CN112817653A - Cloud-side-based federated learning calculation unloading computing system and method - Google Patents
Cloud-side-based federated learning calculation unloading computing system and methodDownload PDFInfo
- Publication number
- CN112817653A CN112817653ACN202110089708.9ACN202110089708ACN112817653ACN 112817653 ACN112817653 ACN 112817653ACN 202110089708 ACN202110089708 ACN 202110089708ACN 112817653 ACN112817653 ACN 112817653A
- Authority
- CN
- China
- Prior art keywords
- edge
- local
- cloud
- data
- local device
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images



Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/44—Arrangements for executing specific programs
- G06F9/445—Program loading or initiating
- G06F9/44594—Unloading
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/48—Program initiating; Program switching, e.g. by interrupt
- G06F9/4806—Task transfer initiation or dispatching
- G06F9/4843—Task transfer initiation or dispatching by program, e.g. task dispatcher, supervisor, operating system
- G06F9/485—Task life-cycle, e.g. stopping, restarting, resuming execution
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5005—Allocation of resources, e.g. of the central processing unit [CPU] to service a request
- G06F9/5027—Allocation of resources, e.g. of the central processing unit [CPU] to service a request the resource being a machine, e.g. CPUs, Servers, Terminals
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/54—Interprogram communication
- G06F9/542—Event management; Broadcasting; Multicasting; Notifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2209/00—Indexing scheme relating to G06F9/00
- G06F2209/50—Indexing scheme relating to G06F9/50
- G06F2209/509—Offload
Landscapes
- Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Multimedia (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本发明涉及了在5G网络驱动下的移动边缘计算网络的计算卸载和资源分配,具体涉及一种基于云边端的联邦学习计算卸载计算系统及方法。The invention relates to computing offloading and resource allocation of a mobile edge computing network driven by a 5G network, in particular to a cloud-edge-terminal-based federated learning computing offloading computing system and method.
背景技术Background technique
近年来,在物联网的普及推动下,网络边缘产生的数据呈现爆炸式增长。不能保证低延迟和位置感知削弱了传统云计算解决方案的能力。据IDC预测,截止2020年底有超过500亿终端和设备联网,其中超过50%的数据需要在网络边缘分析、处理与存储。而传统的“云端二体协同计算”模式已无法满足低时延与高带宽的需求。移动边缘计算(MEC)正在成为一种新的引人注目的计算范式,它推动云计算能力更接近终端用户,支持各种计算密集型但对延迟敏感的应用,如人脸识别、自然语言处理和互动游。MEC的关键功能之一是任务卸载(又名,计算卸载),它能够卸载计算密集型任务的移动应用程序从用户设备(UE)到MEC主机在网络边缘,从而打破移动设备的资源限制,拓展移动设备的计算能力、电池容量和存储能力等。虽然边缘服务器可以为终端提供云功能,但由于其固有的无线和计算能力有限,可能无法为所有终端提供服务。一方面,不确定的卸载任务数据量大小和时变的信道条件使计算卸载难以做出精准的决策。另一方面,分布式异构的边缘基础设施中卸载过程用户个人敏感信息等存在被截获和泄露的风险。In recent years, driven by the popularity of the Internet of Things, the data generated at the edge of the network has exploded. The inability to guarantee low latency and location awareness undermines the capabilities of traditional cloud computing solutions. According to IDC's forecast, by the end of 2020, there will be more than 50 billion terminals and devices connected to the Internet, and more than 50% of the data needs to be analyzed, processed and stored at the edge of the network. The traditional "cloud two-body collaborative computing" model can no longer meet the needs of low latency and high bandwidth. Mobile Edge Computing (MEC) is emerging as a new compelling computing paradigm that pushes cloud computing capabilities closer to end users, enabling a variety of compute-intensive but latency-sensitive applications such as face recognition, natural language processing and interactive tours. One of the key features of MEC is task offloading (aka, computational offloading), which enables offloading of computationally intensive tasks from mobile applications from user equipment (UE) to the MEC host at the network edge, thereby breaking the resource constraints of mobile devices and expanding Computational power, battery capacity, storage capacity, etc. of mobile devices. Although edge servers can provide cloud capabilities to terminals, they may not be able to provide services to all terminals due to their inherent limited wireless and computing capabilities. On the one hand, the uncertain data size of offloading tasks and the time-varying channel conditions make it difficult to make accurate decisions for computational offloading. On the other hand, in the distributed and heterogeneous edge infrastructure, there is a risk of interception and leakage of sensitive personal information of users during the uninstallation process.
发明内容SUMMARY OF THE INVENTION
本发明的目的在于提供一种基于云边端的联邦学习计算卸载计算系统及方法,以克服现有技术的不足。The purpose of the present invention is to provide a cloud-edge-terminal-based federated learning computing offload computing system and method to overcome the deficiencies of the prior art.
为达到上述目的,本发明采用如下技术方案:To achieve the above object, the present invention adopts the following technical solutions:
一种基于云边端的联邦学习计算卸载资源分配方法,包括以下步骤:A cloud-edge-terminal-based federated learning computing offloading resource allocation method, comprising the following steps:
S1,构建全局模型,并将初始化的全局模型和任务广播给任务选择的本地设备;S1, build a global model, and broadcast the initialized global model and task to the local device selected by the task;
S2,基于初始化的全局模型,每个本地设备分别使用其本地数据和本地设备参数更新迭代本地模型参数,当达到设定迭代次数后,将所有本地设备计算的梯度数据超过阈值的重要梯度对应的本地模型参数进行边缘参数聚合,根据边缘参数聚合结果参数更新全局模型参数后将更新后的全局模型反馈至各本地设备;S2, based on the initialized global model, each local device uses its local data and local device parameters to update the iterative local model parameters respectively. When the set number of iterations is reached, the gradient data calculated by all local devices exceeds the threshold corresponding to the important gradient. The local model parameters are aggregated with edge parameters, and the global model parameters are updated according to the result parameters of the edge parameter aggregation, and the updated global model is fed back to each local device;
S3,当边缘参数聚合达到设定聚合次数后,进行一次云端参数聚合;S3, when the edge parameter aggregation reaches the set number of aggregation times, perform a cloud parameter aggregation;
S4,重复步骤S2-S3直到全局损失函数收敛或者达到设定的训练精度,完成全局模型训练;S4, repeating steps S2-S3 until the global loss function converges or reaches the set training accuracy, and the global model training is completed;
S6,利用训练完成的全局模型对每一个计算卸载任务的信息量进行预测得到计算卸载的数据量的大小,根据计算卸载的数据量的大小以成本最小化进行资源分配。S6, using the trained global model to predict the information amount of each computing offloading task to obtain the size of the computing offloading data amount, and performing resource allocation to minimize the cost according to the size of the computing offloading data amount.
进一步的,本地设备分别使用其本地数据和本地设备参数更新本地模型参数:Further, the local device uses its local data and local device parameters to update the local model parameters, respectively:

t为当前迭代指标,i为第i个本地设备,在当前迭代指标t中本地设备i的目标是寻找使损失函数

进一步的,当达到设定迭代次数后,将所有本地设备计算的梯度数据超过阈值的重要梯度上传到边缘服务器。Further, when the set number of iterations is reached, all important gradients whose gradient data calculated by the local device exceeds the threshold are uploaded to the edge server.
进一步的,云参数聚合具体过程如下公式:Further, the specific process of cloud parameter aggregation is as follows:

{Dζ}表示边缘服务器ζ下聚集的数据集,卸载任务的数据集以
进一步的,迭代过程中进行参数稀疏化,采用标准的分散随机梯度下降方法,本地设备通过本地数据集Di更新本地参数

t表示当前迭代,wt表示参数w在迭代t的值;f(x,wt)表示由输入数据x和当前参数wt计算的损失;gk,t表示节点k在t次迭代关于wt的梯度;sparse(gk,t)表示gk,t的稀疏梯度;其中η是学习率,


进一步的,在每次迭代t开始时,在工作节点k上,从当前参数wt和从本地数据块Bk,t采样的数据计算出损失f(x,wt)后,可求得梯度f(x,wt),令
进一步的,利用与资源分配约束相关联的对偶变量进行一维双截面搜索实现资源分配。Further, resource allocation is achieved by performing a one-dimensional dual cross-section search using dual variables associated with resource allocation constraints.
一种计算卸载资源分配系统,包括本地设备、边缘服务器和云端服务器;A computing offloading resource allocation system, including a local device, an edge server and a cloud server;
边缘服务器用于将初始化的全局模型和任务广播给任务选择的本地设备;本地设备基于初始化的全局模型,根据其自身本地数据和本地设备参数更新本地模型参数,并将更新后的本地模型反馈至边缘服务器;The edge server is used to broadcast the initialized global model and tasks to the local device selected by the task; based on the initialized global model, the local device updates the local model parameters according to its own local data and local device parameters, and feeds back the updated local model to the local device. edge server;
边缘服务器对收到不同本地设备反馈的本地模型进行参数聚合,并根据边缘参数聚合结果参数更新全局模型参数后将更新后的全局模型反馈至各本地设备,当边缘参数聚合达到设定聚合次数后,云端服务器根据边缘服务器聚合的全局模型进行一次云参数聚合;本地设备将任务输入至边缘服务器,边缘服务器利用最终的全局模型对每一个计算卸载任务的信息量进行预测得到计算卸载的数据量的大小,根据计算卸载的数据量的大小以成本最小化进行资源分配。The edge server aggregates the parameters of the local models that have received feedback from different local devices, updates the global model parameters according to the edge parameter aggregation result parameters, and feeds back the updated global model to each local device. When the edge parameter aggregation reaches the set aggregation times , the cloud server performs a cloud parameter aggregation according to the global model aggregated by the edge server; the local device inputs the task to the edge server, and the edge server uses the final global model to predict the information amount of each computing offload task to obtain the data volume of computing offloading. Size, according to the size of the amount of data offloaded by the calculation to minimize the cost of resource allocation.
进一步的,本地设备基于初始化的全局模型



当进行k1轮迭代学习后(即达到设定迭代次数后),将计算的梯度数据超过阈值的重要梯度上传到边缘服务器。After k1 rounds of iterative learning (that is, after reaching the set number of iterations), the important gradients whose calculated gradient data exceeds the threshold are uploaded to the edge server.
进一步的,一个云端服务器连接多个边缘服务器,每个边缘服务器连接若干本地设备,每个边缘服务器参数聚合与其连接的本地设备的本地模型参数;云端服务器云参数聚合与其连接的多个边缘服务器参数聚合后的全局模型参数。Further, a cloud server is connected to multiple edge servers, each edge server is connected to several local devices, and the parameters of each edge server aggregate the local model parameters of the local devices connected to it; the cloud parameters of the cloud server aggregate the parameters of multiple edge servers connected to it. Aggregated global model parameters.
与现有技术相比,本发明具有以下有益的技术效果:Compared with the prior art, the present invention has the following beneficial technical effects:
本发明一种基于云边端的联邦学习计算卸载资源分配方法,可以满足在不共享隐私数据的前提下对多方数据进行训练学习的现实需求,以实现对计算任务卸载和资源分配做出准确决策,消除了求解组合优化问题的需要,大大降低了计算复杂度;基于云边端3层联邦学习综合利用了边缘节点距离终端的邻近优势,也利用了云计算中心强大的计算资源,弥补了边缘节点计算资源不足的问题,通过在多个客户端各自训练一个本地模型用以预测卸载任务,通过周期性的在边缘端执行一次参数聚合形成一个全局模型,边缘执行周期性聚合后云端执行一次聚合,如此直到收敛形成一个全局BiLSTM模型,全局模型可以智能的对每一个卸载任务的信息量进行预测,从而更好为计算卸载和资源分配提供指导。The present invention is a cloud-edge-terminal-based federated learning computing offloading resource allocation method, which can meet the practical needs of training and learning on multi-party data without sharing private data, so as to realize accurate decision-making on computing task offloading and resource allocation, Eliminates the need to solve combinatorial optimization problems and greatly reduces computational complexity; based on cloud-edge-end 3-layer federated learning, it comprehensively utilizes the proximity advantages of edge nodes from terminals and the powerful computing resources of cloud computing centers to compensate for edge nodes. For the problem of insufficient computing resources, a local model is trained on multiple clients to predict offloading tasks, and a global model is formed by periodically performing a parameter aggregation on the edge. After the edge performs periodic aggregation, the cloud performs an aggregation. In this way, a global BiLSTM model is formed until convergence. The global model can intelligently predict the amount of information of each offloading task, thereby providing better guidance for computing offloading and resource allocation.
进一步的,为了优化联邦学习的通信量,在本地对各自拥有的数据集进行学习,在经过多轮训练后,将稀疏化的梯度前s%进行压缩上传至边缘参数服务器,边缘参数服务器经过轮聚合后将参数上传至云端服务器聚合,直至收敛,实现了接近集中式学习方法的精度下,有最大限度保护了用户的安全隐私。Further, in order to optimize the communication volume of federated learning, the data sets they own are learned locally. After multiple rounds of training, the first s% of the sparse gradients are compressed and uploaded to the edge parameter server. The edge parameter server passes rounds of training. After aggregation, the parameters are uploaded to the cloud server for aggregation until convergence, which achieves the accuracy close to the centralized learning method and maximizes the security and privacy of users.
进一步的,将上传的梯度所采用参数稀疏化,即每次只将重要梯度压缩后上传至中心服务器对全局模型进行优化合并,这大大降低了联邦学习客户端和服务器端的通信开销,近而更加高效加速模型的聚合,加快了模型收敛速度。Further, the parameters used in the uploaded gradients are sparse, that is, only the important gradients are compressed and uploaded to the central server to optimize and merge the global model, which greatly reduces the communication overhead between the federated learning client and the server, and is more convenient. Efficiently accelerates model aggregation and accelerates model convergence.
本发明一种计算卸载资源分配系统,采用云-边-端3层的联邦学习框架,该框架既利用了边缘服务器与终端节点的天然邻近性和实时性计算优势,也弥补了边缘服务器计算资源有限的缺点,使用基于Bi-LSTM的联邦学习机制,使参与计算卸载的终端设备本地训练一个BiLSTM模型预测任务的数据量大小,之后分别定期在云端和边端执行参数聚合,消除了求解组合优化问题的需要,从而大大降低了计算复杂度。The present invention is a computing offloading resource allocation system, which adopts a cloud-edge-terminal three-layer federated learning framework, which not only utilizes the natural proximity and real-time computing advantages of edge servers and terminal nodes, but also makes up for edge server computing resources. The limited disadvantage is that the Bi-LSTM-based federated learning mechanism is used to enable the terminal equipment participating in computing offload to locally train a BiLSTM model to predict the size of the data of the task, and then periodically perform parameter aggregation in the cloud and on the edge, eliminating the need for combination optimization. problems, thereby greatly reducing the computational complexity.
附图说明Description of drawings
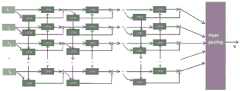
图1是本发明实施例中基于Bi-LSTM的云-边-端联邦学习框架图。FIG. 1 is a framework diagram of the cloud-edge-device federated learning based on Bi-LSTM in an embodiment of the present invention.
图2是本发明实施例中Bi-LSTM预测任务预测图。FIG. 2 is a prediction diagram of a Bi-LSTM prediction task in an embodiment of the present invention.
图3是本发明实施例中云-边-端联邦学习顺序图。FIG. 3 is a sequence diagram of cloud-edge-device federated learning in an embodiment of the present invention.
图4是本发明实施例中两阶段求解优化图。FIG. 4 is a two-stage solution optimization diagram in an embodiment of the present invention.
具体实施方式Detailed ways
下面结合附图对本发明做进一步详细描述:Below in conjunction with accompanying drawing, the present invention is described in further detail:
一种基于云边端的联邦学习计算卸载资源分配方法,包括以下步骤:A cloud-edge-terminal-based federated learning computing offloading resource allocation method, comprising the following steps:
S1,构建全局模型,并将初始化的全局模型
全局模型用于计算目标应用程序和相应的数据需求。The global model is used to calculate the target application and corresponding data requirements.
S2,基于初始化的全局模型



当进行k1轮迭代学习后,将计算的梯度数据超过阈值的重要梯度上传到边缘服务器;本地设备只传输绝对值超过梯度阈值的重要梯度,并在学习过程中本地累积其余梯度,即累计绝对值低于梯度阈值的梯度。After k1 rounds of iterative learning, upload the important gradients whose calculated gradient data exceeds the threshold to the edge server; the local device only transmits the important gradients whose absolute value exceeds the gradient threshold, and accumulates the remaining gradients locally during the learning process, that is, the cumulative absolute value Gradients with values below the gradient threshold.
S3,当本地设备执行k1轮迭代学习后,边缘服务器从每个本地设备i收集上传的本地模型参数


S4,当边缘服务器执行k2轮边缘参数聚合后,通过云端服务器执行一次云参数聚合;即本地客户端每k1轮迭代学习,边缘服务器执行k2轮边缘参数聚合后,云端服务器执行一次参数聚合;云端服务器每轮的参数更新计算

{Dζ}表示每个边缘服务器ζ下聚集的数据集,卸载任务的数据集以



S5,重复步骤S2至S4,直到全局损失函数收敛或者达到设定的训练精度,完成全局模型
S6,利用训练完成的全局模型
迭代过程中进行参数稀疏化,采用标准的分散随机梯度下降(decentralizedstochastic gradient descent,DSGD)方法,本地设备通过本地数据集Di更新本地参数

t表示当前迭代,wt表示参数w在迭代t的值;f(x,wt)表示由输入数据x和当前参数wt计算的损失;本地数据集Di包括本地数据和本地设备参数;gk,t表示节点k在t次迭代关于wt的梯度。sparse(gk,t)表示gk,t的稀疏梯度;其中η是学习率,


如图1所示,在每次迭代t开始时,将移动设备视为N个分布式工作节点(workingnode),工作节点k(1≤k≤N)有他的本地数据块Bk,t,大小为b。在工作节点k上,从当前参数wt和从本地数据块Bk,t采样的数据计算出损失f(x,wt)后,可求得梯度f(x,wt)。令
全局模型基于联邦学习,在全局模型预测的任务基础上,给定任务的数据输入大小
如图1所示,一种基于云边端的联邦学习计算卸载计算系统,包括本地设备、边缘服务器和云端服务器,As shown in Figure 1, a cloud-edge-based federated learning computing offload computing system includes local devices, edge servers, and cloud servers.
边缘服务器用于将初始化的全局模型

边缘服务器对收到不同本地设备反馈的本地模型进行参数聚合,并根据边缘参数聚合结果参数更新全局模型参数后将更新后的全局模型反馈至各本地设备,当边缘参数聚合达到设定聚合次数后,云端服务器根据边缘服务器聚合的全局模型进行一次云参数聚合;本地设备将任务输入至边缘服务器,边缘服务器利用最终的全局模型对每一个计算卸载任务的信息量进行预测得到计算卸载的数据量的大小,根据计算卸载的数据量的大小以成本最小化进行资源分配。The edge server aggregates the parameters of the local models that have received feedback from different local devices, updates the global model parameters according to the edge parameter aggregation result parameters, and feeds back the updated global model to each local device. When the edge parameter aggregation reaches the set aggregation times , the cloud server performs a cloud parameter aggregation according to the global model aggregated by the edge server; the local device inputs the task to the edge server, and the edge server uses the final global model to predict the information amount of each computing offload task to obtain the data volume of computing offloading. Size, according to the size of the amount of data offloaded by the calculation to minimize the cost of resource allocation.
本地设备基于初始化的全局模型



当进行k1轮迭代学习后(即达到设定迭代次数后),将计算的梯度数据超过阈值的重要梯度上传到边缘服务器;本地设备只传输绝对值超过梯度阈值的重要梯度,并在学习过程中本地累积其余梯度,即累计绝对值低于梯度阈值的梯度。After performing k1 rounds of iterative learning (that is, after reaching the set number of iterations), upload the important gradients whose calculated gradient data exceeds the threshold to the edge server; the local device only transmits the important gradients whose absolute value exceeds the gradient threshold, and the important gradients whose absolute value exceeds the gradient threshold are transmitted during the learning process. The remaining gradients are accumulated locally in , that is, the gradients whose absolute value is lower than the gradient threshold.
当本地设备执行k1轮迭代学习后,边缘服务器从每个本地设备i收集上传的本地模型参数


当边缘服务器执行k2轮边缘参数聚合后,通过云端服务器执行一次云参数聚合;即本地客户端每k1轮迭代学习,边缘服务器执行k2轮边缘参数聚合后,云端服务器对边缘服务器参数聚合后的数据进行一次参数聚合;云端服务器每轮的参数更新计算

直到全局损失函数收敛或者达到设定的训练精度,完成全局模型
一个云端服务器连接L个边缘服务器,每个边缘服务器用ζ表示,每个边缘服务器所属的客户端集合为
利用训练完成的全局模型
用户输入(即通过本地设备输入):基于联邦学习算法的用户输入是一个本地数据和本地设备参数样本Xm,它包括每个用户在不同时间段历史请求的任务的数据大小;令



用户输出(即通过本地设备输出):经过本地设备更新迭代的本地模型,即训练的本地Bi-LSTM模型(本地模型)输出是一个向量wm,表示与本地设备确定用户m的任务数据量大小信息的Bi-LSTM模型相关参数;User output (ie, output through the local device): The local model updated and iteratively updated by the local device, that is, the output of the trained local Bi-LSTM model (local model) is a vector wm , indicating the task data size of user m determined with the local device Information about the parameters of the Bi-LSTM model;
边缘服务器输入:基于Bi-LSTM的联邦学习算法将矩阵Wn=[w1,...,wm]作为输入,其中,wm是接受自用户m的模型参数;Edge server input: the Bi-LSTM-based federated learning algorithm takes the matrix Wn = [w1 , . . . , wm ] as input, where wm is the model parameter accepted from user m;
边缘服务器输出:通过汇总接收到的每个客户端的梯度数据,执行参数聚合形成一个全局模型,并将聚合后的更新参数发给每个客户端,客户端收到参数后覆盖本地模型参数,进行下一轮迭代;Edge server output: By aggregating the received gradient data of each client, performing parameter aggregation to form a global model, and sending the aggregated update parameters to each client. After the client receives the parameters, the local model parameters are overwritten, and the the next iteration;
即每个客户端MU i执行k2次本地模型更新,每个边缘服务器聚集与其连接的客户的模型;之后每k2次边缘模型聚合,则云服务器聚集所有边缘服务器的模型,这意味着每k1k2本地更新后执行一次与云通信。如时序图所示,所提出的云边端联邦学习算法主要步骤如下:That is, each client MU i performs k2 local model updates, and each edge server aggregates the models of the clients connected to it; then every k2 edge model aggregations, the cloud server aggregates the models of all edge servers, which means that each edge server aggregates the models of all edge servers. k1 k2 Perform a communication with the cloud after a local update. As shown in the sequence diagram, the main steps of the proposed cloud-edge-device federated learning algorithm are as follows:
图2是Bi-LSTM预测任务预测,目的是为计算写在任务进行预测:Figure 2 is the Bi-LSTM prediction task prediction, the purpose is to predict the task written for the calculation:
设有N个移动用户的计算任务需要卸载到与其蜂窝网络相关联的边缘服务器进行处理;采用基于Bi-LSTM的深度学习算法对计算任务进行预测。如图2所示,在给定时间步T时刻的输入xt条件下,BiLSTM单元的隐层输出Ht可有以下公式计算得出:The computing tasks with N mobile users need to be offloaded to the edge server associated with their cellular network for processing; the Bi-LSTM-based deep learning algorithm is used to predict the computing tasks. As shown in Figure 2, under the condition of input xt at a given time step T, the hidden layer output Ht of the BiLSTM unit can be calculated by the following formula:
gt=tanh*(WxgVt+Whght-1+bg)gt =tanh*(Wxg Vt +Whg ht-1 +bg )
it=sigmoid*(WxiVt+Whiht-1+bi)it =sigmoid*(Wxi Vt +Whi ht-1 +bi )
ft=sigmoid*(WxfVt+Whfht-1+bf)ft =sigmoid*(Wxf Vt +Whf ht-1 +bf )
ot=sigmoid*(WxoVt+Whoht-1+bo)ot =sigmoid*(Wxo Vt +Who ht-1 +bo )

ht=ottanh(Ct)=sigmoid*(WxoVt+Whoht-1+bo)*tanh(Ct)ht =ot tanh(Ct )=sigmoid*(Wxo Vt +Who ht-1 +bo )*tanh(Ct )
其中i,f,o,c分别表示输入门、遗忘门、输出门和细胞状态向量,W代表各权重矩阵(例如Wix为输入到输入门间的权重矩阵),xt代表各时刻的模型输入值,b代表偏置项向量。由于sigmod函数的输入值为[0,1],可以作为平衡信息被“遗忘”或者“记忆”程度的指标,因此门限单元都以此作为激活函数;where i, f, o, and c represent the input gate, forget gate, output gate and cell state vector respectively, W represents each weight matrix (for example, Wix is the weight matrix input to the input gate), and xt represents the model at each moment Input value, b represents the bias term vector. Since the input value of the sigmod function is [0,1], it can be used as an indicator of the degree to which the balance information is "forgotten" or "remembered", so the threshold units use this as the activation function;
最后,最后一个完整的连接层集成了前面提取的特征,得到了输出序列



图3是云-边-端联邦学习顺序图,可以形象的描述了整个云边端联邦学习方法的交互过程,由图3可知,即每个客户端MU i执行k1次本地模型更新,每个边缘服务器聚集其客户的模型;之后每k2次边缘模型聚合,则云服务器聚集所有边缘服务器的模型,这意味着每k1k2本地更新后执行一次与云通信。Figure 3 is the cloud-edge-terminal federated learning sequence diagram, which can vividly describe the interaction process of the entire cloud-edge-terminal federated learning method. It can be seen from Figure 3 that each client MU i performs k1 local model updates, and each Each edge server aggregates the models of its clients; then every k2 edge model aggregations, the cloud server aggregates the models of all edge servers, which means that every k1 k2 local updates are performed after a communication with the cloud.
最后,图4是一个流程图,与现有的许多深度学习方法同时优化所有系统参数从而产生不可行解不同,本申请提出了一种基于智能任务预测和资源分配的两阶段优化方案,即将复杂优化问题分解为智能任务预测,之后通过预测的任务信息进行精准的计算卸载决策和资源分配。因此,它完全消除了解决复杂的MIP(mixed integer programming)问题需要,计算复杂度不会随着网络规模的增加而爆炸。Finally, Figure 4 is a flowchart. Unlike many existing deep learning methods that simultaneously optimize all system parameters to generate infeasible solutions, this application proposes a two-stage optimization scheme based on intelligent task prediction and resource allocation, which is about complex The optimization problem is decomposed into intelligent task prediction, and then accurate computing offloading decisions and resource allocation are made through the predicted task information. Therefore, it completely eliminates the need to solve complex MIP (mixed integer programming) problems, and the computational complexity does not explode as the network size increases.
实施例:Example:
首先在每一个本地设备(客户端)利用历史卸载任务训练一个BiLSTM模型,通过在边缘服务器和云端服务器聚合形成一个全局模型;当下一次任务新的卸载任务到来时,采用聚合形成的全局模型对任务进行预测,预测的输出作为计算卸载决策和资源分配的指导,在训练过程中我们把每次的梯度数据通过数据稀疏化方法进行压缩上传,从而大大降低了通信开销,加快模型收敛和计算决策与资源分配的复杂度。First, a BiLSTM model is trained on each local device (client) using historical offloading tasks, and a global model is formed by aggregating on the edge server and cloud server; when a new offloading task for the next task arrives, the global model formed by the aggregation is used to analyze the task. Make predictions, and the predicted output is used as a guide for computing offloading decisions and resource allocation. During the training process, we compress and upload each gradient data through the data sparsification method, which greatly reduces communication overhead and accelerates model convergence and computing decision making. The complexity of resource allocation.
本发明通过建立一套完整的模型训练预测到通信优化方法,最后可以快速求解计算卸载和资源分配。我们考虑的框架可对应当前5G驱动的MEC网络下一个静态的物联网网络,该网络的发射机和接收机固定在某个位置。以N=30的MEC网络为例,我们设计的BiFOS算法的收敛时间平均为0.061秒,这对于现场部署来说是可以接受的开销。因此BiFOS算法使得信道衰落环境下无线MEC网络的实时卸载和资源分配成为切实可行的。The invention predicts a communication optimization method by establishing a complete set of model training, and finally can quickly solve the calculation offloading and resource allocation. The framework we consider can correspond to a static IoT network under the current 5G-driven MEC network, where the transmitter and receiver are fixed in a certain location. Taking the MEC network with N=30 as an example, the convergence time of our designed BiFOS algorithm is 0.061 seconds on average, which is an acceptable overhead for field deployment. Therefore, the BiFOS algorithm makes the real-time offloading and resource allocation of wireless MEC networks feasible in the channel fading environment.
本发明公开了一种基于云边端的联邦学习计算卸载和资源分配方法,我们首先提出一种基于BiLSTM的联邦学习智能任务预测机制,每个参与计算的边服务器在本地独立地进行训练模型,无需上传数据到边缘服务器。然后定期在边端和云端进行参数聚合,构建的目的是共同训练一个通用的全局Bi-directional Long Short-Term Memory(BiLSTM)模型来预测计算任务的数据量信息等,从而更加精准的指导计算卸载决策和资源分配。该机制消除了求解组合优化问题的需要,大大降低了计算复杂度,特别是在大型网络中。并且该机制确保在分布式异构的边缘基础设施中参与卸载过程的用户个人敏感信息等不被截获和泄露。为了进一步减少联邦学习在模型优化过程中的网络通信开销,我们改进FAVG算法,设计了云-边-端3层的联邦学习框架,将上传的梯度采用参数稀疏化,即每次只将重要梯度压缩后上传至参数服务器。该框架综合利用了边缘服务器与终端设备的邻近性优势和云计算中心强大计算资源,弥补了边缘服务器计算资源不足的缺点。最后,实验结果表明,在不收集用户私有数据的情况下,我们的算法在预测精度优于其他基于学习的卸载算法,且可减少30%的能效。The present invention discloses a cloud-edge-terminal-based federated learning computing offloading and resource allocation method. We first propose a BiLSTM-based federated learning intelligent task prediction mechanism. Each edge server participating in the calculation independently trains the model locally, without the need for Upload data to the edge server. Then, the parameters are aggregated on the edge and the cloud on a regular basis. The purpose of the construction is to jointly train a general global Bi-directional Long Short-Term Memory (BiLSTM) model to predict the data volume information of computing tasks, etc., so as to more accurately guide computing offloading decision-making and resource allocation. This mechanism eliminates the need to solve combinatorial optimization problems and greatly reduces computational complexity, especially in large networks. And this mechanism ensures that sensitive personal information of users participating in the uninstallation process in the distributed and heterogeneous edge infrastructure will not be intercepted and leaked. In order to further reduce the network communication overhead of federated learning in the process of model optimization, we improved the FAVG algorithm and designed a three-layer federated learning framework of cloud-edge-end. The uploaded gradients are parameter sparse, that is, only important gradients are used for each time. Compressed and uploaded to the parameter server. This framework comprehensively utilizes the proximity advantages of edge servers and terminal devices and the powerful computing resources of cloud computing centers, making up for the shortcomings of insufficient computing resources of edge servers. Finally, experimental results show that without collecting user private data, our algorithm outperforms other learning-based offloading algorithms in prediction accuracy and can reduce energy efficiency by 30%.
Claims (10)
Translated fromChinese














Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110089708.9ACN112817653A (en) | 2021-01-22 | 2021-01-22 | Cloud-side-based federated learning calculation unloading computing system and method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110089708.9ACN112817653A (en) | 2021-01-22 | 2021-01-22 | Cloud-side-based federated learning calculation unloading computing system and method |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN112817653Atrue CN112817653A (en) | 2021-05-18 |
Family
ID=75858849
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110089708.9APendingCN112817653A (en) | 2021-01-22 | 2021-01-22 | Cloud-side-based federated learning calculation unloading computing system and method |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN112817653A (en) |
Cited By (45)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113191504A (en)* | 2021-05-21 | 2021-07-30 | 电子科技大学 | Federated learning training acceleration method for computing resource heterogeneity |
| CN113255934A (en)* | 2021-06-07 | 2021-08-13 | 大连理工大学 | Federal learning method and system for sensing network uncertainty in mobile edge cloud |
| CN113312180A (en)* | 2021-06-07 | 2021-08-27 | 北京大学 | Resource allocation optimization method and system based on federal learning |
| CN113361694A (en)* | 2021-06-30 | 2021-09-07 | 哈尔滨工业大学 | Layered federated learning method and system applying differential privacy protection |
| CN113408675A (en)* | 2021-08-20 | 2021-09-17 | 深圳市沃易科技有限公司 | Intelligent unloading optimization method and system based on federal learning |
| CN113435472A (en)* | 2021-05-24 | 2021-09-24 | 西安电子科技大学 | Vehicle-mounted computing power network user demand prediction method, system, device and medium |
| CN113467928A (en)* | 2021-05-20 | 2021-10-01 | 杭州趣链科技有限公司 | Block chain decentralization-based federated learning member reasoning attack defense method and device |
| CN113469367A (en)* | 2021-05-25 | 2021-10-01 | 华为技术有限公司 | Method, device and system for federated learning |
| CN113504999A (en)* | 2021-08-05 | 2021-10-15 | 重庆大学 | Scheduling and resource allocation method for high-performance hierarchical federated edge learning |
| CN113610303A (en)* | 2021-08-09 | 2021-11-05 | 北京邮电大学 | Load prediction method and system |
| CN113642700A (en)* | 2021-07-05 | 2021-11-12 | 湖南师范大学 | Cross-platform multimodal public opinion analysis method based on federated learning and edge computing |
| CN113761525A (en)* | 2021-09-07 | 2021-12-07 | 广东电网有限责任公司江门供电局 | Intelligent intrusion detection method and system based on federal learning |
| CN113839838A (en)* | 2021-10-20 | 2021-12-24 | 西安电子科技大学 | Business type identification method for federal learning based on cloud edge cooperation |
| CN113852692A (en)* | 2021-09-24 | 2021-12-28 | 中国移动通信集团陕西有限公司 | Service determination method, device, equipment and computer storage medium |
| CN113873047A (en)* | 2021-12-03 | 2021-12-31 | 江苏电力信息技术有限公司 | Cooperative computing method for streaming data |
| CN113971090A (en)* | 2021-10-21 | 2022-01-25 | 中国人民解放军国防科技大学 | Hierarchical federated learning method and device for distributed deep neural network |
| CN114040425A (en)* | 2021-11-17 | 2022-02-11 | 中国电信集团系统集成有限责任公司 | Resource allocation method based on global resource availability optimization |
| CN114116198A (en)* | 2021-10-21 | 2022-03-01 | 西安电子科技大学 | Asynchronous federated learning method, system, device and terminal for moving vehicles |
| CN114118437A (en)* | 2021-09-30 | 2022-03-01 | 电子科技大学 | A model update synchronization method for distributed machine learning in micro-cloud |
| CN114125861A (en)* | 2021-11-26 | 2022-03-01 | 北京邮电大学 | A wireless federated learning method and device |
| CN114143212A (en)* | 2021-11-26 | 2022-03-04 | 天津大学 | Social learning method for smart city |
| CN114282646A (en)* | 2021-11-29 | 2022-04-05 | 淮阴工学院 | Optical power prediction method and system based on two-stage feature extraction and improved BiLSTM |
| CN114363923A (en)* | 2021-11-30 | 2022-04-15 | 山东师范大学 | A method and system for industrial Internet of Things resource allocation based on federated edge learning |
| CN114357676A (en)* | 2021-12-15 | 2022-04-15 | 华南理工大学 | Aggregation frequency control method for hierarchical model training framework |
| CN114359963A (en)* | 2021-12-27 | 2022-04-15 | 海信集团控股股份有限公司 | Gesture recognition method and communication system |
| CN114363911A (en)* | 2021-12-31 | 2022-04-15 | 哈尔滨工业大学(深圳) | Wireless communication system for deploying layered federated learning and resource optimization method |
| CN114462573A (en)* | 2022-01-20 | 2022-05-10 | 内蒙古工业大学 | An efficient hierarchical parameter transmission delay optimization method for edge intelligence |
| CN114465900A (en)* | 2022-03-01 | 2022-05-10 | 北京邮电大学 | Data sharing delay optimization method and device based on federal edge learning |
| CN114489964A (en)* | 2021-12-08 | 2022-05-13 | 中国科学院信息工程研究所 | Vehicle-mounted network credit priority task unloading method based on federal learning |
| CN114650228A (en)* | 2022-03-18 | 2022-06-21 | 南京邮电大学 | Federal learning scheduling method based on computation unloading in heterogeneous network |
| CN114818446A (en)* | 2021-12-22 | 2022-07-29 | 安徽继远软件有限公司 | Power service decomposition method and system facing 5G cloud edge-end cooperation |
| CN114916013A (en)* | 2022-05-10 | 2022-08-16 | 中南大学 | Method, system and medium for edge task offloading delay optimization based on vehicle trajectory prediction |
| CN115080249A (en)* | 2022-08-22 | 2022-09-20 | 南京可信区块链与算法经济研究院有限公司 | Vehicle networking multidimensional resource allocation method and system based on federal learning |
| CN115408151A (en)* | 2022-08-23 | 2022-11-29 | 哈尔滨工业大学 | A Federated Learning Training Acceleration Method |
| WO2023061500A1 (en)* | 2021-10-15 | 2023-04-20 | Huawei Technologies Co., Ltd. | Methods and systems for updating parameters of a parameterized optimization algorithm in federated learning |
| CN116074085A (en)* | 2023-01-15 | 2023-05-05 | 浙江工业大学 | A data security protection method for an intelligent networked car machine |
| CN116149838A (en)* | 2022-09-30 | 2023-05-23 | 中国人民解放军国防科技大学 | Privacy-enhanced federal learning system with cloud edge end fusion |
| CN116166406A (en)* | 2023-04-25 | 2023-05-26 | 合肥工业大学智能制造技术研究院 | Personalized edge offload scheduling method, model training method and system |
| WO2023134065A1 (en)* | 2022-01-14 | 2023-07-20 | 平安科技(深圳)有限公司 | Gradient compression method and apparatus, device, and storage medium |
| CN116644802A (en)* | 2023-07-19 | 2023-08-25 | 支付宝(杭州)信息技术有限公司 | Model training method and device |
| CN116821687A (en)* | 2023-07-06 | 2023-09-29 | 河南大学 | Federated deep learning wind power generation prediction method based on data privacy protection |
| CN117076132A (en)* | 2023-10-12 | 2023-11-17 | 北京邮电大学 | Resource allocation and aggregation optimization methods and devices for hierarchical federated learning systems |
| CN118070926A (en)* | 2024-04-22 | 2024-05-24 | 东北大学 | Multi-task federation learning method based on client resource self-adaption |
| CN118504660A (en)* | 2024-07-18 | 2024-08-16 | 湖南红普创新科技发展有限公司 | Heterogeneous data processing method and device for Internet of vehicles, computer equipment and storage medium |
| CN119761529A (en)* | 2024-04-03 | 2025-04-04 | 湖北文理学院 | Personalized federated learning method and system based on edge-end-cloud three-layer architecture |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112181971A (en)* | 2020-10-27 | 2021-01-05 | 华侨大学 | Edge-based federated learning model cleaning and equipment clustering method, system, equipment and readable storage medium |
- 2021
- 2021-01-22CNCN202110089708.9Apatent/CN112817653A/enactivePending
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112181971A (en)* | 2020-10-27 | 2021-01-05 | 华侨大学 | Edge-based federated learning model cleaning and equipment clustering method, system, equipment and readable storage medium |
Non-Patent Citations (1)
| Title |
|---|
| 吴琪 等: "边缘学习:关键技术、应用与挑战", 《无线电通信技术》* |
Cited By (71)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113467928A (en)* | 2021-05-20 | 2021-10-01 | 杭州趣链科技有限公司 | Block chain decentralization-based federated learning member reasoning attack defense method and device |
| CN113467928B (en)* | 2021-05-20 | 2024-12-27 | 杭州趣链科技有限公司 | Method and device for defending against member reasoning attacks of federated learning based on blockchain decentralization |
| CN113191504B (en)* | 2021-05-21 | 2022-06-28 | 电子科技大学 | Federated learning training acceleration method for computing resource isomerism |
| CN113191504A (en)* | 2021-05-21 | 2021-07-30 | 电子科技大学 | Federated learning training acceleration method for computing resource heterogeneity |
| CN113435472A (en)* | 2021-05-24 | 2021-09-24 | 西安电子科技大学 | Vehicle-mounted computing power network user demand prediction method, system, device and medium |
| CN113469367A (en)* | 2021-05-25 | 2021-10-01 | 华为技术有限公司 | Method, device and system for federated learning |
| WO2022247683A1 (en)* | 2021-05-25 | 2022-12-01 | 华为技术有限公司 | Federated learning method, apparatus, and system |
| CN113469367B (en)* | 2021-05-25 | 2024-05-10 | 华为技术有限公司 | A federated learning method, device and system |
| CN113312180A (en)* | 2021-06-07 | 2021-08-27 | 北京大学 | Resource allocation optimization method and system based on federal learning |
| CN113255934A (en)* | 2021-06-07 | 2021-08-13 | 大连理工大学 | Federal learning method and system for sensing network uncertainty in mobile edge cloud |
| CN113361694A (en)* | 2021-06-30 | 2021-09-07 | 哈尔滨工业大学 | Layered federated learning method and system applying differential privacy protection |
| CN113361694B (en)* | 2021-06-30 | 2022-03-15 | 哈尔滨工业大学 | A hierarchical federated learning method and system applying differential privacy protection |
| CN113642700A (en)* | 2021-07-05 | 2021-11-12 | 湖南师范大学 | Cross-platform multimodal public opinion analysis method based on federated learning and edge computing |
| CN113504999A (en)* | 2021-08-05 | 2021-10-15 | 重庆大学 | Scheduling and resource allocation method for high-performance hierarchical federated edge learning |
| CN113504999B (en)* | 2021-08-05 | 2023-07-04 | 重庆大学 | Scheduling and resource allocation method for high-performance hierarchical federal edge learning |
| CN113610303B (en)* | 2021-08-09 | 2024-03-19 | 北京邮电大学 | Load prediction method and system |
| CN113610303A (en)* | 2021-08-09 | 2021-11-05 | 北京邮电大学 | Load prediction method and system |
| CN113408675A (en)* | 2021-08-20 | 2021-09-17 | 深圳市沃易科技有限公司 | Intelligent unloading optimization method and system based on federal learning |
| CN113761525A (en)* | 2021-09-07 | 2021-12-07 | 广东电网有限责任公司江门供电局 | Intelligent intrusion detection method and system based on federal learning |
| CN113852692B (en)* | 2021-09-24 | 2024-01-30 | 中国移动通信集团陕西有限公司 | Service determination methods, devices, equipment and computer storage media |
| CN113852692A (en)* | 2021-09-24 | 2021-12-28 | 中国移动通信集团陕西有限公司 | Service determination method, device, equipment and computer storage medium |
| CN114118437A (en)* | 2021-09-30 | 2022-03-01 | 电子科技大学 | A model update synchronization method for distributed machine learning in micro-cloud |
| CN114118437B (en)* | 2021-09-30 | 2023-04-18 | 电子科技大学 | Model updating synchronization method for distributed machine learning in micro cloud |
| WO2023061500A1 (en)* | 2021-10-15 | 2023-04-20 | Huawei Technologies Co., Ltd. | Methods and systems for updating parameters of a parameterized optimization algorithm in federated learning |
| CN113839838B (en)* | 2021-10-20 | 2023-10-20 | 西安电子科技大学 | Business type identification method based on cloud edge cooperation and federal learning |
| CN113839838A (en)* | 2021-10-20 | 2021-12-24 | 西安电子科技大学 | Business type identification method for federal learning based on cloud edge cooperation |
| CN114116198A (en)* | 2021-10-21 | 2022-03-01 | 西安电子科技大学 | Asynchronous federated learning method, system, device and terminal for moving vehicles |
| CN113971090A (en)* | 2021-10-21 | 2022-01-25 | 中国人民解放军国防科技大学 | Hierarchical federated learning method and device for distributed deep neural network |
| CN114116198B (en)* | 2021-10-21 | 2024-07-19 | 西安电子科技大学 | Asynchronous federal learning method, system, equipment and terminal for mobile vehicle |
| CN113971090B (en)* | 2021-10-21 | 2022-09-13 | 中国人民解放军国防科技大学 | Layered federal learning method and device of distributed deep neural network |
| CN114040425A (en)* | 2021-11-17 | 2022-02-11 | 中国电信集团系统集成有限责任公司 | Resource allocation method based on global resource availability optimization |
| CN114040425B (en)* | 2021-11-17 | 2024-03-15 | 中电信数智科技有限公司 | Resource allocation method based on global resource utility rate optimization |
| CN114125861A (en)* | 2021-11-26 | 2022-03-01 | 北京邮电大学 | A wireless federated learning method and device |
| CN114143212A (en)* | 2021-11-26 | 2022-03-04 | 天津大学 | Social learning method for smart city |
| CN114282646A (en)* | 2021-11-29 | 2022-04-05 | 淮阴工学院 | Optical power prediction method and system based on two-stage feature extraction and improved BiLSTM |
| CN114282646B (en)* | 2021-11-29 | 2023-08-25 | 淮阴工学院 | Optical power prediction method and system based on two-stage feature extraction and improved BiLSTM |
| CN114363923B (en)* | 2021-11-30 | 2024-03-26 | 山东师范大学 | Industrial Internet of things resource allocation method and system based on federal edge learning |
| CN114363923A (en)* | 2021-11-30 | 2022-04-15 | 山东师范大学 | A method and system for industrial Internet of Things resource allocation based on federated edge learning |
| CN113873047B (en)* | 2021-12-03 | 2022-02-15 | 江苏电力信息技术有限公司 | Cooperative computing method for streaming data |
| CN113873047A (en)* | 2021-12-03 | 2021-12-31 | 江苏电力信息技术有限公司 | Cooperative computing method for streaming data |
| CN114489964A (en)* | 2021-12-08 | 2022-05-13 | 中国科学院信息工程研究所 | Vehicle-mounted network credit priority task unloading method based on federal learning |
| CN114357676B (en)* | 2021-12-15 | 2024-04-02 | 华南理工大学 | Aggregation frequency control method for hierarchical model training framework |
| CN114357676A (en)* | 2021-12-15 | 2022-04-15 | 华南理工大学 | Aggregation frequency control method for hierarchical model training framework |
| CN114818446A (en)* | 2021-12-22 | 2022-07-29 | 安徽继远软件有限公司 | Power service decomposition method and system facing 5G cloud edge-end cooperation |
| CN114359963A (en)* | 2021-12-27 | 2022-04-15 | 海信集团控股股份有限公司 | Gesture recognition method and communication system |
| CN114363911B (en)* | 2021-12-31 | 2023-10-17 | 哈尔滨工业大学(深圳) | A wireless communication system and resource optimization method for deploying hierarchical federated learning |
| CN114363911A (en)* | 2021-12-31 | 2022-04-15 | 哈尔滨工业大学(深圳) | Wireless communication system for deploying layered federated learning and resource optimization method |
| WO2023134065A1 (en)* | 2022-01-14 | 2023-07-20 | 平安科技(深圳)有限公司 | Gradient compression method and apparatus, device, and storage medium |
| CN114462573A (en)* | 2022-01-20 | 2022-05-10 | 内蒙古工业大学 | An efficient hierarchical parameter transmission delay optimization method for edge intelligence |
| CN114462573B (en)* | 2022-01-20 | 2023-11-14 | 内蒙古工业大学 | Edge intelligence-oriented efficient hierarchical parameter transmission delay optimization method |
| CN114465900A (en)* | 2022-03-01 | 2022-05-10 | 北京邮电大学 | Data sharing delay optimization method and device based on federal edge learning |
| CN114465900B (en)* | 2022-03-01 | 2023-03-21 | 北京邮电大学 | Data sharing delay optimization method and device based on federated edge learning |
| CN114650228A (en)* | 2022-03-18 | 2022-06-21 | 南京邮电大学 | Federal learning scheduling method based on computation unloading in heterogeneous network |
| CN114650228B (en)* | 2022-03-18 | 2023-07-25 | 南京邮电大学 | Federal learning scheduling method based on calculation unloading in heterogeneous network |
| CN114916013B (en)* | 2022-05-10 | 2024-04-16 | 中南大学 | Edge task unloading delay optimization method, system and medium based on vehicle track prediction |
| CN114916013A (en)* | 2022-05-10 | 2022-08-16 | 中南大学 | Method, system and medium for edge task offloading delay optimization based on vehicle trajectory prediction |
| CN115080249B (en)* | 2022-08-22 | 2022-12-16 | 南京可信区块链与算法经济研究院有限公司 | Vehicle networking multidimensional resource allocation method and system based on federal learning |
| CN115080249A (en)* | 2022-08-22 | 2022-09-20 | 南京可信区块链与算法经济研究院有限公司 | Vehicle networking multidimensional resource allocation method and system based on federal learning |
| CN115408151A (en)* | 2022-08-23 | 2022-11-29 | 哈尔滨工业大学 | A Federated Learning Training Acceleration Method |
| CN116149838A (en)* | 2022-09-30 | 2023-05-23 | 中国人民解放军国防科技大学 | Privacy-enhanced federal learning system with cloud edge end fusion |
| CN116074085A (en)* | 2023-01-15 | 2023-05-05 | 浙江工业大学 | A data security protection method for an intelligent networked car machine |
| CN116166406B (en)* | 2023-04-25 | 2023-06-30 | 合肥工业大学智能制造技术研究院 | Personalized edge unloading scheduling method, model training method and system |
| CN116166406A (en)* | 2023-04-25 | 2023-05-26 | 合肥工业大学智能制造技术研究院 | Personalized edge offload scheduling method, model training method and system |
| CN116821687A (en)* | 2023-07-06 | 2023-09-29 | 河南大学 | Federated deep learning wind power generation prediction method based on data privacy protection |
| CN116644802A (en)* | 2023-07-19 | 2023-08-25 | 支付宝(杭州)信息技术有限公司 | Model training method and device |
| CN117076132B (en)* | 2023-10-12 | 2024-01-05 | 北京邮电大学 | Resource allocation and aggregation optimization method and device for hierarchical federal learning system |
| CN117076132A (en)* | 2023-10-12 | 2023-11-17 | 北京邮电大学 | Resource allocation and aggregation optimization methods and devices for hierarchical federated learning systems |
| CN119761529A (en)* | 2024-04-03 | 2025-04-04 | 湖北文理学院 | Personalized federated learning method and system based on edge-end-cloud three-layer architecture |
| CN118070926A (en)* | 2024-04-22 | 2024-05-24 | 东北大学 | Multi-task federation learning method based on client resource self-adaption |
| CN118070926B (en)* | 2024-04-22 | 2024-08-09 | 东北大学 | Multi-task federation learning method based on client resource self-adaption |
| CN118504660A (en)* | 2024-07-18 | 2024-08-16 | 湖南红普创新科技发展有限公司 | Heterogeneous data processing method and device for Internet of vehicles, computer equipment and storage medium |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN112817653A (en) | Cloud-side-based federated learning calculation unloading computing system and method | |
| CN113222179B (en) | A Federated Learning Model Compression Method Based on Model Sparsification and Weight Quantization | |
| Cui et al. | Optimal rate adaption in federated learning with compressed communications | |
| CN109947545B (en) | A Decision Method for Task Offloading and Migration Based on User Mobility | |
| Wang et al. | A novel reputation-aware client selection scheme for federated learning within mobile environments | |
| Elbir et al. | A hybrid architecture for federated and centralized learning | |
| CN114650228B (en) | Federal learning scheduling method based on calculation unloading in heterogeneous network | |
| CN113595993B (en) | A joint learning method for vehicle sensing equipment based on model structure optimization under edge computing | |
| CN112511336B (en) | Online service placement method in edge computing system | |
| Chen et al. | Communication-efficient design for quantized decentralized federated learning | |
| Cui et al. | A fast blockchain-based federated learning framework with compressed communications | |
| Li et al. | Anycostfl: Efficient on-demand federated learning over heterogeneous edge devices | |
| CN115034390A (en) | Deep learning model reasoning acceleration method based on cloud edge-side cooperation | |
| CN115696296B (en) | An Active Edge Caching Method Based on Community Discovery and Weighted Federated Learning | |
| CN111158912A (en) | Task unloading decision method based on deep learning in cloud and mist collaborative computing environment | |
| CN118612754A (en) | Three-in-one terminal control system and method capable of intelligent networking | |
| CN112836822A (en) | Federated learning strategy optimization method and device based on breadth learning | |
| Li et al. | CBFL: A communication-efficient federated learning framework from data redundancy perspective | |
| Feng et al. | Joint detection and computation offloading with age of information in mobile edge networks | |
| Zhang et al. | Fundamental limits of communication efficiency for model aggregation in distributed learning: A rate-distortion approach | |
| Zhu et al. | Dynamic task offloading in power grid internet of things: A fast-convergent federated learning approach | |
| CN118450438A (en) | Low-energy computing migration method for delay-sensitive tasks in edge-cloud hybrid system | |
| CN112667406A (en) | Task unloading and data caching method in cloud edge fusion heterogeneous network | |
| Chen et al. | Semi-asynchronous hierarchical federated learning over mobile edge networks | |
| Zhu et al. | Efficient model compression for hierarchical federated learning |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| WD01 | Invention patent application deemed withdrawn after publication | ||
| WD01 | Invention patent application deemed withdrawn after publication | Application publication date:20210518 |