CN114333893A - Voice processing method and device, electronic equipment and readable medium - Google Patents
Voice processing method and device, electronic equipment and readable mediumDownload PDFInfo
- Publication number
- CN114333893A CN114333893ACN202111238478.4ACN202111238478ACN114333893ACN 114333893 ACN114333893 ACN 114333893ACN 202111238478 ACN202111238478 ACN 202111238478ACN 114333893 ACN114333893 ACN 114333893A
- Authority
- CN
- China
- Prior art keywords
- gain
- processed
- speech
- voice frame
- neural network
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images










Landscapes
- Telephone Function (AREA)
- Telephonic Communication Services (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本申请涉及计算机技术领域,尤其涉及一种语音处理方法、装置、电子设备和可读介质。The present application relates to the field of computer technology, and in particular, to a voice processing method, apparatus, electronic device, and readable medium.
背景技术Background technique
随着计算机技术的发展,出现了各类语音通信或者语音控制技术。通过此类技术允许用户进行远距离沟通或者可以提高人机互动的效率。在现实环境中,用户在所在的周遭环境中时麦克风等设备会采集到的各类环境噪音,并且对语音交流的质量产生不同程度地影响。因此,语音增强成为一个重要的课题。With the development of computer technology, various voice communication or voice control technologies have appeared. This type of technology allows users to communicate over long distances or can improve the efficiency of human-computer interaction. In the real environment, when the user is in the surrounding environment, all kinds of environmental noises will be collected by devices such as microphones, and will affect the quality of voice communication to varying degrees. Therefore, speech enhancement becomes an important topic.
在相关的技术中,对含噪声的语音音频采用深度学习的方法学习信号特征,从而预测出语音成分和噪声成分的占比,再根据预测的结果对含噪语音进行增强,来达到降噪的效果。In the related art, the deep learning method is used to learn the signal features for the noise-containing speech and audio, so as to predict the proportion of the speech component and the noise component, and then enhance the noisy speech according to the predicted result to achieve noise reduction. Effect.
然而,在上述方案中,需要针对各类噪声收集训练数据来训练模型,从而使得训练处的模型能够处理训练数据中所涵盖的噪声类型,因此模型的处理效果受到训练数据的完备性的影响,在面对训练数据中没有的情况时,降噪效果差。However, in the above scheme, it is necessary to collect training data for various types of noise to train the model, so that the model at the training site can handle the types of noise covered by the training data. Therefore, the processing effect of the model is affected by the completeness of the training data. Noise reduction is poor in the face of situations not present in the training data.
发明内容SUMMARY OF THE INVENTION
基于上述技术问题,本申请提供一种语音处理方法、装置、电子设备和可读介质,以从而降低了训练数据的完备性的影响,并且能够有效处理训练数据中未包含的噪声类型和噪声环境,提升降噪效果。Based on the above technical problems, the present application provides a speech processing method, apparatus, electronic device and readable medium, so as to reduce the influence of the completeness of training data, and can effectively deal with noise types and noise environments not included in the training data. , to improve the noise reduction effect.
本申请的其他特性和优点将通过下面的详细描述变得显然,或部分地通过本申请的实践而习得。Other features and advantages of the present application will become apparent from the following detailed description, or be learned in part by practice of the present application.
根据本申请实施例的一个方面,提供一种语音处理方法,包括:According to an aspect of the embodiments of the present application, a speech processing method is provided, including:
获取待处理语音帧的频谱系数;Obtain the spectral coefficients of the speech frame to be processed;
根据所述待处理语音帧的频谱系数进行声门增益计算,得到第一增益,所述第一增益对应于所述待处理语音帧的声门特征;Calculate the glottal gain according to the spectral coefficient of the speech frame to be processed to obtain a first gain, and the first gain corresponds to the glottal feature of the speech frame to be processed;
根据所述待处理语音帧的频谱系数进行激励增益计算,得到第二增益,所述第二增益对应于所述待处理语音帧的激励信号;Perform excitation gain calculation according to the spectral coefficient of the speech frame to be processed to obtain a second gain, and the second gain corresponds to the excitation signal of the speech frame to be processed;
根据所述待处理语音帧的频谱系数进行补偿预测,得到控制系数,所述控制系数是根据所述待处理音频帧的频谱系数的能量确定的;Perform compensation prediction according to the spectral coefficient of the to-be-processed speech frame to obtain a control coefficient, where the control coefficient is determined according to the energy of the spectral coefficient of the to-be-processed audio frame;
根据所述第一增益、所述第二增益和所述控制系数,对所述待处理语音帧进行增益控制,得到目标语音帧。Gain control is performed on the speech frame to be processed according to the first gain, the second gain and the control coefficient to obtain a target speech frame.
根据本申请实施例的一个方面,提供一种语音处理装置,包括:According to an aspect of the embodiments of the present application, a voice processing apparatus is provided, including:
频谱系数获取模块,用于获取待处理语音帧的频谱系数;a spectral coefficient obtaining module, used to obtain the spectral coefficients of the speech frame to be processed;
声门增益模块,用于根据所述待处理语音帧的频谱系数进行声门增益计算,得到第一增益,所述第一增益对应于所述待处理语音帧的声门特征;A glottal gain module, configured to perform a glottal gain calculation according to the spectral coefficient of the to-be-processed speech frame to obtain a first gain, where the first gain corresponds to the glottal feature of the to-be-processed speech frame;
激励增益模块,用于根据所述待处理语音帧的频谱系数进行激励增益计算,得到第二增益,所述第二增益对应于所述待处理语音帧的激励信号;an excitation gain module, configured to perform an excitation gain calculation according to the spectral coefficient of the speech frame to be processed, to obtain a second gain, and the second gain corresponds to the excitation signal of the speech frame to be processed;
补偿预测模块,用于根据所述待处理语音帧的频谱系数进行补偿预测,得到控制系数,所述控制系数是根据所述待处理音频帧的频谱系数的能量确定的;a compensation prediction module, configured to perform compensation prediction according to the spectral coefficients of the to-be-processed speech frames to obtain control coefficients, where the control coefficients are determined according to the energy of the spectral coefficients of the to-be-processed audio frames;
增益控制模块,用于根据所述第一增益、所述第二增益和所述控制系数,对所述待处理语音帧进行增益控制,得到目标语音帧。The gain control module is configured to perform gain control on the speech frame to be processed according to the first gain, the second gain and the control coefficient to obtain a target speech frame.
在本申请的一些实施例中,基于以上技术方案,声门增益模块包括:In some embodiments of the present application, based on the above technical solutions, the glottal gain module includes:
第一输入子单元,用于将所述待处理语音帧的频谱系数输入第一神经网络,所述第一神经网络是根据噪声语音帧对应的声门特征和所述噪声语音帧对应的去噪语音帧对应的声门特征进行训练得到的;The first input subunit is used to input the spectral coefficient of the speech frame to be processed into the first neural network, and the first neural network is based on the glottal feature corresponding to the noise speech frame and the noise removal corresponding to the noise speech frame. The glottal feature corresponding to the speech frame is obtained by training;
增益预测子模块,用于通过所述第一神经网络根据所述待处理语音帧的频谱系数进行增益预测,得到所述第一增益。A gain prediction sub-module, configured to perform gain prediction according to the spectral coefficients of the speech frames to be processed through the first neural network to obtain the first gain.
在本申请的一些实施例中,基于以上技术方案,语音处理装置还包括:In some embodiments of the present application, based on the above technical solutions, the speech processing apparatus further includes:
历史帧频谱系数获取模块,用于获取所述待处理语音帧的历史语音帧的频谱系数;A historical frame spectral coefficient acquisition module, used for acquiring the spectral coefficients of the historical voice frames of the to-be-processed voice frames;
第一输入子模块包括:历史帧输入单元,用于将所述待处理语音帧的频谱系数和所述历史语音帧的频谱系数输入到第一神经网络。The first input sub-module includes: a historical frame input unit, configured to input the spectral coefficients of the speech frames to be processed and the spectral coefficients of the historical speech frames into the first neural network.
在本申请的一些实施例中,基于以上技术方案,声门增益模块包括:In some embodiments of the present application, based on the above technical solutions, the glottal gain module includes:
第一增益计算子模块,用于通过所述第一神经网络对所述待处理语音帧的频谱系数进行增益计算,得到所述待处理语音帧中各个子带对应的第一声门增益,其中,所述子带对应于所述待处理语音帧的频谱系数中至少一个频带;a first gain calculation submodule, configured to perform gain calculation on the spectral coefficients of the to-be-processed speech frame through the first neural network, to obtain the first glottal gain corresponding to each subband in the to-be-processed speech frame, wherein , the subband corresponds to at least one frequency band in the spectral coefficients of the speech frame to be processed;
子带增益合并子模块,用于将所述各个子带对应的第一声门增益合并作为所述第一增益。The sub-band gain combining sub-module is configured to combine the first glottal gains corresponding to the respective sub-bands as the first gain.
在本申请的一些实施例中,基于以上技术方案,语音处理装置还包括:In some embodiments of the present application, based on the above technical solutions, the speech processing apparatus further includes:
第二增益计算子模块,用于通过所述第一神经网络对所述待处理语音帧的频谱系数和所述待处理语音帧的基音周期进行预测分析,确定第二声门增益,所述第二声门增益对应于所述待处理语音帧的频谱系数的长时相关性特征;The second gain calculation sub-module is used to predict and analyze the spectral coefficient of the speech frame to be processed and the pitch period of the speech frame to be processed through the first neural network, and determine the second glottal gain, the first The glottal gain corresponds to the long-term correlation feature of the spectral coefficients of the speech frame to be processed;
子带增益合并子模块包括:The sub-band gain combining sub-module includes:
声门增益合并单元,用于将所述各个子带对应的第一声门增益和所述第二声门增益合并作为所述第一增益。A glottal gain combining unit, configured to combine the first glottal gain and the second glottal gain corresponding to the respective subbands as the first gain.
在本申请的一些实施例中,基于以上技术方案,第一增益计算子模块包括:In some embodiments of the present application, based on the above technical solutions, the first gain calculation submodule includes:
第一声门参数预测单元,用于通过所述第一神经网络根据所述待处理语音帧的频谱系数进行参数预测,得到第一声门参数,所述第一声门参数用于表示所述待处理语音帧的频谱系数的短时相关性特征;a first glottal parameter prediction unit, configured to perform parameter prediction according to the spectral coefficients of the to-be-processed speech frame through the first neural network to obtain a first glottal parameter, where the first glottal parameter is used to represent the Short-term correlation characteristics of spectral coefficients of to-be-processed speech frames;
第一预测单元,用于通过所述第一神经网络根据所述第一声门参数进行增益预测,得到所述第一预测结果;a first prediction unit, configured to perform gain prediction according to the first glottal parameter through the first neural network to obtain the first prediction result;
结果确定单元,用于根据所述第一预测结果确定所述第一增益。A result determining unit, configured to determine the first gain according to the first prediction result.
在本申请的一些实施例中,基于以上技术方案,语音处理装置还包括:In some embodiments of the present application, based on the above technical solutions, the speech processing apparatus further includes:
第二声门参数预测单元,用于通过所述第一神经网络根据所述待处理语音帧的频谱系数和所述待处理语音帧的基音周期进行参数预测,得到第二声门参数,所述第一声门参数用于表示所述待处理语音帧的频谱系数的长时相关性特征;The second glottal parameter prediction unit is configured to perform parameter prediction according to the spectral coefficient of the speech frame to be processed and the pitch period of the speech frame to be processed through the first neural network to obtain the second glottal parameter, the The first glottal parameter is used to represent the long-term correlation feature of the spectral coefficients of the speech frame to be processed;
第二预测单元,用于通过所述第一神经网络根据所述第二声门参数进行增益预测,得到第二预测结果;a second prediction unit, configured to perform gain prediction according to the second glottal parameter through the first neural network to obtain a second prediction result;
结果确定单元包括:The result determination unit includes:
结果合并子单元,用于将所述第一预测结果和所述第二预测结果合并确定为所述第一增益。A result combining subunit, configured to combine the first prediction result and the second prediction result to determine the first gain.
在本申请的一些实施例中,基于以上技术方案,激励增益模块包括:In some embodiments of the present application, based on the above technical solutions, the excitation gain module includes:
第二输入子模块,用于将所述待处理语音帧的频谱系数输入第二神经网络,所述第二神经网络是根据噪声语音帧的激励信号和所述噪声语音帧对应的去噪语音帧的激励信号进行训练得到的;The second input sub-module is used to input the spectral coefficients of the speech frame to be processed into a second neural network, where the second neural network is based on the excitation signal of the noise speech frame and the denoised speech frame corresponding to the noise speech frame obtained by training the excitation signal;
语音分解子模块,用于通过所述第二神经网络对所述待处理语音帧的频谱系数进行语音分解,得到激励信号;A speech decomposition sub-module, configured to perform speech decomposition on the spectral coefficients of the to-be-processed speech frames through the second neural network to obtain an excitation signal;
增益预测子模块,用于通过所述第二神经网络根据所述激励信号进行增益预测,得到所述第二增益。A gain prediction sub-module, configured to perform gain prediction according to the excitation signal through the second neural network to obtain the second gain.
在本申请的一些实施例中,基于以上技术方案,增益控制模块包括:In some embodiments of the present application, based on the above technical solutions, the gain control module includes:
第一增强子模块,用于根据所述第二增益对所述待处理语音帧进行增强,得到第一增强结果;a first enhancement submodule, configured to enhance the to-be-processed speech frame according to the second gain to obtain a first enhancement result;
第二增强子模块,用于根据所述第一增益对所述第一增强结果中的各个子带进行增益运算,得到第二增强结果;a second enhancement sub-module, configured to perform a gain operation on each subband in the first enhancement result according to the first gain to obtain a second enhancement result;
能量补偿子模块,用于根据所述控制系数,对所述第二增强结果进行能量补偿,得到第三增强结果;an energy compensation sub-module, configured to perform energy compensation on the second enhancement result according to the control coefficient to obtain a third enhancement result;
逆时频转换子模块,用于根据所述第三增强结果进行逆时频转换,得到增强后的语音帧作为目标语音帧。The inverse time-frequency conversion sub-module is configured to perform inverse time-frequency conversion according to the third enhancement result, and obtain the enhanced speech frame as the target speech frame.
在本申请的一些实施例中,基于以上技术方案,补偿预测模块包括:In some embodiments of the present application, based on the above technical solutions, the compensation prediction module includes:
增益控制子模块,用于根据所述第一增益和所述第二增益,对所述待处理语音帧进行增益控制,得到增益控制结果;A gain control submodule, configured to perform gain control on the to-be-processed speech frame according to the first gain and the second gain, to obtain a gain control result;
控制系数预测子模块,用于根据所述增益控制结果和所述待处理语音帧的频谱系数进行补偿预测,得到所述控制系数。A control coefficient prediction sub-module, configured to perform compensation prediction according to the gain control result and the spectral coefficient of the to-be-processed speech frame to obtain the control coefficient.
在本申请的一些实施例中,基于以上技术方案,语音处理装置还包括:In some embodiments of the present application, based on the above technical solutions, the speech processing apparatus further includes:
幅度谱计算模块,用于根据所述待处理语音帧计算所述待处理语音帧对应的幅度谱和相位谱;an amplitude spectrum calculation module, configured to calculate the corresponding amplitude spectrum and phase spectrum of the to-be-processed voice frame according to the to-be-processed voice frame;
增益控制模块包括:The gain control module includes:
幅度谱增益控制子模块,用于根据所述第一增益和所述第二增益,对所述待处理语音帧对应的幅度谱进行增益控制,得到增强后的幅度谱;an amplitude spectrum gain control sub-module, configured to perform gain control on the amplitude spectrum corresponding to the to-be-processed speech frame according to the first gain and the second gain, to obtain an enhanced amplitude spectrum;
幅度谱能量补偿子模块,用于根据所述增强后的幅度谱和所述控制系数进行能量补偿,得到补偿后的幅度谱;Amplitude spectrum energy compensation sub-module for performing energy compensation according to the enhanced amplitude spectrum and the control coefficient to obtain the compensated amplitude spectrum;
幅度谱逆时频转换子模块,用于根据所述补偿后的幅度谱以及所述待处理语音帧对应的相位谱进行逆时频转换,得到目标语音帧。The amplitude spectrum inverse time-frequency conversion sub-module is configured to perform inverse time-frequency conversion according to the compensated amplitude spectrum and the phase spectrum corresponding to the to-be-processed voice frame to obtain a target voice frame.
在本申请的一些实施例中,基于以上技术方案,补偿预测模块包括:In some embodiments of the present application, based on the above technical solutions, the compensation prediction module includes:
历史频谱系数获取子模块,用于获取所述待处理语音帧的历史语音帧的频谱系数;A historical spectral coefficient acquisition submodule, used for acquiring the spectral coefficients of the historical speech frames of the to-be-processed speech frames;
第三输入子模块,用于将所述待处理语音帧的频谱系数和所述历史语音帧的频谱系数输入第三神经网络,所述第三神经网络是根据噪声语音帧对应的频谱系数的能量和所述噪声语音帧对应的去噪语音帧对应的频谱系数的能量进行训练得到的;The third input sub-module is used to input the spectral coefficients of the speech frames to be processed and the spectral coefficients of the historical speech frames into a third neural network, where the third neural network is based on the energy of the spectral coefficients corresponding to the noise speech frames Obtained by training with the energy of the spectral coefficient corresponding to the denoised speech frame corresponding to the noise speech frame;
补偿预测子模块,用于通过所述第三神经网络根据所述待处理语音帧的频谱系数进行补偿预测,得到所述控制系数。The compensation prediction sub-module is configured to perform compensation prediction according to the spectral coefficients of the speech frames to be processed through the third neural network to obtain the control coefficients.
根据本申请实施例的一个方面,提供一种电子设备,该电子设备包括:处理器;以及存储器,用于存储处理器的可执行指令;其中,该处理器配置为经由执行可执行指令来执行如以上技术方案中的语音处理方法。According to an aspect of the embodiments of the present application, there is provided an electronic device, the electronic device includes: a processor; and a memory for storing executable instructions of the processor; wherein the processor is configured to execute by executing the executable instructions Such as the speech processing method in the above technical solutions.
根据本申请实施例的一个方面,提供一种计算机可读存储介质,其上存储有计算机程序,当该计算机程序被处理器执行时实现如以上技术方案中的语音处理方法。According to an aspect of the embodiments of the present application, a computer-readable storage medium is provided on which a computer program is stored, and when the computer program is executed by a processor, the voice processing method in the above technical solution is implemented.
根据本申请实施例的一个方面,提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行上述各种可选实现方式中提供语音处理方法。According to one aspect of the embodiments of the present application, there is provided a computer program product or computer program, where the computer program product or computer program includes computer instructions, and the computer instructions are stored in a computer-readable storage medium. The processor of the computer device reads the computer instructions from the computer-readable storage medium, and the processor executes the computer instructions, so that the computer device executes the voice processing methods provided in the various optional implementations described above.
在本申请的实施例中,针对含噪声的语音信号的声门特征和激励信号分别计算第一增益和第二增益,再根据第一增益和第二增益进行增益控制,从而对含噪声的语音信号进行去噪,并且对去噪的语音信号进行能量补偿。根据声门特征来进行降噪处理能够针对性地识别出语音信号中的人声部分,因此在降噪过程中也针对人声部分进行处理,而不再需要针对各类噪声进行训练,因此,从而降低了训练数据的完备性的影响,并且能够有效处理训练数据中未包含的噪声类型和噪声环境,提升降噪效果。In the embodiment of the present application, the first gain and the second gain are respectively calculated for the glottal feature and the excitation signal of the noise-containing speech signal, and then the gain control is performed according to the first gain and the second gain, so that the noise-containing speech The signal is denoised, and the denoised speech signal is energy compensated. The noise reduction processing based on the glottal feature can identify the human voice in the speech signal in a targeted manner, so the human voice is also processed in the noise reduction process, instead of training for various types of noise. Therefore, Therefore, the influence of the completeness of the training data is reduced, and the noise type and noise environment not included in the training data can be effectively processed, and the noise reduction effect can be improved.
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本申请。It is to be understood that both the foregoing general description and the following detailed description are exemplary and explanatory only and are not limiting of the present application.
附图说明Description of drawings
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本申请的实施例,并与说明书一起用于解释本申请的原理。显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。在附图中:The accompanying drawings, which are incorporated in and constitute a part of this specification, illustrate embodiments consistent with the application and together with the description serve to explain the principles of the application. Obviously, the drawings in the following description are only some embodiments of the present application, and for those of ordinary skill in the art, other drawings can also be obtained from these drawings without creative effort. In the attached image:
图1为本申请技术方案在一个应用场景中的示例性系统构架示意图;1 is a schematic diagram of an exemplary system architecture of the technical solution of the present application in an application scenario;
图2示出了语音信号产生的数字模型的示意图;Fig. 2 shows the schematic diagram of the digital model of speech signal generation;
图3为本申请实施例中声门滤波器的示例实现的示意图;3 is a schematic diagram of an example implementation of a glottal filter in an embodiment of the application;
图4为本申请实施例中声门滤波器的另一示例实现的示意图;4 is a schematic diagram of another example implementation of a glottal filter in an embodiment of the application;
图5示出了不同信噪比下,根据原始语音信号分解出激励信号和声门滤波器的频率响应的示意图;5 shows a schematic diagram of the frequency response of the excitation signal and the glottal filter decomposed according to the original speech signal under different signal-to-noise ratios;
图6示出了根据本申请的一个实施例示出的语音处理方法的流程图;FIG. 6 shows a flowchart of a speech processing method according to an embodiment of the present application;
图7是根据一具体实施例示出的第一神经网络的结构示意图;7 is a schematic structural diagram of a first neural network according to a specific embodiment;
图8是根据一具体实施例示出的第二神经网络的结构示意图;8 is a schematic structural diagram of a second neural network according to a specific embodiment;
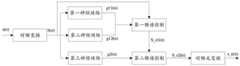
图9为本申请实施例中整体流程的示意图;FIG. 9 is a schematic diagram of an overall process in an embodiment of the application;
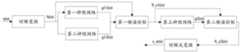
图10为本申请实施例中的另一种方案整体流程的示意图;10 is a schematic diagram of the overall flow of another solution in the embodiment of the application;
图11是根据一具体实施例示出的第三神经网络的结构示意图;11 is a schematic structural diagram of a third neural network according to a specific embodiment;
图12示意性地示出了本申请实施例中语音处理装置的组成框图;FIG. 12 schematically shows a block diagram of the composition of the speech processing apparatus in the embodiment of the present application;
图13示出了适于用来实现本申请实施例的电子设备的计算机系统的结构示意图。FIG. 13 shows a schematic structural diagram of a computer system suitable for implementing the electronic device according to the embodiment of the present application.
具体实施方式Detailed ways
现在将参考附图更全面地描述示例实施方式。然而,示例实施方式能够以多种形式实施,且不应被理解为限于在此阐述的范例;相反,提供这些实施方式使得本申请将更加全面和完整,并将示例实施方式的构思全面地传达给本领域的技术人员。Example embodiments will now be described more fully with reference to the accompanying drawings. Example embodiments, however, can be embodied in various forms and should not be construed as limited to the examples set forth herein; rather, these embodiments are provided so that this application will be thorough and complete, and will fully convey the concept of example embodiments to those skilled in the art.
此外,所描述的特征、结构或特性可以以任何合适的方式结合在一个或更多实施例中。在下面的描述中,提供许多具体细节从而给出对本申请的实施例的充分理解。然而,本领域技术人员将意识到,可以实践本申请的技术方案而没有特定细节中的一个或更多,或者可以采用其它的方法、组元、装置、步骤等。在其它情况下,不详细示出或描述公知方法、装置、实现或者操作以避免模糊本申请的各方面。Furthermore, the described features, structures, or characteristics may be combined in any suitable manner in one or more embodiments. In the following description, numerous specific details are provided in order to give a thorough understanding of the embodiments of the present application. However, those skilled in the art will appreciate that the technical solutions of the present application may be practiced without one or more of the specific details, or other methods, components, devices, steps, etc. may be employed. In other instances, well-known methods, devices, implementations, or operations have not been shown or described in detail to avoid obscuring aspects of the present application.
附图中所示的方框图仅仅是功能实体,不一定必须与物理上独立的实体相对应。即,可以采用软件形式来实现这些功能实体,或在一个或多个硬件模块或集成电路中实现这些功能实体,或在不同网络和/或处理器装置和/或微控制器装置中实现这些功能实体。The block diagrams shown in the figures are merely functional entities and do not necessarily necessarily correspond to physically separate entities. That is, these functional entities may be implemented in software, or in one or more hardware modules or integrated circuits, or in different networks and/or processor devices and/or microcontroller devices entity.
附图中所示的流程图仅是示例性说明,不是必须包括所有的内容和操作/步骤,也不是必须按所描述的顺序执行。例如,有的操作/步骤还可以分解,而有的操作/步骤可以合并或部分合并,因此实际执行的顺序有可能根据实际情况改变。The flowcharts shown in the figures are only exemplary illustrations and do not necessarily include all contents and operations/steps, nor do they have to be performed in the order described. For example, some operations/steps can be decomposed, and some operations/steps can be combined or partially combined, so the actual execution order may be changed according to the actual situation.
语音信号中的噪声会极大降低语音质量,影响用户的听觉体验,因此,为了提高语音信号的质量,有必要对语音信号进行增强处理,以尽可能能地除去噪声,并且保留语音信号中的原始语音信息,即得到去噪之后的纯净信号。The noise in the voice signal will greatly reduce the voice quality and affect the user's listening experience. Therefore, in order to improve the quality of the voice signal, it is necessary to enhance the voice signal to remove the noise as much as possible and retain the noise in the voice signal. The original speech information, that is, the pure signal after denoising is obtained.
本申请的方案可以应用于语音通话的场景中,例如通过即时通讯软件进行语音通话、在游戏应用中进行多人通话等,也可以应用于基于云技术的各类服务中,例如云游戏、云会议、云呼叫和云教育等。其中,可以在语音的发送端、语音的接收端、或者提供语音通信服务的服务端来按照本方案进行语音增强。The solution of the present application can be applied to scenarios of voice calls, such as voice calls through instant messaging software, multi-person calls in game applications, etc., and can also be applied to various services based on cloud technology, such as cloud games, cloud games, etc. Conferencing, cloud calling and cloud education, etc. Wherein, the voice enhancement can be performed according to this solution at the voice sending end, the voice receiving end, or the server providing voice communication service.
云会议是线上办公中一个重要的环节,在云会议中,云会议的参与方的声音采集装置在采集到发言人的语音信号后,需要将所采集到的语音信号发送至其他会议参与方,该过程涉及到语音信号在多个参与方之间的传输和播放,如果不对语音信号中所混有的噪声信号进行处理,会极大影响会议参与方的听觉体验。在该种场景中,可以应用本申请的方案对云会议中的语音信号进行增强,使会议参与方所听到的语音信号是进行增强后的语音信号,提高语音信号的质量。Cloud conference is an important part of online office. In cloud conference, after the voice collection device of the participants of the cloud conference collects the voice signal of the speaker, it needs to send the collected voice signal to other conference participants. , this process involves the transmission and playback of voice signals among multiple participants. If the noise signals mixed in the voice signals are not processed, the auditory experience of the conference participants will be greatly affected. In this scenario, the solution of the present application can be applied to enhance the voice signal in the cloud conference, so that the voice signal heard by the conference participants is the enhanced voice signal, and the quality of the voice signal is improved.
云会议是基于云计算技术的一种高效、便捷、低成本的会议形式。使用者只需要通过互联网界面,进行简单易用的操作,便可快速高效地与全球各地团队及客户同步分享语音、数据文件及视频,而会议中数据的传输、处理等复杂技术由云会议服务提供方帮助使用者进行操作。Cloud conference is an efficient, convenient and low-cost conference form based on cloud computing technology. Users only need to perform simple and easy-to-use operations through the Internet interface, and can quickly and efficiently share voice, data files and videos with teams and customers around the world, and complex technologies such as data transmission and processing in the conference are provided by cloud conference services. The provider assists the user in the operation.
目前国内云会议主要集中在以SaaS(Software as a Service,软件即服务)模式为主体的服务内容,包括电话、网络、视频等服务形式,基于云计算的视频会议就叫云会议。在云会议时代,数据的传输、处理、存储全部由视频会议提供方的计算机资源处理,用户完全无需再购置昂贵的硬件和安装繁琐的软件,只需打开客户端,进入相应界面,就能进行高效的远程会议。At present, domestic cloud conferences mainly focus on the service content of SaaS (Software as a Service) mode, including telephone, network, video and other service forms. Video conferences based on cloud computing are called cloud conferences. In the era of cloud conferencing, data transmission, processing, and storage are all handled by the computer resources of the video conferencing provider. Users do not need to purchase expensive hardware and install cumbersome software at all. They only need to open the client and enter the corresponding interface. Efficient remote meetings.
云会议系统支持多服务器动态集群部署,并提供多台高性能服务器,大大提升了会议稳定性、安全性、可用性。近年来,视频会议因能大幅提高沟通效率,持续降低沟通成本,带来内部管理水平升级,而获得众多用户欢迎,已广泛应用在政务、交通、运输、金融、运营商、教育、企业等各个领域。The cloud conference system supports multi-server dynamic cluster deployment and provides multiple high-performance servers, which greatly improves the stability, security and availability of conferences. In recent years, video conferencing has been welcomed by many users because it can greatly improve communication efficiency, continue to reduce communication costs, and upgrade internal management levels. It has been widely used in government affairs, transportation, transportation, finance, operators, education, enterprises, etc. field.
下面,以网络电话(Voice over Internet Protocol,VoIP)为例介绍本申请实施例的应用场景。请参阅图1,图1为本申请技术方案在一个应用场景中的示例性系统构架示意图。In the following, an application scenario of the embodiment of the present application is introduced by taking Voice over Internet Protocol (Voice over Internet Protocol, VoIP) as an example. Please refer to FIG. 1 , which is a schematic diagram of an exemplary system architecture of the technical solution of the present application in an application scenario.
如图1所示,该系统架构中包括发送端110和接收端120。发送端110与接收端120存在网络连接,发送端110与接收端120可以通过网络连接进行语音通信。As shown in FIG. 1 , the system architecture includes a
如图1所示,发送端110包括采集模块111、前增强模块112和编码模块113,其中,采集模块111用于采集语音信号,其可以将采集到的声学信号转换成数字信号;前增强模块112用于对采集到的语音信号进行增强,以除去所采集到语音信号中的噪声,提高语音信号的质量。编码模块113用于对增强后的语音信号进行编码,以提高语音信号在传输过程中的抗干扰性。前增强模块112可以按照本申请的方法进行语音增强,对语音进行增强后,再进行编码压缩和传输,这样可以保证接收端接收到的信号不再受噪声影响。As shown in FIG. 1 , the sending
接收端120包括解码模块121、后增强模块122和播放模块123。解码模块121用于对接收到的编码语音进行解码,得到解码信号;后增强模块122用于对解码后的语音信号进行增强处理;播放模块123用于播放增强处理后的语音信号。后增强模块122也可以按照本申请的方法进行语音增强。在一些实施例中,接收端120还可以包括音效调节模块,该音效调节模块用于对增强后的语音信号进行音效调节。The receiving
在具体实施例中,可以是仅在接收端120或者仅在发送端110按照本申请的方法进行语音增强,当然,还可以是在发送端110和接收端120均按照本申请的方法进行语音增强。In a specific embodiment, the voice enhancement may be performed only at the receiving
在一些应用场景中,VoIP系统中的终端设备除了可以支持VoIP通信外,还可以支持其他第三方协议,例如传统PSTN(Public Switched Telephone Network,公用电话交换网)电路域电话,而传统的PSTN服务不能进行语音增强,在该种场景中,可以在作为接收端的终端中按照本申请的方法进行语音增强。In some application scenarios, in addition to supporting VoIP communication, the terminal equipment in the VoIP system can also support other third-party protocols, such as traditional PSTN (Public Switched Telephone Network, public switched telephone network) circuit domain phones, while traditional PSTN services Speech enhancement cannot be performed. In this scenario, speech enhancement can be performed in the terminal serving as the receiving end according to the method of the present application.
在对本方案进行具体说明之前,首先对基于激励信号的语音生成方法进行介绍。人的发声方式是由气流经过声带时带动声带振动发声。而基于激励信号的语音生成方法的发声过程包括:在气管处,产生一定能量的类噪声的冲击信号,即激励信号,相当于气流;冲击信号冲击声门滤波器(相当于人的声带),产生类周期性的开合,从而发出声音。可见,该过程模拟了人的发声过程。Before the specific description of this solution, the speech generation method based on the excitation signal is first introduced. The way of human vocalization is that when the airflow passes through the vocal cords, the vocal cords vibrate to make sounds. The vocalization process of the speech generation method based on the excitation signal includes: at the trachea, a noise-like shock signal with a certain energy is generated, that is, the excitation signal, which is equivalent to the airflow; the shock signal shocks the glottal filter (equivalent to human vocal cords), It produces a periodic opening and closing, which produces a sound. It can be seen that this process simulates the process of human vocalization.
图2示出了语音信号产生的数字模型的示意图,通过该数字模型可以描述语音信号的产生过程。如图2所示,激励信号冲击声门滤波器输出语音信号,其中,声门滤波器由通常根据声门参数进行配置。声门滤波器可以采用各类采用源-滤波器模型生成语音的方案中的滤波器。具体地,请参阅图3,图3为本申请实施例中声门滤波器的示例实现的示意图。考虑到语音信号的短时相关性,声门滤波器可以用一个线性预测编码(Linear PredictiveCoding,LPC)滤波器来实现,激励信号冲击LPC滤波器,生成语音信号。FIG. 2 shows a schematic diagram of a digital model of speech signal generation, through which the speech signal generation process can be described. As shown in FIG. 2, the excitation signal impinges the glottal filter to output the speech signal, wherein the glottal filter is usually configured according to the glottal parameters. The glottal filter can employ filters in a variety of schemes that employ source-filter models to generate speech. Specifically, please refer to FIG. 3 , which is a schematic diagram of an example implementation of a glottal filter in an embodiment of the present application. Considering the short-term correlation of the speech signal, the glottal filter can be implemented by a Linear Predictive Coding (LPC) filter, and the excitation signal impinges the LPC filter to generate the speech signal.
另一方面,根据经典的语音信号处理理论,LPC滤波器只反映了发声中的短时相关性,但对于浊音类发音(比如,元音),是具有长时相关性(Long-Term Prediction,LTP)(或者叫准周期性);声门滤波器还可以采用多个滤波器来实现。具体地,请参阅图4,图4为本申请实施例中声门滤波器的另一示例实现的示意图。如图4所示,声门滤波器由LPC滤波器和LTP滤波器两部分组成。其中,LTP滤波器还接收基音周期作为输入。基因周期表示计算第n个样本时,需要第n-p个样本点,其中p就是基因周期。On the other hand, according to the classical speech signal processing theory, the LPC filter only reflects the short-term correlation in vocalization, but for voiced pronunciation (such as vowels), it has long-term correlation (Long-Term Prediction, LTP) (or quasi-periodic); the glottal filter can also be implemented with multiple filters. Specifically, please refer to FIG. 4 , which is a schematic diagram of another example implementation of the glottal filter in the embodiment of the present application. As shown in Figure 4, the glottal filter consists of two parts, the LPC filter and the LTP filter. Among them, the LTP filter also receives the pitch period as an input. The gene cycle indicates that when calculating the nth sample, the n-pth sample point is required, where p is the gene cycle.
图5示出了不同信噪比下根据原始语音信号分解出激励信号和声门滤波器的频率响应的示意图,图5a示出了该原始语音信号的频率响应示意图,图5b示出了根据该原始语音信号所分解出声门滤波器的频率响应示意图,图5c示出了根据该原始语音信号所分解出激励信号的频率响应示意图。图5中示出了两个原始语音信号以及所对应的分解结果,分别用实线和虚线表示,其中一个原始信号为30db的信号,另一个信号为0db的信号。该原始语音信号的频率响应图中起伏的部分对应于声门滤波器的频率响应图中波峰位置,激励信号相当于对该原始语音信号进行线性预测分析后的残差信号(即激励信号),因此其对应的频率响应较平缓。在图5a中,30db和0db的两个原始语音信号虽然存在一定差异,但差异相对不明显,存在较多相互重合的部分,而进行分解过后,图5b中的声门滤波器的频率响应中,二者之间的差异则相对明显,重合部分明显减少,而在图5c中的激励信号中,两个信号之间的差异则被明显放大,能够明确地区分出两个激励信号。可见,信号分解能够将原始语音信号之间的差异进行更充分的体现,而基于分解结果进行增益控制从而也能够使增益结果准确。Fig. 5 shows a schematic diagram of the frequency response of the excitation signal and the glottal filter decomposed according to the original speech signal under different signal-to-noise ratios, Fig. 5a shows a schematic diagram of the frequency response of the original speech signal, Fig. 5b shows the frequency response of the original speech signal A schematic diagram of the frequency response of the glottal filter decomposed from the original speech signal, and FIG. 5c shows a schematic diagram of the frequency response of the excitation signal decomposed according to the original speech signal. Figure 5 shows two original speech signals and the corresponding decomposition results, which are represented by solid lines and dotted lines respectively, one of which is a 30db signal, and the other is a 0db signal. The fluctuating part in the frequency response diagram of the original speech signal corresponds to the peak position in the frequency response diagram of the glottic filter, and the excitation signal is equivalent to the residual signal (ie, excitation signal) after performing linear prediction analysis on the original speech signal, Therefore, its corresponding frequency response is relatively flat. In Figure 5a, although there is a certain difference between the two original speech signals of 30db and 0db, the difference is relatively insignificant, and there are many overlapping parts. After decomposition, the frequency response of the glottal filter in Figure 5b is in the , the difference between the two is relatively obvious, and the overlapped part is significantly reduced, while in the excitation signal in Figure 5c, the difference between the two signals is significantly amplified, and the two excitation signals can be clearly distinguished. It can be seen that the signal decomposition can more fully reflect the difference between the original speech signals, and the gain control based on the decomposition result can also make the gain result accurate.
由上可以看出,根据一原始语音信号(即不包含噪声的语音信号)可以分解出激励信号和声门滤波器,所分解出的激励信号和声门滤波器可以用于表达该原始语音信号,其中,声门滤波器可以通过声门参数来表达。反之,如果已知一原始语音信号对应的激励信号和用于确定声门滤波器的声门参数,则可以根据所对应的激励信号和声门滤波器来重构该原始语音信号。It can be seen from the above that the excitation signal and the glottal filter can be decomposed according to an original speech signal (that is, the speech signal that does not contain noise), and the decomposed excitation signal and the glottal filter can be used to express the original speech signal. , where the glottal filter can be expressed by the glottal parameter. On the contrary, if the excitation signal corresponding to an original speech signal and the glottal parameters used to determine the glottal filter are known, the original speech signal can be reconstructed according to the corresponding excitation signal and the glottal filter.
本申请的方案基于该原理,分别计算对应于声门滤波器的增益和对应于激励信号的增益,来对原始的语音信号进行增益控制,从而实现语音增强。Based on this principle, the solution of the present application calculates the gain corresponding to the glottal filter and the gain corresponding to the excitation signal respectively, so as to perform gain control on the original speech signal, thereby realizing speech enhancement.
以下对本申请实施例的技术方案的实现细节进行详细阐述。为了便于介绍,请参阅图6,图6示出了根据本申请的一个实施例示出的语音处理方法的流程图。该方法可以由具备处理能力的计算机设备执行,例如终端、服务器等,在此不进行具体限定。如图6所示,该方法至少包括如下的步骤S610至S650:The implementation details of the technical solutions of the embodiments of the present application are described in detail below. For the convenience of introduction, please refer to FIG. 6 , which shows a flowchart of a speech processing method according to an embodiment of the present application. The method may be executed by a computer device with processing capability, such as a terminal, a server, etc., which is not specifically limited herein. As shown in FIG. 6 , the method includes at least the following steps S610 to S650:
步骤S610,获取待处理语音帧的频谱系数。Step S610, acquiring the spectral coefficients of the speech frame to be processed.
语音信号是随时间而非平稳随机变化的,但是在短时间内语音信号的特性是强相关的,即语音信号具有短时相关性,因此,在本申请的方案中,以语音帧为单位来进行语音处理。待处理语音帧是当前待进行处理的语音帧,其为原始含噪声的待处理音频中的任意一帧。The voice signal changes randomly with time rather than stationary, but the characteristics of the voice signal are strongly correlated in a short period of time, that is, the voice signal has short-term correlation. Perform voice processing. The speech frame to be processed is the speech frame currently to be processed, which is any frame in the original noise-containing audio to be processed.
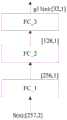
在获取待处理语音帧的待处理语音帧的频谱系数,可以对该待处理语音帧的时域信号进行时频变换获得,时频变换例如短时傅里叶变换(Short-term Fourier transform,STFT)。频谱系数的维度通常取决于待处理语音帧的样本点的数量以及STFT变换时所采用的加窗交叠的比例。例如,对于257个样本点的频域表示,则频谱系数的维度则为[2,257]。After obtaining the spectral coefficients of the to-be-processed speech frame of the to-be-processed speech frame, the time-domain signal of the to-be-processed speech frame can be obtained by performing time-frequency transform, such as a short-term Fourier transform (STFT). ). The dimension of the spectral coefficients usually depends on the number of sample points of the speech frame to be processed and the ratio of windowing and overlapping used in the STFT transformation. For example, for a frequency domain representation of 257 sample points, the dimension of the spectral coefficients is [2, 257].
步骤S620,根据待处理语音帧的频谱系数进行声门增益计算,得到第一增益,第一增益对应于待处理语音帧的声门特征。Step S620: Calculate the glottal gain according to the spectral coefficients of the speech frame to be processed to obtain a first gain, where the first gain corresponds to the glottal feature of the speech frame to be processed.
声门增益计算是针对于待处理语音帧所对应的声门滤波器部分计算增益的过程。计算得到的第一增益关联于待处理语音帧的声门特征。取决于对于待处理语音帧所采用的声门模型,第一增益具体包括多个子增益。例如,对于LPC+LTP的声门模型,第一增益则可以包括对应于LPC的子增益和对应于LTP的自增益。The glottal gain calculation is a process of calculating the gain for the part of the glottal filter corresponding to the speech frame to be processed. The calculated first gain is associated with the glottal feature of the speech frame to be processed. Depending on the glottal model employed for the speech frame to be processed, the first gain specifically comprises a number of sub-gains. For example, for a glottal model of LPC+LTP, the first gain may include a sub-gain corresponding to LPC and a self-gain corresponding to LTP.
声门增益计算可以采用神经网络的方式来进行。通过训练好的神经网络来根据待处理语音帧的频谱系数,从而直接输出对应的第一增益。神经网络采用监督训练的方式进行,训练数据中包括含噪语音以及对于含噪语音计算出每个语音帧对应的数据标注,即去噪语音,根据含噪语音和去噪语音训练出神经网络来输出第一增益。The glottal gain calculation can be performed by means of a neural network. Through the trained neural network, the corresponding first gain is directly output according to the spectral coefficient of the speech frame to be processed. The neural network is performed in a supervised training method. The training data includes noisy speech and the data label corresponding to each speech frame is calculated for the noisy speech, that is, the denoised speech. The neural network is trained according to the noisy speech and the denoised speech. Output the first gain.
声门增益计算也可以采用其他方式。例如,首先根据声门模型来对待处理语音帧进行语音分解,得到对应的声门滤波器的声门参数。然后将声门参数和待处理语音帧的频谱系数都作为输入到神经网络中进行处理,神经网络则根据声门参数和待处理语音帧的频谱系数对去噪语音进行模拟,再通过模拟出的去噪语音与含噪语音来确定第一增益。The glottal gain calculation can also be done in other ways. For example, the speech frame to be processed is firstly decomposed according to the glottal model, and the corresponding glottal parameters of the glottal filter are obtained. Then, both the glottal parameters and the spectral coefficients of the speech frames to be processed are input into the neural network for processing. Denoised speech and noisy speech to determine the first gain.
步骤S630,根据待处理语音帧的频谱系数进行激励增益计算,得到第二增益,第二增益对应于待处理语音帧的激励信号。In step S630, the excitation gain is calculated according to the spectral coefficient of the speech frame to be processed to obtain a second gain, where the second gain corresponds to the excitation signal of the speech frame to be processed.
激励增益计算是针对于待处理语音帧所对应的激励信号部分计算增益的过程。计算得到的第二增益关联于待处理语音帧的激励信号。具体地,第二增益的维度通常与待处理语音帧的频谱系数相对应。The excitation gain calculation is a process of calculating the gain for the excitation signal part corresponding to the speech frame to be processed. The calculated second gain is associated with the excitation signal of the speech frame to be processed. Specifically, the dimension of the second gain generally corresponds to the spectral coefficients of the speech frame to be processed.
激励增益计算可以采用神经网络的方式来进行。通过训练好的神经网络来根据待处理语音帧的频谱系数,从而直接输出对应的第二增益。神经网络采用监督训练的方式进行,训练数据中包括含噪语音以及对含噪语音对应去噪语音进行语音分解后得到的激励信号,根据含噪语音和去噪语音的激励信号训练出神经网络来输出第二增益。The calculation of the excitation gain can be carried out by means of a neural network. Through the trained neural network, the corresponding second gain is directly output according to the spectral coefficient of the speech frame to be processed. The neural network is carried out by means of supervised training. The training data includes the noisy speech and the excitation signal obtained by decomposing the denoised speech corresponding to the noisy speech. The neural network is trained according to the excitation signal of the noisy speech and the denoised speech. Output the second gain.
激励增益计算也可以采用其他方式。例如,首先根据声门模型来对待处理语音帧进行语音分解,得到对应的激励信号。然后将激励信号和待处理语音帧的频谱系数都作为输入到神经网络中进行处理,神经网络则利用待处理语音帧进行分解时得到的声门参数来根据激励信号和待处理语音帧的频谱系数对去噪语音进行模拟,再通过模拟出的去噪语音与含噪语音来确定第二增益。The excitation gain calculation can also be done in other ways. For example, the speech frame to be processed is firstly decomposed according to the glottal model to obtain the corresponding excitation signal. Then, both the excitation signal and the spectral coefficients of the speech frames to be processed are input into the neural network for processing, and the neural network uses the glottal parameters obtained when the speech frames to be processed are decomposed. The denoised speech is simulated, and the second gain is determined by the simulated denoised speech and the noise-containing speech.
步骤S640,根据待处理语音帧的频谱系数进行补偿预测,得到控制系数,控制系数是根据待处理音频帧的频谱系数的能量确定的。Step S640, performing compensation prediction according to the spectral coefficients of the speech frames to be processed to obtain control coefficients, where the control coefficients are determined according to the energy of the spectral coefficients of the audio frames to be processed.
控制系统是用于进行能量补偿的方案。在对待处理语音帧进行增强的过程中,在去噪的同时也会损失一部分能量,从而影响得到的去噪结果的听觉效果。根据待处理语音帧的频谱系数进行补偿预测,得到控制系数。控制系数通常是一组二维向量,分别代表待处理语音帧的频谱系数的实部和虚部。控制系数可以直接作用于第一增益和第二增益的增强结果,从而进行能量补偿。The control system is a scheme for performing energy compensation. In the process of enhancing the speech frame to be processed, a part of energy will be lost while denoising, thereby affecting the auditory effect of the obtained denoising result. Compensation prediction is performed according to the spectral coefficients of the speech frames to be processed to obtain control coefficients. The control coefficients are usually a set of two-dimensional vectors representing the real and imaginary parts of the spectral coefficients of the speech frame to be processed, respectively. The control coefficient can directly act on the enhancement results of the first gain and the second gain, so as to perform energy compensation.
补偿预测的过程可以根据增强的结果与待处理语音帧来进行估计。例如,通过计算出二者的能量差,估计进行补偿所需要的控制系数。补偿预测的过程也可以深度学习的方式来学习待处理语音帧进行去噪后恢复到原本的能量等级所需要的控制系数,例如,将含噪的噪声语音帧作为训练样本,并且人工计算去噪后所需要的控制系数作为训练目标,从而得到对应的模型来预测控制系数。The process of compensating prediction can be estimated based on the enhanced result and the speech frame to be processed. For example, by calculating the energy difference between the two, the control coefficient required for compensation can be estimated. The process of compensation prediction can also use deep learning to learn the control coefficients required to restore the original energy level of the speech frames to be processed after denoising. Then the required control coefficients are used as training targets, so as to obtain the corresponding models to predict the control coefficients.
步骤S650,根据第一增益、第二增益和控制系数,对待处理语音帧进行增益控制,得到目标语音帧。Step S650, according to the first gain, the second gain and the control coefficient, perform gain control on the speech frame to be processed to obtain the target speech frame.
具体地,首先可以根据第二增益对待处理语音帧的频域表示进行增强,之后再根据第一增益对得到的结果进行增益,从而得到增强过后的频域表示。随后,根据控制系数对增强过后的频率表示进行能量补偿计算,从而得到补偿后的频域表示。然后根据补偿后的频域表示进行STFT反变换,从而能够得到增强后的待处理语音帧。Specifically, the frequency domain representation of the speech frame to be processed may be enhanced first according to the second gain, and then the obtained result may be enhanced according to the first gain, thereby obtaining the enhanced frequency domain representation. Then, energy compensation calculation is performed on the enhanced frequency representation according to the control coefficient, so as to obtain the compensated frequency domain representation. Then, inverse STFT transform is performed according to the compensated frequency domain representation, so that the enhanced speech frame to be processed can be obtained.
在本申请的实施例中,针对含噪声的语音信号的声门特征和激励信号分别计算第一增益和第二增益,再根据第一增益和第二增益进行增益控制,从而对含噪声的语音信号进行去噪,并且对去噪的语音信号进行能量补偿。根据声门特征来进行降噪处理能够针对性地识别出语音信号中的人声部分,因此在降噪过程中也针对人声部分进行处理,而不再需要针对各类噪声进行训练,因此,从而降低了训练数据的完备性的影响,并且能够有效处理训练数据中未包含的噪声类型和噪声环境,提升降噪效果。In the embodiment of the present application, the first gain and the second gain are respectively calculated for the glottal feature and the excitation signal of the noise-containing speech signal, and then the gain control is performed according to the first gain and the second gain, so that the noise-containing speech The signal is denoised, and the denoised speech signal is energy compensated. The noise reduction processing based on the glottal feature can identify the human voice in the speech signal in a targeted manner, so the human voice is also processed in the noise reduction process, instead of training for various types of noise. Therefore, Therefore, the influence of the completeness of the training data is reduced, and the noise type and noise environment not included in the training data can be effectively processed, and the noise reduction effect can be improved.
在本申请的一些实施例中,基于上述的技术方案,上述步骤S620,根据待处理语音帧的频谱系数进行声门增益计算,得到第一增益,可以包括如下步骤:In some embodiments of the present application, based on the above-mentioned technical solution, the above-mentioned step S620, calculating the glottal gain according to the spectral coefficient of the speech frame to be processed, to obtain the first gain, may include the following steps:
将待处理语音帧的频谱系数输入第一神经网络,第一神经网络是根据噪声语音帧对应的声门特征和噪声语音帧对应的去噪语音帧对应的声门特征进行训练得到的;Input the spectral coefficient of the speech frame to be processed into the first neural network, and the first neural network is obtained by training according to the glottal feature corresponding to the noise speech frame and the glottal feature corresponding to the denoised speech frame corresponding to the noise speech frame;
通过第一神经网络根据待处理语音帧的频谱系数进行增益预测,得到第一增益。The first gain is obtained by predicting the gain according to the spectral coefficient of the speech frame to be processed by the first neural network.
第一神经网络可以是通过长短时记忆神经网络、卷积神经网络、循环神经网络、全连接神经网络等构建的模型,在此不进行具体限定。The first neural network may be a model constructed by a long-short-term memory neural network, a convolutional neural network, a recurrent neural network, a fully connected neural network, etc., which is not specifically limited here.
在训练的过程中,首先对训练数据中含有噪声的语音帧进行分解,得到声门模型中声门滤波器对应的频率响应,然后根据含有噪声的语音帧的频谱系数和分解的到的声门滤波器对应的频率响应来进行训练,通过调整第一神经网络的模型参数,直至第一神经网络所输出的第一增益能够使得含噪语音帧的声门特征与去噪语音帧的声门特征之间的差异满足预设的要求。其中,预设的要求可以通过均方误差的方式来进行计算。通过训练使得输出的第一增益使得含噪语音帧的声门特征与去噪语音帧的声门特征之间的均方误差满足设定的均方误差门限,从而判断训练得到的模型能够达到预期目的。通过该训练过程,可以使得第一神经网络所预测得到的第一增益能够使得待处理语音帧在声门模型(即声门滤波器+激励信号)下的声门滤波器与纯净语音在声门模型下的声门滤波器足够相似,从而具备降噪能力。In the training process, the speech frames containing noise in the training data are first decomposed to obtain the frequency response corresponding to the glottal filter in the glottal model. Then, according to the spectral coefficient of the speech frames containing noise and the decomposed glottal The frequency response corresponding to the filter is used for training, and the model parameters of the first neural network are adjusted until the first gain output by the first neural network can make the glottal feature of the noisy speech frame and the glottal feature of the denoised speech frame. The difference between meets the preset requirements. Wherein, the preset requirement can be calculated by means of mean square error. Through training, the first gain of the output makes the mean square error between the glottal feature of the noisy speech frame and the glottal feature of the denoised speech frame meet the set mean square error threshold, so as to judge that the model obtained by training can meet the expectation Purpose. Through the training process, the first gain predicted by the first neural network can make the glottal filter of the speech frame to be processed under the glottal model (ie, the glottal filter+excitation signal) and the pure speech at the glottal level. The glottal filters under the model are similar enough to have noise reduction capabilities.
通过第一神经网络根据频谱系数进行增益预测,得到第一增益。图7是根据一具体实施例示出的第一神经网络的结构示意图,如图7所示,第一神经网络包括三个全连接(Full Connected,FC)层。输入的F(n)为[257,2]维的频谱系数。第一个FC层的输出为[256,1]维的向量,第二个FC层的输出为[128,1]维的向量,第三个FC层输出为[32,1]维的向量,即第一增益g1(n)。当然,图7仅仅是第一神经网络的结构的一种示例性举例,不能认为是对本申请使用范围的限制。The first gain is obtained by predicting the gain according to the spectral coefficient through the first neural network. FIG. 7 is a schematic structural diagram of a first neural network according to a specific embodiment. As shown in FIG. 7 , the first neural network includes three fully connected (Full Connected, FC) layers. The input F(n) is a [257,2] dimensional spectral coefficient. The output of the first FC layer is a vector of dimension [256,1], the output of the second FC layer is a vector of dimension [128,1], and the output of the third FC layer is a vector of dimension [32,1], That is, the first gain g1(n). Of course, FIG. 7 is only an exemplary example of the structure of the first neural network, and should not be considered as a limitation on the scope of application of the present application.
在本申请的实施例中,通过神经网络获得针对于声门特征的第一增益,通过神经网络学到声门特征与第一增益之间的关系,从而能够根据有限的训练数据得到模型来处理实际场景中的各类情况,提升方案的灵活性。In the embodiments of the present application, the first gain for the glottal feature is obtained through a neural network, and the relationship between the glottal feature and the first gain is learned through the neural network, so that a model can be obtained according to limited training data for processing Various situations in the actual scene, improve the flexibility of the scheme.
在本申请的一个实施例中,基于上述的技术方案,上述步骤,将待处理语音帧的频谱系数输入第一神经网络之前,该语音处理方法还包括:In an embodiment of the present application, based on the above technical solution, in the above steps, before inputting the spectral coefficients of the speech frame to be processed into the first neural network, the speech processing method further includes:
获取待处理语音帧的历史语音帧的频谱系数;Obtain the spectral coefficients of the historical speech frames of the speech frames to be processed;
上述步骤,将待处理语音帧的频谱系数输入第一神经网络,包括:In the above steps, the spectral coefficients of the speech frames to be processed are input into the first neural network, including:
将待处理语音帧的频谱系数和历史语音帧的频谱系数输入到第一神经网络。The spectral coefficients of the speech frames to be processed and the spectral coefficients of the historical speech frames are input into the first neural network.
声门增益计算的过程可以还可以将待处理语音帧的历史语音帧也融入计算过程,便于根据语音帧之间的关联关系来进一步准确预测所需要的增益。历史语音帧是在待处理语音帧所在的音频中的其他语音帧,例如,对于第n帧,历史语音帧可以是第n-1帧、第n-2帧等。对历史语音帧进行STFT变换,从而得到历史语音帧的频谱系数。随后,在进行第一增益的预测时,将待处理语音帧的频谱系数和历史语音帧的频谱系数输入到第一神经网络。相对应地,在训练第一神经网络时,也需要将训练数据中的噪声语音帧对应的历史语音帧的频谱系数作为训练样本输入到待训练的神经网络中进行训练,从而允许神经网络学习待处理语音帧和历史语音帧与对应的增益时间的关联关系,以便于在实际应用的过程中输出适当的第一增益。In the process of calculating the glottal gain, the historical speech frames of the speech frames to be processed may also be incorporated into the calculation process, so as to further accurately predict the required gain according to the correlation between the speech frames. The historical speech frame is other speech frames in the audio where the speech frame to be processed is located. For example, for the nth frame, the historical speech frame may be the n-1th frame, the n-2th frame, and so on. Perform STFT transformation on historical speech frames, thereby obtaining spectral coefficients of historical speech frames. Then, when predicting the first gain, the spectral coefficients of the speech frame to be processed and the spectral coefficients of the historical speech frames are input into the first neural network. Correspondingly, when training the first neural network, it is also necessary to input the spectral coefficients of the historical speech frames corresponding to the noise speech frames in the training data as training samples into the neural network to be trained for training, thereby allowing the neural network to learn to be trained. The relationship between the speech frame and the historical speech frame and the corresponding gain time is processed, so as to output an appropriate first gain in the process of practical application.
在本申请的实施例中,将历史语音帧作为输入,与待处理语音帧一起进行处理,从而在特征提取的过程中能够更加充分地考虑到相邻语音帧之间的联系,从而提升特征提取的准确性。In the embodiments of the present application, historical speech frames are used as input and processed together with the speech frames to be processed, so that the relationship between adjacent speech frames can be more fully considered in the process of feature extraction, thereby improving feature extraction. accuracy.
在本申请的一个实施例中,基于上述的技术方案,上述步骤,通过第一神经网络根据待处理语音帧的频谱系数进行增益预测,得到第一增益,可以包括如下步骤:In an embodiment of the present application, based on the above technical solution, the above steps, through the first neural network to predict the gain according to the spectral coefficient of the speech frame to be processed, to obtain the first gain, may include the following steps:
通过第一神经网络对待处理语音帧的频谱系数进行增益计算,得到待处理语音帧中各个子带对应的第一声门增益,其中,子带对应于待处理语音帧的频谱系数中至少一个频带;Gain calculation is performed on the spectral coefficients of the speech frame to be processed by the first neural network to obtain the first glottal gain corresponding to each subband in the speech frame to be processed, wherein the subband corresponds to at least one frequency band in the spectral coefficients of the speech frame to be processed ;
将各个子带对应的第一声门增益合并作为第一增益。The first glottal gain corresponding to each subband is combined as the first gain.
具体地,声门滤波器相关的频谱响应是一种类似低通的平滑效果。因此,虽然待处理语音帧的频域表示的维度是257维,但计算第一增益时,并不需要达到257为的分辨率。因此,在计算第一增益的过程中可以向将相邻几个系数进行合并,共用一个第一增益,每个子带包括待处理语音帧的频谱系数中的相邻的至少两个维度中的特征。Specifically, the spectral response associated with the glottal filter is a low-pass-like smoothing effect. Therefore, although the dimension of the frequency domain representation of the speech frame to be processed is 257 dimensions, when calculating the first gain, it is not necessary to reach a resolution of 257 degrees. Therefore, in the process of calculating the first gain, several adjacent coefficients may be combined to share one first gain, and each subband includes features in at least two adjacent dimensions of the spectral coefficients of the speech frame to be processed .
根据待处理语音帧的频域表示沿频率进行分带,可以得到该频域表示中的多个子带。对频域表示所进行的分带可以是对频率进行均匀分带(即每个子带对应的频率宽度相同),也可以是非均匀分带,在此不进行具体限定。可以理解的是,每个子带对应一个频率范围,其中包括多个频点。According to the frequency domain representation of the speech frame to be processed, the frequency domain representation is divided along the frequency, and a plurality of subbands in the frequency domain representation can be obtained. Banding performed on the frequency domain representation may be uniform frequency banding (that is, each subband corresponds to the same frequency width), or non-uniform banding, which is not specifically limited here. It can be understood that each subband corresponds to a frequency range, which includes multiple frequency points.
非均匀分带可以是巴克(Bark)分带。Bark分带是按照Bark频率尺度进行分带的,Bark频率尺度把频率映射到心理声学的多个临界频带上,频带的数量可以根据采样率和实际需要进行设定,例如频点的数量设定为24。Bark分带符合听觉系统的特征,一般地,越是低频,子带包含的系数数量越少、甚至就是单个系数,越是高频,子带包含的系数数量越多。The non-uniform zoning may be a Bark zoning. Bark banding is banded according to the Bark frequency scale. The Bark frequency scale maps frequencies to multiple critical frequency bands of psychoacoustics. The number of frequency bands can be set according to the sampling rate and actual needs, such as the number of frequency points. is 24. The Bark sub-band conforms to the characteristics of the auditory system. Generally, the lower the frequency, the smaller the number of coefficients contained in the sub-band, or even a single coefficient, and the higher the frequency, the greater the number of coefficients contained in the sub-band.
在一个实施例中,对于257个系数,相邻8个系数合并成一个子带(FFT系数的第一个元素是直流分量,可以忽略)。因此,最后输出的第一增益g1(n)的维度是32维。通过第一神经网络,可以输出对应于各个子带的第一声门增益。将各个子带的第一声门增益合并得到第一增益。即,32个子带对应于第一增益的32维。In one embodiment, for 257 coefficients, adjacent 8 coefficients are combined into one subband (the first element of the FFT coefficient is the DC component, which can be ignored). Therefore, the dimension of the finally outputted first gain g1(n) is 32 dimensions. Through the first neural network, the first glottal gain corresponding to each subband can be output. The first gain is obtained by combining the first glottal gains of the respective subbands. That is, 32 subbands correspond to 32 dimensions of the first gain.
在本申请的实施例中,通过子带合并的方式根据待处理语音帧的频谱系数计算第一增益,从而能够对计算过程进行降维,从而能够取降低方案的整体计算量,从而提升计算效率。In the embodiments of the present application, the first gain is calculated according to the spectral coefficients of the speech frames to be processed by means of sub-band combining, so that the dimension of the calculation process can be reduced, the overall calculation amount of the scheme can be reduced, and the calculation efficiency can be improved. .
在本申请的一个实施例中,基于上述的技术方案,该语音处理方法还可以包括如下步骤:In an embodiment of the present application, based on the above technical solution, the voice processing method may further include the following steps:
通过第一神经网络对待处理语音帧的频谱系数和待处理语音帧的基音周期进行预测分析,确定第二声门增益,第二声门增益对应于待处理语音帧的频谱系数的长时相关性特征;The first neural network is used to predict and analyze the spectral coefficients of the speech frame to be processed and the pitch period of the speech frame to be processed, to determine the second glottal gain, and the second glottal gain corresponds to the long-term correlation of the spectral coefficients of the speech frame to be processed. feature;
将各个子带对应的第一声门增益合并作为第一增益,包括:The first glottal gain corresponding to each subband is combined as the first gain, including:
将各个子带对应的第一声门增益和第二声门增益合并作为第一增益。The first glottal gain and the second glottal gain corresponding to each subband are combined as the first gain.
在本实施例中,第一增益包括两个部分,对应于语音帧的短时相关性特征的第一声门特征以及对应于语音帧的长时相关性特征的第二声门特征。待处理语音帧的基音周期可以通过预先对待处理语音帧进行语音分解和分析来获得。第一神经网络可以根据待处理语音帧的频谱系数和基音周期直接输出第二声门增益。第二声门增益对应于声门滤波器中的LTP滤波的声门参数。因此,在训练的过程中,模型基于含在语音以及去噪语音分解得到的对应于LTP滤波器的声门参数进行训练,通过调整模型参数,使得最终输出的第一增益与去噪结果所对应的第一增益之间的均方误差相似度达到均方误差阈值,从而完成训练。第一神经网络可以一并输出第一声门增益和第二声门增益。在一个实施例中,第一神经网络可以由两个子网络构成,分别用于输出第一声门特征和第二声门特征。In this embodiment, the first gain includes two parts, a first glottal feature corresponding to the short-term correlation feature of the speech frame and a second glottal feature corresponding to the long-term correlation feature of the speech frame. The pitch period of the to-be-processed speech frame can be obtained by performing speech decomposition and analysis on the to-be-processed speech frame in advance. The first neural network can directly output the second glottal gain according to the spectral coefficient and the pitch period of the speech frame to be processed. The second glottal gain corresponds to the glottal parameter of the LTP filtering in the glottal filter. Therefore, in the training process, the model is trained based on the glottal parameters corresponding to the LTP filter obtained by decomposing the speech and the denoised speech. By adjusting the model parameters, the first gain of the final output corresponds to the denoising result. The mean square error similarity between the first gains of , reaches the mean square error threshold, thereby completing the training. The first neural network may output the first glottal gain and the second glottal gain together. In one embodiment, the first neural network may be composed of two sub-networks, which are respectively used to output the first glottal feature and the second glottal feature.
在本申请的实施例中,在第一增益的计算过程中进一步考虑到语音帧的长时相关性,使得方案对于语音帧中的语音部分的识别更加精细,从而避免增益对原始语音产生影响,提升方案的准确性。In the embodiment of the present application, the long-term correlation of the speech frame is further considered in the calculation process of the first gain, so that the solution can be more refined for the recognition of the speech part in the speech frame, so as to avoid the gain from affecting the original speech, Improve the accuracy of the program.
在本申请的一个实施例中,基于上述的技术方案,上述步骤,通过第一神经网络根据待处理语音帧的频谱系数进行增益预测,得到第一增益,可以包括如下步骤:In an embodiment of the present application, based on the above technical solution, the above steps, through the first neural network to predict the gain according to the spectral coefficient of the speech frame to be processed, to obtain the first gain, may include the following steps:
通过第一神经网络根据待处理语音帧的频谱系数进行参数预测,得到第一声门参数,第一声门参数用于表示待处理语音帧的频谱系数的短时相关性特征;Perform parameter prediction according to the spectral coefficients of the speech frame to be processed by the first neural network to obtain the first glottal parameter, and the first glottal parameter is used to represent the short-term correlation feature of the spectral coefficients of the speech frame to be processed;
通过第一神经网络根据第一声门参数进行增益预测,得到第一预测结果;The gain prediction is performed according to the first glottal parameter by the first neural network, and the first prediction result is obtained;
根据第一预测结果确定第一增益。The first gain is determined according to the first prediction result.
在本实施例中,第一神经网络会根据待处理语音帧的频谱系数来预测待处理语音帧对应的第一声门参数。第一声门参数用于表示待处理语音帧的频谱系数的短时相关性特征。具体地,第一声门参数对应于LPC滤波器。在第一神经网络的训练过程中,通过预先训练数据中含噪语音对应的去噪语音进行分解,可以确定去噪语音的LPC滤波器的配置参数,根据含噪语音的频谱系数以及去噪语音的LPC滤波器的配置参数,可以对第一神经网络进行训练,使得第一神经网络预测的第一声门参数与去噪语音的LPC滤波器的配置参数之间的均方误差满足设定的精度要求。然后,根据得到第一声门参数,第一神经网络可以预测去噪语音的频谱,并且根据预测的频谱和待处理语音帧的频谱来确定第一预测结果。第一预测结果即第一增益。In this embodiment, the first neural network predicts the first glottal parameter corresponding to the to-be-processed speech frame according to the spectral coefficient of the to-be-processed speech frame. The first glottal parameter is used to represent the short-term correlation feature of the spectral coefficients of the speech frame to be processed. Specifically, the first glottal parameter corresponds to an LPC filter. In the training process of the first neural network, by decomposing the denoised speech corresponding to the noisy speech in the pre-training data, the configuration parameters of the LPC filter of the denoised speech can be determined. According to the spectral coefficient of the noisy speech and the denoised speech The configuration parameters of the LPC filter can be trained on the first neural network, so that the mean square error between the first glottal parameters predicted by the first neural network and the configuration parameters of the LPC filter for denoising speech satisfies the set precision requirements. Then, according to the obtained first glottal parameters, the first neural network can predict the spectrum of the denoised speech, and determine the first prediction result according to the predicted spectrum and the spectrum of the speech frame to be processed. The first prediction result is the first gain.
在本实施例中,通过第一神经网络预测待处理语音帧的对应的第一声门参数,再根据第一声门参数来预测第一增益,将声门滤波器对应的声门参数预测目标,相较于对待处理语音的每个语音帧进行标注的标注结果,简化了训练数据的复杂度,从而提升计算效率。In this embodiment, the first neural network is used to predict the corresponding first glottal parameter of the speech frame to be processed, and then the first gain is predicted according to the first glottal parameter, and the target of the glottal parameter corresponding to the glottal filter is predicted. , compared with the labeling result of labeling each speech frame of the speech to be processed, the complexity of the training data is simplified, thereby improving the computational efficiency.
在本申请的一个实施例中,基于上述的技术方案,该语音处理方法还包括:In an embodiment of the present application, based on the above technical solution, the voice processing method further includes:
通过第一神经网络根据待处理语音帧的频谱系数和待处理语音帧的基音周期进行参数预测,得到第二声门参数,第二声门参数用于表示待处理语音帧的频谱系数的长时相关性特征;Through the first neural network, parameter prediction is performed according to the spectral coefficients of the speech frame to be processed and the pitch period of the speech frame to be processed, and the second glottal parameter is obtained. Correlation characteristics;
通过第一神经网络根据第二声门参数进行增益预测,得到第二预测结果;The gain prediction is performed according to the second glottal parameter by the first neural network, and the second prediction result is obtained;
根据第一预测结果确定第一增益,包括:The first gain is determined according to the first prediction result, including:
将第一预测结果和第二预测结果合并确定为第一增益。The first gain is determined by combining the first prediction result and the second prediction result.
具体地,第一神经网络会根据待处理语音帧的频谱系数和待处理语音帧待处理语音帧的基音周期预测第二声门参数。第一声门参数用于表示待处理语音帧的频谱系数的长时相关性特征。具体地,第二声门参数对应于LTP滤波器。在本实施例中,语音帧的声门模型还包括LTP滤波器。根据第一声门参数配置的LPC滤波器所生成的语音信号通过根据第二声门参数配置的LTP滤波器进行进一步的处理来模拟待处理语音帧中的语音。在训练的过程中,通过预先训练数据中含噪语音对应的去噪语音进行分解,可以确定去噪语音的LTP滤波器的配置参数,根据含噪语音的频谱系数以及去噪语音的LTP滤波器的配置参数,可以对第一神经网络进行训练,使得第一神经网络预测的第二声门参数与去噪语音的LTP滤波器的配置参数之间的均方误差满足设定的精度要求。然后,根据得到第二声门参数,第一神经网络可以结合第一预测结果来预测去噪语音的频谱,从而得到第二预测结果。第二预测结果也是第一增益的一部分,其使得基于第二预测结果得到的去噪结果中的长时相关性特征与去噪语音中的长时相关性特征相似。将第一预测结果与第二预测结果合并,可以得到第一增益。在后续的应用过程中,根据第一预测结果与第二预测结果依次对待处理语音帧进行增强,从而达到降噪的效果。Specifically, the first neural network predicts the second glottal parameter according to the spectral coefficients of the speech frame to be processed and the pitch period of the speech frame to be processed. The first glottal parameter is used to represent the long-term correlation feature of the spectral coefficients of the speech frame to be processed. Specifically, the second glottal parameter corresponds to the LTP filter. In this embodiment, the glottal model of the speech frame further includes an LTP filter. The speech signal generated by the LPC filter configured according to the first glottal parameter is further processed by the LTP filter configured according to the second glottal parameter to simulate the speech in the speech frame to be processed. During the training process, by decomposing the denoised speech corresponding to the noisy speech in the pre-training data, the configuration parameters of the LTP filter of the denoised speech can be determined. According to the spectral coefficient of the noisy speech and the LTP filter of the denoised speech The first neural network can be trained so that the mean square error between the second glottal parameters predicted by the first neural network and the configuration parameters of the LTP filter for denoising speech meets the set accuracy requirements. Then, according to the obtained second glottal parameters, the first neural network can combine the first prediction result to predict the spectrum of the denoised speech, thereby obtaining the second prediction result. The second prediction result is also a part of the first gain, which makes the long-term correlation feature in the denoised result based on the second prediction result similar to the long-term correlation feature in the denoised speech. The first gain can be obtained by combining the first prediction result with the second prediction result. In the subsequent application process, the to-be-processed speech frame is enhanced in turn according to the first prediction result and the second prediction result, so as to achieve the effect of noise reduction.
在本申请的实施例中,通过预测第二声门参数,在第一增益的预测过程中进一步考虑到语音帧的长时相关性,使得方案对于语音帧中的浊音部分的预测更加准确,从而提升方案的准确性。In the embodiment of the present application, by predicting the second glottal parameter, the long-term correlation of the speech frame is further considered in the prediction process of the first gain, so that the prediction of the voiced part in the speech frame by the scheme is more accurate, thereby Improve the accuracy of the program.
在本申请的一个实施例中,基于上述的技术方案,上述步骤S630,根据待处理语音帧的频谱系数进行激励增益计算,得到第二增益,包括:In an embodiment of the present application, based on the above technical solution, in the above step S630, the excitation gain is calculated according to the spectral coefficient of the to-be-processed speech frame to obtain the second gain, including:
将处理语音帧的频谱系数输入第二神经网络,第二神经网络是根据噪声语音帧的激励信号和噪声语音帧对应的去噪语音帧的激励信号进行训练得到的;Input the spectral coefficient of the processed speech frame into the second neural network, and the second neural network is obtained by training according to the excitation signal of the noise speech frame and the excitation signal of the denoised speech frame corresponding to the noise speech frame;
通过第二神经网络根据待处理语音帧的激励信号进行增益预测,得到第二增益。The second gain is obtained by predicting the gain according to the excitation signal of the speech frame to be processed through the second neural network.
第二神经网络是指用于预测激励信号对应的第二增益的神经网络模型,第二神经网络可以是通过长短时记忆神经网络、卷积神经网络、循环神经网络、全连接神经网络等构建的模型,在此不进行具体限定。The second neural network refers to a neural network model used to predict the second gain corresponding to the excitation signal, and the second neural network can be constructed by using a long-short-term memory neural network, a convolutional neural network, a recurrent neural network, a fully connected neural network, etc. The model is not specifically limited here.
在训练的过程中,首先对训练数据中含有噪声的语音帧进行分解,得到声门模型中激励信号对应的频率响应,然后根据含有噪声的语音帧的频谱系数和分解的到的激励信号对应的频率响应来进行训练,通过调整第二神经网络的模型参数,直至第二神经网络所输出的第二增益能够使得含噪语音帧的激励信号与去噪语音帧的激励信号之间的差异满足预设的要求。其中,预设要求可以是使得含噪语音帧的激励信号与去噪语音帧的激励信号之间相似度不低于相似度阈值。通过该训练过程,可以使得第二神经网络所预测得到的第二增益能够使得待处理语音帧在声门模型下的激励信号与纯净语音在声门模型下的激励信号足够相似,从而具备降噪能力。In the training process, the speech frames containing noise in the training data are first decomposed to obtain the frequency response corresponding to the excitation signal in the glottal model, and then according to the spectral coefficient of the speech frame containing noise and the decomposed excitation signal The frequency response is used for training, and the model parameters of the second neural network are adjusted until the second gain output by the second neural network can make the difference between the excitation signal of the noise-containing speech frame and the excitation signal of the de-noised speech frame satisfies the predetermined value. set requirements. The preset requirement may be that the similarity between the excitation signal of the noisy speech frame and the excitation signal of the denoised speech frame is not lower than the similarity threshold. Through this training process, the second gain predicted by the second neural network can make the excitation signal of the to-be-processed speech frame under the glottal model sufficiently similar to the excitation signal of the pure speech under the glottal model, so that the noise reduction can be achieved. ability.
通过第二神经网络根据待处理语音帧的频谱系数进行增益预测,得到第二增益。图8是根据一具体实施例示出的第二神经网络的结构示意图,如图8所示,第一神经网络包括三个全连接(Full Connected,FC)层。输入的F(n)为[257,2]维的频谱系数。第一个FC层的输出为[1024,1]维的向量,第二个FC层的输出为[512,1]维的向量,第三个FC层输出为[257,1]维的向量,即第二增益g12(n)。当然,图8仅仅是第二神经网络的结构的一种示例性举例,不能认为是对本申请使用范围的限制。The second gain is obtained by predicting the gain according to the spectral coefficient of the speech frame to be processed by the second neural network. FIG. 8 is a schematic structural diagram of a second neural network according to a specific embodiment. As shown in FIG. 8 , the first neural network includes three fully connected (Full Connected, FC) layers. The input F(n) is a [257,2] dimensional spectral coefficient. The output of the first FC layer is a vector of dimension [1024,1], the output of the second FC layer is a vector of dimension [512,1], and the output of the third FC layer is a vector of dimension [257,1], That is, the second gain g12(n). Of course, FIG. 8 is only an exemplary example of the structure of the second neural network, and should not be considered as a limitation on the scope of application of the present application.
在本申请的实施例中,通过神经网络获得针对于激励信号的第二增益,通过神经网络学到激励信号与第二增益之间的关系,从而能够根据声门模型对含噪语音进行降噪而不需要对含噪语音进行语音分解,从而节约计算资源。In the embodiment of the present application, the second gain for the excitation signal is obtained through the neural network, and the relationship between the excitation signal and the second gain is learned through the neural network, so that noise reduction can be performed on the noisy speech according to the glottal model. There is no need to perform speech decomposition on noisy speech, thereby saving computing resources.
在本申请的一个实施例中,基于上述的技术方案,上述步骤S650,根据第一增益、第二增益和控制系数,对待处理语音帧进行增益控制,得到目标语音帧,包括:In an embodiment of the present application, based on the above technical solution, in the above step S650, according to the first gain, the second gain and the control coefficient, gain control is performed on the speech frame to be processed to obtain the target speech frame, including:
根据第二增益对待处理语音帧进行增强,得到第一增强结果;Enhance the to-be-processed speech frame according to the second gain to obtain a first enhancement result;
根据第一增益对第一增强结果中的各个子带进行增益运算,得到第二增强结果;Perform a gain operation on each subband in the first enhancement result according to the first gain to obtain a second enhancement result;
根据控制系数,对第二增强结果进行能量补偿,得到第三增强结果;According to the control coefficient, energy compensation is performed on the second enhancement result to obtain the third enhancement result;
根据第三增强结果进行逆时频转换,得到增强后的语音帧作为目标语音帧。Inverse time-frequency conversion is performed according to the third enhancement result, and the enhanced speech frame is obtained as the target speech frame.
具体地,对于待处理语音帧的频域表示,先按照逐个样本点,根据第二增益中对应的参数进行乘法运算,得到第一增强结果。如上文所描述的,第第二增益的维度与待处理语音帧的频域表示是相对应的,即,若待处理语音帧的频域表示为257维,则第二增益也是257维。因此根据第二增益进行增强时,可以直接按照维度的对应关系进行乘法运算,从而得到第一增强结果。基于第一增强结果,根据第一增益进行增益运算。具体地,在计算第一增益时,根据子带的划分而对第一增益进行了合并。因此,在根据第一增益进行计算时,也根据子带合并的对应关系进行乘法。例如,第一增益结果中,每8个维度对应于一个子带,第一增益为32维的变量,则在根据第一增益进行计算时,第一增益结果中的每8个维度对应于第一增益中的一个维度进行计算,从而得到第二增益结果。根据控制系数,对第二增强结果进行能量补偿,得到第三增强结果。具体地,能量补偿的过程是直接将控制系数与第二增益结果求和,来得到第三增强结果,计算公式如下:Specifically, for the frequency domain representation of the to-be-processed speech frame, the first enhancement result is obtained by performing multiplication operation according to the corresponding parameters in the second gain according to the sample points one by one. As described above, the dimension of the second gain corresponds to the frequency domain representation of the speech frame to be processed, that is, if the frequency domain representation of the speech frame to be processed is 257 dimensions, the second gain is also 257 dimensions. Therefore, when the enhancement is performed according to the second gain, the multiplication operation can be directly performed according to the corresponding relationship of the dimensions, thereby obtaining the first enhancement result. Based on the first enhancement result, a gain operation is performed according to the first gain. Specifically, when calculating the first gain, the first gain is combined according to the division of the subbands. Therefore, when the calculation is performed according to the first gain, multiplication is also performed according to the corresponding relationship of sub-band combining. For example, in the first gain result, every 8 dimensions corresponds to a subband, and the first gain is a 32-dimensional variable, then when calculating according to the first gain, every 8 dimensions in the first gain result corresponds to the first gain. One dimension of a gain is calculated to obtain a second gain result. According to the control coefficient, energy compensation is performed on the second enhancement result to obtain the third enhancement result. Specifically, the energy compensation process is to directly sum the control coefficient and the second gain result to obtain the third enhancement result. The calculation formula is as follows:
S_e2(n)=S_e1(n)+g2(n)S_e2(n)=S_e1(n)+g2(n)
其中,S_e2(n)为第三增强结果,g2(n)为控制系数,S_e1(n)为第二增强结果。根据第三增强结果进行STFT反变换,即可以将频域表示变换为时域信号,从而得到增强后的语音帧,即目标语音帧。Among them, S_e2(n) is the third enhancement result, g2(n) is the control coefficient, and S_e1(n) is the second enhancement result. Inverse STFT transform is performed according to the third enhancement result, that is, the frequency domain representation can be transformed into a time domain signal, thereby obtaining an enhanced speech frame, that is, a target speech frame.
在本申请的实施例中,提供了进行增益控制的具体方式,提升了方案的可实施性。In the embodiments of the present application, a specific manner for performing gain control is provided, which improves the practicability of the solution.
下面对本申请的语音处理方法的整体流程进行介绍。为了便于介绍,请参阅图9,图9为本申请实施例中整体流程的示意图。如图9所示,方案的输入为待处理语音帧s(n)。对语音帧s(n)使用STFT时频变换,得到频谱系数S(n)。基于频谱系数S(n),调用第一神经网络,得到第一增益g11(n),并且调用第二神经网络得到第二增益g12(n),将第一增益g11(n)和第二增益g12(n)联合用于对频谱系数S(n)进行第一频谱控制(即增益控制),从而输出第一增强频谱S_e1(n)。第一频谱控制主要用于抑制语音帧中的噪声。特别地,第一神经网络和第二神经网络的输入还可以包含语音帧s(n)的历史帧(比如,第n-1、n-2帧等,依此类推)的频谱系数S_pre(n)。第三神经网络的处理过程与第一神经网络和第二神经网络的过程可以并行执行。基于频谱系数S(n),调用第三神经网络,得到控制系数g2(n)。将控制系数g2(n)应用于第一增强频谱S_e1(n),可以获得第二增强频谱S_e2(n)。第二频谱控制主要用于能量补偿。特别地,第三神经网络的输入也可以包含语音帧s(n)的历史帧的频谱系数S_pre(n)。最后根据第二增强频谱S_e2(n)进行逆时频转换,得到语音帧对应的增强并且补充后的信号s_e(n)。The overall flow of the speech processing method of the present application will be introduced below. For the convenience of introduction, please refer to FIG. 9 , which is a schematic diagram of an overall process in an embodiment of the present application. As shown in Figure 9, the input of the scheme is the speech frame s(n) to be processed. The STFT time-frequency transform is applied to the speech frame s(n) to obtain the spectral coefficients S(n). Based on the spectral coefficient S(n), the first neural network is called to obtain the first gain g11(n), and the second neural network is called to obtain the second gain g12(n), and the first gain g11(n) and the second gain are combined g12(n) is jointly used to perform first spectral control (ie gain control) on the spectral coefficient S(n), thereby outputting the first enhanced spectrum S_e1(n). The first spectral control is mainly used to suppress noise in speech frames. In particular, the input of the first neural network and the second neural network may also include the spectral coefficients S_pre(n) of the historical frames (eg, the n-1th, n-2th frame, etc., etc.) of the speech frame s(n) ). The processing of the third neural network may be performed in parallel with the processes of the first neural network and the second neural network. Based on the spectral coefficient S(n), the third neural network is called to obtain the control coefficient g2(n). Applying the control coefficient g2(n) to the first enhanced spectrum S_e1(n), the second enhanced spectrum S_e2(n) can be obtained. The second spectrum control is mainly used for energy compensation. In particular, the input of the third neural network may also contain spectral coefficients S_pre(n) of historical frames of speech frame s(n). Finally, inverse time-frequency conversion is performed according to the second enhanced spectrum S_e2(n) to obtain the enhanced and supplemented signal s_e(n) corresponding to the speech frame.
在本申请的一个实施例中,基于上述的技术方案,图9中所示的并行过程也可以串行执行。对此,上述步骤S640,根据待处理语音帧的频谱系数进行补偿预测,得到控制系数,包括:In an embodiment of the present application, based on the above technical solution, the parallel process shown in FIG. 9 can also be executed serially. In this regard, in the above step S640, compensation prediction is performed according to the spectral coefficients of the speech frames to be processed to obtain control coefficients, including:
根据第一增益和第二增益,对待处理语音帧进行增益控制,得到增益控制结果;According to the first gain and the second gain, gain control is performed on the speech frame to be processed to obtain a gain control result;
根据增益控制结果和待处理语音帧的频谱系数进行补偿预测,得到控制系数。Compensation prediction is performed according to the gain control result and the spectral coefficient of the speech frame to be processed to obtain the control coefficient.
在本申请的实施例中,上述图9中所示的第一神经网络和第二神经网络的计算过程与第三神经网络的计算过程串行执行。具体地,首先根据第一增益和第二增益,对待处理语音帧进行增益控制,得到增益控制结果,然后再根据增益控制结果和待处理语音帧的频谱系数进行补偿预测,得到控制系数。具体地,为了便于介绍,请参阅图10,图10为本申请实施例中的另一种方案整体流程的示意图。如图10所示,方案的输入为待处理语音帧s(n)。对语音帧s(n)使用STFT时频变换,得到频谱系数S(n)。基于频谱系数S(n),调用第一神经网络,得到第一增益g11(n),并且调用第二神经网络得到第二增益g12(n),将第一增益g11(n)和第二增益g12(n)联合用于对频谱系数S(n)进行第一频谱控制(即增益控制),从而输出第一增强频谱S_e1(n)之后,第三神经网络的计算基于第一增强频谱S_e1(n)执行。具体地,基于S(n)和S_e1(n),调用第三神经网络,获得语音帧的控制系数,g2(n)。将控制系数g2(n)应用于第一增强频谱S_e1(n),获得第二增强频谱,S_e2(n)。第二频谱控制主要用于能量补偿。随后,对第二增强频谱S_e2(n)执行逆时频转换,得到语音帧对应的增强并且补充后的信号第二增强频谱s_e(n)。In the embodiment of the present application, the calculation process of the first neural network and the second neural network shown in FIG. 9 and the calculation process of the third neural network are performed in series. Specifically, first gain control is performed on the speech frame to be processed according to the first gain and the second gain to obtain the gain control result, and then compensation prediction is performed according to the gain control result and the spectral coefficient of the speech frame to be processed to obtain the control coefficient. Specifically, for the convenience of introduction, please refer to FIG. 10 , which is a schematic diagram of the overall flow of another solution in the embodiment of the present application. As shown in Figure 10, the input of the scheme is the speech frame s(n) to be processed. The STFT time-frequency transform is applied to the speech frame s(n) to obtain the spectral coefficients S(n). Based on the spectral coefficient S(n), the first neural network is called to obtain the first gain g11(n), and the second neural network is called to obtain the second gain g12(n), and the first gain g11(n) and the second gain are combined g12(n) is jointly used to perform the first spectral control (ie gain control) on the spectral coefficient S(n), so as to output the first enhanced spectrum S_e1(n), the calculation of the third neural network is based on the first enhanced spectrum S_e1( n) execute. Specifically, based on S(n) and S_e1(n), the third neural network is called to obtain the control coefficient of the speech frame, g2(n). The control coefficient g2(n) is applied to the first enhanced spectrum S_e1(n) to obtain a second enhanced spectrum, S_e2(n). The second spectrum control is mainly used for energy compensation. Then, inverse time-frequency conversion is performed on the second enhanced spectrum S_e2(n) to obtain a second enhanced and supplemented signal second enhanced spectrum s_e(n) corresponding to the speech frame.
可以理解的是,在本申请的方案中,第三神经网络的输入包括根据第一神经网络和第二神经网络的输出结果进行增益控制的增益结果,因此,可以第三神经网络的训练过程与第一神经网络和第二神经网络的训练过程联合执行,在根据最后的结果来调整三个神经网络的模型参数。第三神经网络的训练过程也可以单独执行,其所采用的训练数据可以利用训练好的第一神经网络和第二神经网络根据训练数据中的噪声语音帧生成,也可以通过额外的数据准备过程直接生成,例如通过人工计算得到。It can be understood that, in the solution of the present application, the input of the third neural network includes the gain result of gain control according to the output results of the first neural network and the second neural network. Therefore, the training process of the third neural network can be the same as that of the second neural network. The training process of the first neural network and the second neural network is performed jointly, and the model parameters of the three neural networks are adjusted according to the final results. The training process of the third neural network can also be performed separately, and the training data used can be generated by using the trained first neural network and the second neural network according to the noisy speech frames in the training data, or through an additional data preparation process Generated directly, eg by manual calculation.
在本申请的实施例中,补偿预测过程基于增益控制的结果进行,从而使得补偿过程可以根据增益控制的结果来进行相对应的补偿估计,从而使得所得到的控制系数更符合实际所需要的补偿,提升控制系数的准确性和补偿效果。In the embodiment of the present application, the compensation prediction process is performed based on the result of the gain control, so that the compensation process can perform a corresponding compensation estimation according to the result of the gain control, so that the obtained control coefficient is more in line with the actual compensation required , to improve the accuracy of the control coefficient and the compensation effect.
在本申请的一个实施例中,基于上述的技术方案,本申请的增益控制和补偿控制也可以基于待处理语音帧的幅度谱来进行,对此,该语音处理方法还包括:In an embodiment of the present application, based on the above technical solution, the gain control and compensation control of the present application can also be performed based on the amplitude spectrum of the speech frame to be processed. For this, the speech processing method further includes:
根据待处理语音帧计算待处理语音帧对应的幅度谱和相位谱;Calculate the amplitude spectrum and phase spectrum corresponding to the to-be-processed speech frame according to the to-be-processed speech frame;
上述步骤S650,根据第一增益、第二增益和控制系数,对待处理语音帧进行增益控制,得到目标语音帧,包括:In the above step S650, according to the first gain, the second gain and the control coefficient, gain control is performed on the speech frame to be processed to obtain the target speech frame, including:
根据第一增益和第二增益,对待处理语音帧对应的幅度谱进行增益控制,得到增强后的幅度谱;According to the first gain and the second gain, gain control is performed on the amplitude spectrum corresponding to the speech frame to be processed to obtain an enhanced amplitude spectrum;
根据增强后的幅度谱和控制系数进行能量补偿,得到补偿后的幅度谱;Perform energy compensation according to the enhanced amplitude spectrum and control coefficient to obtain the compensated amplitude spectrum;
根据补偿后的幅度谱以及待处理语音帧对应的相位谱进行逆时频转换,得到目标语音帧。Inverse time-frequency conversion is performed according to the compensated amplitude spectrum and the phase spectrum corresponding to the speech frame to be processed to obtain the target speech frame.
具体地,对待处理语音帧进行时频变换,可以得到待处理语音帧对应的幅度谱和相位谱。随后,根据第一增益和第二增益,对待处理语音帧对应的幅度谱进行增益控制,得到增强后的幅度谱。在一个实施例中,第一增益和第二增益的计算过程也可以根据幅度谱进行计算。具体地,可以将上述实施例中的根据待处理语音帧的频谱系数进行的计算和处理替换为根据幅度谱进行。可以理解的是,在根据第一神经网络和第二神经网络进行增益控制的方案中,这两个神经网络在训练的过程中也会采用幅度谱来进行训练。之后,根据增强后的幅度谱和控制系数进行能量补偿,得到补偿后的幅度谱。复用待处理语音帧的相位谱,与补偿后的幅度谱一起生成第二增强频谱,然后根据第二增强频谱进行逆时频转换,得到目标语音帧。Specifically, by performing time-frequency transformation on the speech frame to be processed, the amplitude spectrum and phase spectrum corresponding to the speech frame to be processed can be obtained. Then, according to the first gain and the second gain, gain control is performed on the amplitude spectrum corresponding to the speech frame to be processed to obtain an enhanced amplitude spectrum. In one embodiment, the calculation process of the first gain and the second gain may also be calculated according to the amplitude spectrum. Specifically, the calculation and processing performed according to the spectral coefficients of the speech frames to be processed in the above-mentioned embodiments may be replaced with performing according to the amplitude spectrum. It can be understood that, in the scheme of performing gain control according to the first neural network and the second neural network, the two neural networks also use the amplitude spectrum for training during the training process. After that, energy compensation is performed according to the enhanced amplitude spectrum and the control coefficient to obtain the compensated amplitude spectrum. The phase spectrum of the speech frame to be processed is multiplexed, a second enhanced spectrum is generated together with the compensated amplitude spectrum, and then inverse time-frequency conversion is performed according to the second enhanced spectrum to obtain the target speech frame.
在一个实施例中,能量补偿可以基于频谱系数来进行,即将增强后的幅度谱与待处理语音帧对应的相位谱进行计算,得到第一增强频谱。随后,在根据第一增强频谱进行后续的能量补偿过程。In one embodiment, the energy compensation may be performed based on spectral coefficients, that is, the first enhanced spectrum is obtained by calculating the enhanced amplitude spectrum and the phase spectrum corresponding to the speech frame to be processed. Then, the subsequent energy compensation process is performed according to the first enhanced spectrum.
在本申请的方案中,根据幅度谱来进行增益控制和能量补偿的计算过程,为本申请的方案提供了另一种具体实现方式,提升方案的多样性。In the solution of the present application, the calculation process of gain control and energy compensation is performed according to the amplitude spectrum, which provides another specific implementation manner of the solution of the present application and improves the diversity of the solution.
在本申请的一个实施例中,基于上述的技术方案,上述步骤S640,根据待处理语音帧的频谱系数进行补偿预测,得到控制系数,可以包括如下步骤:In an embodiment of the present application, based on the above technical solution, the above step S640, performing compensation prediction according to the spectral coefficients of the speech frames to be processed to obtain the control coefficients, may include the following steps:
获取待处理语音帧的历史语音帧的频谱系数;Obtain the spectral coefficients of the historical speech frames of the speech frames to be processed;
将待处理语音帧的频谱系数和历史语音帧的频谱系数输入第三神经网络,第三神经网络是根据噪声语音帧对应的频谱系数的能量和噪声语音帧对应的去噪语音帧对应的频谱系数的能量进行训练得到的;Input the spectral coefficient of the speech frame to be processed and the spectral coefficient of the historical speech frame into the third neural network, and the third neural network is based on the energy of the spectral coefficient corresponding to the noise speech frame and the spectral coefficient corresponding to the denoised speech frame corresponding to the noise speech frame energy obtained from training;
通过第三神经网络根据待处理语音帧的频谱系数进行补偿预测,得到控制系数。The third neural network performs compensation prediction according to the spectral coefficients of the speech frames to be processed to obtain the control coefficients.
第三神经网络是指用于进行补偿预测的神经网络模型,第三神经网络可以是通过长短时记忆神经网络、卷积神经网络、循环神经网络、全连接神经网络等构建的模型,在此不进行具体限定。The third neural network refers to the neural network model used for compensation prediction. The third neural network can be a model constructed by long-short-term memory neural network, convolutional neural network, recurrent neural network, fully connected neural network, etc. Make specific restrictions.
第三神经网络的输入为待处理语音帧的频谱系数,而输出则为待处理语音帧对应的控制系数。控制系数是一组二维向量,分别代表频谱系数的实部和虚部;其中,控制系数将作用于根据第一增益和第二增益的增强结果,获得第二增强频谱,用于能量补偿。The input of the third neural network is the spectral coefficient of the speech frame to be processed, and the output is the control coefficient corresponding to the speech frame to be processed. The control coefficients are a set of two-dimensional vectors, respectively representing the real and imaginary parts of the spectral coefficients; wherein, the control coefficients will act on the enhancement results according to the first gain and the second gain to obtain a second enhanced spectrum for energy compensation.
第三神经网络的训练过程可以独立进行,也可以与第一神经网网络以及第二神经网络的过程一同进行。在训练时,将训练数据中噪声语音帧的频谱系数和噪声语音帧对应的去噪语音帧的频谱系数输入到第三神经网络进行预测,得到输出的预测控制系数。通过调整第三神经网络的模型参数,使得输出的预测控制系数能够使得补偿过后的目标语音帧的能量与未处理之前的噪声语音帧的能量之间的差异满足预设要求。在本实施例中,将待处理语音帧的频谱系数和历史语音帧的频谱系数输入第三神经网络。因此,在训练的过程中,将历史语音帧的频谱系数也一同输入到第三神经网络进行训练。通过第三神经网络根据待处理语音帧的频谱系数进行补偿预测,得到控制系数。The training process of the third neural network may be performed independently, or may be performed together with the processes of the first neural network and the second neural network. During training, the spectral coefficients of the noise speech frames in the training data and the spectral coefficients of the denoised speech frames corresponding to the noise speech frames are input into the third neural network for prediction, and the output prediction control coefficients are obtained. By adjusting the model parameters of the third neural network, the output predictive control coefficient can make the difference between the energy of the compensated target speech frame and the energy of the unprocessed noise speech frame meet the preset requirements. In this embodiment, the spectral coefficients of the speech frames to be processed and the spectral coefficients of the historical speech frames are input into the third neural network. Therefore, in the training process, the spectral coefficients of the historical speech frames are also input into the third neural network for training. The third neural network performs compensation prediction according to the spectral coefficients of the speech frames to be processed to obtain the control coefficients.
图11是根据一具体实施例示出的第三神经网络的结构示意图,如图11所示,预处理神经网络包括6个卷积层和一个长短期记忆网络(Long Short-Term Memory,LSTM)层。输入的S(n)采用频谱系数表示,因此为[2,257]维的频谱系数。图11中每个卷积层和LSTM层均标注了该层输出的变量的维度,第一卷积层输出[16,127]维的变量,第二卷积层输出[32,62]维的变量,第三卷积层输出[64,29]维的变量,第四卷积层输出[128,13]维的变量,第五卷积层输出[128,5]维的变量,第六卷积层输出[128,1]维的变量,LSTM层输出[2,257]维的变量。LSTM增输出的变量就是控制系数g2(n),它是[2,257]维的向量。应理解,图11仅仅是预处理神经网络的结构的一种示例性举例,不能认为是对本申请使用范围的限制。在另一个实施例中,第三神经网络的输入可以是S(n)和第二增强结果S_e1(n),其他结构与上述相同,此处不再赘述。FIG. 11 is a schematic structural diagram of a third neural network according to a specific embodiment. As shown in FIG. 11 , the preprocessing neural network includes 6 convolutional layers and a Long Short-Term Memory (LSTM) layer . The input S(n) is represented by spectral coefficients, so it is a [2,257] dimensional spectral coefficient. In Figure 11, each convolutional layer and LSTM layer are marked with the dimensions of the variables output by the layer. The first convolutional layer outputs [16,127]-dimensional variables, and the second convolutional layer outputs [32,62]-dimensional variables, The third convolutional layer outputs [64,29]-dimensional variables, the fourth convolutional layer outputs [128,13]-dimensional variables, the fifth convolutional layer outputs [128,5]-dimensional variables, and the sixth convolutional layer outputs Output [128, 1] dimensional variables, and the LSTM layer outputs [2, 257] dimensional variables. The variable output by LSTM is the control coefficient g2(n), which is a [2,257]-dimensional vector. It should be understood that FIG. 11 is only an exemplary example of the structure of the preprocessing neural network, and should not be considered as a limitation on the scope of application of the present application. In another embodiment, the input of the third neural network may be S(n) and the second enhancement result S_e1(n), and other structures are the same as the above, and are not repeated here.
在本申请的实施例中,将历史语音帧作为输入,与待处理语音帧一起进行处理,从而在特征提取的过程中能够更加充分地考虑到相邻语音帧之间的联系,从而提升特征提取的准确性。In the embodiments of the present application, historical speech frames are used as input and processed together with the speech frames to be processed, so that the relationship between adjacent speech frames can be more fully considered in the process of feature extraction, thereby improving feature extraction. accuracy.
应当注意,尽管在附图中以特定顺序描述了本申请中方法的各个步骤,但是,这并非要求或者暗示必须按照该特定顺序来执行这些步骤,或是必须执行全部所示的步骤才能实现期望的结果。附加的或备选的,可以省略某些步骤,将多个步骤合并为一个步骤执行,以及/或者将一个步骤分解为多个步骤执行等。It should be noted that although the various steps of the methods of the present application are depicted in the figures in a particular order, this does not require or imply that the steps must be performed in that particular order, or that all illustrated steps must be performed to achieve the desired the result of. Additionally or alternatively, certain steps may be omitted, multiple steps may be combined into one step for execution, and/or one step may be decomposed into multiple steps for execution, and the like.
以下介绍本申请的装置实施,可以用于执行本申请上述实施例中的语音处理方法。图12示意性地示出了本申请实施例中语音处理装置的组成框图。如图12所示,语音处理装置1200主要可以包括:The following describes the implementation of the apparatus of the present application, which can be used to execute the speech processing method in the above-mentioned embodiments of the present application. FIG. 12 schematically shows a block diagram of the composition of the speech processing apparatus in the embodiment of the present application. As shown in FIG. 12 , the
频谱系数获取模块1210,用于获取待处理语音帧的频谱系数;a spectral
声门增益模块1220,用于根据所述待处理语音帧的频谱系数进行声门增益计算,得到第一增益,所述第一增益对应于所述待处理语音帧的声门特征;The
激励增益模块1230,用于根据所述待处理语音帧的频谱系数进行激励增益计算,得到第二增益,所述第二增益对应于所述待处理语音帧的激励信号;The
补偿预测模块1240,用于根据所述待处理语音帧的频谱系数进行补偿预测,得到控制系数,所述控制系数是根据所述待处理音频帧的频谱系数的能量确定的;a
增益控制模块1250,用于根据所述第一增益、所述第二增益和所述控制系数,对所述待处理语音帧进行增益控制,得到目标语音帧。The
在本申请的一些实施例中,基于以上技术方案,声门增益模块1220包括:In some embodiments of the present application, based on the above technical solutions, the
第一输入子单元,用于将所述待处理语音帧的频谱系数输入第一神经网络,所述第一神经网络是根据噪声语音帧对应的声门特征和所述噪声语音帧对应的去噪语音帧对应的声门特征进行训练得到的;The first input subunit is used to input the spectral coefficient of the speech frame to be processed into the first neural network, and the first neural network is based on the glottal feature corresponding to the noise speech frame and the noise removal corresponding to the noise speech frame. The glottal feature corresponding to the speech frame is obtained by training;
增益预测子模块,用于通过所述第一神经网络根据所述待处理语音帧的频谱系数进行增益预测,得到所述第一增益。A gain prediction sub-module, configured to perform gain prediction according to the spectral coefficients of the speech frames to be processed through the first neural network to obtain the first gain.
在本申请的一些实施例中,基于以上技术方案,语音处理装置1200还包括:In some embodiments of the present application, based on the above technical solutions, the
历史帧频谱系数获取模块,用于获取所述待处理语音帧的历史语音帧的频谱系数;A historical frame spectral coefficient acquisition module, used for acquiring the spectral coefficients of the historical voice frames of the to-be-processed voice frames;
第一输入子模块包括:历史帧输入单元,用于将所述待处理语音帧的频谱系数和所述历史语音帧的频谱系数输入到第一神经网络。The first input sub-module includes: a historical frame input unit, configured to input the spectral coefficients of the speech frames to be processed and the spectral coefficients of the historical speech frames into the first neural network.
在本申请的一些实施例中,基于以上技术方案,声门增益模块1220包括:In some embodiments of the present application, based on the above technical solutions, the
第一增益计算子模块,用于通过所述第一神经网络对所述待处理语音帧的频谱系数进行增益计算,得到所述待处理语音帧中各个子带对应的第一声门增益,其中,所述子带对应于所述待处理语音帧的频谱系数中至少一个频带;a first gain calculation submodule, configured to perform gain calculation on the spectral coefficients of the to-be-processed speech frame through the first neural network to obtain the first glottal gain corresponding to each subband in the to-be-processed speech frame, wherein , the subband corresponds to at least one frequency band in the spectral coefficients of the speech frame to be processed;
子带增益合并子模块,用于将所述各个子带对应的第一声门增益合并作为所述第一增益。The sub-band gain combining sub-module is configured to combine the first glottal gains corresponding to the respective sub-bands as the first gain.
在本申请的一些实施例中,基于以上技术方案,语音处理装置1200还包括:In some embodiments of the present application, based on the above technical solutions, the
第二增益计算子模块,用于通过所述第一神经网络对所述待处理语音帧的频谱系数和所述待处理语音帧的基音周期进行预测分析,确定第二声门增益,所述第二声门增益对应于所述待处理语音帧的频谱系数的长时相关性特征;The second gain calculation sub-module is configured to perform predictive analysis on the spectral coefficient of the speech frame to be processed and the pitch period of the speech frame to be processed through the first neural network, and determine the second glottal gain, the first The glottal gain corresponds to the long-term correlation feature of the spectral coefficients of the speech frame to be processed;
子带增益合并子模块包括:The sub-band gain combining sub-module includes:
声门增益合并单元,用于将所述各个子带对应的第一声门增益和所述第二声门增益合并作为所述第一增益。A glottal gain combining unit, configured to combine the first glottal gain and the second glottal gain corresponding to the respective subbands as the first gain.
在本申请的一些实施例中,基于以上技术方案,第一增益计算子模块包括:In some embodiments of the present application, based on the above technical solutions, the first gain calculation submodule includes:
第一声门参数预测单元,用于通过所述第一神经网络根据所述待处理语音帧的频谱系数进行参数预测,得到第一声门参数,所述第一声门参数用于表示所述待处理语音帧的频谱系数的短时相关性特征;a first glottal parameter prediction unit, configured to perform parameter prediction according to the spectral coefficients of the speech frames to be processed through the first neural network to obtain a first glottal parameter, where the first glottal parameter is used to represent the Short-term correlation characteristics of spectral coefficients of to-be-processed speech frames;
第一预测单元,用于通过所述第一神经网络根据所述第一声门参数进行增益预测,得到所述第一预测结果;a first prediction unit, configured to perform gain prediction according to the first glottal parameter through the first neural network to obtain the first prediction result;
结果确定单元,用于根据所述第一预测结果确定所述第一增益。A result determining unit, configured to determine the first gain according to the first prediction result.
在本申请的一些实施例中,基于以上技术方案,语音处理装置1200还包括:In some embodiments of the present application, based on the above technical solutions, the
第二声门参数预测单元,用于通过所述第一神经网络根据所述待处理语音帧的频谱系数和所述待处理语音帧的基音周期进行参数预测,得到第二声门参数,所述第一声门参数用于表示所述待处理语音帧的频谱系数的长时相关性特征;The second glottal parameter prediction unit is configured to perform parameter prediction according to the spectral coefficient of the speech frame to be processed and the pitch period of the speech frame to be processed through the first neural network to obtain the second glottal parameter, the The first glottal parameter is used to represent the long-term correlation feature of the spectral coefficients of the speech frame to be processed;
第二预测单元,用于通过所述第一神经网络根据所述第二声门参数进行增益预测,得到第二预测结果;a second prediction unit, configured to perform gain prediction according to the second glottal parameter through the first neural network to obtain a second prediction result;
结果确定单元包括:The result determination unit includes:
结果合并子单元,用于将所述第一预测结果和所述第二预测结果合并确定为所述第一增益。A result combining subunit, configured to combine the first prediction result and the second prediction result to determine the first gain.
在本申请的一些实施例中,基于以上技术方案,激励增益模块1230包括:In some embodiments of the present application, based on the above technical solutions, the
第二输入子模块,用于将所述待处理语音帧的频谱系数输入第二神经网络,所述第二神经网络是根据噪声语音帧的激励信号和所述噪声语音帧对应的去噪语音帧的激励信号进行训练得到的;The second input sub-module is used to input the spectral coefficients of the speech frame to be processed into a second neural network, where the second neural network is based on the excitation signal of the noise speech frame and the denoised speech frame corresponding to the noise speech frame obtained by training with the excitation signal;
语音分解子模块,用于通过所述第二神经网络对所述待处理语音帧的频谱系数进行语音分解,得到激励信号;A speech decomposition sub-module, configured to perform speech decomposition on the spectral coefficients of the to-be-processed speech frames through the second neural network to obtain an excitation signal;
增益预测子模块,用于通过所述第二神经网络根据所述激励信号进行增益预测,得到所述第二增益。A gain prediction sub-module, configured to perform gain prediction according to the excitation signal through the second neural network to obtain the second gain.
在本申请的一些实施例中,基于以上技术方案,增益控制模块1250包括:In some embodiments of the present application, based on the above technical solutions, the
第一增强子模块,用于根据所述第二增益对所述待处理语音帧进行增强,得到第一增强结果;a first enhancement submodule, configured to enhance the to-be-processed speech frame according to the second gain to obtain a first enhancement result;
第二增强子模块,用于根据所述第一增益对所述第一增强结果中的各个子带进行增益运算,得到第二增强结果;a second enhancement sub-module, configured to perform a gain operation on each subband in the first enhancement result according to the first gain to obtain a second enhancement result;
能量补偿子模块,用于根据所述控制系数,对所述第二增强结果进行能量补偿,得到第三增强结果;an energy compensation sub-module, configured to perform energy compensation on the second enhancement result according to the control coefficient to obtain a third enhancement result;
逆时频转换子模块,用于根据所述第三增强结果进行逆时频转换,得到增强后的语音帧作为目标语音帧。The inverse time-frequency conversion sub-module is configured to perform inverse time-frequency conversion according to the third enhancement result, and obtain the enhanced speech frame as the target speech frame.
在本申请的一些实施例中,基于以上技术方案,补偿预测模块1240包括:In some embodiments of the present application, based on the above technical solutions, the
增益控制子模块,用于根据所述第一增益和所述第二增益,对所述待处理语音帧进行增益控制,得到增益控制结果;A gain control submodule, configured to perform gain control on the to-be-processed speech frame according to the first gain and the second gain, to obtain a gain control result;
控制系数预测子模块,用于根据所述增益控制结果和所述待处理语音帧的频谱系数进行补偿预测,得到所述控制系数。A control coefficient prediction sub-module, configured to perform compensation prediction according to the gain control result and the spectral coefficient of the to-be-processed speech frame to obtain the control coefficient.
在本申请的一些实施例中,基于以上技术方案,语音处理装置1200还包括:In some embodiments of the present application, based on the above technical solutions, the
幅度谱计算模块,用于根据所述待处理语音帧计算所述待处理语音帧对应的幅度谱和相位谱;an amplitude spectrum calculation module, configured to calculate the corresponding amplitude spectrum and phase spectrum of the to-be-processed voice frame according to the to-be-processed voice frame;
增益控制模块1250包括:
幅度谱增益控制子模块,用于根据所述第一增益和所述第二增益,对所述待处理语音帧对应的幅度谱进行增益控制,得到增强后的幅度谱;an amplitude spectrum gain control sub-module, configured to perform gain control on the amplitude spectrum corresponding to the to-be-processed speech frame according to the first gain and the second gain, to obtain an enhanced amplitude spectrum;
幅度谱能量补偿子模块,用于根据所述增强后的幅度谱和所述控制系数进行能量补偿,得到补偿后的幅度谱;an amplitude spectrum energy compensation sub-module, configured to perform energy compensation according to the enhanced amplitude spectrum and the control coefficient to obtain a compensated amplitude spectrum;
幅度谱逆时频转换子模块,用于根据所述补偿后的幅度谱以及所述待处理语音帧对应的相位谱进行逆时频转换,得到目标语音帧。The amplitude spectrum inverse time-frequency conversion sub-module is configured to perform inverse time-frequency conversion according to the compensated amplitude spectrum and the phase spectrum corresponding to the to-be-processed voice frame to obtain a target voice frame.
在本申请的一些实施例中,基于以上技术方案,补偿预测模块1240包括:In some embodiments of the present application, based on the above technical solutions, the
历史频谱系数获取子模块,用于获取所述待处理语音帧的历史语音帧的频谱系数;A historical spectral coefficient acquisition sub-module, used for acquiring the spectral coefficients of the historical voice frames of the to-be-processed voice frames;
第三输入子模块,用于将所述待处理语音帧的频谱系数和所述历史语音帧的频谱系数输入第三神经网络,所述第三神经网络是根据噪声语音帧对应的频谱系数的能量和所述噪声语音帧对应的去噪语音帧对应的频谱系数的能量进行训练得到的;The third input sub-module is used to input the spectral coefficients of the speech frames to be processed and the spectral coefficients of the historical speech frames into a third neural network, where the third neural network is based on the energy of the spectral coefficients corresponding to the noise speech frames Obtained by training with the energy of the spectral coefficient corresponding to the denoised speech frame corresponding to the noise speech frame;
补偿预测子模块,用于通过所述第三神经网络根据所述待处理语音帧的频谱系数进行补偿预测,得到所述控制系数Compensation prediction sub-module for performing compensation prediction according to the spectral coefficients of the speech frames to be processed through the third neural network to obtain the control coefficients
需要说明的是,上述实施例所提供的装置与上述实施例所提供的方法属于同一构思,其中各个模块执行操作的具体方式已经在方法实施例中进行了详细描述,此处不再赘述。It should be noted that the apparatus provided by the above embodiments and the methods provided by the above embodiments belong to the same concept, and the specific manner in which each module performs operations has been described in detail in the method embodiments, which will not be repeated here.
图13示出了适于用来实现本申请实施例的电子设备的计算机系统的结构示意图。FIG. 13 shows a schematic structural diagram of a computer system suitable for implementing the electronic device according to the embodiment of the present application.
需要说明的是,图13示出的电子设备的计算机系统1300仅是一个示例,不应对本申请实施例的功能和使用范围带来任何限制。It should be noted that the
如图13所示,计算机系统1300包括中央处理单元(Central Processing Unit,CPU)1301,其可以根据存储在只读存储器(Read-Only Memory,ROM)1302中的程序或者从储存部分1308加载到随机访问存储器(Random Access Memory,RAM)1303中的程序而执行各种适当的动作和处理。在RAM 1303中,还存储有系统操作所需的各种程序和数据。CPU1301、ROM1302以及RAM 1303通过总线1304彼此相连。输入/输出(Input/Output,I/O)接口1305也连接至总线1304。As shown in FIG. 13 , the
以下部件连接至I/O接口1305:包括键盘、鼠标等的输入部分1306;包括诸如阴极射线管(Cathode Ray Tube,CRT)、液晶显示器(Liquid Crystal Display,LCD)等以及扬声器等的输出部分1307;包括硬盘等的储存部分1308;以及包括诸如LAN(Local AreaNetwork,局域网)卡、调制解调器等的网络接口卡的通信部分1309。通信部分1309经由诸如因特网的网络执行通信处理。驱动器1310也根据需要连接至I/O接口1305。可拆卸介质1311,诸如磁盘、光盘、磁光盘、半导体存储器等等,根据需要安装在驱动器1310上,以便于从其上读出的计算机程序根据需要被安装入储存部分1308。The following components are connected to the I/O interface 1305: an
特别地,根据本申请的实施例,各个方法流程图中所描述的过程可以被实现为计算机软件程序。例如,本申请的实施例包括一种计算机程序产品,其包括承载在计算机可读介质上的计算机程序,该计算机程序包含用于执行流程图所示的方法的程序代码。在这样的实施例中,该计算机程序可以通过通信部分1309从网络上被下载和安装,和/或从可拆卸介质1311被安装。在该计算机程序被中央处理单元(CPU)1301执行时,执行本申请的系统中限定的各种功能。In particular, according to the embodiments of the present application, the processes described in the flowcharts of the respective methods may be implemented as computer software programs. For example, embodiments of the present application include a computer program product comprising a computer program carried on a computer-readable medium, the computer program containing program code for performing the method illustrated in the flowchart. In such an embodiment, the computer program may be downloaded and installed from the network via the
需要说明的是,本申请实施例所示的计算机可读介质可以是计算机可读信号介质或者计算机可读存储介质或者是上述两者的任意组合。计算机可读存储介质例如可以是——但不限于——电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。计算机可读存储介质的更具体的例子可以包括但不限于:具有一个或多个导线的电连接、便携式计算机磁盘、硬盘、随机访问存储器(RAM)、只读存储器(ROM)、可擦式可编程只读存储器(Erasable Programmable Read Only Memory,EPROM)、闪存、光纤、便携式紧凑磁盘只读存储器(Compact Disc Read-Only Memory,CD-ROM)、光存储器件、磁存储器件、或者上述的任意合适的组合。在本申请中,计算机可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。而在本申请中,计算机可读的信号介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了计算机可读的程序代码。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任意合适的组合。计算机可读的信号介质还可以是计算机可读存储介质以外的任何计算机可读介质,该计算机可读介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。计算机可读介质上包含的程序代码可以用任何适当的介质传输,包括但不限于:无线、有线等等,或者上述的任意合适的组合。It should be noted that the computer-readable medium shown in the embodiments of the present application may be a computer-readable signal medium or a computer-readable storage medium, or any combination of the above two. The computer readable storage medium can be, for example, but not limited to, an electrical, magnetic, optical, electromagnetic, infrared, or semiconductor system, apparatus or device, or a combination of any of the above. More specific examples of computer readable storage media may include, but are not limited to, electrical connections having one or more wires, portable computer disks, hard disks, random access memory (RAM), read only memory (ROM), erasable Erasable Programmable Read Only Memory (EPROM), flash memory, optical fiber, portable Compact Disc Read-Only Memory (CD-ROM), optical storage device, magnetic storage device, or any suitable of the above The combination. In this application, a computer-readable storage medium can be any tangible medium that contains or stores a program that can be used by or in conjunction with an instruction execution system, apparatus, or device. In this application, however, a computer-readable signal medium may include a data signal propagated in baseband or as part of a carrier wave, carrying computer-readable program code therein. Such propagated data signals may take a variety of forms, including but not limited to electromagnetic signals, optical signals, or any suitable combination of the foregoing. A computer-readable signal medium can also be any computer-readable medium other than a computer-readable storage medium that can transmit, propagate, or transport the program for use by or in connection with the instruction execution system, apparatus, or device . Program code embodied on a computer-readable medium may be transmitted using any suitable medium, including but not limited to wireless, wired, etc., or any suitable combination of the foregoing.
附图中的流程图和框图,图示了按照本申请各种实施例的系统、方法和计算机程序产品的可能实现的体系架构、功能和操作。在这点上,流程图或框图中的每个方框可以代表一个模块、程序段、或代码的一部分,上述模块、程序段、或代码的一部分包含一个或多个用于实现规定的逻辑功能的可执行指令。也应当注意,在有些作为替换的实现中,方框中所标注的功能也可以以不同于附图中所标注的顺序发生。例如,两个接连地表示的方框实际上可以基本并行地执行,它们有时也可以按相反的顺序执行,这依所涉及的功能而定。也要注意的是,框图或流程图中的每个方框、以及框图或流程图中的方框的组合,可以用执行规定的功能或操作的专用的基于硬件的系统来实现,或者可以用专用硬件与计算机指令的组合来实现。The flowchart and block diagrams in the Figures illustrate the architecture, functionality, and operation of possible implementations of systems, methods and computer program products according to various embodiments of the present application. In this regard, each block in the flowchart or block diagrams may represent a module, segment, or portion of code that contains one or more logical functions for implementing the specified functions executable instructions. It should also be noted that, in some alternative implementations, the functions noted in the blocks may occur out of the order noted in the figures. For example, two blocks shown in succession may, in fact, be executed substantially concurrently, or the blocks may sometimes be executed in the reverse order, depending upon the functionality involved. It is also noted that each block of the block diagrams or flowchart illustrations, and combinations of blocks in the block diagrams or flowchart illustrations, can be implemented in special purpose hardware-based systems that perform the specified functions or operations, or can be implemented using A combination of dedicated hardware and computer instructions is implemented.
应当注意,尽管在上文详细描述中提及了用于动作执行的设备的若干模块或者单元,但是这种划分并非强制性的。实际上,根据本申请的实施方式,上文描述的两个或更多模块或者单元的特征和功能可以在一个模块或者单元中具体化。反之,上文描述的一个模块或者单元的特征和功能可以进一步划分为由多个模块或者单元来具体化。It should be noted that although several modules or units of the apparatus for action performance are mentioned in the above detailed description, this division is not mandatory. Indeed, according to embodiments of the present application, the features and functions of two or more modules or units described above may be embodied in one module or unit. Conversely, the features and functions of one module or unit described above may be further divided into multiple modules or units to be embodied.
通过以上的实施方式的描述,本领域的技术人员易于理解,这里描述的示例实施方式可以通过软件实现,也可以通过软件结合必要的硬件的方式来实现。因此,根据本申请实施方式的技术方案可以以软件产品的形式体现出来,该软件产品可以存储在一个非易失性存储介质(可以是CD-ROM,U盘,移动硬盘等)中或网络上,包括若干指令以使得一台计算设备(可以是个人计算机、服务器、触控终端、或者网络设备等)执行根据本申请实施方式的方法。From the description of the above embodiments, those skilled in the art can easily understand that the exemplary embodiments described herein may be implemented by software, or may be implemented by software combined with necessary hardware. Therefore, the technical solutions according to the embodiments of the present application may be embodied in the form of software products, and the software products may be stored in a non-volatile storage medium (which may be CD-ROM, U disk, mobile hard disk, etc.) or on the network , which includes several instructions to cause a computing device (which may be a personal computer, a server, a touch terminal, or a network device, etc.) to execute the method according to the embodiments of the present application.
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本申请的其它实施方案。本申请旨在涵盖本申请的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本申请的一般性原理并包括本申请未公开的本技术领域中的公知常识或惯用技术手段。Other embodiments of the present application will readily occur to those skilled in the art upon consideration of the specification and practice of the invention disclosed herein. This application is intended to cover any variations, uses or adaptations of this application that follow the general principles of this application and include common knowledge or conventional techniques in the technical field not disclosed in this application .
应当理解的是,本申请并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本申请的范围仅由所附的权利要求来限制。It is to be understood that the present application is not limited to the precise structures described above and illustrated in the accompanying drawings and that various modifications and changes may be made without departing from the scope thereof. The scope of the application is limited only by the appended claims.
Claims (15)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111238478.4ACN114333893B (en) | 2021-10-22 | 2021-10-22 | A speech processing method, device, electronic device and readable medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111238478.4ACN114333893B (en) | 2021-10-22 | 2021-10-22 | A speech processing method, device, electronic device and readable medium |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN114333893Atrue CN114333893A (en) | 2022-04-12 |
| CN114333893B CN114333893B (en) | 2025-06-24 |
Family
ID=81045116
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202111238478.4AActiveCN114333893B (en) | 2021-10-22 | 2021-10-22 | A speech processing method, device, electronic device and readable medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114333893B (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115171709A (en)* | 2022-09-05 | 2022-10-11 | 腾讯科技(深圳)有限公司 | Voice coding method, voice decoding method, voice coding device, voice decoding device, computer equipment and storage medium |
| CN115331690A (en)* | 2022-08-17 | 2022-11-11 | 中邮消费金融有限公司 | Method for eliminating noise of call voice in real time |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2009043287A1 (en)* | 2007-09-28 | 2009-04-09 | Huawei Technologies Co., Ltd. | Apparatus and method for noise generation |
| CN103915103A (en)* | 2014-04-15 | 2014-07-09 | 成都凌天科创信息技术有限责任公司 | Voice quality enhancement system |
| US9159336B1 (en)* | 2013-01-21 | 2015-10-13 | Rawles Llc | Cross-domain filtering for audio noise reduction |
| CN112242147A (en)* | 2020-10-14 | 2021-01-19 | 福建星网智慧科技有限公司 | Voice gain control method and computer storage medium |
- 2021
- 2021-10-22CNCN202111238478.4Apatent/CN114333893B/enactiveActive
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2009043287A1 (en)* | 2007-09-28 | 2009-04-09 | Huawei Technologies Co., Ltd. | Apparatus and method for noise generation |
| US9159336B1 (en)* | 2013-01-21 | 2015-10-13 | Rawles Llc | Cross-domain filtering for audio noise reduction |
| CN103915103A (en)* | 2014-04-15 | 2014-07-09 | 成都凌天科创信息技术有限责任公司 | Voice quality enhancement system |
| CN112242147A (en)* | 2020-10-14 | 2021-01-19 | 福建星网智慧科技有限公司 | Voice gain control method and computer storage medium |
Non-Patent Citations (3)
| Title |
|---|
| WEI XIAO,: "obust sound event classifaication using deep neural networks", IEEE, 31 December 2015 (2015-12-31)* |
| 史裕鹏: "基于深度学习的噪声鲁棒性人工耳蜗信号处理策略", 中国优秀硕士学位论文全文数据库·信息科技辑, 15 October 2021 (2021-10-15)* |
| 戴明扬: "基于声门波码本受限的迭代维纳滤波语音增强", 声学学报, 10 January 2003 (2003-01-10), pages 21 - 27* |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115331690A (en)* | 2022-08-17 | 2022-11-11 | 中邮消费金融有限公司 | Method for eliminating noise of call voice in real time |
| CN115171709A (en)* | 2022-09-05 | 2022-10-11 | 腾讯科技(深圳)有限公司 | Voice coding method, voice decoding method, voice coding device, voice decoding device, computer equipment and storage medium |
Also Published As
| Publication number | Publication date |
|---|---|
| CN114333893B (en) | 2025-06-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7636088B2 (en) | Speech enhancement method, device, equipment, and computer program | |
| CN111489760B (en) | Speech signal anti-reverberation processing method, device, computer equipment and storage medium | |
| WO2022012195A1 (en) | Audio signal processing method and related apparatus | |
| JP7615510B2 (en) | Speech enhancement method, speech enhancement device, electronic device, and computer program | |
| US10262677B2 (en) | Systems and methods for removing reverberation from audio signals | |
| CN118899005B (en) | Audio signal processing method, device, computer equipment and storage medium | |
| US12272371B1 (en) | Real-time target speaker audio enhancement | |
| CN114333893B (en) | A speech processing method, device, electronic device and readable medium | |
| WO2024055751A1 (en) | Audio data processing method and apparatus, device, storage medium, and program product | |
| CN114333892A (en) | Voice processing method and device, electronic equipment and readable medium | |
| CN114333891B (en) | Voice processing method, device, electronic equipment and readable medium | |
| CN115277935A (en) | Background music volume adjusting method and device, electronic equipment and storage medium | |
| CN111326166B (en) | Voice processing method and device, computer readable storage medium and electronic equipment | |
| CN116597854A (en) | An audio noise reduction model training method, device and storage medium | |
| CN113571081B (en) | Speech enhancement method, device, equipment and storage medium | |
| CN117894318A (en) | Audio processing model training method and device, storage medium, and electronic device | |
| CN113450812A (en) | Howling detection method, voice call method and related device | |
| HK40071037A (en) | Voice processing method and apparatus, electronic device, and readable medium | |
| HK40071035A (en) | Voice processing method and apparatus, electronic device, and readable medium | |
| HK40070826A (en) | Voice processing method and apparatus, electronic device, and readable medium | |
| CN113571075A (en) | Audio processing method and device, electronic equipment and storage medium | |
| HK40052886A (en) | Speech enhancement method, device, equipment and storage medium | |
| HK40052887A (en) | Speech enhancement method, device, equipment and storage medium | |
| HK40052885A (en) | Speech enhancement method, device, equipment and storage medium | |
| CN119152874B (en) | Voice signal processing method, device, equipment, medium and product |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| REG | Reference to a national code | Ref country code:HK Ref legal event code:DE Ref document number:40071037 Country of ref document:HK | |
| GR01 | Patent grant | ||
| GR01 | Patent grant |