CN112433670B - Migration task scheduling method for decentralized architecture storage system - Google Patents
Migration task scheduling method for decentralized architecture storage systemDownload PDFInfo
- Publication number
- CN112433670B CN112433670BCN202011177017.6ACN202011177017ACN112433670BCN 112433670 BCN112433670 BCN 112433670BCN 202011177017 ACN202011177017 ACN 202011177017ACN 112433670 BCN112433670 BCN 112433670B
- Authority
- CN
- China
- Prior art keywords
- migration
- bandwidth
- migration task
- hard disk
- data
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images




Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/06—Digital input from, or digital output to, record carriers, e.g. RAID, emulated record carriers or networked record carriers
- G06F3/0601—Interfaces specially adapted for storage systems
- G06F3/0628—Interfaces specially adapted for storage systems making use of a particular technique
- G06F3/0646—Horizontal data movement in storage systems, i.e. moving data in between storage devices or systems
- G06F3/0647—Migration mechanisms
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/06—Digital input from, or digital output to, record carriers, e.g. RAID, emulated record carriers or networked record carriers
- G06F3/0601—Interfaces specially adapted for storage systems
- G06F3/0602—Interfaces specially adapted for storage systems specifically adapted to achieve a particular effect
- G06F3/061—Improving I/O performance
- G06F3/0613—Improving I/O performance in relation to throughput
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/06—Digital input from, or digital output to, record carriers, e.g. RAID, emulated record carriers or networked record carriers
- G06F3/0601—Interfaces specially adapted for storage systems
- G06F3/0628—Interfaces specially adapted for storage systems making use of a particular technique
- G06F3/0638—Organizing or formatting or addressing of data
- G06F3/064—Management of blocks
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/06—Digital input from, or digital output to, record carriers, e.g. RAID, emulated record carriers or networked record carriers
- G06F3/0601—Interfaces specially adapted for storage systems
- G06F3/0668—Interfaces specially adapted for storage systems adopting a particular infrastructure
- G06F3/067—Distributed or networked storage systems, e.g. storage area networks [SAN], network attached storage [NAS]
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本发明属于分布式存储技术领域,具体涉及一种针对去中心化架构存储系统的迁移任务调度方法。The invention belongs to the technical field of distributed storage, and in particular relates to a migration task scheduling method for a storage system with a decentralized architecture.
背景技术Background technique
随着人类进入了大数据时代,数据量成爆炸式的增长对存储系统提出了更高的要求,分布式存储系统的可扩展性遇到了巨大挑战,分布式存储系统的容量不断扩展,一方面存储系统需要保证性能的同步提高,另一方面存储系统还需要保持高可靠性和高可用性。为解决此问题,分布式存储技术得到了极大的发展,更多的研究点都集中在了分布式存储的高性能、高可靠性及高可用性上。As human beings have entered the era of big data, the explosive growth of data volume has put forward higher requirements for storage systems. The scalability of distributed storage systems has encountered huge challenges. The capacity of distributed storage systems has continued to expand. On the one hand, The storage system needs to ensure the synchronous improvement of performance. On the other hand, the storage system also needs to maintain high reliability and high availability. In order to solve this problem, distributed storage technology has been greatly developed, and more research points are focused on the high performance, high reliability and high availability of distributed storage.
传统的分布式存储系统使用中心化的架构,将管理节点和存储节点分开,这样的架构在存储节点有限的时候具有很好的性能。但当面对海量的数据存储请求,中心化的管理节点将成为分布式存储系统的性能瓶颈。因为大量的用户访问在与存储节点建立联系前,都需要请求管理节点查询数据的存储位置,中心化架构面临的单点故障和性能瓶颈问题成为了制约中心化架构存储系统可扩展性的关键问题。Traditional distributed storage systems use a centralized architecture that separates management nodes from storage nodes. This architecture has good performance when storage nodes are limited. However, when faced with massive data storage requests, the centralized management node will become the performance bottleneck of the distributed storage system. Because a large number of user accesses need to request the management node to query the storage location of the data before establishing contact with the storage node, the single point of failure and performance bottlenecks faced by the centralized architecture have become the key issues restricting the scalability of the storage system of the centralized architecture. .
去中心化架构存储系统成为分布式存储系统发展的一个趋势,它在元数据管理上通常使用带权重的哈希算法来确定数据放置的位置,当客户端需要存取数据时,只需要在本地运行一遍特定的哈希算法就可以计算得到需要访问的存储节点,之后客户端可以直接与存储节点交互,这样的方法可以消除元数据服务器的性能瓶颈问题。The decentralized architecture storage system has become a trend in the development of distributed storage systems. It usually uses a weighted hash algorithm in metadata management to determine the location of the data. When the client needs to access the data, it only needs to store the data locally. After running a specific hash algorithm, the storage node to be accessed can be calculated, and then the client can directly interact with the storage node. This method can eliminate the performance bottleneck of the metadata server.
为满足海量的数据存储需求,大规模分布式存储系统面临着严峻的挑战,首先是频繁的硬件故障,其中节点故障和硬盘故障最为频繁,严重影响分布式存储系统的可靠性和可用性,当故障发生时,故障节点或硬盘中的数据需要恢复到存储系统其它的存储节点上,这个恢复过程会触发数据迁移,数据迁移对存储系统有两方面影响:一方面数据迁移的快慢直接影响存储系统的可靠性;另一方面,数据迁移会和存储系统中运行的用户应用的访问产生资源竞争,这将导致存储系统的性能下降。In order to meet the massive data storage requirements, large-scale distributed storage systems face severe challenges. First, frequent hardware failures, among which node failures and hard disk failures are the most frequent, which seriously affect the reliability and availability of distributed storage systems. When it occurs, the data in the faulty node or hard disk needs to be restored to other storage nodes in the storage system. This restoration process will trigger data migration. Data migration has two impacts on the storage system. On the one hand, the speed of data migration directly affects the storage system. Reliability; on the other hand, data migration will generate resource competition with the access of user applications running in the storage system, which will reduce the performance of the storage system.
在大规模存储集群中,运行着大量的用户应用,用户应用造成的负载通常是不均匀的,通常体现在存储节点负载的不均衡和存储设备(硬盘)负载的不均衡,这种不均衡的现象为数据迁移任务调度提出了挑战。In a large-scale storage cluster, a large number of user applications are running, and the load caused by user applications is usually uneven, which is usually reflected in the unbalanced load of storage nodes and the unbalanced load of storage devices (hard disks). The phenomenon presents challenges for data migration task scheduling.
目前国内外分布式存储系统在单点故障或者业务需要迁移数据时,由于数据迁移过程对于存储系统上用户应用访问的影响,往往采取简单的限速策略,将每个硬盘提供给迁移任务的带宽设定为固定值。这会导致硬盘带宽利用率较低,迁移速率较慢,系统的可靠性下降等问题。At present, when the distributed storage systems at home and abroad have a single point of failure or the business needs to migrate data, due to the impact of the data migration process on the user application access on the storage system, a simple rate limiting strategy is often adopted to provide each hard disk with the bandwidth of the migration task. Set to a fixed value. This will lead to problems such as low disk bandwidth utilization, slow migration rate, and reduced system reliability.
发明内容SUMMARY OF THE INVENTION
本发明所要解决的技术问题在于针对上述现有技术中的不足,提供一种针对去中心化架构存储系统的迁移任务调度方法,在确保减少影响用户应用访问质量的同时,提高迁移速度。The technical problem to be solved by the present invention is to provide a migration task scheduling method for a decentralized architecture storage system in view of the deficiencies in the above-mentioned prior art, which can improve the migration speed while reducing the impact on the quality of user application access.
本发明采用以下技术方案:The present invention adopts following technical scheme:
一种针对去中心化架构存储系统的迁移任务调度方法,包括以下步骤:A migration task scheduling method for a decentralized architecture storage system, comprising the following steps:
S1、预估每个迁移任务结束后的数据分布,采集参与迁移硬盘带宽数据,建立基于去中心化架构存储系统的迁移任务干扰系数模型;S1. Estimate the data distribution after each migration task ends, collect the bandwidth data of the hard disks participating in the migration, and establish a migration task interference coefficient model based on the decentralized architecture storage system;
S2、为每个迁移任务建立步骤S1得到的迁移任务干扰系数模型,通过观测硬盘观测窗口采样窗口内干扰系数的平均值,当干扰系数平均值小于设定阈值时,执行数据迁移;S2, establishing the migration task interference coefficient model obtained in step S1 for each migration task, by observing the average value of the interference coefficient in the sampling window of the hard disk observation window, when the average value of the interference coefficient is less than the set threshold, perform data migration;
S3、采集硬盘观测窗口内带宽变化调节迁移任务的速率,对迁移任务干扰系数模型的迁移带宽进行分配,实现迁移任务调度。S3. Collect the bandwidth change in the hard disk observation window to adjust the rate of the migration task, allocate the migration bandwidth of the migration task interference coefficient model, and realize the migration task scheduling.
具体的,步骤S1具体为:Specifically, step S1 is specifically:
S101、将文件分割成大小固定的数据块,然后将数据块哈希到具体的存储设备上;通过运行哈希算法得到存储系统中所有数据块的存放位置;S101. Divide the file into data blocks with a fixed size, and then hash the data blocks to a specific storage device; obtain the storage locations of all data blocks in the storage system by running a hash algorithm;
S102、通过模拟一遍去中心化架构存储系统使用的特定哈希算法,估算出每个需要迁移的数据块在迁移结束后新的位置,统计每个硬盘移出和迁入的数据块数,计算得到每个参与迁移硬盘的读写数据量之和Ddata;定义一个10s大小的观测窗口用来监测每个参与迁移硬盘的窗口平均带宽Bused,建立迁移任务干扰系数模型。S102, by simulating a specific hash algorithm used by the decentralized architecture storage system, estimate the new location of each data block to be migrated after the migration, count the number of data blocks moved out and in from each hard disk, and calculate The sum of the read and write data of each hard disk participating in the migration Ddata ; an observation window of 10s size is defined to monitor the window average bandwidth Bused of each hard disk participating in the migration, and a migration task interference coefficient model is established.
进一步的,步骤S102中,迁移任务干扰系数Finterference具体为:Further, in step S102, the migration task interference coefficient Finterference is specifically:

其中,

具体的,步骤S2中,当在观测窗口中观察到迁移任务干扰系数Finterference的平均值低于阈值α时,调度迁移任务开始执行,当观测窗口中观察到的Finterference超过阈值α,等待一个观测窗口,再判断下个观测窗口的迁移任务干扰函数。Specifically, in step S2, when it is observed in the observation window that the average value of the migration task interference coefficient Finterference is lower than the threshold α, the migration task is scheduled to be executed, and when the Finterference observed in the observation window exceeds the threshold α, wait for a Observation window, and then determine the migration task interference function of the next observation window.
进一步的,阈值α计算如下:Further, the threshold α is calculated as follows:

其中,Bideal是硬盘迁移带宽最大值确定时用户应用与迁移任务互不干扰的最大占用带宽,Ddata为硬盘上的迁移数据量。Wherein, Bideal is the maximum occupied bandwidth that the user application and the migration task do not interfere with each other when the maximum value of the hard disk migration bandwidth is determined, and Ddata is the amount of data to be migrated on the hard disk.
具体的,步骤S3中,在迁移任务开始执行后,持续使用观测窗口采集并计算每个参与迁移硬盘的窗口内平均带宽Bwindow,调整参与迁移硬盘下一个窗口内的迁移带宽Bnew_allocation,通过连续的观测窗口动态调节迁移任务的带宽分配,在一个窗口结束后,由上一个观测窗口的统计值计算出下一个窗口的带宽分配值。Specifically, in step S3, after the migration task starts to execute, the observation window is continuously used to collect and calculate the average bandwidth Bwindow in the window of each hard disk participating in the migration, and the migration bandwidth Bnew_allocation in the next window of the hard disk participating in the migration is adjusted. The observation window dynamically adjusts the bandwidth allocation of the migration task. After a window ends, the bandwidth allocation value of the next window is calculated from the statistical value of the previous observation window.
进一步的,参与迁移硬盘下一个窗口内的迁移带宽Bnew_allocation具体为:Further, the migration bandwidth Bnew_allocation in the next window of participating in the migration of the hard disk is as follows:
Bnew_allocation=max(Bold_allocation-(Bwindow-75%×Btotal),Bmin)Bnew_allocation =max(Bold_allocation -(Bwindow -75%×Btotal ),Bmin )
其中,Bold_allocation表示上一个观测窗口硬盘上分配给迁移任务的带宽,Btotal表示硬盘理论带宽,Bmin表示分配给迁移任务的最小带宽。Among them, Bold_allocation represents the bandwidth allocated to the migration task on the hard disk in the previous observation window, Btotal represents the theoretical bandwidth of the hard disk, and Bmin represents the minimum bandwidth allocated to the migration task.
与现有技术相比,本发明至少具有以下有益效果:Compared with the prior art, the present invention at least has the following beneficial effects:
本发明一种针对去中心化架构存储系统的迁移任务调度方法,利用系统原有的数据放置算法,预估迁移后的数据分布,为迁移任务建立干扰系数模型,调度迁移任务执行,并且动态的为迁移任务分配带宽。可以在不影响用户应用延迟的同时,提高存储系统中硬盘的带宽利用率,缩短迁移任务的完成时间。The present invention is a migration task scheduling method for a decentralized architecture storage system, which utilizes the original data placement algorithm of the system to estimate the data distribution after migration, establishes an interference coefficient model for the migration task, schedules the execution of the migration task, and dynamically Allocate bandwidth for migration tasks. It can improve the bandwidth utilization of the hard disks in the storage system and shorten the completion time of the migration task without affecting the user application delay.
进一步的,本发明通过为迁移任务建立干扰系数模型,可以明确量化迁移任务对用户应用的影响指数,通过这个指数确定迁移启动的时机。Further, by establishing an interference coefficient model for the migration task, the present invention can clearly quantify the influence index of the migration task on the user application, and determine the timing of the migration start by using this index.
进一步的,本发明通过模拟一遍去中心化架构存储系统使用的特定哈希算法,估算出每个需要迁移的数据块在迁移结束后新的位置,统计每个硬盘移出和迁入的数据块数,计算得到每个参与迁移硬盘的读写数据量。这个读写数据量将作为干扰系数模型的输入来帮助建立每个迁移任务的干扰系数模型。Further, the present invention estimates the new position of each data block that needs to be migrated after the migration by simulating a specific hash algorithm used by the decentralized architecture storage system, and counts the number of data blocks moved out and in from each hard disk. , and calculate the read and write data volume of each participating hard disk. This amount of read and write data will be used as the input to the interference coefficient model to help build the interference coefficient model for each transfer task.
进一步的,本发明在建立干扰系数模型后,量化了每个迁移任务对于用户应用的干扰系数,通过设定一个不影响用户应用的最大干扰系数阈值,并不断通过观测窗口观测干扰系数的均值,判断干扰系数均值与阈值的关系,进而确定迁移任务启动的具体时间。Further, after establishing the interference coefficient model, the present invention quantifies the interference coefficient of each migration task to the user application, sets a maximum interference coefficient threshold that does not affect the user application, and continuously observes the average value of the interference coefficient through the observation window, Determine the relationship between the mean value of the interference coefficient and the threshold, and then determine the specific time for starting the migration task.
进一步的,本发明在量化了迁移任务对于用户应用的影响后,需要一个阈值来决定迁移任务的启动时机,当量化的干扰系数低于阈值时启动迁移任务。Further, after quantifying the impact of the migration task on the user application, the present invention needs a threshold to determine the start timing of the migration task, and starts the migration task when the quantified interference coefficient is lower than the threshold.
进一步的,由于用户应用的负载是不断变化的,本发明通过观测窗口动态的调整迁移速率,可以维持干扰系数在阈值以下。Further, since the load of the user application is constantly changing, the present invention can maintain the interference coefficient below the threshold by dynamically adjusting the migration rate through the observation window.
进一步的,本发明通过模型设定迁移带宽,可以在通过上一个观测窗口的观测值调整下一个观测窗口的带宽,达到动态速率调整的目的,保证了迁移任务对于用户应用的低干扰。Further, the present invention sets the migration bandwidth through the model, and can adjust the bandwidth of the next observation window based on the observation value of the previous observation window, so as to achieve the purpose of dynamic rate adjustment and ensure low interference of the migration task to the user application.
综上所述,本发明提高了去中心化架构存储系统的数据迁移速度的同时减少了迁移对于用户应用的影响。To sum up, the present invention improves the data migration speed of the decentralized architecture storage system and reduces the impact of migration on user applications.
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。The technical solutions of the present invention will be further described in detail below through the accompanying drawings and embodiments.
附图说明Description of drawings
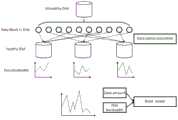
图1为去中心化架构存储系统哈希算法原理示意图;Figure 1 is a schematic diagram of the hash algorithm principle of the decentralized architecture storage system;
图2为迁移任务干扰系数模型示意图;Fig. 2 is a schematic diagram of a migration task interference coefficient model;
图3为迁移任务调度方法流程图;Fig. 3 is the flow chart of the migration task scheduling method;
图4为迁移带宽分配流程图;Fig. 4 is a flow chart of migration bandwidth allocation;
图5为基于观测窗口的迁移调度方法示意图。FIG. 5 is a schematic diagram of a migration scheduling method based on observation windows.
具体实施方式Detailed ways
本发明提供了一种针对去中心化架构存储系统的迁移任务调度方法,针对去中心化架构存储系统的迁移任务干扰系数进行建模,能够准确评估迁移任务(迁移硬盘上的数据)对于分布式存储系统上用户访问的影响;其次,根据迁移任务干扰系数模型调度迁移任务的时机;最后,采集观察窗口内带宽变化调节迁移任务的速率。The present invention provides a migration task scheduling method for a storage system with a decentralized architecture. Modeling is performed on the interference coefficient of a migration task in a storage system with a decentralized architecture, which can accurately evaluate the impact of a migration task (migrating data on a hard disk) on distributed The impact of user access on the storage system; secondly, the timing of migration tasks is scheduled according to the migration task interference coefficient model; finally, the rate of migration tasks is adjusted by collecting bandwidth changes in the observation window.
请参阅图3,本发明一种针对去中心化架构存储系统的迁移任务调度方法,包括以下步骤:Referring to FIG. 3, a method for scheduling migration tasks for a storage system with a decentralized architecture of the present invention includes the following steps:
S1、建立基于去中心化架构存储系统的迁移任务干扰系数模型;S1. Establish a migration task interference coefficient model based on a decentralized architecture storage system;
对每个迁移任务进行迁移后数据分布进行预估,由于去中心化架构存储系统通过特定的哈希算法计算出所有数据块的副本位置。The data distribution after migration is estimated for each migration task, because the decentralized architecture storage system calculates the copy positions of all data blocks through a specific hash algorithm.
S101、请参阅图1,首先将文件分割成大小固定的数据块(block),然后将数据块哈希到具体的存储设备上;通过运行一遍哈希算法,可以得到存储系统中所有数据块的存放位置。S101. Referring to Figure 1, first divide the file into data blocks with fixed size, and then hash the data blocks to a specific storage device; by running the hash algorithm once, the data of all data blocks in the storage system can be obtained. Storage location.
S102、请参阅图2,通过模拟一遍去中心化架构存储系统使用的特定哈希算法,估算出每个需要迁移的数据块在迁移结束后新的位置(存储设备编号),再统计每个硬盘移出和迁入的数据块数,计算得到每个参与迁移硬盘的读写数据量之和Ddata。S102. Please refer to Figure 2. By simulating a specific hash algorithm used by the decentralized architecture storage system, estimate the new location (storage device number) of each data block that needs to be migrated after the migration, and then count each hard disk. The number of data blocks moved out and in, and the sum of the read and write data volumes Ddata of each participating hard disk is calculated.
定义一个10s大小的观测窗口用来监测每个参与迁移硬盘的窗口平均带宽Bused,带宽被用于建立迁移任务干扰系数模型,迁移任务干扰系数Finterference具体为:An observation window with a size of 10s is defined to monitor the average bandwidth Bused of each hard disk participating in the migration. The bandwidth is used to establish the migration task interference coefficient model. The migration task interference coefficient Finterference is specifically:

其中,Buised为编号i磁盘上用户应用占用的带宽,Didata为编号i硬盘上迁移数据量。Among them, Buised is the bandwidth occupied by the user application on the disk numberi , and Didata is the amount of data migrated on the disk number i.
S2、针对迁移任务干扰系数模型的迁移任务进行调度;S2. Scheduling the migration tasks of the migration task interference coefficient model;
请参阅图3,首先为每个迁移任务建立任务干扰系数模型,其次通过观测窗口采样窗口内干扰系数的平均值,并且与设定好的阈值α进行比较,当干扰系数小于阈值时,执行数据迁移。Please refer to Figure 3. First, a task interference coefficient model is established for each migration task. Secondly, the average value of the interference coefficient in the sampling window is observed and compared with the set threshold α. When the interference coefficient is smaller than the threshold, the data is executed. migrate.

Bideal=75%×Btotal-Bmax_migrationBideal = 75%×Btotal -Bmax_migration
其中,Bideal是Bmax_migration(硬盘迁移带宽最大值)确定时,用户应用与迁移任务互不干扰的最大占用带宽。Wherein, Bideal is the maximum occupied bandwidth that the user application and the migration task do not interfere with each other when Bmax_migration (the maximum value of the hard disk migration bandwidth) is determined.
在大规模存储集群中观测到,当用户应用带宽与迁移任务带宽之和超过总带宽的百分之75%时,用户应用的延迟显著增加;阈值α是迁移任务与当前用户应用互不干扰的临界值;当在观测窗口中观察到Finterference的平均值低于阈值α时,判断迁移任务对于用户应用的影响较弱,此时调度迁移任务开始执行,当观测窗口中观察到的Finterference超过阈值α,说明此时执行迁移任务将对用户应用产生较大干扰,此时选择等待一个观测窗口,再判断下个观测窗口的迁移任务干扰函数。It is observed in a large-scale storage cluster that when the sum of user application bandwidth and migration task bandwidth exceeds 75% of the total bandwidth, the latency of user applications increases significantly; the threshold α is the non-interference between migration tasks and current user applications. Critical value; when the average value of Finterference observed in the observation window is lower than the threshold α, it is judged that the impact of the migration task on the user application is weak, and the migration task is scheduled to be executed at this time. When the observed Finterference in the observation window exceeds The threshold α indicates that executing the migration task at this time will cause great interference to the user application. At this time, choose to wait for an observation window, and then judge the migration task interference function of the next observation window.
S3、对迁移任务干扰系数模型的迁移带宽进行分配,采集观察窗口内带宽变化调节迁移任务的速率,在新的观测窗口开始前,根据迁移任务的干扰系数和优先级进行调度,相同优先级的任务干扰系数小的优先调度。S3. Allocate the migration bandwidth of the migration task interference coefficient model, collect bandwidth changes in the observation window to adjust the rate of the migration task, and schedule the migration tasks according to the interference coefficient and priority of the migration task before the new observation window starts. Tasks with small interference coefficients are prioritized for scheduling.
请参阅图4,在迁移任务开始执行后,持续使用观测窗口采集并计算每个参与迁移硬盘的窗口内平均带宽Bwindow,调整参与迁移硬盘下一个窗口内的迁移带宽Bnew_allocation,保证迁移任务与用户应用互不干扰的同时,尽量快速的完成迁移。迁移带宽分配过程如图5所示。Referring to Figure 4, after the migration task starts to execute, continue to use the observation window to collect and calculate the average bandwidth Bwindow within the window of each disk participating in the migration, and adjust the migration bandwidth Bnew_allocation in the next window of the disk participating in the migration to ensure that the migration task is equal to While user applications do not interfere with each other, the migration should be completed as quickly as possible. The migration bandwidth allocation process is shown in Figure 5.
Bnew_allocation=max(Bold_allocation-(Bwindow-75%×Btotal),Bmin)Bnew_allocation =max(Bold_allocation -(Bwindow -75%×Btotal ),Bmin )
其中,Bold_allocation表示上一个观测窗口硬盘上分配给迁移任务的带宽,Btotal表示硬盘理论带宽,Bmin表示分配给迁移任务的最小带宽。Among them, Bold_allocation represents the bandwidth allocated to the migration task on the hard disk in the previous observation window, Btotal represents the theoretical bandwidth of the hard disk, and Bmin represents the minimum bandwidth allocated to the migration task.
请参阅图5,通过连续的观测窗口动态调节迁移任务的带宽分配,在一个窗口结束后,由上一个观测窗口的统计值计算出下一个窗口的带宽分配值。Referring to Figure 5, the bandwidth allocation of the migration task is dynamically adjusted through successive observation windows. After a window ends, the bandwidth allocation value of the next window is calculated from the statistical value of the previous observation window.
本发明在实际部署去中心化架构存储系统的机群上,应用了本发明的方法。在真实采集的用户应用trace下,实现了本发明方法的存储系统比较原始系统,迁移速率提高了约百分之7,而用户应用的平均延迟下降了约百分之19%。In the present invention, the method of the present invention is applied to the machine cluster in which the storage system of the decentralized architecture is actually deployed. Under the actual collected user application trace, the storage system implementing the method of the present invention has a migration rate increased by about 7% compared with the original system, and the average delay of the user application is reduced by about 19%.
综上所述,本发明一种针对去中心化架构存储系统的迁移调度方法,通过对迁移任务建立干扰系数模型,采用阈值决定迁移任务调度时机,并使用观测窗口动态调整迁移速率。提高了去中心化架构存储系统的迁移速率,并且降低了存储系统上用户应用的延迟。In summary, the present invention provides a migration scheduling method for a storage system with a decentralized architecture. By establishing an interference coefficient model for migration tasks, a threshold is used to determine the scheduling timing of migration tasks, and an observation window is used to dynamically adjust the migration rate. It improves the migration rate of the decentralized architecture storage system and reduces the latency of user applications on the storage system.
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。As will be appreciated by those skilled in the art, the embodiments of the present application may be provided as a method, a system, or a computer program product. Accordingly, the present application may take the form of an entirely hardware embodiment, an entirely software embodiment, or an embodiment combining software and hardware aspects. Furthermore, the present application may take the form of a computer program product embodied on one or more computer-usable storage media (including, but not limited to, disk storage, CD-ROM, optical storage, etc.) having computer-usable program code embodied therein.
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。The present application is described with reference to flowchart illustrations and/or block diagrams of methods, apparatus (systems), and computer program products according to embodiments of the present application. It will be understood that each flow and/or block in the flowchart illustrations and/or block diagrams, and combinations of flows and/or blocks in the flowchart illustrations and/or block diagrams, can be implemented by computer program instructions. These computer program instructions may be provided to the processor of a general purpose computer, special purpose computer, embedded processor or other programmable data processing device to produce a machine such that the instructions executed by the processor of the computer or other programmable data processing device produce Means for implementing the functions specified in a flow or flow of a flowchart and/or a block or blocks of a block diagram.
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。These computer program instructions may also be stored in a computer-readable memory capable of directing a computer or other programmable data processing apparatus to function in a particular manner, such that the instructions stored in the computer-readable memory result in an article of manufacture comprising instruction means, the instructions The apparatus implements the functions specified in the flow or flow of the flowcharts and/or the block or blocks of the block diagrams.
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。These computer program instructions can also be loaded on a computer or other programmable data processing device to cause a series of operational steps to be performed on the computer or other programmable device to produce a computer-implemented process such that The instructions provide steps for implementing the functions specified in the flow or blocks of the flowcharts and/or the block or blocks of the block diagrams.
以上内容仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明权利要求书的保护范围之内。The above content is only to illustrate the technical idea of the present invention, and cannot limit the protection scope of the present invention. Any changes made on the basis of the technical solution according to the technical idea proposed by the present invention all fall within the scope of the claims of the present invention. within the scope of protection.
Claims (5)
Translated fromChinese



Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011177017.6ACN112433670B (en) | 2020-10-28 | 2020-10-28 | Migration task scheduling method for decentralized architecture storage system |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011177017.6ACN112433670B (en) | 2020-10-28 | 2020-10-28 | Migration task scheduling method for decentralized architecture storage system |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN112433670A CN112433670A (en) | 2021-03-02 |
| CN112433670Btrue CN112433670B (en) | 2022-02-18 |
Family
ID=74696386
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202011177017.6AActiveCN112433670B (en) | 2020-10-28 | 2020-10-28 | Migration task scheduling method for decentralized architecture storage system |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN112433670B (en) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115309698A (en)* | 2022-06-27 | 2022-11-08 | 中银金融科技有限公司 | Customer information migration method and device |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110351336A (en)* | 2019-06-10 | 2019-10-18 | 西安交通大学 | A kind of edge service moving method based on docker container |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105227645A (en)* | 2015-09-15 | 2016-01-06 | 齐鲁工业大学 | A kind of cloud data migration method |
| US10754575B2 (en)* | 2018-07-16 | 2020-08-25 | EMC IP Holding Company LLC | Storage system with replication process utilizing simulated target responses |
| CN110248247B (en)* | 2019-06-12 | 2021-08-17 | 深圳市大数据研究院 | Embedded dynamic video playback control method and device based on network throughput |
| CN110995620A (en)* | 2019-11-28 | 2020-04-10 | 广东电力通信科技有限公司 | Method for improving cloud migration efficiency by fully utilizing bandwidth |
| CN111294775B (en)* | 2020-02-10 | 2021-04-20 | 西安交通大学 | A resource allocation method based on H2H dynamic characteristics in large-scale MTC and H2H coexistence scenarios |
- 2020
- 2020-10-28CNCN202011177017.6Apatent/CN112433670B/enactiveActive
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110351336A (en)* | 2019-06-10 | 2019-10-18 | 西安交通大学 | A kind of edge service moving method based on docker container |
Also Published As
| Publication number | Publication date |
|---|---|
| CN112433670A (en) | 2021-03-02 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110134495B (en) | A container cross-host online migration method, storage medium and terminal device | |
| US10534542B2 (en) | Dynamic core allocation for consistent performance in a non-preemptive scheduling environment | |
| US10185592B2 (en) | Network storage device using dynamic weights based on resource utilization | |
| CN102404399B (en) | Fuzzy dynamic allocation method for cloud storage resource | |
| WO2013075560A1 (en) | Method and system for controlling quality of service of storage system, and storage system | |
| CN108491159B (en) | A checkpoint data writing method for massively parallel systems based on random delays to alleviate I/O bottlenecks | |
| WO2017020742A1 (en) | Load balancing method and device | |
| CN110795213B (en) | Active memory prediction migration method in virtual machine migration process | |
| CN108595250A (en) | A kind of scheduling of resource efficiency optimization method and system towards IaaS cloud platform | |
| CN111737168A (en) | A cache system, cache processing method, device, device and medium | |
| CN102136993A (en) | Data transfer method, device and system | |
| CN116225696B (en) | Method and device for tuning operator concurrency in stream processing system | |
| TW201702908A (en) | Database elastic scheduling method and device | |
| CN112015765B (en) | Spark cache elimination method and system based on cache value | |
| CN102739785A (en) | Method for scheduling cloud computing tasks based on network bandwidth estimation | |
| CN102932424A (en) | Method and system for synchronizing data caching of distributed parallel file system | |
| CN111176831B (en) | Dynamic thread mapping optimization method and device based on multithreading shared memory communication | |
| CN114063888A (en) | Data storage system, data processing method, terminal and storage medium | |
| CN107092649A (en) | A kind of topological replacement method of unaware towards real-time stream calculation | |
| CN103685544A (en) | Performance pre-evaluation based client cache distributing method and system | |
| CN112433670B (en) | Migration task scheduling method for decentralized architecture storage system | |
| CN104866375B (en) | A kind of method and device for migrating virtual machine | |
| Wang et al. | An Improved Memory Cache Management Study Based on Spark. | |
| CN114297002A (en) | A method and system for mass data backup based on object storage | |
| Zhang et al. | Online nonstop task management for storm-based distributed stream processing engines |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |