CN113505585B - High-speed character string feature matching method, device and equipment based on primitive state machine - Google Patents
High-speed character string feature matching method, device and equipment based on primitive state machineDownload PDFInfo
- Publication number
- CN113505585B CN113505585BCN202110801808.XACN202110801808ACN113505585BCN 113505585 BCN113505585 BCN 113505585BCN 202110801808 ACN202110801808 ACN 202110801808ACN 113505585 BCN113505585 BCN 113505585B
- Authority
- CN
- China
- Prior art keywords
- primitive
- state machine
- node
- character
- current
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images



Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/253—Grammatical analysis; Style critique
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/284—Lexical analysis, e.g. tokenisation or collocates
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Devices For Executing Special Programs (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本发明涉及基因测序和网络报文深度内容匹配技术领域,尤其涉及一种基于原语状态机的高速字符串特征匹配方法、装置和设备。The invention relates to the technical field of gene sequencing and deep content matching of network messages, in particular to a high-speed character string feature matching method, device and equipment based on a primitive state machine.
背景技术Background technique
如何在输入的字符序列中快速匹配指定的关键字特征集合是否出现以及出现的位置,是计算机科学领域的一个长期难点问题,在互联网高速报文分类、互联网应用协议识别、基因组比对定位等领域有广泛用途。How to quickly match the occurrence and location of the specified keyword feature set in the input character sequence is a long-term difficult problem in the field of computer science. There are a wide range of uses.
现有的典型匹配算法包括AC算法、DFA和NFA算法等。其中AC算法是Alfred V.Aho和Margaret J.Corasick发明的字符串搜索算法,用于在输入的一串字符串中匹配有限个字符串特征中的子串,存在效率低下的问题。而DFA和NFA算法通常是由正则表达式编译生成的,DFA算法不提供匹配回溯功能,NFA比DFA算法慢,但提供了匹配回溯功能。DFA和NFA算法在正则表达式数量较多时,存在着严重的状态组合爆炸问题,且匹配性能低于AC算法。同时,上述算法基本匹配过程均为:在输入字符序列中读取一个字符,根据当前算法状态机的位置和输入字符,将状态机推进到下一个位置。每次状态机位置的推进至少涉及一次或以上的内存访问操作,存在低效性问题。同时,算法性能受内存访问主频和时延的影响,很难进行性能提升。因此,设计新的字符特征匹配算法,充分利用CPU强大的计算性能,避免内存的性能约束,是提升算法匹配性能的一个重要途径。Existing typical matching algorithms include AC algorithm, DFA and NFA algorithm, etc. Among them, the AC algorithm is a string search algorithm invented by Alfred V.Aho and Margaret J.Corasick. It is used to match substrings in a limited number of string features in an input string, and there is a problem of low efficiency. The DFA and NFA algorithms are usually compiled and generated by regular expressions. The DFA algorithm does not provide a matching backtracking function. NFA is slower than the DFA algorithm, but it provides a matching backtracking function. DFA and NFA algorithms have a serious problem of state combination explosion when the number of regular expressions is large, and the matching performance is lower than that of AC algorithm. At the same time, the basic matching process of the above algorithm is: read a character in the input character sequence, and advance the state machine to the next position according to the position of the current algorithm state machine and the input character. Each advancement of the position of the state machine involves at least one or more memory access operations, and there is a problem of inefficiency. At the same time, algorithm performance is affected by memory access frequency and latency, making it difficult to improve performance. Therefore, designing a new character feature matching algorithm, making full use of the powerful computing performance of the CPU, and avoiding the performance constraints of the memory is an important way to improve the matching performance of the algorithm.
发明内容Contents of the invention
基于此,本发明要解决的技术问题是突破现有字符特征匹配算法的性能瓶颈,提出一种基于原语状态机的高速字符特征匹配方法及装置,通过将传统匹配算法状态机的简单状态节点替换为具有固定处理功能的操作原语,获得了一种匹配性能高且具有更好灵活性的字符串特征匹配方法。Based on this, the technical problem to be solved in the present invention is to break through the performance bottleneck of the existing character feature matching algorithm, and propose a high-speed character feature matching method and device based on the primitive state machine. Replaced by operation primitives with fixed processing functions, a string feature matching method with high matching performance and better flexibility is obtained.
在本发明实施例中,本发明提出了一种基于原语状态机的高速字符串特征匹配方法,具体包括:In the embodiment of the present invention, the present invention proposes a high-speed character string feature matching method based on a primitive state machine, which specifically includes:
用户输入关键字特征集合,并对每个关键字特征以特征序号和用于存储关键字的字符串序列方式存储所述关键字特征;The user inputs a set of keyword features, and stores the keyword features in the form of a feature sequence number and a character string sequence for storing keywords for each keyword feature;
基于预先定义的基本操作原语,对所述关键字特征集合,按照预设的关键字特征集合编译方法进行编译,获得关键字特征集合对应的原语状态机;Based on the predefined basic operation primitives, compile the keyword feature set according to the preset keyword feature set compiling method, and obtain a primitive state machine corresponding to the keyword feature set;
获取待匹配目标字符串,基于所述原语状态机执行字符串匹配过程,获得命中关键字,并输出命中关键字的特征序号和当前匹配字符的结束位置。Obtain the target character string to be matched, execute the character string matching process based on the primitive state machine, obtain the hit keyword, and output the feature sequence number of the hit keyword and the end position of the current matching character.
进一步的,所述预先定义的基本操作原语包括:Further, the predefined basic operation primitives include:
跳过字符原语:在当前输入字符读取位置,向前或向后跳过N个字符;Skip character primitive: skip N characters forward or backward at the current input character reading position;
在当前位置匹配多个字符串原语:在当前输入字符位置开始匹配多个字符串特征;Match multiple string primitives at the current position: start matching multiple string features at the current input character position;
搜索匹配多个字符串原语:从当前输入字符位置开始搜索匹配多个字符串特征;Search and match multiple string primitives: start to search and match multiple string features from the current input character position;
跳转到指定匹配位置原语:将当前读取位置指向输入字符串的指定位置;Jump to the specified matching position primitive: point the current reading position to the specified position of the input string;
成功命中原语:匹配过程结束,返回匹配命中的关键字特征序号和命中的结束位置;Successful hit primitive: the matching process ends, and returns the sequence number of the keyword feature that matches the hit and the end position of the hit;
失败原语:匹配过程结束,返回失败信息。Failure primitive: the matching process ends and a failure message is returned.
进一步的,所述预设的关键字特征集合编译方法具体包括:Further, the preset keyword feature set compilation method specifically includes:
创建成功命中原语节点、失败原语节点作为基础原语节点,并初始化相关变量,将失败指针指向失败原语节点,当前节点指针指向空节点;Create a successful hit primitive node and a failed primitive node as the basic primitive node, and initialize related variables, point the failure pointer to the failed primitive node, and the current node pointer to an empty node;
获取待编译关键字特征集合,读取当前字符并将读取指针后移,根据所述当前字符和/或下一个字符的类型进行语法分析,并按照预设的编译方法对不同字符或字符组合进行编译构造原语状态机;获得每个关键字对应的原语状态机;Obtain the feature set of keywords to be compiled, read the current character and move the reading pointer backward, perform grammatical analysis according to the type of the current character and/or the next character, and perform different characters or combinations of characters according to the preset compilation method Compile and construct the primitive state machine; obtain the primitive state machine corresponding to each keyword;
根据所述关键字对应的原语状态机根节点的深度,先合并深度相同的原语状态机,再按照从浅到深的原则进行聚合,获得关键字特征集合对应的原语状态机。According to the depth of the root node of the primitive state machine corresponding to the keyword, the primitive state machine with the same depth is first merged, and then aggregated according to the principle from shallow to deep to obtain the primitive state machine corresponding to the keyword feature set.
进一步的,所述根据所述当前字符和/或下一个字符的类型进行语法分析,并按照预设的编译方法对不同字符或字符组合进行编译步骤具体包括:Further, the step of performing grammatical analysis according to the type of the current character and/or the next character, and compiling different characters or character combinations according to a preset compiling method specifically includes:
当前字符为“.”,读取下一个字符,当下一个字符为“*”,设置浮动标志并读取指针后移,否则建立跳过字符原语节点作为当前节点或将当前跳过字符原语的跳过数量加1;The current character is ".", read the next character, when the next character is "*", set the floating flag and move the reading pointer backward, otherwise, establish the skip character primitive node as the current node or use the current skip character primitive node The number of skips is increased by 1;
当前字符为“*”,停止编译并报错;The current character is "*", stop compiling and report an error;
对其它字符,进行“字符串”原语节点的处理过程,具体包括:For other characters, carry out the processing process of the "string" primitive node, including:
当前字符为“\”,读取下一个字符,并将读取指针后移;The current character is "\", read the next character, and move the read pointer backward;
当前节点不为“字符串”类型的原语节点,根据浮动标志是否为True,创建“搜索匹配多个字符串”原语节点或“当前位置匹配多个字符串”原语节点,并将当前节点的成功跳转状态指向新节点,失败跳转状态指向失败指针,最后更新当前节点为新创建的原语节点;将当前字符加入到当前原语的搜索字符串尾;The current node is not a primitive node of the "string" type. According to whether the floating flag is True, create a "search matches multiple strings" primitive node or a "current position matches multiple strings" primitive node, and set the current The successful jump status of the node points to the new node, the failed jump status points to the failure pointer, and finally the current node is updated as the newly created primitive node; the current character is added to the end of the search string of the current primitive;
如果浮动标志为True,且失败指针指向失败原语节点,创建跳转指定位置原语,将其成功和失败跳转状态指向当前节点,字符读取位置指定为前一状态的初始读取位置,并将失败指针指针指向新创建的跳转指定位置原语;If the floating flag is True, and the failure pointer points to the failure primitive node, create a jump specified position primitive, point its success and failure jump states to the current node, and specify the character read position as the initial read position of the previous state, And point the failure pointer to the newly created jump specified location primitive;
设置浮动标志为False。Set the floating flag to False.
进一步的,所述根据所述关键字对应的原语状态机根节点的深度,先合并深度相同的原语状态机,再按照从浅到深的原则进行聚合,获得关键字特征集合对应的原语状态机步骤具体包括:Further, according to the depth of the root node of the primitive state machine corresponding to the keyword, the primitive state machine with the same depth is first merged, and then aggregated according to the principle from shallow to deep to obtain the primitive state machine corresponding to the keyword feature set. The language state machine steps specifically include:
创建按照深度排序的空链表,根据原语状态机深度规则确定各原语状态机的深度值;Create an empty linked list sorted by depth, and determine the depth value of each primitive state machine according to the depth rules of the primitive state machine;
读取所述关键字对应的第一个原语状态机及其深度值,将所述第一个原语状态机和对应的深度值保存至空链表中,获得深度链表;Read the first primitive state machine and its depth value corresponding to the keyword, save the first primitive state machine and the corresponding depth value in an empty linked list, and obtain a deep linked list;
继续读取所述关键字对应的原语状态机以及对应的深度值,并在深度链表中查找相同深度的原语状态机,作为目标状态机;Continue to read the primitive state machine corresponding to the keyword and the corresponding depth value, and search the primitive state machine of the same depth in the deep linked list as the target state machine;
当目标状态机存在时,根据目标状态机当前的状态机类型和原语节点类型进行状态机合并处理;当目标状态机不存在时,则将当前读取的状态机按照深度排序插入至深度链表中,直到所有原语状态机读取结束获得最终深度链表;When the target state machine exists, perform state machine merge processing according to the current state machine type and primitive node type of the target state machine; when the target state machine does not exist, insert the currently read state machine into the deep linked list according to the depth sorting , until the end of reading all primitive state machines to obtain the final deep linked list;
从所述最终深度链表中取首个原语状态机,并将全局根指向首个原语状态机节点,且对于除首个原语状态机外的原语状态机创建跳转到指定匹配位置原语节点,替换前一个状态机的失败原语节点,并将成功失败跳转指针指向下一个原语状态机的根节点;Take the first primitive state machine from the final deep linked list, point the global root to the first primitive state machine node, and jump to the specified matching position for the primitive state machine creation except the first primitive state machine The primitive node replaces the failed primitive node of the previous state machine, and points the success-failure jump pointer to the root node of the next primitive state machine;
删除深度链表,并返回全局根指针获得关键字特征集合对应的原语状态机。Delete the deep linked list, and return the global root pointer to obtain the primitive state machine corresponding to the keyword feature set.
进一步的,所述根据标状态机当前的状态机类型和原语节点类型进行状态机合并处理的步骤具体包括:Further, the step of performing state machine merging processing according to the current state machine type and primitive node type of the marked state machine specifically includes:
将当前状态机的“失败”原语节点替换为目标状态机的“失败”节点;Replace the "failure" primitive node of the current state machine with the "failure" node of the target state machine;
当两个状态机的根节点均指向“跳过字符”原语节点,将源节点和目标节点指针分别指向跳过字符原语节点的成功跳转节点,并删除当前状态机的“跳过字符节点”;When the root nodes of the two state machines both point to the "skip character" primitive node, point the source node and target node pointers to the successful jump node of the skip character primitive node respectively, and delete the "skip character" of the current state machine node";
当源节点和目标节点指针指向“字符串”类型原语,将源节点中的所有字符串特征加入到目标节点中,保证所述字符串特征的成功跳转指向节点不变,并将成功跳转指向节点开始的所有后续节点加入到目标状态机中;When the pointers of the source node and the target node point to the "string" type primitive, add all the string features in the source node to the target node to ensure that the successful jump of the string feature points to the node unchanged, and the successful jump All subsequent nodes starting from the pointing node are added to the target state machine;
所述源节点为当前状态机的当前节点;所述目标节点为目标状态机的目标节点。The source node is the current node of the current state machine; the target node is the target node of the target state machine.
进一步的,所述基于原语状态机执行字符串匹配过程的具体步骤包括:Further, the specific steps of performing the string matching process based on the primitive state machine include:
根据原语状态机的全局根指针,读取第一个原语节点到当前状态节点中,将下一个状态设置为空指针;将待匹配字符串的读取位置指向字符串的首字符;According to the global root pointer of the primitive state machine, read the first primitive node into the current state node, set the next state as a null pointer; point the reading position of the string to be matched to the first character of the string;
循环执行以下过程,直到当前状态为命中原语状态或失败原语状态:The following process is executed in a loop until the current state is a hit primitive state or a fail primitive state:
根据当前状态的原语类型,执行对应的原语节点匹配功能,并根据原语节点功能推进待匹配字符串的读取位置;According to the primitive type of the current state, execute the corresponding primitive node matching function, and advance the reading position of the string to be matched according to the primitive node function;
基于当前原语执行的结果,确定选择成功或失败指向的地址作为读取下一个原语节点的地址;Based on the result of the current primitive execution, it is determined to select the address pointed to by success or failure as the address to read the next primitive node;
读取下一个原语节点到当前状态节点中。Read the next primitive node into the current state node.
基于同一发明构思的,本发明实施例还提供了一种基于原语状态机的高速字符串特征匹配装置,所述编译装置具体包括:Based on the same inventive concept, an embodiment of the present invention also provides a high-speed character string feature matching device based on a primitive state machine, and the compiling device specifically includes:
关键字特征集合库,获取关键字特征集合并对每个关键字特征以特征序号和用于存储关键字的字符串序列方式存储所述关键字特征;A keyword feature collection library, which acquires a keyword feature set and stores the keyword feature in the form of a feature sequence number and a character string sequence for storing keywords for each keyword feature;
关键字特征编译器,基于预先定义的基本操作原语,对所述关键字特征集合,按照预设的关键字特征集合编译方法进行编译,获得关键字特征集合对应的原语状态机;The keyword feature compiler, based on the predefined basic operation primitives, compiles the keyword feature set according to the preset keyword feature set compilation method, and obtains a primitive state machine corresponding to the keyword feature set;
原语状态机信息库,用于存储所述关键字特征编译器编译的关键字特征集合对应的原语状态机;The primitive state machine information library is used to store the primitive state machine corresponding to the keyword feature set compiled by the keyword feature compiler;
状态机执行引擎模块,用于基于所述原语状态机执行字符串匹配过程,获得命中关键字,并输出命中关键字的特征序号和当前匹配字符的结束位置。The state machine execution engine module is used to execute the character string matching process based on the primitive state machine, obtain the hit keyword, and output the characteristic serial number of the hit keyword and the end position of the current matching character.
基于同一发明构思的,本发明实施例还提供了一种基于原语状态机的高速字符串特征匹配的抽取设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述基于原语状态机的高速字符串特征匹配方法的步骤。Based on the same inventive concept, an embodiment of the present invention also provides a primitive state machine-based high-speed character string feature matching extraction device, including a memory, a processor, and stored in the memory and can be used on the processor A running computer program, when the processor executes the computer program, the steps of the above-mentioned high-speed character string feature matching method based on a primitive state machine are realized.
基于同一发明构思的,本发明实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现上述基于原语状态机的高速字符串特征匹配方法的步骤。Based on the same inventive concept, an embodiment of the present invention also provides a computer-readable storage medium, the computer-readable storage medium stores a computer program, and it is characterized in that, when the computer program is executed by a processor, the above-mentioned principle-based The steps of the high-speed character string feature matching method of language state machine.
有益效果:Beneficial effect:
本发明提出了基于原语状态机的高速字符特征匹配方法,通过将传统匹配算法状态机的简单状态节点替换为具有固定处理功能的复杂操作原语,基于CPU进行更为复杂的字符匹配操作计算,大幅降低状态节点的数量和匹配过需要涉及的状态节点迁移次数,有助于充分加大现代高性能CPU的多级Cache命中率,从而提高匹配算法的性能和匹配灵活性。The present invention proposes a high-speed character feature matching method based on a primitive state machine, by replacing the simple state nodes of the traditional matching algorithm state machine with complex operation primitives with fixed processing functions, and performing more complex character matching operation calculations based on the CPU , greatly reducing the number of state nodes and the number of state node migrations that need to be involved in matching, which will help fully increase the multi-level cache hit rate of modern high-performance CPUs, thereby improving the performance and matching flexibility of the matching algorithm.
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。It is to be understood that both the foregoing general description and the following detailed description are exemplary and explanatory only and are not restrictive of the present disclosure.
附图说明Description of drawings
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。In order to more clearly illustrate the technical solutions in the embodiments of the present invention or the prior art, the following will briefly introduce the drawings that need to be used in the description of the embodiments or the prior art. Obviously, the accompanying drawings in the following description are only These are some embodiments of the present invention. Those skilled in the art can also obtain other drawings based on these drawings without creative work.
图1为本发明实施例提供的基于原语状态机的高速字符特征匹配方法的流程示意图;Fig. 1 is a schematic flow chart of a high-speed character feature matching method based on a primitive state machine provided by an embodiment of the present invention;
图2为本发明实施例提供的第一阶段关键字编译方法的流程示意图;Fig. 2 is a schematic flow chart of the first-stage keyword compiling method provided by the embodiment of the present invention;
图3为本发明实施例提供的第二阶段特征集合库多原语状态机的聚合流程示意图;FIG. 3 is a schematic diagram of the aggregation process of the multi-primitive state machine of the second-stage feature collection library provided by the embodiment of the present invention;
图4为本发明实施例提供的执行字符匹配过程图;FIG. 4 is a process diagram of performing character matching provided by an embodiment of the present invention;
图5为本发明实施例提供的基于原语状态机的高速字符特征匹配装置的实现结构示意图;5 is a schematic diagram of the implementation structure of a high-speed character feature matching device based on a primitive state machine provided by an embodiment of the present invention;
图6为本发明实施例提供的基于.*hello…..moon和.*test.*good两个特征构造的原语状态机示意图。Fig. 6 is a schematic diagram of a primitive state machine constructed based on two features of .*hello.....moon and .*test.*good provided by the embodiment of the present invention.
具体实施方式Detailed ways
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。In order to make the object, technical solution and advantages of the present invention clearer, the present invention will be further described in detail below in conjunction with the accompanying drawings and embodiments. It should be understood that the specific embodiments described here are only used to explain the present invention, not to limit the present invention.
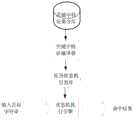
如图1所示,本发明实施例提供的基于原语状态机的高速字符特征匹配方法的流程示意图。As shown in FIG. 1 , it is a schematic flowchart of a high-speed character feature matching method based on a primitive state machine provided by an embodiment of the present invention.
步骤101,用户输入关键字特征集合,并对每个关键字特征以特征序号和用于存储关键字的字符串序列方式存储所述关键字特征。In step 101, the user inputs a keyword feature set, and stores the keyword feature in the form of a feature sequence number and a character string sequence for storing keywords for each keyword feature.
在本发明实施例中,获取用户输入的一组关键字,每个关键字由标准ASCII码字符组成,长度不限。ASCII码中‘.’字符表示匹配任意一个字符,“*”字符需要与“.”字符一起使用表示浮动匹配零个或任意个字符,“\”字符表示转义字符用于将特殊含义字符转义为普通字符,其余ASCII码字符作为普通字符串特征字符。In the embodiment of the present invention, a group of keywords input by the user is acquired, and each keyword is composed of standard ASCII code characters, and the length is not limited. The '.' character in the ASCII code means to match any character. The "*" character needs to be used together with the "." It is defined as ordinary characters, and other ASCII code characters are used as ordinary character strings.
步骤S102,基于预先定义的基本操作原语,对所述关键字特征集合,按照预设的关键字特征集合编译方法进行编译,获得关键字特征集合对应的原语状态机。Step S102, based on the predefined basic operation primitives, compile the keyword feature set according to the preset keyword feature set compiling method, and obtain a primitive state machine corresponding to the keyword feature set.
在本发明实施例中,所述基本操作原语具体包括:In the embodiment of the present invention, the basic operation primitives specifically include:
跳过字符原语:在当前输入字符读取位置,向前或向后跳过N个字符。N取负数时向前跳,N取正数时向后跳,N为0时不进行任何跳转。跳转范围在输入字符串的起始和结束位置间,跳转到成功指向的状态,否则跳转到失败指向的状态。Skip character primitive: skip N characters forward or backward at the current input character reading position. Jump forward when N is negative, jump backward when N is positive, and do not jump when N is 0. The jump range is between the start and end positions of the input string, jump to the state pointed to by success, otherwise jump to the state pointed to by failure.
在当前位置匹配多个字符串原语:在当前输入字符位置开始匹配多个字符串特征,匹配成功时,按照命中的字符串特征跳转到其指向的下一个状态。如果匹配失败,跳转到失败指向的状态Match multiple string primitives at the current position: start matching multiple string features at the current input character position, and jump to the next state pointed to by the matched string feature when the match is successful. If the match fails, jump to the state pointed to by the failure
搜索匹配多个字符串原语:从当前输入字符位置开始搜索匹配多个字符串特征,匹配成功时,按照命中的字符串特征跳转到其指向的下一个状态。如果输入到达字符串终止位置,跳转到失败指向的状态。Search and match multiple string primitives: Search and match multiple string features from the current input character position. When the match is successful, jump to the next state pointed to by the matched string feature. If the input reaches the end of the string, jump to the state pointed to by failure.
跳转到指定匹配位置原语:将当前读取位置指向输入字符串的指定位置。新位置在输入字符串的起始和结束位置间,跳转到成功指向的状态,否则跳转到失败指向的状态。Jump to the specified matching position primitive: point the current reading position to the specified position of the input string. The new position is between the start and end positions of the input string, jump to the state pointed to by success, otherwise jump to the state pointed to by failure.
成功命中原语:匹配过程结束,返回匹配命中的关键字特征序号和命中的结束位置。Successful hit primitive: the matching process is over, and the sequence number of the keyword feature that matches the hit and the end position of the hit are returned.
失败原语:匹配过程结束,返回失败信息。Failure primitive: the matching process ends and a failure message is returned.
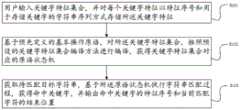
如图2、3所示,所述预设的关键字特征集合编译方法具体包括:As shown in Figures 2 and 3, the preset keyword feature set compilation method specifically includes:
图2展示了本实施例第一阶段关键字编译方法的流程示意图,包括:Fig. 2 has shown the schematic flow chart of the keyword compiling method of the first stage of the present embodiment, including:
创建成功命中原语节点;创建失败原语节点;将读取位置设为当前关键字的起始位置;将当前节点指针和根节点指针指向空节点;将浮动标志设置为False;将失败跳转指针指向失败原语节点;将当前节点的失败跳转状态指向失败跳转指针;循环直到读取位置到达当前关键字的尾部:Create a primitive node that hits successfully; create a primitive node that fails; set the read position as the starting position of the current keyword; set the current node pointer and root node pointer to an empty node; set the floating flag to False; jump to failure The pointer points to the failure primitive node; point the failure jump status of the current node to the failure jump pointer; loop until the read position reaches the end of the current keyword:
读取当前字符,读取位置后移一个字符;如果当前字符为“.”字符:如果下一个字符存在且为“*”字符:将浮动标志设置为True;将读取位置继续后移一个字符;否则,将浮动标志设置为False;如果当前节点类型为“跳过字符”原语,将当前节点的跳过字符数量加1;否则,创建一个新的原语节点,类型为“跳过字符原语”,且跳过字符数量设置为1;将新原语节点的失败跳转状态设置为失败跳转指针的指向节点;如果当前节点不为空,将当前节点的成功跳转状态指向新的原语节点;将当前节点指向新的原语节点;如果根节点指针为空,将其指向新的原语节点;Read the current character, move the reading position back one character; if the current character is a "." character: if the next character exists and is a "*" character: set the floating flag to True; move the reading position back one character ;Otherwise, set the floating flag to False; if the current node type is a "skip character" primitive, add 1 to the number of skip characters of the current node; otherwise, create a new primitive node of type "skip character "Primitive", and the number of skipped characters is set to 1; set the failed jump status of the new primitive node to the pointing node of the failed jump pointer; if the current node is not empty, set the successful jump status of the current node to the new node Primitive node; point the current node to a new primitive node; if the root node pointer is empty, point it to a new primitive node;
如果当前字符为“*”字符:报错并停止编译过程;If the current character is a "*" character: report an error and stop the compilation process;
如果当前字符为“\”字符:如果下一个字符存在:将读取位置的字符赋值给当前字符,读取位置后移一个字符;否则:报错并停止编译过程;If the current character is a "\" character: if the next character exists: assign the character at the read position to the current character, and move the read position backward by one character; otherwise: report an error and stop the compilation process;
如果当前节点类型为“字符串”原语且浮动标志为False,将当前字符加入到当前原语的搜索字符串尾;If the current node type is "string" primitive and the floating flag is False, add the current character to the end of the search string of the current primitive;
否则,如果浮动标志为True,则:创建一个新的原语节点,类型为“搜索匹配多个字符串原语”,将失败跳转状态指向失败跳转指针,并将当前字符加入到新原语的搜索字符串尾部。如果当前节点不为空,则将当前节点的成功跳转状态指向新节点,将当前节点指向新节点。如果失败跳转指针指向的原语节点类型为“失败原语”,则:创建第二个新的原语节点,类型为“跳转到指定匹配位置原语”,并将位置设定为“前一原语开始位置”;将第二个新的原语节点的成功跳转状态和失败跳转状态均指向第一个新原语节点;将失败跳转指针指向第二个新节点,将浮动标志设置为False;Otherwise, if the float flag is True, then: create a new primitive node of type "search matches multiple string primitives", set the fail jump state to the fail jump pointer, and add the current character to the new primitive's Search for the end of the string. If the current node is not empty, point the successful jump status of the current node to the new node, and point the current node to the new node. If the type of the primitive node pointed to by the failure jump pointer is "failure primitive", then: create a second new primitive node with the type of "jump to the specified matching position primitive" and set the position to " The start position of the previous primitive"; the successful jump status and the failed jump status of the second new primitive node point to the first new primitive node; the failure jump pointer points to the second new node, and the floating flag is set to False;
否则:创建一个新的原语节点,类型为“当前位置匹配多个字符串原语”,将失败跳转状态指向失败跳转指针,并将当前字符加入到新原语的搜索字符串尾部。如果当前节点不为空,则将当前节点的成功跳转状态指向新节点。将当前节点指向新节点。Otherwise: Create a new primitive node with the type of "the current position matches multiple string primitives", set the fail jump state to the fail jump pointer, and add the current character to the end of the search string of the new primitive. If the current node is not empty, point the successful jump status of the current node to the new node. Point the current node to the new node.
循环结束后,如果本原语状态机中不包含“字符串原语”,则:报错并停止编译过程。将当前节点的成功跳转状态指向成功命中原语节点,并完成当前关键字的编译。After the loop ends, if the primitive state machine does not contain the "string primitive", then: report an error and stop the compilation process. Point the successful jump status of the current node to the successful hit primitive node, and complete the compilation of the current keyword.
根据上述详细步骤可知,首先进行成功、失败原语节点的创建,并初始化相关变量;然后进行关键字字符串解析阶段,循环读取关键字的每个字符,再根据字符分别进行一下处理:According to the above detailed steps, we can know that, firstly, create success and failure primitive nodes, and initialize related variables; then proceed to the keyword string parsing stage, read each character of the keyword in a loop, and then perform processing according to the characters:
当为“.”字符:根据下一个字符是否为“*”,判断后续原语是否出现搜索匹配,并设置浮动标志。对只包含“.”字符时,如果当前原语是“跳过字符”原语,则将跳过字符数量加一,表示出现了“…”形式的跳过多个字符的情况;对其它情况,表示开始进行跳过字符的处理,需要新建“跳过字符”原语,并将新原语加入到状态机中。When it is a "." character: According to whether the next character is "*", determine whether there is a search match in the subsequent primitive, and set the floating flag. When only "." characters are included, if the current primitive is a "skip character" primitive, add one to the number of skip characters, indicating that there is a situation of skipping multiple characters in the form of "..."; for other cases , indicating that the processing of the skip character is started, and a new "skip character" primitive needs to be created, and the new primitive is added to the state machine.
当为“\”字符:表示转义字符。通过读取下一个字符并后移读取指针,将“.*\”这三种特殊含义的字符转义为普通字符进行处理。When it is a "\" character: it means an escape character. By reading the next character and moving the read pointer backward, the three characters with special meaning ".*\" are escaped into ordinary characters for processing.
其他字符:加入到“字符串”原语的特征字符串中。根据当前节点类型和浮动标志分别进行处理。当前节点类型为“字符串”原语且浮动标志为False时,将当前字符附加到该原语节点特征字符串的尾部。对其它情况,根据浮动标志,创建类型为“搜索匹配多个字符串”或“当前位置匹配多个字符串”的原语节点,并将当前字符作为该原语节点特征字符串的第一个字符。对“搜索匹配多个字符串”原语,其下游原语失败后,需要返回到顶层的“搜索匹配多个字符串”原语,进行后续的搜索匹配;因此需要在首次创建“搜索匹配多个字符串”原语时,将后续的失败跳转指针指向新建的“跳转指定位置”原语,并通过“跳转指定位置”原语将匹配状态重新推进到顶层的“搜索匹配多个字符串”原语处。Other characters: added to the feature string of the "string" primitive. It is processed separately according to the current node type and floating flag. When the current node type is a "string" primitive and the floating flag is False, append the current character to the end of the primitive node's feature string. For other cases, according to the floating flag, create a primitive node whose type is "search matches multiple strings" or "current position matches multiple strings", and use the current character as the first character string of the primitive node character. For the "Search Match Multiple Strings" primitive, after the downstream primitive fails, it needs to return to the top-level "Search Match Multiple Strings" primitive for subsequent search matches; therefore, it is necessary to create the "Search Match Multiple string" primitive, point the subsequent failed jump pointer to the newly created "Jump Specified Position" primitive, and push the matching state back to the top-level "Search Match Multiple" primitive through the "Jump Specified Position" primitive string" primitive.
最后将更新编译后状态机的当前节点的成功状态,将其指向创建的成功命中原语,同时进行状态机的合法性检查,对不包含“字符串”类原语节点的状态机,停止编译并报错。Finally, the success status of the current node of the compiled state machine will be updated, and it will point to the created successful hit primitive, and the validity of the state machine will be checked at the same time, and the compilation of the state machine that does not contain the "string" type primitive node will be stopped And report an error.
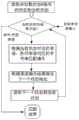
图3展示了本实施例第二阶段特征集合库多原语状态机的聚合流程示意图,用于将每个关键字对应的原语状态机聚合为关键字特征集合库对应的特征库原语状态机。Figure 3 shows a schematic diagram of the aggregation process of the multi-primitive state machine of the feature collection library in the second stage of this embodiment, which is used to aggregate the primitive state machine corresponding to each keyword into the feature library primitive state corresponding to the keyword feature collection library machine.
所述阶段二的处理步骤为:创建一个按照深度排序的状态机链表;对阶段一生成的每个关键字对应的原语状态机,循环执行以下步骤:将深度值设置为0;如果当前原语状态机根指针指向的原语节点类型为“跳过字符原语”,则:取该原语的跳过字符数量作为深度值;如果当前原语状态机根指针指向的原语节点类型为“搜索匹配多个字符串原语”,则:设置深度值为最大值;The processing steps of the second stage are: create a state machine linked list sorted according to the depth; for the primitive state machine corresponding to each keyword generated in the first stage, perform the following steps in a loop: set the depth value to 0; if the current primitive state machine If the primitive node type pointed to by the root pointer of the primitive state machine is "Skipping Character Primitive", then: take the number of skipped characters of the primitive as the depth value; if the primitive node type pointed to by the root pointer of the current primitive state machine is "Search matches multiple string primitives", then: set the depth value to the maximum value;
基于深度值查找状态机链表,如果存在相同深度的原语状态机(目标状态机),则:将目标节点指针指向目标状态机根指针对应的原语节点;将源节点指针指向当前原语状态机根指针对应的原语节点;检查并确保目标节点和源节点的原语类型的一致性,之后将当前原语状态机中的“失败原语”节点删除,全部替换为目标状态机中的“失败原语”节点;如果目标节点的原语类型为“跳过字符原语”,则:将源节点的成功跳转状态指向节点赋值给临时节点;将源节点从当前原语状态机中删除,并将临时节点赋值给源节点;将目标节点的成功跳转状态指向节点赋值给目标节点;如果目标节点的原语类型不是“在当前位置匹配多个字符串原语”,且也不是“搜索匹配多个字符串原语”,则:报错并终止编译过程;将源节点中的所有字符串特征加入到目标节点中,保证上述字符串特征的成功跳转指向节点不变,并将成功跳转指向节点开始的所有后续节点加入到目标状态机中;删除源节点,并删除当前原语状态机中所有没有被目标状态机引用的原语节点;Search the state machine list based on the depth value. If there is a primitive state machine (target state machine) with the same depth, then: point the target node pointer to the primitive node corresponding to the root pointer of the target state machine; point the source node pointer to the current primitive state The primitive node corresponding to the machine root pointer; check and ensure the consistency of the primitive types of the target node and the source node, and then delete the "failure primitive" node in the current primitive state machine, and replace them all with the "failure primitive" node; if the primitive type of the target node is "skip character primitive", then: assign the successful jump state pointing node of the source node to the temporary node; remove the source node from the current primitive state machine Delete, and assign the temporary node to the source node; assign the successful jump state of the target node to the node assigned to the target node; if the primitive type of the target node is not "matching multiple string primitives at the current position", and it is not " Search and match multiple string primitives", then: report an error and terminate the compilation process; add all string features in the source node to the target node, ensure that the successful jump point node of the above string feature remains unchanged, and successfully jump Add all subsequent nodes starting from the pointing node to the target state machine; delete the source node, and delete all primitive nodes in the current primitive state machine that are not referenced by the target state machine;
在不存在深度相同的原语状态机时,以深度值作为排序依据,将当前状态机按深度从小到大顺序插入到状态机链表中;When there is no primitive state machine with the same depth, the current state machine is inserted into the state machine linked list in ascending order of depth based on the depth value;
当所有状态机均插入到链表后,取状态机链表中首个状态机赋值给当前状态机,并将其从状态机链表中删除;将全局根指针设置为当前状态机根指针;对状态机链表中的剩余状态机,循环:取首个状态机赋值给下一个状态机,并将其从状态机链表中删除;新建一个原语节点,类型为“跳转到指定匹配位置原语”,并将跳转位置设置为输入的“起始位置”;将新原语节点的成功跳转状态和失败跳转状态均指向下一个状态机的根节点;将当前状态机的“失败原语”节点替换为新建原语节点;删除当前状态机的“失败原语”,并将下一个状态机赋值给当前状态机;After all the state machines are inserted into the linked list, assign the first state machine in the state machine linked list to the current state machine, and delete it from the state machine linked list; set the global root pointer as the root pointer of the current state machine; Remaining state machines in the linked list, loop: take the first state machine and assign it to the next state machine, and delete it from the state machine linked list; create a new primitive node, the type is "jump to the specified matching position primitive", And set the jump position as the "start position" of the input; point the success jump state and the failure jump state of the new primitive node to the root node of the next state machine; set the "failure primitive" node of the current state machine Replace it with a new primitive node; delete the "failure primitive" of the current state machine, and assign the next state machine to the current state machine;
循环结束后,删除链表并返回全局根指针指向的特征库原语状态机。After the loop ends, delete the linked list and return the feature library primitive state machine pointed to by the global root pointer.
根据上述步骤可知,状态机的聚合过程按照首先合并深度相同的原语状态机,再从浅到深的原则,先创建空链表,并按照原语状态机深度规则进行深度确定:根节点为“搜索匹配多个字符串”原语的状态机为深度最大的状态机;根节点为“跳过字符”原语的状态机,按照跳过字符数从1到N作为状态机从浅到深的深度值;对根节点为“当前位置匹配多个字符串”原语的状态机,深度值为0。从阶段一的编译方法可知,根节点不可能为其它原语类型,当出现其它原语类型时,报错并终止编译。According to the above steps, the aggregation process of the state machine follows the principle of first merging the primitive state machines with the same depth, and then from shallow to deep, first creates an empty linked list, and determines the depth according to the depth rules of the primitive state machine: the root node is " The state machine of the primitive that matches multiple strings is the state machine with the largest depth; the state machine whose root node is the primitive of "skip characters" is the state machine from shallow to deep according to the number of skipped characters from 1 to N Depth value; for a state machine whose root node is the primitive "the current position matches multiple strings", the depth value is 0. It can be known from the compilation method of
然后读取所述关键字对应的第一个原语状态机及其深度值,将所述第一原语状态机和对应的深度值保存至空链表中,获得深度链表;继续读取所述关键字对应的原语状态机以及对应的深度值,并在深度链表中查找相同深度的原语状态机,作为目标状态机;如果不存在这样的状态机,则将当前状态机插入到链表中。找到相同深度的状态机后,首先将当前状态机的失败原语替换为目标状态机的失败原语;然后,判断两个状态机的根节点是否为“跳过字符”原语,均为该原语时,将当前比较节点分别推进到其成功跳转节点并删除当前状态机的“跳过字符”原语节点;第三,检查当前比较节点如果不是“字符串”类型的原语,则报错终止编译;否则将源节点的字符串特征加入到目的节点中,并将源节点的字符串特征指向的后续原语节点加入到目标状态机中;最后,删除当前状态机和状态机中所有没有被目标状态机引用的节点。Then read the first primitive state machine corresponding to the keyword and its depth value, save the first primitive state machine and the corresponding depth value in an empty linked list, and obtain a deep linked list; continue to read the The primitive state machine corresponding to the keyword and the corresponding depth value, and search the primitive state machine of the same depth in the deep linked list as the target state machine; if there is no such state machine, insert the current state machine into the linked list . After finding the state machine with the same depth, first replace the failure primitive of the current state machine with the failure primitive of the target state machine; When the primitive is used, advance the current comparison node to its successful jump node and delete the "skip character" primitive node of the current state machine; thirdly, check if the current comparison node is not a "string" type primitive, then Report an error to terminate compilation; otherwise, add the string feature of the source node to the destination node, and add the subsequent primitive node pointed to by the string feature of the source node to the target state machine; finally, delete the current state machine and all Nodes that are not referenced by the target state machine.
为了合并链表中不同深度状态机的阶段。合并方法为将前一个状态的失败节点替换为“跳转到指定位置”原语节点,并指定将报文读取位置移动到报文起始部分;再将“跳转到指定位置”原语节点的成功和失败跳转指针均指向下一个状态机的根节点,进而将链表中所有的状态机连接成整个关键字特征集合库对应的特征库原语状态机。In order to merge stages of state machines of different depths in linked lists. The merging method is to replace the failed node in the previous state with the "jump to the specified position" primitive node, and specify to move the message reading position to the beginning of the message; then the "jump to the specified position" primitive Both the success and failure jump pointers of the node point to the root node of the next state machine, and then all the state machines in the linked list are connected into the feature library primitive state machine corresponding to the entire keyword feature set library.
步骤103,获取待匹配目标字符串,基于所述原语状态机执行字符串匹配过程,获得命中关键字,并输出命中关键字的特征序号和当前匹配字符的结束位置。Step 103, obtain the target string to be matched, execute the string matching process based on the primitive state machine, obtain the hit keyword, and output the feature sequence number of the hit keyword and the end position of the current matching character.
在本发明实施例中,获取用户输入的目标字符串,并从第一个字符位置开始,按照步骤S102构造的对应原语状态机执行字符匹配过程。如图4所示,提供了执行字符匹配过程的流程图。首先根据原语状态机的全局根指针,读取第一个原语节点到当前状态节点中,将下一个状态设置为空指针;将待匹配字符串的读取位置指向字符串的首字符。之后循环判断当前状态节点是否为命中原语或失败原语节点,为上述两个节点是,结束循环。对其它节点,根据当前状态的原语类型,执行对应的原语节点匹配功能,并根据原语节点功能推进待匹配字符串的读取位置;基于当前原语执行的结果,确定选择成功或失败指向的地址作为读取下一个原语节点的地址,并读取下一个原语节点到当前状态节点中。In the embodiment of the present invention, the target character string input by the user is obtained, and starting from the first character position, the corresponding primitive state machine constructed according to step S102 executes the character matching process. As shown in Figure 4, a flow chart for performing the character matching process is provided. First, according to the global root pointer of the primitive state machine, read the first primitive node into the current state node, set the next state as a null pointer; point the reading position of the string to be matched to the first character of the string. Then loop to judge whether the current state node is a hit primitive node or a failure primitive node, if the above two nodes are yes, end the loop. For other nodes, according to the primitive type of the current state, execute the corresponding primitive node matching function, and advance the reading position of the character string to be matched according to the primitive node function; based on the result of the current primitive execution, determine the success or failure of the selection The address pointed to is used as the address to read the next primitive node, and read the next primitive node into the current state node.
如图5所示,本发明实施例提供了基于原语状态机的高速字符特征匹配装置的实现结构示意图,所述匹配装置具体包括:As shown in Figure 5, the embodiment of the present invention provides a schematic diagram of the implementation structure of a high-speed character feature matching device based on a primitive state machine, and the matching device specifically includes:
关键字特征集合库,获取用户输入关键字特征集合,并对每个关键字特征以特征序号和用于存储关键字的字符串序列方式存储所述关键字特征。The keyword feature collection library acquires the keyword feature set input by the user, and stores the keyword feature in the form of a feature sequence number and a character string sequence for storing keywords for each keyword feature.
在本发明实施例中,所述每个关键字特征包括一个特征序号ID和一个字符串用于存储关键字字符序列。In the embodiment of the present invention, each keyword feature includes a feature serial number ID and a character string for storing the keyword character sequence.
关键字特征编译器,基于预先定义的基本操作原语,获取关键字特征集合,按照预设的关键字特征集合编译方法进行编译获得关键字特征集合对应的原语状态机。在本发明实施例中,基于上述关键字特征集合库,采用分层构造的方式,先将集合库中每个关键字特征按照上述编译方法转换为基于前面定义操作原语的匹配原语状态机;在将每个关键字特征对应的匹配原语状态机连接起来,合并为整个集合库对应的匹配原语状态机。The keyword feature compiler obtains the keyword feature set based on the predefined basic operation primitives, and compiles according to the preset keyword feature set compilation method to obtain the primitive state machine corresponding to the keyword feature set. In the embodiment of the present invention, based on the above-mentioned keyword feature collection library, using a hierarchical structure, first convert each keyword feature in the collection library into a matching primitive state machine based on the previously defined operation primitives according to the above compilation method ;Connect the matching primitive state machine corresponding to each keyword feature, and merge into the matching primitive state machine corresponding to the entire collection library.
原语状态机信息库,用于存储所述关键字特征编译器编译的关键字特征集合原语状态机。在本发明实施例中,采用图的方式,基于匹配原语和匹配原语间连接关系来存储整个特征集合库的原语状态机;状态机执行引擎可以基于本原语状态机信息库,对输入的字符串进行状态匹配。The primitive state machine information library is used to store the keyword feature collection primitive state machine compiled by the keyword feature compiler. In the embodiment of the present invention, the primitive state machine of the entire feature collection library is stored based on the matching primitive and the connection relationship between the matching primitive in the form of a graph; the state machine execution engine can be based on the primitive state machine information library, for The input string performs state matching.
状态机执行引擎模块,用于获取待匹配目标字符串,基于所述原语状态机执行字符串匹配过程,获得命中关键字,并输出命中关键字的特征序号和当前匹配字符的结束位置。在本发明实施例中,采用如图4所示的匹配过程进行执行,从原语状态机信息库的零号状态开始执行状态机匹配过程;匹配过程执行结束后输出关键字特征的命中结果。The state machine execution engine module is used to obtain the target string to be matched, execute the string matching process based on the primitive state machine, obtain the hit keyword, and output the characteristic sequence number of the hit keyword and the end position of the current matching character. In the embodiment of the present invention, the matching process as shown in FIG. 4 is used for execution, and the state machine matching process is executed from the zero state of the primitive state machine information base; after the matching process is executed, the hit result of the keyword feature is output.
如图6所示,为本实施例基于.*hello…..moon和.*test.*good两个关键字特征构造的原语状态机的示例结构,共包括8个操作原语状态。其中,状态0表示匹配过程开始,不对应状态机的操作原语;状态1为搜索匹配多个字符串操作原语,从当前输入的目标字符串中持续读入下一个字符并与hello或test进行匹配,如果到达输入结束,跳转到失败原语(8号状态);如果与hello或test匹配,则分别跳转到2号状态或4号状态。状态2为跳过字符操作原语,将当前输入字符向后跳过5个字符,成功后跳转到3号状态;状态3为在当前位置匹配多个字符串操作原语,从当前位置精确匹配moon字符串,匹配成功后跳转到5号状态,表示成功匹配特征一并结束匹配过程。状态4为搜索匹配多个字符串操作原语,从当前输入的目标字符串中持续读入下一个字符并与good特征串进行匹配,如果到达输入结束,跳转到7号状态;如果与good匹配,则跳转到6号状态,表示成功匹配特征二并结束匹配过程。状态7为跳转到指定匹配位置操作原语,将当前输入目标字符串的位置移动到状态4开始匹配前的位置。As shown in FIG. 6 , it is an example structure of a primitive state machine constructed based on two keyword features of .*hello.....moon and .*test.*good in this embodiment, including 8 operation primitive states in total. Among them,
对目标字符串“aaatestbbbbgoodcc”,按照上述有限状态机的匹配过程为:首先从状态0跳转到状态1,开始搜索关键字子串hello和test,在目标字符串的第4个字符处命中test关键字子串;然后跳转到状态4,继续搜索good关键字子串,在目标字符串的第12个字符处命中good关键字子串;最后跳转到状态6,表明命中了第二个关键字特征。For the target string "aaatestbbbbgoodcc", according to the matching process of the above finite state machine: first jump from
在本发明实施例中,还提供了一种基于原语状态机的高速字符串特征匹配的抽取设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述基于原语状态机的高速字符串特征匹配方法的步骤。In the embodiment of the present invention, there is also provided a primitive state machine-based high-speed character string feature matching extraction device, including a memory, a processor, and a computer stored in the memory and operable on the processor program, when the processor executes the computer program, it realizes the steps of the above-mentioned high-speed character string feature matching method based on a primitive state machine.
在本发明实施例中,本发明实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现上述基于原语状态机的高速字符串特征匹配方法的步骤。In the embodiment of the present invention, the embodiment of the present invention also provides a computer-readable storage medium, the computer-readable storage medium stores a computer program, and it is characterized in that, when the computer program is executed by a processor, the above-mentioned Steps of a high-speed string feature matching method for a primitive state machine.
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。The above-mentioned embodiments only express several implementation modes of the present invention, and the description thereof is relatively specific and detailed, but should not be construed as limiting the patent scope of the present invention. It should be pointed out that those skilled in the art can make several modifications and improvements without departing from the concept of the present invention, and these all belong to the protection scope of the present invention. Therefore, the protection scope of the patent for the present invention should be based on the appended claims.
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本公开的其它实施方案。本申请旨在涵盖本公开的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本公开的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本公开的真正范围和精神由权利要求指出。Other embodiments of the present disclosure will be readily apparent to those skilled in the art from consideration of the specification and practice of the invention disclosed herein. This application is intended to cover any modification, use or adaptation of the present disclosure, and these modifications, uses or adaptations follow the general principles of the present disclosure and include common knowledge or conventional technical means in the technical field not disclosed in the present disclosure . The specification and examples are to be considered exemplary only, with the true scope and spirit of the disclosure indicated by the appended claims.
应该理解的是,虽然本发明各实施例的流程图中的各个步骤按照箭头的指示依次显示,但是这些步骤并不是必然按照箭头指示的顺序依次执行。除非本文中有明确的说明,这些步骤的执行并没有严格的顺序限制,这些步骤可以以其它的顺序执行。而且,各实施例中的至少一部分步骤可以包括多个子步骤或者多个阶段,这些子步骤或者阶段并不必然是在同一时刻执行完成,而是可以在不同的时刻执行,这些子步骤或者阶段的执行顺序也不必然是依次进行,而是可以与其它步骤或者其它步骤的子步骤或者阶段的至少一部分轮流或者交替地执行。It should be understood that although the various steps in the flow charts of the embodiments of the present invention are shown sequentially according to the arrows, these steps are not necessarily executed sequentially in the order indicated by the arrows. Unless otherwise specified herein, there is no strict order restriction on the execution of these steps, and these steps can be executed in other orders. Moreover, at least some of the steps in each embodiment may include multiple sub-steps or multiple stages, these sub-steps or stages are not necessarily executed at the same time, but may be executed at different times, the sub-steps or stages The order of execution is not necessarily performed sequentially, but may be performed alternately or alternately with at least a part of other steps or sub-steps or stages of other steps.
Claims (8)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110801808.XACN113505585B (en) | 2021-07-15 | 2021-07-15 | High-speed character string feature matching method, device and equipment based on primitive state machine |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110801808.XACN113505585B (en) | 2021-07-15 | 2021-07-15 | High-speed character string feature matching method, device and equipment based on primitive state machine |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN113505585A CN113505585A (en) | 2021-10-15 |
| CN113505585Btrue CN113505585B (en) | 2023-03-21 |
Family
ID=78012981
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110801808.XAActiveCN113505585B (en) | 2021-07-15 | 2021-07-15 | High-speed character string feature matching method, device and equipment based on primitive state machine |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN113505585B (en) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116861278A (en)* | 2022-03-24 | 2023-10-10 | 北京京东振世信息技术有限公司 | Information type identification method and device |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101154228A (en)* | 2006-09-27 | 2008-04-02 | 西门子公司 | A segmented pattern matching method and device thereof |
| CN102857493A (en)* | 2012-06-30 | 2013-01-02 | 华为技术有限公司 | Content filtering method and device |
| CN108170812A (en)* | 2017-12-29 | 2018-06-15 | 迈普通信技术股份有限公司 | A kind of data filtering method and equipment |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8775457B2 (en)* | 2010-05-31 | 2014-07-08 | Red Hat, Inc. | Efficient string matching state machine |
- 2021
- 2021-07-15CNCN202110801808.XApatent/CN113505585B/enactiveActive
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101154228A (en)* | 2006-09-27 | 2008-04-02 | 西门子公司 | A segmented pattern matching method and device thereof |
| CN102857493A (en)* | 2012-06-30 | 2013-01-02 | 华为技术有限公司 | Content filtering method and device |
| CN108170812A (en)* | 2017-12-29 | 2018-06-15 | 迈普通信技术股份有限公司 | A kind of data filtering method and equipment |
Non-Patent Citations (2)
| Title |
|---|
| A Finite-State-Machine based string matching system for Intrusion Detection on High-Speed Networks;Gerald Tripp 等;《The 14th EICAR annual conference》;20050503;全文* |
| 入侵检测系统中高速字符串匹配协处理的实现方法;张克农 等;《微电子学与计算机》;20061231;全文* |
Also Published As
| Publication number | Publication date |
|---|---|
| CN113505585A (en) | 2021-10-15 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110187885B (en) | Intermediate code generation method and device for quantum program compiling | |
| US7725510B2 (en) | Method and system for multi-character multi-pattern pattern matching | |
| US10664655B2 (en) | Method and system for linear generalized LL recognition and context-aware parsing | |
| US7941417B2 (en) | Processing structured electronic document streams using look-ahead automata | |
| CN113508385B (en) | Method and system for formal language processing using subroutine graphs | |
| JP2002536711A (en) | Determining the destination of a dynamic branch | |
| CN101894236A (en) | Software Homology Detection Method and Device Based on Abstract Syntax Tree and Semantic Matching | |
| CN117806647A (en) | C program synthesis method and device based on software flow chart, equipment and medium | |
| TW202422404A (en) | Rule expression matching method and device and computer readable storage medium | |
| CN112650680A (en) | Detection method and system for redundant variables and redundant method based on abstract syntax tree | |
| CN109800337B (en) | Multi-mode regular matching algorithm suitable for large alphabet | |
| CN113505585B (en) | High-speed character string feature matching method, device and equipment based on primitive state machine | |
| US9495638B2 (en) | Scalable, rule-based processing | |
| CN100527134C (en) | Method and system for multi-mode search | |
| CN108563561A (en) | A kind of program recessiveness constraint extracting method and system | |
| CN113254025B (en) | Keyword feature set compiling method, device and equipment based on primitive state machine | |
| CN116383070B (en) | A symbolic execution method for high MC/DC | |
| JP6536266B2 (en) | Compilation device, compilation method and compilation program | |
| CN111381814B (en) | Method, device and electronic device for generating syntax tree of code file | |
| KR20050065015A (en) | System and method for checking program plagiarism | |
| CN113961568A (en) | Block chain-based block fast searching method for chain data structure | |
| Pugh | Extending Graham-Glanville techniques for optimal code generation | |
| CN118779498B (en) | Trie tree structure for scanning pen, creating method, word segmentation method and system | |
| CN111381827A (en) | Method, apparatus and electronic device for generating syntax tree of code file | |
| CN113626465B (en) | Database and method for realizing session-level variables in postgresql database |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |