CN114037007A - Data set construction method and device, computer equipment and storage medium - Google Patents
Data set construction method and device, computer equipment and storage mediumDownload PDFInfo
- Publication number
- CN114037007A CN114037007ACN202111300934.3ACN202111300934ACN114037007ACN 114037007 ACN114037007 ACN 114037007ACN 202111300934 ACN202111300934 ACN 202111300934ACN 114037007 ACN114037007 ACN 114037007A
- Authority
- CN
- China
- Prior art keywords
- label
- sample
- target
- sample data
- tag
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images








Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Artificial Intelligence (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Evolutionary Computation (AREA)
- Bioinformatics & Computational Biology (AREA)
- Evolutionary Biology (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Computational Linguistics (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Health & Medical Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Machine Translation (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本公开涉及计算机技术领域,具体而言,涉及一种数据集的构建方法、装置、计算机设备及存储介质。The present disclosure relates to the field of computer technology, and in particular, to a method, apparatus, computer device, and storage medium for constructing a data set.
背景技术Background technique
随着人工智能技术的飞速发展,各种模型的规模越来越大,同时对模型的精度要求也越来越高,使得在相关模型的训练过程中,需要使用大量的训练数据对模型进行训练,以提高模型的训练效果。With the rapid development of artificial intelligence technology, the scale of various models is getting larger and larger, and the accuracy requirements of the models are also getting higher and higher, so that in the process of training related models, it is necessary to use a large amount of training data to train the models. , to improve the training effect of the model.
相关技术中,训练模型时所使用的样本数据往往来自预先构建的样本数据集,因此如何合理且高效的构建数据集成为了相关领域中亟待解决的问题。In the related art, the sample data used in training a model often comes from a pre-built sample data set, so how to construct a data set reasonably and efficiently has become an urgent problem to be solved in related fields.
发明内容SUMMARY OF THE INVENTION
本公开实施例至少提供一种数据集的构建方法、装置、计算机设备及存储介质。The embodiments of the present disclosure provide at least a method, apparatus, computer device, and storage medium for constructing a data set.
第一方面,本公开实施例提供了一种数据集的构建方法,包括:In a first aspect, an embodiment of the present disclosure provides a method for constructing a data set, including:
获取待添加至样本标签集合的目标标签;Obtain the target tag to be added to the sample tag set;
基于所述目标标签与所述样本标签集合的匹配关系,将所述目标标签添加至所述样本标签集合的标签层级结构中;Based on the matching relationship between the target label and the sample label set, adding the target label to the label hierarchy of the sample label set;
获取所述样本标签集合所包含的标签分别对应的样本数据,并基于所述样本数据和所述样本标签集合构建样本数据集。Obtain sample data corresponding to the labels included in the sample label set respectively, and construct a sample data set based on the sample data and the sample label set.
这样,通过基于获取的目标标签与所述样本标签集合的匹配关系,将所述目标标签添加至所述样本标签集合的标签层级结构中,可以自动的完成对数据集的样本标签集合的构建,从而使得构建样本数据集时更为高效便捷,且可以通过添加大量的标签和对应的样本数据,构建标签更为丰富完整的样本数据集,从而提高了样本数据集在不同应用场景下的通用性。In this way, by adding the target label to the label hierarchy of the sample label set based on the matching relationship between the obtained target label and the sample label set, the construction of the sample label set of the data set can be automatically completed, This makes it more efficient and convenient to construct sample data sets, and by adding a large number of labels and corresponding sample data, a sample data set with more abundant and complete labels can be constructed, thereby improving the versatility of the sample data set in different application scenarios. .
一种可能的实施方式中,所述获取待添加至样本标签集合的目标标签,包括:In a possible implementation manner, the acquiring the target tag to be added to the sample tag set includes:
针对所述样本标签集合中的第一标签,将所述第一标签对应的关联词确定为所述目标标签;For the first label in the sample label set, determine the associated word corresponding to the first label as the target label;
所述基于所述目标标签与所述样本标签集合的匹配关系,将所述目标标签添加至所述样本标签集合的标签层级结构中,包括:The adding the target label to the label hierarchy of the sample label set based on the matching relationship between the target label and the sample label set includes:
将所述目标标签添加至,与所述目标标签具有同一语义的第一标签所在的标签层级结构中。The target label is added to the label hierarchy where the first label having the same semantics as the target label is located.
这样,可以使得样本标签集合中的标签更为丰富,从而可以使得最终生成的样本数据集适用于更多的应用场景。In this way, the labels in the sample label set can be made more abundant, so that the finally generated sample data set can be suitable for more application scenarios.
一种可能的实施方式中,所述获取待添加至样本标签集合的目标标签,包括:In a possible implementation manner, the acquiring the target tag to be added to the sample tag set includes:
获取具有层级关系的多个第二标签;Get multiple second tags with hierarchical relationship;
基于所述多个第二标签之间的层级关系,以及所述样本标签集合的标签层级结构,确定添加至所述样本标签集合中的目标标签。Based on the hierarchical relationship between the plurality of second tags and the tag hierarchy structure of the sample tag set, a target tag to be added to the sample tag set is determined.
这样,通过将具有层级关系的标签添加至样本标签集合,可以使得样本标签集合中的标签更为丰富,从而可以使得最终生成的样本数据集适用于更多的应用场景。In this way, by adding labels with a hierarchical relationship to the sample label set, the labels in the sample label set can be enriched, so that the finally generated sample data set can be suitable for more application scenarios.
一种可能的实施方式中,所述基于所述多个第二标签之间的层级关系,以及所述样本标签集合的标签层级结构,确定添加至所述样本标签集合中的目标标签,包括:In a possible implementation manner, the determining a target label to be added to the sample label set based on the hierarchical relationship between the plurality of second labels and the label hierarchy structure of the sample label set includes:
确定所述多个第二标签中,对应的层级关系满足预设要求的第二目标标签;Determining that among the plurality of second labels, the corresponding hierarchical relationship meets the second target label of the preset requirement;
针对任一第二目标标签,从所述多个第二标签中,确定与所述任一第二目标标签具有层级关系的至少一个待匹配标签;For any second target tag, from the plurality of second tags, determine at least one tag to be matched that has a hierarchical relationship with the any second target tag;
在检测到所述待匹配标签与所述样本标签集合中的任一标签匹配的情况下,将所述任一第二目标标签确定为所述目标标签。When it is detected that the to-be-matched label matches any label in the sample label set, the any second target label is determined as the target label.
一种可能的实施方式中,所述基于所述目标标签与所述样本标签集合的匹配关系,将所述目标标签添加至所述样本标签集合的标签层级结构中,包括:In a possible implementation manner, adding the target label to the label hierarchy of the sample label set based on the matching relationship between the target label and the sample label set includes:
确定所述样本标签集合中与所述待匹配标签匹配的标签的第一层级位置;determining the first level position of the tag matching the tag to be matched in the sample tag set;
将所述任一第二目标标签添加至所述样本标签集合中所述第一层级位置的下一层级中。The any second target label is added to the next level of the first level position in the set of sample labels.
一种可能的实施方式中,所述获取待添加至样本标签集合的目标标签,包括:In a possible implementation manner, the acquiring the target tag to be added to the sample tag set includes:
获取至少一个第三标签;其中,所述第三标签中包含有至少两个词语;Obtain at least one third label; wherein, the third label contains at least two words;
确定各第三标签分别对应的待匹配中心词;Determine the center word to be matched corresponding to each third label;
确定至少一个待匹配中心词中与所述样本标签集合中任一标签匹配的目标中心词,并将所述目标中心词对应的第三标签确定为所述目标标签。A target central word matching any label in the sample label set in at least one central word to be matched is determined, and a third label corresponding to the target central word is determined as the target label.
这样,可以使得样本标签集合中的标签更为丰富,从而可以使得最终生成的样本数据集适用于更多的应用场景。In this way, the labels in the sample label set can be made more abundant, so that the finally generated sample data set can be suitable for more application scenarios.
一种可能的实施方式中,所述基于所述目标标签与所述样本标签集合的匹配关系,将所述目标标签添加至所述样本标签集合的标签层级结构中,包括:In a possible implementation manner, adding the target label to the label hierarchy of the sample label set based on the matching relationship between the target label and the sample label set includes:
确定所述样本标签集合中与所述待匹配中心词匹配的标签的第二层级位置;Determine the second level position of the label matching the central word to be matched in the sample label set;
将所述第三标签添加至所述样本标签集合中所述第二层级位置的下一层级中。The third label is added to the next level of the second level position in the set of sample labels.
一种可能的实施方式中,所述样本标签集合对应有初始样本数据集;In a possible implementation manner, the sample label set corresponds to an initial sample data set;
所述获取所述样本标签集合所包含的标签分别对应的样本数据,包括:The obtaining the sample data corresponding to the labels included in the sample label set, including:
获取添加至所述样本标签集合的目标标签分别对应的样本数据;obtaining sample data corresponding to the target labels added to the sample label set respectively;
所述基于所述样本数据和所述样本标签集合构建样本数据集,包括:The constructing a sample data set based on the sample data and the sample label set includes:
基于所述样本数据、所述初始样本数据集以及所述样本标签集合构建样本数据集。A sample data set is constructed based on the sample data, the initial sample data set, and the sample label set.
一种可能的实施方式中,所述获取所述样本标签集合所包含的标签分别对应的样本数据,包括:In a possible implementation manner, the obtaining the sample data corresponding to the labels included in the sample label set, including:
获取与所述标签分别对应的多个待筛选样本数据;acquiring a plurality of sample data to be screened corresponding to the labels respectively;
基于预设的筛选条件对所述多个待筛选样本数据进行筛选,确定所述标签分别对应的目标样本数据。Screen the plurality of sample data to be screened based on preset screening conditions, and determine the target sample data corresponding to the tags respectively.
这样,通过对获取的样本数据进行筛选,可以提高所述样本数据集中样本数据的质量。In this way, by screening the obtained sample data, the quality of the sample data in the sample data set can be improved.
一种可能的实施方式中,所述基于预设的筛选条件对所述多个待筛选样本数据进行筛选,确定所述标签分别对应的目标样本数据,包括:In a possible implementation, the plurality of sample data to be screened are screened based on preset screening conditions, and the target sample data corresponding to the labels are determined, including:
针对任一待筛选样本数据,基于预先训练的分类模型,确定与所述任一待筛选样本数据对应的类别集合;For any sample data to be screened, based on a pre-trained classification model, determine a category set corresponding to the sample data to be screened;
在检测到所述类别集合中存在与所述任一待筛选样本数据对应的标签匹配的目标类别的情况下,将所述任一待筛选样本数据确定为所述目标样本数据。In a case where it is detected that there is a target category matching the label corresponding to any one of the sample data to be screened in the category set, the any one of the sample data to be screened is determined as the target sample data.
第二方面,本公开实施例还提供一种数据集的构建装置,包括:In a second aspect, an embodiment of the present disclosure further provides an apparatus for constructing a data set, including:
获取模块,用于获取待添加至样本标签集合的目标标签;an acquisition module, used to acquire the target tag to be added to the sample tag set;
添加模块,用于基于所述目标标签与所述样本标签集合的匹配关系,将所述目标标签添加至所述样本标签集合的标签层级结构中;An adding module is configured to add the target label to the label hierarchy of the sample label set based on the matching relationship between the target label and the sample label set;
构建模块,用于获取所述样本标签集合所包含的标签分别对应的样本数据,并基于所述样本数据和所述样本标签集合构建样本数据集。A building module is configured to obtain sample data corresponding to the labels included in the sample label set, and construct a sample data set based on the sample data and the sample label set.
一种可能的实施方式中,所述获取模块,在获取待添加至样本标签集合的目标标签时,用于:In a possible implementation manner, the acquisition module, when acquiring the target tag to be added to the sample tag set, is used for:
针对所述样本标签集合中的第一标签,将所述第一标签对应的关联词确定为所述目标标签;For the first label in the sample label set, determine the associated word corresponding to the first label as the target label;
所述添加模块,基于所述目标标签与所述样本标签集合的匹配关系,将所述目标标签添加至所述样本标签集合的标签层级结构中时,用于:The adding module, based on the matching relationship between the target label and the sample label set, when adding the target label to the label hierarchy of the sample label set, is used for:
将所述目标标签添加至,与所述目标标签具有同一语义的第一标签所在的标签层级结构中。The target label is added to the label hierarchy where the first label having the same semantics as the target label is located.
一种可能的实施方式中,所述获取模块,在获取待添加至样本标签集合的目标标签时,用于:In a possible implementation manner, the acquisition module, when acquiring the target tag to be added to the sample tag set, is used for:
获取具有层级关系的多个第二标签;Get multiple second tags with hierarchical relationship;
基于所述多个第二标签之间的层级关系,以及所述样本标签集合的标签层级结构,确定添加至所述样本标签集合中的目标标签。Based on the hierarchical relationship between the plurality of second tags and the tag hierarchy structure of the sample tag set, a target tag to be added to the sample tag set is determined.
一种可能的实施方式中,所述获取模块,在基于所述多个第二标签之间的层级关系,以及所述样本标签集合的标签层级结构,确定添加至所述样本标签集合中的目标标签时,用于:In a possible implementation manner, the acquisition module determines, based on the hierarchical relationship between the plurality of second tags and the tag hierarchy structure of the sample tag set, the target to be added to the sample tag set When labeling, used to:
确定所述多个第二标签中,对应的层级关系满足预设要求的第二目标标签;Determining that among the plurality of second labels, the corresponding hierarchical relationship meets the second target label of the preset requirement;
针对任一第二目标标签,从所述多个第二标签中,确定与所述任一第二目标标签具有层级关系的至少一个待匹配标签;For any second target tag, from the plurality of second tags, determine at least one tag to be matched that has a hierarchical relationship with the any second target tag;
在检测到所述待匹配标签与所述样本标签集合中的任一标签匹配的情况下,将所述任一第二目标标签确定为所述目标标签。When it is detected that the to-be-matched label matches any label in the sample label set, the any second target label is determined as the target label.
一种可能的实施方式中,所述添加模块,在基于所述目标标签与所述样本标签集合的匹配关系,将所述目标标签添加至所述样本标签集合的标签层级结构中时,用于:In a possible implementation manner, the adding module, when adding the target label to the label hierarchy of the sample label set based on the matching relationship between the target label and the sample label set, is used to: :
确定所述样本标签集合中与所述待匹配标签匹配的标签的第一层级位置;determining the first level position of the tag matching the tag to be matched in the sample tag set;
将所述任一第二目标标签添加至所述样本标签集合中所述第一层级位置的下一层级中。The any second target label is added to the next level of the first level position in the set of sample labels.
一种可能的实施方式中,所述获取模块,在获取待添加至样本标签集合的目标标签时,用于:In a possible implementation manner, the acquisition module, when acquiring the target tag to be added to the sample tag set, is used for:
获取至少一个第三标签;其中,所述第三标签中包含有至少两个词语;Obtain at least one third label; wherein, the third label contains at least two words;
确定各第三标签分别对应的待匹配中心词;Determine the center word to be matched corresponding to each third label;
确定至少一个待匹配中心词中与所述样本标签集合中任一标签匹配的目标中心词,并将所述目标中心词对应的第三标签确定为所述目标标签。A target central word matching any label in the sample label set in at least one central word to be matched is determined, and a third label corresponding to the target central word is determined as the target label.
一种可能的实施方式中,所述添加模块,在基于所述目标标签与所述样本标签集合的匹配关系,将所述目标标签添加至所述样本标签集合的标签层级结构中时,用于:In a possible implementation manner, the adding module, when adding the target label to the label hierarchy of the sample label set based on the matching relationship between the target label and the sample label set, is used to: :
确定所述样本标签集合中与所述待匹配中心词匹配的标签的第二层级位置;Determine the second level position of the label matching the central word to be matched in the sample label set;
将所述第三标签添加至所述样本标签集合中所述第二层级位置的下一层级中。The third label is added to the next level of the second level position in the set of sample labels.
一种可能的实施方式中,所述样本标签集合对应有初始样本数据集;In a possible implementation manner, the sample label set corresponds to an initial sample data set;
所述构建模块,在获取所述样本标签集合所包含的标签分别对应的样本数据时,用于:The building module, when acquiring the sample data corresponding to the labels included in the sample label set, is used for:
获取添加至所述样本标签集合的目标标签分别对应的样本数据;obtaining sample data corresponding to the target labels added to the sample label set respectively;
所述构建模块,在基于所述样本数据和所述样本标签集合构建样本数据集时,用于:The construction module, when constructing a sample data set based on the sample data and the sample label set, is used for:
基于所述样本数据、所述初始样本数据集以及所述样本标签集合构建样本数据集。A sample data set is constructed based on the sample data, the initial sample data set, and the sample label set.
一种可能的实施方式中,所述构建模块,在获取所述样本标签集合所包含的标签分别对应的样本数据时,用于:In a possible implementation manner, the building module, when acquiring the sample data corresponding to the labels included in the sample label set, is used to:
获取与所述标签分别对应的多个待筛选样本数据;acquiring a plurality of sample data to be screened corresponding to the labels respectively;
基于预设的筛选条件对所述多个待筛选样本数据进行筛选,确定所述标签分别对应的目标样本数据。Screen the plurality of sample data to be screened based on preset screening conditions, and determine the target sample data corresponding to the tags respectively.
一种可能的实施方式中,所述构建模块,在基于预设的筛选条件对所述多个待筛选样本数据进行筛选,确定所述标签分别对应的目标样本数据时,用于:In a possible implementation, the building module, when screening the plurality of sample data to be screened based on preset screening conditions, and determining the target sample data corresponding to the labels respectively, is used for:
针对任一待筛选样本数据,基于预先训练的分类模型,确定与所述任一待筛选样本数据对应的类别集合;For any sample data to be screened, based on a pre-trained classification model, determine a category set corresponding to the sample data to be screened;
在检测到所述类别集合中存在与所述任一待筛选样本数据对应的标签匹配的目标类别的情况下,将所述任一待筛选样本数据确定为所述目标样本数据。In a case where it is detected that there is a target category matching the label corresponding to any one of the sample data to be screened in the category set, the any one of the sample data to be screened is determined as the target sample data.
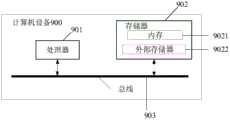
第三方面,本公开实施例还提供一种计算机设备,包括:处理器、存储器和总线,所述存储器存储有所述处理器可执行的机器可读指令,当计算机设备运行时,所述处理器与所述存储器之间通过总线通信,所述机器可读指令被所述处理器执行时执行上述第一方面,或第一方面中任一种可能的实施方式中的步骤。In a third aspect, embodiments of the present disclosure further provide a computer device, including: a processor, a memory, and a bus, where the memory stores machine-readable instructions executable by the processor, and when the computer device runs, the processing A bus communicates between the processor and the memory, and when the machine-readable instructions are executed by the processor, the first aspect or the steps in any possible implementation manner of the first aspect are performed.
第四方面,本公开实施例还提供一种计算机可读存储介质,该计算机可读存储介质上存储有计算机程序,该计算机程序被处理器运行时执行上述第一方面,或第一方面中任一种可能的实施方式中的步骤。In a fourth aspect, embodiments of the present disclosure further provide a computer-readable storage medium, where a computer program is stored on the computer-readable storage medium, and the computer program is executed by a processor to execute the first aspect, or any one of the first aspect. steps in one possible implementation.
关于上述数据集的构建装置、计算机设备及存储介质的效果描述参见上述数据集的构建方法的说明,这里不再赘述。For the description of the effect of the above-mentioned data set construction apparatus, computer equipment and storage medium, please refer to the description of the above-mentioned data set construction method, which will not be repeated here.
为使本公开的上述目的、特征和优点能更明显易懂,下文特举较佳实施例,并配合所附附图,作详细说明如下。In order to make the above-mentioned objects, features and advantages of the present disclosure more obvious and easy to understand, the preferred embodiments are exemplified below, and are described in detail as follows in conjunction with the accompanying drawings.
附图说明Description of drawings
为了更清楚地说明本公开实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,此处的附图被并入说明书中并构成本说明书中的一部分,这些附图示出了符合本公开的实施例,并与说明书一起用于说明本公开的技术方案。应当理解,以下附图仅示出了本公开的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。In order to explain the technical solutions of the embodiments of the present disclosure more clearly, the following briefly introduces the accompanying drawings required in the embodiments, which are incorporated into the specification and constitute a part of the specification. The drawings illustrate embodiments consistent with the present disclosure, and together with the description serve to explain the technical solutions of the present disclosure. It should be understood that the following drawings only show some embodiments of the present disclosure, and therefore should not be regarded as limiting the scope. Other related figures are obtained from these figures.
图1示出了本公开实施例所提供的一种数据集的构建方法的流程图;1 shows a flowchart of a method for constructing a data set provided by an embodiment of the present disclosure;
图2a示出了本公开实施例所提供的数据集的构建方法中,样本标签集合的标签层级关系的示意图;Fig. 2a shows a schematic diagram of a label hierarchy relationship of a sample label set in the method for constructing a data set provided by an embodiment of the present disclosure;
图2b示出了本公开实施例所提供的数据集的构建方法中,添加目标标签“犬”后的标签层级关系的示意图;Fig. 2b shows a schematic diagram of the label hierarchy after adding the target label "dog" in the data set construction method provided by the embodiment of the present disclosure;
图2c示出了本公开实施例所提供的数据集的构建方法中,添加目标标签“秋田犬”后的标签层级关系的示意图;Fig. 2c shows a schematic diagram of the label hierarchy after adding the target label "Akita dog" in the data set construction method provided by the embodiment of the present disclosure;
图2d示出了本公开实施例所提供的数据集的构建方法中,添加目标标签“东北虎”后的标签层级关系的示意图;Fig. 2d shows a schematic diagram of the label hierarchy after adding the target label "Amur tiger" in the data set construction method provided by the embodiment of the present disclosure;
图2e示出了本公开实施例所提供的数据集的构建方法中,添加目标标签“英短”后的标签层级关系的示意图;FIG. 2e shows a schematic diagram of the hierarchical relationship of tags after adding the target tag "English and short" in the data set construction method provided by the embodiment of the present disclosure;
图3示出了本公开实施例所提供的数据集的构建方法中,一种确定添加至样本标签集合中的目标标签的具体方法的流程图;3 shows a flowchart of a specific method for determining a target label to be added to a sample label set in a data set construction method provided by an embodiment of the present disclosure;
图4示出了本公开实施例所提供的数据集的构建方法中,一种获取目标标签的具体方法的流程图;FIG. 4 shows a flowchart of a specific method for acquiring a target label in the method for constructing a data set provided by an embodiment of the present disclosure;
图5示出了本公开实施例所提供的数据集的构建方法中,另一种获取目标标签的具体方法的流程图;5 shows a flowchart of another specific method for acquiring target labels in the method for constructing a data set provided by an embodiment of the present disclosure;
图6示出了本公开实施例所提供的数据集的构建方法中,一种获取标签对应的目标样本数据的具体方法的流程图;6 shows a flowchart of a specific method for obtaining target sample data corresponding to a tag in the method for constructing a data set provided by an embodiment of the present disclosure;
图7示出了本公开实施例所提供的数据集的构建方法中,确定目标样本数据的具体方法的流程图;7 shows a flowchart of a specific method for determining target sample data in the method for constructing a data set provided by an embodiment of the present disclosure;
图8示出了本公开实施例所提供的一种数据集的构建装置的架构示意图;FIG. 8 shows a schematic diagram of the architecture of an apparatus for constructing a data set provided by an embodiment of the present disclosure;
图9示出了本公开实施例所提供的一种计算机设备的结构示意图。FIG. 9 shows a schematic structural diagram of a computer device provided by an embodiment of the present disclosure.
具体实施方式Detailed ways
为使本公开实施例的目的、技术方案和优点更加清楚,下面将结合本公开实施例中附图,对本公开实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本公开一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本公开实施例的组件可以以各种不同的配置来布置和设计。因此,以下对在附图中提供的本公开的实施例的详细描述并非旨在限制要求保护的本公开的范围,而是仅仅表示本公开的选定实施例。基于本公开的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本公开保护的范围。In order to make the purposes, technical solutions and advantages of the embodiments of the present disclosure more clear, the technical solutions in the embodiments of the present disclosure will be clearly and completely described below with reference to the accompanying drawings in the embodiments of the present disclosure. Obviously, the described embodiments are only These are some, but not all, embodiments of the present disclosure. The components of the disclosed embodiments generally described and illustrated in the drawings herein may be arranged and designed in a variety of different configurations. Therefore, the following detailed description of the embodiments of the disclosure provided in the accompanying drawings is not intended to limit the scope of the disclosure as claimed, but is merely representative of selected embodiments of the disclosure. Based on the embodiments of the present disclosure, all other embodiments obtained by those skilled in the art without creative work fall within the protection scope of the present disclosure.
应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。It should be noted that like numerals and letters refer to like items in the following figures, so once an item is defined in one figure, it does not require further definition and explanation in subsequent figures.
本文中术语“和/或”,仅仅是描述一种关联关系,表示可以存在三种关系,例如,A和/或B,可以表示:单独存在A,同时存在A和B,单独存在B这三种情况。另外,本文中术语“至少一种”表示多种中的任意一种或多种中的至少两种的任意组合,例如,包括A、B、C中的至少一种,可以表示包括从A、B和C构成的集合中选择的任意一个或多个元素。The term "and/or" in this paper only describes an association relationship, which means that there can be three kinds of relationships, for example, A and/or B, which can mean: the existence of A alone, the existence of A and B at the same time, the existence of B alone. a situation. In addition, the term "at least one" herein refers to any combination of any one of the plurality or at least two of the plurality, for example, including at least one of A, B, and C, and may mean including from A, B, and C. Any one or more elements selected from the set of B and C.
经研究发现,训练模型时所使用的样本数据往往来自预先构建的样本数据集,因此如何合理且高效的构建数据集成为了相关领域中亟待解决的问题。After research, it is found that the sample data used in training the model often comes from the pre-built sample data set, so how to construct the data set reasonably and efficiently has become an urgent problem to be solved in related fields.
基于上述研究,本公开提供了一种数据集的构建方法、装置、计算机设备及存储介质,通过基于获取的目标标签与所述样本标签集合的匹配关系,将所述目标标签添加至所述样本标签集合的标签层级结构中,可以自动的完成对数据集的样本标签集合的构建,从而使得构建样本数据集时更为高效便捷,且可以通过添加大量的标签和对应的样本数据,构建标签更为丰富完整的样本数据集,从而提高了样本数据集在不同应用场景下的通用性。Based on the above research, the present disclosure provides a method, apparatus, computer equipment and storage medium for constructing a data set. The target label is added to the sample based on the matching relationship between the obtained target label and the sample label set. In the label hierarchy structure of the label set, the construction of the sample label set of the data set can be automatically completed, which makes the construction of the sample data set more efficient and convenient. In order to enrich the complete sample data set, the versatility of the sample data set in different application scenarios is improved.
为便于对本实施例进行理解,首先对本公开实施例所公开的数据集的构建方法进行详细介绍,本公开实施例所提供的数据集的构建方法的执行主体一般为具有一定计算能力的计算机设备,该计算机设备例如包括:终端设备或服务器或其它处理设备,终端设备可以为用户设备(User Equipment,UE)、移动设备、用户终端、终端、手持设备、计算设备、车载设备、可穿戴设备等。在一些可能的实现方式中,该数据集的构建方法可以通过处理器调用存储器中存储的计算机可读指令的方式来实现。In order to facilitate the understanding of this embodiment, the construction method of the data set disclosed in the embodiment of the present disclosure is first introduced in detail. The computer equipment includes, for example, terminal equipment or a server or other processing equipment, and the terminal equipment may be user equipment (User Equipment, UE), mobile equipment, user terminal, terminal, handheld equipment, computing equipment, vehicle-mounted equipment, wearable equipment, and the like. In some possible implementations, the method for constructing the data set may be implemented by the processor invoking computer-readable instructions stored in the memory.
参见图1所示,为本公开实施例提供时数据集的构建方法的流程图,所述方法包括S101~S103,其中:Referring to FIG. 1 , which is a flowchart of a method for constructing a data set according to an embodiment of the present disclosure, the method includes S101 to S103 , wherein:
S101:获取待添加至样本标签集合的目标标签。S101: Acquire a target label to be added to the sample label set.
S102:基于所述目标标签与所述样本标签集合的匹配关系,将所述目标标签添加至所述样本标签集合的标签层级结构中。S102: Based on the matching relationship between the target label and the sample label set, add the target label to the label hierarchy of the sample label set.
S103:获取所述样本标签集合所包含的标签分别对应的样本数据,并基于所述样本数据和所述样本标签集合构建样本数据集。S103: Obtain sample data corresponding to the labels included in the sample label set, and construct a sample data set based on the sample data and the sample label set.
以下是对上述步骤的详细介绍。The following is a detailed description of the above steps.
针对S101和S102,所述样本标签集合中包含有多个样本标签,所述多个样本标签通过关联关系构成了所述样本标签集合的标签层级关系。For S101 and S102, the sample label set includes a plurality of sample labels, and the plurality of sample labels constitute a label hierarchical relationship of the sample label set through an association relationship.
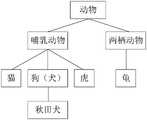
示例性的,所述样本标签集合的标签层级关系的示意图可以如图2a所示,图2a中,所述样本标签集合由样本标签“动物”、“哺乳动物”、“两栖动物”、“猫”、“虎”、“狗”、“龟”构成,根据各样本标签之间关联关系,可以确定“猫”、“虎”、“狗”均属于“哺乳动物”,“龟”属于“两栖动物”,而“哺乳动物”和“两栖动物”均属于“动物”,从而可以构建出所述样本标签集合的标签层级关系。Exemplarily, a schematic diagram of the label hierarchical relationship of the sample label set may be shown in Figure 2a. In Figure 2a, the sample label set consists of sample labels "animal", "mammal", "amphibian", "cat". ”, “tiger”, “dog”, and “turtle”. According to the relationship between the labels of each sample, it can be determined that “cat”, “tiger”, and “dog” belong to “mammal”, and “turtle” belongs to “amphibian”. "animal", and "mammal" and "amphibian" both belong to "animal", so that the label hierarchy relationship of the sample label set can be constructed.
下面,将分别介绍所述目标标签的几种获取方式,以及如何基于目标标签与样本标签集合的匹配关系,将各种获取方式获取的目标标签分别添加至所述样本标签集合的标签层级结构中:Below, several acquisition methods of the target label will be introduced respectively, and how to add target labels obtained by various acquisition methods to the label hierarchy of the sample label set based on the matching relationship between the target label and the sample label set. :
获取方式1、获取所述样本标签集合中的第一标签的关联词。Obtaining method 1. Obtain the associated word of the first label in the sample label set.
这里,针对所述样本标签集合中的第一标签,可以将所述第一标签对应的关联词确定为所述目标标签。其中,所述关联词可以是同义词、近义词、别名、学名、俗称等表示语义相同或相近的词。Here, for the first label in the sample label set, the associated word corresponding to the first label may be determined as the target label. Wherein, the associated words may be synonyms, synonyms, aliases, scientific names, common names, etc., which represent words with the same or similar semantics.
示例性的,以所述样本标签集合中的第一标签为“番茄”为例,则所述“番茄”对应的目标标签可以是“西红柿”。Exemplarily, taking the first label in the sample label set as "tomato" as an example, the target label corresponding to the "tomato" may be "tomato".
进一步的,在获取到所述目标标签(第一标签的关联词)之后,可以将所述目标标签添加至,与所述目标标签具有同一语义的第一标签所在的标签层级结构中。Further, after the target tag (the associated word of the first tag) is acquired, the target tag may be added to the tag hierarchy structure where the first tag having the same semantics as the target tag is located.
示例性的,以所述目标标签为“犬”为例,添加目标标签“犬”后的标签层级关系可以如图2b所示,图2b中,将目标标签“犬”,添加至与“犬”同一语义的第一标签“狗”所在的标签层级结构中,从而完成了对所述样本标签集合的扩展。Exemplarily, taking the target label as "dog" as an example, the label hierarchical relationship after adding the target label "dog" can be as shown in Figure 2b. In Figure 2b, the target label "dog" is added to the ” in the label hierarchy where the first label “dog” of the same semantics is located, thus completing the expansion of the sample label set.
获取方式2、从具有层级关系的多个第二标签中获取。Obtaining method 2: Obtaining from a plurality of second tags having a hierarchical relationship.
实际应用中,为了提高数据集的样本标签集合的扩展效率,可以从现有的数据集或者数据库中获取样本标签,而现有的数据集或数据库中的标签虽然也可以具有层级关系,但其层级关系往往跟进行扩展的所述样本标签集合的层级关系不匹配(或者不满足构建样本数据集的实际需求),从而无法简单的直接将现有的数据集或数据库中具有层级关系的标签添加至所述样本标签集合。In practical applications, in order to improve the expansion efficiency of the sample label set of the dataset, the sample labels can be obtained from the existing dataset or database. Although the labels in the existing dataset or database can also have a hierarchical relationship, their The hierarchical relationship often does not match the hierarchical relationship of the sample label set to be expanded (or does not meet the actual needs of constructing a sample data set), so it is impossible to simply directly add labels with hierarchical relationships in existing data sets or databases. to the sample label set.
示例性的,以所述数据库中的层级结构为“狗(犬)-观赏犬-日本观赏犬-秋田犬”为例,由于构建样本数据集的实际需求为训练模型对不同物体的区分能力,实际应用中往往不需要知道“秋田犬”是“日本观赏犬”还是“美国观赏犬”,只需要知道“秋田犬”是“狗(犬)”就够了,而若直接将全部的层级结构添加到所述样本标签集合的层级结构中,会提高样本标签集合的层级结构的复杂度,从而提高了后续使用所述样本标签集合的层级结构确定各标签之间的关系时所需的计算资源和时间成本。Exemplarily, taking the hierarchical structure in the database as "dog (dog) - ornamental dog - Japanese ornamental dog - Akita dog" as an example, since the actual demand for constructing the sample data set is the ability of the training model to distinguish different objects, In practical applications, it is often not necessary to know whether the "Akita" is a "Japanese ornamental dog" or an "American ornamental dog". It is enough to know that the "Akita" is a "dog (dog)". Adding to the hierarchical structure of the sample label set will increase the complexity of the hierarchical structure of the sample label set, thereby increasing the computing resources required for the subsequent use of the hierarchical structure of the sample label set to determine the relationship between the labels and time cost.
具体的,在获取所述目标标签时,可以获取具有层级关系的多个第二标签,然后基于所述多个第二标签之间的层级关系,以及所述样本标签集合的标签层级结构,确定添加至所述样本标签集合中的目标标签。Specifically, when acquiring the target tag, a plurality of second tags with a hierarchical relationship may be acquired, and then based on the hierarchical relationship between the plurality of second tags and the tag hierarchy structure of the sample tag set, determine A target label to add to the set of sample labels.
一种可能的实施方式中,如图3所示,可以通过以下步骤确定添加至样本标签集合中的目标标签:In a possible implementation manner, as shown in FIG. 3 , the target labels added to the sample label set can be determined through the following steps:
S301:确定所述多个第二标签中,对应的层级关系满足预设要求的第二目标标签。S301: Determine, among the plurality of second labels, a second target label whose hierarchical relationship satisfies a preset requirement.
这里,所述层级关系满足预设要求的第二目标标签,可以是位于所述多个第二标签构成的层级关系中最下层(也即从上到下的最后一层)的标签。Here, the second target tag whose hierarchical relationship satisfies the preset requirement may be a tag located at the bottommost layer (ie, the last layer from top to bottom) in the hierarchical relationship formed by the plurality of second tags.
示例性的,以所述多个第二标签的标签层级结构为“狗(犬)-观赏犬-日本观赏犬-秋田犬”为例,则可以确定层级关系中最下层的“秋田犬”为所述第二目标标签。Exemplarily, taking the label hierarchy structure of the plurality of second labels as "dog (dog)-watch dog-Japanese watch dog-Akita dog" as an example, it can be determined that the lowest "Akita dog" in the hierarchical relationship is the second target tag.
S302:针对任一第二目标标签,从所述多个第二标签中,确定与所述任一第二目标标签具有层级关系的至少一个待匹配标签。S302: For any second target label, from the plurality of second labels, determine at least one to-be-matched label that has a hierarchical relationship with the any second target label.
这里,在确定与第二目标标签具有层级关系的待匹配标签时,可以在由所述第二标签构建的标签层级结构中从下往上进行查找,直至查找至标签层级结构的最上层为止,查找路径上的各所述第二标签均可以是所述待匹配标签。Here, when determining the to-be-matched tag that has a hierarchical relationship with the second target tag, a search can be performed from bottom to top in the tag hierarchy constructed by the second tag until the search reaches the top level of the tag hierarchy, Each of the second labels on the search path may be the to-be-matched label.
示例性的,以所述第二目标标签为图2a中的“猫”为例,则根据图2a中的标签层级结构,可以将“哺乳动物”和“动物”作为所述待匹配标签。Exemplarily, taking the second target tag as "cat" in Fig. 2a as an example, according to the tag hierarchy in Fig. 2a, "mammal" and "animal" can be used as the tags to be matched.
承接上例,与所述第二目标标签“秋田犬”具有层级关系的待匹配标签即为“狗(犬)”、“观赏犬”、“日本观赏犬”。Following the previous example, the tags to be matched that have a hierarchical relationship with the second target tag "Akita dog" are "dog (dog)", "watch dog", and "Japanese watch dog".
S303:在检测到所述待匹配标签与所述样本标签集合中的任一标签匹配的情况下,将所述任一第二目标标签确定为所述目标标签。S303: In a case where it is detected that the to-be-matched label matches any label in the sample label set, determine the any second target label as the target label.
这里,若所述待匹配标签与所述样本标签集合中的任一标签语义相同(比如完全相同或者为同义词)或者语义相近(比如近义词),则可以确定所述待匹配标签与所述样本标签集合中的标签匹配。Here, if the to-be-matched label and any label in the sample label set have the same semantics (such as identical or synonyms) or similar semantics (such as synonyms), it can be determined that the to-be-matched label and the sample label The tags in the collection match.
进一步的,在获取到所述目标标签之后,可以确定所述样本标签集合中与所述待匹配标签匹配的标签的第一层级位置;将所述任一第二目标标签添加至所述样本标签集合中所述第一层级位置的下一层级中。Further, after the target label is acquired, the first level position of the label matching the label to be matched in the sample label set can be determined; the any second target label is added to the sample label. in the next level of the first level position in the collection.
示例性的,以所述目标标签为“秋田犬”为例,添加目标标签“秋田犬”后的标签层级关系可以如图2c所示,图2c中,所述样本标签集合中与所述待匹配标签“狗(犬)”匹配的标签为“狗(犬)”(也即其本身),将目标标签“秋田犬”,添加至“狗(犬)”的下一层级中,从而完成了对所述样本标签集合的扩展。Exemplarily, taking the target label as "Akita dog" as an example, the label hierarchical relationship after adding the target label "Akita dog" may be as shown in Figure 2c. In Figure 2c, the sample label set is the same as the The matching label "dog (dog)" matches the label "dog (dog)" (that is, itself), and the target label "Akita dog" is added to the next level of "dog (dog)", thus completing An extension to the set of sample labels.
此外,若所述样本标签集合中与所述待匹配标签匹配的标签有多个,则可以确定匹配成功的各待匹配标签中,对应的层级最低的待匹配标签为目标匹配标签,确定所述样本标签集合中与所述目标匹配标签匹配的标签的第一层级位置,然后将所述任一第二目标标签添加至所述样本标签集合中所述第一层级位置的下一层级中。In addition, if there are multiple labels matching the to-be-matched label in the sample label set, it may be determined that among the to-be-matched labels that are successfully matched, the corresponding to-be-matched label with the lowest level is the target matching label, and the The first level position of the tag in the sample tag set that matches the target matching tag, and then the any second target tag is added to the next level of the first level position in the sample tag set.
示例性的,以所述多个第二标签的标签层级结构为“哺乳动物-狗(犬)-观赏犬-日本观赏犬-秋田犬”为例,则与所述第二目标标签“秋田犬”具有层级关系的待匹配标签即为“哺乳动物”、“狗(犬)”、“观赏犬”、“日本观赏犬”,其中,在“哺乳动物”和“狗(犬)”均与所述样本标签集合中的标签匹配的情况下,可以将对应的层级最低的“狗(犬)”作为目标匹配标签,并将所述第二目标标签“秋田犬”,添加至所述样本标签集合的标签层级结构中“狗(犬)”的下一层级中,以完成对所述样本标签集合的扩展。Exemplarily, taking the label hierarchy structure of the plurality of second labels as "mammal-dog (dog)-watch dog-Japanese watch dog-Akita dog" as an example, then the second target label "Akita dog" is used as an example. "The tags to be matched with a hierarchical relationship are "Mammal", "Dog (dog)", "Ornamental Dog", "Japanese Ornamental Dog", where "Mammal" and "Dog (Dog)" are both related to the In the case where the labels in the sample label set match, the corresponding lowest level "dog (dog)" can be used as the target matching label, and the second target label "Akita dog" can be added to the sample label set in the next level of "dog (dog)" in the label hierarchy of , to complete the expansion of the sample label set.
这样,通过对具有层级结构的多个标签按照预设的筛选流程进行筛选,得到了符合数据集实际使用需求的目标标签,并通过将所述目标标签添加至所述样本标签集合中,从而实现了对所述样本标签集合的合理扩展,提高了样本数据集的实用性。In this way, by screening multiple labels with a hierarchical structure according to a preset screening process, a target label that meets the actual use requirements of the data set is obtained, and by adding the target label to the sample label set, the realization of A reasonable expansion of the sample label set is achieved, and the practicability of the sample data set is improved.
获取方式3、从包含至少两个词语的第三标签中获取。Obtaining method 3: Obtain from a third tag containing at least two words.
这里,所述包含两个词语表示的是经过分词处理之后,可以得到至少两次词语,也即所述第三标签为可被进行分词处理的标签。Here, the inclusion of two words means that after word segmentation processing, words can be obtained at least twice, that is, the third label is a label that can be subjected to word segmentation processing.
一种可能的实施方式中,在获取所述目标标签时,如图4所示,可以通过以下步骤:In a possible implementation manner, when acquiring the target tag, as shown in FIG. 4 , the following steps may be performed:
S401:获取至少一个第三标签;其中,所述第三标签中包含有至少两个词语。S401: Acquire at least one third label; wherein, the third label contains at least two words.
S402:确定各第三标签分别对应的待匹配中心词。S402: Determine the to-be-matched center word corresponding to each third tag respectively.
这里,针对所述任一第三标签,在确定对应的待匹配中心词时,可以对所述任一第三标签进行分词处理,并从处理处理后得到的至少两个待筛选词中确定所述任一第三标签对应的待匹配中心词。Here, for any third label, when determining the corresponding central word to be matched, word segmentation processing may be performed on the any third label, and the word segmentation process may be performed to determine the corresponding central word from the at least two to-be-screened words obtained after the processing. Describe the central word to be matched corresponding to any third tag.
一种可能的实施方式中,可以将所述任一第三标签和所述任一第三标签对应的至少两个待筛选词分别输入至预先训练好的神经网络中,得到所述任一第三标签对应的第一特征向量,以及所述任一第三标签对应的至少两个待筛选词分别对应的第二特征向量,并通过所述第一特征向量分别与各所述第二特征向量之间的特征相似度,从所述至少两个待筛选词中确定与所述任一第三标签对应的待匹配中心词。In a possible implementation manner, the any third label and at least two words to be screened corresponding to the any third label can be input into the pre-trained neural network respectively, and the any third label can be obtained. The first feature vector corresponding to the three tags, and the second feature vector corresponding to at least two words to be screened corresponding to any third tag, respectively, and the first feature vector and each of the second feature vectors The feature similarity between them is determined from the at least two to-be-screened words to determine the to-be-matched central word corresponding to the any third label.
示例性的,以所述第三标签为“东北虎”为例,在对所述第三标签“东北虎”进行分词处理之后,可以得到待筛选词为“东北”和“虎”,将“东北虎”、“东北”、“虎”依次输入至训练好的神经网络中,并根据所述神经网络输出的特征向量,确定所述“东北虎”和“东北”之间的特征相似度为0.4,所述“东北虎”和“虎”的特征相似度为0.6,则可以将“虎”作为第三标签“东北虎”对应的待匹配中心词。Exemplarily, taking the third label as "Siberian tiger" as an example, after performing word segmentation on the third label "Siberian tiger", the words to be screened can be obtained as "Northeast" and "Tiger", Siberian tiger, "Northeast" and "Tiger" are sequentially input into the trained neural network, and according to the feature vector output by the neural network, the feature similarity between the "Siberian tiger" and "Northeast" is determined as 0.4, the feature similarity between the "Siberian tiger" and "Tiger" is 0.6, then "tiger" can be used as the center word to be matched corresponding to the third label "Siberian tiger".
需要说明的是,在确定各第三标签分别对应的待匹配中心词时,可以使用其他方式进行确定,比如可以根据Jaccard相似度、编辑距离等文本相似度确定分词处理后的待筛选词中的待匹配中心词,又比如还可以根据中心词词库匹配法,通过将待筛选词与预设的中心词词库进行匹配,以确定所述待匹配中心词。具体采取何种方法确定所述待匹配中心词可以根据实际需要进行设置,本公开实施例对此不做限定。It should be noted that when determining the central words to be matched corresponding to the third tags, other methods can be used to determine, for example, according to the text similarity such as Jaccard similarity, edit distance, etc. For the central word to be matched, for example, the to-be-matched central word may be determined by matching the to-be-screened word with a preset central word lexicon according to the central word lexicon matching method. The specific method to be used to determine the central word to be matched may be set according to actual needs, which is not limited in this embodiment of the present disclosure.
S403:确定至少一个待匹配中心词中与所述样本标签集合中任一标签匹配的目标中心词,并将所述目标中心词对应的第三标签确定为所述目标标签。S403: Determine a target central word matching any label in the sample label set in at least one central word to be matched, and determine a third label corresponding to the target central word as the target label.
这里,若所述待匹配中心词与所述样本标签集合中的任一标签语义相同(比如完全相同或者为同义词)或者语义相近(比如近义词),则可以确定所述待匹配中心词与所述样本标签集合中的标签匹配。Here, if the to-be-matched central word is semantically the same as any label in the sample label set (such as identical or synonymous) or semantically similar (such as a synonym), it can be determined that the to-be-matched central word and the The labels in the sample label set match.
进一步的,在获取到所述目标标签之后,可以确定所述样本标签集合中与所述待匹配中心词匹配的标签的第二层级位置;将所述第三标签添加至所述样本标签集合中所述第二层级位置的下一层级中。Further, after acquiring the target label, the second level position of the label in the sample label set that matches the central word to be matched can be determined; the third label is added to the sample label set. in the next level of the second level position.
示例性的,以所述目标标签为“东北虎”为例,添加目标标签“东北虎”后的标签层级关系可以如图2d所示,图2d中,所述样本标签集合中与所述待匹配中心词“虎”匹配的标签为“虎”(也即其本身),将目标标签“东北虎”,添加至“虎”的下一层级中,从而完成了对所述样本标签集合的扩展。Exemplarily, taking the target label as "Siberian tiger" as an example, the label hierarchical relationship after adding the target label "Siberian tiger" can be as shown in Figure 2d. The matching tag of the central word "tiger" is "tiger" (that is, itself), and the target tag "Siberian tiger" is added to the next level of "tiger", thus completing the expansion of the sample tag set .
获取方式4、通过可被语义分析的第四标签获取。Obtaining method 4. Obtain through a fourth tag that can be semantically analyzed.
这里,经过语义分析后,所述第四标签可以被识别出的识别内容可以与所述第四标签不同,比如“英短”被语义分析后可以得到的识别内容为“猫”,“黑曼巴”被语义分析后可以得到的识别内容为“蛇”。Here, after semantic analysis, the identification content that can be identified by the fourth tag may be different from the fourth tag. "Ba" can be recognized as "snake" after semantic analysis.
一种可能的实施方式中,在获取所述目标标签时,如图5所示,可以通过以下步骤:In a possible implementation manner, when acquiring the target tag, as shown in FIG. 5 , the following steps may be performed:
S501:获取至少一个第四标签。S501: Acquire at least one fourth tag.
S502:确定各第四标签经过语义分析后得到的待匹配识别词。S502: Determine to-be-matched recognized words obtained by semantic analysis of each fourth tag.
这里,在对所述第四标签进行语义分析时,可以使用训练好的自然语言处理(Natural Language Processing,NLP)模型,对所述第四标签进行语义分析,得到各第四标签分别对应的待匹配分析词。Here, when performing the semantic analysis on the fourth label, a trained natural language processing (Natural Language Processing, NLP) model may be used to perform semantic analysis on the fourth label, to obtain the corresponding waiting list for each fourth label. Match analysis words.
S503:确定至少一个待匹配识别词中与所述样本标签集合中任一标签匹配的目标识别词,并将所述目标识别词对应的第四标签确定为所述目标标签。S503: Determine a target recognition word matching any label in the sample label set in at least one to-be-matched recognition word, and determine a fourth label corresponding to the target recognition word as the target label.
这里,若所述待匹配识别词与所述样本标签集合中的任一标签语义相同(比如完全相同或者为同义词)或者语义相近(比如近义词),则可以确定所述待匹配识别词与所述样本标签集合中的标签匹配。Here, if the to-be-matched recognized word is semantically the same as any label in the sample label set (for example, identical or synonymous) or semantically similar (for example, a synonym), it can be determined that the to-be-matched recognized word is the same as the The labels in the sample label set match.
进一步的,在获取到所述目标标签之后,可以确定所述样本标签集合中与所述待匹配识别词匹配的标签的第三层级位置;将所述第四标签添加至所述样本标签集合中所述第三层级位置的下一层级中。Further, after acquiring the target label, the third-level position of the label in the sample label set that matches the recognized word to be matched can be determined; the fourth label is added to the sample label set. in the next level of the third level position.
示例性的,以所述目标标签为“英短”为例,添加目标标签“英短”后的标签层级关系可以如图2e所示,图2e中,所述样本标签集合中与所述待匹配识别词“猫”匹配的标签为“猫”(也即其本身),将目标标签“英短”,添加至“猫”的下一层级中,从而完成了对所述样本标签集合的扩展。Exemplarily, taking the target label as "English short" as an example, the label hierarchical relationship after adding the target label "English short" can be as shown in Figure 2e. The matching label of the recognized word "cat" is "cat" (that is, itself), and the target label "English Short" is added to the next level of "cat", thus completing the expansion of the sample label set .
一种可能的实施方式中,还可以响应用户的删除操作,将不符合应用场景需求的目标标签从所述样本标签集合中删除,从而使得最终生成的样本数据集能够更符合应用场景的实际需求。In a possible implementation, the target tag that does not meet the requirements of the application scenario can also be deleted from the sample tag set in response to the user's deletion operation, so that the final generated sample data set can more meet the actual requirements of the application scenario. .
S103:获取所述样本标签集合所包含的标签分别对应的样本数据,并基于所述样本数据和所述样本标签集合构建样本数据集。S103: Obtain sample data corresponding to the labels included in the sample label set, and construct a sample data set based on the sample data and the sample label set.
实际应用中,在初次构建样本数据集时,由于所述数据集中没有样本数据,则可以获取所述样本标签集合所包含的各标签分别对应的样本数据,并基于所述样本数据和所述样本标签集合构建样本数据集。In practical applications, when the sample data set is first constructed, since there is no sample data in the data set, the sample data corresponding to each label included in the sample label set can be obtained, and based on the sample data and the sample A collection of labels builds a sample dataset.
一种可能的实施方式中,所述样本标签集合还可以对应有初始样本数据集,所述初始样本数据集可以是根据未添加所述目标标签前的样本标签集合构建的。In a possible implementation manner, the sample label set may also correspond to an initial sample data set, and the initial sample data set may be constructed according to the sample label set before adding the target label.
在这种情况下,由于已经有了初始样本数据集,因此在获取所述样本标签集合所包含的标签分别对应的样本数据时,可以获取添加至所述样本标签集合的目标标签分别对应的样本数据,然后基于所述样本数据、所述初始样本数据集以及所述样本标签集合构建样本数据集。In this case, since the initial sample data set already exists, when the sample data corresponding to the labels included in the sample label set are obtained, the samples corresponding to the target labels added to the sample label set can be obtained. data, and then construct a sample data set based on the sample data, the initial sample data set, and the sample label set.
一种可能的实施方式中,如图6所示,可以通过以下步骤获取标签对应的目标样本数据:In a possible implementation, as shown in Figure 6, the target sample data corresponding to the label can be obtained through the following steps:
S601:获取与所述标签分别对应的多个待筛选样本数据。S601: Acquire a plurality of sample data to be screened corresponding to the tags respectively.
这里,可以将所述标签作为检索词,从数据库中检索与所述标签分别对应的多个待筛选样本数据。Here, the tag can be used as a search term to retrieve a plurality of sample data to be screened corresponding to the tag respectively from the database.
此外,还可以根据所述样本数据集的应用场景,在检索时设置相应的检索条件,从而使得最终得到目标样本数据能够更符合应用场景。In addition, according to the application scenario of the sample data set, corresponding retrieval conditions can be set during retrieval, so that the final obtained target sample data can be more in line with the application scenario.
示例性的,以所述应用场景为计算机视觉领域为例,在对所述标签进行检索时,可以使用网络爬虫(一种自动获取网页内容的程序),从各网页中检索与所述标签对应的多张图片,并将得到的所述多张图片所述标签对应的多个待筛选样本数据。Exemplarily, taking the application scenario as an example in the field of computer vision, when retrieving the tags, a web crawler (a program for automatically acquiring web page content) can be used to retrieve the tags corresponding to the tags from each web page. multiple pictures, and multiple sample data to be screened corresponding to the labels of the obtained multiple pictures.
S602:基于预设的筛选条件对所述多个待筛选样本数据进行筛选,确定所述标签分别对应的目标样本数据。S602: Screen the plurality of sample data to be screened based on preset screening conditions, and determine the target sample data corresponding to the tags respectively.
实际应用中,由于网络文化的普及等原因,词语在网络传播过程中可能被赋予新的含义,从而导致了检索得到的待筛选样本数据可能跟检索时所使用的标签之间毫无关联,因此检索得到的待筛选样本数据需要进行进一步的筛选才能满足样本数据集的使用。In practical applications, due to the popularization of Internet culture and other reasons, words may be given new meanings in the process of Internet communication, resulting in that the retrieved sample data to be screened may have no relationship with the tags used in retrieval. The retrieved sample data to be screened needs to be further screened to meet the use of the sample data set.
示例性的,以标签为“狗”为例,检索到的待筛选样本数据可能是昵称为“狗子”的用户照片。Exemplarily, taking the tag "dog" as an example, the retrieved sample data to be screened may be a photo of a user nicknamed "dog".
一种可能的实施方式中,如图7所示,可以通过以下步骤确定目标样本数据:In a possible implementation, as shown in Figure 7, the target sample data can be determined through the following steps:
S6021:针对任一待筛选样本数据,基于预先训练的分类模型,确定与所述任一待筛选样本数据对应的类别集合。S6021: For any sample data to be screened, determine a category set corresponding to any sample data to be screened based on a pre-trained classification model.
具体的,可以基于预先训练的分类模型对所述任一待筛选样本数据进行分类,得到所述任一待筛选样本数据对应的分类结果;其中,所述分类结果中包含所述任一待筛选样本数据为至少一个预设类别的置信度信息;然后基于所述至少一个预设类别的置信度信息,确定与所述任一待筛选样本数据对应的类别集合。Specifically, the sample data to be screened can be classified based on a pre-trained classification model, and a classification result corresponding to the sample data to be screened can be obtained; wherein, the classification result includes the sample data to be screened. The sample data is confidence level information of at least one preset category; then, based on the confidence level information of the at least one preset category, a category set corresponding to any one of the sample data to be screened is determined.
其中,在确定所述任一待筛选样本数据对应的类别集合时,可以根据各所述预设类别的置信度信息,对各预设类别由高到低进行排序,并从排序结果中取前N个预设类别作为所述任一待筛选样本数据对应的类别集合,其中,N为预设正整数。Wherein, when the category set corresponding to any of the sample data to be screened is determined, each preset category may be sorted from high to low according to the confidence information of each preset category, and the top category may be selected from the sorting result. The N preset categories are used as the category set corresponding to any one of the sample data to be screened, wherein N is a preset positive integer.
示例性的,以所述待筛选样本数据为昵称为“狗子”的用户照片为例,将所述用户照片输入至预先训练的分类模型,在所述N为3的情况下,可以得到确定所述用户照片对应的类别集合中包含的类别为“人”、“猴子”、“猩猩”。Exemplarily, taking the sample data to be screened as an example of a user's photo nicknamed "Gouzi", the user's photo is input into a pre-trained classification model, and when the N is 3, it can be determined. The categories included in the category set corresponding to the user photo are "people", "monkeys", and "gorillas".
S6022:在检测到所述类别集合中存在与所述任一待筛选样本数据对应的标签匹配的目标类别的情况下,将所述任一待筛选样本数据确定为所述目标样本数据。S6022: In the case of detecting that there is a target category in the category set that matches the label corresponding to the sample data to be screened, determine the sample data to be screened as the target sample data.
这里,若所述类别集合中的任一类别与所述任一待筛选样本数据对应的标签,语义相同(比如完全相同或者为同义词)或者语义相近(比如近义词),则可以确定所述类别集合中存在所述目标类别,并将所述任一待筛选样本数据确定为所述目标样本数据。Here, if any category in the category set and the label corresponding to any of the sample data to be screened have the same semantics (such as identical or synonyms) or similar semantics (such as synonyms), the category set can be determined The target category exists in , and any sample data to be screened is determined as the target sample data.
承接上例,由于所述类别集合中包含的“人”、“猴子”、“猩猩”均与“狗”不匹配,则所述类别集合对应的待筛选样本数据(即昵称为“狗子”的用户照片)不是目标样本数据,可以被删除。Continuing the above example, since the "human", "monkey" and "gorilla" contained in the category set do not match with "dog", the sample data to be screened corresponding to the category set (that is, the nickname is "dog") user photos) are not target sample data and can be deleted.
进一步的,为了提高所述样本数据集中样本数据的质量,还可以响应用户的删除操作,将不符合用户需求的样本数据进行删除。Further, in order to improve the quality of the sample data in the sample data set, the sample data that does not meet the user's requirements can also be deleted in response to the user's deletion operation.
示例性的,可以响应用户的第一删除操作,删除5张相似度较高的样本图片(即样本数据)中的4张,避免使用相似图片进行训练导致的训练效果较差的问题,以确保所述样本数据集中的样本数据的使用价值。Exemplarily, in response to the user's first deletion operation, 4 out of 5 sample pictures (ie, sample data) with high similarity can be deleted, so as to avoid the problem of poor training effect caused by using similar pictures for training, so as to ensure The use value of the sample data in the sample data set.
示例性的,还可以响应用户的第二删除操作,删除分辨率、占用存储空间等因素不符合要求的样本数据,从而确保所述样本数据的使用价值。Exemplarily, in response to the user's second deletion operation, the sample data whose resolution, occupied storage space and other factors do not meet the requirements may be deleted, thereby ensuring the use value of the sample data.
需要说明的是,上述第二删除操作也可以通过添加数据清洗过程自动完成,具体是否需要自动完成可以根据实际情况进行设置,本公开实施例对此不做限定。It should be noted that the above-mentioned second deletion operation can also be automatically completed by adding a data cleaning process, and whether automatic completion is required can be set according to the actual situation, which is not limited in this embodiment of the present disclosure.
另一种可能的实施方式中,在获取所述样本数据时,还可以获取已标注的待筛选样本数据,并通过对所述已标注的待筛选样本数据进行筛选,从而实现对已标注的样本数据的重复使用,提高样本数据的利用率,具体的筛选过程可以参照上文相关描述,在此不再赘述。In another possible implementation, when acquiring the sample data, the marked sample data to be screened can also be acquired, and the marked sample data to be screened can be screened, so as to realize the selection of the marked sample data. The reuse of data improves the utilization rate of sample data. For the specific screening process, please refer to the relevant description above, which will not be repeated here.
在构建好所述样本数据集之后,由于所述样本数据集对应的样本标签集合中的样本标签是具有层级结构的,因此在基于所述样本数据集训练任一神经网络时,可以基于所述层级结构,选择与该神经网络适配的层级的样本标签,并将该样本标签作为监督数据去训练神经网络,因此构建出的样本数据集具有通用性。After the sample data set is constructed, since the sample labels in the sample label set corresponding to the sample data set have a hierarchical structure, when training any neural network based on the sample data set, the Hierarchical structure, select the sample label of the layer suitable for the neural network, and use the sample label as the supervision data to train the neural network, so the constructed sample data set is universal.
本公开实施例提供的数据集的构建方法,通过基于获取的目标标签与所述样本标签集合的匹配关系,将所述目标标签添加至所述样本标签集合的标签层级结构中,可以自动的完成对数据集的样本标签集合的构建,从而使得构建样本数据集时更为高效便捷,且可以通过添加大量的标签和对应的样本数据,构建标签更为丰富完整的样本数据集,从而提高了样本数据集在不同应用场景下的通用性。The data set construction method provided by the embodiment of the present disclosure can be automatically completed by adding the target label to the label hierarchy structure of the sample label set based on the matching relationship between the obtained target label and the sample label set. The construction of the sample label set of the data set makes the construction of the sample data set more efficient and convenient, and by adding a large number of labels and corresponding sample data, a sample data set with more abundant and complete labels can be constructed, thereby improving the sample data. The versatility of the dataset in different application scenarios.
本领域技术人员可以理解,在具体实施方式的上述方法中,各步骤的撰写顺序并不意味着严格的执行顺序而对实施过程构成任何限定,各步骤的具体执行顺序应当以其功能和可能的内在逻辑确定。Those skilled in the art can understand that in the above method of the specific implementation, the writing order of each step does not mean a strict execution order but constitutes any limitation on the implementation process, and the specific execution order of each step should be based on its function and possible Internal logic is determined.
基于同一发明构思,本公开实施例中还提供了与数据集的构建方法对应的数据集的构建装置,由于本公开实施例中的装置解决问题的原理与本公开实施例上述数据集的构建方法相似,因此装置的实施可以参见方法的实施,重复之处不再赘述。Based on the same inventive concept, the embodiment of the present disclosure also provides a data set construction device corresponding to the data set construction method, because the principle of the device in the embodiment of the present disclosure to solve the problem and the above-mentioned data set construction method in the embodiment of the present disclosure Similar, therefore, the implementation of the apparatus may refer to the implementation of the method, and repeated descriptions will not be repeated.
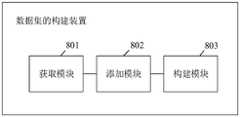
参照图8所示,为本公开实施例提供的一种数据集的构建装置的架构示意图,所述装置包括:获取模块801、添加模块802、构建模块803;其中,Referring to FIG. 8, which is a schematic diagram of the architecture of a data set construction apparatus provided by an embodiment of the present disclosure, the apparatus includes: an
获取模块801,用于获取待添加至样本标签集合的目标标签;an obtaining
添加模块802,用于基于所述目标标签与所述样本标签集合的匹配关系,将所述目标标签添加至所述样本标签集合的标签层级结构中;An adding
构建模块803,用于获取所述样本标签集合所包含的标签分别对应的样本数据,并基于所述样本数据和所述样本标签集合构建样本数据集。The
一种可能的实施方式中,所述获取模块801,在获取待添加至样本标签集合的目标标签时,用于:In a possible implementation manner, the obtaining
针对所述样本标签集合中的第一标签,将所述第一标签对应的关联词确定为所述目标标签;For the first label in the sample label set, determine the associated word corresponding to the first label as the target label;
所述添加模块802,基于所述目标标签与所述样本标签集合的匹配关系,将所述目标标签添加至所述样本标签集合的标签层级结构中时,用于:The adding
将所述目标标签添加至,与所述目标标签具有同一语义的第一标签所在的标签层级结构中。The target label is added to the label hierarchy where the first label having the same semantics as the target label is located.
一种可能的实施方式中,所述获取模块801,在获取待添加至样本标签集合的目标标签时,用于:In a possible implementation manner, the obtaining
获取具有层级关系的多个第二标签;Get multiple second tags with hierarchical relationship;
基于所述多个第二标签之间的层级关系,以及所述样本标签集合的标签层级结构,确定添加至所述样本标签集合中的目标标签。Based on the hierarchical relationship between the plurality of second tags and the tag hierarchy structure of the sample tag set, a target tag to be added to the sample tag set is determined.
一种可能的实施方式中,所述获取模块801,在基于所述多个第二标签之间的层级关系,以及所述样本标签集合的标签层级结构,确定添加至所述样本标签集合中的目标标签时,用于:In a possible implementation manner, the acquiring
确定所述多个第二标签中,对应的层级关系满足预设要求的第二目标标签;Determining that among the plurality of second labels, the corresponding hierarchical relationship meets the second target label of the preset requirement;
针对任一第二目标标签,从所述多个第二标签中,确定与所述任一第二目标标签具有层级关系的至少一个待匹配标签;For any second target tag, from the plurality of second tags, determine at least one tag to be matched that has a hierarchical relationship with the any second target tag;
在检测到所述待匹配标签与所述样本标签集合中的任一标签匹配的情况下,将所述任一第二目标标签确定为所述目标标签。When it is detected that the to-be-matched label matches any label in the sample label set, the any second target label is determined as the target label.
一种可能的实施方式中,所述添加模块802,在基于所述目标标签与所述样本标签集合的匹配关系,将所述目标标签添加至所述样本标签集合的标签层级结构中时,用于:In a possible implementation manner, the adding
确定所述样本标签集合中与所述待匹配标签匹配的标签的第一层级位置;determining the first level position of the tag matching the tag to be matched in the sample tag set;
将所述任一第二目标标签添加至所述样本标签集合中所述第一层级位置的下一层级中。The any second target label is added to the next level of the first level position in the set of sample labels.
一种可能的实施方式中,所述获取模块801,在获取待添加至样本标签集合的目标标签时,用于:In a possible implementation manner, the obtaining
获取至少一个第三标签;其中,所述第三标签中包含有至少两个词语;Obtain at least one third label; wherein, the third label contains at least two words;
确定各第三标签分别对应的待匹配中心词;Determine the center word to be matched corresponding to each third label;
确定至少一个待匹配中心词中与所述样本标签集合中任一标签匹配的目标中心词,并将所述目标中心词对应的第三标签确定为所述目标标签。A target central word matching any label in the sample label set in at least one central word to be matched is determined, and a third label corresponding to the target central word is determined as the target label.
一种可能的实施方式中,所述添加模块802,在基于所述目标标签与所述样本标签集合的匹配关系,将所述目标标签添加至所述样本标签集合的标签层级结构中时,用于:In a possible implementation manner, the adding
确定所述样本标签集合中与所述待匹配中心词匹配的标签的第二层级位置;Determine the second level position of the label matching the central word to be matched in the sample label set;
将所述第三标签添加至所述样本标签集合中所述第二层级位置的下一层级中。The third label is added to the next level of the second level position in the set of sample labels.
一种可能的实施方式中,所述样本标签集合对应有初始样本数据集;In a possible implementation manner, the sample label set corresponds to an initial sample data set;
所述构建模块803,在获取所述样本标签集合所包含的标签分别对应的样本数据时,用于:The
获取添加至所述样本标签集合的目标标签分别对应的样本数据;obtaining sample data corresponding to the target labels added to the sample label set respectively;
所述构建模块803,在基于所述样本数据和所述样本标签集合构建样本数据集时,用于:The
基于所述样本数据、所述初始样本数据集以及所述样本标签集合构建样本数据集。A sample data set is constructed based on the sample data, the initial sample data set, and the sample label set.
一种可能的实施方式中,所述构建模块803,在获取所述样本标签集合所包含的标签分别对应的样本数据时,用于:In a possible implementation manner, the
获取与所述标签分别对应的多个待筛选样本数据;acquiring a plurality of sample data to be screened corresponding to the labels respectively;
基于预设的筛选条件对所述多个待筛选样本数据进行筛选,确定所述标签分别对应的目标样本数据。Screen the plurality of sample data to be screened based on preset screening conditions, and determine the target sample data corresponding to the tags respectively.
一种可能的实施方式中,所述构建模块803,在基于预设的筛选条件对所述多个待筛选样本数据进行筛选,确定所述标签分别对应的目标样本数据时,用于:In a possible implementation manner, the
针对任一待筛选样本数据,基于预先训练的分类模型,确定与所述任一待筛选样本数据对应的类别集合;For any sample data to be screened, based on a pre-trained classification model, determine a category set corresponding to the sample data to be screened;
在检测到所述类别集合中存在与所述任一待筛选样本数据对应的标签匹配的目标类别的情况下,将所述任一待筛选样本数据确定为所述目标样本数据。In a case where it is detected that there is a target category matching the label corresponding to any one of the sample data to be screened in the category set, the any one of the sample data to be screened is determined as the target sample data.
本公开实施例提供的数据集的构建装置,通过基于获取的目标标签与所述样本标签集合的匹配关系,将所述目标标签添加至所述样本标签集合的标签层级结构中,可以自动的完成对数据集的样本标签集合的构建,从而使得构建样本数据集时更为高效便捷,且可以通过添加大量的标签和对应的样本数据,构建标签更为丰富完整的样本数据集,从而提高了样本数据集在不同应用场景下的通用性。The apparatus for constructing a data set provided by the embodiment of the present disclosure can automatically complete the process by adding the target label to the label hierarchy of the sample label set based on the matching relationship between the obtained target label and the sample label set. The construction of the sample label set of the data set makes the construction of the sample data set more efficient and convenient, and by adding a large number of labels and corresponding sample data, a sample data set with more abundant and complete labels can be constructed, thereby improving the sample data. The versatility of the dataset in different application scenarios.
关于装置中的各模块的处理流程、以及各模块之间的交互流程的描述可以参照上述方法实施例中的相关说明,这里不再详述。For the description of the processing flow of each module in the apparatus and the interaction flow between the modules, reference may be made to the relevant descriptions in the foregoing method embodiments, which will not be described in detail here.
基于同一技术构思,本公开实施例还提供了一种计算机设备。参照图9所示,为本公开实施例提供的计算机设备900的结构示意图,包括处理器901、存储器902、和总线903。其中,存储器902用于存储执行指令,包括内存9021和外部存储器9022;这里的内存9021也称内存储器,用于暂时存放处理器901中的运算数据,以及与硬盘等外部存储器9022交换的数据,处理器901通过内存9021与外部存储器9022进行数据交换,当计算机设备900运行时,处理器901与存储器902之间通过总线903通信,使得处理器901在执行以下指令:Based on the same technical concept, an embodiment of the present disclosure also provides a computer device. Referring to FIG. 9 , a schematic structural diagram of a computer device 900 provided by an embodiment of the present disclosure includes a
获取待添加至样本标签集合的目标标签;Obtain the target tag to be added to the sample tag set;
基于所述目标标签与所述样本标签集合的匹配关系,将所述目标标签添加至所述样本标签集合的标签层级结构中;Based on the matching relationship between the target label and the sample label set, adding the target label to the label hierarchy of the sample label set;
获取所述样本标签集合所包含的标签分别对应的样本数据,并基于所述样本数据和所述样本标签集合构建样本数据集。Obtain sample data corresponding to the labels included in the sample label set, and construct a sample data set based on the sample data and the sample label set.
本公开实施例还提供一种计算机可读存储介质,该计算机可读存储介质上存储有计算机程序,该计算机程序被处理器运行时执行上述方法实施例中所述的数据集的构建方法的步骤。其中,该存储介质可以是易失性或非易失的计算机可读取存储介质。Embodiments of the present disclosure further provide a computer-readable storage medium, where a computer program is stored on the computer-readable storage medium, and when the computer program is run by a processor, the steps of the data set construction method described in the foregoing method embodiments are executed. . Wherein, the storage medium may be a volatile or non-volatile computer-readable storage medium.
本公开实施例还提供一种计算机程序产品,该计算机程序产品承载有程序代码,所述程序代码包括的指令可用于执行上述方法实施例中所述的数据集的构建方法的步骤,具体可参见上述方法实施例,在此不再赘述。Embodiments of the present disclosure further provide a computer program product, where the computer program product carries program codes, and the instructions included in the program codes can be used to execute the steps of the data set construction method described in the above method embodiments. For details, please refer to The foregoing method embodiments are not repeated here.
其中,上述计算机程序产品可以具体通过硬件、软件或其结合的方式实现。在一个可选实施例中,所述计算机程序产品具体体现为计算机存储介质,在另一个可选实施例中,计算机程序产品具体体现为软件产品,例如软件开发包(Software Development Kit,SDK)等等。Wherein, the above-mentioned computer program product can be specifically implemented by means of hardware, software or a combination thereof. In an optional embodiment, the computer program product is embodied as a computer storage medium, and in another optional embodiment, the computer program product is embodied as a software product, such as a software development kit (Software Development Kit, SDK), etc. Wait.
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的系统和装置的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。在本公开所提供的几个实施例中,应该理解到,所揭露的系统、装置和方法,可以通过其它的方式实现。以上所描述的装置实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,又例如,多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些通信接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。Those skilled in the art can clearly understand that, for the convenience and brevity of description, for the specific working process of the system and device described above, reference may be made to the corresponding process in the foregoing method embodiments, which will not be repeated here. In the several embodiments provided by the present disclosure, it should be understood that the disclosed system, apparatus and method may be implemented in other manners. The apparatus embodiments described above are only illustrative. For example, the division of the units is only a logical function division. In actual implementation, there may be other division methods. For example, multiple units or components may be combined or Can be integrated into another system, or some features can be ignored, or not implemented. On the other hand, the shown or discussed mutual coupling or direct coupling or communication connection may be through some communication interfaces, indirect coupling or communication connection of devices or units, which may be in electrical, mechanical or other forms.
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。The units described as separate components may or may not be physically separated, and components displayed as units may or may not be physical units, that is, may be located in one place, or may be distributed to multiple network units. Some or all of the units may be selected according to actual needs to achieve the purpose of the solution in this embodiment.
另外,在本公开各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。In addition, each functional unit in each embodiment of the present disclosure may be integrated into one processing unit, or each unit may exist physically alone, or two or more units may be integrated into one unit.
所述功能如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个处理器可执行的非易失的计算机可读取存储介质中。基于这样的理解,本公开的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本公开各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器(Read-OnlyMemory,ROM)、随机存取存储器(Random Access Memory,RAM)、磁碟或者光盘等各种可以存储程序代码的介质。The functions, if implemented in the form of software functional units and sold or used as stand-alone products, may be stored in a processor-executable non-volatile computer-readable storage medium. Based on such understanding, the technical solutions of the present disclosure can be embodied in the form of software products in essence, or the parts that contribute to the prior art or the parts of the technical solutions. The computer software products are stored in a storage medium, including Several instructions are used to cause a computer device (which may be a personal computer, a server, or a network device, etc.) to execute all or part of the steps of the methods described in various embodiments of the present disclosure. The aforementioned storage medium includes: U disk, mobile hard disk, read-only memory (Read-Only Memory, ROM), random access memory (Random Access Memory, RAM), magnetic disk or optical disk and other media that can store program codes.
最后应说明的是:以上所述实施例,仅为本公开的具体实施方式,用以说明本公开的技术方案,而非对其限制,本公开的保护范围并不局限于此,尽管参照前述实施例对本公开进行了详细的说明,本领域的普通技术人员应当理解:任何熟悉本技术领域的技术人员在本公开揭露的技术范围内,其依然可以对前述实施例所记载的技术方案进行修改或可轻易想到变化,或者对其中部分技术特征进行等同替换;而这些修改、变化或者替换,并不使相应技术方案的本质脱离本公开实施例技术方案的精神和范围,都应涵盖在本公开的保护范围之内。因此,本公开的保护范围应所述以权利要求的保护范围为准。Finally, it should be noted that the above-mentioned embodiments are only specific implementations of the present disclosure, and are used to illustrate the technical solutions of the present disclosure rather than limit them. The protection scope of the present disclosure is not limited thereto, although referring to the foregoing The embodiments describe the present disclosure in detail. Those of ordinary skill in the art should understand that: any person skilled in the art can still modify the technical solutions described in the foregoing embodiments within the technical scope disclosed by the present disclosure. Changes can be easily thought of, or equivalent replacements are made to some of the technical features; and these modifications, changes or replacements do not make the essence of the corresponding technical solutions deviate from the spirit and scope of the technical solutions of the embodiments of the present disclosure, and should be covered in the present disclosure. within the scope of protection. Therefore, the protection scope of the present disclosure should be based on the protection scope of the claims.
Claims (13)
Translated fromChinesePriority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111300934.3ACN114037007A (en) | 2021-11-04 | 2021-11-04 | Data set construction method and device, computer equipment and storage medium |
| PCT/CN2022/127643WO2023078136A1 (en) | 2021-11-04 | 2022-10-26 | Data set construction method and apparatus, device, storage medium, and computer program product |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111300934.3ACN114037007A (en) | 2021-11-04 | 2021-11-04 | Data set construction method and device, computer equipment and storage medium |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN114037007Atrue CN114037007A (en) | 2022-02-11 |
Family
ID=80142795
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202111300934.3APendingCN114037007A (en) | 2021-11-04 | 2021-11-04 | Data set construction method and device, computer equipment and storage medium |
Country Status (2)
| Country | Link |
|---|---|
| CN (1) | CN114037007A (en) |
| WO (1) | WO2023078136A1 (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023078136A1 (en)* | 2021-11-04 | 2023-05-11 | 上海商汤智能科技有限公司 | Data set construction method and apparatus, device, storage medium, and computer program product |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116501829B (en)* | 2023-06-29 | 2023-09-19 | 北京法伯宏业科技发展有限公司 | Data management method and system based on artificial intelligence large language model platform |
Citations (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105095288A (en)* | 2014-05-14 | 2015-11-25 | 腾讯科技(深圳)有限公司 | Data analysis method and data analysis device |
| CN107463711A (en)* | 2017-08-22 | 2017-12-12 | 山东浪潮云服务信息科技有限公司 | A kind of tag match method and device of data |
| CN107861944A (en)* | 2017-10-24 | 2018-03-30 | 广东亿迅科技有限公司 | A kind of text label extracting method and device based on Word2Vec |
| CN107958008A (en)* | 2016-10-18 | 2018-04-24 | 中国移动通信有限公司研究院 | A kind of update method and device of unified tag library |
| CN109961094A (en)* | 2019-03-07 | 2019-07-02 | 北京达佳互联信息技术有限公司 | Sample acquiring method, device, electronic equipment and readable storage medium storing program for executing |
| CN111353045A (en)* | 2020-03-18 | 2020-06-30 | 智者四海(北京)技术有限公司 | Method for constructing text classification system |
| CN111639156A (en)* | 2020-05-13 | 2020-09-08 | 广州国音智能科技有限公司 | Query method, device, equipment and storage medium based on hierarchical label |
| CN112597135A (en)* | 2021-01-04 | 2021-04-02 | 天冕信息技术(深圳)有限公司 | User classification method and device, electronic equipment and readable storage medium |
| CN112632964A (en)* | 2020-12-24 | 2021-04-09 | 平安科技(深圳)有限公司 | NLP-based industry policy information processing method, device, equipment and medium |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11972329B2 (en)* | 2018-12-31 | 2024-04-30 | Xerox Corporation | Method and system for similarity-based multi-label learning |
| CN113010705B (en)* | 2021-02-03 | 2023-12-12 | 腾讯科技(深圳)有限公司 | Label prediction method, device, equipment and storage medium |
| CN114037007A (en)* | 2021-11-04 | 2022-02-11 | 北京市商汤科技开发有限公司 | Data set construction method and device, computer equipment and storage medium |
- 2021
- 2021-11-04CNCN202111300934.3Apatent/CN114037007A/enactivePending
- 2022
- 2022-10-26WOPCT/CN2022/127643patent/WO2023078136A1/ennot_activeCeased
Patent Citations (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105095288A (en)* | 2014-05-14 | 2015-11-25 | 腾讯科技(深圳)有限公司 | Data analysis method and data analysis device |
| CN107958008A (en)* | 2016-10-18 | 2018-04-24 | 中国移动通信有限公司研究院 | A kind of update method and device of unified tag library |
| CN107463711A (en)* | 2017-08-22 | 2017-12-12 | 山东浪潮云服务信息科技有限公司 | A kind of tag match method and device of data |
| CN107861944A (en)* | 2017-10-24 | 2018-03-30 | 广东亿迅科技有限公司 | A kind of text label extracting method and device based on Word2Vec |
| CN109961094A (en)* | 2019-03-07 | 2019-07-02 | 北京达佳互联信息技术有限公司 | Sample acquiring method, device, electronic equipment and readable storage medium storing program for executing |
| CN111353045A (en)* | 2020-03-18 | 2020-06-30 | 智者四海(北京)技术有限公司 | Method for constructing text classification system |
| CN111639156A (en)* | 2020-05-13 | 2020-09-08 | 广州国音智能科技有限公司 | Query method, device, equipment and storage medium based on hierarchical label |
| CN112632964A (en)* | 2020-12-24 | 2021-04-09 | 平安科技(深圳)有限公司 | NLP-based industry policy information processing method, device, equipment and medium |
| CN112597135A (en)* | 2021-01-04 | 2021-04-02 | 天冕信息技术(深圳)有限公司 | User classification method and device, electronic equipment and readable storage medium |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023078136A1 (en)* | 2021-11-04 | 2023-05-11 | 上海商汤智能科技有限公司 | Data set construction method and apparatus, device, storage medium, and computer program product |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2023078136A1 (en) | 2023-05-11 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN111026671B (en) | Test case set construction method and test method based on test case set | |
| US9239875B2 (en) | Method for disambiguated features in unstructured text | |
| CN106649818B (en) | Application search intent identification method, device, application search method and server | |
| CN109726274B (en) | Question generation method, device and storage medium | |
| CN111324771B (en) | Video tag determination method and device, electronic equipment and storage medium | |
| CN111353310A (en) | Artificial intelligence-based named entity recognition method, device and electronic device | |
| CN110162771B (en) | Event trigger word recognition method and device and electronic equipment | |
| WO2019153737A1 (en) | Comment assessing method, device, equipment and storage medium | |
| TW202020691A (en) | Feature word determination method and device and server | |
| CN117952209A (en) | Knowledge graph construction method and system | |
| CN108628828A (en) | A kind of joint abstracting method of viewpoint and its holder based on from attention | |
| CN112989208B (en) | Information recommendation method and device, electronic equipment and storage medium | |
| WO2018153215A1 (en) | Method for automatically generating sentence sample with similar semantics | |
| CN113836925A (en) | Training method, device, electronic device and storage medium for pre-trained language model | |
| CN114238653A (en) | A method for the construction, completion and intelligent question answering of programming education knowledge graph | |
| WO2021051864A1 (en) | Dictionary expansion method and apparatus, electronic device and storage medium | |
| CN103853792B (en) | A kind of picture semantic automatic marking method and system | |
| CN114239828A (en) | Supply chain affair map construction method based on causal relationship | |
| CN114661872A (en) | A beginner-oriented API adaptive recommendation method and system | |
| WO2023078136A1 (en) | Data set construction method and apparatus, device, storage medium, and computer program product | |
| CN114840657A (en) | API knowledge graph self-adaptive construction and intelligent question-answering method based on mixed mode | |
| CN111325018A (en) | Domain dictionary construction method based on web retrieval and new word discovery | |
| CN115809334B (en) | Training method, text processing method and device for event correlation classification model | |
| EP4270239A1 (en) | Supervised machine learning method for matching unsupervised data | |
| CN119557500B (en) | A method and system for accurate search of Internet massive data based on AI technology |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| REG | Reference to a national code | Ref country code:HK Ref legal event code:DE Ref document number:40062738 Country of ref document:HK |