CN113869392A - Picture analysis model training method, advertisement picture selection method and electronic equipment - Google Patents
Picture analysis model training method, advertisement picture selection method and electronic equipmentDownload PDFInfo
- Publication number
- CN113869392A CN113869392ACN202111124141.0ACN202111124141ACN113869392ACN 113869392 ACN113869392 ACN 113869392ACN 202111124141 ACN202111124141 ACN 202111124141ACN 113869392 ACN113869392 ACN 113869392A
- Authority
- CN
- China
- Prior art keywords
- image
- picture
- advertisement
- text
- feature vector
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images








Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/241—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches
- G06F18/2415—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches based on parametric or probabilistic models, e.g. based on likelihood ratio or false acceptance rate versus a false rejection rate
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/084—Backpropagation, e.g. using gradient descent
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q30/00—Commerce
- G06Q30/02—Marketing; Price estimation or determination; Fundraising
- G06Q30/0241—Advertisements
- G06Q30/0276—Advertisement creation
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Life Sciences & Earth Sciences (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Computation (AREA)
- Business, Economics & Management (AREA)
- Biophysics (AREA)
- Mathematical Physics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Strategic Management (AREA)
- Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Bioinformatics & Computational Biology (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- Evolutionary Biology (AREA)
- Software Systems (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Accounting & Taxation (AREA)
- Development Economics (AREA)
- Finance (AREA)
- Entrepreneurship & Innovation (AREA)
- Game Theory and Decision Science (AREA)
- Probability & Statistics with Applications (AREA)
- Economics (AREA)
- Marketing (AREA)
- General Business, Economics & Management (AREA)
- Image Analysis (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本申请涉及图像处理技术领域,尤其涉及一种图片分析模型训练方法、广告图片选择方法及电子设备。The present application relates to the technical field of image processing, and in particular, to a method for training an image analysis model, a method for selecting an advertisement image, and an electronic device.
背景技术Background technique
互联网广告大多由文本和图片构成。相关技术中,通过图片的分辨率、纹理、空白量、边缘渐变等特征来评价图片的视觉感官效果,从而将视觉感官效果最佳的图片用于投放广告,然而,这可能出现广告图片的内容与对应的文本不匹配的情况,从而导致广告的点击率较低。Most Internet advertisements consist of text and pictures. In the related art, the visual sensory effect of the picture is evaluated by the features such as the resolution, texture, blank space, and edge gradient of the picture, so that the picture with the best visual sensory effect is used for advertising. However, the content of the advertising picture may appear. A mismatch with the corresponding text, resulting in a lower click-through rate for the ad.
发明内容SUMMARY OF THE INVENTION
有鉴于此,本申请实施例提供一种图片分析模型训练方法、广告图片选择方法及电子设备,以解决相关技术中因选择的广告图片的内容与对应的文本不匹配,导致广告的点击率较低的技术问题。In view of this, the embodiments of the present application provide a method for training an image analysis model, a method for selecting an advertisement image, and an electronic device, so as to solve the problem that the content of the selected advertisement image does not match the corresponding text in the related art, resulting in a higher click-through rate of the advertisement. Low technical issues.
为达到上述目的,本申请的技术方案是这样实现的:In order to achieve the above-mentioned purpose, the technical scheme of the present application is achieved in this way:
本申请实施例提供一种图片分析模型训练方法,包括:The embodiment of the present application provides a method for training an image analysis model, including:
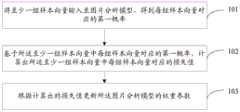
将至少一组样本向量输入至图片分析模型,得到每组样本向量对应的第一概率;其中,每组样本向量基于同一广告位上广告语相同的第一广告和第二广告生成,包括广告语、第一广告使用的第一图片、第一图片使用的第一文本、第二广告使用的第二图片和第二图片使用的第二文本;所述第一概率表征对应的样本向量中第一图片优于第二图片的概率;所述第一广告的点击率高于所述第二广告的点击率;Input at least one group of sample vectors into the image analysis model, and obtain the first probability corresponding to each group of sample vectors; wherein, each group of sample vectors is generated based on the first advertisement and the second advertisement with the same advertisement slogan on the same advertising space, including the advertisement slogan , the first image used by the first advertisement, the first text used by the first image, the second image used by the second advertisement, and the second text used by the second image; the first probability represents the first probability in the corresponding sample vector. The probability that the picture is better than the second picture; the click-through rate of the first advertisement is higher than the click-through rate of the second advertisement;
基于所述至少一组样本向量中每组样本向量对应的第一概率,计算出所述至少一组样本向量中每组样本向量对应的损失值;Calculate, based on the first probability corresponding to each group of sample vectors in the at least one group of sample vectors, a loss value corresponding to each group of sample vectors in the at least one group of sample vectors;
根据计算出的损失值更新所述图片分析模型的权重参数。The weight parameters of the image analysis model are updated according to the calculated loss value.
上述方案中,所述图片分析模型包括文本处理网络、图像处理网络、注意力网络和二分类网络;所述将至少一组样本向量输入至图片分析模型,得到每组样本向量对应的第一概率时,所述方法包括:In the above scheme, the picture analysis model includes a text processing network, an image processing network, an attention network and a two-class network; the at least one group of sample vectors is input into the picture analysis model, and the first probability corresponding to each group of sample vectors is obtained. , the method includes:
将广告语、第一文本和第二文本输入至文本处理网络,得到第一全局特征向量、第二全局特征向量、第一文本特征向量和第二文本特征向量;其中,第一全局特征向量表征广告语和第一文本的全局特征,第二全局特征向量表征广告语和第二文本的全局特征,第一文本特征向量基于第一全局特征向量得到,第二文本特征向量基于第二全局特征向量得到;Input the advertisement slogan, the first text and the second text into the text processing network to obtain the first global feature vector, the second global feature vector, the first text feature vector and the second text feature vector; wherein, the first global feature vector represents the The global feature of the advertisement slogan and the first text, the second global feature vector represents the global feature of the advertisement slogan and the second text, the first text feature vector is obtained based on the first global feature vector, and the second text feature vector is based on the second global feature vector. get;
将第一图片和第一全局特征向量输入至图像处理网络,得到第一图像特征向量,以及将第二图片和第二全局特征向量输入至图像处理网络,得到第二图像特征向量;Inputting the first picture and the first global feature vector to the image processing network to obtain the first image feature vector, and inputting the second picture and the second global feature vector to the image processing network to obtain the second image feature vector;
将第一文本特征向量和第一图像特征向量输入至注意力网络,得到第一图片向量,以及将第二文本特征向量和第二图像特征向量输入至注意力网络,得到第二图片向量;Input the first text feature vector and the first image feature vector to the attention network to obtain the first picture vector, and input the second text feature vector and the second image feature vector to the attention network to obtain the second picture vector;
将第一图片向量和第二图片向量输入至二分类网络,得到对应的第一概率。Input the first image vector and the second image vector into the binary classification network to obtain the corresponding first probability.
上述方案中,所述文本处理网络包括文本编码器和前馈神经网络;所述将广告语、第一文本和第二文本输入至文本处理网络,得到第一全局特征向量、第二全局特征向量、第一文本特征向量和第二文本特征向量,包括:In the above scheme, the text processing network includes a text encoder and a feedforward neural network; the advertisement slogan, the first text and the second text are input into the text processing network to obtain the first global feature vector and the second global feature vector. , the first text feature vector and the second text feature vector, including:
将广告语和第一文本拼接,得到第一语句,以及将广告语和第二文本拼接,得到第二语句;Splicing the advertisement slogan and the first text to obtain the first sentence, and splicing the advertisement slogan and the second text to obtain the second sentence;
将第一语句和第二语句输入至文本编码器,得到第一全局特征向量和第二全局特征向量;Inputting the first sentence and the second sentence into the text encoder to obtain the first global feature vector and the second global feature vector;
将第一全局特征向量和第二全局特征向量输入至前馈神经网络,得到第一文本特征向量和第二文本特征向量。The first global feature vector and the second global feature vector are input to the feedforward neural network to obtain the first text feature vector and the second text feature vector.
上述方案中,所述图像处理网络包括卷积层、残差网络和全连接层;所述将第一图片和第一全局特征向量输入至图像处理网络,得到第一图像特征向量,以及将第二图片和第二全局特征向量输入至图像处理网络,得到第二图像特征向量时,所述方法包括:In the above scheme, the image processing network includes a convolution layer, a residual network and a fully connected layer; the first picture and the first global feature vector are input into the image processing network to obtain the first image feature vector, and the When the two pictures and the second global feature vector are input to the image processing network to obtain the second image feature vector, the method includes:
将第一图片集合输入至卷积层,得到第一图像张量;所述第一图片集合由所述至少一组样本向量中的所有第一图片或所有第二图片构成;Inputting the first picture set to the convolution layer to obtain a first image tensor; the first picture set is composed of all the first pictures or all the second pictures in the at least one group of sample vectors;
将第一图像张量和第一文本张量输入至残差网络,得到第二图像张量;所述第一文本张量由所有第一全局特征向量或所有第二全局特征向量生成;Input the first image tensor and the first text tensor into the residual network to obtain the second image tensor; the first text tensor is generated by all the first global feature vectors or all the second global feature vectors;
将第二图像张量输入至全连接层,得到第一图片集合中每张图片对应的图像特征向量;其中,所述图像特征向量为第一图像特征向量或第二图像特征向量。The second image tensor is input to the fully connected layer to obtain an image feature vector corresponding to each image in the first image set; wherein, the image feature vector is the first image feature vector or the second image feature vector.
上述方案中,所述残差网络包括至少一个残差块,每个残差块包括至少一个残差单元,每个残差单元包括卷积网络、第一卷积层、第一全连接层、第二全连接层和归一化层;所述将第一图像张量和第一文本张量输入至所述残差单元,得到第二图像张量时,所述方法包括:In the above solution, the residual network includes at least one residual block, each residual block includes at least one residual unit, and each residual unit includes a convolutional network, a first convolutional layer, a first fully connected layer, The second fully connected layer and the normalization layer; when the first image tensor and the first text tensor are input to the residual unit to obtain the second image tensor, the method includes:
将第一图像张量输入至卷积网络,得到第三图像张量;Input the first image tensor to the convolutional network to obtain the third image tensor;
将第一图像张量输入至第一卷积层,得到第四图像张量;Input the first image tensor to the first convolutional layer to obtain the fourth image tensor;
将第三图像张量与第四图像张量相加,得到第五图像张量;Add the third image tensor and the fourth image tensor to obtain the fifth image tensor;
将第一文本张量输入至第一全连接层,得到第一参数张量;所述第一参数张量表征第一图片集合中每张图片与对应的文本之间的第一关联强度;Inputting the first text tensor into the first fully connected layer to obtain a first parameter tensor; the first parameter tensor represents the first association strength between each picture in the first picture set and the corresponding text;
将第一文本张量输入至第二全连接层,得到第二参数张量;所述第二参数张量表征第一图片集合中每张图片与对应的文本之间的第二关联强度;Inputting the first text tensor into the second fully connected layer to obtain a second parameter tensor; the second parameter tensor represents the second association strength between each picture in the first picture set and the corresponding text;
将第五图像张量、第一参数张量和第二参数张量输入至归一化层,得到第二图像张量。The fifth image tensor, the first parameter tensor and the second parameter tensor are input to the normalization layer to obtain the second image tensor.
上述方案中,所述将第一图片向量和第二图片向量输入至二分类网络,得到对应的第一概率时,所述方法包括:In the above scheme, when the first picture vector and the second picture vector are input into the two-class network to obtain the corresponding first probability, the method includes:
将第一图片向量和第二图片向量输入至二分类网络,利用设定的激活函数对第一乘积与第二乘积之间的差值进行归一化处理,得到对应的第一概率;其中,所述第一乘积表征第一权重参数与第一图片向量之间的乘积;所述第二乘积表征第二权重参数与第二图片向量之间的乘积。Input the first picture vector and the second picture vector into the two-class network, and use the set activation function to normalize the difference between the first product and the second product to obtain the corresponding first probability; wherein, The first product represents the product between the first weight parameter and the first picture vector; the second product represents the product between the second weight parameter and the second picture vector.
上述方案中,所述将至少一组样本向量输入至图片分析模型,得到每组样本向量对应的第一概率之前,所述方法还包括:In the above solution, before inputting at least one group of sample vectors into the image analysis model and obtaining the first probability corresponding to each group of sample vectors, the method further includes:
获取广告的广告数据;所述广告数据包括广告位标识、广告语、图片和点击率;Obtain the advertisement data of the advertisement; the advertisement data includes the advertisement space identification, advertisement slogan, pictures and click-through rate;
从获取到的广告对应的图片中,确定出广告位标识和广告语均相同的至少一个第二图片集合;每个所述第二图片集合包括对应广告的一张图片;From the obtained pictures corresponding to the advertisement, determine at least one second picture set with the same advertising space identifier and advertisement slogan; each of the second picture sets includes a picture corresponding to the advertisement;
基于图片对应的点击率,对每个所述第二图片集合中的图片进行排序,得到对应的第三图片集合;Based on the click rate corresponding to the pictures, sorting the pictures in each of the second picture sets to obtain a corresponding third picture set;
基于每个所述第三图片集合中图片的排列顺序和对应的广告语,生成第一样本集合;其中,所述第一样本集合包括所述至少一组样本向量。A first sample set is generated based on the arrangement order of pictures in each of the third picture sets and the corresponding advertisement slogan; wherein, the first sample set includes the at least one set of sample vectors.
本申请实施例还提供了一种广告图片选择方法,包括:The embodiment of the present application also provides a method for selecting an advertisement image, including:
基于第一广告语、每两张候选图片和对应的文本信息,生成多张候选图片对应的至少一组第一向量;generating at least one set of first vectors corresponding to the plurality of candidate pictures based on the first advertisement slogan, each of the two candidate pictures and the corresponding text information;
将生成的每组第一向量输入至第一模型,得到每组第一向量对应的第二概率;Inputting each group of generated first vectors into the first model to obtain the second probability corresponding to each group of first vectors;
基于每组第一向量对应的图片排列顺序,以及每组第一向量对应的第二概率,从所述多张候选图片中确定出广告图片;其中,Based on the sequence of pictures corresponding to each group of first vectors and the second probability corresponding to each group of first vectors, an advertisement picture is determined from the plurality of candidate pictures; wherein,
所述第一模型为采用上述任一种所述的图片分析模型训练方法训练得到的图片分析模型;所述第二概率表征第一候选图片优于第二候选图片的概率;所述第一候选图片在所述第二候选图片之前。The first model is an image analysis model trained by using any of the above-mentioned image analysis model training methods; the second probability represents the probability that the first candidate image is better than the second candidate image; the first candidate image The picture precedes the second candidate picture.
本申请实施例还提供了一种电子设备,包括:The embodiment of the present application also provides an electronic device, including:
训练单元,用于将至少一组样本向量输入至图片分析模型,得到每组样本向量对应的第一概率;其中,每组样本向量基于同一广告位上广告语相同的第一广告和第二广告生成,包括广告语、第一广告使用的第一图片、第一图片使用的第一文本、第二广告使用的第二图片和第二图片使用的第二文本;所述第一概率表征对应的样本向量中第一图片优于第二图片的概率;所述第一广告的点击率高于所述第二广告的点击率;A training unit for inputting at least one set of sample vectors into the image analysis model to obtain the first probability corresponding to each set of sample vectors; wherein, each set of sample vectors is based on the first advertisement and the second advertisement with the same slogan on the same advertisement space Generated, including the slogan, the first image used in the first advertisement, the first text used in the first image, the second image used in the second advertisement, and the second text used in the second image; the first probability represents the corresponding The probability that the first picture is better than the second picture in the sample vector; the click-through rate of the first advertisement is higher than the click-through rate of the second advertisement;
计算单元,用于基于所述至少一组样本向量中每组样本向量对应的第一概率,计算出所述至少一组样本向量中每组样本向量对应的损失值;a computing unit, configured to calculate a loss value corresponding to each group of sample vectors in the at least one group of sample vectors based on the first probability corresponding to each group of sample vectors in the at least one group of sample vectors;
更新单元,用于根据计算出的损失值更新所述图片分析模型的权重参数。An update unit, configured to update the weight parameter of the picture analysis model according to the calculated loss value.
本申请实施例还提供了一种电子设备,包括:The embodiment of the present application also provides an electronic device, including:
生成单元,用于基于第一广告语、每两张候选图片和对应的文本信息,生成多张候选图片对应的至少一组第一向量;A generating unit, configured to generate at least one set of first vectors corresponding to multiple candidate pictures based on the first advertisement slogan, every two candidate pictures and the corresponding text information;
处理单元,用于将生成的每组第一向量输入至第一模型,得到每组第一向量对应的第二概率;a processing unit, configured to input each group of generated first vectors into the first model to obtain a second probability corresponding to each group of first vectors;
确定单元,用于基于每组第一向量对应的图片排列顺序,以及每组第一向量对应的第二概率,从所述多张候选图片中确定出广告图片;其中,a determining unit, configured to determine an advertisement picture from the plurality of candidate pictures based on the arrangement order of pictures corresponding to each group of first vectors and the second probability corresponding to each group of first vectors; wherein,
所述第一模型为采用上述任一种所述的图片分析模型训练方法训练得到的图片分析模型;所述第二概率表征第一候选图片优于第二候选图片的概率;所述第一候选图片在所述第二候选图片之前。The first model is an image analysis model trained by using any of the above-mentioned image analysis model training methods; the second probability represents the probability that the first candidate image is better than the second candidate image; the first candidate image The picture precedes the second candidate picture.
本申请实施例还提供了一种电子设备,包括:处理器和用于存储能够在处理器上运行的计算机程序的存储器,Embodiments of the present application also provide an electronic device, including: a processor and a memory for storing a computer program that can be executed on the processor,
其中,所述处理器用于运行所述计算机程序时,执行以下至少之一:Wherein, when the processor is configured to run the computer program, execute at least one of the following:
上述任一种图片分析模型方法的步骤;The steps of any of the above-mentioned image analysis model methods;
上述广告图片选择方法的步骤。The steps of the above advertisement image selection method.
本申请实施例还提供了一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现以下至少之一:Embodiments of the present application also provide a storage medium on which a computer program is stored, and when the computer program is executed by a processor, implements at least one of the following:
上述任一种图片分析模型训练方法的步骤;The steps of any of the above-mentioned image analysis model training methods;
上述广告图片选择方法的步骤。The steps of the above advertisement image selection method.
本申请实施例中,通过至少一组样本向量训练图片分析模型,在训练的过程中,基于至少一组样本向量中每组样本向量对应的第一概率,计算出至少一组样本向量中每组样本向量对应的损失值;根据计算出的损失值更新图片分析模型的权重参数。由于在训练的过程中,每组训练样本基于同一广告位上广告语相同的第一广告和第二广告生成,包括广告语、第一广告使用的第一图片、第一图片使用的第一文本、第二广告使用的第二图片和第二图片使用的第二文本;第一概率表征对应的样本向量中第一图片优于第二图片的概率,第一广告的点击率高于第二广告的点击率,也就是说,每组样本向量对应的广告位和广告语均相同,每组样本向量中不同图片对应的点击率的差异源自图片内容的不同,因此,基于训练后的图片分析模型输出的概率,可以准确地预测出每两张图片中,与广告与匹配,且点击率较高的图片,进而从多张图片中选出广告效果最好的图片投放广告。In this embodiment of the present application, the image analysis model is trained by using at least one set of sample vectors. During the training process, each set of sample vectors in the at least one set of sample vectors is calculated based on the first probability corresponding to each set of sample vectors in the at least one set of sample vectors. The loss value corresponding to the sample vector; update the weight parameters of the image analysis model according to the calculated loss value. During the training process, each set of training samples is generated based on the first advertisement and the second advertisement with the same advertisement language in the same advertisement space, including the advertisement language, the first picture used in the first advertisement, and the first text used in the first picture. , the second image used by the second advertisement and the second text used by the second image; the first probability represents the probability that the first image is better than the second image in the corresponding sample vector, and the click rate of the first advertisement is higher than that of the second advertisement The click-through rate of each group of sample vectors is the same, that is to say, the advertising space and advertisement slogan corresponding to each group of sample vectors are the same, and the difference in the click-through rate corresponding to different pictures in each group of sample vectors is due to the difference in the content of the pictures. Therefore, based on the image analysis after training The probability output by the model can accurately predict the image that matches the advertisement and has a high click-through rate in each two images, and then selects the image with the best advertising effect from multiple images to place the advertisement.
附图说明Description of drawings
图1为本申请实施例提供的图片分析模型训练方法的实现流程示意图;Fig. 1 is the realization flow schematic diagram of the image analysis model training method provided by the embodiment of this application;
图2为本申请实施例提供的一种广告的示意图;2 is a schematic diagram of an advertisement provided by an embodiment of the present application;
图3为本申请实施例提供的图片分析模型处理每组样本向量的示意图;3 is a schematic diagram of processing each group of sample vectors by a picture analysis model provided by an embodiment of the present application;
图4为本申请实施例提供的图片分析模型中文本处理网络对文本进行处理的示意图;4 is a schematic diagram of processing text by a text processing network in a picture analysis model provided by an embodiment of the present application;
图5为本申请实施例提供的图片分析模型中图像处理网络的结构示意图;5 is a schematic structural diagram of an image processing network in an image analysis model provided by an embodiment of the present application;
图6为本申请实施例提供的生成样本集的实现流程示意图;FIG. 6 is a schematic flowchart of an implementation of generating a sample set provided by an embodiment of the present application;
图7为本申请实施例提供的广告图片的示意图;7 is a schematic diagram of an advertisement image provided by an embodiment of the present application;
图8为本申请实施例提供的广告图片选择方法的实现流程示意图;FIG. 8 is a schematic diagram of an implementation flow of a method for selecting an advertisement image provided by an embodiment of the present application;
图9为本申请实施例提供的广告图片选择方法的示意图;9 is a schematic diagram of a method for selecting an advertisement image provided by an embodiment of the present application;
图10为本申请实施例提供的广告图片选择方法的实现流程示意图;FIG. 10 is a schematic diagram of an implementation flow of a method for selecting an advertisement image provided by an embodiment of the present application;
图11为本申请实施例提供的电子设备的结构示意图;11 is a schematic structural diagram of an electronic device provided by an embodiment of the application;
图12为本申请另一实施例提供的电子设备的结构示意图;12 is a schematic structural diagram of an electronic device provided by another embodiment of the present application;
图13为本申请实施例提供的电子设备的硬件组成结构示意图。FIG. 13 is a schematic structural diagram of a hardware composition of an electronic device provided by an embodiment of the present application.
具体实施方式Detailed ways
近年来,互联网广告已经成为最为普遍的广告形式之一。不论是搜索引擎广告、展示包断广告、还是实时竞价广告,普遍由文本与图片搭配。其中,文本为广告的主题。为了提高广告的点击率,需要为广告选择广告图片,合适的广告图片具有以下特点:In recent years, Internet advertising has become one of the most common forms of advertising. Whether it is a search engine advertisement, a display block advertisement, or a real-time bidding advertisement, it is generally composed of text and pictures. Among them, the text is the subject of the advertisement. In order to improve the click-through rate of an advertisement, it is necessary to select an advertisement image for the advertisement. A suitable advertisement image has the following characteristics:
1、较高的图片质量,例如,能让用户辨别细节的分辨率、合适的图片尺寸;1. Higher image quality, for example, the resolution that enables users to identify details and the appropriate image size;
2、合适的图片内容,例如,广告语是某品牌某型号的手机,图片为同品牌同型号的手机的图片;2. Appropriate picture content, for example, the slogan is a mobile phone of a certain brand and model, and the picture is a picture of a mobile phone of the same brand and model;
3、图片中存在具有吸引力的内容要素,例如,带有文字说明、图片色彩、图片展示的产品细节等。3. There are attractive content elements in the picture, such as text description, picture color, product details displayed in the picture, etc.
基于此,在本申请的各实施例中,电子设备基于同一广告位上广告语相同的每两个广告,确定出一组样本向量,基于至少一组样本向量对图片分析模型进行训练,得到训练后的图片分析模型。由于每组样本向量基于同一广告位上广告语相同的第一广告和第二广告生成,包括广告语、第一广告使用的第一图片、第一图片使用的第一文本、第二广告使用的第二图片和第二图片使用的第二文本;第一广告的点击率高于第二广告的点击率,也就是说,每组样本向量对应的广告位和广告语均相同,每组样本向量中不同图片对应的点击率的差异源自图片内容的不同,因此,基于训练后的图片分析模型输出的概率,可以准确地预测出每两张图片中,与广告与匹配,且点击率较高的图片,进而从多张图片中选出广告效果最好的图片投放广告。Based on this, in each embodiment of the present application, the electronic device determines a set of sample vectors based on every two advertisements with the same slogan in the same advertisement space, and trains the image analysis model based on at least one set of sample vectors to obtain the training Post-image analysis model. Since each set of sample vectors is generated based on the first advertisement and the second advertisement with the same advertisement slogan in the same advertisement space, it includes the advertisement slogan, the first image used in the first advertisement, the first text used in the first image, and the second advertisement used in the second advertisement. The second picture and the second text used in the second picture; the click-through rate of the first advertisement is higher than that of the second advertisement, that is to say, the advertising space and advertisement slogan corresponding to each group of sample vectors are the same, and each group of sample vectors The difference in the click-through rate corresponding to different pictures in the picture is due to the difference in the content of the picture. Therefore, based on the probability of the output of the trained picture analysis model, it can be accurately predicted that each two pictures match the advertisement and the click-through rate is high. image, and then select the image with the best advertising effect from multiple images to place the ad.
为了使本申请的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本申请进行进一步详细说明。应当理解,此处描述的具体实施例仅仅用以解释本申请,并不用于限定本申请。In order to make the purpose, technical solutions and advantages of the present application more clearly understood, the present application will be described in further detail below with reference to the accompanying drawings and embodiments. It should be understood that the specific embodiments described herein are only used to explain the present application, but not to limit the present application.
图1为本申请实施例提供的图片分析模型训练方法的实现流程示意图,其中,流程的执行主体为终端、服务器等电子设备。如图1示出的,图片分析模型训练方法包括:FIG. 1 is a schematic diagram of an implementation flow of a method for training a picture analysis model provided by an embodiment of the present application, wherein the execution subject of the flow is an electronic device such as a terminal and a server. As shown in Figure 1, the image analysis model training method includes:
步骤101:将至少一组样本向量输入至图片分析模型,得到每组样本向量对应的第一概率;其中,每组样本向量基于同一广告位上广告语相同的第一广告和第二广告生成,包括广告语、第一广告使用的第一图片、第一图片使用的第一文本、第二广告使用的第二图片和第二图片使用的第二文本;所述第一概率表征对应的样本向量中第一图片优于第二图片的概率;所述第一广告的点击率高于所述第二广告的点击率。Step 101: Input at least one set of sample vectors into the image analysis model to obtain the first probability corresponding to each set of sample vectors; wherein, each set of sample vectors is generated based on the first advertisement and the second advertisement with the same slogan on the same advertisement space, Including the advertisement slogan, the first picture used in the first advertisement, the first text used in the first image, the second image used in the second advertisement, and the second text used in the second image; the first probability represents the corresponding sample vector The probability that the first picture is better than the second picture; the click-through rate of the first advertisement is higher than the click-through rate of the second advertisement.
这里,电子设备确定出至少一组样本向量,将至少一组样本向量输入至图片分析模型,通过图片分析模型对每组样本向量进行处理,得到每组样本向量对应的第一概率。其中,至少一组样本向量中的每组样本向量可以均基于同一广告位上广告语相同的每两个广告生成,当然,不同组的样本向量对应的广告语和广告位也可以不同。电子设备可以按照以下任一方法得到每组样本向量:Here, the electronic device determines at least one set of sample vectors, inputs the at least one set of sample vectors to the image analysis model, and processes each set of sample vectors through the image analysis model to obtain the first probability corresponding to each set of sample vectors. Wherein, each group of sample vectors in the at least one group of sample vectors may be generated based on every two advertisements with the same advertisement slogan in the same advertisement space. Of course, the advertisement slogans and advertisement spaces corresponding to different groups of sample vectors may also be different. The electronic device can obtain each set of sample vectors in any of the following ways:
电子设备可以基于同一广告位上广告语相同的第一广告和第二广告,生成一组样本向量。广告语以及广告位的示意图如图2所示。The electronic device may generate a set of sample vectors based on the first advertisement and the second advertisement with the same slogan in the same advertisement space. The schematic diagram of the advertisement slogan and the advertisement space is shown in Figure 2.
电子设备可以基于广告位和广告语均相同的广告对应的图片集合中的每两张图片,生成一组样本向量。其中,图片集合中包括每个广告的一张图片。The electronic device may generate a set of sample vectors based on each two pictures in the picture set corresponding to the advertisement with the same advertisement space and advertisement slogan. Wherein, the picture set includes one picture of each advertisement.
电子设备也可以从广告位和广告语均相同的广告对应的样本集合中,确定出一组样本,并确定出每组样本中每个样本对应的向量,得到至少一组样本向量。其中,每个样本集合中包括多组样本,每组样本中至少包括第一广告使用的第一图片、第一图片使用的第一文本、第二广告使用的第二图片和第二文本。The electronic device may also determine a set of samples from the sample sets corresponding to advertisements with the same advertisement space and advertisement slogan, and determine a vector corresponding to each sample in each set of samples to obtain at least one set of sample vectors. Wherein, each sample set includes multiple groups of samples, and each group of samples includes at least a first image used in the first advertisement, a first text used in the first image, a second image and a second text used in the second advertisement.
其中,图片集合或样本集合可以存在于电子设备的本地数据库,也可以存在于远程数据库。第一文本和第二文本由电子设备利用字符识别(OCR,Optical CharacterRecognition)技术,从对应的图片中识别出。Wherein, the picture collection or the sample collection may exist in a local database of the electronic device, or may exist in a remote database. The first text and the second text are recognized from the corresponding pictures by the electronic device using a character recognition (OCR, Optical Character Recognition) technology.
考虑到第一文本或第二文本中包括的字符越多,图片分析模型的训练时长会越长,为了降低图片分析模型的训练时长,在从对应的图片中识别出的文本对应的字符总长度大于第一设定阈值的情况下,按照字符从小到大的顺序进行裁剪,得到对应的第一文本或第二文本。Considering that the more characters included in the first text or the second text, the longer the training time of the image analysis model will be. In order to reduce the training time of the image analysis model, the total length of the characters corresponding to the texts identified from the corresponding images is When the value is greater than the first set threshold, the characters are cropped in ascending order to obtain the corresponding first text or second text.
实际应用时,在对应的图片中包括多条文本的情况下,对识别出的多条文本按照字体从大到小的顺序进行排序;在识别出的文本对应的字符总长度大于第一设定阈值的情况下,基于第一设定阈值,对排序后的多条文本,按照由后向前的顺序进行裁剪,得到对应的第一文本或第二文本。In practical application, when the corresponding picture includes multiple texts, sort the identified multiple texts in descending order of font size; when the total length of the characters corresponding to the identified texts is greater than the first setting In the case of the threshold, based on the first set threshold, the sorted plurality of texts are cropped in the order from back to front to obtain the corresponding first text or second text.
下面详细说明通过图片分析模型对每组样本向量进行处理的实现过程:The implementation process of processing each group of sample vectors through the image analysis model is described in detail below:
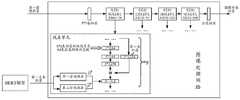
请一并参阅图3,图3为本申请实施例提供的图片分析模型处理每组样本向量的示意图。如图3所示,图片分析模型包括文本处理网络、图像处理网络、注意力网络和二分类网络。Please refer to FIG. 3 together. FIG. 3 is a schematic diagram of processing each group of sample vectors by the image analysis model provided by the embodiment of the present application. As shown in Figure 3, the image analysis model includes a text processing network, an image processing network, an attention network and a binary classification network.
为了提高预测出的第一概率的准确度,在一些实施例中,所述将至少一组样本向量输入至图片分析模型,得到每组样本向量对应的第一概率时,所述方法包括:In order to improve the accuracy of the predicted first probability, in some embodiments, when the at least one group of sample vectors is input into the image analysis model to obtain the first probability corresponding to each group of sample vectors, the method includes:
将广告语、第一文本和第二文本输入至文本处理网络,得到第一全局特征向量、第二全局特征向量、第一文本特征向量和第二文本特征向量;其中,第一全局特征向量表征广告语和第一文本的全局特征,第二全局特征向量表征广告语和第二文本的全局特征,第一文本特征向量基于第一全局特征向量得到,第二文本特征向量基于第二全局特征向量得到;Input the advertisement slogan, the first text and the second text into the text processing network to obtain the first global feature vector, the second global feature vector, the first text feature vector and the second text feature vector; wherein, the first global feature vector represents the The global feature of the advertisement slogan and the first text, the second global feature vector represents the global feature of the advertisement slogan and the second text, the first text feature vector is obtained based on the first global feature vector, and the second text feature vector is based on the second global feature vector. get;
将第一图片和第一全局特征向量输入至图像处理网络,得到第一图像特征向量,以及将第二图片和第二全局特征向量输入至图像处理网络,得到第二图像特征向量;Inputting the first picture and the first global feature vector to the image processing network to obtain the first image feature vector, and inputting the second picture and the second global feature vector to the image processing network to obtain the second image feature vector;
将第一文本特征向量和第一图像特征向量输入至注意力网络,得到第一图片向量,以及将第二文本特征向量和第二图像特征向量输入至注意力网络,得到第二图片向量;Input the first text feature vector and the first image feature vector to the attention network to obtain the first picture vector, and input the second text feature vector and the second image feature vector to the attention network to obtain the second picture vector;
将第一图片向量和第二图片向量输入至二分类网络,得到对应的第一概率。Input the first image vector and the second image vector into the binary classification network to obtain the corresponding first probability.
这里,电子设备通过图片分析模型对每组样本向量进行以下处理:Here, the electronic device performs the following processing on each set of sample vectors through the image analysis model:
将第一组样本向量中的广告语、第一文本和第二文本输入至文本处理网络,获取文本处理网络基于广告语和第一文本输出的第一全局特征向量,基于第一全局特征向量输出的第一文本特征向量,以及获取文本处理网络基于广告语和第二文本输出的第二全局特征向量,基于第二全局特征向量输出的第二文本特征向量。其中,第一组样本向量为输入至图片分析模型中的任一组样本向量。第一全局特征向量、第二全局特征向量、第一文本特征向量和第二文本特征向量均为列向量。在图3中,








为了增强全局特征向量的非线性特征,在一些实施例中,所述文本处理网络包括文本编码器和前馈神经网络;所述将广告语、第一文本和第二文本输入至文本处理网络,得到第一全局特征向量、第二全局特征向量、第一文本特征向量和第二文本特征向量,包括:In order to enhance the nonlinear features of the global feature vector, in some embodiments, the text processing network includes a text encoder and a feedforward neural network; Obtain the first global feature vector, the second global feature vector, the first text feature vector and the second text feature vector, including:
将广告语和第一文本拼接,得到第一语句,以及将广告语和第二文本拼接,得到第二语句;Splicing the advertisement slogan and the first text to obtain the first sentence, and splicing the advertisement slogan and the second text to obtain the second sentence;
将第一语句和第二语句输入至文本编码器,得到第一全局特征向量和第二全局特征向量;Inputting the first sentence and the second sentence into the text encoder to obtain the first global feature vector and the second global feature vector;
将第一全局特征向量和第二全局特征向量输入至前馈神经网络,得到第一文本特征向量和第二文本特征向量。The first global feature vector and the second global feature vector are input to the feedforward neural network to obtain the first text feature vector and the second text feature vector.
这里,如图4所示,文本处理网络包括文本编码器和前馈神经网络,文本编码器为基于转换器的双向编码表征(BERT,Bidirectional Encoder Representations fromTransformers)模型,BERT模型的隐藏层宽度为dT。前馈神经网络由两个级联的全连接层构成,两个全连接层均采用Relu函数作为激活函数。其中,与BERT模型连接的全连接层1的宽度为2048,用于对全局特征向量进行放大处理(或称上采样);全连接层2的宽度为dT,用于对全连接层1输出的特征向量进行缩小处理(或称下采样)。前馈神经网络用于加强全局特征向量的非线性特征,即,增强文本特征向量的表达能力,以实现在不同场景下,表达出特征的差异性。Here, as shown in Figure 4, the text processing network includes a text encoder and a feedforward neural network. The text encoder is a converter-based Bidirectional Encoder Representations from Transformers (BERT) model, and the hidden layer width of the BERT model is dT. The feedforward neural network consists of two cascaded fully connected layers, both of which use the Relu function as the activation function. Among them, the width of the fully connected
将广告语和第一文本按元素进行拼接,得到第一语句,将广告语和第二文本按元素进行拼接,得到第二语句;将第一语句和第二语句输入至文本编码器,得到第一语句对应的第一全局特征向量和第二语句对应的第二全局特征向量;将第一全局特征向量和第二全局特征向量输入至前馈神经网络,得到第一全局特征向量对应的第一文本特征向量,以及第二全局特征向量对应的第二文本特征向量。The advertisement slogan and the first text are spliced according to elements to obtain the first sentence, and the advertisement slogan and the second text are spliced according to elements to obtain the second sentence; the first sentence and the second sentence are input into the text encoder to obtain the first sentence. The first global feature vector corresponding to a sentence and the second global feature vector corresponding to the second sentence; the first global feature vector and the second global feature vector are input into the feedforward neural network, and the first global feature vector corresponding to the first global feature vector is obtained. The text feature vector, and the second text feature vector corresponding to the second global feature vector.
示例性地,在广告语







实际应用时,在将至少一组特征向量中每组特征向量的广告语、第一文本和第二文本输入至文本处理网络时,文本处理网络输出所有第一全局特征向量或所有第二全局特征向量对应的第一文本张量






在得到第一全局特征向量和第二全局特征向量的情况下,将第一图片和第一全局特征向量输入至图像处理网络,得到第一图像特征向量,以及将第二图片和第二全局特征向量输入至图像处理网络,得到第二图像特征向量。其中,在图3中,



为了提取图片中图像特征与对应的文本的文本特征之间的关联强度,以提高预测出的第一概率的准确度,在一些实施例中,所述图像处理网络包括级联的卷积层、残差网络和全连接层;所述将第一图片和第一全局特征向量输入至图像处理网络,得到第一图像特征向量,以及将第二图片和第二全局特征向量输入至图像处理网络,得到第二图像特征向量时,所述方法包括:将第一图片集合输入至卷积层,得到第一图像张量;所述第一图片集合由所述至少一组样本向量中的所有第一图片或所有第二图片构成;In order to extract the correlation strength between the image feature in the picture and the text feature of the corresponding text, so as to improve the accuracy of the predicted first probability, in some embodiments, the image processing network includes cascaded convolutional layers, Residual network and fully connected layer; described inputting the first picture and the first global feature vector to the image processing network to obtain the first image feature vector, and inputting the second picture and the second global feature vector to the image processing network, When the second image feature vector is obtained, the method includes: inputting the first image set into the convolution layer to obtain a first image tensor; the first image set is composed of all the first image sets in the at least one set of sample vectors. The picture or all second pictures constitute;
将第一图像张量和第一文本张量输入至残差网络,得到第二图像张量;所述第一文本张量由所有第一全局特征向量或所有第二全局特征向量生成;Input the first image tensor and the first text tensor into the residual network to obtain the second image tensor; the first text tensor is generated by all the first global feature vectors or all the second global feature vectors;
将第二图像张量输入至全连接层,得到第一图片集合中每张图片对应的图像特征向量;其中,所述图像特征向量为第一图像特征向量或第二图像特征向量。The second image tensor is input to the fully connected layer to obtain an image feature vector corresponding to each image in the first image set; wherein, the image feature vector is the first image feature vector or the second image feature vector.
这里,电子设备通过图片处理网络对每组样本向量进行以下处理:将第一图片集合输入至卷积层进行卷积处理,得到第一图像张量;将第一图像张量和第一文本张量输入至残差网络进行处理,得到第二图像张量;将第二图像张量输入至全连接层进行处理,得到第一图片集合中每张图片对应的图像特征向量。全连接层的宽度为dT。Here, the electronic device performs the following processing on each set of sample vectors through the image processing network: the first image set is input into the convolution layer for convolution processing to obtain the first image tensor; the first image tensor and the first text sheet are The second image tensor is input to the full connection layer for processing, and the image feature vector corresponding to each picture in the first picture set is obtained. The width of the fully connected layer is dT .
其中,残差网络包括至少一个残差块。需要说明的是,当图像处理网络包括多个级联的残差块时,首个残差块的输入为第一图像张量,非首个残差块的输入为相连的上一个残差块输出的图像张量,最后一个残差块输出第二图像张量。多个级联的残差块中每个残差块的层数可以部分相同,也可以完全不同,具体根据实际情况进行设置。Wherein, the residual network includes at least one residual block. It should be noted that when the image processing network includes multiple cascaded residual blocks, the input of the first residual block is the first image tensor, and the input of the non-first residual block is the connected previous residual block. The output image tensor, the last residual block outputs the second image tensor. The number of layers of each residual block in the multiple cascaded residual blocks may be partially the same or completely different, and the number of layers may be set according to the actual situation.
在一些实施例中,每个残差块包括至少一个残差单元,每个残差单元包括卷积网络、第一卷积层、第一全连接层、第二全连接层和归一化层;其中,卷积网络中由多个级联的卷积层构成,第一卷积层与卷积网络中的最后一个卷积层的卷积核的参数相同,卷积核的参数包括卷积核尺寸和总数,卷积核的总数表征卷积层的宽度;第一全连接层和第二全连接层的宽度与第一卷积层的宽度相同。实际应用时,图像处理网络为ResNet网络。如图5所示,图像处理网络中的残差网络包括4个残差块,残差块1和残差块4中的层数相同。每个残差块中包括9个级联的残差单元,每个残差单元包括卷积网络、第一卷积层、第一全连接层、第二全连接层和归一化层。In some embodiments, each residual block includes at least one residual unit, each residual unit including a convolutional network, a first convolutional layer, a first fully connected layer, a second fully connected layer, and a normalization layer ; Among them, the convolutional network is composed of multiple cascaded convolutional layers, the parameters of the convolution kernel of the first convolutional layer and the last convolutional layer in the convolutional network are the same, and the parameters of the convolutional kernel include the convolutional kernel. Kernel size and total number, the total number of convolution kernels represents the width of the convolutional layer; the width of the first fully connected layer and the second fully connected layer is the same as the width of the first convolutional layer. In practical applications, the image processing network is a ResNet network. As shown in Figure 5, the residual network in the image processing network includes 4 residual blocks, and the number of layers in
为了增强图片中与文本特征相关的图像特征,以提高预测出的第一概率的准确度,所述将第一图像张量和第一文本张量输入至所述残差单元,得到第二图像张量时,所述方法包括:In order to enhance the image features related to the text features in the picture to improve the accuracy of the predicted first probability, the first image tensor and the first text tensor are input into the residual unit to obtain a second image tensor, the method includes:
将第一图像张量输入至卷积网络,得到第三图像张量;Input the first image tensor to the convolutional network to obtain the third image tensor;
将第一图像张量输入至第一卷积层,得到第四图像张量;Input the first image tensor to the first convolutional layer to obtain the fourth image tensor;
将第三图像张量与第四图像张量相加,得到第五图像张量;Add the third image tensor and the fourth image tensor to obtain the fifth image tensor;
将第一文本张量输入至第一全连接层,得到第一参数张量;所述第一参数张量表征第一图片集合中每张图片与对应的文本之间的第一关联强度;Inputting the first text tensor into the first fully connected layer to obtain a first parameter tensor; the first parameter tensor represents the first association strength between each picture in the first picture set and the corresponding text;
将第一文本张量输入至第二全连接层,得到第二参数张量;所述第二参数张量表征第一图片集合中每张图片与对应的文本之间的第二关联强度;Inputting the first text tensor into the second fully connected layer to obtain a second parameter tensor; the second parameter tensor represents the second association strength between each picture in the first picture set and the corresponding text;
将第五图像张量、第一参数张量和第二参数张量输入至归一化层,得到第二图像张量。The fifth image tensor, the first parameter tensor and the second parameter tensor are input to the normalization layer to obtain the second image tensor.
这里,以残差网络包括一个残差块,残差块包括1个残差单元为例进行说明:将第一图像张量输入至卷积网络进行卷积处理,得到第三图像张量;将第一图像张量输入至卷积网络进行卷积处理,得到第四图像张量;将第三图像张量与第四图像张量相加,得到第五图像张量;将第一文本张量输入至第一全连接层,得到第一参数张量

需要说明的是,在残差块包括至少两个残差单元的情况下,残差块中首个残差单元的输入为对应的残差块的输入,非首个残差单元的输入为相连的上一个残差单元中归一化层的输出,最后一个残差块中归一化层的输出作为该残差块的输出。It should be noted that, in the case where the residual block includes at least two residual units, the input of the first residual unit in the residual block is the input of the corresponding residual block, and the input of the non-first residual unit is connected. The output of the normalization layer in the previous residual unit of , and the output of the normalization layer in the last residual block is used as the output of the residual block.
需要说明的是,在残差网络包括一个残差块,且残差块包括1个残差单元的情况下,第二图像向量为残差网络的输出;在残差网络包括至少两个残差块,且残差块包括至少两个残差单元的情况下,第一残差块中最后一个残差单元的输出作为第一残差块的输出,且第一残差块的输出作为相连的第二残差块的输入,最后一个残差块中的最后一个残差单元的输出作为残差网络的输出,即,最后一个残差块中最后一个残差单元输出的图像张量为第二图像张量。It should be noted that in the case where the residual network includes one residual block and the residual block includes one residual unit, the second image vector is the output of the residual network; when the residual network includes at least two residuals block, and the residual block includes at least two residual units, the output of the last residual unit in the first residual block is used as the output of the first residual block, and the output of the first residual block is used as the connected The input of the second residual block, the output of the last residual unit in the last residual block is used as the output of the residual network, that is, the image tensor output by the last residual unit in the last residual block is the second image tensor.
实际应用时,采用以下公式进行批量正则化处理:In practical application, the following formula is used for batch regularization:

其中,













需要说明的是,






在得到第一图像特征向量和第二图像特征向量的情况下,将第一文本特征向量和第一图像特征向量输入至注意力网络,得到第一图片向量,以及将第二文本特征向量和第二图像特征向量输入至注意力网络,得到第二图片向量。其中,在图3中,

电子设备将第一文本特征向量



将

按照求和的方式对第一注意力矩阵和第一图像特征向量进行降维,得到附加了文本注意力的第一图片向量

利用注意力网络按照上述方法对第二文本特征向量和第二图像特征向量进行处理,得到附加了文本注意力的第二图片向量

在得到第一图片向量和第二图片向量的情况下,将第一图片向量和第二图片向量输入至二分类网络,利用二分类网络比较第一图片向量和第二图片向量,得到对应的第一概率。In the case of obtaining the first image vector and the second image vector, input the first image vector and the second image vector into the two-class network, and use the two-class network to compare the first image vector and the second image vector to obtain the corresponding first image vector. a probability.
在一些实施例中,所述将第一图片向量和第二图片向量输入至二分类网络,得到对应的第一概率时,所述方法包括:In some embodiments, when the first picture vector and the second picture vector are input into the binary classification network to obtain the corresponding first probability, the method includes:
将第一图片向量和第二图片向量输入至二分类网络,利用设定的激活函数对第一乘积与第二乘积之间的差值进行归一化处理,得到对应的第一概率;其中,所述第一乘积表征第一权重参数与第一图片向量之间的乘积;所述第二乘积表征第二权重参数与第二图片向量之间的乘积。Input the first picture vector and the second picture vector into the two-class network, and use the set activation function to normalize the difference between the first product and the second product to obtain the corresponding first probability; wherein, The first product represents the product between the first weight parameter and the first picture vector; the second product represents the product between the second weight parameter and the second picture vector.
这里,电子设备将第一图片向量和第二图片向量输入至二分类网络,通过二分类网络计算出第一乘积与第二乘积之间的差值,并利用设定的激活函数对该差值进行归一化处理,得到对应的第一概率。Here, the electronic device inputs the first picture vector and the second picture vector into the two-class network, calculates the difference between the first product and the second product through the two-class network, and uses the set activation function to determine the difference. Perform normalization processing to obtain the corresponding first probability.
实际应用时,在每组样本向量中第一图片排在第二图片之前的情况下,利用公式
需要说明的是,在一些实施例中,在每组样本向量中第二图片排在第一图片之前的情况下,利用公式
步骤102:基于所述至少一组样本向量中每组样本向量对应的第一概率,计算出所述至少一组样本向量中每组样本向量对应的损失值。Step 102: Calculate a loss value corresponding to each group of sample vectors in the at least one group of sample vectors based on the first probability corresponding to each group of sample vectors in the at least one group of sample vectors.
这里,电子设备采用设定的损失函数,基于至少一组样本向量中每组样本向量对应的第一概率,计算出至少一组样本向量中每组样本向量对应的损失值。Here, the electronic device uses a set loss function to calculate a loss value corresponding to each group of sample vectors in the at least one group of sample vectors based on the first probability corresponding to each group of sample vectors in the at least one group of sample vectors.
实际应用时,设定的损失函数为:Li=Relu[1-pi]。Li表征第i组样本向量对应的损失值,pi表征第i组样本向量对应的第一概率。Relu函数为线型函数。In practical application, the set loss function is: Li =Relu [1-pi ]. Li represents the loss value corresponding to theith group of sample vectors, and pi represents the first probability corresponding to theith group of sample vectors. The Relu function is a linear function.
步骤103:根据计算出的损失值更新所述图片分析模型的权重参数。Step 103: Update the weight parameters of the image analysis model according to the calculated loss value.
这里,电子设备可以基于至少一组样本向量中每组样本向量对应的损失值,计算出平均损失值,得到图片分析模型的损失值;根据图片分析模型的损失值更新图片分析模型的权重参数,以提升图片分析模型输出的第一概率的准确度。Here, the electronic device can calculate the average loss value based on the loss value corresponding to each group of sample vectors in the at least one group of sample vectors, and obtain the loss value of the image analysis model; update the weight parameter of the image analysis model according to the loss value of the image analysis model, To improve the accuracy of the first probability output by the image analysis model.
其中,电子设备将图片分析模型的损失值在图片分析模型中进行反向传播,在将损失值反向传播至图片分析模型的各个层的过程中,根据损失值计算出损失函数的梯度,并沿梯度的下降方向更新反向传播到当前层的权重参数。The electronic device backpropagates the loss value of the picture analysis model in the picture analysis model, and in the process of backpropagating the loss value to each layer of the picture analysis model, calculates the gradient of the loss function according to the loss value, and calculates the gradient of the loss function according to the loss value. Update the weight parameters backpropagated to the current layer in the descending direction of the gradient.
电子设备将更新后得到的权重参数,作为训练完毕的图片分析模型所使用的权重参数。The electronic device uses the updated weight parameters as the weight parameters used by the trained image analysis model.
这里,可设定更新停止条件,在满足更新停止条件时,将最后一次更新得到的权重参数,确定为训练完毕的图片分析模型所使用的权重参数。更新停止条件如设定的训练轮次(epoch),一个训练轮次即为根据至少一组样本向量对图片分析模型训练一次的过程。当然,更新停止条件并不限于此,例如还可为设定的平均准确率(mAP,mean AveragePrecision)等。Here, an update stop condition can be set, and when the update stop condition is satisfied, the weight parameter obtained by the last update is determined as the weight parameter used by the trained image analysis model. The update stop condition is a set training epoch, and one training epoch is a process of training the image analysis model once according to at least one set of sample vectors. Of course, the update stop condition is not limited to this, for example, it may also be a set mean Average Precision (mAP, mean Average Precision).
需要说明的是,在实际应用中,通过最小化损失函数来实现模型训练。It should be noted that in practical applications, model training is achieved by minimizing the loss function.
反向传播是相对于前向传播而言的,前向传播是指模型的前馈处理过程,而反向传播的方向与前向传播的方向相反。反向传播指根据模型输出的结果对模型各个层的权重参数进行更新。例如,图片分析模型包括文本处理网络、图像处理网络、注意力网络和二分类网络,则前向传播是指按照文本处理网络和图像处理网络-注意力网络-二分类网络的顺序进行处理,反向传播是指按照二分类网络-注意力网络-图像处理网络和文本处理网络的顺序,依次更新各个层的权重参数。Backpropagation is relative to forward propagation, which refers to the feedforward processing of the model, and the direction of backpropagation is opposite to that of forward propagation. Backpropagation refers to updating the weight parameters of each layer of the model according to the results of the model output. For example, the image analysis model includes a text processing network, an image processing network, an attention network, and a binary classification network. The forward propagation refers to processing in the order of the text processing network and the image processing network-attention network-binary classification network, and the reverse Forward propagation refers to updating the weight parameters of each layer in turn in the order of binary classification network-attention network-image processing network and text processing network.
本实施例提供的方案中,通过至少一组样本向量训练图片分析模型,在训练的过程中,基于至少一组样本向量中每组样本向量对应的第一概率,计算出至少一组样本向量中每组样本向量对应的损失值;根据计算出的损失值更新图片分析模型的权重参数。由于在训练的过程中,每组训练样本基于同一广告位上广告语相同的第一广告和第二广告生成,包括广告语、第一广告使用的第一图片、第一图片使用的第一文本、第二广告使用的第二图片和第二图片使用的第二文本;第一概率表征对应的样本向量中第一图片优于第二图片的概率,第一广告的点击率高于第二广告的点击率,也就是说,每组样本向量对应的广告位和广告语均相同,每组样本向量中不同图片对应的点击率的差异源自图片内容的不同,因此,基于训练后的图片分析模型输出的概率,可以准确地预测出每两张图片中,与广告与匹配,且点击率较高的图片,进而从多张图片中选出广告效果最好的图片投放广告。In the solution provided by this embodiment, the image analysis model is trained by at least one set of sample vectors, and in the training process, based on the first probability corresponding to each set of sample vectors in the at least one set of sample vectors, The loss value corresponding to each group of sample vectors; update the weight parameters of the image analysis model according to the calculated loss value. During the training process, each set of training samples is generated based on the first advertisement and the second advertisement with the same advertisement language in the same advertisement space, including the advertisement language, the first picture used in the first advertisement, and the first text used in the first picture. , the second image used by the second advertisement and the second text used by the second image; the first probability represents the probability that the first image is better than the second image in the corresponding sample vector, and the click rate of the first advertisement is higher than that of the second advertisement The click-through rate of each group of sample vectors is the same, that is to say, the advertising space and advertisement slogan corresponding to each group of sample vectors are the same, and the difference in the click-through rate corresponding to different pictures in each group of sample vectors is due to the difference in the content of the pictures. Therefore, based on the image analysis after training The probability output by the model can accurately predict the image that matches the advertisement and has a high click-through rate in each two images, and then selects the image with the best advertising effect from multiple images to place the advertisement.
如图6所示,在一些实施例中,在训练图片分析模型之前,还需要基于在投广告的广告数据生成样本集。在步骤101之前,所述方法还包括:As shown in FIG. 6 , in some embodiments, before training the image analysis model, a sample set needs to be generated based on the advertisement data of the advertisement being advertised. Before
步骤001:获取广告的广告数据;所述广告数据包括广告位标识、广告语、图片和点击率。Step 001: Acquire advertisement data of an advertisement; the advertisement data includes an advertisement space identifier, an advertisement slogan, a picture and a click-through rate.
这里,电子设备从在投的广告中获取每个广告对应的广告位标识、广告语、图片和点击率。Here, the electronic device acquires the advertisement space identifier, advertisement slogan, picture and click-through rate corresponding to each advertisement from the advertisements being cast.
步骤002:从获取到的广告对应的图片中,确定出广告位标识和广告语均相同的至少一个第二图片集合;每个所述第二图片集合包括对应广告的一张图片。Step 002: From the acquired pictures corresponding to the advertisement, determine at least one second picture set with the same advertisement space identifier and advertisement slogan; each of the second picture sets includes a picture corresponding to the advertisement.
考虑到本申请实施例主要关注图片的广告效果,因此,需要收集同一广告位上广告语相同的不同广告的图片。这里,电子设备基于广告数据中的广告位标识和广告语,对获取到的广告对应的图片进行分类,得到至少一个第二图片集合,每个第二图片集合中的每张图片对应的广告位标识和广告语均相同。Considering that the embodiment of the present application mainly focuses on the advertisement effect of pictures, it is necessary to collect pictures of different advertisements with the same advertisement slogan in the same advertisement space. Here, the electronic device classifies the pictures corresponding to the acquired advertisements based on the advertisement space identifiers and advertisement slogans in the advertisement data, and obtains at least one second picture set, and the advertisement space corresponding to each picture in each second picture set Logos and slogans are the same.
考虑到在训练图片分析模型时,每组样本向量中包括的两张图片对应不同的广告,因此,为了便于生成样本向量,在确定第二图片集合时,第二图片集合中包括对应广告的一张图片。Considering that when training the image analysis model, the two images included in each set of sample vectors correspond to different advertisements, therefore, in order to facilitate the generation of sample vectors, when determining the second image set, the second image set includes one of the corresponding advertisements. picture.
步骤003:基于图片对应的点击率,对每个所述第二图片集合中的图片进行排序,得到对应的第三图片集合。Step 003: Sort the pictures in each of the second picture sets based on the click-through rate corresponding to the pictures to obtain a corresponding third picture set.
实际应用时,将广告位和广告语均相同,且图片不同的广告,作为一个单元组。第j个单元组对应的广告数据可以表示为(Tj,Ij,Vj,Pj),Tj表征广告语,广告语可以为一个字符串;Pj表征广告位标识,Ij表征第j个单元组图片集合,Vj表征Ij中每张图片对应的点击率。
这里,可以先对Vj中每张图片对应的点击率,按照点击率从大到小的顺序排列,由于Ij和Vj中每个元素的下标均表征图片的标识,因此,基于排序后的Vj中每张图片的下标,可以确定出Ij中图片的排列顺序,从而保证同一个单元组的图片,都按照点击率从大到小的顺序排列。Here, the click-through rate corresponding to each picture in Vj can be arranged in descending order of click-through rate. Since the subscripts of each element in Ij and Vj represent the identification of the picture, therefore, based on the sorting The subscript of each picture in Vj can determine the order of pictures in Ij , so as to ensure that pictures in the same unit group are arranged in descending order of click rate.
当然,在一些实施例中,也可以按照同样的方法对Ij和Vj按照点击率从小到大的顺序排列,从而保证同一个单元组的图片都按照点击率从小到大的顺序排列。Of course, in some embodiments, Ij and Vj can also be arranged in the order of click rate from small to large according to the same method, so as to ensure that the pictures in the same unit group are arranged in the order of click rate from small to large.
在






步骤004:基于每个所述第三图片集合中图片的排列顺序和对应的广告语,生成第一样本集合;其中,所述第一样本集合包括所述至少一组样本向量。Step 004: Generate a first sample set based on the arrangement order of the pictures in each of the third picture set and the corresponding advertisement slogan; wherein, the first sample set includes the at least one set of sample vectors.
这里,电子设备基于第三图片集合中图片的排列顺序和对应的广告语,确定出多组图片样本,基于每组图片样本确定出一组样本向量,从而得到第一样本集合。其中,每组图片样本包括广告语和已知相对优劣的两张图片。每组图片样本向量中的两张图片可以按照点击率从大到小的顺序排列,也可以按照点击率从小到大的顺序排列。每组图片样本可以表示为

基于每组图片样本确定出一组样本向量的方法为:分别从每组图片样本中的每张图片中识别出对应的文本,基于每组图片样本和每组图片样本中每张图片对应的文本,确定出一组样本向量。其中,每组样本向量可以表示为










考虑到带有文字说明的图片相对于没有文字说明的图片更能吸引用户的注意力,用于投放广告的图片通常带有文字说明,因此,本实施例中,采用带有文字说明的图片对图片分析模型进行训练。但是,如图7所示,并非所有图片中的文本都有助于图片的广告效果,因此,图片中的文本内容对于理解图片的内容相当重要,基于此,本实施例中,利用图文识别技术从每组图片样本中的每张图片中识别出对应的文本,例如,OCR技术。Considering that pictures with text descriptions can attract users' attention more than pictures without text descriptions, pictures used for advertising usually have text descriptions. Therefore, in this embodiment, pictures with text descriptions are used to The image analysis model is trained. However, as shown in FIG. 7 , not all the texts in the pictures contribute to the advertising effect of the pictures. Therefore, the text content in the pictures is very important for understanding the content of the pictures. Techniques identify corresponding text from each image in each set of image samples, eg, OCR techniques.
在识别图片对应的文本的过程中,将不同位置的文本作为一句话,将识别出的所有语句拼接为一条文本。不同的语句可以用句号分隔。考虑到字体更大的文字更显眼也更重要,而且识别出的文字的准确率也更高,因此,在拼接不同语句时,按照字体从大到小的顺序进行拼接。例如,不同位置的文字分别为“Redmi K40”(大字体)和“以旧换新至高补贴3000元E卡”(小字体),拼接后的文本为:“Redmi K40。以旧换新至高补贴3000元E卡”。In the process of recognizing the text corresponding to the picture, the texts in different positions are regarded as one sentence, and all the recognized sentences are spliced into one text. Different statements can be separated by periods. Considering that the text with a larger font is more conspicuous and more important, and the recognized text has a higher accuracy rate, therefore, when splicing different sentences, splicing is performed according to the order of the font from the largest to the smallest. For example, the texts in different positions are "Redmi K40" (large font) and "trade-in to high subsidy 3,000 yuan E-card" (small font), and the spliced text is: "Redmi K40. Trade-in to high subsidy 3,000 yuan E card".
实际应用时可以针对文本长度设置最大阈值,在从图片中识别出的文本长度大于最大阈值d的情况下,在生成每组样本向量之前,需要对识别出的文本进行裁剪。其中,考虑到图片中字体较大的文本相对比较重要,因此,为了避免重要信息被裁减调,可以按照字符从小到大的顺序,对识别出的文本进行裁剪。在对应的图片中包括多条文本的情况下,对识别出的多条文本按照字体从大到小的顺序进行排序;在识别出的文本对应的字符总长度大于d的情况下,基于设定字符长度,对排序后的多条文本,按照由后向前的顺序进行裁剪。In practical applications, a maximum threshold can be set for the text length. When the length of the text identified from the picture is greater than the maximum threshold d, the identified text needs to be cropped before each set of sample vectors is generated. Among them, considering that the text with a larger font in the picture is relatively important, in order to avoid the important information from being trimmed and adjusted, the recognized text can be trimmed in the order of characters from small to large. When the corresponding picture includes multiple texts, sort the identified multiple texts in descending order of font size; when the total length of the characters corresponding to the identified texts is greater than d, based on the setting Character length, the sorted multiple texts are trimmed in the order from back to front.
需要说明的是,考虑到可能相同的图片出现在不同的单元组中。例如,一张运动鞋图片(图片1)、一张高跟鞋图片(图片2),如果广告语是“减震透气,清爽一夏”那么显然图片1更适合;而如果广告语是“最新款式,衬托腿形”则是图片2更适合。因此,为了获得与广告语匹配的图片,确定出的每组图片样本不仅包含图片,还包含广告语。It should be noted that it is considered that the same picture may appear in different unit groups. For example, a picture of sports shoes (picture 1) and a picture of high-heeled shoes (picture 2), if the slogan is "shock absorption and breathable, refreshing for a summer", then obviously picture 1 is more suitable; and if the slogan is "the latest style, Set off the leg shape" is the picture 2 is more suitable. Therefore, in order to obtain a picture matching the advertisement slogan, each group of image samples determined not only includes the picture, but also includes the advertisement slogan.
实际应用时,本实施例中,所有图片的宽均为W,高均为H。其中,W和H可以根据广告位允许的图片尺寸的最大值进行设置。在图片的宽不等于W和/或高不等于H的情况下,基于双线性插值算法对图片进行拉伸或缩减,从而使得处理后的图片的宽为W,高为H。In practical application, in this embodiment, the width of all pictures is W and the height is H. Among them, W and H can be set according to the maximum image size allowed by the advertising space. When the width of the picture is not equal to W and/or the height is not equal to H, the picture is stretched or reduced based on the bilinear interpolation algorithm, so that the width of the processed picture is W and the height is H.
需要说明的是,W、H和d的值越大,基于至少一组样本向量训练得到的图片分析模型的效果越好,但是,相应地训练时长也越长,因此,需要兼顾图片分析模型的效果和训练时长,选择合适的W、H和d。实际应用时,W和H可以均为546,d可以为64。It should be noted that the larger the values of W, H, and d, the better the effect of the image analysis model trained based on at least one set of sample vectors. However, the corresponding training time is longer. Therefore, it is necessary to take into account the image analysis model. Select the appropriate W, H and d for the effect and training duration. In practical application, both W and H can be 546, and d can be 64.
需要说明的是,在实际应用中,执行步骤001至步骤004的电子设备,与执行步骤101至步骤103的电子设备可以相同,也可以不同。It should be noted that, in practical applications, the electronic device that executes
作为本申请的另一实施例,在图片分析模型训练完毕后,即可将图片分析模型投入使用。例如,在选择广告图片的场景中,电子设备可以采用通过上述实施例训练得到的图片分析模型对待投放广告对应的候选图片进行分析,以选出广告效果最好的图片。需要说明的是,训练图片分析模型对应的实施例中的电子设备,与本实施例中采用图片分析模型选择广告图片的电子设备可以不同。As another embodiment of the present application, after the image analysis model is trained, the image analysis model can be put into use. For example, in the scenario of selecting an advertisement image, the electronic device may use the image analysis model trained in the above embodiment to analyze candidate images corresponding to the advertisement to be placed, so as to select the image with the best advertisement effect. It should be noted that the electronic device in the embodiment corresponding to the training image analysis model may be different from the electronic device in this embodiment that uses the image analysis model to select advertisement images.
参照图8,电子设备采用训练完毕后的图片分析模型选择广告图片的实现过程如下:Referring to FIG. 8 , the implementation process for the electronic device to select an advertisement image by using the image analysis model after training is as follows:
步骤801:基于第一广告语、每两张候选图片和对应的文本信息,生成多张候选图片对应的至少一组第一向量。Step 801 : Based on the first advertisement slogan, each two candidate pictures and the corresponding text information, generate at least one set of first vectors corresponding to the plurality of candidate pictures.
这里,电子设备获取待投放的广告的第一广告语和多张候选图片,利用OCR技术从候选图片中识别出对应的文本信息,基于第一广告语、每两张候选图片和对应的文本信息,生成多张候选图片对应的至少一组第一向量。Here, the electronic device obtains the first advertisement slogan and multiple candidate pictures of the advertisement to be placed, and uses the OCR technology to identify the corresponding text information from the candidate pictures. Based on the first advertisement slogan, each two candidate pictures and the corresponding text information , and generate at least one set of first vectors corresponding to the multiple candidate pictures.
示例性地,当前待投放的广告的第一广告语为τ,有n张候选图片为依次为:v0,v1,v2…vn-1;利用OCR技术对每张候选图片进行处理,提取出对应的文本信息为t0,t1,t2…tn-1;基于τ、每两张候选图片和对应的文本信息,生成n张候选图片对应的多组第一向量,每组第一向量可以表示为(τ,vi,ti,vg,tg)。其中,i和g均为小于n的正整数。Exemplarily, the first advertisement slogan of the advertisement to be placed at present is τ, and there are n candidate pictures in sequence: v0 , v1 , v2 ... vn-1 ; each candidate picture is processed by using OCR technology , and extract the corresponding text information as t0 , t1 , t2 ... tn-1 ; based on τ, each two candidate pictures and the corresponding text information, generate multiple sets of first vectors corresponding to n candidate pictures, each The first vector of the group can be represented as (τ,vi ,ti ,vg ,tg ). Among them, i and g are both positive integers less than n.
需要说明的是,在从候选图片中识别出的文本信息的长度大于设定的最大文本长度的情况下,基于设定的最大文本长度,对识别出的文本信息进行裁剪,裁剪方法请参照上文中的相关描述,此处不赘述。It should be noted that when the length of the text information identified from the candidate picture is greater than the set maximum text length, the identified text information is cropped based on the set maximum text length. For the cropping method, please refer to the above. The relevant descriptions in the text will not be repeated here.
每组第一向量包括第一广告语、第一候选图片、第一候选图片使用的第一文本信息、第二候选图片、第二候选图片使用的第二文本信息。Each set of first vectors includes a first advertisement slogan, a first candidate image, first text information used by the first candidate image, a second candidate image, and second text information used by the second candidate image.
步骤802:将生成的每组第一向量输入至第一模型,得到每组第一向量对应的第二概率;其中,所述第一模型为采用上述任一种图片分析模型训练方法训练得到的图片分析模型;所述第二概率表征第一候选图片优于第二候选图片的概率;所述第一候选图片在所述第二候选图片之前。Step 802: Input each group of the first vectors generated into the first model, and obtain the second probability corresponding to each group of the first vectors; wherein, the first model is obtained by training using any of the above-mentioned image analysis model training methods. A picture analysis model; the second probability represents the probability that the first candidate picture is better than the second candidate picture; the first candidate picture precedes the second candidate picture.
这里,第一模型对每组第一向量的处理过程与上文图片分析模型对每组样本向量进行处理的方法类似,此处不赘述。Here, the process of processing each group of first vectors by the first model is similar to the above-mentioned method of processing each group of sample vectors by the image analysis model, and details are not described here.
步骤803:基于每组第一向量对应的图片排列顺序,以及每组第一向量对应的第二概率,从所述多张候选图片中确定出广告图片。Step 803: Determine an advertisement image from the plurality of candidate images based on the sequence of pictures corresponding to each set of first vectors and the second probability corresponding to each set of first vectors.
这里,电子设备基于每组第一向量对应的图片排列顺序,以及每组第一向量对应的第二概率,从多张候选图片中确定出最优的候选图片,得到广告图片。Here, the electronic device determines the optimal candidate picture from the plurality of candidate pictures based on the arrangement order of pictures corresponding to each group of first vectors and the second probability corresponding to each group of first vectors to obtain the advertisement picture.
其中,在多张候选图片的数量为n的情况下,需要进行n-1轮比较,才能从多张候选图片中确定出最优的候选图片。Wherein, when the number of multiple candidate pictures is n, n-1 rounds of comparisons are required to determine the optimal candidate picture from the multiple candidate pictures.
实际应用时,在第一向量(τ,vi,ti,vg,tg)对应的第二概率为1的情况下,表征vi优于vg。In practical application, in the case that the second probability corresponding to the first vector (τ, vi , ti , vg , tg ) is 1, the representation vi is better than vg .
在实施例中,电子设备基于第一广告语、每两张候选图片和对应的文本信息,生成多张候选图片对应的至少一组第一向量;将生成的每组第一向量输入至第一模型,得到每组第一向量对应的第二概率;基于每组第一向量对应的第二概率,从所述多张候选图片中确定出广告图片。由于,第二概率表征第一候选图片优于第二候选图片的概率;所述第一候选图片在所述第二候选图片之前,因此,电子设备可以基于每组第一向量对应的图片排列顺序,以及每组第一向量对应的第二概率,从多张候选图片中确定出最优的候选图片,从而将最优的候选图片投放广告。In an embodiment, the electronic device generates at least one set of first vectors corresponding to multiple candidate pictures based on the first advertisement slogan, each two candidate pictures and corresponding text information; and inputs each generated set of first vectors into the first vector model to obtain a second probability corresponding to each set of first vectors; and based on the second probability corresponding to each set of first vectors, determine an advertisement image from the plurality of candidate images. Because the second probability represents the probability that the first candidate picture is better than the second candidate picture; the first candidate picture is before the second candidate picture, therefore, the electronic device can be based on the picture arrangement order corresponding to each set of first vectors , and the second probability corresponding to each set of first vectors, the optimal candidate image is determined from the multiple candidate images, so that the optimal candidate image is placed in the advertisement.
图9为本申请实施例提供的广告图片选择方法的示意图,图10为本申请实施例提供的广告图片选择方法的实现流程示意图,如图10所示,广告图片选择方法包括:FIG. 9 is a schematic diagram of a method for selecting an advertisement image provided by an embodiment of the present application, and FIG. 10 is a schematic diagram of an implementation flow of the method for selecting an advertisement image provided by an embodiment of the present application. As shown in FIG. 10 , the method for selecting an advertisement image includes:
步骤901:获取广告的广告数据;所述广告数据包括广告位标识、广告语、图片和点击率。Step 901: Acquire advertisement data of an advertisement; the advertisement data includes an advertisement space identifier, an advertisement slogan, a picture and a click-through rate.
步骤902:从获取到的广告对应的图片中,确定出广告位标识和广告语均相同的至少一个第二图片集合;每个所述第二图片集合包括对应广告的一张图片。Step 902 : From the acquired pictures corresponding to the advertisement, determine at least one second picture set with the same advertisement slot ID and advertisement slogan; each of the second picture sets includes a picture corresponding to the advertisement.
其中,图9中的采样器用于确定出同一广告位上广告语相同的不同广告的广告数据。Wherein, the sampler in FIG. 9 is used to determine advertisement data of different advertisements with the same advertisement language in the same advertisement space.
步骤903:基于图片对应的点击率,对每个所述第二图片集合中的图片进行排序,得到对应的第三图片集合。Step 903: Based on the click-through rate corresponding to the pictures, sort the pictures in each of the second picture sets to obtain a corresponding third picture set.
步骤904:基于每个所述第三图片集合中图片的排列顺序和对应的广告语,生成第一样本集合;其中,所述第一样本集合包括所述至少一组样本向量。Step 904: Generate a first sample set based on the arrangement order of the pictures in each of the third picture set and the corresponding advertisement slogan; wherein, the first sample set includes the at least one set of sample vectors.
步骤905:对第一样本集合中的样本进行随机混排,从第一样本集合中取出至少一组样本向量。Step 905: Randomly shuffle the samples in the first sample set, and extract at least one set of sample vectors from the first sample set.
这里,电子设备从第一样本集中按顺序取出至少一组第一样本向量。Here, the electronic device sequentially takes out at least one set of first sample vectors from the first sample set.
为了避免图片分析模型过拟合,在每次训练前,对第一样本集中的每组样本进行随机混排,从混排后的样本集中取出至少一组样本向量。In order to avoid overfitting of the image analysis model, before each training, random shuffle is performed on each group of samples in the first sample set, and at least one set of sample vectors is taken from the shuffled sample set.
其中,可以利用tensorflow的tensorflow.random.shuffle函数,对样本进行混排,从而实现数据随机化,从而避免过拟合。Among them, the tensorflow.random.shuffle function of tensorflow can be used to shuffle the samples to randomize the data and avoid overfitting.
步骤906:将至少一组样本向量输入至图片分析模型,得到每组样本向量对应的第一概率。Step 906: Input at least one set of sample vectors into the image analysis model to obtain a first probability corresponding to each set of sample vectors.
步骤907:基于所述至少一组样本向量中每组样本向量对应的第一概率,计算出所述至少一组样本向量中每组样本向量对应的损失值。Step 907: Calculate a loss value corresponding to each group of sample vectors in the at least one group of sample vectors based on the first probability corresponding to each group of sample vectors in the at least one group of sample vectors.
步骤908:根据计算出的损失值更新所述图片分析模型的权重参数。Step 908: Update the weight parameters of the image analysis model according to the calculated loss value.
步骤909:输出训练后的图片分析模型,得到第一模型。Step 909: Output the trained image analysis model to obtain a first model.
步骤910:获取待投放广告对应的第一广告语和多张候选图片。Step 910: Obtain the first advertisement slogan and a plurality of candidate pictures corresponding to the advertisement to be placed.
步骤911:识别出多张候选图片中每张候选图片使用的文本信息。Step 911: Identify the text information used by each candidate picture in the plurality of candidate pictures.
步骤912:基于第一广告语、每两张候选图片和对应的文本信息,生成多张候选图片对应的至少一组第一向量。Step 912 : Based on the first advertisement slogan, each two candidate pictures and the corresponding text information, generate at least one set of first vectors corresponding to the plurality of candidate pictures.
步骤913:将生成的每组第一向量输入至第一模型,得到每组第一向量对应的第二概率;所述第二概率表征第一候选图片优于第二候选图片的概率;所述第一候选图片在所述第二候选图片之前。Step 913: Input each generated set of first vectors into the first model to obtain a second probability corresponding to each set of first vectors; the second probability represents the probability that the first candidate picture is better than the second candidate picture; the The first candidate picture precedes the second candidate picture.
步骤914:基于每组第一向量对应的图片排列顺序,以及每组第一向量对应的第二概率,从所述多张候选图片中确定出广告图片。Step 914 : Determine an advertisement picture from the plurality of candidate pictures based on the arrangement order of pictures corresponding to each group of first vectors and the second probability corresponding to each group of first vectors.
步骤915:基于第一广告语和确定出的广告图片,生成图文广告。Step 915: Generate a graphic advertisement based on the first advertisement slogan and the determined advertisement image.
为实现本申请实施例的图片分析模型训练方法,本申请实施例还提供了一种电子设备,如图11所示,该电子设备包括:In order to implement the image analysis model training method of the embodiment of the present application, the embodiment of the present application further provides an electronic device, as shown in FIG. 11 , the electronic device includes:
训练单元1101,用于将至少一组样本向量输入至图片分析模型,得到每组样本向量对应的第一概率;其中,每组样本向量基于同一广告位上广告语相同的第一广告和第二广告生成,包括广告语、第一广告使用的第一图片、第一图片使用的第一文本、第二广告使用的第二图片和第二图片使用的第二文本;所述第一概率表征对应的样本向量中第一图片优于第二图片的概率;所述第一广告的点击率高于所述第二广告的点击率;The
计算单元1102,用于基于所述至少一组样本向量中每组样本向量对应的第一概率,计算出所述至少一组样本向量中每组样本向量对应的损失值;a
更新单元1103,用于根据计算出的损失值更新所述图片分析模型的权重参数。The
在一些实施例中,所述图片分析模型包括文本处理网络、图像处理网络、注意力网络和二分类网络;训练单元1101具体用于:In some embodiments, the picture analysis model includes a text processing network, an image processing network, an attention network and a binary classification network; the
将广告语、第一文本和第二文本输入至文本处理网络,得到第一全局特征向量、第二全局特征向量、第一文本特征向量和第二文本特征向量;其中,第一全局特征向量表征广告语和第一文本的全局特征,第二全局特征向量表征广告语和第二文本的全局特征,第一文本特征向量基于第一全局特征向量得到,第二文本特征向量基于第二全局特征向量得到;Input the advertisement slogan, the first text and the second text into the text processing network to obtain the first global feature vector, the second global feature vector, the first text feature vector and the second text feature vector; wherein, the first global feature vector represents the The global feature of the advertisement slogan and the first text, the second global feature vector represents the global feature of the advertisement slogan and the second text, the first text feature vector is obtained based on the first global feature vector, and the second text feature vector is based on the second global feature vector. get;
将第一图片和第一全局特征向量输入至图像处理网络,得到第一图像特征向量,以及将第二图片和第二全局特征向量输入至图像处理网络,得到第二图像特征向量;Inputting the first picture and the first global feature vector to the image processing network to obtain the first image feature vector, and inputting the second picture and the second global feature vector to the image processing network to obtain the second image feature vector;
将第一文本特征向量和第一图像特征向量输入至注意力网络,得到第一图片向量,以及将第二文本特征向量和第二图像特征向量输入至注意力网络,得到第二图片向量;Input the first text feature vector and the first image feature vector to the attention network to obtain the first picture vector, and input the second text feature vector and the second image feature vector to the attention network to obtain the second picture vector;
将第一图片向量和第二图片向量输入至二分类网络,得到对应的第一概率。Input the first image vector and the second image vector into the binary classification network to obtain the corresponding first probability.
在一些实施例中,所述文本处理网络包括文本编码器和前馈神经网络;训练单元1101具体用于:In some embodiments, the text processing network includes a text encoder and a feedforward neural network; the
将广告语和第一文本拼接,得到第一语句,以及将广告语和第二文本拼接,得到第二语句;Splicing the advertisement slogan and the first text to obtain the first sentence, and splicing the advertisement slogan and the second text to obtain the second sentence;
将第一语句和第二语句输入至文本编码器,得到第一全局特征向量和第二全局特征向量;Inputting the first sentence and the second sentence into the text encoder to obtain the first global feature vector and the second global feature vector;
将第一全局特征向量和第二全局特征向量输入至前馈神经网络,得到第一文本特征向量和第二文本特征向量。The first global feature vector and the second global feature vector are input to the feedforward neural network to obtain the first text feature vector and the second text feature vector.
在一些实施例中,所述图像处理网络包括卷积层、残差网络和全连接层;训练单元1101具体用于:In some embodiments, the image processing network includes a convolutional layer, a residual network and a fully connected layer; the
将第一图片集合输入至卷积层,得到第一图像张量;所述第一图片集合由所述至少一组样本向量中的所有第一图片或所有第二图片构成;Inputting the first picture set to the convolution layer to obtain a first image tensor; the first picture set is composed of all the first pictures or all the second pictures in the at least one group of sample vectors;
将第一图像张量和第一文本张量输入至残差网络,得到第二图像张量;所述第一文本张量由所有第一全局特征向量或所有第二全局特征向量生成;Input the first image tensor and the first text tensor into the residual network to obtain the second image tensor; the first text tensor is generated by all the first global feature vectors or all the second global feature vectors;
将第二图像张量输入至全连接层,得到第一图片集合中每张图片对应的图像特征向量;其中,所述图像特征向量为第一图像特征向量或第二图像特征向量。The second image tensor is input to the fully connected layer to obtain an image feature vector corresponding to each image in the first image set; wherein, the image feature vector is the first image feature vector or the second image feature vector.
在一些实施例中,所述残差网络包括至少一个残差块,每个残差块包括至少一个残差单元,每个残差单元包括卷积网络、第一卷积层、第一全连接层、第二全连接层和归一化层;训练单元1101具体用于:In some embodiments, the residual network includes at least one residual block, each residual block includes at least one residual unit, and each residual unit includes a convolutional network, a first convolutional layer, a first fully connected layer, the second fully connected layer and the normalization layer; the
将第一图像张量输入至卷积网络,得到第三图像张量;Input the first image tensor to the convolutional network to obtain the third image tensor;
将第一图像张量输入至第一卷积层,得到第四图像张量;Input the first image tensor to the first convolutional layer to obtain the fourth image tensor;
将第三图像张量与第四图像张量相加,得到第五图像张量;Add the third image tensor and the fourth image tensor to obtain the fifth image tensor;
将第一文本张量输入至第一全连接层,得到第一参数张量;所述第一参数张量表征第一图片集合中每张图片与对应的文本之间的第一关联强度;Inputting the first text tensor into the first fully connected layer to obtain a first parameter tensor; the first parameter tensor represents the first association strength between each picture in the first picture set and the corresponding text;
将第一文本张量输入至第二全连接层,得到第二参数张量;所述第二参数张量表征第一图片集合中每张图片与对应的文本之间的第二关联强度;Inputting the first text tensor into the second fully connected layer to obtain a second parameter tensor; the second parameter tensor represents the second association strength between each picture in the first picture set and the corresponding text;
将第五图像张量、第一参数张量和第二参数张量输入至归一化层,得到第二图像张量。The fifth image tensor, the first parameter tensor and the second parameter tensor are input to the normalization layer to obtain the second image tensor.
在一些实施例中,训练单元1101具体用于:In some embodiments, the
将第一图片向量和第二图片向量输入至二分类网络,利用设定的激活函数对第一乘积与第二乘积之间的差值进行归一化处理,得到对应的第一概率;其中,所述第一乘积表征第一权重参数与第一图片向量之间的乘积;所述第二乘积表征第二权重参数与第二图片向量之间的乘积。Input the first picture vector and the second picture vector into the two-class network, and use the set activation function to normalize the difference between the first product and the second product to obtain the corresponding first probability; wherein, The first product represents the product between the first weight parameter and the first picture vector; the second product represents the product between the second weight parameter and the second picture vector.
在一些实施例中,该电子设备还包括:In some embodiments, the electronic device further includes:
获取单元,用于获取广告的广告数据;所述广告数据包括广告位标识、广告语、图片和点击率;an acquisition unit for acquiring advertisement data of an advertisement; the advertisement data includes an advertisement space identifier, an advertisement slogan, a picture and a click-through rate;
确定单元,用于从获取到的广告对应的图片中,确定出广告位标识和广告语均相同的至少一个第二图片集合;每个所述第二图片集合包括对应广告的一张图片;a determining unit, configured to determine at least one second picture set with the same advertising space identifier and advertisement slogan from the obtained pictures corresponding to the advertisement; each of the second picture sets includes a picture corresponding to the advertisement;
排序单元,用于基于图片对应的点击率,对每个所述第二图片集合中的图片进行排序,得到对应的第三图片集合;a sorting unit, configured to sort the pictures in each of the second picture sets based on the click-through rate corresponding to the pictures to obtain a corresponding third picture set;
生成单元,用于基于每个所述第三图片集合中图片的排列顺序和对应的广告语,生成第一样本集合;其中,所述第一样本集合包括所述至少一组样本向量。A generating unit, configured to generate a first sample set based on the arrangement order of the pictures in each of the third picture sets and the corresponding advertisement slogan; wherein, the first sample set includes the at least one set of sample vectors.
实际应用时,电子设备包括的各单元,可由电子设备中的处理器来实现。当然,处理器需要运行存储器中存储的程序来实现上述各程序模块的功能。In practical application, each unit included in the electronic device may be implemented by a processor in the electronic device. Of course, the processor needs to run the program stored in the memory to realize the functions of the above program modules.
需要说明的是:上述实施例提供的电子设备在训练图片分析模型时,仅以上述各程序模块的划分进行举例说明,实际应用中,可以根据需要而将上述处理分配由不同的程序模块完成,即将电子设备的内部结构划分成不同的程序模块,以完成以上描述的全部或者部分处理。另外,上述实施例提供的电子设备与图片分析模型训练方法实施例属于同一构思,其具体实现过程详见方法实施例,这里不再赘述。It should be noted that when the electronic device provided in the above-mentioned embodiment trains the image analysis model, only the division of the above-mentioned program modules is used as an example to illustrate. That is, the internal structure of the electronic device is divided into different program modules to complete all or part of the processing described above. In addition, the electronic device provided by the above embodiments and the image analysis model training method embodiments belong to the same concept, and the specific implementation process thereof is detailed in the method embodiments, which will not be repeated here.
为实现本申请实施例的广告图片选择方法,本申请实施例还提供了一种电子设备,如图12所示,该电子设备包括:In order to implement the method for selecting an advertisement image in the embodiment of the present application, the embodiment of the present application further provides an electronic device, as shown in FIG. 12 , the electronic device includes:
生成单元1201,用于基于第一广告语、每两张候选图片和对应的文本信息,生成多张候选图片对应的至少一组第一向量;
处理单元1202,用于将生成的每组第一向量输入至第一模型,得到每组第一向量对应的第二概率;a
确定单元1203,用于基于每组第一向量对应的图片排列顺序,以及每组第一向量对应的第二概率,从所述多张候选图片中确定出广告图片;其中,A determining
所述第一模型为采用如权利要求1至7任一项所述的图片分析模型训练方法训练得到的图片分析模型;所述第二概率表征第一候选图片优于第二候选图片的概率;所述第一候选图片在所述第二候选图片之前。The first model is an image analysis model trained by the image analysis model training method according to any one of
实际应用时,电子设备包括的各单元,可由电子设备中的处理器来实现。当然,处理器需要运行存储器中存储的程序来实现上述各程序模块的功能。In practical application, each unit included in the electronic device may be implemented by a processor in the electronic device. Of course, the processor needs to run the program stored in the memory to realize the functions of the above program modules.
需要说明的是:上述实施例提供的电子设备在选择广告图片时,仅以上述各程序模块的划分进行举例说明,实际应用中,可以根据需要而将上述处理分配由不同的程序模块完成,即将电子设备的内部结构划分成不同的程序模块,以完成以上描述的全部或者部分处理。另外,上述实施例提供的电子设备与广告图片选择方法实施例属于同一构思,其具体实现过程详见方法实施例,这里不再赘述。It should be noted that: when the electronic device provided in the above embodiment selects an advertisement image, only the division of the above program modules is used as an example. The internal structure of the electronic device is divided into different program modules to complete all or part of the processes described above. In addition, the electronic device provided by the above embodiments and the embodiment of the advertisement image selection method belong to the same concept, and the specific implementation process is detailed in the method embodiment, which will not be repeated here.
基于上述程序模块的硬件实现,且为了实现本申请实施例的方法,本申请实施例还提供了一种电子设备。图13为本申请实施例电子设备的硬件组成结构示意图,如图13所示,电子设备包括:Based on the hardware implementation of the above program modules, and in order to implement the method of the embodiment of the present application, the embodiment of the present application further provides an electronic device. FIG. 13 is a schematic diagram of a hardware structure of an electronic device according to an embodiment of the present application. As shown in FIG. 13 , the electronic device includes:
通信接口110,能够与其它设备比如网络设备等进行信息交互;A
处理器120,与通信接口110连接,以实现与其它设备进行信息交互,用于运行计算机程序时,执行上述一个或多个技术方案提供的图片分析模型训练方法,和/或,广告图片选择方法。而所述计算机程序存储在存储器130上。The
当然,实际应用时,电子设备中的各个组件通过总线系统140耦合在一起。可理解,总线系统140用于实现这些组件之间的连接通信。总线系统140除包括数据总线之外,还包括电源总线、控制总线和状态信号总线。但是为了清楚说明起见,在图13中将各种总线都标为总线系统140。Of course, in practical applications, various components in the electronic device are coupled together through the bus system 140 . It can be understood that the bus system 140 is used to implement the connection communication between these components. In addition to the data bus, the bus system 140 also includes a power bus, a control bus, and a status signal bus. However, for clarity of illustration, the various buses are labeled as bus system 140 in FIG. 13 .
本申请实施例中的存储器130用于存储各种类型的数据以支持电子设备的操作。这些数据的示例包括:用于在电子设备上操作的任何计算机程序。The
可以理解,存储器130可以是易失性存储器或非易失性存储器,也可包括易失性和非易失性存储器两者。其中,非易失性存储器可以是只读存储器(ROM,Read Only Memory)、可编程只读存储器(PROM,Programmable Read-Only Memory)、可擦除可编程只读存储器(EPROM,Erasable Programmable Read-Only Memory)、电可擦除可编程只读存储器(EEPROM,Electrically Erasable Programmable Read-Only Memory)、磁性随机存取存储器(FRAM,ferromagnetic random access memory)、快闪存储器(Flash Memory)、磁表面存储器、光盘、或只读光盘(CD-ROM,Compact Disc Read-Only Memory);磁表面存储器可以是磁盘存储器或磁带存储器。易失性存储器可以是随机存取存储器(RAM,Random AccessMemory),其用作外部高速缓存。通过示例性但不是限制性说明,许多形式的RAM可用,例如静态随机存取存储器(SRAM,Static Random Access Memory)、同步静态随机存取存储器(SSRAM,Synchronous Static Random Access Memory)、动态随机存取存储器(DRAM,Dynamic Random Access Memory)、同步动态随机存取存储器(SDRAM,SynchronousDynamic Random Access Memory)、双倍数据速率同步动态随机存取存储器(DDRSDRAM,Double Data Rate Synchronous Dynamic Random Access Memory)、增强型同步动态随机存取存储器(ESDRAM,Enhanced Synchronous Dynamic Random Access Memory)、同步连接动态随机存取存储器(SLDRAM,Sync Link Dynamic Random Access Memory)、直接内存总线随机存取存储器(DRRAM,Direct Rambus Random Access Memory)。本申请实施例描述的存储器130旨在包括但不限于这些和任意其它适合类型的存储器。It is to be understood that the
上述本申请实施例揭示的方法可以应用于处理器120中,或者由处理器120实现。处理器120可能是一种集成电路芯片,具有信号的处理能力。在实现过程中,上述方法的各步骤可以通过处理器120中的硬件的集成逻辑电路或者软件形式的指令完成。上述的处理器120可以是通用处理器、DSP,或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。处理器120可以实现或者执行本申请实施例中的公开的各方法、步骤及逻辑框图。通用处理器可以是微处理器或者任何常规的处理器等。结合本申请实施例所公开的方法的步骤,可以直接体现为硬件译码处理器执行完成,或者用译码处理器中的硬件及软件模块组合执行完成。软件模块可以位于存储介质中,该存储介质位于存储器130,处理器120读取存储器130中的程序,结合其硬件完成前述方法的步骤。The methods disclosed in the above embodiments of the present application may be applied to the
处理器120执行所述程序时实现本申请实施例的各个方法中的相应流程,为了简洁,在此不再赘述。When the
在示例性实施例中,本申请实施例还提供了一种存储介质,即计算机存储介质,具体为计算机可读存储介质,例如包括存储计算机程序的存储器130,上述计算机程序可由处理器120执行,以完成前述方法所述步骤。计算机可读存储介质可以是FRAM、ROM、PROM、EPROM、EEPROM、Flash Memory、磁表面存储器、光盘、或CD-ROM等存储器。In an exemplary embodiment, an embodiment of the present application further provides a storage medium, that is, a computer storage medium, specifically a computer-readable storage medium, for example, including a
在本申请所提供的几个实施例中,应该理解到,所揭露的设备和方法,可以通过其它的方式实现。以上所描述的设备实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,如:多个单元或组件可以结合,或可以集成到另一个系统,或一些特征可以忽略,或不执行。另外,所显示或讨论的各组成部分相互之间的耦合、或直接耦合、或通信连接可以是通过一些接口,设备或单元的间接耦合或通信连接,可以是电性的、机械的或其它形式的。In the several embodiments provided in this application, it should be understood that the disclosed apparatus and method may be implemented in other manners. The device embodiments described above are only illustrative. For example, the division of the units is only a logical function division. In actual implementation, there may be other division methods. For example, multiple units or components may be combined, or Can be integrated into another system, or some features can be ignored, or not implemented. In addition, the coupling, or direct coupling, or communication connection between the components shown or discussed may be through some interfaces, and the indirect coupling or communication connection of devices or units may be electrical, mechanical or other forms. of.
上述作为分离部件说明的单元可以是、或也可以不是物理上分开的,作为单元显示的部件可以是、或也可以不是物理单元,即可以位于一个地方,也可以分布到多个网络单元上;可以根据实际的需要选择其中的部分或全部单元来实现本实施例方案的目的。The unit described above as a separate component may or may not be physically separated, and the component displayed as a unit may or may not be a physical unit, that is, it may be located in one place or distributed to multiple network units; Some or all of the units may be selected according to actual needs to achieve the purpose of the solution in this embodiment.
另外,在本申请各实施例中的各功能单元可以全部集成在一个处理模块中,也可以是各单元分别单独作为一个单元,也可以两个或两个以上单元集成在一个单元中;上述集成的单元既可以采用硬件的形式实现,也可以采用硬件加软件功能单元的形式实现。In addition, each functional unit in each embodiment of the present application may all be integrated into one processing module, or each unit may be separately used as a unit, or two or more units may be integrated into one unit; the above integration The unit can be implemented either in the form of hardware or in the form of hardware plus software functional units.
本领域普通技术人员可以理解:实现上述方法实施例的全部或部分步骤可以通过程序指令相关的硬件来完成,前述的程序可以存储于一计算机可读取存储介质中,该程序在执行时,执行包括上述方法实施例的步骤;而前述的存储介质包括:移动存储设备、只读存储器(ROM,Read-Only Memory)、随机存取存储器(RAM,Random Access Memory)、磁碟或者光盘等各种可以存储程序代码的介质。Those of ordinary skill in the art can understand that all or part of the steps of implementing the above method embodiments can be completed by program instructions related to hardware, the aforementioned program can be stored in a computer-readable storage medium, and when the program is executed, execute Including the steps of the above-mentioned method embodiment; and the aforementioned storage medium includes: a mobile storage device, a read-only memory (ROM, Read-Only Memory), a random access memory (RAM, Random Access Memory), a magnetic disk or an optical disk and other various A medium on which program code can be stored.
需要说明的是,本申请实施例所记载的技术方案之间,在不冲突的情况下,可以任意组合。It should be noted that the technical solutions described in the embodiments of the present application may be combined arbitrarily unless there is a conflict.
以上所述,仅为本申请的具体实施方式,但本申请的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应以所述权利要求的保护范围为准。The above are only specific embodiments of the present application, but the protection scope of the present application is not limited to this. should be covered within the scope of protection of this application. Therefore, the protection scope of the present application should be subject to the protection scope of the claims.
Claims (12)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111124141.0ACN113869392A (en) | 2021-09-24 | 2021-09-24 | Picture analysis model training method, advertisement picture selection method and electronic equipment |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111124141.0ACN113869392A (en) | 2021-09-24 | 2021-09-24 | Picture analysis model training method, advertisement picture selection method and electronic equipment |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN113869392Atrue CN113869392A (en) | 2021-12-31 |
Family
ID=78994050
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202111124141.0APendingCN113869392A (en) | 2021-09-24 | 2021-09-24 | Picture analysis model training method, advertisement picture selection method and electronic equipment |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN113869392A (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2025167339A1 (en)* | 2024-02-06 | 2025-08-14 | 北京字跳网络技术有限公司 | Product advertisement image generation method and apparatus, device, storage medium, and program product |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110287343A (en)* | 2019-06-10 | 2019-09-27 | 北京深演智能科技股份有限公司 | Picture Generation Method and device |
| CN110457523A (en)* | 2019-08-12 | 2019-11-15 | 腾讯科技(深圳)有限公司 | The choosing method of cover picture, the training method of model, device and medium |
| US20200019807A1 (en)* | 2017-09-12 | 2020-01-16 | Tencent Technology (Shenzhen) Company Limited | Training method of image-text matching model, bi-directional search method, and relevant apparatus |
| WO2020221298A1 (en)* | 2019-04-30 | 2020-11-05 | 北京金山云网络技术有限公司 | Text detection model training method and apparatus, text region determination method and apparatus, and text content determination method and apparatus |
| CN113283551A (en)* | 2021-07-22 | 2021-08-20 | 智者四海(北京)技术有限公司 | Training method and training device of multi-mode pre-training model and electronic equipment |
- 2021
- 2021-09-24CNCN202111124141.0Apatent/CN113869392A/enactivePending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20200019807A1 (en)* | 2017-09-12 | 2020-01-16 | Tencent Technology (Shenzhen) Company Limited | Training method of image-text matching model, bi-directional search method, and relevant apparatus |
| WO2020221298A1 (en)* | 2019-04-30 | 2020-11-05 | 北京金山云网络技术有限公司 | Text detection model training method and apparatus, text region determination method and apparatus, and text content determination method and apparatus |
| CN110287343A (en)* | 2019-06-10 | 2019-09-27 | 北京深演智能科技股份有限公司 | Picture Generation Method and device |
| CN110457523A (en)* | 2019-08-12 | 2019-11-15 | 腾讯科技(深圳)有限公司 | The choosing method of cover picture, the training method of model, device and medium |
| CN113283551A (en)* | 2021-07-22 | 2021-08-20 | 智者四海(北京)技术有限公司 | Training method and training device of multi-mode pre-training model and electronic equipment |
Non-Patent Citations (2)
| Title |
|---|
| CHRIS等: ""Learning to Rank using Gradient Descent"", 《PROCEEDINGS OF THE 22TH INTERNATIONAL CONFERENCE ON MACHINE LEARNING》, 7 August 2005 (2005-08-07), pages 1 - 8* |
| 贺小娟: ""基于特征优化的广告点击率预测模型研究"", 《华东师范大学学报》, 31 July 2020 (2020-07-31), pages 1 - 9* |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2025167339A1 (en)* | 2024-02-06 | 2025-08-14 | 北京字跳网络技术有限公司 | Product advertisement image generation method and apparatus, device, storage medium, and program product |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110472090B (en) | Image retrieval method based on semantic tags, related device and storage medium | |
| US11544474B2 (en) | Generation of text from structured data | |
| CN110325986B (en) | Article processing method, article processing device, server and storage medium | |
| CN111488931B (en) | Article quality evaluation method, article recommendation method and corresponding devices | |
| CN113987187B (en) | Public opinion text classification method, system, terminal and medium based on multi-label embedding | |
| CN111159485B (en) | Tail entity linking method, device, server and storage medium | |
| CN109493199A (en) | Products Show method, apparatus, computer equipment and storage medium | |
| CN112613293B (en) | Digest generation method, digest generation device, electronic equipment and storage medium | |
| CN116226785A (en) | Target object recognition method, multi-mode recognition model training method and device | |
| CN112347787A (en) | Method, device and equipment for classifying aspect level emotion and readable storage medium | |
| CN117033609B (en) | Text visual question-answering method, device, computer equipment and storage medium | |
| WO2020147409A1 (en) | Text classification method and apparatus, computer device, and storage medium | |
| CN110287341B (en) | Data processing method, device and readable storage medium | |
| CN112364204A (en) | Video searching method and device, computer equipment and storage medium | |
| CN113704623A (en) | Data recommendation method, device, equipment and storage medium | |
| WO2024041483A1 (en) | Recommendation method and related device | |
| CN113627151B (en) | Cross-modal data matching method, device, equipment and medium | |
| CN115186133A (en) | Video generation method, device, electronic device and medium | |
| CN118093882B (en) | Aesthetic-guidance-based text-to-graphic model optimization method, device, equipment and medium | |
| CN111859940A (en) | Keyword extraction method and device, electronic equipment and storage medium | |
| CN117573851B (en) | Automatic question-answering method and system for generating type in futures field | |
| CN115131811A (en) | Target recognition and model training method, device, equipment and storage medium | |
| CN113591857B (en) | Character image processing method, device and ancient Chinese book image recognition method | |
| CN116595252A (en) | A data processing method and related device | |
| CN113869392A (en) | Picture analysis model training method, advertisement picture selection method and electronic equipment |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |