CN114330690A - Convolutional neural network compression method, device and electronic device - Google Patents
Convolutional neural network compression method, device and electronic deviceDownload PDFInfo
- Publication number
- CN114330690A CN114330690ACN202111645899.9ACN202111645899ACN114330690ACN 114330690 ACN114330690 ACN 114330690ACN 202111645899 ACN202111645899 ACN 202111645899ACN 114330690 ACN114330690 ACN 114330690A
- Authority
- CN
- China
- Prior art keywords
- neural network
- network model
- compressed
- target
- sample set
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images


Classifications
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02T—CLIMATE CHANGE MITIGATION TECHNOLOGIES RELATED TO TRANSPORTATION
- Y02T10/00—Road transport of goods or passengers
- Y02T10/10—Internal combustion engine [ICE] based vehicles
- Y02T10/40—Engine management systems
Landscapes
- Compression, Expansion, Code Conversion, And Decoders (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本发明涉及卷积神经网络压缩技术领域,尤其是涉及一种卷积神经网络压缩方法、装置及电子设备。The present invention relates to the technical field of convolutional neural network compression, in particular to a convolutional neural network compression method, device and electronic equipment.
背景技术Background technique
目前,现有的卷积神经网络在实际应用中很大程度上受到高计算量的阻碍,需要采用不同的剪枝策略来减小模型规模,减少模型运行时的内存占用,同时在不影响精度的情况下减少计算操作的次数。模型剪枝通常是一个反复进行训练-剪枝-微调的迭代优化过程,虽然能够得到具有较高准确率的压缩模型,但该过程需要耗费大量时间,时间成本较高。At present, the existing convolutional neural networks are largely hindered by the high amount of computation in practical applications. Different pruning strategies are required to reduce the model size and reduce the memory usage of the model during runtime without affecting the accuracy. In the case of reducing the number of computational operations. Model pruning is usually an iterative optimization process of repeated training-pruning-fine-tuning. Although a compressed model with high accuracy can be obtained, this process requires a lot of time and has a high time cost.
发明内容SUMMARY OF THE INVENTION
有鉴于此,本发明的目的在于提供一种卷积神经网络压缩方法、装置及电子设备,以在保证压缩后模型的准确性的同时提高模型压缩的效率。In view of this, the purpose of the present invention is to provide a convolutional neural network compression method, device and electronic device, so as to improve the efficiency of model compression while ensuring the accuracy of the compressed model.
第一方面,本发明实施例提供了一种卷积神经网络压缩方法,所述方法包括:获取目标应用场景的目标训练样本集;其中,所述目标训练样本集是基于所述目标应用场景对应的待压缩神经网络模型的初始训练样本集确定的;采用方差缩放方法初始化所述待压缩神经网络模型的权重,得到所述待压缩神经网络模型的初始权重向量;以预设稀疏度作为约束条件,确定所述初始权重向量对应的权重优化向量,并根据所述权重优化向量计算所述待压缩神经网络模型中所有连接的灵敏度;其中,所述灵敏度用于表征所述待压缩神经网络模型中各个网络层的连接的重要程度;In a first aspect, an embodiment of the present invention provides a convolutional neural network compression method, the method comprising: acquiring a target training sample set of a target application scenario; wherein the target training sample set is based on the corresponding target application scenario The initial training sample set of the neural network model to be compressed is determined; the weight of the neural network model to be compressed is initialized by using the variance scaling method, and the initial weight vector of the neural network model to be compressed is obtained; the preset sparsity is used as a constraint condition , determine the weight optimization vector corresponding to the initial weight vector, and calculate the sensitivity of all connections in the neural network model to be compressed according to the weight optimization vector; wherein, the sensitivity is used to characterize the neural network model to be compressed. The importance of the connection of each network layer;
根据所述预设稀疏度和所述灵敏度对所述待压缩神经网络模型进行剪枝,得到稀疏神经网络模型;其中,所述稀疏神经网络模型的权重是根据所述预设稀疏度和所述灵敏度确定出来的;The neural network model to be compressed is pruned according to the preset sparsity and the sensitivity to obtain a sparse neural network model; wherein, the weight of the sparse neural network model is based on the preset sparsity and the Sensitivity is determined;
使用所述目标训练样本集训练所述稀疏神经网络模型,直至得到训练完成的目标神经网络模型;其中,所述目标神经网络模型用于对所述目标应用场景对应的数据进行处理。The sparse neural network model is trained using the target training sample set until a trained target neural network model is obtained; wherein the target neural network model is used to process data corresponding to the target application scenario.
结合第一方面,本发明实施例提供了第一方面的第一种可能的实施方式,其中,获取目标样本集的步骤,包括:对所述初始训练样本集进行采样,得到所述目标样本集
结合第一方面,本发明实施例提供了第一方面的第二种可能的实施方式,其中,所述方法还包括:将所述待压缩神经网络模型的剪枝定义为以下公式的约束优化问题:In conjunction with the first aspect, an embodiment of the present invention provides a second possible implementation manner of the first aspect, wherein the method further includes: defining the pruning of the neural network model to be compressed as a constrained optimization problem of the following formula :

s,t.w∈Rm,c∈{0,1}m,||c||0≤ks, tw∈Rm , c∈{0,1}m , ||c||0 ≤k
其中,L(·)表示整体损失函数,l(·)表示部分损失函数,⊙表示哈达玛乘积,c表示所述权重优化向量,w表示所述初始权重向量,∥·∥0表示标准的L0范数,m表示所述待压缩神经网络模型的参数总数,{0,1}m表示元素只有0和1的m维向量,k表示所述预设稀疏度。Among them, L( ) represents the overall loss function, l( ) represents the partial loss function, ⊙ represents the Hadamard product, c represents the weight optimization vector, w represents the initial weight vector, ∥ ∥0 represents the standard L0 norm, m represents the total number of parameters of the neural network model to be compressed, {0,1}m represents an m-dimensional vector with elements only 0 and 1, and k represents the preset sparsity.
结合第一方面,本发明实施例提供了第一方面的第三种可能的实施方式,其中,以预设稀疏度作为约束条件,确定所述初始权重向量对应的权重优化向量,并根据所述权重优化向量计算所述待压缩神经网络模型中所有连接的灵敏度的步骤,包括:In conjunction with the first aspect, an embodiment of the present invention provides a third possible implementation manner of the first aspect, wherein a preset sparsity is used as a constraint to determine a weight optimization vector corresponding to the initial weight vector, and according to the The step of calculating the sensitivity of all connections in the neural network model to be compressed by the weight optimization vector includes:
对于所述待压缩神经网络模型中的每一个连接,采用以下公式计算所述整体损失函数关于所述权重优化向量的导数以近似表征移除连接对所述待压缩神经网络模型的损失的影响:For each connection in the to-be-compressed neural network model, the derivative of the overall loss function with respect to the weight optimization vector is calculated using the following formula to approximately characterize the effect of removing connections on the loss of the to-be-compressed neural network model:

s.t.w∈Rm,c∈{0,1}m,Hc||0≤kstw∈Rm , c∈{0,1}m , Hc||0 ≤k
其中,gj(w;D)表示连接j对应的整体损失函数关于权重优化向量的导数值,ej表示连接j的指示向量;Among them, gj (w; D) represents the derivative value of the overall loss function corresponding to connection j with respect to the weight optimization vector, and ej represents the indicator vector of connection j;
根据计算得到的每一个连接对应的导数值,采用以下公式计算所述待压缩神经网络模型中每一个连接的灵敏度:According to the calculated derivative value corresponding to each connection, the following formula is used to calculate the sensitivity of each connection in the neural network model to be compressed:

其中,sj表示连接j的灵敏度,|gj(w;D)|表示连接j对应的导数值的绝对值,N表示所述待压缩神经网络模型的连接数量。Wherein, sj represents the sensitivity of connection j, |gj (w; D)| represents the absolute value of the derivative value corresponding to connection j, and N represents the number of connections of the neural network model to be compressed.
结合第一方面,本发明实施例提供了第一方面的第四种可能的实施方式,其中,根据所述预设稀疏度和所述灵敏度对所述待压缩神经网络模型进行剪枝,得到稀疏神经网络模型的步骤,包括:按照所述灵敏度由大到小的顺序对所述待压缩神经网络模型中的所有连接进行排序,并保留排序结果中的前k个连接,得到第一稀疏神经网络模型;根据所述预设稀疏度和所述排序结果,对所述第一稀疏神经网络模型中各个网络层的连接进行加权处理,得到所述稀疏神经网络模型。In conjunction with the first aspect, an embodiment of the present invention provides a fourth possible implementation manner of the first aspect, wherein the neural network model to be compressed is pruned according to the preset sparsity and the sensitivity to obtain a sparsity The steps of the neural network model include: sorting all the connections in the neural network model to be compressed in descending order of the sensitivity, and retaining the top k connections in the sorting result to obtain a first sparse neural network model; according to the preset sparsity and the sorting result, weighting the connections of each network layer in the first sparse neural network model to obtain the sparse neural network model.
结合第一方面,本发明实施例提供了第一方面的第五种可能的实施方式,其中,根据所述预设稀疏度和所述排序结果,对所述第一稀疏神经网络模型中各个网络层的连接进行加权处理,得到所述稀疏神经网络模型的步骤,包括:With reference to the first aspect, an embodiment of the present invention provides a fifth possible implementation manner of the first aspect, wherein, according to the preset sparsity and the sorting result, each network in the first sparse neural network model is The connection of the layers is weighted to obtain the steps of the sparse neural network model, including:
采用如下公式计算所述前k个连接中的每一个连接对应的优化权重值:The optimization weight value corresponding to each of the first k connections is calculated using the following formula:

其中,wi’表示第i个连接的优化权重值;Among them, wi ' represents the optimization weight value of the ith connection;
为所述前k个连接中的每一个连接对应分配所述优化权重值,得到所述稀疏神经网络模型。The optimized weight value is correspondingly assigned to each of the first k connections to obtain the sparse neural network model.
结合第一方面,本发明实施例提供了第一方面的第六种可能的实施方式,其中,使用所述目标训练样本集训练所述稀疏神经网络模型,直至得到训练完成的目标神经网络模型的步骤,包括:将所述目标训练样本集中的所有样本输入所述稀疏神经网络模型;根据所述稀疏神经网络模型的预测结果和所述目标训练样本集中的所有样本对应的标签计算损失函数值,直至迭代次数超过预设次数或损失函数值小于预设值,停止训练,得到训练完成的目标神经网络模型。In conjunction with the first aspect, the embodiment of the present invention provides a sixth possible implementation manner of the first aspect, wherein the sparse neural network model is trained by using the target training sample set until the trained target neural network model is obtained. The steps include: inputting all samples in the target training sample set into the sparse neural network model; calculating a loss function value according to the prediction result of the sparse neural network model and the labels corresponding to all samples in the target training sample set, Until the number of iterations exceeds the preset number or the loss function value is smaller than the preset value, the training is stopped, and the trained target neural network model is obtained.
第二方面,本发明实施例还提供一种卷积神经网络压缩装置,所述装置包括:样本获取模块,用于获取目标应用场景的目标训练样本集;其中,所述目标训练样本集是基于所述目标应用场景对应的待压缩神经网络模型的初始训练样本集确定的;初始化模块,用于采用方差缩放方法初始化所述待压缩神经网络模型的权重,得到所述待压缩神经网络模型的初始权重向量;灵敏度计算模块,用于以预设稀疏度作为约束条件,确定所述初始权重向量对应的权重优化向量,并根据所述权重优化向量计算所述待压缩神经网络模型中所有连接的灵敏度;其中,所述灵敏度用于表征所述待压缩神经网络模型中各个网络层的连接的重要程度;剪枝模块,用于根据所述预设稀疏度和所述灵敏度对所述待压缩神经网络模型进行剪枝,得到稀疏神经网络模型;其中,所述稀疏神经网络模型的权重是根据所述预设稀疏度和所述灵敏度确定出来的;训练模块,用于使用所述目标训练样本集训练所述稀疏神经网络模型,直至得到训练完成的目标神经网络模型;其中,所述目标神经网络模型用于对所述目标应用场景对应的数据进行处理。In a second aspect, an embodiment of the present invention further provides a convolutional neural network compression device, the device includes: a sample acquisition module for acquiring a target training sample set of a target application scenario; wherein the target training sample set is based on The initial training sample set of the neural network model to be compressed corresponding to the target application scenario is determined; the initialization module is used to initialize the weight of the neural network model to be compressed by using a variance scaling method, and obtain the initial training sample set of the neural network model to be compressed. A weight vector; a sensitivity calculation module, used to determine a weight optimization vector corresponding to the initial weight vector with a preset sparsity as a constraint, and calculate the sensitivity of all connections in the neural network model to be compressed according to the weight optimization vector ; wherein, the sensitivity is used to characterize the importance of the connection of each network layer in the neural network model to be compressed; the pruning module is used to compress the neural network to be compressed according to the preset sparsity and the sensitivity. The model is pruned to obtain a sparse neural network model; wherein, the weight of the sparse neural network model is determined according to the preset sparsity and the sensitivity; a training module is used for training using the target training sample set the sparse neural network model until a trained target neural network model is obtained; wherein, the target neural network model is used to process the data corresponding to the target application scenario.
第三方面,本发明实施例还提供一种电子设备,包括处理器和存储器,所述存储器存储有能够被所述处理器执行的计算机可执行指令,所述处理器执行所述计算机可执行指令以实现上述卷积神经网络压缩方法。In a third aspect, an embodiment of the present invention further provides an electronic device, including a processor and a memory, where the memory stores computer-executable instructions that can be executed by the processor, and the processor executes the computer-executable instructions In order to realize the above-mentioned convolutional neural network compression method.
第四方面,本发明实施例还提供一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理设备运行时执上述卷积神经网络压缩方法的步骤。In a fourth aspect, an embodiment of the present invention further provides a computer-readable storage medium, where a computer program is stored on the computer-readable storage medium, and the computer program executes the steps of the above-mentioned convolutional neural network compression method when the computer program is run by the processing device. .
本发明实施例提供的卷积神经网络压缩方法、装置及电子设备,该方法包括:获取目标应用场景的目标训练样本集;采用方差缩放方法初始化待压缩神经网络模型的权重以得到待压缩神经网络模型的初始权重向量;以预设稀疏度作为约束条件,确定初始权重向量对应的权重优化向量并根据权重优化向量计算待压缩神经网络模型中所有连接的灵敏度;根据预设稀疏度和灵敏度对待压缩神经网络模型进行剪枝以得到稀疏神经网络模型;使用目标训练样本集训练稀疏神经网络模型,直至得到训练完成的目标神经网络模型。采用上述技术,在初始化神经网络模型的权重后,引入灵敏度作为评判连接重要程度的标准,从而在训练前根据灵敏度识别出待压缩神经网络模型中的冗余连接并根据所需的稀疏度水平对冗余连接进行剪枝,之后再采用标准模型训练流程对剪枝后的稀疏神经网络模型进行训练,该操作方式能够避免反复进行训练-剪枝-微调的迭代优化过程,进而在保证剪枝后的神经网络模型的性能的同时提高了神经网络模型的压缩效率。The convolutional neural network compression method, device, and electronic device provided by the embodiments of the present invention include: acquiring a target training sample set of a target application scenario; using a variance scaling method to initialize the weight of the neural network model to be compressed to obtain the neural network to be compressed The initial weight vector of the model; with the preset sparsity as a constraint, determine the weight optimization vector corresponding to the initial weight vector and calculate the sensitivity of all connections in the neural network model to be compressed according to the weight optimization vector; according to the preset sparsity and sensitivity to be compressed The neural network model is pruned to obtain a sparse neural network model; the target training sample set is used to train the sparse neural network model until a trained target neural network model is obtained. Using the above technique, after initializing the weights of the neural network model, the sensitivity is introduced as a criterion for judging the importance of connections, so that redundant connections in the neural network model to be compressed are identified according to the sensitivity before training, and the required sparsity level is adjusted. Redundant connections are pruned, and then the standard model training process is used to train the pruned sparse neural network model. This operation method can avoid repeated iterative optimization processes of training-pruning-fine-tuning, and then ensure that after pruning The performance of the neural network model is improved while the compression efficiency of the neural network model is improved.
本发明的其他特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点在说明书、权利要求书以及附图中所特别指出的结构来实现和获得。Other features and advantages of the present invention will be set forth in the description which follows, and in part will be apparent from the description, or may be learned by practice of the invention. The objectives and other advantages of the invention will be realized and attained by the structure particularly pointed out in the description, claims and drawings.
为使本发明的上述目的、特征和优点能更明显易懂,下文特举较佳实施例,并配合所附附图,作详细说明如下。In order to make the above-mentioned objects, features and advantages of the present invention more obvious and easy to understand, preferred embodiments are given below, and are described in detail as follows in conjunction with the accompanying drawings.
附图说明Description of drawings
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。In order to illustrate the specific embodiments of the present invention or the technical solutions in the prior art more clearly, the following briefly introduces the accompanying drawings that need to be used in the description of the specific embodiments or the prior art. Obviously, the accompanying drawings in the following description The drawings are some embodiments of the present invention. For those of ordinary skill in the art, other drawings can also be obtained based on these drawings without creative efforts.
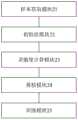
图1为本发明实施例提供的一种卷积神经网络压缩方法的流程示意图;1 is a schematic flowchart of a method for compressing a convolutional neural network according to an embodiment of the present invention;
图2为本发明实施例提供的一种卷积神经网络压缩装置的结构示意图;2 is a schematic structural diagram of a convolutional neural network compression device provided by an embodiment of the present invention;
图3为本发明实施例提供的另一种卷积神经网络压缩装置的结构示意图;3 is a schematic structural diagram of another convolutional neural network compression device provided by an embodiment of the present invention;
图4为本发明实施例提供的一种电子设备的结构示意图。FIG. 4 is a schematic structural diagram of an electronic device according to an embodiment of the present invention.
具体实施方式Detailed ways
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合实施例对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。In order to make the purposes, technical solutions and advantages of the embodiments of the present invention clearer, the technical solutions of the present invention will be described clearly and completely below with reference to the embodiments. Obviously, the described embodiments are part of the embodiments of the present invention, not all of them. example. Based on the embodiments of the present invention, all other embodiments obtained by those of ordinary skill in the art without creative efforts shall fall within the protection scope of the present invention.
目前,现有的卷积神经网络在实际应用中很大程度上受到高计算量的阻碍,需要采用不同的剪枝策略来减小模型规模,减少模型运行时的内存占用,同时在不影响精度的情况下减少计算操作的次数。模型剪枝通常是一个反复进行训练-剪枝-微调的迭代优化过程,虽然能够得到具有较高准确率的压缩模型,但该过程需要耗费大量时间,时间成本较高。At present, the existing convolutional neural networks are largely hindered by the high amount of computation in practical applications. Different pruning strategies are required to reduce the model size and reduce the memory usage of the model during runtime without affecting the accuracy. In the case of reducing the number of computational operations. Model pruning is usually an iterative optimization process of repeated training-pruning-fine-tuning. Although a compressed model with high accuracy can be obtained, this process requires a lot of time and has a high time cost.
基于此,本发明实施提供的一种卷积神经网络压缩方法、装置及电子设备,可以在保证压缩后模型的准确性的同时提高模型压缩的效率。Based on this, the implementation of the present invention provides a convolutional neural network compression method, device and electronic device, which can improve the efficiency of model compression while ensuring the accuracy of the compressed model.
为便于对本实施例进行理解,首先对本发明实施例所公开的一种卷积神经网络压缩方法进行详细介绍,参见图1所示的一种卷积神经网络压缩方法的流程示意图,该方法可以包括以下步骤:In order to facilitate the understanding of this embodiment, a convolutional neural network compression method disclosed in the embodiment of the present invention is first introduced in detail. Referring to the schematic flowchart of a convolutional neural network compression method shown in FIG. 1 , the method may include: The following steps:
步骤S102,获取目标应用场景的目标训练样本集;其中,目标训练样本集是基于目标应用场景对应的待压缩神经网络模型的初始训练样本集确定的。Step S102, acquiring a target training sample set of the target application scenario; wherein, the target training sample set is determined based on the initial training sample set of the neural network model to be compressed corresponding to the target application scenario.
上述目标应用场景主要包括目标识别(如人脸识别、指纹识别)、目标追踪(如车辆追踪)等需要使用神经网络模型完成相应的任务的应用场景,基于此,上述待压缩神经网络模型可根据目标应用场景自行选择,例如,上述待压缩神经网络模型可以采用R-CNN模型、Faster-RCNN模型、YOLO模型等,对此并不进行限定。The above target application scenarios mainly include target recognition (such as face recognition, fingerprint recognition), target tracking (such as vehicle tracking) and other application scenarios that require the use of neural network models to complete corresponding tasks. Based on this, the above-mentioned neural network models to be compressed can be based on The target application scenario is selected by yourself. For example, the above-mentioned neural network model to be compressed can use the R-CNN model, the Faster-RCNN model, the YOLO model, etc., which is not limited.
在实际应用过程中,为了便于操作,可根据先前训练待压缩神经网络模型所使用的训练样本集(即上述初始训练样本集)确定上述目标训练样本集。考虑到模型计算能力、模型参数量、模型处理任务的时效性等因素,上述步骤S102具体可采用以下两种操作方式之一:(1)直接将上述初始训练样本集确定为上述目标训练样本集;(2)对上述初始训练样本集进行采样,并将采样得到的样本所组成的集合确定为上述目标训练样本集。In the actual application process, in order to facilitate the operation, the above target training sample set may be determined according to the training sample set (ie, the above-mentioned initial training sample set) previously used for training the neural network model to be compressed. Taking into account factors such as model computing capability, model parameter quantity, and timeliness of model processing tasks, the above-mentioned step S102 may specifically adopt one of the following two operation modes: (1) directly determine the above-mentioned initial training sample set as the above-mentioned target training sample set (2) Sampling the above-mentioned initial training sample set, and determining the set composed of the samples obtained by sampling as the above-mentioned target training sample set.
具体地,对于待压缩神经网络模型为轻量级模型(如yolov5s等)的情形,在模型计算能力允许的情况下,可以直接选取整个coco128样本集(包含128张图片)作为上述目标训练样本集;还可以对voc2007样本集(包含9963张图片)进行采样并将采样得到的小批量样本集确定为上述目标训练样本集。此外,考虑到模型训练的准确性,在对上述初始训练样本集进行采样时,可采用均匀采样的方式,进而确保采样得到的小批量样本集的类别分布与初始训练样本集的类别分布保持一致,以便剪枝后的神经网络模型可以学习到更全面的特征。Specifically, for the case where the neural network model to be compressed is a lightweight model (such as yolov5s, etc.), the entire coco128 sample set (including 128 pictures) can be directly selected as the above-mentioned target training sample set if the computing power of the model allows. ; It is also possible to sample the voc2007 sample set (containing 9963 pictures) and determine the small batch sample set obtained by sampling as the above target training sample set. In addition, considering the accuracy of model training, uniform sampling can be adopted when sampling the above-mentioned initial training sample set, so as to ensure that the class distribution of the sampled mini-batch sample set is consistent with the class distribution of the initial training sample set , so that the pruned neural network model can learn more comprehensive features.
作为一个示例,上述步骤S102具体可采用以下操作方式:As an example, the above step S102 may specifically adopt the following operation modes:
对初始训练样本集进行采样,得到目标样本集
步骤S104,采用方差缩放方法初始化待压缩神经网络模型的权重,得到待压缩神经网络模型的初始权重向量。Step S104, using the variance scaling method to initialize the weight of the neural network model to be compressed, to obtain an initial weight vector of the neural network model to be compressed.
由于神经网络模型通常具有多个神经元,为了避免神经元输出过大而导致梯度爆炸或消失,需要尽量使待压缩神经网络模型中每个神经元的输入方差和输出方差保持一致,基于此,可采用方差缩放方法初始化待压缩神经网络模型的权重。方差缩放方法具体可以根据实际需要使用Xavier初始化、He初始化等方法,对此并不进行限定。经过上述步骤S104后,会使整个待压缩神经网络模型中每一个神经元的输入方差和输出方差保持不一致,进而确保待压缩神经网络模型在初始化时的鲁棒性。Since the neural network model usually has multiple neurons, in order to avoid the gradient explosion or disappearance caused by the excessive output of the neurons, it is necessary to keep the input variance and output variance of each neuron in the neural network model to be compressed as much as possible. Based on this, The weights of the neural network model to be compressed can be initialized using the variance scaling method. The variance scaling method may specifically use methods such as Xavier initialization and He initialization according to actual needs, which are not limited. After the above step S104, the input variance and output variance of each neuron in the entire neural network model to be compressed will be kept inconsistent, thereby ensuring the robustness of the neural network model to be compressed during initialization.
步骤S106,以预设稀疏度作为约束条件,确定初始权重向量对应的权重优化向量,并根据权重优化向量计算待压缩神经网络模型中所有连接的灵敏度;其中,灵敏度用于表征待压缩神经网络模型中各个网络层的连接的重要程度。Step S106, using the preset sparsity as a constraint, determine the weight optimization vector corresponding to the initial weight vector, and calculate the sensitivity of all connections in the neural network model to be compressed according to the weight optimization vector; wherein, the sensitivity is used to characterize the neural network model to be compressed The importance of the connection of each network layer in the
首先预设好期望的稀疏度(即上述预设稀疏度)k,k指的是对待压缩神经网络模型进行剪枝后得到的模型中保持的k个权重(也即权重矩阵中非零元素的个数)。对于目标样本集
据此可将上述待压缩神经网络模型的剪枝定义为以下公式(1)的约束优化问题:Accordingly, the pruning of the above-mentioned neural network model to be compressed can be defined as the constrained optimization problem of the following formula (1):

s,t.w∈Rm,c∈{0,1}m,||c||0≤ks, tw∈Rm , c∈{0,1}m , ||c||0 ≤k
其中,L(·)表示整体损失函数,l(·)表示部分损失函数,⊙表示哈达玛乘积,c表示所述权重优化向量,w表示所述初始权重向量,∥·∥0表示标准的L0范数,m表示所述待压缩神经网络模型的参数总数,{0,1}m表示元素只有0和1的m维向量,k表示上述预设稀疏度(也即期望的稀疏度)。Among them, L( ) represents the overall loss function, l( ) represents the partial loss function, ⊙ represents the Hadamard product, c represents the weight optimization vector, w represents the initial weight vector, ∥ ∥0 represents the standard L0 norm, m represents the total number of parameters of the neural network model to be compressed, {0,1}m represents an m-dimensional vector with elements only 0 and 1, and k represents the preset sparsity (that is, the desired sparsity).
在上述公式(1)中,可根据实际需要设置c中的元素为0或1,进而通过哈达玛乘积运算对w中对应位置的元素(也即神经网络中的权重值)进行处理,达到权重稀疏化的目的。例如,神经网络模型只有一层,c=[0,0,1,0,1],w=[0.13,0.98,0.56,0.42,1.23],则c⊙w=[0,0,0.56,0,1.23]。In the above formula (1), the element in c can be set to 0 or 1 according to actual needs, and then the element at the corresponding position in w (that is, the weight value in the neural network) is processed by the Hadamard product operation to achieve the weight. purpose of thinning. For example, the neural network model has only one layer, c=[0,0,1,0,1], w=[0.13,0.98,0.56,0.42,1.23], then c⊙w=[0,0,0.56,0 , 1.23].
为了简化描述,下文中所提及的“损失函数”均指的是上述整体损失函数L(·)。In order to simplify the description, the "loss function" mentioned below refers to the above-mentioned overall loss function L(·).
对于连接j来说,可定义c中与连接j对应的元素为cj,cj=1表示网络中的连接是活动的,cj=0表示网络中的连接已经被修剪,为了衡量连接j对待压缩模型损失的影响大小,可以在保持其他参数不变的情况下,采用以下公式(2)计算待压缩模型在cj=1时的损失和在cj=0时的损失之差:For connection j, the element corresponding to connection j in c can be defined as cj , cj =1 indicates that the connection in the network is active, cj =0 indicates that the connection in the network has been pruned, in order to measure the connection j The influence of the loss of the model to be compressed can be calculated by using the following formula (2) while keeping other parameters unchanged, to calculate the difference between the loss of the model to be compressed when cj = 1 and the loss when cj = 0:
ΔLj(w;D)=L(1⊙w;D)-L((1-ej)⊙w;D) (2)ΔLj (w; D)=L(1⊙w;D)−L((1−ej )⊙w;D) (2)
其中,1为一个元素全为1的m维向量,ej表示连接j的指示向量,ej为一个只有索引j位置处的元素为1、其余位置处的元素为0的m维向量;Among them, 1 is an m-dimensional vector whose elements are all 1, ej represents the indicator vector connecting j, and ej is an m-dimensional vector with only 1 elements at the index j position and 0 elements at the other positions;
上述公式(2)中,1⊙w可指示待压缩神经网络模型处于全连接的状态,(1-ej)⊙w可指示待压缩神经网络模型处于连接j被剪枝的状态,因而上述公式(2)中的ΔLj(w;D)指示了移除连接j对待压缩神经网络模型产生的影响。In the above formula (2), 1⊙w can indicate that the neural network model to be compressed is in a fully connected state, and (1-ej )⊙w can indicate that the neural network model to be compressed is in a state where the connection j is pruned, so the above formula ΔLj (w; D) in (2) indicates the effect of removing connection j to compress the neural network model.
在实际应用过程中,考虑到待压缩神经网络模型需要对输入其中的样本进行m+1次的前向传播,因而按照上述公式(2)对待压缩神经网络模型中的每个连接均进行相应的计算所涉及的计算量十分庞大。此外,由于c是可用二进制进行表示的元素只有0和1的m维向量,因而损失函数L对于c是不可微的。基于此,为了简化计算以提高模型压缩整个过程的效率,考虑到ΔLj指示了待压缩神经网络模型在cj=1时的损失和在cj=0时的损失之差,当ΔLj无穷小时,可以使用损失函数L对于权重优化向量cj的导数值gj(w;D)来代替ΔLj以近似表征移除连接j对待压缩神经网络模型的损失的影响,进而将上述公式(2)优化成以下公式(3):In the actual application process, considering that the neural network model to be compressed needs to perform m+1 forward propagation on the input samples, according to the above formula (2), each connection in the neural network model to be compressed is correspondingly performed. The amount of computation involved in the calculation is enormous. Furthermore, since c is an m-dimensional vector with only 0 and 1 elements that can be represented in binary, the loss function L is non-differentiable with respect to c. Based on this, in order to simplify the calculation to improve the efficiency of the whole process of model compression, considering that ΔLj indicates the difference between the loss of the neural network model to be compressed when cj =1 and the loss when cj =0, when ΔLj is infinite is small, the derivative value gj (w; D) of the loss function L with respect to the weight optimization vector cj can be used to replace ΔLj to approximately characterize the effect of removing connection j on the loss of the compressed neural network model, and then the above formula (2 ) is optimized into the following formula (3):

s·t.w∈Rm,c∈{0,1}m,||c||0≤ks·tw∈Rm , c∈{0,1}m , ||c||0 ≤k
其中,gj(w;D)表示连接j对应的损失函数关于权重优化向量的导数值,ej表示连接j的指示向量;Among them, gj (w; D) represents the derivative value of the loss function corresponding to connection j with respect to the weight optimization vector, and ej represents the indicator vector of connection j;
ΔLj表示cj从1变为0所引起的待压缩神经网络模型的损失变化,可以反映连接j的重要性,为了便于前向传播计算,ΔLj可以进一步等价于损失函数L关于cj的导数值。根据导数的定义,导数公式为
基于上述公式(3),上述步骤S106具体可以采用以下操作方式:Based on the above formula (3), the above step S106 can specifically adopt the following operation methods:
步骤11,对于上述待压缩神经网络模型中的每一个连接,采用以下公式(3)对应的简化公式(3.1)计算损失函数关于权重优化向量的导数以近似表征移除连接对待压缩神经网络模型的损失的影响:Step 11, for each connection in the above-mentioned neural network model to be compressed, use the simplified formula (3.1) corresponding to the following formula (3) to calculate the derivative of the loss function with respect to the weight optimization vector to approximate the removal of the connection to be compressed. Neural network model Impact of loss:

s.t.w∈Rm,c∈{0,1}m,||c||0≤kstw∈Rm , c∈{0,1}m , ||c||0 ≤k
其中,gj(w;D)表示连接j对应的损失函数关于权重优化向量的导数值,ej表示连接j的指示向量。Among them, gj (w; D) represents the derivative value of the loss function corresponding to connection j with respect to the weight optimization vector, and ej represents the indicator vector of connection j.
步骤12,根据计算得到的每一个连接对应的导数值,采用以下公式(4)计算待压缩神经网络模型中每一个连接的灵敏度(也可称为初始灵敏度):Step 12: According to the calculated derivative value corresponding to each connection, the following formula (4) is used to calculate the sensitivity (also referred to as the initial sensitivity) of each connection in the neural network model to be compressed:

其中,sj表示连接j的灵敏度,|gj(w;D)|表示连接j对应的导数值的绝对值,N表示所述待压缩神经网络模型的连接数量。Wherein, sj represents the sensitivity of connection j, |gj (w; D)| represents the absolute value of the derivative value corresponding to connection j, and N represents the number of connections of the neural network model to be compressed.
经过上述步骤12,可将上述灵敏度的大小作为显著性的标准,即:连接的灵敏度越大,在本质上意味着该连接对待压缩神经网络模型的损失产生的正影响或负影响越大。基于此,在对待压缩神经网络模型进行剪枝时,可将灵敏度相对较大的连接(也即重要连接)保留而将灵敏度相对较小的连接(也即冗余连接)移除。After the above step 12, the size of the above sensitivity can be used as the criterion of significance, that is, the greater the sensitivity of the connection, the greater the positive or negative impact the connection has on the loss of the neural network model to be compressed. Based on this, when pruning the neural network model to be compressed, connections with relatively high sensitivity (ie, important connections) can be retained and connections with relatively low sensitivity (ie, redundant connections) can be removed.
步骤S108,根据预设稀疏度和灵敏度对待压缩神经网络模型进行剪枝,得到稀疏神经网络模型;其中,稀疏神经网络模型的权重是根据预设稀疏度和灵敏度确定出来的。Step S108, pruning the neural network model to be compressed according to the preset sparsity and sensitivity to obtain a sparse neural network model; wherein, the weight of the sparse neural network model is determined according to the preset sparsity and sensitivity.
为了便于操作,上述步骤S108具体可以采用以下操作方式:In order to facilitate the operation, the above-mentioned step S108 may specifically adopt the following operation methods:
步骤21,按照所述灵敏度由大到小的顺序对所述待压缩神经网络模型中的所有连接进行排序,并保留排序结果中的前k个连接,得到第一稀疏神经网络模型。Step 21: Sort all the connections in the neural network model to be compressed in descending order of the sensitivity, and retain the top k connections in the sorting result to obtain a first sparse neural network model.
步骤22,根据所述预设稀疏度和所述排序结果,对所述第一稀疏神经网络模型中各个网络层的连接进行加权处理,得到所述稀疏神经网络模型。Step 22: Perform weighting processing on the connections of each network layer in the first sparse neural network model according to the preset sparsity and the sorting result to obtain the sparse neural network model.
具体地,对于上述前k个连接依次赋予[0,1]范围内的权重值。具体可采用如下公式计算上述前k个连接中的每一个连接对应的优化权重值:Specifically, weight values in the range of [0, 1] are sequentially assigned to the first k connections. Specifically, the following formula can be used to calculate the optimization weight value corresponding to each of the first k connections:

其中,wi’表示第i个连接的优化权重值。Among them, wi ' represents the optimized weight value of the ith connection.
步骤23,为上述前k个连接中的每一个连接对应分配上述优化权重值,得到所述稀疏神经网络模型。Step 23: Assign the above-mentioned optimization weight value to each of the above-mentioned first k connections correspondingly to obtain the sparse neural network model.
经过上述步骤21至步骤23,上述稀疏神经网络模型中相对重要的连接被激励,上述稀疏神经网络模型中不太重要的连接被抑制,进而放大稀疏神经网络模型中各个连接之间的权重差异,以便根据优化权重值的大小将不同连接更好的区分开来。After the above steps 21 to 23, the relatively important connections in the sparse neural network model are stimulated, and the less important connections in the sparse neural network model are suppressed, thereby amplifying the weight difference between the connections in the sparse neural network model, In order to better distinguish different connections according to the size of the optimization weight value.
步骤S110,使用目标训练样本集训练稀疏神经网络模型,直至得到训练完成的目标神经网络模型;其中,目标神经网络模型用于对目标应用场景对应的数据进行处理。Step S110, use the target training sample set to train the sparse neural network model until a trained target neural network model is obtained; wherein, the target neural network model is used to process data corresponding to the target application scenario.
作为一种可能的实施方式,可将上述目标训练样本集中的所有样本输入上述稀疏神经网络模型;根据上述稀疏神经网络模型的预测结果和上述目标训练样本集中的所有样本对应的标签计算损失函数值,直至迭代次数超过预设次数或损失函数值小于预设值,停止训练,得到训练完成的目标神经网络模型。As a possible implementation manner, all samples in the above target training sample set may be input into the above sparse neural network model; the loss function value is calculated according to the prediction result of the above sparse neural network model and the labels corresponding to all samples in the above target training sample set , until the number of iterations exceeds the preset number of times or the loss function value is less than the preset value, stop training, and obtain the trained target neural network model.
本发明实施例提供的卷积神经网络压缩方法,其核心思想在于:引入灵敏度作为显著性度量,进而将灵敏度较低的权重或神经元确定为移除后性能降低最小的连接,并将灵敏度较高的连接移除,之后对保留下来的连接进行加权处理以放大不同连接之间的差异。由于灵敏度的计算方式能够避免显著性度量对损失价值的依赖,因而本发明消除了神经网络模型预先训练的必要性。The core idea of the convolutional neural network compression method provided by the embodiment of the present invention is to introduce the sensitivity as a saliency measure, and then determine the weight or neuron with lower sensitivity as the connection with the smallest performance degradation after removal, and use the lower sensitivity as the connection with the smallest performance degradation. High connections are removed, and then the remaining connections are weighted to amplify the differences between different connections. The present invention eliminates the necessity of pre-training the neural network model because the sensitivity is calculated in a way that avoids the dependence of the saliency measure on the loss value.
本发明实施例提供的卷积神经网络压缩方法,该方法包括:获取目标应用场景的目标训练样本集;采用方差缩放方法初始化待压缩神经网络模型的权重以得到待压缩神经网络模型的初始权重向量;以预设稀疏度作为约束条件,确定初始权重向量对应的权重优化向量并根据权重优化向量计算待压缩神经网络模型中所有连接的灵敏度;根据预设稀疏度和灵敏度对待压缩神经网络模型进行剪枝以得到稀疏神经网络模型;使用目标训练样本集训练稀疏神经网络模型,直至得到训练完成的目标神经网络模型。采用上述技术,在初始化神经网络模型的权重后,引入灵敏度作为评判连接重要程度的标准,从而在训练前根据灵敏度识别出待压缩神经网络模型中的冗余连接并根据所需的稀疏度水平对冗余连接进行剪枝,之后再采用标准模型训练流程对剪枝后的稀疏神经网络模型进行训练,该操作方式能够避免反复进行训练-剪枝-微调的迭代优化过程,进而在保证剪枝后的神经网络模型的性能的同时提高了神经网络模型的压缩效率。The method for compressing a convolutional neural network provided by an embodiment of the present invention includes: acquiring a target training sample set of a target application scenario; using a variance scaling method to initialize the weight of the neural network model to be compressed to obtain an initial weight vector of the neural network model to be compressed ; Using the preset sparsity as a constraint, determine the weight optimization vector corresponding to the initial weight vector and calculate the sensitivity of all connections in the neural network model to be compressed according to the weight optimization vector; prune the neural network model to be compressed according to the preset sparsity and sensitivity to obtain the sparse neural network model; use the target training sample set to train the sparse neural network model until the trained target neural network model is obtained. Using the above technique, after initializing the weights of the neural network model, the sensitivity is introduced as a criterion for judging the importance of connections, so that redundant connections in the neural network model to be compressed are identified according to the sensitivity before training, and the required sparsity level is adjusted. Redundant connections are pruned, and then the standard model training process is used to train the pruned sparse neural network model. This operation method can avoid repeated iterative optimization processes of training-pruning-fine-tuning, and then ensure that after pruning The performance of the neural network model is improved while the compression efficiency of the neural network model is improved.
基于上述卷积神经网络压缩方法,本发明实施例还提供了一种卷积神经网络压缩装置,参见图2所示,该装置包括:Based on the above-mentioned convolutional neural network compression method, an embodiment of the present invention further provides a convolutional neural network compression device, as shown in FIG. 2 , the device includes:
样本获取模块21,用于获取目标应用场景的目标训练样本集;其中,所述目标训练样本集是基于所述目标应用场景对应的待压缩神经网络模型的初始训练样本集确定的。The sample acquisition module 21 is configured to acquire a target training sample set of a target application scenario; wherein, the target training sample set is determined based on the initial training sample set of the neural network model to be compressed corresponding to the target application scenario.
初始化模块22,用于采用方差缩放方法初始化所述待压缩神经网络模型的权重,得到所述待压缩神经网络模型的初始权重向量。The initialization module 22 is configured to use the variance scaling method to initialize the weight of the neural network model to be compressed to obtain an initial weight vector of the neural network model to be compressed.
灵敏度计算模块23,用于以预设稀疏度作为约束条件,确定所述初始权重向量对应的权重优化向量,并根据所述权重优化向量计算所述待压缩神经网络模型中所有连接的灵敏度;其中,所述灵敏度用于表征所述待压缩神经网络模型中各个网络层的连接的重要程度。A sensitivity calculation module 23, configured to use a preset sparsity as a constraint, determine a weight optimization vector corresponding to the initial weight vector, and calculate the sensitivity of all connections in the neural network model to be compressed according to the weight optimization vector; wherein , and the sensitivity is used to represent the importance of the connection of each network layer in the neural network model to be compressed.
剪枝模块24,用于根据所述预设稀疏度和所述灵敏度对所述待压缩神经网络模型进行剪枝,得到稀疏神经网络模型;其中,所述稀疏神经网络模型的权重是根据所述预设稀疏度和所述灵敏度确定出来的。The pruning module 24 is configured to prune the neural network model to be compressed according to the preset sparsity and the sensitivity to obtain a sparse neural network model; wherein, the weight of the sparse neural network model is based on the The preset sparsity and the sensitivity are determined.
训练模块25,用于使用所述目标训练样本集训练所述稀疏神经网络模型,直至得到训练完成的目标神经网络模型;其中,所述目标神经网络模型用于对所述目标应用场景对应的数据进行处理。The training module 25 is used to train the sparse neural network model by using the target training sample set until the trained target neural network model is obtained; wherein, the target neural network model is used for data corresponding to the target application scenario to be processed.
本发明实施例提供的卷积神经网络压缩装置,在初始化神经网络模型的权重后,引入灵敏度作为评判连接重要程度的标准,从而在训练前根据灵敏度识别出待压缩神经网络模型中的冗余连接并根据所需的稀疏度水平对冗余连接进行剪枝,之后再采用标准模型训练流程对剪枝后的稀疏神经网络模型进行训练,该操作方式能够避免反复进行训练-剪枝-微调的迭代优化过程,进而在保证剪枝后的神经网络模型的性能的同时提高了神经网络模型的压缩效率。In the convolutional neural network compression device provided by the embodiment of the present invention, after initializing the weight of the neural network model, sensitivity is introduced as a criterion for evaluating the importance of connections, so that redundant connections in the neural network model to be compressed are identified according to the sensitivity before training. And prune redundant connections according to the required sparsity level, and then use the standard model training process to train the pruned sparse neural network model, which can avoid repeated training-pruning-fine-tuning iterations The optimization process further improves the compression efficiency of the neural network model while ensuring the performance of the pruned neural network model.
基于上述卷积神经网络压缩装置,本发明实施例还提供了另一种卷积神经网络压缩装置,参见图3所示,该装置还包括:Based on the above-mentioned convolutional neural network compression device, an embodiment of the present invention further provides another convolutional neural network compression device. Referring to FIG. 3 , the device further includes:
定义模块26,用于将所述待压缩神经网络模型的剪枝定义为以下公式的约束优化问题:The definition module 26 is used to define the pruning of the neural network model to be compressed as a constrained optimization problem of the following formula:

s.t.w∈Rm,c∈{0,1}m,||c||0≤kstw∈Rm , c∈{0,1}m , ||c||0 ≤k
其中,L(·)表示整体损失函数,l(·)表示部分损失函数,⊙表示哈达玛乘积,c表示所述权重优化向量,w表示所述初始权重向量,∥·∥0表示标准的L0范数,m表示所述待压缩神经网络模型的参数总数,{0,1}m表示元素只有0和1的m维向量,k表示所述预设稀疏度。Among them, L( ) represents the overall loss function, l( ) represents the partial loss function, ⊙ represents the Hadamard product, c represents the weight optimization vector, w represents the initial weight vector, ∥ ∥0 represents the standard L0 norm, m represents the total number of parameters of the neural network model to be compressed, {0,1}m represents an m-dimensional vector with elements only 0 and 1, and k represents the preset sparsity.
上述样本获取模块21,还用于:The above-mentioned sample acquisition module 21 is also used for:
对所述初始训练样本集进行采样,得到所述目标样本集
上述灵敏度计算模块23,还用于:The above-mentioned sensitivity calculation module 23 is also used for:
对于所述待压缩神经网络模型中的每一个连接,采用以下公式计算所述整体损失函数关于所述权重优化向量的导数以近似表征移除连接对所述待压缩神经网络模型的损失的影响:For each connection in the to-be-compressed neural network model, the derivative of the overall loss function with respect to the weight optimization vector is calculated using the following formula to approximately characterize the effect of removing connections on the loss of the to-be-compressed neural network model:

s.t.w∈Rm,C∈{0,1}m,||c||0≤kstw∈Rm , C∈{0,1}m , ||c||0 ≤k
其中,gj(w;D)表示连接j对应的整体损失函数关于权重优化向量在的导数值,ej表示连接j的指示向量;Among them, gj (w; D) represents the derivative value of the overall loss function corresponding to connection j with respect to the weight optimization vector, and ej represents the indicator vector of connection j;
根据计算得到的每一个连接对应的导数值,采用以下公式计算所述待压缩神经网络模型中每一个连接的灵敏度:According to the calculated derivative value corresponding to each connection, the following formula is used to calculate the sensitivity of each connection in the neural network model to be compressed:

其中,sj表示连接j的灵敏度,|gj(w;D)|表示连接j对应的导数值的绝对值,N表示所述待压缩神经网络模型的连接数量。Wherein, sj represents the sensitivity of connection j, |gj (w; D)| represents the absolute value of the derivative value corresponding to connection j, and N represents the number of connections of the neural network model to be compressed.
上述剪枝模块24,还用于:按照所述灵敏度由大到小的顺序对所述待压缩神经网络模型中的所有连接进行排序,并保留排序结果中的前k个连接,得到第一稀疏神经网络模型;根据所述预设稀疏度和所述排序结果,对所述第一稀疏神经网络模型中各个网络层的连接进行加权处理,得到所述稀疏神经网络模型。The above-mentioned pruning module 24 is further configured to: sort all the connections in the neural network model to be compressed in descending order of the sensitivity, and retain the top k connections in the sorting result to obtain the first sparseness A neural network model; according to the preset sparsity and the sorting result, weighting the connections of each network layer in the first sparse neural network model to obtain the sparse neural network model.
上述剪枝模块24,还用于:The above-mentioned pruning module 24 is also used for:
采用如下公式计算所述前k个连接中的每一个连接对应的优化权重值:The optimization weight value corresponding to each of the first k connections is calculated using the following formula:

其中,wi’表示第i个连接的优化权重值;Among them, wi ' represents the optimization weight value of the ith connection;
为所述前k个连接中的每一个连接对应分配所述优化权重值,得到所述稀疏神经网络模型。The optimized weight value is correspondingly assigned to each of the first k connections to obtain the sparse neural network model.
上述训练模块25,还用于:将所述目标训练样本集中的所有样本输入所述稀疏神经网络模型;根据所述稀疏神经网络模型的预测结果和所述目标训练样本集中的所有样本对应的标签计算损失函数值,直至迭代次数超过预设次数或损失函数值小于预设值,停止训练,得到训练完成的目标神经网络模型。The above training module 25 is further configured to: input all samples in the target training sample set into the sparse neural network model; according to the prediction result of the sparse neural network model and the labels corresponding to all samples in the target training sample set Calculate the loss function value until the number of iterations exceeds the preset number of times or the loss function value is less than the preset value, stop training, and obtain the trained target neural network model.
本发明实施例所提供的装置,其实现原理及产生的技术效果和前述方法实施例相同,为简要描述,装置实施例部分未提及之处,可参考前述方法实施例中相应内容。The implementation principle and technical effects of the device provided by the embodiment of the present invention are the same as those of the foregoing method embodiment. For brief description, for the parts not mentioned in the device embodiment, reference may be made to the corresponding content in the foregoing method embodiment.
本发明实施例提供了一种电子设备,参见图4所示,该电子设备100包括:处理器40,存储器41,总线42和通信接口43,所述处理器40、通信接口43和存储器41通过总线42连接;处理器40用于执行存储器41中存储的可执行模块,例如计算机程序。An embodiment of the present invention provides an electronic device. Referring to FIG. 4 , the
其中,存储器41可能包含高速随机存取存储器(RAM,Random Access Memory),也可能还包括非不稳定的存储器(non-volatile memory),例如至少一个磁盘存储器。通过至少一个通信接口43(可以是有线或者无线)实现该系统网元与至少一个其他网元之间的通信连接,可以使用互联网,广域网,本地网,城域网等。The
总线42可以是ISA总线、PCI总线或EISA总线等。所述总线可以分为地址总线、数据总线、控制总线等。为便于表示,图4中仅用一个双向箭头表示,但并不表示仅有一根总线或一种类型的总线。The bus 42 may be an ISA bus, a PCI bus, an EISA bus, or the like. The bus can be divided into an address bus, a data bus, a control bus, and the like. For ease of presentation, only one bidirectional arrow is used in FIG. 4, but it does not mean that there is only one bus or one type of bus.
其中,存储器41用于存储程序,所述处理器40在接收到执行指令后,执行所述程序,前述本发明实施例任一实施例揭示的流过程定义的装置所执行的方法可以应用于处理器40中,或者由处理器40实现。The
处理器40可能是一种集成电路芯片,具有信号的处理能力。在实现过程中,上述卷积神经网络压缩方法的各步骤可以通过处理器40中的硬件的集成逻辑电路或者软件形式的指令完成。上述的处理器40可以是通用处理器,包括中央处理器(Central ProcessingUnit,简称CPU)、网络处理器(Network Processor,简称NP)等;还可以是数字信号处理器(Digital Signal Processing,简称DSP)、专用集成电路(Application SpecificIntegrated Circuit,简称ASIC)、现成可编程门阵列(Field-Programmable Gate Array,简称FPGA)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。可以实现或者执行本发明实施例中的公开的各方法、步骤及逻辑框图。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。结合本发明实施例所公开的卷积神经网络压缩方法的步骤可以直接体现为硬件译码处理器执行完成,或者用译码处理器中的硬件及软件模块组合执行完成。软件模块可以位于随机存储器,闪存、只读存储器,可编程只读存储器或者电可擦写可编程存储器、寄存器等本领域成熟的存储介质中。该存储介质位于存储器41,处理器40读取存储器41中的信息,结合其硬件完成上述卷积神经网络压缩方法的步骤。The
本发明实施例所提供的卷积神经网络压缩方法、装置及电子设备的计算机程序产品,包括存储了程序代码的计算机可读存储介质,所述程序代码包括的指令可用于执行前面方法实施例中所述的卷积神经网络压缩方法,具体实现可参见前述方法实施例,在此不再赘述。The computer program product of the convolutional neural network compression method, device, and electronic device provided by the embodiments of the present invention includes a computer-readable storage medium storing program codes, and the instructions included in the program codes can be used to execute the foregoing method embodiments. For the specific implementation of the convolutional neural network compression method, reference may be made to the foregoing method embodiments, which will not be repeated here.
所述功能如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器(ROM,Read-Only Memory)、随机存取存储器(RAM,Random Access Memory)、磁碟或者光盘等各种可以存储程序代码的介质。The functions, if implemented in the form of software functional units and sold or used as independent products, may be stored in a computer-readable storage medium. Based on this understanding, the technical solution of the present invention can be embodied in the form of a software product in essence, or the part that contributes to the prior art or the part of the technical solution. The computer software product is stored in a storage medium, including Several instructions are used to cause a computer device (which may be a personal computer, a server, or a network device, etc.) to execute all or part of the steps of the methods described in the various embodiments of the present invention. The aforementioned storage medium includes: U disk, mobile hard disk, Read-Only Memory (ROM, Read-Only Memory), Random Access Memory (RAM, Random Access Memory), magnetic disk or optical disk and other media that can store program codes .
最后应说明的是:以上所述实施例,仅为本发明的具体实施方式,用以说明本发明的技术方案,而非对其限制,本发明的保护范围并不局限于此,尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,其依然可以对前述实施例所记载的技术方案进行修改或可轻易想到变化,或者对其中部分技术特征进行等同替换;而这些修改、变化或者替换,并不使相应技术方案的本质脱离本发明实施例技术方案的精神和范围,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应所述以权利要求的保护范围为准。Finally, it should be noted that the above-mentioned embodiments are only specific implementations of the present invention, and are used to illustrate the technical solutions of the present invention, but not to limit them. The protection scope of the present invention is not limited thereto, although referring to the foregoing The embodiment has been described in detail the present invention, those of ordinary skill in the art should understand: any person skilled in the art who is familiar with the technical field within the technical scope disclosed by the present invention can still modify the technical solutions described in the foregoing embodiments. Or can easily think of changes, or equivalently replace some of the technical features; and these modifications, changes or replacements do not make the essence of the corresponding technical solutions deviate from the spirit and scope of the technical solutions of the embodiments of the present invention, and should be covered in the present invention. within the scope of protection. Therefore, the protection scope of the present invention should be based on the protection scope of the claims.
Claims (10)





Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111645899.9ACN114330690B (en) | 2021-12-30 | 2021-12-30 | Convolutional neural network compression method, device and electronic equipment |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111645899.9ACN114330690B (en) | 2021-12-30 | 2021-12-30 | Convolutional neural network compression method, device and electronic equipment |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN114330690Atrue CN114330690A (en) | 2022-04-12 |
| CN114330690B CN114330690B (en) | 2025-05-27 |
Family
ID=81017594
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202111645899.9AActiveCN114330690B (en) | 2021-12-30 | 2021-12-30 | Convolutional neural network compression method, device and electronic equipment |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114330690B (en) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115034297A (en)* | 2022-06-01 | 2022-09-09 | Oppo广东移动通信有限公司 | Model compression method, recognition method, device, electronic equipment and storage medium |
| CN119902606A (en)* | 2025-03-31 | 2025-04-29 | 苏州元脑智能科技有限公司 | Server heat dissipation control system, method, storage medium and program product |
| CN119962609A (en)* | 2025-04-07 | 2025-05-09 | 之江实验室 | Model pruning method, device and computer-readable storage medium |
Citations (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111178525A (en)* | 2019-12-24 | 2020-05-19 | 重庆邮电大学 | Pruning-based convolutional neural network compression method, system and medium |
| CN111247537A (en)* | 2017-10-06 | 2020-06-05 | 深立方有限公司 | Systems and methods for compact and efficient sparse neural networks |
| US20200311549A1 (en)* | 2017-10-26 | 2020-10-01 | Xilinx, Inc. | Method of pruning convolutional neural network based on feature map variation |
| US20200364573A1 (en)* | 2019-05-15 | 2020-11-19 | Advanced Micro Devices, Inc. | Accelerating neural networks with one shot skip layer pruning |
| CN111985603A (en)* | 2019-05-23 | 2020-11-24 | 耐能智慧股份有限公司 | Method for training sparse connection neural network |
| CN112016672A (en)* | 2020-07-16 | 2020-12-01 | 珠海欧比特宇航科技股份有限公司 | Method and medium for neural network compression based on sensitivity pruning and quantization |
| CN112884149A (en)* | 2021-03-19 | 2021-06-01 | 华南理工大学 | Deep neural network pruning method and system based on random sensitivity ST-SM |
| CN113205182A (en)* | 2021-07-07 | 2021-08-03 | 华东交通大学 | Real-time power load prediction system based on sparse pruning method |
| CN113383346A (en)* | 2018-12-18 | 2021-09-10 | 莫维迪厄斯有限公司 | Neural network compression |
- 2021
- 2021-12-30CNCN202111645899.9Apatent/CN114330690B/enactiveActive
Patent Citations (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111247537A (en)* | 2017-10-06 | 2020-06-05 | 深立方有限公司 | Systems and methods for compact and efficient sparse neural networks |
| US20200311549A1 (en)* | 2017-10-26 | 2020-10-01 | Xilinx, Inc. | Method of pruning convolutional neural network based on feature map variation |
| CN113383346A (en)* | 2018-12-18 | 2021-09-10 | 莫维迪厄斯有限公司 | Neural network compression |
| US20200364573A1 (en)* | 2019-05-15 | 2020-11-19 | Advanced Micro Devices, Inc. | Accelerating neural networks with one shot skip layer pruning |
| CN111985603A (en)* | 2019-05-23 | 2020-11-24 | 耐能智慧股份有限公司 | Method for training sparse connection neural network |
| CN111178525A (en)* | 2019-12-24 | 2020-05-19 | 重庆邮电大学 | Pruning-based convolutional neural network compression method, system and medium |
| CN112016672A (en)* | 2020-07-16 | 2020-12-01 | 珠海欧比特宇航科技股份有限公司 | Method and medium for neural network compression based on sensitivity pruning and quantization |
| CN112884149A (en)* | 2021-03-19 | 2021-06-01 | 华南理工大学 | Deep neural network pruning method and system based on random sensitivity ST-SM |
| CN113205182A (en)* | 2021-07-07 | 2021-08-03 | 华东交通大学 | Real-time power load prediction system based on sparse pruning method |
Non-Patent Citations (4)
| Title |
|---|
| NAMHOON LEE ET AL: "SNIP: SINGLE-SHOT NETWORK PRUNING BASED ON CONNECTION SENSITIVITY", 《ARXIV》, 25 February 2019 (2019-02-25), pages 1 - 15* |
| SONG HAN ET AL: "Learning bothWeights and Connections for Efficient Neural Networks", 《ADVANCES IN NEURAL INFORMATION PROCESSING SYSTEMS》, 31 December 2015 (2015-12-31), pages 1 - 9* |
| 张瑞琰 等: "一种基于连接敏感度的CNN 初始化剪枝方法", 《计算机应用与软件》, vol. 37, no. 11, 30 November 2020 (2020-11-30), pages 268 - 274* |
| 潘茜萌: "卷积神经网络压缩算法优化研究", 《中国优秀硕士学位论文全文数据库信息科技辑》, vol. 2021, no. 9, 30 September 2021 (2021-09-30), pages 140 - 122* |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115034297A (en)* | 2022-06-01 | 2022-09-09 | Oppo广东移动通信有限公司 | Model compression method, recognition method, device, electronic equipment and storage medium |
| CN119902606A (en)* | 2025-03-31 | 2025-04-29 | 苏州元脑智能科技有限公司 | Server heat dissipation control system, method, storage medium and program product |
| CN119962609A (en)* | 2025-04-07 | 2025-05-09 | 之江实验室 | Model pruning method, device and computer-readable storage medium |
| CN119962609B (en)* | 2025-04-07 | 2025-09-12 | 之江实验室 | Model pruning method, equipment and computer readable storage medium |
Also Published As
| Publication number | Publication date |
|---|---|
| CN114330690B (en) | 2025-05-27 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN112052951B (en) | Pruning neural network method, system, equipment and readable storage medium | |
| CN109840589B (en) | Method and device for operating convolutional neural network on FPGA | |
| CN114330690A (en) | Convolutional neural network compression method, device and electronic device | |
| CN113469088B (en) | SAR image ship target detection method and system under passive interference scene | |
| CN113065525A (en) | Age recognition model training method, face age recognition method and related device | |
| CN113011532B (en) | Classification model training method, device, computing equipment and storage medium | |
| CN113239702A (en) | Intention recognition method and device and electronic equipment | |
| CN112800813B (en) | Target identification method and device | |
| CN116502695A (en) | Model compression method, device, equipment and medium based on channel pruning | |
| CN110334262B (en) | Model training method and device and electronic equipment | |
| CN112633299A (en) | Target detection method, network, device, terminal equipment and storage medium | |
| CN114595627A (en) | Model quantization method, device, equipment and storage medium | |
| CN119005364A (en) | AI model iteration updating method and system | |
| CN111126501B (en) | Image identification method, terminal equipment and storage medium | |
| CN116304721A (en) | Data standard making method and system for big data management based on data category | |
| CN114972950A (en) | Multi-target detection method, device, equipment, medium and product | |
| CN113806589A (en) | Video clip positioning method, device and computer readable storage medium | |
| CN114492783A (en) | Pruning method and device for multitask neural network model | |
| CN112668702B (en) | Fixed-point parameter optimization method, system, terminal and storage medium | |
| CN111291862A (en) | Method and apparatus for model compression | |
| CN114925821B (en) | A neural network model compression method and related system | |
| CN112906824B (en) | Vehicle clustering method, system, device and storage medium | |
| CN117746398A (en) | Data labeling methods, neural network model training methods and related equipment | |
| CN114021699A (en) | A gradient-based convolutional neural network pruning method and device | |
| CN112766322A (en) | Training method of classification model, data classification method and device |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |