CN114328532A - Method and apparatus for merging metadata concepts - Google Patents
Method and apparatus for merging metadata conceptsDownload PDFInfo
- Publication number
- CN114328532A CN114328532ACN202111642061.4ACN202111642061ACN114328532ACN 114328532 ACN114328532 ACN 114328532ACN 202111642061 ACN202111642061 ACN 202111642061ACN 114328532 ACN114328532 ACN 114328532A
- Authority
- CN
- China
- Prior art keywords
- metadata
- data
- contrast
- comparison
- blood relationship
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images





Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本发明实施例涉及元数据技术领域,尤其涉及一种元数据概念合并的方法及装置。Embodiments of the present invention relate to the technical field of metadata, and in particular, to a method and apparatus for merging metadata concepts.
背景技术Background technique
元数据是描述数据的数据,为数据质量管理等业务功能提供信息支撑。在医院场景中,一个医院会对接多种系统,在不同系统中,同概念或同定义的元数据可能会存在多种描述方式。在对元数据进行管理或者向第三方提供服务时,用户需要自行理解不同系统中的同概念的元数据,而理解偏差成本需要由用户自行承担。Metadata is data that describes data and provides information support for business functions such as data quality management. In a hospital scenario, a hospital will be connected to multiple systems. In different systems, metadata with the same concept or definition may have multiple descriptions. When managing metadata or providing services to third parties, users need to understand metadata of the same concept in different systems, and the cost of understanding deviations needs to be borne by users.
元数据管理平台本身主要功能之一就是希望能够向外提供数据服务统一归口,现有技术路线无法满足该需求,因此需要进行调整优化。One of the main functions of the metadata management platform itself is to provide data services to the outside world in a unified and centralized manner. The existing technical route cannot meet this requirement, so it needs to be adjusted and optimized.
发明内容SUMMARY OF THE INVENTION
本发明实施例提供了一种元数据概念合并的方法及装置,以解决元数据管理平台不能识别同概念的元数据的问题,优化元数据管理平台的管理功能。Embodiments of the present invention provide a method and device for merging metadata concepts, so as to solve the problem that the metadata management platform cannot identify metadata of the same concept, and optimize the management function of the metadata management platform.
第一方面,本发明实施例提供了一种元数据概念合并的方法,该方法包括:In a first aspect, an embodiment of the present invention provides a method for merging metadata concepts, and the method includes:
获取元数据管理平台中的待测元数据以及对比元数据集;其中,所述对比元数据集包含至少一个对比元数据;Obtaining the metadata to be tested and the comparison metadata set in the metadata management platform; wherein, the comparison metadata set includes at least one comparison metadata;
将所述待测元数据对应的待测血缘关系数据与所述对比元数据集对应的对比血缘关系数据集进行匹配;其中,所述对比血缘关系数据集包含与至少一个对比元数据分别对应的对比血缘关系数据;The blood relationship data to be tested corresponding to the metadata to be tested is matched with the comparison blood relationship data set corresponding to the comparison metadata set; wherein, the comparison blood relationship data set includes at least one comparison metadata corresponding to respectively. Compare blood relationship data;
将匹配成功的对比血缘关系数据对应的对比元数据作为目标元数据,对所述待测元数据的概念命名与所述目标元数据的概念命名执行合并操作。The comparison metadata corresponding to the successfully matched comparison blood relationship data is used as the target metadata, and a merging operation is performed on the concept name of the metadata to be tested and the concept name of the target metadata.
第二方面,本发明实施例还提供了一种元数据概念合并的装置,该装置包括:In a second aspect, an embodiment of the present invention further provides an apparatus for merging metadata concepts, and the apparatus includes:
待测元数据获取模块,用于获取元数据管理平台中的待测元数据以及对比元数据集;其中,所述对比元数据集包含至少一个对比元数据;a metadata acquisition module to be tested, used for acquiring metadata to be tested and a comparison metadata set in the metadata management platform; wherein the comparison metadata set includes at least one comparison metadata;
待测血缘关系数据匹配模块,用于将所述待测元数据对应的待测血缘关系数据与所述对比元数据集对应的对比血缘关系数据集进行匹配;其中,所述对比血缘关系数据集包含与至少一个对比元数据分别对应的对比血缘关系数据;The blood relationship data matching module to be tested is used to match the blood relationship data to be tested corresponding to the metadata to be tested with the comparison blood relationship data set corresponding to the comparison metadata set; wherein, the comparison blood relationship data set Contains comparative blood relationship data corresponding to at least one comparative metadata;
概念合并模块,用于将匹配成功的对比血缘关系数据对应的对比元数据作为目标元数据,对所述待测元数据的概念命名与所述目标元数据的概念命名执行合并操作。The concept merging module is configured to use the comparison metadata corresponding to the successfully matched comparison blood relationship data as the target metadata, and perform a merging operation on the concept name of the metadata to be tested and the concept name of the target metadata.
第三方面,本发明实施例还提供了一种电子设备,该电子设备包括:In a third aspect, an embodiment of the present invention further provides an electronic device, the electronic device comprising:
一个或多个处理器;one or more processors;
存储器,用于存储一个或多个程序;memory for storing one or more programs;
当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器实现上述所涉及的任一所述的元数据概念合并的方法。The one or more programs, when executed by the one or more processors, cause the one or more processors to implement any of the above-mentioned methods for merging metadata concepts.
第四方面,本发明实施例还提供了一种包含计算机可执行指令的存储介质,所述计算机可执行指令在由计算机处理器执行时用于执行上述所涉及的任一所述的元数据概念合并的方法。In a fourth aspect, an embodiment of the present invention further provides a storage medium containing computer-executable instructions, when executed by a computer processor, the computer-executable instructions are used to execute any of the metadata concepts involved in the above method of merging.
本发明实施例通过将元数据管理平台中的待测元数据的待测血缘关系数据与对比元数据集对应的对比血缘关系数据集进行匹配,将匹配成功的对比血缘关系数据对应的对比元数据作为目标元数据,对待测元数据的概念命名与目标元数据的概念命名执行合并操作,解决了现有的元数据管理平台无法识别同概念的元数据的问题,优化了元数据管理平台的管理功能,避免了用户主观判断造成的理解误差,进而提高了元数据管理平台的实用性。In the embodiment of the present invention, by matching the blood relationship data to be tested of the metadata to be tested in the metadata management platform with the comparison blood relationship data set corresponding to the comparison metadata set, the comparison metadata corresponding to the successfully matched comparison blood relationship data is matched. As the target metadata, the conceptual naming of the metadata to be measured and the conceptual naming of the target metadata are merged, which solves the problem that the existing metadata management platform cannot identify the metadata of the same concept, and optimizes the management of the metadata management platform. It avoids the comprehension error caused by the user's subjective judgment, thereby improving the practicability of the metadata management platform.
附图说明Description of drawings
图1是本发明实施例一提供的一种元数据概念合并的方法的流程图;1 is a flowchart of a method for merging metadata concepts according to Embodiment 1 of the present invention;
图2是本发明实施例二提供的一种元数据概念合并的方法的流程图;2 is a flowchart of a method for merging metadata concepts provided by Embodiment 2 of the present invention;
图3是本发明实施例三提供的一种元数据概念合并的方法的流程图;3 is a flowchart of a method for merging metadata concepts according to Embodiment 3 of the present invention;
图4是本发明实施例三提供的一种元数据概念合并的方法的具体实例的流程图;4 is a flowchart of a specific example of a method for merging metadata concepts provided by Embodiment 3 of the present invention;
图5是本发明实施例四提供的一种元数据概念合并的装置的示意图;5 is a schematic diagram of an apparatus for merging metadata concepts according to Embodiment 4 of the present invention;
图6是本发明实施例五提供的一种电子设备的结构示意图。FIG. 6 is a schematic structural diagram of an electronic device according to Embodiment 5 of the present invention.
具体实施方式Detailed ways
下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部结构。The present invention will be further described in detail below in conjunction with the accompanying drawings and embodiments. It should be understood that the specific embodiments described herein are only used to explain the present invention, but not to limit the present invention. In addition, it should be noted that, for the convenience of description, the drawings only show some but not all structures related to the present invention.
实施例一Example 1
图1是本发明实施例一提供的一种元数据概念合并的方法的流程图,本实施例可适用于对元数据管理平台中的多个元数据进行同概念判断的情况,该方法可以由元数据概念合并的装置来执行,该装置可采用软件和/或硬件的方式实现,该装置可以配置于终端设备中,示例性的,终端设备可以是移动终端、笔记本电脑、台式机和平板电脑等智能终端。具体包括如下步骤:FIG. 1 is a flowchart of a method for merging metadata concepts according to Embodiment 1 of the present invention. This embodiment is applicable to the case of judging the same concept for multiple metadata in the metadata management platform. The method can be determined by Metadata concepts are combined to implement the device. The device can be implemented in software and/or hardware. The device can be configured in a terminal device. Exemplarily, the terminal device can be a mobile terminal, a notebook computer, a desktop computer, and a tablet computer. and other smart terminals. Specifically include the following steps:
S110、获取元数据管理平台中的待测元数据以及对比元数据集。S110. Obtain the metadata to be tested in the metadata management platform and compare the metadata set.
元数据是关于数据的数据,是一种用来描述数据化信息资源,特别是网络信息资源的基本特征及相互关系,从而确保这些数字化信息能够被计算机机器网络系统识别、分解、提取和分析归纳的一种框架或一套编码体系。元数据是实现数据发现、数据转换、数据管理和数据应用的最重要的工具和方法之一。Metadata is data about data, which is used to describe the basic characteristics and interrelations of digital information resources, especially network information resources, so as to ensure that these digital information can be identified, decomposed, extracted and analyzed by computer machine network systems. A framework or set of coding systems. Metadata is one of the most important tools and methods to realize data discovery, data transformation, data management and data application.
其中,元数据管理平台可以是一种对某一应用场景中的数据资产进行展示和分析的平台,实现标准化、流程化、自动化和一体化的数据管理体系。其中,示例性的,应用场景可以是企业或医院。以医院为例,医院的数据资产的特点是数据量巨大、内容复杂、形式多样和分散分布。本发明实施例将以医院场景为例进行举例解释说明。Among them, the metadata management platform can be a platform for displaying and analyzing data assets in a certain application scenario, and realizes a standardized, process-oriented, automated and integrated data management system. Wherein, exemplarily, the application scenario may be an enterprise or a hospital. Taking a hospital as an example, the data assets of a hospital are characterized by huge data volume, complex content, diverse forms and scattered distribution. The embodiment of the present invention will take a hospital scene as an example for explanation and description.
其中,示例性的,待测元数据可以是元数据管理平台新采集到的元数据,也可以是元数据管理平台在日常维护中设置的元数据。在本实施例中,对比元数据集包含至少一个对比元数据。Wherein, for example, the metadata to be tested may be metadata newly collected by the metadata management platform, or may be metadata set by the metadata management platform during routine maintenance. In this embodiment, the comparison metadata set contains at least one comparison metadata.
S120、将待测元数据对应的待测血缘关系数据与对比元数据集对应的对比血缘关系数据集进行匹配。S120. Match the blood relationship data to be tested corresponding to the metadata to be tested with the comparison blood relationship data set corresponding to the comparison metadata set.
在本实施例中,对比血缘关系数据集包含与至少一个对比元数据分别对应的对比血缘关系数据。In this embodiment, the comparison blood relationship data set includes comparison blood relationship data corresponding to at least one comparison metadata respectively.
在人类社会中,血缘关系是指由生育而产生的人际管理。大数据时代,数据的产生、加工融合、流转流通到提供应用,数据之间自然会形成一种类似于血缘关系的关系,用于表征这种数据之间的血缘关系的数据称为血缘关系数据。其中,血缘关系数据可用于表征以某一元数据在元数据管理平台中的流转信息,具体的,血缘关系数据的层次结构包括数据流转层级、数据库、数据表和字段。其中,数据流转层级用于表征元数据在元数据管理平台中的流转平台,关于数据流转层级在下述实施例中进行具体解释说明。示例性的,待测血缘关系数据为数据流转层级A-数据库1-数据表1-数据表2-数据流转层级B-数据库2-数据表3。In human society, consanguinity refers to the interpersonal management that results from reproduction. In the era of big data, data is generated, processed, integrated, and circulated to provide applications, and data will naturally form a relationship similar to blood relationship. The data used to characterize the blood relationship between such data is called blood relationship data. . The blood relationship data can be used to represent the flow information of a certain metadata in the metadata management platform. Specifically, the hierarchical structure of the blood relationship data includes a data flow level, a database, a data table, and a field. The data flow level is used to represent the metadata flow platform in the metadata management platform, and the data flow level will be specifically explained in the following embodiments. Exemplarily, the blood relationship data to be tested is data flow level A-database 1-data table 1-data table 2-data flow level B-database 2-data table 3.
其中,具体的,判断对比元数据集中是否存在与待测血缘关系数据相同的对比血缘关系数据,如果存在,则说明匹配成功,与该待测血缘关系数据相同的对比血缘关系数据为匹配成功的对比血缘关系数据,其中,具体的,目标元数据的个数可以为一个,可以是多个。如果不存在,则说明匹配失败。Specifically, it is judged whether the comparison metadata set has the same comparison blood relationship data as the blood relationship data to be tested. If it exists, it means that the matching is successful, and the comparison blood relationship data that is the same as the blood relationship data to be tested is matched successfully. Compare the blood relationship data, where, specifically, the number of target metadata may be one or multiple. If it does not exist, the match failed.
举例而言,假设待测元数据为“主诊断”,假设对比元数据集包括“第一诊断”、“主要诊断”、“诊断(主要)”和“历史使用药品”,其中,“主诊断”对应的待测血缘关系数据为数据流转层级A-患者数据库-入院档案数据表-数据流转层级B-手术数据库-手术器材准备数据表,对比血缘关系数据集中“第一诊断”、“主要诊断”和“诊断(主要)”分别对应的对比血缘关系数据为数据流转层级A-患者数据库-入院档案数据表-数据流转层级B-手术数据库-手术器材准备数据表,“历史使用药品”对应的对比血缘关系数据为数据流转层级A-患者数据库-入院档案数据表。其中,具体的,虽然“历史使用药品”的对比血缘关系数据与“主诊断”的待测血缘关系数据部分相同,但只有待测血缘关系数据与对比血缘关系数据完全相同时,才认为待测血缘关系数据与对比血缘关系数据匹配成功。For example, assuming that the metadata to be tested is "main diagnosis", it is assumed that the comparison metadata set includes "first diagnosis", "main diagnosis", "diagnosis (main)" and "historical use of drugs", wherein "main diagnosis" "The corresponding blood relationship data to be tested is data flow level A-patient database-admission file data table-data flow level B-surgical database-surgical equipment preparation data table, and compare the "first diagnosis" and "main diagnosis" in the blood relationship data set. ” and “Diagnosis (Main)” respectively correspond to the comparative blood relationship data as data flow level A-patient database-admission file data table-data flow level B-surgical database-surgical equipment preparation data table, the corresponding data of "historical use of drugs" The comparative blood relationship data is the data flow level A-patient database-admission file data table. Specifically, although the comparative blood relationship data of the "historical use of drugs" is the same as the blood relationship data to be tested of the "main diagnosis", only when the blood relationship data to be tested and the comparative blood relationship data are exactly the same, the blood relationship data to be tested is considered to be tested. The blood relationship data is successfully matched with the comparative blood relationship data.
S130、将匹配成功的对比血缘关系数据对应的对比元数据作为目标元数据,对待测元数据的概念命名与目标元数据的概念命名执行合并操作。S130. Use the comparison metadata corresponding to the successfully matched comparison blood relationship data as the target metadata, and perform a merging operation on the concept name of the metadata to be measured and the concept name of the target metadata.
其中,具体的,概念命名为元数据在元数据管理平台中的名称。Specifically, the concept name is the name of the metadata in the metadata management platform.
以上述举例为例,待测元数据为“主诊断”,根据待测血缘关系数据与对比血缘关系数据集的匹配结果得到,匹配成功的对比元数据包括“第一诊断”、“主要诊断”和“诊断(主要)”,其中,待测元数据的概念命名为“主诊断”,目标元数据的概念命名包括“第一诊断”、“主要诊断”和“诊断(主要)”。Taking the above example as an example, the metadata to be tested is "main diagnosis", which is obtained according to the matching result between the blood relationship data to be tested and the comparative blood relationship data set. The successfully matched comparison metadata includes "first diagnosis" and "main diagnosis". and "diagnosis (main)", wherein the concept of the metadata to be tested is named "main diagnosis", and the concept names of target metadata include "first diagnosis", "main diagnosis" and "diagnosis (main)".
在一个实施例中,可选的,在对待测元数据的概念命名与目标元数据的概念命名执行合并操作之前,包括:基于待测元数据的概念命名和目标元数据的概念命名生成合并提示信息,当接收到用户基于合并提示信息输入的合并指令时,对待测元数据的概念命名和目标元数据的概念命名执行合并操作。这样设置的好处在于,降低了由于误识别导致的合并误差,保证了元数据的概念命名的准确度。In one embodiment, optionally, before performing the merging operation on the concept naming of the metadata to be measured and the concept naming of the target metadata, the method includes: generating a merge prompt based on the concept naming of the metadata to be measured and the concept naming of the target metadata information, when receiving a merging instruction input by the user based on the merging prompt information, a merging operation is performed on the conceptual naming of the metadata to be measured and the conceptual naming of the target metadata. The advantage of this setting is that it reduces the merging error caused by misidentification, and ensures the accuracy of the conceptual naming of the metadata.
在一个实施例中,当目标元数据的数量为一个时,对待测元数据的概念命名和目标元数据的概念命名执行合并操作,包括:将待测元数据的概念命名更改为目标元数据的概念命名,或者,将目标元数据的概念命名更改为待测元数据的概念命名,或者,基于对待测元数据的概念命名和目标元数据的概念命名,生成新的概念命名,并将新的概念命名作为待测元数据和目标元数据的概念命名。举例而言,假设待测元数据的概念命名为“第一诊断”,目标元数据的概念命名为“主诊断”,则合并操作后的待测元数据和目标元数据的概念命名均为“第一诊断”、“主诊断”或者“主要诊断”,其中,“主要诊断”为生成的新的概念命名,示例性的,新的概念命名可以是用户基于合并提示信息输入的。In one embodiment, when the number of target metadata is one, performing a merging operation on the concept name of the metadata to be measured and the concept name of the target metadata, including: changing the concept name of the metadata to be measured to that of the target metadata. Concept naming, or, changing the concept naming of the target metadata to the concept naming of the metadata to be measured, or, based on the concept naming of the metadata to be measured and the concept naming of the target metadata, generate a new concept name, and assign the new concept name. Concept naming is the conceptual naming of the metadata to be tested and the metadata of the target. For example, assuming that the concept of the metadata to be tested is named "first diagnosis" and the concept of the target metadata is named "main diagnosis", the concept names of the metadata to be tested and the target metadata after the merge operation are both named " "First Diagnosis", "Main Diagnosis" or "Main Diagnosis", wherein "Main Diagnosis" is a name for the generated new concept. Exemplarily, the new concept name may be input by the user based on the combined prompt information.
在另一个实施例中,当目标元数据的数量为多个时,对待测元数据的概念命名和目标元数据的概念命名执行合并操作,包括:将待测元数据和至少两个目标元数据分别对应的概念命名中的任意一个概念命名作为目标概念命名,并将除目标概念命名对应的元数据以外的其他元数据的概念命名更改为目标概念命名,或者,基于对待测元数据的概念命名和目标元数据的概念命名,生成新的概念命名,并将新的概念命名作为待测元数据和目标元数据的概念命名。举例而言,假设待测元数据的概念命名为“第一诊断”,目标元数据的概念命名包括“主诊断”和“诊断(主要)”,则合并操作后的待测元数据和目标元数据的概念命名均为“第一诊断”、“主诊断”、“诊断(主要)”或者“主要诊断”,其中,“主要诊断”为生成的新的概念命名,示例性的,新的概念命名可以是用户基于合并提示信息输入的。In another embodiment, when the number of target metadata is multiple, a merging operation is performed on the concept name of the metadata to be measured and the concept name of the target metadata, including: combining the metadata to be measured and at least two target metadata Any one of the corresponding concept names is used as the target concept name, and the concept names of other metadata other than the metadata corresponding to the target concept name are changed to the target concept name, or, based on the concept name of the metadata to be measured. and the concept name of the target metadata, generate a new concept name, and use the new concept name as the concept name of the metadata to be tested and the target metadata. For example, assuming that the concept of the metadata to be tested is named "First Diagnosis" and the concept names of the target metadata include "Main Diagnosis" and "Diagnosis (Main)", the metadata to be tested and the target metadata after the operation are merged. The concept names of the data are all "first diagnosis", "main diagnosis", "diagnosis (main)" or "main diagnosis", wherein "main diagnosis" is the name of the new concept generated, exemplary, new concept The naming may be entered by the user based on the merge prompt.
在上述实施例的基础上,可选的,在对待测元数据的概念命名与目标元数据的概念命名执行合并操作之后,该方法还包括:将待测元数据对应的数据与目标元数据对应的数据进行合并。这样设置的好处在于,实现元数据的数据从多到一的规范化整理,降低了数据冗余,在对外提供应用服务时,可以采用统一的使用接口,满足了业务方的数据采集需求以及提高了元数据的应用效率。On the basis of the above embodiment, optionally, after performing a merging operation on the concept name of the metadata to be measured and the concept name of the target metadata, the method further includes: corresponding data corresponding to the metadata to be measured and the target metadata. data are merged. The advantage of this setting is that it realizes the standardization of metadata data from many to one, reduces data redundancy, and can use a unified interface when providing application services to the outside world, which satisfies the data collection needs of the business side and improves the efficiency of Metadata application efficiency.
本实施例的技术方案,通过将元数据管理平台中的待测元数据的待测血缘关系数据与对比元数据集对应的对比血缘关系数据集进行匹配,将匹配成功的对比血缘关系数据对应的对比元数据作为目标元数据,对待测元数据的概念命名与目标元数据的概念命名执行合并操作,解决了现有的元数据管理平台无法识别同概念的元数据的问题,优化了元数据管理平台的管理功能,避免了用户主观判断造成的理解误差,进而提高了元数据管理平台的实用性。In the technical solution of this embodiment, by matching the blood relationship data to be tested of the metadata to be tested in the metadata management platform with the comparison blood relationship data set corresponding to the comparison metadata set, the matching blood relationship data corresponding to the successfully matched comparison blood relationship data is matched. By comparing the metadata as the target metadata, the conceptual naming of the metadata to be measured and the conceptual naming of the target metadata are merged, which solves the problem that the existing metadata management platform cannot identify the metadata of the same concept, and optimizes the metadata management. The management function of the platform avoids the comprehension error caused by the user's subjective judgment, thereby improving the practicability of the metadata management platform.
实施例二Embodiment 2
图2是本发明实施例二提供的一种元数据概念合并的方法的流程图,本实施例的技术方案是上述实施例的基础上的进一步细化。可选的,所述元数据管理平台包括至少一个数据流转层级,相应的,所述获取元数据管理平台中的待测元数据以及对比元数据集,包括:针对所述元数据管理平台中的每个数据流转层级,获取与所述数据流转层级对应的待测元数据以及对比元数据集;其中,所述数据流转层级用于表征元数据在元数据管理平台中的流转平台。FIG. 2 is a flowchart of a method for merging metadata concepts according to Embodiment 2 of the present invention. The technical solution of this embodiment is a further refinement on the basis of the foregoing embodiment. Optionally, the metadata management platform includes at least one data flow level. Correspondingly, the obtaining the metadata to be measured and comparing the metadata set in the metadata management platform includes: targeting the metadata in the metadata management platform. At each data flow level, the metadata to be tested and the comparison metadata set corresponding to the data flow level are obtained; wherein, the data flow level is used to represent the metadata flow platform in the metadata management platform.
本实施例的具体实施步骤包括:The specific implementation steps of this embodiment include:
S210、针对元数据管理平台中的每个数据流转层级,获取与数据流转层级对应的待测元数据以及对比元数据集。S210. For each data flow level in the metadata management platform, obtain the metadata to be tested and a comparison metadata set corresponding to the data flow level.
在本实施例中,数据流转层级用于表征元数据在元数据管理平台中的流转平台。其中,具体的,元数据管理平台提供至少一个数据流转层级用于对平台中的元数据执行管理操作,示例性的,管理操作可以是查询、存储和计算等等。在一个实施例中,可选的,数据流转层级包括采集适配层、存储目录层、衍生视图层、业务视图层、产品视图层和指标视图层中至少一种。In this embodiment, the data flow level is used to represent the flow platform of metadata in the metadata management platform. Specifically, the metadata management platform provides at least one data flow level for performing management operations on the metadata in the platform. Exemplarily, the management operations may be query, storage, and calculation. In an embodiment, optionally, the data flow layer includes at least one of a collection adaptation layer, a storage directory layer, a derived view layer, a business view layer, a product view layer, and an indicator view layer.
其中,具体的,采集适配层用于采集元数据管理平台收录的至少一个源数据库中的元数据。示例性的,源数据库可以是医院信息管理系统(Hospital Information System,HIS)的数据库、实验室信息管理系统(Laboratory Information System,LIS)的数据库、医学影像存档与通讯系统(Picture archiving and communication systems,PACS)的数据库和放射信息管理系统(Radioiogy information system,RIS)的数据库等等。Specifically, the collection adaptation layer is used to collect metadata in at least one source database included in the metadata management platform. Exemplarily, the source database may be a database of a hospital information management system (Hospital Information System, HIS), a database of a laboratory information management system (Laboratory Information System, LIS), a medical image archiving and communication system (Picture archiving and communication systems, PACS) database and radiology information management system (Radioiogy information system, RIS) database and so on.
其中,具体的,存储目录层用于存储采集适配层采集到的元数据。在一个实施例中,可选的,存储目录层包括数据湖层、数据中心层、数据领域层和数据集市层。其中,数据中心层、数据领域层和数据集市中的元数据均来源于上一层。具体的,数据湖(Data Lake,DL)层用于存储采集适配层采集到的所有元数据;数据中心(Data Center,DC)层用于存储从DL层抽取的可能会流转到下一数据流转层级中的数据;数据领域(DOMAIN)层包含多个领域,每个领域存储与该领域相关的元数据,示例性的,领域可以是临床数据中心、运营数据中心和科研数据中心等等;数据集市(DATAMARKTET)层属于衍生层,可用于存储元数据管理平台生成的新的元数据。Specifically, the storage directory layer is used to store the metadata collected by the collection adaptation layer. In an embodiment, optionally, the storage directory layer includes a data lake layer, a data center layer, a data domain layer, and a data mart layer. Among them, the metadata in the data center layer, data domain layer and data mart are all derived from the previous layer. Specifically, the Data Lake (DL) layer is used to store all metadata collected by the collection adaptation layer; the Data Center (DC) layer is used to store the data extracted from the DL layer that may flow to the next Data in the flow layer; the data domain (DOMAIN) layer contains multiple domains, and each domain stores metadata related to the domain. Exemplarily, the domain can be a clinical data center, an operational data center, and a scientific research data center, etc.; The DATAMARKTET layer is a derivative layer that can be used to store new metadata generated by the metadata management platform.
其中,具体的,衍生视图层可用于表征衍生维度的元数据的流转平台,衍生视图层中的衍生维度的元数据可用于描述基于原始元数据生成的新的元数据。示例性的,原始元数据包括第一天住院费用和第二天住院费用,衍生视图层包含的元数据可以为总住院费用,其中,总住院费用是对第一天住院费用和第二天住院费用进行加和得到的新的元数据。Specifically, the derived view layer can be used to represent the metadata transfer platform of the derived dimension, and the metadata of the derived dimension in the derived view layer can be used to describe the new metadata generated based on the original metadata. Exemplarily, the original metadata includes the cost of hospitalization on the first day and the cost of hospitalization on the second day, and the metadata contained in the derived view layer may be the total hospitalization cost, where the total hospitalization cost is the difference between the hospitalization cost on the first day and the hospitalization cost on the second day. Fees are added to get new metadata.
其中,具体的,业务视图层用于表征业务维度的元数据的流转平台,业务视图层中的业务维度的元数据可以是基于业务需求聚合得到的至少一个元数据。示例性的,如果业务需求为患者档案,则业务视图层中的元数据可以包括患者姓名、患者性别和患者医保账户等等,如果业务需求为医学研究,则业务视图层中的元数据可以包括诊断结果、康复情况、治疗手段和患者年龄等等。Specifically, the business view layer is used to represent the flow platform of the metadata of the business dimension, and the metadata of the business dimension in the business view layer may be at least one metadata obtained by aggregation based on business requirements. Exemplarily, if the business requirement is patient records, the metadata in the business view layer may include patient name, patient gender, and patient medical insurance account, etc. If the business requirement is medical research, the metadata in the business view layer may include Diagnosis, recovery, treatment and patient age, etc.
其中,具体的,产品视图层可用于表征产品维度的元数据的流转平台,产品视图层中的产品维度的元数据可以是第三方应用定义的元数据。示例性的,如果第三方应用为医院系统,则产品视图层中的元数据可以包括患者姓名、患者医保账户、患者诊断结果和治疗费用等等。如果第三方应用为互联网企业系统,则产品视图层中的元数据可以包括设备名称、网络安全系列、防护墙系列、开发人员和运营人员等等。Specifically, the product view layer can be used to represent a circulation platform of product dimension metadata, and the product dimension metadata in the product view layer can be metadata defined by a third-party application. Exemplarily, if the third-party application is a hospital system, the metadata in the product view layer may include a patient's name, a patient's medical insurance account, a patient's diagnosis result, and a treatment fee, and so on. If the third-party application is an Internet enterprise system, the metadata in the product view layer may include device name, network security series, protection wall series, developers and operators, and so on.
其中,具体的,指标视图层可用于表征指标维度的元数据的流转平台,指标视图层中的指标维度的元数据可以是用于核算、治疗等分析目的定义的元数据。示例性的,指标视图层的元数据可以包括医疗成本、医疗质量、病历质量和门诊收入等等。Specifically, the indicator view layer may be used as a platform for transferring metadata of the indicator dimension, and the metadata of the indicator dimension in the indicator view layer may be metadata defined for analysis purposes such as accounting and treatment. Exemplarily, the metadata of the indicator view layer may include medical cost, medical quality, medical record quality, outpatient income and so on.
在一个实施例中,可选的,获取与数据流转层级对应的待测元数据以及对比元数据集,包括:当检测到元数据新增指令时,将与元数据新增指令对应的元数据作为待测元数据;基于数据流转层级对应的层级标识,获取数据库中的对比元数据集。In one embodiment, optionally, acquiring the metadata to be tested and the comparison metadata set corresponding to the data flow level includes: when a metadata addition instruction is detected, adding metadata corresponding to the metadata addition instruction As the metadata to be tested; based on the level identifier corresponding to the data flow level, obtain the comparison metadata set in the database.
其中,具体的,在当前数据流转层级中,当一个新的元数据流转到当前数据流转层级时,会生成与该元数据对应的元数据新增指令。通过解析与待测元数据对应的SQL语句,可以得到待测元数据与当前数据流程层级对应的待测血缘关系数据。示例性的,待测元数据从数据流转层级A的数据表1中流转到数据流转层级B的数据表2中,则在数据流转层级B中,待测元数据的待测血缘关系数据为“数据流转层级A-数据表1-数据流转层级B-数据表2”。当该待测元数据继续流转到数据流转层级C中的数据表3时,则在数据流转层级C中,待测元数据的待测血缘关系数据为“数据流转层级A-数据表1-数据流转层级B-数据表2-数据流转层级C-数据表3”。Specifically, in the current data flow level, when a new metadata flow is transferred to the current data flow level, a metadata addition instruction corresponding to the metadata will be generated. By parsing the SQL statement corresponding to the metadata to be tested, the blood relationship data to be tested corresponding to the metadata to be tested and the current data flow level can be obtained. Exemplarily, the metadata to be measured is transferred from the data table 1 of the data flow level A to the data table 2 of the data flow level B, then in the data flow level B, the blood relationship data to be measured of the metadata to be measured is " Data Flow Level A - Data Table 1 - Data Flow Level B - Data Table 2". When the metadata to be tested continues to flow to the data table 3 in the data flow level C, then in the data flow level C, the blood relationship data to be tested of the metadata to be tested is "data flow level A-data table 1-data" Flow Tier B - Data Sheet 2 - Data Flow Tier C - Data Sheet 3".
其中,具体的,当元数据在元数据管理平台中进行流转时,元数据每进入一个数据流转层级,会记录与当前的数据流转层级对应的层级标识。层级标识可以是数字、大写字母、特殊字符、小写字母和文字中至少一种,此处对层级标识的具体设置不作限定。示例性的,层级标识包括采集适配、DL、DC、DOMAIN、DATAMARKTET、衍生视图、业务视图、产品视图和指标视图。假设元数据依次进入到衍生视图层和产品视图层,则数据库中记录有该元数据的层级标识包括“衍生视图”和“产品视图”。假设待测元数据在产品视图层中,则将上述元数据添加到对比元数据集中,假设待测元数据在指标视图层中,则对比元数据集中不包含上述元数据。Specifically, when the metadata is circulated in the metadata management platform, each time the metadata enters a data flow level, a level identifier corresponding to the current data flow level is recorded. The level identification can be at least one of numbers, uppercase letters, special characters, lowercase letters and characters, and the specific setting of the level identification is not limited here. Exemplarily, the hierarchical identification includes acquisition adaptation, DL, DC, DOMAIN, DATAMARKTET, derived view, business view, product view and indicator view. Assuming that the metadata enters the derived view layer and the product view layer in turn, the hierarchical identifiers in which the metadata is recorded in the database include "derived view" and "product view". Assuming that the metadata to be measured is in the product view layer, the above metadata is added to the comparison metadata set, and if the metadata to be measured is in the indicator view layer, the above metadata is not included in the comparison metadata set.
在一个实施例中,可选的,获取与数据流转层级对应的待测元数据以及对比元数据集,包括:当检测到当前时间满足预设时间点时,基于数据流转层级对应的层级标识,获取数据库中的至少两个元数据;针对每个元数据,将元数据作为待测元数据,并将除待测元数据以外的元数据添加到对比元数据集中。In one embodiment, optionally, acquiring the metadata to be measured and the comparison metadata set corresponding to the data flow level includes: when it is detected that the current time satisfies a preset time point, based on the level identifier corresponding to the data flow level, Obtain at least two metadata in the database; for each metadata, take the metadata as the metadata to be tested, and add the metadata other than the metadata to be tested into the comparison metadata set.
本实施例可以定时对数据流转层级中的元数据进行同概念检测。具体的,获取与当前的数据流转层级对应的至少两个元数据,将每个元数据依次作为待测元数据,并将除待测元数据以外的元数据作为对比元数据。In this embodiment, the same concept detection can be performed on the metadata in the data flow level at regular intervals. Specifically, at least two metadata corresponding to the current data flow level are acquired, each metadata is sequentially used as the metadata to be measured, and the metadata other than the metadata to be measured is used as the comparison metadata.
S220、将待测元数据对应的待测血缘关系数据与对比元数据集对应的对比血缘关系数据集进行匹配。S220: Match the blood relationship data to be tested corresponding to the metadata to be tested with the comparison blood relationship data set corresponding to the comparison metadata set.
其中,具体的,对数据库的SQL语句进行解析,得到数据库返回的结果集,结果集中的每一列可能来源于不同的表,这些表又依赖别的表。具体的,结果集包含待测血缘关系数据和至少一个对比血缘关系数据。其中,示例性的,数据库的类型包括mysql数据库和/或greenPlum数据库。Specifically, the SQL statement of the database is parsed to obtain a result set returned by the database. Each column in the result set may come from different tables, and these tables depend on other tables. Specifically, the result set includes blood relationship data to be tested and at least one comparative blood relationship data. Wherein, for example, the type of database includes mysql database and/or greenPlum database.
其中,具体的,结果集中的血缘关系数据为与当前的数据流转层级对应的血缘关系数据。示例性的,元数据A在元数据管理平台中的血缘关系数据为数据流转层级A-数据库1-数据表1-数据表2-数据流转层级B-数据库2-数据表3,如果当前的数据流转层级为数据流转层级A,则用于匹配的元数据A的血缘关系数据为数据流转层级A-数据库1-数据表1-数据表2,如果当前的数据流转层级为数据流转层级B,则用于匹配的元数据A的血缘关系数据为数据流转层级A-数据库1-数据表1-数据表2-数据流转层级B-数据库2-数据表3。Specifically, the blood relationship data in the result set is blood relationship data corresponding to the current data flow level. Exemplarily, the blood relationship data of metadata A in the metadata management platform is data flow level A-database 1-data table 1-data table 2-data flow level B-database 2-data table 3, if the current data The flow level is data flow level A, then the blood relationship data of metadata A used for matching is data flow level A-database 1-data table 1-data table 2, if the current data flow level is data flow level B, then The blood relationship data of the metadata A used for matching is data flow level A - database 1 - data table 1 - data table 2 - data flow level B - database 2 - data table 3 .
S230、将匹配成功的对比血缘关系数据对应的对比元数据作为目标元数据,对待测元数据的概念命名与目标元数据的概念命名执行合并操作。S230. Use the comparison metadata corresponding to the successfully matched comparison blood relationship data as the target metadata, and perform a merge operation on the concept name of the metadata to be measured and the concept name of the target metadata.
本实施例的技术方案,通过针对元数据管理平台中的每个数据流转层级,获取与数据流转层级对应的待测元数据以及对比元数据集,在每个数据流转层级中,分别执行血缘关系数据匹配和概念合并的操作,解决了对比元数据的数据量过多的问题,缩小了对比元数据的采集范围,在保证匹配范围的全面性的同时,提高了元数据概念合并的效率。The technical solution of this embodiment is to obtain the metadata to be tested and the comparison metadata set corresponding to the data flow level for each data flow level in the metadata management platform, and in each data flow level, execute the blood relationship respectively. The operation of data matching and concept merging solves the problem of too much data for comparison metadata, narrows the collection scope of comparison metadata, and improves the efficiency of metadata concept merging while ensuring the comprehensiveness of the matching scope.
实施例三Embodiment 3
图3是本发明实施例三提供的一种元数据概念合并的方法的流程图,本实施例的技术方案是上述实施例的基础上的进一步细化。可选的,所述方法还包括:如果所述待测血缘关系数据与所述对比血缘关系数据集匹配失败,则将所述待测元数据对应的待测值域数据与所述对比元数据集对应的对比值域数据集进行匹配;其中,所述对比值域数据集包含与至少一个对比元数据分别对应的对比值域数据;将匹配成功的对比值域数据对应的对比元数据作为目标元数据,并对所述待测元数据的概念命名与所述目标元数据的概念命名执行合并操作。FIG. 3 is a flowchart of a method for merging metadata concepts according to Embodiment 3 of the present invention. The technical solution of this embodiment is a further refinement on the basis of the foregoing embodiment. Optionally, the method further includes: if the blood relationship data to be tested fails to match with the comparison blood relationship data set, then comparing the range data to be measured corresponding to the metadata to be measured with the comparison metadata. The comparison value range data set corresponding to the set is matched; wherein, the comparison value range data set includes the comparison value range data corresponding to at least one comparison metadata respectively; the comparison metadata corresponding to the successfully matched comparison value range data is used as the target metadata, and perform a merging operation on the concept name of the metadata to be tested and the concept name of the target metadata.
本实施例的具体实施步骤包括:The specific implementation steps of this embodiment include:
S310、获取元数据管理平台中的待测元数据以及对比元数据集。S310. Obtain the metadata to be tested in the metadata management platform and compare the metadata set.
S320、将待测元数据对应的待测血缘关系数据与对比元数据集对应的对比血缘关系数据集进行匹配。S320. Match the blood relationship data to be tested corresponding to the metadata to be tested with the comparison blood relationship data set corresponding to the comparison metadata set.
S330、判断匹配结果是否为匹配成功,如果是,则执行S340,如果否,则执行S350。S330. Determine whether the matching result is successful, if yes, execute S340, and if not, execute S350.
其中,具体的,如果对比血缘关系数据集中包含与待测血缘关系数据相同的对比血缘关系数据,则匹配结果为匹配成功;如果对比血缘关系数据集中不包含与待测血缘关系数据相同的对比血缘关系数据,则匹配结果为匹配失败。在一个实施例中,待测血缘关系数据为空,即待测元数据不存在待测血缘关系数据。Specifically, if the comparative blood relation data set contains the same comparative blood relation data as the blood relation data to be tested, the matching result is successful; if the comparative blood relation data set does not contain the same comparative blood relation as the blood relation data to be tested relational data, the matching result is a matching failure. In one embodiment, the blood relationship data to be tested is empty, that is, the blood relationship data to be tested does not exist in the metadata to be tested.
S340、将匹配成功的对比血缘关系数据对应的对比元数据作为目标元数据,对待测元数据的概念命名与目标元数据的概念命名执行合并操作。S340. Use the comparison metadata corresponding to the successfully matched comparison blood relationship data as the target metadata, and perform a merge operation on the conceptual naming of the metadata to be measured and the conceptual naming of the target metadata.
S350、将待测元数据对应的待测值域数据与对比元数据集对应的对比值域数据集进行匹配。S350: Match the to-be-measured range data corresponding to the to-be-measured metadata set with the comparative range data set corresponding to the comparative metadata set.
在本实施例中,对比值域数据集包含与至少一个对比元数据分别对应的对比值域数据。其中,具体的,值域数据可用于表征元数据的取值范围。示例性的,当元数据为“年龄”时,值域数据可以为0-100,当元数据为“性别”时,值域数据为“男、女和未知”。In this embodiment, the comparison range data set includes comparison range data respectively corresponding to at least one comparison metadata. Specifically, the value range data can be used to represent the value range of the metadata. Exemplarily, when the metadata is "age", the range data may be 0-100, and when the metadata is "gender", the range data is "male, female, and unknown".
在上述实施例的基础上,可选的,对比值域数据的类型为字典类值域或格式文本值域,相应的,方法还包括:针对每个对比元数据,当对比元数据的对比值域数据的类型为字典类值域时,获取对比元数据所在数据库对应的外键关系表中与对比元数据对应的对比值域数据;当对比元数据的对比值域数据的类型为格式文本值域时,获取数据库中与对比元数据对应的对比值域数据。On the basis of the above embodiment, optionally, the type of the comparison range data is a dictionary type range or a formatted text range. Correspondingly, the method further includes: for each comparison metadata, when the comparison value of the comparison metadata is compared When the type of the domain data is a dictionary type range, the comparison range data corresponding to the comparison metadata in the foreign key relation table corresponding to the database where the comparison metadata is located is obtained; when the type of the comparison range data of the comparison metadata is a format text value When the domain is selected, obtain the contrast value domain data corresponding to the contrast metadata in the database.
虽然列表(数据行或数据列)能够存储数据,但当用户需要知道列表的取值范围时,需要知道列表内的所有元素。因此,为了精确索引数据的取值范围,采用字典数据类型存储值域数据。其中,具体的,字典类值域可用于描述存在明确取值范围的值域数据。示例性的,字典类值域对应的对比元数据可以是“性别”、“年龄”和“体重”等等。其中,具体的,外键关系表可用于表征与数据库中对比元数据关联的关联数据表,外键关系表中存储有对比元数据的对比值域数据。Although lists (data rows or data columns) can store data, when users need to know the value range of the list, they need to know all the elements in the list. Therefore, in order to accurately index the value range of the data, the dictionary data type is used to store the range data. Specifically, the dictionary-type value domain can be used to describe the value domain data that has a clear value range. Exemplarily, the comparison metadata corresponding to the dictionary-type value domain may be "sex", "age", "weight" and so on. Specifically, the foreign key relationship table can be used to represent the associated data table associated with the comparison metadata in the database, and the foreign key relationship table stores the comparison value range data of the comparison metadata.
其中,具体的,格式文本值域可用于描述不存在明确取值范围的值域数据,也就是说,格式文本值域的对比值域数据不能通过有限的参数值进行归类描述。示例性的,格式文本值域对应的对比元数据可以是“姓名”、“身份证号”和“医保账户”等等。具体的,对比值域数据直接通过读取数据库中与对比元数据对应的数据列或数据行得到。Specifically, the formatted text range can be used to describe range data that does not have a clear value range, that is, the comparative range data of the formatted text range cannot be classified and described by limited parameter values. Exemplarily, the comparison metadata corresponding to the formatted text value field may be "name", "ID number", "medical insurance account" and so on. Specifically, the comparison value range data is directly obtained by reading the data column or data row corresponding to the comparison metadata in the database.
需要说明的是,上述过程描述了对比值域数据的获取步骤,该获取步骤同样适用于获取待测值域数据,具体实施方式与上述过程类似,此处不再赘述。It should be noted that the above process describes the acquisition step of the comparison value range data, and the acquisition step is also applicable to acquiring the to-be-measured range data, and the specific implementation is similar to the above process, and will not be repeated here.
在上述实施例的基础上,可选的,在将待测元数据对应的待测值域数据与对比元数据集对应的对比值域数据集进行匹配之前,方法还包括:获取与待测元数据对应的白名单数据集;其中,白名单数据集包含至少一个元数据,各元数据分别对应的值域数据与待测值域数据相同但各元数据的概念命名与待测值域数据不同;将对比元数据集中与白名单数据集相同的对比元数据删除,得到筛选后的对比元数据集。On the basis of the above embodiment, optionally, before matching the range data to be measured corresponding to the metadata to be measured with the data set of comparative range corresponding to the set of comparative metadata, the method further includes: obtaining the data corresponding to the metadata to be measured The whitelist data set corresponding to the data; wherein, the whitelist data set contains at least one metadata, and the range data corresponding to each metadata is the same as the range data to be measured, but the conceptual naming of each metadata is different from the range data to be measured. ; Delete the same comparison metadata in the comparison metadata set as the whitelisted data set to obtain a filtered comparison metadata set.
其中,具体的,白名单数据集包含对比值域数据与待测值域数据相同的对比元数据,但该对比元数据与待测元数据不是属于同一概念的元数据。举例而言,假设待测元数据为“诊断”,对比元数据集中包含“出院诊断”和“入院诊断”,这三个元数据的值域数据相同,但却属于不同概念的元数据。Specifically, the whitelist data set includes comparison metadata that is the same as the comparison range data and the to-be-measured range data, but the comparison metadata and the to-be-measured metadata are not metadata that belong to the same concept. For example, assuming that the metadata to be tested is "diagnosis", the comparison metadata set includes "discharge diagnosis" and "admission diagnosis". These three metadata have the same range data, but belong to different concepts of metadata.
其中,具体的,白名单数据集可以是用户预先设置好的。Specifically, the whitelist data set may be preset by the user.
在一个实施例中,可选的,获取与待测元数据对应的白名单数据集,包括:获取白名单数据列表中与待测元数据对应的白名单数据集,其中,白名单数据列表包含至少一个元数据以及与各元数据分别对应的白名单数据集。示例性的,白名单数据列表包括元数据A、元数据B以及与元数据A和元数据B分别对应的白名单数据集A和白名单数据集B,假设待测元数据为元数据A,则白名单数据集为白名单数据集A。In one embodiment, optionally, acquiring a whitelist data set corresponding to the metadata to be measured includes: acquiring a whitelist data set corresponding to the metadata to be measured in the whitelist data list, wherein the whitelist data list contains At least one metadata and a whitelist dataset corresponding to each metadata. Exemplarily, the whitelist data list includes metadata A, metadata B, and whitelist data set A and whitelist data set B corresponding to metadata A and metadata B, respectively, assuming that the metadata to be tested is metadata A, Then the whitelist dataset is the whitelist dataset A.
在另一个实施例中,可选的,获取与待测元数据对应的白名单数据集,包括:获取用户基于待测元数据输入的白名单数据集。In another embodiment, optionally, acquiring a whitelist data set corresponding to the metadata to be measured includes: acquiring a whitelist data set input by a user based on the metadata to be measured.
在上述实施例的基础上,可选的,在将待测元数据对应的待测值域数据与对比元数据集对应的对比值域数据集进行匹配之前,方法还包括:将对比元数据集与至少一个预设白名单数据集分别进行对比,针对每个预设白名单数据集,如果对比元数据集中存在至少两个与预设白名单数据集相同的对比元数据,则将至少两个相同的对比元数据从对比元数据集中删除;其中,预设白名单数据集包含至少两个值域数据相同但概念命名不同的元数据。On the basis of the above-mentioned embodiment, optionally, before matching the measured value range data corresponding to the metadata to be measured with the comparison range data set corresponding to the comparison metadata set, the method further includes: comparing the comparison metadata set Compare with at least one preset whitelist dataset respectively. For each preset whitelist dataset, if there are at least two comparison metadata in the comparison metadata set that are the same as the preset whitelist dataset, at least two The same comparison metadata is deleted from the comparison metadata set; wherein, the preset whitelist data set contains at least two metadata with the same value range data but different conceptual names.
举例而言,假设预设白名单数据集为[诊断出院诊断入院诊断],如果对比元数据集为[姓名出院诊断入院诊断],则将“出院诊断”和“入院诊断”从对比元数据集中删除,得到的对比元数据集为[姓名]。如果对比元数据集为[姓名入院诊断],则说明对比元数据集中不存在对比值域数据相同但概念命名不同的至少两个对比元数据,得到的对比元数据集仍为[姓名入院诊断]。For example, assuming the default whitelist dataset is [Diagnosis Discharge Diagnosis Admission Diagnosis], if the comparison metadata set is [Name Discharge Diagnosis Admission Diagnosis], then "Discharge Diagnosis" and "Admission Diagnosis" will be removed from the comparison metadata set Delete, the resulting comparison metadata set is [name]. If the comparison metadata set is [name admission diagnosis], it means that there are no at least two comparison metadata with the same comparison range data but different concept names in the comparison metadata set, and the obtained comparison metadata set is still [name admission diagnosis] .
由于医疗数据复杂,内容多样,容易出现值域数据相同但概念命名不同的元数据,如果不设置白名单,仅根据值域数据的匹配结果进行概念合并,很容易出现将不同概念的元数据合并到一起的情况,从而导致数据混乱,概念理解误差较大。这样设置的好处在于,保证了元数据概念合并的准确度。Due to the complexity and variety of medical data, metadata with the same value range data but different concept names are prone to appear. If a whitelist is not set and concepts are merged only according to the matching results of the value range data, it is easy to merge metadata of different concepts. In the case of coming together, the data is chaotic and the conceptual understanding error is large. The advantage of this setting is that the accuracy of the metadata concept merging is guaranteed.
S360、将匹配成功的对比值域数据对应的对比元数据作为目标元数据,并对待测元数据的概念命名与目标元数据的概念命名执行合并操作。S360. Use the comparison metadata corresponding to the successfully matched comparison value range data as the target metadata, and perform a merge operation on the concept name of the metadata to be measured and the concept name of the target metadata.
本实施例的技术方案,通过在待测血缘关系数据和对比血缘关系匹失败时,继续将待测元数据对应的待测值域数据与对比元数据集对应的对比值域数据集进行匹配,并将匹配成功的对比值域数据对应的对比元数据作为目标元数据,对待测元数据的概念命名与目标元数据的概念命名执行合并操作,解决了单一匹配条件的概念合并准确度不高的问题,尽可能多的查找出概念命名相同的元数据并将其进行概念合并,提高了元数据概念合并的准确度,进一步优化了元数据管理平台的管理功能。In the technical solution of the present embodiment, when the blood relationship data to be tested and the blood relationship to be compared fail to match, continue to match the range data to be measured corresponding to the metadata to be tested with the data set of comparative range corresponding to the metadata set to be compared, The comparison metadata corresponding to the successfully matched comparison range data is used as the target metadata, and the concept name of the metadata to be measured and the concept name of the target metadata are merged, which solves the problem that the concept combination accuracy of a single matching condition is not high. To solve the problem, find out as many metadata with the same concept name as possible and merge them, which improves the accuracy of metadata concept merging and further optimizes the management function of the metadata management platform.
图4是本发明实施例三提供的一种元数据概念合并的方法的具体实例的流程图。具体的,以检测到元数据新增指令的场景为例,获取与数据流转层级标识对应的至少两个元数据,确定待测元数据和对比元数据集,具体的,将至少两个元数据中与元数据新增指令对应的元数据作为待测元数据,除待测元数据以外的元数据构成对比元数据集。以检测到当前时间满足预设时间点的场景为例,获取与数据流转层级标识对应的至少两个元数据,确定待测元数据和对比元数据集,具体的,将至少两个元数据中任一元数据作为待测元数据,除待测元数据以外的元数据构成对比元数据集。FIG. 4 is a flowchart of a specific example of a method for merging metadata concepts according to Embodiment 3 of the present invention. Specifically, taking a scenario where a metadata addition instruction is detected as an example, obtain at least two metadata corresponding to the data flow level identifier, and determine the metadata to be measured and the set of comparison metadata. Specifically, the at least two metadata The metadata corresponding to the metadata addition instruction is regarded as the metadata to be tested, and the metadata other than the metadata to be tested constitutes a comparison metadata set. Taking the scene where the current time is detected to meet the preset time point as an example, obtain at least two metadata corresponding to the data flow level identifier, and determine the metadata to be measured and the set of comparison metadata. Any metadata is used as the metadata to be tested, and the metadata other than the metadata to be tested constitutes a comparison metadata set.
将待测元数据的待测血缘关系数据与对比元数据集对应的对比血缘关系数据集进行匹配,如果对比血缘关系数据集存在与待测血缘关系数据相同的对比血缘关系数据,则认为匹配成功,并对待测元数据的概念命名与匹配成功的对比元数据的概念命名执行合并操作。如果对比血缘关系数据集不存在与待测血缘关系数据相同的对比血缘关系数据,则认为匹配失败,并将待测元数据的待测值域数据与对比元数据集对应的对比值域数据集进行匹配,如果对比值域数据集包含与待测值域数据相同的对比值域数据,则认为匹配成功,并对待测元数据的概念命名与匹配成功的对比元数据的概念命名执行合并操作。如果对比值域数据集不存在与待测血缘关系数据相同的对比值域数据,则认为匹配失败,并保留待测元数据的概念命名。Match the blood relationship data to be tested in the metadata to be tested with the comparison blood relationship data set corresponding to the comparison metadata set. If the comparison blood relationship data set contains the same comparison blood relationship data as the blood relationship data to be tested, the matching is considered successful. , and perform a merging operation on the concept name of the metadata to be tested and the concept name of the successfully matched comparison metadata. If the comparison blood relationship data set does not have the same comparison blood relationship data as the blood relationship data to be tested, it is considered that the matching fails, and the range data to be measured of the metadata to be tested is compared with the comparison range data set corresponding to the comparison metadata set Matching is performed. If the comparison range data set contains the same comparison range data as the test range data, it is considered that the matching is successful, and the concept name of the test metadata and the concept name of the successfully matched comparison metadata are merged. If the comparison range data set does not have the same comparison range data as the blood relationship data to be tested, it is considered that the matching fails, and the conceptual naming of the metadata to be tested is retained.
在检测到元数据新增指令的场景中,执行完上述待测元数据的匹配过程后,认为当前的数据流转层级对应的元数据匹配完成,并获取下一个数据流转层级到的层级标识,重复执行获取与数据流转层级的层级标识对应的至少两个元数据的步骤。在检测到当前时间满足预设时间点的场景中,执行完上述待测元数据的匹配过程后,判断未被作为待测元数据的元数据数量是否为1,如果是,则认为当前的数据流转层级对应的元数据匹配完成,并获取下一个数据流转层级到的层级标识,重复执行获取与数据流转层级的层级标识对应的至少两个元数据的步骤。如果否,则认为当前的数据流转层级对应的元数据匹配未完成,重复执行确定待测元数据和对比元数据集的步骤,具体的,将下一个元数据作为待测元数据,除待测元数据以外的元数据构成对比元数据集。In the scenario where a new instruction of metadata is detected, after the matching process of the metadata to be tested is performed, it is considered that the matching of the metadata corresponding to the current data flow level is completed, and the level identifier of the next data flow level is obtained, repeating The step of obtaining at least two metadata corresponding to the level identification of the data flow level is performed. In the scenario where it is detected that the current time meets the preset time point, after the above-mentioned matching process of the metadata to be measured is performed, it is determined whether the number of metadata that is not used as the metadata to be measured is 1, and if so, it is considered that the current data The metadata corresponding to the flow level is matched, and the level identifier of the next data flow level is obtained, and the steps of acquiring at least two metadata corresponding to the level identifier of the data flow level are repeatedly performed. If not, it is considered that the metadata matching corresponding to the current data flow level has not been completed, and the steps of determining the metadata to be tested and comparing the metadata set are repeated. Metadata other than metadata constitutes a contrastive metadata set.
这样设置的好处在于,由于血缘关系数据可以唯一性的标记元数据,值域数据虽然也可以唯一性的标记元数据,但唯一性的准确度低于血缘关系数据。所以本实施例的技术方案先进行血缘关系数据的匹配,一方面,可以保证匹配得到的对比元数据与待测元数据为同一概念的元数据,提高概念合并结果的准确率。另一方面,由于血缘关系数据中包含数据流转层级,在血缘关系数据解析的过程中已经获取到了元数据的数据流转层级,所以值域数据匹配的过程中可以直接对同一数据流转层级的待测元数据和对比元数据集进行值域数据的匹配,不需要重新执行对元数据的血缘关系数据进行解析获取数据流转层级的步骤,进而提高了元数据概念合并的效率。The advantage of this setting is that, since blood relationship data can uniquely mark metadata, and range data can also uniquely mark metadata, the accuracy of uniqueness is lower than blood relationship data. Therefore, the technical solution of this embodiment first performs the matching of blood relationship data. On the one hand, it can ensure that the comparison metadata obtained by matching and the metadata to be tested are metadata of the same concept, thereby improving the accuracy of the concept merging result. On the other hand, since the blood relationship data contains the data flow level, the data flow level of the metadata has been obtained in the process of analyzing the blood relationship data, so in the process of matching the value range data, the same data flow level can be directly tested. The metadata and the comparison metadata set are matched to the range data, and it is not necessary to re-execute the steps of parsing the blood relationship data of the metadata to obtain the data flow level, thereby improving the efficiency of metadata concept merging.
实施例四Embodiment 4
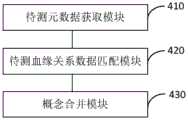
图5是本发明实施例四提供的一种元数据概念合并的装置的示意图。本实施例可适用于对元数据管理平台中的多个元数据进行同概念判断的情况,该装置可采用软件和/或硬件的方式实现,该装置可以配置于终端设备中。该元数据概念合并的装置包括:待测元数据获取模块410、待测血缘关系数据匹配模块420、概念合并模块430。FIG. 5 is a schematic diagram of an apparatus for merging metadata concepts according to Embodiment 4 of the present invention. This embodiment may be applicable to the case of performing the same concept judgment on multiple metadata in the metadata management platform, the apparatus may be implemented by means of software and/or hardware, and the apparatus may be configured in a terminal device. The device for merging metadata concepts includes: a
其中,待测元数据获取模块410,用于获取元数据管理平台中的待测元数据以及对比元数据集;其中,对比元数据集包含至少一个对比元数据;Wherein, the
待测血缘关系数据匹配模块420,用于将待测元数据对应的待测血缘关系数据与对比元数据集对应的对比血缘关系数据集进行匹配;其中,对比血缘关系数据集包含与至少一个对比元数据分别对应的对比血缘关系数据;The blood relationship
概念合并模块430,用于将匹配成功的对比血缘关系数据对应的对比元数据作为目标元数据,对待测元数据的概念命名与目标元数据的概念命名执行合并操作。The
本实施例的技术方案,通过将元数据管理平台中的待测元数据的待测血缘关系数据与对比元数据集对应的对比血缘关系数据集进行匹配,将匹配成功的对比血缘关系数据对应的对比元数据作为目标元数据,对待测元数据的概念命名与目标元数据的概念命名执行合并操作,解决了现有的元数据管理平台无法识别同概念的元数据的问题,优化了元数据管理平台的管理功能,避免了用户主观判断造成的理解误差,进而提高了元数据管理平台的实用性。In the technical solution of this embodiment, by matching the blood relationship data to be tested of the metadata to be tested in the metadata management platform with the comparison blood relationship data set corresponding to the comparison metadata set, the matching blood relationship data corresponding to the successfully matched comparison blood relationship data is matched. By comparing the metadata as the target metadata, the conceptual naming of the metadata to be measured and the conceptual naming of the target metadata are merged, which solves the problem that the existing metadata management platform cannot identify the metadata of the same concept, and optimizes the metadata management. The management function of the platform avoids the comprehension error caused by the user's subjective judgment, thereby improving the practicability of the metadata management platform.
在上述技术方案的基础上,可选的,元数据管理平台包括至少一个数据流转层级,相应的,待测元数据获取模块410,包括:On the basis of the above technical solution, optionally, the metadata management platform includes at least one data flow level, and correspondingly, the
待测元数据获取单元,用于针对元数据管理平台中的每个数据流转层级,获取与数据流转层级对应的待测元数据以及对比元数据集;其中,数据流转层级用于表征元数据在元数据管理平台中的流转平台。The metadata acquisition unit to be measured is used to obtain the metadata to be measured corresponding to the data flow level and the comparison metadata set for each data flow level in the metadata management platform; wherein, the data flow level is used to represent the metadata in the The circulation platform in the metadata management platform.
在上述技术方案的基础上,可选的,待测元数据获取单元,包括:On the basis of the above technical solutions, optionally, the metadata acquisition unit to be measured includes:
第一待测元数据获取子单元,用于当检测到元数据新增指令时,将与元数据新增指令对应的元数据作为待测元数据;基于数据流转层级对应的层级标识,获取数据库中的对比元数据集。The first sub-unit for obtaining metadata to be tested is used to, when a new metadata instruction is detected, take the metadata corresponding to the metadata added instruction as the metadata to be tested; obtain the database based on the level identifier corresponding to the data flow level The comparative metadata set in .
在上述技术方案的基础上,可选的,待测元数据获取单元,包括:On the basis of the above technical solutions, optionally, the metadata acquisition unit to be measured includes:
第二待测元数据获取子单元,用于当检测到当前时间满足预设时间点时,基于数据流转层级对应的层级标识,获取数据库中的至少两个元数据;针对每个元数据,将元数据作为待测元数据,并将除待测元数据以外的元数据添加到对比元数据集中。The second to-be-measured metadata acquisition subunit is used to acquire at least two metadata in the database based on the level identifier corresponding to the data flow level when it is detected that the current time meets the preset time point; for each metadata, the The metadata is used as the metadata to be tested, and the metadata other than the metadata to be tested is added to the comparison metadata set.
在上述技术方案的基础上,可选的,该装置还包括:On the basis of the above technical solution, optionally, the device further includes:
待测值域数据匹配模块,用于如果待测血缘关系数据与对比血缘关系数据集匹配失败,则将待测元数据对应的待测值域数据与对比元数据集对应的对比值域数据集进行匹配;其中,对比值域数据集包含与至少一个对比元数据分别对应的对比值域数据;The data matching module of the range to be measured is used to match the data of the range to be measured corresponding to the metadata to be measured with the data set of the comparative range corresponding to the metadata set to be measured if the blood relationship data to be tested and the comparative blood relationship data set fail to match Matching; wherein, the comparison range data set includes comparison range data corresponding to at least one comparison metadata respectively;
将匹配成功的对比值域数据对应的对比元数据作为目标元数据,并对待测元数据的概念命名与目标元数据的概念命名执行合并操作。The comparison metadata corresponding to the successfully matched comparison range data is used as the target metadata, and the concept name of the metadata to be measured and the concept name of the target metadata are merged.
在上述技术方案的基础上,可选的,对比值域数据的类型为字典类值域或格式文本值域,相应的,该装置还包括:On the basis of the above technical solution, optionally, the type of the comparison range data is a dictionary type range or a formatted text range, and correspondingly, the device further includes:
对比值域数据获取模块,用于针对每个对比元数据,当对比元数据的对比值域数据的类型为字典类值域时,获取对比元数据所在数据库对应的外键关系表中与对比元数据对应的对比值域数据;The comparison range data acquisition module is used for each comparison metadata, when the type of the comparison range data of the comparison metadata is a dictionary type range, obtain the foreign key relationship table corresponding to the database where the comparison metadata is located and the comparison metadata. The data corresponding to the contrast range data;
当对比元数据的对比值域数据的类型为格式文本值域时,获取数据库中与对比元数据对应的对比值域数据。When the type of the comparison range data of the comparison metadata is a format text range, obtain the comparison range data corresponding to the comparison metadata in the database.
在上述技术方案的基础上,可选的,该装置还包括:On the basis of the above technical solution, optionally, the device further includes:
对比元数据集筛选模块,用于在将待测元数据对应的待测值域数据与对比元数据集对应的对比值域数据集进行匹配之前,获取与待测元数据对应的白名单数据集;其中,白名单数据集包含至少一个元数据,各元数据分别对应的值域数据与待测值域数据相同但各元数据的概念命名与待测值域数据不同;The comparison metadata set screening module is used to obtain a whitelist data set corresponding to the metadata to be measured before matching the data of the range to be measured corresponding to the metadata to be measured with the data set of the comparison range corresponding to the metadata set to be measured ; wherein, the whitelist data set includes at least one metadata, and the range data corresponding to each metadata is the same as the range data to be measured, but the conceptual naming of each metadata is different from the range data to be measured;
将对比元数据集中与白名单数据集相同的对比元数据删除,得到筛选后的对比元数据集。Delete the same comparison metadata in the comparison metadata set as the whitelisted data set to obtain a filtered comparison metadata set.
本发明实施例所提供的元数据概念合并的装置可以用于执行本发明实施例所提供的元数据概念合并的方法,具备执行方法相应的功能和有益效果。The apparatus for merging metadata concepts provided by the embodiments of the present invention can be used to execute the method for merging metadata concepts provided by the embodiments of the present invention, and has functions and beneficial effects corresponding to the execution methods.
值得注意的是,上述元数据概念合并的装置的实施例中,所包括的各个单元和模块只是按照功能逻辑进行划分的,但并不局限于上述的划分,只要能够实现相应的功能即可;另外,各功能单元的具体名称也只是为了便于相互区分,并不用于限制本发明的保护范围。It is worth noting that, in the embodiment of the above-mentioned device for merging metadata concepts, the included units and modules are only divided according to functional logic, but are not limited to the above-mentioned division, as long as the corresponding functions can be realized; In addition, the specific names of the functional units are only for the convenience of distinguishing from each other, and are not used to limit the protection scope of the present invention.
实施例五Embodiment 5
图6是本发明实施例五提供的一种电子设备的结构示意图,本发明实施例为本发明上述实施例的元数据概念合并的方法的实现提供服务,可配置上述实施例中的元数据概念合并的装置。图6示出了适于用来实现本发明实施方式的示例性电子设备12的框图。图6显示的电子设备12仅仅是一个示例,不应对本发明实施例的功能和使用范围带来任何限制。6 is a schematic structural diagram of an electronic device according to Embodiment 5 of the present invention. This embodiment of the present invention provides services for the implementation of the method for merging metadata concepts in the above-mentioned embodiments of the present invention, and the metadata concepts in the above-mentioned embodiments can be configured Combined device. Figure 6 shows a block diagram of an exemplary
如图6所示,电子设备12以通用计算设备的形式表现。电子设备12的组件可以包括但不限于:一个或者多个处理器或者处理单元16,系统存储器28,连接不同系统组件(包括系统存储器28和处理单元16)的总线18。As shown in FIG. 6, the
总线18表示几类总线结构中的一种或多种,包括存储器总线或者存储器控制器、外围总线、图形加速端口、处理器或者使用多种总线结构中的任意总线结构的局域总线。举例来说,这些体系结构包括但不限于工业标准体系结构(ISA)总线、微通道体系结构(MAC)总线、增强型ISA总线、视频电子标准协会(VESA)局域总线以及外围组件互连(PCI)总线。
电子设备12典型地包括多种计算机系统可读介质。这些介质可以是任何能够被电子设备12访问的可用介质,包括易失性和非易失性介质,可移动的和不可移动的介质。
系统存储器28可以包括易失性存储器形式的计算机系统可读介质,例如随机存取存储器(RAM)30和/或高速缓存存储器32。电子设备12可以进一步包括其它可移动/不可移动的、易失性/非易失性计算机系统存储介质。仅作为举例,存储系统34可以用于读写不可移动的、非易失性磁介质(图6未显示,通常称为“硬盘驱动器”)。尽管图6中未示出,可以提供用于对可移动非易失性磁盘(例如“软盘”)读写的磁盘驱动器,以及对可移动非易失性光盘(例如CD-ROM,DVD-ROM或者其它光介质)读写的光盘驱动器。在这些情况下,每个驱动器可以通过一个或者多个数据介质接口与总线18相连。存储器28可以包括至少一个程序产品,该程序产品具有一组(例如至少一个)程序模块,这些程序模块被配置以执行本发明各实施例的功能。
具有一组(至少一个)程序模块42的程序/实用工具40,可以存储在例如存储器28中,这样的程序模块42包括但不限于操作系统、一个或者多个应用程序、其它程序模块以及程序数据,这些示例中的每一个或某种组合中可能包括网络环境的实现。程序模块42通常执行本发明所描述的实施例中的功能和/或方法。A program/
电子设备12也可以与一个或多个外部设备14(例如键盘、指向设备、显示器24等)通信,还可与一个或者多个使得用户能与该电子设备12交互的设备通信,和/或与使得该电子设备12能与一个或多个其它计算设备进行通信的任何设备(例如网卡,调制解调器等等)通信。这种通信可以通过输入/输出(I/O)接口22进行。并且,电子设备12还可以通过网络适配器20与一个或者多个网络(例如局域网(LAN),广域网(WAN)和/或公共网络,例如因特网)通信。如图6所示,网络适配器20通过总线18与电子设备12的其它模块通信。应当明白,尽管图中未示出,可以结合电子设备12使用其它硬件和/或软件模块,包括但不限于:微代码、设备驱动器、冗余处理单元、外部磁盘驱动阵列、RAID系统、磁带驱动器以及数据备份存储系统等。The
处理单元16通过运行存储在系统存储器28中的程序,从而执行各种功能应用以及数据处理,例如实现本发明实施例所提供的元数据概念合并的方法。The
通过上述电子设备,解决了现有的元数据管理平台无法识别同概念的元数据的问题,优化了元数据管理平台的管理功能,避免了用户主观判断造成的理解误差,进而提高了元数据管理平台的实用性。Through the above electronic device, the problem that the existing metadata management platform cannot identify the metadata of the same concept is solved, the management function of the metadata management platform is optimized, the understanding error caused by the user's subjective judgment is avoided, and the metadata management is improved. usability of the platform.
实施例六Embodiment 6
本发明实施例六还提供了一种包含计算机可执行指令的存储介质,计算机可执行指令在由计算机处理器执行时用于执行一种元数据概念合并的方法,该方法包括:Embodiment 6 of the present invention further provides a storage medium containing computer-executable instructions, where the computer-executable instructions are used to execute a method for merging metadata concepts when executed by a computer processor, and the method includes:
获取元数据管理平台中的待测元数据以及对比元数据集;其中,对比元数据集包含至少一个对比元数据;Obtain the metadata to be tested and the comparison metadata set in the metadata management platform; wherein, the comparison metadata set includes at least one comparison metadata;
将待测元数据对应的待测血缘关系数据与对比元数据集对应的对比血缘关系数据集进行匹配;其中,对比血缘关系数据集包含与至少一个对比元数据分别对应的对比血缘关系数据;Matching the blood relationship data to be tested corresponding to the metadata to be tested and the comparison blood relationship data set corresponding to the comparison metadata set; wherein the comparison blood relationship data set includes the comparison blood relationship data corresponding to at least one comparison metadata respectively;
将匹配成功的对比血缘关系数据对应的对比元数据作为目标元数据,对待测元数据的概念命名与目标元数据的概念命名执行合并操作。The comparison metadata corresponding to the successfully matched comparison blood relationship data is used as the target metadata, and the conceptual naming of the metadata to be measured and the conceptual naming of the target metadata are merged.
本发明实施例的计算机存储介质,可以采用一个或多个计算机可读的介质的任意组合。计算机可读介质可以是计算机可读信号介质或者计算机可读存储介质。计算机可读存储介质例如可以是但不限于电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:具有一个或多个导线的电连接、便携式计算机磁盘、硬盘、随机存取存储器(RAM)、只读存储器(ROM)、可擦式可编程只读存储器(EPROM或闪存)、光纤、便携式紧凑磁盘只读存储器(CD-ROM)、光存储器件、磁存储器件、或者上述的任意合适的组合。在本文件中,计算机可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。The computer storage medium in the embodiments of the present invention may adopt any combination of one or more computer-readable mediums. The computer-readable medium may be a computer-readable signal medium or a computer-readable storage medium. The computer-readable storage medium may be, for example, but not limited to, an electrical, magnetic, optical, electromagnetic, infrared, or semiconductor system, apparatus or device, or a combination of any of the above. More specific examples (a non-exhaustive list) of computer readable storage media include: electrical connections having one or more wires, portable computer disks, hard disks, random access memory (RAM), read only memory (ROM), Erasable programmable read only memory (EPROM or flash memory), optical fiber, portable compact disk read only memory (CD-ROM), optical storage devices, magnetic storage devices, or any suitable combination of the foregoing. In this document, a computer-readable storage medium can be any tangible medium that contains or stores a program that can be used by or in conjunction with an instruction execution system, apparatus, or device.
计算机可读的信号介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了计算机可读的程序代码。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任意合适的组合。计算机可读的信号介质还可以是计算机可读存储介质以外的任何计算机可读介质,该计算机可读介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。A computer-readable signal medium may include a propagated data signal in baseband or as part of a carrier wave, with computer-readable program code embodied thereon. Such propagated data signals may take a variety of forms, including but not limited to electromagnetic signals, optical signals, or any suitable combination of the foregoing. A computer-readable signal medium can also be any computer-readable medium other than a computer-readable storage medium that can transmit, propagate, or transport the program for use by or in connection with the instruction execution system, apparatus, or device .
计算机可读介质上包含的程序代码可以用任何适当的介质传输,包括但不限于无线、电线、光缆、RF等等,或者上述的任意合适的组合。Program code embodied on a computer readable medium may be transmitted using any suitable medium, including but not limited to wireless, wireline, optical fiber cable, RF, etc., or any suitable combination of the foregoing.
可以以一种或多种程序设计语言或其组合来编写用于执行本发明操作的计算机程序代码,程序设计语言包括面向对象的程序设计语言,诸如Java、Smalltalk、C++,还包括常规的过程式程序设计语言,诸如“C”语言或类似的程序设计语言。程序代码可以完全地在用户计算机上执行、部分地在用户计算机上执行、作为一个独立的软件包执行、部分在用户计算机上部分在远程计算机上执行、或者完全在远程计算机或服务器上执行。在涉及远程计算机的情形中,远程计算机可以通过任意种类的网络包括局域网(LAN)或广域网(WAN),连接到用户计算机,或者,可以连接到外部计算机(例如利用因特网服务提供商来通过因特网连接)。Computer program code for carrying out operations of the present invention may be written in one or more programming languages, including object-oriented programming languages such as Java, Smalltalk, C++, and conventional procedural A programming language, such as the "C" language or similar programming language. The program code may execute entirely on the user's computer, partly on the user's computer, as a stand-alone software package, partly on the user's computer and partly on a remote computer, or entirely on the remote computer or server. Where a remote computer is involved, the remote computer may be connected to the user's computer through any kind of network, including a local area network (LAN) or wide area network (WAN), or may be connected to an external computer (eg, using an Internet service provider to connect through the Internet) ).
当然,本发明实施例所提供的一种包含计算机可执行指令的存储介质,其计算机可执行指令不限于如上的方法操作,还可以执行本发明任意实施例所提供的元数据概念合并的方法中的相关操作。Of course, a storage medium containing computer-executable instructions provided by an embodiment of the present invention is not limited to the above method operations, and can also execute the method for combining metadata concepts provided by any embodiment of the present invention. related operations.
注意,上述仅为本发明的较佳实施例及所运用技术原理。本领域技术人员会理解,本发明不限于这里所述的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本发明的保护范围。因此,虽然通过以上实施例对本发明进行了较为详细的说明,但是本发明不仅仅限于以上实施例,在不脱离本发明构思的情况下,还可以包括更多其他等效实施例,而本发明的范围由所附的权利要求范围决定。Note that the above are only preferred embodiments of the present invention and applied technical principles. Those skilled in the art will understand that the present invention is not limited to the specific embodiments described herein, and various obvious changes, readjustments and substitutions can be made by those skilled in the art without departing from the protection scope of the present invention. Therefore, although the present invention has been described in detail through the above embodiments, the present invention is not limited to the above embodiments, and can also include more other equivalent embodiments without departing from the concept of the present invention. The scope is determined by the scope of the appended claims.
Claims (10)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111642061.4ACN114328532B (en) | 2021-12-29 | 2021-12-29 | Metadata concept merging method and device |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111642061.4ACN114328532B (en) | 2021-12-29 | 2021-12-29 | Metadata concept merging method and device |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN114328532Atrue CN114328532A (en) | 2022-04-12 |
| CN114328532B CN114328532B (en) | 2025-07-29 |
Family
ID=81016339
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202111642061.4AActiveCN114328532B (en) | 2021-12-29 | 2021-12-29 | Metadata concept merging method and device |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114328532B (en) |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20150095299A1 (en)* | 2013-09-30 | 2015-04-02 | International Business Machines Corporation | Merging metadata for database storage regions based on overlapping range values |
| CN109446274A (en)* | 2017-08-31 | 2019-03-08 | 北京京东尚科信息技术有限公司 | The method and apparatus of big data platform BI metadata management |
| CN109739893A (en)* | 2018-12-28 | 2019-05-10 | 上海连尚网络科技有限公司 | A kind of metadata management method, equipment and computer-readable medium |
| CN111125068A (en)* | 2019-11-13 | 2020-05-08 | 深圳市华傲数据技术有限公司 | Metadata management method and system |
| CN113297139A (en)* | 2021-04-28 | 2021-08-24 | 上海淇玥信息技术有限公司 | Metadata query method and system and electronic equipment |
| WO2021218021A1 (en)* | 2020-04-28 | 2021-11-04 | 平安科技(深圳)有限公司 | Data-based blood relationship analysis method, apparatus, and device and computer-readable storage medium |
- 2021
- 2021-12-29CNCN202111642061.4Apatent/CN114328532B/enactiveActive
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20150095299A1 (en)* | 2013-09-30 | 2015-04-02 | International Business Machines Corporation | Merging metadata for database storage regions based on overlapping range values |
| US20150095379A1 (en)* | 2013-09-30 | 2015-04-02 | International Business Machines Corporation | Merging metadata for database storage regions based on overlapping range values |
| CN109446274A (en)* | 2017-08-31 | 2019-03-08 | 北京京东尚科信息技术有限公司 | The method and apparatus of big data platform BI metadata management |
| CN109739893A (en)* | 2018-12-28 | 2019-05-10 | 上海连尚网络科技有限公司 | A kind of metadata management method, equipment and computer-readable medium |
| CN111125068A (en)* | 2019-11-13 | 2020-05-08 | 深圳市华傲数据技术有限公司 | Metadata management method and system |
| WO2021218021A1 (en)* | 2020-04-28 | 2021-11-04 | 平安科技(深圳)有限公司 | Data-based blood relationship analysis method, apparatus, and device and computer-readable storage medium |
| CN113297139A (en)* | 2021-04-28 | 2021-08-24 | 上海淇玥信息技术有限公司 | Metadata query method and system and electronic equipment |
Also Published As
| Publication number | Publication date |
|---|---|
| CN114328532B (en) | 2025-07-29 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN109471863B (en) | Information query method and device based on distributed database and electronic equipment | |
| CN112397159B (en) | Automatic entry method and device for clinical test report, electronic equipment and storage medium | |
| US20140200916A1 (en) | System and method for optimizing and routing health information | |
| US11481411B2 (en) | Systems and methods for automated generation classifiers | |
| CN111475686A (en) | Medicine classification method and device, storage medium and intelligent equipment | |
| CN111081329A (en) | Automatic clinical data entry method and device, electronic equipment and storage medium | |
| CN112559095A (en) | Target service execution method, system, server and storage medium | |
| US20210202111A1 (en) | Method of classifying medical records | |
| CN114242258A (en) | Medical data exploration method and device based on medical knowledge graph | |
| US20230141049A1 (en) | Method and system for consolidating heterogeneous electronic health data | |
| US20180060538A1 (en) | Clinical connector and analytical framework | |
| US20200126642A1 (en) | Cognitive solutions for detection of, and optimization based on, cohorts, arms, and phases in clinical trials | |
| CN111831750A (en) | A block chain data analysis method, device, computer equipment and storage medium | |
| CN115579118A (en) | Medical data management method, system and storage medium based on data fusion | |
| CN116383193A (en) | Data management method and device, electronic equipment and storage medium | |
| CN111046085A (en) | Data source tracing processing method and device, medium and equipment | |
| CN111159158B (en) | Data normalization method and device, computer readable storage medium and electronic equipment | |
| CN107610783A (en) | A kind of brain tumor information platform | |
| US20140278527A1 (en) | Large scale identification and analysis of population health risks | |
| Samra et al. | GENE2D: a NoSQL integrated data repository of genetic disorders data | |
| CN116150475B (en) | Information retrieval method, device, electronic equipment and storage medium | |
| CN114328532B (en) | Metadata concept merging method and device | |
| US20230077056A1 (en) | Systems and methods for automated generation of classifiers | |
| EP3654339A1 (en) | Method of classifying medical records | |
| CN113241153A (en) | Image loading method and device, electronic equipment and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |