CN112506673A - Intelligent edge calculation-oriented collaborative model training task configuration method - Google Patents
Intelligent edge calculation-oriented collaborative model training task configuration methodDownload PDFInfo
- Publication number
- CN112506673A CN112506673ACN202110153068.3ACN202110153068ACN112506673ACN 112506673 ACN112506673 ACN 112506673ACN 202110153068 ACN202110153068 ACN 202110153068ACN 112506673 ACN112506673 ACN 112506673A
- Authority
- CN
- China
- Prior art keywords
- training
- edge
- time slot
- model
- global
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images


Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5061—Partitioning or combining of resources
- G06F9/5072—Grid computing
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2209/00—Indexing scheme relating to G06F9/00
- G06F2209/50—Indexing scheme relating to G06F9/50
- G06F2209/502—Proximity
Landscapes
- Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Medical Informatics (AREA)
- Evolutionary Computation (AREA)
- Data Mining & Analysis (AREA)
- Computing Systems (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Artificial Intelligence (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本发明涉及一种协同模型训练任务配置方法,具体涉及一种面向智能边缘计算的协同模型训练任务配置方法。The invention relates to a collaborative model training task configuration method, in particular to a collaborative model training task configuration method oriented to intelligent edge computing.
背景技术Background technique
在用户使用移动设备,如手机、平板电脑等的过程中会产生大量用户数据,包括浏览记录、打字记录以及各类日志信息等。这些数据在被分析处理后,能够帮助服务提供商进行更好的服务部署与提供。这类分析处理手段往往借助于机器学习模型。具体来说,一个机器学习模型包含模型结构和模型参数,以及该机器学习模型在某一特定数据集上所体现出的精度,如用分类模型对某一数据集进行分类,得到的正确分类比例作为模型精度。那么,服务提供商的目标,就是要利用各用户分布式产生的用户数据,对某一特定的机器学习模型进行训练,以求能够得到最好的模型精度。这样,服务提供商就可以利用这些机器学习模型对外提供更好的推断类服务。例如,在用户浏览商品的时候结合商品分类为用户进行商品推荐;在用户打字的时候,结合上下文进行热词推荐;或者在导航的时候,利用更精确的导航模型进行路线制定。When users use mobile devices, such as mobile phones and tablet computers, a large amount of user data will be generated, including browsing records, typing records, and various log information. After these data are analyzed and processed, they can help service providers to deploy and provide better services. Such analytical processing methods often rely on machine learning models. Specifically, a machine learning model includes the model structure and model parameters, as well as the accuracy of the machine learning model on a specific data set, such as the correct classification ratio obtained by classifying a data set with a classification model as model accuracy. Then, the goal of the service provider is to use the user data distributed by each user to train a specific machine learning model in order to obtain the best model accuracy. In this way, service providers can use these machine learning models to provide better inference-like services to the outside world. For example, when users browse products, they can recommend products for users in combination with product categories; when users are typing, they can recommend hot words in combination with context; or when navigating, use more accurate navigation models to formulate routes.
虽然把所有的用户数据汇聚到数据中心进行处理,就可以按照如上的训练方式得到机器学习模型。但是,在边缘环境下,这样的原始数据汇聚是被禁止的。其原因是:1)出于隐私的保护,用户往往不愿将自己的原始数据进行上传。2)服务提供商往往是租借运营商的边缘设备进行计算和传输。将各移动设备上的用户数据传输至数据中心,会带来高昂的跨域传输。这里的跨域同时包含两个含义:跨地域范围传输以及跨运营商至数据中心传输。Although all user data is aggregated into the data center for processing, the machine learning model can be obtained according to the above training method. However, in edge environments, such aggregation of raw data is prohibited. The reasons are: 1) For the protection of privacy, users are often reluctant to upload their own original data. 2) Service providers often rent operators' edge devices for computing and transmission. Transferring user data from various mobile devices to a data center can result in expensive cross-domain transfers. The cross-domain here also includes two meanings: cross-regional transmission and cross-operator-to-data center transmission.
由于边缘场景下用户使用移动设备的习惯不同,即使用设备的时间、频度不同以及使用过程中产生的数据规模、内容不同,以至于在进行分布式机器学习训练的时候存在着不确定性。即使某一时段内设备固定,所有用户数据均已生成,如何利用移动设备和边缘计算节点进行分布式机器学习训练,以能够在保证模型训练精度下尽可能节省边缘训练资源是关键问题。Due to the different habits of users using mobile devices in edge scenarios, that is, the time and frequency of using the devices, and the scale and content of data generated during use, there is uncertainty when conducting distributed machine learning training. Even if the device is fixed for a certain period of time and all user data has been generated, how to use mobile devices and edge computing nodes for distributed machine learning training to save edge training resources as much as possible while ensuring model training accuracy is a key issue.
发明内容SUMMARY OF THE INVENTION
发明目的:为了克服现有技术中存在的不足,本发明一方面提供一种面向智能边缘计算的协同模型训练任务配置方法,以解决分布式机器学习训练数据难以共享的问题,且在保证精度的情况下,尽量节省资源消耗。Purpose of the invention: In order to overcome the deficiencies in the prior art, on the one hand, the present invention provides a collaborative model training task configuration method oriented to intelligent edge computing, so as to solve the problem that the distributed machine learning training data is difficult to share, and ensure the accuracy. In this case, try to save resource consumption as much as possible.
技术方案:本发明的一种面向智能边缘计算的协同模型训练任务配置方法,用于边缘计算节点且包括一或多个训练时隙。该方法的每一训练时隙包括如下步骤:向一或多个边缘设备发送模型训练请求;接收来自所述一或多个边缘设备响应于所述模型训练请求而汇报的当前时隙的可用状态和用户数据规模;基于上一训练时隙得到的任务配置结果,从当前可用边缘设备中选定参与训练的边缘设备,并确定交互模型训练所需的训练小轮数目;与参与训练的边缘设备进行交互模型训练直至达到确定的训练小轮数目;根据训练效果和各边缘设备汇报的当前时隙的用户数据规模,构建以最小化边缘训练资源的使用为目标的优化问题并求解,得到用于下一训练时隙的新的任务配置结果。Technical solution: A collaborative model training task configuration method for intelligent edge computing of the present invention is used for edge computing nodes and includes one or more training time slots. Each training time slot of the method includes the steps of: sending a model training request to one or more edge devices; receiving the available status of the current time slot reported by the one or more edge devices in response to the model training request and user data scale; based on the task configuration results obtained in the previous training time slot, select edge devices participating in training from the currently available edge devices, and determine the number of training rounds required for interactive model training; Carry out interactive model training until the number of training rounds is reached; according to the training effect and the user data scale of the current time slot reported by each edge device, construct and solve the optimization problem aiming at minimizing the use of edge training resources, and obtain the The new task configuration result for the next training slot.
进一步地,任务配置结果包括:用于决策是否选择第i个边缘设备在训练时隙t内参与训练的参与者决策量

进一步地,训练时隙t内所需训练小轮数目


其中,K为常数。whereK is a constant.
进一步地,与参与训练的边缘设备进行交互模型训练时,训练时隙t内每一训练小轮具体包括:Further, when performing interactive model training with edge devices participating in the training, each training wheel in the training time slott specifically includes:
(1)边缘计算节点将先前训练所得的全局训练模型参数





(2)边缘计算节点在接收到所有参与训练的边缘设备发送的对全局训练模型参数的更新





(3)边缘计算节点基于接收到的各边缘设备的局部精度修正梯度

(4)若当前训练小轮达到当前训练时隙t所需的训练小轮数目




进一步地,步骤(1)中,参与训练的边缘设备根据接收到的数据分别计算各自对全局训练模型参数的更新








其中

进一步地,步骤(2)中,新的全局模型参数

其中,


进一步地,步骤(2)中,新的局部精度






进一步地,步骤(3)中,新的全局精度修正梯度

其中,
进一步地,所述训练效果包括:训练时隙t内达到确定的训练小轮数目




进一步地,所述优化问题表示为:Further, the optimization problem is expressed as:
目标函数:
约束条件:Restrictions:
1)
2)
3)
4)
5)
其中,

















有益效果:与现有技术相比,本发明具有以下优点:Beneficial effect: Compared with the prior art, the present invention has the following advantages:
1、通过在交互训练过程中构建优化函数进行更新,边缘设备无需直接发送自身模型参数的原始数据至边缘计算节点,而是发送与自身原始数据相关的更新数据。这可以解决由于隐私的保护,用户往往不愿将自己的原始数据进行上传的问题,适用于分布式机器学习训练。1. By constructing an optimization function for updating in the interactive training process, the edge device does not need to directly send the original data of its own model parameters to the edge computing node, but sends the updated data related to its own original data. This can solve the problem that users are often reluctant to upload their own original data due to privacy protection, and is suitable for distributed machine learning training.
2、基于交互训练的效果构建最小化边缘训练资源的使用为目标的优化问题并求解,从而决策得到下一训练时隙的任务配置,包括下一训练时隙各边缘设备的选择偏好和训练小轮数目。根据决策结果,从可用边缘设备中选取参与训练的边缘设备进行训练,而不需要使所有边缘设备均参与训练,这使本申请的协同训练任务配置方法至少减少27%的资源消耗开销,训练精度则最多降低4%。换言之,本发明能够在保证训练精度的同时,大幅度减少训练资源消耗。2. Based on the effect of interactive training, an optimization problem with the goal of minimizing the use of edge training resources is constructed and solved, so as to obtain the task configuration of the next training time slot, including the selection preference and training time of each edge device in the next training time slot. number of rounds. According to the decision result, the edge devices participating in the training are selected from the available edge devices for training, and all edge devices do not need to participate in the training, which reduces the resource consumption overhead by at least 27% in the collaborative training task configuration method of the present application, and the training accuracy It is reduced by up to 4%. In other words, the present invention can greatly reduce the consumption of training resources while ensuring the training accuracy.
附图说明Description of drawings
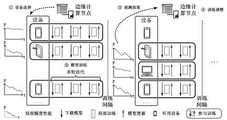
图1是面向智能边缘计算的协同模型训练系统的结构示意图;Figure 1 is a schematic structural diagram of a collaborative model training system for intelligent edge computing;
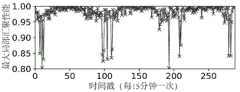
图2是应用任务配置方法后实际使用各边缘计算资源作训练的训练资源花费变化情况;Figure 2 shows the change in the cost of training resources actually using each edge computing resource for training after applying the task configuration method;
图3是应用任务配置方法后全局精度的变化情况;Figure 3 shows the change of global accuracy after applying the task configuration method;
图4是应用任务配置方法后最大局部汇聚性能的变化情况。Figure 4 shows the change of the maximum local convergence performance after applying the task configuration method.
具体实施方式Detailed ways
下面结合附图对本发明所公开的方法做进一步的详细介绍。The method disclosed in the present invention will be further described in detail below with reference to the accompanying drawings.
本发明的面向智能边缘计算的协同模型训练任务配置方法用于边缘计算节点,且包括一或多个训练时隙。每一训练时隙包括如下步骤:The intelligent edge computing-oriented collaborative model training task configuration method of the present invention is used for edge computing nodes, and includes one or more training time slots. Each training slot includes the following steps:
S1:向一或多个边缘设备发送模型训练请求。这里的边缘设备可以是连接边缘计算节点的移动设备、笔记本电脑等。S1: Send a model training request to one or more edge devices. The edge devices here can be mobile devices, laptops, etc. connected to edge computing nodes.
S2:接收来自所述一或多个边缘设备响应于所述模型训练请求而汇报的当前时隙的可用状态和用户数据规模。S2: Receive the available status and user data scale of the current time slot reported by the one or more edge devices in response to the model training request.
S3:基于上一训练时隙得到的任务配置结果,从当前可用边缘设备中选定参与训练的边缘设备,并确定交互模型训练所需的训练小轮数目。其中,该步骤中上一训练时隙得到的任务配置结果包括:用于决策是否选择第i个边缘设备在训练时隙t内参与训练的参与者决策量

其中,当前训练时隙t内所需训练小轮数目


其中,K为常数。whereK is a constant.
当前训练时隙t内参与训练的边缘设备则基于参与者决策量


S4:与参与训练的边缘设备进行交互模型训练直至达到确定的训练小轮数目。S4: Perform interactive model training with edge devices participating in training until a certain number of training rounds is reached.
在步骤S4中,与参与训练的边缘设备进行交互模型训练时,每一训练小轮具体包括如下过程:In step S4, when performing interactive model training with edge devices participating in the training, each training round specifically includes the following processes:
S41:边缘计算节点将先前训练所得的全局训练模型参数





其中,参与训练的边缘设备根据接收到的数据分别计算各自对全局训练模型参数的更新
各参与训练的边缘设备利用获取的







其中

通过构建优化函数
S42:边缘计算节点在接收到所有参与训练的边缘设备发送的对全局训练模型参数的更新





该步骤中:新的全局模型参数

其中,





新的局部精度






S43:边缘计算节点基于接收到的各局部精度修正梯度

该步骤中,新的全局精度修正梯度

其中,
若当前训练小轮达到当前训练时隙t所需的训练小轮数目




S5:根据训练效果和各边缘设备汇报的当前时隙的用户数据规模,构建以最小化边缘训练资源的使用为目标的优化问题并求解,得到用于下一训练时隙的新的任务配置结果。S5: According to the training effect and the user data scale of the current time slot reported by each edge device, construct and solve an optimization problem aiming at minimizing the use of edge training resources, and obtain a new task configuration result for the next training time slot .
在步骤S5中,训练效果包括:训练时隙t内达到确定的训练小轮数目




边缘计算节点的总体目标旨在为所有训练(
优化目标:
约束条件:Restrictions:
1) 对于边缘传输限制:
2) 对于参与者选择控制:
3) 对于全局后验精度要求:
4) 对于决策的定义域限制:
式中,




















由于是在线场景,决策时无法准确观测到实际的训练效果,因此上述优化问题在实际中只能分解到每一训练时隙中,进行每一次子问题的求解。再者,每一次子问题的求解中,并不能提前观测到该次训练的局部汇聚精度


目标函数:
约束条件:Restrictions:
1)
2)
3)
4)
5)
其中,

在上述子问题求解中,虽然目标函数里

图1以四个边缘设备的选择为例展示了本发明的面向智能边缘计算的协同模型训练系统的结构,其中所有的边缘设备均与同一个边缘计算节点相连并进行数据交互,且边缘网络能够允许传输的最大容量可以包含四个边缘设备;下面以两次全局模型训练为例,对本发明的面向智能边缘计算的协同模型训练任务配置方法作进一步的说明:Fig. 1 shows the structure of the intelligent edge computing-oriented collaborative model training system of the present invention by taking the selection of four edge devices as an example, wherein all edge devices are connected to the same edge computing node and perform data exchange, and the edge network can The maximum capacity allowed for transmission can include four edge devices; the following takes two global model training as an example to further illustrate the method for configuring the collaborative model training task for intelligent edge computing of the present invention:
(1)在第一次模型训练请求到达时,需要训练的数据分布在三个可用的边缘设备上;由于没有之前的已训练效果作为参考,因此将这三个可用边缘设备都认为是分布式机器学习训练的参与者,三个参与者向边缘计算节点汇报其用户数据规模;(1) When the first model training request arrives, the data to be trained is distributed on the three available edge devices; since there is no previous training effect as a reference, the three available edge devices are considered distributed. Participants in machine learning training, three participants report their user data scale to edge computing nodes;
(2)边缘计算节点初始化全局模型(边缘计算节点维护)、各边缘设备的精度修正梯度以及全局精度修正梯度;(2) The edge computing node initializes the global model (edge computing node maintenance), the accuracy correction gradient of each edge device, and the global accuracy correction gradient;
(3)边缘计算节点将全局模型参数、各边缘设备的精度修正梯度和全局精度修正梯度下发至三个边缘设备;(3) The edge computing node sends the global model parameters, the accuracy correction gradient of each edge device, and the global accuracy correction gradient to the three edge devices;
(4)各边缘设备接收到来自边缘计算设备的信息后,利用自身设备上的用户数据构造精度损失函数,并以最小化


(5)各边缘设备利用
(6)各边缘设备将
(7)边缘计算节点根据各边缘设备发送的
(8)由于当前参与的为所有边缘设备,所以全局精度仅为各边缘设备局部精度的加权平均;(8) Since all edge devices are currently participating, the global accuracy is only the weighted average of the local accuracy of each edge device;
(9)不断进行步骤(3)到步骤(8),直到训练小轮数达到由

(10)观察到三个边缘设备的局部训练效果,即每次小轮的局部汇聚性能,并根据此进行三个边缘设备的偏好修正;(10) Observe the local training effect of the three edge devices, that is, the local convergence performance of each small round, and carry out the preference correction of the three edge devices according to this;
(11)第二次分布式机器学习模型训练请求到达,当前可用的是四个边缘设备;(11) The second distributed machine learning model training request arrives, and four edge devices are currently available;
(12)由于第一个边缘设备在上一次训练中的局部汇聚性能不好,因此边缘计算节点结合各边缘设备的选择偏好,选择除第一个边缘设备外的其他边缘设备作为参与者;(12) Since the local convergence performance of the first edge device in the last training is not good, the edge computing node selects other edge devices except the first edge device as participants in combination with the selection preferences of each edge device;
(13)为第二次分布式机器学习训练进行步骤(2)到步骤(10);(13) Perform steps (2) to (10) for the second distributed machine learning training;
(14)在第二次分布式机器学习训练的步骤(8)中,虽然第一个边缘设备没有进行分布式机器学习训练的参与,但是在验证的时候,仍然需要从边缘计算节点获取最新的模型参数,并利用自身的精度损失函数进行一次验证,得到局部精度,并发送给边缘计算节点。(14) In step (8) of the second distributed machine learning training, although the first edge device does not participate in the distributed machine learning training, it is still necessary to obtain the latest data from the edge computing node during verification. model parameters, and use its own accuracy loss function to perform a verification to obtain the local accuracy and send it to the edge computing node.
实验的效果如图2至图4所示,图2展示了在应用动态任务调整方法后,在不断进行分布式机器学习训练过程中的边缘计算资源消耗变化(已按最大值进行归一化),边缘训练资源消耗为边缘计算节点和各个边缘设备上计算资源花费和每一小轮传输花费的总和,训练资源消耗对比其他方法总是最少,至少减少27%的开销;图3展示了在应用动态任务调整方法后,在不断进行分布式机器学习训练过程中的全局精度变化,实际上对应的是建模中的全局后验精度



本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。As will be appreciated by one skilled in the art, embodiments of the present invention may be provided as a method, system, or computer program product. Accordingly, the present invention may take the form of an entirely hardware embodiment, an entirely software embodiment, or an embodiment combining software and hardware aspects. Furthermore, the present invention may take the form of a computer program product embodied on one or more computer-usable storage media (including, but not limited to, disk storage, CD-ROM, optical storage, etc.) having computer-usable program code embodied therein.
本发明是参照根据本发明实施例的方法、设备(系统)、计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。The present invention is described with reference to flowchart illustrations and/or block diagrams of methods, apparatus (systems), and computer program products according to embodiments of the invention. It will be understood that each flow and/or block in the flowchart illustrations and/or block diagrams, and combinations of flows and/or blocks in the flowchart illustrations and/or block diagrams, can be implemented by computer program instructions. These computer program instructions may be provided to the processor of a general purpose computer, special purpose computer, embedded processor or other programmable data processing device to produce a machine such that the instructions executed by the processor of the computer or other programmable data processing device produce Means for implementing the functions specified in a flow or flow of a flowchart and/or a block or blocks of a block diagram.
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。These computer program instructions may also be stored in a computer-readable memory capable of directing a computer or other programmable data processing apparatus to function in a particular manner, such that the instructions stored in the computer-readable memory result in an article of manufacture comprising instruction means, the instructions The apparatus implements the functions specified in the flow or flow of the flowcharts and/or the block or blocks of the block diagrams.
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。These computer program instructions can also be loaded on a computer or other programmable data processing device to cause a series of operational steps to be performed on the computer or other programmable device to produce a computer-implemented process such that The instructions provide steps for implementing the functions specified in the flow or blocks of the flowcharts and/or the block or blocks of the block diagrams.
最后应当说明的是:以上实施例仅用以说明本发明的技术方案而非对其限制,尽管参照上述实施例对本发明进行了详细的说明,本发明中的控制节点与边缘计算节点的交互方式,收集反馈信息内容与在线调度方法在各系统中均适用,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者等同替换,而未脱离本发明精神和范围的任何修改或者等同替换,其均应涵盖在本发明的权利要求保护范围之内。Finally, it should be noted that the above embodiments are only used to illustrate the technical solutions of the present invention and not to limit them. Although the present invention has been described in detail with reference to the above embodiments, the interaction mode between the control node and the edge computing node in the present invention , the content of the collected feedback information and the online scheduling method are applicable in each system. Those of ordinary skill in the art should understand that the specific embodiments of the present invention can still be modified or equivalently replaced without departing from the spirit and scope of the present invention. Any modification Or equivalent replacements, all of which should be covered within the protection scope of the claims of the present invention.
Claims (10)















































































Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110153068.3ACN112506673B (en) | 2021-02-04 | 2021-02-04 | A collaborative model training task configuration method for intelligent edge computing |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110153068.3ACN112506673B (en) | 2021-02-04 | 2021-02-04 | A collaborative model training task configuration method for intelligent edge computing |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN112506673Atrue CN112506673A (en) | 2021-03-16 |
| CN112506673B CN112506673B (en) | 2021-06-08 |
Family
ID=74953076
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110153068.3AActiveCN112506673B (en) | 2021-02-04 | 2021-02-04 | A collaborative model training task configuration method for intelligent edge computing |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN112506673B (en) |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2020024585A1 (en)* | 2018-08-03 | 2020-02-06 | 华为技术有限公司 | Method and apparatus for training object detection model, and device |
| CN111339554A (en)* | 2020-02-17 | 2020-06-26 | 电子科技大学 | User data privacy protection method based on mobile edge computing |
| CN111367657A (en)* | 2020-02-21 | 2020-07-03 | 重庆邮电大学 | Computing resource collaborative cooperation method based on deep reinforcement learning |
| CN111459505A (en)* | 2020-05-22 | 2020-07-28 | 南京大学 | Method, device and system for deploying multi-version inference model in edge computing environment |
| CN111582016A (en)* | 2020-03-18 | 2020-08-25 | 宁波送变电建设有限公司永耀科技分公司 | Intelligent maintenance-free power grid monitoring method and system based on cloud-edge collaborative deep learning |
| CN111898763A (en)* | 2020-06-03 | 2020-11-06 | 东南大学 | A Robust Byzantine Fault Tolerant Distributed Gradient Descent Algorithm |
| CN112085321A (en)* | 2020-07-30 | 2020-12-15 | 国家电网有限公司 | Station area state evaluation method based on edge calculation |
- 2021
- 2021-02-04CNCN202110153068.3Apatent/CN112506673B/enactiveActive
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2020024585A1 (en)* | 2018-08-03 | 2020-02-06 | 华为技术有限公司 | Method and apparatus for training object detection model, and device |
| CN111339554A (en)* | 2020-02-17 | 2020-06-26 | 电子科技大学 | User data privacy protection method based on mobile edge computing |
| CN111367657A (en)* | 2020-02-21 | 2020-07-03 | 重庆邮电大学 | Computing resource collaborative cooperation method based on deep reinforcement learning |
| CN111582016A (en)* | 2020-03-18 | 2020-08-25 | 宁波送变电建设有限公司永耀科技分公司 | Intelligent maintenance-free power grid monitoring method and system based on cloud-edge collaborative deep learning |
| CN111459505A (en)* | 2020-05-22 | 2020-07-28 | 南京大学 | Method, device and system for deploying multi-version inference model in edge computing environment |
| CN111898763A (en)* | 2020-06-03 | 2020-11-06 | 东南大学 | A Robust Byzantine Fault Tolerant Distributed Gradient Descent Algorithm |
| CN112085321A (en)* | 2020-07-30 | 2020-12-15 | 国家电网有限公司 | Station area state evaluation method based on edge calculation |
Non-Patent Citations (1)
| Title |
|---|
| SHIQIANG WANG 等: "Adaptive Federated Learning in Resource constrained edge computing systems", 《IEEE》* |
Also Published As
| Publication number | Publication date |
|---|---|
| CN112506673B (en) | 2021-06-08 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110610242B (en) | Method and device for setting weights of participants in federal learning | |
| CN112367109B (en) | Incentive method for digital twin-driven federal learning in air-ground network | |
| CN110782042B (en) | Method, device, equipment and medium for combining horizontal federation and vertical federation | |
| CN110443375B (en) | Method and device for federated learning | |
| WO2023124296A1 (en) | Knowledge distillation-based joint learning training method and apparatus, device and medium | |
| Wang et al. | Reputation-enabled federated learning model aggregation in mobile platforms | |
| KR20180081101A (en) | Method and apparatus for optimizing user credit score | |
| CN115270001B (en) | Privacy protection recommendation method and system based on cloud collaborative learning | |
| US20230145177A1 (en) | Federated learning method and federated learning system based on mediation process | |
| CN108289115B (en) | Information processing method and system | |
| CN119025291A (en) | A resource collaborative scheduling method based on graph neural network in computing power network | |
| CN106528614A (en) | Method for predicting geographical location of user in mobile social network | |
| CN115481752A (en) | Model training method and device, electronic equipment and storage medium | |
| CN119537024A (en) | Edge computing task allocation method, device, system, storage medium and product | |
| CN115016889A (en) | A virtual machine optimization scheduling method for cloud computing | |
| CN114760308A (en) | Edge computing offloading method and device | |
| Panigrahi et al. | A reputation-aware hierarchical aggregation framework for federated learning | |
| CN118070873B (en) | Edge digital twin body deployment method based on transfer learning | |
| CN113298115A (en) | User grouping method, device, equipment and storage medium based on clustering | |
| CN112506673B (en) | A collaborative model training task configuration method for intelligent edge computing | |
| CN116720592B (en) | Federated learning model training method, device, non-volatile storage medium and electronic device | |
| CN113743012B (en) | Cloud-edge collaborative mode task unloading optimization method under multi-user scene | |
| Liu et al. | Mitigating bias in heterogeneous federated learning via stratified client selection | |
| CN114912627A (en) | Recommended model training method, system, computer equipment and storage medium | |
| US20120151491A1 (en) | Redistributing incomplete segments for processing tasks in distributed computing |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |