CN114036364B - Method, apparatus, device, medium, and system for identifying crawlers - Google Patents
Method, apparatus, device, medium, and system for identifying crawlersDownload PDFInfo
- Publication number
- CN114036364B CN114036364BCN202111316197.6ACN202111316197ACN114036364BCN 114036364 BCN114036364 BCN 114036364BCN 202111316197 ACN202111316197 ACN 202111316197ACN 114036364 BCN114036364 BCN 114036364B
- Authority
- CN
- China
- Prior art keywords
- crawler
- request information
- identification
- target
- preset
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images





Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/95—Retrieval from the web
- G06F16/951—Indexing; Web crawling techniques
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/903—Querying
- G06F16/90335—Query processing
- G06F16/90344—Query processing by using string matching techniques
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/95—Retrieval from the web
- G06F16/955—Retrieval from the web using information identifiers, e.g. uniform resource locators [URL]
- G06F16/9566—URL specific, e.g. using aliases, detecting broken or misspelled links
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F21/00—Security arrangements for protecting computers, components thereof, programs or data against unauthorised activity
- G06F21/60—Protecting data
- G06F21/602—Providing cryptographic facilities or services
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Databases & Information Systems (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Health & Medical Sciences (AREA)
- Bioethics (AREA)
- General Health & Medical Sciences (AREA)
- Computer Hardware Design (AREA)
- Computer Security & Cryptography (AREA)
- Software Systems (AREA)
- Computational Linguistics (AREA)
- Information Transfer Between Computers (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本公开涉及计算机技术领域,具体为信息安全技术领域。The present disclosure relates to the field of computer technology, in particular to the field of information security technology.
背景技术Background technique
爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。网页版本的小程序中通常具有一些公开数据供用户浏览,而爬虫攻击会导致这些公开数据被恶意使用。A crawler is a program or script that automatically crawls information on the World Wide Web according to certain rules. The web version of the applet usually has some public data for users to browse, and the crawler attack will cause these public data to be used maliciously.
然而,对于网页版本的小程序而言,并未配置相应的反爬虫手段,从而导致网页版本的小程序中的公开数据存在着一定的安全隐患。However, for the applet of the webpage version, corresponding anti-crawling means are not configured, so that there are certain security risks in the public data in the applet of the webpage version.
发明内容SUMMARY OF THE INVENTION
本公开提供了一种用于识别爬虫的方法、装置、设备、介质和产品。The present disclosure provides a method, apparatus, device, medium and product for identifying crawlers.
根据本公开的一方面,提供了一种用于识别爬虫的方法,包括:获取请求访问页面数据的请求信息;按照预设的爬虫识别顺序,从预设的反爬虫操作集合中确定针对请求信息的目标反爬虫操作;基于目标反爬虫操作,对请求信息进行爬虫识别,得到识别结果;响应于确定识别结果指示请求信息为爬虫,将识别结果确定为目标爬虫识别结果。According to an aspect of the present disclosure, there is provided a method for identifying a crawler, including: obtaining request information for requesting access to page data; Based on the target anti-crawler operation, perform crawler identification on the request information to obtain the identification result; in response to determining that the identification result indicates that the request information is a crawler, the identification result is determined as the target crawler identification result.
根据本公开的另一方面,提供了一种用于识别爬虫的装置,包括:信息获取单元,被配置成获取请求访问页面数据的请求信息;操作确定单元,被配置成按照预设的爬虫识别顺序,从预设的反爬虫操作集合中确定针对请求信息的目标反爬虫操作;爬虫识别单元,被配置成基于目标反爬虫操作,对请求信息进行爬虫识别,得到识别结果;结果确定单元,被配置成响应于确定识别结果指示请求信息为爬虫,将识别结果确定为目标爬虫识别结果。According to another aspect of the present disclosure, there is provided an apparatus for recognizing a crawler, comprising: an information acquisition unit configured to acquire request information for requesting access to page data; an operation determination unit configured to identify a crawler according to a preset sequence, determine the target anti-crawler operation for the request information from the preset anti-crawler operation set; the crawler identification unit is configured to perform crawler identification on the request information based on the target anti-crawler operation, and obtain the identification result; the result determination unit, which is is configured to, in response to determining that the identification result indicates that the requested information is a crawler, determine the identification result as a target crawler identification result.
根据本公开的另一方面,提供了一种电子设备,包括:一个或多个处理器;存储器,用于存储一个或多个程序;当一个或多个程序被一个或多个处理器执行,使得一个或多个处理器实现如上任意一项用于识别爬虫的方法。According to another aspect of the present disclosure, there is provided an electronic device, comprising: one or more processors; a memory for storing one or more programs; when the one or more programs are executed by the one or more processors, One or more processors are caused to implement any of the above methods for identifying crawlers.
根据本公开的另一方面,提供了一种存储有计算机指令的非瞬时计算机可读存储介质,其中,计算机指令用于使计算机执行如上任意一项用于识别爬虫的方法。According to another aspect of the present disclosure, there is provided a non-transitory computer-readable storage medium storing computer instructions, wherein the computer instructions are used to cause a computer to perform any one of the above methods for recognizing a crawler.
根据本公开的另一方面,提供了一种计算机程序系统,包括计算机程序,计算机程序在被处理器执行时实现如上任意一项用于识别爬虫的方法。According to another aspect of the present disclosure, there is provided a computer program system, comprising a computer program, which when executed by a processor implements any one of the above methods for recognizing a crawler.
根据本公开的技术,提供一种用于识别爬虫的方法,能够提高网页版本的小程序的数据安全。According to the technology of the present disclosure, a method for identifying a crawler is provided, which can improve the data security of the applet of the webpage version.
应当理解,本部分所描述的内容并非旨在标识本公开的实施例的关键或重要特征,也不用于限制本公开的范围。本公开的其它特征将通过以下的说明书而变得容易理解。It should be understood that what is described in this section is not intended to identify key or critical features of embodiments of the disclosure, nor is it intended to limit the scope of the disclosure. Other features of the present disclosure will become readily understood from the following description.
附图说明Description of drawings
附图用于更好地理解本方案,不构成对本公开的限定。其中:The accompanying drawings are used for better understanding of the present solution, and do not constitute a limitation to the present disclosure. in:
图1是本公开的一个实施例可以应用于其中的示例性系统架构图;FIG. 1 is an exemplary system architecture diagram to which an embodiment of the present disclosure may be applied;
图2是根据本公开的用于识别爬虫的方法的一个实施例的流程图;2 is a flowchart of one embodiment of a method for identifying a crawler according to the present disclosure;
图3是根据本公开的用于识别爬虫的方法的一个应用场景的示意图;3 is a schematic diagram of an application scenario of the method for identifying a crawler according to the present disclosure;
图4是根据本公开的用于识别爬虫的方法的另一个实施例的流程图;4 is a flowchart of another embodiment of a method for identifying a crawler according to the present disclosure;
图5是根据本公开的用于识别爬虫的装置的一个实施例的结构示意图;5 is a schematic structural diagram of an embodiment of an apparatus for recognizing a crawler according to the present disclosure;
图6是用来实现本公开实施例的用于识别爬虫的方法的电子设备的框图。FIG. 6 is a block diagram of an electronic device used to implement the method for recognizing a crawler according to an embodiment of the present disclosure.
具体实施方式Detailed ways
以下结合附图对本公开的示范性实施例做出说明,其中包括本公开实施例的各种细节以助于理解,应当将它们认为仅仅是示范性的。因此,本领域普通技术人员应当认识到,可以对这里描述的实施例做出各种改变和修改,而不会背离本公开的范围和精神。同样,为了清楚和简明,以下的描述中省略了对公知功能和结构的描述。Exemplary embodiments of the present disclosure are described below with reference to the accompanying drawings, which include various details of the embodiments of the present disclosure to facilitate understanding and should be considered as exemplary only. Accordingly, those of ordinary skill in the art will recognize that various changes and modifications of the embodiments described herein can be made without departing from the scope and spirit of the present disclosure. Also, descriptions of well-known functions and constructions are omitted from the following description for clarity and conciseness.
需要说明的是,在不冲突的情况下,本公开中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本公开。It should be noted that the embodiments of the present disclosure and the features of the embodiments may be combined with each other under the condition of no conflict. The present disclosure will be described in detail below with reference to the accompanying drawings and in conjunction with embodiments.
如图1所示,系统架构100可以包括终端设备101、102、103,网络104、网页小程序代理服务器105、网络106和开发者服务器107。网络104用以在终端设备101、102、103和网页小程序代理服务器105之间提供通信链路的介质,网络106用以在网页小程序代理服务器105和开发者服务器107之间提供通信链路的介质。网络104、网络106可以包括各种连接类型,例如有线、无线通信链路或者光纤电缆等等。As shown in FIG. 1 , the
用户可以使用终端设备101、102、103通过网络104与网页小程序代理服务器105交互,以接收或发送消息等。终端设备101、102、103可以安装有小程序客户端,用户通过运行该小程序客户端,可以获取网页小程序代理服务器105和开发者服务器107为该小程序客户端提供的相应服务。The user can use the
终端设备101、102、103可以是硬件,也可以是软件。当终端设备101、102、103为硬件时,可以是各种电子设备,包括但不限于手机、电脑、平板等等。当终端设备101、102、103为软件时,可以安装在上述所列举的电子设备中。其可以实现成多个软件或软件模块(例如用来提供分布式服务),也可以实现成单个软件或软件模块。在此不做具体限定。The
网页小程序代理服务器105可以是提供各种小程序代理服务的服务器,例如,网页小程序代理服务器105可以获取终端设备101、102、103发送的、上述小程序客户端对应的请求信息,并将请求信息通过网络106发送给开发者服务器107,并接收开发者服务器107返回的与请求信息对应的服务内容,以及将服务内容返回给终端设备101、102、103。The webpage
并且,在网页小程序代理服务器105获取到终端设备101、102、103发送的请求信息之后,以及在将请求信息通过网络106发送给开发者服务器107之前,为了提高数据安全性,还可以按照预设的爬虫识别顺序,从预设的反爬虫操作集合中确定针对请求信息的目标反爬虫操作,并基于目标反爬虫操作对请求信息进行爬虫识别,得到识别结果。如果识别结果指示请求信息为爬虫,则将识别结果确定为目标爬虫识别结果。可选的,网页小程序代理服务器105可以根据目标爬虫识别结果指示请求信息为爬虫,对请求信息进行拦截,或者,也可以向开发者服务器107发送提示消息,以使开发者服务器107对识别为爬虫的请求信息进行相应的处理。In addition, after the web
需要说明的是,网页小程序代理服务器105和开发者服务器107可以是硬件,也可以是软件。当网页小程序代理服务器105和开发者服务器107为硬件时,可以实现成多个服务器组成的分布式服务器集群,也可以实现成单个服务器。当网页小程序代理服务器105和开发者服务器107为软件时,可以实现成多个软件或软件模块(例如用来提供分布式服务),也可以实现成单个软件或软件模块。在此不做具体限定。It should be noted that the web
开发者服务器107可以是提供各种服务的服务器,例如,开发者服务器107可以接收网页小程序代理服务器105基于网络106发送的请求信息,并对请求信息进行响应。The
需要说明的是,本公开实施例所提供的用于识别爬虫的方法通常由网页小程序代理服务器105执行,用于识别爬虫的装置通常设置于网页小程序代理服务器105中。It should be noted that the method for identifying a crawler provided by the embodiments of the present disclosure is generally executed by the web
应该理解,图1中的终端设备、网络和服务器的数目仅仅是示意性的。根据实现需要,可以具有任意数目的终端设备、网络和服务器。It should be understood that the numbers of terminal devices, networks and servers in FIG. 1 are merely illustrative. There can be any number of terminal devices, networks and servers according to implementation needs.
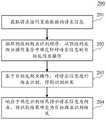
继续参考图2,示出了根据本公开的用于识别爬虫的方法的一个实施例的流程200。本实施例的用于识别爬虫的方法,包括以下步骤:With continued reference to FIG. 2 , a
步骤201,获取请求访问页面数据的请求信息。Step 201: Obtain request information for requesting access to page data.
在本实施例中,执行主体(如图1所示的网页小程序代理服务器105等电子设备)可以获取请求访问页面数据的请求信息,并对请求信息进行校验,识别请求信息为正常用户发出的请求,或者为爬虫发出的请求,从而实现对爬虫的拦截,保证页面数据的数据安全。这里的页面数据可以为网页小程序对应的页面数据,也可以为其他应用对应的页面数据等,本实施例对此不做限定。其中,网页小程序指的是H5(一系列制作网页互动效果的技术集合)版本的小程序。In this embodiment, the execution subject (such as the electronic device such as the web
步骤202,按照预设的爬虫识别顺序,从预设的反爬虫操作集合中确定针对请求信息的目标反爬虫操作。
在本实施例中,预设的爬虫识别顺序是针对预设的反爬虫操作集合中的各个反爬虫操作的识别顺序,例如,如果预设的反爬虫操作集合中的反爬虫操作包括反爬虫操作A、反爬虫操作B、反爬虫操作C以及反爬虫操作D,预设的爬虫识别顺序可以为先利用反爬虫操作D进行爬虫识别,再利用反爬虫操作C进行爬虫识别,再利用反爬虫操作B进行爬虫识别,再利用反爬虫操作A进行爬虫识别。In this embodiment, the preset crawler identification sequence is the identification sequence for each anti-crawler operation in the preset anti-crawler operation set. For example, if the anti-crawler operations in the preset anti-crawler operation set include anti-crawler operations A. Anti-crawler operation B, anti-crawler operation C, and anti-crawler operation D. The preset crawler identification sequence can be: firstly use anti-crawler operation D for crawler identification, then use anti-crawler operation C for crawler identification, and then use anti-crawler operation B performs crawler identification, and then uses the anti-crawler operation A for crawler identification.
其中,预设的反爬虫操作集合中的各个反爬虫操作可以为应对不同级别的爬虫所采取的反爬虫操作。执行主体可以预先建立各个反爬虫操作与相应的爬虫场景之间的对应关系,之后,按照各个爬虫场景的级别,对各个反爬虫操作进行排序,得到上述预设的爬虫识别顺序。其中,各个爬虫场景的级别可以基于爬虫场景的场景特征的复杂程度确定,复杂程度越高,爬虫场景的级别越高。例如,这里可以按照爬虫场景的级别由低至高的顺序,对各个反爬虫操作进行排序,得到上述预设的爬虫识别顺序。通过按照这种预设的爬虫识别顺序选取目标反爬虫操作进行爬虫识别,能够逐级增强爬虫防护,安全性更高。Wherein, each anti-crawler operation in the preset anti-crawler operation set may be an anti-crawler operation taken to deal with crawlers of different levels. The executing subject can pre-establish the correspondence between each anti-crawling operation and the corresponding crawling scene, and then sort each anti-crawling operation according to the level of each crawling scene to obtain the above-mentioned preset crawler identification sequence. The level of each crawler scene may be determined based on the complexity of the scene features of the crawler scene, and the higher the complexity, the higher the level of the crawler scene. For example, each anti-crawler operation can be sorted in order of the level of the crawler scene from low to high, so as to obtain the above-mentioned preset crawler identification order. By selecting the target anti-crawler operation for crawler identification according to this preset crawler identification sequence, crawler protection can be enhanced step by step, and the security is higher.
并且,执行主体可以按照预设的爬虫识别顺序,从预设的反爬虫操作集合中确定目标反爬虫操作,并利用目标反爬虫操作对请求信息进行爬虫识别。可选的,执行主体可以按照爬虫识别顺序,从预设的反爬虫操作集合中确定出初次进行爬虫识别的反爬虫操作,作为目标反爬虫操作,如果目标反爬虫操作识别结果指示请求信息为爬虫,则不再重新确定目标反爬虫操作。如果目标反爬虫操作识别结果指示请求信息为用户,则进一步的重新从反爬虫操作集合中确定出第二次进行爬虫识别的反爬虫操作,作为目标反爬虫操作。执行主体可以重复确定目标反爬虫操作、对请求信息进行爬虫识别得到识别结果的过程,直至判定出请求信息为爬虫,或者直至取完反爬虫操作集合中的各个反爬虫操作判定出请求信息为用户。In addition, the executing subject may determine a target anti-crawler operation from a preset anti-crawler operation set according to a preset crawler identification sequence, and use the target anti-crawler operation to perform crawler identification on the request information. Optionally, the execution subject may determine the anti-crawler operation for initial crawler identification from the preset anti-crawler operation set according to the crawler identification sequence, as the target anti-crawler operation, if the target anti-crawler operation recognition result indicates that the request information is a crawler. , the target anti-crawler operation will not be re-determined. If the identification result of the target anti-crawling operation indicates that the request information is the user, the anti-crawling operation for the second crawling identification is further determined from the anti-crawling operation set as the target anti-crawling operation. The executing subject can repeat the process of determining the target anti-crawler operation, and performing crawler identification on the request information to obtain the identification result, until it is determined that the request information is a crawler, or until each anti-crawler operation in the anti-crawler operation set is finished and it is determined that the request information is the user. .
在本实施例的一些可选的实现方式中,按照预设的爬虫识别顺序,从预设的反爬虫操作集合中确定针对请求信息的目标反爬虫操作可以包括:对请求信息的请求参数进行分析,确定请求信息对应的场景特征;基于请求信息对应的场景特征与爬虫场景的特征之间的相似度以及预设的爬虫识别顺序,从反爬虫操作集合中确定与请求信息对应的目标反爬虫操作。其中,预设的爬虫识别顺序可以为基于爬虫场景的特征确定的反爬虫操作的顺序,执行主体可以确定与请求信息对应的场景特征的相似度最高的爬虫场景的特征,并将该爬虫场景的特征按照预设的爬虫识别顺序对应的反爬虫操作确定为目标反爬虫操作。通过实施这种可选的实施方式,可以针对请求信息的特征确定与之最相匹配的目标反爬虫操作,基于这种目标反爬虫操作进行爬虫识别,能够提高爬虫识别的精准度。In some optional implementations of this embodiment, according to a preset crawler identification sequence, determining a target anti-crawler operation for the request information from a preset anti-crawler operation set may include: analyzing request parameters of the request information , determine the scene characteristics corresponding to the request information; based on the similarity between the scene characteristics corresponding to the request information and the characteristics of the crawler scene and the preset crawler identification sequence, determine the target anti-crawler operation corresponding to the request information from the anti-crawler operation set . The preset crawler identification sequence may be the sequence of anti-crawler operations determined based on the characteristics of the crawler scene, and the execution subject may determine the characteristics of the crawler scene with the highest similarity to the scene characteristics corresponding to the request information, and use the crawler scene The anti-crawler operation corresponding to the feature according to the preset crawler identification sequence is determined as the target anti-crawler operation. By implementing this optional implementation, a target anti-crawler operation that best matches the characteristics of the request information can be determined, and crawler identification based on this target anti-crawler operation can improve the accuracy of crawler identification.
步骤203,基于目标反爬虫操作,对请求信息进行爬虫识别,得到识别结果。
在本实施例中,执行主体在确定出目标反爬虫操作之后,可以按照目标反爬虫操作对请求信息进行爬虫识别,得到识别结果。其中,识别结果可以指示请求信息为用户或者指示请求信息为爬虫。其中,不同的反爬虫操作,对应着不同的爬虫识别手段,通过不同的爬虫识别手段对请求信息进行爬虫识别,能够进一步增强数据安全。In this embodiment, after determining the target anti-crawler operation, the execution body may perform crawler identification on the request information according to the target anti-crawler operation, and obtain the identification result. The identification result may indicate that the request information is a user or that the request information is a crawler. Among them, different anti-crawler operations correspond to different crawler identification methods, and crawler identification of request information through different crawler identification methods can further enhance data security.
步骤204,响应于确定识别结果指示请求信息为爬虫,将识别结果确定为目标爬虫识别结果。
在本实施例中,如果识别结果指示请求信息为爬虫,则直接将识别结果确定为最终的目标爬虫识别结果。在目标爬虫识别结果指示请求信息为爬虫的情况下,执行主体可以将该请求信息进行拦截处理,避免爬虫的异常访问。如果识别结果指示请求信息为用户,执行主体可以重复执行步骤202至步骤204,直至得到指示请求信息为爬虫的目标爬虫识别结果,或者完成反爬虫操作集合中所有反爬虫操作的遍历,得到指示请求信息为用户的目标爬虫识别结果。In this embodiment, if the identification result indicates that the request information is a crawler, the identification result is directly determined as the final target crawler identification result. When the identification result of the target crawler indicates that the request information is a crawler, the execution subject can intercept the request information to avoid abnormal access of the crawler. If the identification result indicates that the request information is the user, the execution body can repeat
继续参见图3,其示出了根据本公开的用于识别爬虫的方法的一个应用场景的示意图。在图3的应用场景中,执行主体可以执行步骤301,在用户或者爬虫请求访问网页(如小程序网页)的情况下,获取请求信息,并按照预设的爬虫识别顺序,从预设的反爬虫操作集合中确定出目标反爬虫操作302,利用目标反爬虫操作302对请求信息进行爬虫识别,得到识别结果303。如果识别结果303指示请求信息为爬虫,则将识别结果303确定为目标爬虫识别结果304。如果识别结果303指示请求信息为用户,则重新从按照预设的爬虫识别顺序,从预设的反爬虫操作集合中确定出目标反爬虫操作302,直至得到识别结果为爬虫的目标爬虫识别结果,或者预设的反爬虫操作集合中的每个反爬虫操作均已遍历完成、得到识别结果为用户的目标爬虫识别结果。Continue to refer to FIG. 3 , which shows a schematic diagram of an application scenario of the method for identifying a crawler according to the present disclosure. In the application scenario shown in FIG. 3 , the execution body may execute
本公开上述实施例提供的用于识别爬虫的方法,能够预设有爬虫识别顺序和反爬虫操作集合,通过按照爬虫识别顺序在反爬虫操作集合中确定目标反爬虫操作,基于目标反爬虫操作对请求信息进行爬虫识别,能够实现对页面数据(如网页版本的小程序的页面数据)的安全防护,从而提高网页版本的小程序的数据安全。The method for identifying crawlers provided by the above embodiments of the present disclosure can preset a crawler identification sequence and an anti-crawler operation set. The request information is identified by the crawler, which can realize the security protection of page data (such as the page data of the applet in the webpage version), thereby improving the data security of the applet in the webpage version.
继续参见图4,其示出了根据本公开的用于识别爬虫的方法的另一个实施例的流程400。如图4所示,本实施例的用于识别爬虫的方法可以包括以下步骤:Continuing to refer to FIG. 4 , a
步骤401,获取请求访问页面数据的请求信息,请求信息用于请求访问网页小程序的页面数据。Step 401: Obtain request information for requesting access to page data, where the request information is used for requesting access to page data of the webpage applet.
在本实施例中,请求信息用于访问网页小程序的页面数据。其中,网页小程序指的是H5(一系列制作网页互动效果的技术集合)版本的小程序。对于步骤401的详细描述请参照对于步骤201的详细描述,在此不再赘述。In this embodiment, the request information is used to access page data of the webpage applet. Among them, the webpage applet refers to the H5 (a series of technology collections for making webpage interactive effects) version of the applet. For the detailed description of
在本实施例的一些可选的实现方式中,还可以执行以下步骤:确定请求信息对应的加密网络地址;确定加密网络地址中的第一加密索引和第二加密索引;基于第一加密索引和第二加密索引,对加密网络地址进行解密,得到解密网络地址;基于解密网络地址,进行网络访问。In some optional implementations of this embodiment, the following steps may also be performed: determine an encrypted network address corresponding to the request information; determine a first encrypted index and a second encrypted index in the encrypted network address; based on the first encrypted index and The second encryption index decrypts the encrypted network address to obtain the decrypted network address; and performs network access based on the decrypted network address.
在本实现方式中,为了避免爬虫攻击对第三方服务进行攻击,采用了URL(UniformResource Locator, 统一资源定位器)加密的方式,对第三方服务对应的URL进行加密。在进行网络访问时,执行主体可以先对请求信息中加密的URL进行解密,得到解密网络地址,并基于解密网络地址进行网络访问。In this implementation manner, in order to avoid the crawler attack from attacking the third-party service, a URL (Uniform Resource Locator, Uniform Resource Locator) encryption method is adopted to encrypt the URL corresponding to the third-party service. When performing network access, the execution subject may first decrypt the encrypted URL in the request information to obtain a decrypted network address, and perform network access based on the decrypted network address.
其中,用户发出的请求信息中的加密网络地址基于以下步骤确定得到:获取随机生成的两个随机数,得到上述的第一加密索引和第二加密索引;基于第一加密索引和第二加密索引,将初始网络地址划分为第一网络子地址和第二网络子地址;对于第一网络子地址中的每个字符,按照第一加密索引对应的偏移量和该字符在第一网络子地址中的位置对应的偏移量,将该字符进行偏移处理,得到偏移处理后的第一网络子地址;对于第二网络子地址中的每个字符,按照第二加密索引对应的偏移量和该字符在第二网络子地址中的位置对应的偏移量,将该字符进行偏移处理,得到偏移处理后的第二网络子地址;将偏移处理后的第一网络子地址和第二网络子地址进行拼接,得到加密后的加密网络地址。Wherein, the encrypted network address in the request information sent by the user is determined based on the following steps: obtaining two random numbers generated randomly, and obtaining the above-mentioned first encrypted index and second encrypted index; based on the first encrypted index and the second encrypted index , divide the initial network address into a first network sub-address and a second network sub-address; for each character in the first network sub-address, according to the offset corresponding to the first encryption index and the character in the first network sub-address the offset corresponding to the position in the offset corresponding to the position of the character in the second network sub-address, perform offset processing on the character to obtain the offset-processed second network sub-address; offset the offset-processed first network sub-address Splicing with the second network sub-address to obtain an encrypted encrypted network address.
举例而言,初始网络地址如果为https://api.tusij.com/v2/get-category




进一步,在对URL进行解密的情况下,执行主体可以确定请求信息对应的加密网络地址,再对加密网络地址进行分析,确定加密网络地址中的第一加密索引和第二加密索引。通过第一加密索引和第二加密索引,可以对加密网络地址进行相对应的偏移处理,得到解密网络地址。执行主体可以通过解密网络地址去访问第三方服务。Further, in the case of decrypting the URL, the execution body can determine the encrypted network address corresponding to the request information, and then analyze the encrypted network address to determine the first encrypted index and the second encrypted index in the encrypted network address. Through the first encryption index and the second encryption index, the encrypted network address can be subjected to corresponding offset processing to obtain the decrypted network address. The execution subject can access third-party services by decrypting the network address.
步骤402,按照预设的爬虫识别顺序,从预设的反爬虫操作集合中确定针对请求信息的目标反爬虫操作,预设的反爬虫操作集合中的反爬虫操作至少包括以下一项:端特征识别操作、令牌识别操作、人机特征识别操作、数据分析识别操作和签名识别操作。
在本实施例中,端特征识别操作可以为针对伪造端特征的爬虫场景的识别操作,其中,端特征指的是请求信息中的特定参数,特定参数可以包括但不限于UA(User Agent,终端的环境信息)、referer(上一个页面的地址)、header(标头)等。具体的,端特征识别操作可以对请求信息中的特定参数进行分析,校验特定参数是否为用户对应的参数,如果不为用户对应的特定参数,则确定请求信息为爬虫,如果为用户对应的特定参数,则确定请求信息为用户。In this embodiment, the terminal feature identification operation may be an identification operation for a crawler scenario with fake terminal characteristics, wherein the terminal characteristic refers to a specific parameter in the request information, and the specific parameter may include but is not limited to a UA (User Agent, terminal) environment information), referer (address of the previous page), header (header), etc. Specifically, the terminal feature identification operation can analyze the specific parameters in the request information, and verify whether the specific parameters are the parameters corresponding to the user. If the specific parameters are not corresponding to the user, the request information is determined to be a crawler. specific parameters, the request information is determined to be the user.
进一步的,令牌识别操作可以为针对伪造端特征请求重放的爬虫场景的识别操作。其中,请求重放指的是不断重试同一个请求的行为。具体的,为了应对该爬虫场景,请求信息中可以携带加密后的令牌信息,执行主体可以通过对令牌信息进行解密,来实现令牌校验。如果令牌校验通过,则确定请求信息为用户;如果令牌校验未通过,则确定请求信息为爬虫。Further, the token identification operation may be an identification operation for the crawler scene that requests the replay of the forged terminal feature. Among them, request replay refers to the behavior of continuously retrying the same request. Specifically, in order to cope with the crawler scenario, the encrypted token information may be carried in the request information, and the execution subject may implement token verification by decrypting the token information. If the token verification passes, the request information is determined to be the user; if the token verification fails, the request information is determined to be a crawler.
进一步的,人机特征识别操作可以为针对使用真实浏览器实现自动化脚本的爬虫场景的识别操作。具体的,执行主体可以通过对请求信息对应的设备身份进行检测、对请求信息对应的网际互连协议进行检测、对请求信息对应的用户代理进行检测等方式,得到识别结果。例如,如果设备身份指示为爬虫对应的设备,则得到识别结果是请求信息为爬虫。Further, the human-machine feature identification operation may be an identification operation for a crawler scenario that uses a real browser to implement automated scripts. Specifically, the execution subject can obtain the identification result by detecting the device identity corresponding to the request information, detecting the Internet interconnection protocol corresponding to the request information, and detecting the user agent corresponding to the request information. For example, if the device identity is indicated as a device corresponding to a crawler, the identification result is that the requested information is a crawler.
进一步的,数据分析识别操作可以为针对上述的伪造端特征、伪造端特征请求重放、使用真实浏览器实现自动化脚本等爬虫场景均无法识别的爬虫场景,进行应对的识别操作。具体的,执行主体可以基于历史爬虫数据、当前请求信息的场景特征等信息,进行统计学处理,对请求信息进行打分,基于打分结果判定请求信息为用户或者爬虫。Further, the data analysis and identification operation may be a corresponding identification operation for a crawler scene that cannot be recognized by the crawler scene such as the above-mentioned fake terminal features, request replay of fake terminal characteristics, and automatic script implementation using a real browser. Specifically, the execution subject may perform statistical processing based on historical crawler data, scene characteristics of the current request information, and other information, score the request information, and determine whether the request information is a user or a crawler based on the scoring result.
进一步的,签名识别操作可以为针对绕过执行主体(网页小程序代理服务器),直接对开发者服务器进行攻击的爬虫场景的识别操作。具体的,为了应对该爬虫场景,执行主体和开发者服务器之间可以使用同一种签名生成算法。在对请求信息中的签名生成算法进行校验时,即使绕过执行主体,开发者服务器端也可以基于同样的方式进行校验,并能够将校验结果返回给执行主体。如果校验结果指示签名校验通过,则确定识别结果是请求信息为用户,如果校验结果指示签名校验未通过,则确定识别结果是请求信息为爬虫。并且,NA(Native App,一种基于智能手机本地操作系统如iOS、Android、WP并使用原生程式编写运行的第三方应用程序,也叫本地app。一般使用的开发语言为JAVA、C++、Objective-C)端小程序和网页小程序代理服务器均会向开发者服务器发送请求信息,对此,NA端小程序和网页小程序代理服务器之间可以使用上述的同一种签名生成算法。对于开发者服务器而言,可以接收来自NA端小程序和网页小程序代理服务器这两种来源的签名,并对签名进行校验,将校验结果返回给NA端小程序和网页小程序代理服务器。Further, the signature identification operation may be an identification operation for a crawler scenario that bypasses the execution body (web applet proxy server) and directly attacks the developer server. Specifically, in order to cope with this crawler scenario, the same signature generation algorithm can be used between the execution body and the developer server. When verifying the signature generation algorithm in the request information, even if the execution body is bypassed, the developer's server can perform the verification based on the same method, and can return the verification result to the execution body. If the verification result indicates that the signature verification has passed, it is determined that the identification result is that the request information is the user, and if the verification result indicates that the signature verification has not passed, it is determined that the identification result is that the request information is a crawler. In addition, NA (Native App, a third-party application based on the local operating system of smartphones such as iOS, Android, WP and written and run using native programs, also called local app. The commonly used development languages are JAVA, C++, Objective- C) Both the terminal applet and the web applet proxy server will send request information to the developer server. For this, the same signature generation algorithm mentioned above can be used between the NA terminal applet and the webpage applet proxy server. For the developer server, it can receive signatures from the NA-side applet and the web applet proxy server, verify the signature, and return the verification result to the NA-side applet and the webpage applet proxy server .
并且,按照预设的爬虫识别顺序对上述的反爬虫操作集合中的各个反爬虫操作进行排序,得到的排序结果可以为:端特征识别操作、令牌识别操作、人机特征识别操作、数据分析识别操作和签名识别操作。执行主体可以按照排序结果依次提取目标反爬虫操作,实现对反爬虫操作集合的遍历。Moreover, according to the preset crawler identification sequence, each anti-crawler operation in the above-mentioned anti-crawler operation set is sorted, and the obtained sorting results may be: terminal feature identification operation, token identification operation, human-machine feature identification operation, data analysis Identify operations and signature identify operations. The execution body can sequentially extract the target anti-crawling operations according to the sorting results, so as to traverse the set of anti-crawling operations.
步骤403,在目标反爬虫操作为令牌识别操作的情况下,确定请求信息对应的令牌索引信息;基于令牌索引信息,确定目标字符;响应于确定目标字符和预设的字符不匹配,确定识别结果为请求信息为爬虫。
在本实施例中,如果目标反爬虫操作为令牌识别操作,则可以对请求信息中携带的令牌信息(token)进行校验。具体的,执行主体可以包括网页渲染模块(web-xrender)和网页接口管理模块(webapi)。在用户请求渲染页面时,执行主体中的网页渲染模块可以向用户发送相应的令牌索引信息,例如,可以向用户发送无填充的、base64url(一种任意二进制到文本字符串的编码方法)加密的令牌信息,令牌信息中包含着上述的令牌索引信息。用户在请求访问页面数据时,会在请求信息中携带该令牌信息。执行主体中的网页接口管理模块可以通过令牌索引信息,确定出需要进行校验的目标字符,并将目标字符和预设的字符进行匹配,如果不匹配,确定识别结果为请求信息为爬虫,如果匹配,确定识别结果为请求信息为用户。In this embodiment, if the target anti-crawling operation is a token identification operation, the token information (token) carried in the request information can be verified. Specifically, the execution body may include a web page rendering module (web-xrender) and a web page interface management module (webapi). When a user requests to render a page, the web page rendering module in the execution body can send the corresponding token index information to the user, for example, it can send the user an unfilled, base64url (an arbitrary binary to text string encoding method) encrypted The token information contains the above token index information. When a user requests to access page data, the token information will be carried in the request information. The web interface management module in the execution body can determine the target characters that need to be verified through the token index information, and match the target characters with the preset characters. If it matches, it is determined that the identification result is that the request information is the user.
其中,预设的字符可以为用户请求渲染页面时,下发的令牌字符信息。如果请求信息是用户发出的,则此时请求信息中的令牌字符信息会和预设的字符相同。如果请求信息是爬虫发出的,则此时请求信息中的令牌字符信息会和预设的字符不同。通过令牌识别操作,可以基于执行主体中预设的字符对请求信息进行校验,如果请求信息被攻破,可以通过修改预设的字符重新校验,安全性修改更加方便。可选的,执行主体还可以对网页小程序前端显示的内容进行代码混淆,用以防止前端的代码被破解,进一步提高网页小程序的安全性。The preset character may be the token character information issued when the user requests to render the page. If the request message is sent by the user, the token character information in the request message at this time will be the same as the preset character. If the request information is sent by a crawler, the token character information in the request information at this time will be different from the preset characters. Through the token recognition operation, the request information can be verified based on the preset characters in the execution body. If the request information is compromised, it can be re-verified by modifying the preset characters, which makes the security modification more convenient. Optionally, the execution body may also code obfuscate the content displayed on the front end of the web page applet, so as to prevent the front end code from being cracked, and further improve the security of the web page applet.
在本实施例的一些可选的实现方式中,还可以执行以下步骤:确定请求信息对应的目标小程序标识和目标时间戳;响应于确定目标小程序标识和预设的小程序标识不匹配、或者目标时间戳已过期,确定识别结果为请求信息为爬虫。In some optional implementations of this embodiment, the following steps may also be performed: determining a target applet identifier and a target timestamp corresponding to the request information; in response to determining that the target applet identifier does not match the preset applet identifier, Or the target timestamp has expired, and it is determined that the recognition result is that the requested information is a crawler.
在本实现方式中,请求信息可以对应着相应的目标小程序标识和目标时间戳。可选的,目标小程序标识、目标时间戳和令牌信息可以关联存储。其中,目标小程序标识为小程序的唯一标识信息,目标时间戳用于描述令牌信息的时效性。并且,执行主体可以基于对当前的网页域名进行分析,得到预设的小程序标识。如果目标小程序标识和预设的小程序标识不匹配,则说明识别结果为请求信息为爬虫。如果目标小程序标识和预设的小程序标识匹配,则说明识别结果为请求信息为用户。以及,执行主体还可以预先存储有效时间,如果当前时间和目标时间戳之间的时间差值大于预设的有效时间,则说明请求信息已过期,可以确定识别结果为爬虫,并拦截请求信息。In this implementation manner, the request information may correspond to the corresponding target applet identifier and target timestamp. Optionally, the target applet identifier, target timestamp and token information may be stored in association. The target applet identifier is the unique identification information of the applet, and the target timestamp is used to describe the timeliness of the token information. In addition, the execution body may obtain a preset applet identifier based on the analysis of the current web page domain name. If the target applet identifier does not match the preset applet identifier, it means that the identification result is that the request information is a crawler. If the target applet identifier matches the preset applet identifier, it means that the identification result is that the request information is the user. In addition, the execution body can also store the valid time in advance. If the time difference between the current time and the target timestamp is greater than the preset valid time, it means that the request information has expired, the recognition result can be determined to be a crawler, and the request information can be intercepted.
举例而言,在用户请求对小程序网页进行渲染时,网页渲染模块向请求渲染的浏览器下发无填充的、base64url加密的令牌信息,令牌信息可以对应有目标小程序标识和目标时间戳。之后,用户可以再向网页接口管理模块发送请求访问页面数据的请求信息,并在请求信息中携带上述的令牌信息、目标小程序标识和目标时间戳。执行主体对无填充的、base64url加密的令牌信息进行解密,并验证目标小程序标识是否正确,以及验证目标时间戳是否过期。如果解密得到的令牌信息正确、目标小程序标识正确以及目标时间戳未过期,可以确定识别结果为用户。如果解密得到的令牌信息错误、目标小程序标识错误以及目标时间戳过期,可以确定识别结果为爬虫。For example, when the user requests to render the applet webpage, the webpage rendering module sends unfilled, base64url-encrypted token information to the browser requesting rendering, and the token information can correspond to the target applet identification and target time. stamp. After that, the user may send request information for requesting access to page data to the web interface management module, and carry the above token information, target applet identifier and target timestamp in the request information. The execution body decrypts the unpadded, base64url-encrypted token information, and verifies whether the target applet identification is correct, and whether the target timestamp has expired. If the token information obtained by decryption is correct, the target applet identification is correct, and the target timestamp has not expired, it can be determined that the identification result is the user. If the decrypted token information is incorrect, the target applet identification is incorrect, and the target timestamp expires, it can be determined that the recognition result is a crawler.
其中,加密的令牌信息可以基于以下步骤生成:生成随机字母数,并将随机字母数转换为二进制的随机数;基于当前时间,生成目标时间戳;基于用户请求的小程序标识,生成目标小程序标识;将随机数、目标时间戳、目标小程序标识拼接,计算无填充的、base64url字符串;按照预设的索引,确定在字符串中插入字符的指定位置;在指定位置插入预设的字符,得到插入字符后的、无填充的、base64url加密的令牌信息。The encrypted token information can be generated based on the following steps: generating a random letter number and converting the random letter number into a binary random number; generating a target timestamp based on the current time; generating a target small program based on the applet identifier requested by the user Program identification; splicing the random number, target timestamp, and target applet identification to calculate the unfilled, base64url string; according to the preset index, determine the specified position to insert characters in the string; insert the preset in the specified position character, get the token information after the inserted character, no padding, base64url encrypted.
进一步的,执行主体对令牌信息进行解密的步骤如下:确定请求信息中的令牌信息,以及针对令牌信息的令牌索引信息,这里的令牌索引信息可以为用于读取字符的索引信息,可以预先存储在执行主体中;基于令牌索引信息,确定令牌信息中相应位置的目标字符。将目标字符和预先存储在执行主体中的预设的字符进行匹配,如果字符匹配、且令牌信息中的目标小程序标识正确以及目标时间戳未过期,确定识别结果为请求信息为用户。如果字符不匹配、或者令牌信息中的目标小程序标识不正确、或者目标时间戳已过期,则确定识别结果为请求信息为爬虫。Further, the step of decrypting the token information by the execution body is as follows: determining the token information in the request information and the token index information for the token information, where the token index information can be an index used for reading characters The information can be pre-stored in the execution body; based on the token index information, the target character at the corresponding position in the token information is determined. Match the target character with the preset character pre-stored in the execution body. If the characters match, and the target applet identification in the token information is correct and the target time stamp has not expired, it is determined that the identification result is that the request information is the user. If the characters do not match, or the target applet identification in the token information is incorrect, or the target timestamp has expired, it is determined that the identification result is that the requested information is a crawler.
步骤404,在目标反爬虫操作为数据分析识别操作的情况下,获取爬虫分析数据;基于爬虫分析数据,对请求信息进行爬虫识别,得到请求信息对应的识别结果。
在本实施例中,执行主体可以预先获取爬虫分析数据,其中,爬虫分析数据可以为对历史爬虫数据、当前请求信息的特征、不同爬虫场景的特征进行分析得到的数据。基于爬虫分析数据,可以对请求信息进行爬虫识别,得到识别结果。识别结果可以为指示请求信息为爬虫,也可以为指示请求信息为用户。可选的,执行主体还可以基于爬虫分析数据和请求信息,生成相对应的等级打分,例如,对于请求信息为爬虫的概率越高的情况,相对应的等级打分可以越高。In this embodiment, the execution body may obtain crawler analysis data in advance, wherein the crawler analysis data may be data obtained by analyzing historical crawler data, characteristics of current request information, and characteristics of different crawler scenarios. Based on the crawler analysis data, the request information can be identified by crawler, and the identification result can be obtained. The identification result may indicate that the request information is a crawler, or may indicate that the request information is a user. Optionally, the execution subject may also generate a corresponding grade score based on the crawler analysis data and the request information. For example, for a situation where the probability that the request information is a crawler is higher, the corresponding grade score may be higher.
步骤405,在目标反爬虫操作为签名同步识别操作的情况下,确定请求信息中的签名信息;基于签名信息和预设的签名信息,得到识别结果。
在本实施例中,执行主体可以和开发者服务器共用签名生成算法。在对请求信息进行校验时,可以将请求信息中的签名信息和预设的、执行主体和开发者服务器共用签名生成算法生成的签名信息进行比对,如果签名相同,则确定识别结果为请求信息为用户,如果签名不相同,则确定识别结果为请求信息为爬虫。其中,对于开发者服务器而言,也可以基于同样的签名比对方式,对请求信息进行识别。In this embodiment, the execution body and the developer server may share the signature generation algorithm. When verifying the request information, the signature information in the request information can be compared with the preset signature information generated by the signature generation algorithm shared by the executive body and the developer server. If the signatures are the same, the identification result is determined to be the request. The information is the user, and if the signatures are not the same, it is determined that the identification result is that the requested information is a crawler. Wherein, for the developer server, the request information can also be identified based on the same signature comparison method.
其中,共用签名生成算法基于以下步骤生成签名:获取小程序密钥;计算小程序密钥对应的md5(一种被广泛使用的密码散列函数)值;将网址中的指定部分(如由后至前若干字符)进行解码,得到第一解码值;将查询信息中的键值对进行解码,并对解码后的键值对进行排序,得到第二解码值;将上述的md5值、第一解码值、第二解码值和时间戳进行拼接,得到拼接后的字符串;将拼接后的字符串进行md5加密,生成加密后的签名。Among them, the shared signature generation algorithm generates the signature based on the following steps: obtaining the applet key; calculating the md5 (a widely used cryptographic hash function) value corresponding to the applet key; to the first few characters) to obtain the first decoded value; decode the key-value pairs in the query information, and sort the decoded key-value pairs to obtain the second decoded value; The decoded value, the second decoded value and the timestamp are spliced to obtain a spliced string; the spliced character string is encrypted by md5 to generate an encrypted signature.
进一步的,在对请求信息中的签名信息进行校验时,执行主体可以先对签名信息进行md5解密,得到解密后的签名信息;分别将解密后的签名信息中的密钥子部分和上述的小程序密钥对应的md5值进行比对,将解密后的签名信息中的网址解码值和上述的第一解码值进行比对,将解密后的签名信息中的排序后的键值对与上述的第二解码值进行比对,将时间戳和当前时间进行比对。如果解密后的签名信息中的密钥子部分和上述的小程序密钥对应的md5值相同、解密后的签名信息中的网址解码值和上述的第一解码值相同、解密后的签名信息中的排序后的键值对与上述的第二解码值相同且时间戳未过期,则确定签名相同,识别结果为请求信息为用户。如果不满足上述条件,则确定签名不相同,识别结果为请求信息为爬虫。Further, when verifying the signature information in the request information, the execution subject can first perform md5 decryption on the signature information to obtain the decrypted signature information; respectively, the key sub-part in the decrypted signature information and the above-mentioned Compare the md5 value corresponding to the applet key, compare the URL decoded value in the decrypted signature information with the above-mentioned first decoded value, and compare the sorted key-value pairs in the decrypted signature information with the above-mentioned first decoded value. The second decoded value is compared, and the timestamp is compared with the current time. If the key sub-part in the decrypted signature information is the same as the md5 value corresponding to the above-mentioned applet key, the URL decoded value in the decrypted signature information is the same as the above-mentioned first decoded value, and the decrypted signature information in the If the sorted key-value pair is the same as the above-mentioned second decoded value and the timestamp has not expired, it is determined that the signatures are the same, and the identification result is that the request information is the user. If the above conditions are not met, it is determined that the signatures are not identical, and the identification result is that the requested information is a crawler.
在本实施例的一些可选的实现方式中,还可以执行以下步骤:基于识别结果,确定请求信息对应的爬虫分数信息;输出爬虫分数信息。In some optional implementation manners of this embodiment, the following steps may also be performed: based on the identification result, determine the crawler score information corresponding to the request information; and output the crawler score information.
在本实现方式中,执行主体可以基于上述的数据分析识别操作对应的识别结果和等级打分,以及上述的人机特征识别操作的识别结果,生成请求信息对应的爬虫分数信息,并将爬虫分数信息输出给开发者服务器,以供开发者服务器采取其他反爬虫手段进行相应的处理。这里的识别结果可以是预设的反爬虫操作集合中的反爬虫操作中至少一项的识别结果。其中,爬虫分数信息用于描述请求信息为爬虫的概率情况。In this implementation manner, the execution subject may generate crawler score information corresponding to the request information based on the identification result and grade score corresponding to the above-mentioned data analysis and identification operation, and the identification result of the above-mentioned human-machine feature identification operation, and use the crawler score information Output to the developer server for the developer server to take other anti-crawling methods for corresponding processing. The identification result here may be the identification result of at least one item of anti-crawling operations in the preset anti-crawling operation set. The crawler score information is used to describe the probability that the requested information is a crawler.
步骤406,响应于确定识别结果指示请求信息为爬虫,将识别结果确定为目标爬虫识别结果。
在本实施例中,对于步骤406的详细描述,请参照对于步骤204的详细描述,在此不再赘述。In this embodiment, for the detailed description of
步骤407,响应于确定识别结果指示请求信息不为爬虫、且预设的反爬虫操作集合未遍历完成,按照预设的爬虫识别顺序,从预设的反爬虫操作集合中重新确定针对请求信息的目标反爬虫操作。
在本实施例中,如果识别结果指示请求信息不为爬虫(为用户)、且预设的反爬虫操作集合未遍历完成,也即是,预设的反爬虫操作集合中存在未使用的反爬虫操作,则按照预设的爬虫识别顺序,从预设的反爬虫操作集合中重新确定目标反爬虫操作,继续确定识别结果。可选的,执行主体可以先存储本次的识别结果,如果识别结果具有相应的爬虫等级等信息,也可以对应存储识别结果与爬虫等级等信息。之后,再重新确定目标反爬虫操作。In this embodiment, if the identification result indicates that the request information is not a crawler (for the user) and the preset anti-crawler operation set has not been traversed, that is, there are unused anti-crawlers in the preset anti-crawler operation set operation, according to the preset crawler identification sequence, re-determine the target anti-crawler operation from the preset anti-crawler operation set, and continue to determine the identification result. Optionally, the execution body may first store the current recognition result, and if the recognition result has information such as the corresponding crawler level, it may also store the information such as the identification result and the crawler level correspondingly. After that, re-determine the target anti-reptile operation.
步骤408,响应于确定识别结果指示请求信息不为爬虫、且预设的反爬虫操作集合遍历完成,将识别结果确定为目标爬虫识别结果。
在本实施例中,如果遍历完成预设的反爬虫操作集合,每次的识别结果均指示请求信息不为爬虫,则将指示请求信息不为爬虫的识别结果确定为目标爬虫识别结果。In this embodiment, if the preset anti-crawler operation set is traversed and completed, and each identification result indicates that the request information is not a crawler, the identification result indicating that the request information is not a crawler is determined as the target crawler identification result.
本公开的上述实施例提供的用于识别爬虫的方法,还可以在识别结果指示请求信息不为爬虫、且反爬虫操作集合未遍历完成的情况下,重新确定目标反爬虫操作,直至识别出爬虫,或者将反爬虫操作集合遍历完成识别出不为爬虫,从而实现了逐级增强对爬虫的安全防护,直至所有反爬虫操作均使用完成,提高了对于爬虫识别的精准度。以及,可以基于令牌识别操作应对伪造端特征请求重放的爬虫场景,基于对第三方网址加密应对攻击第三方服务的爬虫场景,采用数据分析识别操作应对端特征识别操作、令牌识别操作、人机特征识别操作等操作无法识别出的爬虫场景,采用签名同步识别操作,应对攻击开发者服务器的爬虫场景,实现不同爬虫场景的针对性防护。以及,还可以生成爬虫分数信息,以供开发者进一步处理,提高了爬虫处理的灵活性。The method for recognizing a crawler provided by the above-mentioned embodiments of the present disclosure can also re-determine the target anti-crawling operation when the identification result indicates that the request information is not a crawler and the set of anti-crawling operations has not been traversed until the crawler is identified , or complete the traversal of the anti-crawler operation set to identify that it is not a crawler, thereby realizing the step-by-step enhancement of the security protection for the crawler until all anti-crawler operations are completed, which improves the accuracy of crawler identification. And, based on the token recognition operation to deal with the crawler scene of the fake terminal feature request replay, based on the third-party website encryption to deal with the crawler scene of attacking the third-party service, the data analysis and recognition operation can be used to deal with the terminal feature recognition operation, token recognition operation, For crawler scenarios that cannot be identified by operations such as human-machine feature recognition operations, signature synchronization identification operations are used to deal with crawler scenarios that attack the developer server, and to achieve targeted protection for different crawler scenarios. In addition, crawler score information can also be generated for further processing by developers, which improves the flexibility of crawler processing.
进一步参考图5,作为对上述各图所示方法的实现,本公开提供了一种用于识别爬虫的装置的一个实施例,该装置实施例与图2所示的方法实施例相对应,该装置具体可以应用于网页小程序代理服务器中。With further reference to FIG. 5 , as an implementation of the methods shown in the above figures, the present disclosure provides an embodiment of an apparatus for recognizing a crawler. The apparatus embodiment corresponds to the method embodiment shown in FIG. 2 . The device can be specifically applied to a web page applet proxy server.
如图5所示,本实施例的用于识别爬虫的装置500包括:信息获取单元501、操作确定单元502、爬虫识别单元503和结果确定单元504。As shown in FIG. 5 , the apparatus 500 for identifying a crawler in this embodiment includes: an information acquiring unit 501 , an operation determining unit 502 , a crawler identifying unit 503 and a result determining unit 504 .
信息获取单元501,被配置成获取请求访问页面数据的请求信息。The information acquisition unit 501 is configured to acquire request information for requesting to access page data.
操作确定单元502,被配置成按照预设的爬虫识别顺序,从预设的反爬虫操作集合中确定针对请求信息的目标反爬虫操作。The operation determining unit 502 is configured to determine a target anti-crawler operation for the request information from a preset anti-crawler operation set according to a preset crawler identification sequence.
爬虫识别单元503,被配置成基于目标反爬虫操作,对请求信息进行爬虫识别,得到识别结果。The crawler identification unit 503 is configured to perform crawler identification on the request information based on the target anti-crawler operation to obtain an identification result.
结果确定单元504,被配置成响应于确定识别结果指示请求信息为爬虫,将识别结果确定为目标爬虫识别结果。The result determination unit 504 is configured to, in response to determining that the identification result indicates that the request information is a crawler, determine the identification result as the identification result of the target crawler.
在本实施例的一些可选的实现方式中,操作确定单元502进一步被配置成:响应于确定识别结果指示请求信息不为爬虫、且预设的反爬虫操作集合未遍历完成,按照预设的爬虫识别顺序,从预设的反爬虫操作集合中重新确定针对请求信息的目标反爬虫操作。In some optional implementations of this embodiment, the operation determining unit 502 is further configured to: in response to determining that the identification result indicates that the request information is not a crawler, and the preset anti-crawler operation set has not been traversed, according to the preset The crawler identification sequence is to re-determine the target anti-crawler operation for the requested information from the preset anti-crawler operation set.
在本实施例的一些可选的实现方式中,结果确定单元504进一步被配置成:响应于确定识别结果指示请求信息不为爬虫、且预设的反爬虫操作集合遍历完成,将识别结果确定为目标爬虫识别结果。In some optional implementations of this embodiment, the result determination unit 504 is further configured to: in response to determining that the identification result indicates that the request information is not a crawler and the preset anti-crawler operation set traversal is completed, determine the identification result as Target crawler identification result.
在本实施例的一些可选的实现方式中,目标反爬虫操作至少包括令牌识别操作;以及,爬虫识别单元503进一步被配置成:确定请求信息对应的令牌索引信息;基于令牌索引信息,确定目标字符;响应于确定目标字符和预设的字符不匹配,确定识别结果为请求信息为爬虫。In some optional implementations of this embodiment, the target anti-crawler operation includes at least a token identification operation; and the crawler identification unit 503 is further configured to: determine token index information corresponding to the request information; based on the token index information , determine the target character; in response to determining that the target character does not match the preset character, determine that the recognition result is that the request information is a crawler.
在本实施例的一些可选的实现方式中,爬虫识别单元503进一步被配置成:确定请求信息对应的目标小程序标识和目标时间戳;响应于确定目标小程序标识和预设的小程序标识不匹配、或者目标时间戳已过期,确定识别结果为请求信息为爬虫。In some optional implementations of this embodiment, the crawler identification unit 503 is further configured to: determine the target applet identifier and the target time stamp corresponding to the request information; in response to determining the target applet identifier and the preset applet identifier If it does not match, or the target timestamp has expired, it is determined that the identification result is that the requested information is a crawler.
在本实施例的一些可选的实现方式中,还包括:网络访问单元,被配置成确定请求信息对应的加密网络地址;确定加密网络地址中的第一加密索引和第二加密索引;基于第一加密索引和第二加密索引,对加密网络地址进行解密,得到解密网络地址;基于解密网络地址,进行网络访问。In some optional implementations of this embodiment, the method further includes: a network access unit configured to determine an encrypted network address corresponding to the request information; determine a first encrypted index and a second encrypted index in the encrypted network address; The first encrypted index and the second encrypted index decrypt the encrypted network address to obtain the decrypted network address; and perform network access based on the decrypted network address.
在本实施例的一些可选的实现方式中,目标反爬虫操作至少包括数据分析识别操作;以及,爬虫识别单元503进一步被配置成:获取爬虫分析数据;基于爬虫分析数据,对请求信息进行爬虫识别,得到请求信息对应的识别结果。In some optional implementations of this embodiment, the target anti-crawling operation includes at least a data analysis and identification operation; and the crawler identification unit 503 is further configured to: acquire crawler analysis data; and perform crawling on the request information based on the crawler analysis data Identify, and obtain the identification result corresponding to the request information.
在本实施例的一些可选的实现方式中,目标反爬虫操作至少包括签名同步识别操作;以及,爬虫识别单元503进一步被配置成:确定请求信息中的签名信息;基于签名信息和预设的签名信息,得到识别结果。In some optional implementations of this embodiment, the target anti-crawler operation includes at least a signature synchronization identification operation; and the crawler identification unit 503 is further configured to: determine the signature information in the request information; Signature information to get the identification result.
在本实施例的一些可选的实现方式中,还包括:分数输出单元,被配置成基于识别结果,确定请求信息对应的爬虫分数信息;输出爬虫分数信息。In some optional implementations of this embodiment, the method further includes: a score output unit, configured to determine the crawler score information corresponding to the request information based on the identification result; and output the crawler score information.
在本实施例的一些可选的实现方式中,请求信息用于请求访问网页小程序的页面数据。In some optional implementations of this embodiment, the request information is used to request access to page data of the web page applet.
在本实施例的一些可选的实现方式中,预设的反爬虫操作集合中的反爬虫操作至少包括以下一项:端特征识别操作、令牌识别操作、人机特征识别操作、数据分析识别操作和签名识别操作。In some optional implementations of this embodiment, the anti-crawling operations in the preset anti-crawling operation set include at least one of the following: terminal feature recognition operation, token recognition operation, human-machine feature recognition operation, data analysis and recognition operation Actions and Signature Recognition Actions.
应当理解,用于识别爬虫的装置500中记载的单元501至单元504分别与参考图2中描述的方法中的各个步骤相对应。由此,上文针对用于识别爬虫的方法描述的操作和特征同样适用于装置500及其中包含的单元,在此不再赘述。It should be understood that the units 501 to 504 recorded in the apparatus 500 for recognizing crawlers correspond to respective steps in the method described with reference to FIG. 2 . Therefore, the operations and features described above with respect to the method for recognizing a crawler are also applicable to the apparatus 500 and the units included therein, and will not be repeated here.
根据本公开的实施例,本公开还提供了一种电子设备、一种可读存储介质和一种计算机程序系统。According to an embodiment of the present disclosure, the present disclosure also provides an electronic device, a readable storage medium, and a computer program system.
图6示出了可以用来实施本公开的实施例的示例电子设备600的示意性框图。电子设备旨在表示各种形式的数字计算机,诸如,膝上型计算机、台式计算机、工作台、个人数字助理、服务器、刀片式服务器、大型计算机、和其它适合的计算机。电子设备还可以表示各种形式的移动装置,诸如,个人数字处理、蜂窝电话、智能电话、可穿戴设备和其它类似的计算装置。本文所示的部件、它们的连接和关系、以及它们的功能仅仅作为示例,并且不意在限制本文中描述的和/或者要求的本公开的实现。6 shows a schematic block diagram of an example
如图6所示,设备600包括计算单元601,其可以根据存储在只读存储器(ROM)602中的计算机程序或者从存储单元608加载到随机访问存储器(RAM)603中的计算机程序,来执行各种适当的动作和处理。在RAM 603中,还可存储设备600操作所需的各种程序和数据。计算单元601、ROM 602以及RAM 603通过总线604彼此相连。输入/输出(I/O)接口605也连接至总线604。As shown in FIG. 6 , the
设备600中的多个部件连接至I/O接口605,包括:输入单元606,例如键盘、鼠标等;输出单元607,例如各种类型的显示器、扬声器等;存储单元608,例如磁盘、光盘等;以及通信单元609,例如网卡、调制解调器、无线通信收发机等。通信单元609允许设备600通过诸如因特网的计算机网络和/或各种电信网络与其他设备交换信息/数据。Various components in the
计算单元601可以是各种具有处理和计算能力的通用和/或专用处理组件。计算单元601的一些示例包括但不限于中央处理单元(CPU)、图形处理单元(GPU)、各种专用的人工智能(AI)计算芯片、各种运行机器学习模型算法的计算单元、数字信号处理器(DSP)、以及任何适当的处理器、控制器、微控制器等。计算单元601执行上文所描述的各个方法和处理,例如用于识别爬虫的方法。例如,在一些实施例中,用于识别爬虫的方法可被实现为计算机软件程序,其被有形地包含于机器可读介质,例如存储单元608。在一些实施例中,计算机程序的部分或者全部可以经由ROM 602和/或通信单元609而被载入和/或安装到设备600上。当计算机程序加载到RAM 603并由计算单元601执行时,可以执行上文描述的用于识别爬虫的方法的一个或多个步骤。备选地,在其他实施例中,计算单元601可以通过其他任何适当的方式(例如,借助于固件)而被配置为执行用于识别爬虫的方法。
本文中以上描述的系统和技术的各种实施方式可以在数字电子电路系统、集成电路系统、场可编程门阵列(FPGA)、专用集成电路(ASIC)、专用标准产品(ASSP)、芯片上系统的系统(SOC)、负载可编程逻辑设备(CPLD)、计算机硬件、固件、软件、和/或它们的组合中实现。这些各种实施方式可以包括:实施在一个或者多个计算机程序中,该一个或者多个计算机程序可在包括至少一个可编程处理器的可编程系统上执行和/或解释,该可编程处理器可以是专用或者通用可编程处理器,可以从存储系统、至少一个输入装置、和至少一个输出装置接收数据和指令,并且将数据和指令传输至该存储系统、该至少一个输入装置、和该至少一个输出装置。Various implementations of the systems and techniques described herein above can be implemented in digital electronic circuitry, integrated circuit systems, field programmable gate arrays (FPGAs), application specific integrated circuits (ASICs), application specific standard products (ASSPs), systems on chips system (SOC), load programmable logic device (CPLD), computer hardware, firmware, software, and/or combinations thereof. These various embodiments may include being implemented in one or more computer programs executable and/or interpretable on a programmable system including at least one programmable processor that The processor, which may be a special purpose or general-purpose programmable processor, may receive data and instructions from a storage system, at least one input device, and at least one output device, and transmit data and instructions to the storage system, the at least one input device, and the at least one output device an output device.
用于实施本公开的方法的程序代码可以采用一个或多个编程语言的任何组合来编写。这些程序代码可以提供给通用计算机、专用计算机或其他可编程数据处理装置的处理器或控制器,使得程序代码当由处理器或控制器执行时使流程图和/或框图中所规定的功能/操作被实施。程序代码可以完全在机器上执行、部分地在机器上执行,作为独立软件包部分地在机器上执行且部分地在远程机器上执行或完全在远程机器或服务器上执行。Program code for implementing the methods of the present disclosure may be written in any combination of one or more programming languages. These program codes may be provided to a processor or controller of a general purpose computer, special purpose computer or other programmable data processing apparatus, such that the program code, when executed by the processor or controller, performs the functions/functions specified in the flowcharts and/or block diagrams. Action is implemented. The program code may execute entirely on the machine, partly on the machine, partly on the machine and partly on a remote machine as a stand-alone software package or entirely on the remote machine or server.
在本公开的上下文中,机器可读介质可以是有形的介质,其可以包含或存储以供指令执行系统、装置或设备使用或与指令执行系统、装置或设备结合地使用的程序。机器可读介质可以是机器可读信号介质或机器可读储存介质。机器可读介质可以包括但不限于电子的、磁性的、光学的、电磁的、红外的、或半导体系统、装置或设备,或者上述内容的任何合适组合。机器可读存储介质的更具体示例会包括基于一个或多个线的电气连接、便携式计算机盘、硬盘、随机存取存储器(RAM)、只读存储器(ROM)、可擦除可编程只读存储器(EPROM或快闪存储器)、光纤、便捷式紧凑盘只读存储器(CD-ROM)、光学储存设备、磁储存设备、或上述内容的任何合适组合。In the context of the present disclosure, a machine-readable medium may be a tangible medium that may contain or store a program for use by or in connection with the instruction execution system, apparatus or device. The machine-readable medium may be a machine-readable signal medium or a machine-readable storage medium. Machine-readable media may include, but are not limited to, electronic, magnetic, optical, electromagnetic, infrared, or semiconductor systems, devices, or devices, or any suitable combination of the foregoing. More specific examples of machine-readable storage media would include one or more wire-based electrical connections, portable computer disks, hard disks, random access memory (RAM), read only memory (ROM), erasable programmable read only memory (EPROM or flash memory), fiber optics, compact disk read only memory (CD-ROM), optical storage devices, magnetic storage devices, or any suitable combination of the foregoing.
为了提供与用户的交互,可以在计算机上实施此处描述的系统和技术,该计算机具有:用于向用户显示信息的显示装置(例如,CRT(阴极射线管)或者LCD(液晶显示器)监视器);以及键盘和指向装置(例如,鼠标或者轨迹球),用户可以通过该键盘和该指向装置来将输入提供给计算机。其它种类的装置还可以用于提供与用户的交互;例如,提供给用户的反馈可以是任何形式的传感反馈(例如,视觉反馈、听觉反馈、或者触觉反馈);并且可以用任何形式(包括声输入、语音输入或者、触觉输入)来接收来自用户的输入。To provide interaction with a user, the systems and techniques described herein may be implemented on a computer having: a display device (eg, a CRT (cathode ray tube) or LCD (liquid crystal display) monitor) for displaying information to the user ); and a keyboard and pointing device (eg, a mouse or trackball) through which a user can provide input to the computer. Other kinds of devices can also be used to provide interaction with the user; for example, the feedback provided to the user can be any form of sensory feedback (eg, visual feedback, auditory feedback, or tactile feedback); and can be in any form (including acoustic input, voice input, or tactile input) to receive input from the user.
可以将此处描述的系统和技术实施在包括后台部件的计算系统(例如,作为数据服务器)、或者包括中间件部件的计算系统(例如,应用服务器)、或者包括前端部件的计算系统(例如,具有图形用户界面或者网络浏览器的用户计算机,用户可以通过该图形用户界面或者该网络浏览器来与此处描述的系统和技术的实施方式交互)、或者包括这种后台部件、中间件部件、或者前端部件的任何组合的计算系统中。可以通过任何形式或者介质的数字数据通信(例如,通信网络)来将系统的部件相互连接。通信网络的示例包括:局域网(LAN)、广域网(WAN)和互联网。The systems and techniques described herein can be implemented on a computing system that includes back-end components (eg, as a data server), or a computing system that includes middleware components (eg, an application server), or a computing system that includes front-end components (eg, a user computer having a graphical user interface or web browser through which a user can interact with implementations of the systems and techniques described herein), or including such backend components, middleware components, Or any combination of front-end components in a computing system. The components of the system may be interconnected by any form or medium of digital data communication (eg, a communication network). Examples of communication networks include: Local Area Networks (LANs), Wide Area Networks (WANs), and the Internet.
计算机系统可以包括客户端和服务器。客户端和服务器一般远离彼此并且通常通过通信网络进行交互。通过在相应的计算机上运行并且彼此具有客户端-服务器关系的计算机程序来产生客户端和服务器的关系。服务器可以是云服务器,也可以为分布式系统的服务器,或者是结合了区块链的服务器。A computer system can include clients and servers. Clients and servers are generally remote from each other and usually interact through a communication network. The relationship of client and server arises by computer programs running on the respective computers and having a client-server relationship to each other. The server can be a cloud server, a distributed system server, or a server combined with blockchain.
应该理解,可以使用上面所示的各种形式的流程,重新排序、增加或删除步骤。例如,本发公开中记载的各步骤可以并行地执行也可以顺序地执行也可以不同的次序执行,只要能够实现本公开公开的技术方案所期望的结果,本文在此不进行限制。It should be understood that steps may be reordered, added or deleted using the various forms of flow shown above. For example, the steps described in the present disclosure can be executed in parallel, sequentially, or in different orders. As long as the desired results of the technical solutions disclosed in the present disclosure can be achieved, there is no limitation herein.
上述具体实施方式,并不构成对本公开保护范围的限制。本领域技术人员应该明白的是,根据设计要求和其他因素,可以进行各种修改、组合、子组合和替代。任何在本公开的精神和原则之内所作的修改、等同替换和改进等,均应包含在本公开保护范围之内。The above-mentioned specific embodiments do not constitute a limitation on the protection scope of the present disclosure. It should be understood by those skilled in the art that various modifications, combinations, sub-combinations and substitutions may occur depending on design requirements and other factors. Any modifications, equivalent replacements, and improvements made within the spirit and principles of the present disclosure should be included within the protection scope of the present disclosure.
Claims (21)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111316197.6ACN114036364B (en) | 2021-11-08 | 2021-11-08 | Method, apparatus, device, medium, and system for identifying crawlers |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111316197.6ACN114036364B (en) | 2021-11-08 | 2021-11-08 | Method, apparatus, device, medium, and system for identifying crawlers |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN114036364A CN114036364A (en) | 2022-02-11 |
| CN114036364Btrue CN114036364B (en) | 2022-10-21 |
Family
ID=80136842
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202111316197.6AActiveCN114036364B (en) | 2021-11-08 | 2021-11-08 | Method, apparatus, device, medium, and system for identifying crawlers |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114036364B (en) |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114640538A (en)* | 2022-04-01 | 2022-06-17 | 北京明略昭辉科技有限公司 | Crawler program detection method and device, readable medium and electronic equipment |
| CN115098757A (en)* | 2022-06-27 | 2022-09-23 | 平安银行股份有限公司 | A network crawler identification method, device, system and equipment |
| CN115329291A (en)* | 2022-08-08 | 2022-11-11 | 广州鑫景信息科技服务有限公司 | Anti-crawler method, system, computer equipment and storage medium |
| CN116015938A (en)* | 2022-12-30 | 2023-04-25 | 数字广东网络建设有限公司 | Anti-crawler method and device and electronic equipment |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN106790105A (en)* | 2016-12-26 | 2017-05-31 | 携程旅游网络技术(上海)有限公司 | Reptile identification hold-up interception method and system based on business datum |
| CN110858229A (en)* | 2018-08-23 | 2020-03-03 | 阿里巴巴集团控股有限公司 | Data processing method, device, access control system and storage medium |
| CN111611462A (en)* | 2020-04-09 | 2020-09-01 | 北京歌华有线电视网络股份有限公司 | A kind of APP data acquisition method and system |
| CN112417240A (en)* | 2020-02-21 | 2021-02-26 | 上海哔哩哔哩科技有限公司 | Website link detection method and device and computer equipment |
Family Cites Families (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GB2391346A (en)* | 2002-07-31 | 2004-02-04 | Hewlett Packard Co | On-line recognition of robots |
| CN103164446A (en)* | 2011-12-14 | 2013-06-19 | 阿里巴巴集团控股有限公司 | Webpage request information response method and webpage request information response device |
| CN103279516B (en)* | 2013-05-27 | 2016-09-14 | 百度在线网络技术(北京)有限公司 | Web spider identification method |
| CN105812366B (en)* | 2016-03-14 | 2019-09-24 | 携程计算机技术(上海)有限公司 | Server, anti-crawler system and anti-crawler verification method |
| CN107092660A (en)* | 2017-03-28 | 2017-08-25 | 成都优易数据有限公司 | A kind of Website server reptile recognition methods and device |
| CN108777687B (en)* | 2018-06-05 | 2020-04-14 | 掌阅科技股份有限公司 | Crawler intercepting method based on user behavior portrait, electronic equipment and storage medium |
| CN112073412A (en)* | 2020-09-08 | 2020-12-11 | 北京天融信网络安全技术有限公司 | Anti-crawler method, device, processor and computer readable medium |
| CN112688919A (en)* | 2020-12-11 | 2021-04-20 | 杭州安恒信息技术股份有限公司 | APP interface-based crawler-resisting method, device and medium |
- 2021
- 2021-11-08CNCN202111316197.6Apatent/CN114036364B/enactiveActive
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN106790105A (en)* | 2016-12-26 | 2017-05-31 | 携程旅游网络技术(上海)有限公司 | Reptile identification hold-up interception method and system based on business datum |
| CN110858229A (en)* | 2018-08-23 | 2020-03-03 | 阿里巴巴集团控股有限公司 | Data processing method, device, access control system and storage medium |
| CN112417240A (en)* | 2020-02-21 | 2021-02-26 | 上海哔哩哔哩科技有限公司 | Website link detection method and device and computer equipment |
| CN111611462A (en)* | 2020-04-09 | 2020-09-01 | 北京歌华有线电视网络股份有限公司 | A kind of APP data acquisition method and system |
Non-Patent Citations (1)
| Title |
|---|
| 基于网站访问行为的匿名爬虫检测;邹建鑫 等;《基于网站访问行为的匿名爬虫检测》;20171231;第27卷(第12期);103-107,114* |
Also Published As
| Publication number | Publication date |
|---|---|
| CN114036364A (en) | 2022-02-11 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN114036364B (en) | Method, apparatus, device, medium, and system for identifying crawlers | |
| KR102429406B1 (en) | Check user interactions on the content platform | |
| AU2021204543B2 (en) | Digital signature method, signature information verification method, related apparatus and electronic device | |
| CN109241484B (en) | Method and equipment for sending webpage data based on encryption technology | |
| CN104796257A (en) | Flexible data authentication | |
| CN108848058A (en) | Intelligent contract processing method and block catenary system | |
| CN109743161B (en) | Information encryption method, electronic device and computer readable medium | |
| CN114363088B (en) | Method and device for requesting data | |
| CN114500054A (en) | Service access method, service access device, electronic device, and storage medium | |
| CN119961890B (en) | Model fingerprint embedding and model copyright authentication method, device and medium | |
| CN115238310A (en) | Data encryption and decryption method, device, equipment and storage medium | |
| CN115580489B (en) | Data transmission method, device, equipment and storage medium | |
| CN114884714B (en) | Task processing method, device, equipment and storage medium | |
| CN113794706A (en) | Data processing method, apparatus, electronic device and readable storage medium | |
| CN112565156B (en) | Information registration method, device and system | |
| US10013539B1 (en) | Rapid device identification among multiple users | |
| CN113609156B (en) | Data query and write method and device, electronic equipment and readable storage medium | |
| CN115694902A (en) | Second kill request method and second kill verification method, device, system and medium | |
| CN115484080A (en) | Data processing method, device and equipment of small program and storage medium | |
| CN110990822B (en) | Verification code generation and verification method, system, electronic device and storage medium | |
| CN110740112B (en) | Authentication method, apparatus and computer readable storage medium | |
| CN114117388A (en) | Device registration method, device registration device, electronic device, and storage medium | |
| CN115879122A (en) | Open platform management method, device, equipment and storage medium | |
| CN120470632B (en) | A method, system, device and storage medium for verifying sensitive data in a database | |
| CN111294326B (en) | Method, apparatus, device and medium for confirming system data security |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |