CN114330667A - A method, system, computer equipment and storage medium for generating a neural network - Google Patents
A method, system, computer equipment and storage medium for generating a neural networkDownload PDFInfo
- Publication number
- CN114330667A CN114330667ACN202111666463.8ACN202111666463ACN114330667ACN 114330667 ACN114330667 ACN 114330667ACN 202111666463 ACN202111666463 ACN 202111666463ACN 114330667 ACN114330667 ACN 114330667A
- Authority
- CN
- China
- Prior art keywords
- neural network
- trained
- training
- battle
- auxiliary
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 238000013528artificial neural networkMethods0.000titleclaimsabstractdescription883
- 238000000034methodMethods0.000titleclaimsabstractdescription153
- 238000012549trainingMethods0.000claimsabstractdescription626
- 230000004044responseEffects0.000claimsabstractdescription63
- 238000013135deep learningMethods0.000claimsabstractdescription60
- 230000008569processEffects0.000claimsdescription77
- 238000005070samplingMethods0.000claimsdescription43
- 238000011156evaluationMethods0.000claimsdescription33
- 238000004590computer programMethods0.000claimsdescription12
- 238000012216screeningMethods0.000claimsdescription6
- 230000009471actionEffects0.000description32
- 238000011161developmentMethods0.000description10
- 230000008878couplingEffects0.000description6
- 238000010168coupling processMethods0.000description6
- 238000005859coupling reactionMethods0.000description6
- 238000010586diagramMethods0.000description6
- 238000012545processingMethods0.000description5
- 230000000737periodic effectEffects0.000description4
- 238000004891communicationMethods0.000description3
- 230000006870functionEffects0.000description3
- 230000003993interactionEffects0.000description3
- 238000011160researchMethods0.000description3
- 230000008901benefitEffects0.000description2
- 230000000694effectsEffects0.000description2
- 230000036541healthEffects0.000description2
- 230000008685targetingEffects0.000description2
- 238000013473artificial intelligenceMethods0.000description1
- 238000010276constructionMethods0.000description1
- 238000011157data evaluationMethods0.000description1
- 230000007547defectEffects0.000description1
- 238000005516engineering processMethods0.000description1
- 238000001914filtrationMethods0.000description1
- 238000004519manufacturing processMethods0.000description1
- 238000012986modificationMethods0.000description1
- 230000004048modificationEffects0.000description1
- 230000003287optical effectEffects0.000description1
- 230000002787reinforcementEffects0.000description1
Images




Landscapes
- Machine Translation (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本公开涉及深度学习技术领域,具体而言,涉及一种神经网络的生成方法、系统、计算机设备及存储介质。The present disclosure relates to the technical field of deep learning, and in particular, to a method, system, computer device and storage medium for generating a neural network.
背景技术Background technique
随着计算机技术的发展,将人工智能(Artificial Intelligence,AI)应用到游戏领域已经成为当前游戏行业的发展趋势,当前对神经网络进行强化训练的代码耦合在神经网络对应的代码中,需要为不同对战场景设置不同的神经网络、以及对应的强化训练代码,开发成本较高且复杂度较高。With the development of computer technology, the application of artificial intelligence (AI) to the game field has become the development trend of the current game industry. The current code for intensive training of neural networks is coupled to the code corresponding to the neural network. Different neural networks and corresponding reinforcement training codes are set up in the battle scene, and the development cost is high and the complexity is high.
发明内容SUMMARY OF THE INVENTION
本公开实施例至少提供一种神经网络的生成方法、系统、计算机设备及存储介质。Embodiments of the present disclosure provide at least a method, system, computer device, and storage medium for generating a neural network.
第一方面,本公开实施例提供了一种神经网络的生成方法,所述方法包括:在至少两个训练周期中的每个训练周期中执行:响应于接收到当前训练周期的第一训练指令,从当前训练周期的至少两个辅助神经网络中确定目标辅助神经网络;利用所述目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战,得到对所述当前训练周期的待训练神经网络进行训练的第一对战样本数据;向深度学习框架发送所述当前训练周期的第一对战样本数据;其中,至少两个训练周期分别对应的第一对战样本数据,用于所述深度学习框架对待训练神经网络进行至少两个训练周期的强化训练,得到目标神经网络,所述目标神经网络用于控制目标虚拟角色进行对战。In a first aspect, an embodiment of the present disclosure provides a method for generating a neural network, the method comprising: performing in each of at least two training cycles: in response to receiving a first training instruction of the current training cycle , determine a target auxiliary neural network from at least two auxiliary neural networks in the current training cycle; use the target auxiliary neural network to control the first virtual character, and use the to-be-trained neural network of the current training cycle to control the second virtual character to fight, obtaining the first battle sample data for training the neural network to be trained in the current training cycle; sending the first battle sample data of the current training cycle to the deep learning framework; wherein the first battle sample data corresponding to at least two training cycles respectively The battle sample data is used for the deep learning framework to perform intensive training on the neural network to be trained for at least two training cycles, to obtain a target neural network, and the target neural network is used to control the target virtual character to compete.
这样,将神经网络、与对神经网络进行强化训练的代码分开设置在智能体控制框架和深度学习框架中,减少了代码的耦合性,这样使得在不同的对战场景下,可以使用同一深度学习框架以及智能体控制框架,减少了开发成本及开发复杂度;并且利用目标辅助神经网络控制第一虚拟角色、并利用待训练神经网络控制第二虚拟角色进行对战,生成第一对战样本数据;并将生成的第一对战样本数据,发送至深度学习框架,以使深度学习框架基于第一对战样本数据,对待训练神经网络进行至少两个训练周期的强化训练,得到目标神经网络,这样生成的目标神经网络是基于大量的对战样本数据训练生成的,学习到了不同类型的动作、以及对战策略,灵活度较高且具有较强的泛化能力。In this way, the neural network and the code for intensive training of the neural network are separately set in the agent control framework and the deep learning framework, which reduces the coupling of the code, so that the same deep learning framework can be used in different battle scenarios. and an agent control framework, which reduces the development cost and development complexity; and uses the target-assisted neural network to control the first virtual character, and uses the neural network to be trained to control the second virtual character to fight to generate the first battle sample data; and The generated first battle sample data is sent to the deep learning framework, so that the deep learning framework performs intensive training for at least two training cycles on the neural network to be trained based on the first battle sample data to obtain the target neural network. The network is trained and generated based on a large number of battle sample data, and has learned different types of actions and battle strategies, with high flexibility and strong generalization ability.
一种可选的实施方式中,响应于接收到当前训练周期的第一训练指令,从当前训练周期的至少两个辅助神经网络中确定目标辅助神经网络,包括:响应于接收到所述当前训练周期的第一训练指令,确定当前训练周期的至少两个辅助神经网络分别对应的采样概率;基于至少两个所述辅助神经网络分别对应的采样概率,从当前训练周期的至少两个辅助神经网络中确定目标辅助神经网络。In an optional embodiment, determining a target auxiliary neural network from at least two auxiliary neural networks in the current training cycle in response to receiving the first training instruction of the current training cycle includes: in response to receiving the current training cycle. The first training instruction of the cycle determines the sampling probabilities corresponding to the at least two auxiliary neural networks in the current training cycle respectively; based on the sampling probabilities corresponding to the at least two auxiliary neural networks respectively Targeting Auxiliary Neural Networks.
这样,可以在至少两个辅助神经网络中,选择适合用于对待训练神经网络进行对战对抗能力训练和/或对战配合能力训练的目标辅助神经网络。In this way, among the at least two auxiliary neural networks, a target auxiliary neural network suitable for training the neural network to be trained for the training of the combat confrontation ability and/or the training of the combat cooperation ability can be selected.
一种可选的实施方式中,响应于接收到所述当前训练周期的第一训练指令,确定当前训练周期的至少两个辅助神经网络分别对应的采样概率,包括:响应于接收到所述当前训练周期的第一训练指令,确定当前训练周期的至少两个辅助神经网络;至少两个所述辅助神经网络包括:第一辅助神经网络和/或第二辅助神经网络;其中,所述第一辅助神经网络用于对所述待训练神经网络进行对战对抗能力训练;所述第二辅助神经网络用于对所述待训练神经网络进行对战对抗能力训练和/或对战配合能力训练;基于各所述辅助神经网络分别对应的历史对战数据,确定各所述辅助神经网络分别对应的采样概率。In an optional implementation manner, in response to receiving the first training instruction of the current training period, determining the sampling probabilities corresponding to at least two auxiliary neural networks in the current training period respectively includes: in response to receiving the current training period. The first training instruction of the training cycle, determining at least two auxiliary neural networks of the current training cycle; the at least two auxiliary neural networks include: a first auxiliary neural network and/or a second auxiliary neural network; wherein the first auxiliary neural network The auxiliary neural network is used for training the neural network to be trained in combat confrontation ability; the second auxiliary neural network is used for training the neural network to be trained in combat confrontation ability and/or combat cooperation ability; The historical battle data corresponding to the auxiliary neural networks is determined, and the sampling probability corresponding to the auxiliary neural networks is determined.
一种可选的实施方式中,所述历史对战数据,包括:在历史对战对局中的胜负情况信息、和/或,在历史对战对局中的评价数据。In an optional implementation manner, the historical competition data includes: information on the outcome of the historical competition and/or evaluation data in the historical competition.
一种可选的实施方式中,所述基于至少两个所述辅助神经网络分别对应的采样概率,从当前训练周期的至少两个辅助神经网络中确定目标辅助神经网络,包括:基于至少两个所述辅助神经网络分别对应的采样概率、以及预设的筛选规则,从当前训练周期的至少两个辅助神经网络中确定所述目标辅助神经网络。In an optional embodiment, the determining the target auxiliary neural network from at least two auxiliary neural networks in the current training cycle based on the sampling probabilities corresponding to the at least two auxiliary neural networks respectively includes: based on the at least two auxiliary neural networks. The sampling probability corresponding to the auxiliary neural network and the preset screening rule respectively, and the target auxiliary neural network is determined from at least two auxiliary neural networks in the current training cycle.
一种可选的实施方式中,所述利用所述目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战,得到对所述当前训练周期的待训练神经网络进行训练的第一对战样本数据,包括:利用所述目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战,得到所述第二虚拟角色在对战过程中的第一对战状态数据;基于所述第一对战状态数据,生成所述第一对战样本数据。In an optional embodiment, the target-assisted neural network is used to control the first virtual character, and the neural network to be trained in the current training cycle is used to control the second virtual character to play against each other, so as to obtain the accuracy of the current training cycle. The first battle sample data for training the neural network to be trained includes: using the target auxiliary neural network to control the first virtual character, and using the to-be-trained neural network of the current training cycle to control the second virtual character to compete, and obtaining the first virtual character. The first battle state data of the two virtual characters in the battle process; the first battle sample data is generated based on the first battle state data.
一种可选的实施方式中,所述方法还包括:利用所述目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战,得到对所述目标辅助神经网络进行训练的第二对战样本数据;向深度学习框架发送所述当前训练周期的第二对战样本数据;其中,当前训练周期的第二对战样本数据,用于所述深度学习框架对当前训练周期的目标辅助神经网络进行强化训练,得到未来训练周期的辅助神经网络。In an optional embodiment, the method further includes: using the target auxiliary neural network to control the first virtual character, and using the to-be-trained neural network of the current training cycle to control the second virtual character to fight, and obtaining the The second battle sample data for training the target-assisted neural network; send the second battle sample data of the current training cycle to the deep learning framework; wherein, the second battle sample data of the current training cycle is used for the deep learning framework to compare The target auxiliary neural network of the current training cycle is intensively trained, and the auxiliary neural network of the future training cycle is obtained.
一种可选的实施方式中,所述利用所述目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战时,得到对所述目标辅助神经网络进行训练的第二对战样本数据,包括:确定所述目标辅助神经网络是否利用所述待训练神经网络的历史状态生成;响应于所述目标辅助神经网络并非利用所述待训练神经网络的历史状态生成,则利用所述目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战时,得到对所述目标辅助神经网络进行训练的第二对战样本数据。In an optional embodiment, when the target auxiliary neural network is used to control the first virtual character, and the neural network to be trained in the current training cycle is used to control the second virtual character to fight, the target auxiliary neural network is obtained. The second battle sample data for network training includes: determining whether the target auxiliary neural network is generated by using the historical state of the neural network to be trained; in response to the target auxiliary neural network not using the history of the neural network to be trained When the state is generated, use the target auxiliary neural network to control the first virtual character, and use the to-be-trained neural network of the current training cycle to control the second virtual character to fight, and obtain a second battle for training the target auxiliary neural network. sample.
一种可选的实施方式中,响应于确定的目标辅助神经网络包括第一辅助神经网络;所述第一虚拟角色和所述第二虚拟角色均包括一个;所述利用所述目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战,得到对所述当前训练周期的待训练神经网络进行训练的第一对战样本数据,包括:利用所述第一辅助神经网络控制所述第一虚拟角色,并利用当前训练周期的待训练神经网络控制与所述第一虚拟角色属于不同对战阵营的第二虚拟角色进行对战,得到所述第一对战样本数据。In an optional implementation manner, the auxiliary neural network in response to the determined target includes a first auxiliary neural network; the first virtual character and the second virtual character each include one; the target auxiliary neural network using the target auxiliary neural network Controlling the first virtual character, and using the neural network to be trained in the current training period to control the second virtual character to fight, and obtaining the first battle sample data for training the neural network to be trained in the current training period, including: using the neural network to be trained in the current training period. The first auxiliary neural network controls the first virtual character, and uses the neural network to be trained in the current training cycle to control and compete with the second virtual character of the first virtual character belonging to a different battle camp to obtain the first battle sample data.
这样,利用待训练神经网络、与第一辅助神经网络分别控制不同对战阵营的虚拟角色进行对战对局,即利用第一辅助神经网络,对待训练神经网络进行练,使得待训练神经网络与不同类型的对手进行对局,以提升了最终生成的目标神经网络的泛化能力。In this way, the neural network to be trained is used to control the virtual characters of different battle camps with the first auxiliary neural network to conduct a battle, that is, the first auxiliary neural network is used to train the neural network to be trained, so that the neural network to be trained is different from different types of to improve the generalization ability of the final generated target neural network.
一种可选的实施方式中,响应于确定的目标辅助神经网络包括第二辅助神经网络;所述利用所述目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战,得到对所述当前训练周期的待训练神经网络进行训练的第一对战样本数据,包括:利用所述第二辅助神经网络控制所述第一虚拟角色,并利用当前训练周期的待训练神经网络控制与所述第一虚拟角色属于相同对战阵营和/或不同对战阵营的第二虚拟角色进行对战,得到所述第一对战样本数据。In an optional embodiment, the auxiliary neural network includes a second auxiliary neural network in response to the determined target; the first virtual character is controlled by using the target auxiliary neural network, and the neural network to be trained in the current training cycle is used to control the first virtual character. The second virtual character competes against each other, and obtains the first battle sample data for training the neural network to be trained in the current training period, including: using the second auxiliary neural network to control the first virtual character, and using the current training The periodic to-be-trained neural network controls the first avatar to compete with a second avatar belonging to the same battle camp and/or a different battle camp to obtain the first battle sample data.
这样,利用待训练神经网络、与第二辅助神经网络分别控制不同对战阵营和/或相同对战阵营的虚拟角色进行对战对局,即利用第二辅助神经网络,对待训练神经网络进行训练,使得待训练神经网络与不同类型的对手进行对局和/或组队,以提升了最终生成的目标神经网络的泛化能力。In this way, using the neural network to be trained, and the second auxiliary neural network to respectively control the virtual characters of different battle camps and/or the same battle camp to carry out the battle, that is, the second auxiliary neural network is used to train the neural network to be trained, so that the to-be-trained neural network is trained. Training the neural network to play against and/or team up with different types of opponents improves the generalization ability of the resulting target neural network.
一种可选的实施方式中,所述方法还包括:利用所述目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战,得到当前对战对局对应的对战数据;利用所述对战数据,对所述目标辅助神经网络、以及当前训练周期的待训练神经网络分别对应的历史对战数据进行更新处理,得到更新后的对战数据。In an optional embodiment, the method further includes: using the target auxiliary neural network to control the first virtual character, and using the neural network to be trained in the current training cycle to control the second virtual character to play against each other, to obtain the current battle pair. The battle data corresponding to the bureau; using the battle data, update the historical battle data corresponding to the target auxiliary neural network and the neural network to be trained in the current training cycle, respectively, to obtain updated battle data.
一种可选的实施方式中,所述方法还包括:利用所述更新处理后的对战数据,确定所述待训练神经网络是否满足预设辅助神经网络生成条件;响应于所述待训练神经网络满足所述预设辅助神经网络生成条件,则基于所述待训练神经网络、或当前训练周期更新后的待训练神经网络,生成未来训练周期的辅助神经网络。In an optional embodiment, the method further includes: using the updated battle data to determine whether the neural network to be trained satisfies a preset auxiliary neural network generation condition; in response to the neural network to be trained If the preset auxiliary neural network generation condition is satisfied, an auxiliary neural network for a future training period is generated based on the to-be-trained neural network or the to-be-trained neural network updated after the current training period.
一种可选的实施方式中,所述基于所述待训练神经网络、或当前训练周期更新后的待训练神经网络,生成未来训练周期的辅助神经网络,包括:生成基于所述待训练神经网络、或当前训练周期更新后的待训练神经网络的快照;基于所述快照,生成未来训练周期的辅助神经网络。In an optional embodiment, generating an auxiliary neural network for a future training cycle based on the neural network to be trained or the updated neural network to be trained in the current training cycle includes: generating an auxiliary neural network based on the neural network to be trained. , or a snapshot of the neural network to be trained after the current training cycle is updated; based on the snapshot, an auxiliary neural network for a future training cycle is generated.
一种可选的实施方式中,所述方法还包括:响应于接收到当前训练周期的第一训练指令,确定所述当前训练周期的待训练神经网络。In an optional implementation manner, the method further includes: in response to receiving the first training instruction of the current training period, determining the neural network to be trained in the current training period.
一种可选的实施方式中,所述确定当前训练周期的所述待训练神经网络,包括:响应于当前训练周期属于首次迭代训练过程,将初始化神经网络确定为所述待训练神经网络;响应于当前训练周期属于非首次迭代训练过程,基于当前训练周期所属的迭代训练过程的前一次迭代训练过程确定的至少一个备选神经网络分别对应的性能信息,确定所述待训练神经网络;和/或,将所述初始化神经网络确定为所述待训练神经网络。In an optional implementation manner, the determining the neural network to be trained in the current training cycle includes: in response to the current training cycle belonging to the first iterative training process, determining an initialized neural network as the neural network to be trained; responding Where the current training cycle belongs to a non-first iterative training process, the neural network to be trained is determined based on the performance information respectively corresponding to at least one candidate neural network determined in the previous iterative training process of the iterative training process to which the current training cycle belongs; and/ Or, the initialized neural network is determined as the to-be-trained neural network.
一种可选的实施方式中,所述方法还包括:接收深度学习框架反馈的所述当前训练周期的待训练神经网络的更新数据;利用所述更新数据,对所述当前训练周期的待训练神经网络进行更新处理;其中,所述更新数据是所述深度学习框架利用所述当前训练周期的第一对战样本数据,对当前训练周期的待训练神经网络进行强化训练后得到的。In an optional embodiment, the method further includes: receiving updated data of the neural network to be trained in the current training cycle fed back by the deep learning framework; The neural network performs update processing; wherein, the update data is obtained after the deep learning framework performs intensive training on the neural network to be trained in the current training cycle by using the first battle sample data of the current training cycle.
第二方面,本公开实施例还提供了一种神经网络的生成方法,所述方法包括:在至少两个训练周期中的每个训练周期中执行:向智能体控制框架发送当前训练周期的第一训练指令;接收所述智能体控制框架基于所述第一训练指令反馈的当前训练周期的第一对战样本数据、以及待训练神经网络;利用所述第一对战样本数据,对所述待训练神经网络进行强化训练,得到当前训练周期的中间神经网络;基于最后一个训练周期的中间神经网络,得到目标神经网络,所述目标神经网络用于控制目标虚拟角色进行对战。In a second aspect, an embodiment of the present disclosure further provides a method for generating a neural network, the method comprising: performing in each of at least two training cycles: sending the first number of the current training cycle to the agent control framework. a training instruction; receiving the first battle sample data of the current training cycle fed back by the agent control framework based on the first training instruction, and the neural network to be trained; using the first battle sample data, to the to-be-trained The neural network is intensively trained to obtain an intermediate neural network of the current training cycle; based on the intermediate neural network of the last training cycle, a target neural network is obtained, and the target neural network is used to control the target virtual character to compete.
这样,深度学习框架可以基于接收到的第一对战样本数据,对待训练神经网络进行至少两个训练周期的强化训练,得到目标神经网络,所述目标神经网络用于控制目标虚拟角色进行对战,这样生成的目标神经网络是基于大量的对战样本数据训练生成的,学习到了不同类型的动作、以及对战策略,灵活度较高且具有较强的泛化能力,在对战对局过程中,目标神经网络可以相对灵活地根据队友(玩家或其他辅助神经网络)或对手(玩家或其他辅助神经网络)的当前状态信息、以及对战场景的当前状态信息,进行下一步动作的预测。In this way, the deep learning framework can perform intensive training on the neural network to be trained for at least two training cycles based on the received first battle sample data to obtain the target neural network, which is used to control the target virtual character to compete, so that The generated target neural network is generated based on a large number of battle sample data training, and learns different types of actions and battle strategies, with high flexibility and strong generalization ability. In the process of battle, the target neural network The next action can be predicted relatively flexibly according to the current state information of the teammate (player or other auxiliary neural network) or the opponent (player or other auxiliary neural network), and the current state information of the battle scene.
第三方面,本公开实施例还提供一种神经网络的生成系统,包括:智能体控制框架、以及深度学习框架;所述智能体控制框架,用于在至少两个训练周期中的每个训练周期中,响应于接收到当前训练周期的第一训练指令,从当前训练周期的至少两个辅助神经网络中确定目标辅助神经网络;利用所述目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战,得到对所述当前训练周期的待训练神经网络进行训练的第一对战样本数据;向深度学习框架发送所述当前训练周期的第一对战样本数据;所述深度学习框架,用于在至少两个所述训练周期中的每个训练周期中,向智能体控制框架发送当前训练周期的第一训练指令;接收所述智能体控制框架基于所述第一训练指令反馈的当前训练周期的第一对战样本数据、以及待训练神经网络;利用所述第一对战样本数据,对所述待训练神经网络进行强化训练,得到当前训练周期的中间神经网络;基于最后一个训练周期的中间神经网络,得到目标神经网络,所述目标神经网络用于控制目标虚拟角色进行对战。In a third aspect, embodiments of the present disclosure further provide a system for generating a neural network, including: an agent control framework and a deep learning framework; the agent control framework is used for each training in at least two training cycles During the cycle, in response to receiving the first training instruction of the current training cycle, determine a target auxiliary neural network from at least two auxiliary neural networks in the current training cycle; use the target auxiliary neural network to control the first virtual character, and use the current training cycle. The neural network to be trained in the training period controls the second virtual character to fight, and the first battle sample data for training the neural network to be trained in the current training period is obtained; the first battle of the current training period is sent to the deep learning framework sample data; the deep learning framework is used for sending the first training instruction of the current training cycle to the agent control framework in each of the at least two training periods; receiving the agent control framework based on The first battle sample data of the current training cycle fed back by the first training instruction, and the neural network to be trained; using the first battle sample data to perform intensive training on the neural network to be trained, to obtain the middle of the current training cycle Neural network; based on the intermediate neural network of the last training cycle, the target neural network is obtained, and the target neural network is used to control the target virtual character to fight.
一种可选的实施方式中,所述智能体控制框架在执行响应于接收到当前训练周期的第一训练指令,从当前训练周期的至少两个辅助神经网络中确定目标辅助神经网络时,具体用于:响应于接收到所述当前训练周期的第一训练指令,确定当前训练周期的至少两个辅助神经网络分别对应的采样概率;基于至少两个所述辅助神经网络分别对应的采样概率,从当前训练周期的至少两个辅助神经网络中确定目标辅助神经网络。In an optional implementation manner, when the agent control framework determines the target auxiliary neural network from at least two auxiliary neural networks in the current training cycle in response to receiving the first training instruction of the current training cycle, the specific is used for: in response to receiving the first training instruction of the current training cycle, determining the sampling probabilities corresponding to the at least two auxiliary neural networks of the current training cycle respectively; based on the sampling probabilities corresponding to the at least two auxiliary neural networks respectively, A target auxiliary neural network is determined from at least two auxiliary neural networks of the current training epoch.
一种可选的实施方式中,所述智能体控制框架在执行响应于接收到所述当前训练周期的第一训练指令,确定当前训练周期的至少两个辅助神经网络分别对应的采样概率时,具体用于:响应于接收到所述当前训练周期的第一训练指令,确定当前训练周期的至少两个辅助神经网络;至少两个所述辅助神经网络包括:第一辅助神经网络和/或第二辅助神经网络;其中,所述第一辅助神经网络用于对所述待训练神经网络进行对战对抗能力训练;所述第二辅助神经网络用于对所述待训练神经网络进行对战对抗能力训练和/或对战配合能力训练;基于各所述辅助神经网络分别对应的历史对战数据,确定各所述辅助神经网络分别对应的采样概率。In an optional implementation manner, when the agent control framework determines the sampling probabilities corresponding to at least two auxiliary neural networks of the current training period in response to receiving the first training instruction of the current training period, It is specifically used to: in response to receiving the first training instruction of the current training cycle, determine at least two auxiliary neural networks of the current training cycle; the at least two auxiliary neural networks include: the first auxiliary neural network and/or the first auxiliary neural network Two auxiliary neural networks; wherein, the first auxiliary neural network is used for training the neural network to be trained in combat confrontation; the second auxiliary neural network is used for training the neural network to be trained in combat confrontation and/or training on the ability to cooperate in battle; based on the historical battle data corresponding to each of the auxiliary neural networks, respectively, determine the sampling probability corresponding to each of the auxiliary neural networks.
一种可选的实施方式中,所述历史对战数据,包括:在历史对战对局中的胜负情况信息、和/或,在历史对战对局中的评价数据。In an optional implementation manner, the historical competition data includes: information on the outcome of the historical competition and/or evaluation data in the historical competition.
一种可选的实施方式中,所述智能体控制框架在执行所述基于至少两个所述辅助神经网络分别对应的采样概率,从当前训练周期的至少两个辅助神经网络中确定目标辅助神经网络时,具体用于:基于至少两个所述辅助神经网络分别对应的采样概率、以及预设的筛选规则,从当前训练周期的至少两个辅助神经网络中确定所述目标辅助神经网络。In an optional embodiment, the agent control framework determines the target auxiliary neural network from at least two auxiliary neural networks in the current training cycle based on the sampling probabilities corresponding to the at least two auxiliary neural networks respectively. The network is specifically used for: determining the target auxiliary neural network from at least two auxiliary neural networks in the current training cycle based on sampling probabilities corresponding to at least two auxiliary neural networks respectively and preset screening rules.
一种可选的实施方式中,所述智能体控制框架在执行所述利用所述目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战,得到对所述当前训练周期的待训练神经网络进行训练的第一对战样本数据时,具体用于:利用所述目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战,得到所述第二虚拟角色在对战过程中的第一对战状态数据;基于所述第一对战状态数据,生成所述第一对战样本数据。In an optional embodiment, the agent control framework is performing the control of the first virtual character by using the target-assisted neural network, and using the neural network to be trained in the current training cycle to control the second virtual character to compete, When obtaining the first battle sample data for training the neural network to be trained in the current training cycle, it is specifically used for: using the target auxiliary neural network to control the first virtual character, and using the neural network to be trained in the current training cycle to control The second virtual character competes to obtain the first battle state data of the second virtual character during the battle; based on the first battle state data, the first battle sample data is generated.
一种可选的实施方式中,所述智能体控制框架,还用于利用所述目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战,得到对所述目标辅助神经网络进行训练的第二对战样本数据;向深度学习框架发送所述当前训练周期的第二对战样本数据;其中,当前训练周期的第二对战样本数据,用于所述深度学习框架对当前训练周期的目标辅助神经网络进行强化训练,得到未来训练周期的辅助神经网络。In an optional embodiment, the agent control framework is further configured to use the target-assisted neural network to control the first virtual character, and use the neural network to be trained in the current training cycle to control the second virtual character to play against each other, obtaining the second battle sample data for training the target auxiliary neural network; sending the second battle sample data of the current training cycle to the deep learning framework; wherein, the second battle sample data of the current training cycle is used for the The deep learning framework performs intensive training on the target auxiliary neural network in the current training cycle, and obtains the auxiliary neural network in the future training cycle.
一种可选的实施方式中,所述智能体控制框架,在执行所述利用所述目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战时,得到对所述目标辅助神经网络进行训练的第二对战样本数据时,具体用于:确定所述目标辅助神经网络是否利用所述待训练神经网络的历史状态生成;响应于所述目标辅助神经网络并非利用所述待训练神经网络的历史状态生成,则利用所述目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战时,得到对所述目标辅助神经网络进行训练的第二对战样本数据。In an optional embodiment, the agent control framework, when executing the control of the first virtual character by using the target-assisted neural network, and using the neural network to be trained in the current training cycle to control the second virtual character to play against each other. When the second battle sample data for training the target auxiliary neural network is obtained, it is specifically used to: determine whether the target auxiliary neural network is generated by using the historical state of the neural network to be trained; in response to the target auxiliary neural network When the neural network is not generated by using the historical state of the neural network to be trained, the target auxiliary neural network is used to control the first virtual character, and the neural network to be trained in the current training cycle is used to control the second virtual character to fight, and the correct result is obtained. The second battle sample data for training the target-assisted neural network.
一种可选的实施方式中,响应于确定的目标辅助神经网络包括第一辅助神经网络;所述第一虚拟角色和所述第二虚拟角色均包括一个;所述智能体控制框架,在执行所述利用所述目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战,得到对所述当前训练周期的待训练神经网络进行训练的第一对战样本数据时,具体用于:利用所述第一辅助神经网络控制所述第一虚拟角色,并利用当前训练周期的待训练神经网络控制与所述第一虚拟角色属于不同对战阵营的第二虚拟角色进行对战,得到所述第一对战样本数据。In an optional implementation manner, the auxiliary neural network includes a first auxiliary neural network in response to the determined target; both the first virtual character and the second virtual character include one; the agent control framework, when executing The target auxiliary neural network is used to control the first virtual character, and the neural network to be trained in the current training cycle is used to control the second virtual character to fight, and the first virtual character for training the neural network to be trained in the current training cycle is obtained. When playing against sample data, it is specifically used to: use the first auxiliary neural network to control the first virtual character, and use the neural network to be trained in the current training cycle to control the second virtual character belonging to a different battle camp from the first virtual character. The virtual characters compete to obtain the first sample data of the battle.
一种可选的实施方式中,响应于确定的目标辅助神经网络包括第二辅助神经网络;所述智能体控制框架,在执行所述利用所述目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战,得到对所述当前训练周期的待训练神经网络进行训练的第一对战样本数据时,具体用于:利用所述第二辅助神经网络控制所述第一虚拟角色,并利用当前训练周期的待训练神经网络控制与所述第一虚拟角色属于相同对战阵营和/或不同对战阵营的第二虚拟角色进行对战,得到所述第一对战样本数据。In an optional implementation manner, the auxiliary neural network in response to the determined target includes a second auxiliary neural network; the agent control framework, when executing the control of the first virtual character by using the target auxiliary neural network, and using When the neural network to be trained in the current training period controls the second virtual character to fight, and the first battle sample data for training the neural network to be trained in the current training period is obtained, it is specifically used for: using the second auxiliary neural network Controlling the first virtual character, and using the neural network to be trained in the current training cycle to control the first virtual character to play against a second virtual character belonging to the same battle camp and/or different battle camps, to obtain the first battle sample.
一种可选的实施方式中,所述智能体控制框架,还用于:利用所述目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战,得到当前对战对局对应的对战数据;利用所述对战数据,对所述目标辅助神经网络、以及当前训练周期的待训练神经网络分别对应的历史对战数据进行更新处理,得到更新后的对战数据。In an optional embodiment, the agent control framework is further used for: using the target auxiliary neural network to control the first virtual character, and using the neural network to be trained in the current training cycle to control the second virtual character to play against each other. , obtain the battle data corresponding to the current battle match; use the battle data to update the target auxiliary neural network and the historical battle data corresponding to the neural network to be trained in the current training cycle, respectively, to obtain the updated battle data .
一种可选的实施方式中,所述智能体控制框架,还用于:利用所述更新处理后的对战数据,确定所述待训练神经网络是否满足预设辅助神经网络生成条件;响应于所述待训练神经网络满足所述预设辅助神经网络生成条件,则基于所述待训练神经网络、或当前训练周期更新后的待训练神经网络,生成未来训练周期的辅助神经网络。In an optional implementation manner, the agent control framework is further configured to: use the updated battle data to determine whether the neural network to be trained satisfies the preset auxiliary neural network generation conditions; If the neural network to be trained satisfies the preset auxiliary neural network generation condition, an auxiliary neural network for a future training period is generated based on the neural network to be trained or the neural network to be trained after the current training period is updated.
一种可选的实施方式中,所述智能体控制框架,在执行所述基于所述待训练神经网络、或当前训练周期更新后的待训练神经网络,生成未来训练周期的辅助神经网络时,具体用于:生成基于所述待训练神经网络、或当前训练周期更新后的待训练神经网络的快照;基于所述快照,生成未来训练周期的辅助神经网络。In an optional embodiment, the agent control framework, when executing the neural network to be trained based on the neural network to be trained or the updated neural network to be trained in the current training cycle, generates an auxiliary neural network for a future training cycle, It is specifically used for: generating a snapshot of the neural network to be trained based on the neural network to be trained or the updated neural network to be trained in the current training period; and generating an auxiliary neural network for a future training period based on the snapshot.
一种可选的实施方式中,所述智能体控制框架,还用于:响应于接收到当前训练周期的第一训练指令,确定所述当前训练周期的待训练神经网络。In an optional implementation manner, the agent control framework is further configured to: in response to receiving the first training instruction of the current training period, determine the neural network to be trained in the current training period.
一种可选的实施方式中,所述智能体控制框架,在执行所述确定当前训练周期的所述待训练神经网络时,具体用于:响应于当前训练周期属于首次迭代训练过程,将初始化神经网络确定为所述待训练神经网络;响应于当前训练周期属于非首次迭代训练过程,基于当前训练周期所属的迭代训练过程的前一次迭代训练过程确定的至少一个备选神经网络分别对应的性能信息,确定所述待训练神经网络;和/或,将所述初始化神经网络确定为所述待训练神经网络。In an optional implementation manner, the agent control framework, when executing the determination of the neural network to be trained in the current training period, is specifically configured to: in response to the current training period belonging to the first iterative training process, initialize the neural network. The neural network is determined as the neural network to be trained; in response to the current training period belonging to a non-first-time iterative training process, the performance corresponding to the at least one candidate neural network determined based on the previous iterative training process of the iterative training process to which the current training period belongs information, determining the neural network to be trained; and/or, determining the initialized neural network as the neural network to be trained.
一种可选的实施方式中,所述智能体控制框架,还用于:接收深度学习框架反馈的所述当前训练周期的待训练神经网络的更新数据;利用所述更新数据,对所述当前训练周期的待训练神经网络进行更新处理;其中,所述更新数据是所述深度学习框架利用所述当前训练周期的第一对战样本数据,对当前训练周期的待训练神经网络进行强化训练后得到的。In an optional embodiment, the agent control framework is further configured to: receive the update data of the neural network to be trained in the current training cycle fed back by the deep learning framework; The neural network to be trained in the training cycle is updated; wherein, the update data is obtained by the deep learning framework using the first battle sample data of the current training cycle to perform intensive training on the neural network to be trained in the current training cycle of.
第四方面,本公开可选实现方式还提供一种计算机设备,处理器、存储器,所述存储器存储有所述处理器可执行的机器可读指令,所述处理器用于执行所述存储器中存储的机器可读指令,所述机器可读指令被所述处理器执行时,所述机器可读指令被所述处理器执行时执行上述第一方面,或第一方面中任一种可能的实施方式中的步骤,或执行上述第二方面的实施方式中的步骤。In a fourth aspect, an optional implementation manner of the present disclosure further provides a computer device, a processor, and a memory, where the memory stores machine-readable instructions executable by the processor, and the processor is configured to execute the memory stored in the memory. machine-readable instructions, when the machine-readable instructions are executed by the processor, when the machine-readable instructions are executed by the processor, the above-mentioned first aspect, or any possible implementation of the first aspect, is executed method, or perform the steps in the implementation manner of the second aspect above.
第五方面,本公开可选实现方式还提供一种计算机可读存储介质,该计算机可读存储介质上存储有计算机程序,该计算机程序被运行时执行上述第一方面,或第一方面中任一种可能的实施方式中的步骤,或执行上述第二方面的实施方式中的步骤。In a fifth aspect, an optional implementation manner of the present disclosure further provides a computer-readable storage medium, where a computer program is stored on the computer-readable storage medium, and the computer program executes the first aspect, or any one of the first aspect, when the computer program is run. Steps in a possible implementation manner, or perform the steps in an implementation manner of the second aspect above.
关于上述神经网络的生成系统、计算机设备、及计算机可读存储介质的效果描述参见上述神经网络的生成方法的说明,这里不再赘述。For the description of the effects of the above-mentioned neural network generation system, computer equipment, and computer-readable storage medium, reference may be made to the description of the above-mentioned neural network generation method, which will not be repeated here.
为使本公开的上述目的、特征和优点能更明显易懂,下文特举较佳实施例,并配合所附附图,作详细说明如下。In order to make the above-mentioned objects, features and advantages of the present disclosure more obvious and easy to understand, the preferred embodiments are exemplified below, and are described in detail as follows in conjunction with the accompanying drawings.
附图说明Description of drawings
为了更清楚地说明本公开实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,此处的附图被并入说明书中并构成本说明书中的一部分,这些附图示出了符合本公开的实施例,并与说明书一起用于说明本公开的技术方案。应当理解,以下附图仅示出了本公开的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。In order to explain the technical solutions of the embodiments of the present disclosure more clearly, the following briefly introduces the accompanying drawings required in the embodiments, which are incorporated into the specification and constitute a part of the specification. The drawings illustrate embodiments consistent with the present disclosure, and together with the description serve to explain the technical solutions of the present disclosure. It should be understood that the following drawings only show some embodiments of the present disclosure, and therefore should not be regarded as limiting the scope. Other related figures are obtained from these figures.
图1示出了本公开实施例所提供的一种神经网络的生成方法的流程示意图;FIG. 1 shows a schematic flowchart of a method for generating a neural network provided by an embodiment of the present disclosure;
图2示出了本公开实施例所提供的另一种神经网络的生成方法的流程示意图;FIG. 2 shows a schematic flowchart of another method for generating a neural network provided by an embodiment of the present disclosure;
图3示出了本公开实施例所提供的一种神经网络的生成过程中的交互流程示意图;FIG. 3 shows a schematic diagram of an interaction flow in the generation process of a neural network provided by an embodiment of the present disclosure;
图4示出了本公开实施例所提供的一种神经网络的生成系统的示意图;FIG. 4 shows a schematic diagram of a system for generating a neural network provided by an embodiment of the present disclosure;
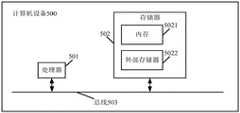
图5示出了本公开实施例所提供的一种计算机设备的示意图。FIG. 5 shows a schematic diagram of a computer device provided by an embodiment of the present disclosure.
具体实施方式Detailed ways
为使本公开实施例的目的、技术方案和优点更加清楚,下面将结合本公开实施例中附图,对本公开实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本公开一部分实施例,而不是全部的实施例。通常在此处描述和示出的本公开实施例的组件可以以各种不同的配置来布置和设计。因此,以下对本公开的实施例的详细描述并非旨在限制要求保护的本公开的范围,而是仅仅表示本公开的选定实施例。基于本公开的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本公开保护的范围。In order to make the purposes, technical solutions and advantages of the embodiments of the present disclosure more clear, the technical solutions in the embodiments of the present disclosure will be clearly and completely described below with reference to the accompanying drawings in the embodiments of the present disclosure. Obviously, the described embodiments are only These are some, but not all, embodiments of the present disclosure. The components of the disclosed embodiments generally described and illustrated herein may be arranged and designed in a variety of different configurations. Thus, the following detailed description of the embodiments of the present disclosure is not intended to limit the scope of the disclosure as claimed, but is merely representative of selected embodiments of the disclosure. Based on the embodiments of the present disclosure, all other embodiments obtained by those skilled in the art without creative work fall within the protection scope of the present disclosure.
经研究发现,当前对神经网络进行强化训练的代码耦合在神经网络对应的代码中,需要为不同对战场景设置不同的神经网络、以及对应的强化训练代码,开发成本较高且复杂度较高。Research has found that the current code for intensive training of neural networks is coupled in the code corresponding to the neural network. It is necessary to set up different neural networks and corresponding intensive training codes for different battle scenarios. The development cost is high and the complexity is high.
基于上述研究,本公开提供了一种神经网络的生成方法,将神经网络、与对神经网络进行强化训练的代码分别甚至在智能体控制框架和深度学习框架中,减少了代码的耦合性,这样使得在不同的对战场景下,可以使用同一深度学习框架以及智能体控制框架,减少了开发成本及开发复杂度;并且利用目标辅助神经网络控制第一虚拟角色、并利用待训练神经网络控制第二虚拟角色进行对战,生成第一对战样本数据;并将生成的第一对战样本数据,发送至深度学习框架,以使深度学习框架基于第一对战样本数据,对待训练神经网络进行至少两个训练周期的强化训练,得到目标神经网络,所述目标神经网络用于控制目标虚拟角色进行对战,这样生成的目标神经网络是基于大量的对战样本数据训练生成的,学习到了不同类型的动作、以及对战策略,灵活度较高且具有较强的泛化能力。Based on the above research, the present disclosure provides a method for generating a neural network, which reduces the coupling between the neural network and the code for intensive training of the neural network, even in the agent control framework and the deep learning framework. In different battle scenarios, the same deep learning framework and intelligent body control framework can be used, which reduces the development cost and development complexity; and uses the target-assisted neural network to control the first virtual character, and uses the neural network to be trained to control the second virtual character. The virtual characters play against each other to generate the first battle sample data; and send the generated first battle sample data to the deep learning framework, so that the deep learning framework can perform at least two training cycles on the neural network to be trained based on the first battle sample data to obtain the target neural network, the target neural network is used to control the target virtual character to fight, and the target neural network generated in this way is generated based on a large number of battle sample data training, and learns different types of actions and battle strategies. , with high flexibility and strong generalization ability.
针对现有方案所存在的缺陷以及本公开所提出的解决方案,均是发明人在经过实践并仔细研究后得出的结果,因此,上述问题的发现过程以及文中本公开针对上述问题所提出的解决方案,都应该是发明人在本公开过程中对本公开做出的贡献。The defects existing in the existing solutions and the solutions proposed in the present disclosure are the results obtained by the inventor after practice and careful research. Therefore, the discovery process of the above problems and the solutions proposed in the present disclosure for the above problems are the results. The solutions should all be contributions made by the inventors to the present disclosure during the present disclosure process.
应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。It should be noted that like numerals and letters refer to like items in the following figures, so once an item is defined in one figure, it does not require further definition and explanation in subsequent figures.
为便于对本实施例进行理解,首先对本公开实施例所公开的一种神经网络的生成方法进行详细介绍,本公开实施例所提供的神经网络的生成方法的执行主体一般为具有一定计算能力的计算机设备,该计算机设备例如包括:终端设备或服务器或其它处理设备。在一些可能的实现方式中,该神经网络的生成方法可以通过处理器调用存储器中存储的计算机可读指令的方式来实现。In order to facilitate the understanding of this embodiment, a method for generating a neural network disclosed by an embodiment of the present disclosure is first introduced in detail. The execution body of the method for generating a neural network provided by the embodiment of the present disclosure is generally a computer with a certain computing capability. Equipment, the computer equipment includes, for example: terminal equipment or server or other processing equipment. In some possible implementations, the method for generating the neural network may be implemented by the processor calling computer-readable instructions stored in the memory.
本公开实施例在开始训练之前,可以构建智能体控制框架,即构建多种类型的玩家、以及计分板和评价器;智能体控制框架由多种类型的玩家、计分板和评价器构成;其中,每种类型的玩家对应有相应的神经网络,一般可以根据实际对战策略、以及实际对战网络参数等设置玩家。Before starting training in the embodiments of the present disclosure, an agent control framework can be constructed, that is, multiple types of players, scoreboards, and evaluators can be constructed; the agent control framework is composed of multiple types of players, scoreboards, and evaluators ; Among them, each type of player corresponds to a corresponding neural network, and players can generally be set according to the actual battle strategy and actual battle network parameters.
在本公开实施例中,可以根据在执行完一个训练周期的训练后的,是否能够在下一训练周期继续对玩家对应的神经网络的网络参数进行更新,将玩家划分为活跃玩家、以及历史玩家;其中,活跃玩家包括在执行完一个训练周期的训练后,能够在下一训练周期继续对玩家对应的神经网络的网络参数进行更新的玩家;历史玩家包括在执行完一个训练周期的训练后,将训练后的神经网络的网络参数冻结,不再更新的玩家;这里,引入历史玩家丰富了玩家的类型,进一步提升后续训练的主玩家对应的目标神经网络的泛化能力、以及决策能力。In the embodiment of the present disclosure, players can be divided into active players and historical players according to whether the network parameters of the neural network corresponding to the players can be updated in the next training period after the training of one training period is completed; Among them, active players include players who can continue to update the network parameters of the player's corresponding neural network in the next training cycle after performing one training cycle; The network parameters of the later neural network are frozen and no longer updated; here, the introduction of historical players enriches the types of players, and further improves the generalization ability and decision-making ability of the target neural network corresponding to the main player for subsequent training.
其中,活跃玩家包括但不限于:主玩家、主探索玩家、智能体控制框架探索玩家等中的至少一种;历史玩家包括但不限于:主玩家对应的历史玩家、主探索玩家对应的历史玩家、智能体控制框架探索玩家对应的历史玩家等中的至少一种。Among them, active players include but are not limited to: at least one of main players, main exploration players, and agent control framework exploration players; historical players include but are not limited to: historical players corresponding to main players, historical players corresponding to main exploration players , the agent control framework explores at least one of the historical players corresponding to the players, etc.
在本公开实施例中,主玩家的训练目标是得到一个对战对抗能力最强、对战配合能力最强、且最稳健的目标神经网络,因此,在对主玩家对应的神经网络进行训练时,可以选择智能体控制框架中的每个玩家控制对战中的虚拟角色、与主玩家控制的虚拟角色进行对战对弈,以对主玩家对应的神经网络进行对战对抗能力训练,使主玩家对应的神经网络学习怎样做出攻击性的动作决策;此外,还可以选择智能体控制框架中的每个玩家、以及主玩家控制属于相同对战阵营的虚拟角色进行对战对局,以对主玩家对应的神经网络进行对战配合能力训练,使主玩家对应的神经网络学习怎样做出和队友进行配合的动作决策。In the embodiment of the present disclosure, the training goal of the main player is to obtain a target neural network with the strongest combat confrontation ability, the strongest combat coordination ability, and the most robust target neural network. Therefore, when training the neural network corresponding to the main player, you can Select each player in the agent control framework to control the virtual character in the battle, and play the game with the virtual character controlled by the main player, so as to train the neural network corresponding to the main player to compete against each other, so that the neural network corresponding to the main player can learn How to make aggressive action decisions; in addition, you can choose each player in the intelligent body control framework, and the main player to control virtual characters belonging to the same battle camp to play against the neural network corresponding to the main player. With the ability training, the neural network corresponding to the main player learns how to make action decisions that cooperate with teammates.
此外,主探索玩家,用于对主玩家进行对战对抗能力训练,主探索玩家的训练目标是找到主玩家的弱点,以使主玩家对应的神经网络更加稳健;因此,一般可以选择主探索玩家控制对战中的虚拟角色、与主玩家控制的虚拟角色进行对战对弈;另外,还可以选择对主玩家的神经网络进行参数冻结生成的历史玩家控制对战中的虚拟角色、与主探索玩家控制的虚拟角色进行对弈。In addition, the main exploratory player is used to train the main player on the ability to fight against each other. The training goal of the main exploratory player is to find the weakness of the main player, so that the neural network corresponding to the main player is more robust; therefore, the main exploratory player can generally be selected to control The avatars in the battle and the avatars controlled by the main player can play against the avatars controlled by the main player; in addition, you can also choose to freeze the parameters of the main player's neural network to generate the historical players to control the avatars in the battle, and the avatars controlled by the main exploration player. Play a game.
另外,智能体控制框架探索玩家,用于探索智能体控制框架的弱点、以及用于进行新的对战玩法和/或对战体系的探索;智能体控制框架探索玩家可以与智能体控制框架中的每个玩家分别控制对战中属于不同阵营的虚拟角色进行对弈;这里,引入智能体控制框架探索玩家丰富了玩家的类型,进一步提升后续训练的主玩家对应的目标神经网络的泛化能力、以及决策能力。In addition, the agent control framework explores the player, which is used to explore the weaknesses of the agent control framework, as well as for the exploration of new combat gameplay and/or combat systems; the agent control framework explores the player's ability to interact with each Each player controls the virtual characters belonging to different camps to play games; here, the introduction of an agent control framework to explore players enriches the types of players, and further improves the generalization ability and decision-making ability of the target neural network corresponding to the main player in subsequent training. .
本公开实施例提供的计分板,用于记录智能体控制框架中任意两个玩家之间进行对战对局后的胜负情况信息;其中,对战信息例如可以包括:对战得分、伤害值、对局结果信息等中的至少一种,该胜负情况信息例如可以包括但不限于:胜、负、平中的至少一种;此外,计分板还用于记录每个玩家在进行多局对战对局后对应的整体胜率、以及对单胜率。The scoreboard provided by the embodiment of the present disclosure is used to record information on the outcome of a battle between any two players in an agent control framework; wherein the battle information may include, for example, battle score, damage value, At least one of game result information, etc., the winning or losing information may include, but is not limited to, at least one of: winning, losing, and drawing; in addition, the scoreboard is also used to record that each player is playing multiple games The corresponding overall win rate after the game, and the single win rate.
本公开实施例提供的评价器,用于利用不同的评价算法,基于智能体控制框架中每个玩家在对战对局过程中的表现,对各玩家的性能进行评价,并基于评价结果,确定各玩家的排名;其中,评价算法例如可以包括但不限于:埃洛等级分系统(Elo rating systEm,ELO)、Trueskill排名系统等中的至少一种。The evaluator provided by the embodiment of the present disclosure is used for using different evaluation algorithms to evaluate the performance of each player based on the performance of each player in the intelligent body control framework during the game, and based on the evaluation results, determine the performance of each player. Player's ranking; wherein, the evaluation algorithm may include, but is not limited to, at least one of the Elo rating system (Elo rating systEm, ELO), the Trueskill ranking system, and the like.
在本公开实施例中,可以将构建的智能体控制框架应用到多种类型的对战场景下,例如可以包括游戏场景,以对智能体控制框架中的神经网络进行游戏对抗能力、和/或游戏配合能力训练;本公开实施例不对具体的对战场景进行限定。In the embodiments of the present disclosure, the constructed agent control framework can be applied to various types of battle scenarios, for example, game scenarios can be included, so that the neural network in the agent control framework can be used for game confrontation capabilities and/or games Cooperate ability training; the embodiments of the present disclosure do not limit specific battle scenarios.
下面对本公开实施例提供的神经网络的生成方法加以说明。The method for generating the neural network provided by the embodiments of the present disclosure will be described below.
参见图1所示,为本公开实施例提供的神经网络的生成方法的流程图,所述方法应用于智能体控制框架,在至少两个训练周期中的每个训练周期中执行下述步骤S101~S103,其中:Referring to FIG. 1 , which is a flowchart of a method for generating a neural network provided by an embodiment of the present disclosure, the method is applied to an agent control framework, and the following step S101 is performed in each of at least two training periods. ~S103, where:
S101、响应于接收到当前训练周期的第一训练指令,从当前训练周期的至少两个辅助神经网络中确定目标辅助神经网络。S101. In response to receiving the first training instruction of the current training cycle, determine a target auxiliary neural network from at least two auxiliary neural networks in the current training cycle.
其中,第一训练指令是深度学习框架发送的,其用于指示当前训练周期对应的待训练神经网络,该待训练神经网络、以及辅助神经网络均可以包括下述至少一种:主玩家对应的初始化神经网络、任一迭代训练过程的前一次迭代训练过程生成的主玩家对应的备选神经网络、主探索玩家对应的初始化神经网络、任一迭代训练过程的前一次迭代训练过程生成的主探索玩家对应的备选神经网络、智能体控制框架探索玩家对应的初始化神经网络、以及任一迭代训练过程的前一次迭代训练过程生成的智能体控制框架探索玩家对应的备选神经网络。The first training instruction is sent by the deep learning framework, which is used to indicate the neural network to be trained corresponding to the current training cycle, and the neural network to be trained and the auxiliary neural network may include at least one of the following: The initialized neural network, the alternate neural network corresponding to the main player generated by the previous iterative training process of any iterative training process, the initialized neural network corresponding to the main exploration player, and the main exploration generated by the previous iterative training process of any iterative training process The candidate neural network corresponding to the player, the agent control framework explores the player's corresponding initialization neural network, and the agent control framework generated by the previous iterative training process of any iterative training process explores the candidate neural network corresponding to the player.
在具体实施中,可以响应于接收到当前训练周期的第一训练指令,确定当前训练周期的待训练神经网络。In a specific implementation, the neural network to be trained in the current training period may be determined in response to receiving the first training instruction of the current training period.
示例性的,可以根据但不限于下述A1~A2中的至少一种方式,确定至少一个待训练神经网络:Exemplarily, at least one neural network to be trained may be determined according to, but not limited to, at least one of the following methods A1 to A2:
A1、响应于当前训练周期属于首次迭代训练过程,将初始化神经网络确定为待训练神经网络。A1. In response to the current training cycle belonging to the first iterative training process, determine the initialized neural network as the neural network to be trained.
A2、响应于当前训练周期属于非首次迭代训练过程,基于当前训练周期所属的迭代训练过程的前一次迭代训练过程确定的至少一个备选神经网络分别对应的性能信息,确定待训练神经网络;和/或,将初始化神经网络确定为待训练神经网络。A2. In response to the current training cycle belonging to a non-first-time iterative training process, determine the neural network to be trained based on the performance information respectively corresponding to at least one candidate neural network determined in the previous iterative training process of the iterative training process to which the current training cycle belongs; and or, determine the initialized neural network as the neural network to be trained.
这里,可以根据但不限于下述B1~B3中的至少一种方式,确定当前训练周期所属的迭代训练过程的前一次迭代训练过程确定的至少一个备选神经网络分别对应的性能信息:Here, the performance information respectively corresponding to at least one candidate neural network determined by the previous iterative training process of the iterative training process to which the current training cycle belongs can be determined according to, but not limited to, at least one of the following methods B1 to B3:
B1、利用当前训练周期所属的迭代训练过程的前一次迭代训练过程确定的至少一个备选神经网络、与基于预设规则生成的对战内置bot分别控制属于不同对战阵营的虚拟角色进行对战,根据对战结果,确定各备选神经网络的性能信息。B1. Use at least one candidate neural network determined in the previous iterative training process of the iterative training process to which the current training cycle belongs, and control the virtual characters belonging to different battle camps with the battle built-in bot generated based on the preset rules to conduct battles. As a result, performance information for each candidate neural network is determined.
B2、将当前训练周期所属的迭代训练过程的前一次迭代训练过程确定的至少一个备选神经网络分别控制属于不同对战阵营的虚拟角色进行两两对局,根据对战结果,确定各备选神经网络的性能信息。B2. At least one candidate neural network determined in the previous iterative training process of the iterative training process to which the current training cycle belongs is controlled respectively to control the virtual characters belonging to different battle camps to play a pairwise game, and each candidate neural network is determined according to the battle result. performance information.
B3、利用当前训练周期所属的迭代训练过程的前一次迭代训练过程确定的至少一个备选神经网络、与人类玩家分别控制属于不同对战阵营的虚拟角色进行对战,根据对战结果、以及人类玩家的对战等级、以及人类玩家的对战评分等信息,确定各备选神经网络的性能信息。B3. Use at least one candidate neural network determined in the previous iterative training process of the iterative training process to which the current training cycle belongs to compete with human players who control virtual characters belonging to different battle camps. Information such as level, and the human player's battle rating to determine the performance information of each candidate neural network.
在具体实施中,在基于上述B1~B3确定至少两个备选神经网络分别对应的性能信息后,可以根据但不限于下述C1~C2中的至少一种,基于当前训练周期所属的迭代训练过程的前一次迭代训练过程确定的至少一个备选神经网络分别对应的性能信息,确定当前训练周期的待训练神经网络:In a specific implementation, after determining the performance information corresponding to the at least two candidate neural networks based on the above B1 to B3, the iterative training to which the current training cycle belongs may be based on, but not limited to, at least one of the following C1 to C2. The performance information respectively corresponding to at least one candidate neural network determined by the previous iterative training process of the process, to determine the neural network to be trained in the current training cycle:
C1、基于当前训练周期所属的迭代训练过程的前一次迭代训练过程确定的至少一个备选神经网络分别对应的性能信息,将性能信息大于预设性能信息阈值的备选神经网络,确定为当前训练周期的待训练神经网络。C1. Based on the performance information respectively corresponding to at least one candidate neural network determined in the previous iterative training process of the iterative training process to which the current training cycle belongs, determine the candidate neural network whose performance information is greater than the preset performance information threshold as the current training Periodic neural network to be trained.
其中,预设性能信息阈值可以根据实际需求设定,此处不做具体限制。The preset performance information threshold may be set according to actual requirements, and no specific limitation is imposed here.
C2、根据当前训练周期所属的迭代训练过程的前一次迭代训练过程确定的至少一个备选神经网络分别对应的性能信息,将至少两个备选神经网络按照性能信息由大到小的顺序进行排列,基于排列结果,将排列顺序位于预设排列顺序位之前的备选神经网络,确定为当前训练周期的待训练神经网络。C2. According to the performance information respectively corresponding to at least one candidate neural network determined in the previous iterative training process of the iterative training process to which the current training cycle belongs, arranging the at least two candidate neural networks in descending order of performance information , based on the arrangement result, the candidate neural network whose arrangement order is located before the preset arrangement order bit is determined as the neural network to be trained in the current training cycle.
其中,预设排列顺序位可以根据实际需求设定,此处不做具体限制。Wherein, the preset arrangement order bits can be set according to actual needs, and no specific limitation is made here.
在具体实施中,除了可以在确定的至少两个备选神经网络中,选取性能信息相对较好的备选神经网络,作为当前训练周期的待训练神经网络外,还可以将初始化神经网络确定为当前训练周期的待训练神经网络。In a specific implementation, in addition to selecting a candidate neural network with relatively better performance information among the determined at least two candidate neural networks as the neural network to be trained in the current training cycle, the initialization neural network can also be determined as The neural network to train for the current training epoch.
在确定待训练神经网络后,可以确定当前训练周期的至少两个辅助神经网络,基于至少两个辅助神经网络分别对应的采样概率,从当前训练周期的至少两个辅助神经网络中确定目标辅助神经网络,具体描述如下:响应于接收到当前训练周期的第一训练指令,确定当前训练周期的至少两个辅助神经网络分别对应的采样概率;基于至少两个辅助神经网络分别对应的采样概率,从当前训练周期的至少两个辅助神经网络中确定目标辅助神经网络。After determining the neural network to be trained, at least two auxiliary neural networks in the current training cycle can be determined, and based on the sampling probabilities corresponding to the at least two auxiliary neural networks respectively, the target auxiliary neural network is determined from the at least two auxiliary neural networks in the current training cycle. The network is specifically described as follows: in response to receiving the first training instruction of the current training cycle, determine the sampling probabilities corresponding to at least two auxiliary neural networks in the current training cycle respectively; based on the sampling probabilities corresponding to the at least two auxiliary neural networks respectively, from The target auxiliary neural network is determined among at least two auxiliary neural networks of the current training cycle.
其中,采样概率用于指示至少两个辅助神经网络中每个辅助神经网络作为目标辅助神经网络的概率。The sampling probability is used to indicate the probability that each of the at least two auxiliary neural networks is the target auxiliary neural network.
在具体实施中,由于第一训练指令除了能够指示当前训练周期的待训练神经网络外,还可以指示当前训练周期的训练目的,其中,训练目的例如可以包括但不限于:对待训练神经网络的对战对抗能力进行训练和对待训练神经网络的对战配合能力进行训练中的至少一种;因此还可以基于训练目的,在辅助神经网络中,确定当前训练周期的至少两个辅助神经网络,再确定各辅助神经网络分别对应的采样概率,具体描述如下:响应于接收到当前训练周期的第一训练指令,确定当前训练周期的至少两个辅助神经网络;基于各辅助神经网络分别对应的历史对战数据,确定各辅助神经网络分别对应的采样概率。In a specific implementation, in addition to indicating the neural network to be trained in the current training cycle, the first training instruction can also indicate the training purpose of the current training cycle, wherein the training purpose may include, but is not limited to, for example, a battle against the neural network to be trained. At least one of the training of the confrontation ability and the training of the combat cooperation ability of the neural network to be trained; therefore, based on the training purpose, in the auxiliary neural network, at least two auxiliary neural networks in the current training cycle can be determined, and then each auxiliary neural network can be determined. The sampling probabilities corresponding to the neural networks are specifically described as follows: in response to receiving the first training instruction of the current training cycle, determine at least two auxiliary neural networks in the current training cycle; based on the historical battle data corresponding to each auxiliary neural network, determine The sampling probability corresponding to each auxiliary neural network.
其中,当前训练周期的至少两个辅助神经网络包括:第一辅助神经网络和/或第二辅助神经网络;其中,第一辅助神经网络用于对待训练神经网络进行对战对抗能力训练;第二辅助神经网络用于对待训练神经网络进行对战对抗能力训练和/或对战配合能力训练。Wherein, the at least two auxiliary neural networks in the current training cycle include: a first auxiliary neural network and/or a second auxiliary neural network; wherein, the first auxiliary neural network is used for training the neural network to be trained for combat ability training; the second auxiliary neural network The neural network is used for training the neural network to be trained on the combat confrontation ability and/or the combat cooperation ability.
此处,对战对抗能力训练,是指用利用辅助神经网络、以及待训练神经网络,分别控制属于不同阵营的虚拟角色进行对战,这样能够使得待训练神经网络学习怎样做出攻击性的动作决策;对战配合能力训练,是指用利用辅助神经网络、以及待训练神经网络,分别控制属于相同阵营的虚拟角色进行对战,这样能够使得待训练神经网络学习怎样做出和队友进行配合的动作决策。Here, the training of combat confrontation ability refers to using the auxiliary neural network and the neural network to be trained to control the virtual characters belonging to different camps to fight, so that the neural network to be trained can learn how to make aggressive action decisions; Battle cooperation ability training refers to using the auxiliary neural network and the neural network to be trained to control the virtual characters belonging to the same camp to fight, so that the neural network to be trained can learn how to make action decisions to cooperate with teammates.
在具体实施中,响应于接收到当前训练周期的第一训练指令,基于训练指令中的训练目的,在当前训练周期的待训练神经网络对应的至少两个辅助神经网络中,选择符合训练目的辅助神经网络,作为当前训练周期的至少两个辅助神经网络。In a specific implementation, in response to receiving the first training instruction of the current training cycle, based on the training purpose in the training instruction, among the at least two auxiliary neural networks corresponding to the neural network to be trained in the current training cycle, the auxiliary neural network that meets the training purpose is selected. Neural network, as at least two auxiliary neural networks for the current training epoch.
示例性的,在当前训练周期的训练目的包括对待训练神经网络进行对战对抗能力训练的情况下,则可以将第一辅助神经网络,确定为当前待训练周期的辅助神经网络;此外,在当前待训练周期的训练目的包括对待训练神经网络进行对战对抗能力训练和/或对战配合能力训练的情况下,则可以将第二辅助神经网络,确定为当前待训练周期的辅助神经网络。Exemplarily, in the case where the training purpose of the current training cycle includes training the neural network to be trained to conduct battle against ability training, the first auxiliary neural network may be determined as the auxiliary neural network of the current training cycle; If the training purpose of the training period includes training the neural network to be trained for combat confrontation ability and/or training for combat cooperation ability, the second auxiliary neural network may be determined as the auxiliary neural network of the current period to be trained.
其中,第一辅助神经网络:由于用于对待训练神经网络进行对战对抗能力训练,因此针对待训练神经网络有至少两个的情况下,每个待训练神经网络均设置一个对应的第一辅助神经网络。在对战过程中,每个待训练神经网络对应的第一辅助神经网络,仅用于待训练神经网络的对手。Among them, the first auxiliary neural network: because it is used for training the neural network to be trained for combat and confrontation, so for the case where there are at least two neural networks to be trained, each neural network to be trained is set with a corresponding first auxiliary neural network network. During the battle, the first auxiliary neural network corresponding to each neural network to be trained is only used for the opponent of the neural network to be trained.
示例性的,可以采用但不限于下述D1~D3中的至少一种,确定当前训练周期的第一辅助神经网络:Exemplarily, but not limited to at least one of the following D1 to D3 may be used to determine the first auxiliary neural network in the current training cycle:
D1、在当前训练周期的待训练神经网络包括:主玩家对应的初始化神经网络和/或任一迭代训练过程的前一次迭代训练过程生成的主玩家对应的备选神经网络的情况下,将主玩家对应的初始化神经网络、任一迭代训练过程的前一次迭代训练过程生成的主玩家对应的备选神经网络(即主玩家对应的历史玩家)、主探索玩家对应的初始化神经网络、任一迭代训练过程的前一次迭代训练过程生成的主探索玩家对应的备选神经网络(即主探索玩家对应的历史玩家)、智能体控制框架探索玩家对应的初始化神经网络、以及任一迭代训练过程的前一次迭代训练过程生成的智能体控制框架探索玩家对应的备选神经网络主探索玩家对应的初始化神经网络(即智能体控制框架探索玩家对应的历史玩家),确定为当前训练周期的第一辅助神经网络。D1. In the case that the neural network to be trained in the current training cycle includes: the initialization neural network corresponding to the main player and/or the candidate neural network corresponding to the main player generated by the previous iterative training process of any iterative training process, the main player The initialized neural network corresponding to the player, the alternate neural network corresponding to the main player generated by the previous iterative training process of any iterative training process (that is, the historical player corresponding to the main player), the initialized neural network corresponding to the main exploration player, any iteration The candidate neural network corresponding to the main exploratory player (that is, the historical player corresponding to the main exploratory player) generated by the previous iteration of the training process, the initialization neural network corresponding to the agent control framework exploratory player, and the previous iteration of any iterative training process. The agent control frame generated by an iterative training process explores the alternative neural network corresponding to the player. The main exploration player corresponds to the initialized neural network (that is, the historical player corresponding to the agent control framework explores the player), and is determined as the first auxiliary neural network for the current training cycle. network.
D2、在当前训练周期的待训练神经网络包括:主探索玩家对应的初始化神经网络和/或任一迭代训练过程的前一次迭代训练过程生成的主探索玩家对应的备选神经网络的情况下,将主玩家对应的初始化神经网络、任一迭代训练过程的前一次迭代训练过程生成的主玩家对应的备选神经网络(即主玩家对应的历史玩家),确定为当前训练周期的第一辅助神经网络。D2. When the neural network to be trained in the current training cycle includes: the initialization neural network corresponding to the main exploratory player and/or the candidate neural network corresponding to the main exploratory player generated by the previous iterative training process of any iterative training process, Determine the initial neural network corresponding to the main player and the candidate neural network corresponding to the main player (that is, the historical player corresponding to the main player) generated by the previous iterative training process of any iterative training process as the first auxiliary neural network of the current training cycle. network.
D3、在当前训练周期的待训练神经网络包括:智能体控制框架探索玩家对应的初始化神经网络、和/或任一迭代训练过程的前一次迭代训练过程生成的智能体控制框架探索玩家对应的备选神经网络的情况下,将主玩家对应的初始化神经网络、任一迭代训练过程的前一次迭代训练过程生成的主玩家对应的备选神经网络(即主玩家对应的历史玩家)、主探索玩家对应的初始化神经网络、任一迭代训练过程的前一次迭代训练过程生成的主探索玩家对应的备选神经网络(即主探索玩家对应的历史玩家)、智能体控制框架探索玩家对应的初始化神经网络、以及任一迭代训练过程的前一次迭代训练过程生成的智能体控制框架探索玩家对应的备选神经网络(即智能体控制框架探索玩家对应的历史玩家),确定为当前训练周期的第一辅助神经网络。D3. The neural network to be trained in the current training cycle includes: the agent control framework explores the initialization neural network corresponding to the player, and/or the agent control framework generated by the previous iterative training process of any iterative training process explores the player's corresponding equipment In the case of selecting a neural network, the initialized neural network corresponding to the main player, the candidate neural network corresponding to the main player generated by the previous iterative training process of any iterative training process (that is, the historical player corresponding to the main player), the main exploration player The corresponding initialization neural network, the candidate neural network corresponding to the main exploration player generated by the previous iterative training process of any iterative training process (that is, the historical player corresponding to the main exploration player), and the agent control framework The initialization neural network corresponding to the exploration player , and the agent control framework generated by the previous iterative training process of any iterative training process to explore the alternative neural network corresponding to the player (that is, the agent control framework explores the historical player corresponding to the player), and is determined as the first assistant of the current training cycle. Neural Networks.
此外,本公开实施例提供的第二辅助神经网络:由于既可以用于对待训练神经网络进行对战对抗能力训练,又能够进行对战配合能力训练,因此,每个待训练神经网络对应的第二辅助神经网络,即可以用于作为对应待训练神经网络的对手,又可以作为队友。In addition, the second auxiliary neural network provided by the embodiments of the present disclosure can be used for both the training of the neural network to be trained for combat confrontation and the training of the ability to cooperate with each other. Therefore, the second auxiliary corresponding to each neural network to be trained The neural network can be used both as an opponent for the neural network to be trained, and as a teammate.
示例性的,第二辅助神经网络例如可以包括下述E1~E2中的至少一种:Exemplarily, the second auxiliary neural network may include, for example, at least one of the following E1 to E2:
E1、至少一历史迭代训练过程分别对应的备选神经网络;例如可以包括:主玩家对应的备选神经网络、主探索玩家对应的备选神经网络、智能体控制框架探索玩家对应的备选神经网络中的至少一种。E1. Candidate neural networks corresponding to at least one historical iterative training process; for example, it may include: candidate neural networks corresponding to the main player, candidate neural networks corresponding to the main exploration player, and candidate neural networks corresponding to the agent control framework exploration player at least one of the networks.
假设当前的迭代训练过程,为N个迭代训练过程中的第i个迭代训练过程,则对应的历史迭代训练过程,包括第1~第(i-1)个迭代训练过程中的任一个。Assuming that the current iterative training process is the ith iterative training process among the N iterative training processes, the corresponding historical iterative training process includes any one of the 1st to (i-1)th iterative training processes.
在具体实施中,可以将任一个历史迭代训练过程中确定的备选神经网络,作为第二辅助神经网络。In a specific implementation, the candidate neural network determined in any historical iterative training process may be used as the second auxiliary neural network.
E2、利用第二辅助神经网络、以及第二训练参数,对待训练神经网络进行第二强化训练后,得到的神经网络。E2. Using the second auxiliary neural network and the second training parameters, the neural network obtained after the second intensive training is performed on the neural network to be trained.
此处,可以为待训练神经网络设置区别于第一训练参数的第二训练参数,然后利用第二辅助神经网络对待训练神经网络进行第二强化训练,当第二强化训练到一定阶段后,将得到的神经网络作为第二辅助神经网络。Here, a second training parameter that is different from the first training parameter can be set for the neural network to be trained, and then the second auxiliary neural network is used to perform second intensive training on the neural network to be trained. When the second intensive training reaches a certain stage, the The resulting neural network serves as the second auxiliary neural network.
这样,能够为待训练神经网络的第一强化训练过程,提供更丰富的对手、和队友,以增强待训练神经网络的泛化能力,提升其决策智能。In this way, more abundant opponents and teammates can be provided for the first intensive training process of the neural network to be trained, so as to enhance the generalization ability of the neural network to be trained and improve its decision-making intelligence.
另外,针对第二辅助神经网络,还可以直接利用第二辅助神经网络构成网络组;该网络组中包括至少两个第二辅助神经网络,通过至少两个第二辅助神经网络、与待训练神经网络分别控制的属于不同对战阵营的虚拟角色进行对战对局。In addition, for the second auxiliary neural network, the second auxiliary neural network can also be directly used to form a network group; the network group includes at least two second auxiliary neural networks, through the at least two second auxiliary neural networks, and the neural network to be trained The virtual characters belonging to different battle camps controlled by the network play against each other.
在具体实施中,确定当前训练周期的至少两个辅助神经网络后,可以基于各辅助神经网络分别对应的历史对战数据,确定各辅助神经网络分别对应的采样概率。In a specific implementation, after determining at least two auxiliary neural networks in the current training period, the sampling probability corresponding to each auxiliary neural network may be determined based on the historical battle data corresponding to each auxiliary neural network.
其中,历史对战数据包括:在历史对战对局中的胜负情况信息、和/或,在历史对战对局中的评价数据;这里,在历史对战对局中的胜负情况信息用于指示辅助神经网络在历史对战对局中的胜负情况,例如可以包括:胜、负、平等中的至少一种;在历史对战对局中的评价数据用于评价辅助神经网络在历史对战对局中的表现,例如可以包括但不限于:辅助神经网络的性能信息。Wherein, the historical battle data includes: information on the outcome of the historical battle and/or evaluation data in the historical game; here, the information on the outcome of the historical game is used to indicate the auxiliary The victory or defeat of the neural network in the historical game, for example, may include: at least one of victory, loss, and equality; the evaluation data in the historical game is used to evaluate the performance of the auxiliary neural network in the historical game. The performance, for example, may include, but is not limited to, the performance information of the auxiliary neural network.
在实施时,可以利用预设的采样算法,对各辅助神经网络在历史对战对局中的胜负情况信息、以及各辅助神经网络在历史对战对局中的评价数据进行分析,计算得到各辅助神经网络分别对应的采样概率;其中,预设的采样算法可以根据实际需求设定,例如可以包括但不限于:带优先级的虚拟自对弈算法。During implementation, the preset sampling algorithm can be used to analyze the information on the victory and defeat of each auxiliary neural network in the historical game, and the evaluation data of each auxiliary neural network in the historical game, and calculate each auxiliary neural network. The sampling probability corresponding to the neural network respectively; wherein, the preset sampling algorithm can be set according to actual requirements, for example, it can include but not limited to: virtual self-play algorithm with priority.
在确定当前训练周期的各辅助神经网络分别对应的采样概率后,可以基于至少两个辅助神经网络分别对应的采样概率、以及预设的筛选规则,从当前待训练周期的至少两个辅助神经网络中确定目标辅助神经网络。After determining the sampling probabilities corresponding to each auxiliary neural network in the current training cycle, the sampling probabilities corresponding to the at least two auxiliary neural networks and the preset screening rules can be used to select the sampling probability from the at least two auxiliary neural networks in the current training cycle. Targeting Auxiliary Neural Networks.
其中,预设的筛选规则可以根据实际需求设定,此处不做具体限制。The preset filtering rules can be set according to actual needs, and no specific restrictions are made here.
示例性的,基于至少两个辅助神经网络分别对应的采样概率、以及选取采样概率大于预设采样概率阈值的辅助神经网络作为目标辅助神经网络的预设的筛选规则,将采样概率大于预设采样概率阈值的辅助神经网络,确定为目标辅助神经网络;其中,预设采样概率阈值可以根据实际需求设定,此处不做具体限制。Exemplarily, based on the sampling probabilities corresponding to the at least two auxiliary neural networks respectively, and selecting the auxiliary neural network whose sampling probability is greater than the preset sampling probability threshold as the preset screening rule of the target auxiliary neural network, the sampling probability is greater than the preset sampling probability. The auxiliary neural network of the probability threshold is determined as the target auxiliary neural network; wherein, the preset sampling probability threshold can be set according to actual needs, and no specific limitation is made here.
承接上述S101,本公开实施例提供的神经网络的生成方法还包括:Following the above S101, the method for generating a neural network provided by the embodiment of the present disclosure further includes:
S102、利用所述目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战,得到对所述当前训练周期的待训练神经网络进行训练的第一对战样本数据。S102, using the target auxiliary neural network to control the first virtual character, and using the to-be-trained neural network of the current training cycle to control the second virtual character to fight, to obtain the first virtual character for training the to-be-trained neural network of the current training cycle Battle sample data.
在具体实施中,可以利用目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战,得到第二虚拟角色在对战过程中的第一对战状态数据;基于第一对战状态数据,生成第一对战样本数据。In a specific implementation, the target auxiliary neural network can be used to control the first virtual character, and the neural network to be trained in the current training cycle can be used to control the second virtual character to fight, so as to obtain the first battle state data of the second virtual character during the battle. ; Based on the first battle state data, generate the first battle sample data.
其中,第一对战样本数据可以包括但不限于:第二虚拟角色在至少两个动作时刻分别对应的第一样本动作信息、以及第一样本对战状态信息;第一样本动作信息可以包括但不限于样本动作时刻、以及样本动作类型、以及执行样本动作的第二虚拟角色、以及用于承受样本动作的第一虚拟角色、以及第二虚拟角色在执行样本动作时在对战场景中的动作位置;其中样本动作类型例如可以包括但不限于攻击、资源采集、建造、生产、侦查、撤退等中的至少一种;此外,第一样本对战状态信息包括样本动作发生时,对战场景中第一虚拟角色的状态信息、第二虚拟角色的状态信息、以及对战场景的状态信息;其中,第一虚拟角色的状态信息可以根据实际对战需求限定,例如包括但不限于下述至少一种:第一虚拟角色具有的第一虚拟资类型、第一虚拟资源量、第一建筑状态、第一技能状态、在对战场景中的第一位置、第一生命值、第一魔法值、第一阵营信息、第一增益数据、第一减益数据;同理,第二虚拟角色的状态信息也可以根据实际对战需求设定,例如包括但不限于下述至少一种:第二虚拟角色具有的第二虚拟资类型、第二虚拟资源量、第二建筑状态、第二技能状态、在对战场景中的第二位置、第二生命值、第二魔法值、第二阵营信息、第二增益数据、第二减益数据;对战场景的状态信息也可以根据实际对战需求设定,例如可以包括第二虚拟角色的可视区域信息、第三虚拟资源类型、虚拟资源位置、以及虚拟资源刷新的剩余时间等中的至少一种。Wherein, the first battle sample data may include but is not limited to: first sample action information corresponding to the second virtual character at at least two action moments respectively, and first sample battle state information; the first sample action information may include However, it is not limited to the sample action time, the sample action type, the second avatar that performs the sample action, the first avatar that is used to withstand the sample action, and the action of the second avatar in the battle scene when the sample action is performed. Location; where the sample action type may include, but is not limited to, at least one of attack, resource collection, construction, production, reconnaissance, retreat, etc.; in addition, the first sample battle state information includes the first sample action in the battle scene when the sample action occurs. Status information of one avatar, status information of the second avatar, and status information of the battle scene; wherein, the status information of the first avatar can be limited according to actual battle requirements, for example, including but not limited to at least one of the following: The first virtual asset type, the first virtual resource amount, the first building state, the first skill state, the first position in the battle scene, the first health value, the first magic value, and the first camp information that a virtual character has , the first gain data, the first debuff data; similarly, the state information of the second virtual character can also be set according to the actual battle requirements, for example, including but not limited to at least one of the following: the second virtual character has a second Virtual asset type, second virtual resource amount, second building status, second skill status, second position in the battle scene, second health value, second magic value, second faction information, second gain data, first Second debuff data; the state information of the battle scene can also be set according to the actual battle requirements, for example, it can include the visible area information of the second virtual character, the third virtual resource type, the virtual resource location, and the remaining time for the virtual resource refresh, etc. at least one of them.
在具体实施中,可以采用但不限于下述F1~F2中的至少一种,利用目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战,得到对当前训练周期的待训练神经网络进行训练的第一对战样本数据:In a specific implementation, at least one of the following F1 to F2 can be used but not limited to, the target auxiliary neural network is used to control the first virtual character, and the neural network to be trained in the current training cycle is used to control the second virtual character to fight, Obtain the first battle sample data for training the neural network to be trained in the current training cycle:
F1、响应于确定的目标辅助神经网络包括第一辅助神经网络,第一虚拟角色和第二虚拟角色均包括一个,利用第一辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制与第一虚拟角色属于不同对战阵营的第二虚拟角色进行对战,得到第一对战样本数据。F1. In response to the determined target, the auxiliary neural network includes a first auxiliary neural network, and both the first virtual character and the second virtual character include one, use the first auxiliary neural network to control the first virtual character, and use the current training cycle to be trained. The neural network controls the first virtual character to compete with the second virtual character belonging to a different battle camp, and obtains the first battle sample data.
在目标辅助神经网络包括第一辅助神经网络的情况下,为了起到对待训练神经网络进行针对性训练的效果,因此在对战对局过程中,将待训练神经网络、以及第一辅助神经网络设置为敌对双方,以确定待训练神经网络中的弱点,从而得到对待训练神经网络进行针对性训练后的第一对战样本数据。In the case where the target auxiliary neural network includes the first auxiliary neural network, in order to achieve the effect of targeted training of the neural network to be trained, in the process of the battle, the neural network to be trained and the first auxiliary neural network are set to To determine the weaknesses in the neural network to be trained for the two opposing sides, so as to obtain the first battle sample data after targeted training of the neural network to be trained.
示例性的,以对战对局为1v1为例,若待训练神经网络控制对战中第一阵营的第二虚拟角色a1、第一辅助神经网络控制对战中第二阵营(即与第一阵营为敌对阵营的阵营)的第一虚拟角色b1进行对战对局,以得到第一对战样本数据。Exemplarily, taking the battle game as 1v1 as an example, if the neural network to be trained controls the second virtual character a1 of the first camp in the battle, and the first auxiliary neural network controls the second camp in the battle (that is, it is hostile to the first camp). The first virtual character b1 of the camp of the camp) performs a battle to obtain the first battle sample data.
F2、响应于确定的目标辅助神经网络包括第二辅助神经网络,利用第二辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制与第一虚拟角色属于相同对战阵营和/或不同对战阵营的第二虚拟角色进行对战,得到第一对战样本数据。F2. In response to the determined target auxiliary neural network including a second auxiliary neural network, the second auxiliary neural network is used to control the first virtual character, and the neural network to be trained in the current training cycle is used to control and belong to the same battle camp as the first virtual character and / or the second virtual characters of different battle camps compete to obtain the first battle sample data.
在目标辅助神经网络包括第二辅助神经网络的情况下,可以对待训练神经网络的对战对抗能力、以及对战配合能力进行训练,因此在对战对局过程中,可以将待训练神经网络、以及第二辅助神经网络设置为敌对双方,以确定待训练神经网络中的弱点,从而得到对待训练神经网络进行针对性训练后的第一对战样本数据;也可以将待训练神经网络、以及第二辅助神经网络设置为同一方,以对待训练神经网络进行对战配合能力训练,从而得到第一对战样本数据。In the case where the target auxiliary neural network includes the second auxiliary neural network, the combat confrontation ability and the combat cooperation ability of the neural network to be trained can be trained. The auxiliary neural network is set as the hostile side to determine the weaknesses in the neural network to be trained, so as to obtain the first battle sample data after targeted training of the neural network to be trained; the neural network to be trained and the second auxiliary neural network can also be Set it to the same party to train the neural network to be trained on the ability to match against each other, so as to obtain the first battle sample data.
在具体实施中,若对战中包括至少两个第一虚拟角色以及至少两个第二虚拟角色,即对战为多人对战对战,则分别控制各第二虚拟角色的待训练神经网络可以相同、也可以不同;另外,分别控制各第一虚拟角色的第二辅助神经网络可以相同、也可以不同;可以根据实际需求设定,此处不做具体限制。In a specific implementation, if the battle includes at least two first virtual characters and at least two second virtual characters, that is, the battle is a multi-player battle, then the neural networks to be trained that respectively control the second virtual characters may be the same or different. may be different; in addition, the second auxiliary neural networks that respectively control each of the first virtual characters may be the same or different; they may be set according to actual needs, and no specific limitation is made here.
示例性的,以对战对局为3v3为例,对战对局中的第一阵营中的第二虚拟角色a1、a2、a3可以由相同的待训练神经网络控制,对战对局中的第二阵营(即与第一阵营敌对的阵营)中的第一虚拟角色b1、b2、b3可以由相同的第二辅助神经网络控制;待训练神经网络通过控制第二虚拟角色a1、a2、a3、与第二辅助神经网络控制的第一虚拟角色b1、b2、b3进行对战对局,得到第二样本对战数据。Exemplarily, taking the game of 3v3 as an example, the second virtual characters a1, a2, and a3 in the first camp in the game can be controlled by the same neural network to be trained, and the second camp in the game can be controlled by the same neural network to be trained. The first virtual characters b1, b2, b3 in the camp (that is, the camp that is hostile to the first camp) can be controlled by the same second auxiliary neural network; the neural network to be trained can control the second virtual characters a1, a2, a3, and The first virtual characters b1, b2, and b3 controlled by the auxiliary neural network perform a battle to obtain a second sample battle data.
在具体实施中,在利用目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战,得到对当前训练周期进行训练的第一对战样本数据时,还包括:可以利用目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战,得到对目标辅助神经网络进行训练的第二对战样本数据;向深度学习框架发送当前训练周期的第二对战样本数据。In a specific implementation, when the target auxiliary neural network is used to control the first virtual character, and the neural network to be trained in the current training period is used to control the second virtual character to fight, and the first battle sample data for training the current training period is obtained, It also includes: the target auxiliary neural network can be used to control the first virtual character, and the neural network to be trained in the current training cycle can be used to control the second virtual character to fight, so as to obtain the second battle sample data for training the target auxiliary neural network; The learning framework sends the second battle sample data for the current training cycle.
其中,当前训练周期的第二对战样本数据,用于深度学习框架对当前训练周期的目标辅助神经网络进行强化训练,得到未来训练周期的辅助神经网络。Among them, the second battle sample data of the current training cycle is used for the deep learning framework to perform intensive training on the target auxiliary neural network of the current training cycle, so as to obtain the auxiliary neural network of the future training cycle.
其中,第二对战样本数据可以包括但不限于:第一虚拟角色在至少两个动作时刻分别对应的第二样本动作信息、以及第二样本对战状态信息;第二样本动作信息可以包括但不限于样本动作时刻、以及样本动作类型、以及执行样本动作的第一虚拟角色、以及用于承受样本动作的第二虚拟角色、以及第一虚拟角色在执行样本动作时在对战场景中的动作位置;此外,第二样本对战状态信息包括样本动作发生时,对战场景中第一虚拟角色的状态信息、第二虚拟角色的状态信息、以及对战场景的状态信息;在具体实施中,针对第一虚拟角色的状态信息、第二虚拟角色的状态信息、以及对战场景的状态信息的相关描述,可以参加上述具体实施方式中的相关描述,重复之处不做赘述。Wherein, the second battle sample data may include but is not limited to: the second sample action information corresponding to the first virtual character at least two action moments respectively, and the second sample battle state information; the second sample action information may include but not limited to The sample action time, the sample action type, the first virtual character that performs the sample action, the second virtual character that is used to withstand the sample action, and the action position of the first virtual character in the battle scene when the sample action is performed; in addition , the second sample battle state information includes the state information of the first avatar in the battle scene, the state information of the second avatar, and the state information of the battle scene when the sample action occurs; The relevant descriptions of the state information, the state information of the second virtual character, and the state information of the battle scene can be found in the relevant descriptions in the above-mentioned specific implementation manner, and repeated descriptions will not be repeated.
在具体实施中,在生成对目标辅助神经网络进行训练的第二对战样本数据时,可以确定目标辅助神经网络是否利用待训练神经网络的历史状态生成,在确定目标辅助神经网络是利用待训练神经网络的历史状态生成,则确定目标辅助神经网络不需要进行再次训练,此时无需再利用目标辅助神经网络控制第一虚拟角色、与当前训练周期的待训练神经网络控制的第二虚拟角色进行对战时,生成对目标辅助神经网络进行训练的第二对战样本数据。In a specific implementation, when generating the second battle sample data for training the target auxiliary neural network, it can be determined whether the target auxiliary neural network is generated by using the historical state of the neural network to be trained, and when it is determined that the target auxiliary neural network is generated by using the neural network to be trained The historical state of the network is generated, it is determined that the target auxiliary neural network does not need to be retrained. At this time, it is no longer necessary to use the target auxiliary neural network to control the first virtual character and compete with the second virtual character controlled by the neural network to be trained in the current training cycle. When , the second battle sample data for training the target auxiliary neural network is generated.
在另一种实施方式中,响应于目标辅助神经网络并非利用待训练神经网络的历史状态生成,则利用目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战时,得到对目标辅助神经网络进行训练的第二对战样本数据。In another embodiment, in response to the target auxiliary neural network is not generated by using the historical state of the neural network to be trained, the target auxiliary neural network is used to control the first virtual character, and the neural network to be trained in the current training cycle is used to control the second virtual character When the virtual characters are in a battle, the second battle sample data for training the target auxiliary neural network is obtained.
在具体实施中,在利用目标辅助神经网络、以及待训练神经网络分别控制不同的虚拟角色进行对战时,可以生成当前对战对局的对战数据,并对历史对战数据进行更新,具体的:利用目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战,得到当前对战对局对应的对战数据;利用对战数据,对目标辅助神经网络、以及当前训练周期的待训练神经网络分别对应的历史对战数据进行更新处理,得到更新后的对战数据。In the specific implementation, when the target-assisted neural network and the neural network to be trained are used to control different virtual characters to fight, the battle data of the current battle can be generated, and the historical battle data can be updated. Specifically: using the target The auxiliary neural network controls the first virtual character, and uses the neural network to be trained in the current training cycle to control the second virtual character to fight, and obtains the battle data corresponding to the current battle game; using the battle data, the target auxiliary neural network and the current training The historical battle data corresponding to the periodic neural networks to be trained are updated and processed to obtain updated battle data.
其中,更新后的对战数据可以包括但不限于:在当前对战对局中的胜负情况信息、在历史对战对局中的胜负情况信息、在当前对战对局中的评价数据、以及在历史对战对局中的评价数据;这里,在当前对战对局中的胜负情况信息用于指示待训练神经网络、以及目标辅助神经网络分别在当前对战对局中的胜负情况,例如可以包括:胜、负、平等中的至少一种;在当前对战对局中的评价数据用于评价目标辅助神经网络、以及待训练神经网络分别在当前对战对局中的表现,例如可以包括但不限于:目标辅助神经网络的性能信息、待训练神经网络的性能信息。Wherein, the updated battle data may include but not limited to: information on the outcome of the current game, information on the outcome of the historical game, evaluation data in the current game, and historical data Evaluation data in the game; here, the information on the outcome of the current game is used to indicate the outcome of the neural network to be trained and the target auxiliary neural network in the current game, for example, it may include: At least one of victory, loss, and equality; the evaluation data in the current game is used to evaluate the performance of the target auxiliary neural network and the neural network to be trained in the current game, for example, it may include but not limited to: The performance information of the target auxiliary neural network and the performance information of the neural network to be trained.
示例性的,利用目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战,得到当前对战对局对应的对战数据;基于待训练神经网络在当前对战对局中的胜负情况信息、以及待训练神经网络在当前对战对局中的评价数据,更新待训练神经网络对应的历史对战数据,生成待训练神经网络对应的更新后的对战数据;基于目标辅助神经网络在当前对战对局中的胜负情况信息、以及目标辅助神经网络在当前对战对局中的评价数据,更新目标辅助神经网络对应的历史对战数据,生成目标辅助神经网络对应的更新后的对战数据。Exemplarily, the target-assisted neural network is used to control the first virtual character, and the neural network to be trained in the current training cycle is used to control the second virtual character to fight, so as to obtain the battle data corresponding to the current game; The information on the outcome of the battle and the evaluation data of the neural network to be trained in the current game, update the historical battle data corresponding to the neural network to be trained, and generate updated battle data corresponding to the neural network to be trained; The information about the outcome of the target auxiliary neural network in the current game, and the evaluation data of the target auxiliary neural network in the current game, update the historical battle data corresponding to the target auxiliary neural network, and generate an update corresponding to the target auxiliary neural network. After the battle data.
在具体实施中,还可以利用更新处理后的对战数据,确定待训练神经网络是否满足预设辅助神经网络生成条件;响应于待训练神经网络满足预设辅助神经网络条件,则基于所述待训练神经网络、或当前训练周期更新后的待训练神经网络,生成未来训练周期的辅助神经网络。In a specific implementation, the updated battle data can also be used to determine whether the neural network to be trained satisfies the preset auxiliary neural network generation conditions; in response to the neural network to be trained meeting the preset auxiliary neural network conditions, based on the The neural network, or the neural network to be trained after the current training cycle is updated, generates an auxiliary neural network for future training cycles.
其中,预设辅助神经网络生成条件可以根据实际需求设定,此处不做具体限制。Wherein, the preset auxiliary neural network generation conditions can be set according to actual needs, and no specific limitation is made here.
示例性的,预设辅助神经网络生成条件例如可以包括但不限于:历史状态生成条件、重置条件等中的至少一种;其中,历史状态生成条件用于指示将待训练神经网络的网络参数冻结,以生成待训练神经网络的历史状态;重置条件用于指示将待训练神经网络的参数重置为初始参数,即将待训练神经网络重置为初始化神经网络。Exemplarily, the preset auxiliary neural network generation conditions may include, but are not limited to, at least one of historical state generation conditions, reset conditions, etc.; wherein the historical state generation conditions are used to indicate the network parameters of the neural network to be trained. Freeze to generate the historical state of the neural network to be trained; the reset condition is used to indicate that the parameters of the neural network to be trained are reset to the initial parameters, that is, the neural network to be trained is reset to the initialized neural network.
示例性的,可以采用但不限于下述G1~G2中的至少一种,响应于待训练神经网络满足预设辅助神经网络生成条件,基于所述待训练神经网络、或当前训练周期更新后的待训练神经网络,生成未来训练周期的辅助神经网络:Exemplarily, but not limited to at least one of the following G1 to G2, in response to the neural network to be trained meeting the preset auxiliary neural network generation conditions, based on the neural network to be trained or the updated value of the current training cycle. The neural network to be trained, generating the auxiliary neural network for future training cycles:
G1、在预设辅助网络生成条件包括:历史状态生成条件的情况下,可以生成待训练神经网络、或当前训练周期更新后的待训练神经网络的快照,基于快照,生成未来训练周期的辅助神经网络。G1. The preset auxiliary network generation conditions include: in the case of historical state generation conditions, a snapshot of the neural network to be trained or the neural network to be trained after the update of the current training cycle can be generated, and based on the snapshot, the auxiliary neural network of the future training cycle can be generated. network.
在具体实施中,根据更新处理后的对战数据,确定待训练神经网络对应的胜负情况信息和评价数据、以及当前训练周期更新后的待训练神经网络对应的胜负情况信息和评价数据;基于待训练神经网络对应的胜负情况信息,确定待训练神经网络对应的胜率;以及基于当前训练周期更新后的待训练神经网络对应的胜负情况信息,确定当前训练周期更新后的待训练神经网络对应的胜率。In a specific implementation, according to the updated battle data, determine the outcome information and evaluation data corresponding to the neural network to be trained, as well as the outcome information and evaluation data corresponding to the neural network to be trained after the update of the current training cycle; The winning and losing situation information corresponding to the neural network to be trained determines the winning ratio corresponding to the neural network to be trained; and based on the information on the winning and losing situation corresponding to the neural network to be trained after the update of the current training cycle, the neural network to be trained after the update of the current training cycle is determined corresponding win rate.
在确定待训练神经网络对应的胜率和评价数据、以及当前训练周期更新后的待训练神经网络对应的胜率和评价数据之后,基于待训练神经网络对应的胜率和评价数据、以及当前训练周期更新后的待训练神经网络对应的胜率和评价数据,在待训练神经网络、以及当前训练周期更新后的待训练神经网络中,选取胜率最高和/或评价数据最高的神经网络,确定为待处理的神经网络;响应于待处理的神经网络对应的胜率大于或等于第一预设胜率阈值,和/或待处理的神经网络对应的评价数据大于或等于第一预设评价数据阈值,确定待处理的神经网络已经达到相对较好的性能,则可以将待处理的神经网络进行快照,即将待处理的神经网络,确定为未来训练周期的辅助神经网络。After determining the winning rate and evaluation data corresponding to the neural network to be trained, and the winning rate and evaluation data corresponding to the neural network to be trained after the update of the current training cycle, based on the winning rate and evaluation data corresponding to the neural network to be trained, and the updated training cycle The winning rate and evaluation data corresponding to the neural network to be trained, among the neural network to be trained and the neural network to be trained after the current training cycle is updated, select the neural network with the highest winning rate and/or the highest evaluation data, and determine it as the neural network to be processed. network; in response to the winning ratio corresponding to the neural network to be processed is greater than or equal to the first preset winning ratio threshold, and/or the evaluation data corresponding to the neural network to be processed is greater than or equal to the first preset evaluation data threshold, determine the neural network to be processed. If the network has achieved relatively good performance, a snapshot of the neural network to be processed can be taken, that is, the neural network to be processed is determined as an auxiliary neural network for a future training cycle.
其中,第一预设胜率阈值、以及第一预设评价数据阈值均可以根据实际需求设定,此处不做具体限制。Wherein, the first preset winning ratio threshold and the first preset evaluation data threshold can be set according to actual needs, and no specific limitation is imposed here.
G2、在预设辅助网络生成条件包括:重置条件的情况下,可以更新后的历史数据,基于待训练神经网络、或当前训练周期更新后的待训练神经网络,生成未来训练周期的辅助神经网络。G2. The preset auxiliary network generation conditions include: in the case of reset conditions, the updated historical data can be used to generate auxiliary neural networks for future training cycles based on the neural network to be trained or the updated neural network to be trained after the current training cycle. network.
在具体实施中,根据更新处理后的对战数据,确定待训练神经网络对应的胜负情况信息和评价数据、以及当前训练周期更新后的待训练神经网络对应的胜负情况信息和评价数据;基于待训练神经网络对应的胜负情况信息,确定待训练神经网络对应的胜率;以及基于当前训练周期更新后的待训练神经网络对应的胜负情况信息,确定当前训练周期更新后的待训练神经网络对应的胜率。In a specific implementation, according to the updated battle data, determine the outcome information and evaluation data corresponding to the neural network to be trained, as well as the outcome information and evaluation data corresponding to the neural network to be trained after the update of the current training cycle; The winning and losing situation information corresponding to the neural network to be trained determines the winning ratio corresponding to the neural network to be trained; and based on the information on the winning and losing situation corresponding to the neural network to be trained after the update of the current training cycle, the neural network to be trained after the update of the current training cycle is determined corresponding win rate.
在确定待训练神经网络对应的胜率和评价数据、以及当前训练周期更新后的待训练神经网络对应的胜率和评价数据之后,基于待训练神经网络对应的胜率和评价数据、以及当前训练周期更新后的待训练神经网络对应的胜率和评价数据,在待训练神经网络、以及当前训练周期更新后的待训练神经网络中,选取胜率最低和/或评价数据最低的神经网络,确定为待处理的神经网络;响应于待处理的神经网络对应的胜率小于第二预设胜率阈值,和/或待处理的神经网络对应的评价数据小于第二预设评价数据阈值,确定待处理的神经网络的性能较差,则可以重置待处理的神经网络的参数,将待处理的神经网络,重置为初始化神经网络,生成未来训练周期的辅助神经网络。After determining the winning rate and evaluation data corresponding to the neural network to be trained, and the winning rate and evaluation data corresponding to the neural network to be trained after the update of the current training cycle, based on the winning rate and evaluation data corresponding to the neural network to be trained, and the updated training cycle The winning rate and evaluation data corresponding to the neural network to be trained, among the neural network to be trained and the neural network to be trained after the current training cycle is updated, the neural network with the lowest winning rate and/or the lowest evaluation data is selected as the neural network to be processed. network; in response to that the winning ratio corresponding to the neural network to be processed is less than the second preset winning ratio threshold, and/or the evaluation data corresponding to the neural network to be processed is less than the second preset evaluation data threshold, it is determined that the performance of the neural network to be processed is relatively high. If it is poor, the parameters of the neural network to be processed can be reset, and the neural network to be processed can be reset to the initialization neural network to generate an auxiliary neural network for future training cycles.
承接上述S102,本公开实施例提供的神经网络的生成方法还包括:Following the above S102, the method for generating a neural network provided by the embodiment of the present disclosure further includes:
S103、向深度学习框架发送所述当前训练周期的第一对战样本数据。S103. Send the first battle sample data of the current training cycle to the deep learning framework.
其中,至少两个训练周期分别对应的第一对战样本数据,用于深度学习框架对待训练神经网络进行至少两个训练周期的强化训练,得到目标神经网络。The first battle sample data corresponding to at least two training periods respectively are used for the deep learning framework to perform intensive training on the neural network to be trained for at least two training periods to obtain the target neural network.
在基于S102生成当前训练周期的第一对战样本数据后,可以向深度学习框架发送当前训练周期的第一对战样本数据,以使深度学习框架可以基于第一对战样本数据,对待训练神经网络进行强化训练,生成目标神经网络,所述目标神经网络用于控制目标虚拟角色进行对战;其中,目标虚拟角色可以包括对战场景中的任一可操控的虚拟角色。After generating the first battle sample data of the current training cycle based on S102, the first battle sample data of the current training cycle may be sent to the deep learning framework, so that the deep learning framework can strengthen the neural network to be trained based on the first battle sample data training to generate a target neural network, where the target neural network is used to control the target virtual character to fight; wherein, the target virtual character may include any controllable virtual character in the battle scene.
在具体实施中,接收深度学习框架反馈的当前训练周期的待训练神经网络的更新数据;利用更新数据,对当前训练周期的待训练神经网络进行更新处理;其中,更新数据是深度学习框架利用所述当前训练周期的第一对战样本数据,对当前训练周期的待训练神经网络进行强化训练后得到的。In a specific implementation, the update data of the neural network to be trained in the current training cycle fed back by the deep learning framework is received; the update data is used to update the neural network to be trained in the current training cycle; wherein the update data is the deep learning framework using all The first battle sample data of the current training cycle is obtained after intensive training of the neural network to be trained in the current training cycle.
参见图2所示,为本公开实施例提供的另一种神经网络的生成方法的流程图,所述方法应用于深度学习框架,在至少两个训练周期中的每个训练周期中执行下述步骤S201~S204,其中:Referring to FIG. 2, which is a flowchart of another method for generating a neural network provided by an embodiment of the present disclosure, the method is applied to a deep learning framework, and the following is performed in each of at least two training cycles. Steps S201-S204, wherein:
S201、向智能体控制框架发送当前训练周期的第一训练指令。S201. Send the first training instruction of the current training cycle to the agent control framework.
S202、接收所述智能体控制框架基于所述第一训练指令反馈的当前训练周期的第一对战样本数据、以及待训练神经网络。S202. Receive the first battle sample data of the current training cycle and the neural network to be trained, which are fed back by the agent control framework based on the first training instruction.
S203、利用所述第一对战样本数据,对所述待训练神经网络进行强化训练,得到当前训练周期的中间神经网络。S203 , using the first battle sample data to perform intensive training on the neural network to be trained to obtain an intermediate neural network of the current training cycle.
S204、基于最后一个训练周期的中间神经网络,得到目标神经网络。S204 , obtaining a target neural network based on the intermediate neural network of the last training cycle.
其中,目标神经网络用于控制目标虚拟角色进行对战。Among them, the target neural network is used to control the target virtual character to fight.
在具体实施中,针对S201~S204的具体实施方式的相关描述可以参见本公开实施例提供的神经网络的生成方法中S101~S103所示的具体实施方式中的描述,重复之处不再赘述。In the specific implementation, for the relevant description of the specific implementations of S201-S204, reference may be made to the descriptions in the specific implementations shown in S101-S103 in the neural network generation method provided by the embodiment of the present disclosure, and repeated descriptions will not be repeated.
在本公开的另一实施方式中,参见图3所示,提供了一种神经网络的生成过程中的交互流程示意图,包括:In another embodiment of the present disclosure, referring to FIG. 3 , a schematic diagram of an interaction flow in the process of generating a neural network is provided, including:
S301、深度学习框架向智能体控制框架发送当前训练周期的第一训练指令。S301. The deep learning framework sends the first training instruction of the current training cycle to the agent control framework.
S302、智能体控制框架响应于接收到当前训练周期的第一训练指令,从当前训练周期的至少两个辅助神经网络中确定目标辅助神经网络。S302. The agent control framework determines a target auxiliary neural network from at least two auxiliary neural networks in the current training period in response to receiving the first training instruction of the current training period.
S303、智能体控制框架利用目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战,得到对当前训练周期的待训练神经网络进行训练的第一对战样本数据。S303. The agent control framework uses the target auxiliary neural network to control the first virtual character, and uses the to-be-trained neural network of the current training cycle to control the second virtual character to fight, and obtains the first virtual character for training the to-be-trained neural network of the current training cycle Battle sample data.
S304、智能体控制框架向深度学习框架发送当前训练周期的第一对战样本数据、以及待训练神经网络。S304 , the agent control framework sends the first battle sample data of the current training cycle and the neural network to be trained to the deep learning framework.
S305、深度学习框架接收智能体控制框架基于所述第一训练指令反馈的当前训练周期的第一对战样本数据、以及待训练神经网络。S305 , the deep learning framework receives the first battle sample data of the current training cycle fed back by the agent control framework based on the first training instruction, and the neural network to be trained.
S306、深度学习框架利用第一对战样本数据,对所述待训练神经网络进行强化训练,得到当前训练周期的中间神经网络。S306 , the deep learning framework uses the first battle sample data to perform intensive training on the neural network to be trained to obtain an intermediate neural network of the current training cycle.
S307、深度学习框架基于最后一个训练周期的中间神经网络,得到目标神经网络。S307, the deep learning framework obtains the target neural network based on the intermediate neural network of the last training cycle.
在具体实施中,针对S301~S307的具体实施方式的相关描述可以参见本公开实施例提供的神经网络的生成方法中S101~S103所示的具体实施方式中的描述,重复之处不再赘述。其中,所述目标神经网络用于控制目标虚拟角色进行对战。In the specific implementation, for the relevant description of the specific implementations of S301-S307, reference may be made to the descriptions in the specific implementations shown in S101-S103 in the neural network generation method provided by the embodiment of the present disclosure, and repeated repetitions will not be repeated. Wherein, the target neural network is used to control the target virtual character to compete.
本公开实施例中,将神经网络、与对神经网络进行强化训练的代码分开设置在智能体控制框架和深度学习框架中,减少了代码的耦合性,这样使得在不同的对战场景下,可以使用同一深度学习框架以及智能体控制框架,减少了开发成本及开发复杂度;并且利用目标辅助神经网络控制第一虚拟角色、并利用待训练神经网络控制第二虚拟角色进行对战,生成第一对战样本数据;并将生成的第一对战样本数据,发送至深度学习框架,以使深度学习框架基于第一对战样本数据,对待训练神经网络进行至少两个训练周期的强化训练,得到目标神经网络,所述目标神经网络用于控制目标虚拟角色进行对战,这样生成的目标神经网络是基于大量的对战样本数据训练生成的,学习到了不同类型的动作、以及对战策略,灵活度较高且具有较强的泛化能力。在对战对局过程中,目标神经网络可以相对灵活地根据队友(玩家或其他辅助神经网络)或对手(玩家或其他辅助神经网络)的当前状态信息、以及对战场景的当前状态信息,进行下一步动作的预测。In the embodiment of the present disclosure, the neural network and the code for intensive training of the neural network are separately set in the agent control framework and the deep learning framework, which reduces the coupling of the codes, so that in different battle scenarios, it is possible to use The same deep learning framework and agent control framework reduce the development cost and development complexity; and use the target-assisted neural network to control the first virtual character, and use the neural network to be trained to control the second virtual character to fight, and generate the first battle sample data; and send the generated first battle sample data to the deep learning framework, so that the deep learning framework can perform intensive training on the neural network to be trained for at least two training cycles based on the first battle sample data to obtain the target neural network, so The target neural network described above is used to control the target virtual character to fight, and the target neural network thus generated is generated based on a large number of battle sample data training, and has learned different types of actions and battle strategies, with high flexibility and strong performance. Generalization. In the course of the battle, the target neural network can relatively flexibly proceed to the next step according to the current state information of the teammate (player or other auxiliary neural network) or opponent (player or other auxiliary neural network) and the current state information of the battle scene Action prediction.
本领域技术人员可以理解,在具体实施方式的上述方法中,各步骤的撰写顺序并不意味着严格的执行顺序而对实施过程构成任何限定,各步骤的具体执行顺序应当以其功能和可能的内在逻辑确定。Those skilled in the art can understand that in the above method of the specific implementation, the writing order of each step does not mean a strict execution order but constitutes any limitation on the implementation process, and the specific execution order of each step should be based on its function and possible Internal logic is determined.
基于同一技术构思,本公开实施例中还提供了与神经网络的生成方法对应的神经网络的生成系统,由于本公开实施例中的系统解决问题的原理与本公开实施例上述神经网络的生成方法相似,因此系统的实施可以参见方法的实施,重复之处不再赘述。Based on the same technical concept, the embodiment of the present disclosure also provides a neural network generation system corresponding to the neural network generation method, because the principle of the system to solve the problem in the embodiment of the present disclosure and the above-mentioned method for generating the neural network in the embodiment of the present disclosure Similar, therefore, the implementation of the system can refer to the implementation of the method, and the repetition will not be repeated.
参照图4所示,为本公开实施例提供的一种神经网络的生成系统的示意图,所述系统包括:智能体控制框架401、以及深度学习框架402;Referring to FIG. 4 , which is a schematic diagram of a system for generating a neural network according to an embodiment of the present disclosure, the system includes: an agent control framework 401 and a deep learning framework 402;
智能体控制框架401,用于在至少两个训练周期中的每个训练周期中,响应于接收到当前训练周期的第一训练指令,从当前训练周期的至少两个辅助神经网络中确定目标辅助神经网络;利用所述目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战,得到对所述当前训练周期的待训练神经网络进行训练的第一对战样本数据;向深度学习框架发送所述当前训练周期的第一对战样本数据;An agent control framework 401 for determining target assistance from at least two auxiliary neural networks in the current training cycle in response to receiving a first training instruction for the current training cycle in each of the at least two training cycles Neural network; use the target auxiliary neural network to control the first virtual character, and use the to-be-trained neural network of the current training cycle to control the second virtual character to fight, and obtain the first avatar for training the to-be-trained neural network of the current training cycle a battle sample data; send the first battle sample data of the current training cycle to the deep learning framework;
深度学习框架402,用于在至少两个所述训练周期中的每个训练周期中,向智能体控制框架发送当前训练周期的第一训练指令;接收所述智能体控制框架基于所述第一训练指令反馈的当前训练周期的第一对战样本数据、以及待训练神经网络;利用所述第一对战样本数据,对所述待训练神经网络进行强化训练,得到当前训练周期的中间神经网络;基于最后一个训练周期的中间神经网络,得到目标神经网络,所述目标神经网络用于控制目标虚拟角色进行对战。The deep learning framework 402 is configured to, in each of the at least two training periods, send the first training instruction of the current training period to the agent control framework; receive the agent control framework based on the first training instruction The first battle sample data of the current training cycle fed back by the training instruction, and the neural network to be trained; using the first battle sample data, the neural network to be trained is intensively trained to obtain the intermediate neural network of the current training cycle; based on The intermediate neural network in the last training cycle obtains the target neural network, and the target neural network is used to control the target virtual character to compete.
一种可选的实施方式中,智能体控制框架401在执行响应于接收到当前训练周期的第一训练指令,从当前训练周期的至少两个辅助神经网络中确定目标辅助神经网络时,具体用于:响应于接收到所述当前训练周期的第一训练指令,确定当前训练周期的至少两个辅助神经网络分别对应的采样概率;基于至少两个所述辅助神经网络分别对应的采样概率,从当前训练周期的至少两个辅助神经网络中确定目标辅助神经网络。In an optional embodiment, when the agent control framework 401 determines the target auxiliary neural network from at least two auxiliary neural networks in the current training cycle in response to receiving the first training instruction of the current training cycle, it specifically uses In: in response to receiving the first training instruction of the current training cycle, determine the sampling probabilities corresponding to the at least two auxiliary neural networks of the current training cycle respectively; based on the sampling probabilities corresponding to the at least two auxiliary neural networks respectively, from The target auxiliary neural network is determined among at least two auxiliary neural networks of the current training cycle.
一种可选的实施方式中,智能体控制框架401在执行响应于接收到所述当前训练周期的第一训练指令,确定当前训练周期的至少两个辅助神经网络分别对应的采样概率时,具体用于:响应于接收到所述当前训练周期的第一训练指令,确定当前训练周期的至少两个辅助神经网络;至少两个所述辅助神经网络包括:第一辅助神经网络和/或第二辅助神经网络;其中,所述第一辅助神经网络用于对所述待训练神经网络进行对战对抗能力训练;所述第二辅助神经网络用于对所述待训练神经网络进行对战对抗能力训练和/或对战配合能力训练;基于各所述辅助神经网络分别对应的历史对战数据,确定各所述辅助神经网络分别对应的采样概率。In an optional implementation manner, when the agent control framework 401 determines the sampling probabilities corresponding to at least two auxiliary neural networks of the current training period in response to receiving the first training instruction of the current training period, the specific for: determining at least two auxiliary neural networks of the current training cycle in response to receiving the first training instruction of the current training cycle; the at least two auxiliary neural networks include: a first auxiliary neural network and/or a second auxiliary neural network Auxiliary neural network; wherein, the first auxiliary neural network is used for training the neural network to be trained in combat confrontation; the second auxiliary neural network is used for training the neural network to be trained in combat confrontation and /or training of combat cooperation ability; based on the historical combat data corresponding to each of the auxiliary neural networks, respectively, determine the sampling probability corresponding to each of the auxiliary neural networks.
一种可选的实施方式中,所述历史对战数据,包括:在历史对战对局中的胜负情况信息、和/或,在历史对战对局中的评价数据。In an optional implementation manner, the historical competition data includes: information on the outcome of the historical competition and/or evaluation data in the historical competition.
一种可选的实施方式中,智能体控制框架401在执行所述基于至少两个所述辅助神经网络分别对应的采样概率,从当前训练周期的至少两个辅助神经网络中确定目标辅助神经网络时,具体用于:基于至少两个所述辅助神经网络分别对应的采样概率、以及预设的筛选规则,从当前训练周期的至少两个辅助神经网络中确定所述目标辅助神经网络。In an optional embodiment, the agent control framework 401 determines the target auxiliary neural network from the at least two auxiliary neural networks in the current training cycle based on the sampling probabilities corresponding to the at least two auxiliary neural networks respectively. is specifically used for: determining the target auxiliary neural network from at least two auxiliary neural networks in the current training cycle based on the sampling probabilities corresponding to the at least two auxiliary neural networks respectively and a preset screening rule.
一种可选的实施方式中,智能体控制框架401在执行所述利用所述目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战,得到对所述当前训练周期的待训练神经网络进行训练的第一对战样本数据时,具体用于:利用所述目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战,得到所述第二虚拟角色在对战过程中的第一对战状态数据;基于所述第一对战状态数据,生成所述第一对战样本数据。In an optional embodiment, the agent control framework 401 is performing the control of the first virtual character by using the target-assisted neural network, and using the neural network to be trained in the current training cycle to control the second virtual character to fight, obtaining: When training the first battle sample data of the neural network to be trained in the current training cycle, it is specifically used for: using the target auxiliary neural network to control the first virtual character, and using the neural network to be trained in the current training cycle to control the first virtual character. The two virtual characters compete to obtain the first battle state data of the second virtual character during the battle; based on the first battle state data, the first battle sample data is generated.
一种可选的实施方式中,智能体控制框架401,还用于利用所述目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战,得到对所述目标辅助神经网络进行训练的第二对战样本数据;向深度学习框架发送所述当前训练周期的第二对战样本数据;其中,当前训练周期的第二对战样本数据,用于所述深度学习框架对当前训练周期的目标辅助神经网络进行强化训练,得到未来训练周期的辅助神经网络。In an optional embodiment, the agent control framework 401 is further configured to use the target auxiliary neural network to control the first virtual character, and use the to-be-trained neural network of the current training cycle to control the second virtual character to fight, obtaining: The second battle sample data for training the target auxiliary neural network; the second battle sample data of the current training cycle is sent to the deep learning framework; wherein, the second battle sample data of the current training cycle is used for the depth The learning framework performs intensive training on the target auxiliary neural network of the current training cycle, and obtains the auxiliary neural network of the future training cycle.
一种可选的实施方式中,智能体控制框架401,在执行所述利用所述目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战时,得到对所述目标辅助神经网络进行训练的第二对战样本数据时,具体用于:确定所述目标辅助神经网络是否利用所述待训练神经网络的历史状态生成;响应于所述目标辅助神经网络并非利用所述待训练神经网络的历史状态生成,则利用所述目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战时,得到对所述目标辅助神经网络进行训练的第二对战样本数据。In an optional embodiment, the agent control framework 401, when executing the control of the first virtual character using the target-assisted neural network, and using the neural network to be trained in the current training cycle to control the second virtual character to fight. , when the second battle sample data for training the target auxiliary neural network is obtained, it is specifically used for: determining whether the target auxiliary neural network is generated by using the historical state of the neural network to be trained; in response to the target auxiliary neural network The network is not generated by using the historical state of the neural network to be trained, then the target auxiliary neural network is used to control the first virtual character, and the neural network to be trained in the current training cycle is used to control the second virtual character to fight. The second battle sample data for training the above-mentioned target-assisted neural network.
一种可选的实施方式中,响应于确定的目标辅助神经网络包括第一辅助神经网络;所述第一虚拟角色和所述第二虚拟角色均包括一个;智能体控制框架401,在执行所述利用所述目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战,得到对所述当前训练周期的待训练神经网络进行训练的第一对战样本数据时,具体用于:利用所述第一辅助神经网络控制所述第一虚拟角色,并利用当前训练周期的待训练神经网络控制与所述第一虚拟角色属于不同对战阵营的第二虚拟角色进行对战,得到所述第一对战样本数据。In an optional implementation manner, the auxiliary neural network in response to the determined target includes a first auxiliary neural network; both the first virtual character and the second virtual character include one; the agent control framework 401, when executing all the Describe the use of the target auxiliary neural network to control the first virtual character, and the use of the neural network to be trained in the current training period to control the second virtual character to fight, to obtain the first battle of the neural network to be trained in the current training period. When the sample data is used, it is specifically used for: using the first auxiliary neural network to control the first virtual character, and using the neural network to be trained in the current training cycle to control the second virtual character belonging to a different battle camp with the first virtual character. The characters compete to obtain the first battle sample data.
一种可选的实施方式中,响应于确定的目标辅助神经网络包括第二辅助神经网络;智能体控制框架401,在执行所述利用所述目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战,得到对所述当前训练周期的待训练神经网络进行训练的第一对战样本数据时,具体用于:利用所述第二辅助神经网络控制所述第一虚拟角色,并利用当前训练周期的待训练神经网络控制与所述第一虚拟角色属于相同对战阵营和/或不同对战阵营的第二虚拟角色进行对战,得到所述第一对战样本数据。In an optional implementation manner, the auxiliary neural network includes a second auxiliary neural network in response to the determined target; the agent control framework 401, when executing the control of the first virtual character by using the target auxiliary neural network, and using the current When the neural network to be trained in the training period controls the second virtual character to fight, and the first battle sample data for training the neural network to be trained in the current training period is obtained, it is specifically used for: using the second auxiliary neural network to control The first virtual character is controlled by the neural network to be trained in the current training cycle to play against the second virtual character belonging to the same battle camp and/or different battle camps with the first virtual character to obtain the first battle sample data.
一种可选的实施方式中,智能体控制框架401,还用于:利用所述目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战,得到当前对战对局对应的对战数据;利用所述对战数据,对所述目标辅助神经网络、以及当前训练周期的待训练神经网络分别对应的历史对战数据进行更新处理,得到更新后的对战数据。In an optional embodiment, the agent control framework 401 is further configured to: use the target auxiliary neural network to control the first virtual character, and use the neural network to be trained in the current training cycle to control the second virtual character to fight, Obtain the battle data corresponding to the current battle game; use the battle data to update the target auxiliary neural network and the historical battle data corresponding to the neural network to be trained in the current training cycle, to obtain updated battle data.
一种可选的实施方式中,智能体控制框架401,还用于:利用所述更新处理后的对战数据,确定所述待训练神经网络是否满足预设辅助神经网络生成条件;响应于所述待训练神经网络满足所述预设辅助神经网络生成条件,则基于所述待训练神经网络、或当前训练周期更新后的待训练神经网络,生成未来训练周期的辅助神经网络。In an optional implementation manner, the agent control framework 401 is further configured to: use the updated battle data to determine whether the neural network to be trained satisfies the preset auxiliary neural network generation conditions; When the neural network to be trained satisfies the preset auxiliary neural network generation condition, an auxiliary neural network for a future training period is generated based on the neural network to be trained or the neural network to be trained after the current training period is updated.
一种可选的实施方式中,智能体控制框架401,在执行所述基于所述待训练神经网络、或当前训练周期更新后的待训练神经网络,生成未来训练周期的辅助神经网络时,具体用于:生成基于所述待训练神经网络、或当前训练周期更新后的待训练神经网络的快照;基于所述快照,生成未来训练周期的辅助神经网络。In an optional embodiment, the agent control framework 401, when executing the auxiliary neural network for the future training cycle based on the neural network to be trained or the updated neural network to be trained in the current training cycle, specifically: It is used for: generating a snapshot of the neural network to be trained based on the neural network to be trained or the updated neural network to be trained in the current training period; and generating an auxiliary neural network for a future training period based on the snapshot.
一种可选的实施方式中,智能体控制框架401,还用于:响应于接收到当前训练周期的第一训练指令,确定所述当前训练周期的待训练神经网络。In an optional implementation manner, the agent control framework 401 is further configured to: in response to receiving the first training instruction of the current training period, determine the neural network to be trained in the current training period.
一种可选的实施方式中,智能体控制框架401,在执行所述确定当前训练周期的所述待训练神经网络时,具体用于:响应于当前训练周期属于首次迭代训练过程,将初始化神经网络确定为所述待训练神经网络;响应于当前训练周期属于非首次迭代训练过程,基于当前训练周期所属的迭代训练过程的前一次迭代训练过程确定的至少一个备选神经网络分别对应的性能信息,确定所述待训练神经网络;和/或,将所述初始化神经网络确定为所述待训练神经网络。In an optional implementation manner, the agent control framework 401, when executing the determination of the neural network to be trained in the current training period, is specifically configured to: in response to the current training period belonging to the first iterative training process, initialize the neural network. The network is determined as the neural network to be trained; in response to the current training period belonging to a non-first iterative training process, the performance information respectively corresponding to at least one candidate neural network determined based on the previous iterative training process of the iterative training process to which the current training period belongs , determining the neural network to be trained; and/or, determining the initialized neural network as the neural network to be trained.
一种可选的实施方式中,智能体控制框架401,还用于:接收深度学习框架反馈的所述当前训练周期的待训练神经网络的更新数据;利用所述更新数据,对所述当前训练周期的待训练神经网络进行更新处理;其中,所述更新数据是所述深度学习框架利用所述当前训练周期的第一对战样本数据,对当前训练周期的待训练神经网络进行强化训练后得到的。In an optional implementation manner, the agent control framework 401 is further configured to: receive the updated data of the neural network to be trained in the current training cycle fed back by the deep learning framework; The periodic neural network to be trained is updated; wherein, the updated data is obtained by the deep learning framework using the first battle sample data of the current training cycle to perform intensive training on the neural network to be trained in the current training cycle. .
关于装置中的各模块的处理流程、以及各模块之间的交互流程的描述可以参照上述方法实施例中的相关说明,这里不再详述。For the description of the processing flow of each module in the apparatus and the interaction flow between the modules, reference may be made to the relevant descriptions in the foregoing method embodiments, which will not be described in detail here.
基于同一技术构思,本申请实施例还提供了一种计算机设备。参照图5所示,为本申请实施例提供的计算机设备500的结构示意图,包括处理器501、存储器502、和总线503。其中,存储器502用于存储执行指令,包括内存5021和外部存储器5022;这里的内存5021也称内存储器,用于暂时存放处理器501中的运算数据,以及与硬盘等外部存储器5022交换的数据,处理器501通过内存5021与外部存储器5022进行数据交换,当计算机设备500运行时,处理器501与存储器502之间通过总线503通信,使得处理器501执行以下指令:Based on the same technical concept, the embodiments of the present application also provide a computer device. Referring to FIG. 5 , a schematic structural diagram of a computer device 500 provided in an embodiment of the present application includes a
响应于接收到当前训练周期的第一训练指令,从当前训练周期的至少两个辅助神经网络中确定目标辅助神经网络;利用所述目标辅助神经网络控制第一虚拟角色,并利用当前训练周期的待训练神经网络控制第二虚拟角色进行对战,得到对所述当前训练周期的待训练神经网络进行训练的第一对战样本数据;向深度学习框架发送所述当前训练周期的第一对战样本数据;其中,至少两个训练周期分别对应的第一对战样本数据,用于所述深度学习框架对待训练神经网络进行至少两个训练周期的强化训练,得到目标神经网络,所述目标神经网络用于控制目标虚拟角色进行对战。In response to receiving the first training instruction of the current training cycle, determine a target auxiliary neural network from at least two auxiliary neural networks in the current training cycle; use the target auxiliary neural network to control the first virtual character, and use the current training cycle. The to-be-trained neural network controls the second virtual character to compete, and obtains the first battle sample data for training the to-be-trained neural network of the current training cycle; and sends the first battle sample data of the current training cycle to the deep learning framework; Wherein, the first battle sample data corresponding to at least two training cycles are used for the deep learning framework to perform intensive training on the neural network to be trained for at least two training cycles to obtain a target neural network, and the target neural network is used to control The target avatar fights.
或者处理器501执行以下指令:Or the
向智能体控制框架发送当前训练周期的第一训练指令;接收所述智能体控制框架基于所述第一训练指令反馈的当前训练周期的第一对战样本数据、以及待训练神经网络;利用所述第一对战样本数据,对所述待训练神经网络进行强化训练,得到当前训练周期的中间神经网络;基于最后一个训练周期的中间神经网络,得到目标神经网络,所述目标神经网络用于控制目标虚拟角色进行对战。Send the first training instruction of the current training period to the agent control framework; receive the first battle sample data of the current training period fed back by the agent control framework based on the first training instruction, and the neural network to be trained; use the In the first battle against sample data, intensive training is performed on the neural network to be trained to obtain the intermediate neural network of the current training cycle; based on the intermediate neural network of the last training cycle, the target neural network is obtained, and the target neural network is used to control the target Virtual characters fight against each other.
其中,处理器501的具体处理流程可以参照上述方法实施例的记载,这里不再赘述。The specific processing flow of the
本公开实施例还提供一种计算机可读存储介质,该计算机可读存储介质上存储有计算机程序,该计算机程序被处理器运行时执行上述方法实施例中所述的神经网络的生成方法的步骤。其中,该存储介质可以是易失性或非易失的计算机可读取存储介质。Embodiments of the present disclosure further provide a computer-readable storage medium, where a computer program is stored on the computer-readable storage medium, and when the computer program is run by a processor, the steps of the method for generating a neural network described in the foregoing method embodiments are executed. . Wherein, the storage medium may be a volatile or non-volatile computer-readable storage medium.
本公开实施例还提供一种计算机程序产品,该计算机程序产品承载有程序代码,所述程序代码包括的指令可用于执行上述方法实施例中所述的神经网络的生成方法的步骤,具体可参见上述方法实施例,在此不再赘述。Embodiments of the present disclosure further provide a computer program product, where the computer program product carries program codes, and the instructions included in the program codes can be used to execute the steps of the method for generating a neural network described in the above method embodiments. For details, please refer to The foregoing method embodiments are not repeated here.
其中,上述计算机程序产品可以具体通过硬件、软件或其结合的方式实现。在一个可选实施例中,所述计算机程序产品具体体现为计算机存储介质,在另一个可选实施例中,计算机程序产品具体体现为软件产品,例如软件开发包(Software Development Kit,SDK)等等。Wherein, the above-mentioned computer program product can be specifically implemented by means of hardware, software or a combination thereof. In an optional embodiment, the computer program product is embodied as a computer storage medium, and in another optional embodiment, the computer program product is embodied as a software product, such as a software development kit (Software Development Kit, SDK), etc. Wait.
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的系统和装置的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。在本公开所提供的几个实施例中,应该理解到,所揭露的系统、装置和方法,可以通过其它的方式实现。以上所描述的装置实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,又例如,多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些通信接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。Those skilled in the art can clearly understand that, for the convenience and brevity of description, for the specific working process of the system and device described above, reference may be made to the corresponding process in the foregoing method embodiments, which will not be repeated here. In the several embodiments provided by the present disclosure, it should be understood that the disclosed system, apparatus and method may be implemented in other manners. The apparatus embodiments described above are only illustrative. For example, the division of the units is only a logical function division. In actual implementation, there may be other division methods. For example, multiple units or components may be combined or Can be integrated into another system, or some features can be ignored, or not implemented. On the other hand, the shown or discussed mutual coupling or direct coupling or communication connection may be through some communication interfaces, indirect coupling or communication connection of devices or units, which may be in electrical, mechanical or other forms.
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。The units described as separate components may or may not be physically separated, and components displayed as units may or may not be physical units, that is, may be located in one place, or may be distributed to multiple network units. Some or all of the units may be selected according to actual needs to achieve the purpose of the solution in this embodiment.
另外,在本公开各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。In addition, each functional unit in each embodiment of the present disclosure may be integrated into one processing unit, or each unit may exist physically alone, or two or more units may be integrated into one unit.
所述功能如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个处理器可执行的非易失的计算机可读取存储介质中。基于这样的理解,本公开的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本公开各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器(Read-OnlyMemory,ROM)、随机存取存储器(Random Access Memory,RAM)、磁碟或者光盘等各种可以存储程序代码的介质。The functions, if implemented in the form of software functional units and sold or used as stand-alone products, may be stored in a processor-executable non-volatile computer-readable storage medium. Based on such understanding, the technical solutions of the present disclosure can be embodied in the form of software products in essence, or the parts that contribute to the prior art or the parts of the technical solutions. The computer software products are stored in a storage medium, including Several instructions are used to cause a computer device (which may be a personal computer, a server, or a network device, etc.) to execute all or part of the steps of the methods described in various embodiments of the present disclosure. The aforementioned storage medium includes: U disk, mobile hard disk, read-only memory (Read-Only Memory, ROM), random access memory (Random Access Memory, RAM), magnetic disk or optical disk and other media that can store program codes.
最后应说明的是:以上所述实施例,仅为本公开的具体实施方式,用以说明本公开的技术方案,而非对其限制,本公开的保护范围并不局限于此,尽管参照前述实施例对本公开进行了详细的说明,本领域的普通技术人员应当理解:任何熟悉本技术领域的技术人员在本公开揭露的技术范围内,其依然可以对前述实施例所记载的技术方案进行修改或可轻易想到变化,或者对其中部分技术特征进行等同替换;而这些修改、变化或者替换,并不使相应技术方案的本质脱离本公开实施例技术方案的精神和范围,都应涵盖在本公开的保护范围之内。因此,本公开的保护范围应所述以权利要求的保护范围为准。Finally, it should be noted that the above-mentioned embodiments are only specific implementations of the present disclosure, and are used to illustrate the technical solutions of the present disclosure rather than limit them. The protection scope of the present disclosure is not limited thereto, although referring to the foregoing The embodiments describe the present disclosure in detail. Those of ordinary skill in the art should understand that: any person skilled in the art can still modify the technical solutions described in the foregoing embodiments within the technical scope disclosed by the present disclosure. Changes can be easily thought of, or equivalent replacements are made to some of the technical features; and these modifications, changes or replacements do not make the essence of the corresponding technical solutions deviate from the spirit and scope of the technical solutions of the embodiments of the present disclosure, and should be covered in the present disclosure. within the scope of protection. Therefore, the protection scope of the present disclosure should be based on the protection scope of the claims.
Claims (20)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111666463.8ACN114330667A (en) | 2021-12-31 | 2021-12-31 | A method, system, computer equipment and storage medium for generating a neural network |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111666463.8ACN114330667A (en) | 2021-12-31 | 2021-12-31 | A method, system, computer equipment and storage medium for generating a neural network |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN114330667Atrue CN114330667A (en) | 2022-04-12 |
Family
ID=81020471
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202111666463.8APendingCN114330667A (en) | 2021-12-31 | 2021-12-31 | A method, system, computer equipment and storage medium for generating a neural network |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114330667A (en) |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110807515A (en)* | 2019-10-30 | 2020-02-18 | 北京百度网讯科技有限公司 | Model generation method and device |
| CN111632379A (en)* | 2020-04-28 | 2020-09-08 | 腾讯科技(深圳)有限公司 | Game role behavior control method and device, storage medium and electronic equipment |
| US20210001229A1 (en)* | 2019-07-02 | 2021-01-07 | Electronic Arts Inc. | Customized models for imitating player gameplay in a video game |
| CN112933604A (en)* | 2021-02-04 | 2021-06-11 | 超参数科技(深圳)有限公司 | Reinforcement learning model processing method, device, computer equipment and storage medium |
| CN113996063A (en)* | 2021-10-29 | 2022-02-01 | 北京市商汤科技开发有限公司 | Method and device for controlling virtual character in game and computer equipment |
- 2021
- 2021-12-31CNCN202111666463.8Apatent/CN114330667A/enactivePending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20210001229A1 (en)* | 2019-07-02 | 2021-01-07 | Electronic Arts Inc. | Customized models for imitating player gameplay in a video game |
| CN110807515A (en)* | 2019-10-30 | 2020-02-18 | 北京百度网讯科技有限公司 | Model generation method and device |
| CN111632379A (en)* | 2020-04-28 | 2020-09-08 | 腾讯科技(深圳)有限公司 | Game role behavior control method and device, storage medium and electronic equipment |
| CN112933604A (en)* | 2021-02-04 | 2021-06-11 | 超参数科技(深圳)有限公司 | Reinforcement learning model processing method, device, computer equipment and storage medium |
| CN113996063A (en)* | 2021-10-29 | 2022-02-01 | 北京市商汤科技开发有限公司 | Method and device for controlling virtual character in game and computer equipment |
Non-Patent Citations (2)
| Title |
|---|
| WANGCHEWEN: "多智能体强化学习及其在游戏AI上的应用与展望", Retrieved from the Internet <URL:https://blog.csdn.net/wangchewen/article/details/120904996>* |
| YUNQI ZHAO ET AL.: "Winning Isn’t Everything: Enhancing Game Development with Intelligent Agents", ARXIV, 28 April 2020 (2020-04-28)* |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Hausknecht et al. | A neuroevolution approach to general atari game playing | |
| WO2023071854A1 (en) | Control method and apparatus for virtual character in game, computer device, storage medium, and program | |
| Wu et al. | Training agent for first-person shooter game with actor-critic curriculum learning | |
| JP7199517B2 (en) | Information prediction method, model training method, server and computer program | |
| CN113952723A (en) | Interactive method and device in game, computer equipment and storage medium | |
| CN112843725A (en) | Intelligent agent processing method and device | |
| CN112044076B (en) | Object control method and device and computer readable storage medium | |
| CN114344889A (en) | Game strategy model generation method and control method of intelligent agent in game | |
| Muñoz-Avila et al. | Learning and game AI | |
| CN115888119A (en) | Game AI training method, device, electronic equipment and storage medium | |
| Nam et al. | Generation of diverse stages in turn-based role-playing game using reinforcement learning | |
| CN114404976A (en) | Method and device for training decision model, computer equipment and storage medium | |
| CN113509726A (en) | Interactive model training method and device, computer equipment and storage medium | |
| Tsay et al. | Evolving intelligent mario controller by reinforcement learning | |
| CN116956007A (en) | Pre-training method, device and equipment for artificial intelligent model and storage medium | |
| CN115804953A (en) | Fighting strategy model training method, device, medium and computer program product | |
| CN111389010B (en) | Virtual robot training method, device, electronic equipment and medium | |
| JP7441365B1 (en) | Information processing system, program, information processing method | |
| CN114330667A (en) | A method, system, computer equipment and storage medium for generating a neural network | |
| CN117861230A (en) | Strategy generation method for deduction of chess, electronic equipment and storage medium | |
| CN116943222A (en) | Intelligent model generation method, device, equipment and storage medium | |
| CN115501600A (en) | Method, system, device and medium for controlling man-machine role in game | |
| França et al. | CreativeStone: a creativity booster for Hearthstone card decks | |
| Pasztor et al. | Online RPG Environment for Reinforcement Learning | |
| O'Connor et al. | Learning Dark Souls Combat Through Pixel Input with Neuroevolution |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |