CN113420166A - Commodity mounting, retrieving, recommending and training processing method and device and electronic equipment - Google Patents
Commodity mounting, retrieving, recommending and training processing method and device and electronic equipmentDownload PDFInfo
- Publication number
- CN113420166A CN113420166ACN202110328304.0ACN202110328304ACN113420166ACN 113420166 ACN113420166 ACN 113420166ACN 202110328304 ACN202110328304 ACN 202110328304ACN 113420166 ACN113420166 ACN 113420166A
- Authority
- CN
- China
- Prior art keywords
- data
- commodity
- multimedia
- feature
- feature vector
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images













Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/40—Information retrieval; Database structures therefor; File system structures therefor of multimedia data, e.g. slideshows comprising image and additional audio data
- G06F16/48—Retrieval characterised by using metadata, e.g. metadata not derived from the content or metadata generated manually
- G06F16/483—Retrieval characterised by using metadata, e.g. metadata not derived from the content or metadata generated manually using metadata automatically derived from the content
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/95—Retrieval from the web
- G06F16/953—Querying, e.g. by the use of web search engines
- G06F16/9535—Search customisation based on user profiles and personalisation
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/22—Matching criteria, e.g. proximity measures
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q30/00—Commerce
- G06Q30/06—Buying, selling or leasing transactions
- G06Q30/0601—Electronic shopping [e-shopping]
- G06Q30/0631—Recommending goods or services
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Databases & Information Systems (AREA)
- General Engineering & Computer Science (AREA)
- Business, Economics & Management (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Life Sciences & Earth Sciences (AREA)
- Evolutionary Biology (AREA)
- Bioinformatics & Computational Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Artificial Intelligence (AREA)
- Accounting & Taxation (AREA)
- Finance (AREA)
- Library & Information Science (AREA)
- Evolutionary Computation (AREA)
- Marketing (AREA)
- Strategic Management (AREA)
- General Business, Economics & Management (AREA)
- Economics (AREA)
- Development Economics (AREA)
- Multimedia (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Image Analysis (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本申请涉及一种商品挂载、检索、推荐、训练处理方法、装置及电子设备,属于计算机技术领域。The present application relates to a method, device, and electronic device for processing, retrieving, recommending, and training commodities, and belongs to the field of computer technology.
背景技术Background technique
随着互联网技术的发展,在电商领域,多媒体内容的参与度越来越高,例如,通过直播、短视频等方式来挂载关联商品,从而起到较好的宣传效果。从用户的角度来说,通过丰富的多媒体内容也能够更好地了解商品的相关知识和应用场景等,从而为用户进行选择提供了缴费为丰富的信息。With the development of Internet technology, in the field of e-commerce, the participation of multimedia content is getting higher and higher. For example, related products are mounted through live broadcasts, short videos, etc., so as to achieve a better publicity effect. From the user's point of view, the rich multimedia content can also better understand the relevant knowledge and application scenarios of the product, so as to provide the user with rich information for payment.
不过,由于多媒体数据和商品数据属于不同的内容域,两者具有不同的组织形态。多媒体数据的展示形式更加自由而没有约束,可以包含各式各样的创作元素,例如复杂的视觉背景,复杂的自然文本标题,多元化的表现题材。而商品数据的组织形式一般遵循电商约束条件并且更加结构化,例如,商品背景要求简洁规范,商品标题为了便于检索命中而进行关键词堆砌等。因此,多媒体数据和商品数据之间,具有巨大的语义鸿沟。由于这种语义鸿沟的存在,现有技术中很难将多媒体数据和商品数据进行匹配和融合,从而为用户提供较好的跨域的内容推荐或者商品挂载。However, since multimedia data and commodity data belong to different content domains, they have different organizational forms. The display form of multimedia data is more free and unconstrained, and can contain a variety of creative elements, such as complex visual backgrounds, complex natural text titles, and diverse presentation themes. The organizational form of commodity data generally follows the constraints of e-commerce and is more structured. For example, commodity backgrounds are required to be concise and standardized, and commodity titles are packed with keywords to facilitate retrieval hits. Therefore, there is a huge semantic gap between multimedia data and commodity data. Due to the existence of this semantic gap, it is difficult to match and fuse multimedia data and commodity data in the prior art, so as to provide users with better cross-domain content recommendation or commodity loading.
发明内容SUMMARY OF THE INVENTION
本发明实施例提供一种商品挂载、检索、推荐、训练处理方法、装置及电子设备,以实现跨内容域的特征比对处理。Embodiments of the present invention provide a method, device, and electronic device for commodity loading, retrieval, recommendation, and training processing, so as to realize feature comparison processing across content domains.
为了实现上述目的,本发明实施例提供了一种特征提取模型的训练方法,包括:In order to achieve the above purpose, an embodiment of the present invention provides a training method for a feature extraction model, including:
获取多个内容域中内容关联的样本组成多个跨域样本组合;Obtain content-related samples in multiple content domains to form multiple cross-domain sample combinations;
使用被训练的特征提取模型,对跨域样本组合中的样本的原始数据进行特征提取,生成与样本对应的特征向量;Using the trained feature extraction model, perform feature extraction on the original data of the samples in the cross-domain sample combination, and generate feature vectors corresponding to the samples;
对所述特征提取模型进行对比学习训练,以缩小跨域样本组合内部的样本对应的特征向量之间的距离,放大跨域样本组合之间的样本对应的特征向量之间的距离作为训练目标。The feature extraction model is subjected to comparative learning and training to reduce the distance between the feature vectors corresponding to the samples within the cross-domain sample combination, and enlarge the distance between the feature vectors corresponding to the samples between the cross-domain sample combinations as a training target.
本发明实施例提供了一种商品挂载的处理方法,包括:An embodiment of the present invention provides a processing method for commodity mounting, including:
获取多媒体数据,对所述多媒体数据进行跨域特征提取,生成与该多媒体数据对应的多媒体特征向量,其中,所述跨域特征提取使得生成的特征向量能够跨域对齐;Obtaining multimedia data, performing cross-domain feature extraction on the multimedia data, and generating a multimedia feature vector corresponding to the multimedia data, wherein the cross-domain feature extraction enables the generated feature vectors to be aligned across domains;
获取多个候选商品数据,对所述候选商品数据进行跨域特征提取,生成多个商品特征向量;Obtaining a plurality of candidate commodity data, performing cross-domain feature extraction on the candidate commodity data, and generating a plurality of commodity feature vectors;
根据所述多个商品特征向量与所述多媒体特征向量之间的相关度,从所述多个候选商品数据中确定进行挂载的商品数据。According to the degree of correlation between the plurality of commodity feature vectors and the multimedia feature vectors, the commodity data to be mounted is determined from the plurality of candidate commodity data.
本发明实施例提供了一种商品挂载的处理方法,包括:An embodiment of the present invention provides a processing method for commodity mounting, including:
获取多媒体数据,对所述多媒体数据进行跨域特征提取,生成与该多媒体数据对应的多媒体特征向量,其中,所述跨域特征提取使得生成的特征向量能够跨域对齐;Obtaining multimedia data, performing cross-domain feature extraction on the multimedia data, and generating a multimedia feature vector corresponding to the multimedia data, wherein the cross-domain feature extraction enables the generated feature vectors to be aligned across domains;
根据所述多媒体特征向量进行商品数据检索,获取与所述多媒体特征向量的相关度大于预设阈值的商品特征向量对应的商品数据;Perform commodity data retrieval according to the multimedia feature vector, and obtain commodity data corresponding to the commodity feature vector whose correlation with the multimedia feature vector is greater than a preset threshold;
将所述商品数据挂载到所述多媒体数据上。Mount the commodity data on the multimedia data.
本发明实施例提供了一种推荐处理方法,包括:An embodiment of the present invention provides a recommendation processing method, including:
获取用户历史访问的历史多媒体数据和/或历史商品数据;Obtain historical multimedia data and/or historical commodity data accessed by users in the past;
对所述历史多媒体数据和/或历史商品数据进行跨域特征提取,生成对应的历史多媒体特征向量和/或历史商品特征向量,其中,所述跨域特征提取使得生成的特征向量能够跨域对齐;Perform cross-domain feature extraction on the historical multimedia data and/or historical commodity data, and generate corresponding historical multimedia feature vectors and/or historical commodity feature vectors, wherein the cross-domain feature extraction enables the generated feature vectors to be aligned across domains ;
根据所述历史多媒体特征向量和/或历史商品特征向量,进行多媒体数据和/或商品数据的检索,获取与所述多媒体特征向量和/或商品特征向量之间的相关度大于预设阈值的多媒体数据和/或商品数据,作为推荐数据。According to the historical multimedia feature vector and/or the historical commodity feature vector, retrieval of multimedia data and/or commodity data is performed, and multimedia data whose correlation with the multimedia feature vector and/or commodity feature vector is greater than a preset threshold value are acquired. data and/or product data, as recommendation data.
本发明实施例提供了一种检索处理方法,包括:An embodiment of the present invention provides a retrieval processing method, including:
根据用户的输入的检索信息,生成查询向量;Generate a query vector according to the retrieval information input by the user;
根据所述查询向量,在商品特征向量数据库和/或多媒体特征向量数据库中进行查询,获取与所述查询向量之间的第一相关度大于预设第一阈值的商品特征向量和/或多媒体特征向量,其中,所述商品特征向量数据库和/或多媒体特征向量数据库中的商品特征向量和/或多媒体特征向量基于跨域特征提取而获得,所述跨域特征提取使得生成的特征向量能够跨域对齐;According to the query vector, perform a query in the commodity feature vector database and/or the multimedia feature vector database, and obtain commodity feature vectors and/or multimedia features whose first correlation with the query vector is greater than a preset first threshold vector, wherein the commodity feature vector and/or the multimedia feature vector in the commodity feature vector database and/or the multimedia feature vector database are obtained based on cross-domain feature extraction, and the cross-domain feature extraction enables the generated feature vector to cross-domain align;
根据获取到的商品特征向量和/或多媒体特征向量,向用户返回对应的商品数据和/或多媒体数据作为检索结果。According to the obtained product feature vector and/or multimedia feature vector, the corresponding product data and/or multimedia data are returned to the user as a retrieval result.
本发明实施例提供了一种特征提取模型的训练装置,包括:An embodiment of the present invention provides a training device for a feature extraction model, including:
样本获取模块,用于获取多个内容域中内容关联的样本组成多个跨域样本组合;The sample acquisition module is used to acquire content-related samples in multiple content domains to form multiple cross-domain sample combinations;
特征向量生成模块,用于使用被训练的特征提取模型,对跨域样本组合中的样本的原始数据进行特征提取,生成与样本对应的特征向量;The feature vector generation module is used to use the trained feature extraction model to perform feature extraction on the original data of the samples in the cross-domain sample combination, and generate feature vectors corresponding to the samples;
训练模块,用于对所述特征提取模型进行对比学习训练,以缩小跨域样本组合内部的样本对应的特征向量之间的距离,放大跨域样本组合之间的样本对应的特征向量之间的距离作为训练目标。The training module is used to perform comparative learning and training on the feature extraction model, so as to reduce the distance between the feature vectors corresponding to the samples inside the cross-domain sample combination, and enlarge the distance between the feature vectors corresponding to the samples between the cross-domain sample combinations. distance as a training target.
本发明实施例提供了一种商品挂载的处理装置,包括:An embodiment of the present invention provides a processing device for commodity mounting, including:
多媒体特征提取模块,用于获取多媒体数据,对所述多媒体数据进行跨域特征提取,生成与该多媒体数据对应的多媒体特征向量,其中,所述跨域特征提取使得生成的特征向量能够跨域对齐;A multimedia feature extraction module, configured to obtain multimedia data, perform cross-domain feature extraction on the multimedia data, and generate a multimedia feature vector corresponding to the multimedia data, wherein the cross-domain feature extraction enables the generated feature vector to be aligned across domains ;
商品特征提取模块,用于获取多个候选商品数据,对所述候选商品数据进行跨域特征提取,生成多个商品特征向量;The commodity feature extraction module is used to obtain a plurality of candidate commodity data, perform cross-domain feature extraction on the candidate commodity data, and generate a plurality of commodity feature vectors;
相关度处理模块,用于根据所述多个商品特征向量与所述多媒体特征向量之间的相关度,从所述多个候选商品数据中确定进行挂载的商品数据。The correlation degree processing module is configured to determine the commodity data to be mounted from the plurality of candidate commodity data according to the correlation degree between the plurality of commodity characteristic vectors and the multimedia characteristic vector.
本发明实施例提供了一种关联商品挂载的处理装置,包括:An embodiment of the present invention provides a processing device for associated commodity mounting, including:
多媒体特征提取模块,用于获取多媒体数据,对所述多媒体数据进行跨域特征提取,生成与该多媒体数据对应的多媒体特征向量,其中,所述跨域特征提取使得生成的特征向量能够跨域对齐;A multimedia feature extraction module, configured to obtain multimedia data, perform cross-domain feature extraction on the multimedia data, and generate a multimedia feature vector corresponding to the multimedia data, wherein the cross-domain feature extraction enables the generated feature vector to be aligned across domains ;
商品检索处理模块,用于根据所述多媒体特征向量进行商品数据检索,获取与所述多媒体特征向量的相关度大于预设阈值的商品特征向量对应的商品数据;a commodity retrieval processing module, configured to retrieve commodity data according to the multimedia feature vector, and obtain commodity data corresponding to the commodity feature vector whose correlation degree of the multimedia feature vector is greater than a preset threshold;
挂载处理模块,用于将所述商品数据挂载到所述多媒体数据上。The mounting processing module is used for mounting the commodity data on the multimedia data.
本发明实施例提供了一种推荐处理装置,包括:An embodiment of the present invention provides a recommendation processing device, including:
历史数据获取模块,用于获取用户历史访问的历史多媒体数据和/或历史商品数据;A historical data acquisition module, used to acquire historical multimedia data and/or historical commodity data accessed by the user;
历史数据特征提取模块,用于对所述历史多媒体数据和/或历史商品数据进行跨域特征提取,生成对应的历史多媒体特征向量和/或历史商品特征向量,其中,所述跨域特征提取使得生成的特征向量能够跨域对齐;The historical data feature extraction module is used to perform cross-domain feature extraction on the historical multimedia data and/or historical commodity data, and generate corresponding historical multimedia feature vectors and/or historical commodity feature vectors, wherein the cross-domain feature extraction makes The generated feature vectors can be aligned across domains;
数据检索处理模块,用于根据所述历史多媒体特征向量和/或历史商品特征向量,进行多媒体数据和/或商品数据的检索,获取与所述多媒体特征向量和/或商品特征向量之间的相关度大于预设阈值的多媒体数据和/或商品数据,作为推荐数据。A data retrieval processing module, configured to retrieve multimedia data and/or commodity data according to the historical multimedia feature vectors and/or historical commodity feature vectors, and obtain correlations between the multimedia feature vectors and/or commodity feature vectors Multimedia data and/or commodity data whose degree is greater than the preset threshold are used as recommendation data.
本发明实施例提供了一种检索处理装置,包括:An embodiment of the present invention provides a retrieval processing device, including:
查询向量生成模块,用于根据用户的输入的检索信息,生成查询向量;The query vector generation module is used to generate a query vector according to the retrieval information input by the user;
查询向量检索模块,用于根据所述查询向量,在商品特征向量数据库和/或多媒体特征向量数据库中进行查询,获取与所述查询向量之间的第一相关度大于预设第一阈值的商品特征向量和/或多媒体特征向量,其中,所述商品特征向量数据库和/或多媒体特征向量数据库中的商品特征向量和/或多媒体特征向量基于跨域特征提取而获得,所述跨域特征提取使得生成的特征向量能够跨域对齐;A query vector retrieval module, configured to perform a query in the commodity feature vector database and/or the multimedia feature vector database according to the query vector, and obtain commodities whose first correlation degree with the query vector is greater than a preset first threshold Feature vector and/or multimedia feature vector, wherein, the product feature vector and/or multimedia feature vector in the product feature vector database and/or multimedia feature vector database are obtained based on cross-domain feature extraction, and the cross-domain feature extraction makes The generated feature vectors can be aligned across domains;
检索结果反馈模块,用于根据获取到的商品特征向量和/或多媒体特征向量,向用户返回对应的商品数据和/或多媒体数据作为检索结果。The retrieval result feedback module is configured to return the corresponding commodity data and/or multimedia data to the user as the retrieval result according to the obtained commodity feature vector and/or multimedia feature vector.
本发明实施例提供了一种商品挂载的处理方法,包括:An embodiment of the present invention provides a processing method for commodity mounting, including:
获取用户上传的多媒体数据;Obtain the multimedia data uploaded by the user;
根据对所述多媒体数据进行跨域特征提取而获得的内容特征,在商品数据库中选择匹配的商品数据,推荐给该用户;According to the content features obtained by performing cross-domain feature extraction on the multimedia data, select matching product data in the product database, and recommend it to the user;
响应于用户的对商品数据的选择,将选择的商品数据挂载到所述多媒体数据中。In response to the user's selection of commodity data, the selected commodity data is loaded into the multimedia data.
本发明实施例提供了一种商品挂载的处理方法,包括:An embodiment of the present invention provides a processing method for commodity mounting, including:
获取用户上传的多媒体数据和多个待挂载的商品数据;Obtain the multimedia data uploaded by the user and multiple commodity data to be mounted;
根据对所述多媒体数据进行跨域特征提取而获得的内容特征和对所述商品数据进行跨域特征提取而获得的商品特征,获取所述商品数据和所述多媒体数据之间的相关度;According to the content features obtained by performing cross-domain feature extraction on the multimedia data and the product features obtained by performing cross-domain feature extraction on the product data, obtain the correlation between the product data and the multimedia data;
根据所述相关度,从多个待挂载的商品数据中进行商品数据推荐。Commodity data recommendation is performed from a plurality of commodity data to be mounted according to the relevancy.
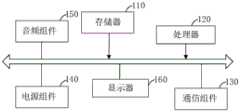
本发明实施例提供了一种电子设备,包括:An embodiment of the present invention provides an electronic device, including:
存储器,用于存储程序;memory for storing programs;
处理器,用于运行所述存储器中存储的所述程序,以执行前述的特征提取模型的训练方法,和/或,前述的商品挂载的处理方法,和/或,前述的推荐处理方法,和/或,前述的检索处理方法。a processor, configured to run the program stored in the memory to execute the aforementioned training method for the feature extraction model, and/or the aforementioned processing method for commodity mounting, and/or the aforementioned recommendation processing method, And/or, the aforementioned retrieval processing method.
本发明实施例所提供的方法、装置及电子设备,通过对比学习的训练方式,对跨内容的特征提取模型进行训练,从而实现对不同内容域的数据进行特征提取,提取出的特征向量具有跨域对齐的性质,从而可以进行进一步的特征比对等处理,有效提高跨域的内容检索以及推荐的匹配效果。The method, device, and electronic device provided by the embodiments of the present invention train cross-content feature extraction models through a training method of comparative learning, thereby realizing feature extraction for data in different content domains, and the extracted feature vectors have cross-content features. Due to the nature of domain alignment, further feature comparison and other processing can be performed, which can effectively improve the matching effect of cross-domain content retrieval and recommendation.
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。The above description is only an overview of the technical solutions of the present invention, in order to be able to understand the technical means of the present invention more clearly, it can be implemented according to the content of the description, and in order to make the above and other purposes, features and advantages of the present invention more obvious and easy to understand , the following specific embodiments of the present invention are given.
附图说明Description of drawings
图1为本发明实施例的对特征提取模型进行训练的处理系统;1 is a processing system for training a feature extraction model according to an embodiment of the present invention;
图2为本发明实施例的特征提取模型的应用场景示意图;2 is a schematic diagram of an application scenario of a feature extraction model according to an embodiment of the present invention;
图3为本发明实施例的商品挂载的处理方法的流程示意图之一;FIG. 3 is one of the schematic flowcharts of the processing method for commodity mounting according to an embodiment of the present invention;
图4为本发明实施例的商品挂载的处理方法的应用场景示意图;FIG. 4 is a schematic diagram of an application scenario of the processing method for commodity mounting according to an embodiment of the present invention;
图5为本发明实施例的商品挂载的处理方法的流程示意图之二;FIG. 5 is the second schematic flowchart of the processing method for commodity mounting according to an embodiment of the present invention;
图6为本发明实施例推荐处理方法的流程示意图;6 is a schematic flowchart of a recommended processing method according to an embodiment of the present invention;
图7为本发明实施例的推荐处理方法的应用场景示意图;7 is a schematic diagram of an application scenario of a recommendation processing method according to an embodiment of the present invention;
图8为本发明实施例检索处理方法的流程示意图;8 is a schematic flowchart of a retrieval processing method according to an embodiment of the present invention;
图9为本发明实施例的检索处理方法的应用场景示意图;9 is a schematic diagram of an application scenario of a retrieval processing method according to an embodiment of the present invention;
图10为本发明实施例的特征提取模型的训练方法的流程示意图;10 is a schematic flowchart of a training method for a feature extraction model according to an embodiment of the present invention;
图11为本发明实施例的商品挂载的处理装置的结构示意图之一;FIG. 11 is one of the schematic structural diagrams of the processing device for commodity mounting according to an embodiment of the present invention;
图12为本发明实施例的商品挂载的处理装置的结构示意图之二;FIG. 12 is a second schematic structural diagram of a processing device for commodity mounting according to an embodiment of the present invention;
图13为本发明实施例推荐处理装置的结构示意图;13 is a schematic structural diagram of a recommendation processing apparatus according to an embodiment of the present invention;
图14为本发明实施例检索处理装置的结构示意图;14 is a schematic structural diagram of a retrieval processing apparatus according to an embodiment of the present invention;
图15为本发明实施例的特征提取模型的训练装置的结构示意图;15 is a schematic structural diagram of a training device for a feature extraction model according to an embodiment of the present invention;
图16为本发明实施例的电子设备的结构示意图。FIG. 16 is a schematic structural diagram of an electronic device according to an embodiment of the present invention.
具体实施方式Detailed ways
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。Exemplary embodiments of the present disclosure will be described in more detail below with reference to the accompanying drawings. While exemplary embodiments of the present disclosure are shown in the drawings, it should be understood that the present disclosure may be embodied in various forms and should not be limited by the embodiments set forth herein. Rather, these embodiments are provided so that the present disclosure will be more thoroughly understood, and will fully convey the scope of the present disclosure to those skilled in the art.
下面通过一些具体实施例来进一步说明本发明的技术方案。The technical solutions of the present invention are further described below through some specific embodiments.
为了实现跨领域数据间的匹配和融合,本发明实施例提供一种特征提取模型的训练方法,该方法基于对比学习和对抗学习技术对特征提取模型进行训练,训练后的模型能够实现跨域的多模态的数据匹配和融合,从而将多媒体数据和商品数据之间的语义差异进行对齐,实现跨域的数据比对和处理。In order to realize the matching and fusion between cross-domain data, an embodiment of the present invention provides a training method for a feature extraction model. The method trains the feature extraction model based on contrastive learning and adversarial learning techniques, and the trained model can realize cross-domain training. Multi-modal data matching and fusion, so as to align the semantic differences between multimedia data and commodity data, and realize cross-domain data comparison and processing.
如图1所示,其为本发明实施例的对特征提取模型进行训练的处理系统。其中,下方的特征提取模型是被训练模型,训练样本输入到特征提取模型后生成特征向量,通过上方的对比学习训练模块和对抗学习训练模块基于训练目标函数的进行训练处理,根据训练反馈结果更新特征提取模型,通过多轮的训练迭代处理,使得特征提取模型输出的特征向量逐渐接近对比学习和对抗学习的训练目标。As shown in FIG. 1 , it is a processing system for training a feature extraction model according to an embodiment of the present invention. Among them, the lower feature extraction model is the trained model, and the training samples are input into the feature extraction model to generate feature vectors, and the training processing is performed based on the training objective function through the upper comparative learning training module and the adversarial learning training module, and is updated according to the training feedback results. The feature extraction model, through multiple rounds of training iterative processing, makes the feature vector output by the feature extraction model gradually approach the training objectives of contrastive learning and adversarial learning.
在本发明实施例中,以多媒体域和商品域作为示例,来说明如何解决跨域多模态的融合与匹配问题。被训练的特征提取模型也是应用于对这两个领域的数据进行特征提取处理,相应的,训练样本也是来自于这两个领域的数据。In the embodiment of the present invention, the multimedia domain and the commodity domain are used as examples to illustrate how to solve the problem of cross-domain and multi-modal fusion and matching. The trained feature extraction model is also used to perform feature extraction processing on the data in these two fields, and correspondingly, the training samples are also from the data in these two fields.
无论多媒体域还是商品域,其数据均可以为多模态的形态,在本实施例中,多模态数据包括图像数据与文本数据。多媒体域中,图像数据可以包括例如用户上传的短视频的图像、直播图像、微博等社交媒体中的照片等,文本数据可以是视频中的字幕、社交媒体上的文字内容,此外,在发明实施例中,将音频数据转换为文字后,作为文本数据处理。同理,在商品域中,图像数据可以包括例如介绍商品的视频、图片等,文本数据可以包括商品的标题、介绍商品的内容等等。Regardless of the multimedia domain or the commodity domain, the data may be in a multimodal form. In this embodiment, the multimodal data includes image data and text data. In the multimedia domain, image data can include, for example, images of short videos uploaded by users, live broadcast images, photos in social media such as Weibo, etc., and text data can be subtitles in videos and text content on social media. In the embodiment, after the audio data is converted into text, it is processed as text data. Similarly, in the commodity domain, the image data may include, for example, videos, pictures, etc. that introduce the commodity, and the text data may include the title of the commodity, the content of the commodity introduction, and the like.
虽然在商品域和多媒体域中均可以包含图像数据与文本数据这两个模态的数据,但是,其组织形态确有很大差别,多媒体数据的展示形式更加自由而没有约束,而商品数据的组织形式一般遵循电商约束条件并且更加结构化。例如其短视频来自于用户的生活拍摄,视觉元素丰富,场景化较强,而商品域中的介绍视频,一般背景比较简洁,需要突出商品本身,图像比较直观,重点突出,并且还要符合电商平台的规定,例如时间长度、背景要求等等。在文本数据方面,多媒体域中的文本数据一般符合自然语言的习惯,并且会描述很多用户的感受等等,而商品域中的文本数据,会存在一些结构化的非自然语言,例如商品标题为了命中检索而堆叠很多关键词,商品说明的文字也都比较简单直接地描述商品本身。由于两个领域中的组织形态的产品,会带来较大的语义鸿沟,通过简单的针对图像或者文本的特征提取,很难将这两个领域的语义特征进行对比,进而也无法进行语义间的比较。Although both image data and text data can be included in the commodity domain and the multimedia domain, their organizational forms are quite different. The display form of multimedia data is more free and unconstrained. Organizational forms generally follow e-commerce constraints and are more structured. For example, its short video comes from the user's life shooting, with rich visual elements and strong scenes, while the introduction video in the commodity domain generally has a relatively simple background and needs to highlight the commodity itself. Business platform regulations, such as length of time, background requirements, etc. In terms of text data, the text data in the multimedia domain generally conforms to the habit of natural language, and will describe the feelings of many users, etc., while the text data in the commodity domain will have some structured non-natural languages, such as commodity titles for Hit the search and stack a lot of keywords, and the text of the product description is relatively simple and direct to describe the product itself. Due to the organizational morphological products in the two fields, there will be a large semantic gap. It is difficult to compare the semantic features of these two fields by simply extracting features from images or texts. Comparison.
本发明实施例中,对特征提取模型的训练目的就是为了跨越不同领域的语义鸿沟,将提取出的特征对齐。特征提取模型的输入为商品域或者多媒体域的原始数据,经过特征提取模型提取后,生成与该原始数据对应的特征向量,该特征向量具有跨域对齐的特性,即无论原始数据来自商品域还是来自多媒体域,经过模型提取出的特征向量能够处于同一向量空间中,能够进行各种相关度的比对或者向量运算等等。其中,原始数据可以包括图像数据和文本数据两路数据,经过特征提取模型的处理后,生成图像特征向量和文本特征向量,而这两个模态的特征向量同样具有对齐特性,能够进行跨模态的比对或者向量运算等等,作为可选的实施例方式,也可以将图像特征向量和文本特征向量融合为一个代表原始数据的特征向量。In the embodiment of the present invention, the training purpose of the feature extraction model is to align the extracted features across the semantic gap in different fields. The input of the feature extraction model is the raw data of the commodity domain or the multimedia domain. After the feature extraction model is extracted, a feature vector corresponding to the original data is generated. The feature vector has the characteristics of cross-domain alignment, that is, whether the original data comes from the commodity domain or the From the multimedia domain, the feature vectors extracted by the model can be in the same vector space, and can perform various correlation comparisons or vector operations, etc. Among them, the original data can include image data and text data. After being processed by the feature extraction model, an image feature vector and a text feature vector are generated, and the feature vectors of these two modalities also have alignment characteristics, which can perform cross-modal analysis. state comparison or vector operation, etc., as an optional embodiment, the image feature vector and the text feature vector can also be fused into a feature vector representing the original data.
对于特征提取模型的内容结构,主要采用对图像数据和文本数据进行特征提取以及融合处理的模型结构,对于图像数据,例如可以采用视觉特征提取模型,例如采用预训练的ResNet(Residual neural network,残余神经网络)等模型进行特征提取。其中,针对每个图像都可以提取出一个视觉特征,而无论是多媒体数据还是商品数据都可能包括多个图像,例如视频会包括多帧图像等,或者通过多张图片来展示某个商品,针对这样的多个视觉特征,可以对这些视觉特征执行max pooling(最大池化)处理,从而获得针对某个多媒体数据或者商品数据的全部图像数据的唯一特征表示,即融合为一个图像特征向量。另一方面,对于文本数据,可以与图像数据类似,采取文本特征提取模型进行特征提取,例如使用预训练的BERT(Bidirectional Encoder Representations from Transformers,基于变换器的双向编码器表示)模型,也可以采取端到端的机器学习模型,将文本中的每个字对应到一个全局唯一的id,然后对每个id进行embedding(词嵌入)操作,最后将输入文本涉及的所有词嵌入进行归一操作,从而得到一个唯一特征表示,即文本特征向量,归一化操作可以采用例如max pooling(最大池化)处理,或者基于attention(注意力)机制的pooling(池化)处理。For the content structure of the feature extraction model, the model structure of feature extraction and fusion processing of image data and text data is mainly used. For image data, for example, a visual feature extraction model can be used, for example, a pre-trained ResNet (Residual neural network, residual neural network) and other models for feature extraction. Among them, a visual feature can be extracted for each image, and both multimedia data and commodity data may include multiple images. For example, a video may include multiple frames of images, or multiple images may be used to display a certain product. For such multiple visual features, max pooling can be performed on these visual features, so as to obtain a unique feature representation of all image data for a certain multimedia data or commodity data, that is, fused into an image feature vector. On the other hand, for text data, similar to image data, a text feature extraction model can be used for feature extraction, for example, a pre-trained BERT (Bidirectional Encoder Representations from Transformers) model can be used. The end-to-end machine learning model maps each word in the text to a globally unique id, then performs the embedding (word embedding) operation on each id, and finally normalizes all word embeddings involved in the input text, thus To obtain a unique feature representation, that is, a text feature vector, the normalization operation can be performed by, for example, max pooling (maximum pooling) processing, or pooling (pooling) processing based on the attention mechanism.
在图1所示的示例中,商品数据用p表示,多媒体数据用s表示,经过特征提取模型进行特征提取后,商品数据对应的图像特征向量表示为vp,商品数据对应的文本特征向量表示为tp,多媒体数据对应的图像特征向量表示为vs,多媒体数据对应的文本特征向量表示为ts。In the example shown in Figure 1, the commodity data is represented by p, and the multimedia data is represented by s. After feature extraction by the feature extraction model, the image feature vector corresponding to the product data is represented asvp , and the text feature vector corresponding to the product data is represented by is tp , the image feature vector corresponding to the multimedia data is denoted as vs , and the text feature vector corresponding to the multimedia data is denoted as ts .
对于模型训练处理,可以分为对比学习和对抗学习两部分。在对比学习的处理中,会从训练样本集合中选择两个样本对作为对比学习组。每个样品对中包含在内容上相关度较强的多媒体数据和商品数据,在对比学习组中的两个样本对之间内容上相关度较弱。For the model training process, it can be divided into two parts: contrastive learning and confrontational learning. In the process of contrastive learning, two pairs of samples are selected from the training sample set as the contrastive learning group. Each sample pair contains multimedia data and commodity data with strong content correlation, and the content correlation between the two sample pairs in the contrastive learning group is weak.
上述的各个样本对可以通过已有的多媒体数据所挂载的商品数据来生成(商品与多媒体之间的相关度已经被确认过),例如某个短视频中挂载了某个商品,那么短视频对应的多媒体数据与商品对应的商品数据就形成了样本对。上述的对比学习组中的两个样本对,可以通过在训练样本集合中进行随机挑选的方式来获得。需要说明的是,挂载于通过一个视频上的多个商品,可以分别与该视频构成样本对,但是由于这些样本对之间的都与该视频相关,因此,其内容上具有较强的相关度,无法形成对比学习组。因此,在上述形成对比学习组的过程中,所挑选的两个样本对应当是排除掉了挂在于同一个视频上的情形。当然,上述的样本对以及对比学习组可以通过人工或者计算机筛选而生成,只要满足上述的样本对内部的内容强相关度,而样本对之间的内容弱相关度的基本原则即可。The above sample pairs can be generated from the commodity data mounted on the existing multimedia data (the correlation between the commodity and the multimedia has been confirmed). The multimedia data corresponding to the video and the commodity data corresponding to the commodity form a sample pair. The two sample pairs in the above-mentioned comparative learning group can be obtained by randomly selecting from the training sample set. It should be noted that multiple commodities mounted on a video can form sample pairs with the video respectively, but since these sample pairs are all related to the video, their content has a strong correlation degree, it is impossible to form a comparative study group. Therefore, in the above-mentioned process of forming a contrastive learning group, the two sample pairs selected should exclude the situation of hanging on the same video. Of course, the above-mentioned sample pairs and comparative study groups can be generated by manual or computer screening, as long as the above-mentioned basic principle of strong content correlation within the sample pair and weak content correlation between the sample pairs is satisfied.
下面介绍一下具体的对比学习过程,对于给定的任意一个包含内容上关联的多媒体数据样本和商品数据样本所构成的正样本对{s+,p+},从作为训练集的整个内容池里,随机挑选另一个包含内容上关联的多媒体数据样本和商品数据样本所构成的负样本对{s_,p_},组成一组对比学习组。需要说明的是,作为一种训练策略,随机挑选的目的是确保所选择样本对之间大概率的具有弱相关度。这里的“+”和“-”主要是为了表示这两个样本对之间在内容上相关度较弱,形成对比关系。The specific comparative learning process is described below. For a given positive sample pair {s+ , p+ } composed of multimedia data samples and commodity data samples that are related to content, from the entire content pool as a training set , randomly select another negative sample pair {s_ , p_ } consisting of multimedia data samples and commodity data samples associated with content to form a set of contrastive learning groups. It should be noted that, as a training strategy, the purpose of random selection is to ensure that the selected sample pairs have a high probability of weak correlation. The "+" and "-" here are mainly to indicate that the content correlation between the two sample pairs is weak, forming a contrasting relationship.
对于上述选定的对比学习组,通过使用被训练的特征提取模型,执行前述的特征提取处理,生成两组多模态特征向量组,



基于上述的特征向量来进行对比训练的学习处理,学习的目标是最小化正样本对中跨域的多模态向量之间的距离,同时最大化负样本对中跨域的多模态向量之间的距离。向量之间的距离可以采用欧式距离来衡量,即d(x,y)=||x-y||2,其中,x和y代表任意两个向量,可以是上述的向量组中的任意的特征向量。Based on the above eigenvectors, the learning processing of comparative training is performed. The goal of learning is to minimize the distance between the cross-domain multimodal vectors in the positive sample pair, while maximizing the distance between the cross-domain multimodal vectors in the negative sample pair. distance between. The distance between the vectors can be measured by the Euclidean distance, that is, d(x, y)=||xy||2 , where x and y represent any two vectors, which can be any eigenvectors in the above-mentioned vector group .
对于视觉模态,即对于上述正样本对和负样本对中的图像特征向量,可以采用如下对偶域的特征约束作为图像特征方面的损失函数。For the visual modality, that is, for the image feature vectors in the above positive sample pair and negative sample pair, the following dual domain feature constraints can be used as the loss function in terms of image features.

其中,函数fh定义为fh(x1,x2)=max(0,μ+x1-x2),μ是边界距离,为正数或者为0,具体取值可以根据实际需要而设定,主要用来调节x1和x2之间所期望的差异性,从而使得模型能够具有一定的容错空间。如公式(1)所示,其包含四个fh求和运算,在每个fh函数中包含了两组向量的距离计算,其中第一组的向量为样本对内部的跨域的向量距离,而第二组的向量为样本对之间的跨域的向量距离。以






上述公式(2)中的各个函数的定义可以参照公式(1),只不过其中的特征向量全部替换为文本特征向量。对于文本特征方面,其训练目标为最小化损失函数
将文本特征和图像特征的对偶域约束合并为针对多模态特征的整体的特征约束,整体上的损失函数可以为:Combining the dual domain constraints of text features and image features into an overall feature constraint for multimodal features, the overall loss function can be:

对比学习的整体目标就是通过不断迭迭代处理,通过调整特征提取模型中的模型参数,使得经过特征提取模型所生成的特征向量能够让公式(3)的损失函数最小。最终的训练结果如图1中对比学习训练模块中所示意的,在形成文本特征向量空间和图像特征向量空间中,同一样本对中的跨域特征向量之间的距离相对较小,而不同样本对中的跨域特征向量之间的距离相对较大。The overall goal of comparative learning is to adjust the model parameters in the feature extraction model through continuous iterative processing, so that the feature vector generated by the feature extraction model can minimize the loss function of formula (3). The final training result is shown in the comparative learning training module in Figure 1. In the formation of the text feature vector space and the image feature vector space, the distance between the cross-domain feature vectors in the same sample pair is relatively small, while the distance between the cross-domain feature vectors in the same sample pair is relatively small. The distance between the cross-domain feature vectors in the pair is relatively large.
以上介绍了对比学习的训练过程,下面再介绍一下对抗学习的训练过程。在本发明实施例中,对抗学习作为对比学习训练的一种补充,目的是更好地克服跨域的多模态语义鸿沟。在对抗学习的过程中,通过设置判别器来对特征向量所属的内容域进行识别,而对抗学习训练模块对特征提取模型的训练目标为希望判别器无法准确地判别出特征向量所属的内容域,换言之,对抗学习部分的训练,实际上是给对比学习增加一定的难度,以提高对比学习的训练效果,使得不同内容域所提取出的特征向量能够较好的实现对齐。The training process of contrastive learning is introduced above, and the training process of adversarial learning is introduced below. In the embodiment of the present invention, adversarial learning is used as a supplement to the contrastive learning training, in order to better overcome the cross-domain multimodal semantic gap. In the process of adversarial learning, the discriminator is set to identify the content domain to which the feature vector belongs, and the training target of the adversarial learning training module for the feature extraction model is to hope that the discriminator cannot accurately identify the content domain to which the feature vector belongs. In other words, the training of the adversarial learning part actually adds a certain degree of difficulty to the comparative learning, so as to improve the training effect of the comparative learning, so that the feature vectors extracted from different content domains can be better aligned.
具体来说,对抗学习训练模块可以由两个判别器Dv和Dt,其中,Dv用来判别输入的图像特征向量来源于多媒体域还是商品域,类似的,Dt用来判别输入的文本特征向量来源于多媒体域还是商品域。在图1的示例中,对抗学习训练模块的训练目标是希望判别器无法准确判别出特征向量来自于多媒体域还是商品域。判别器Dv和Dt可以采用MLP(Multi-LayerPerceptron,多层感知机)和GRL(gradient reversal layer,梯度反转层)相结合的模型结构。Specifically, the adversarial learning training module can be composed of two discriminators Dv and Dt , where Dv is used to discriminate whether the input image feature vector comes from the multimedia domain or the commodity domain. Similarly, Dt is used to discriminate the input image feature vector. Whether the text feature vector comes from the multimedia domain or the commodity domain. In the example in Figure 1, the training objective of the adversarial learning training module is to hope that the discriminator cannot accurately discriminate whether the feature vector comes from the multimedia domain or the commodity domain. The discriminators Dv and Dt can adopt a model structure combining MLP (Multi-Layer Perceptron) and GRL (gradient reversal layer, gradient reversal layer).
在图1所示的示例中,用z表示样本标签值,其取值为0或1,0代表来自多媒体域,1代表来自商品域。
对抗学习的损失函数可以定义为如下形式:The loss function for adversarial learning can be defined as:

将特征提取模型中的模型参数记作θE,将判别器中的模型参数记作θC,在对比学习的基础上,融合对抗学习后,其训练过程可以表示为如下的min-max game(极大极小算法):Denote the model parameters in the feature extraction model as θE , and the model parameters in the discriminator as θC . On the basis of comparative learning, after integrating adversarial learning, the training process can be expressed as the following min-max game ( max min algorithm):

其中,








公式(5)所示的训练过程中,其中第一行的公式用于训练特征提取模型的模型参数,训练目标为使得



公式(5)中的第二行公式用于训练判别器的模型参数,训练目标为使得




在基于公式(5)的模型训练处理中,第一行和第二行对应的训练过程会交替进行,并不断改变特征提取模型和判别器的模型参数,从而实现对比学习和对抗学习的融合。In the model training process based on formula (5), the training process corresponding to the first row and the second row will be alternately performed, and the model parameters of the feature extraction model and the discriminator will be changed continuously, so as to realize the fusion of contrastive learning and adversarial learning.
基于前述的对比学习或者对比学习结合对抗学习的训练方式而训练出的特征提取模型,能够应用于向多媒体进行商品挂载、用户商品推荐以及商品检索等方面。如图2所示,其为本发明实施例的特征提取模型的应用场景示意图。本发明实施例的特征提取模型可以应用与具有内容提供服务的平台上,图中以电商平台作为示例进行说明。在电商平台上,配置存储有海量商品数据和多媒体数据的数据库、用于提供检索推荐服务的检索/推荐引擎、用于提供直播服务的直播处理的模块以及与用户终端进行交互的用户信息交互处理模块,在本发明实施例中,可以在检索/推荐引擎中配置该特征提取模型,从而在进行商品数据或者多媒体数据进行检索和推荐处理的过程中,进行特征提取,以实现跨域的特征处理。此外,电商平台也可以预先对存储有商品数据和多媒体数据的数据库进行预处理,形成与商品数据和多媒体数据对应的向量数据库,从而便于后续在检索和推荐过程中的比对处理。此外,在直播处理中,也可以基于本发明实施例提供的特征提取模型来对直播视频进行特征提取,并基于检索引擎获取匹配的商品数据进行挂载,另外,也可以基于特征提取模型提取出的特征向量,对用户挂载的商品数据与直播视频是否匹配进行审查处理。下面将详细介绍一下,上述的特征提取模型在直播服务以及检索推荐服务方面的应用。The feature extraction model trained based on the aforementioned contrastive learning or the training method of contrastive learning combined with adversarial learning can be applied to the aspects of product uploading to multimedia, user product recommendation, and product retrieval. As shown in FIG. 2 , it is a schematic diagram of an application scenario of the feature extraction model according to an embodiment of the present invention. The feature extraction model in the embodiment of the present invention can be applied to a platform with content providing services, and an e-commerce platform is used as an example for illustration in the figure. On the e-commerce platform, configure a database storing massive commodity data and multimedia data, a retrieval/recommendation engine for providing retrieval and recommendation services, a module for live streaming processing for providing live streaming services, and user information interaction for interacting with user terminals The processing module. In this embodiment of the present invention, the feature extraction model can be configured in the retrieval/recommendation engine, so as to perform feature extraction in the process of retrieval and recommendation processing of commodity data or multimedia data to realize cross-domain features deal with. In addition, the e-commerce platform can also pre-process the database storing commodity data and multimedia data to form a vector database corresponding to the commodity data and multimedia data, so as to facilitate subsequent comparison processing in the retrieval and recommendation process. In addition, in the live broadcast processing, feature extraction can also be performed on the live video based on the feature extraction model provided by the embodiment of the present invention, and matching commodity data can be obtained based on the retrieval engine for mounting. In addition, the feature extraction model can also be used to extract The feature vector of , and review and process whether the product data uploaded by the user matches the live video. The application of the above feature extraction model in live broadcast service and retrieval recommendation service will be introduced in detail below.
如图3所示,其为本发明实施例的商品挂载的处理方法的流程示意图之一,如图4所示,其为本发明实施例的商品挂载的处理方法的应用场景示意图,该方法可以应用于电商平台、具有多媒体发布功能的社交平台以及直播平台等,用于向多媒体数据中挂载具有一定关联性的商品数据,具体地,该方法可以包括:As shown in FIG. 3 , it is one of the schematic flowcharts of the processing method for commodity mounting according to the embodiment of the present invention. As shown in FIG. 4 , it is a schematic diagram of an application scenario of the processing method for commodity mounting according to the embodiment of the present invention. The method can be applied to e-commerce platforms, social platforms with multimedia publishing functions, live broadcast platforms, etc., and is used to mount commodity data with certain relevance into multimedia data. Specifically, the method can include:
S101:获取多媒体数据,对多媒体数据进行跨域特征提取,生成与该多媒体数据对应的多媒体特征向量。其中,跨域特征提取使得生成的特征向量能够跨域对齐。本发明实施例中的多媒体数据可以包括视频网站发布的视频、社交平台发布的短视频、直播平台的直播视频等,本实施例的应用场景可以当视频发布时为该视频寻找合适的挂载商品,也可以是对已经发布的视频匹配合适的挂载商品。上述的跨域特征提取可以使用基于前面介绍的训练方法而获得特征提取模型来实现。在本实施例中,跨域主要是指跨多媒体域和商品域,如前面介绍的,这两个领域的内容组织形态差别较大,通过本发明实施例提供的跨域特征提取处理,实现针对这两个内容域所提取出的特征向量能够处于同一向量空间中,能够进行基于语义相关度的比对或者融合等处理,即具有跨域对齐的特性。S101: Acquire multimedia data, perform cross-domain feature extraction on the multimedia data, and generate a multimedia feature vector corresponding to the multimedia data. Among them, cross-domain feature extraction enables the generated feature vectors to be aligned across domains. The multimedia data in this embodiment of the present invention may include videos released by video websites, short videos released by social platforms, live videos of live broadcast platforms, etc. The application scenario of this embodiment can search for suitable products to be mounted for the video when the video is released. , or it can be a suitable mount product that matches the published video. The above-mentioned cross-domain feature extraction can be implemented by using the feature extraction model obtained based on the training method described above. In this embodiment, cross-domain mainly refers to the cross-media domain and the commodity domain. As mentioned above, the content organization forms of these two domains are quite different. The feature vectors extracted from the two content domains can be in the same vector space, and can be compared or merged based on semantic relevance, that is, they have the characteristics of cross-domain alignment.
S102:获取多个候选商品数据,对候选商品数据进行跨域特征提取,生成多个商品特征向量。候选商品数据可以来自于用户在商品数据库中选定操作而确定,例如,用户拍摄短视频后,上传到社交平台或者电商平台,并且选择了一些想要挂载的商品,在这种情况下,用户所选择的商品并不一定与当前的视频较为匹配,可能用户仅仅是为了增加点击率而随意挂载的商品,因此,需要平台一侧进行一定的审查,以避免出现大量的挂载商品与视频不匹配的情形。此外,候选商品数据也可以是来自于一些商家的推荐或者基于平台广告策略的推荐等,然后再使用本实施例的方法进行进一步筛选。该步骤中所说的跨域特征提取同样可以使用基于前面介绍的训练方法而获得特征提取模型来实现,提取出的商品特征向量与前面步骤提取出的多媒体特征向量能够对齐,可以进行向量间的相关度计算等处理。S102: Acquire multiple candidate product data, perform cross-domain feature extraction on the candidate product data, and generate multiple product feature vectors. The candidate product data can be determined from the user's selected operation in the product database. For example, after the user shoots a short video, uploads it to a social platform or e-commerce platform, and selects some products to be mounted. In this case , the product selected by the user does not necessarily match the current video, and the user may just upload the product at will to increase the click rate. Therefore, a certain review needs to be carried out on the platform side to avoid a large number of uploaded products. Situations that do not match the video. In addition, the candidate product data may also be a recommendation from some merchants or a recommendation based on a platform advertising strategy, etc., and then the method of this embodiment is used for further screening. The cross-domain feature extraction mentioned in this step can also be implemented by using the feature extraction model based on the training method introduced above. The extracted product feature vector can be aligned with the multimedia feature vector extracted in the previous step, and the vector-to-vector extraction can be performed. Correlation calculation, etc.
S103:根据多个商品特征向量与多媒体特征向量之间的相关度,从多个候选商品数据中确定进行挂载的商品数据。在提取出了商品特征向量和多媒体特征向量后,可以通过计算向量间距离的方式来确定相关度,向量间的相关度也就代表了候选商品数据与多媒体数据之间的相关度,从而可以从候选商品数据选择出相关度排名靠前的商品数据进行挂载。S103: Determine the commodity data to be mounted from the plurality of candidate commodity data according to the degree of correlation between the plurality of commodity characteristic vectors and the multimedia characteristic vectors. After the commodity feature vector and the multimedia feature vector are extracted, the correlation can be determined by calculating the distance between the vectors, and the correlation between the vectors also represents the correlation between the candidate commodity data and the multimedia data. The candidate product data selects the product data with the highest relevance ranking for mounting.
结合图4的示例界面,在用户终端上,可以包括位于上部的用于用户进行视频上传或者进行直播的交互界面,以及位于下部的对挂载商品进行选择的功能区域,用户可以从下方的作为候选商品的商品项目中进行选择,并添加到视频画面中,例如,可以添加到视频画面左下方的区域,这样的当观众观看该视频或者直播时,就可以通过点击左下方的区域呈现的商品缩略图而访问商品数据。上部的交互界面中的功能控制区可以用于对视频画面以及挂载商品的缩略展示位置进行调整等操作。挂载商品选择区域中的商品项目可以来自于用户自行的选择,也可以来自于平台商家的一些推荐等。用户选择某些商品作为候选的商品项目后,需要经过上述方法的处理后,才能够挂载到视频画面中,即需要根据相关度从这些候选商品中进行筛查后,再进行挂载。With reference to the example interface of FIG. 4 , on the user terminal, it may include an interactive interface located at the upper part for the user to upload video or perform live broadcast, and a functional area located at the lower part for selecting mounted commodities. Select from the product items of the candidate product and add it to the video screen. For example, it can be added to the lower left area of the video screen, so that when viewers watch the video or live broadcast, they can click on the products presented in the lower left area. Thumbnails to access product data. The function control area in the upper interactive interface can be used to adjust the video screen and the thumbnail display position of the mounted commodity. The commodity items in the mounted commodity selection area can come from the user's own choice or some recommendations from the platform merchants. After the user selects certain commodities as candidate commodity items, they need to be processed by the above method before they can be mounted on the video screen, that is, they need to be screened from these candidate commodities according to the degree of relevancy, and then mounted.
上述的商品特征向量和/或多媒体特征向量可以包括基于图像数据提取出的图像特征向量和/或基于文本数据提取出的文本特征向量。具体地,上述的候选商品数据和多媒体数据中均可以进一步包括图像数据和文本数据这两个模态的数据,其中,图像数据例如图片、视频等,文本数据可以包括文字内容、标题、字幕等,另外,音频数据可以预先转换为文本数据。上述两个模态的数据可以分别进行跨域特征提取处理,生成图像特征向量和文本特征向量。商品数据和多媒体数据对应的图像特征向量和文本特征向量可以分别对应进行特征向量的相关度计算,也可以交叉的相关度计算。如前面所介绍的,本发明实施例的特征提取模型可以基于经过预训练的具有跨模态特征提取能力的特征提取模型,因此,提取出的图像特征向量和基于文本数据之间也可以进行相关度的计算,从而实现在跨模态的基础上的跨域特征比对。The aforementioned commodity feature vector and/or multimedia feature vector may include an image feature vector extracted based on image data and/or a text feature vector extracted based on text data. Specifically, the above-mentioned candidate product data and multimedia data may further include data in two modalities: image data and text data, wherein the image data such as pictures, videos, etc., and the text data may include text content, titles, subtitles, etc. , in addition, audio data can be converted to text data in advance. The data of the above two modalities can be separately processed for cross-domain feature extraction to generate image feature vectors and text feature vectors. The image feature vector and the text feature vector corresponding to the commodity data and the multimedia data can be respectively calculated for the correlation of the feature vectors, and also can be calculated for the cross correlation. As described above, the feature extraction model in this embodiment of the present invention may be based on a pre-trained feature extraction model with cross-modal feature extraction capability. Therefore, correlation between the extracted image feature vector and text-based data may also be performed. Calculation of degree, so as to achieve cross-domain feature comparison on the basis of cross-modality.
本发明实施例的商品挂载的处理方法,基于跨域的特征提取处理,生成了商品域对应的商品特征向量和多媒体域对应的多媒体特征向量,并进行跨域的特征比对,从而对候选商品数据进行筛选,将与多媒体数据匹配性较好的商品数据挂载到媒体数据上,从而让用户在浏览视频或者直播等多媒体内容时,能够获得更加有价值的商品信息。The processing method for commodity mounting according to the embodiment of the present invention generates a commodity feature vector corresponding to the commodity domain and a multimedia feature vector corresponding to the multimedia domain based on the cross-domain feature extraction processing, and performs cross-domain feature comparison, so as to determine the candidate The product data is screened, and the product data that matches the multimedia data better is mounted on the media data, so that users can obtain more valuable product information when browsing multimedia content such as videos or live broadcasts.
如图5所示,其为本发明实施例的商品挂载的处理方法的流程示意图之二,该方法可以应用于电商平台、具有多媒体发布功能的社交平台以及直播平台等,用于向多媒体数据中挂载具有一定关联性的商品数据,具体地,该方法可以包括:As shown in FIG. 5 , which is the second schematic flow chart of the method for processing commodity mounting according to an embodiment of the present invention, the method can be applied to e-commerce platforms, social platforms with multimedia publishing functions, and live broadcast platforms, etc. The commodity data with a certain correlation is mounted in the data. Specifically, the method may include:
S201:获取多媒体数据,对多媒体数据进行跨域特征提取,生成与该多媒体数据对应的多媒体特征向量,其中,跨域特征提取使得生成的特征向量能够跨域对齐。该步骤的处理和前面实施例中的步骤S101是一致的。S201: Acquire multimedia data, perform cross-domain feature extraction on the multimedia data, and generate a multimedia feature vector corresponding to the multimedia data, wherein the cross-domain feature extraction enables the generated feature vectors to be aligned across domains. The processing of this step is the same as that of step S101 in the previous embodiment.
S202:根据多媒体特征向量进行商品数据检索,获取与多媒体特征向量的相关度大于预设阈值的商品特征向量对应的商品数据。本实施例可以应用于电商平台或者社交平台等为用户上传的视频或者正在进行的直播而选择商品进行挂载的场景。平台一侧可以预先构建商品特征向量数据库,即将电商平台中已有商品数据使用本发明实施例提供的特征提取模型,预先提取出具有跨域对齐性质的商品特征向量,并形成商品特征向量数据库。相应地,该步骤可以具体包括:根据多媒体特征向量,在商品特征向量数据库中进行检索,获取与多媒体特征向量之间的相关度大于预设阈值的商品特征向量,然后再根据商品特征向量获取对应的商品数据。S202: Perform commodity data retrieval according to the multimedia feature vector, and obtain commodity data corresponding to the commodity feature vector whose correlation with the multimedia feature vector is greater than a preset threshold. This embodiment may be applied to a scenario where an e-commerce platform or a social platform or the like selects a commodity for mounting for a video uploaded by a user or an ongoing live broadcast. On the platform side, a commodity feature vector database may be pre-built, that is, the commodity feature vector database with cross-domain alignment properties is pre-extracted by using the feature extraction model provided by the embodiment of the present invention for the existing commodity data in the e-commerce platform, and a commodity feature vector database is formed. . Correspondingly, this step may specifically include: searching in the commodity feature vector database according to the multimedia feature vector, obtaining a commodity feature vector whose correlation with the multimedia feature vector is greater than a preset threshold, and then obtaining the corresponding commodity feature vector according to the commodity feature vector. product data.
S203:将商品数据挂载到多媒体数据上。检索到的商品数据可以直接挂载到多媒体数据上,此外,也可以先将检索到的商品数据作为候选商品数据推荐给用户,然后,根据用户对候选商品数据的选择,执行商品数据的挂载处理,从而给用户一定的自主选择性。S203: Mount the commodity data on the multimedia data. The retrieved commodity data can be directly mounted on the multimedia data. In addition, the retrieved commodity data can also be recommended to the user as candidate commodity data, and then, according to the user's selection of the candidate commodity data, the commodity data can be mounted. processing, thereby giving users a certain degree of autonomy.
与前述实施例类似地,上述的商品特征向量和/或多媒体特征向量可以包括基于图像数据提取出的图像特征向量和/或基于文本数据提取出的文本特征向量。商品数据和多媒体数据对应的图像特征向量和文本特征向量可以分别对应进行特征向量的相关度计算,也可以交叉的相关度计算。Similar to the foregoing embodiments, the aforementioned commodity feature vector and/or multimedia feature vector may include an image feature vector extracted based on image data and/or a text feature vector extracted based on text data. The image feature vector and the text feature vector corresponding to the commodity data and the multimedia data can be respectively calculated for the correlation of the feature vectors, and also can be calculated for the cross correlation.
本发明实施例的商品挂载的处理方法,基于跨域的特征提取处理,生成了商品域对应的商品特征向量和多媒体域对应的多媒体特征向量,并进行跨域的基于特征向量的检索,从而获取与多媒体数据匹配性较好的商品数据挂载到媒体数据上,从而让用户在浏览视频或者直播等多媒体内容时,能够获得更加有价值的商品信息。The processing method for commodity loading according to the embodiment of the present invention generates a commodity feature vector corresponding to the commodity domain and a multimedia feature vector corresponding to the multimedia domain based on cross-domain feature extraction processing, and performs cross-domain feature vector-based retrieval, thereby Obtain commodity data that matches the multimedia data and mount it on the media data, so that users can obtain more valuable commodity information when browsing multimedia content such as videos or live broadcasts.
如图6所示,其为本发明实施例推荐处理方法的流程示意图,如图7所示,其为本发明实施例的推荐处理方法的应用场景示意图,该方法可以应用于电商平台、具有多媒体发布功能的社交平台以及直播平台等,用于主动向用户进行内容推荐,具体地,该方法可以包括:As shown in FIG. 6 , it is a schematic flowchart of a recommended processing method according to an embodiment of the present invention. As shown in FIG. 7 , it is a schematic diagram of an application scenario of the recommended processing method according to an embodiment of the present invention. The social platform and live broadcast platform with multimedia publishing function are used to actively recommend content to users. Specifically, the method may include:
S301:获取用户历史访问的历史多媒体数据和/或历史商品数据。在本实施例的应用场景中,可以基于用户的历史访问行为来进行主动推荐,例如用户打开电商APP的页面,在不输入任何关键词的情况下,可以在首页上为用户展示一些相关的内容推荐。上述的历史多媒体数据和/或历史商品数据可以通过用户的APP,在获得用户明确许可的情况下,记录用户的历史访问行为,并上报给电商平台,用以为用户提供更好的内容推荐体验。S301: Acquire historical multimedia data and/or historical commodity data historically accessed by a user. In the application scenario of this embodiment, active recommendation can be made based on the user's historical access behavior. For example, when the user opens the page of an e-commerce APP and does not enter any keywords, the user can display some related information on the home page for the user. Content recommendation. The above-mentioned historical multimedia data and/or historical commodity data can be recorded through the user's APP, with the user's explicit permission, to record the user's historical access behavior and report it to the e-commerce platform, so as to provide the user with a better content recommendation experience. .
S302:对历史多媒体数据和/或历史商品数据进行跨域特征提取,生成对应的历史多媒体特征向量和/或历史商品特征向量,其中,跨域特征提取使得生成的特征向量能够跨域对齐。在该步骤中,跨域特征提取处理和前面实施例中提到的对多媒体数据和商品数据进行特征提取的处理是一样的,可以使用基于前面介绍的训练方法而获得特征提取模型来实现。并且,上述的历史多媒体数据和/或历史商品数据中均可以包括图像数据和/或文本数据,相应地,上述的商品特征向量和/或多媒体特征向量可以包括基于图像数据提取出的图像特征向量和/或基于文本数据提取出的文本特征向量。S302: Perform cross-domain feature extraction on historical multimedia data and/or historical commodity data to generate corresponding historical multimedia feature vectors and/or historical commodity feature vectors, wherein the cross-domain feature extraction enables cross-domain alignment of the generated feature vectors. In this step, the cross-domain feature extraction process is the same as the feature extraction process for multimedia data and commodity data mentioned in the previous embodiment, and can be implemented by obtaining a feature extraction model based on the training method described above. In addition, the above-mentioned historical multimedia data and/or historical commodity data may include image data and/or text data, and accordingly, the above-mentioned commodity feature vectors and/or multimedia feature vectors may include image feature vectors extracted based on image data. and/or text feature vectors extracted based on text data.
S303:根据历史多媒体特征向量和/或历史商品特征向量,进行多媒体数据和/或商品数据的检索,获取与多媒体特征向量和/或商品特征向量之间的相关度大于预设阈值的多媒体数据和/或商品数据,作为推荐数据。在提取出了商品特征向量和多媒体特征向量后,可以通过计算向量间距离的方式来确定相关度,向量间的相关度也就代表了商品数据与多媒体数据之间的相关度,从而可以检索到与用户历史行为相关度较高的商品数据与多媒体数据,为用户进行合理的内容推荐。S303: Perform retrieval of multimedia data and/or commodity data according to historical multimedia feature vectors and/or historical commodity feature vectors, and obtain multimedia data and/or commodity data whose correlations with the multimedia feature vectors and/or commodity feature vectors are greater than a preset threshold. / or product data, as recommendation data. After the commodity feature vector and the multimedia feature vector are extracted, the correlation can be determined by calculating the distance between the vectors. The correlation between the vectors also represents the correlation between the commodity data and the multimedia data, so that the retrieval Commodity data and multimedia data that are highly correlated with the user's historical behavior can make reasonable content recommendations for users.
如图7所示,其示出了用户终端一侧的网购APP的推荐界面,用户可以在不输入任何信息的情况下,在该界面上通过上述的推荐处理方法来生成各类推荐数据在推荐页面上展示给用户。例如,在图7所示的应用界面上,向用户推荐了一些商品项目,同时也推荐了其他用户上传的短视频和商家正在进行的直播,在短视频和直播视频的内部均挂载有关联的商品项目作为进一步的推荐。As shown in Figure 7, it shows the recommendation interface of the online shopping APP on the user terminal side. The user can generate various types of recommendation data on the interface through the above recommendation processing method without inputting any information. displayed to the user on the page. For example, on the application interface shown in Figure 7, some commodity items are recommended to the user, and short videos uploaded by other users and the live broadcast being performed by the merchant are also recommended. The short video and the live video are all related to each other. Items of merchandise as further recommendations.
上述的检索多媒体数据和/或商品数据的过程中,可以在预先生成的存储有多媒体特征向量的数据库和/或商品特征向量的数据库中进行检索。平台可以预先将其存储的多媒体数据和/或商品数据,使用本发明实施例提供的特征提取模型,预先进行特征向量的提取,形成特征向量数据库,在此基础上,可以根据用户的历史多媒体特征向量和/或历史商品特征向量,在该数据库中进行检索,获取与历史多媒体特征向量和/或历史商品特征向量的相关度大于预设阈值的多媒体特征向量和/或商品特征向量;然后,再根据获取到的多媒体特征向量和/或商品特征向量,确定对应的多媒体数据和/或商品数据作为推荐数据。In the above process of retrieving multimedia data and/or commodity data, retrieval may be performed in a pre-generated database storing multimedia feature vectors and/or a database of commodity feature vectors. The platform can pre-store the multimedia data and/or commodity data, and use the feature extraction model provided by the embodiment of the present invention to extract feature vectors in advance to form a feature vector database. vector and/or historical commodity feature vector, perform retrieval in the database to obtain the multimedia feature vector and/or commodity feature vector whose correlation with the historical multimedia feature vector and/or historical commodity feature vector is greater than the preset threshold; According to the acquired multimedia feature vector and/or product feature vector, the corresponding multimedia data and/or product data are determined as recommendation data.
在用户的历史访问行为中,一般会大量的历史多媒体数据和/或历史商品数据,相应地,对条历史多媒体数据和/或历史商品数据提取出的历史多媒体特征向量和/或历史商品特征向量也为多个。在本发明实施例中,可以分别基于各个多媒体特征向量和/或历史商品特征向量进行检索,并将命中次数较多的多媒体数据和/或商品数据作为推荐数据。此外,也可以对多个历史多媒体特征向量和/或历史商品特征向量进行融合处理,生成融合特征向量,该融合特征向量相当于对用户的整体上的历史行为进行了语义抽象,然后,根据融合特征向量进行多媒体数据和/或商品数据的检索,获取与融合特征向量之间的相关度大于预设阈值的多媒体数据和/或商品数据。In the user's historical access behavior, there is generally a large amount of historical multimedia data and/or historical commodity data. Correspondingly, historical multimedia feature vectors and/or historical commodity feature vectors extracted from pieces of historical multimedia data and/or historical commodity data Also for multiple. In this embodiment of the present invention, retrieval may be performed based on each multimedia feature vector and/or historical commodity feature vector, respectively, and the multimedia data and/or commodity data with more hits may be used as recommendation data. In addition, multiple historical multimedia feature vectors and/or historical commodity feature vectors can also be fused to generate a fused feature vector, which is equivalent to semantically abstracting the overall historical behavior of the user, and then, according to the fusion The feature vector retrieves multimedia data and/or commodity data, and obtains multimedia data and/or commodity data whose correlation with the fusion feature vector is greater than a preset threshold.
本发明实施例的推荐处理方法,基于跨域的特征提取处理,对用户的历史访问行为所涉及的历史多媒体数据和/或历史商品数据进行了跨域的特征提取,从基于提取出的特征向量,检索匹配性较好的多媒体数据和/或商品数据推荐给用户,从而让用户能够获得更好的内容推荐体验。The recommendation processing method of the embodiment of the present invention performs cross-domain feature extraction on the historical multimedia data and/or historical commodity data involved in the user's historical access behavior based on cross-domain feature extraction processing, and extracts features from the extracted feature vector based on , retrieving and recommending multimedia data and/or commodity data with better matching to the user, so that the user can obtain a better content recommendation experience.
如图8所示,其为本发明实施例检索处理方法的流程示意图,如图9所示,其为本发明实施例的检索处理方法的应用场景示意图,该方法可以应用于电商平台上,用于根据用户输入的关键词进行内容检索,具体地,该方法可以包括:As shown in FIG. 8 , it is a schematic flowchart of a retrieval processing method according to an embodiment of the present invention. As shown in FIG. 9 , it is a schematic diagram of an application scenario of the retrieval processing method according to an embodiment of the present invention. The method can be applied to an e-commerce platform. For content retrieval based on keywords input by the user, specifically, the method may include:
S401:根据用户的输入的检索信息,生成查询向量。本实施例的应用场景可以为用户通过电商平台的检索页面输入检索信息而发起的检索。其中,对于检索信息的特征提取,可以采用前述的本发明实施例提供的特征提取模型来进行执行。S401: Generate a query vector according to the retrieval information input by the user. The application scenario of this embodiment may be a retrieval initiated by a user entering retrieval information through a retrieval page of an e-commerce platform. The feature extraction of the retrieval information may be performed by using the feature extraction model provided by the foregoing embodiments of the present invention.
S402:根据查询向量,在商品特征向量数据库和/或多媒体特征向量数据库中进行查询,获取与查询向量之间的第一相关度大于预设第一阈值的商品特征向量和/或多媒体特征向量。其中,商品特征向量数据库和/或多媒体特征向量数据库中的商品特征向量和/或多媒体特征向量基于跨域特征提取而获得,具体可以采用前述的本发明实施例提供的特征提取模型来进行,通过跨域特征提取使得生成的特征向量能够跨域对齐。如前面介绍的,电商平台可以预先对多媒体数据和商品数据,使用本发明实施例提供的特征提取模型,进行特征向量的提取,形成特征向量数据库。在此基础上,通过步骤S401将用户的输入的检索信息转换为查询向量后,就可以与向量数据库中的向量进行比对了。S402: Perform a query in the commodity feature vector database and/or the multimedia feature vector database according to the query vector, and obtain a commodity feature vector and/or a multimedia feature vector whose first correlation with the query vector is greater than a preset first threshold. Wherein, the commodity feature vector and/or the multimedia feature vector in the commodity feature vector database and/or the multimedia feature vector database are obtained based on cross-domain feature extraction. Specifically, the feature extraction model provided by the foregoing embodiments of the present invention can be used to perform, through Cross-domain feature extraction enables the generated feature vectors to be aligned across domains. As described above, the e-commerce platform can use the feature extraction model provided by the embodiment of the present invention to extract feature vectors for multimedia data and commodity data in advance to form a feature vector database. On this basis, after the retrieval information input by the user is converted into a query vector through step S401, it can be compared with the vector in the vector database.
S403:根据获取到的商品特征向量和/或多媒体特征向量,向用户返回对应的商品数据和/或多媒体数据作为检索结果。向用户返回的检索结果中,可以包括例如短视频、正在进行的直播等多媒体数据,也可以包括在电商平台上发布的商品数据。此外,在多媒体数据中,还可以进一步挂载有具有商品数据,例如,短视频中关联的商品链接等。S403: Return corresponding product data and/or multimedia data to the user as a retrieval result according to the obtained product feature vector and/or multimedia feature vector. The retrieval results returned to the user may include multimedia data such as short videos and ongoing live broadcasts, as well as commodity data published on the e-commerce platform. In addition, in the multimedia data, commodity data, for example, commodity links associated in the short video, may be further mounted.
如图9所示,其示出了用户在终端的网购APP上进行检索的页面,用户在左侧界面的检索框中输入关键词,经过APP与电商平台的服务器进行交互处理后,返回右侧页面,其中,返回的检索结果中,包括了商品项目以及挂载有商品项目的短视频或者商家直播等项目。As shown in Figure 9, it shows the page where the user searches on the terminal's online shopping APP. The user enters a keyword in the search box on the left interface, and after the APP interacts with the server of the e-commerce platform, it returns to the right The side page, in which the returned retrieval results include items such as commodity items and short videos with commodity items or live broadcasts of merchants.
针对多媒体数据中挂载的商品数据,电商平台可以在向用户返回检索结果时,对挂载的商品数据与多媒体数据之间的相关度进行一下判定,剔除一些不相干的商品。具体地,上述方法还可以包括:获取该多媒体数据中挂载的商品数据对应的商品特征向量;获取该多媒体数据对应的多媒体特征向量和该商品特征向量之间的第二相关度,如果第二相关度大于或等于预设的第二阈值,则在向用户返回的检索结果中保留挂载的商品数据,否则,删除挂载的商品数据。For the commodity data mounted in the multimedia data, the e-commerce platform can judge the correlation between the mounted commodity data and the multimedia data when returning the retrieval result to the user, and eliminate some irrelevant commodities. Specifically, the above method may further include: acquiring a commodity feature vector corresponding to the commodity data mounted in the multimedia data; acquiring a second correlation between the multimedia feature vector corresponding to the multimedia data and the commodity feature vector, if the second If the correlation is greater than or equal to the preset second threshold, the mounted commodity data is retained in the retrieval result returned to the user, otherwise, the mounted commodity data is deleted.
此外,对于检索结果中没有挂载商品数据或者挂载商品数据较少的多媒体数据,可以进一步获取相关的商品数据进行挂载,并推荐给用户。具体地,在向用户返回多媒体数据的情况下,还可以包括:根据多媒体数据对应的多媒体特征向量,在商品特征向量数据库中进行查询,获取与该多媒体特征向量之间的相关度大于预设的第三阈值的商品特征向量;根据该商品特征向量获取对应的商品数据,并挂载到多媒体数据中作为检索结果提供给用。In addition, for multimedia data with no or less commodity data mounted in the retrieval result, relevant commodity data can be further obtained and mounted, and recommended to the user. Specifically, in the case of returning the multimedia data to the user, the method may further include: querying the commodity feature vector database according to the multimedia feature vector corresponding to the multimedia data, and obtaining a correlation with the multimedia feature vector that is greater than a preset value. The commodity feature vector of the third threshold; the corresponding commodity data is obtained according to the commodity feature vector, and is mounted into the multimedia data as a retrieval result to provide for use.
本发明实施例的检索处理方法,基于跨域的特征提取处理所形成的特征向量数据库,可以根据用户输入的检索信息所形成的特征向量,进行跨域的特征向量的匹配查询,获取到符合用户检索需求的多媒体数据和/或商品数据,从而为能够为用户提供丰富的来自不同内容域的检索结果。In the retrieval processing method of the embodiment of the present invention, based on the feature vector database formed by the cross-domain feature extraction process, the matching query of the cross-domain feature vector can be performed according to the feature vector formed by the retrieval information input by the user, and the matching query of the cross-domain feature vector can be obtained. Retrieve the required multimedia data and/or commodity data, so as to provide users with rich retrieval results from different content domains.
以上实施例中,以商品数据和多媒体数据作为两个内容域作为示例,介绍了本发明实施例的特征提取模型的应用以及模型训练原理。实际上,本发明实施例的特征提取模型以及模型训练方法可以实现对多个内容域的数据进行特征提取。In the above embodiments, using commodity data and multimedia data as two content domains as examples, the application of the feature extraction model according to the embodiment of the present invention and the model training principle are introduced. In fact, the feature extraction model and the model training method according to the embodiments of the present invention can implement feature extraction on data of multiple content domains.
如图10所示,其为本发明实施例的特征提取模型的训练方法的流程示意图,本发明实施例的训练方法可以应用于电商平台、搜索引擎、提供云服务的数据服务平台上,用于对搜索引擎、内容推荐等处理系统中的特征提取模型进行训练,以实现对不同内容域的数据进行特征提取,并使得提取出的特征向量能够对齐,从而便于后续的在各个内容域之间进行特征比对或者融合等进一步的处理,该方法可以包括:As shown in FIG. 10 , which is a schematic flowchart of a training method for a feature extraction model according to an embodiment of the present invention, the training method in the embodiment of the present invention can be applied to an e-commerce platform, a search engine, and a data service platform that provides cloud services. It is used to train feature extraction models in processing systems such as search engines and content recommendation, so as to extract features from data in different content domains, and to align the extracted feature vectors, so as to facilitate subsequent analysis between content domains. For further processing such as feature comparison or fusion, the method may include:
S501:获取多个内容域中内容关联的样本组成多个跨域样本组合。为了对特征提取模型进行训练,可以预先构建样本集。其中,样本可以来自于任意一个内容域中的数据,例如来自多媒体域的某个视频或者来自商品域的某个商品数据等。如果这些来自不同内容域的样本之间具有已知的关联性,那么可以将这些样本组合为跨域样本组合,用户进行模型训练。在前面的示例中,以在多媒体数据中挂载的商品数据所组成的样本对作为了跨域样本组合的示例,在实际的应用中,由于内容域可能会有多个,跨域样本组合中的样本个数也可以为多个。S501: Obtain content-related samples in multiple content domains to form multiple cross-domain sample combinations. For training the feature extraction model, a sample set can be pre-built. The sample may come from data in any content domain, such as a video from a multimedia domain or a commodity data from a commodity domain. If these samples from different content domains have known correlations, these samples can be combined into a cross-domain sample combination, and the user can perform model training. In the previous example, the sample pair composed of commodity data mounted in the multimedia data is used as an example of cross-domain sample combination. In practical applications, since there may be multiple content domains, in cross-domain sample combination The number of samples can also be multiple.
S502:使用被训练的特征提取模型,对跨域样本组合中的样本的原始数据进行特征提取,生成与样本对应的特征向量。其中,无论是哪个内容域的样本数据,都可以包括多个模态的数据,这里所说的模态是指数据本身存在的形式,模态一般可以包括:图像、音频、文字等等。因此,在该步骤中的特征提取处理可以包括:对跨域样本组合中的样本的各个模态的原始数据分别进行特征提取,生成与样本对应的多个模态的特征向量。在本发明实施例中,可以选择图像数据和文本数据作为主要的模态,音频数据可以预先转换为文本数据,即上述的样本的原始数据可以包括图像数据和/或文本数据,相应地,该步骤中的特征提取处理可以包括:对跨域样本组合中的样本的图像数据和/或文本数据分别进行特征提取,生成与样本对应的图像特征向量和/或文本特征向量。S502: Using the trained feature extraction model, perform feature extraction on the original data of the samples in the cross-domain sample combination, and generate feature vectors corresponding to the samples. Wherein, no matter which content domain the sample data is, it can include data of multiple modalities. The modality mentioned here refers to the form in which the data itself exists, and the modalities can generally include: image, audio, text, and so on. Therefore, the feature extraction process in this step may include: performing feature extraction on the raw data of each modality of the samples in the cross-domain sample combination, respectively, to generate feature vectors of multiple modalities corresponding to the samples. In this embodiment of the present invention, image data and text data may be selected as the main modalities, and audio data may be converted into text data in advance, that is, the original data of the above-mentioned samples may include image data and/or text data. Accordingly, the The feature extraction process in the step may include: performing feature extraction on the image data and/or text data of the samples in the cross-domain sample combination, respectively, to generate image feature vectors and/or text feature vectors corresponding to the samples.
这里需要说明的是,本发明实施例中对比学习以及后学的对抗学习,主要是针对跨域的特征提取能力所进行的训练,在存在跨模态的特征提取需求的情况下,上述的被训练的特征提取模型可以采用经过预训练的具有跨模态特征提取能力的特征提取模型,例如在模型选择上,对于文本特征提取部分可以采用预训练的BERT模型,也可以采取端到端的机器学习模型等,对于图像特征提取部分可以采用经过预训练的ResNet模型等。It should be noted here that the comparative learning and post-learning confrontation learning in the embodiments of the present invention are mainly training for cross-domain feature extraction capabilities. In the case of cross-modal feature extraction requirements, the above-mentioned The trained feature extraction model can use a pre-trained feature extraction model with cross-modal feature extraction capability. For example, in model selection, a pre-trained BERT model can be used for text feature extraction, or end-to-end machine learning can be used. model, etc. For the image feature extraction part, a pre-trained ResNet model can be used.
S503:对特征提取模型进行对比学习训练,以缩小跨域样本组合内部的样本对应的特征向量之间的距离,放大跨域样本组合之间的样本对应的特征向量之间的距离作为训练目标。在前文中,已经以商品数据和多媒体数据作为示例,说明了相应的训练过程以及损失函数计算等。对于两个以上的内容域的情形,即在样本组合内部存在多个样本的情形,同样可以参照前述示例的方式进行训练以及构建损失函数。在损失函数中,距离计算可以仍然采用两两向量计算距离的方式,只不过,需要计算距离的次数会比两个内容域的情况较多,但是整体原理上一样的,即希望同一样本组合内部的不同域之间的特征向量的距离尽量小,而不同样本组合的不同域之间的特征向量的距离尽量大。对比学习的训练处理可以参照前述实施例中提到的公式(2)和公式(3)进行训练处理。S503: Perform comparative learning and training on the feature extraction model to reduce the distance between feature vectors corresponding to samples within the cross-domain sample combination, and enlarge the distance between the feature vectors corresponding to the samples between the cross-domain sample combinations as a training target. In the foregoing, commodity data and multimedia data have been taken as examples to illustrate the corresponding training process and loss function calculation. For the case of more than two content domains, that is, the case where there are multiple samples within the sample combination, the training and the loss function can also be constructed by referring to the foregoing example. In the loss function, the distance calculation can still use the method of calculating the distance between two vectors, but the number of times that the distance needs to be calculated will be more than the case of two content domains, but the overall principle is the same, that is, it is hoped that the same sample combination will internally The distance between the eigenvectors of different domains is as small as possible, and the distance between the eigenvectors between different domains of different sample combinations is as large as possible. For the training process of contrastive learning, the training process may be performed with reference to the formula (2) and formula (3) mentioned in the foregoing embodiment.
此外,为了提高对比学习的训练效果,本发明实施例可以引入对抗学习进行辅助训练。因此,上述方法还可以包括:对特征提取模型进行对抗学习训练,以降低对抗学习的判别器对于特征向量所属的内容域的判别准确度作为训练目标。在本实施例中,对抗学习的作用在于增加对比学习的难度,并作为检验对比学习效果的鉴别器,即当对抗学习的判别器无法准确判断出特征提取模型所提取出的特征向量来自于哪个内容域时,相当于对比学习已经将不同内容域的特征向量进行了良好的对齐,实现了较好的跨域特征提取的效果。In addition, in order to improve the training effect of the contrastive learning, the embodiment of the present invention may introduce adversarial learning for auxiliary training. Therefore, the above method may further include: performing adversarial learning training on the feature extraction model, so as to reduce the discrimination accuracy of the adversarial learning discriminator for the content domain to which the feature vector belongs as a training target. In this embodiment, the role of adversarial learning is to increase the difficulty of comparative learning and serve as a discriminator for checking the effect of comparative learning, that is, when the discriminator of adversarial learning cannot accurately determine which feature vector extracted by the feature extraction model comes from When the content domain is used, it is equivalent to the contrastive learning that the feature vectors of different content domains have been well aligned, and a better effect of cross-domain feature extraction has been achieved.
具体地,在对抗学习的训练过程中,可以交替执行如下训练处理:Specifically, in the training process of adversarial learning, the following training processes can be performed alternately:
1)固定判别器的模型参数,对特征提取模型进行训练,以降低判别器对于特征向量所属的内容域的判别准确度。该部分的训练处理为在固定判别器的模型参数不变的情况下,同时结合前述的对比学习的损失函数,对特征提取模型进行训练,提高特征提取模型所提取出的特征向量的跨域对齐性。1) The model parameters of the discriminator are fixed, and the feature extraction model is trained to reduce the discriminator's discrimination accuracy for the content domain to which the feature vector belongs. The training process of this part is to train the feature extraction model in combination with the loss function of the aforementioned comparative learning while the model parameters of the fixed discriminator remain unchanged, so as to improve the cross-domain alignment of the feature vectors extracted by the feature extraction model. sex.
2)固定特征提取模型的模型参数,对判别器进行训练,以提升判别器对于特征向量所属的内容域的判别准确度。在该部分的训练处理中,在固定特征提取模型的模型参数的情况下,提高判别器的判别能力,从而上述1)中的训练过程增加难度。2) The model parameters of the feature extraction model are fixed, and the discriminator is trained to improve the discrimination accuracy of the discriminator for the content domain to which the feature vector belongs. In this part of the training process, in the case where the model parameters of the feature extraction model are fixed, the discriminator's ability to discriminate is improved, so that the training process in the above 1) increases the difficulty.
上述的对抗学习的训练过程,可以采用前述实施例中的公式(4)和公式(5)的函数进行训练。In the training process of the above-mentioned adversarial learning, the functions of formula (4) and formula (5) in the foregoing embodiments can be used for training.
本发明实施例所提供的方法、装置及电子设备,通过对比学习的训练方式,对跨内容的特征提取模型进行训练,从而实现对不同内容域的数据进行特征提取,提取出的特征向量具有跨域对齐的性质,从而可以进行进一步的特征比对等处理,有效提高跨域的内容检索以及推荐的匹配效果。The method, device, and electronic device provided by the embodiments of the present invention train cross-content feature extraction models through a training method of comparative learning, thereby realizing feature extraction for data in different content domains, and the extracted feature vectors have cross-content features. Due to the nature of domain alignment, further feature comparison and other processing can be performed, which can effectively improve the matching effect of cross-domain content retrieval and recommendation.
本发明实施例所提供的模型训练方法,通过对比学习或者对比学习结合对抗学习的训练方式,实现对不同内容域的数据进行特征提取,所提取出的特征向量具有跨域对齐的性质,从而可以进行进一步的特征比对等处理,有效提高跨域的内容检索以及推荐的匹配效果。The model training method provided by the embodiment of the present invention realizes feature extraction on data of different content domains through the training method of comparative learning or comparative learning combined with adversarial learning, and the extracted feature vectors have the property of cross-domain alignment, so that the Further feature comparison and other processing are performed to effectively improve the cross-domain content retrieval and the matching effect of recommendation.
本发明实施例还提供了一种商品挂载的处理方法,其可以应用于电商平台或者社交平台上,具体可以应用于面向作为一般消费者的用户提供多媒体数据发布的软件产品上,帮助用户进行商品挂载的推荐和选择,具体地,该方法包括:The embodiment of the present invention also provides a processing method for commodity mounting, which can be applied to an e-commerce platform or a social platform, and specifically can be applied to a software product that provides multimedia data release for users who are ordinary consumers, helping users Carry out recommendation and selection of commodity mounting, specifically, the method includes:
S601:获取用户上传的多媒体数据。本实施例中的用户可以是作为一般的消费者的用户,用户上传的多媒体数据可以是自制的视频,例如生活动态或者产品使用方面的内容,在经过用户允许的情况下,可以向用户推荐一些关联的商品,作为广告推荐而挂载于视频中,用户从中也可以获取一定的报酬。S601: Acquire multimedia data uploaded by a user. The user in this embodiment may be a user who is a general consumer, and the multimedia data uploaded by the user may be a self-made video, such as content about life dynamics or product usage. With the user's permission, some videos may be recommended to the user. The related products are uploaded in the video as an advertisement recommendation, and the user can also get a certain reward from it.
S602:根据对所述多媒体数据进行跨域特征提取而获得的内容特征,在商品数据库中选择匹配的商品数据,推荐给该用户。上述的对于多媒体数据的内容特征的提取处理,可以使用前述实施例中介绍的特征提取模型。S602: According to the content feature obtained by performing cross-domain feature extraction on the multimedia data, select matching product data in the product database, and recommend it to the user. The feature extraction model described in the foregoing embodiments may be used for the above-mentioned extraction processing of the content features of the multimedia data.
S603:响应于用户的对商品数据的选择,将选择的商品数据挂载到所述多媒体数据中。平台可以向用户推荐多个商品数据,用户可以根据自身喜好或者想法来最终决定在多媒体数据中挂载的商品数据。S603: In response to the user's selection of commodity data, mount the selected commodity data into the multimedia data. The platform can recommend multiple commodity data to the user, and the user can finally decide the commodity data to be mounted in the multimedia data according to their own preferences or ideas.
此外,在多媒体数据发布后,可能会收到大量的评论数据,在本发明实施例中,还可以获取这些评论数据,根据评论数据的特征,在商品数据库中选择与评论数据匹配的商品数据,推荐给该用户,以用于对多媒体数据中挂载的商品数据进行更新。这个过程可以随着评论数据的变化而定期执行,从而可以帮助用户不断更新多媒体数据中挂载的商品数据。In addition, after the multimedia data is released, a large amount of comment data may be received. In this embodiment of the present invention, the comment data can also be obtained, and according to the characteristics of the comment data, the commodity data matching the comment data is selected in the commodity database, It is recommended to the user to update the commodity data mounted in the multimedia data. This process can be performed periodically with the change of the comment data, so as to help the user to continuously update the commodity data mounted in the multimedia data.
例如,用户上传了一段旅行生活的视频后,最初挂载的商品为一些旅行用的衣物等方面的产品,由于视频拍摄质量较好,获得了大量的关注,期间涉及到了大量的关于摄影方面的评论,平台可以根据新的评论数据匹配出一些摄影器材或者图书方面商品,推荐给用户,进行商品挂载更新,从而帮助用户和商家取得双赢的效果。For example, after a user uploads a video of travel life, the products initially loaded are some travel clothes and other products. Due to the good quality of the video shooting, it has received a lot of attention. During this period, a lot of photography has been involved. Comments, the platform can match some photographic equipment or book products according to the new comment data, recommend them to users, and update the products, so as to help users and merchants achieve a win-win effect.
此外,上述的评论数据还可以包括商品的一些评论数据,随着商品评论数据的变化,可以影响到与多媒体数据的匹配程度,从而也可以根据商品的评论数据来更新向用户推荐的商品数据。In addition, the above-mentioned review data may also include some review data of the product. With the change of the product review data, the matching degree with the multimedia data may be affected, so that the product data recommended to the user may also be updated according to the product review data.
本发明实施例还提供了一种商品挂载的处理方法,其可以应用于电商平台或者社交平台上,具体可以应用于面向例如商家用户提供多媒体数据发布的软件产品上,帮助商家用户进行商品挂载的选择或者检验,具体地,该方法包括:The embodiment of the present invention also provides a processing method for commodity mounting, which can be applied to an e-commerce platform or a social platform, and specifically can be applied to, for example, a software product that provides multimedia data release for merchant users, and helps merchant users to purchase commodities The selection or inspection of the mount, specifically, the method includes:
S701:获取用户上传的多媒体数据和多个待挂载的商品数据。在商家用户方面,其上传多媒体数据具有较强的目的性,即为了宣传其自身的商品,但是,商家用户可能在商品数据与多媒体数据的匹配判断上有所欠缺,使用本发明实施例的方式,可以帮助用户进行匹配判断,因此,商家用户在上传多媒体数据的同时,也会上传想要挂载的商品数据。S701: Acquire multimedia data uploaded by a user and multiple commodity data to be mounted. In terms of merchant users, uploading multimedia data has a strong purpose, that is, to promote their own products. However, merchant users may be lacking in the matching judgment between commodity data and multimedia data, and the method of the embodiment of the present invention is used. , which can help users make matching judgments. Therefore, while uploading multimedia data, merchant users will also upload product data that they want to mount.
S702:根据对所述多媒体数据进行跨域特征提取而获得的内容特征和对所述商品数据进行跨域特征提取而获得的商品特征,获取所述商品数据和所述多媒体数据之间的相关度。上述的各种特征的提取处理,可以使用前述实施例中介绍的特征提取模型,从而形成能够进行相关度计算的跨域特征内容。S702: Obtain the correlation between the commodity data and the multimedia data according to content features obtained by performing cross-domain feature extraction on the multimedia data and commodity features obtained by performing cross-domain feature extraction on the commodity data . For the extraction processing of the above various features, the feature extraction model introduced in the foregoing embodiment can be used to form cross-domain feature content capable of correlation calculation.
S703:根据所述相关度,从多个待挂载的商品数据中进行商品数据推荐。具体地,可以对多个商品数据与所述多媒体数据的相关度进行排名,基于该排名向所述用户推荐可挂载的商品数据,例如,可以选择排名靠前的一定数量的商品数据作为可挂载商品数据。S703: Perform commodity data recommendation from a plurality of commodity data to be mounted according to the relevancy. Specifically, the degree of relevancy between a plurality of commodity data and the multimedia data may be ranked, and based on the ranking, the user may be recommended the commodity data that can be mounted. For example, a certain amount of commodity data in the top ranking may be selected as the available commodity data. Mount product data.
此外,在多媒体数据发布后,可能会收到大量的评论数据,在本发明实施例中,还可以获取这些评论数据,根据对所述评论数据进行跨域特征提取而获得的特征,更新向所述用户推荐的商品数据,例如可以建议用户是否更换一些挂载的商品数据,或者重新制作多媒体数据等。此外,上述的评论数据还可以包括商品的一些评论数据,随着商品评论数据的变化,可以影响到与多媒体数据的匹配程度,从而也可以根据商品的评论数据来更新向用户的商品数据推荐。In addition, after the multimedia data is released, a large amount of comment data may be received. In the embodiment of the present invention, the comment data can also be obtained, and the update to all comment data can be updated according to the features obtained by performing cross-domain feature extraction on the comment data. The product data recommended by the user, for example, can suggest whether the user should replace some mounted product data, or recreate multimedia data, etc. In addition, the above-mentioned review data may also include some review data of the product. With the change of the product review data, the matching degree with the multimedia data may be affected, so that the product data recommendation to the user may also be updated according to the product review data.
以上在进行商品数据挂载推荐过程中,主要考虑的多媒体数据特征与商品特征之间的关联性,除此之外,还可以引入用户的地理位置信息,来进行商品数据挂载的推荐。例如,对于一些农产品,经常会出现商家用户或者普通消费者用户集中在一个区域的情形,在这种情况下,可以基于该地域特点,推荐一些与该地域相关的商品数据挂载到多媒体数据中,从而促进该地区的商品销售。In the above process of product data mounting recommendation, the main consideration is the correlation between multimedia data features and product features. In addition, the user's geographic location information can also be introduced to recommend product data mounting. For example, for some agricultural products, it often happens that business users or ordinary consumer users are concentrated in one area. In this case, it is possible to recommend some commodity data related to the area to be mounted in the multimedia data based on the characteristics of the area. , thereby promoting the sales of goods in the region.
如图11所示,其为本发明实施例的商品挂载的处理装置的结构示意图之一,该装置可以应用于电商平台、具有多媒体发布功能的社交平台以及直播平台等,用于向多媒体数据中挂载具有一定关联性的商品数据,具体地,该装置可以包括:As shown in FIG. 11 , which is one of the structural schematic diagrams of the processing device for commodity mounting according to the embodiment of the present invention, the device can be applied to an e-commerce platform, a social platform with a multimedia publishing function, a live broadcast platform, etc. Commodity data with certain relevance is mounted in the data. Specifically, the device may include:
多媒体特征提取模块11,用于获取多媒体数据,对多媒体数据进行跨域特征提取,生成与该多媒体数据对应的多媒体特征向量,其中,跨域特征提取使得生成的特征向量能够跨域对齐。本发明实施例中的多媒体数据可以包括视频网站发布的视频、社交平台发布的短视频、直播平台的直播视频等,本实施例的应用场景可以当视频发布时为该视频寻找合适的挂载商品,也可以是对已经发布的视频匹配合适的挂载商品。上述的跨域特征提取可以使用基于前面介绍的训练方法而获得特征提取模型来实现。在本实施例中,跨域主要是指跨多媒体域和商品域,如前面介绍的,这两个领域的内容组织形态差别较大,通过本发明实施例提供的跨域特征提取处理,实现针对这两个内容域所提取出的特征向量能够处于同一向量空间中,能够进行基于语义相关度的比对或者融合等处理,即具有跨域对齐的特性。The multimedia
商品特征提取模块12,用于获取多个候选商品数据,对候选商品数据进行跨域特征提取,生成多个商品特征向量。候选商品数据可以来自于用户在商品数据库中选定操作而确定。此外,候选商品数据也可以是来自于一些商家的推荐或者基于平台广告策略的推荐等。然后再使用本实施例的装置对候选商品进行进一步筛选。上述处理中所说的跨域特征提取同样可以使用基于前面介绍的训练方法而获得特征提取模型来实现,提取出的商品特征向量与多媒体特征向量能够对齐,可以进行向量间的相关度计算等处理。The commodity
相关度处理模块13,用于根据多个商品特征向量与多媒体特征向量之间的相关度,从多个候选商品数据中确定进行挂载的商品数据。在提取出了商品特征向量和多媒体特征向量后,可以通过计算向量间距离的方式来确定相关度,向量间的相关度也就代表了候选商品数据与多媒体数据之间的相关度,从而可以从候选商品数据选择出相关度排名靠前的商品数据进行挂载。The correlation
上述的商品特征向量和/或多媒体特征向量可以包括基于图像数据提取出的图像特征向量和/或基于文本数据提取出的文本特征向量。商品数据和多媒体数据对应的图像特征向量和文本特征向量可以分别对应进行特征向量的相关度计算,也可以交叉的相关度计算。如前面所介绍的,本发明实施例的特征提取模型可以基于经过预训练的具有跨模态特征提取能力的特征提取模型,因此,提取出的图像特征向量和基于文本数据之间也可以进行相关度的计算,从而实现在跨模态的基础上的跨域特征比对。The aforementioned commodity feature vector and/or multimedia feature vector may include an image feature vector extracted based on image data and/or a text feature vector extracted based on text data. The image feature vector and the text feature vector corresponding to the commodity data and the multimedia data can be respectively calculated for the correlation of the feature vectors, and also can be calculated for the cross correlation. As described above, the feature extraction model in this embodiment of the present invention may be based on a pre-trained feature extraction model with cross-modal feature extraction capability. Therefore, correlation between the extracted image feature vector and text-based data may also be performed. Calculation of degree, so as to achieve cross-domain feature comparison on the basis of cross-modality.
本发明实施例的商品挂载的处理装置,基于跨域的特征提取处理,生成了商品域对应的商品特征向量和多媒体域对应的多媒体特征向量,并进行跨域的特征比对,从而对候选商品数据进行筛选,将与多媒体数据匹配性较好的商品数据挂载到媒体数据上,从而让用户在浏览视频或者直播等多媒体内容时,能够获得更加有价值的商品信息。The processing device for commodity mounting according to the embodiment of the present invention generates a commodity feature vector corresponding to the commodity domain and a multimedia feature vector corresponding to the multimedia domain based on the cross-domain feature extraction processing, and performs cross-domain feature comparison, so as to determine the candidate The product data is screened, and the product data that matches the multimedia data better is mounted on the media data, so that users can obtain more valuable product information when browsing multimedia content such as videos or live broadcasts.
如图12所示,其为本发明实施例的商品挂载的处理装置的结构示意图之二,该装置可以应用于电商平台、具有多媒体发布功能的社交平台以及直播平台等,用于向多媒体数据中挂载具有一定关联性的商品数据,具体地,该装置可以包括:As shown in FIG. 12 , which is the second schematic diagram of the structure of a processing device for commodity mounting according to an embodiment of the present invention, the device can be applied to e-commerce platforms, social platforms with multimedia publishing functions, and live broadcast platforms, etc. Commodity data with certain relevance is mounted in the data. Specifically, the device may include:
多媒体特征提取模块21,用于获取多媒体数据,对多媒体数据进行跨域特征提取,生成与该多媒体数据对应的多媒体特征向量,其中,跨域特征提取使得生成的特征向量能够跨域对齐。该步骤的处理和前面实施例中的多媒体特征提取模块11是一致的。The multimedia
商品检索处理模块22,用于根据多媒体特征向量进行商品数据检索,获取与多媒体特征向量的相关度大于预设阈值的商品特征向量对应的商品数据。本实施例可以应用于电商平台或者社交平台等为用户上传的视频或者正在进行的直播而选择商品进行挂载的场景。平台一侧可以预先构建商品特征向量数据库,即将电商平台中已有商品数据使用本发明实施例提供的特征提取模型,预先提取出具有跨域对齐性质的商品特征向量,并形成商品特征向量数据库。相应地,该模块的处理可以具体包括:根据多媒体特征向量,在商品特征向量数据库中进行检索,获取与多媒体特征向量之间的相关度大于预设阈值的商品特征向量,然后再根据商品特征向量获取对应的商品数据。The commodity
挂载处理模块23,用于将商品数据挂载到多媒体数据上。此外,也可以先将检索到的商品数据作为候选商品数据推荐给用户,然后,根据用户对候选商品数据的选择,执行商品数据的挂载处理,从而给用户一定的自主选择性。The mounting
与前述实施例类似地,上述的商品特征向量和/或多媒体特征向量可以包括基于图像数据提取出的图像特征向量和/或基于文本数据提取出的文本特征向量。商品数据和多媒体数据对应的图像特征向量和文本特征向量可以分别对应进行特征向量的相关度计算,也可以交叉的相关度计算。Similar to the foregoing embodiments, the aforementioned commodity feature vector and/or multimedia feature vector may include an image feature vector extracted based on image data and/or a text feature vector extracted based on text data. The image feature vector and the text feature vector corresponding to the commodity data and the multimedia data can be respectively calculated for the correlation of the feature vectors, and also can be calculated for the cross correlation.
本发明实施例的商品挂载的处理装置,基于跨域的特征提取处理,生成了商品域对应的商品特征向量和多媒体域对应的多媒体特征向量,并进行跨域的基于特征向量的检索,从而获取与多媒体数据匹配性较好的商品数据挂载到媒体数据上,从而让用户在浏览视频或者直播等多媒体内容时,能够获得更加有价值的商品信息。The processing device for commodity mounting according to the embodiment of the present invention generates a commodity feature vector corresponding to the commodity domain and a multimedia feature vector corresponding to the multimedia domain based on the cross-domain feature extraction processing, and performs cross-domain retrieval based on the feature vector, thereby Obtain commodity data that matches the multimedia data and mount it on the media data, so that users can obtain more valuable commodity information when browsing multimedia content such as videos or live broadcasts.
如图13所示,其为本发明实施例推荐处理装置的结构示意图,该装置可以应用于电商平台、具有多媒体发布功能的社交平台以及直播平台等,用于主动向用户进行内容推荐,具体地,该装置可以包括:As shown in FIG. 13 , which is a schematic structural diagram of a recommendation processing device according to an embodiment of the present invention, the device can be applied to e-commerce platforms, social platforms with multimedia publishing functions, and live broadcast platforms, etc., to actively recommend content to users. Specifically, Ground, the apparatus may include:
历史数据获取模块31,用于获取用户历史访问的历史多媒体数据和/或历史商品数据。在本实施例的应用场景中,可以基于用户的历史访问行为来进行主动推荐,例如用户打开电商APP的页面,在不输入任何关键词的情况下,可以在首页上为用户展示一些相关的内容推荐。上述的历史多媒体数据和/或历史商品数据可以通过用户的APP,在获得用户明确许可的情况下,记录用户的历史访问行为,并上报给电商平台,用以为用户提供更好的内容推荐体验。The historical
历史数据特征提取模块32,用于对历史多媒体数据和/或历史商品数据进行跨域特征提取,生成对应的历史多媒体特征向量和/或历史商品特征向量,其中,跨域特征提取使得生成的特征向量能够跨域对齐。The historical data feature
跨域特征提取处理和前面实施例中提到的对多媒体数据和商品数据进行特征提取的处理是一样的,可以使用基于前面介绍的训练方法而获得特征提取模型来实现。并且,上述的历史多媒体数据和/或历史商品数据中均可以包括图像数据和/或文本数据,相应地,上述的商品特征向量和/或多媒体特征向量可以包括基于图像数据提取出的图像特征向量和/或基于文本数据提取出的文本特征向量。The cross-domain feature extraction process is the same as the feature extraction process for multimedia data and commodity data mentioned in the previous embodiment, and can be implemented by obtaining a feature extraction model based on the training method described above. In addition, the above-mentioned historical multimedia data and/or historical commodity data may include image data and/or text data, and accordingly, the above-mentioned commodity feature vectors and/or multimedia feature vectors may include image feature vectors extracted based on image data. and/or text feature vectors extracted based on text data.
数据检索处理模块33,用于根据历史多媒体特征向量和/或历史商品特征向量,进行多媒体数据和/或商品数据的检索,获取与多媒体特征向量和/或商品特征向量之间的相关度大于预设阈值的多媒体数据和/或商品数据,作为推荐数据。在提取出了商品特征向量和多媒体特征向量后,可以通过计算向量间距离的方式来确定相关度,向量间的相关度也就代表了商品数据与多媒体数据之间的相关度,从而可以检索到与用户历史行为相关度较高的商品数据与多媒体数据,为用户进行合理的内容推荐。The data
上述的检索多媒体数据和/或商品数据的过程中,可以在预先生成的存储有多媒体特征向量的数据库和/或商品特征向量的数据库中进行检索。平台可以预先将其存储的多媒体数据和/或商品数据,使用本发明实施例提供的特征提取模型,预先进行特征向量的提取,形成特征向量数据库,在此基础上,可以根据用户的历史多媒体特征向量和/或历史商品特征向量,在该数据库中进行检索,获取与历史多媒体特征向量和/或历史商品特征向量的相关度大于预设阈值的多媒体特征向量和/或商品特征向量;然后,再根据获取到的多媒体特征向量和/或商品特征向量,确定对应的多媒体数据和/或商品数据作为推荐数据。In the above process of retrieving multimedia data and/or commodity data, retrieval may be performed in a pre-generated database storing multimedia feature vectors and/or a database of commodity feature vectors. The platform can pre-store the multimedia data and/or commodity data, and use the feature extraction model provided by the embodiment of the present invention to extract feature vectors in advance to form a feature vector database. vector and/or historical commodity feature vector, perform retrieval in the database to obtain the multimedia feature vector and/or commodity feature vector whose correlation with the historical multimedia feature vector and/or historical commodity feature vector is greater than the preset threshold; According to the acquired multimedia feature vector and/or product feature vector, the corresponding multimedia data and/or product data are determined as recommendation data.
本发明实施例的推荐处理装置,基于跨域的特征提取处理,对用户的历史访问行为所涉及的历史多媒体数据和/或历史商品数据进行了跨域的特征提取,从基于提取出的特征向量,检索匹配性较好的多媒体数据和/或商品数据推荐给用户,从而让用户能够获得更好的内容推荐体验。The recommendation processing apparatus according to the embodiment of the present invention performs cross-domain feature extraction on the historical multimedia data and/or historical commodity data involved in the user's historical access behavior based on the cross-domain feature extraction processing, and extracts the features from the extracted feature vector based on the , retrieving and recommending multimedia data and/or commodity data with better matching to the user, so that the user can obtain a better content recommendation experience.
如图14所示,其为本发明实施例检索处理装置的结构示意图,该装置可以应用于电商平台上,用于根据用户输入的关键词进行内容检索,具体地,该装置可以包括:As shown in FIG. 14 , which is a schematic structural diagram of a retrieval processing device according to an embodiment of the present invention, the device can be applied to an e-commerce platform to perform content retrieval according to keywords input by a user. Specifically, the device may include:
查询向量生成模块41,用于根据用户的输入的检索信息,生成查询向量。本实施例的应用场景可以为用户通过电商平台的检索页面输入检索信息而发起的检索。其中,对于检索信息的特征提取,可以采用前述的本发明实施例提供的特征提取模型来进行执行。The query
查询向量检索模块42,用于根据查询向量,在商品特征向量数据库和/或多媒体特征向量数据库中进行查询,获取与查询向量之间的第一相关度大于预设第一阈值的商品特征向量和/或多媒体特征向量,其中,商品特征向量数据库和/或多媒体特征向量数据库中的商品特征向量和/或多媒体特征向量基于跨域特征提取而获得,跨域特征提取使得生成的特征向量能够跨域对齐。如前面介绍的,电商平台可以预先对多媒体数据和商品数据,使用本发明实施例提供的特征提取模型,进行特征向量的提取,形成特征向量数据库。在此基础上,将用户的输入的检索信息转换为查询向量后,就可以与向量数据库中的向量进行比对了。The query
检索结果反馈模块43,用于根据获取到的商品特征向量和/或多媒体特征向量,向用户返回对应的商品数据和/或多媒体数据作为检索结果。向用户返回的检索结果中,可以包括例如短视频、正在进行的直播等多媒体数据,也可以包括在电商平台上发布的商品数据。此外,在多媒体数据中,还可以进一步挂载有具有商品数据,例如,短视频中关联的商品链接等。The retrieval
针对多媒体数据中挂载的商品数据,电商平台可以在向用户返回检索结果时,对挂载的商品数据与多媒体数据之间的相关度进行一下判定,剔除一些不相干的商品。此外,对于检索结果中没有挂载商品数据或者挂载商品数据较少的多媒体数据,可以进一步获取相关的商品数据进行挂载,并推荐给用户。For the commodity data mounted in the multimedia data, the e-commerce platform can judge the correlation between the mounted commodity data and the multimedia data when returning the retrieval result to the user, and eliminate some irrelevant commodities. In addition, for multimedia data with no or less commodity data mounted in the retrieval result, relevant commodity data can be further obtained and mounted, and recommended to the user.
本发明实施例的检索处理装置,基于跨域的特征提取处理所形成的特征向量数据库,可以根据用户输入的检索信息所形成的特征向量,进行跨域的特征向量的匹配查询,获取到符合用户检索需求的多媒体数据和/或商品数据,从而为能够为用户提供丰富的来自不同内容域的检索结果。The retrieval processing apparatus of the embodiment of the present invention, based on the feature vector database formed by the cross-domain feature extraction process, can perform a matching query of the cross-domain feature vector according to the feature vector formed by the retrieval information input by the user, and obtain the matching query of the cross-domain feature vector. Retrieve the required multimedia data and/or commodity data, so as to provide users with rich retrieval results from different content domains.
如图15所示,其为本发明实施例的特征提取模型的训练装置的结构示意图,本发明实施例的训练装置可以应用于电商平台、搜索引擎、提供云服务的数据服务平台上,用于对搜索引擎、内容推荐等处理系统中的特征提取模型进行训练,以实现对不同内容域的数据进行特征提取,并使得提取出的特征向量能够对齐,从而便于后续的在各个内容域之间进行特征比对或者融合等进一步的处理,该装置可以包括:As shown in FIG. 15 , which is a schematic structural diagram of a training device for a feature extraction model according to an embodiment of the present invention, the training device in the embodiment of the present invention can be applied to an e-commerce platform, a search engine, and a data service platform that provides cloud services. It is used to train feature extraction models in processing systems such as search engines and content recommendation, so as to extract features from data in different content domains, and to align the extracted feature vectors, so as to facilitate subsequent analysis between content domains. For further processing such as feature comparison or fusion, the device may include:
样本获取模块51,用于获取多个内容域中内容关联的样本组成多个跨域样本组合。为了对特征提取模型进行训练,可以预先构建样本集。其中,样本可以来自于任意一个内容域中的数据,例如来自多媒体域的某个视频或者来自商品域的某个商品数据等。如果这些来自不同内容域的样本之间具有已知的关联性,那么可以将这些样本组合为跨域样本组合,用户进行模型训练。在前面的示例中,以在多媒体数据中挂载的商品数据所组成的样本对作为了跨域样本组合的示例,在实际的应用中,由于内容域可能会有多个,跨域样本组合中的样本个数也可以为多个。The sample acquisition module 51 is configured to acquire content-related samples in multiple content domains to form multiple cross-domain sample combinations. For training the feature extraction model, a sample set can be pre-built. The sample may come from data in any content domain, such as a video from a multimedia domain or a commodity data from a commodity domain. If these samples from different content domains have known correlations, these samples can be combined into a cross-domain sample combination, and the user can perform model training. In the previous example, the sample pair composed of commodity data mounted in the multimedia data is used as an example of cross-domain sample combination. In practical applications, since there may be multiple content domains, in cross-domain sample combination The number of samples can also be multiple.
特征向量生成模块52,用于使用被训练的特征提取模型,对跨域样本组合中的样本的原始数据进行特征提取,生成与样本对应的特征向量。其中,无论是哪个内容域的样本数据,都可以包括多个模态的数据,这里所说的模态是指数据本身存在的形式,模态一般可以包括:图像、音频、文字等等。因此,特征提取处理可以包括:对跨域样本组合中的样本的各个模态的原始数据分别进行特征提取,生成与样本对应的多个模态的特征向量。在本发明实施例中,可以选择图像数据和文本数据作为主要的模态,音频数据可以预先转换为文本数据,即上述的样本的原始数据可以包括图像数据和/或文本数据,相应地,特征提取处理可以包括:对跨域样本组合中的样本的图像数据和/或文本数据分别进行特征提取,生成与样本对应的图像特征向量和/或文本特征向量。The feature vector generation module 52 is configured to use the trained feature extraction model to perform feature extraction on the original data of the samples in the cross-domain sample combination, and generate feature vectors corresponding to the samples. Wherein, no matter which content domain the sample data is, it can include data of multiple modalities. The modality mentioned here refers to the form in which the data itself exists, and the modalities can generally include: image, audio, text, and so on. Therefore, the feature extraction process may include: performing feature extraction on the raw data of each modality of the samples in the cross-domain sample combination, respectively, to generate feature vectors of multiple modalities corresponding to the samples. In this embodiment of the present invention, image data and text data may be selected as the main modalities, and audio data may be converted into text data in advance, that is, the original data of the above-mentioned samples may include image data and/or text data. The extraction process may include: performing feature extraction on the image data and/or text data of the samples in the cross-domain sample combination, respectively, to generate image feature vectors and/or text feature vectors corresponding to the samples.
这里需要说明的是,本发明实施例中对比学习以及后学的对抗学习,主要是针对跨域的特征提取能力所进行的训练,在存在跨模态的特征提取需求的情况下,上述的被训练的特征提取模型可以采用经过预训练的具有跨模态特征提取能力的特征提取模型,例如在模型选择上,对于文本特征提取部分可以采用预训练的BERT模型,也可以采取端到端的机器学习模型等,对于图像特征提取部分可以采用经过预训练的ResNet模型等。It should be noted here that the comparative learning and post-learning confrontation learning in the embodiments of the present invention are mainly training for cross-domain feature extraction capabilities. In the case of cross-modal feature extraction requirements, the above-mentioned The trained feature extraction model can use a pre-trained feature extraction model with cross-modal feature extraction capability. For example, in model selection, a pre-trained BERT model can be used for text feature extraction, or end-to-end machine learning can be used. model, etc. For the image feature extraction part, a pre-trained ResNet model can be used.
训练模块53,用于对特征提取模型进行对比学习训练,以缩小跨域样本组合内部的样本对应的特征向量之间的距离,放大跨域样本组合之间的样本对应的特征向量之间的距离作为训练目标。The training module 53 is used to perform comparative learning and training on the feature extraction model, so as to reduce the distance between the feature vectors corresponding to the samples inside the cross-domain sample combination, and enlarge the distance between the feature vectors corresponding to the samples between the cross-domain sample combinations as a training target.
此外,为了提高对比学习的训练效果,本发明实施例可以引入对抗学习进行辅助训练。因此,上述训练模块53还可以用于:对特征提取模型进行对抗学习训练,以降低对抗学习的判别器对于特征向量所属的内容域的判别准确度作为训练目标。在本实施例中,对抗学习的作用在于增加对比学习的难度,并作为检验对比学习效果的鉴别器,即当对抗学习的判别器无法准确判断出特征提取模型所提取出的特征向量来自于哪个内容域时,相当于对比学习已经将不同内容域的特征向量进行了良好的对齐,实现了较好的跨域特征提取的效果。In addition, in order to improve the training effect of the contrastive learning, the embodiment of the present invention may introduce adversarial learning for auxiliary training. Therefore, the above-mentioned training module 53 can also be used to perform adversarial learning training on the feature extraction model, so as to reduce the discrimination accuracy of the adversarial learning discriminator for the content domain to which the feature vector belongs as a training target. In this embodiment, the role of adversarial learning is to increase the difficulty of comparative learning and serve as a discriminator for checking the effect of comparative learning, that is, when the discriminator of adversarial learning cannot accurately determine which feature vector extracted by the feature extraction model comes from When the content domain is used, it is equivalent to the contrastive learning that the feature vectors of different content domains have been well aligned, and a better effect of cross-domain feature extraction has been achieved.
关于对比学习以及对抗学习的具体内容示例在前面的训练方法实施例中已经进行了介绍,在此不再赘述。Specific content examples about the contrastive learning and the adversarial learning have been introduced in the foregoing training method embodiments, and will not be repeated here.
本发明实施例所提供的模型训练装置,通过对比学习或者对比学习结合对抗学习的训练方式,能够使得训练后的特征提取模型,针对不同的内容域所提取出的特征向量,能够实现对齐,从而可以实现跨域的特征比对以及特征融合,能够有效提高跨域的内容检索以及推荐的匹配效果。The model training device provided by the embodiment of the present invention, through the training method of contrastive learning or contrastive learning combined with adversarial learning, can make the feature extraction model after training, for the feature vectors extracted from different content domains, to achieve alignment, thereby Cross-domain feature comparison and feature fusion can be realized, which can effectively improve the cross-domain content retrieval and recommendation matching effect.
前面实施例描述了模型训练方法、商品挂载处理方法、检索方法、推荐方法的流程处理及对应的装置结构,上述的方法和装置的功能可借助一种电子设备实现完成,如图16所示,其为本发明实施例的电子设备的结构示意图,具体包括:存储器110和处理器120。The previous embodiments describe the model training method, the commodity loading processing method, the retrieval method, the process flow processing of the recommendation method, and the corresponding device structure. The functions of the above-mentioned methods and devices can be realized with the help of an electronic device, as shown in FIG. 16 . , which is a schematic structural diagram of an electronic device according to an embodiment of the present invention, and specifically includes: a
存储器110,用于存储程序。The
除上述程序之外,存储器110还可被配置为存储其它各种数据以支持在电子设备上的操作。这些数据的示例包括用于在电子设备上操作的任何应用程序或方法的指令,联系人数据,电话簿数据,消息,图片,视频等。In addition to the above-described programs, the
存储器110可以由任何类型的易失性或非易失性存储设备或者它们的组合实现,如静态随机存取存储器(SRAM),电可擦除可编程只读存储器(EEPROM),可擦除可编程只读存储器(EPROM),可编程只读存储器(PROM),只读存储器(ROM),磁存储器,快闪存储器,磁盘或光盘。
处理器120,耦合至存储器110,用于执行存储器110中的程序,以执行前述实施例中所描述的任一方法或者多种方法的操作步骤。The
此外,处理器120也可以包括前述实施例所描述的各种模块以执行前述实施例中所描述的任一方法或者多种方法的处理,并且存储器110可以例如用于存储这些模块执行操作所需要的数据和/或所输出的数据。In addition, the
对于上述处理过程具体说明、技术原理详细说明以及技术效果详细分析在前面实施例中进行了详细描述,在此不再赘述。The specific description of the above-mentioned processing process, the detailed description of the technical principle, and the detailed analysis of the technical effect have been described in detail in the foregoing embodiments, and will not be repeated here.
进一步,如图所示,电子设备还可以包括:通信组件130、电源组件140、音频组件150、显示器160等其它组件。图中仅示意性给出部分组件,并不意味着电子设备只包括图中所示组件。Further, as shown in the figure, the electronic device may further include: a
通信组件130被配置为便于电子设备和其他设备之间有线或无线方式的通信。电子设备可以接入基于通信标准的无线网络,如WiFi,2G、3G、4G/LTE、5G等移动通信网络,或它们的组合。在一个示例性实施例中,通信组件130经由广播信道接收来自外部广播管理系统的广播信号或广播相关信息。在一个示例性实施例中,通信组件130还包括近场通信(NFC)模块,以促进短程通信。例如,在NFC模块可基于射频识别(RFID)技术,红外数据协会(IrDA)技术,超宽带(UWB)技术,蓝牙(BT)技术和其他技术来实现。
电源组件140,为电子设备的各种组件提供电力。电源组件140可以包括电源管理系统,一个或多个电源,及其他与为电子设备生成、管理和分配电力相关联的组件。The
音频组件150被配置为输出和/或输入音频信号。例如,音频组件150包括一个麦克风(MIC),当电子设备处于操作模式,如呼叫模式、记录模式和语音识别模式时,麦克风被配置为接收外部音频信号。所接收的音频信号可以被进一步存储在存储器110或经由通信组件130发送。在一些实施例中,音频组件150还包括一个扬声器,用于输出音频信号。
显示器160包括屏幕,其屏幕可以包括液晶显示器(LCD)和触摸面板(TP)。如果屏幕包括触摸面板,屏幕可以被实现为触摸屏,以接收来自用户的输入信号。触摸面板包括一个或多个触摸传感器以感测触摸、滑动和触摸面板上的手势。触摸传感器可以不仅感测触摸或滑动动作的边界,而且还检测与触摸或滑动操作相关的持续时间和压力。The
此外,本发明实施例还提供了一种计算机程序产品,包括计算机程序或指令,当计算机程序或指令被处理器执行时,致使处理器实现前述的方法。In addition, an embodiment of the present invention also provides a computer program product, including a computer program or instructions, which, when executed by a processor, cause the processor to implement the aforementioned method.
本领域普通技术人员可以理解:实现上述各方法实施例的全部或部分步骤可以通过程序指令相关的硬件来完成。前述的程序可以存储于计算机可读取存储介质中。该程序在执行时,执行包括上述各方法实施例的步骤;而前述的存储介质包括:ROM、RAM、磁碟或者光盘等各种可以存储程序代码的介质。Those of ordinary skill in the art can understand that all or part of the steps of implementing the above method embodiments may be completed by program instructions related to hardware. The aforementioned program can be stored in a computer-readable storage medium. When the program is executed, the steps including the above method embodiments are executed; and the foregoing storage medium includes: ROM, RAM, magnetic disk or optical disk and other media that can store program codes.
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。Finally, it should be noted that the above embodiments are only used to illustrate the technical solutions of the present invention, but not to limit them; although the present invention has been described in detail with reference to the foregoing embodiments, those of ordinary skill in the art should understand that: The technical solutions described in the foregoing embodiments can still be modified, or some or all of the technical features thereof can be equivalently replaced; and these modifications or replacements do not make the essence of the corresponding technical solutions deviate from the technical solutions of the embodiments of the present invention. scope.
Claims (29)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110328304.0ACN113420166B (en) | 2021-03-26 | 2021-03-26 | Product mounting, retrieval, recommendation, training processing method, device and electronic equipment |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110328304.0ACN113420166B (en) | 2021-03-26 | 2021-03-26 | Product mounting, retrieval, recommendation, training processing method, device and electronic equipment |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN113420166Atrue CN113420166A (en) | 2021-09-21 |
| CN113420166B CN113420166B (en) | 2024-11-26 |
Family
ID=77711877
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110328304.0AActiveCN113420166B (en) | 2021-03-26 | 2021-03-26 | Product mounting, retrieval, recommendation, training processing method, device and electronic equipment |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN113420166B (en) |
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113435984A (en)* | 2021-08-27 | 2021-09-24 | 苏州浪潮智能科技有限公司 | Cross-domain recommendation method, system, storage medium and equipment |
| CN114358821A (en)* | 2021-12-27 | 2022-04-15 | 创优数字科技(广东)有限公司 | Commodity detail feature extraction method and device, computer equipment and storage medium |
| CN114372195A (en)* | 2021-12-16 | 2022-04-19 | 阿里巴巴(中国)有限公司 | Product search processing method and electronic device |
| CN114418032A (en)* | 2022-02-22 | 2022-04-29 | 中山大学 | A five-modal commodity pre-training method and retrieval system based on self-coordinated contrastive learning |
| CN115204366A (en)* | 2022-06-30 | 2022-10-18 | 北京明略昭辉科技有限公司 | Model generation method, apparatus, computer equipment and storage medium |
| CN115496559A (en)* | 2022-09-26 | 2022-12-20 | 上海众源网络有限公司 | Recommended method, device, electronic equipment and storage medium for mounting commodities |
| CN116415064A (en)* | 2022-12-26 | 2023-07-11 | 京东城市(北京)数字科技有限公司 | Training method and device for dual-target domain recommendation model |
| CN116562359A (en)* | 2023-07-10 | 2023-08-08 | 深圳须弥云图空间科技有限公司 | CTR prediction model training method and device based on contrast learning and electronic equipment |
Citations (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108766462A (en)* | 2018-06-21 | 2018-11-06 | 浙江中点人工智能科技有限公司 | A kind of phonic signal character learning method based on Meier frequency spectrum first derivative |
| CN109213876A (en)* | 2018-08-02 | 2019-01-15 | 宁夏大学 | Based on the cross-module state search method for generating confrontation network |
| CN109299341A (en)* | 2018-10-29 | 2019-02-01 | 山东师范大学 | An adversarial cross-modal retrieval method and system based on dictionary learning |
| WO2019148898A1 (en)* | 2018-02-01 | 2019-08-08 | 北京大学深圳研究生院 | Adversarial cross-media retrieving method based on restricted text space |
| CN110795613A (en)* | 2018-07-17 | 2020-02-14 | 阿里巴巴集团控股有限公司 | Commodity searching method, device and system and electronic equipment |
| CN110990595A (en)* | 2019-12-04 | 2020-04-10 | 成都考拉悠然科技有限公司 | Zero sample cross-mode retrieval method for cross-domain alignment embedding space |
| US20200251100A1 (en)* | 2019-02-01 | 2020-08-06 | International Business Machines Corporation | Cross-domain multi-task learning for text classification |
| CN111598712A (en)* | 2020-05-18 | 2020-08-28 | 北京邮电大学 | Data feature generator training and search method in social media cross-modal search |
| CN111625667A (en)* | 2020-05-18 | 2020-09-04 | 北京工商大学 | Three-dimensional model cross-domain retrieval method and system based on complex background image |
| WO2020224097A1 (en)* | 2019-05-06 | 2020-11-12 | 平安科技(深圳)有限公司 | Intelligent semantic document recommendation method and device, and computer-readable storage medium |
| CN111931062A (en)* | 2020-08-28 | 2020-11-13 | 腾讯科技(深圳)有限公司 | Training method and related device of information recommendation model |
| CN112528644A (en)* | 2020-12-24 | 2021-03-19 | 北京百度网讯科技有限公司 | Entity mounting method, device, equipment and storage medium |
- 2021
- 2021-03-26CNCN202110328304.0Apatent/CN113420166B/enactiveActive
Patent Citations (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2019148898A1 (en)* | 2018-02-01 | 2019-08-08 | 北京大学深圳研究生院 | Adversarial cross-media retrieving method based on restricted text space |
| CN108766462A (en)* | 2018-06-21 | 2018-11-06 | 浙江中点人工智能科技有限公司 | A kind of phonic signal character learning method based on Meier frequency spectrum first derivative |
| CN110795613A (en)* | 2018-07-17 | 2020-02-14 | 阿里巴巴集团控股有限公司 | Commodity searching method, device and system and electronic equipment |
| CN109213876A (en)* | 2018-08-02 | 2019-01-15 | 宁夏大学 | Based on the cross-module state search method for generating confrontation network |
| CN109299341A (en)* | 2018-10-29 | 2019-02-01 | 山东师范大学 | An adversarial cross-modal retrieval method and system based on dictionary learning |
| US20200251100A1 (en)* | 2019-02-01 | 2020-08-06 | International Business Machines Corporation | Cross-domain multi-task learning for text classification |
| WO2020224097A1 (en)* | 2019-05-06 | 2020-11-12 | 平安科技(深圳)有限公司 | Intelligent semantic document recommendation method and device, and computer-readable storage medium |
| CN110990595A (en)* | 2019-12-04 | 2020-04-10 | 成都考拉悠然科技有限公司 | Zero sample cross-mode retrieval method for cross-domain alignment embedding space |
| CN111598712A (en)* | 2020-05-18 | 2020-08-28 | 北京邮电大学 | Data feature generator training and search method in social media cross-modal search |
| CN111625667A (en)* | 2020-05-18 | 2020-09-04 | 北京工商大学 | Three-dimensional model cross-domain retrieval method and system based on complex background image |
| CN111931062A (en)* | 2020-08-28 | 2020-11-13 | 腾讯科技(深圳)有限公司 | Training method and related device of information recommendation model |
| CN112528644A (en)* | 2020-12-24 | 2021-03-19 | 北京百度网讯科技有限公司 | Entity mounting method, device, equipment and storage medium |
Non-Patent Citations (2)
| Title |
|---|
| 于恩: "面向图文检索的跨模态学习算法研究", 中国优秀硕士学位论文全文数据库(电子期刊)信息科技辑, 31 August 2020 (2020-08-31), pages 1 - 83* |
| 刘欢;郑庆华;罗敏楠;赵洪科;肖阳;吕彦章;: "基于跨域对抗学习的零样本分类", 计算机研究与发展, no. 12* |
Cited By (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113435984A (en)* | 2021-08-27 | 2021-09-24 | 苏州浪潮智能科技有限公司 | Cross-domain recommendation method, system, storage medium and equipment |
| CN114372195A (en)* | 2021-12-16 | 2022-04-19 | 阿里巴巴(中国)有限公司 | Product search processing method and electronic device |
| CN114358821A (en)* | 2021-12-27 | 2022-04-15 | 创优数字科技(广东)有限公司 | Commodity detail feature extraction method and device, computer equipment and storage medium |
| CN114418032A (en)* | 2022-02-22 | 2022-04-29 | 中山大学 | A five-modal commodity pre-training method and retrieval system based on self-coordinated contrastive learning |
| CN114418032B (en)* | 2022-02-22 | 2025-06-20 | 中山大学 | A five-modal product pre-training method and retrieval system based on self-coordinated contrastive learning |
| CN115204366A (en)* | 2022-06-30 | 2022-10-18 | 北京明略昭辉科技有限公司 | Model generation method, apparatus, computer equipment and storage medium |
| CN115496559A (en)* | 2022-09-26 | 2022-12-20 | 上海众源网络有限公司 | Recommended method, device, electronic equipment and storage medium for mounting commodities |
| CN116415064A (en)* | 2022-12-26 | 2023-07-11 | 京东城市(北京)数字科技有限公司 | Training method and device for dual-target domain recommendation model |
| WO2024139666A1 (en)* | 2022-12-26 | 2024-07-04 | 京东城市(北京)数字科技有限公司 | Training method and apparatus for dual-target domain recommendation model |
| CN116415064B (en)* | 2022-12-26 | 2025-03-18 | 京东城市(北京)数字科技有限公司 | Training method and device for dual-target domain recommendation model |
| CN116562359A (en)* | 2023-07-10 | 2023-08-08 | 深圳须弥云图空间科技有限公司 | CTR prediction model training method and device based on contrast learning and electronic equipment |
| CN116562359B (en)* | 2023-07-10 | 2023-11-10 | 深圳须弥云图空间科技有限公司 | CTR prediction model training method and device based on contrast learning and electronic equipment |
Also Published As
| Publication number | Publication date |
|---|---|
| CN113420166B (en) | 2024-11-26 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11974019B2 (en) | Identifying related videos based on relatedness of elements tagged in the videos | |
| CN112313697B (en) | System and method for generating interpretable description-based recommendations for description angle augmentation | |
| CN113420166B (en) | Product mounting, retrieval, recommendation, training processing method, device and electronic equipment | |
| US11797634B2 (en) | System and method for providing a content item based on computer vision processing of images | |
| CN104182449B (en) | Individualized video commending system and method based on user interest modeling | |
| US20190332946A1 (en) | Combining machine-learning and social data to generate personalized recommendations | |
| CN113806588B (en) | Method and device for searching videos | |
| KR102801500B1 (en) | Computing apparatus and operating method thereof | |
| CN114090848A (en) | Data recommendation and classification method, feature fusion model and electronic equipment | |
| CN115086279A (en) | Multimedia content pushing method and device, electronic equipment and storage medium | |
| JP2024055797A (en) | Method for providing product review and purchase integrated interface | |
| US20180011613A1 (en) | Generating interactive menu for contents search based on user inputs | |
| CN116186197A (en) | Topic recommendation method, device, electronic equipment and storage medium | |
| CN119831684B (en) | Article recommendation method and device, storage medium and electronic equipment | |
| CN118193763A (en) | Intelligent data screening method and system based on deep learning | |
| CN118296229A (en) | Resource recommendation method, training device, training medium and training equipment for model | |
| CN113535939A (en) | Text processing method and device, electronic equipment and computer readable storage medium | |
| CN119149804A (en) | Information fusion method, content recommendation method and device, electronic equipment and medium | |
| CN116701766A (en) | Research on Graph-Coupled Time Interval Networks for Serialized Recommendation | |
| CN116975322A (en) | Media data display method and device, computer equipment and storage medium | |
| CN116304185A (en) | An information display method, device, computer equipment and storage medium | |
| US11269940B1 (en) | Related content searching | |
| Xu et al. | Model Can Be Subtle: Two Important Mechanisms for Social Media Popularity Prediction | |
| Harichandan et al. | Empowering Children's Learning: A Personalized Video Recommendation using Graph Convolution | |
| Gupta et al. | SHRSE: Multimodal short video hashtag recommendation based on sentiment enhancement |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| TA01 | Transfer of patent application right | ||
| TA01 | Transfer of patent application right | Effective date of registration:20240307 Address after:Singapore Applicant after:Alibaba Innovation Co. Country or region after:Singapore Address before:Room 01, 45th Floor, AXA Building, 8 Shanton Road, Singapore Applicant before:Alibaba Singapore Holdings Ltd. Country or region before:Singapore | |
| GR01 | Patent grant | ||
| GR01 | Patent grant |