CN114298284A - Network model conversion method, device, system, storage medium and electronic device - Google Patents
Network model conversion method, device, system, storage medium and electronic deviceDownload PDFInfo
- Publication number
- CN114298284A CN114298284ACN202111644376.2ACN202111644376ACN114298284ACN 114298284 ACN114298284 ACN 114298284ACN 202111644376 ACN202111644376 ACN 202111644376ACN 114298284 ACN114298284 ACN 114298284A
- Authority
- CN
- China
- Prior art keywords
- model
- processor
- network model
- file
- training
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images






Landscapes
- Data Exchanges In Wide-Area Networks (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本发明实施例涉及通信领域,具体而言,涉及一种网络模型的转换方法、装置、系统、存储介质及电子装置。Embodiments of the present invention relate to the field of communications, and in particular, to a method, device, system, storage medium, and electronic device for converting a network model.
背景技术Background technique
在相关技术中,通过GPU卡训练得到的深度学习模型,在进行推理端部署之前都需要进行一次模型的转换,需要根据不同的硬件平台进行模型的适配。在进行模型转换时,还需要推理端的硬件环境才可以完成最终的模型转换。比如:训练使用的GPU卡是NVIDIA A卡,推理端GPU卡是NVIDIA B卡,NVIDI A 为了加快推理的速度使用了TensorRT进行加速,因此,在推理端使用的模型都是通过TensorRT加速的模型,由于NVIDIA A卡与NVIDIA B卡两者内核不一样,因此,NVIDIA A卡训练出来的模型是无法在直接在NVIDIA B卡上面通过TensorRT加速使用的,必需在一台有NVIDIA B卡的环境上面进行量化和模型转换,例如,配置一台单独的有NVIDIAB卡的硬件服务器,得到NVIDIA B卡可以使用的TensorRT加速模型,这无形当中增加了用户成本。In the related art, a deep learning model obtained through GPU card training needs to be converted once before being deployed on the inference side, and the model needs to be adapted according to different hardware platforms. When performing model conversion, the hardware environment of the inference side is also required to complete the final model conversion. For example, the GPU card used for training is NVIDIA A card, the GPU card used for inference is NVIDIA B card, and NVIDIA A uses TensorRT for acceleration in order to speed up inference. Therefore, the models used on the inference side are all models accelerated by TensorRT. Because the cores of the NVIDIA A card and the NVIDIA B card are different, the model trained by the NVIDIA A card cannot be directly accelerated by TensorRT on the NVIDIA B card, and must be performed in an environment with an NVIDIA B card. Quantization and model conversion, for example, configure a separate hardware server with NVIDIA B card to obtain the TensorRT accelerated model that NVIDIA B card can use, which invisibly increases user costs.
由此可知,相关技术中存在将网络模型在不同类型的处理器中转换成本高的问题。It can be seen from this that the related art has the problem of high cost of converting the network model into different types of processors.
针对相关技术中存在点的上述问题,目前尚未提出有效的解决方案。For the above problems existing in the related art, no effective solution has been proposed yet.
发明内容SUMMARY OF THE INVENTION
本发明实施例提供了一种网络模型的转换方法、装置、系统、存储介质及电子装置,以至少解决相关技术中存在的将网络模型在不同类型的处理器中转换成本高的问题。Embodiments of the present invention provide a method, device, system, storage medium and electronic device for converting a network model to at least solve the problem of high cost of converting a network model between different types of processors in the related art.
根据本发明的一个实施例,提供了一种网络模型的转换方法,包括:将在第一处理器中训练得到的训练网络模型的第一模型文件转换为预定格式的中间模型文件;确定与第二处理器对应的模型转换模块的第二模型文件,其中,所述第二处理器与所述第一处理器为不同类型的处理器;基于所述中间模型文件以及所述第二模型文件确定推理算子包;将所述推理算子包发送给包括所述第二处理器的第一设备,以指示所述第一设备基于所述推理算子包将所述训练网络模型转换为与所述第二处理器匹配的目标网络模型。According to an embodiment of the present invention, a method for converting a network model is provided, comprising: converting a first model file of a training network model obtained by training in a first processor into an intermediate model file in a predetermined format; The second model file of the model conversion module corresponding to the two processors, wherein the second processor and the first processor are processors of different types; determined based on the intermediate model file and the second model file an inference operator package; sending the inference operator package to a first device including the second processor to instruct the first device to convert the training network model into a The target network model matched by the second processor.
根据本发明的一个实施例,还提供了一种网络模型的转换方法,包括:向包括第一处理器的第二设备发送请求信息,其中,所述请求信息用于请求推理算子包,所述推理算子包为所述第一处理器基于中间模型文件以及与第一设备中包括的第二处理器对应的模型转换模块对应的第二模型文件确定的,所述中间模型文件为在第一处理器中训练得到的训练网络模型的第一模型文件转换成的预定格式的文件;基于所述推理算子包将所述训练网络模型转换为与所述第二处理器匹配的目标网络模型。According to an embodiment of the present invention, a method for converting a network model is also provided, comprising: sending request information to a second device including a first processor, wherein the request information is used to request an inference operator package, and the The inference operator package is determined by the first processor based on an intermediate model file and a second model file corresponding to the model conversion module corresponding to the second processor included in the first device, and the intermediate model file is in the first device. A file in a predetermined format converted from a first model file of a training network model trained in a processor; converting the training network model into a target network model matching the second processor based on the inference operator package .
根据本发明的一个实施例,还提供了一种网络模型的转换方法,包括:第二设备将推理算子包发送给第一设备,其中,所述推理算子包为所述第二设备基于中间模型文件以及与所述第一设备对应的模型转换模块的第二模型文件确定的算子包,所述中间模型文件为在所述第二设备中训练得到的训练网络模型的第一模型文件转换成的预定格式的文件;所述第一设备接收所述推理算子包,并基于所述推理算子包将所述训练网络模型转换为与所述第一设备匹配的目标网络模型,其中,所述第一设备与所述第二设备中包括有不同类型的处理器。According to an embodiment of the present invention, a method for converting a network model is further provided, including: the second device sends an inference operator packet to the first device, wherein the inference operator packet is based on the second device The intermediate model file and the operator package determined by the second model file of the model conversion module corresponding to the first device, where the intermediate model file is the first model file of the training network model obtained by training in the second device The converted file in a predetermined format; the first device receives the inference operator package, and converts the training network model into a target network model matching the first device based on the inference operator package, wherein , the first device and the second device include different types of processors.
根据本发明的另一个实施例,提供了一种网络模型的转换装置,包括:第一转换模块,用于将在第一处理器中训练得到的训练网络模型的第一模型文件转换为预定格式的中间模型文件;第一确定模块,用于确定与第二处理器对应的模型转换模块的第二模型文件,其中,所述第二处理器与所述第一处理器为不同类型的处理器;第二确定模块,用于基于所述中间模型文件以及所述第二模型文件确定推理算子包;第二转换模块,用于将所述推理算子包发送给包括所述第二处理器的第一设备,以指示所述第一设备基于所述推理算子包将所述训练网络模型转换为与所述第二处理器匹配的目标网络模型。According to another embodiment of the present invention, an apparatus for converting a network model is provided, comprising: a first converting module configured to convert the first model file of the training network model obtained by training in the first processor into a predetermined format The intermediate model file; the first determination module is used to determine the second model file of the model conversion module corresponding to the second processor, wherein the second processor and the first processor are different types of processors ; a second determination module for determining an inference operator package based on the intermediate model file and the second model file; a second conversion module for sending the inference operator package to a processor including the second processor the first device to instruct the first device to convert the training network model into a target network model matching the second processor based on the inference operator package.
根据本发明的另一个实施例,还提供了一种网络模型的转换装置,包括:发送模块,用于向包括第一处理器的第二设备发送请求信息,其中,所述请求信息用于请求推理算子包,所述推理算子包为所述第一处理器基于中间模型文件以及与第一设备中包括的第二处理器对应的模型转换模块的第二模型文件确定的,所述中间模型文件为在第一处理器中训练得到的训练网络模型的第一模型文件转换成的预定格式的文件;第三转换模块,用于基于所述推理算子包将所述训练网络模型转换为与所述第二处理器匹配的目标网络模型。According to another embodiment of the present invention, there is also provided an apparatus for converting a network model, comprising: a sending module configured to send request information to a second device including a first processor, wherein the request information is used to request an inference operator package, the inference operator package is determined by the first processor based on an intermediate model file and a second model file of a model conversion module corresponding to the second processor included in the first device, the intermediate The model file is a file in a predetermined format converted from the first model file of the training network model trained in the first processor; a third conversion module is used to convert the training network model into A target network model matched to the second processor.
根据本发明的另一个实施例,还提供了一种网络模型的转换系统,包括:第一设备,其中,所述第一设备用于执行如上述实施例中所述的方法;第二设备,其中,所述第二设备与所述第一设备通信连接,所述第二设备用于执行如上述实施例中所述的方法,其中,所述第一设备与所述第二设备中包括有不同类型的处理器。According to another embodiment of the present invention, a system for converting a network model is also provided, including: a first device, wherein the first device is configured to execute the method described in the above embodiment; a second device, Wherein, the second device is communicatively connected to the first device, and the second device is configured to execute the method described in the foregoing embodiment, wherein the first device and the second device include Different types of processors.
根据本发明的又一个实施例,还提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,其中,所述计算机程序被处理器执行时实现上述任一项中所述的方法的步骤。According to yet another embodiment of the present invention, there is also provided a computer-readable storage medium, where a computer program is stored in the computer-readable storage medium, wherein, when the computer program is executed by a processor, any one of the above-mentioned items is implemented. the steps of the method.
根据本发明的又一个实施例,还提供了一种电子装置,包括存储器和处理器,所述存储器中存储有计算机程序,所述处理器被设置为运行所述计算机程序以执行上述任一项方法实施例中的步骤。According to yet another embodiment of the present invention, there is also provided an electronic device comprising a memory and a processor, wherein the memory stores a computer program, the processor is configured to run the computer program to execute any of the above Steps in Method Examples.
通过本发明,将在第一处理器中训练得到的训练网络模型的第一模型文件转换为预定格式的中间模型文件,确定与第二处理器对应的模型模块的第二模型文件,根据中间模型文件以及第二模型文件确定推理算子包,将推理算子包发送给包括第二处理器的第一设备,以指示第一设备根据推理算子包将训练网络模型转换为与第二处理器匹配的目标网络模型。由于可以在第一处理器和第二处理器类型不同时,将在第一处理器中训练得到的第一模型文件转换为中间模型文件,并确定出与第二处理器对应的模型转换模块的第二模型文件,使第一设备可以根据中间模型文件以及第二模型文件确定的推理算子包将训练网络模型转换为目标网络模型,以使目标网络模型与第二处理器匹配。且第二模型文件在第一处理器侧配置的,第二处理器侧无需配置硬件服务器。因此,可以解决相关技术中存在的将网络模型在不同类型的处理器中转换成本高的问题,达到降低网络模型在不同类型的处理器中转换成本的效果。Through the present invention, the first model file of the training network model trained in the first processor is converted into an intermediate model file in a predetermined format, the second model file of the model module corresponding to the second processor is determined, and according to the intermediate model file and the second model file to determine the inference operator package, and send the inference operator package to the first device including the second processor, to instruct the first device to convert the training network model to the second processor according to the inference operator package. matching target network model. When the types of the first processor and the second processor are different, the first model file trained in the first processor can be converted into an intermediate model file, and the model conversion module corresponding to the second processor can be determined. The second model file enables the first device to convert the training network model into a target network model according to the intermediate model file and the inference operator package determined by the second model file, so that the target network model matches the second processor. Moreover, if the second model file is configured on the first processor side, there is no need to configure a hardware server on the second processor side. Therefore, the problem of high cost of converting the network model to different types of processors in the related art can be solved, and the effect of reducing the cost of converting the network model to different types of processors can be achieved.
附图说明Description of drawings
图1是本发明实施例的一种网络模型的转换方法的移动终端的硬件结构框图;1 is a block diagram of a hardware structure of a mobile terminal of a method for converting a network model according to an embodiment of the present invention;
图2是根据本发明实施例的网络模型的转换方法的流程图一;2 is a flow chart 1 of a method for converting a network model according to an embodiment of the present invention;
图3是根据本发明实施例的网络模型的转换方法的流程图二;3 is a flowchart 2 of a method for converting a network model according to an embodiment of the present invention;
图4是根据本发明实施例的网络模型的转换方法的流程图三;FIG. 4 is a flowchart 3 of a method for converting a network model according to an embodiment of the present invention;
图5是根据本发明具体实施例的运行网络模型的转换方法的装置结构示意图;5 is a schematic structural diagram of an apparatus for a conversion method of a running network model according to a specific embodiment of the present invention;
图6是根据本发明具体实施例的确定推理算子包流程图;6 is a flowchart of determining an inference operator packet according to a specific embodiment of the present invention;
图7是根据本发明具体实施例的网络模型的转换方法流程图;7 is a flowchart of a method for converting a network model according to a specific embodiment of the present invention;
图8是根据本发明实施例的网络模型的转换装置的结构框图一;8 is a structural block diagram 1 of an apparatus for converting a network model according to an embodiment of the present invention;
图9是根据本发明实施例的网络模型的转换装置的结构框图二。FIG. 9 is a second structural block diagram of an apparatus for converting a network model according to an embodiment of the present invention.
具体实施方式Detailed ways
下文中将参考附图并结合实施例来详细说明本发明的实施例。Hereinafter, embodiments of the present invention will be described in detail with reference to the accompanying drawings and in conjunction with the embodiments.
需要说明的是,本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。It should be noted that the terms "first", "second" and the like in the description and claims of the present invention and the above drawings are used to distinguish similar objects, and are not necessarily used to describe a specific sequence or sequence.
本申请实施例中所提供的方法实施例可以在移动终端、计算机终端或者类似的运算装置中执行。以运行在移动终端上为例,图1是本发明实施例的一种网络模型的转换方法的移动终端的硬件结构框图。如图1所示,移动终端可以包括一个或多个(图1中仅示出一个)处理器102(处理器102可以包括但不限于图像处理器GPU、微处理器MCU或可编程逻辑器件FPGA等的处理装置)和用于存储数据的存储器104,其中,上述移动终端还可以包括用于通信功能的传输设备106以及输入输出设备108。本领域普通技术人员可以理解,图1所示的结构仅为示意,其并不对上述移动终端的结构造成限定。例如,移动终端还可包括比图1中所示更多或者更少的组件,或者具有与图1所示不同的配置。The method embodiments provided in the embodiments of this application may be executed in a mobile terminal, a computer terminal, or a similar computing device. Taking running on a mobile terminal as an example, FIG. 1 is a block diagram of a hardware structure of a mobile terminal according to a method for converting a network model according to an embodiment of the present invention. As shown in FIG. 1 , the mobile terminal may include one or more (only one is shown in FIG. 1 ) processors 102 (the processors 102 may include, but are not limited to, an image processor GPU, a microprocessor MCU or a programmable logic device FPGA etc.) and a
存储器104可用于存储计算机程序,例如,应用软件的软件程序以及模块,如本发明实施例中的网络模型的转换方法对应的计算机程序,处理器102通过运行存储在存储器104内的计算机程序,从而执行各种功能应用以及数据处理,即实现上述的方法。存储器104可包括高速随机存储器,还可包括非易失性存储器,如一个或者多个磁性存储装置、闪存、或者其他非易失性固态存储器。在一些实例中,存储器104可进一步包括相对于处理器102远程设置的存储器,这些远程存储器可以通过网络连接至移动终端。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。The
传输设备106用于经由一个网络接收或者发送数据。上述的网络具体实例可包括移动终端的通信供应商提供的无线网络。在一个实例中,传输设备106包括一个网络适配器(Network Interface Controller,简称为NIC),其可通过基站与其他网络设备相连从而可与互联网进行通讯。在一个实例中,传输设备106可以为射频(Radio Frequency,简称为RF)模块,其用于通过无线方式与互联网进行通讯。
在本实施例中提供了一种网络模型的转换方法,图2是根据本发明实施例的网络模型的转换方法的流程图一,如图2所示,该流程包括如下步骤:A method for converting a network model is provided in this embodiment, and FIG. 2 is a flowchart 1 of a method for converting a network model according to an embodiment of the present invention. As shown in FIG. 2 , the process includes the following steps:
步骤S202,将在第一处理器中训练得到的训练网络模型的第一模型文件转换为预定格式的中间模型文件;Step S202, converting the first model file of the training network model obtained by training in the first processor into an intermediate model file of a predetermined format;
步骤S204,确定与第二处理器对应的模型转换模块的第二模型文件,其中,所述第二处理器与所述第一处理器为不同类型的处理器;Step S204, determining the second model file of the model conversion module corresponding to the second processor, wherein the second processor and the first processor are processors of different types;
步骤S206,基于所述中间模型文件以及所述第二模型文件确定推理算子包;Step S206, determining an inference operator package based on the intermediate model file and the second model file;
步骤S208,将所述推理算子包发送给包括所述第二处理器的第一设备,以指示所述第一设备基于所述推理算子包将所述训练网络模型转换为与所述第二处理器匹配的目标网络模型。Step S208, sending the inference operator package to the first device including the second processor, to instruct the first device to convert the training network model to the same as the first device based on the inference operator package. Two-processor matching target network model.
在上述实施例中,第一处理器和第二处理器是不同类型的GPU处理器,第一处理器的算力大于第二处理器的算力,第一处理器可以是训练服务器中的处理器,第二处理器可以是推理服务器中的处理器,即第一设备可以为推理服务器。可以通过第一处理器训练网络模型,得到训练网络模型后,可以将训练网络模型发送给不同的包括第二处理器的第一设备。由于第二处理器和第一处理器是不同类型的处理器,因此,需要将训练网络模型转换为与第二处理器匹配的目标网络模型。在转换目标网络模型时,包括有第一处理器的设备可以将训练网络模型的第一模型文件转换为预定格式的中间模型文件。并确定与第二处理器对应的模型转换模块的第二模型文件,根据中间模型文件以及第二模型文件确定推理算子包,将推理算子包发送给第一设备,第一设备在接收到推理算子包后,可以解析推理算子包,根据推理算子包实现模型转换。其中,预定格式可以是ONNX格式。In the above embodiment, the first processor and the second processor are different types of GPU processors, the computing power of the first processor is greater than the computing power of the second processor, and the first processor may be a processor in the training server The second processor may be a processor in an inference server, that is, the first device may be an inference server. The network model can be trained by the first processor, and after the trained network model is obtained, the trained network model can be sent to different first devices including the second processor. Since the second processor and the first processor are different types of processors, the training network model needs to be converted into a target network model matching the second processor. When converting the target network model, the device including the first processor may convert the first model file for training the network model into an intermediate model file in a predetermined format. and determine the second model file of the model conversion module corresponding to the second processor, determine the inference operator package according to the intermediate model file and the second model file, and send the inference operator package to the first device, and the first device receives the inference operator package. After the inference operator package is created, the inference operator package can be parsed, and model conversion can be implemented according to the inference operator package. Wherein, the predetermined format may be ONNX format.
在上述实施例中,第二模型文件是在第一处理器侧配置的文件,在第二处理器请求网络模型时,包括有第一处理器的设备可以将第二模型文件以及中间模型文件以推理算子包的形式发送给第二处理器,则无需在第二处理器中配置模型转换的硬件服务器,实现了降低成本的效果。In the above-mentioned embodiment, the second model file is a file configured on the side of the first processor. When the second processor requests the network model, the device including the first processor can convert the second model file and the intermediate model file to the If the inference operator package is sent to the second processor, there is no need to configure a hardware server for model conversion in the second processor, thereby achieving the effect of reducing costs.
可选地,上述步骤的执行主体可以是服务器,如包括有第一处理器的训练服务器等,但不限于此。Optionally, the execution body of the above steps may be a server, such as a training server including a first processor, etc., but is not limited thereto.
通过本发明,将在第一处理器中训练得到的训练网络模型的第一模型文件转换为预定格式的中间模型文件,确定与第二处理器对应的模型转换模块的第二模型文件,根据中间模型文件以及第二模型文件确定推理算子包,将推理算子包发送给包括第二处理器的第一设备,以指示第一设备根据推理算子包将训练网络模型转换为与第二处理器匹配的目标网络模型。由于可以在第一处理器和第二处理器类型不同时,将在第一处理器中训练得到的第一模型文件转换为中间模型文件,并确定出与第二处理器对应的模型转换模块的第二模型文件,使第一设备可以根据中间模型文件以及第二模型文件确定的推理算子包将训练网络模型转换为目标网络模型,以使目标网络模型与第二处理器匹配。且第二模型文件是在第一处理器侧配置的,第二处理器侧无需配置硬件服务器。因此,可以解决相关技术中存在的将网络模型在不同类型的处理器中转换成本高的问题,达到降低网络模型在不同类型的处理器中转换成本的效果。Through the present invention, the first model file of the training network model trained in the first processor is converted into an intermediate model file in a predetermined format, the second model file of the model conversion module corresponding to the second processor is determined, and according to the intermediate model file The model file and the second model file determine the inference operator package, and send the inference operator package to the first device including the second processor, to instruct the first device to convert the training network model to the second processor according to the inference operator package. The target network model matched by the machine. When the types of the first processor and the second processor are different, the first model file trained in the first processor can be converted into an intermediate model file, and the model conversion module corresponding to the second processor can be determined. The second model file enables the first device to convert the training network model into a target network model according to the intermediate model file and the inference operator package determined by the second model file, so that the target network model matches the second processor. In addition, the second model file is configured on the first processor side, and there is no need to configure a hardware server on the second processor side. Therefore, the problem of high cost of converting the network model to different types of processors in the related art can be solved, and the effect of reducing the cost of converting the network model to different types of processors can be achieved.
在一个示例性实施例中,基于所述中间模型文件以及所述第二模型文件确定推理算子包包括:获取训练所述训练网络模型所使用的训练数据;确定与所述第二处理器对应的推理算法;按照预定规则打包所述中间模型文件、所述第二模型文件、所述训练数据以及所述推理算法,以得到所述推理算子包。在本实施例中,在确定推理算子包时,可以获取训练数据,确定与第二处理器对应的推理算法,按照预定规则打包中间模型文件、第二模型文件、训练数据以及推理算法,得到推理算子包。其中,第二模型文件可以是模型转换模块对应的数据文件,第二处理器可以运行第二模型文件,对中间模型文件进行转换。训练数据可以是训练网络模型的全部训练数据,也可以是训练网络模型的部分训练数据。训练数据在第二处理器中,用于校验转换的目标网络模型是否正常。In an exemplary embodiment, determining an inference operator package based on the intermediate model file and the second model file includes: acquiring training data used for training the training network model; determining that the package corresponds to the second processor the inference algorithm; package the intermediate model file, the second model file, the training data and the inference algorithm according to a predetermined rule to obtain the inference operator package. In this embodiment, when the inference operator package is determined, the training data can be obtained, the inference algorithm corresponding to the second processor can be determined, and the intermediate model file, the second model file, the training data and the inference algorithm can be packaged according to predetermined rules, and the result is obtained Inference operator package. The second model file may be a data file corresponding to the model conversion module, and the second processor may run the second model file to convert the intermediate model file. The training data may be the entire training data for training the network model, or may be part of the training data for training the network model. The training data is in the second processor, and is used to verify whether the converted target network model is normal.
在上述实施例中,推理算法可以是用于启动目标网络模型的算法,推理算法与第二处理器的类型相对应,在第二处理器中得到目标网络模型后,可以加载推理算法,以启动目标网络模型执行推理操作。In the above embodiment, the inference algorithm may be an algorithm for starting the target network model. The inference algorithm corresponds to the type of the second processor. After the target network model is obtained in the second processor, the inference algorithm can be loaded to start the target network model. The target network model performs inference operations.
在一个示例性实施例中,在基于所述中间模型文件以及所述第二模型文件确定推理算子包之后,所述方法还包括:确定所述推理算子包的统一资源定位符;将所述统一资源定位符发送给第一设备,以指示所述第一设备基于所述统一资源定位符发送请求信息,其中,所述请求信息用于请求所述推理算子包。在本实施例中,在第一处理器中确定出推理算子包后,可以确定推理算子包的统一资源定位符URL,并将URL发送给第一设备,以指示第一设备根据URL发送请求推理算子包的请求信息。其中,第一设备可以是推理服务器、推理设备等。In an exemplary embodiment, after determining an inference operator package based on the intermediate model file and the second model file, the method further includes: determining a uniform resource locator of the inference operator package; The uniform resource locator is sent to the first device, so as to instruct the first device to send request information based on the uniform resource locator, wherein the request information is used to request the inference operator packet. In this embodiment, after the inference operator package is determined in the first processor, the uniform resource locator URL of the inference operator package can be determined, and the URL is sent to the first device to instruct the first device to send the URL according to the URL Request information for the inference operator package. The first device may be an inference server, an inference device, or the like.
在一个示例性实施例中,在将所述统一资源定位符发送给所述第一设备之后,所述方法还包括:接收第一设备发送的所述请求信息;基于所述请求信息向所述第一设备发送所述推理算子包。在本实施例中,第二处理器在接收到URL后,可以根据URL向第一处理器发送请求信息,第一处理器可以根据请求信息向第一设备发送推理算子包。即第一设备可以根据请求信息下载推理算子包。In an exemplary embodiment, after sending the uniform resource locator to the first device, the method further includes: receiving the request information sent by the first device; and sending the request information to the first device based on the request information. The first device sends the inference operator packet. In this embodiment, after receiving the URL, the second processor may send request information to the first processor according to the URL, and the first processor may send an inference operator packet to the first device according to the request information. That is, the first device can download the inference operator package according to the request information.
在一个示例性实施例中,在基于所述中间模型文件以及所述第二模型文件确定推理算子包之后,所述方法还包括:按照预定时间周期向与所述第一处理器通信连接的目标第二处理器发送所述推理算子包。在本实施例中,在第一处理器中确定出推理算子包后,可以直接将推理算子包发送给目标第二处理器,其中,目标第二处理器可以一个也可以是多个,目标第二处理器与第一处理器通信连接。第一处理器在发送推理算子包时,可以向在线的目标第二处理器发送推理算子包。为了防止由于通信故障导致的发送失败,或由于部分目标第二处理器不在线导致的接收失败,可以按照预定时间周期发送推理算子包。In an exemplary embodiment, after the inference operator package is determined based on the intermediate model file and the second model file, the method further includes: sending an inference operator to a processor communicatively connected to the first processor according to a predetermined time period. The target second processor sends the inference operator packet. In this embodiment, after the inference operator package is determined in the first processor, the inference operator package may be directly sent to the target second processor, where the target second processor may be one or more than one, The target second processor is connected in communication with the first processor. When sending the inference operator packet, the first processor may send the inference operator packet to the online target second processor. In order to prevent transmission failure due to communication failure, or reception failure due to part of target second processors being offline, inference operator packets may be sent according to a predetermined time period.
在一个示例性实施例中,在按照预定时间周期向与所述第一处理器通信连接的目标第二处理器发送所述推理算子包之前,所述方法还包括:接收响应消息,基于所述响应消息确定接收到所述推理算子包的第三处理器,确定与所述第一处理器通信连接的第二处理器,将所述第二处理器中除所述第三处理器之外的处理器确定为所述目标第二处理器,其中,所述响应消息为处理器在接收到推理算子包之后发送的消息。在本实施例中,第一处理器在每次发送推理算子包之前,可以确定向哪些处理器发送推理算子包,以避免向已经接收到推理算子包的处理器重复发送。第一处理器可以根据接收到的响应消息,确定已经接收到推理算子包的第三处理器。并确定与第一处理器连接的第二处理器,第二处理器中除第三处理器之外的处理器为未接收到推理算子包的处理器,因此,可以将第二处理器中除第三处理器之外的处理器确定为目标第二处理器。In an exemplary embodiment, before sending the inference operator packet to a target second processor communicatively connected to the first processor according to a predetermined time period, the method further includes: receiving a response message, based on the The response message determines the third processor that has received the inference operator packet, determines the second processor that is communicatively connected to the first processor, and divides the third processor from the second processor. The external processor is determined as the target second processor, wherein the response message is a message sent by the processor after receiving the inference operator packet. In this embodiment, before sending the inference operator packet each time, the first processor may determine which processors to send the inference operator packet to, so as to avoid repeatedly sending the inference operator packet to the processor that has already received the inference operator packet. The first processor may determine, according to the received response message, the third processor that has received the inference operator packet. And determine the second processor connected to the first processor, the processors in the second processor except the third processor are processors that have not received the inference operator packet, therefore, the second processor can be A processor other than the third processor is determined as the target second processor.
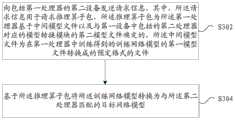
在本实施例中提供了一种网络模型的转换方法,图3是根据本发明实施例的网络模型的转换方法的流程图二,如图3所示,该流程包括如下步骤:A method for converting a network model is provided in this embodiment, and FIG. 3 is a second flowchart of a method for converting a network model according to an embodiment of the present invention. As shown in FIG. 3 , the process includes the following steps:
步骤S302,向包括第一处理器的第二设备发送请求信息,其中,所述请求信息用于请求推理算子包,所述推理算子包为所述第一处理器基于中间模型文件以及与第一设备中包括的第二处理器对应的模型转换模块的第二模型文件确定的,所述中间模型文件为在第一处理器中训练得到的训练网络模型的第一模型文件转换成的预定格式的文件;Step S302, sending request information to the second device including the first processor, wherein the request information is used to request an inference operator package, and the inference operator package is based on the intermediate model file of the first processor and the Determined by the second model file of the model conversion module corresponding to the second processor included in the first device, and the intermediate model file is a predetermined model file converted from the first model file of the training network model trained in the first processor. format file;
步骤S304,基于所述推理算子包将所述训练网络模型转换为与所述第二处理器匹配的目标网络模型。Step S304, converting the training network model into a target network model matching the second processor based on the inference operator package.
在上述实施例中,第一处理器和第二处理器是不同类型的GPU处理器,第一处理器的算力大于第二处理器的算力。第二设备可以是训练服务器中的处理器,第二处理器可以是推理服务器中的处理器,即第一设备可以是推理服务器。可以通过第一处理器训练网络模型,得到训练网络模型后,可以将训练网络模型发送给不同的包括第二处理器的推理设备。由于第二处理器和第一处理器是不同类型的处理器,因此,需要将训练网络模型转换为与第二处理器匹配的目标网络模型。在转换目标网络模型时,可以在第二设备中将训练网络模型的第一模型文件转换为预定格式的中间模型文件。并确定与第二处理器对应的模型转换模块的第二模型文件,根据中间模型文件以及第二模型件确定推理算子包,将推理算子包发送给第一设备,第一设备在接收到推理算子包后,可以解析推理算子包,根据推理算子包实现模型转换。其中,预定格式可以是ONNX格式。In the foregoing embodiment, the first processor and the second processor are different types of GPU processors, and the computing power of the first processor is greater than the computing power of the second processor. The second device may be a processor in a training server, and the second processor may be a processor in an inference server, that is, the first device may be an inference server. The network model can be trained by the first processor, and after the trained network model is obtained, the trained network model can be sent to different inference devices including the second processor. Since the second processor and the first processor are different types of processors, the training network model needs to be converted into a target network model matching the second processor. When converting the target network model, the first model file for training the network model may be converted into an intermediate model file in a predetermined format in the second device. and determine the second model file of the model conversion module corresponding to the second processor, determine the inference operator package according to the intermediate model file and the second model component, and send the inference operator package to the first device, and the first device receives the inference operator package. After the inference operator package is created, the inference operator package can be parsed, and model conversion can be implemented according to the inference operator package. Wherein, the predetermined format may be ONNX format.
在上述实施例中,第二模型文件是在第一处理器侧配置的文件,在第二处理器请求网络模型时,第二设备将第二模型文件以及中间模型文件以推理算子包的形式发送给第一设备,则无需在第一设备中配置模型转换的硬件服务器,实现了降低成本的效果。In the above embodiment, the second model file is a file configured on the side of the first processor. When the second processor requests a network model, the second device stores the second model file and the intermediate model file in the form of an inference operator package. If it is sent to the first device, there is no need to configure a hardware server for model conversion in the first device, thereby achieving the effect of reducing costs.
可选地,上述步骤的执行主体可以是第一设备,但不限于此。Optionally, the execution subject of the above steps may be the first device, but is not limited thereto.
通过本发明,第二设备将在第一处理器中训练得到的训练网络模型的第一模型文件转换为预定格式的中间模型文件,确定与第二处理器对应的模型转换模块的第二模型文件,根据中间模型文件以及第二模型文件确定推理算子包,第一设备向第二设备中包括的第一处理器发送用于请求推理算子包的请求信息,将推理算子包发送给第二设备,以指示第二设备根据推理算子包将训练网络模型转换为与第二处理器匹配的目标网络模型。由于可以在第一处理器和第二处理器类型不同时,将在第一处理器中训练得到的第一模型文件转换为中间模型文件,并确定出与第二处理器对应的模型转换模块的第二模型文件,使第二处理器可以根据中间模型文件以及第二模型文件确定的推理算子包将训练网络模型转换为目标网络模型,以使目标网络模型与第二处理器匹配。且第二模型文件是在第一处理器侧配置的,第二处理器侧无需配置硬件服务器。因此,可以解决相关技术中存在的将网络模型在不同类型的处理器中转换成本高的问题,达到降低网络模型在不同类型的处理器中转换成本的效果。Through the present invention, the second device converts the first model file of the training network model obtained by training in the first processor into an intermediate model file in a predetermined format, and determines the second model file of the model conversion module corresponding to the second processor , determine the inference operator package according to the intermediate model file and the second model file, the first device sends request information for requesting the inference operator package to the first processor included in the second device, and sends the inference operator package to the first processor included in the second device. a second device to instruct the second device to convert the training network model into a target network model matching the second processor according to the inference operator package. When the types of the first processor and the second processor are different, the first model file trained in the first processor can be converted into an intermediate model file, and the model conversion module corresponding to the second processor can be determined. The second model file enables the second processor to convert the training network model into the target network model according to the intermediate model file and the inference operator package determined by the second model file, so that the target network model matches the second processor. In addition, the second model file is configured on the first processor side, and there is no need to configure a hardware server on the second processor side. Therefore, the problem of high cost of converting the network model to different types of processors in the related art can be solved, and the effect of reducing the cost of converting the network model to different types of processors can be achieved.
在一个示例性实施例中,基于所述推理算子包将所述训练网络模型转换为与所述第二处理器匹配的目标网络模型包括:解析所述推理算子包,得到中间模型文件、所述第二模型文件、训练数据;运行所述第二模型文件,得到模型转换模块;基于所述模型转换模块、所述中间模型文件以及所述训练数据进行模型转换,以得到所述目标网络模型。在本实施例中,推理算子包可以是按照预定规则打包的算子包,第二处理器可以按照预定规则进行解析,得到中间模型文件、第二模型文件、训练数据。其中,第二模型文件可以是模型转换模块对应的数据文件,第二处理器可以运行第二模型文件,对中间模型文件进行转换。训练数据可以是训练网络模型的全部训练数据,也可以是训练网络模型的部分训练数据。训练数据在第二处理器中,用于校验转换的目标网络模型是否正常。In an exemplary embodiment, converting the training network model into a target network model matching the second processor based on the inference operator package includes: parsing the inference operator package to obtain an intermediate model file, the second model file and training data; run the second model file to obtain a model conversion module; perform model conversion based on the model conversion module, the intermediate model file and the training data to obtain the target network Model. In this embodiment, the inference operator package may be an operator package packaged according to a predetermined rule, and the second processor may perform analysis according to the predetermined rule to obtain an intermediate model file, a second model file, and training data. The second model file may be a data file corresponding to the model conversion module, and the second processor may run the second model file to convert the intermediate model file. The training data may be the entire training data for training the network model, or may be part of the training data for training the network model. The training data is in the second processor, and is used to verify whether the converted target network model is normal.
在上述实施例中,推理算法可以是用于启动目标网络模型的算法,推理算法与第二处理器的类型相对应,在第二处理器中得到目标网络模型后,可以加载推理算法,以启动目标网络模型执行推理操作。In the above embodiment, the inference algorithm may be an algorithm for starting the target network model. The inference algorithm corresponds to the type of the second processor. After the target network model is obtained in the second processor, the inference algorithm can be loaded to start the target network model. The target network model performs inference operations.
在一个示例性实施例中,基于所述模型转换模块、所述中间模型文件以及所述训练数据进行模型转换,以得到所述目标网络模型包括:通过所述模型转换模块加载所述中间模型文件,得到转换后的转换网络模型;将所述训练数据中包括的训练样本输入至所述转换网络模型,确定训练结果;确定与所述训练样本对应的标签结果与所述训练结果之间的误差;在所述误差小于预定阈值的情况下,将所述转换网络模型确定为所述目标网络模型。在本实施例中,在进行模型转换时,可以根据通过模型转换模块加载中间模型文件得到转换网络模型,并同时根据训练数据验证转换网络模型,确定训练结果,当训练结果与训练样本对应的标签结果之间的误差小于预定阈值时,将转换网络模型确定为目标网络模型。In an exemplary embodiment, performing model conversion based on the model conversion module, the intermediate model file and the training data to obtain the target network model includes: loading the intermediate model file through the model conversion module to obtain the converted conversion network model; input the training samples included in the training data into the conversion network model to determine the training result; determine the error between the label result corresponding to the training sample and the training result ; in the case that the error is smaller than a predetermined threshold, determining the conversion network model as the target network model. In this embodiment, when performing model conversion, the conversion network model can be obtained by loading the intermediate model file through the model conversion module, and at the same time, the conversion network model can be verified according to the training data to determine the training result. When the training result corresponds to the label corresponding to the training sample When the error between the results is less than a predetermined threshold, the conversion network model is determined as the target network model.
在一个示例性实施例中,在将所述转换网络模型确定为所述目标网络模型之后,所述方法还包括:确定所述推理算子包中包括的推理算法,其中,所述推理算法为与所述第二处理器对应的推理算法;运行所述推理算法,以启动所述目标网络模型;基于启动后的所述目标网络模型执行目标操作。在本实施例中,在得到目标网络模型之后,还可以确定推理算子包中包括的推理算法,可以通过运行推理算法的方式启动目标网络模型。其中,推理算法可以是与第二处理器对应的算法。目标网络模型在启动后,可以执行相应的目标操作。例如,当目标网络模型为人脸识别模型时,目标操作可以为人脸识别操作。当目标网络模型为车辆识别模型时,目标操作可以为车辆识别操作。In an exemplary embodiment, after the conversion network model is determined as the target network model, the method further includes: determining an inference algorithm included in the inference operator package, wherein the inference algorithm is an inference algorithm corresponding to the second processor; run the inference algorithm to start the target network model; and execute a target operation based on the start-up target network model. In this embodiment, after the target network model is obtained, the inference algorithm included in the inference operator package can also be determined, and the target network model can be started by running the inference algorithm. The inference algorithm may be an algorithm corresponding to the second processor. After the target network model is started, the corresponding target operation can be performed. For example, when the target network model is a face recognition model, the target operation may be a face recognition operation. When the target network model is a vehicle recognition model, the target operation may be a vehicle recognition operation.
在一个示例性实施例中,在向第一处理器发送请求信息之前,所述方法还包括:接收所述第二设备发送的所述推理算子包的统一资源定位符;基于所述统一资源定位符发送所述请求信息。在本实施例中,在向第二设备发送请求信息之前,可以接收第二设备发送的推理算子包的统一资源定位符URL,根据URL发送请求信息,以在第二设备中下载推理算子包。In an exemplary embodiment, before sending the request information to the first processor, the method further includes: receiving a uniform resource locator of the inference operator packet sent by the second device; based on the uniform resource The locator sends the request information. In this embodiment, before sending the request information to the second device, the URL of the uniform resource locator of the inference operator package sent by the second device may be received, and the request information may be sent according to the URL, so as to download the inference operator in the second device Bag.
在一个示例性实施例中,向第一处理器发送请求信息包括:确定所述目标网络模型的存在状态;在所述存在状态指示不存在所述目标网络模型的情况下,向所述第二设备发送请求信息。在本实施例中,在向第二设备发送请求信息之前,可以确定目标网络模型在第一设备中的存在状态,在第一设备中存在目标网络模型时,则无需发送请求信息,当第一设备中不存在目标网络模型时,发送请求信息。In an exemplary embodiment, sending the request information to the first processor includes: determining the existence state of the target network model; and in the case that the existence state indicates that the target network model does not exist, sending the request to the second processor The device sends the request message. In this embodiment, before sending the request information to the second device, the existence state of the target network model in the first device can be determined. When the target network model exists in the first device, there is no need to send the request information. When the target network model does not exist in the device, the request information is sent.
在一个示例性实施例中,在基于所述推理算子包将所述训练网络模型转换为与所述第二处理器匹配的目标网络模型之后,所述方法还包括:向所述第一处理器发送响应消息,其中,所述响应消息为所述第二处理器在接收到所述推理算子包之后发送的消息。在本实施例中,第二处理器在接收到推理算子包后,可以向第一处理器发送一个响应消息,第一处理器根据响应消息即可确定第二处理器接收到了推理算子包。In an exemplary embodiment, after converting the training network model into a target network model matching the second processor based on the inference operator package, the method further includes: sending the first processing The second processor sends a response message, wherein the response message is a message sent by the second processor after receiving the inference operator packet. In this embodiment, after receiving the inference operator packet, the second processor may send a response message to the first processor, and the first processor can determine according to the response message that the second processor has received the inference operator packet .
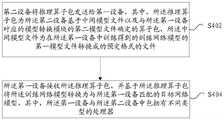
在本实施例中还提供了一种网络模型的转换方法,图4是根据本发明实施例的网络模型的转换方法的流程图三,如图4所示,该流程包括如下步骤:A method for converting a network model is also provided in this embodiment, and FIG. 4 is a third flowchart of a method for converting a network model according to an embodiment of the present invention. As shown in FIG. 4 , the process includes the following steps:
步骤S402,第二设备将推理算子包发送给第一设备,其中,所述推理算子包为所述第二设备基于中间模型文件以及与所述第一设备对应的模型转换模块的第二模型文件确定的算子包,所述中间模型文件为在所述第一设备中训练得到的训练网络模型的第一模型文件转换成的预定格式的文件;Step S402, the second device sends the inference operator package to the first device, wherein the inference operator package is the second device based on the intermediate model file and the model conversion module corresponding to the first device. an operator package determined by a model file, where the intermediate model file is a file in a predetermined format converted from the first model file of the training network model trained in the first device;
步骤S404,所述第一设备接收所述推理算子包,并基于所述推理算子包将所述训练网络模型转换为与所述第一设备匹配的目标网络模型,其中,所述第一设备与所述第二设备中包括有不同类型的处理器。Step S404, the first device receives the inference operator package, and converts the training network model into a target network model matching the first device based on the inference operator package, wherein the first device Different types of processors are included in the device and the second device.
在上述实施例中,第一设备中可以包括第二处理器,第二设备中可以包括第一处理器,第一处理器和第二处理器可以是不同类型的GPU处理器,第一处理器的算力大于第二处理器的算力,第一处理器可以是训练服务器中的处理器,第二处理器可以是推理服务器中的处理器,即第一设备可以为推理服务器。可以通过第一处理器训练网络模型,得到训练网络模型后,可以将训练网络模型发送给不同的包括第二处理器的第一设备。由于第二处理器和第一处理器是不同类型的处理器,因此,需要将训练网络模型转换为与第二处理器匹配的目标网络模型。在转换目标网络模型时,包括有第一处理器的设备可以将训练网络模型的第一模型文件转换为预定格式的中间模型文件。并确定与第二处理器对应的模型转换模块的第二模型文件,根据中间模型文件以及第二模型文件确定推理算子包,将推理算子包发送给第一设备,第一设备在接收到推理算子包后,可以解析推理算子包,根据推理算子包实现模型转换。其中,预定格式可以是ONNX格式。In the above embodiment, the first device may include a second processor, the second device may include a first processor, the first processor and the second processor may be different types of GPU processors, and the first processor The computing power is greater than the computing power of the second processor, the first processor may be a processor in a training server, and the second processor may be a processor in an inference server, that is, the first device may be an inference server. The network model can be trained by the first processor, and after the trained network model is obtained, the trained network model can be sent to different first devices including the second processor. Since the second processor and the first processor are different types of processors, the training network model needs to be converted into a target network model matching the second processor. When converting the target network model, the device including the first processor may convert the first model file for training the network model into an intermediate model file in a predetermined format. and determine the second model file of the model conversion module corresponding to the second processor, determine the inference operator package according to the intermediate model file and the second model file, and send the inference operator package to the first device, and the first device receives the inference operator package. After the inference operator package is created, the inference operator package can be parsed, and model conversion can be implemented according to the inference operator package. Wherein, the predetermined format may be ONNX format.
在上述实施例中,第二模型文件是在第一处理器侧配置的文件,在第二处理器请求网络模型时,包括有第一处理器的设备可以将第二模型文件以及中间模型文件以推理算子包的形式发送给第二处理器,则无需在第二处理器中配置模型转换的硬件服务器,实现了降低成本的效果。In the above-mentioned embodiment, the second model file is a file configured on the side of the first processor. When the second processor requests the network model, the device including the first processor can convert the second model file and the intermediate model file to the If the inference operator package is sent to the second processor, there is no need to configure a hardware server for model conversion in the second processor, thereby achieving the effect of reducing costs.
通过本发明,第二设备根据在第二设备中训练得到的训练网络模型的第一模型文件转成的预定格式的中间模型文件以及第一设备对应的模型转换模块的第二模型文件确定推理算子包,第二设备将推理算子包发送给第一设备,第一设备接收到推理算子包后,根据推理算子包将训练网络模型转换为与第一设备匹配的目标网络模型。由于可以在第一设备和第二设备中包括的处理器类型不同时,将在第二设备中训练得到的第一模型文件转换为中间模型文件,并确定出与第一设备对应的模型转换模块的第二模型文件,使第一设备可以根据中间模型文件以及第二模型文件确定的推理算子包将训练网络模型转换为目标网络模型,以使目标网络模型与第一设备匹配。且第二模型文件是在第二设备侧配置的,第一设备侧无需配置硬件服务器。因此,可以解决相关技术中存在的将网络模型在不同类型的处理器中转换成本高的问题,达到降低网络模型在不同类型的处理器中转换成本的效果。Through the present invention, the second device determines the inference algorithm according to the intermediate model file in a predetermined format converted from the first model file of the training network model trained in the second device and the second model file of the model conversion module corresponding to the first device. The second device sends the inference operator packet to the first device. After receiving the inference operator packet, the first device converts the training network model into a target network model matching the first device according to the inference operator packet. When the types of processors included in the first device and the second device are different, the first model file trained in the second device can be converted into an intermediate model file, and the model conversion module corresponding to the first device can be determined. the second model file, so that the first device can convert the training network model into a target network model according to the intermediate model file and the inference operator package determined by the second model file, so that the target network model matches the first device. In addition, the second model file is configured on the second device side, and there is no need to configure a hardware server on the first device side. Therefore, the problem of high cost of converting the network model to different types of processors in the related art can be solved, and the effect of reducing the cost of converting the network model to different types of processors can be achieved.
下面结合具体实施方式对网络模型的转换方法进行说明:The conversion method of the network model is described below in conjunction with the specific embodiments:
图5是根据本发明具体实施例的运行网络模型的转换方法的装置结构示意图,如图5所示,第一设备可以是推理单元中包括的设备,第二设备可以是训练服务单元。训练服务单元可以包括模型训练模块、中间模型转换模块、推理算子包打包模块、部署模块。模型训练模块通过NVIDIA AGPU卡,负责原始模型的训练;中间模型转换模块主要完成训练出来的原始模型文件转换成标准的ONNX格式的中间模型文件,推理算子打包模块在收到中间模块输出的ONNX中间模型之后,连同适配NVIDIA B模型转换模块、NVIDIA B推理算法包以及校准图片按照一定的打包规则,生成推理算子包;部署模块完成对已生成的推理算子包URL下发给各推理设备。当推理单元接收到训练服务单元下发的推理算子包URL后,向训练服务单元发起请求下载推理算子包,在训练服务单元检验通过之后,获取推理算子包。5 is a schematic structural diagram of an apparatus for running a method for converting a network model according to a specific embodiment of the present invention. As shown in FIG. 5 , the first device may be a device included in an inference unit, and the second device may be a training service unit. The training service unit may include a model training module, an intermediate model conversion module, an inference operator package packaging module, and a deployment module. The model training module is responsible for the training of the original model through the NVIDIA AGPU card; the intermediate model conversion module mainly converts the trained original model file into a standard ONNX format intermediate model file, and the inference operator packaging module receives the ONNX output from the intermediate module. After the intermediate model, together with the adapted NVIDIA B model conversion module, the NVIDIA B inference algorithm package and the calibration image, the inference operator package is generated according to certain packaging rules; the deployment module completes the delivery of the generated inference operator package URL to each inference operator. equipment. After the inference unit receives the inference operator package URL issued by the training service unit, it initiates a request to the training service unit to download the inference operator package, and after the training service unit passes the inspection, the inference operator package is obtained.
图6是根据本发明具体实施例的确定推理算子包流程图,如图6所示,当第一处理器为NVIDIA A GPU卡、第二处理器为NVIDIA B卡时,在收到中间模块输出的ONNX中间模型之后,连同适配NVIDIAB卡模型转换模块、NVIDIAB卡推理算法包以及校准图片(对应于上述训练数据)按照一定的打包规则,生成推理算子包。FIG. 6 is a flowchart of determining an inference operator package according to a specific embodiment of the present invention. As shown in FIG. 6 , when the first processor is an NVIDIA A GPU card and the second processor is an NVIDIA B card, after receiving the intermediate module After the output of the ONNX intermediate model, together with the NVIDIA B card model conversion module, the NVIDIA B card inference algorithm package, and the calibration image (corresponding to the above training data), an inference operator package is generated according to certain packaging rules.
图7是根据本发明具体实施例的网络模型的转换方法流程图,如图7所示,该流程包括:FIG. 7 is a flow chart of a method for converting a network model according to a specific embodiment of the present invention. As shown in FIG. 7 , the flow includes:
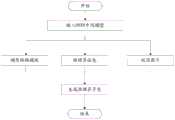
a)推理单元(对应于上述第一设备)启动后,先进行判断基于B推理卡的TensorRT模型是否存在,如果不存在,先解析从训练服务单元下载得到的推理算子包,从而获取中间ONNX模型、模型转换模块、校验图片、推理算法;a) After the inference unit (corresponding to the above-mentioned first device) is started, first determine whether the TensorRT model based on the B inference card exists, if not, first parse the inference operator package downloaded from the training service unit, so as to obtain the intermediate ONNX Model, model conversion module, verification image, reasoning algorithm;
b)启动模型转换模块根据一定的规则传入中间ONNX模型和校验图片,进行基于B推理卡硬件环境下的模型转换;b) Start the model conversion module to import the intermediate ONNX model and the verification picture according to certain rules, and perform model conversion based on the hardware environment of the B reasoning card;
c)经过模型转换得到TensorRT加速模型之后,启动推理算法加载TensorRT模型文件,进行推理业务。c) After the TensorRT acceleration model is obtained through model conversion, start the inference algorithm to load the TensorRT model file and perform inference business.
d)如果TensorRT模型已存在,直接加载TensorRT模型文件,进行推理业务,则无需再次进行TensorRT模型的转换,加快推理算法的启动速度。d) If the TensorRT model already exists, directly load the TensorRT model file to perform the inference business, and there is no need to convert the TensorRT model again, which speeds up the startup of the inference algorithm.
在前述实施例中,通过把模型转换模块前置到推理端,在推理端启动时调用模型转换模块进行TensorRT模型转换,实现TensorRT的加速。推理算法与模型转换模块一体化,不需要单独启动其他工具进行模型转换,减少了用户的使用成本,降低了用户的使用复杂度。In the foregoing embodiment, the acceleration of TensorRT is achieved by prepending the model conversion module to the inference end, and calling the model conversion module to perform TensorRT model conversion when the inference end is started. The inference algorithm is integrated with the model conversion module, and there is no need to start other tools separately for model conversion, which reduces the user's use cost and reduces the user's use complexity.
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到根据上述实施例的方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质(如ROM/RAM、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是手机,计算机,服务器,或者网络设备等)执行本发明各个实施例所述的方法。From the description of the above embodiments, those skilled in the art can clearly understand that the method according to the above embodiment can be implemented by means of software plus a necessary general hardware platform, and of course can also be implemented by hardware, but in many cases the former is better implementation. Based on this understanding, the technical solutions of the present invention can be embodied in the form of software products in essence or the parts that make contributions to the prior art, and the computer software products are stored in a storage medium (such as ROM/RAM, magnetic disk, CD-ROM), including several instructions to make a terminal device (which may be a mobile phone, a computer, a server, or a network device, etc.) to execute the methods described in the various embodiments of the present invention.
在本实施例中还提供了一种网络模型的转换装置,该装置用于实现上述实施例及优选实施方式,已经进行过说明的不再赘述。如以下所使用的,术语“模块”可以实现预定功能的软件和/或硬件的组合。尽管以下实施例所描述的装置较佳地以软件来实现,但是硬件,或者软件和硬件的组合的实现也是可能并被构想的。This embodiment also provides an apparatus for converting a network model, the apparatus is used to implement the above embodiments and preferred implementations, and what has been described will not be repeated. As used below, the term "module" may be a combination of software and/or hardware that implements a predetermined function. Although the apparatus described in the following embodiments is preferably implemented in software, implementations in hardware, or a combination of software and hardware, are also possible and contemplated.
图8是根据本发明实施例的网络模型的转换装置的结构框图一,如图8所示,该装置包括:FIG. 8 is a structural block diagram 1 of an apparatus for converting a network model according to an embodiment of the present invention. As shown in FIG. 8 , the apparatus includes:
第一转换模块82,用于将在第一处理器中训练得到的训练网络模型的第一模型文件转换为预定格式的中间模型文件;The
第一确定模块84,用于确定与第二处理器对应的模型转换模块的第二模型文件,其中,所述第二处理器与所述第一处理器为不同类型的处理器;a first determining
第二确定模块86,用于基于所述中间模型文件以及所述第二模型文件确定推理算子包;A second determining
第二转换模块88,用于将所述推理算子包发送给包括所述第二处理器的第一设备,以指示所述第一设备基于所述推理算子包将所述训练网络模型转换为与所述第二处理器匹配的目标网络模型。A
其中,第一转换模块82对应于上述中间模型转换模块,第一确定模块84、第二确定模块86对应于上述推理算子包打包模块,第二转换模块88对应于部署模块。The
在一个示例性实施例中,第二确定模块86可以通过如下方式实现基于所述中间模型文件以及所述第二模型文件确定推理算子包:获取训练所述训练网络模型所使用的训练数据;确定与所述第二处理器对应的推理算法;按照预定规则打包所述中间模型文件、所述第二模型文件、所述训练数据以及所述推理算法,以得到所述推理算子包。In an exemplary embodiment, the second determining
在一个示例性实施例中,所述装置可以用于在基于所述中间模型文件以及所述第二模型文件确定推理算子包之后,确定所述推理算子包的统一资源定位符;将所述统一资源定位符发送给所述第一设备,以指示所述第一设备基于所述统一资源定位符发送请求信息,其中,所述第一设备包括所述第二处理器,所述请求信息用于请求所述推理算子包。In an exemplary embodiment, the apparatus may be configured to determine the uniform resource locator of the inference operator package after determining the inference operator package based on the intermediate model file and the second model file; sending the uniform resource locator to the first device to instruct the first device to send request information based on the uniform resource locator, wherein the first device includes the second processor, the request information Used to request the inference operator package.
在一个示例性实施例中,所述装置还可以用于在将所述统一资源定位符发送给所述第一设备之后,接收第一设备发送的所述请求信息;基于所述请求信息向所述第一设备发送所述推理算子包。In an exemplary embodiment, the apparatus may be further configured to, after sending the uniform resource locator to the first device, receive the request information sent by the first device; and send the request information to the first device based on the request information. The first device sends the inference operator packet.
在一个示例性实施例中,所述装置还可以用于在基于所述中间模型文件以及所述第二模型文件确定推理算子包之后,按照预定时间周期向与所述第一处理器通信连接的目标第二处理器发送所述推理算子包。In an exemplary embodiment, the apparatus may be further configured to communicate with the first processor according to a predetermined time period after the inference operator package is determined based on the intermediate model file and the second model file The target second processor sends the inference operator packet.
在一个示例性实施例中,所述装置还可以用于在按照预定时间周期向与所述第一处理器通信连接的目标第二处理器发送所述推理算子包之前,接收响应消息,基于所述响应消息确定接收到所述推理算子包的第三处理器,确定与所述第一处理器通信连接的第二处理器,将所述第二处理器中除所述第三处理器之外的处理器确定为所述目标第二处理器,其中,所述响应消息为处理器在接收到推理算子包之后发送的消息。In an exemplary embodiment, the apparatus may be further configured to receive a response message based on a predetermined time period before sending the inference operator packet to a target second processor communicatively connected to the first processor. The response message determines a third processor that has received the inference operator packet, determines a second processor that is communicatively connected to the first processor, and divides the third processor from the second processor The other processor is determined as the target second processor, wherein the response message is a message sent by the processor after receiving the inference operator packet.
图9是根据本发明实施例的网络模型的转换装置的结构框图二,如图9所示,该装置包括:FIG. 9 is a second structural block diagram of an apparatus for converting a network model according to an embodiment of the present invention. As shown in FIG. 9 , the apparatus includes:
发送模块92,用于向包括第一处理器的第二设备发送请求信息,其中,所述请求信息用于请求推理算子包,所述推理算子包为所述第一处理器基于中间模型文件以及与第一设备中包括的第二处理器对应的模型转换模块的第二模型文件确定的,所述中间模型文件为在第一处理器中训练得到的训练网络模型的第一模型文件转换成的预定格式的文件;The sending
第三转换模块94,用于基于所述推理算子包将所述训练网络模型转换为与所述第二处理器匹配的目标网络模型。The
在一个示例性实施例中,第三转换模块94可以通过如下方式实现基于所述推理算子包将所述训练网络模型转换为与所述第二处理器匹配的目标网络模型:解析所述推理算子包,得到中间模型文件、所述第二模型文件、训练数据;运行所述第二模型文件,得到模型转换模块;基于所述模型转换模块、所述中间模型文件以及所述训练数据进行模型转换,以得到所述目标网络模型。In an exemplary embodiment, the
在一个示例性实施例中,第三转换模块94可以通过如下方式实现基于所述模型转换模块、所述中间模型文件以及所述训练数据进行模型转换,以得到所述目标网络模型:通过所述模型转换模块加载所述中间模型文件,得到转换后的转换网络模型;将所述训练数据中包括的训练样本输入至所述转换网络模型,确定训练结果;确定与所述训练样本对应的标签结果与所述训练结果之间的误差;在所述误差小于预定阈值的情况下,将所述转换网络模型确定为所述目标网络模型。In an exemplary embodiment, the
在一个示例性实施例中,所述装置可以用于在将所述转换网络模型确定为所述目标网络模型之后,确定所述推理算子包中包括的推理算法,其中,所述推理算法为与所述第二处理器对应的推理算法;运行所述推理算法,以启动所述目标网络模型;基于启动后的所述目标网络模型执行目标操作。In an exemplary embodiment, the apparatus may be configured to determine an inference algorithm included in the inference operator package after the conversion network model is determined as the target network model, wherein the inference algorithm is an inference algorithm corresponding to the second processor; run the inference algorithm to start the target network model; and execute a target operation based on the start-up target network model.
在一个示例性实施例中,所述装置可以用于在向第一处理器发送请求信息之前,接收所述第二设备发送的所述推理算子包的统一资源定位符;基于所述统一资源定位符发送所述请求信息。In an exemplary embodiment, the apparatus may be configured to, before sending the request information to the first processor, receive the uniform resource locator of the inference operator packet sent by the second device; based on the uniform resource The locator sends the request information.
在一个示例性实施例中,发送模块92可以通过如下方式实现向第一处理器发送请求信息:确定所述目标网络模型的存在状态;在所述存在状态指示不存在所述目标网络模型的情况下,向所述第二设备发送请求信息。In an exemplary embodiment, the sending
在一个示例性实施例中,所述装置还用于,在基于所述推理算子包将所述训练网络模型转换为与所述第二处理器匹配的目标网络模型之后,向所述第一处理器发送响应消息,其中,所述响应消息为所述第二处理器在接收到所述推理算子包之后发送的消息。In an exemplary embodiment, the apparatus is further configured to, after converting the training network model into a target network model matched with the second processor based on the inference operator package, send a message to the first The processor sends a response message, where the response message is a message sent by the second processor after receiving the inference operator packet.
在本实施例中还提供了一种网络模型的转换系统,包括第一设备,其中,所述第一设备用于执行上述实施例所述网络模型的转换的方法一(即网络模型的转换方法的流程图一所对应的实施例中的方法);第二设备,其中,所述第二设备与所述第一设备通信连接,所述第二设备用于执行上述实施例所述网络模型的转换的方法二(即网络模型的转换方法的流程图二所对应的实施例),其中,所述第一设备与所述第二设备中包括有不同类型的处理器。This embodiment also provides a system for converting a network model, including a first device, wherein the first device is configured to perform the first method for converting a network model (that is, a method for converting a network model) according to the foregoing embodiment. The method in the embodiment corresponding to the flow chart 1); the second device, wherein the second device is connected to the first device in communication, and the second device is configured to execute the network model of the above embodiment. The second conversion method (ie, the embodiment corresponding to the second flowchart of the network model conversion method), wherein the first device and the second device include different types of processors.
需要说明的是,上述各个模块是可以通过软件或硬件来实现的,对于后者,可以通过以下方式实现,但不限于此:上述模块均位于同一处理器中;或者,上述各个模块以任意组合的形式分别位于不同的处理器中。It should be noted that the above modules can be implemented by software or hardware, and the latter can be implemented in the following ways, but not limited to this: the above modules are all located in the same processor; or, the above modules can be combined in any combination The forms are located in different processors.
本发明的实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,其中,所述计算机程序被处理器执行时实现上述任一项中所述的方法的步骤。An embodiment of the present invention also provides a computer-readable storage medium, where a computer program is stored in the computer-readable storage medium, wherein the computer program implements any of the methods described above when executed by a processor A step of.
在一个示例性实施例中,上述计算机可读存储介质可以包括但不限于:U盘、只读存储器(Read-Only Memory,简称为ROM)、随机存取存储器(Random Access Memory,简称为RAM)、移动硬盘、磁碟或者光盘等各种可以存储计算机程序的介质。In an exemplary embodiment, the above-mentioned computer-readable storage medium may include, but is not limited to, a USB flash drive, a read-only memory (Read-Only Memory, referred to as ROM for short), and a random access memory (Random Access Memory, referred to as RAM for short) , mobile hard disk, magnetic disk or CD-ROM and other media that can store computer programs.
本发明的实施例还提供了一种电子装置,包括存储器和处理器,该存储器中存储有计算机程序,该处理器被设置为运行计算机程序以执行上述任一项方法实施例中的步骤。An embodiment of the present invention also provides an electronic device, comprising a memory and a processor, where a computer program is stored in the memory, and the processor is configured to run the computer program to execute the steps in any of the above method embodiments.
在一个示例性实施例中,上述电子装置还可以包括传输设备以及输入输出设备,其中,该传输设备和上述处理器连接,该输入输出设备和上述处理器连接。In an exemplary embodiment, the above-mentioned electronic device may further include a transmission device and an input-output device, wherein the transmission device is connected to the above-mentioned processor, and the input-output device is connected to the above-mentioned processor.
本实施例中的具体示例可以参考上述实施例及示例性实施方式中所描述的示例,本实施例在此不再赘述。For specific examples in this embodiment, reference may be made to the examples described in the foregoing embodiments and exemplary implementation manners, and details are not described herein again in this embodiment.
显然,本领域的技术人员应该明白,上述的本发明的各模块或各步骤可以用通用的计算装置来实现,它们可以集中在单个的计算装置上,或者分布在多个计算装置所组成的网络上,它们可以用计算装置可执行的程序代码来实现,从而,可以将它们存储在存储装置中由计算装置来执行,并且在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤,或者将它们分别制作成各个集成电路模块,或者将它们中的多个模块或步骤制作成单个集成电路模块来实现。这样,本发明不限制于任何特定的硬件和软件结合。Obviously, those skilled in the art should understand that the above-mentioned modules or steps of the present invention can be implemented by a general-purpose computing device, which can be centralized on a single computing device, or distributed in a network composed of multiple computing devices On the other hand, they can be implemented in program code executable by a computing device, so that they can be stored in a storage device and executed by the computing device, and in some cases, can be performed in a different order than shown here. Or the described steps, or they are respectively made into individual integrated circuit modules, or a plurality of modules or steps in them are made into a single integrated circuit module to realize. As such, the present invention is not limited to any particular combination of hardware and software.
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。The above descriptions are only preferred embodiments of the present invention, and are not intended to limit the present invention. For those skilled in the art, the present invention may have various modifications and changes. Any modification, equivalent replacement, improvement, etc. made within the principle of the present invention shall be included within the protection scope of the present invention.
Claims (16)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111644376.2ACN114298284A (en) | 2021-12-29 | 2021-12-29 | Network model conversion method, device, system, storage medium and electronic device |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111644376.2ACN114298284A (en) | 2021-12-29 | 2021-12-29 | Network model conversion method, device, system, storage medium and electronic device |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN114298284Atrue CN114298284A (en) | 2022-04-08 |
Family
ID=80971536
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202111644376.2APendingCN114298284A (en) | 2021-12-29 | 2021-12-29 | Network model conversion method, device, system, storage medium and electronic device |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114298284A (en) |
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114997401A (en)* | 2022-08-03 | 2022-09-02 | 腾讯科技(深圳)有限公司 | Adaptive inference acceleration method, apparatus, computer device and storage medium |
| CN115713108A (en)* | 2022-11-08 | 2023-02-24 | 浙江大华技术股份有限公司 | Packing method and device of model, storage medium and electronic device |
| CN115496217B (en)* | 2022-11-16 | 2023-03-24 | 深圳鲲云信息科技有限公司 | Inference verification method and device, electronic equipment and storage medium |
| CN116108901A (en)* | 2022-12-30 | 2023-05-12 | 浙江大华技术股份有限公司 | Model deployment method and device, storage medium and electronic device |
| CN117149270A (en)* | 2023-10-30 | 2023-12-01 | 中国铁塔股份有限公司 | Method, system and related equipment for generating model file crossing hardware platform |
| CN117407299A (en)* | 2023-10-18 | 2024-01-16 | 北京大学 | Model test method and system |
| WO2024230574A1 (en)* | 2023-05-06 | 2024-11-14 | 维沃移动通信有限公司 | Model processing method, model execution method, and model registration method |
| CN119272880A (en)* | 2024-10-09 | 2025-01-07 | 五八畅生活(北京)信息技术有限公司 | Model conversion method, device, storage medium and program product |
Citations (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN107862103A (en)* | 2017-09-20 | 2018-03-30 | 国家电网公司 | A kind of simulation model generation method and system based on ADPSS |
| CN111222636A (en)* | 2020-01-07 | 2020-06-02 | 深圳鲲云信息科技有限公司 | Deep learning model conversion method and device, server and storage medium |
| CN111507476A (en)* | 2019-01-31 | 2020-08-07 | 伊姆西Ip控股有限责任公司 | Method, apparatus and computer program product for deploying machine learning model |
| CN111753948A (en)* | 2020-06-23 | 2020-10-09 | 展讯通信(上海)有限公司 | Model processing method and related equipment |
| CN111860817A (en)* | 2020-07-10 | 2020-10-30 | 苏州浪潮智能科技有限公司 | A network model deployment method, apparatus, device and readable storage medium |
| CN112364744A (en)* | 2020-11-03 | 2021-02-12 | 珠海市卓轩科技有限公司 | TensorRT-based accelerated deep learning image recognition method, device and medium |
| CN112711423A (en)* | 2021-01-18 | 2021-04-27 | 深圳中兴网信科技有限公司 | Engine construction method, intrusion detection method, electronic device and readable storage medium |
| CN112947899A (en)* | 2019-12-11 | 2021-06-11 | 杭州海康威视数字技术股份有限公司 | Deep learning model conversion method, system and device |
| CN113128465A (en)* | 2021-05-11 | 2021-07-16 | 济南大学 | Small target detection method based on improved YOLOv4 for industrial scene |
| US20210256097A1 (en)* | 2020-02-12 | 2021-08-19 | Servicenow, Inc. | Determination of intermediate representations of discovered document structures |
| WO2021169363A1 (en)* | 2020-09-09 | 2021-09-02 | 平安科技(深圳)有限公司 | Optimization method for text recognition system, computer device, and storage medium |
| CN113641337A (en)* | 2021-07-13 | 2021-11-12 | 广州三七互娱科技有限公司 | Data processing method, data processing device, computer equipment and storage medium |
| CN113705799A (en)* | 2020-05-21 | 2021-11-26 | 平头哥(上海)半导体技术有限公司 | Processing unit, computing device and computation graph processing method of deep learning model |
| CN113705404A (en)* | 2021-08-18 | 2021-11-26 | 南京邮电大学 | Face detection method facing embedded hardware |
| CN113780536A (en)* | 2021-10-29 | 2021-12-10 | 平安科技(深圳)有限公司 | Cloud deep learning model conversion method, system, device and medium |
- 2021
- 2021-12-29CNCN202111644376.2Apatent/CN114298284A/enactivePending
Patent Citations (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN107862103A (en)* | 2017-09-20 | 2018-03-30 | 国家电网公司 | A kind of simulation model generation method and system based on ADPSS |
| CN111507476A (en)* | 2019-01-31 | 2020-08-07 | 伊姆西Ip控股有限责任公司 | Method, apparatus and computer program product for deploying machine learning model |
| CN112947899A (en)* | 2019-12-11 | 2021-06-11 | 杭州海康威视数字技术股份有限公司 | Deep learning model conversion method, system and device |
| CN111222636A (en)* | 2020-01-07 | 2020-06-02 | 深圳鲲云信息科技有限公司 | Deep learning model conversion method and device, server and storage medium |
| US20210256097A1 (en)* | 2020-02-12 | 2021-08-19 | Servicenow, Inc. | Determination of intermediate representations of discovered document structures |
| CN113705799A (en)* | 2020-05-21 | 2021-11-26 | 平头哥(上海)半导体技术有限公司 | Processing unit, computing device and computation graph processing method of deep learning model |
| CN111753948A (en)* | 2020-06-23 | 2020-10-09 | 展讯通信(上海)有限公司 | Model processing method and related equipment |
| CN111860817A (en)* | 2020-07-10 | 2020-10-30 | 苏州浪潮智能科技有限公司 | A network model deployment method, apparatus, device and readable storage medium |
| WO2021169363A1 (en)* | 2020-09-09 | 2021-09-02 | 平安科技(深圳)有限公司 | Optimization method for text recognition system, computer device, and storage medium |
| CN112364744A (en)* | 2020-11-03 | 2021-02-12 | 珠海市卓轩科技有限公司 | TensorRT-based accelerated deep learning image recognition method, device and medium |
| CN112711423A (en)* | 2021-01-18 | 2021-04-27 | 深圳中兴网信科技有限公司 | Engine construction method, intrusion detection method, electronic device and readable storage medium |
| CN113128465A (en)* | 2021-05-11 | 2021-07-16 | 济南大学 | Small target detection method based on improved YOLOv4 for industrial scene |
| CN113641337A (en)* | 2021-07-13 | 2021-11-12 | 广州三七互娱科技有限公司 | Data processing method, data processing device, computer equipment and storage medium |
| CN113705404A (en)* | 2021-08-18 | 2021-11-26 | 南京邮电大学 | Face detection method facing embedded hardware |
| CN113780536A (en)* | 2021-10-29 | 2021-12-10 | 平安科技(深圳)有限公司 | Cloud deep learning model conversion method, system, device and medium |
Non-Patent Citations (2)
| Title |
|---|
| 孟伟;袁丽雅;韩炳涛;刘涛;: "深度学习推理侧模型优化架构探索", 信息通信技术与政策, no. 09, 15 September 2020 (2020-09-15)* |
| 解谦;张睿;刘红;: "移动智能终端基于神经网络的人工智能技术与应用", 信息通信技术与政策, no. 12, 15 December 2019 (2019-12-15)* |
Cited By (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114997401A (en)* | 2022-08-03 | 2022-09-02 | 腾讯科技(深圳)有限公司 | Adaptive inference acceleration method, apparatus, computer device and storage medium |
| CN114997401B (en)* | 2022-08-03 | 2022-11-04 | 腾讯科技(深圳)有限公司 | Adaptive inference acceleration method, apparatus, computer device, and storage medium |
| CN115713108A (en)* | 2022-11-08 | 2023-02-24 | 浙江大华技术股份有限公司 | Packing method and device of model, storage medium and electronic device |
| CN115496217B (en)* | 2022-11-16 | 2023-03-24 | 深圳鲲云信息科技有限公司 | Inference verification method and device, electronic equipment and storage medium |
| CN116108901A (en)* | 2022-12-30 | 2023-05-12 | 浙江大华技术股份有限公司 | Model deployment method and device, storage medium and electronic device |
| WO2024230574A1 (en)* | 2023-05-06 | 2024-11-14 | 维沃移动通信有限公司 | Model processing method, model execution method, and model registration method |
| CN117407299A (en)* | 2023-10-18 | 2024-01-16 | 北京大学 | Model test method and system |
| CN117407299B (en)* | 2023-10-18 | 2024-05-07 | 北京大学 | Model testing method and system |
| CN117149270A (en)* | 2023-10-30 | 2023-12-01 | 中国铁塔股份有限公司 | Method, system and related equipment for generating model file crossing hardware platform |
| CN119272880A (en)* | 2024-10-09 | 2025-01-07 | 五八畅生活(北京)信息技术有限公司 | Model conversion method, device, storage medium and program product |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN114298284A (en) | Network model conversion method, device, system, storage medium and electronic device | |
| CN108965484B (en) | Internet of things data transmission method, system and terminal | |
| CN107688538B (en) | Script execution method and device and computing equipment | |
| CN114374632B (en) | Internet of things data platform multi-protocol test efficiency improvement method | |
| CN111026672A (en) | Test method, terminal equipment and mock server | |
| CN111638891B (en) | Device upgrade method, device, terminal device and storage medium | |
| CN114584582A (en) | In-vehicle message processing method and device, vehicle-mounted terminal and storage medium | |
| CN106790724A (en) | Configuration file method for down loading and device | |
| CN108712320A (en) | Information push method and device | |
| CN112399446B (en) | Edge gateway communication method, device, computer equipment and storage medium | |
| WO2020207105A1 (en) | Destination message determination method and apparatus, storage medium and electronic apparatus | |
| CN112526972B (en) | Self-calibration method, self-calibration device, readable storage medium and electronic equipment | |
| CN112800474B (en) | Data desensitization method and device, storage medium and electronic device | |
| CN111680288B (en) | Container command execution method, device, equipment and storage medium | |
| CN111147597B (en) | File transmission method, terminal, electronic device and storage medium | |
| CN111159509B (en) | Data processing method and related product | |
| CN103944832A (en) | PMTU value determining method, device and system | |
| CN113722015B (en) | Method and device for acquiring combined component and storage medium | |
| CN115238895A (en) | Model conversion method, device and related equipment | |
| CN109861999B (en) | Data transmission control method, device and storage medium | |
| CN110580172B (en) | Configuration rule verification method and device, storage medium, electronic device | |
| CN105871927B (en) | Micro-terminal automatic login method and device | |
| CN113364790B (en) | Data transmission method and device | |
| CN111629014B (en) | Request agent implementation method, implementation device, server and storage medium | |
| CN113778956A (en) | Resource processing method and device, electronic equipment and computer readable medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |