CN113807019A - MCMC wind power simulation method based on improved scene classification and de-coarse-graining - Google Patents
MCMC wind power simulation method based on improved scene classification and de-coarse-grainingDownload PDFInfo
- Publication number
- CN113807019A CN113807019ACN202111122162.9ACN202111122162ACN113807019ACN 113807019 ACN113807019 ACN 113807019ACN 202111122162 ACN202111122162 ACN 202111122162ACN 113807019 ACN113807019 ACN 113807019A
- Authority
- CN
- China
- Prior art keywords
- wind power
- output
- algorithm
- probability density
- power output
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images











Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F30/00—Computer-aided design [CAD]
- G06F30/20—Design optimisation, verification or simulation
- G06F30/27—Design optimisation, verification or simulation using machine learning, e.g. artificial intelligence, neural networks, support vector machines [SVM] or training a model
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/23—Clustering techniques
- G06F18/232—Non-hierarchical techniques
- G06F18/2321—Non-hierarchical techniques using statistics or function optimisation, e.g. modelling of probability density functions
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/241—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/12—Computing arrangements based on biological models using genetic models
- G06N3/126—Evolutionary algorithms, e.g. genetic algorithms or genetic programming
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2111/00—Details relating to CAD techniques
- G06F2111/06—Multi-objective optimisation, e.g. Pareto optimisation using simulated annealing [SA], ant colony algorithms or genetic algorithms [GA]
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2113/00—Details relating to the application field
- G06F2113/06—Wind turbines or wind farms
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Life Sciences & Earth Sciences (AREA)
- Evolutionary Computation (AREA)
- General Physics & Mathematics (AREA)
- Artificial Intelligence (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Evolutionary Biology (AREA)
- General Engineering & Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Biophysics (AREA)
- Software Systems (AREA)
- Molecular Biology (AREA)
- Mathematical Physics (AREA)
- Biomedical Technology (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Physiology (AREA)
- Computing Systems (AREA)
- Genetics & Genomics (AREA)
- Probability & Statistics with Applications (AREA)
- Medical Informatics (AREA)
- Computer Hardware Design (AREA)
- Geometry (AREA)
- Wind Motors (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本申请涉及电力系统新能源调度运行技术领域,尤其涉及一种基于改进场景分类和去粗粒化的MCMC风电模拟方法和装置。The present application relates to the technical field of new energy dispatching operation in power systems, and in particular, to an MCMC wind power simulation method and device based on improved scene classification and de-coarse-graining.
背景技术Background technique
近年来,随着能源危机和环境污染问题的日益严重,风力发电、太阳能发电等清洁能源发电得到了大力的发展。然而风能和太阳能资源虽然在我国多个省份十分丰富,但是存在时间分布上波动性大、季节特征明显,在空间上分布不平衡的特点。因此这类电源的并网发电具有不可控性,会对电网的安全稳定运行产生冲击。当新能源大规模并网时,会严重影响电力系统运行的安全性、稳定性和经济性,导致电网弃风、弃光问题时有发生。所以要提前评估电网对新能源的接纳能力,对电力系统的运行调度做好规划。对风电出力的时间序列模拟可以提供与实际运行状态相符的运行数据,为电网的调度规划工作提供参考。而准确性越高,与实际出力过程更匹配的模拟对该工作的贡献越大。In recent years, with the increasingly serious problems of energy crisis and environmental pollution, clean energy power generation such as wind power generation and solar power generation has been vigorously developed. However, although wind energy and solar energy resources are abundant in many provinces in my country, they have the characteristics of large fluctuation in time distribution, obvious seasonal characteristics and unbalanced distribution in space. Therefore, the grid-connected power generation of this type of power source is uncontrollable, which will have an impact on the safe and stable operation of the power grid. When new energy is connected to the grid on a large scale, it will seriously affect the safety, stability and economy of the power system operation, resulting in the occurrence of power grid curtailment of wind and light. Therefore, it is necessary to evaluate the power grid's ability to accept new energy in advance, and make plans for the operation and scheduling of the power system. The time series simulation of wind power output can provide operating data consistent with the actual operating state, and provide a reference for the dispatching and planning of the power grid. And the higher the accuracy, the greater the contribution of a simulation that better matches the actual output process to the job.
要实现对风电出力的模拟,就要建立风电出力模型。基于风电历史出力数据,我们可以对风电场的出力序列进行分类和建模。对风电场的出力序列的划分,主要有K-means法、AP聚类法、模糊聚类法和神经网络法。AP聚类算法与K-means法相比,无需提前设定聚类数和聚类中心等参数,模糊聚类和神经网络聚类法优化了聚类精度和聚类速度,但是适用范围较小,算法较为复杂,K-means算法是最经典的,也是应用最广泛的基本聚类算法之一,但是存在搜索和收敛能力差,聚类精度差等问题。对风电出力的建模,主要有两种方法:基于风速的间接建模法和基于功率的直接建模法。基于风速的间接建模法主要是利用风速模型生成风速序列,再结合发电机和各种因素的实际参数建立风速-功率的函数关系,从而间接得到功率序列。但是风速-功率之间的函数映射关系很复杂,受到多种因素的影响,得到的功率很难满足实际功率分布特性。直接建模法利用历史的风电出力数据,利用统计学原理综合考虑出力特征,有较高的可靠性。常用的用来构建风电出力模型的方法有自回归滑动平均模型(Autoregressive Moving Average Model,ARMA)、Copula相关性模型、蒙特卡洛(Monte Carlo,MC)随机模拟模型。ARMA算法对风电出力进行建模需要对模型的参数进行估计,当历史数据规律性较差时,得到的结果误差较大。传统的与马尔科夫链结合的马尔科夫-蒙特卡洛(Markov Chain Monte Carlo,MCMC)算法将出力区间有限个出力状态,利用纯随机数会导致模拟粗粒化。粗粒化对风电模拟效果有较大影响,会导致较大的概率分布偏差。To realize the simulation of wind power output, it is necessary to establish a wind power output model. Based on the historical output data of wind power, we can classify and model the output sequence of the wind farm. For the division of the output sequence of wind farms, there are mainly K-means method, AP clustering method, fuzzy clustering method and neural network method. Compared with the K-means method, the AP clustering algorithm does not need to set parameters such as the number of clusters and cluster centers in advance. The fuzzy clustering and neural network clustering methods optimize the clustering accuracy and clustering speed, but the scope of application is small. The algorithm is relatively complex. The K-means algorithm is the most classic and one of the most widely used basic clustering algorithms, but there are problems such as poor search and convergence ability and poor clustering accuracy. There are two main methods for modeling wind power output: indirect modeling method based on wind speed and direct modeling method based on power. The indirect modeling method based on wind speed mainly uses the wind speed model to generate the wind speed sequence, and then combines the actual parameters of the generator and various factors to establish the functional relationship between wind speed and power, so as to obtain the power sequence indirectly. However, the function mapping relationship between wind speed and power is very complex, and is affected by many factors, and the obtained power is difficult to meet the actual power distribution characteristics. The direct modeling method uses historical wind power output data and comprehensively considers output characteristics by using statistical principles, and has high reliability. Commonly used methods for building wind power output models include Autoregressive Moving Average Model (ARMA), Copula correlation model, and Monte Carlo (MC) stochastic simulation model. The ARMA algorithm to model the wind power output needs to estimate the parameters of the model. When the regularity of the historical data is poor, the error of the obtained results is large. The traditional Markov Chain Monte Carlo (MCMC) algorithm combined with Markov chain will output a limited number of output states, and the use of pure random numbers will lead to coarse-grained simulation. Coarse graining has a great influence on the wind power simulation effect, which will lead to a large deviation of the probability distribution.
发明内容SUMMARY OF THE INVENTION
本申请旨在至少在一定程度上解决相关技术中的技术问题之一。The present application aims to solve one of the technical problems in the related art at least to a certain extent.
为此,本申请的第一个目的在于提出一种基于改进场景分类和去粗粒化的MCMC风电模拟方法,解决了现有方法搜索能力较差和模拟效率较低的技术问题,通过改进KM算法实现典型日聚类,采用Copula混合模型建立相邻时刻风电出力联合概率密度,降低分类区间带来的粗粒化影响。充分利用风电出力历史数据,将风电出力数据进行分类,在没有其他数据如气象因素、风电机参数等的条件下,实现对风电时间序列出力过程的快速准确模拟,同时充分发掘了风电历史数据的出力特征,通过有效分类和建模建立了有效的风电出力模型,能够为风电的运行调度规划提供支持。Therefore, the first purpose of this application is to propose an MCMC wind power simulation method based on improved scene classification and de-coarse-graining, which solves the technical problems of poor search ability and low simulation efficiency of existing methods. By improving KM The algorithm realizes typical daily clustering, and uses the Copula hybrid model to establish the joint probability density of wind power output at adjacent times, reducing the coarse-grained impact of the classification interval. Make full use of the historical wind power output data, classify the wind power output data, and realize the fast and accurate simulation of the wind power time series output process in the absence of other data such as meteorological factors, wind turbine parameters, etc., and fully explore the wind power historical data. Based on the output characteristics, an effective wind power output model is established through effective classification and modeling, which can provide support for the operation and scheduling of wind power.
本申请的第二个目的在于提出一种基于改进场景分类和去粗粒化的MCMC风电模拟装置。The second purpose of this application is to propose an MCMC wind power simulation device based on improved scene classification and de-coarse-graining.
为达上述目的,本申请第一方面实施例提出了一种基于改进场景分类和去粗粒化的MCMC风电模拟方法,包括:步骤S100:使用改进的KM聚类算法对风电每日历史出力数据进行聚类,将风电出力日划分到不同的典型出力场景;步骤S200:对分类后的各个场景,建立日内相邻时刻的马尔科夫链、相邻时刻风电出力联合概率密度分布函数模型,其中,相邻时刻风电出力联合概率密度分布函数模型使用Copula混合模型拟合得到;步骤S300:基于建立的马尔科夫链和相邻时刻风电出力联合概率密度分布函数模型,改进现有的MCMC流程,进行风电时间序列出力的模拟。In order to achieve the above purpose, an embodiment of the first aspect of the present application proposes an MCMC wind power simulation method based on improved scene classification and de-coarse-graining, including: step S100: using the improved KM clustering algorithm to analyze the daily historical output data of wind power Perform clustering to divide the wind power output days into different typical output scenarios; Step S200 : for each classified scenario, establish a Markov chain at adjacent moments within the day and a joint probability density distribution function model of wind power output at adjacent moments, wherein , the joint probability density distribution function model of wind power output at adjacent moments is obtained by fitting the Copula hybrid model; Step S300: Based on the established Markov chain and the joint probability density distribution function model of wind power output at adjacent moments, improve the existing MCMC process, Simulate the output of wind power time series.
可选地,在本申请的一个实施例中,改进的KM聚类算法包括以下步骤:Optionally, in an embodiment of the present application, the improved KM clustering algorithm comprises the following steps:
步骤S110:设计聚类效果评价指标,根据聚类效果评价指标的大小确定聚类种群数;Step S110: Design a clustering effect evaluation index, and determine the cluster population number according to the size of the clustering effect evaluation index;
步骤S120:利用遗传算法和退火算法对KM算法进行改进,进行种群的选择、交叉和变异。Step S120: Use genetic algorithm and annealing algorithm to improve the KM algorithm, and perform population selection, crossover and mutation.
可选地,在本申请的一个实施例中,聚类效果评价指标表示为:Optionally, in an embodiment of the present application, the clustering effect evaluation index is expressed as:



其中,Din为种群类内间距的平均值,Dout为种群最小类外间距,C为调节常数,d(xi,vj)为样本点xi和聚类中心vj的距离,d(vi,vj)是聚类中心vi和vj的距离。Among them, Din is the average of the intra-class distance of the population, Dout is the minimum out-of-class distance of the population, C is the adjustment constant, d(xi ,vj ) is the distance between the sample point xi and the cluster center vj , d (vi ,vj ) is the distance between the cluster centersvi andvj .
可选地,在本申请的一个实施例中,利用遗传算法和退火算法对KM算法进行改进,进行种群的选择、交叉和变异,包括以下步骤:Optionally, in an embodiment of the present application, the genetic algorithm and the annealing algorithm are used to improve the KM algorithm to perform population selection, crossover and mutation, including the following steps:
步骤S121:确定遗传种群规模、遗传代数、退火初始温度、退火速度,将风电历史数据进行归一化;Step S121: Determine the genetic population size, genetic algebra, annealing initial temperature, and annealing speed, and normalize the wind power historical data;
步骤S122:每个种群个体完成一次完整的KM聚类操作,计算个体适应度,根据适应度大小进行选择操作,淘汰的个体利用轮盘选择算法进行选择性保留;Step S122: Each population individual completes a complete KM clustering operation, calculates the individual fitness, performs a selection operation according to the size of the fitness, and selectively retains the eliminated individuals using the roulette selection algorithm;
步骤S123:选择出来的新个体进行交叉和变异操作;Step S123: Crossover and mutation operations are performed on the selected new individuals;
步骤S124:重新计算个体的适应度值,根据适应度对种群个体进行选择;Step S124: Recalculate the fitness value of the individual, and select the population individual according to the fitness;
步骤S125:重复进行步骤S122、步骤S123、步骤S124,直到达到最大遗传代数。Step S125: Repeat steps S122, S123, and S124 until the maximum genetic generation number is reached.
可选地,在本申请的一个实施例中,使用个体适应度函数计算个体适应度值,个体适应度函数表示为:Optionally, in an embodiment of the present application, an individual fitness value is calculated using an individual fitness function, and the individual fitness function is expressed as:



其中,k为种群聚类数,n为样本总数,vi为第i个种群的聚类中心,

可选地,在本申请的一个实施例中,通过退火算法改进轮盘选择算法,轮盘选择算法接受淘汰个体概率为:Optionally, in an embodiment of the present application, an annealing algorithm is used to improve the roulette wheel selection algorithm, and the probability of the roulette wheel selection algorithm accepting eliminated individuals is:

其中,t为当前退火温度,a为退火速度,T0为退火初始温度,fbest为种群最佳个体的适应度值,K为常数,k为全局寻优次数,即遗传代数,p为被淘汰个体重新被选择概率。Among them, t is the current annealing temperature, a is the annealing speed, T0 is the initial temperature of annealing, fbest is the fitness value of the best individual in the population, K is a constant, k is the global optimization times, that is, the genetic algebra, and p is the The probability that the eliminated individuals will be re-selected.
可选地,在本申请的一个实施例中,进行交叉和变异操作的发生概率为:Optionally, in an embodiment of the present application, the probability of occurrence of crossover and mutation operations is:


其中,pc为交叉概率,pm为变异概率,pcmax和pcmin分别为预置的最大和最小交叉概率,pmmax和pmmin分别为预置的最大和最小变异概率,fmean为种群平均适应度值,f1和f2分别为两个交叉个体的适应度值,fmax为种群最大适应度值。where pc is the crossover probability, pm is the mutation probability, pcmax and pcmin are the preset maximum and minimum crossover probability, respectively, pmmax and p mminare the preset maximum and minimum mutation probability, respectively, fmean is the population The average fitness value, f1 and f2 are the fitness values of the two crossover individuals, respectively, and fmax is the maximum fitness value of the population.
可选地,在本申请的一个实施例中,对于分类后的各个场景,相邻时刻风电出力联合概率密度分布函数模型的建立包括以下步骤:Optionally, in an embodiment of the present application, for each classified scenario, the establishment of a joint probability density distribution function model of wind power output at adjacent moments includes the following steps:
步骤S210:根据所考察分类场景风电出力历史数据,统计计算得到该分类场景下风电出力的分布函数和相邻时刻之间的概率密度分布直方图;Step S210: According to the historical data of the wind power output of the classified scene under investigation, statistical calculation is performed to obtain the distribution function of the wind power output in the classified scene and the probability density distribution histogram between adjacent moments;
步骤S220:根据相邻时刻之间的概率密度分布直方图的形状选择混合Copula函数模型进行建模,生成混合Copula函数模型;Step S220: Selecting a mixed Copula function model for modeling according to the shape of the probability density distribution histogram between adjacent moments to generate a mixed Copula function model;
步骤S230:根据观测数据利用极大似然估计法对混合Copula函数模型的参数进行估计,得到相邻时刻风电出力联合概率密度分布函数模型。Step S230: Estimate the parameters of the hybrid Copula function model by using the maximum likelihood estimation method according to the observation data, and obtain a joint probability density distribution function model of wind power output at adjacent times.
可选地,在本申请的一个实施例中,基于建立的马尔科夫链和相邻时刻风电出力联合概率密度模型,改进现有的MCMC流程,进行风电时间序列出力的模拟,包括以下步骤:Optionally, in an embodiment of the present application, based on the established Markov chain and the combined probability density model of wind power output at adjacent moments, the existing MCMC process is improved, and the simulation of wind power time series output is performed, including the following steps:
步骤S310:利用改进的KM算法得到分类后的典型出力日,建立不同典型日的马尔科夫链、风电出力概率密度函数和波动量概率密度函数,其中,马尔科夫链是将标准的化的风电出力划分为多个出力区间;Step S310: Use the improved KM algorithm to obtain the classified typical output days, and establish Markov chains, wind power output probability density functions, and fluctuation probability density functions for different typical days, where the Markov chain is standardized Wind power output is divided into multiple output intervals;
步骤S320:根据出力概率密度分布,初始化生成第一天和第一小时的发电功率,利用相邻时刻风电出力联合概率密度模型生成下一时刻出力,之后根据马尔科夫链选择下一时刻出力所在的下一时刻出力区间,再利用波动量概率密度生成准确出力,当日间出力长度满足要求后,利用日间转移矩阵生成下一天的出力日类型;Step S320: According to the output probability density distribution, initialize the generation power of the first day and the first hour, use the combined probability density model of wind power output at adjacent times to generate the output at the next moment, and then select the output at the next moment according to the Markov chain. The output interval at the next moment, and then use the probability density of fluctuations to generate accurate output. When the length of the output during the day meets the requirements, use the day-to-day transition matrix to generate the output day type of the next day;
步骤S330:重复进行步骤S320,直到模拟的出力序列长度满足要求。Step S330: Repeat step S320 until the length of the simulated output sequence meets the requirements.
为达上述目的,本申请第二方面实施例提出了一种基于改进场景分类和去粗粒化的MCMC风电模拟装置,包括:划分模块、模型建立模块、模拟模块,其中,In order to achieve the above purpose, an embodiment of the second aspect of the present application proposes an MCMC wind power simulation device based on improved scene classification and de-coarse-graining, including: a division module, a model establishment module, and a simulation module, wherein,
划分模块,用于使用改进的KM聚类算法对风电每日历史出力数据进行聚类,将风电出力日划分到不同的典型出力场景;The division module is used to cluster the daily historical output data of wind power using the improved KM clustering algorithm, and divide the wind power output days into different typical output scenarios;
模型建立模块,用于对分类后的各个场景,建立日内相邻时刻的马尔科夫链、相邻时刻风电出力联合概率密度分布函数模型,其中,相邻时刻风电出力联合概率密度模型使用Copula混合模型拟合得到;The model building module is used to establish the Markov chain at adjacent times in the day and the joint probability density distribution function model of wind power output at adjacent times for each scene after classification. The combined probability density model of wind power output at adjacent times uses Copula mixing. The model is fitted;
模拟模块,用于基于建立的马尔科夫链和相邻时刻风电出力联合概率密度分布函数模型,改进现有的MCMC流程,进行风电时间序列出力的模拟。The simulation module is used to improve the existing MCMC process and simulate the output of wind power time series based on the established Markov chain and the joint probability density distribution function model of wind power output at adjacent times.
本申请实施例的基于改进场景分类和去粗粒化的MCMC风电模拟方法和装置,解决了现有方法搜索能力较差和模拟效率较低的技术问题,通过改进KM算法实现典型日聚类,采用Copula混合模型建立相邻时刻风电出力联合概率密度,充分利用风电出力历史数据,将风电出力数据进行分类,在没有其他数据如气象因素、风电机参数等的条件下,实现对风电时间序列出力过程的快速准确模拟,同时充分发掘了风电历史数据的出力特征,通过有效分类和建模建立了有效的风电出力模型,能够为风电的运行调度规划提供支持。The MCMC wind power simulation method and device based on improved scene classification and de-coarse-graining in the embodiments of the present application solve the technical problems of poor search ability and low simulation efficiency of the existing methods, and realize typical daily clustering by improving the KM algorithm, The Copula hybrid model is used to establish the joint probability density of wind power output at adjacent times, making full use of the historical data of wind power output, classifying the wind power output data, and realizing the output of the time series of wind power without other data such as meteorological factors and wind turbine parameters. The rapid and accurate simulation of the process, while fully exploring the output characteristics of wind power historical data, establishes an effective wind power output model through effective classification and modeling, which can provide support for wind power operation scheduling planning.
本申请附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本申请的实践了解到。Additional aspects and advantages of the present application will be set forth, in part, in the following description, and in part will be apparent from the following description, or learned by practice of the present application.
附图说明Description of drawings
本申请上述的和/或附加的方面和优点从下面结合附图对实施例的描述中将变得明显和容易理解,其中:The above and/or additional aspects and advantages of the present application will become apparent and readily understood from the following description of embodiments taken in conjunction with the accompanying drawings, wherein:
图1为本申请实施例一所提供的一种基于改进场景分类和去粗粒化的MCMC风电模拟方法的流程图;1 is a flowchart of a MCMC wind power simulation method based on improved scene classification and de-coarse-graining provided by
图2为本申请实施例的基于改进场景分类和去粗粒化的MCMC风电模拟方法的改进的KM算法中每个遗传个体的算法流程图;Fig. 2 is the algorithm flow chart of each genetic individual in the improved KM algorithm based on the improved scene classification and the de-coarse-grained MCMC wind power simulation method according to the embodiment of the application;
图3为本申请实施例的基于改进场景分类和去粗粒化的MCMC风电模拟方法的改进的KM算法中改进的子代个体构成图;3 is a diagram of an improved individual composition diagram of the offspring in the improved KM algorithm based on the improved scene classification and de-coarse-grained MCMC wind power simulation method according to an embodiment of the application;
图4为本申请实施例的基于改进场景分类和去粗粒化的MCMC风电模拟方法的利用遗传算法和退火算法改进的KM算法的整体流程图;4 is an overall flow chart of the KM algorithm improved by genetic algorithm and annealing algorithm based on the MCMC wind power simulation method of improved scene classification and de-coarse-graining according to an embodiment of the application;
图5为本申请实施例的基于改进场景分类和去粗粒化的MCMC风电模拟方法的利用风电历史出力数据进行实际风电出力过程模拟的整体流程图;FIG. 5 is an overall flow chart of an actual wind power output process simulation using historical wind power output data based on the MCMC wind power simulation method based on improved scene classification and de-coarse-graining according to an embodiment of the application;
图6为本申请实施例的基于改进场景分类和去粗粒化的MCMC风电模拟方法的不同场景分类数的评价指标曲线图;6 is an evaluation index curve diagram of the number of different scene classifications based on the MCMC wind power simulation method based on improved scene classification and de-coarse-grained according to an embodiment of the application;
图7为本申请实施例的基于改进场景分类和去粗粒化的MCMC风电模拟方法的改进的KM算法和未改进的KM算法的结果对比图;7 is a result comparison diagram of an improved KM algorithm and an unimproved KM algorithm based on the improved scene classification and de-coarse-grained MCMC wind power simulation method according to an embodiment of the application;
图8为本申请实施例的基于改进场景分类和去粗粒化的MCMC风电模拟方法的利用改进的KM算法得到的风电历史发电日的分类结果图;Fig. 8 is the classification result diagram of wind power historical power generation days obtained by using the improved KM algorithm based on the improved scene classification and the de-coarse-grained MCMC wind power simulation method according to the embodiment of the application;
图9为本申请实施例的基于改进场景分类和去粗粒化的MCMC风电模拟方法的风力发电序列相邻时间出力频率分布直方图和Copula拟合结果图;9 is a histogram of the output frequency distribution of a wind power generation sequence in adjacent times and a Copula fitting result diagram based on the MCMC wind power simulation method based on improved scene classification and de-coarse-graining according to an embodiment of the application;
图10为本申请实施例的基于改进场景分类和去粗粒化的MCMC风电模拟方法的风电历史数据和分别利用MCMC算法、未利用KM算法分类的改进MCMC算法和利用KM算法分类的改进MCMC算法进行模拟的概率密度分布图;10 is the wind power historical data of the MCMC wind power simulation method based on the improved scene classification and de-coarse-graining according to the embodiment of the application, and the improved MCMC algorithm classified by the MCMC algorithm, the improved MCMC algorithm not classified by the KM algorithm, and the improved MCMC algorithm classified by the KM algorithm respectively. The probability density distribution map for the simulation;
图11为本申请实施例的基于改进场景分类和去粗粒化的MCMC风电模拟方法的风电历史数据和分别利用MCMC算法、未利用KM算法分类的改进MCMC算法和利用KM算法分类的改进MCMC算法进行模拟得到的出力序列的自相关系数曲线图;11 is the wind power historical data based on the MCMC wind power simulation method based on improved scene classification and de-coarse-graining according to the embodiment of the application, and the improved MCMC algorithm classified by the MCMC algorithm, the improved MCMC algorithm not classified by the KM algorithm, and the improved MCMC algorithm classified by the KM algorithm respectively The autocorrelation coefficient curve graph of the output sequence obtained by the simulation;
图12为本申请实施例的基于改进场景分类和去粗粒化的MCMC风电模拟方法的分类后的各种出力场景24h的模拟出力和历史数据的对比图;12 is a comparison diagram of simulated output and historical data of various output scenarios 24h after classification based on the improved scene classification and de-coarse-grained MCMC wind power simulation method according to an embodiment of the application;
图13为本申请实施例的基于改进场景分类和去粗粒化的MCMC风电模拟方法的风电历史数据和分别利用MCMC算法、未利用KM算法分类的改进MCMC算法和利用KM算法分类的改进MCMC算法进行模拟的150h的模拟结果对比图;13 is the wind power historical data based on the MCMC wind power simulation method based on improved scene classification and de-coarse-graining according to the embodiment of the application, and the improved MCMC algorithm classified by the MCMC algorithm, the improved MCMC algorithm not classified by the KM algorithm, and the improved MCMC algorithm classified by the KM algorithm respectively The comparison chart of the simulation results of 150h of simulation;
图14为本申请实施例二所提供的一种基于改进场景分类和去粗粒化的MCMC风电模拟装置的结构示意图。FIG. 14 is a schematic structural diagram of an MCMC wind power simulation device based on improved scene classification and de-coarse-graining provided by the second embodiment of the application.
具体实施方式Detailed ways
下面详细描述本申请的实施例,实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本申请,而不能理解为对本申请的限制。Embodiments of the present application are described in detail below, examples of which are illustrated in the accompanying drawings, wherein the same or similar reference numerals refer to the same or similar elements or elements having the same or similar functions throughout. The embodiments described below with reference to the accompanying drawings are exemplary, and are intended to be used to explain the present application, but should not be construed as a limitation to the present application.
下面参考附图描述本申请实施例的基于改进场景分类和去粗粒化的MCMC风电模拟方法和装置。The following describes the MCMC wind power simulation method and device based on improved scene classification and de-coarse-graining according to the embodiments of the present application with reference to the accompanying drawings.
图1为本申请实施例一所提供的一种基于改进场景分类和去粗粒化的MCMC风电模拟方法的流程图。FIG. 1 is a flowchart of an MCMC wind power simulation method based on improved scene classification and de-coarse-graining provided by
如图1所示,该基于改进场景分类和去粗粒化的MCMC风电模拟方法包括以下步骤:As shown in Figure 1, the MCMC wind power simulation method based on improved scene classification and de-coarse-graining includes the following steps:
步骤S100:使用改进的KM聚类算法对风电每日历史出力数据进行聚类,将风电出力日划分到不同的典型出力场景;Step S100: Clustering the daily historical output data of wind power by using the improved KM clustering algorithm, and dividing the wind power output days into different typical output scenarios;
步骤S200:对分类后的各个场景,建立日内相邻时刻的马尔科夫链、相邻时刻风电出力联合概率密度分布函数模型,其中,相邻时刻风电出力联合概率密度分布函数模型使用Copula混合模型拟合得到;Step S200: For each classified scene, establish a Markov chain at adjacent times within a day and a joint probability density distribution function model of wind power output at adjacent times, wherein the combined probability density distribution function model of wind power output at adjacent times uses a Copula hybrid model fitted;
步骤S300:基于建立的马尔科夫链和相邻时刻风电出力联合概率密度分布函数模型,改进现有的MCMC流程,进行风电时间序列出力的模拟。Step S300: Based on the established Markov chain and the joint probability density distribution function model of wind power output at adjacent moments, improve the existing MCMC process to simulate the output of wind power time series.
本申请实施例的基于改进场景分类和去粗粒化的MCMC风电模拟方法,通过步骤S100:使用改进的KM聚类算法对风电每日历史出力数据进行聚类,将风电出力日划分到不同的典型出力场景;步骤S200:对分类后的各个场景,建立日内相邻时刻的马尔科夫链、相邻时刻风电出力联合概率密度分布函数模型,其中,相邻时刻风电出力联合概率密度分布函数模型使用Copula混合模型拟合得到;步骤S300:基于建立的马尔科夫链和相邻时刻风电出力联合概率密度分布函数模型,改进现有的MCMC流程,进行风电时间序列出力的模拟。由此,能够解决现有方法搜索能力较差和模拟效率较低的技术问题,通过改进KM算法实现典型日聚类,采用Copula混合模型建立相邻时刻风电出力联合概率密度,充分利用风电出力历史数据,将风电出力数据进行分类,在没有其他数据如气象因素、风电机参数等的条件下,实现对风电时间序列出力过程的快速准确模拟,同时充分发掘了风电历史数据的出力特征,通过有效分类和建模建立了有效的风电出力模型,能够为风电的运行调度规划提供支持。In the MCMC wind power simulation method based on improved scene classification and de-coarse-graining according to the embodiment of the present application, through step S100: use the improved KM clustering algorithm to cluster the daily historical output data of wind power, and divide the wind power output days into different Typical output scenarios; Step S200: For each classified scenario, establish a Markov chain at adjacent moments within a day and a joint probability density distribution function model of wind power output at adjacent moments, wherein the joint probability density distribution function model of wind power output at adjacent moments It is obtained by fitting the Copula mixed model; Step S300: Based on the established Markov chain and the joint probability density distribution function model of wind power output at adjacent times, improve the existing MCMC process to simulate the output of wind power time series. Therefore, the technical problems of poor search ability and low simulation efficiency of the existing methods can be solved. The typical daily clustering can be realized by improving the KM algorithm, and the Copula hybrid model is used to establish the joint probability density of wind power output at adjacent times, and make full use of the history of wind power output. Data, classify wind power output data, and realize fast and accurate simulation of wind power time series output process without other data such as meteorological factors, wind turbine parameters, etc. The classification and modeling establish an effective wind power output model, which can provide support for the operation and scheduling of wind power.
本申请提出了一种改进的风电出力模拟方法,包括以下步骤:S1、对原始数据进行处理,确定改进的KM聚类算法的聚类数目;S2、初始化遗传代数、遗传算法的适应度函数,然后所有个体完成一次KM聚类生成初代种群;S3、对初代种群进行选择、交叉和变异的操作;S4、不断循环上个步骤直到达到最大遗传代数;S5、将分类后的每一种典型出力类型的数据进行统计,得到马尔可夫转换矩阵、出力功率概率密度分布函数、出力波动量概率密度分布函数;S6、建立不同出力场景之间的累积状态转移矩阵,以及相邻出力的联合概率密度分布函数;S7、基于出力概率密度分布生成风电出力初始出力日状态d0和初始时刻状态t0;S8、利用联合概率密度分布函数和波动量概率密度分布函数修正传统MCMC算法的随机状态数v进行出力模拟。The present application proposes an improved wind power output simulation method, which includes the following steps: S1, processing the original data to determine the number of clusters of the improved KM clustering algorithm; S2, initializing the genetic algebra and the fitness function of the genetic algorithm, Then all individuals complete a KM clustering to generate the primary population; S3, select, crossover and mutate the primary population; S4, loop the previous step until the maximum genetic algebra is reached; S5, classify each typical output Perform statistics on types of data to obtain Markov transition matrix, output power probability density distribution function, and output fluctuation probability density distribution function; S6. Establish the cumulative state transition matrix between different output scenarios, and the joint probability density of adjacent outputs Distribution function; S7, generate the initial output daily state d0 and initial time state t0 of wind power output based on the output probability density distribution; S8, use the joint probability density distribution function and the fluctuation probability density distribution function to correct the random state number v of the traditional MCMC algorithm Perform output simulation.
本申请可以在只拥有风电历史出力数据这单一条件下,首先对历史出力日进行分类,通过对不同出力日的单独建模来提高模拟精度。同时,利用改进的KM聚类算法来提高聚类速度和聚类效果。然后在聚类的基础上进一步通过利用统计函数改进的MCMC算法进行出力序列的模拟,能够进一步提高模拟的精度,使模拟过程更加符合实际情况。In the present application, under the single condition that only the historical output data of wind power is available, the historical output days can be classified first, and the simulation accuracy can be improved by separately modeling different output days. At the same time, the improved KM clustering algorithm is used to improve the clustering speed and clustering effect. Then, on the basis of clustering, the simulation of the output sequence is carried out by using the improved MCMC algorithm of statistical functions, which can further improve the accuracy of the simulation and make the simulation process more in line with the actual situation.
本申请提出一种考虑时间相关性和波动性的风电场发电时序模拟场景构建方法,一方面,在只存在风电历史出力数据的条件下,能够通过对数据特征的充分提取,提高建模精确度;另一方面,能够通过构建风电发电模拟模型,来为电网的运行调度提供符合实际情况的运行数据,从而为电力系统的稳定安全运行做贡献。首先,先利用遗传算法和退火算法对KM算法进行改进,提高分类速度和精度,从而将风电历史出力日进行精确分类,通过对不同类的出力数据分析,分别建立不同的数据模型,以最大限度地降低建模误差;然后利用时间上相邻出力的混合Copula模型和波动量的概率密度分布函数,对MCMC算法中的随机抽样过程进行修正,降低纯随机过程中功率区间带来的粗粒化影响,进一步提高模拟效率,使建立的风电出力模型生成的数据更符合实际情况,本申请提高了建模精度,能为风电的运行调度提供支持,从而为提高新能源消纳能力的工作提供参考。The present application proposes a method for constructing a time series simulation scenario for wind farm power generation that considers time correlation and volatility. On the one hand, under the condition that only historical wind power output data exists, the modeling accuracy can be improved by fully extracting data features On the other hand, by constructing a wind power generation simulation model, it can provide operation data in line with the actual situation for the operation and dispatch of the power grid, thereby contributing to the stable and safe operation of the power system. First, the genetic algorithm and annealing algorithm are used to improve the KM algorithm to improve the classification speed and accuracy, so as to accurately classify the historical output days of wind power. By analyzing the output data of different types, different data models are established to maximize the Then, the random sampling process in the MCMC algorithm is modified by using the mixed Copula model of the adjacent output in time and the probability density distribution function of the fluctuation amount to reduce the coarse graining caused by the power interval in the pure random process. It can further improve the simulation efficiency and make the data generated by the established wind power output model more in line with the actual situation. This application improves the modeling accuracy and can provide support for the operation and scheduling of wind power, thus providing a reference for improving the capacity of new energy consumption. .
出力日分类的效果会直接影响风电模型建立的好坏,本申请利用遗传算法来改进传统KM算法搜索能力差,收敛速度慢的缺点。同时,利用模拟退火算法与遗传算法相结合,增加遗传算法的种群多样性,提高种群进化速度,进而提升整个分类过程的速度与精度。The effect of the output day classification will directly affect the quality of the wind power model establishment. The present application uses the genetic algorithm to improve the shortcomings of the traditional KM algorithm, which has poor search ability and slow convergence speed. At the same time, the combination of simulated annealing algorithm and genetic algorithm is used to increase the population diversity of genetic algorithm, improve the speed of population evolution, and then improve the speed and accuracy of the entire classification process.
以甘肃省某风电场的出力数据为样本进行分析,数据采样间隔为15min,并作数据的归一化处理:Taking the output data of a wind farm in Gansu Province as a sample for analysis, the data sampling interval is 15min, and the data is normalized:

其中,Pi为输入的采样功率,PM为风电场的额定容量,Po是归一化后的输出功率。Among them, Pi is the input sampled power,PM is the rated capacity of the windfarm, and P ois the normalized output power.
进一步地,在本申请实施例中,改进的KM聚类算法包括以下步骤:Further, in the embodiment of the present application, the improved KM clustering algorithm comprises the following steps:
步骤S110:设计聚类效果评价指标,根据聚类效果评价指标的大小确定聚类种群数;Step S110: Design a clustering effect evaluation index, and determine the cluster population number according to the size of the clustering effect evaluation index;
步骤S120:利用遗传算法和退火算法对KM算法进行改进,进行种群的选择、交叉和变异。Step S120: Use genetic algorithm and annealing algorithm to improve the KM algorithm, and perform population selection, crossover and mutation.
遗传个体不再采用编码方式进行初始化,而是把一个KM聚类过程当作一个个体。Genetic individuals are no longer initialized by encoding, but a KM clustering process is treated as an individual.
进一步地,在本申请实施例中,聚类效果评价指标表示为:Further, in the embodiment of the present application, the clustering effect evaluation index is expressed as:



其中,Din为种群类内间距的平均值,Dout为种群最小类外间距,C为调节常数,d(xi,vj)为样本点xi和聚类中心vj的距离,d(vi,vj)是聚类中心vi和vj的距离。Among them, Din is the average of the intra-class distance of the population, Dout is the minimum out-of-class distance of the population, C is the adjustment constant, d(xi ,vj ) is the distance between the sample point xi and the cluster center vj , d (vi ,vj ) is the distance between the cluster centersvi andvj .
进一步地,在本申请实施例中,利用遗传算法和退火算法对KM算法进行改进,进行种群的选择、交叉和变异,包括以下步骤:Further, in the embodiment of the present application, the genetic algorithm and the annealing algorithm are used to improve the KM algorithm, and the selection, crossover and mutation of the population are performed, including the following steps:
步骤S121:确定遗传种群规模、遗传代数、退火初始温度、退火速度,将风电历史数据进行归一化;Step S121: Determine the genetic population size, genetic algebra, annealing initial temperature, and annealing speed, and normalize the wind power historical data;
步骤S122:每个种群个体完成一次完整的KM聚类操作,计算个体适应度,根据适应度大小进行选择操作,淘汰的个体利用轮盘选择算法进行选择性保留;Step S122: Each population individual completes a complete KM clustering operation, calculates the individual fitness, performs a selection operation according to the size of the fitness, and selectively retains the eliminated individuals using the roulette selection algorithm;
步骤S123:选择出来的新个体进行交叉和变异操作;Step S123: Crossover and mutation operations are performed on the selected new individuals;
步骤S124:重新计算个体的适应度值,根据适应度对种群个体进行选择;Step S124: Recalculate the fitness value of the individual, and select the population individual according to the fitness;
步骤S125:重复进行步骤S122、步骤S123、步骤S124,直到达到最大遗传代数。Step S125: Repeat steps S122, S123, and S124 until the maximum genetic generation number is reached.
种群父代个体的选择过程包括:计算种群所有个体的适应度值,将适应度最优个体直接保留至子代;剩下的个体采用轮盘选择算法进行选择,直到选出种群规模50%的个体,遗传给子代;被淘汰的个体利用模拟退火算法得到的概率,筛选出种群规模30%的个体遗传给子代。The selection process of the parent individuals of the population includes: calculating the fitness values of all individuals in the population, and directly retaining the individuals with the best fitness to the offspring; the remaining individuals are selected by the roulette selection algorithm until 50% of the population size is selected. Individuals are inherited to the offspring; the eliminated individuals use the probability obtained by the simulated annealing algorithm to screen out 30% of the population size to be inherited to the offspring.
染色体交叉和变异是对每个个体的聚类中心进行操作,交叉是随机交换两个种群的聚类中心,变异是某个种群的聚类中心随即发生改变,两个操作的概率随着种群的进化和个体的适应度值变化,不断对种群进行更新,直到达到最大遗传代数,可以得到的风电发电日分类结果。Chromosome crossover and mutation is to operate on the cluster center of each individual. Crossover is to randomly exchange the cluster center of two populations. Mutation is that the cluster center of a population changes immediately. The probability of the two operations varies with the population. Evolution and individual fitness value changes, and the population is continuously updated until the maximum genetic algebra is reached, and the daily classification results of wind power generation can be obtained.
进一步地,在本申请实施例中,使用个体适应度函数计算个体适应度值,个体适应度函数表示为:Further, in the embodiment of the present application, the individual fitness value is calculated by using the individual fitness function, and the individual fitness function is expressed as:



其中,k为种群聚类数,n为样本总数,vi为第i个种群的聚类中心,

进一步地,在本申请实施例中,通过退火算法改进轮盘选择算法,轮盘选择算法接受淘汰个体概率为:Further, in the embodiment of the present application, the roulette selection algorithm is improved by the annealing algorithm, and the probability that the roulette selection algorithm accepts the eliminated individuals is:

其中,t为当前退火温度,a为退火速度,T0为退火初始温度,fbest为种群最佳个体的适应度值,K为常数,k为全局寻优次数,即遗传代数,p为被淘汰个体重新被选择概率。Among them, t is the current annealing temperature, a is the annealing speed, T0 is the initial temperature of annealing, fbest is the fitness value of the best individual in the population, K is a constant, k is the global optimization times, that is, the genetic algebra, and p is the The probability that the eliminated individuals will be re-selected.
进一步地,在本申请实施例中,进行交叉和变异操作的发生概率为:Further, in the embodiment of the present application, the probability of occurrence of crossover and mutation operations is:


其中,pc为交叉概率,pm为变异概率,pcmax和pcmin分别为预置的最大和最小交叉概率,pmmax和pmmin分别为预置的最大和最小变异概率,fmean为种群平均适应度值,f1和f2分别为两个交叉个体的适应度值,fmax为种群最大适应度值。where pc is the crossover probability, pm is the mutation probability, pcmax and pcmin are the preset maximum and minimum crossover probability, respectively, pmmax and p mminare the preset maximum and minimum mutation probability, respectively, fmean is the population The average fitness value, f1 and f2 are the fitness values of the two crossover individuals, respectively, and fmax is the maximum fitness value of the population.
进一步地,在本申请实施例中,对于分类后的各个场景,相邻时刻风电出力联合概率密度分布函数模型的建立包括以下步骤:Further, in the embodiment of the present application, for each scene after classification, the establishment of a joint probability density distribution function model of wind power output at adjacent moments includes the following steps:
步骤S210:根据所考察分类场景风电出力历史数据,统计计算得到该分类场景下风电出力的分布函数和相邻时刻之间的概率密度分布直方图;Step S210: According to the historical data of the wind power output of the classified scene under investigation, statistical calculation is performed to obtain the distribution function of the wind power output in the classified scene and the probability density distribution histogram between adjacent moments;
步骤S220:根据相邻时刻之间的概率密度分布直方图的形状选择混合Copula函数模型进行建模,生成混合Copula函数模型;Step S220: Selecting a mixed Copula function model for modeling according to the shape of the probability density distribution histogram between adjacent moments to generate a mixed Copula function model;
步骤S230:根据观测数据利用极大似然估计法对混合Copula函数模型的参数进行估计,得到相邻时刻风电出力联合概率密度分布函数模型。Step S230: Estimate the parameters of the hybrid Copula function model by using the maximum likelihood estimation method according to the observation data, and obtain a joint probability density distribution function model of wind power output at adjacent times.
风电出力的分布函数F(x)计算公式为The calculation formula of the distribution function F(x) of wind power output is:

其中,


混合Copula函数模型为:The mixed Copula function model is:

其中,λk为各Copula函数Ck(u,v;θk)在混合函数中的权重系数,θk为第k个Copula函数的参数。Among them, λk is the weight coefficient of each Copula function Ck (u, v; θk ) in the mixing function, and θk is the parameter of the kth Copula function.
根据观测数据利用极大似然估计法对混合Copula函数模型的参数进行估计:The parameters of the mixed Copula function model are estimated by the maximum likelihood estimation method according to the observed data:

利用风电历史数据进行统计分析,分别得到出力功率的概率密度分布、波动量的概率密度分布。Using the historical data of wind power for statistical analysis, the probability density distribution of output power and the probability density distribution of fluctuation amount are obtained respectively.
初始化第一天d=0的出力日类型S0=m和初始时刻t=0的出力数据P0和状态z0。当前一时刻出力为Pt,状态为zt,利用混合Copula函数生成随机数v,若Q(zt,j-1)<v≤Q(zt,j),那么t+1时刻的状态为zt+1=j;Initialize the output day type S0 =m of the first day d=0 and the output data P0 and state z0 of the initial time t=0 . The output at the current moment is Pt , the state is zt , and the random number v is generated by the mixed Copula function. If Q(zt ,j-1)<v≤Q(zt ,j), then the state at time t+1 is zt+1 = j;
进一步地,在本申请实施例中,基于建立的马尔科夫链和相邻时刻风电出力联合概率密度模型,改进现有的MCMC流程,进行风电时间序列出力的模拟,包括以下步骤:Further, in the embodiment of the present application, based on the established Markov chain and the joint probability density model of wind power output at adjacent moments, the existing MCMC process is improved, and the simulation of wind power time series output is performed, including the following steps:
步骤S310:利用改进的KM算法得到分类后的典型出力日,建立不同典型日的马尔科夫链、风电出力概率密度函数和波动量概率密度函数,其中,马尔科夫链是将标准的化的风电出力划分为多个出力区间;Step S310: Use the improved KM algorithm to obtain the classified typical output days, and establish Markov chains, wind power output probability density functions, and fluctuation probability density functions for different typical days, where the Markov chain is standardized Wind power output is divided into multiple output intervals;
步骤S320:根据出力概率密度分布,初始化生成第一天和第一小时的发电功率,利用相邻时刻风电出力联合概率密度模型生成下一时刻出力,之后根据马尔科夫链选择下一时刻出力所在的下一时刻出力区间,再利用波动量概率密度生成准确出力,当日间出力长度满足要求后,利用日间转移矩阵生成下一天的出力日类型;Step S320: According to the output probability density distribution, initialize the generation power of the first day and the first hour, use the combined probability density model of wind power output at adjacent times to generate the output at the next moment, and then select the output at the next moment according to the Markov chain. The output interval at the next moment, and then use the probability density of fluctuations to generate accurate output. When the length of the output during the day meets the requirements, use the day-to-day transition matrix to generate the output day type of the next day;
步骤S330:重复进行步骤S320,直到模拟的出力序列长度满足要求。Step S330: Repeat step S320 until the length of the simulated output sequence meets the requirements.
出力概率密度是对风电所有单一时刻出力进行统计,利用核密度估计得到概率密度分布函数,波动量概率密度函数通过统计相邻时刻风电出力的差值,利用核密度函数进行拟合得到。The output probability density is the statistics of the output of wind power at all single moments, and the probability density distribution function is obtained by using the kernel density estimation.
基于波动量的联合概率密度函数生成随机波动量来进一步修正下一时刻的出力数据。The random fluctuation is generated based on the joint probability density function of the fluctuation to further correct the output data at the next moment.
状态转移矩阵定义为:The state transition matrix is defined as:

其中,nij为从场景i转换到场景j的次数。Among them, nij is the number of transitions from scene i to scene j.
累积状态转移矩阵为:The cumulative state transition matrix is:

建立所有出力日的累积转移概率矩阵Qd,在每个出力场景中,建立相邻时间出力的频率分布直方图,通过相邻时刻出力求取差值得到波动量概率密度:The cumulative transition probability matrix Qd of all output days is established, and in each output scenario, the frequency distribution histogram of output at adjacent times is established, and the probability density of fluctuation is obtained by calculating the difference of output at adjacent times:
ΔP=Pt-Pt-1ΔP=Pt -Pt-1
根据频率分布直方图选择合适的二元Coupla函数C(u,v;θ)进行建模,通过相邻时刻风电出力历史数据
基于之前得到的波动量概率密度函数,生成随机的波动量βt,则下一时刻的预测发电功率为Pt+1=Pt+βt,若Pt+1∈{P|z=zt+1},则继续;否则重新抽取波动量。当生成一天的出力序列后,再利用出力日的累积概率矩阵,采用随机抽样生成下一天的典型日类型。Based on the probability density function of the fluctuation amount obtained before, a random fluctuation amount βt is generated, and the predicted power generation at the next moment is Pt+1 =Pt +βt , if Pt+1 ∈ {P|z=zt+1 }, then continue; otherwise, re-extract the volatility. After generating the output sequence of one day, the cumulative probability matrix of the output day is used to generate the typical day type of the next day by random sampling.
图2为本申请实施例的基于改进场景分类和去粗粒化的MCMC风电模拟方法的改进的KM算法中每个遗传个体的算法流程图。FIG. 2 is an algorithm flowchart of each genetic individual in the improved KM algorithm based on the improved scene classification and de-coarse-grained MCMC wind power simulation method according to an embodiment of the present application.
如图2所示,该改进的KM算法中每个遗传个体的算法为,输入数据X以及参数k,选择k个样本作为初始聚类中心;将所有样本按照距离最近原则分配到不同类中;重新计算各个簇类的平均值;判断每个簇的聚类中心是否变化,若否,则结束;若是,则重新将所有样本按照距离最近原则分配到不同类中,直至每个簇的聚类中心不变。每个遗传个体都为一次KM聚类过程。As shown in Figure 2, the algorithm of each genetic individual in the improved KM algorithm is to input data X and parameter k, select k samples as the initial clustering center, and assign all samples to different classes according to the principle of closest distance; Recalculate the average value of each cluster; judge whether the cluster center of each cluster changes, if not, end; if so, redistribute all samples to different classes according to the principle of closest distance, until the clustering of each cluster The center remains unchanged. Each genetic individual is a KM clustering process.
图3为本申请实施例的基于改进场景分类和去粗粒化的MCMC风电模拟方法的改进的KM算法中改进的子代个体构成图。FIG. 3 is a diagram showing the composition of the improved individual offspring in the improved KM algorithm based on the improved scene classification and de-coarse-grained MCMC wind power simulation method according to an embodiment of the present application.
如图3所示,在基于改进场景分类和去粗粒化的MCMC风电模拟方法的改进的KM算法中,每次种群更新过程,子代种群由最优个体、轮盘选择个体和淘汰个体构成。As shown in Figure 3, in the improved KM algorithm based on the improved scene classification and de-coarse-grained MCMC wind power simulation method, each population update process, the offspring population consists of the optimal individual, the roulette selection individual and the eliminated individual .
图4为本申请实施例的基于改进场景分类和去粗粒化的MCMC风电模拟方法的利用遗传算法和退火算法改进的KM算法的整体流程图。FIG. 4 is an overall flow chart of the KM algorithm improved by the genetic algorithm and the annealing algorithm based on the MCMC wind power simulation method based on improved scene classification and de-coarse-graining according to an embodiment of the present application.
如图4所示,利用遗传算法和退火算法改进KM算法的步骤为,输入数据X,确定样本群聚类数k的取值范围;初始化遗传种群;对遗传种群进行选择操作;对遗传种群进行交叉变异;重新计算种群内个体适应度值;判断是否达到最大遗传次数,若是,则结束;若否,则重新对遗传种群进行选择操作、交叉变异,直至达到最大遗传次数。As shown in Figure 4, the steps of using genetic algorithm and annealing algorithm to improve KM algorithm are: input data X, determine the value range of the sample group clustering number k; initialize the genetic population; perform selection operation on the genetic population; Crossover and mutation; recalculate the fitness value of individuals in the population; judge whether the maximum number of inheritance is reached, if so, end; if not, re-select the genetic population and perform crossover mutation until the maximum number of inheritance is reached.
图5为本申请实施例的基于改进场景分类和去粗粒化的MCMC风电模拟方法的利用风电历史出力数据进行实际风电出力过程模拟的整体流程图。FIG. 5 is an overall flowchart of an actual wind power output process simulation using historical wind power output data based on the MCMC wind power simulation method based on improved scene classification and de-coarse-graining according to an embodiment of the present application.
如图5所示,该基于改进场景分类和去粗粒化的MCMC风电模拟方法,处理风电历史出力数据,删除非正常出力功率,将出力功率进行标准化;将数据进行聚类,完成典型日划分;计算各场景状态转移矩阵、Copula时序相关函数C(U,V);计算累计转移概率矩阵Q;抽样生成下一时刻状态量z,确定下一时刻出力范围;建立波动量概率密度分布模型,生成随机的波动量βt,则下一时刻的预测发电功率为Pt+1=Pt+βt,若Pt+1∈{P|z=zt+1},则继续,否则重新抽取波动量;当生成一天的出力序列后,再利用出力日的累积概率矩阵,采用随机抽样生成下一天的典型日类型;不断重复上面两个步骤,直到生成满足长度的模拟运行序列。As shown in Figure 5, the MCMC wind power simulation method based on improved scene classification and de-coarse-graining processes the historical wind power output data, deletes abnormal output power, and normalizes the output power; the data is clustered to complete the division of typical days ; Calculate the state transition matrix of each scene and the Copula time series correlation function C(U, V); Calculate the cumulative transition probability matrix Q; Sampling to generate the next moment state quantity z, determine the next moment output range; Generate a random fluctuation amount βt , then the predicted power generation at the next moment is Pt+1 =Pt +βt , if Pt+1 ∈ {P|z=zt+1 }, continue, otherwise restart Extract the fluctuation amount; after generating the output sequence of one day, use the cumulative probability matrix of the output day to generate the typical day type of the next day by random sampling; repeat the above two steps continuously until a simulation running sequence of sufficient length is generated.
图6为本申请实施例的基于改进场景分类和去粗粒化的MCMC风电模拟方法的不同场景分类数的评价指标曲线图。FIG. 6 is a graph showing the evaluation index of the number of different scene classifications of the MCMC wind power simulation method based on improved scene classification and de-coarse-grained according to an embodiment of the present application.
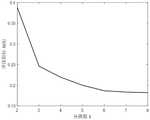
如图6所示,该基于改进场景分类和去粗粒化的MCMC风电模拟方法,由聚类评价指标的公式可知,指标数值越小,表明聚类效果越好。当分类数为6时,分类效果较好,当分类数超过6时,对聚类效果效果改进不明显的同时会加大运算负担,所以选择典型场景分类数k为6。As shown in Figure 6, the MCMC wind power simulation method based on improved scene classification and de-coarse-graining can be seen from the formula of the clustering evaluation index. The smaller the index value, the better the clustering effect. When the number of classifications is 6, the classification effect is better. When the number of classifications exceeds 6, the improvement of the clustering effect is not obvious and the computational burden will be increased. Therefore, the classification number k of the typical scene is selected as 6.
图7为本申请实施例的基于改进场景分类和去粗粒化的MCMC风电模拟方法的改进的KM算法和未改进的KM算法的结果对比图。FIG. 7 is a result comparison diagram of an improved KM algorithm and an unimproved KM algorithm based on the improved scene classification and de-coarse-grained MCMC wind power simulation method according to an embodiment of the present application.
如图7所示,该基于改进场景分类和去粗粒化的MCMC风电模拟方法的改进的KM算法与未改进KM算法相比具有更快的收敛速度和更好的分类效果。As shown in Figure 7, the improved KM algorithm based on the improved scene classification and de-coarse-grained MCMC wind power simulation method has faster convergence speed and better classification effect than the unimproved KM algorithm.
图8为本申请实施例的基于改进场景分类和去粗粒化的MCMC风电模拟方法的利用改进的KM算法得到的风电历史发电日的分类结果图。FIG. 8 is a diagram showing the classification result of historical wind power generation days obtained by using the improved KM algorithm based on the MCMC wind power simulation method of improved scene classification and de-coarse-graining according to an embodiment of the present application.
如图8所示,该基于改进场景分类和去粗粒化的MCMC风电模拟方法,利用评价指标确定KM算法进行出力日分类的聚类数,选择改进算法中的遗传算法的适应度函数,利用改进的KM算法对历史出力日进行分类,得到分类结果。As shown in Figure 8, the MCMC wind power simulation method based on improved scene classification and de-coarse-graining uses the evaluation index to determine the number of clusters for the output day classification of the KM algorithm, and selects the fitness function of the genetic algorithm in the improved algorithm. The improved KM algorithm classifies the historical output days and obtains the classification results.
图9为本申请实施例的基于改进场景分类和去粗粒化的MCMC风电模拟方法的风力发电序列相邻时间出力频率分布直方图和Copula拟合结果图。FIG. 9 is a histogram of the output frequency distribution of a wind power generation sequence in adjacent times and a Copula fitting result diagram based on the MCMC wind power simulation method based on improved scene classification and de-coarse-graining according to an embodiment of the present application.
如图9所示,Copula函数是用来衡量出力序列时间相关性的,建立准确有效的Copula函数模型能很大程度上提高模拟精度和效率,该基于改进场景分类和去粗粒化的MCMC风电模拟方法,通过构建风电相邻时间出力的频率直方图来选择二元联合概率密度模型,得到t时刻和t+1时刻的观测数据
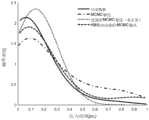
图10为本申请实施例的基于改进场景分类和去粗粒化的MCMC风电模拟方法的风电历史数据和分别利用MCMC算法、未利用KM算法分类的改进MCMC算法和利用KM算法分类的改进MCMC算法进行模拟的概率密度分布图。10 is the wind power historical data of the MCMC wind power simulation method based on the improved scene classification and de-coarse-graining according to the embodiment of the application, and the improved MCMC algorithm classified by the MCMC algorithm, the improved MCMC algorithm not classified by the KM algorithm, and the improved MCMC algorithm classified by the KM algorithm respectively. Plot of the probability density distribution for the simulation.
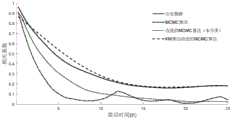
图11为本申请实施例的基于改进场景分类和去粗粒化的MCMC风电模拟方法的风电历史数据和分别利用MCMC算法、未利用KM算法分类的改进MCMC算法和利用KM算法分类的改进MCMC算法进行模拟得到的出力序列的自相关系数曲线图。11 is the wind power historical data based on the MCMC wind power simulation method based on improved scene classification and de-coarse-graining according to the embodiment of the application, and the improved MCMC algorithm classified by the MCMC algorithm, the improved MCMC algorithm not classified by the KM algorithm, and the improved MCMC algorithm classified by the KM algorithm respectively The autocorrelation coefficient curve of the output series obtained by the simulation.
图12为本申请实施例的基于改进场景分类和去粗粒化的MCMC风电模拟方法的分类后的各种出力场景24h的模拟出力和历史数据的对比图。FIG. 12 is a comparison diagram of simulated output and historical data of various output scenarios 24h after classification based on the improved scenario classification and de-coarse-grained MCMC wind power simulation method according to an embodiment of the present application.
图13为本申请实施例的基于改进场景分类和去粗粒化的MCMC风电模拟方法的风电历史数据和分别利用MCMC算法、未利用KM算法分类的改进MCMC算法和利用KM算法分类的改进MCMC算法进行模拟的150h的模拟结果对比图。13 is the wind power historical data based on the MCMC wind power simulation method based on improved scene classification and de-coarse-graining according to the embodiment of the application, and the improved MCMC algorithm classified by the MCMC algorithm, the improved MCMC algorithm not classified by the KM algorithm, and the improved MCMC algorithm classified by the KM algorithm respectively Comparison of simulation results for 150 hours of simulation.
图10、图11、图12和图13分别模拟数据和历史数据在概率密度分布,自相关系数变化趋势,24h时间尺度和150h时间尺度上的对比图,从结果可以看出,本申请提出的建模方法具有更高的模拟精度,运行状态更符合风电的实际发电情况,同时,经过改进KM算法分类的模拟效果更好。Fig. 10, Fig. 11, Fig. 12 and Fig. 13 respectively compare the simulated data and historical data in probability density distribution, autocorrelation coefficient change trend, 24h time scale and 150h time scale. It can be seen from the results that the proposed The modeling method has higher simulation accuracy, and the operating state is more in line with the actual generation of wind power. At the same time, the simulation effect of the improved KM algorithm classification is better.
表一是本申请中风电历史数据和分别利用MCMC算法、未利用KM算法分类的改进MCMC算法和利用KM算法分类的改进MCMC算法进行模拟得到的数据的平均值和标准差的对比。表二是本申请中风电历史数据和分别利用MCMC算法和改进的MCMC算法进行模拟得到的六种分类场景得到的数据的标准差的对比。可以看出经过分类后的模拟数据更加符合实际情况,同时,改进的MCMC算法得到的结果也更加精确。Table 1 is a comparison of the average value and standard deviation of the historical data of wind power in this application and the data obtained by simulation using the MCMC algorithm, the improved MCMC algorithm classified by the KM algorithm, and the improved MCMC algorithm classified by the KM algorithm. Table 2 is a comparison between the historical data of wind power in this application and the standard deviation of the data obtained by using the MCMC algorithm and the improved MCMC algorithm to simulate the six classification scenarios. It can be seen that the simulated data after classification is more in line with the actual situation, and at the same time, the results obtained by the improved MCMC algorithm are also more accurate.
通过传统MCMC算法、未对出力日进行分类的改进的MCMC算法和分类后的改进的MCMC算法对出力日数据进行模拟,得到的出力数据对比如表一和表二所示。The output data is simulated by the traditional MCMC algorithm, the improved MCMC algorithm that does not classify the output days, and the improved MCMC algorithm after classification, and the output data obtained are shown in Tables 1 and 2.

表一Table I


表二Table II
图13为本申请实施例二所提供的一种基于改进场景分类和去粗粒化的MCMC风电模拟装置的结构示意图。FIG. 13 is a schematic structural diagram of an MCMC wind power simulation device based on improved scene classification and de-coarse-graining provided by the second embodiment of the application.
如图13所示,该基于改进场景分类和去粗粒化的MCMC风电模拟装置,包括:划分模块、模型建立模块、模拟模块,其中,As shown in Figure 13, the MCMC wind power simulation device based on improved scene classification and de-coarse-graining includes: a division module, a model establishment module, and a simulation module, wherein,
划分模块10,用于使用改进的KM聚类算法对风电每日历史出力数据进行聚类,将风电出力日划分到不同的典型出力场景;The
模型建立模块20,用于对分类后的各个场景,建立日内相邻时刻的马尔科夫链、相邻时刻风电出力联合概率密度分布函数模型,其中,相邻时刻风电出力联合概率密度模型使用Copula混合模型拟合得到;The
模拟模块30,用于基于建立的马尔科夫链和相邻时刻风电出力联合概率密度分布函数模型,改进现有的MCMC流程,进行风电时间序列出力的模拟。The simulation module 30 is used to improve the existing MCMC process based on the established Markov chain and the joint probability density distribution function model of wind power output at adjacent times, and simulate the output of wind power time series.
本申请实施例的基于改进场景分类和去粗粒化的MCMC风电模拟装置,包括:划分模块、模型建立模块、模拟模块,其中,划分模块,用于使用改进的KM聚类算法对风电每日历史出力数据进行聚类,将风电出力日划分到不同的典型出力场景;模型建立模块,用于对分类后的各个场景,建立日内相邻时刻的马尔科夫链、相邻时刻风电出力联合概率密度分布函数模型,其中,相邻时刻风电出力联合概率密度模型使用Copula混合模型拟合得到;模拟模块,用于基于建立的马尔科夫链和相邻时刻风电出力联合概率密度分布函数模型,改进现有的MCMC流程,进行风电时间序列出力的模拟。由此,能够解决现有方法搜索能力较差和模拟效率较低的技术问题,通过改进KM算法实现典型日聚类,采用Copula混合模型建立相邻时刻风电出力联合概率密度,充分利用风电出力历史数据,将风电出力数据进行分类,在没有其他数据如气象因素、风电机参数等的条件下,实现对风电时间序列出力过程的快速准确模拟,同时充分发掘了风电历史数据的出力特征,通过有效分类和建模建立了有效的风电出力模型,能够为风电的运行调度规划提供支持。The MCMC wind power simulation device based on improved scene classification and de-coarse-graining according to the embodiment of the present application includes: a division module, a model establishment module, and a simulation module, wherein the division module is used for using the improved KM clustering algorithm to analyze the wind power daily The historical output data is clustered, and the wind power output days are divided into different typical output scenarios; the model building module is used to establish the Markov chain of adjacent moments in the day and the joint probability of wind power output at adjacent moments for each scenario after classification. The density distribution function model, in which the joint probability density model of wind power output at adjacent moments is obtained by fitting the Copula hybrid model; the simulation module is used to improve the joint probability density distribution function model of wind power output based on the established Markov chain and adjacent moments The existing MCMC process is used to simulate the output of wind power time series. Therefore, the technical problems of poor search ability and low simulation efficiency of the existing methods can be solved. The typical daily clustering can be realized by improving the KM algorithm, and the Copula hybrid model is used to establish the joint probability density of wind power output at adjacent times, and make full use of the history of wind power output. Data, classify wind power output data, and realize fast and accurate simulation of wind power time series output process without other data such as meteorological factors, wind turbine parameters, etc. The classification and modeling establish an effective wind power output model, which can provide support for the operation and scheduling of wind power.
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本申请的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。In the description of this specification, description with reference to the terms "one embodiment," "some embodiments," "example," "specific example," or "some examples", etc., mean specific features described in connection with the embodiment or example , structure, material or feature is included in at least one embodiment or example of the present application. In this specification, schematic representations of the above terms are not necessarily directed to the same embodiment or example. Furthermore, the particular features, structures, materials or characteristics described may be combined in any suitable manner in any one or more embodiments or examples. Furthermore, those skilled in the art may combine and combine the different embodiments or examples described in this specification, as well as the features of the different embodiments or examples, without conflicting each other.
此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。在本申请的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。In addition, the terms "first" and "second" are only used for descriptive purposes, and should not be construed as indicating or implying relative importance or implying the number of indicated technical features. Thus, a feature delimited with "first", "second" may expressly or implicitly include at least one of that feature. In the description of the present application, "plurality" means at least two, such as two, three, etc., unless expressly and specifically defined otherwise.
流程图中或在此以其他方式描述的任何过程或方法描述可以被理解为,表示包括一个或更多个用于实现定制逻辑功能或过程的步骤的可执行指令的代码的模块、片段或部分,并且本申请的优选实施方式的范围包括另外的实现,其中可以不按所示出或讨论的顺序,包括根据所涉及的功能按基本同时的方式或按相反的顺序,来执行功能,这应被本申请的实施例所属技术领域的技术人员所理解。Any process or method description in the flowcharts or otherwise described herein may be understood to represent a module, segment or portion of code comprising one or more executable instructions for implementing custom logical functions or steps of the process , and the scope of the preferred embodiments of the present application includes alternative implementations in which the functions may be performed out of the order shown or discussed, including performing the functions substantially concurrently or in the reverse order depending upon the functions involved, which should It is understood by those skilled in the art to which the embodiments of the present application belong.
在流程图中表示或在此以其他方式描述的逻辑和/或步骤,例如,可以被认为是用于实现逻辑功能的可执行指令的定序列表,可以具体实现在任何计算机可读介质中,以供指令执行系统、装置或设备(如基于计算机的系统、包括处理器的系统或其他可以从指令执行系统、装置或设备取指令并执行指令的系统)使用,或结合这些指令执行系统、装置或设备而使用。就本说明书而言,"计算机可读介质"可以是任何可以包含、存储、通信、传播或传输程序以供指令执行系统、装置或设备或结合这些指令执行系统、装置或设备而使用的装置。计算机可读介质的更具体的示例(非穷尽性列表)包括以下:具有一个或多个布线的电连接部(电子装置),便携式计算机盘盒(磁装置),随机存取存储器(RAM),只读存储器(ROM),可擦除可编辑只读存储器(EPROM或闪速存储器),光纤装置,以及便携式光盘只读存储器(CDROM)。另外,计算机可读介质甚至可以是可在其上打印程序的纸或其他合适的介质,因为可以例如通过对纸或其他介质进行光学扫描,接着进行编辑、解译或必要时以其他合适方式进行处理来以电子方式获得程序,然后将其存储在计算机存储器中。The logic and/or steps represented in flowcharts or otherwise described herein, for example, may be considered an ordered listing of executable instructions for implementing the logical functions, may be embodied in any computer-readable medium, For use with, or in conjunction with, an instruction execution system, apparatus, or device (such as a computer-based system, a system including a processor, or other system that can fetch instructions from and execute instructions from an instruction execution system, apparatus, or apparatus) or equipment. For the purposes of this specification, a "computer-readable medium" can be any device that can contain, store, communicate, propagate, or transport the program for use by or in connection with an instruction execution system, apparatus, or apparatus. More specific examples (non-exhaustive list) of computer readable media include the following: electrical connections with one or more wiring (electronic devices), portable computer disk cartridges (magnetic devices), random access memory (RAM), Read Only Memory (ROM), Erasable Editable Read Only Memory (EPROM or Flash Memory), Fiber Optic Devices, and Portable Compact Disc Read Only Memory (CDROM). In addition, the computer readable medium may even be paper or other suitable medium on which the program may be printed, as may be done, for example, by optically scanning the paper or other medium, followed by editing, interpretation, or other suitable means as necessary process to obtain the program electronically and then store it in computer memory.
应当理解,本申请的各部分可以用硬件、软件、固件或它们的组合来实现。在上述实施方式中,多个步骤或方法可以用存储在存储器中且由合适的指令执行系统执行的软件或固件来实现。如,如果用硬件来实现和在另一实施方式中一样,可用本领域公知的下列技术中的任一项或他们的组合来实现:具有用于对数据信号实现逻辑功能的逻辑门电路的离散逻辑电路,具有合适的组合逻辑门电路的专用集成电路,可编程门阵列(PGA),现场可编程门阵列(FPGA)等。It should be understood that various parts of this application may be implemented in hardware, software, firmware, or a combination thereof. In the above-described embodiments, various steps or methods may be implemented in software or firmware stored in memory and executed by a suitable instruction execution system. For example, if implemented in hardware as in another embodiment, it can be implemented by any one of the following techniques known in the art, or a combination thereof: discrete with logic gates for implementing logic functions on data signals Logic circuits, application specific integrated circuits with suitable combinational logic gates, Programmable Gate Arrays (PGA), Field Programmable Gate Arrays (FPGA), etc.
本技术领域的普通技术人员可以理解实现上述实施例方法携带的全部或部分步骤是可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,该程序在执行时,包括方法实施例的步骤之一或其组合。Those skilled in the art can understand that all or part of the steps carried by the methods of the above embodiments can be completed by instructing the relevant hardware through a program, and the program can be stored in a computer-readable storage medium, and the program can be stored in a computer-readable storage medium. When executed, one or a combination of the steps of the method embodiment is included.
此外,在本申请各个实施例中的各功能单元可以集成在一个处理模块中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个模块中。上述集成的模块既可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。所述集成的模块如果以软件功能模块的形式实现并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。In addition, each functional unit in each embodiment of the present application may be integrated into one processing module, or each unit may exist physically alone, or two or more units may be integrated into one module. The above-mentioned integrated modules can be implemented in the form of hardware, and can also be implemented in the form of software function modules. If the integrated modules are implemented in the form of software functional modules and sold or used as independent products, they may also be stored in a computer-readable storage medium.
上述提到的存储介质可以是只读存储器,磁盘或光盘等。尽管上面已经示出和描述了本申请的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本申请的限制,本领域的普通技术人员在本申请的范围内可以对上述实施例进行变化、修改、替换和变型。The above-mentioned storage medium may be a read-only memory, a magnetic disk or an optical disk, and the like. Although the embodiments of the present application have been shown and described above, it should be understood that the above embodiments are exemplary and should not be construed as limitations to the present application. Embodiments are subject to variations, modifications, substitutions and variations.
Claims (10)
Translated fromChinese










Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111122162.9ACN113807019A (en) | 2021-09-24 | 2021-09-24 | MCMC wind power simulation method based on improved scene classification and de-coarse-graining |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111122162.9ACN113807019A (en) | 2021-09-24 | 2021-09-24 | MCMC wind power simulation method based on improved scene classification and de-coarse-graining |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN113807019Atrue CN113807019A (en) | 2021-12-17 |
Family
ID=78940354
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202111122162.9APendingCN113807019A (en) | 2021-09-24 | 2021-09-24 | MCMC wind power simulation method based on improved scene classification and de-coarse-graining |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN113807019A (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114896765A (en)* | 2022-04-19 | 2022-08-12 | 国网甘肃省电力公司电力科学研究院 | Multi-scene switching wind power sequence simulation method and device based on flexible time boundary |
| CN116431988A (en)* | 2023-03-22 | 2023-07-14 | 浙江大学 | Resident trip activity time sequence generation method based on activity mode-Markov chain |
Citations (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20060023723A1 (en)* | 2004-07-27 | 2006-02-02 | Michele Morara | Object oriented library for markov chain monte carlo simulation |
| CN107464007A (en)* | 2016-06-02 | 2017-12-12 | 南京理工大学 | Continuous time Probabilistic Load Flow Forecasting Methodology based on Markov theory and pro rate principle |
| CN109524993A (en)* | 2018-12-19 | 2019-03-26 | 中国农业大学 | The typical week power output scene generating method of wind-powered electricity generation photovoltaic for Mid-long Term Optimized Scheduling |
| CN109783841A (en)* | 2018-11-28 | 2019-05-21 | 河海大学 | A kind of photovoltaic power output time series analogy method based on more scene state transfer matrixes and conditional probability sampling |
| CN109904878A (en)* | 2019-02-28 | 2019-06-18 | 西安交通大学 | A method for constructing a multi-wind farm power generation sequence simulation scenario |
| CN110570122A (en)* | 2019-09-10 | 2019-12-13 | 重庆大学 | A Reliability Assessment Method for Offshore Wind Farms Considering Wind Velocity Seasonal Characteristics and Collecting System Component Failures |
| CN110909911A (en)* | 2019-09-29 | 2020-03-24 | 中国农业大学 | Aggregation method for multidimensional time series data considering spatiotemporal correlation |
| CN111639808A (en)* | 2020-05-29 | 2020-09-08 | 国网山东省电力公司经济技术研究院 | Multi-wind-farm output scene generation method and system considering time-space correlation |
| CN111859812A (en)* | 2020-07-30 | 2020-10-30 | 南方电网科学研究院有限责任公司 | Reliability evaluation method of offshore wind farm and flexible grid-connected system under the influence of weather |
| CN112307590A (en)* | 2019-10-16 | 2021-02-02 | 国网福建省电力有限公司 | Wind power plant output time sequence curve simulation method considering correlation |
| CN112884270A (en)* | 2020-12-31 | 2021-06-01 | 国网山东省电力公司聊城供电公司 | Multi-scene power distribution network planning method and system considering uncertainty factors |
- 2021
- 2021-09-24CNCN202111122162.9Apatent/CN113807019A/enactivePending
Patent Citations (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20060023723A1 (en)* | 2004-07-27 | 2006-02-02 | Michele Morara | Object oriented library for markov chain monte carlo simulation |
| CN107464007A (en)* | 2016-06-02 | 2017-12-12 | 南京理工大学 | Continuous time Probabilistic Load Flow Forecasting Methodology based on Markov theory and pro rate principle |
| CN109783841A (en)* | 2018-11-28 | 2019-05-21 | 河海大学 | A kind of photovoltaic power output time series analogy method based on more scene state transfer matrixes and conditional probability sampling |
| CN109524993A (en)* | 2018-12-19 | 2019-03-26 | 中国农业大学 | The typical week power output scene generating method of wind-powered electricity generation photovoltaic for Mid-long Term Optimized Scheduling |
| CN109904878A (en)* | 2019-02-28 | 2019-06-18 | 西安交通大学 | A method for constructing a multi-wind farm power generation sequence simulation scenario |
| CN110570122A (en)* | 2019-09-10 | 2019-12-13 | 重庆大学 | A Reliability Assessment Method for Offshore Wind Farms Considering Wind Velocity Seasonal Characteristics and Collecting System Component Failures |
| CN110909911A (en)* | 2019-09-29 | 2020-03-24 | 中国农业大学 | Aggregation method for multidimensional time series data considering spatiotemporal correlation |
| CN112307590A (en)* | 2019-10-16 | 2021-02-02 | 国网福建省电力有限公司 | Wind power plant output time sequence curve simulation method considering correlation |
| CN111639808A (en)* | 2020-05-29 | 2020-09-08 | 国网山东省电力公司经济技术研究院 | Multi-wind-farm output scene generation method and system considering time-space correlation |
| CN111859812A (en)* | 2020-07-30 | 2020-10-30 | 南方电网科学研究院有限责任公司 | Reliability evaluation method of offshore wind farm and flexible grid-connected system under the influence of weather |
| CN112884270A (en)* | 2020-12-31 | 2021-06-01 | 国网山东省电力公司聊城供电公司 | Multi-scene power distribution network planning method and system considering uncertainty factors |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114896765A (en)* | 2022-04-19 | 2022-08-12 | 国网甘肃省电力公司电力科学研究院 | Multi-scene switching wind power sequence simulation method and device based on flexible time boundary |
| CN116431988A (en)* | 2023-03-22 | 2023-07-14 | 浙江大学 | Resident trip activity time sequence generation method based on activity mode-Markov chain |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Haque et al. | Short-term electrical load forecasting through heuristic configuration of regularized deep neural network | |
| CN110969290B (en) | A method and system for runoff probability prediction based on deep learning | |
| CN112381137B (en) | Reliability assessment method, device, equipment and storage medium for new energy power system | |
| CN103488869A (en) | A method for short-term load forecasting of wind power generation based on least squares support vector machine | |
| CN118647092B (en) | Comprehensive management method and system for power distribution communication network | |
| Zhang et al. | Wind speed prediction research considering wind speed ramp and residual distribution | |
| CN114578087B (en) | Wind speed uncertainty measurement method based on non-dominated sorting and stochastic simulation algorithm | |
| CN113629778B (en) | A Design Method for Photovoltaic Storage System of Distributed Photovoltaic Distribution Network | |
| CN110837915B (en) | Low-voltage load point prediction and probability prediction method for power system based on hybrid integrated deep learning | |
| CN114817571B (en) | Dynamic knowledge graph-based achievement quoted quantity prediction method, medium and equipment | |
| CN112329339B (en) | Short-term wind speed prediction method for wind power plant | |
| CN108985515A (en) | A kind of new energy based on independent loops neural network goes out force prediction method and system | |
| CN113361776A (en) | Power load probability prediction method based on user power consumption behavior clustering | |
| Feng et al. | Saturated load forecasting based on clustering and logistic iterative regression | |
| CN116187835A (en) | A data-driven method and system for estimating theoretical line loss intervals in station areas | |
| CN113256018B (en) | Wind power ultra-short term probability prediction method based on conditional quantile regression model | |
| CN113807019A (en) | MCMC wind power simulation method based on improved scene classification and de-coarse-graining | |
| CN114707422A (en) | Intelligent power check method based on load prediction | |
| CN115409317A (en) | Transformer area line loss detection method and device based on feature selection and machine learning | |
| CN118863981A (en) | A multi-level power demand forecasting method and system | |
| CN113033898A (en) | Electrical load prediction method and system based on K-means clustering and BI-LSTM neural network | |
| CN116579479A (en) | Wind farm power ultra-short-term prediction method, system, computer and storage medium | |
| Li et al. | A precise and efficient K-means-ELM model to improve ultra-short-term solar irradiance forecasting | |
| Wang et al. | Wind power forecasting based on manifold learning and a double-layer SWLSTM model | |
| CN115718875A (en) | Photovoltaic convergence trend quantification method based on hierarchical clustering and scene division |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| WD01 | Invention patent application deemed withdrawn after publication | Application publication date:20211217 | |
| WD01 | Invention patent application deemed withdrawn after publication |