邮消费金融有限公司 | Image segmentation method and system |
| CN115579129A (en)* | 2022-10-24 | 2023-01-06 | 西交利物浦大学 | Down syndrome screening method, device, equipment and storage medium based on Transformer |
| CN115775350A (en)* | 2022-11-07 | 2023-03-10 | 上海理工大学 | Image enhancement method and device, and computing device |
| CN116188431A (en)* | 2023-02-21 | 2023-05-30 | 北京长木谷医疗科技有限公司 | Hip joint segmentation method and device based on CNN and Transformer |
| CN116630334A (en)* | 2023-04-23 | 2023-08-22 | 中国科学院自动化研究所 | Method, device, equipment and medium for real-time automatic segmentation of multi-segment blood vessel |
| WO2024108660A1 (en)* | 2022-11-25 | 2024-05-30 | 深圳先进技术研究院 | Retinal vessel segmentation method fusing pixel connectivity and system therefor |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2019182520A1 (en)* | 2018-03-22 | 2019-09-26 | Agency For Science, Technology And Research | Method and system of segmenting image of abdomen of human into image segments corresponding to fat compartments |
| WO2021003821A1 (en)* | 2019-07-11 | 2021-01-14 | 平安科技(深圳)有限公司 | Cell detection method and apparatus for a glomerular pathological section image, and device |
| CN113205534A (en)* | 2021-05-17 | 2021-08-03 | 广州大学 | Retinal vessel segmentation method and device based on U-Net + |
| CN113674253A (en)* | 2021-08-25 | 2021-11-19 | 浙江财经大学 | Rectal cancer CT image automatic segmentation method based on U-transducer |
| CN113888556A (en)* | 2021-09-15 | 2022-01-04 | 山东师范大学 | Retinal blood vessel image segmentation method and system based on differential attention |
| CN113902757A (en)* | 2021-10-09 | 2022-01-07 | 天津大学 | Blood vessel segmentation method based on self-attention mechanism and convolution neural network hybrid model |
- 2022
- 2022-01-19CNCN202210059594.8Apatent/CN114419054B/enactiveActive
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2019182520A1 (en)* | 2018-03-22 | 2019-09-26 | Agency For Science, Technology And Research | Method and system of segmenting image of abdomen of human into image segments corresponding to fat compartments |
| WO2021003821A1 (en)* | 2019-07-11 | 2021-01-14 | 平安科技(深圳)有限公司 | Cell detection method and apparatus for a glomerular pathological section image, and device |
| CN113205534A (en)* | 2021-05-17 | 2021-08-03 | 广州大学 | Retinal vessel segmentation method and device based on U-Net + |
| CN113674253A (en)* | 2021-08-25 | 2021-11-19 | 浙江财经大学 | Rectal cancer CT image automatic segmentation method based on U-transducer |
| CN113888556A (en)* | 2021-09-15 | 2022-01-04 | 山东师范大学 | Retinal blood vessel image segmentation method and system based on differential attention |
| CN113902757A (en)* | 2021-10-09 | 2022-01-07 | 天津大学 | Blood vessel segmentation method based on self-attention mechanism and convolution neural network hybrid model |
Non-Patent Citations (2)
| Title |
|---|
| YANG LI等: ""multiple Self-attention Network for Intracranial Vessel Segmentation"", 《2021 INTERNATIONAL JOINT CONFERENCE ON NEURAL NETWORKS》, 22 September 2021 (2021-09-22)* |
| 陈小龙: ""基于注意力编码的轻量化语义分割网络"", 《激光与光电子学进展》, 25 July 2021 (2021-07-25)* |
Cited By (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115063351B (en)* | 2022-05-24 | 2025-09-19 | 中国科学院深圳先进技术研究院 | Fetal MRI brain tissue segmentation method and device based on deep learning |
| CN114998366A (en)* | 2022-05-24 | 2022-09-02 | 苏州微清医疗器械有限公司 | A method and system for segmentation and integration of lesions in fundus sugar network images |
| CN115063351A (en)* | 2022-05-24 | 2022-09-16 | 中国科学院深圳先进技术研究院 | A deep learning-based fetal MRI brain tissue segmentation method and device |
| CN115115656A (en)* | 2022-06-30 | 2022-09-27 | 中国科学院宁波材料技术与工程研究所 | Cerebrovascular segmentation method and neural network segmentation model based on multicenter TOF-MRA images |
| CN115018874A (en)* | 2022-07-04 | 2022-09-06 | 浙江工业大学 | Fundus blood vessel segmentation domain generalization method based on frequency domain analysis |
| CN114926460B (en)* | 2022-07-19 | 2022-10-25 | 合肥综合性国家科学中心人工智能研究院(安徽省人工智能实验室) | Training method of fundus image classification model, and fundus image classification method and system |
| CN114926460A (en)* | 2022-07-19 | 2022-08-19 | 合肥综合性国家科学中心人工智能研究院(安徽省人工智能实验室) | Training method of fundus image classification model, and fundus image classification method and system |
| CN115170808A (en)* | 2022-09-05 | 2022-10-11 | 中邮消费金融有限公司 | Image segmentation method and system |
| CN115579129A (en)* | 2022-10-24 | 2023-01-06 | 西交利物浦大学 | Down syndrome screening method, device, equipment and storage medium based on Transformer |
| CN115775350A (en)* | 2022-11-07 | 2023-03-10 | 上海理工大学 | Image enhancement method and device, and computing device |
| WO2024108660A1 (en)* | 2022-11-25 | 2024-05-30 | 深圳先进技术研究院 | Retinal vessel segmentation method fusing pixel connectivity and system therefor |
| CN116188431A (en)* | 2023-02-21 | 2023-05-30 | 北京长木谷医疗科技有限公司 | Hip joint segmentation method and device based on CNN and Transformer |
| CN116188431B (en)* | 2023-02-21 | 2024-02-09 | 北京长木谷医疗科技股份有限公司 | Hip joint segmentation method and device based on CNN and Transformer |
| CN116630334A (en)* | 2023-04-23 | 2023-08-22 | 中国科学院自动化研究所 | Method, device, equipment and medium for real-time automatic segmentation of multi-segment blood vessel |
| CN116630334B (en)* | 2023-04-23 | 2023-12-08 | 中国科学院自动化研究所 | Method, device, equipment and medium for real-time automatic segmentation of multi-segment blood vessel |
Also Published As
| Publication number | Publication date |
|---|---|
| CN114419054B (en) | 2024-12-17 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN114419054A (en) | Retinal blood vessel image segmentation method and device and related equipment | |
| CN109345538B (en) | Retinal vessel segmentation method based on convolutional neural network | |
| Kumar et al. | CSNet: A new DeepNet framework for ischemic stroke lesion segmentation | |
| CN110097554B (en) | Retina blood vessel segmentation method based on dense convolution and depth separable convolution | |
| CN113689954B (en) | Hypertension risk prediction method, device, equipment and medium | |
| CN113793348B (en) | A retinal blood vessel segmentation method and device | |
| CN115205300A (en) | Fundus blood vessel image segmentation method and system based on cavity convolution and semantic fusion | |
| CN115908358B (en) | A myocardial image segmentation and classification method based on multi-task learning | |
| Sun et al. | A retinal vessel segmentation method based improved U-Net model | |
| CN111882566B (en) | Blood vessel segmentation method, device, equipment and storage medium for retina image | |
| CN113592843B (en) | Method and device for segmenting fundus retinal blood vessel images based on improved U-Net | |
| CN110473188A (en) | A kind of eye fundus image blood vessel segmentation method based on Frangi enhancing and attention mechanism UNet | |
| CN113012163A (en) | Retina blood vessel segmentation method, equipment and storage medium based on multi-scale attention network | |
| CN113397475B (en) | OCT image-based prediction method, system and medium for Alzheimer disease risk | |
| CN112085745A (en) | Retinal vessel image segmentation method of multi-channel U-shaped full convolution neural network based on balanced sampling splicing | |
| CN108363979A (en) | Neonatal pain expression recognition method based on binary channels Three dimensional convolution neural network | |
| CN115035127B (en) | Retina blood vessel segmentation method based on generation type countermeasure network | |
| CN118470031B (en) | A retinal vessel segmentation method based on a multi-level full-resolution feature selection network | |
| CN117934824A (en) | Target region segmentation method and system for ultrasonic image and electronic equipment | |
| CN112270366A (en) | Micro target detection method based on self-adaptive multi-feature fusion | |
| CN115049682A (en) | Retina blood vessel segmentation method based on multi-scale dense network | |
| CN112085162A (en) | Magnetic resonance brain tissue segmentation method, device, computing device and storage medium based on neural network | |
| CN116503593A (en) | A method for segmentation of retinal OCT image effusion based on deep learning | |
| CN117726646A (en) | A spatial reconstruction feature interactive Transformer retinal blood vessel segmentation method | |
| CN116740076A (en) | Network model and method for pigment segmentation in retinal pigment degeneration fundus image |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |