CN112650246B - Ship autonomous navigation method and device - Google Patents
Ship autonomous navigation method and deviceDownload PDFInfo
- Publication number
- CN112650246B CN112650246BCN202011535524.2ACN202011535524ACN112650246BCN 112650246 BCN112650246 BCN 112650246BCN 202011535524 ACN202011535524 ACN 202011535524ACN 112650246 BCN112650246 BCN 112650246B
- Authority
- CN
- China
- Prior art keywords
- ship
- action
- navigation
- track
- point
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000000034methodMethods0.000titleclaimsabstractdescription61
- 239000003643water by typeSubstances0.000claimsabstractdescription52
- 230000009471actionEffects0.000claimsdescription73
- 238000005457optimizationMethods0.000claimsdescription43
- 239000003016pheromoneSubstances0.000claimsdescription26
- 238000004590computer programMethods0.000claimsdescription11
- 238000000605extractionMethods0.000claimsdescription8
- 238000013519translationMethods0.000claimsdescription7
- 230000003993interactionEffects0.000claimsdescription6
- 230000006870functionEffects0.000claimsdescription5
- 241000257303HymenopteraSpecies0.000claimsdescription3
- 238000010276constructionMethods0.000claimsdescription3
- XLYOFNOQVPJJNP-UHFFFAOYSA-NwaterSubstancesOXLYOFNOQVPJJNP-UHFFFAOYSA-N0.000abstractdescription7
- 230000000875corresponding effectEffects0.000description11
- 230000008901benefitEffects0.000description6
- 238000010586diagramMethods0.000description5
- 230000000694effectsEffects0.000description5
- 238000013461designMethods0.000description4
- 230000008569processEffects0.000description4
- 238000005516engineering processMethods0.000description3
- 238000004387environmental modelingMethods0.000description2
- 238000002474experimental methodMethods0.000description2
- 239000002245particleSubstances0.000description2
- 238000012360testing methodMethods0.000description2
- 238000013473artificial intelligenceMethods0.000description1
- 230000009286beneficial effectEffects0.000description1
- 230000001186cumulative effectEffects0.000description1
- 230000007423decreaseEffects0.000description1
- 230000007547defectEffects0.000description1
- 238000011161developmentMethods0.000description1
- 238000012986modificationMethods0.000description1
- 230000004048modificationEffects0.000description1
- 230000009467reductionEffects0.000description1
- 238000011160researchMethods0.000description1
- 238000004088simulationMethods0.000description1
- 238000012549trainingMethods0.000description1
- 238000012795verificationMethods0.000description1
Images









Classifications
- G—PHYSICS
- G05—CONTROLLING; REGULATING
- G05D—SYSTEMS FOR CONTROLLING OR REGULATING NON-ELECTRIC VARIABLES
- G05D1/00—Control of position, course, altitude or attitude of land, water, air or space vehicles, e.g. using automatic pilots
- G05D1/02—Control of position or course in two dimensions
- G05D1/0206—Control of position or course in two dimensions specially adapted to water vehicles
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02T—CLIMATE CHANGE MITIGATION TECHNOLOGIES RELATED TO TRANSPORTATION
- Y02T10/00—Road transport of goods or passengers
- Y02T10/10—Internal combustion engine [ICE] based vehicles
- Y02T10/40—Engine management systems
Landscapes
- Engineering & Computer Science (AREA)
- Aviation & Aerospace Engineering (AREA)
- Radar, Positioning & Navigation (AREA)
- Remote Sensing (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Automation & Control Theory (AREA)
- Control Of Position, Course, Altitude, Or Attitude Of Moving Bodies (AREA)
- Traffic Control Systems (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本发明涉及船舶控制与决策技术领域,尤其涉及一种船舶自主导航方法、装置及计算机存储介质。The invention relates to the technical field of ship control and decision-making, in particular to a ship autonomous navigation method, device and computer storage medium.
背景技术Background technique
随着人工智能、物联网等高新技术的蓬勃发展,船舶作为一种广泛应用于货物流通,军事巡航,民众通行的载具,得到了研究人员地高度重视。由于船舶的运动不同于陆上、空中载具,受环境影响较大,航行存在大量不确定性和风险性。为了实现船舶的正常航行,需要解决船舶全局航迹规划和局部风险避碰这两个关键性问题。With the vigorous development of high-tech such as artificial intelligence and the Internet of Things, ships, as a vehicle widely used in cargo circulation, military cruise, and public access, have received great attention from researchers. Since the movement of ships is different from land and air vehicles, they are greatly affected by the environment, and there are a lot of uncertainties and risks in navigation. In order to realize the normal navigation of the ship, it is necessary to solve the two key problems of the ship's global track planning and local risk collision avoidance.
对于全局航迹规划问题,目前多种算法被应用于船舶自主导航的研究,如Dijkstra算法、A*算法、人工势场法、粒子群优化算法、蚁群优化算法等。但这些经典的离线方法,需要预先获取完整的环境先验知识,这是目前难以完全实现的,同时这也加大了环境建模的难度,因此单独使用上述方法不适用于船舶实时的自主导航。For the problem of global track planning, a variety of algorithms are currently used in the research of ship autonomous navigation, such as Dijkstra algorithm, A* algorithm, artificial potential field method, particle swarm optimization algorithm, ant colony optimization algorithm, etc. However, these classic offline methods need to obtain complete prior knowledge of the environment in advance, which is currently difficult to fully realize. At the same time, it also increases the difficulty of environmental modeling. Therefore, using the above methods alone is not suitable for real-time autonomous navigation of ships. .
对于局部风险避碰问题,主流方法侧重于对环境进行实时建模。如通过分析船体一定范围内的障碍物信息进行复杂度聚类,结合蚁群优化算法实现了动态避障,这种方法在避障上有优秀的表现,但当起始点距离目标较远时,易产生冗余的轨迹。而另一些研究人员采用试错法弱化环境建模的复杂度,考虑到了海上风浪影响,提出了基于Q-learning的自主导航算法,实现了未知环境下机器人的智能避碰;在Q-learning算法上,引入了人工势场法,进一步提高了Q-learning算法的收敛速度。但基于栅格的Q-learning算法受水域尺寸的影响较大,在大型水域中进行自主导航将会增大航迹随机性,不利于航迹收敛。For the local risk collision avoidance problem, mainstream methods focus on real-time modeling of the environment. For example, by analyzing the obstacle information within a certain range of the hull for complexity clustering, combined with the ant colony optimization algorithm to achieve dynamic obstacle avoidance, this method has excellent performance in obstacle avoidance, but when the starting point is far from the target, prone to redundant trajectories. Other researchers used the trial-and-error method to weaken the complexity of environmental modeling, taking into account the influence of sea waves, and proposed an autonomous navigation algorithm based on Q-learning, which realized the intelligent collision avoidance of robots in unknown environments; in the Q-learning algorithm In addition, the artificial potential field method is introduced to further improve the convergence speed of the Q-learning algorithm. However, the grid-based Q-learning algorithm is greatly affected by the size of the water area. Autonomous navigation in large water areas will increase the randomness of the track, which is not conducive to track convergence.
发明内容Contents of the invention
有鉴于此,有必要提供一种船舶自主导航方法及装置,用以解决全局航迹规划无法适用于实时导航,局部风险避碰不适用于大型水域、航迹收敛慢的问题。In view of this, it is necessary to provide a ship autonomous navigation method and device to solve the problems that global track planning cannot be applied to real-time navigation, local risk collision avoidance is not suitable for large water areas, and track convergence is slow.
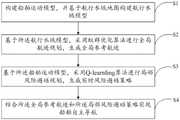
本发明提供一种船舶自主导航方法,包括以下步骤:The invention provides a method for autonomous navigation of a ship, comprising the following steps:
构建船舶运动模型,并基于航行水域地图构建航行水域模型;Build a ship motion model and build a navigation waters model based on the navigation waters map;
基于所述航行水域模型,采用蚁群优化算法进行全局航迹规划,生成全局参考航迹;Based on the navigation waters model, an ant colony optimization algorithm is used to carry out global track planning to generate a global reference track;
基于所述船舶运动模型,采用Q-learning算法进行局部风险避碰规划,生成实时风险避碰策略;Based on the ship motion model, the Q-learning algorithm is used for local risk collision avoidance planning to generate real-time risk collision avoidance strategies;
结合所述全局参考航迹和所述局部风险避碰策略实现船舶自主导航。Combining the global reference track and the local risk collision avoidance strategy to realize autonomous navigation of the ship.
进一步地,构建船舶运动模型,具体为:Further, build a ship motion model, specifically:
建立船舶模型;Build a ship model;
将船舶的运动分解为随中心点的平动以及绕中心点的转动,将船舶的运动简化为在水平面的运动,得到船舶的运动学描述;The motion of the ship is decomposed into translation with the center point and rotation around the center point, and the motion of the ship is simplified to the motion on the horizontal plane to obtain the kinematic description of the ship;
设置转向阈值,对船舶的转向进行约束;Set the steering threshold to restrict the steering of the ship;
以中心点为圆心、以安全距离为半径,设置船舶的安全区域;Set the safety area of the ship with the center point as the center and the safety distance as the radius;
结合所述船舶模型、运动学描述、转向阈值以及安全区域,得到所述船舶运动模型。The ship motion model is obtained by combining the ship model, kinematics description, turning threshold and safe area.
进一步地,基于航行水域地图构建航行水域模型,具体为:Further, construct the navigation waters model based on the navigation waters map, specifically:
获取航行水域地图,对所述航行水域地图中障碍物进行边缘提取;Obtaining a navigation waters map, and performing edge extraction on obstacles in the navigation waters map;
利用Graham扫描法提取边缘的凸包,设置最小边长阈值与最小周长阈值,滤除边长小于最小边长阈值或周长小于最小周长阈值的凸包;Use the Graham scanning method to extract the convex hull of the edge, set the minimum edge length threshold and the minimum perimeter threshold, and filter out the convex hull whose edge length is less than the minimum edge length threshold or whose perimeter is less than the minimum perimeter threshold;
对所述凸包进行等距离缩放,使之完全包围相应的障碍物;Scaling the convex hull equidistantly so that it completely surrounds the corresponding obstacle;
以凸包顶点构造MAKLINK全局连通图,选取MAKLINK全局连通图中所有MAKLINK线的中点、起点和终点作为网络节点;Construct the MAKLINK global connectivity graph with convex hull vertices, and select the midpoint, starting point and end point of all MAKLINK lines in the MAKLINK global connectivity graph as network nodes;
连接相邻的网络节点得到轨迹规划的无向网络图,以所述无向网络图作为所述航行水域模型。An undirected network graph of trajectory planning is obtained by connecting adjacent network nodes, and the undirected network graph is used as the navigation waters model.
进一步地,基于所述航行水域模型,采用蚁群优化算法进行全局航迹规划,生成全局参考航迹,具体为:Further, based on the navigation waters model, the ant colony optimization algorithm is used for global track planning to generate a global reference track, specifically:
所述航行水域模型为无向网络图,所述无向网络图包括多条连接线;The navigation waters model is an undirected network graph, and the undirected network graph includes a plurality of connecting lines;
获取起点和终点,基于所述无向网络图构建从起点到终点的初始航迹;Obtain the starting point and the ending point, and construct an initial track from the starting point to the ending point based on the undirected network graph;
建立节点优化的目标函数:Build the objective function for nodal optimization:

其中,
所述比例系数用于调节Vi(hi)在第i条连接线上的具体位置:The proportional coefficient is used to adjust the specific position of Vi (hi ) on the i-th connecting line:
Vi(hi)=Vi(0)+hi(Vi(1)-Vi(0));Vi (hi ) = Vi(0) + hi (Vi(1) -Vi(0) );
其中,Vi(0)、Vi(1)分别为航迹所经过的第i条连接线的两个端点;Among them, Vi(0) and Vi(1) are the two endpoints of the i-th connection line passed by the track respectively;
通过调整所述比例系数,得到多条路径,构成可行路径的解集;By adjusting the proportional coefficient, multiple paths are obtained to form a solution set of feasible paths;
采用蚁群优化算法对可行路径进行寻优,得到最短路径作为所述全局参考航迹。An ant colony optimization algorithm is used to optimize the feasible path, and the shortest path is obtained as the global reference track.
进一步地,采用蚁群优化算法对可行路径进行寻优,得到最短路径作为所述全局参考航迹,具体为:Further, the ant colony optimization algorithm is used to optimize the feasible path, and the shortest path is obtained as the global reference track, specifically:
根据所述无向网络图构建路径的节点集,对蚁群优化算法的参数进行初始化;Constructing the node set of the path according to the undirected network graph, and initializing the parameters of the ant colony optimization algorithm;
根据信息素从所述节点集中为每一只蚂蚁选择下一个路径节点;Selecting the next path node for each ant from the node set according to the pheromone;
对蚂蚁所选择的对应路径上的进行单步更新:Perform a single-step update on the corresponding path selected by the ant:
τij(t+1)=(1-ρ)τij(t)+ρτ0;τij (t+1)=(1-ρ)τij (t)+ρτ0 ;
其中,τij(t)表示前一条连接线上的第i个节点到后一条连接线上第j个节点之间的信息素,τij(t+1)为对τij(t)进行更新后的信息素,τ0为初始信息素,ρ为信息素的挥发系数,ρ∈[0,1];Among them, τij (t) represents the pheromone between the i-th node on the previous connection line and the j-th node on the next connection line, and τij (t+1) is the update of τij (t) The final pheromone, τ0 is the initial pheromone, ρ is the volatilization coefficient of the pheromone, ρ∈[0,1];
各蚂蚁完成一个回合的路径选择后,选择最短的一条路径进行信息素回合更新,信息素回合更新公式为:After each ant completes a round of path selection, it selects the shortest path for pheromone round update. The pheromone round update formula is:
τij(t+1)=(1-ρ)τij(t)+ρΔτij(t);τij (t+1)=(1-ρ)τij (t)+ρΔτij (t);
Δτij(t)=1/L*;Δτij (t) = 1/L* ;
其中,L*为所选路径的长度,Δτij(t)表示所有蚂蚁在这两点间释放的信息素之和,t表示回合;Among them, L* is the length of the selected path, Δτij (t) represents the sum of pheromones released by all ants between these two points, and t represents the round;
检查是否达到终止条件,如果是,则输出各蚂蚁所走的路径中的最短路径作为所述全局参考航迹,否则进行下一次路径寻优。Check whether the termination condition is met, if yes, output the shortest path among the paths taken by each ant as the global reference track, otherwise proceed to the next path optimization.
进一步地,基于所述航行水域模型,构建初始航迹,具体为:Further, based on the navigation waters model, an initial track is constructed, specifically:
在构建的无向网络图中,以MAKLINK线的中点作为中间节点,采用Dijkstra算法搜索出自起点到终点的最短路径作为所述初始航迹。In the undirected network graph constructed, the midpoint of the MAKLINK line is used as the intermediate node, and the shortest path from the starting point to the ending point is searched by Dijkstra algorithm as the initial track.
进一步地,基于所述船舶运动模型,采用Q-learning算法进行局部风险避碰规划,生成实时风险避碰策略,具体为:Further, based on the ship motion model, the Q-learning algorithm is used for local risk collision avoidance planning, and a real-time risk collision avoidance strategy is generated, specifically:
初始化船舶的状态集、动作集和奖励策略;所述状态集包括船舶的多种状态,所述状态包括船舶安全区域之内的障碍物与船舶之间的相对位置信息以及船舶当前航向角;所述动作集包括船舶每一状态下对应的多种动作,所述动作包括平动信息和转动信息;所述奖励策略包括船舶航行过程中与环境交互所反馈的碰撞情况和目标抵达情况;Initialize the state set, action set and reward strategy of the ship; the state set includes a variety of states of the ship, and the state includes the relative position information between the obstacles in the safe area of the ship and the ship and the current heading angle of the ship; The action set includes a variety of actions corresponding to each state of the ship, and the actions include translation information and rotation information; the reward strategy includes the collision situation and target arrival situation fed back by the interaction between the ship and the environment during navigation;
计算所述动作集中每一动作的Q值,用于表征动作价值;Calculating the Q value of each action in the action set to represent the action value;
采用ε-greedy策略从所述动作集中选择动作价值最高的动作;Use the ε-greedy strategy to select the action with the highest action value from the action set;
采用Q-learning算法对当前状态下各动作的Q值进行更新:Use the Q-learning algorithm to update the Q value of each action in the current state:
Q(st,at)←Q(st,at)+α[rt+γmaxQ(st+1,at)-Q(st,at)];Q(st ,at )←Q(st ,at )+α[rt +γmaxQ(st+1 ,at )-Q(st ,at )];
st←st+1;st ← st+1 ;
其中,st为当前状态,at为所选动作,st+1为执行动作at后的下一状态,rt为当前状态下反馈的奖励,α为学习率,γ为折扣因子,Q(st,at)为状态st下动作at的Q值,Q(st+1,at)表示状态st+1下动作at的Q值,max表示取最大值,←表示更新;Among them,st is the current state, at is the selected action,st+1 is the next state after executing the action at , rt is the feedback reward in the current state, α is the learning rate, γ is the discount factor, Q(stt , at ) is the Q value of action at in state st , Q(stt+1 , at ) is the Q value of action at in state st+1 , max means taking the maximum value, ← means update;
判断更新前后的Q值之差是否小于设定差值,如果是,则输出Q值最高的动作作为所述实时风险避碰策略,否则进行下一次Q值的更新。It is judged whether the difference between the Q values before and after the update is smaller than the set difference, and if so, the action with the highest Q value is output as the real-time risk collision avoidance strategy, otherwise, the next update of the Q value is performed.
进一步地,结合所述全局参考航迹和所述局部风险避碰策略实现船舶自主导航,具体为:Further, the autonomous navigation of the ship is realized in combination with the global reference track and the local risk collision avoidance strategy, specifically:
获取起始点、目标点以及相应的所述全局参考航迹;Acquiring the starting point, the target point and the corresponding global reference track;
根据所述全局参考航迹所包含的节点以及节点次序,依次将各节点置为子目标点,并依次向各子目标点航行;According to the nodes contained in the global reference track and the order of nodes, each node is set as a sub-target point in turn, and sails to each sub-target point in turn;
在航行过程中实时获取当前航行区域内的障碍物信息;Obtain real-time obstacle information in the current navigation area during navigation;
判断船舶是否已经到达当前目标点,如果已经到达当前目标点,则进一步判断当前目标点是否为终点,如果是终点,则导航完毕,如果不是终点,则对当前目标点进行更新,如果还未到达当前目标点,则转下一步;Determine whether the ship has reached the current target point. If it has reached the current target point, further determine whether the current target point is the end point. If it is the end point, the navigation is completed. If it is not the end point, update the current target point. If it has not yet arrived For the current target point, go to the next step;
判断所述障碍物信息是否在船舶的安全区域内,如果是,则基于所述障碍物信息生成相应的所述实时风险避碰策略,并根据所述实时风险避碰策略进行风险规避,否则调整船舶航向向当前目标点航行,并继续监测所述障碍物信息是否在船舶的安全区域内。Judging whether the obstacle information is within the safe area of the ship, if so, generating the corresponding real-time risk collision avoidance strategy based on the obstacle information, and performing risk avoidance according to the real-time risk collision avoidance strategy, otherwise adjusting The ship is heading towards the current target point, and continues to monitor whether the obstacle information is within the safe area of the ship.
本发明还提供一种船舶自主导航装置,包括处理器以及存储器,所述存储器上存储有计算机程序,所述计算机程序被所述处理器执行时,实现所述船舶自主导航方法。The present invention also provides an autonomous ship navigation device, which includes a processor and a memory, where a computer program is stored on the memory, and when the computer program is executed by the processor, the ship autonomous navigation method is realized.
本发明还提供一种计算机存储介质,其上存储有计算机程序,所述计算机该程序被处理器执行时,实现所述船舶自主导航方法。The present invention also provides a computer storage medium, on which a computer program is stored. When the computer program is executed by a processor, the ship autonomous navigation method is realized.
有益效果:本发明提供基于蚁群优化算法和Q-learning的船舶自主导航方法,首先构建船舶运动模型,并基于原始地图构建航行水域模型;然后基于蚁群优化算法设计全局航迹规划策略,生成全局参考航迹,提取航迹分段节点,减小后续局部风险避碰中因Q-learning带来的路径随机性;然后基于Q-learning设计局部风险避碰策略,指导实时风险避碰;最后结合全局航迹规划与局部风险避碰策略,生成基于航行水域的自主导航航迹;根据实际模型存在的差异,根据条件进行适当调整模型参数以移植于现有的船舶自主导航控制中。由于在全局航迹规划的基础上结合了局部风险避碰策略,因此可以用于实时导航,同时,局部风险避碰策略基于全局航迹规划进行实施,因此能够适用于大型水域。Beneficial effects: the present invention provides a ship autonomous navigation method based on ant colony optimization algorithm and Q-learning, first constructs a ship motion model, and constructs a navigation waters model based on the original map; then designs a global track planning strategy based on ant colony optimization algorithm, generates Globally refer to the track, extract track segment nodes, and reduce the path randomness caused by Q-learning in the subsequent local risk collision avoidance; then design a local risk collision avoidance strategy based on Q-learning to guide real-time risk collision avoidance; finally Combined with the global track planning and local risk collision avoidance strategy, the autonomous navigation track based on the navigation waters is generated; according to the differences in the actual model, the model parameters are appropriately adjusted according to the conditions to transplant into the existing ship autonomous navigation control. Since the local risk collision avoidance strategy is combined with the global track planning, it can be used for real-time navigation. At the same time, the local risk collision avoidance strategy is implemented based on the global track planning, so it can be applied to large waters.
附图说明Description of drawings
图1为本发明提供的船舶自主导航方法第一实施例的方法流程图;Fig. 1 is the method flowchart of the first embodiment of the ship's autonomous navigation method provided by the present invention;
图2为本发明提供的船舶自主导航方法第一实施例的船舶运动模型图;Fig. 2 is a ship motion model diagram of the first embodiment of the ship autonomous navigation method provided by the present invention;
图3为本发明提供的船舶自主导航方法第一实施例的航行水域示意图;Fig. 3 is a schematic diagram of the navigation waters of the first embodiment of the ship's autonomous navigation method provided by the present invention;
图4为本发明提供的船舶自主导航方法第一实施例的航行水域模型图;Fig. 4 is a model diagram of the navigation waters of the first embodiment of the ship's autonomous navigation method provided by the present invention;
图5a为本发明提供的船舶自主导航方法第一实施例的全局参考航迹寻优过程中的长度收敛曲线;Fig. 5a is the length convergence curve in the global reference track optimization process of the first embodiment of the ship autonomous navigation method provided by the present invention;
图5b为本发明提供的船舶自主导航方法第一实施例的全局参考航迹示意图;Fig. 5b is a schematic diagram of the global reference track of the first embodiment of the ship autonomous navigation method provided by the present invention;
图6a为本发明提供的船舶自主导航方法第一实施例的实时风险避碰策略寻优过程中的累计奖励收敛曲线;Fig. 6a is the cumulative reward convergence curve in the real-time risk collision avoidance strategy optimization process of the first embodiment of the ship autonomous navigation method provided by the present invention;
图6b为本发明提供的船舶自主导航方法第一实施例的实时风险避碰策略示意图;Fig. 6b is a schematic diagram of the real-time risk collision avoidance strategy of the first embodiment of the ship autonomous navigation method provided by the present invention;
图7a为本发明提供的船舶自主导航方法第一实施例在第一种航行状况下得到的自主导航航迹;Fig. 7a is the autonomous navigation track obtained under the first navigation condition of the first embodiment of the ship autonomous navigation method provided by the present invention;
图7b为本发明提供的船舶自主导航方法第一实施例在第二种航行状况下得到的自主导航航迹。Fig. 7b is the autonomous navigation track obtained under the second navigation condition in the first embodiment of the ship autonomous navigation method provided by the present invention.
具体实施方式detailed description
下面结合附图来具体描述本发明的优选实施例,其中,附图构成本申请一部分,并与本发明的实施例一起用于阐释本发明的原理,并非用于限定本发明的范围。Preferred embodiments of the present invention will be described in detail below in conjunction with the accompanying drawings, wherein the accompanying drawings constitute a part of the application and together with the embodiments of the present invention are used to explain the principle of the present invention and are not intended to limit the scope of the present invention.
实施例1Example 1
如图1所示,本发明的实施例1提供了船舶自主导航方法,包括以下步骤:As shown in Figure 1, Embodiment 1 of the present invention provides a ship autonomous navigation method, comprising the following steps:
S1、构建船舶运动模型,并基于航行水域地图构建航行水域模型;S1. Construct a ship motion model, and construct a navigation waters model based on a navigation waters map;
S2、基于所述航行水域模型,采用蚁群优化算法进行全局航迹规划,生成全局参考航迹;S2. Based on the navigation waters model, an ant colony optimization algorithm is used for global track planning to generate a global reference track;
S3、基于所述船舶运动模型,采用Q-learning算法进行局部风险避碰规划,生成实时风险避碰策略;S3. Based on the ship motion model, a Q-learning algorithm is used for local risk collision avoidance planning, and a real-time risk collision avoidance strategy is generated;
S4、结合所述全局参考航迹和所述局部风险避碰策略实现船舶自主导航。S4. Realize autonomous navigation of the ship by combining the global reference track and the local risk collision avoidance strategy.
本实施例提供基于蚁群优化算法和Q-learning的船舶自主导航方法,首先、构建船舶运动模型,并基于原始地图构建航行水域模型;然后基于蚁群优化算法设计全局航迹规划策略,生成全局参考航迹,提取航迹分段节点,减小后续局部风险避碰中因Q-learning带来的路径随机性;然后基于Q-learning设计局部风险避碰策略,指导实时风险避碰;最后结合全局航迹规划与局部风险避碰策略,生成基于航行水域的自主导航航迹;根据实际模型存在的差异,根据条件进行适当调整模型参数以移植于现有的船舶自主导航控制中。This embodiment provides a ship autonomous navigation method based on ant colony optimization algorithm and Q-learning. First, build a ship motion model, and build a navigation waters model based on the original map; then design a global track planning strategy based on ant colony optimization algorithm to generate a global Refer to the track and extract track segment nodes to reduce the path randomness caused by Q-learning in the subsequent local risk collision avoidance; then design a local risk collision avoidance strategy based on Q-learning to guide real-time risk collision avoidance; finally combine Global track planning and local risk collision avoidance strategies generate autonomous navigation tracks based on navigation waters; according to the differences in actual models, model parameters are appropriately adjusted according to conditions to be transplanted into existing ship autonomous navigation control.
本发明提供的基于蚁群优化算法和Q-learning的船舶自主导航方法可以为船舶自主导航控制提供有效参考。The ship autonomous navigation method based on ant colony optimization algorithm and Q-learning provided by the invention can provide effective reference for ship autonomous navigation control.
优选地,构建船舶运动模型,具体为:Preferably, a ship motion model is constructed, specifically:
建立船舶模型;Build a ship model;
将船舶的运动分解为随中心点的平动以及绕中心点的转动,将船舶的运动简化为在水平面的运动,得到船舶的运动学描述;The motion of the ship is decomposed into translation with the center point and rotation around the center point, and the motion of the ship is simplified to the motion on the horizontal plane to obtain the kinematic description of the ship;
设置转向阈值,对船舶的转向进行约束;Set the steering threshold to restrict the steering of the ship;
以中心点为圆心、以安全距离为半径,设置船舶的安全区域;Set the safety area of the ship with the center point as the center and the safety distance as the radius;
结合所述船舶模型、运动学描述、转向阈值以及安全区域,得到所述船舶运动模型。The ship motion model is obtained by combining the ship model, kinematics description, turning threshold and safe area.
对船舶进行建模时,首先对船舶运动进行降维,将船舶的运动分解成两个部分:随中心点平动(包括纵移、横移、垂荡)和绕中心点转动(包括横摇、纵摇、首摇),这两部分运动叠加构成了船舶的六自由度运动学描述。在航道规划问题中,所描述的是船舶在水平面上的运动,因此将自主导航问题简化为水平面上的二维路径规划问题;When modeling a ship, the dimensionality reduction of the ship’s motion is first performed, and the ship’s motion is decomposed into two parts: translation with the center point (including longitudinal, lateral, and heave) and rotation around the center point (including roll , pitch, and yaw), the superposition of these two parts constitutes the six-degree-of-freedom kinematics description of the ship. In the channel planning problem, the movement of the ship on the horizontal plane is described, so the autonomous navigation problem is simplified to a two-dimensional path planning problem on the horizontal plane;
设置转向阈值δmax,由于船舶的运动并不是简单的质点运动,应对其施加一定的约束条件,因此令船舶转向角δ小于阈值δmax;Set the steering threshold δmax , since the motion of the ship is not a simple particle motion, certain constraints should be imposed on it, so the ship steering angle δ is smaller than the threshold δmax ;
设置船舶的安全区域,出于船舶行驶的安全性考虑,应为船舶保留一定的安全余量。为此,以中心点为圆心,安全距离为半径的圆包裹整个船体,当障碍物与中心点的最小距离小于安全距离即视为有碰撞危险。To set the safety area of the ship, for the sake of the safety of the ship, a certain safety margin should be reserved for the ship. For this reason, a circle with the center point as the center and a safety distance as the radius wraps the entire hull. When the minimum distance between an obstacle and the center point is less than the safety distance, it is considered to be in danger of collision.
具体地,图2示出了本实施例所建立的船舶运动模型,其中:XYZO表示航行水域坐标系,xyzo表示船舶坐标系,实线所示为船舶模型,虚线所示为安全区域,l表示安全距离。Specifically, Fig. 2 shows the ship motion model established in this embodiment, wherein: XYZO represents the navigation waters coordinate system, xyzo represents the ship coordinate system, the solid line shows the ship model, the dotted line shows the safe area, l represents safe distance.
优选地,基于航行水域地图构建航行水域模型,具体为:Preferably, the navigation waters model is constructed based on the navigation waters map, specifically:
获取航行水域地图,对所述航行水域地图中障碍物进行边缘提取;Obtaining a navigation waters map, and performing edge extraction on obstacles in the navigation waters map;
利用Graham扫描法提取边缘的凸包,设置最小边长阈值与最小周长阈值,滤除边长小于最小边长阈值或周长小于最小周长阈值的凸包;Use the Graham scanning method to extract the convex hull of the edge, set the minimum edge length threshold and the minimum perimeter threshold, and filter out the convex hull whose edge length is less than the minimum edge length threshold or whose perimeter is less than the minimum perimeter threshold;
对所述凸包进行等距离缩放,使之完全包围相应的障碍物;Scaling the convex hull equidistantly so that it completely surrounds the corresponding obstacle;
以凸包顶点构造MAKLINK全局连通图,选取MAKLINK全局连通图中所有MAKLINK线的中点、起点和终点作为网络节点;Construct the MAKLINK global connectivity graph with convex hull vertices, and select the midpoint, starting point and end point of all MAKLINK lines in the MAKLINK global connectivity graph as network nodes;
连接相邻的网络节点得到轨迹规划的无向网络图,以所述无向网络图作为所述航行水域模型。An undirected network graph of trajectory planning is obtained by connecting adjacent network nodes, and the undirected network graph is used as the navigation waters model.
具体地,如图3所示,本发明实施例从高德地图中截取航行水域地图作为原始地图,可航行区域表示为灰色,障碍物区表示为白色,再人为添加船舶无法直接从地图中获取的小型障碍,标记为黑色。Specifically, as shown in Figure 3, the embodiment of the present invention intercepts the navigable waters map from the Gaode map as the original map, the navigable area is represented as gray, and the obstacle area is represented as white, and artificially added ships cannot be obtained directly from the map , marked in black.
采用边缘提取,凸包提取,凸多边形拟合的方法对原始地图进行预处理,简化大型障碍,滤除小型障碍,构建了MAKLINK全局连通图,简化了水域环境模型;Using edge extraction, convex hull extraction, and convex polygon fitting methods to preprocess the original map, simplify large obstacles, filter out small obstacles, build a MAKLINK global connectivity map, and simplify the water environment model;
本实施例使用Canny算子对航行水域地图进行边缘提取。边缘提取具体为:用高斯滤波器平滑航行水域地图,用一阶偏导有限差分计算航行水域地图的梯度幅值和方向,对梯度幅值进行非极大值抑制,用双阈值算法检测和连接边缘。In this embodiment, the Canny operator is used to extract the edge of the navigation waters map. Edge extraction is specifically as follows: use Gaussian filter to smooth navigation waters map, use first-order partial derivative finite difference to calculate gradient magnitude and direction of navigation waters map, suppress non-maximum value of gradient magnitude, use double threshold algorithm to detect and connect edge.
利用Graham扫描法提取凸包,设置凸多边形(即凸包)最小边长阈值为地图边长的1/32,最小周长阈值为地图边长的1/16,通过最小边长阈值和最小周长阈值滤除小型岛屿及暗礁,将大型岛屿抽象为凸多边形;Use the Graham scanning method to extract the convex hull, set the minimum side length threshold of the convex polygon (that is, the convex hull) to 1/32 of the map side length, and the minimum perimeter threshold to 1/16 of the map side length, pass the minimum side length threshold and the minimum perimeter Long threshold filters out small islands and reefs, and abstracts large islands into convex polygons;
对凸多边形进行等距离缩放,使之完全包围障碍物;Scale the convex polygon equidistantly so that it completely surrounds the obstacle;
以凸多边形顶点构造MAKLINK全局连通图:选取所有MAKLINK线的中点、起点和终点,将相邻点相互连接,构成轨迹规划无向网络图,如图4所示,图4中黑色填充块即凸多边形,虚线为MAKLINK线,各虚线构成MAKLINK全局连通图,实线为连接线,各实线构成无向网络图。Construct the MAKLINK global connectivity graph with convex polygon vertices: select the midpoint, starting point and end point of all MAKLINK lines, and connect the adjacent points to form an undirected network graph for trajectory planning, as shown in Figure 4. The black filled block in Figure 4 is Convex polygon, dotted lines are MAKLINK lines, each dotted line constitutes the MAKLINK global connectivity graph, solid lines are connecting lines, and each solid line constitutes an undirected network graph.
优选地,基于所述航行水域模型,采用蚁群优化算法进行全局航迹规划,生成全局参考航迹,具体为:Preferably, based on the navigation waters model, an ant colony optimization algorithm is used for global track planning to generate a global reference track, specifically:
所述航行水域模型为无向网络图,所述无向网络图包括多条连接线;The navigation waters model is an undirected network graph, and the undirected network graph includes a plurality of connecting lines;
获取起点和终点,基于所述无向网络图构建从起点到终点的初始航迹;Obtain the starting point and the ending point, and construct an initial track from the starting point to the ending point based on the undirected network graph;
建立节点优化的目标函数:Build the objective function for nodal optimization:

其中,
所述比例系数用于调节Vi(hi)在第i条连接线上的具体位置:The proportional coefficient is used to adjust the specific position of Vi (hi ) on the i-th connecting line:
Vi(hi)=Vi(0)+hi(Vi(1)-Vi(0));Vi (hi ) = Vi(0) + hi (Vi(1) -Vi(0) );
其中,Vi(0)、Vi(1)分别为航迹所经过的第i条连接线的两个端点;Among them, Vi(0) and Vi(1) are the two endpoints of the i-th connection line passed by the track respectively;
通过调整所述比例系数,得到多条路径,构成可行路径的解集;By adjusting the proportional coefficient, multiple paths are obtained to form a solution set of feasible paths;
采用蚁群优化算法对可行路径进行寻优,得到最短路径作为所述全局参考航迹。An ant colony optimization algorithm is used to optimize the feasible path, and the shortest path is obtained as the global reference track.
在构建好的无向网络图中,构建初始航迹。In the constructed undirected network graph, construct the initial trajectory.
然后建立节点优化函数:Then build the node optimization function:
将初始航迹所经过的中心节点所处的连接线记为Li,设连接线的端点为Vi(0)、Vi(1),则连接线上任意一点可以表示为:Denote the connecting line where the central node that the initial track passes through is Li , and set the endpoints of the connecting line as Vi(0) and Vi(1) , then any point on the connecting line can be expressed as:
Vi(hi)=Vi(0)+hi(Vi(1)-Vi(0))Vi (hi )=Vi(0) +hi (Vi(1) -Vi(0) )
其中,hi为比例系数,hi∈[0,1],i=1,2,…,d,d为经过的节点数目;Among them, hi is the proportional coefficient, hi ∈ [0,1], i=1,2,...,d, d is the number of nodes passed;
建立的节点优化函数如下:The established node optimization function is as follows:

其中,Length(Vi(hi),Vi+1(hi+1))表示两节点间的距离,当i=0时,Vi(hi)表示起点,当i=d时,Vi(hi)表示终点;Among them, Length(Vi (hi ),Vi+1 (hi+1 )) represents the distance between two nodes, when i=0, Vi (hi ) represents the starting point, when i=d, Vi (hi ) represents the end point;
航迹节点优化:通过调整比例系数hi,构成可行路径的解集(h1,h2,…,hd),采用蚁群优化算法寻找最优的参数集合,通过比例系数集合(h1,h2,…,hd)得到优化后节点位置,连接起点、终点以及各节点构成船舶全局航迹。Track node optimization: By adjusting the proportional coefficient hi , the solution set (h1 ,h2 ,…,hd ) of the feasible path is formed, and the ant colony optimization algorithm is used to find the optimal parameter set, and the proportional coefficient set (h1 ,h2 ,…,hd ) to obtain the optimized node position, and connect the starting point, the ending point and each node to form the global track of the ship.
优选地,采用蚁群优化算法对可行路径进行寻优,得到最短路径作为所述全局参考航迹,具体为:Preferably, an ant colony optimization algorithm is used to optimize the feasible path, and the shortest path is obtained as the global reference track, specifically:
根据所述无向网络图构建路径的节点集,对蚁群优化算法的参数进行初始化;Constructing the node set of the path according to the undirected network graph, and initializing the parameters of the ant colony optimization algorithm;
根据信息素从所述节点集中为每一只蚂蚁选择下一个路径节点;Selecting the next path node for each ant from the node set according to the pheromone;
对蚂蚁所选择的对应路径上的信息素进行单步更新:Perform a single-step update of the pheromone on the corresponding path selected by the ant:
τij(t+1)=(1-ρ)τij(t)+ρτ0;τij (t+1)=(1-ρ)τij (t)+ρτ0 ;
其中,τij(t)表示前一条连接线Lk上的第i个节点到后一条连接线Lk+1上第j个节点之间的信息素,τij(t+1)为对τij(t)进行更新后的信息素,τ0为初始信息素,ρ为信息素的挥发系数,ρ∈[0,1];Among them, τij (t) represents the pheromone between the i-th node on the previous connection line Lk and the j-th node on the next connection line Lk+1 , and τij (t+1) is the pair of τij (t) is the updated pheromone, τ0 is the initial pheromone, ρ is the volatilization coefficient of the pheromone, ρ∈[0,1];
各蚂蚁完成一个回合的路径选择后,选择最短的一条路径进行信息素回合更新,信息素回合更新公式为:After each ant completes a round of path selection, it selects the shortest path for pheromone round update. The pheromone round update formula is:
τij(t+1)=(1-ρ)τij(t)+ρΔτij(t);τij (t+1)=(1-ρ)τij (t)+ρΔτij (t);
Δτij(t)=1/L*;Δτij (t) = 1/L* ;
其中,L*为所选路径的长度,Δτij(t)表示所有蚂蚁在这两点间释放的信息素之和,t表示回合;Among them, L* is the length of the selected path, Δτij (t) represents the sum of pheromones released by all ants between these two points, and t represents the round;
检查是否达到终止条件,如果是,则输出各蚂蚁所走的路径中的最短路径作为所述全局参考航迹,否则进行下一次路径寻优。Check whether the termination condition is met, if yes, output the shortest path among the paths taken by each ant as the global reference track, otherwise proceed to the next path optimization.
优选地,基于所述航行水域模型,构建初始航迹,具体为:Preferably, based on the navigation waters model, an initial track is constructed, specifically:
在构建的无向网络图中,以MAKLINK线的中点作为中间节点,采用Dijkstra算法搜索出自起点到终点的最短路径作为所述初始航迹。In the undirected network graph constructed, the midpoint of the MAKLINK line is used as the intermediate node, and the shortest path from the starting point to the ending point is searched by Dijkstra algorithm as the initial track.
以MAKLINK线的中点作为中间节点,采用Dijkstra算法搜索出自起点到终点的最短路径。本实施例在全局航迹规划上结合了传统的Dijkstra算法和蚁群优化算法使全局航迹趋于最短,减小了路径的冗余,有利于船舶的运输效率与经济效益。Taking the midpoint of the MAKLINK line as the intermediate node, the Dijkstra algorithm is used to search for the shortest path from the start point to the end point. This embodiment combines the traditional Dijkstra algorithm and ant colony optimization algorithm in the global track planning to make the global track tend to be the shortest, reduce the redundancy of the path, and benefit the transportation efficiency and economic benefits of the ship.
优选地,基于所述船舶运动模型,采用Q-learning算法进行局部风险避碰规划,生成实时风险避碰策略,具体为:Preferably, based on the ship motion model, the Q-learning algorithm is used for local risk collision avoidance planning to generate a real-time risk collision avoidance strategy, specifically:
初始化船舶的状态集、动作集和奖励策略;所述状态集包括船舶的多种状态,所述状态包括船舶安全区域之内的障碍物与船舶之间的相对位置信息以及船舶当前航向角;所述动作集包括船舶每一状态下对应的多种动作,所述动作包括平动信息和转动信息;所述奖励策略包括船舶航行过程中与环境交互所反馈的碰撞情况和目标抵达情况;Initialize the state set, action set and reward strategy of the ship; the state set includes a variety of states of the ship, and the state includes the relative position information between the obstacles in the safe area of the ship and the ship and the current heading angle of the ship; The action set includes a variety of actions corresponding to each state of the ship, and the actions include translation information and rotation information; the reward strategy includes the collision situation and target arrival situation fed back by the interaction between the ship and the environment during navigation;
计算所述动作集中每一动作的Q值,用于表征动作价值;Calculating the Q value of each action in the action set to represent the action value;
采用ε-greedy策略从所述动作集中选择动作价值最高的动作;Use the ε-greedy strategy to select the action with the highest action value from the action set;
采用Q-learning算法对当前状态下各动作的Q值进行更新:Use the Q-learning algorithm to update the Q value of each action in the current state:
Q(st,at)←Q(st,at)+α[rt+γmaxQ(st+1,at)-Q(st,at)];Q(st ,at )←Q(st ,at )+α[rt +γmaxQ(st+1 ,at )-Q(st ,at )];
st←st+1;st ← st+1 ;
其中,st为当前状态,at为所选动作,st+1为执行动作at后的下一状态,rt为当前状态下反馈的奖励,α为学习率,γ为折扣因子,Q(st,at)为状态st下动作at的Q值,Q(st+1,at)表示状态st+1下动作at的Q值,max表示取最大值,←表示更新;Among them,st is the current state, at is the selected action,st+1 is the next state after executing the action at , rt is the feedback reward in the current state, α is the learning rate, γ is the discount factor, Q(stt , at ) is the Q value of action at in state st , Q(stt+1 , at ) is the Q value of action at in state st+1 , max means taking the maximum value, ← means update;
判断更新前后的Q值之差是否小于设定差值,如果是,则输出Q值最高的动作作为所述实时风险避碰策略,否则进行下一次Q值的更新。It is judged whether the difference between the Q values before and after the update is smaller than the set difference, and if so, the action with the highest Q value is output as the real-time risk collision avoidance strategy, otherwise, the next update of the Q value is performed.
相应地,局部的实时风险避碰需要考虑到航行水域地图中被滤除的小型障碍及未标识障碍的避碰,因此在局部风险避碰上引入了Q-learning算法,通过与环境的交互来学习避障策略,达到了进一步降低环境建模的难度的效果。Correspondingly, the local real-time risk collision avoidance needs to consider the small obstacles filtered out in the navigation waters map and the collision avoidance of unmarked obstacles. Therefore, the Q-learning algorithm is introduced in the local risk collision avoidance, and the interaction with the environment Learning the obstacle avoidance strategy achieves the effect of further reducing the difficulty of environment modeling.
具体地,首先初始化状态集、动作集与奖励策略。现有技术中,进行船舶状态集建立时,一般是基于大地坐标系建立的,因此在某一环境内训练得到的结果,无法移植于另一新的环境;此外,这种基于全局环境的状态集会随着海域的增大而骤增,不利于存储与收敛。不同于这种状态集定义方法,本实施例提出的状态集定义方法如下:对于船舶状态集的构建,以船舶位置为圆心,设定阈值为半径所构成的圆内的障碍,与船舶的相对位置信息,结合船舶的当前航向角作为一个状态,记为s;动作包括前进与转向,记为a,对每个状态下的动作初始化,用Q值来表征动作的价值,某一动作的Q值越大表示在该状态下这一动作的价值越高;此外,根据船舶航行过程中与环境交互所反馈的碰撞情况和目标抵达情况,设置奖励策略以作为价值导向。Specifically, first initialize the state set, action set and reward strategy. In the prior art, when the ship state set is established, it is generally established based on the earth coordinate system, so the training results obtained in a certain environment cannot be transplanted to another new environment; in addition, this state based on the global environment As the sea area increases, the gathering increases sharply, which is not conducive to storage and convergence. Different from this state set definition method, the state set definition method proposed in this embodiment is as follows: For the construction of the ship state set, take the ship position as the center of the circle, set the threshold as the obstacle in the circle formed by the radius, and the relative distance between the ship and the ship. The position information, combined with the current course angle of the ship as a state, is denoted as s; the action includes forward and turning, denoted as a, the action in each state is initialized, and the value of the action is represented by the Q value. The Q value of a certain action The larger the value, the higher the value of this action in this state; in addition, according to the collision situation and target arrival situation fed back by the interaction between the ship and the environment during the navigation process, the reward strategy is set as a value guide.
动作选择。动作选择采用ε-greedy策略,以一定概率ε选择价值最高的动作,否则进行随机选择,其数学表达为:Action selection. The action selection adopts the ε-greedy strategy, and the action with the highest value is selected with a certain probability ε, otherwise it is randomly selected, and its mathematical expression is:

其中,at为所选动作,Q(st,a)为状态st下动作a的Q值,argmax表示取Q(st,a)最大值时对应的动作,A表示可选动作集合,p为选择概率,ε为贪婪度,ε∈[0,1]。Among them, at is the selected action, Q(st , a)is the Q value of action a in state s t, argmax indicates the corresponding action when the maximum value of Q(st ,a) is taken, and A indicates the set of optional actions , p is the selection probability, ε is the degree of greed, ε∈[0,1].
动作价值更新。采用Q-learning算法对动作的Q值进行更新。The action value is updated. Use the Q-learning algorithm to update the Q value of the action.
通过迭代,使Q值收敛,输出最终策略π(a|s)=argmaxQ(s,a)。Through iteration, the Q value is converged, and the final strategy π(a|s)=argmaxQ(s,a) is output.
优选地,结合所述全局参考航迹和所述局部风险避碰策略实现船舶自主导航,具体为:Preferably, the autonomous navigation of the ship is realized in combination with the global reference track and the local risk collision avoidance strategy, specifically:
获取起始点、目标点以及相应的所述全局参考航迹;Acquiring the starting point, the target point and the corresponding global reference track;
根据所述全局参考航迹所包含的节点以及节点次序,依次将各节点置为子目标点,并依次向各子目标点航行;According to the nodes contained in the global reference track and the order of nodes, each node is set as a sub-target point in turn, and sails to each sub-target point in turn;
在航行过程中实时获取当前航行区域内的障碍物信息;Obtain real-time obstacle information in the current navigation area during navigation;
判断船舶是否已经到达当前目标点,如果已经到达当前目标点,则进一步判断当前目标点是否为终点,如果是终点,则导航完毕,如果不是终点,则对当前目标点进行更新,如果还未到达当前目标点,则转下一步;Determine whether the ship has reached the current target point. If it has reached the current target point, further determine whether the current target point is the end point. If it is the end point, the navigation is completed. If it is not the end point, update the current target point. If it has not yet arrived For the current target point, go to the next step;
判断所述障碍物信息是否在船舶的安全区域内,如果是,则基于所述障碍物信息生成相应的所述实时风险避碰策略,并根据所述实时风险避碰策略进行风险规避,否则调整船舶航向向当前目标点航行,并继续监测所述障碍物信息是否在船舶的安全区域内。Judging whether the obstacle information is within the safe area of the ship, if so, generating the corresponding real-time risk collision avoidance strategy based on the obstacle information, and performing risk avoidance according to the real-time risk collision avoidance strategy, otherwise adjusting The ship is heading towards the current target point, and continues to monitor whether the obstacle information is within the safe area of the ship.
完成全局轨迹规划和局部风险避碰策略规划后,结合全局轨迹规划及局部风险避碰策略,根据实际模型存在的差异,对模型参数间的衔接进行适当调整。基于船舶模型可以在获取航行水域地图的先验知识下,完成自起点至终点的无碰撞自主导航,具体流程为:After the global trajectory planning and local risk collision avoidance strategy planning are completed, the connection between model parameters is properly adjusted according to the differences in the actual model in combination with the global trajectory planning and local risk collision avoidance strategy. Based on the ship model, the collision-free autonomous navigation from the start point to the end point can be completed under the prior knowledge of the navigable waters map. The specific process is as follows:
S41、输入起始点和目标点,算法开始;S41. Input the starting point and the target point, and the algorithm starts;
S42、从起点位置出发,通过全局航迹规划算法获取自起点至终点所历经的中间节点,将中间节点设置为子目标点,且保持历经的次序不变;S42. Starting from the starting point, obtain the intermediate nodes traversed from the starting point to the end point through the global track planning algorithm, set the intermediate nodes as sub-target points, and keep the sequence of the traversed unchanged;
S43、通过船舶传感系统检测航行区域内障碍物信息,如果判断到达当前目标点,则进入步骤S46;如果判断为危险,则进入步骤S44;如果判断为安全,则进入步骤S45;S43. Detect obstacle information in the navigation area through the ship sensor system, if it is judged to reach the current target point, then enter step S46; if it is judged as dangerous, then enter step S44; if it is judged as safe, then enter step S45;
S44、采用局部风险避碰策略规避当前风险,再转入步骤S43判断是否脱离危险;S44. Use local risk collision avoidance strategies to avoid current risks, and then turn to step S43 to judge whether to escape from danger;
S45、调整航向朝当前目标点航行,再转入步骤S43判断危险情况;S45. Adjust the course and sail towards the current target point, and then turn to step S43 to judge the dangerous situation;
S46、如果当前目标点为终点,则进入步骤S47,否则更新当前目标点为下一目标点,转入步骤S43;S46, if the current target point is the end point, then enter step S47, otherwise update the current target point as the next target point, and proceed to step S43;
S47、算法结束,输出船舶行驶航迹。S47. The algorithm is finished, and the track of the ship is output.
本发明提出的船舶自主导航模型,采用边缘提取,凸包提取,凸多边形拟合的方法对原始地图进行预处理,简化大型障碍,滤除小型障碍,构建了MAKLINK全局连通图,简化了水域环境模型;在全局航迹规划上结合了传统的Dijkstra算法和蚁群优化算法使全局航迹趋于最短,减小了路径的冗余,有利于船舶的运输效率与经济效益;相应地,局部的实时风险避碰需要考虑到原始地图中被滤除的小型障碍及未标识障碍的避碰,因此在局部风险避碰上引入了Q-learning算法,通过与环境的交互来学习避障策略,达到了进一步降低环境建模的难度的效果。结合全局航迹规划和局部风险避碰策略,该模型实现了船舶自起点至终点的无碰撞自主导航,从而能投入到大型港口数字化建设中。The ship's autonomous navigation model proposed by the present invention uses edge extraction, convex hull extraction, and convex polygon fitting methods to preprocess the original map, simplify large obstacles, filter out small obstacles, and construct a MAKLINK global connectivity graph, simplifying the water environment model; the traditional Dijkstra algorithm and ant colony optimization algorithm are combined in the global track planning to make the global track tend to be the shortest, reduce the redundancy of the path, and benefit the transportation efficiency and economic benefits of the ship; correspondingly, the local Real-time risk collision avoidance needs to consider the small obstacles filtered out in the original map and the collision avoidance of unmarked obstacles. Therefore, the Q-learning algorithm is introduced for local risk collision avoidance, and the obstacle avoidance strategy is learned through interaction with the environment to achieve It has the effect of further reducing the difficulty of environment modeling. Combining the global track planning and local risk collision avoidance strategy, the model realizes the collision-free autonomous navigation of the ship from the starting point to the destination point, so it can be put into the digital construction of large ports.
1、本发明提供的基于蚁群优化算法和Q-learning的船舶自主导航模型,弥补了背景技术中提到的方法,针对水域中未被地图标识出的暗礁无法实现实时避碰的缺陷,仅需要较少的环境先验知识,减少了建模的难度。1. The ship autonomous navigation model based on ant colony optimization algorithm and Q-learning provided by the present invention makes up for the method mentioned in the background technology, and aims at the defect that real-time collision avoidance cannot be realized for hidden reefs not marked by maps in the water area. Requires less prior knowledge of the environment, reducing the difficulty of modeling.
2、与背景技术中提到的现有技术相比,本发明提供的基于蚁群优化算法和Q-learning的船舶自主导航模型的优势则体现在无需由船舶实时对障碍物进行复杂建模,对船舶传感系统需求低,不同功能条件的传感系统可根据采集信息类型的不同,建立适合于船舶自身功能条件的状态集再进行学习,具有一定的普适性。2. Compared with the prior art mentioned in the background technology, the advantage of the ship autonomous navigation model based on ant colony optimization algorithm and Q-learning provided by the present invention is that it does not need complex modeling of obstacles by the ship in real time, The demand for the ship sensing system is low, and the sensing system with different functional conditions can establish a state set suitable for the ship's own functional conditions according to the different types of collected information, and then learn, which has a certain degree of universality.
3、传统的Q-learning算法应用于栅格地图中普遍存在状态空间大,收敛速度慢,规划航迹随机性较大的问题,而背景技术中所提及的人工势场法作为奖励策略作为价值导向仍然不能较好地解决这些问题。本发明提供的基于蚁群优化算法和Q-learning的船舶自主导航模型,既在局部避障上保留了栅格法带来的航行的高自由度,又确保了全局航迹始终趋向于最短,有利于提高船舶的运输效率与经济效益。3. The traditional Q-learning algorithm applied to the grid map generally has the problems of large state space, slow convergence speed, and large randomness of the planned track. However, the artificial potential field method mentioned in the background technology is used as a reward strategy. Value orientation still cannot solve these problems well. The ship autonomous navigation model based on ant colony optimization algorithm and Q-learning provided by the present invention not only retains the high degree of freedom of navigation brought by the grid method in local obstacle avoidance, but also ensures that the global track always tends to be the shortest. It is conducive to improving the transportation efficiency and economic benefits of ships.
基于上述理由,本发明提供的基于蚁群优化算法和Q-learning的船舶自主导航模型可以为船舶自主导航控制提供有效参考。Based on the above reasons, the ship autonomous navigation model based on ant colony optimization algorithm and Q-learning provided by the present invention can provide an effective reference for ship autonomous navigation control.
为了检验本发明所提出的基于蚁群优化算法和Q-learning的船舶自主导航模型的有效性,在本实施例中分别设置验证性实验对模型性能进行测试。In order to test the effectiveness of the ship autonomous navigation model based on the ant colony optimization algorithm and Q-learning proposed by the present invention, a verification experiment is set up in this embodiment to test the performance of the model.
验证性实验:Confirmatory experiment:
将原始地图映射到航行水域,假设相邻像素点间距为最小单位,对应水域中1km,从而设置船舶模型参数值、全局航迹规划策略参数值、局部风险避碰策略参数值分别如表1、表2、表3所示。Map the original map to the navigation waters, assuming that the distance between adjacent pixels is the smallest unit, which corresponds to 1km in the waters, and then set the ship model parameter values, the global track planning strategy parameter values, and the local risk collision avoidance strategy parameter values as shown in Table 1, respectively. Shown in Table 2 and Table 3.
表1、Table 1,

表2、Table 2,


图5a中,可以清楚地看出当迭代次数到达120次后,路径总长度已收敛至650km,随后收敛速度逐渐降低,图5b中Dijkstra算法生成初始路径,用短虚线表示,路径长为671.36km,经500次迭代后,取最短路径为631.53km,用长虚线表示,即为参考航迹。In Figure 5a, it can be clearly seen that when the number of iterations reaches 120, the total path length has converged to 650km, and then the convergence speed gradually decreases. In Figure 5b, the Dijkstra algorithm generates the initial path, which is represented by a short dashed line, and the path length is 671.36km , after 500 iterations, the shortest path is 631.53km, which is represented by a long dotted line, which is the reference track.
表3、table 3,

如图6a所示,经过100次学习,该算法已基本收敛,在图6b所示局部区域具有独立避开障碍物的能力。As shown in Figure 6a, after 100 times of learning, the algorithm has basically converged, and has the ability to independently avoid obstacles in the local area shown in Figure 6b.
本发明提供的基于蚁群优化算法和Q-learning的船舶自主导航模型在两处不同的原始水域中进行了验证性仿真实验。在图7a中,轨迹大致可分为6段,在轨迹的第5段,船舶探测到周围障碍物后,调整导航轨迹,绕过障碍物,排除危险后,再次调整轨迹,朝当前目标点航行,最后实现了从起始点到目标点的无碰撞导航。图7b中,更改起点与目标点位置,同样达到了类似的效果。The ship autonomous navigation model based on the ant colony optimization algorithm and Q-learning provided by the present invention has been verified by simulation experiments in two different original waters. In Figure 7a, the trajectory can be roughly divided into 6 sections. In the fifth section of the trajectory, after the ship detects the surrounding obstacles, it adjusts the navigation trajectory, bypasses the obstacles, eliminates the danger, adjusts the trajectory again, and sails towards the current target point. , and finally realize the collision-free navigation from the starting point to the goal point. In Fig. 7b, changing the positions of the starting point and the target point also achieves a similar effect.
实施例2Example 2
本发明的实施例2提供了船舶自主导航装置,包括处理器以及存储器,所述存储器上存储有计算机程序,所述计算机程序被所述处理器执行时,实现实施例1提供的船舶自主导航方法。Embodiment 2 of the present invention provides a ship's autonomous navigation device, including a processor and a memory, and a computer program is stored on the memory, and when the computer program is executed by the processor, the ship's autonomous navigation method provided in Embodiment 1 is realized. .
本发明实施例提供的船舶自主导航装置,用于实现船舶自主导航方法,因此,船舶自主导航方法所具备的技术效果,船舶自主导航装置同样具备,在此不再赘述。The ship's autonomous navigation device provided by the embodiment of the present invention is used to realize the ship's autonomous navigation method. Therefore, the ship's autonomous navigation device also possesses the technical effects of the ship's autonomous navigation method, and will not be repeated here.
实施例3Example 3
本发明的实施例3提供了计算机存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现实施例1提供的船舶自主导航方法。Embodiment 3 of the present invention provides a computer storage medium on which a computer program is stored. When the computer program is executed by a processor, the ship autonomous navigation method provided in Embodiment 1 is implemented.
本发明实施例提供的计算机存储介质,用于实现船舶自主导航方法,因此,船舶自主导航方法所具备的技术效果,计算机存储介质同样具备,在此不再赘述。The computer storage medium provided by the embodiment of the present invention is used to implement the ship autonomous navigation method. Therefore, the computer storage medium also possesses the technical effects of the ship autonomous navigation method, and will not be repeated here.
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。The above is only a preferred embodiment of the present invention, but the scope of protection of the present invention is not limited thereto. Any person skilled in the art can easily conceive of changes or modifications within the technical scope disclosed in the present invention. Replacement should be covered within the protection scope of the present invention.
Claims (9)
Translated fromChinese


































































Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011535524.2ACN112650246B (en) | 2020-12-23 | 2020-12-23 | Ship autonomous navigation method and device |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011535524.2ACN112650246B (en) | 2020-12-23 | 2020-12-23 | Ship autonomous navigation method and device |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN112650246A CN112650246A (en) | 2021-04-13 |
| CN112650246Btrue CN112650246B (en) | 2022-12-09 |
Family
ID=75359307
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202011535524.2AActiveCN112650246B (en) | 2020-12-23 | 2020-12-23 | Ship autonomous navigation method and device |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN112650246B (en) |
Families Citing this family (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113110453B (en)* | 2021-04-15 | 2022-06-21 | 哈尔滨工业大学 | Artificial potential field obstacle avoidance method based on graph transformation |
| CN113190026B (en)* | 2021-05-10 | 2022-06-28 | 河海大学 | Energy-saving underwater path planning method based on re-excitation mechanism particle swarm algorithm |
| CN117452954B (en)* | 2023-12-20 | 2024-04-02 | 北京海兰信数据科技股份有限公司 | Navigation method of ship and terminal equipment |
| CN119336014A (en)* | 2024-09-02 | 2025-01-21 | 北京理工大学 | AGV path planning method and system based on ant colony-reinforcement learning |
| CN119311003A (en)* | 2024-10-14 | 2025-01-14 | 上海船舶研究设计院 | Ship navigation method, device, electronic equipment and storage medium |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN107037809A (en)* | 2016-11-02 | 2017-08-11 | 哈尔滨工程大学 | A kind of unmanned boat collision prevention method based on improvement ant group algorithm |
| CN109597417A (en)* | 2019-01-14 | 2019-04-09 | 哈尔滨工程大学 | A kind of more USV multi-agent synergy collision-avoidance planning methods based on collision prevention criterion |
| AU2020101965A4 (en)* | 2020-08-25 | 2020-10-01 | Wuhan University Of Technology | A method of navigational early warming for ship encounter, and system thereof |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108820157B (en)* | 2018-04-25 | 2020-03-10 | 武汉理工大学 | Intelligent ship collision avoidance method based on reinforcement learning |
| CN109241552B (en)* | 2018-07-12 | 2022-04-05 | 哈尔滨工程大学 | A Motion Planning Method for Underwater Robot Based on Multiple Constraints |
| CN109540136A (en)* | 2018-10-25 | 2019-03-29 | 广东华中科技大学工业技术研究院 | A collaborative path planning method for multiple unmanned vehicles |
| US11119250B2 (en)* | 2019-01-15 | 2021-09-14 | International Business Machines Corporation | Dynamic adaption of vessel trajectory using machine learning models |
- 2020
- 2020-12-23CNCN202011535524.2Apatent/CN112650246B/enactiveActive
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN107037809A (en)* | 2016-11-02 | 2017-08-11 | 哈尔滨工程大学 | A kind of unmanned boat collision prevention method based on improvement ant group algorithm |
| CN109597417A (en)* | 2019-01-14 | 2019-04-09 | 哈尔滨工程大学 | A kind of more USV multi-agent synergy collision-avoidance planning methods based on collision prevention criterion |
| AU2020101965A4 (en)* | 2020-08-25 | 2020-10-01 | Wuhan University Of Technology | A method of navigational early warming for ship encounter, and system thereof |
Non-Patent Citations (2)
| Title |
|---|
| 基于三维卷积神经网络的点云图像船舶分类方法;任永梅 等;《激光与光电子学进展》;20200831;第57卷(第16期);161022-1-161022-9* |
| 规则约束下基于深度强化学习的船舶避碰方法;周双林 等;《中国航海》;20200930;第43卷(第3期);27-32+46* |
Also Published As
| Publication number | Publication date |
|---|---|
| CN112650246A (en) | 2021-04-13 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN112650246B (en) | Ship autonomous navigation method and device | |
| Lakshmanan et al. | Complete coverage path planning using reinforcement learning for tetromino based cleaning and maintenance robot | |
| Wu et al. | An adaptive conversion speed Q-learning algorithm for search and rescue UAV path planning in unknown environments | |
| Chen et al. | Stabilization approaches for reinforcement learning-based end-to-end autonomous driving | |
| Xia et al. | Research on collision avoidance algorithm of unmanned surface vehicle based on deep reinforcement learning | |
| Lan et al. | Path planning for underwater gliders in time-varying ocean current using deep reinforcement learning | |
| CN108762281A (en) | It is a kind of that intelligent robot decision-making technique under the embedded Real-time Water of intensified learning is associated with based on memory | |
| Liu et al. | A hierarchical reinforcement learning algorithm based on attention mechanism for UAV autonomous navigation | |
| Zheng et al. | A partially observable multi-ship collision avoidance decision-making model based on deep reinforcement learning | |
| CN106096729A (en) | A kind of towards the depth-size strategy learning method of complex task in extensive environment | |
| CN115167447B (en) | Intelligent obstacle avoidance method for unmanned boat based on end-to-end deep reinforcement learning of radar images | |
| CN107168309A (en) | A kind of underwater multi-robot paths planning method of Behavior-based control | |
| Miao et al. | Coordination of distributed unmanned surface vehicles via model-based reinforcement learning methods | |
| CN111781922A (en) | A multi-robot collaborative navigation method based on deep reinforcement learning suitable for complex dynamic scenes | |
| Su et al. | A constrained locking sweeping method and velocity obstacle based path planning algorithm for unmanned surface vehicles in complex maritime traffic scenarios | |
| Zhao et al. | Global path planning of unmanned vehicle based on fusion of A∗ algorithm and Voronoi field | |
| Li et al. | Sim-real joint experimental verification for an unmanned surface vehicle formation strategy based on multi-agent deterministic policy gradient and line of sight guidance | |
| Lan et al. | Based on Deep Reinforcement Learning to path planning in uncertain ocean currents for Underwater Gliders | |
| Cheng et al. | A neural network based mobile robot navigation approach using reinforcement learning parameter tuning mechanism | |
| CN117968703A (en) | Autonomous navigation method based on aerial view angle space-time contrast reinforcement learning | |
| CN117666577A (en) | Mobile robot motion planning method based on deep reinforcement learning | |
| He et al. | MARL-based AUV formation for underwater intelligent autonomous transport systems supported by 6G network | |
| CN116300913A (en) | Unmanned ship multi-constraint local path planning method based on visual information | |
| Liu et al. | Attention-based distributional reinforcement learning for safe and efficient autonomous driving | |
| Yang et al. | Sampling-efficient path planning and improved actor-critic-based obstacle avoidance for autonomous robots |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |