CN113704392A - Method, device and equipment for extracting entity relationship in text and storage medium - Google Patents
Method, device and equipment for extracting entity relationship in text and storage mediumDownload PDFInfo
- Publication number
- CN113704392A CN113704392ACN202110393735.5ACN202110393735ACN113704392ACN 113704392 ACN113704392 ACN 113704392ACN 202110393735 ACN202110393735 ACN 202110393735ACN 113704392 ACN113704392 ACN 113704392A
- Authority
- CN
- China
- Prior art keywords
- target
- subject
- entity
- text
- relationship
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images









Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/3331—Query processing
- G06F16/334—Query execution
- G06F16/3346—Query execution using probabilistic model
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/335—Filtering based on additional data, e.g. user or group profiles
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/36—Creation of semantic tools, e.g. ontology or thesauri
- G06F16/367—Ontology
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/12—Use of codes for handling textual entities
- G06F40/126—Character encoding
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/289—Phrasal analysis, e.g. finite state techniques or chunking
- G06F40/295—Named entity recognition
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- General Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- General Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Databases & Information Systems (AREA)
- Biomedical Technology (AREA)
- Computing Systems (AREA)
- Molecular Biology (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Evolutionary Computation (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Biophysics (AREA)
- Animal Behavior & Ethology (AREA)
- Probability & Statistics with Applications (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本申请实施例涉及人工智能领域,特别涉及一种文本中实体关系的抽取方法、装置、设备及存储介质。The embodiments of the present application relate to the field of artificial intelligence, and in particular, to a method, apparatus, device, and storage medium for extracting entity relationships in text.
背景技术Background technique
自然语言处理(Nature Language Processing,NLP)是计算机科学领域与人工智能领域中的一个重要方向。自然语言处理技术通常包括文本处理、语义理解、机器翻译、机器人问答、知识图谱等技术。Natural Language Processing (NLP) is an important direction in the field of computer science and artificial intelligence. Natural language processing technology usually includes text processing, semantic understanding, machine translation, robot question answering, knowledge graph and other technologies.
在进行知识图谱构建时,需要对大量的文本进行结构化处理,将文本中的非结构化数据转化为结构化数据并召回。比如,当抽取文本中的实体关系时,召回的结构化数据为三元组,该三元组中包含主体(subject)、关系(relationship)以及客体(object)。When constructing a knowledge graph, a large amount of text needs to be structured, and the unstructured data in the text is converted into structured data and recalled. For example, when extracting entity relationships in text, the recalled structured data is a triple, which contains subject, relationship, and object.
然而,由于文本中实体之间的关系复杂,因此在对文本进行实体关系抽取时,存在大量误召回结果,导致文本中实体关系抽取的准确性较差。However, due to the complex relationship between entities in text, there are a large number of false recall results when extracting entity relationship from text, resulting in poor accuracy of entity relationship extraction in text.
发明内容SUMMARY OF THE INVENTION
本申请实施例提供了一种文本中实体关系的抽取方法、装置、设备及存储介质,可以减少实体关系抽取时的误召回结果,提高文本中实体关系抽取的准确性。所述技术方案如下:The embodiments of the present application provide a method, device, device and storage medium for extracting entity relationships in text, which can reduce false recall results during entity relationship extraction and improve the accuracy of entity relationship extraction in text. The technical solution is as follows:
一方面,本申请实施例提供了一种文本中实体关系的抽取方法,所述方法包括:On the one hand, an embodiment of the present application provides a method for extracting entity relationships in text, the method comprising:
对目标文本进行编码,得到所述目标文本中各个词对应的词向量;Encoding the target text to obtain word vectors corresponding to each word in the target text;
基于各个词对应的所述词向量,确定所述目标文本对应的潜在实体关系,所述目标文本中存在所述潜在实体关系的概率高于存在所述潜在实体关系外其它候选实体关系的概率;Based on the word vector corresponding to each word, determine the potential entity relationship corresponding to the target text, and the probability of the potential entity relationship in the target text is higher than the probability of other candidate entity relationships other than the potential entity relationship;
基于所述潜在实体关系以及各个词对应的所述词向量,确定所述目标文本中的目标主体和目标客体,所述目标主体和所述目标客体属于实体;Determine the target subject and the target object in the target text based on the potential entity relationship and the word vector corresponding to each word, and the target subject and the target object belong to entities;
基于所述目标主体、所述潜在实体关系以及所述目标客体,从所述目标文本中抽取实体关系三元组。Based on the target subject, the potential entity-relationship, and the target object, entity-relationship triples are extracted from the target text.
另一方面,本申请实施例提供了一种文本中实体关系的抽取装置,所述装置包括:On the other hand, an embodiment of the present application provides an apparatus for extracting entity relationships in text, the apparatus comprising:
编码模块,用于对目标文本进行编码,得到所述目标文本中各个词对应的词向量;an encoding module, configured to encode the target text to obtain word vectors corresponding to each word in the target text;
关系确定模块,用于基于各个词对应的所述词向量,确定所述目标文本对应的潜在实体关系,所述目标文本中存在所述潜在实体关系的概率高于存在所述潜在实体关系外其它候选实体关系的概率;A relationship determination module, configured to determine a potential entity relationship corresponding to the target text based on the word vector corresponding to each word, and the probability that the potential entity relationship exists in the target text is higher than the existence of the potential entity relationship other than the potential entity relationship Probability of candidate entity relationship;
主客体确定模块,用于基于所述潜在实体关系以及各个词对应的所述词向量,确定所述目标文本中的目标主体和目标客体,所述目标主体和所述目标客体属于实体;a subject-object determining module, configured to determine a target subject and a target object in the target text based on the potential entity relationship and the word vector corresponding to each word, and the target subject and the target object belong to entities;
抽取模块,基于所述目标主体、所述潜在实体关系以及所述目标客体,从所述目标文本中抽取实体关系三元组。The extraction module extracts entity relationship triples from the target text based on the target subject, the potential entity relationship and the target object.
另一方面,本申请实施例提供了一种计算机设备,所述计算机设备包括处理器和存储器,所述存储器中存储有至少一条指令,所述至少一条指令由所述处理器加载并执行以实现如上述方面所述的文本中实体关系的抽取方法。On the other hand, an embodiment of the present application provides a computer device, the computer device includes a processor and a memory, the memory stores at least one instruction, and the at least one instruction is loaded and executed by the processor to implement The method for extracting entity relations in text as described in the above aspects.
另一方面,本申请实施例提供了一种计算机可读存储介质,所述可读存储介质中存储有至少一条指令,所述至少一条指令由处理器加载并执行以实现如上述方面所述的文本中实体关系的抽取方法。On the other hand, an embodiment of the present application provides a computer-readable storage medium, where at least one instruction is stored in the readable storage medium, and the at least one instruction is loaded and executed by a processor to implement the above-mentioned aspects A method for extracting entity relations from text.
另一方面,本申请实施例提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行上述方面提供的文本中实体关系的抽取方法。On the other hand, an embodiment of the present application provides a computer program product or computer program, where the computer program product or computer program includes computer instructions, and the computer instructions are stored in a computer-readable storage medium. The processor of the computer device reads the computer instructions from the computer-readable storage medium, and the processor executes the computer instructions, so that the computer device executes the method for extracting entity relationships in text provided by the above aspects.
在进行实体关系提取过程中,首先基于对目标文本编码得到的词向量,确定目标文本中高概率存在的潜在实体关系,过滤低概率存在的候选实体关系,然后基于确定出的潜在实体关系以及词向量,从目标文本中确定出目标主体和目标客体,最终从目标文本中抽取出包含目标主体、潜在实体关系以及目标客体的实体关系三元组;采用本申请实施例提供的方案,在进行主客体提取前,通过对候选实体关系进行筛选得到潜在实体关系,能够减少与目标文本无关的冗余实体关系造成的误召回结果,提高文本中实体关系提取的准确性,并有助于提高实体关系的提取效率。In the process of entity relationship extraction, firstly, based on the word vector obtained by encoding the target text, determine the potential entity relationship with high probability in the target text, filter the candidate entity relationship with low probability, and then based on the determined potential entity relationship and word vector , determine the target subject and target object from the target text, and finally extract the entity relationship triplet including the target subject, potential entity relationship and target object from the target text; adopt the scheme provided by the embodiment of the present application, in the process of subject and object Before extraction, the potential entity relationship is obtained by screening the candidate entity relationship, which can reduce the false recall result caused by redundant entity relationship unrelated to the target text, improve the accuracy of entity relationship extraction in the text, and help to improve the entity relationship. extraction efficiency.
附图说明Description of drawings
为了更清楚地说明本申请实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。In order to illustrate the technical solutions in the embodiments of the present application more clearly, the following briefly introduces the drawings that are used in the description of the embodiments. Obviously, the drawings in the following description are only some embodiments of the present application. For those of ordinary skill in the art, other drawings can also be obtained from these drawings without creative effort.
图1示出了本申请实施例提供的文本中实体关系的抽取方法的原理示意图;FIG. 1 shows a schematic diagram of the principle of a method for extracting entity relationships in a text provided by an embodiment of the present application;
图2示出了本申请一个示例性实施例提供的实施环境的示意图;FIG. 2 shows a schematic diagram of an implementation environment provided by an exemplary embodiment of the present application;
图3示出了本申请一个示例性实施例提供的文本中实体关系的抽取方法的流程图;3 shows a flowchart of a method for extracting entity relationships in text provided by an exemplary embodiment of the present application;
图4示出了本申请另一个示例性实施例提供的文本中实体关系的抽取方法的流程图;FIG. 4 shows a flowchart of a method for extracting entity relationships in text provided by another exemplary embodiment of the present application;
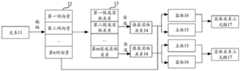
图5是本申请一个示例性实施例示出的实体关系抽取过程的实施示意图;5 is a schematic diagram of the implementation of an entity relationship extraction process shown in an exemplary embodiment of the present application;
图6是本申请一个示例性实施例示出的实体关系三元组生成过程的流程图;FIG. 6 is a flowchart of an entity relationship triple generation process shown in an exemplary embodiment of the present application;
图7是本申请另一个示例性实施例示出的实体关系抽取过程的实施示意图;7 is a schematic diagram of the implementation of the entity relationship extraction process shown in another exemplary embodiment of the present application;
图8示出了本申请一个示例性实施例提供的实体关系抽取模型训练过程的流程图;FIG. 8 shows a flowchart of an entity relationship extraction model training process provided by an exemplary embodiment of the present application;
图9示出了本申请另一个示例性实施例提供的实体关系抽取模型训练过程的流程图;FIG. 9 shows a flowchart of an entity relationship extraction model training process provided by another exemplary embodiment of the present application;
图10是本申请一个示例性实施例提供的文本中实体关系的抽取装置的结构框图;10 is a structural block diagram of an apparatus for extracting entity relationships in text provided by an exemplary embodiment of the present application;
图11示出了本申请一个示例性实施例提供的计算机设备的结构示意图。FIG. 11 shows a schematic structural diagram of a computer device provided by an exemplary embodiment of the present application.
具体实施方式Detailed ways
为使本申请的目的、技术方案和优点更加清楚,下面将结合附图对本申请实施方式作进一步地详细描述。In order to make the objectives, technical solutions and advantages of the present application clearer, the embodiments of the present application will be further described in detail below with reference to the accompanying drawings.
为了方便理解,下面首先对本申请实施例中涉及的名词进行说明。For the convenience of understanding, the terms involved in the embodiments of the present application are first described below.
实体关系三元组:由主体、客体以及主客体关系构成的三元组。其中,主体和客体均为特定领域的实体。以医学领域为例,主体可以为医学症状,主客体关系可以为医学症状的性质、部位、时间等属性,客体则是主客体关系所指示属性对应的实体。在一个示意性的例子中,实体关系三元组为(皮炎,部位,腿部),或者(皮炎,性质,中度)。本申请实施例提供的方法,即用于从特定领域的文本中,抽取出包含特定领域实体间关系的实体关系三元组。Entity-relationship triples: triples consisting of subject, object, and subject-object relationship. Among them, the subject and the object are entities in a specific field. Taking the medical field as an example, the subject can be a medical symptom, the subject-object relationship can be attributes such as the nature, location, and time of the medical symptom, and the object is the entity corresponding to the attribute indicated by the subject-object relationship. In an illustrative example, the entity-relationship triple is (dermatitis, site, leg), or (dermatitis, nature, moderate). The method provided by the embodiment of the present application is used to extract entity relationship triples including the relationship between entities in a specific field from text in a specific field.
序列标注(Sequence Tagging):NLP中的基础任务,用于解决对字符进行分类的问题,如分词、词性标注、命名实体识别、关系抽取等等。本申请实施例中的序列标注即用于标注文本中的主体和客体,且在序列标注过程中采用BIO(Begin Inside Outside)标注,其中,B标签表示词位于实体开头,I标签表示词位于实体内部,O标签表示词不属于实体。Sequence Tagging: The basic task in NLP to solve the problem of classifying characters, such as word segmentation, part-of-speech tagging, named entity recognition, relation extraction, etc. The sequence labeling in the embodiment of the present application is used to label the subject and object in the text, and the BIO (Begin Inside Outside) labeling is used in the sequence labeling process, where the B label indicates that the word is located at the beginning of the entity, and the I label indicates that the word is located at the entity. Internally, the O label indicates that the word does not belong to an entity.
人工标注:指训练神经网络模型前,通过标注人员对训练数据集中的训练样本进行真实值(ground-truth)标注的过程。人工标注得到的标注标签作为模型训练过程中对模型输出结果的监督,相应的,模型训练的过程即通过调整模型参数,使模型输出结果趋向于标注标签的过程。本申请实施例中涉及的人工标注过程包括对样本文本中的主体、客体、客体关系进行标注。Manual labeling: refers to the process of labeling the training samples in the training data set with ground-truth labels by labelers before training the neural network model. The labels obtained by manual annotation are used as the supervision of the model output results during the model training process. Correspondingly, the model training process is the process of adjusting the model parameters to make the model output results tend to be labeled labels. The manual labeling process involved in the embodiments of the present application includes labeling the subject, object, and object relationship in the sample text.
损失函数(loss function):又被称为代价函数(cost function),是一种用于评价神经网络模型的预测值与真实值之间差异程度的函数,损失函数越小,表明神经网络模型的性能越好,模型的训练过程即通过调整模型参数,最小化损失函数的过程。对于不同的神经网络模型,所采用的损失函数也不同,常见的损失函数包括0-1损失函数、绝对值损失函数、对数损失函数、指数损失函数、感知损失函数、交叉熵损失函数等等。Loss function: Also known as cost function, it is a function used to evaluate the degree of difference between the predicted value of the neural network model and the actual value. The smaller the loss function, the better the performance of the neural network model. The better the performance, the training process of the model is the process of minimizing the loss function by adjusting the model parameters. For different neural network models, different loss functions are used. Common loss functions include 0-1 loss function, absolute value loss function, logarithmic loss function, exponential loss function, perceptual loss function, cross entropy loss function, etc. .
自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,所以它与语言学的研究有着密切的联系。自然语言处理技术通常包括文本处理、语义理解、机器翻译、机器人问答、知识图谱等技术。本申请实施例提供的文本中实体关系的抽取方法即在知识图谱领域的应用。Natural language processing is an important direction in the field of computer science and artificial intelligence. It studies various theories and methods that can realize effective communication between humans and computers using natural language. Natural language processing is a science that integrates linguistics, computer science, and mathematics. Therefore, research in this field will involve natural language, the language that people use on a daily basis, so it is closely related to the study of linguistics. Natural language processing technology usually includes text processing, semantic understanding, machine translation, robot question answering, knowledge graph and other technologies. The method for extracting entity relationships in text provided by the embodiments of this application is an application in the field of knowledge graphs.
知识图谱是一种基于图的数据结构,由节点和边组成,每一个节点表示一个实体,而节点之间的边则表示实体与实体之间的关系,因此为了实现特定领域的知识图谱构建,首先需要从特定领域的海量文本数据中抽取出实体之间的关系。相关技术中,为了提高实体关系的抽取效率,通过采用神经网络模型进行实体关系抽取。由于实体间的关系复杂多样,因此在进行实体关系抽取时,需要对各种实体关系进行逐一判别。然而在实际应用中发现,对于一条文本而言,该文本中实体之间的实体关系仅占实体关系总量的极小部分,而其他冗余的实体关系不仅会对实体关系提取的准确性造成影响,还会影响实体关系的提取效率。Knowledge graph is a graph-based data structure composed of nodes and edges. Each node represents an entity, and the edges between nodes represent the relationship between entities. Therefore, in order to realize the construction of knowledge graphs in specific fields, First, the relationship between entities needs to be extracted from massive text data in a specific domain. In the related art, in order to improve the extraction efficiency of the entity relationship, the entity relationship extraction is performed by using a neural network model. Because the relationship between entities is complex and diverse, it is necessary to discriminate each entity relationship one by one when performing entity relationship extraction. However, in practical applications, it is found that for a text, the entity relationship between entities in the text only accounts for a very small part of the total entity relationship, and other redundant entity relationships will not only affect the accuracy of entity relationship extraction. It will also affect the extraction efficiency of entity relations.
本申请实施例提供了一种文本中实体关系的抽取方法,通过从候选实体关系中筛选出文本中高概率存在的潜在实体关系,降低冗余实体关系对实体关系提取造成的影响,在提高实体关系提取准确率的同时,提高实体关系的提取效率。图1示出了本申请实施例提供的文本中实体关系的抽取方法的原理示意图。The embodiment of the present application provides a method for extracting entity relationships in text, which reduces the influence of redundant entity relationships on entity relationship extraction by screening out potential entity relationships that exist in a text with high probability from candidate entity relationships. While the extraction accuracy rate is improved, the extraction efficiency of entity relationships is improved. FIG. 1 shows a schematic diagram of the principle of a method for extracting entity relationships in text provided by an embodiment of the present application.
如图1所示,计算机设备首先对文本11进行编码,得到文本11中n个词各自对应的词向量12,从而基于词向量12从m种候选实体关系13中,筛选出潜在实体关系14,其中,文本11中存在潜在实体关系14的概率高于存在其它候选实体关系的概率。进一步的,计算机设备基于潜在实体关系14以及词向量12,确定文本11中包含主体15以及客体16,进而基于主体15、客体16以及潜在实体关系14生成实体关系三元组17,完成对文本11的实体关系抽取。由于在确定主体和客体前筛选出了潜在实体关系,因此在确定主体客体时,无需逐一遍历各种候选实体关系,降低了确定主客体过程的计算量;同时,最终抽取得到的实体关系三元组中仅包含潜在实体关系,避免冗余实体关系造成的误召回,提高了实体关系抽取的准确性。As shown in FIG. 1 , the computer device first encodes the text 11 to obtain word vectors 12 corresponding to each of the n words in the text 11, so as to screen out the potential entity relationships 14 from the m candidate entity relationships 13 based on the word vectors 12, Among them, the probability that the potential entity relationship 14 exists in the text 11 is higher than the probability that other candidate entity relationships exist. Further, the computer device determines that the subject 15 and the object 16 are included in the text 11 based on the potential entity relationship 14 and the word vector 12, and then generates an entity relationship triplet 17 based on the subject 15, the object 16 and the potential entity relationship 14, and completes the analysis of the text 11. entity relation extraction. Since the potential entity relationship is screened out before the subject and object are determined, it is not necessary to traverse various candidate entity relationships one by one when determining the subject and object, which reduces the amount of calculation in the process of determining the subject and object; at the same time, the final extracted entity relationship ternary Only potential entity relationships are included in the group, which avoids false recall caused by redundant entity relationships and improves the accuracy of entity relationship extraction.
本申请实施例提供的文本中实体关系的抽取方法,可用于特定领域知识图谱的构建过程。以医学领域知识图谱的构建过程为例,开发人员首先对部分医学领域的文本语料进行人工标注,从而利用人工标注的文本语料训练实体关系抽取模型,该实体关系抽取模型即用于基于输入文本输出实体关系三元组。训练完成的实体关系抽取模型部署在计算机设备上后,计算机设备将医学领域文本语料库中的未标注文本语料输入实体关系抽取模型,得到实体关系抽取模型输出的实体关系三元组。基于抽取得到的海量实体关系三元组,计算机设备即可进一步构建医学领域知识图谱。The method for extracting entity relationships in text provided by the embodiments of the present application can be used in the process of constructing a knowledge graph in a specific domain. Taking the construction of a knowledge graph in the medical field as an example, developers first manually annotate some text corpora in the medical field, and then use the manually annotated text corpus to train an entity relationship extraction model, which is used to output based on the input text. Entity-relationship triples. After the trained entity relation extraction model is deployed on the computer equipment, the computer equipment inputs the unlabeled text corpus in the medical field text corpus into the entity relation extraction model, and obtains the entity relation triplet output by the entity relation extraction model. Based on the extracted massive entity-relationship triples, the computer equipment can further construct the knowledge graph in the medical field.
进一步的,构建得到的医学领域知识图谱可以用于各类下游业务中。比如,可以基于医学领域知识图谱设计医学领域的自动问答系统,利用自动问答系统对用户的医学提问进行自动回复;或者,利用医学领域知识图谱作为自然语言理解中实体与实体关系的背景信息,提高自然语言理解的准确性;或者,将医学领域知识图谱作为辅助信息集成到推荐系统中,以提高推荐结果的准确性。Further, the constructed knowledge graph in the medical field can be used in various downstream businesses. For example, an automatic question answering system in the medical field can be designed based on the knowledge graph in the medical field, and the automatic question answering system can be used to automatically reply to the user's medical questions; Accuracy of natural language understanding; or, integrating medical domain knowledge graphs as auxiliary information into recommender systems to improve the accuracy of recommendation results.
当然,本申请实施例提供的文本中实体关系的抽取方法,还可以应用于其他领域知识图谱的构建过程,比如客服领域、金融领域等等,本申请实施例仅以医学领域为例进行示意性说明,但并不对此构成限定。Of course, the method for extracting entity relationships in text provided by the embodiments of this application can also be applied to the construction process of knowledge graphs in other fields, such as the customer service field, the financial field, etc. The embodiments of this application only take the medical field as an example to illustrate description, but not limiting.
图2示出了本申请一个示例性实施例提供的实施环境的示意图。该实施环境中包括终端210和服务器220。其中,终端210与服务器220之间通过通信网络进行数据通信,可选地,通信网络可以是有线网络也可以是无线网络,且该通信网络可以是局域网、城域网以及广域网中的至少一种。FIG. 2 shows a schematic diagram of an implementation environment provided by an exemplary embodiment of the present application. The implementation environment includes a terminal 210 and a
终端210是用于提供文本语料的电子设备,该电子设备可以是智能手机、平板电脑或个人计算机等等,本实施例并此不作限定。图2中,以终端210为医护人员使用的计算机为例进行说明。The terminal 210 is an electronic device for providing text corpus, and the electronic device may be a smart phone, a tablet computer, a personal computer, etc., which is not limited in this embodiment. In FIG. 2 , the terminal 210 is taken as an example of a computer used by medical staff for description.
终端210获取到文本语料后,将文本语料发送至服务器220,由服务器220从文本语料中提取用于构建知识图谱的实体关系。如图2所示,医护人员通过终端210录入对患者的症状描述后,终端210将症状描述作为医学领域的文本语料发送至服务器220。After acquiring the text corpus, the terminal 210 sends the text corpus to the
服务器220可以是独立的物理服务器,也可以是多个物理服务器构成的服务器集群或者分布式系统,还可以是提供云服务、云数据库、云计算、云函数、云存储、网络服务、云通信、中间件服务、域名服务、安全服务、内容分发网络(Content Delivery Network,CDN)、以及大数据和人工智能平台等基础云计算服务的云服务器。The
本实施例中,服务器220中设置有实体关系提取模型,用于从特定领域文本中提取出包含实体以及实体关系的实体关系三元组。可选的,该实体关系提取模型预先根据人工标注的文本训练得到。此外,服务器220还用于基于抽取到的实体关系三元组构建特定领域的知识图谱。在一种可能的实施方式中,文本语料以及从文本语料中抽取到的实体关系三元组可以保存在区块链上。In this embodiment, the
示意性的,如图2所示,服务器220接收到终端210发送的文本语料后,将文本语料中的医学文本221输入实体关系提取模型222,得到实体关系提取模型222抽取到的实体关系三元组223。当实体关系三元组223的数据量满足知识图谱构建(或更新)要求时,服务器220基于实体关系三元组223构建(或更新)医学领域知识图谱224。Illustratively, as shown in FIG. 2 , after receiving the text corpus sent by the terminal 210, the
当然,服务器220除了从终端210处获取文本语料外,还可以从网络中抓取文本语料,或者,从语料库中获取文本语料,本实施例对此不作限定。Certainly, the
在其他可能的实施方式中,实体关系提取模型222也可以部署在终端侧,由终端从文本中提取出实体关系三元组,并将实体关系三元组上报至服务器(避免服务器直接获取原始文本语料),以便服务器进行知识图谱构建。本实施例对此不作限定。为了方便表述,下述各个实施例以文本中实体关系的抽取方法由计算机设备执行为例进行说明。In other possible implementations, the entity relationship extraction model 222 can also be deployed on the terminal side, the terminal extracts entity relationship triples from the text, and reports the entity relationship triples to the server (to avoid the server directly obtaining the original text corpus) for the server to construct knowledge graph. This embodiment does not limit this. For convenience of description, the following embodiments are described by taking an example that the method for extracting entity relationships in text is executed by a computer device.
图3示出了本申请一个示例性实施例提供的文本中实体关系的抽取方法的流程图。本实施例以该方法用于计算机设备为例进行说明,该方法包括如下步骤。FIG. 3 shows a flowchart of a method for extracting entity relationships in text provided by an exemplary embodiment of the present application. This embodiment is described by taking the method for a computer device as an example, and the method includes the following steps.
步骤301,对目标文本进行编码,得到目标文本中各个词对应的词向量。Step 301: Encode the target text to obtain word vectors corresponding to each word in the target text.
目标文本为特定领域的文本语料,该目标文本由若干词(token)构成,对目标文本进行编码(encode)时,即以词为单位进行编码,得到各个词对应的词向量。其中,当目标文本为英文时,对目标文本编码得到各个英文单词对应的词向量;当目标文本为中文时,对目标文本编码得到各个中文汉字对应的词向量。为了方便表述,本申请实施例以目标文本为中文为例进行说明。The target text is a text corpus in a specific field, and the target text is composed of several words (tokens). When the target text is encoded (encoded), it is encoded in units of words, and the word vector corresponding to each word is obtained. Wherein, when the target text is English, the target text is encoded to obtain word vectors corresponding to each English word; when the target text is Chinese, the target text is encoded to obtain word vectors corresponding to each Chinese character. For the convenience of description, the embodiment of the present application takes the target text in Chinese as an example for description.
关于文本编码的方式,在一种可能的实施方式中,计算机设备将目标文本输入预训练的BERT(Bidirectional Encoder Representations from Transformers)模型,由BERT模型对目标文本进行编码,输出各个词对应的词向量。在其他可能的实施方式中,计算机设备还可以采用Word2Vec、Glove、RoBerta等编码器对目标文本进行编码,本申请实施例并不对具体编码方式进行限定。Regarding the way of text encoding, in a possible implementation, the computer device inputs the target text into a pre-trained BERT (Bidirectional Encoder Representations from Transformers) model, the BERT model encodes the target text, and outputs the word vector corresponding to each word . In other possible implementations, the computer device may also use encoders such as Word2Vec, Glove, RoBerta, etc. to encode the target text, and the embodiments of the present application do not limit the specific encoding method.
示意性的,当输入的目标文本表示为S={x1,x2,…,xn}时(n为目标文本的长度,即包含词的个数),经过编码后,各个词对应的词向量可以表征为
步骤302,基于各个词对应的词向量,确定目标文本对应的潜在实体关系,目标文本中存在潜在实体关系的概率高于存在潜在实体关系外其它候选实体关系的概率。Step 302: Determine the potential entity relationship corresponding to the target text based on the word vector corresponding to each word. The probability of the potential entity relationship in the target text is higher than the probability of other candidate entity relationships other than the potential entity relationship.
可选的,在进行实体关系提取前,开发人员首先设置特定领域中实体之间的候选实体关系。虽然候选实体关系的类型多样,但是单一文本中存在的实体关系仅占候选实体关系总量的极小部分(通常单一文本中存在的实体关系在5个以下)。因此为了避免无效冗余实体关系对实体关系抽取速度以及准确性造成影响,本实施例中,计算机设备首先从候选实体关系中筛选出至少一种潜在实体关系,该潜在实体关系为目标文本中高概率存在的实体关系。Optionally, before performing entity relationship extraction, the developer first sets candidate entity relationships between entities in a specific domain. Although the types of candidate entity relationships are diverse, the entity relationships existing in a single text only account for a very small part of the total number of candidate entity relationships (usually there are less than 5 entity relationships in a single text). Therefore, in order to avoid the influence of invalid and redundant entity relationship on the extraction speed and accuracy of entity relationship, in this embodiment, the computer device first selects at least one potential entity relationship from the candidate entity relationship, and the potential entity relationship is a high probability in the target text. Existing entity relationships.
其中,不同文本对应的潜在实体关系的数量可能不同,且潜在实体关系的类型可能不同。Among them, the number of potential entity relationships corresponding to different texts may be different, and the types of potential entity relationships may be different.
在一个示意性的例子中,当特定领域中实体之间的候选实体关系共100种时,计算机设备基于词向量,将100种候选实体关系中的2种候选实体关系确定为目标文本对应的潜在实体关系。In an illustrative example, when there are a total of 100 candidate entity relationships between entities in a specific field, the computer device determines, based on word vectors, 2 candidate entity relationships among the 100 candidate entity relationships as potential potential corresponding to the target text. entity relationship.
步骤303,基于潜在实体关系以及各个词对应的词向量,确定目标文本中的目标主体和目标客体,目标主体和目标客体属于实体。
由于已经筛选出高概率存在的潜在实体关系,因此只需要基于潜在实体关系确定目标文本中的主客体,无需基于其它低概率存在的候选实体关系,一方面能够降低确定主客体时的计算量,另一方面能够避免因低概率候选实体关系造成的误召回。比如,当候选实体关系共100种,而目标文本对应的潜在实体关系仅为2种时,计算机设备仅需要基于2种潜在实体关系确定主客体,无需基于其他98种候选实体关系。Since the potential entity relationship with high probability has been screened out, it is only necessary to determine the subject and object in the target text based on the potential entity relationship, and there is no need to base on other candidate entity relationship with low probability. On the other hand, it can avoid false recalls caused by low-probability candidate entity relationships. For example, when there are 100 candidate entity relationships and only two potential entity relationships corresponding to the target text, the computer device only needs to determine the subject and object based on the two potential entity relationships, and does not need to be based on the other 98 candidate entity relationships.
在一种可能的实施方式中,计算机设备对潜在实体关系和各个词对应的词向量进行组合,得到赋予特定实体关系的词向量,从而基于赋予特定实体关系的词向量确定目标主体和目标客体。其中,目标主体和目标客体均为特定领域的实体,且目标主体是具有潜在实体关系的主体,而目标客体是具有潜在实体关系的客体。In a possible implementation, the computer device combines the potential entity relationship and the word vector corresponding to each word to obtain a word vector assigned a specific entity relationship, so as to determine the target subject and target object based on the word vector assigned to the specific entity relationship. Among them, the target subject and the target object are entities in a specific field, and the target subject is the subject with potential entity relationship, and the target object is the object with potential entity relationship.
在一种可能的实施方式中,当目标文本为医学领域文本时,目标主体和目标客体为医学文本实体,目标主体与目标客体之间的实体关系包括部位、时间和性质中的至少一种。In a possible implementation, when the target text is medical field text, the target subject and the target object are medical text entities, and the entity relationship between the target subject and the target object includes at least one of location, time and nature.
比如,当目标主体为症状时,目标客体可以包括症状出现的部位、症状的性质(严重程度)、症状的持续时间等等。For example, when the target subject is a symptom, the target object may include the location where the symptom occurs, the nature (severity) of the symptom, the duration of the symptom, and so on.
步骤304,基于目标主体、潜在实体关系以及目标客体,从目标文本中抽取实体关系三元组。
确定出目标主体、目标客体和潜在实体关系后,计算机设备对三者进行组合,生成实体关系三元组,其中,实体关系三元组中的目标主体和目标客体具有潜在实体关系。After determining the target subject, the target object and the potential entity relationship, the computer device combines the three to generate an entity relationship triple, wherein the target subject and the target object in the entity relationship triple have a potential entity relationship.
在一种可能的实施方式中,计算机设备可以采用启发式的最近邻方法将主客体组合,即按时序将目标文本中距离最近的目标主客体和潜在实体关系组合,得到实体关系三元组。In a possible implementation, the computer device may use a heuristic nearest neighbor method to combine subject and object, that is, combine the nearest target subject and object in the target text with a potential entity relationship in time sequence to obtain entity relationship triples.
在另一种可能的实施方式中,计算机设备确定目标主客体之间组合时的置信度,从而基于该置信度组合得到实体关系三元组,提高实体关系三元组中主客体之间实体关系的准确性。In another possible implementation, the computer device determines the confidence level when combining the target subject and object, so as to obtain an entity relationship triplet based on the combination of the confidence level, and improve the entity relationship between the subject and object in the entity relationship triplet accuracy.
在一个示意性的例子中,目标文本为“患者两天前出现阵发性腹痛,为右下腹,呈隐痛状”,计算机设备确定目标文本对应的潜在实体关系包括“性质”和“部位”,且确定出的目标主体包括腹痛,目标客体包括阵发性和右下部,抽取到的实体关系三元组包括:(腹痛,性质,阵发性),(腹痛,部位,右下腹)。In an illustrative example, the target text is "the patient had episodic abdominal pain two days ago, in the right lower abdomen, with dull pain", and the computer equipment determines that the potential entity relationship corresponding to the target text includes "nature" and "site", And the determined target subject includes abdominal pain, the target object includes paroxysmal and lower right abdomen, and the extracted entity relation triples include: (abdominal pain, nature, paroxysmal), (abdominal pain, location, right lower abdomen).
综上所述,本申请实施例中,在进行实体关系提取过程中,首先基于对目标文本编码得到的词向量,确定目标文本中高概率存在的潜在实体关系,过滤低概率存在的候选实体关系,然后基于确定出的潜在实体关系以及词向量,从目标文本中确定出目标主体和目标客体,最终从目标文本中抽取出包含目标主体、潜在实体关系以及目标客体的实体关系三元组;采用本申请实施例提供的方案,在进行主客体提取前,通过对候选实体关系进行筛选得到潜在实体关系,能够减少与目标文本无关的冗余实体关系造成的误召回结果,提高文本中实体关系提取的准确性,并有助于提高实体关系的提取效率。To sum up, in the embodiment of the present application, in the process of entity relationship extraction, firstly, based on the word vector obtained by encoding the target text, determine the potential entity relationship with high probability in the target text, and filter the candidate entity relationship with low probability. Then, based on the determined potential entity relationship and word vector, the target subject and target object are determined from the target text, and finally the entity relationship triplet including the target subject, potential entity relationship and target object is extracted from the target text; In the solution provided by the application embodiment, before subject-object extraction is performed, potential entity relationships are obtained by screening candidate entity relationships, which can reduce false recall results caused by redundant entity relationships unrelated to the target text, and improve the efficiency of entity relationship extraction in texts. accuracy, and help to improve the extraction efficiency of entity relations.
在一种可能的实施方式中,计算机设备通过预先训练的实体关系抽取模型进行实体关系三元组抽取,该实体关系抽取模型由编码层、潜在关系判断层以及关系特定的序列标注层构成。其中,编码层用于对输入文本进行编码得到词向量,潜在关系判断层用于基于词向量确定文本中存在的潜在实体关系,关系特定的序列标注层用于将潜在实体关系与词向量进行融合,从而基于具有潜在实体关系的词向量进行序列标注,确定出目标主客体。下面采用示例性的实施例进行说明。In a possible implementation, the computer device extracts entity relationship triples through a pre-trained entity relationship extraction model, where the entity relationship extraction model consists of a coding layer, a potential relationship judgment layer, and a relationship-specific sequence labeling layer. Among them, the encoding layer is used to encode the input text to obtain the word vector, the latent relationship judgment layer is used to determine the potential entity relationship existing in the text based on the word vector, and the relationship-specific sequence annotation layer is used to fuse the potential entity relationship with the word vector. , so as to perform sequence labeling based on word vectors with potential entity relationships, and determine the target subject and object. Exemplary embodiments are used for description below.
图4示出了本申请另一个示例性实施例提供的文本中实体关系的抽取方法的流程图。本实施例以该方法用于计算机设备为例进行说明,该方法包括如下步骤。FIG. 4 shows a flowchart of a method for extracting entity relationships in text provided by another exemplary embodiment of the present application. This embodiment is described by taking the method for a computer device as an example, and the method includes the following steps.
步骤401,对目标文本进行编码,得到目标文本中各个词对应的词向量。Step 401: Encode the target text to obtain word vectors corresponding to each word in the target text.
本步骤的实施方式可以参考上述步骤301,本实施例在此不再赘述。For the implementation of this step, reference may be made to the foregoing
示意性的,如图5所示,目标文本51输入编码层52后,得到各个词对应的词向量53(h)。Illustratively, as shown in FIG. 5 , after the
步骤402,基于各个词对应的词向量,确定目标文本对应的文本向量。Step 402: Determine the text vector corresponding to the target text based on the word vector corresponding to each word.
本申请实施例中,文本中潜在实体关系的确定过程被建模为基于文本全局表征的多标签二分类问题,因此计算机设备基于各个词对应的词向量,得到目标文本的全局表征,即文本向量。In the embodiment of the present application, the process of determining the potential entity relationship in the text is modeled as a multi-label binary classification problem based on the global representation of the text. Therefore, the computer device obtains the global representation of the target text based on the word vector corresponding to each word, that is, the text vector .
在一种可能的实施方式中,计算机设备对各个词对应的词向量进行平均池化处理,得到目标文本对应的文本向量,该文本向量与词向量具有相同维度,从而实现对编码层输出的降维。示意性的,基于词向量确定文本向量的过程可以采用如下公式表示:In a possible implementation, the computer device performs an average pooling process on the word vectors corresponding to each word to obtain a text vector corresponding to the target text. The text vector and the word vector have the same dimension, so as to reduce the output of the coding layer. dimension. Illustratively, the process of determining the text vector based on the word vector can be expressed by the following formula:

其中,Avgpool为平均池化方法,即在每个维度上对各个词的词向量进行平均,h为目标文本中各个词的词向量。Among them, Avgpool is the average pooling method, that is, the word vector of each word is averaged in each dimension, and h is the word vector of each word in the target text.
当然,除了通过对词向量进行平均池化外,计算机设备还可以通过其他方式得到目标文本的全局表征,本实施例并不对此进行限定。Of course, in addition to performing average pooling on word vectors, the computer device can also obtain the global representation of the target text in other ways, which is not limited in this embodiment.
步骤403,通过全连接层对文本向量进行分类,得到各种候选实体关系对应的存在概率,存在概率指目标文本中存在候选实体关系的概率。Step 403: Classify the text vector through the fully connected layer to obtain the existence probabilities corresponding to various candidate entity relationships, where the existence probability refers to the probability that the candidate entity relationship exists in the target text.
在一种可能的实施方式中,采用全连接层(Fully Connected,FC)实现成为实体关系抽取模型中的潜在关系判断层。相应的,确定目标文本中潜在实体关系的过程,即为利用全连接层对文本向量进行多标签二分类。In a possible implementation, a fully connected layer (Fully Connected, FC) is used to realize the potential relationship judgment layer in the entity relationship extraction model. Correspondingly, the process of determining the potential entity relationship in the target text is to use the fully connected layer to perform multi-label binary classification on the text vector.
可选的,计算机设备将文本向量输入全连接层,由全连接层对文本向量进行卷积处理(比如利用1×1的卷积核),得到各种候选实体关系各自对应的存在概率。其中,候选实体关系对应的存在概率越高,表明目标文本中的实体越有可能存在该候选实体关系。其中,各种候选实体关系对应的存在概率可以表示为:Optionally, the computer device inputs the text vector into the fully connected layer, and the fully connected layer performs convolution processing on the text vector (for example, using a 1×1 convolution kernel) to obtain the corresponding existence probabilities of various candidate entity relationships. Among them, the higher the existence probability corresponding to the candidate entity relationship, the more likely the entity in the target text has the candidate entity relationship. Among them, the existence probability corresponding to various candidate entity relationships can be expressed as:
Prel=σ(Wrhavg+br)Prel =σ(Wr havg +br )
其中,havg为文本向量,
示意性的,如图5所示,计算机设备将文本向量(对词向量53进行平均池化得到)输入潜在关系判断层54,得到各种候选实体对应关系对应的存在概率541。Illustratively, as shown in FIG. 5 , the computer device inputs the text vector (obtained by average pooling of the word vector 53 ) into the latent relationship judgment layer 54 to obtain the
步骤404,基于存在概率从候选实体关系中确定潜在实体关系。
在一种可能的实施方式中,若候选实体关系对应的存在概率高于概率阈值,计算机设备则将该候选实体关系确定为目标文本对应的潜在实体关系,若候选实体关系对应的存在概率低于概率阈值,计算机设备则过滤该候选实体关系。In a possible implementation, if the existence probability corresponding to the candidate entity relationship is higher than the probability threshold, the computer device determines the candidate entity relationship as the potential entity relationship corresponding to the target text, if the existence probability corresponding to the candidate entity relationship is lower than probability threshold, the computer equipment filters the candidate entity relationship.
示意性的,如图5所示,计算机设备基于各种候选实体对应关系对应的存在概率541,将“性质”和“部位”确定为潜在实体关系。Illustratively, as shown in FIG. 5 , the computer device determines “properties” and “parts” as potential entity relationships based on the
步骤405,对词向量和潜在实体关系对应的关系向量进行融合,得到具有潜在实体关系的词向量。In
在一种可能的实施方式,计算机设备获取各个潜在实体关系对应的关系向量,从而将该关系向量与各个词向量进行融合,得到具有潜在实体关系的词向量。其中,潜在实体关系对应的关系向量与词向量具有相同维度。In a possible implementation manner, the computer device acquires a relationship vector corresponding to each potential entity relationship, so as to fuse the relationship vector with each word vector to obtain a word vector with a potential entity relationship. Among them, the relationship vector corresponding to the potential entity relationship has the same dimension as the word vector.
示意性的,具有潜在实体关系的词向量可以表示为hi+uj,其中,hi为目标文本中的第i个词的词向量,uj为第j个潜在实体关系,且hi,
步骤406,基于具有潜在实体关系的词向量进行序列标注,确定目标文本中的目标主体和目标客体。
本申请实施例中,从文本中抽取主客体的过程被建模为序列标注任务,在进行序列标注时,计算机设备使用BIO标签模式,为文本中各个词赋予表征实体位置以及类别的标签,其中,该实体位置用于表征词在实体中所处的位置,类别则用于表征主体和客体。In the embodiment of the present application, the process of extracting the subject and object from the text is modeled as a sequence labeling task. When performing sequence labeling, the computer device uses the BIO label mode to assign labels representing entity locations and categories to each word in the text, wherein , the entity position is used to characterize the position of the word in the entity, and the category is used to characterize the subject and object.
在一种可能的实施方式中,计算机设备基于具有潜在实体关系的词向量,通过关系特定的序列标注层进行序列标注,得到目标文本中的目标主体和目标客体。其中,该关系特定的序列标注层可以使用循环神经网络(RNN,Recurrent Neural Network)或长短期记忆(Long Short-Term Memory,LSTM)网络实现序列标注,本申请实施例并不对序列标注时采用的具体网络结构进行限定。In a possible implementation, the computer device performs sequence labeling through a relation-specific sequence labeling layer based on word vectors with potential entity relationships, to obtain the target subject and target object in the target text. The sequence labeling layer specific to the relationship may use a Recurrent Neural Network (RNN, Recurrent Neural Network) or a Long Short-Term Memory (Long Short-Term Memory, LSTM) network to realize sequence labeling, and the embodiment of this application does not use the sequence labeling method used in sequence labeling. The specific network structure is limited.
为了保证主客体抽取的准确性,本申请实施例中,主体和客体的序列标注分开执行,在一种可能的实施方式中,本步骤可以包括如下子步骤。In order to ensure the accuracy of subject-object extraction, in this embodiment of the present application, the sequence labeling of subject and object is performed separately. In a possible implementation, this step may include the following sub-steps.
一、基于具有潜在实体关系的词向量进行主体序列标注,得到主体标注结果,主体标注结果用于表征具有潜在实体关系的词向量的第一实体位置,第一实体位置包括主体开头、主体内部或主体外部。1. Perform subject sequence tagging based on word vectors with potential entity relationships, and obtain subject tagging results. The subject tagging results are used to represent the first entity positions of word vectors with potential entity relationships. The first entity positions include the beginning of the subject, inside the subject, or outside the main body.
可选的,计算机设备通过关系特定的序列标注层对具有潜在实体关系的词向量进行主体序列标注,得到指示目标文本中各个词对应第一实体位置的主体标注结果。其中,主体注结果包括:B-OBJ(表示词属于主体,且位于主体开头)、I-OBJ(表示词属于主体,且位于主体内部)和O(表示词位于主体外部)。Optionally, the computer device performs subject sequence tagging on word vectors with potential entity relationships through a relationship-specific sequence tagging layer, to obtain subject tagging results indicating that each word in the target text corresponds to the position of the first entity. Among them, the main body annotation results include: B-OBJ (indicates that the word belongs to the main body and is located at the beginning of the main body), I-OBJ (indicates that the word belongs to the main body and is located inside the main body), and O (indicates that the word is located outside the main body).
其中,主体序列标注过程可以表示为:Among them, the subject sequence labeling process can be expressed as:

其中,

示意性的,如图5所示,计算机设备将编码层52输出的词向量h以及潜在关系判断层54输出的潜在实体关系r输入关系特定的序列标注层55。关系特定的序列标注层55对词向量h以及实体关系r对应的关系向量进行拼接,并对拼接向量进行主体标注,得到主体标注结果,其中,“腹”对应的主体标注结果为“B-SUB”,“痛”对应的主体标注结果为“I-SUB”,而其余词对应的主体标注结果均为“O”。Illustratively, as shown in FIG. 5 , the computer device inputs the word vector h output by the encoding layer 52 and the potential entity relationship r output by the potential relationship judgment layer 54 into the relationship-specific sequence labeling layer 55 . The relationship-specific sequence labeling layer 55 splices the word vector h and the relationship vector corresponding to the entity relationship r, and performs subject labeling on the spliced vector to obtain a body labeling result, where the body labeling result corresponding to "belly" is "B-SUB" ”, the subject labeling result corresponding to “pain” is “I-SUB”, and the body labeling results corresponding to the other words are all “O”.
二、基于具有潜在实体关系的词向量进行客体序列标注,得到客体标注结果,客体标注结果用于表征具有潜在实体关系的词向量的第二实体位置,第二实体位置包括客体开头、客体内部或客体外部。2. Perform object sequence labeling based on the word vector with potential entity relationship, and obtain the object labeling result. The object labeling result is used to represent the second entity position of the word vector with potential entity relationship. The second entity position includes the beginning of the object, the interior of the object or outside the object.
可选的,计算机设备通过关系特定的序列标注层对具有潜在实体关系的词向量进行客体序列标注,得到指示目标文本中各个词对应第二实体位置的客体标注结果。其中,客体注结果包括:B-SUB(表示词属于客体,且位于客体开头)、I-SUB(表示词属于客体,且位于客体内部)、O(表示词位于客体外部)。Optionally, the computer device performs object sequence tagging on word vectors with potential entity relationships through a relationship-specific sequence tagging layer, and obtains object tagging results indicating that each word in the target text corresponds to the position of the second entity. Among them, the object annotation results include: B-SUB (indicates that the word belongs to the object and is located at the beginning of the object), I-SUB (indicates that the word belongs to the object and is located inside the object), and O (indicates that the word is located outside the object).
其中,客体序列标注过程可以表示为:Among them, the object sequence labeling process can be expressed as:

其中,

示意性的,如图5所示,关系特定的序列标注层55对词向量h以及实体关系r对应的关系向量进行拼接,并对拼接向量进行客体标注,得到客体标注结果,其中,“阵”、“发”、“性”对应的主体标注结果依次为“B-OBJ”、“I-OBJ”、“I-OBJ”,“右”、“下”、“腹”对应的主体标注结果依次为“B-OBJ”、“I-OBJ”、“I-OBJ”,而其余词对应的客体标注结果均为“O”。Schematically, as shown in FIG. 5 , the relation-specific sequence labeling layer 55 splices the word vector h and the relation vector corresponding to the entity relationship r, and performs object labeling on the spliced vector to obtain the object labeling result, where “array” , "Fa", and "Sex" corresponding to the subject labeling results are "B-OBJ", "I-OBJ", "I-OBJ", "Right", "Lower", "Belly" The corresponding body labeling results are in order are "B-OBJ", "I-OBJ", "I-OBJ", and the object labeling results corresponding to the remaining words are all "O".
三、基于主体标注结果和客体标注结果,确定目标文本中的目标主体和目标客体。3. Determine the target subject and target object in the target text based on the subject labeling result and the object labeling result.
完成主客体序列标注后,计算机设备基于目标文本中各个词对应的主体标注结果和客体标注结果,确定目标主体和目标客体。在一种可能的实施方式中,计算机将主体标注结果为主体开头对应的词,以及连续的主体内部对应的词确定为目标主体;将客体标注结果为客体开头对应的词,以及连续的客体内部对应的词确定为目标客体。After completing the subject-object sequence tagging, the computer device determines the target subject and the target object based on the subject tagging results and the object tagging results corresponding to each word in the target text. In a possible implementation, the computer determines the subject labeling result as the word corresponding to the beginning of the body, and the words corresponding to the continuous subject as the target body; the object labeling result is the word corresponding to the beginning of the object, and the continuous internal The corresponding word is determined as the target object.
示意性的,如图5所示,计算机设备基于“B-SUB”以及“I-SUB”对应的词,确定目标主体为“腹痛”;基于“B-OBJ”以及“I-OBJ”对应的词,确定目标客体为“阵发性”和“右下腹”。Illustratively, as shown in Figure 5, the computer device determines the target subject as "abdominal pain" based on the words corresponding to "B-SUB" and "I-SUB"; words, and identified the target objects as "paroxysmal" and "right lower quadrant".
步骤407,基于目标主体、潜在实体关系以及目标客体,从目标文本中抽取实体关系三元组。
示意性的,如图5所示,计算机设备基于确定出的目标主体、目标客体以及潜在实体关系,生成实体关系三元组56。Illustratively, as shown in FIG. 5 , the computer device generates an entity relationship triple 56 based on the determined target subject, target object and potential entity relationship.
本实施例中,计算机设备通过对目标文本中各个词的词向量进行平均池化处理,得到目标文本对应的文本向量,从而基于文本向量从候选实体关系中筛选出潜在实体关系,提高后续进行主客体提取的效率,并避免冗余实体关系对主客体提取的准确性造成影响。In this embodiment, the computer device obtains the text vector corresponding to the target text by performing the average pooling process on the word vectors of each word in the target text, so as to screen out the potential entity relationship from the candidate entity relationship based on the text vector, so as to improve the follow-up main Efficiency of object extraction, and avoid redundant entity relationship to affect the accuracy of subject-object extraction.
此外,本实施例中,通过对词向量与潜在实体关系对应的关系向量进行融合,得到若干关系特定的文本表征,并对文本表征分别进行主体序列标注和客体序列标注,有助于提高主客体标注的准确性,进而提高生成的实体关系三元组的准确性。In addition, in this embodiment, several relation-specific text representations are obtained by fusing the word vector and the relationship vector corresponding to the potential entity relationship, and the subject sequence labeling and the object sequence labeling are respectively performed on the text representation, which helps to improve the subject-object sequence. The accuracy of the annotation, thereby improving the accuracy of the generated entity-relationship triples.
在一个示意性的例子中,如图表一所示,采用相关技术方案对文本进行实体关系抽取时,由于并未进行潜在实体关系筛选,导致最终抽取出包含“性质”这一错误实体关系的实体关系三元组。而采用本申请实施例提供方案进行实体关系抽取时,由于在潜在实体关系筛选阶段即可过滤实体关系“性质”,因此最终抽取出的实体关系三元组中不包含实体关系“性质”,提高了实体关系抽取的准确性。In a schematic example, as shown in Figure 1, when using the related technical solution to extract the entity relationship from the text, because the potential entity relationship is not screened, the entity containing the wrong entity relationship of "nature" is finally extracted. Relational triples. However, when using the solution provided by the embodiment of the present application for entity relationship extraction, since the entity relationship "nature" can be filtered in the potential entity relationship screening stage, the entity relationship triplet finally extracted does not contain the entity relationship "nature", which improves the The accuracy of entity relation extraction is improved.
表一Table I

由于启发式最近邻方法是一种理想化方法,而真实场景中文本的语序存在多样性,因此采用启发式最近邻方法生成实体关系三元组时存在较大误差。为了进一步提高实体关系提取的准确性,在一种可能的实施方式中,实体关系抽取模型中还包括主客体对齐层,该主客体对齐层用于对关系特定的序列标注层输出的主客体进行对齐,并结合潜在实体关系输出实体关系三元组。可选的,如图6所示,上述步骤407可以包括如下步骤:Since the heuristic nearest neighbor method is an idealized method, and the word order of text in real scenes is diverse, there is a large error when using the heuristic nearest neighbor method to generate entity-relation triples. In order to further improve the accuracy of entity relationship extraction, in a possible implementation, the entity relationship extraction model further includes a subject-object alignment layer, which is used to perform subject-object alignment on the subject-object output from the relation-specific sequence annotation layer. Align and combine the latent entity-relations to output entity-relation triples. Optionally, as shown in FIG. 6 , the foregoing
步骤407A,对具有相同潜在实体关系的目标主体和目标客体进行组合,得到至少一个主客体对。
在一种可能的实施方式中,计算机设备对同一潜在实体关系下提取到的目标主体和目标客体(即具有相同潜在实体关系)进行组合,得到主客体对。在一个示意性的例子中,当具有相同潜在实体关系的目标主体包括主体A和主体B,且目标客体包括客体A和客体B时,得到的主客体对包括:(主体A,客体A)、(主体A,客体B)、(主体B,客体A)、(主体B,客体B)。In a possible implementation manner, the computer device combines the extracted target subject and target object under the same potential entity relationship (ie, has the same potential entity relationship) to obtain a subject-object pair. In an illustrative example, when the target subject with the same potential entity relationship includes subject A and subject B, and the target object includes object A and object B, the resulting subject-object pair includes: (subject A, object A), (Subject A, Object B), (Subject B, Object A), (Subject B, Object B).
步骤407B,确定各个主客体对的置信度。
在一种可能的实施方式中,在训练阶段,计算机设备预先学习得到全局对应关系矩阵,在确定主客体对的置信度时,计算机设备将全局对应关系矩阵中,主客体对中目标主体和目标客体之间的置信度确定为主客体对的置信度,该全局对应关系矩阵是由不同实体间置信度构成的矩阵,即全局对应关系矩阵中不同位置对应不同实体间的置信度,其中,置信度越高,表明实体间存在实体关系的概率越高。In a possible implementation, in the training phase, the computer device pre-learns the global correspondence matrix, and when determining the confidence of the subject-object pair, the computer device aligns the subject-object pair in the global correspondence matrix with the target subject and the target. The confidence between objects is determined as the confidence of the subject-object pair. The global correspondence matrix is a matrix composed of confidences between different entities, that is, the confidences between different entities corresponding to different positions in the global correspondence matrix. Among them, the confidence The higher the degree, the higher the probability that there is an entity relationship between entities.
示意性的,全局对应关系矩阵中各个位置对应的置信度通过如下公式计算得到:Illustratively, the confidence level corresponding to each position in the global correspondence matrix is calculated by the following formula:

其中,

需要说明的时,全局对应关系矩阵在构造关系特定的词向量前学习得到,即独立于实体关系,仅关注实体本身。It should be noted that the global correspondence matrix is learned before constructing relation-specific word vectors, that is, independent of entity relations and only concerned with the entity itself.
示意性的,在图5的基础上,如图7所示,计算机设备确定目标主体“腹痛”在全局对应关系矩阵571中的位置,以及目标客体“阵发性”和“右下腹”在全局对应关系矩阵571中的位置,从而确定主客体对(腹痛,阵发性)的置信度,以及主客体对(腹痛,右下腹)的置信度。Illustratively, on the basis of FIG. 5, as shown in FIG. 7, the computer device determines the position of the target subject "abdominal pain" in the
可选的,计算机设备检测主客体对的置信度是否高于置信度阈值,若高于,则执行步骤407C,基于主客体对和潜在实体关系生成实体关系三元组;若主客体对的置信度低于置信度阈值,计算机设备则过滤主客体对。Optionally, the computer device detects whether the confidence of the subject-object pair is higher than the confidence threshold, and if it is higher, then execute
步骤407C,若主客体对的置信度高于置信度阈值,基于主客体对中的目标主体、目标客体以及潜在实体关系生成实体关系三元组。
示意性的,如图7所示,主客体对(腹痛,阵发性)和主客体对(腹痛,右下腹)的置信度均高于置信度阈值,因此计算机设备保留主客体对,并基于主客体对以及潜在实体关系“性质”和“部位”,生成实体关系三元组56。Illustratively, as shown in Figure 7, the confidence of the subject-object pair (abdominal pain, paroxysmal) and the subject-object pair (abdominal pain, right lower quadrant) are both higher than the confidence threshold, so the computer equipment retains the subject-object pair, and based on the The subject-object pair, along with the underlying entity-relationship "properties" and "locations," generate entity-
本实施例中,计算机设备利用预先学习得到的全局对应关系矩阵,确定主客体对的置信度,从而基于该置信度过滤不合理主客体对,实现主客体对齐,有助于提高最终提取到的实体关系三元组的准确性。In this embodiment, the computer device uses the pre-learned global correspondence matrix to determine the confidence of the subject-object pair, so as to filter unreasonable subject-object pairs based on the confidence, realize subject-object alignment, and help improve the final extracted data. Accuracy of entity-relationship triples.
在一个示意性的例子中,如图表二所示,采用相关技术方案对文本进行实体关系抽取时,由于启发式最近邻方法缺乏约束性,因此存在大量主客体对齐错误(将邻近的皮疹和腿部错误对齐)。而采用本申请实施例提供方案进行实体关系抽取时,基于主客体对的置信度对主客体对齐进行约束,过滤错误对齐方式的主客体对,提高了抽取结果的准确性。In a schematic example, as shown in Figure 2, when using related technical solutions to extract entity relations from text, due to the lack of constraints of the heuristic nearest neighbor method, there are a large number of subject-object alignment errors (the adjacent skin rash and leg wrong alignment). When using the solution provided by the embodiment of the present application to extract the entity relationship, the subject-object alignment is constrained based on the confidence of the subject-object pair, and the subject-object pair with wrong alignment is filtered, which improves the accuracy of the extraction result.
表二Table II

在真实病例数据上,采用相关技术和本申请实施例提供的方案进行实体关系抽取,以三元组匹配的F1-score(当主客体以及主客体之间的实体关系均正确时认为三元组正确)作为评测指标,得到的评测结果如表三所示。On real case data, entity relationship extraction is carried out by using the relevant technology and the scheme provided in the embodiment of the present application, and the F1-score matching the triplet (when the entity relationship between the subject and the object and the entity relationship between the subject and the object is correct, the triplet is considered to be correct ) as the evaluation index, and the evaluation results obtained are shown in Table 3.
表三Table 3
以三元组中实体关系的F1-score(忽略主客体的准确性)作为评测指标,得到的评测结果如表四所示。Taking the F1-score of the entity relationship in the triplet (ignoring the accuracy of subject and object) as the evaluation index, the evaluation results obtained are shown in Table 4.
表四Table 4
以三元组中主客体的F1-score(忽略客体关系的准确性)作为评测指标,得到的评测结果如表五所示。Taking the F1-score of the subject and object in the triplet (the accuracy of ignoring the object relationship) as the evaluation index, the evaluation results obtained are shown in Table 5.
表五Table 5
可见,相较于相关技术方案,本申请实施例提供的方案通过潜在关系判断以及主客体对齐,显著提高了实体关系的提取性能,尤其是在准确率方面大幅领先相关技术方案。It can be seen that, compared with the related technical solutions, the solutions provided by the embodiments of the present application significantly improve the extraction performance of entity relationships through potential relationship judgment and subject-object alignment, and in particular, are significantly ahead of related technical solutions in terms of accuracy.
上述实施例对实体关系的抽取过程进行了说明。在实现实体关系抽取前,开发人员首先需要利用样本文本完成实体关系抽取模型训练,下面采用示例性的实施例对实体关系抽取模型的训练过程进行说明。The above embodiments describe the extraction process of entity relationships. Before implementing entity relationship extraction, developers first need to use sample text to complete entity relationship extraction model training. The following uses exemplary embodiments to describe the entity relationship extraction model training process.
图8示出了本申请一个示例性实施例提供的实体关系抽取模型训练过程的流程图。本实施例以该方法用于计算机设备为例进行说明,该方法包括如下步骤。FIG. 8 shows a flowchart of an entity relationship extraction model training process provided by an exemplary embodiment of the present application. This embodiment is described by taking the method for a computer device as an example, and the method includes the following steps.
步骤801,对样本文本进行编码,得到样本文本中各个词对应的样本词向量。Step 801: Encode the sample text to obtain sample word vectors corresponding to each word in the sample text.
可选的,计算机设备将样本文本输入实体关系抽取模型的编码层,得到样本文本中各个词对应的样本词向量。其中,编码层对样本文本进行编码的过程可以参考上述实施例,本实施例在此不再赘述。Optionally, the computer device inputs the sample text into the coding layer of the entity relationship extraction model to obtain sample word vectors corresponding to each word in the sample text. For the process of encoding the sample text by the encoding layer, reference may be made to the foregoing embodiment, and details are not described herein again in this embodiment.
步骤802,基于各个词对应的样本词向量,确定样本文本对应的样本潜在实体关系。Step 802: Determine the sample latent entity relationship corresponding to the sample text based on the sample word vector corresponding to each word.
与应用过程类似的,可选的,计算机设备将各个词对应的样本词向量输入实体关系抽取模型的潜在关系判断层,得到样本文本对应的样本潜在实体关系。其中,潜在关系判断层基于样本词向量确定样本潜在实体关系的过程可以参考上述实施例,本实施例在此不再赘述。Similar to the application process, optionally, the computer device inputs the sample word vector corresponding to each word into the latent relationship judgment layer of the entity relationship extraction model to obtain the sample latent entity relationship corresponding to the sample text. The process of determining the potential entity relationship of the sample based on the sample word vector by the potential relationship judging layer may refer to the above-mentioned embodiment, which will not be repeated in this embodiment.
步骤803,基于样本潜在实体关系以及各个词对应的样本词向量,确定样本文本中的样本主体和样本客体。Step 803: Determine the sample subject and the sample object in the sample text based on the sample latent entity relationship and the sample word vector corresponding to each word.
与应用过程类似的,可选的,计算机设备将样本潜在实体关系以及各个词对应的样本词向量,输入实体关系抽取模型的关系特定的序列标注层,得到样本文本中的样本主体和样本客体。其中,关系特定的序列标注层进行主客体标注的过程可以参考上述实施例,本实施例在此不再赘述。Similar to the application process, optionally, the computer equipment inputs the sample latent entity relationship and the sample word vector corresponding to each word into the relationship-specific sequence annotation layer of the entity relationship extraction model to obtain the sample subject and sample object in the sample text. Wherein, for the process of subject-object tagging performed by the sequence tagging layer with a specific relationship, reference may be made to the foregoing embodiment, which will not be repeated in this embodiment.
步骤804,基于样本文本对应的实体关系标签和样本潜在实体关系,确定潜在关系判断损失。Step 804: Determine the potential relationship judgment loss based on the entity relationship label corresponding to the sample text and the sample potential entity relationship.
为了确定潜在关系判断层的判断损失,计算机设备以样本文本对应的实体关系标签为监督,将实体关系标签与样本潜在实体关系之间的差异确定为潜在关系判断损失。其中,该实体关系标签用于表示样本文本中包含的实体关系。In order to determine the judgment loss of the latent relationship judgment layer, the computer equipment uses the entity relationship label corresponding to the sample text as supervision, and determines the difference between the entity relationship label and the sample latent entity relationship as the latent relationship judgment loss. Among them, the entity relationship label is used to represent the entity relationship contained in the sample text.
在一种可能的实施方式中,计算机设备将实体关系标签与样本潜在实体关系之间的多标签二分类交叉熵损失确定为潜在关系判断损失。该潜在关系判断损失可以表示为:In a possible implementation, the computer device determines the multi-label binary cross-entropy loss between the entity relationship label and the sample potential entity relationship as the potential relationship judgment loss. The potential relationship judgment loss can be expressed as:

其中,nr为候选实体关系的数量,yi为样本文本对应的实体关系标签,Prel为样本文本中潜在实体关系的存在概率。Among them, nr is the number of candidate entity relationships,yi is the entity relationship label corresponding to the sample text, and Prel is the existence probability of the potential entity relationship in the sample text.
步骤805,基于样本主体、样本客体以及样本文本中各个词对应的词标签,确定主客体判断损失。Step 805: Determine the subject-object judgment loss based on the sample subject, the sample object, and the word labels corresponding to each word in the sample text.
为了确定关系特定的主客体标注层的判断损失,计算机设备以样本文本中各个词对应的词标签为监督,将实体关系标签与样本潜在实体关系之间的差异确定为潜在关系判断损失。其中,该词标签为人工标注的BIO标签,该实体关系标签包括如下至少一种:B-SUB标签、I-SUB标签、B-OBJ标签、I-OBJ标签和O标签。In order to determine the judgment loss of the relationship-specific subject-object labeling layer, the computer equipment uses the word labels corresponding to each word in the sample text as supervision, and determines the difference between the entity relationship label and the sample potential entity relationship as the potential relationship judgment loss. The word label is a manually labeled BIO label, and the entity relationship label includes at least one of the following: a B-SUB label, an I-SUB label, a B-OBJ label, an I-OBJ label, and an O label.
在一种可能的实施方式中,计算机设备将多分类交叉熵损失确定为主客体判断损失。该主客体判断损失可以表示为:In a possible implementation, the computer device determines the multi-class cross-entropy loss as the subject-object judgment loss. The subject-object judgment loss can be expressed as:

其中,


步骤806,基于潜在关系判断损失和主客体判断损失训练实体关系抽取模型,实体关系抽取模型用于基于输入的文本输出实体关系三元组。
在一种可能的实施方式中,计算机设备采用联合训练策略,共同优化潜在关系判断层以及关系特定的序列标注层损失的梯度下降最优解,即利用潜在关系判断损失和主客体判断损失的总损失训练实体关系抽取模型。该实体关系抽取模型的总损失可以表示为:In a possible implementation, the computer equipment adopts a joint training strategy to jointly optimize the gradient descent optimal solution of the loss of the potential relationship judgment layer and the relationship-specific sequence labeling layer, that is, the total loss of the potential relationship judgment loss and the subject-object judgment loss is used. loss to train an entity relation extraction model. The total loss of this entity relation extraction model can be expressed as:

其中,α和β为损失权重。where α and β are loss weights.
综上所述,本申请实施例中,基于潜在关系判断层的潜在关系判断损失,以及关系特定的主客体标注层的主客体判断损失训练实体关系抽取模型,使得实体关系抽取模型能够在训练过程中学习如何筛选潜在实体关系以及如何进行主客体标注;后续利用训练得到的实体关系抽取模型进行实体关系抽取时,能够通过筛选潜在实体关系,减少冗余实体关系造成的误召回结果,提高文本中实体关系提取的准确性,进而提高实体关系的提取效率。To sum up, in the embodiment of the present application, the entity relationship extraction model is trained based on the potential relationship judgment loss of the potential relationship judgment layer and the subject-object judgment loss of the relationship-specific subject-object annotation layer, so that the entity relationship extraction model can be used in the training process. Learn how to screen potential entity relationships and how to label subject and object; when using the trained entity relationship extraction model for entity relationship extraction, you can filter potential entity relationships to reduce false recall results caused by redundant entity relationships, and improve text content. The accuracy of entity relationship extraction, thereby improving the extraction efficiency of entity relationships.
在另一种可能的实施方式中,当实体关系抽取模型中包含主客体对齐层时,在图8的基础上,如图9所示,步骤803之后还可以包括步骤807至809,步骤806可以被替换为步骤8061。In another possible implementation, when the entity relationship extraction model includes a subject-object alignment layer, on the basis of FIG. 8, as shown in FIG. 9,
步骤807,将样本主体和样本客体组合为样本主客体对。
与应用过程类似的,计算机设备对提取到的样本主体和样本客体(具有相同的样本潜在实体关系)进行组合,得到样本主客体对。Similar to the application process, the computer device combines the extracted sample subject and sample object (with the same sample potential entity relationship) to obtain a sample subject-object pair.
步骤808,确定样本主客体对的样本置信度。Step 808: Determine the sample confidence of the sample subject-object pair.
在一种可能的实施方式中,计算机设备根据样本主体对应主体向量表征以及样本客体对应客体向量表征,确定样本主客体对的样本置信度。其中,计算样本置信度的方式可以参考步骤407B,本实施例在此不再赘述。In a possible implementation manner, the computer device determines the sample confidence of the sample subject-object pair according to the sample subject-corresponding subject-vector representation and the sample-object-corresponding object vector representation. The method for calculating the confidence level of the sample may refer to step 407B, which will not be repeated in this embodiment.
步骤809,基于样本文本对应的置信度标签以及样本置信度,确定全局对应关系损失。Step 809: Determine the global correspondence loss based on the confidence label corresponding to the sample text and the sample confidence.
为了确定主客体对齐层的判断损失,计算机设备以样本文本中主客体对的置信度标签(即人工标注的主客体对)为监督,将样本置信度与置信度标签之间的差异确定为全局对应关系损失。在一种可能的实施方式中,计算机设备将置信度标签与样本置信度之间的多标签二分类交叉熵损失确定为全局对应关系损失。该全局对应关系损失可以表示为:In order to determine the judgment loss of the subject-object alignment layer, the computer equipment uses the confidence labels of the subject-object pairs in the sample text (that is, the manually annotated subject-object pairs) as supervision, and determines the difference between the sample confidence and the confidence label as a global Correspondence loss. In a possible implementation, the computer device determines the multi-label binary cross-entropy loss between the confidence label and the sample confidence as the global correspondence loss. This global correspondence loss can be expressed as:

其中,n为样本文本的长度,yi,j为主客体对(第i个词,第j个词)的置信度标签,
步骤8061,基于潜在关系判断损失、主客体判断损失以及全局对应关系损失训练实体关系抽取模型。Step 8061: Train an entity relationship extraction model based on the potential relationship judgment loss, the subject-object judgment loss, and the global correspondence loss.
在一种可能的实施方式中,计算机设备采用联合训练策略,共同优化潜在关系判断层、关系特定的序列标注层、主客体对齐层损失的梯度下降最优解,即利用潜在关系判断损失、主客体判断损失和全局对应关系的总损失训练实体关系抽取模型。可选的,潜在关系判断损失、主客体判断损失以及全局对应关系损失对应的损失权重相同。该实体关系抽取模型的总损失可以表示为:In a possible implementation, the computer equipment adopts a joint training strategy to jointly optimize the potential relationship judgment layer, the relationship-specific sequence labeling layer, and the gradient descent optimal solution of the loss of the subject-object alignment layer, that is, using the potential relationship judgment loss, the main The object judgment loss and the total loss of global correspondence train the entity relation extraction model. Optionally, the loss weights corresponding to the potential relationship judgment loss, the subject-object judgment loss, and the global correspondence loss are the same. The total loss of this entity relation extraction model can be expressed as:

其中,α、β、γ为损失权重。Among them, α, β, γ are loss weights.
本实施例中,将全局对应关系损失作为实体关系抽取模型对应总损失的一部分,使训练过程中能够学习得到全局对应关系矩阵,从而在后续利用全局对应关系矩阵过滤不合理主客体对,实现主客体对齐,有助于提高实体关系抽取模型的实体关系抽取准确性。In this embodiment, the global correspondence loss is used as a part of the total loss corresponding to the entity relationship extraction model, so that the global correspondence matrix can be learned during the training process, so that the unreasonable subject-object pair can be filtered by the global correspondence matrix in the future, and the main Object alignment helps to improve the entity relation extraction accuracy of the entity relation extraction model.
图10是本申请一个示例性实施例提供的文本中实体关系的抽取装置的结构框图,该装置包括:FIG. 10 is a structural block diagram of an apparatus for extracting entity relationships in text provided by an exemplary embodiment of the present application, and the apparatus includes:
编码模块1001,用于对目标文本进行编码,得到所述目标文本中各个词对应的词向量;The
关系确定模块1002,用于基于各个词对应的所述词向量,确定所述目标文本对应的潜在实体关系,所述目标文本中存在所述潜在实体关系的概率高于存在所述潜在实体关系外其它候选实体关系的概率;A
主客体确定模块1003,用于基于所述潜在实体关系以及各个词对应的所述词向量,确定所述目标文本中的目标主体和目标客体,所述目标主体和所述目标客体属于实体;a subject-
抽取模块1004,基于所述目标主体、所述潜在实体关系以及所述目标客体,从所述目标文本中抽取实体关系三元组。The
可选的,关系确定模块1002,包括:Optionally, the
文本向量确定单元,用于基于各个词对应的所述词向量,确定所述目标文本对应的文本向量;a text vector determination unit, configured to determine the text vector corresponding to the target text based on the word vector corresponding to each word;
分类单元,用于通过全连接层对所述文本向量进行分类,得到各种候选实体关系对应的存在概率,所述存在概率指所述目标文本中存在所述候选实体关系的概率;A classification unit, configured to classify the text vector through a fully connected layer to obtain the existence probabilities corresponding to various candidate entity relationships, where the existence probability refers to the probability that the candidate entity relationship exists in the target text;
关系确定单元,用于基于所述存在概率从所述候选实体关系中确定所述潜在实体关系。A relationship determination unit, configured to determine the potential entity relationship from the candidate entity relationship based on the existence probability.
可选的,所述文本向量确定单元,用于:Optionally, the text vector determination unit is used for:
对各个词对应的所述词向量进行平均池化处理,得到所述目标文本对应的所述文本向量,所述文本向量与所述词向量具有相同维度。Average pooling is performed on the word vectors corresponding to each word to obtain the text vector corresponding to the target text, where the text vector and the word vector have the same dimension.
可选的,所述主客体确定模块1003,包括:Optionally, the subject-
融合单元,用于对所述词向量和所述潜在实体关系对应的关系向量进行融合,得到具有潜在实体关系的词向量;a fusion unit, configured to fuse the word vector and the relationship vector corresponding to the potential entity relationship to obtain a word vector with a potential entity relationship;
标注单元,用于基于所述具有潜在实体关系的词向量进行序列标注,确定所述目标文本中的所述目标主体和所述目标客体。A labeling unit, configured to perform sequence labeling based on the word vector with the potential entity relationship, and determine the target subject and the target object in the target text.
可选的,所述标注单元,用于:Optionally, the labeling unit is used for:
基于所述具有潜在实体关系的词向量进行主体序列标注,得到主体标注结果,所述主体标注结果用于表征所述具有潜在实体关系的词向量的第一实体位置,所述第一实体位置包括主体开头、主体内部或主体外部;Perform subject sequence tagging based on the word vector with potential entity relationship, and obtain subject tagging result, where the subject tagging result is used to represent the first entity position of the word vector with potential entity relationship, and the first entity position includes Beginning of the main body, inside the main body or outside the main body;
基于所述具有潜在实体关系的词向量进行客体序列标注,得到客体标注结果,所述客体标注结果用于表征所述具有潜在实体关系的词向量的第二实体位置,所述第二实体位置包括客体开头、客体内部或客体外部;Object sequence labeling is performed based on the word vector with potential entity relationship, and an object labeling result is obtained, and the object labeling result is used to represent the second entity position of the word vector with potential entity relationship, and the second entity position includes Beginning of the object, inside the object or outside the object;
基于所述主体标注结果和所述客体标注结果,确定所述目标文本中的所述目标主体和所述目标客体。Based on the subject annotation result and the object annotation result, the target subject and the target object in the target text are determined.
可选的,所述抽取模块1004,包括:Optionally, the
组合单元,用于对具有相同潜在实体关系的所述目标主体和所述目标客体进行组合,得到至少一个主客体对;a combining unit, configured to combine the target subject and the target object with the same potential entity relationship to obtain at least one subject-object pair;
置信度确定单元,用于确定各个所述主客体对的置信度;a confidence level determination unit, configured to determine the confidence level of each of the subject-object pairs;
生成单元,用于若所述主客体对的置信度高于置信度阈值,基于所述主客体对中的所述目标主体、所述目标客体以及所述潜在实体关系生成所述实体关系三元组。A generating unit, configured to generate the entity-relationship triple based on the target subject, the target object and the potential entity relationship in the subject-object pair if the confidence of the subject-object pair is higher than a confidence threshold Group.
可选的,所述置信度确定单元,用于:Optionally, the confidence level determination unit is used for:
将全局对应关系矩阵中,所述主客体对中所述目标主体和所述目标客体之间的置信度确定为所述主客体对的置信度,所述全局对应关系矩阵是由不同实体间置信度构成的矩阵。In the global correspondence matrix, the confidence between the target subject and the target object in the subject-object pair is determined as the confidence of the subject-object pair, and the global correspondence matrix is determined by the confidence between different entities. degree matrix.
可选的,所述装置还包括:Optionally, the device further includes:
过滤模块,用于若所述主客体对的置信度低于所述置信度阈值,过滤所述主客体对。A filtering module, configured to filter the subject-object pair if the confidence of the subject-object pair is lower than the confidence threshold.
可选的,所述装置还包括:训练模块,用于:Optionally, the device further includes: a training module for:
对样本文本进行编码,得到所述样本文本中各个词对应的样本词向量;Encoding the sample text to obtain sample word vectors corresponding to each word in the sample text;
基于各个词对应的所述样本词向量,确定所述样本文本对应的样本潜在实体关系;Determine the sample potential entity relationship corresponding to the sample text based on the sample word vector corresponding to each word;
基于所述样本潜在实体关系以及各个词对应的所述样本词向量,确定所述样本文本中的样本主体和样本客体;Determine the sample subject and the sample object in the sample text based on the sample potential entity relationship and the sample word vector corresponding to each word;
基于所述样本文本对应的实体关系标签和所述样本潜在实体关系,确定潜在关系判断损失;Determine the potential relationship judgment loss based on the entity relationship label corresponding to the sample text and the sample potential entity relationship;
基于所述样本主体、所述样本客体以及所述样本文本中各个词对应的词标签,确定主客体判断损失;Determine the subject-object judgment loss based on the sample subject, the sample object, and the word labels corresponding to each word in the sample text;
基于所述潜在关系判断损失和所述主客体判断损失训练实体关系抽取模型,所述实体关系抽取模型用于基于输入的文本输出实体关系三元组。An entity relationship extraction model is trained based on the latent relationship judgment loss and the subject-object judgment loss, and the entity relationship extraction model is used to output entity relationship triples based on the input text.
可选的,所述训练模块,还用于:Optionally, the training module is also used for:
将所述样本主体和所述样本客体组合为样本主客体对;combining the sample subject and the sample object into a sample subject-object pair;
确定所述样本主客体对的样本置信度;determining the sample confidence of the sample subject-object pair;
基于所述样本文本对应的置信度标签以及所述样本置信度,确定全局对应关系损失;determining a global correspondence loss based on the confidence label corresponding to the sample text and the sample confidence;
基于所述潜在关系判断损失、所述主客体判断损失以及所述全局对应关系损失训练所述实体关系抽取模型。The entity relationship extraction model is trained based on the latent relationship judgment loss, the subject-object judgment loss, and the global correspondence loss.
可选的,所述潜在关系判断损失、所述主客体判断损失以及所述全局对应关系损失对应的损失权重相同。Optionally, the loss weights corresponding to the potential relationship judgment loss, the subject-object judgment loss, and the global correspondence loss are the same.
可选的,所述目标主体和目标客体为医学文本实体,所述目标主体与所述目标客体之间的实体关系包括部位、时间和性质中的至少一种。Optionally, the target subject and the target object are medical text entities, and the entity relationship between the target subject and the target object includes at least one of location, time and nature.
综上所述,本申请实施例中,在进行实体关系提取过程中,首先基于对目标文本编码得到的词向量,确定目标文本中高概率存在的潜在实体关系,过滤低概率存在的候选实体关系,然后基于确定出的潜在实体关系以及词向量,从目标文本中确定出目标主体和目标客体,最终从目标文本中抽取出包含目标主体、潜在实体关系以及目标客体的实体关系三元组;采用本申请实施例提供的方案,在进行主客体提取前,通过对候选实体关系进行筛选得到潜在实体关系,能够减少与目标文本无关的冗余实体关系造成的误召回结果,提高文本中实体关系提取的准确性,并有助于提高实体关系的提取效率。To sum up, in the embodiment of the present application, in the process of entity relationship extraction, firstly, based on the word vector obtained by encoding the target text, determine the potential entity relationship with high probability in the target text, and filter the candidate entity relationship with low probability. Then, based on the determined potential entity relationship and word vector, the target subject and target object are determined from the target text, and finally the entity relationship triplet including the target subject, potential entity relationship and target object is extracted from the target text; In the solution provided by the application embodiment, before subject-object extraction is performed, potential entity relationships are obtained by screening candidate entity relationships, which can reduce false recall results caused by redundant entity relationships unrelated to the target text, and improve the efficiency of entity relationship extraction in texts. accuracy, and help to improve the extraction efficiency of entity relations.
需要说明的是:上述实施例提供的装置,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将装置的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。另外,上述实施例提供的装置与方法实施例属于同一构思,其实现过程详见方法实施例,这里不再赘述。It should be noted that: the device provided in the above-mentioned embodiment is only illustrated by the division of the above-mentioned various functional modules. In practical applications, the above-mentioned function allocation can be completed by different functional modules as required, that is, the internal structure of the device is divided into Different functional modules to complete all or part of the functions described above. In addition, the apparatus and method embodiments provided in the above embodiments belong to the same concept, and the implementation process thereof is detailed in the method embodiments, which will not be repeated here.
请参考图11,其示出了本申请一个示例性实施例提供的计算机设备的结构示意图。具体来讲:所述计算机设备1300包括中央处理单元(Central Processing Unit,CPU)1301、包括随机存取存储器1302和只读存储器1303的系统存储器1304,以及连接系统存储器1304和中央处理单元1301的系统总线1305。所述计算机设备1300还包括帮助计算机内的各个器件之间传输信息的基本输入/输出系统(Input/Output,I/O系统)1306,和用于存储操作系统1313、应用程序1314和其他程序模块1315的大容量存储设备1307。Please refer to FIG. 11 , which shows a schematic structural diagram of a computer device provided by an exemplary embodiment of the present application. Specifically, the
所述基本输入/输出系统1306包括有用于显示信息的显示器1308和用于用户输入信息的诸如鼠标、键盘之类的输入设备1309。其中所述显示器1308和输入设备1309都通过连接到系统总线1305的输入输出控制器1310连接到中央处理单元1301。所述基本输入/输出系统1306还可以包括输入输出控制器1310以用于接收和处理来自键盘、鼠标、或电子触控笔等多个其他设备的输入。类似地,输入输出控制器1310还提供输出到显示屏、打印机或其他类型的输出设备。The basic input/
所述大容量存储设备1307通过连接到系统总线1305的大容量存储控制器(未示出)连接到中央处理单元1301。所述大容量存储设备1307及其相关联的计算机可读介质为计算机设备1300提供非易失性存储。也就是说,所述大容量存储设备1307可以包括诸如硬盘或者驱动器之类的计算机可读介质(未示出)。The
不失一般性,所述计算机可读介质可以包括计算机存储介质和通信介质。计算机存储介质包括以用于存储诸如计算机可读指令、数据结构、程序模块或其他数据等信息的任何方法或技术实现的易失性和非易失性、可移动和不可移动介质。计算机存储介质包括随机存取记忆体(RAM,Random Access Memory)、只读存储器(ROM,Read Only Memory)、闪存或其他固态存储其技术,只读光盘(Compact Disc Read-Only Memory,CD-ROM)、数字通用光盘(Digital Versatile Disc,DVD)或其他光学存储、磁带盒、磁带、磁盘存储或其他磁性存储设备。当然,本领域技术人员可知所述计算机存储介质不局限于上述几种。上述的系统存储器1304和大容量存储设备1307可以统称为存储器。Without loss of generality, the computer-readable media can include computer storage media and communication media. Computer storage media includes volatile and nonvolatile, removable and non-removable media implemented in any method or technology for storage of information such as computer readable instructions, data structures, program modules or other data. Computer storage media include Random Access Memory (RAM, Random Access Memory), Read Only Memory (ROM, Read Only Memory), flash memory or other solid-state storage technologies, Compact Disc Read-Only Memory (CD-ROM) ), Digital Versatile Disc (DVD) or other optical storage, cassette, magnetic tape, magnetic disk storage or other magnetic storage device. Of course, those skilled in the art know that the computer storage medium is not limited to the above-mentioned ones. The
存储器存储有一个或多个程序,一个或多个程序被配置成由一个或多个中央处理单元1301执行,一个或多个程序包含用于实现上述方法的指令,中央处理单元1301执行该一个或多个程序实现上述各个方法实施例提供的方法。The memory stores one or more programs, the one or more programs are configured to be executed by the one or more
根据本申请的各种实施例,所述计算机设备1300还可以通过诸如因特网等网络连接到网络上的远程计算机运行。也即计算机设备1300可以通过连接在所述系统总线1305上的网络接口单元1311连接到网络1312,或者说,也可以使用网络接口单元1311来连接到其他类型的网络或远程计算机系统(未示出)。According to various embodiments of the present application, the
所述存储器还包括一个或者一个以上的程序,所述一个或者一个以上程序存储于存储器中,所述一个或者一个以上程序包含用于进行本申请实施例提供的方法中由计算机设备所执行的步骤。The memory further includes one or more programs, the one or more programs are stored in the memory, and the one or more programs include steps for performing the steps performed by the computer device in the method provided by the embodiment of the present application .
本申请实施例还提供一种计算机可读存储介质,该可读存储介质中存储有至少一条指令,至少一条指令由处理器加载并执行以实现上述任一实施例所述的文本中实体关系的抽取方法。Embodiments of the present application further provide a computer-readable storage medium, where at least one instruction is stored in the readable storage medium, and at least one instruction is loaded and executed by a processor to implement the entity relationship in the text described in any of the foregoing embodiments. extraction method.
可选地,该计算机可读存储介质可以包括:ROM、RAM、固态硬盘(SSD,Solid StateDrives)或光盘等。其中,RAM可以包括电阻式随机存取记忆体(ReRAM,Resistance RandomAccess Memory)和动态随机存取存储器(DRAM,Dynamic Random Access Memory)。Optionally, the computer-readable storage medium may include: ROM, RAM, Solid State Drives (SSD, Solid State Drives), or an optical disc. The RAM may include Resistive Random Access Memory (ReRAM, Resistance Random Access Memory) and Dynamic Random Access Memory (DRAM, Dynamic Random Access Memory).
本申请实施例提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行上述实施例所述的文本中实体关系的抽取方法。Embodiments of the present application provide a computer program product or computer program, where the computer program product or computer program includes computer instructions, and the computer instructions are stored in a computer-readable storage medium. The processor of the computer device reads the computer instructions from the computer-readable storage medium, and the processor executes the computer instructions, so that the computer device executes the method for extracting entity relationships in text described in the foregoing embodiments.
本领域普通技术人员可以理解实现上述实施例的全部或部分步骤可以通过硬件来完成,也可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,上述提到的存储介质可以是只读存储器,磁盘或光盘等。Those of ordinary skill in the art can understand that all or part of the steps of implementing the above embodiments can be completed by hardware, or can be completed by instructing relevant hardware through a program, and the program can be stored in a computer-readable storage medium. The storage medium mentioned may be a read-only memory, a magnetic disk or an optical disk, etc.
以上所述仅为本申请的可选的实施例,并不用以限制本申请,凡在本申请的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。The above are only optional embodiments of the present application, and are not intended to limit the present application. Any modifications, equivalent replacements, improvements, etc. made within the spirit and principles of the present application shall be included in the scope of the present application. within the scope of protection.
Claims (15)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110393735.5ACN113704392A (en) | 2021-04-13 | 2021-04-13 | Method, device and equipment for extracting entity relationship in text and storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110393735.5ACN113704392A (en) | 2021-04-13 | 2021-04-13 | Method, device and equipment for extracting entity relationship in text and storage medium |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN113704392Atrue CN113704392A (en) | 2021-11-26 |
Family
ID=78647981
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110393735.5APendingCN113704392A (en) | 2021-04-13 | 2021-04-13 | Method, device and equipment for extracting entity relationship in text and storage medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN113704392A (en) |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114220505A (en)* | 2021-11-29 | 2022-03-22 | 中国科学院深圳先进技术研究院 | Information extraction method, terminal device and readable storage medium for medical record data |
| CN114385787A (en)* | 2021-12-28 | 2022-04-22 | 北京惠及智医科技有限公司 | Medical text detection method, model training method and related device |
| CN114528394A (en)* | 2022-04-22 | 2022-05-24 | 杭州费尔斯通科技有限公司 | Text triple extraction method and device based on mask language model |
| CN114781398A (en)* | 2022-05-09 | 2022-07-22 | 携程旅游信息技术(上海)有限公司 | Relation extraction joint model training method, relation extraction method, equipment and medium |
| CN114817562A (en)* | 2022-04-26 | 2022-07-29 | 马上消费金融股份有限公司 | Knowledge graph construction method, knowledge graph training method, information recommendation method and information recommendation device |
| CN115309915A (en)* | 2022-09-29 | 2022-11-08 | 北京如炬科技有限公司 | Knowledge graph construction method, device, equipment and storage medium |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110427623A (en)* | 2019-07-24 | 2019-11-08 | 深圳追一科技有限公司 | Semi-structured document Knowledge Extraction Method, device, electronic equipment and storage medium |
| CN111241209A (en)* | 2020-01-03 | 2020-06-05 | 北京百度网讯科技有限公司 | Method and apparatus for generating information |
| CN111709240A (en)* | 2020-05-14 | 2020-09-25 | 腾讯科技(武汉)有限公司 | Entity relationship extraction method, device, device and storage medium thereof |
| CN111881683A (en)* | 2020-06-28 | 2020-11-03 | 吉林大学 | Method and device for generating relation triples, storage medium and electronic equipment |
| CN111967242A (en)* | 2020-08-17 | 2020-11-20 | 支付宝(杭州)信息技术有限公司 | Text information extraction method, device and equipment |
- 2021
- 2021-04-13CNCN202110393735.5Apatent/CN113704392A/enactivePending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110427623A (en)* | 2019-07-24 | 2019-11-08 | 深圳追一科技有限公司 | Semi-structured document Knowledge Extraction Method, device, electronic equipment and storage medium |
| CN111241209A (en)* | 2020-01-03 | 2020-06-05 | 北京百度网讯科技有限公司 | Method and apparatus for generating information |
| CN111709240A (en)* | 2020-05-14 | 2020-09-25 | 腾讯科技(武汉)有限公司 | Entity relationship extraction method, device, device and storage medium thereof |
| CN111881683A (en)* | 2020-06-28 | 2020-11-03 | 吉林大学 | Method and device for generating relation triples, storage medium and electronic equipment |
| CN111967242A (en)* | 2020-08-17 | 2020-11-20 | 支付宝(杭州)信息技术有限公司 | Text information extraction method, device and equipment |
Cited By (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114220505A (en)* | 2021-11-29 | 2022-03-22 | 中国科学院深圳先进技术研究院 | Information extraction method, terminal device and readable storage medium for medical record data |
| CN114220505B (en)* | 2021-11-29 | 2025-07-18 | 中国科学院深圳先进技术研究院 | Information extraction method of medical record data, terminal equipment and readable storage medium |
| CN114385787A (en)* | 2021-12-28 | 2022-04-22 | 北京惠及智医科技有限公司 | Medical text detection method, model training method and related device |
| CN114385787B (en)* | 2021-12-28 | 2025-06-03 | 北京惠及智医科技有限公司 | Medical text detection method, model training method and related device |
| CN114528394A (en)* | 2022-04-22 | 2022-05-24 | 杭州费尔斯通科技有限公司 | Text triple extraction method and device based on mask language model |
| CN114817562A (en)* | 2022-04-26 | 2022-07-29 | 马上消费金融股份有限公司 | Knowledge graph construction method, knowledge graph training method, information recommendation method and information recommendation device |
| CN114781398A (en)* | 2022-05-09 | 2022-07-22 | 携程旅游信息技术(上海)有限公司 | Relation extraction joint model training method, relation extraction method, equipment and medium |
| CN115309915A (en)* | 2022-09-29 | 2022-11-08 | 北京如炬科技有限公司 | Knowledge graph construction method, device, equipment and storage medium |
| CN115309915B (en)* | 2022-09-29 | 2022-12-09 | 北京如炬科技有限公司 | Knowledge graph construction method, device, equipment and storage medium |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7592095B2 (en) | Multimodal machine learning-based translation method, device, equipment, and computer program | |
| CN112084331B (en) | Text processing, model training method, device, computer equipment and storage medium | |
| CN113704392A (en) | Method, device and equipment for extracting entity relationship in text and storage medium | |
| CN113326374B (en) | Short Text Sentiment Classification Method and System Based on Feature Enhancement | |
| CN111444709A (en) | Text classification method, device, storage medium and equipment | |
| CN113704460B (en) | Text classification method and device, electronic equipment and storage medium | |
| CN114565104A (en) | Language model pre-training method, result recommendation method and related device | |
| CN112131883B (en) | Language model training method, device, computer equipment and storage medium | |
| WO2023029506A1 (en) | Illness state analysis method and apparatus, electronic device, and storage medium | |
| CN110781302B (en) | Method, device, equipment and storage medium for processing event roles in text | |
| CN111881292B (en) | Text classification method and device | |
| CN110347836A (en) | Incorporate the more bilingual the emotion of news classification method of the Chinese of viewpoint sentence feature | |
| CN113535949A (en) | Multi-mode combined event detection method based on pictures and sentences | |
| CN113705159A (en) | Merchant name labeling method, device, equipment and storage medium | |
| CN114328931A (en) | Question correction method, model training method, computer equipment and storage medium | |
| CN114282058A (en) | Method, device and equipment for model training and video theme prediction | |
| CN117033720A (en) | Model training method, device, computer equipment and storage medium | |
| CN114357167A (en) | Bi-LSTM-GCN-based multi-label text classification method and system | |
| CN114357151A (en) | Processing method, device and equipment of text category identification model and storage medium | |
| CN114579741A (en) | Syntactic information fused GCN-RN aspect level emotion analysis method and system | |
| CN114281934A (en) | Text recognition method, device, equipment and storage medium | |
| CN114330476A (en) | Model training method for media content recognition and media content recognition method | |
| CN118427631A (en) | A cross-modal matching method and device based on knowledge enhancement | |
| Lei et al. | An input information enhanced model for relation extraction | |
| Yang et al. | Adaptive syncretic attention for constrained image captioning |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |