CN112949818A - Model distillation method, device, equipment and storage medium - Google Patents
Model distillation method, device, equipment and storage mediumDownload PDFInfo
- Publication number
- CN112949818A CN112949818ACN202110097718.7ACN202110097718ACN112949818ACN 112949818 ACN112949818 ACN 112949818ACN 202110097718 ACN202110097718 ACN 202110097718ACN 112949818 ACN112949818 ACN 112949818A
- Authority
- CN
- China
- Prior art keywords
- probability distribution
- model
- distillation
- training
- predicted
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images







Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/241—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches
- G06F18/2415—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches based on parametric or probabilistic models, e.g. based on likelihood ratio or false acceptance rate versus a false rejection rate
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- Life Sciences & Earth Sciences (AREA)
- Artificial Intelligence (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Software Systems (AREA)
- Mathematical Physics (AREA)
- Computing Systems (AREA)
- Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Probability & Statistics with Applications (AREA)
- Evolutionary Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Vaporization, Distillation, Condensation, Sublimation, And Cold Traps (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本申请公开了一种模型蒸馏方法、装置、设备以及存储介质,尤其涉及自然语言处理,具体涉及深度学习和大数据技术领域。The present application discloses a model distillation method, device, device and storage medium, in particular to natural language processing, and in particular to the technical fields of deep learning and big data.
背景技术Background technique
由于存储空间和功耗的限制,神经网络模型在嵌入式设备上的存储和计算仍然是一个巨大的挑战。模型压缩是针对这一问题的有效解决方法。知识蒸馏是一种常见的模型压缩方法,其可以将一个或多个复杂模型的知识迁移到另一个轻量级神经网络模型之中。典型的深度神经网络蒸馏,将体积较大或多个模型集成的深度网络模型称为教师模型,用于提取知识;将体积较小的轻量级模型称为学生模型,用于接收教师模型的知识,蒸馏训练后即可享有小模型体积小、速度快的优势,也可以获得与大模型更相近的精度表现。但是,在很多深度学习实际应用场景下难以找到一个完美的教师模型,或者由于教师模型计算量过大、训练周期长等难题,蒸馏技术难以实际应用。针对这一问题,需要一种新的模型蒸馏技术来克服这些困难。Due to the limitation of storage space and power consumption, the storage and computation of neural network models on embedded devices is still a huge challenge. Model compression is an effective solution to this problem. Knowledge distillation is a common model compression method, which can transfer the knowledge of one or more complex models into another lightweight neural network model. In a typical deep neural network distillation, a deep network model with a larger volume or an integrated model of multiple models is called a teacher model, which is used to extract knowledge; a lightweight model with a smaller volume is called a student model, which is used to receive the information of the teacher model. Knowledge, after distillation training, the small model can enjoy the advantages of small size and fast speed, and can also obtain the accuracy performance closer to the large model. However, in many practical application scenarios of deep learning, it is difficult to find a perfect teacher model, or the distillation technology is difficult to be practically applied due to problems such as excessive computational load and long training period of the teacher model. In response to this problem, a new model distillation technique is needed to overcome these difficulties.
发明内容SUMMARY OF THE INVENTION
本申请提供了一种模型蒸馏方法、装置、设备以及存储介质。The present application provides a model distillation method, apparatus, device and storage medium.
根据本申请的一方面,提供了一种模型蒸馏方法,包括:According to an aspect of the present application, a model distillation method is provided, comprising:
获取学生模型对第一训练样本进行预测所得到的第一预测概率分布;Obtain the first predicted probability distribution obtained by predicting the first training sample by the student model;
采用所述学生模型对第二训练样本进行预测,得到第二预测概率分布;Using the student model to predict the second training sample to obtain a second predicted probability distribution;
将所述第二训练样本的标签概率分布与所述第一预测概率分布叠加,以得到叠加概率分布;superimposing the label probability distribution of the second training sample and the first prediction probability distribution to obtain a superimposed probability distribution;
根据所述叠加概率分布与所述第二预测概率分布之间的差异,对所述学生模型进行蒸馏训练。Distillation training is performed on the student model according to the difference between the superimposed probability distribution and the second predicted probability distribution.
根据本申请的另一方面,提供了一种模型蒸馏装置,包括:According to another aspect of the present application, a model distillation apparatus is provided, comprising:
获取模块,用于获取学生模型对第一训练样本进行预测所得到的第一预测概率分布;an acquisition module for acquiring the first predicted probability distribution obtained by the student model predicting the first training sample;
预测模块,用于采用所述学生模型对第二训练样本进行预测,得到第二预测概率分布;a prediction module, configured to use the student model to predict the second training sample to obtain a second predicted probability distribution;
叠加模块,用于将所述第二训练样本的标签概率分布与所述第一预测概率分布叠加,以得到叠加概率分布;a superposition module, configured to superimpose the label probability distribution of the second training sample and the first prediction probability distribution to obtain a superimposed probability distribution;
训练模块,用于根据所述叠加概率分布与所述第二预测概率分布之间的差异,对所述学生模型进行蒸馏训练。A training module, configured to perform distillation training on the student model according to the difference between the superimposed probability distribution and the second predicted probability distribution.
根据本申请的另一方面,提供了一种电子设备,包括:According to another aspect of the present application, an electronic device is provided, comprising:
至少一个处理器;以及at least one processor; and
与所述至少一个处理器通信连接的存储器;其中,a memory communicatively coupled to the at least one processor; wherein,
所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行上述实施例所述的模型蒸馏方法。The memory stores instructions executable by the at least one processor, the instructions being executed by the at least one processor to enable the at least one processor to execute the model distillation method described in the above embodiments.
根据本申请的另一方面,提供了一种存储有计算机指令的非瞬时计算机可读存储介质,其中,所述计算机指令用于使所述计算机执行上述实施例所述的模型蒸馏方法。According to another aspect of the present application, a non-transitory computer-readable storage medium storing computer instructions is provided, wherein the computer instructions are used to cause the computer to execute the model distillation method described in the above embodiments.
根据本申请的另一方面,提供了一种计算机程序产品,包括计算机程序,所述计算机程序在被处理器执行时实现根据上述实施例中所述的模型蒸馏方法According to another aspect of the present application, there is provided a computer program product, comprising a computer program that, when executed by a processor, implements the model distillation method according to the above embodiments
应当理解,本部分所描述的内容并非旨在标识本申请的实施例的关键或重要特征,也不用于限制本申请的范围。本申请的其它特征将通过以下的说明书而变得容易理解。It should be understood that the content described in this section is not intended to identify key or critical features of the embodiments of the application, nor is it intended to limit the scope of the application. Other features of the present application will become readily understood from the following description.
附图说明Description of drawings
附图用于更好地理解本方案,不构成对本申请的限定。其中:The accompanying drawings are used for better understanding of the present solution, and do not constitute a limitation to the present application. in:
图1为本申请实施例一提供的模型蒸馏方法的流程示意图;Fig. 1 is the schematic flow sheet of the model distillation method that the first embodiment of the application provides;
图2为第二训练样本的标签概率分布与第一预测概率分布的示例图;Fig. 2 is the example diagram of the label probability distribution of the second training sample and the first prediction probability distribution;
图3为本申请实施例提供的一种叠加概率分布的示例图;FIG. 3 is an example diagram of a superimposed probability distribution provided by an embodiment of the present application;
图4为本申请实施例提供的一种用于对学生模型进行蒸馏训练的方法的流程示意图;4 is a schematic flowchart of a method for performing distillation training on a student model provided by an embodiment of the present application;
图5为本申请实施例提供的另一种模型蒸馏方法的流程示意图;5 is a schematic flowchart of another model distillation method provided by the embodiment of the application;
图6为本申请实施例提供的一种模型蒸馏方法的流程示例图;FIG. 6 is an example flow diagram of a model distillation method provided by an embodiment of the application;
图7为本申请实施例提供的一种模型蒸馏装置的结构示意图;7 is a schematic structural diagram of a model distillation apparatus provided by an embodiment of the application;
图8是用来实现本申请实施例的模型蒸馏方法的电子设备的框图。FIG. 8 is a block diagram of an electronic device used to implement the model distillation method of the embodiment of the present application.
具体实施方式Detailed ways
以下结合附图对本申请的示范性实施例做出说明,其中包括本申请实施例的各种细节以助于理解,应当将它们认为仅仅是示范性的。因此,本领域普通技术人员应当认识到,可以对这里描述的实施例做出各种改变和修改,而不会背离本申请的范围和精神。同样,为了清楚和简明,以下的描述中省略了对公知功能和结构的描述。Exemplary embodiments of the present application are described below with reference to the accompanying drawings, which include various details of the embodiments of the present application to facilitate understanding, and should be considered as exemplary only. Accordingly, those of ordinary skill in the art will recognize that various changes and modifications of the embodiments described herein can be made without departing from the scope and spirit of the present application. Also, descriptions of well-known functions and constructions are omitted from the following description for clarity and conciseness.
模型蒸馏是深度神经网络压缩的一个重要方法,其目的是将预先得到的知识从复杂模型或其他载体中提取出来,然后通过某种方法将提取到的知识迁移到小模型当中。模型蒸馏难点在于让体积受限的小模型充分学习复杂知识中包含的信息,所谓知识就是输入样本到输出向量之间的映射关系。充分学习后的小模型可以获得与大模型媲美的准确率性能,同时可以保持小模型本身的预测速度和体积,从而减少在部署网络模型时对硬件存储和计算资源的需求,加快推理速度。模型蒸馏技术现在已经广泛应用在计算机视觉,自然语言处理等多个领域,神经网络进行模型蒸馏的基本流程可以概括如下:Model distillation is an important method of deep neural network compression. Its purpose is to extract pre-obtained knowledge from complex models or other carriers, and then transfer the extracted knowledge to small models by some method. The difficulty of model distillation is to allow the small model with limited volume to fully learn the information contained in complex knowledge. The so-called knowledge is the mapping relationship between input samples and output vectors. A fully learned small model can achieve an accuracy performance comparable to that of a large model, while maintaining the prediction speed and volume of the small model itself, thereby reducing the demand for hardware storage and computing resources when deploying network models, and speeding up inference. Model distillation technology has been widely used in computer vision, natural language processing and other fields. The basic process of model distillation by neural network can be summarized as follows:
首先用人工标注的硬标签训练复杂的教师模型;用已经训练好的教师模型提取出软化之后的特征分布;在小模型原来的训练目标上再添加一个额外的软目标损失函数,通过比例来平衡两个损失函数;训练完成后丢弃掉教师模型,仅使用小模型来预测推理。First, train a complex teacher model with manually labeled hard labels; use the already trained teacher model to extract the softened feature distribution; add an additional soft target loss function to the original training target of the small model, and balance by proportion Two loss functions; the teacher model is discarded after training and only the small model is used to predict inference.
根据蒸馏使用的隐藏知识的来源,可以将现有模型蒸馏方法分为单教师模型蒸馏,多教师模型蒸馏以及无教师模型蒸馏三种方案:According to the source of the hidden knowledge used in distillation, existing model distillation methods can be divided into three schemes: single-teacher model distillation, multi-teacher model distillation and no-teacher model distillation:
单教师蒸馏使用的隐藏知识由单个教师模型产生,隐藏知识代表输入样本与输出分布之间的某种映射,学生模式可以单独从这一个教师模型的输出进行学习。例如,可以将一个教师模型输出的向量分布经过软化操作后,用学生网络来拟合,从而获得近似教师网络的表现。The hidden knowledge used by single-teacher distillation is generated by a single teacher model, the hidden knowledge represents some kind of mapping between the input samples and the output distribution, and the student model can learn from the output of this one teacher model alone. For example, the vector distribution output by a teacher model can be softened and fitted by the student network to obtain the approximate performance of the teacher network.
多教师模型蒸馏使用多个模型进行集成,学生模型学习集成之后的隐藏知识。例如,可以将多个教师模型预测的结果进行组合后指导学生模型训练,或组合后用于重新标注、增广数据并再次进行模型训练。Multi-teacher model distillation uses multiple models for ensemble, and the student model learns the hidden knowledge after the ensemble. For example, the results predicted by multiple teacher models can be combined to guide student model training, or the combined results can be used to relabel, augment data, and retrain the model.
但是,单教师模型蒸馏和多教师模型蒸馏使用难度相对较大,应用门槛较高。需要提前找到准确率较好的大模型,并经过蒸馏过程将大模型知识迁移到小模型。整个过程对计算资源的需求很高,对一些数据量很大的场景模型训练时间成本会成倍增长,训练周期较长。However, single-teacher model distillation and multi-teacher model distillation are relatively difficult to use, and the application threshold is high. It is necessary to find a large model with better accuracy in advance, and transfer the knowledge of the large model to the small model through the distillation process. The entire process requires high computing resources, and the training time cost of some scene models with a large amount of data will increase exponentially, and the training period will be long.
无教师模型蒸馏是指蒸馏过程无需引入额外的教师模型。用学生模型本身或引入其他包含隐藏知识的分布指导学生模型。例如,学生模型经过训练后作为自己的教师模型再次进行蒸馏训练;或者首先人工设计一个概率分布,用这个分布指导学生模型的学习。相比有教师模型的蒸馏方案,这种方法无需额外教师模型,使用难度较低,并且训练过程所需的计算资源相对较低。Teacher-less model distillation refers to the distillation process without introducing an additional teacher model. Guide the student model with the student model itself or by introducing other distributions that contain hidden knowledge. For example, after the student model is trained, it is used as its own teacher model for distillation training again; or a probability distribution is manually designed first, and this distribution is used to guide the learning of the student model. Compared with the distillation scheme with a teacher model, this method does not require an additional teacher model, is less difficult to use, and requires relatively low computational resources for the training process.
其中,无教师模型蒸馏的蒸馏方式还可以细分为两种:一种是通过原模型进行自蒸馏,即先训练好原模型,再用训练好的模型蒸馏一个重新训练的模型。另一种是通过预先设计的特征分布进行蒸馏,无需多次模型训练。第一种方法虽然可以起到蒸馏的效果,但是整个过程训练流程长。需要先完成原模型的训练再完成一次蒸馏训练,相比普通模型蒸馏方法并没有显著的计算资源减少,依然存在训练周期长、计算成本高的问题。第二种蒸馏方法的隐藏知识来源于人工设计的特征分布,训练成本可以大幅降低。但是,由于人工设计的特征分布在蒸馏过程中只能作为标签平滑项辅助训练,缺失了对于类间相似性的学习,尽管相比原模型仍会有一定的效果提升,但提升效果往往是比较弱的。Among them, the distillation methods of the teacher-free model distillation can also be subdivided into two types: one is self-distillation through the original model, that is, the original model is trained first, and then a retrained model is distilled with the trained model. The other is distillation through pre-designed feature distributions without multiple model training. Although the first method can have the effect of distillation, the training process of the whole process is long. It is necessary to complete the training of the original model first and then complete the distillation training. Compared with the ordinary model distillation method, there is no significant reduction in computing resources, and there are still problems of long training period and high computing cost. The hidden knowledge of the second distillation method comes from the artificially designed feature distribution, and the training cost can be greatly reduced. However, since the artificially designed feature distribution can only be used as a label smoothing item to assist training in the distillation process, the learning of inter-class similarity is missing. Although there will still be a certain improvement compared to the original model, the improvement effect is often relatively high. weak.
针对现有的模型蒸馏方法存在的技术问题,本申请提出了一种模型蒸馏方法,通过获取学生模型对第一训练样本进行预测所得到的第一预测概率分布,采用学生模型对第二训练样本进行预测,得到第二预测概率分布,将第二训练样本的标签概率分布与第一预测概率分布叠加,以得到叠加概率分布,根据叠加概率分布与第二预测概率分布之间的差异,对学生模型进行蒸馏训练。In view of the technical problems existing in the existing model distillation methods, the present application proposes a model distillation method, which obtains the first predicted probability distribution obtained by predicting the first training sample by the student model, and uses the student model to predict the second training sample. Make predictions to obtain a second predicted probability distribution, and superimpose the label probability distribution of the second training sample with the first predicted probability distribution to obtain a superimposed probability distribution. The model is trained by distillation.
下面参考附图描述本申请实施例的模型蒸馏方法、装置、设备及存储介质。The model distillation method, apparatus, device, and storage medium of the embodiments of the present application are described below with reference to the accompanying drawings.
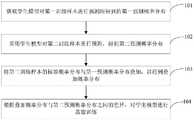
图1为本申请实施例一提供的模型蒸馏方法的流程示意图。FIG. 1 is a schematic flowchart of a model distillation method provided in
本申请实施例以该模型蒸馏方法被配置于模型蒸馏装置中来举例说明,该模型蒸馏装置可以应用于任一电子设备中,以使该电子设备可以执行模型蒸馏功能。In the embodiment of the present application, it is exemplified that the model distillation method is configured in a model distillation apparatus, and the model distillation apparatus can be applied to any electronic device, so that the electronic device can perform the model distillation function.
其中,电子设备可以为个人电脑(Personal Computer,简称PC)、云端设备、移动设备等,移动设备例如可以为手机、平板电脑、个人数字助理、穿戴式设备、车载设备等具有各种操作系统的硬件设备。The electronic device may be a personal computer (Personal Computer, PC for short), a cloud device, a mobile device, etc. The mobile device may be, for example, a mobile phone, a tablet computer, a personal digital assistant, a wearable device, a vehicle-mounted device, etc. with various operating systems. hardware equipment.
如图1所示,该模型蒸馏方法,可以包括以下步骤:As shown in Figure 1, the model distillation method can include the following steps:
步骤101,获取学生模型对第一训练样本进行预测所得到的第一预测概率分布。Step 101: Obtain a first predicted probability distribution obtained by predicting the first training sample by the student model.
其中,学生模型是指体积较小的轻量级的神经网络模型。Among them, the student model refers to a small and lightweight neural network model.
为了便于区分,本申请中将已经采用学生模型训练过的样本命名为第一训练样本,将学生模型当前正在训练的样本命名为第二训练样本。For the convenience of distinction, in this application, the sample that has been trained by the student model is named as the first training sample, and the sample currently being trained by the student model is named as the second training sample.
需要解释的是,在学生模型的蒸馏训练过程中,可以将每一个训练回合得到的预测概率分布预先存储起来,以在后续过程中获取预测概率分布。It should be explained that during the distillation training process of the student model, the predicted probability distribution obtained in each training round can be stored in advance to obtain the predicted probability distribution in the subsequent process.
作为一种示例,可以首先对学生模型进行n个回合的训练,如,n可以取值为1至5,每一个回合的训练当中,把训练样本的ID(Identity Document,标识号)与对应的预测概率分布的映射存入一个字典中,将得到的字典不断压入缓存队列的尾端,直到队列达到预设的长度n。As an example, the student model can be trained for n rounds first, for example, n can take a value from 1 to 5. In each round of training, the ID (Identity Document, identification number) of the training sample is compared with the corresponding The mapping of the predicted probability distribution is stored in a dictionary, and the obtained dictionary is continuously pushed into the end of the cache queue until the queue reaches the preset length n.
本申请实施例中,预先存储了学生模型对大量的训练样本进行预测所得到的预测概率分布。因此,可以获取到学生模型对第一训练样本进行预测所得到的第一预测概率分布。其中,第一预测概率分布可以包含有类间相似度信息。In the embodiment of the present application, the predicted probability distribution obtained by predicting a large number of training samples by the student model is pre-stored. Therefore, the first predicted probability distribution obtained by the student model predicting the first training sample can be obtained. The first predicted probability distribution may include inter-class similarity information.
需要说明的是,本申请中对第一训练样本的类型不做限定,可以为图像、文字文本、语音数据,等等。It should be noted that the type of the first training sample is not limited in this application, and may be an image, text, voice data, and so on.
步骤102,采用学生模型对第二训练样本进行预测,得到第二预测概率分布。
其中,第二预测概率分布,是指学生模型对当前正在训练的样本进行预测得到的概率分布。The second predicted probability distribution refers to the probability distribution obtained by the student model predicting the sample currently being trained.
在模型蒸馏训练过程中,采用学生模型对第二训练样本进行预测,可以得到第二预测概率分布。During the model distillation training process, the student model is used to predict the second training sample, and the second predicted probability distribution can be obtained.
步骤103,将第二训练样本的标签概率分布与第一预测概率分布叠加,以得到叠加概率分布。
其中,标签概率分布是指预先设定好的概率分布形式,可以起到标签概率平滑的作用。Among them, the label probability distribution refers to the pre-set probability distribution form, which can play the role of label probability smoothing.
本申请实施例中,获取到学生模型对第一训练样本进行预测得到的第一预测概率分布后,可以将第一预测概率分布与第二训练样本的标签概率分布进行叠加,以得到叠加概率分布。In the embodiment of the present application, after obtaining the first predicted probability distribution obtained by the student model predicting the first training sample, the first predicted probability distribution and the label probability distribution of the second training sample may be superimposed to obtain the superimposed probability distribution .
作为一种示例,如图2所示,图2为第二训练样本的标签概率分布与第一预测概率分布的示例图。将图2中第二训练样本的标签概率分布与第一预测概率分布进行叠加,可以得到图3中所示的叠加后的叠加概率分布。As an example, as shown in FIG. 2 , FIG. 2 is an example diagram of the label probability distribution of the second training sample and the first prediction probability distribution. By superimposing the label probability distribution of the second training sample in FIG. 2 and the first predicted probability distribution, the superimposed superimposed probability distribution shown in FIG. 3 can be obtained.
在一种可能的情况下,在得到叠加概率分布后,可以对叠加概率分布进行归一化处理,以使得归一化处理后的叠加概率分布之和为1。In a possible case, after the superposition probability distribution is obtained, the superposition probability distribution may be normalized, so that the sum of the normalized superposition probability distribution is 1.
步骤104,根据叠加概率分布与第二预测概率分布之间的差异,对学生模型进行蒸馏训练。Step 104: Perform distillation training on the student model according to the difference between the superimposed probability distribution and the second predicted probability distribution.
本申请实施例中,确定叠加概率分布和第二预测概率分布之后,可以根据叠加概率分布与第二预测概率分布之间的差异,对学生模型进行蒸馏训练,以使得训练后的学生模型对训练样本的预测概率分布和标签概率分布之间的差异最小。In the embodiment of the present application, after determining the superimposed probability distribution and the second predicted probability distribution, distillation training may be performed on the student model according to the difference between the superimposed probability distribution and the second predicted probability distribution, so that the trained student model can The difference between the predicted probability distribution of the sample and the label probability distribution is minimal.
相较于现有的无教师模型蒸馏方法中,通过人工预先设计特征分布,缺失类间相似性的学习,本申请中获取学生模型预先对第一训练样本进行预测得到的第一预测概率分布,采用学生模型对第二训练样本进行预测,得到第二预测概率分布,将第二训练样本的标签概率分布与第一预测概率分布叠加,以得到叠加概率分布,根据叠加概率分布与第二预测概率分布之间的差异,对学生模型进行蒸馏训练。由此,通过学生模型预先训练得到的概率分布与标签概率分布叠加后得到的叠加概率分布对学生模型进行蒸馏训练,在不引入额外模型的前提下有效提升了蒸馏的效果,进而大大减小了模型大小,降低了训练过程中所需的计算资源,减小了蒸馏后的模型的存储空间,从而降低了硬件需求,提升硬件效率。Compared with the existing teacher-less model distillation method, the feature distribution is manually designed in advance, and the learning of the similarity between classes is missing. In this application, the first predicted probability distribution obtained by the student model predicting the first training sample in advance is obtained, Use the student model to predict the second training sample to obtain a second predicted probability distribution, and superimpose the label probability distribution of the second training sample and the first predicted probability distribution to obtain a superimposed probability distribution. According to the superimposed probability distribution and the second predicted probability The difference between the distributions, the student model is trained by distillation. As a result, the student model is distilled and trained through the superimposed probability distribution obtained by the pre-training of the student model and the superimposed probability distribution of the label, which effectively improves the effect of distillation without introducing additional models, which greatly reduces the The size of the model reduces the computing resources required in the training process and the storage space of the distilled model, thereby reducing hardware requirements and improving hardware efficiency.
在上述实施例的基础上,在上述步骤104中根据叠加概率分布与第二预测概率分布之间的差异,对学生模型进行蒸馏训练时,可以根据损失函数对学生模型进行蒸馏训练,具体的实现过程参见图4,图4为本申请实施例提供的一种用于对学生模型进行蒸馏训练的方法的流程示意图。On the basis of the above embodiment, in the
如图4所示,该蒸馏训练方法可以包括以下步骤:As shown in Figure 4, the distillation training method may include the following steps:
步骤401,根据叠加概率分布和第二预测概率分布之间的差异,得到第一损失项。Step 401: Obtain a first loss term according to the difference between the superimposed probability distribution and the second predicted probability distribution.
步骤402,根据第二训练样本的期望标签和预测标签之间的差异,得到第二损失项。Step 402: Obtain a second loss term according to the difference between the expected label and the predicted label of the second training sample.
可以理解的是,采用学生模型对第二训练样本进行分类预测时,第二训练样本的期望标签与预测标签之间可能存在差异,本申请中,可以根据第二训练样本的期望标签和预测标签之间的差异,得到第二损失项。It can be understood that when the student model is used to classify and predict the second training sample, there may be differences between the expected label and the predicted label of the second training sample. In this application, the expected label and predicted label of the second training sample can be The difference between, the second loss term is obtained.
步骤403,根据第一损失项和第二损失项,确定损失函数值。Step 403: Determine the loss function value according to the first loss term and the second loss term.
本申请实施例中,学生模型的损失函数值可以由两部分组成:根据叠加概率分布和第二预测概率分布之间的差异贡献的损失项和根据第二训练样本的期望标签和预测标签之间的差异贡献的损失项。In the embodiment of the present application, the loss function value of the student model may be composed of two parts: a loss term contributed according to the difference between the superimposed probability distribution and the second predicted probability distribution, and a difference between the expected label and the predicted label according to the second training sample The difference contributed by the loss term.
对分类问题,常用的损失项有:铰链损失(hinge loss),对数损失(log loss)。For classification problems, commonly used loss terms are: hinge loss, log loss.
作为一种示例,损失函数值可以用如下公式表示:As an example, the loss function value can be expressed by the following formula:
Loss=(1-α)CE(Label,Pred)+αKL(Knowledget,Predt)Loss=(1-α)CE(Label,Pred)+αKL(Knowledget ,Predt )
其中CE()为根据第二损失项;α为尺度调节系数,是一个用于平衡两项损失函数的超参;KL()为第一损失项;Knowledget可以是叠加概率分布;Predt可以是第二预测概率分布。Where CE() is the second loss term; α is the scale adjustment coefficient, which is a hyperparameter used to balance the two loss functions; KL() is the first loss term; Knowledget can be the superposition probability distribution; Predt can be is the second predicted probability distribution.
作为一种可能的实现方式,根据叠加概率分布和第二预测概率分布之间的差异,得到第一损失项;以及根据第二训练样本的期望标签和预测标签之间的差异,得到第二损失项后,可以将第一损失项和第二损失项进行加权,以得到损失函数。As a possible implementation, the first loss term is obtained according to the difference between the superimposed probability distribution and the second predicted probability distribution; and the second loss is obtained according to the difference between the expected label and the predicted label of the second training sample After the term, the first loss term and the second loss term can be weighted to obtain a loss function.
可以理解的是,可以将第一损失项和第二损失项进行加权,通过加权系数平衡第一损失项和第二损失项,以得到损失函数。It can be understood that the first loss term and the second loss term may be weighted, and the first loss term and the second loss term are balanced by a weighting coefficient to obtain a loss function.
步骤404,根据损失函数值对学生模型进行蒸馏训练。
本申请实施例中,确定用于对学生模型进行训练的损失函数值,可以根据损失函数值对学生模型进行蒸馏训练。如,可以对学生使得训练后的学生模型进行参数调整,以使得训练后的模型参数的损失函数值最小。In the embodiment of the present application, the loss function value used for training the student model is determined, and the student model may be subjected to distillation training according to the loss function value. For example, the student may adjust the parameters of the trained student model so that the loss function value of the trained model parameters is minimized.
由此,通过损失函数值对学生模型进行蒸馏训练,在训练过程中,不断地提高了模型蒸馏的效果。Therefore, the student model is distilled and trained through the loss function value, and the effect of model distillation is continuously improved during the training process.
在一种可能的情况下,可以将学生模型对训练样本进行预测得到的预测概率分布存储在缓存队列中,以在模型蒸馏过程中从缓存队列中获取预测概率分布。下面结合图5进行详细介绍,图5为本申请实施例提供的另一种模型蒸馏方法的流程示意图。In a possible case, the predicted probability distribution obtained by the student model's prediction of the training samples can be stored in the cache queue to obtain the predicted probability distribution from the cache queue during the model distillation process. A detailed introduction will be given below with reference to FIG. 5 , which is a schematic flowchart of another model distillation method provided by an embodiment of the present application.
如图5所示,该模型蒸馏方法,可以包括以下步骤:As shown in Figure 5, the model distillation method may include the following steps:
步骤501,从缓存队列中,取出第一预测概率分布。Step 501: Take out the first predicted probability distribution from the cache queue.
在一种可能的情况下,学生模型对第一训练样进行预测,得到第一预测概率分布后,可以将第一预测概率分布存储在缓存队列中,以使得对学生模型进行模型蒸馏的过程中,可以从缓存队列中,取出第一预测概率分布。In a possible case, the student model predicts the first training sample, and after obtaining the first predicted probability distribution, the first predicted probability distribution can be stored in the cache queue, so that the process of model distillation on the student model can be performed. , the first predicted probability distribution can be retrieved from the cache queue.
步骤502,采用学生模型对第二训练样本进行预测,得到第二预测概率分布。
需要说明的是,步骤502的实现过程,可以参见上述实施例中步骤102的实现过程,在此不再赘述。It should be noted that, for the implementation process of
步骤503,将第二预测概率分布存入缓存队列中。Step 503: Store the second predicted probability distribution in the cache queue.
本申请实施例中,采用学生模型对第二训练样本进行预测,得到第二预测概率分布之后,可以将第二预测概率分布存入缓存队列中,以在后续模型蒸馏过程中,从缓存队列中获取第二预测概率分布对学生模型进行蒸馏训练。由此,确保了缓存队列中存储有对训练样本进行预测得到的预测概率分布,使得缓存队列中包含有类间相似性的隐藏知识。In the embodiment of the present application, the student model is used to predict the second training sample, and after obtaining the second predicted probability distribution, the second predicted probability distribution can be stored in the cache queue, so that in the subsequent model distillation process, the second predicted probability distribution can be removed from the cache queue. Obtain the second predicted probability distribution to perform distillation training on the student model. Thus, it is ensured that the predicted probability distribution obtained by predicting the training samples is stored in the cache queue, so that the cache queue contains hidden knowledge of inter-class similarity.
步骤504,对第二训练样本的期望标签采用设定扩散函数进行扩展,以得到标签概率分布。
其中,设定扩散函数,可以为高斯函数。Among them, the set diffusion function can be a Gaussian function.
本申请实施例中,可以采用设定扩散函数对第二训练样本的期望标签进行扩展,以得到标签概率分布。由此,通过标签概率分布与第一预测概率分布叠加,大大降低了模型蒸馏所需的时间成本,提高了模型蒸馏效果。In this embodiment of the present application, a set diffusion function may be used to expand the expected label of the second training sample, so as to obtain a label probability distribution. Therefore, by superimposing the label probability distribution and the first prediction probability distribution, the time cost required for model distillation is greatly reduced, and the effect of model distillation is improved.
步骤505,将第二训练样本的标签概率分布与第一预测概率分布叠加,以得到叠加概率分布。
在一种可能的情况下,在得到叠加概率分布之后,可以对叠加概率分布采用设定平滑参数进行平滑。其中,平滑参数可以为预先设定的值,为一个超参。In a possible case, after the superimposed probability distribution is obtained, the superimposed probability distribution may be smoothed by setting a smoothing parameter. Among them, the smoothing parameter can be a preset value, which is a hyperparameter.
可以理解的是,平滑的实质就是促使叠加概率分布的分类概率结果向正确分类靠近,即正确的分类概率输出大,并且同样尽可能的远离错误分类,即错误的分类概率输出小。It can be understood that the essence of smoothing is to make the classification probability result of the superimposed probability distribution approach the correct classification, that is, the output of the correct classification probability is large, and it is also as far away from the wrong classification as possible, that is, the output of the wrong classification probability is small.
步骤506,根据叠加概率分布与第二预测概率分布之间的差异,对学生模型进行蒸馏训练。Step 506: Perform distillation training on the student model according to the difference between the superimposed probability distribution and the second predicted probability distribution.
需要说明的是,步骤505和步骤506的实现过程,可以参见上述实施例中步骤103和步骤104的实现过程,在此不再赘述。It should be noted that, for the implementation process of
作为一种示例,如图6所示,采用学生模型对输入的训练样本进行预测,得到第二预测概率分布后,可以将第二预测概率分布存入缓存队列。可选地,可以从缓存队列中获取学生模型对训练样本进行预测所得到的第一预测概率分布,将第二训练样本的标签概率分布与第一预测概率分布叠加,以得到叠加概率分布。根据叠加概率分布和第二预测概率分布之间的差异,得到第一损失项,根据第二训练样本的期望标签和预测标签之间的差异,得到第二损失项,进而,根据第一损失项和第二损失项,确定损失函数值,以根据损失函数值对学生模型进行蒸馏训练。As an example, as shown in FIG. 6 , after using the student model to predict the input training samples, and after obtaining the second predicted probability distribution, the second predicted probability distribution may be stored in the cache queue. Optionally, the first predicted probability distribution obtained by the student model predicting the training samples can be obtained from the cache queue, and the label probability distribution of the second training sample is superimposed with the first predicted probability distribution to obtain the superimposed probability distribution. According to the difference between the superimposed probability distribution and the second predicted probability distribution, the first loss term is obtained, the second loss term is obtained according to the difference between the expected label and the predicted label of the second training sample, and further, according to the first loss term and the second loss term, determine the loss function value to perform distillation training on the student model according to the loss function value.
可选地,采用学生模型对训练样本进行预测,得到第二预测概率分布之后,可以采用平滑参数对第二预测概率分布进行平滑。Optionally, after using the student model to predict the training samples to obtain the second predicted probability distribution, a smoothing parameter may be used to smooth the second predicted probability distribution.
可选地,将第二训练样本的标签概率分布与第一预测概率分布叠加,以得到叠加概率分布后,还可以采用平滑参数对叠加概率分布进行平滑。Optionally, after superimposing the label probability distribution of the second training sample and the first prediction probability distribution to obtain the superimposed probability distribution, a smoothing parameter may also be used to smooth the superimposed probability distribution.
需要说明的是,上述平滑参数可以是预先设定的一个超参数。It should be noted that the above-mentioned smoothing parameter may be a preset hyperparameter.
为了实现上述实施例,本申请提出了一种模型蒸馏装置。In order to realize the above embodiments, the present application proposes a model distillation device.
图7为本申请实施例提供的一种模型蒸馏装置的结构示意图。FIG. 7 is a schematic structural diagram of a model distillation apparatus provided in an embodiment of the present application.
如图7所示,该模型蒸馏装置700,可以包括:获取模块710、预测模块720、叠加模块730以及训练模块740。As shown in FIG. 7 , the model distillation apparatus 700 may include: an acquisition module 710 , a prediction module 720 , a superposition module 730 and a training module 740 .
其中,获取模块710,用于获取学生模型对第一训练样本进行预测所得到的第一预测概率分布。The obtaining module 710 is configured to obtain the first predicted probability distribution obtained by predicting the first training sample by the student model.
预测模块720,用于采用学生模型对第二训练样本进行预测,得到第二预测概率分布。The prediction module 720 is configured to use the student model to predict the second training sample to obtain a second predicted probability distribution.
叠加模块730,用于将第二训练样本的标签概率分布与第一预测概率分布叠加,以得到叠加概率分布。The superposition module 730 is configured to superimpose the label probability distribution of the second training sample and the first predicted probability distribution to obtain the superimposed probability distribution.
训练模块740,用于根据叠加概率分布与第二预测概率分布之间的差异,对学生模型进行蒸馏训练。The training module 740 is configured to perform distillation training on the student model according to the difference between the superimposed probability distribution and the second predicted probability distribution.
作为一种可能的情况,训练模块740,还可以包括:As a possible situation, the training module 740 may further include:
第一处理单元,用于根据所述叠加概率分布和所述第二预测概率分布之间的差异,得到第一损失项;a first processing unit, configured to obtain a first loss term according to the difference between the superimposed probability distribution and the second predicted probability distribution;
第二处理单元,用于根据所述第二训练样本的期望标签和预测标签之间的差异,得到第二损失项;a second processing unit, configured to obtain a second loss term according to the difference between the expected label and the predicted label of the second training sample;
确定单元,用于根据所述第一损失项和所述第二损失项,确定损失函数值;a determining unit, configured to determine a loss function value according to the first loss term and the second loss term;
训练单元,用于根据所述损失函数值对所述学生模型进行蒸馏训练。A training unit, configured to perform distillation training on the student model according to the loss function value.
作为另一种可能的情况,确定单元,还可以用于:将所述第一损失项和所述第二损失项加权,以得到所述损失函数。As another possible situation, the determining unit may be further configured to: weight the first loss term and the second loss term to obtain the loss function.
作为另一种可能的情况,该模型蒸馏装置700,还可以包括:As another possible situation, the model distillation apparatus 700 may further include:
扩展模块,用于对第二训练样本的期望标签采用设定扩散函数进行扩展,以得到标签概率分布。The expansion module is used to expand the expected label of the second training sample by using a set diffusion function, so as to obtain the label probability distribution.
作为另一种可能的情况,获取模块710,还用于:As another possible situation, the obtaining module 710 is also used for:
从缓存队列中,取出第一预测概率分布;From the cache queue, take out the first predicted probability distribution;
该模型蒸馏装置700,还可以包括:存入模块,用于将第二预测概率分布存入缓存队列中。The model distillation apparatus 700 may further include: a storing module for storing the second predicted probability distribution in the buffer queue.
作为另一种可能的情况,该模型蒸馏装置700,还可以包括:As another possible situation, the model distillation apparatus 700 may further include:
平滑模块,用于对叠加概率分布采用设定平滑参数进行平滑。The smoothing module is used to smooth the superposition probability distribution by setting the smoothing parameters.
需要说明的是,前述实施例中对模型蒸馏方法实施例的解释说明也适用于该模型蒸馏装置,此处不再赘述。It should be noted that, the explanations and descriptions of the embodiment of the model distillation method in the foregoing embodiments are also applicable to the model distillation apparatus, which will not be repeated here.
本申请实施例的模型蒸馏装置,通过获取学生模型预先对第一训练样本进行预测得到的第一预测概率分布,采用学生模型对第二训练样本进行预测,得到第二预测概率分布,将第二训练样本的标签概率分布与第一预测概率分布叠加,以得到叠加概率分布,根据叠加概率分布与第二预测概率分布之间的差异,对学生模型进行蒸馏训练。由此,通过学生模型预先训练得到的概率分布对学生模型进行蒸馏训练,在不引入额外模型的前提下有效提升了蒸馏的效果。The model distillation apparatus of the embodiment of the present application obtains the first predicted probability distribution obtained by predicting the first training sample in advance by the student model, and uses the student model to predict the second training sample to obtain the second predicted probability distribution, and the second predicted probability distribution is obtained. The label probability distribution of the training samples is superimposed with the first predicted probability distribution to obtain the superimposed probability distribution, and the student model is subjected to distillation training according to the difference between the superposed probability distribution and the second predicted probability distribution. Therefore, the distillation training of the student model is performed through the probability distribution obtained by the pre-training of the student model, which effectively improves the effect of distillation without introducing additional models.
根据本申请的实施例,本申请还提供了一种电子设备、一种可读存储介质和一种计算机程序产品。According to the embodiments of the present application, the present application further provides an electronic device, a readable storage medium, and a computer program product.
为了实现上述实施例,本申请提出了一种电子设备,包括:In order to realize the above-mentioned embodiments, the present application proposes an electronic device, including:
至少一个处理器;以及at least one processor; and
与所述至少一个处理器通信连接的存储器;其中,a memory communicatively coupled to the at least one processor; wherein,
所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行上述实施例中所述的模型蒸馏方法。The memory stores instructions executable by the at least one processor, the instructions being executed by the at least one processor to enable the at least one processor to perform the model distillation method described in the above embodiments.
为了实现上述实施例,本申请提出了一种存储有计算机指令的非瞬时计算机可读存储介质,其中,所述计算机指令用于使所述计算机执行上述实施例中所述的模型蒸馏方法。In order to implement the above embodiments, the present application proposes a non-transitory computer-readable storage medium storing computer instructions, wherein the computer instructions are used to cause the computer to execute the model distillation method described in the above embodiments.
为了实现上述实施例,本申请提出了一种计算机程序产品,包括计算机程序,所述计算机程序在被处理器执行时实现上述实施例中所述的模型蒸馏方法。In order to implement the above-mentioned embodiments, the present application proposes a computer program product, including a computer program, which, when executed by a processor, implements the model distillation method described in the above-mentioned embodiments.
图8是用来实现本申请实施例的模型蒸馏方法的电子设备的框图。电子设备旨在表示各种形式的数字计算机,诸如,膝上型计算机、台式计算机、工作台、个人数字助理、服务器、刀片式服务器、大型计算机、和其它适合的计算机。电子设备还可以表示各种形式的移动装置,诸如,个人数字处理、蜂窝电话、智能电话、可穿戴设备和其它类似的计算装置。本文所示的部件、它们的连接和关系、以及它们的功能仅仅作为示例,并且不意在限制本文中描述的和/或者要求的本申请的实现。FIG. 8 is a block diagram of an electronic device used to implement the model distillation method of the embodiment of the present application. Electronic devices are intended to represent various forms of digital computers, such as laptops, desktops, workstations, personal digital assistants, servers, blade servers, mainframe computers, and other suitable computers. Electronic devices may also represent various forms of mobile devices, such as personal digital processors, cellular phones, smart phones, wearable devices, and other similar computing devices. The components shown herein, their connections and relationships, and their functions are by way of example only, and are not intended to limit implementations of the application described and/or claimed herein.
如图8所示,设备800包括计算单元801,其可以根据存储在ROM(Read-OnlyMemory,只读存储器)802中的计算机程序或者从存储单元808加载到RAM(Random AccessMemory,随机访问/存取存储器)803中的计算机程序,来执行各种适当的动作和处理。在RAM803中,还可存储设备800操作所需的各种程序和数据。计算单元801、ROM 802以及RAM 803通过总线804彼此相连。I/O(Input/Output,输入/输出)接口805也连接至总线804。As shown in FIG. 8, the
设备800中的多个部件连接至I/O接口805,包括:输入单元806,例如键盘、鼠标等;输出单元807,例如各种类型的显示器、扬声器等;存储单元808,例如磁盘、光盘等;以及通信单元809,例如网卡、调制解调器、无线通信收发机等。通信单元809允许设备800通过诸如因特网的计算机网络和/或各种电信网络与其他设备交换信息/数据。Various components in the
计算单元801可以是各种具有处理和计算能力的通用和/或专用处理组件。计算单元801的一些示例包括但不限于CPU(Central Processing Unit,中央处理单元)、GPU(Graphic Processing Units,图形处理单元)、各种专用的AI(Artificial Intelligence,人工智能)计算芯片、各种运行机器学习模型算法的计算单元、DSP(Digital SignalProcessor,数字信号处理器)、以及任何适当的处理器、控制器、微控制器等。计算单元801执行上文所描述的各个方法和处理,例如模型蒸馏方法。例如,在一些实施例中,模型蒸馏方法可被实现为计算机软件程序,其被有形地包含于机器可读介质,例如存储单元808。在一些实施例中,计算机程序的部分或者全部可以经由ROM 802和/或通信单元809而被载入和/或安装到设备800上。当计算机程序加载到RAM 803并由计算单元801执行时,可以执行上文描述的模型蒸馏方法的一个或多个步骤。备选地,在其他实施例中,计算单元801可以通过其他任何适当的方式(例如,借助于固件)而被配置为执行模型蒸馏方法。
本文中以上描述的系统和技术的各种实施方式可以在数字电子电路系统、集成电路系统、FPGA(Field Programmable Gate Array,现场可编程门阵列)、ASIC(Application-Specific Integrated Circuit,专用集成电路)、ASSP(Application Specific StandardProduct,专用标准产品)、SOC(System On Chip,芯片上系统的系统)、CPLD(ComplexProgrammable Logic Device,复杂可编程逻辑设备)、计算机硬件、固件、软件、和/或它们的组合中实现。这些各种实施方式可以包括:实施在一个或者多个计算机程序中,该一个或者多个计算机程序可在包括至少一个可编程处理器的可编程系统上执行和/或解释,该可编程处理器可以是专用或者通用可编程处理器,可以从存储系统、至少一个输入装置、和至少一个输出装置接收数据和指令,并且将数据和指令传输至该存储系统、该至少一个输入装置、和该至少一个输出装置。Various implementations of the systems and techniques described herein above may be implemented in digital electronic circuitry, integrated circuit systems, FPGAs (Field Programmable Gate Arrays), ASICs (Application-Specific Integrated Circuits) , ASSP (Application Specific Standard Product), SOC (System On Chip, System On Chip), CPLD (Complex Programmable Logic Device), computer hardware, firmware, software, and/or their implemented in combination. These various embodiments may include being implemented in one or more computer programs executable and/or interpretable on a programmable system including at least one programmable processor that The processor, which may be a special purpose or general-purpose programmable processor, may receive data and instructions from a storage system, at least one input device, and at least one output device, and transmit data and instructions to the storage system, the at least one input device, and the at least one output device an output device.
用于实施本申请的方法的程序代码可以采用一个或多个编程语言的任何组合来编写。这些程序代码可以提供给通用计算机、专用计算机或其他可编程数据处理装置的处理器或控制器,使得程序代码当由处理器或控制器执行时使流程图和/或框图中所规定的功能/操作被实施。程序代码可以完全在机器上执行、部分地在机器上执行,作为独立软件包部分地在机器上执行且部分地在远程机器上执行或完全在远程机器或服务器上执行。Program code for implementing the methods of the present application may be written in any combination of one or more programming languages. These program codes may be provided to a processor or controller of a general purpose computer, special purpose computer or other programmable data processing apparatus, such that the program code, when executed by the processor or controller, performs the functions/functions specified in the flowcharts and/or block diagrams. Action is implemented. The program code may execute entirely on the machine, partly on the machine, partly on the machine and partly on a remote machine as a stand-alone software package or entirely on the remote machine or server.
在本申请的上下文中,机器可读介质可以是有形的介质,其可以包含或存储以供指令执行系统、装置或设备使用或与指令执行系统、装置或设备结合地使用的程序。机器可读介质可以是机器可读信号介质或机器可读储存介质。机器可读介质可以包括但不限于电子的、磁性的、光学的、电磁的、红外的、或半导体系统、装置或设备,或者上述内容的任何合适组合。机器可读存储介质的更具体示例会包括基于一个或多个线的电气连接、便携式计算机盘、硬盘、RAM、ROM、EPROM(Electrically Programmable Read-Only-Memory,可擦除可编程只读存储器)或快闪存储器、光纤、CD-ROM(Compact Disc Read-Only Memory,便捷式紧凑盘只读存储器)、光学储存设备、磁储存设备、或上述内容的任何合适组合。In the context of this application, a machine-readable medium may be a tangible medium that may contain or store the program for use by or in connection with the instruction execution system, apparatus or device. The machine-readable medium may be a machine-readable signal medium or a machine-readable storage medium. Machine-readable media may include, but are not limited to, electronic, magnetic, optical, electromagnetic, infrared, or semiconductor systems, devices, or devices, or any suitable combination of the foregoing. More specific examples of machine-readable storage media would include one or more wire-based electrical connections, portable computer disks, hard disks, RAM, ROM, EPROM (Electrically Programmable Read-Only-Memory) Or flash memory, optical fiber, CD-ROM (Compact Disc Read-Only Memory), optical storage device, magnetic storage device, or any suitable combination of the above.
为了提供与用户的交互,可以在计算机上实施此处描述的系统和技术,该计算机具有:用于向用户显示信息的显示装置(例如,CRT(阴极射线管)或者LCD(液晶显示器)监视器);以及键盘和指向装置(例如,鼠标或者轨迹球),用户可以通过该键盘和该指向装置来将输入提供给计算机。其它种类的装置还可以用于提供与用户的交互;例如,提供给用户的反馈可以是任何形式的传感反馈(例如,视觉反馈、听觉反馈、或者触觉反馈);并且可以用任何形式(包括声输入、语音输入或者、触觉输入)来接收来自用户的输入。To provide interaction with a user, the systems and techniques described herein may be implemented on a computer having a display device (eg, a CRT (cathode ray tube) or LCD (liquid crystal display) monitor) for displaying information to the user ); and a keyboard and pointing device (eg, a mouse or trackball) through which a user can provide input to the computer. Other kinds of devices can also be used to provide interaction with the user; for example, the feedback provided to the user can be any form of sensory feedback (eg, visual feedback, auditory feedback, or tactile feedback); and can be in any form (including acoustic input, voice input, or tactile input) to receive input from the user.
可以将此处描述的系统和技术实施在包括后台部件的计算系统(例如,作为数据服务器)、或者包括中间件部件的计算系统(例如,应用服务器)、或者包括前端部件的计算系统(例如,具有图形用户界面或者网络浏览器的用户计算机,用户可以通过该图形用户界面或者该网络浏览器来与此处描述的系统和技术的实施方式交互)、或者包括这种后台部件、中间件部件、或者前端部件的任何组合的计算系统中。可以通过任何形式或者介质的数字数据通信(例如,通信网络)来将系统的部件相互连接。通信网络的示例包括:LAN(LocalArea Network,局域网)、WAN(Wide Area Network,广域网)、互联网和区块链网络。The systems and techniques described herein may be implemented on a computing system that includes back-end components (eg, as a data server), or a computing system that includes middleware components (eg, an application server), or a computing system that includes front-end components (eg, a user's computer having a graphical user interface or web browser through which a user may interact with implementations of the systems and techniques described herein), or including such backend components, middleware components, Or any combination of front-end components in a computing system. The components of the system may be interconnected by any form or medium of digital data communication (eg, a communication network). Examples of communication networks include: LAN (Local Area Network, Local Area Network), WAN (Wide Area Network, Wide Area Network), Internet, and blockchain network.
计算机系统可以包括客户端和服务器。客户端和服务器一般远离彼此并且通常通过通信网络进行交互。通过在相应的计算机上运行并且彼此具有客户端-服务器关系的计算机程序来产生客户端和服务器的关系。服务器可以是云服务器,又称为云计算服务器或云主机,是云计算服务体系中的一项主机产品,以解决了传统物理主机与VPS服务("Virtual Private Server",或简称"VPS")中,存在的管理难度大,业务扩展性弱的缺陷。A computer system can include clients and servers. Clients and servers are generally remote from each other and usually interact through a communication network. The relationship of client and server arises by computer programs running on the respective computers and having a client-server relationship to each other. The server can be a cloud server, also known as a cloud computing server or a cloud host. It is a host product in the cloud computing service system to solve the traditional physical host and VPS service ("Virtual Private Server", or "VPS" for short). , there are the defects of difficult management and weak business expansion.
应该理解,可以使用上面所示的各种形式的流程,重新排序、增加或删除步骤。例如,本申请中记载的各步骤可以并行地执行也可以顺序地执行也可以不同的次序执行,只要能够实现本申请公开的技术方案所期望的结果,本文在此不进行限制。It should be understood that steps may be reordered, added or deleted using the various forms of flow shown above. For example, the steps described in the present application can be executed in parallel, sequentially or in different orders, as long as the desired results of the technical solutions disclosed in the present application can be achieved, no limitation is imposed herein.
上述具体实施方式,并不构成对本申请保护范围的限制。本领域技术人员应该明白的是,根据设计要求和其他因素,可以进行各种修改、组合、子组合和替代。任何在本申请的精神和原则之内所作的修改、等同替换和改进等,均应包含在本申请保护范围之内。The above-mentioned specific embodiments do not constitute a limitation on the protection scope of the present application. It should be understood by those skilled in the art that various modifications, combinations, sub-combinations and substitutions may occur depending on design requirements and other factors. Any modifications, equivalent replacements and improvements made within the spirit and principles of this application shall be included within the protection scope of this application.
Claims (15)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110097718.7ACN112949818A (en) | 2021-01-25 | 2021-01-25 | Model distillation method, device, equipment and storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110097718.7ACN112949818A (en) | 2021-01-25 | 2021-01-25 | Model distillation method, device, equipment and storage medium |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN112949818Atrue CN112949818A (en) | 2021-06-11 |
Family
ID=76236495
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110097718.7APendingCN112949818A (en) | 2021-01-25 | 2021-01-25 | Model distillation method, device, equipment and storage medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN112949818A (en) |
Cited By (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113361621A (en)* | 2021-06-18 | 2021-09-07 | 北京百度网讯科技有限公司 | Method and apparatus for training a model |
| CN113408638A (en)* | 2021-06-30 | 2021-09-17 | 北京百度网讯科技有限公司 | Model training method, device, equipment and computer storage medium |
| CN113705206A (en)* | 2021-08-13 | 2021-11-26 | 北京百度网讯科技有限公司 | Emotion prediction model training method, device, equipment and storage medium |
| CN114037052A (en)* | 2021-10-29 | 2022-02-11 | 北京百度网讯科技有限公司 | Training method and device for detection model, electronic equipment and storage medium |
| CN114298148A (en)* | 2021-11-19 | 2022-04-08 | 华能(浙江)能源开发有限公司清洁能源分公司 | Method and device for monitoring energy efficiency state of wind turbine generator and storage medium |
| CN114357152A (en)* | 2021-09-03 | 2022-04-15 | 北京大学 | Information processing method, apparatus, computer-readable storage medium, and computer device |
| CN115620074A (en)* | 2022-11-11 | 2023-01-17 | 浪潮(北京)电子信息产业有限公司 | Method, device and medium for classifying image data |
- 2021
- 2021-01-25CNCN202110097718.7Apatent/CN112949818A/enactivePending
Cited By (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113361621A (en)* | 2021-06-18 | 2021-09-07 | 北京百度网讯科技有限公司 | Method and apparatus for training a model |
| CN113361621B (en)* | 2021-06-18 | 2023-12-15 | 北京百度网讯科技有限公司 | Methods and apparatus for training models |
| CN113408638A (en)* | 2021-06-30 | 2021-09-17 | 北京百度网讯科技有限公司 | Model training method, device, equipment and computer storage medium |
| CN113705206A (en)* | 2021-08-13 | 2021-11-26 | 北京百度网讯科技有限公司 | Emotion prediction model training method, device, equipment and storage medium |
| CN114357152A (en)* | 2021-09-03 | 2022-04-15 | 北京大学 | Information processing method, apparatus, computer-readable storage medium, and computer device |
| CN114357152B (en)* | 2021-09-03 | 2024-12-03 | 北京大学 | Information processing method, device, computer readable storage medium and computer equipment |
| CN114037052A (en)* | 2021-10-29 | 2022-02-11 | 北京百度网讯科技有限公司 | Training method and device for detection model, electronic equipment and storage medium |
| CN114298148A (en)* | 2021-11-19 | 2022-04-08 | 华能(浙江)能源开发有限公司清洁能源分公司 | Method and device for monitoring energy efficiency state of wind turbine generator and storage medium |
| CN115620074A (en)* | 2022-11-11 | 2023-01-17 | 浪潮(北京)电子信息产业有限公司 | Method, device and medium for classifying image data |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN112560912B (en) | Classification model training methods, devices, electronic equipment and storage media | |
| CN112466288B (en) | Voice recognition method and device, electronic equipment and storage medium | |
| CN112949818A (en) | Model distillation method, device, equipment and storage medium | |
| US20220004811A1 (en) | Method and apparatus of training model, device, medium, and program product | |
| CN110502976B (en) | Text recognition model training method and related products | |
| CN113792854A (en) | A method, device, equipment and storage medium for model training and font library establishment | |
| CN115063875B (en) | Model training method, image processing method and device and electronic equipment | |
| US20230215136A1 (en) | Method for training multi-modal data matching degree calculation model, method for calculating multi-modal data matching degree, and related apparatuses | |
| CN115482395B (en) | Model training method, image classification device, electronic equipment and medium | |
| CN114611532B (en) | Language model training method and device, and target translation error detection method and device | |
| CN113361572B (en) | Training method and device for image processing model, electronic equipment and storage medium | |
| US12094469B2 (en) | Voice recognition method and device | |
| CN115690443B (en) | Feature extraction model training method, image classification method and related devices | |
| US20220374678A1 (en) | Method for determining pre-training model, electronic device and storage medium | |
| CN113361621B (en) | Methods and apparatus for training models | |
| EP4057283A2 (en) | Method for detecting voice, method for training, apparatuses and smart speaker | |
| CN114186681A (en) | Method, apparatus and computer program product for generating model clusters | |
| CN114417878B (en) | Semantic recognition method and device, electronic equipment and storage medium | |
| CN114972877A (en) | An image classification model training method, device and electronic device | |
| CN113657468A (en) | Pre-training model generation method and device, electronic equipment and storage medium | |
| CN114817476A (en) | Language model training method and device, electronic equipment and storage medium | |
| CN114861758A (en) | Multi-modal data processing method and device, electronic equipment and readable storage medium | |
| CN117671409A (en) | Sample generation, model training, image processing methods, devices, equipment and media | |
| CN117573817A (en) | Model training method, correlation determining method, device, equipment and storage medium | |
| CN116597454A (en) | Image processing method, training method and device of image processing model |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |