CN112541356B - Method and system for recognizing biomedical named entities - Google Patents
Method and system for recognizing biomedical named entitiesDownload PDFInfo
- Publication number
- CN112541356B CN112541356BCN202011519249.5ACN202011519249ACN112541356BCN 112541356 BCN112541356 BCN 112541356BCN 202011519249 ACN202011519249 ACN 202011519249ACN 112541356 BCN112541356 BCN 112541356B
- Authority
- CN
- China
- Prior art keywords
- attention
- embedding
- named entity
- word
- words
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images







Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/289—Phrasal analysis, e.g. finite state techniques or chunking
- G06F40/295—Named entity recognition
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/044—Recurrent networks, e.g. Hopfield networks
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- General Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- General Engineering & Computer Science (AREA)
- Biomedical Technology (AREA)
- Evolutionary Computation (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- Data Mining & Analysis (AREA)
- Biophysics (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Life Sciences & Earth Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Machine Translation (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本公开属于自然语言处理和深度学习的技术领域,具体涉及一种生物医学命名实体识别的方法和系统。The disclosure belongs to the technical field of natural language processing and deep learning, and specifically relates to a method and system for biomedical named entity recognition.
背景技术Background technique
本部分的陈述仅仅是提供了与本公开相关的背景技术信息,不必然构成在先技术。The statements in this section merely provide background information related to the present disclosure and do not necessarily constitute prior art.
自然语言处理(NLP)是人工智能和语言学领域的一个分支学科,是人工智能中最为困难的问题之一。NLP是指用计算机对自然语言的形、音、义等信息进行处理,即对字、词、句、篇章的输入、输出、识别、分析、理解、生成等的操作和加工。它对计算机和人类的交互方式有许多重要的影响。其基本任务有语音识别、信息检索、问答系统,机器翻译等等,像循环神经网络、朴素贝叶斯就是NLP经常用到的模型。自然语言处理的语言处理一词是指能够处理口语和书面语的计算机技术。使用相关技术,能将海量的数据进行高效快捷的检索和存储。随着深度学习技术在众多领域的发展,自然语言处理也有了很大突破。Natural Language Processing (NLP) is a subdiscipline in the field of artificial intelligence and linguistics, and it is one of the most difficult problems in artificial intelligence. NLP refers to the use of computers to process information such as shape, sound, and meaning of natural language, that is, the operation and processing of input, output, recognition, analysis, understanding, and generation of words, words, sentences, and texts. It has many important implications for the way computers and humans interact. Its basic tasks include speech recognition, information retrieval, question answering system, machine translation, etc., such as recurrent neural network and naive Bayesian are models often used in NLP. The term language processing in natural language processing refers to computer technology capable of processing spoken and written language. Using related technologies, massive data can be retrieved and stored efficiently and quickly. With the development of deep learning technology in many fields, natural language processing has also made great breakthroughs.
注意力机制(Attention Mechanism)是近年来在自然语言处理领域中提升任务性能的重要工具。通过句子内部的嵌入向量进行多次乘法计算再进行注意力分数计算,最后对句子的词嵌入向量的各维度数值依据注意力分数进行加权,最后得到经过注意力计算的词嵌入向量。在命名实体识别领域中使用注意力机制对句子中的词嵌入信息进行注意力探索已经成为一种成熟的技术。Attention Mechanism is an important tool to improve task performance in the field of natural language processing in recent years. The embedding vector inside the sentence is multiplied multiple times and then the attention score is calculated. Finally, the value of each dimension of the word embedding vector of the sentence is weighted according to the attention score, and finally the word embedding vector calculated by attention is obtained. It has become a mature technology to use attention mechanism to explore word embedding information in sentences in the field of named entity recognition.
命名实体识别(Named Entity Recognition,NER),是NLP领域中的基础任务,也是问答系统、机器翻译、句法分析等多数NLP任务的重要基础工具。以前的方法主要是基于词典和基于规则的。基于词典的方法是通过字符串模糊查找或者完全匹配的方法,但是随着新的实体名称不断涌现,词典的质量与大小有局限性;基于规则的方法是通过实体名成自身的特征和短语的常见搭配,来人为的指定一些规则,扩充规则集合,但是需要耗费巨大的人力资源和时间成本,规则一般只在某个特定的领域内有效,进行人工迁移的代价高,且规则移植性不强。进行命名实体识别,多采用机器学习的方法,通过不断地优化模型训练,是训练的模型在测试评估时表现出较好的性能。目前应用较多的模型有隐马尔可夫模型(Hidden Markov Model,HMM)、支持向量机(Support Vector Machine,SVM)、最大熵马尔可夫模型(Maximum Entropy Markov Model,MEMM)、条件随机场(Conditional RandomField,CRF)等。条件随机场模型能对邻近标签对预测序列的影响问题进行有效地处理,所以在实体识别中应用较多,且效果不错。目前,针对序列标注问题,一般采用深度学习算法。与传统算法相比,深度学习算法去掉了手工提取特征这一步,能有效的提取判别特征。Named Entity Recognition (NER) is a basic task in the NLP field and an important basic tool for most NLP tasks such as question answering systems, machine translation, and syntax analysis. Previous methods are mainly dictionary-based and rule-based. The dictionary-based method is a method of fuzzy search or complete matching through strings, but as new entity names continue to emerge, the quality and size of the dictionary are limited; the rule-based method is to use the entity name to form its own characteristics and phrases Common collocations, artificially specify some rules and expand the rule set, but it takes huge human resources and time costs, the rules are generally only valid in a specific field, the cost of manual migration is high, and the rule portability is not strong . For named entity recognition, machine learning methods are mostly used. Through continuous optimization of model training, the trained model shows better performance in test evaluation. At present, the most widely used models are Hidden Markov Model (HMM), Support Vector Machine (SVM), Maximum Entropy Markov Model (MEMM), Conditional Random Field ( Conditional RandomField, CRF) and so on. The conditional random field model can effectively deal with the influence of adjacent tags on the prediction sequence, so it is widely used in entity recognition, and the effect is good. At present, for sequence labeling problems, deep learning algorithms are generally used. Compared with the traditional algorithm, the deep learning algorithm removes the step of manually extracting features, and can effectively extract discriminant features.
近年来,随着互联网的高速运转,信息也有了各式各样的存储形式。在生物医学领域,文献资源每年都在数以千倍的增加,这些信息的构成多以非结构化文本的形式存储,生物医学命名实体识别的任务是将非结构化文本转为结构化文本,将生物医学文本中的特定实体名称如基因、蛋白质、疾病等进行识别和分类。目前,从庞大的数据中如何快速高效的检索相关信息是一项巨大的挑战。In recent years, with the high-speed operation of the Internet, information has also been stored in various forms. In the field of biomedicine, literature resources are increasing by thousands of times every year. The composition of these information is mostly stored in the form of unstructured text. The task of biomedical named entity recognition is to convert unstructured text into structured text. Identify and classify specific entity names such as genes, proteins, diseases, etc. in biomedical texts. At present, how to quickly and efficiently retrieve relevant information from huge data is a huge challenge.
发明内容Contents of the invention
本公开为了解决上述问题,提出了一种生物医学命名实体识别的方法和系统,本公开主要分为两个部分,即多层次的注意力嵌入向量计算和交叉注意力融合;多层次注意力嵌入向量计算主要有,基于字符的局部注意力计算、基于字符的全局注意力计算以及基于词的局部注意力计算。In order to solve the above problems, this disclosure proposes a method and system for biomedical named entity recognition. This disclosure is mainly divided into two parts, namely, multi-level attention embedding vector calculation and cross-attention fusion; multi-level attention embedding Vector calculations mainly include character-based local attention calculations, character-based global attention calculations, and word-based local attention calculations.
根据一些实施例,本公开采用如下技术方案:According to some embodiments, the present disclosure adopts the following technical solutions:
第一方面,本公开提供了一种生物医学命名实体识别的方法;In a first aspect, the present disclosure provides a method for biomedical named entity recognition;
一种生物医学命名实体识别的方法,包括:A method for biomedical named entity recognition, comprising:
对于字符、词利用注意力机制进行特征采样分别得到单词嵌入的拓展,然后使用最大池化层来提取单词嵌入;For characters and words, use the attention mechanism to perform feature sampling to obtain the expansion of the word embedding, and then use the maximum pooling layer to extract the word embedding;
采用注意机制将不同层次的单词嵌入进行融合,得到多层次的单词嵌入;The attention mechanism is used to fuse different levels of word embeddings to obtain multi-level word embeddings;
将所述多层次的单词嵌入输入命名实体识别神经网络模型中进行训练,获得训练好的命名实体识别神经网络模型;Embedding the multi-level words into the named entity recognition neural network model for training to obtain the trained named entity recognition neural network model;
将待识别的生物医学命名实体输入训练好的命名实体识别神经网络模型,得到实体识别结果。Input the biomedical named entity to be recognized into the trained named entity recognition neural network model to obtain the entity recognition result.
第二方面,本公开提供了一种生物医学命名实体识别的系统;In a second aspect, the present disclosure provides a biomedical named entity recognition system;
一种生物医学命名实体识别的系统,包括:A system for biomedical named entity recognition, comprising:
词嵌入模块,被配置为:对于字符、词利用注意力机制进行特征采样分别得到单词嵌入的拓展,然后使用最大池化层来提取单词嵌入;The word embedding module is configured to: use the attention mechanism to perform feature sampling for characters and words to obtain the expansion of word embeddings, and then use the maximum pooling layer to extract word embeddings;
特征融合模块,被配置为:采用注意机制将不同层次的单词嵌入进行融合,得到多层次的单词嵌入;The feature fusion module is configured to: use an attention mechanism to fuse word embeddings at different levels to obtain multi-level word embeddings;
模型训练模块,被配置为:将所述多层次的单词嵌入输入命名实体识别神经网络模型中进行训练,获得训练好的命名实体识别神经网络模型;The model training module is configured to: embed the multi-level words into the named entity recognition neural network model for training, and obtain the trained named entity recognition neural network model;
输出模块,被配置为:将待识别的生物医学命名实体输入训练好的命名实体识别神经网络模型,得到实体识别结果。The output module is configured to: input the biomedical named entity to be recognized into the trained named entity recognition neural network model to obtain the entity recognition result.
第三方面,本公开提供了一种计算机可读存储介质;In a third aspect, the present disclosure provides a computer-readable storage medium;
本公开提供了一种计算机可读存储介质,用于存储计算机指令,所述计算机指令被处理器执行时,完成如第一方面所述的生物医学命名实体识别的方法。The present disclosure provides a computer-readable storage medium for storing computer instructions, and when the computer instructions are executed by a processor, the method for identifying biomedical named entities as described in the first aspect is completed.
与现有技术相比,本公开的有益效果为:Compared with the prior art, the beneficial effects of the present disclosure are:
1、本公开处理生物医学命名实体识别时,采用命名实体识别神经网络模型,将多层次的注意力嵌入向量计算和交叉注意力融合等算法相结合,提高了命名实体识别的准确率。1. When this disclosure deals with biomedical named entity recognition, it adopts the named entity recognition neural network model and combines multi-level attention embedding vector calculation and cross-attention fusion algorithms to improve the accuracy of named entity recognition.
2、本公开在进行命名实体识别任务时,经过条件随机场(CRF)对序列结构数据进行标记和划分,可以实现较为准确的最终序列标注效果。2. When performing the task of named entity recognition in the present disclosure, the sequence structure data is marked and divided by a conditional random field (CRF), so that a more accurate final sequence labeling effect can be achieved.
本发明附加方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。Advantages of additional aspects of the invention will be set forth in the description which follows, and in part will be obvious from the description, or may be learned by practice of the invention.
附图说明Description of drawings
构成本公开的一部分的说明书附图用来提供对本公开的进一步理解,本公开的示意性实施例及其说明用于解释本公开,并不构成对本公开的不当限定。The accompanying drawings constituting a part of the present disclosure are used to provide a further understanding of the present disclosure, and the exemplary embodiments and descriptions of the present disclosure are used to explain the present disclosure, and do not constitute improper limitations to the present disclosure.
图1是本公开的生物医学命名实体识别的方法流程图;FIG. 1 is a flowchart of a method for biomedical named entity recognition of the present disclosure;
图2是本公开实施例中基于字符的局部注意力机制原理图;FIG. 2 is a schematic diagram of a character-based local attention mechanism in an embodiment of the present disclosure;
图3是本公开的实施例中基于字符的全局注意力机制原理图;FIG. 3 is a schematic diagram of a character-based global attention mechanism in an embodiment of the present disclosure;
图4是本公开的实施例中基于字符的局部注意力实验效果;Fig. 4 is the experiment result of local attention based on character in the embodiment of the present disclosure;
图5是本公开的实施例中交叉注意力融合方法针在字符局部注意力实验效果;Fig. 5 is the experimental effect of the cross-attention fusion method in the embodiment of the present disclosure on the partial attention of characters;
图6是本公开的实施例中基于字符的全局注意力实验效果;Fig. 6 is the result of the global attention experiment based on characters in the embodiment of the present disclosure;
图7是本公开的实施例中交叉注意力融合方法针在字符全局注意力实验效果;Fig. 7 is the experimental effect of the cross-attention fusion method on the global attention of characters in the embodiment of the present disclosure;
图8是本公开的实施例中基于词的局部注意力实验效果。Fig. 8 is an experimental result of word-based partial attention in an embodiment of the present disclosure.
具体实施方式:detailed description:
下面结合附图与实施例对本公开作进一步说明。The present disclosure will be further described below in conjunction with the accompanying drawings and embodiments.
应该指出,以下详细说明都是例示性的,旨在对本公开提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本公开所属技术领域的普通技术人员通常理解的相同含义。It should be noted that the following detailed description is exemplary and intended to provide further explanation of the present disclosure. Unless defined otherwise, all technical and scientific terms used herein have the same meaning as commonly understood by one of ordinary skill in the art to which this disclosure belongs.
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本公开的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。It should be noted that the terminology used herein is only for describing specific embodiments, and is not intended to limit the exemplary embodiments according to the present disclosure. As used herein, unless the context clearly dictates otherwise, the singular is intended to include the plural, and it should also be understood that when the terms "comprising" and/or "comprising" are used in this specification, they mean There are features, steps, operations, means, components and/or combinations thereof.
术语解释:Explanation of terms:
自然语言处理(NLP)是人工智能和语言学领域的一个分支学科,是人工智能中最为困难的问题之一。NLP是指用计算机对自然语言的形、音、义等信息进行处理,即对字、词、句、篇章的输入、输出、识别、分析、理解、生成等的操作和加工。它对计算机和人类的交互方式有许多重要的影响。其基本任务有语音识别、信息检索、问答系统,机器翻译等等,像循环神经网络、朴素贝叶斯就是NLP经常用到的模型。自然语言处理的语言处理一词是指能够处理口语和书面语的计算机技术。使用相关技术,能将海量的数据进行高效快捷的检索和存储。随着深度学习技术在众多领域的发展,自然语言处理也有了很大突破。Natural Language Processing (NLP) is a subdiscipline in the field of artificial intelligence and linguistics, and it is one of the most difficult problems in artificial intelligence. NLP refers to the use of computers to process information such as shape, sound, and meaning of natural language, that is, the operation and processing of input, output, recognition, analysis, understanding, and generation of words, words, sentences, and texts. It has many important implications for the way computers and humans interact. Its basic tasks include speech recognition, information retrieval, question answering system, machine translation, etc., such as recurrent neural network and naive Bayesian are models often used in NLP. The term language processing in natural language processing refers to computer technology capable of processing spoken and written language. Using related technologies, massive data can be retrieved and stored efficiently and quickly. With the development of deep learning technology in many fields, natural language processing has also made great breakthroughs.
注意力机制(Attention Mechanism)是近年来在自然语言处理领域中提升任务性能的重要工具。通过句子内部的嵌入向量进行多次乘法计算再进行注意力分数计算,最后对句子的词嵌入向量的各维度数值依据注意力分数进行加权,最后得到经过注意力计算的词嵌入向量。在命名实体识别领域中使用注意力机制对句子中的词嵌入信息进行注意力探索已经成为一种成熟的技术。Attention Mechanism is an important tool to improve task performance in the field of natural language processing in recent years. The embedding vector inside the sentence is multiplied multiple times and then the attention score is calculated. Finally, the value of each dimension of the word embedding vector of the sentence is weighted according to the attention score, and finally the word embedding vector calculated by attention is obtained. It has become a mature technology to use attention mechanism to explore word embedding information in sentences in the field of named entity recognition.
命名实体识别(Named Entity Recognition,NER),是NLP领域中的基础任务,也是问答系统、机器翻译、句法分析等多数NLP任务的重要基础工具。Named Entity Recognition (NER) is a basic task in the NLP field and an important basic tool for most NLP tasks such as question answering systems, machine translation, and syntax analysis.
真如背景技术中所介绍的,随着科技的发展,非结构化的生物医学数据不断涌现,目前生物医学命名实体识别面临着很多困难:实体名称带有多个修饰词,辨别实体边界难度加大;多个实体名称共享一个单词;缺乏严格的命名标准;缩写词存在歧义等等。为了解决这些难题,采用多过滤器的卷积神经网络可以大大提升系统的性能,提高识别准确率。As mentioned in the background technology, with the development of science and technology, unstructured biomedical data are constantly emerging. At present, biomedical named entity recognition is facing many difficulties: entity names have multiple modifiers, and it is more difficult to identify entity boundaries ; multiple entity names sharing a single word; lack of strict naming standards; ambiguities in abbreviations, etc. In order to solve these problems, the convolutional neural network with multiple filters can greatly improve the performance of the system and improve the recognition accuracy.
实施例一Embodiment one
图1是本实施例提供的生物医学命名实体识别的方法流程图,如图1所示,本实施例提供了一种生物医学命名实体识别的方法,包括:Fig. 1 is a flow chart of the method for biomedical named entity recognition provided in this embodiment. As shown in Fig. 1, the present embodiment provides a method for biomedical named entity recognition, including:
对于字符、词利用注意力机制进行特征采样分别得到单词嵌入的拓展,然后使用最大池化层来提取单词嵌入;For characters and words, use the attention mechanism to perform feature sampling to obtain the expansion of the word embedding, and then use the maximum pooling layer to extract the word embedding;
具体的,对句子中的词嵌入使用注意力机制对句子内部的词嵌入进行特征提取;Specifically, use the attention mechanism for the word embedding in the sentence to extract the feature of the word embedding inside the sentence;
采用注意机制将不同层次的单词嵌入进行融合,得到多层次的单词嵌入;The attention mechanism is used to fuse different levels of word embeddings to obtain multi-level word embeddings;
将所述多层次的单词嵌入输入命名实体识别神经网络模型中进行训练,获得训练好的命名实体识别神经网络模型;Embedding the multi-level words into the named entity recognition neural network model for training to obtain the trained named entity recognition neural network model;
将待识别的生物医学命名实体输入训练好的命名实体识别神经网络模型,得到实体识别结果。Input the biomedical named entity to be recognized into the trained named entity recognition neural network model to obtain the entity recognition result.
作为另一种实施方式,所述对于字符、词利用注意力机制进行特征采样分别得到单词嵌入的拓展,包括:采用多层次的注意力嵌入向量计算分别在局部字符、全局字符以及局部词中进行注意力探索,在不同的层次提取单词嵌入信息。As another implementation, the feature sampling of characters and words using the attention mechanism to obtain the expansion of word embedding includes: using multi-level attention embedding vector calculations to perform in local characters, global characters and local words respectively Attention exploration extracts word embedding information at different levels.
多层次的注意力嵌入向量计算,包括:基于字符的局部注意力计算、基于字符的全局注意力计算以及基于词的局部注意力计算。Multi-level attention embedding vector calculation, including: character-based local attention calculation, character-based global attention calculation and word-based local attention calculation.
其中,基于字符的局部注意力计算主要对单词内部的字符使用单热(ont-hot)编码的形式进行建模,然后分别对建模的字符嵌入矩阵进行注意力计算,最后输出的对计算的注意力字符嵌入使用池化层采样选择合适维度信息。Among them, the local attention calculation based on characters mainly models the characters inside the word using the form of one-hot (ont-hot) encoding, and then performs attention calculations on the modeled character embedding matrix respectively, and finally outputs the pair of calculated Attentional character embedding uses pooling layer sampling to select appropriate dimension information.
基于字符的全局注意力计算主要对建模的字符嵌入矩阵先使用Bi-GRU在句子字符上进行上下文信息探索,然后在进行注意力计算,最后同样使用池化层进行采样形成对应的单词嵌入。The character-based global attention calculation mainly uses Bi-GRU to explore the context information on the sentence characters of the modeled character embedding matrix, then performs attention calculations, and finally uses the pooling layer to sample to form the corresponding word embedding.
基于词的局部注意力计算主要对单词嵌入进行注意力分布计算,提取单词嵌入之间的注意分布。The word-based local attention calculation mainly calculates the attention distribution of word embeddings, and extracts the attention distribution between word embeddings.
值得注意的是我们需要在计算注意力分布之前,先在句子内部对词嵌入进行上下文探索,提取上下文信息;这样需要进行注意力计算的词嵌入向量蕴含了句子内部的嵌入信息。It is worth noting that before calculating the attention distribution, we need to explore the context of the word embedding in the sentence to extract context information; in this way, the word embedding vector that requires attention calculation contains the embedding information inside the sentence.
作为另一种实施方式,所述采用注意机制将不同层次的单词嵌入进行融合,得到多层次的单词嵌入,包括:采用交叉注意力融合将两个不同层次的注意力加权到相应的嵌入信息之中进行融合,得到多层次的单词嵌入。As another implementation, the use of the attention mechanism to fuse word embeddings of different levels to obtain a multi-level word embedding includes: using cross-attention fusion to weight the attention of two different levels to the corresponding embedding information In the fusion, a multi-level word embedding is obtained.
交叉注意力融合算法指的是,传统针对不同采样方法得到的嵌入信息通常使用直接拼接的方式然后进入下一步的处理,在本实施例中采用了双方注意力计算,并将相互之间的注意力加权到相应的嵌入信息之中,最后再进行拼接进行下一步处理。The cross-attention fusion algorithm refers to the fact that the traditional embedded information obtained by different sampling methods usually uses direct splicing and then enters the next step of processing. In this embodiment, both parties' attention calculations are used, and the mutual attention The force is weighted into the corresponding embedded information, and finally spliced for the next step of processing.
作为另一种实施方式,对于字符、词利用注意力机制进行特征采样分别得到单词嵌入的拓展之前,还包括采用条件随机场对所述生物医学命名实体进行标记和划分。As another implementation manner, before using the attention mechanism to perform feature sampling for characters and words to obtain word embeddings respectively, it also includes marking and dividing the biomedical named entities by using a conditional random field.
具体的,本实施例还提供了更细化的实施方式:生物医学命名实体识别的方法也可以划分为如下几个过程:Specifically, this embodiment also provides a more detailed implementation: the biomedical named entity recognition method can also be divided into the following several processes:
(1)词嵌入。在进行命名实体识别任务时,文本中的句子可以从字符级和词级两方面去考虑其识别性能,在本实施例中,使用多层次注意力的形式分别在局部字符、全局字符以及局部词中进行注意力探索,所以使用注意力机制在不同的维度提取词嵌入信息,最后使用注意力融合方式,对不同维度的词嵌入进行融合生成的下游任务需要的嵌入向量,使用此方案可以稳定的提升模型的训练性能。在众多NLP的过程中,通过词嵌入信息进行特征提取的功能已经被证明是有效的,如近期的句子相似度计算,词性标注问题,文本的词嵌入方式令他们的系统的性能得到了提升,词级表示可以极大地提升我们的模型所能处理的词汇量。(1) Word embedding. When performing named entity recognition tasks, the sentences in the text can consider their recognition performance from both the character level and the word level. For attention exploration, the attention mechanism is used to extract word embedding information in different dimensions, and finally the attention fusion method is used to fuse word embeddings of different dimensions to generate embedding vectors required for downstream tasks. Using this scheme can stabilize Improve the training performance of the model. In many NLP processes, the function of feature extraction through word embedding information has been proven to be effective, such as the recent sentence similarity calculation, part-of-speech tagging, and the word embedding method of the text has improved the performance of their system. Word-level representations can greatly increase the vocabulary size our models can handle.
(2)多层次注意力特征提取。在医学文本中,通常使用预训练的词嵌入向量进行下一步的模型训练,然而在常用的预训练词嵌入中,对于专门词汇的支持性存在局限性,即存在大量的OOV形式的词嵌入向量。因此,本实施例中使用了多维度的注意力计算来探索词嵌入信息,进而弥补专业词汇的词嵌入信息。(2) Multi-level attention feature extraction. In medical texts, pre-trained word embedding vectors are usually used for the next step of model training. However, in commonly used pre-trained word embeddings, there are limitations to the support for specialized vocabulary, that is, there are a large number of word embedding vectors in the form of OOV . Therefore, in this embodiment, multi-dimensional attention calculation is used to explore the word embedding information, and then supplement the word embedding information of professional vocabulary.
(3)上下文信息提取。在生物医学文本中,想要提取高效有利的实体名称,就需要考虑句子中单词所处的位置和邻近单词的语义信息,也就是说上下文信息对NER任务非常有益,所以本实施例主要采用了双向长短期记忆网络(BLSTM),BiLSTM由前向LSTM和后向LSTM组成,它有效地解决了梯度消失和梯度爆炸问题。(3) Context information extraction. In biomedical text, if you want to extract efficient and beneficial entity names, you need to consider the position of the word in the sentence and the semantic information of adjacent words, that is to say, the context information is very beneficial to the NER task, so this embodiment mainly uses Bidirectional long short-term memory network (BLSTM), BiLSTM is composed of forward LSTM and backward LSTM, which effectively solves the problem of gradient disappearance and gradient explosion.
(4)标记和划分标签。进行命名实体识别任务时,经过条件随机场(CRF)对序列结构数据进行标记和划分,可以实现较为准确的最终序列标注效果。CRF是马尔可夫随机场的变体,是在BiLSTM上构建的,一般是对于给定的输出识别标签和观测序列,通过条件概率来表示模型,对全部的特征做全局归一化处理,相比较其他机器学习方法更有优势。(4) Mark and divide labels. When carrying out the task of named entity recognition, the sequence structure data is marked and divided by conditional random field (CRF), which can achieve a more accurate final sequence labeling effect. CRF is a variant of Markov Random Field, which is constructed on BiLSTM. Generally, for a given output identification label and observation sequence, the model is represented by conditional probability, and all features are globally normalized. Compared with other machine learning methods, it has more advantages.
近年来,双向长短期记忆(BiLSTM)和条件随机场(CRF)相结合的神经网络方法在各种NER数据集上取得了较好的效果。虽然BiLSTM探索了大量的上下文信息,但在现有的训练词嵌入中,医学专业词汇出现的频率较少,不能获得更准确的词义,并且不能保证每次获得的单词标签都被正确预测。以BioBERT和SciBERT为代表的预训练模型使用BERT模型通过训练特定的专业医学语料库来获取更高级的嵌入信息,从而提高下游任务的性能。In recent years, neural network methods combining bidirectional long short-term memory (BiLSTM) and conditional random fields (CRF) have achieved good results on various NER datasets. Although BiLSTM explores a large amount of contextual information, in the existing training word embeddings, medical professional words appear less frequently, cannot obtain more accurate word meanings, and cannot guarantee that the word labels obtained every time are correctly predicted. The pre-training models represented by BioBERT and SciBERT use the BERT model to obtain more advanced embedding information by training a specific professional medical corpus, thereby improving the performance of downstream tasks.
虽然预先训练的模型可以获得更快的收敛速度和稳定的模型性能,但它使用了大量的计算资源,训练一个优秀的模型的成本是巨大的。所以,使用多层次注意力机制这种不需要预先训练的简单、低成本的方法使得字符级和词级别编码器对特定的单词信息更有意义。Although the pre-trained model can obtain faster convergence speed and stable model performance, it uses a lot of computing resources, and the cost of training an excellent model is huge. Therefore, a simple and low-cost method that does not require pre-training using a multi-level attention mechanism makes character-level and word-level encoders more meaningful for specific word information.
在NER任务中,梯度消失或梯度爆炸问题是我们经常遇到的,但是通过使用双向长短期记忆网络(BLSTM),本实施例的命名实体识别神经网络模型可以在任何生物医学文本语句的两侧获取上下文信息,消除了前馈神经网络中的有限环境问题。CRF作为马尔可夫随机场的变体,有效的处理了标记和划分序列结构数据的概率问题。In NER tasks, we often encounter the problem of gradient disappearance or gradient explosion, but by using the bidirectional long short-term memory network (BLSTM), the named entity recognition neural network model of this embodiment can be used on both sides of any biomedical text sentence Obtaining contextual information eliminates the bounded-environment problem in feed-forward neural networks. As a variant of Markov Random Field, CRF effectively deals with the probability problem of labeling and dividing sequence structure data.
实施例二Embodiment two
本公开的目的是为了提高生物学命名实体识别的准确率。为了使本发明更加清楚,下面将结合附图和具体实例对本发明进行详细描述。The purpose of the present disclosure is to improve the accuracy of biological named entity recognition. In order to make the present invention clearer, the present invention will be described in detail below in conjunction with the accompanying drawings and specific examples.
在之前的研究中,我们可以了解到,通过卷积神经网络对字符进行特征采样作为单词嵌入的扩展,可以提高命名实体识别任务的性能。在本实施例中,介绍了两种基于字符的技术:局部注意机制、全局注意机制以及基于单词的单词嵌入注意机制;最后介绍了一种多层次交叉注意力信息融合机制,称之为多维融合技术。In previous studies, we can learn that character feature sampling via convolutional neural networks as an extension of word embeddings can improve the performance of named entity recognition tasks. In this example, two character-based techniques are introduced: local attention mechanism, global attention mechanism, and word-based word embedding attention mechanism; finally, a multi-level cross-attention information fusion mechanism is introduced, which is called multidimensional fusion technology.
基于字符的局部注意机制(LAM)如图2所示。采用注意机制来挖掘局部字符的关键成分,以便将字符嵌入到单词中,然后使用最大池化来提取单词嵌入。作为原生词嵌入的扩展,它增加了嵌入词的信息量。LAM的细节如下:The character-based local attention mechanism (LAM) is shown in Fig. 2. An attention mechanism is employed to mine key components of local characters in order to embed characters into words, and then max-pooling is used to extract word embeddings. As an extension of native word embedding, it increases the information content of embedded words. The details of the LAM are as follows:

实施例三Embodiment three
基于字符的全局注意机制(GAM)如图3所示。在训练过程中,对每一批中所有句子的字符进行合并,然后利用注意机制在全局字符级提取单词嵌入。直接在全局字符集上使用注意机制可能会丢失上下文信息。在以往的工作中,首先利用BiLSTM提取字符上下文信息,然后利用注意力机制进行计算。在我们的实验中,我们发现使用BiGRU不仅可以获得更好的上下文信息,而且可以获得更好的计算效率。GAM描述的具体算法如下:The character-based global attention mechanism (GAM) is shown in Fig. 3. During training, the characters of all sentences in each batch are merged, and then an attention mechanism is used to extract word embeddings at the global character level. Using the attention mechanism directly on the global character set may lose contextual information. In previous work, BiLSTM is first used to extract character context information, and then the attention mechanism is used for calculation. In our experiments, we found that using BiGRU not only obtains better context information, but also achieves better computational efficiency. The specific algorithm described by GAM is as follows:


词汇水平的局部注意机制在以往的研究中被多次使用。单词注意机制可以准确地提取单词嵌入之间的注意分布。另外,已有研究表明,在计算注意机制后,使用BiLSTM进行特征提取的效果并不理想。因此,本实施例使用BiGRU来提取上下文信息。The local attention mechanism at the vocabulary level has been used many times in previous studies. The word attention mechanism can accurately extract the attention distribution among word embeddings. In addition, existing studies have shown that the effect of using BiLSTM for feature extraction after computing the attention mechanism is not ideal. Therefore, this embodiment uses BiGRU to extract context information.


NER任务的多层次特征融合是一种强大而有效的策略,可以利用最重要的功能来获得更好的结果。本实施例并不是简单地将多维特征信息直接连接起来。在连接两种不同维度的特征时,首次引入了交叉注意机制。对于这两个层次的特征,采用注意机制来计算双方的注意分数,然后对它们进行融合,得到多层次的单词嵌入。值得注意的是,为了使这两个层次的特征能够计算注意力,BiLSTM或BiGRU被用来标准化维度。具体计算过程如下:Multi-level feature fusion for NER tasks is a powerful and effective strategy to exploit the most important features to achieve better results. This embodiment does not simply directly connect multi-dimensional feature information. For the first time, a cross-attention mechanism is introduced when concatenating features of two different dimensions. For these two levels of features, an attention mechanism is adopted to calculate the attention scores of both sides, and then they are fused to obtain multi-level word embeddings. It is worth noting that in order to enable the computation of attention on these two levels of features, BiLSTM or BiGRU is used to normalize the dimensions. The specific calculation process is as follows:
f1=BiRNN[f1]f1 =BiRNN[f1 ]
f2=BiRNN[f2]f2 =BiRNN[f2 ]


n1=softmax[m1]n1 =softmax[m1]
n2=softmax[m2]n2 =softmax[m2]


a1=o1⊙f1a1 =o1 ⊙f1
a2=o2⊙f2a2 =o2 ⊙f2
Att=[a1,a2]Att=[a1 ,a2 ]
在双向长短期记忆(BiLSTM)这一层,有输入、忘记和输出三个控制门,来保护和控制细胞状态,捕捉更好的双向语义依赖,通过调整上下文中相关信息的权重,来掌握该信息对预测对象的影响程度。隐藏层使用一个sigmod函数。单个的LSTM单元,其控制结构为:In the bidirectional long short-term memory (BiLSTM) layer, there are three control gates of input, forget and output to protect and control the cell state, capture better bidirectional semantic dependencies, and adjust the weight of relevant information in the context to master the The degree of influence of information on the predicted object. The hidden layer uses a sigmod function. For a single LSTM unit, its control structure is:
it=σ(Wiht-1+UiXt+bi)it =σ(Wi ht-1 +UiXt +bi )
ft=σ(Wfht-1+UfXt+bf)ft =σ(Wf ht-1 +UfXt +bf )


ot=σ(Woht-1+UoX1+bo)ot =σ(Wo ht-1 +UoX1 +bo )
ht=ot⊙tanh(ct)ht =ot ⊙tanh(ct )
在生物医学领域,对基因、疾病、蛋白质进行命名时,一般采用{B,I,O}、{B,I,O,E,S}等标签方式对实体进行标注,B指实体的起始,I指实体的内部,E指实体的结尾,O指非实体的组成部分。例如,“B-GENE”是指基因结构的起始位置标签。BiLSTM输出的是标签分值,如果从中挑选分值最高的最为该单元的标签,这种方法是不准确的,需要借助CRF层来确保标签的合法性。In the field of biomedicine, when naming genes, diseases, and proteins, labels such as {B,I,O}, {B,I,O,E,S} are generally used to label entities, and B refers to the starting point of the entity , I refers to the interior of the entity, E refers to the end of the entity, and O refers to the non-component of the entity. For example, "B-GENE" refers to the start position label of the gene structure. The output of BiLSTM is the label score. If the label with the highest score is selected as the label of the unit, this method is not accurate, and the CRF layer is needed to ensure the legitimacy of the label.
实施例四Embodiment four
本实施例提供了一种生物医学命名实体识别的系统;This embodiment provides a biomedical named entity recognition system;
一种生物医学命名实体识别的系统,包括:A system for biomedical named entity recognition, comprising:
词嵌入模块,被配置为:对于字符、词利用注意力机制进行特征采样分别得到单词嵌入的拓展,然后使用最大池化层来提取单词嵌入;The word embedding module is configured to: use the attention mechanism to perform feature sampling for characters and words to obtain the expansion of word embeddings, and then use the maximum pooling layer to extract word embeddings;
特征融合模块,被配置为:采用注意机制将不同层次的单词嵌入进行融合,得到多层次的单词嵌入;The feature fusion module is configured to: use an attention mechanism to fuse word embeddings at different levels to obtain multi-level word embeddings;
模型训练模块,被配置为:将所述多层次的单词嵌入输入命名实体识别神经网络模型中进行训练,获得训练好的命名实体识别神经网络模型;The model training module is configured to: embed the multi-level words into the named entity recognition neural network model for training, and obtain the trained named entity recognition neural network model;
输出模块,被配置为:将待识别的生物医学命名实体输入训练好的命名实体识别神经网络模型,得到实体识别结果。The output module is configured to: input the biomedical named entity to be recognized into the trained named entity recognition neural network model to obtain the entity recognition result.
此处需要说明的是,上述词嵌入模块、特征融合模块、模型训练模块以及输出模块,对应于实施例一中的具体步骤,上述模块与对应的步骤所实现的示例和应用场景相同,但不限于上述实施例一所公开的内容。需要说明的是,上述模块作为系统的一部分可以在诸如一组计算机可执行指令的计算机系统中执行。What needs to be explained here is that the above-mentioned word embedding module, feature fusion module, model training module and output module correspond to the specific steps in Embodiment 1. The examples and application scenarios implemented by the above-mentioned modules are the same as those of the corresponding steps, but not It is limited to the content disclosed in the first embodiment above. It should be noted that, as a part of the system, the above-mentioned modules can be executed in a computer system such as a set of computer-executable instructions.
实施例五Embodiment five
一种计算机可读存储介质,用于存储计算机指令,所述计算机指令被处理器执行时,完成如上述实施例中所述的生物医学命名实体识别的方法。A computer-readable storage medium is used for storing computer instructions, and when the computer instructions are executed by a processor, the method for biomedical named entity recognition as described in the above-mentioned embodiments is completed.
实施例六Embodiment six
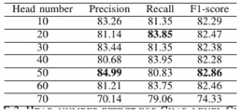
图4是本公开的实施例中基于字符的局部注意力实验效果图,如图4所示,在字符级别上面的数据对不同的注意力头数目的影响,也就是指的是通过增加头的数目探索,一个效果最好的参数;Fig. 4 is an effect diagram of a local attention experiment based on characters in an embodiment of the present disclosure. As shown in Fig. 4, the influence of the data on the character level on the number of different attention heads, that is, by increasing the number of heads number exploration, a parameter with the best effect;
实施例七Embodiment seven
图5是本公开的实施例中交叉注意力融合方法针在字符局部注意力实验效果图,如图5所示,在得到字符注意力的情况下,对比了直接拼接输入步骤三,利用注意力交叉融合的方式拼接输入步骤三,再进行交叉融合人以后的词嵌入再与原始嵌入做拼接。Fig. 5 is an experimental effect diagram of the cross-attention fusion method in the embodiment of the present disclosure aimed at the local attention of characters. Step 3 of splicing input in the way of cross-fusion, and then perform cross-fusion after word embedding and splicing with the original embedding.
实施例八Embodiment Eight
图6是本公开的实施例中基于字符的全局注意力实验效果图,如图6所示,测试了在不同的word级别的注意力头数对于性能影响。FIG. 6 is an experimental effect diagram of character-based global attention in an embodiment of the present disclosure. As shown in FIG. 6 , the influence of the number of attention heads at different word levels on performance is tested.
实施例九Embodiment nine
图7是本公开的实施例中交叉注意力融合方法针在字符全局注意力实验效果图,如图7所示,对比了词级别的数据影响。FIG. 7 is an experimental effect diagram of the cross-attention fusion method in the embodiment of the present disclosure for the global attention of characters. As shown in FIG. 7 , the impact of word-level data is compared.
实施例十Embodiment ten
图8是本公开的实施例中基于词的局部注意力实验效果图,如图8所示,对比了词级信息,对于直接利用注意力嵌入、利用b i l stm以后再注意力提取、利用交叉注意力增加字符信息影响以后的区分效果对比。Fig. 8 is an experimental effect diagram of local attention based on words in the embodiment of the present disclosure. As shown in Fig. 8, comparing word-level information, for direct use of attention embedding, use of b i l stm and then attention extraction, and use of cross-attention The comparison of the effect of distinguishing after the effect of increasing the character information.
以上所述仅为本公开的优选实施例而已,并不用于限制本公开,对于本领域的技术人员来说,本公开可以有各种更改和变化。凡在本公开的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本公开的保护范围之内。The above descriptions are only preferred embodiments of the present disclosure, and are not intended to limit the present disclosure. For those skilled in the art, the present disclosure may have various modifications and changes. Any modifications, equivalent replacements, improvements, etc. made within the spirit and principles of the present disclosure shall be included within the protection scope of the present disclosure.
上述虽然结合附图对本公开的具体实施方式进行了描述,但并非对本公开保护范围的限制,所属领域技术人员应该明白,在本公开的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本公开的保护范围以内。Although the specific implementation of the present disclosure has been described above in conjunction with the accompanying drawings, it does not limit the protection scope of the present disclosure. Those skilled in the art should understand that on the basis of the technical solutions of the present disclosure, those skilled in the art do not need to pay creative work Various modifications or variations that can be made are still within the protection scope of the present disclosure.
Claims (9)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011519249.5ACN112541356B (en) | 2020-12-21 | 2020-12-21 | Method and system for recognizing biomedical named entities |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011519249.5ACN112541356B (en) | 2020-12-21 | 2020-12-21 | Method and system for recognizing biomedical named entities |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN112541356A CN112541356A (en) | 2021-03-23 |
| CN112541356Btrue CN112541356B (en) | 2022-12-06 |
Family
ID=75019343
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202011519249.5AActiveCN112541356B (en) | 2020-12-21 | 2020-12-21 | Method and system for recognizing biomedical named entities |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN112541356B (en) |
Families Citing this family (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20220159213A (en)* | 2021-05-25 | 2022-12-02 | 삼성에스디에스 주식회사 | Method and apparatus for embedding neural network architecture |
| CN113779993B (en)* | 2021-06-09 | 2023-02-28 | 北京理工大学 | Medical entity identification method based on multi-granularity text embedding |
| CN113486666A (en)* | 2021-07-07 | 2021-10-08 | 济南超级计算技术研究院 | Medical named entity recognition method and system |
| CN113723051B (en)* | 2021-08-26 | 2023-09-15 | 泰康保险集团股份有限公司 | Text labeling method and device, electronic equipment and storage medium |
| CN113901843B (en)* | 2021-09-07 | 2025-05-30 | 昆明理工大学 | Chinese-Vietnamese neural machine translation method integrating BERT and word embedding dual representation |
| CN113838524B (en)* | 2021-09-27 | 2024-04-26 | 电子科技大学长三角研究院(衢州) | S-nitrosylation site prediction method, model training method and storage medium |
| CN113962223B (en)* | 2021-09-30 | 2024-10-29 | 西安交通大学 | Named entity recognition method, system, equipment and storage medium based on representation learning |
| CN114282539A (en)* | 2021-12-14 | 2022-04-05 | 重庆邮电大学 | A Named Entity Recognition Method Based on Pre-trained Models in Biomedical Domain |
| CN115238698B (en)* | 2022-08-12 | 2025-06-17 | 山东海量信息技术研究院 | Biomedical named entity recognition method and system |
| CN116451690B (en)* | 2023-03-21 | 2024-12-27 | 麦博(上海)健康科技有限公司 | A method for named entity recognition in the medical field |
| CN116611436B (en)* | 2023-04-18 | 2024-07-09 | 广州大学 | Threat information-based network security named entity identification method |
| CN116861977A (en)* | 2023-06-20 | 2023-10-10 | 上海蜜度信息技术有限公司 | Natural language processing methods, systems, model training methods, media and equipment |
| CN119623470A (en)* | 2024-11-21 | 2025-03-14 | 重庆邮电大学 | A genome variation named entity recognition method and system based on feature fusion and multi-task learning |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110059217A (en)* | 2019-04-29 | 2019-07-26 | 广西师范大学 | A kind of image text cross-media retrieval method of two-level network |
| CN110750992A (en)* | 2019-10-09 | 2020-02-04 | 吉林大学 | Named entity recognition method, device, electronic equipment and medium |
| CN111813907A (en)* | 2020-06-18 | 2020-10-23 | 浙江工业大学 | A Question Intention Recognition Method in Natural Language Question Answering Technology |
| CN111914097A (en)* | 2020-07-13 | 2020-11-10 | 吉林大学 | Entity extraction method and device based on attention mechanism and multi-level feature fusion |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110334213B (en)* | 2019-07-09 | 2021-05-11 | 昆明理工大学 | Method for identifying time sequence relation of Hanyue news events based on bidirectional cross attention mechanism |
| CN110675860A (en)* | 2019-09-24 | 2020-01-10 | 山东大学 | Speech information recognition method and system based on improved attention mechanism combined with semantics |
- 2020
- 2020-12-21CNCN202011519249.5Apatent/CN112541356B/enactiveActive
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110059217A (en)* | 2019-04-29 | 2019-07-26 | 广西师范大学 | A kind of image text cross-media retrieval method of two-level network |
| CN110750992A (en)* | 2019-10-09 | 2020-02-04 | 吉林大学 | Named entity recognition method, device, electronic equipment and medium |
| CN111813907A (en)* | 2020-06-18 | 2020-10-23 | 浙江工业大学 | A Question Intention Recognition Method in Natural Language Question Answering Technology |
| CN111914097A (en)* | 2020-07-13 | 2020-11-10 | 吉林大学 | Entity extraction method and device based on attention mechanism and multi-level feature fusion |
Non-Patent Citations (2)
| Title |
|---|
| 基于结合多头注意力机制BiGRU网络的生物医学命名实体识别;徐凯等;《计算机应用与软件》;20200512(第05期);全文* |
| 融合注意力机制和BiLSTM+CRF的渔业标准命名实体识别;程名等;《大连海洋大学学报》;20200415(第02期);全文* |
Also Published As
| Publication number | Publication date |
|---|---|
| CN112541356A (en) | 2021-03-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN112541356B (en) | Method and system for recognizing biomedical named entities | |
| CN108460013B (en) | A sequence tagging model and method based on a fine-grained word representation model | |
| CN108829801B (en) | An event-triggered word extraction method based on document-level attention mechanism | |
| CN112926324B (en) | Vietnamese Event Entity Recognition Method Fusion Dictionary and Adversarial Transfer | |
| CN109325231B (en) | A method for generating word vectors by a multi-task model | |
| Gao et al. | Named entity recognition method of Chinese EMR based on BERT-BiLSTM-CRF | |
| CN111738007B (en) | Chinese named entity identification data enhancement algorithm based on sequence generation countermeasure network | |
| CN110232192A (en) | Electric power term names entity recognition method and device | |
| CN112818118B (en) | Reverse translation-based Chinese humor classification model construction method | |
| CN116151256A (en) | A Few-Shot Named Entity Recognition Method Based on Multi-task and Hint Learning | |
| CN113190656A (en) | Chinese named entity extraction method based on multi-label framework and fusion features | |
| CN111666758A (en) | Chinese word segmentation method, training device and computer readable storage medium | |
| CN112765956A (en) | Dependency syntax analysis method based on multi-task learning and application | |
| CN110597997A (en) | A military scenario text event extraction corpus iterative construction method and device | |
| CN110110324A (en) | A kind of biomedical entity link method that knowledge based indicates | |
| CN114818717A (en) | Chinese named entity recognition method and system fusing vocabulary and syntax information | |
| CN113360667B (en) | Biomedical trigger word detection and named entity identification method based on multi-task learning | |
| CN114692615B (en) | Small sample intention recognition method for small languages | |
| CN115600597A (en) | Named entity identification method, device and system based on attention mechanism and intra-word semantic fusion and storage medium | |
| CN111191464A (en) | Semantic similarity calculation method based on combined distance | |
| CN119272774B (en) | Chinese named entity recognition method based on hierarchical label enhanced contrast learning | |
| CN114722818A (en) | Named entity recognition model based on anti-migration learning | |
| CN115455144A (en) | Data enhancement method of completion type space filling type for small sample intention recognition | |
| CN115510230A (en) | Mongolian emotion analysis method based on multi-dimensional feature fusion and comparative reinforcement learning mechanism | |
| CN116401373B (en) | A method, storage medium and device for marking test knowledge points |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |