CN113705562A - Target area determination method, device, equipment and storage medium - Google Patents
Target area determination method, device, equipment and storage mediumDownload PDFInfo
- Publication number
- CN113705562A CN113705562ACN202110234692.6ACN202110234692ACN113705562ACN 113705562 ACN113705562 ACN 113705562ACN 202110234692 ACN202110234692 ACN 202110234692ACN 113705562 ACN113705562 ACN 113705562A
- Authority
- CN
- China
- Prior art keywords
- sample
- depth
- image
- data
- color
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images












Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/25—Fusion techniques
- G06F18/253—Fusion techniques of extracted features
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T5/00—Image enhancement or restoration
- G06T5/50—Image enhancement or restoration using two or more images, e.g. averaging or subtraction
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T5/00—Image enhancement or restoration
- G06T5/77—Retouching; Inpainting; Scratch removal
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/30—Determination of transform parameters for the alignment of images, i.e. image registration
- G06T7/33—Determination of transform parameters for the alignment of images, i.e. image registration using feature-based methods
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/10—Image acquisition modality
- G06T2207/10024—Color image
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/10—Image acquisition modality
- G06T2207/10028—Range image; Depth image; 3D point clouds
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20081—Training; Learning
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20212—Image combination
- G06T2207/20221—Image fusion; Image merging
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Bioinformatics & Computational Biology (AREA)
- Evolutionary Biology (AREA)
- Evolutionary Computation (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Engineering & Computer Science (AREA)
- Artificial Intelligence (AREA)
- Life Sciences & Earth Sciences (AREA)
- Image Analysis (AREA)
Abstract
Description
Technical Field
The present application relates to the field of image processing, and in particular, to a method, an apparatus, a device, and a storage medium for determining a target area.
Background
And the saliency target detection is used for carrying out data processing on the image, realizing a series of related technologies for detecting the most important target area in the image and dividing the target area to improve the identification precision of the image.
In the related art, the salient object detection based on the RGB image has a good detection effect, but when an object has a similar appearance to the surrounding environment or the background scene is severely cluttered, the performance is still limited. As a compensation, depth data is added in RGB-D saliency target detection, because of the rich spatial structure and 3D layout information embedded in the depth map, the performance of the model in challenging scenes is greatly improved.
In the above technical solution, the depth map is often low in quality, and may contain a large amount of noise and misleading information, which results in a poor target detection effect based on the RGB-D image.
Disclosure of Invention
The embodiment of the application provides a method, a device, equipment and a storage medium for determining a target area, which can improve the accuracy of determining the target area, and the technical scheme is as follows:
in one aspect, a method for determining a target area is provided, where the method includes:
acquiring a first image; the first image comprises first color image data and first depth image data;
obtaining first estimated depth data based on the first color image data; the first estimated depth data is used to indicate depth information to which the first color image data corresponds;
obtaining first calibration depth data based on the first estimated depth data and the first depth image data;
performing weighting processing based on the first color image data and the first calibration depth data to obtain a first fusion feature map;
and determining a target area corresponding to the first image based on the first fusion feature map.
In another aspect, a target area determination method is provided, and the method includes:
acquiring a third sample image; the third sample image includes third sample color image data and third sample depth image data;
obtaining third sample estimated depth data based on the third sample color image data; the third sample estimated depth data is used to indicate depth information to which the third sample color image data corresponds;
obtaining third sample calibration depth data based on the third sample estimated depth data and the third sample depth image data;
based on the third sample color image data and the third sample calibration depth data, performing weighting processing through a feature fusion branch in a target area determination model to obtain a third sample fusion feature map;
training a target area determination model based on the third sample fusion feature map and a target area corresponding to the third sample image;
the trained target area determination model is used for processing color image data corresponding to the first image and calibration depth data corresponding to the first image to obtain a target area corresponding to the first image.
In still another aspect, an apparatus for determining a target area is provided, the apparatus comprising:
the first image acquisition module is used for acquiring a first image; the first image comprises first color image data and first depth image data;
an estimated depth obtaining module, configured to obtain first estimated depth data based on the first color image data; the first estimated depth data is used to indicate depth information to which the first color image data corresponds;
a calibration depth obtaining module, configured to obtain first calibration depth data based on the first estimated depth data and the first depth image data;
a fusion feature obtaining module, configured to perform weighting processing based on the first color image data and the first calibration depth data to obtain a first fusion feature map;
and the target area determining module is used for determining a target area corresponding to the first image based on the first fusion feature map.
In one possible implementation, the apparatus further includes:
the confidence coefficient acquisition module is used for acquiring the confidence coefficient corresponding to the first depth image data based on the first depth image data; the confidence corresponding to the first depth image data is used for indicating the accuracy of the image data corresponding to the target area in the first depth image data;
the calibration depth acquisition module is further configured to,
and performing weighting processing based on the confidence degree corresponding to the first depth image data on the first estimated depth data and the first depth image data to obtain the first calibration depth data.
In one possible implementation, the confidence level obtaining module is further configured to,
processing the first depth image data through a confidence coefficient discrimination model based on the first depth image data to obtain a confidence coefficient corresponding to the first depth image data;
the estimated depth obtaining module is further configured to,
based on the first color image data, performing data processing through a depth estimation model to obtain first estimated depth data;
the confidence coefficient distinguishing model is a machine learning model trained by taking a first sample image as a sample and taking a confidence type corresponding to the first sample image as a label;
the depth estimation model is a machine learning model trained by taking a second sample image as a sample and taking depth image data corresponding to the second sample image as a label; the second sample image is a sample image whose confidence satisfies a first specified condition.
In one possible implementation, the apparatus further includes:
the first sample set acquisition module is used for acquiring a first training sample set; the first training sample set comprises a first sample image and a confidence type corresponding to the first sample image;
a first confidence probability obtaining module, configured to perform data processing through the confidence discrimination model based on the first sample image to obtain a confidence probability corresponding to the first sample image; the confidence probability is indicative of a probability that the first sample image is a positive sample;
and the confidence discrimination model training module is used for training the confidence discrimination model based on the confidence probability corresponding to the first sample image and the confidence type corresponding to the first sample image.
In one possible implementation manner, the first sample set obtaining module includes:
a second sample set obtaining submodule for obtaining a second training sample set; the second training sample set comprises training sample images and target areas corresponding to the training sample images; the training sample image comprises training color sample data and training depth sample data;
the color prediction region acquisition submodule is used for determining a color image processing branch in a model through a target region, processing the training color sample data and acquiring a prediction region corresponding to the training color sample data;
the depth prediction region acquisition submodule is used for determining a depth image processing branch in a model through the target region, processing the training depth sample data and acquiring a prediction region corresponding to the training depth sample data;
a confidence score obtaining submodule for determining a confidence score of the training sample image based on the prediction region corresponding to the training color sample data, the prediction region corresponding to the training depth sample data and the target region corresponding to the training sample image;
a first sample image determining submodule, configured to determine a confidence type of the training sample image in response to that a confidence score of the training sample image satisfies a specified condition, and determine the training sample image as the first sample image;
the color image processing branch in the target area determination model is a machine learning model obtained by pre-training by taking a sample color image as a sample and taking a target area corresponding to the sample color image as a label;
the depth image processing branch in the target area determination model is a machine learning model obtained by pre-training with a sample depth image as a sample and a target area corresponding to the sample depth image as an annotation.
In one possible implementation, the confidence scores include a color confidence score and a depth confidence score;
the confidence score obtaining sub-module comprises:
the color confidence score acquisition unit is used for determining the color confidence score corresponding to the training sample image based on the contact ratio between the prediction region corresponding to the training color sample data and the target region corresponding to the training sample image;
and the depth confidence score acquisition unit is used for determining the depth confidence score corresponding to the training sample image based on the contact ratio between the prediction region corresponding to the training depth sample data and the target region corresponding to the training sample image.
In a possible implementation manner, the fused feature obtaining module includes:
the attention weighting submodule is used for carrying out weighting processing based on an attention mechanism through a feature fusion branch in a target area determination model based on the first color image data and the first calibration depth data to obtain a first fusion feature map;
the device further comprises:
the color characteristic map acquisition module is used for carrying out data processing through a depth image processing branch in the target area determination model based on the first color image data to obtain a first color characteristic map;
the depth feature map acquisition module is used for performing data processing through a depth image processing branch in the target area determination model based on the first depth image data to obtain a first depth feature map;
the target area determination module is further configured to,
and determining a target area corresponding to the first image based on the first fusion feature map, the first depth feature map and the first color feature map.
The target area determination model is a machine learning model obtained by training with a third sample image as a sample and a target area corresponding to the third sample image as an annotation.
In one possible implementation, the feature fusion branch includes a first pooling layer, a second pooling layer, a first fully-connected layer, and a second fully-connected layer;
the fusion feature obtaining module includes:
the first pooling submodule is used for carrying out global pooling through a first pooling layer based on the first color image data to obtain first color pooling data;
the first full-connection submodule is used for carrying out data processing through a first full-connection layer based on the first color pooling data to obtain a first color vector;
the second pooling sub-module is used for carrying out global pooling through a second pooling layer based on the first depth image data to obtain first depth pooling data;
the second full-connection submodule is used for carrying out data processing through a second full-connection layer based on the first depth pooling data to obtain a first depth vector;
a fusion feature obtaining sub-module, configured to perform channel attention weighting processing through a first color vector and a first depth vector based on the first color image data and the first calibration depth data, to obtain the first fusion feature map; the first color vector is used for indicating the weight corresponding to the first color image data; the first depth vector is used to indicate a weight to which the first depth image data corresponds.
In one possible implementation, the apparatus further includes:
the third image acquisition module is used for acquiring a third sample image; the third sample image includes third sample color image data and third sample depth image data;
a third estimation data obtaining module, configured to obtain third sample estimation depth data based on the third sample color image data;
a third calibration data obtaining module, configured to obtain third sample calibration depth data based on the third sample estimated depth data and the third sample depth image data;
a third fused feature obtaining module, configured to perform weighting processing on a feature fusion branch in a target area determination model based on the third sample color image data and the third sample calibration depth data, to obtain a third sample fused feature map;
and the region determination model training module is used for training the target region determination model based on the third sample fusion feature map and the target region corresponding to the third sample image.
In one possible implementation, the apparatus further includes:
the third color characteristic acquisition module is used for carrying out data processing through a color image processing branch in the target area determination model based on the third sample color image data to obtain a third sample color characteristic diagram;
a third depth feature obtaining module, configured to perform data processing through a depth image processing branch in the target region determination model based on the third sample depth image data, so as to obtain a third sample color feature map;
the region determination model training module is further configured to,
and training the target area determination model based on the third sample color feature map, the third sample depth feature map, the third sample fusion feature map and the target area corresponding to the third sample image.
In yet another aspect, a target area determination apparatus is provided, the apparatus comprising:
the third sample image acquisition module is used for acquiring a third sample image; the third sample image includes third sample color image data and third sample depth image data;
a third sample estimation obtaining module, configured to obtain third sample estimation depth data based on the third sample color image data; the third sample estimated depth data is used to indicate depth information to which the third sample color image data corresponds;
a third sample calibration acquisition module, configured to obtain third sample calibration depth data based on the third sample estimated depth data and the third sample depth image data;
a third sample fusion feature obtaining module, configured to perform weighting processing on a feature fusion branch in a target area determination model based on the third sample color image data and the third sample calibration depth data, to obtain a third sample fusion feature map;
the region determination model training module is used for training the target region determination model based on the third sample fusion feature map and a target region corresponding to the third sample image;
the trained target area determination model is used for processing color image data corresponding to the first image and calibration depth data corresponding to the first image to obtain a target area corresponding to the first image.
In yet another aspect, a computer-readable storage medium is provided, in which at least one instruction, at least one program, a set of codes, or a set of instructions is stored, which is loaded and executed by a processor to implement the above-mentioned target area determination method.
In yet another aspect, a computer program product or computer program is provided that includes computer instructions stored in a computer-readable storage medium. The processor of the computer device reads the computer instructions from the computer-readable storage medium, and the processor executes the computer instructions to cause the computer device to execute the target area determination method.
The beneficial effects brought by the technical scheme provided by the embodiment of the application at least comprise:
obtaining estimated depth data corresponding to the first image through first color image data in the first image, correcting the first depth image data corresponding to the first image according to the estimated depth data to obtain calibrated depth data, fusing the calibrated depth data and the color image data, and determining a target area according to a fused fusion feature map. According to the scheme, the depth information corresponding to the first image is estimated through the color image, the depth image corresponding to the first image is corrected, the target area corresponding to the first image is obtained according to the corrected depth image data and the color image data, and the accuracy of determining the target area is improved.
Drawings
The accompanying drawings, which are incorporated in and constitute a part of this specification, illustrate embodiments consistent with the present application and together with the description, serve to explain the principles of the application.
FIG. 1 illustrates a schematic diagram of a computer system provided by an exemplary embodiment of the present application;
FIG. 2 is a flow diagram illustrating a target area determination method according to an exemplary embodiment;
FIG. 3 is a flow diagram illustrating a target area determination method according to an exemplary embodiment;
FIG. 4 is a method flow diagram illustrating a target area determination method in accordance with an exemplary embodiment;
FIG. 5 is a diagram illustrating an RGB-D image channel according to the embodiment shown in FIG. 4;
FIG. 6 is a schematic view of a channel attention weighting scheme according to the embodiment of FIG. 4;
FIG. 7 is a schematic diagram illustrating cross-modal feature fusion according to the embodiment shown in FIG. 4;
FIG. 8 is a diagram illustrating a model network framework to which the embodiment shown in FIG. 4 relates;
FIG. 9 is a block flow diagram illustrating a target area determination method in accordance with an exemplary embodiment;
fig. 10 is a block diagram illustrating a structure of a target area determining apparatus according to an exemplary embodiment;
fig. 11 is a block diagram illustrating a structure of a target area determining apparatus according to an exemplary embodiment;
FIG. 12 is a block diagram illustrating a computer device according to an example embodiment.
Detailed Description
To make the objects, technical solutions and advantages of the present application more clear, embodiments of the present application will be described in further detail below with reference to the accompanying drawings.
First, terms related to embodiments of the present application will be described.
1) Artificial Intelligence (AI)
Artificial intelligence is a theory, method, technique and application system that uses a digital computer or a machine controlled by a digital computer to simulate, extend and expand human intelligence, perceive the environment, acquire knowledge and use the knowledge to obtain the best results. In other words, artificial intelligence is a comprehensive technique of computer science that attempts to understand the essence of intelligence and produce a new intelligent machine that can react in a manner similar to human intelligence. Artificial intelligence is the research of the design principle and the realization method of various intelligent machines, so that the machines have the functions of perception, reasoning and decision making.
The artificial intelligence technology is a comprehensive subject and relates to the field of extensive technology, namely the technology of a hardware level and the technology of a software level. The artificial intelligence infrastructure generally includes technologies such as sensors, dedicated artificial intelligence chips, cloud computing, distributed storage, big data processing technologies, operation/interaction systems, mechatronics, and the like. The artificial intelligence software technology mainly comprises a computer vision technology, a voice processing technology, a natural language processing technology, machine learning/deep learning and the like.
2) Computer Vision (Computer Vision, CV)
Computer vision is a science for researching how to make a machine "see", and further, it means that a camera and a computer are used to replace human eyes to perform machine vision such as identification, tracking and measurement on a target, and further image processing is performed, so that the computer processing becomes an image more suitable for human eyes to observe or transmitted to an instrument to detect. As a scientific discipline, computer vision research-related theories and techniques attempt to build artificial intelligence systems that can capture information from images or multidimensional data. The computer vision technology generally includes image processing, image Recognition, image semantic understanding, image retrieval, Optical Character Recognition (OCR), video processing, video semantic understanding, video content/behavior Recognition, three-dimensional object reconstruction, 3D technology, virtual reality, augmented reality, synchronous positioning, map construction, and other technologies, and also includes common biometric technologies such as face Recognition and fingerprint Recognition.
3) Machine Learning (Machine Learning, ML)
Machine learning is a multi-field cross discipline, and relates to a plurality of disciplines such as probability theory, statistics, approximation theory, convex analysis, algorithm complexity theory and the like. The special research on how a computer simulates or realizes the learning behavior of human beings so as to acquire new knowledge or skills and reorganize the existing knowledge structure to continuously improve the performance of the computer. Machine learning is the core of artificial intelligence, is the fundamental approach for computers to have intelligence, and is applied to all fields of artificial intelligence. Machine learning and deep learning generally include techniques such as artificial neural networks, belief networks, reinforcement learning, transfer learning, inductive learning, and teaching learning.
4) Depth image (RGB-D, Red Green Blue-Depth)
In 3D computer graphics, the RGB color scheme is a color standard in the industry, and various colors are obtained by changing three color channels of red (R), green (G), and blue (B) and superimposing them on each other, where RGB represents the colors of the three channels of red, green, and blue, the color standard includes almost all colors that can be perceived by human vision, and is one of the most widely used color systems, and the RGB-D image scheme is one in which depth map information is added on the basis of the RGB color scheme. A Depth Map (Depth Map) is an image or image channel containing information about the distance of the surface of a scene object of a viewpoint. Where the Depth Map is similar to a grayscale image except that each pixel value thereof is the actual distance of the sensor from the object. Usually, the RGB image and the Depth image are registered, so that there is a one-to-one correspondence between the pixel points.
The target area determining method provided by the embodiment of the application can be applied to computer equipment with stronger data processing capacity. In one possible implementation, the target area determination provided by the embodiment of the application can be applied to a personal computer, a workstation or a server. In one possible implementation, the training of the confidence discrimination model, the depth estimation model, and the target region determination model according to the embodiments of the present application is performed by a personal computer, a workstation, or a server. In a possible implementation manner, the confidence coefficient discrimination model, the depth estimation model and the target region determination model trained by the training method provided by the embodiment of the application can be applied to an application scene needing salient target detection, so that the target region corresponding to the RGB-D image is determined by the acquired RGB-D image, and the accuracy of determining the target region in the RGB-D image is improved.
Referring to FIG. 1, a schematic diagram of a computer system provided by an exemplary embodiment of the present application is shown. The computer system includes a terminal 110 and aserver 120, wherein the terminal 110 and theserver 120 perform data communication through a communication network, optionally, the communication network may be a wired network or a wireless network, and the communication network may be at least one of a local area network, a metropolitan area network, and a wide area network.
The terminal 110 has an application program with an image processing function installed therein, and the application program may be a virtual reality application program, a game application program, an image processing program, or an Artificial Intelligence (AI) application program with an image processing function, which is not limited in this embodiment.
Optionally, the terminal 110 may be a mobile terminal such as a smart phone, a tablet computer, a laptop portable notebook computer, or the like, or may be a terminal such as a desktop computer, a projection computer, or the like, or an intelligent terminal having an RGB-D image acquisition component and a data processing component, which is not limited in this embodiment of the present application.
Theserver 120 may be implemented as one server, or may be implemented as a server cluster formed by a group of servers, which may be physical servers, or may be implemented as a cloud server. In one possible implementation, theserver 120 is a backend server for applications in theterminal 110.
In a possible implementation manner of this embodiment, theserver 120 trains the target area determination model through a preset training sample set, where the training sample set may include RGB-D sample images. After the training process of the target area determination model by theserver 120 is completed, the trained target area determination model is sent to the terminal 110 through wired or wireless connection. The terminal 110 receives the trained target area determination model, and inputs data information corresponding to the target area determination model into an application program with an image processing function, so that when a user calls the image processing function by using the application program, the target area determination can be performed according to the trained target area determination model, so as to implement all or part of steps of the target area determination function.
Fig. 2 is a flowchart illustrating a target area determination method according to an exemplary embodiment. The method may be performed by a computer device, which may be an image processing device, wherein the image processing device may be the terminal 110 in the embodiment illustrated in fig. 1 described above. As shown in fig. 2, the flow of the target area determination method may include the following steps:
To sum up, in the scheme shown in the embodiment of the present application, estimated depth data corresponding to a first image is obtained through first color image data in the first image, the first depth image data corresponding to the first image is corrected according to the estimated depth data to obtain calibrated depth data, the calibrated depth data and the color image data are fused, and a target area is determined according to a fused feature map. According to the scheme, the depth information corresponding to the first image is estimated through the color image, the depth image corresponding to the first image is corrected, the target area corresponding to the first image is obtained according to the corrected depth image data and the color image data, and the accuracy of determining the target area is improved.
Fig. 3 is a flowchart illustrating a target area determination method according to an exemplary embodiment. The method may be performed by a computer device, which may be a model training device, wherein the model training device may be theserver 120 in the embodiment illustrated in FIG. 1 described above. As shown in fig. 3, the flow of the target area determination method may include the following steps:
The trained target area determination model is used for processing color image data corresponding to the first image and calibration depth data corresponding to the first image to obtain a target area corresponding to the first image.
To sum up, in the scheme shown in the embodiment of the present application, estimated depth data corresponding to a first image is obtained through first color image data in the first image, the first depth image data corresponding to the first image is corrected according to the estimated depth data to obtain calibrated depth data, the calibrated depth data and the color image data are fused, and a target area is determined according to a fused feature map. According to the scheme, the depth information corresponding to the first image is estimated through the color image, the depth image corresponding to the first image is corrected, the target area corresponding to the first image is obtained according to the corrected depth image data and the color image data, and the accuracy of determining the target area is improved.
Fig. 4 is a method flow diagram illustrating a target area determination method according to an example embodiment. The method may be performed by a model processing device, which may be theserver 120 in the above-described embodiment shown in fig. 1, together with an image processing device, which may be the terminal 110 in the above-described embodiment shown in fig. 1. As shown in fig. 4, the flow of the target area determination method may include the following steps:
The first image comprises first color image data and first depth image data.
In a possible implementation manner, the first image is an RGB-D image, that is, the first image includes an RGB image and a Depth Map (Depth Map), that is, the first color image data is image data corresponding to the RGB image included in the first image, and the first Depth image data is image data corresponding to the Depth Map included in the first image.
In one possible implementation, at least two image channels exist in the first image, and the at least two image channels include a color (RGB) image channel and a Depth (Depth) image channel.
Please refer to fig. 5, which illustrates a RGB-D image channel diagram according to an embodiment of the present application. As shown in fig. 5, when the first image is an RGB-D image, the color image data corresponding to theRGB image 501 in the first image is shown aspart 502 in fig. 5, and in thecolor image data 502, there are three image channels, respectively, wherein the three image channels correspond to pixel data corresponding to three primary colors of red, green, and blue, respectively; depth image data corresponding to adepth image 503 in the first image is shown aspart 504 in fig. 5, and in thedepth image data 504, a depth image channel exists, and each data in the depth image channel is used for indicating pixel data of each pixel point in the depth image.
In one possible implementation, the first color image data is an RGB image included in the first image; the first depth image data is a depth image included in the first image.
In another possible implementation manner, the first color image data is obtained by performing feature extraction based on an RGB image included in the first image; the first depth image data is obtained by performing feature extraction based on a depth image included in the first image.
Wherein the confidence level is used to indicate the accuracy of the image data corresponding to the target region in the first depth image data.
Since the accuracy of the depth acquisition device is generally not high and is easily affected by the natural environment, the accuracy of the first color image data included in the first image acquired by the depth acquisition device is generally not high, and therefore, a judgment can be made on the accuracy of the first depth image data through the confidence of the first depth image data to determine the authenticity of the first depth image data. When the confidence of the first depth image data is higher, the data in the first depth image data has higher reliability, so that the result obtained by processing the first depth image data is more real; when the confidence of the first depth image data is low, it indicates that the data in the first depth image data does not have sufficient reliability, and therefore, the result obtained by processing the first depth image data does not have sufficient confidence.
In a possible implementation manner, based on the first depth image data, processing is performed through a confidence coefficient discrimination model, so as to obtain a confidence coefficient corresponding to the first depth image data.
The confidence coefficient distinguishing model is a machine learning model trained by taking a first sample image as a sample and taking a confidence type corresponding to the first sample image as a label.
In a possible implementation manner, the confidence type corresponding to the first sample image may include a positive sample and a negative sample, and when the confidence type of the first sample image is the positive sample, it indicates that the first sample image is the sample image with higher accuracy, and when the confidence type of the first sample image is the negative sample, it indicates that the first sample image is the sample image with lower accuracy.
In a possible implementation manner, the first depth image data is input into the confidence coefficient discrimination model, and a confidence coefficient probability distribution corresponding to the first depth image data is obtained, where the confidence coefficient probability distribution includes a probability that the first depth image data is a positive sample and a probability that the first depth image data is a negative sample; and acquiring the probability that the first depth image data is a positive sample as the confidence corresponding to the first depth image data.
Wherein the first depth image data is image data of which a positive sample represents that the first depth image data is credible; the negative examples of the first depth image data represent image data for which the first depth image data is not authentic.
In one possible implementation, a first set of training samples is obtained; the first training sample set comprises a first sample image and a confidence type corresponding to the first sample image; based on the first sample image, performing data processing through the confidence coefficient discrimination model to obtain a confidence probability corresponding to the first sample image; the confidence probability is indicative of a probability that the first sample image is a positive sample; and training the confidence coefficient distinguishing model based on the confidence probability corresponding to the first sample image and the confidence type corresponding to the first sample image.
In the process of training the confidence coefficient discrimination model, the first sample image included in the first training sample set may be input into the confidence coefficient discrimination model, so as to obtain a probability distribution corresponding to the first sample image. The probability distribution corresponding to the first sample image comprises the probability of the first sample image corresponding to the positive sample and the probability of the first sample image corresponding to the negative sample, wherein the confidence probability corresponding to the first sample image is the probability of the first sample image corresponding to the positive sample. And training the confidence coefficient discrimination model according to the confidence type corresponding to the first sample image and the confidence probability corresponding to the first sample image, wherein the trained confidence coefficient discrimination model can perform data processing on the input image data to obtain the confidence probability of the input image data.
In a possible implementation manner, the first sample image is a depth image, and the confidence coefficient discrimination model trained according to the first sample image can realize the judgment of the confidence coefficient of the depth image.
In another possible implementation manner, the first sample image includes a depth image and an RGB color image, so that the confidence level discrimination model trained according to the first sample image can judge the confidence level of the depth image and can also judge the confidence level of the RGB color image.
In one possible implementation, the confidence discrimination model may be a machine learning model that includes convolutional layers and fully-connected layers.
The convolution layer in the confidence judgment model extracts the features of the input first sample image, performs linear conversion on the extracted features through a full connection layer to obtain a two-dimensional confidence vector corresponding to the first sample image, and obtains probability distribution corresponding to the first sample image based on the confidence vector.
In one possible implementation, in response to the first sample image including a depth image and an RGB color image, the confidence discrimination model may further include a depth confidence discrimination branch and a color confidence discrimination branch.
When the first sample image contains the depth image and the RGB color image, because the depth image and the RGB color image belong to images of different modalities, when the confidence degrees of the depth image and the RGB color image are trained simultaneously through the same machine-learned model structure, the possibly actual confidence degree discrimination effect of the trained machine-learned model is poor. Therefore, the confidence coefficient distinguishing model can include a depth confidence distinguishing branch and a color confidence distinguishing branch, the depth confidence distinguishing branch is obtained based on the depth image in the first sample image and the confidence class training corresponding to the depth image in the first sample image, and the color confidence distinguishing branch is obtained based on the color image in the first sample image and the confidence class training corresponding to the color image in the first sample image.
The trained confidence coefficient distinguishing model has a good distinguishing effect on the confidence coefficient of the color image and the confidence coefficient of the depth image.
In a possible implementation manner, when the depth image and the RGB color image are included in the first sample image, the confidence type of the first sample image may include a confidence type corresponding to the depth image in the first sample image and a confidence type corresponding to the color image in the first sample image, respectively.
The confidence type corresponding to the depth image in the first sample image and the confidence type corresponding to the color image in the first sample image may be the same confidence type or different confidence types. For example, when the precision of the color image and the precision of the depth image in the first sample image are both high, the confidence type corresponding to the color image in the first sample image may be a positive sample, and the confidence type corresponding to the depth image in the first sample image is also a positive sample; when the precision of the color image in the first sample image is high, but the precision of the depth image in the first sample image is low, the confidence type corresponding to the depth image in the first sample image is a negative sample, and the confidence type corresponding to the color image in the first sample image is a negative sample.
In one possible implementation, a second set of training samples is obtained; the second training sample set comprises training sample images and target areas corresponding to the training sample images; the training sample image comprises training color sample data and training depth sample data; determining a color image processing branch in the model through the target area, and processing the training color sample data to obtain a prediction area corresponding to the training color sample data; determining a depth image processing branch in the model through the target area, and processing the training depth sample data to obtain a prediction area corresponding to the training depth sample data; determining a confidence score of the training sample image based on the prediction region corresponding to the training color sample data, the prediction region corresponding to the training depth sample data and the target region corresponding to the training sample image; in response to the confidence score of the training sample image satisfying a specified condition, a confidence type of the training sample image is determined, and the training sample image is determined to be the first sample image.
The color image processing branch in the target area determination model is a machine learning model obtained by pre-training by taking a sample color image as a sample and taking a target area corresponding to the sample color image as a label; the depth image processing branch in the target area determination model is a machine learning model obtained by pre-training with a sample depth image as a sample and a target area corresponding to the sample depth image as an annotation.
The second training sample set comprises training sample images and target areas corresponding to the training sample images, and for one of the training sample images in the second training sample set, the training sample image comprises training color sample data and training depth sample data, and the training color sample data and the training depth sample data correspond to the target area corresponding to the training sample image.
The training color sample data is subjected to data processing through a color image processing branch in a target area determination model to obtain a prediction area corresponding to the training color sample data; the training depth sample data is subjected to data processing through a depth image processing branch in a target region determination model to obtain a prediction region corresponding to the training depth sample data, the confidence type of the training sample image can be determined according to the prediction region corresponding to the training color sample data, the prediction region corresponding to the training depth sample data and the target region, and the training of the confidence discrimination model is realized through the first sample image determined by the training sample image.
In a possible implementation manner, the sample color image is used as a training sample and input into a color image processing branch in the target area determination model, and a prediction area corresponding to the sample color image is obtained; and training the color image processing branch in the target area determination model based on the prediction area corresponding to the sample color image and the target area corresponding to the sample color image to obtain the color image processing branch after pre-training. The color image processing branch after pre-training can process the input color image to obtain the corresponding prediction region in the color image, and at this time, it can be considered that when the quality of the input color image is better, the coincidence degree of the prediction region of the input color image and the target region actually corresponding to the color image should be higher, so that according to the coincidence degree of the prediction region of the color image and the target region actually corresponding to the color image, whether the color image is the color image with better quality can be determined, and the confidence coefficient of the color image can be obtained.
Inputting the sample depth image as a training sample into a depth image processing branch in the target area determination model to obtain a prediction area corresponding to the sample depth image; and training the depth image processing branch in the target area determination model based on the prediction area corresponding to the sample depth image and the target area corresponding to the sample depth image to obtain the depth image processing branch after pre-training. The pre-trained depth image processing branch may process an input depth image to obtain a prediction region in the depth image, and at this time, it may be considered that when the quality of the input depth image is good, the coincidence degree of the prediction region of the input depth image and a target region actually corresponding to the depth image should be high, so that it may be determined whether the depth image is a depth image with good quality according to the coincidence degree of the prediction region of the depth image and the target region actually corresponding to the depth image, and obtain the confidence of the depth image.
In one possible implementation, the confidence score includes a color confidence score and a depth confidence score; determining a color confidence score corresponding to the training sample image based on the contact ratio between a prediction region corresponding to the training color sample data and a target region corresponding to the training sample image; and determining a depth confidence score corresponding to the training sample image based on the contact ratio between the prediction region corresponding to the training depth sample data and the target region corresponding to the training sample image.
Wherein the confidence scores comprise color confidence scores and depth confidence scores; the color confidence score is determined based on the contact degree between the prediction region corresponding to the training color sample data and the target region corresponding to the training sample image, and the higher the contact degree between the prediction region corresponding to the training color sample data and the target region corresponding to the training sample image is, the higher the color confidence score corresponding to the training sample image is; the depth confidence score is determined based on the contact degree between the prediction region corresponding to the training depth sample data and the target region corresponding to the training sample image, and the higher the contact degree between the prediction region corresponding to the training depth sample data and the target region corresponding to the training sample image is, the higher the depth confidence score corresponding to the training sample image is.
In one possible implementation, in response to the depth confidence score of the training sample image satisfying a specified condition, a confidence type of the training sample image is obtained, and the training sample image is obtained as a first sample image.
In one possible implementation, in response to the depth confidence score of the training sample image being greater than a first confidence threshold, the confidence type of the training sample image is determined to be a positive sample, and the training sample image is acquired as a first sample image.
In one possible implementation, in response to the depth confidence score of the training sample image being less than a second confidence threshold, the confidence type of the training sample image is determined to be a negative sample, and the training sample image is acquired as a first sample image.
When the depth confidence score of the training sample image is greater than a first confidence threshold value, namely a prediction region obtained after data processing is carried out on training depth sample data corresponding to the training sample image through a depth image processing branch in a target region determination model, the coincidence degree with the target region is high, the training depth sample data in the training sample image can be regarded as data with high confidence level, so that the confidence type of the training sample image is determined as a positive sample, and the training sample image is determined as a first sample image, so that training on a confidence level discrimination model is realized; when the depth confidence score of the training sample image is smaller than a second confidence threshold value, that is, the prediction region obtained after the training depth sample data corresponding to the training sample image is subjected to data processing through the depth image processing branch in the target region determination model is low in overlap with the target region, the training depth sample data in the training sample image can be regarded as data with low confidence, so that the confidence type of the training sample image is determined as a negative sample, the training sample image is determined as a first sample image, the training of the confidence discrimination model is realized, and at this time, the confidence discrimination model obtained after training through a sufficient number of training sample images can realize the confidence judgment of the input sample image, so as to determine the quality of the depth image data in the input sample image.
In a possible implementation manner, based on each training sample image in the second training sample set, determining a depth image processing branch in the model through a target region respectively, and determining a depth confidence score corresponding to each training sample image respectively; and sequencing the depth confidence scores corresponding to the training sample images from large to small, determining the confidence type of the training sample image with the depth confidence score of the first a% in the training sample images as a positive sample, and acquiring the positive sample image as a first sample image, wherein a is larger than 0.
In another possible implementation manner, the confidence type of the training sample image with the depth confidence score of the last b% in each training sample image is determined as a negative sample, and is obtained as the first sample image, wherein b is greater than 0.
At this time, the training sample image with the depth confidence score of the first a% in the second training sample set may be regarded as a training sample image with higher accuracy, so that the depth image data of the training sample image of the first a% is more accurate data, and at this time, the training sample image of the first a% may be acquired as a first sample image and determined as a positive sample; the training sample image with the depth confidence score of b% in the second training sample set can be regarded as a training sample image with low accuracy, so that the training sample image with b% in the second training sample set can be also acquired as the first sample image and determined as a negative sample, so as to realize training of the confidence coefficient discrimination model.
In one possible implementation, in response to the depth confidence score and the color confidence score of the training sample image satisfying a specified condition, a confidence type of the training sample image is obtained, and the training sample image is obtained as a first sample image.
The confidence type of the training sample image may also be determined according to the training depth sample data of the training sample image and the confidence score of the training color image data.
In one possible implementation, in response to the depth confidence score of the training sample image being greater than the color confidence score of the training sample image, the confidence type of the training sample image is captured as a positive sample and the training sample image is captured as a first sample image for training a confidence discriminative model.
Because the accuracy of the RGB image in the training sample image (i.e., the RGB-D image) is generally higher than that of the depth image, when the depth confidence score corresponding to the depth image is greater than the color confidence score for the RGB image pair, it is indicated that the training depth sample image has more accurate information of the target region than the training color sample image in the training sample image, and the training sample image may also be acquired as the first sample image to train the model.
Instep 403, first estimated depth data is obtained based on the first color image data.
The first estimated depth data is obtained based on the first color image data, i.e., the first estimated depth data is depth information of a first image contained in the first color image.
In one possible implementation, the first estimated depth data is obtained by performing data processing through a depth estimation model based on the first color image data.
The depth estimation model is a machine learning model trained by taking a second sample image as a sample and taking depth image data corresponding to the second sample image as a label; the second sample image is a sample image whose confidence satisfies a first specified condition.
In one possible implementation, the second sample image is a sample image with a confidence level greater than a third confidence threshold.
In another possible implementation manner, an estimation model training sample set is obtained, and the estimation model training sample set comprises at least two estimation sample images; the estimated sample image comprises color image data and depth image data; and training depth image data of each estimation sample image in the sample set based on the estimation model, performing data processing through the confidence degree discrimination model to obtain depth confidence scores corresponding to the estimation sample images respectively, and obtaining the depth confidence scores in the estimation sample images meeting the confidence condition as the second sample image.
In a possible implementation manner, the depth confidence scores corresponding to each estimation sample image in the estimation model training sample set are obtained, the depth confidence scores corresponding to each estimation sample image are ranked from large to small, and the estimation sample image with the confidence score of the top c% in each estimation sample image is obtained as the second sample image.
That is, according to the above-mentioned scheme, an estimated sample image with a high depth confidence score can be screened out and obtained as a second sample image, where the second sample image includes depth image data and color image data, and the depth confidence score is high, which indicates that the quality of the depth image data corresponding to the second sample image is good, so that a depth estimation model trained by using the second sample image as a sample (i.e., using the color image data corresponding to the second sample image as a sample) and using the depth image data corresponding to the second sample image as a label can obtain the depth image data with good quality through data processing based on the input color image data, so as to achieve estimation of the depth image data of the second sample image through the color image data corresponding to the second sample image.
In a possible implementation manner, the confidence corresponding to the first depth image is obtained by performing data processing according to the first depth image data through the confidence discrimination model, that is, the confidence corresponding to the first depth image data may be used to indicate the accuracy of the first depth image data in the first image, and the first estimated depth data is depth image data obtained by processing first color image data corresponding to the first image based on the depth estimation model, so that the first estimated depth data and the first depth image data are weighted and summed based on the confidence corresponding to the first depth image data to obtain first calibrated depth data, the first calibrated depth data is compared with the directly obtained first depth image data, which considers the accuracy of the first depth image data itself and combines depth information included in the first color image, therefore, the first calibration depth image data can more accurately represent the depth information of the first image.
In one possible implementation manner, based on the first color image data and the first calibration depth data, the first fused feature map is obtained by performing attention-based weighting processing on a feature fusion branch in a target region determination model.
In one possible implementation, the feature fusion branch includes a first pooling layer, a second pooling layer, a first fully-connected layer, and a second fully-connected layer; performing global pooling through a first pooling layer based on the first color image data to obtain first color pooling data; performing data processing through a first full-connection layer based on the first color pooling data to obtain a first color vector; performing global pooling through a second pooling layer based on the first depth image data to obtain first depth pooling data; based on the first depth pooling data, performing data processing through a second full-link layer to obtain a first depth vector; based on the first color image data and the first calibration depth data, channel attention weighting processing is performed through a first color vector and a first depth vector to obtain the first fusion feature map.
The first color vector is used for indicating the weight corresponding to the first color image data; the first depth vector is used to indicate a corresponding weight of the first depth image data.
In the process of fusing the first color image data and the first calibration depth data to obtain the first fused feature map, the first color image data may be globally pooled through a first pooling layer to obtain the first color pooled data, and the first color pooled data may represent an overall data size of the first color image data, that is, an importance degree of the first color image data to the target area. According to the first color pooling data, performing data processing through a first full-connection layer, namely converting the data into a first color vector through linear conversion, wherein the first color vector can be used for indicating the weight ratio of each channel in the first color image data (the weight ratio indicates the importance of the characteristics of each channel); the first depth pooling data may be obtained by globally pooling the first depth image data through a second pooling layer, and the first depth pooling data may represent an overall data size of the first depth pooling data, that is, an importance degree of the first depth image data to the target area. And performing data processing through a second full-link layer according to the first depth pooling data, namely, linearly converting the data into a first depth vector, wherein the second depth vector can indicate the weight proportion of an image channel corresponding to the first depth image data, and performing attention weighting processing of the channels according to the first color vector and the first depth vector and then performing fusion to obtain the first fusion feature map.
Please refer to fig. 6, which illustrates a schematic diagram of a channel attention weighting according to an embodiment of the present application. As shown in fig. 6. For afeature map 601 with a channel of C and a size of W × H, firstly, global pooling is performed on feature maps of all channels to obtain an average feature map, the average feature map is transformed by a layer of full connection layer to form a channel attention value, and finally, the channel attention value is multiplied by all the channel feature maps to form a channelattention feature map 602. Because the channel attention mechanism is mapped into a channel attention value through a full connection layer according to the respective corresponding mean values of the channels, the attention feature map obtained after weighting according to the channel attention value will pay more attention to the channel with a larger mean value (i.e., the image feature of the channel with a larger mean value corresponds to a larger weight).
Please refer to fig. 7, which illustrates a cross-modal feature fusion diagram according to an embodiment of the present application. As shown in fig. 7, for firstcolor image data 701 corresponding to a first image, the firstcolor image data 701 may be input into a GAP (Global Average Pooling)first Pooling layer 702 for Global Pooling, and a value obtained after Global Pooling may be input into an FC (full connected) first Fully connectedlayer 703 and then processed by anactivation function 704 to obtain acolor vector 705 corresponding to the first color image data.
For the firstdepth image data 706 corresponding to the first image, the firstdepth image data 706 may be input to the GAPsecond pooling layer 707 to perform global pooling, and a value obtained after the global pooling may be input to the FC secondfull link layer 708 and then processed by anactivation function 709, so as to obtain adepth vector 710 corresponding to the first depth image data.
The first color image data may be image features obtained by feature extraction based on an RGB image of the first image; the first depth image data may be an image feature obtained by performing feature extraction based on a depth image of the first image.
Thecolor vector 705 and thedepth vector 710 can be simultaneously input into the maxvalue obtaining module 711, and the larger value of each dimension in the color vector and the depth vector is obtained as the most valuedvector 712.
For the firstcolor image data 701, thecolor vector 705 is used as the weight of the channel attention to perform channel attention weighting, so as to obtain a first color weighted feature map; the firstcolor image data 701 performs channel attention weighting according to the weight of the most valued vector as channel attention to obtain a second color weighted feature map; then, the first color-weighted feature map and the second color-weighted feature map are fused to obtain thecolor feature map 713. For the firstdepth image data 706, thedepth vector 710 is used as a channel attention weight to perform channel attention weighting, so as to obtain a first depth weighted feature map; the firstdepth image data 706 performs channel attention weighting according to the most significant vector as the weight of channel attention to obtain a second depth weighted feature map; the first depth weighted feature map and the second depth weighted feature map are fused to obtain thedepth feature map 714. Finally, thecolor feature map 713 and thedepth feature map 714 are input into a convolution module C to realize the fusion of the color feature map and the depth feature map, so as to obtain the fusedfeature map 715.
That is, fig. 7 described above shows a cross-reference module according to an embodiment of the present application. After the depth image data is corrected, the corrected depth image and the RGB image are input into a double-current feature extraction network (namely a color image processing branch and a depth image processing branch at a pre-training position) together, and multi-level features are generated. Features extracted from the RGB channel contain rich semantic information and texture information, and features from the depth channel contain more discriminative scene layout clues and are complementary with the RGB features. The embodiment of the present application proposes a cross-reference module as a fusion strategy for cross-modal features, and is illustrated in fig. 7. The proposed cross-referencing module aims at mining and combining the most distinctive channels of depth and RGB features (i.e. feature detectors) and generating more informative features. I.e. given the two input features generated by the RGB and depth streams, global statistics for the RGB view and depth view are first obtained using global average pooling. And then inputting the two feature vectors into a full connection layer and a softmax activation function respectively to obtain channel attention vectors which respectively reflect the importance of the RGB feature and the depth feature. Then, note that the vector is applied to the input features in a channel multiplication. In this way, the cross-referencing module will focus specifically on important features while suppressing unnecessary scene understanding features. Based on the decoded RGB and depth features, a convolutional layer is used to generate cross-modal fusion features. In addition, one triplet loss constrains the cross-modal fusion features, so that the fusion features are closer to the foreground, and the distance between the foreground features and the background features is enlarged.
In a possible implementation manner, based on the first color image data, performing data processing through a depth image processing branch in the target area determination model to obtain a first color feature map; based on the first depth image data, performing data processing through a depth image processing branch in a target area determination model to obtain a first depth feature map; and determining a target area corresponding to the first image based on the first fusion feature map, the first depth feature map and the first color feature map.
The target area determination model is a machine learning model obtained by training with a third sample image as a sample and a target area corresponding to the third sample image as an annotation.
The target region corresponding to the first image may be obtained by simultaneously considering a first depth feature map corresponding to the first image, a first color feature map corresponding to the first image, and a first fusion feature map corresponding to the first image. The first depth feature map corresponding to the first image is obtained by inputting the first depth image data into a depth image processing branch in the target area determination model, so that the first depth feature map can indicate a prediction area corresponding to the first depth image data; the first color feature map corresponding to the first image is obtained by inputting the first color image data into a color image processing branch in the target area determination model, so that the first color feature map can indicate a prediction area corresponding to the first color image data; on the basis of the first fusion feature map, the target region is obtained by considering the first color feature map and the first depth feature map, so that the original features in the color feature map and the original features in the depth feature map are considered while the first fusion feature map is obtained after depth image data are calibrated, and the identification accuracy of the target region is improved.
In one possible implementation, a third sample image is obtained; the third sample image comprises third sample color image data and third sample depth image data; obtaining third sample estimated depth data based on the third sample color image data; obtaining third sample calibration depth data based on the third sample estimated depth data and the third sample depth image data; based on the third sample color image data and the third sample calibration depth data, performing weighting processing through a feature fusion branch in a target area determination model to obtain a third sample fusion feature map; and training the target area determination model based on the third sample fusion feature map and the target area corresponding to the third sample image.
In the process of determining a model for a target area, acquiring the third sample image and a target area corresponding to the third sample image, where the third sample image includes the third sample color image data and the third sample depth image data, so that the third sample depth image data may be calibrated according to the third sample color image data and the third sample depth image data to obtain the third sample calibration depth data, and fusion of image features of different modalities is implemented according to the third sample calibration depth data and the third sample color image data to obtain the third sample fusion feature map, and a prediction area corresponding to the third sample image is determined based on the third sample fusion feature map, and then the prediction area corresponding to the third sample image and the target area corresponding to the third sample image are combined, the target region determination model is trained.
In a possible implementation manner, based on the third sample color image data, performing data processing through a color image processing branch in the target area determination model to obtain a third sample color feature map; based on the third sample depth image data, performing data processing through a depth image processing branch in the target area determination model to obtain a third sample color feature map; and training the target area determination model based on the third sample color feature map, the third sample depth feature map, the third sample fusion feature map and the target area corresponding to the third sample image.
Because the target area determination model comprises a color image processing branch, a depth image processing branch and a feature fusion branch, the third sample color image data can be processed through the color image processing branch to obtain a third sample color feature map corresponding to the third sample color image data; processing the third sample depth image data through a depth image processing branch to obtain a third sample depth feature map corresponding to the third sample depth image data; and simultaneously training the target area determination model based on the third sample color feature map, the third sample depth feature map, the third sample fusion feature map and the target area corresponding to the third sample image, wherein the trained target area determination model can simultaneously process color image data to obtain a feature map corresponding to the color image data, process depth image data to obtain a feature map corresponding to the depth image data, and fuse color image data and calibrated depth image data to obtain a fusion feature map, wherein the feature maps are all used for indicating respectively corresponding prediction areas, so that the target area determination model can respectively obtain a prediction area corresponding to the color image data according to the color image data, obtain a prediction area corresponding to the depth image data according to the depth image data, and obtain a fusion feature map pair according to the color image data and the calibrated depth image data And acquiring a target area of the input image according to the three prediction areas.
In one possible implementation, the overall optimization objective L of the networktotalConsists of 4 parts including cross entropy loss for RGB, depth and blend branches and triplet loss in the cross reference module as follows:

wherein L isRGB、LDepth and LfuseAre loss functions corresponding to the outputs of the three decoders described above, the triplet loss function is associated with each convolution layer, N — 3 represents the number of convolution layers involved in the triplet loss function, and α may be 0.2.
the triplet loss function is associated with each convolution layer, N — 3 represents the number of convolution layers involved in the triplet loss function, and α may be 0.2.

In a possible implementation manner, the cross entropy loss function can also be edge-defined BCE of boundary information to promote learning of the prediction result on the object boundary.
Please refer to fig. 8, which illustrates a model network framework diagram according to an embodiment of the present application. As shown in fig. 8, it shows a solution framework of the embodiment of the present application:
for the inputcolor image data 801 of the first image, processing is carried out through a colorimage processing branch 802 in the target area determination model to obtain a color feature map corresponding to the first image; processing the inputdepth image data 803 of the first image through a depthimage processing branch 804 in the target area determination model to obtain a depth feature map corresponding to the first image; inputting the features extracted from part of the convolutional layer in the colorimage processing branch 802 and the features extracted from part of the convolutional layer in the depthimage processing branch 804 into a feature fusion branch formed by a cross reference module CRM to obtain a fusion feature map; and respectively decoding the color feature map, the depth feature map and the fusion feature map through three decoders, and summing corresponding outputs into a final significance map.
That is, the above-mentioned fig. 8 is based on the dual-flow feature extraction network, and is composed of two core parts, namely, a deep calibration strategy and a fusion strategy. Firstly, a depth calibration strategy is provided to correct potential noise generated by an unreliable original depth map, and the corrected depth can reflect scene layout and identify a foreground region better than the original depth. Given the corrected RGB-D data, the RGB image and the corrected depth are simultaneously input into a dual-stream feature extraction network to generate multi-level features. A fusion strategy cross-referencing module is then designed to integrate efficient cues from RGB features and depth features to cross-modality fusion features, which allows the three decoding branches to process RGB, depth, and fusion features separately. All features are processed separately and the corresponding outputs are summed into a final saliency map.
Salient Object Detection (SOD) is an important computer vision problem that aims to identify and segment the most salient objects in a scene. It has been successfully applied to various tasks such as object recognition, image retrieval, SLAM (simultaneous localization and mapping) and video analysis. To address the challenges inherent in dealing with difficult scenes with low texture contrast or cluttered backgrounds, depth information is included as a supplemental input source, adding depth information as an additional input to the RGB image, and the localization of salient objects can be achieved in challenging scenes.
In the embodiment of the application, the double-flow feature extraction network based on fig. 8 includes two core parts, namely a deep calibration part and a fusion strategy. Based on the dual-stream feature extraction network shown in fig. 8, the embodiment of the present application further proposes a Depth Calibration (DC) strategy to correct potential noise caused by an unreliable original depth map and obtain a calibrated depth. The corrected depth can reflect the scene layout more than the original depth, and the foreground area is identified. Now, given the corrected RGB-D paired data, an RGB image And corrected depth image FiDepthIs input into a dual-flow feature extraction network to generate hierarchical features. For each stream, a codec net is used as a backbone. This is the subsequent fusion strategy: design of cross-reference modules (CRMs) to integrate features, from RGB features and depth features to cross-modality fusion features; this results in three decoding branches processing RGB, depth features and fused hierarchy features. These features are processed separately and the corresponding outputs are summed to a final saliency map Smap。
And corrected depth image FiDepthIs input into a dual-flow feature extraction network to generate hierarchical features. For each stream, a codec net is used as a backbone. This is the subsequent fusion strategy: design of cross-reference modules (CRMs) to integrate features, from RGB features and depth features to cross-modality fusion features; this results in three decoding branches processing RGB, depth features and fused hierarchy features. These features are processed separately and the corresponding outputs are summed to a final saliency map Smap。

Effective spatial information from depth maps plays a crucial role in helping to locate salient areas of challenging scenes, such as cluttered backgrounds and low contrast situations. However, unreliable raw depths and potential depth acquisition errors prevent the model from extracting accurate information from the depth map due to observation distance, occlusion or reflection. In order to solve the performance bottleneck caused by the noise of the depth map, the original depth is calibrated so as to better express the scene layout. Two key problems that this application solves are: 1. how the model learns to distinguish a depth map with poor quality (negative case) from a depth map with good quality (positive case); 2. how to make a corrected/corrected depth map can not only retain the useful clues of a high-quality depth map, but also correct unreliable information in a low-quality depth map. Thus, the present application proposes a Deep Calibration (DC) strategy, which is a core component of DCF. Two successive steps are required to select a representative sample and generate a corrected depth map.
Aiming at the first key problem, a difficulty awareness selection strategy is provided, and the purpose is to select the most typical positive and negative samples in the training database. These samples are then used to train a discriminator/classifier to predict the quality of the depth map, reflecting the reliability of the depth map. Firstly, the same architecture can be used for pre-training two model branches, RGB data and depth data are respectively used as input under the supervision of significance mapping and are respectively recorded as input under the supervision of significance mapping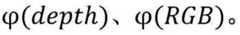 Then, based on the significance of the two baseline model predictions, an option was devised to gauge whether the depth map could provide reliable information. Specifically, from the saliency results produced by the RGB stream and the depth stream, the intersection (IoU) measure between the predicted saliency and the ground-truth saliency of the two streams, denoted iou (depth) and iou (RGB), respectively, is first computed, for each training sample. Then, the IOU (depth) scores of all training samples are sequentially ordered from large to small. Based on the score ranking, the top 20% of the training samples will be considered as a typical positive sample set pset(that is, the quality of the depth map is acceptable) and the bottom 20% will be considered as a typical negative sample set Nset(that is, the quality of the depth map is bad and unacceptable). In addition, when IOU (depth)>Iou (RGB), these samples will also be considered as positive samples, which means that the raw depth data provides a richer global cue in identifying foreground regions than the RGB input.
Then, based on the significance of the two baseline model predictions, an option was devised to gauge whether the depth map could provide reliable information. Specifically, from the saliency results produced by the RGB stream and the depth stream, the intersection (IoU) measure between the predicted saliency and the ground-truth saliency of the two streams, denoted iou (depth) and iou (RGB), respectively, is first computed, for each training sample. Then, the IOU (depth) scores of all training samples are sequentially ordered from large to small. Based on the score ranking, the top 20% of the training samples will be considered as a typical positive sample set pset(that is, the quality of the depth map is acceptable) and the bottom 20% will be considered as a typical negative sample set Nset(that is, the quality of the depth map is bad and unacceptable). In addition, when IOU (depth)>Iou (RGB), these samples will also be considered as positive samples, which means that the raw depth data provides a richer global cue in identifying foreground regions than the RGB input.

Based on the selected representative positive and negative examples, a binary discriminator/classifier based on the ResNet-18 model structure is trained to evaluate the reliability of the depth map. Thus, the trained discriminators are able to predict a reliability score pposIndicating the probability that the depth map is positive or negative, respectively. p is a radical ofposThe higher the quality of the original depth map.
Furthermore, a depth estimator is established, which comprises a plurality of convolution blocks. The depth estimator is trained using RGB images and positive focus better quality depth data to mitigate the inherent noise caused by inaccuracies in the original depth data. At the depth calibration module, it may not be reliable to directly use the original depth map, so the original depth map may be replaced by a weighted sum between the original depth map and an estimated depth, which is obtained based on the depth estimator. Thus, obtaining DepthcalThe calibrated depth map is shown in the following formula:
Depthcal=Depthraw*ppos+Depthest*(1-ppos)
wherein, the term "Depthest"and" Depthraw"denotes the depth estimated by the depth estimator and the original depth map, respectively.
After the Depth correction process is finished, the calibrated Depth map Depth is usedcalAnd the RGB image is sent into a double-current feature extraction network to generate hierarchical features which are respectively And
And note that in the embodiment of the present application, the last three volume blocks with rich semantic features are retained, and the first two volume blocks with high resolution are removed to balance the computation cost. Generally, features extracted from RGB channels contain rich semantic information and texture information; meanwhile, the features from the depth channel contain more discriminative scene layout clues, complementary to the RGB features. To integrate the Cross-modal information, a fusion strategy named Cross Reference Module (CRM) was designed, as shown in fig. 7 of the present embodiment.
note that in the embodiment of the present application, the last three volume blocks with rich semantic features are retained, and the first two volume blocks with high resolution are removed to balance the computation cost. Generally, features extracted from RGB channels contain rich semantic information and texture information; meanwhile, the features from the depth channel contain more discriminative scene layout clues, complementary to the RGB features. To integrate the Cross-modal information, a fusion strategy named Cross Reference Module (CRM) was designed, as shown in fig. 7 of the present embodiment.


The proposed CRM aims to mine and combine the most distinctive channels of depth and RGB features (i.e. feature detectors) and generate more informative features. Specifically, two input features are generated for the ith convolution block of RGB steam and depth steam And FiDepthFirst, global statistics of RGB view and depth view are obtained using global average pooling. Then, the two feature vectors are respectively fed into a full connected layer (FC) and a softmax activation function to obtain a channel attention vector
And FiDepthFirst, global statistics of RGB view and depth view are obtained using global average pooling. Then, the two feature vectors are respectively fed into a full connected layer (FC) and a softmax activation function to obtain a channel attention vector And
And reflecting the importance of the RGB features and the depth features, respectively. Then, attention vector and channelThe manner of multiplication is applied to the input features. Thus, CRM can focus on important features explicitly and suppress unnecessary scene understanding features, and the whole process can be defined as:
reflecting the importance of the RGB features and the depth features, respectively. Then, attention vector and channelThe manner of multiplication is applied to the input features. Thus, CRM can focus on important features explicitly and suppress unnecessary scene understanding features, and the whole process can be defined as:



Atti=δ(wi*AvgPooling(Fi)+bi)
wherein wiAnd biIs a parameter in the fully connected layer corresponding to the characteristics of the ith layer and AvgPooling indicates that an average pooling operation is performed. Then according to the channel attention characteristics The channel attention weighting operation of, wherein
The channel attention weighting operation of, wherein Representing a channel-based multiplication operation.
Representing a channel-based multiplication operation.


Will additionally follow the attention vector And
And aggregating through a maximum function to obtain more prominent characteristic channels from RGB (red, green and blue) streams and depth streams, then sending the more prominent characteristic channels into normalization operation, and normalizing the output to be within a range of 0-1, thereby obtaining a channel attention vector of mutual reference
aggregating through a maximum function to obtain more prominent characteristic channels from RGB (red, green and blue) streams and depth streams, then sending the more prominent characteristic channels into normalization operation, and normalizing the output to be within a range of 0-1, thereby obtaining a channel attention vector of mutual reference This step may be defined as:
This step may be defined as:




channel attention vector based on fusion To be inputted
To be inputted And
And weighting to obtain enhanced features
weighting to obtain enhanced features And
And the enhanced features of the RGB branch and the Depth branch are further connected and fed as a 1 x 1 convolution layer to generate a cross-modal fusion feature FiThe process may be defined as:
the enhanced features of the RGB branch and the Depth branch are further connected and fed as a 1 x 1 convolution layer to generate a cross-modal fusion feature FiThe process may be defined as:







then, the characteristics F are fused across the modes through the triple loss functioniAnd processing to make the fusion feature closer to the foreground and enlarge the distance between the foreground feature and the background feature. By mixing FiThe feature corresponding to the salient region is set as a positive feature, and the feature corresponding to the background region is set as a negative feature, as follows:


wherein S represents the annotated saliency image region.
The triplet loss function can be calculated by the following formula:

where d represents the euclidean distance and m represents the margin parameter, set to 1.0.
On the basis of CRM, cross-modal characteristics can be acquired And simultaneously characterizing RGB streams
And simultaneously characterizing RGB streams And depth flow characteristics
And depth flow characteristics Decoding by three decoders respectively, finally adding the outputs of the three decoders to obtain the final significance region Smap。
Decoding by three decoders respectively, finally adding the outputs of the three decoders to obtain the final significance region Smap。



The optimization objective of the scheme as a whole can be described as
 Wherein L isRGB、LDepthAnd LfuseEach loss function corresponds to the output of the three decoders, where N-3 represents the number of convolution layers involved in the triple loss function, and α may be 0.2 in this application.
Wherein L isRGB、LDepthAnd LfuseEach loss function corresponds to the output of the three decoders, where N-3 represents the number of convolution layers involved in the triple loss function, and α may be 0.2 in this application.


In salient object detection, the similarity of complex backgrounds, objects and surroundings is widely considered to be a challenging scenario. This naturally leads to a natural introduction of additional depth information, so-called depth-induced (RGB-D) saliency target detection, in addition to the traditional RGB image as input. At the same time, this emerging direction of research is largely hampered by the noise and blur that is prevalent in the original depth image. In order to solve the above problem, the embodiment of the present application proposes a depth calibration fusion framework, which includes two components: a novel learning strategy to calibrate potential deviations in the original depth image to improve detection performance; an efficient cross-referencing module fuses cross-complementary features from both RGB and depth map modalities. A large number of experiments have shown that the method has better performance than the most advanced methods.
The significance target detection has important value in real life. Salient Object Detection (SOD) is to identify the most interesting target regions in a scene. The salient object detection is different from fixation point prediction originating from the cognitive and psychological research fields, and is widely applied to different fields. In computer vision, applications of salient object detection include image understanding, image description generation, object detection, unsupervised video object segmentation, semantic segmentation, pedestrian re-recognition, and the like. In computer graphics, a saliency object detection task is widely applied to tasks such as VR (Virtual Reality) rendering, automatic image clipping, image redirection, video summarization, and the like. Example applications in the field of robotics, such as human-computer interaction and target discovery, as well as scene understanding of obstacle avoidance robots, also benefit from salient target detection. However, the mainstream saliency target detection methods are typically based on single input RGB images, which makes the representation generic in some complex scenes. Therefore, the introduction of the depth image greatly improves the positioning capability of the salient object detection field in the challenging scene. But also due to the depth acquisition equipment and the effects of natural environmental conditions, portions of the depth map may be significantly noisy. Therefore, it is necessary to introduce a depth calibration strategy in the current RGB-D saliency target detection field, to improve the utilization efficiency of depth information, and further to improve the detection accuracy.
The embodiment of the application provides a solution for detecting a salient target based on depth map quality calibration. First, two salient discriminating networks are pre-trained based on RGB and depth maps, respectively, as inputs. And then, a deep calibration learning strategy is designed by comparing the performances of the two pre-training networks, so that the quality of the depth map is improved. And a cross reference module is introduced to effectively fuse information fusion of two complementary features of depth and RGB, so that the utilization of depth information on salient target detection is greatly enhanced.
Meanwhile, the embodiment of the application provides a universal depth map calibration framework. Can be utilized in other advanced RGB-D saliency target detection methods and all bring a huge gain in performance.
Table 1 shows data representation of other schemes and the scheme shown in the examples of the present application on SIP data sets, which verifies the excellent performance of the method. In addition, the method provided by the embodiment of the application achieves excellent performance on a plurality of large-scale public significance target detection data sets.
TABLE 1

Table 2 verifies the performance gains from each component in the method proposed by this patent. Table 2 takes RGB data and the original depth map as input, respectively. It can be seen that the performance of the RGB branch is superior to the depth branch using the original depth map, indicating that the RGB input contains more semantic and texture information than the depth input. To evaluate the effectiveness of the depth calibration strategy, the original depth is compared to the reference network using the calibrated depth. As shown in table 2, the calibration depth reduced the MAE error index by 14.51% on average over the four data sets. Furthermore, to verify the generalization capability of the proposed depth calibration module, the generated calibration depth was also applied to two most advanced models, including D3Net and DMRA. As shown in Table 3, training D3Net and DMRA with the corrected depth instead of the original depth map resulted in significant performance improvements for both the DUT-D dataset and the NJU2K dataset. The MAE index of D3Net and DMRA decreased by 12.5% and 9.1%, respectively. Thus, a large number of experiments demonstrate the advantages of the proposed depth calibration strategy.
TABLE 2

Furthermore, for integrating RGB and depth features across modal fusion modules, a simple solution is to use concatenation followed by a convolution operation to fuse the complementary features. In table 2, it can be seen by comparing (d) and (f) that the cross-referencing module proposed herein is able to better fuse complementary information of RGB features and depth features than direct feature fusion. Meanwhile, comparing (f), after the triple loss function is removed, the performance of all experiments is reduced, and the effectiveness of the three groups of losses in the aspect of enhancing feature representation is shown.
Table 3 shows the effect of the calibration depth scheme according to the embodiment of the present application on the determination of the target area.
TABLE 3

To sum up, in the solution shown in the embodiment of the present application, estimated depth data corresponding to a first image is obtained through first color image data in the first image, the first depth image data corresponding to the first image is corrected according to the estimated depth data to obtain calibrated depth data, the calibrated depth data and the color image data are fused, and a target area is determined according to a fused feature map. According to the scheme, the depth information corresponding to the first image is estimated through the color image, the depth image corresponding to the first image is corrected, the target area corresponding to the first image is obtained according to the corrected depth image data and the color image data, and the accuracy of determining the target area is improved.
Fig. 9 is a block flow diagram illustrating a target area determination method according to an example embodiment. As shown in fig. 9, a flow chart of the target area determining method in the embodiment of the present application is formed by theparts parts
As shown inpart 900 of fig. 9, a training sample set may include a color image set 901 and a depth image set 903, where the color image set 901 includes at least two sample color images; the depth image set 903 includes at least two sample depth images; the color image set 901 corresponds to the images in the depth image set 903 in a one-to-one manner. Processing each sample color image in the color image set through a colorimage processing branch 902 in the target area determination model, so as to obtain a prediction area corresponding to each sample color image; processing each sample depth image in the depth image set through a depthimage processing branch 904 in the target region determination model, so as to obtain a prediction region 905 corresponding to each sample depth image; through the prediction region 905 corresponding to each sample depth image and the target region corresponding to each sample depth image, the confidence score corresponding to each sample depth image can be obtained, the sample depth images are ranked from large to small according to the confidence score corresponding to each sample depth image, a ranked sample depth image set 906 is obtained, a% before the confidence score is determined as a positive sample, and b% after the confidence score is determined as a negative sample.
As shown in theportion 910 of fig. 9, a confidencecoefficient discrimination model 912 exists in theportion 910 of fig. 9, the confidencecoefficient discrimination model 902 is obtained by training the positive samples and the negative samples in the sorted sample depth image set 906 in theportion 900 of fig. 9, and the confidence coefficient discrimination model may determine the confidence coefficient corresponding to the sample depth image according to the input sample depth image. Therefore, for eachsample depth image 911 in the training sample set, the sample depth images are respectively input into the confidencedegree discrimination model 912 to obtain the confidence degree corresponding to each sample depth image in the training sample set and are ranked, so as to obtain the rankedsample depth image 913, then the sample depth image with the middle confidence degree ranked c% of the rankedsample depth image 913 and the corresponding sample color image are trained on thedepth estimation model 915, so that the traineddepth estimation model 915 processes the input color image 914, so as to obtain the estimateddepth data 916 corresponding to the color image 914, and then the estimateddepth data 916 and the depth image corresponding to the color image 914 are weighted based on the confidence degree of the depth image corresponding to the color image, so as to obtain the correcteddepth image 917, wherein, the confidence degree of the depth image corresponding to the color image, may be obtained from the confidence measurediscriminative model 912.
In fig. 9, a color image is included in the color image set 921, and a corrected depth image corresponding to each color image in the color image set 921 is included in the corrected depth image set 922; inputting the color image corresponding to the first image in the color image set 921 into a color image processing branch in the target area determination model, so as to obtain a color feature map corresponding to the color image; inputting the depth image corresponding to the first image in the depth image set 922 into a depth image processing branch in the target area determination model, so as to obtain a depth feature map corresponding to the depth image; and respectively inputting the data extracted by the N convolutional layers in the color image processing branch and the data extracted by the N convolutional layers in the depth image processing branch into N cross reference modules CRM shown in figure 7 to realize the feature fusion between the depth image and the color image to obtain a fusion feature map, and acquiring the target area of the first image according to the fusion feature map, the depth feature map and the color feature map.
As shown in fig. 9, the goal is to select the most typical difficult and easy sample in the training database. These samples are then used to train a discriminator/classifier to predict the quality of the depth map, thereby reflecting the reliability of the depth map. And training a basic binary classifier based on the screened representative positive and negative samples to evaluate the reliability of the depth map. Thus, the trained arbiter can predict a reliability score for each datum, representing the probability of the depth map being positive or negative. In addition, the embodiment of the application also establishes a depth estimator, and the depth estimator comprises a plurality of convolution operations. The depth estimator is trained by using RGB images and depth data with better quality to reduce inherent noise caused by inaccurate original depth data. In the depth calibration module, the original depth map which may not be reliable is not directly used, but the result of weighted summation of the original depth map and the estimated depth map is used as input, thereby improving the utilization of the depth information.
Fig. 10 is a block diagram illustrating a structure of a target area determining apparatus according to an exemplary embodiment. The target area determination apparatus may implement all or part of the steps in the method provided by the embodiment shown in fig. 2 or fig. 4, and the target area determination apparatus includes:
a firstimage acquisition module 1001 configured to acquire a first image; the first image comprises first color image data and first depth image data;
an estimateddepth obtaining module 1002, configured to obtain first estimated depth data based on the first color image data; the first estimated depth data is used to indicate depth information to which the first color image data corresponds;
a calibrationdepth obtaining module 1003, configured to obtain first calibration depth data based on the first estimated depth data and the first depth image data;
a fusionfeature obtaining module 1004, configured to perform weighting processing based on the first color image data and the first calibration depth data to obtain a first fusion feature map;
a targetregion determining module 1005, configured to determine a target region corresponding to the first image based on the first fusion feature map.
In one possible implementation, the apparatus further includes:
the confidence coefficient acquisition module is used for acquiring the confidence coefficient corresponding to the first depth image data based on the first depth image data; the confidence corresponding to the first depth image data is used for indicating the accuracy of the image data corresponding to the target area in the first depth image data;
the calibrationdepth obtaining module 1003 is further configured to,
and performing weighting processing based on the confidence degree corresponding to the first depth image data on the first estimated depth data and the first depth image data to obtain the first calibration depth data.
In one possible implementation, the confidence level obtaining module is further configured to,
processing the first depth image data through a confidence coefficient discrimination model based on the first depth image data to obtain a confidence coefficient corresponding to the first depth image data;
the estimateddepth obtaining module 1002 is further configured to,
based on the first color image data, performing data processing through a depth estimation model to obtain first estimated depth data;
the confidence coefficient distinguishing model is a machine learning model trained by taking a first sample image as a sample and taking a confidence type corresponding to the first sample image as a label;
the depth estimation model is a machine learning model trained by taking a second sample image as a sample and taking depth image data corresponding to the second sample image as a label; the second sample image is a sample image whose confidence satisfies a first specified condition.
In one possible implementation, the apparatus further includes:
the first sample set acquisition module is used for acquiring a first training sample set; the first training sample set comprises a first sample image and a confidence type corresponding to the first sample image;
a first confidence probability obtaining module, configured to perform data processing through the confidence discrimination model based on the first sample image to obtain a confidence probability corresponding to the first sample image; the confidence probability is indicative of a probability that the first sample image is a positive sample;
and the confidence discrimination model training module is used for training the confidence discrimination model based on the confidence probability corresponding to the first sample image and the confidence type corresponding to the first sample image.
In one possible implementation manner, the first sample set obtaining module includes:
a second sample set obtaining submodule for obtaining a second training sample set; the second training sample set comprises training sample images and target areas corresponding to the training sample images; the training sample image comprises training color sample data and training depth sample data;
the color prediction region acquisition submodule is used for determining a color image processing branch in a model through a target region, processing the training color sample data and acquiring a prediction region corresponding to the training color sample data;
the depth prediction region acquisition submodule is used for determining a depth image processing branch in a model through the target region, processing the training depth sample data and acquiring a prediction region corresponding to the training depth sample data;
a confidence score obtaining submodule for determining a confidence score of the training sample image based on the prediction region corresponding to the training color sample data, the prediction region corresponding to the training depth sample data and the target region corresponding to the training sample image;
a first sample image determining submodule, configured to determine a confidence type of the training sample image in response to that a confidence score of the training sample image satisfies a specified condition, and determine the training sample image as the first sample image;
the color image processing branch in the target area determination model is a machine learning model obtained by pre-training by taking a sample color image as a sample and taking a target area corresponding to the sample color image as a label;
the depth image processing branch in the target area determination model is a machine learning model obtained by pre-training with a sample depth image as a sample and a target area corresponding to the sample depth image as an annotation.
In one possible implementation, the confidence scores include a color confidence score and a depth confidence score;
the confidence score obtaining sub-module comprises:
the color confidence score acquisition unit is used for determining the color confidence score corresponding to the training sample image based on the contact ratio between the prediction region corresponding to the training color sample data and the target region corresponding to the training sample image;
and the depth confidence score acquisition unit is used for determining the depth confidence score corresponding to the training sample image based on the contact ratio between the prediction region corresponding to the training depth sample data and the target region corresponding to the training sample image.
In one possible implementation manner, the fusedfeature obtaining module 1004 includes:
the attention weighting submodule is used for carrying out weighting processing based on an attention mechanism through a feature fusion branch in a target area determination model based on the first color image data and the first calibration depth data to obtain a first fusion feature map;
the device further comprises:
the color characteristic map acquisition module is used for carrying out data processing through a depth image processing branch in the target area determination model based on the first color image data to obtain a first color characteristic map;
the depth feature map acquisition module is used for performing data processing through a depth image processing branch in the target area determination model based on the first depth image data to obtain a first depth feature map;
the targetarea determination module 1005, further configured to,
and determining a target area corresponding to the first image based on the first fusion feature map, the first depth feature map and the first color feature map.
The target area determination model is a machine learning model obtained by training with a third sample image as a sample and a target area corresponding to the third sample image as an annotation.
In one possible implementation, the feature fusion branch includes a first pooling layer, a second pooling layer, a first fully-connected layer, and a second fully-connected layer;
the fusedfeature obtaining module 1004 includes:
the first pooling submodule is used for carrying out global pooling through a first pooling layer based on the first color image data to obtain first color pooling data;
the first full-connection submodule is used for carrying out data processing through a first full-connection layer based on the first color pooling data to obtain a first color vector;
the second pooling sub-module is used for carrying out global pooling through a second pooling layer based on the first depth image data to obtain first depth pooling data;
the second full-connection submodule is used for carrying out data processing through a second full-connection layer based on the first depth pooling data to obtain a first depth vector;
a fusion feature obtaining sub-module, configured to perform channel attention weighting processing through a first color vector and a first depth vector based on the first color image data and the first calibration depth data, to obtain the first fusion feature map; the first color vector is used for indicating the weight corresponding to the first color image data; the first depth vector is used to indicate a weight to which the first depth image data corresponds.
In one possible implementation, the apparatus further includes:
the third image acquisition module is used for acquiring a third sample image; the third sample image includes third sample color image data and third sample depth image data;
a third estimation data obtaining module, configured to obtain third sample estimation depth data based on the third sample color image data;
a third calibration data obtaining module, configured to obtain third sample calibration depth data based on the third sample estimated depth data and the third sample depth image data;
a third fused feature obtaining module, configured to perform weighting processing on a feature fusion branch in a target area determination model based on the third sample color image data and the third sample calibration depth data, to obtain a third sample fused feature map;
and the region determination model training module is used for training the target region determination model based on the third sample fusion feature map and the target region corresponding to the third sample image.
In one possible implementation, the apparatus further includes:
the third color characteristic acquisition module is used for carrying out data processing through a color image processing branch in the target area determination model based on the third sample color image data to obtain a third sample color characteristic diagram;
a third depth feature obtaining module, configured to perform data processing through a depth image processing branch in the target region determination model based on the third sample depth image data, so as to obtain a third sample color feature map;
the region determination model training module is further configured to,
and training the target area determination model based on the third sample color feature map, the third sample depth feature map, the third sample fusion feature map and the target area corresponding to the third sample image.
To sum up, in the scheme shown in the embodiment of the present application, estimated depth data corresponding to a first image is obtained through first color image data in the first image, the first depth image data corresponding to the first image is corrected according to the estimated depth data to obtain calibrated depth data, the calibrated depth data and the color image data are fused, and a target area is determined according to a fused feature map. According to the scheme, the depth information corresponding to the first image is estimated through the color image, the depth image corresponding to the first image is corrected, the target area corresponding to the first image is obtained according to the corrected depth image data and the color image data, and the accuracy of determining the target area is improved.
Fig. 11 is a block diagram illustrating a structure of a target area determining apparatus according to an exemplary embodiment. The target area determination apparatus may implement all or part of the steps in the method provided by the embodiment shown in fig. 2 or fig. 4, and the target area determination apparatus includes:
a third sampleimage obtaining module 1101, configured to obtain a third sample image; the third sample image includes third sample color image data and third sample depth image data;
a third sampleestimation obtaining module 1102, configured to obtain third sample estimation depth data based on the third sample color image data; the third sample estimated depth data is used to indicate depth information to which the third sample color image data corresponds;
a third samplecalibration obtaining module 1103, configured to obtain third sample calibration depth data based on the third sample estimated depth data and the third sample depth image data;
a third sample fusionfeature obtaining module 1104, configured to perform weighting processing on a feature fusion branch in a target area determination model based on the third sample color image data and the third sample calibration depth data, to obtain a third sample fusion feature map;
a region determinationmodel training module 1105, configured to train the target region determination model based on the third sample fusion feature map and a target region corresponding to the third sample image;
the trained target area determination model is used for processing color image data corresponding to the first image and calibration depth data corresponding to the first image to obtain a target area corresponding to the first image.
To sum up, in the scheme shown in the embodiment of the present application, estimated depth data corresponding to a first image is obtained through first color image data in the first image, the first depth image data corresponding to the first image is corrected according to the estimated depth data to obtain calibrated depth data, the calibrated depth data and the color image data are fused, and a target area is determined according to a fused feature map. According to the scheme, the depth information corresponding to the first image is estimated through the color image, the depth image corresponding to the first image is corrected, the target area corresponding to the first image is obtained according to the corrected depth image data and the color image data, and the accuracy of determining the target area is improved.
FIG. 12 is a block diagram illustrating a computer device according to an example embodiment. The computer device may be implemented as the model processing device and/or the text image matching device in the above-described respective method embodiments. Thecomputer apparatus 1200 includes a Central Processing Unit (CPU) 1201, asystem Memory 1204 including a Random Access Memory (RAM) 1202 and a Read-Only Memory (ROM) 1203, and asystem bus 1205 connecting thesystem Memory 1204 and theCentral Processing Unit 1201. Thecomputer device 1200 also includes a basic input/output system 1206, which facilitates transfer of information between various components within the computer, and amass storage device 1207, which stores anoperating system 1213,application programs 1214, andother program modules 1215.
Themass storage device 1207 is connected to thecentral processing unit 1201 through a mass storage controller (not shown) connected to thesystem bus 1205. Themass storage device 1207 and its associated computer-readable media provide non-volatile storage for thecomputer device 1200. That is, themass storage device 1207 may include a computer-readable medium (not shown) such as a hard disk or Compact disk Read-Only Memory (CD-ROM) drive.
Without loss of generality, the computer-readable media may comprise computer storage media and communication media. Computer storage media includes volatile and nonvolatile, removable and non-removable media implemented in any method or technology for storage of information such as computer readable instructions, data structures, program modules or other data. Computer storage media includes RAM, ROM, flash memory or other solid state storage technology, CD-ROM, or other optical storage, magnetic cassettes, magnetic tape, magnetic disk storage or other magnetic storage devices. Of course, those skilled in the art will appreciate that the computer storage media is not limited to the foregoing. Thesystem memory 1204 andmass storage device 1207 described above may be collectively referred to as memory.
Thecomputer device 1200 may be connected to the internet or other network devices through anetwork interface unit 1211 connected to thesystem bus 1205.
The memory further includes one or more programs, the one or more programs are stored in the memory, and thecentral processing unit 1201 implements all or part of the steps of the method shown in fig. 2, 3, or 4 by executing the one or more programs.
In an exemplary embodiment, a non-transitory computer readable storage medium comprising instructions, such as a memory comprising computer programs (instructions), executable by a processor of a computer device to perform the methods shown in the various embodiments of the present application, is also provided. For example, the non-transitory computer readable storage medium may be a Read-Only Memory (ROM), a Random Access Memory (RAM), a Compact Disc Read-Only Memory (CD-ROM), a magnetic tape, a floppy disk, an optical data storage device, and the like.
In an exemplary embodiment, a computer program product or computer program is also provided, the computer program product or computer program comprising computer instructions stored in a computer readable storage medium. The processor of the computer device reads the computer instructions from the computer-readable storage medium, and the processor executes the computer instructions to cause the computer device to perform the methods shown in the various embodiments described above.
Other embodiments of the present application will be apparent to those skilled in the art from consideration of the specification and practice of the invention disclosed herein. This application is intended to cover any variations, uses, or adaptations of the invention following, in general, the principles of the application and including such departures from the present disclosure as come within known or customary practice within the art to which the invention pertains. It is intended that the specification and examples be considered as exemplary only, with a true scope and spirit of the application being indicated by the following claims.
It will be understood that the present application is not limited to the precise arrangements described above and shown in the drawings and that various modifications and changes may be made without departing from the scope thereof. The scope of the application is limited only by the appended claims.
Claims (15)
1. A method for determining a target area, the method comprising:
acquiring a first image; the first image comprises first color image data and first depth image data;
obtaining first estimated depth data based on the first color image data; the first estimated depth data is used to indicate depth information to which the first color image data corresponds;
obtaining first calibration depth data based on the first estimated depth data and the first depth image data;
performing weighting processing based on the first color image data and the first calibration depth data to obtain a first fusion feature map;
and determining a target area corresponding to the first image based on the first fusion feature map.
2. The method of claim 1, wherein prior to obtaining first estimated depth data based on the first color image data, further comprising:
obtaining a confidence corresponding to the first depth image data based on the first depth image data; the confidence corresponding to the first depth image data is used for indicating the accuracy of the image data corresponding to the target area in the first depth image data;
obtaining first calibration depth data based on the first estimated depth data and the first depth image data, comprising:
and performing weighting processing based on the confidence degree corresponding to the first depth image data on the first estimated depth data and the first depth image data to obtain the first calibration depth data.
3. The method of claim 2, wherein obtaining the confidence level corresponding to the first depth image data based on the first depth image data comprises:
processing the first depth image data through a confidence coefficient discrimination model based on the first depth image data to obtain a confidence coefficient corresponding to the first depth image data;
said obtaining first estimated depth data based on said first color image data comprises:
based on the first color image data, performing data processing through a depth estimation model to obtain first estimated depth data;
the confidence coefficient distinguishing model is a machine learning model trained by taking a first sample image as a sample and taking a confidence type corresponding to the first sample image as a label;
the depth estimation model is a machine learning model trained by taking a second sample image as a sample and taking depth image data corresponding to the second sample image as a label; the second sample image is a sample image whose confidence satisfies a first specified condition.
4. The method of claim 3, further comprising:
acquiring a first training sample set; the first training sample set comprises a first sample image and a confidence type corresponding to the first sample image;
based on the first sample image, performing data processing through the confidence coefficient discrimination model to obtain a confidence probability corresponding to the first sample image; the confidence probability is indicative of a probability that the first sample image is a positive sample;
and training the confidence coefficient distinguishing model based on the confidence probability corresponding to the first sample image and the confidence type corresponding to the first sample image.
5. The method of claim 4, wherein the obtaining a first set of training samples comprises:
acquiring a second training sample set; the second training sample set comprises training sample images and target areas corresponding to the training sample images; the training sample image comprises training color sample data and training depth sample data;
determining a color image processing branch in a model through a target area, and processing the training color sample data to obtain a prediction area corresponding to the training color sample data;
determining a depth image processing branch in a model through the target region, and processing the training depth sample data to obtain a prediction region corresponding to the training depth sample data;
determining a confidence score of the training sample image based on a prediction region corresponding to the training color sample data, a prediction region corresponding to the training depth sample data and a target region corresponding to the training sample image;
in response to the confidence score of the training sample image satisfying a specified condition, determining a confidence type of the training sample image and determining the training sample image as the first sample image;
the color image processing branch in the target area determination model is a machine learning model obtained by pre-training by taking a sample color image as a sample and taking a target area corresponding to the sample color image as a label;
the depth image processing branch in the target area determination model is a machine learning model obtained by pre-training with a sample depth image as a sample and a target area corresponding to the sample depth image as an annotation.
6. The method of claim 5, wherein the confidence scores comprise a color confidence score and a depth confidence score;
determining a confidence score of the training sample image based on the prediction region corresponding to the training color sample data, the prediction region corresponding to the training depth sample data, and the target region corresponding to the training sample image, including:
determining a color confidence score corresponding to the training sample image based on the contact ratio between a prediction region corresponding to the training color sample data and a target region corresponding to the training sample image;
and determining a depth confidence score corresponding to the training sample image based on the contact ratio between the prediction region corresponding to the training depth sample data and the target region corresponding to the training sample image.
7. The method of claim 1, wherein the performing a weighting process based on the first color image data and the first calibration depth data to obtain a first fused feature map comprises:
based on the first color image data and the first calibration depth data, performing weighting processing based on an attention mechanism through a feature fusion branch in a target area determination model to obtain a first fusion feature map;
before determining the target region corresponding to the first image based on the first fusion feature map, the method further includes:
based on the first color image data, performing data processing through a depth image processing branch in the target area determination model to obtain a first color feature map;
based on the first depth image data, performing data processing through a depth image processing branch in a target area determination model to obtain a first depth feature map;
the determining a target region corresponding to the first image based on the first fusion feature map includes:
determining a target area corresponding to the first image based on the first fusion feature map, the first depth feature map and the first color feature map;
the target area determination model is a machine learning model obtained by training with a third sample image as a sample and a target area corresponding to the third sample image as an annotation.
8. The method of claim 7, wherein the feature fusion branch comprises a first pooling layer, a second pooling layer, a first fully-connected layer, and a second fully-connected layer;
the obtaining the first fused feature map by performing attention-based weighting processing on a feature fusion branch in a target region determination model based on the first color image data and the first calibration depth data includes:
based on the first color image data, performing global pooling through a first pooling layer to obtain first color pooling data;
based on the first color pooling data, performing data processing through a first full-connection layer to obtain a first color vector;
performing global pooling through a second pooling layer based on the first depth image data to obtain first depth pooling data;
based on the first depth pooling data, performing data processing through a second full-link layer to obtain a first depth vector;
based on the first color image data and the first calibration depth data, performing channel attention weighting processing through a first color vector and a first depth vector to obtain the first fusion feature map; the first color vector is used for indicating the weight corresponding to the first color image data; the first depth vector is used to indicate a weight to which the first depth image data corresponds.
9. The method of claim 7, further comprising:
acquiring a third sample image; the third sample image includes third sample color image data and third sample depth image data;
obtaining third sample estimated depth data based on the third sample color image data;
obtaining third sample calibration depth data based on the third sample estimated depth data and the third sample depth image data;
based on the third sample color image data and the third sample calibration depth data, performing weighting processing through a feature fusion branch in a target area determination model to obtain a third sample fusion feature map;
and training the target area determination model based on the third sample fusion feature map and the target area corresponding to the third sample image.
10. The method according to claim 9, wherein before training the target area determination model based on the third sample fusion feature map and the target area corresponding to the third sample image, the method further comprises:
based on the third sample color image data, performing data processing through a color image processing branch in the target area determination model to obtain a third sample color feature map;
based on the third sample depth image data, performing data processing through a depth image processing branch in the target area determination model to obtain a third sample color feature map;
the training of the target area determination model based on the third sample fusion feature map and the target area corresponding to the third sample image includes:
and training the target area determination model based on the third sample color feature map, the third sample depth feature map, the third sample fusion feature map and the target area corresponding to the third sample image.
11. A method for determining a target area, the method comprising:
acquiring a third sample image; the third sample image includes third sample color image data and third sample depth image data;
obtaining third sample estimated depth data based on the third sample color image data; the third sample estimated depth data is used to indicate depth information to which the third sample color image data corresponds;
obtaining third sample calibration depth data based on the third sample estimated depth data and the third sample depth image data;
based on the third sample color image data and the third sample calibration depth data, performing weighting processing through a feature fusion branch in a target area determination model to obtain a third sample fusion feature map;
training a target area determination model based on the third sample fusion feature map and a target area corresponding to the third sample image;
the trained target area determination model is used for processing color image data corresponding to the first image and calibration depth data corresponding to the first image to obtain a target area corresponding to the first image.
12. A target area determination apparatus, the apparatus comprising:
the first image acquisition module is used for acquiring a first image; the first image comprises first color image data and first depth image data;
an estimated depth obtaining module, configured to obtain first estimated depth data based on the first color image data; the first estimated depth data is used to indicate depth information to which the first color image data corresponds;
a calibration depth obtaining module, configured to obtain first calibration depth data based on the first estimated depth data and the first depth image data;
a fusion feature obtaining module, configured to perform weighting processing based on the first color image data and the first calibration depth data to obtain a first fusion feature map;
and the target area determining module is used for determining a target area corresponding to the first image based on the first fusion feature map.
13. A target area determination apparatus, the apparatus comprising:
the third sample image acquisition module is used for acquiring a third sample image; the third sample image includes third sample color image data and third sample depth image data;
a third sample estimation obtaining module, configured to obtain third sample estimation depth data based on the third sample color image data; the third sample estimated depth data is used to indicate depth information to which the third sample color image data corresponds;
a third sample calibration acquisition module, configured to obtain third sample calibration depth data based on the third sample estimated depth data and the third sample depth image data;
a third sample fusion feature obtaining module, configured to perform weighting processing on a feature fusion branch in a target area determination model based on the third sample color image data and the third sample calibration depth data, to obtain a third sample fusion feature map;
the region determination model training module is used for training the target region determination model based on the third sample fusion feature map and a target region corresponding to the third sample image;
the trained target area determination model is used for processing color image data corresponding to the first image and calibration depth data corresponding to the first image to obtain a target area corresponding to the first image.
14. A computer device comprising a processor and a memory, said memory having stored therein at least one instruction, at least one program, set of codes, or set of instructions, said at least one instruction, said at least one program, said set of codes, or set of instructions being loaded and executed by said processor to implement a target area determination method as claimed in any one of claims 1 to 11.
15. A computer readable storage medium having stored therein at least one instruction, at least one program, a set of codes, or a set of instructions, which is loaded and executed by a processor to implement a target area determination method as claimed in any one of claims 1 to 11.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110234692.6ACN113705562A (en) | 2021-03-03 | 2021-03-03 | Target area determination method, device, equipment and storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110234692.6ACN113705562A (en) | 2021-03-03 | 2021-03-03 | Target area determination method, device, equipment and storage medium |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN113705562Atrue CN113705562A (en) | 2021-11-26 |
Family
ID=78647811
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110234692.6APendingCN113705562A (en) | 2021-03-03 | 2021-03-03 | Target area determination method, device, equipment and storage medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN113705562A (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114332559A (en)* | 2021-12-17 | 2022-04-12 | 安徽理工大学 | An RGB-D Saliency Object Detection Method Based on Adaptive Cross-modal Fusion Mechanism and Deep Attention Network |
| WO2024222197A1 (en)* | 2023-04-27 | 2024-10-31 | 腾讯科技(深圳)有限公司 | Depth image generation method and apparatus, electronic device, computer readable storage medium, and computer program product |
- 2021
- 2021-03-03CNCN202110234692.6Apatent/CN113705562A/enactivePending
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114332559A (en)* | 2021-12-17 | 2022-04-12 | 安徽理工大学 | An RGB-D Saliency Object Detection Method Based on Adaptive Cross-modal Fusion Mechanism and Deep Attention Network |
| WO2024222197A1 (en)* | 2023-04-27 | 2024-10-31 | 腾讯科技(深圳)有限公司 | Depth image generation method and apparatus, electronic device, computer readable storage medium, and computer program product |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN113657400A (en) | A Text-Guided Image Segmentation Method Based on Attention Mechanism for Cross-modal Text Retrieval | |
| CN111050219A (en) | Spatio-temporal memory network for locating target objects in video content | |
| WO2022156640A1 (en) | Gaze correction method and apparatus for image, electronic device, computer-readable storage medium, and computer program product | |
| CN112836625A (en) | Face living body detection method and device and electronic equipment | |
| WO2021208601A1 (en) | Artificial-intelligence-based image processing method and apparatus, and device and storage medium | |
| CN115050064A (en) | Face living body detection method, device, equipment and medium | |
| CN114283315A (en) | An RGB-D Saliency Object Detection Method Based on Interactive Guided Attention and Trapezoid Pyramid Fusion | |
| CN110210492B (en) | Stereo image visual saliency detection method based on deep learning | |
| CN112329662B (en) | Multi-view saliency estimation method based on unsupervised learning | |
| CN114282059A (en) | Method, device, device and storage medium for video retrieval | |
| CN117557775A (en) | Substation power equipment detection method and system based on infrared and visible light fusion | |
| KR20240144139A (en) | Facial pose estimation method, apparatus, electronic device and storage medium | |
| CN115661482B (en) | A RGB-T Salient Object Detection Method Based on Joint Attention | |
| AU2021240205B1 (en) | Object sequence recognition method, network training method, apparatuses, device, and medium | |
| CN114693951A (en) | An RGB-D Saliency Object Detection Method Based on Global Context Information Exploration | |
| CN116958267B (en) | Pose processing method and device, electronic equipment and storage medium | |
| CN116051944A (en) | Defect image generation method, system, and storage medium based on attribute semantic separation | |
| CN119762847A (en) | Small sample anomaly detection and classification framework based on reconstruction guided cross-modal alignment | |
| Zong et al. | A cascaded refined rgb-d salient object detection network based on the attention mechanism | |
| CN113705562A (en) | Target area determination method, device, equipment and storage medium | |
| CN114743162A (en) | Cross-modal pedestrian re-identification method based on generation of countermeasure network | |
| CN120147111B (en) | Method for automatically processing portrait photo into standard certificate photo | |
| CN116452914A (en) | Self-adaptive guide fusion network for RGB-D significant target detection | |
| He et al. | Sihenet: Semantic interaction and hierarchical embedding network for 360 salient object detection | |
| CN116630758A (en) | Space-time action detection method based on double-branch multi-stage feature fusion |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |