CN112583904A - File uploading method, device, equipment and storage medium - Google Patents
File uploading method, device, equipment and storage mediumDownload PDFInfo
- Publication number
- CN112583904A CN112583904ACN202011406833.XACN202011406833ACN112583904ACN 112583904 ACN112583904 ACN 112583904ACN 202011406833 ACN202011406833 ACN 202011406833ACN 112583904 ACN112583904 ACN 112583904A
- Authority
- CN
- China
- Prior art keywords
- data block
- target file
- data
- file
- target
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images






Classifications
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L67/00—Network arrangements or protocols for supporting network services or applications
- H04L67/01—Protocols
- H04L67/06—Protocols specially adapted for file transfer, e.g. file transfer protocol [FTP]
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/10—File systems; File servers
- G06F16/13—File access structures, e.g. distributed indices
- G06F16/137—Hash-based
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/10—File systems; File servers
- G06F16/18—File system types
- G06F16/182—Distributed file systems
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Computer Networks & Wireless Communication (AREA)
- Signal Processing (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Information Transfer Between Computers (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本申请涉及互联网领域中的云计算、云存储技术,尤其涉及一种文件上传方法、装置、设备以及存储介质。The present application relates to cloud computing and cloud storage technologies in the Internet field, and in particular, to a file uploading method, apparatus, device, and storage medium.
背景技术Background technique
随着云存储技术的发展和普及,越来越多的用户喜欢将文件存储在云端服务器。实际应用中,当文件较大时,文件的上传成功率较低。With the development and popularization of cloud storage technology, more and more users like to store files on cloud servers. In practical applications, when the file is large, the upload success rate of the file is low.
现有技术中,为了保证较大文件的成功上传,云端服务器提供了分块上传接口,以使终端设备将较大的文件划分为多个数据块,并将多个数据块逐个发送给云端服务器。云端服务器为了便于后续的文件查询流程,在接收到多个数据块之后,需要生成并存储文件元信息,并通过多个索引来标识文件元信息。In the prior art, in order to ensure the successful upload of large files, the cloud server provides a block upload interface, so that the terminal device divides the large file into multiple data blocks, and sends the multiple data blocks to the cloud server one by one. . In order to facilitate the subsequent file query process, the cloud server needs to generate and store file metadata after receiving multiple data blocks, and use multiple indexes to identify the file metadata.
然而上述方式中,文件元信息的索引结构导致分块数量不能无限制增加,因此云端服务器在分块上传接口中限制了最大分块数量。这样,当面对超大文件时,即使按照最大分块数量来进行分块,每个数据块的大小可能依然较大,当网络环境较差时,文件上传成功率依然较低。However, in the above method, the index structure of the file meta information makes the number of blocks unable to increase indefinitely. Therefore, the cloud server limits the maximum number of blocks in the block upload interface. In this way, when faced with a very large file, even if it is divided according to the maximum number of blocks, the size of each data block may still be large. When the network environment is poor, the file upload success rate is still low.
发明内容SUMMARY OF THE INVENTION
本申请提供了一种文件上传方法、装置、设备以及存储介质。The present application provides a file uploading method, apparatus, device and storage medium.
第一方面,本申请提供一种文件上传方法,包括:In a first aspect, the present application provides a method for uploading files, including:
从终端设备接收目标文件对应的上传请求;Receive an upload request corresponding to the target file from the terminal device;
根据当前网络参数,确定所述目标文件对应的目标分块大小,并向所述终端设备发送所述目标分块大小;所述目标分块大小小于或等于所述当前网络参数对应的分块大小阈值,且用于使所述终端设备将所述目标文件划分为多个数据块,其中,每个数据块的大小小于或等于所述目标分块大小;Determine the target block size corresponding to the target file according to the current network parameters, and send the target block size to the terminal device; the target block size is less than or equal to the block size corresponding to the current network parameters a threshold, and is used to enable the terminal device to divide the target file into a plurality of data blocks, wherein the size of each data block is less than or equal to the target block size;
从所述终端设备接收所述多个数据块,并采用单层的索引结构存储所述目标文件的元信息。The plurality of data blocks are received from the terminal device, and the meta-information of the target file is stored in a single-layer index structure.
第二方面,本申请提供一种文件上传装置,包括:In a second aspect, the present application provides a file uploading device, comprising:
收发模块,用于从终端设备接收目标文件对应的上传请求;The transceiver module is used to receive the upload request corresponding to the target file from the terminal device;
确定模块,用于根据当前网络参数,确定所述目标文件对应的目标分块大小;a determining module, configured to determine the target block size corresponding to the target file according to the current network parameters;
所述收发模块,还用于向所述终端设备发送所述目标分块大小;所述目标分块大小小于或等于所述当前网络参数对应的分块大小阈值,且用于使所述终端设备将所述目标文件划分为多个数据块,其中,每个数据块的大小小于或等于所述目标分块大小;The transceiver module is further configured to send the target block size to the terminal device; the target block size is less than or equal to the block size threshold corresponding to the current network parameter, and is used to make the terminal device dividing the target file into a plurality of data blocks, wherein the size of each data block is less than or equal to the target block size;
所述收发模块,还用于从所述终端设备接收所述多个数据块;The transceiver module is further configured to receive the plurality of data blocks from the terminal device;
存储模块,用于采用单层的索引结构存储所述目标文件的元信息。The storage module is used for storing the meta information of the target file by adopting a single-layer index structure.
第三方面,本申请提供一种电子设备,包括:In a third aspect, the application provides an electronic device, comprising:
至少一个处理器;以及at least one processor; and
与所述至少一个处理器通信连接的存储器;其中,a memory communicatively coupled to the at least one processor; wherein,
所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行第一方面中任一项所述的方法。the memory stores instructions executable by the at least one processor, the instructions being executed by the at least one processor to enable the at least one processor to perform the method of any one of the first aspects .
第四方面,本申请提供一种存储有计算机指令的非瞬时计算机可读存储介质,所述计算机指令用于使所述计算机执行第一方面中任一项所述的方法。In a fourth aspect, the present application provides a non-transitory computer-readable storage medium storing computer instructions for causing the computer to perform the method of any one of the first aspects.
第五方面,本申请提供一种计算机程序产品,包括计算机指令,所述计算机指令被处理器执行时实现第一方面中任一项所述的方法。In a fifth aspect, the present application provides a computer program product, comprising computer instructions that, when executed by a processor, implement the method described in any one of the first aspects.
本申请提供的文件上传方法、装置、设备以及存储介质,该方法包括:从终端设备接收目标文件对应的上传请求;根据当前网络参数,确定目标文件对应的目标分块大小,并向终端设备发送目标分块大小,该目标分块大小小于或等于当前网络参数对应的分块大小阈值,且用于使终端设备将目标文件划分为多个数据块,其中,每个数据块的大小小于或等于该目标分块大小;从终端设备接收多个数据块,并采用单层的索引结构存储目标文件的元信息。上述过程中,通过采用单层的索引结构存储目标文件的元信息,以取消对最大分块数量的限制,从而使得“尽可能减少每次上传的数据量”能够得以实现。进一步的,通过根据当前网络参数确定目标文件对应的目标分块大小,使得确定出的目标分块大小是满足当前网络环境的,保证了该目标文件划分得到的数据块均能被成功上传,从而提高文件上传成功率。The file uploading method, device, device and storage medium provided by this application include: receiving an upload request corresponding to a target file from a terminal device; determining a target block size corresponding to the target file according to current network parameters, and sending the data to the terminal device Target block size, the target block size is less than or equal to the block size threshold corresponding to the current network parameter, and is used for the terminal device to divide the target file into multiple data blocks, wherein the size of each data block is less than or equal to The target block size; multiple data blocks are received from the terminal device, and a single-layer index structure is used to store the meta information of the target file. In the above process, a single-layer index structure is used to store the meta-information of the target file, so as to cancel the restriction on the maximum number of blocks, so that "reducing the amount of data uploaded each time as much as possible" can be realized. Further, by determining the target block size corresponding to the target file according to the current network parameters, the determined target block size satisfies the current network environment, ensuring that the data blocks divided by the target file can be successfully uploaded, thereby Improve file upload success rate.
应当理解,本部分所描述的内容并非旨在标识本申请的实施例的关键或重要特征,也不用于限制本申请的范围。本申请的其它特征将通过以下的说明书而变得容易理解。It should be understood that the content described in this section is not intended to identify key or critical features of the embodiments of the application, nor is it intended to limit the scope of the application. Other features of the present application will become readily understood from the following description.
附图说明Description of drawings
附图用于更好地理解本方案,不构成对本申请的限定。其中:The accompanying drawings are used for better understanding of the present solution, and do not constitute a limitation to the present application. in:
图1为本申请提供的文件上传应用场景的示意图;1 is a schematic diagram of a file upload application scenario provided by the present application;
图2为文件分块的示意图;Fig. 2 is the schematic diagram of file partition;
图3为现有技术中文件的元信息的索引结构示意图;3 is a schematic diagram of the index structure of the meta-information of a file in the prior art;
图4为本申请提供的一种文件上传方法的流程示意图;4 is a schematic flowchart of a file uploading method provided by the application;
图5为本申请提供的一种文件元信息的索引结构示意图;5 is a schematic diagram of an index structure of file meta information provided by the present application;
图6为本申请提供的另一种文件上传方法的流程示意图;6 is a schematic flowchart of another file uploading method provided by the application;
图7为本申请提供的一种文件上传装置的结构示意图;7 is a schematic structural diagram of a file uploading device provided by the present application;
图8为本申请提供的另一种文件上传装置的结构示意图;8 is a schematic structural diagram of another file uploading device provided by the application;
图9为本申请提供的电子设备的结构示意图。FIG. 9 is a schematic structural diagram of an electronic device provided by the present application.
具体实施方式Detailed ways
以下结合附图对本申请的示范性实施例做出说明,其中包括本申请实施例的各种细节以助于理解,应当将它们认为仅仅是示范性的。因此,本领域普通技术人员应当认识到,可以对这里描述的实施例做出各种改变和修改,而不会背离本申请的范围和精神。同样,为了清楚和简明,以下的描述中省略了对公知功能和结构的描述。Exemplary embodiments of the present application are described below with reference to the accompanying drawings, which include various details of the embodiments of the present application to facilitate understanding, and should be considered as exemplary only. Accordingly, those of ordinary skill in the art will recognize that various changes and modifications of the embodiments described herein can be made without departing from the scope and spirit of the present application. Also, descriptions of well-known functions and constructions are omitted from the following description for clarity and conciseness.
本申请提供一种文件上传方法、装置、设备及存储介质,应用于互联网领域中的云存储、云计算等技术领域,以提高文件上传成功率。The present application provides a file uploading method, apparatus, device and storage medium, which are applied to technical fields such as cloud storage and cloud computing in the Internet field to improve the success rate of file uploading.
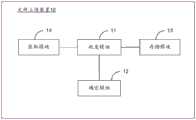
图1为本申请提供的文件上传应用场景的示意图。如图1所示,该应用场景包括:终端设备和云端服务器。终端设备和云端服务器之间通过网络连接。FIG. 1 is a schematic diagram of a file upload application scenario provided by the present application. As shown in Figure 1, the application scenario includes: a terminal device and a cloud server. The terminal device and the cloud server are connected through the network.
其中,终端设备可以为智能手机、平板电脑或者台式电脑等具有信息处理能力的电子设备。终端设备可以通过网页或者客户端的方式访问云端服务器,并向云端服务器发送文件上传请求,以实现向云端服务器上传文件的目的。终端设备还可以通过网页或者客户端的方式访问云端服务器,并向云端服务器发送文件查询请求或者文件下载请求,以实现从云端服务器查询/下载文件的目的。The terminal device may be an electronic device with information processing capability, such as a smart phone, a tablet computer, or a desktop computer. The terminal device can access the cloud server through a web page or a client, and send a file upload request to the cloud server to achieve the purpose of uploading files to the cloud server. The terminal device can also access the cloud server through a web page or a client, and send a file query request or a file download request to the cloud server, so as to query/download files from the cloud server.
本实施例的云端服务器,例如可以是向用户提供网盘存储服务的网盘服务器。云端服务器可以采用分布式存储技术,或者是结合了区块链的服务器。当然,云端服务器还可以采用其他存储技术。The cloud server in this embodiment may be, for example, a network disk server that provides a network disk storage service to a user. The cloud server can use distributed storage technology, or a server combined with blockchain. Of course, the cloud server can also adopt other storage technologies.
云端服务器接收到终端设备发送的文件上传请求后,接收待上传的文件,并存储该文件。云端服务器接收到终端设备发送的文件下载请求后,查询所请求的文件,并将该文件下发至终端设备。云端服务器接收到终端设备发送的文件查询请求后,查询该请求的文件,并向终端设备返回该文件的相关信息。After receiving the file upload request sent by the terminal device, the cloud server receives the file to be uploaded and stores the file. After receiving the file download request sent by the terminal device, the cloud server queries the requested file, and delivers the file to the terminal device. After receiving the file query request sent by the terminal device, the cloud server queries the requested file, and returns the relevant information of the file to the terminal device.
云端服务器为用户提供通用的云存储服务。“通用”是指用户可以存储任意类型、任意大小的文件。而且,对于用户而言,任何文件的存储与访问都应该提供相同的服务保障,例如,文件上传成功率。Cloud servers provide users with general cloud storage services. "Universal" means that users can store files of any type and size. Moreover, for users, the storage and access of any file should provide the same service guarantee, for example, the success rate of file upload.
但是,在实际应用中,越大的文件其上传成功率越低。主要原因在于:当文件越大时,终端设备与云端服务器之间的网络交互时间越长,使得数据在网络上传输出错的概率也就越大。即使网络协议层和业务层有失败重传策略,也无法百分百保证成功上传。However, in practical applications, the larger the file, the lower the upload success rate. The main reason is that when the file size is larger, the network interaction time between the terminal device and the cloud server is longer, which increases the probability of data transmission errors on the network. Even if the network protocol layer and the service layer have failure retransmission policies, there is no 100% guarantee of successful uploading.
为了保证较大文件的成功上传,云端服务器提供了分块上传接口。终端设备将较大的文件划分为多个数据块,针对每个数据块调用一次该上传接口,以将该数据块发送给云端服务器。通过将较大的文件划分为多个数据块,使得终端设备和云端服务器之间每次交互时传输的数据量较小,从而一定程度上提高文件的上传成功率。In order to ensure the successful upload of large files, the cloud server provides a block upload interface. The terminal device divides the larger file into multiple data blocks, and calls the upload interface once for each data block to send the data block to the cloud server. By dividing a large file into multiple data blocks, the amount of data transmitted in each interaction between the terminal device and the cloud server is small, thereby improving the success rate of file upload to a certain extent.
为了便于对本申请技术方案的理解,下面先结合图2和图3对文件分块上传过程进行介绍。In order to facilitate the understanding of the technical solution of the present application, the following describes the file uploading process in blocks with reference to FIG. 2 and FIG. 3 .
云端服务器为终端设备提供了三个上传接口,分别为初始上传接口、分块上传接口和提交上传接口。The cloud server provides three upload interfaces for terminal devices, namely initial upload interface, block upload interface and submission upload interface.
当终端设备接收到用户输入的文件上传操作指令时,终端设备通过调用初始上传接口向云端服务器发送文件上传请求。云端服务器接收到该文件上传请求后,为该文件生成全局唯一的索引标识。一方面,云端服务器将该文件的索引标识通知给终端设备,使得终端设备可以将该文件的索引标识关联到该文件的分块传输过程。另一方面,云端服务器还可以将该文件的索引标识存储到该文件的元信息中,以便在后续的文件查询、下载等流程中可以通过该文件的索引标识查询到该文件。When the terminal device receives the file upload operation instruction input by the user, the terminal device sends a file upload request to the cloud server by calling the initial upload interface. After receiving the file upload request, the cloud server generates a globally unique index identifier for the file. On the one hand, the cloud server notifies the terminal device of the index identifier of the file, so that the terminal device can associate the index identifier of the file with the block transmission process of the file. On the other hand, the cloud server may also store the index identifier of the file in the meta information of the file, so that the file can be queried through the index identifier of the file in subsequent file query, download and other processes.
终端设备从云端服务器获取到该文件的索引标识后,可以将待上传文件划分为多个数据块。图2为文件分块的示意图。如图2所示,示例性的,假设文件被划分为数据块0、数据块1、数据块2、……、数据块n。终端设备针对每个数据块调用一次分块上传接口,以将该数据块上传到云端服务器。After obtaining the index identifier of the file from the cloud server, the terminal device can divide the file to be uploaded into multiple data blocks. FIG. 2 is a schematic diagram of file partitioning. As shown in FIG. 2, exemplarily, it is assumed that the file is divided into data block 0, data block 1, data block 2, . . . , data block n. The terminal device calls the block upload interface once for each data block to upload the data block to the cloud server.
相应的,云端服务器接收到每个数据块后,将该数据块进行分片存储。具体的,云端服务器为每个数据块随机分配索引标识,并按照其存储系统所要求的分片大小,将每个数据块划分为多个数据片(如图2所示,将数据块0划分为数据片0、数据片1、数据片2、……、数据片m),并且,还为每个数据片也随机分配索引标识。云端服务器对每个数据块存储之后,保存该数据块的元信息。其中,数据块的元信息中包括该数据块的索引标识、指纹信息、以及数据块中的各数据片的索引标识等。Correspondingly, after the cloud server receives each data block, the data block is stored in shards. Specifically, the cloud server randomly assigns an index identifier to each data block, and divides each data block into multiple data slices according to the fragment size required by its storage system (as shown in Figure 2, data block 0 is divided into data slice 0, data slice 1, data slice 2, . . . , data slice m), and also randomly assign an index identifier to each data slice. After the cloud server stores each data block, it saves the meta information of the data block. The meta information of the data block includes an index identifier of the data block, fingerprint information, and an index identifier of each data piece in the data block, and the like.
终端设备将所有数据块上传完毕后,通过调用提交上传接口告知云端服务器该文件的所有数据块上传完成。云端服务器将该文件对应的所有数据块的元信息组织成文件的元信息,并对文件的元信息进行存储,从而完成整个文件的上传过程。After the terminal device uploads all the data blocks, it informs the cloud server that the upload of all the data blocks of the file is completed by calling the submit upload interface. The cloud server organizes the meta information of all data blocks corresponding to the file into the meta information of the file, and stores the meta information of the file, thereby completing the uploading process of the entire file.
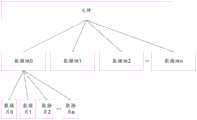
图3为现有技术中文件的元信息的索引结构示意图。如图3所示,云端服务器存储的文件的元信息中包括:文件的索引标识、文件的大小、文件的指纹信息等,并且,文件的元信息中还存储有所有数据块的索引标识列表。这样,当用户后续查询该文件时,云端服务器可以根据存储的文件的元信息,获取到该文件对应的各数据块的索引标识。根据每个数据块的索引标识可以进一步获取到每个数据块的元信息,并从每个数据块的元信息中获取到该数据块对应的各数据片的索引标识,从而查询到该文件的内容。FIG. 3 is a schematic diagram of an index structure of meta-information of a file in the prior art. As shown in FIG. 3 , the meta information of the file stored by the cloud server includes: the index identifier of the file, the size of the file, the fingerprint information of the file, etc., and the meta information of the file also stores a list of index identifiers of all data blocks. In this way, when the user queries the file subsequently, the cloud server can obtain the index identifier of each data block corresponding to the file according to the stored meta information of the file. According to the index identifier of each data block, the meta information of each data block can be further obtained, and the index identifier of each data slice corresponding to the data block can be obtained from the meta information of each data block, so as to query the file content.
通过上述过程可见,云端服务器为了便于文件查询/下载流程,需要采用至少两层的索引结构(例如图3所示的索引结构)保存文件信息。It can be seen from the above process that in order to facilitate the file query/download process, the cloud server needs to use at least two layers of index structures (eg, the index structure shown in FIG. 3 ) to store file information.
由于云端服务器需要在文件的元信息中存储所有数据块的索引标识,该存储方式导致了文件的分块数量不能无限制增加。因此,云端服务器提供的分块上传接口中通常限制了最大分块数量。比如,有些云端服务器限制最大分块数量为10000个,有些云端服务器限制最大分块数量为2000个。这种分块数量的限制,也就限制了分块大小的最小值。比如,若待上传文件的大小为10GB,按照最大分块数量为2000个进行分块的话,每个数据块的大小为5MB(这里的1GB=1000MB)。若待上传文件的大小为100GB,按照最大分块数量为2000个进行分块的话,每个数据块的大小为50MB。当网络环境较差时,单次请求传输50MB的数据块的成功率同样得不到保证。根据线上实际数据统计,当文件大于10GB的情况下,文件上传失败率可能达到10%以上,严重影响用户体验。Since the cloud server needs to store the index identifiers of all data blocks in the metadata information of the file, this storage method results in that the number of file blocks cannot be increased indefinitely. Therefore, the block upload interface provided by the cloud server usually limits the maximum number of blocks. For example, some cloud servers limit the maximum number of blocks to 10,000, and some cloud servers limit the maximum number of blocks to 2,000. This limitation on the number of blocks also limits the minimum block size. For example, if the size of the file to be uploaded is 10GB, and the maximum number of blocks is 2000, the size of each data block is 5MB (1GB=1000MB here). If the size of the file to be uploaded is 100GB, and the maximum number of blocks is 2000, the size of each data block is 50MB. When the network environment is poor, the success rate of a single request to transmit a 50MB data block cannot be guaranteed either. According to actual online statistics, when the file size is larger than 10GB, the file upload failure rate may reach more than 10%, which seriously affects the user experience.
可见,上述现有技术中,当面对超大文件时,即使按照最大分块数量来进行划分,每个数据块的大小可能依然较大(例如,大于10MB,甚至大于50MB)。在网络环境较差的情况下,这些文件即使采用上述分块传输过程,其上传成功率依然较低。It can be seen that, in the above-mentioned prior art, when faced with a very large file, even if it is divided according to the maximum number of blocks, the size of each data block may still be relatively large (for example, larger than 10MB, or even larger than 50MB). In the case of a poor network environment, even if the above-mentioned block transfer process is used for these files, the upload success rate is still low.
另外,上述现有技术中,由于需要在文件的元信息中存储大量的数据块的元信息,导致文件的元信息的容量增大,一方面需要占用较大的存储空间,另一方面当需要查询文件时,对文件的元信息进行解析所需计算量也较大,导致文件查询效率较低。In addition, in the above-mentioned prior art, due to the need to store a large number of meta-information of data blocks in the meta-information of the file, the capacity of the meta-information of the file is increased. On the one hand, it needs to occupy a large storage space; When querying a file, a large amount of computation is required to parse the meta-information of the file, resulting in low file query efficiency.
为了解决上述技术问题中的至少一个,本申请提供一种文件上传方法,其核心思想是尽可能减少每次上传的数据量,也就是说,尽可能将文件的数据块划分的较小。对于同一个文件,划分的数据块越小,对应的数据块的数量就越多。因此,本申请需要解决的核心问题为,如何打破现有技术中对最大分块数量的限制。本申请的文件上传方法通过对文件的元信息的索引结构进行改进,以取消对最大分块数量的限制,从而使得“尽可能减少每次上传的数据量”能够得以实现。进一步的,通过根据当前网络参数确定目标文件对应的目标分块大小,使得确定出的目标分块大小是满足当前网络环境的,保证了该目标文件划分得到的数据块均能被成功上传,从而提高文件上传成功率。In order to solve at least one of the above technical problems, the present application provides a file uploading method, the core idea of which is to reduce the amount of data uploaded each time as much as possible, that is, to divide the data blocks of the file as small as possible. For the same file, the smaller the divided data blocks, the greater the number of corresponding data blocks. Therefore, the core problem to be solved in this application is how to break the limitation on the maximum number of blocks in the prior art. The file uploading method of the present application improves the index structure of the meta-information of the file, so as to cancel the restriction on the maximum number of blocks, so that "reducing the amount of data uploaded each time as much as possible" can be realized. Further, by determining the target block size corresponding to the target file according to the current network parameters, the determined target block size satisfies the current network environment, ensuring that the data blocks divided by the target file can be successfully uploaded, thereby Improve file upload success rate.
下面结合几个具体的实施例对本申请的技术方案进行详细说明。下面这几个具体的实施例可以相互结合,对于相同或相似的概念或过程可能在某些实施例不再赘述。The technical solutions of the present application will be described in detail below with reference to several specific embodiments. The following specific embodiments may be combined with each other, and the same or similar concepts or processes may not be repeated in some embodiments.
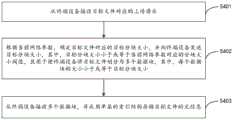
图4为本申请提供的一种文件上传方法的流程示意图。本实施例的方法可以由云端服务器执行。如图4所示,本实施例的方法可以包括:FIG. 4 is a schematic flowchart of a file uploading method provided by the present application. The method of this embodiment may be executed by a cloud server. As shown in FIG. 4 , the method of this embodiment may include:
S401:从终端设备接收目标文件对应的上传请求。S401: Receive an upload request corresponding to a target file from a terminal device.
具体的,终端设备接收到用户输入的文件上传指令时,终端设备确定待上传的目标文件,并向云端服务器发送上传请求,以请求上传该目标文件。其中,待上传的目标文件包括但不限于:文本文件、音频文件、视频文件等。Specifically, when the terminal device receives the file upload instruction input by the user, the terminal device determines the target file to be uploaded, and sends an upload request to the cloud server to request to upload the target file. The target files to be uploaded include but are not limited to: text files, audio files, video files, and the like.
示例性的,终端设备可以通过调用云端服务器提供的初始上传接口发送目标文件对应的上传请求。云端服务器接收该目标文件对应的上传请求。Exemplarily, the terminal device may send the upload request corresponding to the target file by invoking the initial upload interface provided by the cloud server. The cloud server receives the upload request corresponding to the target file.
可选的,云端服务器接收到该上传请求后,可以为目标文件生成全局唯一的索引标识。云端服务器还可以将该目标文件的索引标识通知给终端设备,使得终端设备可以将该目标文件的索引标识关联到该文件的分块传输过程。例如,终端设备在上传每个数据块时,携带该目标文件的索引标识,以指示当前传输的数据块是该目标文件中的数据块。Optionally, after receiving the upload request, the cloud server may generate a globally unique index identifier for the target file. The cloud server can also notify the terminal device of the index identifier of the target file, so that the terminal device can associate the index identifier of the target file with the block transmission process of the file. For example, when uploading each data block, the terminal device carries the index identifier of the target file to indicate that the currently transmitted data block is the data block in the target file.
该目标文件的索引标识还可用于存储到该目标文件的元信息中,以便在后续的文件查询、下载等流程中可以通过该索引标识查询到该目标文件。The index identifier of the target file can also be used to store in the meta information of the target file, so that the target file can be queried through the index identifier in subsequent file query, download and other processes.
S402:根据当前网络参数,确定目标文件对应的目标分块大小,并向终端设备发送目标分块大小,其中,目标分块大小小于或等于当前网络参数对应的分块大小阈值,且用于使终端设备将目标文件划分为多个数据块,其中,每个数据块的大小小于或等于目标分块大小。S402: Determine the target block size corresponding to the target file according to the current network parameters, and send the target block size to the terminal device, wherein the target block size is less than or equal to the block size threshold corresponding to the current network parameters, and is used to make The terminal device divides the target file into a plurality of data blocks, wherein the size of each data block is less than or equal to the target block size.
本实施例与现有技术的一个不同之处在于,本实施例中在确定目标文件对应的目标分块大小时,不考虑最大分块数量的限制,而是尽量将每个数据块划分的越小越好,以保证每个数据块的成功上传。示例性的,云端服务器可以配置默认的较小的分块大小(例如1MB),以保证在弱网环境下,数据块也可以成功上传。One difference between this embodiment and the prior art is that in this embodiment, when determining the size of the target block corresponding to the target file, the restriction on the maximum number of blocks is not considered, but each data block is divided as much as possible. Smaller is better to guarantee successful upload of each chunk. Exemplarily, the cloud server may be configured with a smaller default block size (for example, 1MB) to ensure that the data block can also be successfully uploaded in a weak network environment.
当然,分块越小的话,IO次数越多,吞吐率也会相应降低。因此,本申请实施例中,为了平衡成功率和吞吐率,云端服务器可以根据当前网络参数,确定目标分块大小。也就是说,云端服务器确定出在当前网络环境下能够上传成功的目标分块大小。Of course, the smaller the block size, the more IO times, and the throughput rate will decrease accordingly. Therefore, in this embodiment of the present application, in order to balance the success rate and the throughput rate, the cloud server may determine the target block size according to the current network parameters. That is to say, the cloud server determines the target block size that can be uploaded successfully under the current network environment.
云端服务器接收到目标文件对应的上传请求后,可以根据该上传请求获取当前网络参数。例如,终端设备在发送上传请求时,可以在上传请求中携带当前网络参数。或者,云端服务器根据上传请求的接收情况,测量得到当前网络参数。或者,云端服务器在接收到上传请求后,通过与终端设备的消息交互过程,获取到当前网络参数。本实施例对此不作限定。After receiving the upload request corresponding to the target file, the cloud server can obtain the current network parameters according to the upload request. For example, when the terminal device sends an upload request, it may carry the current network parameters in the upload request. Alternatively, the cloud server can measure and obtain the current network parameters according to the reception of the upload request. Or, after receiving the upload request, the cloud server obtains the current network parameters through a message interaction process with the terminal device. This embodiment does not limit this.
本实施例中,网络参数可以是用于指示网络环境质量的任意参数。可选的,网络参数可以包括下述中的一项或者多项:终端设备的位置信息、终端设备所接入的运营商信息、网络传输速率、网络信号强度等。In this embodiment, the network parameter may be any parameter used to indicate the quality of the network environment. Optionally, the network parameters may include one or more of the following: location information of the terminal device, information of the operator accessed by the terminal device, network transmission rate, network signal strength, and the like.
当前网络参数指示的网络环境质量较好时,目标分块大小可以设置为较大的值;当前网络参数指示的网络环境质量较差时,目标分块大小可以设置为较小的值。通过根据当前网络参数动态确定目标分块大小,在保证文件成功上传的前提下,还能保证较高的吞吐率,提高上传效率。When the network environment quality indicated by the current network parameters is good, the target block size can be set to a larger value; when the network environment quality indicated by the current network parameters is poor, the target block size can be set to a smaller value. By dynamically determining the target block size according to the current network parameters, on the premise of ensuring the successful upload of the file, it can also ensure a higher throughput rate and improve the upload efficiency.
一种可能的实施方式中,可以根据历史文件上传情况,或者根据文件上传测试情况,确定出不同网络参数对应的分块大小阈值。其中,每种网络参数对应的分块大小阈值指示的是:在该种网络参数对应的网络环境中,能够保证成功上传的最大分块大小。例如,某种网络参数对应的分块大小阈值为10MB,则说明该网络参数对应的网络环境中能够保证成功上传最大10MB的数据块,若数据块大于10MB则无法保证成功上传。In a possible implementation manner, block size thresholds corresponding to different network parameters may be determined according to historical file upload conditions or according to file upload test conditions. The block size threshold corresponding to each network parameter indicates the maximum block size that can be guaranteed to be successfully uploaded in the network environment corresponding to the network parameter. For example, if the block size threshold corresponding to a certain network parameter is 10MB, it means that the network environment corresponding to the network parameter can guarantee the successful upload of a data block with a maximum size of 10MB. If the data block is larger than 10MB, the successful upload cannot be guaranteed.
云端服务器在根据当前网络参数,确定目标文件对应的目标分块大小时,可以将当前网络参数对应的分块大小阈值作为目标分块大小。或者,将目标分块大小设置为小于该分块大小阈值的某个值。例如,当前网络参数对应的分块大小阈值为10MB,则云端服务器可以将目标分块大小确定为10MB,或者8MB,或者5MB等。When determining the target block size corresponding to the target file according to the current network parameters, the cloud server may use the block size threshold corresponding to the current network parameters as the target block size. Alternatively, set the target chunk size to some value less than the chunk size threshold. For example, if the block size threshold corresponding to the current network parameter is 10MB, the cloud server may determine the target block size as 10MB, 8MB, or 5MB, etc.
云端服务器确定出目标文件对应的目标分块大小后,将该目标分块大小发送给终端设备,以使终端设备按照该目标分块大小将目标文件划分为多个数据块。其中,每个数据块的大小小于或者等于该目标分块大小。After determining the target block size corresponding to the target file, the cloud server sends the target block size to the terminal device, so that the terminal device divides the target file into multiple data blocks according to the target block size. The size of each data block is less than or equal to the target block size.
本实施例中,通过根据当前网络参数确定目标文件对应的目标分块大小,使得确定出的目标分块大小是满足当前网络环境的,保证了该目标文件划分得到的数据块均能被成功上传,从而提高文件上传成功率。In this embodiment, the size of the target block corresponding to the target file is determined according to the current network parameters, so that the determined size of the target block satisfies the current network environment, and it is ensured that all the data blocks obtained by dividing the target file can be uploaded successfully , so as to improve the success rate of file upload.
S403:从终端设备接收多个数据块,并采用单层的索引结构存储目标文件的元信息。S403: Receive multiple data blocks from the terminal device, and use a single-layer index structure to store the meta information of the target file.
终端设备将目标文件划分为多个数据块之后,可以通过分块上传接口将每个数据块上传给云端服务器。云端服务器接收到每个数据块之后,对每个数据块进行分片存储。当云端服务器接收到所述多个数据块之后,生成并存储目标文件的元信息。After the terminal device divides the target file into multiple data blocks, each data block can be uploaded to the cloud server through the block upload interface. After the cloud server receives each data block, each data block is stored in shards. After the cloud server receives the multiple data blocks, it generates and stores the meta information of the target file.
本实施例与现有技术的另一不同之处在于,本实施例不再采用现有技术中的至少两层的索引结构存储目标文件的元信息,而是采用单层的索引结构存储目标文件的元信息。应理解,此处的“单层的索引结构”指的是目标文件的元信息中只存储文件级别的信息,而不存储各数据块的索引标识。也就是说,本实施例中的目标文件的元信息中不再存储各数据块的元信息。Another difference between this embodiment and the prior art is that this embodiment no longer uses the at least two-layer index structure in the prior art to store the meta information of the target file, but uses a single-layer index structure to store the target file meta information. It should be understood that the "single-level index structure" here refers to that only file-level information is stored in the meta-information of the target file, but the index identifier of each data block is not stored. That is to say, the meta information of each data block is no longer stored in the meta information of the target file in this embodiment.
图5为本申请提供的一种文件元信息的索引结构示意图。如图5所示,目标文件的元信息中只存储文件级别的信息,例如:文件的大小、文件的索引标识、文件的指纹信息等。与图3所示的文件元信息的区别在于,不存储各数据块的索引标识。FIG. 5 is a schematic diagram of an index structure of file meta information provided by the present application. As shown in FIG. 5 , only file-level information is stored in the meta-information of the target file, such as file size, file index identifier, file fingerprint information, and the like. The difference from the file meta information shown in FIG. 3 is that the index identifier of each data block is not stored.
需要说明的是,本实施例中,“不存储各数据块的索引标识”指的是不显式存储各数据块的索引标识。当然,为了在后续文件查询流程中能够索引到目标文件的各数据块的信息,可以在目标文件的元信息中隐式存储各数据块的索引标识,或者隐式指示各数据块的索引标识。本实施例对于隐式存储或者隐式指示的方式不作限定,一种可能的实施方式可以参见后续实施例的详细描述。It should be noted that, in this embodiment, "not storing the index identifier of each data block" refers to not explicitly storing the index identifier of each data block. Of course, in order to index the information of each data block of the target file in the subsequent file query process, the index identifier of each data block may be implicitly stored in the meta information of the target file, or the index identifier of each data block may be implicitly indicated. This embodiment does not limit the manner of implicit storage or implicit indication. For a possible implementation manner, reference may be made to the detailed description of subsequent embodiments.
由于本实施例中的目标文件的元信息中不再存储数据块的索引标识列表,使得目标文件的元信息不受到分块数量的影响,从而本实施例无须限制最大分块数量。也就是说,本实施例通过采用单层的索引结构存储目标文件的元信息,以取消对最大分块数量的限制,从而使得“尽可能减少每次上传的数据量”能够得以实现。Since the meta information of the target file in this embodiment no longer stores the index identifier list of the data block, the meta information of the target file is not affected by the number of blocks, so this embodiment does not need to limit the maximum number of blocks. That is to say, in this embodiment, a single-layer index structure is used to store the meta information of the target file, so as to cancel the restriction on the maximum number of blocks, so that "reducing the amount of data uploaded each time as much as possible" can be realized.
本实施例提供的文件上传方法,包括:从终端设备接收目标文件对应的上传请求;根据当前网络参数,确定目标文件对应的目标分块大小,并向终端设备发送目标分块大小,该目标分块大小小于或等于当前网络参数对应的分块大小阈值,且用于使终端设备将目标文件划分为多个数据块,其中,每个数据块的大小小于或等于该目标分块大小;从终端设备接收多个数据块,并采用单层的索引结构存储目标文件的元信息。上述过程中,通过采用单层的索引结构存储目标文件的元信息,以取消对最大分块数量的限制,从而使得“尽可能减少每次上传的数据量”能够得以实现。进一步的,通过根据当前网络参数确定目标文件对应的目标分块大小,使得确定出的目标分块大小是满足当前网络环境的,保证了该目标文件划分得到的数据块均能被成功上传,从而提高文件上传成功率。The file upload method provided by this embodiment includes: receiving an upload request corresponding to a target file from a terminal device; determining a target block size corresponding to the target file according to current network parameters, and sending the target block size to the terminal device, the target block size The block size is less than or equal to the block size threshold corresponding to the current network parameter, and is used to make the terminal device divide the target file into multiple data blocks, wherein the size of each data block is less than or equal to the target block size; from the terminal The device receives multiple data blocks and uses a single-level index structure to store the meta-information of the target file. In the above process, a single-layer index structure is used to store the meta-information of the target file, so as to cancel the restriction on the maximum number of blocks, so that "reducing the amount of data uploaded each time as much as possible" can be realized. Further, by determining the target block size corresponding to the target file according to the current network parameters, the determined target block size satisfies the current network environment, ensuring that the data blocks divided by the target file can be successfully uploaded, thereby Improve file upload success rate.
在上述任意实施例的基础上,下面结合图6,对本申请技术方案进行更详细的描述。On the basis of any of the above embodiments, the technical solution of the present application will be described in more detail below with reference to FIG. 6 .
图6为本申请提供的另一种文件上传方法的流程示意图。如图6所示,本实施例的方法包括:FIG. 6 is a schematic flowchart of another file uploading method provided by the present application. As shown in Figure 6, the method of this embodiment includes:
S601:终端设备向云端服务器发送目标文件对应的上传请求。S601: The terminal device sends an upload request corresponding to the target file to the cloud server.
相应的,云端服务器从终端设备接收目标文件对应的上传请求。Correspondingly, the cloud server receives an upload request corresponding to the target file from the terminal device.
S602:云端服务器根据当前网络参数,确定目标文件对应的目标分块大小。其中,目标分块大小小于或者等于当前网络参数对应的分块大小阈值。S602: The cloud server determines the target block size corresponding to the target file according to the current network parameters. The target block size is less than or equal to the block size threshold corresponding to the current network parameters.
可选的,云端服务器在接收到目标文件对应的上传请求后,还可以确定该上传请求是否是针对该目标文件的第一次上传请求。也就是说,确定该目标文件是首次上传,还是重新上传。Optionally, after receiving the upload request corresponding to the target file, the cloud server may further determine whether the upload request is the first upload request for the target file. That is, determine whether the target file is being uploaded for the first time, or is being uploaded again.
一些场景中,若确定该上传请求是针对该目标文件的第一次上传请求,则执行S602。也就是说,若确定该目标文件为首次上传,则获取当前网络参数,并根据所述当前网络参数,确定目标文件对应的目标分块大小。In some scenarios, if it is determined that the upload request is the first upload request for the target file, S602 is performed. That is, if it is determined that the target file is uploaded for the first time, the current network parameters are obtained, and the target block size corresponding to the target file is determined according to the current network parameters.
另一些场景中,若确定该上传请求不是针对该目标文件的第一次上传请求,则说明该目标文件为重新上传。该情况下,可以获取该目标文件对应的历史分块大小,并对该历史分块大小进行调整处理,得到目标文件对应的目标分块大小。示例性的,可以将历史分块大小调整为较小的值,将调整后的分块大小作为目标分块大小。In other scenarios, if it is determined that the upload request is not the first upload request for the target file, it means that the target file is re-uploaded. In this case, the size of the historical block corresponding to the target file can be obtained, and the size of the historical block can be adjusted to obtain the size of the target block corresponding to the target file. Exemplarily, the historical block size may be adjusted to a smaller value, and the adjusted block size may be used as the target block size.
本实施例中,若目标文件在首次上传时,由于目标分块大小设置的较大导致上传失败,则在终端设备发起重新上传时,云端服务器可以向终端设备下发较小的目标分块大小(例如,重新上传时的目标分块大小可以为首次上传对应的分块大小的一半),以保证文件成功上传。In this embodiment, if the target file is uploaded for the first time and the upload fails due to the large target block size setting, when the terminal device initiates re-uploading, the cloud server may issue a smaller target block size to the terminal device (For example, the target chunk size when re-uploading can be half of the chunk size corresponding to the first upload) to ensure that the file is uploaded successfully.
S603:云端服务器向终端设备发送目标分块大小。S603: The cloud server sends the target block size to the terminal device.
S604:终端设备根据目标分块大小将目标文件划分为多个数据块,其中,每个数据块的大小小于或者等于目标分块大小。S604: The terminal device divides the target file into multiple data blocks according to the target block size, wherein the size of each data block is smaller than or equal to the target block size.
S605:终端设备向云端服务器分别发送每个数据块。S605: The terminal device sends each data block to the cloud server respectively.
相应的,云端服务器从终端设备分别接收每个数据块。Correspondingly, the cloud server separately receives each data block from the terminal device.
S606:云端服务器根据目标文件的索引标识,对每个数据块进行存储,生成并缓存每个数据块的元信息。S606: The cloud server stores each data block according to the index identifier of the target file, and generates and caches the meta information of each data block.
针对多个数据块中的任意第一数据块,云端服务器可以采用如下可行的方式存储第一数据块,生成并缓存第一数据块的元信息。For any first data block in the multiple data blocks, the cloud server may store the first data block in the following feasible manner, and generate and cache the meta information of the first data block.
(1)根据目标文件的索引标识,确定第一数据块的索引标识。(1) Determine the index identifier of the first data block according to the index identifier of the target file.
可选的,终端设备向云端服务器发送每个数据块时,携带该数据块的序号。云端服务器可以采用第一哈希运算对目标文件的索引标识和每个数据块的序号进行计算,确定出该数据块的索引标识。如下述公式所示:Optionally, when the terminal device sends each data block to the cloud server, it carries the sequence number of the data block. The cloud server may use the first hash operation to calculate the index identifier of the target file and the serial number of each data block, and determine the index identifier of the data block. As shown in the following formula:
PartIDi=Func1(FileID,i)PartIDi =Func1(FileID,i)
其中,i为数据块的序号,PartIDi为第i个数据块的索引标识,FileID为目标文件的索引标识,Func1()为第一哈希运算。Wherein, i is the serial number of the data block, PartIDi is the index identifier of the i-th data block, FileID is the index identifier of the target file, and Func1() is the first hash operation.
(2)将第一数据块划分为多个数据片,根据第一数据块的索引标识,确定每个数据片的索引标识,并根据多个数据片的索引标识对多个数据片进行存储。(2) Divide the first data block into multiple data slices, determine the index identifier of each data slice according to the index identifier of the first data block, and store the multiple data slices according to the index identifiers of the multiple data slices.
可选的,云端服务器可以根据自身存储系统所要求的分片大小,将第一数据块划分为多个数据片。云端服务器采用第二哈希运算对第一数据块的索引标识和每个数据片的序号进行计算,确定出每个数据片的索引标识。如下述公式所示:Optionally, the cloud server may divide the first data block into multiple data slices according to the fragment size required by its own storage system. The cloud server uses the second hash operation to calculate the index identifier of the first data block and the serial number of each data slice, and determines the index identifier of each data slice. As shown in the following formula:
SliceIDj=Func2(PartIDi,j)SliceIDj =Func2(PartIDi ,j)
其中,j为数据片的序号,SliceIDj为第i个数据块中的第j个数据片的索引标识,PartIDi为第i个数据块的索引标识,Func2()为第二哈希运算。Among them, j is the serial number of the data slice, SliceIDj is the index identifier of the j-th data slice in the i-th data block, PartIDi is the index identifier of the i-th data block, and Func2() is the second hash operation.
(3)生成并缓存所述第一数据块的元信息,所述第一数据块的元信息包括所述第一数据块的索引标识和指纹信息。(3) Generating and caching meta information of the first data block, where the meta information of the first data block includes an index identifier and fingerprint information of the first data block.
本实施例与现有技术的又一个不同之处在于,云端服务器生成数据块的元信息后,不对数据块的元信息进行持久化存储(即,不将数据块的元信息存储到目标文件的元信息中),而是将数据块的元信息缓存到缓存系统中。例如,缓存系统可以为redis缓存系统。缓存的数据块的元信息可用于校验目标文件是否成功上传。Another difference between this embodiment and the prior art is that after the cloud server generates the meta information of the data block, it does not perform persistent storage of the meta information of the data block (that is, does not store the meta information of the data block in the target file's metadata). meta information), but cache the meta information of the data block in the cache system. For example, the cache system can be the redis cache system. The meta information of the cached data block can be used to verify whether the target file was successfully uploaded.
S607:终端设备向云端服务器发送文件提交请求。S607: The terminal device sends a file submission request to the cloud server.
相应的,云端服务器从终端设备接收文件提交请求。该文件提交请求用于通知云端服务器目标文件的所有数据块已上传完毕。可选的,终端设备可以通过调用提交上传接口向云端服务器发送文件提交请求。Correspondingly, the cloud server receives the file submission request from the terminal device. This file submission request is used to notify the cloud server that all data blocks of the target file have been uploaded. Optionally, the terminal device may send a file submission request to the cloud server by calling the submit upload interface.
S608:云端服务器在根据多个数据块的元信息,校验多个数据块均正确上传时,生成并存储目标文件的元信息。S608: The cloud server generates and stores the meta information of the target file when verifying that the multiple data blocks are uploaded correctly according to the meta information of the multiple data blocks.
云端服务器根据缓存系统中缓存的多个数据块的元信息,检验目标文件的所有数据块是否均正确上传。若确定目标文件的所有数据块均正确上传,则生成并存储目标文件的元信息。目标文件的元信息采用单层的索引结构,目标文件的元信息中包括目标文件的索引标识,并且不包括该目标文件中的各数据块的元信息(即,不包括该目标文件中的各数据块的索引标识)。The cloud server verifies whether all data blocks of the target file are correctly uploaded according to the meta information of multiple data blocks cached in the cache system. If it is determined that all data blocks of the target file are correctly uploaded, then the meta information of the target file is generated and stored. The meta-information of the target file adopts a single-layer index structure, and the meta-information of the target file includes the index identifier of the target file, and does not include the meta-information of each data block in the target file (that is, does not include each data block in the target file). the index identifier of the data block).
S609:云端服务器将缓存的多个数据块的元信息清除。S609: The cloud server clears the cached meta information of multiple data blocks.
本实施例中,通过根据目标文件的索引标识以及第一哈希运算确定各数据块的索引标识,并根据数据块的索引标识以及第二哈希运算确定各数据片的索引标识,使得仅根据目标文件的索引标识即可计算得到该目标文件对应的各数据块以及各数据片的索引标识,也就是说,只根据目标文件的索引标识即可索引得到目标文件的内容。因此,实现了采用单层的索引结构存储目标文件的元信息,以取消对最大分块数量的限制,从而使得“尽可能减少每次上传的数据量”能够得以实现。进一步的,通过根据当前网络参数确定目标文件对应的目标分块大小,使得确定出的目标分块大小是满足当前网络环境的,保证了该目标文件划分得到的数据块均能被成功上传,从而提高文件上传成功率。In this embodiment, the index identifier of each data block is determined according to the index identifier of the target file and the first hash operation, and the index identifier of each data slice is determined according to the index identifier of the data block and the second hash operation, so that only the index identifier of each data piece is determined according to the index identifier of the data block and the second hash operation. The index identifier of the target file can be calculated to obtain the index identifier of each data block and each data slice corresponding to the target file, that is, the content of the target file can be indexed only according to the index identifier of the target file. Therefore, a single-layer index structure is used to store the meta information of the target file, so as to cancel the restriction on the maximum number of blocks, so that "reducing the amount of data uploaded each time as much as possible" can be realized. Further, by determining the target block size corresponding to the target file according to the current network parameters, the determined target block size satisfies the current network environment, ensuring that the data blocks divided by the target file can be successfully uploaded, thereby Improve file upload success rate.
在图6所示实施例的基础上,下面描述目标文件的查询流程。On the basis of the embodiment shown in FIG. 6 , the query flow of the target file is described below.
终端设备接收到用户输入的文件查询操作时,终端设备确定待查询的目标文件,并向云端服务器发送目标文件对应的文件查询请求。该文件查询请求用于请求查询目标文件的内容。云端服务器根据该目标文件的元信息,获取目标文件的索引标识。云端服务器根据目标文件的索引标识以及第一哈希运算,获取目标文件对应的多个数据块的索引标识。进一步的,云端服务器根据每个数据块的索引标识以及第二哈希运算,获取每个数据块对应的多个数据片的索引标识。进而,云端服务器可以从与各数据片的索引标识对应的存储空间中获取到目标文件的内容。经过上述过程,实现对目标文件的查询流程。When the terminal device receives the file query operation input by the user, the terminal device determines the target file to be queried, and sends a file query request corresponding to the target file to the cloud server. The file query request is used to request to query the content of the target file. The cloud server obtains the index identifier of the target file according to the meta information of the target file. The cloud server obtains the index identifiers of multiple data blocks corresponding to the target file according to the index identifier of the target file and the first hash operation. Further, the cloud server obtains the index identifiers of multiple data slices corresponding to each data block according to the index identifier of each data block and the second hash operation. Furthermore, the cloud server may acquire the content of the target file from the storage space corresponding to the index identifier of each data piece. After the above process, the query process for the target file is realized.
本实施例中,由于目标文件的元信息中不再存储各数据块的元信息,降低了文件元信息的存储量,并降低了文件查询时对文件元信息解析计算量,提高了文件查询效率。In this embodiment, since the meta information of each data block is no longer stored in the meta information of the target file, the storage amount of the file meta information is reduced, the amount of parsing and calculation of the file meta information during file query is also reduced, and the file query efficiency is improved .
实际应用中,文件上传过程中可能存在某个数据块重新上传的现象。例如,一个文件在上传过程中发生了部分变更,该发生变更的数据块可能被重新上传。在图6所示实施例的基础上,由于数据块的索引标识是通过采用第一哈希运算对目标文件的索引标识和数据块的序号进行计算得到的。这样,当某个数据块被重新上传时,重新上传的数据块的索引标识和之前上传的数据块的索引标识是相同的(因为该数据块的索引标识的计算公式相同)。In practical applications, a certain data block may be re-uploaded during the file uploading process. For example, if a file is partially changed during upload, the changed chunk may be re-uploaded. On the basis of the embodiment shown in FIG. 6 , since the index identifier of the data block is obtained by calculating the index identifier of the target file and the serial number of the data block by using the first hash operation. In this way, when a certain data block is re-uploaded, the index identifier of the re-uploaded data block is the same as that of the previously uploaded data block (because the calculation formula of the index identifier of the data block is the same).
若云端服务器采用分布式存储系统,由于分布式存储系统无法保证数据的写入时序,当某个数据重复接收时,通常采用覆盖写的方式。这样,当数据块n被重新上传时,有可能出现新数据块n先写入,而老数据块n后写入并覆盖新数据块n,导致文件数据错乱。If the cloud server adopts a distributed storage system, because the distributed storage system cannot guarantee the writing timing of data, when a certain data is received repeatedly, the method of overwriting is usually adopted. In this way, when the data block n is re-uploaded, it is possible that the new data block n is written first, and the old data block n is written and overwritten after the new data block n, resulting in disordered file data.
本实施例中,为了避免由于数据块重新上传导致的数据错乱问题,云端服务器在接收到每个数据块并对数据块进行存储时,可以采用加锁方式。In this embodiment, in order to avoid the problem of data confusion caused by re-uploading the data blocks, the cloud server may adopt a locking method when receiving each data block and storing the data block.
一种可能的实施方式中,云端服务器接收到第一数据块,并确定第一数据块的索引标识之后,还可以根据第一数据块的索引标识,确定该第一数据块是否是第一次接收到。例如,可以查询缓存系统中是否存在第一数据块的元信息,若存在,则说明不是第一次接收到,若不存在,则说明是第一次接收到。In a possible implementation manner, after the cloud server receives the first data block and determines the index identifier of the first data block, it can also determine whether the first data block is the first time according to the index identifier of the first data block. received. For example, it is possible to query whether there is meta information of the first data block in the cache system. If it exists, it means that it is not received for the first time; if it does not exist, it means that it is received for the first time.
若确定第一数据块是第一次接收到,则可以按照上述实施例的过程对第一数据块进行存储。If it is determined that the first data block is received for the first time, the first data block may be stored according to the process of the foregoing embodiment.
若确定第一数据块不是第一次接收到,则将该第一数据块的内容与第二数据块的内容进行比对。其中,第二数据块为第一次接收到的与该第一数据块的索引标识相同的数据块。若比对结果为一致,则认为该第一数据块上传成功。若比对结果为不一致,则认为该第一数据块上传失败,并向终端设备发送上传失败消息。If it is determined that the first data block is not received for the first time, the content of the first data block is compared with the content of the second data block. The second data block is the first received data block with the same index identifier as the first data block. If the comparison result is consistent, it is considered that the first data block is uploaded successfully. If the comparison result is inconsistent, it is considered that the upload of the first data block fails, and an upload failure message is sent to the terminal device.
可选的,云端服务器向终端设备发送上传失败消息之后,还可以向终端设备发送提示信息,该提示信息用于提示用户中断该目标文件的传输,并重新上传该目标文件。Optionally, after sending the upload failure message to the terminal device, the cloud server may also send prompt information to the terminal device, where the prompt information is used to prompt the user to interrupt the transmission of the target file and re-upload the target file.
本实施例中,通过在对数据块写入时进行加锁操作,能够避免由于数据块重新上传导致的数据错乱问题,从而保证文件的正确上传。In this embodiment, by performing the locking operation when writing the data block, the problem of data confusion caused by re-uploading the data block can be avoided, thereby ensuring the correct upload of the file.
图7为本申请提供的一种文件上传装置的结构示意图。本实施例的文件上传装置可以为软件和/或硬件的形式。本实施例的文件上传装置可以设置在云端服务器中。如图7所示,本实施例的文件上传装置10可以包括:收发模块11、确定模块12和存储模块13。FIG. 7 is a schematic structural diagram of a file uploading apparatus provided by the present application. The file uploading apparatus in this embodiment may be in the form of software and/or hardware. The file uploading apparatus in this embodiment may be set in a cloud server. As shown in FIG. 7 , the file uploading apparatus 10 in this embodiment may include: a
其中,所述收发模块11,用于从终端设备接收目标文件对应的上传请求;Wherein, the
所述确定模块12,用于根据当前网络参数,确定所述目标文件对应的目标分块大小;The determining
所述收发模块11,还用于向所述终端设备发送所述目标分块大小;所述目标分块大小小于或等于所述当前网络参数对应的分块大小阈值,且用于使所述终端设备将所述目标文件划分为多个数据块,其中,每个数据块的大小小于或等于所述目标分块大小;The
所述收发模块11,还用于从所述终端设备接收所述多个数据块;The
所述存储模块13,用于采用单层的索引结构存储所述目标文件的元信息。The
一种可能的实现方式中,所述收发模块11具体用于:分别从所述终端设备接收所述多个数据块中的每个数据块;In a possible implementation manner, the
所述存储模块13具体用于:The
根据所述目标文件的索引标识,对每个数据块进行存储,生成并缓存每个数据块的元信息;According to the index identification of the target file, each data block is stored, and the meta information of each data block is generated and cached;
在根据所述多个数据块的元信息检验所述多个数据块均正确上传时,生成并存储所述目标文件的元信息,并将缓存的所述多个数据块的元信息清除;When verifying that the multiple data blocks are all uploaded correctly according to the meta information of the multiple data blocks, generating and storing the meta information of the target file, and clearing the cached meta information of the multiple data blocks;
其中,所述目标文件的元信息包括所述目标文件的索引标识。Wherein, the meta information of the target file includes the index identifier of the target file.
一种可能的实现方式中,所述存储模块13具体用于:针对所述多个数据块中的任意第一数据块,根据所述目标文件的索引标识,确定所述第一数据块的索引标识;In a possible implementation manner, the
将所述第一数据块划分为多个数据片,根据所述第一数据块的索引标识,确定每个数据片的索引标识,并根据所述多个数据片的索引标识对所述多个数据片进行存储;The first data block is divided into a plurality of data slices, the index identifier of each data slice is determined according to the index identifier of the first data block, and the multiple data slices are identified according to the index identifier of the multiple data slices data slices for storage;
生成并缓存所述第一数据块的元信息,所述第一数据块的元信息包括所述第一数据块的索引标识和指纹信息。Meta information of the first data block is generated and cached, where the meta information of the first data block includes an index identifier and fingerprint information of the first data block.
一种可能的实现方式中,所述存储模块13具体用于:In a possible implementation manner, the
采用第一哈希运算对所述目标文件的索引标识和所述第一数据块的序号进行计算,确定所述第一数据块的索引标识;Calculate the index identifier of the target file and the sequence number of the first data block by using the first hash operation, and determine the index identifier of the first data block;
采用第二哈希运算对所述第一数据块的索引标识和每个数据片的序号进行计算,确定每个数据片的索引标识。The index identifier of the first data block and the serial number of each data slice are calculated by using the second hash operation, and the index identifier of each data slice is determined.
图8为本申请提供的另一种文件上传装置的结构示意图。如图8所示,在图7所示实施例的基础上,本实施例的装置还包括:获取模块14。FIG. 8 is a schematic structural diagram of another file uploading apparatus provided by the present application. As shown in FIG. 8 , on the basis of the embodiment shown in FIG. 7 , the apparatus of this embodiment further includes: an
所述收发模块11还用于:从所述终端设备接收文件查询请求,所述文件查询请求用于请求查询所述目标文件的内容;The
所述获取模块14用于:根据所述目标文件的元信息,获取所述目标文件的索引标识;The obtaining
根据所述目标文件的索引标识以及所述第一哈希运算,获取所述目标文件对应的多个数据块的索引标识,并根据每个数据块的索引标识以及所述第二哈希运算,获取每个数据块对应的多个数据片的索引标识;Obtain the index identifiers of multiple data blocks corresponding to the target file according to the index identifier of the target file and the first hash operation, and according to the index identifier of each data block and the second hash operation, Obtain the index identifiers of multiple data slices corresponding to each data block;
从与所述多个数据片的索引标识对应的存储空间中获取所述目标文件的内容。The content of the target file is acquired from the storage space corresponding to the index identifiers of the plurality of data pieces.
一种可能的实现方式中,所述确定模块12具体用于:In a possible implementation manner, the determining
确定所述上传请求是否是针对所述目标文件的第一次上传请求;determining whether the upload request is the first upload request for the target file;
若确定所述上传请求是针对所述目标文件的第一次上传请求,则获取当前网络参数,并根据所述当前网络参数,确定所述目标文件对应的目标分块大小。If it is determined that the upload request is the first upload request for the target file, current network parameters are acquired, and the target block size corresponding to the target file is determined according to the current network parameters.
一种可能的实现方式中,所述确定模块12还用于:In a possible implementation manner, the determining
若确定所述上传请求不是针对所述目标文件的第一次上传请求,则获取所述目标文件对应的历史分块大小,并对所述历史分块大小进行调整处理,得到所述目标文件对应的目标分块大小。If it is determined that the upload request is not the first upload request for the target file, obtain the size of the historical block corresponding to the target file, and adjust the size of the historical block to obtain the corresponding size of the target file. target chunk size.
一种可能的实现方式中,所述存储模块13还用于:In a possible implementation manner, the
根据所述第一数据块的索引标识,确定所述第一数据块是否是第一次接收到;According to the index identifier of the first data block, determine whether the first data block is received for the first time;
若确定所述第一数据块不是第一次接收到,则将所述第一数据块的内容与第二数据块的内容进行比对,所述第二数据块为第一次接收到的与所述第一数据块的索引标识相同的数据块;If it is determined that the first data block is not received for the first time, the content of the first data block is compared with the content of the second data block, and the second data block is received for the first time and The index of the first data block identifies the same data block;
所述收发模块11还用于:在比对结果为不一致时,向所述终端设备发送上传失败消息。The
一种可能的实现方式中,所述收发模块11还用于:向所述终端设备发送提示信息,所述提示信息用于提示用户中断所述目标文件的传输,并重新上传所述目标文件。In a possible implementation manner, the
一种可能的实现方式中,所述当前网络参数包括下述中的至少一项:所述终端设备的位置信息、所述终端设备接入的运营商信息、网络传输速率、网络信号强度。In a possible implementation manner, the current network parameter includes at least one of the following: location information of the terminal device, operator information accessed by the terminal device, network transmission rate, and network signal strength.
根据本申请的实施例,本申请还提供了一种电子设备和一种可读存储介质。该电子设备可以作为云端服务器。According to the embodiments of the present application, the present application further provides an electronic device and a readable storage medium. The electronic device can act as a cloud server.
如图9所示,是根据本申请实施例的文件上传方法的电子设备的框图。电子设备旨在表示各种形式的数字计算机,诸如,膝上型计算机、台式计算机、工作台、个人数字助理、服务器、刀片式服务器、大型计算机、和其它适合的计算机。电子设备还可以表示各种形式的移动装置,诸如,个人数字处理、蜂窝电话、智能电话、可穿戴设备和其它类似的计算装置。本文所示的部件、它们的连接和关系、以及它们的功能仅仅作为示例,并且不意在限制本文中描述的和/或者要求的本申请的实现。As shown in FIG. 9 , it is a block diagram of an electronic device according to a file uploading method according to an embodiment of the present application. Electronic devices are intended to represent various forms of digital computers, such as laptops, desktops, workstations, personal digital assistants, servers, blade servers, mainframe computers, and other suitable computers. Electronic devices may also represent various forms of mobile devices, such as personal digital processors, cellular phones, smart phones, wearable devices, and other similar computing devices. The components shown herein, their connections and relationships, and their functions are by way of example only, and are not intended to limit implementations of the application described and/or claimed herein.
如图9所示,该电子设备包括:一个或多个处理器101、存储器102,以及用于连接各部件的接口,包括高速接口和低速接口。各个部件利用不同的总线互相连接,并且可以被安装在公共主板上或者根据需要以其它方式安装。处理器可以对在电子设备内执行的指令进行处理,包括存储在存储器中或者存储器上以在外部输入/输出装置(诸如,耦合至接口的显示设备)上显示GUI的图形信息的指令。在其它实施方式中,若需要,可以将多个处理器和/或多条总线与多个存储器一起使用。同样,可以连接多个电子设备,各个设备提供部分必要的操作(例如,作为服务器阵列、一组刀片式服务器、或者多处理器系统)。图9中以一个处理器101为例。As shown in FIG. 9, the electronic device includes: one or more processors 101, a
存储器102即为本申请所提供的非瞬时计算机可读存储介质。其中,所述存储器存储有可由至少一个处理器执行的指令,以使所述至少一个处理器执行本申请所提供的文件上传方法。本申请的非瞬时计算机可读存储介质存储计算机指令,该计算机指令用于使计算机执行本申请所提供的文件上传方法。The
存储器102作为一种非瞬时计算机可读存储介质,可用于存储非瞬时软件程序、非瞬时计算机可执行程序以及模块,如本申请实施例中的文件上传方法对应的程序指令/模块(例如,附图7所示的收发模块11、确定模块12和存储模块13,附图8所示的获取模块14)。处理器101通过运行存储在存储器102中的非瞬时软件程序、指令以及模块,从而执行服务器的各种功能应用以及数据处理,即实现上述方法实施例中的文件上传方法。As a non-transitory computer-readable storage medium, the
存储器102可以包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需要的应用程序;存储数据区可存储根据文件上传方法的电子设备的使用所创建的数据等。此外,存储器102可以包括高速随机存取存储器,还可以包括非瞬时存储器,例如至少一个磁盘存储器件、闪存器件、或其他非瞬时固态存储器件。在一些实施例中,存储器102可选包括相对于处理器101远程设置的存储器,这些远程存储器可以通过网络连接至文件上传方法的电子设备。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。The
文件上传方法的电子设备还可以包括:输入装置103和输出装置104。处理器101、存储器102、输入装置103和输出装置104可以通过总线或者其他方式连接,图9中以通过总线连接为例。The electronic device of the file uploading method may further include: an
输入装置103可接收输入的数字或字符信息,以及产生与文件上传方法的电子设备的用户设置以及功能控制有关的键信号输入,例如触摸屏、小键盘、鼠标、轨迹板、触摸板、指示杆、一个或者多个鼠标按钮、轨迹球、操纵杆等输入装置。输出装置104可以包括显示设备、辅助照明装置(例如,LED)和触觉反馈装置(例如,振动电机)等。该显示设备可以包括但不限于,液晶显示器(LCD)、发光二极管(LED)显示器和等离子体显示器。在一些实施方式中,显示设备可以是触摸屏。The
此处描述的系统和技术的各种实施方式可以在数字电子电路系统、集成电路系统、专用ASIC(专用集成电路)、计算机硬件、固件、软件、和/或它们的组合中实现。这些各种实施方式可以包括:实施在一个或者多个计算机程序中,该一个或者多个计算机程序可在包括至少一个可编程处理器的可编程系统上执行和/或解释,该可编程处理器可以是专用或者通用可编程处理器,可以从存储系统、至少一个输入装置、和至少一个输出装置接收数据和指令,并且将数据和指令传输至该存储系统、该至少一个输入装置、和该至少一个输出装置。Various implementations of the systems and techniques described herein can be implemented in digital electronic circuitry, integrated circuit systems, application specific ASICs (application specific integrated circuits), computer hardware, firmware, software, and/or combinations thereof. These various embodiments may include being implemented in one or more computer programs executable and/or interpretable on a programmable system including at least one programmable processor that The processor, which may be a special purpose or general-purpose programmable processor, may receive data and instructions from a storage system, at least one input device, and at least one output device, and transmit data and instructions to the storage system, the at least one input device, and the at least one output device an output device.
这些计算机程序(也称作程序、软件、软件应用、或者代码)包括可编程处理器的机器指令,并且可以利用高级过程和/或面向对象的编程语言、和/或汇编/机器语言来实施这些计算机程序。如本文使用的,术语“机器可读介质”和“计算机可读介质”指的是用于将机器指令和/或数据提供给可编程处理器的任何计算机程序产品、设备、和/或装置(例如,磁盘、光盘、存储器、可编程逻辑装置(PLD)),包括,接收作为机器可读信号的机器指令的机器可读介质。术语“机器可读信号”指的是用于将机器指令和/或数据提供给可编程处理器的任何信号。These computer programs (also referred to as programs, software, software applications, or codes) include machine instructions for programmable processors and may be implemented using high-level procedural and/or object-oriented programming languages, and/or assembly/machine languages Computer program. As used herein, the terms "machine-readable medium" and "computer-readable medium" refer to any computer program product, apparatus, and/or apparatus for providing machine instructions and/or data to a programmable processor ( For example, magnetic disks, optical disks, memories, programmable logic devices (PLDs), including machine-readable media that receive machine instructions as machine-readable signals. The term "machine-readable signal" refers to any signal used to provide machine instructions and/or data to a programmable processor.
为了提供与用户的交互,可以在计算机上实施此处描述的系统和技术,该计算机具有:用于向用户显示信息的显示装置(例如,CRT(阴极射线管)或者LCD(液晶显示器)监视器);以及键盘和指向装置(例如,鼠标或者轨迹球),用户可以通过该键盘和该指向装置来将输入提供给计算机。其它种类的装置还可以用于提供与用户的交互;例如,提供给用户的反馈可以是任何形式的传感反馈(例如,视觉反馈、听觉反馈、或者触觉反馈);并且可以用任何形式(包括声输入、语音输入或者、触觉输入)来接收来自用户的输入。To provide interaction with a user, the systems and techniques described herein may be implemented on a computer having a display device (eg, a CRT (cathode ray tube) or LCD (liquid crystal display) monitor) for displaying information to the user ); and a keyboard and pointing device (eg, a mouse or trackball) through which a user can provide input to the computer. Other kinds of devices can also be used to provide interaction with the user; for example, the feedback provided to the user can be any form of sensory feedback (eg, visual feedback, auditory feedback, or tactile feedback); and can be in any form (including acoustic input, voice input, or tactile input) to receive input from the user.
可以将此处描述的系统和技术实施在包括后台部件的计算系统(例如,作为数据服务器)、或者包括中间件部件的计算系统(例如,应用服务器)、或者包括前端部件的计算系统(例如,具有图形用户界面或者网络浏览器的用户计算机,用户可以通过该图形用户界面或者该网络浏览器来与此处描述的系统和技术的实施方式交互)、或者包括这种后台部件、中间件部件、或者前端部件的任何组合的计算系统中。可以通过任何形式或者介质的数字数据通信(例如,通信网络)来将系统的部件相互连接。通信网络的示例包括:局域网(LAN)、广域网(WAN)和互联网。The systems and techniques described herein may be implemented on a computing system that includes back-end components (eg, as a data server), or a computing system that includes middleware components (eg, an application server), or a computing system that includes front-end components (eg, a user computer having a graphical user interface or web browser through which a user may interact with implementations of the systems and techniques described herein), or including such backend components, middleware components, Or any combination of front-end components in a computing system. The components of the system may be interconnected by any form or medium of digital data communication (eg, a communication network). Examples of communication networks include: Local Area Networks (LANs), Wide Area Networks (WANs), and the Internet.
计算机系统可以包括客户端和服务器。客户端和服务器一般远离彼此并且通常通过通信网络进行交互。通过在相应的计算机上运行并且彼此具有客户端-服务器关系的计算机程序来产生客户端和服务器的关系。A computer system can include clients and servers. Clients and servers are generally remote from each other and usually interact through a communication network. The relationship of client and server arises by computer programs running on the respective computers and having a client-server relationship to each other.
应该理解,可以使用上面所示的各种形式的流程,重新排序、增加或删除步骤。例如,本发申请中记载的各步骤可以并行地执行也可以顺序地执行也可以不同的次序执行,只要能够实现本申请公开的技术方案所期望的结果,本文在此不进行限制。It should be understood that steps may be reordered, added or deleted using the various forms of flow shown above. For example, the steps described in the present application can be performed in parallel, sequentially or in different orders, and as long as the desired results of the technical solutions disclosed in the present application can be achieved, no limitation is imposed herein.
本申请还提供一种计算机程序产品,该计算机程序产品中包括计算机指令,所述计算机指令被处理器执行时实现上述任意方法实施例中的技术方案。其实现原理和技术效果类似,此处不作赘述。The present application also provides a computer program product, where the computer program product includes computer instructions, and when the computer instructions are executed by a processor, implement the technical solutions in any of the foregoing method embodiments. The implementation principle and technical effect thereof are similar, and are not repeated here.
上述具体实施方式,并不构成对本申请保护范围的限制。本领域技术人员应该明白的是,根据设计要求和其他因素,可以进行各种修改、组合、子组合和替代。任何在本申请的精神和原则之内所作的修改、等同替换和改进等,均应包含在本申请保护范围之内。The above-mentioned specific embodiments do not constitute a limitation on the protection scope of the present application. It should be understood by those skilled in the art that various modifications, combinations, sub-combinations and substitutions may occur depending on design requirements and other factors. Any modifications, equivalent replacements and improvements made within the spirit and principles of this application shall be included within the protection scope of this application.
Claims (21)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011406833.XACN112583904B (en) | 2020-12-04 | 2020-12-04 | File upload method, device, equipment and storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011406833.XACN112583904B (en) | 2020-12-04 | 2020-12-04 | File upload method, device, equipment and storage medium |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN112583904Atrue CN112583904A (en) | 2021-03-30 |
| CN112583904B CN112583904B (en) | 2023-05-19 |
Family
ID=75127228
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202011406833.XAActiveCN112583904B (en) | 2020-12-04 | 2020-12-04 | File upload method, device, equipment and storage medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN112583904B (en) |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113886138A (en)* | 2021-09-29 | 2022-01-04 | 深信服科技股份有限公司 | A user profile management method, apparatus, device and computer medium |
| CN114039735A (en)* | 2021-11-19 | 2022-02-11 | 广州金山移动科技有限公司 | Method and device for transmitting data between devices |
| CN114327282A (en)* | 2021-12-30 | 2022-04-12 | 上海商汤科技开发有限公司 | Data operation method and device and communication equipment |
| CN114584556A (en)* | 2022-03-14 | 2022-06-03 | 中国工商银行股份有限公司 | File transmission method and device |
| CN115065676A (en)* | 2022-05-17 | 2022-09-16 | 深圳市绿联科技股份有限公司 | Method and device for uploading files and electronic equipment |
| CN117459525A (en)* | 2023-12-20 | 2024-01-26 | 宁德时代新能源科技股份有限公司 | File upload methods, devices, equipment and media |
Citations (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20100094817A1 (en)* | 2008-10-14 | 2010-04-15 | Israel Zvi Ben-Shaul | Storage-network de-duplication |
| CN102163199A (en)* | 2010-02-24 | 2011-08-24 | 富士通株式会社 | Index construction method and device thereof and query method |
| CN102332027A (en)* | 2011-10-15 | 2012-01-25 | 西安交通大学 | A method for associative storage of massive non-independent small files based on Hadoop |
| US8370315B1 (en)* | 2010-05-28 | 2013-02-05 | Symantec Corporation | System and method for high performance deduplication indexing |
| US20140250155A1 (en)* | 2011-11-17 | 2014-09-04 | Huawei Technologies Co., Ltd. | Metadata storage and management method for cluster file system |
| CN104091129A (en)* | 2014-06-26 | 2014-10-08 | 腾讯科技(深圳)有限公司 | Data processing method and device |
| US8935446B1 (en)* | 2013-09-26 | 2015-01-13 | Emc Corporation | Indexing architecture for deduplicated cache system of a storage system |
| CN104731516A (en)* | 2013-12-18 | 2015-06-24 | 腾讯科技(深圳)有限公司 | Method and device for accessing files and distributed storage system |
| US20150178007A1 (en)* | 2013-03-15 | 2015-06-25 | Cloudifyd, Inc. | Method and system for integrated cloud storage management |
| CN105138632A (en)* | 2015-08-20 | 2015-12-09 | 浪潮(北京)电子信息产业有限公司 | Organization and management method for file data and file management server |
| US9430156B1 (en)* | 2014-06-12 | 2016-08-30 | Emc Corporation | Method to increase random I/O performance with low memory overheads |
| US20170344573A1 (en)* | 2016-05-26 | 2017-11-30 | Research & Business Foundation Sungkyunkwan University | Data discard method for journaling file system and memory management apparatus thereof |
| CN107872489A (en)* | 2016-09-28 | 2018-04-03 | 杭州海康威视数字技术股份有限公司 | A file slice upload method, device and cloud storage system |
| CN110569213A (en)* | 2018-05-18 | 2019-12-13 | 北京果仁宝软件技术有限责任公司 | File access method, device and equipment |
| CN111327694A (en)* | 2020-02-10 | 2020-06-23 | 北京达佳互联信息技术有限公司 | File uploading method and device, storage medium and electronic equipment |
- 2020
- 2020-12-04CNCN202011406833.XApatent/CN112583904B/enactiveActive
Patent Citations (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20100094817A1 (en)* | 2008-10-14 | 2010-04-15 | Israel Zvi Ben-Shaul | Storage-network de-duplication |
| CN102163199A (en)* | 2010-02-24 | 2011-08-24 | 富士通株式会社 | Index construction method and device thereof and query method |
| US8370315B1 (en)* | 2010-05-28 | 2013-02-05 | Symantec Corporation | System and method for high performance deduplication indexing |
| CN102332027A (en)* | 2011-10-15 | 2012-01-25 | 西安交通大学 | A method for associative storage of massive non-independent small files based on Hadoop |
| US20140250155A1 (en)* | 2011-11-17 | 2014-09-04 | Huawei Technologies Co., Ltd. | Metadata storage and management method for cluster file system |
| US20150178007A1 (en)* | 2013-03-15 | 2015-06-25 | Cloudifyd, Inc. | Method and system for integrated cloud storage management |
| US8935446B1 (en)* | 2013-09-26 | 2015-01-13 | Emc Corporation | Indexing architecture for deduplicated cache system of a storage system |
| CN104731516A (en)* | 2013-12-18 | 2015-06-24 | 腾讯科技(深圳)有限公司 | Method and device for accessing files and distributed storage system |
| US9430156B1 (en)* | 2014-06-12 | 2016-08-30 | Emc Corporation | Method to increase random I/O performance with low memory overheads |
| CN104091129A (en)* | 2014-06-26 | 2014-10-08 | 腾讯科技(深圳)有限公司 | Data processing method and device |
| CN105138632A (en)* | 2015-08-20 | 2015-12-09 | 浪潮(北京)电子信息产业有限公司 | Organization and management method for file data and file management server |
| US20170344573A1 (en)* | 2016-05-26 | 2017-11-30 | Research & Business Foundation Sungkyunkwan University | Data discard method for journaling file system and memory management apparatus thereof |
| CN107872489A (en)* | 2016-09-28 | 2018-04-03 | 杭州海康威视数字技术股份有限公司 | A file slice upload method, device and cloud storage system |
| CN110569213A (en)* | 2018-05-18 | 2019-12-13 | 北京果仁宝软件技术有限责任公司 | File access method, device and equipment |
| CN111327694A (en)* | 2020-02-10 | 2020-06-23 | 北京达佳互联信息技术有限公司 | File uploading method and device, storage medium and electronic equipment |
Non-Patent Citations (2)
| Title |
|---|
| 付松龄;廖湘科;黄辰林;王蕾;李姗姗;: "FlatLFS:一种面向海量小文件处理优化的轻量级文件系统"* |
| 孙竞;余宏亮;郑纬民;: "支持分布式存储删冗的相似文件元数据集合索引"* |
Cited By (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113886138A (en)* | 2021-09-29 | 2022-01-04 | 深信服科技股份有限公司 | A user profile management method, apparatus, device and computer medium |
| CN113886138B (en)* | 2021-09-29 | 2025-08-08 | 深信服科技股份有限公司 | User profile management method, device, equipment and computer medium |
| CN114039735A (en)* | 2021-11-19 | 2022-02-11 | 广州金山移动科技有限公司 | Method and device for transmitting data between devices |
| CN114327282A (en)* | 2021-12-30 | 2022-04-12 | 上海商汤科技开发有限公司 | Data operation method and device and communication equipment |
| CN114584556A (en)* | 2022-03-14 | 2022-06-03 | 中国工商银行股份有限公司 | File transmission method and device |
| CN115065676A (en)* | 2022-05-17 | 2022-09-16 | 深圳市绿联科技股份有限公司 | Method and device for uploading files and electronic equipment |
| CN115065676B (en)* | 2022-05-17 | 2025-03-18 | 深圳市绿联科技股份有限公司 | Method, device and electronic device for uploading files |
| CN117459525A (en)* | 2023-12-20 | 2024-01-26 | 宁德时代新能源科技股份有限公司 | File upload methods, devices, equipment and media |
| CN117459525B (en)* | 2023-12-20 | 2024-04-12 | 宁德时代新能源科技股份有限公司 | File upload method, device, equipment and medium |
Also Published As
| Publication number | Publication date |
|---|---|
| CN112583904B (en) | 2023-05-19 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN112583904B (en) | File upload method, device, equipment and storage medium | |
| US10795817B2 (en) | Cache coherence for file system interfaces | |
| CN112000394B (en) | Method, apparatus, device and storage medium for accessing applet | |
| EP3566127B1 (en) | File system hierarchies and functionality with cloud object storage | |
| US20130238876A1 (en) | Efficient Inline Data De-Duplication on a Storage System | |
| US11347647B2 (en) | Adaptive cache commit delay for write aggregation | |
| CN112565356B (en) | Data storage method and device and electronic equipment | |
| CN110688270A (en) | Video element resource processing method, apparatus, device and storage medium | |
| CN111767169B (en) | Data processing methods, devices, electronic equipment and storage media | |
| US11675806B2 (en) | Aggregate and transactional networked database query processing | |
| JP7210642B2 (en) | File directory traversal method, device, facility, medium, and program | |
| CN114143328B (en) | Data migration method, device, equipment and medium of cloud mobile phone | |
| WO2021155656A1 (en) | Data processing method and apparatus, and access system, electronic device and storage medium | |
| US10802922B2 (en) | Accelerated deduplication block replication | |
| CN111770176B (en) | Traffic scheduling method and device | |
| CN113010811B (en) | Webpage acquisition method and device, electronic equipment and computer readable storage medium | |
| CN115587119A (en) | A database query method, device, electronic equipment and storage medium | |
| CN110168513A (en) | The part of big file is stored in different storage systems | |
| US20230081324A1 (en) | Shared cache for multiple index services in nonrelational databases | |
| KR102583532B1 (en) | Scheduling method and apparatus, device and storage medium | |
| CN111427910A (en) | Data processing method and device | |
| CN111090783A (en) | Recommended method, apparatus and system, walk method for graph embedding, electronic device | |
| CN117667879A (en) | Data access method and device, storage medium and electronic equipment | |
| CN117009693A (en) | http request front-end caching method and device, electronic equipment and readable medium | |
| KR102586892B1 (en) | Data mining system, method, apparatus, electronic device and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |