CN113316185A - LTE network uplink interference category identification method and system based on classifier - Google Patents
LTE network uplink interference category identification method and system based on classifierDownload PDFInfo
- Publication number
- CN113316185A CN113316185ACN202110577785.9ACN202110577785ACN113316185ACN 113316185 ACN113316185 ACN 113316185ACN 202110577785 ACN202110577785 ACN 202110577785ACN 113316185 ACN113316185 ACN 113316185A
- Authority
- CN
- China
- Prior art keywords
- lte network
- classifier
- noise reduction
- uplink interference
- layer
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images




Classifications
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04W—WIRELESS COMMUNICATION NETWORKS
- H04W24/00—Supervisory, monitoring or testing arrangements
- H04W24/08—Testing, supervising or monitoring using real traffic
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/241—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches
- G06F18/2411—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches based on the proximity to a decision surface, e.g. support vector machines
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/243—Classification techniques relating to the number of classes
- G06F18/24323—Tree-organised classifiers
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/25—Fusion techniques
- G06F18/254—Fusion techniques of classification results, e.g. of results related to same input data
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/048—Activation functions
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/088—Non-supervised learning, e.g. competitive learning
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04B—TRANSMISSION
- H04B17/00—Monitoring; Testing
- H04B17/30—Monitoring; Testing of propagation channels
- H04B17/309—Measuring or estimating channel quality parameters
- H04B17/345—Interference values
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02D—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN INFORMATION AND COMMUNICATION TECHNOLOGIES [ICT], I.E. INFORMATION AND COMMUNICATION TECHNOLOGIES AIMING AT THE REDUCTION OF THEIR OWN ENERGY USE
- Y02D30/00—Reducing energy consumption in communication networks
- Y02D30/70—Reducing energy consumption in communication networks in wireless communication networks
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- Life Sciences & Earth Sciences (AREA)
- Artificial Intelligence (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Computing Systems (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Molecular Biology (AREA)
- Computational Linguistics (AREA)
- Biophysics (AREA)
- Biomedical Technology (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Health & Medical Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Bioinformatics & Computational Biology (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Evolutionary Biology (AREA)
- Computer Networks & Wireless Communication (AREA)
- Signal Processing (AREA)
- Quality & Reliability (AREA)
- Electromagnetism (AREA)
- Mobile Radio Communication Systems (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本发明涉及LTE网络上行干扰类别识别技术领域,特别是涉及基于分类器的LTE网络上行干扰类别识别方法及系统。The present invention relates to the technical field of LTE network uplink interference category identification, in particular to a classifier-based LTE network uplink interference category identification method and system.
背景技术Background technique
本部分的陈述仅仅是提到了与本发明相关的背景技术,并不必然构成现有技术。The statements in this section merely provide background related to the present disclosure and do not necessarily constitute prior art.
当前移动通信网络发展迅速,2G/3G/4G等多种网络制式共存,5G也大规模商用,使得无线环境日益复杂。同时社会生产、生活对无线网络的可靠性要求也逐步提高,这对通信运营商的网络运维和优化工作提出更高的要求,而干扰优化是网络优化的重要内容之一,对提升无线网络的传输质量起关键作用。当前干扰排查工作主要依靠工程师观察干扰功率底噪曲线来判断干扰类型,定位干扰源。但网络规模的不断扩大,使得传统人工识别的方法难以满足当前工作需求,因此建立智能化的通信网络干扰识别算法势在必行。为实现自动化的LTE网络上行干扰识别,部分学者将机器学习算法引入到通信网络的优化工作中。翁文迪针对时分双工长期演进(TD-LTE,Time Division Duplexing-Long Term Evolution)系统F频段上行干扰,提取了不同干扰的波形特征,结合共站址信息匹配实现TD-LTE系统间干扰识别。刘思基于时域、频域波形等多维度特征来识别TD-LTE网络自系统上干扰。李颖等同样对TD-LTE中F频段提取干扰波形特征,通过随机森林算法进行干扰建模。孙黎明利用受干扰小区的不同频域特征基于BP神经网络实现自动干扰排查。一方面传统的人工特征提取过程中受多方面因素影响,需要丰富的工程经验和专业知识。另一方面深度神经网络参数随机初始化,基于梯度下降的优化使算法容易陷入局部最优值,造成模型分类精度不理想。At present, the rapid development of mobile communication networks, the coexistence of various network standards such as 2G/3G/4G, and the large-scale commercial use of 5G make the wireless environment increasingly complex. At the same time, the reliability requirements of social production and life for wireless networks are also gradually increasing, which puts forward higher requirements for communication operators' network operation, maintenance and optimization work, and interference optimization is one of the important contents of network optimization. transmission quality plays a key role. The current interference investigation work mainly relies on engineers to observe the noise floor curve of the interference power to determine the type of interference and locate the source of interference. However, the continuous expansion of the network scale makes it difficult for the traditional manual identification method to meet the current work needs. Therefore, it is imperative to establish an intelligent communication network interference identification algorithm. In order to realize automatic LTE network uplink interference identification, some scholars have introduced machine learning algorithms into the optimization of communication networks. Weng Wendi extracted the waveform characteristics of different interferences for the uplink interference in the F-band of the Time Division Duplexing-Long Term Evolution (TD-LTE) system, and combined the co-site information matching to realize the interference identification between TD-LTE systems. Liu Si identifies TD-LTE network self-system interference based on multi-dimensional features such as time-domain and frequency-domain waveforms. Li Ying et al. also extracted the interference waveform characteristics of the F-band in TD-LTE, and used the random forest algorithm to model the interference. Sun Liming used the different frequency domain characteristics of the interfered cells to realize automatic interference investigation based on BP neural network. On the one hand, the traditional manual feature extraction process is affected by many factors and requires rich engineering experience and professional knowledge. On the other hand, the parameters of the deep neural network are initialized randomly, and the optimization based on gradient descent makes the algorithm easy to fall into the local optimal value, resulting in unsatisfactory model classification accuracy.
发明内容SUMMARY OF THE INVENTION
为了解决现有技术的不足,本发明提供了基于分类器的LTE网络上行干扰类别识别方法及系统;In order to solve the deficiencies of the prior art, the present invention provides a classifier-based LTE network uplink interference category identification method and system;
第一方面,本发明提供了基于分类器的LTE网络上行干扰类别识别方法;In a first aspect, the present invention provides a classifier-based LTE network uplink interference category identification method;
基于分类器的LTE网络上行干扰类别识别方法,包括:A classifier-based method for identifying uplink interference types in LTE networks, including:
获取待分类的LTE网络上行数据;Obtain the uplink data of the LTE network to be classified;
对待分类的LTE网络上行数据进行特征提取;Perform feature extraction on the LTE network uplink data to be classified;
对提取的特征采用不同的分类器进行分类,得到不同的分类结果;Different classifiers are used to classify the extracted features to obtain different classification results;
对不同的分类结果进行加权求和,得到最终的分类结果。The weighted summation of different classification results is performed to obtain the final classification result.
第二方面,本发明提供了基于分类器的LTE网络上行干扰类别识别系统基于分类器的LTE网络上行干扰类别识别系统,包括:In a second aspect, the present invention provides a classifier-based LTE network uplink interference category identification system The classifier-based LTE network uplink interference category identification system includes:
获取模块,其被配置为:获取待分类的LTE网络上行数据;an acquisition module, which is configured to: acquire uplink data of the LTE network to be classified;
特征提取模块,其被配置为:对待分类的LTE网络上行数据进行特征提取;A feature extraction module, which is configured to: perform feature extraction on the uplink data of the LTE network to be classified;
分类模块,其被配置为:对提取的特征采用不同的分类器进行分类,得到不同的分类结果;A classification module, which is configured to: classify the extracted features by using different classifiers to obtain different classification results;
加权求和模块,其被配置为:对不同的分类结果进行加权求和,得到最终的分类结果。A weighted summation module, which is configured to: perform weighted summation on different classification results to obtain a final classification result.
第三方面,本发明还提供了一种电子设备,包括:一个或多个处理器、一个或多个存储器、以及一个或多个计算机程序;其中,处理器与存储器连接,上述一个或多个计算机程序被存储在存储器中,当电子设备运行时,该处理器执行该存储器存储的一个或多个计算机程序,以使电子设备执行上述第一方面所述的方法。In a third aspect, the present invention also provides an electronic device, comprising: one or more processors, one or more memories, and one or more computer programs; wherein the processor is connected to the memory, and one or more of the above The computer program is stored in the memory, and when the electronic device runs, the processor executes one or more computer programs stored in the memory, so that the electronic device performs the method described in the first aspect above.
第四方面,本发明还提供了一种计算机可读存储介质,用于存储计算机指令,所述计算机指令被处理器执行时,完成第一方面所述的方法。In a fourth aspect, the present invention further provides a computer-readable storage medium for storing computer instructions, and when the computer instructions are executed by a processor, the method described in the first aspect is completed.
与现有技术相比,本发明的有益效果是:Compared with the prior art, the beneficial effects of the present invention are:
建立栈式降噪自编码网络SDAE(Stacked Denoising Autoencoder)与自适应权值多分类器组合的LTE网络上行干扰分析模型。SDAE通过无监督逐层预训练来学习上行干扰功率的波型特征,利用支持向量机(Support Vector Machine,SVM)和随机森林(RandomForest,RF)分类器对LTE网络的上行干扰进行精准识别,并通过自适应权值方法组合两种分类器进一步提高干扰识别精度。实验结果表明,组合方式有助于进一步提高LTE网络上行。A LTE network uplink interference analysis model is established based on the combination of Stacked Denoising Autoencoder (SDAE) and adaptive weight multi-classifier. SDAE learns the waveform characteristics of uplink interference power through unsupervised layer-by-layer pre-training, and uses Support Vector Machine (SVM) and Random Forest (RF) classifiers to accurately identify the uplink interference of LTE networks. The interference identification accuracy is further improved by combining the two classifiers by the adaptive weight method. The experimental results show that the combination method is helpful to further improve the uplink of LTE network.
本发明附加方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。Advantages of additional aspects of the invention will be set forth in part in the description which follows, and in part will become apparent from the description which follows, or may be learned by practice of the invention.
附图说明Description of drawings
构成本发明的一部分的说明书附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。The accompanying drawings forming a part of the present invention are used to provide further understanding of the present invention, and the exemplary embodiments of the present invention and their descriptions are used to explain the present invention, and do not constitute an improper limitation of the present invention.
图1为第一个实施例的降噪自编码器网络结构;Fig. 1 is the noise reduction autoencoder network structure of the first embodiment;
图2为第一个实施例的LTE网络上行干扰分类策略;Fig. 2 is the LTE network uplink interference classification strategy of the first embodiment;
图3为第一个实施例的数据提取流程图;Fig. 3 is the data extraction flow chart of the first embodiment;
图4为第一个实施例的原始MR数据格式;Fig. 4 is the original MR data format of the first embodiment;
图5为第一个实施例的某小区12小时上行干扰功率数据可视化。FIG. 5 is a visualization of 12-hour uplink interference power data of a cell in the first embodiment.
具体实施方式Detailed ways
应该指出,以下详细说明都是示例性的,旨在对本发明提供进一步的说明。除非另有指明,本发明使用的所有技术和科学术语具有与本发明所属技术领域的普通技术人员通常理解的相同含义。It should be noted that the following detailed description is exemplary and intended to provide further explanation of the invention. Unless otherwise defined, all technical and scientific terms used herein have the same meaning as commonly understood by one of ordinary skill in the art to which this invention belongs.
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本发明的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。It should be noted that the terminology used herein is for the purpose of describing specific embodiments only, and is not intended to limit the exemplary embodiments according to the present invention. As used herein, unless the context clearly dictates otherwise, the singular is intended to include the plural as well, furthermore, it is to be understood that the terms "including" and "having" and any conjugations thereof are intended to cover the non-exclusive A process, method, system, product or device comprising, for example, a series of steps or units is not necessarily limited to those steps or units expressly listed, but may include those steps or units not expressly listed or for such processes, methods, Other steps or units inherent to the product or equipment.
在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。Embodiments of the invention and features of the embodiments may be combined with each other without conflict.
深度学习中的自编码器作为一种常用的无监督学习方法,能够从大量的无标签数据中学习数据有效特征,甚至不需要任何领域知识和相关技能,同时采贪婪逐层预训练的方式,使得网络参数处在合适的区间范围,避免了监督学习中的梯度传播问题,自编码器及其改进方法在模式识别领域的广泛应用均证明自编码器作为机器学习中一种无监督的学习方法,能够有效提取特征实现数据分类。As a common unsupervised learning method, the autoencoder in deep learning can learn the effective features of data from a large amount of unlabeled data, even without any domain knowledge and related skills. The network parameters are in a suitable range, which avoids the problem of gradient propagation in supervised learning. The wide application of autoencoders and their improved methods in the field of pattern recognition proves that autoencoders are an unsupervised learning method in machine learning. , which can effectively extract features to achieve data classification.
诸多研究表明,通过对多分类器进行有效组合可以提高模型的分类精度,常见多分类器组合方法有投票法、权值重置和组合算法等。大多数分类器的组合策略都依据各分类器的性能表现赋予分类器相应的权值,组合过程按照设定好的权值进行线性集成,而未充分考虑分类器对具体样本的识别能力。因此本发明采用栈式降噪自编码算法提取LTE网络上行干扰功率的特征,作为分类器的输入,同时应用自适应权值法结合SVM和RFC分类器,根据各分类器输出概率矩阵的特征值动态调整分类器的权值,充分结合2种分类器的优势,使得多分类器组合策略更合理,有效提升LTE网络上行干扰的识别精度。Many studies have shown that the classification accuracy of the model can be improved by effectively combining multiple classifiers. Common methods of combining multiple classifiers include voting method, weight reset and combination algorithm. The combination strategy of most classifiers assigns the corresponding weights to the classifiers according to the performance of each classifier, and the combination process performs linear integration according to the set weights, but does not fully consider the ability of the classifiers to identify specific samples. Therefore, the present invention adopts the stack noise reduction self-encoding algorithm to extract the characteristics of the uplink interference power of the LTE network as the input of the classifier, and simultaneously applies the adaptive weight method combined with the SVM and the RFC classifier, and outputs the eigenvalues of the probability matrix according to each classifier. Dynamically adjust the weights of the classifiers and fully combine the advantages of the two classifiers to make the multi-classifier combination strategy more reasonable and effectively improve the identification accuracy of the LTE network uplink interference.
本实施例所有数据的获取都在符合法律法规和用户同意的基础上,对数据的合法应用。All data acquisition in this embodiment is based on compliance with laws and regulations and the user's consent, and the legal application of the data.
实施例一Example 1
本实施例提供了基于分类器的LTE网络上行干扰类别识别方法;This embodiment provides a classifier-based method for identifying uplink interference types in an LTE network;
基于分类器的LTE网络上行干扰类别识别方法,包括:A classifier-based method for identifying uplink interference types in LTE networks, including:
S101:获取待分类的LTE网络上行数据;S101: Acquire uplink data of the LTE network to be classified;
S102:对待分类的LTE网络上行数据进行特征提取;S102: Perform feature extraction on the uplink data of the LTE network to be classified;
S103:对提取的特征采用不同的分类器进行分类,得到不同的分类结果;S103: Use different classifiers to classify the extracted features to obtain different classification results;
S104:对不同的分类结果进行加权求和,得到最终的分类结果。S104: Perform weighted summation on different classification results to obtain a final classification result.
进一步地,所述S101:获取待分类的LTE网络上行数据;具体包括:Further, the S101: obtain the uplink data of the LTE network to be classified; specifically, it includes:
获取待分类的PRB(物理资源块,Physical Resource Block)粒度上行干扰功率值、主服务小区标号和/或上报时间等数据指标。Acquire data indicators such as the granular uplink interference power value of the PRB (Physical Resource Block, Physical Resource Block) to be classified, the ID of the primary serving cell, and/or the reporting time.
进一步地,所述S102:对待分类的LTE网络上行数据进行特征提取;具体包括:Further, the S102: perform feature extraction on the LTE network uplink data to be classified; specifically include:
采用训练后的栈式降噪自编码器SDAE,对待分类的LTE网络上行数据进行特征提取。The trained stack noise reduction autoencoder SDAE is used to extract features from the uplink data of the LTE network to be classified.
进一步地,所述训练后的栈式降噪自编码器SDAE,训练步骤包括:Further, the stack noise reduction autoencoder SDAE after the training, the training step includes:
构建第一堆栈式降噪自编码模型;其中,第一堆栈式降噪自编码模型,包括依次连接的输入层A1、加噪层A2、隐含层A3和输出层A4;constructing a first stack-type noise reduction auto-encoding model; wherein, the first stack-type noise reduction auto-encoding model includes an input layer A1, a noise-adding layer A2, a hidden layer A3 and an output layer A4 connected in sequence;
构建第一训练集;其中,第一训练集为无标签的LTE网络上行数据;constructing a first training set; wherein, the first training set is unlabeled LTE network uplink data;
采用第一训练集对第一堆栈式降噪自编码模型进行训练,得到训练后第一堆栈式降噪自编码模型;训练前的隐含层A3经过训练后变成了隐含层A3’;Use the first training set to train the first stacked noise reduction auto-encoding model, and obtain the first stacked noise reduction auto-encoding model after training; the hidden layer A3 before training becomes the hidden layer A3' after training;
构建第二堆栈式降噪自编码模型;其中,第二堆栈式降噪自编码模型,包括依次连接的隐含层A3’、加噪层B2、隐含层B3和输出层B4;Build a second stack-type noise reduction auto-encoding model; wherein, the second stack-type noise reduction auto-encoding model includes a hidden layer A3', a noise-added layer B2, a hidden layer B3 and an output layer B4 connected in sequence;
采用第一训练集对第二堆栈式降噪自编码模型进行训练,得到训练后第二堆栈式降噪自编码模型;训练前的隐含层B3经过训练后变成了隐含层B3’;Use the first training set to train the second stacked noise reduction auto-encoding model, and obtain the second stacked noise reduction auto-encoding model after training; the hidden layer B3 before training becomes the hidden layer B3' after training;
将隐含层B3’堆叠在隐含层A3’上,去掉输出层A4和加噪层A2,就得到了训练后的栈式降噪自编码器SDAE;训练后的栈式降噪自编码器SDAE,包括:依次连接的输入层A1、隐含层A3’和隐含层B3’。Stack the hidden layer B3' on the hidden layer A3', remove the output layer A4 and the noise layer A2, and get the trained stack noise reduction autoencoder SDAE; the trained stack noise reduction autoencoder SDAE, including: input layer A1, hidden layer A3' and hidden layer B3' connected in sequence.
进一步地,所述加噪层,是指以设定概率分布对原始的输入数据进行随机置0,即以设定的概率把输入层节点的值置为0得到的数据所在层。Further, the noise-adding layer refers to the layer where the data is obtained by randomly setting the original input data to 0 with a set probability distribution, that is, setting the value of the input layer node to 0 with a set probability.
进一步地,所述隐含层,是指输入数据经过编码后得到的数据特征所在层。Further, the hidden layer refers to the layer where the data features obtained after the input data is encoded.
进一步地,所述S103:对提取的特征采用不同的分类器进行分类,得到不同的分类结果;具体包括:Further, the S103: classify the extracted features using different classifiers to obtain different classification results; specifically including:
对提取的特征采用支持向量机分类器进行分类,得到第一分类结果;The extracted features are classified by the support vector machine classifier, and the first classification result is obtained;
对提取的特征采用随机森林分类器进行分类,得到第二分类结果。The extracted features are classified using a random forest classifier to obtain a second classification result.
进一步地,所述S104:对不同的分类结果进行加权求和,得到最终的分类结果;具体包括:Further, the S104: weighting and summing different classification results to obtain a final classification result; specifically including:
计算概率矩阵
其中,
对不同的分类结果进行加权求和,得到最终的分类结果。The weighted summation of different classification results is performed to obtain the final classification result.
降噪自编码器由Vincent等人于2008年提出,它在传统自编码器的基础上加入对原始数据的退化处理,迫使模型从被破坏数据中重构出原始数据,使模型对噪声有更强的鲁棒性。降噪自编码器主要通过退化、编码和解码三个过程实现对原始数据的重构,它通过对原始输入信号进行退化处理得到被局部破坏的信号,然后将受损害信号输入到DAE中,使其尽可能的重建出未受干扰的原始信号,具体过程如图1所示。The noise reduction autoencoder was proposed by Vincent et al. in 2008. It adds degradation of the original data to the traditional autoencoder, forcing the model to reconstruct the original data from the corrupted data, making the model more resistant to noise. Strong robustness. The noise reduction autoencoder mainly realizes the reconstruction of the original data through the three processes of degradation, encoding and decoding. It obtains the locally damaged signal by degrading the original input signal, and then inputs the damaged signal into the DAE, so that the It reconstructs the undisturbed original signal as much as possible, and the specific process is shown in Figure 1.
假定输入数据x∈Rn×l,对x按照设定的退化率v进行一定比例的随机置0得到


其中w∈Rn×d为编码层的权重矩阵,b∈Rn为编码层的偏置,g(·)为激活函数,如sigmoid函数。where w∈Rn×d is the weight matrix of the coding layer,b∈Rn is the bias of the coding layer, and g( ) is the activation function, such as the sigmoid function.
解码过程可以看作编码过程的逆变换,通过解码将h转换为原始数据的重构y,具体过程为The decoding process can be regarded as the inverse transformation of the encoding process. By decoding, h is converted into a reconstruction y of the original data. The specific process is as follows:
y=g(wTh+b2); (2)y=g(wTh +b2 ); (2)
其中wT、b2为解码的权重和偏置。where wT , b2 are the decoding weights and biases.
降噪自编码器的损失函数表达式为The loss function expression of the denoising autoencoder is

通过最小化损失函数L(x,y)来学习样本数据的原始抽象特征。该训练过程无需数据标签,是一个无监督的过程。The original abstract features of the sample data are learned by minimizing the loss function L(x,y). The training process requires no data labels and is an unsupervised process.
在高维数据的特征提取中,单层的降噪自编码属于浅层网络,学习能力有限。栈式降噪自编码器通过对多个单层降噪自编码器堆栈组成深度网络,前一个自编码器的隐含层输出作为后一个自编码器的输入进行逐层连接,每一层自编码器进行逐层的无监督预训练,相当于每一层参数都经过合理的初始化,这样就保证了提取特征的可靠性,同时逐层的预训练使得网络更易收敛,对复杂数据的特征提取效果要优于浅层网络。In the feature extraction of high-dimensional data, the single-layer noise reduction auto-encoder belongs to a shallow network with limited learning ability. Stacked denoising autoencoders form a deep network by stacking multiple single-layer denoising autoencoders. The output of the hidden layer of the previous autoencoder is used as the input of the latter autoencoder to connect layer by layer. The encoder performs layer-by-layer unsupervised pre-training, which means that the parameters of each layer are properly initialized, which ensures the reliability of the extracted features. At the same time, the layer-by-layer pre-training makes the network easier to converge and the feature extraction of complex data. The effect is better than the shallow network.
本发明以传统的SVM和RFC分类器为基础,利用两种分类器在LTE网络上行干扰分类中的互补性,通过自适应权值法实现多分类器线性组合。Based on the traditional SVM and RFC classifiers, the invention utilizes the complementarity of the two classifiers in the LTE network uplink interference classification, and realizes the linear combination of multiple classifiers through the adaptive weight method.
(1)支持向量机。SVM是一种基于统计学的结构风险最小化样本学习方法,它在解决小样本学习,高维及非线性问题上有运算速度快,泛化性能好等优点。它的基本思想是通过非线性变换函数将原始数据映射到高维特征空间,在这个空间寻找一个最优分类超平面,从而实现对线性可分数据的最优分类。在目前的大多数研究中,经常使用的核函数有径向基(RBF)核函数、多项式核函数、双曲正切(Sigmoid)核函数等。由于RBF核函数具有收敛速度快、非线性映射、参数少等优点,在实际问题中应用较为广泛。因此本发明选取RBF核函数为SVM的非线性映射函数,其形式如式(4)所示:(1) Support vector machine. SVM is a statistical-based structural risk minimization sample learning method. It has the advantages of fast operation speed and good generalization performance in solving small sample learning, high-dimensional and nonlinear problems. Its basic idea is to map the original data to a high-dimensional feature space through a nonlinear transformation function, and find an optimal classification hyperplane in this space, so as to achieve the optimal classification of linearly separable data. In most of the current research, the frequently used kernel functions include radial basis (RBF) kernel function, polynomial kernel function, hyperbolic tangent (Sigmoid) kernel function and so on. Because the RBF kernel function has the advantages of fast convergence speed, nonlinear mapping, and few parameters, it is widely used in practical problems. Therefore, the present invention selects the RBF kernel function as the nonlinear mapping function of the SVM, and its form is shown in formula (4):

其中σ为核函数的重要参数,它会影响支持向量的数量从而影响SVM算法的复杂程度。Among them, σ is an important parameter of the kernel function, which will affect the number of support vectors and thus the complexity of the SVM algorithm.
(2)随机森林。RFC是由多颗决策树组成的机器学习算法,它通过(bootstrap)重采样技术从原始数据中有放回的重复随机抽取N个样本组成新的训练样本集,然后为每个训练集分别构建决策树,在单颗树的生长过程中,从全部的M个特征中随机选取m个(m<M),在选取的m个特征根据Gini系数最小原则确定最优特征属性进行节点分支。考虑单颗树的分类能力较弱,通过重复产生由N颗彼此不同的树组成的森林。最终的分类结果按照投票法确定,其实质是将多个决策树进行组合,可以对测试样本在每棵树的分类结果进行统计,选择可能性最大的分类结果。在随机森林构建过程中每棵树都随机选择部分样本及特征,一定程度上提升系统多样性,避免过拟合。(2) Random Forest. RFC is a machine learning algorithm composed of multiple decision trees. It uses (bootstrap) resampling technology to randomly select N samples from the original data with repeated repetitions to form a new training sample set, and then construct a new training sample set for each training set. In the decision tree, in the growth process of a single tree, m are randomly selected from all M features (m<M), and the selected m features are determined according to the minimum Gini coefficient principle to determine the optimal feature attributes for node branching. Considering the weak classification ability of a single tree, a forest consisting of N trees that are different from each other is generated by repetition. The final classification result is determined according to the voting method. The essence is to combine multiple decision trees. The classification results of the test samples in each tree can be counted, and the classification result with the highest probability can be selected. In the process of random forest construction, each tree randomly selects some samples and features, which improves the system diversity to a certain extent and avoids overfitting.
多分类器组合源于模式识别领域它通过融合不同的特征或具有互补性的分类器来提高最终的分类精度,是一种测量级分类器组合策略。其主要理论依据是,在分类算法中虽然不同分类器的分类性能存在差异,并且同一分类器对不同类别的识别精度也不相同,但在不同分类器产生的结果中被错分的样本集合是不完全相同的,因此,在某个分类器下被错分的样本在其他分类器下可能被准确识别,这说明不同的分类器之间存在互补性,我们可以利用这种互补性把不同分类器的输出信息进行加权组合,从而获得比单一分类器更高的精度。Multi-classifier combination originated from the field of pattern recognition. It improves the final classification accuracy by fusing different features or classifiers with complementarity. It is a measurement-level classifier combination strategy. The main theoretical basis is that in the classification algorithm, although the classification performance of different classifiers is different, and the recognition accuracy of the same classifier for different categories is also different, the set of samples that are misclassified in the results generated by different classifiers is are not exactly the same, therefore, samples that are misclassified under a certain classifier may be accurately identified under other classifiers, which indicates that there is complementarity between different classifiers, and we can use this complementarity to classify different classifications. The output information of the classifier is weighted and combined to obtain higher accuracy than a single classifier.
目前常用的多分类器组合策略主要是根据不同分类器的性能表现赋予该分类器相应的权重,该权重代表此分类器在组合中的重要程度,如:线性模型中各分类器的权值。这种组合策略在一定条件下确实可以提高分类器的性能,但在分类器线性组合过程中该权重是固定不变的,无法根据不同分类器对数据的识别能力进行动态调整。At present, the commonly used multi-classifier combination strategy mainly assigns the corresponding weight to the classifier according to the performance of different classifiers, and the weight represents the importance of the classifier in the combination, such as the weight of each classifier in the linear model. This combination strategy can indeed improve the performance of the classifier under certain conditions, but in the process of linear combination of the classifiers, the weight is fixed and cannot be dynamically adjusted according to the ability of different classifiers to identify the data.
自适应权值多分类器组合法根据分类器输出的可靠性概率矢量矩阵的特征值,动态调整各个分类器的权重,构建基于矩阵特征值的自适应权值多分类器组合模型。张华等通过该方法对最大似然法、马氏距离法、最小距离法进行组合分类,并成功应用在遥感数据分类中。The adaptive weight multi-classifier combination method dynamically adjusts the weight of each classifier according to the eigenvalues of the reliability probability vector matrix output by the classifier, and constructs an adaptive weight multi-classifier combination model based on the matrix eigenvalues. Zhang Hua et al. used this method to combine the maximum likelihood method, Mahalanobis distance method and minimum distance method, and successfully applied it to remote sensing data classification.
本发明应用自适应权值组合多分类器来提高LTE网络上行干扰的识别精度:The present invention uses adaptive weight combination multi-classifier to improve the identification accuracy of LTE network uplink interference:
假设第k个分类器得到某个样本X的分类后验概率矢量为




如果Y的值越小,说明
k个分类器构成的概率矩阵如公式(6)所示:The probability matrix composed of k classifiers is shown in formula (6):

其中矩阵第一列为第一个分类器对N个类别的判断概率,第k列为第k个分类器对N个类别的判别概率。The first column of the matrix is the judgment probability of the first classifier for N categories, and the kth column is the judgment probability of the kth classifier for N categories.
N为分类数目,k为分类器个数,多分类器组合后的最终后验概率表示为:N is the number of classifications, k is the number of classifiers, and the final posterior probability after the combination of multiple classifiers is expressed as:

其中,

设λk为矩阵


最后通过公式(7)综合每个样本属于各个类别的概率p(X),按照概率最大化的原则,将该样本确定为概率值最大的类别。Finally, the probability p(X) of each sample belonging to each category is synthesized by formula (7), and the sample is determined as the category with the largest probability value according to the principle of maximizing the probability.
本发明将SDAE与自适应权值多分类器组合方法应用到LTE网络的上行干扰识别中,通过SDAE对LTE网络的频域干扰波形进行特征提取,通过SVM与RF实现分类,并通过分类器的概率输出矩阵特征值对2种分类器进行自适应权值组合,基于矩阵特征值的多分类器组合实现LTE网络上行干扰分类流程图如图2所示。The invention applies the SDAE and the adaptive weight multi-classifier combination method to the uplink interference identification of the LTE network, performs feature extraction on the frequency domain interference waveform of the LTE network through SDAE, realizes the classification through SVM and RF, and uses the classifier's The eigenvalue of the probability output matrix performs adaptive weight combination for the two classifiers, and the multi-classifier combination based on the matrix eigenvalue realizes the LTE network uplink interference classification flow chart as shown in Figure 2.
具体步骤为:The specific steps are:
(1)通过运营商网管中心获取统计类测量报告,提取PRB(物理资源块,(1) Obtain statistical measurement reports through the operator's network management center, extract PRBs (Physical Resource Blocks,
Physical Resource Block)粒度上行干扰功率值、主服务小区标号、上报时间等数据指标。通过SDAE网络提取LTE网络上行干扰数据的特征,将此特征作为SVM和随机森林分类器的输入,根据分类器的输出获取样本判定为每个类别的概率,将两个分类器的结果进行组合,构成概率矩阵;Physical Resource Block) granular uplink interference power value, primary serving cell label, reporting time and other data indicators. The characteristics of the LTE network uplink interference data are extracted through the SDAE network, and the characteristics are used as the input of the SVM and random forest classifiers. form a probability matrix;
(2)计算概率矩阵
(3)各分类器输出
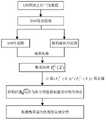
FDD-LTE系统的干扰参量主要来源于网管中心统计类测量报告MRS(MeasurementReport Statistics,统计类测量报告),具体流程如图3所示。The interference parameters of the FDD-LTE system mainly come from the statistical measurement report MRS (Measurement Report Statistics, statistical measurement report) of the network management center. The specific process is shown in Figure 3.
首先从后台网管中心获取MRS文件,然后对原始数据进行初步筛选,剔除格式损坏的数据和空白数据的小区。接下来通过算法编程实现批量提取所需要的数据指标,例如eNBid、主服务小区标号、上报时间、PRB粒度上行干扰功率值(MR.RIPPRB)。如图4所示,是某小区15分钟为上报周期的PRB粒度上行干扰功率指标的原始数据。First, obtain the MRS file from the background network management center, and then perform preliminary screening of the original data, and eliminate the data with corrupted format and the cells with blank data. Next, algorithm programming is used to achieve batch extraction of required data indicators, such as eNBid, primary serving cell number, reporting time, and PRB granularity uplink interference power value (MR.RIPPRB). As shown in FIG. 4 , it is the original data of the PRB granularity uplink interference power indicator with a reporting period of 15 minutes in a certain cell.
为计算后每个小区对应的部分PRB的上行干扰功率。通过原始数据得到每个取值区间内采样点个数,从而计算每个PRB点对应的上行干扰功率,已PRB0为例,计算公式为:is the uplink interference power of the partial PRBs corresponding to each cell after calculation. The number of sampling points in each value interval is obtained from the original data, so as to calculate the uplink interference power corresponding to each PRB point. Taking PRB0 as an example, the calculation formula is:

其中,ni(i=1、2……52)为每个取值区间内的采样点数,RIPi(i=1、2……52)为每个取值区间对应的功率值。Among them, ni (i=1, 2...52) is the number of sampling points in each value interval, and RIPi (i=1, 2...52) is the power value corresponding to each value interval.
表1部分PRB上行干扰功率统计表Table 1 Partial PRB Uplink Interference Power Statistics

同时数据构建过程中增加时间维度,选取小区12小时的PRB上行干扰功率,上报周期15分钟,频率带宽25RB,每个小区的样本可以表示为49*25的数据矩阵,数据可视化如图5所示,横轴表示PRB序号,纵轴为时间,颜色深浅表示上行干扰功率值的大小,范围是从-80dBm到-120dBm。根据提取的样本数据,结合每个小区上行干扰频域波形特征图和时间维度变化根据网络优化专家的分析完成标定工作。At the same time, the time dimension is added in the data construction process. The PRB uplink interference power of the cell is selected for 12 hours, the reporting period is 15 minutes, and the frequency bandwidth is 25RB. The sample of each cell can be represented as a 49*25 data matrix. The data visualization is shown in Figure 5. , the horizontal axis represents the PRB serial number, the vertical axis represents the time, and the color depth represents the magnitude of the uplink interference power value, ranging from -80dBm to -120dBm. According to the extracted sample data, combined with each cell's uplink interference frequency domain waveform feature map and time dimension changes, the calibration work is completed according to the analysis of network optimization experts.
选取山东某地区LTE网络PRB上行干扰功率指标,根据保密要求数据脱敏后作为数据集,共3495条数据,其中包括互调干扰795个,阻塞干扰900个,外部干扰900个和无干扰904个,其中随机划分70%为训练集完成栈式自编码分类模型的训练,30%为测试集用来检测模型效果。数据集分配如表2所示。Select the LTE network PRB uplink interference power index in a certain area of Shandong, and desensitize the data according to the confidentiality requirements as a data set, a total of 3495 data, including 795 intermodulation interference, 900 blocking interference, 900 external interference and 904 non-interference. , 70% of which are randomly divided into the training set to complete the training of the stacked self-encoding classification model, and 30% of the test set is used to detect the effect of the model. The dataset assignments are shown in Table 2.
表2数据集组成分配表Table 2 Data set composition allocation table

本实验运行环境为Windows7系统,处理器Intel(R)Core i5-5200U,运行内存4G,编程环境python3.7。SDAE网络超参数根据输入数据维度,采用试错法确定,隐含层设置为2层,经过反复迭代,数据重构误差在可接受范围内,可判断经过栈式降噪自编码网络提取的数据特征是对原始数据的一种特定表达方式,并且通过该特征可以最大程度恢复原始数据,经过自编码网络提取的数据特征作为原始数据的一种特定形式输入到后续分类器进行干扰识别分类是合理。The operating environment of this experiment is Windows7 system, the processor is Intel(R) Core i5-5200U, the running memory is 4G, and the programming environment is python3.7. The SDAE network hyperparameters are determined by the trial and error method according to the input data dimension. The hidden layer is set to 2 layers. After repeated iterations, the data reconstruction error is within an acceptable range, and the data extracted by the stack noise reduction auto-encoding network can be judged. The feature is a specific expression of the original data, and the original data can be restored to the greatest extent through the feature. The data feature extracted by the self-encoding network is a specific form of the original data and input to the subsequent classifier for interference identification and classification. It is reasonable .
分类器部分,SVM通过网格化参数寻优获取最优的参数,具体如下In the classifier part, SVM obtains the optimal parameters through gridding parameter optimization, as follows
(1)SVM分类器:线性核函数、惩罚系数C为9;(1) SVM classifier: linear kernel function, penalty coefficient C is 9;
(2)RFC分类器:决策树数目200、树的最大深度、最小叶子节点数2、变量纯度度量指标为Gini系数、CART算法;(2) RFC classifier: the number of decision trees is 200, the maximum depth of the tree, the minimum number of leaf nodes is 2, the variable purity measurement index is the Gini coefficient, and the CART algorithm;
实验1为评估SADE算法的特征提取能力,本发明选取LTE网络上行干扰分类中常用的人工设计的特征进行对比,提取的LTE网络上行干扰功率频域特征如下表3所示,分类器均选择RFC,SDAE选择含有2层隐含层,使用某地区LTE网络上行干扰数据,并在其基础上加入一定比例的高斯白噪声,增强数据集的多样性。Experiment 1 is to evaluate the feature extraction capability of the SADE algorithm. The present invention selects the commonly used artificially designed features in the LTE network uplink interference classification for comparison. The extracted LTE network uplink interference power frequency domain features are shown in Table 3 below, and the classifiers all select RFC , SDAE chooses to contain 2 hidden layers, uses the uplink interference data of the LTE network in a certain area, and adds a certain proportion of Gaussian white noise on the basis of it to enhance the diversity of the data set.
表3干扰特征说明Table 3 Interference characteristics description


表4不同噪声比例数据集分类准确率比较Table 4 Comparison of classification accuracy of datasets with different noise ratios
由表4中可以看出,在数据不含噪声的情况下,基于SDAE提取的特征在分类中表现出更好的性能,同时数据中加入一定比例的噪声对SDAE提取特征过程影响较小,在含有30%高斯白噪声时准确率仍有95%,主要是因为SDAE算法在训练过程中对原始数据进行加噪处理,使得模型具备从含噪声数据中提取原始数据的能力,从而对噪声由更强的鲁棒性。It can be seen from Table 4 that when the data does not contain noise, the features extracted based on SDAE show better performance in classification. At the same time, adding a certain proportion of noise to the data has little effect on the process of SDAE feature extraction. With 30% white Gaussian noise, the accuracy rate is still 95%, mainly because the SDAE algorithm adds noise to the original data during the training process, so that the model has the ability to extract the original data from the noisy data, so as to reduce the noise from the noise. Strong robustness.
实验2为综合对比SVM、RFC以及自适应权值组合分类的性能,保证模型尽可能准确识别出上行干扰同时正常的小区不会被误检,本发明采用总体准确率,精准率、召回率、F1score Kappa系数等多项指标来对模型进行评价,SVM、RFC以及自适应权组合分类器在LTE网络上行干扰数据测试集中的表5-1所示。
表5-1不同分类器准确率比较Table 5-1 Comparison of Accuracy Rates of Different Classifiers

表5-2不同分类器准确率比较Table 5-2 Comparison of Accuracy Rates of Different Classifiers

表5-3不同分类器准确率比较Table 5-3 Comparison of Accuracy Rates of Different Classifiers

由表5-1、表5-2和表5-3可以看出SVM分类器对外部强干扰的识别精度要高于RFC,而RFC分类器对互调干扰、阻塞干扰的识别精度高于SVM分类器,说明这两个分类器在LTE网络上行干扰分类中具有互补性。本发明采用的基于矩阵特征值的自适应权值组合方法在组合SVM和RFC后总体准确率为97.8%,Kappa系数为0.97,均高于单个分类器的分类性能。同时自适应权值组合分类器的分类效果比较稳定,对各干扰类别的识别精度相对平均,主要是因为在组合分类器的过程中,通过概率矩阵的特征值来动态的调整各个分类器的权值,提高分类性能有的分类器的权重,降低分类性能差的分类器权重,从而提高组合分类器的稳定性。From Table 5-1, Table 5-2 and Table 5-3, it can be seen that the SVM classifier has higher recognition accuracy for external strong interference than RFC, and the RFC classifier has higher recognition accuracy for intermodulation interference and blocking interference than SVM. classifier, indicating that the two classifiers are complementary in the classification of uplink interference in the LTE network. The self-adaptive weight combination method based on matrix eigenvalues adopted in the present invention has an overall accuracy rate of 97.8% and a Kappa coefficient of 0.97 after combining SVM and RFC, which are all higher than the classification performance of a single classifier. At the same time, the classification effect of the adaptive weight combination classifier is relatively stable, and the recognition accuracy of each interference category is relatively average, mainly because in the process of combining the classifiers, the weight of each classifier is dynamically adjusted through the eigenvalues of the probability matrix. value, improve the weight of some classifiers with poor classification performance, and reduce the weight of classifiers with poor classification performance, thereby improving the stability of the combined classifier.
本发明提出一种栈式降噪自编码网络与组合分类器结合的模型,并应用在LTE网络上行干扰分析中,通过山东某地区LTE网络上行干扰数据进行验证。实验1结果表明,相比于现有技术的人工特征,本发明基于SDAE提取的特征有更高的准确率,且特征提取过程减少对专家知识的依赖,同时对噪声的鲁棒性更强,更适宜移动通信网络无线环境复杂,干扰较多的场景。由实验2结果可以看出,自适应权值多分类器组合方法根据每个样本的概率矩阵特征值动态调整单个分类器的权值,避免人为因素影响,可综合各分类器的优势,有效提高了LTE网络上行干扰总体分类精度。The invention proposes a model combining a stack noise reduction self-encoding network and a combined classifier, which is applied in the analysis of the uplink interference of the LTE network, and is verified by the uplink interference data of the LTE network in a certain area of Shandong. The results of experiment 1 show that, compared with the artificial features of the prior art, the features extracted based on SDAE of the present invention have higher accuracy, and the feature extraction process reduces the dependence on expert knowledge, and is more robust to noise at the same time, It is more suitable for scenarios where the wireless environment of the mobile communication network is complex and there is more interference. It can be seen from the results of
实施例二
本实施例提供了基于分类器的LTE网络上行干扰类别识别系统;This embodiment provides a classifier-based LTE network uplink interference category identification system;
基于分类器的LTE网络上行干扰类别识别系统,包括:A classifier-based LTE network uplink interference category identification system, including:
获取模块,其被配置为:获取待分类的LTE网络上行数据;an acquisition module, which is configured to: acquire uplink data of the LTE network to be classified;
特征提取模块,其被配置为:对待分类的LTE网络上行数据进行特征提取;A feature extraction module, which is configured to: perform feature extraction on the uplink data of the LTE network to be classified;
分类模块,其被配置为:对提取的特征采用不同的分类器进行分类,得到不同的分类结果;A classification module, which is configured to: classify the extracted features by using different classifiers to obtain different classification results;
加权求和模块,其被配置为:对不同的分类结果进行加权求和,得到最终的分类结果。A weighted summation module, which is configured to: perform weighted summation on different classification results to obtain a final classification result.
此处需要说明的是,上述获取模块、特征提取模块、分类模块和加权求和模块对应于实施例一中的步骤S101至S104,上述模块与对应的步骤所实现的示例和应用场景相同,但不限于上述实施例一所公开的内容。需要说明的是,上述模块作为系统的一部分可以在诸如一组计算机可执行指令的计算机系统中执行。It should be noted here that the above-mentioned acquisition module, feature extraction module, classification module and weighted summation module correspond to steps S101 to S104 in the first embodiment, and the examples and application scenarios implemented by the above-mentioned modules and the corresponding steps are the same, but It is not limited to the content disclosed in the first embodiment. It should be noted that the above modules may be executed in a computer system such as a set of computer-executable instructions as part of the system.
上述实施例中对各个实施例的描述各有侧重,某个实施例中没有详述的部分可以参见其他实施例的相关描述。The description of each embodiment in the foregoing embodiments has its own emphasis. For the part that is not described in detail in a certain embodiment, reference may be made to the relevant description of other embodiments.
所提出的系统,可以通过其他的方式实现。例如以上所描述的系统实施例仅仅是示意性的,例如上述模块的划分,仅仅为一种逻辑功能划分,实际实现时,可以有另外的划分方式,例如多个模块可以结合或者可以集成到另外一个系统,或一些特征可以忽略,或不执行。The proposed system can be implemented in other ways. For example, the system embodiments described above are only illustrative. For example, the division of the above modules is only a logical function division. In actual implementation, there may be other division methods. For example, multiple modules may be combined or integrated into other A system, or some feature, can be ignored, or not implemented.
实施例三
本实施例还提供了一种电子设备,包括:一个或多个处理器、一个或多个存储器、以及一个或多个计算机程序;其中,处理器与存储器连接,上述一个或多个计算机程序被存储在存储器中,当电子设备运行时,该处理器执行该存储器存储的一个或多个计算机程序,以使电子设备执行上述实施例一所述的方法。This embodiment also provides an electronic device, comprising: one or more processors, one or more memories, and one or more computer programs; wherein the processor is connected to the memory, and the one or more computer programs are Stored in the memory, when the electronic device runs, the processor executes one or more computer programs stored in the memory, so that the electronic device executes the method described in the first embodiment.
应理解,本实施例中,处理器可以是中央处理单元CPU,处理器还可以是其他通用处理器、数字信号处理器DSP、专用集成电路ASIC,现成可编程门阵列FPGA或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。It should be understood that, in this embodiment, the processor may be a central processing unit CPU, and the processor may also be other general-purpose processors, digital signal processors DSP, application-specific integrated circuits ASIC, off-the-shelf programmable gate array FPGA or other programmable logic devices , discrete gate or transistor logic devices, discrete hardware components, etc. A general purpose processor may be a microprocessor or the processor may be any conventional processor or the like.
存储器可以包括只读存储器和随机存取存储器,并向处理器提供指令和数据、存储器的一部分还可以包括非易失性随机存储器。例如,存储器还可以存储设备类型的信息。The memory may include read-only memory and random access memory and provide instructions and data to the processor, and a portion of the memory may also include non-volatile random access memory. For example, the memory may also store device type information.
在实现过程中,上述方法的各步骤可以通过处理器中的硬件的集成逻辑电路或者软件形式的指令完成。In the implementation process, each step of the above-mentioned method can be completed by a hardware integrated logic circuit in a processor or an instruction in the form of software.
实施例一中的方法可以直接体现为硬件处理器执行完成,或者用处理器中的硬件及软件模块组合执行完成。软件模块可以位于随机存储器、闪存、只读存储器、可编程只读存储器或者电可擦写可编程存储器、寄存器等本领域成熟的存储介质中。该存储介质位于存储器,处理器读取存储器中的信息,结合其硬件完成上述方法的步骤。为避免重复,这里不再详细描述。The method in the first embodiment can be directly embodied as being executed by a hardware processor, or executed by a combination of hardware and software modules in the processor. The software modules may be located in random access memory, flash memory, read-only memory, programmable read-only memory or electrically erasable programmable memory, registers and other storage media mature in the art. The storage medium is located in the memory, and the processor reads the information in the memory, and completes the steps of the above method in combination with its hardware. To avoid repetition, detailed description is omitted here.
本领域普通技术人员可以意识到,结合本实施例描述的各示例的单元及算法步骤,能够以电子硬件或者计算机软件和电子硬件的结合来实现。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。Those skilled in the art can realize that the units and algorithm steps of each example described in conjunction with this embodiment can be implemented by electronic hardware or a combination of computer software and electronic hardware. Whether these functions are performed in hardware or software depends on the specific application and design constraints of the technical solution. Skilled artisans may implement the described functionality using different methods for each particular application, but such implementations should not be considered beyond the scope of the present invention.
实施例四Embodiment 4
本实施例还提供了一种计算机可读存储介质,用于存储计算机指令,所述计算机指令被处理器执行时,完成实施例一所述的方法。This embodiment also provides a computer-readable storage medium for storing computer instructions, and when the computer instructions are executed by a processor, the method described in the first embodiment is completed.
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。The above descriptions are only preferred embodiments of the present invention, and are not intended to limit the present invention. For those skilled in the art, the present invention may have various modifications and changes. Any modification, equivalent replacement, improvement, etc. made within the spirit and principle of the present invention shall be included within the protection scope of the present invention.
Claims (10)


Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110577785.9ACN113316185B (en) | 2021-05-26 | 2021-05-26 | LTE network uplink interference category identification method and system based on classifier |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110577785.9ACN113316185B (en) | 2021-05-26 | 2021-05-26 | LTE network uplink interference category identification method and system based on classifier |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN113316185Atrue CN113316185A (en) | 2021-08-27 |
| CN113316185B CN113316185B (en) | 2023-09-12 |
Family
ID=77375128
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110577785.9AActiveCN113316185B (en) | 2021-05-26 | 2021-05-26 | LTE network uplink interference category identification method and system based on classifier |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN113316185B (en) |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN107734507A (en)* | 2016-08-12 | 2018-02-23 | 索尼公司 | Wireless scene identification device and method and Wireless Telecom Equipment and system |
| CN107770813A (en)* | 2017-09-30 | 2018-03-06 | 华南理工大学 | LTE uplink interference sorting techniques based on PCA Yu two-dimentional degree of bias feature |
| CN112633315A (en)* | 2020-10-21 | 2021-04-09 | 广东电网有限责任公司广州供电局 | Electric power system disturbance classification method |
- 2021
- 2021-05-26CNCN202110577785.9Apatent/CN113316185B/enactiveActive
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN107734507A (en)* | 2016-08-12 | 2018-02-23 | 索尼公司 | Wireless scene identification device and method and Wireless Telecom Equipment and system |
| CN107770813A (en)* | 2017-09-30 | 2018-03-06 | 华南理工大学 | LTE uplink interference sorting techniques based on PCA Yu two-dimentional degree of bias feature |
| CN112633315A (en)* | 2020-10-21 | 2021-04-09 | 广东电网有限责任公司广州供电局 | Electric power system disturbance classification method |
Non-Patent Citations (3)
| Title |
|---|
| XIONGHUI LUO等: ""Link Quality Estimation Method for Wireless Sensor Networks Based on Stacked Autoencoder""* |
| 王怀警等: ""多分类器组合森林类型精细分类""* |
| 许鸿奎等: ""基于加权随机森林的FDD-LTE上行干扰分类研究""* |
Also Published As
| Publication number | Publication date |
|---|---|
| CN113316185B (en) | 2023-09-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110135167B (en) | A random forest edge computing terminal security level assessment method | |
| CN110334580A (en) | The equipment fault classification method of changeable weight combination based on integrated increment | |
| CN109547133A (en) | A kind of SVM high-efficiency frequency spectrum cognitive method decomposing sample covariance matrix based on Cholesky | |
| CN105487526A (en) | FastRVM (fast relevance vector machine) wastewater treatment fault diagnosis method | |
| CN113541834A (en) | Abnormal signal semi-supervised classification method and system and data processing terminal | |
| CN112307927A (en) | Research on recognition of MPSK signal in non-cooperative communication based on BP network | |
| CN112132266A (en) | Signal Modulation Identification System and Modulation Identification Method Based on Convolutional Recurrent Network | |
| WO2023165139A1 (en) | Model quantization method and apparatus, device, storage medium and program product | |
| Yang et al. | One-dimensional deep attention convolution network (ODACN) for signals classification | |
| CN114626435A (en) | High-accuracy rolling bearing intelligent fault feature selection method | |
| CN114764577A (en) | Lightweight modulation recognition model based on deep neural network and method thereof | |
| CN108478216A (en) | A kind of epileptic seizure intelligent Forecasting early period based on convolutional neural networks | |
| CN118396036B (en) | Wind power prediction method, system, equipment and medium | |
| CN109525994A (en) | High energy efficiency frequency spectrum sensing method based on support vector machines | |
| CN110084126A (en) | A kind of satellite communication jamming signal type recognition methods based on Xgboost | |
| CN110224771A (en) | Frequency spectrum sensing method and device based on BP neural network and information geometry | |
| CN107770813A (en) | LTE uplink interference sorting techniques based on PCA Yu two-dimentional degree of bias feature | |
| CN114337883A (en) | CNN cooperative spectrum sensing method and system based on covariance matrix Cholesky decomposition | |
| CN119652714A (en) | A method for unknown signal recognition based on adversarial learning | |
| CN110852344A (en) | Intelligent substation network fault classification based method | |
| CN111343115B (en) | A 5G communication modulated signal identification method and system | |
| CN119167146A (en) | A method and device for automatic modulation recognition of small sample signals | |
| CN113316185B (en) | LTE network uplink interference category identification method and system based on classifier | |
| CN115883301B (en) | Signal modulation classification model and learning method based on sample recall incremental learning | |
| CN110781832B (en) | Hyperspectral image abnormal target detection method based on combined depth confidence network |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |