CN114398520A - Data retrieval method, system, device, electronic device and storage medium - Google Patents
Data retrieval method, system, device, electronic device and storage mediumDownload PDFInfo
- Publication number
- CN114398520A CN114398520ACN202210053020.XACN202210053020ACN114398520ACN 114398520 ACN114398520 ACN 114398520ACN 202210053020 ACN202210053020 ACN 202210053020ACN 114398520 ACN114398520 ACN 114398520A
- Authority
- CN
- China
- Prior art keywords
- candidate
- data
- index
- target
- retrieval
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images







Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/903—Querying
- G06F16/90335—Query processing
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/901—Indexing; Data structures therefor; Storage structures
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/903—Querying
- G06F16/9035—Filtering based on additional data, e.g. user or group profiles
Landscapes
- Engineering & Computer Science (AREA)
- Databases & Information Systems (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- Software Systems (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本公开涉及计算机技术领域,尤其涉及大数据处理技术领域。The present disclosure relates to the field of computer technology, and in particular, to the field of big data processing technology.
背景技术Background technique
随着计算机技术的发展,数据量飞速上涨,用户对日志检索的要求也越来越高。然而,日志的数量较大并且也较为分散的保存在多个服务器中,因此,如何提供更为快速高效的数据检索方法,就成为需要解决的问题。With the development of computer technology, the amount of data is increasing rapidly, and users' requirements for log retrieval are also getting higher and higher. However, the number of logs is relatively large and is stored in multiple servers in a scattered manner. Therefore, how to provide a faster and more efficient data retrieval method becomes a problem that needs to be solved.
发明内容SUMMARY OF THE INVENTION
本公开提供了一种数据检索方法、系统、装置、电子设备及存储介质。The present disclosure provides a data retrieval method, system, device, electronic device and storage medium.
根据本公开的第一方面,提供了一种数据检索方法,包括:According to a first aspect of the present disclosure, there is provided a data retrieval method, comprising:
接收第一设备发来的检索请求;receiving a retrieval request sent by the first device;
基于候选索引包含的候选索引值,确定与所述检索请求匹配的目标索引;其中,所述候选索引为基于本地保存的候选数据构建的;Determine the target index matching the retrieval request based on the candidate index value contained in the candidate index; wherein, the candidate index is constructed based on locally stored candidate data;
基于所述目标索引包含的目标文件偏移量,从本地保存的所述候选数据中获取目标数据;Based on the target file offset included in the target index, obtain target data from the locally stored candidate data;
将所述目标数据作为检索结果反馈至所述第一设备。The target data is fed back to the first device as a retrieval result.
根据本公开的第二方面,提供了一种数据检索系统,包括:数据检索装置,第一设备;其中,According to a second aspect of the present disclosure, there is provided a data retrieval system, comprising: a data retrieval apparatus, a first device; wherein,
所述数据检索装置,用于接收第一设备发来的检索请求;基于候选索引包含的候选索引值,确定与所述检索请求匹配的目标索引;其中,所述候选索引为基于本地保存的候选数据构建的;基于所述目标索引包含的目标文件偏移量,从本地保存的所述候选数据中获取目标数据;将所述目标数据作为检索结果反馈至所述第一设备;The data retrieval device is configured to receive a retrieval request sent by a first device; determine a target index matching the retrieval request based on a candidate index value included in the candidate index; wherein the candidate index is a locally saved candidate index based on the target file offset contained in the target index, obtain target data from the locally stored candidate data; feed back the target data to the first device as a retrieval result;
所述第一设备,用于向所述数据检索装置发送检索请求;接收所述数据检索装置反馈的所述检索结果。The first device is configured to send a retrieval request to the data retrieval apparatus; and receive the retrieval result fed back by the data retrieval apparatus.
根据本公开的第三方面,提供了一种数据检索装置,包括:According to a third aspect of the present disclosure, there is provided a data retrieval apparatus, comprising:
接收模块,用于接收第一设备发来的检索请求;a receiving module, configured to receive a retrieval request sent by the first device;
索引匹配模块,用于基于候选索引包含的候选索引值,确定与所述检索请求匹配的目标索引;其中,所述候选索引为基于本地保存的候选数据构建的;an index matching module, configured to determine a target index matching the retrieval request based on the candidate index value contained in the candidate index; wherein, the candidate index is constructed based on locally stored candidate data;
检索模块,用于基于所述目标索引包含的目标文件偏移量,从本地保存的所述候选数据中获取目标数据;a retrieval module, configured to obtain target data from the locally stored candidate data based on the target file offset contained in the target index;
发送模块,用于将所述目标数据作为检索结果反馈至所述第一设备。A sending module, configured to feed back the target data as a retrieval result to the first device.
根据本公开的第四方面,提供了一种电子设备,包括:According to a fourth aspect of the present disclosure, there is provided an electronic device, comprising:
至少一个处理器;以及at least one processor; and
与该至少一个处理器通信连接的存储器;其中,a memory communicatively coupled to the at least one processor; wherein,
该存储器存储有可被该至少一个处理器执行的指令,该指令被该至少一个处理器执行,以使该至少一个处理器能够执行前述第一方面的检索方法。The memory stores instructions executable by the at least one processor, the instructions being executed by the at least one processor to enable the at least one processor to perform the retrieval method of the aforementioned first aspect.
根据本公开的第五方面,提供了一种存储有计算机指令的非瞬时计算机可读存储介质,该计算机指令用于使该计算机执行前述方法。According to a fifth aspect of the present disclosure, there is provided a non-transitory computer-readable storage medium storing computer instructions for causing the computer to perform the aforementioned method.
根据本公开的第六方面,提供了一种计算机程序产品,包括计算机程序,该计算机程序在被处理器执行时实现前述方法。According to a sixth aspect of the present disclosure, there is provided a computer program product comprising a computer program which, when executed by a processor, implements the aforementioned method.
应当理解,本部分所描述的内容并非旨在标识本公开的实施例的关键或重要特征,也不用于限制本公开的范围。本公开的其它特征将通过以下的说明书而变得容易理解。It should be understood that what is described in this section is not intended to identify key or critical features of embodiments of the disclosure, nor is it intended to limit the scope of the disclosure. Other features of the present disclosure will become readily understood from the following description.
本实施例提供的方案,在接收到检索请求后,基于所述检索请求匹配的目标索引值确定目标文件偏移量,进而获取到目标数据,将该目标数据作为检索结果反馈至第一设备。如此,可以直接在本地完成目标数据的检索以及读取,避免通过网络再连接到保存候选数据的服务器进行目标数据的读取的处理,降低网络开销且提升检索效率。In the solution provided by this embodiment, after receiving the retrieval request, the offset of the target file is determined based on the target index value matched with the retrieval request, and then the target data is obtained, and the target data is fed back to the first device as the retrieval result. In this way, the retrieval and reading of the target data can be directly completed locally, avoiding the process of reading the target data by connecting to the server storing the candidate data through the network, reducing the network overhead and improving the retrieval efficiency.
附图说明Description of drawings
附图用于更好地理解本方案,不构成对本公开的限定。其中:The accompanying drawings are used for better understanding of the present solution, and do not constitute a limitation to the present disclosure. in:
图1是根据本公开一实施例的数据检索方法的流程示意图;FIG. 1 is a schematic flowchart of a data retrieval method according to an embodiment of the present disclosure;
图2是根据本公开一实施例的目标数据在目标文件中保存的位置示意图;2 is a schematic diagram of a location where target data is stored in a target file according to an embodiment of the present disclosure;
图3是根据本公开一实施例的数据检索系统的一种组成结构示意图;3 is a schematic diagram of a composition structure of a data retrieval system according to an embodiment of the present disclosure;
图4是根据ELK集群架构示意图;Figure 4 is a schematic diagram according to the ELK cluster architecture;
图5是根据本公开一实施例的数据检索系统中数据检索装置的一种处理场景示意图;5 is a schematic diagram of a processing scenario of a data retrieval device in a data retrieval system according to an embodiment of the present disclosure;
图6是根据本公开另一实施例的数据检索系统的一种处理场景示意图;6 is a schematic diagram of a processing scenario of a data retrieval system according to another embodiment of the present disclosure;
图7是根据本公开另一实施例的数据检索装置的一种组成结构示意图;7 is a schematic diagram of a composition structure of a data retrieval apparatus according to another embodiment of the present disclosure;
图8是根据本公开另一实施例的数据检索装置的另一种组成结构示意图;8 is a schematic diagram of another composition structure of a data retrieval apparatus according to another embodiment of the present disclosure;
图9是用来实现本公开实施例的检索方法的电子设备的框图。FIG. 9 is a block diagram of an electronic device used to implement the retrieval method of an embodiment of the present disclosure.
具体实施方式Detailed ways
以下结合附图对本公开的示范性实施例做出说明,其中包括本公开实施例的各种细节以助于理解,应当将它们认为仅仅是示范性的。因此,本领域普通技术人员应当认识到,可以对这里描述的实施例做出各种改变和修改,而不会背离本公开的范围和精神。同样,为了清楚和简明,以下的描述中省略了对公知功能和结构的描述。Exemplary embodiments of the present disclosure are described below with reference to the accompanying drawings, which include various details of the embodiments of the present disclosure to facilitate understanding and should be considered as exemplary only. Accordingly, those of ordinary skill in the art will recognize that various changes and modifications of the embodiments described herein can be made without departing from the scope and spirit of the present disclosure. Also, descriptions of well-known functions and constructions are omitted from the following description for clarity and conciseness.
本公开第一方面实施例提供一种数据检索方法,如图1所示,包括:The embodiment of the first aspect of the present disclosure provides a data retrieval method, as shown in FIG. 1 , including:
S101:接收第一设备发来的检索请求;S101: Receive a retrieval request sent by a first device;
S102:基于候选索引包含的候选索引值,确定与所述检索请求匹配的目标索引;其中,所述候选索引为基于本地保存的候选数据构建的;S102: Determine a target index matching the retrieval request based on the candidate index value contained in the candidate index; wherein, the candidate index is constructed based on locally stored candidate data;
S103:基于所述目标索引包含的目标文件偏移量,从本地保存的所述候选数据中获取目标数据;S103: Based on the target file offset included in the target index, obtain target data from the locally stored candidate data;
S104:将所述目标数据作为检索结果反馈至所述第一设备。S104: Feed back the target data to the first device as a retrieval result.
本实施例提供的所述数据检索方法可以应用于服务器,再具体来说,可以应用于服务器中的服务代理,比如log-agent(日志代理);所述服务器可以为用于存储日志的服务器。应理解,上述服务器可以为整个系统中多个服务器中任意之一,也就是说,所述多个服务器中的任意一个服务器中的服务代理都可以执行本实施例提供的数据检索方法,只是不做一一赘述。The data retrieval method provided in this embodiment can be applied to a server, and more specifically, can be applied to a service agent in a server, such as a log-agent (log agent); the server can be a server for storing logs. It should be understood that the above server may be any one of multiple servers in the entire system, that is, the service agent in any one of the multiple servers may execute the data retrieval method provided in this embodiment, but not Do one by one.
所述第一设备可以为客户端的设备;所述第一设备可以将所述检索请求并发至多个服务器的服务代理,本实施例提供的服务器的服务代理为所述多个服务器的服务代理中任意之一。The first device may be a client device; the first device may send the retrieval request to service proxies of multiple servers, and the service proxies of the servers provided in this embodiment are any of the service proxies of the multiple servers. one.
所述候选索引为基于本地保存的候选数据构建得到的。The candidate index is constructed based on locally stored candidate data.
所述候选数据的数量也可以为一个或多个。再具体的,任意一个所述候选数据具体可以为历史日志;所述历史日志可以是基于用户的历史查询操作得到的,比如,用户A的一个历史查询操作为:在时间B查询天气信息;则基于该历史查询操作可以生成一个历史日志。The number of the candidate data may also be one or more. More specifically, any one of the candidate data may specifically be a historical log; the historical log may be obtained based on a user's historical query operation, for example, a historical query operation of user A is: query weather information at time B; then A historical log can be generated based on the historical query operation.
所述候选索引中包含所述候选索引值以及候选文件偏移量。所述候选索引值可以包含多个维度的关键信息。所述候选索引为Key-Value(KV,关键值)形式。The candidate index includes the candidate index value and the candidate file offset. The candidate index value may contain key information of multiple dimensions. The candidate index is in the form of Key-Value (KV, key value).
其中,所述候选索引的数量可以为一个或多个。任意一个所述候选索引中可以包含的所述候选文件偏移量可以为一个或多个。一个或多个所述候选文件偏移量中每个候选文件偏移量用于指示一个候选数据在本地保存的位置。The number of the candidate indexes may be one or more. The number of candidate file offsets that may be included in any one of the candidate indexes may be one or more. Each candidate file offset in the one or more candidate file offsets is used to indicate a location where one candidate data is saved locally.
所述目标数据的数量可以为一个或多个,本实施例不对其进行限定。The quantity of the target data may be one or more, which is not limited in this embodiment.
可见,通过采用上述方案,就可以在接收到检索请求后,基于所述检索请求匹配的目标索引值确定目标文件偏移量,进而获取到目标数据,将该目标数据作为检索结果反馈至第一设备。如此,可以直接在本地完成目标数据的检索以及读取,避免通过网络再连接到保存候选数据的服务器进行目标数据的读取的处理,降低网络开销且提升检索效率。It can be seen that by adopting the above scheme, after receiving the retrieval request, the offset of the target file can be determined based on the target index value matched by the retrieval request, and then the target data can be obtained, and the target data can be fed back to the first retrieval result as the retrieval result. equipment. In this way, the retrieval and reading of the target data can be directly completed locally, avoiding the process of reading the target data by connecting to the server storing the candidate data through the network, reducing the network overhead and improving the retrieval efficiency.
在一种实施方式中,所述候选索引中的所述候选索引值可以包含N个维度的关键信息,以及一个或多个候选文件偏移量;N为大于等于1的整数。In one embodiment, the candidate index value in the candidate index may include key information of N dimensions and one or more candidate file offsets; N is an integer greater than or equal to 1.
所述N个维度的关键信息可以包括以下至少之一:候选窗口终止时间戳、候选数据相关标识、对象相关标识、候选数据内容关键字。The key information of the N dimensions may include at least one of the following: a candidate window termination timestamp, a candidate data related identifier, an object related identifier, and a candidate data content keyword.
其中,所述候选窗口终止时间戳用于表征所述候选索引所对应的预设时间窗口的终止时间戳。在所述候选索引中包含所述候选窗口终止时间戳的情况下,该候选索引为基于其对应的预设时间窗口中的具备相同的关键字的一个或多个候选数据构建的。The termination timestamp of the candidate window is used to represent the termination timestamp of the preset time window corresponding to the candidate index. When the candidate index includes the candidate window termination timestamp, the candidate index is constructed based on one or more candidate data with the same keyword in the corresponding preset time window.
所述候选数据相关标识,具体可以为候选数据的ID(标识,Identity)。具体可以指的是某一个候选日志的ID,可以将其表示为log-ID(即日志的ID)。The candidate data-related identifier may specifically be an ID (identity, Identity) of the candidate data. Specifically, it may refer to the ID of a certain candidate log, which may be expressed as log-ID (ie, the ID of the log).
所述对象相关标识,具体可以为对象的ID;该对象可以为查询用户,比如具体可以为用户的ID。The object-related identifier may specifically be the ID of the object; the object may be the query user, for example, the ID of the user.
所述候选数据内容关键字,具体可以为候选日志中包含的内容关键字。比如,用户A的历史查询操作为:在时间B查询天气信息;则基于该历史查询操作可以生成历史日志;该历史日志即为前述候选数据;相应的,该候选数据内容关键字可以为“天气”。The candidate data content keyword may specifically be the content keyword contained in the candidate log. For example, user A's historical query operation is: query weather information at time B; then a historical log can be generated based on the historical query operation; the historical log is the aforementioned candidate data; correspondingly, the content keyword of the candidate data can be "weather" ".
需要说明的是,若所述候选索引的构建方式不同,则所述候选索引中包含所述候选索引值以及所述候选文件偏移量也是不同的。比如,所述候选索引可以是基于一个候选数据构建的,一个候选索引包括N个维度的关键信息组成的候选索引值及其对应的一个候选文件偏移量;该候选文件偏移量对应一个候选数据。这种情况下,所述N个维度的关键信息可以包括以下至少之一:候选数据相关标识、对象相关标识、候选数据内容关键字。It should be noted that, if the construction methods of the candidate indexes are different, the candidate index values contained in the candidate indexes and the offsets of the candidate files are also different. For example, the candidate index may be constructed based on a candidate data, and a candidate index includes a candidate index value composed of key information of N dimensions and a corresponding candidate file offset; the candidate file offset corresponds to a candidate data. In this case, the key information of the N dimensions may include at least one of the following: candidate data related identifiers, object related identifiers, and candidate data content keywords.
又比如,所述候选索引可以是基于位于同一个预设时间窗口中、具备相同候选索引值的多个候选数据构建的,相应的,一个候选索引包括N个维度的关键信息组成的候选索引值,及其对应的多个候选文件偏移量;该多个候选文件偏移量中每个候选文件偏移量对应一个候选数据。应理解,这种情况中,所述N个维度的关键信息组成的候选索引值可以为多个候选数据所具备的共同的候选索引值。所述N个维度的关键信息可以包括以下至少之一:候选窗口终止时间戳、候选数据相关标识、候选数据内容关键字。For another example, the candidate index may be constructed based on multiple candidate data located in the same preset time window and having the same candidate index value. Correspondingly, a candidate index includes a candidate index value composed of key information of N dimensions. , and its corresponding multiple candidate file offsets; each candidate file offset in the multiple candidate file offsets corresponds to one candidate data. It should be understood that, in this case, the candidate index value formed by the key information of the N dimensions may be a common candidate index value possessed by multiple candidate data. The key information of the N dimensions may include at least one of the following: a candidate window termination timestamp, a candidate data correlation identifier, and a candidate data content keyword.
所述基于候选索引包含的候选索引值,确定与所述检索请求匹配的目标索引,包括以下至少之一:Determining the target index matching the retrieval request based on the candidate index value contained in the candidate index includes at least one of the following:
在所述检索请求中包含待检索数据相关标识的情况下,基于所述候选索引中的候选数据相关标识,确定与所述待检索数据相关标识匹配的目标索引;In the case that the retrieval request includes the relevant identifier of the data to be retrieved, based on the relevant identifier of the candidate data in the candidate index, determine a target index that matches the relevant identifier of the data to be retrieved;
在所述检索请求中包含待检索对象相关标识的情况下,基于所述候选索引中的对象相关标识,确定与所述待检索对象相关标识匹配的目标索引;In the case that the retrieval request includes the relevant identifier of the object to be retrieved, based on the relevant identifier of the object in the candidate index, determine the target index that matches the relevant identifier of the object to be retrieved;
在所述检索请求中包含待检索内容关键字的情况下,基于所述候选索引中的候选数据内容关键字,确定与所述待检索内容关键字匹配的目标索引;In the case where the retrieval request includes the content keyword to be retrieved, based on the candidate data content keyword in the candidate index, determine a target index that matches the to-be-retrieved content keyword;
在所述检索请求中包含待检索时间范围的情况下,基于所述候选索引中的候选窗口终止时间戳,确定在所述待检索时间范围内的目标索引。When the retrieval request includes a to-be-retrieved time range, a target index within the to-be-retrieved time range is determined based on the candidate window termination timestamp in the candidate index.
分别来说:Separately:
所述待检索数据相关标识,具体可以包括:待检索的日志的ID。前述实施例已经说明,所述候选索引的数量可以为一个或多个,每个候选索引中的候选索引值可以为N个维度的关键信息。The relevant identifier of the data to be retrieved may specifically include: the ID of the log to be retrieved. As described in the foregoing embodiments, the number of candidate indexes may be one or more, and the candidate index value in each candidate index may be key information of N dimensions.
相应的,在所述检索请求中包含待检索数据相关标识的情况下,基于所述候选索引中的候选数据相关标识,确定与所述待检索数据相关标识匹配的目标索引,可以包括:Correspondingly, in the case where the retrieval request includes the relevant identifier of the data to be retrieved, determining the target index matching the relevant identifier of the data to be retrieved based on the relevant identifier of the candidate data in the candidate index may include:
在所述检索请求中包含待检索的日志的ID的情况下,从一个或多个候选索引中,确定所述候选索引值中的候选日志的ID与所述待检索的日志的ID匹配的一个或多个目标索引。In the case where the retrieval request includes the ID of the log to be retrieved, from one or more candidate indexes, determine one of the IDs of the candidate log in the candidate index value that matches the ID of the log to be retrieved or multiple target indexes.
所述待检索对象相关标识具体可以包括:待检索的用户的ID。在所述检索请求中包含待检索对象相关标识的情况下,基于所述候选索引中的对象相关标识,确定与所述待检索对象相关标识匹配的目标索引,可以包括:The relevant identifier of the object to be retrieved may specifically include: the ID of the user to be retrieved. In the case where the retrieval request includes the relevant identifier of the object to be retrieved, determining the target index matching the relevant identifier of the object to be retrieved based on the relevant identifier of the object in the candidate index may include:
在所述检索请求中包含待检索的用户的ID的情况下,从一个或多个候选索引中,确定所述候选索引值中的候选用户的ID与所述待检索的用户的ID匹配的一个或多个目标索引。In the case where the retrieval request includes the ID of the user to be retrieved, from one or more candidate indexes, determine one of the candidate user IDs in the candidate index value that matches the ID of the user to be retrieved or multiple target indexes.
在所述检索请求中包含待检索内容关键字的情况下,基于所述候选索引中的候选数据内容关键字,确定与所述待检索内容关键字匹配的目标索引,可以包括:In the case where the retrieval request includes the content keyword to be retrieved, determining the target index matching the content keyword to be retrieved based on the candidate data content keyword in the candidate index may include:
在所述检索请求中包含待检索内容关键字的情况下,从一个或多个候选索引中,确定所述候选索引值中的候选内容关键字与所述待检索内容关键字匹配的一个或多个目标索引。In the case where the retrieval request contains the content keyword to be retrieved, from one or more candidate indexes, determine one or more candidate content keywords in the candidate index value that match the to-be-retrieved content keyword. target index.
在所述检索请求中包含待检索时间范围的情况下,基于所述候选索引中的候选窗口终止时间戳,确定在所述待检索时间范围内的目标索引,可以包括:When the retrieval request includes a time range to be retrieved, determining a target index within the time range to be retrieved based on the candidate window termination timestamp in the candidate index may include:
在所述检索请求中包含待检索时间范围的情况下,基于一个或多个候选索引中分别包含的所述候选索引值中的候选窗口终止时间戳,确定所述一个或多个候选索引所对应的候选数据的时间范围;从所述一个或多个候选索引中,确定所述候选数据的时间范围在所述待检索时间范围内的一个或多个目标索引。In the case where the retrieval request includes the time range to be retrieved, determine the corresponding one or more candidate indices based on the candidate window termination timestamps in the candidate index values respectively included in the one or more candidate indices The time range of the candidate data; from the one or more candidate indexes, determine one or more target indexes whose time range of the candidate data is within the to-be-retrieved time range.
其中,所述待检索时间范围可以为根据实际情况设置的,比如可以为10点-12点;或者,可以是某一个指定日期,比如今天、昨天或前天等等;再或者,可以为1周或1个月等等,这里不进行穷举。The time range to be retrieved may be set according to the actual situation, for example, it may be 10:00-12:00; or, it may be a specified date, such as today, yesterday, or the day before yesterday, etc.; or, it may be 1 week Or 1 month, etc., not exhaustive here.
所述基于一个或多个候选索引中分别包含的所述候选索引值中的候选窗口终止时间戳,确定所述一个或多个候选索引所对应的候选数据的时间范围,具体可以包括:The determining the time range of the candidate data corresponding to the one or more candidate indexes based on the candidate window termination timestamps in the candidate index values respectively included in the one or more candidate indexes may specifically include:
基于候选索引包含的候选索引值中的候选窗口终止时间戳,以及预设时间窗口的时长,确定候选窗口起始时间戳;将所述候选窗口起始时间戳至所述候选窗口终止时间戳之间的范围,作为所述候选索引所对应的候选数据的时间范围。Determine the candidate window start timestamp based on the candidate window termination timestamp in the candidate index value included in the candidate index and the duration of the preset time window; The range between them is taken as the time range of the candidate data corresponding to the candidate index.
还需要指出的是,上述几种情况可以结合使用,举例来说:It should also be noted that the above situations can be used in combination, for example:
在所述检索请求中包含待检索数据相关标识以及待检索对象相关标识的情况下,基于所述候选索引中的候选数据相关标识,确定与所述待检索数据相关标识匹配的至少一个待筛选索引;基于所述至少一个待筛选索引中的对象相关标识,确定与所述待检索对象相关标识匹配的一个或多个目标索引。In the case where the retrieval request includes the relevant identifiers of the data to be retrieved and the relevant identifiers of the objects to be retrieved, based on the relevant identifiers of the candidate data in the candidate index, determine at least one index to be screened that matches the relevant identifiers of the data to be retrieved ; Determine one or more target indexes that match the object-related identifiers to be retrieved based on the object-related identifiers in the at least one to-be-screened index.
在所述检索请求中包含待检索时间范围以及待检索内容关键字的情况下,基于所述候选索引中的候选窗口终止时间戳,确定在所述待检索时间范围内的至少一个待筛选索引;基于所述至少一个待筛选索引中包含的候选数据相关标识,确定与所述待检索内容关键字匹配的一个或多个目标索引。In the case where the retrieval request includes a to-be-retrieved time range and a to-be-retrieved content keyword, determining at least one to-be-screened index within the to-be-retrieved time range based on the candidate window termination timestamp in the candidate index; One or more target indexes matching the keywords of the content to be retrieved are determined based on the relevant identifiers of candidate data contained in the at least one index to be screened.
应理解,以上仅为上述两种情况结合的部分示例性说明,不代表上述几种情况仅可以两两结合,实际处理中还可以3个或4个情况结合使用,只是不做穷举。It should be understood that the above is only a partial illustration of the combination of the above two cases, which does not mean that the above several cases can only be combined in two cases. In actual processing, three or four cases can also be used in combination, but it is not exhaustive.
可见,通过采用上述方案,就可以基于所述检索请求所包含的检索关键字的不同情况,从候选索引值中确定匹配的目标索引值,如此,就能够更加准确的从本地保存的大量候选索引值中选取得到目标索引值,进而更加准确的获取到目标数据,保证了整体处理效率以及准确性。It can be seen that, by adopting the above solution, the matching target index value can be determined from the candidate index values based on the different conditions of the retrieval keywords contained in the retrieval request. In this way, a large number of candidate indexes stored locally can be more accurately obtained. The target index value is selected from the value, and then the target data is obtained more accurately, which ensures the overall processing efficiency and accuracy.
在一种实施方式中,所述基于所述目标索引包含的目标文件偏移量,从本地保存的所述候选数据中获取目标数据,包括:In one embodiment, the obtaining target data from the locally saved candidate data based on the target file offset included in the target index includes:
基于所述目标索引包含的目标文件偏移量,确定所述目标数据在本地的目标文件中保存的位置;Determine the location where the target data is saved in the local target file based on the target file offset included in the target index;
基于所述目标数据在所述目标文件中保存的位置,从所述目标文件保存的所述候选数据中,获取所述目标数据。The target data is acquired from the candidate data saved in the target file based on the location where the target data is saved in the target file.
所述目标文件偏移量具体可以包括:目标文件的标识,目标数据在所述目标文件中相对于所述目标文件开头位置的偏移量;和/或,所述目标文件偏移量具体可以包括:目标文件的标识,目标数据在所述目标文件中相对于所述目标文件结束位置的偏移量。The target file offset may specifically include: an identifier of the target file, the offset of the target data in the target file relative to the beginning of the target file; and/or, the target file offset may specifically be Including: the identifier of the target file, the offset of the target data in the target file relative to the end position of the target file.
应理解,所述目标文件的数量可以为一个或多个;所述目标文件为本地保存的多个候选文件中的一个或多个。所述目标数据的数量也可以为一个或多个,进一步地,所述目标数据具体可以为一个或多个目标文件中分别包含的一个或多个目标数据。It should be understood that the number of the target files may be one or more; the target file is one or more of multiple candidate files saved locally. The quantity of the target data may also be one or more, and further, the target data may specifically be one or more target data contained in one or more target files respectively.
所述目标文件具体可以为在本地用于保存一个或多个候选数据的文件。并且,所述目标文件的标识可以是目标文件在本地的唯一标识,比如可以将一个目标文件的标识表示为:iNode=A1。所述目标文件的存储容量可以为预先设置的,比如一个目标文件可以存储300个字节。The target file may specifically be a file locally used to save one or more candidate data. Moreover, the identifier of the target file may be a local unique identifier of the target file, for example, the identifier of a target file may be expressed as: iNode=A1. The storage capacity of the target file may be preset, for example, one target file may store 300 bytes.
所述目标数据在所述目标文件中相对于所述目标文件开头位置的偏移量可以用具体的数值来表示。The offset of the target data in the target file relative to the beginning of the target file may be represented by a specific numerical value.
所述目标索引在对应了一个目标数据的情况下,目标文件偏移量可以为一个。举例来说,参见图2,假设目标文件偏移量表示为“iNode=A1+100”,则目标数据a1的位置即为相对于目标文件A1开头位置的偏移量为100位置处的数据。When the target index corresponds to one target data, the target file offset may be one. For example, referring to FIG. 2 , assuming that the target file offset is represented as “iNode=A1+100”, the position of the target data a1 is the data at the position whose offset is 100 from the beginning of the target file A1.
所述目标索引在对应了同一个目标文件中的多个目标数据的情况下,目标文件偏移量可以为多个。举例来说,假设目标文件偏移量表示为“iNode=A1+1-300”,则表示在目标文件A1中相对于目标文件A1开头位置的偏移量为1,至在目标文件A1中相对于目标文件A1开头位置的偏移量为300之间的数据,均为所述目标数据。When the target index corresponds to multiple target data in the same target file, the target file offsets may be multiple. For example, assuming that the target file offset is expressed as "iNode=A1+1-300", it means that the offset relative to the beginning of the target file A1 in the target file A1 is 1, and the relative offset in the target file A1 is 1. The data whose offset is between 300 at the beginning of the target file A1 is the target data.
如此,就可以基于目标文件偏移量确定目标数据在本地的存储位置,进而获取该目标数据。从而,避免了通过网络到服务器侧获取对应的目标数据,所带来的网络开销较大的问题,保证了检索效率以及准确性。In this way, the local storage location of the target data can be determined based on the offset of the target file, and then the target data can be obtained. Therefore, the problem of large network overhead caused by obtaining the corresponding target data from the server side through the network is avoided, and the retrieval efficiency and accuracy are ensured.
在上述实施例提供的方案执行之前,还需要预先构建上述候选索引。下面具体进行说明:Before the solution provided by the foregoing embodiment is executed, the foregoing candidate index also needs to be constructed in advance. The specific description is as follows:
在一种实施方式中,可以包括:In one embodiment, it can include:
基于本地保存的所述候选数据,生成所述候选索引值;generating the candidate index value based on the locally stored candidate data;
基于所述候选数据对应的候选文件偏移量以及所述候选索引值,生成所述候选索引。The candidate index is generated based on the candidate file offset corresponding to the candidate data and the candidate index value.
所述候选数据对应的候选文件偏移量的获取方式可以为:基于所述候选数据在本地的候选文件中保存的位置,确定所述候选数据对应的候选文件偏移量。The way of obtaining the candidate file offset corresponding to the candidate data may be: determining the candidate file offset corresponding to the candidate data based on the location where the candidate data is saved in the local candidate file.
可见,通过采用上述方案,就可以针对本地保存的候选数据预先构建候选索引,因此就可以避免现有技术中针对大量其他服务器的候选数据生成候选索引,所带来的效率较低的问题。It can be seen that by adopting the above solution, candidate indexes can be pre-built for locally stored candidate data, so the problem of low efficiency caused by generating candidate indexes for a large number of candidate data of other servers in the prior art can be avoided.
其中,所述基于本地保存的所述候选数据,生成所述候选索引值,包括:Wherein, generating the candidate index value based on the locally stored candidate data includes:
从本地保存的所述候选数据中,筛选得到关键信息;将所述关键信息作为所述候选数据的候选索引。From the locally stored candidate data, key information is obtained by screening; and the key information is used as a candidate index of the candidate data.
也就是说,可以针对每个候选数据都生成对应的候选索引值。That is, a corresponding candidate index value may be generated for each candidate data.
其中,所述从本地保存的所述候选数据中,筛选得到关键信息,具体可以为从本地保存的所述候选数据中,筛选得到N个维度的关键信息。Wherein, the screening to obtain key information from the locally stored candidate data may specifically be to obtain key information of N dimensions by screening the locally stored candidate data.
具体的处理方式可以包括:Specific processing methods can include:
基于正则表达式,从所述候选数据中抽取得到所述N个维度的关键信息。所述正则表达式可以为根据实际情况设置的,这里不对其进行限定。比如,用户A在一个时间B查询天气,相应的,候选数据(即相应的候选日志)中会产生用户A发送了查询请求,该查询请求包含了天气信息。如果正则表达式中包含了用户ID、请求ID以及搜索关键词,则基于该正则表达式可以从上述查询请求所产生的日志中提取得到:用户A、请求ID、搜索关键词这几个维度的关键信息。Based on the regular expression, the key information of the N dimensions is extracted from the candidate data. The regular expression may be set according to the actual situation, which is not limited here. For example, when user A queries the weather at a time B, correspondingly, the candidate data (ie, the corresponding candidate log) will generate a query request sent by user A, and the query request includes the weather information. If the regular expression contains the user ID, request ID and search keyword, then based on the regular expression, it can be extracted from the log generated by the above query request: user A, request ID, search keyword and these dimensions Key Information.
或者,基于过滤条件,从所述候选数据中得到所述N个维度的关键信息。所述过滤条件可以为根据实际情况设置的,比如,可以是从所述候选数据中过滤得到包含用户ID、数据ID、预设类型的内容关键字等等,这里不对其进行限定。Or, based on the filtering condition, the key information of the N dimensions is obtained from the candidate data. The filtering conditions may be set according to actual conditions, for example, content keywords including user IDs, data IDs, preset types, etc. may be obtained by filtering the candidate data, which are not limited here.
所述基于所述候选数据对应的候选文件偏移量以及所述候选索引值,生成所述候选索引,包括:基于所述候选数据在本地的候选文件中保存的位置,确定所述候选数据的候选文件偏移量;基于所述候选文件偏移量以及所述候选索引值,生成所述候选数据的所述候选索引。The generating the candidate index based on the candidate file offset corresponding to the candidate data and the candidate index value includes: determining the position of the candidate data based on the location where the candidate data is saved in the local candidate file. candidate file offset; generating the candidate index of the candidate data based on the candidate file offset and the candidate index value.
举例来说,假设候选数据在本地的候选文件中保存的位置为:相对于候选文件的开头位置的偏移量为offset-C1,则所述候选数据对应的候选文件偏移量表示为:候选文件的标识(比如表示为inodeA1)以及该偏移量offset-C1。假设所述候选数据的候选索引值表示为index1(索引1),则该候选数据的所述候选索引可以表示为index1:inodeA1,offset-C1。For example, assuming that the position where the candidate data is saved in the local candidate file is: the offset relative to the beginning of the candidate file is offset-C1, then the candidate file offset corresponding to the candidate data is expressed as: candidate The identification of the file (denoted as inodeA1, for example) and the offset offset-C1. Assuming that the candidate index value of the candidate data is represented as index1 (index 1), the candidate index of the candidate data may be represented as index1: inodeA1, offset-C1.
如此,就可以针对每一个候选数据生成对应的关键信息,并基于关键信息构建该候选数据的候选索引值。可以使得后续进行候选数据的检索的时候能够具备更加丰富的维度,保证了检索结果的准确性。In this way, corresponding key information can be generated for each candidate data, and a candidate index value of the candidate data can be constructed based on the key information. This can enable the subsequent retrieval of candidate data to have more abundant dimensions and ensure the accuracy of retrieval results.
在一种实施方式中,所述基于本地保存的所述候选数据,生成所述候选索引值,包括:In one embodiment, generating the candidate index value based on the locally stored candidate data includes:
从本地保存的所述候选数据中,筛选得到关键信息;Obtain key information from the locally stored candidate data;
将预设时间窗口内具备相同关键信息的所述候选数据进行汇聚,得到候选数据组;Aggregating the candidate data with the same key information within a preset time window to obtain a candidate data group;
基于所述相同关键信息以及所述预设时间窗口的窗口终止时间戳,确定所述候选数据组的候选索引值。A candidate index value of the candidate data group is determined based on the same key information and the window termination timestamp of the preset time window.
所述从本地保存的所述候选数据中,筛选得到关键信息,具体可以为从本地保存的所述候选数据中,筛选得到N个维度的关键信息。关于得到所述N个维度的关键信息的方式与前述实施例相同,这里不做重复说明。The screening to obtain key information from the locally stored candidate data may specifically be to obtain N-dimension key information from the locally stored candidate data. The manner of obtaining the key information of the N dimensions is the same as that in the foregoing embodiment, and the description is not repeated here.
其中,所述预设时间窗口可以称为汇聚窗口,所述预设时间窗口的长度可以根据实际情况进行设置,比如可以为3秒、或者可以为2秒、或者可以为5秒,还可以更长或更短,本实施例不对其进行穷举。The preset time window may be called a convergence window, and the length of the preset time window may be set according to the actual situation, for example, it may be 3 seconds, or it may be 2 seconds, or it may be 5 seconds, or it may be more long or short, this embodiment does not list them exhaustively.
所述将预设时间窗口内具备相同关键信息的所述候选数据进行汇聚,得到候选数据组,具体可以包括:The gathering of the candidate data with the same key information within the preset time window to obtain a candidate data group may specifically include:
提取所述预设时间窗口内包含的多个候选数据;extracting a plurality of candidate data contained in the preset time window;
基于所述多个候选数据分别对应的N个维度的关键信息,对所述多个候选数据进行汇聚,得到具备相同关键信息的候选数据组。Based on the key information of N dimensions corresponding to the plurality of candidate data respectively, the plurality of candidate data are aggregated to obtain a candidate data group having the same key information.
其中,所述相同关键信息可以为所述N个维度的关键信息中的一个或多个关键信息。Wherein, the same key information may be one or more key information in the key information of the N dimensions.
其中,所述基于所述多个候选数据分别对应的N个维度的关键信息,对所述多个候选数据进行汇聚,得到具备相同关键信息的候选数据组,可以为以下至少之一:Wherein, based on the key information of the N dimensions corresponding to the multiple candidate data, the multiple candidate data are aggregated to obtain a candidate data group with the same key information, which may be at least one of the following:
基于所述多个候选数据分别对应的N个维度的关键信息中的内容关键词,对所述多个候选数据进行汇聚,得到具备相同内容关键词的多个候选数据组;Based on the content keywords in the key information of the N dimensions corresponding to the plurality of candidate data respectively, the plurality of candidate data are aggregated to obtain a plurality of candidate data groups having the same content keywords;
基于所述多个候选数据分别对应的N个维度的关键信息中的对象相关信息,对所述多个候选数据进行汇聚,得到具备相同对象相关信息的多个候选数据组。Based on the object-related information in the key information of N dimensions corresponding to the plurality of candidate data respectively, the plurality of candidate data are aggregated to obtain a plurality of candidate data groups having the same object-related information.
比如,在所述预设时间窗口中包含“天气”这个内容关键词的候选数据可能有多个,将这多个候选数据作为具备“天气”这个相同内容关键词的候选数据组。比如,在所述预设时间窗口中包含用户A的多个候选数据,可以将用户A的全部候选数据作为一个候选数据组。For example, there may be multiple candidate data containing the content keyword "weather" in the preset time window, and these multiple candidate data are regarded as candidate data groups with the same content keyword "weather". For example, if the preset time window includes multiple candidate data of user A, all candidate data of user A may be used as one candidate data group.
应理解,若基于所述关键信息进行多个候选数据的汇聚,则可能候选数据组中存在部分候选数据出现在多个候选数据组中。比如用户A可以搜索“天气”这个关键词,因此,用户A搜索天气所产生的候选数据,可能同时被归于以天气为内容关键词的一个候选数据组中,和用户A的另一个候选数据组中。It should be understood that if the aggregation of multiple candidate data is performed based on the key information, there may be some candidate data in the candidate data group that appear in the multiple candidate data groups. For example, user A can search for the keyword "weather". Therefore, the candidate data generated by user A's search for weather may be classified into a candidate data group with weather as the content keyword and another candidate data group of user A at the same time. middle.
所述基于所述相同关键信息以及所述预设时间窗口的窗口终止时间戳,确定所述候选数据组的候选索引值,可以包括:The determining the candidate index value of the candidate data group based on the same key information and the window termination timestamp of the preset time window may include:
将所述预设时间窗口的窗口终止时间戳作为一个新的关键信息,将所述新的关键信息与所述相同关键信息共同作为所述候选数据组的候选索引值。The window termination timestamp of the preset time window is used as a new key information, and the new key information and the same key information are used as a candidate index value of the candidate data group.
也就是说,在候选数据组具备的相同关键信息的基础上添加所述预设时间窗口的窗口终止时间戳,共同作为所述候选数据组的候选索引值。That is to say, the window termination timestamp of the preset time window is added on the basis of the same key information possessed by the candidate data group, which is used as the candidate index value of the candidate data group together.
可见,通过采用上述方案,以预设时间窗口为单位,对该预设时间窗口内的候选数据进行汇聚,从而一个候选索引可以对应一个或多个候选文件偏移量。如此,可以进一步减小保存索引所占用的存储空间。It can be seen that, by adopting the above solution, the candidate data in the preset time window is aggregated in units of the preset time window, so that one candidate index may correspond to one or more candidate file offsets. In this way, the storage space occupied by the index can be further reduced.
在一种实施方式中,所述基于所述候选数据对应的候选文件偏移量以及所述候选索引值,生成所述候选索引,包括:In an embodiment, the generating the candidate index based on the candidate file offset corresponding to the candidate data and the candidate index value includes:
基于所述候选数据组中包含的所述候选数据在本地的候选文件中保存的位置,确定所述候选数据组对应的候选文件偏移量;Determine the candidate file offset corresponding to the candidate data group based on the location where the candidate data contained in the candidate data group is saved in the local candidate file;
基于所述候选数据组的候选索引值,以及所述候选数据组对应的候选文件偏移量,生成所述候选数据组的所述候选索引。The candidate index of the candidate data group is generated based on the candidate index value of the candidate data group and the candidate file offset corresponding to the candidate data group.
上述候选数据组为全部候选数据组中任意之一,也就是说针对每个候选数据组都可以使用以上方案进行处理,只是不做一一赘述。The above-mentioned candidate data group is any one of all the candidate data groups, that is to say, each candidate data group can be processed by using the above scheme, but it will not be described in detail.
所述基于所述候选数据组中包含的所述候选数据在本地的候选文件中保存的位置,确定所述候选数据组对应的候选文件偏移量,可以包括:The determining the offset of the candidate file corresponding to the candidate data group based on the location where the candidate data contained in the candidate data group is saved in the local candidate file may include:
基于所述候选数据组包含的全部候选数据在本地的候选文件中保存的位置,确定所述候选数据组中所述全部候选数据分别对应的候选文件偏移量。Based on the positions where all the candidate data included in the candidate data group are saved in the local candidate file, the candidate file offsets corresponding to all the candidate data in the candidate data group are determined respectively.
所述基于所述候选数据组的候选索引值,以及所述候选数据组对应的候选文件偏移量,生成所述候选数据组的所述候选索引,可以包括:The generating the candidate index of the candidate data group based on the candidate index value of the candidate data group and the candidate file offset corresponding to the candidate data group may include:
基于所述候选数据组的候选索引值,以及所述候选数据组中全部候选数据分别对应的候选文件偏移量,生成所述候选数据组对应的所述候选索引。The candidate index corresponding to the candidate data group is generated based on the candidate index value of the candidate data group and the candidate file offsets respectively corresponding to all the candidate data in the candidate data group.
也就是说,所述候选数据组所对应的候选索引中可以包含了一组候选索引值,以及该候选索引值所共同对应的全部候选数据的候选文件偏移量。That is to say, the candidate index corresponding to the candidate data group may include a group of candidate index values and candidate file offsets of all the candidate data jointly corresponding to the candidate index values.
可见,通过采用上述方案,就可以以预设时间窗口为单位,对该预设时间窗口内的候选数据进行汇聚,从而一个候选索引可以对应一个或多个候选文件偏移量。如此,可以进一步减小索引占用的存储空间。并且,由于针对一个候选数据组生成对应的候选索引值,因此可以在检索处理中,可以一次性的获取与检索请求匹配的多个候选数据的候选文件偏移量,并获取对应的候选数据作为目标数据,从而进一步提升了检索效率。It can be seen that by adopting the above solution, the candidate data in the preset time window can be aggregated in units of the preset time window, so that one candidate index can correspond to one or more candidate file offsets. In this way, the storage space occupied by the index can be further reduced. In addition, since the corresponding candidate index value is generated for one candidate data group, in the retrieval process, the candidate file offsets of multiple candidate data matching the retrieval request can be obtained at one time, and the corresponding candidate data can be obtained as target data, thereby further improving the retrieval efficiency.
本公开第二方面实施例还提供一种数据检索系统,如图3所示,包括:数据检索装置301,第一设备302;其中,The embodiment of the second aspect of the present disclosure further provides a data retrieval system, as shown in FIG. 3 , including: a data retrieval apparatus 301, and a first device 302; wherein,
所述数据检索装置301,用于接收第一设备发来的检索请求;基于候选索引包含的候选索引值,确定与所述检索请求匹配的目标索引;其中,所述候选索引为基于本地保存的候选数据构建的;基于所述目标索引包含的目标文件偏移量,从本地保存的所述候选数据中获取目标数据;将所述目标数据作为检索结果反馈至所述第一设备;The data retrieval device 301 is configured to receive a retrieval request sent by the first device; based on the candidate index value contained in the candidate index, determine a target index that matches the retrieval request; wherein, the candidate index is based on a locally saved The candidate data is constructed; based on the target file offset contained in the target index, the target data is obtained from the locally saved candidate data; the target data is fed back to the first device as a retrieval result;
所述第一设备302,用于向所述数据检索装置发送检索请求;接收所述数据检索装置反馈的所述检索结果。The first device 302 is configured to send a retrieval request to the data retrieval apparatus; and receive the retrieval result fed back by the data retrieval apparatus.
所述数据检索装置301,可以为一个或多个,示例性的,在所述数据检索系统中可以包含K个数据检索装置(K为大于等于2的整数),所述K个数据检索装置分别设置在K个服务器中;每个数据检索装置具体可以为其所在的服务器中的log-agent(日志代理)服务(或服务代理)。The data retrieval device 301 may be one or more. Exemplarily, the data retrieval system may include K data retrieval devices (K is an integer greater than or equal to 2), and the K data retrieval devices are respectively It is set in K servers; each data retrieval device can specifically serve (or service agent) a log-agent (log agent) in the server where it is located.
所述第一设备可以为用户侧使用的设备,在所述第一设备中可以设置log-query(日志请求)代码或服务;所述第一设备通过该log-query(日志请求)代码或服务分别向所述数据检索装置发送检索请求,并接收所述数据检索装置反馈的所述检索结果。The first device may be a device used by the user side, and a log-query (log request) code or service may be set in the first device; the first device uses the log-query (log request) code or service A retrieval request is respectively sent to the data retrieval device, and the retrieval result fed back by the data retrieval device is received.
所述第一设备302,用于对所述数据检索装置反馈的所述检索结果中包含的所述目标数据进行聚合,得到聚合后的检索结果。The first device 302 is configured to aggregate the target data included in the retrieval result fed back by the data retrieval apparatus to obtain an aggregated retrieval result.
具体的,所述第一设备通过该log-query(日志请求)代码或服务接收所述数据检索装置反馈的所述检索结果中,可以包含一个或多个目标数据,因此在所述第一设备通过该log-query(日志请求)代码或服务对接收到的所述目标数据(即目标日志)进行聚合,最终得到所述聚合后的检索结果。比如所述第一设备通过该log-query(日志请求)代码或服务从数据检索装置总共获取到1000条目标数据,对1000条目标数据进行聚合得到100条,将这100条目标数据作为最终聚合后的检索结果。Specifically, the first device receives the retrieval result fed back by the data retrieval device through the log-query (log request) code or service, and may include one or more target data. Therefore, in the first device The received target data (that is, the target log) is aggregated through the log-query (log request) code or service, and finally the aggregated retrieval result is obtained. For example, the first device obtains a total of 1,000 pieces of target data from the data retrieval device through the log-query (log request) code or service, aggregates the 1,000 pieces of target data to obtain 100 pieces, and uses the 100 pieces of target data as the final aggregation subsequent search results.
其中,所述第一设备通过该log-query(日志请求)代码或服务具体可以是基于数据检索装置和/或IP(互联网协议,Internet Protocol)地址进行聚合。Specifically, the first device may perform aggregation based on the data retrieval device and/or IP (Internet Protocol, Internet Protocol) address through the log-query (log request) code or service.
所述数据检索装置301,用于执行以下至少之一:The data retrieval device 301 is configured to execute at least one of the following:
在所述检索请求中包含待检索数据相关标识的情况下,基于所述候选索引中的候选数据相关标识,确定与所述待检索数据相关标识匹配的目标索引;In the case that the retrieval request includes the relevant identifier of the data to be retrieved, based on the relevant identifier of the candidate data in the candidate index, determine a target index that matches the relevant identifier of the data to be retrieved;
在所述检索请求中包含待检索对象相关标识的情况下,基于所述候选索引中的对象相关标识,确定与所述待检索对象相关标识匹配的目标索引;In the case that the retrieval request includes the relevant identifier of the object to be retrieved, based on the relevant identifier of the object in the candidate index, determine the target index that matches the relevant identifier of the object to be retrieved;
在所述检索请求中包含待检索内容关键字的情况下,基于所述候选索引中的候选数据内容关键字,确定与所述待检索内容关键字匹配的目标索引;In the case where the retrieval request includes the content keyword to be retrieved, based on the candidate data content keyword in the candidate index, determine a target index that matches the to-be-retrieved content keyword;
在所述检索请求中包含待检索时间范围的情况下,基于所述候选索引中的候选窗口终止时间戳,确定在所述待检索时间范围内的目标索引。When the retrieval request includes a to-be-retrieved time range, a target index within the to-be-retrieved time range is determined based on the candidate window termination timestamp in the candidate index.
所述数据检索装置301,用于基于所述目标索引包含的目标文件偏移量,确定所述目标数据在本地的目标文件中保存的位置;基于所述目标数据在所述目标文件中保存的位置,从所述目标文件保存的所述候选数据中,获取所述目标数据。The data retrieval device 301 is configured to determine the location where the target data is saved in the local target file based on the target file offset included in the target index; based on the target data saved in the target file; position, and obtain the target data from the candidate data stored in the target file.
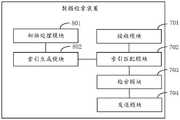
所述数据检索装置301,用于基于本地保存的所述候选数据,生成候选索引值;基于所述候选数据对应的候选文件偏移量以及所述候选索引值,生成所述候选索引。The data retrieval device 301 is configured to generate a candidate index value based on the candidate data stored locally; and generate the candidate index based on the candidate file offset corresponding to the candidate data and the candidate index value.
所述数据检索装置301,用于从本地保存的所述候选数据中,筛选得到关键信息;将所述关键信息作为所述候选数据的候选索引值;基于所述候选数据在本地的候选文件中保存的位置,确定所述候选数据的候选文件偏移量;基于所述候选文件偏移量以及所述候选索引值,生成所述候选数据的所述候选索引。The data retrieval device 301 is configured to obtain key information from the candidate data stored locally; use the key information as a candidate index value of the candidate data; based on the candidate data in the local candidate file The storage location is to determine the candidate file offset of the candidate data; based on the candidate file offset and the candidate index value, the candidate index of the candidate data is generated.
所述数据检索装置301,用于从本地保存的所述候选数据中,筛选得到关键信息;将预设时间窗口内具备相同关键信息的所述候选数据进行汇聚,得到候选数据组;基于所述相同关键信息以及所述预设时间窗口的窗口终止时间戳,确定所述候选数据组的候选索引值。The data retrieval device 301 is configured to filter and obtain key information from the candidate data stored locally; gather the candidate data with the same key information within a preset time window to obtain a candidate data group; based on the The same key information and the window termination timestamp of the preset time window are used to determine the candidate index value of the candidate data group.
所述数据检索装置301,用于基于所述候选数据组中包含的所述候选数据在本地的候选文件中保存的位置,确定所述候选数据组对应的候选文件偏移量;基于所述候选数据组的候选索引值,以及所述候选数据组对应的候选文件偏移量,生成所述候选数据组的所述候选索引。The data retrieval device 301 is configured to determine the candidate file offset corresponding to the candidate data group based on the location where the candidate data contained in the candidate data group is saved in the local candidate file; based on the candidate data group The candidate index value of the data group and the candidate file offset corresponding to the candidate data group are used to generate the candidate index of the candidate data group.
在相关技术中,ELK(Elasticsearch(弹性搜索),Logstash(日志存放),Kibana)集群架构如图4所示,其中:ELK集群中的应用服务集群中的每个应用服务器通过其FileBeat(文件日志采集器)收集日志;LogStash服务集群(可以包含图4中多个“LogStash”,其中每个LogStash为一个LogStash(日志存放)服务器)进行日志的过滤并转发给ES服务集群(可以包含图4中的多个ES,其中每个ES可以为一个ES服务器);ES服务集群是ELK集群架构的核心,ES服务集群接收Logstash服务集群发送过来日志的进行存储并建立索引,可供kibana进行搜索获取数据。图4中的kibana是一个使用开源协议,基于浏览器的Elasticsearch分析和搜索仪表板,是一个web项目,部署后可通过浏览器进行访问。所述ES服务集群具有收集日志、建立索引及接受检索查询的功能。在实际应用中,每分钟或每秒钟产生的日志条数很多,所述ES服务集群不断的从日志服务器中接收到新的日志,产生的网络开销较大,且所述ES服务集群针对每条日志产生一个索引,需要存储的索引数据量较大;由于网络开销和索引数据量大的存在,拖延了索引建立的时间,如此造成索引建立的效率低下的问题,进而导致检索效率较低。In related technologies, the ELK (Elasticsearch (elastic search), Logstash (log storage), Kibana) cluster architecture is shown in Figure 4, where: each application server in the application service cluster in the ELK cluster passes its FileBeat (file log collector) to collect logs; the LogStash service cluster (which can include multiple "LogStash" in Figure 4, where each LogStash is a LogStash (log storage) server) filters the logs and forwards them to the ES service cluster (which can be included in Figure 4). multiple ESs, each of which can be an ES server); ES service cluster is the core of ELK cluster architecture, ES service cluster receives logs sent by Logstash service cluster for storage and indexing, which can be used for kibana to search and obtain data . Kibana in Figure 4 is a browser-based Elasticsearch analytics and search dashboard using an open source protocol. It is a web project that can be accessed through a browser after deployment. The ES service cluster has the functions of collecting logs, building indexes and accepting retrieval queries. In practical applications, a large number of logs are generated per minute or per second. The ES service cluster continuously receives new logs from the log server, which incurs a large network overhead. Logs generate an index, which requires a large amount of index data to be stored; due to the existence of network overhead and large amount of index data, the time for index establishment is delayed, which leads to the problem of low index establishment efficiency, which in turn leads to low retrieval efficiency.
最后,结合图5和图6,以所述数据检索装置具体为分别设置在K个服务器中的log-agent(日志代理),以所述K个服务器为log(日志)服务器,以第一设备生成检索请求并获取检索结果的代码或服务为log-query,以候选数据为候选日志,目标数据为目标日志为例,对本实施例提供的系统中的处理进行说明:Finally, with reference to FIG. 5 and FIG. 6 , the data retrieval device is specifically a log-agent (log agent) set in K servers, the K servers are log (log) servers, and the first device The code or service that generates the retrieval request and obtains the retrieval result is log-query. Taking the candidate data as the candidate log and the target data as the target log as an example, the processing in the system provided by this embodiment is described:
参见图5,针对K个服务器中任意之一为例进行说明,图5中将K个服务器中任意之一表示为一个log(日志)服务器;图5中的log-agent即log(日志)服务器中设置的数据检索装置。Referring to FIG. 5 , the description is given by taking any one of the K servers as an example. In FIG. 5 , any one of the K servers is represented as a log (log) server; the log-agent in FIG. 5 is the log (log) server. The data retrieval device set in .
所述log-agent(即所述数据检索装置)基于在log服务器本地保存的候选日志,确定所述候选日志的候选索引值以及候选文件偏移量。将该候选索引值以及该候选文件偏移量作为所述候选日志的候选索引。The log-agent (that is, the data retrieval device) determines the candidate index value and the candidate file offset of the candidate log based on the candidate log stored locally on the log server. The candidate index value and the candidate file offset are used as candidate indexes of the candidate log.
比如,以用户A在某个时间B查询天气信息为例,利用正则表达式或筛选条件将候选日志中的查询请求ID(即log-ID)、用户ID(比如用户A)以及内容关键词(比如keyword为天气信息)等关键信息从所述候选日志中筛选出作为上述候选索引值;基于上述候选索引值进行候选索引的建立。For example, taking user A querying weather information at a certain time B as an example, the query request ID (ie log-ID), user ID (such as user A) and content keywords ( For example, key information such as keyword is weather information) is selected from the candidate log as the candidate index value; the candidate index is established based on the candidate index value.
在上述候选索引的建立过程中,由于是log服务器本地存储的候选日志,所以log-agent(即所述数据检索装置)可以不保存原始日志,只保存候选索引值(比如可以是8byte)和候选文件偏移量((比如可以是8byte)作为所述候选日志的所述候选索引。这样,可以极大的降低存储成本。In the process of establishing the above candidate index, since it is a candidate log stored locally by the log server, the log-agent (that is, the data retrieval device) may not save the original log, but only the candidate index value (for example, it may be 8 bytes) and the candidate index value. The file offset (for example, it can be 8 bytes) is used as the candidate index of the candidate log. In this way, the storage cost can be greatly reduced.
所述log-agent(即所述数据检索装置)会基于一个预设时间窗口(比如可以称为汇聚窗口)对具备相同关键信息的候选日志进行汇聚,得到候选日志组;基于所述相同关键信息以及所述预设时间窗口的窗口终止时间戳,确定所述候选日志组的候选索引值。其中,所述候选日志组的所述候选文件偏移量可以指的是该候选日志组中包含的全部候选日志所分别对应的起始和/或终止偏移量。进而,基于所述候选日志组的候选索引值,以及所述候选日志组对应的候选文件偏移量,生成候选日志组的所述候选索引。其中,所述候选索引可以为(Key-Value)形式的,其中key可以包括所述相同关键信息以及窗口终止时间戳,value可以为上述多个候选日志所在的候选日志文件的唯一标识符(比如表示为inode),以及多个候选日志在所述候选日志文件中的起始/结束偏移量。The log-agent (that is, the data retrieval device) will aggregate candidate logs with the same key information based on a preset time window (for example, it may be called a convergence window) to obtain a candidate log group; based on the same key information and the window termination timestamp of the preset time window to determine the candidate index value of the candidate log group. Wherein, the candidate file offset of the candidate log group may refer to the start and/or end offsets respectively corresponding to all the candidate logs included in the candidate log group. Further, the candidate index of the candidate log group is generated based on the candidate index value of the candidate log group and the candidate file offset corresponding to the candidate log group. The candidate index may be in the form of (Key-Value), where the key may include the same key information and the window termination timestamp, and the value may be the unique identifier of the candidate log file where the above multiple candidate logs are located (such as denoted as inode), and the start/end offsets of multiple candidate logs in the candidate log file.
比如,参见图5,所述log-agent(即所述数据检索装置)首先执行了收集的处理,具体为:对候选日志进行筛选,得到候选日志的候选索引值;所述log-agent(即所述数据检索装置)再执行索引(即生成索引)处理,具体为:基于一个预设时间窗口将具备相同关键信息的候选日志进行汇聚得到候选日志组,基于该相同关键信息以及预设时间窗口的窗口终止时间戳,生成该候选日志组的候选索引值(比如图5中的idx1),该候选日志组中每个候选日志对应了一个候选文件偏移量(比如可以表示为offset),最终构建得到该候选日志组的候选索引。其中,所述候选索引如图5中示意出的,一个idx1分别对应了offset1、offset2~offset1+N个候选文件偏移量。For example, referring to FIG. 5, the log-agent (that is, the data retrieval device) first performs the collection process, specifically: screening candidate logs to obtain candidate index values of the candidate logs; the log-agent (that is, the data retrieval device) The data retrieval device) then performs indexing (ie, generating an index) processing, specifically: gathering candidate logs with the same key information based on a preset time window to obtain a candidate log group, and based on the same key information and the preset time window , generate the candidate index value of the candidate log group (such as idx1 in Figure 5), and each candidate log in the candidate log group corresponds to a candidate file offset (for example, it can be expressed as offset), and finally Build a candidate index to obtain the candidate log group. The candidate index is shown in FIG. 5 , and one idx1 corresponds to offset1, offset2˜offset1+N candidate file offsets, respectively.
所述log-agent(即所述数据检索装置)存储所述候选索引时,可以对当前存储的候选索引按照小时进行拆分,并按照预设时长进行清理(或查询)。When the log-agent (that is, the data retrieval device) stores the candidate index, the currently stored candidate index may be split by hour, and cleaned (or queried) according to a preset duration.
上述候选索引的生成、写入以及读取等处理,可以基于图5所示的kv存储引擎实现。图5所示的kv存储引擎中每个候选索引可以对应leveldb(即kv数据库)的一个db(database,数据库)。The processes of generating, writing, and reading the above candidate indexes can be implemented based on the kv storage engine shown in FIG. 5 . Each candidate index in the kv storage engine shown in FIG. 5 may correspond to a db (database, database) of the leveldb (ie, the kv database).
进一步地,所述log-agent(即所述数据检索装置)进行检索处理,即图5中所示的检索部分,具体的:所述log-agent(即所述数据检索装置)接收到检索请求之后,可以从kv存储引擎中读取该检索请求匹配的目标日志作为检索结果。Further, the log-agent (that is, the data retrieval device) performs retrieval processing, that is, the retrieval part shown in FIG. 5 , specifically: the log-agent (that is, the data retrieval device) receives a retrieval request Afterwards, the target log matching the retrieval request can be read from the kv storage engine as the retrieval result.
结合图6对第一设备的代码或服务(即图6中的log-query)向多个log-agent(即所述数据检索装置)发起检索请求并获取检索结果的处理,进行示例性说明,假设K=2,具体的:With reference to FIG. 6, an exemplary description is given of the processing of initiating retrieval requests to multiple log-agents (that is, the data retrieval apparatus) and obtaining retrieval results from the code or service of the first device (ie, the log-query in FIG. 6), Assuming K=2, specifically:
所述第一设备的代码或服务(即图6中的log-query)同时向2个log服务器(图6中的log)中的log-agent(即所述数据检索装置)发送检索请求;The code or service of the first device (that is, the log-query in FIG. 6 ) simultaneously sends a retrieval request to the log-agent (that is, the data retrieval device) in the two log servers (the log in FIG. 6 );
由2个log服务器中的log-agent(即所述数据检索装置)基于所述检索请求从各自所在的log服务器获取目标日志,将所述目标日志作为将检索结果返回给所述第一设备的代码或服务(即图6中的log-query);The log-agent (that is, the data retrieval device) in the two log servers obtains the target log from the respective log server based on the retrieval request, and uses the target log as the target log for returning the retrieval result to the first device. code or service (i.e. log-query in Figure 6);
所述第一设备的代码或服务(即图6中的log-query)接收到2个log服务器中的log-agent(即所述数据检索装置)发来的检索结果之后,根据模块和/或IP地址进行聚合,得到聚合后的检索结果,并最终反馈给调用方。After the code or service of the first device (that is, the log-query in FIG. 6 ) receives the retrieval results sent by the log-agents (that is, the data retrieval device) in the two log servers, according to the module and/or The IP addresses are aggregated to obtain the aggregated retrieval results, which are finally fed back to the caller.
本公开第三方面实施例提供一种数据检索装置,如图7所示,包括:An embodiment of a third aspect of the present disclosure provides a data retrieval apparatus, as shown in FIG. 7 , including:
接收模块701,用于接收第一设备发来的检索请求;A receiving
索引匹配模块702,用于基于候选索引包含的候选索引值,确定与所述检索请求匹配的目标索引;其中,所述候选索引为基于本地保存的候选数据构建的;An
检索模块703,用于基于所述目标索引包含的目标文件偏移量,从本地保存的所述候选数据中获取目标数据;A
发送模块704,用于将所述目标数据作为检索结果反馈至所述第一设备。The sending
所述索引匹配模块,用于执行以下至少之一:The index matching module is configured to perform at least one of the following:
在所述检索请求中包含待检索数据相关标识的情况下,基于所述候选索引中的候选数据相关标识,确定与所述待检索数据相关标识匹配的目标索引;In the case that the retrieval request includes the relevant identifier of the data to be retrieved, based on the relevant identifier of the candidate data in the candidate index, determine a target index that matches the relevant identifier of the data to be retrieved;
在所述检索请求中包含待检索对象相关标识的情况下,基于所述候选索引中的对象相关标识,确定与所述待检索对象相关标识匹配的目标索引;In the case that the retrieval request includes the relevant identifier of the object to be retrieved, based on the relevant identifier of the object in the candidate index, determine the target index that matches the relevant identifier of the object to be retrieved;
在所述检索请求中包含待检索内容关键字的情况下,基于所述候选索引中的候选数据内容关键字,确定与所述待检索内容关键字匹配的目标索引;In the case where the retrieval request includes the content keyword to be retrieved, based on the candidate data content keyword in the candidate index, determine a target index that matches the to-be-retrieved content keyword;
在所述检索请求中包含待检索时间范围的情况下,基于所述候选索引中的候选窗口终止时间戳,确定在所述待检索时间范围内的目标索引。When the retrieval request includes a to-be-retrieved time range, a target index within the to-be-retrieved time range is determined based on the candidate window termination timestamp in the candidate index.
所述检索模块,用于基于所述目标索引包含的目标文件偏移量,确定所述目标数据在本地的目标文件中保存的位置;基于所述目标数据在所述目标文件中保存的位置,从所述目标文件保存的所述候选数据中,获取所述目标数据。The retrieval module is configured to determine the position where the target data is saved in the local target file based on the target file offset included in the target index; based on the position where the target data is saved in the target file, Obtain the target data from the candidate data stored in the target file.
如图8所示,所述装置还包括:As shown in Figure 8, the device further includes:
初始处理模块801,用于基于本地保存的所述候选数据,生成所述候选索引值;an
索引生成模块802,用于基于所述候选数据对应的候选文件偏移量以及所述候选索引值,生成所述候选索引。The
所述初始处理模块801,用于从本地保存的所述候选数据中,筛选得到关键信息;将所述关键信息作为所述候选数据的候选索引值。The
所述索引生成模块802,用于基于所述候选数据在本地的候选文件中保存的位置,确定所述候选数据的候选文件偏移量;基于所述候选文件偏移量以及所述候选索引值,生成所述候选数据的所述候选索引。The
所述初始处理模块801,用于从本地保存的所述候选数据中,筛选得到关键信息;将预设时间窗口内具备相同关键信息的所述候选数据进行汇聚,得到候选数据组;基于所述相同关键信息以及所述预设时间窗口的窗口终止时间戳,确定所述候选数据组的候选索引值。The
所述索引生成模块802,用于基于所述候选数据组中包含的所述候选数据在本地的候选文件中保存的位置,确定所述候选数据组对应的候选文件偏移量;基于所述候选数据组的候选索引值,以及所述候选数据组对应的候选文件偏移量,生成所述候选数据组的所述候选索引。The
本公开的技术方案中,所涉及的用户个人信息的获取,存储和应用等,均符合相关法律法规的规定,且不违背公序良俗。In the technical solution of the present disclosure, the acquisition, storage and application of the user's personal information involved are all in compliance with the provisions of relevant laws and regulations, and do not violate public order and good customs.
根据本公开的实施例,本公开还提供了一种电子设备、一种可读存储介质和一种计算机程序产品。According to embodiments of the present disclosure, the present disclosure also provides an electronic device, a readable storage medium, and a computer program product.
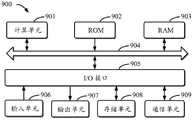
图9示出了可以用来实施本公开的实施例的示例电子设备900的示意性框图。电子设备旨在表示各种形式的数字计算机,诸如,膝上型计算机、台式计算机、工作台、个人数字助理、服务器、刀片式服务器、大型计算机、和其它适合的计算机。电子设备还可以表示各种形式的移动装置,诸如,个人数字处理、蜂窝电话、智能电话、可穿戴设备和其它类似的计算装置。本文所示的部件、它们的连接和关系、以及它们的功能仅仅作为示例,并且不意在限制本文中描述的和/或者要求的本公开的实现。FIG. 9 shows a schematic block diagram of an example
如图9所示,电子设备900包括计算单元901,其可以根据存储在只读存储器(ROM)902中的计算机程序或者从存储单元908加载到随机访问存储器(RAM)903中的计算机程序,来执行各种适当的动作和处理。在RAM 903中,还可存储电子设备900操作所需的各种程序和数据。计算单元901、ROM 902以及RAM 903通过总线904彼此相连。输入/输出(I/O)接口905也连接至总线904。As shown in FIG. 9 , the
电子设备900中的多个部件连接至I/O接口905,包括:输入单元906,例如键盘、鼠标等;输出单元907,例如各种类型的显示器、扬声器等;存储单元908,例如磁盘、光盘等;以及通信单元909,例如网卡、调制解调器、无线通信收发机等。通信单元909允许电子设备900通过诸如因特网的计算机网络和/或各种电信网络与其他设备交换信息/数据。Various components in the
计算单元901可以是各种具有处理和计算能力的通用和/或专用处理组件。计算单元901的一些示例包括但不限于中央处理单元(CPU)、图形处理单元(GPU)、各种专用的人工智能(AI)计算芯片、各种运行机器学习模型算法的计算单元、数字信号处理器(DSP)、以及任何适当的处理器、控制器、微控制器等。计算单元901执行上文所描述的各个方法和处理。例如,在一些实施例中,上文所描述的各个方法可被实现为计算机软件程序,其被有形地包含于机器可读介质,例如存储单元908。在一些实施例中,计算机程序的部分或者全部可以经由ROM 902和/或通信单元909而被载入和/或安装到电子设备900上。当计算机程序加载到RAM903并由计算单元901执行时,可以执行上文所描述的各个方法的一个或多个步骤。备选地,在其他实施例中,计算单元901可以通过其他任何适当的方式(例如,借助于固件)而被配置为执行上文所描述的各个方法。
本文中以上描述的系统和技术的各种实施方式可以在数字电子电路系统、集成电路系统、场可编程门阵列(FPGA)、专用集成电路(ASIC)、专用标准产品(ASSP)、芯片上系统的系统(SOC)、负载可编程逻辑设备(CPLD)、计算机硬件、固件、软件、和/或它们的组合中实现。这些各种实施方式可以包括:实施在一个或者多个计算机程序中,该一个或者多个计算机程序可在包括至少一个可编程处理器的可编程系统上执行和/或解释,该可编程处理器可以是专用或者通用可编程处理器,可以从存储系统、至少一个输入装置、和至少一个输出装置接收数据和指令,并且将数据和指令传输至该存储系统、该至少一个输入装置、和该至少一个输出装置。Various implementations of the systems and techniques described herein above may be implemented in digital electronic circuitry, integrated circuit systems, field programmable gate arrays (FPGAs), application specific integrated circuits (ASICs), application specific standard products (ASSPs), systems on chips system (SOC), load programmable logic device (CPLD), computer hardware, firmware, software, and/or combinations thereof. These various embodiments may include being implemented in one or more computer programs executable and/or interpretable on a programmable system including at least one programmable processor that The processor, which may be a special purpose or general-purpose programmable processor, may receive data and instructions from a storage system, at least one input device, and at least one output device, and transmit data and instructions to the storage system, the at least one input device, and the at least one output device an output device.
用于实施本公开的方法的程序代码可以采用一个或多个编程语言的任何组合来编写。这些程序代码可以提供给通用计算机、专用计算机或其他可编程数据处理装置的处理器或控制器,使得程序代码当由处理器或控制器执行时使流程图和/或框图中所规定的功能/操作被实施。程序代码可以完全在机器上执行、部分地在机器上执行,作为独立软件包部分地在机器上执行且部分地在远程机器上执行或完全在远程机器或服务器上执行。Program code for implementing the methods of the present disclosure may be written in any combination of one or more programming languages. These program codes may be provided to a processor or controller of a general purpose computer, special purpose computer or other programmable data processing apparatus, such that the program code, when executed by the processor or controller, performs the functions/functions specified in the flowcharts and/or block diagrams. Action is implemented. The program code may execute entirely on the machine, partly on the machine, partly on the machine and partly on a remote machine as a stand-alone software package or entirely on the remote machine or server.
在本公开的上下文中,机器可读介质可以是有形的介质,其可以包含或存储以供指令执行系统、装置或设备使用或与指令执行系统、装置或设备结合地使用的程序。机器可读介质可以是机器可读信号介质或机器可读储存介质。机器可读介质可以包括但不限于电子的、磁性的、光学的、电磁的、红外的、或半导体系统、装置或设备,或者上述内容的任何合适组合。机器可读存储介质的更具体示例会包括基于一个或多个线的电气连接、便携式计算机盘、硬盘、随机存取存储器(RAM)、只读存储器(ROM)、可擦除可编程只读存储器(EPROM或快闪存储器)、光纤、便捷式紧凑盘只读存储器(CD-ROM)、光学储存设备、磁储存设备、或上述内容的任何合适组合。In the context of the present disclosure, a machine-readable medium may be a tangible medium that may contain or store a program for use by or in connection with the instruction execution system, apparatus or device. The machine-readable medium may be a machine-readable signal medium or a machine-readable storage medium. Machine-readable media may include, but are not limited to, electronic, magnetic, optical, electromagnetic, infrared, or semiconductor systems, devices, or devices, or any suitable combination of the foregoing. More specific examples of machine-readable storage media would include one or more wire-based electrical connections, portable computer disks, hard disks, random access memory (RAM), read only memory (ROM), erasable programmable read only memory (EPROM or flash memory), fiber optics, compact disk read only memory (CD-ROM), optical storage, magnetic storage, or any suitable combination of the foregoing.
为了提供与用户的交互,可以在计算机上实施此处描述的系统和技术,该计算机具有:用于向用户显示信息的显示装置(例如,CRT(阴极射线管)或者LCD(液晶显示器)监视器);以及键盘和指向装置(例如,鼠标或者轨迹球),用户可以通过该键盘和该指向装置来将输入提供给计算机。其它种类的装置还可以用于提供与用户的交互;例如,提供给用户的反馈可以是任何形式的传感反馈(例如,视觉反馈、听觉反馈、或者触觉反馈);并且可以用任何形式(包括声输入、语音输入、或者触觉输入)来接收来自用户的输入。To provide interaction with a user, the systems and techniques described herein may be implemented on a computer having a display device (eg, a CRT (cathode ray tube) or LCD (liquid crystal display) monitor) for displaying information to the user ); and a keyboard and pointing device (eg, a mouse or trackball) through which a user can provide input to the computer. Other kinds of devices can also be used to provide interaction with the user; for example, the feedback provided to the user can be any form of sensory feedback (eg, visual feedback, auditory feedback, or tactile feedback); and can be in any form (including acoustic input, voice input, or tactile input) to receive input from the user.
可以将此处描述的系统和技术实施在包括后台部件的计算系统(例如,作为数据服务器)、或者包括中间件部件的计算系统(例如,应用服务器)、或者包括前端部件的计算系统(例如,具有图形用户界面或者网络浏览器的用户计算机,用户可以通过该图形用户界面或者该网络浏览器来与此处描述的系统和技术的实施方式交互)、或者包括这种后台部件、中间件部件、或者前端部件的任何组合的计算系统中。可以通过任何形式或者介质的数字数据通信(例如,通信网络)来将系统的部件相互连接。通信网络的示例包括:局域网(LAN)、广域网(WAN)和互联网。The systems and techniques described herein may be implemented on a computing system that includes back-end components (eg, as a data server), or a computing system that includes middleware components (eg, an application server), or a computing system that includes front-end components (eg, a user's computer having a graphical user interface or web browser through which a user may interact with implementations of the systems and techniques described herein), or including such backend components, middleware components, Or any combination of front-end components in a computing system. The components of the system may be interconnected by any form or medium of digital data communication (eg, a communication network). Examples of communication networks include: Local Area Networks (LANs), Wide Area Networks (WANs), and the Internet.
计算机系统可以包括客户端和服务器。客户端和服务器一般远离彼此并且通常通过通信网络进行交互。通过在相应的计算机上运行并且彼此具有客户端-服务器关系的计算机程序来产生客户端和服务器的关系。服务器可以是云服务器,也可以为分布式系统的服务器,或者是结合了区块链的服务器。A computer system can include clients and servers. Clients and servers are generally remote from each other and usually interact through a communication network. The relationship of client and server arises by computer programs running on the respective computers and having a client-server relationship to each other. The server can be a cloud server, a distributed system server, or a server combined with blockchain.
应该理解,可以使用上面所示的各种形式的流程,重新排序、增加或删除步骤。例如,本公开中记载的各步骤可以并行地执行也可以顺序地执行也可以不同的次序执行,只要能够实现本公开公开的技术方案所期望的结果,本文在此不进行限制。It should be understood that steps may be reordered, added or deleted using the various forms of flow shown above. For example, the steps described in the present disclosure can be executed in parallel, sequentially, or in different orders, as long as the desired results of the technical solutions disclosed in the present disclosure can be achieved, no limitation is imposed herein.
上述具体实施方式,并不构成对本公开保护范围的限制。本领域技术人员应该明白的是,根据设计要求和其他因素,可以进行各种修改、组合、子组合和替代。任何在本公开的精神和原则之内所作的修改、等同替换和改进等,均应包含在本公开保护范围之内。The above-mentioned specific embodiments do not constitute a limitation on the protection scope of the present disclosure. It should be understood by those skilled in the art that various modifications, combinations, sub-combinations and substitutions may occur depending on design requirements and other factors. Any modifications, equivalent replacements, and improvements made within the spirit and principles of the present disclosure should be included within the protection scope of the present disclosure.
Claims (25)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210053020.XACN114398520A (en) | 2022-01-18 | 2022-01-18 | Data retrieval method, system, device, electronic device and storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210053020.XACN114398520A (en) | 2022-01-18 | 2022-01-18 | Data retrieval method, system, device, electronic device and storage medium |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN114398520Atrue CN114398520A (en) | 2022-04-26 |
Family
ID=81231094
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210053020.XAPendingCN114398520A (en) | 2022-01-18 | 2022-01-18 | Data retrieval method, system, device, electronic device and storage medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114398520A (en) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115309739A (en)* | 2022-06-28 | 2022-11-08 | 北京娜迦信息科技发展有限公司 | Vehicle-mounted data retrieval method, device, electronic equipment, medium and product |
| CN117130998A (en)* | 2023-08-25 | 2023-11-28 | 北京火山引擎科技有限公司 | Log information processing method, device, equipment and storage medium |
| CN117149777A (en)* | 2023-10-27 | 2023-12-01 | 腾讯科技(深圳)有限公司 | Data query method, device, equipment and storage medium |
| CN119988367A (en)* | 2025-04-14 | 2025-05-13 | 巽风科技(贵州)有限公司 | User data extraction method, device, electronic device and storage medium |
Citations (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| AU2004200013A1 (en)* | 2003-01-14 | 2004-07-29 | Canon Kabushiki Kaisha | Process and format for reliable storage of data |
| JP2009134467A (en)* | 2007-11-29 | 2009-06-18 | Ricoh Co Ltd | SEARCH DEVICE, SEARCH METHOD, AND SEARCH PROGRAM |
| CN102201007A (en)* | 2011-06-14 | 2011-09-28 | 悠易互通(北京)广告有限公司 | Large-scale data retrieving system |
| CN103037203A (en)* | 2012-12-11 | 2013-04-10 | 浙江宇视科技有限公司 | Method and device for index recovery based on block storage |
| CN103309890A (en)* | 2012-03-15 | 2013-09-18 | 华北计算机系统工程研究所 | Technology for merging Linux file system and real-time database index |
| WO2015030645A1 (en)* | 2013-08-29 | 2015-03-05 | Telefonaktiebolaget L M Ericsson (Publ) | Methods, computer program, computer program product and indexing systems for indexing or updating index |
| CN106649627A (en)* | 2016-12-06 | 2017-05-10 | 杭州迪普科技股份有限公司 | Log searching method and device |
| CN111143422A (en)* | 2019-12-31 | 2020-05-12 | 医渡云(北京)技术有限公司 | Data retrieval method, data retrieval device, storage medium, and electronic device |
| WO2021073241A1 (en)* | 2019-10-18 | 2021-04-22 | 蚂蚁区块链科技(上海)有限公司 | Disk storage-based data reading method and device, and apparatus |
- 2022
- 2022-01-18CNCN202210053020.XApatent/CN114398520A/enactivePending
Patent Citations (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| AU2004200013A1 (en)* | 2003-01-14 | 2004-07-29 | Canon Kabushiki Kaisha | Process and format for reliable storage of data |
| JP2009134467A (en)* | 2007-11-29 | 2009-06-18 | Ricoh Co Ltd | SEARCH DEVICE, SEARCH METHOD, AND SEARCH PROGRAM |
| CN102201007A (en)* | 2011-06-14 | 2011-09-28 | 悠易互通(北京)广告有限公司 | Large-scale data retrieving system |
| CN103309890A (en)* | 2012-03-15 | 2013-09-18 | 华北计算机系统工程研究所 | Technology for merging Linux file system and real-time database index |
| CN103037203A (en)* | 2012-12-11 | 2013-04-10 | 浙江宇视科技有限公司 | Method and device for index recovery based on block storage |
| WO2015030645A1 (en)* | 2013-08-29 | 2015-03-05 | Telefonaktiebolaget L M Ericsson (Publ) | Methods, computer program, computer program product and indexing systems for indexing or updating index |
| CN106649627A (en)* | 2016-12-06 | 2017-05-10 | 杭州迪普科技股份有限公司 | Log searching method and device |
| WO2021073241A1 (en)* | 2019-10-18 | 2021-04-22 | 蚂蚁区块链科技(上海)有限公司 | Disk storage-based data reading method and device, and apparatus |
| CN111143422A (en)* | 2019-12-31 | 2020-05-12 | 医渡云(北京)技术有限公司 | Data retrieval method, data retrieval device, storage medium, and electronic device |
Non-Patent Citations (1)
| Title |
|---|
| 万冬娥;: "基于云计算的大数据信息检索技术", 电子技术与软件工程, no. 03, 31 January 2018 (2018-01-31)* |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115309739A (en)* | 2022-06-28 | 2022-11-08 | 北京娜迦信息科技发展有限公司 | Vehicle-mounted data retrieval method, device, electronic equipment, medium and product |
| CN117130998A (en)* | 2023-08-25 | 2023-11-28 | 北京火山引擎科技有限公司 | Log information processing method, device, equipment and storage medium |
| CN117149777A (en)* | 2023-10-27 | 2023-12-01 | 腾讯科技(深圳)有限公司 | Data query method, device, equipment and storage medium |
| CN117149777B (en)* | 2023-10-27 | 2024-02-06 | 腾讯科技(深圳)有限公司 | Data query method, device, equipment and storage medium |
| CN119988367A (en)* | 2025-04-14 | 2025-05-13 | 巽风科技(贵州)有限公司 | User data extraction method, device, electronic device and storage medium |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN113342564B (en) | Log auditing method and device, electronic equipment and medium | |
| US11775501B2 (en) | Trace and span sampling and analysis for instrumented software | |
| CN114398520A (en) | Data retrieval method, system, device, electronic device and storage medium | |
| CN112269789B (en) | Method and device for storing data, and method and device for reading data | |
| CN103620601B (en) | Merge tables during map-reduce | |
| CN109034993A (en) | Account checking method, equipment, system and computer readable storage medium | |
| CN111639078A (en) | Data query method and device, electronic equipment and readable storage medium | |
| CN111625552B (en) | Data collection method, device, equipment and readable storage medium | |
| CN110532347A (en) | A kind of daily record data processing method, device, equipment and storage medium | |
| CN113722600A (en) | Data query method, device, equipment and product applied to big data | |
| CN113312539B (en) | A method, device, equipment and medium for providing retrieval services | |
| CN113568938A (en) | Data stream processing method and device, electronic equipment and storage medium | |
| CN112860811A (en) | Method and device for determining data blood relationship, electronic equipment and storage medium | |
| CN113886434A (en) | Database cluster-based query and storage method, device and equipment | |
| CN110727727A (en) | Statistical method and device for a database | |
| CN112395333B (en) | Method, device, electronic equipment and storage medium for checking data abnormality | |
| CN110515979B (en) | Data query method, device, device and storage medium | |
| CN112528067A (en) | Graph database storage method, graph database reading method, graph database storage device, graph database reading device and graph database reading equipment | |
| US11836146B1 (en) | Storing indexed fields per source type as metadata at the bucket level to facilitate search-time field learning | |
| WO2021027331A1 (en) | Graph data-based full relationship calculation method and apparatus, device, and storage medium | |
| CN115168440A (en) | Data reading and writing method, distributed storage system, device, equipment and storage medium | |
| CN114491253B (en) | Method and device for processing observation information, electronic equipment and storage medium | |
| CN111427910A (en) | Data processing method and device | |
| CN114449031B (en) | Information acquisition method, device, equipment and storage medium | |
| CN116955856A (en) | Information display method, device, electronic equipment and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |