CN113052159A - Image identification method, device, equipment and computer storage medium - Google Patents
Image identification method, device, equipment and computer storage mediumDownload PDFInfo
- Publication number
- CN113052159A CN113052159ACN202110400954.1ACN202110400954ACN113052159ACN 113052159 ACN113052159 ACN 113052159ACN 202110400954 ACN202110400954 ACN 202110400954ACN 113052159 ACN113052159 ACN 113052159A
- Authority
- CN
- China
- Prior art keywords
- image
- sample
- recognized
- feature
- determining
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images




Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/20—Image preprocessing
- G06V10/22—Image preprocessing by selection of a specific region containing or referencing a pattern; Locating or processing of specific regions to guide the detection or recognition
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/25—Fusion techniques
- G06F18/253—Fusion techniques of extracted features
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/20—Image preprocessing
- G06V10/25—Determination of region of interest [ROI] or a volume of interest [VOI]
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/40—Extraction of image or video features
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- General Physics & Mathematics (AREA)
- Evolutionary Computation (AREA)
- Life Sciences & Earth Sciences (AREA)
- Artificial Intelligence (AREA)
- General Engineering & Computer Science (AREA)
- Evolutionary Biology (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Bioinformatics & Computational Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Multimedia (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- General Health & Medical Sciences (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Health & Medical Sciences (AREA)
- Computational Linguistics (AREA)
- Biophysics (AREA)
- Biomedical Technology (AREA)
- Image Analysis (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本申请属于图像检测领域,尤其涉及一种图像识别方法、装置、设备及计算机存储介质。The present application belongs to the field of image detection, and in particular, relates to an image recognition method, apparatus, device and computer storage medium.
背景技术Background technique
在图像中识别目标对象是计算机视觉领域的重要研究方向之一,在公共安全、道路交通、视频监控等领域均有着重要的作用。现有技术中,可以利用图像中的目标对象的空间关系特征,对上述目标对象进行识别;也可以通过对神经网络中的图像特征权重进行合理匹配,以提高上述神经网络对目标对象的识别精度。Recognizing target objects in images is one of the important research directions in the field of computer vision, and plays an important role in public safety, road traffic, video surveillance and other fields. In the prior art, the spatial relationship features of the target objects in the image can be used to identify the above-mentioned target objects; it is also possible to reasonably match the image feature weights in the neural network to improve the recognition accuracy of the target objects by the above-mentioned neural network. .
但现有技术中,由于图像所包含场景的复杂多样性和图像中待检测目标位置的不确定性,无法适应更多场景,进而导致无法提高图像识别的准确率。However, in the prior art, due to the complexity and diversity of the scenes contained in the image and the uncertainty of the position of the target to be detected in the image, it is impossible to adapt to more scenes, and thus the accuracy of image recognition cannot be improved.
发明内容SUMMARY OF THE INVENTION
本申请实施例提供一种图像识别方法、装置、设备及计算机存储介质,用以提高图像识别的准确率。Embodiments of the present application provide an image recognition method, apparatus, device, and computer storage medium, so as to improve the accuracy of image recognition.
第一方面,本申请实施例提供一种图像识别方法,方法包括:In a first aspect, an embodiment of the present application provides an image recognition method, the method comprising:
获取待识别图像,待识别图像中有至少一个待识别对象;Acquire an image to be recognized, and there is at least one object to be recognized in the image to be recognized;
将待识别图像输入至预先训练的图像识别模型中的第一网络,确定待识别图像的文本特征;Input the image to be recognized into the first network in the pre-trained image recognition model, and determine the text feature of the image to be recognized;
将待识别图像输入至图像识别模型中的第二网络,确定至少一个待识别对象的池化特征图像和空间关系特征;Input the image to be recognized into the second network in the image recognition model, and determine the pooled feature image and spatial relationship feature of at least one object to be recognized;
对待识别图像的文本特征、至少一个待识别对象的池化特征图像和空间关系特征进行特征融合,确定与待识别图像对应的共享特征图像;Perform feature fusion on the text feature of the image to be recognized, the pooled feature image of at least one object to be recognized, and the spatial relationship feature, and determine a shared feature image corresponding to the image to be recognized;
将共享特征图像输入至图像识别模型中的第三网络,确定待识别图像的识别信息,识别信息包括每一待识别对象的类别信息和位置信息。The shared feature image is input to the third network in the image recognition model, and the identification information of the image to be identified is determined, and the identification information includes the category information and location information of each object to be identified.
第二方面,本申请实施例提供一种图像识别装置,装置包括:In a second aspect, an embodiment of the present application provides an image recognition device, the device comprising:
第一获取模块,用于获取待识别图像,待识别图像中有至少一个待识别对象;a first acquisition module, configured to acquire an image to be recognized, and there is at least one object to be recognized in the image to be recognized;
第一确定模块,用于将待识别图像输入至预先训练的图像识别模型中的第一网络,确定待识别图像的文本特征;a first determination module, used to input the image to be recognized into the first network in the pre-trained image recognition model, and determine the text feature of the image to be recognized;
第二确定模块,用于将待识别图像输入至图像识别模型中的第二网络,确定至少一个待识别对象的池化特征图像和空间关系特征;The second determination module is used to input the image to be recognized into the second network in the image recognition model, and determine the pooled feature image and the spatial relationship feature of at least one object to be recognized;
融合模块,用于对待识别图像的文本特征、至少一个待识别对象的池化特征图像和空间关系特征进行特征融合,确定与待识别图像对应的共享特征图像;The fusion module is used for feature fusion of the text feature of the image to be recognized, the pooled feature image of at least one object to be recognized, and the spatial relationship feature, to determine the shared feature image corresponding to the image to be recognized;
识别模块,用于将共享特征图像输入至图像识别模型中的第三网络,确定待识别图像的识别信息,识别信息包括每一待识别对象的类别信息和位置信息。The identification module is used for inputting the shared feature image to the third network in the image identification model, and determining identification information of the image to be identified, the identification information including category information and position information of each object to be identified.
第三方面,本申请实施例提供了一种图像识别设备,设备包括:In a third aspect, an embodiment of the present application provides an image recognition device, the device includes:
处理器,以及存储有计算机程序指令的存储器;处理器读取并执行计算机程序指令,以实现如本申请实施例第一方面所提供的图像识别方法。A processor, and a memory storing computer program instructions; the processor reads and executes the computer program instructions to implement the image recognition method provided by the first aspect of the embodiments of the present application.
第四方面,本申请实施例提供了一种计算机存储介质,计算机存储介质上存储有计算机程序指令,计算机程序指令被处理器执行时实现如本申请实施例第一方面所提供的图像识别方法。In a fourth aspect, the embodiments of the present application provide a computer storage medium, where computer program instructions are stored thereon, and when the computer program instructions are executed by a processor, the image recognition method provided by the first aspect of the embodiments of the present application is implemented.
本申请实施例提供的图像识别方法,提取待检测图像的文本特征、以及上述待检测图像中至少一个第一目标对象的池化特征图像和空间关系特征,并将上述三个特征进行特征融合,将融合后的共享特征图,输入至图像识别模型中的第三网络,确定待识别图像的识别信息,识别信息包括每一待识别对象的类别信息和位置信息。相比于现有技术,通过特征融合实现图像信息的互补,在避免冗余噪声的同时,弥补了图像特征信息在细节和场景上的不足,同时文本特征的提取,能够反应图像在不同场景下的差异与共性,进而能够适用于更多复杂场景,并提高图像识别的准确率。The image recognition method provided in the embodiment of the present application extracts the text feature of the image to be detected, the pooled feature image and the spatial relationship feature of at least one first target object in the above-mentioned image to be detected, and performs feature fusion on the above three features, Input the fused shared feature map to the third network in the image recognition model to determine the identification information of the image to be identified, and the identification information includes category information and location information of each object to be identified. Compared with the prior art, the complementation of image information is realized through feature fusion, which makes up for the lack of image feature information in details and scenes while avoiding redundant noise. At the same time, the extraction of text features can reflect the image in different scenes. The differences and commonalities can be applied to more complex scenes and improve the accuracy of image recognition.
附图说明Description of drawings
为了更清楚地说明本申请实施例的技术方案,下面将对本申请实施例中所需要使用的附图作简单的介绍,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。In order to illustrate the technical solutions of the embodiments of the present application more clearly, the following briefly introduces the accompanying drawings that need to be used in the embodiments of the present application. For those of ordinary skill in the art, without creative work, the Additional drawings can be obtained from these drawings.
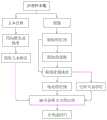
图1是本申请实施例提供的一种图像识别模型的训练方法的流程示意图;1 is a schematic flowchart of a training method for an image recognition model provided by an embodiment of the present application;
图2是本申请实施例提供的一种多模态特征融合模块的结构示意图;2 is a schematic structural diagram of a multimodal feature fusion module provided by an embodiment of the present application;
图3是本申请实施例提供的一种图像识别方法的流程示意图;3 is a schematic flowchart of an image recognition method provided by an embodiment of the present application;
图4是本申请实施例提供的一种图像识别装置的流程示意图;4 is a schematic flowchart of an image recognition apparatus provided by an embodiment of the present application;
图5是本申请实施例提供的一种图像识别设备的结构示意图。FIG. 5 is a schematic structural diagram of an image recognition device provided by an embodiment of the present application.
具体实施方式Detailed ways
下面将详细描述本申请的各个方面的特征和示例性实施例,为了使本申请的目的、技术方案及优点更加清楚明白,以下结合附图及具体实施例,对本申请进行进一步详细描述。应理解,此处所描述的具体实施例仅意在解释本申请,而不是限定本申请。对于本领域技术人员来说,本申请可以在不需要这些具体细节中的一些细节的情况下实施。下面对实施例的描述仅仅是为了通过示出本申请的示例来提供对本申请更好的理解。The features and exemplary embodiments of various aspects of the present application will be described in detail below. In order to make the purpose, technical solutions and advantages of the present application more clear, the present application will be further described in detail below with reference to the accompanying drawings and specific embodiments. It should be understood that the specific embodiments described herein are only intended to explain the present application, but not to limit the present application. It will be apparent to those skilled in the art that the present application may be practiced without some of these specific details. The following description of the embodiments is merely to provide a better understanding of the present application by illustrating examples of the present application.
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。It should be noted that, in this document, relational terms such as first and second are only used to distinguish one entity or operation from another entity or operation, and do not necessarily require or imply any relationship between these entities or operations. any such actual relationship or sequence exists. Moreover, the terms "comprising", "comprising" or any other variation thereof are intended to encompass a non-exclusive inclusion such that a process, method, article or device that includes a list of elements includes not only those elements, but also includes not explicitly listed or other elements inherent to such a process, method, article or apparatus. Without further limitation, an element defined by the phrase "comprises" does not preclude the presence of additional identical elements in a process, method, article, or device that includes the element.
图像识别算法是计算机视觉领域的重要研究方向之一,在公共安全、道路交通、视频监控等领域均有着重要的作用。近年来,基于深度学习的图像识别算法的发展,图像识别在准确率方面不断提高。Image recognition algorithm is one of the important research directions in the field of computer vision, and plays an important role in public safety, road traffic, video surveillance and other fields. In recent years, with the development of image recognition algorithms based on deep learning, the accuracy of image recognition has been continuously improved.
现有技术中,通过以下两种方式来进行图像识别:In the prior art, image recognition is performed in the following two ways:
一、基于视觉显著性的多视角图像目标检测方法1. Multi-view image object detection method based on visual saliency
针对前景目标未被遮挡的场景,计算多个视角图像的显著性图,利用视角之间的空间关系,将两侧视角的显著性图投影到中间目标视角,并将投影显著性图和中间视角的显著性图相融合得到融合显著性图。被前景物体遮挡的区域在投影时不能真实映射到目标视角,投影显著性图中前景目标周围会产生投影空洞,在融合显著性图中将该投影空洞区域视为背景区域。利用多视角投影空洞划分图像区域,投影空洞和图像边缘之间的区域以及不同前景物体的投影空洞之间的区域均视为背景区域。在融合显著性图中,将以上得到的背景区域的显著性值置为零,并二值化后便可得到边缘清晰、无背景干扰的目标物体。For the scene where the foreground target is not occluded, calculate the saliency maps of images from multiple perspectives, use the spatial relationship between the perspectives, project the saliency maps of the two perspectives to the middle target perspective, and project the saliency map and the middle perspective. The saliency maps are fused to obtain a fused saliency map. The area occluded by the foreground object cannot be truly mapped to the target perspective during projection, and there will be projection holes around the foreground object in the projected saliency map, which is regarded as the background area in the fusion saliency map. The image area is divided by multi-view projection holes, and the area between the projection hole and the image edge and the area between the projection holes of different foreground objects are regarded as the background area. In the fusion saliency map, the saliency value of the background region obtained above is set to zero, and after binarization, the target object with clear edges and no background interference can be obtained.
二、复杂背景下的小目标检测算法2. Small target detection algorithm in complex background
借鉴特征金字塔算法的思想,将Conv4-3层的特征与Conv7、Conv3-3层的特征进行融合,同时增加融合后特征图每个位置对应的默认框数量。在网络结构中增加裁剪-权重分配网络(SENet),对每层的特征通道进行权重分配,提升有用的特征权重并抑制无效的特征权重。同时为了增强网络的泛化能力,对训练数据集进行一系列增强处理。Drawing on the idea of the feature pyramid algorithm, the features of the Conv4-3 layers are fused with the features of the Conv7 and Conv3-3 layers, and at the same time, the number of default boxes corresponding to each position of the fused feature map is increased. A clipping-weight assignment network (SENet) is added to the network structure to assign weights to the feature channels of each layer, improve useful feature weights and suppress invalid feature weights. At the same time, in order to enhance the generalization ability of the network, a series of enhancement processing is performed on the training data set.
上述两种算法都是图像中对目标对象进行检测识别的常用技术,然而由于图像所包含场景的复杂多样性和图像中待检测目标位置的不确定性,常规的目标检测方法在不同的应用场景中具有较差的鲁棒性。上述基于视觉显著性的多视角图像目标检测方法,只考虑了图像中待检测目标的空间关系特征,但未充分利用图像中的多种特征信息进行信息补充以提升最终图像识别的准确率。复杂背景下的小目标检测算法,未考虑复杂背景中的上下文信息和待检测目标的空间关系,应用范围较窄,主要是针对图像中的小目标的检测识别准确率进行改进,忽略了算法在更多复杂场景中的应用。The above two algorithms are common techniques for detecting and identifying target objects in images. However, due to the complexity and diversity of the scenes contained in the images and the uncertainty of the location of the targets to be detected in the images, conventional target detection methods are used in different application scenarios. has poor robustness. The above-mentioned multi-view image target detection method based on visual saliency only considers the spatial relationship characteristics of the target to be detected in the image, but does not make full use of various feature information in the image to supplement information to improve the accuracy of the final image recognition. The small target detection algorithm in the complex background does not consider the context information in the complex background and the spatial relationship of the target to be detected, and the application range is narrow. More applications in complex scenarios.
基于此,本申请实施例提供一种图像识别方法,通过特征融合实现图像信息的互补,在避免冗余噪声的同时,弥补了图像特征信息在细节和场景上的不足,同时文本特征的提取,能够反应图像在不同场景下的差异与共性,进而能够适用于更多复杂场景,并提高图像识别的准确率。Based on this, the embodiments of the present application provide an image recognition method, which realizes the complementarity of image information through feature fusion, makes up for the lack of image feature information in details and scenes while avoiding redundant noise, and extracts text features. It can reflect the differences and commonalities of images in different scenes, which can be applied to more complex scenes and improve the accuracy of image recognition.
需要说明的是,本申请实施例提供的图像识别方法中,需要利用预先训练好的图像识别模型对图像进行识别,因此,在利用图像识别模型进行图像识别之前,需要先训练好图像识别模型。因此,下面首先结合附图描述本申请实施例提供的图像识别模型的训练方法的具体实施方式。It should be noted that, in the image recognition method provided by the embodiment of the present application, a pre-trained image recognition model needs to be used to recognize the image. Therefore, before using the image recognition model for image recognition, the image recognition model needs to be trained first. Therefore, the specific implementation of the training method for the image recognition model provided by the embodiments of the present application will be described below first with reference to the accompanying drawings.
如图1所示,本申请实施例提供一种图像识别模型的训练方法,首先获取样本图像,对在样本图像中所提取的池化特征图、文本特征和空间关系特征等信息进行融合,以形成信息更丰富的共享特征图,对预设的图像识别模型通过分类和回归检测算法进行迭代训练,直到满足训练停止条件。上述方法,可以通过以下步骤来实现:As shown in FIG. 1 , an embodiment of the present application provides a training method for an image recognition model. First, a sample image is obtained, and information such as pooling feature maps, text features, and spatial relationship features extracted from the sample images is fused to obtain A shared feature map with richer information is formed, and the preset image recognition model is iteratively trained through classification and regression detection algorithms until the training stop condition is met. The above method can be achieved by the following steps:
一、获取多张待标注图像。1. Obtain multiple images to be labeled.
在一些实施例中,可以通过车载摄像头获取多张待标注图像或者对获取到的视频进行抽帧处理得到多张待标注图像。In some embodiments, a plurality of images to be labeled may be obtained by using a vehicle-mounted camera or by performing frame extraction processing on the obtained video to obtain a plurality of images to be labeled.
二、对上述多张待标注图像进行人工标注,需要标注的内容为目标对象的标签识别信息,标签识别信息包括目标识别对象的分类信息和位置信息,其中位置信息为包围目标对象边界框的坐标值。2. Manually label the above-mentioned multiple images to be labeled. The content to be labeled is the label identification information of the target object. The label identification information includes the classification information and position information of the target identification object, and the position information is the coordinates of the bounding box surrounding the target object. value.
在一些实施例中,车载摄像头拍摄的图像主要以道路交通为主要场景,因此对待标注图像的标注对象可以包括行人、骑手、自行车、摩托车、汽车、卡车、公交车、火车、交通标志和交通灯等目标对象,标注结果为目标对象的类别和包围该目标对象边界框的坐标值;同时,对每张待标注图像从时间、地点、天气三个角度做文本注释。In some embodiments, the images captured by the in-vehicle camera mainly take road traffic as the main scene, so the annotated objects to be annotated in the image may include pedestrians, riders, bicycles, motorcycles, cars, trucks, buses, trains, traffic signs and traffic For target objects such as lights, the annotation results are the category of the target object and the coordinate value of the bounding box surrounding the target object; at the same time, text annotations are made for each image to be annotated from the perspectives of time, location, and weather.
具体地,对于每张待标注图像,从时间角度注释,可选值包括白天、黄昏/黎明、夜晚;从地点角度注释,可选值包括高速公路、城市街道、住宅、停车场、加油站、隧道;从天气角度注释,可选值包括雪、多云、晴、阴、雨、雾。Specifically, for each to-be-labeled image, annotate from a time perspective, and the optional values include daytime, dusk/dawn, and night; from a location perspective, the optional values include highways, city streets, houses, parking lots, gas stations, Tunnel; annotated from a weather perspective, optional values include snow, cloudy, clear, overcast, rain, fog.
三、将上述经过人工标注的图像及其每一图像对应的标注信息整合成训练样本集,训练样本集中包括多个样本图像组。3. Integrate the above manually annotated images and the annotation information corresponding to each image into a training sample set, and the training sample set includes multiple sample image groups.
需要说明的是,由于图像识别模型需要进行多次迭代训练,以调整其损失函数值,至损失函数值满足训练停止条件,得到训练后的图像识别模型,而每次迭代训练中,若只输入一张样本图像,样本量太少不利于图像识别模型的训练调整,因此将训练样本集分为多个样本图像组,每一样本图像组中包含多张样本图像,进行利用训练样本集中的多个样本图像组对图像识别模型进行迭代训练。It should be noted that since the image recognition model needs to be trained for multiple iterations to adjust its loss function value, until the loss function value meets the training stop condition, the trained image recognition model is obtained, and in each iteration training, if only input A sample image, the sample size is too small, which is not conducive to the training and adjustment of the image recognition model. Therefore, the training sample set is divided into multiple sample image groups. Each sample image group contains multiple sample images. The image recognition model is iteratively trained on each sample image group.
四、利用训练样本集中的样本图像组训练图像识别模型,直至满足训练停止条件,得到训练后的图像识别模型。具体可以有以下步骤:Fourth, the image recognition model is trained by using the sample image groups in the training sample set until the training stop condition is satisfied, and the trained image recognition model is obtained. Specifically, the following steps can be taken:
4.1、利用预设图像识别模型中的第二网络提取样本图像中可识别对象的样本池化特征图和样本空间关系特征。4.1. Use the second network in the preset image recognition model to extract the sample pooling feature map and the sample space relationship feature of the recognizable object in the sample image.
在一些实施例中,预设图像识别模型中的第二网络可以为快速区域卷积神经网络Faster RCNN网络,本申请对此不做限定。In some embodiments, the second network in the preset image recognition model may be a Faster RCNN network, which is not limited in this application.
具体地,获取样本图像中可识别对象的样本池化特征图和样本空间关系特征,可以通过以下步骤实现:Specifically, obtaining the sample pooling feature map and the sample spatial relationship feature of the identifiable objects in the sample image can be achieved by the following steps:
4.1.1、将训练集中的样本图像统一调整到1000×600像素的固定大小,得到调整大小后的样本图像。4.1.1. Uniformly adjust the sample images in the training set to a fixed size of 1000 × 600 pixels to obtain the resized sample images.
4.1.2、将调整大小后的样本图像组输入深度残差网络ResNet、区域生成网络RPN以及快速区域卷积神经网络提取图像特征,得到池化特征图。4.1.2. Input the resized sample image group into the deep residual network ResNet, the region generation network RPN and the fast region convolutional neural network to extract image features, and obtain the pooled feature map.
1)首先将调整大小后的样本图像输入7×7×64的卷积层conv1,然后依次经过卷积层conv2_x、conv3_x、conv4_x、conv5_x和一个全连接层fc提取样本图像的原始特征图;1) First, input the resized sample image into the 7×7×64 convolutional layer conv1, and then sequentially pass through the convolutional layers conv2_x, conv3_x, conv4_x, conv5_x and a fully connected layer fc to extract the original feature map of the sample image;
2)将ResNet网络结构中conv4_x输出的原始特征图,输入到区域提取网络RPN中,从中挑选出预测结果中得分最高的前300个锚框(anchor)和与之对应的候选框;2) Input the original feature map output by conv4_x in the ResNet network structure into the region extraction network RPN, and select the top 300 anchor boxes with the highest scores in the prediction results and the corresponding candidate boxes;
3)比照conv4_x输出的原特征图,将300候选框的位置映射图输入到快速区域卷积神经网络中的感兴趣区域池化层ROI Pooling,得到可识别对象的固定大小的池化特征图。3) Comparing with the original feature map output by conv4_x, input the position map of 300 candidate boxes into the region-of-interest pooling layer ROI Pooling in the fast region convolutional neural network, and obtain a fixed-size pooling feature map of identifiable objects.
4.1.3、利用300个anchor和与之对应的候选框的坐标,计算候选框之间的交并比(Intersection over union,IOU),并通过下述公式1计算可识别对象间的空间关系特征,4.1.3. Using the coordinates of 300 anchors and their corresponding candidate frames, calculate the Intersection over Union (IOU) between candidate frames, and calculate the spatial relationship features between identifiable objects through the following formula 1 ,
Fr=f(w,h,area,dx,dy,IOU) 公式1Fr =f(w,h,area,dx ,dy ,IOU) Equation 1
其中,w和h代表候选框的宽和高,area表示候选框面积,dx和dy是两候选框几何中心的横向、纵向距离,IOU是指候选框之间的交并比,f(·)表示激活函数,Fr表示预测到的可识别对象之间的空间关系特征。Among them,w and h represent the width and height of the candidate frame,area represents the area of the candidate frame,dx anddy are the horizontal and vertical distances between the geometric centers of the two candidate frames, IOU refers to the intersection ratio between the candidate frames, f( ) represents the activation function, and Fr represents the predicted spatial relationship features between identifiable objects.
4.2、将样本图像输入至预设图像识别模型中的第一网络,根据样本图像的上下文信息,确定至少一个文本向量,拼接上述至少一个文本向量,确定样本图像对应的样本文本特征Ft。4.2. Input the sample image into the first network in the preset image recognition model, determine at least one text vector according to the context information of the sample image, splicing the above at least one text vector, and determine the sample text feature Ft corresponding to the sample image.
需要说明的是,图像识别模型中的第一网络可以是Word2vec、Glove或BERT等预训练模型;根据样本图像的上下文信息所确定的文本向量,可以是将描述样本图像的时间、地点和天气的文本注释信息转换的词向量,本申请对此均不做限定。It should be noted that the first network in the image recognition model can be a pre-training model such as Word2vec, Glove or BERT; the text vector determined according to the context information of the sample image can be the time, location and weather that will describe the sample image. The word vector converted from the text annotation information is not limited in this application.
4.3、如图2所示,构建多模态特征融合模块,将根据样本图像上下文信息所提取出的样本文本特征、以及基于图像识别模型的第二网络确定的样本空间关系特征和样本池化特征图互补融合得到样本共享特征图像。其融合计算方法,可以通过公式2和公式3实现:4.3. As shown in Figure 2, a multi-modal feature fusion module is constructed, and the sample text features extracted according to the context information of the sample images, as well as the sample spatial relationship features and sample pooling features determined by the second network based on the image recognition model. Graph complementary fusion obtains sample shared feature images. Its fusion calculation method can be realized by formula 2 and formula 3:
Fv=ReLu(Froi,Fr) 公式2Fv =ReLu(Froi ,Fr ) Equation 2
Fout=Fv*Ft 公式3Fout = Fv *Ft formula 3
其中,Froi表示经过池化层ROI Pooling后输出的固定尺寸特征图,Fv表示原始特征图,Fout表示样本文本特征、样本空间关系特征和样本池化特征图融合以后得到的样本共享特征图像。Among them, Froi represents the fixed-size feature map output after the pooling layer ROI Pooling, Fv represents the original feature map, and Fout represents the sample text features, sample spatial relationship features, and sample pooling feature maps obtained after fusion of the sample shared features image.
4.4、将样本共享特征图像输入至预设图像识别模型中的第三网络,确定每一可识别对象的参考识别信息,参考识别信息包括可识别对象的分类信息和参考位置信息。4.4. Input the sample shared characteristic image into the third network in the preset image recognition model, and determine the reference identification information of each identifiable object. The reference identification information includes the classification information and reference position information of the identifiable object.
4.5、对每一可识别对象的参考位置信息进行非极大值抑制处理,过滤不符合预设要求的参考位置信息,确定每一样本图像的预测识别信息,预测识别信息包括所有可识别对象的分类信息和预测位置信息。4.5. Perform non-maximum suppression processing on the reference position information of each identifiable object, filter the reference position information that does not meet the preset requirements, and determine the predicted identification information of each sample image. The predicted identification information includes the information of all identifiable objects. Classification information and predicted location information.
在一些实施例中,对每一类可识别对象的参考位置信息,分别进行非极大值抑制处理(Non Maximum Suppression,NMS),NMS获取按照分数排列的预测列表并对已排序的预测列表进行迭代,丢弃那些IOU值大于预定义阈值的预测结果,此处设置阈值为0.7,过滤掉重叠度较大的候选框,将抑制后的位置信息,确定为预测位置信息。In some embodiments, a non-maximum suppression (NMS) process is performed on the reference position information of each type of identifiable object, and the NMS obtains a prediction list arranged according to the score and performs Iteratively, discard those prediction results whose IOU value is greater than the predefined threshold. Here, set the threshold to 0.7 to filter out candidate frames with a large degree of overlap, and determine the suppressed location information as the predicted location information.
4.6、计算预测识别信息和标注识别信息之间的损失值,按照公式4所示的目标损失函数优化图像识别模型,利用梯度下降算法反向更新网络参数,得到更新后的图像识别模型,直到损失函数值小于预设值,停止优化训练,确定训练后的图像识别模型。4.6. Calculate the loss value between the predicted identification information and the labeled identification information, optimize the image recognition model according to the objective loss function shown in Equation 4, and use the gradient descent algorithm to reversely update the network parameters to obtain the updated image recognition model until the loss If the function value is less than the preset value, the optimization training is stopped, and the image recognition model after training is determined.

其中,i表示anchor的索引,pi表示第i个anchor预测为目标的概率,




需要说明,为了提高图像识别模型的准确度,该图像识别模型还可以在实际应用中不断地利用新的训练样本进行训练,以不断更新图像识别模型,提高图像识别模型的准确度,进而提高图像识别的准确率。It should be noted that in order to improve the accuracy of the image recognition model, the image recognition model can also be continuously trained with new training samples in practical applications, so as to continuously update the image recognition model, improve the accuracy of the image recognition model, and then improve the image recognition model. recognition accuracy.
以上为本申请实施例提供的图像识别模型训练方法的具体实施方式,经上述训练得到的图像识别模型可应用于如下实施例提供的图像识别方法中。The above are the specific implementations of the image recognition model training method provided by the embodiment of the present application, and the image recognition model obtained through the above training can be applied to the image recognition method provided by the following embodiments.
下面结合附图3详细描述本申请提供的图像识别方法的具体实现方式。The specific implementation of the image recognition method provided by the present application will be described in detail below with reference to FIG. 3 .
如图3所示,本申请实施例提供一种图像识别方法,所述方法包括:As shown in FIG. 3 , an embodiment of the present application provides an image recognition method, and the method includes:
S301,获取待识别图像,待识别图像中有至少一个待识别对象。S301 , an image to be recognized is acquired, and there is at least one object to be recognized in the image to be recognized.
在一些实施例中,待识别对象可以通过车载摄像头来获取,或者对预先获取到的视频进行抽帧处理,确定待识别图像。In some embodiments, the object to be recognized may be acquired by a vehicle-mounted camera, or a frame extraction process is performed on a pre-acquired video to determine the image to be recognized.
以道路交通场景为例,上述待识别图像中的待识别对象可以是行人、骑手、自行车、摩托车、汽车、卡车、公交车、火车、交通标志和交通灯等。Taking a road traffic scene as an example, the objects to be recognized in the above image to be recognized may be pedestrians, riders, bicycles, motorcycles, cars, trucks, buses, trains, traffic signs, and traffic lights.
S302,将待识别图像输入至预先训练的图像识别模型中的第一网络,确定待识别图像的文本特征。S302: Input the image to be recognized into the first network in the pre-trained image recognition model, and determine the text feature of the image to be recognized.
在一些实施例中,将上述待识别图像输入至预先训练的图像识别模型中的第一网络,根据待识别图像的上下文信息,确定至少一个文本向量;拼接上述至少一个文本向量,确定待识别图像的文本特征。In some embodiments, the image to be recognized is input into a first network in a pre-trained image recognition model, and at least one text vector is determined according to context information of the image to be recognized; the at least one text vector is spliced to determine the image to be recognized text features.
需要说明的是,上述文本向量是基于第一网络,根据待识别图像的上下文信息,将描述样本图像的时间、地点和天气的文本注释信息转换确定的词向量,因此,通过拼接多个文本向量确定的文本特征,可以表征待识别图像的环境信息,进而反映待识别图像在不同场景下的差异与共性,以增强待识别对象的辨识度。It should be noted that the above-mentioned text vector is based on the first network, and according to the context information of the image to be recognized, the text annotation information describing the time, location and weather of the sample image is converted into a determined word vector. Therefore, by splicing multiple text vectors. The determined text features can represent the environmental information of the to-be-recognized image, thereby reflecting the differences and commonalities of the to-be-recognized image in different scenarios, so as to enhance the recognition degree of the to-be-recognized object.
S303,将待识别图像输入至图像识别模型中的第二网络,确定至少一个待识别对象的池化特征图像和空间关系特征。S303: Input the image to be recognized into the second network in the image recognition model, and determine the pooled feature image and the spatial relationship feature of at least one object to be recognized.
需要说明的是,在对待识别对象进行识别时,由于待识别图像中存在大量冗余信息,因此需要对图像进行卷积处理,在通过卷积处理确定图像特征后,可以用所提取到的图像特征去训练图像识别模型,但是这样计算成本比较高,因此需要对图像进行池化处理,以对图像特征降维,减小计算量和参数个数,同时防止过拟合,提高模型的容错性。It should be noted that when recognizing the object to be recognized, since there is a large amount of redundant information in the image to be recognized, the image needs to be convoluted. After the image features are determined through convolution processing, the extracted image can be used Features to train the image recognition model, but the computational cost is relatively high, so the image needs to be pooled to reduce the dimension of image features, reduce the amount of calculation and the number of parameters, and at the same time prevent overfitting and improve the fault tolerance of the model. .
另一方面,空间关系是指从图像中分割出来的多个目标对象之间的相对空间位置和相对方向关系,这些关系也可以分为连接关系、交叠/重叠关系和包含/包容关系。因此,空间关系特征的提取,可以增强对图像内容的区分能力。On the other hand, spatial relationship refers to the relative spatial position and relative orientation relationship between multiple target objects segmented from an image, and these relationships can also be divided into connection relationship, overlapping/overlapping relationship, and inclusion/inclusion relationship. Therefore, the extraction of spatial relationship features can enhance the ability to distinguish image content.
在一些实施例中,确定待识别对象中至少一个待识别对象的池化特征图像和空间关系特征,可以通过以下步骤:In some embodiments, determining the pooled feature image and spatial relationship feature of at least one of the objects to be identified may be performed through the following steps:
1、调整样本图像组中每一样本图像的分辨率为预设分辨率,确定调整后的样本图像组。1. Adjust the resolution of each sample image in the sample image group to the preset resolution, and determine the adjusted sample image group.
此步骤中,可以将训练集中的样本图像统一调整到1000×600像素的固定大小。In this step, the sample images in the training set can be uniformly resized to a fixed size of 1000×600 pixels.
2、将调整后的样本图像组输入至深度残差网络,确定原始图像集,原始图像集中的图像与调整后的样本图像组中的图像一一对应。2. Input the adjusted sample image group to the depth residual network to determine the original image set, and the images in the original image set correspond one-to-one with the images in the adjusted sample image group.
具体地,可以将调整大小后的样本图像输入7×7×64的卷积层conv1,然后依次经过卷积层conv2_x、conv3_x、conv4_x、conv5_x和一个全连接层fc提取样本图像的原始特征图。Specifically, the resized sample image can be input into the convolutional layer conv1 of 7×7×64, and then the original feature map of the sample image can be extracted through the convolutional layers conv2_x, conv3_x, conv4_x, conv5_x and a fully connected layer fc in sequence.
3、将原始图像集输入至区域提取网络,确定N个锚框及与每一锚框对应的位置坐标,其中,锚框为区域提取网络预测的包围可识别对象的边界框,N为大于1的整数;基于所述N个锚框的置信度,在N个锚框中,提取所述置信度大于预设置信度阈值的M个锚框,其中,M为小于N的正整数。3. Input the original image set to the region extraction network, and determine N anchor boxes and the position coordinates corresponding to each anchor box, where the anchor box is the bounding box that surrounds the recognizable object predicted by the region extraction network, and N is greater than 1 based on the confidence of the N anchor frames, extract M anchor frames whose confidence is greater than a preset confidence threshold from the N anchor frames, where M is a positive integer smaller than N.
作为一个示例,可以将ResNet网络结构中conv4_x输出的原始特征图,输入到区域提取网络RPN中,确定多个锚框和与之对应的候选框,基于每一锚框的置信度,从中挑选出置信度较高的300个锚框和与之对应的候选框。As an example, the original feature map output by conv4_x in the ResNet network structure can be input into the region extraction network RPN to determine multiple anchor boxes and corresponding candidate boxes, and select them based on the confidence of each anchor box. 300 anchor boxes with high confidence and their corresponding candidate boxes.
4、将M个锚框的映射区域图像输入至区域卷积神经网络的感兴趣区域池化层,调整M个锚框的映射区域图像的分辨率,确定分辨率相同的M个样本池化特征图,其中,每一可识别对象对应至少一个锚框。4. Input the mapping region images of the M anchor boxes into the region of interest pooling layer of the regional convolutional neural network, adjust the resolution of the mapping region images of the M anchor boxes, and determine the M sample pooling features with the same resolution Figure, wherein each recognizable object corresponds to at least one anchor box.
此步骤中,可以按照conv4_x输出的原特征图,将300候选框的位置映射图输入到快速区域卷积神经网络中的感兴趣区域池化层,得到可识别对象的固定大小的池化特征图。In this step, according to the original feature map output by conv4_x, the position map of the 300 candidate boxes can be input into the region of interest pooling layer in the fast region convolutional neural network to obtain a fixed-size pooling feature map of recognizable objects. .
S304,对待识别图像的文本特征、至少一个待识别对象的池化特征图像和空间关系特征进行特征融合,确定与待识别图像对应的共享特征图像。S304 , feature fusion is performed on the text feature of the image to be recognized, the pooled feature image of at least one object to be recognized, and the spatial relationship feature, and a shared feature image corresponding to the image to be recognized is determined.
上述S202及S203中,分别对待识别图像的文本特征、至少一个待识别对象的池化特征图像和空间关系特征进行了提取,虽然空间关系特征对图像或者图像中目标对象的旋转、反转、尺寸变化的识别更加敏感、且池化特征图可以减少图像识别中计算量,但在实际应用中,仅仅利用空间关系特征和/或池化特征是不够的,不能有效准确的表达场景信息,因此,需要对待识别图像的文本特征、至少一个待识别对象的池化特征图像和空间关系特征进行特征融合,充分利用图像中的多种特征信息进行信息补充,以反映图像在不同场景下的差异与共性,在避免冗余噪声的同时,弥补了图像特征信息在细节和场景上的不足。In the above S202 and S203, the text feature of the image to be recognized, the pooled feature image of at least one object to be recognized, and the spatial relationship feature are extracted, although the spatial relationship feature affects the rotation, inversion, and size of the image or the target object in the image. The identification of changes is more sensitive, and pooling feature maps can reduce the amount of computation in image recognition, but in practical applications, only using spatial relationship features and/or pooling features is not enough, and cannot effectively and accurately express scene information. Therefore, It is necessary to perform feature fusion of the text features of the image to be recognized, the pooled feature image of at least one object to be recognized, and the spatial relationship features, and make full use of various feature information in the image to supplement information to reflect the differences and commonality of images in different scenarios. , while avoiding redundant noise, it makes up for the lack of image feature information in details and scenes.
S305,将共享特征图像输入至图像识别模型中的第三网络,确定待识别图像的识别信息,识别信息包括每一待识别对象的类别信息和位置信息。S305: Input the shared feature image to the third network in the image recognition model, and determine the identification information of the image to be identified, where the identification information includes category information and location information of each object to be identified.
本申请实施例提供的图像识别方法,通过图像识别模型确定待识别图像的文本特征、至少一个待识别对象的池化特征图像和空间关系特征。将多种特征信息互补融合,增强了图像中待识别对象的辨识度,从而优化最终的图像识别性能,适用于更多复杂场景,并提高图像识别的准确率。In the image recognition method provided by the embodiment of the present application, the text feature of the to-be-recognized image, the pooled feature image of at least one to-be-recognized object, and the spatial relationship feature are determined by an image recognition model. The complementary fusion of various feature information enhances the recognition of the object to be recognized in the image, thereby optimizing the final image recognition performance, suitable for more complex scenes, and improving the accuracy of image recognition.
为了验证上述实施例中提供的图像识别方法相比于现有技术中的图像识别方法,能够提高图像识别的准确度,本申请实施例还提供一种图像识别的测试方法,对本申请图像识别方法中所应用的图像识别模型进行测试。具体地,可以包括以下步骤:In order to verify that the image recognition method provided in the above embodiment can improve the accuracy of image recognition compared with the image recognition method in the prior art, the embodiment of the present application also provides a test method for image recognition. The image recognition model applied in the test. Specifically, the following steps may be included:
一、将样本图像输入训练好的图像识别模型进行测试。1. Input the sample image into the trained image recognition model for testing.
具体地,按照公式5和公式6计算所有类别目标对象的平均检测精度,输出各预测框的分类和预测精度:Specifically, calculate the average detection accuracy of all categories of target objects according to formula 5 and formula 6, and output the classification and prediction accuracy of each prediction frame:


其中,N表示待检测目标类别数,AP表示平均精度,mAP表示所有类别的平均精度均值。Among them, N represents the number of target categories to be detected, AP represents the average precision, and mAP represents the average precision of all categories.
二、根据上述AP和mAP计算公式得出检测结果,比较现有技术中利用Faster RCNN网络算法和利用本申请实施例提供的图像识别模型的图像识别算法的优劣,得出结论:2. Draw the detection result according to the above-mentioned AP and mAP calculation formula, compare the advantages and disadvantages of the image recognition algorithm utilizing the Faster RCNN network algorithm and the image recognition model provided by the embodiment of the present application in the prior art, and draw the conclusion:
将本申请实施例提供的图像识别方法用于经典的图像识别网络中,对图像识别效果有显著改进,即使在图像的背景差异较大的情况下,图像中目标对象的识别精度仍维持在较稳定的水平且相较于原有的算法有更佳的识别效果。The image recognition method provided by the embodiment of the present application is used in a classic image recognition network, and the image recognition effect is significantly improved. Even when the background difference of the image is large, the recognition accuracy of the target object in the image is still maintained at a relatively high level. It has a stable level and has a better recognition effect than the original algorithm.
具体的,以一个施例具体对本申请实施例提供的图像识别模型的测试方法,通过以下仿真实验做进一步说明。Specifically, the testing method of the image recognition model provided by the embodiment of the present application is further described by the following simulation experiments with an embodiment.
本申请提供的仿真实验中所采用的现有技术为更快速的区域卷积神经网络Faster RCNN;图像识别模型选用ResNet101结构提取图像特征,设置初始学习率为0.005,学习率衰减系数为0.1,epoch设为15,默认优化器选择SGD。The existing technology used in the simulation experiment provided by this application is the faster regional convolutional neural network Faster RCNN; the image recognition model selects the ResNet101 structure to extract image features, the initial learning rate is set to 0.005, the learning rate decay coefficient is 0.1, and the epoch Set to 15, the default optimizer selects SGD.
1、仿真条件:本申请仿真的硬件环境是:Intel Core i7-7700@3.60GHz,8G内存;软件环境:ubuntu 16.04,python3.7,pycharm2019。1. Simulation conditions: The hardware environment simulated by this application is: Intel Core i7-7700@3.60GHz, 8G memory; software environment: ubuntu 16.04, python3.7, pycharm2019.
2、仿真内容与结果分析:2. Simulation content and result analysis:
首先将样本图像集作为输入,在传统的Faster RCNN算法基础上引入基于上下文信息进行文本特征提取、空间关系特征提取和池化特征图获取,然后将上述三种特征融合检测方法的基本思路,借助此方法训练图像识别模型,将测试样本集输入至训练好的改进模型,以AP指标评估各类别的平均精度和所有类别的平均精度。First, the sample image set is used as input, and based on the traditional Faster RCNN algorithm, text feature extraction, spatial relationship feature extraction and pooled feature map acquisition based on context information are introduced. This method trains the image recognition model, inputs the test sample set into the trained improved model, and evaluates the average precision of each category and the average precision of all categories by AP index.
本申请基于BDD100k公开驾驶数据集进行实验,仿真实验结果如表1所示,表中显示了经典的Faster RCNN算法和基于上下文信息的多模态特征融合检测方法在相同数据集上测试的对比结果。This application conducts experiments based on the BDD100k public driving data set. The simulation results are shown in Table 1. The table shows the comparison results of the classic Faster RCNN algorithm and the multimodal feature fusion detection method based on context information on the same data set. .
表1图像识别方法的性能对比Table 1 Performance comparison of image recognition methods


从表1的实验结果可以看出,与经典的Faster RCNN算法在测试数据集上的检测精度相比,本申请实施例提供的图像识别方法在不同场景的任务中在其中五个类别目标的平均检测精度上提升近4.3%。多次实验证明:多模态特征融合技术利用信息间的互补性增强了输入特征的表示性,能够有效改善目标检测算法的性能,在不同图像识别场景中的大部分类别中的平均精度明显提升。由于在现实生活场景中,图像/视频数据获取难度高且经常出现缺失,此时并不适用传统的基于图像和视频的目标检测方法,而本申请实施例提供的图像识别方法能够增强信息间的互补性,对不同场景中的检测任务有着重要意义。It can be seen from the experimental results in Table 1 that, compared with the detection accuracy of the classic Faster RCNN algorithm on the test data set, the image recognition method provided by this embodiment of the present application has an average of five categories of objects in tasks in different scenes. The detection accuracy is improved by nearly 4.3%. Multiple experiments have proved that the multimodal feature fusion technology uses the complementarity between information to enhance the representation of input features, which can effectively improve the performance of target detection algorithms, and the average accuracy in most categories in different image recognition scenarios is significantly improved. . In real-life scenarios, image/video data is difficult to obtain and often lacks, so traditional image and video-based target detection methods are not applicable at this time, and the image recognition method provided by the embodiment of the present application can enhance the information Complementarity is important for detection tasks in different scenarios.
基于上述图像识别方法的相同发明构思,本申请实施例还提供一种图像识别装置。Based on the same inventive concept of the above image recognition method, an embodiment of the present application further provides an image recognition device.
如图4所示,本申请实施例提供一种图像识别装置,可以包括:As shown in FIG. 4 , an embodiment of the present application provides an image recognition device, which may include:
第一获取模块401,用于获取待识别图像,待识别图像中有至少一个待识别对象;The
第一确定模块402,用于将待识别图像输入至预先训练的图像识别模型中的第一网络,确定待识别图像的文本特征;The
第二确定模块403,用于将待识别图像输入至图像识别模型中的第二网络,确定至少一个待识别对象的池化特征图像和空间关系特征;The
融合模块404,用于对待识别图像的文本特征、至少一个待识别对象的池化特征图像和空间关系特征进行特征融合,确定与待识别图像对应的共享特征图像;The
识别模块405,用于将共享特征图像输入至图像识别模型中的第三网络,确定待识别图像的识别信息,识别信息包括每一待识别对象的类别信息和位置信息。The
在一些实施例中,装置还可以包括:In some embodiments, the apparatus may further include:
第二获取模块,用于获取训练样本集,训练样本集中包括多个样本图像组,每一样本图像组包括样本图像及其对应的标签图像,标签图像中标注有目标识别对象的标签识别信息以及样本图像的场景信息,标签识别信息包括目标识别对象的类别信息和位置信息;The second acquisition module is used to acquire a training sample set, the training sample set includes a plurality of sample image groups, each sample image group includes a sample image and its corresponding label image, and the label image is marked with the label identification information of the target recognition object and The scene information of the sample image, and the label identification information includes the category information and location information of the target identification object;
训练模块,用于利用训练样本集中的样本图像组训练预设的图像识别模型,直至满足训练停止条件,得到训练后的图像识别模型。The training module is used to train the preset image recognition model by using the sample image groups in the training sample set until the training stop condition is satisfied, and the trained image recognition model is obtained.
在一些实施例中,训练模块具体可以用于:In some embodiments, the training module can be specifically used for:
对每个样本图像组,分别执行以下步骤:For each sample image group, perform the following steps separately:
将样本图像组输入至预设图像识别模型中的第一网络,确定与每一样本图像对应的样本文本特征;Input the sample image group to the first network in the preset image recognition model, and determine the sample text feature corresponding to each sample image;
将样本图像组输入至预设图像识别模型中的第二网络,确定每一可识别对象的样本池化特征图和样本空间关系特征;Input the sample image group to the second network in the preset image recognition model, and determine the sample pooling feature map and the sample spatial relationship feature of each recognizable object;
根据与每一样本图像对应的样本文本特征、每一可识别对象的样本池化特征图和样本空间关系特征,对每一样本图像进行特征融合,确定与每一样本图像对应的样本共享特征图像;According to the sample text features corresponding to each sample image, the sample pooling feature map of each recognizable object, and the sample spatial relationship features, feature fusion is performed on each sample image to determine the sample shared feature image corresponding to each sample image. ;
将样本共享特征图像输入至预设图像识别模型中的第三网络,确定每一可识别对象的参考识别信息,参考识别信息包括可识别对象的分类信息和参考位置信息;inputting the sample sharing feature image into the third network in the preset image recognition model, and determining the reference identification information of each identifiable object, the reference identification information including the classification information and reference position information of the identifiable object;
对每一可识别对象的参考位置信息进行非极大值抑制处理,过滤不符合预设要求的参考位置信息,确定每一样本图像的预测识别信息,预测识别信息包括所有可识别对象的分类信息和预测位置信息;Perform non-maximum suppression processing on the reference position information of each identifiable object, filter the reference position information that does not meet the preset requirements, and determine the predicted identification information of each sample image. The predicted identification information includes the classification information of all identifiable objects. and predicted location information;
根据目标样本图像的预测识别信息和目标样本图像上所有目标识别对象的标签识别信息,确定预设图像识别模型的损失函数值,目标样本图像是样本图像组中的任一个;Determine the loss function value of the preset image recognition model according to the predicted recognition information of the target sample image and the label recognition information of all target recognition objects on the target sample image, and the target sample image is any one of the sample image groups;
在损失函数值不满足训练停止条件的情况下,调整图像识别模型的模型参数,并利用样本图像组训练参数调整后的图像识别模型,直至损失函数值满足训练停止条件,得到训练后的图像识别模型。If the loss function value does not meet the training stop condition, adjust the model parameters of the image recognition model, and use the sample image group to train the adjusted image recognition model until the loss function value meets the training stop condition, and obtain the image recognition model after training. Model.
在一些实施例中,训练模块具体可以用于:In some embodiments, the training module can be specifically used for:
对每一样本图像,分别执行以下步骤:For each sample image, perform the following steps separately:
将样本图像输入至预设图像识别模型中的第一网络,根据样本图像的上下文信息,确定至少一个文本向量;Input the sample image to the first network in the preset image recognition model, and determine at least one text vector according to the context information of the sample image;
拼接至少一个文本向量,确定与样本图像对应的样本文本特征。Splicing at least one text vector to determine the sample text feature corresponding to the sample image.
5、根据权利要求3的方法,预设图像识别模型中的第二网络至少包括深度残差网络、区域提取网络和区域卷积神经网络,5. The method according to claim 3, wherein the second network in the preset image recognition model comprises at least a deep residual network, a region extraction network and a region convolutional neural network,
将样本图像组输入至预设图像识别模型中的第二网络,确定每一可识别对象的样本池化特征图和样本空间关系特征,包括:Input the sample image group to the second network in the preset image recognition model, and determine the sample pooling feature map and sample spatial relationship characteristics of each recognizable object, including:
调整样本图像组中每一样本图像的分辨率为预设分辨率,确定调整后的样本图像组;Adjust the resolution of each sample image in the sample image group to a preset resolution, and determine the adjusted sample image group;
将调整后的样本图像组输入至深度残差网络,确定原始图像集,原始图像集中的图像与调整后的样本图像组中的图像一一对应;Input the adjusted sample image group to the depth residual network, determine the original image set, and the images in the original image set correspond one-to-one with the images in the adjusted sample image group;
将原始图像集输入至区域提取网络,确定N个锚框及与每一锚框对应的位置坐标,其中,锚框为区域提取网络预测的包围可识别对象的边界框,N为大于1的整数;Input the original image set to the region extraction network, and determine N anchor boxes and the position coordinates corresponding to each anchor box, where the anchor box is the bounding box that surrounds the recognizable object predicted by the region extraction network, and N is an integer greater than 1 ;
基于N个锚框的置信度,在N个锚框中,提取置信度大于预设置信度阈值的M个锚框,其中,M为小于N的正整数;Based on the confidence of the N anchor frames, in the N anchor frames, extract M anchor frames with a confidence greater than a preset reliability threshold, where M is a positive integer less than N;
将M个锚框的映射区域图像输入至区域卷积神经网络的感兴趣区域池化层,调整M个锚框的映射区域图像的分辨率,确定分辨率相同的M个样本池化特征图,其中,每一可识别对象对应至少一个锚框;Input the mapping region images of the M anchor boxes to the region of interest pooling layer of the regional convolutional neural network, adjust the resolution of the mapping region images of the M anchor boxes, and determine the M sample pooling feature maps with the same resolution, Wherein, each identifiable object corresponds to at least one anchor frame;
根据每一可识别对象对应的至少一个锚框之间的交并比和相对位置,确定每一可识别对象的样本空间关系特征。According to the intersection ratio and relative position between at least one anchor box corresponding to each recognizable object, the sample spatial relationship feature of each recognizable object is determined.
在一些实施例中,训练模块具体可以用于:In some embodiments, the training module can be specifically used for:
基于每一可识别对象的分类信息,将所有可识别对象分为多组,确定多组不同类别的可识别对象的参考位置信息;Based on the classification information of each identifiable object, all identifiable objects are divided into multiple groups, and the reference position information of multiple groups of different types of identifiable objects is determined;
对每一类可识别对象的参考位置信息,进行过滤处理;Filter the reference position information of each type of identifiable object;
根据过滤之后的可识别对象的参考位置信息和过滤之后的可识别对象的分类信息,确定每一样本图像的预测识别信息。The predicted identification information of each sample image is determined according to the filtered reference position information of the identifiable object and the filtered classification information of the identifiable object.
在一些实施例中,训练模块具体可以用于:In some embodiments, the training module can be specifically used for:
依次计算目标框与其他参考框之间的交并比,目标框为多个参考框中的任一个,参考框是参考位置信息中所确定的包围可识别对象的边界框;Calculate the intersection ratio between the target frame and other reference frames in turn, where the target frame is any one of multiple reference frames, and the reference frame is a bounding box that surrounds the identifiable object determined in the reference position information;
将交并比大于预设交并比阈值的参考框过滤,直到任意两个参考框之间的交并比均小于预设交并比阈值;Filter the reference frames whose intersection ratio is greater than the preset intersection ratio threshold until the intersection ratio between any two reference frames is smaller than the preset intersection ratio threshold;
将过滤之后的参考框确定为可识别对象的预测位置信息。The filtered reference frame is determined as the predicted position information of the recognizable object.
根据本申请实施例提供的图像识别装置的其他细节与以上结合图1描述的根据本申请实施例的图像识别方法类似,在此不再赘述。Other details of the image recognition apparatus provided according to the embodiment of the present application are similar to the image recognition method according to the embodiment of the present application described above with reference to FIG. 1 , and details are not described herein again.
图5示出了本申请实施例提供的图像识别的硬件结构示意图。FIG. 5 shows a schematic diagram of a hardware structure of image recognition provided by an embodiment of the present application.
结合图1、图4描述的根据本申请实施例提供的图像识别方法和装置可以由图像识别设备来实现。图5是示出根据发明实施例的图像识别设备的硬件结构500示意图。The image recognition method and apparatus provided according to the embodiments of the present application described in conjunction with FIG. 1 and FIG. 4 may be implemented by an image recognition device. FIG. 5 is a schematic diagram illustrating a hardware structure 500 of an image recognition device according to an embodiment of the invention.
在图像识别设备中可以包括处理器501以及存储有计算机程序指令的存储器502。A
具体地,上述处理器501可以包括中央处理器(Central Processing Unit,CPU),或者特定集成电路(Application Specific Integrated Circuit,ASIC),或者可以被配置成实施本申请实施例的一个或多个集成电路。Specifically, the above-mentioned
存储器502可以包括用于数据或指令的大容量存储器。举例来说而非限制,存储器502可包括硬盘驱动器(Hard Disk Drive,HDD)、软盘驱动器、闪存、光盘、磁光盘、磁带或通用串行总线(Universal Serial Bus,USB)驱动器或者两个或更多个以上这些的组合。在一个实例中,存储器502可以包括可移除或不可移除(或固定)的介质,或者存储器502是非易失性固态存储器。存储器502可在综合网关容灾设备的内部或外部。
在一个实例中,存储器502可以是只读存储器(Read Only Memory,ROM)。在一个实例中,该ROM可以是掩模编程的ROM、可编程ROM(PROM)、可擦除PROM(EPROM)、电可擦除PROM(EEPROM)、电可改写ROM(EAROM)或闪存或者两个或更多个以上这些的组合。In one example, the
处理器501通过读取并执行存储器502中存储的计算机程序指令,以实现图3所示实施例中的方法/步骤S301至S305,并达到图3所示实例执行其方法/步骤达到的相应技术效果,为简洁描述在此不再赘述。The
在一个示例中,图像识别设备还可包括通信接口503和总线510。其中,如图5所示,处理器501、存储器502、通信接口503通过总线510连接并完成相互间的通信。In one example, the image recognition device may also include a
通信接口503,主要用于实现本申请实施例中各模块、装置、单元和/或设备之间的通信。The
总线510包括硬件、软件或两者,将在线数据流量计费设备的部件彼此耦接在一起。举例来说而非限制,总线可包括加速图形端口(Accelerated Graphics Port,AGP)或其他图形总线、增强工业标准架构(Extended Industry Standard Architecture,EISA)总线、前端总线(Front Side Bus,FSB)、超传输(Hyper Transport,HT)互连、工业标准架构(Industry Standard Architecture,ISA)总线、无限带宽互连、低引脚数(LPC)总线、存储器总线、微信道架构(MCA)总线、外围组件互连(PCI)总线、PCI-Express(PCI-X)总线、串行高级技术附件(SATA)总线、视频电子标准协会局部(VLB)总线或其他合适的总线或者两个或更多个以上这些的组合。在合适的情况下,总线510可包括一个或多个总线。尽管本申请实施例描述和示出了特定的总线,但本申请考虑任何合适的总线或互连。The
本申请实施例提供的图像识别设备,通过特征融合实现图像信息的互补,在避免冗余噪声的同时,弥补了图像特征信息在细节和场景上的不足,充分利用图像中的多种特征信息进行信息补充,同时文本特征的提取,能够反应图像在不同场景下的差异与共性,进而能够适用于更多复杂场景,并提高图像识别的准确率。The image recognition device provided by the embodiment of the present application realizes the complementation of image information through feature fusion, and at the same time avoids redundant noise, makes up for the lack of image feature information in details and scenes, and makes full use of various feature information in the image. The information supplement and the extraction of text features can reflect the differences and commonalities of images in different scenes, which can be applied to more complex scenes and improve the accuracy of image recognition.
另外,结合上述实施例中的图像识别方法,本申请实施例可提供一种计算机存储介质来实现。该计算机存储介质上存储有计算机程序指令;该计算机程序指令被处理器执行时实现上述实施例中的任意一种图像识别方法。In addition, in combination with the image recognition methods in the above embodiments, the embodiments of the present application may provide a computer storage medium for implementation. Computer program instructions are stored on the computer storage medium; when the computer program instructions are executed by the processor, any one of the image recognition methods in the foregoing embodiments is implemented.
需要明确的是,本申请并不局限于上文所描述并在图中示出的特定配置和处理。为了简明起见,这里省略了对已知方法的详细描述。在上述实施例中,描述和示出了若干具体的步骤作为示例。但是,本申请的方法过程并不限于所描述和示出的具体步骤,本领域的技术人员可以在领会本申请的精神后,作出各种改变、修改和添加,或者改变步骤之间的顺序。To be clear, the present application is not limited to the specific configurations and processes described above and illustrated in the figures. For the sake of brevity, detailed descriptions of known methods are omitted here. In the above-described embodiments, several specific steps are described and shown as examples. However, the method process of the present application is not limited to the specific steps described and shown, and those skilled in the art can make various changes, modifications and additions, or change the sequence of steps after comprehending the spirit of the present application.
以上所述的结构框图中所示的功能块可以实现为硬件、软件、固件或者它们的组合。当以硬件方式实现时,其可以例如是电子电路、专用集成电路(Application SpecificIntegrated Circuit,ASIC)、适当的固件、插件、功能卡等等。当以软件方式实现时,本申请的元素是被用于执行所需任务的程序或者代码段。程序或者代码段可以存储在机器可读介质中,或者通过载波中携带的数据信号在传输介质或者通信链路上传送。“机器可读介质”可以包括能够存储或传输信息的任何介质。机器可读介质的例子包括电子电路、半导体存储器设备、ROM、闪存、可擦除ROM(EROM)、软盘、CD-ROM、光盘、硬盘、光纤介质、射频(RadioFrequency,RF)链路,等等。代码段可以经由诸如因特网、内联网等的计算机网络被下载。The functional blocks shown in the above-described structural block diagrams may be implemented as hardware, software, firmware, or a combination thereof. When implemented in hardware, it can be, for example, an electronic circuit, an application specific integrated circuit (ASIC), suitable firmware, a plug-in, a function card, and the like. When implemented in software, elements of the present application are programs or code segments used to perform the required tasks. The program or code segments may be stored in a machine-readable medium or transmitted over a transmission medium or communication link by a data signal carried in a carrier wave. A "machine-readable medium" may include any medium that can store or transmit information. Examples of machine-readable media include electronic circuits, semiconductor memory devices, ROM, flash memory, erasable ROM (EROM), floppy disks, CD-ROMs, optical disks, hard disks, fiber optic media, Radio Frequency (RF) links, and the like . The code segments may be downloaded via a computer network such as the Internet, an intranet, or the like.
还需要说明的是,本申请中提及的示例性实施例,基于一系列的步骤或者装置描述一些方法或系统。但是,本申请不局限于上述步骤的顺序,也就是说,可以按照实施例中提及的顺序执行步骤,也可以不同于实施例中的顺序,或者若干步骤同时执行。It should also be noted that the exemplary embodiments mentioned in this application describe some methods or systems based on a series of steps or devices. However, the present application is not limited to the order of the above steps, that is, the steps may be performed in the order mentioned in the embodiment, or may be different from the order in the embodiment, or several steps may be performed simultaneously.
上面参考根据本公开的实施例的方法、装置(系统)和计算机程序产品的流程图和/或框图描述了本申请的各方面。应当理解,流程图和/或框图中的每个方框以及流程图和/或框图中各方框的组合可以由计算机程序指令实现。这些计算机程序指令可被提供给通用计算机、专用计算机、或其它可编程数据处理装置的处理器,以产生一种机器,使得经由计算机或其它可编程数据处理装置的处理器执行的这些指令使能对流程图和/或框图的一个或多个方框中指定的功能/动作的实现。这种处理器可以是但不限于是通用处理器、专用处理器、特殊应用处理器或者现场可编程逻辑电路。还可理解,框图和/或流程图中的每个方框以及框图和/或流程图中的方框的组合,也可以由执行指定的功能或动作的专用硬件来实现,或可由专用硬件和计算机指令的组合来实现。Aspects of the present application are described above with reference to flowchart illustrations and/or block diagrams of methods, apparatus (systems) and computer program products according to embodiments of the present disclosure. It will be understood that each block of the flowchart illustrations and/or block diagrams, and combinations of blocks in the flowchart illustrations and/or block diagrams, can be implemented by computer program instructions. These computer program instructions may be provided to a processor of a general purpose computer, special purpose computer, or other programmable data processing apparatus to produce a machine such that execution of the instructions via the processor of the computer or other programmable data processing apparatus enables the Implementation of the functions/acts specified in one or more blocks of the flowchart and/or block diagrams. Such processors may be, but are not limited to, general purpose processors, special purpose processors, application specific processors, or field programmable logic circuits. It will also be understood that each block of the block diagrams and/or flowchart illustrations, and combinations of blocks in the block diagrams and/or flowchart illustrations, can also be implemented by special purpose hardware for performing the specified functions or actions, or by special purpose hardware and/or A combination of computer instructions is implemented.
以上所述,仅为本申请的具体实施方式,所属领域的技术人员可以清楚地了解到,为了描述的方便和简洁,上述描述的系统、模块和单元的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。应理解,本申请的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本申请的保护范围之内。The above are only specific implementations of the present application. Those skilled in the art can clearly understand that, for the convenience and brevity of description, the specific working process of the above-described systems, modules and units may refer to the foregoing method embodiments. The corresponding process in , will not be repeated here. It should be understood that the protection scope of the present application is not limited to this. Any person skilled in the art can easily think of various equivalent modifications or replacements within the technical scope disclosed in the present application, and these modifications or replacements should all cover within the scope of protection of this application.
Claims (10)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110400954.1ACN113052159B (en) | 2021-04-14 | 2021-04-14 | Image recognition method, device, equipment and computer storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110400954.1ACN113052159B (en) | 2021-04-14 | 2021-04-14 | Image recognition method, device, equipment and computer storage medium |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN113052159Atrue CN113052159A (en) | 2021-06-29 |
| CN113052159B CN113052159B (en) | 2024-06-07 |
Family
ID=76519713
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110400954.1AActiveCN113052159B (en) | 2021-04-14 | 2021-04-14 | Image recognition method, device, equipment and computer storage medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN113052159B (en) |
Cited By (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113591967A (en)* | 2021-07-27 | 2021-11-02 | 南京旭锐软件科技有限公司 | Image processing method, device and equipment and computer storage medium |
| CN114332599A (en)* | 2021-11-26 | 2022-04-12 | 腾讯科技(深圳)有限公司 | Image recognition method, device, computer equipment, storage medium and product |
| CN114648478A (en)* | 2022-03-29 | 2022-06-21 | 北京小米移动软件有限公司 | Image processing method, device, chip, electronic equipment and storage medium |
| CN114741546A (en)* | 2022-03-02 | 2022-07-12 | 商汤国际私人有限公司 | An image processing and model training method, device, equipment, and storage medium |
| CN115019333A (en)* | 2022-06-27 | 2022-09-06 | 万翼科技有限公司 | Space identification method and device, electronic equipment and storage medium |
| CN115861720A (en)* | 2023-02-28 | 2023-03-28 | 人工智能与数字经济广东省实验室(广州) | A Small Sample Subcategory Image Classification and Recognition Method |
| WO2023178930A1 (en)* | 2022-03-23 | 2023-09-28 | 北京京东乾石科技有限公司 | Image recognition method and apparatus, training method and apparatus, system, and storage medium |
| CN116993963A (en)* | 2023-09-21 | 2023-11-03 | 腾讯科技(深圳)有限公司 | Image processing method, device, equipment and storage medium |
| CN117710234A (en)* | 2024-02-06 | 2024-03-15 | 青岛海尔科技有限公司 | Image generation methods, devices, equipment and media based on large models |
| US20250005947A1 (en)* | 2023-06-30 | 2025-01-02 | Nielsen Consumer Llc | Methods, systems, articles of manufacture, and apparatus for image recognition based on visual and textual information |
Citations (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109271967A (en)* | 2018-10-16 | 2019-01-25 | 腾讯科技(深圳)有限公司 | The recognition methods of text and device, electronic equipment, storage medium in image |
| CN109299274A (en)* | 2018-11-07 | 2019-02-01 | 南京大学 | A natural scene text detection method based on fully convolutional neural network |
| US10198671B1 (en)* | 2016-11-10 | 2019-02-05 | Snap Inc. | Dense captioning with joint interference and visual context |
| CN110458165A (en)* | 2019-08-14 | 2019-11-15 | 贵州大学 | A Natural Scene Text Detection Method Introducing Attention Mechanism |
| CN111028235A (en)* | 2019-11-11 | 2020-04-17 | 东北大学 | Image segmentation method for enhancing edge and detail information by utilizing feature fusion |
| CN111368893A (en)* | 2020-02-27 | 2020-07-03 | Oppo广东移动通信有限公司 | Image recognition method, device, electronic device and storage medium |
| CN111598214A (en)* | 2020-04-02 | 2020-08-28 | 浙江工业大学 | Cross-modal retrieval method based on graph convolution neural network |
| CN111985369A (en)* | 2020-08-07 | 2020-11-24 | 西北工业大学 | Multimodal document classification method in course domain based on cross-modal attention convolutional neural network |
| WO2020232867A1 (en)* | 2019-05-21 | 2020-11-26 | 平安科技(深圳)有限公司 | Lip-reading recognition method and apparatus, computer device, and storage medium |
| CN112070069A (en)* | 2020-11-10 | 2020-12-11 | 支付宝(杭州)信息技术有限公司 | Method and device for identifying remote sensing image |
| CN112101165A (en)* | 2020-09-07 | 2020-12-18 | 腾讯科技(深圳)有限公司 | Interest point identification method and device, computer equipment and storage medium |
| US20210073982A1 (en)* | 2018-07-21 | 2021-03-11 | Beijing Sensetime Technology Development Co., Ltd. | Medical image processing method and apparatus, electronic device, and storage medium |
- 2021
- 2021-04-14CNCN202110400954.1Apatent/CN113052159B/enactiveActive
Patent Citations (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10198671B1 (en)* | 2016-11-10 | 2019-02-05 | Snap Inc. | Dense captioning with joint interference and visual context |
| US20210073982A1 (en)* | 2018-07-21 | 2021-03-11 | Beijing Sensetime Technology Development Co., Ltd. | Medical image processing method and apparatus, electronic device, and storage medium |
| CN109271967A (en)* | 2018-10-16 | 2019-01-25 | 腾讯科技(深圳)有限公司 | The recognition methods of text and device, electronic equipment, storage medium in image |
| CN109299274A (en)* | 2018-11-07 | 2019-02-01 | 南京大学 | A natural scene text detection method based on fully convolutional neural network |
| WO2020232867A1 (en)* | 2019-05-21 | 2020-11-26 | 平安科技(深圳)有限公司 | Lip-reading recognition method and apparatus, computer device, and storage medium |
| CN110458165A (en)* | 2019-08-14 | 2019-11-15 | 贵州大学 | A Natural Scene Text Detection Method Introducing Attention Mechanism |
| CN111028235A (en)* | 2019-11-11 | 2020-04-17 | 东北大学 | Image segmentation method for enhancing edge and detail information by utilizing feature fusion |
| CN111368893A (en)* | 2020-02-27 | 2020-07-03 | Oppo广东移动通信有限公司 | Image recognition method, device, electronic device and storage medium |
| CN111598214A (en)* | 2020-04-02 | 2020-08-28 | 浙江工业大学 | Cross-modal retrieval method based on graph convolution neural network |
| CN111985369A (en)* | 2020-08-07 | 2020-11-24 | 西北工业大学 | Multimodal document classification method in course domain based on cross-modal attention convolutional neural network |
| CN112101165A (en)* | 2020-09-07 | 2020-12-18 | 腾讯科技(深圳)有限公司 | Interest point identification method and device, computer equipment and storage medium |
| CN112070069A (en)* | 2020-11-10 | 2020-12-11 | 支付宝(杭州)信息技术有限公司 | Method and device for identifying remote sensing image |
Non-Patent Citations (3)
| Title |
|---|
| ZOU, X等: "A Novel Water-Shore-Line Detection Method for USV Autonomous Navigation", SENSORS, vol. 20, no. 6, pages 1682* |
| 于玉海;林鸿飞;孟佳娜;郭海;赵哲焕;: "跨模态多标签生物医学图像分类建模识别", 中国图象图形学报, no. 06, pages 143 - 153* |
| 李中益;杨观赐;李杨;何玲;: "基于图像语义的服务机器人视觉隐私行为识别与保护系统", 计算机辅助设计与图形学学报, no. 10, pages 146 - 154* |
Cited By (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113591967A (en)* | 2021-07-27 | 2021-11-02 | 南京旭锐软件科技有限公司 | Image processing method, device and equipment and computer storage medium |
| CN113591967B (en)* | 2021-07-27 | 2024-06-11 | 南京旭锐软件科技有限公司 | Image processing method, device, equipment and computer storage medium |
| CN114332599A (en)* | 2021-11-26 | 2022-04-12 | 腾讯科技(深圳)有限公司 | Image recognition method, device, computer equipment, storage medium and product |
| CN114332599B (en)* | 2021-11-26 | 2025-06-06 | 腾讯科技(深圳)有限公司 | Image recognition method, device, computer equipment, storage medium and product |
| CN114741546A (en)* | 2022-03-02 | 2022-07-12 | 商汤国际私人有限公司 | An image processing and model training method, device, equipment, and storage medium |
| WO2023178930A1 (en)* | 2022-03-23 | 2023-09-28 | 北京京东乾石科技有限公司 | Image recognition method and apparatus, training method and apparatus, system, and storage medium |
| CN114648478A (en)* | 2022-03-29 | 2022-06-21 | 北京小米移动软件有限公司 | Image processing method, device, chip, electronic equipment and storage medium |
| CN115019333A (en)* | 2022-06-27 | 2022-09-06 | 万翼科技有限公司 | Space identification method and device, electronic equipment and storage medium |
| CN115861720A (en)* | 2023-02-28 | 2023-03-28 | 人工智能与数字经济广东省实验室(广州) | A Small Sample Subcategory Image Classification and Recognition Method |
| US20250005947A1 (en)* | 2023-06-30 | 2025-01-02 | Nielsen Consumer Llc | Methods, systems, articles of manufacture, and apparatus for image recognition based on visual and textual information |
| CN116993963A (en)* | 2023-09-21 | 2023-11-03 | 腾讯科技(深圳)有限公司 | Image processing method, device, equipment and storage medium |
| CN116993963B (en)* | 2023-09-21 | 2024-01-05 | 腾讯科技(深圳)有限公司 | Image processing method, device, equipment and storage medium |
| CN117710234A (en)* | 2024-02-06 | 2024-03-15 | 青岛海尔科技有限公司 | Image generation methods, devices, equipment and media based on large models |
| CN117710234B (en)* | 2024-02-06 | 2024-05-24 | 青岛海尔科技有限公司 | Image generation method, device, equipment and medium based on large model |
Also Published As
| Publication number | Publication date |
|---|---|
| CN113052159B (en) | 2024-06-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN113052159B (en) | Image recognition method, device, equipment and computer storage medium | |
| CN111912416B (en) | Method, device and device for device positioning | |
| CN111860227B (en) | Method, apparatus and computer storage medium for training trajectory planning model | |
| CN117058646B (en) | Complex road target detection method based on multi-mode fusion aerial view | |
| CN111814621A (en) | A multi-scale vehicle pedestrian detection method and device based on attention mechanism | |
| CN107563372A (en) | A kind of license plate locating method based on deep learning SSD frameworks | |
| Piccioli et al. | Robust road sign detection and recognition from image sequences | |
| CN110659601B (en) | Dense vehicle detection method for remote sensing images based on deep fully convolutional network based on central points | |
| CN110119148A (en) | A kind of six-degree-of-freedom posture estimation method, device and computer readable storage medium | |
| CN112733885A (en) | Point cloud identification model determining method and point cloud identification method and device | |
| Yebes et al. | Learning to automatically catch potholes in worldwide road scene images | |
| CN111274942A (en) | Traffic cone identification method and device based on cascade network | |
| CN113723377A (en) | Traffic sign detection method based on LD-SSD network | |
| CN112738470A (en) | A method of parking detection in expressway tunnel | |
| CN115797736A (en) | Object detection model training and object detection method, device, equipment and medium | |
| Huu et al. | Proposing Lane and Obstacle Detection Algorithm Using YOLO to Control Self‐Driving Cars on Advanced Networks | |
| CN117789160A (en) | Multi-mode fusion target detection method and system based on cluster optimization | |
| Asgarian Dehkordi et al. | Vehicle type recognition based on dimension estimation and bag of word classification | |
| CN108491828B (en) | Parking space detection system and method based on level pairwise similarity PVAnet | |
| Song et al. | Automatic detection and classification of road, car, and pedestrian using binocular cameras in traffic scenes with a common framework | |
| Coronado et al. | Detection and classification of road signs for automatic inventory systems using computer vision | |
| Imad et al. | Navigation system for autonomous vehicle: A survey | |
| CN111428567B (en) | Pedestrian tracking system and method based on affine multitask regression | |
| CN111160282B (en) | Traffic light detection method based on binary Yolov3 network | |
| CN117710415A (en) | A small target pedestrian tracking method based on deep learning |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant |