CN113643173A - Watermark removing method, watermark removing device, terminal equipment and readable storage medium - Google Patents
Watermark removing method, watermark removing device, terminal equipment and readable storage mediumDownload PDFInfo
- Publication number
- CN113643173A CN113643173ACN202110955089.7ACN202110955089ACN113643173ACN 113643173 ACN113643173 ACN 113643173ACN 202110955089 ACN202110955089 ACN 202110955089ACN 113643173 ACN113643173 ACN 113643173A
- Authority
- CN
- China
- Prior art keywords
- watermark
- file
- target area
- area
- present application
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images









Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T1/00—General purpose image data processing
- G06T1/0021—Image watermarking
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- General Physics & Mathematics (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- Biomedical Technology (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- Life Sciences & Earth Sciences (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Health & Medical Sciences (AREA)
- Image Processing (AREA)
- Editing Of Facsimile Originals (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本申请属于图像处理技术领域,尤其涉及一种水印去除方法、装置、终端设备及可读存储介质。The present application belongs to the technical field of image processing, and in particular, relates to a watermark removal method, apparatus, terminal device and readable storage medium.
背景技术Background technique
当前市场上的书本水印去除方法主要有:使用后期图像修复软件来去除,或者购买相应的付费软件来实现特定水印的批量去除,或者使用传统图像处理的方案来去除水印。The current book watermark removal methods on the market mainly include: use post-image restoration software to remove, or purchase corresponding paid software to achieve batch removal of specific watermarks, or use traditional image processing solutions to remove watermarks.
但是使用现有的书本水印去除方法进行水印去除时,需要对包含水印的整个图像的所有像素点进行处理,导致去除水印的速度较慢,以及去除水印的计算量较大。However, when using the existing book watermark removal method for watermark removal, it is necessary to process all pixels of the entire image including the watermark, resulting in a slow watermark removal speed and a large amount of computation for watermark removal.
发明内容SUMMARY OF THE INVENTION
本申请实施例提供的水印去除方法、装置、终端设备及可读存储介质,提高去除水印的速度,降低去除水印的计算量。The watermark removal method, device, terminal device, and readable storage medium provided by the embodiments of the present application improve the watermark removal speed and reduce the calculation amount for watermark removal.
第一方面,本申请实施例提供了一种水印去除方法,所述方法包括:In a first aspect, an embodiment of the present application provides a method for removing a watermark, the method comprising:
获取包含水印的文件;Get the file containing the watermark;
确定所述水印在所述文件中的位置信息;determining the location information of the watermark in the file;
根据所述位置信息获取所述文件中的目标区域,所述目标区域为所述文件中包含所述水印的区域;Acquire a target area in the file according to the location information, where the target area is an area in the file containing the watermark;
对所述目标区域进行水印去除处理,得到去水印后的文件。A watermark removal process is performed on the target area to obtain a watermark-removed file.
在第一方面一种可能实现的方式中,所述确定所述水印在所述文件中的位置信息,包括:In a possible implementation manner of the first aspect, the determining the location information of the watermark in the file includes:
将所述文件输入至第一神经网络模型进行处理,得到所述第一神经网络模型输出的所述水印在所述文件中的位置信息。Inputting the file into a first neural network model for processing, and obtaining position information of the watermark in the file output by the first neural network model.
其中,所述第一神经网络模型为YOLO v3模型。Wherein, the first neural network model is the YOLO v3 model.
其中,所述根据所述位置信息获取所述文件中的目标区域,包括:Wherein, the acquiring the target area in the file according to the location information includes:
根据所述位置信息裁剪所述文件,得到所述目标区域。Crop the file according to the location information to obtain the target area.
其中,所述对所述目标区域进行水印去除处理,得到去水印后的文件,包括:Wherein, the watermark removal process is performed on the target area to obtain a de-watermarked file, including:
将所述目标区域输入至第二神经网络模型进行处理,得到所述第二神经网络模型输出的第一区域,所述第一区域为所述目标区域去除水印后的区域;Inputting the target area into the second neural network model for processing, to obtain a first area output by the second neural network model, where the first area is the area from which the watermark is removed from the target area;
将所述第一区域与所述文件中的第二区域进行融合,得到去水印后的文件,所述第二区域为所述文件中除所述目标区域以外的区域。The first area is fused with a second area in the file to obtain a file after watermark removal, where the second area is an area other than the target area in the file.
其中,所述将第二神经网络模型对所述目标区域进行处理的过程,包括:Wherein, the process of processing the target area by the second neural network model includes:
获取与所述目标区域对应的第三区域,所述第三区域为所述目标区域对应的背景区域,且所述第三区域不包含所述水印;acquiring a third area corresponding to the target area, where the third area is a background area corresponding to the target area, and the third area does not include the watermark;
确定所述水印在所述目标区域中的位置信息;determining the location information of the watermark in the target area;
根据所述水印在所述目标区域中的位置信息,确定所述第三区域中与所述水印对应的第四区域;determining a fourth area corresponding to the watermark in the third area according to the position information of the watermark in the target area;
利用所述第四区域替换所述目标区域中的所述水印。Replace the watermark in the target area with the fourth area.
其中,所述确定所述水印在所述目标区域中的位置信息,包括:Wherein, the determining the location information of the watermark in the target area includes:
对所述目标区域进行掩码处理,得到所述目标区域的掩码信息,并根据所述掩码信息确定所述水印在所述目标区域中的位置信息。Perform mask processing on the target area to obtain mask information of the target area, and determine position information of the watermark in the target area according to the mask information.
第二方面,本申请实施例提供一种水印去除装置其特征在于,所述装置包括:In a second aspect, an embodiment of the present application provides a watermark removal device, characterized in that the device includes:
第一获取模块,用于获取包含水印的文件;The first obtaining module is used to obtain the file containing the watermark;
确定模块,用于确定所述水印在所述文件中的位置信息;a determining module for determining the location information of the watermark in the file;
第二获取模块,用于根据所述位置信息获取所述文件中的目标区域,所述目标区域为所述文件中包含所述水印的区域;A second acquiring module, configured to acquire a target area in the file according to the location information, where the target area is an area containing the watermark in the file;
处理模块,用于对所述目标区域进行水印去除处理,得到去水印后的文件。The processing module is configured to perform watermark removal processing on the target area to obtain a watermark-removed file.
第三方面,本申请实施例提供一种终端设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如第一方面所述的水印去除方法。In a third aspect, an embodiment of the present application provides a terminal device, including a memory, a processor, and a computer program stored in the memory and running on the processor, and the processor implements the computer program when the processor executes the computer program. The watermark removal method according to the first aspect.
第四方面,本申请实施例提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如第一方面所述的水印去除方法。In a fourth aspect, an embodiment of the present application provides a computer-readable storage medium, where the computer-readable storage medium stores a computer program, and when the computer program is executed by a processor, implements the watermark removal method according to the first aspect.
本申请实施例与现有技术相比存在的有益效果是:本申请通过获取包含水印的文件;确定水印在文件中的位置信息;根据位置信息获取文件中的目标区域,目标区域为文件中包含水印的区域;对目标区域进行水印去除处理,得到去水印后的文件。即本申请通过确定水印在文件中的位置信息;根据位置信息获取文件中的目标区域,并不需要对整个文件进行处理,只需对目标区域进行水印去除处理,即可得到去水印后的文件,提高去除水印的速度,降低去除水印的计算量。Compared with the prior art, the embodiments of the present application have the following beneficial effects: the present application obtains a file containing a watermark; determines the location information of the watermark in the file; obtains a target area in the file according to the location information, and the target area is a Watermark area; perform watermark removal processing on the target area to obtain the watermarked file. That is, the present application determines the location information of the watermark in the file; obtains the target area in the file according to the location information, and does not need to process the entire file, but only needs to perform the watermark removal process on the target area, and then the watermarked file can be obtained. , to improve the speed of watermark removal and reduce the calculation amount of watermark removal.
附图说明Description of drawings
为了更清楚地说明本申请实施例中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。In order to illustrate the technical solutions in the embodiments of the present application more clearly, the following briefly introduces the accompanying drawings that need to be used in the description of the embodiments or the prior art. Obviously, the drawings in the following description are only for the present application. In some embodiments, for those of ordinary skill in the art, other drawings can also be obtained according to these drawings without any creative effort.
图1是本申请一实施例提供的水印去除方法的一种网络架构的示意图;1 is a schematic diagram of a network architecture of a watermark removal method provided by an embodiment of the present application;
图2是本申请一实施例提供的一种水印去除方法的流程示意图;2 is a schematic flowchart of a watermark removal method provided by an embodiment of the present application;
图3a是本申请一实施例提供的YOLO v3模型的网络结构的示例图;3a is an example diagram of a network structure of a YOLO v3 model provided by an embodiment of the present application;
图3b是本申请一实施例提供的一种目标检测模型的训练方法的流程示意图;3b is a schematic flowchart of a training method for a target detection model provided by an embodiment of the present application;
图3c是本申请一实施例提供的矩形框的位置信息的示例图;3c is an example diagram of position information of a rectangular frame provided by an embodiment of the present application;
图4是本申请一实施例提供的一种对目标区域进行水印去除处理的方法的流程示意图;4 is a schematic flowchart of a method for performing watermark removal processing on a target area provided by an embodiment of the present application;
图5a是本申请一实施例提供的第二神经网络模型的网络结构的示例图;5a is an exemplary diagram of a network structure of a second neural network model provided by an embodiment of the present application;
图5b是本申请一实施提供的编码器的网络结构的示例图;5b is an example diagram of a network structure of an encoder provided by an implementation of the present application;
图5c是本申请一实施例提供的解码器的网络结构的示例图;5c is an example diagram of a network structure of a decoder provided by an embodiment of the present application;
图6是本申请一实施例提供的一种第二神经网络模型的训练方法的流程示意图;6 is a schematic flowchart of a training method for a second neural network model provided by an embodiment of the present application;
图7是本申请一实施例提供的一种获得去除水印后的第一区域的示例图;FIG. 7 is an exemplary diagram of obtaining a first area after removing the watermark provided by an embodiment of the present application;
图8是本申请一实施例提供的一种应用第二神经网络模型获得去除水印后的第一区域的方法的流程示意图;8 is a schematic flowchart of a method for obtaining a watermark-removed first region by applying a second neural network model according to an embodiment of the present application;
图9是本申请实施例提供的一种水印去除装置的结构示意图;9 is a schematic structural diagram of a watermark removing apparatus provided by an embodiment of the present application;
图10是本申请一实施例提供的终端设备的结构示意图。FIG. 10 is a schematic structural diagram of a terminal device provided by an embodiment of the present application.
具体实施方式Detailed ways
以下描述中,为了说明而不是为了限定,提出了诸如特定系统结构、技术之类的具体细节,以便透彻理解本申请实施例。然而,本领域的技术人员应当清楚,在没有这些具体细节的其他实施例中也可以实现本申请。在其他情况中,省略对众所周知的系统、装置、电路以及方法的详细说明,以免不必要的细节妨碍本申请的描述,在其他情况中,各个实施例中的具体技术细节可以互相参考,在一个实施例中没有描述的具体系统可参考其他实施例。In the following description, for the purpose of illustration rather than limitation, specific details such as a specific system structure and technology are set forth in order to provide a thorough understanding of the embodiments of the present application. However, it will be apparent to those skilled in the art that the present application may be practiced in other embodiments without these specific details. In other instances, detailed descriptions of well-known systems, devices, circuits, and methods are omitted so as not to obscure the description of the present application with unnecessary detail. For specific systems not described in the embodiments, reference may be made to other embodiments.
应当理解,当在本申请说明书和所附权利要求书中使用时,术语“包括”指示所描述特征、整体、步骤、操作、元素和/或组件的存在,但并不排除一个或多个其他特征、整体、步骤、操作、元素、组件和/或其集合的存在或添加。It is to be understood that the term "comprising" when used in the specification of this application and the appended claims indicates the presence of the described feature, integer, step, operation, element and/or component, but does not exclude one or more other The presence or addition of features, integers, steps, operations, elements, components and/or sets thereof.
还应当理解,在本申请说明书和所附权利要求书中使用的术语“和/或”是指相关联列出的项中的一个或多个的任何组合以及所有可能组合,并且包括这些组合。It will also be understood that, as used in this specification and the appended claims, the term "and/or" refers to and including any and all possible combinations of one or more of the associated listed items.
在本申请说明书中描述的参考“本申请实施例”或“一些实施例”等意味着在本申请的一个或多个实施例中包括结合该实施例描述的特定特征、结构或特点。由此,在本说明书中的不同之处出现的语句“在另一些实施例中”、“本申请一实施例”、“本申请其他实施例”等不是必然都参考相同的实施例,而是意味着“一个或多个但不是所有的实施例”,除非是以其他方式另外特别强调。术语“包括”、“包含”、“具有”及它们的变形都意味着“包括但不限于”,除非是以其他方式另外特别强调。References in the specification of the present application to "embodiments of the present application" or "some embodiments" and the like mean that a particular feature, structure or characteristic described in connection with the embodiment is included in one or more embodiments of the present application. Therefore, the phrases "in other embodiments", "one embodiment of the present application", "other embodiments of the present application", etc. appearing in different places in this specification do not necessarily all refer to the same embodiment, but Means "one or more but not all embodiments" unless specifically emphasized otherwise. The terms "including", "including", "having" and their variants mean "including but not limited to" unless specifically emphasized otherwise.
另外,在本申请说明书和所附权利要求书的描述中,术语“第一”、“第二”等仅用于区分描述,而不能理解为指示或暗示相对重要性。In addition, in the description of the specification of the present application and the appended claims, the terms "first", "second" and the like are only used to distinguish the description, and should not be construed as indicating or implying relative importance.
现有的书本水印去除方法进行水印去除时,需要对包含水印的整个图像的所有像素点进行处理,导致去除水印的速度较慢,以及去除水印的计算量较大。When the existing book watermark removal method is used for watermark removal, it is necessary to process all pixel points of the entire image including the watermark, resulting in a slow watermark removal speed and a large amount of computation for watermark removal.
为了解决上述缺陷,本申请的发明构思为:In order to solve the above-mentioned defects, the inventive concept of the present application is:
通过确定水印在文件中的位置信息,根据位置信息获取文件中的目标区域,并不需要对整个文件进行处理,只需对目标区域进行水印去除处理,即可得到去水印后的文件,提高去除水印的速度,降低去除水印的计算量。By determining the location information of the watermark in the file, and obtaining the target area in the file according to the location information, it is not necessary to process the entire file, but only need to perform watermark removal processing on the target area, and then the watermarked file can be obtained. The speed of watermarking reduces the computational cost of removing watermarks.
为了说明本申请的技术方案,下面通过具体实施例来进行说明。In order to illustrate the technical solutions of the present application, the following specific embodiments are used for description.
请参阅图1,图1是本申请一实施例提供的水印去除方法的一种网络架构的示意图。为了方便说明,仅示出与本申请相关的部分。该网络架构包括:终端设备100和服务器200。Please refer to FIG. 1. FIG. 1 is a schematic diagram of a network architecture of a watermark removal method provided by an embodiment of the present application. For the convenience of description, only the parts related to the present application are shown. The network architecture includes: a
在该网络架构中,终端设备100可以包括但不限于手机、平板电脑、可穿戴设备、车载设备、笔记本电脑、超级移动个人计算机(ultra-mobile personal computer,UMPC)、上网本、个人数字助理(personal digital assistant,PDA)等。终端设备100可用于部署第一神经网络模型和第二神经网络模型。In this network architecture, the
在该网络架构中,服务器200本质上是具备计算能力的电子设备,该服务器200部署在云端,也可用于部署第一神经网络模型和第二神经网络模型。该服务器200主要为终端设备100提供服务。In this network architecture, the
终端设备100通过公知的网络接入方式接入互联网,与云端的服务器200建立数据通信链路,以便启动对第一神经网络模型和第二神经网络模型的训练、对包含水印区域的文件进行水印处理等操作。The
请参阅图2,图2是本申请一实施例提供的一种水印去除方法的流程示意图。作为一实现方式,图2中的方法的执行主体可以为图1中的终端设备100,作为其他实现方式,图2中的方法的执行主体也可以为图1中的服务器200,如图2所示,该方法包括:S201至S204。Please refer to FIG. 2 , which is a schematic flowchart of a watermark removal method provided by an embodiment of the present application. As an implementation manner, the execution body of the method in FIG. 2 may be the
S201、获取包含水印的文件。S201. Obtain a file containing a watermark.
具体的,本申请实施例中包含水印的文件可以是包含水印的图像、包含水印的便携式文档格式(Portable Document Format,PDF)和包含水印的网页等,本申请实施例对包含水印的文件类型不作限定。Specifically, the file containing the watermark in this embodiment of the present application may be an image containing a watermark, a Portable Document Format (PDF) containing a watermark, a web page containing a watermark, and the like. The embodiment of the present application does not make any difference to the file type containing a watermark. limited.
本申请实施例中,当需要对一组包含水印的文件进行去除水印操作时,将一组包含水印的文件输入至终端设备或服务器,终端设备或服务器即可获取一组包含水印的文件。In the embodiment of the present application, when a watermark removal operation needs to be performed on a group of files containing a watermark, a group of files containing a watermark is input to a terminal device or server, and the terminal device or server can obtain a group of files containing a watermark.
本申请其他实施例中,当需要对多组包含水印的文件进行去除水印操作时,将多组包含水印的文件输入至终端设备或服务器,终端设备或服务器即可获取多组包含水印的文件。即本申请实施例的终端设备或服务器可以对多组包含水印的文件进行批量处理,提高去除水印的速度。In other embodiments of the present application, when multiple groups of files containing watermarks need to be removed, input multiple groups of files containing watermarks into a terminal device or server, and the terminal device or server can obtain multiple groups of files containing watermarks. That is, the terminal device or server in this embodiment of the present application can perform batch processing on multiple groups of files containing watermarks, thereby improving the speed of removing watermarks.
S202、确定水印在文件中的位置信息。S202. Determine the location information of the watermark in the file.
具体的,本申请实施例中,在获取包含水印的文件之后,通过第一神经网络模型确定水印在文件中的位置信息。Specifically, in the embodiment of the present application, after the file containing the watermark is acquired, the location information of the watermark in the file is determined through the first neural network model.
本申请实施例中,第一神经网络模型为目标检测模型,目标检测模型包括更快速的基于区域的卷积神经网络模型(Faster R-CNN模型)、单个深层神经网络检测模型(Single Shot MultiBox Detector,SSD模型)模型和先进的实时目标检测模型(Real-TimeObject Detetion,YOLO模型)等。其中,YOLO模型包含YOLO v1模型、YOLO v2模型和YOLO v3模型。本申请实施例用YOLOv3模型进行举例说明。请参考图3a,图3a是本申请一实施例提供的YOLO v3模型的网络结构的示例图。In the embodiment of the present application, the first neural network model is a target detection model, and the target detection model includes a faster region-based convolutional neural network model (Faster R-CNN model), a single deep neural network detection model (Single Shot MultiBox Detector) , SSD model) model and advanced real-time object detection model (Real-TimeObject Detetion, YOLO model) and so on. Among them, the YOLO model includes the YOLO v1 model, the YOLO v2 model and the YOLO v3 model. The embodiments of the present application use the YOLOv3 model for illustration. Please refer to FIG. 3a, which is an example diagram of a network structure of a YOLO v3 model provided by an embodiment of the present application.
YOLO v3模型的基础网络是Darknet53网络,Darknet53网络包括52层卷积层,1个平均池化层,1个全连接层和1个激活函数层(softmax)。The basic network of the YOLO v3 model is the Darknet53 network. The Darknet53 network includes 52 convolutional layers, 1 average pooling layer, 1 fully connected layer and 1 activation function layer (softmax).
其中,52层卷积层包括:1个具有32个过滤器的卷积核,5个下采样层以及5组重复的残差单元resblock_body(这5组残差单元采用残差网络(Residual Neural Network,ResNet)这种跳层连接方式,每个单元由1个单独的卷积层与一组重复执行的卷积层构成,重复执行的卷积层分别重复1次、2次、8次、8次和4次;在每个重复执行的卷积层中,先执行1x1的卷积操作,再执行3x3的卷积操作),一共是52层。Among them, the 52-layer convolution layer includes: 1 convolution kernel with 32 filters, 5 downsampling layers, and 5 groups of repeated residual units resblock_body (the 5 groups of residual units use Residual Neural Network (Residual Neural Network) , ResNet) this skip layer connection method, each unit consists of a single convolutional layer and a set of repeated convolutional layers, and the repeated convolutional layers are repeated 1, 2, 8, 8 times respectively. times and 4 times; in each repeated convolutional layer, a 1x1 convolution operation is performed first, followed by a 3x3 convolution operation), a total of 52 layers.
卷积层计算方法为:The calculation method of the convolution layer is:
52=1+5+(1*2)+(2*2)+(8*2)+(8*2)+(4*2)。52=1+5+(1*2)+(2*2)+(8*2)+(8*2)+(4*2).
YOLO v3模型中设置的Darknet53网络是为了得到输入文件的不同尺寸的特征。示例性的,输入文件为图像文件,图像文件的尺寸为416*416*3,416*416表示图像的分辨率,3表示图像的通道数。图像文件经过5个下采样层以及5组重复的残差单元的处理,即图像分别经过了2倍下采样(2)得到208*208*64尺寸的特征图像,4倍下采样(22)得到104*104*128尺寸的特征图像、8倍下采样(23)得到52*52*256尺寸的特征图像,16倍下采样(24)得到26*26*512尺寸的特征图像,32倍下采样(25)得到13*13*1024尺寸的特征图像。The Darknet53 network set in the YOLO v3 model is to obtain features of different sizes of the input file. Exemplarily, the input file is an image file, the size of the image file is 416*416*3, 416*416 represents the resolution of the image, and 3 represents the number of channels of the image. The image file is processed by 5 downsampling layers and 5 groups of repeated residual units, that is, the image is downsampled by 2 times (2) to obtain a feature image of size 208*208*64, and downsampled by 4 times (22 ) Obtain a feature image of size 104*104*128,
YOLO v3模型的网络结构中还包括3个预测层,3个预测层与Darknet53网络中最后3层残差单元通过多个卷积层、多个上采样层与多个张量拼接层进行连接。The network structure of the YOLO v3 model also includes 3 prediction layers. The 3 prediction layers and the last 3 residual units in the Darknet53 network are connected through multiple convolutional layers, multiple upsampling layers and multiple tensor stitching layers.
在YOLO v3模型中设置3个预测层是为了对输入文件的多尺寸的特征进行检测。示例性的,利用YOLO v3模型中的3个预测层对输入文件进行了3次检测,分别是在32倍下采样,16倍下采样,8倍下采样时进行检测,进而实现对输入文件不同尺寸的特征进行检测,输出检测结果。Three prediction layers are set up in the YOLO v3 model to detect the multi-dimensional features of the input file. Exemplarily, the three prediction layers in the YOLO v3 model are used to detect the
在YOLO v3模型中设置上采样层是为了扩大经过低倍下采样处理得到的特征,使经过低倍下采样得到的特征表达效果更好。示例性的,经过低倍下采样处理得到的特征为13*13,经过上采样层的扩大操作,得到的特征为26*26。The upsampling layer is set in the YOLO v3 model to expand the features obtained by low-power downsampling, so that the feature expression effect obtained by low-power downsampling is better. Exemplarily, the features obtained through the low-power downsampling process are 13*13, and the features obtained through the enlargement operation of the upsampling layer are 26*26.
本申请实施例中,在YOLO v3模型中设置张量拼接层是为了将Darknet53网络输出的特征图像与经过上采样处理得到的特征图像进行拼接。In the embodiment of the present application, the tensor splicing layer is set in the YOLO v3 model in order to splicing the feature image output by the Darknet53 network and the feature image obtained by the upsampling process.
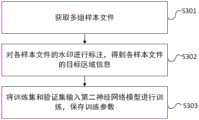
请参考图3b,图3b是本申请一实施例提供的一种目标检测模型的训练方法的流程示意图。如图3a所示,该方法包括:S301至S303。Please refer to FIG. 3b. FIG. 3b is a schematic flowchart of a training method for a target detection model provided by an embodiment of the present application. As shown in Figure 3a, the method includes: S301 to S303.
S301、获取多组样本文件。S301. Obtain multiple sets of sample files.
具体的,样本文件为包含水印的文件。在一些实施例中,可以预先收集一批需要去除水印的文件,示例性的,预先收集1000张至3000张(例如1500张)需要去除水印的图像。本申请实施例对需要去除水印的文件数量不作限定。Specifically, the sample file is a file containing a watermark. In some embodiments, a batch of files that need to be watermarked can be collected in advance, for example, 1000 to 3000 (eg 1500) images that need to be watermarked are collected in advance. This embodiment of the present application does not limit the number of files that need to be removed from the watermark.
获取多组样本文件即获取预先收集的1000张至3000张需要去除水印的图像。Obtaining multiple sets of sample files means obtaining pre-collected 1000 to 3000 images that need to be watermarked.
S302、对各样本文件中的水印进行标注,得到各样本文件的目标区域信息。S302: Mark the watermarks in each sample file to obtain target area information of each sample file.
具体的,目标区域为样本文件中包含水印的区域。在获取多组样本文件之后,需要对各样本文件进行标注,示例性的,本申请实施例可以利用通用文本标注工具(Labelme)在1500张图像中分别标注水印(例如可以利用标注框标注水印),将标注结果以json文件格式进行存储,即可得到1500组json文件,json文件包括水印的标注框的位置信息。本申请实施例中将这1500组json文件包含的信息称为各样本文件的目标区域信息。Specifically, the target area is the area containing the watermark in the sample file. After acquiring multiple sets of sample files, each sample file needs to be marked. Exemplarily, in this embodiment of the present application, a general text marking tool (Labelme) can be used to mark watermarks in 1500 images respectively (for example, a marking frame can be used to mark watermarks) , and store the annotation results in the json file format, you can get 1500 sets of json files, and the json files include the location information of the annotation box of the watermark. In this embodiment of the present application, the information contained in these 1500 groups of json files is referred to as target area information of each sample file.
本申请实施例中,标注框的形式包括:多边形、矩形和圆形等,本申请实施例以标注框为矩形框进行举例说明。In the embodiment of the present application, the form of the labeling frame includes: polygon, rectangle, circle, etc., and the embodiment of the present application uses the labeling frame as a rectangular frame for illustration.
本申请实施例中,矩形框的位置信息为水印在样本文件中的位置信息,该水印在样本文件中的位置信息可用矩形框的四个顶点坐标进行表示。示例性的,请参考图3c,图3c是本申请一实施例提供的矩形框的位置信息的示例图。在图3c中,w表示矩形框。H表示样本文件。坐标系是以图像左上角为坐标原点,以图像宽度方向为x轴的正方向,以图像高度方向为y轴的正方向建立坐标系,在该坐标系中,四个顶点坐标表示为(x_top_left,y_top_left),(x_top_right,y_top_right),(x_bottom_left,y_bottom_left)和(x_bottom_right,y_bottom_right)。In the embodiment of the present application, the position information of the rectangular frame is the position information of the watermark in the sample file, and the position information of the watermark in the sample file can be represented by the coordinates of the four vertices of the rectangular frame. Illustratively, please refer to FIG. 3c, which is an example diagram of position information of a rectangular frame provided by an embodiment of the present application. In Figure 3c, w represents a rectangular box. H stands for sample file. The coordinate system takes the upper left corner of the image as the coordinate origin, the image width direction as the positive direction of the x-axis, and the image height direction as the positive direction of the y-axis to establish a coordinate system. In this coordinate system, the coordinates of the four vertices are expressed as (x_top_left , y_top_left), (x_top_right, y_top_right), (x_bottom_left, y_bottom_left) and (x_bottom_right, y_bottom_right).
本申请实施例中,将S301中获取的各样本文件和S302中获取的各样本文件的目标区域信息作为数据集,从数据集中随机挑选一定比例的数据作为第一神经网络模型的训练集,将剩余比例的数据作为第一神经网络模型的验证集。示例性的,从数据集中随机挑选70%至90%,例如可以是80%的数据作为第一神经网络模型的训练集,将30%至10%,例如可以是20%的数据作为第一神经网络模型的验证集。In the embodiment of the present application, the target area information of each sample file obtained in S301 and each sample file obtained in S302 is used as a data set, and a certain proportion of data is randomly selected from the data set as the training set of the first neural network model, and the The remaining proportion of data is used as the validation set of the first neural network model. Exemplarily, 70% to 90% of the data are randomly selected from the data set, for example, 80% of the data can be used as the training set of the first neural network model, and 30% to 10% of the data, for example, 20% of the data can be used as the first neural network model. Validation set for the network model.
S303、将训练集和验证集输入第一神经网络模型中进行训练,保存训练参数。S303, input the training set and the validation set into the first neural network model for training, and save the training parameters.
具体的,将训练集中的各样本文件和各样本文件的目标区域信息输入YOLO v3模型中。YOLO v3模型中的Darknet53网络将各样本文件和各样本文件的目标区域信息生成不同尺寸的特征图像。对不同尺寸的特征图像进行检测时,将特征图划分为S*S个网格单元(例如:16*16尺寸的特征图像被划分为16*16个网格单元),特征图像中的目标区域落入任一网格单元,则由该网格单元对目标区域进行检测。Specifically, each sample file in the training set and the target area information of each sample file are input into the YOLO v3 model. The Darknet53 network in the YOLO v3 model generates feature images of different sizes from each sample file and the target area information of each sample file. When detecting feature images of different sizes, the feature map is divided into S*S grid units (for example, a feature image of 16*16 size is divided into 16*16 grid units), and the target area in the feature image If it falls into any grid unit, the target area will be detected by the grid unit.
本申请实施例中,每个网格单元均设定3个边界框。YOLO v3模型对目标区域进行检测时,利用各特征图像的边界框分别与提前标注的目标区域的矩形框进行计算,得到测量标准(Intersection Over Union,IOU),只用IOU最大的边界框才能用来预测该目标区域。In the embodiment of the present application, three bounding boxes are set for each grid unit. When the YOLO v3 model detects the target area, the bounding box of each feature image is used to calculate the rectangular box of the target area marked in advance to obtain the measurement standard (Intersection Over Union, IOU). Only the bounding box with the largest IOU can be used. to predict the target area.
IOU是一种测量在特定数据集中检测相应物体准确度的一个标准,这个标准用于测量真实与预测之间的相关度,IOU的值越大,则相关度越高。IOU is a standard that measures the accuracy of detecting corresponding objects in a specific data set. This standard is used to measure the correlation between the real and the predicted. The larger the value of IOU, the higher the correlation.
IOU的计算公式为:The formula for calculating IOU is:

本申请实施例通过上述IOU的计算公式,即可分别计算出边界框与目标区域的IOU。In this embodiment of the present application, the IOUs of the bounding box and the target area can be calculated respectively by using the above-mentioned IOU calculation formula.
本申请实施例中的YOLO v3模型是在多个尺寸的图像特征上做检测。预测得到的输出特征有两个维度是提取到的特征图像的维度(比如13*13),还有一个维度(深度)是B*(5+C),其中B表示每个网格单元预测的边界框的数量,C表示边界框的类别数,5表示4个边界框的坐标信息和一个目标区域的置信度。The YOLO v3 model in the embodiment of the present application performs detection on image features of multiple sizes. The predicted output feature has two dimensions, which are the dimensions of the extracted feature image (such as 13*13), and one dimension (depth) is B*(5+C), where B represents the predicted value of each grid cell. The number of bounding boxes, C represents the number of categories of bounding boxes, and 5 represents the coordinate information of 4 bounding boxes and the confidence of a target area.
本申请实施例中,将训练集和验证集中各样本文件和各样本文件的目标区域信息输入模型中进行训练,当训练的次数(epoch)达到100次,或者训练的验证集准确率到达某个阈值(如90%),则认为模型训练完毕。保存最优的模型权重参数用于提取水印在样本文件中的位置信息。In the embodiment of the present application, the target area information of each sample file and each sample file in the training set and the verification set is input into the model for training. Threshold (such as 90%), the model is considered to be trained. Save the optimal model weight parameters for extracting the location information of the watermark in the sample file.
本申请实施例中,将文件输入至第一神经网络模型进行处理,得到第一神经网络模型输出的水印在文件中的位置信息。In the embodiment of the present application, the file is input into the first neural network model for processing, and the position information in the file of the watermark output by the first neural network model is obtained.
具体的,将需要去除水印的文件输入至已训练完成的YOLO v3模型中进行处理,即可识别文件中包含水印的目标区域以及获得目标区域的信息,目标区域的信息包括水印的标注框的位置信息,即标注框的顶点坐标信息。Specifically, the file that needs to be removed from the watermark is input into the trained YOLO v3 model for processing, so that the target area containing the watermark in the file can be identified and the information of the target area can be obtained. The information of the target area includes the position of the label box of the watermark. information, that is, the vertex coordinate information of the callout box.
S203、根据位置信息获取文件中的目标区域。S203. Acquire the target area in the file according to the location information.
具体的,根据位置信息裁剪文件,得到目标区域。Specifically, the file is cropped according to the location information to obtain the target area.
在一些实施例中,根据S202获取的矩形框的4个顶点坐标区域信息裁剪文件,即可得到文件的目标区域。In some embodiments, the target area of the file can be obtained by cropping the file according to the coordinate area information of the four vertices of the rectangular frame obtained in S202.
在一些实施例中,根据位置信息裁剪文件,得到目标区域之后,对目标区域进行掩码处理,得到目标区域的掩码信息。In some embodiments, the file is cropped according to the position information, and after the target area is obtained, mask processing is performed on the target area to obtain mask information of the target area.
该掩码信息中,水印区域的像素值不为0,其他区域的像素值为0。In the mask information, the pixel value of the watermark area is not 0, and the pixel value of other areas is 0.
S204、对目标区域进行水印去除处理,得到去水印后的文件。S204. Perform watermark removal processing on the target area to obtain a file after watermark removal.
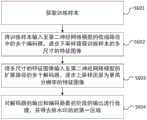
具体的,请参考图4,图4是本申请一实施例提供的一种对目标区域进行水印去除处理的方法的流程示意图。作为一实现方式,图4中的方法的执行主体可以为图1中的终端设备100,作为其他实现方式,图4中的方法的执行主体也可以为图1中的服务器200。如图4所示,该方法包括:S401至S402。Specifically, please refer to FIG. 4 , which is a schematic flowchart of a method for performing watermark removal processing on a target area provided by an embodiment of the present application. As an implementation manner, the execution body of the method in FIG. 4 may be the
S401、将目标区域输入至第二神经网络模型进行处理,得到第二神经网络模型输出的第一区域。S401. Input the target area into the second neural network model for processing, and obtain the first area output by the second neural network model.
具体的,本申请实施例中,第一区域为目标区域去除水印后的区域。Specifically, in the embodiment of the present application, the first area is the area from which the watermark is removed from the target area.
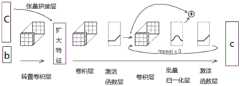
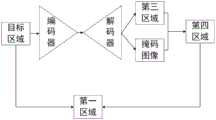
本申请实施例中,第二神经网络模型是具有编码解码结构的神经网络模型。请参考图5a,图5a是本申请一实施例提供的第二神经网络模型的网络结构的示例图。In the embodiment of the present application, the second neural network model is a neural network model with an encoding-decoding structure. Please refer to FIG. 5a. FIG. 5a is an example diagram of a network structure of a second neural network model provided by an embodiment of the present application.
第二神经网络模型包括一个由多个编码器构成的收缩路径、一个由多个解码器构成的扩展路径以及替换模块,本申请实施例的编码器为6个,为了便于描述,将这6个编码器记为A、B、C、D、E、F,本申请实施例的解码器为5个,为了便于描述,将这5个解码器记为a、b、c、d、e,为了便于描述,将替换模块记为G。The second neural network model includes a contraction path composed of a plurality of encoders, an expansion path composed of a plurality of decoders, and a replacement module. The number of encoders in this embodiment of the present application is 6. For the convenience of description, these 6 The encoders are denoted as A, B, C, D, E, and F, and the number of decoders in this embodiment of the present application is 5. For the convenience of description, these 5 decoders are denoted as a, b, c, d, and e. For convenience of description, the replacement module is denoted as G.
收缩路径主要通过各级编码器实施下采样来逐步进行特征提取,扩展路径主要通过各级解码器实施上采样来逐步还原出越来越高分辨率的特征图像。在扩展路径逐级下采样的过程中会选择上下文信息,因此,为了补偿特征丢失,每个解码器将其上一级的上采样特征与其同级的编码器的上采样特征的级联作为输入,用于补偿上下文信息,以便确保所还原的图像质量。最后一级解码器还原的图片再经过一个后处理步骤便可还原出更接近原图的色彩。The shrinking path mainly performs feature extraction step by step by performing downsampling at all levels of encoders, and the expanding path mainly performs upsampling by all levels of decoders to gradually restore higher and higher resolution feature images. Context information is selected in the step-by-step downsampling process of the extended path, so to compensate for feature loss, each decoder takes as input the concatenation of the upsampled features of its previous stage and the upsampled features of its sibling encoders , which is used to compensate for context information in order to ensure the restored image quality. The image restored by the last-level decoder can be restored to a color closer to the original image after a post-processing step.
本申请实施例中,每个编码器的网络结构请参考图5b,图5b是本申请一实施提供的编码器的网络结构的示例图。In this embodiment of the present application, for the network structure of each encoder, please refer to FIG. 5b, which is an example diagram of the network structure of the encoder provided by an implementation of the present application.
每个编码器均包含卷积层,激活函数层(Relu),批量归一化层(BatchNorm)和最大池化层。在每个编码器中,特征图像的通道数变为原来通道数量的2倍且逐层增加,但空间尺寸逐层减少,变为原特征图像的空间尺寸的1/2。Each encoder consists of a convolutional layer, an activation function layer (Relu), a batch normalization layer (BatchNorm), and a max pooling layer. In each encoder, the number of channels of the feature image becomes twice the original number of channels and increases layer by layer, but the spatial size decreases layer by layer, becoming 1/2 the spatial size of the original feature image.
本申请实施例中,每个解码器的网络结构请参考图5c,图5c是本申请一实施例提供的解码器的网络结构的示例图。In the embodiment of the present application, please refer to FIG. 5c for the network structure of each decoder, and FIG. 5c is an example diagram of the network structure of the decoder provided by an embodiment of the present application.
每个解码器均包含张量拼接层、转置卷积层、卷积层,激活函数层(Relu)和批量归一化层(BatchNorm),张量拼接层用于连接与该解码器同级的编码器,转置卷积层用于扩大特征图像的尺寸。在每个解码器中,特征图像的通道数变为原来通道数量的1/2且逐层减少,但空间尺寸逐层增加,变为原特征图像的空间尺寸的2倍。Each decoder includes a tensor splicing layer, a transposed convolutional layer, a convolutional layer, an activation function layer (Relu) and a batch normalization layer (BatchNorm). The tensor splicing layer is used to connect the same level as the decoder. The encoder, the transposed convolutional layer is used to enlarge the size of the feature image. In each decoder, the number of channels of the feature image becomes 1/2 of the original channel number and decreases layer by layer, but the spatial size increases layer by layer, becoming twice the spatial size of the original feature image.
对于第二神经网络模型,其残差连接体现在每一个编码器和解码器的网络结构中,如图5b和图5c所示,repeat x 3表示的意思是残差连接重复3次,这样做的好处是可以扩大感受野,同时有助于提升恢复图像的质量。For the second neural network model, the residual connection is embodied in the network structure of each encoder and decoder, as shown in Figure 5b and Figure 5c, repeat x 3 means that the residual connection is repeated 3 times, so The advantage is that it can expand the receptive field and at the same time help to improve the quality of the restored image.
本申请实施例中,替换模块G与解码器连接,替换模块中包含1*1的卷积层,激活函数层(sigmoid)。替换模块对处理编码器和解码器的输出的特征图像进行处理。In the embodiment of the present application, the replacement module G is connected to the decoder, and the replacement module includes a 1*1 convolution layer and an activation function layer (sigmoid). The replacement module processes feature images that process the output of the encoder and decoder.
请参考图6,图6是本申请一实施例提供的一种第二神经网络模型的训练方法的流程示意图。如图6所示,该方法包括:S601至S604。Please refer to FIG. 6 , which is a schematic flowchart of a training method for a second neural network model provided by an embodiment of the present application. As shown in FIG. 6 , the method includes: S601 to S604.
S601、获取训练样本。S601. Obtain training samples.
具体的,本申请实施例对文件中的水印进行去除时,为了提高去除水印的速度,并不需要对整个文件进行处理,而是通过第一神经网络模型的输出结果,确定水印在文件中的位置信息。根据位置信息获取文件中的目标区域,进而只需在第二神经网络模型中对目标区域进行水印去除处理。因此,本申请实施例中,可以将S301中多组样本文件经过第一神经网络模型的处理,进而得到的多组样本文件中的目标区域作为第二神经网络模型的训练样本。Specifically, when removing the watermark in the file in the embodiment of the present application, in order to improve the speed of removing the watermark, the entire file does not need to be processed, but the output result of the first neural network model is used to determine the watermark in the file. location information. The target area in the file is obtained according to the location information, and then the watermark removal process only needs to be performed on the target area in the second neural network model. Therefore, in this embodiment of the present application, the multiple groups of sample files in S301 may be processed by the first neural network model, and then the target regions in the multiple sets of sample files obtained may be used as training samples of the second neural network model.
S602、将训练样本输入至第二神经网络模型的收缩路径中的多个编码器,逐步下采样提取训练样本的多尺寸的特征图像。S602. Input the training samples to multiple encoders in the contraction path of the second neural network model, and gradually downsample to extract multi-sized feature images of the training samples.
示例性的,请参考图5a,将训练样本中各目标区域为128*128*3(长*宽*高,其中,高可理解为通道数)的尺寸特征,经过编码器A下采样提取特征之后变成64*64*32的特征图像输出给编码器B,同理,经过编码器C之后,输出32*32*64的特征图像,再经过编码器D即成为16*16*128的特征图像,经编码器E即成为8*8*256的特征图像,经编码器F即成为4*4*512的特征图像,获得的多尺寸的特征图像被传入扩展路径。Exemplarily, please refer to Fig. 5a, each target area in the training sample is a size feature of 128*128*3 (length*width*height, where the height can be understood as the number of channels), and the feature is extracted by downsampling by the encoder A. After that, the feature image of 64*64*32 is output to encoder B. Similarly, after encoder C, the feature image of 32*32*64 is output, and then encoder D becomes the feature of 16*16*128. The image becomes an 8*8*256 feature image via the encoder E, and a 4*4*512 feature image via the encoder F, and the obtained multi-size feature image is passed into the extension path.
步骤S603、将多尺寸的特征图输入第二神经网络模型的扩展路径中的多个解码器,逐步上采样还原为更高分辨率的特征图像。Step S603: Input the multi-size feature map into multiple decoders in the expansion path of the second neural network model, and gradually upsample and restore it to a feature image with a higher resolution.
具体的,每个解码器以其对应的一个编码器所获得的特征图像为参照实施还原。Specifically, each decoder uses a feature image obtained by a corresponding encoder as a reference to perform restoration.
请参照图5a,第二神经网络模型中除了中间的编码器F外,两侧的编码器与解码器呈对称结构,其中,每个解码器均获取两路输入,一路为其上一级的解码器的上采样的图像特征,另一路为其对称级的编码器的上采样的图像特征的级联。Referring to FIG. 5a, in the second neural network model, except for the encoder F in the middle, the encoders and decoders on both sides have a symmetrical structure, wherein each decoder obtains two inputs, and one is the upper level of the input. The decoder's up-sampled image features, and the other is a concatenation of the encoder's up-sampled image features at its symmetric stage.
本申请实施例中,4*4*512的特征图像经过解码器a之后,被还原为8*8*256的特征图像,然后经解码器b还原为16*16*128的特征图像,再经解码器c还原为32*32*64的特征图像,再经编码器d还原为64*64*32,最后经编码器e还原为128*128*3,与编码器输入时的特征图像的尺寸相同。In the embodiment of the present application, the 4*4*512 feature image is restored to the 8*8*256 feature image after passing through the decoder a, and then the 16*16*128 feature image is restored by the decoder b. The decoder c is restored to the feature image of 32*32*64, and then restored to 64*64*32 by the encoder d, and finally restored to 128*128*3 by the encoder e, which is the same as the size of the feature image input by the encoder. same.
S604、对解码器的输出和编码器最后阶段的输出进行处理,获得去除水印后的第一区域。S604. Process the output of the decoder and the output of the final stage of the encoder to obtain the first region after removing the watermark.
具体的,本申请实施例中,解码器输出的特征图像及编码器输出的特征图像均被传输到一个替换模块G中进行替换,在替换模块中,根据该第二神经网络模型固有的原理运用sigmoid函数和正则化处理对解码器输出的特征图像及编码器输出的特征图像进行处理,以便获得去除水印后的第一区域。Specifically, in the embodiment of the present application, both the feature image output by the decoder and the feature image output by the encoder are transmitted to a replacement module G for replacement. In the replacement module, the second neural network model is used according to the inherent principle of the second neural network model. The sigmoid function and the regularization process process the feature image output by the decoder and the feature image output by the encoder, so as to obtain the first region after removing the watermark.
请参考图7,图7是本申请一实施例提供的一种获得去除水印后的第一区域的示例图,在图7中,目标区域Cr,经过解码器处理,输出的特征图中包含与目标区域对应的第三区域

在一些实施例中,第三区域为目标区域对应的背景区域,且第三区域不包含水印。在一些实施例中,目标区域的特征图像为掩码图像,在掩码图像中,水印区域的像素值不为0,其他区域的像素值为0。In some embodiments, the third area is a background area corresponding to the target area, and the third area does not contain a watermark. In some embodiments, the feature image of the target area is a mask image, and in the mask image, the pixel value of the watermark area is not 0, and the pixel value of other areas is 0.
本申请实施例中,在替换模块G中,确定水印在目标区域中的位置信息。In the embodiment of the present application, in the replacement module G, the position information of the watermark in the target area is determined.
具体的,对目标区域进行掩码处理,得到目标区域的掩码信息,并根据掩码信息确定水印在目标区域中的位置信息Specifically, mask processing is performed on the target area to obtain mask information of the target area, and the position information of the watermark in the target area is determined according to the mask information
在一些实施例中,通过对目标区域进行掩码处理,获得掩码图像,根据掩码图像中水印区域的掩码即可确定水印在目标区域中的位置信息。In some embodiments, a mask image is obtained by performing mask processing on the target area, and the position information of the watermark in the target area can be determined according to the mask of the watermark area in the mask image.
本申请实施例中,根据水印在目标区域中的位置信息,确定第三区域中与水印对应的第四区域。In the embodiment of the present application, according to the position information of the watermark in the target area, the fourth area corresponding to the watermark in the third area is determined.
具体的,通过将第三区域与目标区域中的水印图像进行异或处理,即可确定第三区域中与水印对应的第四区域

本申请实施例中,利用第四区域替换目标区域中的水印。In this embodiment of the present application, the watermark in the target area is replaced by the fourth area.
具体的,利用下述公式,即可完成第四区域对目标区域的替换,获得去除水印后的第一区域。Specifically, by using the following formula, the replacement of the target area by the fourth area can be completed, and the first area after removing the watermark can be obtained.

其中,
本申请实施例中,在第二神经网络模型训练的迭代次数达到一定次数时(例如100次),神经网络模型即完成训练,保存的模型权重参数用于获得去除水印后的第一区域。In the embodiment of the present application, when the number of iterations of the second neural network model training reaches a certain number of times (for example, 100 times), the neural network model completes the training, and the saved model weight parameters are used to obtain the first region after removing the watermark.
在一些实施例中,为了监督第二神经网络模型的训练效果,将第三区域作为目标值,将去除水印后的第一区域作为预测值,采用由多个损失函数线性叠加而成的总损失函数监督样本训练过程,以使训练所得的预测值随迭代次数的增加而最大化趋近于目标值。In some embodiments, in order to supervise the training effect of the second neural network model, the third area is used as the target value, the first area after removing the watermark is used as the predicted value, and the total loss formed by the linear superposition of multiple loss functions is adopted The function supervises the sample training process so that the predicted value obtained from the training maximizes and approaches the target value as the number of iterations increases.
请参考图8,图8是本申请一实施例提供的一种应用第二神经网络模型获得去除水印后的第一区域的方法的流程示意图。作为一实现方式,图8中的方法的执行主体可以为图1中的终端设备100,作为其他实现方式,图8中的方法的执行主体也可以为图1中的服务器200。如图8所示,该方法包括:S801至S804。Please refer to FIG. 8 , which is a schematic flowchart of a method for obtaining a watermark-removed first region by applying a second neural network model according to an embodiment of the present application. As an implementation manner, the execution body of the method in FIG. 8 may be the
S801、获取与目标区域对应的第三区域。S801. Acquire a third area corresponding to the target area.
本申请实施例中,将目标区域输入已训练完成的第二神经网络模型,第二神经网络模型经过训练,其相关参数得到优化,其解码器输出的特征图像即为与目标区域对应的第三区域。In the embodiment of the present application, the target area is input into the trained second neural network model, the second neural network model is trained, and its related parameters are optimized, and the feature image output by the decoder is the third neural network model corresponding to the target area. area.
S802、确定水印在目标区域中的位置信息。S802. Determine the location information of the watermark in the target area.
本申请实施例中,确定水印在目标区域中的位置信息的方法与S604中确定水印在目标区域中的位置信息的方法相同,此处不再赘述。In the embodiment of the present application, the method for determining the position information of the watermark in the target area is the same as the method for determining the position information of the watermark in the target area in S604, and details are not repeated here.
S803、根据水印在目标区域中的位置信息,确定第三区域中与水印对应的第四区域。S803. Determine a fourth area corresponding to the watermark in the third area according to the location information of the watermark in the target area.
本申请实施例中,确定第四区域的方法与S604中确定第四区域的方法相同,此处不再赘述。In this embodiment of the present application, the method for determining the fourth area is the same as the method for determining the fourth area in S604, and details are not repeated here.
S804、利用第四区域替换目标区域中的水印。S804. Use the fourth area to replace the watermark in the target area.
本申请实施例中,利用第四区域替换目标区域中的水印进而获得去除水印后的第一区域。In the embodiment of the present application, the watermark in the target area is replaced by the fourth area to obtain the first area after removing the watermark.
利用第四区域替换目标区域中的水印的方法与S604中利用第四区域替换目标区域中的水印的方法相同,此处不再赘述。The method of using the fourth area to replace the watermark in the target area is the same as the method of using the fourth area to replace the watermark in the target area in S604, and will not be repeated here.
S402、将第一区域与文件中的第二区域进行融合,得到去水印后的文件。S402 , fuse the first area with the second area in the file to obtain a watermark-removed file.
具体的,第一区域为目标区域去除水印后的区域。第二区域为文件中除目标区域以外的区域。Specifically, the first area is the area from which the watermark is removed from the target area. The second area is an area other than the target area in the file.
本申请实施例中,目标区域的信息包括水印的标注框的位置信息,即标注框的顶点坐标信息,根据标注框的顶点坐标信息将第一区域与第二区域进行融合,得到去水印后的文件。In the embodiment of the present application, the information of the target area includes the position information of the annotation frame of the watermark, that is, the vertex coordinate information of the annotation frame, and the first area and the second area are fused according to the vertex coordinate information of the annotation frame to obtain the watermarked document.
本申请实施例中。可以利用加权平均、小波变换、模糊神经网络、塔形分解等方法将第一区域与第二区域进行融合,本申请实施例对第一区域与第二区域的融合方法不作限定。In the examples of this application. The first area and the second area may be fused by methods such as weighted average, wavelet transform, fuzzy neural network, tower decomposition, etc. The embodiment of the present application does not limit the fusion method of the first area and the second area.
综上所述,本申请实施例通过获取包含水印的文件;利用第一神经网络模型确定水印在文件中的位置信息;根据位置信息获取文件中的目标区域,目标区域为文件中包含水印的区域;利用第二神经网络模型对目标区域进行水印去除处理,得到去水印后的文件。即本申请通过确定水印在文件中的位置信息;根据位置信息获取文件中的目标区域,并不需要对整个文件进行处理,只需对目标区域进行水印去除处理,即可得到去水印后的文件,提高去除水印的速度。To sum up, the embodiment of the present application obtains a file containing a watermark; uses the first neural network model to determine the location information of the watermark in the file; acquires a target area in the file according to the location information, and the target area is the area containing the watermark in the file ; Use the second neural network model to remove the watermark on the target area, and obtain the watermarked file. That is, the present application determines the location information of the watermark in the file; obtains the target area in the file according to the location information, and does not need to process the entire file, but only needs to perform the watermark removal process on the target area, and then the watermarked file can be obtained. , to increase the speed of removing watermarks.
应理解,上述实施例中各步骤的序号的大小并不意味着执行顺序的先后,各过程的执行顺序应以其功能和内在逻辑确定,而不应对本申请实施例的实施过程构成任何限定。It should be understood that the size of the sequence numbers of the steps in the above embodiments does not mean the sequence of execution, and the execution sequence of each process should be determined by its function and internal logic, and should not constitute any limitation to the implementation process of the embodiments of the present application.
请参阅图9,图9是本申请实施例提供的一种水印去除装置的结构示意图,作为一实现方式,该装置可以应用于图1的终端设备100,作为其他实现方式,该装置也可以应用于图1的服务器200。该装置包括:Please refer to FIG. 9. FIG. 9 is a schematic structural diagram of a watermark removing apparatus provided by an embodiment of the present application. As an implementation, the apparatus can be applied to the
第一获取模块91,用于获取包含水印的文件。The first obtaining
确定模块92,用于确定水印在文件中的位置信息。The determining
第二获取模块93,用于根据位置信息获取文件中的目标区域,目标区域为文件中包含水印的区域。The second obtaining
处理模块94,用于对目标区域进行水印去除处理,得到去水印后的文件。The
其中,确定模块92,包括:Wherein, the
第一处理单元921,用于将文件输入至第一神经网络模型进行处理,得到第一神经网络模型输出的水印在文件中的位置信息。The
其中,第二获取模块93,包括:Wherein, the
裁剪单元931,用于根据位置信息裁剪文件,得到目标区域。The
其中,处理模块94,包括:Wherein, the
第二处理单元941,用于将目标区域输入至第二神经网络模型进行处理,得到第二神经网络模型输出的第一区域,第一区域为目标区域去除水印后的区域。The
融合单元942,用于将第一区域与文件中的第二区域进行融合,得到去水印后的文件,第二区域为文件中除目标区域以外的区域。The
其中,第二处理单元941,包括:Wherein, the
第一获取子单元9411,用于获取与目标区域对应的第三区域,第三区域为目标区域对应的背景区域,且第三区域不包含水印。The first obtaining
第二获取子单元9412,用于确定水印在目标区域中的位置信息。The second obtaining
确定子单元9413,用于根据水印在目标区域中的位置信息,确定第三区域中与水印对应的第四区域。The determining
替换子单元9414,用于利用第四区域替换目标区域中的水印。The
其中,第二获取子单元9412,包括:Wherein, the
掩码处理子单元9415,用于对目标区域进行掩码处理,得到目标区域的掩码信息,并根据掩码信息确定水印在目标区域中的位置信息。The
所属领域的技术人员可以清楚地了解到,为了描述的方便和简洁,仅以上述各功能单元、模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能单元、模块完成,即将装置的内部结构划分成不同的功能单元或模块,以完成以上描述的全部或者部分功能。实施例中的各功能单元、模块可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中,上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。另外,各功能单元、模块的具体名称也只是为了便于相互区分,并不用于限制本申请的保护范围。上述系统中单元、模块的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。Those skilled in the art can clearly understand that, for the convenience and simplicity of description, only the division of the above-mentioned functional units and modules is used as an example. Module completion means dividing the internal structure of the device into different functional units or modules to complete all or part of the functions described above. Each functional unit and module in the embodiment may be integrated in one processing unit, or each unit may exist physically alone, or two or more units may be integrated in one unit, and the above-mentioned integrated units may adopt hardware. It can also be realized in the form of software functional units. In addition, the specific names of the functional units and modules are only for the convenience of distinguishing from each other, and are not used to limit the protection scope of the present application. For the specific working processes of the units and modules in the above-mentioned system, reference may be made to the corresponding processes in the foregoing method embodiments, which will not be repeated here.
如图10所示,本申请实施例还提供一种终端设备20,包括存储器21、处理器22以及存储在存储器21中并可在处理器22上运行的计算机程序23,处理器22执行计算机程序23时实现上述各实施例的显示屏瑕疵定位方法。As shown in FIG. 10 , an embodiment of the present application further provides a terminal device 20, including a
所述处理器22可以是中央处理单元(Central Processing Unit,CPU),还可以是其他通用处理器、数字信号处理器(Digital Signal Processor,DSP)、专用集成电路(Application Specific Integrated Circuit,ASIC)、现场可编程门阵列(Field-Programmable Gate Array,FPGA)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。The
所述存储器21可以是终端设备200的内部存储单元。所述存储器21也可以是终端设备200的外部存储设备,例如终端设备200上配备的插接式硬盘,智能存储卡(SmartMedia Card,SMC),安全数字(Secure Digital,SD)卡,闪存卡(Flash Card)等。进一步地,存储器21还可以既包括终端设备200的内部存储单元也包括外部存储设备。存储器21用于存储计算机程序以及终端设备200所需的其他程序和数据。存储器21还可以用于暂时地存储已经输出或者将要输出的数据。The
本申请实施例还提供了一种计算机可读存储介质,计算机可读存储介质存储有计算机程序,计算机程序被处理器执行时实现上述各实施例的水印去除方法。Embodiments of the present application further provide a computer-readable storage medium, where the computer-readable storage medium stores a computer program, and when the computer program is executed by a processor, the watermark removal methods of the foregoing embodiments are implemented.
本申请实施例提供了一种计算机程序产品,当计算机程序产品在终端设备上运行时,使得终端设备执行时实现上述各实施例的水印去除方法。The embodiments of the present application provide a computer program product, which, when the computer program product runs on a terminal device, enables the terminal device to implement the watermark removal methods of the foregoing embodiments.
集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读存储介质中。基于这样的理解,本申请实现上述实施例方法中的全部或部分流程,可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于计算机可读存储介质中,该计算机程序在被处理器执行时,可实现上述各个方法实施例的步骤。其中,计算机程序包括计算机程序代码,计算机程序代码可以为源代码形式、对象代码形式、可执行文件或某些中间形式等。计算机可读存储介质至少可以包括:能够将计算机程序代码携带到拍照装置/终端设备的任何实体或装置、记录介质、计算机存储器、只读存储器(read-only memory,ROM)、随机存取存储器(random access memory,RAM)、电载波信号、电信信号以及软件分发介质。例如U盘、移动硬盘、磁碟或者光盘等。在某些司法管辖区,根据立法和专利实践,计算机可读存储介质不可以是电载波信号和电信信号。The integrated unit, if implemented in the form of a software functional unit and sold or used as a stand-alone product, may be stored in a computer-readable storage medium. Based on this understanding, all or part of the processes in the methods of the above embodiments can be implemented by the present application, which can be completed by instructing the relevant hardware through a computer program. The computer program can be stored in a computer-readable storage medium, and the computer program is When executed by the processor, the steps of the foregoing method embodiments can be implemented. Wherein, the computer program includes computer program code, and the computer program code may be in the form of source code, object code, executable file or some intermediate forms, and the like. The computer-readable storage medium may include at least: any entity or device capable of carrying the computer program code to the photographing device/terminal device, recording medium, computer memory, read-only memory (ROM), random access memory ( random access memory, RAM), electrical carrier signals, telecommunication signals, and software distribution media. For example, U disk, mobile hard disk, disk or CD, etc. In some jurisdictions, under legislation and patent practice, computer-readable storage media may not be electrical carrier signals and telecommunications signals.
在上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述或记载的部分,可以参见其他实施例的相关描述。In the foregoing embodiments, the description of each embodiment has its own emphasis. For parts that are not described or described in detail in a certain embodiment, reference may be made to the relevant descriptions of other embodiments.
本领域普通技术人员可以意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、或者计算机软件和电子硬件的结合来实现。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本申请的范围。Those of ordinary skill in the art can realize that the units and algorithm steps of each example described in conjunction with the embodiments disclosed herein can be implemented in electronic hardware, or a combination of computer software and electronic hardware. Whether these functions are performed in hardware or software depends on the specific application and design constraints of the technical solution. Skilled artisans may implement the described functionality using different methods for each particular application, but such implementations should not be considered beyond the scope of this application.
作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本申请实施例方案的目的。Units described as separate components may or may not be physically separated, and components shown as units may or may not be physical units, that is, may be located in one place, or may be distributed to multiple network units. Some or all of the units may be selected according to actual needs to achieve the purpose of the solutions of the embodiments of the present application.
以上实施例仅用以说明本申请的技术方案,而非对其限制;尽管参照前述实施例对本申请进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本申请各实施例技术方案的精神和范围,均应包含在本申请的保护范围之内。The above embodiments are only used to illustrate the technical solutions of the present application, but not to limit them; although the present application has been described in detail with reference to the foregoing embodiments, those of ordinary skill in the art should understand that: The recorded technical solutions are modified, or some technical features thereof are equivalently replaced; and these modifications or replacements do not make the essence of the corresponding technical solutions deviate from the spirit and scope of the technical solutions of the embodiments of the application, and should be included in the application. within the scope of protection.
Claims (10)
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110955089.7ACN113643173B (en) | 2021-08-19 | 2021-08-19 | Watermark removal method, device, terminal equipment and readable storage medium |
| PCT/CN2021/119725WO2023019682A1 (en) | 2021-08-19 | 2021-09-22 | Watermark removal method and apparatus, terminal device and readable storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110955089.7ACN113643173B (en) | 2021-08-19 | 2021-08-19 | Watermark removal method, device, terminal equipment and readable storage medium |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN113643173Atrue CN113643173A (en) | 2021-11-12 |
| CN113643173B CN113643173B (en) | 2025-04-25 |
Family
ID=78422893
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110955089.7AActiveCN113643173B (en) | 2021-08-19 | 2021-08-19 | Watermark removal method, device, terminal equipment and readable storage medium |
Country Status (2)
| Country | Link |
|---|---|
| CN (1) | CN113643173B (en) |
| WO (1) | WO2023019682A1 (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114495110A (en)* | 2022-01-28 | 2022-05-13 | 北京百度网讯科技有限公司 | Image processing method, generator training method, device and storage medium |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116342363B (en)* | 2023-05-31 | 2023-07-28 | 齐鲁工业大学(山东省科学院) | Visible watermark removing method based on two-stage deep neural network |
| CN117292117A (en)* | 2023-10-30 | 2023-12-26 | 青岛本原微电子有限公司 | Small target detection method based on attention mechanism |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20050025337A1 (en)* | 2003-07-29 | 2005-02-03 | Wei Lu | Techniques and systems for embedding and detecting watermarks in digital data |
| WO2017016294A1 (en)* | 2015-07-24 | 2017-02-02 | 乐视控股(北京)有限公司 | Method and apparatus for removing watermark from video |
| CN111062854A (en)* | 2019-12-26 | 2020-04-24 | Oppo广东移动通信有限公司 | Method, device, terminal and storage medium for detecting watermark |
| CN111160335A (en)* | 2020-01-02 | 2020-05-15 | 腾讯科技(深圳)有限公司 | Image watermarking processing method and device based on artificial intelligence and electronic equipment |
| CN111242824A (en)* | 2019-12-05 | 2020-06-05 | 北京万里红科技股份有限公司 | Watermark embedding method, tracing method, device and storage medium |
| CN111626912A (en)* | 2020-04-09 | 2020-09-04 | 智者四海(北京)技术有限公司 | Watermark removing method and device |
| CN112967166A (en)* | 2021-03-19 | 2021-06-15 | 北京星汉博纳医药科技有限公司 | OpenCV-based automatic image watermark identification processing method and system |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10169838B2 (en)* | 2016-08-01 | 2019-01-01 | International Business Machines Corporation | Multiple source watermarking for surveillance |
| CN111798360B (en)* | 2020-06-30 | 2023-08-15 | 百度在线网络技术(北京)有限公司 | Watermark detection method and device, electronic equipment and storage medium |
| CN111932431B (en)* | 2020-07-07 | 2023-07-18 | 华中科技大学 | Visible watermark removal method and electronic equipment based on watermark decomposition model |
| CN112419132B (en)* | 2020-11-05 | 2024-06-18 | 广州海外扛把子网络科技有限公司 | Video watermark detection method, device, electronic equipment and storage medium |
- 2021
- 2021-08-19CNCN202110955089.7Apatent/CN113643173B/enactiveActive
- 2021-09-22WOPCT/CN2021/119725patent/WO2023019682A1/ennot_activeCeased
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20050025337A1 (en)* | 2003-07-29 | 2005-02-03 | Wei Lu | Techniques and systems for embedding and detecting watermarks in digital data |
| WO2017016294A1 (en)* | 2015-07-24 | 2017-02-02 | 乐视控股(北京)有限公司 | Method and apparatus for removing watermark from video |
| CN111242824A (en)* | 2019-12-05 | 2020-06-05 | 北京万里红科技股份有限公司 | Watermark embedding method, tracing method, device and storage medium |
| CN111062854A (en)* | 2019-12-26 | 2020-04-24 | Oppo广东移动通信有限公司 | Method, device, terminal and storage medium for detecting watermark |
| CN111160335A (en)* | 2020-01-02 | 2020-05-15 | 腾讯科技(深圳)有限公司 | Image watermarking processing method and device based on artificial intelligence and electronic equipment |
| CN111626912A (en)* | 2020-04-09 | 2020-09-04 | 智者四海(北京)技术有限公司 | Watermark removing method and device |
| CN112967166A (en)* | 2021-03-19 | 2021-06-15 | 北京星汉博纳医药科技有限公司 | OpenCV-based automatic image watermark identification processing method and system |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114495110A (en)* | 2022-01-28 | 2022-05-13 | 北京百度网讯科技有限公司 | Image processing method, generator training method, device and storage medium |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2023019682A1 (en) | 2023-02-23 |
| CN113643173B (en) | 2025-04-25 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN109493350B (en) | Portrait segmentation method and device | |
| CN111681273B (en) | Image segmentation method and device, electronic equipment and readable storage medium | |
| CN113643173A (en) | Watermark removing method, watermark removing device, terminal equipment and readable storage medium | |
| US20150228045A1 (en) | Methods for embedding and extracting a watermark in a text document and devices thereof | |
| CN111461070B (en) | Text recognition method, device, electronic equipment and storage medium | |
| CN112183517B (en) | Card edge detection method, device and storage medium | |
| CN116797590B (en) | Mura defect detection method and system based on machine vision | |
| CN119130863B (en) | Image recovery method and system based on multiple attention mechanisms | |
| KR20160130769A (en) | Method and device for processing a picture | |
| CN114399729B (en) | Monitoring object movement identification method, system, terminal and storage medium | |
| CN110827301B (en) | Method and apparatus for processing image | |
| CN114283343A (en) | Map updating method, training method and equipment based on remote sensing satellite image | |
| WO2024174726A1 (en) | Handwritten and printed text detection method and device based on deep learning | |
| CN113570725A (en) | Three-dimensional surface reconstruction method and device based on clustering, server and storage medium | |
| CN116994000A (en) | Part edge feature extraction method and device, electronic equipment and storage medium | |
| CN114926734B (en) | Solid waste detection device and method based on feature aggregation and attention fusion | |
| CN118799705B (en) | A tunnel disease identification method, device and medium based on deep learning | |
| CN111028197A (en) | Method and terminal for detecting metal rust | |
| WO2024260264A1 (en) | Image processing method and apparatus, device, storage medium, and program product | |
| WO2019109410A1 (en) | Fully convolutional network model training method for splitting abnormal signal region in mri image | |
| CN117765493A (en) | Target recognition method for fish-eye image, electronic device and storage medium | |
| CN114332890B (en) | Table structure extraction method, device, electronic device and storage medium | |
| CN114359007B (en) | Image tracing method, device, equipment and storage medium | |
| CN113743413B (en) | Visual SLAM method and system combining image semantic information | |
| CN116402997A (en) | Focus region determination method, device and storage medium based on fusion attention |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| TA01 | Transfer of patent application right | Effective date of registration:20230829 Address after:523860 No. 168 Dongmen Middle Road, Xiaobian Community, Chang'an Town, Dongguan City, Guangdong Province Applicant after:Guangdong GENIUS Technology Co., Ltd. Address before:523000 east side of the 15th floor, 168 dongmenzhong Road, Xiaobian community, Chang'an Town, Dongguan City, Guangdong Province Applicant before:GUANGDONG AIMENG ELECTRONIC TECHNOLOGY CO.,LTD. | |
| TA01 | Transfer of patent application right | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |