CN113326856B - Self-adaptive two-stage feature point matching method based on matching difficulty - Google Patents
Self-adaptive two-stage feature point matching method based on matching difficultyDownload PDFInfo
- Publication number
- CN113326856B CN113326856BCN202110884790.4ACN202110884790ACN113326856BCN 113326856 BCN113326856 BCN 113326856BCN 202110884790 ACN202110884790 ACN 202110884790ACN 113326856 BCN113326856 BCN 113326856B
- Authority
- CN
- China
- Prior art keywords
- picture
- matching
- feature point
- layer
- descriptor
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images


Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/40—Extraction of image or video features
- G06V10/44—Local feature extraction by analysis of parts of the pattern, e.g. by detecting edges, contours, loops, corners, strokes or intersections; Connectivity analysis, e.g. of connected components
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/047—Probabilistic or stochastic networks
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/048—Activation functions
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/74—Image or video pattern matching; Proximity measures in feature spaces
- G06V10/75—Organisation of the matching processes, e.g. simultaneous or sequential comparisons of image or video features; Coarse-fine approaches, e.g. multi-scale approaches; using context analysis; Selection of dictionaries
- G06V10/751—Comparing pixel values or logical combinations thereof, or feature values having positional relevance, e.g. template matching
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Software Systems (AREA)
- Computing Systems (AREA)
- Evolutionary Computation (AREA)
- Biophysics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Data Mining & Analysis (AREA)
- General Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Mathematical Physics (AREA)
- Biomedical Technology (AREA)
- Molecular Biology (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Multimedia (AREA)
- Probability & Statistics with Applications (AREA)
- Databases & Information Systems (AREA)
- Medical Informatics (AREA)
- Image Analysis (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本发明属于图像处理技术领域,具体涉及一种基于匹配困难度的自适应的两阶段特征点匹配方法。The invention belongs to the technical field of image processing, and in particular relates to an adaptive two-stage feature point matching method based on matching difficulty.
背景技术Background technique
特征点匹配是指在图片提取特征点集合后,如何正确对不同图片的特征点集合进行匹配。在基于几何学的计算机视觉任务中,有很重要的应用。比如同时定位与建图技术是无人驾驶的关键技术,通过对摄像机拍摄的图片对进行特征点提取与匹配,根据匹配关系,可以计算出在各个时刻机器人或者车辆的位置信息。良好的匹配结果不仅有助于提高后续计算出的位置的准确性,而且可以为后续的迭代算法提供一个不错的初始值,帮助迭代算法尽快达到最优结果。Feature point matching refers to how to correctly match feature point sets of different pictures after extracting feature point sets from pictures. There are important applications in geometry-based computer vision tasks. For example, simultaneous positioning and mapping technology is the key technology for unmanned driving. By extracting and matching the feature points of the pictures taken by the camera, according to the matching relationship, the position information of the robot or vehicle at each moment can be calculated. A good matching result not only helps to improve the accuracy of the position calculated subsequently, but also provides a good initial value for the subsequent iterative algorithm, helping the iterative algorithm to reach the optimal result as soon as possible.
特征点匹配早期主要是使用最近邻匹配算法。当特征点提取完成时,会得到一个描述其周围信息的向量,称为描述子。而最近邻匹配算法,就是计算描述子之间的欧式距离作为衡量标准,距离越小的特征点越有可能匹配。In the early stage of feature point matching, the nearest neighbor matching algorithm was mainly used. When the feature point extraction is completed, a vector describing its surrounding information, called a descriptor, will be obtained. The nearest neighbor matching algorithm is to calculate the Euclidean distance between the descriptors as a measure. The smaller the distance, the more likely the feature points to match.
虽然最近邻匹配在一些简单环境中有良好的表现,但是当面对困难场景(比如模糊,遮挡,大视角变换)下的匹配,就很难取得令人满意的结果。所以近些年来随着神经网络在图像处理方面的优秀表现,人们开始使用神经网络进行匹配。Although nearest neighbor matching has good performance in some simple environments, it is difficult to achieve satisfactory results when faced with matching in difficult scenes (such as blur, occlusion, large perspective transformation). So in recent years, with the excellent performance of neural network in image processing, people began to use neural network for matching.
虽然用神经网络算法来完成匹配任务,在准确率上取得了较大进步。但是随之而来的是计算量的增加,这让特征点匹配任务很难应用到实时应用中,比如同时定位与建图。Although the neural network algorithm is used to complete the matching task, great progress has been made in the accuracy. But the accompanying increase in computation makes it difficult to apply feature point matching tasks to real-time applications, such as simultaneous localization and mapping.
发明内容SUMMARY OF THE INVENTION
本发明实施例提供了一种基于匹配困难度的自适应的两阶段特征点匹配方法,用于提高图片特征点匹配的准确率。The embodiment of the present invention provides an adaptive two-stage feature point matching method based on matching difficulty, which is used to improve the accuracy of image feature point matching.
本发明实施例提供的一种基于匹配困难度的自适应的两阶段特征点匹配方法,包括下列步骤:An adaptive two-stage feature point matching method based on matching difficulty provided by an embodiment of the present invention includes the following steps:
步骤1,输入待匹配的图片对,其中,输入的图片对的图片信息包括图片的亮度信息和图片的特征点信息,所述特征点信息包括位置信息和描述子,其中位置信息包括特征点的空间位置坐标和置信值;Step 1, input the picture pair to be matched, wherein, the picture information of the input picture pair includes the brightness information of the picture and the feature point information of the picture, and the feature point information includes the position information and the descriptor, wherein the position information includes the feature point. Spatial location coordinates and confidence values;
步骤2,基于图片的亮度信息计算待匹配的图片对之间的图片差异度,若图片差异度达大于或等于差异阈值,则执行步骤3至5,否则执行步骤6;Step 2, based on the brightness information of the picture, calculate the picture difference degree between the pair of pictures to be matched, if the picture difference degree is greater than or equal to the difference threshold, then perform steps 3 to 5, otherwise perform step 6;
步骤3,对各图片的特征点的位置信息进行升维处理,使得升维之后的特征点的位置信息的维度与描述子的维度一致,再将描述子与升维之后的位置信息相加,得到每个特征点的新的描述子;Step 3, performing dimension-raising processing on the position information of the feature points of each picture, so that the dimension of the position information of the feature points after the dimension-raising is consistent with the dimension of the descriptor, and then adding the descriptor and the position information after the dimension-raising, Get a new descriptor for each feature point;
步骤4,对每个特征点的新的描述子进行注意力聚合处理,得到每个特征点的匹配描述子;Step 4: Perform attention aggregation processing on the new descriptor of each feature point to obtain the matching descriptor of each feature point;
步骤5,内积方式计算匹配结果:Step 5, inner product method to calculate the matching result:
将图片对的两张图片分别定义为第一图片和第二图片;Define the two pictures of the picture pair as the first picture and the second picture respectively;
遍历第一图片的每个特征点,采用内积方式计算第一图片的各当前特征点分别与第二图片中的每个特征点的匹配描述子之间的匹配度,若最大匹配度大于或等于第一匹配阈值,则将最大匹配度所对应的第二图片的特征点作为第一图片的当前特征点的匹配结果;Traverse each feature point of the first picture, and use the inner product method to calculate the matching degree between each current feature point of the first picture and the matching descriptor of each feature point in the second picture, if the maximum matching degree is greater than or is equal to the first matching threshold, then the feature point of the second picture corresponding to the maximum matching degree is used as the matching result of the current feature point of the first picture;
步骤6,欧式距离方式计算匹配结果:Step 6, the Euclidean distance method calculates the matching result:
将图片对的两张图片分别定义为第一图片和第二图片;Define the two pictures of the picture pair as the first picture and the second picture respectively;
遍历第一图片的每个特征点,采用欧式距离方式计算第一图片的各当前特征点分别与第二图片中的每个特征点的描述子之间的匹配度,若最小匹配度小于或等于第二匹配阈值,则将最小匹配度所对应的第二图片的特征点作为第一图片的当前特征点的匹配结果。Traverse each feature point of the first picture, and use the Euclidean distance method to calculate the matching degree between each current feature point of the first picture and the descriptor of each feature point in the second picture, if the minimum matching degree is less than or equal to For the second matching threshold, the feature point of the second picture corresponding to the minimum matching degree is used as the matching result of the current feature point of the first picture.
本发明实施例中,首先对图片对之间的图片差异度来选择后续的具体匹配方式,若图片差异度较小,即小于指定的差异阈值,则直接基于特征点的描述子进行匹配处理;否则,在经过一系列的计算处理之后,获取更能表征特征点的匹配描述子,并采用两个匹配描述子之间的内积运算结果作为其匹配度的计算值,将最大且大于第一匹配度阈值的对象作为最终的匹配结果,以提升匹配的准确性。即本发明实施例中,基于第一阶段的差异度检测和第二阶段的特征点聚合(步骤3)以及注意力聚合(步骤4)来实现自适应的两阶段特征点匹配,提升匹配的准确性和处理效率。In this embodiment of the present invention, firstly, a subsequent specific matching method is selected for the degree of difference between the picture pairs. If the degree of difference between the pictures is small, that is, less than a specified difference threshold, the matching process is performed directly based on the descriptor of the feature point; Otherwise, after a series of calculation processing, a matching descriptor that can better characterize the feature points is obtained, and the result of the inner product operation between the two matching descriptors is used as the calculation value of its matching degree, which will be the largest and greater than the first The object with the matching degree threshold is used as the final matching result to improve the matching accuracy. That is, in the embodiment of the present invention, adaptive two-stage feature point matching is realized based on the first-stage difference detection and the second-stage feature point aggregation (step 3) and attention aggregation (step 4) to improve the accuracy of matching performance and processing efficiency.
进一步的,步骤2中,基于图片的亮度信息计算待匹配的图片对之间的图片差异度为:对图片对的两张图片进行尺寸归一化处理,再根据亮度信息的绝对误差和计算图片差异度。Further, in step 2, the degree of picture difference between the picture pairs to be matched is calculated based on the brightness information of the pictures as follows: size normalization is performed on the two pictures of the picture pair, and then the pictures are calculated according to the absolute error of the brightness information and degree of difference.
进一步的,步骤3中,对各图片的特征点的位置信息进行升维处理的方式为:通过多层感知机对各图片的特征点的位置信息进行升维处理。Further, in step 3, the method of performing dimension-raising processing on the position information of the feature points of each picture is: performing a dimension-raising process on the position information of the feature points of each picture by using a multi-layer perceptron.
进一步的,步骤3中,所述多层感知机为:定义L表示多层感知机的网络层数,其中,前L-1层为L-1个第一卷积块的堆叠结构,第L层为加法层;第1个第一卷积块的输入为图片的所有特征点的位置信息,第L-1个第一卷积块输出的特征图的通道数与描述子的维度相同,且所述加法层的输入为图片的所有特征点的描述子和第L-1个第一卷积块的输出特征图,所述第一卷积块包括依次连接的卷积层、批处理层和激活函数ReLu层。Further, in step 3, the multilayer perceptron is defined as: defining L to represent the number of network layers of the multilayer perceptron, wherein the first L-1 layer is the stacking structure of L-1 first convolution blocks, and the Lth layer The layer is an addition layer; the input of the first convolution block is the position information of all feature points of the picture, the number of channels of the feature map output by the L-1 first convolution block is the same as the dimension of the descriptor, and The input of the addition layer is the descriptors of all feature points of the picture and the output feature map of the L-1th first convolution block. The first convolution block includes sequentially connected convolution layers, batch layers and Activation function ReLu layer.
进一步的,步骤4中,对每个特征点的新的描述子进行注意力聚合处理为:Further, in step 4, the attention aggregation processing is performed on the new descriptor of each feature point as follows:
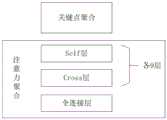
采用LG 层的图网络对特征点的新的描述子进行注意力聚合处理,其中LG为大于1的奇数;The graph network of theLG layer is used to perform attention aggregation processing on the new descriptors of the feature points, whereLG is an odd number greater than 1;
所述图网络的前面LG-1层为self层和cross层的交错层结构,最后一层为全连接层;The front LG -1 layer of the graph network is a staggered layer structure of the self layer and the cross layer, and the last layer is a fully connected layer;
其中,self层和cross层的网络结构相同,均为带注意力机制的神经网络层,所述self层的输入为待匹配的图片对的同一张图片的不同特征点,所述cross层的输入为待匹配的图片对的两张图片的不同特征点。Among them, the network structures of the self layer and the cross layer are the same, and they are both neural network layers with an attention mechanism. The input of the self layer is the different feature points of the same picture of the picture pair to be matched, and the input of the cross layer is are the different feature points of the two images of the image pair to be matched.
进一步的,步骤4中,所述图网络的前LG-1层的每一层的网络结构为两个堆叠的第二卷积块,按照前向传播的方向,每一层的第1个第二卷积块的输入通道数为2M,输出通道数为2M,该第1个第二卷积块的卷积核大小为1×2M×2M;每一层的第2个第二卷积块的输入通道数为2M,输出通道数为M,该第2个第二卷积块的卷积核大小为1×2M×M,其中,M表示描述子的维度,所述第二卷积块包括依次连接的卷积层和激活函数ReLu层。Further, in step 4, the network structure of each layer of the firstLG -1 layer of the graph network is two stacked second convolution blocks. According to the direction of forward propagation, the first layer of each layer is The number of input channels of the second convolution block is 2M, the number of output channels is 2M, and the size of the convolution kernel of the first second convolution block is 1×2M×2M; the second second convolution of each layer The number of input channels of the block is 2M, the number of output channels is M, and the size of the convolution kernel of the second second convolution block is 1×2M×M, where M represents the dimension of the descriptor, and the second convolution block has a size of 1×2M×M. The block consists of sequentially connected convolutional layers and activation function ReLu layers.
进一步的,步骤5中,所述第一匹配阈值的取值范围设置为9~11。Further, in step 5, the value range of the first matching threshold is set to 9-11.
进一步的,步骤6中,所述第二匹配阈值的取值范围设置为0.8~1。Further, in step 6, the value range of the second matching threshold is set to 0.8~1.
本发明实施例提供的技术方案至少带来如下有益效果:The technical solutions provided by the embodiments of the present invention bring at least the following beneficial effects:
(1)本发明实施例通过加入图片差异度检测可以根据匹配困难度灵活的选择匹配方式,在保证准确率的同时又尽可能地提升了速度。相比于传统神经网络的处理方案,在混合环境(复杂环境和简单环境混合)下,速度有明显提升。(1) The embodiment of the present invention can flexibly select the matching method according to the matching difficulty by adding the detection of the difference degree of the pictures, which can improve the speed as much as possible while ensuring the accuracy. Compared with the traditional neural network processing scheme, the speed is significantly improved in a mixed environment (mixed complex environment and simple environment).
(2)相比于传统简单的匹配处理方案,本发明实施例使用了二阶段的神经网络,保证了在复杂情况下,依旧可以达到较高的匹配准确率。(2) Compared with the traditional simple matching processing scheme, the embodiment of the present invention uses a two-stage neural network, which ensures that a high matching accuracy rate can still be achieved in a complex situation.
附图说明Description of drawings
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。In order to illustrate the technical solutions in the embodiments of the present invention more clearly, the following briefly introduces the accompanying drawings used in the description of the embodiments. Obviously, the accompanying drawings in the following description are only some embodiments of the present invention. For those of ordinary skill in the art, other drawings can also be obtained from these drawings without any creative effort.
图1是本发明实施例提供的一种基于匹配困难度的自适应的两阶段特征点匹配方法的流程图;1 is a flowchart of an adaptive two-stage feature point matching method based on matching difficulty provided by an embodiment of the present invention;
图2是本发明实施例一种基于匹配困难度的自适应的两阶段特征点匹配方法中,采用的判断模块的结构示意图;2 is a schematic structural diagram of a judgment module adopted in an adaptive two-stage feature point matching method based on matching difficulty according to an embodiment of the present invention;
图3是本发明实施例一种基于匹配困难度的自适应的两阶段特征点匹配方法中,采用的聚集模块的结构示意图。3 is a schematic structural diagram of an aggregation module used in an adaptive two-stage feature point matching method based on matching difficulty according to an embodiment of the present invention.
具体实施方式Detailed ways
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方式作进一步地详细描述。In order to make the objectives, technical solutions and advantages of the present invention clearer, the embodiments of the present invention will be further described in detail below with reference to the accompanying drawings.
特征点匹配在众多基于几何学的计算机视觉任务中扮演着十分重要的角色,比如三维重建,同时定位与建图。本发明实施例提供了一种可以根据匹配困难程度自适应开启两阶段神经网络的特征点匹配方法,相比于传统匹配方案,在各个环境下都大幅度提高了匹配准确率。并在简单环境下,相较于基于神经网络的匹配方案,有较大的速度提升。Feature point matching plays an important role in many geometry-based computer vision tasks, such as 3D reconstruction, simultaneous localization and mapping. The embodiment of the present invention provides a feature point matching method that can adaptively open a two-stage neural network according to the degree of matching difficulty. Compared with the traditional matching scheme, the matching accuracy is greatly improved in each environment. And in a simple environment, compared with the neural network-based matching scheme, there is a greater speed improvement.
参见图1,本发明实施例提供的一种基于匹配困难度的自适应的两阶段特征点匹配方法,包括下列步骤:Referring to FIG. 1 , an adaptive two-stage feature point matching method based on matching difficulty provided by an embodiment of the present invention includes the following steps:
步骤1,输入待匹配的图片对,其中,输入的图片信息包括图片的亮度信息和图片的特征点信息,所述特征点信息包括位置信息(空间位置坐标和置信值)和描述子;Step 1, input the picture pair to be matched, wherein, the input picture information includes the brightness information of the picture and the feature point information of the picture, and the feature point information includes position information (spatial position coordinates and confidence values) and descriptors;
步骤2,图片差异度检测:基于图片的亮度信息,计算待匹配的图片对之间的图片差异度,若图片差异度达大于或等于差异阈值,则执行步骤3至5,否则执行步骤6;Step 2, detection of picture difference degree: based on the brightness information of the picture, calculate the picture difference degree between the pair of pictures to be matched, if the picture difference degree is greater than or equal to the difference threshold, then perform steps 3 to 5, otherwise, perform step 6;
步骤3,关键点聚合处理:对各图片的特征点的位置信息进行升维处理,使得升维之后的特征点的位置信息的维度与描述子的维度一致,再将描述子与升维之后的位置信息相加,得到每个特征点的新的描述子;Step 3, key point aggregation processing: perform dimension increase processing on the position information of the feature points of each picture, so that the dimension of the position information of the feature points after the dimension increase is consistent with the dimension of the descriptor, and then the descriptor and the dimension after the increase are consistent. The position information is added to obtain a new descriptor for each feature point;
步骤4,注意力聚合后处理:对每个特征点的新的描述子进行注意力聚合处理,得到每个特征点的匹配描述子;Step 4, attention aggregation post-processing: perform attention aggregation processing on the new descriptor of each feature point to obtain the matching descriptor of each feature point;
步骤5,内积方式计算匹配结果:Step 5, inner product method to calculate the matching result:
将图片对的两张图片分别定义为第一图片和第二图片;Define the two pictures of the picture pair as the first picture and the second picture respectively;
遍历第一图片的每个特征点,采用内积方式计算第一图片的各当前特征点分别与第二图片中的每个特征点的匹配描述子之间的匹配度,若最大匹配度大于或等于第一匹配阈值,则将最大匹配度所对应的第二图片的特征点作为第一图片的当前特征点的匹配结果;Traverse each feature point of the first picture, and use the inner product method to calculate the matching degree between each current feature point of the first picture and the matching descriptor of each feature point in the second picture, if the maximum matching degree is greater than or is equal to the first matching threshold, then the feature point of the second picture corresponding to the maximum matching degree is used as the matching result of the current feature point of the first picture;
步骤6,欧式距离方式计算匹配结果:Step 6, the Euclidean distance method calculates the matching result:
将图片对的两张图片分别定义为第一图片和第二图片;Define the two pictures of the picture pair as the first picture and the second picture respectively;
遍历第一图片的每个特征点,采用欧式距离方式计算第一图片的各当前特征点分别与第二图片中的每个特征点的描述子之间的匹配度,若最小匹配度小于或等于第二匹配阈值,则将最小匹配度所对应的第二图片的特征点作为第一图片的当前特征点的匹配结果。Traverse each feature point of the first picture, and use the Euclidean distance method to calculate the matching degree between each current feature point of the first picture and the descriptor of each feature point in the second picture, if the minimum matching degree is less than or equal to For the second matching threshold, the feature point of the second picture corresponding to the minimum matching degree is used as the matching result of the current feature point of the first picture.
本发明实施例中,步骤2至4中的相关处理均采用神经网络实现,本发明实施例的整体处理过程可以分为两个部分:判断模块和两阶段模块,其中两阶段模块具体为:第一阶段聚合模块和第二阶段计算模块,且第二阶段计算模块包括内积计算模块和欧式距离计算模块。In the embodiment of the present invention, the relevant processing in steps 2 to 4 is implemented by neural networks, and the overall processing process of the embodiment of the present invention can be divided into two parts: a judgment module and a two-stage module, wherein the two-stage module is specifically: the first A first-stage aggregation module and a second-stage calculation module, and the second-stage calculation module includes an inner product calculation module and an Euclidean distance calculation module.
两张待匹配的图片(待匹配的图片对)首先经判断模块进行图片差异度检测,若图片差异度达到指定的差异阈值,则开启第一阶段聚合模块和第二阶段的内积计算模块;否则,则只开启第二阶段的欧式距离计算模块,最后基于第二阶段的计算模块的输出结果得到匹配结果。The two pictures to be matched (the pair of pictures to be matched) are first detected by the judgment module for the degree of difference between the pictures. If the degree of difference between the pictures reaches the specified difference threshold, the first-stage aggregation module and the second-stage inner product calculation module are turned on; Otherwise, only the Euclidean distance calculation module of the second stage is turned on, and finally a matching result is obtained based on the output result of the calculation module of the second stage.
在一种可能的实现方式中,所述判断模块主要是用于判断匹配的困难程度。而匹配的困难程度主要由图片之间的差异来决定当两幅图差异较小时,特征点没有发生较大变化,匹配起来难度较小。但是当两幅图片差异较大时,比如发生了光照的剧烈变化,视觉的大幅度变化,模糊的出现,遮挡物的出现,特征点发生了较大变化,此时匹配起来难度较大。参见图2,所述判断模块包括归一化模块(reshape模块)和差异判断模块(SAD(Sum ofAbsolute Differences)模块)。即判断模块首先利用reshape模块将两张图片变成一样大小,即进行尺寸的归一化处理,然后利用绝对误差和算法(SAD)进行图片差异的判断。这样既可以简单判断出图片的差异程度,而且在GPU(图像处理器)上并行程度很高,不会浪费大量时间,具体的计算公式如下。In a possible implementation manner, the judging module is mainly used for judging the difficulty of matching. The difficulty of matching is mainly determined by the difference between the pictures. When the difference between the two pictures is small, the feature points do not change greatly, and the matching is less difficult. However, when the difference between the two pictures is large, such as a dramatic change in illumination, a large change in vision, the appearance of blur, the appearance of occlusions, and the large changes in feature points, it is more difficult to match. Referring to FIG. 2 , the judgment module includes a normalization module (reshape module) and a difference judgment module (SAD (Sum of Absolute Differences) module). That is, the judgment module first uses the reshape module to make the two pictures the same size, that is, normalizes the size, and then uses the sum of absolute error algorithm (SAD) to judge the difference between the pictures. In this way, the degree of difference between the pictures can be easily judged, and the degree of parallelism on the GPU (image processor) is very high, and a lot of time will not be wasted. The specific calculation formula is as follows.
对于待匹配的图片对,分别记为图片IA和IB,并定义IA(i,j)、IB(i,j)分别表示图片IA和IB在像素点(i,j)处的像素亮度值。图片IA和IB经过归一化模块后,尺寸归一化为W*H,W表示宽,H表示高,定义Dscore表示两张图片的差异程度,可以由公式(1)计算得到。For the pair of pictures to be matched, they are denoted as picturesIA andIB respectively, and defineIA (i,j) andIB (i,j) to represent picturesIA andIB at pixel point (i,j) respectively The pixel brightness value at . After the picturesIA andIB go through the normalization module, the size is normalized to W*H, W means width, H means height, and Dscore is defined to indicate the degree of difference between the two pictures, which can be calculated by formula (1).

参见图3,在一种可能的实现方式中,所述聚合模块包括关键点聚合和注意力聚合两部分。Referring to Fig. 3, in a possible implementation manner, the aggregation module includes two parts: key point aggregation and attention aggregation.
定义图片A的特征点数为NA,图片B的特征点数为NB,其中,特征点是基于对图像的特征点提取处理所获得,可以采用现有的任一惯用方式。以及定义diA和diB分别表示图片A和图片B输入的第i个特征点的描述子,描述子的维度取为认为设定,本实施例中,描述子的维度为256。piA和piB分别表示图片A和图片B输入的第i个特征点的位置信息,维度是3,表示特征点的空间坐标(x,y)和置信度。


关键点聚合是指将特征点的位置信息与描述子进行融合,通过多层感知机(MLP)将特征点的位置信息进行升维,再与描述子相加得到新的描述子,这个新的描述子用于后面的注意力聚合。定义


其中,
在一种可能的实现方式中,所采用的用于获取新的描述子的多层感知机的网络结构如表1所示,其中N表示特征点个数,N为NA或者NB。In a possible implementation manner, the adopted network structure of the multilayer perceptron for acquiring new descriptors is shown in Table1 , where N represents the number of feature points, and N is NA orNB .

即本发明实施例中,关键点聚合时采用的多层感知机的网络结构为:定义L表示多层感知机的网络层数,其中前面L-1层为L-1个第一卷积块的堆叠结构,第L层为加法层,所述第一卷积块包括依次连接的卷积层(Convlutionld)、批处理层(BatchNormld)和激活函数ReLu层。其中,多层感知机的输入为一张图片的所有特征点,通道数(维数)为3,即特征点的空间位置信息和置信度;输出为所有特征点,通道数为M,且M的取值与描述子的维度数相同。在L-1个第一卷积块的堆叠结构中,前L-2层的输出通道数逐层增加,直到第L-2层卷积块的输出通道数为M。加法层用于对升维后的位置信息与描述子相加得到新的描述子。That is, in the embodiment of the present invention, the network structure of the multi-layer perceptron used in the aggregation of key points is as follows: L is defined to represent the number of network layers of the multi-layer perceptron, and the first L-1 layer is the L-1 first convolution block. The Lth layer is an addition layer, and the first convolution block includes a convolution layer (Convlutionld), a batch layer (BatchNormld) and an activation function ReLu layer that are connected in sequence. Among them, the input of the multi-layer perceptron is all the feature points of a picture, the number of channels (dimension) is 3, that is, the spatial position information and confidence of the feature points; the output is all the feature points, the number of channels is M, and M The value of is the same as the number of dimensions of the descriptor. In the stacking structure of L-1 first convolution blocks, the number of output channels of the first L-2 layer increases layer by layer until the number of output channels of the L-2 layer convolution block is M. The addition layer is used to add the position information and the descriptor after the dimension increase to obtain a new descriptor.
作为一种优选结构,所述卷积块的数量设置为5,其中,第1层至第5层的输出通道数依次为:32、64、128、256、256。As a preferred structure, the number of the convolution blocks is set to 5, wherein the number of output channels of the first layer to the fifth layer are: 32, 64, 128, 256, 256 in sequence.
所述注意力聚合是为了更好地聚合信息,本发明实施例中,整体的网络架构采用了图网络。即将每一个描述子作为一个节点,用来聚合通过注意力机制得到的信息。The attention aggregation is to better aggregate information. In the embodiment of the present invention, the overall network architecture adopts a graph network. That is, each descriptor is used as a node to aggregate the information obtained through the attention mechanism.
作为一种优选的结构,所述图网络总共设置为19层,将前面18层中的奇数层设置为self层,偶数层设置为cross层。第19层是一个全连接层,称为Final层。As a preferred structure, the graph network is set to 19 layers in total, and the odd-numbered layers in the previous 18 layers are set as the self layer, and the even-numbered layers are set as the cross layer. The 19th layer is a fully connected layer, called the Final layer.
其中,self与cross是指引入的self-cross机制,类似于人类的反复比对,可以决定注意力机制聚合的对象的。之前聚合周围信息时,只停留在了本图片。事实上,还需要聚合对面图片的信息。也就是说self层的聚合对象来自本图片,cross层的聚合对象来自图片对的对方图片,两种层交错出现。Among them, self and cross refer to the introduced self-cross mechanism, similar to the repeated comparison of humans, which can determine the object of the attention mechanism aggregation. When I aggregated the surrounding information before, I only stayed in this picture. In fact, it is also necessary to aggregate the information of the opposite pictures. That is to say, the aggregated object of the self layer comes from this picture, and the aggregated object of the cross layer is from the opposite picture of the picture pair, and the two layers appear alternately.
即本发明实施例中,定义图网络的层数为LG,其前面LG-1层为self层和cross层的交错层,即LG-1的值为偶数,最后一层为全连接层。That is, in the embodiment of the present invention, the number of layers of the defined graph network is LG , and the front LG -1 layer is the interleaved layer of the self layer and the cross layer, that is, the value of LG -1 is an even number, and the last layer is fully connected. Floor.
下面对每一层的计算进行数学表达:The calculation of each layer is mathematically expressed as follows:
定义




定义



基于上一层的描述子进行更新运算,得到当前层的描述子,其具体计算公式如公式(3)所示:The update operation is performed based on the descriptor of the previous layer to obtain the descriptor of the current layer. The specific calculation formula is shown in formula (3):

其中,


表2中,在卷积核大小的表达形式k1*k2*k3中,k1*k2表示卷积核形状,k3表示输出通道数。In Table 2, in the expression k1*k2*k3 of the convolution kernel size, k1*k2 represents the shape of the convolution kernel, and k3 represents the number of output channels.
聚合信息

注意力机制是为了计算聚合信息,注意力机制类似于数据库查询。定义图片A的第l层的输入集合为
















其中,




同理,可以得到图片B的注意力机制的查询列,索引和值:







在self层:In the self layer:
对于图片A,For picture A,

对于图片B,For picture B,

在cross层:On the cross layer:
对于图片A,For picture A,

对于图片B,For picture B,

那么聚合信息




其中,




最后,当经过前面的LG-1层聚合完信息后,全连接层分别对图片A和图片B聚合后得到的描述子进行线性映射,得到匹配描述子(matching descriptors),见公式(6),其中,fiA和fiB就是最终的匹配描述子,记


其中,xiA、xjB分别表示第LG-1层得到的描述子(根据公式(3)计算得到),上标用于区分不同的图片,下标用于区分不同的特征点,Wf和bf表示全连接层的参数,即分别表示全连接层的权重和偏置。Among them, xiA , xjB respectively represent the descriptors obtained from the LG -1 layer (calculated according to formula (3)), the superscript is used to distinguish different pictures, and the subscript is used to distinguish different feature points, Wf and bf represent the parameters of the fully connected layer, that is, the weight and bias of the fully connected layer, respectively.
第二阶段计算模块主要是基于计算匹配得分进行匹配。分为两种计算方式,分别是内积和欧式距离计算。在得到FA和FB后,定义

当两张图片之间的差异度大于或等于指定的差异度阈值时(即第一阶段开启),选择内积计算匹配分数,此时是越大越好。对于FA中的每一个fiA而言,都按照公式(7)与FB中的所有描述子计算匹配分数。对于每一个fiA而言,如果计算出来的最大匹配分数大于阈值threshold1,则这个对应的描述子就是fiA的匹配描述子,进而得到特征点匹配关系。比如f1A与f3B之间的匹配分数最大并大于threshold1,则说明图片A中的第1个特征点与图片B中的第3个特征点匹配。When the difference between the two images is greater than or equal to the specified difference threshold (that is, the first stage is turned on), select the inner product to calculate the matching score, and the bigger the better. For each fiA in FA , the matching score is calculated according to formula (7) and all the descriptors in FB. For each fiA , if the calculated maximum matching score is greater than the threshold threshold1, the corresponding descriptor is the matching descriptor of fiA , and then the feature point matching relationship is obtained. For example, the matching score between f1A and f3B is the largest and greater than threshold1, which means that the first feature point in picture A matches the third feature point in picture B.

优选的,阈值threshold1的取值范围可以设置为9~11。Preferably, the value range of the threshold threshold1 can be set to 9-11.
当两张图片之间的差异度小于指定的差异度阈值时(即第一阶段关闭),选择欧式距离计算匹配分数,此时是越小越好。由于没有经过第一阶段网络的聚合,所以直接对输入的描述子集合DA和DB进行计算。对于DA中的每一个diA而言,都按照公式(8)与DB中所有描述子计算匹配分数。对于每一个diA而言,如果计算出来的最小匹配分数小于阈值threshold2,则这个对应的描述子就是diA匹配描述子,进而得到特征点匹配关系。比如d2A与d3B之间的匹配分数最小并小于threshold2,则说明图片A中的第2个特征点与图片B中的第3个特征点匹配。When the difference between the two images is less than the specified difference threshold (that is, the first stage is closed), select the Euclidean distance to calculate the matching score, and the smaller the better. Since there is no aggregation in the first-stage network, the input descriptor setsDA and DB are directly calculated. For each diA inDA , the matching score is calculated according to formula (8) and all the descriptors in DB. For each diA , if the calculated minimum matching score is less than the threshold threshold2, the corresponding descriptor is the diA matching descriptor, and then the feature point matching relationship is obtained. For example, the matching score between d2A and d3B is the smallest and smaller than threshold2, which means that the second feature point in picture A matches the third feature point in picture B.

优选的,阈值threshold2的取值范围可以设置为0.8~1.0。Preferably, the value range of the threshold threshold2 can be set to 0.8~1.0.
本发明实施例提出了一种基于匹配困难度的自适应的两阶段特征点匹配方法,是面向计算机视觉中涉及到几何学的任务,既能达到高匹配准确度,又能灵活地调整网络使得在各种环境下高效利用计算资源,相比于传统单纯使用神经网络模式,速度有明显提升。且本发明实施例针对不同环境的匹配都能达到高准确率,以及针对不同匹配困难度,能自适应地调整网络架构,高效地利用计算资源,相比传统神经网络,速度有很大提升。The embodiment of the present invention proposes an adaptive two-stage feature point matching method based on matching difficulty, which is oriented to tasks involving geometry in computer vision, which can not only achieve high matching accuracy, but also flexibly adjust the network so that Efficient use of computing resources in various environments, compared with the traditional simple use of neural network mode, the speed is significantly improved. Moreover, the embodiments of the present invention can achieve high accuracy for matching in different environments, and can adaptively adjust the network architecture for different matching difficulties, efficiently utilize computing resources, and greatly improve the speed compared with traditional neural networks.
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。Finally, it should be noted that the above embodiments are only used to illustrate the technical solutions of the present invention, but not to limit them; although the present invention has been described in detail with reference to the foregoing embodiments, those of ordinary skill in the art should understand that it can still be The technical solutions described in the foregoing embodiments are modified, or some technical features thereof are equivalently replaced; and these modifications or replacements do not make the essence of the corresponding technical solutions deviate from the spirit and scope of the technical solutions of the embodiments of the present invention.
以上所述的仅是本发明的一些实施方式。对于本领域的普通技术人员来说,在不脱离本发明创造构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。The foregoing are merely some of the embodiments of the present invention. For those of ordinary skill in the art, without departing from the inventive concept of the present invention, several modifications and improvements can be made, which all belong to the protection scope of the present invention.
Claims (7)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110884790.4ACN113326856B (en) | 2021-08-03 | 2021-08-03 | Self-adaptive two-stage feature point matching method based on matching difficulty |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110884790.4ACN113326856B (en) | 2021-08-03 | 2021-08-03 | Self-adaptive two-stage feature point matching method based on matching difficulty |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN113326856A CN113326856A (en) | 2021-08-31 |
| CN113326856Btrue CN113326856B (en) | 2021-12-03 |
Family
ID=77426909
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110884790.4AActiveCN113326856B (en) | 2021-08-03 | 2021-08-03 | Self-adaptive two-stage feature point matching method based on matching difficulty |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN113326856B (en) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114612531B (en)* | 2022-02-22 | 2024-07-16 | 腾讯科技(深圳)有限公司 | Image processing method and device, electronic equipment and storage medium |
| CN117765084B (en)* | 2024-02-21 | 2024-05-03 | 电子科技大学 | Vision-oriented localization method based on iterative solution of dynamic branch prediction |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2019084804A1 (en)* | 2017-10-31 | 2019-05-09 | 深圳市大疆创新科技有限公司 | Visual odometry and implementation method therefor |
| CN113159043A (en)* | 2021-04-01 | 2021-07-23 | 北京大学 | Feature point matching method and system based on semantic information |
Family Cites Families (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101251926B (en)* | 2008-03-20 | 2011-08-17 | 北京航空航天大学 | Remote sensing image registration method based on local configuration covariance matrix |
| CN101547359B (en)* | 2009-04-17 | 2011-01-05 | 西安交通大学 | Rapid motion estimation self-adaptive selection method based on motion complexity |
| CN102322864B (en)* | 2011-07-29 | 2014-01-01 | 北京航空航天大学 | An Airborne Optical Robust Scene Matching Navigation and Positioning Method |
| CN102592129B (en)* | 2012-01-02 | 2013-10-16 | 西安电子科技大学 | Scenario-driven image characteristic point selection method for smart phone |
| TWI486906B (en)* | 2012-12-14 | 2015-06-01 | Univ Nat Central | Using Image Classification to Strengthen Image Matching |
| CN106358029B (en)* | 2016-10-18 | 2019-05-03 | 北京字节跳动科技有限公司 | A kind of method of video image processing and device |
| CN109934857B (en)* | 2019-03-04 | 2021-03-19 | 大连理工大学 | A Loop Closure Detection Method Based on Convolutional Neural Network and ORB Features |
| CN110246169B (en)* | 2019-05-30 | 2021-03-26 | 华中科技大学 | A Gradient-based Window Adaptive Stereo Matching Method and System |
| CN111814839B (en)* | 2020-06-17 | 2023-09-01 | 合肥工业大学 | Template matching method of longicorn group optimization algorithm based on self-adaptive variation |
| CN111767960A (en)* | 2020-07-02 | 2020-10-13 | 中国矿业大学 | An image matching method and system applied to image 3D reconstruction |
| CN112734747B (en)* | 2021-01-21 | 2024-06-25 | 腾讯科技(深圳)有限公司 | Target detection method and device, electronic equipment and storage medium |
- 2021
- 2021-08-03CNCN202110884790.4Apatent/CN113326856B/enactiveActive
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2019084804A1 (en)* | 2017-10-31 | 2019-05-09 | 深圳市大疆创新科技有限公司 | Visual odometry and implementation method therefor |
| CN113159043A (en)* | 2021-04-01 | 2021-07-23 | 北京大学 | Feature point matching method and system based on semantic information |
Non-Patent Citations (2)
| Title |
|---|
| "Structure adaptive feature point matching for urban area wide-based line images with viewpoint variation";Chen M等;《Acta Geodaetica et Cartographica Sinica》;20191231;第1129-1140页* |
| "基于环境差异度的自适应角点匹配算法";刘芳萍等;《数字视频》;20151231;第39卷(第1期);第24-31页* |
Also Published As
| Publication number | Publication date |
|---|---|
| CN113326856A (en) | 2021-08-31 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN112435282B (en) | A real-time binocular stereo matching method based on adaptive candidate disparity prediction network | |
| CN109064514B (en) | A 6-DOF Pose Estimation Method Based on Projected Point Coordinate Regression | |
| CN113592927B (en) | A cross-domain image geometric registration method guided by structural information | |
| CN111696148A (en) | End-to-end stereo matching method based on convolutional neural network | |
| CN113326856B (en) | Self-adaptive two-stage feature point matching method based on matching difficulty | |
| CN113538401B (en) | A crowd counting method and system combining cross-modal information in complex scenes | |
| CN110032951A (en) | A kind of convolutional neural networks compression method decomposed based on Plutarch with principal component analysis | |
| CN110533724B (en) | A computational method for monocular visual odometry based on deep learning and attention mechanism | |
| CN111626159A (en) | Human body key point detection method based on attention residual error module and branch fusion | |
| CN113763446A (en) | A Stereo Matching Method Based on Guidance Information | |
| CN117058456B (en) | A visual object tracking method based on multi-phase attention mechanism | |
| CN113283407A (en) | Twin network target tracking method based on channel and space attention mechanism | |
| CN109005398A (en) | A kind of stereo image parallax matching process based on convolutional neural networks | |
| CN115423847A (en) | Twin Multimodal Target Tracking Method Based on Transformer | |
| CN110443849B (en) | Target positioning method for double-current convolution neural network regression learning based on depth image | |
| CN114821249A (en) | Vehicle weight recognition method based on grouping aggregation attention and local relation | |
| CN115861418A (en) | Single-view attitude estimation method and system based on multi-mode input and attention mechanism | |
| CN118799393B (en) | Bidirectional fusion 6D object pose estimation method | |
| CN111914639A (en) | Driving action recognition method of lightweight convolution space-time simple cycle unit model | |
| Wu et al. | Sc-wls: Towards interpretable feed-forward camera re-localization | |
| CN114066844A (en) | Pneumonia X-ray image analysis model and method based on attention superposition and feature fusion | |
| CN113239771A (en) | Attitude estimation method, system and application thereof | |
| CN114492755A (en) | Object Detection Model Compression Method Based on Knowledge Distillation | |
| CN113222016B (en) | Change detection method and device based on cross enhancement of high-level and low-level features | |
| CN117173226B (en) | Multi-mode image registration method based on prediction correction and convergence attention transducer |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |